

簡介
ChatGPT 訓練至 2022 年。
但是,如果您希望它專門為您提供有關您網站的資訊怎麼辦?最有可能的是,這是不可能的,但不再是了!
OpenAI 推出了他們的新功能 - 助手。
現在您可以輕鬆地為您的網站建立索引,然後向 ChatGPT 詢問有關該網站的問題。在本教程中,我們將建立一個系統來索引您的網站並讓您查詢它。我們將:
-
抓取文件網站地圖。
-
從網站上的所有頁面中提取資訊。
-
使用新資訊建立新助理。
-
建立一個簡單的ChatGPT前端介面並查詢助手。

你的後台工作平台🔌
Trigger.dev 是一個開源程式庫,可讓您使用 NextJS、Remix、Astro 等為您的應用程式建立和監控長時間執行的作業!

請幫我們一顆星🥹。
這將幫助我們建立更多這樣的文章💖
讓我們開始吧🔥
讓我們建立一個新的 NextJS 專案。
npx create-next-app@latest💡 我們使用 NextJS 新的應用程式路由器。安裝專案之前請確保您的節點版本為 18+
讓我們建立一個新的資料庫來保存助手和抓取的頁面。
對於我們的範例,我們將使用 Prisma 和 SQLite。
安裝非常簡單,只需執行:
npm install prisma @prisma/client --save然後加入架構和資料庫
npx prisma init --datasource-provider sqlite轉到“prisma/schema.prisma”並將其替換為以下架構:
// This is your Prisma schema file,
// learn more about it in the docs: https://pris.ly/d/prisma-schema
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "sqlite"
url = env("DATABASE_URL")
}
model Docs {
id Int @id @default(autoincrement())
content String
url String @unique
identifier String
@@index([identifier])
}
model Assistant {
id Int @id @default(autoincrement())
aId String
url String @unique
}然後執行
npx prisma db push這將建立一個新的 SQLite 資料庫(本機檔案),其中包含兩個主表:“Docs”和“Assistant”
-
「Docs」包含所有抓取的頁面
-
Assistant包含文件的 URL 和內部 ChatGPT 助理 ID。
讓我們新增 Prisma 客戶端。
建立一個名為「helper」的新資料夾,並新增一個名為「prisma.ts」的新文件,並在其中新增以下程式碼:
import {PrismaClient} from '@prisma/client';
export const prisma = new PrismaClient();我們稍後可以使用“prisma”變數來查詢我們的資料庫。
刮擦和索引
建立 Trigger.dev 帳戶
抓取頁面並為其建立索引是一項長期執行的任務。 我們需要:
-
抓取網站地圖的主網站元 URL。
-
擷取網站地圖內的所有頁面。
-
前往每個頁面並提取內容。
-
將所有內容儲存到 ChatGPT 助手中。
為此,我們使用 Trigger.dev!
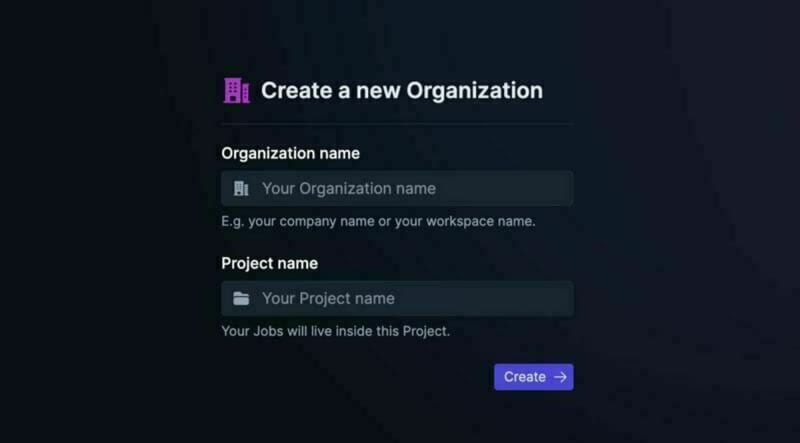
註冊 Trigger.dev 帳號。
註冊後,建立一個組織並為您的工作選擇一個專案名稱。
選擇 Next.js 作為您的框架,並按照將 Trigger.dev 新增至現有 Next.js 專案的流程進行操作。

否則,請點選專案儀表板側邊欄選單上的「環境和 API 金鑰」。

複製您的 DEV 伺服器 API 金鑰並執行下面的程式碼片段來安裝 Trigger.dev。
仔細按照說明進行操作。
npx @trigger.dev/cli@latest init在另一個終端中執行以下程式碼片段,在 Trigger.dev 和您的 Next.js 專案之間建立隧道。
npx @trigger.dev/cli@latest dev安裝 ChatGPT (OpenAI)
我們將使用OpenAI助手,因此我們必須將其安裝到我們的專案中。
建立新的 OpenAI 帳戶 並產生 API 金鑰。
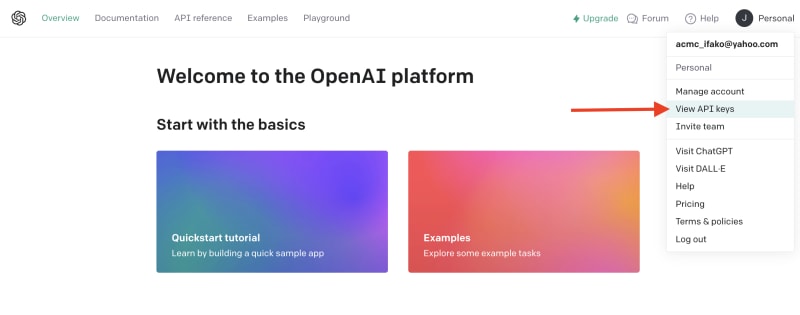
點擊下拉清單中的「檢視 API 金鑰」以建立 API 金鑰。
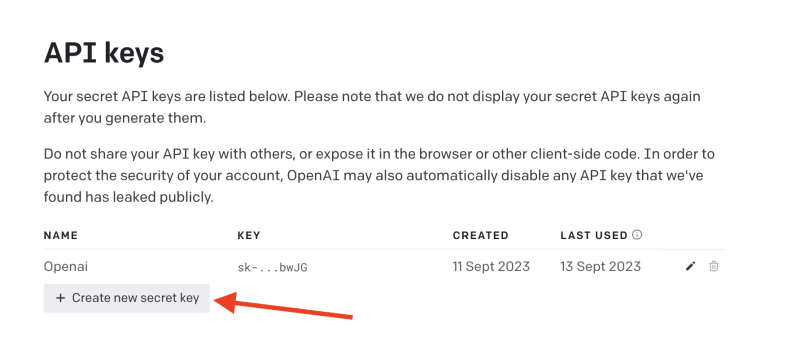
接下來,透過執行下面的程式碼片段來安裝 OpenAI 套件。
npm install @trigger.dev/openai將您的 OpenAI API 金鑰新增至「.env.local」檔案。
OPENAI_API_KEY=<your_api_key>建立一個新目錄“helper”並新增一個新檔案“open.ai.tsx”,其中包含以下內容:
import {OpenAI} from "@trigger.dev/openai";
export const openai = new OpenAI({
id: "openai",
apiKey: process.env.OPENAI_API_KEY!,
});這是我們透過 Trigger.dev 整合封裝的 OpenAI 用戶端。
建立後台作業
讓我們繼續建立一個新的後台作業!
前往“jobs”並建立一個名為“process.documentation.ts”的新檔案。 新增以下程式碼:
import { eventTrigger } from "@trigger.dev/sdk";
import { client } from "@openai-assistant/trigger";
import {object, string} from "zod";
import {JSDOM} from "jsdom";
import {openai} from "@openai-assistant/helper/open.ai";
client.defineJob({
// This is the unique identifier for your Job; it must be unique across all Jobs in your project.
id: "process-documentation",
name: "Process Documentation",
version: "0.0.1",
// This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction
trigger: eventTrigger({
name: "process.documentation.event",
schema: object({
url: string(),
})
}),
integrations: {
openai
},
run: async (payload, io, ctx) => {
}
});我們定義了一個名為「process.documentation.event」的新作業,並新增了一個名為 URL 的必要參數 - 這是我們稍後要傳送的文件 URL。
正如您所看到的,該作業是空的,所以讓我們向其中加入第一個任務。
我們需要獲取網站網站地圖並將其返回。
抓取網站將返回我們需要解析的 HTML。
為此,我們需要安裝 JSDOM。
npm install jsdom --save並將其導入到我們文件的頂部:
import {JSDOM} from "jsdom";現在,我們可以新增第一個任務。
用「runTask」包裝我們的程式碼很重要,這可以讓 Trigger.dev 將其與其他任務分開。觸發特殊架構將任務拆分為不同的進程,因此 Vercel 無伺服器逾時不會影響它們。 這是第一個任務的程式碼:
const getSiteMap = await io.runTask("grab-sitemap", async () => {
const data = await (await fetch(payload.url)).text();
const dom = new JSDOM(data);
const sitemap = dom.window.document.querySelector('[rel="sitemap"]')?.getAttribute('href');
return new URL(sitemap!, payload.url).toString();
});-
我們透過 HTTP 請求從 URL 取得整個 HTML。
-
我們將其轉換為 JS 物件。
-
我們找到網站地圖 URL。
-
我們解析它並返回它。
接下來,我們需要抓取網站地圖,提取所有 URL 並返回它們。
讓我們安裝“Lodash”——陣列結構的特殊函數。
npm install lodash @types/lodash --save這是任務的程式碼:
export const makeId = (length: number) => {
let text = '';
const possible = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
for (let i = 0; i < length; i += 1) {
text += possible.charAt(Math.floor(Math.random() * possible.length));
}
return text;
};
const {identifier, list} = await io.runTask("load-and-parse-sitemap", async () => {
const urls = /(http|ftp|https):\/\/([\w_-]+(?:(?:\.[\w_-]+)+))([\w.,@?^=%&:\/~+#-]*[\w@?^=%&\/~+#-])/g;
const identifier = makeId(5);
const data = await (await fetch(getSiteMap)).text();
// @ts-ignore
return {identifier, list: chunk(([...new Set(data.match(urls))] as string[]).filter(f => f.includes(payload.url)).map(p => ({identifier, url: p})), 25)};
});-
我們建立一個名為 makeId 的新函數來為所有頁面產生隨機辨識碼。
-
我們建立一個新任務並加入正規表示式來提取每個可能的 URL
-
我們發送一個 HTTP 請求來載入網站地圖並提取其所有 URL。
-
我們將 URL「分塊」為 25 個元素的陣列(如果有 100 個元素,則會有四個 25 個元素的陣列)
接下來,讓我們建立一個新作業來處理每個 URL。
這是完整的程式碼:
function getElementsBetween(startElement: Element, endElement: Element) {
let currentElement = startElement;
const elements = [];
// Traverse the DOM until the endElement is reached
while (currentElement && currentElement !== endElement) {
currentElement = currentElement.nextElementSibling!;
// If there's no next sibling, go up a level and continue
if (!currentElement) {
// @ts-ignore
currentElement = startElement.parentNode!;
startElement = currentElement;
if (currentElement === endElement) break;
continue;
}
// Add the current element to the list
if (currentElement && currentElement !== endElement) {
elements.push(currentElement);
}
}
return elements;
}
const processContent = client.defineJob({
// This is the unique identifier for your Job; it must be unique across all Jobs in your project.
id: "process-content",
name: "Process Content",
version: "0.0.1",
// This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction
trigger: eventTrigger({
name: "process.content.event",
schema: object({
url: string(),
identifier: string(),
})
}),
run: async (payload, io, ctx) => {
return io.runTask('grab-content', async () => {
// We first grab a raw html of the content from the website
const data = await (await fetch(payload.url)).text();
// We load it with JSDOM so we can manipulate it
const dom = new JSDOM(data);
// We remove all the scripts and styles from the page
dom.window.document.querySelectorAll('script, style').forEach((el) => el.remove());
// We grab all the titles from the page
const content = Array.from(dom.window.document.querySelectorAll('h1, h2, h3, h4, h5, h6'));
// We grab the last element so we can get the content between the last element and the next element
const lastElement = content[content.length - 1]?.parentElement?.nextElementSibling!;
const elements = [];
// We loop through all the elements and grab the content between each title
for (let i = 0; i < content.length; i++) {
const element = content[i];
const nextElement = content?.[i + 1] || lastElement;
const elementsBetween = getElementsBetween(element, nextElement);
elements.push({
title: element.textContent, content: elementsBetween.map((el) => el.textContent).join('\n')
});
}
// We create a raw text format of all the content
const page = `
----------------------------------
url: ${payload.url}\n
${elements.map((el) => `${el.title}\n${el.content}`).join('\n')}
----------------------------------
`;
// We save it to our database
await prisma.docs.upsert({
where: {
url: payload.url
}, update: {
content: page, identifier: payload.identifier
}, create: {
url: payload.url, content: page, identifier: payload.identifier
}
});
});
},
});-
我們從 URL 中獲取內容(之前從網站地圖中提取)
-
我們用
JSDOM解析它 -
我們刪除頁面上存在的所有可能的“<script>”或“<style>”。
-
我們抓取頁面上的所有標題(
h1、h2、h3、h4、h5、h6) -
我們迭代標題並獲取它們之間的內容。我們不想取得整個頁面內容,因為它可能包含不相關的內容。
-
我們建立頁面原始文字的版本並將其保存到我們的資料庫中。
現在,讓我們為每個網站地圖 URL 執行此任務。
觸發器引入了名為“batchInvokeAndWaitForCompletion”的東西。
它允許我們批量發送 25 個專案進行處理,並且它將同時處理所有這些專案。下面是接下來的幾行程式碼:
let i = 0;
for (const item of list) {
await processContent.batchInvokeAndWaitForCompletion(
'process-list-' + i,
item.map(
payload => ({
payload,
}),
86_400),
);
i++;
} 我們以 25 個為一組手動觸發之前建立的作業。
完成後,讓我們將保存到資料庫的所有內容並連接它:
const data = await io.runTask("get-extracted-data", async () => {
return (await prisma.docs.findMany({
where: {
identifier
},
select: {
content: true
}
})).map((d) => d.content).join('\n\n');
});我們使用之前指定的標識符。
現在,讓我們在 ChatGPT 中使用新資料建立一個新檔案:
const file = await io.openai.files.createAndWaitForProcessing("upload-file", {
purpose: "assistants",
file: data
});createAndWaitForProcessing 是 Trigger.dev 建立的任務,用於將檔案上傳到助手。如果您在沒有整合的情況下手動使用“openai”,則必須串流傳輸檔案。
現在讓我們建立或更新我們的助手:
const assistant = await io.openai.runTask("create-or-update-assistant", async (openai) => {
const currentAssistant = await prisma.assistant.findFirst({
where: {
url: payload.url
}
});
if (currentAssistant) {
return openai.beta.assistants.update(currentAssistant.aId, {
file_ids: [file.id]
});
}
return openai.beta.assistants.create({
name: identifier,
description: 'Documentation',
instructions: 'You are a documentation assistant, you have been loaded with documentation from ' + payload.url + ', return everything in an MD format.',
model: 'gpt-4-1106-preview',
tools: [{ type: "code_interpreter" }, {type: 'retrieval'}],
file_ids: [file.id],
});
});-
我們首先檢查是否有針對該特定 URL 的助手。
-
如果我們有的話,讓我們用新文件更新助手。
-
如果沒有,讓我們建立一個新的助手。
-
我們傳遞「你是文件助理」的指令,需要注意的是,我們希望最終輸出為「MD」格式,以便稍後更好地顯示。
對於拼圖的最後一塊,讓我們將新助手儲存到我們的資料庫中。
這是程式碼:
await io.runTask("save-assistant", async () => {
await prisma.assistant.upsert({
where: {
url: payload.url
},
update: {
aId: assistant.id,
},
create: {
aId: assistant.id,
url: payload.url,
}
});
});如果該 URL 已經存在,我們可以嘗試使用新的助手 ID 來更新它。
這是該頁面的完整程式碼:
import { eventTrigger } from "@trigger.dev/sdk";
import { client } from "@openai-assistant/trigger";
import {object, string} from "zod";
import {JSDOM} from "jsdom";
import {chunk} from "lodash";
import {prisma} from "@openai-assistant/helper/prisma.client";
import {openai} from "@openai-assistant/helper/open.ai";
const makeId = (length: number) => {
let text = '';
const possible = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
for (let i = 0; i < length; i += 1) {
text += possible.charAt(Math.floor(Math.random() * possible.length));
}
return text;
};
client.defineJob({
// This is the unique identifier for your Job; it must be unique across all Jobs in your project.
id: "process-documentation",
name: "Process Documentation",
version: "0.0.1",
// This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction
trigger: eventTrigger({
name: "process.documentation.event",
schema: object({
url: string(),
})
}),
integrations: {
openai
},
run: async (payload, io, ctx) => {
// The first task to get the sitemap URL from the website
const getSiteMap = await io.runTask("grab-sitemap", async () => {
const data = await (await fetch(payload.url)).text();
const dom = new JSDOM(data);
const sitemap = dom.window.document.querySelector('[rel="sitemap"]')?.getAttribute('href');
return new URL(sitemap!, payload.url).toString();
});
// We parse the sitemap; instead of using some XML parser, we just use regex to get the URLs and we return it in chunks of 25
const {identifier, list} = await io.runTask("load-and-parse-sitemap", async () => {
const urls = /(http|ftp|https):\/\/([\w_-]+(?:(?:\.[\w_-]+)+))([\w.,@?^=%&:\/~+#-]*[\w@?^=%&\/~+#-])/g;
const identifier = makeId(5);
const data = await (await fetch(getSiteMap)).text();
// @ts-ignore
return {identifier, list: chunk(([...new Set(data.match(urls))] as string[]).filter(f => f.includes(payload.url)).map(p => ({identifier, url: p})), 25)};
});
// We go into each page and grab the content; we do this in batches of 25 and save it to the DB
let i = 0;
for (const item of list) {
await processContent.batchInvokeAndWaitForCompletion(
'process-list-' + i,
item.map(
payload => ({
payload,
}),
86_400),
);
i++;
}
// We get the data that we saved in batches from the DB
const data = await io.runTask("get-extracted-data", async () => {
return (await prisma.docs.findMany({
where: {
identifier
},
select: {
content: true
}
})).map((d) => d.content).join('\n\n');
});
// We upload the data to OpenAI with all the content
const file = await io.openai.files.createAndWaitForProcessing("upload-file", {
purpose: "assistants",
file: data
});
// We create a new assistant or update the old one with the new file
const assistant = await io.openai.runTask("create-or-update-assistant", async (openai) => {
const currentAssistant = await prisma.assistant.findFirst({
where: {
url: payload.url
}
});
if (currentAssistant) {
return openai.beta.assistants.update(currentAssistant.aId, {
file_ids: [file.id]
});
}
return openai.beta.assistants.create({
name: identifier,
description: 'Documentation',
instructions: 'You are a documentation assistant, you have been loaded with documentation from ' + payload.url + ', return everything in an MD format.',
model: 'gpt-4-1106-preview',
tools: [{ type: "code_interpreter" }, {type: 'retrieval'}],
file_ids: [file.id],
});
});
// We update our internal database with the assistant
await io.runTask("save-assistant", async () => {
await prisma.assistant.upsert({
where: {
url: payload.url
},
update: {
aId: assistant.id,
},
create: {
aId: assistant.id,
url: payload.url,
}
});
});
},
});
export function getElementsBetween(startElement: Element, endElement: Element) {
let currentElement = startElement;
const elements = [];
// Traverse the DOM until the endElement is reached
while (currentElement && currentElement !== endElement) {
currentElement = currentElement.nextElementSibling!;
// If there's no next sibling, go up a level and continue
if (!currentElement) {
// @ts-ignore
currentElement = startElement.parentNode!;
startElement = currentElement;
if (currentElement === endElement) break;
continue;
}
// Add the current element to the list
if (currentElement && currentElement !== endElement) {
elements.push(currentElement);
}
}
return elements;
}
// This job will grab the content from the website
const processContent = client.defineJob({
// This is the unique identifier for your Job; it must be unique across all Jobs in your project.
id: "process-content",
name: "Process Content",
version: "0.0.1",
// This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction
trigger: eventTrigger({
name: "process.content.event",
schema: object({
url: string(),
identifier: string(),
})
}),
run: async (payload, io, ctx) => {
return io.runTask('grab-content', async () => {
try {
// We first grab a raw HTML of the content from the website
const data = await (await fetch(payload.url)).text();
// We load it with JSDOM so we can manipulate it
const dom = new JSDOM(data);
// We remove all the scripts and styles from the page
dom.window.document.querySelectorAll('script, style').forEach((el) => el.remove());
// We grab all the titles from the page
const content = Array.from(dom.window.document.querySelectorAll('h1, h2, h3, h4, h5, h6'));
// We grab the last element so we can get the content between the last element and the next element
const lastElement = content[content.length - 1]?.parentElement?.nextElementSibling!;
const elements = [];
// We loop through all the elements and grab the content between each title
for (let i = 0; i < content.length; i++) {
const element = content[i];
const nextElement = content?.[i + 1] || lastElement;
const elementsBetween = getElementsBetween(element, nextElement);
elements.push({
title: element.textContent, content: elementsBetween.map((el) => el.textContent).join('\n')
});
}
// We create a raw text format of all the content
const page = `
----------------------------------
url: ${payload.url}\n
${elements.map((el) => `${el.title}\n${el.content}`).join('\n')}
----------------------------------
`;
// We save it to our database
await prisma.docs.upsert({
where: {
url: payload.url
}, update: {
content: page, identifier: payload.identifier
}, create: {
url: payload.url, content: page, identifier: payload.identifier
}
});
}
catch (e) {
console.log(e);
}
});
},
});我們已經完成建立後台作業來抓取和索引文件🎉
詢問助理
現在,讓我們建立一個任務來詢問我們的助手。
前往“jobs”並建立一個新檔案“question.assistant.ts”。 新增以下程式碼:
import {eventTrigger} from "@trigger.dev/sdk";
import {client} from "@openai-assistant/trigger";
import {object, string} from "zod";
import {openai} from "@openai-assistant/helper/open.ai";
client.defineJob({
// This is the unique identifier for your Job; it must be unique across all Jobs in your project.
id: "question-assistant",
name: "Question Assistant",
version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction
trigger: eventTrigger({
name: "question.assistant.event", schema: object({
content: string(),
aId: string(),
threadId: string().optional(),
})
}), integrations: {
openai
}, run: async (payload, io, ctx) => {
// Create or use an existing thread
const thread = payload.threadId ? await io.openai.beta.threads.retrieve('get-thread', payload.threadId) : await io.openai.beta.threads.create('create-thread');
// Create a message in the thread
await io.openai.beta.threads.messages.create('create-message', thread.id, {
content: payload.content,
role: 'user',
});
// Run the thread
const run = await io.openai.beta.threads.runs.createAndWaitForCompletion('run-thread', thread.id, {
model: 'gpt-4-1106-preview',
assistant_id: payload.aId,
});
// Check the status of the thread
if (run.status !== "completed") {
console.log('not completed');
throw new Error(`Run finished with status ${run.status}: ${JSON.stringify(run.last_error)}`);
}
// Get the messages from the thread
const messages = await io.openai.beta.threads.messages.list("list-messages", run.thread_id, {
query: {
limit: "1"
}
});
const content = messages[0].content[0];
if (content.type === 'text') {
return {content: content.text.value, threadId: thread.id};
}
}
});-
該事件需要三個參數
-
content- 我們想要傳送給助理的訊息。 -
aId- 我們先前建立的助手的內部 ID。 -
threadId- 對話的執行緒 ID。正如您所看到的,這是一個可選參數,因為在第一個訊息中,我們還沒有線程 ID。
-
-
然後,我們建立或取得前一個執行緒的執行緒。
-
我們在助理提出的問題的線索中加入一條新訊息。
-
我們執行線程並等待它完成。
-
我們取得訊息清單(並將其限制為 1),因為第一則訊息是對話中的最後一則訊息。
-
我們返回訊息內容和我們剛剛建立的線程ID。
新增路由
我們需要為我們的應用程式建立 3 個 API 路由:
1、派新助理進行處理。
-
透過URL獲取特定助手。
-
新增訊息給助手。
在「app/api」中建立一個名為assistant的新資料夾,並在其中建立一個名為「route.ts」的新檔案。裡面加入如下程式碼:
import {client} from "@openai-assistant/trigger";
import {prisma} from "@openai-assistant/helper/prisma.client";
export async function POST(request: Request) {
const body = await request.json();
if (!body.url) {
return new Response(JSON.stringify({error: 'URL is required'}), {status: 400});
}
// We send an event to the trigger to process the documentation
const {id: eventId} = await client.sendEvent({
name: "process.documentation.event",
payload: {url: body.url},
});
return new Response(JSON.stringify({eventId}), {status: 200});
}
export async function GET(request: Request) {
const url = new URL(request.url).searchParams.get('url');
if (!url) {
return new Response(JSON.stringify({error: 'URL is required'}), {status: 400});
}
const assistant = await prisma.assistant.findFirst({
where: {
url: url
}
});
return new Response(JSON.stringify(assistant), {status: 200});
}第一個「POST」方法取得一個 URL,並使用用戶端傳送的 URL 觸發「process.documentation.event」作業。
第二個「GET」方法從我們的資料庫中透過客戶端發送的 URL 取得助手。
現在,讓我們建立向助手新增訊息的路由。
在「app/api」內部建立一個新資料夾「message」並新增一個名為「route.ts」的新文件,然後新增以下程式碼:
import {prisma} from "@openai-assistant/helper/prisma.client";
import {client} from "@openai-assistant/trigger";
export async function POST(request: Request) {
const body = await request.json();
// Check that we have the assistant id and the message
if (!body.id || !body.message) {
return new Response(JSON.stringify({error: 'Id and Message are required'}), {status: 400});
}
// get the assistant id in OpenAI from the id in the database
const assistant = await prisma.assistant.findUnique({
where: {
id: +body.id
}
});
// We send an event to the trigger to process the documentation
const {id: eventId} = await client.sendEvent({
name: "question.assistant.event",
payload: {
content: body.message,
aId: assistant?.aId,
threadId: body.threadId
},
});
return new Response(JSON.stringify({eventId}), {status: 200});
}這是一個非常基本的程式碼。我們從客戶端獲取訊息、助手 ID 和線程 ID,並將其發送到我們之前建立的「question.assistant.event」。
最後要做的事情是建立一個函數來獲取我們所有的助手。
在「helpers」內部建立一個名為「get.list.ts」的新函數並新增以下程式碼:
import {prisma} from "@openai-assistant/helper/prisma.client";
// Get the list of all the available assistants
export const getList = () => {
return prisma.assistant.findMany({
});
}非常簡單的程式碼即可獲得所有助手。
我們已經完成了後端🥳
讓我們轉到前面。

建立前端
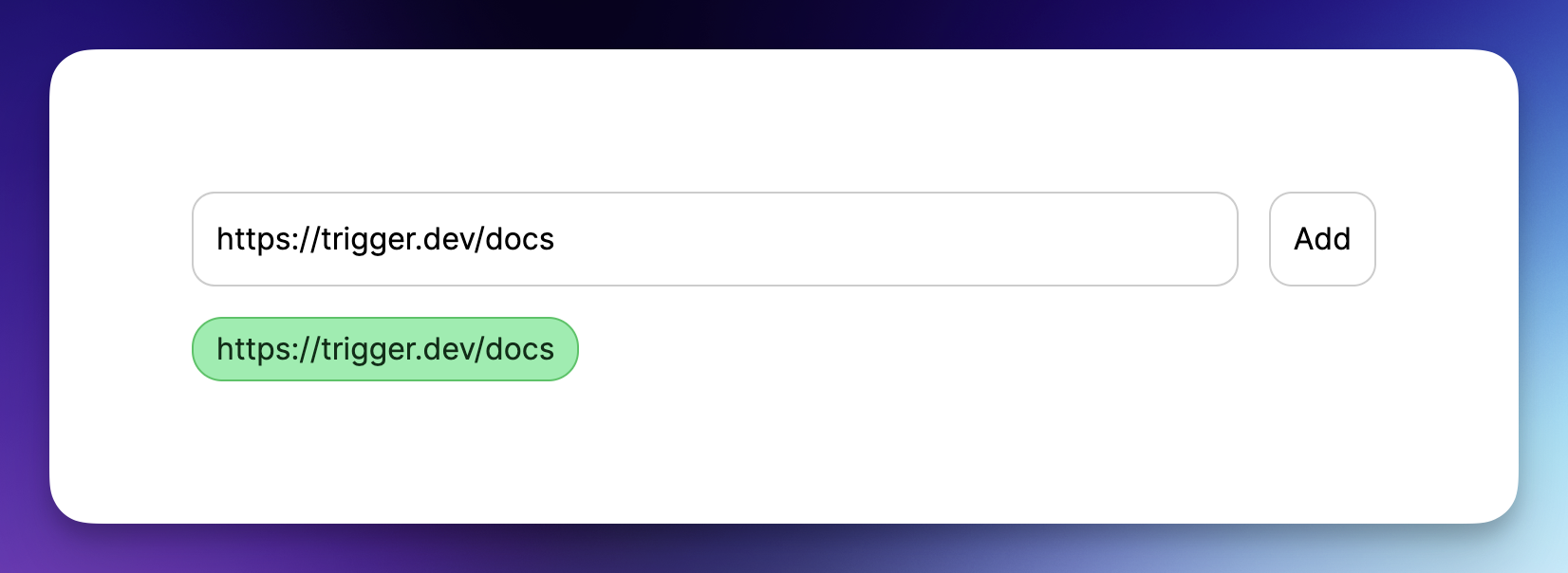
我們將建立一個基本介面來新增 URL 並顯示已新增 URL 的清單:
首頁
將 app/page.tsx 的內容替換為以下程式碼:
import {getList} from "@openai-assistant/helper/get.list";
import Main from "@openai-assistant/components/main";
export default async function Home() {
const list = await getList();
return (
<Main list={list} />
)
}這是一個簡單的程式碼,它從資料庫中取得清單並將其傳遞給我們的 Main 元件。
接下來,讓我們建立“Main”元件。
在「app」內建立一個新資料夾「components」並新增一個名為「main.tsx」的新檔案。 新增以下程式碼:
"use client";
import {Assistant} from '@prisma/client';
import {useCallback, useState} from "react";
import {FieldValues, SubmitHandler, useForm} from "react-hook-form";
import {ChatgptComponent} from "@openai-assistant/components/chatgpt.component";
import {AssistantList} from "@openai-assistant/components/assistant.list";
import {TriggerProvider} from "@trigger.dev/react";
export interface ExtendedAssistant extends Assistant {
pending?: boolean;
eventId?: string;
}
export default function Main({list}: {list: ExtendedAssistant[]}) {
const [assistantState, setAssistantState] = useState(list);
const {register, handleSubmit} = useForm();
const submit: SubmitHandler<FieldValues> = useCallback(async (data) => {
const assistantResponse = await (await fetch('/api/assistant', {
body: JSON.stringify({url: data.url}),
method: 'POST',
headers: {
'Content-Type': 'application/json'
}
})).json();
setAssistantState([...assistantState, {...assistantResponse, url: data.url, pending: true}]);
}, [assistantState])
const changeStatus = useCallback((val: ExtendedAssistant) => async () => {
const assistantResponse = await (await fetch(`/api/assistant?url=${val.url}`, {
method: 'GET',
headers: {
'Content-Type': 'application/json'
}
})).json();
setAssistantState([...assistantState.filter((v) => v.id), assistantResponse]);
}, [assistantState])
return (
<TriggerProvider publicApiKey={process.env.NEXT_PUBLIC_TRIGGER_PUBLIC_API_KEY!}>
<div className="w-full max-w-2xl mx-auto p-6 flex flex-col gap-4">
<form className="flex items-center space-x-4" onSubmit={handleSubmit(submit)}>
<input className="flex-grow p-3 border border-black/20 rounded-xl" placeholder="Add documentation link" type="text" {...register('url', {required: 'true'})} />
<button className="flex-shrink p-3 border border-black/20 rounded-xl" type="submit">
Add
</button>
</form>
<div className="divide-y-2 divide-gray-300 flex gap-2 flex-wrap">
{assistantState.map(val => (
<AssistantList key={val.url} val={val} onFinish={changeStatus(val)} />
))}
</div>
{assistantState.filter(f => !f.pending).length > 0 && <ChatgptComponent list={assistantState} />}
</div>
</TriggerProvider>
)
}讓我們看看這裡發生了什麼:
-
我們建立了一個名為「ExtendedAssistant」的新接口,其中包含兩個參數「pending」和「eventId」。當我們建立一個新的助理時,我們沒有最終的值,我們將只儲存
eventId並監聽作業處理直到完成。 -
我們從伺服器元件取得清單並將其設定為新狀態(以便我們稍後可以修改它)
-
我們新增了「TriggerProvider」來幫助我們監聽事件完成並用資料更新它。
-
我們使用「react-hook-form」建立一個新表單來新增助手。
-
我們新增了一個帶有一個輸入「URL」的表單來提交新的助理進行處理。
-
我們迭代並顯示所有現有的助手。
-
在提交表單時,我們將資訊傳送到先前建立的「路由」以新增助理。
-
事件完成後,我們觸發「changeStatus」以從資料庫載入助手。
-
最後,我們有了 ChatGPT 元件,只有在沒有等待處理的助手時才會顯示(
!f.pending)
讓我們建立 AssistantList 元件。
在「components」內,建立一個新檔案「assistant.list.tsx」並在其中加入以下內容:
"use client";
import {FC, useEffect} from "react";
import {ExtendedAssistant} from "@openai-assistant/components/main";
import {useEventRunDetails} from "@trigger.dev/react";
export const Loading: FC<{eventId: string, onFinish: () => void}> = (props) => {
const {eventId} = props;
const { data, error } = useEventRunDetails(eventId);
useEffect(() => {
if (!data || error) {
return ;
}
if (data.status === 'SUCCESS') {
props.onFinish();
}
}, [data]);
return <div className="pointer bg-yellow-300 border-yellow-500 p-1 px-3 text-yellow-950 border rounded-2xl">Loading</div>
};
export const AssistantList: FC<{val: ExtendedAssistant, onFinish: () => void}> = (props) => {
const {val, onFinish} = props;
if (val.pending) {
return <Loading eventId={val.eventId!} onFinish={onFinish} />
}
return (
<div key={val.url} className="pointer relative bg-green-300 border-green-500 p-1 px-3 text-green-950 border rounded-2xl hover:bg-red-300 hover:border-red-500 hover:text-red-950 before:content-[attr(data-content)]" data-content={val.url} />
)
}我們迭代我們建立的所有助手。如果助手已經建立,我們只顯示名稱。如果沒有,我們渲染<Loading />元件。
載入元件在螢幕上顯示“正在載入”,並長時間輪詢伺服器直到事件完成。
我們使用 Trigger.dev 建立的 useEventRunDetails 函數來了解事件何時完成。
事件完成後,它會觸發「onFinish」函數,用新建立的助手更新我們的客戶端。
聊天介面
現在,讓我們加入 ChatGPT 元件並向我們的助手提問!
-
選擇我們想要使用的助手
-
顯示訊息列表
-
新增我們要傳送的訊息的輸入和提交按鈕。
在「components」內部新增一個名為「chatgpt.component.tsx」的新文件
讓我們繪製 ChatGPT 聊天框:
"use client";
import {FC, useCallback, useEffect, useRef, useState} from "react";
import {ExtendedAssistant} from "@openai-assistant/components/main";
import Markdown from 'react-markdown'
import {useEventRunDetails} from "@trigger.dev/react";
interface Messages {
message?: string
eventId?: string
}
export const ChatgptComponent = ({list}: {list: ExtendedAssistant[]}) => {
const url = useRef<HTMLSelectElement>(null);
const [message, setMessage] = useState('');
const [messagesList, setMessagesList] = useState([] as Messages[]);
const [threadId, setThreadId] = useState<string>('' as string);
const submitForm = useCallback(async (e: any) => {
e.preventDefault();
setMessagesList((messages) => [...messages, {message: `**[ME]** ${message}`}]);
setMessage('');
const messageResponse = await (await fetch('/api/message', {
method: 'POST',
body: JSON.stringify({message, id: url.current?.value, threadId}),
})).json();
if (!threadId) {
setThreadId(messageResponse.threadId);
}
setMessagesList((messages) => [...messages, {eventId: messageResponse.eventId}]);
}, [message, messagesList, url, threadId]);
return (
<div className="border border-black/50 rounded-2xl flex flex-col">
<div className="border-b border-b-black/50 h-[60px] gap-3 px-3 flex items-center">
<div>Assistant:</div>
<div>
<select ref={url} className="border border-black/20 rounded-xl p-2">
{list.filter(f => !f.pending).map(val => (
<option key={val.id} value={val.id}>{val.url}</option>
))}
</select>
</div>
</div>
<div className="flex-1 flex flex-col gap-3 py-3 w-full min-h-[500px] max-h-[1000px] overflow-y-auto overflow-x-hidden messages-list">
{messagesList.map((val, index) => (
<div key={index} className={`flex border-b border-b-black/20 pb-3 px-3`}>
<div className="w-full">
{val.message ? <Markdown>{val.message}</Markdown> : <MessageComponent eventId={val.eventId!} onFinish={setThreadId} />}
</div>
</div>
))}
</div>
<form onSubmit={submitForm}>
<div className="border-t border-t-black/50 h-[60px] gap-3 px-3 flex items-center">
<div className="flex-1">
<input value={message} onChange={(e) => setMessage(e.target.value)} className="read-only:opacity-20 outline-none border border-black/20 rounded-xl p-2 w-full" placeholder="Type your message here" />
</div>
<div>
<button className="border border-black/20 rounded-xl p-2 disabled:opacity-20" disabled={message.length < 3}>Send</button>
</div>
</div>
</form>
</div>
)
}
export const MessageComponent: FC<{eventId: string, onFinish: (threadId: string) => void}> = (props) => {
const {eventId} = props;
const { data, error } = useEventRunDetails(eventId);
useEffect(() => {
if (!data || error) {
return ;
}
if (data.status === 'SUCCESS') {
props.onFinish(data.output.threadId);
}
}, [data]);
if (!data || error || data.status !== 'SUCCESS') {
return (
<div className="flex justify-end items-center pb-3 px-3">
<div className="animate-spin rounded-full h-3 w-3 border-t-2 border-b-2 border-blue-500" />
</div>
}
return <Markdown>{data.output.content}</Markdown>;
};這裡正在發生一些令人興奮的事情:
-
當我們建立新訊息時,我們會自動將其呈現在螢幕上作為「我們的」訊息,但是當我們將其發送到伺服器時,我們需要推送事件 ID,因為我們還沒有訊息。這就是我們使用
{val.message ? <Markdown>{val.message}</Markdown> : <MessageComponent eventId={val.eventId!} onFinish={setThreadId} />} -
我們用「Markdown」元件包裝訊息。如果您還記得,我們在前面的步驟中告訴 ChatGPT 以 MD 格式輸出所有內容,以便我們可以正確渲染它。
-
事件處理完成後,我們會更新線程 ID,以便我們從以下訊息中獲得相同對話的上下文。
我們就完成了🎉

讓我們聯絡吧! 🔌
作為開源開發者,您可以加入我們的社群 做出貢獻並與維護者互動。請隨時造訪我們的 GitHub 儲存庫,貢獻並建立與 Trigger.dev 相關的問題。
本教學的源程式碼可在此處取得:
https://github.com/triggerdotdev/blog/tree/main/openai-assistant
感謝您的閱讀!
原文出處:https://dev.to/triggerdotdev/train-chatgpt-on-your-documentation-1a9g
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式