作為前端開發人員,我們通常專注於建立漂亮的使用者介面。然而,重要的是要記住,美麗也在於內部,像素完美的方法也應該轉化為我們的程式碼組織和結構。在本文中,我們將探討每個前端開發人員都應該了解並在其專案中應用的一些基本軟體工程原理。 1. DRY(不要重複) ------------ DRY 原則強調程式碼可重複使用性和維護的重要性。透過將通用功能提取到可重複使用元件、函數或模組中來避免重複程式碼。透過堅持 DRY 原則,您可以減少程式碼重複,提高可維護性,並使您的程式碼庫更加模組化。 React 鼓勵元件驅動的架構,其中職責被隔離,以便於未來的開發和可擴展性。 我們以一個簡單的電子商務應用程式中的產品頁面為例。我們希望看到待售產品清單。我們可以將頁面分解為更小的、可重複使用的元件。 成分: 1. 產品卡:顯示單一產品及其名稱、價格和描述。 2. 產品清單:顯示產品清單。 ``` // ProductCard.js import React from 'react'; const ProductCard = ({ product }) => { return ( <div> <h2>{product.name}</h2> <p>Price: ${product.price}</p> <p>Description: {product.description}</p> </div> ); }; export default ProductCard; ``` ``` // ProductList.js import React, { useState } from 'react'; import ProductCard from './ProductCard'; const ProductList = () => { const [products, setProducts] = useState([ { id: 1, name: 'Product 1', price: 9.99, description: 'Description 1' }, { id: 2, name: 'Product 2', price: 19.99, description: 'Description 2' }, // ... ]); return ( <div> {products.map((product) => ( <ProductCard key={product.id} product={product} /> ))} </div> ); }; export default ProductList; ``` 在此範例中,我們看到,透過將與產品相關的邏輯分離到`ProductCard`元件中,我們可以在`ProductList`元件的`map`功能中重複使用它,並避免清單頁面中每個產品專案的重複程式碼。 2. SOLID 原則 -------- SOLID 是一個縮寫詞,代表物件導向設計的五個關鍵原則: - **單一**責任原則 (SRP):每個模組或類別應該只有一個更改理由。 - **開放**/封閉原則(OCP):軟體實體應該對擴展開放,對修改關閉。 - **李斯科夫**替換原則(LSP):子類型應該可以替換其基本類型,而不改變程式的正確性。 - **介面**隔離原則 (ISP):不應強迫客戶端依賴他們不使用的介面。 - **依賴**倒置原則(DIP):高層模組不應該依賴低層模組。兩者都應該依賴抽象。 讓我們來看看如何在 React TypeScript 元件中應用里氏替換原則 (LSP): ``` // Vehicle.ts interface Vehicle { drive(): void; name: string; } // Car.ts class Car implements Vehicle { constructor(private name: string) { this.name = name; } drive(): void { console.log(`Driving a ${this.name}`); } } // Motorcycle.ts class Motorcycle implements Vehicle { constructor(private name: string) { this.name = name; } drive(): void { console.log(`Riding a ${this.name}`); } } // App.tsx import React from 'react'; import { Vehicle } from './Vehicle'; import Car from './Car'; import Motorcycle from './Motorcycle'; function VehicleComponent(props: { vehicle: Vehicle }) { props.vehicle.drive(); return <div>Driving a {props.vehicle.name}</div>; } const App = () => { const car = new Car(); const motorcycle = new Motorcycle(); return ( <div> <VehicleComponent vehicle={car} /> <VehicleComponent vehicle={motorcycle} /> </div> ); }; export default App; ``` 在此範例中,我們有一個`Vehicle`接口,它定義了`name`屬性和`drive`方法。然後我們有兩個具體的實作: `Car`和`Motorcycle` ,它們都實作了`Vehicle`介面。 在 App 元件中,我們建立`Car`和`Motorcycle`的實例並將它們傳遞給 VehicleComponent。 `VehicleComponent`對傳入的車輛物件呼叫驅動方法。 LSP 確保我們可以用`Car`或`Motorcycle`代替`Vehicle`接口,而不改變程序的正確性。 `VehicleComponent`可與`Car`和`Motorcycle`實例無縫協作,展示子類型對其基本類型的可替換性。 3. KISS(保持簡單,愚蠢) ---------------- KISS 原則提倡設計和實現的簡單性。編寫易於理解、簡單且能做好一件事的程式碼。避免不必要的複雜性和過度設計,因為從長遠來看,這可能會導致混亂和維護挑戰。 讓我們來看看`Counter`元件的 2 個實作。 ``` // Complex Counter import React, { useState, useEffect } from 'react'; import { debounce } from 'lodash'; const ComplexCounter = () => { const [count, setCount] = useState(0); const [clicked, setClicked] = useState(false); const [error, setError] = useState(null); useEffect(() => { if (clicked) { setCount(prev => prev + 1) setClicked(false) } }, [clicked, setClicked]); const handleClick = (clicked: boolean) => { setClicked(!clicked); }; return ( <div> <p>Count: {count}</p> <button onClick={() => handleClick(clicked)}>Increment</button> </div> ); }; export default ComplexCounter; ``` ``` // Simple Counter import React, { useState } from 'react'; const SimpleCounter = () => { const [count, setCount] = useState(0); const handleClick = () => { setCount(count + 1); }; return ( <div> <p>Count: {count}</p> <button onClick={handleClick}>Increment</button> </div> ); }; export default SimpleCounter; ``` 我們發現`ComplexCounter`實作更難理解和維護,而且更容易出錯。 它引入了一個不必要的`clicked`狀態變數和一個`useEffect`掛鉤。 這是一個如何不實作 React 元件的範例。 4. YAGNI(你不需要它) --------------- YAGNI 提醒我們避免基於推測的未來需求過早加入功能。相反,應專注於正確實現當前所需的功能。當您建立一個非常以用戶為中心的產品時,這一點變得非常重要。最好不要根據您認為用戶可能想要的假設來引入新功能。使用適當的使用者研究框架和原型設計方法。 遵循 YAGNI,您可以防止不必要的複雜性、減少開發時間並維護精簡的程式碼庫。 5. 乾淨的程式碼 --------- 乾淨的程式碼是可讀的、可理解的、可維護的。遵循編碼約定和最佳實踐,使用有意義的變數名稱,並編寫不言自明的程式碼。保持函數和類別小而集中,堅持一致的格式,並努力使程式碼庫清晰。 讓我們來看一個簡單的實用函數,用於出於資料安全目的隱藏部分使用者的私人資訊。 ``` const hashUsersPrivateInformation = (privateInformation: string): string => { // Calculate the length of the private info to determine how many characters to mask const maxLength = privateInformation.length > 4 ? privateInformation.length - 4 : privateInformation.length; // Create a regular expression pattern to match the desired number of characters const regexPattern = `.{1,${maxLength}}`; const regex = new RegExp(regexPattern); return privateInformation.replace(regex, (match) => '*'.repeat(match.length)); }; ``` 我們看到: 1. 函數的名稱是自我描述的 2. 它包含可以幫助其他開發人員的有用註釋。 3. 它有一個可以理解的主要目的。 我們應該以類似的方式建立我們的程式碼。 結論 -- 將這些軟體工程原理融入您的前端開發工作流程中,您可以編寫更高品質的程式碼,改善與團隊成員的協作,並建立強大且可擴展的應用程式。軟體工程不僅僅是編寫程式碼;還涉及編寫程式碼。它是為複雜問題建立可靠、可維護且優雅的解決方案。 --- 原文出處:https://dev.to/gboladetrue/software-engineering-principles-every-frontend-developer-should-know-1ej7
介紹 -- 在當今資料驅動的世界中,有效儲存和管理資訊對於各種規模的企業和組織都至關重要。關聯式資料庫已成為以結構化和可擴展的方式組織和操作資料的強大解決方案。在這篇文章中,我們將探討關聯式資料庫的基礎知識、它們的管理系統以及支援有效資料庫設計的原則。 --- 什麼是資料庫? ------- 資料庫是資料的結構化集合,其組織和儲存方式有利於高效檢索、操作和管理。將其視為數位文件櫃,其中不是實體資料夾和文件,而是整齊排列的表格和記錄,以便於存取。 什麼是關係資料庫? --------- 關聯式資料庫是一種將資料組織成具有行(記錄)和列(欄位)的表(關係)的資料庫。這些表透過關係互連,允許以各種方式存取和組合資料。想像一下電子表格的集合,每個電子表格代表資料的不同方面,但能夠無縫連結和組合它們之間的資訊。 關係型資料庫管理系統 ---------- 關聯式資料庫管理系統 (RDBMS) 是一種軟體應用程式,旨在建立、管理關聯式資料庫並與之互動。它提供了一個用於在資料庫中儲存、檢索和操作資料的結構化框架。 RDBMS 的一些熱門範例包括 MySQL、PostgreSQL、Oracle 和 Microsoft SQL Server。 --- SQL簡介 ----- SQL(結構化查詢語言)是用於與關聯式資料庫互動的標準程式語言。它允許您建立、讀取、更新和刪除資料庫中的資料,以及定義和修改資料庫結構本身。 SQL 就像一種通用語言,可讓您與不同的 RDBMS 平台進行通訊。 命名約定 ---- 在 SQL 中,遵循一致的命名約定對於清晰度和可維護性至關重要。這是一個例子: ``` -- Good naming conventions CREATE TABLE customers ( customer_id INT PRIMARY KEY, first_name VARCHAR(100), last_name VARCHAR(100), email VARCHAR(100) ); ``` 什麼是資料庫設計? --------- 資料庫設計是建立用於儲存和管理資料庫中的資料的高效且有組織的結構的過程。它涉及定義表、列、關係和約束,以確保資料完整性、最小化冗餘並優化效能。正確的資料庫設計是建立健全且可擴展的應用程式的基礎。 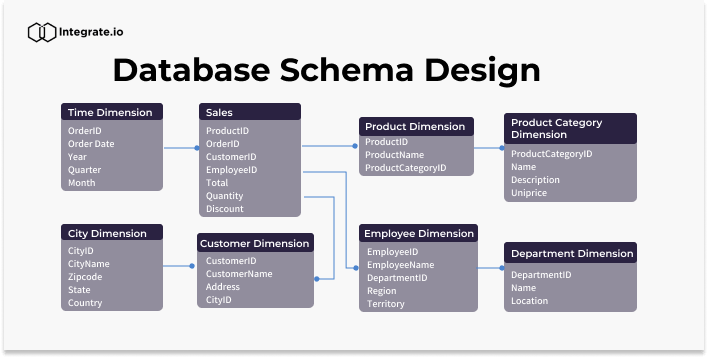 資料的完整性 ------ 資料完整性是指資料庫中儲存的資料的準確性、一致性和可靠性。它確保資料遵循特定的規則和約束,防止錯誤和不一致。資料完整性分為三種: 1. **實體完整性**:確保表中的每一行都可以透過主鍵唯一標識,且主鍵不能有空值。 2. **參照完整性**:透過確保一個表中的外鍵值與另一表中的主鍵值相符來維護表之間的關係。 3. **域完整性**:透過限制可儲存的資料類型、格式和值範圍,強制給定列輸入有效的條目。 ``` -- Example: Enforcing data integrity CREATE TABLE orders ( order_id INT PRIMARY KEY, -- Entity integrity customer_id INT FOREIGN KEY REFERENCES customers(customer_id), -- Referential integrity order_date DATE NOT NULL, -- Domain integrity total_amount DECIMAL(10, 2) CHECK (total_amount >= 0) -- Domain integrity ); ``` 資料庫術語 ----- - **表**:按行和列組織的相關資料的集合。 - **行**:表中的單一實例或條目(也稱為記錄或元組)。 - **列**:表中資料的特定特徵或屬性(也稱為欄位或屬性)。 - **主鍵**:唯一標識表中每一行的列或列組合。 - **外鍵**:引用另一個表的主鍵的列或列的組合,在兩個表之間建立關係。 - **連接**:根據相關列組合兩個或多個表中的行的操作。 - **索引**:一種資料結構,透過建立表格中資料的排序表示來提高資料檢索操作的效能。 - **視圖**:從一個或多個基礎表動態產生的虛擬表。 - **預存程序**:預先編譯的 SQL 語句集合,可以作為單一單元執行。 - **觸發器**:特殊類型的預存程序,當表中發生特定事件(例如 INSERT、UPDATE 或 DELETE 語句)時會自動執行。 原子值 --- 在資料庫設計中,儲存原子值非常重要,這意味著儲存無法進一步劃分的最小資訊片段。這項原則有助於保持資料完整性並避免冗餘。 例如,與其將客戶的全名儲存在單一欄位中,不如將其分成名字和姓氏欄位。這樣,您可以輕鬆地獨立搜尋、排序或操作名稱的每個部分。 ``` -- Example: Storing atomic values CREATE TABLE customers ( customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100) ); ``` --- 按鍵簡介 ---- 鍵是資料庫設計中的重要組成部分,有助於確保資料完整性並建立表之間的關係。它們充當記錄的唯一標識符,並實現高效的資料檢索和操作。 主鍵索引 ---- 主鍵是唯一標識表中每筆記錄的列或列的組合。它確保每個記錄都是唯一的並且可以輕鬆找到。通常會對主鍵建立索引以提高查詢效能。 ``` CREATE TABLE customers ( customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100) ); ``` 查找表 --- 查找表也稱為參考表或程式碼表,是包含預定義值集的表,這些值可用於填入其他表中的列。查找表透過確保一致性和減少冗餘來幫助維護資料完整性。 ``` -- Lookup table for product categories CREATE TABLE product_categories ( category_id INT PRIMARY KEY, category_name VARCHAR(100) ); -- Products table referencing the lookup table CREATE TABLE products ( product_id INT PRIMARY KEY, product_name VARCHAR(100), category_id INT, FOREIGN KEY (category_id) REFERENCES product_categories(category_id) ); ``` 超級密鑰和候選密鑰 --------- 超級鍵是表中唯一標識每筆記錄的一組或多列。候選鍵是最小超鍵,這意味著它不包含不必要的列。換句話說,候選鍵是一個超級鍵,具有唯一標識每個記錄所需的最少列數。 主鍵和備用鍵 ------ 主鍵是選擇作為表的主要唯一辨識符的候選鍵。備用鍵也稱為唯一鍵,是任何其他本來可以被選為主鍵但沒有被選為主鍵的候選鍵。 ``` CREATE TABLE employees ( employee_id INT PRIMARY KEY, email VARCHAR(100) UNIQUE, -- Alternate key first_name VARCHAR(50), last_name VARCHAR(50) ); ``` 代理鍵和自然鍵 ------- 代理鍵是用作表中主鍵的人工鍵(通常是序號或 GUID)。它與資料本身沒有固有的意義或關係。另一方面,自然金鑰是從資料本身衍生的金鑰,例如員工 ID 或產品程式碼。 ``` -- Surrogate key CREATE TABLE orders ( order_id INT PRIMARY KEY IDENTITY(1,1), -- Surrogate key customer_name VARCHAR(100), order_date DATE ); -- Natural key CREATE TABLE products ( product_code VARCHAR(10) PRIMARY KEY, -- Natural key product_name VARCHAR(100), price DECIMAL(10,2) ); ``` 我應該使用代理鍵還是自然鍵? -------------- 代理鍵和自然鍵之間的選擇取決於多個因素,包括資料的性質、資料變更的可能性以及重複或衝突的可能性。 代理鍵通常是首選,因為它們是: - 不可變:即使資料發生變化,它們也不會隨著時間而改變。 - 保證唯一性:由資料庫系統生成,保證唯一性。 - 不透明:它們不會洩露有關資料本身的任何訊息,這對於安全和隱私來說是有益的。 另一方面,自然鍵在以下情況下可能會很有優勢: - 資料具有固有的唯一性,例如產品程式碼或員工 ID。 - 資料不太可能隨著時間的推移而改變,從而降低了衝突或重複的風險。 - 需要人類可讀且有意義的辨識符。 外鍵 -- 外鍵是一個表中引用另一個表的主鍵的列或列的組合。它在兩個表之間建立連結並強制引用完整性,確保子表中的資料有效且與父表中的資料一致。 ``` CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, order_date DATE, FOREIGN KEY (customer_id) REFERENCES customers(customer_id) ); ``` NOT NULL 外鍵 ----------- 在某些情況下,可能需要對外鍵列設定 NOT NULL 約束,這表示該列不能有空值。此約束可確保子表中的每筆記錄都與父表中的有效記錄相關聯。 ``` CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT NOT NULL, order_date DATE, FOREIGN KEY (customer_id) REFERENCES customers(customer_id) ); ``` 外鍵約束 ---- 外鍵約束定義表之間引用完整性的規則。這些約束可以包括更新或刪除父表中引用的記錄時要採取的操作,例如: - `CASCADE` :當父表中的記錄被更新或刪除時,子表中對應的記錄也會被更新或刪除。 - `SET NULL` :當父表中的記錄被更新或刪除時,子表中對應的外鍵值被設定為NULL。 - `NO ACTION` :當父表中的記錄被更新或刪除時,子表中對應的外鍵值保持不變,如果違反引用完整性則回滾操作。 ``` CREATE TABLE orders ( order_id INT PRIMARY KEY, customer_id INT, order_date DATE, FOREIGN KEY (customer_id) REFERENCES customers(customer_id) ON UPDATE CASCADE ON DELETE SET NULL ); ``` 簡單鍵、複合鍵、複合鍵 ----------- - 簡單鍵是用作主鍵或外鍵的單一欄位。 - 複合鍵是用作主鍵或外鍵的兩個或多個列的組合。 - 複合鍵是用作外鍵的兩個或多個簡單鍵的組合。 ``` -- Simple key CREATE TABLE orders ( order_id INT PRIMARY KEY, ... ); -- Composite key CREATE TABLE order_items ( order_id INT, product_id INT, quantity INT, PRIMARY KEY (order_id, product_id) ); -- Compound key CREATE TABLE shipments ( shipment_id INT PRIMARY KEY, order_id INT, product_id INT, FOREIGN KEY (order_id, product_id) REFERENCES order_items(order_id, product_id) ); ``` --- 關係 ---- 關係是關聯式資料庫的基石,可讓您連接和組合來自不同表的資料。關係主要分為三種:  一對一的關係 ------ 在一對一關係中,一個表中的每筆記錄都與另一個表中的一筆記錄相關聯,反之亦然。例如,考慮一個資料庫,其中每位員工都有一名且僅有一名經理,且每位經理管理一名且僅有一名員工。這種關係在實務上比較少見。 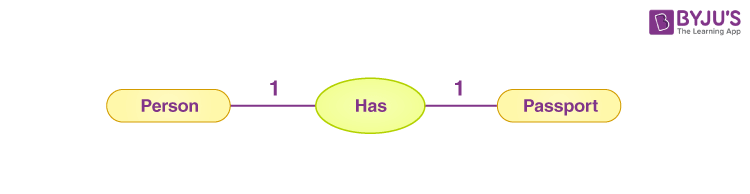 一對多關係 ----- 在一對多關係中,一個表格(「一」側)中的每筆記錄都可以與另一個表(「多」側)中的多個記錄關聯。例如,在學校的資料庫中,一位老師可以教授多個班級,但每個班級只有一位老師授課。 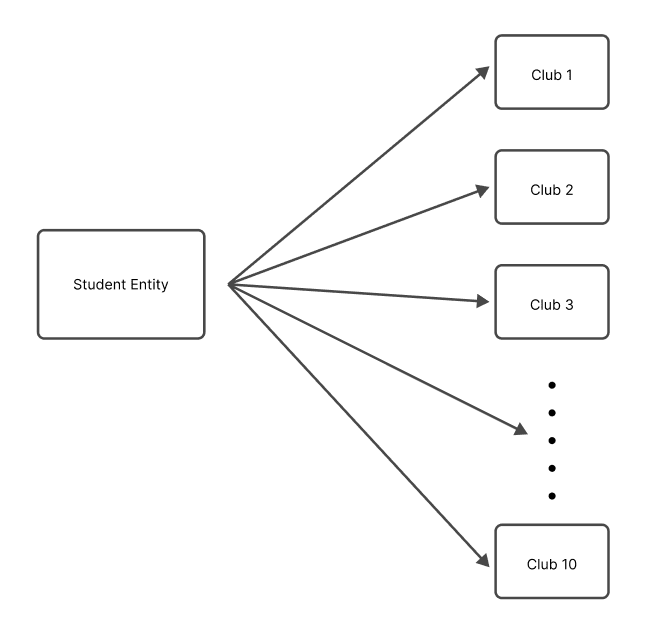 多對多關係 ----- 在多對多關係中,一個表中的每筆記錄可以與另一表中的多筆記錄關聯,反之亦然。例如,在大學的資料庫中,一個學生可以註冊多個課程,每個課程可以有多個學生註冊。 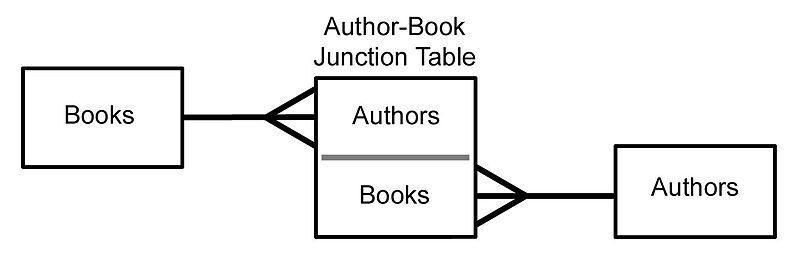 ### 關係摘要 - 一對一:表A中的一筆記錄與表B中的一筆且只有一筆記錄相關,反之亦然。 - 一對多:A表中的一筆記錄可以與B表中的多筆記錄相關,但B表中的一筆記錄只能與A表中的一筆記錄相關。 - 多對多:表A中的多筆記錄可以與表B中的多筆記錄相關,反之亦然。 設計關係(SQL 實作) ------------ **1 - 設計一對一關係** 要設計一對一關係,您可以將兩個表中的所有列包含在一個表中,也可以建立兩個單獨的表並使用外鍵約束來連結它們。 ``` -- Option 1: Single table CREATE TABLE employees ( employee_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), manager_first_name VARCHAR(50), manager_last_name VARCHAR(50) ); -- Option 2: Two tables with foreign key CREATE TABLE employees ( employee_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), manager_id INT UNIQUE, FOREIGN KEY (manager_id) REFERENCES employees(employee_id) ); ``` 2 -**設計一對多關係** 要設計一對多關係,通常會建立兩個表:父表(“一”側)和子表(“多”側)。子表包含引用父表主鍵的外鍵列。 ``` -- Parent table CREATE TABLE teachers ( teacher_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50) ); -- Child table CREATE TABLE classes ( class_id INT PRIMARY KEY, class_name VARCHAR(100), teacher_id INT, FOREIGN KEY (teacher_id) REFERENCES teachers(teacher_id) ); ``` **3 - 設計多對多關係** 要設計多對多關係,通常會建立第三個表(稱為聯結表或關聯表),將兩個主表連結在一起。此聯結表包括引用主表的外鍵列 ``` -- Table 1 CREATE TABLE students ( student_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50) ); -- Table 2 CREATE TABLE courses ( course_id INT PRIMARY KEY, course_name VARCHAR(100), description TEXT ); -- Junction or Intemediary table CREATE TABLE enrollments ( enrollment_id INT PRIMARY KEY, student_id INT, course_id INT, FOREIGN KEY (student_id) REFERENCES students(student_id), FOREIGN KEY (course_id) REFERENCES courses(course_id) ); ``` 父表和子表 ----- 在一對多或多對多關係中, **“一”**側的表通常稱為父表,而**“多”**側的表稱為子表。子表包含引用父表主鍵的外鍵。 例如,在教師-班級關係中, `teachers`表是父表, `classes`表是子表。同樣,在學生-課程關係中, `students`和`courses`表是父表,而`enrollm`是父表。 實體關係建模簡介 -------- 實體關係建模(ER Modeling)是資料庫設計中使用的一種技術,用於直觀地表示資料庫的邏輯結構。它有助於辨識實體(表)、屬性(列)以及它們之間的關係,從而更容易理解和傳達資料庫設計。 ER 圖由以下部分組成: - **實體**:以矩形表示,實體是資料庫中的表或物件。 - **屬性**:在實體矩形內列出,屬性是描述實體的列或欄位。 - **關係**:以連接實體的線表示,關係描述了實體之間的關聯。 基數 -- 基數定義了兩個實體之間的數值關係。它指定一個實體可以與另一個實體的單一實例關聯的最大實例數。最常見的基數是: - 一對一(1:1):實體 A 的一個實例最多可以與實體 B 的一個實例關聯,反之亦然。 - 一對多(1:N):實體 A 的一個實例可以與實體 B 的多個實例關聯,但實體 B 的一個實例只能與實體 A 的一個實例關聯。 - 多對多 (M:N):實體 A 的多個實例可以與實體 B 的多個實例關聯,反之亦然。 在 ER 圖中,基數以特定的符號表示,例如單線表示一對一,帶箭頭的線表示一對多,兩端帶箭頭的線表示多對多關係。 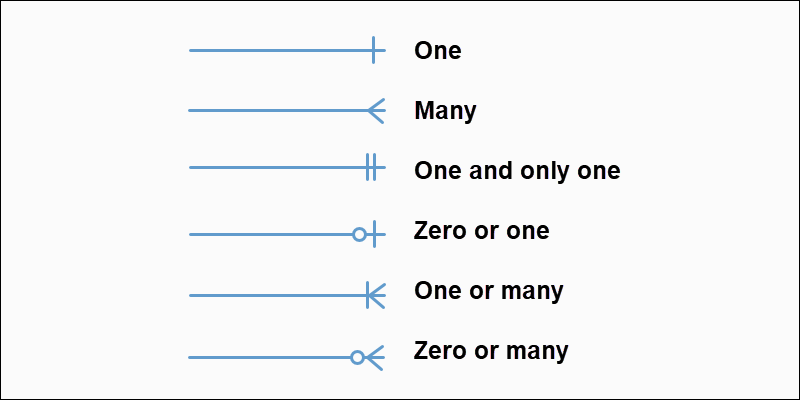 模態 -- 模態是指一個實體實例的存在是否依賴它與另一個實體的關係。有兩種類型的模態: - 部分模態:實例的存在不依賴它與另一個實體的關係。例如,客戶可以在沒有任何訂單的情況下存在。 - 總模態:實例的存在取決於它與另一個實體的關係。例如,沒有訂單,訂單項就不可能存在。 在 ER 圖中,模態使用特定的符號表示,例如單一條表示部分模態,雙條表示總模態。 --- 資料庫規範化簡介 -------- 資料庫規範化是組織資料庫中的資料以減少冗餘、最大限度地減少資料異常(插入、更新和刪除異常)並提高資料完整性的過程。它涉及將資料庫分解為較小的表,並根據特定規則或範式定義它們之間的關係。 資料庫規範化的主要目標是: - 消除冗餘資料 - 確保資料完整性 - 促進資料操作和維護 資料庫規範化有多種範式,每種都建立在前一種範式的基礎上。最常用的範式是: 1. 第一範式 (1NF) 2. 第二範式 (2NF) 3. 第三範式 (3NF) 1NF(資料庫規範化第一範式) --------------- 第一範式(1NF)是最基本的規範化形式。它規定表中的屬性(列)必須具有原子值,這意味著表中的每個單元格應包含單一值,而不是一組值。 例如,假設一個表格具有名為「PhoneNumbers」的資料列,該資料列儲存客戶的多個電話號碼。這違反了 1NF,因為該列包含一組值而不是單一值。為了符合 1NF,您需要將電話號碼分成單獨的列或為電話號碼建立單獨的表。 ``` -- Violates 1NF CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(100), phone_numbers VARCHAR(200) -- Stores multiple phone numbers, violating 1NF ); -- Conforms to 1NF CREATE TABLE customers ( customer_id INT PRIMARY KEY, name VARCHAR(100), phone1 VARCHAR(20), phone2 VARCHAR(20), phone3 VARCHAR(20) ); ``` 2NF(資料庫規範化的第二範式) ---------------- 第二範式 (2NF) 建立在 1NF 的基礎上,解決了部分依賴問題。如果表屬於 1NF,且每個非主屬性(列)完全依賴整個主鍵,則該表屬於 2NF。 換句話說,如果一個表有一個複合主鍵(由多個列組成),那麼所有非鍵列必須依賴整個主鍵,而不僅僅是它的一部分。 例如,考慮一個具有複合主鍵`(student_id, course_id)`和列`grade`的表。如果`grade`欄位僅取決於`course_id` ,而不取決於`student_id`和`course_id`的組合,則該表違反了 2NF。 ``` -- Violates 2NF CREATE TABLE student_courses ( student_id INT, course_id INT, course_name VARCHAR(100), grade CHAR(2), -- Depends only on course_id, not the entire primary key PRIMARY KEY (student_id, course_id) ); -- Conforms to 2NF CREATE TABLE student_courses ( student_id INT, course_id INT, grade CHAR(2), PRIMARY KEY (student_id, course_id) ); CREATE TABLE courses ( course_id INT PRIMARY KEY, course_name VARCHAR(100) ); ``` 3NF(資料庫規範化的第三範式) ---------------- 第三範式 (3NF) 建立在 2NF 的基礎上,解決了傳遞依賴問題。如果表屬於 2NF,且每個非主屬性都非傳遞依賴於主鍵,則該表屬於 3NF。 換句話說,如果一個非鍵列依賴另一個非鍵列,那麼該表就違反了 3NF,並且非鍵列應該分離到它們自己的表中。 例如,考慮一個包含`student_id` 、 `student_name` 、 `class_id`和`class_name`欄位的表。 `student_name`欄位取決於`student_id` ,而`class_name`欄位取決於`class_id` 。但是, `class_name`欄位也透過`class_id`欄位傳遞依賴`student_id` 。這違反了 3NF。 ``` -- Violates 3NF CREATE TABLE student_classes ( student_id INT, student_name VARCHAR(100), class_id INT, class_name VARCHAR(100), PRIMARY KEY (student_id, class_id) ); -- Conforms to 3NF CREATE TABLE students ( student_id INT PRIMARY KEY, student_name VARCHAR(100) ); CREATE TABLE classes ( class_id INT PRIMARY KEY, class_name VARCHAR(100) ); CREATE TABLE student_classes ( student_id INT, class_id INT, PRIMARY KEY (student_id, class_id), FOREIGN KEY (student_id) REFERENCES students(student_id), FOREIGN KEY (class_id) REFERENCES classes(class_id) ); ``` 透過遵循資料庫規範化的原則,您可以建立結構良好且高效的資料庫,從而最大限度地減少冗餘、保持資料完整性並促進資料操作和維護。 --- 索引(聚集索引、非聚集索引、複合索引) ------------------- 索引是提高資料庫中資料檢索操作效能的資料結構。它們在表中建立資料的排序表示,從而允許更快的搜尋和查詢。索引有幾種類型: - **聚集索引**:聚集索引根據索引鍵值對表中的行進行實體重新排序。每個表只能有一個聚集索引。 - **非聚集索引**:非聚集索引是一個單獨的物件,其中包含索引鍵值和指向表中相應行的指標。一個表可以有多個非聚集索引。 - **複合索引**:複合索引是索引鍵中包含多個欄位的索引。它可以是集群的,也可以是非集群的。 ``` -- Clustered index CREATE CLUSTERED INDEX idx_customers_name ON customers (last_name, first_name); -- Nonclustered index CREATE NONCLUSTERED INDEX idx_orders_date ON orders (order_date); -- Composite index CREATE INDEX idx_products_category_price ON products (category_id, price); ``` 資料類型 ---- 在資料庫領域,資料類型就像是保存特定類型資訊的不同形狀的容器。就像您不會將液體儲存在籃子中或將固體物體儲存在罐子中一樣,資料庫需要強制執行特定的資料類型以確保資料的完整性和一致性。 SQL 中的一些常見資料類型包括: - `INT`或`INTEGER` :儲存整數,例如`42`或`17` 。 - `FLOAT`或`DOUBLE` :儲存十進制數,例如`3.14159`或`0.00005` 。 - `VARCHAR`或`TEXT` :儲存文字資料,例如名稱或描述。 - `DATE`或`DATETIME` :儲存日期和時間值,例如`'2023-05-06'`或`'2024-01-01 12:34:56'` 。 - `BOOLEAN` :儲存真/假值,例如`1` (真)或`0` (假)。 選擇正確的資料類型至關重要,因為它會影響資料的儲存、查詢和操作方式。例如,嘗試在`INT`列中儲存大字串會導致錯誤或資料截斷。 ``` CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(50) NOT NULL, age INT, is_active BOOLEAN DEFAULT 1 ); ``` 在此範例中,我們建立一個`users`表,其中包含`id` (整數)、 `name` (最多 50 個字元的字串)、 `age` (整數)和`is_active` (布林值,預設值為`1`或 true)欄位。 --- 連接簡介 ---- 連接就像連接資料庫中不同表的橋樑,允許您組合和檢索來自多個來源的相關資料。它們是關係資料庫中的基本概念,對於有效查詢和操作資料至關重要。 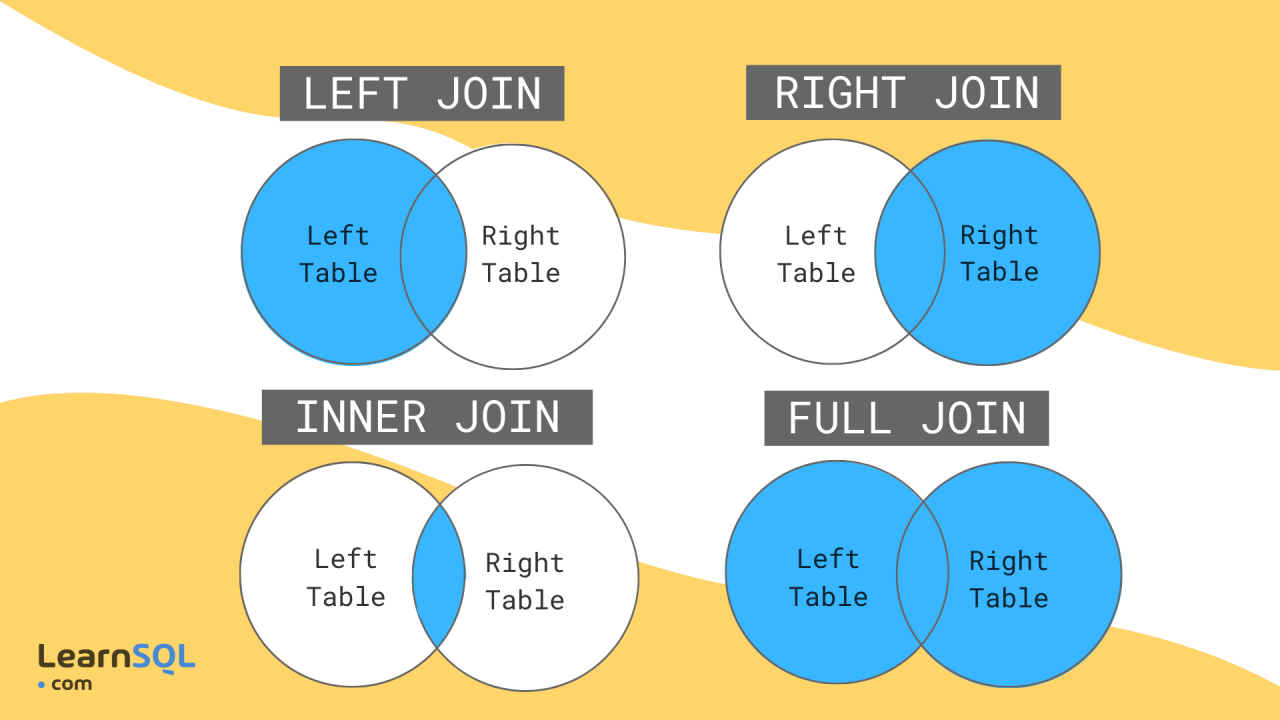 內部聯接 ---- 內部聯結就像兩個表之間的友好握手,其中只有在兩個表中具有匹配值的行才會包含在結果集中。這是一種基於公共列或列集組合多個表中的資料的方法。 ``` SELECT users.name, orders.order_date FROM users INNER JOIN orders ON users.id = orders.user_id; ``` 在這個範例中,我們從`users`表中檢索`name`列,從`orders`表中檢索`order_date`列,但僅限於`users`表中的`id`與`orders`表中的`user_id`相符的行。 3 個表上的內連接(範例) ------------- 假設我們有三個表: `users` 、 `orders`和`products` 。我們想要檢索每個訂單的使用者名稱、訂單日期和產品名稱。我們可以透過在所有三個表之間執行內部聯結來實現這一點: ``` SELECT users.name, orders.order_date, products.product_name FROM users INNER JOIN orders ON users.id = orders.user_id INNER JOIN products ON orders.product_id = products.id; ``` 在這裡,我們首先在`id`和`user_id`列上連接`users`和`orders`表。然後,我們將該連接的結果與`products`表的`product_id`和`id`列連接起來。這樣,我們可以在單一查詢中從所有三個表中檢索資料,但僅限於滿足連接條件的行。 外連接簡介 ----- 內部連接就像友好的握手,而外部連接更像是歡迎的擁抱。它們不僅包括兩個表中的匹配行,還包括一個或兩個表中的不匹配行,具體取決於外連接的類型。 右外連接 ---- 右外連接就像從右表到左表的溫暖擁抱。它包括右表中的所有行以及左表中的匹配行。如果左表中沒有符合的行,則結果將包含左表列的`NULL`值。 ``` SELECT users.name, orders.order_date FROM users RIGHT OUTER JOIN orders ON users.id = orders.user_id; ``` 在此範例中,我們從`orders`表(右表)中檢索所有行,以及`users`表(左表)中的符合`name`值。如果訂單沒有符合的用戶,則`name`列將包含`NULL` 。 JOIN 與 NOT NULL 列 ----------------- 有時,您可能只想對不為空的列執行聯接。當您想要從結果集中排除缺少資料的行時,這會很有用。 ``` SELECT users.name, orders.order_date FROM users INNER JOIN orders ON users.id = orders.user_id AND users.name IS NOT NULL; ``` 在此範例中,我們在`users`和`orders`表之間執行內部聯接,但我們新增了一個附加條件`users.name IS NOT NULL`以確保結果集中僅包含具有非空`name`值的行。 跨 3 個表的外連接 ---------- 與內連接範例類似,我們可以跨多個表執行外連接。假設我們想要檢索所有訂單以及使用者名稱和產品名稱,即使`users`或`products`表中缺少值。 ``` SELECT users.name, orders.order_date, products.product_name FROM orders LEFT OUTER JOIN users ON orders.user_id = users.id LEFT OUTER JOIN products ON orders.product_id = products.id; ``` 在這裡,我們從`orders`表開始,並對`users`和`products`表執行左外連接。這可確保所有訂單以及符合的使用者名稱和產品名稱(如果可用)都包含在結果集中。如果`users`或`products`表中沒有符合的行,則對應的列將包含`NULL`值。 別名 -- 別名就像 SQL 查詢中表格或欄位的暱稱。它們可以使查詢更具可讀性和更容易理解,特別是在處理長表或列名時,或在查詢中多次引用同一個表時。 ``` SELECT u.name, o.order_date, p.product_name FROM users u INNER JOIN orders o ON u.id = o.user_id INNER JOIN products p ON o.product_id = p.id; ``` 在此範例中,我們對`users`表使用別名`u` ,對`orders`表使用別名`o` ,對`products`表使用`p` 。這使得查詢更加簡潔且更易於閱讀,而不必多次重複完整的表名稱。 自加入 --- 自連結就像一張表在與自己對話。這是一種根據同一個表中的特定條件或關係將表與其自身連接的方法。這在處理分層或遞歸資料結構(例如員工-經理關係或巢狀類別)時非常有用。 ``` SELECT e.name AS employee, m.name AS manager FROM employees e LEFT OUTER JOIN employees m ON e.manager_id = m.id; ``` 在此範例中,我們對`employees`表執行自聯接以檢索每位員工的姓名及其對應經理的姓名。我們使用左外連接來確保所有員工都包含在結果集中,即使他們沒有指派經理。 --- 資料庫標記語言 (DBML) -------------- 資料庫建模語言(DBML)是一種簡單直觀的標記語言,用於描述關係型資料庫的結構。它提供了一種人類可讀的方式來定義表、列、關係和約束,從而使資料庫設計方面的溝通和協作變得輕鬆。 **DBML 入門** 要開始使用 DBML,您需要一個文字編輯器並對資料庫概念有基本的了解。讓我們建立第一個 DBML 檔案: ``` // my_database.dbml Table users { id int [pk, increment] username varchar email varchar [unique] created_at datetime [default: `now()`] } ``` 在這個範例中,我們定義了一個`users`表,其中包含`id` 、 `username` 、 `email`和`created_at`列。 `[pk]`標記指定`id`為主鍵, `[increment]`表示自動遞增, `[unique]`確保`email`的唯一性, `[default:` now() `]`將`created_at`的預設值設為目前時間戳記。 **建立表** DBML 可讓您在單一檔案中定義多個表格及其列。讓我們為資料庫新增更多表: ``` // my_database.dbml Table users { id int [pk, increment] username varchar email varchar [unique] created_at datetime [default: `now()`] } Table posts { id int [pk, increment] title varchar content text user_id int [ref: > users.id] created_at datetime [default: `now()`] } ``` 在這個範例中,我們新增了一個`posts`表,其中包含`id` 、 `title` 、 `content` 、 `user_id`和`created_at`欄位。 `[ref: > users.id]`標籤在`posts`表中的`user_id`欄位和`users`表中的`id`列之間建立外鍵關係。 **定義關係** DBML 支援表之間各種類型的關係,包括一對一、一對多和多對多。讓我們在資料庫中定義一些關係: ``` // my_database.dbml Table users { id int [pk, increment] username varchar email varchar [unique] created_at datetime [default: `now()`] } Table posts { id int [pk, increment] title varchar content text user_id int [ref: > users.id] created_at datetime [default: `now()`] } Ref: users.id < posts.user_id ``` 在此範例中,我們定義了`users`和`posts`表之間的一對多關係。 `Ref: users.id < posts.user_id`行指定`users`表中的`user_id`欄位引用`posts`表中的`id`列。 **新增約束** 約束確保資料完整性並在資料庫上強制執行規則。 DBML 支援各種約束,例如主鍵、外鍵、唯一約束和預設值。讓我們在表格中加入一些約束: ``` // my_database.dbml Table users { id int [pk, increment] username varchar [unique] email varchar [unique] created_at datetime [default: `now()`] } Table posts { id int [pk, increment] title varchar content text user_id int [ref: > users.id] created_at datetime [default: `now()`] } Ref: users.id < posts.user_id ``` 在此更新的範例中,我們為`users`表中的`username`名列新增了`[unique]`約束,以確保每個使用者名稱都是唯一的。 **記錄您的資料庫** DBML 可讓您為資料庫模式新增註解和註釋,使其更易於理解和維護。讓我們用註釋來記錄我們的表格: ``` // my_database.dbml Table users { id int [pk, increment] // Unique identifier for users username varchar [unique] // User's username email varchar [unique] // User's email address created_at datetime [default: `now()`] // Date and time when the user was created } Table posts { id int [pk, increment] // Unique identifier for posts title varchar // Title of the post content text // Content of the post user_id int [ref: > users.id] // ID of the user who created the post created_at datetime [default: `now()`] // Date and time when the post was created } Ref: users.id < posts.user_id // Relationship between users and posts ``` **DBML 的好處** - 簡單且人類可讀的語法 - 與資料庫無關的方法 - [dbdiagram.io](dbdiagram.io)上的免費視覺化工具 - 一致的可讀性和可維護性約定 - 豐富的文件和範例 --- 結論 -- 總而言之,關聯式資料庫設計構成了現代應用程式中高效能資料組織的支柱。了解其原理使您能夠建立強大且可擴展的資料庫。接下來,我們將深入研究 SQL 語法,釋放與資料庫有效互動的能力。請繼續關注我們對 SQL 世界的探索! --- 原文出處:https://dev.to/louaiboumediene/mastering-relational-database-design-a-comprehensive-guide-3jh8
你好呀!你最近怎麼樣?你沒事吧?但願如此! 今天我要談一個每個人都在談論或寫到的主題。但有時要理解每一個原則是很困難的。我說的是固體。 當我問及 SOLID 時,很多人可能總是記得第一個原則(單一職責原則)。但當我問起另一個人時,有些人不記得了,或覺得很難解釋。我明白了。 確實,如果不編碼或重新修改每個原則的定義,就很難解釋。但在本文中,我想以簡單的方式介紹每個原則。所以我會用Typescript來舉例。 那麼就讓我們開始吧! 單一職責原則 - SRP ------------ 更容易理解和記住的原則。 當我們編碼時,很容易發現我們何時忘記了原則。 假設我們有一個 TaskManager 類別: ``` class TaskManager { constructor() {} connectAPI(): void {} createTask(): void { console.log("Create Task"); } updateTask(): void { console.log("Update Task"); } removeTask(): void { console.log("Remove Task"); } sendNotification(): void { console.log("Send Notification"); } sendReport(): void { console.log("Send Report"); } } ``` 好的!也許你注意到你的問題了,不是嗎? TaskManager 類別有很多不屬於她的職責。例如:sendNotification 和 sendReport 方法。 現在,讓我們重構並應用該解決方案: ``` class APIConnector { constructor() {} connectAPI(): void {} } class Report { constructor() {} sendReport(): void { console.log("Send Report"); } } class Notificator { constructor() {} sendNotification(): void { console.log("Send Notification"); } } class TaskManager { constructor() {} createTask(): void { console.log("Create Task"); } updateTask(): void { console.log("Update Task"); } removeTask(): void { console.log("Remove Task"); } } ``` 很簡單,不是嗎?我們只是將通知和報告分離到指定的類別中。現在我們尊重單一原則責任! 定義: `Each class must have one, and only one, reason to change` 。 開閉原則-OCP -------- 第二個原則。另外,我認為很容易理解。給您一個提示,如果您發現在某種方法中需要滿足很多條件來驗證某些內容,那麼您可能遇到了 OCP。 讓我們想像一下下面的考試類別範例: ``` type ExamType = { type: "BLOOD" | "XRay"; }; class ExamApprove { constructor() {} approveRequestExam(exam: ExamType): void { if (exam.type === "BLOOD") { if (this.verifyConditionsBlood(exam)) { console.log("Blood Exam Approved"); } } else if (exam.type === "XRay") { if (this.verifyConditionsXRay(exam)) { console.log("XRay Exam Approved!"); } } } verifyConditionsBlood(exam: ExamType): boolean { return true; } verifyConditionsXRay(exam: ExamType): boolean { return false; } } ``` 是的,您可能已經多次看到這段程式碼了。首先,我們打破了SRP的第一原則,並提出了許多條件。 現在想像一下如果出現另一種類型的檢查,例如超音波。我們需要加入另一個方法來驗證和另一個條件。 讓我們重構一下這段程式碼: ``` type ExamType = { type: "BLOOD" | "XRay"; }; interface ExamApprove { approveRequestExam(exam: NewExamType): void; verifyConditionExam(exam: NewExamType): boolean; } class BloodExamApprove implements ExamApprove { approveRequestExam(exam: ExamApprove): void { if (this.verifyConditionExam(exam)) { console.log("Blood Exam Approved"); } } verifyConditionExam(exam: ExamApprove): boolean { return true; } } class RayXExamApprove implements ExamApprove { approveRequestExam(exam: ExamApprove): void { if (this.verifyConditionExam(exam)) { console.log("RayX Exam Approved"); } } verifyConditionExam(exam: NewExamType): boolean { return true; } } ``` 哇,好多了!現在,如果出現另一種類型的檢查,我們只需實作`ExamApprove`介面。如果出現另一種類型的考試驗證,我們只更新介面。 定義: `Software entities (such as classes and methods) must be open for extension but closed for modification` 里氏替換原理 - LSP ------------ 理解和解釋比較複雜的一種。但我怎麼說,我會讓你更容易理解。 想像一下,您有一所大學和兩種類型的學生。學生和研究生。 ``` class Student { constructor(public name: string) {} study(): void { console.log(`${this.name} is studying`); } deliverTCC() { /** Problem: Post graduate Students don't delivery TCC */ } } class PostgraduateStudent extends Student { study(): void { console.log(`${this.name} is studying and searching`); } } ``` 我們這裡有一個問題,我們正在延長學生的時間,但研究生不需要提供 TCC。他只是研究和尋找。 我們要怎麼解決這個問題呢?簡單的!讓我們建立一個學生類,並將畢業學生和畢業後學生分開: ``` class Student { constructor(public name: string) {} study(): void { console.log(`${this.name} is studying`); } } class StudentGraduation extends Student { study(): void { console.log(`${this.name} is studying`); } deliverTCC() {} } class StudentPosGraduation extends Student { study(): void { console.log(`${this.name} is studying and searching`); } } ``` 現在我們有更好的方法來分離他們各自的職責。這個原理的名字可能很可怕,但它的原理很簡單。 定義: `Derived classes (or child classes) must be able to replace their base classes (or parent classes)` 介面隔離原則-ISP ---------- 要理解這個原理,訣竅是記住定義。不應強迫類別實作不會使用的方法。 因此,假設您有一個類別實作了一個從未使用過的介面。 讓我們想像一下某個商店的賣家和接待員的場景。賣家和接待員都有薪水,但只有賣家有佣金。 讓我們看看問題: ``` interface Employee { salary(): number; generateCommission(): void; } class Seller implements Employee { salary(): number { return 1000; } generateCommission(): void { console.log("Generating Commission"); } } class Receptionist implements Employee { salary(): number { return 1000; } generateCommission(): void { /** Problem: Receptionist don't have commission */ } } ``` 兩者都實現了 Employee 接口,但接待員沒有佣金。所以我們被迫實施一種永遠不會被使用的方法。 所以解決方法: ``` interface Employee { salary(): number; } interface Commissionable { generateCommission(): void; } class Seller implements Employee, Commissionable { salary(): number { return 1000; } generateCommission(): void { console.log("Generating Commission"); } } class Receptionist implements Employee { salary(): number { return 1000; } } ``` 輕鬆輕鬆!現在我們有兩個介面了!雇主類別和佣金介面。現在只有賣方將實現將獲得佣金的兩個介面。接待員不僅負責員工的工作。因此,接待員不必被迫實施永遠不會使用的方法。 定義: `A class should not be forced to implement interfaces and methods that will not be used.` 依賴倒置原則—DIP ---------- 最後一個!光看名字就會覺得很難記!但也許你每次都已經看到這個原則了。 想像一下,您有一個 Service 類,它與一個將呼叫資料庫的 Repository 類別集成,例如 Postgress。但是,例如,如果 MongoDB 的儲存庫類別發生變化並且資料庫發生變化。 讓我們來看看例子: ``` interface Order { id: number; name: string; } class OrderRepository { constructor() {} saveOrder(order: Order) {} } class OrderService { private orderRepository: OrderRepository; constructor() { this.orderRepository = new OrderRepository(); } processOrder(order: Order) { this.orderRepository.saveOrder(order); } } ``` 我們注意到,儲存庫是 OrderService 類,直接耦合到 OrderRepository 類別的具體實作。 讓我們重構一下這個例子: ``` interface Order { id: number; name: string; } class OrderRepository { constructor() {} saveOrder(order: Order) {} } class OrderService { private orderRepository: OrderRepository; constructor(repository: OrderRepository) { this.orderRepository = repository; } processOrder(order: Order) { this.orderRepository.saveOrder(order); } } ``` 好的!好多了!現在我們接收儲存庫作為建構函數的參數來實例化和使用。現在我們依賴抽象,我們不需要知道我們正在使用哪個儲存庫。 定義: `depend on abstractions rather than concrete implementations` 結論 --- 那你現在感覺怎麼樣?我希望透過這個簡單的範例,您可以記住並理解在程式碼中使用這些原則的內容和原因。除了應用乾淨的程式碼之外,它還更容易理解和擴展。 我希望你喜歡! 非常感謝您,祝您永遠健康! 聯絡方式: 領英:https://www.linkedin.com/in/kevin-uehara/ Instagram:https://www.instagram.com/uehara\_kevin/ 推特:https://twitter.com/ueharaDev Github:https://github.com/kevinuehara dev.to:https://dev.to/kevin-uehara Youtube:https://www.youtube.com/@ueharakevin/ --- 原文出處:https://dev.to/kevin-uehara/solid-the-simple-way-to-understand-47im
轉職快一年了,輪流跟幾個後端合作,目前我觀察到的如下(因為是在接案公司,常常在趕進度或同時進行多個專案) 有的後端很好心,且可以快速切割工作內容(前後端沒有分離),直接留言告訴你做什麼改什麼,他負責做什麼改什麼,甚至幫你程式碼第幾行都標示出來。 有的是後端api開發完不會通知,要一直去追問進度才知道對方是否開發完成 有的是後端給的api缺東缺西或是沒有說要傳遞什麼資料給後端,要特別去問,回應的態度要看對方心情,但有的雖然缺東缺西但至少標示清楚,可以馬上知道缺少什麼欄位資料,請後端補齊 比較誇張的一次是多個後端一起開發專案,我前端串接完api測試沒問題,交測後發現網頁報錯,看起來是api沒回應資料,查了才知道後端們整合api後沒通知前端api路徑有更改... 想問問,前端前輩們是如何與後端溝通的? 或是分享工作上合作經驗,感激不盡 >_<
*揭露:這篇文章包含附屬連結;如果您透過本文中提供的不同連結購買產品或服務,我可能會獲得補償。* [](https://bit.ly/3cNF0vw) image\_credit -[指數](https://bit.ly/3cNF0vw) 您好,作為開發人員,充分理解基本系統設計概念對於開發可擴展、可靠和高效能的軟體系統至關重要。 [**系統設計**](https://medium.com/javarevisited/7-system-design-problems-to-crack-software-engineering-interviews-in-2023-13a518467c3e)涉及設計軟體系統的體系結構和元件,以滿足特定要求並實現所需的性能特徵。 隨著技術的快速進步和軟體應用的複雜性不斷增加,掌握系統設計概念對於程式設計師建立高效且有效的系統至關重要。 在上幾篇文章中,我回答了流行的系統設計問題,例如[API 網關與負載平衡器](https://dev.to/somadevtoo/difference-between-api-gateway-and-load-balancer-in-system-design-54dd)以及[水平與垂直擴展](https://dev.to/somadevtoo/horizontal-scaling-vs-vertical-scaling-in-system-design-3n09),今天,我們將看看每個程式設計師都應該學習的 10 個關鍵系統設計概念。 這些概念為設計能夠處理大規模資料、容納並髮用戶並提供最佳效能的軟體系統奠定了堅實的基礎。 無論您是初學者還是經驗豐富的開發人員,了解這些系統設計概念都將使您能夠建立強大且可擴展的軟體系統,以滿足現代應用程式的需求。那麼,讓我們深入探討這些基本的系統設計原則吧! 順便說一句,如果您正在準備系統設計面試並想深入學習系統設計,那麼您還可以查看[**ByteByteGo**](https://bit.ly/3P3eqMN) 、 [**Design Guru**](https://bit.ly/3pMiO8g) 、 [**Exponent**](https://bit.ly/3cNF0vw) 、 [**Educative**](https://bit.ly/3Mnh6UR)和[**Udemy**](https://bit.ly/3vFNPid)等網站,它們有許多很棒的系統設計課程 以下是每個程式設計師都應該考慮學習的 10 個重要的系統設計概念: 1. **可擴展性** 2. **可用性** 3. **可靠性** 4. **容錯能力** 5. **快取策略** 6. **負載平衡** 7. **安全** 8. **可擴展的資料管理** 9. **設計模式** 10. **效能最佳化** 理解和應用這些系統設計概念可以幫助程式設計師和開發人員建立強大的、可擴展的、高效能的軟體系統,以滿足現代應用程式和使用者的需求。 現在,讓我們深入研究它們中的每一個並了解它們是什麼以及如何在您的應用程式中實現它們。 ### 1. 可擴展性 可擴展性是指系統或應用程式處理不斷增加的工作負載或使用者而不顯著降低效能或功能的能力。 它是系統設計中的一個重要概念,因為它允許系統成長並適應不斷變化的需求,**例如增加的資料量、使用者流量或處理需求,**而不會遇到效能瓶頸或限制。 在現代運算環境中,系統需要處理大量且不斷成長的資料和用戶,可擴展性至關重要。例如,流行的網站、行動應用程式和基於雲端的服務需要能夠同時處理數百萬甚至數十億個請求,而分散式資料庫和大資料平台需要擴展以處理 PB 或 EB 的資料。 對於需要適應尖峰負載的系統來說,可擴展性也很重要,例如假期期間的線上購物或因病毒事件導致的用戶活動突然激增。 > 可擴展性主要有兩種:**垂直可擴展性和水平可擴展性**。垂直可擴展性涉及向單一伺服器或節點加入更多資源(例如 CPU、記憶體或儲存)以處理增加的工作負載。另一方面,水平可擴展性涉及向系統加入更多伺服器或節點以分配工作負載並處理增加的需求。 水平可擴展性通常透過[負載平衡](https://medium.com/javarevisited/difference-between-api-gateway-and-load-balancer-in-microservices-8c8b552a024)、 [分片](https://medium.com/javarevisited/what-is-database-sharding-scaling-your-data-horizontally-1dc12b33193f)、分區和分散式處理等技術來實現。 實現可擴展性需要仔細的系統設計、架構和實作。它涉及設計能夠有效處理不斷增加的工作負載、有效利用資源、最大限度地減少依賴性以及跨多個節點或伺服器分佈處理的系統。 > 快取、非同步處理、平行處理和分散式資料庫等技術通常用於提高可擴展性。測試和效能監控對於確保系統在擴展時繼續保持良好效能也至關重要。 可擴展性是建立強大的高效能係統的重要考慮因素,這些系統可以處理成長並適應隨時間變化的需求。它使系統能夠滿足不斷增長的需求,提供無縫的用戶體驗,並支援業務成長,而不會遇到效能限製或停機。 這是來自[**ByteByteGo**](https://bit.ly/3P3eqMN)的一個很好的圖表,這是準備系統設計面試的好地方,它顯示了[*垂直擴展和水平擴展之間的區別*](https://medium.com/javarevisited/difference-between-horizontal-scalability-vs-vertical-scalability-67455efc91c) [](https://bit.ly/3P3eqMN) --- ### 2. 可用性 可用性是指軟體系統即使在發生故障或中斷時也能保持運作並可供使用者存取的能力。 高可用性是許多系統的關鍵要求,特別是那些任務關鍵型或時間敏感型系統,例如線上服務、電子商務網站、金融系統和通訊網路。 此類系統的停機可能會導致重大的財務損失、聲譽受損和客戶不滿。因此,保證高可用性是系統設計時重點考慮的問題。 可用性通常**使用正常運作時間(衡量系統運作時間的百分比)和停機時間(衡量系統不可用的時間)等指標**來量化。 實現**高可用性涉及設計具有冗餘、容錯和故障轉移機制的系統**,以最大限度地降低因硬體故障、軟體故障或其他意外事件而導致停機的風險。 > 在系統設計中,採用了各種技術和策略來提高可用性,例如負載平衡、叢集、複製、備份和復原、監控和主動維護。 實施這些措施是為了最大限度地減少單點故障、檢測故障並從故障中恢復,並確保系統即使在發生故障或中斷時也能保持運作。 透過設計具有高可用性的系統,工程師可以確保系統可以長時間存取和執行,從而提高客戶滿意度、減少停機時間並提高業務連續性。 [](https://www.linkedin.com/pulse/top-20-system-design-interview-questions-answers-soma-sharma-g0pqc/) --- ### 3、可靠性 可靠性是指**軟體系統在交付預期結果時的一致性和可靠性**。建立具有可靠元件、錯誤處理機制和備份/復原策略的系統對於確保系統按預期運作並產生準確的結果至關重要。 可靠性是系統設計的關鍵因素,因為它直接影響系統的整體性能和品質。可靠的系統應始終按預期執行,不會出現意外故障、錯誤或中斷。 **關鍵任務應用通常需要高可靠性,**因為系統故障可能會造成嚴重後果,例如在航空、醫療保健、金融和其他安全關鍵領域。 可靠性通常使用各種指標來量化,例如**平均故障間隔時間 (MTBF)** (測量故障之間的平均持續時間)和故障率 (FR)(測量一段時間內故障發生的速率)。 > 可靠性可以透過各種技術和策略來實現,例如冗餘、錯誤檢測和糾正、容錯和穩健設計。 在系統設計中,要實現高可靠性需要仔細考慮各種因素,包括元件品質、系統架構、錯誤處理、容錯機制、監控和維護策略。 透過**設計高可靠性的系統**,工程師可以確保系統始終如一地按預期執行,從而提高客戶滿意度、減少停機時間並提高系統效能和可用性。 --- ### 4. 容錯性 容錯是指系統或元件在故障或故障(例如硬體故障、軟體錯誤或其他不可預見的問題)時繼續正常運作的能力。 容錯系統旨在檢測、隔離故障並從故障中恢復,而不會完全故障或停機。 容錯是系統設計中的重要概念,特別是在分散式系統或需要在具有挑戰性的環境中可靠運作的系統中。 它涉及實現冗餘、錯誤檢測、錯誤糾正和錯誤恢復機制,以確保即使某些元件或子系統發生故障,系統也能繼續運作。 > 有多種技術和策略可以實現容錯,例如**複製**,即在不同位置維護相同資料或服務的多個副本,以便在一個發生故障時,其他副本可以接管;檢查點,定期保存系統狀態,以便在發生故障時,系統可以恢復到先前已知的良好狀態;優雅降級,即係統在故障時可以繼續執行,但功能會減少。 容錯對於確保系統的高可用性、可靠性和彈性至關重要,特別是在系統故障可能造成嚴重後果的關鍵任務應用程式中。 透過在系統設計中納入容錯機制,工程師可以建立強大且可靠的系統,即使在遇到意外故障時也可以繼續運作並提供預期結果。 [](https://bit.ly/3P3eqMN) --- ### 5. 快取策略 快取策略是一種用於優化系統效能的技術,它透過將經常存取的資料或結果儲存在稱為快取的臨時儲存位置中,以便可以快速檢索資料,而無需重新計算或從原始來源取得。 系統設計中常用的快取策略有以下幾種: 1. **完全緩存** 在此策略中,整個資料集或結果都會快取在快取中,提供對所有資料或結果的快速存取。當資料或結果相對較小且可以輕鬆儲存在記憶體或本地快取中時,此策略非常有用。 2. **部分快取** 在此策略中,通常基於使用模式或頻繁存取的資料,僅快取資料或結果的子集。當資料或結果規模很大,或並非所有資料或結果都被頻繁存取,並且快取整個資料集不可行時,此策略很有用。 3. \*\*基於時間的到期時間 在此策略中,資料或結果被快取特定的時間,之後快取被認為是陳舊的,並且資料或結果從原始來源獲取並在快取中更新。當資料或結果相對穩定且不經常變化時,此策略很有用。 4. **LRU(最近最少使用)或 LFU(最不常使用)替換策略** 在這些策略中,最近最少使用或最不頻繁使用的資料或結果被從快取中逐出,以為新資料或結果騰出空間。當快取的儲存容量有限且需要驅逐不常存取的資料以容納新資料時,這些策略非常有用。 5. **直寫式或後寫式緩存** 在這些策略中,資料或結果在更新或插入時寫入快取和原始來源(直寫)或僅寫入快取(後寫)。當系統需要保持快取和原始來源之間的一致性或原始來源無法直接更新時,這些策略就非常有用。 6. **分散式快取** 在此策略中,快取分佈在多個節點或伺服器上,通常使用分散式快取框架或技術。當系統跨多個節點或伺服器分佈或擴展並且需要保持分散式快取的一致性和效能時,此策略就非常有用。 7. **自訂快取** 可以根據系統或應用程式的特定要求和特徵來實施自訂快取策略。這些策略可能涉及上述策略或其他自訂方法的組合,以滿足系統的獨特需求。 選擇*合適的快取策略取決於資料或結果的大小、存取頻率、資料或結果的易變性、儲存容量、一致性要求以及系統的效能目標等多種因素*。仔細考慮和實施快取策略可以顯著提高系統效能、降低資源利用率、提高可擴展性並增強使用者體驗。 [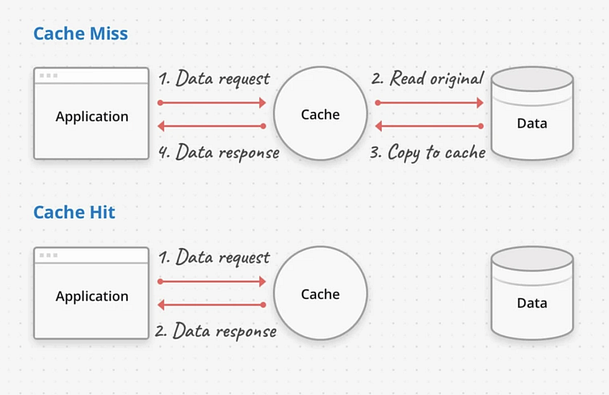](https://bit.ly/3P3eqMN) --- ### **6.負載平衡** 負載平衡是分散式系統或網路中使用的技術,用於在多個伺服器或資源之間均勻分配傳入的網路流量或工作負載,確保沒有任何單一伺服器或資源因過多的流量或工作負載而不堪負荷。 負載平衡的目的是優化資源利用率,最大化系統可用性,提高系統整體效能和可靠性。在微服務架構中, [*負載平衡和 API 閘道*](https://medium.com/javarevisited/difference-between-api-gateway-and-load-balancer-in-microservices-8c8b552a024)通常指的是相同的,但事實並非如此,API 閘道可以做更多的事情,如[本文](https://medium.com/javarevisited/what-is-api-gateway-pattern-in-microservices-architecture-what-problem-does-it-solve-ebf75ae84698)所述。 負載平衡可以透過各種演算法或方法來實現,例如: 1. **循環:**傳入請求以輪流方式依序分發到每個伺服器或資源,確保所有伺服器或資源之間的流量平均分配 2. **最少連線:**傳入請求分發到活動連線數最少的伺服器或資源,確保負載最少的伺服器或資源接收新請求。 3. **來源 IP 關聯性:**來自相同客戶端 IP 位址的傳入請求將導向至相同伺服器或資源,確保來自特定用戶端的請求始終由相同伺服器或資源處理。 4. **加權循環:**傳入請求根據分配給每個伺服器或資源的預定義權重進行分配,從而允許根據伺服器或資源容量或功能採用不同的流量分配比率。 5. **自適應負載平衡:**負載平衡演算法根據伺服器或資源健康、效能或其他指標的即時監控,動態調整流量分配,確保最佳的資源利用率和系統效能。 負載平衡可以使用基於硬體的負載平衡器、基於軟體的負載平衡器或基於雲端的負載平衡服務來實現。 它在具有高流量負載或資源密集型工作負載的分散式系統或網路中發揮著至關重要的作用,可以實現資源的高效利用,增強系統的可用性和可靠性,並提供無縫的用戶體驗。 這裡還有一個來自[DesignGuru.io](https://bit.ly/3pMiO8g)的漂亮圖表,這是一個學習面試準備系統設計的優秀網站,它強調了負載平衡器和 API 閘道之間的區別: [](https://bit.ly/3pMiO8g) --- ### **7. 安全** 系統設計中的安全性是指考慮和實施保護系統免受潛在安全威脅、漏洞或攻擊的措施。 它涉及設計和實施具有內建安全功能和實踐的系統,以防止未經授權的存取、資料外洩、資料外洩、惡意軟體攻擊和其他安全風險。 系統設計中的安全性通常涉及以下原則: 1. **身份驗證:**確保使用者或實體經過驗證並根據其身分和憑證被授予適當的存取權限。 2. **授權**:實施存取控制和權限,限制使用者或實體存取未經授權的資源或執行未經授權的操作。 3. **加密**:透過使用加密技術來保護敏感資料,以防止未經授權的存取或資料外洩。 4. **稽核和日誌記錄**:實施機制來追蹤和記錄系統活動和事件,以用於監視、稽核和取證目的。 5. **輸入驗證:**驗證和清理所有輸入資料,以防止常見的安全漏洞,例如 SQL 注入、跨站腳本 (XSS) 和跨站請求偽造 (CSRF) 攻擊。 6. **修補程式和更新**:使用最新的安全性修補程式和更新使系統保持最新狀態,以解決已知的安全漏洞。 7. **深度防禦**:實施多層安全控制,例如防火牆、入侵偵測系統和防毒軟體,以提供針對安全威脅的多層防禦。 8. **最小權限原則**:將使用者或實體的存取權限限製到執行其任務所需的最低限度,減少安全漏洞或攻擊的潛在影響。 9. **安全通訊**:使用安全通訊協定(例如 HTTPS 或 SSL/TLS)來保護傳輸中的資料免於攔截或竊聽。 系統設計中的安全性對於保護資料和資源的完整性、機密性和可用性以及確保系統的整體安全狀況至關重要。應考慮並納入系統的設計、開發和部署階段,以減輕潛在的安全風險並防範安全威脅。 --- ### **8. 可擴展的資料管理** 可擴展的資料管理是指系統或應用程式有效處理不斷增長的資料量而不會出現效能下降或功能遺失的能力。 它涉及設計和實施資料管理實務和技術,這些實務和技術可以處理不斷增加的資料量、使用者負載和處理要求,同時保持可接受的效能和可靠性水準。 可擴展的資料管理通常涉及以下原則: 1. **資料分區:**將大型資料集分割成更小的、可管理的區塊或分區,以將資料分佈在多個儲存或處理資源上。這有助於減少單一資源的負載,並允許並行處理和提高效能。 2. **分散式資料庫系統:**使用分散式資料庫或資料儲存解決方案,可以將資料分佈在多個節點或伺服器上,從而實現水平擴展並提高效能。 3. **資料複製**:跨多個節點或伺服器複製資料,以確保資料可用性和容錯性。這可能涉及資料鏡像、資料分片或資料快取等技術,以提高效能和可靠性。 4. **快取和記憶體中資料儲存:快取**經常存取的資料或將資料儲存在記憶體中,以便更快地檢索和處理,減少對昂貴的磁碟 I/O 操作的需求並提高效能。 5. **索引和查詢最佳化**:使用高效的索引和查詢最佳化技術來加速資料檢索和處理操作,尤其是在大型資料集中。 6. **資料壓縮:**實施資料壓縮技術以減少儲存佔用空間並提高資料傳輸效率,特別是對於大型資料集。 7. **資料歸檔和清除**:實施資料歸檔和清除實踐以刪除或歸檔舊的或不經常存取的資料,減少儲存和處理開銷並提高效能。 8. **可擴展的資料處理框架:**使用可擴展的資料處理框架,例如 Apache Hadoop、Apache Spark 或 Apache Flink,可以分散式並行方式處理大規模資料處理和分析任務。 9. **雲端的資料管理**:利用雲端的資料管理服務,例如 Amazon S3、Amazon RDS 或 Google Bigtable,提供可擴充和託管的資料儲存和處理功能。 10. **監控和可擴展性測試**:定期監控系統效能並進行可擴展性測試,以辨識和解決效能瓶頸、資源限製或其他可擴展性挑戰,並確保資料管理實踐能夠有效處理不斷增長的資料量和負載。 簡而言之,可擴展的資料管理對於需要處理大量資料、使用者負載和處理要求的現代應用程式和系統至關重要。 它使系統能夠成長並適應不斷變化的需求,而無需犧牲效能或可靠性,從而確保資料管理實踐能夠有效地處理不斷增加的資料量和負載。 --- ### **9. 設計模式** 系統設計中的[設計模式](https://medium.com/javarevisited/top-10-microservice-design-patterns-for-experienced-developers-f4f5f782810e)是指用於解決軟體系統開發過程中遇到的常見設計挑戰或問題的可重複使用解決方案或最佳實踐。 [設計模式](https://medium.com/javarevisited/21-software-design-pattern-interview-questions-and-answers-b7d1774b5dd2)是被廣泛接受和經過驗證的設計和架構軟體系統的方法,它們為設計高效、可維護和可擴展的系統提供了一組明確的指南。 系統設計中的設計模式可分為多種類型,包括: 1. **建立模式:**這些模式專注於物件建立機制,並提供以靈活且可重複使用的方式建立物件的方法。建立模式的範例包括 Singleton、Factory Method、Abstract Factory、Builder 和 Prototype 模式。 2. **結構模式:**這些模式著重於類別和物件的組織以形成更大的結構或系統。結構模式的範例包括適配器、橋、複合、裝飾器和外觀模式。 3. **行為模式:**這些模式著重於系統內物件或元件之間的互動和通訊。行為模式的範例包括觀察者、策略、命令、迭代器和模板方法模式。 4. **架構模式:**這些模式為設計系統的整體架構提供了高階指南和策略。架構模式的範例包括模型-視圖-控制器 (MVC)、模型-視圖-視圖模型 (MVVM)、分層架構、微服務和事件驅動架構模式。 設計模式在系統設計中非常重要,因為它們提供了經過驗證的標準化方法來解決常見的設計挑戰、提高程式碼品質並確保軟體系統的可維護性和可擴展性。 它們促進程式碼的可重複使用性、關注點分離和功能封裝,從而更容易管理複雜的系統並使其適應不斷變化的需求。 透過使用設計模式,開發人員可以利用現有知識和最佳實踐來設計強大而高效的系統,以滿足使用者和利害關係人的需求。 在過去的幾篇文章中,我還討論了常見的微服務設計模式,如[**事件來源**](https://medium.com/javarevisited/what-is-event-sourcing-design-pattern-in-microservices-architecture-how-does-it-work-b38c996d445a)**、** [**CQRS**](https://medium.com/javarevisited/what-is-cqrs-command-and-query-responsibility-segregation-pattern-7b1b38514edd) \*\*、SAGA\*\*、 [**每個微服務的資料庫**](https://medium.com/javarevisited/what-is-database-per-microservices-pattern-what-problem-does-it-solve-60b8c5478825)**、** [**API 閘道**](https://medium.com/javarevisited/difference-between-api-gateway-and-load-balancer-in-microservices-8c8b552a024)、 [**斷路器**](https://medium.com/javarevisited/what-is-circuit-breaker-design-pattern-in-microservices-java-spring-cloud-netflix-hystrix-example-f285929d7f68),並分享了[*設計微服務的最佳實踐*](https://medium.com/javarevisited/10-microservices-design-principles-every-developer-should-know-44f2f69e960f),您也可以查看這些文章以了解有關微服務通訊的更多訊息,包括同步和非同步通訊。 --- ### 10. 性能 雖然我們已經知道效能意味著什麼,但還記得速度慢的筆記型電腦嗎?在系統設計中,效能是指軟體系統處理資料和交付結果的速度、反應能力和效率。 透過高效的演算法、快取、索引和其他技術來優化系統效能對於建立能夠處理大規模資料處理並提供最佳回應時間的系統至關重要。 系統設計中的效能是指軟體系統或應用程式有效率且有效地執行其預期功能或任務,同時滿足效能要求和期望的能力。它涵蓋了系統的回應時間、吞吐量、資源利用率、可擴展性和效率等各個方面。 效能是系統設計中的關鍵因素,因為它直接影響使用者體驗、系統可靠性和整體系統效率。效能不佳的系統可能會導致反應時間慢、吞吐量低、資源利用率高以及系統資源使用效率低下,導致系統效能下降和使用者不滿意。 系統設計人員在設計過程中需要考慮各種與效能相關的因素,例如選擇適當的演算法和資料結構、最佳化程式碼、最大限度地減少不必要的開銷、有效管理系統資源以及確保正確的系統配置和調優。 效能測試和分析技術還可用於辨識和解決效能瓶頸並優化系統效能。 優化系統設計中的效能需要在功能、複雜性和資源利用率之間進行仔細的平衡。它涉及做出明智的設計決策、使用最佳實踐以及持續監控和優化系統性能,以確保系統滿足其性能要求並提供流暢高效的用戶體驗。 ### 結論 這就是面試的基本系統設計概念。理解和掌握這些關鍵的系統設計概念對於程式設計師建立健壯、可擴展且高效的軟體系統至關重要。 這些概念,包括容錯、可靠性、可用性、快取策略、負載平衡、安全性、可擴展資料管理、設計模式和效能,在確保軟體系統滿足其預期目標、最佳執行並提供卓越的效能方面發揮著關鍵作用。 透過對這些系統設計概念的深入理解,您可以做出明智的設計決策,選擇適當的技術和技巧,並優化系統效能。 它還允許您設計具有彈性、可擴展、安全和高效的系統,能夠應對現代軟體開發的挑戰並滿足最終用戶的期望。 順便說一句,如果您正在*準備系統設計面試*並想要深入學習系統設計,那麼您還可以查看[**ByteByteGo**](https://bit.ly/3P3eqMN) 、 [**DesignGuru**](https://bit.ly/3pMiO8g) 、 [**Exponent**](https://bit.ly/3cNF0vw) 、 [**Educative**](https://bit.ly/3Mnh6UR)和[**Udemy**](https://bit.ly/3vFNPid)等網站,它們有許多很棒的系統設計課程,如果您需要免費的系統設計課程您也可以查看下面的文章。 --- 原文出處:https://dev.to/somadevtoo/10-must-know-system-design-concepts-for-interviews-2fii
在 React 元件中組織程式碼有時經常被忽視,但在處理高階元件 (HoC)、 `forwardRef`和`memo`時,事情可能會變得複雜。如果處理不當,可能會導致程式碼混亂且難以維護。本文旨在透過提出一種更易於管理的方式來建立程式碼並提高工作效率來解決這些問題。 1️⃣ 在 React 元件中管理 HoC、 `forwardRef`和`memo` ------------------------------------------ ### 問題陳述 身為 React 開發人員,我經常在組織元件方面遇到困難,尤其是在合併`memo`和`forwardRef`時。以下的範例取自[React TypeScript Cheatsheet](https://react-typescript-cheatsheet.netlify.app/docs/basic/getting-started/forward_and_create_ref) ,示範了這個挑戰: ``` import { forwardRef } from 'react'; interface FancyButtonProps { type: 'submit' | 'button'; children?: React.ReactNode; } export const FancyButton = forwardRef<HTMLButtonElement, FancyButtonProps>((props, ref) => ( <button ref={ref} className="MyClassName" type={props.type}> {props.children} </button> )); ``` 根據我自己的經驗,這段程式碼有幾個問題: - 與「裸」元件相比,由於元件包裝在`forwardRef`中,程式碼顯得混亂。 - 類型並不是真正處於最佳位置。與元件中使用的實際參數相比, `forwardRef`的泛型具有相反的順序: `<HTMLButtonElement, FancyButtonProps>`與`(props, ref)` 。 - 重構變得很麻煩,因為它需要仔細注意方括號和圓括號。假設您不再需要`forwardRef` 。即使有了彩虹括號之類的幫助,處理這些括號和圓括號有時也會令人沮喪,尤其是當元件很大時。 - 如果您想要為元件新增`memo`或某些類型的自訂 HoC,以及其中的某些狀態或函數,該怎麼辦?它會變得更加混亂: ``` import { forwardRef, memo } from 'react'; import { useStyles } from '@/modules/core/styles'; interface FancyButtonProps { type: 'submit' | 'button'; children?: React.ReactNode; } export const FancyButton = memo( forwardRef<HTMLButtonElement, FancyButtonProps>(({ type, children }, ref) => { const classes = useStyles(); return <button ref={ref} className={classes.button} type={props.type}> {children} </button> }) ); ``` ### 建議的解決方案 在厭倦了以這種方式組織元件程式碼時遇到的所有麻煩之後,我最終想出了一種方法來解決這些問題。考慮以下方法: ``` import { forwardRef, memo } from 'react'; import { useStyles } from '@/modules/core/styles'; interface FancyButtonProps { type: 'submit' | 'button'; children?: React.ReactNode; } const FancyButtonBase = ( { type, children }: FancyButtonProps, ref: React.ForwardedRef<HTMLButtonElement> ) => { const classes = useStyles(); return ( <button ref={ref} className={classes.button} type={type}> {children} </button> ); }; export const FancyButton = memo(forwardRef(FancyButtonBase)); ``` 該程式碼是不言自明的。元件的實際程式碼位於名稱帶有`Base`後綴的函陣列件中。然後我們匯出下面的元件,以及所有 HoC、 `memo`和`forwardRef` 。 此解決方案具有以下幾個優點: - 實際的元件程式碼與 HoC、 `memo`和`forwardRef`分離,使其類似於「裸」元件。 - 類型位於它們應該在的位置: `(props: FancyButtonProps, ref: React.ForwardedRef<HTMLButtonElement>` 。 - 如果您需要重構此程式碼,例如不再使用`ref` ,您只需刪除第二個參數和`forwardRef`而無需處理方括號和圓括號。 - 如果需要嵌套的 HoC,加入或修改它們很簡單,並且程式碼仍然可讀: ``` import { forwardRef, memo } from 'react'; import { useStyles } from '@/modules/core/styles'; import { withWhatever } from '@/modules/core/hocs'; interface FancyButtonProps { type: 'submit' | 'button'; children?: React.ReactNode; } const FancyButtonBase = ( { type, children }: FancyButtonProps, ref: React.ForwardedRef<HTMLButtonElement> ) => { const classes = useStyles(); return ( <button ref={ref} className={classes.button} type={type}> {children} </button> ); }; export const FancyButton = memo(forwardRef(withWhatever(FancyButtonBase))); ``` 這種方法為元件加入了一行程式碼,但顯著提高了可讀性和可維護性。即使不使用任何 HoC、 `memo`或`forwardRef` ,我仍然對「裸」元件執行此操作: `export const FancyButton = FancyButtonBase` 。 我們可以更進一步,嘗試使用一個非常有用但不太知名的 VSCode 擴充功能來提高我們的工作效率。 2️⃣ 透過「資料夾模板」擴充功能提高工作效率 ----------------------- 下面的 GIF 演示了[VSCode 中「資料夾模板」擴充功能](https://marketplace.visualstudio.com/items?itemName=Huuums.vscode-fast-folder-structure)的強大功能(載入 GIF 可能需要一點時間): 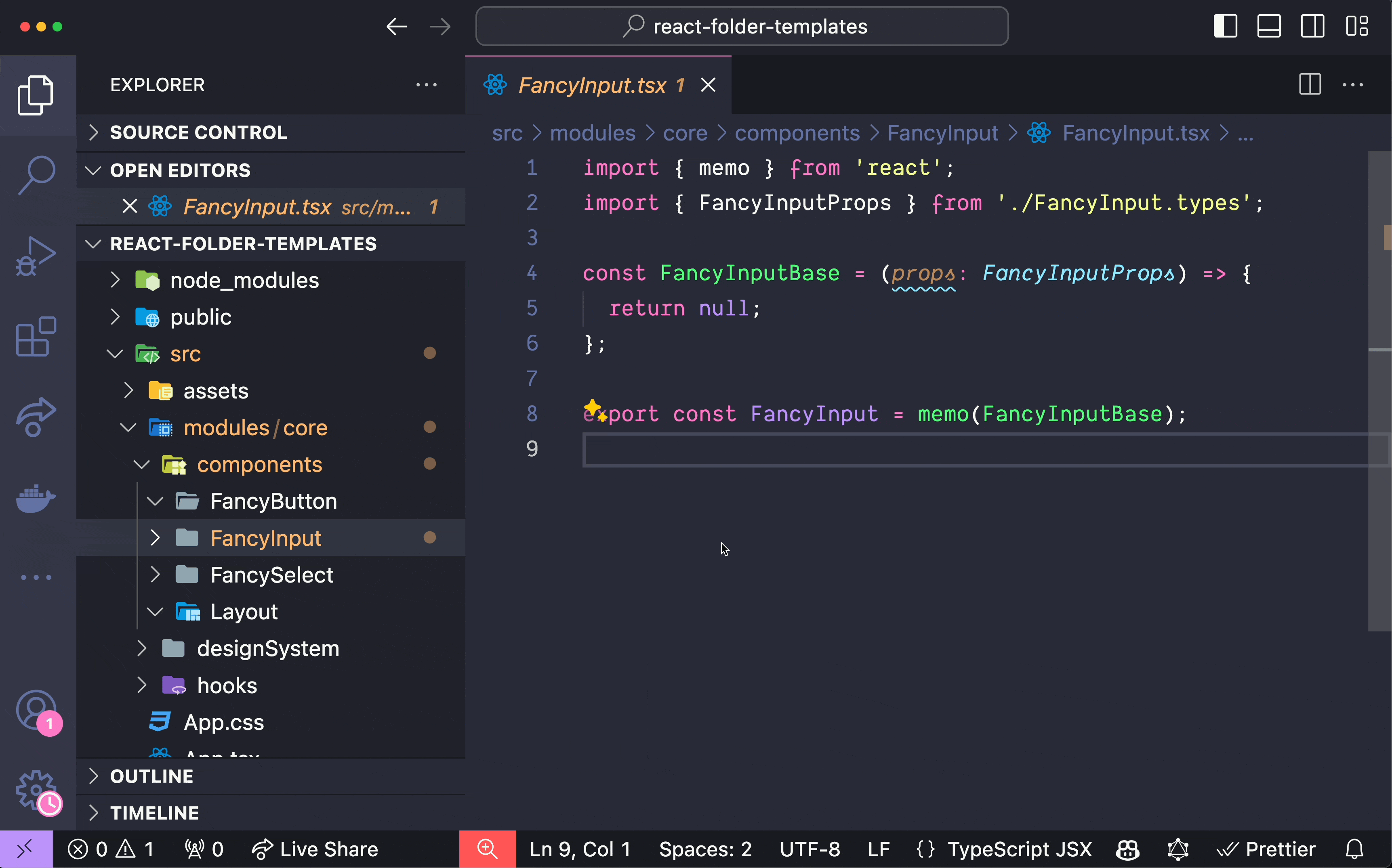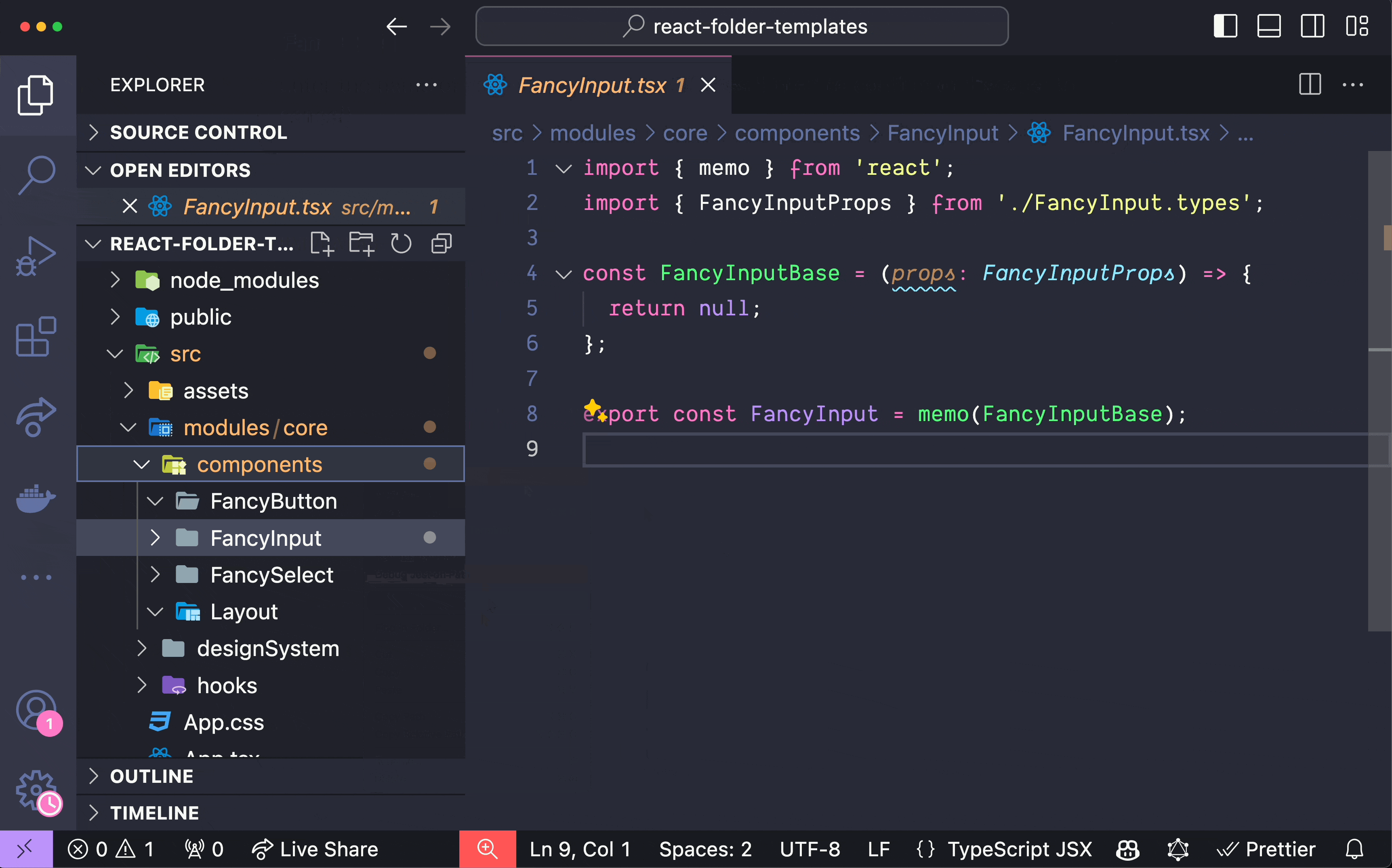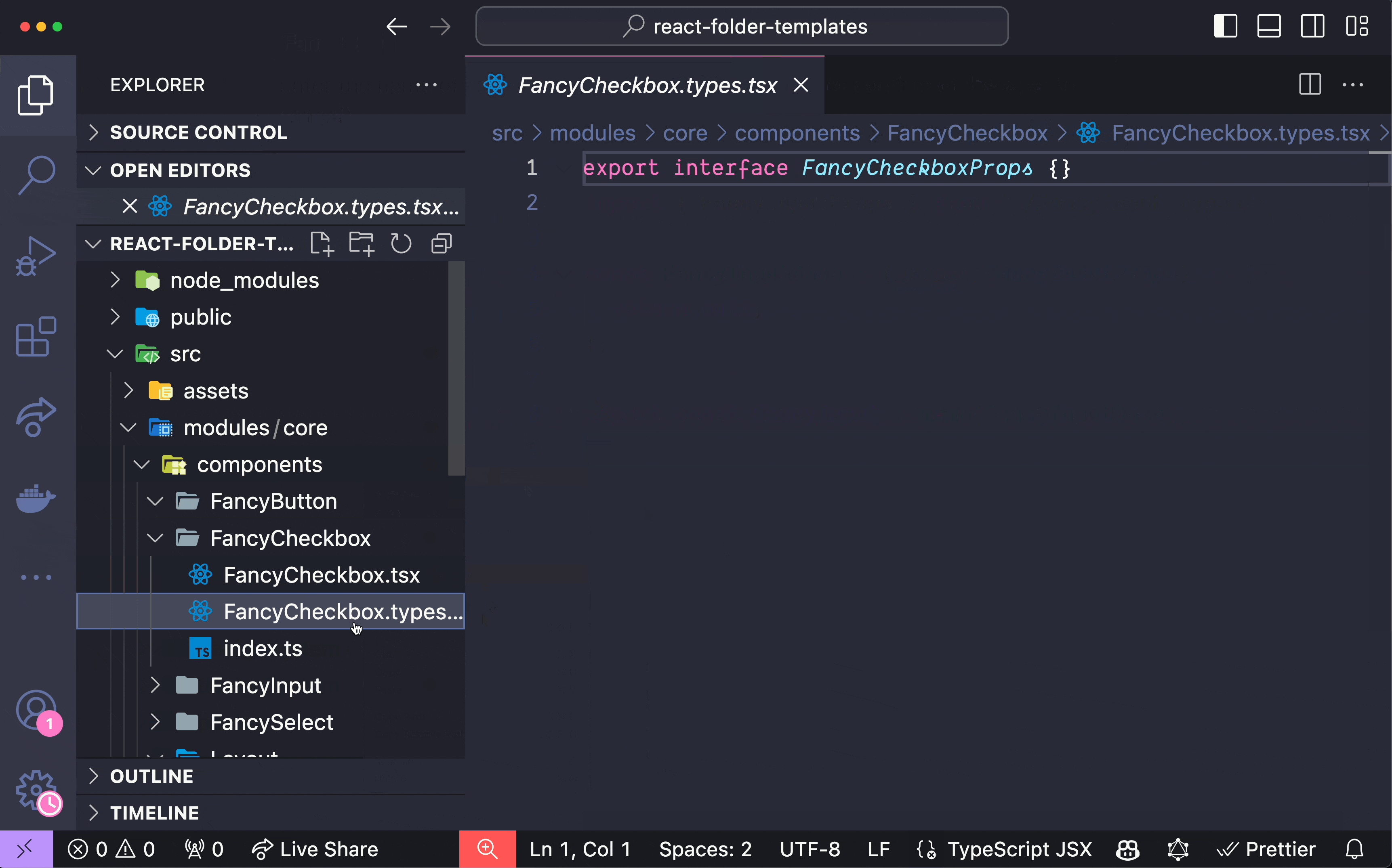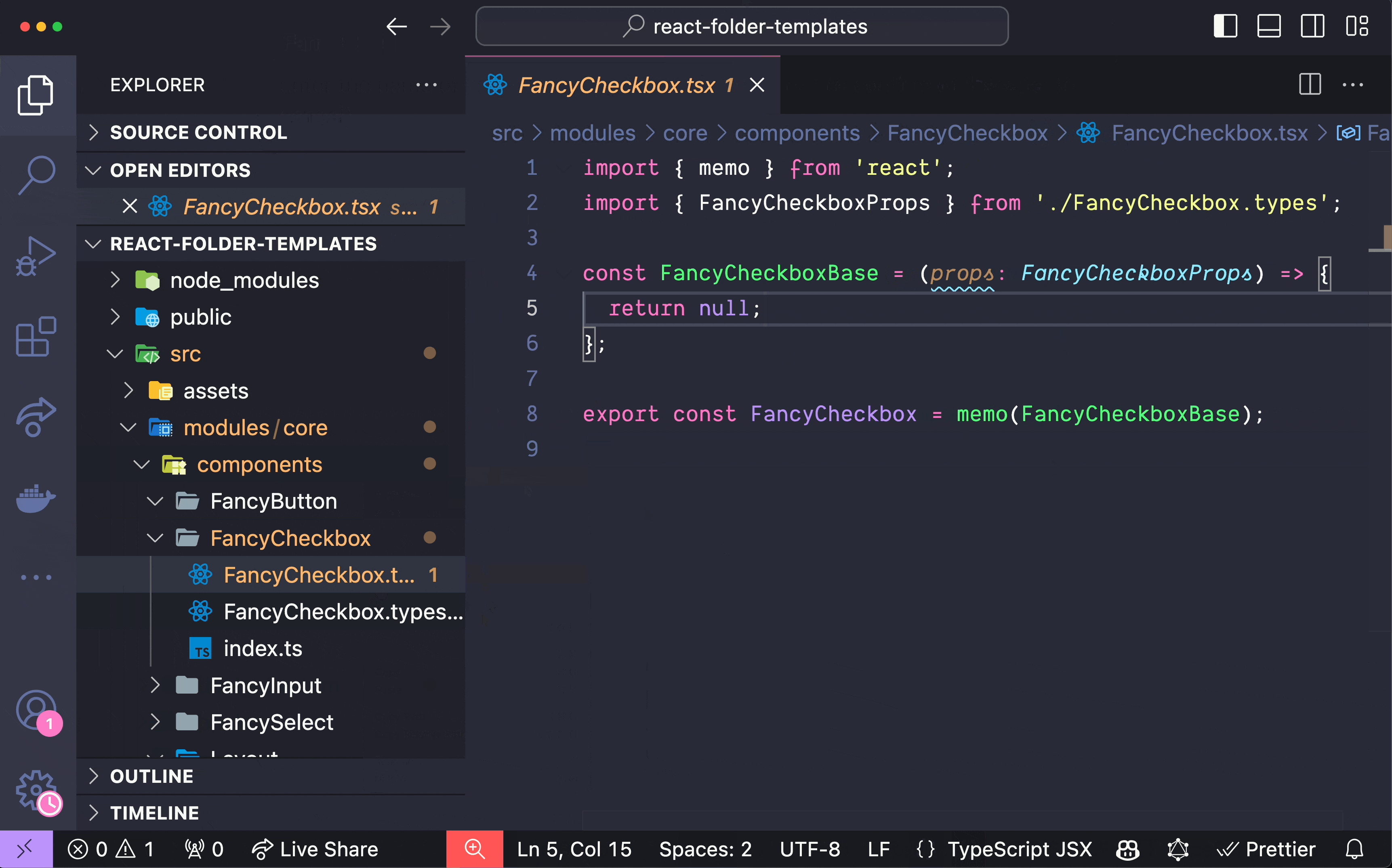 您只需輸入元件的名稱,瞧! 基本上,您也可以告訴 AI 為您編寫此樣板程式碼,但我發現使用此擴充功能要快得多,而且它是高度可自訂的。 如果您需要我分享我預先定義的 React 特定資料夾範本設置,請在評論中告訴我。 🏁 結論 ---- 在 React 元件中組織程式碼,尤其是在使用`memo` 、 `forwardRef`和 HoC 時,可能會是一項艱鉅的任務。然而,透過將實際的元件程式碼與 HoC 分開並確保正確的類型聲明,您可以建立更清晰、更易於維護的程式碼。此外,使用 VSCode 中的「資料夾範本」擴充功能等工具可以幫助簡化您的開發流程並提高工作效率。 如果你認為這是一篇好文章,你可能會發現我之前的文章也很有用: https://dev.to/itswillt/folder-structs-in-react-projects-3dp8 --- 原文出處:https://dev.to/itswillt/organizing-code-in-a-react-component-4coa
React 設計模式是開發人員用來解決使用 React 建立應用程式時遇到的常見問題和挑戰的既定實踐和解決方案。這些模式封裝了針對重複出現的設計問題的可重複使用解決方案,從而提高了可維護性、可擴展性和效率。它們提供了一種結構化的方法來組織元件、管理狀態、處理資料流和最佳化效能。 **請考慮以下 6 種 React 設計模式:** 1. 容器和呈現模式 2. HOC(高階元件)模式 3. 複合元件模式 4. 提供者模式(使用提供者進行資料管理) 5. 狀態減速器模式 6. 元件組成模式 1. 容器和呈現模式 ---------- 在此模式中,容器元件負責管理資料和狀態邏輯。它們從外部來源獲取資料,在必要時對其進行操作,並將其作為 props 傳遞給展示元件。它們通常連接到外部服務、Redux 儲存或上下文提供者。 另一方面,展示元件僅專注於 UI 元素的展示。他們透過 props 從容器元件接收資料,並以視覺上吸引人的方式呈現它。展示元件通常是無狀態的功能元件或純元件,這使得它們更容易測試和重複使用。 **讓我們考慮一個複雜的範例來說明這些模式:** 假設我們正在建立一個社群媒體儀表板,用戶可以在其中查看朋友的貼文並與他們互動。以下是我們建立元件的方式: **容器元件(FriendFeedContainer):** 該元件將負責從 API 獲取有關好友貼文的資料、處理任何必要的資料轉換以及管理提要的狀態。它將相關資料傳遞給展示元件。 ``` import React, { useState, useEffect } from 'react'; import FriendFeed from './FriendFeed'; const FriendFeedContainer = () => { const [friendPosts, setFriendPosts] = useState([]); useEffect(() => { // Fetch friend posts from API const fetchFriendPosts = async () => { const posts = await fetch('https://api.example.com/friend-posts'); const data = await posts.json(); setFriendPosts(data); }; fetchFriendPosts(); }, []); return <FriendFeed posts={friendPosts} />; }; export default FriendFeedContainer; ``` **展示元件(FriendFeed):** 該元件將從其父容器元件 (FriendFeedContainer) 接收好友貼文資料作為 props,並以視覺上吸引人的方式呈現它們。 ``` import React from 'react'; const FriendFeed = ({ posts }) => { return ( <div> <h2>Friend Feed</h2> <ul> {posts.map(post => ( <li key={post.id}> <p>{post.content}</p> <p>Posted by: {post.author}</p> </li> ))} </ul> </div> ); }; export default FriendFeed; ``` 透過以這種方式建立我們的元件,我們將獲取資料和管理狀態的問題與 UI 渲染邏輯分開。這種分離使得我們的 React 應用程式在擴充時可以更輕鬆地進行測試、重複使用和維護。 2.HOC(高階元件)模式 ------------- 高階元件 (HOC) 是 React 中的一種模式,可讓您跨多個元件重複使用元件邏輯。它們是接受元件並傳回具有附加功能的新元件的函數。 為了示範 HOC 在具有 React hook 的社群媒體儀表板範例中的使用,讓我們考慮一個場景,其中您有多個元件需要從 API 取得使用者資料。您可以建立一個 HOC 來處理資料獲取並將獲取的資料作為 props 傳遞給包裝的元件,而不是在每個元件中重複取得邏輯。 這是一個基本範例: ``` import React, { useState, useEffect } from 'react'; // Define a higher-order component for fetching user data const withUserData = (WrappedComponent) => { return (props) => { const [userData, setUserData] = useState(null); const [loading, setLoading] = useState(true); useEffect(() => { // Simulate fetching user data from an API const fetchData = async () => { try { const response = await fetch('https://api.example.com/user'); const data = await response.json(); setUserData(data); setLoading(false); } catch (error) { console.error('Error fetching user data:', error); setLoading(false); } }; fetchData(); }, []); return ( <div> {loading ? ( <p>Loading...</p> ) : ( <WrappedComponent {...props} userData={userData} /> )} </div> ); }; }; // Create a component to display user data const UserProfile = ({ userData }) => { return ( <div> <h2>User Profile</h2> {userData && ( <div> <p>Name: {userData.name}</p> <p>Email: {userData.email}</p> {/* Additional user data fields */} </div> )} </div> ); }; // Wrap the UserProfile component with the withUserData HOC const UserProfileWithUserData = withUserData(UserProfile); // Main component where you can render the wrapped component const SocialMediaDashboard = () => { return ( <div> <h1>Social Media Dashboard</h1> <UserProfileWithUserData /> </div> ); }; export default SocialMediaDashboard; ``` 在這個例子中: - `withUserData`是一個高階元件,用於處理從 API 取得使用者資料。它包裝傳遞的元件 ( `WrappedComponent` ) 並將取得的使用者資料作為 prop ( `userData` ) 提供給它。 - `UserProfile`是一個功能元件,它接收`userData`屬性並顯示使用者設定檔資訊。 - `UserProfileWithUserData`是透過使用`withUserData`包裝`UserProfile`傳回的元件。 - `SocialMediaDashboard`是主要元件,您可以在其中呈現`UserProfileWithUserData`或任何其他需要使用者資料的元件。 使用此模式,您可以輕鬆地跨社交媒體儀表板應用程式中的多個元件重複使用資料取得邏輯,而無需重複程式碼。 3. 複合元件模式 --------- React 中的複合元件模式是一種設計模式,可讓您建立協同工作以形成有凝聚力的 UI 的元件,同時仍保持明確的關注點分離並提供自訂元件行為和外觀的靈活性。 在此模式中,父元件充當一個或多個子元件(稱為「複合元件」)的容器。這些子元件協同工作以實現特定的功能或行為。複合元件的關鍵特徵是它們透過父元件彼此共享狀態和功能。 以下是使用 hooks 在 React 中實作複合元件模式的簡單範例: ``` import React, { useState } from 'react'; // Parent component that holds the compound components const Toggle = ({ children }) => { const [isOn, setIsOn] = useState(false); // Function to toggle the state const toggle = () => { setIsOn((prevIsOn) => !prevIsOn); }; // Clone the children and pass the toggle function and state to them const childrenWithProps = React.Children.map(children, (child) => { if (React.isValidElement(child)) { return React.cloneElement(child, { isOn, toggle }); } return child; }); return <div>{childrenWithProps}</div>; }; // Child component for the toggle button const ToggleButton = ({ isOn, toggle }) => { return ( <button onClick={toggle}> {isOn ? 'Turn Off' : 'Turn On'} </button> ); }; // Child component for the toggle status const ToggleStatus = ({ isOn }) => { return <p>The toggle is {isOn ? 'on' : 'off'}.</p>; }; // Main component where you use the compound components const App = () => { return ( <Toggle> <ToggleStatus /> <ToggleButton /> </Toggle> ); }; export default App; ``` 在這個例子中: - `Toggle`是保存複合元件( `ToggleButton`和`ToggleStatus` )的父元件。 - `ToggleButton`是負責渲染切換按鈕的子元件。 - `ToggleStatus`是另一個負責顯示切換狀態的子元件。 - `Toggle`元件管理狀態 ( `isOn` ) 並提供`toggle`功能來控制狀態。它克隆其子級並將`isOn`狀態和`toggle`函數作為 props 傳遞給它們。 透過使用複合元件模式,您可以建立可重複使用和可組合的元件,封裝複雜的 UI 邏輯,同時仍允許自訂和靈活性。 ### 4. Provider Pattern(使用Provider進行資料管理) React 中的提供者模式是一種設計模式,用於跨多個元件管理和共用應用程式狀態或資料。它涉及建立一個封裝狀態或資料的提供者元件,並透過 React 的上下文 API 將其提供給其後代元件。 讓我們透過一個範例來說明 React 中用於管理使用者身份驗證資料的 Provider 模式: ``` // UserContext.js import React, { createContext, useState } from 'react'; // Create a context for user data const UserContext = createContext(); // Provider component export const UserProvider = ({ children }) => { const [user, setUser] = useState(null); // Function to login user const login = (userData) => { setUser(userData); }; // Function to logout user const logout = () => { setUser(null); }; return ( <UserContext.Provider value={{ user, login, logout }}> {children} </UserContext.Provider> ); }; export default UserContext; ``` 在這個例子中: - 我們使用 React 的`createContext`函數來建立一個名為`UserContext`上下文。此上下文將用於跨元件共享用戶資料和與身份驗證相關的功能。 - 我們定義一個`UserProvider`元件作為`UserContext`的提供者。該元件使用`useState`鉤子管理使用者狀態,並提供`login`和`logout`等方法來更新使用者狀態。 - 在`UserProvider`內部,我們用`UserContext.Provider`包裝`children` ,並將`user`狀態以及`login`和`logout`函數作為提供者的值傳遞。 - 現在,任何需要存取使用者資料或驗證相關功能的元件都可以使用`useContext`掛鉤來使用`UserContext` 。 讓我們建立一個使用上下文中的使用者資料的元件: ``` // UserProfile.js import React, { useContext } from 'react'; import UserContext from './UserContext'; const UserProfile = () => { const { user, logout } = useContext(UserContext); return ( <div> {user ? ( <div> <h2>Welcome, {user.username}!</h2> <button onClick={logout}>Logout</button> </div> ) : ( <div> <h2>Please log in</h2> </div> )} </div> ); }; export default UserProfile; ``` 在此元件中: 我們匯入`UserContext`並使用`useContext`鉤子來存取`UserProvider`提供的使用者資料和`logout`功能。 根據使用者是否登錄,我們呈現不同的 UI 元素。 最後,我們用`UserProvider`包裝我們的應用程式,以使用戶資料和身份驗證相關的功能可供所有元件使用: ``` // App.js import React from 'react'; import { UserProvider } from './UserContext'; import UserProfile from './UserProfile'; const App = () => { return ( <UserProvider> <div> <h1>My App</h1> <UserProfile /> </div> </UserProvider> ); }; export default App; ``` 透過這種方式,Provider 模式允許我們跨多個元件管理和共享應用程式狀態或資料,而無需進行 prop 鑽取,從而使我們的程式碼更乾淨、更易於維護。 --- 原文出處:https://dev.to/fpaghar/react-component-design-patterns-part-1-5f0g
在 React 專案中組織文件和目錄對於可維護性、可擴充性和易於導航至關重要。本文探討了不同規模的 React 專案的一般架構和資料夾結構,為每個層級提供了清晰的演示。 第 1 種:依「檔案類型」分組 ----------------- 這種結構的特點是簡單 - 按文件類型對文件進行分組: ``` └── src/ ├── actions/ ├── assets/ ├── components/ │ ├── Dialog.tsx │ ├── DistributionGraph.tsx │ ├── Employees.tsx │ ├── PaymentForm.tsx │ └── HoorayDialog.tsx ├── helpers/ ├── reducers/ ├── storage/ ├── store/ └── utils/ ``` - **專案規模**:小型至中型 - **優點**: - 簡單明了 - **缺點**: - 會迅速膨脹並變得難以維護 - 業務關注點沒有分離 假設您有很多與付款相關的程式碼。有一天,整個業務發生變化或不再需要,更換或刪除它有多容易?使用此資料夾結構,您必須檢查*每個資料夾及其中的檔案*才能進行必要的變更。如果專案不斷擴大,它很快就會變成維護地獄,隨著時間的推移只會變得更糟。 第 2 種:按「檔案類型」和功能分組 -------------------- 隨著專案的成長,「2 級」結構引入了按每種類型中的功能進行分組: ``` └── src/ ├── actions/ ├── assets/ ├── components/ │ ├── auth/ │ │ └── SignUpForm.tsx │ ├── payment/ │ │ └── PaymentForm.tsx │ ├── common/ │ │ └── Button.tsx │ └── employees/ │ ├── EmployeeList.tsx │ └── EmployeeSummary.tsx ├── helpers/ ├── reducers/ └── services/ ``` - **專案規模**:中型到大型 - **優點**: - 簡單明了 - 內容按功能分組 - **缺點**: - 與功能相關的邏輯仍然分佈在多個資料夾類型中 現在讓我們回到需要修改或刪除支付模組的問題陳述。有了這個結構,現在做起來就容易多了。 「2 級」資料夾結構是我**為大多數專案推薦的**結構。 第 3 種:依功能/模組分組 ---------------- 對於較大的專案,「3 級」結構提供了高度模組化的方法,為每個模組內應用程式的不同方面定義了清晰的邊界: ``` └── src/ ├── assets/ ├── modules/ | ├── core/ │ │ ├── components/ │ │ ├── design-system/ │ │ ├── hooks/ │ │ ├── persistence/ │ │ └── utils/ │ ├── payment/ │ │ ├── components/ │ │ ├── hooks/ │ │ ├── utils/ │ │ └── services/ │ ├── auth/ │ │ ├── components/ │ │ ├── hooks/ │ │ ├── utils/ │ │ └── services/ │ └── employees/ │ ├── components/ │ │ ├── EmployeeList.tsx │ │ └── EmployeeSummary.tsx │ ├── design-system/ │ ├── hooks/ │ ├── lib/ │ └── utils/ └── ``` - **專案規模**:大型且複雜 - **優點**: - 內容按功能/模組清晰地分組 - 特徵/模組是現實世界中物件的清晰表示 - **缺點**: - 您必須充分了解業務邏輯才能做出正確的分組決策 有了這個,如果您要刪除或修改支付邏輯,您將立即知道從哪裡開始。 為資料夾名稱賦予一致的含義 ------------- 無論結構層級如何,某些資料夾名稱都應具有特定的含義。資料夾名稱的含義可能會根據您的偏好或專案的約定而有所不同。 以下是我通常對資料夾名稱的看法: - **Components** :React 元件 - 主要的 UI 建構塊。 - **design-system** :基於設計系統的基本 UI 元素和模式。 - **icon** :用於內嵌使用的 SVG 圖示。 - **hooks** :用於共享邏輯的自訂 React 鉤子。 - **hocs** :反應高階元件。 - **contexts** / **providers** :包含 React Contexts 和 Providers。 - **utils** :與業務邏輯或任何技術無關的通用邏輯實用程序,例如字串操作、數學計算等。 - **lib** :與某些技術相關的實用程序,例如 DOM 操作、HTML 相關邏輯、localStorage、IndexedDB 等。 - **plugins** :第三方插件應該放在這裡(例如 i18n、Sentry 等) - **services** :封裝主要業務邏輯。 - **helpers** :提供特定於業務的實用程式。 - **styles** :包含(全域)CSS 或 CSS-in-JS 樣式。 - **types** :適用於一般 TypeScript 類型、枚舉和介面。 - **configs** :應用程式的配置(例如環境變數) - **Constants** :常數,未更改的值(例如`export const MINUTES_PER_HOUR = 60` )。 - **api** :用於與伺服器通訊的邏輯。 - **graphql** :GraphQL 特定的程式碼。 - **states** 、 **reducers** 、 **store** 、 **actions** 、 **selectors** :全域狀態管理邏輯(Redux、Zustand、Valtio、Jotai 等) - **路線**/**路由器**:定義路線(如果您使用React Router或類似的)。 - **測試**:程式碼的單元測試和其他類型的測試。 結論 -- 在 React 專案中選擇正確的資料夾結構至關重要,並且應該基於專案的大小和複雜性。雖然「Level 1」可能足以滿足小型專案的需要,但「Level 2」和「Level 3」為中型和大型專案提供了更有組織性和模組化的結構。就我個人而言,我經常**推薦「Level 2」資料夾結構**。此外,了解常見資料夾名稱有助於在 React 應用程式中保持一致且直覺的架構。 --- 原文出處:https://dev.to/itswillt/folder-structures-in-react-projects-3dp8
時間越長,我就越成為函數式程式設計的愛好者。即使當我在 OOP 程式碼庫中工作時,我也會嘗試應用旨在簡化程式碼並更輕鬆地預測結果的小概念。身為 Ruby 專家,我也喜歡使用功能程式碼編寫單元測試是多麼簡單。 本文的目的是分享我對函數式程式設計概念的看法,並提出一種可以在已編寫的 OOP 程式碼中使用函數式概念的方法。希望我們能夠停止爭論哪種範式更好,並開始編寫好的想法,每次都能產生更好的程式碼! 目錄 -- - [一開始,有函數式編程](#in-the-beginning-there-was-functional-programming) - [進入OOP,這個範式是什麼?](#entering-oop-what-is-this-paradigm) - [什麼是類別以及我們如何以不同的方式思考它](#what-is-a-class-and-how-can-we-think-about-it-differently) - [變異還是不變異:什麼是不變性](#to-mutate-or-not-to-mutate-what-is-immutability) - [床下的怪物:有什麼副作用](#the-monster-under-the-bed-what-are-side-effects) - [隔離一切:什麼是純函數](#isolate-everything-what-are-pure-functions) - [使用函數式模式而不需要完整的 haskell](#using-functional-patterns-without-going-full-haskell) - [結論](#conclusion) 一開始,有函數式編程 ----------  函數式程式設計範式於 1958 年隨著第一個 Lisp 語言的出現而出現(美好的時光)。它的根源可以追溯到 Alonzo Church 的 lambda 演算。函數式程式設計的核心原則圍繞著最小化對程式碼庫中狀態的依賴。 與允許狀態但強調封裝的物件導向程式設計 (OOP) 不同,函數式程式設計師努力優先編寫無狀態元件。這種方法鼓勵建立獨立於外部狀態變數的程式碼。 此外,即使引入了狀態,在編寫狀態時也必須考慮不變性、函數的純度,甚至避免副作用。隨著本文的深入,所有這些概念都將進一步介紹。 進入OOP,這個範式是什麼? --------------  OOP,或更廣為人知的名稱為“物件導向程式設計”,是一種可以追溯到 1967 年的範式。其最偉大的代表是 Simula、Smalltalk 和 Java。背後的思想過程是透過強制封裝實踐來將這些狀態以及修改它們的任何行為分組到公共「實體」或「物件」下,從而減少「全局」狀態的數量。 事實上,「物件導向程式設計」這個名字多年來一直被廣泛討論。 OOP 的建立者之一 Alan Key 實際上希望更多地關注該範例的訊息傳遞方面。這意味著我們應該強調封裝並允許物件之間進行狀態和行為的通訊。也許在不同的宇宙中,我們可以擁有「面向訊息的程式」。然而,OOP 這個名字已經經久不衰,而我們就在這裡! 我不知道你怎麼想,但是這個考慮範式的另一個可能名稱的簡單過程讓我的思維變得瘋狂,重新思考了一些概念,並實際上簡化了我建置軟體的方式。 什麼是類別以及我們如何以不同的方式思考它 --------------------  我想每個人都聽過那個經典的講座,其中我們學到了“動物”類,其中包括“狗”類,對嗎?你可能聽過同樣的話(至少我聽過)。 > 類別是現實世界中實體的藍圖,描述其特徵和操作。 雖然不正確,但我想建議稍微改變一下單字的用法,以幫助澄清封裝,以便更好地理解,就像它對我所做的那樣。讓我們考慮以下新引文: > 類別是一種封裝狀態和在該狀態上操作的行為的方法。 這個簡單的字的改變確實讓我的思想改變了。我不再嘗試將類別視為現實世界的實體,而是開始簡單地將其視為將具有相似上下文的狀態分組在一起並公開對這些狀態進行操作的函數的另一種方式。我希望這個小小的改變也能幫助你回顧自己的概念! 以這種方式抽象化這個概念的重要性是,在從具有不同結構(例如模組)的語言中讀取程式碼時變得熟練。我們可以觀察到這段 OOP 程式碼是用 typescript 寫的: ``` class Github { private _url: string; privale _repo: string; private _username: string; constructor(url: string, repo: string, username: string) { this._repo = repo this._username = username this._url = url } public createRepo(name: string): void { // TODO: do stuff here using the provided state in _url, _repo and _username } } ``` 與此 Elixir 程式碼完全等效,即使 Elixir 程式碼使用“模組”而不是“類別”: ``` defmodule Github do @url "" @repo "" @username "" defstruct url: @url, repo: @repo, username: @username def new(url, repo, username) do %Github{url: url, repo: repo, username: username} end def create_repo(%Github{repo: repo, username: username}, name) do # TODO: do stuff here using the provided state in url, repo, and username end end ``` 接下來我們將研究一些功能概念並進一步討論這些範例的合併,讓我們開始吧! 變異還是不變異:什麼是不變性 --------------  現在我們正在達到第一個真正的功能概念,而且是一個非常重要的概念,我可以補充一下(一切都在這裡計劃)!為了正確理解不變性,讓我們回顧一下在程式設計中處理值的方式: 通常,我們將值綁定到變數,以便稍後可以對它們進行操作,對嗎?就像簡單的事情 ``` # Bounding values to variables name = 'Cherry' age = 23 # Operating on it and bounding to another variable year_born = Time.now.year - age # Printing it puts "#{name} has #{age} years old and was born at #{year_born}" ``` 對於這些變數,透過更新其值來更改原始變數是很常見的,但這裡缺少的是:修改變數是一種**破壞性**操作。 但為什麼?好吧,讓我們想像一下多個操作(函數或程式碼區塊)在不同時刻和頻率修改相同變數。在這種情況下,我們會產生很多問題,例如: - **1. 無法對操作重新排序或根本無法更改它們:**當我們有如此多的依賴程式碼時,甚至很難對程式碼進行重新排序或更改,因為所有內容都綁定到特定的更改順序。 - **2. 理解程式碼在做什麼的心理負擔:**雖然這是個人觀點,但我認為這是一個廣受認可的觀點。高度可變的程式碼很容易變得混亂且難以理解資料流,需要除錯器等工具來逐步完成轉換。 - **3. 測試時的困難:**模擬函數轉換的特定狀態確實很困難,這將逐漸擴展您的單元測試,直到它們不再是單元。 不變性可以定義為避免更改(或變異)程式內任何變數的做法。儘管根據語言的不同,我們可能需要做出讓步並改變一些控制變數,但這裡要學到的總體教訓是: > 我們應該不惜一切代價避免改變沒有定義範圍的變數。 透過這句話,我的意思是可以在函數內建立作用域變數並在那裡對其進行變異。然而,一旦您將這個可變變數傳遞給另一個函數,您就會增加改變相同變數的目標數量,並且您將慢慢失去控制。這正是我們想要避免的情況! 床底下的怪物:有什麼副作用 -------------  每當有人提出這個話題來討論時,這個話題就會引起很大的熱度。我可能不會涵蓋這個主題的每一個細微差別,但我一定會向您解釋它們是什麼以及我如何在我自己的軟體中管理副作用,好嗎? 那麼,副作用就是透過呼叫協定(HTTP、WebSocket、GraphQL 等)甚至操作 stdin/stdout 與外部資源(或「外部世界」)互動的每一次計算。是的,我知道,即使是我們無害的`print`也會在這裡受到指責。 😔 但與變異性不同的是,我們不應該盡可能避免使用它,而應該將其隔離在單獨處理副作用的特定函數中。這樣,我們將程式碼分為「不執行任何副作用的函數」和「執行副作用的函數」。但為什麼要擔心這種分離呢? 每次我們觸發對「外部世界」的任何操作時,我們都會失去對這個特定計算部分可能發生的情況的控制(例如在執行 HTTP 呼叫時,伺服器可能會關閉或可能根本不存在)。其他問題包括測試困難和程式碼可預測性降低。 由於我們無法編寫沒有副作用的任何現實世界軟體,因此一般建議是將其聚集成小函數,透過對錯誤的適當抽象來單獨處理它。這樣,就可以只測試我們 100% 控制的函數,並模擬所有執行副作用的函數。 例如,請考慮以下執行 HTTP 請求的函數以及轉換從該請求傳回的資料的小函數。 ``` require 'faraday' module MyServiceModule # This function perform side effects def perform_http_request conn = Faraday.new(url: "fakeapi.com") begin response = conn.get {ok: true, data: response.body} rescue => e {ok: false, error: e} end end # These functions doens't perform any side effects def upcase_name(name) return '' unless name.is_a?(String) name.upcase end def retrieve_born_year(age) return 0 unless age.is_a?(Integer) Time.now.year - age end end ``` > 看到我怎麼說「錯誤周圍的抽象」了嗎?這正是上面的程式碼範例中實現的,而不是讓異常在我們針對雜湊抽象的程式碼中冒泡。 在使用「副作用」和「無副作用」之間的明確定義來定義這些函數之後,很容易預測程式碼中會發生什麼,也更容易測試,如下所示: ``` require 'minitest/autorun' class TestingStuff < Minitest::Test def test_upcase_name assert_equal MyServiceModule.upcase_name "cherry", "CHERRY" assert_equal MyServiceModule.upcase_name "kalane", "KALANE" assert_equal MyServiceModule.upcase_name "Thales", "THALES" end def test_retrieve_born_year Time.stub :now, Time.new(2024, 3, 5) do assert_equal MyServiceModule.retrieve_born_year 23, 2001 assert_equal MyServiceModule.retrieve_born_year 20, 2004 assert_equal MyServiceModule.retrieve_born_year 14, 2010 end end end ``` 這個策略真的很棒,因為您甚至不需要在測試時擔心副作用部分,只需為實際執行某些操作的程式碼轉換部分編寫斷言,您最終會得到更好的測試,真正驗證重要的內容您的程式碼庫的一部分!整齊吧? 隔離一切:什麼是純函數 -----------  現在是時候總結到目前為止所獲得的所有知識了。在前面的範例中,我們觀察到程式碼分為「副作用」和「無副作用」。我們還看到了這些功能如何更容易測試,並且我們的主要轉換業務邏輯應該保持隔離。您想知道這些函數叫什麼嗎?它們是**純函數**! 讓我們檢查純函數的正確形式定義並逐步探索這個概念。 > 純函數是尊重不變性、不執行任何副作用並且在給定相同參數的情況下傳回相同輸出的函數。 基本上,純函數遵循我們之前提到的所有原則,而且它們總是為相同的參數產生相同的返回。讓我們來看看之前的函數。 ``` def upcase_name(name) return '' unless name.is_a?(String) name.upcase end upcase_name('cherry') # => Will be *always* CHERRY ``` 使用純函數,我們可以輕鬆定義多個斷言,因為我們不受任何需要大量模擬的上下文的約束。我們只需用靜態值傳遞所需的參數,就這樣! 由於純函數非常小且可組合,因此它們的數量增加得非常快。為了解決這個問題,像 Elixir 這樣的函數式語言提供了像管道這樣的組合運算符,這使得按順序執行多個純函數變得非常容易。 ``` "cherry " |> trim |> upcase # => "CHERRY" ``` > 管道運算子源自 Bash 等函數。您可以在這裡閱讀更多相關資訊:\[ <https://dev.to/cherryramatis/linux-filters-how-to-streamline-text-like-a-boss-2dp4#what-is-a-pipeline> \] 使用函數式模式而不需要完整的 haskell ----------------------  我一直害怕學習函數範式,因為社群透過使用現成的句子和大概念讓每個試圖學習一些小技巧的人變得非常複雜。在掌握了許多函數式語言並嘗試盡可能多地學習之後,我的目標是簡化這些概念,最重要的是,提倡在 OOP 程式碼中使用函數式概念。 應用純函數(或純方法,如果您願意)、不變性和副作用分離可以使您的 OOP 程式碼看起來更乾淨和解耦。你不需要知道什麼是 monad 或如何在 Haskell 中手動編寫編譯器;您可以使用簡單而有效的函數概念來堅持使用 Ruby on Rails! 我希望透過這篇小文章(以及本系列中的文章),無論您選擇哪種語言和框架,您都可以透過可組合性和簡單性來改進您的程式碼庫。 結論 -- 這篇文章是我嘗試使函數範式的知識民主化(在我的能力和專業知識範圍內)。需要強調的是,我不是函數式專家,本文針對的是了解 OOP 並對函數式程式設計感興趣的初學者。我希望它有用,並且我願意提供任何需要的幫助。願原力與你同在🍒 --- 原文出處:https://dev.to/cherryramatis/ending-the-war-or-continuing-it-lets-bring-functional-programming-to-oop-codebases-3mhd
在軟體開發領域,這個以其多樣化和強烈持有觀點而聞名的領域,很少有實踐能夠像 SOLID 原則那樣達成共識,作為成為更好的軟體工程師的保證途徑。 Robert C. Martin 在 2000 年代初期正式製定的 5 條黃金法則極大地影響了軟體開發產業,並為更好的程式碼品質和決策過程製定了新標準,至今仍具有相關性。  SOLID 原則是專門為支援 OOP(物件導向程式設計)範例而設計的。因此,本文是為希望提高開發技能並編寫更優雅、可維護和可擴展程式碼的 OOP 開發人員而設計的。 這裡使用的語言是 TypeScript,遵循常見的跨語言 OOP 概念。需要基本的 OOP 知識。 --- 1. S = 單一職責原則(SRP) ------------------ 單一職責原則 (SRP) 是五個 SOLID 原則之一,它規定每個類別應該只有一個職責,以保持有意義的關注點分離。 此模式是一種稱為「上帝物件」的常見反模式的解決方案,「上帝物件」只是指承擔太多職責的類別或物件,使其難以理解、測試和維護。 遵循 SRP 規則有助於使程式碼元件可重複使用、鬆散耦合且易於理解。讓我們探討這項原則,展示 SRP 違規情況和解決方案。 ### 全域宣告 ``` enum Color { BLUE = 'blue', GREEN = 'green', RED = 'red' } enum Size { SMALL = 'small', MEDIUM = 'medium', LARGE = 'large' } class Product { private _name: string; private _color: Color; private _size: Size; constructor (name: string, color: Color, size: Size) { this._name = name; this._color = color; this._size = size; } public get name(): string { return this._name; } public get color(): Color { return this._color; } public get size(): Size { return this._size; } } ``` ### 違反 在下面的程式碼中, `ProductManager`類別負責**products 的建立和存儲**,違反了單一職責原則。 ``` class ProductManager { private _products: Product[] = []; createProduct (name: string, color: Color, size: Size): Product { return new Product(name, color, size); } storeProduct (product: Product): void { this._products.push(product); } getProducts (): Product[] { return this._products; } } const productManager: ProductManager = new ProductManager(); const product: Product = productManager.createProduct('Product 1', Color.BLUE, Size.LARGE); productManager.storeProduct(product); const allProducts: Product[] = productManager.getProducts(); ``` ### 解決 將產品建立和儲存的處理分離到兩個不同的類別可以減少`ProductManager`類別的職責數量。這種方法進一步模組化了程式碼並使其更易於維護。 ``` class ProductManager { createProduct (name: string, color: Color, size: Size): Product { return new Product(name, color, size); } } class ProductStorage { private _products: Product[] = []; storeProduct (product: Product): void { this._products.push(product); } getProducts (): Product[] { return this._products; } } ``` #### 用法: ``` const productManager: ProductManager = new ProductManager(); const productStorage: ProductStorage = new ProductStorage(); const product: Product = productManager.createProduct("Product 1", Color.BLUE, Size.LARGE); productStorage.storeProduct(product); const allProducts: Product[] = productStorage.getProducts(); ``` --- 2. O = 開閉原理 (OCP) ----------------- > “軟體實體應該對擴展開放,但對修改關閉” 開閉原則 (OCP) 是*「寫一次,寫得夠好以便可擴展,然後就忘記它」。* 這項原則的重要性取決於這樣一個事實:模組可能會根據新的需求不時發生變化。如果在模組編寫、測試並上傳到生產環境後出現新需求,則修改此模組通常是不好的做法,尤其是當其他模組依賴它時。為了防止這種情況,我們可以使用開閉原則。 ### 全域宣告 ``` enum Color { BLUE = 'blue', GREEN = 'green', RED = 'red' } enum Size { SMALL = 'small', MEDIUM = 'medium', LARGE = 'large' } class Product { private _name: string; private _color: Color; private _size: Size; constructor (name: string, color: Color, size: Size) { this._name = name; this._color = color; this._size = size; } public get name(): string { return this._name; } public get color(): Color { return this._color; } public get size(): Size { return this._size; } } class Inventory { private _products: Product[] = []; public add(product: Product): void { this._products.push(product); } addArray(products: Product[]) { for (const product of products) { this.add(product); } } public get products(): Product[] { return this._products; } } ``` ### 違反 讓我們描述一個實作產品過濾類別的場景。讓我們加入按顏色過濾產品的功能。 ``` class ProductsFilter { byColor(inventory: Inventory, color: Color): Product[] { return inventory.products.filter(p => p.color === color); } } ``` 我們已經測試了此程式碼並將其部署到生產中。 幾天后,客戶請求一項新功能 - 也按大小過濾。然後我們修改該類別以支援新的要求。 **現在違反了開閉原則!** ``` class ProductsFilter { byColor(inventory: Inventory, color: Color): Product[] { return inventory.products.filter(p => p.color === color); } bySize(inventory: Inventory, size: Size): Product[] { return inventory.products.filter(p => p.size === size); } } ``` ### 解決 在不違反 OCP 的情況下實現過濾機制的正確方法應該使用「規範」類別。 ``` abstract class Specification { public abstract isValid(product: Product): boolean; } class ColorSpecification extends Specification { private _color: Color; constructor (color) { super(); this._color = color; } public isValid(product: Product): boolean { return product.color === this._color; } } class SizeSpecification extends Specification { private _size: Size; constructor (size) { super(); this._size = size; } public isValid(product: Product): boolean { return product.size === this._size; } } // A robust mechanism to allow different combinations of specifications class AndSpecification extends Specification { private _specifications: Specification[]; // "...rest" operator, groups the arguments into an array constructor ((...specifications): Specification[]) { super(); this._specifications = specifications; } public isValid (product: Product): boolean { return this._specifications.every(specification => specification.isValid(product)); } } class ProductsFilter { public filter (inventory: Inventory, specification: Specification): Product[] { return inventory.products.filter(product => specification.isValid(product)); } } ``` #### 用法: ``` const p1: Product = new Product('Apple', Color.GREEN, Size.LARGE); const p2: Product = new Product('Pear', Color.GREEN, Size.LARGE); const p3: Product = new Product('Grapes', Color.GREEN, Size.SMALL); const p4: Product = new Product('Blueberries', Color.BLUE, Size.LARGE); const p5: Product = new Product('Watermelon', Color.RED, Size.LARGE); const inventory: Inventory = new Inventory(); inventory.addArray([p1, p2, p3, p4, p5]); const greenColorSpec: ColorSpecification = new ColorSpecification(Color.GREEN); const largeSizeSpec: SizeSpecification = new SizeSpecification(Size.LARGE); const andSpec: AndSpecification = new AndSpecification(greenColorSpec, largeSizeSpec); const productsFilter: ProductsFilter = new ProductsFilter(); const filteredProducts: Product[] = productsFilter.filter(inventory, andSpec); // All large green products ``` 過濾機制現在是完全可擴展的。現有的類別不應該再被修改。 如果有新的過濾要求,我們只需建立一個新規範即可。或者如果需要更改規範組合,可以透過使用`AndSpecification`類別輕鬆完成。 --- 3. L=里氏替換原理(LSP) ---------------- 里氏替換原則(LSP)是軟體元件靈活性和穩健性的重要規則。它由 Barbara Liskov 提出,並成為 SOLID 原則的基本要素。 LSP 規定**超類別的物件應該可以用子類別的物件替換,而不影響程式的正確性。**換句話說,子類別應該擴展超類別的行為而不改變其原始功能。採用這種方法可以提高軟體元件的質量,確保可重複使用性並減少意外的副作用。 ### 違反 下面的範例說明了違反里氏替換原則 (LSP) 的場景。當`Rectangle`物件被`Square`物件取代時,透過檢查程序的行為可以觀察到這種違規的跡象。 #### 聲明: ``` class Rectangle { protected _width: number; protected _height: number; constructor (width: number, height: number) { this._width = width; this._height = height; } get width (): number { return this._width; } get height (): number { return this._height; } set width (width: number) { this._width = width; } set height (height: number) { this._height = height; } getArea (): number { return this._width * this._height; } } // A square is also rectangle class Square extends Rectangle { get width (): number { return this._width; } get height (): number { return this._height; } set height (height: number) { this._height = this._width = height; // Changing both width & height } set width (width: number) { this._width = this._height = width; // Changing both width & height } } function increaseRectangleWidth(rectangle: Rectangle, byAmount: number) { rectangle.width += byAmount; } ``` #### 用法: ``` const rectangle: Rectangle = new Rectangle(5, 5); const square: Square = new Square(5, 5); console.log(rectangle.getArea()); // Expected: 25, Got: 25 (V) console.log(square.getArea()); // Expected: 25, Got: 25 (V) // LSP Violation Indication: Can't replace object 'rectangle' (superclass) with 'square' (subclass) since the results would be different. increaseRectangleWidth(rectangle, 5); increaseRectangleWidth(square, 5); console.log(rectangle.getArea()); // Expected: 50, Got: 50 (V) // LSP Violation, increaseRectangleWidth() changed both width and height of the square, unexpected behavior. console.log(square.getArea()); //Expected: 50, Got: 100 (X) ``` ### 解決 重構的程式碼現在遵循 LSP,確保超類別`Shape`的物件可以替換為子類別`Rectangle`和`Square`的物件,而不會影響計算面積的正確性,也不會引入任何改變程式行為的不必要的副作用。 #### 聲明: ``` abstract class Shape { public abstract getArea(): number; } class Rectangle extends Shape { private _width: number; private _height: number; constructor (width: number, height: number) { super(); this._width = width; this._height = height; } getArea (): number { return this._width * this._height; } } class Square extends Shape { private _side: number; constructor (side: number) { super(); this._side = side; } getArea (): number { return this._side * this._side; } } function displayArea (shape: Shape): void { console.log(shape.getArea()); } ``` #### 用法: ``` const rectangle: Rectangle = new Rectangle(5, 10); const square: Square = new Square(5); // The rectangle's area is correctly calculated displayArea(rectangle); // Expected: 50, Got: 50 (V) // The square's area is correctly calculated displayArea(square); // Expected: 25, Got: 25 (V) ``` --- 4. I = 介面隔離原則 (ISP) ------------------- 介面隔離原則 (ISP) 強調建立特定於客戶端的介面而不是一刀切的重要性。 這種方法根據客戶的需求集中類,消除了類別必須實現它實際上不使用或不需要的方法的情況。 透過應用介面隔離原則,軟體系統可以以更靈活、易於理解和易於重構的方式建構。讓我們來看一個例子。 ### 違反 這裡違反了 ISP 規則,因為`Robot`必須實現完全沒有必要的`eat()`函數。 ``` interface Worker { work(): void; eat(): void; } class Developer implements Worker { public work(): void { console.log('Coding..'); } public eat(): void { console.log('Eating..'); } } class Robot implements Worker { public work(): void { console.log('Building a car..'); } // ISP Violation: Robot is forced to implement this function even when unnecessary public eat(): void { throw new Error('Cannot eat!'); } } ``` ### 解決 下面的範例代表了我們之前遇到的問題的解決方案。現在,介面更加簡潔且更加特定於客戶端,允許客戶端類別僅實現與其相關的方法。 ``` interface Workable { work(): void; } interface Eatable { eat(): void; } class Developer implements Workable, Eatable { public work(): void { console.log('Coding..'); } public eat(): void { console.log('Eating...'); } } class Robot implements Workable { public work(): void { console.log('Building a car..'); } // No need to implement eat(), adhering ISP. } ``` #### ISP 前後:  --- 5. D = 依賴倒置原理(DIP) ------------------ 依賴倒置原則(DIP)是最終的SOLID原則,重點是透過使用抽象來減少低層模組(例如資料讀取/寫入)和高層模組(執行關鍵操作)之間的耦合。 DIP 對於設計能夠適應變化、模組化且易於更新的軟體至關重要。 **DIP 的關鍵準則是:** 1. **高層模組不應該依賴低層模組。兩者都應該依賴抽象。**這意味著應用程式的功能不應該依賴特定的實現,以便使系統更加靈活並且更容易更新或替換低階實現。 2. **抽像不應該依賴細節。細節應該取決於抽象。**這鼓勵設計專注於實際需要什麼操作,而不是如何實現這些操作。 ### 違反 讓我們來看一個展示依賴倒置原則 (DIP) 違規的範例。 `MessageProcessor` (高階模組)緊密耦合並直接依賴`FileLogger` (低階模組),違反了原則,因為它不依賴抽象層,而是依賴特定的類別實作。 **額外獎勵:**這也違反了開閉原則(OCP)。如果我們想要更改日誌記錄機制以寫入資料庫而不是文件,我們將被迫直接修改`MessageProcessor`函數。 ``` import fs from 'fs'; // Low Level Module class FileLogger { logMessage(message: string): void { fs.writeFileSync('somefile.txt', message); } } // High Level Module class MessageProcessor { // DIP Violation: This high-level module is is tightly coupled with the low-level module (FileLogger), making the system less flexible and harder to maintain or extend. private logger = new FileLogger(); processMessage(message: string): void { this.logger.logMessage(message); } } ``` ### 解決 以下重構的程式碼表示為了遵守依賴倒置原則 (DIP) 所需進行的變更。與前面的範例相反,高階類別`MessageProcessor`持有特定低階類別`FileLogger`的私有屬性,現在它持有`Logger`類型的私有屬性(表示抽象層的介面)。 這種更好的方法減少了類別之間的依賴關係,從而使程式碼更具可擴展性和可維護性。 #### 聲明: ``` import fs from 'fs'; // Abstraction Layer interface Logger { logMessage(message: string): void; } // Low Level Module #1 class FileLogger implements Logger { logMessage(message: string): void { fs.writeFileSync('somefile.txt', message); } } // Low Level Module #2 class ConsoleLogger implements Logger { logMessage(message: string): void { console.log(message); } } // High Level Module class MessageProcessor { // Resolved: The high level module is now loosely coupled with the low level logger modules. private _logger: Logger; constructor (logger: Logger) { this._logger = logger; } processMessage (message: string): void { this._logger.logMessage(message); } } ``` #### 用法: ``` const fileLogger = new FileLogger(); const consoleLogger = new ConsoleLogger(); // Now the logging mechanism can be easily replaced const messageProcessor = new MessageProcessor(consoleLogger); messageProcessor.processMessage('Hello'); ``` #### DIP 之前和之後:  結論 -- 透過遵循 SOLID 原則,開發人員在開發或維護任何規模的軟體系統時,可以避免常見的陷阱,例如緊密耦合、缺乏靈活性、程式碼可重複使用性差以及一般維護困難。掌握這些原則是成為更好的軟體工程師的又一步。 --- 原文出處:https://dev.to/idanref/solid-the-5-golden-rules-to-level-up-your-coding-skills-2p82
介紹 -- 在 SPA 出現之前,Web 應用程式通常是多頁面的。這意味著每次用戶與應用程式互動時,伺服器都會發送完整的新頁面,然後瀏覽器會再次載入它。每次用戶在頁面之間導航時,都會發生完整的頁面重新加載,這可能會減慢速度並造成不太流暢的用戶體驗。類似的應用程式通常是使用伺服器端技術建立的,例如 PHP、Ruby on Rails、ASP.NET 等,這些技術在伺服器端產生 HTML 程式碼並將其發送到瀏覽器。  Web開發人員是通用專家,他們同時負責前端和後端部分。隨著網路技術的發展和用戶的需求,需要新的解決方案,使他們能夠在沒有任何問題或等待的情況下使用互動式介面。 這就是第一個使用 BackboneJs 或 AngularJs 的 SPA 解決方案的出現。它們使我們能夠減少伺服器的負載(當時伺服器的資源有限),並在透過 JS 處理網頁時提供互動性,因為無需等待伺服器更新的新頁面。 這就是前端和後端部分的劃分。純粹前端開發人員的角色變得更加需求和多樣化。他們開始專注於建立使用者介面、使用 HTML、CSS 和 JavaScript,以及與 API 和伺服器互動。另一方面,後端開發人員變得更加關注資料處理、應用程式業務邏輯、使用資料庫和建立伺服器 API。 這就是我們進入 React、Angular2、Vue 和其他 Web 應用程式開發工具時代的方式。現在我們不再建立簡單的表單和列表,而是有 js 路由、狀態管理、瀏覽器 API、將授權令牌綁定到請求、資料映射等。 > ### 我們開始把簡單的事情複雜化。 透過這種方法,出現了以下問題: - **溝通協調困難**。 Api 合約與通訊方法 — HTTP 1.1、Websocket、GraphQL。 JSON 解析和驗證。 - **理解和認識上的分歧**。例如,您可以開發一個建立許多查詢的前端應用程式,並將其視為正常且最佳化的 SPA。但對於後端來說,這是一個非常危險的情況,因為它現在需要大量的資料庫存取以及對這些資料的適當聚合,這會影響它的效能和維護。 - **重複工作**。後端的大多數 CRUD 操作在前端都有類似的行為。我們不只是從伺服器獲取列表,現在我們將其放入 store() 中,每個用戶操作都透過dispatch() 處理並等待請求執行,之後我們透過reducer() 更新store根據結果——**後端對資料庫所做的一切,我們都會在前端重複**。 (頁面重新加載和從伺服器將 SPA 恢復到當前狀態也值得一提 - 目前是一個單獨的痛苦) - **除錯和測試困難**。現在您需要考慮可能的整合問題並在應用程式雙方的上下文中測試它們。是的,您可以為前端應用程式建立隔離的 e2e 測試,但它們不能保證生產中的可靠性。是的,有 ZoD 用於驗證伺服器回應,但它的使用百分比是多少? - **增加了開發時間和成本**。對 API 合約的任何更改都需要兩個人同時進行。您不能像以前那樣直接將模板變更為伺服器。你需要集會、分成單獨的任務、商業分析專家等等來讓改變順利進行。 - **搜尋引擎優化**。由於我們的應用程式完全是透過 JS 建構的,搜尋引擎無法取得應用程式內容及其導航來正確索引它,因此需要 SSR 和 SSG 解決方案。 - **安全**。在頁面上輸入的任何關鍵資料在傳遞到伺服器之前都需要隱藏。此外,應用程式需要向伺服器請求大量個人訊息,從而洩露存取權杖。 那麼,通常的前端為什麼會消亡呢? ---------------- 只需存取任何資源,您就會看到有多少職位空缺: - Python + Django - PHP + Laravel - NextJs + React - Nuxt + Vue 這些都是用於基於伺服器的 Web 應用程式開發的捆綁包。由於採用 Hydration 和 Resumability 方法,伺服器只能渲染介面的修改部分,而無需重新載入頁面。 他們提供什麼: - 伺服器應用程式現在不需要複雜的 HTTP 或 WS 合約並且雙方都支援它們,它可以使用更好的方法與 gRPC 等其他服務交換資訊。 - 由於缺乏中間批准,更改過程更快,對於 1 人,用戶看到的結果會立即更改。 - 測試可以全面檢查應用程式,消除整合測試並減少錯誤。 - 您僅交換 HTML 標記,所有「請求-回應」邏輯對使用者來說都是隱藏的 - 當您可以傳遞現成的範本時,為什麼還要傳遞大量 JSON 資料來將 SPA 還原到正確的狀態呢? - 你不需要擔心瀏覽器相容性,也不需要使用babel等工具,因為頁面上的JS程式碼很少。 隨著No-Code解決方案的出現、透過AI生成模板、龐大的伺服器資源和SEO需求——目前數量的前端開發人員和工具不再需要只開發前端部分。 企業主有一個合理的問題——“*為什麼我需要雇用一個純粹的前端開發人員和一個純粹的後端開發人員來做一個簡單的應用程式?”* 全端開發人員並不是一種管理時尚,就節省人員配備而言,現在它已成為中流砥柱。你不需要一個純粹的前端開發人員,你需要一個能夠製作整個應用程式、直接對資料庫或其他服務執行簡單操作並顯示結果的開發人員。 是的,毫無疑問仍然會存在需要前端和後端分離的複雜或“無頭”應用程式,但大多數應用程式將脫離 SPA 並沿著已經存在的方式發展,但現在我們有一個解決方案那些問題。隨著 HTMX 的出現,任何具有基礎知識的後端開發人員都可以建立 Web 應用程式。現在你甚至不需要了解 JS 就可以建立一個幾乎沒有邏輯的單頁應用程式。 你可能會問,「*前端開發人員不僅負責 JS 邏輯,還負責 CSS 和適當的選擇器、HTML 及其語義,後端開發人員現在必須知道嗎?* 」 — 不,現在人工智慧或「HTML 佈局設計師」可以根據 Figma 的佈局產生模板。 HTML 範本的邏輯和互動性現在在伺服器上定義。 結論 -- 現在是思考您是否真的需要所有這些複雜的前端開發工具以及您是否應該保持純粹的前端開發人員的好時機。 我預計目前的前端開發人員將採用 60% 前端和 40% 後端的比例轉向全端資格,以保持相關專家的地位。 HTMX 只是開始,NextJs 或 Nuxt 工具的向量將會成長,Angular 類型的框架如果不能適應新的實作就會消亡,儘管 Angular 生態系統已經在 AnalogJs 上有了原型 資源 -- - [**htmx - 強大的 html 工具**](https://htmx.org/) - [**模擬**](https://analogjs.org/) - [按「前端開發人員」角色搜尋職位](https://www.indeed.com/jobs?q=front+end+developer&l=Remote) - [按「全端開發人員」角色搜尋職位](https://www.indeed.com/jobs?q=full+stack+developer&l=Remote) - [**Vercel 的 Next.js - React 框架**](https://nextjs.org/) - [**Nuxt:直覺的 Vue 框架**](https://nuxt.com/) --- 原文出處:https://dev.to/misterion96/the-front-end-development-were-used-to-is-dying-4e19
剛開始接觸**物件導向編程**,對**SOLID**感到有點迷失?不用擔心,在本文中,我將向您解釋它並提供如何在程式碼開發中使用它的範例。 什麼是固體? ------ 在物件導向程式設計中, **SOLID**是五個設計原則的縮寫,旨在增強對軟體的理解、開發和維護。 透過應用這組原則,您應該注意到錯誤的減少、程式碼品質的提高、程式碼組織性更強、耦合性降低、重構增強以及程式碼重用的鼓勵。讓我們來看看他們。 1. S-單一職責原則 -----------  > SRP - 單一職責原則 這確實很簡單,但非常重要:**一個類別應該有一個且只有一個改變的理由。** 不再建立具有多種功能和職責的類,是嗎?您可能遇到甚至建立了一個可以完成所有操作的類,即所謂的*God Class* 。目前看起來似乎沒問題,但是當您需要更改該類別的邏輯時,肯定會出現問題。 > 上帝類別:在OOP中,這是一個`do`或`knows`太多事情的類別。 ``` class ProfileManager { authenticateUser(username: string, password: string): boolean { // Authenticate logic } showUserProfile(username: string): UserProfile { // Show user profile logic } updateUserProfile(username: string): UserProfile { // Update user profile logic } setUserPermissions(username: string): void { // Set permission logic } } ``` 此**ProfileManager**類別執行**四個**不同的任務,違反了 SRP 原則。它正在驗證和更新資料、進行演示,最重要的是,它正在設定權限,所有這些都是同時進行的。 ### 這可能導致的問題 - `Lack of cohesion -`一個類別不應該承擔不屬於它自己的責任; - `Too much information in one place -`你的類別最終會產生許多依賴性並且難以進行更改; - `Challenges in implementing automated tests -`很難模擬這樣的類別。 現在,將**SRP**應用到`ProfileManager`類別中,讓我們來看看這個原則可以帶來的改進: ``` class AuthenticationManager { authenticateUser(username: string, password: string): boolean { // Authenticate logic } } class UserProfileManager { showUserProfile(username: string): UserProfile { // Show user profile logic } updateUserProfile(username: string): UserProfile { // Update user profile logic } } class PermissionManager { setUserPermissions(username: string): void { // Set permission logic } } ``` 您可能想知道, `can I apply this only to classes?`答案是:**完全不是**。您也可以(並且應該)將其應用於方法和函數。 ``` // ❌ function processTasks(taskList: Task[]): void { taskList.forEach((task) => { // Processing logic involving multiple responsibilities updateTaskStatus(task); displayTaskDetails(task); validateTaskCompletion(task); verifyTaskExistence(task); }); } // ✅ function updateTaskStatus(task: Task): Task { // Logic for updating task status return { ...task, completed: true }; } function displayTaskDetails(task: Task): void { // Logic for displaying task details console.log(`Task ID: ${task.id}, Description: ${task.description}`); } function validateTaskCompletion(task: Task): boolean { // Logic for validating task completion return task.completed; } function verifyTaskExistence(task: Task): boolean { // Logic for verifying task existence return tasks.some((t) => t.id === task.id); } ``` 美麗、優雅、有組織的程式碼。這個原則是其他原則的基礎;透過應用它,您應該建立高品質、可讀且可維護的程式碼。 2. O——開閉原則 ----------  > OCP-開閉原則 **物件或實體應該對擴充開放,但對修改關閉。**如果您需要加入功能,最好擴展而不是修改原始程式碼。 想像一下,您需要一個類別來計算某些多邊形的面積。 ``` class Circle { radius: number; constructor(radius: number) { this.radius = radius; } area(): number { return Math.PI * this.radius ** 2; } } class Square { sideLength: number; constructor(sideLength: number) { this.sideLength = sideLength; } calculateArea(): number { return this.sideLength ** 2; } } class areaCalculator { totalArea(shapes: Shape[]): number { let total = 0; shapes.forEach((shape) => { if (shape instanceof Square) { total += (shape as any).calculateArea(); } else { total += shape.area(); } }); return total; } } ``` `areaCalculator`類別的任務是計算不同多邊形的面積,每個多邊形都有自己的面積邏輯。如果您,'lil dev,需要加入新形狀,例如三角形或矩形,您會發現自己**需要**更改此類來進行更改,對吧?這就是你遇到問題的地方,違反了`Open-Closed Principle` 。 我想到了什麼解決方案?可能會在類別中加入另一個方法並完成,問題解決了🤩。不完全是,年輕學徒😓,這就是問題所在! **修改現有類別以新增行為會帶來嚴重的風險,可能會將錯誤引入到已執行的內容中。** > 請記住:OCP 堅持認為類別應該對修改關閉,對擴展開放。 看看重構程式碼帶來的美妙之處: ``` interface Shape { area(): number; } class Circle implements Shape { radius: number; constructor(radius: number) { this.radius = radius; } area(): number { return Math.PI * this.radius ** 2; } } class Square implements Shape { sideLength: number; constructor(sideLength: number) { this.sideLength = sideLength; } area(): number { return this.sideLength ** 2; } } class AreaCalculator { totalArea(shapes: Shape[]): number { let total = 0; shapes.forEach((shape) => { total += shape.area(); }); return total; } } ``` 查看`AreaCalculator`類別:它不再需要知道要呼叫哪些方法來註冊該類別。它可以透過呼叫介面強加的契約來正確地呼叫區域方法,這是它唯一需要的。 > 只要它們實作了 Shape 接口,一切就可以正常運作。 <br/> > 分離介面背後的可擴展行為並反轉依賴關係。 > > [鮑伯叔叔](https://en.wikipedia.org/wiki/Robert_C._Martin) - `Open for extension:`您可以為類別新增功能或行為,而無需變更其原始程式碼。 - `Closed for modification:`如果您的類別已經具有可以正常工作的功能或行為,請不要更改其原始程式碼以加入新內容。 3. L——里氏代換原理 ------------  > LSP - 里氏替換原理 里氏替換原則指出**衍生類別必須可替換其基底類別。** 這個原則由 Barbara Liskov 在 1987 年提出,閱讀她的解釋可能會有點複雜。不過,不用擔心,我將提供另一個解釋和範例來幫助您理解。 > 如果對於 S 類型的每個物件 o1 都有一個 T 類型的物件 o2,使得對於所有用 T 定義的程式 P,當 o1 取代 o2 時 P 的行為保持不變,則 S 是 T 的子類型。 > > 芭芭拉‧利斯科夫,1987 你做對了?不,可能不是。是的,我第一次讀時不明白(接下來的一百遍也不明白),但等等,還有另一種解釋: > 如果 S 是 T 的子類型,則程式中類型 T 的物件可以用類型 S 的物件替換,而不改變該程式的屬性。 > > [維基百科](https://en.wikipedia.org/wiki/Liskov_substitution_principle) 如果您更喜歡視覺學習者,請不要擔心,這裡有一個例子: ``` class Person { speakName() { return "I am a person!"; } } class Child extends Person { speakName() { return "I am a child!"; } } const person = new Person(); const child = new Child(); function printName(message: string) { console.log(message); } printName(person.speakName()); // I am a person! printName(child.speakName()); // I am a child! ``` 父類別和衍生類別作為參數傳遞,程式碼繼續按預期工作。魔法?是的,這就是我們的朋友倒鉤的魔力。 ### 違規行為範例: - 重寫/實作一個不執行任何操作的方法; - 從基類傳回不同類型的值。 - 拋出意外的異常; 4. I——介面隔離原則 ------------  > ISP-介面隔離原則 這句話說**不應該強迫一個類別實作它不使用的介面和方法。**建立更具體的介面比建立大而通用的介面更好。 在下面的範例中,建立一個**Book**介面來抽象化書籍行為,然後類別實作該介面: ``` interface Book { read(): void; download(): void; } class OnlineBook implements Book { read(): void { // does something } download(): void { // does something } } class PhysicalBook implements Book { read(): void { // does something } download(): void { // This implementation doesn't make sense for a book // it violates the Interface Segregation Principle } } ``` 通用`Book`介面迫使`PhysicalBook`類別做出毫無意義的行為(*或者我們在 Matrix 中下載實體書籍?* )並且違反了**ISP**和**LSP**原則。 使用**ISP**解決此問題: ``` interface Readable { read(): void; } interface Downloadable { download(): void; } class OnlineBook implements Readable, Downloadable { read(): void { // does something } download(): void { // does something } } class PhysicalBook implements Readable { read(): void { // does something } } ``` 現在好多了。我們從`Book`介面中刪除了`download()`方法,並將其加入到派生介面`Downloadable`中。這樣,行為就可以在我們的上下文中正確隔離,並且我們仍然尊重**介面隔離原則**。 5.D-依賴倒置原則 ----------  > DIP - 依賴倒置原理 這個是這樣的:**依賴抽象而不是實現。** > 高層模組不應該依賴低層模組。兩者都應該依賴抽象。 > > 抽像不應該依賴細節。細節應該取決於抽象。 > > 鮑伯叔叔 現在我將展示一個簡單的程式碼來說明 DIP。在此範例中,有一個從資料庫取得使用者的服務。首先,讓我們建立一個與資料庫連接的具體類別: ``` // Low-level module class MySQLDatabase { getUserData(id: number): string { // Logic to fetch user data from MySQL database } } ``` 現在,讓我們建立一個取決於具體實作的服務類別: ``` // High-level module class UserService { private database: MySQLDatabase; constructor() { this.database = new MySQLDatabase(); } getUser(id: number): string { return this.database.getUserData(id); } } ``` 在上面的範例中, `UserService`直接依賴`MySQLDatabase`的具體實作。這違反了**DIP** ,因為**高級**類別 UserService 直接依賴**低階**類別。 如果我們想要切換到不同的資料庫系統(例如PostgreSQL),我們需要修改UserService類,這`AWFUL`了! 讓我們使用**DIP**修復此程式碼。高級類別`UserService`不應依賴特定實現,而應依賴抽象。讓我們建立一個`Database`介面作為抽象: ``` // Abstract interface (abstraction) for the low-level module interface Database { getUserData(id: number): string; } ``` 現在, `MySQLDatabase`和`PostgreSQLDatabase`的具體實作應該要實作這個介面: ``` class MySQLDatabase implements Database { getUserData(id: number): string { // Logic to fetch user data from MySQL database } } // Another low-level module implementing the Database interface class PostgreSQLDatabase implements Database { getUserData(id: number): string { // Logic to fetch user data from PostgreSQL database } } ``` 最後,UserService 類別可以依賴`Database`抽象: ``` class UserService { private database: Database; constructor(database: Database) { this.database = database; } getUser(id: number): string { return this.database.getUserData(id); } } ``` 這樣, `UserService`類別依賴`Database`抽象,而不是具體實現,滿足**依賴倒置原則**。 結論 -- 透過採用這些原則,開發人員可以建立更能適應變化的系統,使維護變得更容易,並隨著時間的推移提高程式碼品質。 本文的全部內容源自各種其他文章、我的個人筆記以及我**在深入研究物件導向程式設計 (OOP) 領域**時遇到的數十個線上影片。範例中使用的程式碼片段是基於我對這些原則的解釋和理解而建立的。我真的希望,我的小學徒,我能為促進你的理解和學習進步做出貢獻。 衷心希望您喜歡這篇文章,別忘了關注! 註:圖片取自[本文](https://medium.com/backticks-tildes/the-s-o-l-i-d-principles-in-pictures-b34ce2f1e898) --- 原文出處:https://dev.to/lukeskw/solid-principles-theyre-rock-solid-for-good-reason-31hn
解決 DEV 上的點擊誘餌:我們的策略和行動 ====================== 最近,我們採取了措施來解決 DEV 上的點擊誘餌問題。這篇文章旨在解釋我們的方法及其背後的基本原理。 定義點擊誘餌 ------ 點擊誘餌通常是指標題中具有特定模式的內容,例如清單或聳人聽聞的標題。例如,雖然清單文章在推動 DEV 參與度方面獲得了關注,但它們有時會導致不平衡,正如 Chrome 插件等社群舉措所表明的那樣: {% 嵌入 https://dev.to/lnahrf/no-listicles-the-chrome-add-on-that-removes-list-type-articles-from-your-devto-feed-3i8 %} 我們的方法 ----- ### 強調緩解而非嚴格過濾 我們沒有實施嚴格的過濾,而是選擇了更細緻的方法。原因如下: - **內容平衡**:並非所有清單文章都是負面的;它們可以提供豐富的資訊。然而,由於我們基於參與的系統,他們常常獲得不成比例的獎勵。 - **點擊誘餌的多樣性**:點擊誘餌有多種形式,嚴格的過濾器可能無法有效地捕捉所有這些形式。 - **主觀性問題**:確定標題誘餌的主觀性使得嚴格過濾變得不切實際。 ### 評分中的人工智慧和人類判斷 我們在應用程式中引入了`clickbait_score`字段,範圍從`0.0`到`1.0` 。 {% 嵌入 https://github.com/forem/forem/pull/20493 %} 這個分數不只由演算法決定。我們利用人工智慧和人類判斷來為貼文分配分數,認識到任務的主觀性和細微差別。 ### 透過 A/B 測試實施 我們正在仔細整合點擊誘餌分數。作為我們正在進行的 A/B 測試的一部分,使用者可能會遇到不同程度的點擊誘餌緩解措施。這些資料將幫助我們在未來幾週內完善我們的方法。 ### 展望未來:可自訂的用戶設置 雖然我們正在研究管理點擊誘餌的預設設置,但我們認識到個性化的必要性。未來的更新可能包括用戶特定的設置,以根據標題誘餌分數自訂提要偏好。 *我們將在不久的將來分享更多關於我們正在採取的各種策略,以改善核心體驗並幫助**分離 DEV 上的訊號和雜訊***。 快樂編碼❤️ --- 原文出處:https://dev.to/devteam/tackling-clickbait-on-dev-strategy-and-technical-approach-3dh9
我正在寫這些隨機筆記作為**公開信,寫給我在 React**(更廣泛地說,開源)**社區**中深深信任的人。像是坦納·林斯利、勞裡·沃斯、卡西迪·威廉斯、麥可·傑克森、馬克·艾瑞克森、凱爾·馬修斯、蘇菲·阿爾珀特等人。 **在過去的幾個月裡,我一直對 React 感到矛盾**。它始於伺服器元件基本上在框架會議上宣布的日子,React 文件開始建議使用外部框架進行 React 開發。昨晚閱讀了 [Cassidy 的帖子](https://blog.cassidoo.co/post/annoyed-at-react/) 並分享了她的願景後,我也有表達我的擔憂的衝動。 **我在 2016 年愛上了 React**,當時 Angular 發布了 Angular 2,我們擔心會發生重大變化。我立即愛上了 React 社區,儘管我從未積極參與。 我記得蘇菲·阿爾珀特和丹·阿布拉莫夫之間的推文。我還記得 2016 年 Michele Bertoli 在 ReactJsDay(義大利)上的第一次演講,讓我眼前一亮。我無法忘記 2018 年版的 ReactJsDay,當時 Michael Jackson 在我們面前重新建立了大部分 React Router 實時編碼 - 那真是美好的日子! 無論是作為 Web 開發機構還是現在作為產品公司,React 一直是我們的成功選擇。當我想起那一天(我相信是2020 年1 月2 日)時,我仍然很激動,當時我向Guillermo Rauch 展示了React Bricks 的第一個MVP,他是第一個相信這個專案的人,並給了我繼續下去的信心。 。 **然而,今天我看到兩個問題,讓我對 React 的喜愛少了一些**,並讓我擔心新開發人員可能會被它嚇倒:所有權和復雜性。 ## 所有權 至於所有權,我不是特別喜歡: 1. React [建議使用框架](https://react.dev/learn/start-a-new-react-project)啟動專案,建議使用三大主流開源框架之一,而不是僅使用反應。 2. 在框架會議期間,React Server 元件等新的 React 功能首次向社群的很大一部分介紹,就好像這只是一個框架成就一樣。 3. 最受歡迎的框架,它僱用了一些來自React 核心團隊的人員(這不是一件壞事,但肯定為他們提供了對開發的特權洞察力)使用金絲雀版本,而[React 的最後一個版本](https://github.com/facebook/react/releases) (18.2) 是2022 年6 月。透過這種方式,金絲雀功能進入了許多新React 專案的程式碼庫,成為“事實上的”穩定版本,但僅適用於 a可以安全地利用金絲雀功能的框架。 此外,諸如伺服器操作之類的功能(在雲端平台上託管時會觸發計量無伺服器函數呼叫)可能會增加未來前端應用程式的託管成本。雖然目前這不是問題,因為不存在壟斷,我們有選擇的自由,但**我希望**為社區提供一種方式**以保證明天仍然有多種選擇**可用。請理解,在這方面我不認為任何人是「邪惡的」。私人公司和社區之間的合作可以帶來偉大的成就。這只是一個分離關注點和責任的問題。 ## 複雜性 我從 1996 年開始建立網站,當時我 17 歲。當時,您建立了 HTML 檔案並將它們上傳到 FTP 伺服器上由 Web 伺服器提供服務的資料夾中。我管理自己的實體伺服器(Pentium 120),將其安置在當地的網路供應商。它在 Windows NT4 IIS 上執行作為 Web 伺服器,在 BIND 上執行 DNS,在 IPSwitch IMail 伺服器上執行電子郵件。一切都簡單明了。 如今,Web 開發變得更加強大,但也更加複雜。隨著轉譯器、捆綁器和框架的引入,我們已經失去了對幕後發生的事情的了解。然而,React 以其乾淨的單向資料流而脫穎而出。鉤子的事情變得有點複雜(它有一些幕後黑魔法:),但它是可以管理的,並且最終是一個不錯的選擇。 **使用伺服器元件,一切都變得更加複雜,難以掌握**。而且,事實上它們是最廣泛使用的 React 框架的預設選擇,這在某種程度上迫使新手也學習這種新範例。我了解 RSC 的優勢,但現在我們甚至可以在同一個 React 框架內使用[兩種不同的方式](https://overreacted.io/the-two-reacts/)來建立東西。 我們最近完成了讓 React Bricks 函式庫與 RSC 相容的任務。這需要一個月的工作和數千行程式碼。然而,結果是,最終為開發者提供的 API 並不像以前那麼乾淨。我不確定為了輕微的效能提升而犧牲簡單性是否會真正使我們的客戶受益。儘管如此,由於它既是「預設」又是閃亮的新事物,我們必須擁有它。 **同時,隨著新框架的出現,React 世界之外發生了許多有趣的事情**。我不想成為新程式設計師現在就嘗試選擇他們的第一個框架,因為這個決定非常艱難。 React 是最受歡迎的,Vue 更容易使用,Svelte 是一個很酷的想法,Astro 真的很棒,然後還有由非常聰明和謙遜的 Ryan Carniato 開發的信號和 SolidJS。 Qwik 也非常聰明,我喜歡這種方法(它是由 React Bricks 的競爭對手建立的……但我非常尊重他們:)。所以……基礎框架的選擇已經這麼複雜了! ## 一個夢? 在這種複雜的場景中,**擁有一個「預設的官方」React 框架將是有益的,該框架涵蓋建立 SEO 友善網站的基本需求**,具有路由、SSG、SSR、ISR(以及所有排列)這些字母;)。我知道 Remix 團隊不會同意 SSG 的必要性,但我認為它有一個有效的用例。我希望它始終能夠在 Linux 機器上自行託管。 我設想這個預設框架由 React 社群開發,並有一個由來自 React 生態系統的公認貢獻者組成的**指導委員會(透過投票過程?)**。我知道通常開源不會以這種方式工作,但是......我夢想著這個“probi viri Fellowship of the Ring”做出決定。 這個預設框架**不應該旨在包含所有閃亮的新東西**,這些新東西可以在我使用和喜愛的 Remix 或 Next.js 等其他框架中找到。我相信它應該作為社區創造的堅實起點。我認為我們今天已經有了一些很棒的東西可以開始(坦納?)。 至於 RSC,我認為避免水合的概念很棒,但我們需要一種新型的伺服器客戶端整合來使它們易於使用。如果它們仍然很複雜,在當前的限制下,以簡單性換取效能對大多數網站來說不會有好處。無論如何,與 Qwik 之類的東西相比,RSC 可能在效能方面有所損失,因為它們執行相同的工作兩次,處理客戶端上序列化 JSON 的區塊。然而,這是需要單獨討論的材料。 ## 開放問題 所以,經過這麼長時間的意識流,我想向社區提出一些問題: 1. 您對React的未來有何看法? 2. 您認為在沒有贊助公司但有選舉的指導委員會的情況下建立一個社區驅動的框架是否可行?這個獨立的指導委員會如何能夠得到社區或企業用戶的經濟支持,以保持其獨立性? 馬泰奧·弗拉納 2023 年 1 月 16 日 --- 原文出處:https://dev.to/matfrana/react-where-are-you-going-5284
Docker 是一個工具,允許開發人員將他們的應用程式及其所有依賴項打包到一個容器中。然後,這個容器就可以輕鬆地在任何安裝了 Docker 的機器上傳輸和執行,而不必擔心環境的差異。這就像是打包和執行軟體的標準化方式。 **容器是什麼?**  容器就像一個小包,其中包含程式執行所需的一切,可以輕鬆地在不同電腦上移動和執行,而不會造成任何麻煩。 最酷的部分是這個迷你電腦(容器)就像一個披著斗篷的超級英雄。它可以在任何電腦上執行,無論它們有多麼不同,因為它自帶特殊的環境。這是一種保持軟體井然有序的方式,並確保它無論在哪裡都能以相同的方式運作。 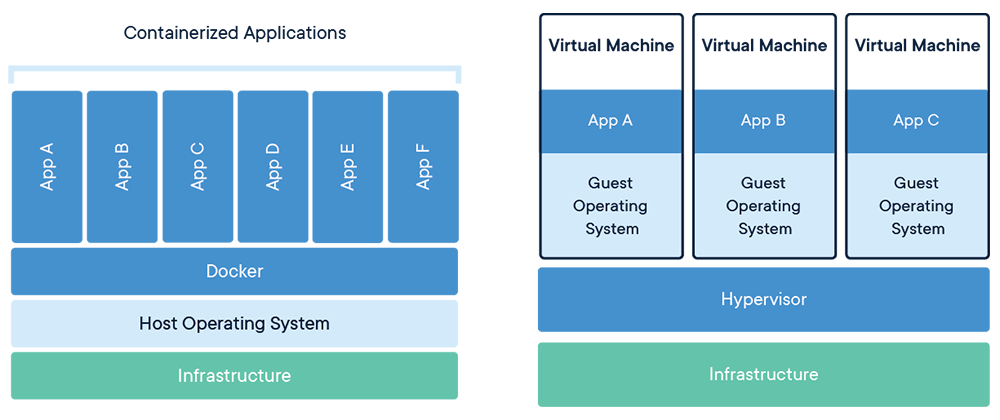 **為什麼我們需要 Docker?** 1. **一致性:** Docker 確保軟體在您的電腦、您朋友的電腦或任何電腦上以相同的方式運作。它使事情保持一致。 2. **可移植性:** 您可以將您的軟體及其朋友打包到 Docker 容器中,並且它可以移動到任何地方。這就像將您的遊戲及其所有規則放在手提箱中並在朋友家中玩。 3. **隔離:** Docker 容器就像小氣泡。氣泡內發生的事只會留在氣泡內。這意味著容器中的一個程式不會幹擾容器外的另一個程式。 4. **效率:** Docker有助於節省電腦資源。您可以讓許多容器在同一台電腦上執行,而不會相互妨礙,而不是讓一整台電腦只用於一個程式。 5. **速度:** Docker 讓啟動、停止和共享軟體變得快速、輕鬆。這就像打開和關閉遊戲機一樣 - 快速而簡單。 **什麼是 Docker 映像?** 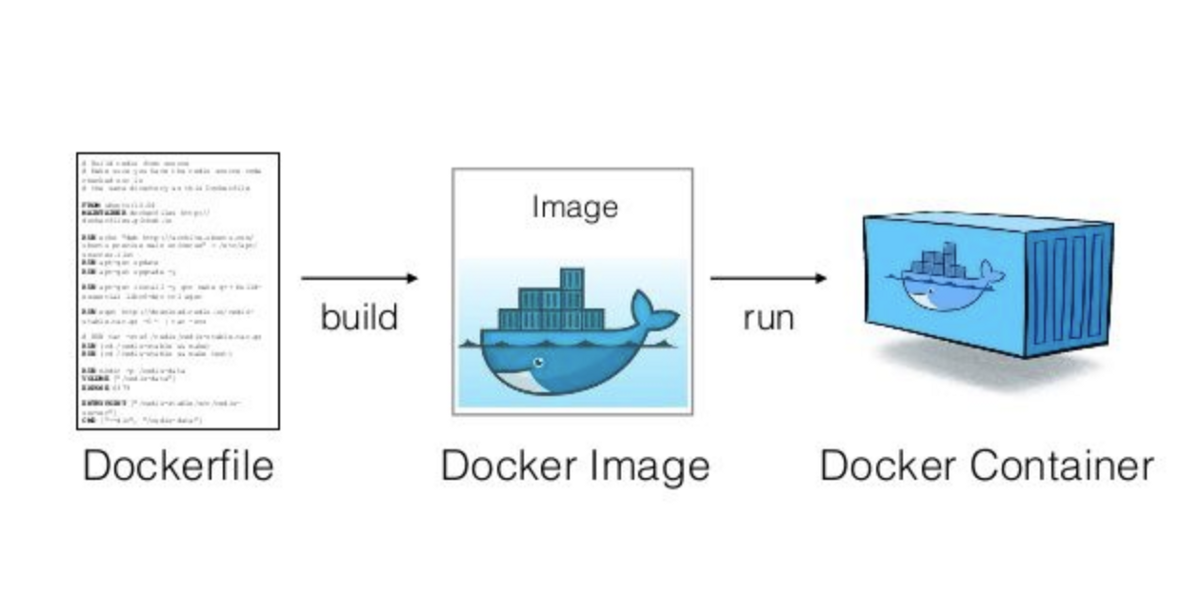 Docker 映像像是程式及其運作所需的所有內容的快照。它是一個打包版本,包括程式碼、工具和設置,就像包含所有成分的餅乾食譜的快照一樣。 **圖像是配方,容器是當您按照該配方實際製作和執行程序時所得到的。** **一些基本的 Docker 命令。**  1. **`docker執行nginx`** - 此命令告訴 Docker 使用「nginx」映像執行容器。這就像告訴 Docker 啟動一個預製程式的新實例(nginx,它是一個 Web 伺服器)。 2. **`docker ps`** - 顯示正在執行的容器的清單。這就像檢查當前正在執行哪些程式。 3. **`docker ps -a`** - 顯示所有容器的列表,包括已停止的容器。這就像檢查您執行過的所有程式的歷史記錄。 4. **`docker stopsilly_sammet'** - 停止名為「silly_sammet」的正在運作的容器。這就像關閉當前正在執行的程式。 5. **`docker rmsilly_sammet'** - 刪除名為「silly_sammet」的已停止容器。這就像丟掉你不再需要的程式的指令一樣。 6. **`docker 映像`** - 列出您擁有的所有 Docker 映像。這就像查看您可以執行的所有不同程式的選單一樣。 7. **`docker rmi nginx`** - 刪除“nginx”圖像。這就像刪除您不想再使用的程式的配方。 8. **`docker拉nginx`** - 從網路下載「nginx」映像。這就像從食譜中獲取新食譜一樣。 9. **`docker 執行 ubuntu sleep 5`** - 使用「ubuntu」映像檔執行容器並使其休眠 5 秒。這就像啟動一個程序,只是等待一小會兒,然後就停止了。 10. **`docker exectracted_mcclintock cat /etc/hosts`** - 在名為「distracted_mcclintock」的正在執行的容器內執行命令。這就像在食譜書中偷看特定頁面一樣。 11. **`docker run -d kodekloud/simple-webapp`** - 從「kodekloud/simple-webapp」鏡像以分離模式執行容器。這就像啟動一個程式並讓它在背景執行。 12. **`docker Attach a043d`** - 將您的終端附加到 ID 為「a043d」的正在執行的容器。這就像跳入正在執行的程式來查看發生了什麼。 **一些 Docker 概念:** 1. **使用標籤執行:** - 標籤就像程式的版本。它指定您要執行哪個版本。 - 範例程式碼:`docker run nginx:latest` - 這將執行最新版本的 Nginx 程式。 2. **使用標準輸入執行:** - STDIN 就像在鍵盤上打字一樣。有些程式需要您的輸入。 - 範例程式碼:`docker run -i -t ubuntu` - 這會在 Ubuntu 容器內執行互動終端,讓您可以鍵入命令。 3. **使用連接埠映射執行:** - 連接埠就像門。程式使用它們與外界進行通訊。 - 範例程式碼:`docker run -p 8080:80 nginx` - 這將執行 Nginx,並打開電腦連接埠 8080 上的門,將其連接到容器的連接埠 80。 4. **使用磁碟區映射執行:** - 磁碟區就像共用資料夾。它們讓您可以將東西存放在容器之外。 - 範例程式碼:`docker run -v /your/local/folder:/container/folder nginx` - 這將執行 Nginx 並將電腦上的資料夾連接到容器內的資料夾。 5. **檢查容器:** - 檢查就像仔細檢查正在執行的程式。 - 範例程式碼:`docker檢查container_name` - 這為您提供有關正在執行或已停止的容器的詳細資訊。 6. **容器日誌:** - 日誌就像日記。他們記錄程式正在做什麼。 - 範例程式碼:“docker 日誌容器名稱” - 這會向您顯示特定容器的日誌或活動。 ##環境變數 環境變數就像程式用來尋找重要資訊的便利筆記,有點像是程式可以理解和更好工作的秘密訊息! 1. **Python腳本(app.py)中的環境變數:** - 假設您有一個用 Python 寫的程式 (app.py)。您可能想要在不更改程式碼的情況下自訂它。您可以使用環境變數。 - 範例程式碼(app.py): ``` import os app_color = os.getenv("APP_COLOR", "default_color") print(f"The app color is {app_color}") ``` - 正常運作腳本:`python app.py` - 以特定顏色執行:`export APP_COLOR=blue; python 應用程式.py` 2. **在 Docker 中使用 ENV 變數:** - Docker 容器也可以使用環境變數。這就像是向容器內的程式發出指令。 - 範例程式碼: - `docker run -e APP_COLOR=green simple-webapp-color` - 這會執行 Docker 容器(`simple-webapp-color`)並將環境變數 `APP_COLOR` 設為「綠色」。 3. **檢查環境變數:** - 有時,您會想要檢查正在執行的容器正在使用哪些環境變數。 - 範例程式碼:`docker檢查blissful_hopper` - 此命令提供有關名為“blissful_hopper”的容器的詳細訊息,包括其環境變數。 簡單來說,環境變數就像程式(或 Docker 容器)可以讀取以了解如何行為的小註釋。您可以在執行程式之前設定這些註釋,程式將使用它們來自訂自身。第二個範例中的「export」指令就像在執行程式之前寫一條註釋,告訴它如何運作。 “docker Inspect”指令就像是在容器內部查看它有什麼註解。 ## Docker 映像 **Docker 檔案:** Dockerfile 就像是 Docker 建立映像的一組指令。這就像是烤蛋糕的食譜。 ``` # Use the Ubuntu base image FROM Ubuntu # Update apt repository RUN apt-get update # Install dependencies using apt RUN apt-get install -y python # Install Python dependencies using pip RUN pip install flask RUN pip install flask-mysql # Copy source code to /opt folder COPY . /opt/source-code # Set the working directory WORKDIR /opt/source-code # Specify entry point to run the web server ENTRYPOINT ["flask", "run"] ``` **建立自己的圖像的步驟:** 1. 使用上述內容建立一個名為「Dockerfile」的檔案。 2. 將其保存在與原始碼相同的目錄中。 **建置 Docker 映像:** 在終端機中執行以下命令: ``` docker build -t your-image-name . ``` 此命令告訴 Docker 使用目前目錄中的 Dockerfile (`.`) 建置映像,並使用您選擇的名稱對其進行標記 (`-t your-image-name`)。 **分層架構:** 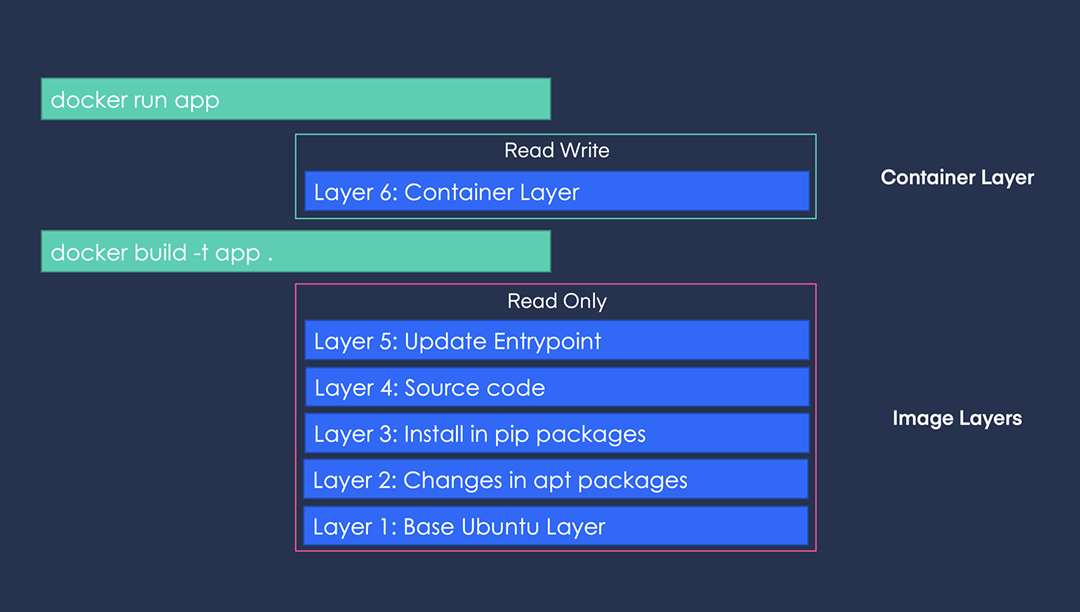 - 將 Docker 映像視為一個分層蛋糕。 Dockerfile 中的每個指令都會在映像上新增一層。 - 圖層可重複使用。如果您變更程式碼中的某些內容,Docker 只會重建受影響的層,從而提高效率。 **Docker 建置輸出:** - 當您建置映像檔時,Docker 會顯示流程中的每個步驟。如果發生故障,它會給您錯誤訊息。 **你可以容器化什麼?** - 幾乎所有東西!應用程式、服務、資料庫、網站,基本上任何軟體都可以容器化。 - 這就像將您的軟體放入一個盒子中,以便它可以在任何地方執行而不會造成麻煩。 ## 什麼是 Docker CMD 與 ENTRYPOINT **Docker 中的`CMD`:** - 將 CMD 視為啟動容器時程式執行的預設操作。 - 這就像說,“嘿,當你執行這個容器時,默認執行此操作。” - 範例:`CMD ["flask", "run"]` 表示當容器啟動時,它會自動執行 Flask Web 伺服器。 **CMD 範例:** ``` FROM alpine CMD ["sleep", "5"] ``` 在此範例中,當您使用此映像執行容器時,它會自動休眠 5 秒。 **Docker 中的`ENTRYPOINT`:** - 將 ENTRYPOINT 視為容器所做的主要事情。就好像boss的命令一樣。 - 它設定一個預設應用程式在容器啟動時執行,但您仍然可以根據需要覆蓋它。 - 範例:`ENTRYPOINT ["flask", "run"]` 表示容器主要用於執行 Flask Web 伺服器,但如果需要,您仍可新增更多指令。 **入口點範例:** ``` FROM alpine ENTRYPOINT ["sleep"] CMD ["5"] ``` 在這裡,主要目的是睡眠,如果您願意,您仍然可以覆蓋睡眠持續時間。 在這兩種情況下,容器在啟動時只會休眠幾秒鐘。主要區別在於如何提供參數以及它們是否可以輕鬆覆蓋。 CMD 就像在說,“這是默認要做的事情”,而 ENTRYPOINT 就像在說,“這是主要要做的事情,但如果你願意,你可以稍微調整一下。”它們都有助於定義容器啟動時執行的操作。 ## Docker 中的網路: Docker 網路幫助容器(程式)相互通信,確保它們可以順利地協同工作。 **預設網路:** - Docker 建立預設網路供容器通訊。 - 範例程式碼:`docker run ubuntu --network=host` - 這使用主機網路執行 Ubuntu 容器,這意味著它與主機共享網路命名空間。 **使用者定義的網路:** - 您可以建立自己的網路以更好地組織和控制。 - 範例程式碼: ``` docker network create --driver=bridge --subnet=182.18.0.0/16 custom-isolated-network ``` - 這將建立一個名為「custom-isolated-network」的使用者定義的橋接網絡,具有特定的子網。 **上市網路:** - 您可以查看您擁有的所有網路。 - 範例程式碼:`docker network ls` **檢查網路:** - 您可以檢查特定網路的詳細資訊。 - 範例程式碼:`docker網路檢查blissful_hopper` - 這顯示有關名為「blissful_hopper」的網路的詳細資訊。 **嵌入式 DNS:** - Docker 有一個內建的 DNS 系統,供容器透過名稱相互查找。 - 範例程式碼:`mysql.connect(mysql)` - 這可能是程式碼中的一行,其中名為「mysql」的服務使用 Docker 的 DNS 連接到另一個名為「mysql」的服務。 ## Docker 儲存: 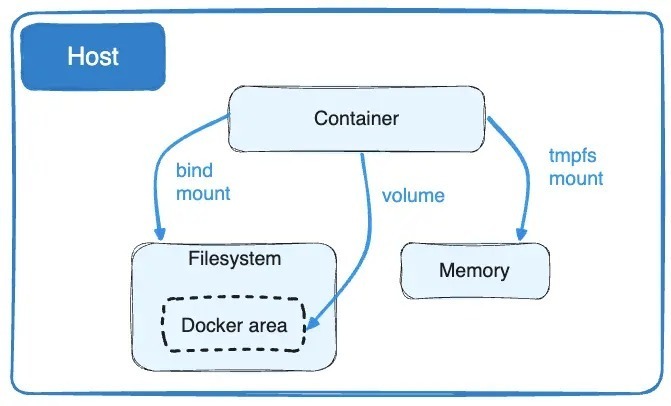 Docker 儲存就像使用容器時決定將資料保存在哪裡一樣。您可以將它們保留在容器內,使用磁碟區在容器之間共用它們,或將它們儲存在容器外部以妥善保管。 **Docker中的檔案系統:** - Docker 使用分層架構來建立映像。 Dockerfile 中的每個指令都會在檔案系統中新增一個新圖層。 ``` # Dockerfile FROM Ubuntu RUN apt-get update && apt-get install -y python RUN pip install flask flask-mysql COPY . /opt/source-code WORKDIR /opt/source-code ENTRYPOINT ["flask", "run"] ``` - Dockerfile 中的層: - 第 1 層:Ubuntu 基礎層 - 第 2 層:apt 軟體包的更改 - 第 3 層:pip 套件的變化 - 第 4 層:原始碼 - 第 5 層:使用「flask」指令更新入口點 - 第 6 層:容器層 **影像圖層:** - 當您建立 Docker 映像時,它由唯讀層組成。每一層代表影像的變化或加入。 - 第 1 層:Ubuntu 基礎層 - 第 2 層:apt 軟體包的更改 - 第 3 層:pip 套件的變化 - 第 4 層:原始碼 - 第 5 層:使用「flask」指令更新入口點 ``` # Build the Docker image docker build -t mmumshad/my-custom-app . ``` **容器層:** - 當您執行 Docker 容器時,會在唯讀映像層上方新增一個讀寫層。該層特定於正在執行的容器。 - 第 6 層. 容器層 ``` # Run the Docker container docker run mmumshad/my-custom-app ``` **數量:** - 卷是一種在容器外部保存資料的方法。它們就像外部記憶體。 ``` # Create a Docker volume docker volume create data_volume # Use the volume in a container docker run -v data_volume:/var/mysql mysql ``` - 您也可以使用「-v」將特定目錄從主機掛載到容器: ``` # Mount a host directory to a container directory docker run -v /path/on/host:/var/mysql/mysql -d mysql ``` - docker run --mount 指令用於將主機上的特定目錄或檔案掛載到正在執行的 Docker 容器中。 ``` docker run --mount type=bind,source=/mysql,target=/var/mysql mysql ``` **儲存驅動程式:** - Docker 使用儲存驅動程式來管理資料的儲存和存取方式。一些常見的儲存驅動程式包括 AUFS、ZFS、BTRFS、Device Mapper、Overlay 和 Overlay2。 [在 Docker 管理資料](https://docs.docker.com/storage/) [關於儲存驅動程式](https://docs.docker.com/storage/storagedriver/) [卷](https://docs.docker.com/storage/volumes/) ## Docker 組合  Docker Compose 是一個方便的工具,可幫助您輕鬆執行和連接不同的軟體服務,就好像它們都是同一事件的一部分一樣。 **Docker Compose 基礎:** 1. **執行單一容器:** - 通常,您可以像這樣執行單獨的 Docker 容器: ``` docker run mmumshad/simple-webapp docker run mongodb docker run redis:alpine docker run ansible ``` 2. **Docker 撰寫文件(`docker-compose.yml`):** - Docker Compose 允許您在一個簡單的檔案中定義所有這些服務: ``` # docker-compose.yml version: '3' services: web: image: 'mmumshad/simple-webapp' database: image: 'mongodb' messaging: image: 'redis:alpine' orchestration: image: 'ansible' ``` - 此檔案描述您要執行的服務(「web」、「database」、「messaging」、「orchestration」)、它們各自的映像以及任何其他配置。 3. **使用 Docker Compose 執行:** - 要一起啟動所有這些服務: ``` docker-compose up ``` - Docker Compose 負責啟動「docker-compose.yml」檔案中定義的所有容器。 4. **使用 Docker Compose 建置:** - 您也可以使用 Docker Compose 建置映像: ``` docker-compose build ``` - 此指令建置「docker-compose.yml」檔案中指定的映像。 **執行連結容器:** - 如果您要透過連結執行單一容器: ``` docker run -d --name redis redis docker run --name voting-app -p 5000:80 --link redis:redis voting-app docker run --name result-app -p 5001:80 --link db:db result-app docker run -d --name worker --link db:db --link redis:redis worker ``` - 在 Docker 中撰寫: ``` # docker-compose.yml version: '3' services: vote: image: 'voting-app' ports: - '5000:80' links: - 'redis:redis' result: image: 'result-app' ports: - '5001:80' links: - 'db:db' worker: image: 'worker' links: - 'db:db' - 'redis:redis' db: image: 'db' redis: image: 'redis' ``` Docker Compose 可讓您在單一檔案中描述整個應用程式堆疊,從而輕鬆管理、執行和連接不同的服務。這就像在一份計劃中寫下活動的所有任務,然後 Docker Compose 為您處理設定。 [Docker Compose 概述](https://docs.docker.com/compose/) [Docker 撰寫文件](https://docs.docker.com/engine/reference/commandline/compose/) ## Docker 註冊表 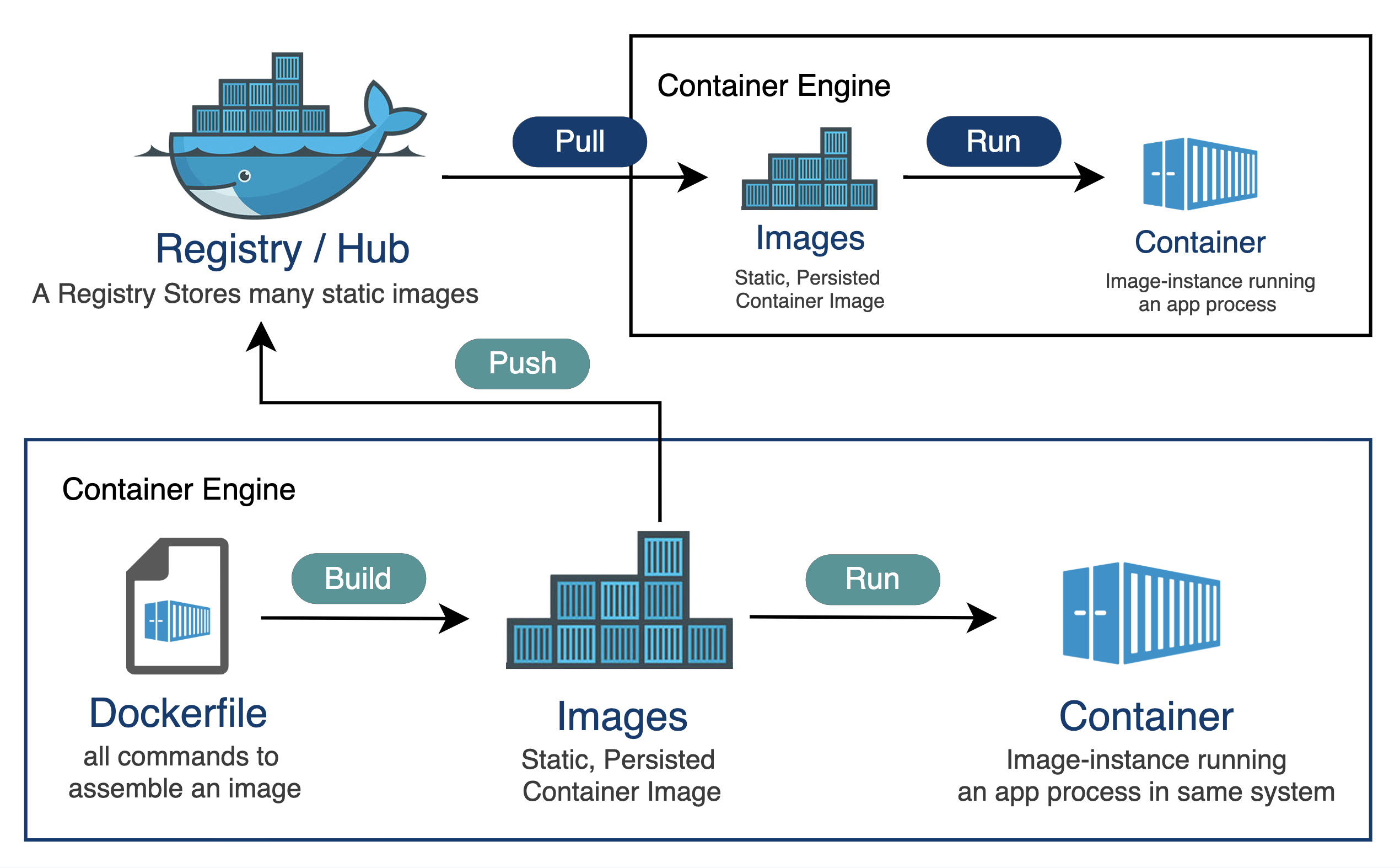 Docker 註冊表是人們儲存和分享 Docker 映像的地方,使其他人可以輕鬆使用和執行他們的軟體。它就像一個大型線上程式庫,可以輕鬆下載並在不同電腦上使用。 **Docker 註冊表基礎知識:** 1. **公共登記處:** - Docker 映像可以在 Docker Hub 等公共註冊表中儲存和共用。 - 例: ``` docker pull nginx ``` 2. **私人登記處:** - 有時,您可能希望將圖像保存在您自己的私人註冊表中。 - 例: - 登入私人註冊表: ``` bash docker login private-registry.io ``` - 從私有註冊表中的映像執行容器: ``` docker run private-registry.io/apps/internal-app ``` 3. **部署您自己的私有註冊表:** - 您可以為您的團隊或公司部署自己的私人註冊表。 - 例: - 在您的電腦上執行私有註冊表: ``` docker run -d -p 5000:5000 --name registry registry:2 ``` - 為私人註冊表標記您的圖像: ``` bash docker image tag my-image localhost:5000/my-image ``` - 將映像推送到您的私人註冊表: ``` bash docker push localhost:5000/my-image ``` - 從您的私人註冊表中提取映像: ``` bash docker pull localhost:5000/my-image ``` 4. **從遠端私有註冊表中提取:** - 您也可以使用 IP 位址或網域從遠端私有註冊表中提取映像。 - 例: ``` docker pull 192.168.56.100:5000/my-image ``` Docker 註冊表就像一個儲存空間,人們在其中保存和共享 Docker 映像。您可以將公用註冊表用於廣泛使用的映像,也可以根據您的特定需求設定自己的私人註冊表。它就像一個用於共享和儲存軟體藍圖(圖像)的特殊庫。 ## Docker 引擎 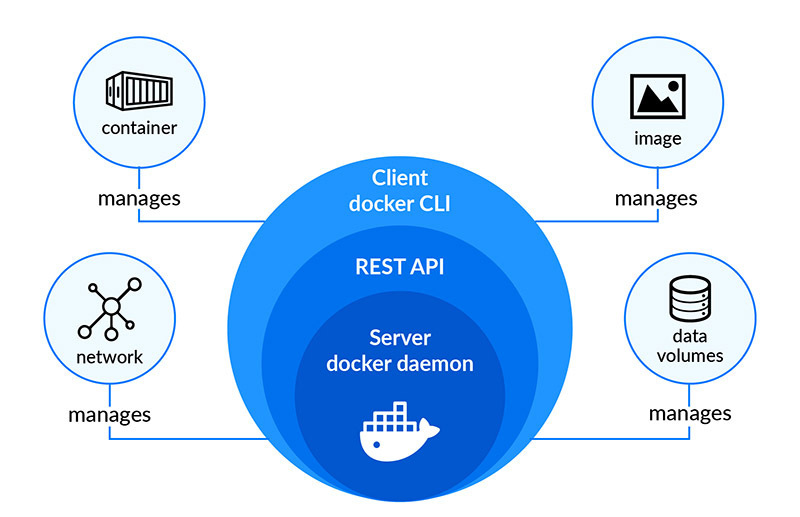 想像一下,你有一個魔盒(Docker Engine),可以為你執行和管理各種程式(容器)。 Docker Engine 就像是這個魔盒的大腦。 1. **Docker 守護程式:** - 守護程式就像魔法盒的看門人。它始終在那裡,隨時準備接受指示並確保一切順利進行。 2. **REST API:** - 將 REST API 視為一組允許您與魔盒對話的規則。它就像你和守護程式用來溝通的語言。你告訴守護程式要做什麼,它會理解,因為你們說的是同一種語言。 3. **Docker CLI(命令列介面):** - Docker CLI 就像是用來命令守護程式的魔杖。您輸入指令,守護程式就會按照您的指示進行操作。這就像說「Abracadabra」就能讓事情發生。 **連線到遠端 Docker 引擎:** 連接到遠端 Docker 引擎可讓您控制另一台機器上的容器,且設定約束可確保容器僅使用指定的資源。 1. **Docker主機IP:** - 您可以使用 IP 位址和連接埠連接到不同電腦上的 Docker 引擎。 - 例: ``` docker -H=remote-docker-engine:2375 run nginx ``` - 這告訴您的本機 Docker CLI 與遠端 Docker 引擎進行通訊。 2. **有約束地執行容器:** - Docker 允許您設定容器的資源限制,例如 CPU 和記憶體限制。 - 例: ``` docker run --cpus=0.5 ubuntu docker run --memory=100m ubuntu ``` - 這些指令限制容器僅使用半個 CPU 核心和 100 MB 記憶體。 當然,讓我們簡化一下PID命名空間的概念: **命名空間PID:** PID 命名空間可讓您為容器中的進程(如程式或任務)建立單獨的區域,因此它們有自己的一組「票號」(進程 ID),不會與容器外的進程發生衝突。 **範例程式碼:** 1. **使用主機 PID 命名空間執行容器:** - 這表示容器與主機共用相同的「票號」。 ``` docker run --pid=host ubuntu ``` 2. **執行具有隔離 PID 命名空間的容器:** - 這表示容器有自己的一組獨立於主機的「票號」。 ``` docker run --pid=container ubuntu ``` 在第一個範例中,容器與進程交互,就好像它與主機位於同一空間中一樣。在第二個範例中,容器有自己的進程隔離空間。這就像在大型活動中擁有一個私人區域,您的團隊有自己的一套票號,讓您可以獨立於活動的其餘部分進行操作。 **容器化概念:** 1. **進程 ID 命名空間:** - 容器有自己獨立的流程 ID (PID) 空間,因此容器內的流程與容器外的流程是分開的。 - 例: ``` docker run --pid=host ubuntu ``` - 此指令使用主機的 PID 命名空間來執行容器,因此它共用相同的程序。 2. **網路命名空間:** - 容器也有自己獨立的網路命名空間,這意味著它們可以有自己的網路配置。 - 例: ``` docker run --net=host nginx ``` - 此指令使用主機的網路命名空間來執行容器。 3. **Unix分時命名空間:** - 此命名空間允許容器擁有自己的時間視圖,與主機和其他容器分開。 - 例: ``` docker run --uts=host ubuntu ``` - 此指令使用主機的 Unix 時間共用命名空間來執行容器。 4. **進程間掛載命名空間:** - Mount命名空間隔離檔案系統,讓容器擁有自己的檔案系統視圖。 - 例: ``` docker run --mount=type=bind,source=/host/folder,target=/container/folder ubuntu ``` - 此指令將主機中的資料夾安裝到容器中。 當然!我們來簡化一下cgroup的概念: **C組:** cgroup(控制組的縮寫)可協助在不同進程或容器之間管理和分配系統資源,例如 CPU 和記憶體。它們確保沒有任何一個進程或容器耗盡所有可用資源,從而保持一切平衡。 **範例程式碼:** 1. **使用 Cgroup 設定 CPU 限制:** - 這就像說聚會上的每位客人只能吃一定數量的食物。 ``` docker run --cpus=0.5 ubuntu ``` - 這限制容器僅使用一半的 CPU 核心。 2. **使用 Cgroup 設定記憶體限制:** - 這就像說每位客人只能在舞池上佔據一定的空間。 ``` docker run --memory=100m ubuntu ``` - 這限制容器僅使用 100 MB 記憶體。 [Docker 引擎概述](https://docs.docker.com/engine/) [使用 Docker Engine API 進行開發](https://docs.docker.com/engine/api/) [執行時指標](https://docs.docker.com/config/containers/runmetrics/#control-groups) ## Linux容器與Windows容器的概念: **Linux 容器(預設):** Linux 容器是一種打包和執行軟體及其所需一切的方法,它們最適合執行 Linux 的電腦。 **Windows 容器:** Windows 容器是一種打包和執行軟體的方式,就像 Linux 容器一樣,但它們設計用於執行 Windows 的電腦。 **Windows 容器基礎:** 1. **集裝箱類型:** - Windows 容器有兩種主要類型:Windows Server Core 和 Nano Server。 - **Windows Server Core:** 將其視為功能更齊全的容器,適合各種應用程式。 - **Nano Server:** 將其視為一個輕量級容器,專為特定的、簡約的用例而設計。 2. **基礎鏡像:** - 基礎映像就像是建立容器時開始使用的空白畫布。 - 例: ``` docker pull mcr.microsoft.com/windows/servercore:ltsc2019 ``` - 此指令擷取 Windows Server Core 基礎映像。 - 例: ``` docker pull mcr.microsoft.com/windows/nanoserver:ltsc2019 ``` - 此命令提取 Nano Server 基礎映像。 3. **支援的環境:** - Windows 容器可以在特定版本的 Windows 作業系統上運作。 - 例: - 您可以在 Windows Server 2016 上執行 Windows 容器。 - 例: - 您可以在 Windows 10 專業版和企業版上執行 Windows 容器,並使用 Hyper-V 隔離容器進行額外隔離。 ## 容器編排 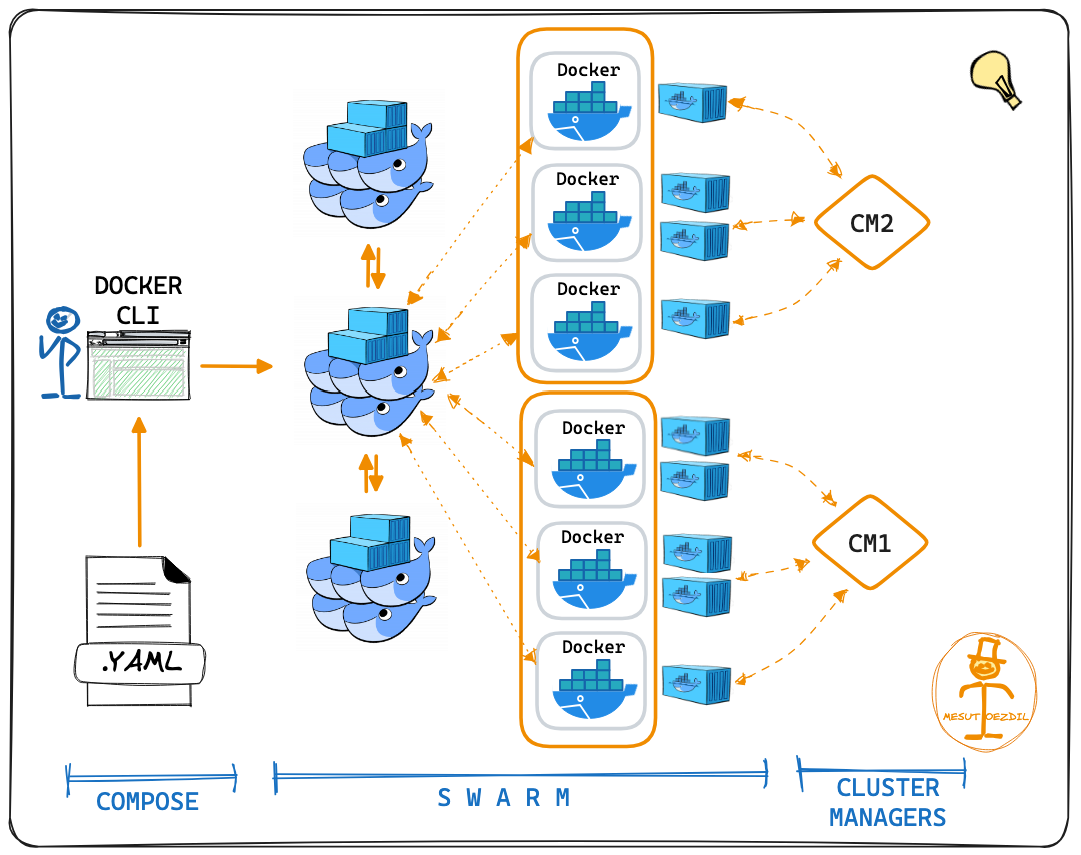 容器編排是一種管理和協調多個容器的方法,確保它們無縫協作來執行應用程式,就像一個超級智能的管理器確保所有機器人一起工作來建置完美的塔一樣。 **為什麼要編曲?** 1. **多項任務,一名經理:** - 想像一下您有許多機器人(容器)執行不同的工作。編排就像有一位超級聰明的經理(編排者),他告訴每個機器人該做什麼,並確保一切順利進行。 2. **一致性:** - 編排確保所有任務每次都以相同的方式完成。這就像為您的機器人提供了一套要遵循的指令,以確保其行為的一致性。 3. **效率:** - 編排有助於優化任務,確保資源(如時間和材料)有效利用。這就像經理確保所有機器人一起工作而不浪費能源。 4. **縮放比例:** - 當您需要完成更多工作時,編排可以輕鬆建立額外的機器人(容器)。這就像當有很多事情需要完成時神奇地召喚更多機器人來提供幫助。 5. **可靠性:** - 編排確保任務可靠地完成,即使機器人(容器)出現故障。這就像製定備份計劃來確保無論如何都能完成工作。 6. **協調:** - 編排協調任務,確保機器人無縫協作。這就像經理確保每個機器人都知道自己的角色並協作以實現總體目標。 **容器編排程式碼:** ``` # Create a Docker service with 100 replicas (instances) of a Node.js application docker service create --replicas 100 --name my-nodejs-app nodejs ``` 在這個例子中: - `docker service create`:該指令告訴 Docker 建立一個服務,該服務是一組正在執行的容器。 - `--replicas 100`:此標誌指定您需要 100 個服務實例(副本)。 - `--name my-nodejs-app`:此標誌為您的服務提供名稱,在本例中為「my-nodejs-app」。 - `nodejs`:這是 Node.js 應用程式的圖片或配方。這就像是烘焙紙杯蛋糕的藍圖。 因此,這段簡單的程式碼就像告訴您神奇的廚師助手 (Docker Swarm) 建立 Node.js 應用程式的 100 個副本,確保您有大量容器正在執行並準備好提供服務。 ## Docker 群  Docker Swarm 是一個工具,可以幫助協調和管理一組電腦(節點)作為一個機器人團隊一起工作,使它們能夠以協調的方式部署和執行多個容器。這就像有一個首席機器人經理,確保所有單一機器人一起建造出偉大而令人驚嘆的東西。 **設定 Docker Swarm:** 1. **群組管理器:** - 想像你有一個首席機器人(Swarm Manager)來領導團隊。主機器人決定需要做什麼,並指導其他機器人(節點)如何協同工作。 ``` # Initiate Docker Swarm on the Swarm Manager docker swarm init ``` 2. **節點工作人員:** - 現在,您的工作機器人(節點工作人員)已準備好加入團隊。 Swarm Manager 共享一個特殊的程式碼(令牌)來邀請他們一起工作。 ``` # Join a Node Worker to the Docker Swarm docker swarm join --token <token> <Swarm Manager IP> ``` **Docker Swarm 服務:** 現在您已經有了一個協調的團隊,您想要建立一項服務,例如與您的機器人團隊一起建造塔: ``` # Create a Docker service (a group of containers) with 3 replicas (instances) docker service create --replicas 3 --network frontend --name my-web-server my-web-image ``` - `--replicas 3`:此標誌告訴 Docker 建立服務的三個實例(副本)。 - `--network frontend`:此標誌指定您的服務屬於名為「frontend」的網路。 - `--name my-web-server`:這會為您的服務命名,在本例中為「my-web-server」。 - `my-web-image`:這是您的網頁伺服器的圖片或藍圖。這就像建造塔樓的配方。 您建立了一個由隊長(Swarm Manager)和工作機器人(Node Workers)組成的機器人團隊。然後,您指示他們建立一個執行您的 Web 伺服器應用程式的服務(容器群組)。主機器人確保建立 Web 伺服器的三個副本並將其連接到「前端」網路。這就像有一個首席機器人經理在工作機器人的幫助下監督多個塔(貨櫃)的建造。  **好的,這就是本文的內容。** 另外,如果您對此或其他任何問題有任何疑問,請隨時在下面的評論中或在 [Instagram](https://www.instagram.com/_abhixsh/) 、[Facebook](https://www.facebook.com/abhi.haththakage/) 或[Twitter](https://twitter.com/abhixsh)。 感謝您閱讀這篇文章,我們下一篇再見! ❤️ --- 原文出處:https://dev.to/abhixsh/docker-for-the-absolute-beginner-3h1p
科技愛好者常有遠大的夢想,渴望實現突破創新和個人發展界限的目標。為了幫助建立這些雄心壯志,我為科技愛好者量身定制了廣泛的願望清單。此清單不僅概述了各種目標,還包括「靈感」、「如何」、「年份」、「狀態」和「紀念品」等附加欄,為您的技術之旅提供全面的路線圖。 ## 清單中有什麼? 該清單涵蓋了廣泛的目標,從培養特定技能(例如達到 150 WPM 的打字速度)到雄心勃勃的專案(例如製作 DIY 電動滑板或自行車)。它包括參加重大活動,例如參加大型技術會議,以及個人發展的里程碑,例如指導初級開發人員。每個目標都經過分類以便於參考,涵蓋 DIY 專案、程式設計、開發、學習等領域。 ## 列表 [我的遺願清單進度](https://syki.dev/bucket-list) |目標|類別|靈感|年份|狀態|紀念品| |---------------------------|----------------|----------------| ----|------|--------| |成為大型專案的貢獻者 |開發 |[如何像專業人士一樣開源](https://www.youtube.com/watch?v=MT6M_sqAuZo) | | | | |建立新聞聚合器 |開發 |[Feedly](https://feedly.com/) | | | | |建立實體引擎 |開發 |[我正在從頭開始編寫整個實體引擎](https://www.youtube.com/watch?v=iSMbRGTBOHU) | | | | |建立推薦系統 |開發 |[推薦系統如何運作 (Netflix/Amazon)](https://www.youtube.com/watch?v=n3RKsY2H-NE) | | | | |建構情緒分析工具 |開發 |【2023 如何掌握人工智慧驅動的情緒分析?】(https://brand24.com/blog/sentiment-analysis/) | | | | |建立擴增實境 (AR) 應用程式 |開發 |[關於如何在 2023 年建立擴增實境應用程式的指南](https://www.tekrevol.com/blogs/how-to-build-an-augmented-reality -應用程式/) | | | | |建置與部署聊天伺服器 |開發 |[IRC](https://en.wikipedia.org/wiki/Internet_Relay_Chat) | | | | |建立網路安全工具|開發|[Kali Tools](https://www.kali.org/tools/) | | | | |建立多人線上遊戲|開發|[Dani](https://www.youtube.com/watch?v=_ze26M_Fm6g) | | | | |建立 PWA(漸進式 Web 應用程式)|開發 |[PWA](https://developer.mozilla.org/en-US/docs/Web/Progressive_web_apps) | | | | |建立 AI 影響者 |開發 |[AI 影響者變得非常富有...讓我們建立一個](https://www.youtube.com/watch?v=ky5ZB-mqZKM&t=11s) | | | | |開發區塊鏈應用程式 |開發 |[使用以太坊智能合約和 Solidity 建置您的第一個區塊鏈應用程式](https://www.youtube.com/watch?v=coQ5dg8wM2o) | | | | |開發一種加密貨幣 |開發 |[您需要立即建立一種加密貨幣!!](https://www.youtube.com/watch?v=befUVytFC80) | | | | |開發VR 應用程式|開發|[教學 - 在Meta Quest 耳機上建立您的第一個VR 應用程式](https://developer.oculus.com/documentation/unity/unity-tutorial-hello-vr/) | | | | |開發一個電子商務網站 |開發 |[Next.js Commerce](https://nextjs.org/commerce) | | | | |開發開源遊戲引擎 |開發 |[C++ 中的 GameDev](https://www.youtube.com/watch?v=LyJkcv_rL9Y&list=PLpM-Dvs8t0Va6RoHkaLuPbRh7Fwpy4nbV) | | | | |開發瀏覽器擴充 |開發 |[Chrome 擴充應該會嚇到你。](https://www.youtube.com/watch?v=xIKwkPWUgOA) | | | | |在 github 上有一個擁有 100 顆星的專案 |開發 |[Linus Torvalds](https://github.com/torvalds?achievement=starstruck&tab=achievements) | | | | |擁有自己的 Tor 頁面 |開發 |[我在 Raspberry Pi 上放置了一個 DARK WEB 網站!!](https://www.youtube.com/watch?v=bllS9tkCkaM) | | | | |發明手勢控制介面 |開發 |[鋼鐵人](https://www.youtube.com/watch?v=P5k-4-OEuTk) | | | | |建立持續整合/持續部署管道|開發|[自動化您的工作流程](https://github.com/features/actions)從想法到生產]| | | | |設定 Kubernetes 叢集 |開發 |[為什麼要建置 Raspberry Pi 叢集?](https://www.youtube.com/watch?v=8zXG4ySy1m8) | | | | |贊助開源專案 |開發 |[投資為您的世界提供動力的軟體](https://github.com/sponsors) | | | | |使用查詢機制編寫自己的資料庫|開發|[製作我們自己的資料庫](https://acmiitr.medium.com/making-our-own-database-part-1-6cd9c49ed924) | | | | |在靜態網站產生器中撰寫頁面 |開發 |[Gatsby](https://www.gatsbyjs.com/) | | | | |編寫單頁應用程式 |開發 |[React](https://react.dev/) | | | | |使用 Raspberry Pi 專案實現家居自動化 |DIY |[我建立了一個更聰明的智慧家庭](https://www.youtube.com/watch?v=0rIvB3LZiKA) | | | | |建立自訂鍵盤 |DIY |[建立自己的機械鍵盤......正確的方式](https://www.youtube.com/watch?v=bBon6WwkdJE) | | | | |DIY電動滑板或自行車 |DIY |[我做了一個電動滑板!](https://www.youtube.com/watch?v=3bcvFzecg2Q) | | | | |以自訂遊戲建立迷你街機 |DIY |[終極 DIY 街機指南](https://www.youtube.com/watch?v=oTydZBIGAuk) | | | | |組裝一台 PC |DIY |[為 Minecraft 組裝一台價值 100,000 美元的 PC](https://www.youtube.com/watch?v=AHR80l7od2Q) | | | | |建立個人雲端儲存系統 |DIY |【這是我的終局之戰 - Mother Vault 伺服器機房更新】(https://www.youtube.com/watch?v=pLC0FUnko-M) | | | | |利用 IoT 建造自動澆水花園系統 |DIY |[Arduino 花園控制器 - 自動澆水和資料記錄](https://www.youtube.com/watch?v=O_Q1WKCtWiA) | | | | |打造小型自動駕駛汽車或機器人 |DIY |[快速巡線機器人](https://www.youtube.com/watch?v=lnP32gzHdvI) | | | | |建造水下ROV |DIY |[建造一艘DIY潛水艇](建造一艘DIY潛水艇) | | | | |搭建並飛行 FPV 無人機 |DIY |[為什麼要以 800mW 功率自由式飛行? | [FPV](https://www.youtube.com/watch?v=bBb_kSO3vTo) | | | | |設計具有互動功能的智慧鏡子|DIY |[DIY智慧鏡子 - 完整教學](https://www.youtube.com/watch?v=OYlloiaBINo) | | | | | 以 3D 方式設計和列印一些東西 |DIY |[我在房間中央製作了一個機器人手臂!](https://www.youtube.com/watch?v=nRsaf16EdNM) | | | | |設計您自己的 PCB |DIY |[PCB 建立初學者 - 10 分鐘內開始完成教程](https://www.youtube.com/watch?v=MsdJgEinb34) | | | | |修復損壞的電子產品 |DIY |[ElectroBOOM](https://www.youtube.com/@ElectroBOOM) | | | | |在本地擁有自己的伺服器 |DIY |[為什麼要建立 Raspberry Pi 叢集?](https://www.youtube.com/watch?v=8zXG4ySy1m8) | | | | |實現智慧家庭|DIY |[我建造了一個更聰明的智慧家庭](https://www.youtube.com/watch?v=0rIvB3LZiKA) | | | | |製作機械手臂 |DIY |[我在房間中央製作了機械手臂!](https://www.youtube.com/watch?v=nRsaf16EdNM) | | | | | 用 Flipper Zero 開啟一些東西 |DIY |[這讓駭客攻擊太容易了 - Flipper Zero](https://www.youtube.com/watch?v=nLIp4wd0oXs) | | | | |成為智慧型手機應用程式的擁有者|創業|[VoidLog](https://www.youtube.com/watch?v=LY4rxYe-jKI&list=PLN3n1USn4xllDDLwgJ4avEqgj4dWynofp) | | | | |開發 SaaS 產品 |創業精神|[我如何在一天內建立一個新的 SaaS 產品](https://www.youtube.com/watch?v=v_3lcqUOaOA) | | | | |在店裡擁有自己的遊戲 |創業|[Dani](https://www.youtube.com/watch?v=_ze26M_Fm6g) | | | | |在新創公司工作 |創業精神|[新創工程師在家工作的一天](https://www.youtube.com/watch?v=TLysAkFM4cA) | | | | |一週多相睡眠|創業|| | | | |參加播客 |創業|[Lex Fridman](https://www.youtube.com/lexfridman) | | | | |完全存取伺服器 - 黑客 |黑客 |[先生。機器人](https://www.youtube.com/watch?v=QqknSms8VVI&t=16s) | | | | |獲得錯誤賞金 |駭客 |[HackerOne](https://www.hackerone.com/) | | | | |在奪旗大賽中進行駭客攻擊 |駭客攻擊 |[Mr.機器人](https://www.youtube.com/watch?v=6MrQ-mN8HM8) | | | | |編寫惡意軟體 |駭客 |[惡意軟體開發:進程、執行緒與句柄](https://www.youtube.com/watch?v=aNEqC-U5tHM) | | | | |150 wpm 速度打字 |程式設計 |[Monkeytype](https://github.com/monkeytypegame/monkeytype) | | | | |使用 Python 腳本自動化您的日常任務 |程式設計 |[開始使用 Python 自動化您的生活! (Python檔案管理教學)](https://www.youtube.com/watch?v=NCvI-K0Gp90) | | | | |建立 Twitter 機器人 |程式設計 |[如何使用人工智慧發布熱門推文 // Twitter 機器人教學](https://www.youtube.com/watch?v=V7LEihbOv3Y) | | | | |編譯您自己的 Linux 核心 |程式設計 |[如何編譯自訂 Linux 核心](https://www.youtube.com/watch?v=APQY0wUbBow) | | | | |建立聊天機器人 |程式設計 |[使用深度學習、Python 和 TensorFlow 建立聊天機器人 p.1](https://www.youtube.com/watch?v=dvOnYLDg8_Y&list=PLQVvvaa0QuDdc2k5dwtDTyT9aCja0on8j) | | | | |使用 D3.js 建立資料視覺化專案 |程式設計 |[使用 D3.js 進行資料視覺化 - 完整教學課程](https://www.youtube.com/watch?v=_8V5o2UHG0E) | | | | |建立照片編輯工具 |程式設計 |[如何製作照片編輯應用程式的完整指南](https://www.cleveroad.com/blog/how-to-build-a-photo-editing-app-like-棱鏡並使其蓬勃發展/) | | | | |開發數位藝術作品產生器 |程式設計 |[如何為初學者產生瘋狂的人工智慧藝術(Midjourney V4)](https://www.youtube.com/watch?v=zf4z8A-OWBY) | | | | |開發檔案加密工具 |程式設計 |[製作您自己的加密程式](https://www.youtube.com/watch?v=TZT7wvTeVyY) | | | | |開發影片編輯軟體|程式設計|[我寫了一個影片編輯器(有點糟糕)](https://www.youtube.com/watch?v=iydG-e1dQGA) | | | | |開發語音助理應用程式 |程式設計 |[建立由 OpenAI 和 Python 驅動的 Jarvis | ChatGPT](https://www.youtube.com/watch?v=BEw5EFqCCEI) | | | | |開發智慧手錶應用程式 |程式設計 |[使用 Android Studio 在 WearOS 上建立並執行穿戴式應用程式](https://www.youtube.com/watch?v=-JO5oHRkybk) | | | | |開發您自己的 Slack/Discord 機器人 |程式設計 |[使用 Python 編寫 Discord 機器人 - 在雲端免費託管](https://www.youtube.com/watch?v=SPTfmiYiuok) | | | | |實現臉部辨識系統 |程式設計 |[從紙張到程式碼建立深度臉部辨識應用程式](https://www.youtube.com/watch?v=bK_k7eebGgc&list=PLgNJO2hghbmhHuhURAGbe6KWpiYZt0AMH) | | | | |學習函數式程式語言 |程式設計 |[函數式程式設計 - 概述](https://www.youtube.com/watch?v=8z_bUIl_uPo) | | | | |學習古老的語言 |程式設計 |[100 秒內的 COBOL](https://www.youtube.com/watch?v=7d7-etf-wNI) | | | | |學習並使用 Docker 進行容器化 |程式設計 |[Docker](https://www.docker.com/) | | | | |學習極快的語言 |程式設計 |[ThePrimeagen](https://www.youtube.com/@ThePrimeagen) | | | | |學習一門不尋常的語言(例如 Brainfuck) |程式設計 |[100 秒內完成 Brainfuck](https://www.youtube.com/watch?v=hdHjjBS4cs8) | | | | |學習量子運算基礎 |程式設計 |[在量子電腦上編碼](https://www.youtube.com/watch?v=q3ecPsMd4tA) | | | | |掌握高階演算法與資料結構(100道LeatCode) |程式設計|【569道 Leetcode 題後的我的大腦】(https://www.youtube.com/watch?v=8wysIxzqgPI) | | | | |對自訂語音控製家庭助理進行程式設計 |程式設計 |[建立由 OpenAI 和 Python 提供支援的 Jarvis | ChatGPT](https://www.youtube.com/watch?v=BEw5EFqCCEI) | | | | |對微控制器進行程式設計 |程式設計 |[微控制器程式設計駭客指南 [教學]](https://www.youtube.com/watch?v=XlFO5Iat178) | | | | |在 Vim 中編程 |程式設計 |[Vim 作為你的編輯器](https://www.youtube.com/watch?v=X6AR2RMB5tE&list=PLm323Lc7iSW_wuxqmKx_xxNtJC_hJbQ7R) | | | | |使用分離式鍵盤|編程|[拆箱新鍵盤!!! (也進行打字測試!)](https://www.youtube.com/watch?v=nh-BAxbithc&t=156s) | | | | |網頁抓取資料 |程式 |[使用 AI 和代理網路進行工業規模的網頁抓取](https://www.youtube.com/watch?v=qo_fUjb02ns) | | | | |用組合語言寫程式 |程式設計 |[Tsoding](https://www.youtube.com/watch?v=WnBXLmKk_qw&t=82s) | | | | |寫一個 NPM 模組 |程式設計 |[NPM](https://www.npmjs.com/) | | | | |編寫伺服器端應用程式 |程式設計 |[Next.js](https://nextjs.org/) | | | | |編寫您自己的人工智慧模型 |程式設計 |[讓我們建立 GPT:從頭開始,用程式碼,拼寫出來。](https://www.youtube.com/watch?v=kCc8FmEb1nY) | | | | |編寫您自己的作業系統 |程式設計 |[Linus Torvalds](https://github.com/torvalds) | | | | |寫你自己的程式語言 |程式設計 |[我製作了自己的程式語言](https://www.youtube.com/watch?v=pgeSGBwtHW8&t=132s) | | | | |擁有私人部落格 |教學 |[Dan Abramov](https://overreacted.io/) | | | | |對學生的講座 |教學 |[馬克·祖克柏的 CS50 講座 - 2005 年 12 月 7 日](https://www.youtube.com/watch?v=xFFs9UgOAlE&t=807s) | | | | |指導初級開發人員 |教學 |[如何正確指導初級開發人員](https://stablekernel.com/article/how-to-properly-mentor-a-junior-developer/) | | | | |寫一篇關於科技主題的論文並發表 |教學 |[兩分鐘論文](https://www.youtube.com/@TwoMinutePapers) | | | | |編寫技術書籍或電子書 |教學 |[編寫技術書籍](https://paulcunningham.me/writing-technical-books/) | | | | |參加大型科技會議 |旅遊 |[CES](https://www.ces.tech/) | | | | |參加黑客松 |旅行 |[我挑戰自己贏得黑客馬拉松](https://www.youtube.com/watch?v=mAJlZUKhOGs) | | | | |參觀電腦歷史博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀 NASA 約翰遜航天中心 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀國家航空暨太空博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀歷史科學儀器收藏 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀大型強子對撞機 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀麻省理工學院博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀國家核科學與歷史博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | ### 下載列表 [下載 CSV](https://syki.dev/uploads/bucket-list.csv) [下載 JSON](https://syki.dev/uploads/bucket-list.json) ## 附加列解釋 ### 靈感 本專欄反映了是什麼激發了追求特定目標的想法或願望。它可以是一個人、一個事件、一本書,甚至一部電影,點燃了人們對特定成就的熱情。例如,DIY 電動滑板的靈感可能是對永續交通的熱情或最喜歡的科技影片部落客的專案。 ### 年 本專欄提出了實現該目標的時間表或目標年份。它有助於規劃和設定現實的時間表。例如,您可能計劃在 2025 年之前參加一次大型技術會議。 ### 地位 狀態追蹤您的進度。它可以是“未開始”“進行中”“已完成”或“暫停”這有助於追蹤您的旅程並保持動力。 ### 紀念品 本專欄是一個獨特的補充,旨在紀念這一成就。它可以是實體、數位徽章、部落格文章,甚至是照片。例如,組裝 PC 的紀念品可能是已完成設定的第一張照片。 ## 結論 技術愛好者的願望清單不僅僅是目標的集合;這是技術領域個人和職業成長的路線圖。透過附加專欄提供靈感、方法、計時、追蹤和紀念成就的框架,此列表對於任何熱衷於技術的人來說都是一個動態工具。 快樂的科技冒險! --- 原文出處:https://dev.to/syki/100-bucket-list-ideas-for-programmers-506m
--- 標題:我如何教 Git 發表:真實 描述: 標籤: git, 學習 canonical_url:https://blog.ltgt.net/teaching-git/ 封面圖片:https://marklodato.github.io/visual-git-guide/conventions.svg.png # 使用 100:42 的比例以獲得最佳效果。 # 發佈時間: 2023-11-26 19:17 +0000 --- 我使用 Git 已經十幾年了。八年前,我必須為一家即將建立開源專案的合作夥伴公司舉辦有關 Git(和 GitHub)的培訓課程,我將在這裡向您介紹我的教學方式。順便說一句,從那時起,我們在工作中建立了使用相同(或類似)方法的內部培訓課程。話雖如此,我並沒有發明任何東西:這很大程度上受到了其他人之前寫的內容的啟發,包括[the <cite>Pro Git</cite> book](https://git-scm. com/book/),儘管順序不同,但 <abbr title="in my view">IMO</abbr> 可以有所作為。 我寫這篇文章的原因是,多年來,我不斷看到人們實際上使用 Git,但沒有真正理解他們在做什麼;他們正在使用 Git。他們要么被鎖定在一個非常具體的工作流程中,他們被告知要遵循,並且無法適應另一個開源專案正在使用的工作流程(這也適用於開源維護人員並不真正了解外部貢獻者如何使用 Git) ),或者如果任何事情沒有按照他們想像的方式執行,或者他們在呼叫Git 命令時犯了錯誤,他們就會完全迷失。我受到 [Julia Evans](https://jvns.ca) 對 Git 的(更新)興趣的啟發而寫下來,因為她有時會在社交網絡上徵求評論。 我的目標不是真正教你有關 Git 的知識,而是更多地分享我教授 Git 的方法,以便其他可能會教導的人從中獲得靈感。因此,如果您正在學習 Git,那麼這篇文章並不是專門為您而寫的(抱歉),因此可能不是自給自足的,但希望其他學習資源的連結足以填補空白,使其成為也是有用的學習資源。如果您是視覺學習者,這些外部學習資源都是有插圖的,甚至是視覺學習的。 ## 心理模型 一旦我們清楚了為什麼我們使用VCS(版本控制系統)來記錄_commits_ 中的更改(或者換句話說,我們_將我們的更改_提交到歷史記錄;我假設你對這個術語有一定的熟悉),讓我們多了解一下Git具體來說。 我認為理解 Git 至關重要的一件事是獲得其背後概念的準確心理模型。 首先,這並不是很重要,但Git 實際上並沒有記錄_changes_,而是記錄我們文件的_snapshots_(至少在概念上是這樣;它將使用_packfiles_ 來有效地儲存內容,並且在某些情況下方實際上會儲存_changes_ –diffs–),並且會按需產生差異。不過,這有時會顯示在某些命令的結果中(例如為什麼某些命令顯示一個檔案被刪除而另一個檔案被加入,而其他命令顯示一個檔案被重新命名)。 現在讓我們深入探討一些 Git 概念,或是 Git 如何實現一些常見的 VCS 概念。 ### 犯罪 Git _commit_ 是: * 一個或多個父親提交,或第一次提交沒有父親提交 (_root_) * 提交訊息 * 作者和作者日期(實際上是帶有時區偏移的時間戳) * 提交者和提交日期 * 和我們的檔案:相對於儲存庫根的路徑名、_mode_(UNIX 檔案系統權限)及其內容 每次提交都會獲得一個標識符,該標識符是透過計算該資訊的 SHA1 雜湊值確定的:更改逗號,您將獲得不同的 SHA1,即不同的_提交物件_。 (<abbr title="For What it's value">Fwiw</abbr>,Git 正在慢慢[轉向 SHA-256](https://git-scm.com/docs/hash-function-transition) 作為哈希功能)。 #### 旁白:SHA1 是如何計算的? Git 的儲存是_內容尋址_,這表示每個_物件_都使用直接從其內容派生的名稱進行存儲,並採用 SHA1 雜湊的形式。 從歷史上看,Git 將所有內容儲存在文件中,我們仍然可以這樣推理。文件的內容儲存為 _blob_,目錄儲存為 _tree_(一個文字文件,列出目錄中的文件及其名稱、模式和表示其內容的 _blob_ 的 SHA1,以及其子目錄及其名稱和 SHA1他們的_樹_) 如果您想了解詳細訊息,Julia Evans(再次)寫了一篇令人驚嘆的[博客文章](https://jvns.ca/blog/2023/09/14/in-a-git-repository-- where-do-your-檔案-即時-/);或者您可以[從 <cite>Pro Git</cite> 書中閱讀](https://git-scm.com/book/en/v2/Git-Internals-Git-Objects)。 <圖> <img src=https://git-scm.com/book/en/v2/images/commit-and-tree.png width=800 height=443 alt='包含5 個框的圖表,分為3 列,每個框標有 5 位 SHA1 前綴;左邊的子標籤為“commit”,包含元資料“tree”,中間是框的 SHA1,“author”和“committer”的值均為“Scott”,文字為“The initial commit of我的專案”;中間的框被子標記為“tree”,包括三行,每行標記為“blob”,其餘 3 個框的 SHA1 以及看起來像文件名的內容:“README”、“LICENSE”和“test.rb” ”;最後 3 個框,在右側垂直對齊,都是子標籤為「blob」的內容,包含看起來像是 README、LICENSE 和 Ruby 原始檔內容開頭的內容;有箭頭連結框:提交指向樹,樹指向 blob。'> <figcaption>提交及其樹(來源:<a src=https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell><cite>Pro Git</引用></a>)</figcaption> </圖> _commit_ 中的_父親提交_ 建立一個代表我們歷史的[有向無環圖](https://en.wikipedia.org/wiki/Directed_acirclic_graph):_有向無環圖_ 由連結的節點(我們的提交)組成與有向邊一起(每個提交連結到其父提交,有一個方向,因此_directed_)並且不能有循環/循環(提交永遠不會是它自己的祖先,它的祖先提交都不會連結到它作為父提交)。 <圖> <img src=https://git-scm.com/book/en/v2/images/commits-and-parents.png width=800 height=265 alt='包含 6 個框排列成 2 行 3 列的圖表;第一行的每個框都標有 5 位 SHA1 前綴,子標籤為“commit”,元資料“tree”和“parent”均帶有 5 位 SHA1 前綴(每次都不同)、“author”和“ committer」的值都是“Scott”,以及一些代表提交訊息的文字;左邊的盒子沒有「父」值,另外兩個盒子將左邊的盒子的 SHA1 作為「父」;這些框之間有一個箭頭,指向代表「父」的左側;順便說一句,左邊的框與上圖中的提交框具有相同的 SHA1 和相同的內容;最後,每個提交框也指向其下方的一個框,每個框都標記為「快照 A」、「快照 B」等,並且可能代表從每個提交連結的「樹」物件。'> <figcaption>提交及其父級(來源:<a src=https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell><cite>Pro Git</ cite ></a>)</figcaption> </圖> ### 參考文獻、分支和標籤 現在 SHA1 哈希對於人類來說是不切實際的,雖然 Git 允許我們使用唯一的 SHA1 前綴而不是完整的 SHA1 哈希,但我們需要更簡單的名稱來引用我們的提交:輸入 _references_。這些是我們選擇的提交的_標籤_(而不是 Git)。 有幾種_參考_: * _branches_ 是_moving_ 引用(請注意,`main` 或`master` 並不特殊,它們的名稱只是一個約定) *_標籤_是_不可變_引用 * `HEAD` 是一個特殊的引用,指向_當前提交_。它通常指向一個分支而不是直接指向一個提交(稍後我們會看到原因)。當一個引用指向另一個引用時,這稱為[_符號引用_](https://blog.ltgt.net/confusing-git-terminology/#reference-symbolic-reference)。 * Git 會在某些操作期間為您設定其他特殊參考(`FETCH_HEAD`、`ORIG_HEAD` 等) <圖> <img src=https://git-scm.com/book/en/v2/images/branch-and-history.png width=800 height=430 alt='帶有 9 個框的圖; 6 個盒子的排列方式與上圖相同,並且標記相同(三個提交及其 3 個樹);最右邊(最新)提交上方的兩個框,箭頭指向它,分別標記為“v1.0”和“master”;最後一個框位於“master”框上方,有一個箭頭指向它,並標記為“HEAD”。'> <figcaption>分支及其提交歷史記錄(來源:<a src=https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell><cite>Pro Git< /引用></a>)</figcaption> </圖> ### 三個狀態 當您在 Git 儲存庫中工作時,您在 Git 歷史記錄中操作和記錄的檔案位於您的_工作目錄_中。要建立提交,您需要在 [_index_](https://blog.ltgt.net/confusing-git-terminology/#index-staged-cached) 或_暫存區域_中_暫存_檔案。完成後,您附加一則提交訊息並將您的_staged_檔案移至_history_。 為了關閉循環,_工作目錄_是根據_歷史記錄_中的給定提交進行初始化的。 <圖> <img src=https://git-scm.com/book/en/v2/images/areas.png width=800 height=441 alt='包含3 位參與者的序列圖:「工作目錄」、「暫存區域」和「.git directpry(儲存庫)」;有一條“簽出專案”訊息從“.git 目錄”到“工作目錄”,然後從“工作目錄”到“暫存區域”進行“階段修復”,最後從“暫存區域”進行“提交”區域」到「.git 目錄」。'> <figcaption>工作樹、暫存區域和 Git 目錄(來源:<a href="https://git-scm.com/book/en/v2/Getting-Started-What-is-Git%3F#_the_third_states" ><cite>Pro Git</cite></a>)</figcaption> </圖> ### 旁白:忽略文件 並非所有檔案都需要_追蹤_歷史記錄:由建置系統(如果有)產生的檔案、特定於您的編輯器的檔案以及特定於您的作業系統或其他工作環境的檔案。 Git 允許定義要忽略的檔案或目錄的命名模式。這實際上並不意味著Git 會忽略它們並且無法_跟踪_,但如果不跟踪它們,多個Git 操作將不會向您顯示它們或操縱它們(但您可以手動將它們加入到歷史記錄中,並且從那時起,他們將不再被_忽略_)。 忽略檔案是透過將路徑名稱(可能使用 glob)放入忽略檔案中來完成的: * 儲存庫中任何位置的 `.gitignore` 檔案定義了包含目錄的忽略模式;這些忽略文件會在歷史記錄中被跟踪,作為開發人員之間共享它們的一種方式;在這裡,您將忽略建置系統產生的那些檔案(Gradle 專案的“build/”,Eleventy 網站的“_site/”等) * `.git/info/excludes` 是您機器上的本機儲存庫;很少使用,但有時很有用,所以很高興了解一下 * 最後 `~/.config/git/ignore` 對機器來說是全域的(對你的使用者);在這裡,您將忽略特定於您的電腦的文件,例如特定於您使用的編輯器的文件,或特定於您的作業系統的文件(例如macOS 上的“.DS_Store”或Windows 上的“Thumbs. db”) ) ### 加起來 這是所有這些概念的另一種表示: <圖> <img src=https://marklodato.github.io/visual-git-guide/conventions.svg width=907 height=529 alt='有 10 個框的圖; 5 個框在中心排成一行,標有 5 位 SHA1 前綴,它們之間有從右向左指向的箭頭;一條註釋將它們描述為“提交物件,由 SHA-1 哈希標識”,另一條註釋將其中一個箭頭描述為“子項指向父項”;一對框(看起來像一個水平分割成兩個框的單一框)位於最右邊(最新)提交的上方,有一個向下指向它的箭頭,該對的上面的框被標記為“HEAD”並描述為“引用當前分支”;下面的框被標記為“main”並被描述為“目前分支”;第七個框位於另一個提交上方,有一個向下指向它的箭頭;它被標記為“穩定”並被描述為“另一個分支”;最後兩個框位於提交歷史記錄下,一個在另一個之上;最底部的框標記為“工作目錄”並描述為“您'看到'的文件”,它和提交歷史記錄之間的另一個框標記為“階段(索引)”並描述為“要存取的文件”在下次提交中”。'> <figcaption>提交、引用和區域(來源:<a href=https://marklodato.github.io/visual-git-guide/index-en.html#conventions><cite>可視化 Git 參考</cite >< /a>,馬克‧洛達托)</figcaption> </圖> ## 基本操作 這就是我們開始討論 Git 指令以及它們如何與圖表互動的地方: * `git init` 初始化一個新的儲存庫 * `git status` 取得檔案狀態的摘要 * `git diff` 顯示任意兩個工作目錄、索引、`HEAD` 之間的更改,或實際上任何提交之間的更改 * `git log` 顯示並搜尋您的歷史記錄 * 建立提交 * `git add` 將檔案加入_index_ * `git commit` 將_index_ 轉換為_commit_ (帶有新增的_commit 訊息_) * `git add -p` 以互動方式將檔案新增至 _index_:選擇要新增的變更以及僅將哪些變更保留在工作目錄中,逐一檔案、逐個部分(稱為 _hunk_) * 管理分支機構 * `gitbranch` 顯示分支,或建立分支 *`git switch`(也稱為`git checkout`)將分支(或任何提交,實際上是任何_樹_)簽出到您的工作目錄 * `git switch -b` (也稱為 `git checkout -b`)作為 `gitbranch` 和 `gitswitch` 的捷徑 * `git grep` 搜尋您的工作目錄、索引或任何提交;這是一種增強的“grep -R”,它支援 Git * `gitblame` 來了解更改給定文件每一行的最後一次提交(因此,誰應該為錯誤負責) * `git stash` 將未提交的更改放在一邊(這包括_staged_文件,以及工作目錄中的_tracked_文件),然後_unstash_它們。 ### 提交、分支切換和 HEAD 當您建立提交(使用「git commit」)時,Git 不僅建立_提交物件_,還移動「HEAD」以指向它。如果「HEAD」實際上指向一個分支(通常是這種情況),Git 會將該分支移動到新的提交(並且「HEAD」將繼續指向該分支)。每當當前分支是另一個分支的祖先(該分支指向的提交也是另一個分支的一部分)時,提交將使“HEAD”移動相同,並且分支將_發散_。 當您切換到另一個分支(使用“git switch”或“git checkout”)時,“HEAD”會移至新的目前分支,並且您的工作目錄和索引將設定為重新組合該提交的狀態(未提交的更改將暫時保留;如果 Git 無法做到這一點,它將拒絕切換)。 如需更多詳細資訊和視覺表示,請參閱[commit](https://marklodato.github.io/visual-git-guide/index-en.html#commit) 和[checkout](https://marklodato. github .io/visual-git-guide/index-en.html#checkout)Mark Lotato 的<cite>可視化Git 參考</cite>的部分(請注意,該參考是幾年前寫的,當時`git switch ` 和 ` git Restore` 不存在,而 `git checkout` 是我們所擁有的一切;因此 _checkout_ 部分涵蓋的內容比 `git switch` 多一點)。 當然,<cite>Pro Git</cite> 這本書也是一個很好的視覺表示參考; [<cite>Branches in a Nutshell</cite> 子章節](https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell) 涵蓋了所有內容的很大一部分上述的。 ### 旁白:Git 是保守的 正如我們在上面所看到的,由於其_內容尋址存儲_,對提交的任何“更改”(例如使用“git commit --amend”)實際上都會導致不同的提交(不同的 SHA1)。 _舊提交_不會立即消失:Git 使用_垃圾收集_最終刪除無法從任何_引用_存取的提交。這意味著,如果您設法找回提交SHA1,則可以恢復許多錯誤(“git reflog”可以在此處提供幫助,或者符號“<branch-name>@{<n>}”,例如“main@{ 1}”) ` main` 在更改之前指向的最後一次提交)。 ### 使用分支機構 我們在上面已經看到了分支是如何發散的。 但分歧要求最終_合併_變回來(使用“git merge”)。 Git 在這方面非常擅長(我們稍後會看到)。 合併的一個特殊情況是目前分支是要合併到的分支的祖先。在這種情況下,Git 可以執行 [_fast-forward merge_](https://blog.ltgt.net/confusing-git-terminology/#can-be-fast-forwarded)。 由於兩個分支之間的操作可能始終針對同一對分支,因此 Git 允許您設定一個分支來追蹤另一個分支。另一個分支被稱為_追蹤_它的分支的_上游_。例如,設定時,「git status」將告訴您兩個分支彼此之間有多少分歧:目前分支是[_最新_](https://blog.ltgt.net/confusing-git-terminology /#your- branch-is-up-to-date-with-originmain) 及其上游分支,_後面_和[可以快轉](https://blog.ltgt.net/confusing-git-terminology/ #can-be- fast-forwarded),_超前_許多提交,或它們有分歧,每個提交都有一定數量。其他命令將使用該資訊為參數提供良好的預設值,以便可以省略它們。 要整合來自另一個分支的更改,而不是合併,另一種選擇是_cherry-pick_(使用同名命令)單一提交,而不包含其歷史記錄:Git 將計算該提交帶來的更改並將相同的更改應用於當前分支,建立一個與原始分支類似的新提交(如果您想了解更多有關Git 實際操作方式的訊息,請參閱Julia Evans 的[<cite>如何gitcherry-pick 和revert 使用3 路合併< /cite> ](https://jvns.ca/blog/2023/11/10/how-cherry-pick-and-revert-work/))。 最後,工具帶中的另一個指令是「rebase」。 您可以將其視為一次進行許多選擇的方法,但它實際上更強大(正如我們將在下面看到的)。但在其基本用途中,它只是這樣:您給它一系列提交(在作為起點的任何提交和作為終點的現有分支之間,預設為當前分支)和一個目標,並且它會挑選所有這些提交位於目標之上,並最終更新用作終點的分支。這裡的指令的形式是`git rebase --onto=<target> <start> <end>`。與許多 Git 命令一樣,參數可以省略,並且具有預設值和/或特定含義:因此,`git rebase` 是 `git rebase --fork-point upper` 的簡寫,其中 `upstream` 是 [upstream]當前分支的(https://blog.ltgt.net/confusing-git-terminology/#untracked-files-remote-tracking-branch-track-remote-branch)(我會忽略`--fork-point`這裡,它的作用很微妙,在日常使用上並不那麼重要),它本身就是`git rebase upper HEAD` 的簡寫(其中`HEAD` 必須指向一個分支),它本身就是`git rebase 的簡寫-- on=upstream uploaded `,`git rebase --onto=upstream $(git merge-baseupstream HEAD) HEAD` 的簡寫,並將rebase `upstream` 的最後一個共同祖先與當前分支之間的所有提交另一方面,手和當前分支(即自從它們分歧以來的所有提交),並將它們重新應用到“上游”之上,然後更新當前分支以指向新的提交。明確使用`--onto` (其值與起始點不同)實際上很少見,請參閱[我之前的文章](https://blog.ltgt.net/confusing-git-terminology/#git- rebase- --onto) 對於一個用例。 我們無法在沒有互動式變體「git rebase -i」的情況下呈現「git rebase」:它以與非互動式變體完全相同的行為開始,但在計算需要完成的操作之後,它將允許您對其進行編輯(作為編輯器中的文字文件,每行一個操作)。預設情況下,所有選定的提交都是精心挑選的,但您可以對它們重新排序,跳過某些提交,甚至將某些提交合併到單一提交中。實際上,您可以挑選最初未選擇的提交,甚至建立合併提交,從而完全重寫整個歷史記錄!最後,您還可以停止對其進行編輯(然後使用“git commit --amend”,和/或可能在繼續變基之前建立新的提交),和/或在兩次提交之間執行給定的命令。最後一個選項非常有用(例如,驗證您沒有在歷史記錄的每個點上破壞您的專案),您可以在`--exec` 選項中傳遞該命令,Git 將在每個重新基底提交之間執行它(這也適用於非互動式變基;在互動模式下,當能夠編輯變基場景時,您將看到在每個櫻桃選擇行之間插入執行行)。 更多詳細資訊和視覺表示,請參閱[merge](https://marklodato.github.io/visual-git-guide/index-en.html#merge)、[cherry pick](https://marklodato . github.io/visual-git-guide/index-en.html#cherry-pick) 和 [rebase](https://marklodato.github.io/visual-git-guide/index-en.html#rebase) Mark Lodato 的<cite>視覺化Git 參考</cite> 部分,以及[<cite>基本分支和合併</cite>](https://git-scm.com/book/en/v2/Git-分支-基本-分支和合併),[<cite>變基</cite>](https://git-scm.com/book/en/v2/Git-Branching-Rebasing)和[<cite>重寫歷史< /cite>](https://git-scm.com/book/en/v2/Git-Tools-Rewriting-History) <cite>Pro Git</cite> 書的子章節。 您也可以查看 David Drysdale 的 [<cite>Git Visual Reference</cite>](https://lurklurk.org/gitpix/gitpix.html) 中的「分支和合併」圖。 ## 與他人合作 目前,我們只在我們的儲存庫中進行本地工作。 但 Git 是專門為與他人合作而建構的。 讓我介紹一下_遙控器_。 ### 遙控器 當您_複製_儲存庫時,該儲存庫將成為本機儲存庫的_遠端_,名為「origin」(就像「main」分支一樣,這只是預設值,名稱本身沒有什麼特別的,除了有時用作省略命令參數時的預設值)。然後,您將開始工作,建立本地提交和分支(因此從遠端_forking_),同時遠端可能會從其作者那裡獲得更多提交和分支。因此,您需要將這些遠端變更同步到本機儲存庫,並希望快速了解與遠端相比您在本機所做的變更。 Git 處理這個問題的方式是在一個特殊的命名空間中記錄它所知道的遠端(主要是分支)的狀態:「refs/remote/」。這些被稱為[_遠端追蹤分支_](https://blog.ltgt.net/confusing-git-terminology/#untracked-files-remote-tracking-branch-track-remote-branch)。 Fwiw,本機分支儲存在「refs/heads/」命名空間中,標籤儲存在「refs/tags/」中(來自遠端的標籤通常直接「匯入」到「refs/tags/」中,因此例如您會遺失位置資訊他們來自)。您可以根據需要擁有任意多個遙控器,每個遙控器都有一個名稱。 (請注意,遙控器不一定位於其他電腦上,它們實際上可以位於同一台電腦上,直接從檔案系統存取,因此您無需進行任何設定即可使用遙控器。) ### 取得 每當你從遠端 _fetch_ 時(使用 `git fetch`、`git pull` 或 `git Remote update`),Git 都會與它對話以下載它還不知道的提交,並更新 _remote-tracking遠端分支_ 。要取得的確切引用集以及取得它們的位置將傳遞給 `git fetch` 命令(如 [refspecs](https://blog.ltgt.net/confusing-git-terminology/#refspecs) )以及儲存庫的` .git/config` 中定義的預設值,預設由`git clone` 或`git remote add` 配置以取得所有分支(遠端上的`refs/heads/` 中的所有內容)並放置它們位於` refs/remote/<remote>` 中(因此`origin` 遙控器的`refs/remote/origin/` )具有相同的名稱(因此遙控器上的`refs/heads/main` 變成`refs/remote / origin/main` 本地)。 <圖> <img src=https://git-scm.com/book/en/v2/images/remote-branches-5.png width=800 height=577 alt='帶有3 個大方框的圖表,代表機器或儲存庫,包含代表提交歷史的較小框和箭頭;一個框標記為“git.outcompany.com”,子標記為“origin”,並包含名為“master”的分支中的提交;另一個框標記為“git.team1.outcompany.com”,子標記為“teamone”,並包含名為“master”的分支中的提交; 「origin」和「teamone」中的提交 SHA1 雜湊值相同,除了「origin」在其「master」分支上多了一個提交,即「teamone」在「後面」;第三個框標記為“我的電腦”,它包含與其他兩個框相同的提交,但這次分支被命名為“origin/master”和“teamone/master”;它還在名為“master”的分支中包含另外兩個提交,與遠端分支的較早點不同。'> <figcaption>遠端和遠端追蹤分支(來源:<a href=https://git-scm.com/book/en/v2/Git-Branching-Remote-Branches><cite>Pro Git</cite>< / a>)</figcaption> </圖> 然後,您將使用與分支相關的命令來獲取從_遠端追蹤分支_到本地分支的更改(“git merge”或“git rebase”),或“git pull”,這只不過是“git fetch”的簡寫` 後面跟著 `git merge` 或 `git rebase`。 <abbr title="By the way">順便說一句</abbr>,在很多情況下,當你建立本地分支時,Git 會自動將_遠端追蹤分支_設定為本地分支的_上游_(它會告訴你相關資訊)當這種情況發生時)。 ### 推 要與其他人共用您的更改,他們可以將您的儲存庫新增為遠端儲存庫並從中_pull_(意味著透過網路存取您的電腦),或者您可以_push_到遠端儲存庫。 (如果您要求某人從您的遙控器中提取更改,這稱為..._拉請求_,您可能在 GitHub 或類似服務中聽說過這個術語。) 推送與提取類似,相反:您將提交發送到遠端並更新其分支以指向新提交。作為安全措施,Git 只允許遠端分支_快速轉送_;如果您想推送以非快轉方式更新遠端分支的更改,則必須使用「git push --force-with-lease」(或「git push --force」)_force_它,但要小心:`-- force-with-lease`將首先確保您的_遠端追蹤分支_與遠端分支是最新的,以確保自上次_fetched_以來沒有人將變更推送到分支;` --force` 不會執行該檢查,而是按照您的指示執行操作,風險由您自己承擔)。 與「git fetch」一樣,您可以將要更新的分支傳遞給「git push」命令,但如果您不這樣做,Git 會提供良好的預設行為。如果你不指定任何東西,Git 會從目前分支的上游推斷遠程,所以大多數時候 `git push` 相當於 `git push origin`。這實際上是“git Push origin main”的簡寫(假設當前分支是“main”),它本身是“git Push origin main:main”的簡寫,是“git Push origin refs/heads/main:refs/”的簡寫heads/main`,意思是將本地的`refs/heads/main`推送到`origin`遠端的`refs/heads/main`。有關使用不同來源和目標指定 _refspecs_ 的一些用例,請參閱[我之前的文章](https://blog.ltgt.net/confusing-git-terminology/#refspecs)。 <圖> <img src=https://lurklurk.org/gitpix/push2.svg width=1052 height=744 alt='代表「git push」指令的圖表,有四個 git 圖表(點,有些有標籤,用線連接) 排列成兩行兩列;列之間的箭頭表示左列是「之前」狀態,右列是「之後」狀態;上面一行中的圖位於雲內部,代表遠端儲存庫,並且有兩個分支,“master”和“other”,它們偏離了共同的祖先;左下圖與上面的圖形狀相同,只是標籤更改為“origin/master”和“origin/other”,並且每個分支有更多提交:與“origin”分支相比,“master”分支有兩個額外的提交/master”,而“other”比“origin/other”多了一個提交;與左上圖相比,右上圖在其「master」分支中多了兩次提交;右下圖與左下圖相同,除了「origin/master」現在指向與「master」相同的提交;換句話說,在「之前」狀態下,遠端缺少三個提交,而在「git Push」之後,本地「master」分支的兩個提交被複製到遠端,而「其他」保持不變。'> <figcaption><code>git Push</code>(資料來源:<a href=https://lurklurk.org/gitpix/gitpix.html><cite>Git 視覺參考</cite></a>,David Drysdale )</圖標題> </圖> 更多詳細資訊和視覺表示,請參閱[<cite>遠端分支</cite>](https://git-scm.com/book/en/v2/Git-Branching-Remote-Branches),[< cite >使用遙控器</cite>](https://git-scm.com/book/en/v2/Git-Basics-Working-with-Remotes),以及[<cite>為專案做出貢獻</ cite> ](https://git-scm.com/book/en/v2/Distributed-Git-Contributing-to-a-Project) <cite>Pro Git</cite> 書的子章節,以及「處理遠程來自David Drysdale 的[<cite>Git Visual Reference</cite>](https://lurklurk.org/gitpix/gitpix.html) 的「儲存庫」圖表。 <cite>Pro Git</cite> 的<cite>為專案做出貢獻</cite>一章也涉及在GitHub 等平台上為開源專案做出貢獻,您必須先_fork_儲存庫,然後透過_pull requests_進行貢獻(或_合併請求_)。 ## 最佳實踐 這些是針對初學者的,希望不會引起太多爭議。 嘗試保留_clean_歷史記錄: * 明智地使用合併提交 * 清晰且高品質的提交訊息(請參閱[<cite>提交指南</cite>](https://git-scm.com/book/en/v2/Distributed-Git-Contributing-to-a-Project #_commit_guidelines)在<cite>Pro Git</cite> 中) * make _atomic_ commits:每個提交應該獨立於歷史記錄中跟隨它的提交進行編譯和執行 這僅適用於您與他人分享的歷史記錄。 在本地,想怎麼做就怎麼做。對於初學者,我會給以下建議: * 不要直接在“main”(或“master”,或您在遠端上沒有專門擁有的任何分支)上工作,而是建立本機分支;它有助於解耦不同任務的工作:即將開始處理另一個錯誤或功能,同時等待有關當前任務的說明的更多詳細資訊?切換到另一個分支,稍後您可以透過切換回來回到該分支;它還使從遠端更新變得更容易,因為如果您的本地分支只是同名遠端分支的副本,沒有任何本地更改(除非您想推送這些更改),您確信不會發生衝突到該分支) * 毫不猶豫地重寫你的提交歷史記錄(`git commit --amend` 和/或 `git rebase -i`),但不要太早這樣做;在工作時堆疊許多小提交是完全可以的,並且只在共享之前重寫/清理歷史記錄 * 同樣,請毫不猶豫地重新調整本機分支以整合上游變更(直到您共用該分支,此時您將遵循專案的分支工作流程) 如果出現任何問題並且您迷路了,我的建議是使用 `gitk` 或 `gitk HEAD @{1}`,也可能使用 `gitk --all` (我在這裡使用 `gitk` 但使用任何工具你喜歡),可視化你的Git 歷史並嘗試了解發生了什麼。由此,您可以回滾到先前的狀態(`git reset @{1}`)或嘗試修復問題(擇優選擇提交等)。合併失敗,您可以使用“git rebase --abort”或“git merge - -abort」等命令中止並回滾到先前的狀態。 為了讓事情變得更簡單,請不要猶豫,在任何可能具有破壞性的命令(`git rebase`)之前,建立一個分支或標籤作為“書籤”,如果事情沒有按預期進行,您可以輕鬆重置。當然,在執行這樣的命令後,請檢查歷史記錄和文件,以確保結果是您所期望的。 ## 進階概念 這只是其中的一小部分,還有更多值得探索! * 分離的「HEAD」:[`git checkout` 手冊頁](https://git-scm.com/docs/git-checkout#_detached_head) 有一個關於該主題的很好的部分,另請參閱[我之前的帖子](https ://blog.ltgt.net/confusing-git-terminology/#detached-head-state),要獲得良好的視覺表示,請參閱[<cite>使用分離的HEAD 進行提交</ cite>](https:// /marklodato.github.io/visual-git-guide/index-en.html#detached) Mark Lodato 的 <cite>視覺化 Git 參考</cite> 部分。 * Hooks:這些是可執行檔(大多數情況下是 shell 腳本),Git 將執行它們來回應儲存庫上的操作;人們使用它們在每次提交之前檢查程式碼(如果失敗則中止提交),產生或後處理提交訊息,或在有人推送到儲存庫後觸發伺服器上的操作(觸發建置和/或部署)。 * 一些很少需要的命令可以在您真正需要時節省您的時間: * `git bisect`:一個進階命令,透過測試多個提交(手動或透過腳本)來幫助您找出哪個提交引入了錯誤;對於線性歷史,這是使用二分法並且可以手動完成,但是一旦您有許多合併提交,這就會變得更加複雜,並且最好讓 git bisect 來完成繁重的工作。 * `git filter-repo`:實際上是一個[第三方命令](https://github.com/newren/git-filter-repo),作為Git 自己的`filter-branch` 的替代品,它允許重寫儲存庫的整個歷史記錄,以刪除錯誤新增的文件,或協助將儲存庫的一部分提取到另一個儲存庫。 我們完成了。 有了這些知識,人們應該能夠將任何 Git 命令映射到如何修改提交的_有向無環圖_,並了解如何修復錯誤(在錯誤的分支上執行合併?基於錯誤的分支重新建置?)並不是說理解這些事情會很容易,但至少應該是可能的。 --- 原文出處:https://dev.to/tbroyer/how-i-teach-git-3nj3
目前大環境不好,但作為開發人員,我們擁有一套獨特的技能,如果您知道在哪裡尋找,這些技能的需求量很大! 這篇文章簡要概述了 50 個作為開發人員可以用來賺取額外收入的副業 --- ### 1. 銷售注意力 基於參與度的收入是指您將根據使用者在您的網站、個人資料或消費您的內容上花費的時間來獲得收入分成。它通常很小,至少對於較小的網站或創作者來說是這樣,但隨著時間的推移,它會增加,任何人都可以啟用它 - 所以你不會有任何損失。 - [Brave](https://creators.brave.com/) - 為使用 Brave 瀏覽器造訪您的網站、個人資料或查看您的內容的使用者付費。資金以 [BAT](https://basicattentiontoken.org/) 形式存入您的 Uphold 帳戶,然後可以以美元、英鎊或歐元形式提取至您的銀行帳戶 - [Flattr](https://flattr.com/) - 付費使用 Flattr 的用戶將其資金分配給用戶存取過其內容的創作者 > 幾年前,我親自報名了 Brave Rewards。在驗證了我的網域和個人資料的所有權後,我每月一直賺幾英鎊 - 到目前為止大約 200 英鎊以上(儘管我是 Firefox 用戶!)。雖然不多,但只需付出很少的努力,就值得了。 有關其工作原理的更多訊息,請查看 [webmonetization.org](https://webmonetization.org/) 規範,該規範利用了 [付款指針](https://paymentpointers.org/)通過[ILP](https://interledger.org/) 透過使用簡單的`<link rel="monetization" href="your-pointer-here" />` 標籤來串流來自支援WM 的訪客的收入。 --- ### 2. API 即服務 RapidAPI 等平台可讓您從 API 中[賺取被動收入](https://rapidapi.com/guides/earn-a-passive-venue-by-monetizing-apis-as-a-developer)。 建置並部署簡單的 API 後,您可以將其匯入 RapidAPI Hub,選擇使用和定價計劃,然後點擊發布。您的 API 可大可小,如您所願。 如果您正在為一個簡單的第一個專案尋找靈感,請考慮將開放資料集轉換為 API。對於初學者,RapidAPI 有一個關於如何入門的[影片系列](https://rapidapi.com/courses/build-and-sell-your-own-api)。其他想法可能包括將現有套件包裝為 API、向其他服務(如 OpenAI)加入功能或建置執行一些簡單計算的端點。 --- ### 3. 發放賞金 這些是開源專案的熱門功能請求。用戶可以在承諾一定金額的情況下提供“賞金”,然後將其支付給第一個完成並合併該功能的開發人員。 - [BOSS.dev](https://www.boss.dev/) - 完成功能請求和錯誤修復,獎金從 30 美元到 1000 美元不等。 --- ### 4. 贊助商 如果您在 GitHub 或其他平台上有業務,那麼啟用贊助是一種為您的工作帶來收入的有益方式。 不要忘記啟用贊助商按鈕。這適用於各種平台以及 GitHub 贊助商 - [GitHub Sponsors](https://github.com/sponsors) - 對於開發人員(無論規模大小)來說都是一個不錯的選擇。如果支持者已經在 GitHub 上,則零費用且進入門檻低 - [Patreon](https://www.patreon.com/) - 允許向您的支持者提供福利和獨家內容。如果您在 GitHub 以外的其他平台上有業務,這是一個不錯的選擇 - [LibrePay](https://liberapay.com/) - 針對那些建立開源內容的人 - [Open Collective](https://opencollective.com/) - 如果您正在為特定專案籌集資金,並使用收益來支持該專案(而不是個人),那麼這是一個不錯的選擇 - [Steday](https://steadyhq.com/en) - [TideLift](https://tidelift.com) - 更針對那些開發企業級開源專案的人,潛在收入更大,但僅限於最大的專案 - [LFX](https://lfx.linuxfoundation.org/) - 由 Linux 基金會提供 > 贊助(特別是GitHub 贊助商)是我個人最喜歡的方法之一,因為付費是可選的,所以你不會阻止那些無力承擔費用的人存取,而且那些支持你的人已經知道他們會預先得到什麼,所以您永遠不會讓客戶失望。 --- ### 5. 小費 您可能遇到過這樣的情況,您發現某個部落格文章、SO 答案、GitHub 儲存庫或論壇回應非常有幫助,以至於您希望可以為作者買一杯啤酒來表示感謝。 支援這些小額一次性付款的平台可以免費註冊,並且在您的個人資料中或在部落格文章末尾加入「提示」按鈕不會有任何損失。 - [Ko-fi](https://ko-fi.com/) - [請我喝杯咖啡](https://www.buymeacoffee.com/) - [Tipeee](https://en.tipeee.com/) - [PayPal Me](https://www.paypal.com/paypalme/) 提示:不要乞求。建立一些有用的內容,然後將提示連結放在底部。 --- ### 6. 企業贊助 許多具有一定下載量/經常性用戶的開源專案將開始被希望贊助創作者作品的公司接洽,以換取他們的公司徽標+連結包含在自述文件頂部附近。與個人贊助不同,這些贊助通常起價為 100-500 美元/月,專案使用量越大,贊助金額就越多。 --- ### 7. 黑客松 編碼競賽一直在遠端進行。這些通常由公司贊助,並向獲獎者支付現金獎勵。 - [程式碼之夏](https://summerofcode.withgoogle.com/) - 由 Google 執行,您將收到[貢獻者津貼](https://developers.google.com/open-source/gsoc/help/student-stipends) 成功接受後,金額從750 美元到6000 美元不等,金額取決於您所在的國家/地區和專案規模 - [CodeHeat](https://codeheat.org/) - 由 FOSS Asia 運營,每兩週 100 新元,外加較小的獎品 - [HackerEarth](https://www.hackerearth.com/challenges/hackathon/) - [Hackathon.com](https://www.hackathon.com/online) - [Devfolio 黑客松](https://devfolio.co/hackathons/upcoming) > 當我還是學生時,我[曾經參加過很多](https://alicia.omg.lol/hackathons) 黑客馬拉松(大部分是面對面的),並且經常能夠通過參加各種活動來資助我的暑假活動!這也是認識新朋友、學習新事物的好方法,而且非常有趣! --- ### 8. 依賴套件的贊助 如果您有一個軟體包(例如 NPM 模組),那麼在您的設定檔中啟用贊助將允許您的程式碼的使用者在財務上做出貢獻。 - NPM 資金 - 您可能熟悉執行“npm 基金”,並查看您正在使用的正在尋求資金的軟體包清單。新增了 [npm 基金](https://docs.npmjs.com/cli/v6/commands/npm-fund),以便更輕鬆地向專案所依賴的依賴項的維護者捐款。如果您維護 NPM 包,只需在 package.json 中包含「funding」字段,用戶將能夠更輕鬆地支援您。 - [StackAid](https://www.stackaid.us/) - 只需安裝 StackAid GitHub 應用程式並連結您的 Stripe 帳戶,直接或間接使用您專案的支持者捐贈的部分資金將分配給您每個月 - GitHub Sponsors - GitHub Sponsors 再次出現,因為它[讓用戶提供他們最常用的依賴項](https://github.com/sponsors/explore) - 儘管這是一個手動過程,而不是自動的。 --- ### 9. 回報問題 如果您注重安全性,或喜歡在應用程式中尋找錯誤和漏洞,那麼這款就適合您。最受歡迎的平台是[HackerOne](https://hackerone.com/opportunities/all/search?ordering=Highest+bounties),每個負責任地披露的錯誤都可以在其中賺取20 到200,000 美元的收入。 許多其他網站也直接提供負責任的揭露政策,他們會獎勵您的工作。如果您對此感興趣,我在以下位置保留了 1000 多個賞金計劃的清單:[https://bug-bounties.as93.net](https://bug-bounties.as93.net) > 我個人透過這種方法取得了很大的成功,而且也很有趣 - 所以我強烈推薦它! 其他值得查看的平台包括: - [HackerOne](https://www.hackerone.com/) - 排名第一的平台,最多的賞金以及良好的保護和支付率 - [Immunefi](https://immunefi.com/) - 專門針對 Web3 - [BugCrowd](https://www.bugcrowd.com/bug-bounty-list/) - [Intigriti](https://www.intigriti.com/) - [issuehunt](https://issuehunt.io/) --- ### 10.開放核心模型 這是您的大部分程式碼都是開源的,但某些擴充功能或附加元件(特別是針對企業客戶的擴充或附加元件)被授權為專有的。 因此,開發者可以在其他開源專案中自由使用該軟體。然而,公司必須為使用企業特定的模組或整合付費。 請記住,這通常說起來容易做起來難。您需要能夠分離專有功能,而大公司通常會採取一切措施(包括違反許可限制)來避免付費。 --- ### 11. 付費升級套件 這些服務可以輕鬆為常見註冊管理機構提供高級/付費方案。例如,如果您希望分發 NPM 模組的高級版本,或對特定軟體包功能收費,這可能是個不錯的選擇。 - [PrivJS](https://www.privjs.com/) - 分發 Node 套件的進階版本 - [CodeShip](https://codecodeship.com/) - 私人註冊中心,用戶需要付費才能使用你的包 --- ### 12.贊助支持 在開源專案中加入專業支援計劃選項使客戶能夠支付一次性或持續的幫助和支援費用,以啟動和執行。 這可以透過您自己的系統啟用,也可以使用現有的贊助平台(例如Patreon 和GitHub Sponsors),或使用專門的服務(例如[Otechie](https://otechie.com/))來啟用,該服務加入了付費功能+ 支援通過嵌入的聊天對話框。 [Calendly](https://calendly.com/) 等工具可以讓客戶將時間放入日曆中,或者對於較大的專案,投資專用的客戶支援平台,例如[HelpScout](https://www.helpscout.com/) 可能會讓這件事變得更容易。 --- ### 13. 寫文件 - [撰寫文件](https://www.writethedocs.org/) 是所有文件的首選位置。 - [文件季節](https://developers.google.com/season-of-docs) - 在 Google 的支持下,每年都有技術作家為開源專案做出貢獻。參與專案將獲得 5,000 至 15,000 美元的贈款,然後通常透過 Open Collective 分發給貢獻者。 - 如果你環顧四周,你會發現還有很多產品正在尋找技術作家。 Julia 列出了一份[好名單](https://dev.to/juliafmorgado/get-paid-to-write-technical-articles-16cl),列出了願意付費讓你撰寫技術內容的公司 - 版權也屬於這一類。 [scripted](https://www.scripted.com/) 等服務可讓您透過校對或編輯其他文字內容來賺錢。 即使只是記錄您自己的和其他開發人員的儲存庫也是一個不錯的起點。 如果專案被記錄下來,它的價值就會大幅增加。如果沒有文件,潛在使用者、客戶或開發人員將不知道它的用途、如何使用它、如何在其基礎上建立或如何做出貢獻。 > 我可能是唯一的一個,但我個人喜歡寫文件。 [我的所有專案](https://github.com/Lissy93?tab=repositories) 包括完整的使用、開發和貢獻文件。這促進了它們的成功和採用。我覺得如果你不花一點時間向人們展示如何使用它,那麼花幾個小時建立一些很棒的東西是沒有意義的。 --- ### 14. 廣告 在你跳過這一點之前——我也討厭廣告。它們很煩人,並且經常涉及某種形式的跟踪,從而損害用戶的隱私。但是,對於開源專案,還有一些其他選項沒有這些缺點。 - [Ethical Ads](https://www.ethicalads.io/) - [Carbon Ads](https://www.carbonads.net/open-source) 如果您正在維護獲得穩定流量的 GitHub 儲存庫、網站、部落格或服務,那麼這是一個不錯的選擇。通常每月至少需要約 10,000 個用戶,但如果您每月獲得 50,000 以上的用戶,您將獲得更好的回報。 --- ### 15. 出售你的程式碼 > 我個人不同意這種方法,只是因為出售的許多程式碼都是開源軟體的糟糕的重新設計版本,並且並不總是給予原始作者適當的榮譽。也就是說,一些開發商確實設法讓它發揮作用,建造簡單的專案然後將其出售。 - [IndieMaker](https://indiemaker.co/) - 出售您的整個專案 - [PieceX](https://www.piecex.com/) - 出售現成的原始碼 - [Codester](https://www.codester.com/info/seller) - 針對 PHP 和 Wordpress --- ### 16.銷售內容 當您查看開發人員的副業時,這是一個常見的建議。但有充分的理由 - 如果您能夠建立高品質的內容,您可以賺到很多錢。特別是如果您對新興領域有深入的了解。 銷售內容的熱門網站包括: - [GumRoad](https://gumroad.com/) - 程式碼、課程、貼文、藝術、設計、媒體(10% 費用) - [AppSumo](https://sell.appsumo.com/) - 程式碼、應用程式、擴充功能、課程、範本等 --- ### 17.寫作 這是一套獨特的技能。要么您非常擅長編寫引人入勝的內容,要么您對特定的熱門領域有深入的了解。否則,如果您對此感興趣,請考慮電子書出版,如果您的書不成功,也不會造成任何損失。 - [LeanPub](https://leanpub.com/) - 一個自助出版技術/開發電子書和課程的平台,具有豐厚的收入模式(您可以保留 70%) - [Amazon KDP](https://kdp.amazon.com/en_US/) - 發佈至 Amazon Kindle,並立即向全球數百萬用戶提供(亞馬遜將收取至少 30% 的佣金,可能會更多)小出版商) - [SmashWords](https://www.smashwords.com/) 和 [Draft2Digital](https://draft2digital.com/sw/) - 分發給全球其他電子書賣家,這是一種簡單的開始出版。他們收取的佣金比亞馬遜少,但比 LeanPub 多。 --- ### 18.補助金 補助金和企業贊助涉及多個領域,包括開源、創新、DeFi、人工智慧等。它們通常是為了幫助您在從事特定工作時支付短期生活費用。 - [GitHub Sponsors](https://github.com/sponsors) - 為個人和組織提供經濟支援開源開發者的平台。金額依贊助情況而有所不同。 - [Google Summer of Code (GSoC)](https://summerofcode.withgoogle.com/) - 學生開發者為開源專案做出貢獻的全球計劃,津貼通常為 1500 美元到 3300 美元不等。 - [Mozilla 開源支援 (MOSS)](https://www.mozilla.org/en-US/moss/) - 為開源軟體開發提供資助,特別是與 Mozilla 使命相符的專案。 - [Linux 基金會資助](https://www.linuxfoundation.org/) - 為從事 Linux 基金會專案的開發人員提供各種資助和獎學金。 - [NumFOCUS 小額發展補助金](https://numfocus.org/programs/small-development-grants) - 支援資料科學和科學計算的小型專案。資助金額各不相同(所有申請人均分配 285,000 美元)。 - [Apache 軟體基金會贊助](https://www.apache.org/foundation/sponsorship.html) - 對 Apache 軟體專案的財務支持,重點關注 Apache 軟體生態系統。 - [Outreachy](https://www.outreachy.org/) - 為技術領域代表性不足的群體提供為期三個月的實習機會,津貼通常約為 5,500 美元。 - [奈特基金會](https://knightfoundation.org/grants/) - 為促進優質新聞業的技術專案提供資助。根據專案範圍的不同,贈款金額差異很大。 - [原型基金](https://prototypefund.de/) - 在六個月內提供高達 47,500 歐元的開源原型支持,重點支持德國的軟體開發人員。 - [斯隆基金會](https://sloan.org/programs/digital-technology) - 為開放科學社群計畫提供資助,特別是那些增強研究中的開源軟體的計畫。 - [Chan Zuckerberg Initiative 開源軟體專案](https://chanzuckerberg.com/rfa/) - 專注於支援對生物醫學研究至關重要的開源軟體。資助金額各不相同。 - [Raspberry Pi 基金會](https://www.raspberrypi.org/grants/) - 為涉及 Raspberry Pi 和計算教育的教育計畫提供補助。 - [GitCoin](https://gitcoin.co/) - 一個為開源專案提供資金的眾籌平台,特別是在以太坊和 Web3 領域。資金根據社區支持而有所不同。 - [NLnet 基金會](https://nlnet.nl/foundation/) - 支援網路科技與網路研究計畫。補助金額各不相同。 - [開放技術基金](https://www.opentech.fund/) - 支持開發促進人權和開放社會的開放技術的專案。資金各不相同。 --- ### 19. 舉辦活動 活動空間是一個利潤豐厚的行業,尤其是如果您能夠舉辦一場精彩的活動並為自己贏得大型贊助商的話。雖然不適合所有人,但舉辦活動可以帶來以下 10 個潛在收入來源: - **門票銷售**:透過收取入場費來產生收入。使用 [Eventbrite](https://www.eventbrite.co.uk/)、[Meetup](https://meetup.com/) 或 [Ticketmaster](https://ticketmaster.com) 等平台取得門票管理。 - **贊助**:確保科技公司的財務捐助,以換取活動中的促銷機會。 - **研討會和培訓課程**:提供特定技術或程式語言的專業實務學習經驗,收取額外費用。 - **虛擬活動**:使用[Zoom](https://zoom.us/)、[WebEx](https://www.webex.com/) 或 [Hopin](https://hopin.com/)。 - **黑客馬拉松**:舉辦收取報名費的程式設計競賽,或尋找贊助商來支付費用並提供獎金。 - **社交活動**:針對技術專業人士的社交活動收費,可能會吸引招聘公司的贊助。 - **演講活動**:利用您在特定技術領域的專業知識,組織並負責演講活動或小組討論。 - **企業培訓及靜修**:為企業內部培訓或團隊建立活動提供活動組織服務。 - **聯盟行銷**:在活動期間利用科技產品或服務的聯盟行銷來獲取額外收入。 - **產品發布**:與科技公司合作舉辦產品發布活動,為您提供收費的組織服務。 --- ### 20.研究 您的意見很有價值,尤其是作為開發人員。有些研究人員會付錢給你參加他們的研究、調查或智庫。通常,好的研究機會很少而且相距甚遠,或者報酬相當低。 這類工作的熱門平台包括:[Testable Minds](https://minds.testable.org/)、[Respondent](https://app.respondent.io/signup) --- ### 21. 建立課程 - [Skillshare](https://www.skillshare.com/teach) - 根據課程觀看分鐘數提供付款以及推薦獎金。 - [Coursera](https://www.coursera.org/for-universities) - 與機構合作提供課程;付款通常基於收入分享協議。 - [LinkedIn Learning](https://www.linkedin.com/learning/instructors) - 講師可以為專業人士建立課程;薪酬詳細資訊由 LinkedIn 安排。 - [Thinkific](https://www.thinkific.com/) - 提供建立、行銷和銷售線上課程的工具,具有各種定價計劃,包括免費選項。 - [Kajabi](https://kajabi.com/) - 線上課程、行銷、支付和網站建立的一體化平台。 - [Podia](https://www.podia.com/) - 提供一個用於舉辦課程、網路研討會和數位下載的平台,並直接向觀眾銷售。 - [Pluralsight](https://www.pluralsight.com/teach) - 專注於科技與創意課程;根據課程的受歡迎程度向教師支付版稅。 - [MasterClass](https://www.masterclass.com/teach) - 高品質、名人主導的課程;講師通常是各自領域的知名專家或名人。 - [uTeach](https://ueach.io/) - [NewLine](https://www.newline.co/) --- ### 22.時事通訊 隨著流行的社群媒體管道變得更加集中和受控,電子郵件通訊和基於訂閱的 RSS 來源正在慢慢捲土重來。 這種模式的工作方式要么是提供對技術主題或新聞的有價值的見解,並建立一個龐大的(因此有價值的)訂閱者基礎,要么是向少數用戶收取更新費用。 提供此功能的流行平台包括: - [子堆疊](https://substack.com) - [ButtonDown](https://buttondown.email/) - [ConvertKit](https://convertkit.com/) - [穩定](https://steadyhq.com) - [幽靈](https://ghost.org/) --- ### 23. 僅限會員的網站 - [MemberSpace](https://www.memberspace.com/) - 讓您能夠為網站的某些部分付費,僅供會員使用 - [Patreon](https://www.patreon.com/) - 因設定具有獨家內容和福利的會員等級而廣受歡迎。 - [Substack](https://substack.com/) - 新聞通訊的理想選擇;提供付費訂閱獨家內容的能力。 - [Ghost](https://ghost.org/) - 內建會員和訂閱功能的專業發布平台。 - [Podia](https://www.podia.com/) - 允許銷售會員資格、線上課程和數位下載。 - WordPress 與 [MemberPress 外掛程式](https://memberpress.com/) - 供 WP 使用者建立會員網站的外掛程式。 - [Wild Apricot](https://www.wildapricot.com/) - 與您的網站整合的會員管理軟體。 - [Kajabi](https://kajabi.com/) - 提供用於建立線上課程、會員網站等的工具,重點是行銷。 - [Mighty Networks](https://www.mightynetworks.com/) - 建立一個包含會員資格、訂閱和課程的社群。 --- ### 24. VIP 貼文 還有許多公司會為您在其平台上分享的優質貼文付費。這既可以提高您的知名度(幫助您擴大人脈並獲得未來的工作),也可以帶來一些短期收入。 如果您正在努力獲得這些計劃的錄取,請先編寫自己的帖子並將其發佈到流行的基於開發的社交網絡(例如 DEV.to!)。這將增強您的寫作技巧,並幫助您向潛在公司展示您的知識。 例如,以下網站將為高品質的訪客貼文付費: - [Linode](https://www.linode.com/lp/write-for-linode/) - [日誌火箭](https://blog.logrocket.com/become-a-logrocket-guest-author/) - [Smashing 雜誌](https://www.smashingmagazine.com/contact/?Becoming%20an%20Author/Reviewer%20(自動回覆)) - [Auth0](https://auth0.com/apollo-program) - [CSS 技巧](https://css-tricks.com/guest-writing-for-css-tricks/) - [DelftStack](https://www.delftstack.com/write-for-us/) - [DigitalOcean](https://www.digitalocean.com/community/pages/write-for-digitalocean) - [Infatica](https://infatica.io/contribute/) - [蜜罐](https://blog.honeypot.io/write-for-honeypot/) - [進階編碼](https://premiumcoding.com/write-for-us-premiumcoding/) - [反思](https://reflectoring.io/contribute/become-an-author/) - [Strapi](https://strapi.io/write-for-the-community) - [Android 權威](https://www.authoritymedia.com/jobs) - [SitePoint](https://www.sitepoint.com/write-for-us/) - [TutorialsPoint](https://www.tutorialspoint.com/about/tutorials_writing.htm) - [真正的Python](https://realpython.com/jobs/tutorial-writer/) - [Dart Creations](https://www.dart-creations.com/about-us/write-for-us.html) Dmytro Spilka 編制了一份包含 300 多個[接受訪客貼文的網站](https://solvid.co.uk/180-websites-that-accept-guest-posts/) 的清單。另一個很棒的清單[由 Julia 在 Dev.to 上整理](https://dev.to/juliafmorgado/get-paid-to-write-technical-articles-16cl)。 --- ### 25. 諮詢 您可能沒有意識到,您從日常工作中累積的技能和經驗對許多公司來說可能非常有價值。尤其是尚無法聘請全職專家的新創公司和小型企業。對能夠提供最新趨勢、工具和最佳實踐見解的專業人士的需求非常高。 尖端: - 以適當的速度開始的最佳方式是透過網路和口碑。但如果做不到這一點,總有自由工作網站可以幫助您累積經驗。 - 記錄你所獲得的經驗,或在你工作的過程中建立一個投資組合,因為這將幫助你在未來獲得更好的工作。 - 在開始任何專案之前,請先明確您的空閒時間、條款、日薪和工作範圍。 - 切勿拒絕潛在的聯絡人。您會驚訝地發現,即使多年後,誰可能會重新與您聯繫並尋求諮詢支援。 --- ### 26. 指導 無論您的級別如何,您作為開發人員的經驗都可以真正幫助經驗不足的其他人。指導是一種非常有益的方式,可以幫助他人,同時也能帶來一些額外的收入。 - [MentorCruise](https://mentorcruise.com/) - 主要是長期的,按月付費,非常適合建立專業關係(每個學員每月賺取 50-500 美元) - [CodeMentor](https://www.codementor.io/) - 更適合短期,按小時收費,非常適合解決特定問題(每小時賺取 60-300 美元) --- ### 27.輔導 隨著 CompSci 現在成為國家課程的一部分(至少在英國和大部分歐洲),大量學生(11 歲至 18 歲以上)正在尋找導師來幫助他們獲得編碼技能並準備考試。收入範圍為每小時 15 美元到 150 美元以上,具體取決於級別、經驗和背景。 - [Super Prof](https://www.superprof.co.uk/) - 列出您的全球服務(30-300 美元/小時) - [The Profs](https://www.theprofs.co.uk/become-a-private-tutor/) - 經過驗證的導師(收入未知) - [我的導師](https://www.mytutor.co.uk/) - 僅限英國,(22-55 英鎊/小時) - [Tutor.com](https://www.tutor.com/) - 美國高中學費($75-$100/小時) --- ### 28.社群媒體 市場存在巨大空白,等待主流社群媒體平台上真正優秀的、注重發展的影響者來填補。 許多社群媒體平台允許您透過內容貨幣化,您通常會按觀看次數付費,金額根據內容類別、地區和聲譽而有所不同。但請注意,您通常必須擁有一定數量的追蹤者才有資格,而且您還將受到「演算法」的支配。 - YouTube - 每年至少需要 1,000 訂閱者 + 4,000 小時觀看時間 - X - 需要 Twitter Blue 訂閱,無最低追蹤人數 - TikTok - 需要至少 10k 追蹤者 + 100k 瀏覽量/月 - Instagram - 需要至少 10k 追蹤者 - Snap - 1,000 名追蹤者,1,000 次瀏覽/月,10 多個每月貼文 - Facebook - 10k 追蹤者或 600k 影片觀看分鐘 - Twitch - 350 位每月付費訂閱者 --- ### 29.品牌優惠 繼上面的社群媒體部分之後,一旦您成功突破了數百名訂閱者,您可能還可以開始考慮品牌交易,這有助於帶來額外收入。同樣,這些需要您的受眾達到一定程度的參與度,您可能還需要同意提供贊助的公司的條款。 --- ### 30.串流媒體 開發串流是一個快速成長的利基市場,不要指望立即[加入排行榜](https://twitch.pages.dev/),但它可能是一個很好的起點,特別是如果您已經有串流媒體經驗(例如影片遊戲)。 Nick Taylor 寫了一篇關於 [開發串流媒體入門的精彩文章](https://dev.to/nickytonline/getting-started-with-streaming-on-twitch-4im7)。 --- ### 31.SaaS 如果您能夠做到這一點,那麼它就是開源專案的最佳收入模式之一。您的程式碼仍然是 100% 免費和開源的,用戶仍然可以免費下載和自行託管它,但您還提供付費/託管計劃,您可以在其中託管應用程式並負責小型伺服器的所有伺服器管理經常性費用。 此模型符合開源精神,同時也使您的應用程式可供更廣泛的用戶使用。 [Stripe](https://stripe.com/docs/payments) 等服務讓您的應用程式接受付款和新增訂閱功能變得非常簡單。 --- ### 32.微型 SaaS 如果從頭開始建立一個生產就緒的應用程式聽起來像是一項艱鉅的任務(因為它確實如此!),那麼另一種方法就是 Micro-SaaS 應用程式。這些是較小的應用程式,它們執行一項非常具體的任務,例如: - 自動執行重複和/或乏味的任務。 - 執行目前手動計算的計算。 - 連接不同的系統。 - 取代 Excel 電子表格解決方法。 - 填補宿主生態系中缺失功能的空白 - 加強報告 --- ### 33. 寫外掛 與 SaaS 應用程式不同,一旦建置並發布了擴展,通常不需要太多的持續管理。您也可能會發現,如果您的專案為已經完善的網站加入功能,那麼您的專案會更容易快速獲得關注。 儘管網路擴展似乎是一個過時的或完全飽和的市場,但仍然有很多可以做的事情,而且這些對於新開發人員來說都是很棒的專案。 以下是一些可以幫助您入門的想法: - [WA Web Plus](https://chrome.google.com/webstore/detail/wa-web-plus-by-elbruz-tec/ekcgkejcjdcmonfpmnljobemcbpnkamh) 已下載 200 萬次(22k 評級),收費 12 美元/每個用戶的月。為什麼不為 Telegram、Threema、Wire、Messenger 等建立類似的東西呢? - Runkeeper擁有4500萬用戶,但UI在資料顯示方式方面有所欠缺。為什麼不建立一個擴充功能來加入更好的報告、過濾以及與相關外部資料的組合? (與 [Elevate for Strava](https://chrome.google.com/webstore/detail/elevate-for-strava/dhiaggccakkgdfcadnklkbljcgicpckn) 類似,但適用於 RunKeeper) - 選擇一個提供基本服務但 UI 過於不切實際的網站(也許是 Microsoft Azure?),然後建立一個擴充功能以簡化導覽、顯示關鍵指標或提供不那麼難看的使用者體驗 - 使用人工智慧增強任何現有網站。這比聽起來容易得多,您的擴充功能可以利用 OpenAI 的 API 等服務來總結網頁,或重新措辭選定的內容(用於複製/貼上到作業中!?) - 如果您知道某個網站的使用者數量很高,但 UI 很糟糕,那麼一個簡單的擴充想法可以是應用 CSS 覆蓋來重新設計它的樣式。例如亞馬遜、雅虎、Instagram 都是高流量網站,設計改善空間巨大(深色模式?!) - 即使是簡單的獨立擴展應用程式也可能具有很大的潛力。就像番茄計時器、貨幣轉換器、IP 位址小部件或只是一個網路應用程式快捷方式。 --- ### 34. 發布應用程式 建立簡單的應用程式或遊戲,並將其在平台應用程式商店上提供,使您能夠透過簡單的盈利模型來瞄準數百萬客戶。所有主流應用程式商店 - Google Play、Apple App Store、Windows Store、Steam 等都提供對付費應用程式、進階功能和應用程式內購買的支援。 請記住,在發布第一個應用程式之前通常需要支付安裝費,應用程式商店也會從您的收入中抽取一部分,並且小型創作者獲得單次或雙次下載的情況並不罕見。人物。 --- ### 35. 為小型企業開發網站 許多小型企業都專注於自己的業務,沒有時間或專業知識建立自己的網站。作為開發人員,這是我們能夠很快完成的事情,如果您也託管他們的網站,您將能夠收取定期付款。 一旦您開始進行網頁設計和開發,並為一些客戶提供服務,您就會發現透過口碑和展示您的作品集來找到未來的工作要容易得多。 為了在這方面取得成功,您可能還需要設計、溝通和銷售方面的技能。 --- ### 36. 兜售網域 隨著新 TLD 的湧入,域名經銷商市場正在迎來第二波受歡迎。域名翻轉涉及註冊未來可能有價值的域名,然後將其轉售給想要將該名稱用於企業或專案的買家。 雖然這可能有利可圖,但它確實涉及高風險,並且需要對市場有充分的了解。 尖端: - 研究簡短或令人難忘的域名,或者可能具有較高關鍵字潛力的域名(您可以使用諸如使用 Google 關鍵字規劃師等工具來幫助進行這項研究) - 停放您目前未使用的域名,以便您同時獲得一些廣告收入 - 查看最近過期的域名,特別是那些正在使用的域名,因為這些域名可能會收到流量 - 接收流量的網域更有價值。因此,請考慮在您持有網域時為其建立網站、應用程式或登入頁面 --- ### 37. 使用者測試 開發應用程式的公司通常需要獲得用戶的回饋。這就是用戶測試服務的用武之地。您花 10-30 分鐘嘗試給定的網站或應用程式,然後提供反饋或填寫調查,並獲得報酬! 儘管並非特定於開發人員,但憑藉您的技術背景,您會發現自己具有獨特的優勢,可以快速完成這些工作並提供良好的反饋,從而使您比普通用戶更快地賺錢。您還將獲得有關用戶測試流程如何運作的寶貴見解,這可能對您在自己的應用程式上進行委託測試時有用。 - [嘗試我的 UI](https://www.trymyui.com/) - 每個網站或應用程式測試平均費用為 10 美元 - [Userlytics](https://www.userlytics.com/user-experience-research/paid-ux-testing/) - 根據測試的複雜程度和長度,賺取 5 至 50 美元之間 - [使用者測試](https://www.usertesting.com/get-paid-to-test) - 透過 PayPal 付款,在測試會話期間需要螢幕共用和/或網路攝影機存取。每次測試賺取約 10 美元,較長時間或現場會議的某些測試最高可支付 50 美元 - [TestingTime](https://www.testingtime.com/en/become-a-paid-testuser/) - 面對面或視訊通話測試的選項。不太定期,但測試時間更長。當您考慮到會話之間的延遲時,報酬比其他選擇更低 - [IntelliZoom](https://www.intellizoom.com/) - 每 10 分鐘學習可賺取 2 至 10 美元。透過 PayPal 付款,延遲 3-5 天 --- ### 38.微任務 與開發人員的具體關係不大,但如果您來自技術背景,您可能會發現這些工作比那些沒有開發技能的工作更有利可圖。 - [Amazon Mechanical Turk](https://www.mturk.com/) - 外包虛擬微任務的眾包市場 - [Sequence Works](https://sequence.work/contributors/) - 影像標註、資料標記與分類 - [App Jobber](https://en.appjobber.com/) - 市場調查,去商店拍攝特定植入式廣告的照片 - [GigWalk](https://www.gigwalk.com/gigwalkers/) - 應用程式為基礎的行動微任務 - 請造訪 [GigWorker.com](https://gigworker.com/) 以了解更多微任務和零工工作 --- ### 39. 調查 儘管對具有某些技能(如軟體工程)的參與者的需求較高,但調查的報酬往往很低,因此可以賺更多一點。即便如此,除非您有大量時間,或使用比美元弱得多的貨幣,否則這可能不是一個好的選擇。 這些通常涉及測試新產品或服務,並提供回饋 - 或回答問題以協助市場研究活動。 有很多不同的基於調查的公司,所以我不會全部連結到它們。但 [Swagbucks](https://www.swagbucks.com/)、[20Cogs](https://20cogs.co.uk/)、[TestingTime](https://www.testingtime.com/en/become-a-paid-testuser) 是一些著名的。 --- ### 40.去中心化節點 這可能不適合所有人,因為收益通常以加密貨幣形式支付,而加密貨幣的波動性非常大。但是,您可以自願為許多 Web3 專案執行節點(通常在 Rasperry Pi、雲端伺服器或備用筆記型電腦上),這將為您支付正常執行時間、頻寬、磁碟空間、運算、IP/代理或其他一些費用。計算資源。 作為開發人員,管理基礎設施是我們所擅長的,因此,如果您有任何閒置資源,您也許可以將它們投入使用,並在睡覺時賺取一些額外的現金。 - [Storj](https://www.storj.io/node):執行Storj節點,用於去中心化雲端運算 - [Network3](https://network3.io/):用於訓練和驗證模型的 AIoT 第 2 層 - [Flux](https://runonflux.io/):去中心化基礎設施 - [Mysterium](https://mystnodes.com/): P2P VPN 節點 - [Koii](https://www.koii.network/node): 分散式雲 - [Helium](https://www.helium.com/mine):提供遠端物聯網設備無線連接 - [Filecoin](https://filecoin.io/):它是一個去中心化儲存網絡,將雲端儲存轉變為演算法市場。用戶可以出租閒置的儲存空間並賺取 Filecoin 代幣。 - [Sia Network](https://sia.tech/host):這是一個由區塊鏈技術所保障的去中心化儲存平台。 Sia 透過去中心化網路儲存和加密您的檔案。您可以透過出租未使用的硬碟空間來賺取 Siacoins。 - [Crust Network](https://wiki.crust.network/docs/en/nodeOverview):與 Filecoin、Sia 類似,Crust 支援 IPFS 等多種儲存層協議,並為應用層提供儲存介面。 - [Arweave](https://www.arweave.org/):一個基於區塊鏈的平台,以永久和去中心化的方式提供資料儲存。透過託管資料,用戶可以獲得 Arweave 代幣獎勵。 - [BitTorrent](https://docs.btfs.io/v2.0/docs/install-run-btfs20-node):該平台標記了世界上最大的文件共享協議,使用戶能夠通過在網路上。 - [HOLO](https://holo.host/):Holochain 應用程式 (hApps) 的點對點託管平台。在電腦上託管 hApp 的用戶將獲得 HOT 代幣獎勵。 --- ### 41.其他 Web3 方法 加密產業還有許多其他賺取被動收入的方式,從PoS 質押、持有生息數位資產、借貸、流動性挖礦、雲端挖礦、賺取股息的代幣、流動性挖礦、交易、本地/ PoW 思維、NFT 等等。很少。 我不會在這裡連結到任何具體細節,因為這是一個風險非常高的行業,因此您自己進行研究很重要。但作為技術專家,我們能夠理解任何給定協議或 Web3 資產背後的基本概念,並確定其可行性。 我的建議是閱讀白皮書,如果你不能立即理解它,那就遠離它!這是狂野的西部,所以除非一個專案的基本面是堅實的,否則你應該做好失去投資的任何資金的準備。 --- ### 42. 聯盟行銷 聯盟行銷對於那些剛開始的人來說是眾所周知的無利可圖,但我將其包含在此處是因為作為開發人員,有一定的空間來自動化許多過程。此外,您行銷的服務越細分,支付的佣金通常就越高。因此,如果您融入了技術社區,您可能處於銷售小批量高回報服務的有利位置。 同樣,如果您已經有了追蹤者(社交、部落格、YouTube 頻道...),那麼聯盟行銷可能更有意義,因為如果您獲得了大量點擊。 值得注意的是,您可能不應該在未透露它是附屬連結的情況下共享附屬連結。並儘量避免宣傳您自己沒有使用過或不會推薦給朋友的產品。 > 作為範例,[此處](https://notes.aliciasykes.com/p/3Ia4JzPw43) 是我使用過且擁有附屬帳戶的一些服務。我從未從其中任何一個身上賺過任何有意義的錢。 --- ### 43.經銷商 這涉及建立一個應用程式來包裝現有服務,同時加入 USP - 技術、客戶支援、UI 或其他功能。如果您有行銷或銷售背景,這可能適合您。如果您想加入功能或使流程自動化,那麼將需要大量的前期工作,但您將能夠更好地獲得收入。 您可以在大多數主要行業中找到提供經銷商計劃的服務提供者。 一些例子包括: - [Supermetrics](https://supermetrics.com/):行銷報告、分析、資料整合、20% 經常性佣金。 - [Keap](https://keap.com/):CRM、銷售與行銷自動化、20-30% 經常性佣金。 - [Klaviyo](https://www.klaviyo.com/):電子郵件與簡訊行銷,5–15% 一次性付款,10–20% 收入分成。 - [Drift](https://www.drift.com/):即時聊天軟體,20%收益分成。 - [ActiveCampaign](https://www.activecampaign.com/):電子郵件行銷、CRM、20–30% 佣金或折扣模式。 - [HubSpot](https://www.hubspot.com/):CRM、入站行銷、銷售、20% 營收分成。 - [Gorgias](https://www.gorgias.com/):電子商務幫助台,20% 收入分成。 - [Shopify](https://www.shopify.com/):電子商務平台,佣金20%,Shopify Plus 10%。 - [LiveChat](https://partners.livechat.com/):客戶服務平台,即時聊天,委託20%。 - [GetResponse](https://www.getresponse.com/):電子郵件行銷、線上活動管理、子帳號 35% 折扣、35% 經常性佣金。 --- ### 44. 人體實驗 這與技術根本無關。但作為程式設計師,我們通常可以在任何地方工作 - 那麼為什麼不在有報酬的地方編寫程式碼呢? 通常,您的收入在 2,000 美元到 10,000 美元之間,具體取決於試用期、持續時間、是否為住宅和具體情況。 像[流感營](https://flucamp.com/) 這樣的地方將支付您 4,000 英鎊,讓您在舒適的酒店式套房中入住兩週,同時他們會測試新的治療方法。那些患有氣喘等特定疾病的人可能可以透過參加更專業的試驗來賺取更多收入 --- ### 45.自由職業 自由職業可能會根據您的技能、經驗和您所在的領域而有所不同。對於新自由工作者來說,某些領域(例如網頁開發)的費率往往非常低,但您擁有的經驗和客戶滿意度越高,您就越能夠充電。 開發人員零工工作的三個主要平台是: - [Fiverr](https://www.Fiverr.com/):Fiverr 以其多元化的市場而聞名,非常適合剛開始從事自由職業的開發人員 - [Upwork](https://www.upwork.com/work):Upwork 迎合了廣泛的專業人士,但它對經驗豐富的開發人員特別有利。它提供了長期合約和高薪工作的潛力。該平台適合喜歡從事更實質專案的人。 - [People per Hour](https://www.peopleperhour.com/):這個平台對歐洲市場的開發者有好處。它強調當地的商業聯繫,並在短期和長期專案之間提供良好的平衡。 --- ### 46. 說話 面對面的和移除的開發者聚會和活動在全球各地不斷發生。這些活動需要演講者,許多人願意付費以獲得良好的演講。支付的金額根據規模、觀眾、主題、演講者(你!)和其他因素而有很大差異。通常,您必須先自願在當地的小型技術聚會上發表演講,然後逐步提高。 --- ### 47. 遠端技術支持 這不是最迷人的角色,但較小的公司通常無法聘請全職的專門技術支援人員,因此您可以找到很多兼職工作。如果您擁有雲端經驗或認證,這些的薪資等級會大幅提高。只需查看任何求職板(例如 [WeWorkRemotley](https://weworkremotely.com/)),您就會看到大量職位。 請注意,您通常需要在特定時間內有空,並期望您可以在給定的時間內回覆。在申請之前,請確保這是您可以解決的問題。 --- ### 49. 投資 是的,這不是副業——但聽我說完… 如果您每年的收入為 6 萬美元,生活成本為 4 萬美元,那麼 5 年後您可能會有 10 萬美元的儲蓄。如果您將其投資於年平均回報率為10 - 15% 的標準普爾500 指數- 您每月可能會從您的投資中獲得超過1,000 美元的額外收入,並且您的投資能力越強,收入就會不斷增加儲蓄(當然,投資可以減少也可以增加)。這已經比這裡列出的許多副業更好的回報了! --- ### 50. 就業 我們不要忘記,儘管目前情況看起來很艱難,但身為開發人員,即使只有一兩年的經驗,我們也處於非常幸運的地位,與平均收入者相比,我們的薪水很高。 如果你的工作不適合你——換公司通常是提高薪資的可靠方法,如果你不喜歡目前的工作,這可能是值得考慮的事情。 也許經歷了這一切之後,你所追求的不是副業,而是更好的「主業」? --- ## 真實的說話 儘管您可能會在 IndieHackers 和 Instagram 上看到一些內容,但副業並不是全部。這通常需要大量的工作,但回報卻非常有限。因此,在在這裡或其他地方進行任何事情之前,請退後一步,思考「我為什麼要這樣做?」。如果您這樣做是為了累積經驗、學習新技能並享受樂趣——那就太好了。如果你這樣做是為了快速致富 - 你可能會非常失望。 還有一點要注意的是,儘管看起來不公平,但與那些剛起步的人相比,那些已經擁有強大追隨者或幾個成功的開源專案的人將處於更好的位置來利用機會。 因此,從短期來看,作為一名開發人員,您的時間可能會更好地花在提升自己身上。如果您不確定從哪裡開始,這裡有 5 個關鍵提示: - **網絡** - 建立你的網絡,參加聚會、黑客馬拉松和開發活動,加入社區,結交朋友 - **開源** - 將您的工作放在那裡,公開學習,建立您感興趣的迷你專案,並且不要害怕失敗 - **經驗** - 獲得實務經驗,申請實習機會,作為自由開發人員提供服務 - **基礎知識** - 確保您對電腦科學基礎知識有深入的了解,其餘的就會容易得多 - **玩得開心!** - 你自然會在你真正熱愛的領域做得更好。如果你不喜歡你正在做的事情,請退一步,考慮不同的方法是否更適合你 --- ## 免責聲明 - 以上列表僅供您參考。 - 我沒有親自測試過這裡列出的所有服務。 - 如果您有 - 我很想聽聽您的回饋。同樣,如果有任何需要加入或刪除的內容,請在下面告訴我。 - 並非所有服務都在所有國家/地區提供(此清單主要針對英國/歐洲和美國🇬🇧🇪🇺🇺🇸) - 有些平台會抽取您的收入。這通常是一個很小的數額,但重要的是你要考慮到 - 如果您已經擁有大量追隨者或流行的開源專案,賺錢通常會容易得多 - 有些方法涉及風險。儘管我已盡力強調這一點,但請記住,您的投資可能會下降而不是上升 - 您的結果可能會有所不同 - 沒有保證 --- 原文出處:https://dev.to/lissy93/50-ways-to-bring-in-extra-cash-as-a-developer-19b6
 ## 介紹: React 開發人員可以透過使用設計模式來節省時間和精力,設計模式提供了一種使用經過測試且可信賴的解決方案來解決問題的快速方法。它們支援低耦合的內聚模組,從而幫助 React 開發人員建立可維護、可擴展且高效的應用程式。在本文中,我們將探索 React 設計模式並研究它們如何改進 React 應用程式的開發。 ## 容器和表示模式 容器和表示模式是一種旨在將反應程式碼中的表示邏輯與業務邏輯分離的模式,從而使其模組化、可測試並遵循關注點分離原則。 大多數情況下,在 React 應用程式中,我們需要從後端/儲存取得資料或計算邏輯並在 React 元件上表示該計算的結果。在這些情況下,容器和表示模式大放異彩,因為它可用於將元件分為兩類,即: * 容器元件,充當負責資料取得或計算的元件。 * 表示元件,其工作是將獲取的資料或計算值呈現在 UI(使用者介面)上。 容器和表示模式的範例如下所示: ``` import React, { useEffect } from 'react'; import CharacterList from './CharacterList'; const StarWarsCharactersContainer:React.FC = () => { const [characters, setCharacters] = useState<Character>([]) const [isLoading, setIsLoading] = useState<boolean>(false); const [error, setError] = useState<boolean>(false); const getCharacters = async () => { setIsLoading(true); try { const response = await fetch("https://akabab.github.io/starwars-api/api/all.json"); const data = await response.json(); setIsLoading(false); if (!data) return; setCharacters(data); } catch(err) { setError(true); } finally { setIsLoading(true); } }; useEffect(() => { getCharacters(); }, []); return <CharacterList loading={loading} error={error} characters={characters} />; }; export default StarWarsCharactersContainer; ``` ``` // the component is responsible for displaying the characters import React from 'react'; import { Character } from './types'; interface CharacterListProps { loading: boolean; error: boolean; users: Character[]; } const CharacterList: React.FC<CharacterListProps> = ({ loading, error, characters }) => { if (loading && !error) return <div>Loading...</div>; if (!loading && error) return <div>error occured.unable to load characters</div>; if (!characters) return null; return ( <ul> {characters.map((user) => ( <li key={user.id}>{user.name}</li> ))} </ul> ); }; export default CharacterList; ``` ## 有 Hooks 的元件組合 Hooks 是 React 16.8 中首次推出的全新功能。從那時起,他們在開發 React 應用程式中發揮了至關重要的作用。掛鉤是基本函數,可授予功能元件存取狀態和生命週期方法(以前僅可用於類別元件)的功能。另一方面,掛鉤可以專門設計來滿足元件要求並具有其他用例。 我們現在可以隔離所有狀態邏輯(一種需要反應性狀態變數的邏輯),並使用自訂掛鉤在元件中組合或使用它。因此,程式碼更加模組化和可測試,因為鉤子鬆散地綁定到元件,因此可以單獨測試。 帶有鉤子的元件組合示例如下所示: ``` // creating a custom hook that fetches star wars characters export const useFetchStarWarsCharacters = () => { const [characters, setCharacters] = useState<Character>([]) const [isLoading, setIsLoading] = useState(false); const [error, setError] = useState(false); const controller = new AbortController() const getCharacters = async () => { setIsLoading(true); try { const response = await fetch( "https://akabab.github.io/starwars-api/api/all.json", { method: "GET", credentials: "include", mode: "cors", headers: { 'Content-Type': 'application/json', 'Access-Control-Allow-Origin': '*' }, signal: controller.signal } ); const data = await response.json(); setIsLoading(false); if (!data) return; setCharacters(data); } catch(err) { setError(true); } finally { setIsLoading(true); } }; useEffect(() => { getCharacters(); return () => { controller.abort(); } }, []); return [ characters, isLoading, error ]; }; ``` 建立自訂鉤子後,我們將其導入到我們的 **StarWarsCharactersContainer** 元件中並使用它; ``` // importing the custom hook to a component and fetch the characters import React from 'react'; import { Character } from './types'; import { useFetchStarWarsCharacters } from './useFetchStarWarsCharacters'; const StarWarsCharactersContainer:React.FC = () => { const [ characters, isLoading, error ] = useFetchStarWarsCharacters(); return <CharacterList loading={loading} error={error} characters={characters} />; }; export default StarWarsCharactersContainer; ``` --- <橫幅隨機/> --- ## 使用Reducers進行狀態管理 大多數情況下,處理元件中的許多狀態會導致許多未分組狀態的問題,這可能是處理起來很麻煩且具有挑戰性的。在這種情況下,減速器模式可能是有用的選擇。我們可以使用減速器將狀態分類為某些操作,這些操作在執行時可以變更分組的狀態。 此模式允許使用它的開發人員控制元件和/或掛鉤的狀態管理,讓他們在發送事件時管理狀態變更。 使用減速器模式的範例如下所示: 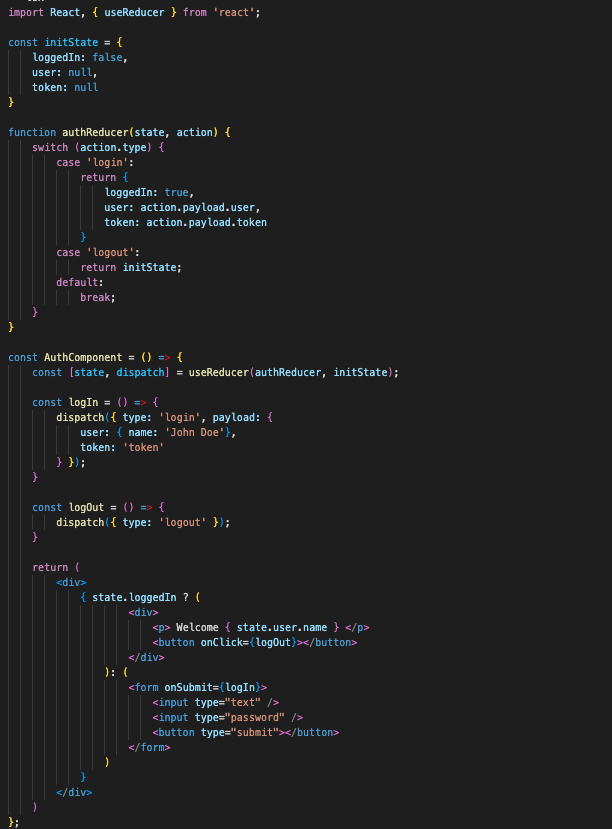 在上面的程式碼中,元件調度兩個操作: * “**login**”操作類型會觸發狀態更改,影響三個狀態值,即 **loggedIn**、**user**、**token**。 *“**註銷**”操作只是將狀態重設為其初始值。 ## 提供者的資料管理 提供者模式對於資料管理非常有用,因為它利用上下文 API 透過應用程式的元件樹傳遞資料。這種模式是一種有效的解決支柱鑽井問題的方法,這一直是 React 開發中普遍關注的問題。 為了實現提供者模式,我們首先建立一個提供者元件。 Provider 是 Context 物件提供給我們的一個高階元件。我們可以利用React提供的createContext方法來建構一個Context物件。 ``` export const ThemeContext = React.createContext(null); export function ThemeProvider({ children }) { const [theme, setTheme] = React.useState("light"); return ( <ThemeContext.Provider value={{ theme, setTheme }}> {children} </ThemeContext.Provider> ); } ``` 建立提供者後,我們將使用建立的提供者元件封裝依賴上下文 API 中的資料的元件。 為了從上下文 API 取得資料,我們呼叫 useContext 鉤子,它接受上下文作為參數(在本例中為 **ThemeContext**)。 ``` import { useContext } from 'react'; import { ThemeProvider, ThemeContext } from "../context"; const HeaderSection = () => { <ThemeProvider> <TopNav /> </ThemeProvider>; }; const TopNav = () => { const { theme, setTheme } = useContext(ThemeContext); return ( <div style={{ backgroundColor: theme === "light" ? "#fff" : "#000 " }}> ... </div> ); }; ``` ## 使用 HOC(高階元件)增強元件 高階元件接受一個元件作為參數,並傳回一個注入了附加資料或功能的增壓元件。 React 中 HOC 的可能性是由於 React 更喜歡組合而不是繼承。 高階元件 (HOC) 模式提供了一種增加或修改元件功能的機制,促進元件重複使用和程式碼共用。 HOC 模式的範例如下所示: ``` import React from 'react' const higherOrderComponent = Component => { return class HOC extends React.Component { state = { name: 'John Doe' } render() { return <Component name={this.state.name {...this.props} /> } } const AvatarComponent = (props) => { return ( <div class="flex items-center justify-between"> <div class="rounded-full bg-red p-4"> {props.name} </div> <div> <p>I am a {props.description}.</p> </div> </div> ) } const SampleHOC = higherOrderComponent(AvatarComponent); const App = () => { return ( <div> <SampleHOC description="Frontend Engineer" /> </div> ) } export default App; ``` 在上面的程式碼中, **<AvatarComponent/>** 由 **higherOrderComponent** 提供 props,它將在內部使用。 ## 複合元件 複合元件模式是一種 React 設計模式,用於管理由子元件組成的父元件。 這種模式背後的原理是將父元件分解為更小的元件,然後使用 props、上下文或其他反應資料管理技術來管理這些較小元件之間的互動。 當需要建立由較小元件組成的可重複使用、多功能元件時,這種模式會派上用場。它使開發人員能夠建立複雜的 UI 元件,這些元件可以輕鬆自訂和擴展,同時保持清晰簡單的程式碼結構。 複合元件模式的用例範例如下所示: ``` import React, { createContext, useState } from 'react'; const ToggleContext = createContext(); function Toggle({ children }) { const [on, setOn] = useState(false); const toggle = () => setOn(!on); return ( <ToggleContext.Provider value={{ on, toggle }}> {children} </ToggleContext.Provider> ); } Toggle.On = function ToggleOn({ children }) { const { on } = useContext(ToggleContext); return on ? children : null; } Toggle.Off = function ToggleOff({ children }) { const { on } = useContext(ToggleContext); return on ? null : children; } Toggle.Button = function ToggleButton(props) { const { on, toggle } = useContext(ToggleContext); return <button onClick={toggle} {...props} />; } function App() { return ( <Toggle> <Toggle.On>The button is on</Toggle.On> <Toggle.Off>The button is off</Toggle.Off> <Toggle.Button>Toggle</Toggle.Button> </Toggle> ); } ``` ## 道具組合 這需要從幾個相關的 props 建立一個物件,並將其作為單個 props 傳遞給元件。 這種模式允許我們清理程式碼並使管理 props 變得更簡單,當我們想要將大量相關屬性傳遞給元件時,它特別有用。 ``` import React from 'react'; function P(props) { const { color, size, children, ...rest } = props; return ( <p style={{ color, fontSize: size }} {...rest}> { children } </p> ); } function App() { const paragraphProps = { color: "red", size: "20px", lineHeight: "22px" }; return <P {...paragraphProps}>This is a P</P>; } ``` ## 受控輸入 受控輸入模式可用於處理輸入欄位。此模式涉及使用事件處理程序在輸入欄位的值發生變更時更新元件狀態,以及將輸入欄位的目前值儲存在元件狀態中。 由於React 控制元件的狀態和行為,因此該模式使程式碼比不受控制的輸入模式更具可預測性和可讀性,後者不使用元件的狀態,而是直接透過DOM(文件物件模型)對其進行控制。 受控輸入模式的用例範例如下所示: ``` import React, { useState } from 'react'; function ControlledInput() { const [inputValue, setInputValue] = useState(''); const handleChange = (event) => { setInputValue(event.target.value); }; return ( <input type="text" value={inputValue} onChange={handleChange} /> ); } ``` ## 使用forwardRefs 管理自訂元件 稱為 ForwardRef 的高階元件將另一個元件作為輸入並輸出一個傳遞原始元件引用的新元件。透過這樣做,子元件的 ref(可用於檢索底層 DOM 節點或元件實例)可供父元件存取。 當建立與第三方程式庫或應用程式中的另一個自訂元件互動的自訂元件時,在工作流程中包含 ForwardRef 模式非常有幫助。透過授予對庫的 DOM 節點或另一個元件的 DOM 實例的存取權限,它有助於將此類元件的控制權轉移給您。 forwardRef 模式的用例範例如下所示: ``` import React from "react"; const CustomInput = React.forwardRef((props, ref) => ( <input type="text" {...props} ref={ref} /> )); const ParentComponent = () => { const inputRef = useRef(null); useEffect(() => { inputRef.current.focus(); }, []); return <CustomInput ref={inputRef} />; }; ``` 在上面的程式碼中,我們使用「forwardRefs」從元件「<ParentComponent/>」觸發了另一個元件「<CustomInput/>」的焦點。 # 結論 我們在本文中討論了 React 設計模式,包括高階元件、容器呈現元件模式、複合元件、受控元件等等。透過將這些設計模式和最佳實踐合併到您的 React 專案中,您可以提高程式碼質量,促進團隊協作,並使您的應用程式更具可擴展性、靈活性和可維護性。 --- 原文出處:https://dev.to/refine/react-design-patterns-230o
> _“信任,但驗證”_(“信任,但驗證”) > -- [俄羅斯諺語](https://en.wikipedia.org/wiki/Trust,_but_verify) --- 我整理了數十位程式設計師、經理、職業教練和其他行業專業人士的建議,為您帶來一份__軟體開發人員最推薦的20 本書__的清單,並附有一些簡短的摘要(亞馬遜提供)。我用於編制此清單的所有資料都可以作為 [GitHub 上的單一 Excel 工作簿](https://github.com/awwsmm/2020books) 免費提供。截至 __2019 年 10 月 19 日星期六__,我的元列表引用了 36 個來源,並包括 297 本獨特書籍的推薦。 我這樣做主要是為了幫助自己整理我在不久的將來想讀的書籍,同時也是為了幫助其他想要打下良好基礎,但可能會因網路上提出不同建議的不同列表而感到沮喪的人。當你可以綜合考慮_每個人的意見_時,為什麼要相信他們中的_一個_?不客氣,網路。 以下是我用來撰寫此清單的__經驗法則__: 1. 盡可能_不_包括_尋求_推薦的文章。 1. 對一本書的不同版本的推薦視為對同一本書的推薦,但對一篇文章內的多個版本的推薦不會重複計算。 1. 作者只_列出_他們已讀過或正在閱讀的書籍的文章_不_包括在內。文章必須以_推薦_書籍清單的形式呈現。 1. 包含針對特定_等級_開發人員(即 CTO、初級開發人員、新手)的清單。 1. 我嘗試跳過針對特定技術(即 PHP、CSS、Java)的列表,但有些列表中散佈著這些類型的書籍;關於所包含文章的每一本書都包含在我的書籍清單中,即使它是一本小說、特定於技術的或與程式設計無關的。 1. 儘管某些人的解釋可能略有不同,但就本列表而言,「軟體開發人員」、「軟體工程師」、「開發人員」、「程式設計師」和「編碼員」都是等效的。除非第 (5) 點也適用,否則包括針對上述任何內容的文章。 就我所知,這是__網路上最完整的軟體開發書籍推薦元列表__。我查看了 Google 返回的“圖書軟體開發人員”的“每一個結果”以及 Dev.To 上標題中包含“圖書”的每篇文章,這就是結果。如果您發現通用軟體開發的書籍推薦清單未包含在我在 GitHub 上的來源電子表格中,請告訴我。如果它符合我上面列出的標準,我很樂意將其加入到列表中。 言歸正傳,列表如下: ---  ## \#20。 [企業應用架構模式](https://amzn.to/2jSqwQ5) ### 作者:Martin Fowler(_3 路並列 #19 和 #18_) #### 推薦 13.0% > 這本書其實是兩本書合而為一。第一部分是有關開發企業應用程式的簡短教程,您可以從頭到尾閱讀該教程以了解本書課程的範圍。下一部分,即本書的大部分內容,是對模式本身的詳細參考。每個模式都提供使用和實現訊息,以及詳細的 Java 或 C# 程式碼範例。整本書還配有豐富的UML圖來進一步解釋概念。 > > 有了這本書,您將擁有做出有關建立企業應用程式的重要架構決策所需的知識,以及建立它們時使用的經過驗證的模式。 > > -- [Amazon.com](https://amzn.to/2jSqwQ5) ---  ## \#19。 [清潔架構:軟體結構與設計工匠指南](https://amzn.to/2jTxLHt) ### 作者:羅伯特·C·「鮑伯叔叔」·馬丁 #### 建議 13.0%(_3 路與 #20 和 #18 平手_) > - 了解軟體架構師需要實現什麼目標,以及實現它的核心規則和實踐 > - 掌握尋址功能、元件分離和資料管理的基本軟體設計原則 > - 了解程式設計範式如何透過限制開發人員可以執行的操作來施加紀律 > - 了解什麼是至關重要的,什麼只是“細節” > - 為 Web、資料庫、胖客戶端、控制台和嵌入式應用程式實施最佳的高級結構 > - 定義適當的邊界和層,並組織元件和服務 > - 了解設計和架構為何出錯,以及如何預防(或修復)這些故障 > > -- [Amazon.com](https://amzn.to/2jTxLHt) ---  ## \#18。 [電腦程式設計的藝術](https://amzn.to/2XKk8Ik) ### 作者:唐納德高德納 #### 建議 13.0%(_3 路與 #20 和 #19 平手_) > 這部宏偉的傑作全面概述了各種演算法及其分析。現在,《電腦程式設計的藝術》已經是第三版了,其中包含作者的大量修訂,並包括許多新練習。 > > 儘管這本書是幾十年前構思的,但它仍然是一部永恆的經典。本書最大的優點之一是每一章都包含大量問題。作者精心挑選問題,並根據難度進行索引。解決大量此類問題將幫助您深入了解圍繞給定主題的問題。此外,練習還包含各種經典問題。 > > -- [Amazon.com](https://amzn.to/2XKk8Ik) ---  ## \#17。 [程式碼:電腦硬體與軟體的隱藏語言](https://amzn.to/2XYXZKA) ### 查爾斯·佩措爾德 #### 15.9% 推薦(_與 #16_ 並列) > 手電筒、英國入侵、黑貓和蹺蹺板與電腦有什麼關係?在《程式碼》中,他們向我們展示了操縱語言和發明新的相互交流方式的巧妙方式。透過 _CODE_,我們看到這種獨創性和我們人類的溝通衝動是如何推動過去兩個世紀的技術創新的。 > > 作者 Charles Petzold 使用日常物品和熟悉的語言系統(例如點字和莫爾斯電碼),為任何想了解電腦和其他智慧機器的秘密內部生活的人編織了一個富有啟發性的敘述。 > > 這是一個插圖巧妙且非常易於理解的故事,在整個過程中,您會發現自己獲得了理解當今 PC、數位媒體和網路世界的真實背景。無論您的技術水平如何,CODE 都會讓您著迷,甚至可能喚醒您內心的技術愛好者。 > > -- [Amazon.com](https://amzn.to/2XYXZKA) ---  ## \#16。 [敏捷軟體開發:原則、模式與實踐](https://amzn.to/2XT4fj3) ### 作者:羅伯特·C·「鮑伯叔叔」·馬丁 #### 15.9% 推薦(_與 #17_ 並列) > 本書由軟體開發人員為軟體開發人員撰寫,是最新軟體開發方法的獨特集合。作者包括 OOD、UML、設計模式、敏捷和 XP 方法,並詳細描述了 C++ 和 Java 中可重複使用程式的完整軟體設計。它使用實用的解決問題的方法,展示瞭如何開發物件導向的應用程式——從分析的早期階段,到底層設計,再到實現。引導讀者了解設計師的想法—展示整個軟體設計過程中出現的錯誤、死胡同和創意見解。本書涵蓋:靜力學和動力學;類設計原則;複雜性管理;包裝設計原理;分析與設計;模式和範式交叉。一一解釋 OOD 的原理,然後透過大量範例、完整的設計和案例研究來示範它們。涵蓋 C++ 和 OOD 應用程式中的陷阱、缺陷和解決方法,然後展示如何使用敏捷方法。詳細討論了大型軟體的設計和開發方法。對建築安全系統進行了三章深入的單一案例研究。適合想要了解如何使用最先進的方法設計物件導向軟體的軟體工程師、程式設計師和分析師。 > > -- [Amazon.com](https://amzn.to/2XT4fj3) ---  ## \#15。 [演算法介紹](https://amzn.to/2XRR81s) ### 作者:Thomas H. Cormen、Charles E. Leiserson、Ronald L. Rivest 與 Clifford Stein #### 建議 17.4%(_3 路與 #14 和 #13 平手_) > 有些演算法書籍嚴謹但不完整;其他的涵蓋大量材料但缺乏嚴謹性。 《演算法導論》獨特地結合了嚴謹性和全面性。本書深入涵蓋了廣泛的演算法,同時使各個層級的讀者都可以理解它們的設計和分析。每一章都相對獨立,可以作為學習單元。這些演算法以英語和偽程式碼進行描述,任何稍微編程過的人都可以閱讀。這些解釋保持基本,但沒有犧牲覆蓋深度或數學嚴謹性。 > > 第一版成為全球大學廣泛使用的教材以及專業人士的標準參考書。第二版新增了關於演算法的作用、機率分析和隨機演算法以及線性規劃的章節。第三版進行了全面修訂和更新。它包括關於 van Emde Boas 樹和多線程演算法的兩個全新章節,對遞歸章節(現在稱為“分而治之”)的大量補充,以及關於矩陣的附錄。它改進了動態規劃和貪婪演算法的處理,以及流網路材料中基於邊緣的流的新概念。此版本加入了許多練習和問題 > > -- [Amazon.com](https://amzn.to/2XRR81s) ---  ## \#14。 [Head First 設計模式:大腦友善指南](https://amzn.to/2XNEdxz) ### 作者:Eric Freeman、Elizabeth Robson、Kathy Sierra 和 Bert Bales #### 建議 17.4%(_3 路與 #15 和 #13 平手_) > 在任何特定時刻,都會有人遇到與您相同的軟體設計問題。而且,很可能其他人已經解決了您的問題。這一版的《Head First Design Patterns》(現已針對 Java 8 進行了更新)向您展示了開發人員用來建立實用、優雅、可重用且靈活的軟體的可靠、經過實際檢驗的模式。當你讀完本書時,你將能夠利用那些與軟體設計的野獸戰鬥並取得勝利的人的最佳設計實踐和經驗。 > > -- [Amazon.com](https://amzn.to/2XNEdxz) ---  ## \#13。 [破解程式設計面試:189題程式設計題及解答](https://amzn.to/2XPSwlg) ### 作者:蓋爾‧拉克曼‧麥克道威爾 #### 建議 17.4%(_3 路與 #15 和 #14 並列_) > - 189 道程式設計面試問題,從基礎知識到最棘手的演算法問題。 > - 如何匯出每個解決方案的演練,以便您可以學習如何自己實現。 > - 有關如何解決 189 個問題的提示,就像您在真實面試中得到的一樣。 > - 五種經過驗證的解決演算法問題的策略,讓你可以解決你沒見過的問題。 > - 廣泛涵蓋基本主題,例如大 O 時間、資料結構和核心演算法。 > - 深入了解 Google 和 Facebook 等頂尖公司如何聘用開發人員。 > - 準備和應對面試軟性方面的技巧:行為問題。 > - 對於面試官和公司:關於什麼是好的面試問題和招募流程的詳細資訊。 > > -- [Amazon.com](https://amzn.to/2XPSwlg) ---  ## \#12. [不要讓我思考:網路可用性的常識性方法](https://amzn.to/2XPjDwF) ### 史蒂夫·克魯格 #### 18.8% 推薦(_與#11_並列) > _Don't Make Me Think_ 是 Steve Krug 寫的一本關於人機互動和網路可用性的書。本書的前提是,一個好的軟體程式或網站應該讓使用者盡可能輕鬆、直接地完成他們的預期任務。克魯格指出,人們善於滿足問題,或採用第一個可用的解決方案來解決問題,因此設計應該利用這一點。他經常引用 Amazon.com 作為精心設計的網站的例子,該網站能夠實現高品質的交互,儘管該網站每天都變得越來越大、越來越複雜。 > > 這本書本身旨在成為簡潔(簡潔)和重點突出的寫作範例。根據該書的介紹,其目標是製作一篇可供高管在兩個小時的飛機飛行中閱讀的文本。 > > -- [維基百科](http://bit.ly/2XSAhLY) ---  ## \#11。 [The Clean Coder:專業程式設計師行為準則](https://amzn.to/2XMluCs) ### 作者:羅伯特·C·「鮑伯叔叔」·馬丁 #### 18.8% 推薦(_與 #12_ 並列) > 在不斷的不確定性和不間斷的壓力中忍受並取得成功的程式設計師有一個共同的屬性:他們非常關心建立軟體的實踐。他們把它當作一門手藝。他們是專業人士。 > > 在《乾淨的編碼器:專業程式設計師的行為準則》中,傳奇軟體專家 Robert C. Martin 介紹了真正的軟體工藝的學科、技術、工具和實踐。本書充滿了實用的建議——從估計和編碼到重構和測試。它涵蓋的不僅僅是技術:它是關於態度。馬丁展示瞭如何以榮譽、自尊和自豪的態度進行軟體開發;工作良好,工作乾淨;忠實地溝通和評估;清晰而誠實地面對困難的決定;並理解深刻的知識伴隨著採取行動的責任。 > > -- [Amazon.com](https://amzn.to/2XMluCs) ---  ## \#10. [軟體技能:軟體開發人員的生活手冊](https://amzn.to/2XR9u2y) ### 約翰‧桑梅茲 #### 23.2% 推薦(_與#11_並列) > _軟技能:軟體開發人員生活手冊_ 是作為技術專業人員全面、令人滿意的生活的指南。在其中,開發人員兼生活教練 John Sonmez 就重要的「軟」主題向開發人員提供建議,例如職業和生產力、個人理財和投資,甚至健身和人際關係。這本有趣的書由 71 個短章組成,邀請您隨心所欲地閱讀。每章末尾的「採取行動」部分向您展示如何快速獲得結果。軟技能將幫助您成為更好的程式設計師、更有價值的員工以及更快樂、更健康的人。 > > -- [Amazon.com](https://amzn.to/2XR9u2y) ---  ## \#9。 [Peopleware:高效率的專案與團隊](https://amzn.to/2XR6keY) ### 湯姆·德馬科和提摩西·利斯特 #### 23.2% 推薦(_與 #12_ 並列) > _Peopleware_ 是一本有關軟體組織管理的熱門書籍。書的第一章聲稱,「我們工作的主要問題本質上與其說是技術問題,不如說是社會學問題」。這本書探討了社會學或「政治」議題,例如團隊化學反應和團隊凝聚力、工作環境中的「流動時間」和安靜以及高流動成本。其他主題包括個人工作觀點與企業意識形態之間的衝突、企業熵、「團隊滅絕」和工作空間理論。 > > 作者將大多數主題呈現為由一些具體故事或其他資訊支持的原則。例如,「義大利麵晚餐」一章介紹了一個虛構的例子,一位經理邀請一個新團隊來吃晚飯,然後讓他們作為一個團隊購買和準備飯菜,以便讓一線團隊取得成功。其他章節使用現實生活中的故事或引用各種研究來說明所提出的原則 > > -- [維基百科](http://bit.ly/2XMFrJf) ---  ## \#8。 [程式珍珠](https://amzn.to/2XNxWlf) ### 喬恩‧本特利 #### 26.1% 推薦 > 電腦程式設計有很多面貌。弗雷德布魯克斯 (Fred Brooks) 在《人月神話》中描繪了一幅宏偉的圖畫。他的文章強調了管理在大型軟體專案中的關鍵作用。 Steve McConnell 在 Code Complete 中更詳細地教授了良好的程式設計風格。這些書中的主題是優秀軟體的關鍵,也是專業程式設計師的標誌。然而不幸的是,這些合理的工程原理的熟練應用並不總是令人興奮——直到軟體按時完成並且不出意外地工作。 > > 本書中的專欄介紹了該行業更迷人的方面:編程珍珠,其起源超出了紮實的工程,而是在洞察力和創造力的領域。正如天然珍珠是從激怒牡蠣的沙粒中生長出來的一樣,這些編程珍珠也是從激怒真正程式設計師的實際問題中生長出來的。這些程式很有趣,並且教授重要的程式技術和基本設計原理。 > > -- [Amazon.com](https://amzn.to/2XNxWlf) ---  ## \#7。 [有效處理遺留程式碼](https://amzn.to/2Y5hNvR) ### 麥可費瑟斯 #### 27.5% 推薦(_與#6_並列) > 你的程式碼容易修改嗎?當你改變它時,你能得到幾乎即時的回饋嗎?你到底懂不懂呢?如果這些問題中任何一個的答案是否定的,那麼您就有遺留程式碼,並且它會消耗您的開發工作的時間和金錢。 > > 在本書中,Michael Feathers 提供了從頭到尾的策略,以便更有效地處理大型、未經測試的遺留程式碼庫。本書借鑒了邁克爾為其著名的物件導師研討會建立的材料:邁克爾在指導中使用的技術,幫助數百名開發人員、技術經理和測試人員控制他們的遺留系統。涵蓋的主題包括: > > - 了解軟體變更的機制:新增功能、修復錯誤、改進設計、優化效能 > - 將遺留程式碼放入測試工具中 > - 編寫測試來防止引入新問題 > - 可用於任何語言或平台的技術 - 包含 Java、C++、C 和 C# 範例 > - 準確地辨識需要更改程式碼的位置 > - 處理非物件導向的遺留系統 > - 處理看起來沒有任何結構的應用程式 > > -- [Amazon.com](https://amzn.to/2Y5hNvR) ---  ## \#6。 [人月神話:軟體工程論文](https://amzn.to/2XMoXAY) ### 作者:弗雷德里克·P·布魯克斯 #### 27.5% 推薦(_與 #7_ 並列) > 很少有關於軟體專案管理的書籍能像《人月神話》一樣具有影響力和永恆性。 Fred Brooks 融合了軟體工程事實和發人深省的觀點,為任何管理複雜專案的人提供了見解。這些文章借鑒了他作為 IBM System/360 電腦系列以及其大型軟體系統 OS/360 專案經理的經驗。現在,在他的書首次出版 20 年後,布魯克斯重新審視了他最初的想法,並加入了新的想法和建議,無論是對於已經熟悉他的作品的讀者還是第一次發現它的讀者。 > > -- [Amazon.com](https://amzn.to/2XMoXAY) #### 在 Dev.To 上閱讀[我對《人月神話》的評論](https://dev.to/awwsmm/book-review-the-mythical-man-month-1995-1hpn) ---  ## \#5。 [重構:改進現有程式碼的設計](https://amzn.to/2XQ2KlF) ### 馬丁·福勒 #### 33.3% 推薦(_與#4_並列) > 二十多年來,全世界經驗豐富的程式設計師一直依靠 Martin Fowler 的_重構_來改進現有程式碼的設計並增強軟體的可維護性,並使現有程式碼更易於理解。 > > 這個備受期待的新版本已經全面更新,以反映程式設計領域的重大變化。 _Refactoring_,第二版,提供更新的重構目錄,包括 JavaScript 程式碼範例,以及演示無需類別的重構的新功能範例。 > > 與原版一樣,此版本解釋了什麼是重構;為什麼你應該重構;如何辨識需要重構的程式碼;以及如何真正成功地做到這一點,無論您使用什麼語言。 > > - 了解重構的流程和一般原則 > - 快速應用有用的重構,使程式更易於理解和更改 > - 辨識程式碼中預示重構機會的“難聞氣味” > - 探索重構,每個重構都有解釋、動機、機制和簡單的範例 > - 為您的重建置立可靠的測試 > - 認識重構的權衡與障礙 > > -- [Amazon.com](https://amzn.to/2XQ2KlF) ---  ## \#4。 [設計模式:可重複使用物件導向軟體的要素](https://amzn.to/2jY1a37) ### 作者:Erich Gamma、Richard Helm 與 Ralph Johnson #### 33.3% 推薦(_與 #5_ 並列) > 本書不是物件導向技術或設計的介紹。許多書已經在這方面做得很好......這也不是一篇高級論文。這是一本關於設計模式的書,描述了物件導向軟體設計中特定問題的簡單而優雅的解決方案...一旦您理解了設計模式並有一個「啊哈!」的感覺。 (不僅僅是與它們的「嗯?」體驗,您將永遠不會以相同的方式思考物件導向的設計。您將擁有可以使您自己的設計更加靈活、模組化、可重用和易於理解的見解- -這就是您首先對物件導向技術感興趣的原因,對吧? > > -- [Amazon.com](https://amzn.to/2jY1a37) ---  ## \#3。 [程式碼大全:軟體建置實用手冊](https://amzn.to/2jY2PWp) ### 史蒂夫麥康奈爾 #### 44.9% 推薦 > Steve McConnell 的原始《Code Complete》被廣泛認為是最好的實用程式指南之一,十多年來一直在幫助開發人員編寫更好的軟體。現在,這本經典書籍已通過前沿實踐和數百個新程式碼示例進行了全面更新和修訂,闡釋了軟體建置的藝術和科學。麥康奈爾從研究、學術界和日常商業實踐中獲得了豐富的知識體系,將最有效的技術和必須了解的原則綜合成清晰、務實的指導。無論您的經驗水平、開發環境或專案規模如何,本書都會啟發並激發您的思考,並幫助您建立最高品質的程式碼。 > > - 發現永恆的技術和策略,幫助您: > - 最小複雜度、最大創造力的設計 > - 獲得協作開發的好處 > - 應用防禦性程式設計技術來減少和清除錯誤 > - 利用機會重構或改進程式碼,並安全地進行 > - 使用適合您專案的施工實踐 > - 快速有效地除錯問題 > - 及早正確解決關鍵施工問題 > - 將品質貫穿專案的開始、中期和結束階段 > > -- [Amazon.com](https://amzn.to/2jY2PWp) ---  ## \#2。 [務實的程式設計師:從新手到大師](https://amzn.to/2jY48Vh) ### 安德魯·亨特和戴夫·托馬斯 #### 47.8% 推薦 > 程式設計師是經過訓練的工匠,可以使用一組特定的工具(編輯器、物件管理器、版本追蹤器)來產生將在某些環境(硬體元件上的作業系統)中執行的特定類型的產品(程式).與其他工藝一樣,電腦程式設計催生了一系列智慧,其中大部分不是在大學或認證課程中教授的。隨著時間的推移,大多數程式設計師透過獨立實驗掌握了所謂的技巧。在《務實的程式設計師》中,安德魯·亨特和大衛·托馬斯將他們在各自作為軟體設計師和程式碼編寫者的職業生涯中發現的許多真理編入了法律。 > > 作者的一些實用主義要點是具體的,其實施路徑也很明確。例如,他們建議讀者學習一種文字編輯器,並將其用於所有用途。他們還建議即使是最小的專案也使用版本追蹤軟體,並宣傳學習正規表示式語法和文字操作語言的優點。其他(也許更有價值)的建議則更加輕鬆。在除錯部分,有人指出,“如果您看到蹄印,請想到馬,而不是斑馬。”也就是說,懷疑一切,但開始在最明顯的地方尋找問題。有一些關於估算時間和費用以及將測試整合到開發過程中的建議。你需要一本《務實的程式設計師》有兩個原因:它比你費心去表達的更清晰地展示了你自己累積的智慧,它向你介紹了你可能還沒有考慮過的工作方法。正在工作的程式設計師會喜歡這本書。 > > -- [大衛沃爾來自 Amazon.com](https://amzn.to/2jY48Vh) --- ## 最後,最受軟體開發人員推薦的一本書: ---  ## \#1。 [整潔程式碼:敏捷軟體流程手冊](https://amzn.to/2k1ogG7) ### 作者:羅伯特·C·「鮑伯叔叔」·馬丁 #### 52.2% 推薦 > 即使是糟糕的程式碼也能運作。但如果程式碼不乾淨,它可能會讓開發組織陷入困境。每年,都會因為程式碼編寫不當而浪費無數的時間和大量資源。但事實並非一定如此。 > > 著名軟體專家 Robert C. Martin 在《乾淨程式碼:敏捷軟體工藝手冊》中提出了革命性範例。 Martin 與Object Mentor 的同事合作,將他們「即時」清理程式碼的最佳敏捷實踐提煉成一本書,這本書將向您灌輸軟體工匠的價值觀,並使您成為更好的程式設計師——但前提是您工作在它。 > > 您將從事什麼類型的工作?你將閱讀程式碼——大量的程式碼。你將面臨著思考該程式碼哪些是正確的、哪些是錯誤的挑戰。更重要的是,您將面臨重新評估您的專業價值觀和對您的技能的承諾的挑戰。 > > _Clean Code_ 分為三個部分。第一部分描述了編寫簡潔程式碼的原則、模式和實踐。第二部分由幾個日益複雜的案例研究組成。每個案例研究都是一次清理程式碼的練習,即將存在一些問題的程式碼庫轉變為健全且高效的程式碼庫。第三部分是回報:一章包含一系列啟發式方法和建立案例研究時收集的「氣味」。結果是一個知識庫,描述了我們編寫、閱讀和清理程式碼時的思維方式。 > > 讀者將從本書中解脫出來 > - 如何區分好程式碼和壞程式碼 > - 如何寫好程式碼以及如何將壞程式碼轉換為好程式碼 > - 如何建立好名字、好函數、好物件、好類 > - 如何格式化程式碼以獲得最大的可讀性 > - 如何在不模糊程式碼邏輯的情況下實現完整的錯誤處理 > - 如何進行單元測試並實踐測試驅動開發 > - 對於任何有興趣產生更好程式碼的開發人員、軟體工程師、專案經理、團隊領導或系統分析師來說,這本書都是必讀的。 > > -- [Amazon.com](https://amzn.to/2k1ogG7) --- 上述「建議百分比」是包含該書的所有調查清單的比例。因此,即使一本書只有“12.5% 的推薦度”,也意味著平均每 8 個開發人員中就有 1 個已經閱讀過該書並推薦給其他開發人員。上述所有書籍都通過了八分之一的門檻。 更令人驚訝的是前 10 名的書籍。平均每 4 個開發人員中有 __1 人推薦 10 到 6 本書。每 3 人中就有 1 人推薦書籍#5 和#4。排名前三的書籍《__Code Complete__》、《The Pragmatic Programmer__》和《__Clean Code__》受到大約__其他軟體開發人員__的推薦。這對現代社會最關鍵的行業之一產生了巨大影響。如果您想加強您的軟體開發知識,但您尚未閱讀這三本書,那麼您的同事很可能會建議您這樣做。 --- --- 如果您喜歡上面的文章,也許您想關注我在 [Dev.To](https://dev.to/awwsmm) 上的工作?或在 [The Tweeter](https://twitter.com/_awwsmm) 上閱讀我的愚蠢推文?或[請我喝杯咖啡](https://ko-fi.com/awwsmm)? (我有令人衰弱的咖啡因成癮。) 不管怎樣,感謝您的光臨! --- 原文出處:https://dev.to/awwsmm/20-most-recommended-books-for-software-developers-5578
你的轉職路上,還缺少一份自學作業包!寫完這幾包,直接拿作品去面試上班!
本論壇另有附設一個 LINE 新手發問&交流群組!歡迎加入討論!




























