

介紹
在當今資料驅動的世界中,有效儲存和管理資訊對於各種規模的企業和組織都至關重要。關聯式資料庫已成為以結構化和可擴展的方式組織和操作資料的強大解決方案。在這篇文章中,我們將探討關聯式資料庫的基礎知識、它們的管理系統以及支援有效資料庫設計的原則。
什麼是資料庫?
資料庫是資料的結構化集合,其組織和儲存方式有利於高效檢索、操作和管理。將其視為數位文件櫃,其中不是實體資料夾和文件,而是整齊排列的表格和記錄,以便於存取。
什麼是關係資料庫?
關聯式資料庫是一種將資料組織成具有行(記錄)和列(欄位)的表(關係)的資料庫。這些表透過關係互連,允許以各種方式存取和組合資料。想像一下電子表格的集合,每個電子表格代表資料的不同方面,但能夠無縫連結和組合它們之間的資訊。
關係型資料庫管理系統
關聯式資料庫管理系統 (RDBMS) 是一種軟體應用程式,旨在建立、管理關聯式資料庫並與之互動。它提供了一個用於在資料庫中儲存、檢索和操作資料的結構化框架。 RDBMS 的一些熱門範例包括 MySQL、PostgreSQL、Oracle 和 Microsoft SQL Server。
SQL簡介
SQL(結構化查詢語言)是用於與關聯式資料庫互動的標準程式語言。它允許您建立、讀取、更新和刪除資料庫中的資料,以及定義和修改資料庫結構本身。 SQL 就像一種通用語言,可讓您與不同的 RDBMS 平台進行通訊。
命名約定
在 SQL 中,遵循一致的命名約定對於清晰度和可維護性至關重要。這是一個例子:
-- Good naming conventions
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
first_name VARCHAR(100),
last_name VARCHAR(100),
email VARCHAR(100)
);什麼是資料庫設計?
資料庫設計是建立用於儲存和管理資料庫中的資料的高效且有組織的結構的過程。它涉及定義表、列、關係和約束,以確保資料完整性、最小化冗餘並優化效能。正確的資料庫設計是建立健全且可擴展的應用程式的基礎。
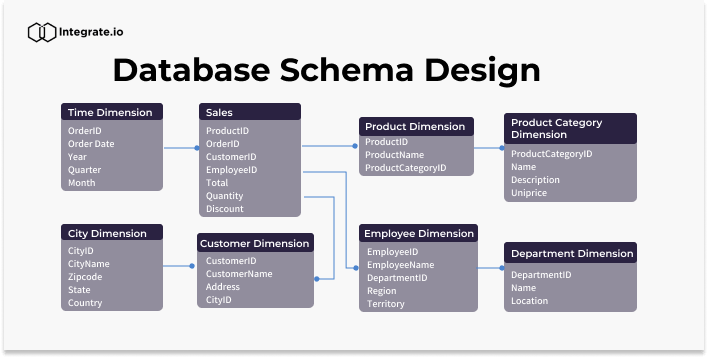
資料的完整性
資料完整性是指資料庫中儲存的資料的準確性、一致性和可靠性。它確保資料遵循特定的規則和約束,防止錯誤和不一致。資料完整性分為三種:
-
實體完整性:確保表中的每一行都可以透過主鍵唯一標識,且主鍵不能有空值。
-
參照完整性:透過確保一個表中的外鍵值與另一表中的主鍵值相符來維護表之間的關係。
-
域完整性:透過限制可儲存的資料類型、格式和值範圍,強制給定列輸入有效的條目。
-- Example: Enforcing data integrity
CREATE TABLE orders (
order_id INT PRIMARY KEY, -- Entity integrity
customer_id INT FOREIGN KEY REFERENCES customers(customer_id), -- Referential integrity
order_date DATE NOT NULL, -- Domain integrity
total_amount DECIMAL(10, 2) CHECK (total_amount >= 0) -- Domain integrity
);
資料庫術語
-
表:按行和列組織的相關資料的集合。
-
行:表中的單一實例或條目(也稱為記錄或元組)。
-
列:表中資料的特定特徵或屬性(也稱為欄位或屬性)。
-
主鍵:唯一標識表中每一行的列或列組合。
-
外鍵:引用另一個表的主鍵的列或列的組合,在兩個表之間建立關係。
-
連接:根據相關列組合兩個或多個表中的行的操作。
-
索引:一種資料結構,透過建立表格中資料的排序表示來提高資料檢索操作的效能。
-
視圖:從一個或多個基礎表動態產生的虛擬表。
-
預存程序:預先編譯的 SQL 語句集合,可以作為單一單元執行。
-
觸發器:特殊類型的預存程序,當表中發生特定事件(例如 INSERT、UPDATE 或 DELETE 語句)時會自動執行。
原子值
在資料庫設計中,儲存原子值非常重要,這意味著儲存無法進一步劃分的最小資訊片段。這項原則有助於保持資料完整性並避免冗餘。
例如,與其將客戶的全名儲存在單一欄位中,不如將其分成名字和姓氏欄位。這樣,您可以輕鬆地獨立搜尋、排序或操作名稱的每個部分。
-- Example: Storing atomic values
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100)
);
按鍵簡介
鍵是資料庫設計中的重要組成部分,有助於確保資料完整性並建立表之間的關係。它們充當記錄的唯一標識符,並實現高效的資料檢索和操作。
主鍵索引
主鍵是唯一標識表中每筆記錄的列或列的組合。它確保每個記錄都是唯一的並且可以輕鬆找到。通常會對主鍵建立索引以提高查詢效能。
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100)
);
查找表
查找表也稱為參考表或程式碼表,是包含預定義值集的表,這些值可用於填入其他表中的列。查找表透過確保一致性和減少冗餘來幫助維護資料完整性。
-- Lookup table for product categories
CREATE TABLE product_categories (
category_id INT PRIMARY KEY,
category_name VARCHAR(100)
);
-- Products table referencing the lookup table
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(100),
category_id INT,
FOREIGN KEY (category_id) REFERENCES product_categories(category_id)
);
超級密鑰和候選密鑰
超級鍵是表中唯一標識每筆記錄的一組或多列。候選鍵是最小超鍵,這意味著它不包含不必要的列。換句話說,候選鍵是一個超級鍵,具有唯一標識每個記錄所需的最少列數。
主鍵和備用鍵
主鍵是選擇作為表的主要唯一辨識符的候選鍵。備用鍵也稱為唯一鍵,是任何其他本來可以被選為主鍵但沒有被選為主鍵的候選鍵。
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
email VARCHAR(100) UNIQUE, -- Alternate key
first_name VARCHAR(50),
last_name VARCHAR(50)
);代理鍵和自然鍵
代理鍵是用作表中主鍵的人工鍵(通常是序號或 GUID)。它與資料本身沒有固有的意義或關係。另一方面,自然金鑰是從資料本身衍生的金鑰,例如員工 ID 或產品程式碼。
-- Surrogate key
CREATE TABLE orders (
order_id INT PRIMARY KEY IDENTITY(1,1), -- Surrogate key
customer_name VARCHAR(100),
order_date DATE
);
-- Natural key
CREATE TABLE products (
product_code VARCHAR(10) PRIMARY KEY, -- Natural key
product_name VARCHAR(100),
price DECIMAL(10,2)
);我應該使用代理鍵還是自然鍵?
代理鍵和自然鍵之間的選擇取決於多個因素,包括資料的性質、資料變更的可能性以及重複或衝突的可能性。
代理鍵通常是首選,因為它們是:
-
不可變:即使資料發生變化,它們也不會隨著時間而改變。
-
保證唯一性:由資料庫系統生成,保證唯一性。
-
不透明:它們不會洩露有關資料本身的任何訊息,這對於安全和隱私來說是有益的。
另一方面,自然鍵在以下情況下可能會很有優勢:
-
資料具有固有的唯一性,例如產品程式碼或員工 ID。
-
資料不太可能隨著時間的推移而改變,從而降低了衝突或重複的風險。
-
需要人類可讀且有意義的辨識符。
外鍵
外鍵是一個表中引用另一個表的主鍵的列或列的組合。它在兩個表之間建立連結並強制引用完整性,確保子表中的資料有效且與父表中的資料一致。
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
NOT NULL 外鍵
在某些情況下,可能需要對外鍵列設定 NOT NULL 約束,這表示該列不能有空值。此約束可確保子表中的每筆記錄都與父表中的有效記錄相關聯。
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT NOT NULL,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
外鍵約束
外鍵約束定義表之間引用完整性的規則。這些約束可以包括更新或刪除父表中引用的記錄時要採取的操作,例如:
-
CASCADE:當父表中的記錄被更新或刪除時,子表中對應的記錄也會被更新或刪除。 -
SET NULL:當父表中的記錄被更新或刪除時,子表中對應的外鍵值被設定為NULL。 -
NO ACTION:當父表中的記錄被更新或刪除時,子表中對應的外鍵值保持不變,如果違反引用完整性則回滾操作。
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id) ON UPDATE CASCADE ON DELETE SET NULL
);
簡單鍵、複合鍵、複合鍵
-
簡單鍵是用作主鍵或外鍵的單一欄位。
-
複合鍵是用作主鍵或外鍵的兩個或多個列的組合。
-
複合鍵是用作外鍵的兩個或多個簡單鍵的組合。
-- Simple key
CREATE TABLE orders (
order_id INT PRIMARY KEY,
...
);
-- Composite key
CREATE TABLE order_items (
order_id INT,
product_id INT,
quantity INT,
PRIMARY KEY (order_id, product_id)
);
-- Compound key
CREATE TABLE shipments (
shipment_id INT PRIMARY KEY,
order_id INT,
product_id INT,
FOREIGN KEY (order_id, product_id) REFERENCES order_items(order_id, product_id)
);
關係
關係是關聯式資料庫的基石,可讓您連接和組合來自不同表的資料。關係主要分為三種:
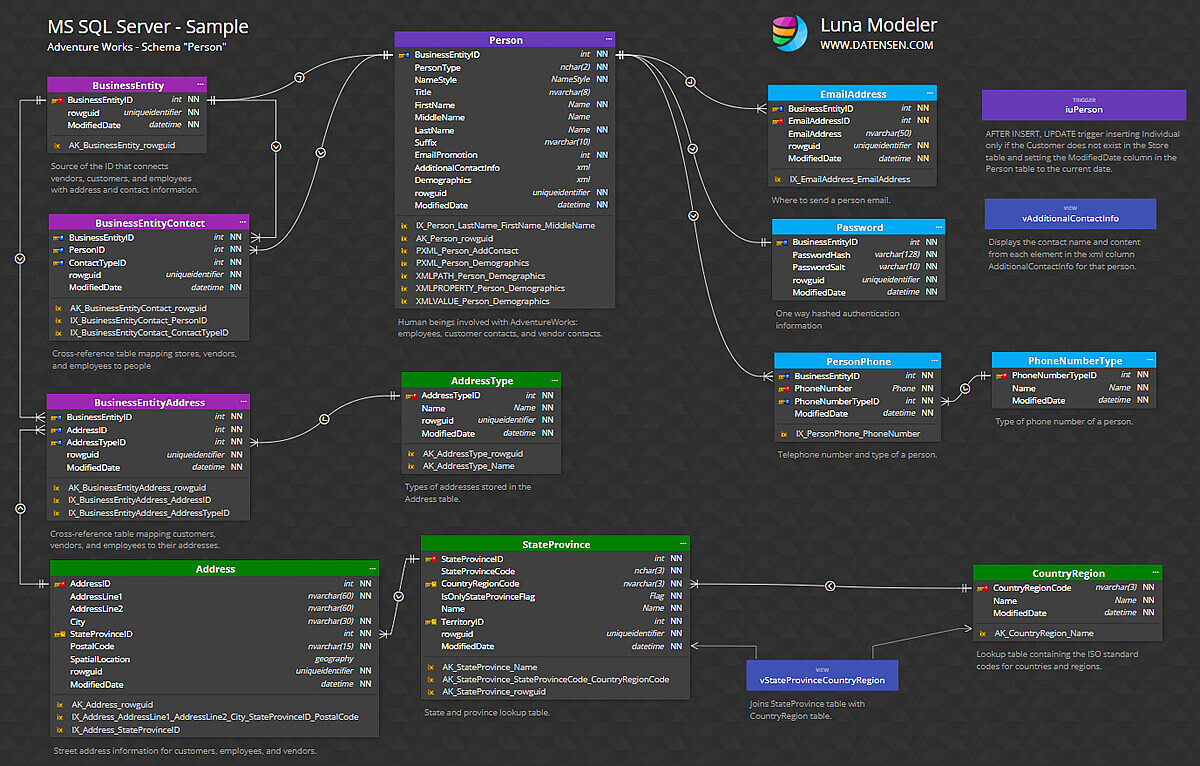
一對一的關係
在一對一關係中,一個表中的每筆記錄都與另一個表中的一筆記錄相關聯,反之亦然。例如,考慮一個資料庫,其中每位員工都有一名且僅有一名經理,且每位經理管理一名且僅有一名員工。這種關係在實務上比較少見。
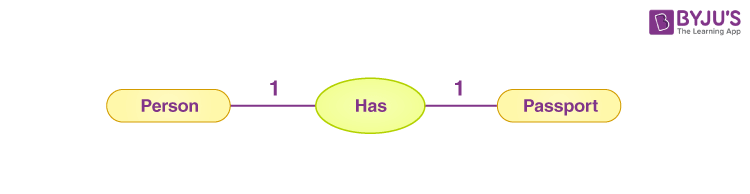
一對多關係
在一對多關係中,一個表格(「一」側)中的每筆記錄都可以與另一個表(「多」側)中的多個記錄關聯。例如,在學校的資料庫中,一位老師可以教授多個班級,但每個班級只有一位老師授課。
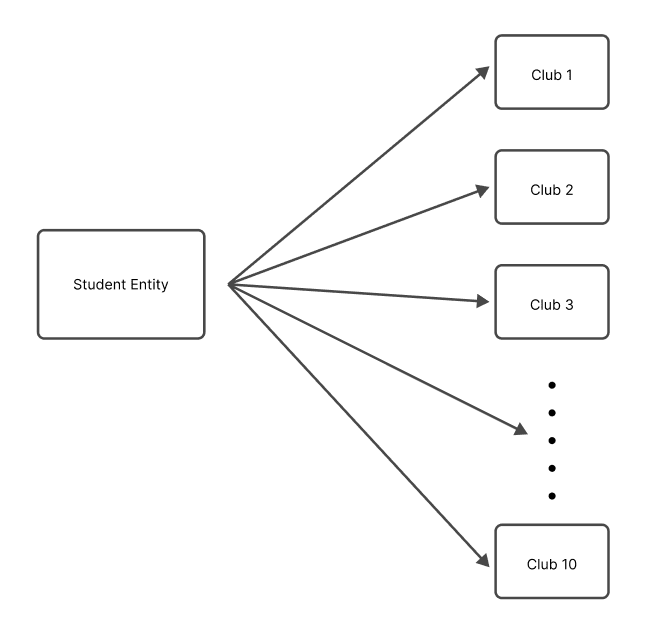
多對多關係
在多對多關係中,一個表中的每筆記錄可以與另一表中的多筆記錄關聯,反之亦然。例如,在大學的資料庫中,一個學生可以註冊多個課程,每個課程可以有多個學生註冊。
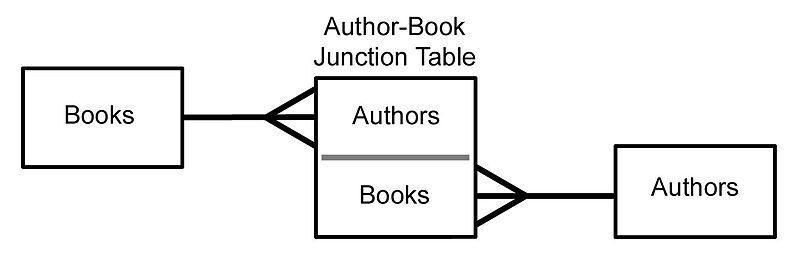
關係摘要
-
一對一:表A中的一筆記錄與表B中的一筆且只有一筆記錄相關,反之亦然。
-
一對多:A表中的一筆記錄可以與B表中的多筆記錄相關,但B表中的一筆記錄只能與A表中的一筆記錄相關。
-
多對多:表A中的多筆記錄可以與表B中的多筆記錄相關,反之亦然。
設計關係(SQL 實作)
1 - 設計一對一關係
要設計一對一關係,您可以將兩個表中的所有列包含在一個表中,也可以建立兩個單獨的表並使用外鍵約束來連結它們。
-- Option 1: Single table
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
manager_first_name VARCHAR(50),
manager_last_name VARCHAR(50)
);
-- Option 2: Two tables with foreign key
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
manager_id INT UNIQUE,
FOREIGN KEY (manager_id) REFERENCES employees(employee_id)
);2 -設計一對多關係
要設計一對多關係,通常會建立兩個表:父表(“一”側)和子表(“多”側)。子表包含引用父表主鍵的外鍵列。
-- Parent table
CREATE TABLE teachers (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50)
);
-- Child table
CREATE TABLE classes (
class_id INT PRIMARY KEY,
class_name VARCHAR(100),
teacher_id INT,
FOREIGN KEY (teacher_id) REFERENCES teachers(teacher_id)
);3 - 設計多對多關係
要設計多對多關係,通常會建立第三個表(稱為聯結表或關聯表),將兩個主表連結在一起。此聯結表包括引用主表的外鍵列
-- Table 1
CREATE TABLE students (
student_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50)
);
-- Table 2
CREATE TABLE courses (
course_id INT PRIMARY KEY,
course_name VARCHAR(100),
description TEXT
);
-- Junction or Intemediary table
CREATE TABLE enrollments (
enrollment_id INT PRIMARY KEY,
student_id INT,
course_id INT,
FOREIGN KEY (student_id) REFERENCES students(student_id),
FOREIGN KEY (course_id) REFERENCES courses(course_id)
);父表和子表
在一對多或多對多關係中, “一”側的表通常稱為父表,而“多”側的表稱為子表。子表包含引用父表主鍵的外鍵。
例如,在教師-班級關係中, teachers表是父表, classes表是子表。同樣,在學生-課程關係中, students和courses表是父表,而enrollm是父表。
實體關係建模簡介
實體關係建模(ER Modeling)是資料庫設計中使用的一種技術,用於直觀地表示資料庫的邏輯結構。它有助於辨識實體(表)、屬性(列)以及它們之間的關係,從而更容易理解和傳達資料庫設計。
ER 圖由以下部分組成:
-
實體:以矩形表示,實體是資料庫中的表或物件。
-
屬性:在實體矩形內列出,屬性是描述實體的列或欄位。
-
關係:以連接實體的線表示,關係描述了實體之間的關聯。
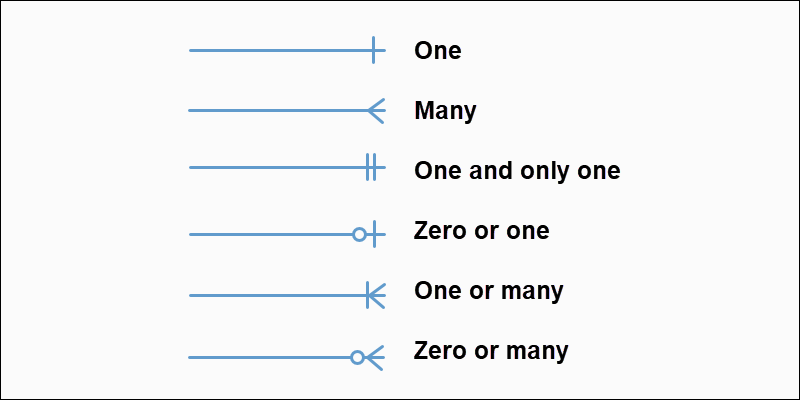
基數
基數定義了兩個實體之間的數值關係。它指定一個實體可以與另一個實體的單一實例關聯的最大實例數。最常見的基數是:
-
一對一(1:1):實體 A 的一個實例最多可以與實體 B 的一個實例關聯,反之亦然。
-
一對多(1:N):實體 A 的一個實例可以與實體 B 的多個實例關聯,但實體 B 的一個實例只能與實體 A 的一個實例關聯。
-
多對多 (M:N):實體 A 的多個實例可以與實體 B 的多個實例關聯,反之亦然。
在 ER 圖中,基數以特定的符號表示,例如單線表示一對一,帶箭頭的線表示一對多,兩端帶箭頭的線表示多對多關係。
模態
模態是指一個實體實例的存在是否依賴它與另一個實體的關係。有兩種類型的模態:
-
部分模態:實例的存在不依賴它與另一個實體的關係。例如,客戶可以在沒有任何訂單的情況下存在。
-
總模態:實例的存在取決於它與另一個實體的關係。例如,沒有訂單,訂單項就不可能存在。
在 ER 圖中,模態使用特定的符號表示,例如單一條表示部分模態,雙條表示總模態。
資料庫規範化簡介
資料庫規範化是組織資料庫中的資料以減少冗餘、最大限度地減少資料異常(插入、更新和刪除異常)並提高資料完整性的過程。它涉及將資料庫分解為較小的表,並根據特定規則或範式定義它們之間的關係。
資料庫規範化的主要目標是:
-
消除冗餘資料
-
確保資料完整性
-
促進資料操作和維護
資料庫規範化有多種範式,每種都建立在前一種範式的基礎上。最常用的範式是:
-
第一範式 (1NF)
-
第二範式 (2NF)
-
第三範式 (3NF)
1NF(資料庫規範化第一範式)
第一範式(1NF)是最基本的規範化形式。它規定表中的屬性(列)必須具有原子值,這意味著表中的每個單元格應包含單一值,而不是一組值。
例如,假設一個表格具有名為「PhoneNumbers」的資料列,該資料列儲存客戶的多個電話號碼。這違反了 1NF,因為該列包含一組值而不是單一值。為了符合 1NF,您需要將電話號碼分成單獨的列或為電話號碼建立單獨的表。
-- Violates 1NF
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
phone_numbers VARCHAR(200) -- Stores multiple phone numbers, violating 1NF
);
-- Conforms to 1NF
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
phone1 VARCHAR(20),
phone2 VARCHAR(20),
phone3 VARCHAR(20)
);2NF(資料庫規範化的第二範式)
第二範式 (2NF) 建立在 1NF 的基礎上,解決了部分依賴問題。如果表屬於 1NF,且每個非主屬性(列)完全依賴整個主鍵,則該表屬於 2NF。
換句話說,如果一個表有一個複合主鍵(由多個列組成),那麼所有非鍵列必須依賴整個主鍵,而不僅僅是它的一部分。
例如,考慮一個具有複合主鍵(student_id, course_id)和列grade的表。如果grade欄位僅取決於course_id ,而不取決於student_id和course_id的組合,則該表違反了 2NF。
-- Violates 2NF
CREATE TABLE student_courses (
student_id INT,
course_id INT,
course_name VARCHAR(100),
grade CHAR(2), -- Depends only on course_id, not the entire primary key
PRIMARY KEY (student_id, course_id)
);
-- Conforms to 2NF
CREATE TABLE student_courses (
student_id INT,
course_id INT,
grade CHAR(2),
PRIMARY KEY (student_id, course_id)
);
CREATE TABLE courses (
course_id INT PRIMARY KEY,
course_name VARCHAR(100)
);3NF(資料庫規範化的第三範式)
第三範式 (3NF) 建立在 2NF 的基礎上,解決了傳遞依賴問題。如果表屬於 2NF,且每個非主屬性都非傳遞依賴於主鍵,則該表屬於 3NF。
換句話說,如果一個非鍵列依賴另一個非鍵列,那麼該表就違反了 3NF,並且非鍵列應該分離到它們自己的表中。
例如,考慮一個包含student_id 、 student_name 、 class_id和class_name欄位的表。 student_name欄位取決於student_id ,而class_name欄位取決於class_id 。但是, class_name欄位也透過class_id欄位傳遞依賴student_id 。這違反了 3NF。
-- Violates 3NF
CREATE TABLE student_classes (
student_id INT,
student_name VARCHAR(100),
class_id INT,
class_name VARCHAR(100),
PRIMARY KEY (student_id, class_id)
);
-- Conforms to 3NF
CREATE TABLE students (
student_id INT PRIMARY KEY,
student_name VARCHAR(100)
);
CREATE TABLE classes (
class_id INT PRIMARY KEY,
class_name VARCHAR(100)
);
CREATE TABLE student_classes (
student_id INT,
class_id INT,
PRIMARY KEY (student_id, class_id),
FOREIGN KEY (student_id) REFERENCES students(student_id),
FOREIGN KEY (class_id) REFERENCES classes(class_id)
);透過遵循資料庫規範化的原則,您可以建立結構良好且高效的資料庫,從而最大限度地減少冗餘、保持資料完整性並促進資料操作和維護。
索引(聚集索引、非聚集索引、複合索引)
索引是提高資料庫中資料檢索操作效能的資料結構。它們在表中建立資料的排序表示,從而允許更快的搜尋和查詢。索引有幾種類型:
-
聚集索引:聚集索引根據索引鍵值對表中的行進行實體重新排序。每個表只能有一個聚集索引。
-
非聚集索引:非聚集索引是一個單獨的物件,其中包含索引鍵值和指向表中相應行的指標。一個表可以有多個非聚集索引。
-
複合索引:複合索引是索引鍵中包含多個欄位的索引。它可以是集群的,也可以是非集群的。
-- Clustered index
CREATE CLUSTERED INDEX idx_customers_name
ON customers (last_name, first_name);
-- Nonclustered index
CREATE NONCLUSTERED INDEX idx_orders_date
ON orders (order_date);
-- Composite index
CREATE INDEX idx_products_category_price
ON products (category_id, price);資料類型
在資料庫領域,資料類型就像是保存特定類型資訊的不同形狀的容器。就像您不會將液體儲存在籃子中或將固體物體儲存在罐子中一樣,資料庫需要強制執行特定的資料類型以確保資料的完整性和一致性。
SQL 中的一些常見資料類型包括:
-
INT或INTEGER:儲存整數,例如42或17。 -
FLOAT或DOUBLE:儲存十進制數,例如3.14159或0.00005。 -
VARCHAR或TEXT:儲存文字資料,例如名稱或描述。 -
DATE或DATETIME:儲存日期和時間值,例如'2023-05-06'或'2024-01-01 12:34:56'。 -
BOOLEAN:儲存真/假值,例如1(真)或0(假)。
選擇正確的資料類型至關重要,因為它會影響資料的儲存、查詢和操作方式。例如,嘗試在INT列中儲存大字串會導致錯誤或資料截斷。
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT,
is_active BOOLEAN DEFAULT 1
);
在此範例中,我們建立一個users表,其中包含id (整數)、 name (最多 50 個字元的字串)、 age (整數)和is_active (布林值,預設值為1或 true)欄位。
連接簡介
連接就像連接資料庫中不同表的橋樑,允許您組合和檢索來自多個來源的相關資料。它們是關係資料庫中的基本概念,對於有效查詢和操作資料至關重要。
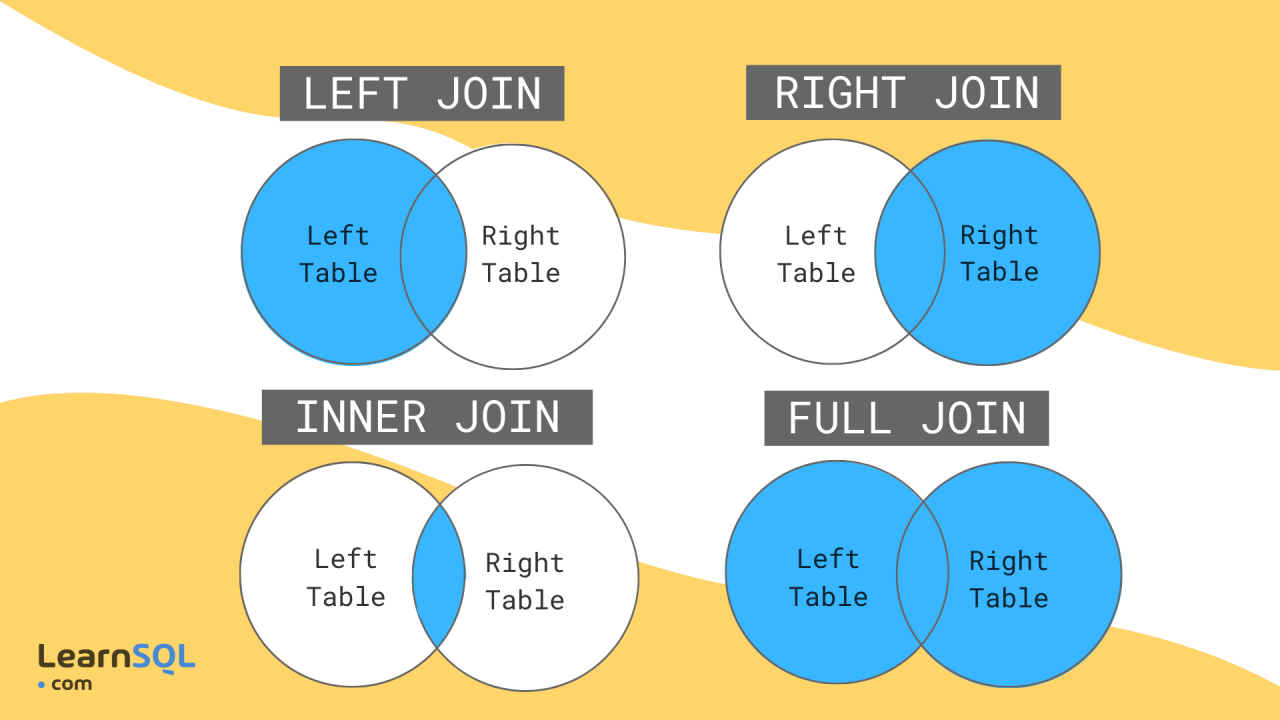
內部聯接
內部聯結就像兩個表之間的友好握手,其中只有在兩個表中具有匹配值的行才會包含在結果集中。這是一種基於公共列或列集組合多個表中的資料的方法。
SELECT users.name, orders.order_date
FROM users
INNER JOIN orders ON users.id = orders.user_id;在這個範例中,我們從users表中檢索name列,從orders表中檢索order_date列,但僅限於users表中的id與orders表中的user_id相符的行。
3 個表上的內連接(範例)
假設我們有三個表: users 、 orders和products 。我們想要檢索每個訂單的使用者名稱、訂單日期和產品名稱。我們可以透過在所有三個表之間執行內部聯結來實現這一點:
SELECT users.name, orders.order_date, products.product_name
FROM users
INNER JOIN orders ON users.id = orders.user_id
INNER JOIN products ON orders.product_id = products.id;在這裡,我們首先在id和user_id列上連接users和orders表。然後,我們將該連接的結果與products表的product_id和id列連接起來。這樣,我們可以在單一查詢中從所有三個表中檢索資料,但僅限於滿足連接條件的行。
外連接簡介
內部連接就像友好的握手,而外部連接更像是歡迎的擁抱。它們不僅包括兩個表中的匹配行,還包括一個或兩個表中的不匹配行,具體取決於外連接的類型。
右外連接
右外連接就像從右表到左表的溫暖擁抱。它包括右表中的所有行以及左表中的匹配行。如果左表中沒有符合的行,則結果將包含左表列的NULL值。
SELECT users.name, orders.order_date
FROM users
RIGHT OUTER JOIN orders ON users.id = orders.user_id;在此範例中,我們從orders表(右表)中檢索所有行,以及users表(左表)中的符合name值。如果訂單沒有符合的用戶,則name列將包含NULL 。
JOIN 與 NOT NULL 列
有時,您可能只想對不為空的列執行聯接。當您想要從結果集中排除缺少資料的行時,這會很有用。
SELECT users.name, orders.order_date
FROM users
INNER JOIN orders ON users.id = orders.user_id AND users.name IS NOT NULL;
在此範例中,我們在users和orders表之間執行內部聯接,但我們新增了一個附加條件users.name IS NOT NULL以確保結果集中僅包含具有非空name值的行。
跨 3 個表的外連接
與內連接範例類似,我們可以跨多個表執行外連接。假設我們想要檢索所有訂單以及使用者名稱和產品名稱,即使users或products表中缺少值。
SELECT users.name, orders.order_date, products.product_name
FROM orders
LEFT OUTER JOIN users ON orders.user_id = users.id
LEFT OUTER JOIN products ON orders.product_id = products.id;
在這裡,我們從orders表開始,並對users和products表執行左外連接。這可確保所有訂單以及符合的使用者名稱和產品名稱(如果可用)都包含在結果集中。如果users或products表中沒有符合的行,則對應的列將包含NULL值。
別名
別名就像 SQL 查詢中表格或欄位的暱稱。它們可以使查詢更具可讀性和更容易理解,特別是在處理長表或列名時,或在查詢中多次引用同一個表時。
SELECT u.name, o.order_date, p.product_name
FROM users u
INNER JOIN orders o ON u.id = o.user_id
INNER JOIN products p ON o.product_id = p.id;
在此範例中,我們對users表使用別名u ,對orders表使用別名o ,對products表使用p 。這使得查詢更加簡潔且更易於閱讀,而不必多次重複完整的表名稱。
自加入
自連結就像一張表在與自己對話。這是一種根據同一個表中的特定條件或關係將表與其自身連接的方法。這在處理分層或遞歸資料結構(例如員工-經理關係或巢狀類別)時非常有用。
SELECT e.name AS employee, m.name AS manager
FROM employees e
LEFT OUTER JOIN employees m ON e.manager_id = m.id;在此範例中,我們對employees表執行自聯接以檢索每位員工的姓名及其對應經理的姓名。我們使用左外連接來確保所有員工都包含在結果集中,即使他們沒有指派經理。
資料庫標記語言 (DBML)
資料庫建模語言(DBML)是一種簡單直觀的標記語言,用於描述關係型資料庫的結構。它提供了一種人類可讀的方式來定義表、列、關係和約束,從而使資料庫設計方面的溝通和協作變得輕鬆。
DBML 入門
要開始使用 DBML,您需要一個文字編輯器並對資料庫概念有基本的了解。讓我們建立第一個 DBML 檔案:
// my_database.dbml
Table users {
id int [pk, increment]
username varchar
email varchar [unique]
created_at datetime [default: `now()`]
}
在這個範例中,我們定義了一個users表,其中包含id 、 username 、 email和created_at列。 [pk]標記指定id為主鍵, [increment]表示自動遞增, [unique]確保email的唯一性, [default: now() ]將created_at的預設值設為目前時間戳記。
建立表
DBML 可讓您在單一檔案中定義多個表格及其列。讓我們為資料庫新增更多表:
// my_database.dbml
Table users {
id int [pk, increment]
username varchar
email varchar [unique]
created_at datetime [default: `now()`]
}
Table posts {
id int [pk, increment]
title varchar
content text
user_id int [ref: > users.id]
created_at datetime [default: `now()`]
}
在這個範例中,我們新增了一個posts表,其中包含id 、 title 、 content 、 user_id和created_at欄位。 [ref: > users.id]標籤在posts表中的user_id欄位和users表中的id列之間建立外鍵關係。
定義關係
DBML 支援表之間各種類型的關係,包括一對一、一對多和多對多。讓我們在資料庫中定義一些關係:
// my_database.dbml
Table users {
id int [pk, increment]
username varchar
email varchar [unique]
created_at datetime [default: `now()`]
}
Table posts {
id int [pk, increment]
title varchar
content text
user_id int [ref: > users.id]
created_at datetime [default: `now()`]
}
Ref: users.id < posts.user_id
在此範例中,我們定義了users和posts表之間的一對多關係。 Ref: users.id < posts.user_id行指定users表中的user_id欄位引用posts表中的id列。
新增約束
約束確保資料完整性並在資料庫上強制執行規則。 DBML 支援各種約束,例如主鍵、外鍵、唯一約束和預設值。讓我們在表格中加入一些約束:
// my_database.dbml
Table users {
id int [pk, increment]
username varchar [unique]
email varchar [unique]
created_at datetime [default: `now()`]
}
Table posts {
id int [pk, increment]
title varchar
content text
user_id int [ref: > users.id]
created_at datetime [default: `now()`]
}
Ref: users.id < posts.user_id
在此更新的範例中,我們為users表中的username名列新增了[unique]約束,以確保每個使用者名稱都是唯一的。
記錄您的資料庫
DBML 可讓您為資料庫模式新增註解和註釋,使其更易於理解和維護。讓我們用註釋來記錄我們的表格:
// my_database.dbml
Table users {
id int [pk, increment] // Unique identifier for users
username varchar [unique] // User's username
email varchar [unique] // User's email address
created_at datetime [default: `now()`] // Date and time when the user was created
}
Table posts {
id int [pk, increment] // Unique identifier for posts
title varchar // Title of the post
content text // Content of the post
user_id int [ref: > users.id] // ID of the user who created the post
created_at datetime [default: `now()`] // Date and time when the post was created
}
Ref: users.id < posts.user_id // Relationship between users and posts
DBML 的好處
-
簡單且人類可讀的語法
-
與資料庫無關的方法
-
dbdiagram.io上的免費視覺化工具
-
一致的可讀性和可維護性約定
-
豐富的文件和範例
結論
總而言之,關聯式資料庫設計構成了現代應用程式中高效能資料組織的支柱。了解其原理使您能夠建立強大且可擴展的資料庫。接下來,我們將深入研究 SQL 語法,釋放與資料庫有效互動的能力。請繼續關注我們對 SQL 世界的探索!
原文出處:https://dev.to/louaiboumediene/mastering-relational-database-design-a-comprehensive-guide-3jh8
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式