🔧 阿川の電商水電行

本文將透過一個簡單的範例來示範如何將 PySpark 與 Taipy 整合,以將您的 大資料處理需求 與 智慧作業執行 結合。
讓我們開始吧!

<小時/>
將 PySpark 與 Taipy 結合使用
Taipy 是一個強大的工作流程編排工具,具有易於使用的框架,可輕鬆應用於您現有的資料應用程式。
Taipy 建立在堅實的概念基礎上: - 場景、任務和資料節點 - 這些概念非常強大,允許開發人員輕鬆地對其管道進行建模,即使在沒有明確支援的情況下使用第3 方包也是如此。
<小時/>

{% cta https://github.com/Avaiga/taipy %} Star ⭐ Taipy 儲存庫 {% endcta %}
我們感謝任何幫助我們發展社區的幫助🌱
<小時/>
*如果您已經熟悉 PySpark 和 Taipy,則可以跳至「2.
Taipy 設定 (config.py)」。
該部分深入探討了為 Taipy 任務定義函數來執行 PySpark 應用程式的本質。否則,請繼續閱讀!
<小時/>
一個簡單的例子:palmerpenguins
我們以 palmerpenguins 資料集為例:
>>> penguin_df
┌───────┬─────────┬───────────┬────────────────┬───────────────┬───────────────────┬─────────────┬────────┬──────┐
│ index │ species │ island │ bill_length_mm │ bill_depth_mm │ flipper_length_mm │ body_mass_g │ sex │ year │
├───────┼─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼──────┤
│ 0 │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181.0 │ 3750.0 │ male │ 2007 │
│ 1 │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186.0 │ 3800.0 │ female │ 2007 │
│ 2 │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195.0 │ 3250.0 │ female │ 2007 │
│ 3 │ Adelie │ Torgersen │ NaN │ NaN │ NaN │ NaN │ NaN │ 2007 │
│ 4 │ Adelie │ Torgersen │ 36.7 │ 19.3 │ 193.0 │ 3450.0 │ female │ 2007 │
│ ... │ ... │ ... │ ... │ ... │ ... │ ... │ ... │ ... │
└───────┴─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴──────┘<小時/>
該資料集僅包含 344 筆記錄——幾乎不是一個需要 Spark 處理的資料集。
然而,該資料集是可存取的,且其大小與演示 Spark 與 Taipy 的整合無關。
如果必須使用更大的資料集進行測試,您可以根據需要多次複製資料。
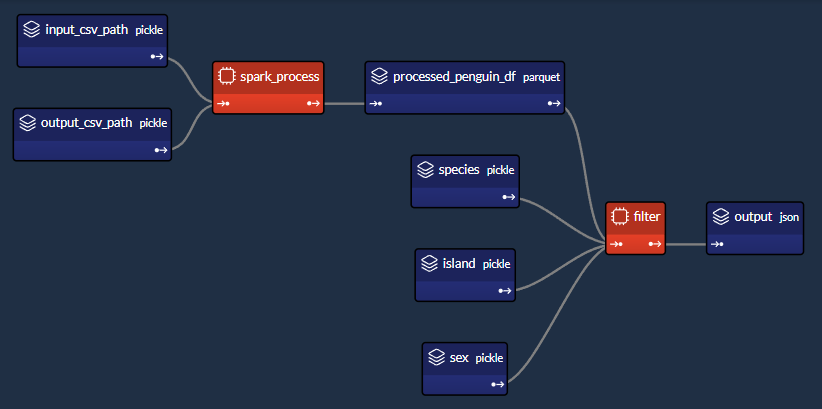
我們簡單的企鵝應用程式的 DAG
<小時/>
我們將設計一個執行兩個主要任務的工作流程:
1- Spark 任務(spark_process):
-
載入資料;
-
依「物種」、「島嶼」和「性別」將資料分組;
-
求其他欄位的平均值(「bill_length_mm」、「bill_depth_mm」、「flipper_length_mm」、「body_mass_g」);
-
儲存資料。
2- Python 任務(過濾器):
-
載入Spark任務之前儲存的輸出資料;
-
給定“物種”、“島嶼”和“性別”,傳回聚合值。
我們的小專案將包含 4 個檔案:
app/
├─ penguin_spark_app.py # the spark application
├─ config.py # the configuration for our taipy workflow
├─ main.py # the main script (including our application gui)
├─ penguins.csv # the data as downloaded from the palmerpenguins git repo<小時/>
您可以找到每個檔案的內容(penguins.csv 除外,您可以從 [palmerpenguins 儲存庫](https://github.com/allisonhorst/palmerpenguins/blob/main/inst/extdata/penguins.csv 取得) )在本文的程式碼區塊中。
<小時/>
1. Spark 應用程式 (penguin_spark_app.py)
通常,我們使用 spark-submit 命令列實用程式來執行 PySpark 任務。
您可以在他們自己的文件中閱讀有關以這種方式提交Spark 作業的內容和原因的更多資訊此處 。
當使用 Taipy 進行工作流程編排時,我們可以繼續做同樣的事情。
唯一的區別是,我們不是在命令列中執行命令,而是讓工作流程管道產生一個子進程,它使用以下命令執行Spark 應用程式火花提交。
在開始討論之前,我們首先看看我們的 Spark 應用程式。
只需瀏覽一下程式碼,然後繼續閱讀有關此腳本功能的簡短說明:
### app/penguin_spark_app.py
import argparse
import os
import sys
parser = argparse.ArgumentParser()
parser.add_argument("--input-csv-path", required=True, help="Path to the input penguin CSV file.")
parser.add_argument("--output-csv-path", required=True, help="Path to save the output CSV file.")
args = parser.parse_args()
import pyspark.pandas as ps
from pyspark.sql import SparkSession
def read_penguin_df(csv_path: str):
penguin_df = ps.read_csv(csv_path)
return penguin_df
def clean(df: ps.DataFrame) -> ps.DataFrame:
return df[df.sex.isin(["male", "female"])].dropna()
def process(df: ps.DataFrame) -> ps.DataFrame:
"""The mean of measured penguin values, grouped by island and sex."""
mean_df = df.groupby(by=["species", "island", "sex"]).agg("mean").drop(columns="year").reset_index()
return mean_df
if __name__ == "__main__":
spark = SparkSession.builder.appName("Mean Penguin").getOrCreate()
penguin_df = read_penguin_df(args.input_csv_path)
cleaned_penguin_df = clean(penguin_df)
processed_penguin_df = process(cleaned_penguin_df)
processed_penguin_df.to_pandas().to_csv(args.output_csv_path, index=False)
sys.exit(os.EX_OK)<小時/>
我們可以透過在終端機中輸入以下命令來提交此 Spark 應用程式以供執行:
spark-submit --master local[8] app/penguin_spark_app.py \
--input-csv-path app/penguins.csv \
--output-csv-path app/output.csv<小時/>
它將執行以下操作:
1.提交penguin_spark_app.py應用程式在8個CPU核心上本地執行;
-
從 app/penguins.csv CSV 檔案載入資料;
-
依「物種」、「島嶼」和「性別」分組,然後按平均值聚合其餘欄位;
-
將產生的 DataFrame 儲存到 app/output.csv。
此後,app/output.csv 的內容應如下所示:
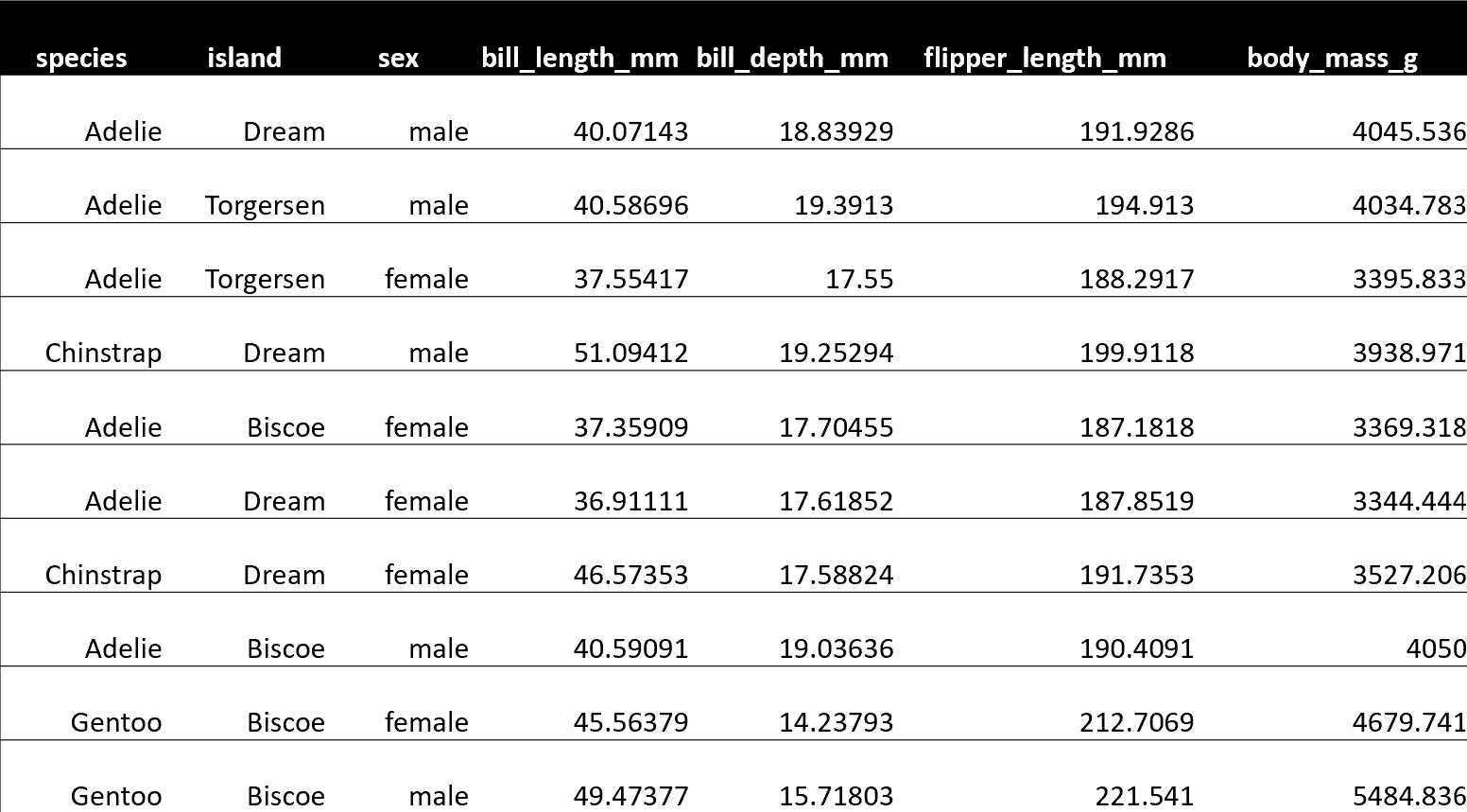
<小時/>
另請注意,我們已對 Spark 應用程式進行了編碼以接收 2 個命令列參數:
-
- input-csv-path :輸入企鵝 CSV 檔案的路徑;和
-
- output-csv-path :Spark 應用程式處理後儲存輸出 CSV 檔案的路徑。
<小時/>
2. Taipy 設定 (config.py)
此時,我們有了 penguin_spark_app.py PySpark 應用程式,並且需要建立一個 Taipy 任務來執行此 PySpark 應用程式。
再次快速瀏覽 app/config.py 腳本,然後繼續閱讀:
### app/config.py
import datetime as dt
import os
import subprocess
import sys
from pathlib import Path
import pandas as pd
import taipy as tp
from taipy import Config
SCRIPT_DIR = Path(__file__).parent
SPARK_APP_PATH = SCRIPT_DIR / "penguin_spark_app.py"
input_csv_path = str(SCRIPT_DIR / "penguins.csv")
# -------------------- Data Nodes --------------------
input_csv_path_cfg = Config.configure_data_node(id="input_csv_path", default_data=input_csv_path)
# Path to save the csv output of the spark app
output_csv_path_cfg = Config.configure_data_node(id="output_csv_path")
processed_penguin_df_cfg = Config.configure_parquet_data_node(
id="processed_penguin_df", validity_period=dt.timedelta(days=1)
)
species_cfg = Config.configure_data_node(id="species") # "Adelie", "Chinstrap", "Gentoo"
island_cfg = Config.configure_data_node(id="island") # "Biscoe", "Dream", "Torgersen"
sex_cfg = Config.configure_data_node(id="sex") # "male", "female"
output_cfg = Config.configure_json_data_node(
id="output",
)
# -------------------- Tasks --------------------
def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame:
proc = subprocess.Popen(
[
str(Path(sys.executable).with_name("spark-submit")),
str(SPARK_APP_PATH),
"--input-csv-path",
input_csv_path,
"--output-csv-path",
output_csv_path,
],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
try:
outs, errs = proc.communicate(timeout=15)
except subprocess.TimeoutExpired:
proc.kill()
outs, errs = proc.communicate()
if proc.returncode != os.EX_OK:
raise Exception("Spark training failed")
df = pd.read_csv(output_csv_path)
return df
def filter(penguin_df: pd.DataFrame, species: str, island: str, sex: str) -> dict:
df = penguin_df[(penguin_df.species == species) & (penguin_df.island == island) & (penguin_df.sex == sex)]
output = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]].to_dict(orient="records")
return output[0] if output else dict()
spark_process_task_cfg = Config.configure_task(
id="spark_process",
function=spark_process,
skippable=True,
input=[input_csv_path_cfg, output_csv_path_cfg],
output=processed_penguin_df_cfg,
)
filter_task_cfg = Config.configure_task(
id="filter",
function=filter,
skippable=True,
input=[processed_penguin_df_cfg, species_cfg, island_cfg, sex_cfg],
output=output_cfg,
)
scenario_cfg = Config.configure_scenario(
id="scenario", task_configs=[spark_process_task_cfg, filter_task_cfg]
)您也可以使用Taipy Studio 建立Taipy 配置,這是一個Visual Studio Code 擴展,它提供了圖形編輯器建構 Taipy .toml 設定檔。
<小時/>
Taipy 中的 PySpark 任務
我們對產生這部分 DAG 的程式碼部分特別感興趣:
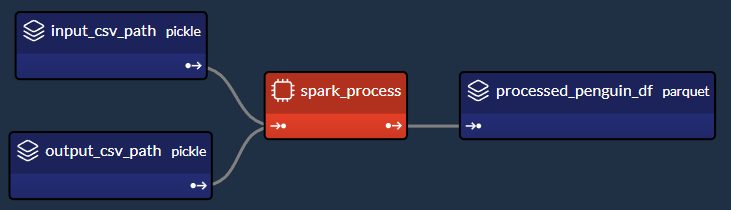
<小時/>
讓我們提取並檢查 config.py 腳本的相關部分,該腳本在 Taipy 中建立「spark_process」Spark 任務(及其 3 個關聯的資料節點),如上圖所示:
### Code snippet: Spark task in Taipy
# -------------------- Data Nodes --------------------
input_csv_path_cfg = Config.configure_data_node(id="input_csv_path", default_data=input_csv_path)
# Path to save the csv output of the spark app
output_csv_path_cfg = Config.configure_data_node(id="output_csv_path")
processed_penguin_df_cfg = Config.configure_parquet_data_node(
id="processed_penguin_df", validity_period=dt.timedelta(days=1)
)
# -------------------- Tasks --------------------
def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame:
proc = subprocess.Popen(
[
str(Path(sys.executable).with_name("spark-submit")),
str(SPARK_APP_PATH),
"--input-csv-path",
input_csv_path,
"--output-csv-path",
output_csv_path,
],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
try:
outs, errs = proc.communicate(timeout=15)
except subprocess.TimeoutExpired:
proc.kill()
outs, errs = proc.communicate()
if proc.returncode != os.EX_OK:
raise Exception("Spark training failed")
df = pd.read_csv(output_csv_path)
return df
spark_process_task_cfg = Config.configure_task(
id="spark_process",
function=spark_process,
skippable=True,
input=[input_csv_path_cfg, output_csv_path_cfg],
output=processed_penguin_df_cfg,
)<小時/>
由於我們設計 penguin_spark_app.py Spark 應用程式來接收 2 個參數(input_csv_path 和 output_csv_path),因此我們選擇將這 2 個參數表示為 Taipy 資料節點。
請注意,您的用例可能有所不同,您可以(並且應該!)根據您的需求修改任務、函數和關聯的資料節點。
例如,您可以:
-
有一個 Spark 任務,執行一些例行 ETL 並且不回傳任何內容;
-
偏好對輸入和輸出路徑進行硬編碼,而不是將它們持久化為資料節點;或者
-
將其他應用程式參數儲存為資料節點並將其傳遞給 Spark 應用程式。
然後,我們將 spark-submit 作為 Python 子進程執行,如下所示:
subprocess.Popen(
[
str(Path(sys.executable).with_name("spark-submit")),
str(SPARK_APP_PATH),
"--input-csv-path",
input_csv_path,
"--output-csv-path",
output_csv_path,
],
)<小時/>
回想一下,清單元素的順序應保留以下格式,就像它們在命令列上執行一樣:
$ spark-submit [spark-arguments] <pyspark-app-path> [application-arguments]<小時/>
同樣,根據我們的用例,我們可以根據需要指定不同的 Spark-submit 腳本路徑、Spark 參數(我們在範例中未提供任何參數)或不同的應用程式參數。
<小時/>
讀取並回傳output_csv_path
請注意,spark_process 函數的結束如下:
def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame:
...
df = pd.read_csv(output_csv_path)
return df<小時/>
在我們的例子中,我們希望 Taipy 任務在 Spark - 處理資料後輸出資料,以便可以將其寫入 processed_penguin_df_cfg [Parquet 資料節點](https://docs.taipy.io/en/latest /手冊/核心/配置/資料節點配置/#parquet)。
我們可以做到這一點的一種方法是手動讀取輸出目標(在本例中為 output_csv_path),然後將其作為 Pandas DataFrame 傳回。
但是,如果您不需要 Spark 應用程式的返回資料,您可以簡單地讓 Taipy 任務(透過 spark_process 函數)返回 None。
<小時/>
快取 Spark 任務
由於我們將 spark_process_task_cfg 配置為 True,當重新執行該場景時,Taipy 將 跳過 spark_process 的重新執行 任務 並重複使用持久化任務輸出: processed_penguin_df_cfg Pandas DataFrame。
但是,我們也為 processed_penguin_df_cfg 資料節點定義了 1 天的 validity_period,因此如果 DataFrame 最後一次快取超過一天,Taipy 仍會重新執行任務。
<小時/>
3. 建構 GUI (main.py)
我們將透過建立我們在本文開頭看到的 GUI 來完成我們的應用程式:
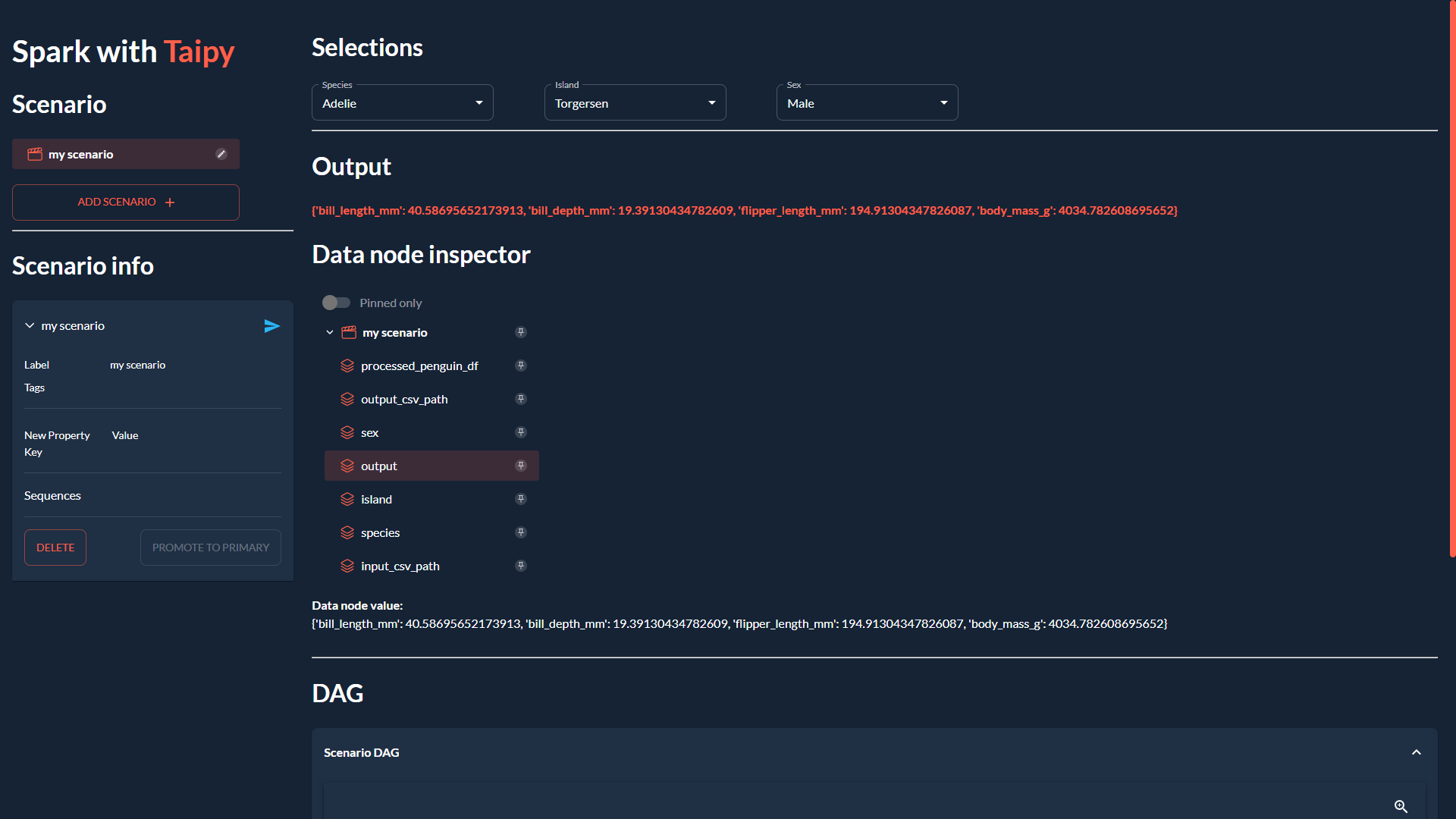
<小時/>
如果您不熟悉 Taipy 的 GUI 功能,可以在此處找到快速入門。
無論如何,您只需為 app/main.py 複製並貼上以下程式碼,因為它不是我們的重點:
### app/main.py
from pathlib import Path
from typing import Optional
import taipy as tp
from config import scenario_cfg
from taipy.gui import Gui, notify
valid_features: dict[str, list[str]] = {
"species": ["Adelie", "Chinstrap", "Gentoo"],
"island": ["Torgersen", "Biscoe", "Dream"],
"sex": ["Male", "Female"],
}
selected_species = valid_features["species"][0]
selected_island = valid_features["island"][0]
selected_sex = valid_features["sex"][0]
selected_scenario: Optional[tp.Scenario] = None
data_dir = Path(__file__).with_name("data")
data_dir.mkdir(exist_ok=True)
def scenario_on_creation(state, id, payload):
_ = payload["config"]
date = payload["date"]
label = payload["label"]
properties = payload["properties"]
# Create scenario with selected configuration
scenario = tp.create_scenario(scenario_cfg, creation_date=date, name=label)
scenario.properties.update(properties)
# Write the selected GUI values to the scenario
scenario.species.write(state.selected_species)
scenario.island.write(state.selected_island)
scenario.sex.write(state.selected_sex.lower())
output_csv_file = data_dir / f"{scenario.id}.csv"
scenario.output_csv_path.write(str(output_csv_file))
notify(state, "S", f"Created {scenario.id}")
return scenario
def scenario_on_submission_change(state, submittable, details):
"""When the selected_scenario's submission status changes, reassign selected_scenario to force a GUI refresh."""
state.selected_scenario = submittable
selected_data_node = None
main_md = """
<|layout|columns=1 4|gap=1.5rem|
<lhs|part|
# Spark with **Taipy**{: .color-primary}
## Scenario
<|{selected_scenario}|scenario_selector|on_creation=scenario_on_creation|>
----------
## Scenario info
<|{selected_scenario}|scenario|on_submission_change=scenario_on_submission_change|>
|lhs>
<rhs|part|render={selected_scenario}|
## Selections
<selections|layout|columns=1 1 1 2|gap=1.5rem|
<|{selected_species}|selector|lov={valid_features["species"]}|dropdown|label=Species|>
<|{selected_island}|selector|lov={valid_features["island"]}|dropdown|label=Island|>
<|{selected_sex}|selector|lov={valid_features["sex"]}|dropdown|label=Sex|>
|selections>
----------
## Output
**<|{str(selected_scenario.output.read()) if selected_scenario and selected_scenario.output.is_ready_for_reading else 'Submit the scenario using the left panel.'}|text|raw|class_name=color-primary|>**
## Data node inspector
<|{selected_data_node}|data_node_selector|display_cycles=False|>
**Data node value:**
<|{str(selected_data_node.read()) if selected_data_node and selected_data_node.is_ready_for_reading else None}|>
<br/>
----------
## DAG
<|Scenario DAG|expandable|
<|{selected_scenario}|scenario_dag|>
|>
|rhs>
|>
"""
def on_change(state, var_name: str, var_value):
if var_name == "selected_species":
state.selected_scenario.species.write(var_value)
elif var_name == "selected_island":
state.selected_scenario.island.write(var_value)
elif var_name == "selected_sex":
state.selected_scenario.sex.write(var_value.lower())
if __name__ == "__main__":
tp.Core().run()
gui = Gui(main_md)
gui.run(title="Spark with Taipy")
<小時/>
然後,從專案資料夾中,您可以執行主腳本,如下所示:
$ taipy run app/main.py<小時/>
結論
現在您已經看到如何將 PySpark 與 Taipy 結合使用的範例,請繼續嘗試使用這兩個工具來增強您自己的資料應用程式!
如果您一直在努力應對其他工作流程編排工具減慢您的工作並妨礙您的工作,請不要讓它阻止您嘗試 Taipy。
Taipy 易於使用,並且努力不限制自己可以使用的第 3 方軟體包 - 其強大而靈活的框架使其可以輕鬆適應任何資料應用程式。
<小時/>

希望您喜歡這篇文章!
<小時/>
您可以在此儲存庫上找到所有程式碼和資料。
原文出處:https://dev.to/taipy/how-to-master-big-data-pipelines-with-taipy-and-pyspark-14oe
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式