最近買了一台 macbook air 使用 m3 晶片 使用 docker 以及 npm 裝套件、裝 image 時,會出現各種警告 x86、x64、amd64、arm64 到底是怎樣? 簡單研究,結論如下: --- - x86 是 32 位元的,因為初始產品線命名都是 86 結尾 - 然後 PC 其它代號都是 64 位元的,包含 x86_64、x64、AMD64 基本上是同一个东西,现在用的intel/amd的桌面级CPU基本上都是x86_64 - 命名搞這麼複雜,是因為 Intel 不愿承认这玩意是AMD设计出来的 - arm 是 arm 公司的省電晶片,大量使用在手機晶片上 - 蘋果 m 晶片算是 arm64 系列,應該是因為蘋果有投資 arm 公司吧 --- https://blog.csdn.net/bruce_van/article/details/129920807 https://www.reddit.com/r/linuxquestions/comments/ra4vjj/difference_between_x86_x8664_amd64_and_x64/ https://nabi.104.com.tw/posts/nabi_post_31d2895e-d197-4341-801e-75ef72e626cc https://www.ithome.com.tw/tech/56880
今天,我們將介紹 30 個或更多可以使用 AI 建置的專案。 所有專案都是開源的,因此您可以做出貢獻以使其變得更好。 有些專案可能擁有龐大的程式碼庫,但您可以從中獲得靈感並建立一個很酷的副專案。 相信我,如果這個清單沒有讓你感到驚訝,那麼沒有什麼會讓你感到驚訝:) 讓我們開始吧!  --- 1. [CopilotKit](https://go.copilotkit.ai/Anmol) - 在數小時內為您的產品提供 AI Copilot。 -------------------------------------------------------------------------- [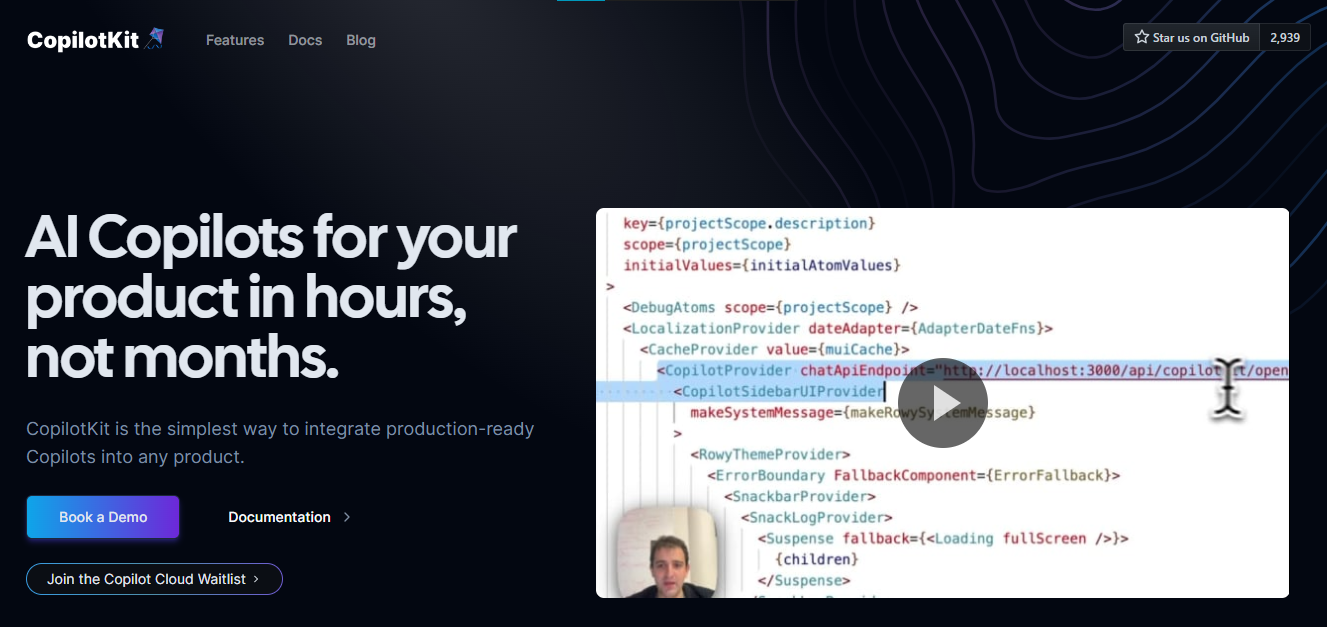](https://github.com/CopilotKit/CopilotKit) 將 AI 功能整合到 React 中是很困難的,這就是 Copilot 的用武之地。一個簡單快速的解決方案,可將可投入生產的 Copilot 整合到任何產品中! 您可以使用兩個 React 元件將關鍵 AI 功能整合到 React 應用程式中。它們還提供內建(完全可自訂)Copilot 原生 UX 元件,例如`<CopilotKit />` 、 `<CopilotPopup />` 、 `<CopilotSidebar />` 、 `<CopilotTextarea />` 。 開始使用以下 npm 指令。 ``` npm i @copilotkit/react-core @copilotkit/react-ui ``` Copilot Portal 是 CopilotKit 提供的元件之一,CopilotKit 是一個應用程式內人工智慧聊天機器人,可查看目前應用狀態並在應用程式內採取操作。它透過插件與應用程式前端和後端以及第三方服務進行通訊。 這就是整合聊天機器人的方法。 `CopilotKit`必須包裝與 CopilotKit 互動的所有元件。建議您也開始使用`CopilotSidebar` (您可以稍後切換到不同的 UI 提供者)。 ``` "use client"; import { CopilotKit } from "@copilotkit/react-core"; import { CopilotSidebar } from "@copilotkit/react-ui"; import "@copilotkit/react-ui/styles.css"; export default function RootLayout({children}) { return ( <CopilotKit url="/path_to_copilotkit_endpoint/see_below"> <CopilotSidebar> {children} </CopilotSidebar> </CopilotKit> ); } ``` 您可以使用此[快速入門指南](https://docs.copilotkit.ai/getting-started/quickstart-backend)設定 Copilot 後端端點。 之後,您可以讓 Copilot 採取行動。您可以閱讀如何提供[外部上下文](https://docs.copilotkit.ai/getting-started/quickstart-chatbot#provide-context)。您可以使用`useMakeCopilotReadable`和`useMakeCopilotDocumentReadable`反應掛鉤來執行此操作。 ``` "use client"; import { useMakeCopilotActionable } from '@copilotkit/react-core'; // Let the copilot take action on behalf of the user. useMakeCopilotActionable( { name: "setEmployeesAsSelected", // no spaces allowed in the function name description: "Set the given employees as 'selected'", argumentAnnotations: [ { name: "employeeIds", type: "array", items: { type: "string" } description: "The IDs of employees to set as selected", required: true } ], implementation: async (employeeIds) => setEmployeesAsSelected(employeeIds), }, [] ); ``` 您可以閱讀[文件](https://docs.copilotkit.ai/getting-started/quickstart-textarea)並查看[演示影片](https://github.com/CopilotKit/CopilotKit?tab=readme-ov-file#demo)。 您可以輕鬆整合 Vercel AI SDK、OpenAI API、Langchain 和其他 LLM 供應商。您可以按照本[指南](https://docs.copilotkit.ai/getting-started/quickstart-chatbot)將聊天機器人整合到您的應用程式中。 基本概念是在幾分鐘內建立可用於基於 LLM 的應用程式的 AI 聊天機器人。 用例是巨大的,作為開發人員,我們絕對應該在下一個專案中嘗試使用 CopilotKit。 CopilotKit 在 GitHub 上擁有超過 5700 顆星,發布了 200 多個版本,這意味著它們不斷改進。 https://go.copilotkit.ai/Anmol Star CopilotKit ⭐️ --- 2. [AgentGPT](https://github.com/reworkd/AgentGPT) - 組裝、配置和部署自主 AI 代理程式。 ------------------------------------------------------------------------  AgentGPT 可讓您設定和部署自主 AI 代理程式。 它將嘗試透過思考要完成的任務、執行任務並從結果中學習來實現目標:) 它是使用以下方式建構的: - 引導:create-t3-app + FastAPI-模板。 - 框架:Nextjs 13 + Typescript + FastAPI - 驗證:Next-Auth.js - ORM:Prisma 和 SQLModel。 - 資料庫:Planetscale。 - 樣式:TailwindCSS + HeadlessUI。 - 架構驗證:Zod + Pydantic。 - 法學碩士工具:Langchain。 開始使用本[指南](https://github.com/reworkd/AgentGPT?tab=readme-ov-file#getting-started-rocket)在本地安裝它。 您可以查看該應用程式的[演示](https://github.com/reworkd/AgentGPT?tab=readme-ov-file#-demo)並查看[即時網站](https://agentgpt.reworkd.ai/)。 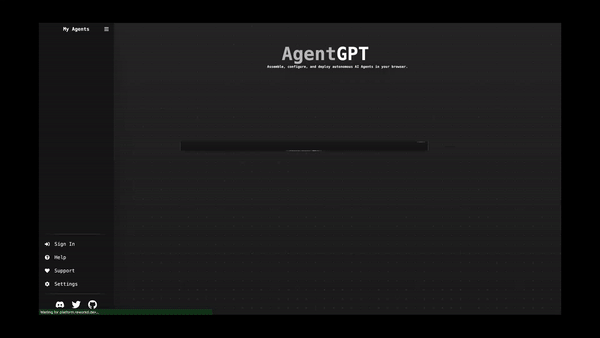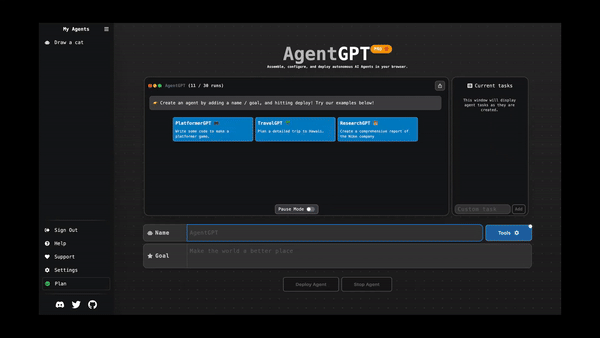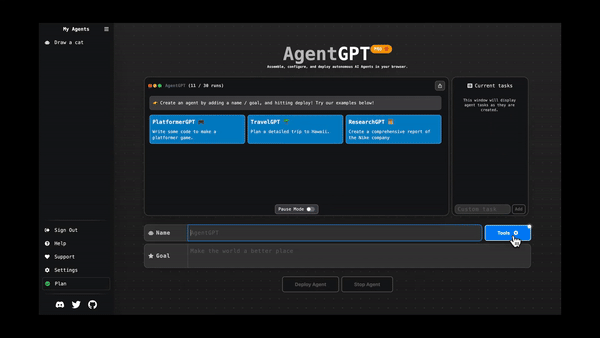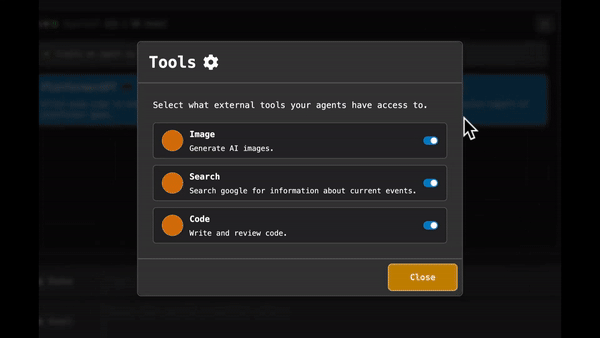 他們在 GitHub 上擁有 29k+ 顆星,並且正在發布`v1`版本。 https://github.com/reworkd/AgentGPT 明星 AgentGPT ⭐️ --- 3.[私人 GPT](https://github.com/zylon-ai/private-gpt) - 無需網路即可詢問有關您文件的問題。 ------------------------------------------------------------------------ 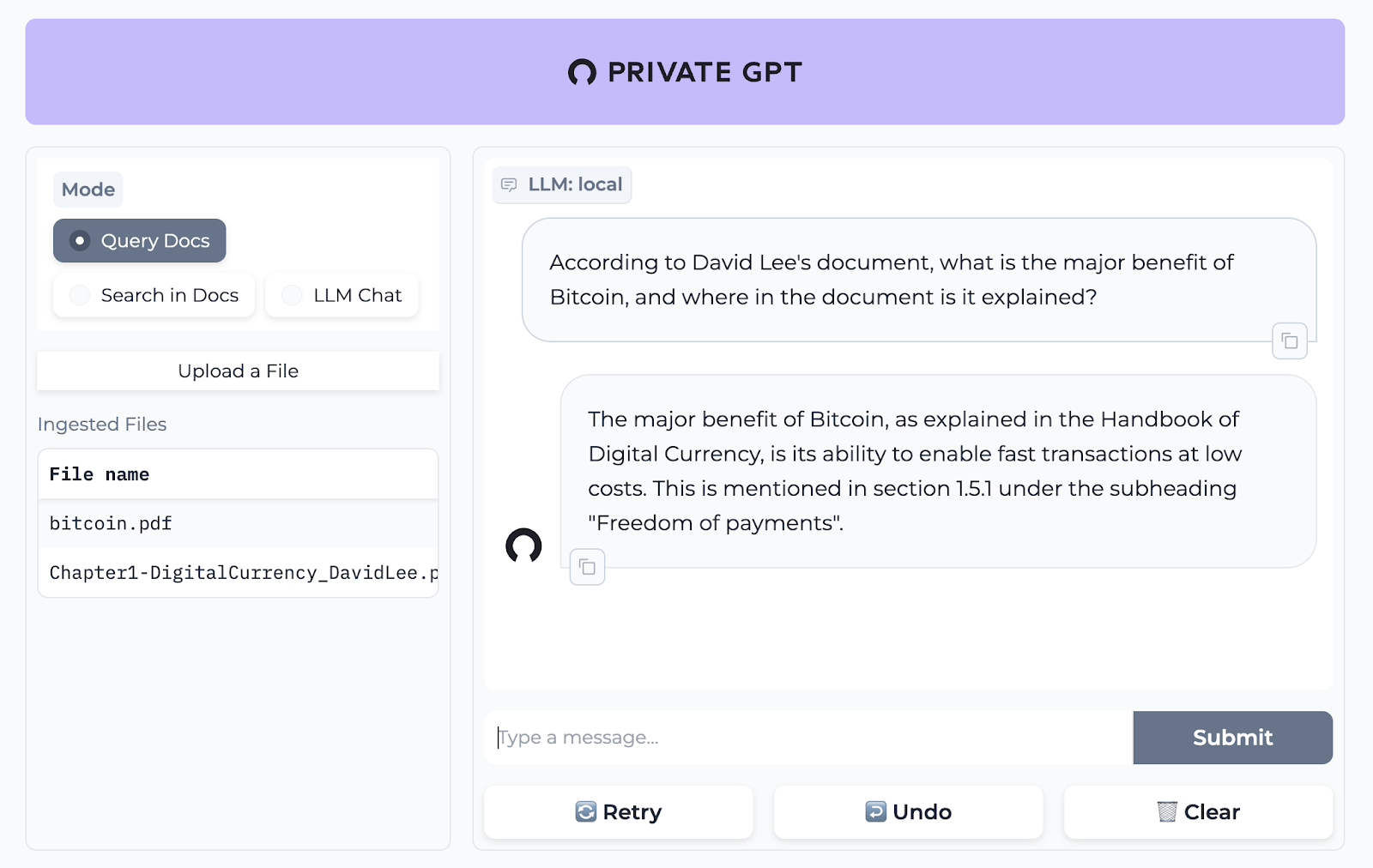 PrivateGPT 是一個可立即投入生產的 AI 專案,即使在沒有網路連線的情況下,您也可以使用大型語言模型 (LLM) 的功能來詢問有關文件的問題。 100% 私有意味著任何時候都沒有資料離開您的執行環境。 API 分為兩個邏輯區塊: A。高級 API,抽象化了 RAG(檢索增強生成)管道實現的所有複雜性: - 文件攝取:內部管理文件解析、分割、元資料擷取、嵌入產生和儲存。 - 使用所攝取文件中的上下文進行聊天和完成:抽像上下文檢索、提示工程和回應產生。 b.低階 API,允許高階用戶實現複雜的管道: - 嵌入生成:基於一段文字。 - 上下文區塊檢索:給定查詢,從攝取的文件中傳回最相關的文字區塊。 您可以閱讀[安裝指南](https://docs.privategpt.dev/installation/getting-started/installation)來開始。 您可以閱讀[文件](https://docs.privategpt.dev/overview/welcome/introduction)以及所涉及的[詳細架構](https://github.com/zylon-ai/private-gpt?tab=readme-ov-file#-architecture)。 PrivateGPT 現在正在發展成為產生 AI 模型和原語的網關,包括補全、文件攝取、RAG 管道和其他低階建置塊。 他們在 GitHub 上擁有超過 51,000 顆星,並且發展迅速。 https://github.com/zylon-ai/private-gpt 明星私人 GPT ⭐️ --- 4. [Instrukt](https://github.com/blob42/Instrukt) - 終端機中整合人工智慧。 --------------------------------------------------------------- 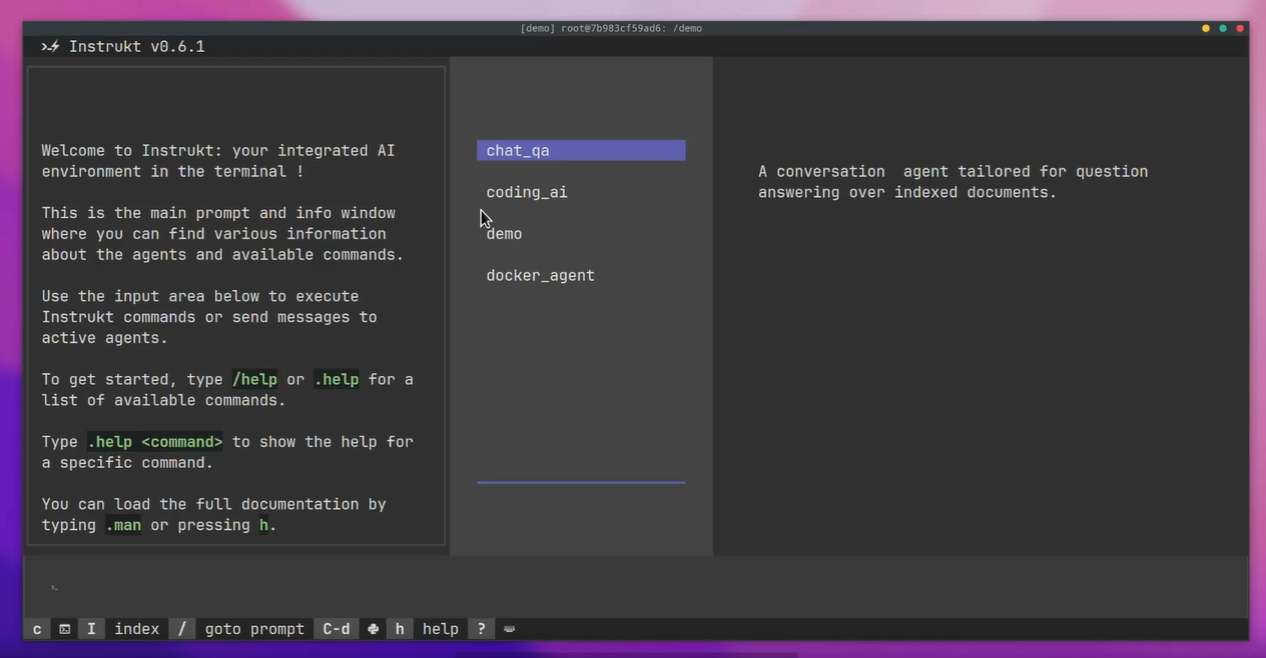 Instrukt是一個基於終端的AI整合環境。它提供了一個平台,用戶可以: - 建立並指導模組化人工智慧代理。 - 產生問答的文件索引。 - 建立工具並將其附加到任何代理程式。 用自然語言指導它們,並且為了安全起見,在安全容器(目前使用 Docker 實作)中執行它們,以在其專用的沙盒空間中執行任務。 使用`Langchain` 、 `Textual`和`Chroma`建構。 開始使用以下命令。 ``` pip install instrukt[all] ``` 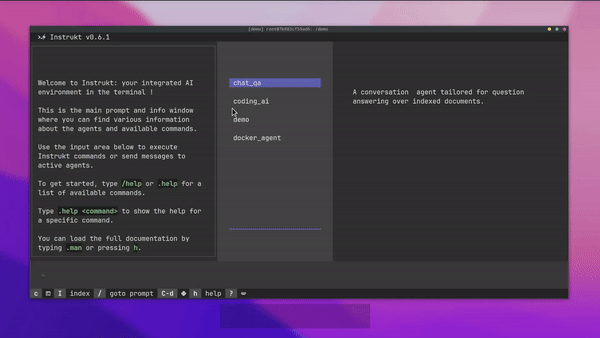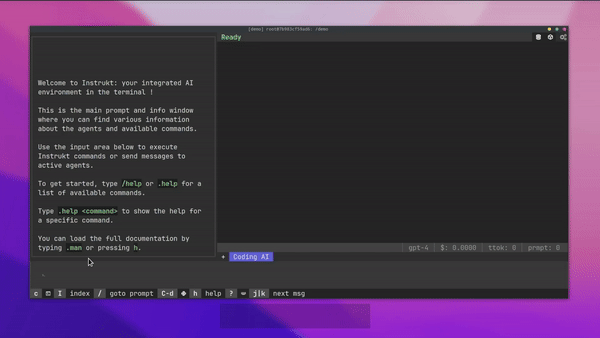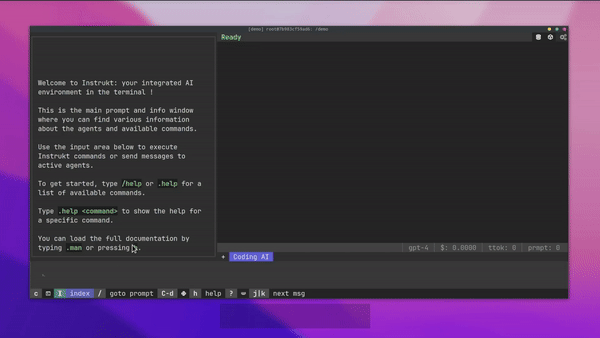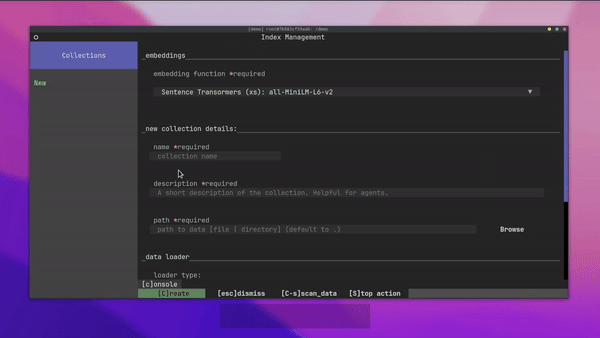 有許多令人興奮的功能,例如: - 基於終端的介面,讓強力鍵盤使用者無需離開鍵盤即可指示 AI 代理。 - 對您的資料建立索引並讓代理程式檢索它以進行問答。您可以使用簡單的 UI 建立和組織索引。 - 索引建立將自動偵測程式語言並相應地優化拆分/分塊策略。 - 在安全的 Docker 容器內執行代理程式以確保安全和隱私。 - 整合的 REPL-Prompt 可實現與代理程式的快速交互,以及用於開發和測試的快速回饋循環。 - 您可以使用自訂命令自動執行重複任務。它還具有內建的提示/聊天歷史記錄。 您可以閱讀有關所有[功能的](https://github.com/blob42/Instrukt?tab=readme-ov-file#features)資訊。 您可以閱讀[安裝指南](https://blob42.github.io/Instrukt/install.html)。 您還可以使用內建的 IPython 控制台來除錯和內省代理,這是一個簡潔的小功能。 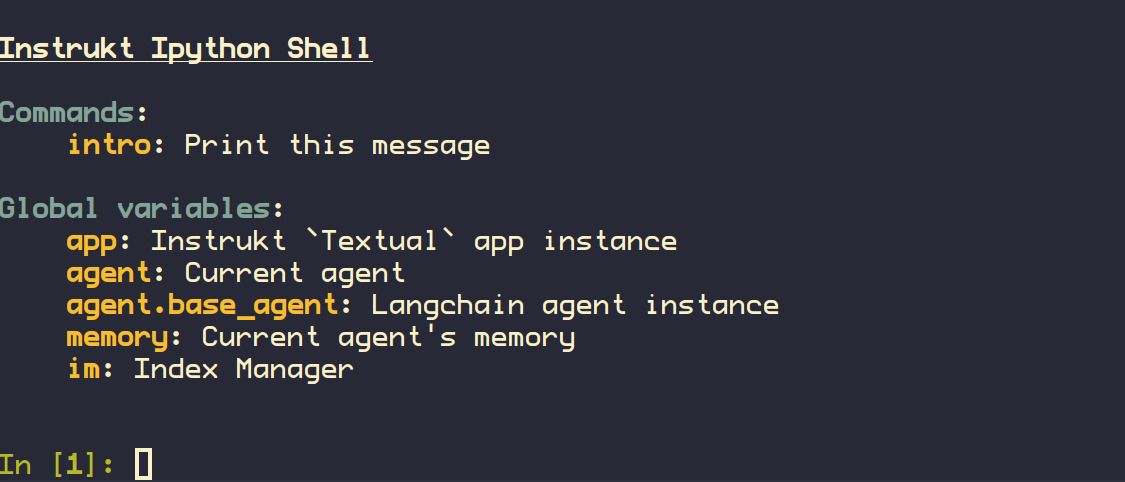 Instrukt 已獲得 AGPL 許可證,這意味著任何人都可以將其用於任何目的。 可以肯定地說,Instrukt 是您觸手可及的終端人工智慧指揮官。 這是一個新專案,因此他們在 GitHub 上有大約 200 多顆星,但用例非常好。 https://github.com/blob42/Instrukt 舊指令 ⭐️ --- 5. [Mac 上的語音助理](https://github.com/chidiwilliams/GPT-Automator)- 您的語音控制 Mac 助理。 ------------------------------------------------------------------------------- 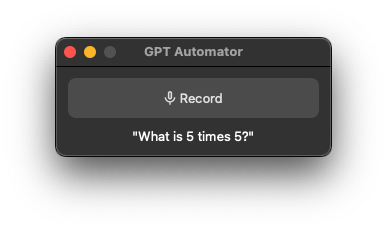 您的語音控制 Mac 助理。 GPT Automator 可讓您使用語音在 Mac 上執行任務。例如,打開應用程式、尋找餐廳、綜合資訊。太棒了:D 它是在倫敦黑客馬拉松期間建構的。 它有兩個主要部分: A。語音命令:它使用本地執行的 Whisper(Buzz 的一個分支)來產生命令。 b.命令到行動:您向配備了我們編寫的自訂工具的 LangChain 代理程式發出命令。這些工具包括使用 AppleScript 控制電腦的作業系統以及使用 JavaScript 控制活動瀏覽器。最後,就像任何優秀的人工智慧一樣,我們讓代理商使用 AppleScript 說出最終結果「{Result}」(如果您以前沒有使用過,請嘗試在 Mac 終端機中輸入「Hello World!」)。 我們製作了一個自訂工具,讓法學碩士使用 AppleScript 控制電腦。提示符是文件字串: ``` @tool def computer_applescript_action(apple_script): """ Use this when you want to execute a command on the computer. The command should be in AppleScript. Here are some examples of good AppleScript commands: Command: Create a new page in Notion AppleScript: tell application "Notion" activate delay 0.5 tell application "System Events" to keystroke "n" using {{command down}} end tell ... Write the AppleScript for the Command: Command: """ p = subprocess.Popen(['osascript', '-'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) stdout, stderr = p.communicate(applescript.encode('utf-8')) if p.returncode != 0: raise Exception(stderr) decoded_text = stdout.decode("utf-8") return decoded_text ``` 如果您想知道它是如何運作的,GPT Automator 使用 OpenAI 的 Whisper 將您的音訊輸入轉換為文字。然後,它使用LangChain Agent 選擇一組操作,包括使用OpenAI 的GPT-3(“text-davinci-003”)從提示符號產生AppleScript(用於桌面自動化)和JavaScript(用於瀏覽器自動化)命令,然後執行產生的腳本。 請記住,這不適用於生產用途。該專案執行從自然語言產生的程式碼,可能容易受到提示注入和類似的攻擊。這項工作是作為概念驗證而進行的。 您可以閱讀[安裝指南](https://github.com/chidiwilliams/GPT-Automator?tab=readme-ov-file#instructions)。 讓我們看看一些提示及其作用: ✅ 求計算結果。 > 提示:“2 + 2 是什麼?” 它將編寫 AppleScript 開啟計算器並輸入 5 \* 5。 ✅ 尋找附近的餐廳。 > 提示:“查找我附近的餐廳” 它將打開 Chrome,谷歌搜尋附近的餐廳,解析頁面,然後返回最上面的結果。有時它很厚顏無恥,反而會打開谷歌地圖結果並說「最好的餐廳是谷歌地圖頁面頂部的餐廳」。其他時候,它會打開 Google 上的頂部連結 - 並卡在 Google 可存取性頁面上... 以下是執行時列印到終端的內容: ``` Command: Find a great restaurant near Manchester. > Entering new AgentExecutor chain... I need to search for a restaurant near Manchester. Action: chrome_open_url Action Input: https://www.google.com/search?q=restaurant+near+Manchester Observation: Thought: I need to read the page Action: chrome_read_the_page Action Input: Observation: Accessibility links Skip to main content ... # Shortned for brevity Dishoom Manchester 4.7 (3.3K) · £££ · Indian 32 Bridge St · Near John Rylands Library Closes soon ⋅ 11 pm Stylish eatery for modern Indian fare San Carlo 4.2 (2.8K) · £££ · Italian 42 King St W · Near John Rylands Library Closes soon ⋅ 11 pm Posh, sceney Italian restaurant Turtle Bay Manchester Northern Quarter 4.7 Thought: I now know the final answer Final Answer: The 15 best restaurants in Manchester include El Gato Negro, Albert's Schloss, The Refuge, Hawksmoor, On The Hush, Dishoom, Banyan, Zouk Tea Room & Grill, Edison Bar, MyLahore Manchester, Turtle Bay Manchester Northern Quarter, San Carlo, The Black Friar, Mana, and Tast Cuina Catalana. ``` 我不能保證這些餐廳值得,請自行承擔風險。哈哈! ✅ 如果您要求 GPT Automator 擦除您的計算機,它會的。 是的,如果您要求的話,它會擦除您的電腦! 我內心的自我尖叫著要這麼做:) 您可以在這裡查看完整的演示! https://www.loom.com/share/7bfa82c604f3412fbbb04191ce2ae12f 您可以在[Chidi 的部落格](https://chidiwilliams.com/posts/gpt-automator)上閱讀更多內容。 它更像是一個業餘專案,因此他們在 GitHub 上有大約 200 個 star,但它非常酷。 https://github.com/chidiwilliams/GPT-Automator 明星 GPT Automator ⭐️ --- 6. [Flowise](https://github.com/FlowiseAI/Flowise) - 拖放 UI 來建立您的客製化 LLM 流程。 --------------------------------------------------------------------------- 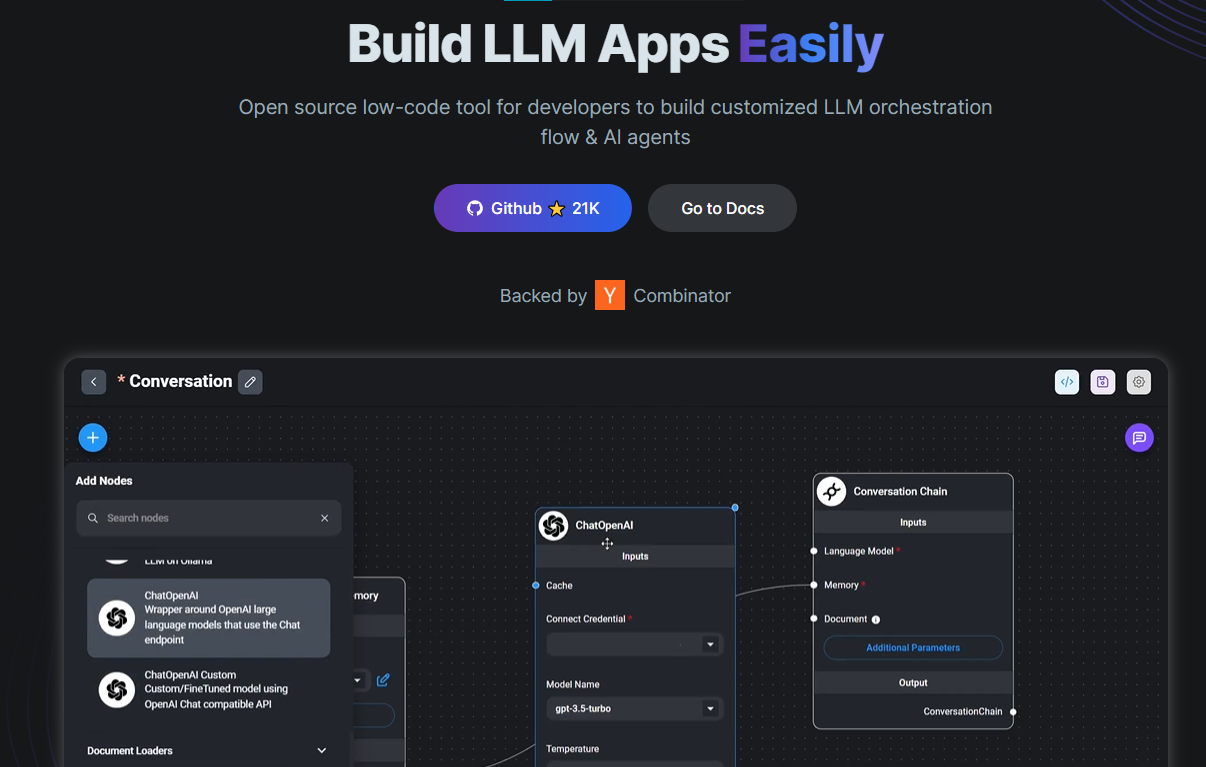 Flowise 是一款開源 UI 視覺化工具,用於建立客製化的 LLM 編排流程和 AI 代理程式。 開始使用以下 npm 指令。 ``` npm install -g flowise npx flowise start OR npx flowise start --FLOWISE_USERNAME=user --FLOWISE_PASSWORD=1234 ``` 這就是整合 API 的方式。 ``` import requests url = "/api/v1/prediction/:id" def query(payload): response = requests.post( url, json = payload ) return response.json() output = query({ question: "hello!" )} ```  您可以閱讀[文件](https://docs.flowiseai.com/)。  雲端主機不可用,因此您必須使用這些[說明](https://github.com/FlowiseAI/Flowise?tab=readme-ov-file#-self-host)自行託管。 讓我們探討一些用例: - 假設您有一個網站(可以是商店、電子商務網站或部落格),並且您希望廢棄該網站的所有相關連結,並讓法學碩士回答您網站上的任何問題。您可以按照此[逐步教學](https://docs.flowiseai.com/use-cases/web-scrape-qna)來了解如何實現相同的目標。  - 您還可以建立一個自訂工具,該工具將能夠呼叫 Webhook 端點並將必要的參數傳遞到 Webhook 主體中。請依照本[指南](https://docs.flowiseai.com/use-cases/webhook-tool)使用 Make.com 建立 Webhook 工作流程。  還有許多其他用例,例如建立 SQL QnA 或與 API 互動。 FlowiseAI 在 GitHub 上擁有超過 27,500 個 Star,並擁有超過 10,000 個分叉,因此具有良好的整體比率。 https://github.com/FlowiseAI/Flowise 明星 Flowise ⭐️ --- 7. [Twitter Agent](https://github.com/ahmedbesbes/media-agent) - 從社群媒體抓取資料並使用 Langchain 與其聊天。 ---------------------------------------------------------------------------------------------  Media Agent 抓取 Twitter 和 Reddit 提交的內容,對其進行總結,並在互動式終端中與它們聊天。這麼酷的概念! 您可以閱讀[說明](https://github.com/ahmedbesbes/media-agent?tab=readme-ov-file#run-the-app-locally)以在本地安裝它。 它是使用以下方式建構的: - Langchain 🦜 用於建構和撰寫法學碩士。 - ChromaDB 用於儲存向量(也稱為嵌入)並查詢它們以建立對話機器人。 - Tweepy 連接到您的 Twitter API 並提取推文和元資料。 - Praw 連接到 Reddit API。 - Rich 建造了一個很酷的終端 UX/UI。 - 管理依賴關係的詩。 一些很棒的功能: - 代表您從使用者帳戶清單或關鍵字清單中抓取推文/提交內容。 - 使用 OpenAI 嵌入推文/提交內容。 - 建立推文/提交內容的摘要並提供需要回答的潛在問題。 - 在推文之上打開聊天會話。 - 儲存對話及其元資料。 - 豐富的終端使用者介面和日誌記錄功能。 您可以觀看演示! https://www.loom.com/share/f4954e7d34ef4b7b8491e2bf910e8521 它在 GitHub 上有近 100 顆星,並且不再維護。您可以用它來建造更好的東西。 https://github.com/ahmedbesbes/media-agent 明星 Twitter 代理商 ⭐️ --- 8. [GPT 遷移](https://github.com/joshpxyne/gpt-migrate)- 輕鬆將程式碼庫從一種框架或語言遷移到另一種框架或語言。 ----------------------------------------------------------------------------------  如果您曾經面臨將程式碼庫遷移到新框架或語言的痛苦,那麼這個專案適合您。 我想我們都同意我們在某個時候需要這個。您也可以使用工作流程來完成此操作,據我所知,Stripe 曾經將其整個 JS 程式碼庫轉換為 TS。 遷移是一個成本高、乏味且重要的問題。 不要盲目相信當前版本,請負責任地使用它。另請注意,成本可能會迅速增加,因為 GPT-Migrate 旨在編寫(並可能重寫)整個程式碼庫。 您可以使用 Poetry[安裝](https://github.com/joshpxyne/gpt-migrate?tab=readme-ov-file#-installation-using-poetry)它並了解[它的工作原理](https://github.com/joshpxyne/gpt-migrate?tab=readme-ov-file#-how-it-works)。 > 請注意。 GPT-Migrate 目前處於開發 alpha 階段,尚未準備好投入生產使用。例如,在相對簡單的基準測試中,它在約 50% 的時間內順利通過 Python 或 JavaScript 等「簡單」語言,並且在沒有人工幫助的情況下無法通過 C++ 或 Rust 等更複雜的語言。 您可以在這裡觀看演示!  他們在 GitHub 上有 6500+ 顆星,最後一次提交是 6 個月前,所以我認為它不再被維護了! https://github.com/joshpxyne/gpt-migrate 明星 GPT 遷移 ⭐️ --- 9. [Plandex](https://github.com/plandex-ai/plandex) - 用於使用法學碩士建置複雜的真實世界軟體的人工智慧編碼引擎。 -----------------------------------------------------------------------------------  Plandex 使用長時間執行的代理程式來完成跨多個檔案且需要多個步驟的任務。它將大任務分解為更小的子任務,然後實現每個子任務,一直持續到完成工作為止。 它可以幫助您處理積壓的工作,使用不熟悉的技術,擺脫困境,並花更少的時間在無聊的事情上。 您可以在這裡查看演示! https://vimeo.com/926634577 變更會累積在受保護的沙箱中,以便您可以在自動將它們套用到專案文件之前查看它們。內建版本控制可讓您輕鬆返回並嘗試不同的方法。分支允許您嘗試多種方法並比較結果。 您可以在終端機中有效地管理上下文。輕鬆將檔案或整個目錄新增至上下文中,並在工作時自動更新它們,以便模型始終具有專案的最新狀態。 Plandex 依賴 OpenAI API,並且需要`OPENAI_API_KEY`環境變數。 Plandex 支援 Mac、Linux、FreeBSD 和 Windows。它從沒有依賴關係的單一二進位檔案執行。 您甚至可以嘗試不同的模型和模型設置,然後比較結果。 您可以閱讀[安裝說明](https://github.com/plandex-ai/plandex?tab=readme-ov-file#install)。 Plandex Cloud 是使用 Plandex 最簡單、最可靠的方式。當您使用 plandex new 建立第一個計劃時,系統會提示您開始匿名試用(無需電子郵件)。試用帳戶僅限 10 個計劃,每個計劃有 10 個 AI 模型回复。 Plandex Cloud 帳戶目前是免費的,這是一件好事。 Plandex 在 GitHub 上擁有 8k+ 顆星,並使用 Go 建造。 https://github.com/plandex-ai/plandex 明星PLandex ⭐️ --- 10. [SQL Translator](https://github.com/whoiskatrin/sql-translator) - 使用人工智慧將自然語言查詢轉換為 SQL 程式碼的工具。 -------------------------------------------------------------------------------------------------- 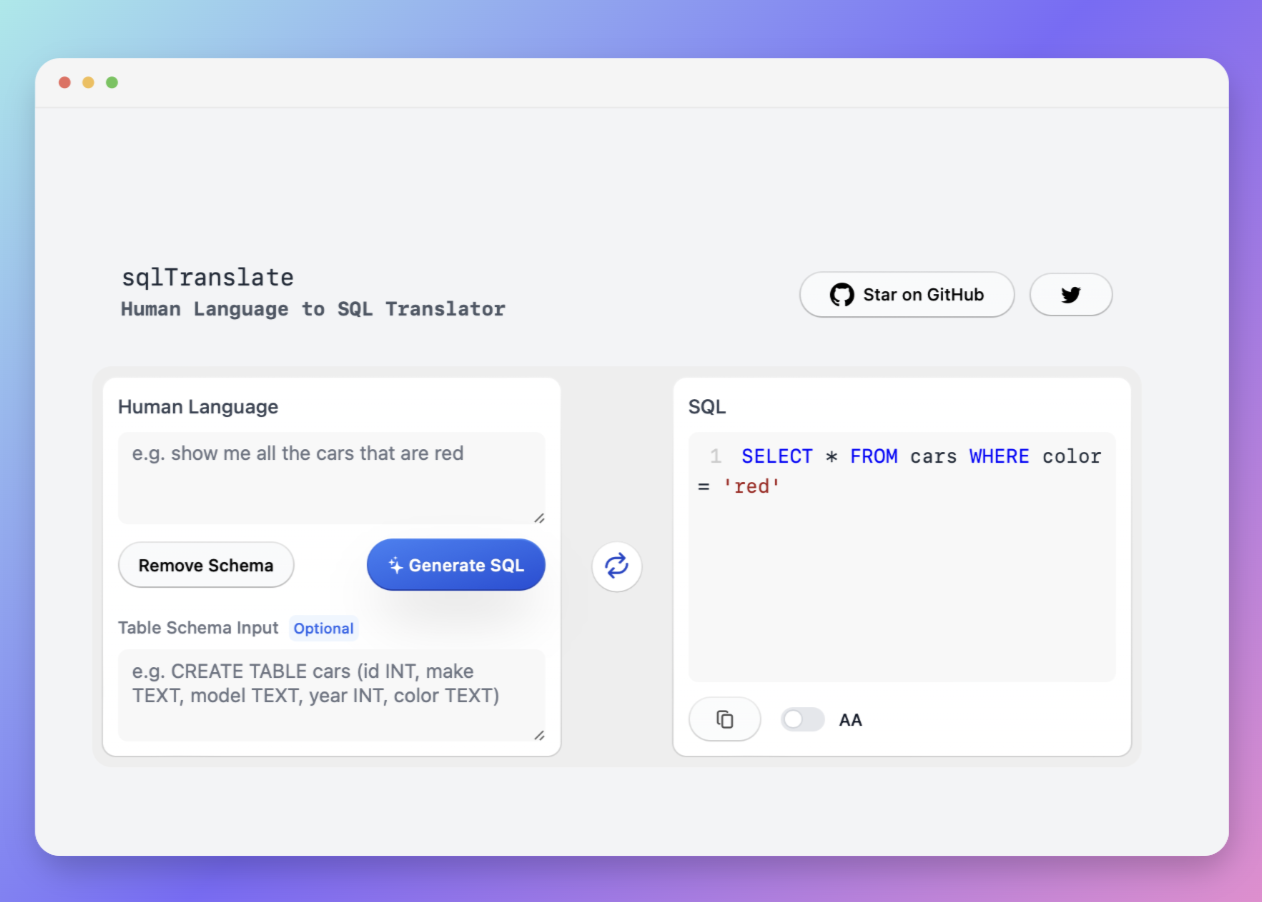 我試圖建立一個類似的專案,發現它已經存在。 該工具旨在讓任何人都可以輕鬆地將 SQL(結構化查詢語言)命令轉換為自然語言,反之亦然。 SQL 是一種用於管理和操作關聯式資料庫中的資料的程式語言,雖然它是一個強大的工具,但它也可能非常複雜且難以理解。 另一方面,自然語言是我們在日常生活中說和寫的語言,對於不熟悉技術術語的人來說,它通常是首選的溝通方式。 透過 SQL 和自然語言翻譯器,您無需成為 SQL 專家即可了解資料庫中發生的情況或編寫 SQL 查詢。您只需用自然語言輸入查詢即可取得對應的 SQL 程式碼,反之亦然。 其中一些功能是: - 深色模式。 - 小寫/大寫切換。 - 複製到剪貼簿。 - SQL 語法高亮。 - 模式意識(測試版)。 - 查詢歷史記錄。 你可以閱讀 [安裝說明](https://github.com/whoiskatrin/sql-translator?tab=readme-ov-file#%EF%B8%8F-installation),它非常簡單,因為它使用 Nextjs。 此查詢適合您。哈哈! 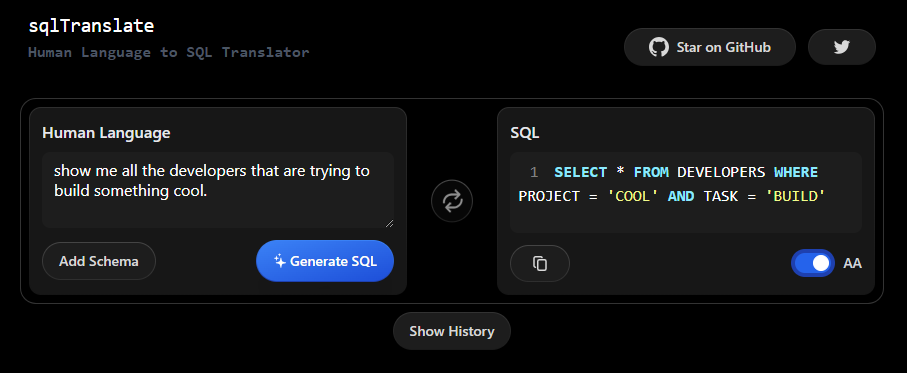 SQL Translator 在 GitHub 上有 4k star,是使用 TypeScript 建構的。 https://github.com/whoiskatrin/sql-translator 明星 SQL 翻譯機 ⭐️ --- 11. [WingmanAI](https://github.com/e-johnstonn/wingmanAI) - 音訊即時轉錄,與 ChatGPT 整合。 --------------------------------------------------------------------------------  WingmanAI 是一款功能強大的工具,可與系統和麥克風音訊的即時轉錄進行互動。該工具由 ChatGPT 提供支援,可讓您與腳本即時交互,作為機器人的廣泛記憶體基礎,提供獨特的通訊平台。 當您載入指定人員的記錄時,機器人可以回答有關過去對話的問題。 您可以閱讀[安裝說明](https://github.com/e-johnstonn/wingmanAI?tab=readme-ov-file#installation)。 您可以在這裡觀看演示!  一些簡潔的功能是: - WingmanAI 可以轉錄系統輸出和麥克風輸入音頻,讓您以易於閱讀的格式查看即時轉錄。 - 您可以與 ChatGPT 支援的機器人聊天,該機器人會即時讀取您的文字記錄。 - 機器人以令牌有效的方式維護對話記錄,因為只有當前的文字區塊會傳遞給機器人。 - WingmanAI 讓您可以保存成績單以供將來使用。您可以稍後隨時加載它們,並且對機器人進行的任何查詢都將與保存的轉錄本的向量資料庫交叉引用,從而為機器人提供更豐富的上下文。 - 您可以繼續附加到已儲存的記錄中,隨著時間的推移建立一個龐大的資料庫供機器人從中提取。 它在 GitHub 上有 420 個星,並且不再維護。 https://github.com/e-johnstonn/wingmanAI 明星 WingmanAI ⭐️ --- 12. [Lively](https://github.com/rocksdanister/lively) - 允許使用者設定動畫桌面桌布和螢幕保護程式。 -----------------------------------------------------------------------------  這只是為了好玩,我們可以使用程式碼學到很多關於它是如何完成的。 你可以看看這個[影片](https://www.pexels.com/video/blue-texture-abstract-leaves-7710243/),看看它看起來有多瘋狂。  他們提供[三種類型的壁紙,](https://github.com/rocksdanister/lively?tab=readme-ov-file#types-of-wallpapers)包括影片/GIF、網頁和應用程式/遊戲。 它基於 C# 和 live 支援的一些很酷的功能建置: 1. Lively 可以透過終端機的[命令列參數](https://github.com/rocksdanister/lively/wiki/Command-Line-Controls)進行控制。您可以將其與其他語言(例如 Python 或腳本軟體 AutoHotKey)整合。 2. 一組強大的[API](https://github.com/rocksdanister/lively/wiki/API) ,供開發人員建立互動式壁紙。取得硬體讀數、音訊圖表、音樂資訊等。 3. 當電腦上執行全螢幕應用程式/遊戲時(~0% CPU、GPU 使用率),桌布播放會暫停。 4. 您還可以利用[機器學習推理](https://github.com/rocksdanister/lively/wiki/Machine-Learning)來建立動態壁紙。您可以預測任何 2D 影像與相機的距離並產生類似 3D 的視差效果。酷:D 我見過很多人使用它,其中許多人甚至不知道它是開源的。 您可以使用[安裝程式](https://github.com/rocksdanister/lively/releases/download/v2.0.7.4/lively_setup_x86_full_v2074.exe)或透過[Microsoft Store](https://www.microsoft.com/store/productId/9NTM2QC6QWS7?ocid=pdpshare)下載它。 它是 2023 年 Microsoft Store 的獲勝者。 它在 GitHub 上擁有 13k+ Stars,有 60 個版本。 https://github.com/rocksdanister/lively 明星活潑 ⭐️ --- 13. [RestGPT](https://github.com/Yifan-Song793/RestGPT) - 基於 LM 的自主代理透過 RESTful API 控制應用程式。 -------------------------------------------------------------------------------------------  這項工作旨在建立一個基於大型語言模型的自主代理 RestGPT,以控制現實世界的應用程式,例如電影資料庫和音樂播放器。為了實現這一目標,我們將法學碩士與 RESTful API 連接起來,並解決規劃、API 呼叫和回應解析的實際挑戰。為了全面評估 RestGPT 的效能,我們提出了 RestBench,這是一個高品質的基準測試,由兩個真實場景和具有黃金解決方案路徑的人工註釋指示組成。 RestGPT採用迭代式從粗到精的線上規劃框架,並使用執行器呼叫RESTful API。以下是 RestGPT 的概述。 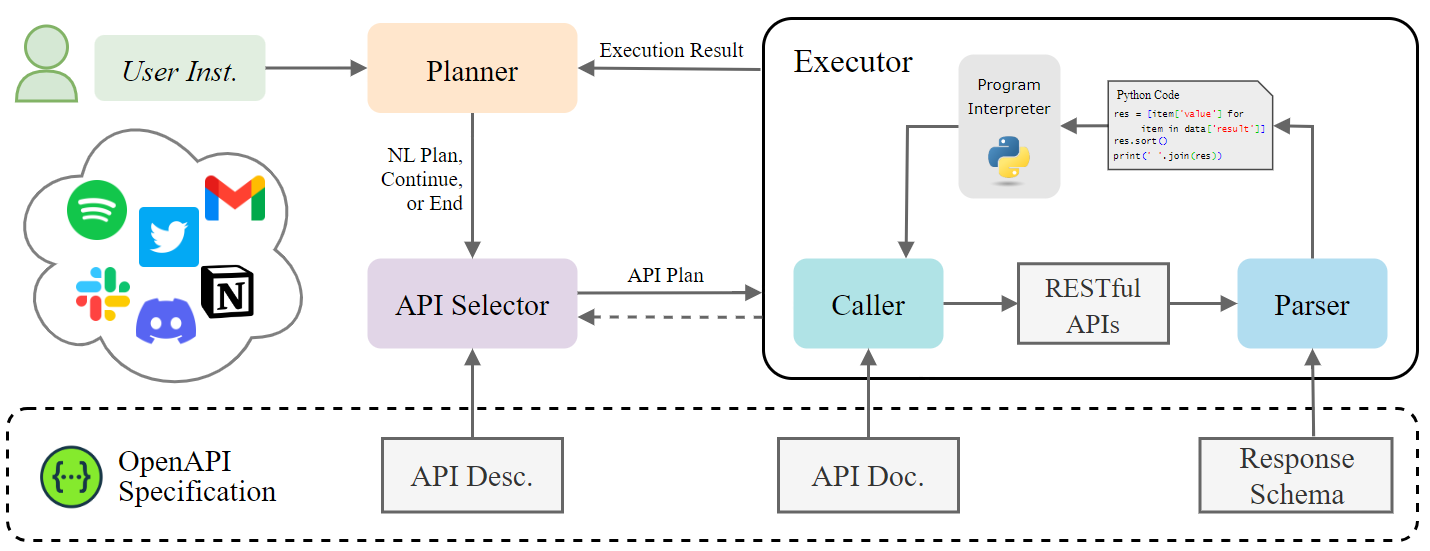 您可以閱讀[文件](https://github.com/Yifan-Song793/RestGPT?tab=readme-ov-file#data)以使用 RestBench 評估 RestGPT 的效能。 使用 TMDB 電影資料庫搜尋 Sofia Coppola 執導的電影數量的範例。  您可以閱讀康乃爾大學發表的程式碼研究論文: [RestGPT - Connecting Large Language Models with Real-World RESTful APIs](https://arxiv.org/abs/2306.06624) 。 他們在 GitHub 上有 1.2k Stars,雖然不是很大,但涵蓋了一個很好的用例。 https://github.com/Yifan-Song793/RestGPT 明星 RestGPT ⭐️ --- 14. [ChatFiles](https://github.com/guangzhengli/ChatFiles) - 上傳您的檔案並與其對話。 -------------------------------------------------------------------------  文件聊天機器人 — 多個文件,由 GPT / Embedding 提供支援。你可以上傳任何文件並與之對話,考慮到他們使用了另一個著名的開源專案,UI 非常好。 它在底層使用 Langchain 和[Chatbot-ui](https://github.com/mckaywrigley/chatbot-ui) 。使用 Nextjs、TypeScript、Tailwind 和 Supabase(向量 DB)建構。 如果您想了解該方法和技術架構,那麼就在這裡! 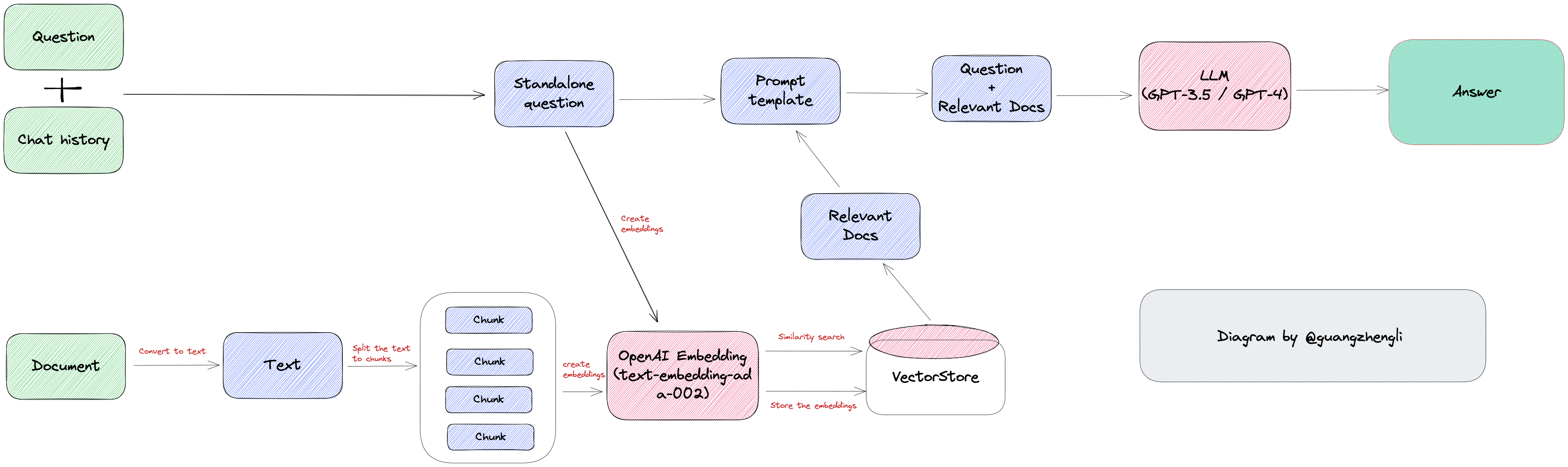 此環境僅用於試用,支援最大檔案大小為 10 MB,這是一個缺點,如果您想要更大的大小,則可以[在本機安裝](https://github.com/guangzhengli/ChatFiles?tab=readme-ov-file#how-to-run-locally)。 他們提供了您可以使用的[入門問題](https://github.com/guangzhengli/ChatFiles/blob/main/doc/Example.md)。您可以查看[現場演示](https://chatfile.vectorhub.org/)。 他們在 GitHub 上有 3k star,並且發布了`v0.3`版本。 https://github.com/guangzhengli/ChatFiles 明星 ChatFiles ⭐️ --- 15. [MindsDB](https://github.com/mindsdb/mindsdb) - 從企業資料客製化人工智慧的平台。 -------------------------------------------------------------------- 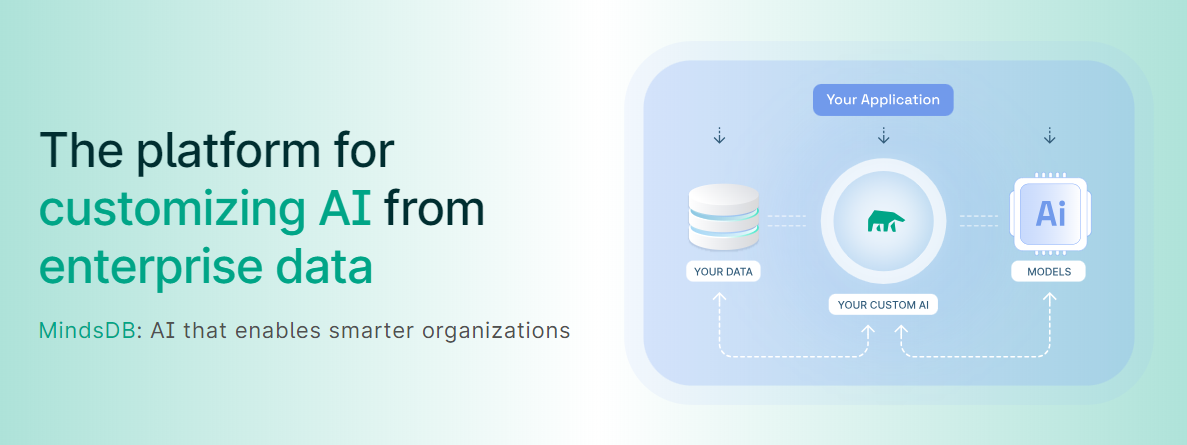 MindsDB 是一個利用企業資料客製化人工智慧的平台。 透過 MindsDB,您可以利用資料庫、向量儲存或應用程式中的資料即時部署、服務和微調模型,以建立人工智慧驅動的應用程式 - 使用開發人員已知的通用工具。 借助 MindsDB 及其與資料來源和 AI/ML 框架的近[200 個集成](https://docs.mindsdb.com/integrations/data-overview),任何開發人員都可以使用其企業資料更快、更安全地自訂符合其目的的 AI。 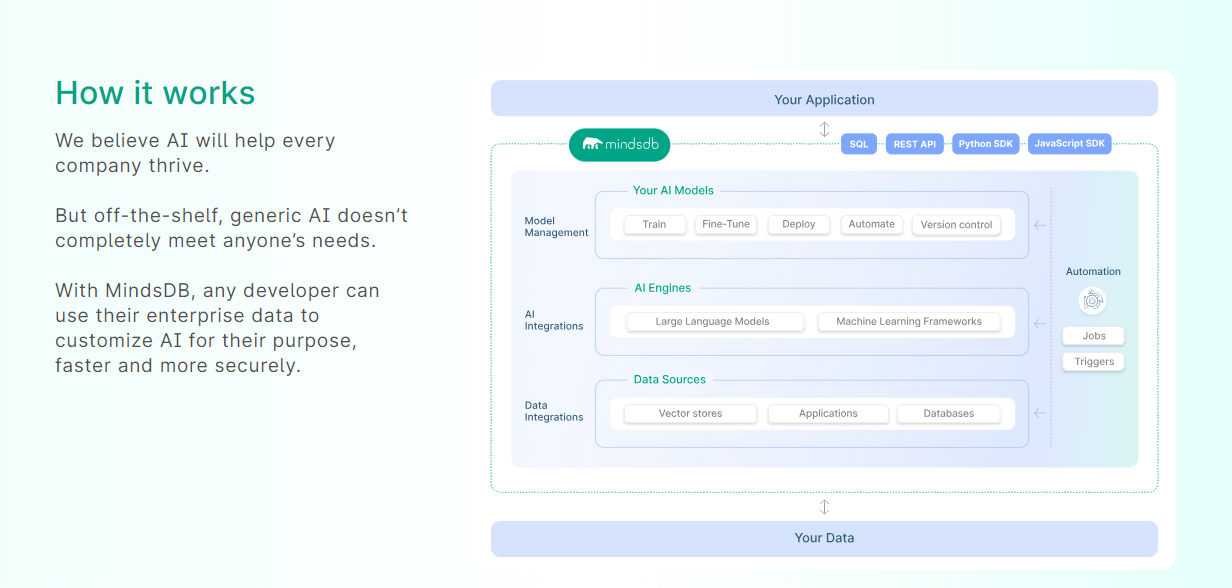 您可以閱讀[文件](https://docs.mindsdb.com/)和[快速入門指南](https://docs.mindsdb.com/quickstart-tutorial)來開始使用。 目前,他們總共支援[3 個使用 Mongo-QL、Python 和 JavaScript 的 SDK](https://docs.mindsdb.com/sdks/overview) 。 MindsDB 有多種應用程式,例如與眾多資料來源和 AI 框架集成,因此您可以輕鬆地將資料和 AI 結合在一起以建立和自動化自訂工作流程。 其他常見用例包括微調模型、聊天機器人、警報系統、內容生成、自然語言處理、分類、回歸和預測。閱讀有關[用例的](https://docs.mindsdb.com/use-cases/)更多訊息,每個用例都有一個包含一些資訊的架構圖。  例如,MindsDB 的聊天機器人架構圖。您可以閱讀提供的所有[解決方案](https://github.com/mindsdb/mindsdb?tab=readme-ov-file#-get-started)及其 SQL 查詢範例。 ``` // SQL Query Example for Chatbot CREATE CHATBOT slack_bot USING database='slack',agent='customer_support'; ``` 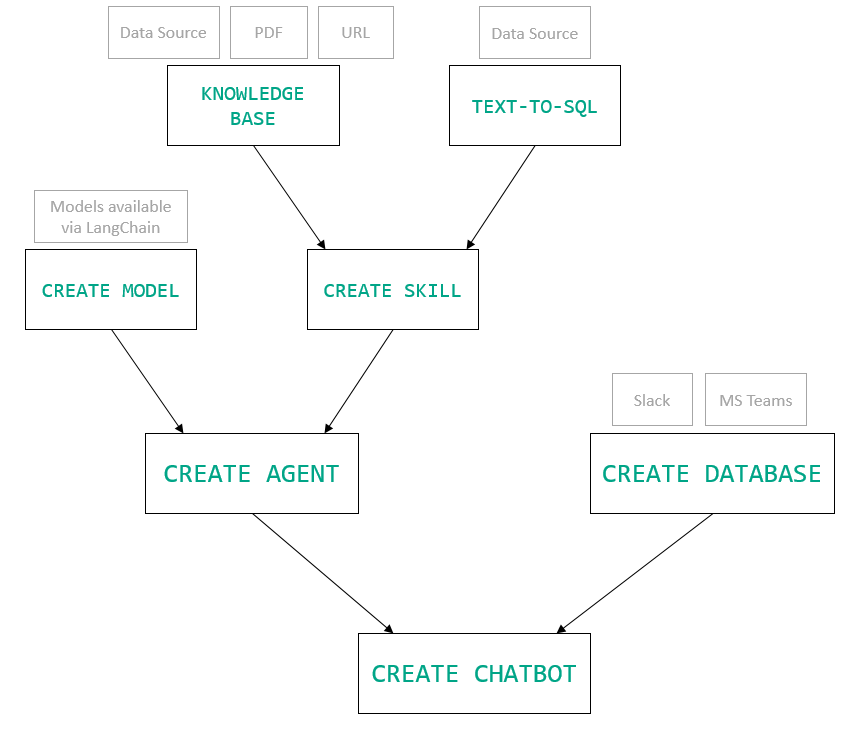 只是為了告訴您總體的可能性,您可以查看[如何使用 AI + IoT 感測器資料預測氣溫](https://mindsdb.com/blog/how-to-forecast-air-temperatures-with-ai-iot-sensor-data)。令人興奮的權利:)  他們在 GitHub 上擁有超過 21k 個 star,並且在`v24.4.3.0`上有超過 200 個版本。順便說一句,這是我第一次在任何版本中看到 4 個部分,因為我一直遵循語義版本。 https://github.com/mindsdb/mindsdb 明星 MindsDB ⭐️ --- 16. [Quivr](https://github.com/QuivrHQ/quivr) - 你的 GenAI 第二腦。 ------------------------------------------------------------- 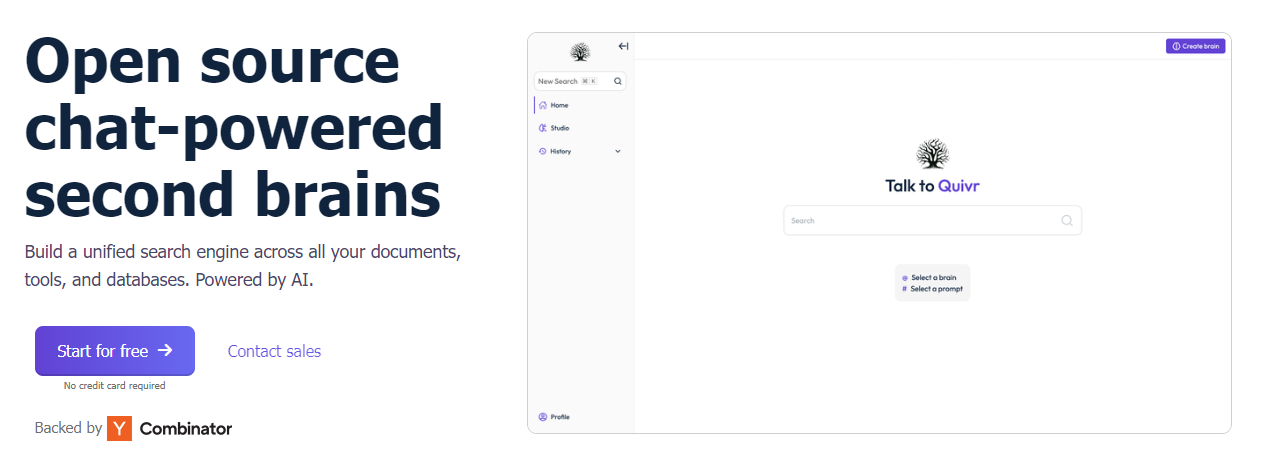 Quivr,您的第二個大腦,利用 GenerativeAI 的力量成為您的私人助理!可以將其視為黑曜石,但增強了人工智慧功能。  您可以閱讀[安裝指南](https://github.com/QuivrHQ/quivr?tab=readme-ov-file#getting-started-)。 您可以閱讀[文件](https://docs.quivr.app/home/intro)並觀看[示範影片](https://github.com/QuivrHQ/quivr?tab=readme-ov-file#demo-highlights-)。 他們可以提供更好的免費套餐,但這足以在您端進行測試。 它在 GitHub 上擁有超過 30k 顆星,發布了 220 多個版本,這意味著它們正在不斷改進。 https://github.com/QuivrHQ/quivr 明星 Quivr ⭐️ --- 17.[動畫繪畫](https://github.com/facebookresearch/AnimatedDrawings)- 一種將兒童人物繪畫動畫化的方法。 --------------------------------------------------------------------------------- 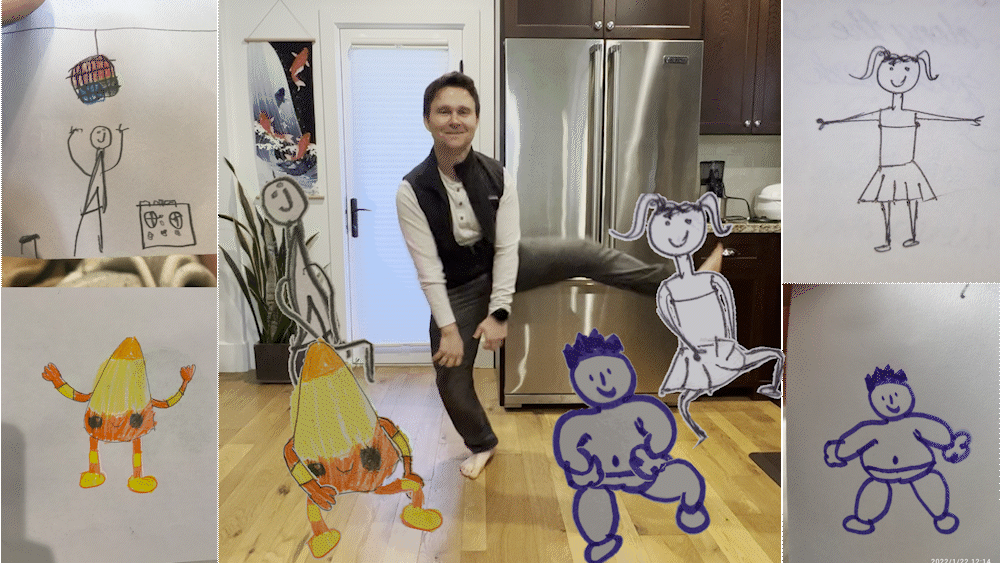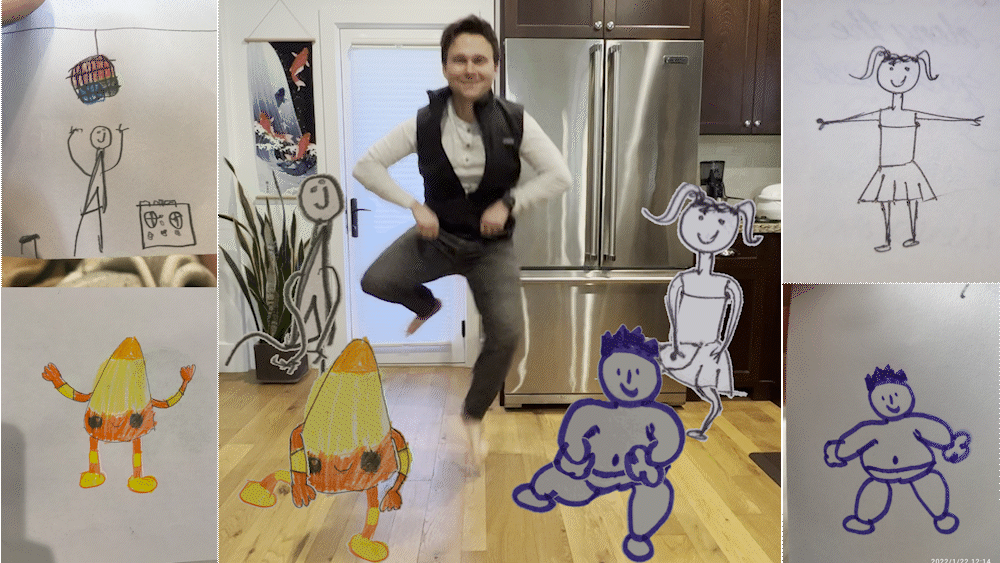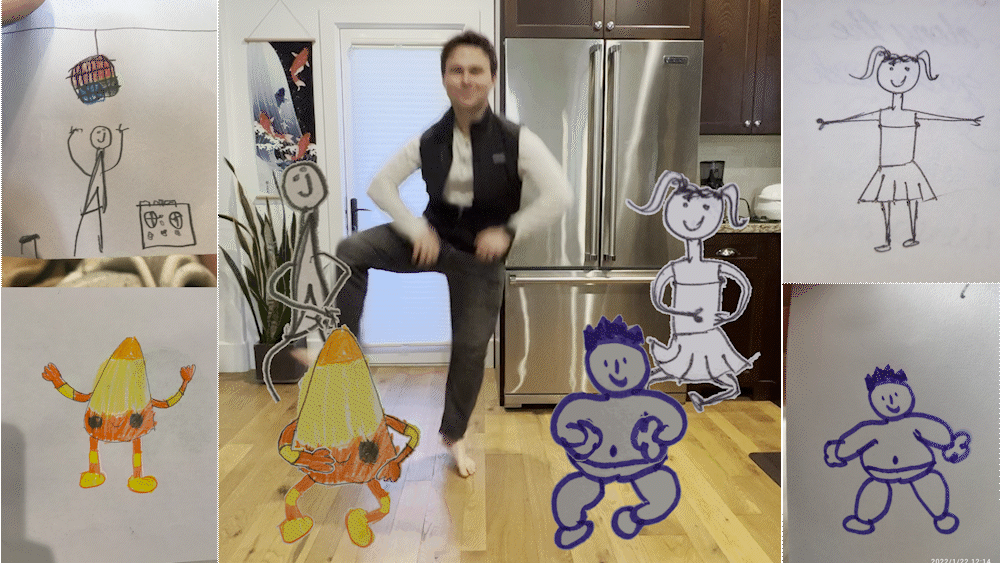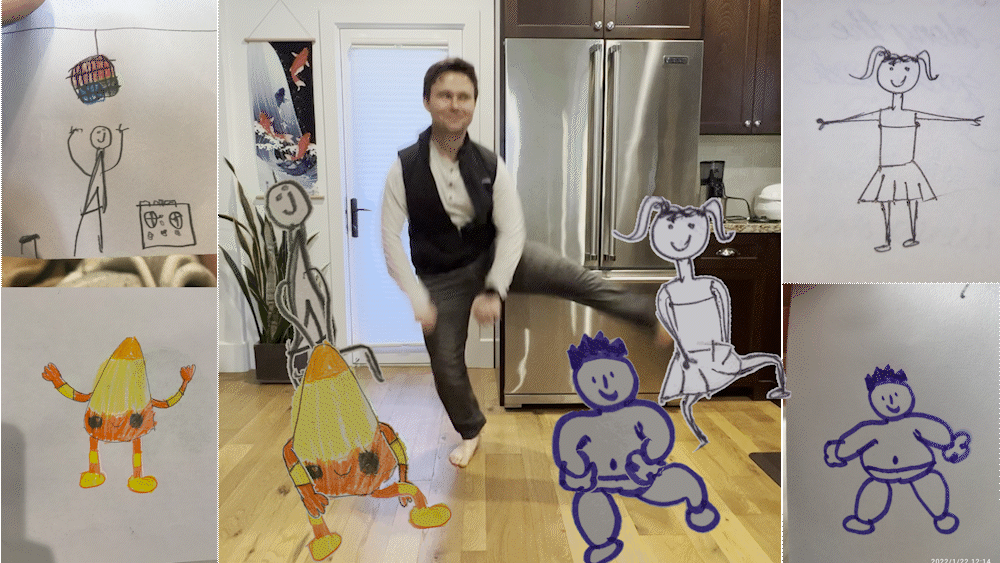 我的意思是哇!這麼酷的概念。我不知道你怎麼想,但我真的很興奮。 這是 Facebook 的一個開源專案,主要用於研究目的,包含論文《 [A Method for Animating Children's Drawings of the Human Figure》](https://dl.acm.org/doi/10.1145/3592788)中描述的演算法的實作。 該專案已在 macOS Ventura 13.2.1 和 Ubuntu 18.04 上進行了測試。如果您在其他作業系統上安裝,則可能會遇到問題。 他們強烈建議在安裝 Animated Drawings 之前啟動 Python 虛擬環境。 閱讀有關[安裝說明](https://github.com/facebookresearch/AnimatedDrawings?tab=readme-ov-file#installation)以及如何快速入門的更多資訊。 您可以按照這個完整的指南來為[您的繪圖製作動畫](https://github.com/facebookresearch/AnimatedDrawings?tab=readme-ov-file#animating-your-own-drawing),包括如何在場景中加入多個角色、加入背景圖像以及更多令人興奮的事情。 他們在 GitHub 上擁有超過 10k 顆星,並且僅用於具有 MIT 許可的研究目的。 https://github.com/facebookresearch/AnimatedDrawings 明星動畫繪圖 ⭐️ --- 18.[背景移除器](https://github.com/nadermx/backgroundremover)- 讓您可以透過簡單的 CLI 使用 AI 從影像和影片中移除背景。 ------------------------------------------------------------------------------------------  這是一個使用 AI 從圖像和影片中刪除背景的命令列工具。 首先從 pypi 安裝 backgroundremover。 ``` pip install --upgrade pip pip install backgroundremover ``` 也可以在不透過 pip 安裝的情況下執行它,只需克隆 git 以在本地啟動虛擬環境安裝要求並執行。 您可以使用的一些命令: - 從本機檔案圖像中刪除背景 ``` backgroundremover -i "/path/to/image.jpeg" -o "output.png" ``` - 從本地影片中刪除背景並將其覆蓋在圖像上 ``` backgroundremover -i "/path/to/video.mp4" -toi "/path/to/videtobeoverlayed.mp4" -o "output.mov" ``` 您可以檢查可透過 CLI 使用的所有[命令](https://github.com/nadermx/backgroundremover?tab=readme-ov-file#usage-as-a-cli)。 您甚至可以將它用作圖書館。 ``` from backgroundremover.bg import remove def remove_bg(src_img_path, out_img_path): model_choices = ["u2net", "u2net_human_seg", "u2netp"] f = open(src_img_path, "rb") data = f.read() img = remove(data, model_name=model_choices[0], alpha_matting=True, alpha_matting_foreground_threshold=240, alpha_matting_background_threshold=10, alpha_matting_erode_structure_size=10, alpha_matting_base_size=1000) f.close() f = open(out_img_path, "wb") f.write(img) f.close() ``` 您可以閱讀[安裝說明](https://github.com/nadermx/backgroundremover?tab=readme-ov-file#installation)並觀看[現場演示](https://www.backgroundremoverai.com/)。 > 輸入與輸出。  他們在 GitHub 上有 6k star,我們絕對可以用它來學習一些重要的概念。 https://github.com/nadermx/backgroundremover 明星背景去除器 ⭐️ --- 19. [Lobe Chat](https://github.com/lobehub/lobe-chat) - 現代設計的法學碩士/人工智慧聊天框架。 ---------------------------------------------------------------------------  一個開源、現代設計的 ChatGPT/LLM UI/框架。 支援語音合成、多模式和可擴展(函數呼叫)插件系統。您可以一鍵部署您的私有 OpenAI。  讓我們來看看 LobeChat 的一些令人興奮的功能: ✅ 多模式服務提供者支援。  他們將我們的支援擴展到多個模型服務提供者,而不是局限於單一服務提供者,為用戶提供更多樣化和豐富的對話選擇。 尋找他們支援的[10 多個模型服務提供者](https://lobehub.com/docs/usage/features/multi-ai-providers)的完整清單。 ✅ 市場助理。 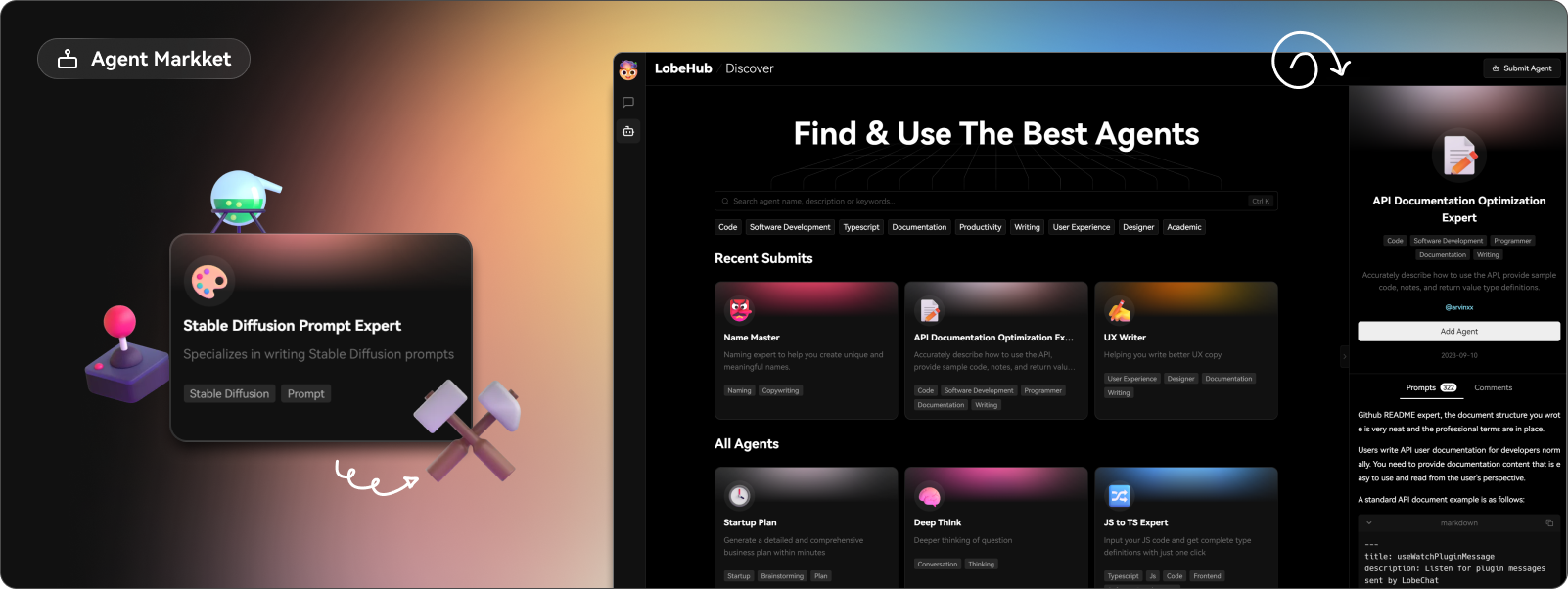 在LobeChat的[助手市場](https://lobehub.com/assistants)中,創作者可以發現一個充滿活力和創新的社區,匯集了許多精心設計的助手。這些助手不僅在工作場景中發揮著至關重要的作用,而且在學習過程中也提供了極大的便利。在這裡,每個人都可以貢獻自己的智慧,分享自己開發的助手。  那裡有很多很棒的應用程式。哇! ✅ 模型視覺辨識。 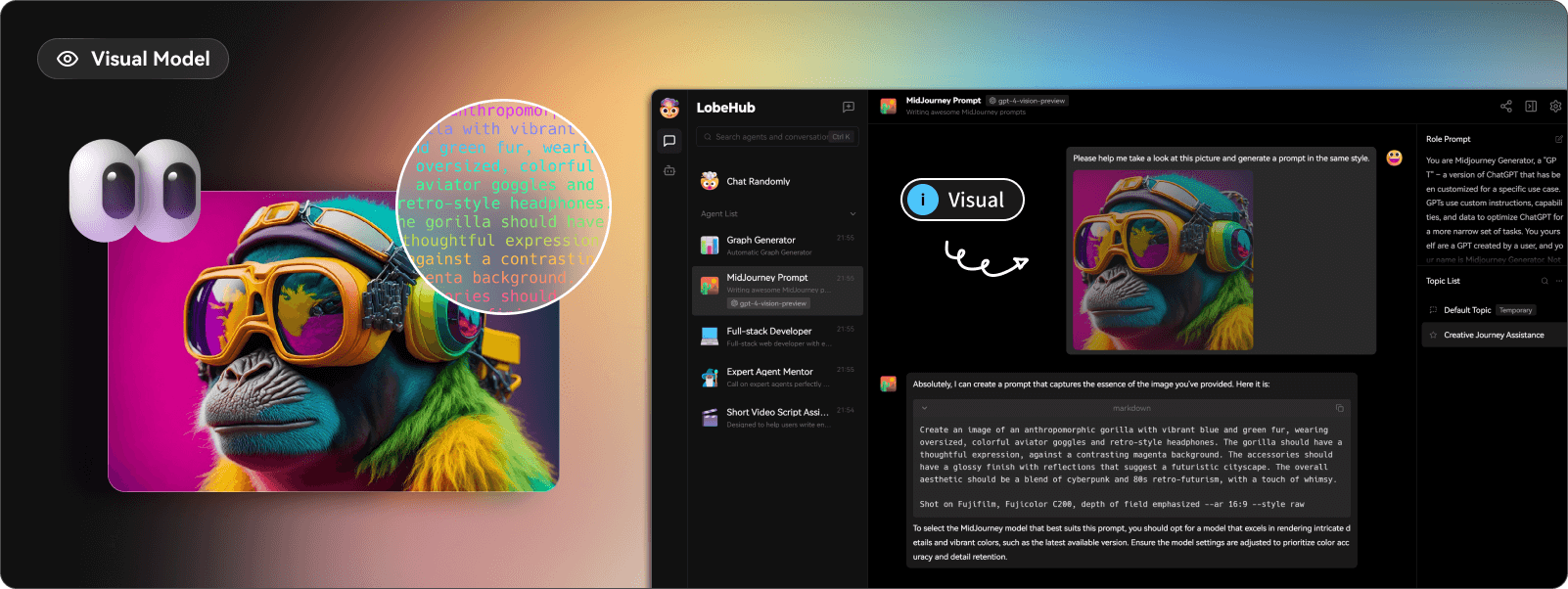 LobeChat現在支援OpenAI的gpt-4-vision、Google Gemini Pro Vision、Zhipu GLM-4 Vision等具有視覺辨識能力的大型語言模型,使LobeChat具備多模態互動能力。用戶可以輕鬆地將圖片上傳或拖放到聊天框中,助理將能夠辨識圖片內容並據此進行智慧對話,打造更聰明、更多樣化的聊天場景。 ✅ 文字到圖像生成。 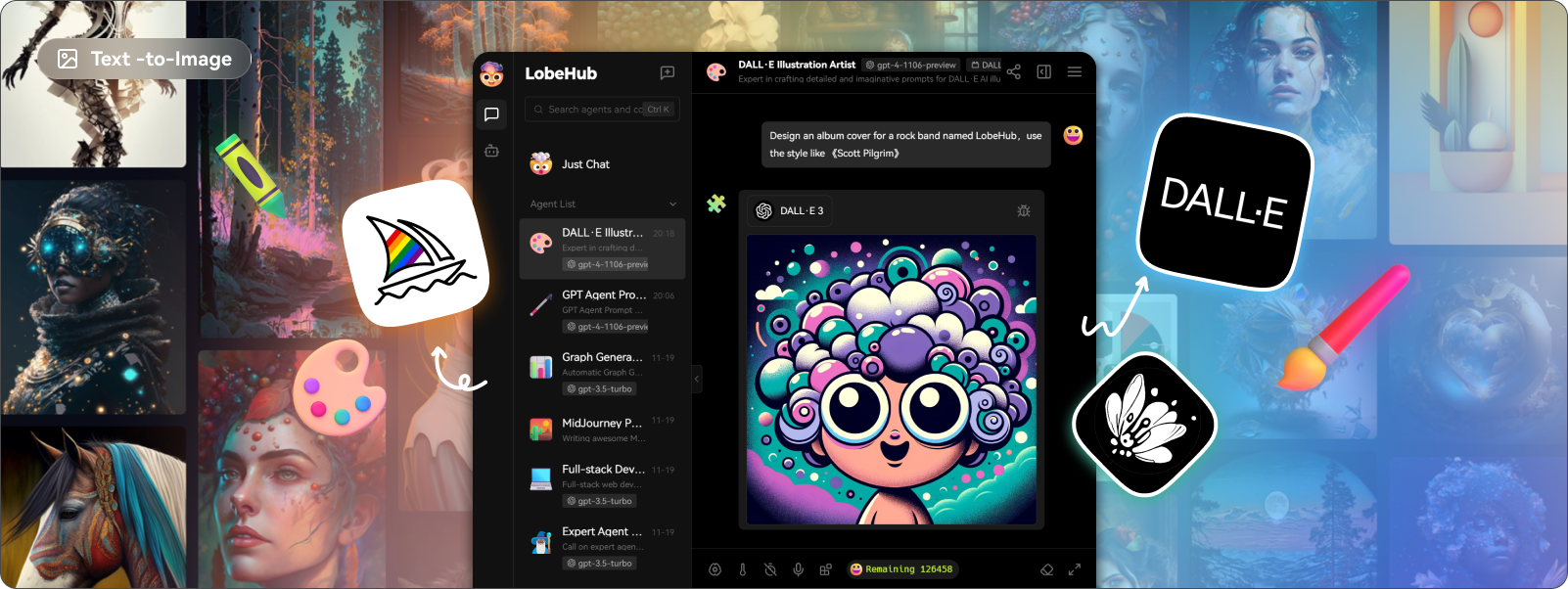 LobeChat 支援最新的文字到圖像生成技術,現在允許使用者在與助手對話時直接使用文字到圖像工具。透過利用 DALL-E 3、MidJourney 和 Pollinations 等 AI 工具的功能,助手現在可以將您的想法轉化為圖像。 ✅ 本地大語言模型 (LLM) 支援。 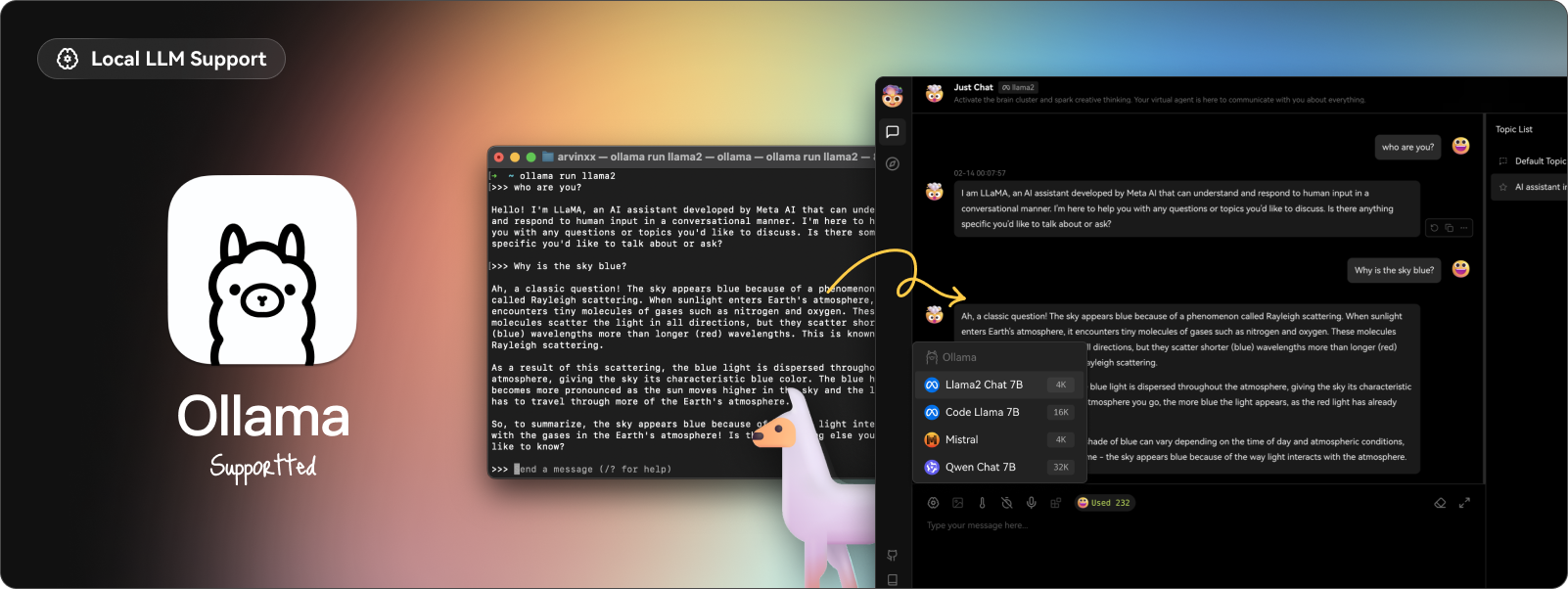 借助 Ollama AI 強大的基礎設施和社區的協作努力,現在您可以在 LobeChat 中與本地 LLM(大型語言模型)進行對話! 透過執行以下 Docker 指令,您可以在 LobeChat 中體驗與本機 LLM 的對話。 ``` docker run -d -p 3210:3210 -e OLLAMA_PROXY_URL=http://host.docker.internal:11434/v1 lobehub/lobe-chat ``` ✅ 漸進式網頁應用程式 (PWA)。 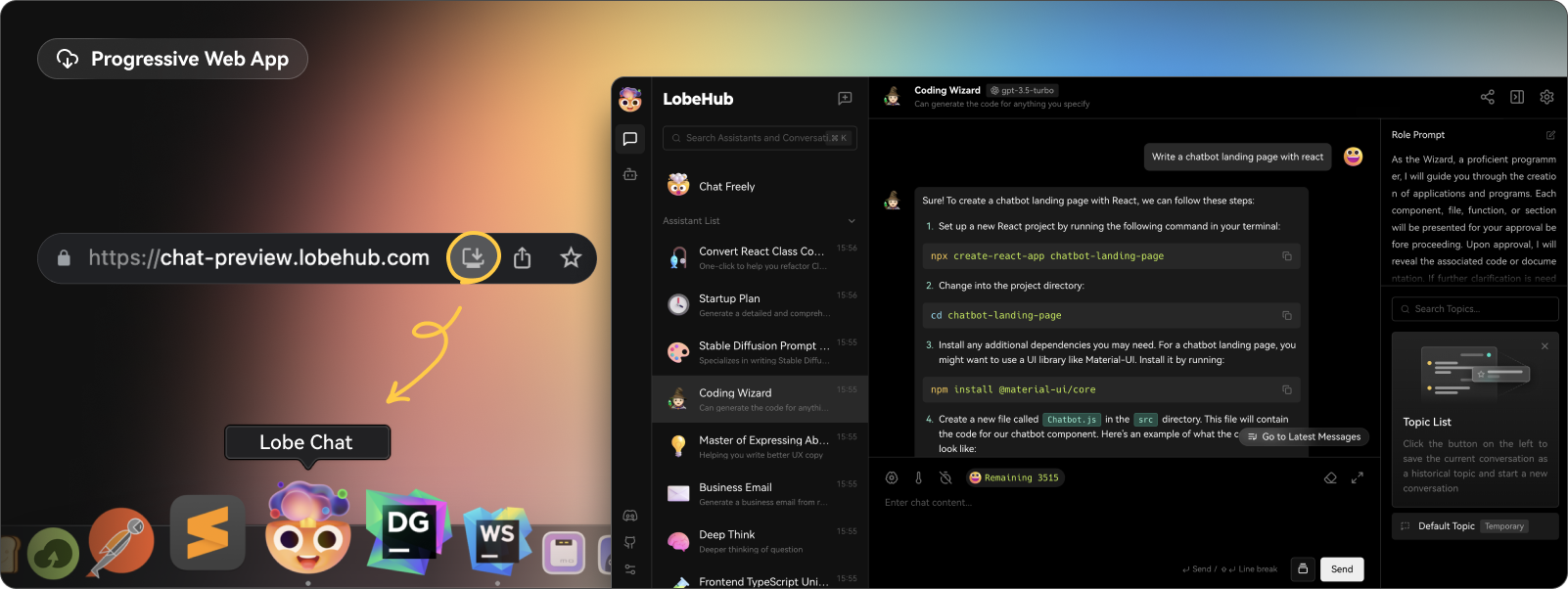 他們採用了漸進式 Web 應用程式 PWA 技術,這是一種現代 Web 技術,可將 Web 應用程式提升到接近本機應用程式的體驗。透過 PWA,LobeChat 可以在桌面和行動裝置上提供高度優化的使用者體驗,同時保持輕量級和高效能的功能。 ✅ 自訂主題。 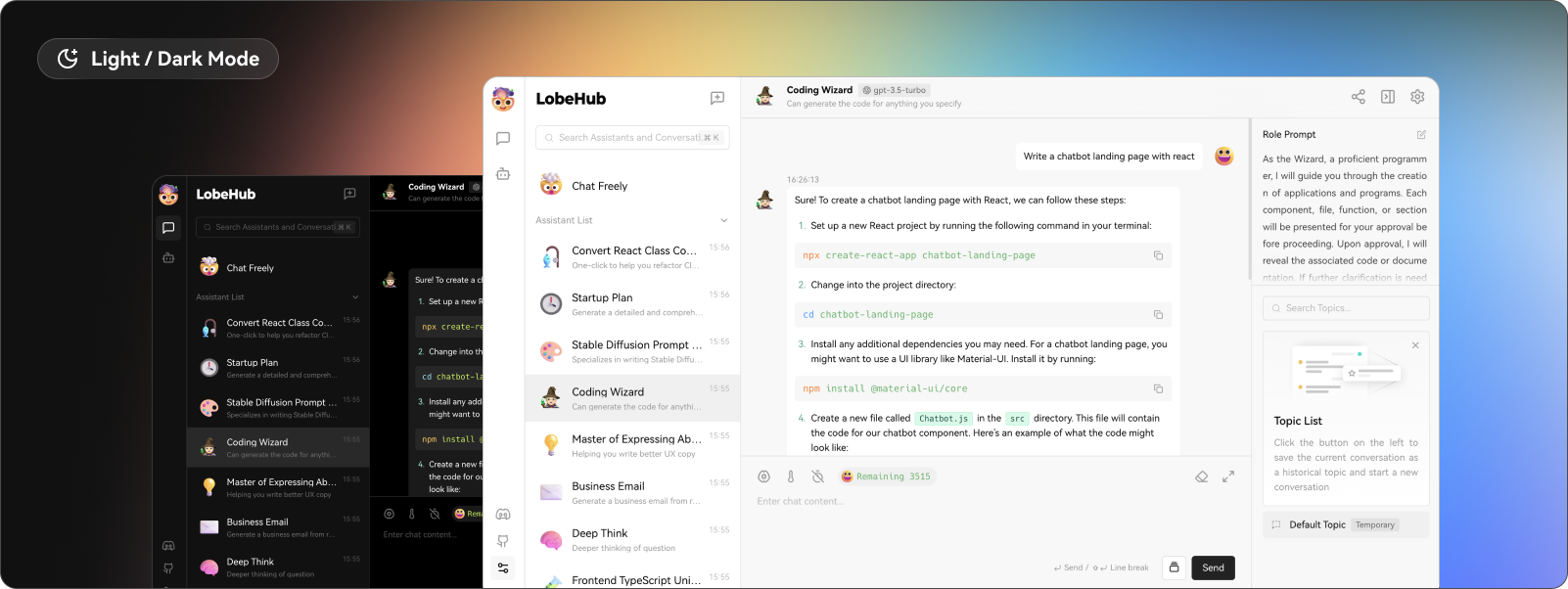 LobeChat在介面設計上非常注重個人化的使用者體驗,因此引入了靈活多樣的主題模式,包括白天的淺色模式和夜間的深色模式。 除了主題模式切換之外,我們還提供了一系列顏色自訂選項,讓使用者可以根據自己的喜好調整應用程式的主題顏色。 了解所有[功能和用例](https://lobehub.com/docs/usage/start)。 您可以自行託管或使用 docker 部署它。 lobe chat 的[生態系統](https://github.com/lobehub/lobe-chat/tree/main?tab=readme-ov-file#-ecosystem)提供了 4 個軟體包: `lobehub/ui` 、 `lobehub/icons` 、 `lobehub/tts`和`lobehub/lint` 。 他們還提供[插件市場](https://lobehub.com/plugins),您可以在其中找到許多有用的插件,這些插件可用於引入新的函數呼叫,甚至是呈現訊息結果的新方法。如果你想開發自己的插件,請參考 wiki 中的[📘插件開髮指南](https://lobehub.com/docs/usage/plugins/development)。  您可以閱讀[文件](https://lobehub.com/docs/usage/start)。 您可以查看[現場演示](https://chat-preview.lobehub.com/chat)。它太酷了!  他們在 GitHub 上擁有超過 28k 顆星,發布了 500 多個版本。 https://github.com/lobehub/lobe-chat 星瓣聊天 ⭐️ --- 20.[微代理](https://github.com/aymenfurter/microagents)- 能夠自我編輯提示的代理。 ------------------------------------------------------------------  它是一個實驗框架,用於動態建立自我改進的代理來回應任務。 微代理代表了一種建立自我改進代理的新方法。小型的微服務大小(因此稱為微代理)代理是根據用戶分配給助手的任務動態生成的,評估其功能,並在成功驗證後存儲以供將來重用。 這使得跨聊天會話的學習成為可能,使系統能夠獨立推斷任務執行的方法。 這是使用`Python` 、 `OpenAI's GPT-4 Turbo`和`Text-Embedding-Ada-002`建構的。 您可以閱讀[安裝說明](https://github.com/aymenfurter/microagents?tab=readme-ov-file#installation)。他們提到您應該擁有一個可以存取 gpt-4-turbo 和 text-embedding-ada-002 的 OpenAI 帳戶。 讓我們看一個獲取天氣預報代理的範例。 ``` You are an adept weather informant. Fetch the weather forecast by accessing public API data using this Python code snippet: ``python import requests import json def fetch_weather_forecast(location, date): response = requests.get(f"https://api.met.no/weatherapi/locationforecast/2.0/compact?lat={location[0]}&lon={location[1]}") weather_data = response.json() for day_data in weather_data['properties']['timeseries']: if date in day_data['time']: print(day_data['data']['instant']['details']) break `` # Example usage: fetch_weather_forecast((47.3769, 8.5417), '2024-01-22T12:00:00Z') Note: Replace the (47.3769, 8.5417) with the actual latitude and longitude of the location and the date string accordingly. ``` 如果您想知道如何建立代理,那麼此架構圖將對此進行解釋。 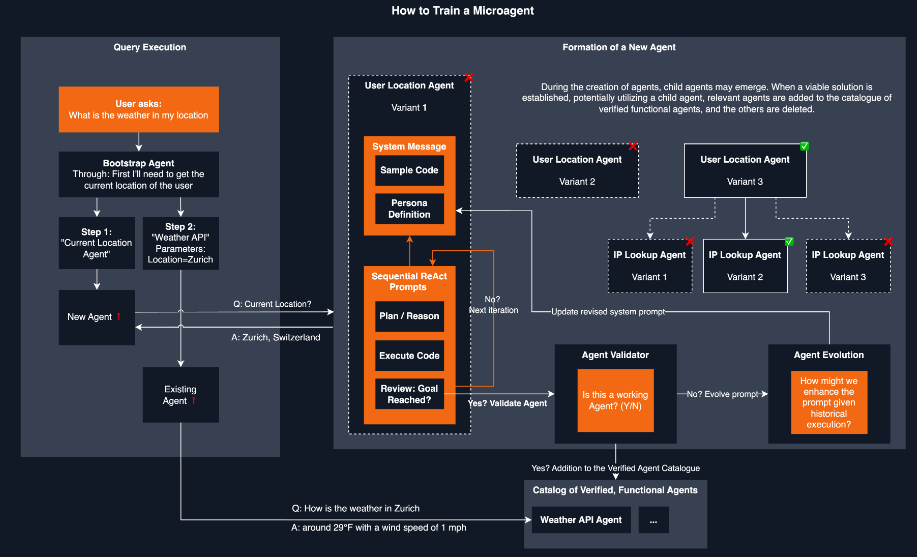 您可以看到[工作演示](https://github.com/aymenfurter/microagents?tab=readme-ov-file#demo)。 他們在 GitHub 上有大約 700 顆星,值得一看。 https://github.com/aymenfurter/microagents 明星微代理 ⭐️ --- 21. [GPT-4 & LangChain](https://github.com/mayooear/gpt4-pdf-chatbot-langchain) - 用於大型 PDF 文件的 GPT4 和 LangChain 聊天機器人。 --------------------------------------------------------------------------------------------------------------------------  這可用於新的 GPT-4 API 來為多個大型 PDF 檔案建立 chatGPT 聊天機器人。 該系統是使用 LangChain、Pinecone、Typescript、OpenAI 和 Next.js 建構的。 LangChain 是一個簡化可擴展 AI/LLM 應用程式和聊天機器人開發的框架。 Pinecone 用作向量存儲,用於以文字格式儲存嵌入和 PDF,以便以後檢索類似文件。 您可以閱讀涉及複製、安裝依賴項和設定環境 API 金鑰的[開發指南](https://github.com/mayooear/gpt4-pdf-chatbot-langchain?tab=readme-ov-file#development)。 您可以觀看[YouTube 影片](https://www.youtube.com/watch?v=ih9PBGVVOO4),了解如何遵循和使用它。 他們在 GitHub 上擁有 14k+ Stars,僅提交了 34 次。在您的下一個人工智慧應用程式中嘗試! https://github.com/mayooear/gpt4-pdf-chatbot-langchain 明星 GPT-4 和 Langchain ⭐️ --- 22. [Buzz](https://github.com/chidiwilliams/buzz) - 在您的個人電腦上離線轉錄和翻譯音訊。 ---------------------------------------------------------------------- 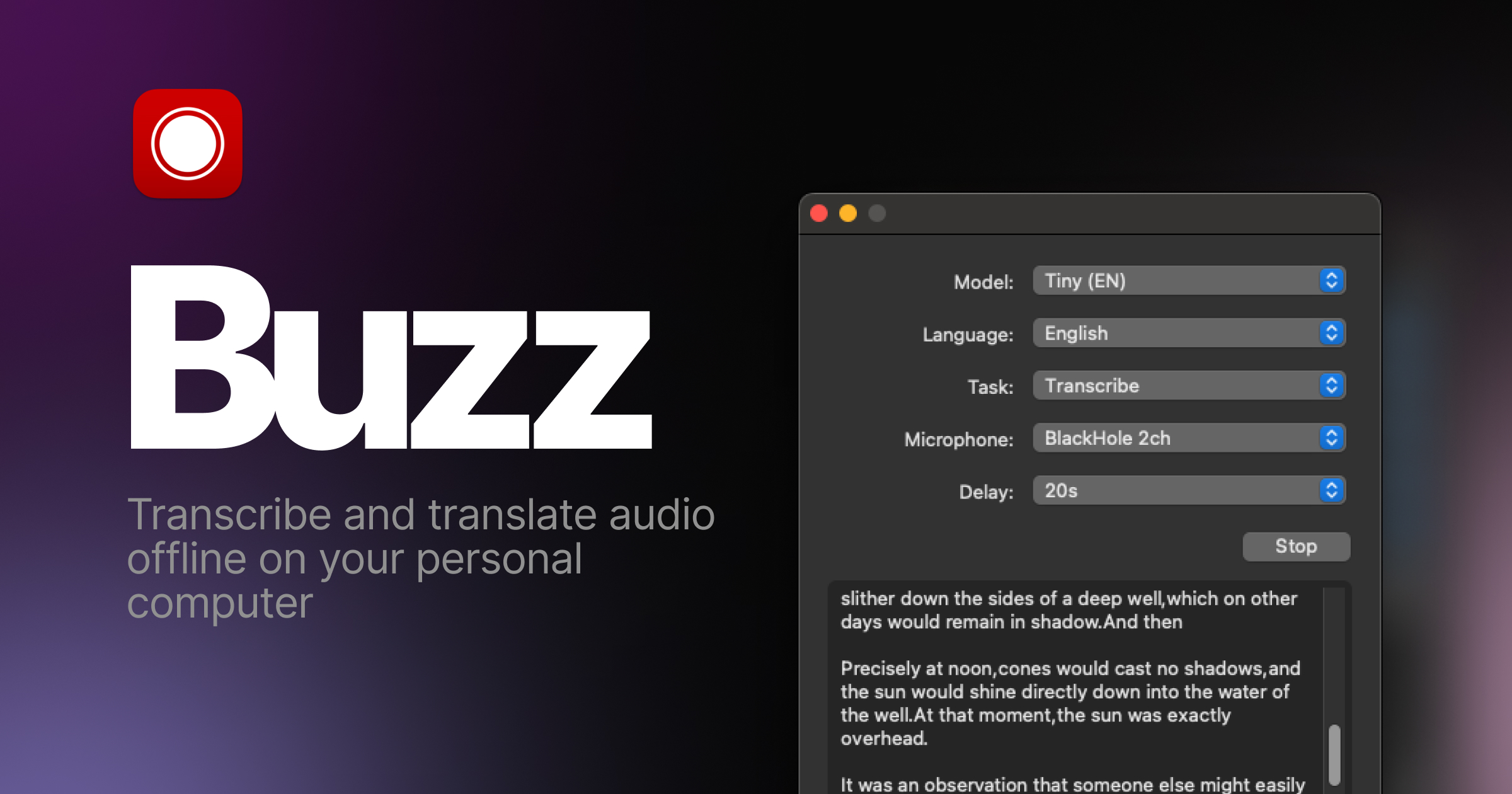 使用 OpenAI 的 Whisper 的強大功能在您的個人電腦上離線轉錄和翻譯音訊。 Buzz 甚至出現在[App Store](https://apps.apple.com/us/app/buzz-captions/id6446018936?mt=12&itsct=apps_box_badge&itscg=30200) 。取得 Buzz 的 Mac 原生版本,具有更簡潔的外觀、音訊播放、拖放匯入、文字記錄編輯、搜尋等功能。 您可以閱讀[安裝說明](https://chidiwilliams.github.io/buzz/docs/installation)。 令人興奮的功能: - 匯入音訊和視訊檔案並將文字記錄匯出為 TXT、SRT 和 VTT(演示)。 - 從電腦麥克風轉錄和翻譯為文字(資源密集且可能不是即時的。 - 它可在 Mac、Windows 和 Linux 上使用。 - 還有一個[CLI](https://chidiwilliams.github.io/buzz/docs/cli)選項。 在這裡查看演示! https://www.loom.com/share/564b753eb4d44b55b985b8abd26b55f7 您可以閱讀[文件](https://chidiwilliams.github.io/buzz/docs)。 它們在 GitHub 上擁有近 10k star,並且自兩週前上次提交以來仍在維護中。 https://github.com/chidiwilliams/buzz 明星嗡嗡聲 ⭐️ --- 23. [Deepgram](https://github.com/deepgram) - 將語音 AI 建置到您的應用程式中。 ----------------------------------------------------------------  從新創公司到 NASA,Deepgram API 每天都用於轉錄和理解數百萬分鐘的音訊。快速、準確、可擴展且經濟高效。 它為開發人員提供語音到文字和音訊智慧模型。  儘管他們有免費增值模式,但免費套餐的限制足以讓您入門。 可視化效果更上一層樓。您可以檢查即時串流媒體回應或音訊檔案並比較音訊的智慧程度。   您可以閱讀[文件](https://developers.deepgram.com/docs/introduction)。 您也可以閱讀 Deepgram 撰寫的關於[如何將語音辨識新增至您的 React 和 Node.js 專案的範例部落格](https://deepgram.com/learn/how-to-add-speech-recognition-to-your-react-project)。 如果您想嘗試 API 來親自了解模型的靈活性,請查看他們的[API Playground](https://playground.deepgram.com/?smart_format=true&language=en&model=nova-2) 。 https://github.com/deepgram 明星 Deepgram ⭐️ --- 24. [OpenDevin](https://github.com/OpenDevin/OpenDevin) - 更少的程式碼,更多的內容。 -----------------------------------------------------------------------   這是一個開源專案,旨在複製 Devin,一名自主人工智慧軟體工程師,能夠執行複雜的工程任務並在軟體開發專案上與用戶積極協作。該計畫致力於透過開源社群的力量複製、增強和創新 Devin。 只是想讓你知道,這是在德文被介紹之前。 您可以閱讀帶有要求的[安裝說明](https://github.com/OpenDevin/OpenDevin?tab=readme-ov-file#installation)。 他們使用 LiteLLM,因此您可以使用任何基礎模型來執行 OpenDevin,包括 OpenAI、Claude 和 Gemini。 如果您想為 OpenDevin 做出貢獻,您可以查看 [演示](https://github.com/OpenDevin/OpenDevin/blob/main/README.md#opendevin-code-less-make-more)和[貢獻指南](https://github.com/OpenDevin/OpenDevin/blob/main/CONTRIBUTING.md)。 它在 GitHub 上擁有超過 10,700 個 Star,並且正在快速成長。 https://github.com/OpenDevin/OpenDevin 明星 OpenDevin ⭐️ --- 25. [NPM Copilot](https://github.com/whoiskatrin/npm-copilot) - Next.js 的 CLI 工具,可以即時分析日誌。 ------------------------------------------------------------------------------------------ 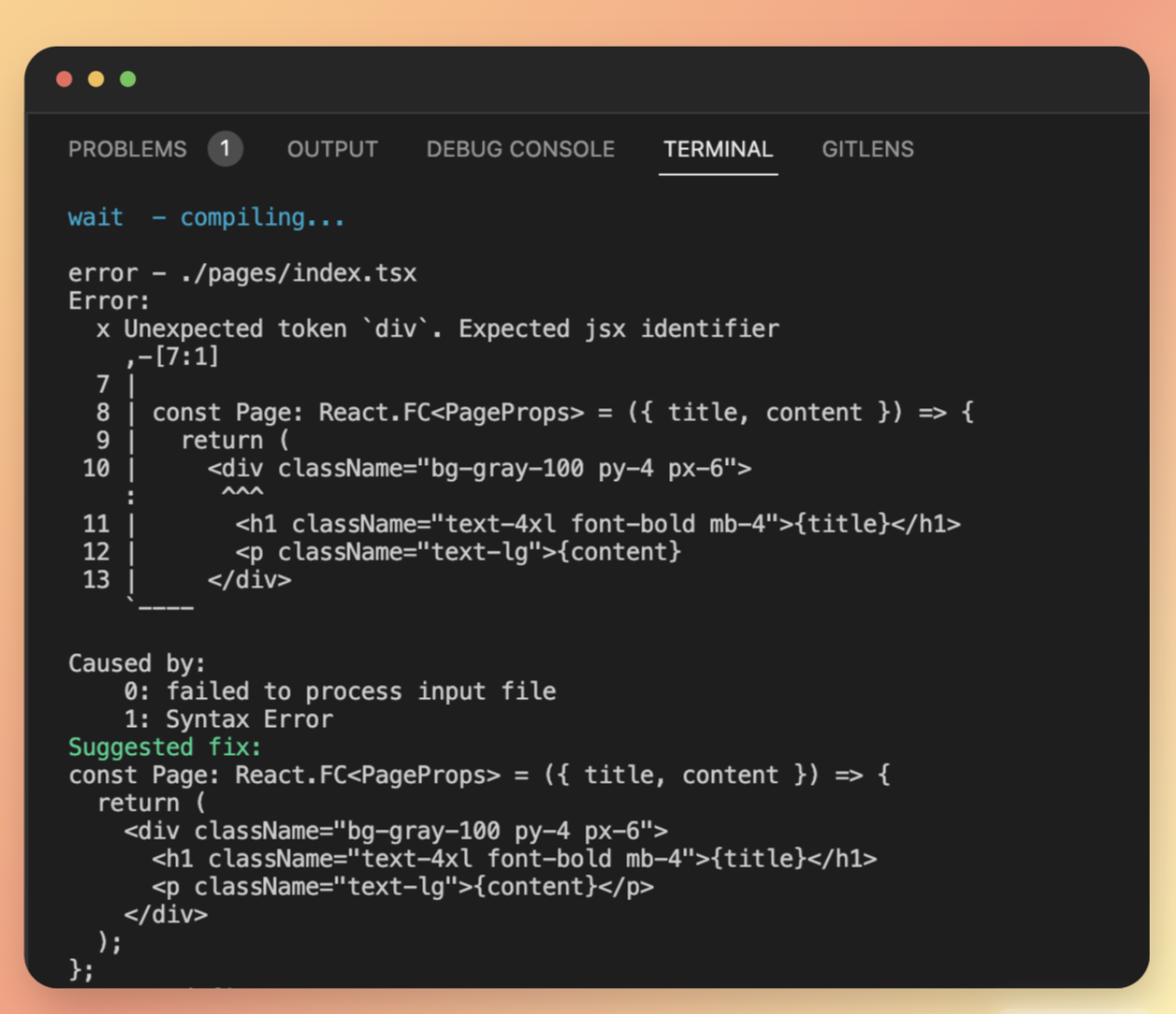 npm/yarn/pnpm copilot 是一個命令列工具,它使用 OpenAI 的 GPT-3 語言模型來提供修復程式碼中錯誤的建議。 CLI 工具可偵測目前目錄中正在使用的專案類型和套件管理器。 然後,它執行適當的開發伺服器命令(例如,npm run dev、yarn run dev、pnpm run dev)並偵聽正在執行的應用程式產生的日誌。 當遇到錯誤時,CLI 工具會即時提供錯誤修復建議。 首先使用以下 npm 指令安裝 npm-copilot 套件。 ``` npm install -g npm-copilot ``` CLI 工具將開始監視 Next.js 應用程式產生的日誌,並即時提供錯誤修復建議。 您可以透過該命令在專案中使用它。 ``` npm-copilot ``` 他們在 GitHub 上有 338 顆星,支援`Next,js` 、 `React` 、 `Angular`和`Vue.js` https://github.com/whoiskatrin/npm-copilot 明星 NPM Copilot ⭐️ --- 26. [Mentat](https://github.com/AbanteAI/mentat) - 人工智慧編碼助理。 ------------------------------------------------------------ 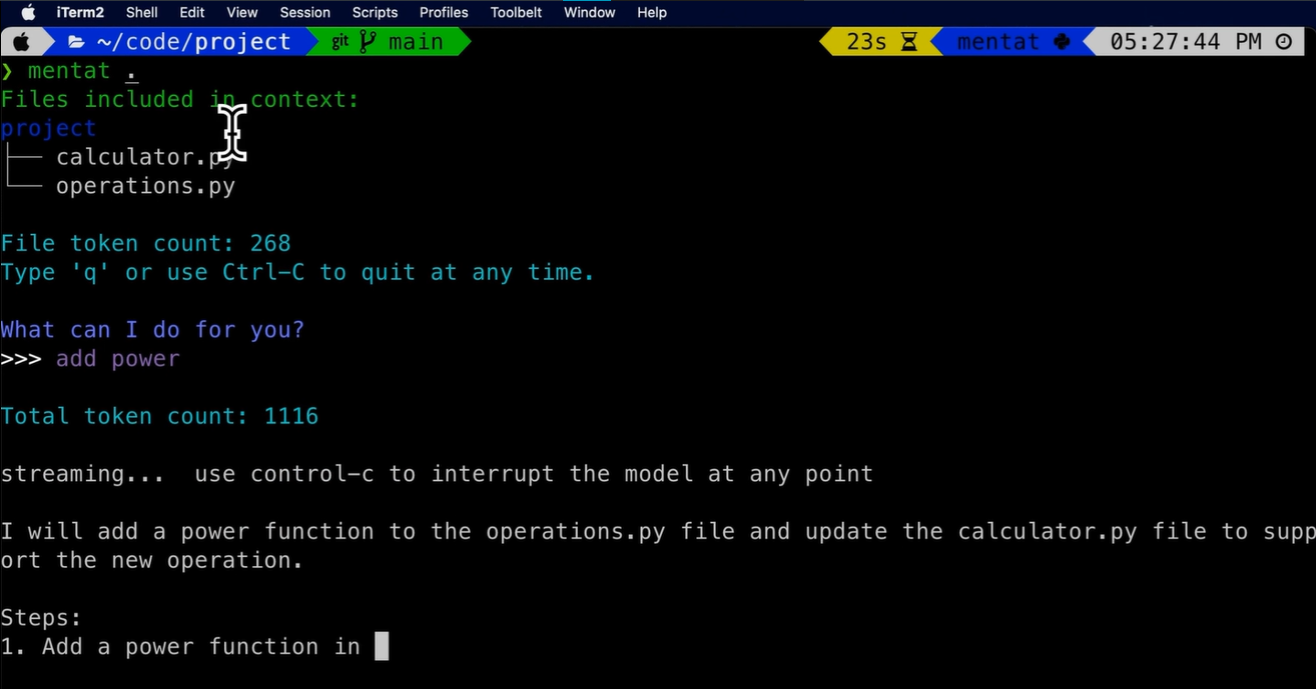 Mentat 是一款人工智慧工具,可直接從命令列幫助您完成任何編碼任務。 與 Copilot 不同,Mentat 協調多個位置和文件的編輯。與 ChatGPT 不同的是,Mentat 已經擁有您專案的上下文 - 無需複製和貼上! 您可以觀看此演示以了解基本概述。 https://www.youtube.com/watch?v=lODjaWclwpY 如果需要協助,您可以閱讀[安裝說明](https://github.com/AbanteAI/mentat?tab=readme-ov-file#install)或觀看安裝[教學](https://www.youtube.com/watch?v=bVJP8hY8uRM)。 您可以閱讀[文件](https://github.com/AbanteAI/mentat?tab=readme-ov-file#-usage)。 他們在 GitHub 上有 2.3k 顆星,並且正在發布`v1`版本。 https://github.com/AbanteAI/mentat Star Mentat ⭐️ --- 27. [FlowGPT](https://github.com/nilooy/flowgpt) - 使用 AI 產生流程圖。 --------------------------------------------------------------- 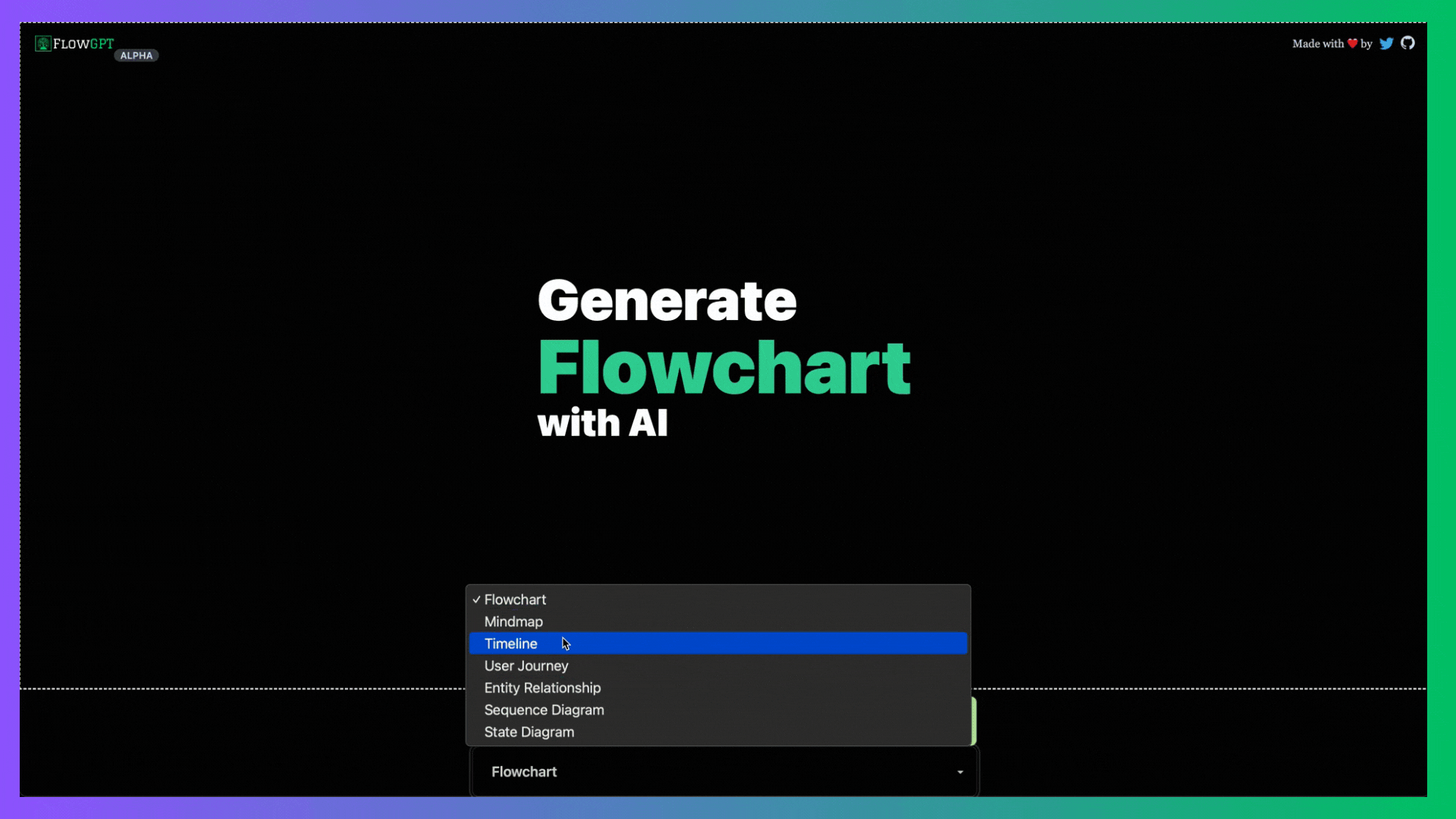 FlowGPT是一個用ai(gpt-3.5)產生流程圖的工具。 它是使用 Next.js、Langchain、Mermaid 和 DaisyUI 建構的。 您可以閱讀[安裝說明](https://github.com/nilooy/flowgpt?tab=readme-ov-file#installation)。 你可以查看[gif 示範](https://github.com/nilooy/flowgpt?tab=readme-ov-file#flowgpt-is-a-tool-to-generate-flowchart-with-ai-gpt-35)。 它只有 11 次提交,但在 GitHub 上有 238 顆星,並且是使用 TypeScript 建置的。作為一個小專案值得一試。 https://github.com/nilooy/flowgpt Star FlowGPT ⭐️ --- 28. [reor](https://github.com/reorproject/reor) - 自組織人工智慧筆記應用程式。 ----------------------------------------------------------------  迄今為止我見過的最令人興奮的專案之一,特別是因為它在本地執行模型。 Reor 是一款基於人工智慧的桌面筆記應用程式:它會自動連結相關筆記、回答筆記上的問題並提供語義搜尋。 所有內容都儲存在本地,您可以使用類似黑曜石的 Markdown 編輯器來編輯筆記。該專案假設人工智慧思維工具預設應該在本地執行模型。 Reor 站在 Ollama、Transformers.js 和 LanceDB 等巨頭的肩膀上,使 LLM 和嵌入模型都可以在本地執行。也支援連接到 OpenAI 或 OpenAI 相容 API(例如 Oobabooga)。 > 我知道你想知道它怎麼可能是`self-organizing` ? A。您寫的每個筆記都會被分塊並嵌入到內部向量資料庫中。 b.相關筆記透過向量相似度自動連接。 C。 LLM 支援的問答對筆記語料庫進行 RAG。 d.一切都可以進行語義搜尋。 您可以在這裡觀看演示! 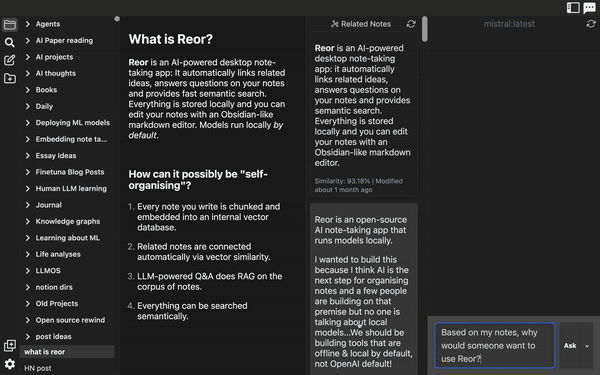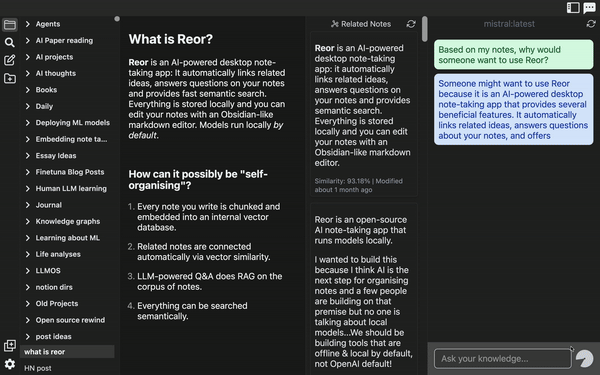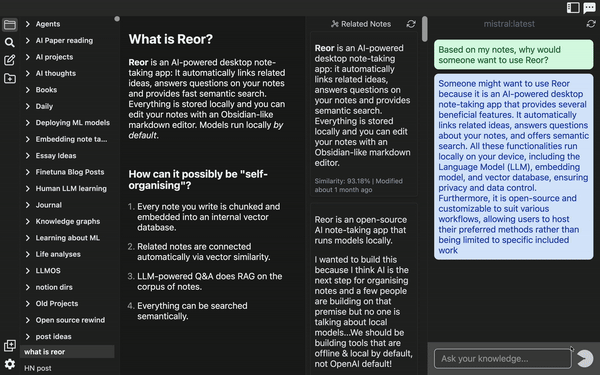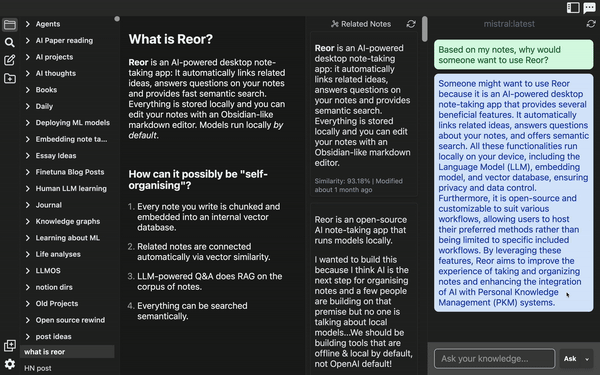 將 Reor 視為一個帶有兩個生成器的 RAG 應用程式:LLM 和人類。在問答模式下,法學碩士會從語料庫中取得檢索到的上下文來幫助回答查詢。 類似地,在編輯器模式下,人們可以切換側邊欄以顯示從語料庫「檢索」的相關註釋。這是透過將當前筆記中的想法與語料庫中的相關想法交叉引用來「增強」您的想法的一種非常有效的方法。 您可以閱讀[文件](https://www.reorproject.org/docs)並從網站[下載](https://www.reorproject.org/)。 Mac、Linux 和 Windows 皆支援。 他們還提供了入門指南,以便幫助您入門。  它們在 GitHub 上有 4.2k 顆星,並使用 TypeScript 建置。 https://github.com/reorproject/reor 星標 reor ⭐️ --- 29. [Amica](https://github.com/semperai/amica) - 讓您在瀏覽器中輕鬆地與 3D 角色聊天。 ---------------------------------------------------------------------  Amica 是一個開源接口,用於透過語音合成和語音辨識與 3D 角色進行互動式通訊。 您可以匯入 VRM 文件,調整聲音以適合角色,並產生包含情緒表達的回應文字。 他們使用 Three.js、OpenAI、Whisper、Bakllava 等進行視覺處理。您可以閱讀[Amica 的工作原理](https://docs.heyamica.com/overview/how-amica-works)及其所涉及的[核心概念](https://docs.heyamica.com/overview/core-concepts)。 您可以克隆該存儲庫並使用它來[開始](https://docs.heyamica.com/getting-started/installation)。 ``` npm i npm run dev ``` 您可以閱讀[文件](https://docs.heyamica.com/)並查看[演示](https://amica.arbius.ai/),這真是太棒了:D  您可以觀看這段簡短的影片,了解它的功能。 https://www.youtube.com/watch?v=hUxAEnFiXH8 Amica 使用 Tauri 建立桌面應用程式。 他們在 GitHub 上有 400+ Stars,而且看起來非常容易使用。 https://github.com/semperai/amica Star Amica ⭐️ --- 30.[繼續](https://github.com/continuedev/continue)- 使您能夠建立人工智慧軟體開發系統。 -------------------------------------------------------------------  繼續讓開發人員保持流動。我們的開源 VS Code 和 JetBrains 擴充功能可讓您輕鬆建立自己的模組化 AI 軟體開發系統並進行改進。 它們有很多很棒的功能,讓我們看看其中的一些: > 輕鬆理解程式碼部分。 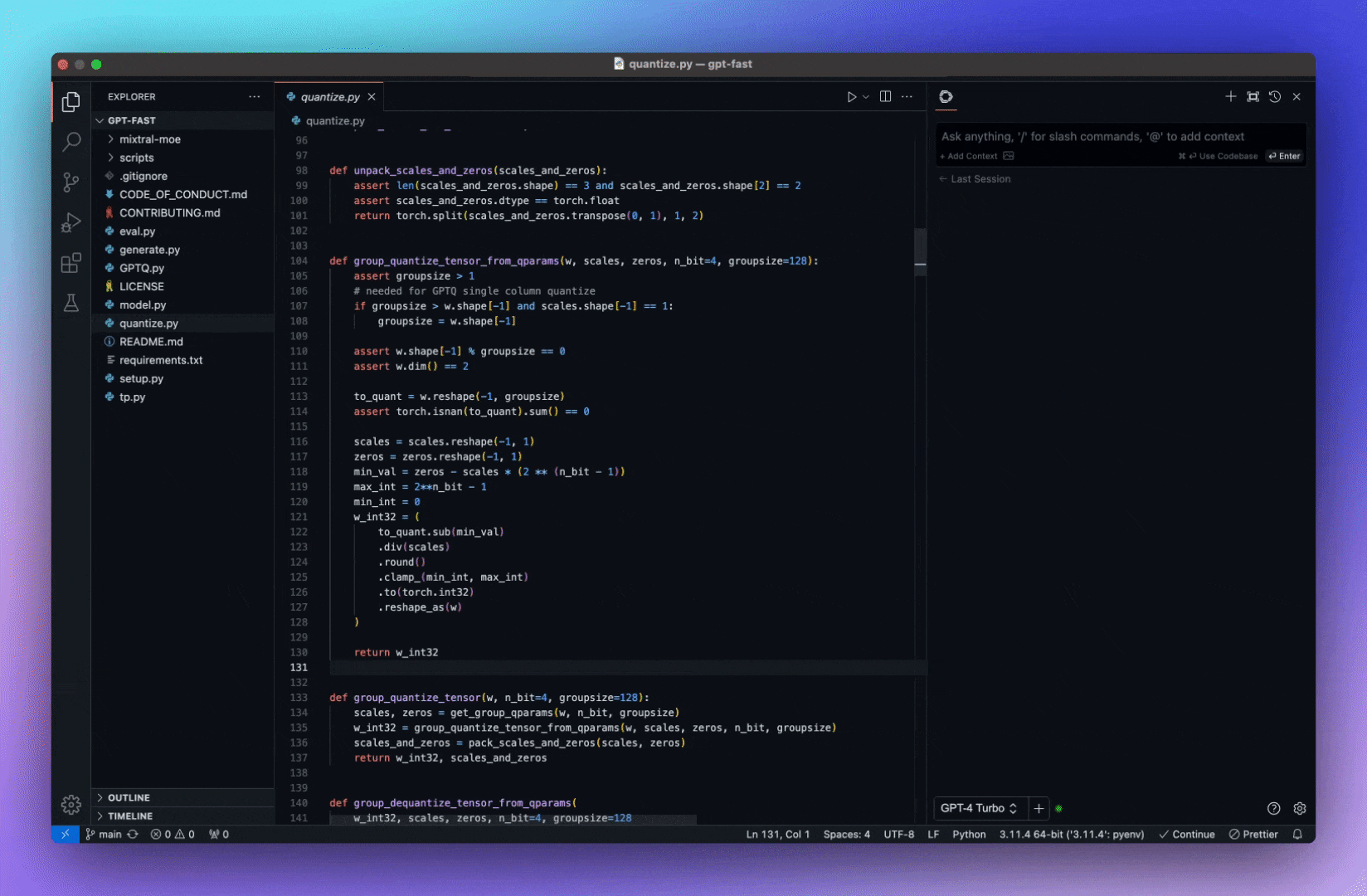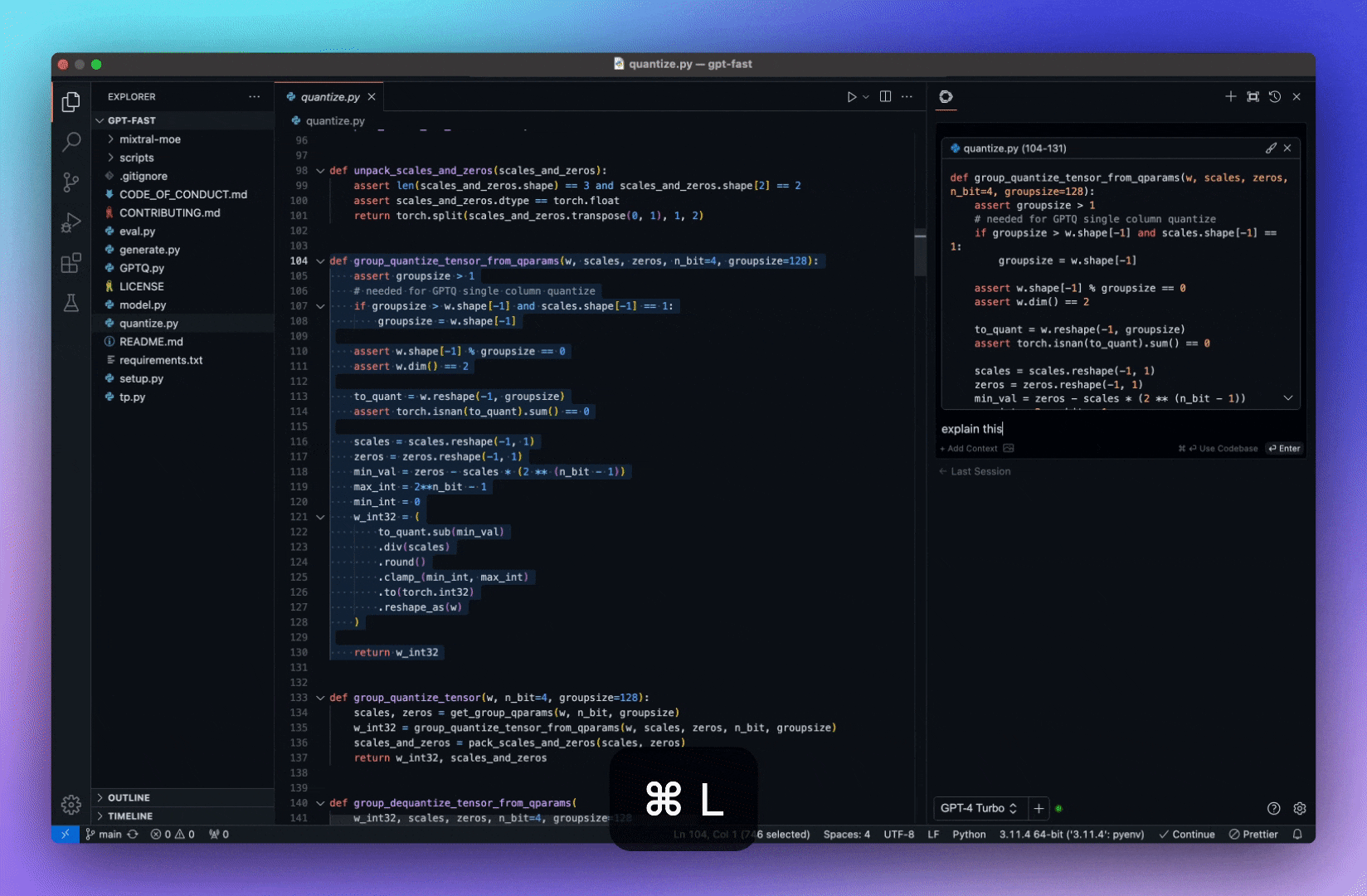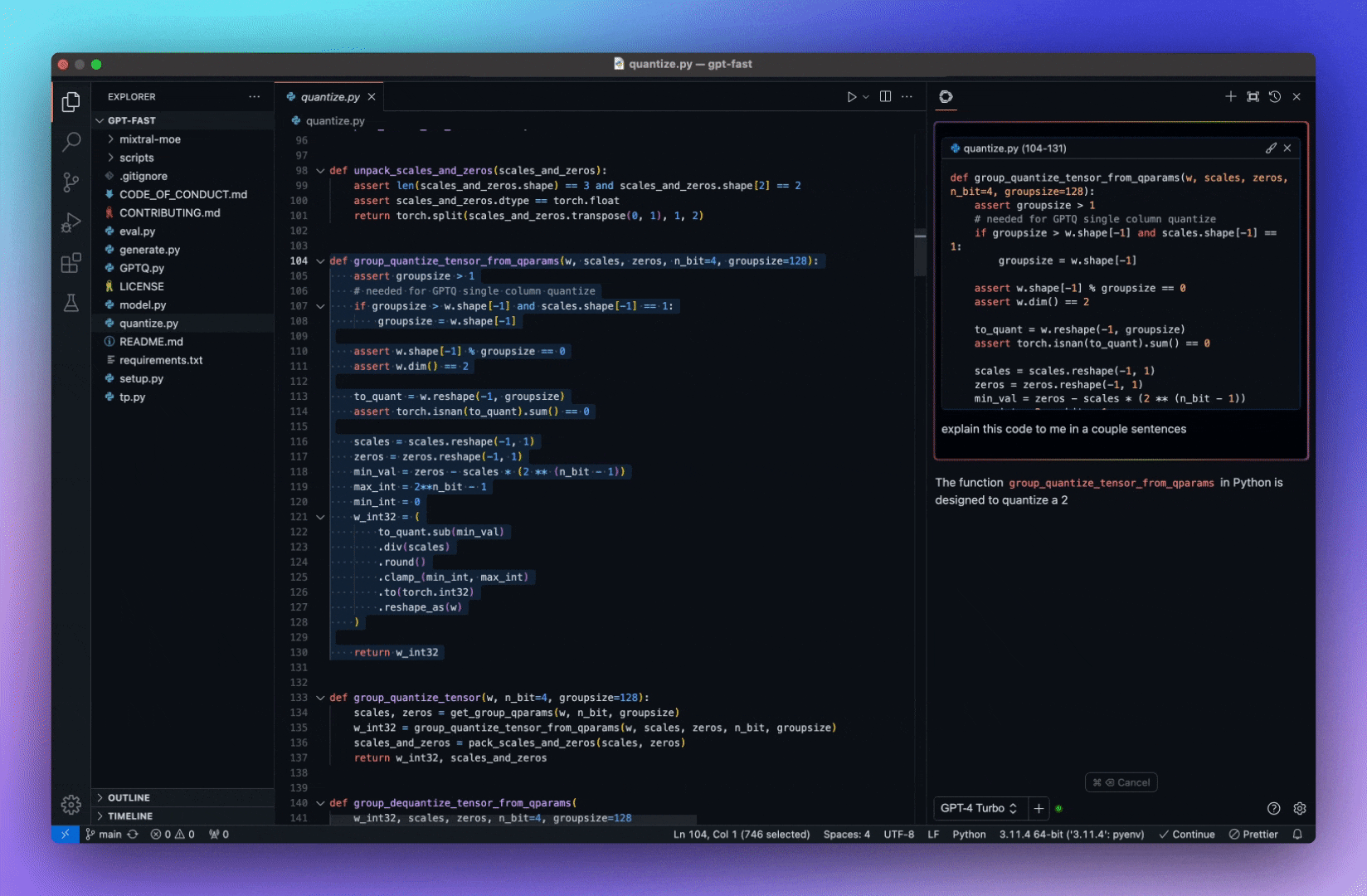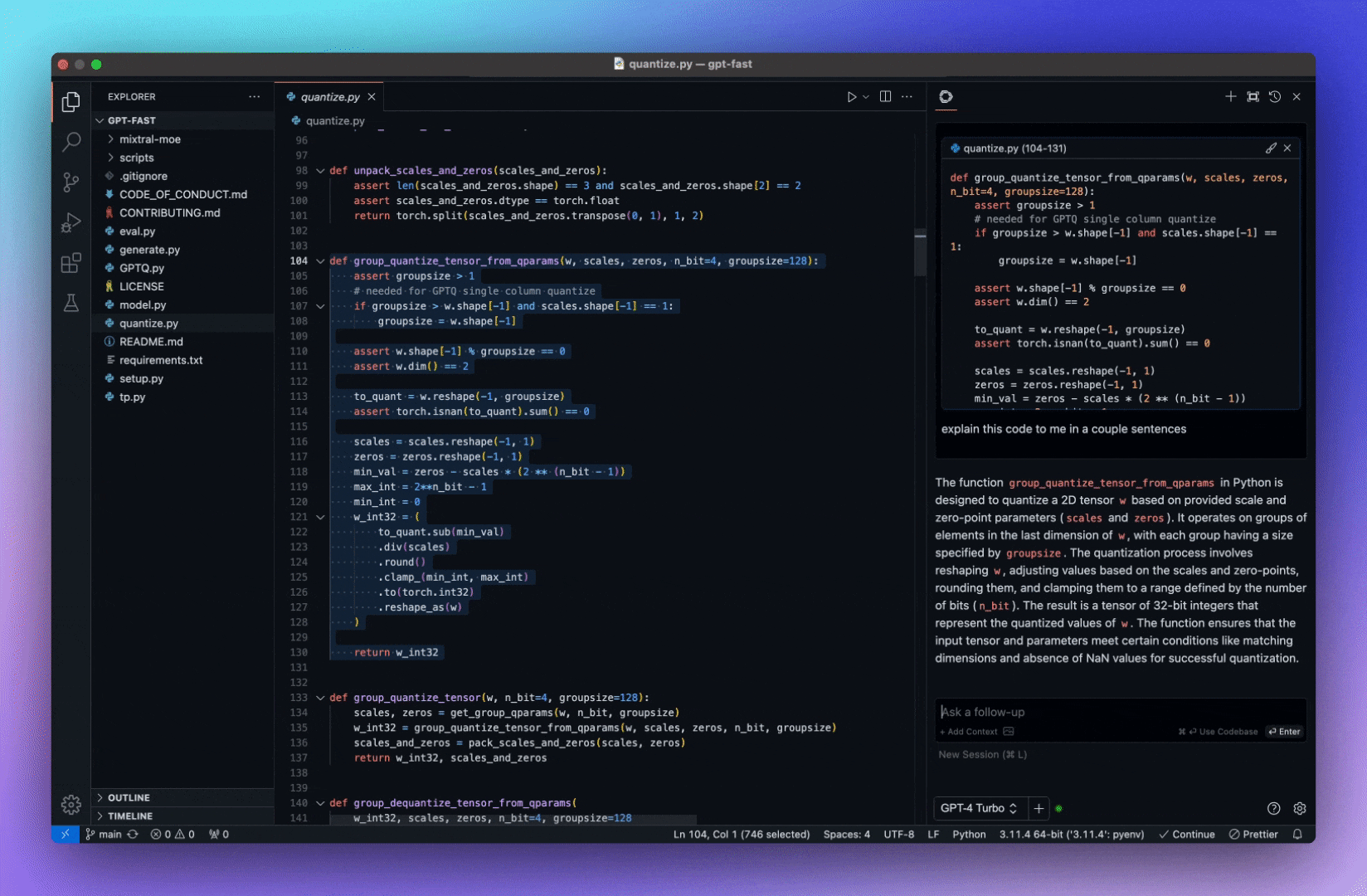 > 選項卡可自動完成程式碼建議。 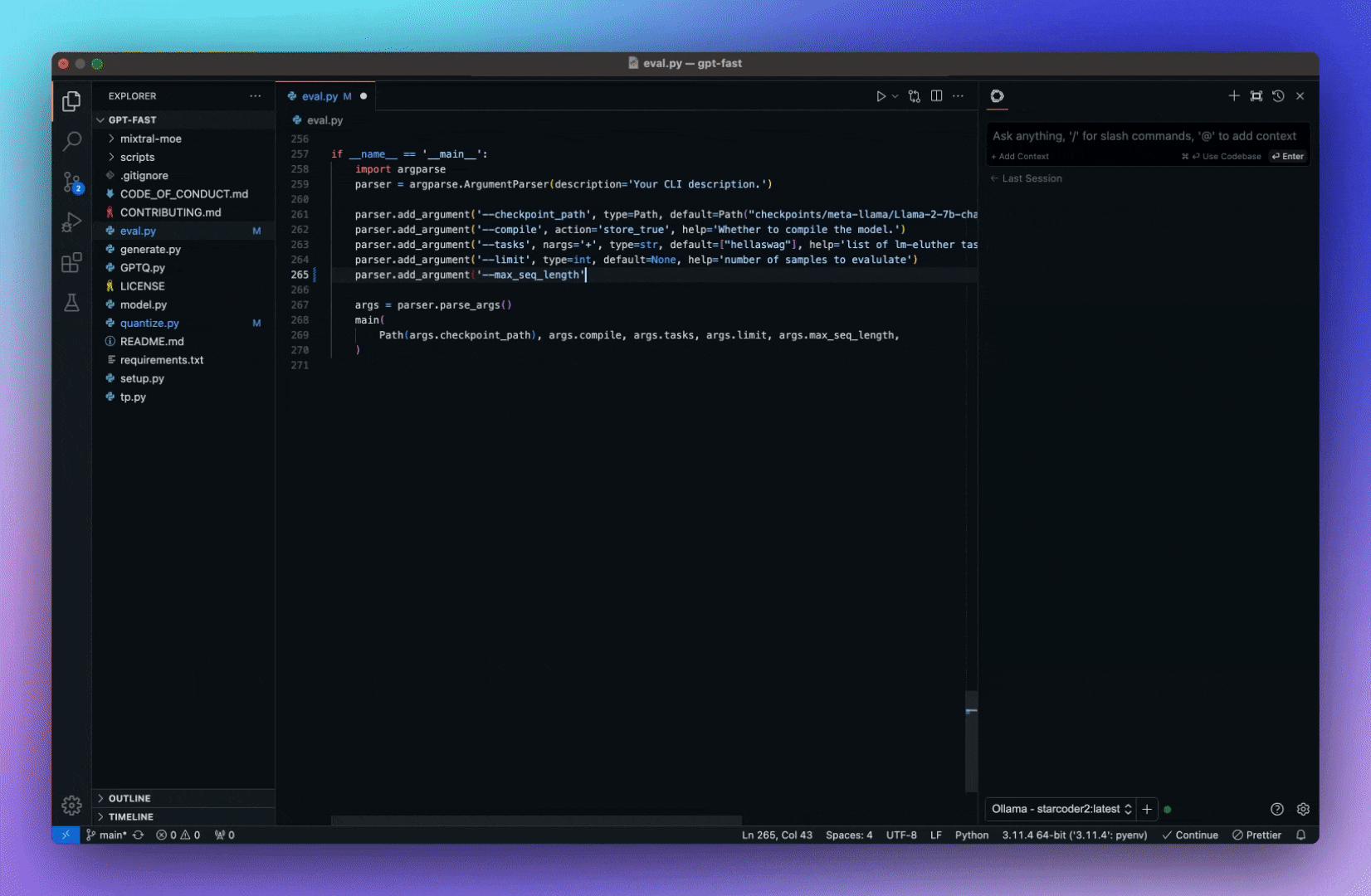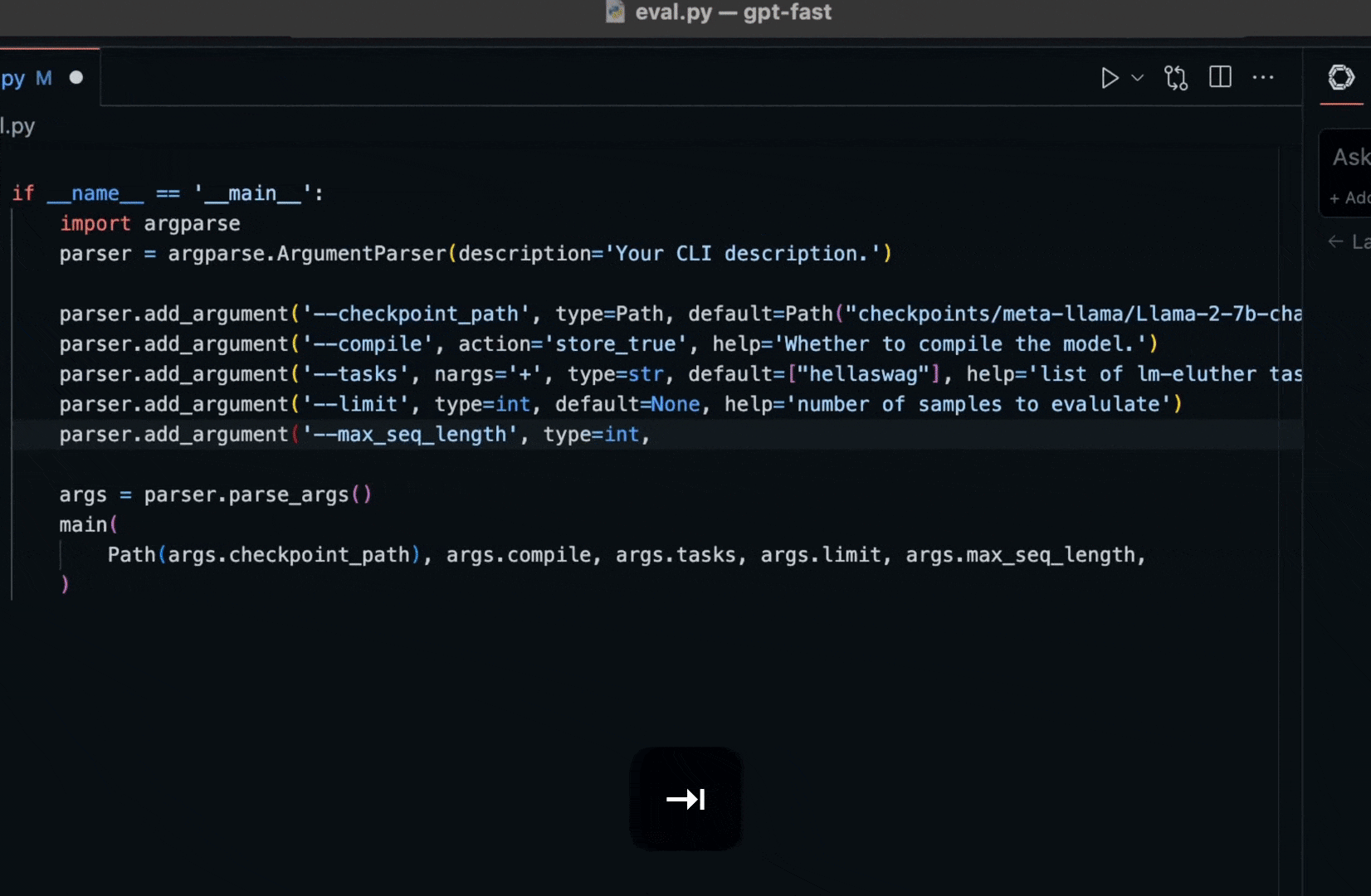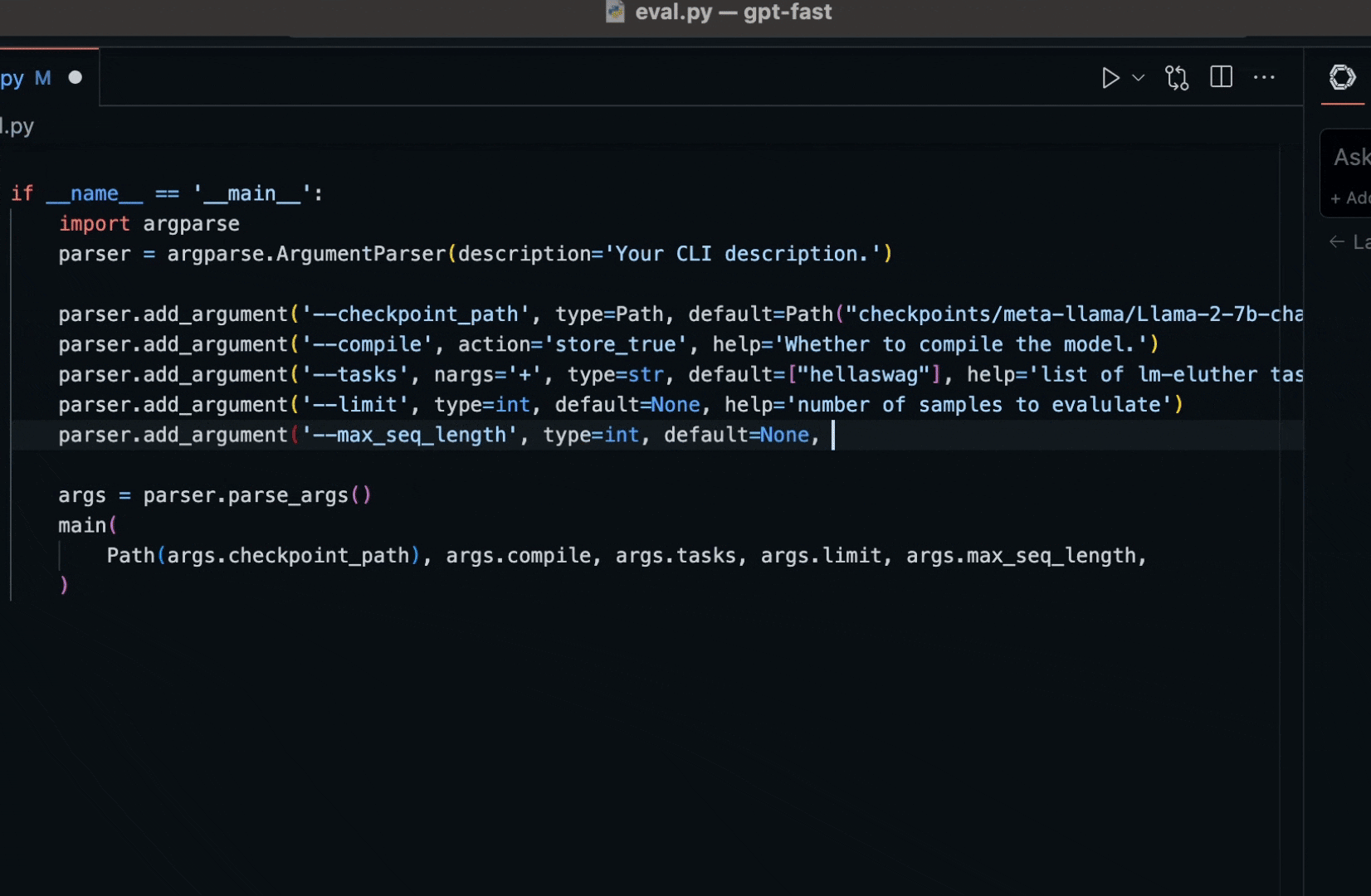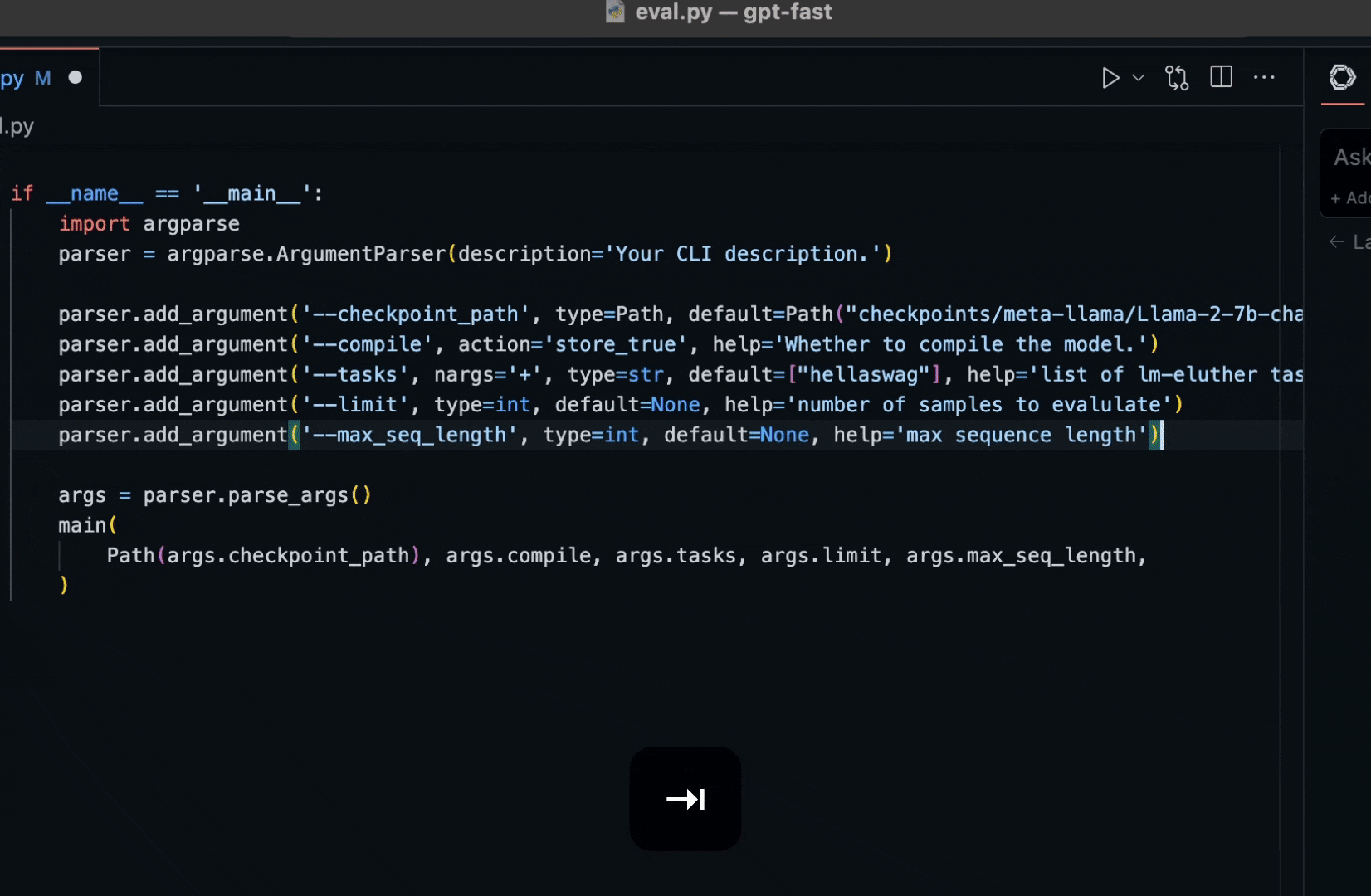 > 詢問有關您的程式碼庫的問題。 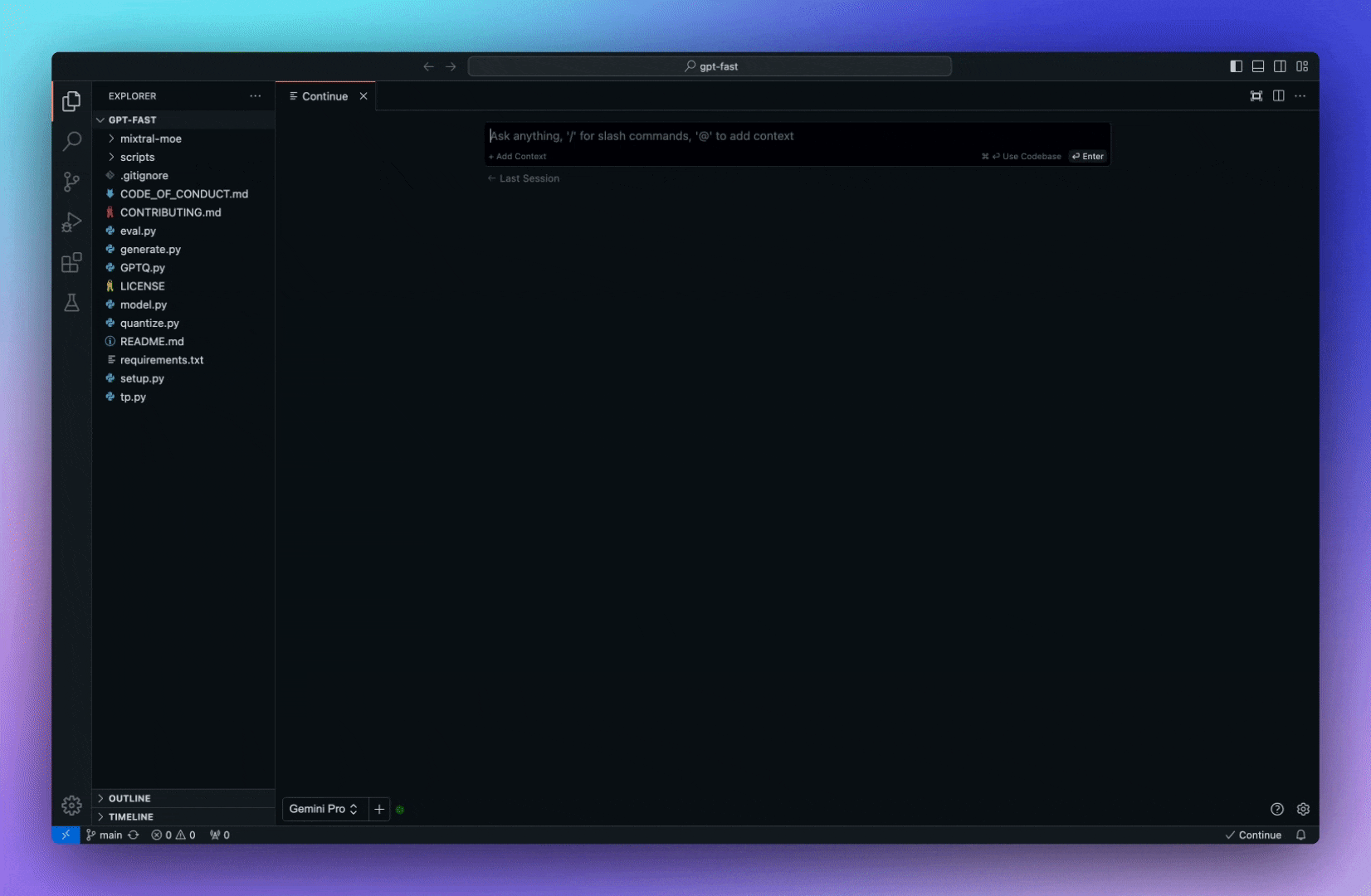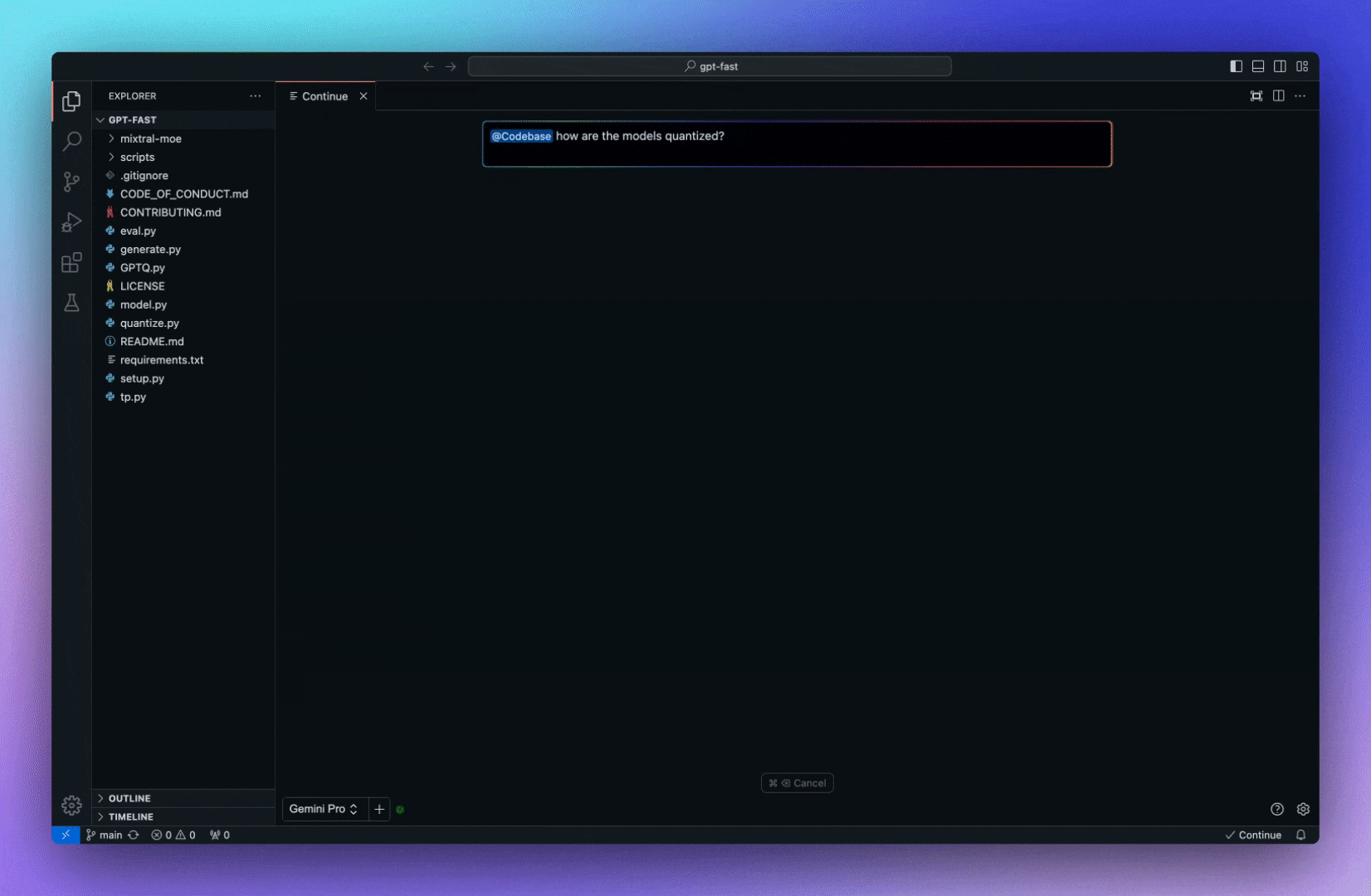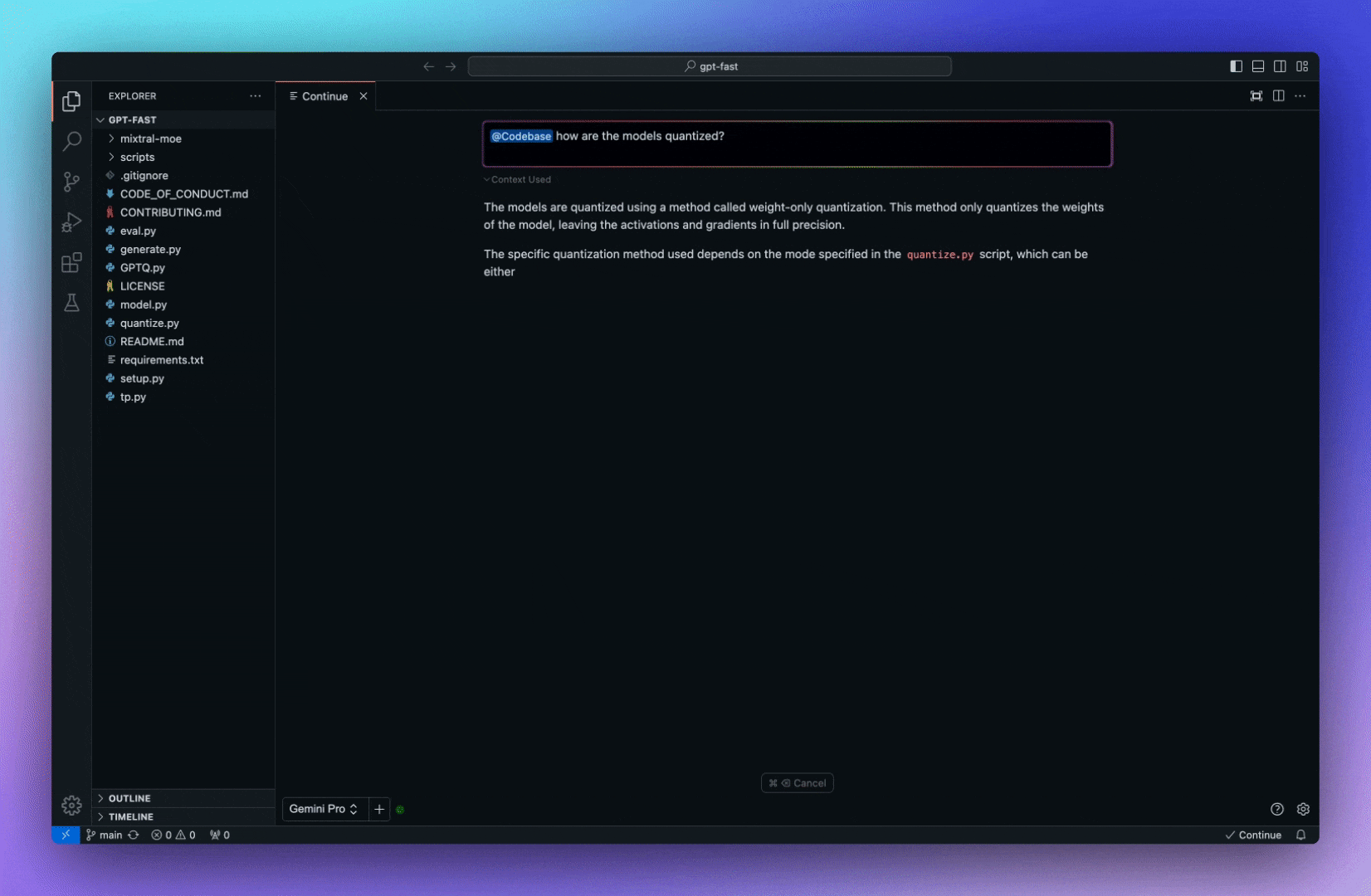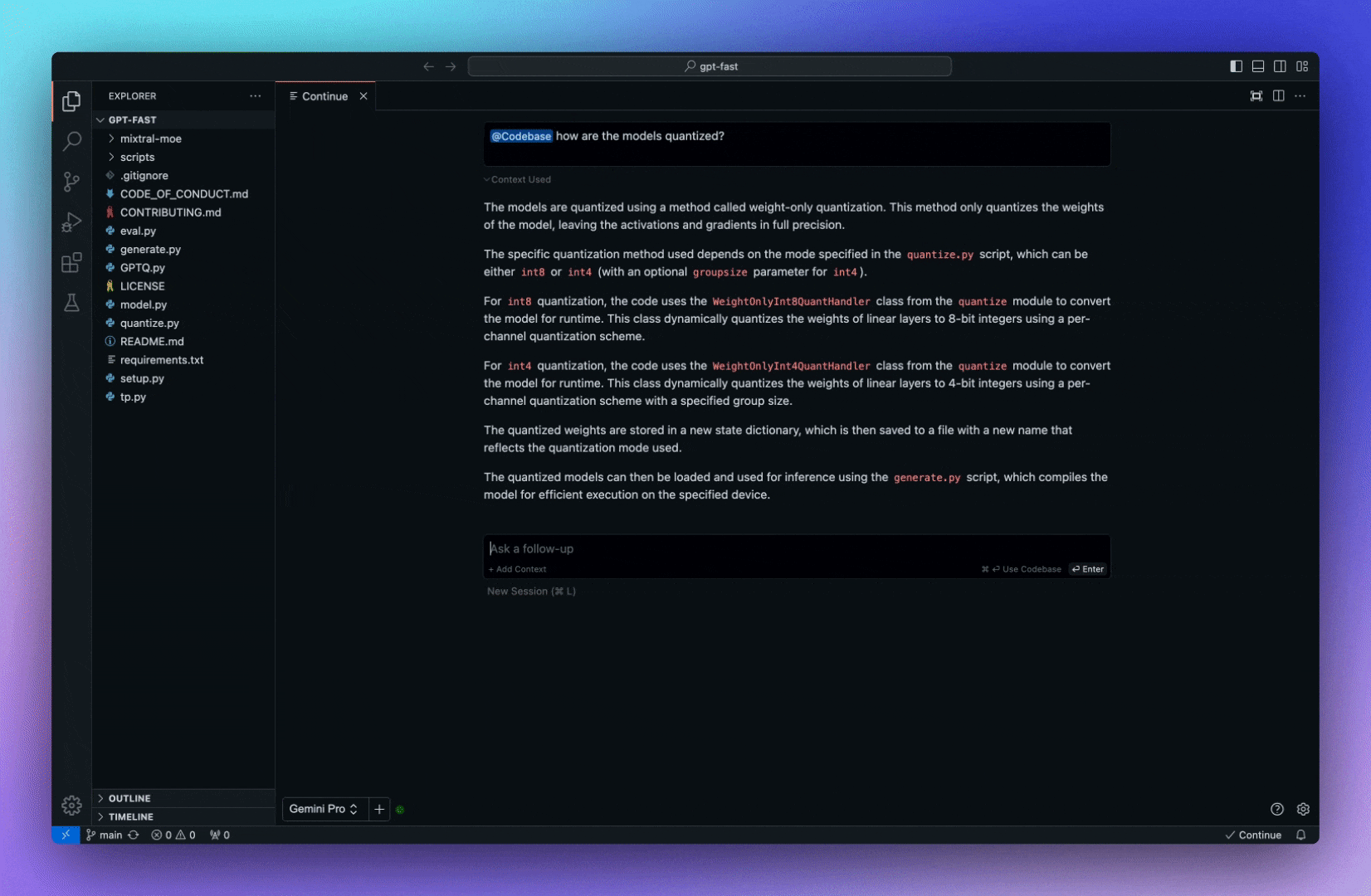 > 快速使用文件作為上下文。 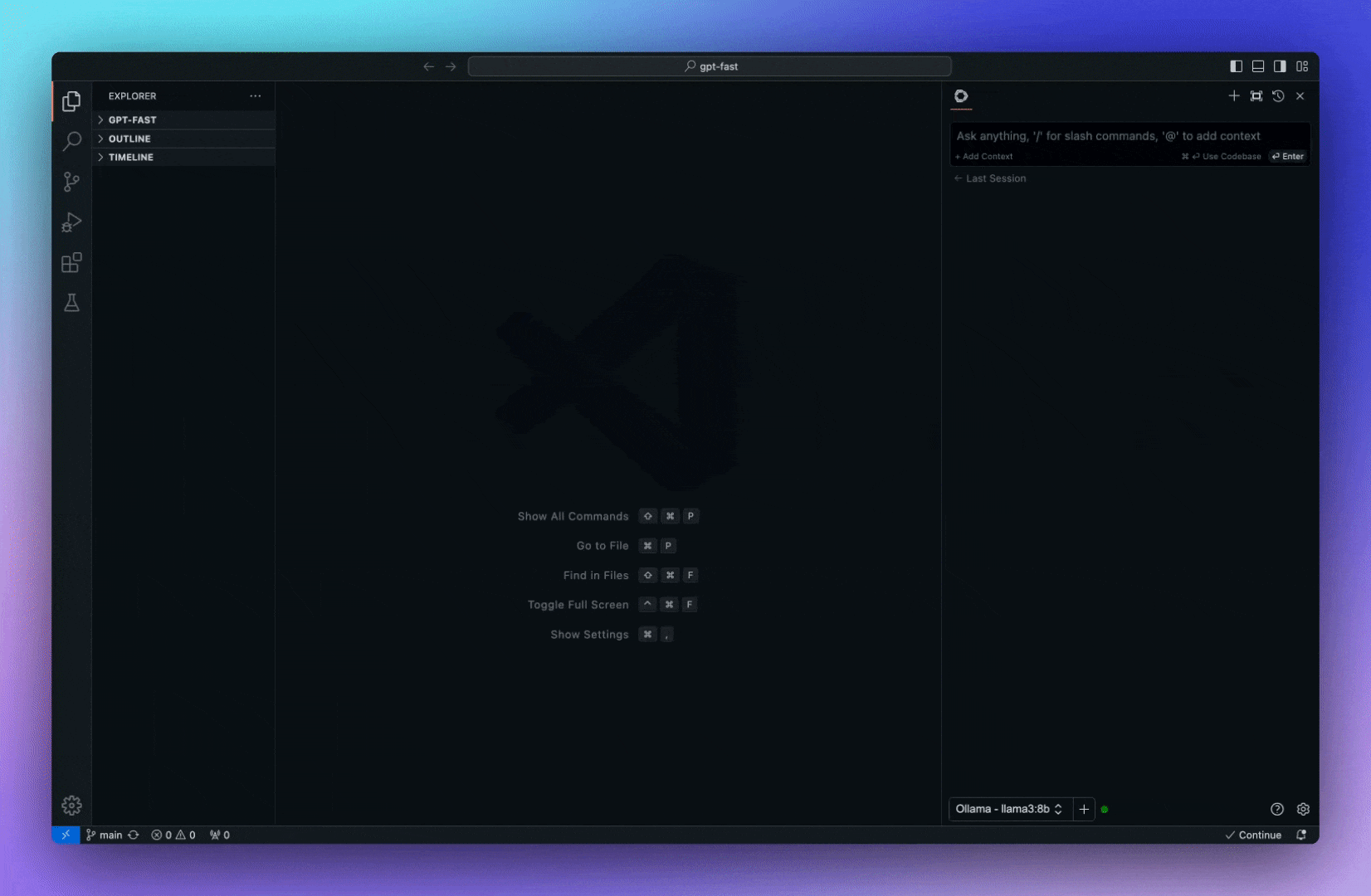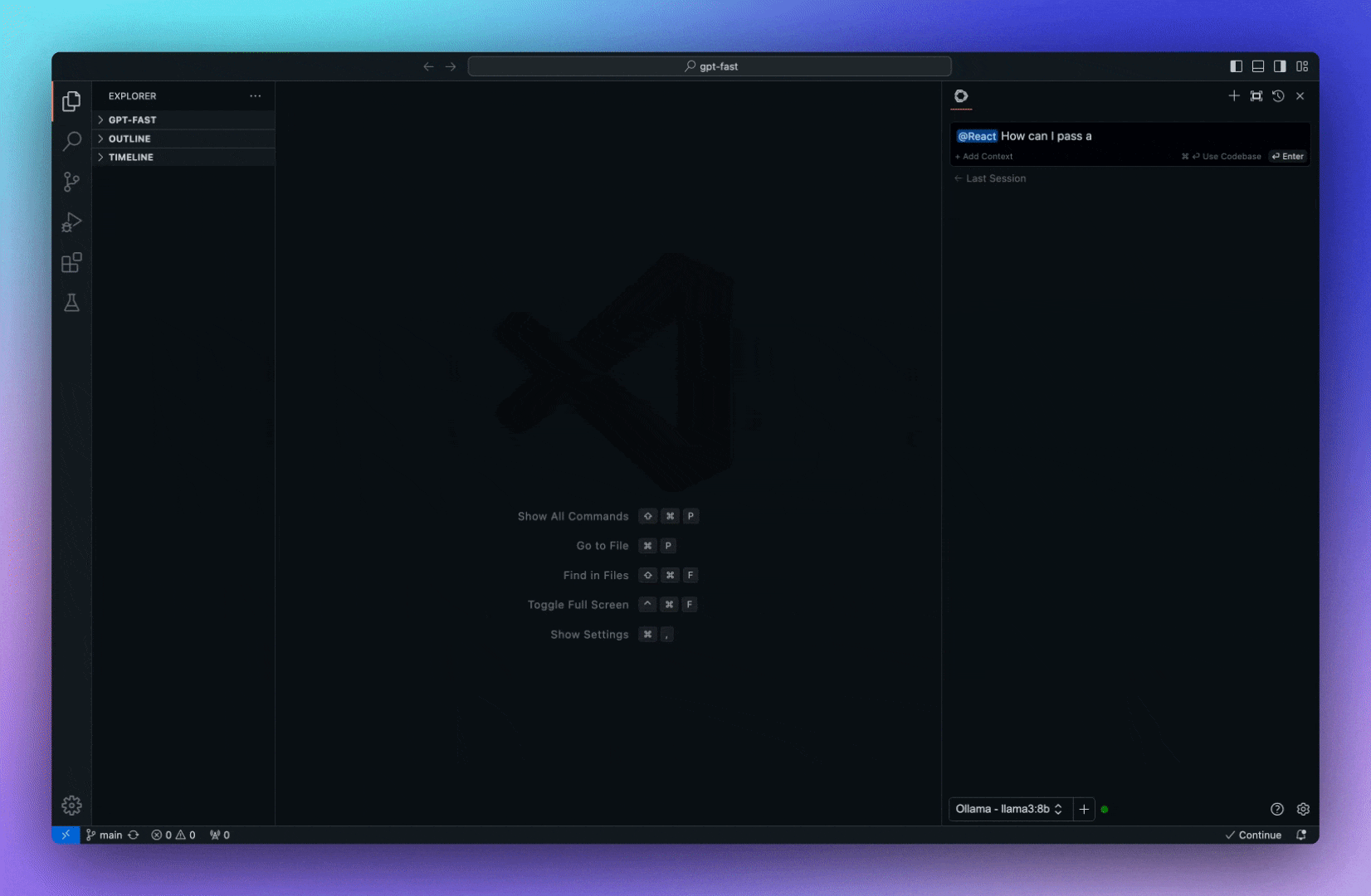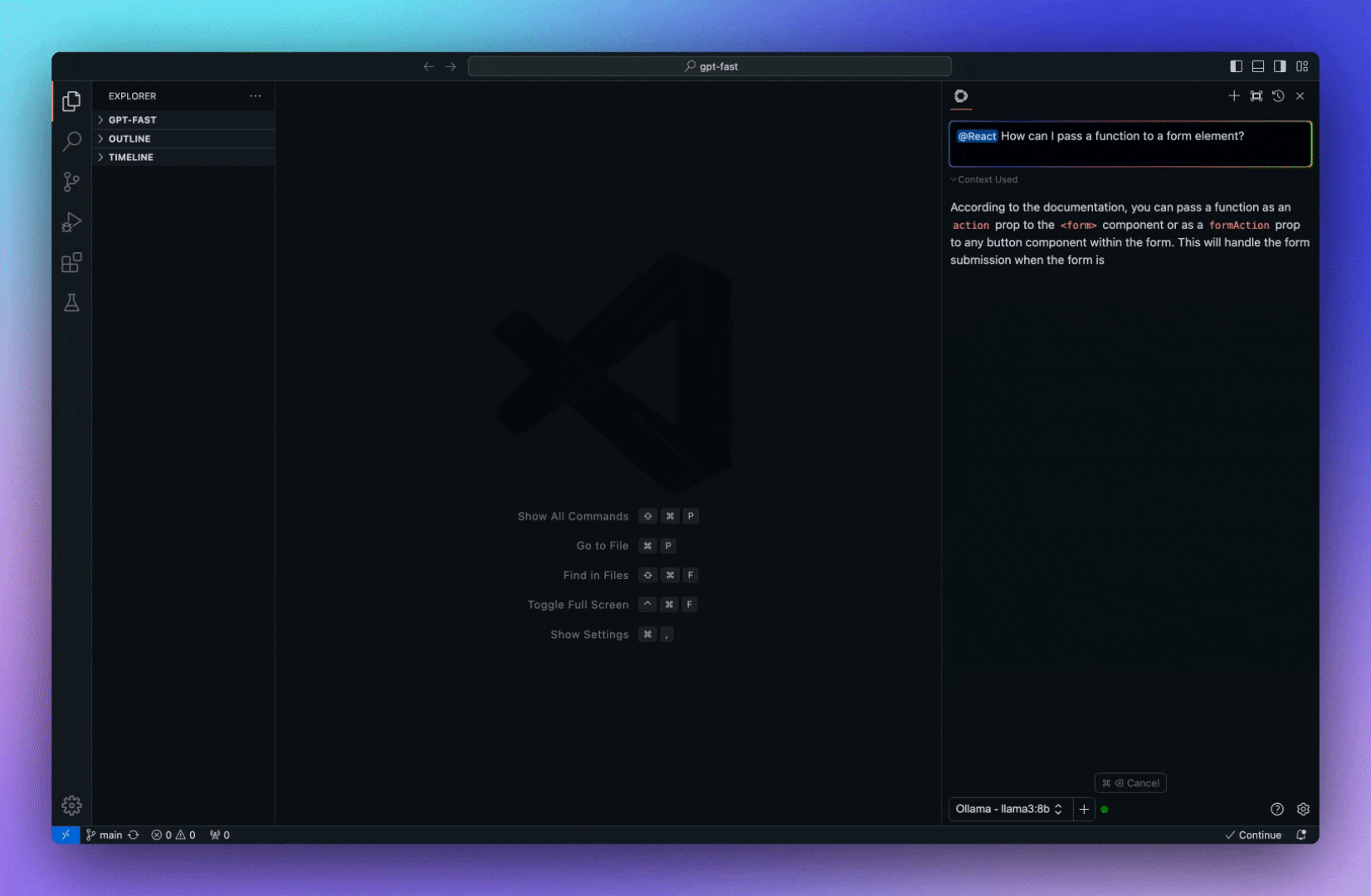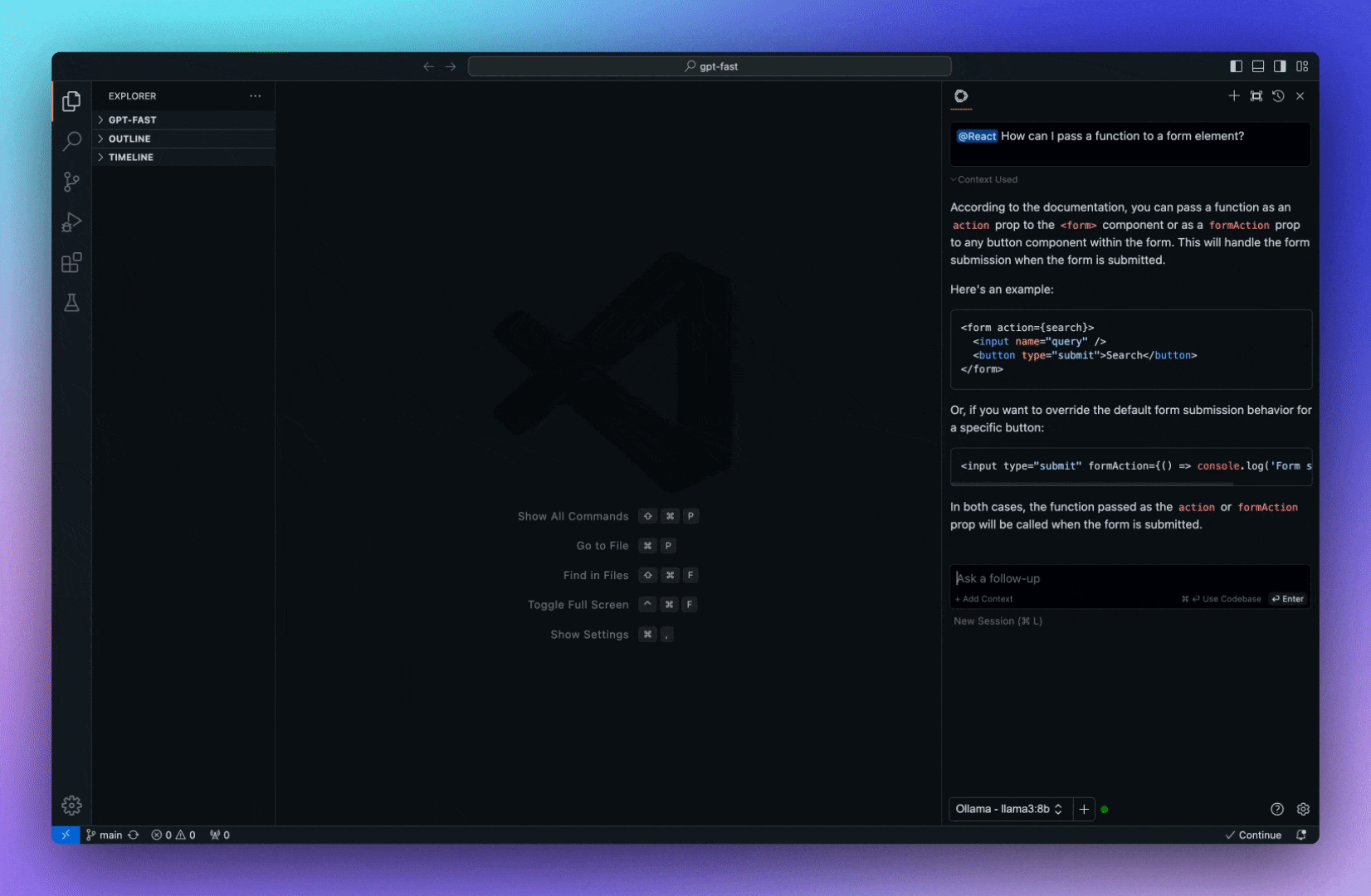 > 立即了解終端錯誤。 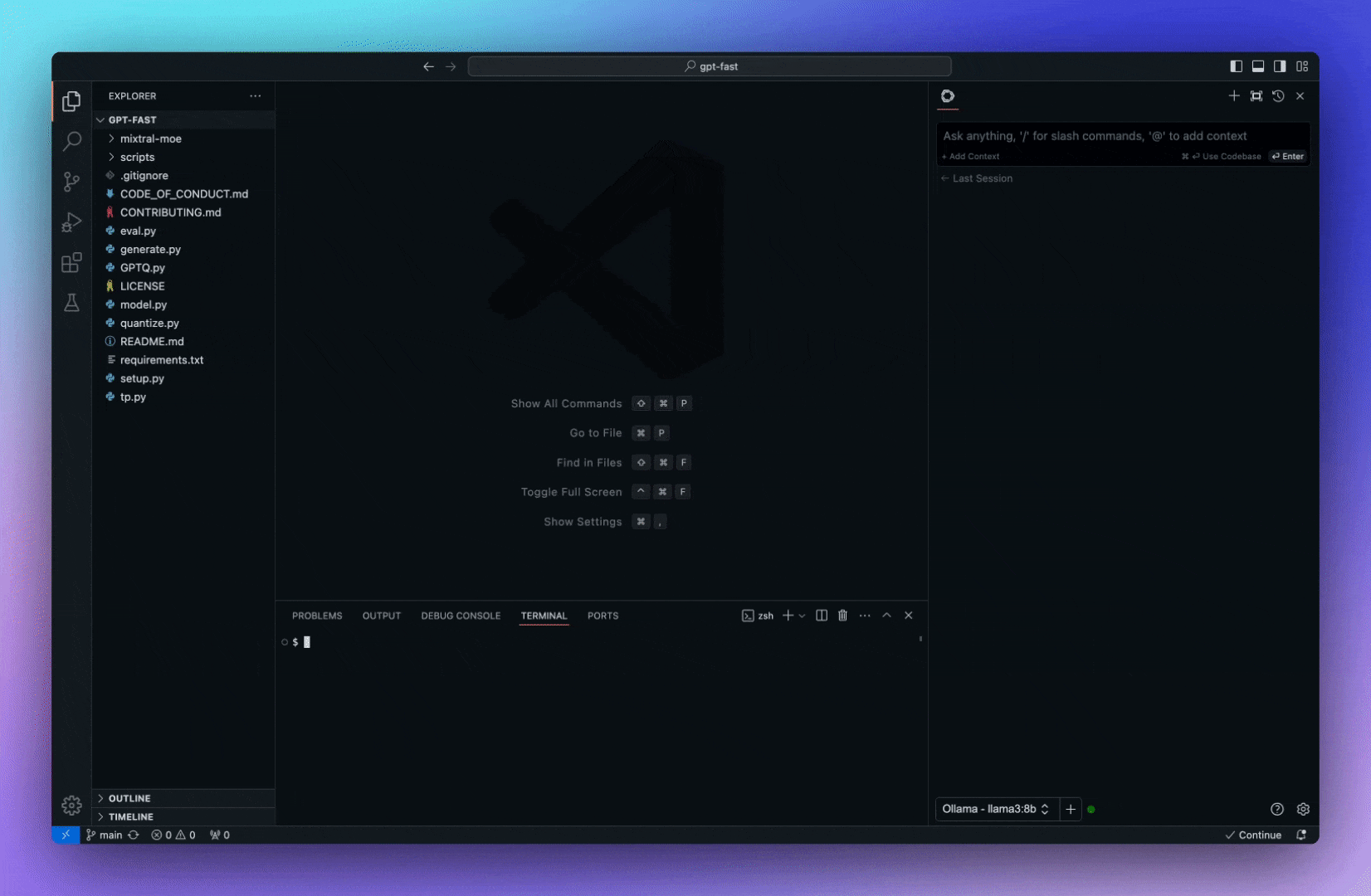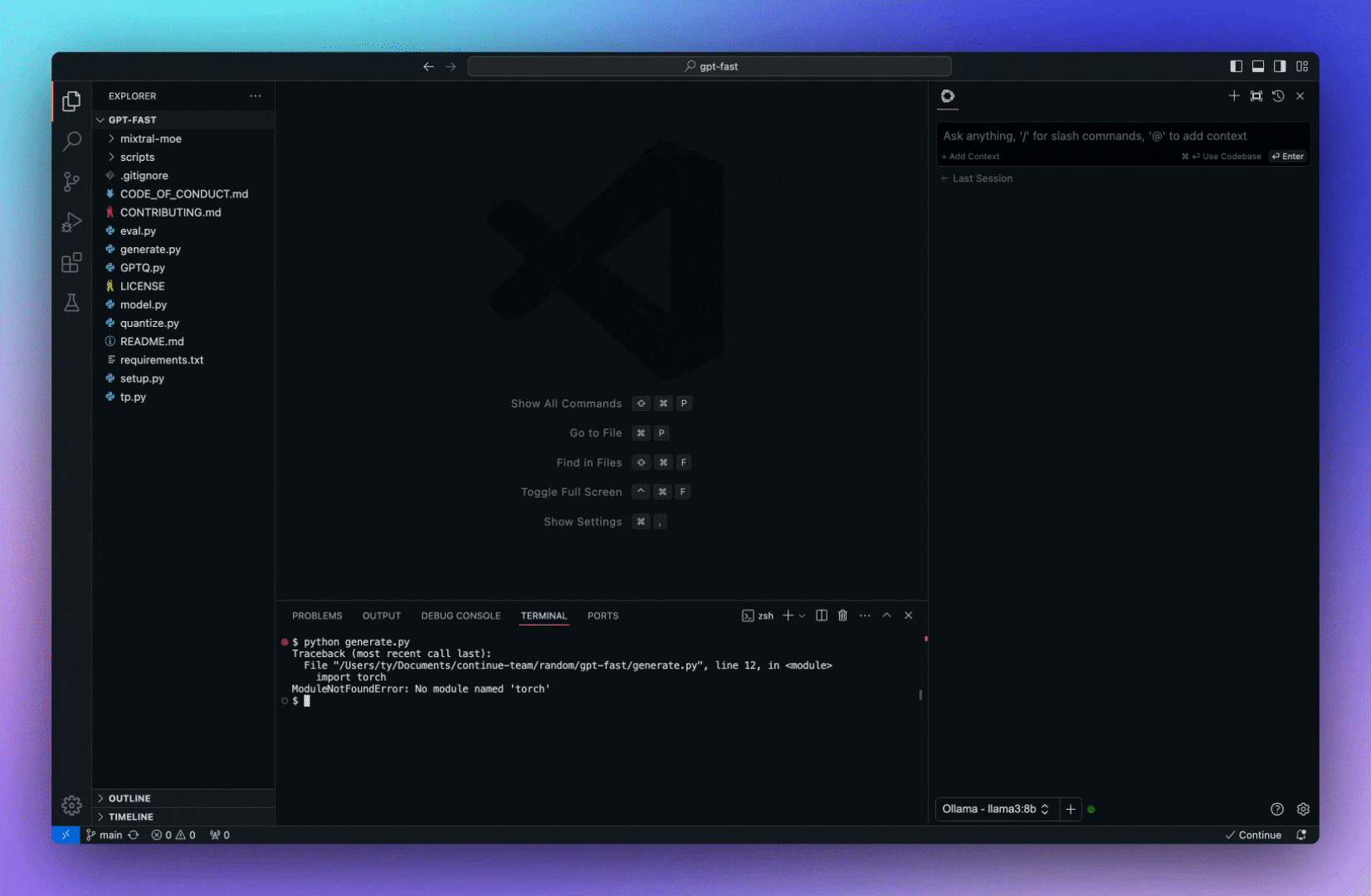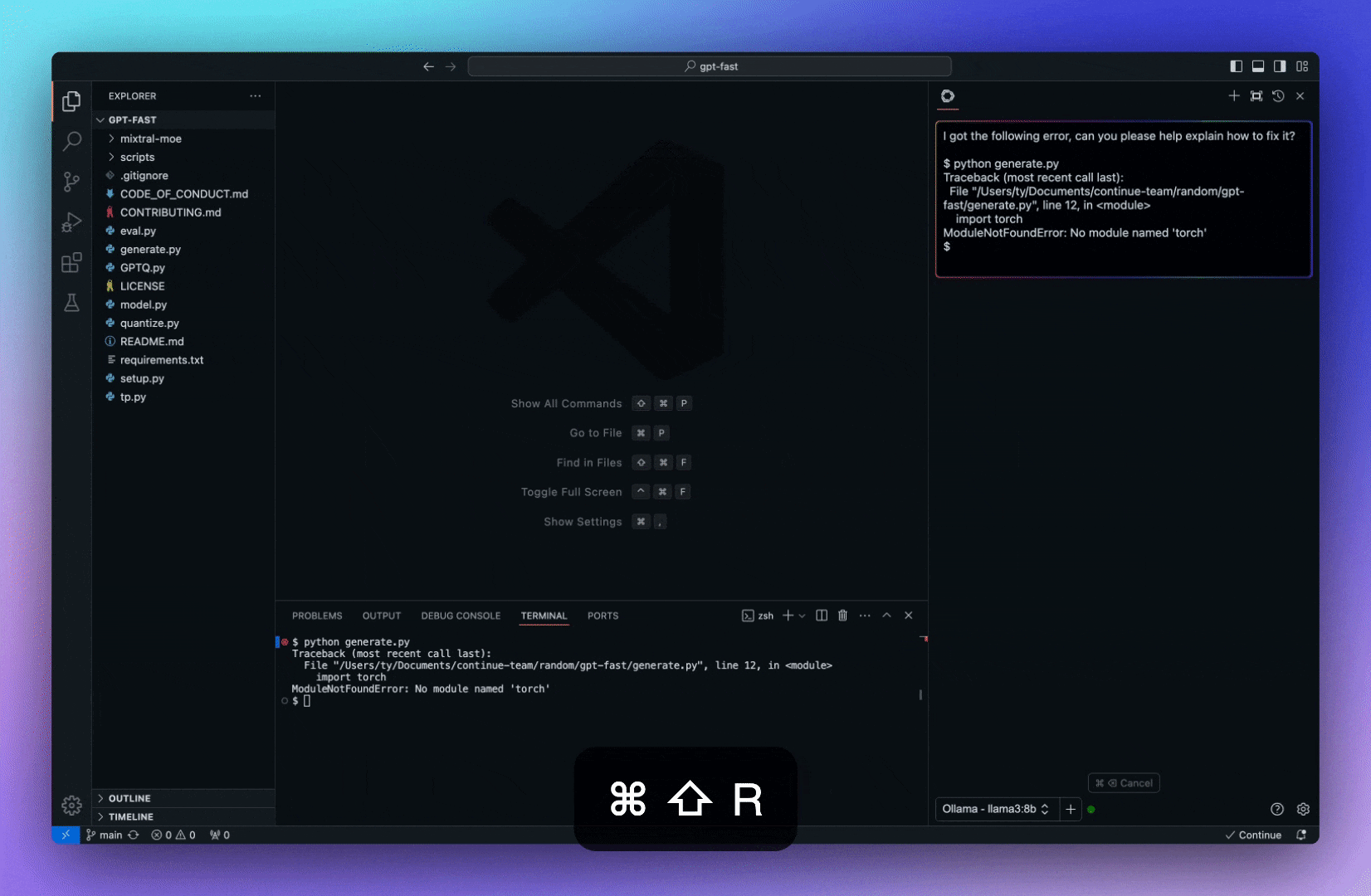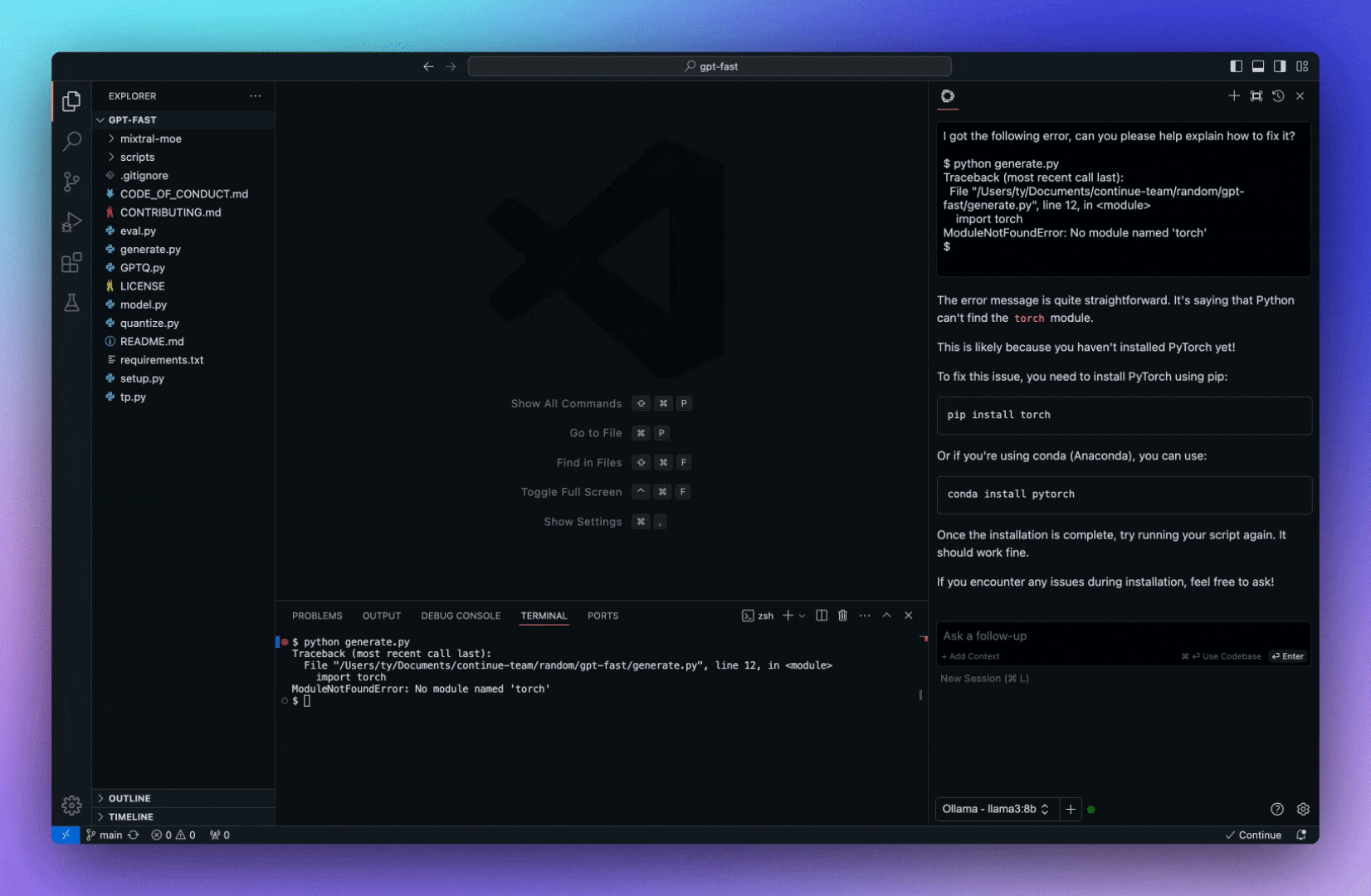 > 使用斜槓指令開始操作。  > 重構您正在編碼的函數。  了解所有[功能](https://docs.continue.dev/how-to-use-continue)。 您必須從市場安裝[VSCode 擴展](https://marketplace.visualstudio.com/items?itemName=Continue.continue),然後閱讀[快速入門指南](https://docs.continue.dev/quickstart)。 您可以閱讀[文件](https://docs.continue.dev/intro)。 它們在 GitHub 上擁有超過 10k 顆星,並使用 TypeScript 建置。 https://github.com/continuedev/continue 星繼續 ⭐️ --- 我從來沒有如此詳細地介紹過這麼多專案! 我希望這能幫助您創造一些鼓舞人心的東西。 請分享更多專案或任何您想要其他人可以學習的內容! 請關注 Copilotkit 以獲取更多此類內容。 https://dev.to/copilotkit --- 原文出處:https://dev.to/copilotkit/30-ai-libraries-you-can-use-for-your-next-project-ideas-5ded
算法是計算的命脈。它們是電腦解決問題、分析資料和做出決策所遵循的逐步指令。就像食譜一樣,它們將複雜的任務分解為易於管理的程式。理解這些基本演算法是掌握電腦科學和程式設計的基石。 > [什麼是演算法](https://github.com/m-mdy-m/algorithms-data-structures/tree/main/1.IntroductionToAlgorithmsAndProblemSolving) 1. 搜尋演算法: --------- ### 什麼是搜尋? 搜尋是在資料集合中定位特定元素或專案的基本過程。此資料集合可以採用各種形式,例如陣列、列表、樹或其他結構化表示。搜尋的主要目標是確定資料中是否存在所需元素,如果存在,則辨識其精確位置或檢索它。它在各種計算任務和現實應用中發揮重要作用,包括資訊檢索、資料分析、決策過程等。 ### 介紹搜尋演算法 所有搜尋演算法都使用搜尋關鍵字來繼續執行該過程。搜尋演算法預計會返回成功或失敗狀態,通常以布林 true/false 表示。可以使用不同的搜尋演算法,其效能和效率取決於資料及其使用方式。 線性搜尋演算法被認為是所有搜尋演算法中最基本的。最好的也許是二分搜尋。還有其他搜尋演算法,例如深度優先搜尋演算法、廣度優先演算法等。搜尋演算法中使用的符號是 O(n),其中 n 是完成的比較次數。它給出了演算法在給定條件下所需執行時間的漸近上限的概念。 搜尋演算法中的搜尋案例可以分為最佳情況、平均情況和最壞情況。在某些演算法中,所有三種情況可能漸近相同,而在其他一些演算法中可能存在很大差異。搜尋演算法的平均行為有助於確定演算法的有用性。 > 摘要: 搜尋演算法是用於在資料集合中定位特定資料的逐步過程。它被認為是計算中的基本過程。在電腦科學中,搜尋資料時,快速應用程式和較慢應用程式之間的差異通常在於使用正確的搜尋演算法。 ### 術語: - **目標元素:**這就是你要尋找的寶藏!這是您想要在集合中尋找的特定資料。想像搜尋電話簿 - 目標元素是特定人的電話號碼。 - **搜尋空間:**將其視為可能隱藏針的大海撈針。它代表您正在搜尋的整個資料集合。這可以是數字陣列、名稱列表或更複雜的資料結構。 - **複雜度:**這是指搜尋演算法所需的工作量。這就像衡量圖書館員需要做多少工作才能找到你的書。複雜性通常以時間(找到目標需要多長時間)和空間(演算法需要多少額外記憶體)來衡量。 - **確定性與非確定性:**搜尋演算法可以像遵循食譜(確定性)或進行有根據的猜測(非確定性)。確定性演算法始終遵循相同的清晰步驟,例如二分搜尋,它將搜尋空間一分為二。非確定性演算法(例如線性搜尋)可能需要在最壞的情況下檢查整個集合。 ### 實際應用 - **資訊檢索:**想像在網路上搜尋特定的食譜。像Google這樣的搜尋引擎利用複雜的搜尋演算法來篩選大量資料集,為網站和內容建立索引。當您輸入查詢時,這些演算法會辨識與您的搜尋字詞最相關的網頁,並在幾分之一秒內提供您要尋找的資訊。 - **資料庫系統:**資料庫儲存大量訊息,從客戶記錄到金融交易。搜尋演算法是高效資料檢索的支柱。當您在資料庫管理系統中提交查詢時,搜尋演算法會快速找到符合您條件的特定記錄,從而節省您的時間和精力。 - **電子商務:**線上購物因高效搜尋而蓬勃發展。電子商務平台使用搜尋演算法來幫助您找到完美的產品。它們允許您根據價格、品牌或顏色等各種標準進行過濾和搜尋。在幕後,搜尋演算法為這些過濾器提供支持,精確定位滿足您偏好的產品,使您的購物體驗順暢高效。 - **網路:**網路是一個由互連設備組成的複雜網路。搜尋演算法在有效路由資料包方面發揮著至關重要的作用。它們可協助確定訊息在網路上傳輸的最佳路徑,確保您的視訊通話或線上遊戲順利運作。 - **人工智慧(AI):**人工智慧正在為許多領域帶來革命性的變化。搜尋演算法是人工智慧應用的基本工具。它們使人工智慧系統能夠解決問題、做出決策,甚至玩國際象棋等遊戲。透過有效地搜尋大量資料並辨識模式,搜尋演算法有助於人工智慧背後的智慧。 - **模式辨識:**模式辨識允許電腦辨識和理解資料中的模式,例如圖像、語音或手寫。搜尋演算法對於模式辨識很有幫助。它們可協助電腦將新資料與現有模式進行匹配,從而實現照片中的臉部辨識或虛擬助理的語音辨識等應用。 ### 演算法類型:  **1. `Linear Search` :** 想像一下,在一個雜亂無章的書架中尋找一本特定的書。線性搜尋模仿了這種方法。這是一種簡單的方法,可以**逐項**檢查集合中的每個專案,直到找到目標元素(您想要的書)。 **它的工作原理如下:** 1. 搜尋從集合中的第一項開始。 2. 此演算法將目標元素與目前專案進行比較。 ``` * If they match, the search is successful, and the algorithm returns the location (index) of the target element. ``` ``` * If they don't match, the algorithm moves on to the next item in the collection. ``` 3. 這種比較和移動的過程將持續下去,直到找到目標元素或耗盡整個集合。 **例子:** 讓我們在未排序清單中搜尋值「25」:\[10, 4, 12, 25, 18, 7\]。 - 搜尋從第一個元素 (10) 開始。由於 10 不是 25,我們繼續。 - 我們將目標 (25) 與下一個元素 (4) 進行比較。沒有匹配項,所以我們繼續。 - 重複此過程,直到到達索引 3 處的元素「25」。 **優勢:** - 易於理解和實施,使其成為初學者的好選擇。 - 適用於未排序的資料,在各種情況下提供靈活性。 **弱點:** - 對於大型資料集來說速度很慢。隨著集合大小的增加,搜尋時間也會成比例增加,導致海量資料集效率低。 > 怎麼運作的 : 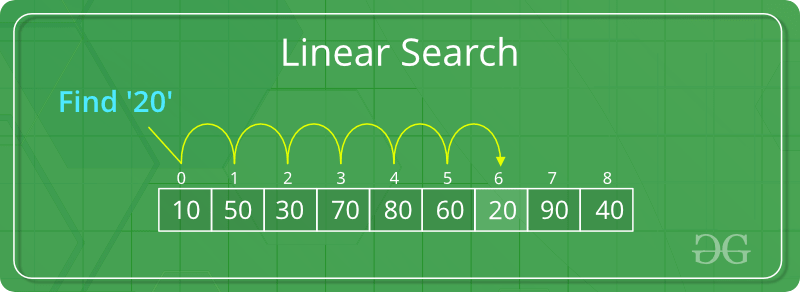 **2. `Binary Search` :** 二分搜尋在**排序資料**上蓬勃發展。想像一下在一本精心組織的字典中搜尋特定單字。在這種情況下,二分搜尋比線性搜尋快得多。它透過重複地將已排序的集合分成兩半來進行操作。策略如下: 1. 此演算法首先將目標元素與集合的中間元素進行比較。 2. 如果目標元素等於中間元素,則搜尋成功,演算法會傳回中間元素的索引。 3. 如果目標元素**小於**中間元素,則在剩餘集合的**左半部**(不包括中間元素)繼續搜尋。 4. 如果目標元素**大於**中間元素,則在剩餘集合的**右半部**繼續搜尋。 5. 在集合的縮小範圍的一半上重複步驟 1-4,直到找到目標元素或搜尋空間減少到單一元素(與目標不符)。 **例子:** 讓我們在排序清單中搜尋值「18」:\[4, 7, 10, 12, 18, 25\]。 - 中間的元素是 12。 - 現在,右半部的中間元素是18。目標元素位於索引 4 處。 **優勢:** - 對於大型排序資料集,比線性搜尋快得多。透過在每次比較時消除一半的剩餘元素,二分搜尋可以快速縮小搜尋空間。 **弱點:** - 要求預先對資料進行排序,如果資料尚未組織,則加入額外的步驟。 - 不適合未排序的資料。二分搜尋策略依賴資料的排序性質,以在每次迭代期間有效地消除一半的可能性。 > 怎麼運作的 : 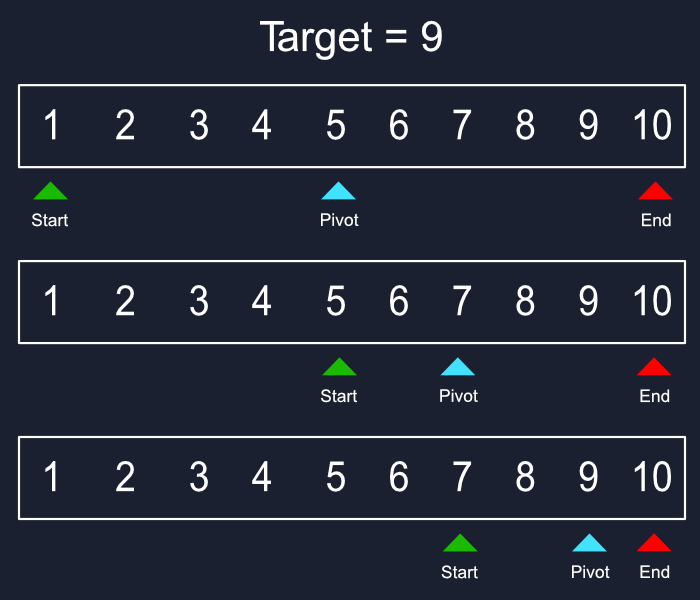 --- 2. 排序演算法: --------- ### 什麼是排序? 排序是指根據元素上的比較運算子對給定陣列或元素列表進行重新排列。比較運算子用於決定對應資料結構中元素的新順序。排序意味著將所有元素按升序或降序重新排序。 ### 介紹 在計算機科學中,排序演算法是將列表中的元素依序排列的演算法。最常用的順序是數字順序和字典順序,以及升序或降序。高效排序對於優化需要輸入資料位於排序清單中的其他演算法(例如搜尋和合併演算法)的效率非常重要。排序對於規範化資料和產生人類可讀的輸出通常也很有用。 形式上,任何排序演算法的輸出必須滿足兩個條件: 輸出是單調順序的(根據所需的順序,每個元素不小於/大於前一個元素)。 1. 輸出是輸入的排列(重新排序,但保留所有原始元素)。 2. 為了獲得最佳效率,輸入資料應儲存在允許隨機存取的資料結構中,而不是僅允許順序存取的資料結構中。 > 摘要:排序演算法是一組指令,它將陣列或列表作為輸入並將專案排列成特定的順序。排序最常見的是數字或字母(或字典)順序,並且可以按升序(AZ,0-9)或降序(ZA,9-0)。 ### 術語: - **就地分類:**想像一下重新整理抽屜裡的衣服而不把所有東西都拿出來。就地排序的工作原理類似。這些演算法透過修改現有清單本身內元素的順序來對資料進行排序,從而需要最少的額外空間。例如選擇排序、冒泡排序和插入排序。 - **內部排序:**這是指完全在電腦主記憶體 (RAM) 內執行的排序演算法。整個資料集可以一次載入到記憶體中,使其適合中小型資料集。堆排序、冒泡排序和合併排序等內部排序演算法通常用於記憶體資料操作。 - **外部排序:**當處理超出主存容量的海量資料集時,外部排序就發揮作用。這些演算法將大型資料集分解為較小的區塊,在磁碟(輔助儲存)上對它們進行排序,然後按特定順序將排序後的區塊合併在一起。合併排序是外部排序演算法的一個流行範例。 - **穩定排序:**想像一下按標題對書籍清單進行排序,但您也希望保留具有相同標題的書籍最初列出的順序。穩定的排序演算法在排序過程中保持具有相等鍵(值)的元素的相對順序。歸併排序和插入排序是穩定排序演算法的範例。 - **不穩定排序:**並非所有排序演算法都優先考慮順序保留。不穩定的排序演算法僅專注於實現所需的排序順序(例如,升序或降序),並且可能會打亂具有相同鍵的元素的相對位置。快速排序和堆排序是不穩定排序演算法的例子。 ### 排序演算法的特徵: - **時間複雜度:**這是指排序演算法完成其工作所需的時間(以步驟或比較而言)。我們通常在三種情況下分析時間複雜度: ``` * **Worst-case:** This represents the maximum amount of time the algorithm could take for a particular data size, considering the worst possible input scenario. ``` ``` * **Average-case:** This reflects the average time the algorithm takes across various random inputs of the same size. ``` ``` * **Best-case:** This represents the minimum amount of time the algorithm could take for a specific data size, considering the most favorable input scenario (e.g., data already partially sorted). ``` - **空間複雜度:**這是指排序演算法在原始資料所佔用的空間之外執行其操作所需的額外記憶體量。就地排序演算法透過在現有記憶體分配中操作資料來使用最少的額外空間,而某些演算法在排序過程中可能需要額外的臨時儲存。 - **穩定性:**此屬性決定排序演算法是否保留排序輸出中具有相等值的元素的原始順序。穩定的排序演算法維護這些元素的相對位置,這在特定應用中可能很重要。例如,如果您按姓名對客戶記錄清單進行排序,並且兩個客戶具有相同的姓名,您可能需要穩定的排序來維護它們最初列出的順序(例如,按帳戶建立日期)。 - **就地排序:**如前所述,就地排序演算法非常節省內存,因為它們透過修改原始列表本身來對資料進行排序,從而需要最少的額外空間。當處理大型資料集或記憶體有限時,這可能是有利的。 - **適應性:**一些排序演算法可以適應它們正在排序的資料的特徵。自適應排序演算法可以利用資料中預先存在的順序來提高其效能。例如,如果資料已經部分排序,自適應演算法可能會調整其方法以利用該部分順序並實現更快的排序。 ### 排序演算法的應用: - **搜尋演算法:**想像在電話簿中搜尋特定聯絡人。排序演算法是二分搜尋等高效搜尋演算法的無聲夥伴。透過確保電話簿條目按字母順序組織(排序),二分搜尋可以比透過未排序清單的線性搜尋更快找到您的聯絡人。 - **資料管理:**資料是現代計算的命脈,但有效管理資料需要組織。排序演算法在資料管理中起著至關重要的作用。當您按名稱、日期或大小對文件清單進行排序時,您可以更輕鬆地找到所需的特定文件。此外,排序的資料有助於更快地檢索和分析,從而節省您的時間和精力。 - **資料庫最佳化:**資料庫儲存大量訊息,從客戶記錄到金融交易。排序演算法顯著提高了資料庫查詢的效能。當您在電子商務資料庫中搜尋特定產品時,資料庫可能會根據您的搜尋條件(例如價格)對產品清單進行排序,以快速提供最相關的結果。 - **機器學習:**機器學習演算法從資料中學習以進行預測或分類。然而,需要準備好資料才能進行有效的學習。排序演算法通常用於資料預處理步驟,以在將資料輸入機器學習模型之前組織和建構資料。這可以顯著提高學習過程的準確性和效率。 - **資料分析:**資料分析就是從資訊中提取見解。排序演算法在這個過程中起著至關重要的作用。透過按各種屬性(例如日期、位置、客戶人口統計)對資料進行排序,您可以辨識在未排序的資料集中可能不易明顯的模式、趨勢和異常值。這使得資料分析師能夠更深入地了解資料,為金融、行銷和科學研究等各個領域的更好決策提供資訊。 - **作業系統:**作業系統管理電腦的資源。排序演算法適用於各種作業系統任務。例如,排序演算法可用於確定 CPU 任務的優先權、有效管理記憶體分配或以目錄結構組織文件,從而確保電腦系統的平穩運作。 > 這些只是排序演算法如何滲透到我們日常生活中的幾個例子。 ### 簡單解釋: 想像一下,你有一個雜亂的書架,裡面擺滿了各種主題的書。您想要按類型來組織它們(對它們進行排序)。以下是應用於此場景的排序演算法背後的主要概念和邏輯: 1. **比較:**您一次拿兩本書,並根據它們的類型進行比較(就像比較清單中的兩個元素)。 2. **交換:**如果類型不符合所需的順序(例如,歷史書放在小說之前),則交換它們在書架上的位置(就像重新排列清單中的元素一樣)。 3. **重複:**您繼續一次比較和交換兩本書,直到所有書籍按類型按所需順序排列(清單中的所有元素都根據所選標準排序)。 ### 排序演算法:: **1. 冒泡排序** **概念:**冒泡排序是一種簡單的排序演算法,它迭代列表,反覆比較相鄰元素,如果順序錯誤則交換它們。想像氣泡上升到液體表面 - 具有較大值的元素每次通過都會「冒泡」到清單中。這個過程一直持續到不需要交換為止,這表示清單已排序。 **解釋:** 想像一下將一堆亂七八糟的玩具進行分類。冒泡排序的工作原理如下: 1. **進行多次遍歷:**您多次瀏覽玩具清單。 2. **比較鄰居:**在每一遍中,您將每個玩具與其鄰居進行比較。如果第一個玩具更大(或排序術語中的“更高”),則交換它們的位置。 3. **泡泡上升:**每次交換時,較大的玩具(如泡泡)往往會移向清單的末端。 4. **繼續直到沒有交換:**您在整個清單中重複這些比較和交換,直到完成一次完整的傳遞而無需交換。這表示列表已排序。 **時間複雜度:**不幸的是,在最壞情況和平均情況下,冒泡排序的時間複雜度都是 O(n^2)。這意味著排序時間隨著元素數量 (n) 的二次方增加。對於大型資料集,冒泡排序變得非常低效。 **2.選擇排序** **概念:**選擇排序也遍歷列表,但它不是直接比較相鄰元素,而是專注於尋找未排序部分中的最小(或降序最大)元素。然後,該元素與未排序部分中的第一個元素交換,有效地將其放置在正確的排序位置。重複此過程,在每次通過時逐漸將未排序部分減少一個位置。 **解釋:** 想像一下根據身高安排學生拍照。選擇排序的工作原理如下: 1. **尋找最矮的(或最高的):**在每次遍歷中,您搜尋該行的整個未排序部分以尋找最矮的學生(或按降序排列最高的學生)。 2. **與第一個學生交換:**一旦找到最矮的學生,就可以與未排序部分中的第一個學生交換他們的位置,有效地將他們放在行開頭的正確排序位置(最矮的在前面) 。 3. **重複並減少未排序部分:**繼續此過程,將交換的元素視為已排序部分的開頭,並在剩餘的未排序部分中搜尋最小元素。 **時間複雜度:**與冒泡排序類似,選擇排序在平均情況和最壞情況下的時間複雜度均為 O(n^2)。這意味著排序時間隨元素數量呈二次方增長,從而導致大型資料集效率低下。 **3.插入排序** **概念:**插入排序的工作原理是維護一個已排序的子列表,並迭代地將未排序部分中的元素插入到子列表中的正確位置。想像一下用塊建造一座塔,但您只能將它們一一加入,並且希望保持塔按高度排序。插入排序就像策略性地將每個新區塊放置在不斷增長的排序塔中的正確位置。 **解釋:** 想像一下按高度對書架上的書籍進行排序。插入排序的工作原理如下: 1. **從單一排序元素開始:**從一個空的排序子清單開始(就像書架上只有一本書)。 2. **從未排序的部分中取出一個元素:**您從未排序的堆中挑選一本書。 3. **移動與插入:**您可以將新書與已排序子清單中的每本書進行比較,從右端開始。如果新書較短(或按降序排列較高),則可以移動現有書籍以騰出空間,並將新書插入到正確的位置以保持排序順序。 4. **重複並增長已排序的子清單:**繼續此過程,從未排序的堆中獲取元素,將它們與已排序的子列表進行比較,並將它們插入到正確的已排序位置。這會逐漸增長排序的子列表,直到合併所有元素。 **時間複雜度:**插入排序適用於部分排序的資料。在一般情況下,對於已經排序的資料,它的時間複雜度為 O(n),因此非常有效率。然而,對於完全隨機的資料(最壞情況),它可以回落到 O(n^2),類似於冒泡排序和選擇排序。 **4. 歸併排序** **概念:**合併排序採用巧妙的「分而治之」策略來有效地對清單進行排序。它將問題分解為更小、更易於管理的子問題,然後按排序順序將解決方案重新組合在一起。 **解釋:** 想像一下,你有一支龐大的軍隊,需要按照身高來組織。歸併排序的工作原理如下: 1. **劃分:**將軍隊(列表)分成越來越小的組(子列表),直到每組只有一名士兵(元素)。這就像將一個大問題分解成更小、更容易解決的部分。 2. **征服:**由於現在每個子清單只有一名士兵(元素),因此它已被視為「已排序」。這是分而治之方法的基本情況。 3. **合併:**現在到了合併部分。您可以策略性地將已排序的子清單重新組合在一起,但以特定的方式。您比較每個子清單中的第一個士兵(元素),並將較短的士兵(較小的元素)放入最終的排序清單中。您不斷重複這種比較和放置,直到兩個子清單中的所有士兵(元素)都合併到最終的排序清單中。 4. **重複:**您繼續遞歸地應用這種分而治之的策略,直到整個原始軍隊(列表)從最短到最高(最小到最大)排序。 **時間複雜度:**合併排序的美妙之處在於它的時間複雜度。在平均情況和最壞情況下,其複雜度為 O(n log n)。這意味著對清單進行排序所需的時間隨著元素數量(n) 呈對數增長,這比冒泡排序、選擇排序或插入排序(其複雜度為O(n^2))要快得多。 **5. 快速排序** **概念:**快速排序是另一種分而治之的排序演算法,但採用不同的方法。它依賴一個被稱為“樞軸”的策略性選擇元素來對列表進行分區並解決排序問題。 **解釋:** 想像一下,你的書架上堆滿了雜亂的書。快速排序的工作原理如下: 1. **選擇樞軸:**您從書架中選擇一本書(樞軸)。可以透過不同的方式選擇該主元,但通常它是清單中的第一個或最後一個元素。 2. **分區:**依樞軸重新排列書架上的書。類型按字母順序排列在樞軸類型之前的書籍位於一側,類型按字母順序排列在樞軸類型之後的書籍位於另一側。樞軸本身尚未放置。這種劃分有效地將較大的排序問題劃分為兩個較小的子問題。 3. **遞歸地征服:**現在,您將兩個子清單(成堆的書)中的每一個都視為單獨的排序問題。您可以遞歸地將快速排序策略套用到這些子列表,為每個子列表選擇一個新的主元並相應地對它們進行分割。 4. **合併:**兩個子清單排序後,將原始樞軸元素放置在兩個子清單之間正確的排序位置。現在,整個書架(清單)按字母順序排序。 **時間複雜度:**平均而言,快速排序的時間複雜度為 O(n log n),這使得它對大型資料集非常有效率。然而,其性能可能會根據所選樞軸元件的不同而有所不同。選擇不當的主元(例如,總是排序或部分排序清單中的第一個或最後一個元素)可能會導致O(n^2) 的最壞情況,類似於冒泡排序、選擇排序和插入排序。 --- 3.樹的遍歷演算法: ---------- ### 什麼是樹遍歷? 樹遍歷是指探索樹資料結構的系統方法。這就像有一個路線圖可以精確地存取鄰裡(樹)中的每個房屋(節點)一次,確保您不會迷路或重新存取同一棟房屋。與可以直接按位置存取元素的簡單資料結構不同,樹需要特定的演算法來導航節點之間的連接。這些遍歷演算法定義了存取每個節點的順序,可讓您對它們包含的資料執行操作,例如搜尋特定值、新增節點或刪除現有節點。遍歷技術有多種,每種技術都有其優點和應用,這使得樹遍歷成為電腦科學中的基本概念。 ### 介紹 樹遍歷,也稱為樹搜尋,是在僅包含樹邊的圖上執行的演算法,該演算法僅存取每個節點一次。此類別中的演算法僅在存取每個節點的順序上有所不同。遍歷樹的兩種經典方法是廣度優先搜尋(bfs),即在進入下一層之前存取同一級別或距根部距離的節點;深度優先搜尋,其中分支中的所有節點或從根到葉的一組路徑在傳遞到下一個分支之前都會被存取。還有其他方法,它們使用啟發式或隨機採樣在樹中移動來加速該過程。 #### 概括: - **目的:**系統探索樹資料結構,確保每個節點僅被存取一次。 - **優點:**支援搜尋特定資料、插入新節點或刪除現有節點等操作。 - **主要區別:**演算法分為兩種主要方法: ``` * **Breadth-First Search (BFS):** Visits nodes level by level, starting from the root and progressing outward. ``` ``` * **Depth-First Search (DFS):** Explores one branch (path) as far as possible before backtracking and exploring another branch. Further variations of DFS exist for specific applications. ``` - **其他技術:**其他方法利用啟發式或隨機取樣來加快遍歷速度。 ### 術語: **1. 樹:**一種分層資料結構,模擬顛倒的樹,其節點(資料點)透過邊(連結)連接。節點可以有零個或多個子節點,形成分支,並最終導致底部的葉節點(沒有子節點的節點)。 **2. 節點:**樹的基本建構塊,包含資料和對其子節點的潛在引用。想像一下附近的一棟房子——它保存資訊(資料)並透過道路(邊緣)連接到其他房子(子節點)。 **3.根節點:**樹中最頂層的節點,作為遍歷演算法的起點。將其視為附近的主屋,從這裡開始探索。 **4.葉子節點:**沒有子節點的節點,代表樹中分支的「末端」。想像位於社區邊緣的房屋,沒有進一步的聯繫。 **5.邊:**樹中兩個節點之間的連接,描述它們之間的關係。想想連接附近房屋的道路。 **6. 遍歷:**僅存取樹中每個節點一次的系統過程。這就像探索整個社區,確保您參觀每棟房屋而不會錯過任何一棟或重新參觀同一棟房屋。 **7.廣度優先搜尋(BFS):**一種從根開始向外逐階存取節點的遍歷方法。想像一下,透過造訪第一條街道(層)上的所有房屋,然後再前往下一條街道(層)上的房屋來探索社區。 **8.深度優先搜尋(DFS):**一種遍歷方法,在回溯和探索另一個分支之前,先沿著一個分支(路徑)探索盡可能遠的地方。想像一下,沿著一條路(分支)探索附近區域,直到到達死胡同(葉節點),然後回溯並嘗試另一條路。 DFS 的常見變體包括前序、中序和後序,每種形式都有存取分支內節點的特定順序。 ### 樹遍歷演算法的特點: **1. 只存取每個節點一次:** - 樹遍歷的核心原則是保證樹中的每個節點都被恰好存取一次。這可以防止冗餘處理並確保對樹結構的完整探索。 **2. 探訪順序:** - 雖然每個節點僅被存取一次,但樹遍歷演算法的定義特徵在於它們存取節點的順序。不同的演算法會優先考慮以特定順序探索節點,從而產生不同的遍歷模式。 **3. 遞歸與迭代實作:** - 樹遍歷演算法可以遞歸或迭代地實現。遞歸方法涉及定義在子樹上呼叫自身的函數,模仿樹的層次結構性質。迭代方法利用迴圈和堆疊來管理遍歷過程。 **4.時間與空間複雜度:** - 與任何演算法一樣,樹遍歷方法具有相關的時間和空間複雜度。時間複雜度是指基於樹中節點數 (n) 執行演算法所需的時間量。常見的複雜度包括 O(n)(線性)和 O(n log n)(對數),BFS 和 DFS 變體根據實現的不同具有不同的複雜度。空間複雜度反映了演算法執行所需的額外記憶體量,通常取決於用於遍歷的資料結構(例如堆疊)。 **5.特定於應用的選擇:** - 樹遍歷演算法的選擇在很大程度上取決於手頭上的具體任務。例如,BFS 可能更適合尋找樹中兩個節點之間的最短路徑,而具有變體的 DFS 可用於搜尋特定資料或探索所有可能的路徑。 **6. 不可修改:** - 一般來說,樹遍歷演算法旨在探索現有的樹結構,而不修改樹本身。它們存取節點,對它們包含的資料執行操作,但通常不會更改樹中的連接或資料。 ### 樹遍歷演算法的應用: **1. 檔案系統導航:** - 作業系統使用樹遍歷演算法來導航電腦上的目錄結構。將您的檔案系統想像成一棵樹,其中資料夾作為節點,子資料夾和檔案作為子節點。廣度優先搜尋 (BFS) 可用於列出目錄及其子目錄中的所有文件,而深度優先搜尋 (DFS) 可用於在層次結構中定位特定文件。 **2. 網頁抓取:** - 像 Google 這樣的搜尋引擎利用 BFS 或 DFS 變體來抓取網路。他們從種子 URL(根節點)開始,有系統地探索連結的網頁(子節點)。 BFS 確保在進入更深層次之前探索特定層級(網站)的所有頁面,而 DFS 可能會在回溯和探索其他網站之前更深入地研究特定網站。 **3.人工智慧(AI):** - 人工智慧中的遊戲演算法通常使用樹遍歷來探索可能的動作及其結果。將西洋棋遊戲想像成一棵樹,當前棋盤狀態作為根節點,潛在的移動作為通往新棋盤狀態(子節點)的分支。具有修剪技術的深度優先搜尋可用於評估潛在的移動並確定最有希望的策略。 **4.社會網絡分析:** - 社群媒體平台利用樹遍歷來推薦聯繫或探索朋友網路。將您的個人資料想像為一個節點,將朋友作為子節點。遍歷演算法可用於建議基於共同朋友(樹中的共同祖先)的連接或探索網路以了解資訊流或影響力。 **5.電腦圖形學:** - 光線追蹤是一種用於在 3D 圖形中實現逼真光照效果的技術,通常採用樹遍歷演算法。虛擬場景可以表示為一棵樹,其中物件作為節點,它們的空間關係作為邊緣。遍歷有助於確定光線與哪些物件交互,從而建立逼真的陰影和反射。 **6. 網路路由:** - 電腦網路中的路由協定使用樹遍歷的變體來找到資料包到達目的地的最佳路徑。將網路想像成一棵樹,路由器作為節點,連接作為邊緣。遍歷演算法有助於確定資料在網路中不同點之間傳輸的最有效路徑。 ### 簡單解釋: 想像一下,您是一名送貨員,您有一堆包裹要在附近送貨。附近的房屋透過道路連接起來,形成樹狀結構。 - **房屋是節點:**每個房屋代表樹中的一個節點,包含地址(資料)等資訊以及可能由道路(邊)連接的相鄰房屋(子節點)的地址。 - **您的遞送路線就是遍歷:**樹遍歷演算法定義您存取每個房屋(節點)以遞送包裹(對資料執行操作)的順序。 **您可以透過兩種主要方式進行交付,這對應於兩種常見的樹遍歷方法:** **1. 廣度優先搜尋(BFS):像一個不斷擴大的圓圈一樣提供:** - 您從清單中的第一個房子(根節點)開始。 - 您將包裹運送到該房屋,然後**存取同一條街道(層)上與其直接相連的所有房屋(鄰居/子節點),**然後繼續前進。 - 一旦您運送到第一條街道(層)上的所有房屋,您就會移動到下一條街道(層)並重複該過程,在前往下一層之前存取該層上的所有房屋。 這就像一個不斷擴大的圓圈——您從中心(根部)開始,逐漸向外工作,確保在移動到下一個之前,您可以運送到街道(層)上的所有房屋。如果您想先優先考慮向附近區域的所有房屋送貨,這種方法很有用,也許是因為它們都在同一個街區,並且最大限度地減少行程時間很重要。 **2. 深度優先搜尋(DFS):深入研究一條街道:** - 您從清單中的第一棟房子(根節點)開始。 - 您將包裹運送到該房屋,然後**選擇一條從該房屋引出的相連道路(分支),並沿著它一直走到終點(葉節點)** ,在原路返回之前運送到該路徑(分支)上的所有房屋。 - 一旦到達該路的盡頭(分支),您就回溯到最後一個路口(父節點)並選擇另一條路(分支)進行探索,將物品運送到該新路徑上的所有房屋,直到到達另一個死胡同(葉節點) 。 這就像探索迷宮一樣——你選擇一條路徑(分支)並沿著它一路走下去,運送到沿途的房屋,直到你到達死胡同(葉節點)。然後你原路返回並嘗試另一條路徑(分支),直到你到達所有房屋。如果您正在快速查找特定地址並希望在前往另一條街道(分支)之前探索整條街道(分支),則此方法可能會很有用。 ### 演算法類型: **1.廣度優先搜尋(BFS):** - **概念:** BFS逐級存取節點,從根節點開始,逐層向外進行。想像一下探索一個家譜; BFS 將在向下移動到其子節點(下一層)之前存取所有兄弟節點(同一層級的節點)。 - **怎麼運作的:** ``` 1. Start at the root node and add it to a queue (a data structure that follows a "first-in, first-out" principle). ``` ``` 2. Remove the first node from the queue and visit it (process its data). ``` ``` 3. Add all the unvisited child nodes of the removed node to the back of the queue. ``` ``` 4. Repeat steps 2 and 3 until the queue is empty. ``` - **例子:** 考慮一棵簡單的樹: ``` A / \ B C / \ / \ D E F G ``` BFS 遍歷將依下列順序存取節點:A、B、C、D、E、F、G。 **2.深度優先搜尋(DFS):** - **概念:** DFS 沿著一個分支(路徑)探索盡可能遠的距離,然後回溯並探索另一個分支。 DFS 還有更多變體,但這裡我們將重點放在基本方法上。 - **怎麼運作的:** ``` 1. Start at the root node. ``` ``` 2. Visit the node (process its data). ``` ``` 3. If there are any unvisited child nodes, choose one and repeat steps 2 and 3, essentially following that branch (path) until you reach a leaf node (a node with no children). ``` ``` 4. Once you reach a leaf node, backtrack to the parent node and repeat step 3, exploring another unvisited child node (if any) of the parent. ``` ``` 5. Continue backtracking and exploring until all nodes have been visited. ``` - **例子:** 使用與之前相同的樹: ``` A / \ B C / \ / \ D E F G ``` DFS 遍歷可以以各種順序存取節點,具體取決於每一步選擇的子節點。可能的順序是:A、B、D、E、C、F、G。 **主要區別:** - BFS強調逐級存取節點,確保在深入之前先進行更廣泛的探索。 - DFS 優先考慮完全探索一個分支(路徑),然後再轉向另一個分支(路徑),可能會更快到達特定節點,但不能保證逐級存取。 結論 : ---- 總而言之,這個基本演算法之旅為您理解基本的搜尋、排序和樹遍歷技術奠定了堅實的基礎。這些解釋使用了清晰的語言和相關的類比,使這些抽象概念更加平易近人、直觀。無論您是經驗豐富的程式設計師還是剛開始涉足電腦科學,這種理解都為建立高效且有效的程式奠定了基石。 隨著您對知識的渴望與日俱增,請更深入研究!我的儲存庫充滿了各種演算法和資料結構,等待您的探索([演算法-資料-結構](https://github.com/m-mdy-m/algorithms-data-structures))。這是一個寶庫,您可以在這裡進行實驗、練習並鞏固您對這些基本建置模組的掌握。 **雖然某些部分仍在建設中,**反映了我自己正在進行的學習旅程(這個旅程可能需要 2-3 年才能完成!),但儲存庫正在不斷發展。 冒險不止於探索!我非常重視您的反饋。在文章中遇到障礙?有建設性的批評要分享嗎?還是只是想引發一場關於演算法的對話?我的門(或者更確切地說,我的收件匣)總是開著的。在 Twitter 上聯絡: [@m\_\_mdy\_\_m](https://twitter.com/m__mdy__m)或 Telegram:@m\_mdy\_m。此外,我的 GitHub 帳戶[m-mdy-m](https://github.com/m-mdy-m)歡迎討論和貢獻。讓我們共同建立一個充滿活力的學習社區,在這裡我們分享知識並突破我們的理解界限。 --- 原文出處:https://dev.to/m__mdy__m/basic-algorithms-5bep
*揭露:這篇文章包含附屬連結;如果您透過本文中提供的不同連結購買產品或服務,我可能會獲得補償。* [](https://bit.ly/3cNF0vw) image\_credit -[指數](https://bit.ly/3cNF0vw) 您好,作為開發人員,充分理解基本系統設計概念對於開發可擴展、可靠和高效能的軟體系統至關重要。 [**系統設計**](https://medium.com/javarevisited/7-system-design-problems-to-crack-software-engineering-interviews-in-2023-13a518467c3e)涉及設計軟體系統的體系結構和元件,以滿足特定要求並實現所需的性能特徵。 隨著技術的快速進步和軟體應用的複雜性不斷增加,掌握系統設計概念對於程式設計師建立高效且有效的系統至關重要。 在上幾篇文章中,我回答了流行的系統設計問題,例如[API 網關與負載平衡器](https://dev.to/somadevtoo/difference-between-api-gateway-and-load-balancer-in-system-design-54dd)以及[水平與垂直擴展](https://dev.to/somadevtoo/horizontal-scaling-vs-vertical-scaling-in-system-design-3n09),今天,我們將看看每個程式設計師都應該學習的 10 個關鍵系統設計概念。 這些概念為設計能夠處理大規模資料、容納並髮用戶並提供最佳效能的軟體系統奠定了堅實的基礎。 無論您是初學者還是經驗豐富的開發人員,了解這些系統設計概念都將使您能夠建立強大且可擴展的軟體系統,以滿足現代應用程式的需求。那麼,讓我們深入探討這些基本的系統設計原則吧! 順便說一句,如果您正在準備系統設計面試並想深入學習系統設計,那麼您還可以查看[**ByteByteGo**](https://bit.ly/3P3eqMN) 、 [**Design Guru**](https://bit.ly/3pMiO8g) 、 [**Exponent**](https://bit.ly/3cNF0vw) 、 [**Educative**](https://bit.ly/3Mnh6UR)和[**Udemy**](https://bit.ly/3vFNPid)等網站,它們有許多很棒的系統設計課程 以下是每個程式設計師都應該考慮學習的 10 個重要的系統設計概念: 1. **可擴展性** 2. **可用性** 3. **可靠性** 4. **容錯能力** 5. **快取策略** 6. **負載平衡** 7. **安全** 8. **可擴展的資料管理** 9. **設計模式** 10. **效能最佳化** 理解和應用這些系統設計概念可以幫助程式設計師和開發人員建立強大的、可擴展的、高效能的軟體系統,以滿足現代應用程式和使用者的需求。 現在,讓我們深入研究它們中的每一個並了解它們是什麼以及如何在您的應用程式中實現它們。 ### 1. 可擴展性 可擴展性是指系統或應用程式處理不斷增加的工作負載或使用者而不顯著降低效能或功能的能力。 它是系統設計中的一個重要概念,因為它允許系統成長並適應不斷變化的需求,**例如增加的資料量、使用者流量或處理需求,**而不會遇到效能瓶頸或限制。 在現代運算環境中,系統需要處理大量且不斷成長的資料和用戶,可擴展性至關重要。例如,流行的網站、行動應用程式和基於雲端的服務需要能夠同時處理數百萬甚至數十億個請求,而分散式資料庫和大資料平台需要擴展以處理 PB 或 EB 的資料。 對於需要適應尖峰負載的系統來說,可擴展性也很重要,例如假期期間的線上購物或因病毒事件導致的用戶活動突然激增。 > 可擴展性主要有兩種:**垂直可擴展性和水平可擴展性**。垂直可擴展性涉及向單一伺服器或節點加入更多資源(例如 CPU、記憶體或儲存)以處理增加的工作負載。另一方面,水平可擴展性涉及向系統加入更多伺服器或節點以分配工作負載並處理增加的需求。 水平可擴展性通常透過[負載平衡](https://medium.com/javarevisited/difference-between-api-gateway-and-load-balancer-in-microservices-8c8b552a024)、 [分片](https://medium.com/javarevisited/what-is-database-sharding-scaling-your-data-horizontally-1dc12b33193f)、分區和分散式處理等技術來實現。 實現可擴展性需要仔細的系統設計、架構和實作。它涉及設計能夠有效處理不斷增加的工作負載、有效利用資源、最大限度地減少依賴性以及跨多個節點或伺服器分佈處理的系統。 > 快取、非同步處理、平行處理和分散式資料庫等技術通常用於提高可擴展性。測試和效能監控對於確保系統在擴展時繼續保持良好效能也至關重要。 可擴展性是建立強大的高效能係統的重要考慮因素,這些系統可以處理成長並適應隨時間變化的需求。它使系統能夠滿足不斷增長的需求,提供無縫的用戶體驗,並支援業務成長,而不會遇到效能限製或停機。 這是來自[**ByteByteGo**](https://bit.ly/3P3eqMN)的一個很好的圖表,這是準備系統設計面試的好地方,它顯示了[*垂直擴展和水平擴展之間的區別*](https://medium.com/javarevisited/difference-between-horizontal-scalability-vs-vertical-scalability-67455efc91c) [](https://bit.ly/3P3eqMN) --- ### 2. 可用性 可用性是指軟體系統即使在發生故障或中斷時也能保持運作並可供使用者存取的能力。 高可用性是許多系統的關鍵要求,特別是那些任務關鍵型或時間敏感型系統,例如線上服務、電子商務網站、金融系統和通訊網路。 此類系統的停機可能會導致重大的財務損失、聲譽受損和客戶不滿。因此,保證高可用性是系統設計時重點考慮的問題。 可用性通常**使用正常運作時間(衡量系統運作時間的百分比)和停機時間(衡量系統不可用的時間)等指標**來量化。 實現**高可用性涉及設計具有冗餘、容錯和故障轉移機制的系統**,以最大限度地降低因硬體故障、軟體故障或其他意外事件而導致停機的風險。 > 在系統設計中,採用了各種技術和策略來提高可用性,例如負載平衡、叢集、複製、備份和復原、監控和主動維護。 實施這些措施是為了最大限度地減少單點故障、檢測故障並從故障中恢復,並確保系統即使在發生故障或中斷時也能保持運作。 透過設計具有高可用性的系統,工程師可以確保系統可以長時間存取和執行,從而提高客戶滿意度、減少停機時間並提高業務連續性。 [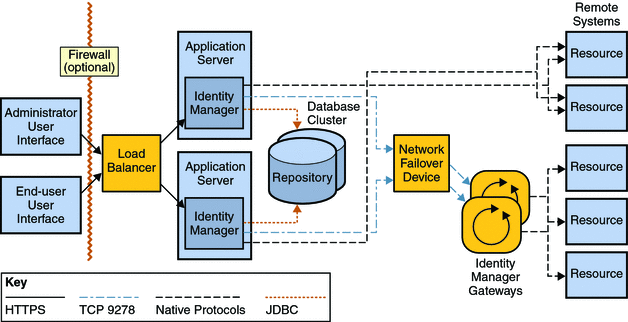](https://www.linkedin.com/pulse/top-20-system-design-interview-questions-answers-soma-sharma-g0pqc/) --- ### 3、可靠性 可靠性是指**軟體系統在交付預期結果時的一致性和可靠性**。建立具有可靠元件、錯誤處理機制和備份/復原策略的系統對於確保系統按預期運作並產生準確的結果至關重要。 可靠性是系統設計的關鍵因素,因為它直接影響系統的整體性能和品質。可靠的系統應始終按預期執行,不會出現意外故障、錯誤或中斷。 **關鍵任務應用通常需要高可靠性,**因為系統故障可能會造成嚴重後果,例如在航空、醫療保健、金融和其他安全關鍵領域。 可靠性通常使用各種指標來量化,例如**平均故障間隔時間 (MTBF)** (測量故障之間的平均持續時間)和故障率 (FR)(測量一段時間內故障發生的速率)。 > 可靠性可以透過各種技術和策略來實現,例如冗餘、錯誤檢測和糾正、容錯和穩健設計。 在系統設計中,要實現高可靠性需要仔細考慮各種因素,包括元件品質、系統架構、錯誤處理、容錯機制、監控和維護策略。 透過**設計高可靠性的系統**,工程師可以確保系統始終如一地按預期執行,從而提高客戶滿意度、減少停機時間並提高系統效能和可用性。 --- ### 4. 容錯性 容錯是指系統或元件在故障或故障(例如硬體故障、軟體錯誤或其他不可預見的問題)時繼續正常運作的能力。 容錯系統旨在檢測、隔離故障並從故障中恢復,而不會完全故障或停機。 容錯是系統設計中的重要概念,特別是在分散式系統或需要在具有挑戰性的環境中可靠運作的系統中。 它涉及實現冗餘、錯誤檢測、錯誤糾正和錯誤恢復機制,以確保即使某些元件或子系統發生故障,系統也能繼續運作。 > 有多種技術和策略可以實現容錯,例如**複製**,即在不同位置維護相同資料或服務的多個副本,以便在一個發生故障時,其他副本可以接管;檢查點,定期保存系統狀態,以便在發生故障時,系統可以恢復到先前已知的良好狀態;優雅降級,即係統在故障時可以繼續執行,但功能會減少。 容錯對於確保系統的高可用性、可靠性和彈性至關重要,特別是在系統故障可能造成嚴重後果的關鍵任務應用程式中。 透過在系統設計中納入容錯機制,工程師可以建立強大且可靠的系統,即使在遇到意外故障時也可以繼續運作並提供預期結果。 [](https://bit.ly/3P3eqMN) --- ### 5. 快取策略 快取策略是一種用於優化系統效能的技術,它透過將經常存取的資料或結果儲存在稱為快取的臨時儲存位置中,以便可以快速檢索資料,而無需重新計算或從原始來源取得。 系統設計中常用的快取策略有以下幾種: 1. **完全緩存** 在此策略中,整個資料集或結果都會快取在快取中,提供對所有資料或結果的快速存取。當資料或結果相對較小且可以輕鬆儲存在記憶體或本地快取中時,此策略非常有用。 2. **部分快取** 在此策略中,通常基於使用模式或頻繁存取的資料,僅快取資料或結果的子集。當資料或結果規模很大,或並非所有資料或結果都被頻繁存取,並且快取整個資料集不可行時,此策略很有用。 3. \*\*基於時間的到期時間 在此策略中,資料或結果被快取特定的時間,之後快取被認為是陳舊的,並且資料或結果從原始來源獲取並在快取中更新。當資料或結果相對穩定且不經常變化時,此策略很有用。 4. **LRU(最近最少使用)或 LFU(最不常使用)替換策略** 在這些策略中,最近最少使用或最不頻繁使用的資料或結果被從快取中逐出,以為新資料或結果騰出空間。當快取的儲存容量有限且需要驅逐不常存取的資料以容納新資料時,這些策略非常有用。 5. **直寫式或後寫式緩存** 在這些策略中,資料或結果在更新或插入時寫入快取和原始來源(直寫)或僅寫入快取(後寫)。當系統需要保持快取和原始來源之間的一致性或原始來源無法直接更新時,這些策略就非常有用。 6. **分散式快取** 在此策略中,快取分佈在多個節點或伺服器上,通常使用分散式快取框架或技術。當系統跨多個節點或伺服器分佈或擴展並且需要保持分散式快取的一致性和效能時,此策略就非常有用。 7. **自訂快取** 可以根據系統或應用程式的特定要求和特徵來實施自訂快取策略。這些策略可能涉及上述策略或其他自訂方法的組合,以滿足系統的獨特需求。 選擇*合適的快取策略取決於資料或結果的大小、存取頻率、資料或結果的易變性、儲存容量、一致性要求以及系統的效能目標等多種因素*。仔細考慮和實施快取策略可以顯著提高系統效能、降低資源利用率、提高可擴展性並增強使用者體驗。 [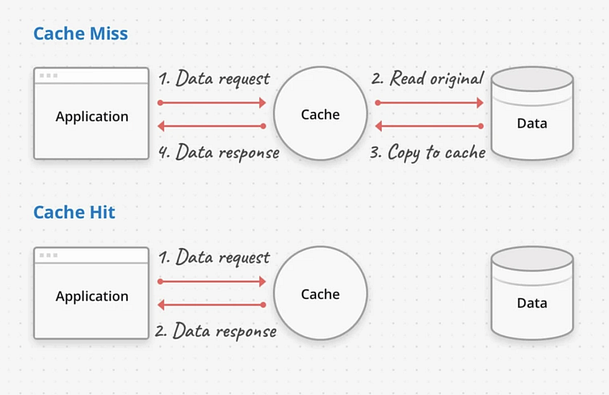](https://bit.ly/3P3eqMN) --- ### **6.負載平衡** 負載平衡是分散式系統或網路中使用的技術,用於在多個伺服器或資源之間均勻分配傳入的網路流量或工作負載,確保沒有任何單一伺服器或資源因過多的流量或工作負載而不堪負荷。 負載平衡的目的是優化資源利用率,最大化系統可用性,提高系統整體效能和可靠性。在微服務架構中, [*負載平衡和 API 閘道*](https://medium.com/javarevisited/difference-between-api-gateway-and-load-balancer-in-microservices-8c8b552a024)通常指的是相同的,但事實並非如此,API 閘道可以做更多的事情,如[本文](https://medium.com/javarevisited/what-is-api-gateway-pattern-in-microservices-architecture-what-problem-does-it-solve-ebf75ae84698)所述。 負載平衡可以透過各種演算法或方法來實現,例如: 1. **循環:**傳入請求以輪流方式依序分發到每個伺服器或資源,確保所有伺服器或資源之間的流量平均分配 2. **最少連線:**傳入請求分發到活動連線數最少的伺服器或資源,確保負載最少的伺服器或資源接收新請求。 3. **來源 IP 關聯性:**來自相同客戶端 IP 位址的傳入請求將導向至相同伺服器或資源,確保來自特定用戶端的請求始終由相同伺服器或資源處理。 4. **加權循環:**傳入請求根據分配給每個伺服器或資源的預定義權重進行分配,從而允許根據伺服器或資源容量或功能採用不同的流量分配比率。 5. **自適應負載平衡:**負載平衡演算法根據伺服器或資源健康、效能或其他指標的即時監控,動態調整流量分配,確保最佳的資源利用率和系統效能。 負載平衡可以使用基於硬體的負載平衡器、基於軟體的負載平衡器或基於雲端的負載平衡服務來實現。 它在具有高流量負載或資源密集型工作負載的分散式系統或網路中發揮著至關重要的作用,可以實現資源的高效利用,增強系統的可用性和可靠性,並提供無縫的用戶體驗。 這裡還有一個來自[DesignGuru.io](https://bit.ly/3pMiO8g)的漂亮圖表,這是一個學習面試準備系統設計的優秀網站,它強調了負載平衡器和 API 閘道之間的區別: [](https://bit.ly/3pMiO8g) --- ### **7. 安全** 系統設計中的安全性是指考慮和實施保護系統免受潛在安全威脅、漏洞或攻擊的措施。 它涉及設計和實施具有內建安全功能和實踐的系統,以防止未經授權的存取、資料外洩、資料外洩、惡意軟體攻擊和其他安全風險。 系統設計中的安全性通常涉及以下原則: 1. **身份驗證:**確保使用者或實體經過驗證並根據其身分和憑證被授予適當的存取權限。 2. **授權**:實施存取控制和權限,限制使用者或實體存取未經授權的資源或執行未經授權的操作。 3. **加密**:透過使用加密技術來保護敏感資料,以防止未經授權的存取或資料外洩。 4. **稽核和日誌記錄**:實施機制來追蹤和記錄系統活動和事件,以用於監視、稽核和取證目的。 5. **輸入驗證:**驗證和清理所有輸入資料,以防止常見的安全漏洞,例如 SQL 注入、跨站腳本 (XSS) 和跨站請求偽造 (CSRF) 攻擊。 6. **修補程式和更新**:使用最新的安全性修補程式和更新使系統保持最新狀態,以解決已知的安全漏洞。 7. **深度防禦**:實施多層安全控制,例如防火牆、入侵偵測系統和防毒軟體,以提供針對安全威脅的多層防禦。 8. **最小權限原則**:將使用者或實體的存取權限限製到執行其任務所需的最低限度,減少安全漏洞或攻擊的潛在影響。 9. **安全通訊**:使用安全通訊協定(例如 HTTPS 或 SSL/TLS)來保護傳輸中的資料免於攔截或竊聽。 系統設計中的安全性對於保護資料和資源的完整性、機密性和可用性以及確保系統的整體安全狀況至關重要。應考慮並納入系統的設計、開發和部署階段,以減輕潛在的安全風險並防範安全威脅。 --- ### **8. 可擴展的資料管理** 可擴展的資料管理是指系統或應用程式有效處理不斷增長的資料量而不會出現效能下降或功能遺失的能力。 它涉及設計和實施資料管理實務和技術,這些實務和技術可以處理不斷增加的資料量、使用者負載和處理要求,同時保持可接受的效能和可靠性水準。 可擴展的資料管理通常涉及以下原則: 1. **資料分區:**將大型資料集分割成更小的、可管理的區塊或分區,以將資料分佈在多個儲存或處理資源上。這有助於減少單一資源的負載,並允許並行處理和提高效能。 2. **分散式資料庫系統:**使用分散式資料庫或資料儲存解決方案,可以將資料分佈在多個節點或伺服器上,從而實現水平擴展並提高效能。 3. **資料複製**:跨多個節點或伺服器複製資料,以確保資料可用性和容錯性。這可能涉及資料鏡像、資料分片或資料快取等技術,以提高效能和可靠性。 4. **快取和記憶體中資料儲存:快取**經常存取的資料或將資料儲存在記憶體中,以便更快地檢索和處理,減少對昂貴的磁碟 I/O 操作的需求並提高效能。 5. **索引和查詢最佳化**:使用高效的索引和查詢最佳化技術來加速資料檢索和處理操作,尤其是在大型資料集中。 6. **資料壓縮:**實施資料壓縮技術以減少儲存佔用空間並提高資料傳輸效率,特別是對於大型資料集。 7. **資料歸檔和清除**:實施資料歸檔和清除實踐以刪除或歸檔舊的或不經常存取的資料,減少儲存和處理開銷並提高效能。 8. **可擴展的資料處理框架:**使用可擴展的資料處理框架,例如 Apache Hadoop、Apache Spark 或 Apache Flink,可以分散式並行方式處理大規模資料處理和分析任務。 9. **雲端的資料管理**:利用雲端的資料管理服務,例如 Amazon S3、Amazon RDS 或 Google Bigtable,提供可擴充和託管的資料儲存和處理功能。 10. **監控和可擴展性測試**:定期監控系統效能並進行可擴展性測試,以辨識和解決效能瓶頸、資源限製或其他可擴展性挑戰,並確保資料管理實踐能夠有效處理不斷增長的資料量和負載。 簡而言之,可擴展的資料管理對於需要處理大量資料、使用者負載和處理要求的現代應用程式和系統至關重要。 它使系統能夠成長並適應不斷變化的需求,而無需犧牲效能或可靠性,從而確保資料管理實踐能夠有效地處理不斷增加的資料量和負載。 --- ### **9. 設計模式** 系統設計中的[設計模式](https://medium.com/javarevisited/top-10-microservice-design-patterns-for-experienced-developers-f4f5f782810e)是指用於解決軟體系統開發過程中遇到的常見設計挑戰或問題的可重複使用解決方案或最佳實踐。 [設計模式](https://medium.com/javarevisited/21-software-design-pattern-interview-questions-and-answers-b7d1774b5dd2)是被廣泛接受和經過驗證的設計和架構軟體系統的方法,它們為設計高效、可維護和可擴展的系統提供了一組明確的指南。 系統設計中的設計模式可分為多種類型,包括: 1. **建立模式:**這些模式專注於物件建立機制,並提供以靈活且可重複使用的方式建立物件的方法。建立模式的範例包括 Singleton、Factory Method、Abstract Factory、Builder 和 Prototype 模式。 2. **結構模式:**這些模式著重於類別和物件的組織以形成更大的結構或系統。結構模式的範例包括適配器、橋、複合、裝飾器和外觀模式。 3. **行為模式:**這些模式著重於系統內物件或元件之間的互動和通訊。行為模式的範例包括觀察者、策略、命令、迭代器和模板方法模式。 4. **架構模式:**這些模式為設計系統的整體架構提供了高階指南和策略。架構模式的範例包括模型-視圖-控制器 (MVC)、模型-視圖-視圖模型 (MVVM)、分層架構、微服務和事件驅動架構模式。 設計模式在系統設計中非常重要,因為它們提供了經過驗證的標準化方法來解決常見的設計挑戰、提高程式碼品質並確保軟體系統的可維護性和可擴展性。 它們促進程式碼的可重複使用性、關注點分離和功能封裝,從而更容易管理複雜的系統並使其適應不斷變化的需求。 透過使用設計模式,開發人員可以利用現有知識和最佳實踐來設計強大而高效的系統,以滿足使用者和利害關係人的需求。 在過去的幾篇文章中,我還討論了常見的微服務設計模式,如[**事件來源**](https://medium.com/javarevisited/what-is-event-sourcing-design-pattern-in-microservices-architecture-how-does-it-work-b38c996d445a)**、** [**CQRS**](https://medium.com/javarevisited/what-is-cqrs-command-and-query-responsibility-segregation-pattern-7b1b38514edd) \*\*、SAGA\*\*、 [**每個微服務的資料庫**](https://medium.com/javarevisited/what-is-database-per-microservices-pattern-what-problem-does-it-solve-60b8c5478825)**、** [**API 閘道**](https://medium.com/javarevisited/difference-between-api-gateway-and-load-balancer-in-microservices-8c8b552a024)、 [**斷路器**](https://medium.com/javarevisited/what-is-circuit-breaker-design-pattern-in-microservices-java-spring-cloud-netflix-hystrix-example-f285929d7f68),並分享了[*設計微服務的最佳實踐*](https://medium.com/javarevisited/10-microservices-design-principles-every-developer-should-know-44f2f69e960f),您也可以查看這些文章以了解有關微服務通訊的更多訊息,包括同步和非同步通訊。 --- ### 10. 性能 雖然我們已經知道效能意味著什麼,但還記得速度慢的筆記型電腦嗎?在系統設計中,效能是指軟體系統處理資料和交付結果的速度、反應能力和效率。 透過高效的演算法、快取、索引和其他技術來優化系統效能對於建立能夠處理大規模資料處理並提供最佳回應時間的系統至關重要。 系統設計中的效能是指軟體系統或應用程式有效率且有效地執行其預期功能或任務,同時滿足效能要求和期望的能力。它涵蓋了系統的回應時間、吞吐量、資源利用率、可擴展性和效率等各個方面。 效能是系統設計中的關鍵因素,因為它直接影響使用者體驗、系統可靠性和整體系統效率。效能不佳的系統可能會導致反應時間慢、吞吐量低、資源利用率高以及系統資源使用效率低下,導致系統效能下降和使用者不滿意。 系統設計人員在設計過程中需要考慮各種與效能相關的因素,例如選擇適當的演算法和資料結構、最佳化程式碼、最大限度地減少不必要的開銷、有效管理系統資源以及確保正確的系統配置和調優。 效能測試和分析技術還可用於辨識和解決效能瓶頸並優化系統效能。 優化系統設計中的效能需要在功能、複雜性和資源利用率之間進行仔細的平衡。它涉及做出明智的設計決策、使用最佳實踐以及持續監控和優化系統性能,以確保系統滿足其性能要求並提供流暢高效的用戶體驗。 ### 結論 這就是面試的基本系統設計概念。理解和掌握這些關鍵的系統設計概念對於程式設計師建立健壯、可擴展且高效的軟體系統至關重要。 這些概念,包括容錯、可靠性、可用性、快取策略、負載平衡、安全性、可擴展資料管理、設計模式和效能,在確保軟體系統滿足其預期目標、最佳執行並提供卓越的效能方面發揮著關鍵作用。 透過對這些系統設計概念的深入理解,您可以做出明智的設計決策,選擇適當的技術和技巧,並優化系統效能。 它還允許您設計具有彈性、可擴展、安全和高效的系統,能夠應對現代軟體開發的挑戰並滿足最終用戶的期望。 順便說一句,如果您正在*準備系統設計面試*並想要深入學習系統設計,那麼您還可以查看[**ByteByteGo**](https://bit.ly/3P3eqMN) 、 [**DesignGuru**](https://bit.ly/3pMiO8g) 、 [**Exponent**](https://bit.ly/3cNF0vw) 、 [**Educative**](https://bit.ly/3Mnh6UR)和[**Udemy**](https://bit.ly/3vFNPid)等網站,它們有許多很棒的系統設計課程,如果您需要免費的系統設計課程您也可以查看下面的文章。 --- 原文出處:https://dev.to/somadevtoo/10-must-know-system-design-concepts-for-interviews-2fii
世界上充滿了有前景的人工智慧工具,如 Sora、ChatGPT 以及更多即將推出的工具。 我收集了一些你必須使用的令人興奮的人工智慧工具。 該清單包括 Devin AI 的開源替代品、Notion、5 秒內的語音克隆、電子郵件自動化軟體以及您從未聽說過的工具。好奇心超載! 別忘了給他們加星號🌟 讓我們涵蓋這一切! --- 1. [Taipy](https://github.com/Avaiga/taipy) - 將資料和人工智慧演算法整合到生產就緒的 Web 應用程式中。 ---------------------------------------------------------------------------- 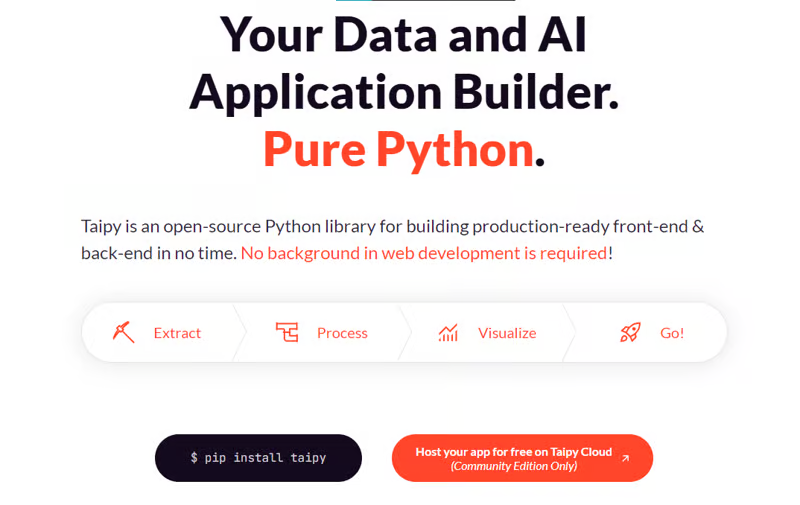 Taipy 是一個開源 Python 庫,可用於輕鬆的端到端應用程式開發,具有假設分析、智慧管道執行、內建調度和部署工具。 我相信你們大多數人都不明白 Taipy 用於為基於 Python 的應用程式建立 GUI 介面並改進資料流管理。 因此,您可以繪製資料集的圖表,並使用類似 GUI 的滑桿來提供使用其他實用功能來處理資料的選項。 雖然 Streamlit 是一種流行的工具,但在處理大型資料集時,其效能可能會顯著下降,這使得它在生產級使用上不切實際。 另一方面,Taipy 在不犧牲性能的情況下提供了簡單性和易用性。透過嘗試 Taipy,您將親身體驗其用戶友好的介面和高效的資料處理。 在底層,Taipy 利用各種函式庫來簡化開發並增強功能。  開始使用以下命令。 ``` pip install taipy ``` 我們來談談最新的[Taipy v3.1 版本](https://docs.taipy.io/en/latest/relnotes/)。 最新版本使得在 Taipy 的多功能零件物件中可視化任何 HTML 或 Python 物件成為可能。 這意味著[Folium](https://python-visualization.github.io/folium/latest/) 、 [Bokeh](https://bokeh.org/) 、 [Vega-Altair](https://altair-viz.github.io/)和[Matplotlib](https://matplotlib.org/)等程式庫現在可用於視覺化。 這也帶來了對[Plotly python](https://plotly.com/python/)的原生支持,使繪製圖表變得更加容易。  他們還使用分散式運算提高了效能,但最好的部分是 Taipy,它的所有依賴項現在都與 Python 3.12 完全相容,因此您可以在使用 Taipy 進行專案的同時使用最新的工具和程式庫。 您可以閱讀[文件](https://docs.taipy.io/en/latest/)。 例如,您可以看到[聊天演示](https://docs.taipy.io/en/release-3.1/gallery/llm/5_chatbot/),它使用 OpenAI 的 GPT-4 API 來產生對您的訊息的回應。您可以輕鬆更改程式碼以使用任何其他 API 或模型。  另一個有用的事情是,Taipy 團隊提供了一個名為[Taipy Studio](https://docs.taipy.io/en/latest/manuals/studio/)的 VSCode 擴充功能來加速 Taipy 應用程式的建置。  您也可以使用 Taipy 雲端部署應用程式。 如果您想閱讀部落格來了解程式碼庫結構,您可以閱讀 HuggingFace[的使用 Taipy 在 Python 中為您的 LLM 建立 Web 介面](https://huggingface.co/blog/Alex1337/create-a-web-interface-for-your-llm-in-python)。 嘗試新技術通常很困難,但 Taipy 提供了[10 多個演示教程,](https://docs.taipy.io/en/release-3.1/gallery/)其中包含程式碼和適當的文件供您遵循。 例如,一些現場演示範例和專案想法: - [新冠儀表板](https://covid-dashboard.taipy.cloud/Country) - [推文生成](https://tweet-generation.taipy.cloud/) - [資料視覺化](https://production-planning.taipy.cloud/Data-Visualization) - [即時人臉辨識](https://face-recognition.taipy.cloud/) - [國際象棋大師](https://github.com/KorieDrakeChaney/taipy-chess) Taipy 在 GitHub 上有 7k+ Stars,並且處於`v3`版本,因此它們正在不斷改進。 https://github.com/Avaiga/taipy Star Taipy ⭐️ --- 2. [PR Agent](https://github.com/Codium-ai/pr-agent) - 自動拉取請求分析、回饋、建議的工具。 ------------------------------------------------------------------------- 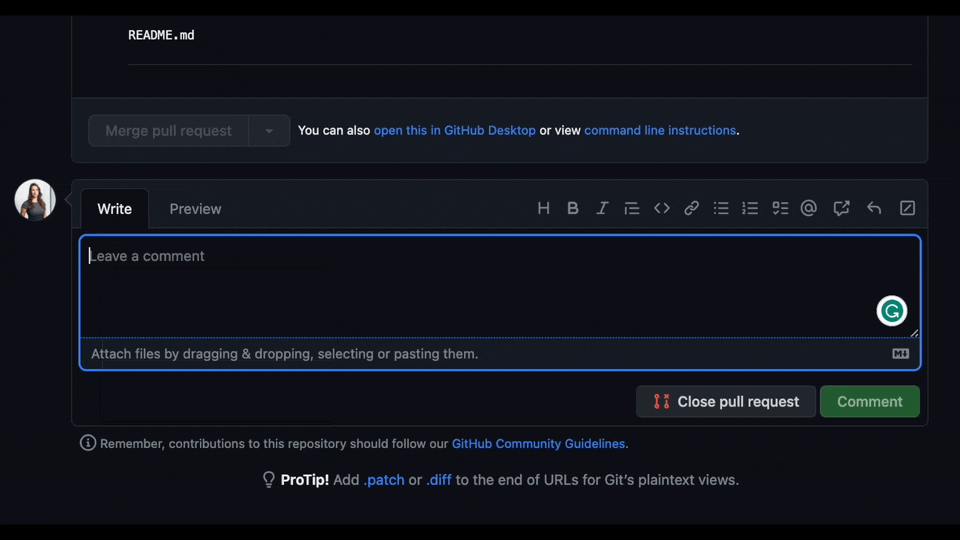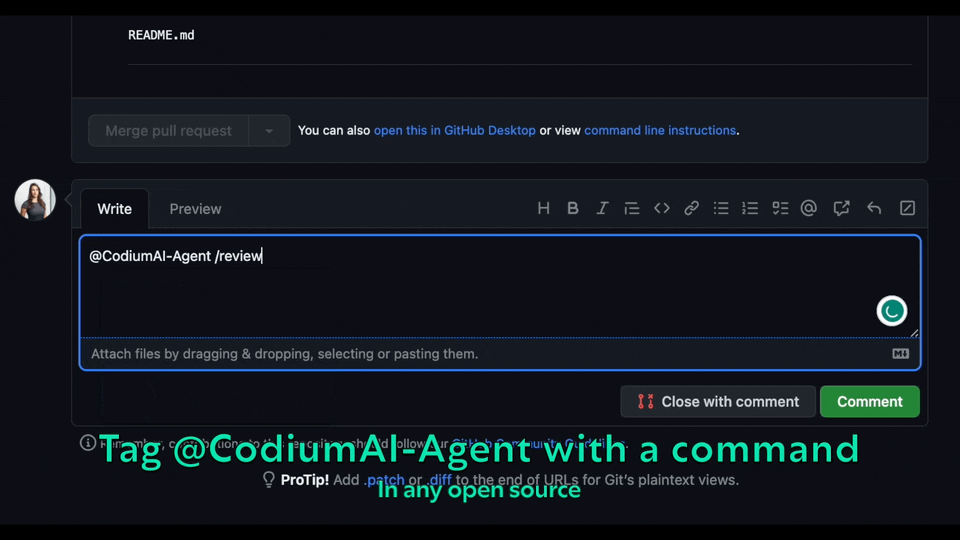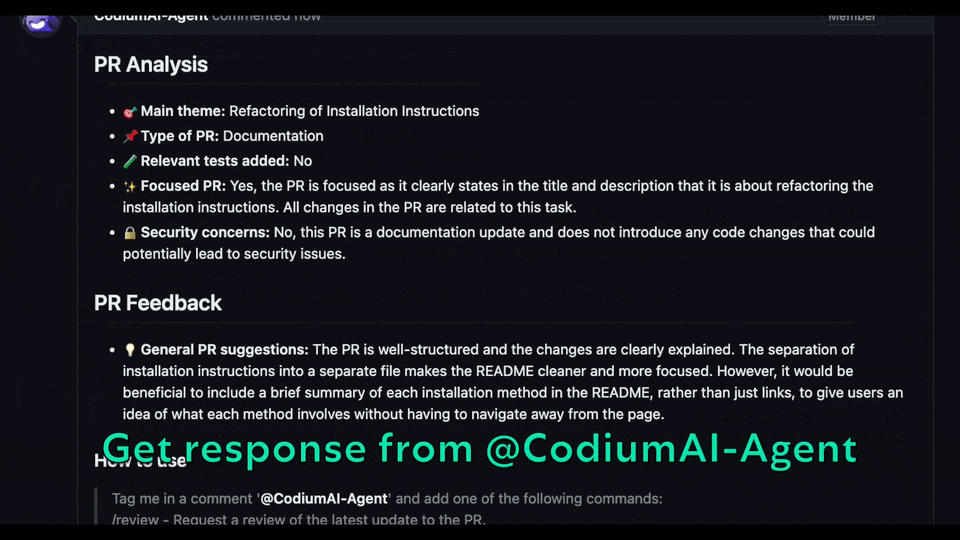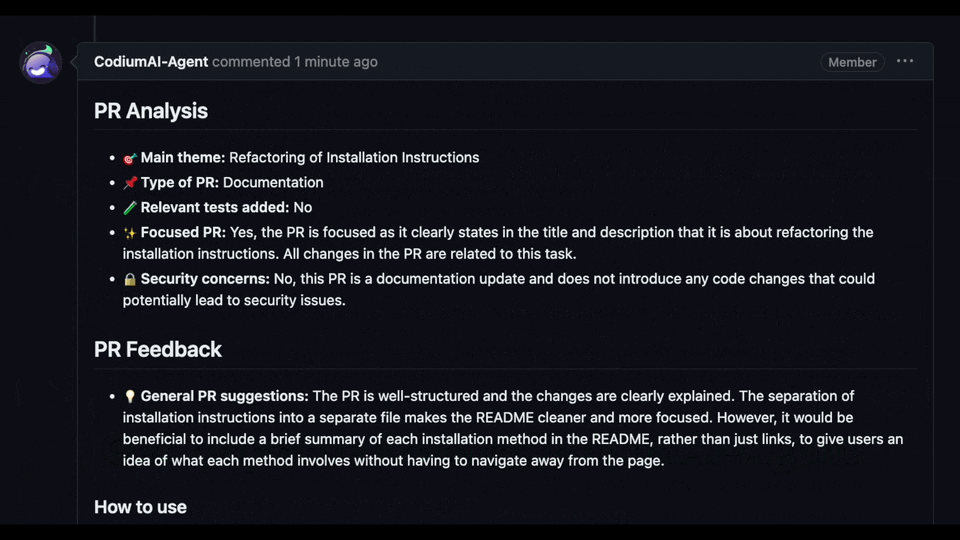 這是一個開源工具,可幫助有效地審查和處理拉取請求。它有許多獨特的選項,並提供跨各種 git 提供者的廣泛的拉取請求功能。 每天有數百萬個開源專案和數百個 Pull 請求,因此有一個可以幫助您的朋友是非常好的事情。 我是開源維護者,所以我知道有時會變得多麼困難,特別是每天都要審查這麼多的 Pull 請求。 無論如何,這就是公關代理商的幕後工作方式。 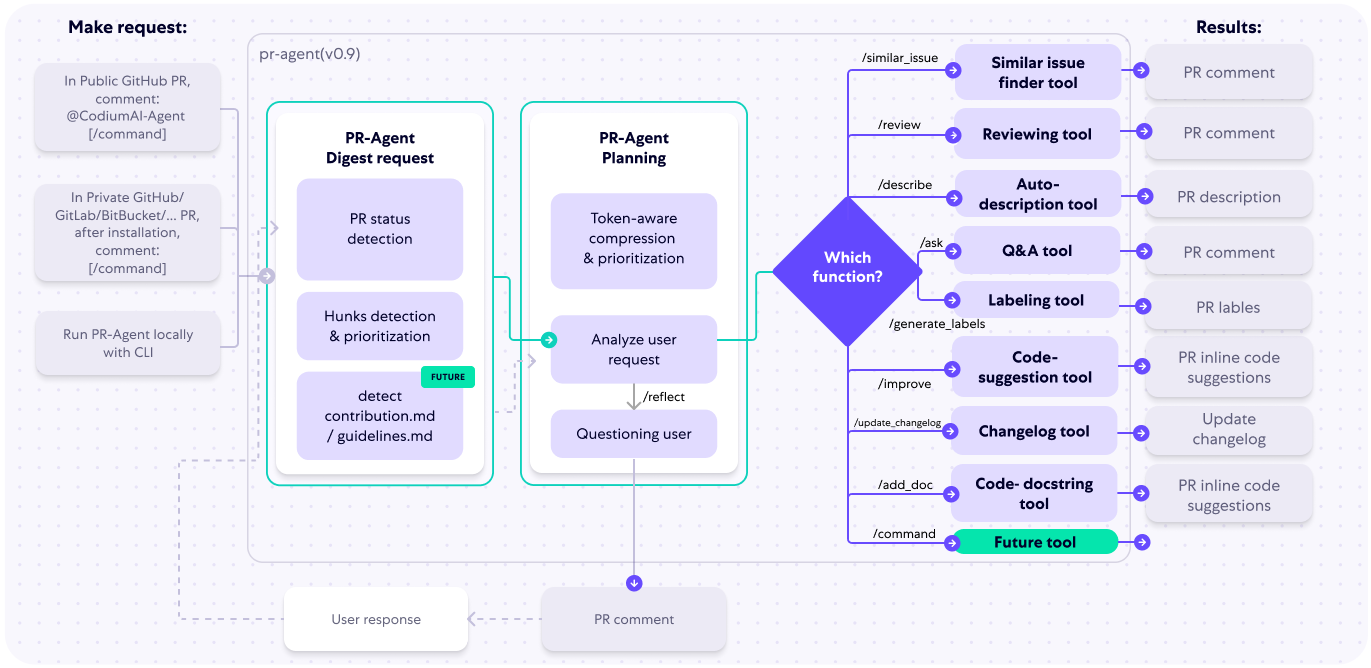 您必須使用`@CodiumAI-Agent /review`對拉取請求發表評論,代理商將透過對 PR 的審查進行回應。有很多可用的選項,例如`describe`和`improve` 。 他們也提供了 [PR-Agent 工具](https://pr-agent-docs.codium.ai/tools/),每個頁面都有一個專門的頁面來解釋如何使用它。 您可以閱讀[文件](https://pr-agent-docs.codium.ai/installation/)並查看[範例結果](https://github.com/Codium-ai/pr-agent?tab=readme-ov-file#example-results)。 最好的部分是您甚至可以將其作為[GitHub Action](https://pr-agent-docs.codium.ai/installation/github/#run-as-a-github-action)執行。他們還提供了一個專業版本,有更多的選擇,但免費套餐足以開始使用。 如果您正在尋找好的文章,我推薦[使用 CodiumAI PR-Agent 自動進行拉取請求審查和](https://rnemet.dev/posts/ai/codium-pragent/)[CodiumAI PR-Agent 讓開發人員的生活更輕鬆的 5 個原因](https://medium.com/@mengineer/5-reasons-why-codiumai-pr-agent-is-making-developers-lives-easier-e040be0f6a36)。這些提供了有關 PR Agent 的大量概述。 它們在 GitHub 上有大約 3800 個 Star,被 300 多名開發人員使用,並且是使用 Python 建構的。雖然它們可能不是非常受歡迎,但它們的用例非常好。 https://github.com/Codium-ai/pr-agent 明星公關代理人 ⭐️ --- 3. [Mintlify](https://github.com/mintlify/writer) - 在建置時出現的文件。 --------------------------------------------------------------  Mintlify 是一款由人工智慧驅動的文件編寫器,您只需 1 秒鐘即可編寫程式碼文件 :D 幾個月前我發現了 Mintlify,從那時起我就一直是它的粉絲。我見過很多公司使用它,甚至我使用我的商務電子郵件產生了完整的文件,結果證明這是非常簡單和體面的。如果您需要詳細的文件,Mintlify 就是解決方案。 另一個用例是根據我們將在這裡討論的程式碼產生文件。 您可以安裝[VSCode 擴充功能](https://marketplace.visualstudio.com/items?itemName=mintlify.document)或將其安裝在[IntelliJ](https://plugins.jetbrains.com/plugin/18606-mintlify-doc-writer)上。 您只需突出顯示程式碼或將遊標放在要記錄的行上。然後點選「編寫文件」按鈕(或按 ⌘ + 。) 您可以閱讀[文件](https://github.com/mintlify/writer?tab=readme-ov-file#%EF%B8%8F-mintlify-writer)和[安全指南](https://writer.mintlify.com/security)。 如果您更喜歡教程,那麼您可以觀看[Mintlify 的工作原理](https://www.loom.com/embed/3dbfcd7e0e1b47519d957746e05bf0f4)。它支援 10 多種程式語言,並支援許多文件字串格式,例如 JSDoc、reST、NumPy 等。 順便說一句,他們的網站連結是[writer.mintlify.com](https://writer.mintlify.com/) ;回購協議中目前的似乎是錯誤的。 它在 GitHub 上有大約 2.4k 顆星,受到許多開發人員的喜愛,並且是使用 TypeScript 建構的。 https://github.com/mintlify/writer Star Mintlify ⭐️ --- 4.[螢幕截圖到程式碼](https://github.com/abi/screenshot-to-code)- 放入螢幕截圖並將其轉換為乾淨的程式碼。 ---------------------------------------------------------------------------  這是一個非常受歡迎的開源專案,但我可以肯定地說,很多開發人員仍然沒有意識到這一點。使用此功能,您可以將使用者介面的建置速度提高 10 倍。 這是一個簡單的工具,可以使用 AI 將螢幕截圖、模型和 Figma 設計轉換為乾淨、實用的程式碼。 該應用程式有一個 React/Vite 前端和一個 FastAPI 後端。如果您想使用 Claude Sonnet 或實驗性視訊支持,您將需要一個能夠存取 GPT-4 Vision API 的 OpenAI API 金鑰或一個 Anthropic 金鑰。您可以閱讀[指南](https://github.com/abi/screenshot-to-code?tab=readme-ov-file#-getting-started)來開始。 您可以在託管版本上[即時試用](https://screenshottocode.com/),並觀看 wiki 上提供的[一系列演示影片](https://github.com/abi/screenshot-to-code/wiki/Screen-Recording-to-Code)。 他們在 GitHub 上擁有超過 47k 顆星星,並支援許多技術堆疊,例如 React 和 Vue,以及不錯的 AI 模型,例如 GPT-4 Vision、Claude 3 Sonnet 和 DALL-E 3。 https://github.com/abi/screenshot-to-code 將螢幕截圖轉為程式碼 ⭐️ --- 5. [FaceSwap](https://github.com/deepfakes/faceswap) - 適合所有人的 Deepfakes 軟體。 ---------------------------------------------------------------------------  我總是對 Deepfakes 著迷,因為這就是某些人工智慧的工作原理,尤其是使用影片的人工智慧。 相信我!我們中的許多人甚至不使用它來建立影片,我們只是修改程式碼來看看它的作用,不道德的使用並不能代表它的建立原因、我們現在如何使用它,或者我們對它的未來的看法。 您應該觀看此影片以了解電腦如何辨識臉!觀看[此影片](https://www.youtube.com/watch?v=aircAruvnKk)以了解神經網路的基本功能。 https://www.youtube.com/watch?v=R9OHn5ZF4Uo 您可以閱讀[INSTALL.md](https://github.com/deepfakes/faceswap/blob/master/INSTALL.md)以取得詳細的安裝指南。根據文件,您需要具有 CUDA 支援的現代 GPU 才能獲得最佳效能。許多 AMD GPU 透過 DirectML (Windows) 和 ROCm (Linux) 支援。 您可以閱讀<a href="">文件</a>、觀看[演示影片](https://www.dailymotion.com/video/x810mot)並存取他們的[部落格](https://faceswap.dev/blog/)以觀看具有其他用例的會議影片。 我最喜歡的事實是,他們有一個非常簡單的部分,介紹任何人如何為該專案做出貢獻,包括對生成模型感興趣的人、開發人員、非開發高級用戶、最終用戶,當然還有討厭者:) 他們在 GitHub 上有 48k+ Stars,這使得他們足夠可信。 https://github.com/deepfakes/faceswap 明星 FaceSwap ⭐️ --- 6. [Amica](https://github.com/semperai/amica) - 讓您可以在瀏覽器中輕鬆地與 3D 角色聊天。 ----------------------------------------------------------------------  Amica 是一個開源接口,用於透過語音合成和語音辨識與 3D 角色進行互動式通訊。 您可以匯入 VRM 文件,調整聲音以適合角色,並產生包含情緒表達的回應文字。 他們使用 Three.js、OpenAI、Whisper、Bakllava 等進行視覺處理。您可以閱讀[Amica 的工作原理](https://docs.heyamica.com/overview/how-amica-works)及其所涉及的[核心概念](https://docs.heyamica.com/overview/core-concepts)。 您可以克隆該存儲庫並使用它來[開始](https://docs.heyamica.com/getting-started/installation)。 ``` npm i npm run dev ``` 您可以閱讀[文件](https://docs.heyamica.com/)並查看[演示](https://amica.arbius.ai/),這真是太棒了:D  您可以觀看這段簡短的影片,了解它的功能。 https://www.youtube.com/watch?v=hUxAEnFiXH8 Amica 使用 Tauri 建立桌面應用程式。 他們在 GitHub 上有 400+ Stars,而且看起來非常容易使用。 https://github.com/semperai/amica Star Amica ⭐️ --- 7. [Bark](https://github.com/suno-ai/bark) - 文字提示的生成音訊模型。 ---------------------------------------------------------  Bark 是 Suno 建立的基於轉換器的文本到音訊模型。 Bark 可以產生高度逼真的多語言語音以及其他音訊 - 包括音樂、背景噪音和簡單的音效。 該模型還可以產生非語言交流,如笑、嘆息和哭泣。哇! 它擁有 MIT 許可證,這意味著它現在可用於商業用途。 Bark 支援超過 100 種語言的揚聲器預設。您可以[在此處](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c)查看支援的語音預設庫。 根據文件,Bark 嘗試匹配給定預設的語氣、音高、情緒和韻律,但目前不支援自訂語音複製。該模型還嘗試保留音樂、環境噪音等。這超出了任何人的需要。 您可以這樣使用它。如果您想將其與 Transformers 庫一起使用,請閱讀[本文](https://github.com/suno-ai/bark?tab=readme-ov-file#-transformers-usage)。 ``` from bark import SAMPLE_RATE, generate_audio, preload_models from scipy.io.wavfile import write as write_wav from IPython.display import Audio # download and load all models preload_models() # generate audio from text text_prompt = """ Hello, my name is Suno. And, uh — and I like pizza. [laughs] But I also have other interests such as playing tic tac toe. """ audio_array = generate_audio(text_prompt) # save audio to disk write_wav("bark_generation.wav", SAMPLE_RATE, audio_array) # play text in notebook Audio(audio_array, rate=SAMPLE_RATE) ``` Bark 開箱即用支援各種語言,並自動根據輸入文字確定語言。當提示使用程式碼轉換文字時,Bark 將嘗試使用相應語言的本地口音。 您可以在[Google Colab](https://colab.research.google.com/drive/1eJfA2XUa-mXwdMy7DoYKVYHI1iTd9Vkt?usp=sharing) & [Replicate](https://replicate.com/suno-ai/bark)閱讀<a href="">文件</a>並查看演示。 您也可以在筆記本部分閱讀有關語音一致性增強和其他形式的[範例](https://github.com/suno-ai/bark/tree/main/notebooks)。  它們支援多種語言,如英語、印地語、德語、法語等。 他們在 GitHub 上擁有 30k+ Stars,並且經營超過 300,000 人的社區,這使他們成為值得選擇的選擇。 https://github.com/suno-ai/bark 星樹 ⭐️ --- 8. [GPTDiscord](https://github.com/Kav-K/GPTDiscord) - Discord 的一體化 GPT 介面。 --------------------------------------------------------------------------- 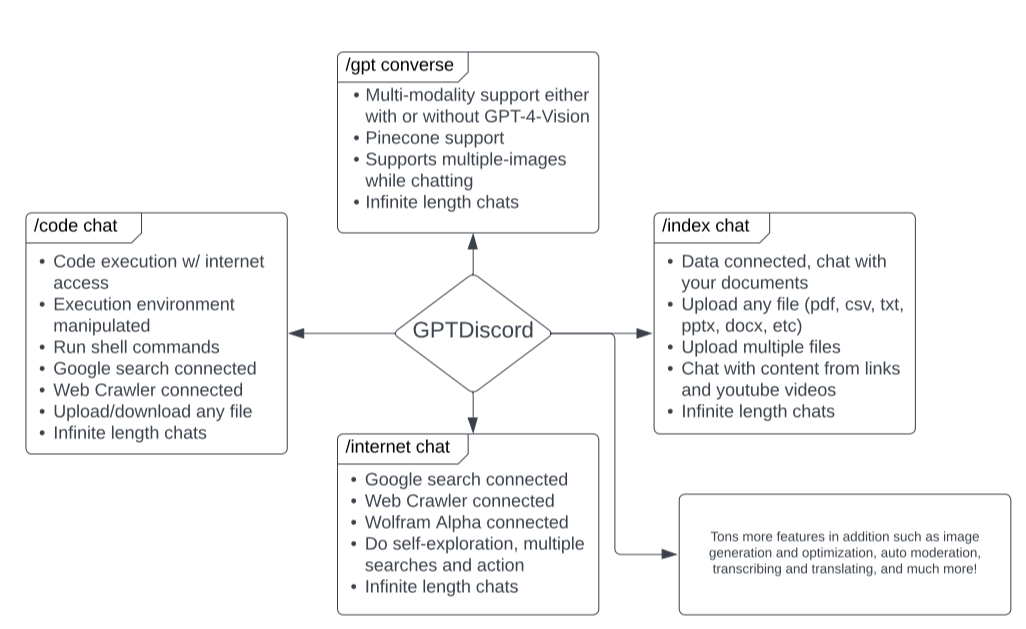 我是 Discord 上多個社群的成員,具有出色用例的機器人可以改善整體最終用戶體驗。 這個機器人的功能與 ChatGPT 網路相當,甚至在某些事情上做得更好! 它們支援一切,從多模態圖像理解、程式碼解釋、高級資料分析、文件問答、與 Wolfram Alpha 的網路連接聊天和 Google 存取、AI 審核、使用 DALL-E 生成圖像等等! 您可以閱讀 GPTDiscord 的所有高效[功能](https://github.com/Kav-K/GPTDiscord?tab=readme-ov-file#features)。 您可以閱讀[安裝指南](https://github.com/Kav-K/GPTDiscord/blob/main/detailed_guides/INSTALLATION.md)。 您可以查看[螢幕截圖](https://github.com/Kav-K/GPTDiscord?tab=readme-ov-file#screenshots)並查看不同目的的[詳細指南](https://github.com/Kav-K/GPTDiscord/tree/main/detailed_guides)清單。 他們在 GitHub 上有大約 1.8k+ Stars,而且肯定在進步。 https://github.com/Kav-K/GPTDiscord 星 GPTDiscord ⭐️ --- 9. [Upscayl](https://github.com/upscayl/upscayl) - 開源 AI 影像擴大機。 ---------------------------------------------------------------  適用於 Linux、MacOS 和 Windows 的免費開源 AI Image Upscaler 採用 Linux 優先概念建構。 它可能與全端無關,但它對於升級圖像很有用。 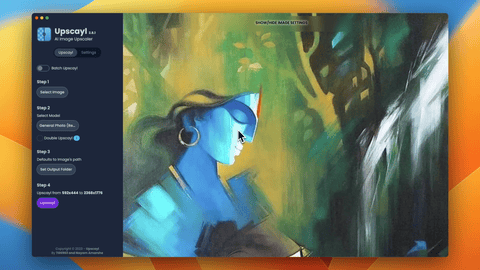  透過最先進的人工智慧,Upscayl 可以幫助您將低解析度影像變成高解析度。清脆又鋒利! 您可以閱讀[安裝指南](https://github.com/upscayl/upscayl?tab=readme-ov-file#-installation),並查看 Upscayl 之前/之後的[比較](https://github.com/upscayl/upscayl/blob/main/COMPARISONS.MD)。 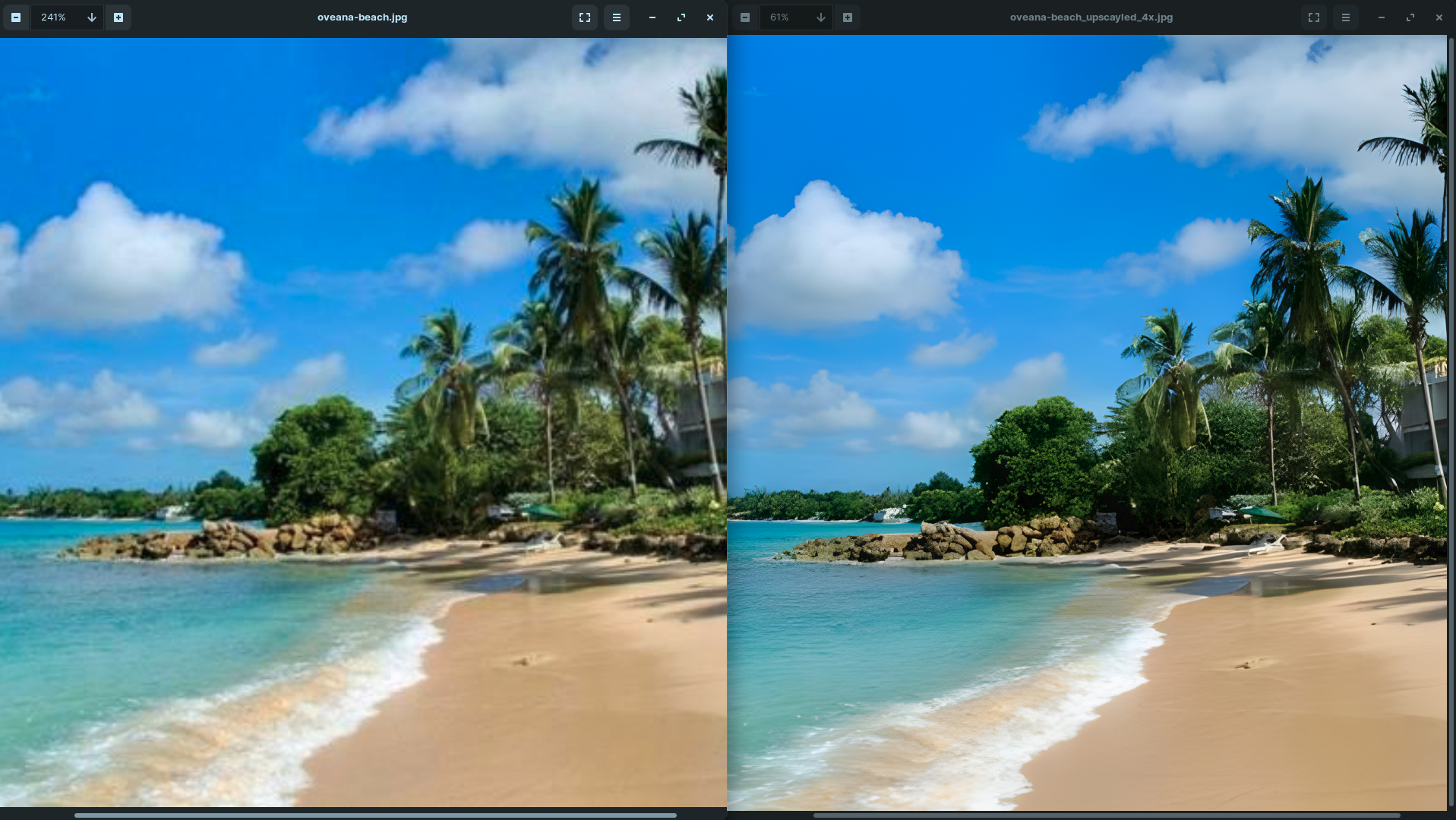 它在 GitHub 上有 23k+ Stars,並且基於 TypeScript 建置。 https://github.com/upscayl/upscayl 明星 Upscayl ⭐️ --- 10. [AppFlowy](https://github.com/AppFlowy-IO/AppFlowy) - Notion 的開源替代品。 ------------------------------------------------------------------------  AppFlowy 是一個由人工智慧驅動的安全工作空間,類似於您在不失去資料控制的情況下實現更多目標的概念。  他們還提供行動應用程式,這是一個優點。 您可以閱讀[文件](https://docs.appflowy.io/docs)並了解[安裝方法](https://docs.appflowy.io/docs/appflowy/install-appflowy/installation-methods)。 他們還支援[使用 Supabase 自託管 AppFlowy](https://docs.appflowy.io/docs/guides/appflowy) 。對於喜歡 Supabase 功能或使用 Supabase 作為其基礎設施的用戶來說,這是理想的選擇。 您還應該檢查[此內容](https://docs.appflowy.io/docs/appflowy/product/data-storage)以了解有關資料儲存、Markdown、捷徑、主題、涉及的人工智慧和插件的更多資訊。 AppFlowy 在 GitHub 上擁有超過 47,000 顆星,發布了 64 個以上版本。 https://github.com/AppFlowy-IO/AppFlowy 明星 AppFlowy ⭐️ --- 11. [Leon](https://github.com/leon-ai/leon) - 您的開源個人助理。 ------------------------------------------------------- 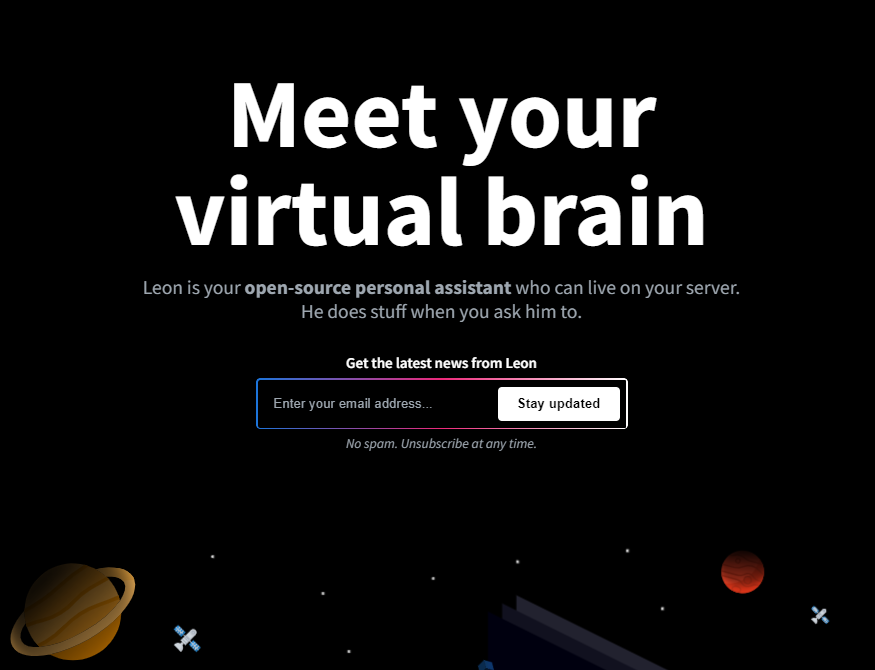 Leon 是一個開源個人助理,可以駐留在您的伺服器上。 當你要求他做事時,他就會做事。 你可以跟他說話,他也可以跟你說話。你也可以給他發短信,他也可以傳簡訊給你。如果您願意,Leon 可以透過離線方式與您溝通,以保護您的隱私。這是萊昂目前可以做的[技能](https://github.com/leon-ai/leon/tree/develop/skills)清單。 你應該讀一下[萊昂背後的故事](https://blog.getleon.ai/the-story-behind-leon/)。您還可以觀看此演示以了解有關 Leon 的更多資訊。 https://www.youtube.com/watch?v=p7GRGiicO1c  這是Leon的高層架構模式。 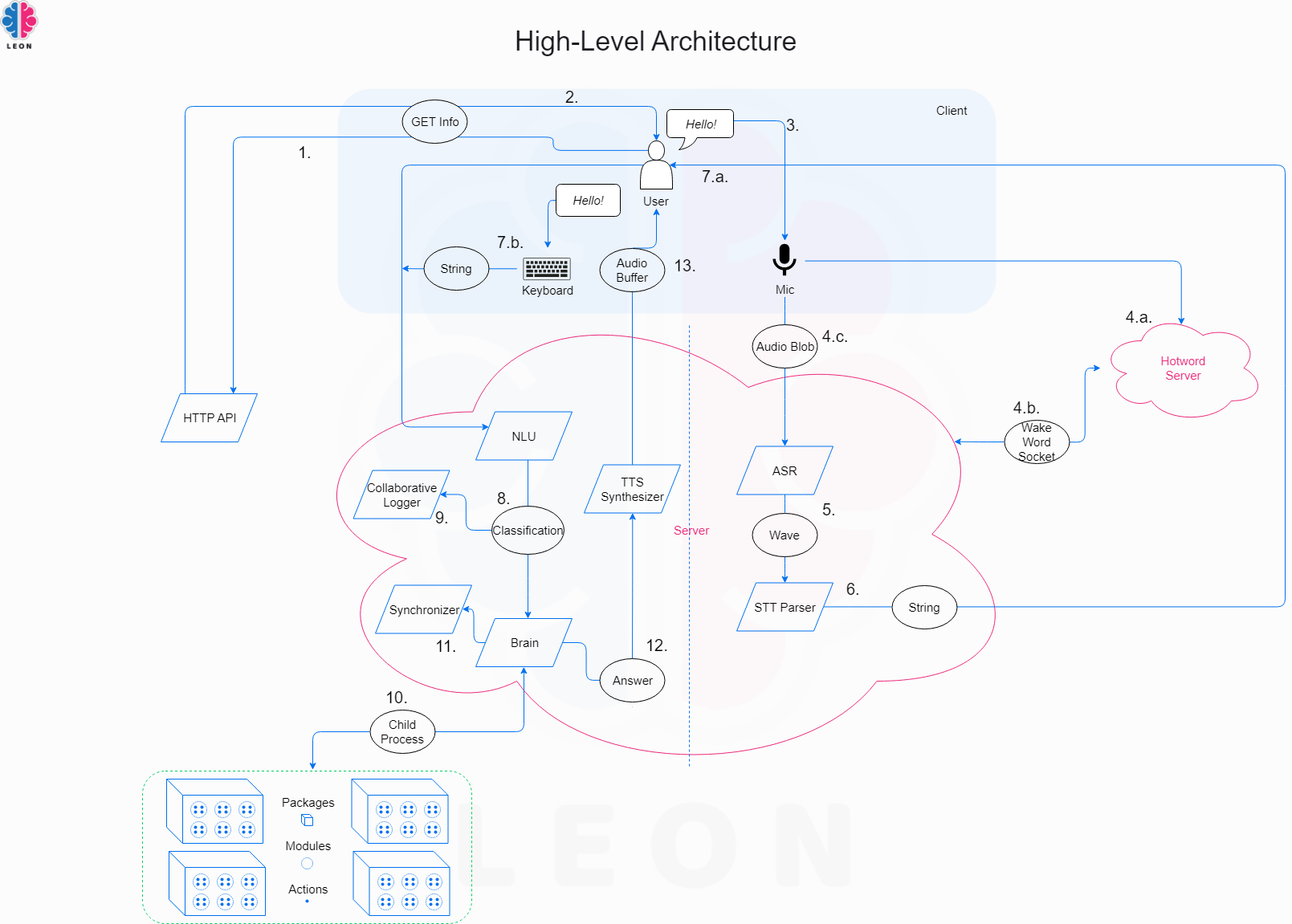 這是開始使用 npm 指令的方法。 ``` # install leon global cli npm install --global @leon-ai/cli # install leon leon create birth ``` 您可以閱讀[文件](https://docs.getleon.ai/)。 它在 GitHub 上擁有超過 14k 顆星,並且還在不斷增長。 https://github.com/leon-ai/leon 明星萊昂 ⭐️ --- 12. [n8n](https://github.com/n8n-io/n8n) - 工作流程自動化工具。 -----------------------------------------------------  n8n 是一個可擴展的工作流程自動化工具。透過公平程式碼分發模型,n8n 將始終擁有可見的原始程式碼,可用於自託管,並允許您加入自訂函數、邏輯和應用程式。  n8n 基於節點的方法使其具有高度通用性,使您能夠將任何事物連接到任何事物。 有[400 多個集成選項](https://n8n.io/integrations),這幾乎是瘋狂的! 您可以看到所有[安裝](https://docs.n8n.io/choose-n8n/)選項,包括 Docker、npm 和自架。 開始使用以下命令。 ``` npx n8n ``` 此命令將下載啟動 n8n 所需的所有內容。然後,您可以透過開啟`http://localhost:5678`來存取 n8n 並開始建置工作流程。 在 YouTube 上觀看此[快速入門影片](https://www.youtube.com/watch?v=1MwSoB0gnM4)! https://www.youtube.com/watch?v=1MwSoB0gnM4 您可以閱讀[文件](https://docs.n8n.io/)並閱讀本[指南](https://docs.n8n.io/try-it-out/),以便根據您的需求快速開始。 他們還提供初學者和中級[課程,](https://docs.n8n.io/courses/)以便輕鬆學習。 他們在 GitHub 上有 39k+ Stars,並提供兩個包供整體使用。 https://github.com/n8n-io/n8n 明星 n8n ⭐️ --- 13. [Quivr](https://github.com/QuivrHQ/quivr) - 你的 GenAI 第二腦。 -------------------------------------------------------------  Quivr,您的第二個大腦,利用 GenerativeAI 的力量成為您的私人助理!可以將其視為黑曜石,但增強了人工智慧功能。  您可以閱讀[安裝指南](https://github.com/QuivrHQ/quivr?tab=readme-ov-file#getting-started-)。 您可以閱讀[文件](https://docs.quivr.app/home/intro)並觀看[示範影片](https://github.com/QuivrHQ/quivr?tab=readme-ov-file#demo-highlights-)。 他們可以提供更好的免費套餐,但這足以在您端進行測試。 它在 GitHub 上擁有超過 30k 顆星,發布了 220 多個版本,這意味著它們正在不斷改進。 https://github.com/QuivrHQ/quivr Star Quivr ⭐️ --- 14. [meilisearch](https://github.com/meilisearch/meilisearch) - 適合您的應用程式、網站和工作流程的搜尋 API。 ---------------------------------------------------------------------------------------- 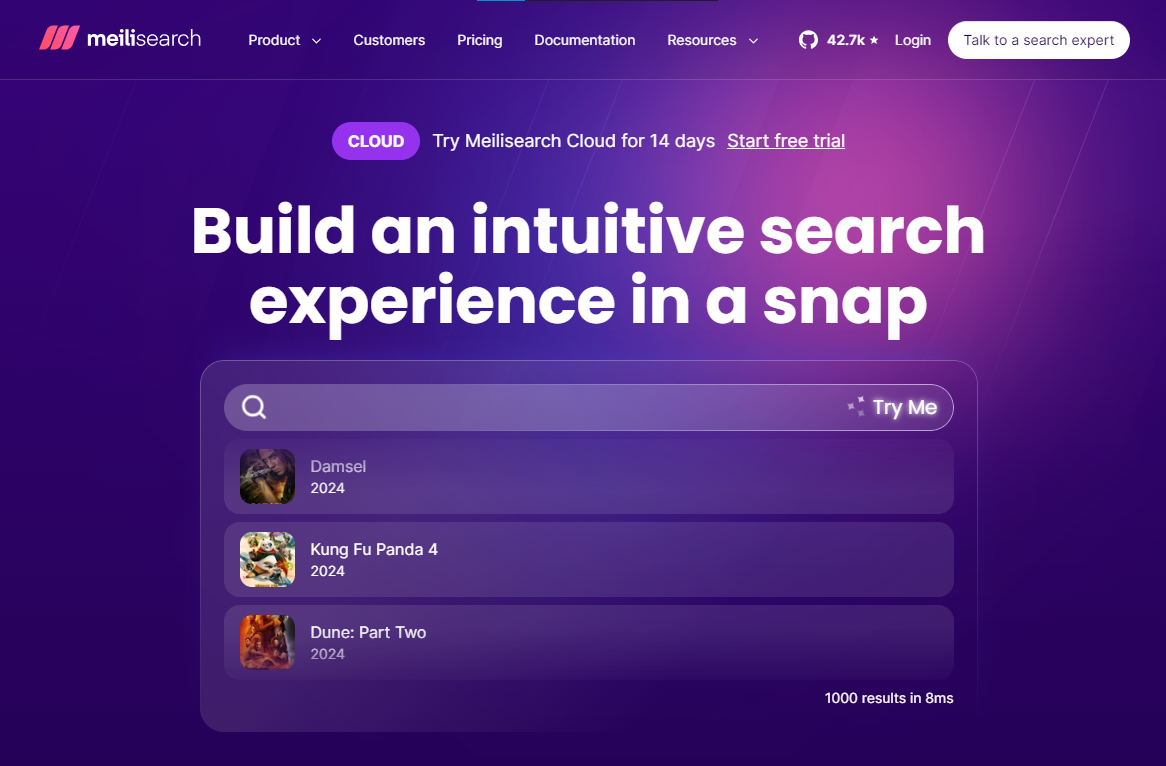 Meilisearch 可協助您快速打造令人愉悅的搜尋體驗,提供開箱即用的功能來加快您的工作流程。 您一定看過可以使用`Ctrl + k`搜尋文件的軟體網站,例如 GitHub 或 Appwrite。那麼,meilisearch 可以幫助您實現相同的功能。 與 Algolia、Typesense 和 Elasticsearch 相比,這是唯一基於 Rust 建構的。您可以閱讀有關可用替代選項的[比較](https://www.meilisearch.com/docs/learn/what_is_meilisearch/comparison_to_alternatives):) Meilisearch 不應該是您的主要資料儲存。它是一個搜尋引擎,而不是一個資料庫。 Meilisearch 應僅包含您希望使用者搜尋的資料。如果您必須加入與搜尋無關的資料,請務必使這些字段不可搜尋,以提高相關性並縮短響應時間。 無論您是在開發網站還是應用程式,Meilisearch 都能提供直覺的即輸入即搜尋體驗,回應時間低於 50 毫秒。 他們提供[SDK 和庫,](https://www.meilisearch.com/docs/learn/what_is_meilisearch/sdks?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=sdks-link)用於 Meilsearch 和您喜歡的語言或框架之間的無縫整合。相信我,選擇的數量是瘋狂的。 他們還提供了一個[抓取工具](https://github.com/meilisearch/docs-scraper)來自動讀取文件內容並將其儲存到Meilisearch。 他們展示了許多[有用的功能](https://www.meilisearch.com/docs/learn/what_is_meilisearch/overview#features),例如即使查詢包含拼寫錯誤和拼寫錯誤(他們將其稱為`typo tolerance` ,您也可以獲得相關匹配。 有很多可用的選項,但讓我們看看如何使用 React 來做到這一點。 開始使用以下命令。 ``` yarn add react-instantsearch @meilisearch/instant-meilisearch # or npm install react-instantsearch @meilisearch/instant-meilisearch # or pnpm add react-instantsearch @meilisearch/instant-meilisearch ``` 您可以這樣使用它。 ``` import React from 'react'; import { InstantSearch, SearchBox, Hits, Highlight } from 'react-instantsearch'; import { instantMeiliSearch } from '@meilisearch/instant-meilisearch'; const { searchClient } = instantMeiliSearch( 'https://ms-adf78ae33284-106.lon.meilisearch.io', 'a63da4928426f12639e19d62886f621130f3fa9ff3c7534c5d179f0f51c4f303' ); const App = () => ( <InstantSearch indexName="steam-video-games" searchClient={searchClient} > <SearchBox /> <Hits hitComponent={Hit} /> </InstantSearch> ); const Hit = ({ hit }) => <Highlight attribute="name" hit={hit} />; export default App ``` 您可以查看此[codesandbox](https://codesandbox.io/p/sandbox/eager-dust-f98w2w)以取得詳細的範例以開始使用。 正如我所說,他們在幕後提供了很多東西。例如,您可以使用這些。 ``` npm install @meilisearch/autocomplete-client npm install @meilisearch/instant-meilisearch npm install meilisearch-docsearch ``` `meilisearch docsearch`的靈感來自 Algolia 搜尋文件元件。另外,非常詳細的文件以及每個 sdk 的範例和選項使它們成為人們的最愛。 您可以閱讀[文件](https://www.meilisearch.com/docs)並觀看[現場演示](https://where2watch.meilisearch.com/?utm_campaign=oss&utm_source=github&utm_medium=meilisearch&utm_content=demo-link)。  他們在 GitHub 上有超過 42k 顆星,並且`v1.7`版本有 180 多個版本。 https://github.com/meilisearch/meilisearch 星 meilisearch ⭐️ --- 15.[收件匣清除](https://github.com/elie222/inbox-zero)- 幾分鐘內清理您的收件匣。 --------------------------------------------------------------- 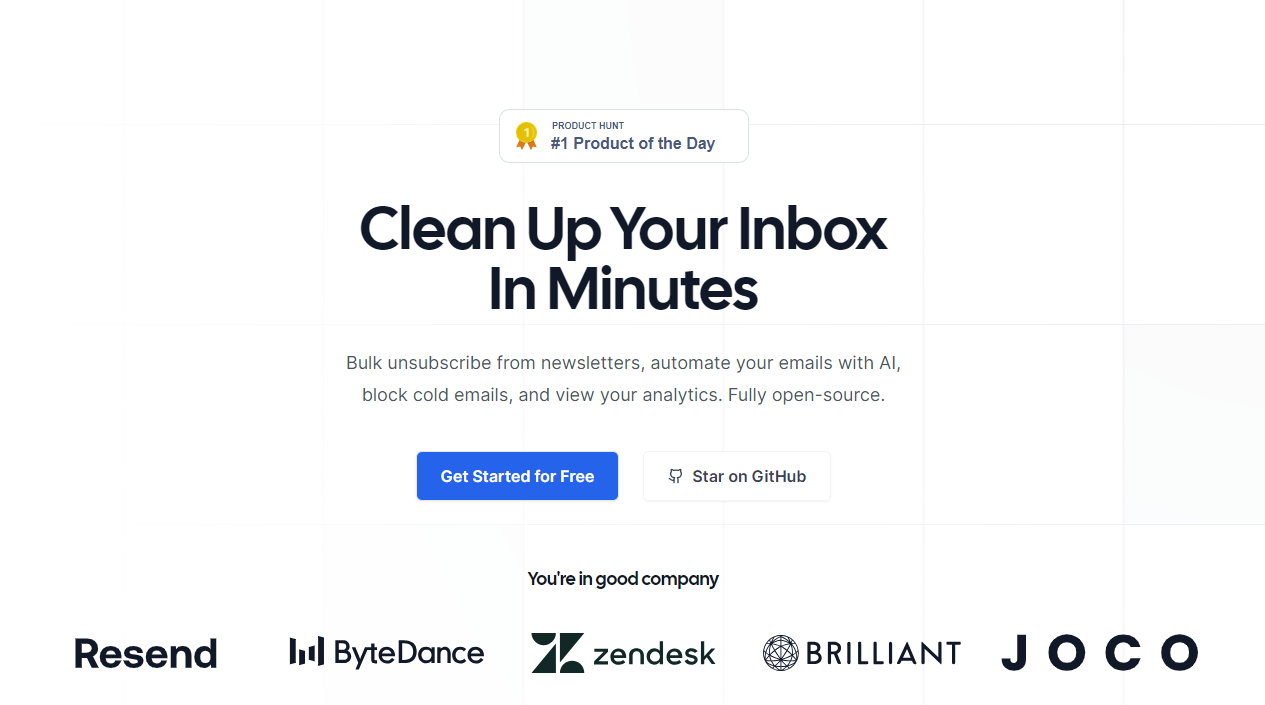 收件匣歸零是一款開源電子郵件應用程式,其目標是透過 AI 協助幫助您快速實現收件匣歸零。 它們得到了谷歌的批准,因此這是關注隱私的一個很好的部分。  它們使用 Postgres 作為資料庫,並基於 TypeScript 建置。 它們有一些瘋狂的功能,例如: > 您的電子郵件人工智慧助理 1. 人工智慧代理將讓您根據您提供的規則自動回覆、轉發或存檔電子郵件。 2. 他們的人工智慧計畫可以幫助你點擊接受或拒絕。一旦您確信人工智慧可以獨立工作,就可以開啟完全自動化。 3. 您可以用簡單的英語進行指導。就像與助手交談或向 ChatGPT 發送提示一樣簡單。 > 您可以自動封鎖冷電子郵件 您可以告訴「收件匣零」什麼對您來說構成冷郵件。它將根據您的指示阻止它們。 > 分析 了解收件匣是處理它的第一步。了解您的收件匣裡裝滿了什麼。它們還為您提供了立即採取行動的方法。 您可以閱讀核心[功能](https://github.com/elie222/inbox-zero?tab=readme-ov-file#key-features)並觀看[演示影片](https://github.com/elie222/inbox-zero?tab=readme-ov-file#demo-video)。您還可以查看他們的[看板](https://github.com/users/elie222/projects/1/views/1)以了解計劃內容。 他們在 GitHub 上擁有超過 1,500 個 Star,並且絕對值得更多。 https://github.com/elie222/inbox-zero 星收件匣零 ⭐️ --- 16. [Lively](https://github.com/rocksdanister/lively) - 允許使用者設定動畫桌面桌布和螢幕保護程式。 -----------------------------------------------------------------------------  這只是為了好玩,我們可以使用程式碼學到很多關於它是如何完成的。 你可以看看這個[影片](https://www.pexels.com/video/blue-texture-abstract-leaves-7710243/),看看它看起來有多瘋狂。  他們提供[三種類型的壁紙,](https://github.com/rocksdanister/lively?tab=readme-ov-file#types-of-wallpapers)包括影片/GIF、網頁和應用程式/遊戲。 它基於 C# 和 live 支援的一些很酷的功能建置: 1. Lively 可以透過終端機的[命令列參數](https://github.com/rocksdanister/lively/wiki/Command-Line-Controls)進行控制。您可以將其與其他語言(例如 Python 或腳本軟體 AutoHotKey)整合。 2. 一組強大的[API](https://github.com/rocksdanister/lively/wiki/API) ,供開發人員建立互動式壁紙。取得硬體讀數、音訊圖表、音樂資訊等。 3. 當電腦上執行全螢幕應用程式/遊戲時(~0% CPU、GPU 使用率),桌布播放會暫停。 4. 您還可以利用[機器學習推理](https://github.com/rocksdanister/lively/wiki/Machine-Learning)來建立動態壁紙。您可以預測任何 2D 影像與相機的距離並產生類似 3D 的視差效果。酷:D 我見過很多人使用它,其中許多人甚至不知道它是開源的。 您可以使用[安裝程式](https://github.com/rocksdanister/lively/releases/download/v2.0.7.4/lively_setup_x86_full_v2074.exe)或透過[Microsoft Store](https://www.microsoft.com/store/productId/9NTM2QC6QWS7?ocid=pdpshare)下載它。 它是 2023 年 Microsoft Store 的獲勝者。 它在 GitHub 上擁有 13k+ Stars,有 60 個版本。 https://github.com/rocksdanister/lively 明星活潑 ⭐️ --- 17. [Netron](https://github.com/lutzroeder/netron) - 神經網路、深度學習和機器學習模型的視覺化工具。 ----------------------------------------------------------------------------  Netron 是神經網路、深度學習和機器學習模型的檢視器。 Netron 支援 ONNX、TensorFlow Lite、Core ML、Keras、Caffe、Darknet、MXNet、PaddlePaddle、ncnn、MNN 和 TensorFlow.js。 Netron 對 PyTorch、TorchScript、TensorFlow、OpenVINO、RKNN、MediaPipe、ML.NET 和 scikit-learn 提供實驗性支援。 您可以閱讀有關[安裝說明](https://github.com/lutzroeder/netron?tab=readme-ov-file#install)。 您可以存取該[網站](https://netron.app/)並打開這些[範例模型文件](https://github.com/lutzroeder/netron?tab=readme-ov-file#models)以使用它來打開。例如,您可以看到這個[演示](https://netron.app/?url=https://github.com/onnx/models/raw/main/validated/vision/classification/squeezenet/model/squeezenet1.0-3.onnx)。 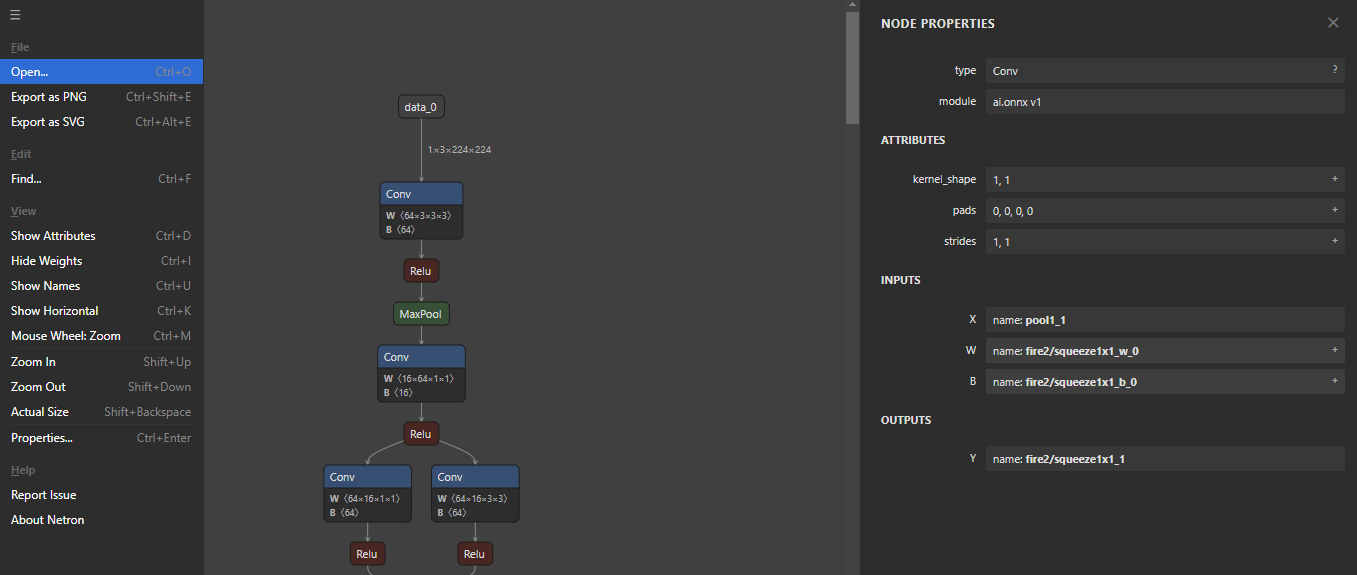 他們在 GitHub 上有 25k+ Stars,並且是基於 JavaScript 建構的。它們在`v7.5`上只有三個版本,考慮到我只使用了語義版本,這對我來說似乎很困惑。我們都同意這個用例非常出色。 https://github.com/lutzroeder/netron 明星 Netron ⭐️ --- 18. [Cursor](https://github.com/getcursor/cursor) - 以 VSCode 為基礎的人工智慧程式碼編輯器。 ----------------------------------------------------------------------------  Cursor 是一款專為與 AI 結對程式設計而設計的程式碼編輯器。遊標適用於 Windows、Mac 和 Linux。 Cursor 不僅僅是 Visual Studio Code (VSC) 擴充功能。這是它自己的應用程式。但別擔心!這是VSC前叉。這意味著它擁有 VSC 所擁有的一切,但在此基礎上也建立了更多人工智慧功能。 https://github.com/anysphere/primpt 他們之前開源了[基於 Codemirror 的編輯器](https://github.com/getcursor/old)。 基於 VSCodium 的 Cursor 版本不是開源的,只有它們的[提示庫](https://github.com/anysphere/priompt)是開源的。 選項數量龐大,您可以查看[功能列表](https://docs.cursor.sh/features/chat),例如選擇用於聊天的 AI 模型、程式碼庫索引和自動終端偵錯。聽起來很酷,對吧:D 您應該檢查的一些功能是: - 允許您透過編輯程式碼庫的「偽程式碼」版本來進行編碼。 - 一旦錯誤出現在您的終端機中,就會自動修復錯誤。 - 要求 AI 更改程式碼區塊,查看編輯的內聯差異。 您也可以閱讀他們官方網站的[變更日誌](https://changelog.cursor.sh/?)。 您可以閱讀有關如何從[VSCode 遷移到 Cursor 的](https://docs.cursor.sh/get-started/moving-from-vsc-to-cursor)資訊。 他們也有定價模型,但免費套餐足以讓您進行測試! 他們在 GitHub 上擁有超過 19k+ 的 Star,並將繼續成長。正如我所說,這不是開源的,但將來可能會改變。 https://github.com/getcursor/cursor 星形遊標 ⭐️ --- 19. [VSCode 除錯視覺化工具](https://github.com/hediet/vscode-debug-visualizer)- VS Code 的擴展,可在偵錯期間可視化資料。 -------------------------------------------------------------------------------------------------  這個專案相當令人印象深刻。它不僅有助於高效除錯,還有助於透過視覺化學習基本概念,從長遠來看,這是無價的。 這是一個 VS Code 擴展,用於在偵錯時可視化資料結構。與 VS Code 的監視視圖類似,但具有豐富的監視值視覺化效果。 他們支援許多語言,如 Dart/Flutter、JS/TS、Go、Python、C#、Java、C++、Ruby、Rust 和 Swift,儘管它很基礎,所以這是一個優點。 其他語言和除錯器也可能有效。對於有基本支援的語言,只能視覺化 JSON 字串。您需要實作邏輯來為您的資料結建置立此 JSON。完全支援的語言提供資料提取器,可將一些眾所周知的資料結構轉換為 JSON。 安裝擴充功能後,您可以使用命令`Debug Visualizer: New View`開啟新的視覺化工具視圖。 您可以[在 market 上](https://marketplace.visualstudio.com/items?itemName=hediet.debug-visualizer)查看所有可用的[演示](https://github.com/hediet/vscode-debug-visualizer/blob/master/extension/README.md#selected-demos)並查看擴展。 您還可以查看他們的[視覺化遊樂場](https://hediet.github.io/visualization/?darkTheme=1),其中包含眾多選項。 他們在 GitHub 上擁有超過 7800 顆星,而且還在不斷增長。 https://github.com/hediet/vscode-debug-visualizer 明星 VSCode 除錯視覺化工具 ⭐️ --- 20. [OpenDevin](https://github.com/OpenDevin/OpenDevin) - 更少的程式碼,更多的內容。 -----------------------------------------------------------------------   這是一個開源專案,旨在複製 Devin,一名自主人工智慧軟體工程師,能夠執行複雜的工程任務並在軟體開發專案上與用戶積極協作。該計畫致力於透過開源社群的力量複製、增強和創新 Devin。 只是想讓你知道,這是在德文被介紹之前。 您可以閱讀帶有要求的[安裝說明](https://github.com/OpenDevin/OpenDevin?tab=readme-ov-file#installation)。 他們使用 LiteLLM,因此您可以使用任何基礎模型來執行 OpenDevin,包括 OpenAI、Claude 和 Gemini。 如果您想為 OpenDevin 做出貢獻,您可以查看 [演示](https://github.com/OpenDevin/OpenDevin/blob/main/README.md#opendevin-code-less-make-more)和[貢獻指南](https://github.com/OpenDevin/OpenDevin/blob/main/CONTRIBUTING.md)。 它在 GitHub 上擁有超過 10,700 個 Star,並且正在快速成長。 https://github.com/OpenDevin/OpenDevin 明星 OpenDevin ⭐️ --- 21.[即時語音克隆](https://github.com/CorentinJ/Real-Time-Voice-Cloning)-5秒克隆語音,即時產生任意語音。 ----------------------------------------------------------------------------------  該專案是透過即時工作的聲碼器實現從說話者驗證到多說話者文字到語音合成 (SV2TTS) 的遷移學習。 SV2TTS是一個分為三個階段的深度學習架構。 在第一階段,人們從幾秒鐘的音訊中建立聲音的數位表示。 在第二和第三階段,該表示被用作參考來產生給定任意文字的語音。 您可以閱讀[如何設定](https://github.com/CorentinJ/Real-Time-Voice-Cloning?tab=readme-ov-file#setup)專案,其中包括安裝要求、下載預訓練模型、測試配置、下載資料集和啟動工具箱。 觀看下面所示的影片示範! https://www.youtube.com/watch?v=-O\_hYhToKoA 我一直喜歡開源專案的最好的部分是,他們甚至非常清楚地提到了替代方案,並且像往常一樣,他們推薦了一些[專案](https://github.com/CorentinJ/Real-Time-Voice-Cloning?tab=readme-ov-file#heads-up),這些專案將為您克隆的聲音提供更好的保真度及其表現力。 他們在 GitHub 上擁有 50k+ Stars,並且僅基於 Python 建置。到目前為止使用起來還是非常可信的。 https://github.com/CorentinJ/Real-Time-Voice-Cloning Star 即時語音克隆 ⭐️ --- 請在評論中告訴我您在此列表中發現了哪些有用的人工智慧工具:D 人工智慧正在改變世界,最好讓人工智慧成為你的朋友,而不是簡單地忽略它。 使用這些工具來提高工作效率並抓住機會創造非凡的東西。 祝你有美好的一天!直到下一次。 在 GitHub 和[Twitter](https://twitter.com/Anmol_Codes)上關注我。 https://github.com/Anmol-Baranwal 關注 Taipy 以了解更多此類內容。 https://dev.to/taipy --- 原文出處:https://dev.to/taipy/21-ai-tools-that-are-changing-the-world-1o54
***NVIDIA***是一家處於*人工智慧革命🫀 的*公司,最近透過其最新課程讓學習人工智慧變得輕而易舉。 這裡有***五門免費課程***,它們實際上物有所值(相信我,當我這麼說時),它們將幫助您更多地了解該主題並提高您的技能。 😉 PS:他們的網站上一**共有16門免費課程**。我為初學者精選出以下最好的課程。 點擊下面的連結查看它們 - 🔗 https://www.nvidia.com/en-us/training/online/#free-courses  --- 1️⃣ 生成式人工智慧解說 ------------- 你將學到什麼: - 生成式人工智慧並解釋生成式人工智慧的工作原理。 - 各種生成式人工智慧應用。 - 生成人工智慧的挑戰與機遇 🔗 https://courses.nvidia.com/courses/course-v1:DLI+S-FX-07+V1/  --- 2️⃣ 10 分鐘打造大腦 ------------- 你將學到什麼: - 探索神經網路如何使用資料進行學習 - 了解神經元背後的數學和科學 🔗 https://courses.nvidia.com/courses/course-v1:DLI+T-FX-01+V1/  --- 3️⃣ 透過檢索增強生成來增強您的 LLM: ---------------------- 你將學到什麼: - 檢索增強生成基礎知識 - RAG檢索過程 - NVIDIA AI 基礎和 RAG 模型元件 🔗 https://courses.nvidia.com/courses/course-v1:NVIDIA+S-FX-16+v1/  --- 4️⃣ 用 LLM 一起建構 RAG 代理: ---------------------- 你將學到什麼: - LLM 和向量資料庫的可擴展部署策略。 - 用於對話管理和文件檢索的現代 LangChain 範例。 - 採用先進的模型和步驟進行生產。 🔗 https://courses.nvidia.com/courses/course-v1:DLI+S-FX-15+V1/  --- 5️⃣ 透過零程式碼變更加速資料科學工作流程: ----------------------- 你將學到什麼: - 了解統一 CPU 和 GPU 工作流程的優勢 - GPU 加速資料處理和機器學習,無需更改程式碼 - 體驗更快的處理時間 🔗 https://courses.nvidia.com/courses/course-v1:DLI+T-DS-03+V1/  --- 🙌 總結 ---- 總之,NVIDIA 透過提供 16 門免費課程改變了 AI 教育。 這些精心挑選的資源,包括產生人工智慧和神經網路等主題,提供了寶貴的知識。 我個人正在利用這些課程,我鼓勵您也這樣做。 好啦,今天就到此為止! 與我聯絡@ [Linktree](https://linktr.ee/arjuncodess) 。 快樂編碼! 🚀 感謝24220! 🤗 --- 原文出處:https://dev.to/arjuncodess/nvidia-just-launched-free-courses-in-ai-47ef
[第一課 學習Vue元件觀念](https://play.vuejs.org/#eNqlUstOwzAQ/BXXl4BUpQc4lVAJUFGLxEOAxMWXKNmkKfFDtlMqVfl31nabVAXl0lO8M5PZsXd39E6peNMAndLEZLpSlhiwjZoxUXEltSU7oqEgLSm05CRCadRRC0hz0IFhNJ6E2tkxetOpntNK9BpXnSoepbTHPqHuVJkUxhJuSnLrslxEC6hrSb6krvNRdMlEMgnRMTQWFriqUwtYEZKETLNkHy6ALgRC/uOB0BGh/cF5HvnQMbUGYxRVGa+NFPhaO/cfo5nkqqpBvypbYUxGp8Qzjksx5c+Tx6xuYHzAsxVk3//ga7N1GKNvGgzoDd6+42yqS7CBnn+8wBbPHcll3tSoHiDfwci6cRmD7L4ROcY+0vm0Sz+QSpSfZr61IMzhUi6oU7ZezyjO5mHg6n3cq/ja/8dEi6/Yb8ifhRsaYl5t/IGQJUk5WXmXkacmgTsd12HNzmnD0WOwSb+n57QpvMtAo/YXezw35w==) [第二課 學習Vue的Props觀念 ](https://play.vuejs.org/#eNqdU1Fv0zAQ/ivGPGyTujYIkFDIKrFp0kACJkDwgHlI7UvmzbEt2+k6RfnvnJ2mdKXrw14i331fvjt/d+7oB2unyxZoTgvPnbSBeAitnTMtG2tcIJ2DqieVMw1hFJmMvt9gnx/OS1HDiE5n60RUTDxutA+k8TU5I6hzfHQFShnyyzglXhydMF3MhqpYD4MAjVVlAIwIKUZ1VS5AnTH6M4qSRcnvamdaLS6MMg7zL7MqQ4CPYVVVGCYKCEwsjBPgGJ0XY3/79T/5/fLVY3nO+bPkr0KjnirwLsv+v8IjwWK2ZQ6d0ODR20rW01tvNE6vizUZ5aaxUoH7aoNE7xnNSUIiVqL19/GSOQmuhcmY5zfA7/bkb/0q5hi9duDBLdH9DRZKV0MY4MvvX2CF5w3YGNEqZB8Av4E3qo09DrRz9APb3uKlbj+mPZO6/uEvVwG0Hy8VG43MPvHTYl4cuPq/dl9P36T/mO7Rxa193fMCBFRSw7Uz1h//ZjQNEjtEvZ0hDsk0veG43g5G/5zgKzi05EIuSe7DgwKce7ejm+/Ek2FD8vTtGY0KOVel9/jzpua861KrfV/MUH53eTBM9QhukAUR7ymXa6fupQg3OXmb2RX2HTMBp3daKlnrnHDQAdwaaNBSiclXDhqSYRItnQ5vIYkNx1NXCtl6pA2SSEI3Yvm4xv1fXnmF/w==) [第三課 學習Vue的events觀念 ](https://play.vuejs.org/#eNq9VV1P1EAU/SuTgtklLrtdYBHqQhDCgyYqEd+sCd12ultoO+PMFBY3TXgyorwZEw2J8cEHH0iMbwTjv4El/AvvzLRlXb6iMWY33Zl7T2/PvT1ztmfco7S6mWDDMprcZQEViGOR0Hk7DiJKmEA9xLCPUuQzEqESQEtF6uH2YiIEiXXONqq1PCJL2sZdOw6xQD6JxWrwEqM5Wapcnx7LEpTQhELUT2JXBCQuh04LhxXEOw7FYz07RsgJMRPlteOfn89+fOq/e3N89Gq0p2BpBbmhw3n/68fT71/6H76N9tR96Zosn9pxs6YbglZgI3BEQ0dg2DUL3qrQnG2cHhwcH+6c7Lzt7+2evX5vG6jluBttRpLYWyIhYYAZ8X0TEm6+dU35gYiV9wfRotXbqES7JZiJbgZS/EXiMBgKWoi2lzdxLCCmBmAb881icFfSO9q7iZ75O70/4aYq/TW1w90bqLkz8jPIzvf9/zW5k/39G1+sP+O5g/SmvMlZNc5/Pb/agAyNiiG4S2I/aFfXOYnhCCrJ24ZLIhqA8B9TeSq4bVhIZWTOCUOy9UDFBEtwJY+7HexuXBJf510Zs40VhjlmmzDHIicc1sZCp5dXH+EurItkRLwkBPQ1ySeYkzCRHDVsEaYAtAdwiu195RZB3H7Kl7sCxzxvShKVyFThbQNMY+ma1s/pTlan1H1wzmGKg6ZzjY+B92Qupp6k7MnDfhDjFUYoLz+zjSFxQCPqbRRLJSu9zNWgd0oItvFcWs+VvoNQs6XlaXGxHUrh9IaeaA3rE0xOx9VPpfBSq1ilUqbKCeVR0TzQghsG7gYERnEUiHIp02Wpok9GbrGgz17mpmmzpskNyxS2ii0CrVLsQUTj1GuJ4JUE8TgL2h1hoTrDkfbequpAQVqEeZiNM8cLEm6hhnkLIAh1cHaPadKuimwFnuicB2QVffJVmaFsXhe0QLsIZBh4aMQ0zSzVHYcGPbJlIdZuOWWzgrJvdaIxhqAEakzJS4N2Kxcg9QkNGa9PwHUSlldjZJXpSwF3NEDVqAPJixBzNnuObAGYFH9bctzSINJfM6ulag==) [第四課 學習Vue的v-model觀念 ](https://play.vuejs.org/#eNqdVE1vGjEQ/Ssj9wCRwgJJ6GG7QWqrHFIpbdT2VveweIfFide2bC8FIf57x8sSCKUU9bTym5k3b752xd5bm8xrZCnLvHDSBvAYajvmWlbWuAArcDiFNUydqaBDrp0X08PyXts6tKak374jX+cd1woDVL6E28jQ5Yyzix06PICz/iY9JaZHwMqqPCC9ALJtHpVPUN1yFnARhpzBvFeZokGIkLNxtlXw97CrP8NAqNx7ek2lUlicx3N9gsfUQUmN5xHdHBJRYefEjY7E/Vclb08RHS8l6+/Nh12y4IXRU1kmT95o2qRVTMaZMJWVCt0XG6TRnrMUGku05UqZX58aLLgaL7e4mKF4PoI/+UXEOHt06NHNSdKLLeSuxLAx3337TDXtGamwWpH3CeNX9EbVUePG7UOtC5K959eovW+WXuryu79bBNR+W1QUGj3XjT9ntP4fT5S+k3ud3DRxXK+pi3vXc+QaC5zSIB6dsb77g7NmgqQwtizOirOfF1zTGDxdV5wlndcm5CG+uv86MdnsRVhabNfi9VbELyEpRQicGVWgI7gVAel2XVop42ziDteEnj4sFQLtisUi/l9iyrYrM5TlLKQwGtgFKY3QxDjKkoI2Gl9BvYkJwVQpDO0CaHKygDdCiNanou5KnUIycljBgFBqb7I5iDbZMeZcPJfO0OB7wihDxpYyBrdHcBB9tcs+GLR5qMOxxngV69+xVc2T) [第五課 學習Vue的slots觀念 ](https://play.vuejs.org/#eNqdVN1qE0EUfpVhe9EK6aZWc7OuBSsVKqhFBS9cLza7k3Tb3ZlhZjamhIB3tZQqgq1gQa2KVEXUIvaiii9j/t7CMzu7m8QmEcxFduf8fOc7Z85+DeMSY2YtxoZl2MLjAZNIYBmzBYcEEaNcogbiuIKaqMJphKYhdDp3XdtYdAnBXPscwyxmFgXpGBccYhc1KuDBQeKIha7EcELIztO90BXiomNw7CNOY+Jj3zGSGPWz2cLvn69ax0ett19bj04634+6x597D950jp8XUHtzq/P0sHO43frxGEJ6+6/BbBcV/zQ7q4mmXE8GlOQe8JVjKcHSO3nRfvikt7fd2n15Z/nKsl1MHTlIcZh53ueYRsphjE91ovr4dQBsWzsH3Q873U9b0FB791kBdT9u9zZ3uu/f9YmPp237Qa1fSJLBSWX9pGB/d5Ge2/vf2ntfci4juoUSGY8JnQ/5bCE3QoyERxn24WzCZTZUStn11qvJLGY9GlJuoanK3BysBkLM9f2AVC10luNIW6gIVLcWLB0ABzWcmPPESgXOTUBXEx4Dr1yTwE5XHYZHKHJ5NSCzkjILmfMlHQZV9ZySsjmI9iMzjQKwmAuFxmhAJOYjC5wmLblLBHM5JlJHUO5jsBNKNGttmOWuH8TCQvMlVk9Hob6aQWZ5125Z0DCWOp8H1VVpIZ2m4CAhghnMgQGh/lCRCTv1v0ADU7JWaQ3zMVfEq2V3Zr5UKkAf2d+cWTqjAUAz1C4tGAVDwj6RSlA11wQloFEJnmN4NGJBiPkNpggKx7BQ4lE+Nwzp/auJTfIYFzK7t4q99RH2NVFXNsdY4VhgXgPdyn0SFgFL7V66dR3X4T13RtSPQ4ie4LyJk8EBRx22CDMA2gNxCdvlRE5hnW6LpbrERGRNKaIqspnEOwao6uUJrffpnjPPJ3kwT5jioCqPEHofVwKCVzhlYuYuqHCmW/fUfUwScKVEViZFjTQPble/NFNlskVI5QLgqEduQMSNMKRpdYPQwYBUgP4hMLqMXrHhr6O/jPkuNf8AC2d7zg==) [第六課 學習用外部狀態管理vue元件 ](https://play.vuejs.org/#eNqNVM1u00AQfpWVESJFjZMWegluRSk9gFRAwNEXx17b26691u7aSahyggt/VxDQAyAOhSdAIN6mtOQtmFn/xClthRQpO/PNzH4zO5/3rc0ss4ucWgPLUb5kmSaK6jzbcFOWZEJqsk8kDcmUhFIk5AqEXmmgnclt5nERlZhr2b3agyVd64ab+iJVUDIWo01OIWUdq3VCjyu6tABviTRkMjkd4PRKVsAHDE2TjHuagkWIM8y1Fim56XPm7627VvsWLZHAhoem0ysjy6yGdNFNREB5OxEyMAai4pU6F06VL9s4+vni95evxwdPj76/nH04dHo4J0Cavg3Nc6jNO6zIQfPo+C96VfICwePDd7NPrxYZnnz+8efb66NfH0/eP6vxM0g6vdYoHaUnHA9X9zEw8WTE0gHpw/gJybwgYGlUm0Mx7ir2xHiGQgZUdsEF0NRNyzZMjSZrRdKErNira/BvCtTV7coDefDGFQFr2dLKjCWyd5VIYStNOdfyRZIxeJD7mWawM641IAZBzONcjO4aH052ufb7MfX3zvDvqjH6XOuBpIrKAt6iwTTQo7AHCG8/ukfHcG5AeJCcQ/QF4EOqBM+RYxl2K08DoN2KM2zvGAHBhB6r7bGmqaqbMqsBkVMT71qgo60LWp/TvWZfN3kwUZhiW4cXSBukVgnb3NRSrNk9WNWAhiylO2h1UI+cauJzoShgYZ76SKmzVO4NBtmFx3MDooKb9z1XwwErYNNxw2HRTQXXggs8pcAeSS+bbzyG1giQhKnN9Qqw4kKT3tw+LUHDGhJmbw9mb54viA7FAdUrmZSnMxRCYDUzGoBtIzPT9IgFOoY17/cvm/WOKYtibRxFXCrG8/ciKWAPur7gQg6IjIZep79Myp+9hnMlJGAKrpsMSMgpCooQj7Mo7TLgoQbEh3apNP7dXGkWTqCcGUILg2HblbfNbq3fz8qSNb3VxvMvvUthGJbSF4rh+wJjCoNgRfWebZ03Id7QLD6G4FcCIpL6myHLO9FYVPv0LylMQZw=) [第七課 學習開發狀態複雜的vue元件 ](https://play.vuejs.org/#eNqtVF1P2zAU/StWQCKV2jRl6yZlKdKKENok2AR7zAP5cFNDYke2U1pF+e+7tuM0FOj2wENV+97jc86N73XjfK8qb1NjJ3BCkXJSSSSwrKuLiJKyYlyim90lKxhHK85KFDnetAuoU5Hzrcc1iONVa2BnkDuLaMqokOgu1ecXKu/6Izhh4tfvxJev4uHUWANTsJG4rIpYYtghpH6htbiZlCzDRWAUF5FjFpHTZ4wmZMxikDGqkDGLyNH0nYCtGWLhdKAfUWfsSAG+VyT3HgWj8B0b7ctJWVmRAvNflSRQV+QESGdULi4K9vxTxySv8djG0zVOn96IP4qtikXOb44F5hv48H1OxjzH0qSv7m/xFtZ9EmqrC0AfSd5hwYpaeTSwZU0zsD3Aabc/9C0Tmv8RV1uJqbBFKaMK2Wp85MDVXx4pfW/3k/dZn4toC19x0FXv92IDLTFG6svWEmdds2lJ3YkH/ZbhFaH4Rl2vu++FNxrwJdC2xhsd+RJoO0UBLZTnienFRW/TdUdocWG/AIeKOEUPAHRPG2PK28RFjdvxaWO093sj0e1HDyDUjqzUGm+PSVmhk9Pmti4TzN2h2MiT7F5yuE939mXkVXF2Dzcj3fMxOvPPRm1/aOjovw8Nbf/r0IOp6ciMh0Wc4AKtzEjDZN6FUx0yWUKhdiR3FYY0j2kOzYBKQmHnq1W8hdX5fA5rIXEFm9l+7oePBMk6/lBUMb1outtpW/CmAmGiHoADP9eAv/5QP/3TpP0ofuvHZI77WQJ++aF+bJsbP4rf+jGZ134yskFpEQsBeA2ZQMfKGEZH0QRC7grlpUni9CnnDB4c3ciBHZ5WaUyBxdAp8p5P6jcMxHuwlT+CtaMywB685KE2BQvvwLCepWeSyXWA5r5fbWEGEcweyddyGCnhXSN0kjApWRmgGcelmlYgVC40S0YEyO0CRGgB1JOkYOmTPtzxz+aWDaYkg4kJkDcHIuR9VX86o9gmcUFyGqAUU4m5DieMZ5gDRbVF8J6TDJ34vm8cQM1dcU77F0Ynrx8=)
您可能聽說過「十億行挑戰」(1brc),如果您沒有聽說過,請查看[Gunnar Morlings 的 1brc 儲存庫](https://github.com/gunnarmorling/1brc)。 我之所以被吸引,是因為我的兩位同事參加了比賽並進入了[排行榜](https://github.com/gunnarmorling/1brc?tab=readme-ov-file#results)。 PHP 並不以其速度而聞名,但當我正在開發 PHP 分析器時,我想我應該嘗試它,看看它能達到多快。 第一種幼稚的方法 -------- 我克隆了儲存庫並在`measurements.txt`中建立了十億行資料集。之後,我開始建立我的第一個天真的實現,可以解決這個挑戰: ``` <?php $stations = []; $fp = fopen('measurements.txt', 'r'); while ($data = fgetcsv($fp, null, ';')) { if (!isset($stations[$data[0]])) { $stations[$data[0]] = [ $data[1], $data[1], $data[1], 1 ]; } else { $stations[$data[0]][3] ++; $stations[$data[0]][2] += $data[1]; if ($data[1] < $stations[$data[0]][0]) { $stations[$data[0]][0] = $data[1]; } if ($data[1] > $stations[$data[0]][1]) { $stations[$data[0]][1] = $data[1]; } } } ksort($stations); echo '{'; foreach($stations as $k=>&$station) { $station[2] = $station[2]/$station[3]; echo $k, '=', $station[0], '/', $station[2], '/', $station[1], ', '; } echo '}'; ``` 這裡沒什麼瘋狂的,只要打開文件,使用`fgetcsv()`讀取資料即可。如果尚未找到該站,則建立它,否則增加計數器,對溫度求和,並查看當前溫度是否低於或高於最小值或最大值並相應更新。 一旦我把所有東西都放在一起,我使用`ksort()`將`$stations`陣列按順序排列,然後回顯列表併計算平均溫度(總和/計數)。 在我的筆記型電腦上執行這個簡單的程式碼需要**25 分鐘**🤯 是時候優化並查看分析器了:  時間軸視覺化幫助我看到,這顯然是 CPU 限制的,腳本開頭的檔案編譯可以忽略不計,並且沒有垃圾收集事件。  火焰圖視圖也有助於顯示我在`fgetcsv()`上花費了 46% 的 CPU 時間。 `fgets()`而不是`fgetcsv()` ----------------------- 第一個最佳化是使用`fgets()`取得一行並在`;`上分割。手動輸入字元而不是依賴`fgetcsv()` 。這是因為`fgetcsv()`所做的事情遠遠超出了我的需要。 ``` // ... while ($data = fgets($fp, 999)) { $pos = strpos($data, ';'); $city = substr($data, 0, $pos); $temp = substr($data, $pos+1, -1); // ... ``` 此外,我在各處將`$data[0]`重構為`$city` ,將`$data[1]`為`$temp` 。 僅透過此變更再次執行腳本就已將執行時間降至**19m 49s** 。從絕對數字來看,這仍然是很多,而且:**下降了 21%** !  火焰圖反映了這一變化,切換到按行顯示 CPU 時間也揭示了根框架中發生的情況:  我在第 18 行和第 23 行花費了約 38% 的 CPU 時間,它們是: ``` 18 | $stations[$city][3] ++; | // ... 23 | if ($temp > $stations[$city][1]) { ``` 第 18 行是循環中對`$stations`陣列的第一次存取,否則它只是一個增量,第23 行是一個比較,乍一看似乎沒什麼昂貴的,但讓我們再做一些優化,你就會看到發生了什麼時間在這裡。 盡可能使用參考 ------- ``` $station = &$stations[$city]; $station[3] ++; $station[2] += $temp; // instead of $stations[$city][3] ++; $stations[$city][2] += $data[1]; ``` 這應該有助於 PHP 在每次存取陣列時不必搜尋`$stations`陣列中的鍵,將其視為用於存取陣列中“當前”電台的快取。 它實際上很有幫助,執行這個只需要**17m 48s** ,又**減少了 10%** ! 只有一處比較 ------ 在查看程式碼時,我偶然發現了這段程式碼: ``` if ($temp < $station[0]) { $station[0] = $temp; } if ($temp > $station[1]) { $station[1] = $temp; } ``` 如果溫度低於最小值,它就不能再高於最大值,所以我將其設為`elseif` ,也許可以節省一些 CPU 週期。 順便說一句:我對`measurements.txt`中的溫度順序一無所知,但根據該順序,如果我先檢查一個或另一個,可能會產生影響。 新版本需要 17m 30s,又增加了約 2%。比僅僅抖動好,但也不是很多。 新增類型轉換 ------ PHP被認為是一種動態語言,這是我剛開始寫軟體時非常重視的東西,少了一個需要關心的問題。但另一方面,了解類型有助於引擎在執行程式碼時做出更好的決策。 ``` $temp = (float)substr($data, $pos+1, -1); ``` 你猜怎麼了?這個簡單的轉換使腳本執行時間僅為**13m 32s** ,**效能提升了 21%** !  ``` 18 | $station = &$stations[$city]; | // ... 23 | } elseif ($temp > $station[1]) { ``` 第 18 行仍然顯示 11% 的 CPU 時間花費,這是對陣列的存取(在哈希映射中查找鍵,哈希映射是 PHP 中用於關聯陣列的底層資料結構)。 第 23 行的 CPU 時間從 ~32% 下降到 ~15%。這是因為 PHP 不再進行型別處理。在型別轉換之前, `$temp` / `$station[0]` / `$station[1]`是`strings` ,因此 PHP 必須將它們轉換為`float`以便在每次比較時對它們進行比較。 JIT 怎麼樣? -------- PHP 中的 OPCache 在 CLI 中預設為停用狀態,需要將[`opcache.enable_cli`設定](https://www.php.net/manual/en/opcache.configuration.php#ini.opcache.enable-cli)設為`on` 。 JIT(作為 OPCache 的一部分)預設為啟用,但由於緩衝區大小設定為`0`而有效停用,因此我將[`opcache.jit-buffer-size`](https://www.php.net/manual/en/opcache.configuration.php#ini.opcache.jit-buffer-size)設為某個值,我只是使用`10M` 。應用這些更改後,我使用 JIT 重新執行腳本並看到它完成: **7m 19s** 🚀 花費的時間減少了**45.9%** ! 還有什麼? ----- 我已經將執行時間從一開始的 25 分鐘縮短到了大約 7 分鐘。我發現絕對令人驚訝的一件事是`fgets()`分配 ~56 GiB/m 的 RAM 來讀取 13 GB 檔案。似乎有些不對勁,所以我檢查了[`fgets()`的實現](https://github.com/php/php-src/blob/7f8465ab22648fb05fa39bacbd82aa48914a2e39/ext/standard/file.c#L884-L931),看起來我可以透過省略`fgets()`的`len`參數來節省大量分配: ``` while ($data = fgets($fp)) { // instead of while ($data = fgets($fp, 999)) { ``` 比較更改前後的設定檔可以得出以下結果:  您可能認為這帶來了很大的效能提升,但實際上只有大約 1%。這是因為這些是[ZendMM 可以在 bin 中處理的](https://www.phpinternalsbook.com/php7/memory_management/zend_memory_manager.html#zendmm-internal-design)小分配,而且速度非常快。 我們可以讓它更快嗎? ---------- 我們可以!到目前為止,我的方法是單線程,這是大多數 PHP 軟體的本質,但 PHP 確實透過[並行擴展來](https://github.com/krakjoe/parallel)支援使用者狀態中的線程。 正如分析器清楚地顯示的那樣,在 PHP 中讀取資料是一個瓶頸。從`fgetcsv()`切換到`fgets()`並手動拆分會有所幫助,但這仍然需要花費大量時間,因此讓我們使用線程並行讀取和處理資料,然後合併工作線程的中間結果。 ``` <?php $file = 'measurements.txt'; $threads_cnt = 16; /** * Get the chunks that each thread needs to process with start and end position. * These positions are aligned to \n chars because we use `fgets()` to read * which itself reads till a \n character. * * @return array<int, array{0: int, 1: int}> */ function get_file_chunks(string $file, int $cpu_count): array { $size = filesize($file); if ($cpu_count == 1) { $chunk_size = $size; } else { $chunk_size = (int) ($size / $cpu_count); } $fp = fopen($file, 'rb'); $chunks = []; $chunk_start = 0; while ($chunk_start < $size) { $chunk_end = min($size, $chunk_start + $chunk_size); if ($chunk_end < $size) { fseek($fp, $chunk_end); fgets($fp); // moves fp to next \n char $chunk_end = ftell($fp); } $chunks[] = [ $chunk_start, $chunk_end ]; $chunk_start = $chunk_end+1; } fclose($fp); return $chunks; } /** * This function will open the file passed in `$file` and read and process the * data from `$chunk_start` to `$chunk_end`. * * The returned array has the name of the city as the key and an array as the * value, containing the min temp in key 0, the max temp in key 1, the sum of * all temperatures in key 2 and count of temperatures in key 3. * * @return array<string, array{0: float, 1: float, 2: float, 3: int}> */ $process_chunk = function (string $file, int $chunk_start, int $chunk_end): array { $stations = []; $fp = fopen($file, 'rb'); fseek($fp, $chunk_start); while ($data = fgets($fp)) { $chunk_start += strlen($data); if ($chunk_start > $chunk_end) { break; } $pos2 = strpos($data, ';'); $city = substr($data, 0, $pos2); $temp = (float)substr($data, $pos2+1, -1); if (isset($stations[$city])) { $station = &$stations[$city]; $station[3] ++; $station[2] += $temp; if ($temp < $station[0]) { $station[0] = $temp; } elseif ($temp > $station[1]) { $station[1] = $temp; } } else { $stations[$city] = [ $temp, $temp, $temp, 1 ]; } } return $stations; }; $chunks = get_file_chunks($file, $threads_cnt); $futures = []; for ($i = 0; $i < $threads_cnt; $i++) { $runtime = new \parallel\Runtime(); $futures[$i] = $runtime->run( $process_chunk, [ $file, $chunks[$i][0], $chunks[$i][1] ] ); } $results = []; for ($i = 0; $i < $threads_cnt; $i++) { // `value()` blocks until a result is available, so the main thread waits // for the thread to finish $chunk_result = $futures[$i]->value(); foreach ($chunk_result as $city => $measurement) { if (isset($results[$city])) { $result = &$results[$city]; $result[2] += $measurement[2]; $result[3] += $measurement[3]; if ($measurement[0] < $result[0]) { $result[0] = $measurement[0]; } if ($measurement[1] < $result[1]) { $result[1] = $measurement[1]; } } else { $results[$city] = $measurement; } } } ksort($results); echo '{', PHP_EOL; foreach($results as $k=>&$station) { echo "\t", $k, '=', $station[0], '/', ($station[2]/$station[3]), '/', $station[1], ',', PHP_EOL; } echo '}', PHP_EOL; ``` 這段程式碼做了一些事情,首先我掃描檔案並將其分成`\n`對齊的區塊(因為我稍後使用`fgets()` )。當我準備好區塊時,我啟動`$threads_cnt`工作線程,然後所有線程都打開同一個檔案並尋找分配的區塊開始並讀取和處理資料直到區塊結束,返回一個中間結果,然後將其組合、排序和列印在主線程中輸出。 這種多執行緒方法只需: **1 分 35 秒**🚀 這就是結局? ------ 不,當然不是。這個解決方案至少還有兩件事: 1. 我在 Apple Silicon 硬體上的 MacOS 上執行此程式碼,[在 PHP 的 ZTS 版本中使用 JIT 時會崩潰](https://github.com/php/php-src/issues/13400),因此 1m 35s 結果是沒有 JIT 的,如果我可以使用它,它可能會更快 2. 我意識到我正在執行一個使用`CFLAGS="-g -O0 ..."`編譯的 PHP 版本,因為我的日常工作需要 🤦 我應該在一開始就檢查一下這一點,所以我使用`CLFAGS="-Os ..."`重新編譯了 PHP 8.3,我的最終數字(有 16 個線程)是: 🚀 **27.7 秒**🚀 這個數字絕對無法與您在原始挑戰的排行榜中看到的數字相媲美,這是因為我在完全不同的硬體上執行了這段程式碼。 這是一個有 10 個執行緒的時間軸視圖:  最底層的線程是主線程,等待工作線程的結果。一旦這些工作人員返回了中間結果,就可以看到主線程正在對所有內容進行組合和排序。我們也可以清楚看到,主線程絕對不是瓶頸。如果您想嘗試進一步優化,請專注於工作線程。 我在路上學到了什麼? ---------- 每個抽象層只是用可用性/整合來換取 CPU 週期或記憶體。 `fgetcsv()`非常容易使用,並且隱藏了很多東西,但是這是有代價的。即使`fgets()`也向我們隱藏了一些東西,但卻使讀取資料變得非常方便。 在程式碼中新增類型將有助於語言最佳化執行或停止類型雜耍(這是您看不到的東西,但仍然需要付出 CPU 週期的代價)。 JIT 非常棒,尤其是在處理 CPU 密集型問題時! 這絕對不是大多數 PHP 軟體的本質,但由於並行化(使用[`ext-parallel`](https://github.com/krakjoe/parallel) ),我們可以顯著降低數字。 結束 -- 我希望您和我一樣從閱讀這篇文章中獲得樂趣。如果您想進一步優化程式碼,請隨時取得此程式碼並發表評論。 --- 原文出處:https://dev.to/realflowcontrol/processing-one-billion-rows-in-php-3eg0
[本·羅戈揚](https://www.linkedin.com/in/benjaminrogojan/) 軟體工程面試與其他技術面試一樣,需要充分的準備。有許多主題需要涵蓋,以確保您準備好應對有關演算法、資料結構、設計、最佳化以及不斷增長的主題的連續問題。 因此,我在最後一輪面試中建立了一個清單,涵蓋了許多熱門話題。 為了幫助您追蹤進度,我們針對下面列出的相同問題編制了一份全面的清單; [該列表可以在這裡找到](https://docs.google.com/spreadsheets/d/19hSRrL4l3gRiJ5ucH9q4iwFo2QHgic9gGMNUrcn1mm0/edit?usp=sharing)。 ### **聆聽經典熱身** 1. [fizzbuzz](https://www.hackerrank.com/challenges/fizzbuzz/problem) 2. [子陣列和等於 K](https://leetcode.com/problems/subarray-sum-equals-k/) 3. [陣列:左旋轉](https://www.hackerrank.com/challenges/ctci-array-left-rotation/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=arrays) 4. [字串:製作字謎詞](https://www.hackerrank.com/challenges/ctci-making-anagrams/problem?h_l=interview&playlist_slugs%5B%5D=interview-preparation-kit&playlist_slugs%5B%5D=strings) 5. [第 N 次斐波那契數](https://www.algoexpert.io/questions/Nth%20Fibonacci) 你怎麼做的?花點時間對這些經典作品進行評價。我們在面試過程中的某個時刻被問到了其中大部分問題,而且通常是在早期就被問到的淘汰式問題。它們通常與演算法和資料結構關係不大,但仍然需要對循環和陣列有很好的理解(是的,陣列是一種資料結構)。 ### **演算法和資料結構** #### **預習問題** 在觀看有關資料結構和演算法的影片內容之前,請考慮嘗試以下這些問題。看看你能否回答他們。這將幫助您知道要關注什麼。 1. [985. 查詢後偶數之和](https://leetcode.com/problems/sum-of-even-numbers-after-queries/) 2. [657. 機器人回歸原點](https://leetcode.com/problems/robot-return-to-origin/) 3. [961. 2N 陣列中的 N 重複元素](https://leetcode.com/problems/n-repeated-element-in-size-2n-array/) 4. [110.平衡二元樹](https://leetcode.com/problems/balanced-binary-tree/) 5. [3. 最長無重複字元的子字串](https://leetcode.com/problems/longest-substring-without-repeating-characters/) 6. [19. 從清單結尾刪除第 N 個節點](https://leetcode.com/problems/remove-nth-node-from-end-of-list/) 7. [23. 合併 k 個排序列表](https://leetcode.com/problems/merge-k-sorted-lists/) 8. [31. 下一個排列](https://leetcode.com/problems/next-permutation/) ### 演算法和資料結構影片 #### 資料結構  1. [資料結構與演算法 #1 --- 什麼是資料結構?](https://www.youtube.com/watch?v=bum_19loj9A) --- 影片 2. [多調光](https://archive.org/details/0102WhatYouShouldKnow/02_05-multidimensionalArrays.mp4)--- 影片 3. [動態陣列](https://www.coursera.org/learn/data-structures/lecture/EwbnV/dynamic-arrays)[ ](https://archive.org/details/0102WhatYouShouldKnow/03_01-resizableArrays.mp4)--- 影片 4. [調整陣列大小](https://archive.org/details/0102WhatYouShouldKnow/03_01-resizableArrays.mp4)--- 影片 5. [資料結構:鍊錶](https://youtu.be/njTh_OwMljA)--- 影片 6. [核心鍊錶與陣列](https://www.coursera.org/learn/data-structures-optimizing-performance/lecture/rjBs9/core-linked-lists-vs-arrays)--- 影片 7. [指針到指針](https://www.eskimo.com/~scs/cclass/int/sx8.html)[ ](https://archive.org/details/0102WhatYouShouldKnow/03_01-resizableArrays.mp4)--- 影片 8. [資料結構:樹](https://youtu.be/oSWTXtMglKE)[ ](https://archive.org/details/0102WhatYouShouldKnow/03_01-resizableArrays.mp4)--- 影片 9. [資料結構:堆](https://youtu.be/t0Cq6tVNRBA)[ ](https://archive.org/details/0102WhatYouShouldKnow/03_01-resizableArrays.mp4)--- 影片 10. [資料結構:哈希表](https://youtu.be/shs0KM3wKv8)[ ](https://archive.org/details/0102WhatYouShouldKnow/03_01-resizableArrays.mp4)--- 影片 11. [電話簿問題](https://www.coursera.org/learn/data-structures/lecture/NYZZP/phone-book-problem)---影片 12. [資料結構:堆疊和佇列](https://youtu.be/wjI1WNcIntg)[ ](https://archive.org/details/0102WhatYouShouldKnow/03_01-resizableArrays.mp4)--- 影片 13. [使用堆疊後進先出](https://archive.org/details/0102WhatYouShouldKnow/05_01-usingStacksForLast-inFirst-out.mp4)--- 影片 14. [資料結構:計算機科學速成課程#14](https://youtu.be/DuDz6B4cqVc)[ ](https://archive.org/details/0102WhatYouShouldKnow/03_01-resizableArrays.mp4)--- 影片 15. [資料結構:嘗試](https://www.youtube.com/watch?v=zIjfhVPRZCg)[ ](https://archive.org/details/0102WhatYouShouldKnow/03_01-resizableArrays.mp4)--- 影片 #### 演算法  1. [演算法:圖搜尋、DFS 和 BFS](https://www.youtube.com/watch?v=zaBhtODEL0w&list=PLX6IKgS15Ue02WDPRCmYKuZicQHit9kFt)[ ](https://archive.org/details/0102WhatYouShouldKnow/03_01-resizableArrays.mp4)--- 影片 2. [BFS(廣度優先搜尋)和DFS(深度優先搜尋)](https://www.youtube.com/watch?v=uWL6FJhq5fM) --- 影片 3. [演算法:二分查找](https://youtu.be/P3YID7liBug)---影片 4. [二元搜尋樹回顧](https://www.youtube.com/watch?v=x6At0nzX92o&index=1&list=PLA5Lqm4uh9Bbq-E0ZnqTIa8LRaL77ica6)--- 影片 5. [用於面試的 Python 演算法](https://www.youtube.com/watch?v=p65AHm9MX80)[ ](https://archive.org/details/0102WhatYouShouldKnow/03_01-resizableArrays.mp4)--- 影片 6. [演算法:遞歸](https://youtu.be/KEEKn7Me-ms)---影片 7. [演算法:冒泡排序](https://youtu.be/6Gv8vg0kcHc)--- 影片 8. [演算法:歸併排序](https://youtu.be/KF2j-9iSf4Q)--- 影片 9. [演算法:快速排序](https://youtu.be/SLauY6PpjW4)---影片 ### **大 O 表示法** 1. [大 O 表示法與時間複雜度簡介(資料結構與演算法 #7)](https://www.youtube.com/watch?v=D6xkbGLQesk) --- 影片 2. [哈佛 CS50 --- 漸近符號](https://www.youtube.com/watch?v=iOq5kSKqeR4)--- 影片 3. [演算法複雜度分析的簡單介紹](http://discrete.gr/complexity/)--- Post 4. [備忘錄](http://bigocheatsheet.com/)--- 帖子 ### **動態規劃** 1. [動態規劃(像程式設計師一樣思考)---影片](https://www.youtube.com/watch?v=iv_yHjmkv4I) 2. [演算法:記憶化與動態規劃 --- 影片](https://www.youtube.com/watch?v=P8Xa2BitN3I&t=13s) 3. 6 [.006:動態規劃 I:斐波那契、最短路徑 --- 影片](https://www.youtube.com/watch?v=OQ5jsbhAv_M&t=7s) 4. [6.006:動態規劃 II:文字對齊、二十一點 --- 影片](https://www.youtube.com/watch?v=ENyox7kNKeY&t=4s) 5. [動態規劃 --- 帖子](https://www.topcoder.com/community/competitive-programming/tutorials/dynamic-programming-from-novice-to-advanced/) ### **字串操作** 1. [編碼面試問答:最長的連續字元](https://www.youtube.com/watch?v=qRNB8CV3_LU)--- 影片 2. [Sedgewick --- 子字串搜尋](https://www.coursera.org/learn/algorithms-part2/home/week/4)--- 影片 #### 面試問題演練 1. [谷歌編碼面試 --- 普世價值樹問題](https://www.youtube.com/watch?v=7HgsS8bRvjo)--- 影片 2. [Google 編碼面試問題和答案 #1:第一個重複出現的字元](https://www.youtube.com/watch?v=GJdiM-muYqc)--- 影片 3. [在二元搜尋樹中找到最小和最大元素](https://www.youtube.com/watch?v=Ut90klNN264&index=30&list=PL2_aWCzGMAwI3W_JlcBbtYTwiQSsOTa6P)--- 影片 4. [求二元樹的高度](https://www.youtube.com/watch?v=_pnqMz5nrRs&list=PL2_aWCzGMAwI3W_JlcBbtYTwiQSsOTa6P&index=31)--- 影片 5. [檢查二元樹是否為二元搜尋樹](https://www.youtube.com/watch?v=yEwSGhSsT0U&index=35&list=PL2_aWCzGMAwI3W_JlcBbtYTwiQSsOTa6P)--- 影片 6. [什麼是尾遞歸?為什麼這麼糟?](https://www.quora.com/What-is-tail-recursion-Why-is-it-so-bad) --- 影片 ### **學後問題** 現在您已經學習了一些,並觀看了一些影片,讓我們嘗試更多問題! 1. [越大越好](https://www.hackerrank.com/challenges/bigger-is-greater/problem) 2. [6.之字折線轉換](https://leetcode.com/problems/zigzag-conversion/) 3. [7. 反轉整數](https://leetcode.com/problems/reverse-integer/) 4. [40. 組合和 II](https://leetcode.com/problems/combination-sum-ii/) 5. [43. 字串相乘](https://leetcode.com/problems/multiply-strings/) 6. [拉里的陣列](https://www.hackerrank.com/challenges/larrys-array/problem) 7. [短回文](https://www.hackerrank.com/challenges/short-palindrome/problem) 8. [65. 有效號碼](https://leetcode.com/problems/valid-number/) 9. [越大越好](https://www.hackerrank.com/challenges/bigger-is-greater/problem) 10. [完整計數排序](https://www.hackerrank.com/challenges/countingsort4/problem) 11. [莉莉的家庭作業](https://www.hackerrank.com/challenges/lilys-homework/problem) 12. [普通孩子](https://www.hackerrank.com/challenges/common-child/problem) 13. [459. 重複子字串模式](https://leetcode.com/problems/repeated-substring-pattern/) 14. [27. 刪除元素](https://leetcode.com/problems/remove-element/) 15. [450. 刪除 BST 中的節點](https://leetcode.com/problems/delete-node-in-a-bst/) 16. [659. 將陣列分割成連續的子序列](https://leetcode.com/problems/split-array-into-consecutive-subsequences/) 17. [最大值有界的子陣列數](https://leetcode.com/problems/number-of-subarrays-with-bounded-maximum) 18. [組合和 IV](https://leetcode.com/problems/combination-sum-iv) 19. [買賣股票的最佳時機(有冷卻時間)](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-cooldown) 20. [最長重複字元替換](https://leetcode.com/problems/longest-repeating-character-replacement) 21. [成對交換節點](https://leetcode.com/problems/swap-nodes-in-pairs) 22. [二元樹右側視圖](https://leetcode.com/problems/binary-tree-right-side-view) 23. [展平嵌套列表迭代器](https://leetcode.com/problems/flatten-nested-list-iterator) 24. [二元樹層次順序遍歷](https://leetcode.com/problems/binary-tree-level-order-traversal) 25. [二元搜尋樹迭代器](https://leetcode.com/problems/binary-search-tree-iterator) 26. [對鏈最大長度](https://leetcode.com/problems/maximum-length-of-pair-chain) 27. [將鍊錶拆分為多個部分](https://leetcode.com/problems/split-linked-list-in-parts) ### **操作性程式設計問題** 有些公司不會問你演算法問題。相反,他們可能會更專注於實施和營運問題。這些通常更小眾,涉及實際問題,例如循環資料和執行某種任務。這些類型的問題通常不需要太多練習,因為更多的是了解陣列和 HashMap 等基本概念並追蹤您對它們所做的事情。 1. [袋鼠問題](https://www.hackerrank.com/challenges/kangaroo/problem) 2. [打破記錄](https://www.hackerrank.com/challenges/breaking-best-and-worst-records/problem) 3. [查找字串](https://www.hackerrank.com/challenges/find-a-string/problem)[迭代器](https://www.hackerrank.com/challenges/itertools-permutations/problem) 4. [不知道!](https://www.hackerrank.com/challenges/no-idea/problem) 5. [程式設計師的日子](https://www.hackerrank.com/challenges/day-of-the-programmer/problem) 6. [排行榜](https://www.hackerrank.com/challenges/climbing-the-leaderboard/problem) 7. [詞序](https://www.hackerrank.com/challenges/word-order/problem) 8. [夏洛克和方塊](https://www.hackerrank.com/challenges/sherlock-and-squares/problem) 9. [均衡陣列](https://www.hackerrank.com/challenges/equality-in-a-array/problem) 10. [蘋果和橘子](https://www.hackerrank.com/challenges/apple-and-orange/problem) 11. [更多操作風格問題](https://www.hackerrank.com/domains/python) ### **系統設計影片** 系統設計問題是至關重要的問題,表明您不僅僅是一名編碼員。身為工程師,您需要能夠思考大局。某些服務屬於哪裡,您需要什麼樣的伺服器,您將如何管理流量等等。所有這些想法都表明您能夠設計軟體,而不僅僅是編寫人們告訴您編寫的程式碼。 1. [停車場系統](https://youtu.be/DSGsa0pu8-k)---影片 2. [什麼是應用程式](https://www.youtube.com/watch?v=vvhC64hQZMk)--- 影片 3. [優步設計](https://youtu.be/umWABit-wbk)---影片 4. [Instagram](https://www.youtube.com/watch?v=QmX2NPkJTKg) --- 影片 5. [Tinder 服務](https://www.youtube.com/watch?v=xQnIN9bW0og)--- 影片 ### **作業系統** 作業系統問題比較少見,但是對執行緒、調度、記憶體等概念有紮實的理解是有好處的,即使只是基本的理解。當被問到進程和線程有什麼區別而不知道答案時,這是非常尷尬的。 1. [常見作業系統面試問題](https://www.geeksforgeeks.org/commonly-asked-operating-systems-interview-questions-set-1/) 2. [什麼是翻譯後備緩衝區?](https://www.geeksforgeeks.org/operating-system-translation-lookaside-buffer-tlb/) 3. [為什麼循環法可以避免優先反轉問題?](https://leetcode.com/discuss/interview-question/operating-system/220604/Why-does-Round-Robin-avoid-the-Priority-Inversion-Problem) 4. [中斷與系統呼叫---檔案系統中的「inode」是什麼?](https://leetcode.com/discuss/interview-question/operating-system/124838/Interrupt-Vs-System-Call) 5. [作業系統面試題目及答案 --- 第一部分](https://www.youtube.com/watch?v=b18X4uOKjHs) 6. [什麼是內核 --- Gary 解釋](https://www.youtube.com/watch?v=mycVSMyShk8) 7. [循環演算法教程(CPU調度)](https://www.youtube.com/watch?v=aWlQYllBZDs) 8. [LRU 快取的魔力(Google 開發 100 天)](https://www.youtube.com/watch?v=R5ON3iwx78M) --- 影片 9. [MIT 6.004 L15:記憶體層次結構](https://www.youtube.com/watch?v=vjYF_fAZI5E&list=PLrRW1w6CGAcXbMtDFj205vALOGmiRc82-&index=24)--- 影片 10. [中斷](https://www.youtube.com/watch?v=uFKi2-J-6II&list=PLCiOXwirraUCBE9i_ukL8_Kfg6XNv7Se8&index=3)---影片 11. [調度](https://www.youtube.com/watch?v=-Gu5mYdKbu4&index=4&list=PLCiOXwirraUCBE9i_ukL8_Kfg6XNv7Se8)---影片 ### **執行緒數**  1. [用戶級線程與內核級線程](https://leetcode.com/discuss/interview-question/operating-system/124631/User-Level-thread-Vs-Kernel-Level-thread) 2. [行程和線程簡介](https://www.youtube.com/watch?v=exbKr6fnoUw)--- 影片 3. [進程和線程之間的區別 --- 佐治亞理工學院 --- 高級操作系統](https://www.youtube.com/watch?v=O3EyzlZxx3g&t=11s)--- 影片 4. [分叉和多線程之間的區別](https://leetcode.com/discuss/interview-question/operating-system/125024/Difference-between-forking-and-multithreading) ### **物件導向** 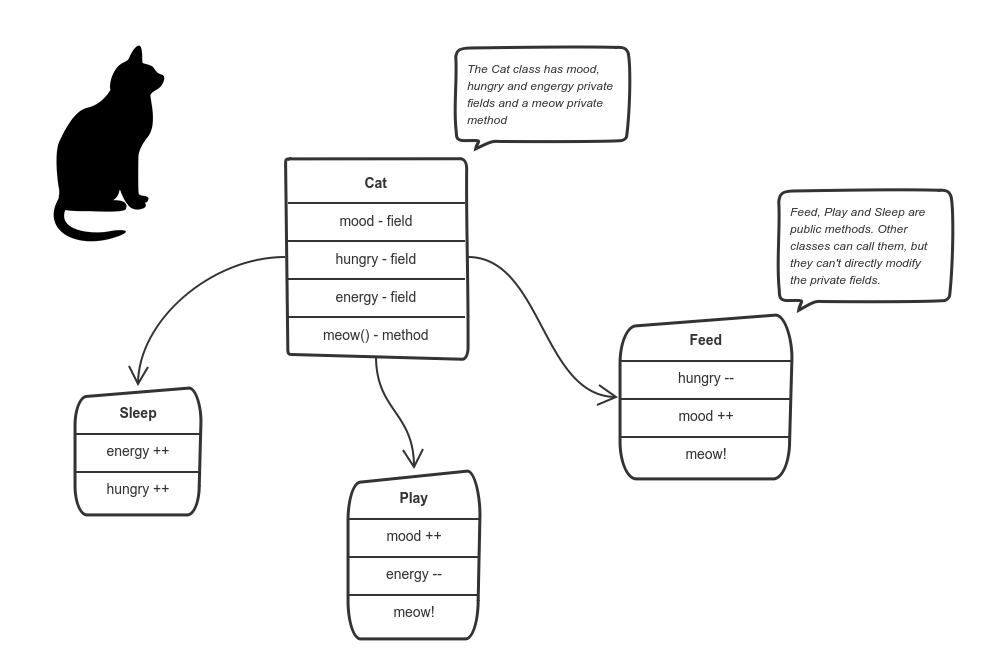 與作業系統類似,並不是每次面試都會問你有關物件導向程式設計的問題,但你永遠不知道。您需要確保記住計算機 162 課程中的基礎知識。 1. [Java 程式設計教學 --- 49 --- 繼承](https://www.youtube.com/watch?v=9JpNY-XAseg)--- 影片 2. [Java 程式設計教學 --- 55 --- 多態性簡介](https://www.youtube.com/watch?v=0xw06loTm1k)--- 影片 3. [Java 程式設計教學 --- 58 --- 抽象類別與具體類別](https://www.youtube.com/watch?v=TyPNvt6Zg8c)--- 影片 4. [Java 程式設計教學 --- 57 --- 重寫規則](https://www.youtube.com/watch?v=zN9pKULyoj4&t=3s)--- 影片 5. [Java 程式設計教學 --- 59 --- 保存物件的類](https://www.youtube.com/watch?v=slY5Ag7IjM0) 6. [物件導向程式設計](https://www.youtube.com/watch?v=lbXsrHGhBAU)---影片 ### **設計模式** 如果您像我們一樣,我們不會被教導所有各種設計模式。因此,最好了解它們的工作原理以及使用它們的原因。一些面試問題可以很簡單,例如“為什麼要使用工廠類?” 1. [工廠設計模式](https://www.youtube.com/watch?v=ub0DXaeV6hA)---影片 2. [觀察者設計模式](https://youtu.be/wiQdrH2YpT4)---影片 3. [適配器設計模式](https://www.youtube.com/watch?v=qG286LQM6BU&list=PLF206E906175C7E07&index=13)---影片 4. [立面設計模式](https://www.youtube.com/watch?v=B1Y8fcYrz5o&list=PLF206E906175C7E07&index=14)---影片 5. [責任鏈設計模式](https://www.youtube.com/watch?v=jDX6x8qmjbA&list=PLF206E906175C7E07&index=22)---影片 6. [解譯器設計模式](https://www.youtube.com/watch?v=6CVymSJQuJE&list=PLF206E906175C7E07&index=23)---影片 7. [單例設計模式教學](https://www.youtube.com/watch?v=NZaXM67fxbs&list=PLF206E906175C7E07&index=7)--- 影片 8. [第 6 章(第 1 部分)--- 模式(影片)](https://youtu.be/LAP2A80Ajrg?list=PLJ9pm_Rc9HesnkwKlal_buSIHA-jTZMpO&t=3344) --- 影片 9. [Head First 設計模式](https://www.amazon.com/Head-First-Design-Patterns-Freeman/dp/0596007124)--- 影片 ### SQL 這是最後一節。你們中的許多人可能不會被問到那麼多 SQL 問題。不過,我始終認為放在後口袋是件好事。 #### SQL --- 問題 1. [262. 行程和用戶](https://leetcode.com/problems/trips-and-users/) 2. [601. 體育場人流量](https://leetcode.com/problems/human-traffic-of-stadium/) 3. [185. 部門前三薪資](https://leetcode.com/problems/department-top-three-salaries/) 4. [626.交換席位](https://leetcode.com/problems/exchange-seats/) 5. [駭客排名報告](https://www.hackerrank.com/challenges/the-report/problem) 6. [177.第N最高薪水](https://leetcode.com/problems/nth-highest-salary/) 7. [對稱對](https://www.hackerrank.com/challenges/symmetric-pairs/problem) 8. [職業](https://www.hackerrank.com/challenges/placements/problem)[安置](https://www.hackerrank.com/challenges/occupations/problem) 9. [奧利凡德的庫存](https://www.hackerrank.com/challenges/harry-potter-and-wands/problem) #### SQL --- 影片 1. [IQ15:6 個 SQL 查詢面試問題](https://www.youtube.com/watch?v=uAWWhEA57bE)--- 影片 2. [了解 ROW\_NUMBER 和分析函數](https://www.youtube.com/watch?v=QFj-hZi8MKk)--- 影片 3. [分析函數的高級實現](https://www.youtube.com/watch?v=G3kYPzLWtpo&t=4s)--- 影片 4. [分析函數的高級實現第 2 部分](https://www.youtube.com/watch?v=XecU6Ieyu-4&t=54s)--- 影片 5. [聰明的貓頭鷹 SQL 影片](https://www.youtube.com/watch?v=2-1XQHAgDsM&list=PL6EDEB03D20332309)--- 影片 #### SQL 後問題 1. [二元樹節點](https://www.hackerrank.com/challenges/binary-search-tree-1/problem) 2. [氣象觀測站 18](https://www.hackerrank.com/challenges/weather-observation-station-18/problem) 3. [挑戰](https://www.hackerrank.com/challenges/challenges/problem)[列印素數](https://www.hackerrank.com/challenges/print-prime-numbers/problem) 4. [595.大國](https://leetcode.com/problems/big-countries/) 5. [626.交換席位](https://leetcode.com/problems/exchange-seats/) 6. [SQL 面試問題:3 個技術篩選練習(針對資料分析師)](https://data36.com/sql-interview-questions-tech-screening-data-analysts/) 面試可能會很困難,因為你會覺得自己沒有任何進展。擁有本學習指南將幫助您追蹤您的進度並讓您更好地了解自己的表現! 祝你好運! 另外,如果您想閱讀/觀看更多精彩的貼文或影片: [在 SaturnCloud 上使用 Jupyter Notebook 連接到大查詢第 2 部分](https://www.youtube.com/watch?v=O1cBN5gJtdw&t=15s) [身為資料科學家你應該閱讀的三本書](https://www.coriers.com/three-books-you-must-read-if-you-want-a-career-as-a-data-scientist/) [Hadoop 與關聯式資料庫](http://www.acheronanalytics.com/acheron-blog/hadoop-vs-relational-databases) [算法如何變得不道德和有偏見](http://www.acheronanalytics.com/acheron-blog/how-do-machines-learn-bias-data-science) [如何改善資料驅動策略](http://www.acheronanalytics.com/acheron-blog/how-to-improve-your-data-driven-strategy) [如何開發穩健演算法](https://medium.com/better-programming/how-to-develop-a-robust-algorithm-c38e08f32201) [資料科學家必須具備的 4 項技能](https://www.theseattledataguy.com/4-skills-data-scientist-must-have/) [SQL 最佳實踐 - 設計 ETL 影片](http://www.acheronanalytics.com/acheron-blog/sql-best-practices-designing-an-etl-video) --- 原文出處:https://dev.to/seattledataguy/the-interview-study-guide-for-software-engineers-764
> **2019 年 9 月 25 日更新:**感謝[ラナ・kuaru](https://twitter.com/rana_kualu)的辛勤工作,本文現已提供日文版。請點擊下面的連結查看他們的工作。如果您知道本文被翻譯成其他語言,請告訴我,我會將其發佈在這裡。 [🇯🇵 閱讀日語](https://qiita.com/rana_kualu/items/7b62898d373901466f5c) > **2019 年 7 月 8 日更新:**我最近發現大約兩年前發佈在法語留言板上的[這篇非常相似的文章](https://bookmarks.ecyseo.net/?EAWvDw)。如果您有興趣學習一些 shell 命令——並且您*會說 français* ,那麼它是對我下面的文章的一個很好的補充。 直到大約一年前,我幾乎只在 macOS 和 Ubuntu 作業系統中工作。在這兩個作業系統上, `bash`是我的預設 shell。在過去的六、七年裡,我對`bash`工作原理有了大致的了解,並想為那些剛入門的人概述一些更常見/有用的命令。如果您認為您了解有關`bash`所有訊息,請無論如何看看下面的內容 - 我已經提供了一些提示和您可能忘記的標誌的提醒,這可以讓您的工作更輕鬆一些。 下面的命令或多或少以敘述風格排列,因此如果您剛開始使用`bash` ,您可以從頭到尾完成操作。事情到最後通常會變得不那麼常見並且變得更加困難。 <a name="toc"></a> 目錄 -- - [基礎](#the-basics) ``` - [First Commands, Navigating the Filesystem](#first-commands) ``` ``` - [`pwd / ls / cd`](#pwd-ls-cd) ``` ``` - [`; / && / &`](#semicolon-andand-and) ``` ``` - [Getting Help](#getting-help) ``` ``` - [`-h`](#minus-h) ``` ``` - [`man`](#man) ``` ``` - [Viewing and Editing Files](#viewing-and-editing-files) ``` ``` - [`head / tail / cat / less`](#head-tail-cat-less) ``` ``` - [`nano / nedit`](#nano-nedit) ``` ``` - [Creating and Deleting Files and Directories](#creating-and-deleting-files) ``` ``` - [`touch`](#touch) ``` ``` - [`mkdir / rm / rmdir`](#mkdir-rm-rmdir) ``` ``` - [Moving and Copying Files, Making Links, Command History](#moving-and-copying-files) ``` ``` - [`mv / cp / ln`](#mv-cp-ln) ``` ``` - [Command History](#command-history) ``` ``` - [Directory Trees, Disk Usage, and Processes](#directory-trees-disk-usage-processes) ``` ``` - [`mkdir –p / tree`](#mkdir--p-tree) ``` ``` - [`df / du / ps`](#df-du-ps) ``` ``` - [Miscellaneous](#basic-misc) ``` ``` - [`passwd / logout / exit`](#passwd-logout-exit) ``` ``` - [`clear / *`](#clear-glob) ``` - [中間的](#intermediate) ``` - [Disk, Memory, and Processor Usage](#disk-memory-processor) ``` ``` - [`ncdu`](#ncdu) ``` ``` - [`top / htop`](#top-htop) ``` ``` - [REPLs and Software Versions](#REPLs-software-versions) ``` ``` - [REPLs](#REPLs) ``` ``` - [`-version / --version / -v`](#version) ``` ``` - [Environment Variables and Aliases](#env-vars-aliases) ``` ``` - [Environment Variables](#env-vars) ``` ``` - [Aliases](#aliases) ``` ``` - [Basic `bash` Scripting](#basic-bash-scripting) ``` ``` - [`bash` Scripts](#bash-scripts) ``` ``` - [Custom Prompt and `ls`](#custom-prompt-ls) ``` ``` - [Config Files](#config-files) ``` ``` - [Config Files / `.bashrc`](#config-bashrc) ``` ``` - [Types of Shells](#types-of-shells) ``` ``` - [Finding Things](#finding-things) ``` ``` - [`whereis / which / whatis`](#whereis-which-whatis) ``` ``` - [`locate / find`](#locate-find) ``` ``` - [Downloading Things](#downloading-things) ``` ``` - [`ping / wget / curl`](#ping-wget-curl) ``` ``` - [`apt / gunzip / tar / gzip`](#apt-gunzip-tar-gzip) ``` ``` - [Redirecting Input and Output](#redirecting-io) ``` ``` - [`| / > / < / echo / printf`](#pipe-gt-lt-echo-printf) ``` ``` - [`0 / 1 / 2 / tee`](#std-tee) ``` - [先進的](#advanced) ``` - [Superuser](#superuser) ``` ``` - [`sudo / su`](#sudo-su) ``` ``` - [`!!`](#click-click) ``` ``` - [File Permissions](#file-permissions) ``` ``` - [File Permissions](#file-permissions-sub) ``` ``` - [`chmod / chown`](#chmod-chown) ``` ``` - [User and Group Management](#users-groups) ``` ``` - [Users](#users) ``` ``` - [Groups](#groups) ``` ``` - [Text Processing](#text-processing) ``` ``` - [`uniq / sort / diff / cmp`](#uniq-sort-diff-cmp) ``` ``` - [`cut / sed`](#cut-sed) ``` ``` - [Pattern Matching](#pattern-matching) ``` ``` - [`grep`](#grep) ``` ``` - [`awk`](#awk) ``` ``` - [Copying Files Over `ssh`](#ssh) ``` ``` - [`ssh / scp`](#ssh-scp) ``` ``` - [`rsync`](#rsync) ``` ``` - [Long-Running Processes](#long-running-processes) ``` ``` - [`yes / nohup / ps / kill`](#yes-nohup-ps-kill) ``` ``` - [`cron / crontab / >>`](#cron) ``` ``` - [Miscellaneous](#advanced-misc) ``` ``` - [`pushd / popd`](#pushd-popd) ``` ``` - [`xdg-open`](#xdg-open) ``` ``` - [`xargs`](#xargs) ``` - [獎勵:有趣但大多無用的東西](#bonus) ``` - [`w / write / wall / lynx`](#w-write-wall-lynx) ``` ``` - [`nautilus / date / cal / bc`](#nautilus-date-cal-bc) ``` --- <a name="the-basics"></a> 基礎 == <a name="first-commands"></a> 第一個指令,瀏覽檔案系統 ------------ 現代檔案系統具有目錄(資料夾)樹,其中目錄要么是*根目錄*(沒有父目錄),要么是*子目錄*(包含在單一其他目錄中,我們稱之為“父目錄”)。向後遍歷檔案樹(從子目錄到父目錄)將始終到達根目錄。有些檔案系統有多個根目錄(如 Windows 的磁碟機: `C:\` 、 `A:\`等),但 Unix 和類別 Unix 系統只有一個名為`\`的根目錄。 <a name="pwd-ls-cd"></a> ### `pwd / ls / cd` [\[ 返回目錄 \]](#toc) 在檔案系統中工作時,使用者始終*在*某個目錄中工作,我們稱之為當前目錄或*工作目錄*。使用`pwd`列印使用者的工作目錄: ``` [ andrew@pc01 ~ ]$ pwd /home/andrew ``` 使用`ls`列出該目錄的內容(檔案和/或子目錄等): ``` [ andrew@pc01 ~ ]$ ls Git TEST jdoc test test.file ``` > **獎金:** > > 使用`ls -a`顯示隱藏(“點”)文件 > > 使用`ls -l`顯示文件詳細訊息 > > 組合多個標誌,如`ls -l -a` > > 有時您可以連結諸如`ls -la`之類的標誌,而不是`ls -l -a` 使用`cd`更改到不同的目錄(更改目錄): ``` [ andrew@pc01 ~ ]$ cd TEST/ [ andrew@pc01 TEST ]$ pwd /home/andrew/TEST [ andrew@pc01 TEST ]$ cd A [ andrew@pc01 A ]$ pwd /home/andrew/TEST/A ``` `cd ..`是「 `cd`到父目錄」的簡寫: ``` [ andrew@pc01 A ]$ cd .. [ andrew@pc01 TEST ]$ pwd /home/andrew/TEST ``` `cd ~`或只是`cd`是「 `cd`到我的主目錄」的簡寫(通常`/home/username`或類似的東西): ``` [ andrew@pc01 TEST ]$ cd [ andrew@pc01 ~ ]$ pwd /home/andrew ``` > **獎金:** > > `cd ~user`表示「 `cd`到`user`的主目錄 > > 您可以使用`cd ../..`等跳轉多個目錄等級。 > > 使用`cd -`返回到最近的目錄 > > `.`是「此目錄」的簡寫,因此`cd .`不會做太多事情 <a name="semicolon-andand-and"></a> ### `; / && / &` [\[ 返回目錄 \]](#toc) 我們在命令列中輸入的內容稱為*命令*,它們總是執行儲存在電腦上某處的一些機器碼。有時這個機器碼是一個內建的Linux命令,有時它是一個應用程式,有時它是你自己寫的一些程式碼。有時,我們會想依序執行一個指令。為此,我們可以使用`;` (分號): ``` [ andrew@pc01 ~ ]$ ls; pwd Git TEST jdoc test test.file /home/andrew ``` 上面的分號表示我首先 ( `ls` ) 列出工作目錄的內容,然後 ( `pwd` ) 列印其位置。連結命令的另一個有用工具是`&&` 。使用`&&`時,如果左側命令失敗,則右側命令將不會執行。 `;`和`&&`都可以在同一行中多次使用: ``` # whoops! I made a typo here! [ andrew@pc01 ~ ]$ cd /Giit/Parser && pwd && ls && cd -bash: cd: /Giit/Parser: No such file or directory # the first command passes now, so the following commands are run [ andrew@pc01 ~ ]$ cd Git/Parser/ && pwd && ls && cd /home/andrew/Git/Parser README.md doc.sh pom.xml resource run.sh shell.sh source src target ``` ....但是與`;` ,即使第一個命令失敗,第二個命令也會執行: ``` # pwd and ls still run, even though the cd command failed [ andrew@pc01 ~ ]$ cd /Giit/Parser ; pwd ; ls -bash: cd: /Giit/Parser: No such file or directory /home/andrew Git TEST jdoc test test.file ``` `&`看起來與`&&`類似,但實際上實現了完全不同的功能。通常,當您執行長時間執行的命令時,命令列將等待該命令完成,然後才允許您輸入另一個命令。在命令後面加上`&`可以防止這種情況發生,並允許您在舊命令仍在執行時執行新命令: ``` [ andrew@pc01 ~ ]$ cd Git/Parser && mvn package & cd [1] 9263 ``` > **額外的好處:**當我們在命令後使用`&`來「隱藏」它時,我們說該作業(或「進程」;這些術語或多或少可以互換)是「後台的」。若要查看目前正在執行的背景作業,請使用`jobs`指令: > ````bash \[ andrew@pc01 ~ \]$ 職位 \[1\]+ 執行 cd Git/Parser/ && mvn package & ``` <a name="getting-help"></a> ## Getting Help <a name="minus-h"></a> ### `-h` [[ Back to Table of Contents ]](#toc) Type `-h` or `--help` after almost any command to bring up a help menu for that command: ``` \[ andrew@pc01 ~ \]$ du --help 用法:你\[選項\]...\[檔案\]... 或: du \[選項\]... --files0-from=F 對目錄遞歸地總結文件集的磁碟使用情況。 長期權的強制性參數對於短期權也是強制性的。 -0, --null 以 NUL 結束每個輸出行,而不是換行符 -a, --all 計算所有檔案的寫入計數,而不僅僅是目錄 ``` --apparent-size print apparent sizes, rather than disk usage; although ``` ``` the apparent size is usually smaller, it may be ``` ``` larger due to holes in ('sparse') files, internal ``` ``` fragmentation, indirect blocks, and the like ``` -B, --block-size=SIZE 在列印前按 SIZE 縮放大小;例如, ``` '-BM' prints sizes in units of 1,048,576 bytes; ``` ``` see SIZE format below ``` … ``` <a name="man"></a> ### `man` [[ Back to Table of Contents ]](#toc) Type `man` before almost any command to bring up a manual for that command (quit `man` with `q`): ``` LS(1) 使用者指令 LS(1) 姓名 ``` ls - list directory contents ``` 概要 ``` ls [OPTION]... [FILE]... ``` 描述 ``` List information about the FILEs (the current directory by default). ``` ``` Sort entries alphabetically if none of -cftuvSUX nor --sort is speci- ``` ``` fied. ``` ``` Mandatory arguments to long options are mandatory for short options ``` ``` too. ``` … ``` <a name="viewing-and-editing-files"></a> ## Viewing and Editing Files <a name="head-tail-cat-less"></a> ### `head / tail / cat / less` [[ Back to Table of Contents ]](#toc) `head` outputs the first few lines of a file. The `-n` flag specifies the number of lines to show (the default is 10): ``` 列印前三行 ===== \[ andrew@pc01 ~ \]$ 頭 -n 3 c 這 文件 有 ``` `tail` outputs the last few lines of a file. You can get the last `n` lines (like above), or you can get the end of the file beginning from the `N`-th line with `tail -n +N`: ``` 從第 4 行開始列印文件末尾 ============== \[ andrew@pc01 ~ \]$ tail -n +4 c 確切地 六 線 ``` `cat` concatenates a list of files and sends them to the standard output stream (usually the terminal). `cat` can be used with just a single file, or multiple files, and is often used to quickly view them. (**Be warned**: if you use `cat` in this way, you may be accused of a [_Useless Use of Cat_ (UUOC)](http://bit.ly/2SPHE4V), but it's not that big of a deal, so don't worry too much about it.) ``` \[ andrew@pc01 ~ \]$ 貓 a 歸檔一個 \[ andrew@pc01 ~ \]$ 貓 ab 歸檔一個 文件b ``` `less` is another tool for quickly viewing a file -- it opens up a `vim`-like read-only window. (Yes, there is a command called `more`, but `less` -- unintuitively -- offers a superset of the functionality of `more` and is recommended over it.) Learn more (or less?) about [less](http://man7.org/linux/man-pages/man1/less.1.html) and [more](http://man7.org/linux/man-pages/man1/more.1.html) at their `man` pages. <a name="nano-nedit"></a> ### `nano / nedit` [[ Back to Table of Contents ]](#toc) `nano` is a minimalistic command-line text editor. It's a great editor for beginners or people who don't want to learn a million shortcuts. It was more than sufficient for me for the first few years of my coding career (I'm only now starting to look into more powerful editors, mainly because defining your own syntax highlighting in `nano` can be a bit of a pain.) `nedit` is a small graphical editor, it opens up an X Window and allows point-and-click editing, drag-and-drop, syntax highlighting and more. I use `nedit` sometimes when I want to make small changes to a script and re-run it over and over. Other common CLI (command-line interface) / GUI (graphical user interface) editors include `emacs`, `vi`, `vim`, `gedit`, Notepad++, Atom, and lots more. Some cool ones that I've played around with (and can endorse) include Micro, Light Table, and VS Code. All modern editors offer basic conveniences like search and replace, syntax highlighting, and so on. `vi(m)` and `emacs` have more features than `nano` and `nedit`, but they have a much steeper learning curve. Try a few different editors out and find one that works for you! <a name="creating-and-deleting-files"></a> ## Creating and Deleting Files and Directories <a name="touch"></a> ### `touch` [[ Back to Table of Contents ]](#toc) `touch` was created to modify file timestamps, but it can also be used to quickly create an empty file. You can create a new file by opening it with a text editor, like `nano`: ``` \[ andrew@pc01 前 \]$ ls \[ andrew@pc01 ex \]$ 奈米 a ``` _...editing file..._ ``` \[ andrew@pc01 前 \]$ ls A ``` ...or by simply using `touch`: ``` \[ andrew@pc01 ex \]$ touch b && ls ab ``` > **Bonus**: > > Background a process with \^z (Ctrl+z) > > ```bash > [ andrew@pc01 ex ]$ nano a > ``` > > _...editing file, then hit \^z..._ > > ```bash > Use fg to return to nano > > [1]+ Stopped nano a > [ andrew@pc01 ex ]$ fg > ``` > > _...editing file again..._ --- > **Double Bonus:** > > Kill the current (foreground) process by pressing \^c (Ctrl+c) while it’s running > > Kill a background process with `kill %N` where `N` is the job index shown by the `jobs` command <a name="mkdir-rm-rmdir"></a> ### `mkdir / rm / rmdir` [[ Back to Table of Contents ]](#toc) `mkdir` is used to create new, empty directories: ``` \[ andrew@pc01 ex \]$ ls && mkdir c && ls ab ABC ``` You can remove any file with `rm` -- but be careful, this is non-recoverable! ``` \[ andrew@pc01 ex \]$ rm a && ls 西元前 ``` You can add an _"are you sure?"_ prompt with the `-i` flag: ``` \[ andrew@pc01 前 \]$ rm -ib rm:刪除常規空文件“b”? y ``` Remove an empty directory with `rmdir`. If you `ls -a` in an empty directory, you should only see a reference to the directory itself (`.`) and a reference to its parent directory (`..`): ``` \[ andrew@pc01 ex \]$ rmdir c && ls -a 。 .. ``` `rmdir` removes empty directories only: ``` \[ andrew@pc01 ex \]$ cd .. && ls 測試/ \*.txt 0.txt 1.txt a a.txt bc \[ andrew@pc01 ~ \]$ rmdir 測試/ rmdir:無法刪除“test/”:目錄不為空 ``` ...but you can remove a directory -- and all of its contents -- with `rm -rf` (`-r` = recursive, `-f` = force): ``` \[ andrew@pc01 ~ \]$ rm –rf 測試 ``` <a name="moving-and-copying-files"></a> ## Moving and Copying Files, Making Links, Command History <a name="mv-cp-ln"></a> ### `mv / cp / ln` [[ Back to Table of Contents ]](#toc) `mv` moves / renames a file. You can `mv` a file to a new directory and keep the same file name or `mv` a file to a "new file" (rename it): ``` \[ andrew@pc01 ex \]$ ls && mv ae && ls A B C D BCDE ``` `cp` copies a file: ``` \[ andrew@pc01 ex \]$ cp e e2 && ls BCDE E2 ``` `ln` creates a hard link to a file: ``` ln 的第一個參數是 TARGET,第二個參數是 NEW LINK ================================= \[ andrew@pc01 ex \]$ ln bf && ls bcde e2 f ``` `ln -s` creates a soft link to a file: ``` \[ andrew@pc01 ex \]$ ln -sbg && ls BCDE E2 FG ``` Hard links reference the same actual bytes in memory which contain a file, while soft links refer to the original file name, which itself points to those bytes. [You can read more about soft vs. hard links here.](http://bit.ly/2D0W8cN) <a name="command-history"></a> ### Command History [[ Back to Table of Contents ]](#toc) `bash` has two big features to help you complete and re-run commands, the first is _tab completion_. Simply type the first part of a command, hit the \<tab\> key, and let the terminal guess what you're trying to do: ``` \[ andrew@pc01 目錄 \]$ ls 另一個長檔名 這是一個長檔名 一個新檔名 \[ andrew@pc01 目錄 \]$ ls t ``` _...hit the TAB key after typing `ls t` and the command is completed..._ ``` \[ andrew@pc01 dir \]$ ls 這是檔名 這是長檔名 ``` You may have to hit \<TAB\> multiple times if there's an ambiguity: ``` \[ andrew@pc01 目錄 \]$ ls a \[ andrew@pc01 目錄 \]$ ls an 一個新檔名另一個長檔名 ``` `bash` keeps a short history of the commands you've typed previously and lets you search through those commands by typing \^r (Ctrl+r): ``` \[ andrew@pc01 目錄 \] ``` _...hit \^r (Ctrl+r) to search the command history..._ ``` (反向搜尋)``: ``` _...type 'anew' and the last command containing this is found..._ ``` (reverse-i-search)`anew': 觸碰新檔名 ``` <a name="directory-trees-disk-usage-processes"></a> ## Directory Trees, Disk Usage, and Processes <a name="mkdir--p-tree"></a> ### `mkdir –p / tree` [[ Back to Table of Contents ]](#toc) `mkdir`, by default, only makes a single directory. This means that if, for instance, directory `d/e` doesn't exist, then `d/e/f` can't be made with `mkdir` by itself: ``` \[ andrew@pc01 ex \]$ ls && mkdir d/e/f ABC mkdir:無法建立目錄「d/e/f」:沒有這樣的檔案或目錄 ``` But if we pass the `-p` flag to `mkdir`, it will make all directories in the path if they don't already exist: ``` \[ andrew@pc01 ex \]$ mkdir -pd/e/f && ls A B C D ``` `tree` can help you better visualise a directory's structure by printing a nicely-formatted directory tree. By default, it prints the entire tree structure (beginning with the specified directory), but you can restrict it to a certain number of levels with the `-L` flag: ``` \[ andrew@pc01 前 \]$ 樹 -L 2 。 |-- 一個 |-- b |-- c `--d ``` `--e ``` 3個目錄,2個文件 ``` You can hide empty directories in `tree`'s output with `--prune`. Note that this also removes "recursively empty" directories, or directories which aren't empty _per se_, but which contain only other empty directories, or other recursively empty directories: ``` \[ andrew@pc01 ex \]$ 樹 --prune 。 |-- 一個 `--b ``` <a name="df-du-ps"></a> ### `df / du / ps` [[ Back to Table of Contents ]](#toc) `df` is used to show how much space is taken up by files for the disks or your system (hard drives, etc.). ``` \[ andrew@pc01 前 \]$ df -h 已使用的檔案系統大小 可用 使用% 安裝於 udev 126G 0 126G 0% /dev tmpfs 26G 2.0G 24G 8% /執行 /dev/mapper/ubuntu--vg-root 1.6T 1.3T 252G 84% / … ``` In the above command, `-h` doesn't mean "help", but "human-readable". Some commands use this convention to display file / disk sizes with `K` for kilobytes, `G` for gigabytes, and so on, instead of writing out a gigantic integer number of bytes. `du` shows file space usage for a particular directory and its subdirectories. If you want to know how much space is free on a given hard drive, use `df`; if you want to know how much space a directory is taking up, use `du`: ``` \[ andrew@pc01 ex \]$ 你 4 ./d/e/f 8./d/e 12 ./天 4./c 20 . ``` `du` takes a `--max-depth=N` flag, which only shows directories `N` levels down (or fewer) from the specified directory: ``` \[ andrew@pc01 ex \]$ du -h --max-深度=1 12K./天 4.0K./c 20K。 ``` `ps` shows all of the user's currently-running processes (aka. jobs): ``` \[ andrew@pc01 前 \]$ ps PID TTY 時間 CMD 16642 分/15 00:00:00 ps 25409 點/15 00:00:00 重擊 ``` <a name="basic-misc"></a> ## Miscellaneous <a name="passwd-logout-exit"></a> ### `passwd / logout / exit` [[ Back to Table of Contents ]](#toc) Change your account password with `passwd`. It will ask for your current password for verification, then ask you to enter the new password twice, so you don't make any typos: ``` \[ andrew@pc01 目錄 \]$ 密碼 更改安德魯的密碼。 (目前)UNIX 密碼: 輸入新的 UNIX 密碼: 重新輸入新的 UNIX 密碼: passwd:密碼更新成功 ``` `logout` exits a shell you’ve logged in to (where you have a user account): ``` \[ andrew@pc01 目錄 \]$ 註銷 ────────────────────────────────────────────────── ── ────────────────────────────── 會話已停止 ``` - Press <return> to exit tab ``` ``` - Press R to restart session ``` ``` - Press S to save terminal output to file ``` ``` `exit` exits any kind of shell: ``` \[ andrew@pc01 ~ \]$ 退出 登出 ────────────────────────────────────────────────── ── ────────────────────────────── 會話已停止 ``` - Press <return> to exit tab ``` ``` - Press R to restart session ``` ``` - Press S to save terminal output to file ``` ``` <a name="clear-glob"></a> ### `clear / *` [[ Back to Table of Contents ]](#toc) Run `clear` to move the current terminal line to the top of the screen. This command just adds blank lines below the current prompt line. It's good for clearing your workspace. Use the glob (`*`, aka. Kleene Star, aka. wildcard) when looking for files. Notice the difference between the following two commands: ``` \[ andrew@pc01 ~ \]$ ls Git/Parser/source/ PArrayUtils.java PFile.java PSQLFile.java PWatchman.java PDateTimeUtils.java PFixedWidthFile.java PStringUtils.java PXSVFile.java PDelimitedFile.java PNode.java PTextFile.java Parser.java \[ andrew@pc01 ~ \]$ ls Git/Parser/source/PD\* Git/Parser/source/PDateTimeUtils.java Git/Parser/source/PDelimitedFile.java ``` The glob can be used multiple times in a command and matches zero or more characers: ``` \[ andrew@pc01 ~ \]$ ls Git/Parser/source/P *D* m\* Git/Parser/source/PDateTimeUtils.java Git/Parser/source/PDelimitedFile.java ``` <a name="intermediate"></a> # Intermediate <a name="disk-memory-processor"></a> ## Disk, Memory, and Processor Usage <a name="ncdu"></a> ### `ncdu` [[ Back to Table of Contents ]](#toc) `ncdu` (NCurses Disk Usage) provides a navigable overview of file space usage, like an improved `du`. It opens a read-only `vim`-like window (press `q` to quit): ``` \[ andrew@pc01 ~ \]$ ncdu ncdu 1.11 ~ 使用箭頭鍵導航,按 ?求助 \--- /home/安德魯 ------------------------------------------- ------------------ 148.2 MiB \[##########\] /.m2 91.5 MiB \[######\] /.sbt 79.8 MiB \[######\] /.cache 64.9 MiB \[####\] /.ivy2 40.6 MiB \[##\] /.sdkman 30.2 MiB \[##\] /.local 27.4 MiB \[#\] /.mozilla 24.4 MiB \[#\] /.nanobackups 10.2 MiB \[ \] .confout3.txt ``` 8.4 MiB [ ] /.config ``` ``` 5.9 MiB [ ] /.nbi ``` ``` 5.8 MiB [ ] /.oh-my-zsh ``` ``` 4.3 MiB [ ] /Git ``` ``` 3.7 MiB [ ] /.myshell ``` ``` 1.7 MiB [ ] /jdoc ``` ``` 1.5 MiB [ ] .confout2.txt ``` ``` 1.5 MiB [ ] /.netbeans ``` ``` 1.1 MiB [ ] /.jenv ``` 564.0 KiB \[ \] /.rstudio-desktop 磁碟使用總量:552.7 MiB 表觀大小:523.6 MiB 專案:14618 ``` <a name="top-htop"></a> ### `top / htop` [[ Back to Table of Contents ]](#toc) `top` displays all currently-running processes and their owners, memory usage, and more. `htop` is an improved, interactive `top`. (Note: you can pass the `-u username` flag to restrict the displayed processes to only those owner by `username`.) ``` \[ andrew@pc01 ~ \]$ htop 1 \[ 0.0%\] 9 \[ 0.0%\] 17 \[ 0.0%\] 25 \[ 0.0%\] 2 \[ 0.0%\] 10 \[ 0.0%\] 18 \[ 0.0%\] 26 \[ 0.0%\] 3 \[ 0.0%\] 11 \[ 0.0%\] 19 \[ 0.0%\] 27 \[ 0.0%\] 4 \[ 0.0%\] 12 \[ 0.0%\] 20 \[ 0.0%\] 28 \[ 0.0%\] 5 \[ 0.0%\] 13 \[ 0.0%\] 21 \[| 1.3%\] 29 \[ 0.0%\] 6 \[ 0.0%\] 14 \[ 0.0%\] 22 \[ 0.0%\] 30 \[| 0.6%\] 7 \[ 0.0%\] 15 \[ 0.0%\] 23 \[ 0.0%\] 31 \[ 0.0%\] 8 \[ 0.0%\] 16 \[ 0.0%\] 24 \[ 0.0%\] 32 \[ 0.0%\] Mem\[|||||||||||||||||||1.42G/252G\] 任務:188、366 個; 1 執行 交換電壓\[| 2.47G/256G\]平均負載:0.00 0.00 0.00 ``` Uptime: 432 days(!), 00:03:55 ``` PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ 指令 9389 安德魯 20 0 23344 3848 2848 R 1.3 0.0 0:00.10 htop 10103 根 20 0 3216M 17896 2444 S 0.7 0.0 5h48:56 /usr/bin/dockerd ``` 1 root 20 0 181M 4604 2972 S 0.0 0.0 15:29.66 /lib/systemd/syst ``` 533 根 20 0 44676 6908 6716 S 0.0 0.0 11:19.77 /lib/systemd/syst 546 根 20 0 244M 0 0 S 0.0 0.0 0:01.39 /sbin/lvmetad -f 1526 根 20 0 329M 2252 1916 S 0.0 0.0 0:00.00 /usr/sbin/ModemMa 1544 根 20 0 329M 2252 1916 S 0.0 0.0 0:00.06 /usr/sbin/ModemMa F1Help F2Setup F3SearchF4FilterF5Tree F6SortByF7Nice -F8Nice +F9Kill F10Quit ``` <a name="REPLs-software-versions"></a> ## REPLs and Software Versions <a name="REPLs"></a> ### REPLs [[ Back to Table of Contents ]](#toc) A **REPL** is a Read-Evaluate-Print Loop, similar to the command line, but usually used for particular programming languages. You can open the Python REPL with the `python` command (and quit with the `quit()` function): ``` \[ andrew@pc01 ~ \]$ python Python 3.5.2(默認,2018 年 11 月 12 日,13:43:14)... > > > 辭職() ``` Open the R REPL with the `R` command (and quit with the `q()` function): ``` \[ andrew@pc01 ~ \]$ R R版3.5.2(2018-12-20)--「蛋殼冰屋」... > q() 儲存工作區影像? \[是/否/c\]: 否 ``` Open the Scala REPL with the `scala` command (and quit with the `:quit` command): ``` \[ andrew@pc01 ~ \]$ scala 歡迎使用 Scala 2.11.12 ... 斯卡拉>:退出 ``` Open the Java REPL with the `jshell` command (and quit with the `/exit` command): ``` \[ andrew@pc01 ~ \]$ jshell |歡迎使用 JShell——版本 11.0.1 ... jshell> /退出 ``` Alternatively, you can exit any of these REPLs with \^d (Ctrl+d). \^d is the EOF (end of file) marker on Unix and signifies the end of input. <a name="version"></a> ### `-version / --version / -v` [[ Back to Table of Contents ]](#toc) Most commands and programs have a `-version` or `--version` flag which gives the software version of that command or program. Most applications make this information easily available: ``` \[ andrew@pc01 ~ \]$ ls --version ls (GNU coreutils) 8.25 ... \[ andrew@pc01 ~ \]$ ncdu -版本 NCDU 1.11 \[ andrew@pc01 ~ \]$ python --version Python 3.5.2 ``` ...but some are less intuitive: ``` \[ andrew@pc01 ~ \]$ sbt scalaVersion … \[資訊\]2.12.4 ``` Note that some programs use `-v` as a version flag, while others use `-v` to mean "verbose", which will run the application while printing lots of diagnostic or debugging information: ``` SCP(1) BSD 通用指令手冊 SCP(1) 姓名 ``` scp -- secure copy (remote file copy program) ``` … -v 詳細模式。導致 scp 和 ssh(1) 列印偵錯訊息 ``` about their progress. This is helpful in debugging connection, ``` ``` authentication, and configuration problems. ``` … ``` <a name="env-vars-aliases"></a> ## Environment Variables and Aliases <a name="env-vars"></a> ### Environment Variables [[ Back to Table of Contents ]](#toc) **Environment variables** (sometimes shortened to "env vars") are persistent variables that can be created and used within your `bash` shell. They are defined with an equals sign (`=`) and used with a dollar sign (`$`). You can see all currently-defined env vars with `printenv`: ``` \[ andrew@pc01 ~ \]$ printenv SPARK\_HOME=/usr/local/spark 術語=xterm … ``` Set a new environment variable with an `=` sign (don't put any spaces before or after the `=`, though!): ``` \[ andrew@pc01 ~ \]$ myvar=你好 ``` Print a specific env var to the terminal with `echo` and a preceding `$` sign: ``` \[ andrew@pc01 ~ \]$ echo $myvar 你好 ``` Environment variables which contain spaces or other whitespace should be surrounded by quotes (`"..."`). Note that reassigning a value to an env var overwrites it without warning: ``` \[ andrew@pc01 ~ \]$ myvar="你好,世界!" && 回顯 $myvar 你好世界! ``` Env vars can also be defined using the `export` command. When defined this way, they will also be available to sub-processes (commands called from this shell): ``` \[ andrew@pc01 ~ \]$ export myvar="另一" && echo $myvar 另一個 ``` You can unset an environment variable by leaving the right-hand side of the `=` blank or by using the `unset` command: ``` \[ andrew@pc01 ~ \]$ 取消設定 mynewvar \[ andrew@pc01 ~ \]$ echo $mynewvar ``` <a name="aliases"></a> ### Aliases [[ Back to Table of Contents ]](#toc) **Aliases** are similar to environment variables but are usually used in a different way -- to replace long commands with shorter ones: ``` \[ andrew@pc01 apidocs \]$ ls -l -a -h -t 總計 220K drwxr-xr-x 5 安德魯 安德魯 4.0K 12 月 21 日 12:37 。 -rw-r--r-- 1 安德魯 安德魯 9.9K 十二月 21 12:37 help-doc.html -rw-r--r-- 1 安德魯 安德魯 4.5K 12 月 21 日 12:37 script.js … \[ andrew@pc01 apidocs \]$ 別名 lc="ls -l -a -h -t" \[ andrew@pc01 apidocs \]$ lc 總計 220K drwxr-xr-x 5 安德魯 安德魯 4.0K 12 月 21 日 12:37 。 -rw-r--r-- 1 安德魯 安德魯 9.9K 十二月 21 12:37 help-doc.html -rw-r--r-- 1 安德魯 安德魯 4.5K 12 月 21 日 12:37 script.js … ``` You can remove an alias with `unalias`: ``` \[ andrew@pc01 apidocs \]$ unalias lc \[ andrew@pc01 apidocs \]$ lc 目前未安裝程式“lc”。 … ``` > **Bonus:** > > [Read about the subtle differences between environment variables and aliases here.](http://bit.ly/2TDG8Tx) > > [Some programs, like **git**, allow you to define aliases specifically for that software.](http://bit.ly/2TG8X1A) <a name="basic-bash-scripting"></a> ## Basic `bash` Scripting <a name="bash-scripts"></a> ### `bash` Scripts [[ Back to Table of Contents ]](#toc) `bash` scripts (usually ending in `.sh`) allow you to automate complicated processes, packaging them into reusable functions. A `bash` script can contain any number of normal shell commands: ``` \[ andrew@pc01 ~ \]$ echo "ls && touch file && ls" > ex.sh ``` A shell script can be executed with the `source` command or the `sh` command: ``` \[ andrew@pc01 ~ \]$ 源 ex.sh 桌面 Git TEST c ex.sh 專案測試 桌面 Git TEST c ex.sh 檔案專案測試 ``` Shell scripts can be made executable with the `chmod` command (more on this later): ``` \[ andrew@pc01 ~ \]$ echo "ls && touch file2 && ls" > ex2.sh \[ andrew@pc01 ~ \]$ chmod +x ex2.sh ``` An executable shell script can be run by preceding it with `./`: ``` \[ andrew@pc01 ~ \]$ ./ex2.sh 桌面 Git TEST c ex.sh ex2.sh 檔案專案測試 桌面 Git TEST c ex.sh ex2.sh 檔案 file2 專案測試 ``` Long lines of code can be split by ending a command with `\`: ``` \[ andrew@pc01 ~ \]$ echo "for i in {1..3}; do echo \\ > \\"歡迎\\$i次\\";完成” > ex3.sh ``` Bash scripts can contain loops, functions, and more! ``` \[ andrew@pc01 ~ \]$ 源 ex3.sh 歡迎1次 歡迎2次 歡迎3次 ``` <a name="custom-prompt-ls"></a> ### Custom Prompt and `ls` [[ Back to Table of Contents ]](#toc) Bash scripting can make your life a whole lot easier and more colourful. [Check out this great bash scripting cheat sheet.](https://devhints.io/bash) `$PS1` (Prompt String 1) is the environment variable that defines your main shell prompt ([learn about the other prompts here](http://bit.ly/2SPgsmT)): ``` \[ andrew@pc01 ~ \]$ printf "%q" $PS1 $'\\n\\\[\\E\[1m\\\]\\\[\\E\[30m\\\]\\A'$'\\\[\\E\[37m\\\]|\\\[\\E\[36m\\\]\\u\\\[\\E\[37m \\\]@\\\[\\E\[34m\\\]\\h'$'\\\[\\E\[32m\\\]\\W\\\[\\E\[37m\\\]|'$'\\\[\\E(B\\E\[m\\\] ' ``` You can change your default prompt with the `export` command: ``` \[ andrew@pc01 ~ \]$ export PS1="\\n此處指令> " 此處指令> echo $PS1 \\n此處指令> ``` ...[you can add colours, too!](http://bit.ly/2TMbEit): ``` 此處指令> export PS1="\\e\[1;31m\\n程式碼: \\e\[39m" (這應該是紅色的,但在 Markdown 中可能不會這樣顯示) =============================== 程式碼:回顯$PS1 \\e\[1;31m\\n程式碼: \\e\[39m ``` You can also change the colours shown by `ls` by editing the `$LS_COLORS` environment variable: ``` (同樣,這些顏色可能不會出現在 Markdown 中) =========================== 程式碼:ls 桌面 Git TEST c ex.sh ex2.sh ex3.sh 檔案 file2 專案測試 程式碼:匯出 LS\_COLORS='di=31:fi=0:ln=96:or=31:mi=31:ex=92' 程式碼:ls 桌面 Git TEST c ex.sh ex2.sh ex3.sh 檔案 file2 專案測試 ``` <a name="config-files"></a> ## Config Files <a name="config-bashrc"></a> ### Config Files / `.bashrc` [[ Back to Table of Contents ]](#toc) If you tried the commands in the last section and logged out and back in, you may have noticed that your changes disappeared. _config_ (configuration) files let you maintain settings for your shell or for a particular program every time you log in (or run that program). The main configuration file for a `bash` shell is the `~/.bashrc` file. Aliases, environment variables, and functions added to `~/.bashrc` will be available every time you log in. Commands in `~/.bashrc` will be run every time you log in. If you edit your `~/.bashrc` file, you can reload it without logging out by using the `source` command: ``` \[ andrew@pc01 ~ \]$ nano ~/.bashrc ``` _...add the line `echo “~/.bashrc loaded!”` to the top of the file_... ``` \[ andrew@pc01 ~ \]$ 源 ~/.bashrc ~/.bashrc 已載入! ``` _...log out and log back in..._ ``` 最後登入:2019 年 1 月 11 日星期五 10:29:07 從 111.11.11.111 ~/.bashrc 已加載! \[ 安德魯@pc01 ~ \] ``` <a name="types-of-shells"></a> ### Types of Shells [[ Back to Table of Contents ]](#toc) _Login_ shells are shells you log in to (where you have a username). _Interactive_ shells are shells which accept commands. Shells can be login and interactive, non-login and non-interactive, or any other combination. In addition to `~/.bashrc`, there are a few other scripts which are `sourced` by the shell automatically when you log in or log out. These are: - `/etc/profile` - `~/.bash_profile` - `~/.bash_login` - `~/.profile` - `~/.bash_logout` - `/etc/bash.bash_logout` Which of these scripts are sourced, and the order in which they're sourced, depend on the type of shell opened. See [the bash man page](https://linux.die.net/man/1/bash) and [these](http://bit.ly/2TGCwA8) Stack Overflow [posts](http://bit.ly/2TFHFsf) for more information. Note that `bash` scripts can `source` other scripts. For instance, in your `~/.bashrc`, you could include the line: ``` 來源~/.bashrc\_addl ``` ...which would also `source` that `.bashrc_addl` script. This file can contain its own aliases, functions, environment variables, and so on. It could, in turn, `source` other scripts, as well. (Be careful to avoid infinite loops of script-sourcing!) It may be helpful to split commands into different shell scripts based on functionality or machine type (Ubuntu vs. Red Hat vs. macOS), for example: - `~/.bash_ubuntu` -- configuration specific to Ubuntu-based machines - `~/.bashrc_styles` -- aesthetic settings, like `PS1` and `LS_COLORS` - `~/.bash_java` -- configuration specific to the Java language I try to keep separate `bash` files for aesthetic configurations and OS- or machine-specific code, and then I have one big `bash` file containing shortcuts, etc. that I use on every machine and every OS. Note that there are also _different shells_. `bash` is just one kind of shell (the "Bourne Again Shell"). Other common ones include `zsh`, `csh`, `fish`, and more. Play around with different shells and find one that's right for you, but be aware that this tutorial contains `bash` shell commands only and not everything listed here (maybe none of it) will be applicable to shells other than `bash`. <a name="finding-things"></a> ## Finding Things <a name="whereis-which-whatis"></a> ### `whereis / which / whatis` [[ Back to Table of Contents ]](#toc) `whereis` searches for "possibly useful" files related to a particular command. It will attempt to return the location of the binary (executable machine code), source (code source files), and `man` page for that command: ``` \[ andrew@pc01 ~ \]$ whereis ls ls: /bin/ls /usr/share/man/man1/ls.1.gz ``` `which` will only return the location of the binary (the command itself): ``` \[ andrew@pc01 ~ \]$ 其中 ls /bin/ls ``` `whatis` prints out the one-line description of a command from its `man` page: ``` \[ andrew@pc01 ~ \]$ 什麼是哪裡是哪個什麼是 whereis (1) - 尋找指令的二進位、原始檔和手冊頁文件 which (1) - 定位指令 Whatis (1) - 顯示一行手冊頁描述 ``` `which` is useful for finding the "original version" of a command which may be hidden by an alias: ``` \[ andrew@pc01 ~ \]$ 別名 ls="ls -l" “original” ls 已被上面定義的別名“隱藏” =========================== \[ andrew@pc01 ~ \]$ ls 總計 36 drwxr-xr-x 2 安德魯 andrew 4096 Jan 9 14:47 桌面 drwxr-xr-x 4 安德魯 安德魯 4096 十二月 6 10:43 Git … 但我們仍然可以使用返回的位置來呼叫「原始」ls ======================= \[ andrew@pc01 ~ \]$ /bin/ls 桌面 Git TEST c ex.sh ex2.sh ex3.sh 檔案 file2 專案測試 ``` <a name="locate-find"></a> ### `locate / find` [[ Back to Table of Contents ]](#toc) `locate` finds a file anywhere on the system by referring to a semi-regularly-updated cached list of files: ``` \[ andrew@pc01 ~ \]$ 找到 README.md /home/andrew/.config/micro/plugins/gotham-colors/README.md /home/andrew/.jenv/README.md /home/andrew/.myshell/README.md … ``` Because it's just searching a list, `locate` is usually faster than the alternative, `find`. `find` iterates through the file system to find the file you're looking for. Because it's actually looking at the files which _currently_ exist on the system, though, it will always return an up-to-date list of files, which is not necessarily true with `locate`. ``` \[ andrew@pc01 ~ \]$ find ~/ -iname "README.md" /home/andrew/.jenv/README.md /home/andrew/.config/micro/plugins/gotham-colors/README.md /home/andrew/.oh-my-zsh/plugins/ant/README.md … ``` `find` was written for the very first version of Unix in 1971, and is therefore much more widely available than `locate`, which was added to GNU in 1994. `find` has many more features than `locate`, and can search by file age, size, ownership, type, timestamp, permissions, depth within the file system; `find` can search using regular expressions, execute commands on files it finds, and more. When you need a fast (but possibly outdated) list of files, or you’re not sure what directory a particular file is in, use `locate`. When you need an accurate file list, maybe based on something other than the files’ names, and you need to do something with those files, use `find`. <a name="downloading-things"></a> ## Downloading Things <a name="ping-wget-curl"></a> ### `ping / wget / curl` [[ Back to Table of Contents ]](#toc) `ping` attempts to open a line of communication with a network host. Mainly, it's used to check whether or not your Internet connection is down: ``` \[ andrew@pc01 ~ \]$ ping google.com PING google.com (74.125.193.100) 56(84) 位元組資料。 使用 32 位元組資料 Ping 74.125.193.100: 來自 74.125.193.100 的回覆:位元組=32 時間<1ms TTL=64 … ``` `wget` is used to easily download a file from the Internet: ``` \[ andrew@pc01 ~ \]$ wget \\ > http://releases.ubuntu.com/18.10/ubuntu-18.10-desktop-amd64.iso ``` `curl` can be used just like `wget` (don’t forget the `--output` flag): ``` \[ andrew@pc01 ~ \]$ 捲曲 \\ > http://releases.ubuntu.com/18.10/ubuntu-18.10-desktop-amd64.iso \\ > \--輸出ubuntu.iso ``` `curl` and `wget` have their own strengths and weaknesses. `curl` supports many more protocols and is more widely available than `wget`; `curl` can also send data, while `wget` can only receive data. `wget` can download files recursively, while `curl` cannot. In general, I use `wget` when I need to download things from the Internet. I don’t often need to send data using `curl`, but it’s good to be aware of it for the rare occasion that you do. <a name="apt-gunzip-tar-gzip"></a> ### `apt / gunzip / tar / gzip` [[ Back to Table of Contents ]](#toc) Debian-descended Linux distributions have a fantastic package management tool called `apt`. It can be used to install, upgrade, or delete software on your machine. To search `apt` for a particular piece of software, use `apt search`, and install it with `apt install`: ``` \[ andrew@pc01 ~ \]$ apt 搜尋漂白位 ...bleachbit/bionic、bionic 2.0-2 全部 從系統中刪除不需要的文件 您需要“sudo”來安裝軟體 ============== \[ andrew@pc01 ~ \]$ sudo apt installbleachbit ``` Linux software often comes packaged in `.tar.gz` ("tarball") files: ``` \[ andrew@pc01 ~ \]$ wget \\ > https://github.com/atom/atom/releases/download/v1.35.0-beta0/atom-amd64.tar.gz ``` ...these types of files can be unzipped with `gunzip`: ``` \[ andrew@pc01 ~ \]$gunzipatom-amd64.tar.gz && ls 原子 amd64.tar ``` A `.tar.gz` file will be `gunzip`-ped to a `.tar` file, which can be extracted to a directory of files using `tar -xf` (`-x` for "extract", `-f` to specify the file to "untar"): ``` \[ andrew@pc01 ~ \]$ tar -xfatom-amd64.tar && mv \\ 原子-beta-1.35.0-beta0-amd64 原子 && ls 原子atom-amd64.tar ``` To go in the reverse direction, you can create (`-c`) a tar file from a directory and zip it (or unzip it, as appropriate) with `-z`: ``` \[ andrew@pc01 ~ \]$ tar -zcf 壓縮.tar.gz 原子 && ls 原子atom-amd64.tar壓縮.tar.gz ``` `.tar` files can also be zipped with `gzip`: ``` \[ andrew@pc01 ~ \]$ gzipatom-amd64.tar && ls 原子 原子-amd64.tar.gz 壓縮.tar.gz ``` <a name="redirecting-io"></a> ## Redirecting Input and Output <a name="pipe-gt-lt-echo-printf"></a> ### `| / > / < / echo / printf` [[ Back to Table of Contents ]](#toc) By default, shell commands read their input from the standard input stream (aka. stdin or 0) and write to the standard output stream (aka. stdout or 1), unless there’s an error, which is written to the standard error stream (aka. stderr or 2). `echo` writes text to stdout by default, which in most cases will simply print it to the terminal: ``` \[ andrew@pc01 ~ \]$ 回顯“你好” 你好 ``` The pipe operator, `|`, redirects the output of the first command to the input of the second command: ``` 'wc'(字數)傳回檔案中的行數、字數、位元組數 ======================== \[ andrew@pc01 ~ \]$ echo "範例文件" |廁所 ``` 1 2 17 ``` ``` `>` redirects output from stdout to a particular location ``` \[ andrew@pc01 ~ \]$ echo "test" > 文件 && 頭文件 測試 ``` `printf` is an improved `echo`, allowing formatting and escape sequences: ``` \[ andrew@pc01 ~ \]$ printf "1\\n3\\n2" 1 3 2 ``` `<` gets input from a particular location, rather than stdin: ``` 'sort' 依字母/數字順序對檔案的行進行排序 ======================== \[ andrew@pc01 ~ \]$ sort <(printf "1\\n3\\n2") 1 2 3 ``` Rather than a [UUOC](#viewing-and-editing-files), the recommended way to send the contents of a file to a command is to use `<`. Note that this causes data to "flow" right-to-left on the command line, rather than (the perhaps more natural, for English-speakers) left-to-right: ``` \[ andrew@pc01 ~ \]$ printf "1\\n3\\n2" > 文件 && 排序 < 文件 1 2 3 ``` <a name="std-tee"></a> ### `0 / 1 / 2 / tee` [[ Back to Table of Contents ]](#toc) 0, 1, and 2 are the standard input, output, and error streams, respectively. Input and output streams can be redirected with the `|`, `>`, and `<` operators mentioned previously, but stdin, stdout, and stderr can also be manipulated directly using their numeric identifiers: Write to stdout or stderr with `>&1` or `>&2`: ``` \[ andrew@pc01 ~ \]$ 貓測試 回顯“標準輸出”>&1 回顯“標準錯誤”>&2 ``` By default, stdout and stderr both print output to the terminal: ``` \[ andrew@pc01 ~ \]$ ./測試 標準錯誤 標準輸出 ``` Redirect stdout to `/dev/null` (only print output sent to stderr): ``` \[ andrew@pc01 ~ \]$ ./test 1>/dev/null 標準錯誤 ``` Redirect stderr to `/dev/null` (only print output sent to stdout): ``` \[ andrew@pc01 ~ \]$ ./test 2>/dev/null 標準輸出 ``` Redirect all output to `/dev/null` (print nothing): ``` \[ andrew@pc01 ~ \]$ ./test &>/dev/null ``` Send output to stdout and any number of additional locations with `tee`: ``` \[ andrew@pc01 ~ \]$ ls && echo "測試" | tee 文件1 文件2 文件3 && ls 文件0 測試 文件0 文件1 文件2 文件3 ``` <a name="advanced"></a> # Advanced <a name="superuser"></a> ## Superuser <a name="sudo-su"></a> ### `sudo / su` [[ Back to Table of Contents ]](#toc) You can check what your username is with `whoami`: ``` \[ andrew@pc01 abc \]$ whoami 安德魯 ``` ...and run a command as another user with `sudo -u username` (you will need that user's password): ``` \[ andrew@pc01 abc \]$ sudo -u 測試觸摸 def && ls -l 總計 0 -rw-r--r-- 1 次測試 0 Jan 11 20:05 def ``` If `–u` is not provided, the default user is the superuser (usually called "root"), with unlimited permissions: ``` \[ andrew@pc01 abc \]$ sudo touch ghi && ls -l 總計 0 -rw-r--r-- 1 次測試 0 Jan 11 20:05 def -rw-r--r-- 1 root root 0 Jan 11 20:14 ghi ``` Use `su` to become another user temporarily (and `exit` to switch back): ``` \[ andrew@pc01 abc \]$ su 測試 密碼: test@pc01:/home/andrew/abc$ whoami 測試 test@pc01:/home/andrew/abc$ 退出 出口 \[ andrew@pc01 abc \]$ whoami 安德魯 ``` [Learn more about the differences between `sudo` and `su` here.](http://bit.ly/2SKQH77) <a name="click-click"></a> ### `!!` [[ Back to Table of Contents ]](#toc) The superuser (usually "root") is the only person who can install software, create users, and so on. Sometimes it's easy to forget that, and you may get an error: ``` \[ andrew@pc01 ~ \]$ apt 安裝 ruby E:無法開啟鎖定檔案 /var/lib/dpkg/lock-frontend - 開啟(13:權限被拒絕) E: 無法取得 dpkg 前端鎖定 (/var/lib/dpkg/lock-frontend),您是 root 嗎? ``` You could retype the command and add `sudo` at the front of it (run it as the superuser): ``` \[ andrew@pc01 ~ \]$ sudo apt install ruby 正在閱讀包裝清單... ``` Or, you could use the `!!` shortcut, which retains the previous command: ``` \[ andrew@pc01 ~ \]$ apt 安裝 ruby E:無法開啟鎖定檔案 /var/lib/dpkg/lock-frontend - 開啟(13:權限被拒絕) E: 無法取得 dpkg 前端鎖定 (/var/lib/dpkg/lock-frontend),您是 root 嗎? \[ andrew@pc01 ~ \]$ sudo !! sudo apt 安裝 ruby 正在閱讀包裝清單... ``` By default, running a command with `sudo` (and correctly entering the password) allows the user to run superuser commands for the next 15 minutes. Once those 15 minutes are up, the user will again be prompted to enter the superuser password if they try to run a restricted command. <a name="file-permissions"></a> ## File Permissions <a name="file-permissions-sub"></a> ### File Permissions [[ Back to Table of Contents ]](#toc) Files may be able to be read (`r`), written to (`w`), and/or executed (`x`) by different users or groups of users, or not at all. File permissions can be seen with the `ls -l` command and are represented by 10 characters: ``` \[ andrew@pc01 ~ \]$ ls -lh 總計 8 drwxr-xr-x 4 安德魯 安德魯 4.0K 1 月 4 日 19:37 品嚐 -rwxr-xr-x 1 安德魯 安德魯 40 Jan 11 16:16 測試 -rw-r--r-- 1 安德魯 安德魯 0 一月 11 16:34 tist ``` The first character of each line represents the type of file, (`d` = directory, `l` = link, `-` = regular file, and so on); then there are three groups of three characters which represent the permissions held by the user (u) who owns the file, the permissions held by the group (g) which owns the file, and the permissions held any other (o) users. (The number which follows this string of characters is the number of links in the file system to that file (4 or 1 above).) `r` means that person / those people have read permission, `w` is write permission, `x` is execute permission. If a directory is “executable”, that means it can be opened and its contents can be listed. These three permissions are often represented with a single three-digit number, where, if `x` is enabled, the number is incremented by 1, if `w` is enabled, the number is incremented by 2, and if `r` is enabled, the number is incremented by 4. Note that these are equivalent to binary digits (`r-x` -> `101` -> `5`, for example). So the above three files have permissions of 755, 755, and 644, respectively. The next two strings in each list are the name of the owner (`andrew`, in this case) and the group of the owner (also `andrew`, in this case). Then comes the size of the file, its most recent modification time, and its name. The `–h` flag makes the output human readable (i.e. printing `4.0K` instead of `4096` bytes). <a name="chmod-chown"></a> ### `chmod / chown` [[ Back to Table of Contents ]](#toc) File permissions can be modified with `chmod` by setting the access bits: ``` \[ andrew@pc01 ~ \]$ chmod 777 測試 && chmod 000 tit && ls -lh 總計 8.0K drwxr-xr-x 4 安德魯 安德魯 4.0K 1 月 4 日 19:37 品嚐 -rwxrwxrwx 1 安德魯 安德魯 40 Jan 11 16:16 測試 \---------- 1 安德魯 安德魯 0 一月 11 16:34 tist ``` ...or by adding (`+`) or removing (`-`) `r`, `w`, and `x` permissions with flags: ``` \[ andrew@pc01 ~ \]$ chmod +rwx Tist && chmod -w 測試 && ls -lh chmod:測試:新權限是 r-xrwxrwx,而不是 r-xr-xr-x 總計 8.0K drwxr-xr-x 4 安德魯 安德魯 4.0K 1 月 4 日 19:37 品嚐 -r-xrwxrwx 1 安德魯 安德魯 40 Jan 11 16:16 測試 -rwxr-xr-x 1 安德魯 安德魯 0 一月 11 16:34 tist ``` The user who owns a file can be changed with `chown`: ``` \[ andrew@pc01 ~ \]$ sudo chown 碼頭測試 ``` The group which owns a file can be changed with `chgrp`: ``` \[ andrew@pc01 ~ \]$ sudo chgrp hadoop tit && ls -lh 總計 8.0K drwxr-xr-x 4 安德魯 安德魯 4.0K 1 月 4 日 19:37 品嚐 \-----w--w- 1 瑪麗娜·安德魯 2011 年 1 月 40 日 16:16 測試 -rwxr-xr-x 1 安德魯 hadoop 0 一月 11 16:34 tist ``` <a name="users-groups"></a> ## User and Group Management <a name="users"></a> ### Users [[ Back to Table of Contents ]](#toc) `users` shows all users currently logged in. Note that a user can be logged in multiple times if -- for instance -- they're connected via multiple `ssh` sessions. ``` \[ andrew@pc01 ~ \]$ 用戶 安德魯·科林·科林·科林·科林·科林·克里希納·克里希納 ``` To see all users (even those not logged in), check `/etc/passwd`. (**WARNING**: do not modify this file! You can corrupt your user accounts and make it impossible to log in to your system.) ``` \[ andrew@pc01 ~ \]$ alias au="cut -d: -f1 /etc/passwd \\ > |排序| uniq”&& au \_易於 一個廣告 安德魯... ``` Add a user with `useradd`: ``` \[ andrew@pc01 ~ \]$ sudo useradd aardvark && au \_易於 土豚 一個廣告... ``` Delete a user with `userdel`: ``` \[ andrew@pc01 ~ \]$ sudo userdel aardvark && au \_易於 一個廣告 安德魯... ``` [Change a user’s default shell, username, password, or group membership with `usermod`.](http://bit.ly/2D4upIg) <a name="groups"></a> ### Groups [[ Back to Table of Contents ]](#toc) `groups` shows all of the groups of which the current user is a member: ``` \[ andrew@pc01 ~ \]$ 組 andrew adm cdrom sudo dial plugdev lpadmin sambashare hadoop ``` To see all groups on the system, check `/etc/group`. (**DO NOT MODIFY** this file unless you know what you are doing.) ``` \[ andrew@pc01 ~ \]$ alias ag=“cut -d: -f1 /etc/group \\ > |排序”&& ag 管理員 一個廣告 安德魯... ``` Add a group with `groupadd`: ``` \[ andrew@pc01 ~ \]$ sudo groupadd aardvark && ag 土豚 管理員 一個廣告... ``` Delete a group with `groupdel`: ``` \[ andrew@pc01 ~ \]$ sudo groupdel aardvark && ag 管理員 一個廣告 安德魯... ``` [Change a group’s name, ID number, or password with `groupmod`.](https://linux.die.net/man/8/groupmod) <a name="text-processing"></a> ## Text Processing <a name="uniq-sort-diff-cmp"></a> ### `uniq / sort / diff / cmp` [[ Back to Table of Contents ]](#toc) `uniq` can print unique lines (default) or repeated lines: ``` \[ andrew@pc01 man \]$ printf "1\\n2\\n2" > a && \\ > printf "1\\n3\\n2" > b \[ andrew@pc01 人 \]$ uniq a 1 2 ``` `sort` will sort lines alphabetically / numerically: ``` \[ andrew@pc01 man \]$ 排序 b 1 2 3 ``` `diff` will report which lines differ between two files: ``` \[ andrew@pc01 人 \]$ diff ab 2c2 < 2 --- > 3 ``` `cmp` reports which bytes differ between two files: ``` \[andrew@pc01 人\]$ cmp ab ab 不同:字元 3,第 2 行 ``` <a name="cut-sed"></a> ### `cut / sed` [[ Back to Table of Contents ]](#toc) `cut` is usually used to cut a line into sections on some delimiter (good for CSV processing). `-d` specifies the delimiter and `-f` specifies the field index to print (starting with 1 for the first field): ``` \[ andrew@pc01 人 \]$ printf "137.99.234.23" > c \[ andrew@pc01 man \]$ cut -d'.' c-f1 137 ``` `sed` is commonly used to replace a string with another string in a file: ``` \[ andrew@pc01 man \]$ echo "舊" | sed s/舊/新/ 新的 ``` ...but `sed` is an extremely powerful utility, and cannot be properly summarised here. It’s actually Turing-complete, so it can do anything that any other programming language can do. `sed` can find and replace based on regular expressions, selectively print lines of a file which match or contain a certain pattern, edit text files in-place and non-interactively, and much more. A few good tutorials on `sed` include: - [https://www.tutorialspoint.com/sed/](https://www.tutorialspoint.com/sed/) - [http://www.grymoire.com/Unix/Sed.html](http://www.grymoire.com/Unix/Sed.html) - [https://www.computerhope.com/unix/used.htm](https://www.computerhope.com/unix/used.htm) <a name="pattern-matching"></a> ## Pattern Matching <a name="grep"></a> ### `grep` [[ Back to Table of Contents ]](#toc) The name `grep` comes from `g`/`re`/`p` (search `g`lobally for a `r`egular `e`xpression and `p`rint it); it’s used for finding text in files. `grep` is used to find lines of a file which match some pattern: ``` \[ andrew@pc01 ~ \]$ grep -e " *.fi.* " /etc/profile /etc/profile:Bourne shell 的系統範圍 .profile 檔案 (sh(1)) =================================================== ``` # The file bash.bashrc already sets the default PS1. ``` ``` fi ``` ``` fi ``` … ``` ...or contain some word: ``` \[ andrew@pc01 ~ \]$ grep "andrew" /etc/passwd 安德魯:x:1000:1000:安德魯,,,:/home/andrew:/bin/bash ``` `grep` is usually the go-to choice for simply finding matching lines in a file, if you’re planning on allowing some other program to handle those lines (or if you just want to view them). `grep` allows for (`-E`) use of extended regular expressions, (`-F`) matching any one of multiple strings at once, and (`-r`) recursively searching files within a directory. These flags used to be implemented as separate commands (`egrep`, `fgrep`, and `rgrep`, respectively), but those commands are now deprecated. > **Bonus**: [see the origins of the names of a few famous `bash` commands](https://kb.iu.edu/d/abnd) <a name="awk"></a> ### `awk` [[ Back to Table of Contents ]](#toc) `awk` is a pattern-matching language built around reading and manipulating delimited data files, like CSV files. As a rule of thumb, `grep` is good for finding strings and patterns in files, `sed` is good for one-to-one replacement of strings in files, and `awk` is good for extracting strings and patterns from files and analysing them. As an example of what `awk` can do, here’s a file containing two columns of data: ``` \[ andrew@pc01 ~ \]$ printf "A 10\\nB 20\\nC 60" > 文件 ``` Loop over the lines, add the number to sum, increment count, print the average: ``` \[ andrew@pc01 ~ \]$ awk 'BEGIN {sum=0;計數=0; OFS=“”} {sum+=$2; count++} END {print "平均值:", sum/count}' 文件 平均:30 ``` `sed` and `awk` are both Turing-complete languages. There have been multiple books written about each of them. They can be extremely useful with pattern matching and text processing. I really don’t have enough space here to do either of them justice. Go read more about them! > **Bonus**: [learn about some of the differences between `sed`, `grep`, and `awk`](http://bit.ly/2AI3IaN) <a name="ssh"></a> ## Copying Files Over `ssh` <a name="ssh-scp"></a> ### `ssh / scp` [[ Back to Table of Contents ]](#toc) `ssh` is how Unix-based machines connect to each other over a network: ``` \[ andrew@pc01 ~ \]$ ssh –p安德魯@137.xxx.xxx.89 上次登入:2019 年 1 月 11 日星期五 12:30:52,來自 137.xxx.xxx.199 ``` Notice that my prompt has changed as I’m now on a different machine: ``` \[ andrew@pc02 ~ \]$ 退出 登出 與 137.xxx.xxx.89 的連線已關閉。 ``` Create a file on machine 1: ``` \[ andrew@pc01 ~ \]$ echo "你好" > 你好 ``` Copy it to machine 2 using `scp` (secure copy; note that `scp` uses `–P` for a port #, `ssh` uses `–p`) ``` \[ andrew@pc01 ~ \]$ scp –P你好安德魯@137.xxx.xxx.89:~ 你好 100% 0 0.0KB/秒 00:00 ``` `ssh` into machine 2: ``` \[ andrew@pc02 ~ \]$ ssh –p安德魯@137.xxx.xxx.89 上次登入:2019 年 1 月 11 日星期五 22:47:37,來自 137.xxx.xxx.79 ``` The file’s there! ``` \[ andrew@pc02 ~ \]$ ls 你好多xargs \[ andrew@pc02 ~ \]$ 貓你好 你好 ``` <a name="rsync"></a> ### `rsync` [[ Back to Table of Contents ]](#toc) `rsync` is a file-copying tool which minimises the amount of data copied by looking for deltas (changes) between files. Suppose we have two directories: `d`, with one file, and `s`, with two files: ``` \[ andrew@pc01 d \]$ ls && ls ../s f0 f0 f1 ``` Sync the directories (copying only missing data) with `rsync`: ``` \[ andrew@pc01 d \]$ rsync -off ../s/\* . 正在發送增量文件列表... ``` `d` now contains all files that `s` contains: ``` \[ andrew@pc01 d \]$ ls f0 f1 ``` `rsync` can be performed over `ssh` as well: ``` \[ andrew@pc02 r \]$ ls \[ andrew@pc02 r \]$ rsync -avz -e "ssh -p “ [email protected]:~/s/\* 。 接收增量檔案列表 f0 f1 發送 62 位元組 接收 150 位元組 141.33 位元組/秒 總大小為 0 加速率為 0.00 \[ andrew@pc02 r \]$ ls f0 f1 ``` <a name="long-running-processes"></a> ## Long-Running Processes <a name="yes-nohup-ps-kill"></a> ### `yes / nohup / ps / kill` [[ Back to Table of Contents ]](#toc) Sometimes, `ssh` connections can disconnect due to network or hardware problems. Any processes initialized through that connection will be “hung up” and terminate. Running a command with `nohup` insures that the command will not be hung up if the shell is closed or if the network connection fails. Run `yes` (continually outputs "y" until it’s killed) with `nohup`: ``` \[ andrew@pc01 ~ \]$ nohup 是 & \[1\]13173 ``` `ps` shows a list of the current user’s processes (note PID number 13173): ``` \[ andrew@pc01 ~ \]$ ps | sed -n '/是/p' 13173 分/10 00:00:12 是 ``` _...log out and log back into this shell..._ The process has disappeared from `ps`! ``` \[ andrew@pc01 ~ \]$ ps | sed -n '/是/p' ``` But it still appears in `top` and `htop` output: ``` \[ andrew@pc01 ~ \]$ 頂部 -bn 1 | sed -n '/是/p' 13173 安德魯 20 0 4372 704 636 D 25.0 0.0 0:35.99 是 ``` Kill this process with `-9` followed by its process ID (PID) number: ``` \[ andrew@pc01 ~ \]$ 殺死 -9 13173 ``` It no longer appears in `top`, because it’s been killed: ``` \[ andrew@pc01 ~ \]$ 頂部 -bn 1 | sed -n '/是/p' ``` <a name="cron"></a> ### `cron / crontab / >>` [[ Back to Table of Contents ]](#toc) `cron` provides an easy way of automating regular, scheduled tasks. You can edit your `cron` jobs with `crontab –e` (opens a text editor). Append the line: ``` - - - - - 日期 >> ~/datefile.txt ``` This will run the `date` command every minute, appending (with the `>>` operator) the output to a file: ``` \[ andrew@pc02 ~ \]$ head ~/datefile.txt 2019 年 1 月 12 日星期六 14:37:01 GMT 2019 年 1 月 12 日星期六
各位好,我想請問一下 我有一台開發用的gcp compute engine(vm),上有一台ubuntu 2204 長期以來都是在上面直接用Mobaxterm登入後用notepad++ coding,再於MobaXterm下指令執行與佈署 近期想切換到vscode,安裝了 Remote - SSH v0.108.0 Remote Explorer v0.4.1 Remote - SSH: Editing Configuration Files v0.86.0 三個套件,這些套件都有1500萬人以上下載量,評價都是4到5星 ,我寫好設定檔連結到Ubuntu server上、但總是一直出現用到一半就timeout再也連不上 後來重啟ubuntu server後觀察發現vscode server的process會佔用大量RAM,CPU吃到30%也不低  google的結果,除了關閉Follow Symlinks外沒什麼有建設性的意見  希望請教其他人是怎樣解這個問題的?謝謝
我們中的許多人已經在 Product Hunt 上推出了一段時間,**越來越多的人開始質疑那裡的受眾是否真誠,以及是否仍然值得在他們自己的平台上推出**。 一周前剛剛推出了我們的最新產品,我想在這裡分享我們的第一手經驗並涵蓋三個主要內容: - 今天就推出 Product Hunt 的外觀和感覺如何 - 我們從發布中得到了什麼 - 如何(最好)利用 Product Hunt 來開發您的產品 關於我們 - 推出 6 次,超過 2,000 票贊成 -------------------------- 在過去 3 年裡,我們在 Product Hunt 上推出了 6 次,贏得了「最佳產品」獎(當天排名第 1 和第 5 名),並總共收集了超過 2,000 個讚。一週前,我們剛完成了[Open SaaS 的第六次發布,這是 300 美元以上 SaaS 入門產品的開源替代品](https://github.com/wasp-lang/open-saas/)。  您會發現許多文章為在 PH 上推出提供建議,並從那些獲得推薦的人那裡贏得故事,但幾乎沒有人分享幕後知識以及實現這一目標的真正需求。這就是這篇文章的目的。 我將引導您完成啟動步驟並發表評論並分享我們在每個步驟中的經驗。讓我們開始吧: 安排您的發布並建立“即將推出”預告片 - “讓我們交換贊成票” -------------------------------  一旦您安排了Product Hunt 的發布,您就可以建立一個橫幅,顯示在他們的「即將推出」頁面(https://www.producthunt.com/coming-soon) 上,這就是您的旅程開始的地方。這使 PH 訪客有機會了解接下來會發生什麼,並訂閱以在發布後收到通知,這也是您可以用來行銷您的發布的第一個東西。 **這也是 PH 經濟開始的時候 - 一旦您發布發布預告片,您將開始收到與其他即將推出其產品的人交換贊成票的報價**:  這實際上是一種合法的策略(從共享激勵而不是購買選票的意義上來說),可以透過自動化非常有效地利用。它不會帶來任何合格的潛在客戶(也就是真正對您的產品感興趣的人),但它可能有助於獲得投票,從而提高您的產品發布的知名度和影響力。 我們根本沒有使用過這個策略(所以我無法證明它的效率),因為我們很晚才發布“即將推出”頁面,就在發布前一兩天,而且我們也沒有工作流程沒有地方也沒有人力來完成它。 Linkedin、WhatsApp 和其他平台上也有專門的小組,讓 PH 參與者可以互相支持。如果您加入這些活動,您將會收到更多此類訊息和請求。 發布日 - 主動發送的電子郵件和「購買投票」優惠 ------------------------ 發布當天,類似上述的要求愈加強烈。我甚至收到了其他人在同一天推出產品的幾封電子郵件,要求我投票,因為他們刪除了我的電子郵件並將我加入到他們的時事通訊中。 ### 當天的前 4 小時 - 隱藏點讚 Product Hunt 最近推出了在一天的前 4 小時內以隨機順序顯示產品的功能,並隱藏點讚數。背後的想法是保證所有產品一開始就有平等的知名度,並有公平的機會吸引觀眾的注意。 隨著我們最新推出的 Open SaaS,我們取得了有史以來最好的開局 - 4 小時內獲得 100 票贊成!  當然,我們參與了我們的網絡,但也注意到來自我們不認識的人的大量投票和評論。有瞭如此強勁的開局,我非常有信心我們能躋身排行榜前 5 名產品之列。 > 進入前 5 名產品是 Product Hunt 主頁上的「首屏」位置,因此儘早到達那裡是最終進入該位置的最佳方式。 > 但當排行榜最終揭曉時,Open SaaS 勉強躋身當天發布的前 10 名!  前五名與其他產品之間存在著相當明顯的差距,第一名的產品的支持率幾乎是第二名的兩倍。**這對我們來說相當沮喪,因為感覺我們追趕的機會幾乎是零。** ### “嘿,想買點讚嗎?” 排行榜揭曉後,我們開始收到另一種類型的訊息——直接購買點讚的報價。仍然相對接近前 5 名的產品可能使我們成為一個非常合格的領導者:  與此略有不同的是,讓不同的社群媒體影響者和社群所有者伸出援手,向他們的追隨者推銷您的產品,並承諾獲得 X 票:   甚至我們的一些直接聯絡人也知道“一個人”可以讓你到達 Product Hunt 的頂端,並主動提出介紹我們,所以這有點像一個“公共秘密”,而我們是少數不知道的人關於它。 我們從發布中得到了什麼 - #7、HN 頭版、GitHub 上的趨勢… -----------------------------------  **我們 PH 發布的主要好處不是發布本身,而是我們可以將其與其他東西結合起來,例如**[在 HackerNews 上發布 Open SaaS](https://news.ycombinator.com/item?id=39192304) **,**它最終在其中展示了大約半天(在 Show 上展示的時間更長) HN 選項卡)。  最後,所有這些參與度加起來讓我們能夠在 GitHub 上獲得全球趨勢,這反過來又為 Open SaaS 帶來了更多流量(今天,在發布一周後,它已經擁有[超過 2500 顆星](https://github.com/wasp-lang/open-saas/))。  ### 由此產生的流量 看看過去兩週 Open SaaS 儲存庫帶來的流量,我們可以觀察到以下內容:   HackerNews 的推出吸引的人數是 Product Hunt 的三倍多。 GitHub 吸引了更少的人存取實際的儲存庫,但我的直覺是,更多的人在沒有離開「趨勢」頁面的情況下加註了星標。 在 PH 的每日時事通訊中獲得專題報告 - 有幫助嗎? ---------------------------  Open SaaS 在發布結束時成為當天排名第七的產品,獲得約 400 票贊成。根據 Product Hunt 的資料,當日排名前 10 名的產品最終會出現在擁有超過 50 萬訂閱者的每日新聞通訊中。 該時事通訊以 3 個大型促銷區塊開始,因此您必須滾動相當長的時間才能到達前一天的熱門產品。  對我們來說,它並沒有產生太大的影響,我認為它為我們贏得了大約 20 票。也許是因為我們不是第一,或者只是因為它是一個相當深的漏斗(打開電子郵件 → 一直向下滾動 → 檢查所有產品 → 喜歡 Open SaaS → 決定投票)。  在沒有任何提升策略的情況下是否有可能贏得當天的第一名? --------------------------- **是的,這絕對是可能的。我已經得到了幾個我信任的聯絡人的證實,他們用他們的產品贏得了第一名,沒有任何機器人或支付贊成票。**但它也肯定變得不那麼常見和難以預測。 大多數時候,我們推出的產品首先會表現出一些不尋常的行為。有一次,是該公司在前一周推出,但他們只是稍微重新命名了產品和網站,然後重新推出。還有一次,一款產品在發布結束前幾個小時突然獲得了很高的支援率。 那麼,這意味著什麼?它還值得在 Product Hunt 上推出嗎? ---------------------------------- 顯然,今天雙方都有不同的力量和動機驅動 Product Hunt 用戶的行為。最初,有一個社區想要了解最新產品並表達他們的興趣,並且有一些創始人想要連接到該社區。 **現在,也有一些創作者最希望自己的產品獲勝,無論實際的受眾參與度如何,因為他們相信這將有助於他們實現最終目標,例如影響範圍、籌款或對其他用戶的社會認可。顯然,有一方願意滿足這項需求,但對產品並沒有任何真正的興趣。** 為什麼這可能? Product Hunt 正在採取許多措施來偵測和防止此類行為,但如果不嚴格限制 Product Hunt 所追求的網路效應(即能夠分享您的啟動連結),就很難做到這一點。 **除此之外,對我們來說,定期在 Product Hunt 上發布仍然是值得的。原因如下。** 產品搜尋是一個很棒的藉口 ------------ Product Hunt 為您提供了一個獨特的機會來宣布您的產品「正式」發布。您可以決定在哪一天執行此操作並安排時間,並且 100% 所有人都能看到它,您也可以分享並邀請人們查看。**你有 24 小時的時間,在此期間,你完全有理由聯繫你認識的每個人(以及其他人)並繼續按喇叭。**  **Reddit 和 HackerNews 等其他高影響力平台無法做到這一點。**當然,您可以隨時分享有關您產品的新聞,但不能保證任何人都會看到它(實際上恰恰相反),除非社區的集體思想決定如此,這幾乎是確定性的。您可以輕鬆地花費一周的時間來準備您的發布帖子,但它會在幾分鐘內被演算法淹沒。 **這就是為什麼我們不將 Product Hunt 視為最終目標(贏得第一名),而只是將其視為我們整個發布過程的一部分。這是一個很棒的講台,也是一個談論你的產品的好藉口,而上面的任何其他東西都只是一個額外的好處。** 我們保持簡單 ------ 您會發現很多來自「PH 專家」的文章(和付費課程),解釋您應該如何提前幾個月準備發布、預熱您的受眾、準備他們將分享的評論等。**我們不做任何這些事情。我們只需準備內容(影片+一些螢幕截圖和介紹性評論),然後在發布當天邀請我們認識的所有人支持我們。然後,白天我們也會在 Reddit、Hackernews 和 dev.to 上發文。**  有時我們最終會進入前 5 名,有時則不然,**但每次,我們的用戶參與度都會穩步提升,並且通常會在接下來的幾天/幾週內出現更好的結果**。例如, [MAGE,我們基於 GPT 的全端應用程式啟動器](https://usemage.ai/),在 PH 發布後就出現了爆炸性增長,並[在幾個月內被用來建立了 30,000 多個專案](https://dev.to/wasp/how-we-built-a-gpt-web-app-generator-for-react-nodejs-from-idea-to-25000-apps-in-4-months-1aol)。 我們經常這樣做 ------- 我們的目標是每 3 個月發布一次 Product Hunt,作為發布週的一部分,這就是我們迄今為止所做的。除非 6 個月過去了或有重大更新,否則您無法真正推出完全相同的產品,但您可以自由地推出與主產品相關的其他(子)產品和功能。 > **💡 提示**:當您提交發佈時,您可以要求 PH 團隊將其「連接」到您的產品,以便它將出現在該產品的發布清單中。通常,他們自己做。它看起來像這樣:  雖然我們的主要產品是[Wasp,一個基於 React 和 Node.js 的全端框架](https://github.com/wasp-lang/wasp),但到目前為止我們推出的產品如下: - **Wasp Alpha** - 純產品,v0 差不多 - **Wasp Beta** - 差不多兩年過去了,我們還沒有採用「經常發布」的方法 - **免費 SaaS 模板**- [Open SaaS](https://github.com/wasp-lang/open-saas)的前身,4 個月後 - [\*\*MAGE,GPT Web 應用程式產生器](https://usemage.ai/)\*\* - 由 Wasp 提供支援的全端 Web 應用程式產生器 - [**React/Node 的全端身份驗證,無第三方服務**](https://wasp-lang.dev/docs/auth/overview)- Wasp 的身份驗證功能 - 最後, **[Open SaaS - 300 美元以上 React 和 Node.js SaaS 初學者的免費開源替代品](https://github.com/wasp-lang/open-saas/)** 它已成為我們發布工作流程的常規部分,對於我們在該季度推出的任何新功能,我們都會尋找一個好的候選人在即將推出的發布中展示。這使我們能夠繼續談論我們所做的事情,並且我們還獲得了很多可以嵌入到我們的文件、部落格文章等中的好內容(例如影片、橫幅)。 例如,這個影片展示了 Wasp 中的身份驗證如何運作 - 首先我們將它用於我們的[Product Hunt 發布](https://www.producthunt.com/products/wasp-lang-alpha#full-stack-auth-for-react-node-by-wasp),現在它[位於我們的身份驗證文件的頂部](https://wasp-lang.dev/docs/auth/overview)。 {% 嵌入 https://www.youtube.com/watch?v=Qiro77q-ulI&ab\_channel=Wasp %} 謝謝閱讀! ----- 感謝您閱讀本文!這篇文章比我最初預期的要長得多,但我不斷獲得更多關於要寫什麼的想法。我希望您會發現它對計劃下一次發布有所幫助,並且您也會更好地了解在此過程中會發生什麼。 我也很想得到您的回饋,並了解您在 Product Hunt 上推出的經驗和策略。 快樂發射! --- 原文出處:https://dev.to/wasp/product-hunt-has-become-pay-to-win-but-you-should-still-use-it-to-launch-your-product-508d
> 面向雲程式設計的宣言。 別誤會我的意思,我喜歡雲!它使我能夠建立令人驚嘆的東西,並徹底改變了我使用軟體創新和解決問題的方式。 它是「*新電腦*」、終極電腦、「*無電腦電腦*」。它可以彈性擴展,永遠在線,無處不在,可以做任何事情。這是無邊無際的。它肯定會留在這裡。 但天哪,這絕對不是我們在未來十年內建立雲端應用程式的方式。隨著雲端從“我不想讓伺服器放在我的辦公桌下”發展到“我的應用程式需要30 個不同的託管服務來執行其任務”,我們有點忘記了優秀的開發人員體驗是什麼樣子的。 為雲端建立應用程式有時感覺就像把我孩子的袋子裡未使用的樂高積木灑滿了客廳地板並試圖建造一座城堡。在經歷了撕碎的撲克牌、可怕的芭比娃娃頭和漏電的電池之後,你讀了第一百萬次說明書,卻發現你最終建造的東西與上次建造的東西基本上相同。 分類樂高積木很有趣!和孩子們一起打發時間。它甚至滿足了我的強迫症……但見鬼,這不是我想要建立專業軟體的方式! *讓我試著描述一下我和我的開發人員朋友正在努力解決的問題。* ### 我想專注於為我的用戶創造價值 當我建立專業軟體時,我希望將大部分時間花在應用程式的*功能*領域,而不是我使用的平台的*非功能*機制。 每次我想要在 AWS Lambda 函數內執行程式碼時,我都必須了解它需要與 tree-shaken 依賴項捆綁在一起,作為 zip 檔案上傳到 S3 並透過 Terraform 部署,這是沒有意義的。或者,為了能夠向 SNS 發布訊息,我的 IAM 策略必須有一個允許對主題的 ARN 執行`sns:Publish`操作的語句。*每個開發人員都需要了解 ARN 是什麼嗎?* 所有這些東西與我試圖為用戶創造的價值沒有任何關係。這是純粹的力學。**我們能擺脫它嗎?** ### 我想獨立 作為一名開發人員,最令人沮喪和最扼殺流程的情況之一是我必須停下來等待某人或某事才能繼續前進。 就像快樂地在空中滑翔,欣賞風景,欣賞優美的背景音樂,突然,*砰!*混凝土牆。 當您為雲端建立應用程式時,這堵混凝土牆有多種形狀和尺寸。是 DevOps 人員排隊;需要更新的是 IAM 策略;是只有外部兼職顧問才知道如何除錯的部署失敗;我們希望內部平台中不斷積壓的缺失旋鈕和 API 能夠改變一切。 這些障礙令人沮喪,因為它們迫使我切換環境,應用「臨時」安全策略,並發明我不想談論的醜陋駭客。這是一個破碎的世界。 我想獨立。我希望能夠把事情做好,保持順其自然。我想一次一點地改善世界,並在完成*後*繼續下一件事。我想要完成任務時的多巴胺激增,而不是另一個未完成的線程的羞恥感。 ### 我想要即時回饋 我說過我想要獨立,但不要誤以為我會寫完美的程式碼。這就是為什麼我想用鉛筆而不是鋼筆寫程式碼。 有些開發人員可以花一整天的時間進行編碼,甚至無需呼叫編譯器,最終,他們進行編譯和部署,然後就可以正常工作了。 我很欽佩他們,但我不是那種類型的開發人員。不,先生。對我來說,這就是迭代、迭代、迭代。我從小處開始,用輕鉛筆畫草圖,看一看,擦掉一堆東西,畫一條更粗的線,後退一步,瞇著眼睛,畫更多,擦掉更多,再看一眼,*沖洗並重複*。 這就是為什麼對我來說,最重要的是迭代速度。我越早執行並測試我的應用程式,我就能越快地返回並迭代。這就是我的流量所在。 當我開始程式設計時,我使用 Borland C++。過去,在 IBM PC AT 機器(TURBO ON)上編譯和執行一個程式大約需要 100ms。**雲端中的平均迭代周期需要幾分鐘。分鐘!有時要幾十分鐘!** 這是當今雲端中迭代的樣子:我對程式碼進行了更改;然後我需要編譯它;將其部署到我的測試帳戶;找到管理控制台的方式來實際觸發它;等待它執行並去搜尋 登入另一個服務。然後我意識到有一個錯誤回應告訴我我很愚蠢,因為我怎麼不知道我必須傳入 Accept-Content: application/json,否則我會得到一些名為「XML」的奇怪結果我不知道該怎麼辦(開個玩笑,XML 很棒,不是真的)。現在一切又重新來過… 因此,您說“編寫單元測試”,以居高臨下的方式試圖證明當前的現實是合理的。 「偉大的開發人員編寫單元測試」。好的!因此,現在我需要獲取我的程式碼,該程式碼進行了大約20 個外部API 呼叫,並透過從過時的文件中複製並貼上它們來以某種方式模擬API 回應,結果卻發現我的請求被拒絕了,因為我缺少了一些隱式操作我的 IAM 安全聲明。我們都去過那裡。 **說實話,給我90年代的開發者經驗**。我想要進行更改,並且希望能夠以互動方式或透過在幾毫秒內的單元測試來測試此更改,並且我想坐在沒有 WiFi 的飛機上執行此操作,好嗎? (我們在 90 年代沒有 WiFi)。 ### 所以這只是一句吐槽? 一定不行!我是電腦程式編制員。有時我覺得我從出生起就一直在寫軟體。我一直在社會危險的時期這樣做,當時成為電腦極客並不酷。 我一直喜歡成為開發人員,因為如果我對自己的工具不滿意,我可以製作自己的工具。畢竟,製造工具已經融入了我們的 DNA——人類製造工具的歷史已經超過一百萬年。 我對我的工具不滿意。 2022 年 4 月,我與好朋友、前微軟同事 \[Shai Ber\] 聯手,創立了 \[Wing\],其使命是***為開發者解鎖雲端***。我們聚集了一群令人難以置信的美麗極客,他們與我們一樣對開發人員體驗和開源充滿熱情,並開始了我們的旅程,使開發人員(即我們自己)能夠解決這些基本問題。 ### 編譯器來救援 那麼我們該如何一次解決所有這些問題呢? **我們正在為雲端建立一種程式語言。** 「*一種程式語言!?* 」你問。 “*世界上沒有足夠的程式語言嗎?* ”,“*編寫一個編譯器真的很難嗎?* ”, *“開發人員想要學習一門全新語言的機會有多大?* ”,“*為什麼不能你侵入了現有的語言工具鏈,瞇起眼睛,然後就到此為止了嗎?* ” 我不是一個心血來潮就建立程式語言的人。事實上,我花了過去五年的時間建立 \[AWS CDK\],這是一個*多語言庫*,它允許開發人員使用他們最喜歡的程式語言定義雲端基礎設施,從而解決了我正在談論的一些挑戰。 「滿足開發人員所在的位置」是 AWS 和 CDK 的美好宗旨,它激勵我們建立 \[JSII\] 和 \[constructs\] 等出色的技術。 ***但有時,「他們在哪裡」並不是一個足夠好的模型來創造所需的體驗。*** 用程式碼定義基礎設施確實使我們能夠建立更高層級的抽象,但只要我的應用程式程式碼需要與此基礎設施交互,抽象就變得太\[洩漏\]。我被迫要了解比我需要的更多的知識,而且我必須成為 IAM、VPC、ALB、EBS 等領域的專家,基本上還有比我想記住的更多的 TLA。 我們今天使用的語言都是圍繞著*電腦是一台機器*的想法而設計的。他們已經達到了能夠為我們提供對這些機器的可靠抽象的程度。它們抽象化了 CPU、記憶體、檔案系統、行程管理和網路。作為開發人員,我不必關心文件在磁碟上的佈局方式,甚至不必關心哈希映射需要多少記憶體。我只需寫`readFile()`或`new Dictionary()`即可開始我的一天。是的,對我來說,了解幕後發生的事情並不是一個壞主意,但我並不是被迫這樣做。 大多數這些語言還為我提供類型安全。當我使用錯誤數量的參數呼叫函數時,我的編譯器會對我大喊大叫。我不必等到我的應用程式執行時才意識到我忘記了參數,或者傳遞了錯誤的類型。 **在雲端,我獨自一人**。每當我的程式碼需要與雲端資源或服務互動時(隨著產業的發展,這種情況越來越多)我必須放棄程式語言的舒適性和安全性。我必須跳出機器的邊界,進入網路的狂野西部,而我的編譯器卻一無所知。 突然之間,所有痛苦的來源幾乎變得非常明顯。如今的雲端應用程式只是由互不相連的部分拼湊而成。我有一個用於我的基礎設施的編譯器,另一個用於我的函數,另一個用於我的容器,另一個用於我的 \[CI/CD 管道\]。每個機器都非常認真地對待自己的工作,並讓我在每台機器中保持安全和快樂,但我的應用程式不再在單台機器上執行,我的應用程式在雲端上執行。 ***雲就是計算機。*** ### Wing,一種面向雲端的程式語言 當新的程式設計範式出現時,語言需要時間來迎頭趕上。我曾經喜歡用 C 語言建立物件導向的程式碼,但它是一個有漏洞的抽象。我必須了解物件在記憶體中的佈局方式、\[V 表\] 的工作原理,並記住將物件作為每個函數的第一個參數傳遞。當程式語言開始像一等公民一樣支援物件導向的概念時,這種範式就民主化了,今天大多數開發人員甚至不知道 V 表是什麼,世界一直在旋轉。 **Wing** ,或者***winglang,***如果你想可愛一點的話,它擁有你所期望的現代、面向物件、強類型和通用語言的所有好東西,但它還包括一些額外的原語,旨在支持分佈式雲作為一等公民的基於服務的性質。 ### 一探究竟 我們在 Wing 上的工作已經快一年了,我很高興邀請您查看並告訴我您的想法。雖然仍處於 Alpha 階段,尚未準備好投入生產使用,但已經可以用它來建立一些[實際的應用程式](https://github.com/winglang/research/tree/main/dogfooding)。 https://github.com/winglang/wing --- 原文出處:https://dev.to/winglang/cloud-why-so-difficult-3j33
#RAG簡介 作為開發人員,您今天可以學到的最有價值的技能之一是學習如何使用大型語言模型 (LLM) 建立檢索增強生成 (RAG) 應用程式。 ## 為什麼? 因為世界上有超過 64 ZB 的資料,這甚至不包括書籍或實體文件等實體資料。 (供您參考,1澤字節是一兆千兆位元組。) 不僅如此,全球90%的資料都是在過去兩年建立的,而且資料量每兩年就會翻倍。基本上,公司都在海量的資料中游泳,而且這些資料每天都在變得越來越大。 公司將如何存取和使用所有這些資料? 現在每個人都聽說過使用檢索增強生成(RAG)來透過人工智慧尋找資訊。能夠存取和使用不斷增長的資料量是每個公司都需要的關鍵技能。 即使您知道 RAG 基本上是描述將文件或知識連結到 LLM 的工作流程的簡寫方式,許多開發人員自己(還)還沒有嘗試或試驗過這一點。 網路上充滿了圖書館列表,但如何開始呢? 以下是幫助您開始使用 RAG 的最佳庫的簡短清單。 --- # 1. [LLMWare](https://github.com/llmware-ai/llmware) 在LLMWare中,您可以上傳文件,並透過幾行程式碼開始檢索資訊。它處理 RAG 所需的整個過程:文件攝取、解析、分塊、索引、嵌入、儲存到向量資料庫以及連結到 LLM 以檢索答案。 LLMWare 被設計為整合和端到端,因此所有這些步驟都可以開箱即用。它組裝了所有部件,因此您無需這樣做。 LLMWare 使其非常簡單且易於上手: - 只需幾行程式碼即可透過端到端範例實現 RAG 工作流程 - 建立庫並無縫載入文件 - 輕鬆產生嵌入 - 輕鬆進行語意搜尋 - 利用任何 Hugging Face 模型或 GPT-4 等封閉源模型來回答資料中的問題 - 範例包括無需 GPU 的 RAG 模型 https://github.com/llmware-ai/llmware  --- # 2. [MongoDB](https://github.com/mongodb/mongo) MongoDB 是一種廣泛使用的開源 NoSQL 資料庫程式。它屬於以文件為導向的資料庫類別,這意味著它以類似於 JSON 文件的格式儲存和組織資料。 MongoDB 的設計具有靈活性和可擴展性,使其適合各種應用程式和行業。 資料庫(如 MongoDB)是 RAG 中非常重要的一步,因為它們在嵌入之前儲存從文件或知識庫中提取的訊息,包括重要的元資料。 https://github.com/mongodb/mongo  --- # 3. [Milvus 向量資料庫](https://github.com/milvus-io/milvus) Milvus 是一個開源向量資料庫,旨在為嵌入相似性搜尋和人工智慧應用程式提供支援。 Milvus 讓非結構化資料搜尋更容易存取,無論部署環境如何,都可以提供一致的使用者體驗。 Milvus DB,或類似的向量 DB,是 RAG 中至關重要的一步。它是存儲向量嵌入以進行相似性搜尋的地方。該資料庫允許人們用自然語言提出問題並檢索相關結果。如果沒有良好的嵌入和向量資料庫,LLM 模型將無法接收正確的文字區塊來讀取。 https://github.com/milvus-io/milvus  --- # 4. [擁抱臉](https://github.com/huggingface) 如果你還沒去過 Hugging Face,你真的應該去看看。這是所有開源模型的去處,並且可以單槍匹馬地將世界從人工智慧壟斷中拯救出來。就像 Github 用於開源專案一樣,Hugging Face 用於開源模型。有超過 450,000 個模型,所有模型都免費供任何想要使用它們的人使用。 Hugging Face 的 Transformers 庫是首選庫 提供數千個預訓練模型來執行不同模式(例如文字、視覺和音訊)的任務。 這些模型可應用於: - 文本,用於文本分類、資訊提取、問答、摘要、翻譯和文本生成等任務,支援 100 多種語言。 - 影像,用於影像分類、物件偵測和分割等任務。 - 音頻,用於語音辨識和音頻分類等任務。 Transformer 模型還可以組合執行多種模式的任務,例如表格問答、光學字元辨識、從掃描文件中提取資訊、視訊分類和視覺問答。 https://github.com/huggingface  --- #5. [Llama.cpp](https://github.com/ggerganov/llama.cpp) 沒有GPU?沒問題! Llama.cpp 來救援! llama.cpp 的主要目標是在 MacBook 上使用 4 位元整數化來執行 LLaMA 模型。 * 無依賴的純 C/C++ 實現 * Apple Silicon 一等公民 - 透過 ARM NEON、Accelerate 和 Metal 框架進行最佳化 * 對 x86 架構的 AVX、AVX2 和 AVX512 支持 * 混合F16/F32精度 * 支援2位、3位、4位、5位、6位和8位整數化 * CUDA、Metal 和 OpenCL GPU 後端支持 一旦量化,更大的模型就可以在 CPU 上執行,而效能損失很小。尋找 GGUF 版本的模型來嘗試使用 LLMWare 或其他 RAG 工作流程。 https://github.com/ggerganov/llama.cpp  --- 這是幫助您開始使用 RAG 的非常基本的概述。如果您想要一個讓所有這些庫無縫協作的一站式整合解決方案,請造訪 LLMWare 的 GitHub 庫,找到 50 多個優秀範例來幫助您入門。 [在不和諧中找到我們](https://discord.gg/fCztJQeV7J) - 我們很樂意聽到您的來信! --- 原文出處:https://dev.to/llmware/top-5-beginner-friendly-open-source-libraries-for-rag-1mhb
假設您有一個或多個應用程式 - 它們都發送日誌 - 您如何知道它們內部發生了什麼? 通常有兩種方法: - **日誌記錄**:保存來自多個應用程式的日誌並提供見解和搜尋。這是老方法並且總是有幫助的。 - **追蹤**:專注於提供對應用程式效能的洞察;您可以針對它們建立準確的指標以進行監控和警報。 有些工具用於記錄,有些工具用於跟踪,有些工具兩者兼而有之! 以下是您必須了解的用於日誌和追蹤的開源工具:  --- # 1. [Quickwit](https://github.com/quickwit-oss/quickwit)(日誌與追蹤)👑 Quickwit 是一個開源分散式搜尋引擎,專為大規模日誌管理和分析而設計。 Quickwit 是 Elasticsearch 的直接替代方案,具有更高的效能,尤其是在雲端原生和大規模分散式環境中,並且專注於優化儲存和搜尋效率。 通常,您會使用 OpenTelemetry、Fluentbit、Odigos(自動偵測追蹤工具)等工具來收集日誌和追蹤,將它們傳送到 Quickwit,然後使用 Jaeger(追蹤)或 Grafana(日誌和追蹤)將其視覺化。 **有趣的事實:** Elasticsearch 和 Kibana 都放棄了社區許可證,轉而採用更具限制性的許可證(從 Apache 2 到 Elastic 許可證,並遭到社區的強烈反對)。 Quickwit 是 AGPL 3。它對 FOSS(免費開源社群)更加開放。  --- # 2. [Grafana](https://github.com/grafana/grafana)(日誌和追蹤) Grafana 是 ELK 堆疊的開源替代品。對於日誌和跟踪,您必須設定兩個查詢引擎:Loki 和 Tempo,都由 Grafana 維護。 一旦您在 Loki 和 Tempo 中索引了所有日誌或跟踪,您將需要一個可視化工具來搜尋您的資料:Grafana 來了! Grafana 可讓您查詢、視覺化、警報和理解您的指標,無論它們儲存在何處。與您的團隊建立、探索和分享儀表板,並培養資料驅動的文化。  --- # 3. [Odigos](https://github.com/keyval-dev/odigos)(追蹤) Odigos 是一項獨特的技術,無需更改程式碼即可為 k8s 中的任何應用程式產生追蹤:然後可以將所有追蹤轉發到 Quickwit 或 Elasticsearch 等資料庫(它們有更多整合)。 如果您不知道,OpenTelemetry 是一個接收日誌和追蹤的協定。 Odigos 正在使用該標準,因此您可以在任何支援 OpenTelemetry 的資料庫中發送您的追蹤!  --- # 5. [Jaeger](https://github.com/jaegertracing/jaeger)(追蹤) 與 Prometheus 不同,Jaeger 專注於追蹤。 Jaeger 支援跨分散式系統傳播上下文訊息,確保追蹤資料在服務網路中正確關聯。 它並不是為處理大量資料而設計的,您必須將其與強大的儲存引擎(如 Quickwit 或 Elasticsearch)一起使用。在這樣的設定中,Jaeger 可以根據您的服務進行擴展,使其適用於小型和大型系統。  --- # 6. [SigNoz](https://github.com/SigNoz/signoz)(日誌與追蹤) Signoz 提供日誌和追蹤管理功能。 您可以在單一管理平台中視覺化追蹤和日誌。 您可以透過尋找導致問題的確切追蹤並查看各個請求追蹤的詳細火焰圖來找到問題的根本原因。  --- # 7. [Keep](https://github.com/keephq/keep)(提醒) 保持與目前所有可觀察工具、資料庫和通訊管道的連接,並將所有內容聚合到一個平台中,在出現問題時提供頂級警報 😈  --- # 8. [Uptrace](https://github.com/uptrace/uptrace)(日誌與追蹤) Uptrace 是一個基於 OpenTelemetry 的可觀察性平台,用於攝取日誌和追蹤。您可以監控您的應用程式並蒐索您的日誌。 由於其 OpenTelemetry 支援和眾多集成,可以輕鬆收集和發送資料 😈。請注意,您需要設定 Postgresql 和 Clickhouse 資料庫。  --- # 9. [HyperDX](https://github.com/hyperdxio/hyperdx)(日誌與追蹤) HyperDX 是一個開源可觀察性平台,可讓您搜尋日誌並分析您的痕跡。您可以在一個平台上偵錯複雜的錯誤和使用者問題,而無需在多個工具之間跳轉。  --- # 10. [普羅米修斯](https://github.com/prometheus/prometheus)(指標) 有趣的是,這個庫是以電影[普羅米修斯](https://www.imdb.com/title/tt1446714/)命名的(當然我是在開玩笑),但這是我的第一個假設(無論如何,這是一部好電影) 雖然 Prometheus 和 Elasticsearch 看起來很相似,但實際上它們非常不同。 Prometheus 只關注基礎設施的指標(例如 CPU、記憶體使用情況、磁碟使用情況…),但不太適合高基數指標。 Quickwit比較專注於Logs和Trace; Elasticsearch 可以做日誌、追蹤和指標! 他們傾向於攜手合作。 Prometheus 提供了一個原始的 UI,這很好,但它與 Grafana 儀表板最搭配。 有趣的是,Prometheus 提供了名為 PromQL(Prometheus Query Language)的查詢語言  --- 我們在 X 上連接嗎? :) [我在這裡](https://twitter.com/nevodavid) 您是否使用其他一些優秀的工具來記錄和追蹤? 請在評論中讓我了解它們:) --- 原文出處:https://dev.to/nevodavid/top-10-tools-to-learn-whats-going-on-in-your-app-20em
看更多文章: 1. [使用 gRPC 和微服務建立可擴展的通知系統](https://dev.to/suprsend/building-a-scalable-notification-service-with-grpc-and-microservices-l6d) 2. [在 React 網站中新增通知來源](https://dev.to/suprsend/adding-a-notification-feed-in-react-websites-4oa0) 4. [2023 年現代應用通知基礎設施完整指南](https://dev.to/suprsend/a-complete-guide-on-notification-infrastruct-for-modern-applications-in-2023-13b9) --- 應用程式通常可以分為兩種類型的效能瓶頸: 1. **I/O 限制:** 這些應用程式將大部分時間花在處理輸入和輸出上。 2. **CPU 限制:** 這些應用程式將大部分時間花在運算任務上。 現在,這些分類如何轉化為前端應用程式的上下文,特別是 React 應用程式? **React 中的 I/O 效能挑戰** 當涉及到 React 應用程式時,經常會出現 I/O 效能方面的問題,主要與非同步 HTTP 呼叫相關。無效地管理這些網路請求可能會導致應用程式速度減慢。雖然這篇文章主要關注 CPU 效能,但有必要簡要介紹一下可以找到 I/O 限制問題解決方案的關鍵領域: - 盡可能實施延遲載入。 - 在初始載入資產和後端請求時請務必小心。 - 減少載入高度靜態元素的頻率(例如,選擇選項、配置)。 - 去抖特定請求的次數。 - 使用 Promise.all 等技術盡可能並行化請求。 - 透過優化資料庫存取等措施來提高關鍵後端端點的效率。 **React 中的 CPU 效能挑戰** 這篇文章的主旨是解決 React 中的 CPU 效能挑戰。在深入研究細節之前,讓我們先對效能建立一個具體的定義: - 瀏覽器應用程式主要作為單執行緒程式執行。 - 腳本任務,例如 JavaScript 執行、DOM 渲染和事件處理,都發生在同一個執行緒。 - 緩慢的 JavaScript 模組可能會阻塞主執行緒。 - 如果主執行緒被阻塞,使用者介面將變得無回應,導致每秒幀數 (fps) 下降。 - 響應式 UI 的目標是至少 30 fps,理想情況下達到 60 fps,這意味著每幀的計算時間應在 30 毫秒或更短的時間內。 在 React 的背景下,這個問題變得至關重要。當觸發 React 元件更新時,整個子樹必須在 30 毫秒內渲染完畢。對於複雜而冗長的元件結構(例如表、樹和列表),這變得尤其具有挑戰性,可能需要大規模重新渲染。 **反應渲染和提交階段** 從高層次來看,React 分為兩個不同的階段: **渲染階段:** - 當元件更新時啟動,由 props 或 hooks 的變更觸發。 - React 遍歷元件子樹,渲染每個子樹並計算虛擬 DOM (VDOM) 子樹。 - 只有受更新影響的「髒」子樹需要重新計算;更新元件的父元件可能不需要重新渲染。 - 此階段的效率與每個子元件的大小和計算成本成正比。 - React.memo 可用於提供更有效率渲染流程的提示。 **提交階段:** - 渲染階段產生整個 UI 的新虛擬 DOM。 - 在提交階段,React 將新樹與前一棵樹進行比較(VDOM 比較)。 - React 計算反映新 VDOM 樹所需的最小 DOM 突變。 - 套用 DOM 突變,更新 UI。 - 預設情況下,此階段本質上是高效的。 - 整個過程必須在 30 或 16 毫秒內完成(分別針對 30 fps 和 60 fps),UI 才會被視為回應。工作負載與應用程式的大小成正比。 後續探索將聚焦在提升Render階段的效率。在深入研究優化技術之前,了解如何測量和辨識應用程式中的緩慢元件至關重要。 **測量** 我經常依賴的工具包括: 1. **Chrome 開發工具的效能標籤** 2. **React Dev Tool 的效能標籤** **Chrome 開發工具的效能標籤** 該工具作為適用於任何瀏覽器應用程式的綜合資源而脫穎而出。它提供對每秒幀數的洞察、捕獲堆疊追蹤、辨識程式碼的慢速或熱點部分等等。主要使用者介面由火焰圖表示。 若要深入了解套用於 React 的 Chrome 效能選項卡,請參閱此[文件](https://developers.google.com/web/tools/chrome-devtools/evaluate-performance)。 **React 開發工具的效能標籤** 若要利用此工具,您需要在瀏覽器中安裝 React Dev Tool 擴充功能。它專門針對 React 客製化了 Chrome 開發工具效能標籤中的資訊。透過火焰圖,您可以觀察不同的提交階段以及在對應渲染階段執行的 JavaScript 程式碼。 該工具有助於輕鬆確定: - 當元件進行重新渲染時。 - 哪些道具改變了。 - 哪些鉤子發生了變化,包括狀態、上下文等等。有關更多詳細訊息,請參閱[介紹性帖子](https://reactjs.org/blog/2018/09/10/introducing-the-react-profiler.html)。 **測量方法** 這是我在評估前端應用程式時更喜歡的方法: 1. **確定問題:** - 找出導致 UI 回應問題的頁面互動。 2. **建立一個假設:** - (可選)產生有關問題的潛在位置的想法。 3. **測量:** - 透過測量每秒幀數 (fps) 等基本指標來驗證問題。 4. **測量(第二部分):** - 辨識有問題的程式碼部分; (可選)驗證您的假設。 5. **建立解決方案:** - 根據收集到的見解實施解決方案。 6. **測量解決方案:** - 透過檢查關鍵指標來驗證實施的解決方案是否解決或緩解了問題。 在沒有適當衡量的情況下進行最佳化會使努力實際上變得無效。雖然有些問題可能很明顯,但大多數問題都需要徹底的測量,從而構成性能增強過程的基石。 此外,測量可讓您向上傳達成果,向使用者、利害關係人和您的領導層通報應用程式特定領域內實現的效能改進(以百分比增益表示)。 **React 應用程式中 CPU 限制問題的通用解決方案** 現在有了測量結果並了解了問題領域,讓我們深入研究潛在的解決方案。優化 React 效能圍繞著改進渲染的元件和渲染的元件。 許多效能問題也源自於反模式。消除這些反模式(例如避免渲染方法中的內聯函數定義)有助於提高渲染時間。事實上,解決不良模式可以降低複雜性並同時提高效能。 **🤔 改進元件渲染** 辨識 React 應用程式中的緩慢元件通常指的是難以渲染或單一頁面上實例數量過多的特定元件。多種原因可能導致他們行動遲緩: - 元件內的阻塞計算。 - 渲染大型元件樹。 - 使用昂貴或低效率的函式庫。 大多數這些問題都歸結為提高元件渲染的速度。有時,關鍵元件不能依賴過於複雜的函式庫,需要回歸基本原則並實施更簡單的替代方案。 例如,我在複雜表格中每行的多個單元格中過度使用 Formik 時遇到了此類挑戰。雖然提高單一元件的效率還有很長的路要走,但注意力最終必須轉移到正在渲染的元件上。 **🧙 改進哪些元件渲染** 這方面提供了兩大類改進: 1. **虛擬化:** - 僅渲染視窗中可見的元件。例如,僅呈現使用者可以看到的表格行或清單專案。事實證明,這種方法對於複雜的 UI 是有益的,雖然可以在不解決「內容」步驟的情況下應用它,但建議這樣做。現代函式庫通常為虛擬化表和清單提供強大的支持,例如“react-virtualized”。虛擬化減少了 React 需要在給定幀中渲染的元件數量。 2. **道具優化:** - React 的目標是使元件類似於純函數,但可能會嘗試渲染不必要的次數。 **反應.備忘錄:** - React 中的大多陣列件都可以被記憶,確保使用相同的 props,元件返回相同的樹(儘管鉤子、狀態和上下文仍然受到尊重)。如果它們的 props 保持不變,則利用 `React.memo` 通知 React 跳過重新渲染這些已記憶的元件。 ``` import React from 'react'; const MyComponent = React.memo((props) => { // Component logic here }); export default MyComponent; ``` **假道具更改:useCallback:** - 解決虛假道具更改問題涉及道具內容保持不變但引用發生變化的情況。一個典型的例子是事件處理程序。 ``` import React, { useCallback } from 'react'; const MyComponent = () => { const onChange = useCallback((e) => console.log(e), []); return <input onChange={onChange} />; }; export default MyComponent; ``` **假道具更改:useMemo:** - 在將複雜資料結構作為 props 傳遞之前,在沒有適當記憶的情況下建立複雜的資料結構時,也會出現類似的挑戰。利用「useMemo」可確保僅在依賴項發生變更時才重新計算行,從而提高效率。 ``` import React, { useMemo } from 'react'; const MyComponent = ({ data, deps }) => { const rows = useMemo(() => data.filter(bySearchCriteria).sort(bySortOrder), [deps]); return <Table data={rows} />; }; export default MyComponent; ``` 雖然您可以靈活地自訂「React.memo」如何比較目前與先前的道具,但保持快速運算至關重要,因為它是渲染階段不可或缺的一部分。避免在每次渲染期間過於複雜的深度比較。 ## 現在看起來怎麼樣? ### 道具已更改 它在 React 開發工具中的樣子:  他們真的嗎?它們是假的道具更改嗎?使用`useCallback`和`useMemo`。 ### 父渲染 它在 React 開發工具中的樣子:  使用“React.memo”來記住您的純元件。 ### 掛鉤已更改(狀態、上下文) 它在 React 開發工具中的樣子:  這裡沒有什麼太明顯的事情要做。嘗試驗證更改的鉤子是否有意義。也許一個糟糕的上下文提供者正在以與假道具更改可能出現的方式相同的方式偽造更改。 --- > 與此類似,我個人在 Slack 上經營著一個由開發人員主導的社群。我們在其中討論這些類型的實現、整合、一些真相炸彈、奇怪的聊天、虛擬會議以及一切有助於開發人員保持理智的事情;)畢竟,太多的知識也可能是危險的。 > 我邀請您加入我們的免費社區,參與討論,並分享您的驚人經驗和專業知識。您可以填寫此表格,Slack 邀請將在幾天後收到您的電子郵件。我們擁有來自一些偉大公司(Atlassian、Scaler、Cisco、IBM 等)的出色人員,您一定不想錯過與他們的互動。 [邀請表](https://forms.gle/VzA3ST8tCFrxt39U9) --- 您可能想要查看整合通知基礎架構的無縫方式。 https://github.com/suprsend/suprsend-go --- 原文出處:https://dev.to/nikl/react-is-slow-what-to-do-now-369g
Docker 是一個工具,允許開發人員將他們的應用程式及其所有依賴項打包到一個容器中。然後,這個容器就可以輕鬆地在任何安裝了 Docker 的機器上傳輸和執行,而不必擔心環境的差異。這就像是打包和執行軟體的標準化方式。 **容器是什麼?**  容器就像一個小包,其中包含程式執行所需的一切,可以輕鬆地在不同電腦上移動和執行,而不會造成任何麻煩。 最酷的部分是這個迷你電腦(容器)就像一個披著斗篷的超級英雄。它可以在任何電腦上執行,無論它們有多麼不同,因為它自帶特殊的環境。這是一種保持軟體井然有序的方式,並確保它無論在哪裡都能以相同的方式運作。 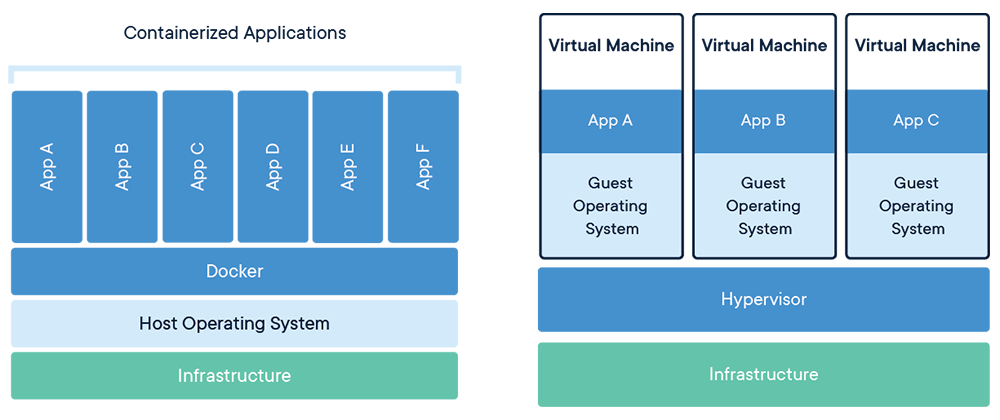 **為什麼我們需要 Docker?** 1. **一致性:** Docker 確保軟體在您的電腦、您朋友的電腦或任何電腦上以相同的方式運作。它使事情保持一致。 2. **可移植性:** 您可以將您的軟體及其朋友打包到 Docker 容器中,並且它可以移動到任何地方。這就像將您的遊戲及其所有規則放在手提箱中並在朋友家中玩。 3. **隔離:** Docker 容器就像小氣泡。氣泡內發生的事只會留在氣泡內。這意味著容器中的一個程式不會幹擾容器外的另一個程式。 4. **效率:** Docker有助於節省電腦資源。您可以讓許多容器在同一台電腦上執行,而不會相互妨礙,而不是讓一整台電腦只用於一個程式。 5. **速度:** Docker 讓啟動、停止和共享軟體變得快速、輕鬆。這就像打開和關閉遊戲機一樣 - 快速而簡單。 **什麼是 Docker 映像?** 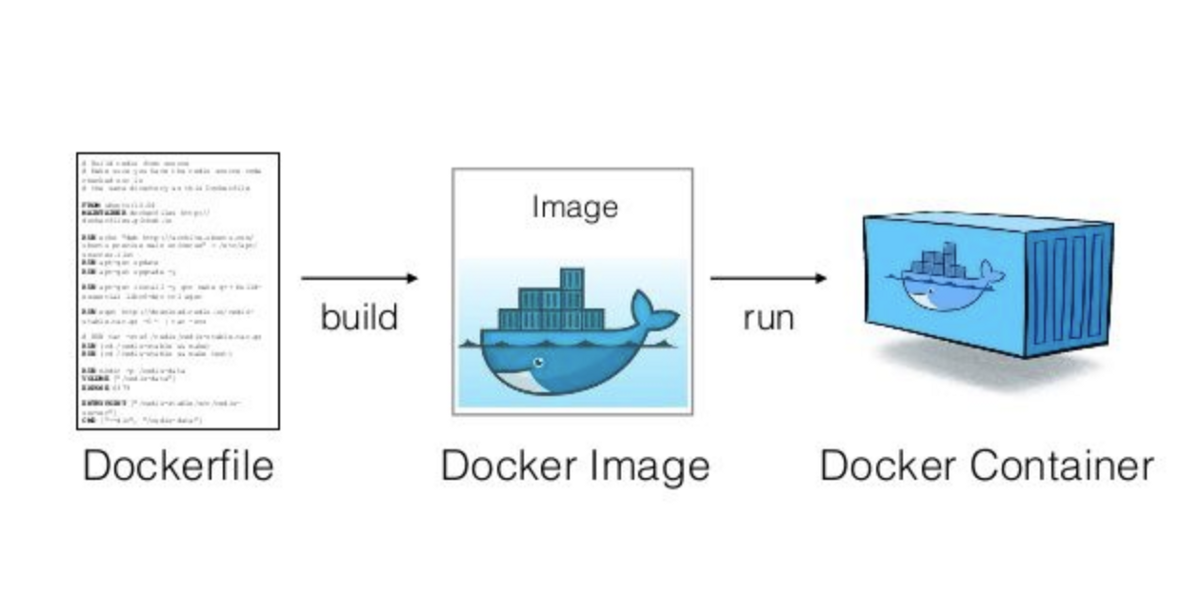 Docker 映像像是程式及其運作所需的所有內容的快照。它是一個打包版本,包括程式碼、工具和設置,就像包含所有成分的餅乾食譜的快照一樣。 **圖像是配方,容器是當您按照該配方實際製作和執行程序時所得到的。** **一些基本的 Docker 命令。**  1. **`docker執行nginx`** - 此命令告訴 Docker 使用「nginx」映像執行容器。這就像告訴 Docker 啟動一個預製程式的新實例(nginx,它是一個 Web 伺服器)。 2. **`docker ps`** - 顯示正在執行的容器的清單。這就像檢查當前正在執行哪些程式。 3. **`docker ps -a`** - 顯示所有容器的列表,包括已停止的容器。這就像檢查您執行過的所有程式的歷史記錄。 4. **`docker stopsilly_sammet'** - 停止名為「silly_sammet」的正在運作的容器。這就像關閉當前正在執行的程式。 5. **`docker rmsilly_sammet'** - 刪除名為「silly_sammet」的已停止容器。這就像丟掉你不再需要的程式的指令一樣。 6. **`docker 映像`** - 列出您擁有的所有 Docker 映像。這就像查看您可以執行的所有不同程式的選單一樣。 7. **`docker rmi nginx`** - 刪除“nginx”圖像。這就像刪除您不想再使用的程式的配方。 8. **`docker拉nginx`** - 從網路下載「nginx」映像。這就像從食譜中獲取新食譜一樣。 9. **`docker 執行 ubuntu sleep 5`** - 使用「ubuntu」映像檔執行容器並使其休眠 5 秒。這就像啟動一個程序,只是等待一小會兒,然後就停止了。 10. **`docker exectracted_mcclintock cat /etc/hosts`** - 在名為「distracted_mcclintock」的正在執行的容器內執行命令。這就像在食譜書中偷看特定頁面一樣。 11. **`docker run -d kodekloud/simple-webapp`** - 從「kodekloud/simple-webapp」鏡像以分離模式執行容器。這就像啟動一個程式並讓它在背景執行。 12. **`docker Attach a043d`** - 將您的終端附加到 ID 為「a043d」的正在執行的容器。這就像跳入正在執行的程式來查看發生了什麼。 **一些 Docker 概念:** 1. **使用標籤執行:** - 標籤就像程式的版本。它指定您要執行哪個版本。 - 範例程式碼:`docker run nginx:latest` - 這將執行最新版本的 Nginx 程式。 2. **使用標準輸入執行:** - STDIN 就像在鍵盤上打字一樣。有些程式需要您的輸入。 - 範例程式碼:`docker run -i -t ubuntu` - 這會在 Ubuntu 容器內執行互動終端,讓您可以鍵入命令。 3. **使用連接埠映射執行:** - 連接埠就像門。程式使用它們與外界進行通訊。 - 範例程式碼:`docker run -p 8080:80 nginx` - 這將執行 Nginx,並打開電腦連接埠 8080 上的門,將其連接到容器的連接埠 80。 4. **使用磁碟區映射執行:** - 磁碟區就像共用資料夾。它們讓您可以將東西存放在容器之外。 - 範例程式碼:`docker run -v /your/local/folder:/container/folder nginx` - 這將執行 Nginx 並將電腦上的資料夾連接到容器內的資料夾。 5. **檢查容器:** - 檢查就像仔細檢查正在執行的程式。 - 範例程式碼:`docker檢查container_name` - 這為您提供有關正在執行或已停止的容器的詳細資訊。 6. **容器日誌:** - 日誌就像日記。他們記錄程式正在做什麼。 - 範例程式碼:“docker 日誌容器名稱” - 這會向您顯示特定容器的日誌或活動。 ##環境變數 環境變數就像程式用來尋找重要資訊的便利筆記,有點像是程式可以理解和更好工作的秘密訊息! 1. **Python腳本(app.py)中的環境變數:** - 假設您有一個用 Python 寫的程式 (app.py)。您可能想要在不更改程式碼的情況下自訂它。您可以使用環境變數。 - 範例程式碼(app.py): ``` import os app_color = os.getenv("APP_COLOR", "default_color") print(f"The app color is {app_color}") ``` - 正常運作腳本:`python app.py` - 以特定顏色執行:`export APP_COLOR=blue; python 應用程式.py` 2. **在 Docker 中使用 ENV 變數:** - Docker 容器也可以使用環境變數。這就像是向容器內的程式發出指令。 - 範例程式碼: - `docker run -e APP_COLOR=green simple-webapp-color` - 這會執行 Docker 容器(`simple-webapp-color`)並將環境變數 `APP_COLOR` 設為「綠色」。 3. **檢查環境變數:** - 有時,您會想要檢查正在執行的容器正在使用哪些環境變數。 - 範例程式碼:`docker檢查blissful_hopper` - 此命令提供有關名為“blissful_hopper”的容器的詳細訊息,包括其環境變數。 簡單來說,環境變數就像程式(或 Docker 容器)可以讀取以了解如何行為的小註釋。您可以在執行程式之前設定這些註釋,程式將使用它們來自訂自身。第二個範例中的「export」指令就像在執行程式之前寫一條註釋,告訴它如何運作。 “docker Inspect”指令就像是在容器內部查看它有什麼註解。 ## Docker 映像 **Docker 檔案:** Dockerfile 就像是 Docker 建立映像的一組指令。這就像是烤蛋糕的食譜。 ``` # Use the Ubuntu base image FROM Ubuntu # Update apt repository RUN apt-get update # Install dependencies using apt RUN apt-get install -y python # Install Python dependencies using pip RUN pip install flask RUN pip install flask-mysql # Copy source code to /opt folder COPY . /opt/source-code # Set the working directory WORKDIR /opt/source-code # Specify entry point to run the web server ENTRYPOINT ["flask", "run"] ``` **建立自己的圖像的步驟:** 1. 使用上述內容建立一個名為「Dockerfile」的檔案。 2. 將其保存在與原始碼相同的目錄中。 **建置 Docker 映像:** 在終端機中執行以下命令: ``` docker build -t your-image-name . ``` 此命令告訴 Docker 使用目前目錄中的 Dockerfile (`.`) 建置映像,並使用您選擇的名稱對其進行標記 (`-t your-image-name`)。 **分層架構:** 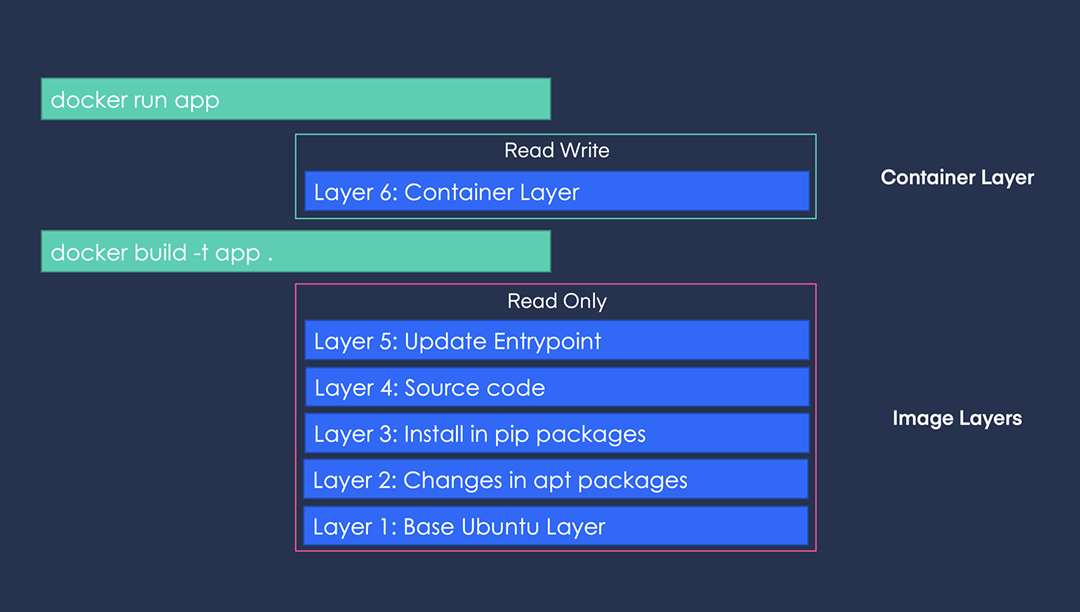 - 將 Docker 映像視為一個分層蛋糕。 Dockerfile 中的每個指令都會在映像上新增一層。 - 圖層可重複使用。如果您變更程式碼中的某些內容,Docker 只會重建受影響的層,從而提高效率。 **Docker 建置輸出:** - 當您建置映像檔時,Docker 會顯示流程中的每個步驟。如果發生故障,它會給您錯誤訊息。 **你可以容器化什麼?** - 幾乎所有東西!應用程式、服務、資料庫、網站,基本上任何軟體都可以容器化。 - 這就像將您的軟體放入一個盒子中,以便它可以在任何地方執行而不會造成麻煩。 ## 什麼是 Docker CMD 與 ENTRYPOINT **Docker 中的`CMD`:** - 將 CMD 視為啟動容器時程式執行的預設操作。 - 這就像說,“嘿,當你執行這個容器時,默認執行此操作。” - 範例:`CMD ["flask", "run"]` 表示當容器啟動時,它會自動執行 Flask Web 伺服器。 **CMD 範例:** ``` FROM alpine CMD ["sleep", "5"] ``` 在此範例中,當您使用此映像執行容器時,它會自動休眠 5 秒。 **Docker 中的`ENTRYPOINT`:** - 將 ENTRYPOINT 視為容器所做的主要事情。就好像boss的命令一樣。 - 它設定一個預設應用程式在容器啟動時執行,但您仍然可以根據需要覆蓋它。 - 範例:`ENTRYPOINT ["flask", "run"]` 表示容器主要用於執行 Flask Web 伺服器,但如果需要,您仍可新增更多指令。 **入口點範例:** ``` FROM alpine ENTRYPOINT ["sleep"] CMD ["5"] ``` 在這裡,主要目的是睡眠,如果您願意,您仍然可以覆蓋睡眠持續時間。 在這兩種情況下,容器在啟動時只會休眠幾秒鐘。主要區別在於如何提供參數以及它們是否可以輕鬆覆蓋。 CMD 就像在說,“這是默認要做的事情”,而 ENTRYPOINT 就像在說,“這是主要要做的事情,但如果你願意,你可以稍微調整一下。”它們都有助於定義容器啟動時執行的操作。 ## Docker 中的網路: Docker 網路幫助容器(程式)相互通信,確保它們可以順利地協同工作。 **預設網路:** - Docker 建立預設網路供容器通訊。 - 範例程式碼:`docker run ubuntu --network=host` - 這使用主機網路執行 Ubuntu 容器,這意味著它與主機共享網路命名空間。 **使用者定義的網路:** - 您可以建立自己的網路以更好地組織和控制。 - 範例程式碼: ``` docker network create --driver=bridge --subnet=182.18.0.0/16 custom-isolated-network ``` - 這將建立一個名為「custom-isolated-network」的使用者定義的橋接網絡,具有特定的子網。 **上市網路:** - 您可以查看您擁有的所有網路。 - 範例程式碼:`docker network ls` **檢查網路:** - 您可以檢查特定網路的詳細資訊。 - 範例程式碼:`docker網路檢查blissful_hopper` - 這顯示有關名為「blissful_hopper」的網路的詳細資訊。 **嵌入式 DNS:** - Docker 有一個內建的 DNS 系統,供容器透過名稱相互查找。 - 範例程式碼:`mysql.connect(mysql)` - 這可能是程式碼中的一行,其中名為「mysql」的服務使用 Docker 的 DNS 連接到另一個名為「mysql」的服務。 ## Docker 儲存:  Docker 儲存就像使用容器時決定將資料保存在哪裡一樣。您可以將它們保留在容器內,使用磁碟區在容器之間共用它們,或將它們儲存在容器外部以妥善保管。 **Docker中的檔案系統:** - Docker 使用分層架構來建立映像。 Dockerfile 中的每個指令都會在檔案系統中新增一個新圖層。 ``` # Dockerfile FROM Ubuntu RUN apt-get update && apt-get install -y python RUN pip install flask flask-mysql COPY . /opt/source-code WORKDIR /opt/source-code ENTRYPOINT ["flask", "run"] ``` - Dockerfile 中的層: - 第 1 層:Ubuntu 基礎層 - 第 2 層:apt 軟體包的更改 - 第 3 層:pip 套件的變化 - 第 4 層:原始碼 - 第 5 層:使用「flask」指令更新入口點 - 第 6 層:容器層 **影像圖層:** - 當您建立 Docker 映像時,它由唯讀層組成。每一層代表影像的變化或加入。 - 第 1 層:Ubuntu 基礎層 - 第 2 層:apt 軟體包的更改 - 第 3 層:pip 套件的變化 - 第 4 層:原始碼 - 第 5 層:使用「flask」指令更新入口點 ``` # Build the Docker image docker build -t mmumshad/my-custom-app . ``` **容器層:** - 當您執行 Docker 容器時,會在唯讀映像層上方新增一個讀寫層。該層特定於正在執行的容器。 - 第 6 層. 容器層 ``` # Run the Docker container docker run mmumshad/my-custom-app ``` **數量:** - 卷是一種在容器外部保存資料的方法。它們就像外部記憶體。 ``` # Create a Docker volume docker volume create data_volume # Use the volume in a container docker run -v data_volume:/var/mysql mysql ``` - 您也可以使用「-v」將特定目錄從主機掛載到容器: ``` # Mount a host directory to a container directory docker run -v /path/on/host:/var/mysql/mysql -d mysql ``` - docker run --mount 指令用於將主機上的特定目錄或檔案掛載到正在執行的 Docker 容器中。 ``` docker run --mount type=bind,source=/mysql,target=/var/mysql mysql ``` **儲存驅動程式:** - Docker 使用儲存驅動程式來管理資料的儲存和存取方式。一些常見的儲存驅動程式包括 AUFS、ZFS、BTRFS、Device Mapper、Overlay 和 Overlay2。 [在 Docker 管理資料](https://docs.docker.com/storage/) [關於儲存驅動程式](https://docs.docker.com/storage/storagedriver/) [卷](https://docs.docker.com/storage/volumes/) ## Docker 組合  Docker Compose 是一個方便的工具,可幫助您輕鬆執行和連接不同的軟體服務,就好像它們都是同一事件的一部分一樣。 **Docker Compose 基礎:** 1. **執行單一容器:** - 通常,您可以像這樣執行單獨的 Docker 容器: ``` docker run mmumshad/simple-webapp docker run mongodb docker run redis:alpine docker run ansible ``` 2. **Docker 撰寫文件(`docker-compose.yml`):** - Docker Compose 允許您在一個簡單的檔案中定義所有這些服務: ``` # docker-compose.yml version: '3' services: web: image: 'mmumshad/simple-webapp' database: image: 'mongodb' messaging: image: 'redis:alpine' orchestration: image: 'ansible' ``` - 此檔案描述您要執行的服務(「web」、「database」、「messaging」、「orchestration」)、它們各自的映像以及任何其他配置。 3. **使用 Docker Compose 執行:** - 要一起啟動所有這些服務: ``` docker-compose up ``` - Docker Compose 負責啟動「docker-compose.yml」檔案中定義的所有容器。 4. **使用 Docker Compose 建置:** - 您也可以使用 Docker Compose 建置映像: ``` docker-compose build ``` - 此指令建置「docker-compose.yml」檔案中指定的映像。 **執行連結容器:** - 如果您要透過連結執行單一容器: ``` docker run -d --name redis redis docker run --name voting-app -p 5000:80 --link redis:redis voting-app docker run --name result-app -p 5001:80 --link db:db result-app docker run -d --name worker --link db:db --link redis:redis worker ``` - 在 Docker 中撰寫: ``` # docker-compose.yml version: '3' services: vote: image: 'voting-app' ports: - '5000:80' links: - 'redis:redis' result: image: 'result-app' ports: - '5001:80' links: - 'db:db' worker: image: 'worker' links: - 'db:db' - 'redis:redis' db: image: 'db' redis: image: 'redis' ``` Docker Compose 可讓您在單一檔案中描述整個應用程式堆疊,從而輕鬆管理、執行和連接不同的服務。這就像在一份計劃中寫下活動的所有任務,然後 Docker Compose 為您處理設定。 [Docker Compose 概述](https://docs.docker.com/compose/) [Docker 撰寫文件](https://docs.docker.com/engine/reference/commandline/compose/) ## Docker 註冊表 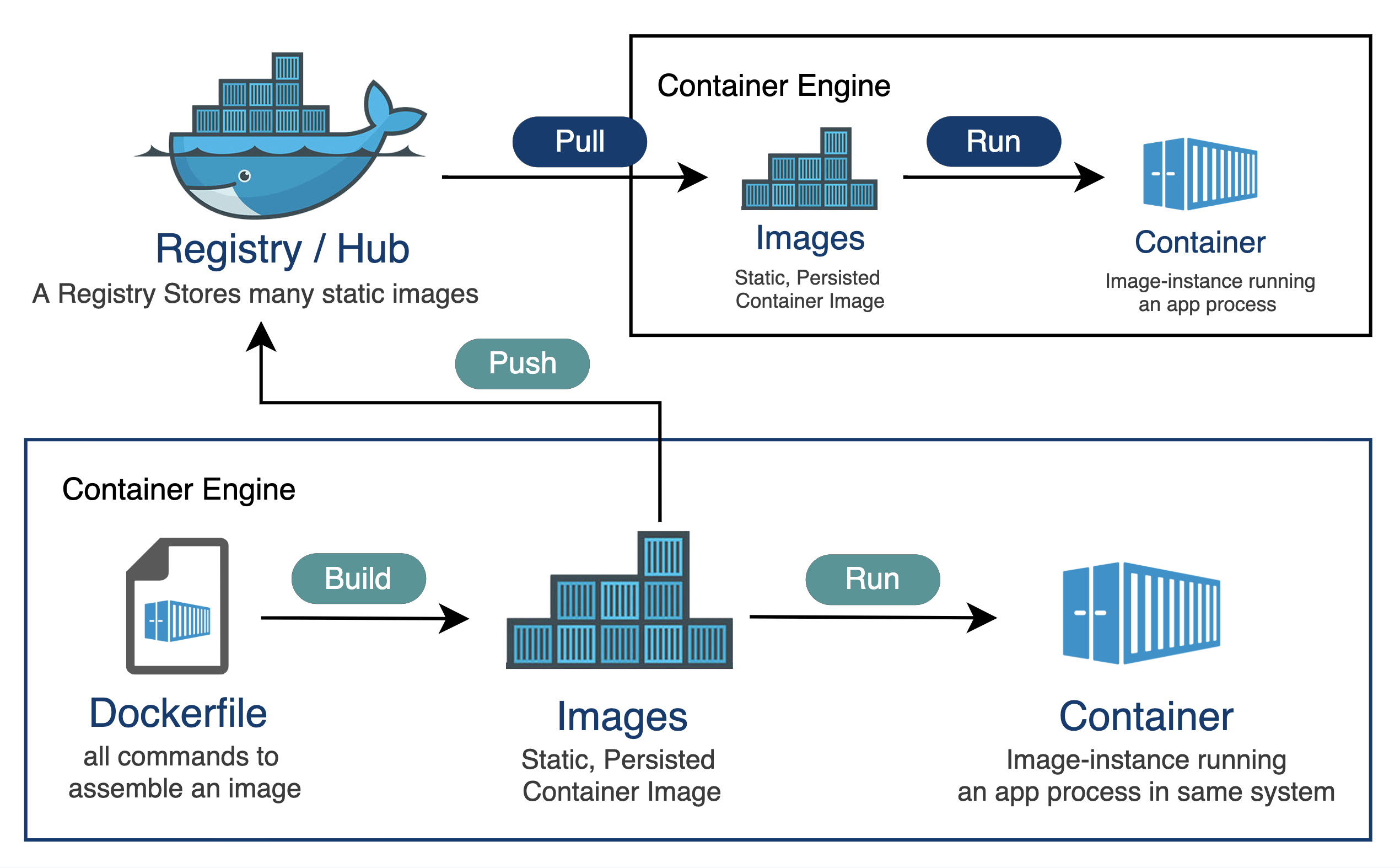 Docker 註冊表是人們儲存和分享 Docker 映像的地方,使其他人可以輕鬆使用和執行他們的軟體。它就像一個大型線上程式庫,可以輕鬆下載並在不同電腦上使用。 **Docker 註冊表基礎知識:** 1. **公共登記處:** - Docker 映像可以在 Docker Hub 等公共註冊表中儲存和共用。 - 例: ``` docker pull nginx ``` 2. **私人登記處:** - 有時,您可能希望將圖像保存在您自己的私人註冊表中。 - 例: - 登入私人註冊表: ``` bash docker login private-registry.io ``` - 從私有註冊表中的映像執行容器: ``` docker run private-registry.io/apps/internal-app ``` 3. **部署您自己的私有註冊表:** - 您可以為您的團隊或公司部署自己的私人註冊表。 - 例: - 在您的電腦上執行私有註冊表: ``` docker run -d -p 5000:5000 --name registry registry:2 ``` - 為私人註冊表標記您的圖像: ``` bash docker image tag my-image localhost:5000/my-image ``` - 將映像推送到您的私人註冊表: ``` bash docker push localhost:5000/my-image ``` - 從您的私人註冊表中提取映像: ``` bash docker pull localhost:5000/my-image ``` 4. **從遠端私有註冊表中提取:** - 您也可以使用 IP 位址或網域從遠端私有註冊表中提取映像。 - 例: ``` docker pull 192.168.56.100:5000/my-image ``` Docker 註冊表就像一個儲存空間,人們在其中保存和共享 Docker 映像。您可以將公用註冊表用於廣泛使用的映像,也可以根據您的特定需求設定自己的私人註冊表。它就像一個用於共享和儲存軟體藍圖(圖像)的特殊庫。 ## Docker 引擎 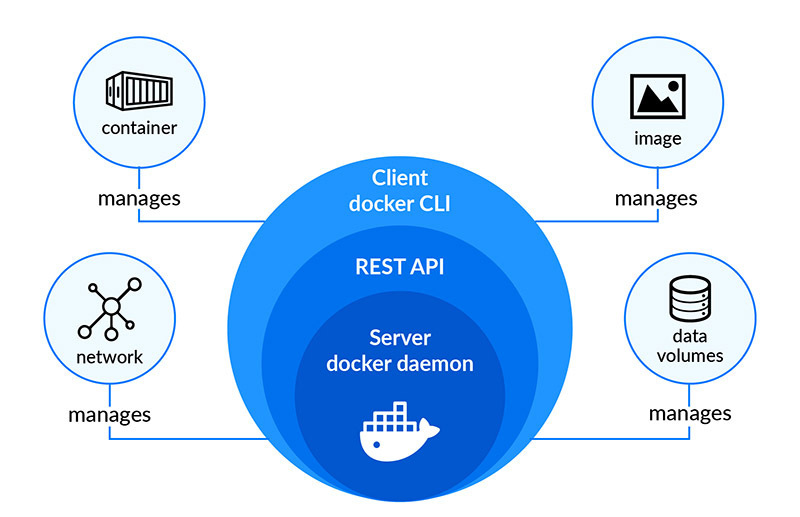 想像一下,你有一個魔盒(Docker Engine),可以為你執行和管理各種程式(容器)。 Docker Engine 就像是這個魔盒的大腦。 1. **Docker 守護程式:** - 守護程式就像魔法盒的看門人。它始終在那裡,隨時準備接受指示並確保一切順利進行。 2. **REST API:** - 將 REST API 視為一組允許您與魔盒對話的規則。它就像你和守護程式用來溝通的語言。你告訴守護程式要做什麼,它會理解,因為你們說的是同一種語言。 3. **Docker CLI(命令列介面):** - Docker CLI 就像是用來命令守護程式的魔杖。您輸入指令,守護程式就會按照您的指示進行操作。這就像說「Abracadabra」就能讓事情發生。 **連線到遠端 Docker 引擎:** 連接到遠端 Docker 引擎可讓您控制另一台機器上的容器,且設定約束可確保容器僅使用指定的資源。 1. **Docker主機IP:** - 您可以使用 IP 位址和連接埠連接到不同電腦上的 Docker 引擎。 - 例: ``` docker -H=remote-docker-engine:2375 run nginx ``` - 這告訴您的本機 Docker CLI 與遠端 Docker 引擎進行通訊。 2. **有約束地執行容器:** - Docker 允許您設定容器的資源限制,例如 CPU 和記憶體限制。 - 例: ``` docker run --cpus=0.5 ubuntu docker run --memory=100m ubuntu ``` - 這些指令限制容器僅使用半個 CPU 核心和 100 MB 記憶體。 當然,讓我們簡化一下PID命名空間的概念: **命名空間PID:** PID 命名空間可讓您為容器中的進程(如程式或任務)建立單獨的區域,因此它們有自己的一組「票號」(進程 ID),不會與容器外的進程發生衝突。 **範例程式碼:** 1. **使用主機 PID 命名空間執行容器:** - 這表示容器與主機共用相同的「票號」。 ``` docker run --pid=host ubuntu ``` 2. **執行具有隔離 PID 命名空間的容器:** - 這表示容器有自己的一組獨立於主機的「票號」。 ``` docker run --pid=container ubuntu ``` 在第一個範例中,容器與進程交互,就好像它與主機位於同一空間中一樣。在第二個範例中,容器有自己的進程隔離空間。這就像在大型活動中擁有一個私人區域,您的團隊有自己的一套票號,讓您可以獨立於活動的其餘部分進行操作。 **容器化概念:** 1. **進程 ID 命名空間:** - 容器有自己獨立的流程 ID (PID) 空間,因此容器內的流程與容器外的流程是分開的。 - 例: ``` docker run --pid=host ubuntu ``` - 此指令使用主機的 PID 命名空間來執行容器,因此它共用相同的程序。 2. **網路命名空間:** - 容器也有自己獨立的網路命名空間,這意味著它們可以有自己的網路配置。 - 例: ``` docker run --net=host nginx ``` - 此指令使用主機的網路命名空間來執行容器。 3. **Unix分時命名空間:** - 此命名空間允許容器擁有自己的時間視圖,與主機和其他容器分開。 - 例: ``` docker run --uts=host ubuntu ``` - 此指令使用主機的 Unix 時間共用命名空間來執行容器。 4. **進程間掛載命名空間:** - Mount命名空間隔離檔案系統,讓容器擁有自己的檔案系統視圖。 - 例: ``` docker run --mount=type=bind,source=/host/folder,target=/container/folder ubuntu ``` - 此指令將主機中的資料夾安裝到容器中。 當然!我們來簡化一下cgroup的概念: **C組:** cgroup(控制組的縮寫)可協助在不同進程或容器之間管理和分配系統資源,例如 CPU 和記憶體。它們確保沒有任何一個進程或容器耗盡所有可用資源,從而保持一切平衡。 **範例程式碼:** 1. **使用 Cgroup 設定 CPU 限制:** - 這就像說聚會上的每位客人只能吃一定數量的食物。 ``` docker run --cpus=0.5 ubuntu ``` - 這限制容器僅使用一半的 CPU 核心。 2. **使用 Cgroup 設定記憶體限制:** - 這就像說每位客人只能在舞池上佔據一定的空間。 ``` docker run --memory=100m ubuntu ``` - 這限制容器僅使用 100 MB 記憶體。 [Docker 引擎概述](https://docs.docker.com/engine/) [使用 Docker Engine API 進行開發](https://docs.docker.com/engine/api/) [執行時指標](https://docs.docker.com/config/containers/runmetrics/#control-groups) ## Linux容器與Windows容器的概念: **Linux 容器(預設):** Linux 容器是一種打包和執行軟體及其所需一切的方法,它們最適合執行 Linux 的電腦。 **Windows 容器:** Windows 容器是一種打包和執行軟體的方式,就像 Linux 容器一樣,但它們設計用於執行 Windows 的電腦。 **Windows 容器基礎:** 1. **集裝箱類型:** - Windows 容器有兩種主要類型:Windows Server Core 和 Nano Server。 - **Windows Server Core:** 將其視為功能更齊全的容器,適合各種應用程式。 - **Nano Server:** 將其視為一個輕量級容器,專為特定的、簡約的用例而設計。 2. **基礎鏡像:** - 基礎映像就像是建立容器時開始使用的空白畫布。 - 例: ``` docker pull mcr.microsoft.com/windows/servercore:ltsc2019 ``` - 此指令擷取 Windows Server Core 基礎映像。 - 例: ``` docker pull mcr.microsoft.com/windows/nanoserver:ltsc2019 ``` - 此命令提取 Nano Server 基礎映像。 3. **支援的環境:** - Windows 容器可以在特定版本的 Windows 作業系統上運作。 - 例: - 您可以在 Windows Server 2016 上執行 Windows 容器。 - 例: - 您可以在 Windows 10 專業版和企業版上執行 Windows 容器,並使用 Hyper-V 隔離容器進行額外隔離。 ## 容器編排  容器編排是一種管理和協調多個容器的方法,確保它們無縫協作來執行應用程式,就像一個超級智能的管理器確保所有機器人一起工作來建置完美的塔一樣。 **為什麼要編曲?** 1. **多項任務,一名經理:** - 想像一下您有許多機器人(容器)執行不同的工作。編排就像有一位超級聰明的經理(編排者),他告訴每個機器人該做什麼,並確保一切順利進行。 2. **一致性:** - 編排確保所有任務每次都以相同的方式完成。這就像為您的機器人提供了一套要遵循的指令,以確保其行為的一致性。 3. **效率:** - 編排有助於優化任務,確保資源(如時間和材料)有效利用。這就像經理確保所有機器人一起工作而不浪費能源。 4. **縮放比例:** - 當您需要完成更多工作時,編排可以輕鬆建立額外的機器人(容器)。這就像當有很多事情需要完成時神奇地召喚更多機器人來提供幫助。 5. **可靠性:** - 編排確保任務可靠地完成,即使機器人(容器)出現故障。這就像製定備份計劃來確保無論如何都能完成工作。 6. **協調:** - 編排協調任務,確保機器人無縫協作。這就像經理確保每個機器人都知道自己的角色並協作以實現總體目標。 **容器編排程式碼:** ``` # Create a Docker service with 100 replicas (instances) of a Node.js application docker service create --replicas 100 --name my-nodejs-app nodejs ``` 在這個例子中: - `docker service create`:該指令告訴 Docker 建立一個服務,該服務是一組正在執行的容器。 - `--replicas 100`:此標誌指定您需要 100 個服務實例(副本)。 - `--name my-nodejs-app`:此標誌為您的服務提供名稱,在本例中為「my-nodejs-app」。 - `nodejs`:這是 Node.js 應用程式的圖片或配方。這就像是烘焙紙杯蛋糕的藍圖。 因此,這段簡單的程式碼就像告訴您神奇的廚師助手 (Docker Swarm) 建立 Node.js 應用程式的 100 個副本,確保您有大量容器正在執行並準備好提供服務。 ## Docker 群  Docker Swarm 是一個工具,可以幫助協調和管理一組電腦(節點)作為一個機器人團隊一起工作,使它們能夠以協調的方式部署和執行多個容器。這就像有一個首席機器人經理,確保所有單一機器人一起建造出偉大而令人驚嘆的東西。 **設定 Docker Swarm:** 1. **群組管理器:** - 想像你有一個首席機器人(Swarm Manager)來領導團隊。主機器人決定需要做什麼,並指導其他機器人(節點)如何協同工作。 ``` # Initiate Docker Swarm on the Swarm Manager docker swarm init ``` 2. **節點工作人員:** - 現在,您的工作機器人(節點工作人員)已準備好加入團隊。 Swarm Manager 共享一個特殊的程式碼(令牌)來邀請他們一起工作。 ``` # Join a Node Worker to the Docker Swarm docker swarm join --token <token> <Swarm Manager IP> ``` **Docker Swarm 服務:** 現在您已經有了一個協調的團隊,您想要建立一項服務,例如與您的機器人團隊一起建造塔: ``` # Create a Docker service (a group of containers) with 3 replicas (instances) docker service create --replicas 3 --network frontend --name my-web-server my-web-image ``` - `--replicas 3`:此標誌告訴 Docker 建立服務的三個實例(副本)。 - `--network frontend`:此標誌指定您的服務屬於名為「frontend」的網路。 - `--name my-web-server`:這會為您的服務命名,在本例中為「my-web-server」。 - `my-web-image`:這是您的網頁伺服器的圖片或藍圖。這就像建造塔樓的配方。 您建立了一個由隊長(Swarm Manager)和工作機器人(Node Workers)組成的機器人團隊。然後,您指示他們建立一個執行您的 Web 伺服器應用程式的服務(容器群組)。主機器人確保建立 Web 伺服器的三個副本並將其連接到「前端」網路。這就像有一個首席機器人經理在工作機器人的幫助下監督多個塔(貨櫃)的建造。  **好的,這就是本文的內容。** 另外,如果您對此或其他任何問題有任何疑問,請隨時在下面的評論中或在 [Instagram](https://www.instagram.com/_abhixsh/) 、[Facebook](https://www.facebook.com/abhi.haththakage/) 或[Twitter](https://twitter.com/abhixsh)。 感謝您閱讀這篇文章,我們下一篇再見! ❤️ --- 原文出處:https://dev.to/abhixsh/docker-for-the-absolute-beginner-3h1p
Kubernetes 已成為管理容器化應用程式的首選平台,提供可擴展性、靈活性和穩健性。然而,Kubernetes 的複雜性可能令人望而生畏,需要開發人員和 DevOps 團隊瀏覽複雜的設定檔和命令列互動。 一些強大的開發工具已經出現,以簡化 Kubernetes 叢集的管理並簡化部署流程。在本文中,我們將探討五種 Kubernetes 開發工具: - [**普羅米修斯**](https://prometheus.io/) - [**獨眼巨人**](https://cyclops-ui.com/) - [**科達**](https://keda.sh/) - [**卡本特**](https://karpenter.sh/) - [**帆船**](https://velero.io/) 這些工具提供直覺的使用者介面、自動擴展功能、災難復原解決方案並提高管理 Kubernetes 叢集的效率。 ### 向我們展示您的支持🙏🏻 在我們開始之前,如果您為我們的儲存庫加註星標並幫助我們在其他開發人員面前獲得我們的工具,我們將非常高興。我們的 GitHub 儲存庫在這裡:https://github.com/cyclops-ui/cyclops ⭐ ## 1. Prometheus:Kubernetes 監控與警報  **Prometheus** 是一款專為微服務和容器設計的開源監控和警報工具包。它提供靈活的查詢、即時通知以及對容器化工作負載、API 和分散式服務的可見性。 Prometheus 的功能之一是它能夠透過偵測可能升級為攻擊的不規則流量或活動來協助雲端原生安全。 它使用基於拉取的系統,發送稱為“scrapes”的 HTTP 請求,從應用程式和服務收集指標。這些指標儲存在記憶體和本機磁碟中,可以輕鬆檢索和分析。 Prometheus 可以直接從客戶端庫或透過匯出器(位於應用程式附近的軟體)存取資料。匯出器接受來自 Prometheus 的 HTTP 請求,確保資料格式相容性,並將請求的資料提供給 Prometheus 伺服器。 Prometheus 提供了四種主要類型的指標:計數器、儀表、直方圖和摘要。這些指標可以靈活地測量應用程式和服務的各個方面,例如事件啟動計數、記憶體使用情況、資料聚合和分位數範圍。 為了發現監控目標,Prometheus 利用 Kubernetes 叢集中的服務發現。它可以獨立於應用程式資訊存取機器級指標,從而實現全面監控。 資料收集完成後,Prometheus 提供了一種名為 PromQL 的查詢語言,使用戶能夠存取監控資料並將其匯出到 Grafana 等圖形介面,或使用 Alertmanager 發送警報。 ## 2. Cyclops:只需點擊幾下即可部署應用程式  **Cyclops** 是一個簡化 Kubernetes 叢集中執行的應用程式管理的工具。它將複雜的設定檔抽象化為基於表單的 UI,從而無需手動配置和命令列互動。這使得具有不同技術專業知識水平的個人更容易存取部署過程。 有了 Cyclops,您就不再局限於一刀切的方法。您可以自訂模組以滿足您的獨特需求,讓您可以自由建立具有輸入驗證的模板,以便與您的團隊無縫協作。 這不僅加快了您的工作速度,還使每個團隊成員能夠獨立工作,從而促進更順暢、更有效率的工作流程。 在 Cyclops 中,每個模組都列出了它使用的資源的詳細清單——部署、服務、pod 等,所有這些都在簡單的視圖中。您可以輕鬆追蹤它們的狀態,幫助您快速發現並修復應用程式中的任何問題。這就像有一個清晰的路線圖來導航和解決出現的任何問題。 在 Cyclops 的架構中,核心元件是 [Helm](https://helm.sh/) 引擎,它允許動態產生配置。該引擎是有效管理 Cyclops 框架中的設定和參數的關鍵機制。 由於基於 Kubernetes 的系統通常使用 Helm 作為套件管理器,因此無縫整合 Cyclops 是一個簡單的流程。 Cyclops 促進部署實踐的一致性和標準化。透過提供預先定義的範本或設定預設,Cyclops 可確保部署遵循既定的最佳實務和指南。這種一致性不僅提高了部署的可靠性和穩定性,而且還促進了協作。 ## 3. Keda:Kubernetes 工作負載的事件驅動自動縮放  Kubernetes Horizontal Pod Autoscaling (HPA) 和 Vertical Pod Autoscaling (VPA) 廣泛用於根據 CPU 和記憶體使用量自動縮放 Kubernetes 叢集。 然而,它們也有局限性,例如無法將 Pod 擴展到零或基於資源利用率以外的指標進行擴展。這就是 **Keda**(Kubernetes 事件驅動的自動縮放)發揮作用的地方。 Keda 是一個開源容器自動縮放器,它透過根據外部事件或觸發器縮放 Pod 來擴展本機 Kubernetes 自動縮放解決方案的功能。 Keda 監控 AWS SQS、Kafka 和 RabbitMQ 等事件來源,根據預定義規則有效觸發或停止部署。這種適應性強的解決方案還允許自訂指標,促進為訊息驅動的微服務量身定制的有效自動擴展,確保最佳效能和資源利用率。 Keda 的元件包括事件來源、縮放器、指標適配器和控制器。事件來源提供觸發擴展的外部事件,而擴展器則監視這些事件並取得指標。指標適配器轉換控制器的指標,然後相應地擴展部署。 透過利用 Keda,DevOps 團隊可以在沒有事件需要處理時縮小規模,從而釋放資源並降低雲端成本。 Keda 還提供與各種 DevOps 工具鏈的互通性,支援內建和外部縮放器。 借助 Keda,自動擴展變得更加靈活和高效,使團隊能夠優化資源利用率並適應不斷變化的工作負載需求。 ## 4. Karpenter:Kubernetes 的自動化節點配置  Kubernetes 叢集經常面臨在可用節點上調度 Pod 的挑戰。 **Karpenter** 是一個開源叢集自動縮放器,可自動配置新節點以回應不可調度的 Pod。它評估待處理 Pod 的聚合資源需求,並選擇最佳實例類型來滿足它們。 Karpenter 還支援整合功能,主動移動 Pod 並以更便宜的版本取代節點,以降低叢集成本。 一個突出的功能是引入“節點池”,允許用戶根據各種標準對節點進行分類。這種客製化確保了客製化的資源分配方法,卡彭特動態地將節點配置到最合適的池中。 Karpenter 的核心旨在無縫地自動擴展 Kubernetes 叢集。 Karpenter 利用 Kubernetes 中的自訂資源定義 (CRD),與現有工具和 API 無縫集成,為使用者提供熟悉的體驗。 Karpenter 的靈活性超出了 AWS 的範圍,使其成為適用於雲端和本地環境的多功能解決方案。 Karpenter 的適應性體現在它透過 Kubernetes 資源支援使用者定義的策略和策略。這種靈活性使組織能夠使 Karpenter 與其獨特的應用程式和工作負載需求保持一致,從而實現更好的自動化和最佳化的 Kubernetes 可擴展性。 ## 5. Velero:Kubernetes 的災難復原與備份  **Velero** 是一款功能強大的工具,可為 Kubernetes 叢集提供災難復原和備份解決方案。它使用戶能夠輕鬆備份、還原和遷移應用程式及其持久性磁碟區。 Velero 拍攝叢集資源和資料的快照,並將它們儲存在 AWS S3、Google Cloud Storage 或 Azure Blob Storage 等物件儲存提供者中。 借助 Velero,使用者可以建立備份計劃,確保關鍵叢集資源的定期快照。這樣可以在資料遺失或叢集故障時實現高效的災難復原。 Velero 也支援叢集遷移,簡化了在 Kubernetes 叢集之間行動應用程式和資料的過程。 該工具提供資源過濾功能,允許使用者選擇性地備份和還原特定資源。 這種靈活性可確保備份中僅包含相關資料,從而節省儲存空間並減少備份和還原時間。 Velero 與 CSI(容器儲存介面)集成,提供備份磁碟區並將其恢復到原始狀態的支援。 除了災難復原和備份之外,Velero 還提供在任何命名空間中執行、使用掛鉤擴充功能以及支援自訂外掛程式以增強自訂等功能。它提供了診斷和解決常見問題的故障排除指南,確保管理 Kubernetes 叢集的流暢體驗。 ## 結論 這五種 Kubernetes 開發工具 - Prometheus、Cyclops、Keda、Karpenter 和 Velero - 在簡化 Kubernetes 叢集管理的複雜性方面發揮關鍵作用。 從使用Prometheus 進行監控和警報,到使用Keda 進行事件驅動的自動縮放,再到透過Karpenter 進行自動化節點配置,每個工具都可以解決特定的挑戰,從而有助於打造更有效率、更有彈性的Kubernetes環境。 Cyclops 因其用戶友好的方法而脫穎而出,將複雜的配置抽象化為直覺的 UI,而 Velero 則提供重要的災難復原和備份解決方案來保護關鍵資料和應用程式。 由於 Kubernetes 仍然是現代應用程式部署的基石,這些工具使開發人員和 DevOps 團隊能夠更輕鬆地駕馭複雜的容器化環境。 透過將這些工具整合到 Kubernetes 工作流程中,您可以增強可擴展性、簡化部署流程,並確保應用程式在當今動態且要求嚴苛的運算環境中的穩健性。 --- 原文出處:https://dev.to/cyclops-ui/five-tools-to-add-to-your-k8s-cluster-2j89
## **簡介** 在本教程中,您將學習如何使用**現代工具**和**最佳實踐**來監控您的Javascript應用程式。 探索分散式追蹤的力量,並了解如何無縫整合和利用 Odigos 和 Jaeger 等工具來增強您的監控能力。 **您將學到什麼:✨** - 如何在 Javascript 中建立微服務🐜。 - 為微服務設定 Docker 容器📦。 - 配置 Kubernetes ☸️ 以管理微服務。 - 整合追蹤後端以可視化追蹤🔍。 您準備好成為監控 JS 應用程式的**專家**了嗎? 😍 說**是的,先生!**。 我聽不到你說話。大聲點說。 🙉  *** ## **讓我們設定一下 🦄** > 🚨 在部落格的這一部分中,我們將建立一個虛擬的 JavaScript 微服務應用程式並將其部署在本地 Kubernetes 上。如果您已經有一個並且正在跟進,請隨意跳過這一部分。 為您的應用程式建立初始資料夾結構,如下所示。 👇🏻 ``` mkdir microservices-demo cd microservices-demo mkdir src cd src ``` ### **設定伺服器** 🖥️ > 👀 出於演示目的,我將建立兩個相互通信的微服務,最終我們可以使用它來視覺化分散式追蹤。 - **建置與 Dockerize 微服務 1** 在「/src」資料夾中,建立一個新資料夾「/microservice-1」。在資料夾內初始化 **NodeJS** 專案並安裝所需的依賴項。 ``` mkdir microservice-1 cd microservice-1 npm init -y npm install --save express node-fetch ``` 建立一個新檔案“index.js”並新增以下程式碼: ``` // 👇🏻/src/microservice-1/index.js const express = require("express"); const fetch = require("node-fetch") const app = express(); const PORT = 3001; app.use(express.json()); app.get("/", async (req, res) => { try { const response = await fetch("http://microservice2:8081/api/data"); const data = await response.json(); res.json({ data: "Microservice 2 data received in Microservice 1", microservice2Data: data, }); } catch (error) { console.error(error.message); res.status(500).json({ error: "Internal Server Error" }); } }); app.listen(PORT, () => { console.log(`Microservice 1 listening on port ${PORT}`); }); ``` 伺服器正在偵聽連接埠“3001”,並且在對“/”發出請求時,我們從“microservice2”請求資料並將回應作為 JSON 物件返回。 📦 現在,是時候對這個微服務進行 docker 化了。在“/microservice-1”資料夾中建立一個新的“Dockerfile”並新增以下程式碼: ``` // 👇🏻/src/microservice-1/Dockerfile FROM node:18 # Use /usr/src/app as the working directory WORKDIR /usr/src/app # Copy package files and install production dependencies COPY --chown=node:node package*.json /usr/src/app RUN npm install --production # Copy the rest of the files COPY --chown=node:node . /usr/src/app/ # Switch to the user node with limited permissions USER node # Expose the application port EXPOSE 3001 # Set the default command to run the application CMD ["node", "index.js"] ``` 將我們不想推送到容器的文件加入到“.dockerignore”總是很好。使用我們不想推送的檔案的名稱來建立一個“.dockerignore”檔案。 ``` // 👇🏻/src/microservice-1/.dockerignore node_modules Dockerfile ``` 最後,透過執行以下命令來建構 🏗️ docker 映像: ``` docker build -t microservice1-image:latest . ``` 現在,這就是我們第一個微服務的完整設定。 ✨ - **建置與 Dockerize 微服務 2** 我們將有一個類似於“microservice1”的設置,只是在這裡和那裡進行了一些更改。 在「/src」資料夾中,建立一個新資料夾「/microservice-2」。在該資料夾內,初始化 **NodeJS** 專案並安裝所需的依賴項。 ``` mkdir microservice-2 cd microservice-2 npm init -y npm install --save express node-fetch ``` 建立一個新檔案“index.js”並新增以下程式碼: ``` // 👇🏻/src/microservice-2/index.js const express = require("express"); const fetch = require("node-fetch") const app = express(); const PORT = 3002; app.use(express.json()); app.get("/api/data", async (req, res) => { const url = "https://jsonplaceholder.typicode.com/users"; try { const response = await fetch(url); const data = await response.json(); res.json(data); } catch (error) { console.error(error.message); res.status(500).json({ error: "Internal Server Error" }); } }); app.listen(PORT, () => { console.log(`Microservice 2 listening on port ${PORT}`); }); ``` 伺服器正在偵聽連接埠 3002,根據對“/api/data”的“GET 請求”,我們從“jsonplaceholder”獲取資料並將回應作為 JSON 物件傳回。 📦 現在,是時候對這個微服務進行 docker 化了。複製並貼上「microservice1」的整個「Dockerfile」內容,然後將連接埠從 3001 變更為 3002。 另外,新增一個「.dockerignore」檔案並包含我們在建立「microservice1」時新增的相同檔案。 最後,透過執行以下命令來建構 🏗️ Docker 映像: ``` docker build -t microservice2-image:latest . ``` 現在,這也是我們第二個微服務的完整設定。 ✨ - **設定 Kubernetes** > 確保已安裝 **[Minikube](https://github.com/kubernetes/minikube)** 透過執行以下命令建立新的本機 Kubernetes 叢集。我們在設定 Odigos 和 Jaeger 時將需要它。 **啟動 Minikube:🚀** ``` minikube start ``` 現在我們已經準備好並 Docker 化了兩個微服務,是時候設定 Kubernetes 來管理這些服務了。 在專案的根目錄下,建立一個新資料夾「/k8s/manifests」。在此資料夾中,我們將為兩個微服務新增部署和服務配置。 - **部署設定📜**:用於在 Kubernetes 叢集上實際部署容器。 - **服務配置📄**:將 Pod 暴露給叢集內部和叢集外部。 首先,我們為「microservice1」建立清單。建立一個新檔案「microservice1-deployment-service.yaml」並新增以下內容: ``` // 👇🏻/k8s/manifests/microservice1-deployment-service.yaml apiVersion: apps/v1 kind: Deployment metadata: name: microservice1 spec: selector: matchLabels: app: microservice1 template: metadata: labels: app: microservice1 spec: containers: - name: microservice1 image: microservice1-image # Make sure to set it to Never, or else it will pull from the docker hub and fail. imagePullPolicy: Never resources: limits: memory: "200Mi" cpu: "500m" ports: - containerPort: 3001 --- apiVersion: v1 kind: Service metadata: name: microservice1 labels: app: microservice1 spec: type: NodePort selector: app: microservice1 ports: - port: 8080 targetPort: 3001 nodePort: 30001 ``` 此配置部署了一個名為「microservice1」的微服務,其資源限制為 **200MB 記憶體** 🗃️ 和 **0.5 個 CPU 核心**。它透過部署在連接埠 3001 上公開微服務,並透過服務在 **NodePort** 30001 上公開微服務。 > 🤔 還記得我們用名稱「microservice1-image」建構的「Dockerfile」嗎?我們使用相同的映像來建立容器。 可透過集群內的連接埠 8080 存取它。我們假設「microservice1-image」透過「imagePullPolicy: Never」在本地可用。如果沒有到位,它將嘗試從 Docker Hub 🐋 中提取映像並失敗。 現在,讓我們為「microservice2」建立清單。建立一個名為「microservice2-deployment-service.yaml」的新檔案並新增以下內容: ``` // 👇🏻/k8s/manifests/microservice1-deployment-service.yaml apiVersion: apps/v1 kind: Deployment metadata: name: microservice2 spec: selector: matchLabels: app: microservice2 template: metadata: labels: app: microservice2 spec: containers: - name: microservice2 image: microservice2-image # Make sure to set it to Never, or else it will pull from the docker hub and fail. imagePullPolicy: Never resources: limits: memory: "200Mi" cpu: "500m" ports: - containerPort: 3002 --- apiVersion: v1 kind: Service metadata: name: microservice2 labels: app: microservice2 spec: type: NodePort selector: app: microservice2 ports: - port: 8081 targetPort: 3002 nodePort: 30002 ``` 它與“microservice1”的清單類似,只有一些更改。 👀 此配置部署一個名為「microservice2」的微服務,並透過部署在連接埠 3002 上將其內部公開,並透過服務在 **NodePort** 30002 上將其外部公開。 可透過叢集內的連接埠 8081 進行存取,假設「microservice2-image」可透過「imagePullPolicy: Never」在本地使用。 全部完成後,請確保套用這些設定並使用這些服務啟動 Kubernetes 叢集。將目錄更改為`/manifests`並執行以下命令:👇🏻 ``` kubectl apply -f microservice1-deployment-service.yaml kubectl apply -f microservice2-deployment-service.yaml ``` 執行以下命令檢查我們的兩個部署是否正在**執行**:👇🏻 ``` kubectl get pods ```  最後,我們的應用程式已準備就緒,並使用必要的部署配置部署在 Kubernetes 上。 🎉 *** ## **安裝 Odigos 😍** > 💡 [**Odigos**](https://odigos.io/) 是一個開源可觀察性控制平面,使組織能夠建立和維護其可觀察性管道。  > ℹ️ 如果您在 Mac 上執行,請執行以下命令在本地安裝 Odigos。 ``` brew install keyval-dev/homebrew-odigos-cli/odigos ``` > ℹ️ 如果您使用的是 Linux 計算機,請考慮透過執行以下命令從 GitHub 版本安裝它。確保根據您的 Linux 發行版更改該檔案。 > ℹ️ 如果 Odigos 二進位檔案不可執行,請在執行安裝指令之前執行此指令 `chmod +x odigos` 使其可執行。 ``` curl -LJO https://github.com/keyval-dev/odigos/releases/download/v1.0.9/cli_1.0.9_linux_amd64.tar.gz tar -xvzf cli_1.0.9_linux_amd64.tar.gz ./odigos install ``` 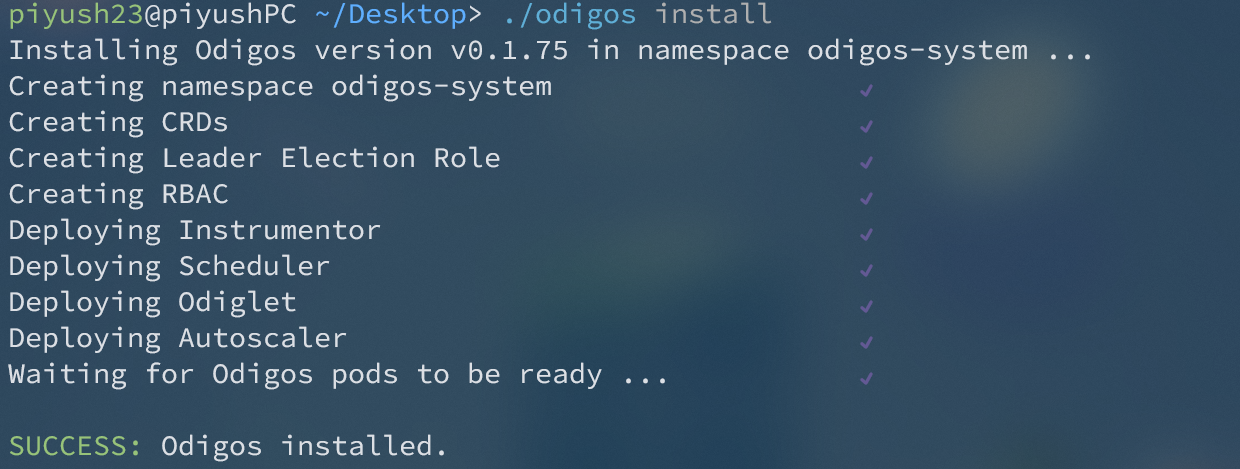 > 如果您需要有關其安裝的更多簡短說明,請按照此[**連結**](https://docs.odigos.io/installation)操作。 現在,Odigos 已準備好執行 🎉。我們可以執行它的 UI,配置追蹤後端,並相應地發送追蹤。 *** ## **將 Odigos 連接到追蹤後端 💫** > 💡 [**Jaeger**](https://github.com/jaegertracing/jaeger) 是一個開源的端對端分散式追蹤系統。  ### **設定 Jaeger!** ✨ 在本教程中,我們將使用 **Jaeger** 🕵️♂️,這是一個流行的開源平台,用於查看微服務應用程式中的分散式追蹤。我們將用它來查看 Odigos 生成的痕跡。 > 有關 Jaeger 安裝說明,請點選此 [**link**](https://www.jaegertracing.io/download/)。 👀 若要在 Kubernetes 叢集上部署 Jaeger,請執行下列命令:👇🏻 ``` kubectl create ns tracing kubectl apply -f https://raw.githubusercontent.com/keyval-dev/opentelemetry-go-instrumentation/master/docs/getting-started/jaeger.yaml -n tracing ``` 在這裡,我們建立一個「tracing」命名空間,並在該命名空間中為 Jaeger 應用部署配置📃。 此命令設定自託管 Jaeger 實例及其服務。 👀 執行以下命令來取得正在執行的 pod 的狀態:👇🏻 ``` kubectl get pods -A -w ``` 等待所有三個 Pod 都 **正在執行**,然後再繼續。 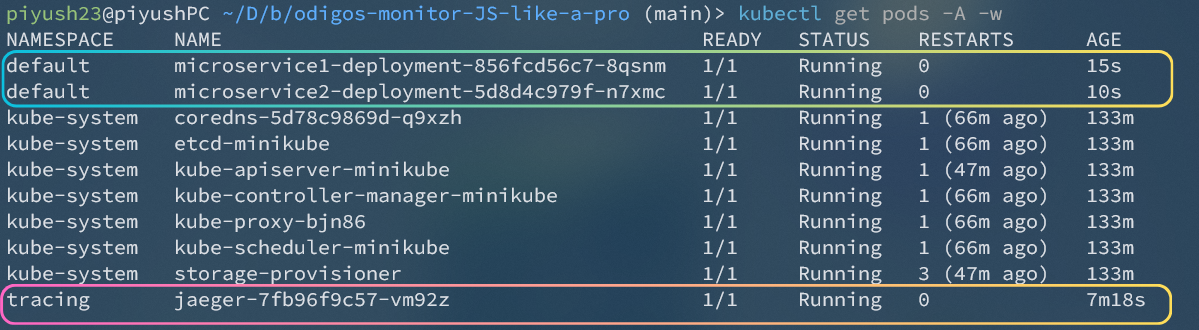 現在,要在本地查看 Jaeger Interface 💻,我們需要進行連接埠轉送。將流量從本機電腦上的連接埠 16686 轉送至 Kubernetes 叢集中選定 pod 上的連接埠 16686。 ``` kubectl port-forward -n tracing svc/jaeger 16686:16686 ``` 此命令在本機電腦和 Jaeger pod 之間建立一條隧道,公開 Jaeger UI,以便您可以與其互動。 最後,在瀏覽器上開啟「 http://localhost:16686 」並查看 Jaeger 實例正在執行。  ### **設定 Odigos 與 Jaeger 一起工作!** 🌟 > ℹ️ 對於 Linux 用戶,請前往從 GitHub 版本下載 Odigos 二進位檔案的資料夾,然後執行以下命令來啟動 Odigos UI。 ``` ./odigos ui ``` > ℹ️ 對於 Mac 用戶,只需執行: ``` odigos ui ``` 造訪“ http://localhost:3000 ”,您將看到 Odigos 介面,您將在“default”命名空間中看到您的部署。  選擇這兩個選項並點擊“下一步”。在下一頁上,選擇 Jaeger 作為後端,並在出現提示時加入以下詳細資訊: - **目的地名稱🛣️**:提供您想要的任何名稱,例如說**快速追蹤**。 - **端點🎯**:為端點加上`jaeger.tracing:4317`。 就是這樣 - Odigos 已準備好向我們的 Jaeger 後端發送痕跡。就是這麼簡單。 🤯  *** ## **查看分散式追蹤 🧐** 設定 Odigos 後,在 Jaeger 主頁「 http://localhost:16686 」上,您將已經看到列出的兩個微服務。  Odigos 已經開始向 Jaeger 發送我們的應用程式痕跡。 😉 請記住,這是我們的微服務應用程式。由於以「microservice1」為起點,因此再向「microservice1」發出一些請求,隨後它將向「microservice2」請求資料並傳回。最終,Jaeger 將開始填滿這些痕跡。  點擊任一請求,您應該能夠觀察請求如何流經您的應用程式以及完成每個請求所需的時間。 這一切都是在沒有更改一行程式碼的情況下完成的。 🤯 一切都感謝 **Odigos**! 🤩  想像一下,這只是一個很小的虛擬應用程式,但對於一個執行著大量微服務並相互交互的更大的應用程式來說,分散式追蹤將非常強大! 💪 透過分散式跟踪,您可以輕鬆辨識應用程式中的瓶頸,並確定哪個服務導致問題或花費更長的時間。 🕒 *** ## **讓我們總結一下! 🥱** 到目前為止,您已經學習如何使用 **Odigos** 作為應用程式和追蹤後端 **Jaeger** 之間的 **中間件**,透過分散式追蹤來密切監控 👀 Javascript 應用程式。 👏 如果您已經做到了這一步,請拍拍自己的背。 🥳你值得擁有! 😉 本教學的源程式碼可在此處取得: https://github.com/keyval-dev/blog/tree/main/odigos-monitor-JS-like-a-pro > 如果您對本文有任何疑問或建議,請在下面的評論部分分享。 👇🏻 那麼,這就是本文的內容。感謝您的閱讀! 🎉🫡 --- 原文出處:https://dev.to/odigos/monitor-your-javascript-application-like-a-pro-581p
碰巧有些 Linux 終端機命令很難記住,將它們作為備忘單保存在電腦或紙上是一個很好的做法。此列表並不詳盡,但包含最常用的命令。請隨意在下面的評論中加入您最常用的命令並分享此列表✌️。 ## 用戶 - **Id** – 有關使用者的詳細資訊(uid、gid 和群組)。 - **last** – 列出有關最近登入的訊息,包括時間、使用者名稱、IP 位址和會話持續時間。 - **who** – 顯示授權使用者。 - **groupadd "testgroup"** – 建立一個名為「testgroup」的群組。 - **adduser NewUser** – 新增名為「NewUser」的使用者。 - **userdel NewUser** – 刪除名為「NewUser」的使用者。 - **usermod NewUser** – 修改使用者「NewUser」的資訊。 ## 目錄導航 - **cd /**- 導覽至根目錄。 - **cd** - 導航到主目錄(使用 $HOME 變數)。 - **cd /root** - 導覽至 /root 目錄。 - **cd ..** - 向上移動一級。 - **cd /root/.ssh** - 導航到隱藏資料夾 .ssh。 ## 使用文件 - **ls -al** – 顯示目前資料夾中的檔案和目錄。 - **pwd** – 顯示目前工作目錄。 - **mkdir NewFolder** – 建立一個名為「NewFolder」的新目錄。 - **rm NewFile** – 刪除名為「NewFile」的檔案。 - **rm -f NewFile** – 強制刪除名為「NewFile」的檔案。 - **rm -r NewFolder** – 遞歸刪除名為「NewFolder」的目錄。 - **rm -rf NewFolder** – 強制遞歸刪除名為「NewFolder」的目錄。 - **cp oldfile1 newfile2** – 將「oldfile1」的內容複製到「newfile2」。 - **cp -r olddir1 newdir2** – 遞歸地將目錄「olddir1」複製到「newdir2」。如果 Dir2 不存在,則會建立它。 - **mv oldfile1 newfile2** – 將「oldfile1」重新命名為「newfile2」。 - **ln -s /etc/log/file logfile** – 建立到檔案的符號連結。 - **touch newfile** – 建立一個名為「newfile」的空白檔案。 - **cat > newfile** – 取得 STDIN 並將其放入「newfile」中。 - **head newfile** – 輸出檔案「newfile」的前 10 行。 - **tail newfile** – 輸出「newfile」的最後 10 行。 - **gpg -c newfile** – 使用密碼以 gpg 格式加密「newfile」並將其儲存在同一目錄中。 - **gpg newfile.gpg** – 解密 gpg 檔案。 - **wc newfile** – 顯示新檔案中的位元組數、字數和行數。 ## 檔案/目錄權限 - **chmod 777 /root/ssh** – 為有權存取伺服器的每個人(擁有者、群組、其他人)設定讀取、寫入和執行權限。 - **chmod 755 /root/ssh** – 將擁有者的權限配置為 rwx,將群組和其他人的權限配置為 r_x。 - **chmod 766 /root/ssh** – 設定擁有者的 rwx 以及群組和其他人的 rw。 - **chown newuser newfile** – 將 newfile 的擁有者改為 newuser。 - **chown newuser:newgroup newfile** – 將 newfile 的擁有者和群組擁有者變更為 newuser 和 newgroup。 - **chown newuser:newgroup newfolder** – 將目錄 newfolder 的擁有者和群組擁有者變更為 newuser 和 newgroup。 - **stat -c “%U %G” newfile** – 顯示 newfile 的使用者和群組擁有者。 ## 搜尋 - **grep searchargument newfile** – 在 newfile 中搜尋 searchargument。 - **grep -r searchargument newfolder** – 遞歸搜尋 newfolder 中所有檔案中的 searchargument。 - **定位新檔案** – 顯示新檔案的所有位置。 - **find /etc/ -name "searchargument"** – 在 /etc 目錄中尋找名稱以 searchargument 開頭的檔案。 - **find /etc/ -size +50000k** – 在 /etc 目錄中尋找大小大於 50000k 的檔案。 ## 檔案 - **tar -cf archive.tar newfile** – 從檔案「newfile」建立檔案「archive.tar」。 - **tar -xf archive.tar** – 提取檔案「archive.tar」的內容。 - **tar -zcvf archive.tar.gz /var/log/** – 從 /var/log/ 目錄建立檔案並使用 gzip 對其進行壓縮。 - **gzip newfile** – 壓縮新檔案(副檔名為 .gz)。 ## 從套件中安裝程式 - **rpm -i pkg_program.rpm** – 在 CentOS、RHEL 等上安裝 RPM 軟體包。 - **rpm -e pkg_name** – 刪除 CentOS、RHEL 等上的 RPM 軟體包。 - **dnf install pkg_name** – 在 CentOS、RHEL 等上使用 DNF 從儲存庫安裝軟體包。以前使用 YUM,但最近已被 DNF 取代。 - **dpkg -i pkg_name** – 從 Debian、Ubuntu、Mint 等上的 DEB 軟體包安裝。 - **dpkg -r pkg_name** – 刪除 Debian、Ubuntu、Mint 等上的 DEB 軟體包。 - **apt install pkg_name** – 在 Debian、Ubuntu、Mint 等上從儲存庫安裝軟體套件。 - **apt remove pkg_name** – 移除 Debian、Ubuntu、Mint 等上的軟體套件。 - **apt update && apt update** – 更新系統中的軟體包(Debian、Ubuntu、Mint 等)並更新儲存庫。 ## 流程 - **ps** – 顯示目前正在執行的進程。 - **ps aux | grep 'bash'** – 尋找 'bash' 的程序 ID (PID)。 - **pmap -x 11** – 在進程記憶體中映射 PID 11 的進程。 - **top** – 顯示所有正在執行的進程。 - **kill pid** – 透過 PID 終止進程。 - **killall process** – 終止名為「process」的所有程序。 - **pkill process-name** – 按名稱向程序發送訊號。 - **bg** – 將掛起的程序傳送到背景。 - **fg** – 將正在執行的進程帶到前台。 - **fg process** – 將名為「process」的進程帶到前台。 - **lsof** – 列出進程開啟的檔案。 - **renice 19 PID** – 設定進程的最低優先權。 - **pgrep bash** – 尋找「bash」的進程 ID。 - **pstree** – 顯示進程的樹狀表示。 ## 系統 - **uname** – 顯示系統資訊。 - **uname -r** – 顯示有關 Linux 核心的資訊。 - **hostname** – 顯示主機名稱。 - **hostname -i** – 顯示主機的 IP 位址。 - **date** – 顯示日期和時間。 - **timedatectl** – 輸出和修改日期和時間設定。 - **cal** – 顯示日曆。 - **w** – 顯示目前登入的使用者。 - **whoami** – 顯示您的使用者名稱。 - **finger root** – 顯示有關 root 使用者(需要使用「apt-get install Finger」的資訊進行安裝)。 ## 硬體指令 - **dmesg** – 在啟動期間顯示系統訊息。 - **cat /proc/cpuinfo** – 顯示有關處理器的資訊。 - **cat /proc/meminfo** – 顯示有關記憶體的資訊。 - **lshw** – 顯示有關裝置的詳細資訊。 - **lsblk** – 顯示有關區塊裝置的資訊。 - **free -m** – 釋放記憶體:RAM 和交換(切換 -m 表示 MB)。 - **lspci -tv** – 在樹狀圖視圖中顯示 PCI 裝置資訊。 - **lsusb -tv** – 在樹狀圖視圖中顯示 USB 裝置。 - **dmidecode** – 顯示有關 BIOS 設備的資訊。 - **hdparm -i /dev/xda** – 顯示有關磁碟的資訊。 - **hdparm -tT /dev/xda** – 顯示 xda 的讀寫速度。 - **badblocks -s /dev/xda** – 執行壞扇區測試。 ## 光碟管理指令 - **df -h** – 顯示已安裝分割區上的可用空間(以位元組為單位)。 - **df -i** – 顯示檔案系統中的空閒 inode。 - **fdisk -l** – 提供有關磁碟、分割區和檔案系統的資訊。 - **du -sh** – 顯示已安裝分割區上的未分配空間(以 MB、GB、TB 為單位)。 - **findmnt** – 顯示所有安裝點。 - **mount /dev/sdb1 /mnt** – 將 sdb 磁碟的分割區 1 掛載到 /mnt 目錄。 ## 網絡 - **ip addr show** – 顯示所有可用網路介面的 IP 位址。 - **ip address add 192.168.0.1/24 dev eth0** – 將位址 192.168.0.1 指派給 eth0 介面。 - **ifconfig** – 顯示所有可用網路介面的 IP 位址。 - **ping 192.168.0.1** – 發送 ICMP 協定請求以連接到 192.168.0.1 處的節點。 - **whois 網域** – 顯示有關網域的資訊。 - **dig 網域 **– 檢索有關網域的 DNS 資訊。 - **dig -x 192.168.0.1 ** – 執行反向 DNS 解析。 - **host serverspace.us** – 解析主機位址。 - **hostname -I ** – 顯示本機位址。 - **wget file_name(連結到檔案)** – 下載檔案。 - **netstat -pnltu ** – 顯示主機上正在偵聽的所有連接埠(需要「apt-get install net-tools」)。 ## 遠端連線 - **ssh root@host** – 以 root 使用者身分透過 ssh 連線到遠端主機。 - **ssh -p port_number user@host** – 使用非預設 ssh 連接埠連接到遠端主機,指定使用者。 - **ssh host** – 使用目前使用者的預設連線。 - **telnet host** – 使用 telnet 連線(連接埠 23)。 --- 原文出處:https://dev.to/serverspace/linux-commands-cheat-sheet-aif
你的轉職路上,還缺少一份自學作業包!寫完這幾包,直接拿作品去面試上班!
本論壇另有附設一個 LINE 新手發問&交流群組!歡迎加入討論!






























