

揭露:這篇文章包含附屬連結;如果您透過本文中提供的不同連結購買產品或服務,我可能會獲得補償。

信用 - Sandeep/CodeKarle
大家好,如果您正在準備系統設計面試並尋找常見的系統設計問題和資源,那麼您來對地方了。
過去,我討論過基本的系統設計概念,例如API 網關與負載平衡器、水平與垂直擴展、 正向代理與反向代理以及常見的系統設計問題,今天我將討論一個流行的系統設計問題-- -設計 Twitter 或 X.com。
設計像 Twitter 這樣的複雜系統可能具有挑戰性,尤其是在系統設計面試中。
最大的挑戰不是複雜性,而是時間,因為您需要在 40 分鐘內讓面試官相信您了解自己的知識,而這只有在您準備充分並在回答此類問題時遵循結構化方法的情況下才有可能實現。
在這個系統設計教程中,我還將為您提供一個簡單的指南,幫助您建立和系統設計模板(見下文),以收集您的想法並呈現清晰的設計。
順便說一句,如果您正在準備系統設計面試並希望在有限的時間內學習系統設計,那麼您還可以查看ByteByteGo 、 DesignGurus.io 、 Exponent 、 Educative.io 、 Codemia.io和Udemy等網站,這些網站有很多很棒的內容系統設計課程
同樣,在回答系統設計問題時,您也可以遵循DesignGurus.io中的系統設計模板,以便在有限的時間內更好地闡明您的答案。
遵循此範本是開始準備任何系統設計面試時可以做的最好的事情之一。

現在,讓我們開始討論問題和解決方案。
如何設計 Twitter 或 X.com?
設計像 Twitter 這樣的系統是系統設計面試中的常見場景,但如果您想從頭開始練習這個問題,您可以在Codemia.io上開始,這是一個用於系統設計面試的 Leetcode 風格平台。
它有超過 120 多個系統設計問題並且還在增加,其中包括 Designing Twitter。它還提供由知名公司的高級工程師建立的編輯解決方案。
它還提供免費的系統設計問題, 設計 Twitter 就是其中之一。您可以在這裡存取它。
現在回到問題本身,這是展示您對大規模分散式系統的理解的好方法,因為它涉及處理大量用戶群、確保高可用性以及在重負載下保持穩定性等各個方面。
本解決方案指南將引導您完成 Twitter 的設計流程,涵蓋系統需求、容量估算、API 設計、資料庫設計、高層設計、請求流程、詳細元件設計、權衡和潛在故障場景。
閱讀本指南後,您將對如何在面試環境中處理和展示此設計有深入的了解。
下面是一個 Twitter 架構圖,可以讓您了解整體思路:

正如我所說,我們將逐步解決這個問題,我們將涵蓋:
-
要求
-
容量估算
-
QPS(每秒查詢數)
-
API設計
-
資料庫設計
-
表格
-
貯存
-
高層次設計
-
詳細的元件設計
-
失敗場景和瓶頸
-
權衡
那麼,還在等什麼,讓我們開始吧。
推特系統要求
首先你應該得到正確的需求,它從功能需求開始。
如果您要複製真實的應用程式(例如在亞馬遜上購買商品或在 Facebook 或 Twitter 上發送訊息),請選擇您最熟悉的應用程式。
功能要求
為了設計一個強大且用戶友好的類似 Twitter 的系統,我們需要概述核心功能。
用戶應該能夠撰寫和分享推文,這是該平台的主要功能。
這包括建立新推文、附加可選媒體並與追蹤者分享。此外,用戶應該能夠關注其他用戶,以在他們的來源中查看他們的更新。
這意味著管理關注用戶的清單並確保他們的推文出現在用戶的時間軸中。
另一個重要功能是允許用戶收藏推文,表示他們的欣賞,並可能為這些推文加入書籤以供將來參考。
以下是主要功能需求供您參考:
-
撰寫和分享推文:用戶應該能夠建立和分享推文。
-
關注用戶:用戶應該能夠關注其他用戶並查看他們的更新。
-
最喜歡的推文:用戶應該能夠最喜歡的推文以表達讚賞。
非功能性需求
對於Twitter這樣規模的平台來說,非功能性需求至關重要。可擴展性至關重要,因為系統必須在不降低效能的情況下處理大量使用者、推文和互動。
高可用性確保平台即使在流量高峰期或硬體故障時也能保持可存取性和功能性。
穩定性是另一個關鍵方面,因為即使在高並發情況下,服務也必須可靠、最少的停機時間和一致的效能。
以下是您在面試時應提及的關鍵非功能性要求:
-
可擴展性:系統應該處理大量的使用者、推文和互動。
-
高可用性:即使在高流量下,系統也應該可用。
-
穩定性:系統應該穩定且可存取,不會頻繁出現問題或停機。
容量估算
估計用戶群是了解系統規模的第一步。對於此設計,我們假設用戶群為 5 億。這有助於我們評估預期負載和支援如此大量用戶所需的基礎設施。
使用者群
- 假設用戶群為 5 億。
交通
為了了解日常營運情況,我們需要估計流量。假設每個用戶每天發一次推文,我們預計每天會有 5 億則推文。
此外,如果每個使用者每天查看其主頁的 10 頁,則會導致大量的讀取操作。
關注關係也增加了複雜性,每個用戶平均關注 100 個其他用戶,導致 500 億個關注關係。
最後,如果每個用戶每天收藏 5 條推文,那麼我們每天就有 25 億次收藏作業。
以下是您應該考慮或提及的關鍵流量需求:
-
推文:每天 5 億則推文(每個用戶每天一則推文)。
-
Home Feed :每位使用者每天查看 10 個頁面。
-
關注:每位用戶平均關注 100 個其他用戶,產生 500 億個關注關係。
-
收藏:每位用戶每天收藏 5 則推文,每天收藏數量達 25 億。
QPS(每秒查詢數)
將這些操作分解為每秒查詢數 (QPS) 有助於我們了解即時負載。
對於寫入操作,我們計算出大約 15k QPS,對於讀取操作,大約 75k QPS,對於最喜歡的操作,大約 30k QPS。
這些數字有助於規劃必要的基礎設施和負載平衡策略。
-
寫入:500M×23600×24≈15k\frac{500M \times 2}{3600 \times 24} \約15k3600×24500M×2≈15k QPS
-
讀取:500M×103600×24≈75k\frac{500M \times 10}{3600 \times 24} \約75k3600×24500M×10≈75k QPS
-
收藏夾:500M×53600×24≈30k\frac{500M \times 5}{3600 \times 24} \約30k3600×24500M×5≈30k QPS
資料大小
了解資料大小對於儲存規劃至關重要。每天有 5 億條推文,考慮編碼後每條推文平均為 300 字節,每天總共有 140GB 的新資料,或每年 50TB。
對於媒體內容,如果我們假設其大小是推文的 100 倍,則每天的容量為 10TB,或每年的容量為 4PB。
這項估計強調了對分散式儲存架構的需求。
-
推文:每天 5 億條推文,每條包含 140 個字元(每條 300 位元組)。總計每天 140GB,每年 50TB。
-
媒體(圖片/影片) :假設推文大小的 100 倍,每天 10TB,每年 4PB。
API設計
現在,我們來談談 API 設計,這是系統設計面試中的另一個重要領域:
發推文
用於推文的 API 需要有效地處理推文的建立和發布。這涉及捕獲用戶資訊、推文內容、位置資料和時間戳記。正確的錯誤處理和驗證對於確保流暢的使用者體驗至關重要。
public Result postTweet(Long userId, String tweetText, String location, DateTime date);追蹤者
追蹤者能需要 API 來管理使用者之間的關係。這包括追蹤和取消追蹤用戶、確保資料完整性以及及時更新用戶的追蹤清單。
public Result followUser(Long userId, Long followedUserId);\
public Result unfollowUser(Long userId, Long followedUserId);收藏夾
收藏 API 允許用戶喜歡或不喜歡推文。這些操作應該是高效的,並具有適當的索引和錯誤處理,以確保快速更新和每條推文上的收藏夾的準確計數。
public Result favoriteTweet(Long userId, Long tweetId);\
public Result unfavoriteTweet(Long userId, Long tweetId);feed 渲染 API 對於取得和顯示關注用戶的推文至關重要。這需要高效的查詢和分頁,以確保快速的載入時間和無縫的用戶體驗。
public Result getFeeds(Long userId, String location, int pageNo);資料庫設計
說完API設計,我們來談談資料庫設計
表格
資料庫設計涉及為使用者、推文和追蹤者關係定義表。 UserInfo表儲存使用者詳細訊息, Tweets表處理推文內容和元資料, Follower表管理關注關係。正確的索引對於快速查找和更新至關重要。
-
使用者資訊表
-
使用者 ID(主鍵)
-
使用者名稱
-
地位
-
其他個人資料(頭像、年齡等)
-
推文表
-
tweetId(主鍵)
-
使用者ID(索引)
-
內容
-
發佈時間(索引)
-
修改時間
-
地位
-
追隨者表
-
使用者身分
-
追蹤者ID(索引)
-
注意時間
這是一個簡單的 ERD 圖,可以更好地理解 Twitter Schema 架構:

貯存
選擇正確的儲存解決方案至關重要。對於用戶個人資料和推文等結構化資料,MySQL 是一個不錯的選擇,因為它支援複雜的查詢和事務。
對於媒體存儲,Amazon S3 為圖像和影片提供可擴展且經濟高效的存儲。
-
使用 MySQL 儲存結構化資料(使用者、推文、關注關係)。
-
使用 Amazon S3 進行媒體儲存(影像和影片)。
高層設計
讓我們先來看看高層設計:
客戶端層
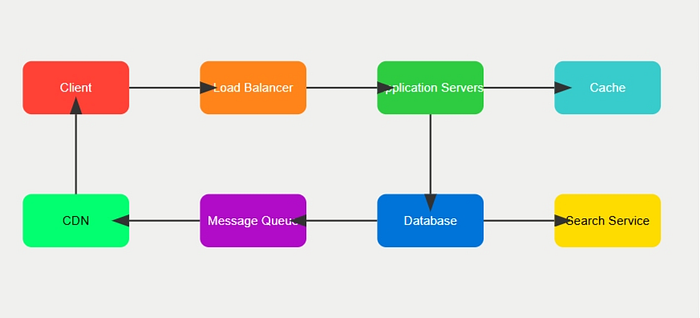
客戶端層涉及向伺服器發送請求的網站和應用程式。這些請求透過負載平衡器進行分發,以確保負載均勻分佈和高可用性。對靜態檔案使用 CDN 有助於減少延遲並縮短載入時間。
-
客戶端(網站/應用程式)向伺服器發送請求。
-
請求透過負載平衡器分發。
-
使用速率限制器來保護後端伺服器。
-
對靜態檔案(影像、影片)使用 CDN。
伺服器層
客戶端層涉及向伺服器發送請求的網站和應用程式。這些請求透過負載平衡器進行分發,以確保負載均勻分佈和高可用性。
對靜態檔案使用 CDN 有助於減少延遲並縮短載入時間。
-
伺服器叢集處理請求和不同的服務:
-
推文服務:發推文。
-
用戶服務:用戶註冊和個人資料管理。
-
關注服務:追蹤/取消關注用戶。
-
Home Feed 服務:呈現使用者 feed。
資料層
資料層採用Redis快取資料提高回應速度,採用MySQL進行持久化存儲,主從架構保證一致性與可用性。 Amazon S3 用於儲存媒體文件,確保可擴充性和持久性。
-
使用Redis進行緩存,提高響應速度。
-
使用主從架構的MySQL,確保資料的一致性和可用性。
-
使用 Amazon S3 儲存媒體檔案。
請求流程
解釋請求流有助於理解不同元件如何互動。當客戶端發送請求時,它首先到達負載平衡器,負載平衡器將請求分發到適當的伺服器。
伺服器處理請求、更新資料庫並快取必要的資料。對於讀取請求,從快取或資料庫檢索資料,並從 CDN 取得媒體文件,確保快速回應時間。
-
客戶端向負載平衡器發送請求。
-
負載平衡器將請求分發到伺服器。
-
速率限制器檢查流量。
-
伺服器處理請求並將資料儲存在MySQL和Redis中。
-
媒體檔案儲存在 CDN 中。
-
對於讀取請求,伺服器從 CDN 檢索文件,從 Redis 或 MySQL 檢索資料。
這是一個很好的美人魚圖,可以更好地理解 Twitter 架構中的請求流,當我在Codemia.io上練習系統設計問題時,我也使用他們的介面來建立這樣的美人魚圖。

詳細的元件設計
現在,讓我們來看看詳細的元件設計以及我們可以用來設計 Twitter 的各種軟體架構元件。
負載平衡器
在叢集中部署多個負載平衡器可以確保高可用性和均勻的負載分佈。
將負載平衡器放置在不同的位置可以減少用戶的延遲,並且使用循環或最少連接等各種演算法有助於有效地管理負載。
-
在叢集中部署多個負載平衡器。
-
將負載平衡器放置在不同位置以減少延遲。
-
使用循環法、最少連接或 IP 雜湊等演算法。
如果您不知道什麼是負載平衡器,這裡有一個來自DesignGurus.io的漂亮圖表,這是我最喜歡的學習系統設計的網站之一:

CDN
對靜態內容使用 CDN 可以減少來源伺服器上的負載並縮短使用者的載入時間。優化快取規則和調整 TTL 有助於實現更高的快取命中率,確保快速提供內容。
-
同時使用拉取和推送快取方法。
-
優化快取規則和TTL,實現更高的快取命中率。
-
透過增加更多伺服器節點來擴展系統。
雷迪斯
使用 Redis 進行快取需要設定 Redis 叢集以實現可擴展性,並採用主從複製來實現高可用性。 Sentinel 監視叢集並處理故障轉移,確保即使在節點故障期間快取也保持可用。
-
大規模資料使用Redis集群。
-
採用主從複製來實現高可用性。
-
使用 Sentinel 監控叢集並處理故障轉移。
MySQL
MySQL的主從架構支援大流量,並透過複製保證資料一致性。水平分區有助於在多個伺服器之間分配負載,從而有效地處理大型資料集。
-
對於大流量使用主從架構。
-
使用水平分區來處理更多資料。
權衡和技術選擇
這可能是系統設計面試中最重要的部分,因為您必須解釋您所做的選擇和權衡以及它們如何提供幫助。讓我們來看看:
資料庫
選擇 MySQL 而不是 NoSQL 是因為需要複雜的查詢和事務支援。雖然 NoSQL 提供了架構靈活性,但它缺乏對結構化資料和複雜事務的支持,而這對於 Twitter 的業務模型至關重要。
- 由於需要複雜的查詢和事務支持,因此選擇 MySQL 而不是 NoSQL。
快取
Redis 優於 Memcached,因為它支援各種資料類型和水平擴展。 Memcached 對於基本鍵值儲存非常高效,而 Redis 則提供高級功能和更好的可擴充性,使其適合大型系統。
我選擇 Redis 而不是 Memcached 是因為它的高級功能和水平擴展。
失敗場景和瓶頸
現在,讓我們看看我們的系統有多強大和有彈性
混合模型
為了處理追蹤多個帳戶的用戶,結合拉動和推送方法的混合模型可以減少延遲。對於追蹤多人的用戶來說,推播新推文可以減少 Feed 聚合期間的負載,從而改善用戶體驗。
- 如果用戶關注很多人,請結合拉動和推送模型來減少延遲。
閱讀熱點
處理讀取熱點(例如擁有許多追蹤者的熱門用戶)需要在 Redis 中快取他們的推文,並使用快取旁路策略來保證一致性。在Redis伺服器中新增熱區並使用本地快取可以分散負載,避免對相同伺服器的過多呼叫。
-
透過cache-aside策略在Redis中快取熱資料。
-
使用本地快取來處理高流量。
未來的改進
未來的改進包括實施多區域主動-主動策略以實現災難復原和高可用性。
多地部署服務集群和資料庫集群,自動故障轉移和負載平衡,確保無單點故障,保持服務連續性和可靠性。
-
實施多區域雙活策略以實現災難復原和高可用性。
-
繼續優化快取、負載平衡和資料儲存策略以應對未來的成長。
最佳系統設計訪談資源 (2024)
如果您正在準備系統設計面試並尋找最佳資源,那麼這裡列出了最佳系統設計書籍、線上課程和練習網站,您可以查看這些內容以更好地準備系統設計面試。這些課程中的大多數也回答了我在這裡分享的問題。
-
DesignGuru 的 Grokking 系統設計課程:一個互動式學習平台,提供實作練習和真實場景,以增強您的系統設計技能。
-
Codemia.io :這是另一個練習面試系統設計問題的好平台。它有超過 120 多個系統設計問題,其中許多是免費的,並且還有解決這些問題的適當結構。
-
ByteByteGo :Alex Xu 的一本現場書籍和課程,用於系統設計面試準備。它包含《系統設計訪談》第 1 捲和第 2 卷的所有內容,並將隨即將推出的第 3 卷進行更新。
-
Exponent :一個專為面試準備的網站,特別是針對亞馬遜和谷歌等 FAANG 公司,他們還有很棒的系統設計課程和許多其他材料,可以幫助您破解 FAAN 面試。
-
Alex Xu 的《系統設計面試》 :本書深入探討了系統設計概念、策略和麵試準備技巧。
-
Martin Kleppmann 的「設計資料密集型應用程式」 :綜合指南,涵蓋了設計可擴展且可靠的系統的原則和實踐。
-
LeetCode 系統設計 標籤:LeetCode 是一個受歡迎的技術面試準備平台。 LeetCode 上的系統設計標籤包含各種練習問題。
-
GitHub 上的「系統設計入門」 :精選的資源列表,包括文章、書籍和影片,可幫助您準備系統設計面試。
-
Educative 的系統設計課程:一個互動式學習平台,提供實作練習和真實場景,可增強您的系統設計技能。
-
高可擴展性部落格:該部落格包含有關高流量網站和可擴展系統架構的文章和案例研究。
-
YouTube 頻道:請參閱「Gaurav Sen」和「Tech Dummies」等頻道,以取得有關係統設計概念和麵試準備的富有洞察力的影片。
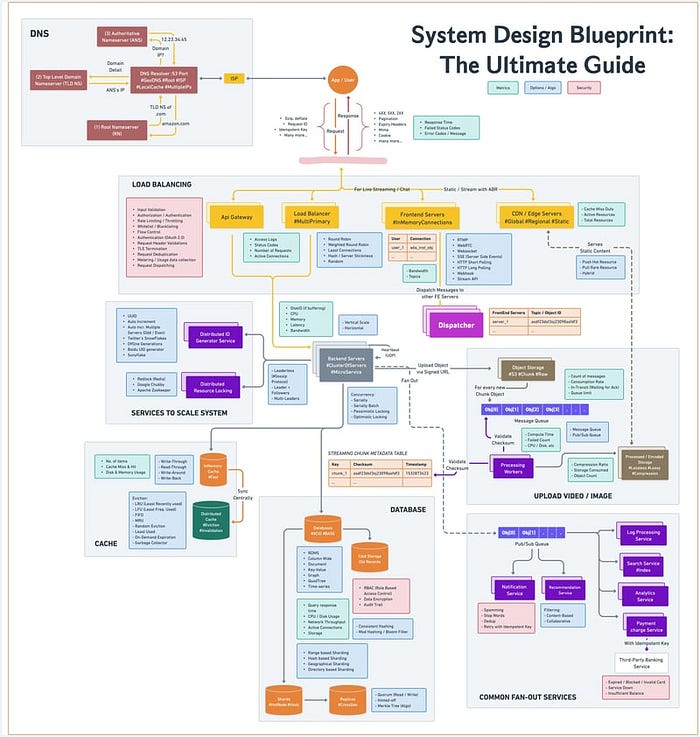
image_credit --- ByteByteGo
請記住透過參與實際專案和參加模擬面試將理論知識與實際應用結合。
不斷的練習和學習將使您對系統設計面試充滿信心。
這就是系統設計面試中如何設計 Twitter 或 X.com 的全部內容。透過遵循這個結構,您可以設計一個類似於 Twitter 的健壯且可擴展的系統。本指南將幫助您在系統設計面試中有效地展示您的設計。
祝您系統設計面試一切順利
原文出處:https://dev.to/somadevtoo/twitter-system-design-example-for-tech-interviews-1ihb
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式