

大家好! 👋
我是塔拉,一名高級軟體工程師兼顧問。多年來,我曾在許多不同的程式碼庫中工作過。
每次加入新專案,我都會發現同樣的問題:新工程師需要 3 到 6 個月的時間才能真正理解一個複雜系統是如何運作的。像 Copilot 和 Cursor 這樣的 AI 工具雖然能顯著提升程式碼編寫速度,但開發人員仍然要花費近 50% 的時間來閱讀和理解程式碼。
沒有人解決閱讀理解層的問題。所以,我決定自己開發一個工具。
我非常興奮地向大家分享我一直在開發的專案: AuraCode (歡迎大家去體驗那裡的線上互動演示!)
🤔 它有什麼作用?
AuraCode 是一個神經程式碼代理,可以將混亂、無文件的儲存庫轉換為互動式視覺化地圖和上下文感知聊天。
以下是我目前已實現的主要功能:
-
互動式架構畫布🗺️:貼上 GitHub URL,即可產生美觀的互動式 D3.js 徑向樹,繪製元件關係和系統結構。
-
上下文聊天 + 文字轉語音 🗣️:您可以提出諸如「如果我更改此身份驗證工具,會發生什麼問題?」之類的問題,並獲得基於您實際程式碼結構的答案。我還將輸出連接到 ElevenLabs 的文字轉語音引擎,這樣您就可以在查看程式碼的同時,無需手動操作即可讓它朗讀流程。
-
智慧型引導 ✅:告別過時的 setup.md 檔案。 AuraCode 會自動產生結構化的引導清單,這些清單專門針對掃描的程式碼庫架構量身定制。
-
程式碼審查摘要🚀:將其指向 PR,它將執行趨勢分析並根據增量輸出審查摘要。
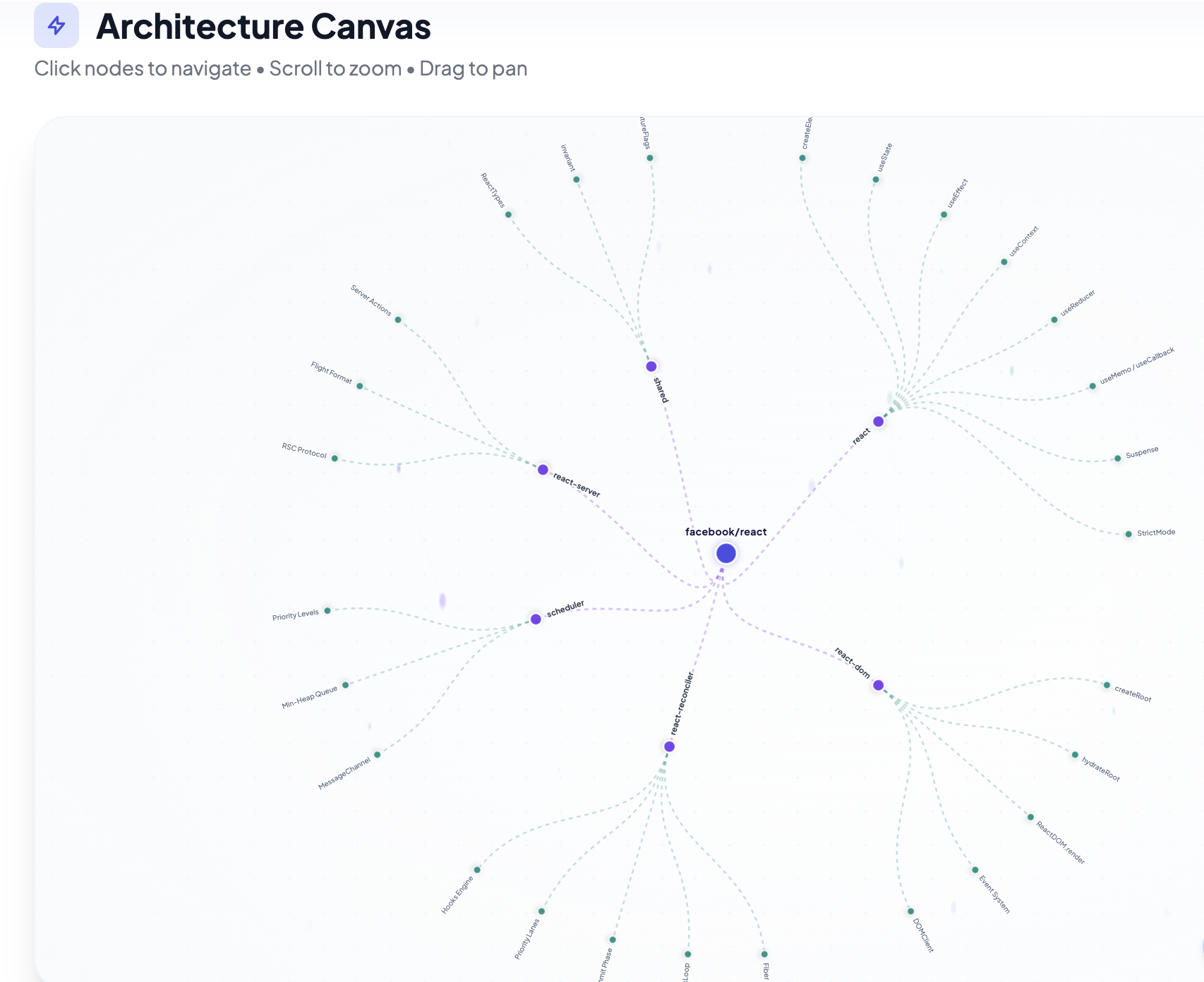
🛠️ 其底層運作原理
建構此功能需要在上下文視窗和精確檢索之間取得平衡。以下是我的方法:
AI架構:將程式碼視為「平面文字」會失去所有重要的結構關係(呼叫圖、依賴鍊等)。為了解決這個問題,AuraCode 根據程式碼庫的大小採用了兩種不同的方法:
對於中小型程式碼庫:我直接將抽象語法樹(AST)注入到模型的上下文視窗中。這樣可以保留架構模式,讓 AI 真正理解程式碼之間的連接方式。
對於大型單體倉庫,我使用一種名為 Lean RAG 的輕量級檢索層。它會在註入上下文之前,選擇性地提取結構上最相關的節點。這樣既能保持較高的準確率,又不會超出令牌限制。
接下來會發生什麼事? 🚀
目前,AuraCode 處於預發布階段。由於我完全依靠自有資金,而且 LLM 代幣的成本會隨著使用量迅速增長,因此我目前只向候補名單上的前 50 位開發者開放完整的私有程式碼庫存取權限。
不過,演示版已全面上線,並在網站上向公眾開放!
我開發這個工具的原因是,每當我受聘諮詢龐大的遺留程式碼庫時,我都希望自己能擁有這樣一款工具。
我很想聽聽你們的想法!你們通常是如何處理龐大且缺乏文件的程式碼庫的?
如果您對技術堆疊、精益 RAG 方法或 D3 視覺化有任何疑問,請告訴我。我很樂意在評論區與您交流! 👇
原文出處:https://dev.to/tworrell/how-im-using-asts-and-gemini-to-solve-the-codebase-onboarding-problem-1la9
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式