

您是否嘗試過實際建立神經網路?不,我也沒有……直到今天!
在這篇文章中,我們將介紹我學到的一些東西,以及一些用 vanilla JS 編寫的非常簡單的神經網路的 2 個演示。
介紹
今天早些時候,我正在閱讀 @supabase_io “AI 內容風暴” 文章。
我突然意識到一件事。我得到了神經網路......但我實際上根本沒有得到它們!
就像,我得到了神經元的概念。但數學是如何運作的呢?
特別是如何使用「反向傳播」來訓練神經網路?偏差和權重如何發揮作用?什麼或誰是 sigmoid? ETC。
現在,明智的做法是閱讀大量文章,獲取一個庫並使用它。
但我不懂事。
因此,我閱讀了大量文章……然後決定建立我的第一個神經網路。
但這還不夠難,所以我決定用 JavaScript 來做(因為每個人似乎都使用 Python...)。哦,我決定在沒有任何庫的情況下完成它。哦,我也想在其中建立一個視覺化工具。
我有些不對勁……我似乎在痛苦中茁壯成長。
無論如何,我做到了,這就是我學到的東西。
注意:這不是教學課程
聽著,我想澄清一下,這不是教學!
這只是我分享一些我在學習和我的第一個神經網路時發現有趣的事情。
請注意,這裡強調第一,所以請不要將其視為除了有趣的東西之外的任何東西。
我也盡力解釋每個部分及其作用,但與所有事情一樣,你對某些東西越熟練,你就越能更好地解釋它......所以我的一些解釋可能有點“偏離” !
無論如何,既然所有這些都已經解決了,讓我們繼續吧!
如果您想直接跳到最終演示,請繼續!
第一步
好的,首先,我可以建立的最基本的神經網路是什麼?
經過一番閱讀後,我發現神經網路可以像一些輸入神經元和一些輸出神經元一樣簡單。
每個輸入神經元都連接到一個輸出神經元,然後我們可以為每個連接加入權重。
考慮到這一點,我必須想出一個易於理解的問題來解決,但又足夠複雜以確保我的網路正常運作。
我決定建立一個神經網絡,它獲取圖表上某個點的 X 和 Y 座標,然後根據它們是正還是負為它們分配一個「團隊」(顏色)。
這樣我們就有了 2 個輸入(X 和 Y 位置),然後有 4 個輸出:
-
X > 0 且 Y > 0
-
X < 0 且 Y > 0
-
X > 0 且 Y < 0
-
X < 0 且 Y < 0
由於這裡的要求非常簡單,我們可以擺脫一些「隱藏」神經元(這是我稍後將介紹的內容)並讓事情變得超級簡單!
所以本質上我們必須建構一個看起來像這樣的神經網路:
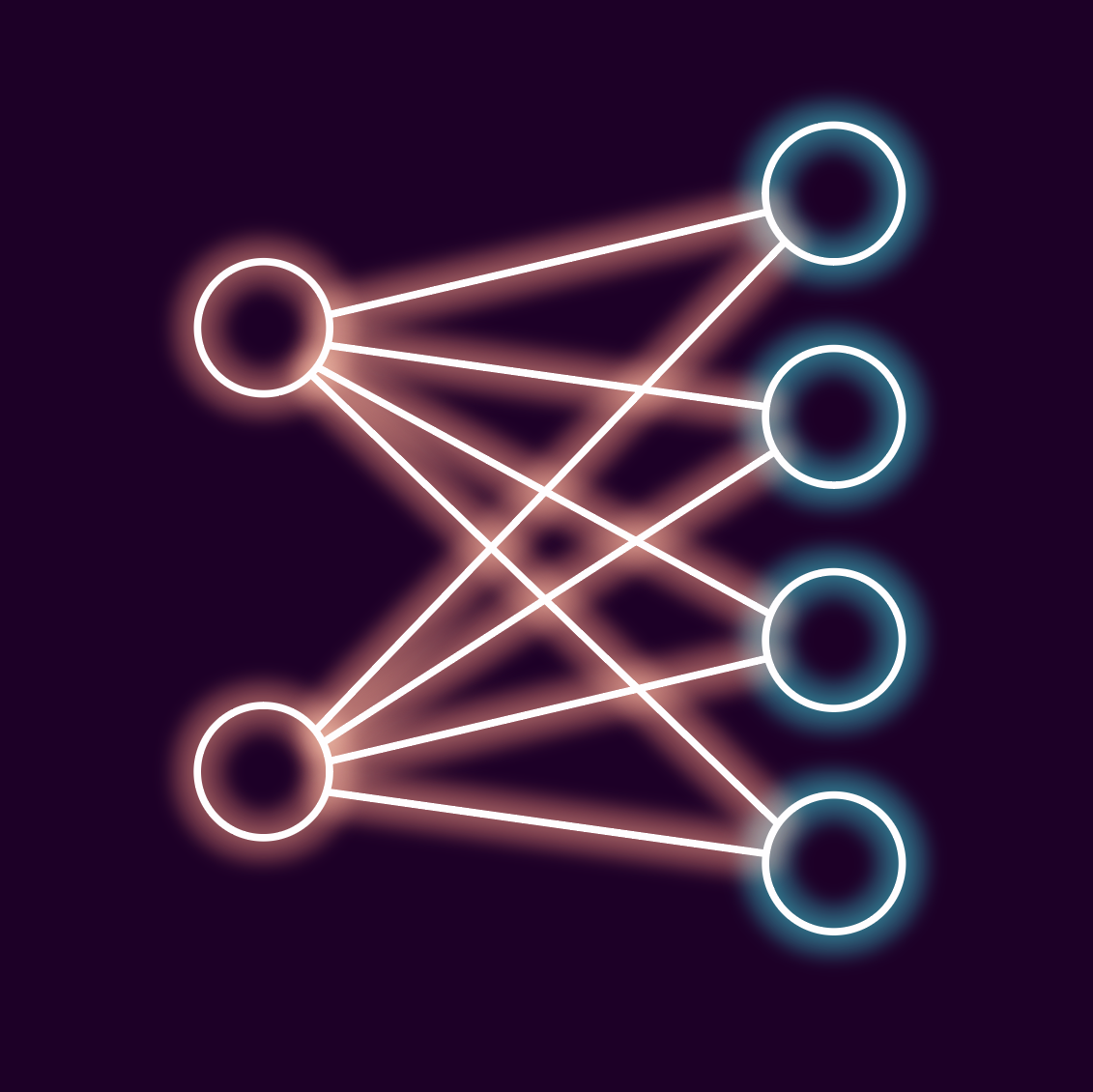
左邊的圓圈是我們的輸入(X 和 Y 位置),右邊的圓圈是我們之前討論的輸出。
我們的第一個神經元
好的,現在我們可以真正開始了。
現在我實際上並沒有先建置神經元。事實上,我實際上首先建立了一個視覺化工具,因為這是查看事情是否正常運作的最簡單方法,但我稍後會介紹這一點。
因此,讓我們建立一個神經元(或更具體地說,一些神經元及其連接)。
幸運的是,神經元其實非常簡單! (或者我應該說,它們可以非常簡單......它們在大型語言模型(LLM)等中變得更加複雜。)
簡單神經元具有偏差(將其視為內部權重,我們將加入到最終計算中以對每個神經元進行加權的數字),並透過每個連接之間的權重連接到其他神經元。
現在回想起來,單獨加入到每個神經元的連接可能是一個更好的主意,但我決定將每層神經元和每層連接作為單獨的專案加入,因為這樣更容易理解。
所以建構我的第一個神經網路的程式碼如下所示:
class NeuralNetwork {
constructor(inputLen, outputLen) {
this.inputLen = inputLen;
this.outputLen = outputLen;
this.weights = Array.from({ length: this.outputLen }, () =>
Array.from({ length: this.inputLen }, () => Math.random())
);
this.bias = Array(this.outputLen).fill(0);
}
}
const neuralNetwork = new NeuralNetwork(2, 4);
好的,我跳過了一些步驟,所以讓我們簡要介紹一下每個部分。
this.inputLen = inputLen; 和 this.outputLen = outputLen; 只是為了讓我們可以引用輸入和輸出的數量。
this.weights = [...] 是連線。現在看起來可能有點嚇人,但這就是我們正在做的事情:
-
建立輸出神經元陣列(
outputLen) -
將長度為“inputLen”的陣列加入到每個陣列條目,並用 0 到 1 之間的一些隨機值填充它以開始我們的工作。
該程式碼的輸出範例如下所示:
this.weights = [
[0.7583747881712366,0.4306037998314902],
[0.40553698492617807,0.4419651593960727],
[0.852978801662627,0.9762509253699836],
[0.8701610553353811,0.5583309725764114]
]
它們本質上代表以下內容:
[input 1 to output 1, input 2 to output 1],
[input 1 to output 2, input 2 to output 2],
[input 1 to output 3, input 2 to output 3],
[input 1 to output 4, input 2 to output 4],然後我們還有「this.bias」。
這適用於輸出層中的每個神經元。我們稍後用它來加入輸出值,使一些神經元更強,一些神經元更弱。
它只是一個由 4 個 0 組成的陣列來讓我們開始,因為我們不想要初始偏差!
現在,雖然這是一個神經網絡,但它完全沒有用。
我們無法實際使用它......如果我們確實使用它,它產生的結果將是完全隨機的!
所以我們需要解決這些問題!
使用我們的網路!
我們需要做的第一件事是實際獲取一些輸入,透過我們的網路執行它們並收集輸出。
這是我想出來的:
propagate(inputs) {
const output = new Array(this.outputLen);
for (let i = 0; i < this.outputLen; i++) {
output[i] = 0;
for (let j = 0; j < this.inputLen; j++) {
output[i] += this.weights[i][j] * inputs[j];
}
output[i] += this.bias[i];
output[i] = this.sigmoid(output[i]);
}
return output;
}
sigmoid(x) {
return 1 / (1 + Math.exp(-x));
}
現在這裡有兩件有趣的事情。
乙狀結腸
首先,一件有趣的事情是我們的“sigmoid”函數。它所做的只是沿著「S 形」曲線將我們輸入的值(例如 12)轉換為 0 到 1 之間的值。
這是我們將價值觀從極端標準化為更統一的且始終為正值的方式。
進一步閱讀後,這裡還有其他關於如何將值更改為 0 到 1 之間的選項,但我還沒有完全探索它們(例如 ReLU 如果你想閱讀相關內容)。
我確信有一些很好的解釋為什麼需要這樣做,但在我的猴腦中,這只是將值保持在 0 和 1 之間的方法,以便乘法保持在一定範圍內並且值被「展平」。
這樣你就不會在過於強大的神經元之間出現「失控」的路徑。
例如,假設您有一個權重為 16 的連接和一個權重為 1 的連接,使用我們的 sigmoid 函數,我們可以將其從 16 倍的差異減少到大約 35% 的差異(「sigmoid(1)」為0.73 ,執行我們的函數後,sigmoid(16) 為0.99)。
這也意味著負值變成正值。
因此,透過 sigmoid 函數執行值意味著負數會轉換為 0 到 0.5 之間的值,0 的值恰好變成 0.5,大於 0 的值變成 0.5 到 1 之間的值。

如果你考慮一下,這是有道理的,因為當我們開始將負數和正數相乘時,我們可以極大地改變我們的輸出。
例如,如果我們在 100 的路徑中有一個負神經元,而其餘的都是正神經元,這會將強值更改為弱值,並且可能會導致問題。
不管怎樣,隨著我閱讀更多和實驗更多,我相信我會更好地理解這一部分!
我需要偏見嗎?
第二個有趣的是「output[i] += this.bias[i];」。
好吧,在這個神經網路中,所有 4 個輸出都同樣重要,而且我們沒有隱藏神經元,所以我後來刪除了它以簡化程式碼!
但諷刺的是,在我們更複雜的神經網路上,由於網路反向傳播的工作方式,我需要重新加入輸出神經元的偏差。否則,一個輸出神經元會一直啟動。
我無法弄清楚這是否是必要的步驟,或者我的神經網路是否犯了一個錯誤,而這是為了彌補它。
再次提醒大家,我還在學習中,只是掌握了基礎知識,所以我不知道它是什麼! 🤣
我們快到了
上面的其餘程式碼相當簡單。我們只是將每個輸入乘以與每個輸出相關的權重(並加入不必要的偏差!)。
事實上,我們現在就可以執行它,但結果會很糟糕!讓我們來解決這個問題!
訓練時間到了!
好吧,神經網路的最後一個重要部分是訓練它!
現在,隨著這篇文章越來越長,我將只介紹以下訓練程式碼的要點(順便說一下,我花了將近一個小時來編寫......我告訴過你我對此是個菜鳥! )
train(inputs, target) {
const output = this.propagate(inputs);
const errors = new Array(this.outputLen);
for (let i = 0; i < this.outputLen; i++) {
errors[i] = target[i] - output[i];
for (let j = 0; j < this.inputLen; j++) {
this.weights[i][j] +=
this.learningRate *
errors[i] *
output[i] *
(1 - output[i]) *
inputs[j];
}
this.bias[i] += this.learningRate * errors[i];
}
}
“為什麼花了這麼長時間?”我聽到你問了!好吧,它讓我思考了所有需要相乘才能更新每個權重的位元。
另外 this.learningRate 也需要一點時間來適應。這只是降低我們改變權重的速率,這樣我們就不會“超過”每個權重的目標值,但是將其調整到合理的值需要經驗......我沒有經驗並且設置得太低,所以我的程式碼看起來被破壞了!
經過一番擺弄後,我將數值定為 0.1(而不是 0.01 🤦🏼♂️),突然間事情開始變得更好了!
是的,所以我們有一個訓練函數。但請記住,此訓練功能僅進行一次訓練。
我們需要對我們的網路進行多次訓練,希望每次訓練都能使其更加準確。
我們將在一秒鐘內討論這一點,但我想分享一個快速的側面/我學到的東西。
訓練資料調整
我知道我們甚至還沒有涵蓋最終的訓練資料,但這是我學到的一個有趣的觀點,適合這裡(因為它解釋了為什麼我花了這麼長時間來編寫這個訓練函數)。
最初我產生了數百個不同的訓練 X 和 Y 座標,全部都是隨機的。
但經過進一步閱讀後,我只產生 4 個靜態訓練點,得到了更好的結果:
const trainingData = [
{ x: -0.5, y: -0.5, label: "blue" },
{ x: 0.5, y: -0.5, label: "red" },
{ x: -0.5, y: 0.5, label: "green" },
{ x: 0.5, y: 0.5, label: "purple" }
];一旦你明白了,就很有意義了!
我們希望「拉」值更接近目標,上述值是我們每個區域的確切「中心點」。
因此,對於給定的距離,我們的錯誤率將始終保持一致。
這意味著我們的神經網路學習得更快,因為我們的錯誤率更大,這取決於它們距離 X 更遠還是距離 Y 更遠。
我可以更好地解釋這一點,但這超出了本文的範圍。希望如果您仔細考慮一下,那麼它也會像對我一樣為您「點擊」!
諷刺的是,我回到了更大模型的更隨機的資料集,因為我想真正測試我對學習率、過度訓練等的理解。
我們有一個有效且有用的神經網路!
實際上,這就是我們的整個神經網路。
不過,我們需要做一件事。
我們的訓練函數需要執行很多次!
因此,我們需要最後一個函數來做到這一點,它獲取我們的訓練資料並執行我們的訓練函數數百次:
function train() {
for (let i = 0; i < 10000; i++) {
const data =
trainingData[Math.floor(Math.random() * trainingData.length)];
neuralNetwork.train([data.x, data.y], encode(data.label));
}
console.log("Training complete");
}
金髮女孩迭代
請注意,我們在「for」循環中訓練網路 10,000 次。
10,000 次迭代足以訓練這個特定的神經網路。但對於我們稍後將介紹的更複雜的問題,我需要更多的迭代(並降低學習率)。
這是機器學習有趣的部分之一,您需要足夠地訓練神經網路(這很難做到正確),但如果訓練太多,就會發生“過度擬合”,並且實際上開始得到更糟糕的結果。因此,為了獲得最佳結果,需要完美平衡!
不管怎樣,已經很多了,我們終於迎來了第一個示範!
簡單的普通 JS 神經網路演示
雖然有點亂,但我們的神經網路和所有訓練部分都在下面 CodePen 的前 67 行。
其餘程式碼行實際上執行我們的網路(“neuralNetwork.propagate([x, y]);”大約第 85 行),然後將點及其預測顏色輸出到“<canvas>”上。
「encode」和「decode」純粹是為了獲取我們的輸出神經元,找到哪個神經元具有最高的激活,然後將其映射到我們可視化的顏色。
這是最後要理解的事。我們的輸出神經元都會有一個值。神經網路不僅僅輸出 1, 0, 0, 0。
相反,它會輸出每個輸出神經元的「確定性」或猜測。因此我們將得到類似「0.92,0.76,0.55,0.87」的輸出。
這就是為什麼我們有“解碼”函數,它找到最高輸出的神經元並將其作為我們的最終猜測!
// this line finds the max value of all of our output neurons and then returns its index so we can use that to classify our X and Y coordinates.
const maxIndex = output.indexOf(Math.max(...output));用法和實際演示
要使用該範例,您有 3 個按鈕:
-
訓練 - 在我們的神經網路開始未經訓練和隨機化時對其進行訓練。
-
分類點 - 這是為了執行我們的神經網路。它將在圖表上繪製點並為它們分配顏色。我建議在訓練之前和之後執行這個。
-
重設 - 這將建立一個未經訓練的新神經網路。非常適合在訓練前後測試點的分類。
另請注意,每個區域都根據該區域應顯示的顏色進行著色。它真的可以讓您看到隨機且未經訓練的神經網路距離成功還有多遠(重置然後對測試點進行分類)!
玩吧!
https://codepen.io/GrahamTheDev/pen/abPxoqb
我們最基本的神經網路結束
這樣我們就有了最基本的神經網路!
它可以很好地滿足我們的需求,並且我們設法了解了一些關於反向傳播(我們在主類別中的“train”函數)以及權重和偏差的知識。
但這是非常有限的。如果我們將來想做更高級的事情,我們需要加入一些隱藏神經元!
版本 2 - 隱藏神經元
好的,那為什麼要隱藏神經元呢?他們的目的是什麼?
在更複雜的範例中,它們充當獲取輸入並為它們的分類方式加入更多維度的方式。
我們仍然使用 2 個輸入神經元和 4 個輸出神經元,但這次我們在中間加入了一個附加層(我們可以更改和調整其中神經元的數量)。
所以我們的神經網路看起來像這樣:

由於神經網路需要處理更多的輸入並進行更複雜的計算,隱藏層中的額外神經元使它們能夠更好地對輸入進行分類並提供更好的結果。
隱藏層也可以是不同的「深度」。
假設我們有 2 個輸入神經元。我們可以將它們連接到 6 個「隱藏」神經元,然後將它們連接到 4 個輸出神經元。
但我們也可以將第一層的 6 個神經元連結到第二層隱藏神經元。第二層可能有 8 個神經元,然後連接到我們的 4 個輸出神經元。
但要遵循的內容還有很多,這是為了讓我學習基礎知識,所以我選擇加入一個隱藏層。這也意味著我可以將每個連接層保留為單獨的陣列,這在現階段更容易理解!
那麼有什麼新內容呢?
沒有太大變化,只是我們有了更多的連結和更多的神經元!
您可以將其視為串聯加入 2 個原始神經網絡,只是第一個神經網路的輸出現在充當第二個神經網路的輸入。
雖然程式碼可能更加複雜,但我們的神經網路遵循相同的原則。
這是程式碼:
class NeuralNetwork {
constructor(inputSize, hiddenSize, outputSize) {
this.inputSize = inputSize;
this.hiddenSize = hiddenSize;
this.outputSize = outputSize;
this.weightsInputToHidden = Array.from({ length: hiddenSize }, () =>
Array.from({ length: inputSize }, () => Math.random() * 2 - 1)
);
this.biasHidden = Array(hiddenSize).fill(0);
this.weightsHiddenToOutput = Array.from({ length: outputSize }, () =>
Array.from({ length: hiddenSize }, () => Math.random() * 2 - 1)
);
this.biasOutput = Array(outputSize).fill(0);
this.learningRate = document.querySelector('#learningRate').value; // Adjusted learning rate
this.hiddenLayer = new Array(this.hiddenSize);
}
feedForward(inputs) {
for (let i = 0; i < this.hiddenSize; i++) {
this.hiddenLayer[i] = 0;
for (let j = 0; j < this.inputSize; j++) {
this.hiddenLayer[i] +=
this.weightsInputToHidden[i][j] * inputs[j];
}
this.hiddenLayer[i] += this.biasHidden[i];
this.hiddenLayer[i] = sigmoid(this.hiddenLayer[i]);
}
const output = new Array(this.outputSize);
for (let i = 0; i < this.outputSize; i++) {
output[i] = 0;
for (let j = 0; j < this.hiddenSize; j++) {
output[i] +=
this.weightsHiddenToOutput[i][j] * this.hiddenLayer[j];
}
output[i] += this.biasOutput[i];
output[i] = sigmoid(output[i]);
}
return output;
}
train(inputs, target) {
for (let i = 0; i < this.hiddenSize; i++) {
this.hiddenLayer[i] = 0;
for (let j = 0; j < this.inputSize; j++) {
this.hiddenLayer[i] +=
this.weightsInputToHidden[i][j] * inputs[j];
}
this.hiddenLayer[i] += this.biasHidden[i];
this.hiddenLayer[i] = sigmoid(this.hiddenLayer[i]);
}
const output = new Array(this.outputSize);
for (let i = 0; i < this.outputSize; i++) {
output[i] = 0;
for (let j = 0; j < this.hiddenSize; j++) {
output[i] += this.weightsHiddenToOutput[i][j] * this.hiddenLayer[j];
}
output[i] += this.biasOutput[i];
output[i] = sigmoid(output[i]);
}
const errorsOutput = new Array(this.outputSize);
const errorsHidden = new Array(this.hiddenSize);
for (let i = 0; i < this.outputSize; i++) {
errorsOutput[i] = target[i] - output[i];
for (let j = 0; j < this.hiddenSize; j++) {
this.weightsHiddenToOutput[i][j] +=
this.learningRate *
errorsOutput[i] *
output[i] *
(1 - output[i]) *
this.hiddenLayer[j];
}
this.biasOutput[i] += this.learningRate * errorsOutput[i];
}
for (let i = 0; i < this.hiddenSize; i++) {
errorsHidden[i] = 0;
for (let j = 0; j < this.outputSize; j++) {
errorsHidden[i] += this.weightsHiddenToOutput[j][i] * errorsOutput[j];
}
this.biasHidden[i] += this.learningRate * errorsHidden[i];
for (let j = 0; j < this.inputSize; j++) {
this.weightsInputToHidden[i][j] +=
this.learningRate *
errorsHidden[i] *
this.hiddenLayer[i] *
(1 - this.hiddenLayer[i]) *
inputs[j];
}
}
}
}
現在,不要被嚇倒,我剛剛複製了幾個循環,其中要操作的目標資料集略有不同。
我們加入了一組額外的偏差(對於我們的隱藏層)和一組額外的連接:我們的輸入層到我們的隱藏層,然後我們的隱藏層現在連接到我們的輸出層。
最後,我們的「train」函數有一些額外的循環,只是為了透過每個步驟進行反向傳播。
唯一值得一提的其他變化是我們現在有第三個輸入參數(中間),用於隱藏神經元的數量。
醜陋,但似乎有用
看,我想再說一遍,這是我一邊學習一邊學習,所以程式碼反映了這一點。
這裡有很多重複,可擴展性不太好。
然而,據我所知,它是有效的。
話雖如此,雖然它有效,但它的性能似乎比我們原來的、簡單得多的神經網路要差。
這要么意味著我犯了一個錯誤(可能),要么是我沒有「撥入」正確的訓練設定。
說到這裡...
加入一些變數來玩
由於這更複雜,我在一些快速設定中「迴避」了。
現在我們可以更新:
-
訓練資料大小 - 我們產生的不同隨機點的數量
-
訓練迭代 - 我們從訓練集中選擇隨機資料點並將其輸入神經網路上的「訓練」函數的次數。
-
學習率 - 我們根據錯誤調整速度的乘數。
-
隱藏節點(超過2個!) - 調整第二層有多少個隱藏節點(需要您再次初始化網絡,否則會損壞!)
-
要分類的點 - 傳遞給我們訓練過的神經網路並繪製在圖表上的點數。
這意味著我們可以更快地處理這些值,看看它們對我們的神經網路及其準確性有什麼影響!
最後一件事
哦,我加入了一個按鈕來視覺化神經網路的樣子。
無論如何按“可視化神經元和權重”,但它還沒有完成。我也沒有立即完成它的打算,因為我想完全重新設計建構神經網路的方法,使其更具可擴展性。
不過,按鈕就在那裡,請隨意按下。更好的是,請隨時為我修復它! 🤣💗
演示
控制項與以前相同,加上前面 2 個小節中提到的輸入。
試試一下,看看是否可以微調學習率、神經元數量和訓練設定以獲得真正準確的結果!
https://codepen.io/GrahamTheDev/pen/qBLwBxP
請務必更新一些值,重新初始化神經網絡,嘗試使用不同數量的隱藏神經元等。
如果您像我一樣是初學者,希望您能開始理解一些事情!
結論
用 vanilla JS 建立神經網路真的很有趣。
我沒有見過很多人這樣做,所以我希望它對你或至少對某人有用!
我學到了很多關於偏差、反向傳播(神經網路的關鍵)等的知識。
顯然這個例子和這裡學到的東西只是機器學習的1%。但對於像我這樣的微小的、未優化的神經網路和巨大的數十億參數模型來說,核心原理是相同的。
這個例子就像機器學習 (ML) 和神經網路的「hello world」。
接下來,我真的想嘗試建立一個更大的、結構更好、更容易擴展的神經網絡,看看我們是否可以進行一些光學字元辨識(OCR)。您可以將其視為機器學習和神經網路的“待辦事項清單”!
發表評論。
您是神經網路專家嗎?告訴我我哪裡錯了!
你是像我一樣的初學者嗎?那麼請告訴我這是否有助於您理解,至少一點點!或者,如果這實際上讓事情變得更加混亂! 😱
最重要的是,如果這篇文章激發了您對我糟糕的編碼做鬼臉,或者想要建置您自己的神經網絡......那麼我很高興它對您產生了一些影響,並且很樂意聽到它! 💗
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式