

我們正在開發一個 React 和 Node.js 的全端 Web 框架,它使用簡單的設定語言來擺脫樣板檔案。很多次,我們被問到,「為什麼你要費心去建立一個新的 Web 應用程式開發框架?無論如何,ChatGPT / LLM X 不是很快就會為開發人員生成所有程式碼嗎?」。
這是我們對當前情勢的看法,也是我們相信未來的情況。
為什麼我們需要(AI)程式碼產生?
為了讓開發速度更快,我們首先提出了 IDE 自動補全 - 如果您正在使用 React 並開始輸入 use,IDE 將自動向 useState() 或 useEffect() 提供補全。除了節省擊鍵次數之外,也許更有價值的是能夠查看目前範圍內有哪些方法/屬性可供我們使用。 IDE 對專案結構和程式碼層次結構的感知也使重構變得更加容易。
雖然這已經很棒了,但是我們如何將其提升到一個新的水平? 傳統的 IDE 支援是基於人類編寫的規則,例如,如果我們想讓 IDE 能夠為我們實現常用功能(例如, 使用API Y 取得X,或實現快速排序),其中的數量太多,無法手動進行分類和維護。
如果有一種方法可以讓電腦分析我們迄今為止編寫的所有程式碼,並自行學習如何自動完成我們的程式碼以及如何對待人類,而不是我們做所有艱苦的工作...
除了美味又濕潤的蛋糕,我們其實已經做到了!由於機器學習的最新進展,IDE 現在可以做一些非常酷的事情,例如根據函數的名稱和頂部的簡短註釋來建議函數的完整實現:
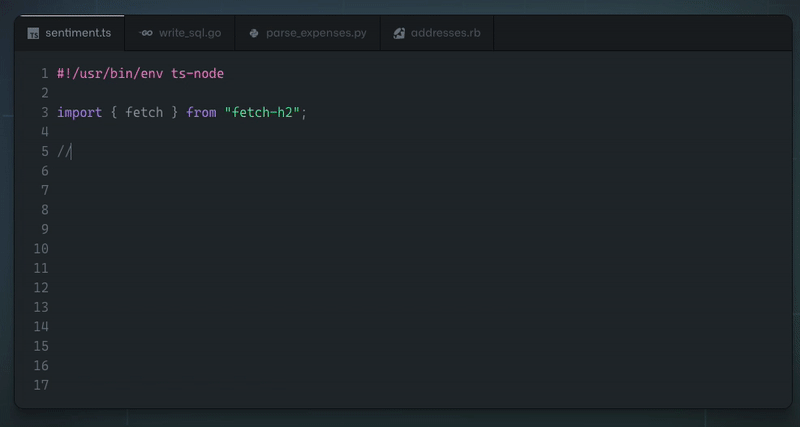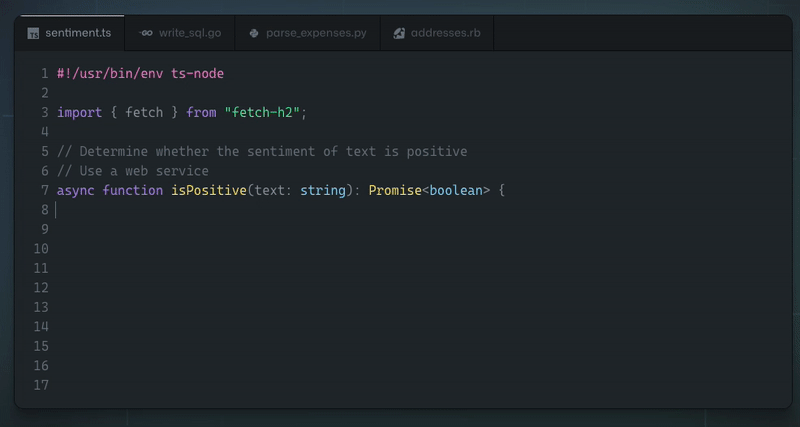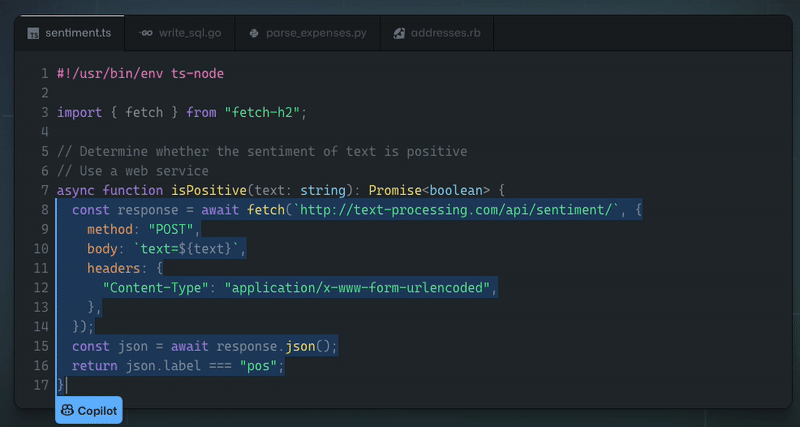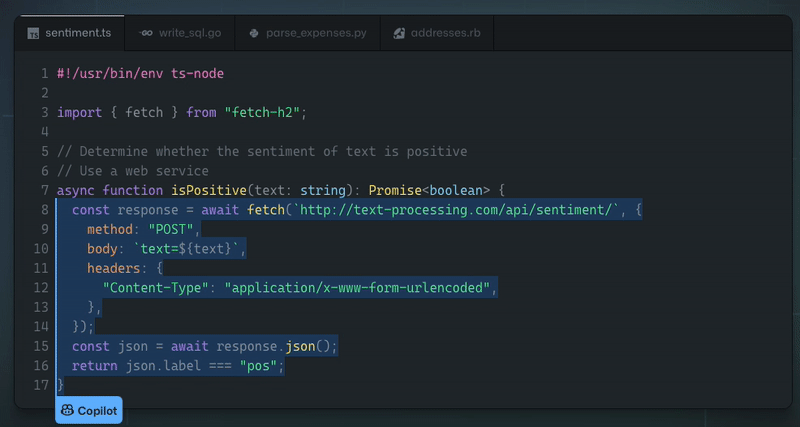
這真是太神奇了!上面的範例由 Github Copilot 提供支援 - 它本質上是一個在大量公開可用程式碼上訓練的神經網路。我不會深入了解其幕後工作原理的技術細節,但有很多精彩的文章和影片涵蓋了背後的科學知識。
看到這一點,問題出現了 - 這對程式設計的未來意味著什麼? 這只是 IDE 自動補全功能還是其他什麼?如果我們只需在註釋中輸入我們想要的內容就可以了,我們還需要繼續手動編寫程式碼嗎?
支持我們! 🙏⭐️

如果您想表達對我們正在做的事情的支持,請考慮在 Github 上給我們一顆星!我們在 Wasp 所做的一切都是開源的,您的支持激勵我們並幫助我們不斷簡化 Web 應用程式開發並減少樣板程式碼。

大問題:程式碼產生後由誰維護?
在思考 ML 程式碼產生如何影響整個開發過程時,有一點需要考慮,但在查看所有令人印象深刻的範例時,通常不會立即想到這一點。
問題是 - 生成程式碼後會發生什麼?誰負責,將來誰來維護和重構?
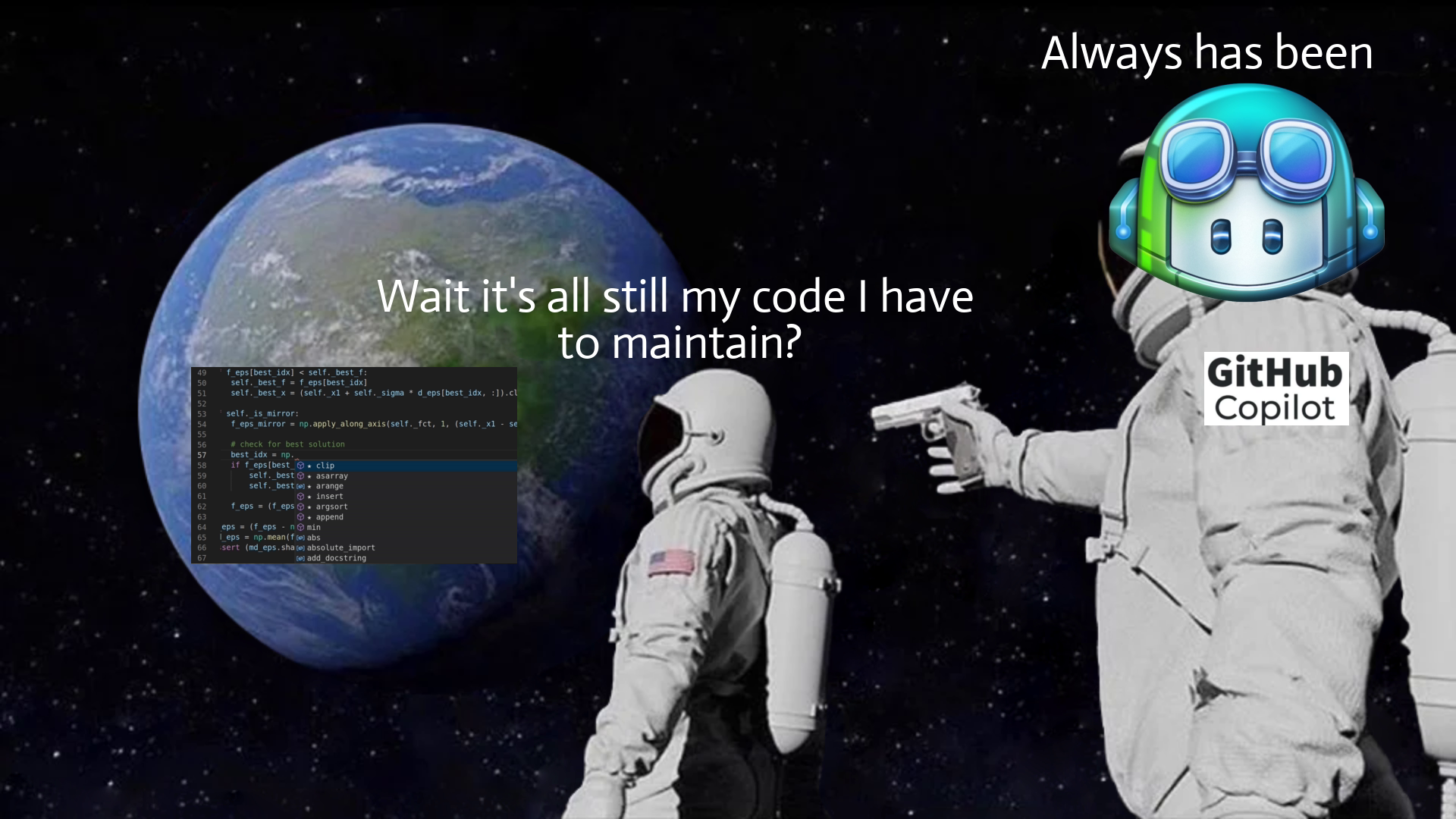
儘管 ML 程式碼產生有助於編寫特定功能的初始程式碼,但它不能做更多的事情 - 如果將來要維護和更改該程式碼(如果有人使用該產品,那麼開發人員仍然會這樣做)需要完全擁有並理解它。你可以再次使用人工智慧來幫助你,但最終,你是負責的人。
想像一下,我們擁有的只是一種彙編語言,但程式碼生成非常適合它,你可以說“實現一個對陣列進行升序排序的函數”,它將完美地生成所需的程式碼。一旦您需要將排序更改為降序,您是否仍想在將來返回該功能?
或者,更貼近我們的日常生活,如果產生的 React 程式碼使用舊的類別語法,或者函數式元件和鉤子,對你來說是否都是一樣的?
換句話說,這意味著GPT 和其他LLM 不會降低程式碼複雜性,也不會降低建置功能所需的知識量,它們只是幫助更快地編寫初始程式碼並使知識/範例更接近程式碼(其中真的很有幫助)。 如果開發人員盲目接受生成的程式碼,他們只是在創造技術債並推動其向前發展。
認識大 A - 抽象 👆
如果 ChatGPT 和這群人無法解決我們學習如何編碼和詳細理解(例如透過 JWT 進行會話管理)工作原理的所有麻煩,還有什麼可以呢?
抽象化——這就是程式設計師幾十年來透過建立庫、框架和語言來處理程式碼重複和降低複雜性的方式。這就是我們從普通 JS 和直接 DOM 操作到 jQuery,最後到 React 和 Vue 等 UI 函式庫的方式。
引入抽像不可避免地意味著放棄一定的功能和靈活性(例如,在 Python 中對數字求和時,您無法準確指定將使用哪些 CPU 寄存器),但重點是,如果如果做得好,在大多數情況下你不需要也不想要這樣的權力。

不對一段程式碼負責的唯一方法是它從一開始就不存在。
因為一旦螢幕上的像素改變顏色,你就必須擔心,這就是為什麼所有框架、語言等的主要好處是更少的程式碼==更少的決策==更少的責任。
擁有更少程式碼的唯一方法是做出更少的決定,並向計算機提供更少的關於如何完成某項任務的細節- 理想情況下,我們只需要說明我們想要什麼,我們甚至不會關心它是如何完成的,只要它在我們擁有的時間/記憶體/成本邊界內(所以我們可能也需要說明這些)。
讓我們來看看網路應用程式世界中非常常見(也是每個人最喜歡的)功能 - 身份驗證(yaay ☠️ 🔫)!它的典型程式碼如下所示:
import jwt from 'jsonwebtoken'
import SecurePassword from 'secure-password'
import util from 'util'
import prisma from '../dbClient.js'
import { handleRejection } from '../utils.js'
import config from '../config.js'
const jwtSign = util.promisify(jwt.sign)
const jwtVerify = util.promisify(jwt.verify)
const JWT_SECRET = config.auth.jwtSecret
export const sign = (id, options) => jwtSign({ id }, JWT_SECRET, options)
export const verify = (token) => jwtVerify(token, JWT_SECRET)
const auth = handleRejection(async (req, res, next) => {
const authHeader = req.get('Authorization')
if (!authHeader) {
return next()
}
if (authHeader.startsWith('Bearer ')) {
const token = authHeader.substring(7, authHeader.length)
let userIdFromToken
try {
userIdFromToken = (await verify(token)).id
} catch (error) {
if (['TokenExpiredError', 'JsonWebTokenError', 'NotBeforeError'].includes(error.name)) {
return res.status(401).send()
} else {
throw error
}
}
const user = await prisma.user.findUnique({ where: { id: userIdFromToken } })
if (!user) {
return res.status(401).send()
}
const { password, ...userView } = user
req.user = userView
} else {
return res.status(401).send()
}
next()
})
const SP = new SecurePassword()
export const hashPassword = async (password) => {
const hashedPwdBuffer = await SP.hash(Buffer.from(password))
return hashedPwdBuffer.toString("base64")
}
export const verifyPassword = async (hashedPassword, password) => {
try {
return await SP.verify(Buffer.from(password), Buffer.from(hashedPassword, "base64"))
} catch (error) {
console.error(error)
return false
}
}這只是後端程式碼的一部分(僅適用於用戶名和密碼方法)!正如您所看到的,我們在這裡有很大的靈活性,可以執行/指定以下操作:
-
選擇身份驗證的實作方法(例如會話或基於 JWT)
-
選擇我們想要用於令牌(如果使用 JWT)和密碼管理的確切 npm 套件
-
解析 auth 標頭並指定每個值(授權、承載等)如何回應
-
為每個可能的結果選擇回傳程式碼(例如 401、403)
-
選擇密碼的解碼/編碼方式 (base64)
一方面,在我們的程式碼中擁有這種程度的控制和靈活性確實很酷,但另一方面,需要做出很多決定(==錯誤),特別是對於像身份驗證這樣常見的事情!
如果後來有人問“那麼你到底為什麼選擇secure-password npm 包,或者為什麼到底是base64 編碼?”,我們可能應該用其他東西來回答,而不是“好吧,2012 年有一篇看起來相當合法的帖子,它有近 50 票贊成。嗯,不過現在找不到了。另外,它的名字裡有‘安全’,聽起來不錯,對吧?”
另一件要記住的事情是,我們還應該追蹤事情如何隨著時間的推移而變化,並確保幾年後,我們仍然使用最佳實踐,並且軟體包定期更新。
如果我們嘗試應用上面的原則(更少的程式碼,更少的詳細說明,說明我們想要什麼而不是需要做什麼),身份驗證的程式碼可能如下所示:
auth: {
userEntity: User,
externalAuthEntity: SocialLogin,
methods: {
usernameAndPassword: {},
google: {}
},
onAuthFailedRedirectTo: "/login",
onAuthSucceededRedirectTo: "/dashboard"
}基於此,計算機/編譯器可以處理上面提到的所有內容,然後根據抽象級別,提供某種接口(例如表單元件或函數)來“掛鉤”我們自己的接口,例如React/Node.js 程式碼(順便說一句,這就是它實際上在 Wasp 中工作 的方式)。
我們不需要關心底層使用了什麼確切的套件或加密方法 - 這是我們信任抽象層的作者和維護者的責任,就像我們相信 Python 最了解如何將兩個數字相加一樣裝配水平,並與該領域的最新進展保持同步。當我們依賴內建資料結構或依靠垃圾收集器來很好地管理程式記憶體時,也會發生同樣的情況。
但是我產生的漂亮程式碼😿💻!那麼會發生什麼事呢?
別擔心,一切都還在這裡,您可以產生您想要的所有程式碼!這裡要理解的要點是,人工智慧程式碼生成和框架/語言開發是相互補充而不是替代,並且將繼續存在,這最終對開發人員社群來說是一個巨大的勝利——它們將繼續讓我們的生活更輕鬆,讓我們能夠做更多有趣的事情(而不是第 n 次實作 auth 或 CRUD API)!
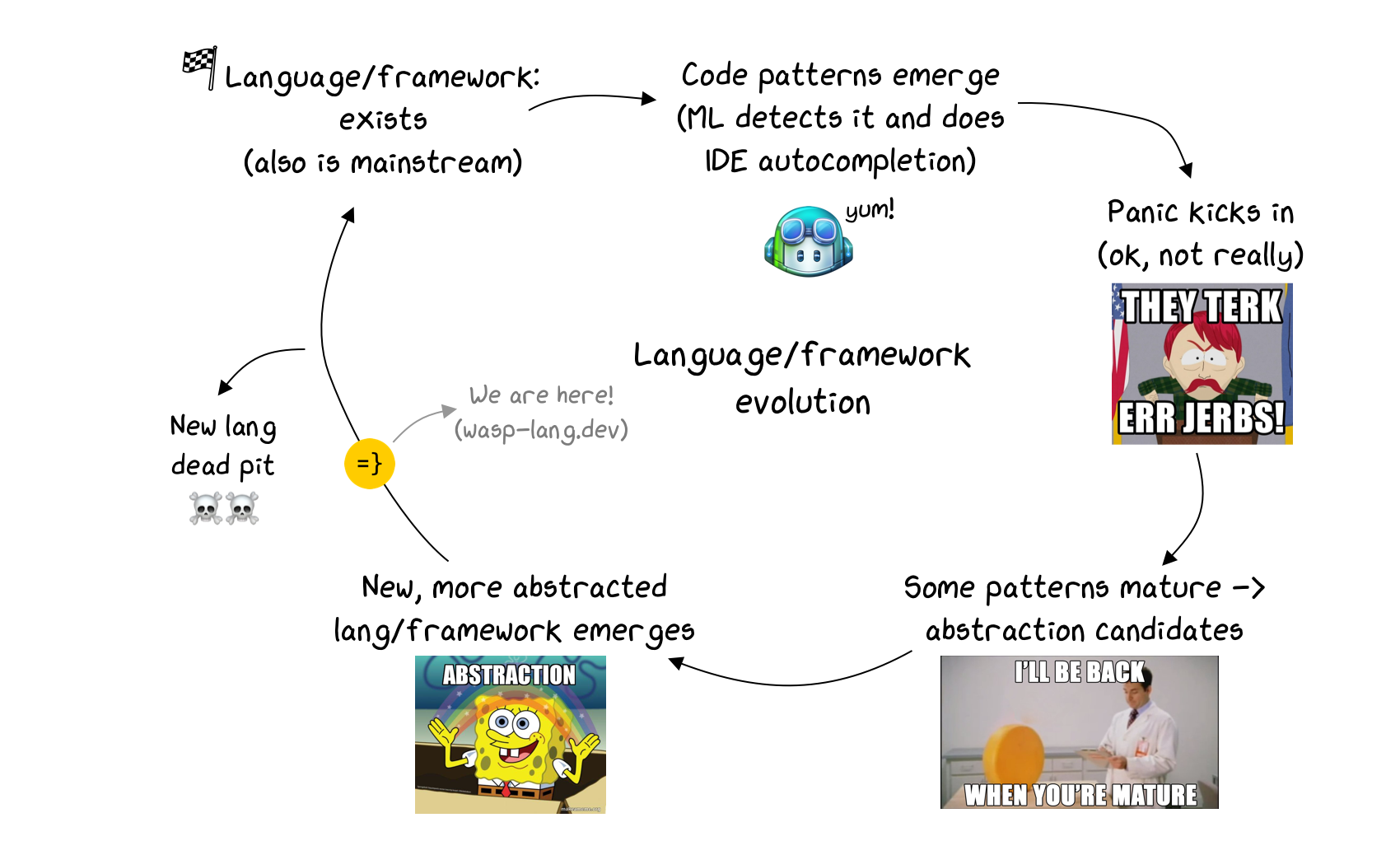
我將這裡的演變視為一個循環(或實際上是螺旋式上升,但這超出了我的繪圖能力):
-
語言/框架:存在,是主流,很多人使用它
-
模式開始出現(例如實作身份驗證,或進行 API 呼叫)→ AI 學習它們,透過自動完成提供
-
其中一些模式成熟並變得穩定→抽象的候選者
-
新的、更抽象的語言/框架出現
-
返回步驟 1。
結論
這意味著我們雙贏——當語言成為主流時,我們可以從人工智慧驅動的程式碼產生中受益,幫助我們更快地編寫程式碼。另一方面,當我們不想重複/處理的程式碼模式出現並變得穩定時,我們就得到了一種全新的語言或框架,它允許我們編寫更少的程式碼並關心更少的實作細節!

感謝您的閱讀,並希望您發現這篇文章內容豐富!我很想聽聽您是否同意(或不同意)這一點,以及您如何看待人工智慧工具驅動的程式設計的未來。

1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式