

Hello,我是 Maneshwar。我正在打造 git-lrc,一個會在每次 commit 時執行的微型 AI 程式碼審查工具。它在 GitHub 上免費且原始碼可用。請給 git-lrc 按星,幫助開發者發現這個專案。歡迎試用並分享你的回饋。
我剛剛丟給 Claude 一個很蠢的小點點謎題。
. .. . ... . .... . .... . ... .它回覆說缺少的結尾是:
.. .一開始我想:
「等等……LLM 只會預測下一個 token。
它們不會執行演算法。
它們不會推理。
那它到底是怎麼推理出來的?」
這個問題把我帶進了一個無底洞。
因為如果你檢查答案,會發現它是對的。
單獨的點只是分隔符;真正的群組依序上升成 2 3 4,再鏡像回落成 4 3 2。
把點的數量從頭讀到尾,會得到一個漂亮的回文:
1 2 1 3 1 4 1 4 1 3 1 2 1而且重點是,這個謎題模型可能從來沒看過。
我一直帶在身邊的那種民間版模型告訴我,LLM「只是根據向量和訓練時看過的內容猜下一個詞」。
如果它只做這件事,那麼一個棘手的謎題應該會把它難倒。
因為根本沒有什麼「下一個詞」的統計可以依賴。
所以,不是那個心智模型錯了,就是背後其實有更有趣的事情在發生。
答案是後者。以下是我挖到的東西。
「預測下一個 token」是目標,不是方法
是的,這些模型的訓練目標就是預測下一個 token(大致上就是下一段文字)。
這部分民間說法是對的。
但大家常常跳過一件事:那只是它被評分的目標,不是它學會了什麼的描述。
想像一個學生,只有在考試題目上才會被評分。
嚴格來說,他們「做」的事情就是回答考試題目。
但要在大量不同題型上都表現好,他們不能只是死背答案。
他們必須真的學會算術、邏輯、怎麼讀懂題目。
考試是壓力。
理解力是在壓力之下長出來的東西。
道理一樣。若要在數兆個 token 上都能很好地預測下一個 token——也就是包含數學、程式碼、論證、故事,還有對,包含謎題的文字——光靠記住「詞 X 往往接在詞 Y 後面」是行不通的。
可供輸入的空間幾乎是無限的,而你餵給它的大多數內容都會是新內容。
在那種規模下,要把預測誤差降下來,唯一的方法就是發展出能泛化的內部機制:計數、比較、辨識對稱、延續模式。
這些能力之所以湧現,是因為它們對預測任務有幫助。
沒有人手工寫一個「偵測回文」函式。
那是一種在持續最佳化中自然長出來的能力,就像學生真正的理解力會在持續測驗中長出來一樣。
如果「學生」這個比喻對你沒感覺,那麼大多數開發者會比較有共鳴的是:壓縮。
想像你必須把人類寫過的每一本書都壓縮成最小可能的表示。
你不可能只存原始文字就想過關,你會被迫去發現底層規律:文法、反覆出現的敘事結構、算術、化學規則、程式碼的形狀。
不是因為有人教你這些概念,而是因為把資料表示得更有效率,最終就會逼你把這些概念抓出來。
訓練 LLM 去預測文字也是同樣的擠壓。
好的預測需要對世界中的模式建立緊湊的內部模型,所以模型就會把它們建出來。
這是對民間模型最重要的一次升級:下一個 token 預測是訓練訊號,而廣泛的能力是模型為了滿足這個訊號所找到的策略。
劇情反轉:我的謎題其實不是在講點
在談機制之前,有一件事改變了我對這個問題的看法。
模型根本不「看見」點。
它看見的是 token,也就是 tokenizer 將輸入切分後的各種片段。而實際怎麼切其實不重要,因為對模型來說,我這個謎題在結構上完全等同於:
A AA A AAA A AAAA A AAAA A AAA A或是
1 2 1 3 1 4 1 4 1 3 1 ...點只是外衣。
模型真正處理的是序列的抽象形狀:分隔符交錯出現,接著是先上升再下降的計數。
這就是它能泛化的一個重要線索:它不是在比對「點」,而是在操作承載這些符號的、與符號本身無關的結構。
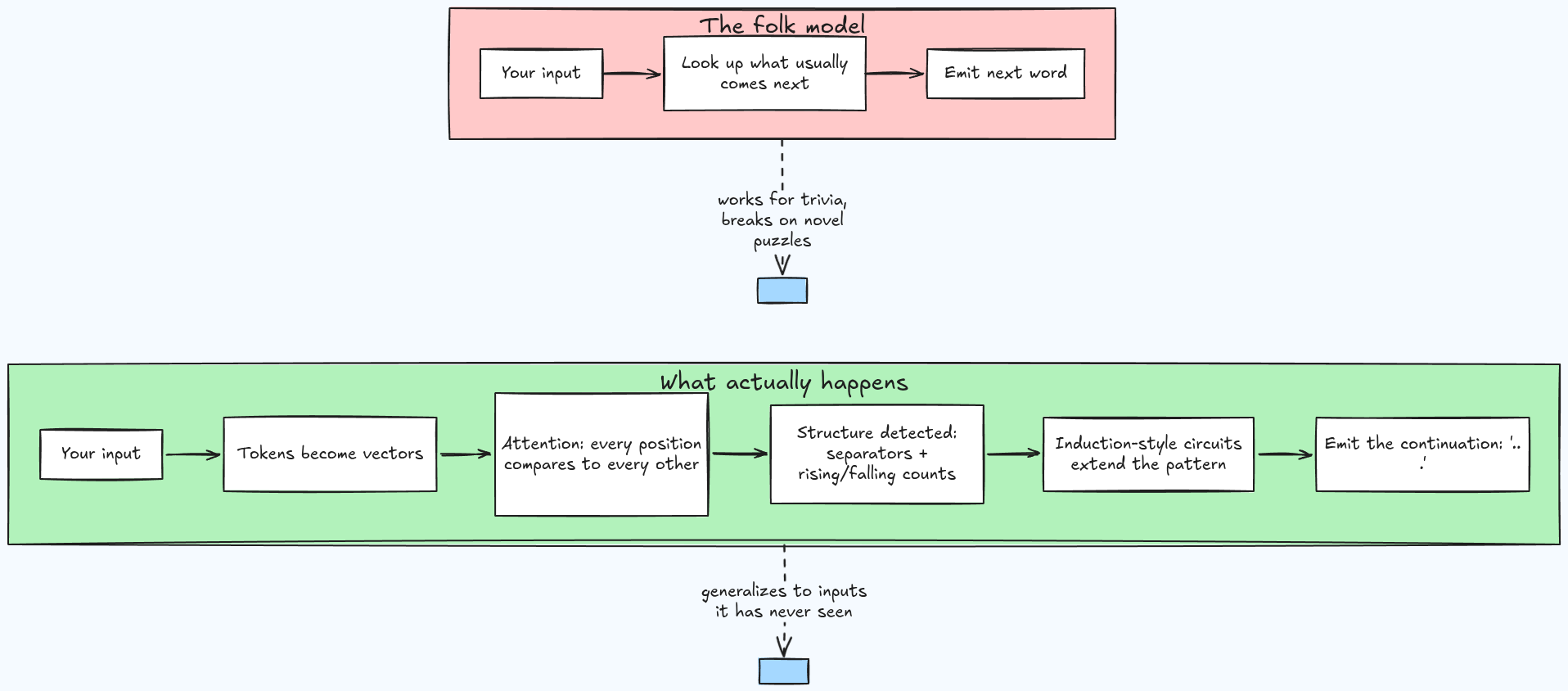
民間模型完全漏掉的部分:注意力
那種「每個詞都只和前一個詞有關,這些關係在訓練時就固定了」的想像,漏掉了真正負責大部分工作的機制。
它叫做注意力(attention),而且是所有現代 LLM 所用 Transformer 架構的核心。
直覺上是這樣:
模型處理輸入時,每個位置都可以「看向」其他每個位置,並即時計算它們之間的關係,針對這一次的輸入臨時算出來。
這不是訓練時就烤死在模型裡的固定查表。
每次你按下 Enter,它都會重新計算一次。
所以對那個點點謎題來說,並不是某個地方叫出了一個儲存好的「點點謎題答案」。比較像是:
- 重複出現的單獨點被辨識成分隔元素。
- 各個區塊彼此被拿來比較。
- 先上升再下降的數量(
2, 3, 4, 4, 3, …)被表徵成一種結構,而這種結構「傾向」繼續往下。
而那些 token 向量呢?它們不只是「這個符號的意思」。
它們攜帶的是可被幾何式操作的抽象特徵。
「把這個序列鏡像回來」正是當資料以合適的向量形式存在時,變得可處理的那種操作。
計數與反射不再像魔法,而開始像是在表徵上做算術。
還有一個值得點出的深度維度。
注意力不是一次就結束的過程,表徵會在數十層中流動時被持續修正,每一層都多加一點抽象。
一個鬆散、用來說明的直覺(不是任何單層真的「在想」這句話):
- 前面幾層:「這些符號在重複。」
- 中間幾層:「每一段更長的串之間都隔著一個單獨的點。」
- 後面幾層:「整體是對稱的,我們大概是在補成一個鏡像。」
沒有任何一層真的存著一句英文句子。
但內部向量會逐步編碼更高層次的屬性,直到在那個學到的空間裡,「完成回文」就成了顯而易見的延續。
下面就是我們腦中那個模型,和實際在運作的東西之間的差異:
為什麼它能解出從沒看過的謎題
這才是「它怎麼解出我的謎題」的真正答案。
它不是背下了我那串點的序列。
它學會了通用操作——計數、比較、偵測對稱、延續模式——而這些操作可以組合起來處理新輸入。
給它點、給它數字、給它字母:同一套「找出結構並延伸它」的機制都能套用。
這方面有不少研究,部分來自像 Anthropic 這樣的可解釋性團隊。
他們找到了特定的內部迴路,其中一個著名例子是 induction head,它負責模式延續。
其機制本質上就是:「在這個輸入前面,A 後面接的是 B;現在又看到 A,所以接下來大概率是 B。」
那是一個可以被辨識出的網路內部元件,真的在做模式比對與延伸。
這正是讓模型延續新模式,而不是回想既有模式的東西。
這樣一看,那個點點謎題就不再神祕。
它是一個模式。
而模型有一套找出並延伸模式的機制。它找到了,然後把它延伸下去。

給開發者的重點
如果你用這些模型來做產品,實際上的教訓是:你不是在跟一個會照搬訓練資料的高級自動完成功能打交道。
你是在跟一個在下一個 token 壓力下學會了可遷移操作的系統合作,而且它會把這些操作套用到從沒看過的輸入上。
這樣的重新框架,會改變你怎麼寫提示、怎麼除錯奇怪輸出,以及你怎麼判斷它在哪些地方可靠、在哪些地方會自信地翻車。
「它只是預測下一個字」這種說法雖然沒錯,但沒什麼用,還會把你帶向錯誤的直覺。
一個蠢蠢的點點謎題,讓我去查了這些東西。
聲明:這篇文章由我撰寫;使用 AI 來修正文法並提升可讀性。

AI 代理寫程式很快。它們也會在不告訴你的情況下,悄悄移除邏輯、改變行為,還會引入 bug——而你通常要到上線後才發現。
git-lrc 解決了這個問題。它會接到 git commit,並在每個 diff 合併前先進行審查。只要 60 秒就能完成設定。完全免費。
歡迎任何回饋或貢獻者!它已上線、原始碼可用,任何人都能使用。
⭐ 到 GitHub 幫它按星:
{% github=https://github.com/HexmosTech/git-lrc
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式