

摘要
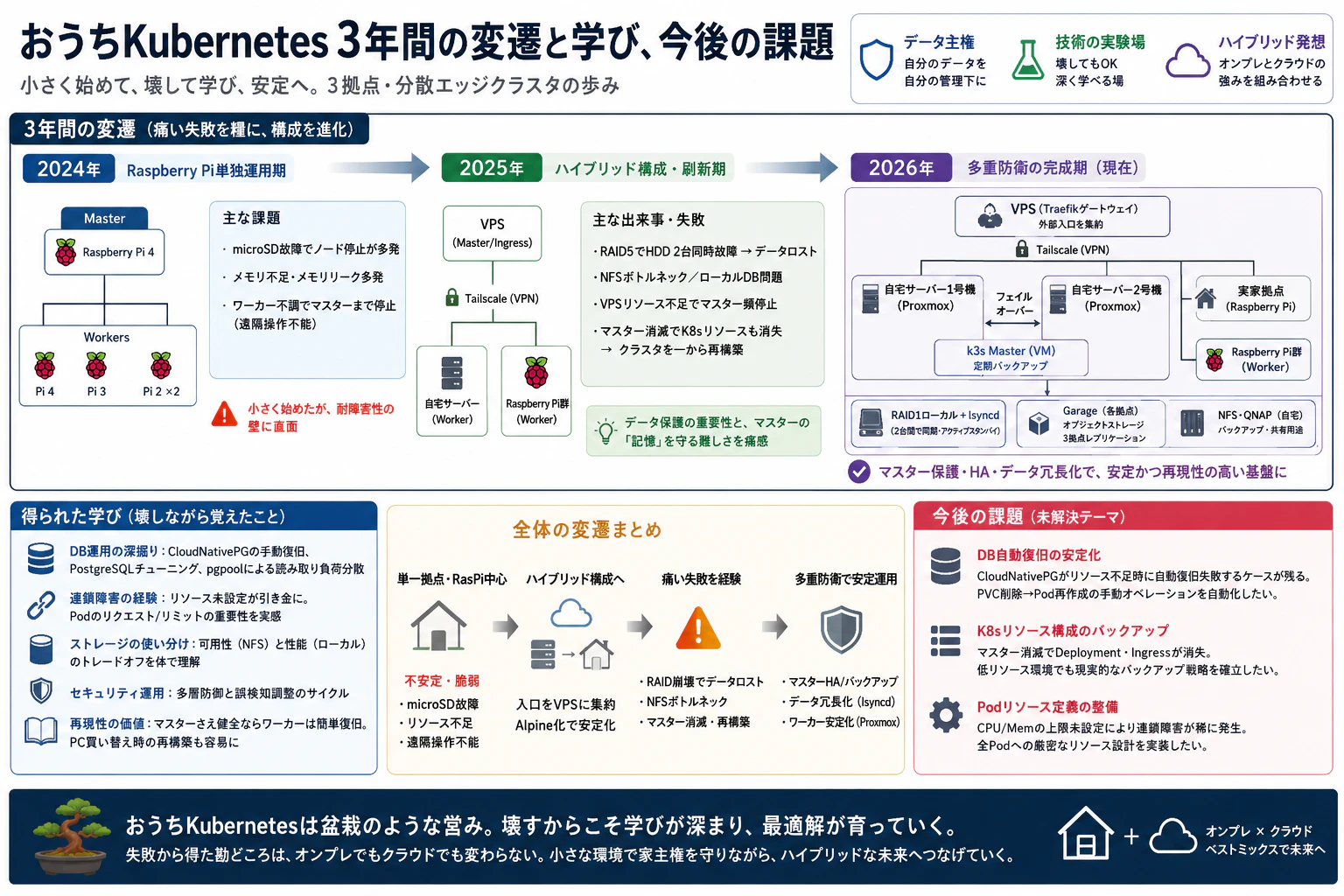
- 分享在自宅、老家、雲端三個據點之間的分散式 Kubernetes 環境,歷經 3 年建置與維運後的體悟
- 記錄從單一 Raspberry Pi 架構開始,反覆經歷 RAID 崩潰、主節點消失、NFS 瓶頸、連鎖故障等痛苦失敗後,逐步走到目前穩定架構的演進
- 在個人環境中積極嘗試工作場合不易導入的技術,透過反覆失敗來累積技術能力,正是 Home Lab 的價值所在
不做的事
- Kubernetes 的安裝步驟與指令細節說明
- 各 OSS 的功能細節說明
- 以類似 hyperscaler 的大規模架構為前提的討論
為什麼要做 Home Lab——「資料主權」與「技術實驗場」
全球正因 GDPR 等法規遵循與個資保護的潮流而加速推進。「自己的資料是存在哪個國家的伺服器上、受哪個國家的法律約束」的控制權,也就是 資料主權(Data Sovereignty),其重要性正不斷提升。
平常習以為常使用的雲端硬碟、相片管理 App、密碼管理器,是否有想過它們的資料實際存放在哪裡?雲端代管服務在可擴充性與降低維運負擔方面是很好的選擇,未來也仍會持續具有很高價值。不過,「把自己的資料放在自己掌控之下」也是另一種選項。以個人身分正視這個問題,就是 Home Lab 建置的起點。
另一個動機是它作為 技術實驗場 的價值。工作系統中因導入風險高而不易嘗試的技術——分散式儲存、資料庫叢集備援、連線池、讀取負載分散——在個人環境裡就可以積極導入,不必害怕失敗去試驗。壞掉了也只是自己受影響,因此反而能更深入學習。基礎架構、資安、網路的知識,也會在維護 Home Lab 的過程中自然累積。這正是一種盆栽般的活動。
與其將雲端與地端(On-premises)視為二元對立,不如在資料主權、資安、成本、便利性之間權衡後,整合兩者優勢的混合式思維更為重要。
做了什麼
目前架構——3 據點分散式邊緣叢集
透過 Tailscale(基於 WireGuard 的 VPN)將自宅、老家、雲端 VPS 這 3 個據點串接起來,作為單一個 K3s 叢集運作,K3s 是一種輕量級 Kubernetes 發行版。以下是整體架構圖。
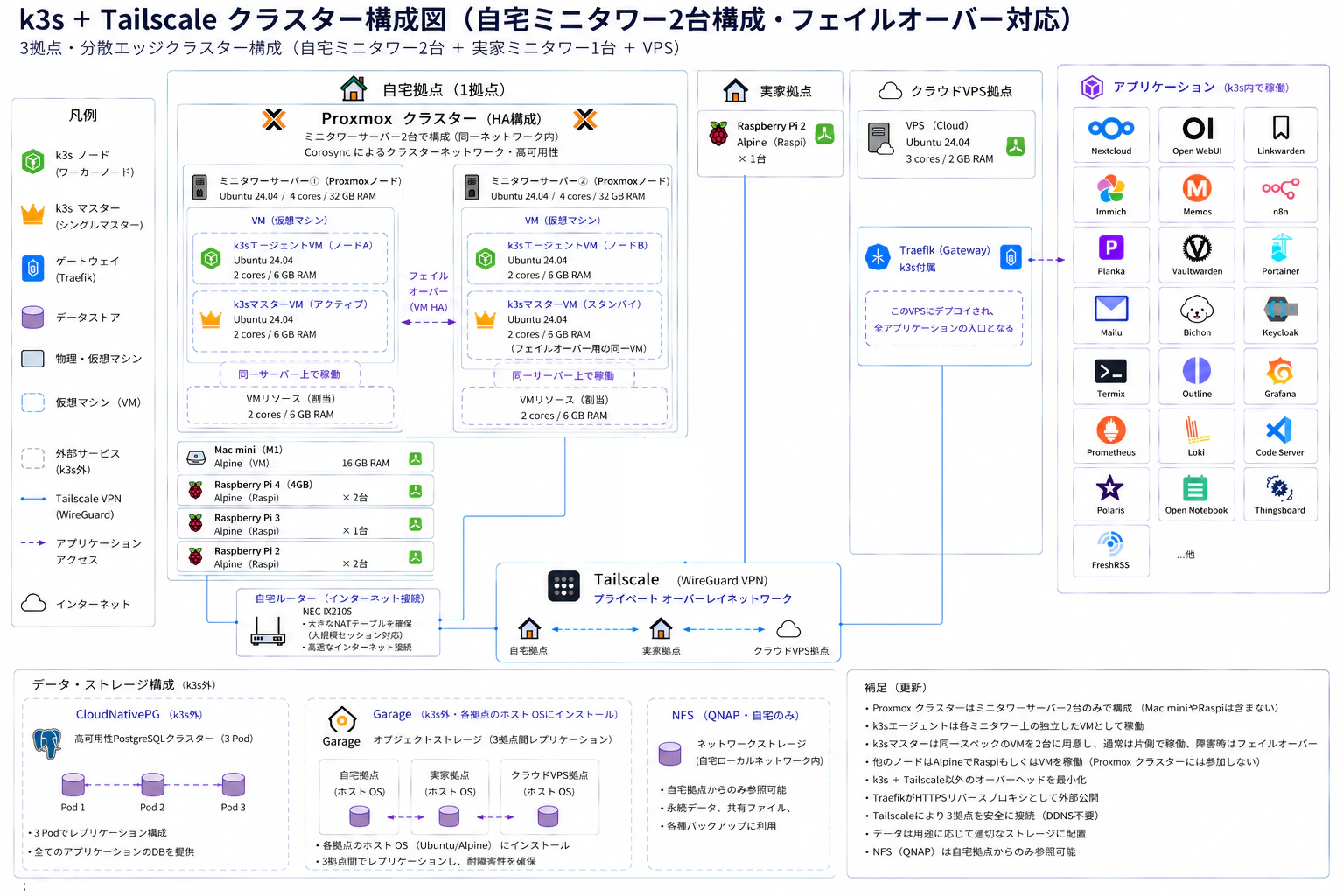
來自網際網路的入口只收斂到雲端 VPS 上的 Traefik(反向代理),所有據點都透過 Tailscale 私有網路安全連線。
節點組成
據點硬體作業系統角色自宅迷你塔式伺服器 1 號機(4 核 / 32GB RAM)Ubuntu 24.04Proxmox 主機。k3s 主節點 VM(2 核 / 6GB)+ k3s 工作節點自宅迷你塔式伺服器 2 號機(4 核 / 32GB RAM)Ubuntu 26.04Proxmox 主機(新增)。主節點故障切換備援 + k3s 工作節點自宅 Mac mini M1(16GB)Alpine(VM)k3s 工作節點自宅 Raspberry Pi 4(4GB)× 2 台Alpinek3s 工作節點自宅 Raspberry Pi 3 × 1 台Alpinek3s 工作節點自宅 Raspberry Pi 2 × 2 台Alpinek3s 工作節點老家 Raspberry Pi 2 × 1 台Alpinek3s 工作節點(邊緣據點)雲端 VPSVPS(3 核 / 2GB RAM)Ubuntu 24.04Traefik 閘道。外部 HTTP/HTTPS 的入口
資料/儲存架構
儲存用途冗餘方式CloudNativePG(k3s 內)所有應用程式的 PostgreSQL 叢集(3 個 Pod)Pod 複寫Garage(各據點主機 OS)物件儲存(3 據點間複寫)據點間複寫NFS・QNAP(僅自宅)一般型持久化資料、共享檔案、備份自宅本機冗餘 RAID1 本機 + lsyncd(自宅 2 台)對儲存效能要求高的資料、本機資料庫檔案透過 lsyncd 進行主動待命同步
運作中的服務
類別服務檔案/內容管理Nextcloud, Immich, FreshRSS, Linkwarden生產力/筆記Memos, Outline, Open Notebook, Planka認證/資安Vaultwarden, Keycloak自動化/開發n8n, Code Server, Termix, Open WebUI監控/可視化Grafana, Prometheus, Loki基礎架構/其他Traefik, Portainer, Thingsboard, Polaris, Bichon, Mailu
3 年間的演進 〜從失敗變得更強的叢集〜
2024 年:Raspberry Pi 單獨運作期
Raspberry Pi 單獨構成並開始運行 k3s 叢集。主節點配置在 Raspberry Pi 4,工作節點則由 Raspberry Pi 4/3/2 組成。
面臨的問題如下:
- microSD 卡上的 I/O 負載很大,因卡片故障造成節點停機的情況頻繁發生
- 記憶體洩漏問題變多。RasPi 本身資源並不充裕,而某些運作中的 OSS 會要求接近 PC 等級的記憶體量,因此僅靠 RasPi 很難撐起服務
- 工作節點出問題時,連主節點也可能一起停掉,導致無法遠端操作,只能靠實體斷電重啟,這種情況愈來愈多
2025 年:混合式架構、Alpine 化、RAID 與主節點更新期
為了擴充資源,新增迷你塔式伺服器與 VPS(2GB RAM),並將主節點配置在 VPS 上。透過 Tailscale 將 VPS 與自宅串成叢集,將來自網際網路的入口集中到 VPS,建立出目前架構的雛形。同時也在 Raspberry Pi 節點採用 Alpine Linux,讓作業系統部分與 log rotation 在 RAM 上執行,大幅減輕 microSD 過度耗損的問題。
隨著迷你塔式伺服器的導入,也開始使用 RAID5 進行儲存運作。然而這段期間由於無法確保足夠的維護時間,在未察覺 HDD 異常的情況下,2 顆 HDD 同時故障,最終導致資料遺失。
這裡得到一個重要體悟:叢集可以重建,但資料一旦消失就再也回不來。 之後便開始把資料保護擺在優先位置。
在這次失敗後,於 2025 年下半年將 RAID5 改為 RAID1。 也建立了透過 SMART 監控與電子郵件通知,及早偵測單顆硬碟故障徵兆的機制,強化 RAID1 伺服器本身的冗餘能力。
這段時期也開始浮現透過 NFS 存取儲存體所帶來的問題。出現了下列 NFS 瓶頸與本機資料庫問題:
- NFS 的效能會直接受到 QNAP 處理能力與網路延遲影響,因此對儲存效能要求高的服務會出現明顯延遲
- 某些應用程式以本機檔案形式持有資料庫(例如 SQLite)時,透過 NFS 掛載進行檔案鎖定可能產生不一致,甚至導致 Pod 無法重新啟動
從這些經驗中,開始依照資料特性與存取模式來區分儲存方式。
- NFS(QNAP):限定用於低頻存取的共享檔案與備份用途。
- RAID1 本機儲存:對儲存效能要求高的資料,以及不得不使用本機資料庫的應用程式,直接存放在 RAID1 伺服器的本機目錄。不過此時伺服器仍只有 1 台,因此冗餘僅止於 RAID1 單機層級。
此外,持續運作數個月後,由於 VPS 長期資源不足,主節點開始頻繁停止。當想把主節點移到自宅迷你塔式伺服器時,發現主節點一旦消失,Deployment、Ingress 等所有 K8s 資源配置也會一併消失。 雖然有 Velero 等備份工具,但在當時的低資源環境下,完整備份無法在合理時間內完成,結果只能從零重建整個叢集。
主節點承載的是整個叢集的「記憶」。當時嚴重低估了以低規格運作的風險。
之後,把主節點重新以 VM 形式建在自宅迷你塔式伺服器上,曾經穩定了一段時間,但隨著服務持續增加,又開始出現不穩定的徵兆。
2026 年:以 Proxmox 進行虛擬化、以 lsyncd 實現儲存冗餘、多重防線完成
再新增一台迷你塔式伺服器,兩台伺服器都導入 Proxmox。其目的如下:
- 保護主節點
- 將主節點作為 Proxmox 上的 VM 運作,並定期進行備份。
- 讓兩台 Proxmox 主機之間可進行主節點 VM 的故障切換。
- 即使發生緊急狀況,也能只靠其中一台 x86_64 伺服器與 Raspberry Pi 節點維持叢集。
- 提升工作節點穩定性
- 將 x86_64 伺服器虛擬化為 Proxmox 上的 VM 後,可以預先限制工作節點的記憶體上限。即使發生記憶體洩漏等問題,也能從 Proxmox 主機遠端重啟,且不影響其他 VM。
另外,這也帶來附帶好處:透過 Proxmox,可以很容易地為 Kubernetes 以外的用途建立 VM,像是以 FreeBSD 建置 IoT 裝置用 Wi-Fi AP 這類用過即丟的實驗環境也能輕鬆學習。
此外,新增第二台伺服器後,便能將原本儲存在 RAID1 本機的資料透過 lsyncd 在兩台之間進行近乎即時同步,實現主動待命(Active-Standby)架構。即使其中一台故障,也能在保留資料的情況下切換到另一台。
透過這些改善,開始能享受到 Kubernetes 的可重現性優勢。只要主節點健全,工作節點的復原很容易,既有 Pod 也能重新啟動。即使更換電腦,也能以高可重現性還原相同架構,這點對個人運作來說也非常有價值。
邊壞邊學 〜在 Home Lab 累積的維運經驗〜
在工作系統中必須謹慎評估的技術,在 Home Lab 裡可以主動嘗試。以下是具體例子。
CloudNativePG 與 PVC 故障的手動復原
曾經遇到因資源不足等原因,CloudNativePG 自動復原失敗的情況。這時需要手動刪除 PVC 再重新建立 Pod。資料庫叢集的自動故障切換涉及複雜的狀態轉移,能透過親手操作理解自動化背後的行為,是很大的收穫。
PostgreSQL 參數調校
由於多個服務會連到單一個 CloudNativePG 叢集,連線數上限與 work memory 等參數調校就成為無法避免的課題。當連線數達到上限、服務開始回傳錯誤時,便反覆調整 max_connections 與 work_mem。
挑戰使用 pgpool 進行讀取負載分散
進一步還嘗試把 pgpool 放在叢集前端,將讀取查詢分散到複本。設定的複雜度與故障切換時的行為確認都不簡單,但也因此能在實際運作中掌握連線池與負載分散的機制。
節點連鎖故障的經驗
曾經發生某個節點停止後,該節點上運作的 Pod 退避到其他節點,進而造成負載集中,連帶讓其他 Pod 也一併當掉的連鎖故障。這讓我深刻體會到為每個 Pod 設定 CPU/記憶體資源的重要性。理論上,只要正確設定 Pod 的 resources requests/limits,排程器就能更合理地配置 Pod,避免這類連鎖事件。
儲存可用性與效能的平衡
如前所述,若為了可用性而使用 NFS 儲存,Pod 的回應會變差;反之若使用本機儲存,Pod 就只能在持有該儲存的節點上啟動。本機儲存還需要各自做冗餘設計,並妥善運用 RAID。這些都必須綜合考量後再決定儲存策略。
資安對策與誤判調整
這裡不詳述,但整體上會在各層做基本資安防護;若因誤判導致無法存取,也會反過來檢討規則,持續進行調整。
未來課題
以下課題目前仍未完全解決,會成為接下來的學習主題。
課題概要資料庫自動復原的穩定化CloudNativePG 在資源不足時仍會有自動復原失敗的案例。希望將 PVC 刪除 → Pod 重建的手動操作自動化K8s 資源配置備份主節點消失時,Deployment、Ingress 全部遺失的結構尚未解決。需要建立低資源環境下可行的備份策略Pod 資源定義整備因 CPU/記憶體上限未設定而偶發連鎖故障。需要為所有 Pod 實作嚴謹的資源設計
總結與心得
這 3 年的居家 Kubernetes,正是一段如同照顧盆栽般的過程。追求理想形狀、每天修剪照料,在反覆失敗的過程中,自然而然學會了基礎架構、資安、網路、資料庫等知識。
我認為,Home Lab 的最大價值,在於能在個人環境中積極嘗試工作場合難以採用的技術。RAID 崩潰、主節點消失、NFS 瓶頸、連鎖故障、資料庫調校——這些就算書上有寫,若不親手操作並經歷失敗,是無法真正理解的經驗。無論是地端還是雲端,要讓系統穩定下來的訣竅其實相通;而能在一個即使壞掉也可以被允許的環境中累積這些訣竅,正是 Home Lab 的醍醐味。
與其將雲端與地端視為二元對立,不如在資料主權、資安、成本、便利性之間取得平衡,整合兩者優勢的混合式思維更為重要。透過這個小小的 Home Lab,我切身感受到這一點。即使規模不同,這份感受其實也直接對應到組織層級的混合雲策略問題。
原文出處:https://qiita.com/takumiida1/items/39907f41be86431a58e7
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式