

我從事經紀人相關工作已經有一段時間了,雖然這很令人興奮,但其中確實有一些部分很難做好。
隨著時間的推移,我一直在心裡記下那些總是拖慢我速度的事情。毫不奇怪,許多新的SDK和框架應運而生,旨在解決這些痛點。
在這篇文章中,我將分享我在建立代理程式時遇到的最棘手的問題,以及您可以如何嘗試解決這些問題。
-
過於複雜的框架
更嚴肅地說,我認為最大的挑戰是使用那些試圖包辦一切的代理框架,結果卻感覺有點過度設計。
這些框架功能強大,可以完成很多令人驚嘆的事情,但實際上,你最終可能只用到 10% 的功能,然後你會發現,即使是一些簡單的、特定的任務,它也過於複雜。這就像是和框架對抗,而不是利用框架來開發。
真正有幫助的是:
相反,我更喜歡一個簡單的框架,我最終會用到其中 90% 的內容,剩下的工作也足夠簡單,可以在此基礎上進行擴展。
舉個具體的例子:在LangChain中,定義一個包含單一工具的簡單代理程式可能需要設定鏈、記憶體物件、執行器和回呼函數。這未免太繁瑣了,而你真正需要的可能只是一個 LLM 呼叫和一個函數。
相較之下,像Pydantic AI或Hugging Face's SmolAgents這樣的輕量級函式庫,只需幾行程式碼就能實現相同的功能。
from pydantic_ai import Agent, RunContext
roulette_agent = Agent(
'openai:gpt-4o',
deps_type=int,
output_type=bool,
system_prompt=(
'Use the `roulette_wheel` function to see if the '
'customer has won based on the number they provide.'
),
)
@roulette_agent.tool
async def roulette_wheel(ctx: RunContext[int], square: int) -> str:
"""check if the square is a winner"""
return 'winner' if square == ctx.deps else 'not a winner'
# run the agent
success_number = 18
result = roulette_agent.run_sync('Put my money on square eighteen', deps=success_number)
print(result.output) # True另一個例子是Composio ,你只需安裝composio ,初始化一個客戶端,然後代表使用者呼叫工具,幾乎不需要任何設定(不需要自訂執行器或回調鏈)。
如果你透過 Gmail 發送電子郵件,你可能會這樣做:
from composio import Composio
from openai import OpenAI
openai = OpenAI()
composio = Composio(api_key="YOUR_COMPOSIO_API_KEY")
user_id = "[email protected]"
# authorize Gmail for this user (opens an OAuth URL)
connection_request = composio.toolkits.authorize(user_id=user_id, toolkit="gmail")
print(f"Visit URL to authorize: {connection_request.redirect_url}")
connection_request.wait_for_connection()
# fetch the Gmail tools and let the LLM call them
tools = composio.tools.get(user_id=user_id, toolkits=["GMAIL"])
completion = openai.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Send an email to Alice"}],
tools=tools,
)
result = composio.provider.handle_tool_calls(user_id=user_id, response=completion)
print(result)您可以獲得結構化的輸出和便利的複用功能。如果以後需要更多功能,您可以根據需要逐步增加複雜性。
-
無需“人為幹預”
使用代理的最大風險之一是賦予他們過多的自主權而缺乏監督。完全自主的代理商可能會做出不可預測的行為或不安全的決定(例如預訂錯誤的航班或以您的名義發送敏感電子郵件)。
如果沒有斷點或審核步驟,你基本上就是把車鑰匙交給代理人,然後祈禱他不會把車撞壞。
我當時正在嘗試開發一款適用於 LinkedIn 的 MCP 代理程式。原型設計很有趣,但我很快就意識到它缺乏自然的斷點。賦予代理商發布或發送訊息的完全控制權感覺很冒險(一旦出錯就可能造成嚴重後果)。
真正有幫助的是:
解決方案是將human-in-the-loop (HITL) controls直接整合到代理程式中。設定安全斷點,代理程式會在這些斷點暫停,顯示其計畫或操作,並等待您的批准後再繼續執行。
CrewAI、LangChain 和 CopilotKit 等大多數現代框架都支持這種方法。
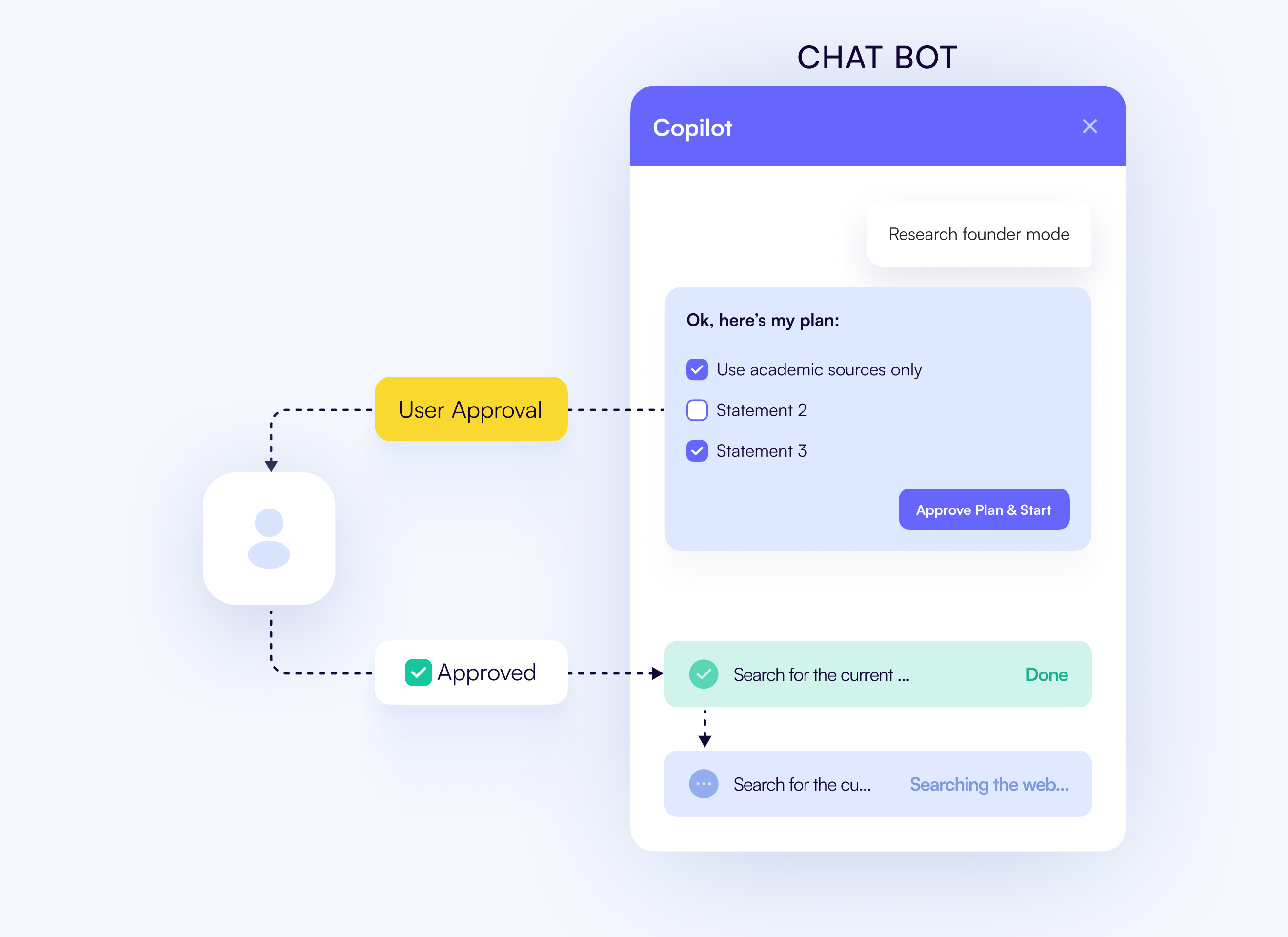
CopilotKit HITL 設計
以下是一個簡單的範例模式:
# Pseudo-code for HITL approval
def approval_hook(action, context):
print(f"Agent wants to: {action}")
user_approval = input("Approve? (y/n): ")
return user_approval.lower().startswith('y')
# Use in agent workflow
if approval_hook("send_email", email_context):
agent.execute_action("send_email")
else:
agent.abort("User rejected action")最終結果是:一切盡在掌控。經紀人負責前期準備工作,但每個重要步驟都由你審批。
-
黑盒推理
很多時候,我無法解釋我的經紀人為什麼會那麼做。它會採取一些奇怪的行動,跳過一些顯而易見的步驟,或者乾脆編造一些東西,因為它覺得那就是我想要的。
缺少輸入會導致錯誤輸出,而且沒有留下任何痕跡,你只能猜測是模型、資料還是你自己的邏輯出了問題。
整個過程感覺就像一個黑盒子,計畫就隱藏在模特兒的腦袋裡。
真正有幫助的是:
一個簡單的辦法是強制模型展示其執行過程。與其讓它默默地做出決定,不如讓它產生一個structured plan ,並逐步記錄整個過程。你也可以使用追蹤工具(例如Langfuse 、 OpenTelemetry )來追蹤代理循環,記錄每個決策步驟,以便稍後重播執行過程。
LangGraph使用基於節點的圖,其中每個決策都是明確的,可以重播或審核。
以下是一個簡單的例子。
from langgraph.graph import StateGraph, END
from typing_extensions import TypedDict
class State(TypedDict):
x: int
y: int
def step1(state: State) -> dict:
print("Step 1")
return {"x": 1}
def step2(state: State) -> dict:
print(f"Step 2 (got x={state['x']})")
return {"y": state["x"] + 1}
graph = StateGraph(State)
graph.add_node("step1", step1)
graph.add_node("step2", step2)
graph.set_entry_point("step1")
graph.add_edge("step1", "step2")
graph.add_edge("step2", END)
app = graph.compile()
print("Final:", app.invoke({}))輸出結果大致如下:
Step 1
Step 2 (got x=1)
Final: {'x': 1, 'y': 2}這種清晰明確的流程也讓除錯變得更容易。
-
代幣消耗爆炸性成長
代理程式的一個隱藏問題是它們消耗令牌的速度太快。最糟糕的是,我甚至看不到底層發生了什麼事。我無法了解 LLM 中具體的提示資訊、令牌數量、快取命中率和成本。
我看過這樣的設定:一次執行就能悄無聲息地累積數千個令牌,這並不是因為模型做了什麼了不起的事情,而是因為框架把stuffing the entire execution history了上下文視窗。
真正有幫助的是:
主要原因是大多數框架都以簡潔性為優化目標,而非效率。以下幾種方法可以控制這種情況:
✅ 不要將每次工具查詢結果保留在對話中,而是將它們移到共享的圖狀態中(LangGraph 可以很好地實現這一點)。僅在需要時才將它們傳遞給 LLM,而不是每次呼叫都傳遞。
✅ 您可以定期將過往的互動記錄壓縮成滾動摘要,僅保留必要部分。這樣,智能體既能保留上下文,又無需承載完整的歷史記錄。
✅ 有些框架提供內建最佳化功能,例如 AutoGen,它可以快取 LLM API 呼叫,從而避免使用相同輸入重複呼叫。它支援多種快取後端,包括磁碟、Redis 和 Cosmos DB。
這裡提供一個簡單的方法:
context.append(user_message)
if token_count(context) > MAX_TOKENS:
summary = llm("Summarize: " + " ".join(context))
context = [summary]Composio 等平台也能在這方面提供幫助,因為它們的工具呼叫返回的是結構化的 JSON 資料,而不是原始文本。這意味著您可以將輸出保存到提示符號之外,並在之後僅反饋最基本的上下文資訊。
如果您想了解更多,可以閱讀Letta 撰寫的《代理記憶:如何建立能夠學習和記憶的代理》 。書中指出,一個簡單的策略是在上下文視窗填滿時清除 70% 的舊訊息。
-
狀態和上下文遺失
經紀人最惱人的地方之一就是他們太容易忘記自己之前在做什麼。你制定了一個多步驟的計劃,一切看起來都很順利→結果做到一半,他們要么漏掉了一個細節,要么乾脆就完全忘了這回事。
這是因為上下文通常只是在提示訊息內部傳遞。一旦達到令牌限製或系統崩潰,除非您設定了保存方法,否則該狀態就會遺失。
真正有幫助的是:
您可以將文件儲存在向量資料庫(例如Pinecone或Weaviate )中,並在回答問題之前透過檢索步驟來取得最相關的資訊。以下是一些框架及其功能:
✅ <a href="">LangGraph</a> → 包含基於圖的流程,其中每個節點都保存其狀態,因此部分進展可以在崩潰後仍然存在。
✅ LlamaIndex → ChatMemoryBuffer + 儲存連接器,用於持久化對話狀態。
✅ Mem0 → 外部記憶體,代理可以查詢過去的步驟/詳細資料。
以下是一個簡單的程式碼片段,可以幫助代理程式偵測到進程是否在中途崩潰。
# resuming agent run after failure
state = load_state("run_state.json") or {"completed": []}
for step in plan.steps:
if step.name in state["completed"]:
continue
result = agent.execute(step)
state["completed"].append(step.name)
save_state("run_state.json", state)-
多智能體協調的惡夢
有時候一個代理人是不夠的。你需要將工作分成幾個角色:「計劃者」負責制定步驟,「研究員」負責收集資料,「撰稿人」負責撰寫最終成果。
但是協調多個代理會引入複雜性:誰來決定哪個代理應該執行以及何時執行?它們如何共享記憶體而不互相干擾?
如果擴展到 5 到 10 個代理,同步開銷可能會感覺更糟(當你自己寫整個程式碼時)。
真正有幫助的是:
目前有兩種(最近推出的)協議可以解決這個問題:
✅ Agent2Agent (A2A) 協議:這是 Google 開發的協議,它使用JSON-RPC & SSE standard來解決這個問題。代理程式發布一個JSON Agent Card (包含功能、端點和身份驗證資訊)。其他代理商則取得該代理卡,以確定「應該聯絡誰以及如何聯絡」。
✅ ACP(代理通訊協定) :用於人工智慧代理、應用程式和人類之間通訊的開放協定。它基於標準化的 RESTful API 執行,並借鑒了 A2A 的許多理念。
如果 A2A 專注於代理之間的協作,那麼 ACP 則將其擴展到包括人與應用程式的交互,並使用 REST、OpenAPI、多部分格式。
如果您是這些協議的新手,並且想要了解更多訊息,您可以閱讀這篇博客,深入了解所有代理協議。
以下是一些專為多代理設計的框架選項。
✅ CrewAI :您可以定義一個由基於角色的代理(撰稿人、研究員、編輯)組成的“團隊” ,這些代理共享對話上下文。它負責路由,以便每個代理依次做出貢獻。
✅自動產生:將流程建構成代理之間的非同步對話,這有利於需要長時間等待的任務。
✅ Strands Agents SDK :當您混合使用提供者(OpenAI、Anthropic、本地模型)並且具有強大的可觀測性時非常有用。
在實踐中,我從最簡單的設計開始:如果我真的需要子代理,我可能會手動編寫代理到代理的交接程式碼。
plan = planner_agent.run_sync("Outline the solution steps.")
for step in plan.steps:
if step.type == "research":
content = researcher_agent.run_sync(step.text)
elif step.type == "write":
content = writer_agent.run_sync(step.text)
memory.append(content)這種明確的邏輯(而不是完全動態的LLM決策)保持了協調的清晰性。
-
長期記憶問題
其次是長期記憶問題。保持上下文資訊是智能體效能的核心,但決定記住哪些資訊卻很棘手。
記憶體佔用過高,導致上下文視窗溢出。
資訊太少,代理人會忘記有用的資訊。
這就是“記憶體瓶頸”,你必須決定。 “應該記住什麼,應該忘記什麼,以及何時忘記”有條不紊地進行。
真正有幫助的是:
簡單粗暴的方法行不通。把所有歷史記錄一股腦地塞進提示框會超出令牌限制。我見過一些客服人員重複過時的訊息,僅僅因為他們根本不知道“hey, that no longer matters” 。
將short-term memory (當前對話語境)與long-term memory (持久性知識)分開。盡可能壓縮或刪除過時的語境。將重要事實儲存在長期記憶索引中。
這段程式碼片段將最新的使用者訊息加入到對話context中,然後使用函數token_count()和llm()來執行以下操作:
-
檢查總令牌數是否超過
MAX_TOKENS。 -
如果是這樣,請使用 LLM 產生整個上下文的簡明摘要(
llm("Summarize: " + ...))。 -
用此摘要取代完整上下文,減少標記數,同時保留重要資訊。
context.append(user_message)
if token_count(context) > MAX_TOKENS:
summary = llm("Summarize: " + " ".join(context))
context = [summary]以下是一些您可以嘗試的框架:
✅ Letta → 使用記憶圖,其中內建了明確的「何時/如何遺忘」規則。
✅ Mem0 → 專為具有相關性評分和長期記憶的智能體而設計的記憶層。
✅ LlamaIndex → 提供可擴充記憶體的向量儲存、檢索和摘要功能。
✅ LangGraph → 支援圖工作流程中的持久狀態和記憶體重播。
-
“幾乎正確”的程式碼問題
即使擁有完美的框架,大型語言模型仍然可能帶來意想不到的結果。開發者(包括我)面臨的最大挫折就是處理那些人工智慧產生的解決方案。 “幾乎正確,但還不夠完美” 。
除錯這種“幾乎正確”的輸出通常比自己編寫函數花費的時間更長。
真正有幫助的是:
我們對此能做的並不多(這是模型層面的問題),但您可以加入一些防護措施和健全性檢查。例如,始終驗證工具輸出或模型答案:
→ 如果代理應該輸出日期或數字,請檢查格式。
→ 如果模型循環或重複,則透過設定最大步數或強制其繼續執行來打破循環。
有些框架支持chain-of-thought reflection或self-correction steps 。沒有哪個框架能神奇地讓程式碼變得更好,但驗證步驟可以讓流程在執行前進行稽核。類似地,LangGraph 工作流程允許你插入明確的審核步驟。
在程式碼中,你可能會這樣做:
def validate_output(output, expected_type):
if expected_type == "date":
try:
datetime.strptime(output, "%Y-%m-%d")
return True
except ValueError:
return False
# Add more validation logic
return True
result = agent.execute(task)
if not validate_output(result, "date"):
result = agent.retry_with_feedback("Please provide date in YYYY-MM-DD format")
您可能會發現本節與人機互動(因為兩者都與信任和控制有關)略有相關,但這裡我們專注於程式碼品質和準確性,而人機互動則更側重於安全性和監督。
-
身份驗證與安全信任問題
大多數框架的設計宗旨是“開箱即用”,與 API 無縫整合。安全性通常是代理架構中事後考慮的因素。
因此,使用代理處理身份驗證非常棘手。理論上,這似乎很簡單:給代理一個 API 金鑰,讓它呼叫服務即可。但實際上,這卻是最容易造成安全漏洞(例如 MCP 代理)的方法之一。
基於角色的存取控制必須傳播到所有代理,並且 LLM 接觸到的任何資料都會「毫不費力地完全公開」。
真正有幫助的是:
每次都採用類似的模式,以涵蓋所有極端情況:
-
授予必要的最低權限。
-
允許代理僅在需要時請求存取權限(使用 OAuth 流程或令牌庫機制)。
-
將敏感操作視為可審查事項(透過引入人為幹預檢查)。
-
妥善儲存令牌,不要儲存在提示訊息或日誌中。
-
盡可能在隔離環境中執行工具。
-
在將使用者輸入傳送到 LLM 之前對其進行清理(一旦 PII 進入上下文,就無法挽回)。
讓我們來看一些框架,看看它們是如何處理安全性的:
✅ AgentAuth (Composio) → 為 OAuth、API 金鑰、JWT 等提供統一的平台,涵蓋數百個應用程式。
以下是一個典型的 Composio OAuth 流程(Python):
from composio import Composio
from openai import OpenAI
openai = OpenAI()
composio = Composio(api_key="YOUR_COMPOSIO_API_KEY")
user_id = "[email protected]"
# Step 1: Initiate OAuth authorization (e.g., Gmail)
conn_req = composio.toolkits.authorize(user_id=user_id, toolkit="gmail")
print(f"Visit this URL to authorize Gmail: {conn_req.redirect_url}")
# [User visits URL and grants access...]
# Step 2: Wait for the user to complete OAuth
conn_req.wait_for_connection()
# Now the user_id is linked to Gmail and we can fetch Gmail tools
tools = composio.tools.get(user_id=user_id, toolkits=["GMAIL"])使用者完成 OAuth 流程後,Composio 會自動處理令牌刷新並將憑證與該user_id關聯。此後,任何代表該使用者進行的工具呼叫都會使用已儲存的令牌。
您可以在任何受支援的工具包上使用相同的簡單authorize呼叫。 authorize後,您可以將傳回的tools清單傳遞給 LLM 聊天完成功能。然後,代理程式會將這些工具用作內建函數。更多資訊請參閱文件。
✅ Auth0(GenAI 的驗證) → 提供令牌庫、非同步身分驗證流程(CIBA/PAR)和細粒度的文件級權限。
✅ AgentAuth (Composio) → 統一的 SDK,用於處理 250 多個應用程式的 OAuth 認證。可與 LangChain、LlamaIndex 和 CrewAI 搭配使用。
✅ Progent(學術版) → 一項概念驗證研究,旨在定義/強制執行代理程式執行時內部的權限策略。它引入了一個實驗性框架,但您絕對應該閱讀一下。
選擇內建身份驗證的框架,並設計自己的流程,確保每個敏感步驟都清晰明確、記錄在案且可審查。否則,可能會出現很多問題。
-
工具呼叫可靠性問題
代理的關鍵在於:它們的效力取決於它們所連接的工具。而這些工具呢?它們一直在變化。
我遇過不只一次這種情況。一切原本運作都很順利,直到工作流程突然中斷。不是因為我的程式碼發生了變化,而是因為外部 API 發生了變化。
或許谷歌日曆悄悄更新了某個欄位名稱。
或許Stripe增加了更嚴格的速率限制。
或許是API暫時宕機了幾分鐘。
代理程式不知道如何處理這種情況,所以會在任務進行到一半時失敗。更糟的是,LLM 程式在格式化請求方面並不總是很擅長。
真正有幫助的是:
-
強制執行模式,使代理不能僅僅「猜測」參數。
-
讓工具實現即插即用,而不是硬編碼整合。
-
不要因為第一次錯誤就放棄,重試或更換工具。
-
選擇能夠讓你了解 API 呼叫、令牌問題或錯誤參數的選項。
今天大家都在做什麼:
-
LangChain → 具有 Pydantic 驗證的結構化工具呼叫。
-
LlamaIndex → 內建重試模式和驗證引擎,以幫助自我修正查詢。
-
CrewAI → 錯誤復原/處理和結構化重試流程。
-
Composio → 500 多個集成,預置 OAuth 處理和強大的工具呼叫架構。
以下範例展示如何讓工具呼叫更加可靠:
from composio_openai import ComposioToolSet, Action
# Get structured, validated tools
toolset = ComposioToolSet()
tools = toolset.get_tools(actions=[Action.GITHUB_STAR_A_REPOSITORY_FOR_THE_AUTHENTICATED_USER])
# Tools come with built-in validation and error handling
response = openai.chat.completions.create(
model="gpt-4",
tools=tools,
messages=[{"role": "user", "content": "Star the composio repository"}]
)
# Handle tool calls with automatic retry logic
result = toolset.handle_tool_calls(response)在 Composio 中,每個工具都使用 JSON 模式完整描述其輸入和輸出。如果 JSON 與預期模式不匹配,Composio 的 API 將傳回錯誤程式碼( Error 603: Invalid App Schema )。
您可以在程式碼中捕獲此問題並優雅地處理它(例如,提示 LLM 重試或回退到澄清步驟)。
try:
result = composio.provider.handle_tool_calls(user_id=user_id, response=llm_response)
print("Tool executed:", result)
except Exception as e:
# Handle known schema mismatch error
if "Invalid App Schema" in str(e):
print("LLM sent bad schema, asking to retry or clarifying.")
else:
raiseComposio 的 SDK 還提供模式修改器和處理器(中間件),以便您可以自訂工具在代理程式中的顯示方式。例如,您可以將某些欄位標記為必填項、新增範例或重新命名欄位以適應您的使用場景。
對工具定義的這種微調進一步指導 LLM 正確使用工具。
順便一提,如果您使用 Composio,還可以存取功能強大的工具庫。他們集中維護這些集成,因此當 API 發生變更時,修復程式會自動部署,無需您更新程式碼。

-
無即時感知(事件觸發)
我學到的一點是:如果經紀人只是等你問他們什麼,那他們就沒什麼用。
真正的魔力在於它們能夠自動對現實世界中發生的事情做出反應。如今大多數智能體都基於簡單的請求-響應循環建置。你發送一個查詢,它們就回覆。
但是,一旦你嘗試建立一個可靠的事件驅動系統(例如,當 API 開始返回 500 錯誤時通知隊友,或在建置完成後立即將部署狀態發佈到 Slack),你就會遇到瓶頸。
你必須兼顧 webhook、身份驗證、重試、過濾、擴展……並確保不會出現任何靜默失敗的情況。
真正有幫助的是:
最簡單的方法是使用託管觸發平台,而不是自己建立 Webhook 系統。這樣可以獲得一致的事件介面、結構化的有效負載、重試機制以及與數百個應用程式的內建整合。
例如: Composio 觸發器可以根據應用程式中的事件向您的 AI 代理或系統發送有效負載。您可以使用 Composio 控制面板建立觸發器,也可以透過 SDK 以程式設計方式建立觸發器。
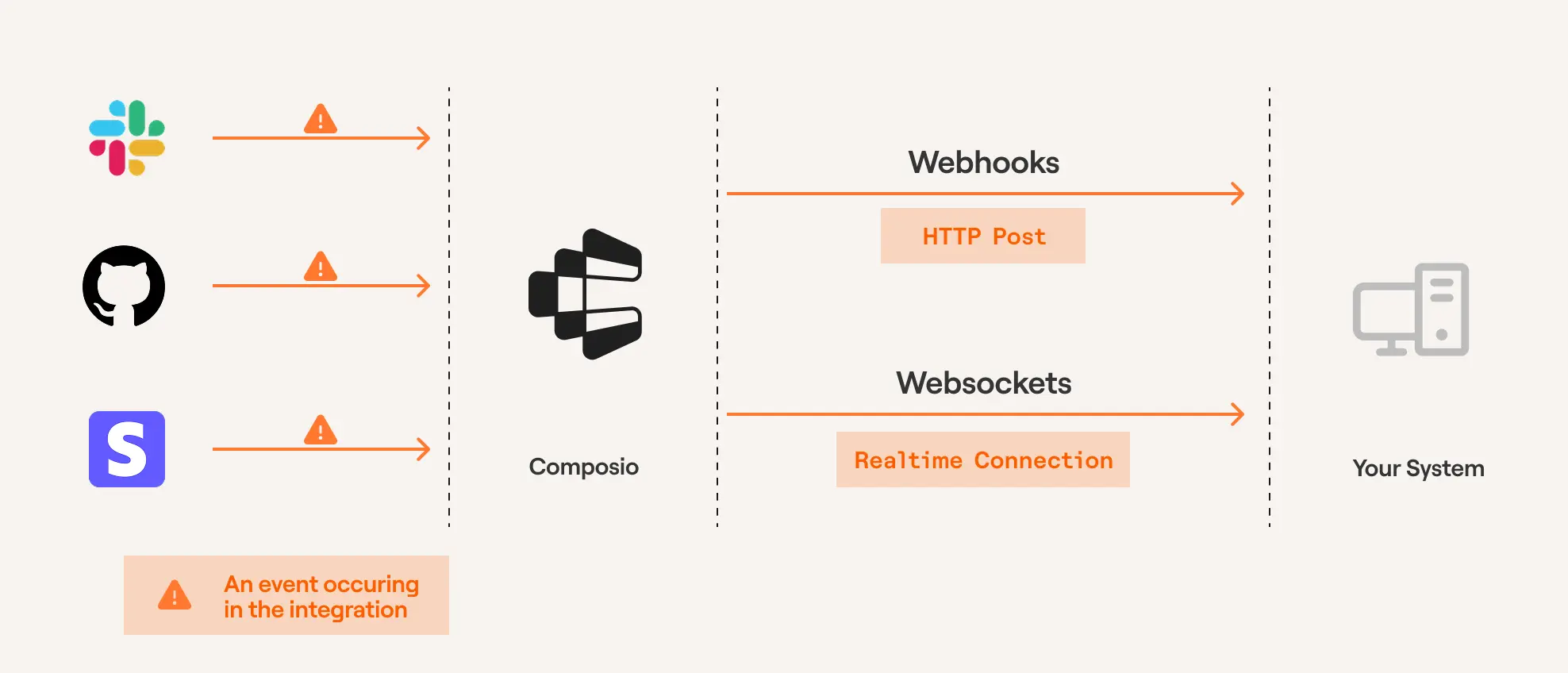
您可以在文件中找到透過控制面板建立它的完整步驟說明。
讓我們來看一個簡單的例子,假設你的代理人對新的 Slack 訊息做出反應並自動回覆。
from composio import Composio
from composio.client.collections import TriggerEventData, ComposioToolSet
composio = Composio(api_key="your-api-key")
user_id = "user-123"
# Slack trigger for new messages
trigger = composio.triggers.create(
slug="SLACK_NEW_MESSAGE",
user_id=user_id
)
# Create a listener for trigger events
toolset = ComposioToolSet()
listener = toolset.create_trigger_listener()
@listener.callback(filters={"trigger_name": "SLACK_NEW_MESSAGE"})
def handle_new_message(event: TriggerEventData) -> None:
message = event.payload["text"]
sender = event.payload["user"]
channel = event.payload["channel"]
# Let your agent decide how to respond
reply = your_agent.generate_reply(message, sender)
# Send reply back to Slack
composio.tools.execute(
action="SLACK_SEND_MESSAGE",
params={
"channel": channel,
"text": reply
},
user_id=user_id
)
# Start listening for new messages
listener.listen()完整的事件生命週期包括:
-
託管式 OAuth,支援自動令牌刷新
-
只接收你感興趣的活動訊息
-
所有應用程式的結構保持一致
-
內建重試邏輯和錯誤處理
-
雲端管理基礎設施
如果您喜歡使用 webhook 方法(建議用於生產環境)而不是 SDK 監聽器,那也很容易:
from fastapi import FastAPI, Request
from composio_openai import ComposioToolSet, Action
from openai import OpenAI
app = FastAPI()
client = OpenAI()
toolset = ComposioToolSet()
@app.post("/webhook")
async def webhook_handler(request: Request):
payload = await request.json()
# Handle Slack message events
if payload.get("type") == "slack_receive_message":
text = payload["data"].get("text", "")
# Pass the event to your LLM agent
tools = toolset.get_tools([Action.SLACK_SENDS_A_MESSAGE_TO_A_SLACK_CHANNEL])
resp = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a witty Slack bot."},
{"role": "user", "content": f"User says: {text}"},
],
tools=tools
)
# Execute the tool call (sends a reply to Slack)
toolset.handle_tool_calls(resp, entity_id="default")
return {"status": "ok"}Composio 會負責驗證觸發事件並格式化工具呼叫。您只需編寫常規的代理邏輯即可。
trigger payload包含上下文(訊息文字、使用者、頻道等),因此您的代理可以將其用作推理的一部分,或直接將其傳遞給工具。
這種模式適用於任何應用程式整合:Slack 訊息、日曆事件、CRM 更新、GitHub 提交以及數百種其他觸發器。
我最近幾天讀了很多書,所以這裡推薦一些深入探討框架的免費部落格(這些部落格會讓你重新思考框架的使用):
-
放棄智能體AI框架,從零開始建構智能體- Vishal Rajput(medium)
-
何時(不)使用智能體人工智慧- Paul Simmering(個人部落格)
-
智能體人工智慧的隱性成本:為什麼大多數專案在投入生產前就失敗了- 多位作者(伽利略團隊)
-
我們不需要更多框架。我們需要的是智慧體基礎設施-關注點分離-Reddit (r/AI_Agents)
歸根究底,代理商故障的原因總是老生常談。大多數可能的解決方法都是些枯燥乏味、沒人願意做的瑣事。
框架越來越完善,但大多數代理仍然只是脆弱的演示版本。如果基礎工作做好,它或許就能像一個值得信賴的系統一樣運作。
我花了很長時間才寫完這篇文章。希望你從中有所收穫 :)
您可以查看
我在anmolbaranwal.com上的工作。
感謝閱讀! 🥰 | 

 |
|
| --------- | -------- |

1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式