🔧 阿川の電商水電行

標題:“Kimi K2 與 Qwen-3 Coder:12 小時測試!”
已發布:真實
描述:“Kimi K2 與 Qwen-3 Coder:12 小時測試!——哪種 AI 編碼模型真正在實際開發中發揮作用?我們花了超過 12 個小時使用 Rust 和 React 任務測試 Kimi K2 和 Qwen-3 Coder,以比較輸出質量、速度和對開發人員的價值。”
標籤:Web 開發、程式設計、JavaScript、AI
canonical_url:“https://forgecode.dev/blog/kimi-k2-vs-qwen-3-coder-coding-comparison/”
在花了 12 個小時對 Kimi K2 和 Qwen-3 Coder 進行相同的 Rust 開發任務和前端重構任務測試後,我發現了一些基準測試分數無法揭示的問題:在這個測試環境中,一個模型始終能夠交付有效的程式碼,而另一個模型在基本指令執行方面卻舉步維艱。這些發現挑戰了圍繞 Qwen-3 Coder 基準測試效能的炒作,並說明了為什麼在程式碼庫上進行測試比綜合評分更重要。
🚀嘗試 AI Shell
>
您的智能編碼伴侶可無縫整合到您的工作流程中。
測試方法:真實開發場景
我根據實際開發場景設計了本次比較,這些場景反映了 Rust 的日常開發工作。沒有模擬基準測試或小問題,只有 13 個具有挑戰性的 Rust 任務,這些任務涉及一個成熟的 38,000 行 Rust 程式碼庫,其中包含複雜的非同步模式、錯誤處理和架構約束,以及 2 個前端重構任務,這些任務涉及一個 12,000 行的 React 程式碼庫。
測試環境規範
專案背景:
-
Rust 1.86 和 tokio 非同步執行時
-
跨多個模組的 38,000 行
-
遵循控制反轉(IoC)的複雜依賴注入模式
-
廣泛使用特徵、泛型和非同步/等待模式
-
具有整合測試的綜合測試套件
-
使用現代鉤子和元件模式的 12,000 行 React 前端
-
記錄詳盡的編碼指南(以自訂規則/遊標規則/克勞德規則的形式提供,在不同的編碼代理中)
測試類別:
-
指向檔案變更(4 個任務):對指定檔案進行具體修改
-
錯誤尋找和修復(5 個任務):真實錯誤及其重現步驟和失敗測試
-
功能實現(4 項任務):明確需求,實現新功能
-
前端重構(2 個任務):使用Forge 代理程式和 Playwright MCP 改進 UI
評估標準:
-
程式碼正確性和編譯成功率
-
遵守指示並遵守範圍
-
完成時間
-
所需迭代次數
-
最終實施的品質
-
代幣使用效率
性能分析:綜合結果
整體任務完成情況總結
| 類別 | Kimi K2 成功率 | Qwen-3 Coder 成功率 | 時差 |
|------------------------|-----------------------|----------------------------|-----------------|
| 指向檔案變更 | 4/4 (100%) | 3/4 (75%) | 速度提高 2.1 倍 |
| 錯誤偵測與修復 | 4/5 (80%) | 1/5 (20%) | 速度提升 3.2 倍 |
| 功能實現 | 4/4 (100%) | 2/4 (50%) | 速度提高 2.8 倍 |
| 前端重構 | 2/2 (100%) | 1/2 (50%) | 速度提升 1.9 倍 |
| 整體 | 14/15 (93%) | 7/15 (47%) | 速度快 2.5 倍 |
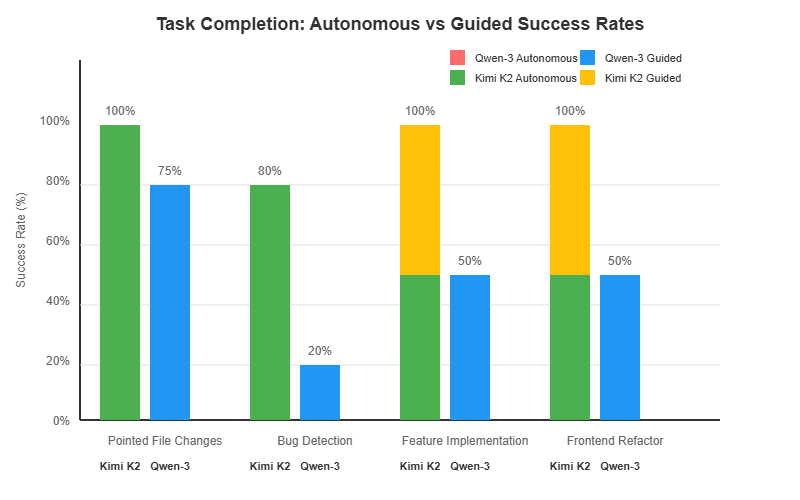 圖 1:任務完成分析 - 自主與引導成功率(僅顯示成功完成的情況)
圖 1:任務完成分析 - 自主與引導成功率(僅顯示成功完成的情況)
工具呼叫和補丁生成分析
| 公制 | Kimi K2 | Qwen-3 編碼器 | 分析 |
|------------------------|-----------------|-----------------|-------------------------|
| 總補丁呼叫次數 | 811 | 701 | 相似量 |
| 工具呼叫錯誤 | 185 (23%) | 135 (19%) | Qwen-3 略好 |
| 成功補丁 | 626 (77%) | 566 (81%) | 可比較可靠性 |
| 乾淨編譯率 | 89% | 72% | Kimi K2 優勢 |
兩種模型在處理工具模式(尤其是補丁操作)時都遇到了困難。不過,AI 代理會重試失敗的工具呼叫,因此最終補丁產生的成功不會受到初始錯誤的影響。關鍵區別在於程式碼品質和編譯成功率。
錯誤檢測和解決比較
K2 的一些表現:
-
首次嘗試即可正確修復 4/5 個錯誤
-
平均解答時間:8.5分鐘
-
維護原始測試邏輯並修復潛在問題
-
只遇到 tokio::RwLock 死鎖的情況
-
保留業務邏輯完整性
Qwen-3 編碼器效能:
-
1/5 的錯誤已正確修復
-
頻繁修改測試斷言而不是修復錯誤
-
引入硬編碼值以使測試通過
-
改變業務邏輯而不是解決根本原因
-
平均解決時間:22 分鐘(成功時)
功能實現:自主開發能力
任務完成度分析
Kimi K2 成績:
-
2/4 項任務獨立完成(分別為 12 分鐘和 15 分鐘)
-
2/4 的任務需要最少的指導(1-2 個提示)
-
在現有功能增強方面表現良好
-
需要更多指導,以獲得沒有範例的全新功能
-
始終如一地維護程式碼風格和架構模式
Qwen-3 編碼器結果:
-
0/4 的任務自主完成
-
每個任務至少需要 3-4 次重複提示
-
經常刪除工作程式碼以“重新開始”
-
經過 40 分鐘的提示,只有 2/4 的任務完成了
-
2 個任務因迭代周期過長而放棄
指令遵循分析
最大的差異體現在指令遵循方面。儘管系統提示提供了編碼指南,但模型的行為卻有所不同:
| 指令類型 | Kimi K2 合規性 | Qwen-3 Coder 合規性 |
|--------------------------|-----------------------|------------------------|
| 錯誤處理模式 | 7/8 個任務 (87%) | 3/8 個任務 (37%) |
| API 相容性 | 8/8 個任務 (100%) | 4/8 個任務 (50%) |
| 程式碼風格指南 | 7/8 個任務 (87%) | 2/8 個任務 (25%) |
| 文件修改範圍 | 8/8 個任務 (100%) | 5/8 個任務 (62%) |
Kimi K2 行為:
-
始終遵循專案編碼標準
-
尊重文件修改邊界
-
維護現有的函數簽名
-
當要求不明確時詢問澄清問題
-
提交前編譯並測試程式碼
Qwen-3 編碼器模式:
// Guidelines specified: "Use Result<T, E> for error handling"
// Qwen-3 Output:
panic!("This should never happen"); // or .unwrap() in multiple places
// Guidelines specified: "Maintain existing API compatibility"
// Qwen-3 Output: Changed function signatures breaking 15 call sites這種模式在各個任務中重複出現,表示有指令處理問題,而不是孤立事件。
前端開發:無需圖像的視覺推理
使用帶有 Playwright MCP 和 Context7 MCP 的 Forge 代理對前端重構任務上的這兩個模型進行測試,儘管缺乏直接圖像支持,但仍揭示了有關其視覺推理能力的見解。
Kimi K2方法:
-
智慧分析現有元件結構
-
對 UI 佈局做出合理的假設
-
提供以可維護性為重點的建議
-
保留的可存取性模式
-
在極少的指導下完成重構
-
保持反應能力和設計系統的一致性
-
有效地重複使用現有元件
-
在不破壞功能的情況下進行了漸進式改進
Qwen-3 編碼器方法:
-
刪除現有元件而不是重構
-
忽略了已建立的設計系統模式
-
需要多次迭代才能理解元件關係
-
未經考慮就破壞了響應式佈局
-
刪除了分析和追蹤程式碼
-
使用硬編碼值而不是變數綁定
🚀嘗試 AI Shell
>
您的智能編碼伴侶可無縫整合到您的工作流程中。
成本和背景分析
開發效率指標
| 公制 | Kimi K2 | Qwen-3 編碼器 | 差分 |
|--------------------------------|---------------------|---------------------|-----------------------|
| 每項完成任務的平均時間 | 13.3 分鐘 | 18 分鐘 | 速度提升 26% |
| 專案總成本 | 42.50 美元 | 69.50 美元 | 便宜 39% |
| 已完成的任務 | 14/15 (93%) | 7/15 (47%) | 2 倍完成率 |
| 放棄的任務 | 1/15 (7%) | 2/15 (13%) | 更好的持久性 |
不同的供應商收費不同,由於我們使用了 OpenRouter,它會在多個供應商之間分配負載,因此精確計算成本非常困難。 Kimi K2 的總費用為 42.50 美元,平均每個任務耗時 13.3 分鐘(包括需要時提示的時間)。
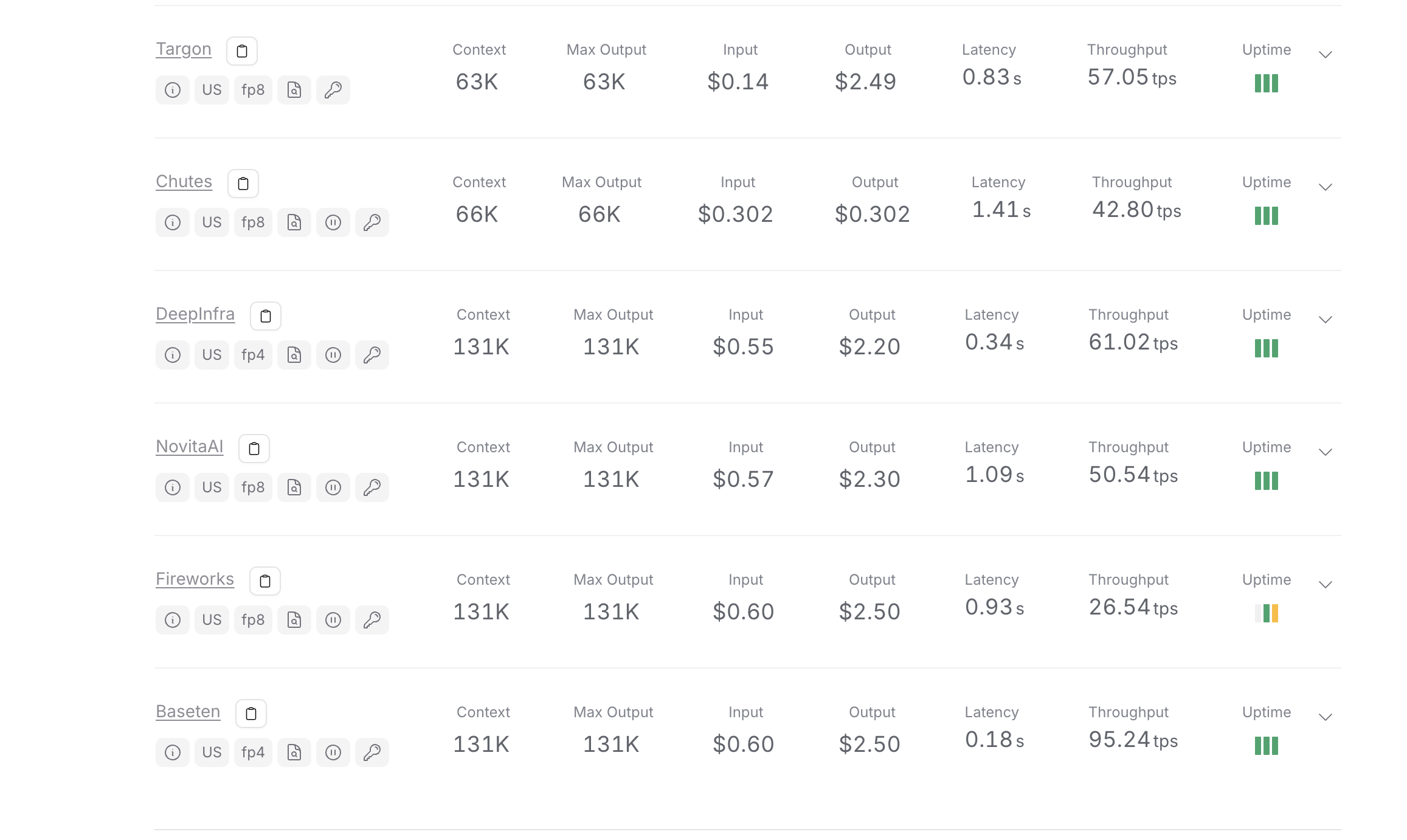
Kimi K2 在各個 OpenRouter 提供者中的使用成本 - 顯示一致的 131K 上下文長度,輸入價格從 0.55 美元到 0.60 美元不等,輸出價格從 2.20 美元到 2.50 美元不等
然而,Qwen-3 Coder 的成本幾乎是 Kimi K2 的兩倍。每項任務的平均時間約為 18 分鐘(包括必要的提示),15 項任務的總成本為 69.50 美元,其中 2 項任務被放棄。
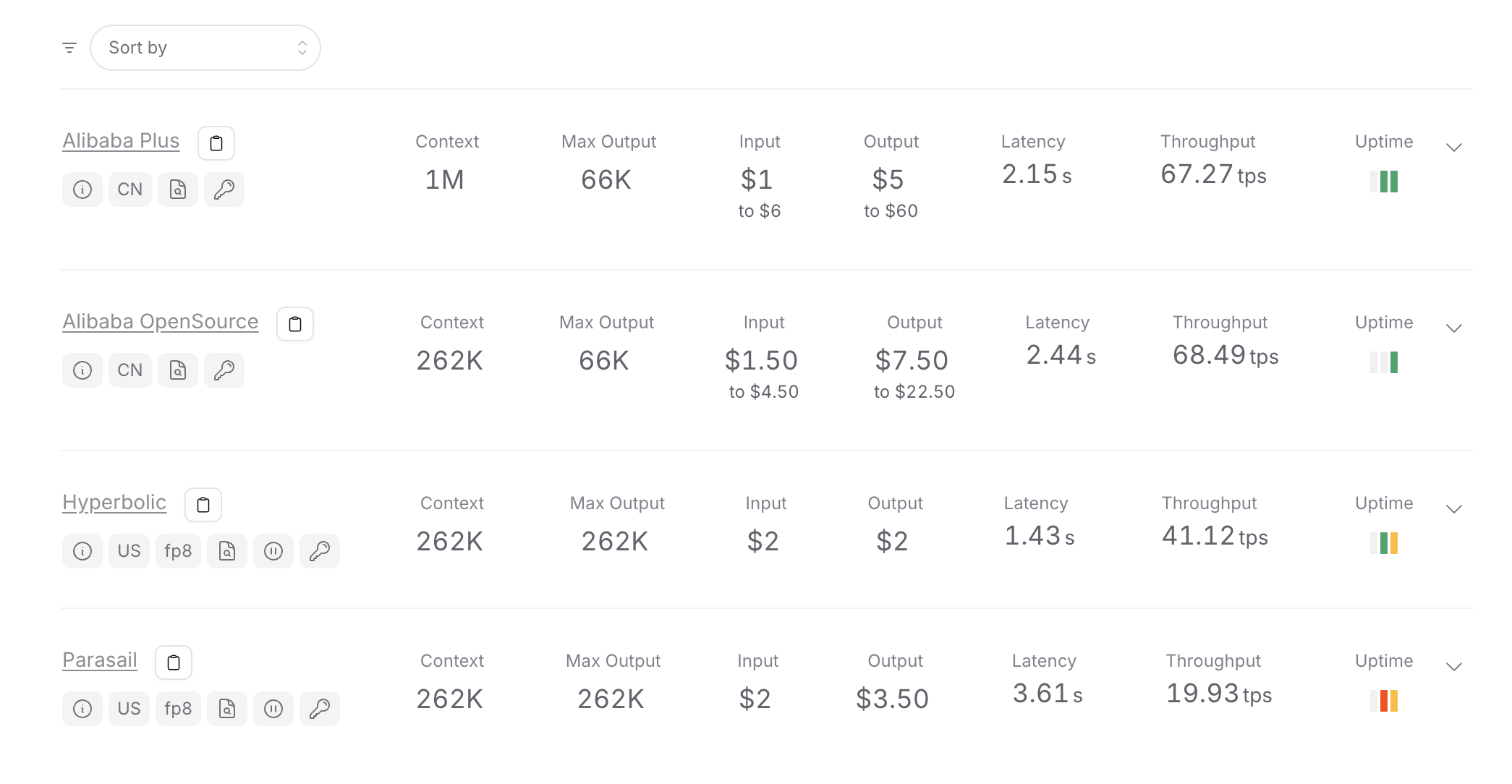
不同 OpenRouter 供應商的 Qwen-3 Coder 使用成本 - 定價結構相同,但總使用量較高,導致成本增加
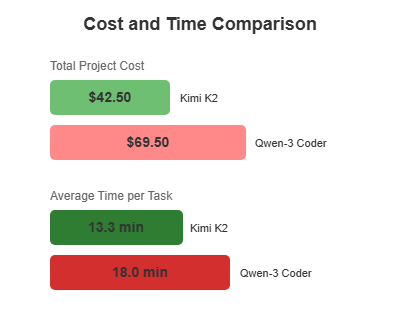 圖3:成本與時間比較-直接專案投資分析
圖3:成本與時間比較-直接專案投資分析
效率指標
| 公制 | Kimi K2 | Qwen-3 編碼器 | Advantage |
|--------------------------|------------------|------------------|------------------------|
| 每完成一項任務的成本 | 3.04 美元 | 9.93 美元 | 便宜 3.3 倍 |
| 時間效率 | 快 26% | 基線 | Kimi K2 |
| 成功率 | 93% | 47% | 提升 2 倍 |
| 已完成的任務 | 14/15 (93%) | 7/15 (47%) | 2 倍完成率 |
| 放棄的任務 | 1/15 (7%) | 2/15 (13%) | 更好的持久性 |
上下文長度和性能
像 K2 一樣:
-
上下文長度:131k 個令牌(各提供者之間一致)
-
推理速度:快,尤其是使用 Groq 時
-
記憶體使用:高效的上下文利用
Qwen-3 編碼器:
-
上下文長度:262k 至 1M 個令牌(因提供者而異)
-
推理速度:不錯,但比 Kimi K2 慢
-
記憶體使用情況:更高的上下文開銷
僵局挑戰:技術深度剖析
最能說明問題的測試涉及 tokio::RwLock 死鎖場景,該場景凸顯了解決問題方法的差異:
Kimi K2的18分鐘分析:
-
系統地分析鎖定獲取模式
-
已辨識潛在死鎖場景
-
嘗試多種解決策略
-
最終承認了複雜性並請求指導
-
在整個過程中保持程式碼完整性
Qwen-3 Coder 的方法:
-
立即建議刪除所有鎖(破壞線程安全)
-
建議使用不安全程式碼作為解決方案
-
改變測試預期而不是解決僵局
-
從未展現出對底層並發問題的理解
基準與現實:效能差距
Qwen-3 Coder 令人印象深刻的基準測試分數並不能轉化為實際的開發效率。這種脫節揭示了我們評估 AI 程式設計助理的重大限制。
為什麼基準測試沒有達到預期目標
基準限制:
-
具有清晰、獨立解決方案的綜合問題
-
無需遵守指令或約束
-
成功僅以最終產出而非開發過程來衡量
-
缺少對可維護性和程式碼品質的評估
-
沒有對合作發展模式的評估
實際要求:
-
在現有程式碼庫和架構約束內工作
-
遵循團隊編碼標準和風格指南
-
保持向後相容性
-
隨著需求的變化而迭代開發
-
程式碼審查和可維護性考慮
🚀嘗試 AI Shell
>
您的智能編碼伴侶可無縫整合到您的工作流程中。
限制和背景
在深入研究結果之前,重要的是要了解此比較的範圍:
測試限制:
-
單一程式碼庫測試(38k 行 Rust 專案 + 12k 行 React 前端)
-
結果可能不適用於其他程式碼庫、語言或開發風格
-
由於樣本量較小,沒有進行統計顯著性檢定
-
對特定編碼模式和偏好的潛在偏見
-
透過 OpenRouter 測試的型號,供應商不同
本次比較未涵蓋的內容:
-
除了 Rust 和 React 之外的其他程式語言上的效能
-
採用不同提示工程方法的行為
-
具有不同架構模式的企業程式碼庫
這些結果反映了特定的測試環境,在做出模型選擇決策之前應與其他評估一起考慮。
結論
本次測試表明,Qwen-3 Coder 的基準測試分數無法很好地反映到此特定的開發工作流程中。雖然它在處理單獨的編碼挑戰時可能表現出色,但在處理本專案中使用的協作式、約束感知的開發模式時卻遇到了困難。
在此測試環境中,Kimi K2 在極少的監督下始終如一地交付了可執行的程式碼,展現出更佳的指令遵循性和程式碼品質。其方法更符合既定的開發工作流程和編碼標準。

Qwen-3 Coder 的上下文長度優勢(高達 1M 個 token vs. 131k 個 token)未能彌補其在本次測試中存在的指令追蹤問題。兩種模型的推理速度都不錯,但搭載 Groq 的 Kimi K2 的反應速度明顯更快。
雖然這些開源模型正在快速改進,但在本次測試中,它們仍然落後於 Claude Sonnet 4 和 Opus 4 等閉源模型。不過,根據本次評估,Kimi K2 在這些特定的 Rust 開發需求方面表現更佳。
相關文章
原文出處:https://dev.to/forgecode/kimi-k2-vs-qwen-3-coder-12-hours-of-testing-3dil
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式