

每個 ML/AI 專案利害關係人需要專門的工具,使他們能夠有效地管理 ML/AI 專案的各個階段,從資料準備和模型開發到部署和監控。他們傾向於使用專門的開源工具,因為它們對人工智慧專案的進步、發展和易用性起到了重要的催化劑作用。因此,多年來出現了大量開源人工智慧工具,使得從可用選項中進行選擇變得具有挑戰性。
本文重點介紹了選擇開源工具時需要考慮的一些因素,並向您介紹了 25 個可用於 AI 專案的開源選項。
為人工智慧專案選擇開源工具
開源工具模型可讓公司開發各種機器學習工具來幫助您處理人工智慧專案中的特定問題。 AI 工具領域的工具已經相當飽和,豐富的選項使得工具選擇變得困難。其中一些工具甚至提供類似的解決方案。您可能會因為工具所提供的誘人功能而傾向於採用工具。但是,在選擇工具之前您還應該考慮其他關鍵因素,其中包括:
-
人氣
-
影響
-
創新
-
社區參與
-
與新興人工智慧趨勢的相關性。
人氣
廣泛採用的工具通常表明積極的開發、定期更新和強大的社區支持,確保了可靠性和壽命。
影響
一個具有解決痛點、提供可衡量的改進、提供長期專案可持續性以及適應人工智慧專案問題不斷變化的需求的工具,可以很好地衡量利益相關者有興趣利用的有影響力的工具。
創新
採用更現代技術並提供獨特功能的工具表明了對持續改進的承諾,並且有潛力推動進步並釋放新的可能性。
社區參與
積極的社區參與可以促進協作、提供支持並確保工具的持續相關性和改進。
與新興人工智慧趨勢的相關性
與法學碩士等新興趨勢一致的工具使組織能夠利用最新的功能,確保他們的專案始終處於創新的前沿。
適用於您的 AI 專案的 25 個開源工具
基於這些因素,您和團隊中的不同利害關係人可以在 AI 專案的各個階段使用以下 25 種工具。
1. KitOps
機器學習開發生命週期涉及多個利益相關者,在人工智慧專案的各個階段需要不同的 MLOps 工具和環境,這使得很難保證有組織、可移植、透明和安全的模型開發流程。
這帶來了模型開發過程中模型沿襲中斷以及意外或惡意模型篡改或修改的機會。由於模型的內容是一個「黑盒子」(沒有有效的儲存和沿襲),因此無法知道模型或模型工件的內容在模型開發、暫存、部署和退役管道之間是否已被篡改。

KitOps為 AI 專案利害關係人提供了一個名為 ModelKit 的安全包,他們可以使用該套件在整個 ML 開發生命週期中共享和管理模型、程式碼、元資料和工件。
ModelKit 是一個不可變的 OCI 標準工件,它利用普通的容器原生技術(類似於 Docker 和 Kubernetes),使它們能夠使用通用軟體工具和環境在各個利益相關者之間無縫互通和移植。作為一個不可變的包,ModelKit 是防篡改的。這種防篡改屬性為利害關係人提供了一個版本控制系統,該系統可以追蹤整個 ML 開發和部署管道中任何內容(即模型、程式碼、元資料和工件)的每一次更新。
2.LangChain
LangChain是一個機器學習框架,使ML工程師和軟體開發人員能夠快速建立端到端的LLM應用程式。其模組化架構使他們能夠輕鬆混合和匹配其廣泛的元件套件,以建立定制的法學碩士應用程式。
LangChain 透過其互連部分的生態系統(包括LangSmith 、 LangServe和LangGraph )簡化了 LLM 應用程式的開發和部署階段。它們共同使機器學習工程師和軟體開發人員能夠高效地建立強大、多樣化且可擴展的法學碩士應用程式。

LangChain讓沒有強大人工智慧背景的專業人士能夠輕鬆建立具有大型語言模型(LLM)的應用程式。
3.Pachyderm
Pachyderm是一個資料版本控制和管理平台,使工程師能夠自動執行複雜的資料轉換。它使用資料基礎設施,透過資料驅動的版本控制管道提供資料沿襲。版本控制的管道會根據資料的變化自動觸發。它追蹤對資料的每次修改,從而可以輕鬆複製先前的結果並使用各種管道版本進行測試。

Pachyderm 的資料基礎設施提供具有版本控制和沿襲的「資料感知」管道。
4.ZenML
ZenML是一個結構化的 MLOps 框架,它抽象化了 MLOps 管道的建立,使資料科學家和 ML 工程師能夠專注於資料預處理、模型訓練、評估和部署的核心步驟,而無需陷入基礎設施細節。

ZenML 框架抽象化了 MLOps 基礎架構的複雜性並簡化了 MLOps 的採用,使 AI 專案元件可存取、可重複使用且可複製。
5. Prefect
Prefect是用於機器學習管道的 MLOps 編排框架。它使用任務(單一工作單元)和流程(任務序列)的概念來建立 ML 管道,用於執行 ML 程式碼的不同步驟,例如特徵工程和訓練。這種模組化結構使機器學習工程師能夠簡化複雜機器學習工作流程的建立和管理。
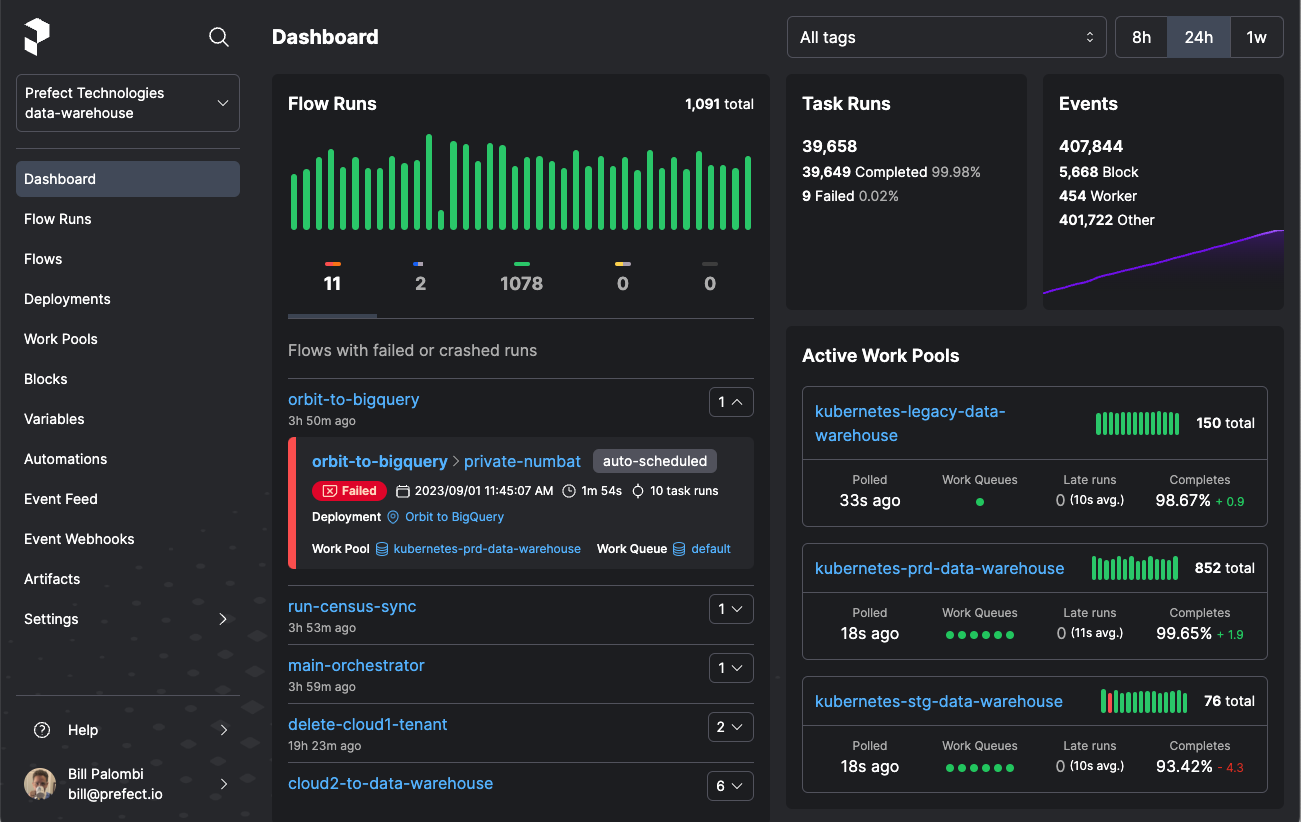
Prefect 簡化了資料工作流程管理、強大的錯誤處理、狀態管理和廣泛的監控。
6.Ray
Ray是一個分散式運算框架,讓資料科學家和機器學習工程師可以在模型開發過程中輕鬆擴展機器學習工作負載。它簡化了計算密集型工作負載的擴展,例如從單一機器到大型叢集的載入和處理大量資料或深度學習模型訓練。

Ray 的核心分散式執行時,可輕鬆擴充 ML 工作負載。
7. Metaflow
Metaflow是一種 MLOps 工具,可透過統一的 API 提高資料科學家和 ML 工程師的工作效率。該 API 提供了一種程式碼優先的方法來建立資料科學工作流程,它包含資料科學家和機器學習工程師執行從原型到生產的人工智慧專案所需的整個基礎設施堆疊。

8.MLflow
MLflow允許資料科學家和工程師管理模型開發和實驗。它簡化了從實驗到部署的整個模型開發生命週期。

MLflow 的主要功能包括:
MLflow 追蹤:它提供 API 和 UI,用於在訓練機器學習模型時記錄和查詢您的實驗、參數、程式碼版本、指標和輸出檔案。然後,您可以在記錄結果後比較幾次執行。
MLflow 專案:它提供了標準的可重複使用格式來打包資料科學程式碼,並包括 API 和 CLI 來執行專案以連結到工作流程中。任何 Git 儲存庫/本機目錄都可以視為 MLflow 專案。
MLflow 模型:它提供了在不同服務環境中部署 ML 模型的標準格式。
MLflow 模型登錄:它為您提供集中式模型儲存、API 集和 UI,以協作管理模型的整個生命週期。它還支援模型沿襲(來自模型實驗和執行)、模型版本控制和開發階段轉換(即,將模型從暫存階段轉移到生產階段)。
9. Kubeflow
Kubeflow是 Kubernetes 的 MLOps 工具包。它旨在簡化 Kubernetes 叢集上的 ML 工作流程的編排和部署。其主要目的是使複雜的機器學習系統的擴展和管理變得更容易、可移植且可跨不同基礎設施進行擴展。

Kubeflow 是 MLOps 領域的關鍵參與者,它引入了一個強大且靈活的平台,用於在 Kubernetes 上建置、部署和管理機器學習系統。這個用於開發、部署和管理 ML 模型的統一平台支援資料科學家、ML 工程師和 DevOps 團隊之間的協作。
10.Seldon core
Seldon core是一個 MLOps 平台,透過將 ML 模型(TensorFlow、PyTorch、H2o 等)或語言包裝器(Python、Java 等)轉換為生產就緒的 REST/ 來簡化機器學習模型的部署、服務和管理。服務。將它們視為預先打包的推理伺服器或自訂伺服器。 Seldon 核心還支援這些伺服器的容器化,並提供開箱即用的功能,例如進階指標、請求日誌記錄、解釋器、異常值偵測器、A/B 測試和金絲雀。

Seldon Core 的解決方案著重於模型管理和治理。它的採用面向 ML 和 DevOps 工程師,特別是模型部署和監控,而不是小型資料科學團隊。
11.DVC(資料版本控制)
為機器學習專案實施版本控制需要管理程式碼和資料集、ML 模型、效能指標和其他與開發相關的工件。其目的是將軟體工程的最佳實踐(例如版本控制和可重複性)引入資料科學和機器學習領域。 DVC使資料科學家和機器學習工程師能夠像 Git 對程式碼一樣追蹤資料和模型的更改,使其能夠在任何 Git 儲存庫之上執行。它可以管理模型實驗。

DVC 與 Git 的整合可以更輕鬆地將軟體工程原理應用於資料科學工作流程。
12.EvidentlyAI
EvidentlyAI是一個可觀察平台,旨在分析和監控生產機器學習 (ML) 模型。其主要目的是幫助機器學習從業者了解並維護其部署模型隨著時間的推移的性能。顯然,它提供了一套全面的工具來追蹤關鍵模型性能指標,例如準確性、精確度、召回率和漂移檢測。它還使利害關係人能夠產生互動式報告和視覺化,從而輕鬆辨識問題和趨勢。

13. Mage AI
Mage AI是一個資料轉換和整合框架,允許資料科學家和機器學習工程師建立和自動化資料管道,而無需進行大量編碼。資料科學家可以輕鬆連接到他們的資料來源、提取資料並在 Mage 筆記本中建立生產就緒的資料管道。

14. ML Run
ML Run提供了一種用於編排端對端 MLOps 系統的無伺服器技術。無伺服器平台將機器學習程式碼轉換為可擴展和託管的微服務。這簡化了資料科學家、ML、軟體和 DevOps/MLOps 工程師在整個機器學習 (ML) 生命週期、跨各種環境的開發和管理流程。

15. Kedro
Kedro是一個機器學習開發框架,用於建立可重複、可維護、模組化的資料科學程式碼。 Kedro 透過資料抽象化和程式碼組織改善 AI 專案開發體驗。使用輕量級資料連接器,它提供了一個集中的資料目錄來管理和追蹤整個專案的資料集。這使得資料科學家能夠專注於透過 Kedro 的資料管道建立生產級程式碼,從而使其他利害關係人能夠在系統的不同部分使用相同的管道。

Kedro 透過為資料科學家實施 SWE 最佳實踐來專注於資料管道開發。
16.WhyLogs
WhyLabs 的WhyLogs是一個開源資料記錄庫,專為機器學習 (ML) 模型和資料管道而設計。其主要目的是提供隨時間變化的資料品質和模型性能的可見性。
借助 WhyLogs,MLOps 工程師可以有效地生成資料集的緊湊摘要(稱為配置檔案),以捕獲基本的統計屬性和特徵。這些配置檔案追蹤資料集隨時間的變化,幫助檢測資料漂移——模型效能下降的常見原因。它還提供了用於視覺化資料集設定檔中的關鍵摘要統計資料的工具,從而可以輕鬆了解資料分佈並辨識異常情況。

17. Feast
在孤島(即來自不同位置)中定義、儲存和存取模型訓練和線上推理的特徵可能會導致特徵定義不一致、資料重複、複雜的資料存取和檢索等。挑戰開發和生產環境中的學習 (ML) 功能。
Feast 是一個彌合資料和機器學習模型之間差距的特徵儲存。它提供了一個用於定義功能模式的集中儲存庫,確保不同團隊和專案之間的一致性。這可以確保用於模型推理的特徵值與請求時特徵的狀態一致,即使對於歷史資料也是如此。

Feast 是一個用於管理、儲存和服務功能的集中式儲存庫,可確保整個培訓和服務環境的一致性和可靠性。
18. Flyte
資料科學家以及資料和分析管道工程師通常依靠機器學習和平台工程師將模型和訓練管道轉換為生產就緒系統。
Flyte賦予資料科學家以及資料和分析工程師獨立工作的自主權。它為他們提供了用於建置工作流程的 Python SDK,然後可以輕鬆地將其部署到 Flyte 後端。透過大規模建置和執行可靠且可重複的管道,簡化了複雜機器學習和資料工作流程的開發、部署和管理。

19. Featureform
資料科學家單獨開發模型開發功能的臨時實踐使得其他人工智慧專案利害關係人很難理解、重複使用或基於現有工作進行建構。這會導致重複工作、特徵定義不一致以及重現結果的困難。
Featureform是一個虛擬特徵存儲,可簡化資料科學家管理和服務機器學習模型特徵的能力。它充當 Databricks 和 Snowflake 等現有資料基礎設施之上的「虛擬」層。這使得資料科學家能夠直接為其他利害關係人設計和部署功能到資料基礎設施。其結構化、集中式的功能儲存庫和元資料管理方法使資料科學家能夠將他們的工作從實驗無縫過渡到生產,確保整個機器學習生命週期的可重複性、協作和治理。

20.Deepchecks
Deepchecks是一種機器學習監控工具,用於持續測試和驗證從人工智慧專案的實驗到部署階段的機器學習模型和資料。它提供了廣泛的內建檢查來驗證模型效能、資料完整性和資料分佈。這些檢查有助於辨識模型偏差、資料漂移、概念漂移和洩漏等問題。
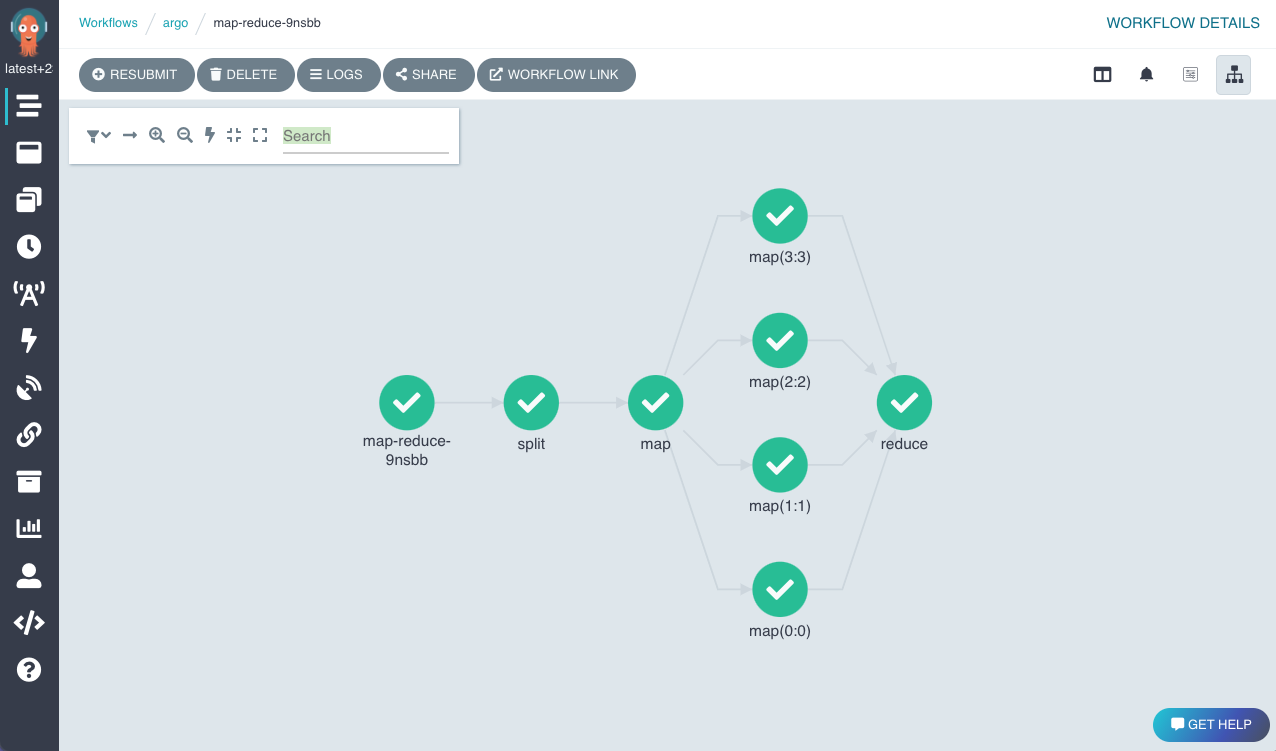
21.Argo
Argo提供了 Kubernetes 原生工作流程引擎,用於在 Kubernetes 上編排並行作業。其主要目的是簡化複雜、多步驟工作流程的執行,使其特別適合機器學習 (ML) 和資料處理任務。它使機器學習工程師能夠將機器學習工作流程的每個步驟(資料預處理、模型訓練、評估、部署)定義為單獨的容器,從而更輕鬆地管理依賴項並確保可重複性。
Argo 工作流程是使用 DAG 定義的,其中每個節點代表工作流程中的一個步驟(通常是容器化任務),邊代表步驟之間的依賴關係。工作流程可以定義為任務序列(步驟)或有向無環圖 (DAG) 以捕捉任務之間的依賴關係。
22. Deep Lake
Deep Lake (以前稱為 Activeloop Hub)是一種特定於 ML 的資料庫工具,旨在充當深度學習的資料湖和 RAG 應用程式的向量儲存。其主要目的是透過提供對大規模資料集(無論格式或位置如何)的快速有效的存取來加速模型訓練。

23.Hopsworks特徵商店
至少具有MLOps 成熟度等級 1架構的高階 MLOps 管道需要集中式特徵儲存。 Hopsworks是此類架構的完美特徵儲存。它提供了用於管理 ML 功能生命週期的端到端解決方案,從資料擷取和功能工程到模型訓練、部署和監控。這有利於功能重複使用、一致性和更快的模型開發。

24. NannyML
NannyML是一個專門用於機器學習 (ML) 模型的部署後監控和維護的 Python 函式庫。它使資料科學家能夠檢測和解決靜默模型故障,在沒有直接真實資料的情況下估計模型性能,並辨識可能導致性能下降的資料漂移。

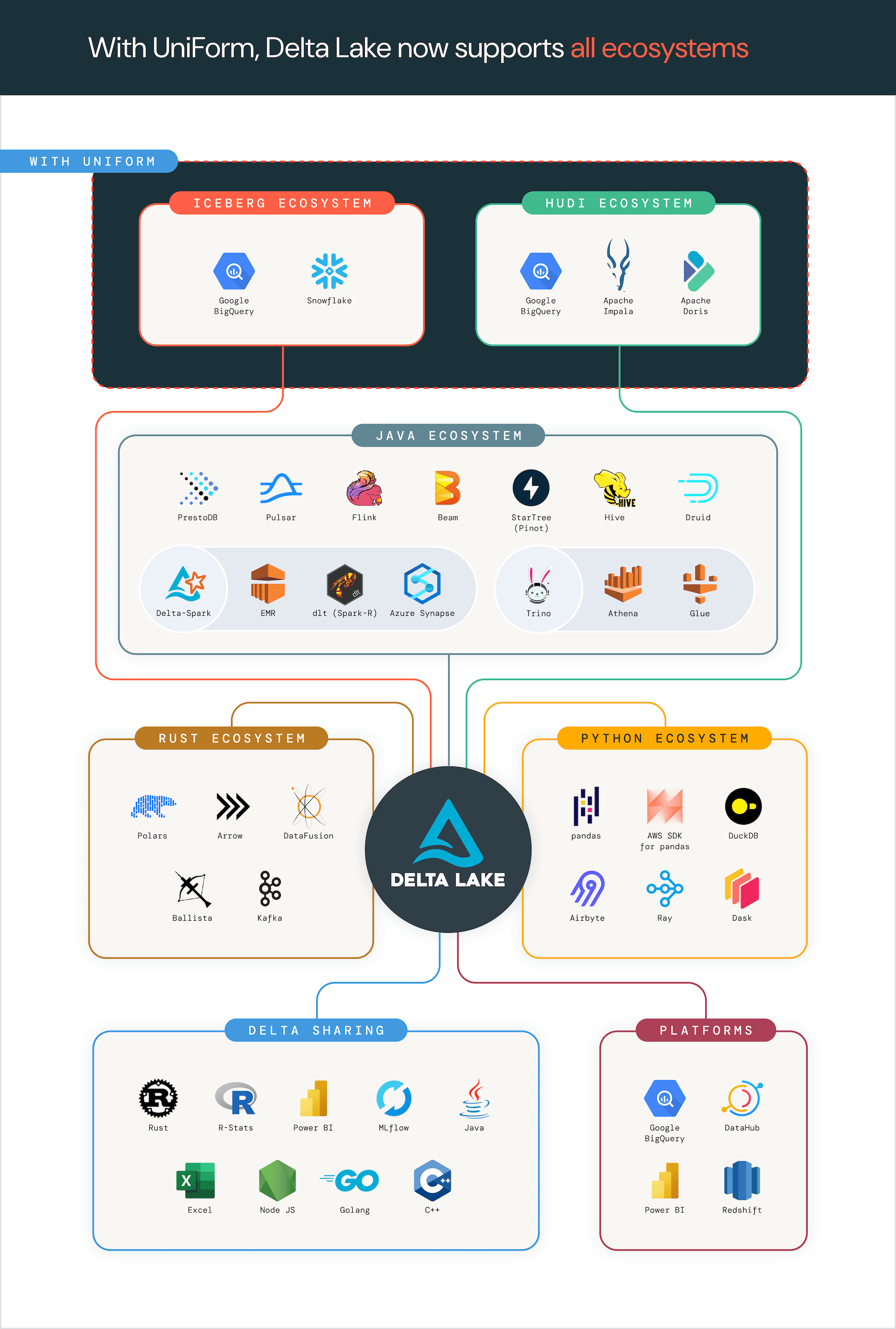
25. Delta Lake
Delta Lake是一個為資料湖提供可靠性的儲存層框架。它解決了在 Lakehouse 架構中管理大規模資料的挑戰,其中資料以開放格式儲存並用於各種目的,例如機器學習 (ML)。資料工程師可以使用 Delta Lake 建立即時管道或機器學習應用程式,因為它支援批次和串流資料處理。它還為資料湖帶來了 ACID(原子性、一致性、隔離性、持久性)事務,即使在多個管道並發讀寫的情況下也能確保資料完整性。
考慮受歡迎程度、影響力、創新、社區參與度以及與新興人工智慧趨勢的相關性等因素,可以幫助您在選擇開源人工智慧/機器學習工具時做出決策,特別是對於那些提供相同價值主張的工具。在某些情況下,此類工具可能有不同的方式為相同用例提供解決方案,或具有獨特的功能,使其非常適合特定的專案用例。
例如,一些模型開發、部署和管理工具(例如 MLRun 或 Kubeflow)提供了一個平台或 API,可以輕鬆開發 AI 專案。這通常決定利害關係人對平台環境、基礎設施和工作流程的使用。 KitOps 將其解決方案作為一個套件提供,讓 AI 專案中的利害關係人在使用現有工具、環境和開發實踐的同時對他們的工作進行版本控制和共享。要嘗試 KitOps 解決方案,請按照本指南開始。
原文出處:https://dev.to/kitops/25-open-source-ai-tools-to-cut-your-development-time-in-half-4h5j
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式