🔧 阿川の電商水電行

目次
初步介紹
通過優化SHAP值處理,成功實現99.99%以上的處理時間減少,並且將AWS計算成本降低超過440萬元每年。
透過省略每次執行批次處理時產生的龐大中間表,成功年減少Athena掃描費用超過60萬元。
這在商業上應該是非常有影響力且意義重大的工程成果。
但是,為什麼會這樣呢?
這種沒有具體形象感的感受。
為什麼會沒有那種「我做到了」的感覺呢?
真是空虛...
因此,我決定整理這份空虛感,同時把所做的事情整理出來。
執行內容與結果
之前也提到過,本次執行的內容有以下兩項:
- 通過優化SHAP值處理,實現99.99%以上的處理時間減少,並且將AWS計算成本降低超過440萬元
- 省略每次執行批次處理時生成的重型中間表,成功年減少Athena掃描費用超過60萬元
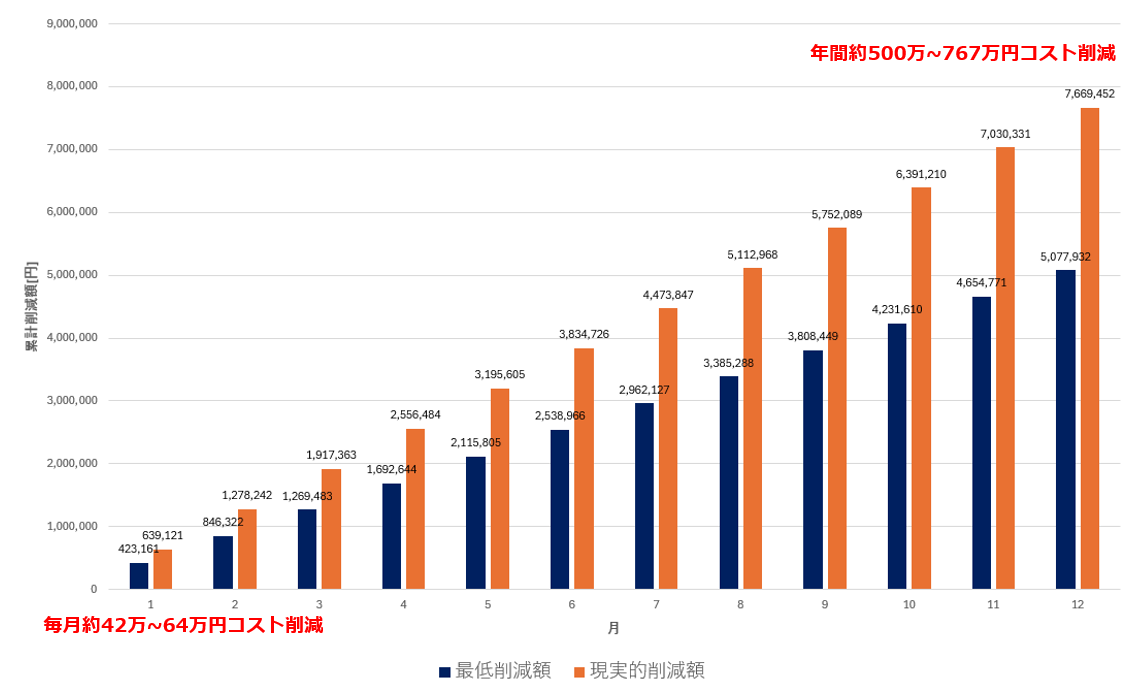
結果,實現了累計每年超過500萬元的成本削減。
接下來將整理各自的背景與具體應對方法。
SHAP值處理的修正
背景
這是關於成本避免。
這裡所謂的成本避免,是指提前防止了本來應該發生的成本。
雖然新加入SHAP值處理,但因為其他功能實施的SHAP處理成本高昂,於是對其進行了優化,以便於在大規模模型中使用。
SHAP值是對模型預測結果進行的各特徵量對結果的貢獻度的公平量化,是用來解釋機器學習模型輸出的值為何會成為這個值的指標。
這一努力的背景是過度學習的問題。
訓練誤差極小,但泛化誤差卻超過20%,一些情況甚至超過45%的誤差,因此將SHAP作為切分過度學習原因的一種手段來添加。
(實際上這不是過度學習,而是目標洩漏的問題,但那是另外的機會再說。)
課題1:在for迴圈中使用lambda表達式
由於其他模型採用了SHAP處理,所以使用它來執行處理時,SHAP處理過程中的日誌停止了。
雖然沒有錯誤,但處理也看不出任何動作,處於無回應的狀態。
經過調查,我發現在下面這種處理中停住了。
for i in Series.index:
if Series.loc[:, i].max() == Series_median[i]:
Series.loc[:, i] = Series.loc[:, i].apply(lambda x: 1 if x == Series_median.loc[:, i].max() else 0)
else:
...這是為了SHAP解釋的前處理,但問題不在於處理邏輯,而在於實現方式。
上述使用的lambda表達式(當條件滿足時回傳1,否則回傳0)是基於Series級別調用Python函數的。
使用lambda的apply實現可以減少代碼量,但內部實際上是對元素進行逐個調用Python函數的方式,這樣就無法進行矢量化。
結果,函數調用的開銷與for迴圈重複次數的乘積,容易成為大數據的瓶頸。
在現有SHAP值處理中,這樣的for迴圈就存在了三個,並且需要花費很長時間。
課題2:將int更改為str
由於上面的例子,我向其他處理較慢的區域進行搜索,發現了下面這個處理。
計算SHAP值時,正負的影響是非常重要的。
這裡的正負指的是特徵量本身的大小與對預測的影響。
若特徵量的大小較大且對預測有正面影響,則分為++,以此類推,劃分為++、+-、-+、--四個象限來確認影響度。
為了計算上述,現有SHAP值處理中使用了int轉為str的方式來了解四個象限。
Series = Series.astype(str)
shap_values = shap_values.astype(str)
answer = Series + shap_value
...
for i in Series:
df_shap.loc[df_shap["fea_name"]==i, "fea+_shap+"] = len(answer[answer[i]=="11"])
...這是一個相當反模式的做法,
int轉為str的成本高str會增加內存使用量- 由於是
str,無法進行矢量運算,只能回落到Python處理 - Python處理也會增加開銷
這樣的處理的確相當繁瑣。
解決方案
因此進行重構。
首先對於課題1,進行了如下修改。
for i in X_median.index:
if X.loc[:, i].max() == X_median[i]:
X.loc[:, i] = np.where(X.loc[:, i] == X.loc[:, i].max(), 1, 0)
else:
...意識到的關鍵點是,「通過廢除lambda處理,統一使用numpy,充分發揮矢量運算的優勢」。
矢量運算是指,不是針對每個元素一個個處理,而是對numpy整個數組同時進行相同的計算。
過去因為調用Python函數使用lambda來逐個計算,因此需要消耗大量時間,但上述處理可對X.loc[:, i] == X.loc[:, i].max()一次性應用到整個系列,因此能夠瞬間結束。
課題2同樣也進行了調整,使其能進行矢量運算,並且能夠有效表現++等四象限。
df_shap["fea+_shap+"] = 0
df_shap["fea+_shap-"] = 0
df_shap["fea-_shap+"] = 0
df_shap["fea-_shap-"] = 0
for i in Z_median.index:
# 從兩個0/1列中生成能表達四種狀態的唯一數值列
# (Z=1, S=1) -> 3 (++)
# (Z=1, S=0) -> 2 (+-)
# (Z=0, S=1) -> 1 (-+)
# (Z=0, S=0) -> 0 (--)
combined_code = Z[i] * 2 + shap_values_df[i]
counts = combined_code.value_counts()
row_index = df_shap["fea_name"] == i
df_shap.loc[row_index, "fea+_shap+"] = counts.get(3, 0)
df_shap.loc[row_index, "fea+_shap-"] = counts.get(2, 0)
df_shap.loc[row_index, "fea-_shap+"] = counts.get(1, 0)
df_shap.loc[row_index, "fea-_shap-"] = counts.get(0, 0)同樣,讓其可以完結於矢量運算,並且不再通過++等表現形式,如使用11等,而是使用類似位運算的計算combined_code = Z[i] * 2 + shap_values_df[i]。
這使得++返回3、+-返回2,因而能夠獲得獨立的數值來計算貢獻度。
| Z | SHAP | combined_code |
|---|---|---|
| + | + | 3 |
| + | - | 2 |
| - | + | 1 |
| - | - | 0 |
當我想到這種處理時,心中不禁感慨「學習算法是多麼有用」。
你永遠無法預測到什麼會派上用場。
執行時間
這個模型是對特定媒體的接洽率進行計算的模型,通常需要學習大約48個媒體。
特徵量也對每個媒體接近150個,因此for迴圈所遍歷的特徵量總數為7200個,規模相當龐大。
在改修前後,總結每個步驟的執行時間如下。
| 改修前 | 改修後 | |
|---|---|---|
| for迴圈1 | 117秒 | 0.5秒 |
| for迴圈2 | 測試未能進行(因為處理凍住) | 5.6秒 |
| for迴圈3 | 測試未能進行 | 15秒 |
| SHAP值計算 | 測試未能進行 | 0.015秒 |
| 總計 | 測試未能進行 | 30秒(每個媒體) |
在改修前,第一個for迴圈便因為發生swap thrashing而凍住,因此無法測試後續的for迴圈。
觀察到改修後的值,可能之前每個迴圈都是超過30秒的...
避免成本計算
為了計算最低避免成本,假設SHAP值計算前所有的改修前執行時間與for迴圈一次的時間相同。
在四個階段中,學習一個媒體所需的時間為:
$17[s] 150[特徵量] 48[媒體] = 122400[s] = 34[h]$
每一階段需要34小時,因此四個階段的總處理時間為:
$34[h/階段] * 4[階段] = 136[h] = 5.66[天]$
那麼,僅計算所有媒體的SHAP值計算,便需要花費五天半以上的時間。
這些都是批次處理,每月初定期執行。
而當代碼修改時,則需要在複製的生產環境中進行測試調試,每月執行2~6次,預估每月至少會發生3次。
批次處理是在AWS的EC2上進行,所使用的實例是每小時$6.05的r5.24xlarge這種怪物級高性能機器,因此每年計算成本為:
$6.05[$/h] 150[円/$] 136[h] 3[次/month] 12[month]= 4,443,120[円/年]$
相較之下,如果在改修後進行相同的計算,使用48媒體則結果為1440秒=0.4小時,則:
$6.05[$/h] 150[円/$] 0.4[h] 3[次/month] 12[month]= 13,068[円/年]$
因此,最低的避免成本為:
$4,443,120[円/年] - 13,068[円/年] = 4,430,052[円/年]$
這樣便實現了超過440萬元的成本避免。
嗯,真是棒!

嗯,這真是讓人費解。
這是字面上不同尋常的成本避免表現嗎?
模型建立中的前處理跳過
背景
接下來是關於成本削減。
如先前所述,這個模型是批次處理,並且有生產環境與測試環境。以下是架構圖。

生產環境每月至少會運行一次,測試環境則會運行至少兩次,但因為是要學習數十億條記錄的大型模型,所以Athena的掃描費用非常高昂。
大約每次執行要花費5.5萬元。
然而,由於從事管道自動化工作,在未來進行數據洩漏以及細微重構時,進行測試調試是無法迴避的。
這使得測試調試的執行成本成為了瓶頸。
解決方案
在之前的工作中,已經明白Athena掃描費普遍高是因為特徵量數據的獲取,而不是前處理中間表的生成。
之前的努力是:
之前的工作
後來發現,如果能跳過中間表的生成,就能大幅削減成本,並調查發現中間表是CTAS並存放在S3中。
因此,對參數傳遞特定字符進行改修,可以跳過前處理的中間表生成。
生產環境不帶參數執行,因此可以如下面一樣將影響範圍限制在測試環境中。

減少成本計算
在改修後進行測試調試,確認Athena掃描量,並將與改修前的比較整理如下。
計算方法為:$掃描量 5[$/TB] × 0.000000000001[TB] * 150[円/$]$。
| 改修前 | 改修後 | |
|---|---|---|
| 掃描量 | 72314455573227 | 1347775563955 |
| 收費 | 約55,000元 | 約1,010元 |
因此,每次重執行可節省約5.4萬元。
要計算最低的成本削減額,依然按每月定期執行一次,測試調試兩次來計算,因此僅可期待第二次的測試調試能獲得削減成效。
每年的最低削減成本為:
$54,000[円/回] 1[次/月] 12[月] = 648,000[円]$
如圖所示。

與成本避免方案相比較,雖然在易懂性上提高了,但金額方面似乎不算什麼。
不過,上個月的測試調試費用約為每月34萬元,已經大約完整執行了6次。如果在未來持續改修,假使每個月能削減5次的費用,則為:
$54,000[円/回] 5[回/月] 12[月] = 3,240,000[円]$
這樣將會節省非常大的成本。
再呈現圖示如下。

...因為比率並無改變,所以視覺上當然不會有所變化。
不過,數值的確變多,因此與成本避免相加,我認為最終能夠達到最低500萬元,實際上則超過760萬元的成本削減。

為何感到空虛
此次的改修,從數字上看應該是相當有影響力的成果。
然而,卻有一種說不出的「我做到了」的感覺沒有出現,讓我感到空虛。
經過仔細思考,我突然意識到了。
沒有人讚美我...
此次的努力不是「新創造了什麼工作」,而是「消除了本來會發生的問題」。
既然消除了問題,問題就不會自然而然發生,但MLOps等基礎設施改善工作,往往被視為「運行理所當然」,結果顯得好像「什麼都沒發生 = 什麼都沒有」。
此次感受到的平淡和空虛,並不是因為成果小,而是負責地修改了根幹,並創造了超過500萬元的成本節省,卻周遭反應冷淡,由此產生的心態。
讚美與認可是非常重要的。
以後有了後輩,我一定會多多讚美他們。
感想
此次改修旨在從根本上降低模型持續運行的風險和運作成本。
我個人從事這份工作,目標是「通過工程學產生商業價值」,因此此次的成果在我看來是理想的價值實現方式。
文章中計算了最低削減成本,但也包括了:
- 被削減的長時間執行中,包含因網絡錯誤或OOM導致的中斷重執行的風險,這也一併得以抑制
- 進行到學習過程中的測試調試是非常頻繁的
- 定期執行也以每三個月一次的頻率失敗,導致每月執行兩次生產環境
等等,實際會帶來更高成本的風險,本次改修可防止這些問題出現才是關鍵所在。
這不是一次性的成本削減,而是藉由結構改善而進行的持續性成本削減,因此使用此模型的時間越長,效果就會越顯著,這也是值得讚賞的地方(自我欣賞)。
雖然實際的削減成本無法明確計算,但或許年年有可能達到數千萬元的範疇... 這是一個令人振奮的工程。
即使如此,MLOps的工作往往被視為「運行理所當然」,而且自身的工作內容也比較單調,因此很少受到讚賞,因此根本無法感受到自己做了什麼了不起的事情,這實在令人感到悲傷。
然而,正因如此,這樣用語言表達出來的價值是非常重要的,為了向周圍展示自己的努力和成果,我認為這是至關重要的。
讓別人注意到自己的成果,爭取認可的提升、加薪和升遷的機會也是自己的工作,
從此次的改進中,我學到能夠在其他大型批次處理和MLOps案件中推廣的思維方式,因此將繼續努力,願意在可能的情況下,促進更多的讚美。
原文出處:https://qiita.com/qiita_mita/items/23781b97f6477d84db17
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式