
我在[這篇關於幻覺的部落格文章](https://dev.to/aws/why-does-ai-lie-hallucinations-explained-simply-1c7g) 收到以下留言。
https://dev.to/ai_made_tools/comment/37ke2
https://dev.to/ai_made_tools/comment/37mb0
模型基本上是舉手說:「嘿,我們已經在這裡待一段時間了。」這其實已經是最好的情況。
很多模型不會這麼做。它們只會默默地變差。同樣自信的語氣,卻提供更不可靠的答案。你不會知道這件事正在發生,直到某個地方明顯出錯。
你貼入一份很長的文件,問其中間某段的內容,結果得到一個很自信但錯誤的答案。或者你進行了二十輪對話,模型開始自相矛盾。
不是因為它在產生幻覺,而是因為它的空間用完了。
在[上一篇文章](https://dev.to/aws/bigger-ai-models-arent-always-better-heres-how-to-actually-choose-56pc) 裡,我們談過模型大小。當時,Token 是成本的單位。今天,它們變成了記憶的單位。
什麼是 context window
每個模型都有一個 context window。那就是它一次能放在「腦中」處理的 token 總數。你的輸入,加上它的輸出,都必須裝得進這個視窗。
你可以把它想成一張桌子,而且是尺寸固定的桌子。模型需要同時思考的所有內容,都必須放在這張桌子上。你的問題、你貼上的文件、對話紀錄、系統指令,全都要放得下。
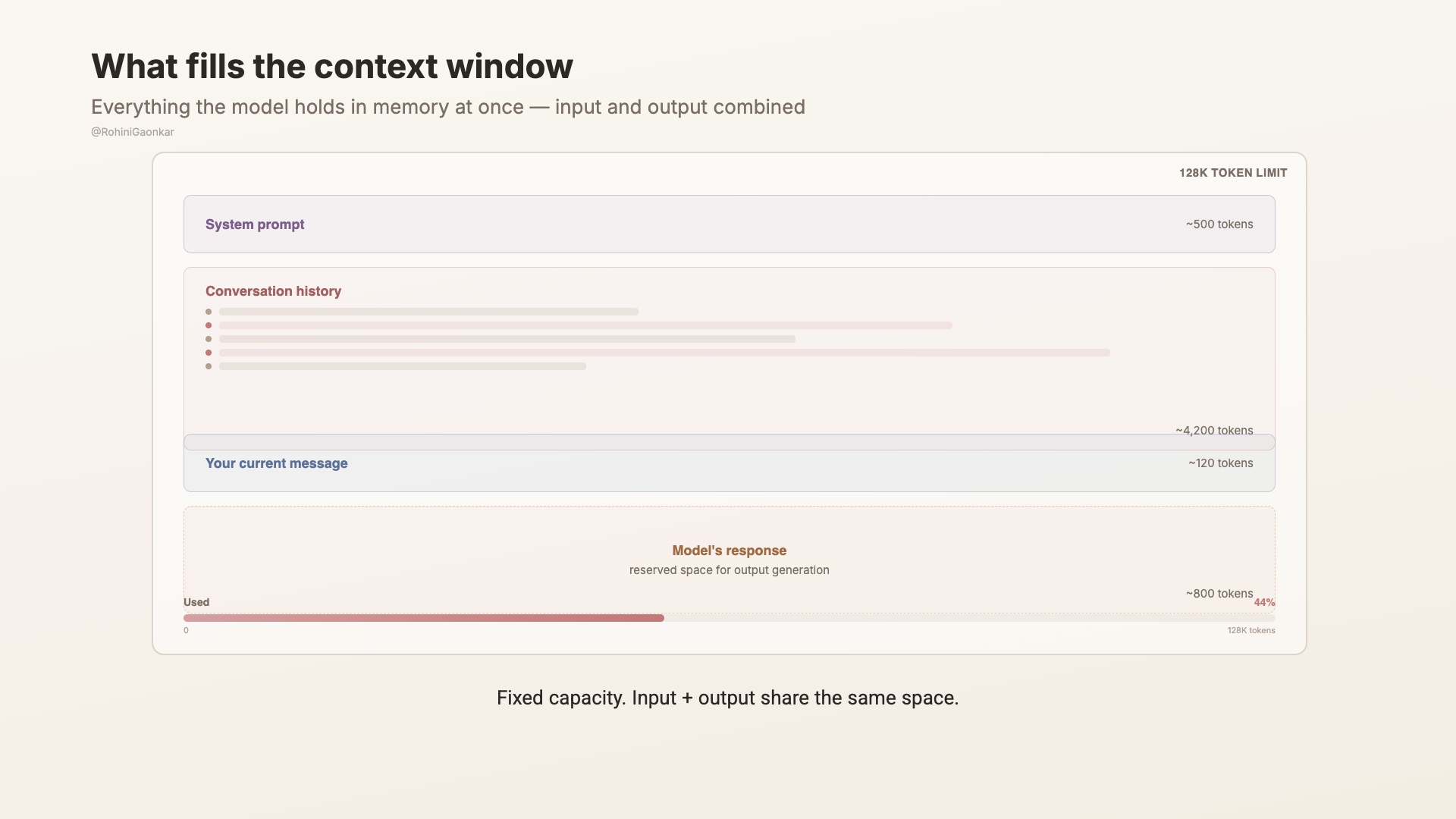
如果你把太多東西放在桌上,有些內容就會被蓋住。模型不會跟你說「嘿,這些我放不下。」它只會用它目前能專注到的內容去運作,悄悄忽略掉剩下的部分。
桌子有多大?這要看模型。
有些較早期的模型 context window 只有 4,000 tokens,大約相當於 3,000 個英文單字,差不多六頁。
有些有 128,000 tokens。那大概是一部短篇小說的長度。
有些更新的模型有一百萬個 token 以上。那是好幾本書,甚至是完整的程式碼庫。
但這裡有件很多人會忽略的事:更大的 context window,不代表模型會同等關注裡面的每一部分。它只是表示桌上放得下更多東西,不代表模型會用同樣的仔細程度去讀每一頁。
同一個問題的兩種樣貌
我們用兩種方式來看這個限制。
文件
你把二十頁文字貼進模型裡,像是法律合約、保險條款、內部文件。你問的是第 15 章中的第 7 節內容。模型可能找得到,也可能找不到,甚至可能完全引用錯誤的章節。
圍繞著目標資訊的文字越多,模型的注意力就越被稀釋。即使 window 還沒滿也一樣。
對話
這是大多數人最先遇到的情況,就像上面的留言者一樣。
預設情況下,模型並沒有一個獨立用來保存對話的「記憶」。有些產品會在外層加上一層持久化機制(像是 ChatGPT 的記憶、Claude 的專案),但底下的模型本質上仍是同樣的運作方式。每一次你送出訊息時,模型都會從頭重新讀一遍整段對話。你的第一則訊息、它的第一個回覆、你的第二則訊息、它的第二個回覆,一路到你剛剛輸入的內容。
那整段對話紀錄會在每一次請求時重新送回模型。而每一輪互動都會讓 token 的總量再往上疊。
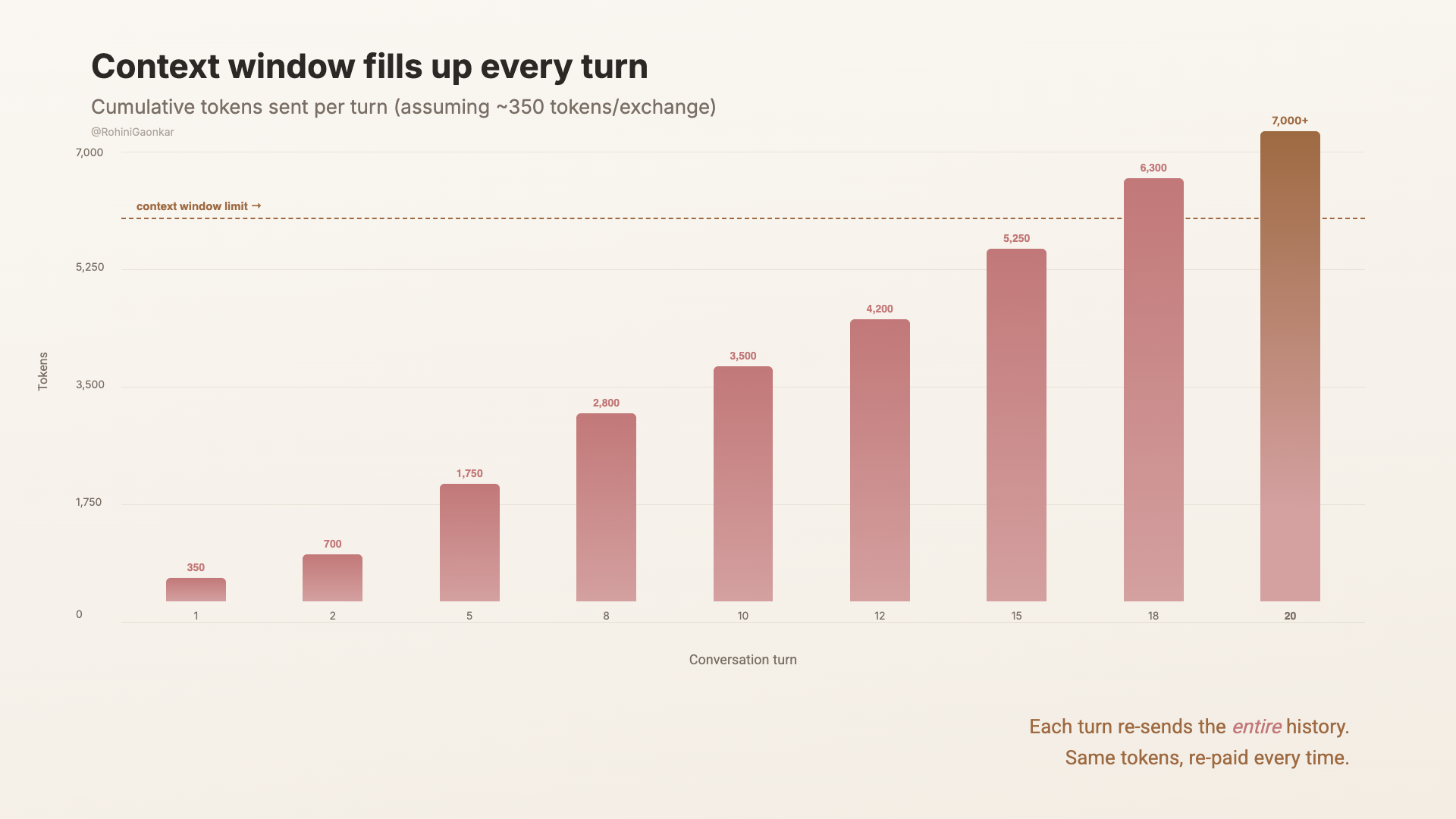
一個典型問題可能是 50 tokens,模型的回覆可能是 300 tokens,所以一輪互動就是 350 tokens。
十輪互動?3,500 tokens。
二十輪?7,000。
如果你問的是細節很多的問題,而且回覆也很長,一個下午就可能累積到 20,000 或 30,000 tokens。
而且重點是,你不只是用掉記憶空間,你是在每一輪都重新傳送、重新支付整段對話紀錄的成本。
Token 既是記憶的單位,也是成本的單位。是同一種資源,帶來兩種後果。
模型在處理長輸入方面已經進步很多。現在你可以丟進去相當大的文件。但限制仍然存在,而輸入越長,就越容易漏掉某些內容。
中間消失了
研究人員替這個現象取了一個名字,叫做「lost in the middle」。
當你給模型一段很長的輸入,無論是文件還是對話紀錄,它通常最會注意兩個地方:最前面和最後面。中間的內容受到的關注較少。
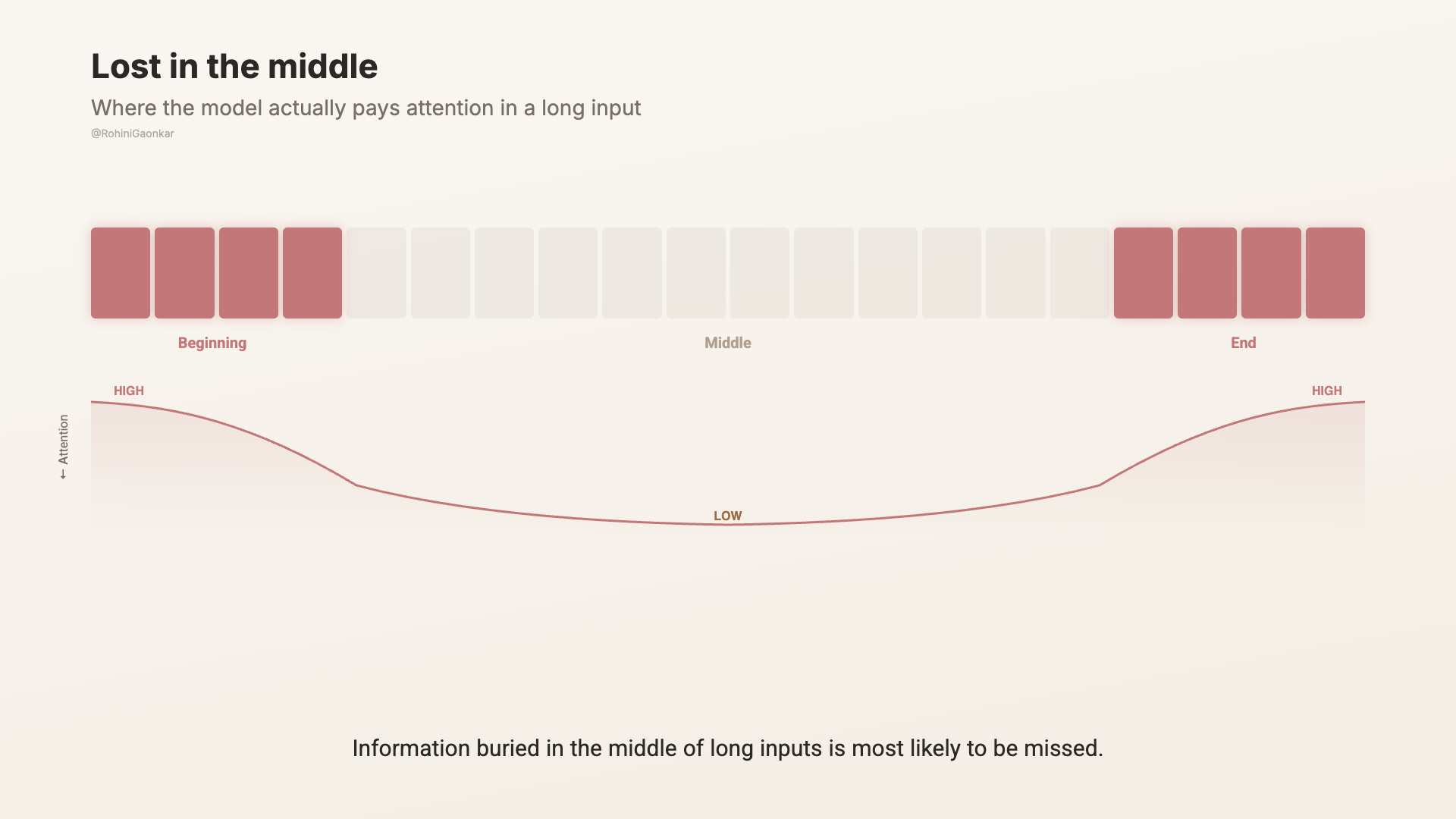
這就像在讀一長串 Email 討論串。你記得它怎麼開始,也記得最後一則訊息。但埋在第十四則訊息深處、星期二下午 2 點那封回覆?祝你好運。
這就是為什麼對話一長,你前面說過的內容會開始偏掉。你早期的訊息會落到視窗中間,而中間正是注意力最弱的地方。
大多數模型不會提醒你。它們只會維持一貫自信的語氣,不管它是在清楚、聚焦的輸入上運作,還是已經被 context 淹沒。前面留言者遇到的 Opus 情況,其實是少數例外,不是常態。
你可以怎麼做
更大的視窗
如果你已經碰到限制,就改用更大 context window 的模型。更大的視窗就像更大的背包,可以裝更多東西。但這不代表你能立刻找到你要的內容。所以後面這些方法還是很重要。
分段
如果不需要全部,就不要全部貼上。
如果你的問題只跟第 3 節有關,就只給模型第 3 節,不要整份文件。少了雜訊,訊號會更清楚。
摘要
先摘要,再提問。
如果你需要模型處理長文件,先叫它把文件摘要出來,再針對摘要問真正的問題。這雖然要呼叫兩次,但第二次會有更聚焦的 context。只是要注意,摘要不要漏掉重要資訊。
位置
把重要內容放在開頭或結尾。
如果你的提示詞包含參考資料,把真正的問題放在最後。或者把最關鍵的背景資訊放在最前面。不要把重點埋在中間。
重申
重新重申重要限制。 如果你在第一則訊息已經告訴模型某個關鍵條件,而現在已經到了第十五則,請再說一次。只多花幾個 token,卻能避免一次錯誤答案。
System prompt
把持久規則放進 system prompt。 多數平台都有一個位置可以放持續引導模型的指令。在 ChatGPT 或 Claude.ai 裡,這通常叫做自訂指示;在 Amazon Bedrock 裡,則是 system prompt 欄位。把穩定不變的規則寫進去,語意要清楚且不含糊。但不要假設它們會永遠被完美遵守。在長對話裡,仍然在目前訊息中重申關鍵指令會有幫助。
重新開始
當對話開始偏離時,就開新對話。 如果你已經聊了 20 輪,而且主題轉了三次,就開一個新的對話。把重要的內容帶過去,把不重要的留在舊對話裡。
自建記憶層
你可以把較早的輪次摘要成精簡版摘要,存到某個地方(資料庫、檔案,甚至是一個簡單變數),然後在每次新呼叫時把這份摘要注入開頭。這基本上就是一種自己做的對話 context 快取。你可以打造一個更符合你使用情境的版本。
如果你是開發者,這應該會很熟悉。我們以前會在 Postgres 前面放 Redis,這樣就不是每個請求都直接打到資料庫。這裡也是同樣的模式。有些平台提供 prompt caching,讓 system prompt 或重複出現的 context 只處理一次,之後在多次呼叫中重複使用,而不是每次都重新 token 化。你不必每次請求都重新付一次相同靜態 context 的成本。概念一樣,只是層級不同:把昂貴、重複的工作快取起來,只把新的內容即時送進去。
如果你想更深入了解,可以閱讀 Amazon Bedrock 上的 prompt caching。
對文件來說,檢索才是答案。 不要把整份文件硬塞進 context window,而是只檢索相關的區塊再送進去。這就是 RAG(Retrieval-Augmented Generation,檢索增強生成)在做的事,我們會在下一篇提到。
兩種情況的原則都一樣:給模型少一點,但要給對少一點。
重點整理
如果你剛開始接觸: 模型有一個叫做 context window 的記憶限制。它同時適用於文件和對話。輸入越長,注意力越分散。如果你在貼長內容,就只問特定段落;如果你在長對話中,就重申重要資訊;如果開始覺得不對勁,就開新 session。
如果你比較偏開發者: context window 的大小只是規格,不是保證。一百萬 token 的視窗,不代表一百萬 token 都能完美記住。把關鍵資訊放在邊緣,不要放在中間。對話方面,請實作舊輪次摘要。而且開始思考檢索,因為接下來就是這個方向。
下一步
所以,當你給模型太多東西時,它就會忘記一些內容。那如果有一種方法,能在正確的時間,把文件中正確的片段給它,而你甚至從來沒有把整份文件貼進去過呢?
下一篇,我們會更深入探討檢索:在正確的時間,給模型正確的片段。
一起上路吧。
這篇文章是「Learning AI Out Loud」系列的一部分,一位雲端架構師以第一性原理學習 AI。
https://dev.to/rohini_gaonkar 持續關注這個系列
{% user rohini_gaonkar
原文出處:https://dev.to/aws/why-does-ai-forget-what-you-said-and-how-to-fix-it-52f6
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式