
在<a href="">上一篇文章</a>中,我向大家展示了一個人工智慧如何完成一項真正有用的任務:幫我調整一份適合晚宴的食譜。我們討論了它的基本流程:向基礎模型發送提示,然後取得回應。
今天我們來聊聊為什麼人工智慧會對你說謊。
你知道人工智慧在完全錯誤的情況下聽起來很有自信嗎?這叫做幻覺,它要嘛會讓你長期信任人工智慧,要嘛會讓你遭受重創。
示範:同樣的問題,兩種模型
我在亞馬遜 Bedrock Playground 中向兩個不同的模型提出了同樣的問題:
“最近的天琴座流星雨發生了什麼?”
型號 1:亞馬遜 Nova Micro 1.0
Nova Micro 給了我詳細資料。日期、地點、數字,全都一一呈現,語氣自信滿滿。它毫不猶豫,也沒有任何保留,就好像什麼都知道一樣直接回答了我。
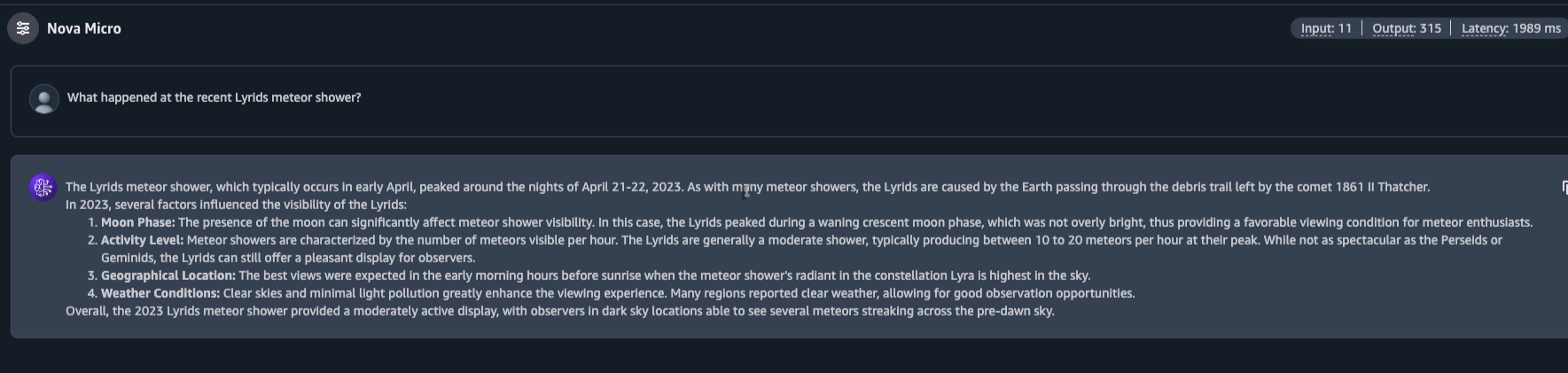
但它並不知道。它的訓練資料截止到2023年。之後的任何資料對它來說都是一個無法辨識的空白。它沒有標記出這一點,只是用一些看似合理的資料填補了空白。
這是幻覺。模型虛構出一個看似合理的解釋來填補它無法承認的空白。它並非故意說謊。它只是在執行其設計任務:預測一個聽起來有用的答案是什麼樣子。它根本不知道這個答案是否正確。
模型 2:克勞德·海庫 4.5
同樣的問題,但模型更新,訓練資料也更新。
Haiku 直截了當地告訴我:「我無法獲得最新資訊。我的知識上次更新是在 2024 年 4 月。」 然後它提供了一些關於天琴座流星雨的一般訊息,並建議我查看最新的天文網站。
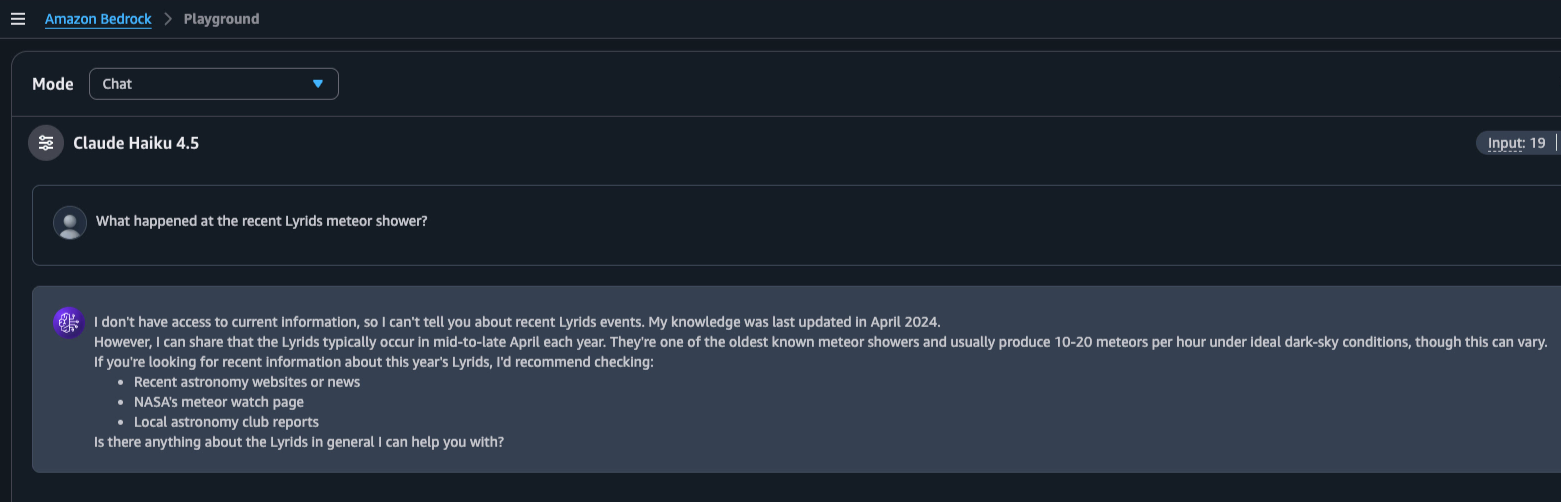
進步。新模型更擅長辨識已知事物的邊界。
我給它提供了一個Space.com網站文章的連結。它告訴我它無法瀏覽網路。

所以我上傳了那篇網站文章的PDF檔。由於檔案大小有限制,我只上傳了前幾頁。之後,它準確地回答了我的問題,並從原文中提取了真實的資訊。
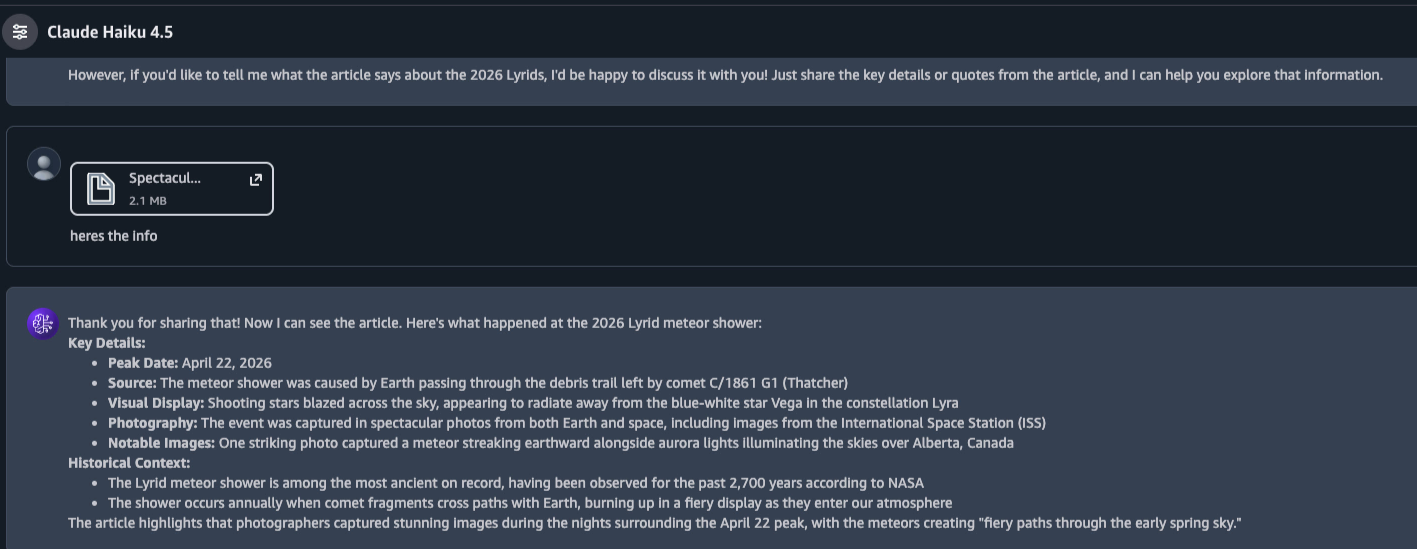
所以,在這種情況下,我們為模型提供了一些背景訊息,它根據這些背景訊息給了我一個答案。
傳記測試
我問了Nova Micro:
“跟我說說羅希尼·高恩卡爾的事吧。”
它毫不猶豫地告訴我,我是一位「知名的印度作家、學者和文化評論家」。它說我擁有杜克大學比較文學博士學位,是明尼蘇達大學的教授,也編輯過相當有影響力的後殖民理論文集。

這一切都不是真的。一個細節都不是。
這個模型不知道我是誰,但它知道學術履歷長什麼樣,於是就產生了一份。裡麵包含了研究興趣、代表作和獲得的榮譽,全都是編造的,卻又無比自信。
所以Haiku知道何時該停止,而Nova Micro卻不知道。
但兩種模型的基本機制是相同的:預測。
一個有更完善的護欄,另一個則只會填補它找到的所有縫隙。
幻覺不僅僅關乎訓練閾值。它指的是模型填補了自身知識的任何空白,例如它從未見過的名稱、小眾主題以及從未學習過的組合。更好的防護措施固然有幫助,但並不能徹底解決問題。
關於姓名測試的說明:我特意使用了自己的名字。如果模型對我做出一些奇怪的判斷,只會影響我自己。如果你嘗試用其他人的名字,尤其是私密姓名,或任何未經同意參與實驗的人的名字進行測試,請務必謹慎。無論模型對他們做出什麼判斷,你都已經生成並有可能將其傳播出去。所以,請小心行事。
造成這種情況的原因:架構
還記得上一篇文章中提到的循環嗎?
Input (prompt) → Foundation Model → Output (response)該模型根據訓練過程中學到的所有知識,預測一個有用的答案應該是什麼樣的。
「訓練期間」是關鍵字詞。
訓練會在某個特定日期結束,這個日期稱為訓練截止日。之後,模型將被凍結。當你詢問模型關於該日期之後的內容,或者它從未完全學習過的內容時,它有兩個選擇:要么回答“我不知道”,要么執行它被設計用來執行的操作,即預測。
很長一段時間以來,這些模型都不擅長說「我不知道」。訓練時,獎勵機制並非針對這種表達方式,而是針對流暢、聽起來有用的答案。所以,它們就只能給出這樣的答案,即使答案是編造的。
幻覺以多種形式出現:捏造事實(傳記)、將過時資訊當作最新資訊(流星雨)、即使來源就在眼前卻前後矛盾(引用測試)。還有其他一些表現形式,例如錯誤的歸屬、阿諛奉承(即使自己說的是錯的也附和)、盲目推斷(將某種模式延伸到資料不支持的範圍之外)。
機制始終如一,預測填補了漏洞,但了解其具體表現形式有助於設計合適的緩解措施。我們將在後續文章中討論這些緩解措施,屆時我們將探討基礎性措施、評估措施和防護措施。
如果你是開發者,這應該很熟悉。想想 DNS 快取。你把應用程式遷移到新伺服器,更新了 DNS 記錄,但接下來的一個小時裡,部分使用者仍然會被路由到舊的 IP 位址。快取並不知道記錄已經更改。它只是自信地提供現有的資源,因為它的設計初衷就是為了快速回應。
或者說,自動擴縮容的指標錯了。你基於 CPU 使用率進行擴縮容。 CPU 使用率很低,所以系統認為一切正常。同時,你的隊列裡積壓了 10,000 條未處理的訊息。系統針對響應單一訊號進行了最佳化,因此它自信地什麼也不做,任由訊息堆積。
人工智慧模型的工作原理也類似。它經過訓練,總是能給出聽起來有用的答案。所以即使它不知道某些訊息,也能給聽起來有用的答案。它沒有「什麼都不說」的本能,而是有「給出看似有用的答案」的本能。
現代模型更擅長拒絕錯誤訊息,但問題的本質仍然存在。模型本身並不了解它所知道的,它只是進行預測。
“但是 ChatGPT 可以搜尋網路嗎?”
是的,現在大多數聊天工具都能在線上找到資訊。但這並非模型本身的功能,而是模型內建的工具在進行搜尋。
我們將在後續文章中詳細介紹其工作原理。今天,我們先來看看這個模型本身。不借助任何網路或工具,只看它自己學到的東西。
修復方案,以及修復方案失效的地方
我把文章的PDF檔案寄給了Nova Lite,讓它引用第二段。
它給了我一個回覆。然後我又問了一次同樣的問題。答案卻不一樣了。同樣的來源,同樣的對話,同一段話卻有兩個不同的版本。
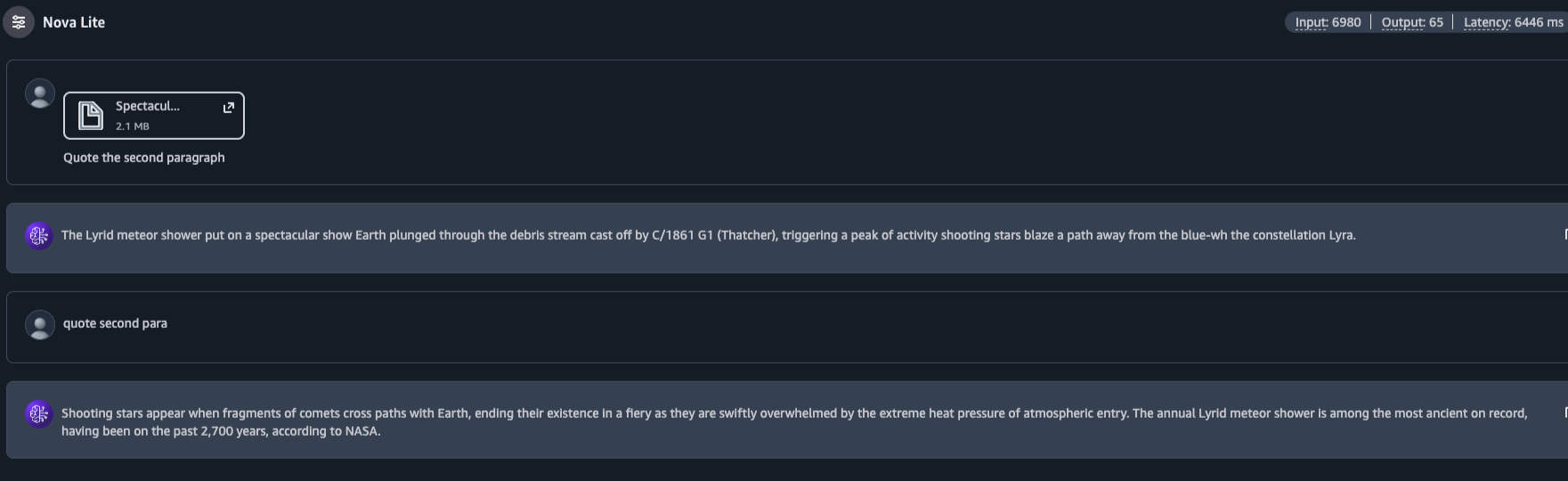
即使原文就在眼前,它也沒能逐字逐句地提取出段落內容。我問了兩次同樣的問題,同樣的對話,同樣的文件,卻得到了兩個不同的版本。它根本沒有檢索原文,而是在預測該段落的可能形式。而預測本身並不準確。
這一點很重要,因為很多人認為「只要把文件交給人工智慧,一切就都沒問題了」。
雖然有所改進,但並不完美。情況可能會變得複雜混亂,尤其是在涉及精確措辭的情況下,例如法律文本、醫療劑量或合約條款。您仍然需要核實回覆。
情境可以減輕幻覺,但並不能消除幻覺。
你應該仔細檢查的三個跡象
如果你每天都在使用人工智慧,以下是一些跡象:
1. 無法核實的具體細節。例如姓名、日期、數字、網址等,這些資訊位於您無法核實的區域。請自行判斷其真實性。
2. 對本應模糊不清的話題卻能侃侃而談。問一些冷門或近期發生的話題,對方卻能給予自信詳盡的回答,這時就要提高警覺了。真正的專業知識是有保留的,而胡言亂語則不然。
3. 引用來源,尤其是網址。騙子會編造看似真實的來源。如果你收到網址,請開啟查看。十有八九沒問題,但第十次很可能是一篇偽造的論文。
自己試試
如果你更傾向於建造者一方:
記住,幻覺不是可以修補的漏洞,而是系統本身的屬性。你可以透過設定情境(賦予模型真實的上下文)、設定指令(告訴模型在不確定時拒絕執行)以及後續的評估來緩解幻覺。設計時就應該考慮幻覺的影響。
如果你是新手:
記住,人工智慧不是搜尋引擎,而是預測引擎,它能說出聽起來很可靠的話。對待人工智慧的具體說法,就像對待聚會上自信滿滿的陌生人一樣。友好地回應,但在複述之前務必核實。
以下是我在網路上找到的一些例子,僅供娛樂和學習之用:(隨著車型更新換代,答案可能會有所變化)
-
單字 strawberry 有多少個字母「r」?
-
如果我要去洗車,洗車場離我家只有100英尺,我應該開車去還是走路去?
接下來會發生什麼事?
為什麼會有這麼多東西?俳句、十四行詩、作品集。迷你版、大型版、專業版。說實話,你到底該選哪一個呢?
那是下一篇文章的內容。敬請期待。
本文是「大聲學習人工智慧」系列文章的一部分,講述了一位雲端架構師從基本原理學習人工智慧的故事。
https://dev.to/rohini\_gaonkar 關注本系列
原文出處:https://dev.to/aws/why-does-ai-lie-hallucinations-explained-simply-1c7g
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式