

這是關於資料工程的文章,如果你在 Google 上搜尋該主題,並在點擊 Feeling Lucky 後進入將會找到這篇文章。
此外,這篇文章是由一位經驗豐富的網頁開發工程師撰寫,他在職業生涯中開始了新的主題,也就是:這是我的學習,我的研究,如果你有任何補充,請隨時在下面留言告訴我!我很想學習更多!
內容大綱
1. 前言
我必須承認:每當有人提到 資料工程,我通常會失去興趣。這總聽起來像是一件不可思議的複雜事務 — 幾乎是 魔法。
這周,我終於決定深入了解。我以為會相對直接,但不久後,就意識到這個兔子洞是多麼深邃。
這個領域不僅僅是一些腳本或 SQL 查詢;它是一整個 生態系統,這些工具、概念和責任相互聯繫,構成了現代資料系統的骨幹。
像是這些概念:
- 資料目錄與治理: 了解誰擁有資料、如何確保品質與如何追蹤沿革。
- 協調: 用像是 Apache Airflow 或 Dagster 的工具協調依賴和工作流程。
- 轉換(ETL/ELT): 使用像是 dbt 或 Fivetran 的工具清理和標準化資料。
- 匯入與串流: 使用 Kafka、Airbyte 或 Confluent Cloud 連接來源並實時移動資料。
- 可觀察性與品質: 透過像是 Monte Carlo 和 Datafold 的解決方案來監控資料健康。
每點擊一篇文章,就開啟了一個全新的工具、詞彙、框架、架構和最佳實踐的世界。
而且,不知怎的,所有這些都必須 協同工作 — 治理、協調、轉換、匯入、可觀察性、基礎設施。
作為一名開發者,我習慣於學習一種 語言 和一個 框架,然後開始工作。
但在資料工程中,情況有所不同。
這關於理解整個 生態系統 以及每一個部分是如何互相連結的。
經過數小時的閱讀文件、追蹤 GitHub 倉庫和在工具、文章及無盡定義之間跳來跳去後,我終於找到了 使所有事情連結起來的工具 — Bruin。
想像一個單一框架可以:
- 管道作為代碼 — 一切都瀏覽於版本控制的文本(YAML、SQL、Python)。沒有隱藏的 UI 或資料庫。可重現、可審查且可自動化。
- 自然而然多語言支持 — 原生支持 SQL 和 Python,並能接入二進制或容器來處理更複雜的用例。
- 可組合的管道 — 在一個無縫的流程中結合技術、來源和目的地 — 沒有膠水代碼,沒有黑客手段。
- 無鎖定 — 100% 開源的 (Apache 授權) CLI,能在任何地方運行:本地、CI 或生產環境。你完全控制自己的管道和資料。
- 為開發者和資料品質而生 — 快速的本地運行、集成檢查和快速的反饋循環。資料產品經過測試、可被信任且易於發佈。
…而且它 符合我之前提到的所有核心資料工程概念。
我必須承認 — 我是那種擁抱 生產性懶惰 的人。如果有更少的工具和摩擦可以完成更多工作,我就願意進行。
所以在我們開始之前,這裡是計劃:
在大多數設定中,資料流從 OLTP 資料庫 → 匯入 → 資料湖/資料倉儲 → 轉換 → 集市 → 分析儀表板。
像是 Airbyte 這樣的工具負責匯入,dbt 負責轉換,Airflow 協調依賴 — 而 Bruin 將這些層組合成一個統一的框架。
這篇文章將介紹 資料工程的基本原則,並探討 Bruin 如何通過一個簡單的、現實世界的管道將它們結合在一起。
2. 初步印象:探索 Bruin 的結構
我必須坦誠 — 我曾對資料科學/工程項目有些偏見。每當我查看一個項目時,它總給我一種混亂且無結構的感覺,隨處都是檔案和筆記本。作為一名軟體開發背景的人,這種混亂總是讓我感到困擾。
但一旦我開始查看 Bruin 的項目結構,那種認知完全改變了。一切突然變得 有條理且有意圖。
這個框架通過其層級自然地強制結構 — 一旦你遵循它們,一切就開始變得有意義。
例子:項目結構
├── duckdb.db
├── ecommerce-mart
│ ├── assets
│ │ ├── ingestion
│ │ │ ├── raw.customers.asset.yml
│ │ │ ├── raw.order_items.asset.yml
│ │ │ ├── raw.orders.asset.yml
│ │ │ ├── raw.products.asset.yml
│ │ │ └── raw.product_variants.asset.yml
│ │ ├── mart
│ │ │ ├── mart.customers-by-age.asset.py
│ │ │ ├── mart.customers-by-country.asset.yml
│ │ │ ├── mart.product_performance.sql
│ │ │ ├── mart.sales_daily.sql
│ │ │ └── mart.variant_profitability.sql
│ │ └── staging
│ │ ├── stg.customers.asset.yml
│ │ ├── stg.order_items.sql
│ │ ├── stg.orders.sql
│ │ ├── stg.products.sql
│ │ └── stg.product_variants.sql
│ └── pipeline.yml
├── glossary.yml
├── policy.yml
└── .bruin.yml每一部分的功能
.bruin.yml- Bruin 環境的主要配置檔案。
- 定義所有管道的 全域設置,例如預設的 連接、變數和 行為。
policy.yml- 你的資料治理和驗證政策檔案。
- 定義資料質量規則、存取控制和合規檢查,Bruin 可以在發佈資料產品之前自動強制執行。
glossary.yml- 作為你的專案的輕量資料目錄。
- 記錄術語、指標和數據集以確保團隊間溝通一致。
- 也有助於沿革、文件化和可搜尋性。
some-feature/pipeline.yml- 定義特定領域或專案的管道(在這個例子中為 ecommerce)。
- 描述端到端的資料流程 — 需要運行的資產、它們的依賴關係和排程。
- 管道是模組化的,因此你可以為不同的業務領域維護單獨的管道。
- *`some-feature/assets/`**
- 包含所有資產 — 你的資料管道的構建模塊。
- 每個資產執行一個特定任務:匯入原始資料、轉換資料或生成分析表。
- 由於每個資產都是一個檔案,因此它是 版本控制、可測試和可重用的 — 就像代碼一樣。
有了這些,我們能夠運行整個管道。然而,我仍然認為我們需要逐步查看每一步和每個檔案 — 我保證這會很快!
2.1. 核心檔案:.bruin.yml
把 .bruin.yml 看作是你專案的 根配置 — 告訴 Bruin 如何 和 在哪裡 運行所有內容的檔案。
Bruin 將設定集中在一起,而不是分散在腳本或環境變數中:連接、憑證和特定於環境的配置都位於一個地方。
它還作為 Bruin 的 預設秘密後端,以便你的管道可以安全且一致地訪問資料庫或資料倉庫。
bruin run ecommerce/pipeline.yml --config-file /path/to/.bruin.yml簡單的例子:
default_environment: default
environments:
default:
connections:
postgres:
- name: pg-default
username: postgres # (也硬編碼)
password: ${PG_PASSWORD}
host: ${PG_HOST}
port: ${PG_PORT}
database: ${PG_DATABASE}
duckdb:
- name: duckdb-default
path: duckdb.db這裡發生了什麼
default_environment— 設定 Bruin 將使用的環境,除非另有指定。environments— 定義多個設定(例如 dev、staging、prod),每個都有其自己的配置。connections— 列出 Bruin 可以連接的每個系統,如 Postgres 或 DuckDB。
每個連接都有一個名稱(例如pg-default),你可以在管道和資產中引用。- 支持環境變量 — 用
${...}包圍的任何值將自動從系統環境中讀取。
這意味著你可以保持憑證不被版本控制,同時仍然在本地或 CI/CD 環境中運行。
這個設計保持一切 集中、安全和版本控制,同時給予你靈活性,通過環境變數動態注入秘密 — 完美適合在不觸及代碼的情況下在本地、暫存和生產間切換。
2.2. 管道:更簡單的 Apache Airflow
每個功能都必須配備 pipeline.yml 文件。
這是將所有資產分組的檔案,並理解這不是單一資產在運行,而是一系列資產的鏈接。
- ecommerce-mart/
├─ pipeline.yml -> 你在這裡
└─ assets/
├─ some-asset.sql
├─ definitely-an-asset.yml
└─ another-asset.py在這裡,你也配置想要在特定管道上使用的每個連接:
name: product_ecommerce_marts
schedule: daily # 對 Bruin Cloud 部署相關
default_connections:
duckdb: "duckdb-default"
postgres: "pg-default"2.3. 資產:資料產品的基礎構件
每個資料管道在 Bruin 中由 資產 組成 — 模組化、自含的單元,定義特定操作:匯入、轉換或生成資料集。
每個資產都作為 assets/ 目錄下的檔案存在,其檔名也作為其在管道圖中的身份。
如果你還記得最開始的檔案結構,你必須記得我在管道中有多種類型的資產。這是最酷的部分,因為你可以用多種語言來編寫,並且仍然保持簡單。這裡有一些可能性:
| 類型 | 描述 | 檔名(在檔案樹中) |
|---|---|---|
| YAML | 用於匯入或元資料重的資產的聲明型配置 | raw.customers.asset.yml |
| SQL | 純轉換邏輯 — 想想 dbt 風格的模型 | stg.orders.sql |
| Python | 自定義邏輯或整合(例如,API、驗證或機器學習步驟) | mart.sales_daily.asset.py |
你可以隨意組織資產 — 沒有嚴格的層級可遵循。
關鍵的見解是 協調是通過依賴隱式發生的,而不是通過像 Airflow 一樣的外部 DAG 引擎。
每個資產聲明它所依賴的內容,而 Bruin 自動為你構建並執行依賴圖。
例子:
-
raw.orders.asset.yml
# raw.orders.asset.yml name: raw.orders type: ingestr description: 從 Postgres 將 OLTP 訂單匯入 DuckDB 原始層。 parameters: source_connection: pg-default source_table: "public.orders" destination: duckdb -
raw.order_items.asset.yml
# raw.order_items.asset.yml name: raw.order_items type: ingestr description: 從 Postgres 將 OLTP 訂單項匯入 DuckDB 原始層。 depends: - raw.orders # 聲明依賴於 'raw.orders' 資產 parameters: source_connection: pg-default source_table: "public.order_items" destination: duckdb... 轉變為:
graph TD raw.orders --> raw.order_items;
通過這樣鏈接資產,你描述的是 資料操作之間的邏輯關係,而不是手動協調步驟。
結果是一個 聲明式、可組合和可維護的管道 — 像應用程式代碼一樣易於閱讀、版本控制和擴展。
Bruin 最強大的方面之一是它如何將 資料品質 和 治理 直接整合進你的資產中。
通過在每一列下定義檢查,你不僅是在驗證資料,還在記錄所有權、期望和限制 — 所有這些都是版本控制的,並在運行時可被強制執行。
這意味著 Bruin 不僅僅是 運行 管道 — 它還 審核、文件化 和 治理 它們,作為相同工作流程的一部分。
2.4. 政策:強化品質與治理
在 Bruin 中,政策作為規則手冊,確保你的資料管道保持一致、合規且高品質。
它們確保每個資產和管道遵循最佳實踐 — 從命名約定、所有權到驗證和元資料完整性。
政策的核心是定義在專案根目錄的單一 policy.yml 檔案中。
這個檔案讓你 自動檢查、驗證 和 強制執行標準,在管道運行之前。
簡要概述
rulesets:
- name: standard
selector:
- path: .*/ecommerce/.*
rules:
- asset-has-owner
- asset-name-is-lowercase
- asset-has-description每個 ruleset 定義:
- 規則適用的位置 (
selector→ 通過路徑、標籤或名稱匹配), - 需要強制執行的內容 (
rules→ 內建或自定義驗證規則)。
一旦定義,你可以驗證整個專案:
bruin validate ecommerce
# 正在驗證 'ecommerce' 中的管道以適用於 'default' 環境...
# 管道: ecommerce_pg_to_duckdb (.)
# raw.order_items (assets/ingestion/raw.order_items.asset.yml)
# └── 資產必須有所有者 (policy:standard:asset-has-owner)Bruin 在執行之前自動為資產進行檢查 — 確保 不合規的管道絕對不會運行。
內建和自定義規則
| 規則 | 目標 | 描述 |
|---|---|---|
asset-has-owner |
資產 | 每個資產必須定義一個所有者。 |
asset-has-description |
資產 | 資產必須包括描述。 |
asset-name-is-lowercase |
資產 | 資產名稱必須為小寫。 |
pipeline-has-retries |
管道 | 管道必須定義重試設置。 |
你也可以定義自己的規則:
custom_rules:
- name: asset-has-owner
description: 每個資產都應該有一個所有者
criteria: asset.Owner != ""規則可以針對 資產 或 管道,使用邏輯表達式來判斷合規性。
政策將 Bruin 轉變為一個 自我治理的資料平台 — 一个最佳實踐不再是選項,而是被強制執行的。
通過將你的規則提交到版本控制中,讓資料治理成為開發工作流的一部分,而不是事後考量。
2.5. 字彙表:說相同的語言
在資料項目中,最難解決的問題之一不是技術上的 — 而是 溝通。
不同團隊經常使用相同的詞來表示不同的事物。
這就是 Bruin 的字彙表 發揮作用的地方。
字彙表在專案根目錄的 glossary.yml 中定義。
它充當一個 共享字典,記錄商業概念(如 客戶 或 訂單)及其屬性,保持團隊在管道間的一致性。
entities:
Customer:
description: 我們平台上的註冊用戶或商業實體。
attributes:
ID:
type: integer
description: 唯一的客戶識別碼。你可以在資產內使用 extends 引用這些定義,避免重複並確保一致性:
# raw.customers.asset.yml
name: raw.customers
type: ingestr
columns:
- name: customer_id
extends: Customer.ID這自動繼承字彙表中的 type 和 description。
這是一個簡單的想法,但卻非常強大 — 你的 資料定義變得像代碼一樣可版本控制和共享。
3. 建立我們的第一個管道
現在,我們已經探索了 Bruin 背後的結構和哲學,是時候建立一個端到端的管道了。
我們將從 原始資料匯入 到 乾淨的暫存層,最後到 分析準備好的集市 — 所有內容都定義為代碼。
我們將假設你已經擁有:
- 一個 Postgres 資料庫作為資料來源。
- 一個 DuckDB 資料庫作為你的分析儲存。
- 一個配置了連接的有效
.bruin.yml檔案。
3.1 步驟 1:從來源資料匯入資料湖
第一步是將資料從 Postgres 移動到 DuckDB。
這創建了你的 原始層 — 來自來源的資料,幾乎不做轉換。
創建一個匯入資產檔案:
touch assets/ingestion/raw.customers.asset.yml然後定義該資產:
# assets/ingestion/raw.customers.asset.yml
name: raw.customers
type: ingestr
description: 從 Postgres 匯入 OLTP 客戶到 DuckDB 原始層。
parameters:
source_connection: pg-default
source_table: "public.customers"
destination: duckdb
columns:
- name: id
type: integer
primary_key: true
checks:
- name: not_null
- name: unique
- name: email
type: string
checks:
- name: not_null
- name: unique
- name: country
type: string
checks:
- name: not_null這告訴 Bruin 從你的 Postgres 表 public.customers 提取資料,驗證列的質量,並將其存儲在 DuckDB 的原始層中。
執行資產
bruin run ecommerce/assets/ingestion/raw.customers.asset.yml 預期輸出:
分析管道 'ecommerce_pg_to_duckdb',共 13 個資產。
僅運行資產 'raw.customers'
管道: ecommerce_pg_to_duckdb (../../..)
未發現問題
✓ 成功驗證 13 個資產,所有良好。
時間範圍: 2025-10-12T00:00:00Z - 2025-10-12T23:59:59Z
開始管道執行...
PASS raw.customers ........
bruin run 成功地在 2.095 秒內完成
✓ 資產執行完成 1 個成功
現在你可以查詢匯入的資料:
bruin query --connection duckdb-default --query "SELECT * FROM raw.customers LIMIT 5"結果:
┌────┬───────────────────┬───────────────────────────┬───────────┬──────────────────┬──────────────────────────────────────┬──────────────────────────────────────┐
│ ID │ FULL_NAME │ EMAIL │ COUNTRY │ CITY │ CREATED_AT │ UPDATED_AT │
├────┼───────────────────┼───────────────────────────┼───────────┼──────────────────┼──────────────────────────────────────┼──────────────────────────────────────┤
│ 1 │ Allison Hill │ [email protected] │ Uganda │ New Roberttown │ 2025-10-10 18:19:13.083281 +0000 UTC │ 2025-10-10 00:42:59.71112 +0000 UTC │
│ 2 │ David Guzman │ [email protected] │ Cyprus │ Lawrencetown │ 2025-10-10 07:52:47.643619 +0000 UTC │ 2025-10-10 06:23:42.864287 +0000 UTC │
│ 3 │ Caitlin Henderson │ [email protected] │ Hong Kong │ West Melanieview │ 2025-10-10 21:06:02.639412 +0000 UTC │ 2025-10-10 19:23:17.540169 +0000 UTC │
│ 4 │ Monica Herrera │ [email protected] │ Niger │ Barbaraland │ 2025-10-11 01:33:43.032929 +0000 UTC │ 2025-10-10 02:29:27.22515 +0000 UTC │
│ 5 │ Darren Roberts │ [email protected] │ Fiji │ Reidstad │ 2025-10-10 12:05:18.734246 +0000 UTC │ 2025-10-10 00:51:13.406526 +0000 UTC │
└────┴───────────────────┴───────────────────────────┴───────────┴──────────────────┴──────────────────────────────────────┴──────────────────────────────────────┘你的 原始層 現在已建立並驗證。
3.2 步驟 2:格式化與驗證資料(暫存層)
接下來,我們將清理和標準化匯入的資料,然後再在分析中使用。
這一層稱為 暫存(stg) — 這是你強制執行架構、列一致性和應用業務規則的地方。
創建檔案:
touch ecommerce/assets/staging/stg.customers.asset.sql然後定義它如下:
/* @bruin
name: stg.customers
type: duckdb.sql
materialization:
type: table
depends:
- raw.customers
checks:
columns:
id:
- not_null
email:
- not_null
- unique
country:
- not_null
@bruin */
SELECT id::INT AS customer_id,
COALESCE(TRIM(email), '') AS email,
COALESCE(TRIM(country), 'Unknown') AS country,
created_at,
updated_at
FROM raw.customers
WHERE email IS NOT NULL;
這裡發生了什麼:
- Bruin 註釋區塊(
@bruin) 定義資產的元資料。 depends鍵確保此暫存步驟 僅在raw.customers完成後運行 — Bruin 自動管理依賴鏈。- 列檢查 確保資料質量在轉換前後。
- SQL 查詢本身執行輕量清理並強制類型一致性。
這個設計模擬了像 Airflow 這樣的協調工具,但不需要外部調度器 — 依賴和檢查在你的代碼內部聲明。
驗證和執行
在運行之前,先驗證資產:
bruin validate ecommerce/assets/staging/stg.customers.asset.sql預期輸出:
管道: ecommerce_pg_to_duckdb (.)
未發現問題
✓ 成功驗證 13 個資產,所有良好。 現在執行它:
bruin run ecommerce/assets/staging/stg.customers.asset.sql結果:
bruin run ecommerce/assets/staging/stg.customers.asset.sql
分析管道 'ecommerce_pg_to_duckdb',共 15 個資產。
僅運行資產 'stg.customers'
管道: ecommerce_pg_to_duckdb (../../..)
未發現問題
✓ 成功驗證 15 個資產,所有良好。
時間範圍: 2025-10-12T00:00:00Z - 2025-10-12T23:59:59Z
開始管道執行...
[21:28:16] 正在運行: stg.customers
[21:28:16] 完成: stg.customers (41ms)
==================================================
PASS stg.customers
bruin run 成功地在 41ms 內完成
✓ 資產執行完成 1 個成功確認轉換是否成功:
bruin query "SELECT country, COUNT(*) AS customers FROM stg.customers GROUP BY country ORDER BY customers DESC;"樣本輸出:
country | customers
--------------+-----------
BRAZIL | 420
GERMANY | 255
UNITED STATES | 198
ARGENTINA | 190
SOUTH KOREA | 182此時,你擁有一個 乾淨的、驗證過的資料集 來進行分析。
3.3 步驟 3:設計分析(集市)層
最後一步是建立你的 集市層,業務準備好的資料就存放在這裡。
這是分析師和儀表板直接查詢的層。
每個集市資產將暫存資料聚合或重塑成有意義的數據集以供報告和分析。
3.3.1 資產:mart.customers_by_country.asset.sql
創建以下檔案:
touch ecommerce/assets/mart/mart.customers_by_country.asset.sql然後定義該資產:
/* @bruin
name: mart.customers_by_country
type: duckdb.sql
materialization:
type: table
depends:
- stg.customers
@bruin */
SELECT
country,
COUNT(*) AS total_customers
FROM stg.customers
GROUP BY country
ORDER BY total_customers DESC;這個 SQL 資產根據國家對客戶進行聚合,並依賴 stg.customers,確保暫存層首先運行。
它作為表在 DuckDB 中具現化。
運行它:
bruin run ecommerce/assets/mart/mart.customers_by_country.asset.sql預期輸出:
管道: ecommerce_pg_to_duckdb (.)
正在運行 mart.customers_by_country
✓ 表已在 DuckDB 中成功具現化驗證結果:
bruin query --connection duckdb-default --query "SELECT * FROM mart.customers_by_country LIMIT 5;"結果:
┌───────────────┬───────────────────┐
│ COUNTRY │ TOTAL_CUSTOMERS │
├───────────────┼───────────────────┤
│ BRAZIL │ 420 │
│ GERMANY │ 255 │
│ UNITED STATES │ 198 │
│ ARGENTINA │ 190 │
│ SOUTH KOREA │ 182 │
└───────────────┴───────────────────┘3.3.2 資產:mart.customers_by_age.asset.sql
現在,讓我們創建第二個集市,將客戶劃分為年齡組。
創建該檔案:
touch ecommerce/assets/mart/mart.customers_by_age.asset.sql定義如下:
/* @bruin
name: mart.customers_by_age
type: duckdb.sql
materialization:
type: table
depends:
- stg.customers
@bruin */
WITH src AS (
SELECT
CASE
WHEN age < 25 THEN '18-24'
WHEN age BETWEEN 25 AND 34 THEN '25-34'
WHEN age BETWEEN 35 AND 49 THEN '35-49'
ELSE '50+'
END AS age_group
FROM stg.customers
)
SELECT
age_group,
COUNT(*) AS total_customers
FROM src
GROUP BY age_group
ORDER BY total_customers DESC;這個資產使用簡單的 CASE 表達式計算客戶按年齡組的分佈並聚合結果。
運行它:
bruin run ecommerce/assets/mart/mart.customers_by_age.asset.sql預期輸出:
bruin run ecommerce/assets/mart/mart.customers_by_age.asset.sql
分析管道 'ecommerce_pg_to_duckdb',共 15 個資產。
僅運行資產 'mart.customers_by_age'
管道: ecommerce_pg_to_duckdb (../../..)
未發現問題
✓ 成功驗證 15 個資產,所有良好。
時間範圍: 2025-10-12T00:00:00Z - 2025-10-12T23:59:59Z
開始管道執行...
[21:10:24] 正在運行: mart.customers_by_age
[21:10:24] 完成: mart.customers_by_age (39ms)
==================================================
PASS mart.customers_by_age
bruin run 成功地在 39ms 內完成
✓ 資產執行完成 1 個成功確認集市是否被正確填充:
bruin query --connection duckdb-default --query "SELECT * FROM mart.customers_by_age;"結果:
┌─────────────┬───────────────────┐
│ AGE_GROUP │ TOTAL_CUSTOMERS │
├─────────────┼───────────────────┤
│ 25-34 │ 460 │
│ 35-49 │ 310 │
│ 18-24 │ 250 │
│ 50+ │ 225 │
└─────────────┴───────────────────┘4. 完整預覽資料流程
希望如果我理解正確,前面解釋的概念不會變得那麼混亂,我們實際上只是使用 Bruin 和幾條查詢便將管道變為現實!
我們的範例管道看起來像這樣:
graph TD
raw.customers --> stg.customers
stg.customers --> mart.customers_by_country
stg.customers --> mart.customers_by_age在這個階段,你已建立一個 完全聲明式、端到端的資料管道 透過 Bruin — 匯入、暫存和分析 — 全部受到治理、驗證且可重現,沒有任何外部協調層。
5. 過度強大的 VS Code 擴充功能
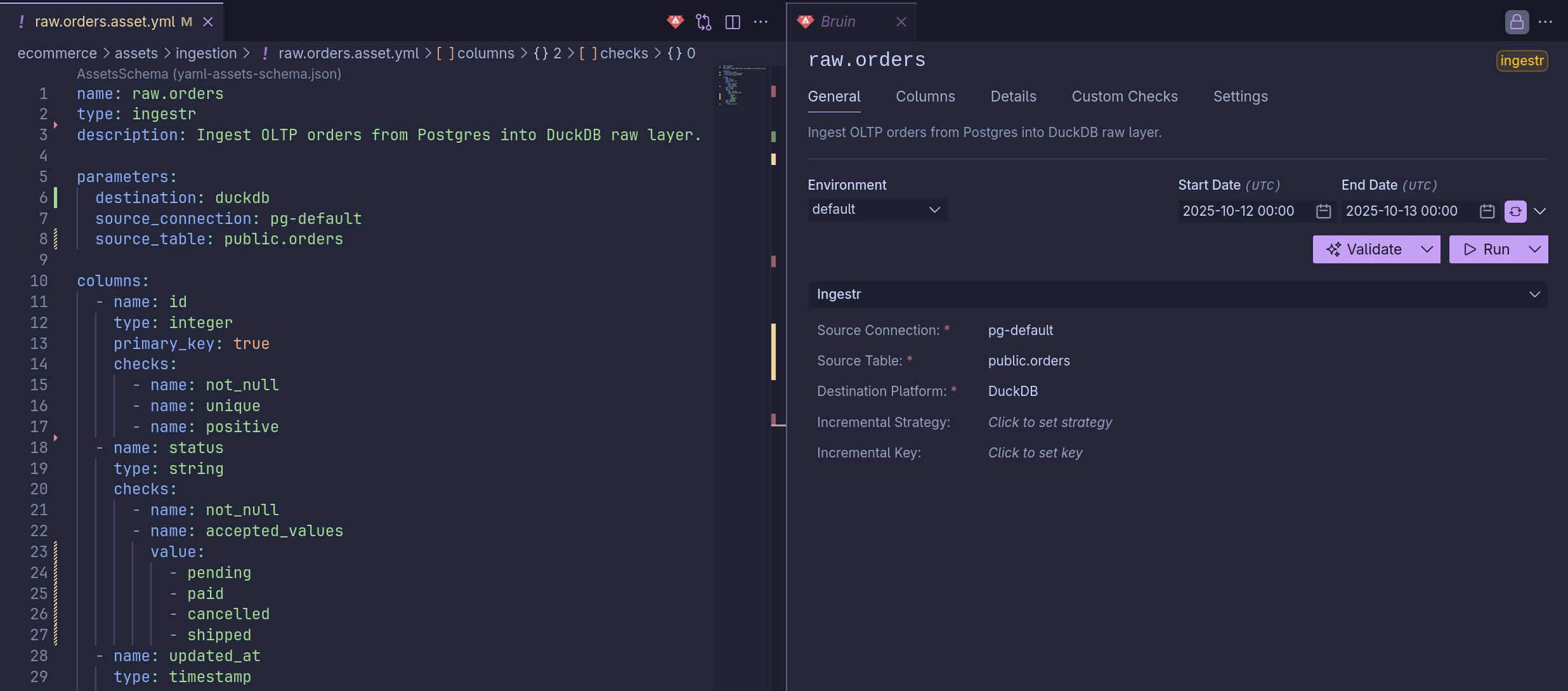
當我第一次安裝 Bruin VS Code 擴充功能 時,我完全不知道自己在做什麼。
那時,我並不真正理解 Bruin — 或甚至 資料工程 — 怎麼運作。
我隨意點擊,看到一堆 YAML 和元資料標記,然後很快就放棄了。
一周後,當我終於了解生態系統 — 匯入、暫存、集市和治理 — 我決定再次打開這個擴充功能,然後那一切 終於點亮。
這不僅僅是一個輔助工具。它是 缺失的部分。
這個擴充功能將 Bruin CLI 的聲明性功能帶入了一個 可視化、開發者友好的環境。
它自動掃描你的資產,驗證配置,直接對資料庫運行查詢,甚至實時管理你的 YAML。
一切都在 VS Code 內發生 — 驗證、沿革探究、元資料檢查和查詢預覽。
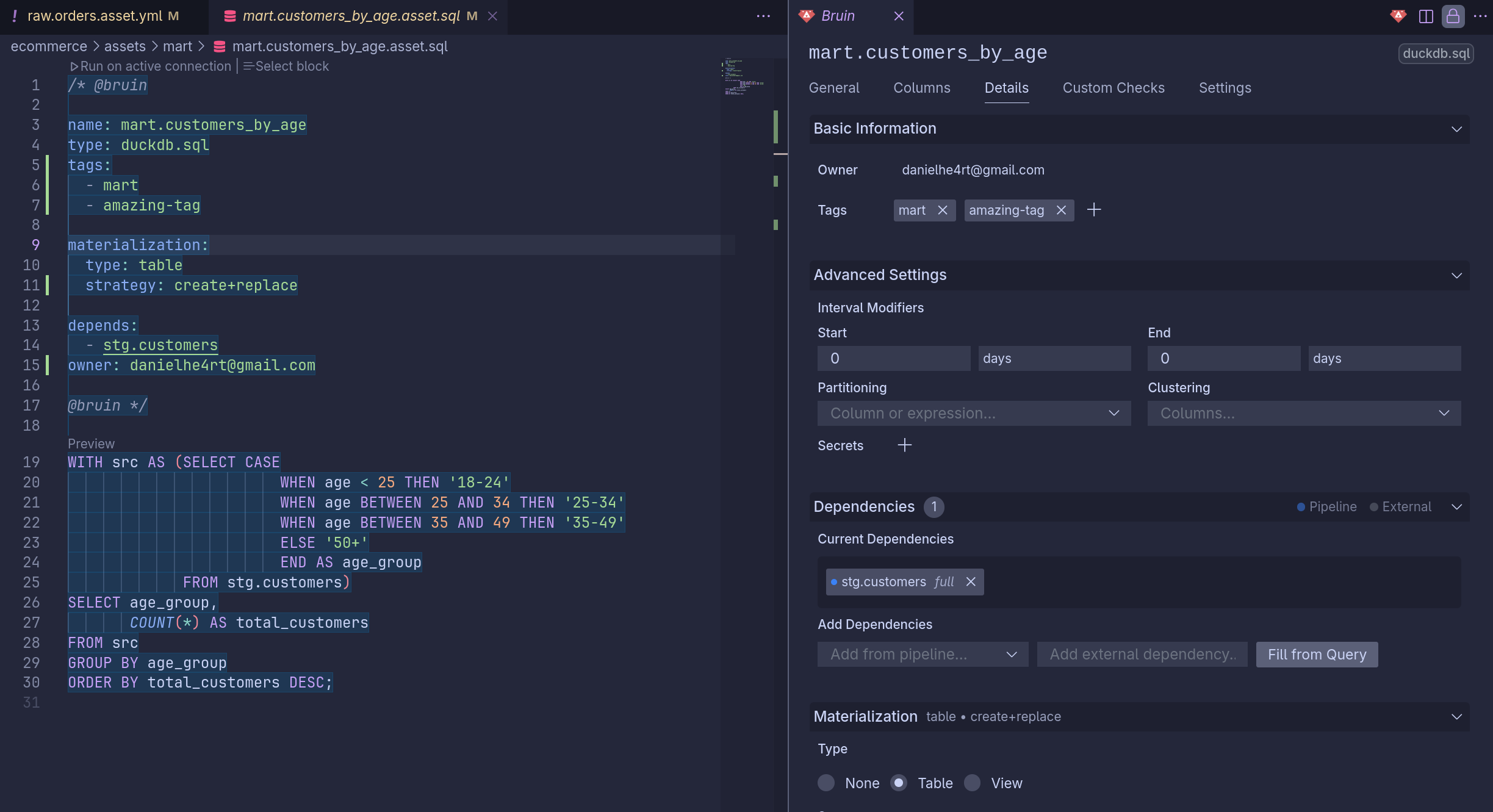
讓我印象最深刻的是它的 流暢和開放性。這裡沒有 供應商鎖定 — 它完全是開源的。
你可以將其分支、擴展,或貢獻回社群,就像 CLI 本身一樣。
簡而言之,Bruin VS Code 擴充功能不僅僅是伴侶 — 它是真正工作流程的自然演進。一旦你掌握了 Bruin,這個工具讓你感覺就像是魔法終於得到了說明。
6. 結論
這次研究是我第一次真實嘗試理解 Bruin 以及 資料工程 在實踐中實際意味著什麼。曾經感到抽象和複雜的事情,在逐步拆解、實驗和米粒一步步連結後,開始變得有些明朗。
我不會說我完全理解一切,還遠非如此—但我終於看到這些片段是如何拼合的:匯入、暫存、集市、驗證和治理。Bruin 幫助我以一種感覺友好的方式接觸到這些概念,而不是讓我感到不知所措。
探索、失敗、閱讀和重建的過程,成為了最有價值的部分。還有很多要學習的內容,但這是一個堅實的第一步,旨在真正理解資料是如何流動、轉換和講述故事的(就像這篇文章一樣)。
GitHub 示範:與 Bruin 的電子商務管道
Bruin 網站
原文出處:https://dev.to/danielhe4rt/data-engineering-101-a-real-beginners-approach-25a8

1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式