🔧 阿川の電商水電行

如果你曾經將基於 LLM 的應用程式擴展到簡報之外的規模,你可能已經體會到了這一點。
一切起初都運作得非常完美。簡潔的API,快速的實驗,快速的迭代。
然後車流量成長。
延遲峰值。
成本變得難以預測。
重試、回退、速率限制和提供者的特殊機制開始滲透到您的應用程式程式碼中。
在某種程度上, LLM 網關(原本旨在簡化您的堆疊)卻悄悄地成為您最大的瓶頸。
這正是Bifrost所要解決的問題。
在本文中,我們將探討 Bifrost 成為當今最快的生產就緒型 LLM 閘道之一的原因,它在實際負載下與 LiteLLM 的比較,以及為什麼其基於 Go 的架構、語義快取和內建可觀測性使其成為擴展 AI 系統的理想選擇。
什麼是 Bifrost?一個可用於生產的 LLM 門戶
Bifrost是用 Go 語言寫的高效能開源 LLM 閘道。它統一了對 15 個以上 AI 供應商的存取:OpenAI、Anthropic、AWS Bedrock、Google Vertex、Mistral 等…所有這些都整合在一個與 OpenAI 相容的 API之後。
但彩虹橋不僅僅是另一個代理伺服器。
它是為執行生產級人工智慧系統的團隊設計的,其中:
-
每秒數千次請求是正常的。
-
尾延遲直接影響使用者體驗
-
服務中斷不應導致產品停用。
-
成本、治理和可觀測性與原始效能同等重要。
核心承諾很簡單:
幾乎不增加任何額外開銷(以微秒而非毫秒衡量),同時為您提供一流的可靠性、控制力和可視性。
與許多一開始很強大但隨著規模擴大而崩潰的網關不同,Bifrost 從一開始就被設計用於高吞吐量、長時間執行的生產工作負載。
{% cta https://www.getmaxim.ai/bifrost %} 探索 Bifrost 網站 {% endcta %}
為什麼LLM網關會成為生產瓶頸
在實際系統中,網關成為每個 AI 功能共享的依賴項。
它影響:
-
尾延遲
-
重試和回退行為
-
提供者路由
-
成本歸因
-
故障隔離
像LiteLLM這樣的工具作為輕量級 Python 代理程式運作良好。但在高並發情況下,基於 Python 的網關就開始出現效能瓶頸:
-
每次請求的額外開銷
-
每個實例的記憶體使用量更高
-
規模化營運的複雜性增加
在內部類似生產環境的基準測試中(啟用日誌記錄和重試),LiteLLM每次請求都會引入數百微秒的開銷。
車流量低的時候,這一點是看不見的。
每秒數千次的請求會迅速累積,推高成本並增加延遲。
Bifrost採取了截然不同的方法。
Bifrost 與 LiteLLM:大規模效能比較
Bifrost 使用Go語言編寫,編譯成單一靜態連結的二進位文件,並針對並發性進行了最佳化。
在持續負載測試中,每秒請求 5,000 次:
| 公制 | LiteLLM | Bifrost |
| ------------------------------ | ------- | ----------- |
| 閘道開銷 | 約 440 微秒 |約 11 微秒|
| 記憶體使用量 | 基準值 |降低約 68% |
| 佇列等待時間 | 47 微秒 | 1.67 微秒|
網關等級故障 | 11% | 0% |
| 總延遲(含服務提供者) | 2.12 秒 | 1.61 秒|
以下是 Bifrost 官方基準測試結果的快照,重點展示了網關在每秒 5,000 次請求的持續真實流量下的表現。

在 5,000 RPS 下對 Bifrost 和 LiteLLM 進行基準測試,比較網關開銷、總延遲、記憶體使用情況、佇列等待時間和持續負載下的故障率。
這比之前的網關開銷降低了大約 40 倍,這不是透過合成基準測試得出的結論,而是透過持續的真實世界流量得出的結論。
{% cta https://www.getmaxim.ai/bifrost %} 查看 Bifrost 在生產環境中的運作情況 {% endcta %}
如果你對原始資料有興趣,可以深入研究完整的基準測試,但結論很簡單:
當網關從你的延遲預算中消失時,其他一切都更容易優化。
為什麼 Go 語言能讓 Bifrost 成為更快的 LLM 門戶
Bifrost 背後的最大架構決策是其基於 Go 的設計。
1. 並發性不妥協
Python 網關依賴非同步 I/O 和工作進程。這在並發量激增之前都行得通。
Go 使用goroutine :
-
輕量級線程(每個約 2 KB)
-
跨CPU核心的真正平行
-
最小的調度開銷
當收到 1000 個請求時,Bifrost 會產生 1000 個 goroutine。無需頻繁切換工作流程,也不會出現協調瓶頸。

此圖僅為概念簡化。實際上,Python 閘道依賴非同步 I/O 和多個工作線程,而 Go 則使用在作業系統線程上重複使用的 goroutine。關鍵差異在於 Go 的單次請求開銷和調度成本顯著降低。
2. 大規模下的可預測記憶體使用情況
典型的 Python 網關在框架和依賴項載入後,即使在空閒狀態下也通常會消耗 100 MB 以上的記憶體。
在類似的負載下,Bifrost 使用的記憶體始終比 LiteLLM 等基於 Python 的網關少約 68% 。
更低的基準記憶體佔用提高了容器密度,降低了基礎設施成本,並使自動擴展更加可預測,尤其是在持續的生產流量下。
效率之所以重要,是因為:
-
自動縮放
-
容器密度
-
無伺服器和邊緣部署
3. 更快、更可預測的啟動時間
基於 Python 的網關通常需要幾秒鐘才能初始化,因為框架、依賴項和執行時間狀態需要載入。
由於使用了編譯後的 Go 二進位文件,且執行時間開銷極低,Bifrost 的啟動速度顯著提升。雖然啟動時間取決於配置,例如載入的提供者和模型數量,但它始終比基於 Python 的替代方案更快、更穩定。
這意味著:
-
更快的部署速度
-
更平滑的自動縮放行為
-
重啟和部署期間摩擦更小
超越速度:生產中真正重要的特性
表現才能吸引眼球。
但控制平面特性才是Bifrost成功的關鍵。
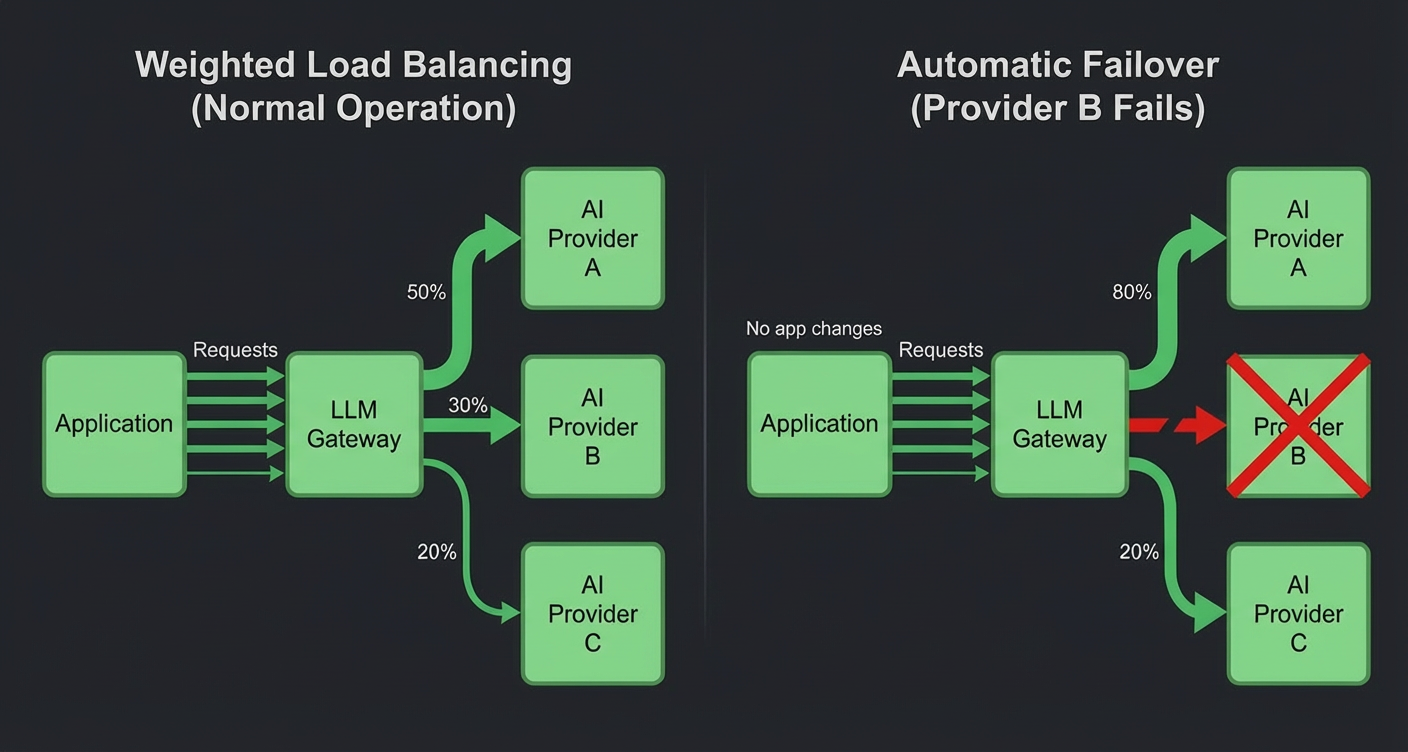
自適應負載平衡與自動故障轉移
Bifrost 可智慧地將流量指派至以下位置:
-
多家供應商
-
多個 API 金鑰
-
加權配置
如果提供者達到速率限製或發生故障,請求將自動故障轉移,而無需應用程式層級的重試邏輯。
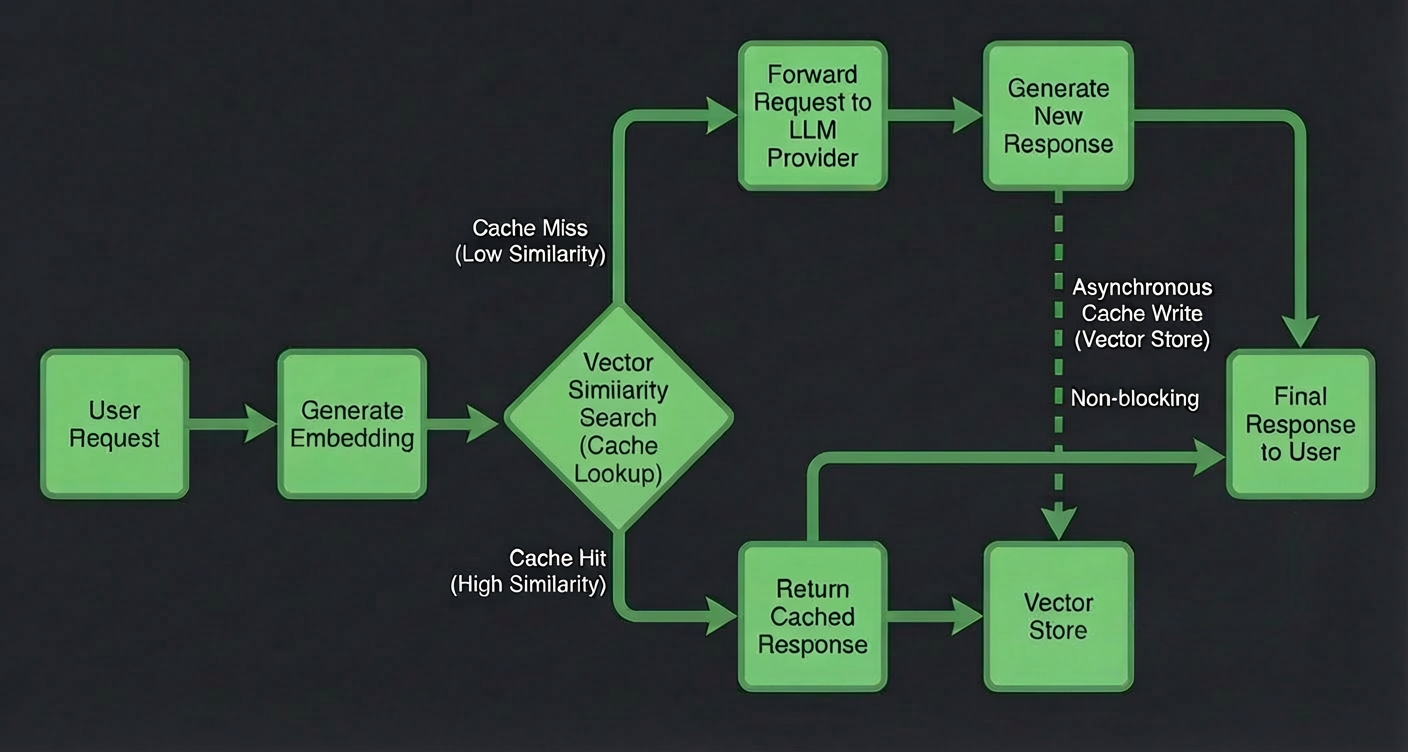
語義緩存(不僅僅是字串匹配)
傳統快取只對完全相同的提示有效。
Bifrost 將語意快取作為核心功能提供:
-
基於嵌入的相似性檢查
-
向量儲存整合(Weaviate)
-
快取命中後的毫秒響應
意思相同,措詞不同,快取的答案相同。
結果:
-
顯著降低延遲
-
規模化顯著降低成本
跨所有提供者的統一接口
不同的供應商。不同的API。
Bifrost 將所有內容統一到一個與 OpenAI 相容的端點之後。
只需更改一行程式碼即可切換運營商:
base_url = http://localhost:8080/openai無需重構。無需重寫SDK。
這使得 Bifrost 可以真正取代OpenAI、Anthropic、Bedrock 等。
內建可觀測性和治理
Bifrost 包括:
-
普羅米修斯指標
-
結構化請求日誌
-
按供應商和關鍵要素進行成本跟踪
-
預算、速率限制和虛擬鑰匙
所有設定均透過Web 使用者介面完成,無需查閱設定檔。
一分鐘內即可上手
Bifrost 最令人耳目一新的地方之一就是它能迅速為你讓路。
只需幾秒鐘即可在本機安裝並執行 Bifrost LLM 閘道:
npx -y @maximhq/bifrost打開:
http://localhost:8080新增您的API金鑰。
就這樣。你現在擁有:
-
一個可用於生產的AI網關
-
可視化配置使用者介面
-
即時指標和日誌
📌如果您覺得有用,請考慮為 GitHub 倉庫加星標;這有助於專案發展,並表明對開源基礎設施的支援。
{% cta https://github.com/maximhq/bifrost %} ⭐ GitHub 上的 Star Bifrost {% endcta %}
輕鬆學習 Bifrost(強烈推薦)
如果您喜歡透過觀看和探索真實案例來學習,而不是閱讀冗長的文件,那麼 Bifrost 可以滿足您的需求。
🎥 Bifrost 官方 YouTube 播放清單透過清晰易懂的解釋,逐步講解了設定、架構和實際用例。
{% cta https://www.youtube.com/playlist?list=PLJh32rQ0yHHKvqdt0ApfoMfj7jFMUserf %} 觀看 Bifrost YouTube 教學 {% endcta %}
📚 如果您喜歡更深入的技術文章, Bifrost 部落格會定期更新基準測試、架構深度解析和新功能公告。
{% cta https://www.getmaxim.ai/bifrost/blog %} 閱讀 Bifrost 部落格 {% endcta %}
這些資源結合起來,可以加快新用戶上手速度,並幫助您在生產環境中最大限度地發揮 Bifrost 的優勢。
什麼時候使用彩虹橋才有意義?
彩虹橋在以下情況會發光:
-
你每天處理超過 1000 個請求
-
尾部延遲很重要
-
您需要可靠的提供者故障轉移功能
-
成本追蹤並非可選項。
-
你需要一個無需重寫程式碼即可擴展的基礎設施。
即使對於規模較小的團隊來說,從 Bifrost 開始也能避免以後痛苦的遷移。
最後想說的話
Bifrost 不想標新立異。
它力求做到乏味的可靠。
當您的 AI 網關退居幕後時,您可以專注於真正重要的事情:創造出色的產品。
如果你認真看待生產級人工智慧系統,那麼 Bifrost 是目前你可以建立的最簡潔的基礎架構之一。
⭐ 別忘了給GitHub 倉庫點贊,瀏覽YouTube 教程,並關注Bifrost 博客以獲取最新更新。
祝您建造愉快,並能安心發貨,無需擔心 LLM 網關的問題 🔥
感謝閱讀! 🙏🏻
希望這對您有幫助✅
請按讚並關注,以獲得更多精彩內容😍
由Hadil Ben Abdallah傾情打造 | 

 |
|
|---------|----------|---------|
{% embed https://dev.to/hadil %}
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式