
這是系列文章 Building TinyAgent 的第一篇,我們要從零開始在 Node.js 裡打造一個小型代理,完全不使用框架,只靠 API 呼叫。
不過,在我們撰寫代理之前,得先了解呼叫 LLM 時實際發生了什麼。如果你只用過 SDK,可能從沒看過原始請求,也不清楚它是怎麼運作的。六行程式碼、一把 API 金鑰,然後一切看起來都能正常運作,但你其實不知道請求送出後發生了什麼,也不知道回應是怎麼被印到畫面上的。
1. 請求
以下是範例 API 呼叫,並逐一詳細說明每個部分。

這個 API 呼叫有幾個值得注意的地方。
API 是無狀態的:每一次新的 API 呼叫都不會記住前一次的上下文。如果你想做一個能「記得」先前訊息的聊天機器人,就必須自己保存 messages 陣列,並在每次請求時把整份內容重新送出。
max_tokens 是硬性上限,不是目標值。 如果達到上限,回應就會在句子中間被截斷。
API 呼叫的模式是通用的。 只是 URL 不同、Authorization 改成 Bearer 而不是 x-api-key、system prompt 放在 messages 裡而不是頂層。不過本質上還是同一個 POST、同一個 JSON、同樣的 {model, messages, max_tokens}。一旦你理解了這個結構,切換供應商就只是做搜尋取代而已。
2. 回應
API 會回傳一個 JSON 資料塊。裡面大約有 10 個欄位,但真正重要的只有四個:
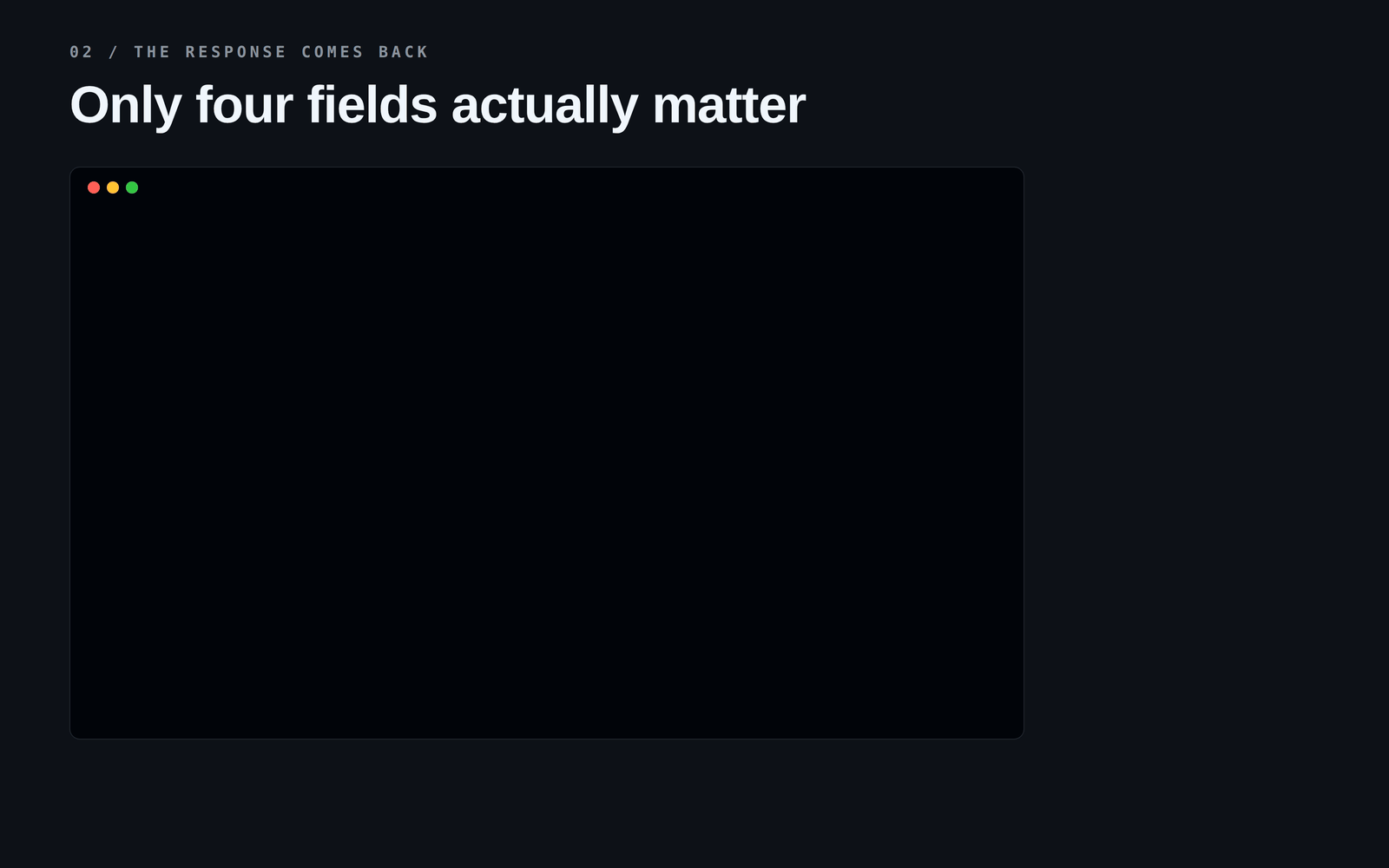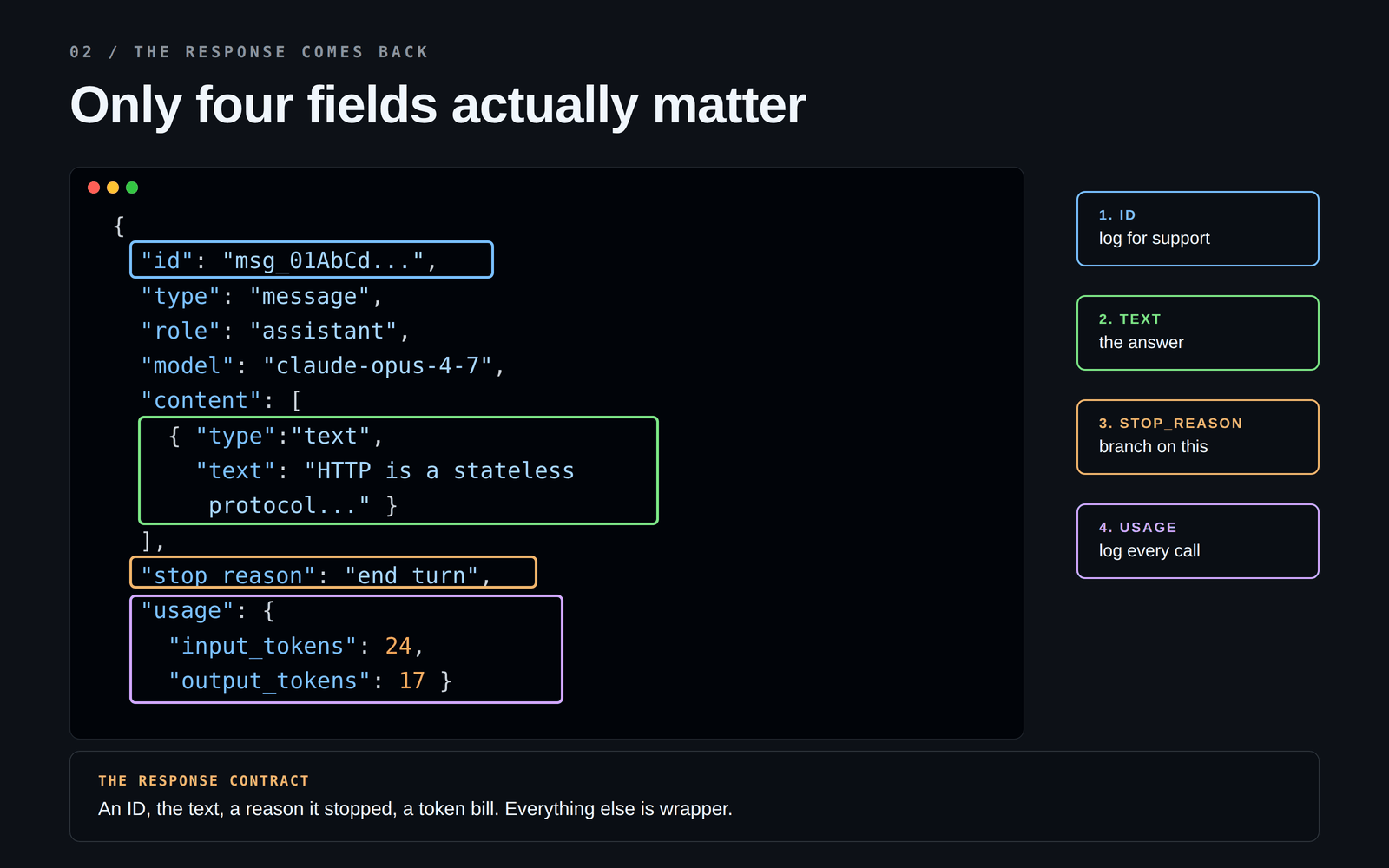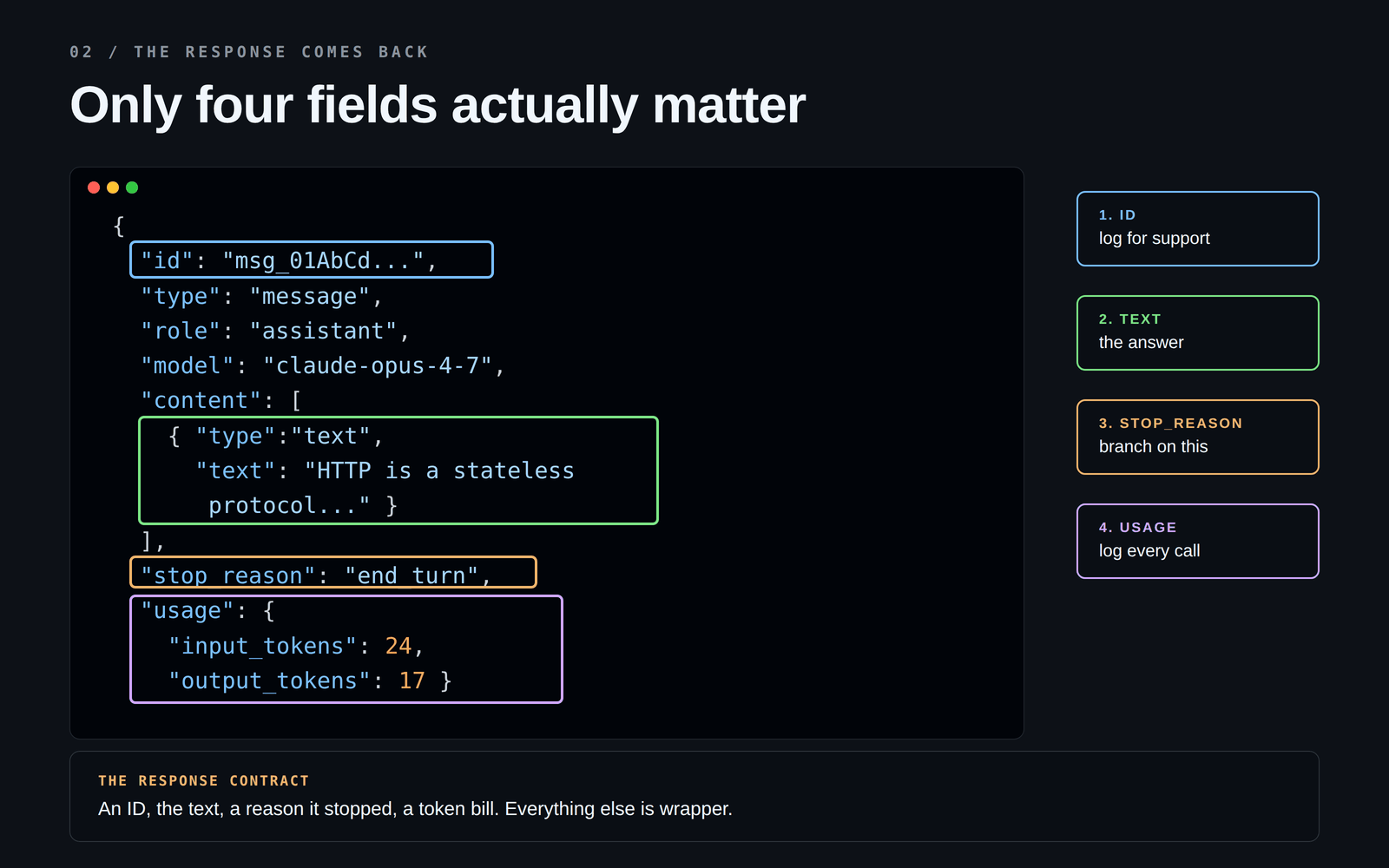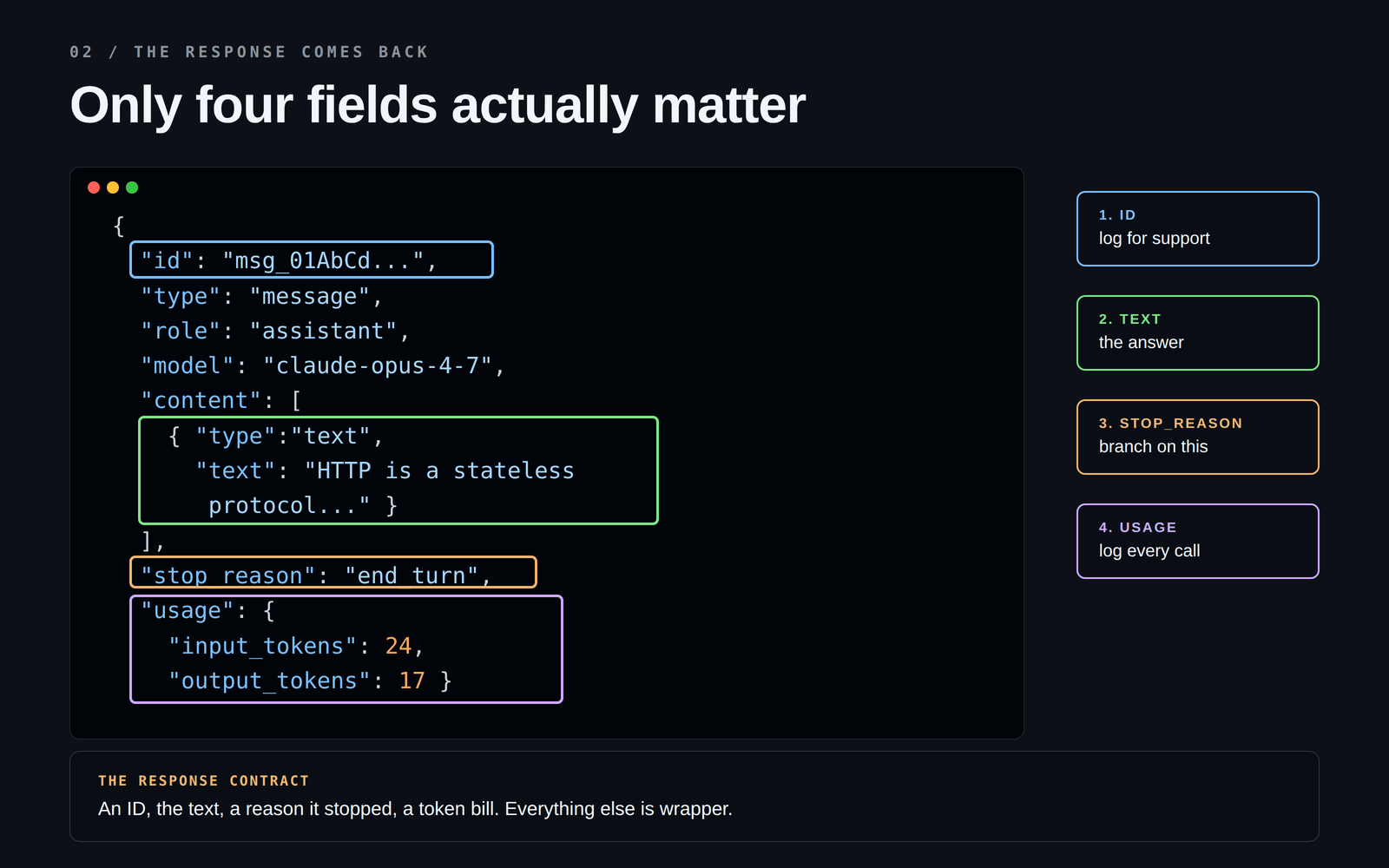
最常被忽略的是:stop_reason。
它會告訴你模型是為什麼停止,而在實際系統中,背後可能有幾種原因:
end_turn → 正常完成,結束了
max_tokens → 到達上限,回應被截斷
tool_use → 模型想要呼叫工具(下一篇會提到!)
stop_sequence → 符合了你設定的某個停止字串如果你只檢查文字內容而忽略 stop_reason,遲早會把 bug 帶進正式環境。回應看起來都正常,直到它不正常為止。
另一個值得牢記的欄位是:usage。它會顯示輸入和輸出了多少 token。你應該從第一天就把這個數字記錄到日誌裡,而不是等到收到驚喜帳單之後。🤯
3. Token
我一直在說「24 個輸入 token」。這是什麼意思:

有些事情常讓人意外,而且值得注意:
字數不等於 token 數。 "Unbelievable" 是一個字,但有四個 token。Tokenizer 是依照常見子字串切分,而不是依照空白。
程式碼的成本比看起來更高 def add(a, b): 是 8 個 token。每個括號和逗號都會各自算一個 token。
JSON 很貴。 {"a":1} 是 7 個 token。如果你的工具 schema 寫得很肥,每一次請求都會默默吃掉你的額度。
非英文內容成本更高 日文、印地文、阿拉伯文的 token 數通常會是相同英文內容的 2~4 倍。如果你是為全球使用者設計,這會大幅改變你的成本估算。
英文文章的經驗法則:~1 個 token ≈ 4 個字元 ≈ 0.75 個字。其他語言請先自己丟進 tokenizer 算過,再做假設。
4. 帳單
每次呼叫都會跑兩個計量器,而且它們的計價方式不同。

輸出 token 的成本大約是輸入 token 的 3~5 倍。這是你需要先內化的 LLM 定價重點。
cost = (input_tokens / 1,000,000) × input_price
+ (output_tokens / 1,000,000) × output_price由這種不對稱性可以得出三件事:
- 長提示詞便宜,長回應昂貴。 把 50 KB 的上下文塞進 system prompt 沒問題;但要求輸出 50 KB,成本大約會高 5 倍。
- 「思考」token 也算輸出。 推理模型會以輸出費率計算其內部思考,即使你看不到那些內容。
- 工具 schema 每次呼叫都會吃掉輸入額度。 它們會像 system prompt 一樣,在每次請求時重新送出。
以每次 0.006 美元計算,一天 10 萬次呼叫就是每月 600 美元,而且只是一個小功能。現在就加入使用量記錄,不要等到收到警報才做。🚨
5. 用 20 行程式碼看完整件事
以下是我們前面討論的 API 呼叫完整程式碼:
https://github.com/Jasmin2895/TinyAgent
沒有依賴套件,也不需要安裝設定;它只是一個帶有 API 金鑰的 Node 檔案。
在下一篇之前,先試試這三件事
-
實際執行並觀察數字。連續呼叫十次,改變提示詞長度,看看 usage 如何變化。透過這種方式,你會比讀任何文件都更快建立真正的成本直覺。
-
設定
max_tokens: 20,然後要求它產生長內容。 看它被截斷,檢查stop_reason。這是你遲早會在正式環境遇到的 bug,不如現在就刻意碰一次。 -
手動打造一個多輪對話。 保留一個 messages 陣列,把每次使用者訊息和模型回覆都推進去,並在每一輪重新送出整份內容。一旦你這樣做,你會立刻理解為什麼長對話會變貴——因為每次呼叫都要付完整歷史的費用。
接下來是什麼
在後續的系列文章中,我們會擴充 TinyAgent 的能力,讓它不只會回應,而是能實際處理更多事情。
Happy Coding! 👩💻
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式