

Andrej Karpathy 的LLM Wiki 模式本月爆紅,獲得了超過 5000 個星標、3700 個 fork 和數十種實現方式。其核心理念非常正確:停止在每次查詢中重複推導知識,而是將其一次性編譯成結構化的 wiki。讓 LLM 來完成那些導致人們放棄知識庫的繁瑣記帳工作。
如果你還沒看過,簡單來說就是:原始原始碼進入一個目錄,LLM(層級管理)將其處理成相互連結的 Markdown 頁面,然後 Obsidian 用作檢視器。三層架構,三個操作(導入、查詢、程式碼檢查),LLM 負責維護所有內容。
這是一個不錯的起點。但如果你嘗試將這種模式應用到幾百個音符以上,很可能就已經遇到瓶頸了。這種模式有三個結構性缺陷,會在規模化後失效,而這些問題並非透過改進提示或更精細的索引檔案就能解決的。
以下是缺失的部分以及如何解決它。
差距1:你的連結毫無意義
在 Karpathy 風格的維基上開啟 Obsidian 的圖形視圖。你看到了什麼?由相同的灰色線條組成的網。每個連結看起來都一樣,因為每個[[wikilink]]都只攜帶一則訊息:「這兩個筆記是相連的」。
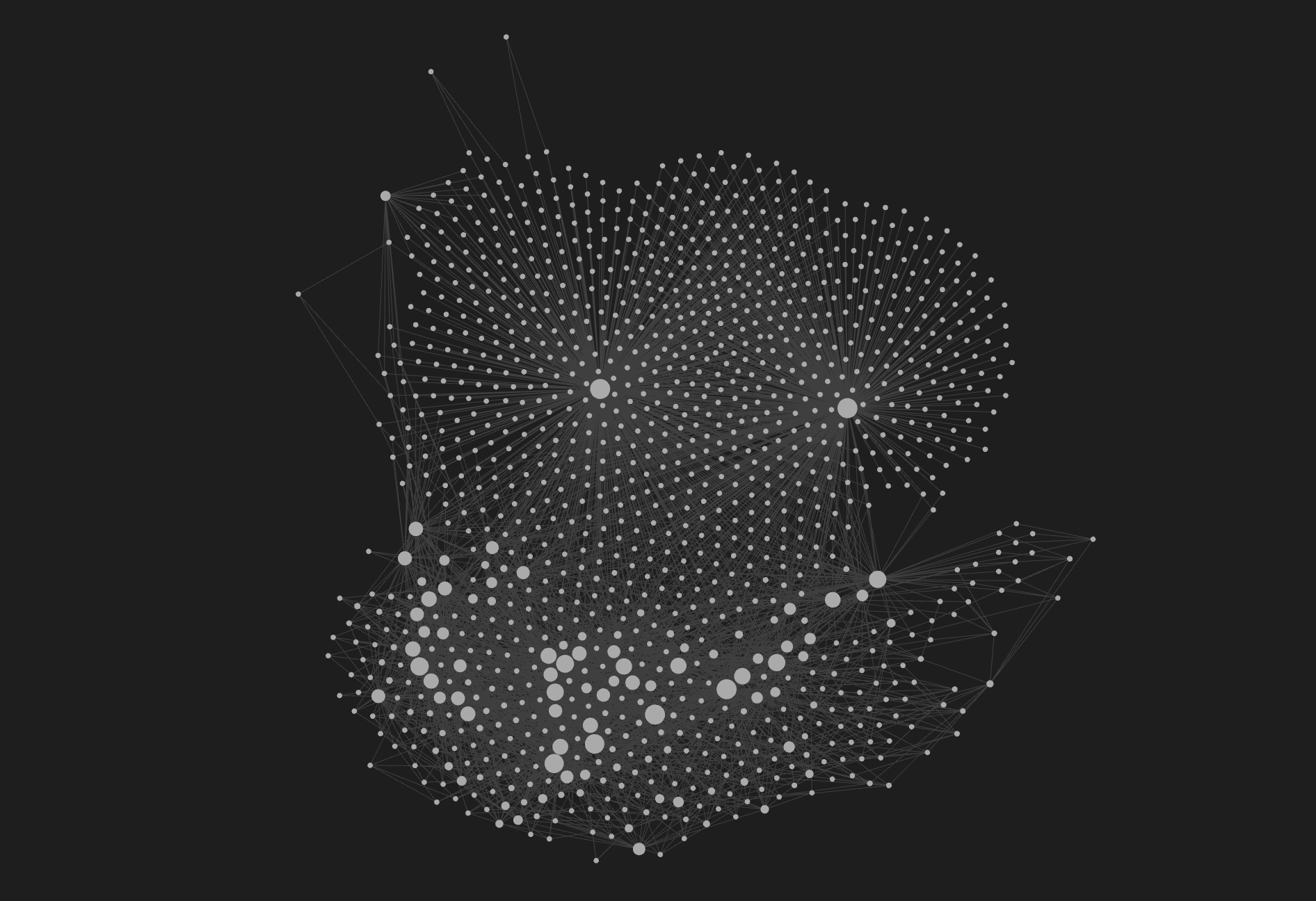
這還不夠。
當 Karpathy 談到 LLM 的「指出新資料與舊論點相矛盾」和「標記矛盾」時,他描述的是語義關係。但底層連結格式無法表達這些關係。 [[Note A]]不會告訴你註釋 A 是支持、反駁、取代當前註釋,還是由當前註釋引起的。其意義存在於連結周圍的文字中,而 Obsidian 生態系統中的所有工具都無法辨識這些文字。
這點至關重要,因為編譯型維基的全部意義在於其結構能夠為你服務。如果你的圖表無法區分“此內容取代彼內容”和“此內容與彼內容相矛盾”,那麼一些最有價值的資訊就會被困在非結構化的文本中,而這恰恰是你試圖解決的問題。
解決方法:在維基連結內部定義類型化關係
obsidian-wikilink-types使用@語法為標準 Obsidian wikilinks 新增語意關係型別:
[[Previous Analysis|The new research @supersedes the previous analysis]]
[[Redis Paper|This @supports the caching architecture in @references the Redis paper]]在 wikilink 別名中輸入@ ,即可獲得 24 種關係類型的自動完成下拉清單: supersedes 、 contradicts 、 causes 、 supports 、 evolution_of 、 prerequisite_for等等。
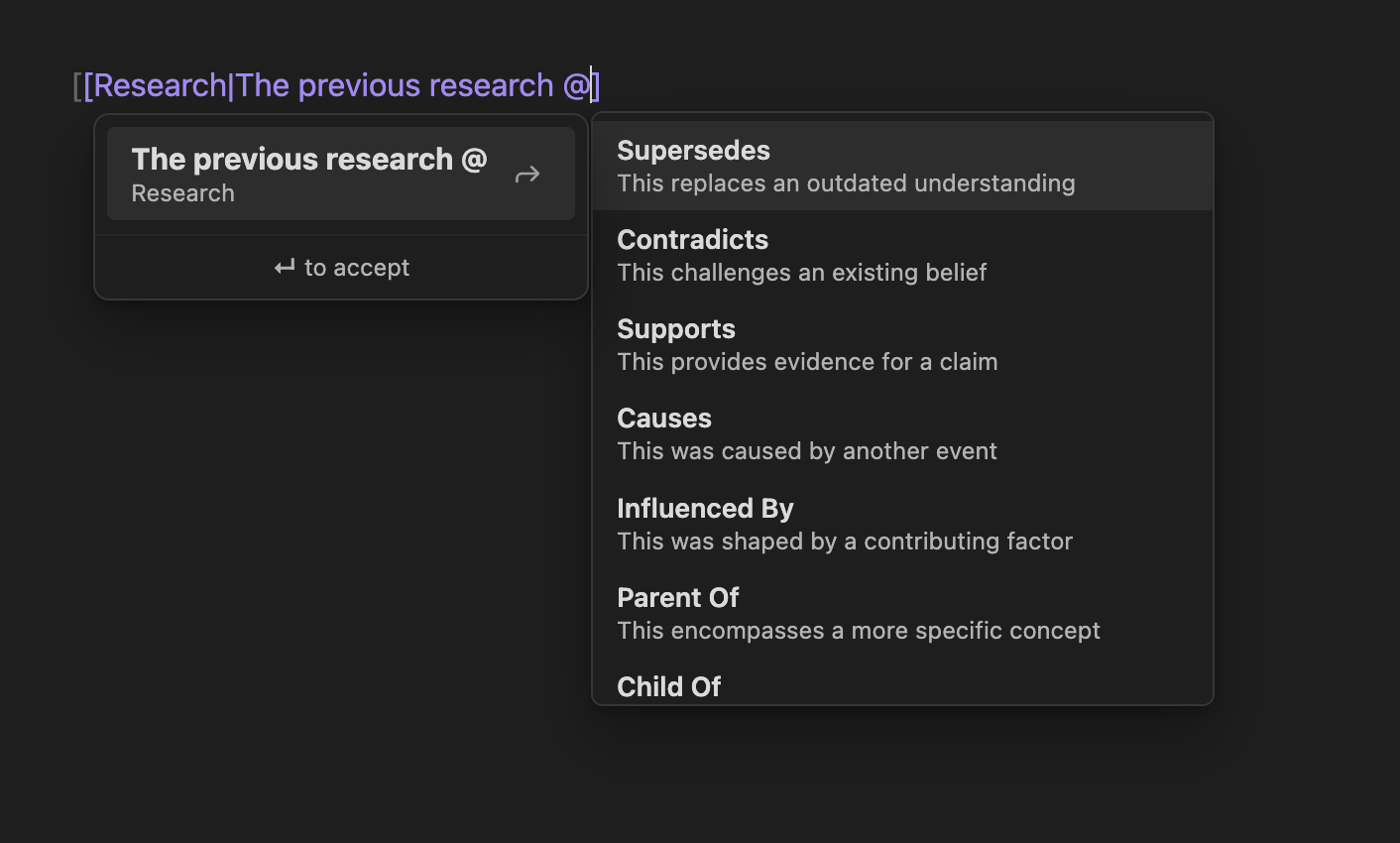
儲存時,插件會自動將符合的類型同步到 YAML frontmatter:
---
supersedes:
- "[[Previous Analysis]]"
supports:
- "[[Redis Paper]]"
references:
- "[[Redis Paper]]"
---就是這樣。標準的 YAML 前元資料。 Dataview 可以查詢它。一切正常。
特意選擇了@語法:它不會與任何現有的 Obsidian 語法衝突( ^是塊引用, ::是資料視圖內聯字段),並且只有在前面有空格或緊跟在|豎線之後時才會觸發自動完成。顯示文字中的[email protected]保持不變。只有配置的關係類型才會產生 frontmatter。 @monkeyballs只是顯示文字。
使用BRAT和penfieldlabs/obsidian-wikilink-types安裝它。
這將帶來哪些改變?
借助類型化連結,您的知識庫可以從一堆相同的連接線轉變為可查詢的知識圖譜。您可以編寫類似「顯示所有與我目前假設相矛盾的內容」的資料視圖查詢。您可以追蹤因果鏈。您可以一目了然地查看哪些筆記已被取代,哪些筆記是最新的。
這就是 Karpathy 的模式所需要但所缺乏的:承載意義的連結。
差距2:你不應該自己輸入每段關係。
帶有文字連結的維基比沒有文字連結的更有用。但是,在每個註釋中手動輸入@supersedes和@contradicts很繁瑣,而且你會錯過一些不明顯的關聯。
LLM Wiki 的整個前提是 LLM 負責記帳。所以也讓它去發現其中的關係吧。
解決方案:人工智慧發現的類型化關係
Vault Linker 技能與外掛程式位於同一程式碼庫中。它是一個適用於 AI 代理(Claude Code、OpenClaw 或任何可以讀寫文件的程式)的技能規範,用於分析您的庫並發現筆記之間的關聯。
工作流程:
-
讓你的AI代理指向你的金庫,並載入金庫連結器技能。
-
代理人閱讀你的筆記並找出其中的關聯:“這條筆記取代了那條。這條筆記與那項聲明相矛盾。這是由那項決定造成的。”
-
代理以 Wikilink Types 格式寫入關係:向 Wikilink 新增
@supersedes、@contradicts等,並同步 frontmatter。 -
您審核並批准
人類會參與最終判斷。人工智慧則負責閱讀數百條筆記,並找出你手動永遠無法發現的關聯,完成繁重的閱讀工作。
LLM Wiki 模式規定 LLM 應負責所有「匯總、交叉引用、歸檔和記帳」工作。類型連結為 LLM 提供了這些交叉引用的詞彙。 Vault Linker 技能則為其提供了實際執行這些工作的流程。
自主模式:一夜之間連結整個金庫
上述技能是互動的:智能體發現訊息,你進行審核。但是,如果你有 500 條筆記,並且想要一次性將它們全部連結起來,該怎麼辦呢?
該倉庫包含兩個旨在作為管道工作的提示符:
自主 Vault 連結是建置階段。您只需將 Vault 路徑交給代理程式即可。代理程式會建立一個 Git 分支,掃描 Vault,將筆記分類為中心節點或分支節點,然後按優先順序處理它們:首先處理中心節點之間的關聯(價值最高的連接),然後處理分支節點之間的關聯(工作量最大),最後處理分支節點之間的橫向關聯。它每處理 20-50 條筆記提交一次,寫入包含統計資料和置信度的連結日誌,並且絕不會觸及您的主分支。如果您並行執行多個代理程式(例如,每個資料夾一個代理程式),則提示訊息中包含協調規則:每個代理程式僅寫入其指派的筆記,在連結之前驗證目標檔案是否存在,並記錄任何必須跳過的筆記。
驗證和修復是清理階段。建置完成後,在同一分支上執行此步驟。它會建立完整的檔案索引,掃描每個註解中的斷鍊(正確地排除程式碼區塊和標註),修復可以修復的問題(近似匹配解析、移除並行代理工件),檢查 frontmatter 和內聯@type連結是否一致,移除重複項,對孤立註解進行分類,並驗證所有 YAML 程式碼。輸出結果是驗證報告,其中會詳細說明哪些問題已修復,哪些問題仍需手動判斷。只有驗證通過後才能合併。
這種兩階段設計是經過深思熟慮的:建置階段優化吞吐量,驗證階段優化正確性。兩者都是冪等的。對已連結的儲存庫重新執行不會產生任何變更。
差距3:你的知識被困在一台機器裡。
這是大多數實現方案未能解決的差距。
LLM Wiki 將所有內容以純 Markdown 格式儲存。您可以將這些檔案與 Git 同步,將多個工具指向相同目錄,並從任何地方存取它們。文件本身沒有問題。
代理人的理解是。
每次啟動新會話時,LLM 都會讀取索引文件,重新解析 wiki 結構,並重新發現上次會話中已存在的內容。記憶體中沒有持久化圖。因此,如果不重新讀取每個相關頁面,就無法查詢「什麼內容與我關於 X 的假設相矛盾?」。也無法遍歷數百條筆記中的類型化關係index.md目錄在小規模下可以工作,但它只是一個平面文件,而不是查詢引擎。
Git 提供了檔案可移植性。但它無法提供代理級別的內存、關係感知搜尋,或者任何工具都可以查詢而無需從頭開始重新解析所有內容的持久化知識圖譜。
解:持久化知識圖譜後端
Penfield是一個用於人工智慧代理的持久化記憶和知識圖譜系統。它將記憶、工件和類型化關係儲存在後端,任何相容的客戶端都可以透過 MCP(模型上下文協定)存取後端。
相關能力:
-
混合搜尋:BM25(關鍵字)+ 向量(語意)+ 圖遍歷,三者融合,而非「二選一」。而是將三者進行加權與融合。
-
類型化關係:Penfield 圖原生包含 wikilink-types 中的 24 種關係類型,
supersedes、contradicts、causes等。詞彙表完全相符。 -
跨平台存取:可透過 Claude Code、Claude.ai、OpenClaw、Cursor、Gemini CLI 或任何其他支援 MCP 的工具進行連線。無論您使用哪種工具,都使用相同的知識圖譜和關係。
-
跨會話持久性:關閉標籤頁後,圖表不會消失。記憶、關聯和資料將永久保留。開始新會話後,即可從上次中斷的地方繼續。
管道:從黑曜石到彭菲爾德
penfield-import是一座橋樑。它讀取 Obsidian Vault(或任何 Markdown 文件集合),並將所有內容作為記憶、關係和文物匯入 Penfield。
該工具分七個階段執行,並具有崩潰安全檢查點:
-
解析:讀取所有
.md和.txt文件,提取 YAML 前元資料和類型化關係 -
記憶:每張紙條創造一個彭菲爾德記憶
-
文物:上傳超過 10K 字元記憶體限制的筆記的完整內容
-
匯出工件:上傳預先存在的工件文件
-
文件:上傳文件(PDF、程式碼檔案等)
-
關係:批量創造記憶之間的關係,每次創造 100 個記憶。
-
驗證:確認進口數量匹配
快速入門:
# Install
pip install .
# Authenticate (opens browser, takes 2 seconds)
penfield-import --login
# Preview what will be imported
penfield-import /path/to/your/vault --dry-run
# Run the import
penfield-import /path/to/your/vault如果你的資料庫包含來自 obsidian-wikilink-types 的類型化關係,它們會以圖邊的形式匯入 Penfield 中。如果沒有,你仍然可以獲得所有筆記的可搜尋記憶。類型化連結可以豐富導入內容,但並非必要。
我們已在一次自主執行中大規模執行過,導入了超過 4,000 條筆記和超過 20,000 個關係。檢查點系統意味著,如果在第 5 階段出現故障,它會從第 5 階段恢復執行,而不是從頭開始。
完整的管道
以下是完整的工作流程,無論您是升級現有保險庫還是從頭開始建立:
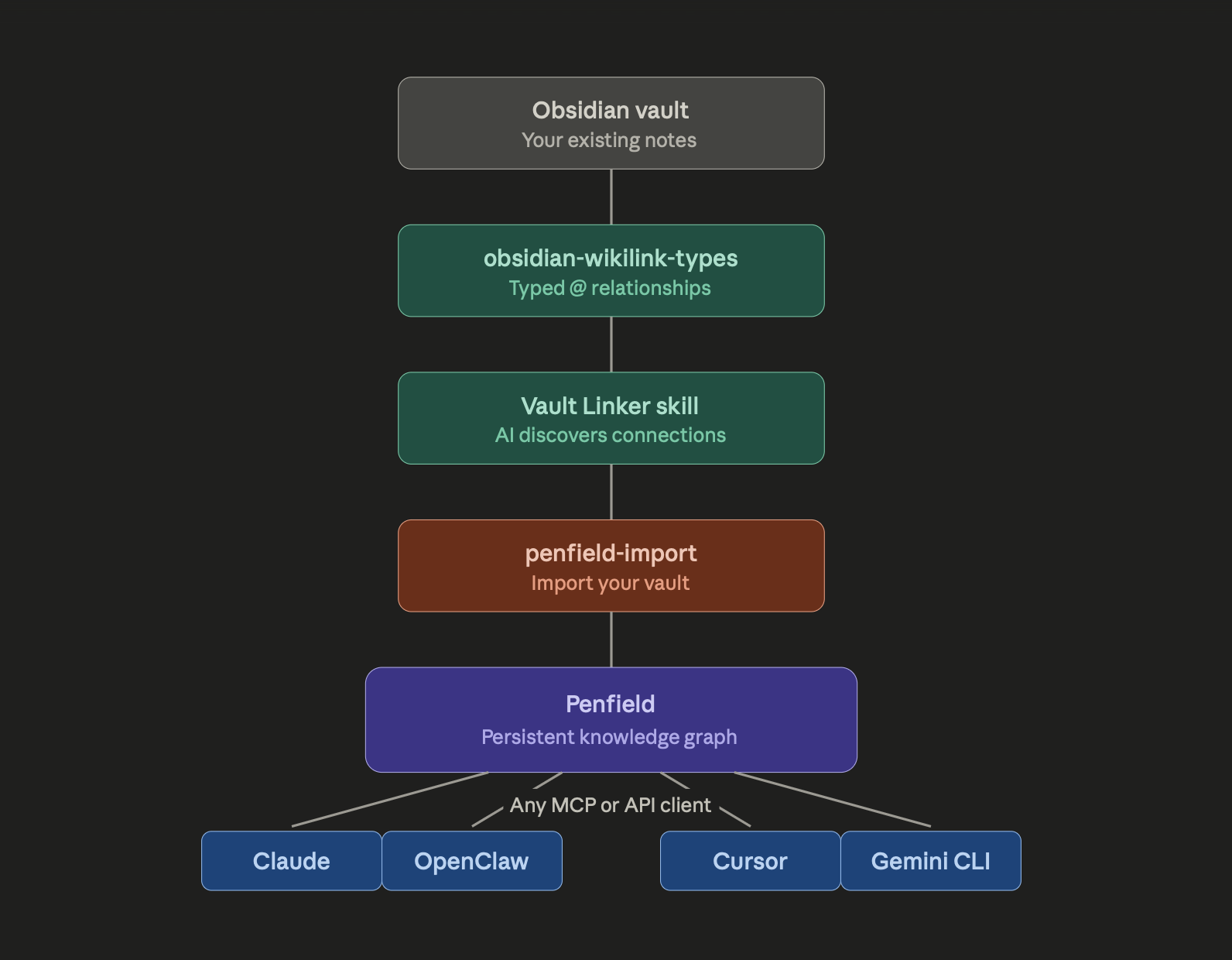
方案A:你已經擁有一個黑曜石金庫。
-
在您的保險庫中安裝 obsidian-wikilink-types
-
使用 Claude Code 或 OpenClaw執行 Vault Linker 技能,以發現現有筆記之間的關聯。
-
審核並批准人工智慧建議的關係
-
執行 penfield-import 指令將所有內容匯入 Penfield 資料庫。
-
在任何裝置上,透過任何相容於 MCP 的 AI 工具存取您的知識
方案 B:從頭開始,採用 LLM Wiki 模式
-
遵循卡帕西的做法:收集資料,讓LLMs(LLM)寫維基百科。
-
但從一開始就使用 obsidian-wikilink-types 。當 LLM 建立交叉引用時,讓它使用
@語法,以便從一開始就對關係進行類型化。 -
定期執行「金庫連結器」技能,以發現LLM遺漏的關係。
-
當您的維基內容足夠豐富時,可將其匯入 Penfield以實現持久的跨平台存取。
你得到的與你曾經擁有的對比
| | Karpathy 的 LLM Wiki | 包含文字連結 + Penfield |
|---|---|---|
| 連結語意 | [[Note]] - 已連接,無型別 | [[Note @supersedes]] - 24 關係類型 |
| 搜尋 | index.md 平面文件,規模擴大時會中斷 | 混合:BM25 + 向量 + 圖表遍歷 |
| 持久性 | 無 - LLM 在會話之間遺忘 | 完全 - 知識圖譜無限期保留 |
| 設備存取權限 | 一台筆記型電腦,一個目錄 | 任何設備,任何 MCP 或 API 用戶端 |
| 代理相容性 | 一次只能執行一個代理程式 | Claude、OpenClaw、Cursor、Gemini CLI 等 |
| 關係發現 | 手冊,散文體 | 由人工智慧透過 Vault Linker 發現,經人工審核 |
工具
本文中提到的所有產品現已上市:
-
obsidian-wikilink-types :Obsidian 外掛。為 wiki 連結新增類型化的
@關係,並自動同步到 YAML 前元資料。包含 Vault Linker 技能,用於辨識 AI 發現的關係。 AGPL-3.0 許可。 -
penfield-import :用來匯入 Obsidian Vault 和其他 Markdown 集合的工具。七階段管線,具有崩潰安全檢查點機制。 AGPL-3.0 許可。
-
Penfield :面向人工智慧代理的持久記憶體和知識圖譜。免費試用請造訪portal.penfield.app/sign-up。 MCP伺服器設定位於github.com/penfieldlabs/penfield-mcp 。
Karpathy 的 LLM Wiki 模式奠定了堅實的基礎。類型化的關係、人工智慧發現的關聯以及持久化的後端,使其從一個巧妙的筆記工具轉變為一個真正能夠不斷累積知識的系統。
如果您有任何疑問或想做出貢獻,請在上面的任何儲存庫中提出問題,或透過@penfieldlabs與我們聯繫。
原文出處:https://dev.to/penfieldlabs/what-karpathys-llm-wiki-is-missing-and-how-to-fix-it-1988
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式