

MCP是否因為特工技能不足而消亡?
有時感覺人工智慧不僅顛覆了舊世界(例如SaaS),還在新世界中吞噬著它自己的「孩子」。不到一年前,模型上下文協議(MCP)還是業界的“寵兒”,所有供應商和平台都爭相整合。然而僅僅六個月後,焦點再次轉移——這次轉移到了代理技能(Agent Skills)身上,這個MCP的「小弟」似乎搶走了MCP的大部分風頭。
突然間,「MCP已死」的說法在社群媒體上鋪天蓋地,就像之前的「SaaS已死」一樣。然而,這正是社群媒體慣用的伎倆:利用極端言論煽動情緒,製造病毒式傳播。讓我們先來看看他們的母公司 Anthropico 在將 MCP 捐贈給 Linux 基金會,並在 2025 年底將 Agent Skills 作為開放標準發佈時是怎麼說的:
我們也看到了技能和MCP伺服器之間的互補性。 MCP提供與外部軟體和資料的安全連接,而技能則提供有效使用這些工具所需的程式知識。那些已投入大量資源進行強大MCP整合的合作夥伴自然而然地成為了我們的起點。
—— Anthropic 產品經理 Mahesh Murag
以下是來自業界實際經驗的佐證:
如果你想深入了解MCP的雙刃劍效應,這裡有一篇在HackerNews上引起熱議的好文章:
{% embed https://chrlschn.dev/blog/2026/03/mcp-is-dead-long-live-mcp/#auth-and-security
我同意作者的觀點,即遠端 http MCP 伺服器實際上是改變遊戲規則的關鍵,並將成為組織和企業採用的關鍵支柱,從直覺式編碼轉向智慧工程。
因此,內建的 OAuth 支援即使不是最好的,也是迄今為止加入的非常實用的功能。這對於組織和企業適應 OAuth 至關重要,上文中的範例可以很好地說明這一點:
工程師離職了?撤銷他們的 OAuth 令牌和對 MCP 伺服器的存取權限;他們一開始就沒有權限存取其他金鑰和機密資訊。
因此,我還寫了一篇文章,示範如何從頭開始建立一個支援 OAuth 的 HTTP MCP 伺服器,以便安全地實現 AI 對資料庫的存取:
https://dev.to/zenstack/turning-your-database-into-an-mcp-server-with-auth-32mp
MCP腫脹
我的部落格文章在 ZenStack 社群引起了很多關注。鑑於 ZenStack 解決方案的簡潔性,我原本預期會看到各種整合了身份驗證功能的 MCP 伺服器發布。
很遺憾,這種情況從未發生過。直到有位使用者在 GitHub 上建立了以下 issue,我才意識到原因:
https://github.com/zenstackhq/zenstack/issues/2277
簡而言之,即使使用者嘗試載入 MCP 伺服器提供的單一工具,上下文視窗也會膨脹到400K ,導致其無法使用。這種「上下文膨脹」問題是 MCP 最受詬病的問題之一,也是人們轉而使用 Skill 的原因。例如,以下是 Playwright 官方 GitHub 上關於Playwright CLI 與 Playwright MCP 的說明。
現代編碼代理越來越傾向於使用基於 CLI 的工作流程(以 SKILL 的形式公開),而不是 MCP,因為 CLI 呼叫效率更高:它們避免將大型工具模式和冗長的存取樹加載到模型上下文中,從而允許代理透過簡潔、專門建置的命令來執行操作。
ZenStack 的方法實際上將這個問題放大到了極致。原因在於 ZenStack MCP 伺服器公開的工具是 ORM 的查詢 API,而它是 Prisma ORM 查詢 API 的超集。它的優勢之一在於支援嵌套關係查詢。這意味著你可以透過一次函數呼叫遍歷整個資料庫中的所有模型,例如:
const users = await db.user.findMany({
select: {
id: true,
name: true,
posts: {
// relation-level filter
where: {
tags: { some: { name: "typescript" } },
},
select: {
id: true,
title: true,
tags: {
// deep filter
where: { name: "typescript" },
select: { name: true },
},
comments: {
where: {
body: { contains: "great" },
},
// switch to include here — we want all Comment columns
include: {
author: {
select: { id: true, name: true },
},
},
},
},
},
},
});水能承載船隻,也能掀翻。即使只為一個 MCP 伺服器工具產生的 JSON 模式也會變得臃腫不堪,最終涵蓋整個應用程式的模式。
一個簡單的解決方法是限制巢狀關係遍歷的深度,以簡化 JSON 模式。但是,我認為這更像是權宜之計,而不是真正的解決方案:
-
它既不實用也不可擴展,因為它只能選擇模型的有限部分,因此不適用於大型專案。
-
這會削弱查詢 API 的優勢。原本一次查詢就能完成的任務,現在需要多次請求/回應週期,這會影響效能並導致更高的令牌使用量。
程式碼模式 MCP 的出現
軟體開發領域的一大優點是,無論你遇到什麼問題,大多數情況下你都不是第一個遇到的。更棒的是,人們很可能會分享他們的問題和解決方案。以下是 Cloudflare 提供的解決方案:
https://blog.cloudflare.com/code-mode-mcp/
光看標題就知道,這正是我需要的。 😄 他們採用的解決方案是,不再將每個操作描述為一個單獨的工具,而是讓LLM直接編寫程式碼,他們稱之為「程式碼模式」。更具體地說,整個Cloudflare API的MCP伺服器隻公開了兩個工具: search和execute 。這樣一來,無論有多少個API端點,其佔用空間都保持不變。最終,他們成功地將輸入令牌的數量減少了99.9%,降至約1000個令牌。
讓我們看看如何運用這種方法來解決我們的問題!
ZenStack 的解決方案
我們本來可以採用與 Cloudflare 相同的方法來公開search和execute工具。但由於 ZenStack 案例的兩個固有特點,我們可以做得更好:
-
一個模型在技術上與整個資料庫中的所有其他模型都存在關聯。如上所述,這正是導致上下文膨脹問題的罪魁禍首。
-
由於 Prisma 的幫助,LLM 已經非常熟悉如何編寫 Query API,因為它在其訓練資料集中遇到了 GitHub 和部落格文章中的無數範例。
因此,它提供了 3 種工具:
模式
我們不會提供search工具,而是提供一個schema工具,該工具會將整個模式發送到 LLM,透過一些簡單的範例,讓 LLM 全面了解應用程式。雖然這種方法意味著工具的佔用空間不再固定,但如今大多數 LLM 都能處理整個模式文字檔案的大小。
執行
excute僅此而已。實際上,它甚至更簡單,因為它只會執行與查詢 API 對應的固定數量的函數呼叫,例如findMany 、 createMany 、 updateMany等,而不是執行任意程式碼。
查看
這個工具用於 LLM 在execute函數呼叫之前檢查其參數是否有效。這算是錦上添花,因為我認為 LLM 仍然可以從execute傳回的錯誤訊息中推斷出正確的參數。事實上,在 Claude 中測試 MCP 伺服器並收到幾個成功回應後,我才意識到它實際上從未呼叫過這個check 。以下是我詢問它為什麼沒有按提示呼叫check時得到的回應:
你說得對,這確實是個中緣由。 gym
gym:check工具的描述中明確指出:
“請先使用‘檢查’工具驗證呼叫,然後再執行呼叫。”
我完全跳過了類型檢查這一步——這意味著我直接執行了查詢,而沒有事先進行類型檢查。幸運的是,這些查詢恰好有效,但這並非正確的做法。類型檢查步驟的存在是為了在查詢結果到達資料庫之前,捕獲無效的欄位名稱、錯誤的參數格式或不支援的操作。
我必須在excute的提示字元中新增一個 MUST 參數,以確保它被呼叫。
You MUST use the "check" tool first to validate the query before calling this tool加入此check的原因是為了遵循「高內聚、低耦合」的軟體工程原則,這有利於人類和人工智慧。例如, execute只會執行有效的函數呼叫,因此它返回的任何錯誤都是執行時問題,使用者必須了解這些問題。
與克勞德一起測試
我模擬了一個包含 50 多個模型和 AI 生成的模擬資料的複雜健身房應用程式,並使用 Claude 桌面和 Sonnet 4.6 進行了測試。說實話,結果看起來相當不錯。
它可以產生涉及 10 多個模型的非常複雜的嵌套查詢,而且渲染結果相當不錯:
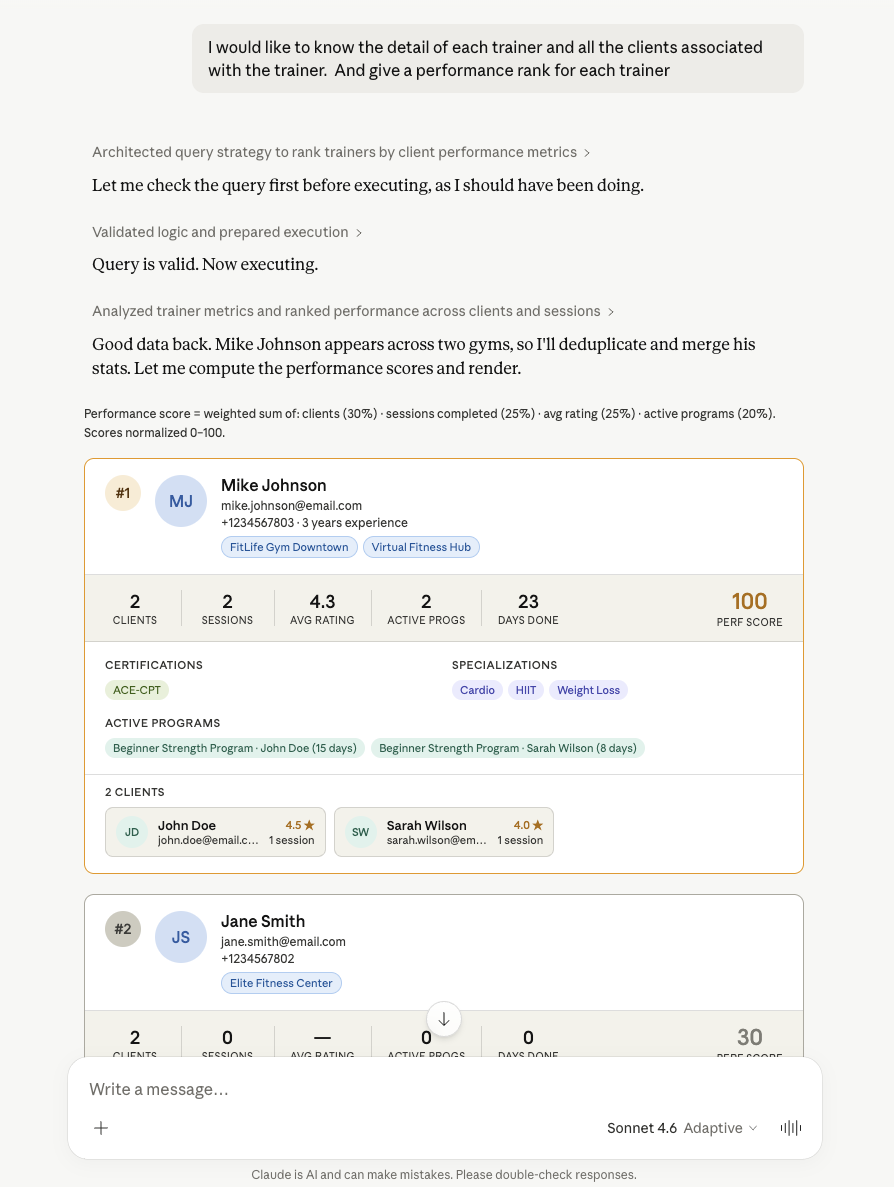
如果一次操作無法完成任務,它就知道要使用多次操作來完成任務。

更令人印象深刻的是,在我的整個實驗過程中,LLM 建立的初始函數呼叫只有一次出錯,而且這次錯誤被「 check'工具捕獲了。它只是換了一條路徑就完成了任務。

在您的應用程式中試用一下
這是一個可以在本地執行的簡單專案:
https://github.com/jiashengguo/zenstack-code-mode-mcp
你可以透過修改schema.zmodel檔案來測試自己的應用程式。根據我的經驗,我相當肯定你會遇到一些問題。如果你能告訴我這些問題,我們將不勝感激,這樣我們就可以不斷改進,使其更加實用。
原文出處:https://dev.to/zenstack/how-to-save-bloated-mcp-with-code-mode-33e3
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式