

揭露:這篇文章包含附屬連結;如果您透過本文中提供的不同連結購買產品或服務,我可能會獲得補償。
image_credit - DesignGuru.io
你好朋友,快取不僅是系統設計面試的重要主題,它也是軟體開發中的技術,可以實現更快的資料檢索、減少載入時間並增強使用者體驗。
對於開發人員來說,掌握快取概念至關重要,因為它可以顯著優化應用程式效能和可擴展性。
過去,我討論過常見的系統設計問題,例如API 網關與負載平衡器、水平與垂直擴展、 正向代理與反向代理以及常見的系統設計問題,在本文中,我們將探討系統設計中緩存的基礎知識和學習不同的快取策略,這是技術面試的必備知識。
這也是面試必備的系統設計題目之一,一定要做好準備。
在本文中,您將學習十個基本的快取概念,從客戶端和伺服器端策略到分散式快取和快取替換策略等更高級的技術
那我們還在等什麼?開始吧
順便說一句,如果您正在準備系統設計面試並想深入學習系統設計,那麼您還可以查看ByteByteGo 、 Design Guru 、 Exponent 、 Educative和Udemy等網站,這些網站有許多很棒的系統設計課程和系統設計面試模板像這樣你可以用它來回答任何系統設計問題。

如果您需要更多選擇,您還可以查看最佳系統設計課程、 書籍和網站的列表
PS 繼續閱讀直到最後。我有一份免費獎金給你。
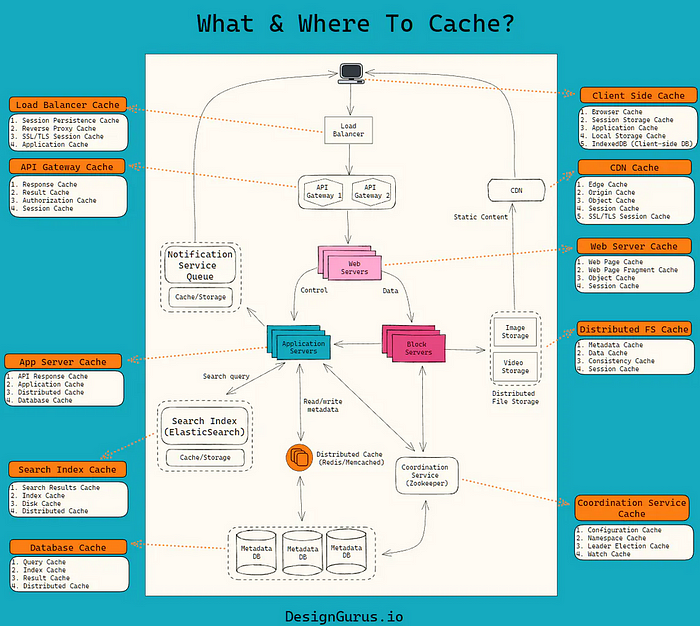
什麼是緩存?快取哪些資料?在哪裡快取?
在設計分散式系統時,應策略性地放置緩存,以優化效能、減少延遲並最大限度地減少後端服務的負載。
快取可以在多個層實現,例如
- 客戶端緩存
這涉及將頻繁存取的資料儲存在客戶端設備上,從而減少對伺服器重複請求的需要。它對於不經常變化的資料非常有效,並且可以透過減少延遲來顯著改善用戶體驗。
- 邊緣快取(內容傳遞網路 - CDN)
CDN 在最靠近最終用戶的邊緣節點快取內容,這有助於透過從地理分佈的伺服器提供靜態內容(例如圖像、影片和樣式表)來更快地交付這些內容。
- 應用程式級快取
這包括應用程式層內的記憶體緩存,例如 Redis 或 Memcached。這些快取儲存昂貴的資料庫查詢結果、會話資料和其他頻繁存取的資料,以減少資料庫負載並縮短應用程式回應時間。
- 資料庫快取
資料庫層的查詢快取等技術儲存頻繁查詢的結果。這減少了資料庫的讀取操作次數並加快了資料檢索速度。
- 分散式快取
在分散式系統中,分散式快取跨越多個節點以提供高可用性和可擴展性。它確保快取的資料在分散式環境中保持一致,並且可以處理大型系統所需的高吞吐量。
在設計快取策略時,透過分析使用模式、資料波動性和存取頻率來確定要快取的資料至關重要。
實作適當的快取逐出策略(例如 LRU - 最近最少使用或 TTL - 生存時間)可確保清除陳舊資料,從而維護快取的相關性。
此外,考慮一致性模型和快取失效策略對於確保快取資料在整個系統中保持準確和最新至關重要。
而且,這裡有一個來自DesignGuru.io的關於快取的漂亮圖表來說明我剛才所說的內容。
系統設計面試的 10 個快取基礎知識
以下是每個程式設計師在參加任何系統設計面試之前都必須了解的 10 個與快取相關的基本知識和概念。
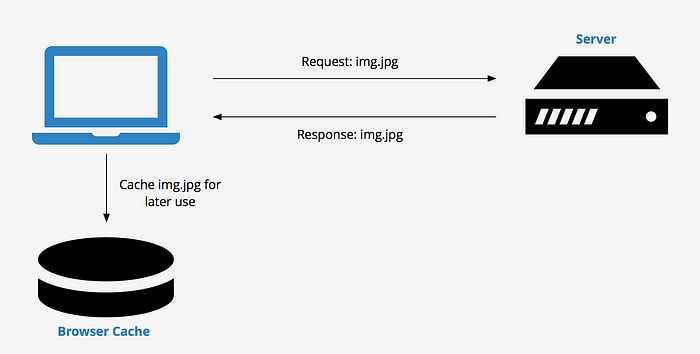
1)客戶端緩存
客戶端快取是一項基本技術,將資料儲存在用戶設備上,以最大限度地減少伺服器請求並縮短載入時間。兩種主要方法包括:
- 瀏覽器快取:
在本機上儲存 CSS、JavaScript 和圖片等資源,以減少後續造訪時的頁面載入時間。
- 服務人員:
透過快取回應啟用離線存取,允許應用程式在沒有網路連線的情況下運作。
簡而言之:
- 瀏覽器快取:儲存 CSS、js、圖片以減少載入時間\
- service workers: enable offline access by caching response
客戶端快取如下所示:
2)伺服器端快取
這是另一種類型的緩存,涉及在伺服器上儲存資料以加快用戶請求的回應時間。
主要策略包括:
- 頁面快取:
儲存整個網頁,以便更快地交付後續請求
。
- 片段快取:
快取頁面的特定部分,例如側邊欄或導覽欄,以提高載入效率。
- 物件緩存:
儲存昂貴的查詢結果以防止重複計算
簡而言之:
- 頁面快取:快取整個網頁
- fragment caching: cache page components like sidebars, navigation bar\
- object caching: cache expensive query results
伺服器端快取如下所示:
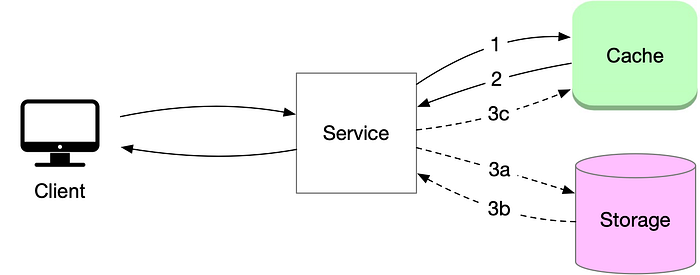
image_credit --- ByteByteGo
3)資料庫緩存
資料庫快取對於減少資料庫負載和提高查詢效能至關重要。重要的技術包括:
- 查詢快取:
儲存資料庫查詢的結果以快速服務重複請求。
- 行級快取:
快取經常存取的行以避免重複的資料庫提取。
簡而言之:
- 查詢快取:快取資料庫查詢結果以減少負載
- row level caching: cache popular rows to avoid repeated fetches
以下是 AWS 上的資料庫快取範例:
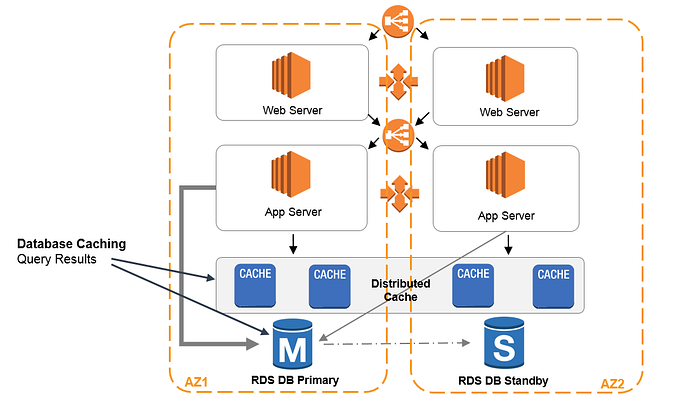
4)應用程式級緩存
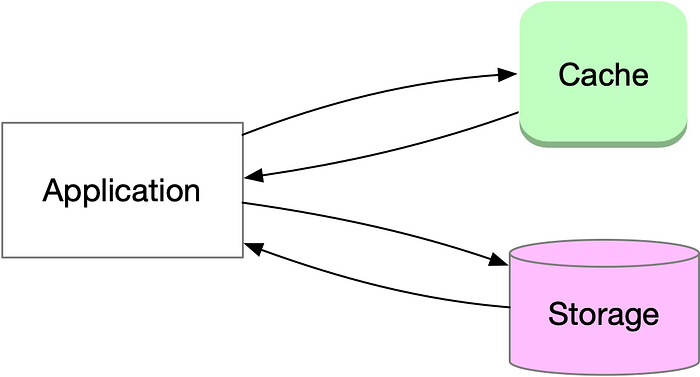
應用程式級快取側重於應用程式內的緩存,以減少計算和資料檢索時間。策略包括:
-
資料快取:儲存特定資料點或整個資料集以便快速存取。
-
計算快取:快取昂貴計算的結果以避免重複處理。
簡而言之:
- 資料緩存:快取特定資料點或整個資料集\
- computational caching: cache expensive computation results to avoid recalculation
[  ](https://www.linkedin.com/pulse/8-best-places-prepare-system-design-interview-2024-soma-sharma-ug4ic/)
](https://www.linkedin.com/pulse/8-best-places-prepare-system-design-interview-2024-soma-sharma-ug4ic/)
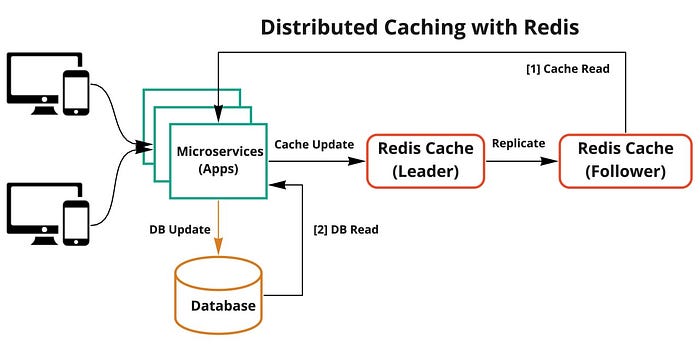
5)分散式快取
分散式快取透過將快取資料分佈在多個伺服器上來增強可擴展性,從而實現高可用性和容錯能力。
簡而言之,這種類型的快取只是將快取分散到許多伺服器以實現可擴展性
Redis 的分散式快取如下所示:
6)內容傳遞網絡
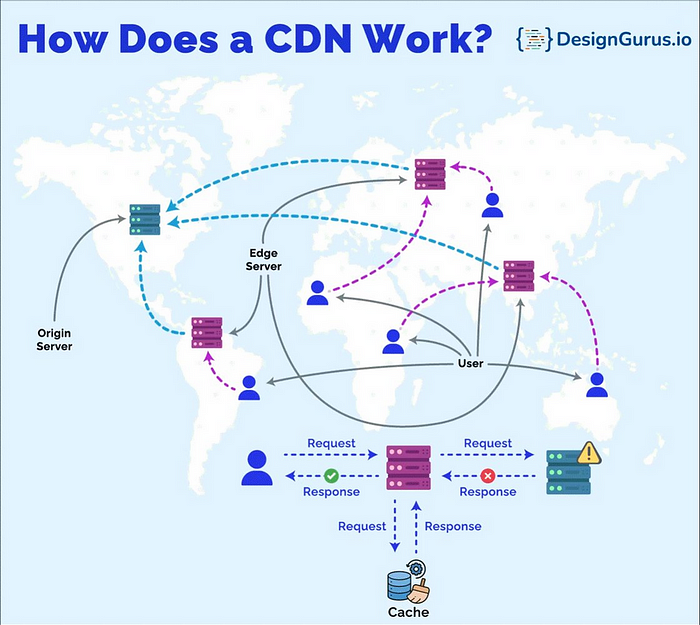
內容交付網路 (CDN)用於透過邊緣伺服器快取靠近使用者的靜態文件,從而顯著減少延遲並加快內容交付速度。
簡而言之,CDN 使用邊緣伺服器將靜態檔案儲存在用戶附近以實現低延遲
另外,這是 DeisgnGuru.io 提供的關於 CDN 如何運作的精美圖表
7)快取替換策略
快取替換策略決定快取如何處理資料逐出。常見政策包括:
-
最近最少使用 (LRU):首先逐出最近最少存取的專案。
-
最近使用的 (MRU):首先逐出最近存取的專案。
-
最不常用 (LFU):逐出最不常存取的專案。
簡而言之:
- LRU: removes the least recently accessed items first\
- MRU: removes the most recently accessed items first\
- LFU: removes items that are accessed least often

8)分層緩存
分層快取涉及多個快取等級(例如,L1、L2)以平衡速度和儲存容量。這個模型在CPU上已經不再流行了。
簡而言之:
- 多層快取(L1、L2 快取)以提高速度和容量

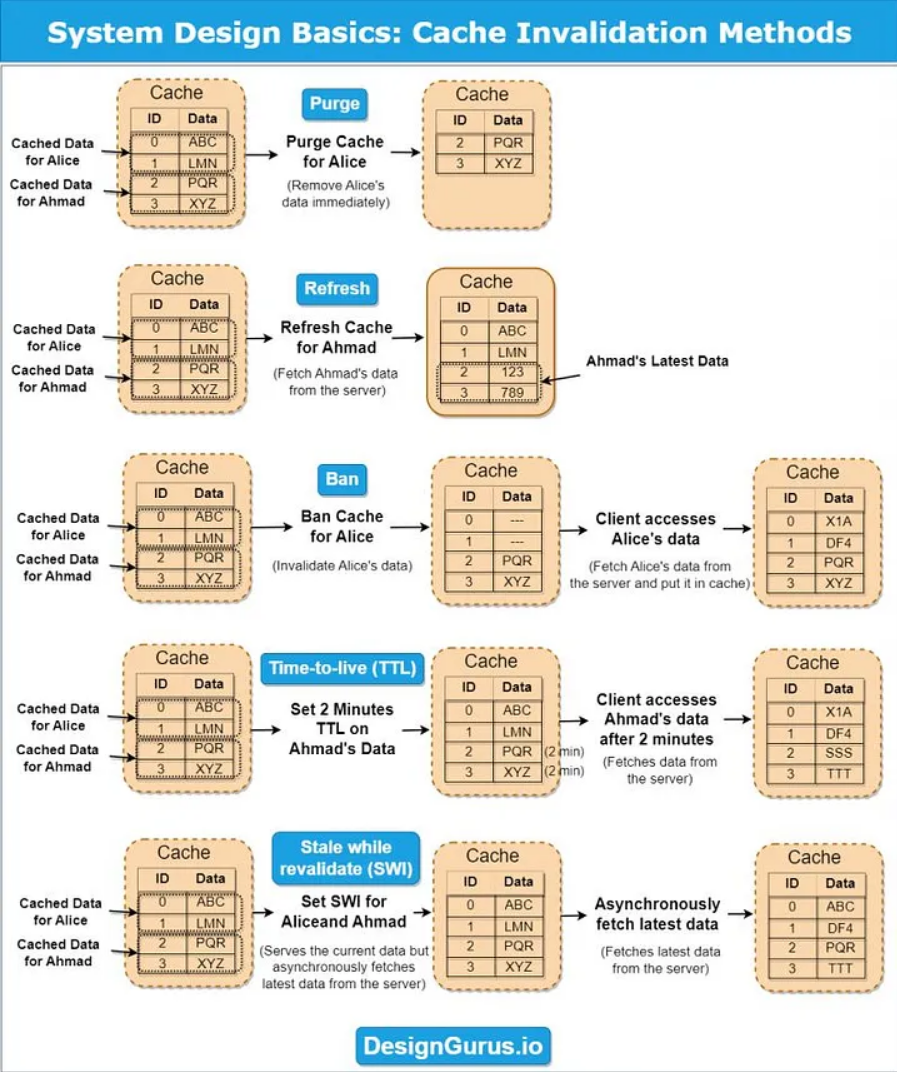
9) 緩存失效
快取失效可確保從快取中刪除陳舊資料。方法包括:
-
生存時間 (TTL):設定快取資料的到期時間。
-
基於事件的失效:根據特定事件或條件觸發失效。
-
手動失效:允許開發者使用工具手動更新快取。
簡而言之:
- TTL: set expiry time\
- event based: invalidate based on events or conditions\
- manual: update cache using tools
這是DesignGuru.io提供的關於快取失效方法的系統設計備忘單,可以更好地理解這個概念:
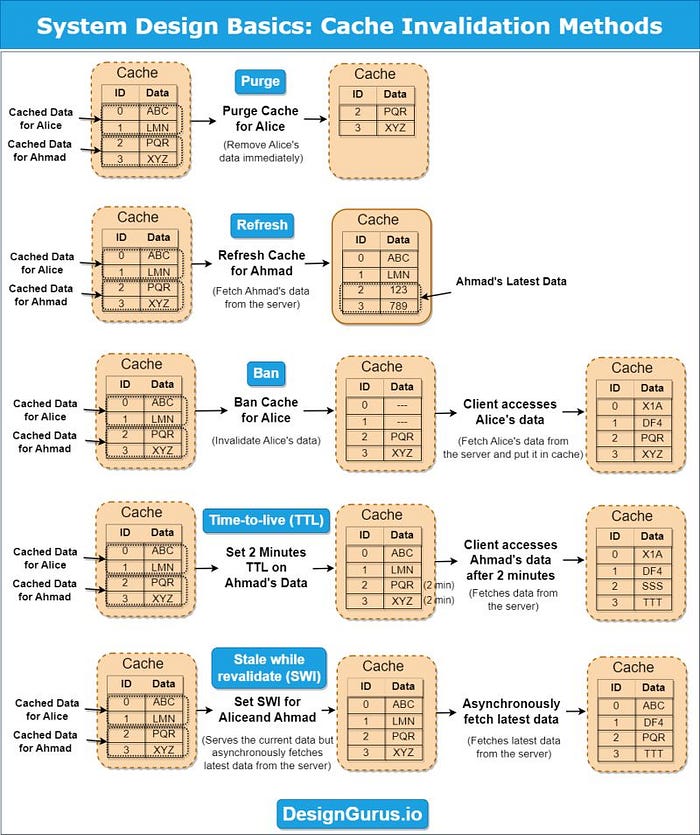
10) 快取模式
最後,快取模式是快取與資料庫同步的策略。常見模式包括:
-
Write-through:將資料同時寫入快取和資料庫。
-
Write-behind:立即將資料寫入快取並非同步寫入資料庫。
-
Write-around:直接將資料寫入資料庫,繞過快取以避免後續讀取時快取未命中。
簡而言之:
- write-through: data is written to the cache and the database at once\
- write-behind: data is written to the cache and asynchronously to database\
- write-around: data is written directly to the database, bypassing the cache
這是另一個了解各種快取策略的精彩圖表,由DesignGuru.io提供,這是學習系統設計的最佳地點之一。
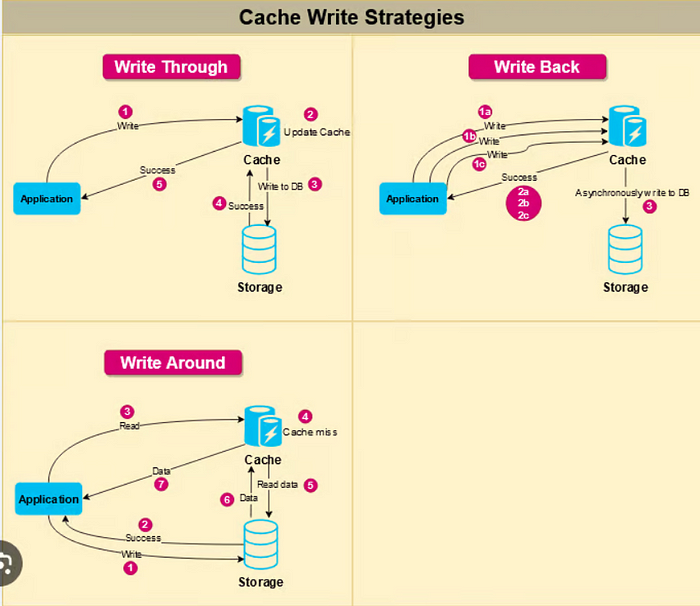
結論
這就是系統設計面試中與快取相關的 10 個基本概念。快取可以提高應用程式的效能和可擴展性。所以要小心使用。了解和實施這些快取概念可以顯著提高應用程式效能、可擴展性和使用者滿意度。
獎金\
正如承諾的,這是給你的獎金,一本免費的書。我剛剛找到一本新的免費書籍來學習分散式系統設計,您也可以在 Microsoft 上閱讀它 --- https://info.microsoft.com/rs/157-GQE-382/images/EN-CNTNT -eBook-設計分散式系統.pdf

原文出處:https://dev.to/somadevtoo/system-design-basics-caching-4fge
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式