

TL;DR
除非你一直住在石頭下,否則你一定聽說過 OpenAI 的重大發布:o1-preview。
作為一名 AI 愛好者和 AI 初創公司 Composio 的成員,我花了數小時通過無數提示測試這個模型,看看它究竟有多優秀。
它是否符合炒作,還是又一次被過度宣傳的發布?我們將會找出來。
我對該模型進行了以下測試:
- 推理
- 數學
- 編程
- 創意寫作
以下是我對它表現的詳細分析。

什麼是 o1-preview?
o1-preview 是 OpenAI 新系列的 AI 模型,能夠在回答問題之前“思考”和“分析”。
該模型據報導已經在 IOI(國際資訊奧林匹亞)和 Codeforces 中表現出色,經測試智商為 120(根據挪威 MENSA 測試)。

模型的思考能力歸功於在大量鏈接思維數據集上的強化學習。這使得模型能夠模仿思考過程以獲得更好的解決方案。
o1-preview 的本地 Chain of Thought
在進入討論之前,這是我對 o1 本地思維鏈能力的看法。
- 推理能力顯著提高。
- 有時,它在完成思考過程後未能輸出答案。我想知道這是否與模型有關。
幾次它正確回答,即使思維鏈的痕跡有些不一致。再次,我不確定這是否是預期,而且沒有辦法知道原因。 - CoT 的強化學習有效,不會卡住或崩潰,這是一個重大改進。
推理
邏輯推理是它顯著優於現有模型的地方,多虧了本地思維鏈的思考過程。這是該模型的整體賣點,完全不讓人失望,並在各方面都超越了其他模型。
讓我們從一個基本的推理問題開始。
#1. 計算回應中的單詞數
提示:你對這個提示的回應中有多少個單詞?
我用 GPT-4o 和 Sonnet 3.5 試過相同的提示,但兩者都沒能正確回答。然而,O1 模型在第一次嘗試中就答對了。

讓我們給它一個新任務。
提示:你對這個提示的回應中有多少個字母?
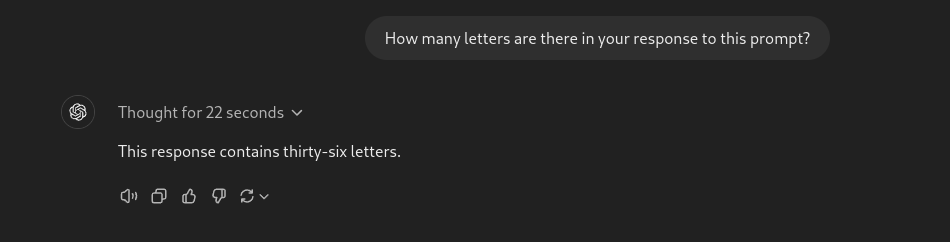
它完全正確,沒有依賴任何工具。與之前的模型不同,它沒有將特殊字符和數字誤認為字母。
讓我們再深入一點。
提示:你對這個提示的回應中的第四個單詞是什麼?
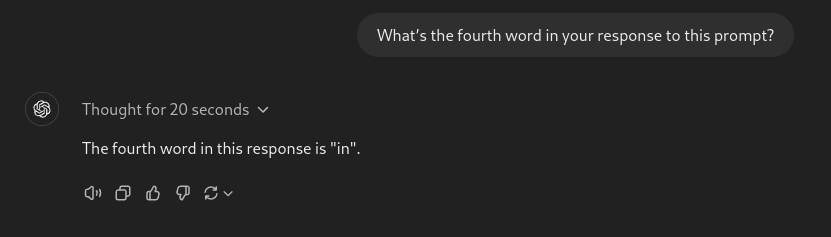
o1-preview 模型在第一次嘗試中正確回答,而 GPT-4o 和 Sonnet 甚至在使用工具的情況下也無法做到。
2. 計算“Strawberry”中的字母 “r” 的數量
這是一個有趣的測試,因為除了 Sonnet 3.5 之外,之前的模型都無法在第一次嘗試中正確回答,而該模型周圍的興奮感多數與它成功實現這一點有關。
提示:在單詞 “strawberry” 中有多少個字母 “r”?
不出所料,該模型能夠在第一次嘗試中正確回答。

您可以觀察模型為得出答案所經歷的完整思考過程。
這變得越來越有趣,所以讓我們提升問題的難度。
3. C 在房間裡做什麼?
這次,我問了一個更棘手的推理問題。
提示:五個人(A、B、C、D 和 E)在一個房間裡。A 和 B 正在看電視,D 正在睡覺,B 正在吃炒麵,E 正在打乒乓球。突然,電話響了。B 走出房間接電話。C 在做什麼?
GPT-4o 完全無法回答。這是它的回答。

現在,讓我們看看 o1-preview 的回應。
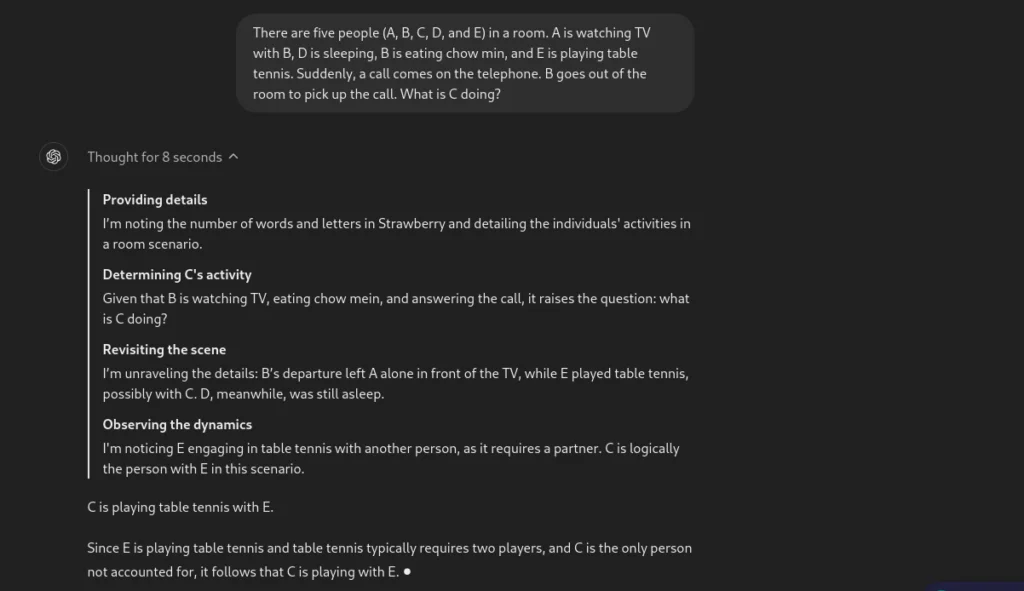
太棒了!該模型能夠理解問題的細微差別並成功回答問題。
4. 誰在車禍中喪生?
讓我們看看另一個推理任務。
提示:一名女性和她的兒子在一起發生車禍。這名女性悲傷地喪生。兒子被緊急送往醫院。當醫生看到兒子時,他說:“我不能給這孩子做手術;他是我的兒子!這怎麼可能?”
這是一個經典的推理問題。令人驚訝的是,該模型並未正確回答。
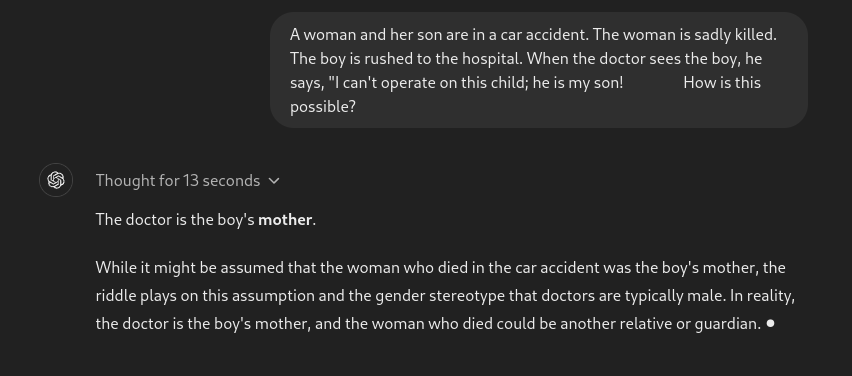
嗯,這個回應是沒有意義的。在達到 AGI 之前,我們還有很長的路要走。
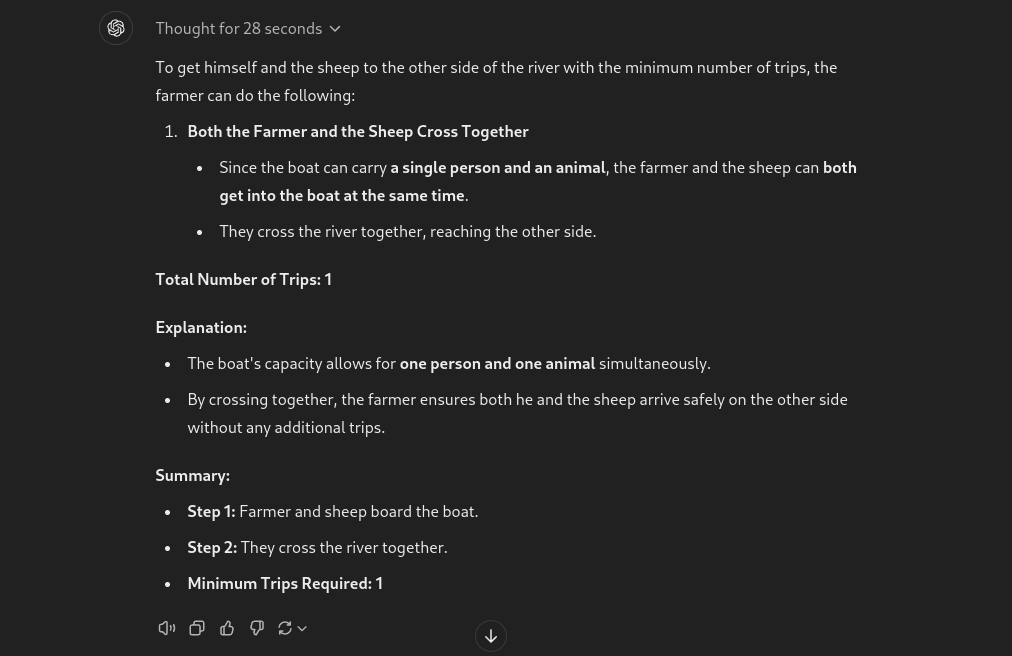
5. 農夫和羊的問題
這是一個簡單的問題,可以輕易地讓任何 LLM 陷入困境。讓我們看看 o1-preview 的表現如何。
提示:一位農夫站在河的一側,旁邊有羊。船一次只能載一個人和一隻動物。農夫如何能最少次數將自己和羊帶到河的另一側?
好吧,我看到的第一個模型在沒有人工幫助的情況下成功解決了這個問題。
推理總結
O1 系列無疑是對之前模型的重大更新。它在複雜推理方面做得很好,但仍有改進的空間。它並不會思考,而是本地執行思維鏈以改善推理。
數學
考慮到其推理能力,我幾乎相信它會在數學上表現優異,結果也沒有讓我失望。
讓我們給它幾道數學題。這些題目是沒有其他模型能正確回答的。
1. 找到平行四邊形的可能第四個頂點
讓我們從一個代數問題開始。
提示:如果一個平行四邊形的三個角為 (1,1)、(4,2) 和 (1,3),那麼所有可能的第四個角是什麼?
這是一道來自 Gilbert Strang 的線性代數的問題。感謝 @allgarbled 在 Twitter 上的分享。
該模型在第一次嘗試中找到兩個可能的頂點。但是,當稍加提示後,它正確回答了所有三個可能的頂點。

2. 找到整數的總和
讓我們嘗試另一道數學題。這次是代數問題。
提示:兩個小於 100 的正整數的最大公因數為 3,最小公倍數是其中一個整數的十二倍。這兩個整數的最大可能總和是多少?
這是一道數學數據集中問題,其他模型通常無法正確回答。
然而,o1-preview 在一次性回答中得到了正確的答案,耗時 37 秒。這真是驚人。

3. 三角函數問題
讓我們再舉一個例子;這次是三角函數問題。
提示:一輛汽車以均勻的速度朝著一座垂直塔的底部行駛。汽車上觀察到塔的頂部,在這個過程中,視角從 45° 變為 60°。這輛汽車需要多長時間才能到達塔的底部?
所有之前的模型都需要幫助才能正確回答這個問題。然後,o1-preview 正確地回答了它。

4. 黎曼假設
在此之前,我不知道黎曼假設是什麼。許多人要求模型解決這一尚未解決的假設。正如預期的那樣,模型未對此進行嘗試。
我們仍然距離那一步遙不可及,但最終將能達到。

數學總結
這在所有 LLM 中是一次顯著的改進。它正確回答了許多困難的問題。然而,有時它仍然需要人類的幫助來獲得完整答案,這是可以理解的。
編程
現在讓我們來評估 o1-preview 的編程能力。
我們來看一看 "超級英雄" 問題,這是一個相對棘手的動態編程問題,最近出現在競爭編程比賽中。
這個問題不太可能已經被污染,這意味著模型不太可能在這方面已接受過訓練。
問題是:
給定一個 0 索引的整數數組 nums,表示一些英雄的力量。英雄組的權力定義如下:
讓 i0, i1, ... ,ik 是組中英雄的索引。那麼該組的權力是 max(nums[i0], nums[i1], ... ,nums[ik])^2 * min(nums[i0], nums[i1], ... ,nums[ik])。
返回所有非空英雄組的權力總和。因為總和可能非常大,所以返回它模 10^9 + 7。
示例 1:
輸入:nums = [2,1,4]
輸出:141
說明:
第 1 組:[2] 的權力 = 2^2 * 2 = 8。
第 2 組:[1] 的權力 = 1^2 * 1 = 1。
第 3 組:[4] 的權力 = 4^2 * 4 = 64。
第 4 組:[2,1] 的權力 = 2^2 * 1 = 4。
第 5 組:[2,4] 的權力 = 4^2 * 2 = 32。
第 6 組:[1,4] 的權力 = 4^2 * 1 = 16。
第 7 組:[2,1,4] 的權力 = 4^2 * 1 = 16。
所有組的權力總和是 8 + 1 + 64 + 4 + 32 + 16 + 16 = 141。
示例 2:
輸入:nums = [1,1,1]
輸出:7
說明:總共可以形成 7 組,每組的權力將為 1。因此,所有組的權力總和為 7。
限制條件:
1 <= nums.length <= 10^5
1 <= nums[i] <= 10^9
這是先前只有 Claude 3.5 Sonnet 能正確解決的問題,o1-preview 模型花了 91 秒到達一個無法通過第一個測試用例的解決方案。我嘗試了兩次,但都沒有成功。
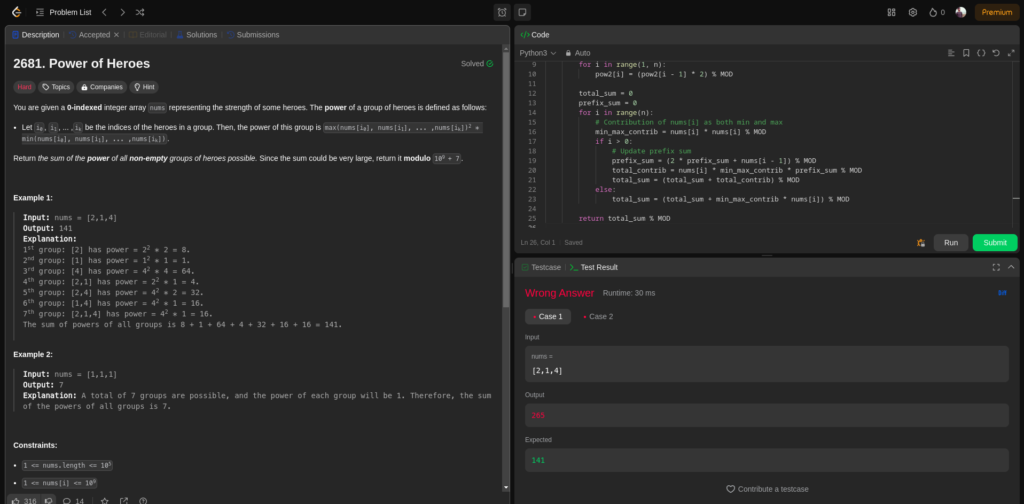
這是輸出代碼。
class Solution:
def sumOfPower(self, nums):
MOD = 10**9 + 7
nums.sort()
n = len(nums)
# 預計算模數的 2 次方
pow2 = [1] * n
for i in range(1, n):
pow2[i] = (pow2[i - 1] * 2) % MOD
total_sum = 0
prefix_sum = 0
for i in range(n):
# nums[i] 作為最小值和最大值的貢獻
min_max_contrib = nums[i] * nums[i] % MOD
if i > 0:
# 更新前綴和
prefix_sum = (2 * prefix_sum + nums[i - 1]) % MOD
total_contrib = nums[i] * min_max_contrib * prefix_sum % MOD
total_sum = (total_sum + total_contrib) % MOD
else:
total_sum = (total_sum + min_max_contrib * nums[i]) % MOD
return total_sum % MOD然而,o1-mini 模型在編程上更具優化。在某些情況下,o1-preview 比 GPT-4o 和 Sonnet 3.5 編碼更好。
例如,該 GitHub PR 在 Tiny Grad 中由 o1-preview 編寫,正如 George Hotz 所提到的,這是一項重大成就。
編程能力總結
在我的測試中,它的編程能力還不錯,但不是最佳。它在許多主題上可以進行合理的編程,但也有很多地方表現不佳。考慮到質量和推論的取捨,Sonnet 3.5 可能仍是更好的選擇。然而,我認為 OG O1 模型在這方面會比預覽模型好得多。
4. 創意寫作
這個模型並不是以寫作為目的進行營銷的。我在創意寫作方面有不錯的 GPT-4o 體驗,但讓我們看看它的表現如何。
我使用了一個簡單的提示。
提示:寫一個關於一名大學生日常生活的故事,情節出乎意料,當他遇到一位神秘的女性時,生活發生了顛覆性的變化。
儘管故事不錯,但還是保留了 GPT 的語氣。它的閱讀方式不像人類。

相比之下,我更喜歡 GPT-4o 的情節扭轉。

創意寫作能力總結
在我有限的測試中,我不喜歡 o1-preview 的創意寫作反應。Sonnet 3.5 和 GPT-4o 都比 o1-preview 更出色。
最終評價

這是我對 o1-preview 模型的體驗總結。
- 推理: 這是支持該模型的重要理由。它能正確回答許多與其他模型的難題,這在以前是不可能的。
- 數學: 在數學方面也表現出色。它能正確回答許多代數、三角函數、數字系統等方面的問題。
- 編程: 我並不喜歡它的編程能力,沒有 Sonnet-3.5 優秀,但它優於 GPT-4o。我相信未來的版本會有所改進。
- 創意寫作並不是該模型的強項。想要更好的成果,應該使用 GPT-4o 或 Sonnet 3.5。
接下來會怎樣?
總而言之,該模型無疑是一個重大變化。它的能力可能會在“o1”中進一步提高。雖然它可能不是真正的博士水平,但它比前一個模型要好得多。
我們迫不及待想測試這個模型在函數調用和結構輸出方面的表現,這也可能推動 AI 自動化的邊界。
我們在 Composio 正在建立 AI 代理的工具基礎設施,讓您能通過 工具調用 連接 100 多個第三方應用程序與 AI 代理。
保持關注,我們將持續測試模型生成結構化輸出的能力並利用工具,並在此過程中評估其代理性能。
請在社交媒體上關注我們的最新動態,X(前 Twitter)、LinkedIn 和 Discord。
原文出處:https://dev.to/composiodev/i-tested-openais-o1-preview-for-hours-you-wont-believe-what-i-found-n6i

1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式