

聲明:此文章包含聯盟連結;如果您從本文提供的不同連結中購買產品或服務,我可能會獲得報酬。

image_credit - Exponent
各位開發者好,今天在之前的幾篇文章中,我談到了基本的軟體架構組件和系統設計概念,例如 API Gateway 與 Load Balancer 和 水平擴展與垂直擴展、正向代理與反向代理,今天,我將討論一個有趣的主題以及一項熱門技能,Apache Kafka。
我曾在不同的訊息平台工作,從 TIBCO RV 到 JMS,再到 MQ 服務,再到 ActiveMQ、RabbitMQ,現在我在使用 Apache Kafka。
在最近的一次面試中,我被問到 Apache Kafka 是如何運作的,為什麼它被認為是一個快速的訊息平台,我無法令人信服地回答這個問題,因此我進行了研究並學習了更多關於 Kafka 內部運作的知識,今天我將與大家分享這段經驗。
如果你是在軟體開發中,尤其是應用程式開發,那麼你可能知道 Apache Kafka 已成為分散式資料串流領域的標準技術,以其卓越的速度和擴展性聞名。
各行各業的組織,從科技巨頭(LinkedIn)到金融機構,都依賴 Kafka 來即時處理大量數據。
之前,我談過 Kafka、RabbitMQ 和 ActiveMQ 之間的差異,在這篇文章中,我們深入探討使 Kafka 這麼快的因素,並檢視促進其速度的基本原則。
順便說一下,如果你正在準備系統設計面試,並希望深入學習系統設計,那麼你也可以查看像 ByteByteGo、Design Guru、Exponent、Educative 和 Udemy 等網站,它們提供許多優秀的系統設計課程。

為什麼 Apache Kafka 這麼快?
在資料串流的世界中,速度往往至關重要。無論是追踪網站上的用戶活動、處理金融交易還是監控物聯網設備,組織都需要能夠以最小延遲處理持續流動的數據的系統。
Kafka 在這方面表現出色,其速度可歸因於幾個關鍵因素。
1. 分散式架構
Kafka 速度的核心在於其分散式架構。與傳統的訊息排隊系統不同,Kafka 不依賴單一的中央伺服器來處理所有數據。
相反,它將數據分散到多個節點或中介伺服器中。
這種 平行處理能力使得 Kafka 能夠橫向擴展, 意味著可以通過增加更多機器來處理不斷增長的數據量。
在分散式 Kafka 設置中,每個中介伺服器負責一部分數據,並可以獨立運行。
這種平行性確保了隨著更多中介伺服器的增加,系統的整體吞吐量增長,使 Kafka 高度可擴展。
有效分配工作負載的能力是 Kafka 速度的根本原因,使其能夠即時處理大量數據。
如果你是 Kafka 的完全初學者,參加一個入門級的 Kafka 課程,如 Apache Kafka 系列 - 針對初學者學習 Apache Kafka V2,將有助於你更好地理解 Kafka 的架構。
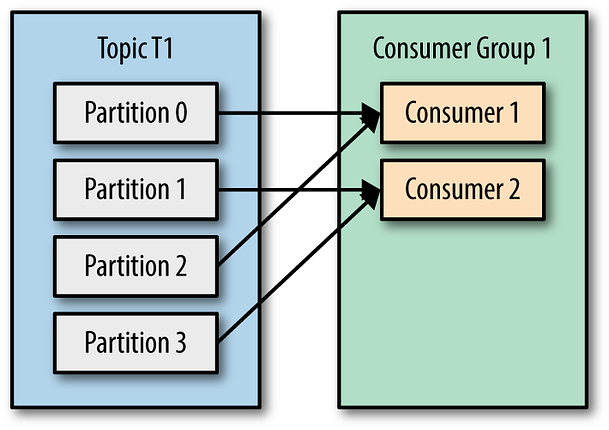
2. 分區
分區是 Kafka 的核心概念,對其速度貢獻良多。 數據被分為多個分區,每個分區分配給特定的中介伺服器。
這種數據的劃分使 Kafka 能夠平行處理訊息。
當訊息被生產和消費時,Kafka 確保在任何給定時間內,每個分區都由單一消費者處理。
使用分區的好處使 Kafka 能夠實現平行處理及順序。在一個分區內,訊息是按順序處理的,確保事件的順序得以維持。
不過,由於不同的分區可以由不同的中介伺服器或消費者獨立處理,Kafka 可以實現高水平的平行處理。
這裡有一個精美的圖表,展示 Apache Kafka 中的分區:
3. 寫入和讀取優化
Kafka 針對寫入和讀取操作進行了優化,這有助於其在處理數據時的卓越速度。
在寫入方面,Kafka 得益於其追加式存儲機制。訊息被追加到分區的末尾,這種順序寫入操作高度有效。
磁碟 I/O 被最小化,寫入吞吐量被最大化,使 Kafka 能以低延遲吸收大量數據。
在讀取方面,Kafka 利用內存存儲和高效的基於磁碟的存儲的組合。經常訪問的數據保留在內存中,減少了磁碟讀取的需求,顯著提高了讀取性能。
此外,Kafka 還採用了批量處理和壓縮等技術,以優化生產者和消費者之間數據的傳輸。
你可以進一步參考 Grokking System Design Interview 的系統設計課程,以更好地理解 Kafka 及其用法。

4. 零複製技術
Kafka 採用零複製技術,這對於實現高性能至關重要。零複製是指將數據從一個緩衝區轉移到另一個緩衝區,而不涉及操作系統的過程。
在傳統系統中,數據通常在用戶空間和內核空間之間被複製多次,造成開銷。
Kafka 使用零複製技術消除了這些開銷。當數據被讀取或寫入時,Kafka 可以有效地在緩衝區之間移動,而無需不必要的複製。
這導致 CPU 利用率降低,數據傳輸速度加快,使 Kafka 非常適合高吞吐量場景。
5. 批次和壓縮
Kafka 採用批次策略來優化訊息的處理。生產者可以將訊息分組為批次,而不是單獨發送每條訊息,然後將批次發送到中介伺服器。
批次處理減少了與網路通訊相關的開銷,因為傳輸一批訊息所需的網路來回次數比單個訊息少。
此外,Kafka 還結合了壓縮算法來減少傳輸和存儲過程中數據的大小。
通過在訊息被寫入磁碟或通過網路傳輸之前進行壓縮,Kafka 最小化了需要傳輸的數據量,提高了寫入和讀取性能。
總之,Kafka 的速度源於其分散式架構、有效的分區設計、針對寫入和讀取操作的優化、零複製技術以及批次和壓縮的策略性使用。
這些因素共同使 Kafka 成為高性能的數據串流平台,能夠滿足現代實時數據處理的需求。
現在,來看看幾個系統設計面試準備的資源
系統設計面試資源:
以下是精選的最佳系統設計書籍、線上課程和練習網站,您可以查看以更好地準備系統設計面試。這些課程中的大多數也解答了我在此分享的問題。
-
DesignGuru 的 Grokking System Design Course:一個互動學習平台,提供實踐練習和真實世界場景,以增強您的系統設計技能。
-
"System Design Interview" by Alex Xu:這本書深入探討了系統設計概念、策略和面試準備技巧。
-
"Designing Data-Intensive Applications" by Martin Kleppmann:一本全面指南,涵蓋設計可擴展和可靠系統的原則和實踐。
-
LeetCode 系統設計標籤:LeetCode 是一個流行的技術面試準備平台。LeetCode 的系統設計標籤包含各種問題供您練習。
-
"System Design Primer" 在 GitHub 上:精心策劃的資源列表,包括文章、書籍和視頻,以幫助您準備系統設計面試。
-
Educative 的系統設計課程:一個互動學習平台,提供實踐練習和真實世界場景,以增強您的系統設計技能。
-
High Scalability Blog:一個載有文章和案例研究的博客,探討高流量網站和可擴展系統的架構。
-
YouTube 頻道:查看像 "Gaurav Sen" 和 "Tech Dummies" 等頻道,獲取有關系統設計概念和面試準備的深刻視頻。
-
ByteByteGo:由 Alex Xu 主持的系統設計面試準備直播書籍和課程。它包含《系統設計面試》書籍第一和第二卷的所有內容,並將隨著即將推出的第三卷進行更新。
-
Exponent:一個專門針對 FAANG 公司(如亞馬遜和谷歌)面試準備的網站,提供優秀的系統設計課程和其他許多資料,幫助您通過 FAANG 面試。

image_credit - ByteByteGo
記得將理論知識與實際應用相結合,通過參與真實世界項目和模擬面試來提高技能。持續的實踐和學習無疑會增強您在系統設計面試中的熟練度。
如果你喜歡視頻,ByteByteGo 在同一主題上有很好的視頻。你可以觀看它,以進一步鞏固對 Apache Kafka 內部運作及其如何提高速度的學習。
原文出處:https://dev.to/somadevtoo/how-does-apache-kafka-work-why-is-kafka-so-fast-463i

1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式