

今天,我們將介紹 25 個可以使用 Python 和 AI 模型建構的副專案。
大多數專案都會有生產級程式碼,因此您可以學到很多東西。
我們開始做吧!
Taipy - 將資料和人工智慧演算法整合到生產就緒的 Web 應用程式中。
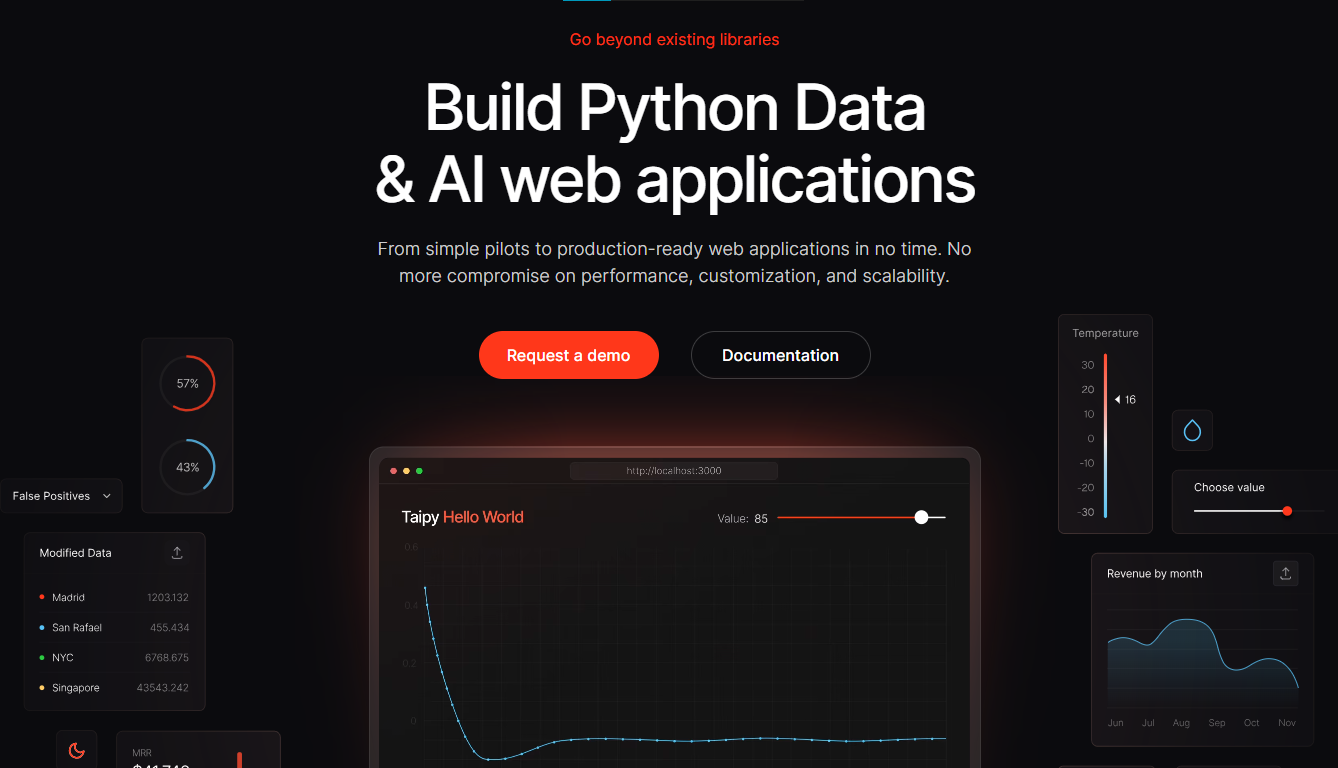
大多數初始專案都會使用 Taipy,所以讓我們討論一下這個概念的用例。
Taipy 是一個開源 Python 庫,可用於輕鬆的端到端應用程式開發,具有假設分析、智慧管道執行、內建調度和部署工具。
需要明確的是,Taipy 用於為基於 Python 的應用程式建立 GUI 介面並改進資料流管理。
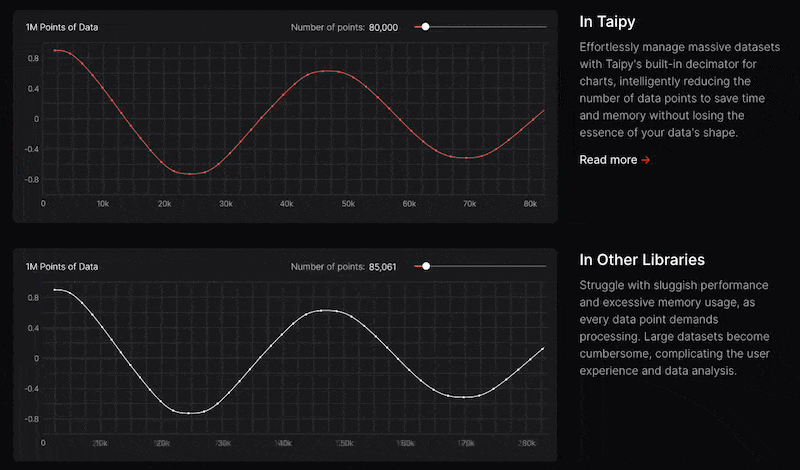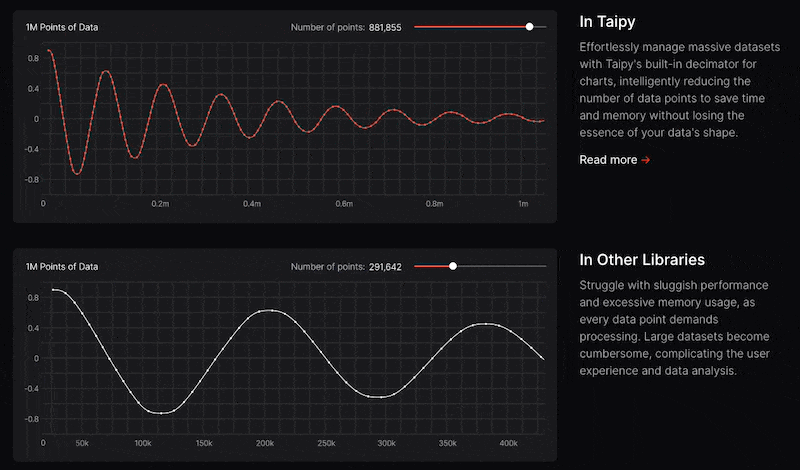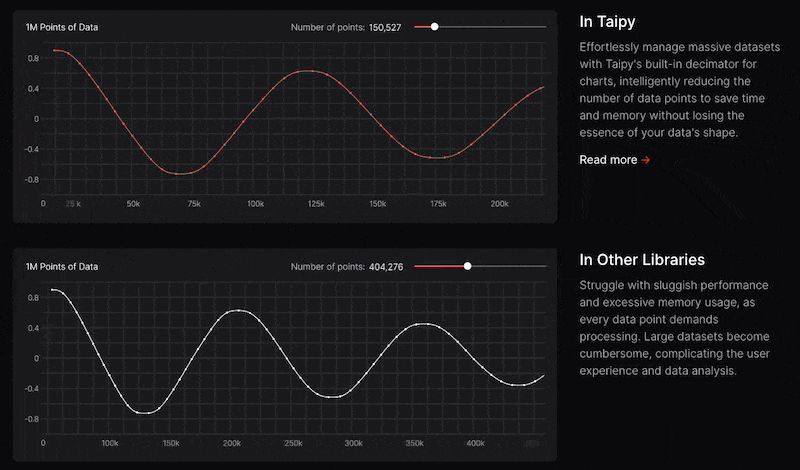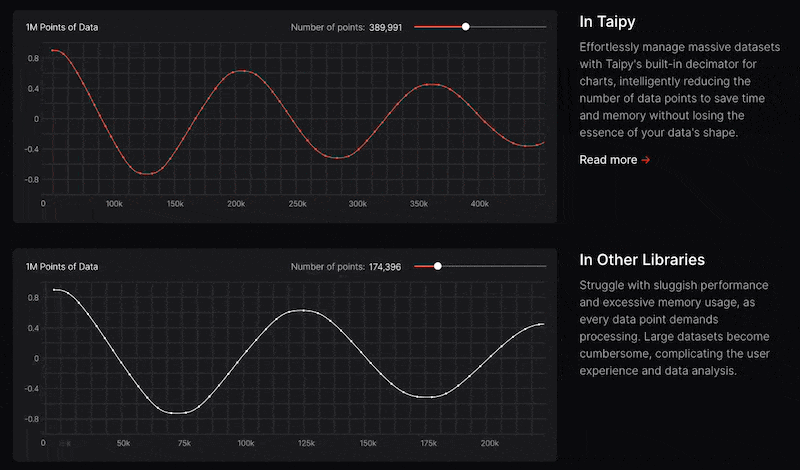
關鍵是性能,而 Taipy 是最佳選擇。
雖然 Streamlit 是一種流行的工具,但在處理大型資料集時,其效能可能會顯著下降,這使得它在生產級使用上不切實際。
另一方面,Taipy 在不犧牲性能的情況下提供了簡單性和易用性。透過嘗試 Taipy,您將親身體驗其用戶友好的介面和高效的資料處理。
Taipy 有許多整合選項,可以輕鬆地與領先的資料平台連接。

開始使用以下命令。
pip install taipy他們還使用分散式運算提高了效能,但最好的部分是 Taipy,它的所有依賴項現在都與 Python 3.12 完全相容,因此您可以在使用 Taipy 進行專案的同時使用最新的工具和程式庫。
您可以閱讀文件。

另一個有用的事情是,Taipy 團隊提供了一個名為Taipy Studio的 VSCode 擴充功能來加速 Taipy 應用程式的建置。
如果您想閱讀部落格來了解程式碼庫結構,您可以閱讀 HuggingFace的使用 Taipy 在 Python 中為您的 LLM 建立 Web 介面。
嘗試新技術通常很困難,但 Taipy 提供了 10 多個演示教程,其中包含程式碼和適當的文件供您遵循。我將詳細討論其中一些專案!
這些用例非常驚人,所以一定要檢查一下。
Taipy 在 GitHub 上有超過 8,500 個 Star,並且處於v3.1版本,因此它們正在不斷改進。
https://github.com/Avaiga/taipy Star Taipy ⭐️
1.實時污染儀表板
使用工廠周圍的感測器測量空氣品質的用例,展示 Taipy 儀表板流資料的能力。
資料在另一台伺服器上產生並透過 WebSocket 發送到此 Taipy 應用程式。
然後 Taipy 處理資料並將其顯示在儀表板上。
當收到新資料時,儀表板會即時更新。

如果您想要有關可視化資料流的教程,請查看有關多線程的文件。
它討論瞭如何建立發送者腳本和接收者腳本,包括套接字參數等。
它涉及到前端和後端的概念。
查看現場演示。
https://github.com/Avaiga/demo-realtime-pollution Star 即時污染儀表板 ⭐️
2.詐欺檢測
Taipy 應用程式可分析信用卡交易以偵測詐欺行為。

它顯示信用卡交易清單。
用戶可以選擇一個日期範圍來預測詐欺。
然後,該應用程式將使用 XGB 模型將潛在的詐欺交易標記為紅色或黃色。
用戶可以選擇一個交易來查看模型預測的解釋,以及客戶的其他交易。

使用者還可以選擇模型的閾值。閾值是模型輸出,高於該閾值的交易將被視為詐欺。使用者可以根據顯示的混淆矩陣並透過查看誤報和漏報交易來選擇模型。

查看現場演示。
https://github.com/Avaiga/demo-fraud-detection 明星詐欺偵測 ⭐️
3.新冠儀表板
這裡使用 2020 年的 Covid 資料集。
頁面顯示有關 COVID-19 的不同圖表和資訊。還有一個預測頁面來預測傷亡人數。
該應用程式包括四個部分,如下所示:
✅ 國。
-
特定國家/地區的 COVID-19 統計資料。
-
在累積資料視圖和密度資料視圖之間輕鬆切換。
-
用於動態資料探索的互動式長條圖。
-
餅圖顯示病例分佈(確診、復健、死亡)。

✅ 地圖。
透過動態可縮放顏色編碼地圖直觀地展示 COVID-19 的影響。

✅ 預測。
透過為不同的預測日期和不同的國家建立場景來產生 COVID-19 預測。
這會分別使用 ARIMA 模型和線性迴歸模型產生 2 個不同的預測(橘色的預測_x 和綠色的預測_y)。
透過指定名稱、指定預測日期、選擇國家/地區並點擊「提交」按鈕繼續來啟動新場景。
您可以在“結果”部分的“場景”選項卡中存取它。

✅ 世界。
全球 COVID-19 統計資料透過折線圖和圓餅圖進行匯總。透過更改Absolute和Relative之間的切換可以看到 Covid 國家/地區影響的比較。

總的來說,對於您的業餘專案和建立非常酷的專案來說,這是一個非常有用的應用程式:)
您可以查看現場演示。
https://github.com/Avaiga/demo-covid-dashboard Star Covid 儀表板 ⭐️
4.建立 LLM 聊天機器人
該演示展示了 Taipy 使最終用戶能夠使用 LLM 執行推理的能力。在這裡,我們使用 GPT-3 建立一個聊天機器人,並將對話顯示在互動式聊天介面中。

下面給出了主要函數,該函數將字串提示(即用戶訊息)作為輸入,並從 LLM 傳回回應字串。
def request(state: State, prompt: str) -> str:
"""
Send a prompt to the GPT-3 API and return the response.
Args:
- state: The current state.
- prompt: The prompt to send to the API.
Returns:
The response from the API.
"""
response = state.client.chat.completions.create(
messages=[
{
"role": "user",
"content": f"{prompt}",
}
],
model="gpt-3.5-turbo",
)
return response.choices[0].message.content您可以閱讀有關如何建立此 LLM 聊天機器人的完整文件。
最好的部分是,您可以根據您的使用情況輕鬆更改程式碼以使用任何其他 API 或模型。
您可以查看現場演示。
https://github.com/Avaiga/demo-chatbot 明星聊天機器人 ⭐️
5.即時人臉辨識
該演示將人臉辨識無縫整合到我們的平台中,借助 OpenCV 庫,使用網路攝影機提供即時人臉偵測體驗。

您可以非常輕鬆地使用它:
A。打開應用程式時,您會透過網路攝影機看到自己。你的臉周圍有一個紅色方塊,上面寫著別人的名字。
b.透過點擊Capture按鈕並多次輸入您的名字來訓練模型辨識您。
C。現在點選Re-train按鈕。現在應該會出現您的名字。模型現在認出了您。
查看現場演示。
確保在瀏覽器中啟用相機設置,這是首要條件!
進行人臉偵測和人臉辨識的程式碼位於src/demo/faces.py下。自述文件中提供了完整的目錄結構。
https://github.com/Avaiga/demo-face-recognition 明星人臉辨識 ⭐️
6.庫存可視化
在金融市場領域,資料為王。快速、輕鬆地視覺化歷史股票資料並做出預測的能力對於投資者和金融分析師來說至關重要。
這是一個股票資料儀表板,具有互動式視覺元素,可以視覺化歷史股票資料並對 1 至 5 年內的股票進行預測。

由 Facebook 使用 Taipy 和Prophet Library建構。此示範適用於高於 3.8 的 Python 版本。
您可以這樣使用它:
A。選擇您想要預測的股票程式碼。
b.打開歷史資料面板。
C。選擇預測週期(從 1 到 5)。
d.點選PREDICT按鈕。
e.在預測資料面板中查看您的預測。
F。使用不同的程式碼重複嘗試以比較結果。
您也可以透過點擊底部的More info按鈕以表格形式取得預測範圍。
您可以在src 目錄下找到負責的主要原始碼。
這個完全互動的 Web 應用程式只需不到 120 行 Python 程式碼即可建立。
查看現場演示。
https://github.com/Avaiga/demo-stock-visualization 明星股票視覺化 ⭐️
7.情感分析。
情感分析就像一個機器人,可以從人們的言語中讀出他們的感受。
它會根據快樂、悲傷或憤怒等字眼來判斷它們的感覺是好是壞。然後,它告訴我們大多數人在說話時是高興還是悲傷。
因此,只需看看人們所說的內容,它就可以幫助我們了解人們對事物(例如電影或遊戲)的感受!
簡而言之,它是自然語言處理(NLP)中的一種技術,用於確定文本中傳達的情緒基調。它可以幫助企業和個人更好地掌握書面內容所表達的情感和語氣。
結果是一個兩頁的應用程式,它使用情感分析模型來分析輸入和整個文本。
第一頁分析使用者輸入,而第二頁讓使用者選擇要上傳的檔案(文字)。該文本將被分析並顯示背後的情感。
✅ 第 1 頁:Line - 分析使用者輸入
我們的情緒分析應用程式的初始頁面名為“Line”,用於即時分析使用者輸入。無論是簡短的句子還是較長的段落,只需將文字輸入或貼到輸入框中,Taipy 就會快速評估文本中傳達的情感。

✅ 文字 - 上傳和分析文字文件
第二個頁面名為“文字”,允許使用者上傳整個文字檔案 (.txt) 以進行全面的情感分析。
用戶可以從他們的設備中選擇一個文字文件,該應用程式將提供對整個文件所表達的情緒的洞察。
此功能對於處理較長的文字(例如文章、報告或廣泛的客戶回饋)非常有用。

您可以查看現場演示。
https://github.com/Avaiga/demo-sentiment-analysis 明星情感分析 ⭐️
8.漂移檢測- 檢測糖尿病資料集中的漂移。

資料漂移是主要在機器學習中使用的概念,其中推理資料的分佈偏離訓練資料的分佈。
各種因素,例如底層資料來源的變化、資料收集過程的變化或資料儲存過程的變化,都可能導致資料漂移。
這通常會導致稱為訓練服務偏差的效能問題,其中用於推理的模型不用於推理資料的分佈並且無法泛化。
存在統計測試來檢測資料集中的漂移。這些檢定計算兩個系列來自同一分佈的機率。如果機率低於閾值,我們認為存在漂移。
如何使用該應用程式?
✅ 選擇比較資料集。
在這裡,我們選擇 data_big,這是一個與參考資料集類似的資料集,但其中的行具有較高的血壓值。我們在血壓分佈圖上看到,與綠色參考資料集相比,紅色比較資料集的分佈向右移動。

✅ 按一下此處執行場景。

✅ 在頁面底部可視化結果。
在這裡,我們看到血壓列的柯爾莫哥洛夫檢定的 p 值低於 0.05,這意味著兩個血壓資料集來自同一分佈的機率低於 5%。我們可以拒絕兩個資料集來自相同分佈的假設,並得出血壓列存在漂移的結論。

您可以按照下面所附的即時示範中的步驟操作,並在 GitHub 上查看原始程式碼。
這使用資料管道來比較資料集並檢測漂移。

查看現場演示。
https://github.com/Avaiga/demo-drift-detection 星漂移偵測 ⭐️
9.錢包明智
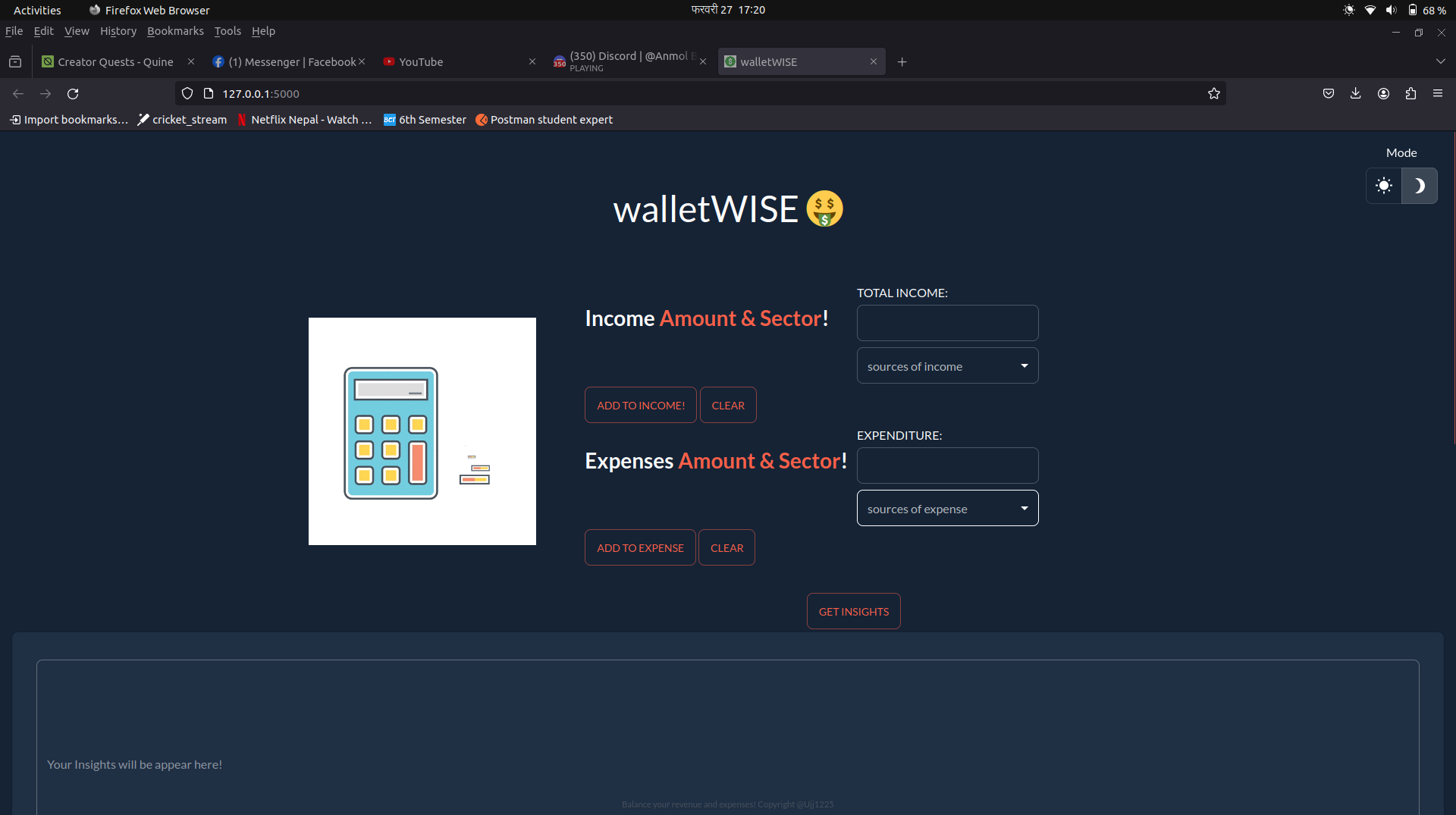
WalletWise 就像是我們財務的友善幫手,幫助我們追蹤收入和支出。它使用 Gemini 進行交易,使用 Taipy 來了解支出。
一些不錯的功能是:
✅ 使用者可以輸入他們的收入和支出以及部門作為標題。這使他們能夠了解和探索他們從哪個部門賺了多少錢以及在哪個部門花了多少錢。
✅ 對使用者的收入和支出進行分析,以數學方式顯示,並顯示 7 個做出更好、更明智的財務決策的提示。
✅ 實現了一個視覺化工具,您可以在其中看到您賺錢的不同標題和您花錢的不同標題。
這是一個非常優秀的用例,並且在創造力方面非常好。
https://github.com/Ujj1225/from\_Taipy-walletWISE Star WalletWise ⭐️
10.太皮象棋
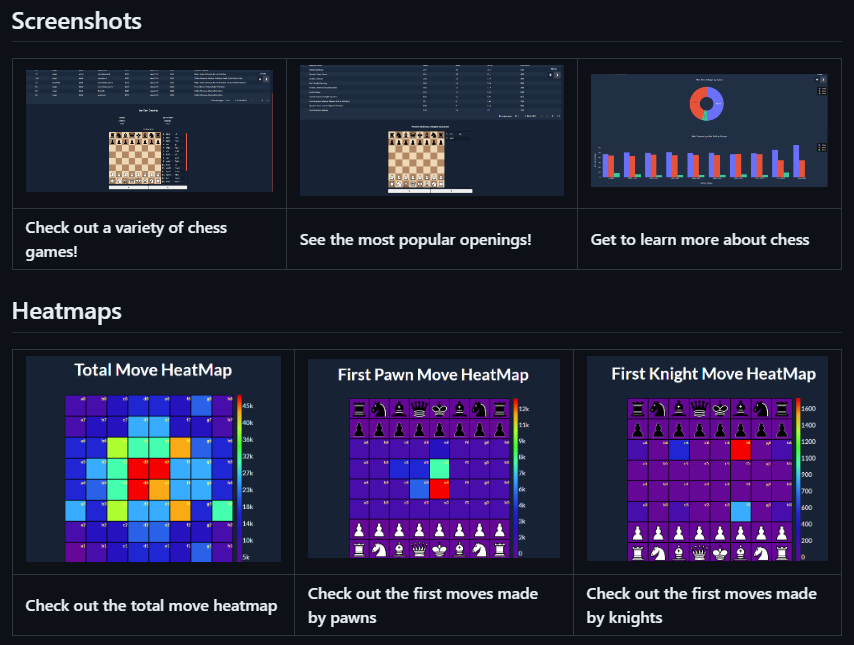
所有應用程式中我最喜歡的一個,因為我喜歡國際象棋。哈哈!
這是一個基於20,000盤棋的國際象棋視覺化工具。您可以查看所有比賽、他們參加的開局、對手、表現最好的開局以及最成功的開局。
您可以查看資料的熱圖和圖表。

總移動熱圖

棋子的第一個動作
您可以觀看 Korie 的示範。我愛它 :)
這清楚地表明我們使用 Taipy 的可能性沒有限制。
https://github.com/KorieDrakeChaney/taipy-chess Star Taipy Chess ⭐️
11.奧運獎牌

這是一個 Taipy 儀表板,顯示從現代奧運會開始到 2024 年初頒發的奧運獎牌資訊(即不包括 2024 年巴黎奧運會)。
✅ 儀表板有兩個選項卡:
-
一個選項卡顯示所有奧運獎牌的總結資料
-
第二個選項卡重點關注奧林匹克委員會(國家,但也包括特別委員會,例如難民委員會等)獲得的獎牌。
它還具有多種類型的圖表,例如長條圖、旭日圖、折線圖、分區統計圖和網格圖。
另外,儀表板會根據所選年份和區域類型動態更新資料。
您可以在這裡觀看演示!
https://www.youtube.com/watch?v=\_1X7etBFTk0
其中涉及到許多概念,而 Eric 實現了一個非常優秀的用例!
https://github.com/enarroied/Olympic-Medals-Taipy-App 奧運明星獎牌 ⭐️
-
GPT Researcher - 基於 GPT 的線上研究自主代理。

GPT Researcher 是領先的自主代理,負責處理從準確的來源收集到研究結果組織的一切事務。
好的一點是它也引用了研究結果的來源,從而提高了可信度。我喜歡整個概念:)
一些瘋狂的功能是:
✅ 可以產生長而詳細的研究報告(超過2K字)。
✅ 每項研究總結 20 多個網路資源,以形成客觀和事實的結論。
✅ 包括易於使用的網路介面(HTML/CSS/JS)。
✅ 透過 JavaScript 支援抓取網路資源。
✅ 追蹤存取和使用的網路資源的追蹤和上下文。
✅ 將研究報告匯出為 PDF、Word 等。

開始使用以下命令。
pip install gpt-researcher您可以這樣使用它。
from gpt_researcher import GPTResearcher
query = "why is Nvidia stock going up?"
researcher = GPTResearcher(query=query, report_type="research_report")
# Conduct research on the given query
await researcher.conduct_research()
# Write the report
report = await researcher.write_report()請閱讀下面隨附的安裝說明和快速入門指南。
如果您想了解架構的細節,代理商會利用 gpt3.5-turbo 和 gpt-4-turbo(128K 上下文)來完成研究任務。我們僅在必要時才使用每種方法來優化成本。研究任務平均需要大約 3 分鐘才能完成,成本約為 0.1 美元。

您可以閱讀官方部落格了解GPT Researcher 的工作原理。
您可以閱讀常見問題以了解有關準確性等的更多資訊。
在這裡觀看演示!

它在 GitHub 上有 8700 顆星,並且正在不斷改進。
https://github.com/assafelovic/gpt-researcher GPT 明星研究員 ⭐️
13.私人 GPT - 在沒有網路的情況下詢問有關您的文件的問題。
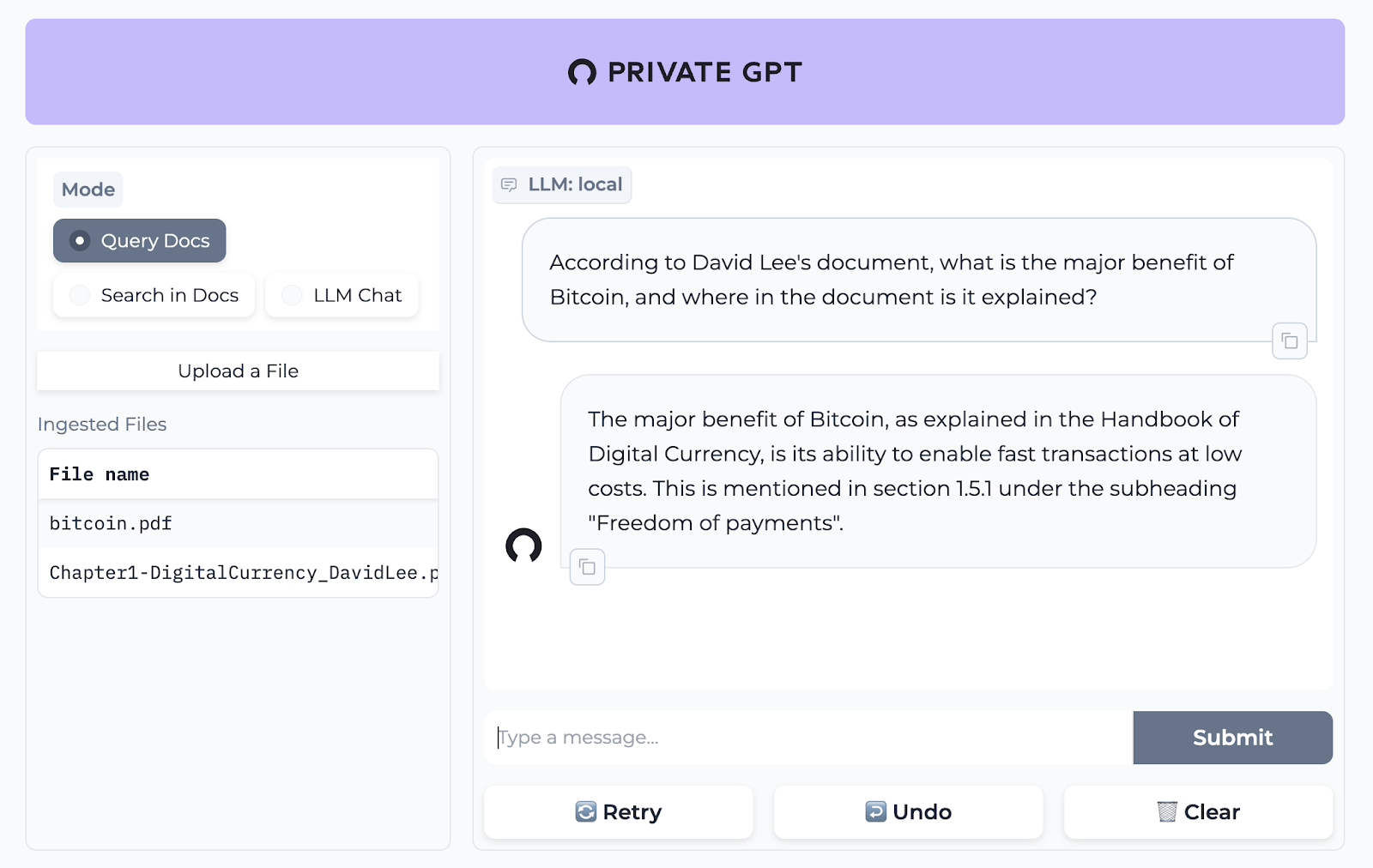
PrivateGPT 是一個可立即投入生產的 AI 專案,即使在沒有網路連線的情況下,您也可以使用大型語言模型 (LLM) 的功能來詢問有關文件的問題。
100% 私有意味著任何時候都沒有資料離開您的執行環境。
API 分為兩個邏輯區塊:
A。高級 API,抽象化了 RAG(檢索增強生成)管道實現的所有複雜性:
-
文件攝取:內部管理文件解析、分割、元資料擷取、嵌入產生和儲存。
-
使用所攝取文件中的上下文進行聊天和完成:抽像上下文檢索、提示工程和回應產生。
b.低階 API,允許高階用戶實現複雜的管道:
-
嵌入生成:基於一段文字。
-
上下文區塊檢索:給定查詢,從攝取的文件中傳回最相關的文字區塊。
您可以閱讀安裝指南來開始。
PrivateGPT 現在正在發展成為產生 AI 模型和原語的網關,包括補全、文件攝取、RAG 管道和其他低階建置塊。
他們在 GitHub 上擁有超過 51,000 顆星,並且發展迅速。
https://github.com/zylon-ai/private-gpt 明星私人 GPT ⭐️
14.facefusion - 下一代臉部交換器和增強器。

這是下一代臉部交換器和增強器。有多種用途,您可以輕鬆做到。
他們還提供了一個研討會部分,您可以在其中了解如何建立 UI 元件和定義框架處理器。
例如,這就是建立 UI 元件的方式。
// create a new file
facefusion/uis/components/example.py
// Implement the essential methods of the UI component
from typing import Optional
import gradio
from facefusion.uis.typing import Update
EXAMPLE_IMAGE : Optional[gradio.Image] = None
def render() -> None:
global EXAMPLE_IMAGE
EXAMPLE_IMAGE = gradio.Image()
def listen() -> None:
EXAMPLE_IMAGE.change(update, inputs = EXAMPLE_IMAGE, outputs = EXAMPLE_IMAGE)
def update() -> Update:
return gradio.update()您只需加入該元件即可。
from facefusion.uis.components import example
安裝可能有點複雜,所以我建議根據您使用的特定環境閱讀安裝指南。
您可以使用此命令檢查基準測試。
python run.py --ui-layouts benchmark
他們在 GitHub 上擁有超過 14k 個 star,並且發布了v2.5版本。
https://github.com/facefusion/facefusion 明星facefusion ⭐️
-
H2O LLMStudio - 用於微調 LLM 的無程式碼 GUI。

H2O LLM Studio 是一個開源、無程式碼的 LLM 圖形使用者介面 (GUI),專為微調最先進的大型語言模型而設計。
微調預訓練的語言模型需要編碼專業知識以及有關模型及其超參數的廣泛知識,但是,H2O LLM Studio 使 NLP 從業者能夠輕鬆微調他們的 LLM,無需編碼,並且比定制具有更好的靈活性。
H2O LLM Studio 還可讓您與微調模型聊天並接收有關模型效能的即時回饋。
NLP 從業者和資料科學家尤其可能會發現輕鬆有效地建立和微調大型語言模型很有用。您可以閱讀詳細的效能統計資料及其雲端架構。
如果您正在開始,我建議您觀看此內容!
https://www.youtube.com/watch?v=u48QaIAIFw4
您可以閱讀有關核心功能的訊息,例如:
✅ 無程式碼微調
✅ 高度可自訂
✅ 關於模型性能的即時回饋
您可以使用以下命令啟動 H2O LLM Studio。
make llmstudio如果你不知道這些概念,他們也有清晰的概念指南,包括 Generative AI、LoRA、Quantization、LLM Backbone 等等。
您可以閱讀文件。
您可以使用它非常輕鬆且符合標準地製作一個副專案。
他們在 GitHub 上有 3,600 顆星,並且發布了v1.5版本。
https://github.com/h2oai/h2o-llmstudio 明星 H2O LLMStudio ⭐️
-
Mac 上的語音助理- 您的語音控制 Mac 助理。
您的語音控制 Mac 助理。 GPT Automator 可讓您使用語音在 Mac 上執行任務。例如,打開應用程式、尋找餐廳、綜合資訊。太棒了:D
它是在倫敦黑客馬拉松期間建構的。
它有兩個主要部分:
A。語音命令:它使用本地執行的 Whisper(Buzz 的一個分支)來產生命令。
b.命令到行動:您向配備了我們編寫的自訂工具的 LangChain 代理程式發出命令。這些工具包括使用 AppleScript 控制電腦的作業系統以及使用 JavaScript 控制活動瀏覽器。最後,就像任何優秀的人工智慧一樣,我們讓代理商使用 AppleScript 說出最終結果「{Result}」(如果您以前沒有使用過,請嘗試在 Mac 終端機中輸入「Hello World!」)。
我們製作了一個自訂工具,讓法學碩士使用 AppleScript 控制電腦。提示符是文件字串:
@tool
def computer_applescript_action(apple_script):
"""
Use this when you want to execute a command on the computer. The command should be in AppleScript.
Here are some examples of good AppleScript commands:
Command: Create a new page in Notion
AppleScript: tell application "Notion"
activate
delay 0.5
tell application "System Events" to keystroke "n" using {{command down}}
end tell
...
Write the AppleScript for the Command:
Command:
"""
p = subprocess.Popen(['osascript', '-'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout, stderr = p.communicate(applescript.encode('utf-8'))
if p.returncode != 0:
raise Exception(stderr)
decoded_text = stdout.decode("utf-8")
return decoded_text如果您想知道它是如何運作的,GPT Automator 使用 OpenAI 的 Whisper 將您的音訊輸入轉換為文字。然後,它使用LangChain Agent 選擇一組操作,包括使用OpenAI 的GPT-3(“text-davinci-003”)從提示符號產生AppleScript(用於桌面自動化)和JavaScript(用於瀏覽器自動化)命令,然後執行產生的腳本。
請記住,這不適用於生產用途。該專案執行從自然語言產生的程式碼,可能容易受到提示注入和類似的攻擊。這項工作是作為概念驗證而進行的。
您可以閱讀安裝指南。
讓我們看看一些提示及其作用:
✅ 求計算結果。
提示:“2 + 2 是什麼?”
它將編寫 AppleScript 開啟計算器並輸入 5 * 5。
✅ 尋找附近的餐廳。
提示:“查找我附近的餐廳”
它將打開 Chrome,谷歌搜尋附近的餐廳,解析頁面,然後返回最上面的結果。有時它很厚顏無恥,反而會打開谷歌地圖結果並說「最好的餐廳是谷歌地圖頁面頂部的餐廳」。其他時候,它會打開 Google 上的頂部連結 - 並卡在 Google 可存取性頁面上...
以下是執行時列印到終端的內容:
Command: Find a great restaurant near Manchester.
> Entering new AgentExecutor chain...
I need to search for a restaurant near Manchester.
Action: chrome_open_url
Action Input: https://www.google.com/search?q=restaurant+near+Manchester
Observation:
Thought: I need to read the page
Action: chrome_read_the_page
Action Input:
Observation: Accessibility links
Skip to the main content
... # Shortned for brevity
Dishoom Manchester
4.7
(3.3K) · £££ · Indian
32 Bridge St · Near John Rylands Library
Closes soon ⋅ 11 pm
Stylish eatery for modern Indian fare
San Carlo
4.2
(2.8K) · £££ · Italian
42 King St W · Near John Rylands Library
Closes soon ⋅ 11 pm
Posh, sceney Italian restaurant
Turtle Bay Manchester Northern Quarter
4.7
Thought: I now know the final answer
Final Answer: The 15 best restaurants in Manchester include El Gato Negro, Albert's Schloss, The Refuge, Hawksmoor, On The Hush, Dishoom, Banyan, Zouk Tea Room & Grill, Edison Bar, MyLahore Manchester, Turtle Bay Manchester Northern Quarter, San Carlo, The Black Friar, Mana, and Tast Cuina Catalana.我不能保證這些餐廳值得,請自行承擔風險。哈哈!
✅ 如果您要求 GPT Automator 擦除您的計算機,它會的。
是的,如果您要求的話,它會擦除您的電腦!
我內心的自我尖叫著要這麼做:)
您可以在這裡查看完整的演示!
https://www.loom.com/share/7bfa82c604f3412fbbb04191ce2ae12f
-
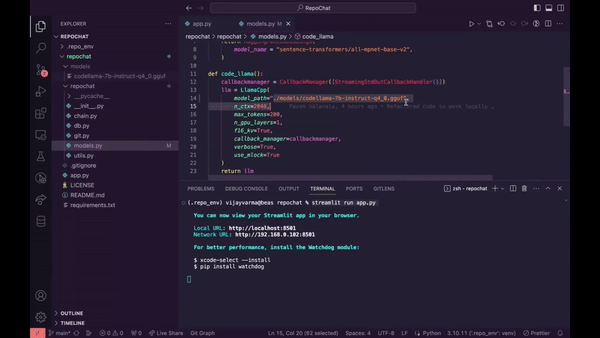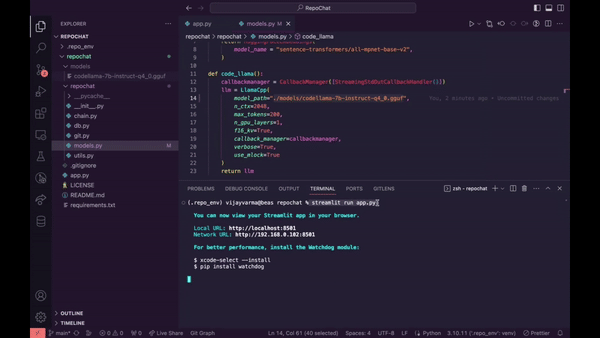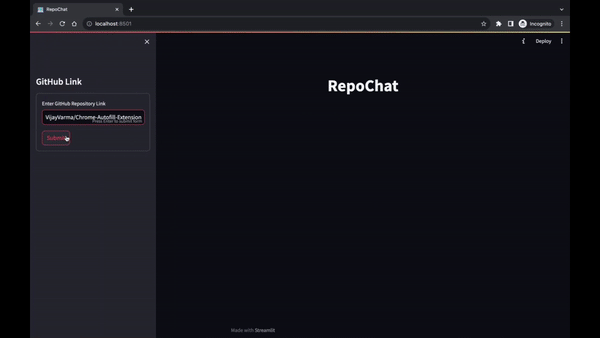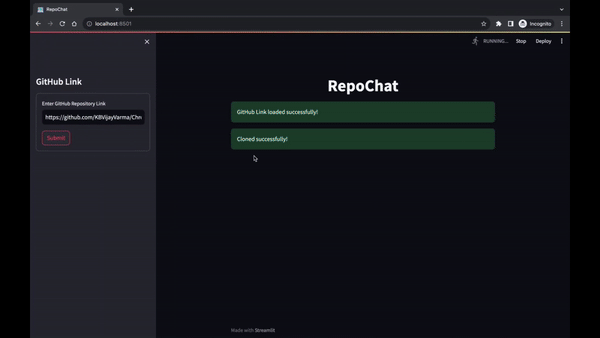
RepoChat - 支援 GitHub 儲存庫互動的聊天機器人助理。
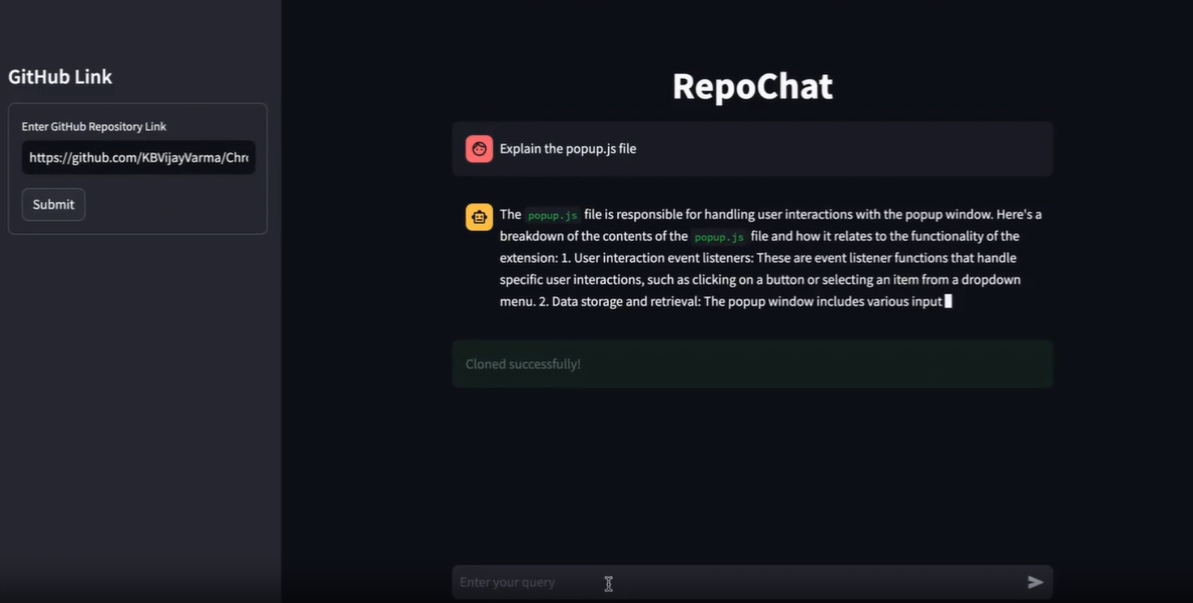
Repochat 是一個互動式聊天機器人專案,旨在使用大型語言模型 (LLM) 參與有關 GitHub 儲存庫的對話。
它允許用戶進行有意義的討論、提出問題並從 GitHub 儲存庫檢索相關資訊。本自述文件提供了在本機電腦上設定和使用 Repochat 的逐步說明。
他們建立了兩個具有不同功能的分支,這對我來說有點新鮮。
✅ Repochat 的主要分支被設計為完全在您的本機電腦上執行。此版本的 Repochat 不依賴外部 API 呼叫,並且可以更好地控制您的資料和處理。如果您正在尋找獨立的解決方案,那麼主分支就是您的最佳選擇。
✅ Repochat 的雲端分支主要依賴對外部服務的 API 呼叫來進行模型推理和儲存。它非常適合那些喜歡基於雲端的解決方案並且不想設定本地環境的人。
您可以閱讀安裝說明。
Repochat 讓您與聊天機器人進行對話。您可以提出問題或提供輸入,聊天機器人將從向量資料庫中檢索相關文件。
然後,它將您的輸入以及檢索到的文件傳送到語言模型以產生回應。
預設情況下,我已將模型設為codellama-7b-instruct ,但您可以根據計算機的速度更改它,甚至可以嘗試 13b 量化模型進行回應。
聊天機器人在對話過程中保留記憶以提供上下文相關的回應。
您可以查看即時網站,您可以使用 API 金鑰進行檢查。
你可以觀看這個演示!
如果您想查看的話,我找到了另一種選擇。
Repochat 擁有 200 多顆星,並部署在 Streamlit 上。
https://github.com/pnkvalavala/repochat 明星 RepoChat ⭐️
-
myGPTReader - 閱讀並與 AI 機器人聊天。

myGPTReader 是 Slack 上的機器人,可以閱讀和總結任何網頁、文件(包括電子書),甚至來自 YouTube 的影片。它可以透過語音與您交流。
一些有價值的功能是:
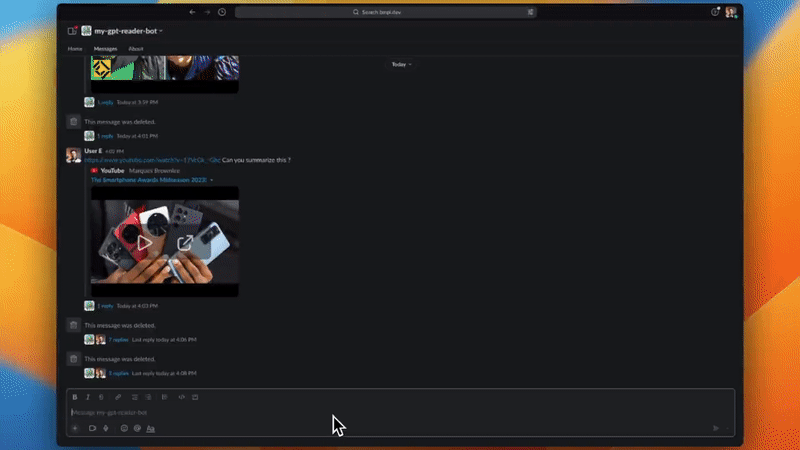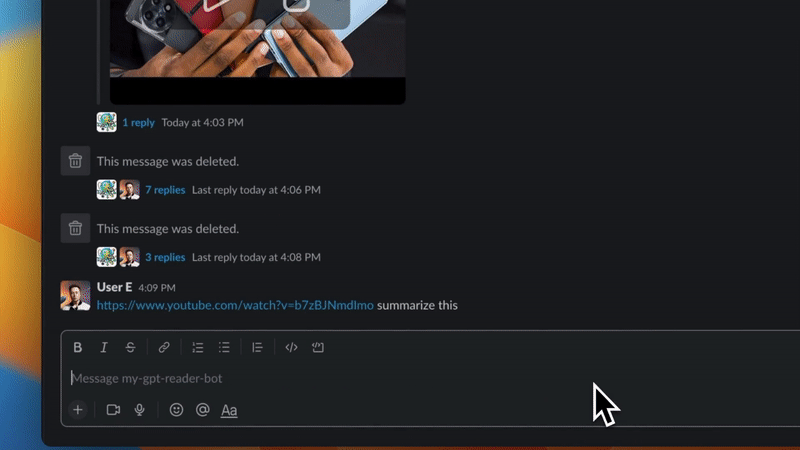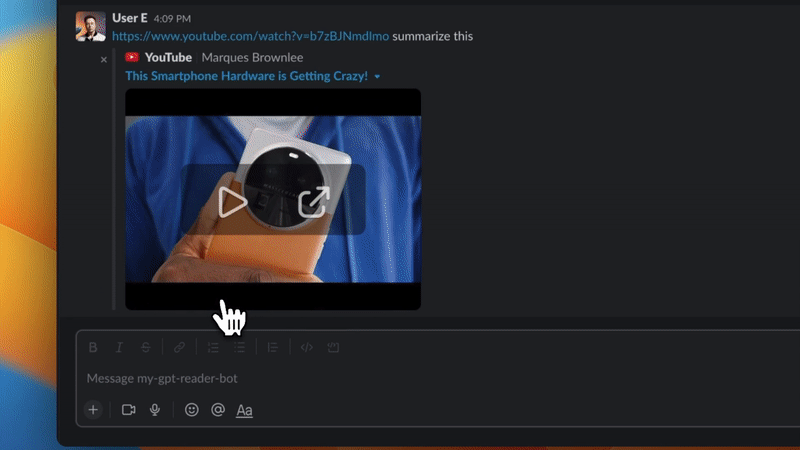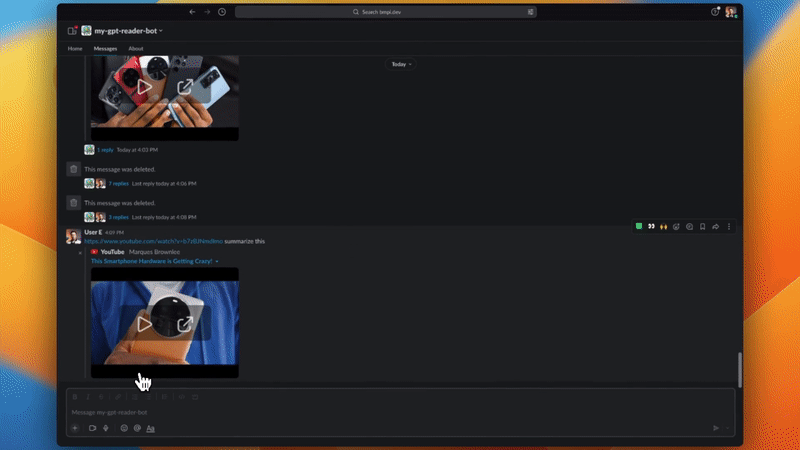
✅ 使用 myGPTReader 透過對話快速閱讀和理解任何網頁內容,甚至是影片(目前僅支援帶有字幕的 YouTube 影片)。
✅ 使用 myGPTReader 快速閱讀任何文件的內容,支援電子書、PDF、DOCX、TXT 和 Markdown。
✅ 透過與 myGPTReader 語音對話來練習外語,它可以成為您的私人導師,支援中文、英語、德語和日語。
✅ 內建大量提示模板,使用它們可以更好地與chatGPT對話。
✅ myGPTReader 每天都會發出最新的熱門新聞,並自動產生摘要,讓您快速了解今日熱點。
您可以造訪官方網站。
您可以加入擁有超過 5000 名會員的儲存庫上的 Slack 頻道,免費體驗所有這些功能。
它們在 GitHub 上有 4.4k 顆星,並且像此列表中的其他專案一樣使用 Python 建置。
https://github.com/madawei2699/myGPTReader 星 myGPTReader ⭐️
-
Marker - 將 PDF 快速且高精度地轉換為 Markdown。

Marker 將 PDF、EPUB 和 MOBI 轉換為 Markdown。它比牛軋糖快 10 倍,在大多數文件上更準確,並且產生幻覺的風險較低。
我們都知道這有多大幫助,尤其是對於研究論文來說。
✅ 支援一系列 PDF 文件(針對書籍和科學論文進行了最佳化)。
✅ 刪除頁首/頁尾/其他工件。
✅ 將大多數方程式轉換為乳膠。
✅ 設定程式碼區塊和表格的格式。
✅ 支援多種語言(儘管大多數測驗是用英語完成的)。請參閱 settings.py 以取得語言列表,或新增您自己的語言列表。
✅ 適用於 GPU、CPU 或 MPS。
他們也清楚地記錄了範例以及 Marker 和 Nougat 的結果。

性能結果採用標記和牛軋糖設置,因此它們在 A6000 上均佔用約 3GB 的 VRAM。
閱讀速度和準確性基準測試以及有關如何執行您自己的基準測試的說明。
例如,請參閱此 PDF: Think Python和Marker vs Nougat的 markdown 檔案。
閱讀安裝說明。
他們也記錄瞭如何正確使用它:
他們在 GitHub 上有 8k+ 星,我認為它不再被維護了。
https://github.com/VikParuchuri/marker 星標 ⭐️
-
Instrukt - 終端機中整合人工智慧。
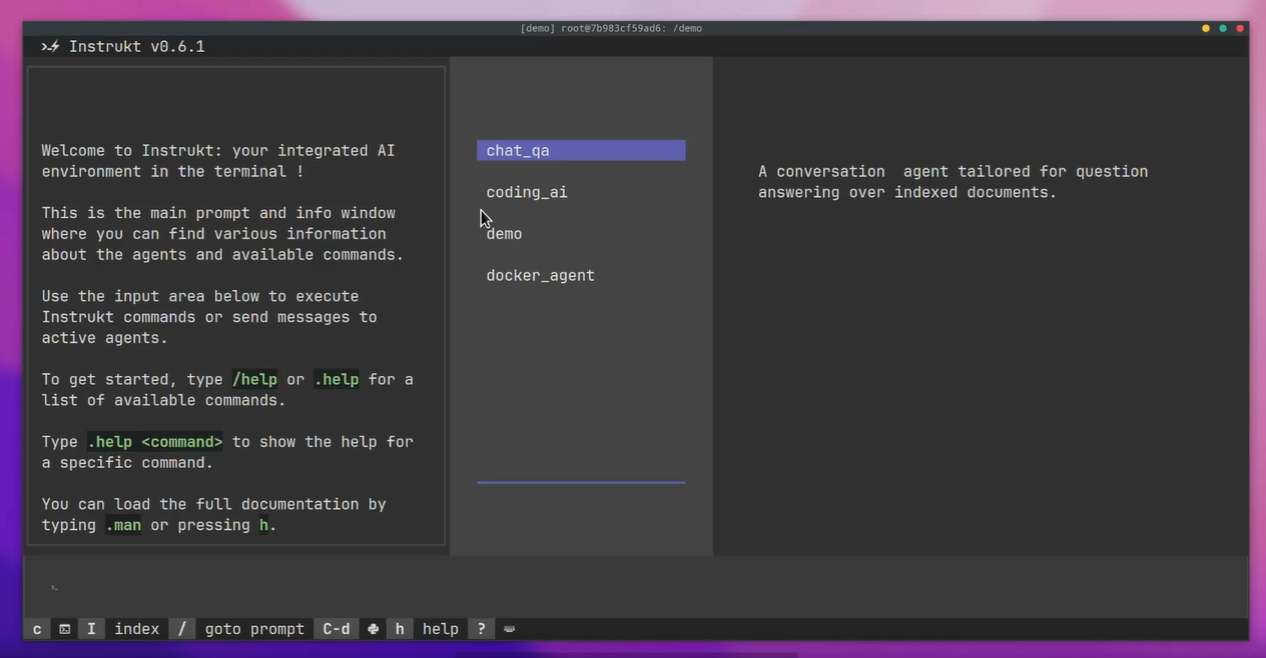
Instrukt是一個基於終端的AI整合環境。它提供了一個平台,用戶可以:
-
建立並指導模組化人工智慧代理。
-
產生問答的文件索引。
-
建立工具並將其附加到任何代理程式。
用自然語言指導它們,並且為了安全起見,在安全容器(目前使用 Docker 實作)中執行它們,以在其專用的沙盒空間中執行任務。
使用Langchain 、 Textual和Chroma建構。
開始使用以下命令。
pip install instrukt[all]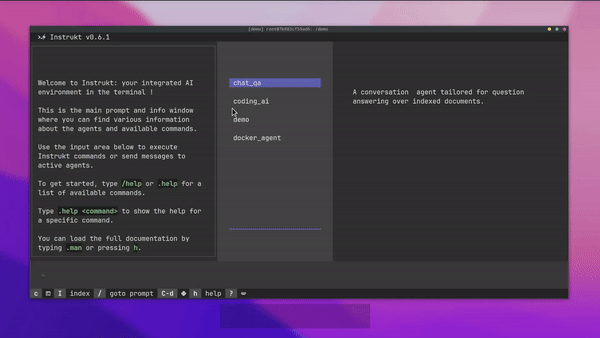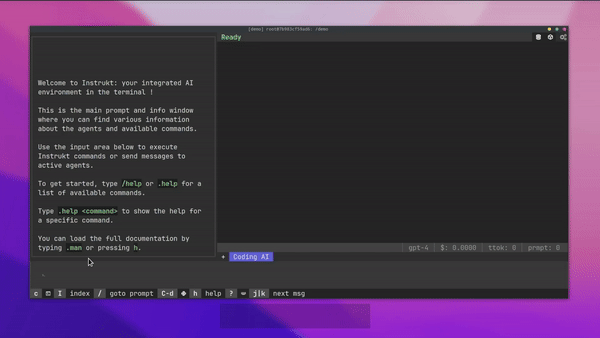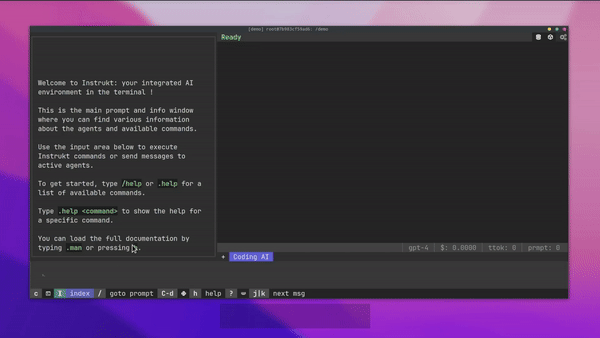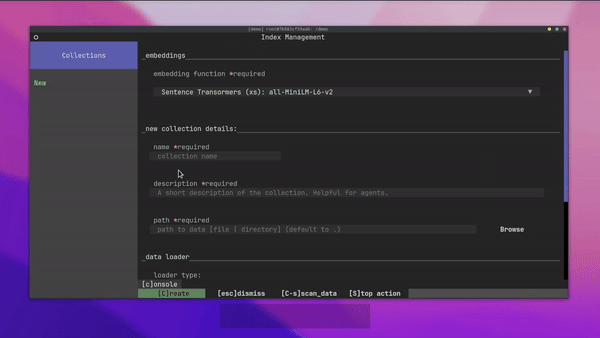
有許多令人興奮的功能,例如:
-
基於終端的介面,讓強力鍵盤使用者無需離開鍵盤即可指示 AI 代理。
-
對您的資料建立索引並讓代理程式檢索它以進行問答。您可以使用簡單的 UI 建立和組織索引。
-
索引建立將自動偵測程式語言並相應地優化拆分/分塊策略。
-
在安全的 Docker 容器內執行代理程式以確保安全和隱私。
-
整合的 REPL-Prompt 可實現與代理程式的快速交互,以及用於開發和測試的快速回饋循環。
-
您可以使用自訂命令自動執行重複任務。它還具有內建的提示/聊天歷史記錄。
您可以閱讀有關所有功能的資訊。
您可以閱讀安裝指南。
您還可以使用內建的 IPython 控制台來除錯和內省代理,這是一個簡潔的小功能。
Instrukt 已獲得 AGPL 許可證,這意味著任何人都可以將其用於任何目的。
可以肯定地說,Instrukt 是您觸手可及的終端人工智慧指揮官。
這是一個新專案,因此他們在 GitHub 上有大約 200 多顆星,但用例非常好。
https://github.com/blob42/Instrukt 舊指令 ⭐️
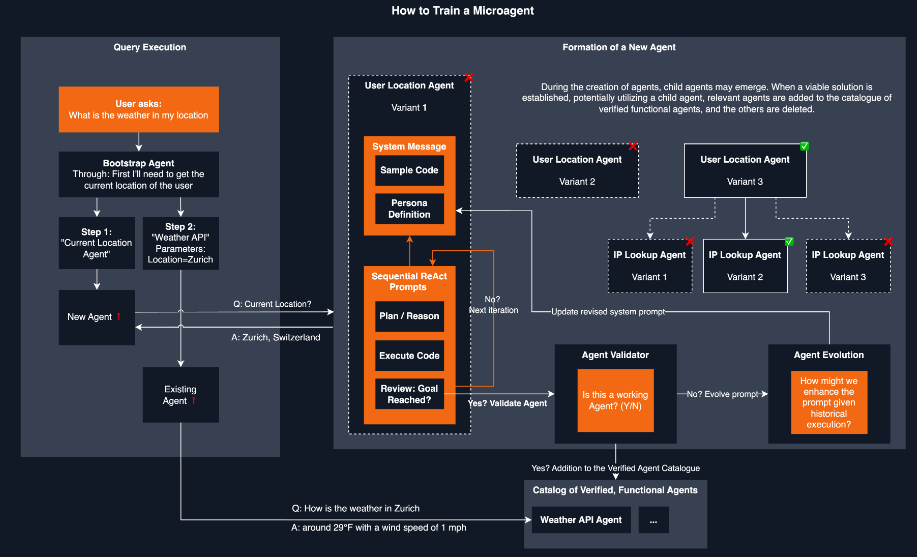
21.微代理- 能夠自我編輯提示的代理。

它是一個實驗框架,用於動態建立自我改進的代理來回應任務。
微代理代表了一種建立自我改進代理的新方法。小型微服務大小(因此稱為微代理)代理是根據用戶分配給助手的任務動態生成的,評估其功能,並在成功驗證後存儲以供將來重用。
這使得跨聊天會話的學習成為可能,使系統能夠獨立推斷任務執行的方法。
這是使用Python 、 OpenAI's GPT-4 Turbo和Text-Embedding-Ada-002建構的。
您可以閱讀安裝說明。他們提到您應該擁有一個可以存取 gpt-4-turbo 和 text-embedding-ada-002 的 OpenAI 帳戶。
讓我們看一個獲取天氣預報代理的範例。
You are an adept weather informant. Fetch the weather forecast by accessing public API data using this Python code snippet:
``python
import requests
import json
def fetch_weather_forecast(location, date):
response = requests.get(f"https://api.met.no/weatherapi/locationforecast/2.0/compact?lat={location[0]}&lon={location[1]}")
weather_data = response.json()
for day_data in weather_data['properties']['timeseries']:
if date in day_data['time']:
print(day_data['data']['instant']['details'])
break
``
# Example usage: fetch_weather_forecast((47.3769, 8.5417), '2024-01-22T12:00:00Z')
Note: Replace the (47.3769, 8.5417) with the actual latitude and longitude of the location and the date string accordingly.如果您想知道如何建立代理,那麼此架構圖將對此進行解釋。
您可以看到工作演示。
他們在 GitHub 上有大約 700 顆星,值得一看。
https://github.com/aymenfurter/microagents 明星微代理 ⭐️
-
Resume Matcher - 一個改進你的履歷的免費工具。

Resume Matcher 是一款開源免費工具,可用於完善您的履歷。根據職位描述自訂您的履歷。找到匹配的關鍵字,提高可讀性,並深入了解您的履歷。
它是如何運作的?
履歷表匹配器使用 Python 讀取您的履歷和職位描述,就像 ATS 一樣。
它建議透過以下方式進行更改,使您的履歷適合 ATS:
✅ 解析:它使用 Python 分解你的履歷和工作描述。
✅ 關鍵字提取:該工具從職位描述中尋找重要關鍵字,例如技能和資格。
✅ 關鍵術語提取:辨識職位描述中的主題以了解其上下文。
✅ 向量相似度:使用 FastEmbedd,它將您的履歷與職位描述進行比較,看看它們的匹配程度。配對得越好,通過 ATS 篩選的機會就越高。

您可以閱讀安裝說明。
您可以查看現場演示或自述文件中附帶的演示。
Resume Matcher 是由 Saurabh Rai 建立的一個令人驚嘆的專案,他還在 DEV 上寫了很棒的帖子!
它在 GitHub 上有 4.5k 顆星,並且仍然維護良好。
https://github.com/srbhr/Resume-Matcher 明星簡歷匹配器 ⭐️
23.背景移除器- 讓您可以透過簡單的 CLI 使用 AI 從影像和影片中移除背景。

這是一個使用 AI 從圖像和影片中刪除背景的命令列工具。
首先從 pypi 安裝 backgroundremover。
pip install --upgrade pip
pip install backgroundremover也可以在不透過 pip 安裝的情況下執行它,只需克隆 git 以在本地啟動虛擬環境安裝要求並執行。
您可以使用的一些命令:
- 從本機檔案圖像中刪除背景
backgroundremover -i "/path/to/image.jpeg" -o "output.png"- 從本地影片中刪除背景並將其覆蓋在圖像上
backgroundremover -i "/path/to/video.mp4" -toi "/path/to/videtobeoverlayed.mp4" -o "output.mov"您可以檢查可以透過 CLI 使用的所有命令。
您甚至可以將它用作圖書館。
from backgroundremover.bg import remove
def remove_bg(src_img_path, out_img_path):
model_choices = ["u2net", "u2net_human_seg", "u2netp"]
f = open(src_img_path, "rb")
data = f.read()
img = remove(data, model_name=model_choices[0],
alpha_matting=True,
alpha_matting_foreground_threshold=240,
alpha_matting_background_threshold=10,
alpha_matting_erode_structure_size=10,
alpha_matting_base_size=1000)
f.close()
f = open(out_img_path, "wb")
f.write(img)
f.close()輸入與輸出。

他們在 GitHub 上有 6k star,我們絕對可以用它來學習一些重要的概念。
https://github.com/nadermx/backgroundremover 明星背景去除器 ⭐️
-
Tkinter Designer - 建立 Python GUI 的簡單快速的方法。

Tkinter Designer 的建立是為了加快 Python 中的 GUI 開發過程。它使用著名的設計軟體Figma,讓用Python建立漂亮的Tkinter GUI變得輕而易舉。
Tkinter Designer 使用 Figma API 來分析設計檔案並建立 GUI 所需的對應程式碼和檔案。
如果您想知道它是如何工作的?
使用者唯一需要做的就是使用 Figma 設計一個介面,然後將 Figma 檔案 URL 和 API 令牌貼到 Tkinter Designer 中。
Tkinter Designer 將自動產生在 Tkinter 中建立 GUI 所需的所有程式碼和映像。

您可以閱讀逐步指南](https://github.com/ParthJadhav/Tkinter-Designer/blob/master/docs/instructions.md),了解如何正確使用它,該指南有多種語言版本。
您可以在這裡觀看演示!
https://www.youtube.com/watch?v=Qd-jJjduWeQ
他們還展示了您可以使用它輕鬆複製的網站範例。

它們在 GitHub 上有 8,300 顆星,並被大約 100 名開發人員使用。
https://github.com/ParthJadhav/Tkinter-Designer Tkinter 明星設計師 ⭐️
-
Open Interpreter - 電腦自然語言介面。

Open Interpreter 允許法學碩士在本地執行程式碼(Python、Javascript、Shell 等)。您可以在安裝後執行 $terpreter,透過終端機中類似 ChatGPT 的介面與 Open Interpreter 聊天。
這為電腦的通用功能提供了自然語言介面:
✅ 建立和編輯照片、影片、PDF 等。
✅ 控制 Chrome 瀏覽器執行研究、繪製、清理和分析大型資料集。
我不了解你,但他們的網站讓我驚嘆不已!
使用此命令快速啟動。
pip install open-interpreter
// After installation, simply run:
interpreter您可以閱讀快速入門指南。
您應該閱讀與 ChatGPT 程式碼解釋器的比較以及可以使用的命令。
您可以閱讀文件。
Open Interpreter 可與託管語言模型和本機語言模型搭配使用。託管模型速度更快、功能更強大,但需要付費。本地模型是私有且免費的,但能力往往較差。
它們在 GitHub 上擁有超過 48k 顆星,並被 300 多名開發人員使用。
https://github.com/OpenInterpreter/open-interpreter Star 開放式解釋器 ⭐️
獲得經驗並提高編碼水平的最佳方法是建立業餘專案。
我希望您能夠建立其中一些專案,或至少獲得靈感。
評論下來告訴其他人任何其他很酷的 Python 專案:)
祝你有美好的一天!
關注 Taipy 以了解更多此類內容。
原文出處:https://dev.to/taipy/25-projects-that-you-can-build-with-python-and-ai-12i9

1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式