

您可能已經聽說過 Grok 4 的發布,這是 Elon Musk 的 xAI 團隊的最新突破。
在這篇文章中,我們將深入探討這個模型是什麼、它的統計資料、它是否有用或只是另一個常規的人工智慧模型、它是否實現了 AGI,以及迄今為止社區的整體印象。
閱讀本文後,您將獲得所有需要的資訊來決定是否要使用 Grok 4。
不用多說,讓我們開始吧!
Grok 4 簡介
Grok 4 是一個推理模型,也是迄今為止最聰明的模型,正如您在下面的基準測試中看到的那樣。說實話,這個模型不僅可以與其他 AI 模型競爭,還可以與人類競爭,使其成為同類中的首創(我們稍後會討論這一點)。
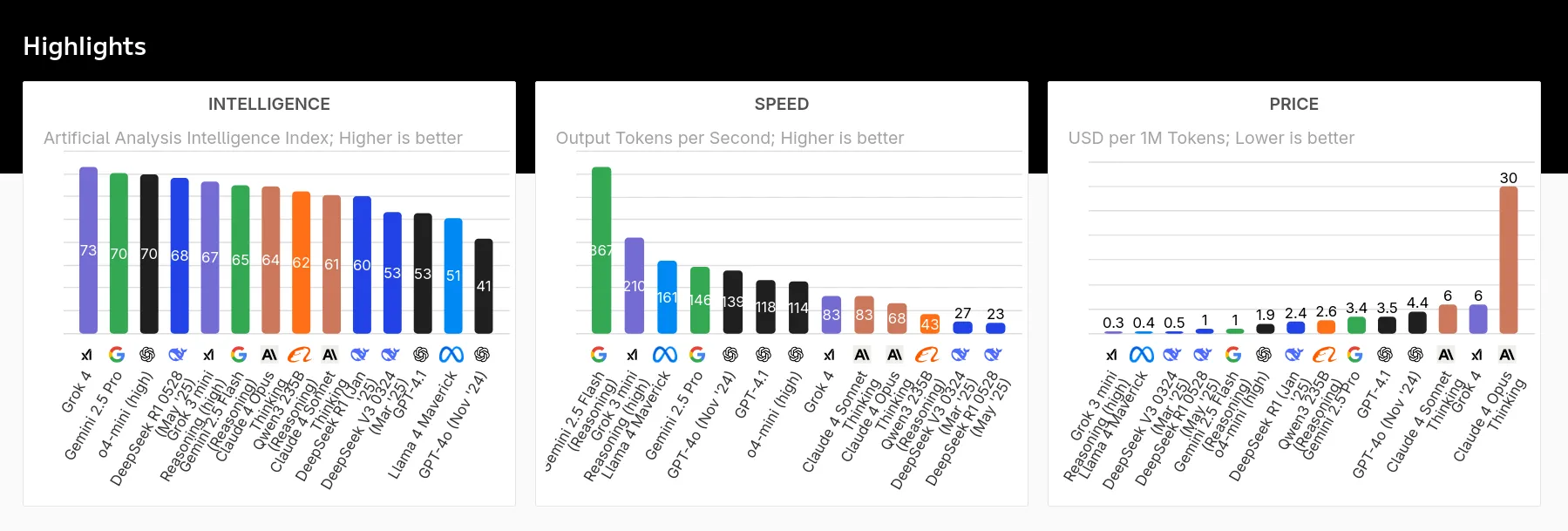
如上圖所示,與近期的AI模型相比,它在智慧、速度和定價方面都取得了優異的成績。它在人工智慧排行榜上名列前茅,但如果仔細觀察,就會發現它在產生回應方面略慢。 Grok 4 的延遲(第一個令牌時間)約為 13.58 秒,該延遲衡量的是接收 AI 模型回應第一部分的時間。這略低於 OpenAI o4-mini-high,與 Claude Sonnet 4 模型相當。
它的訓練資料比 xAI 的第一個公共 AI 模型 Grok 2 多100 倍,強化學習運算量比目前市場上任何其他 AI 模型多約10 倍。

它配備了 256k 個 token 上下文視窗(即模型可以一次讀取和記憶的資訊量),與最近的 Gemini 2.5 Pro(1M 個 token 上下文視窗)相比相當低。它只比擁有約 20 萬個 token 的 Claude 4 系列略勝一籌。
Grok 4 的定價相當標準,但也有一個限制。它與 Grok 3 的定價相同,每百萬輸入代幣 3 美元(超過 128k 後翻倍),每百萬輸出代幣 15 美元(超過 128k 後翻倍)。
Grok 4 的關鍵基準測試結果
- 該型號在 GPQA 鑽石評分中以 87.5% 創下歷史新高,大大高於 Gemini 2.5 Pro 的 86.4%。
*(GPQA Diamond tests the model’s ability to answer graduate-level, expert-domain questions (e.g., physics, law, medicine))*
- 它在人類期末考中取得了 25.4% 的歷史最高分,超過了 Gemini 2.5 Pro 之前的 21.6% 的得分。
*(Humanity Last Exam tests the capabilities of large language models (LLMs) at the frontier of human knowledge)*
- 其 MMLU-Pro 和 AIME 2025 的得分分別為 87% 和 94%。
*(MMLU-Pro tests the model across 57+ professional-level subjects, including law, engineering, medicine, and more. AIME 2024 measures the model's performance on high school olympiad-level math problems)*
- 它還打破了編碼基準測試的記錄,在 LiveCodeBench 中以 79.4% 排名第一,第二名是 74.2%。
*(LiveCodeBench is a real-time coding benchmark that tests models in live, interactive programming tasks and not just in static code generation)*
是的,它在其他一些基準測試中領先所有模型,但這些幾乎是最有趣的。
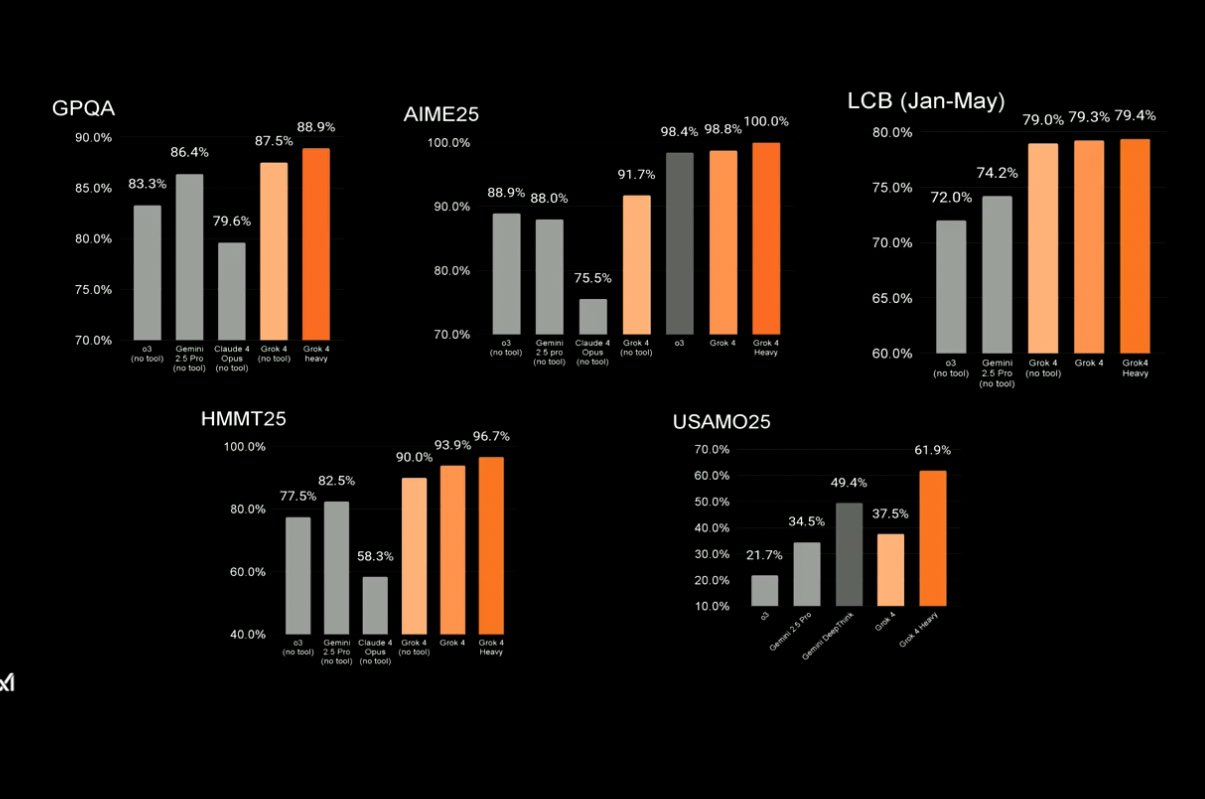
因此,總而言之,目前,如果您進行任何基準測試,Grok 4 很可能處於領先地位。
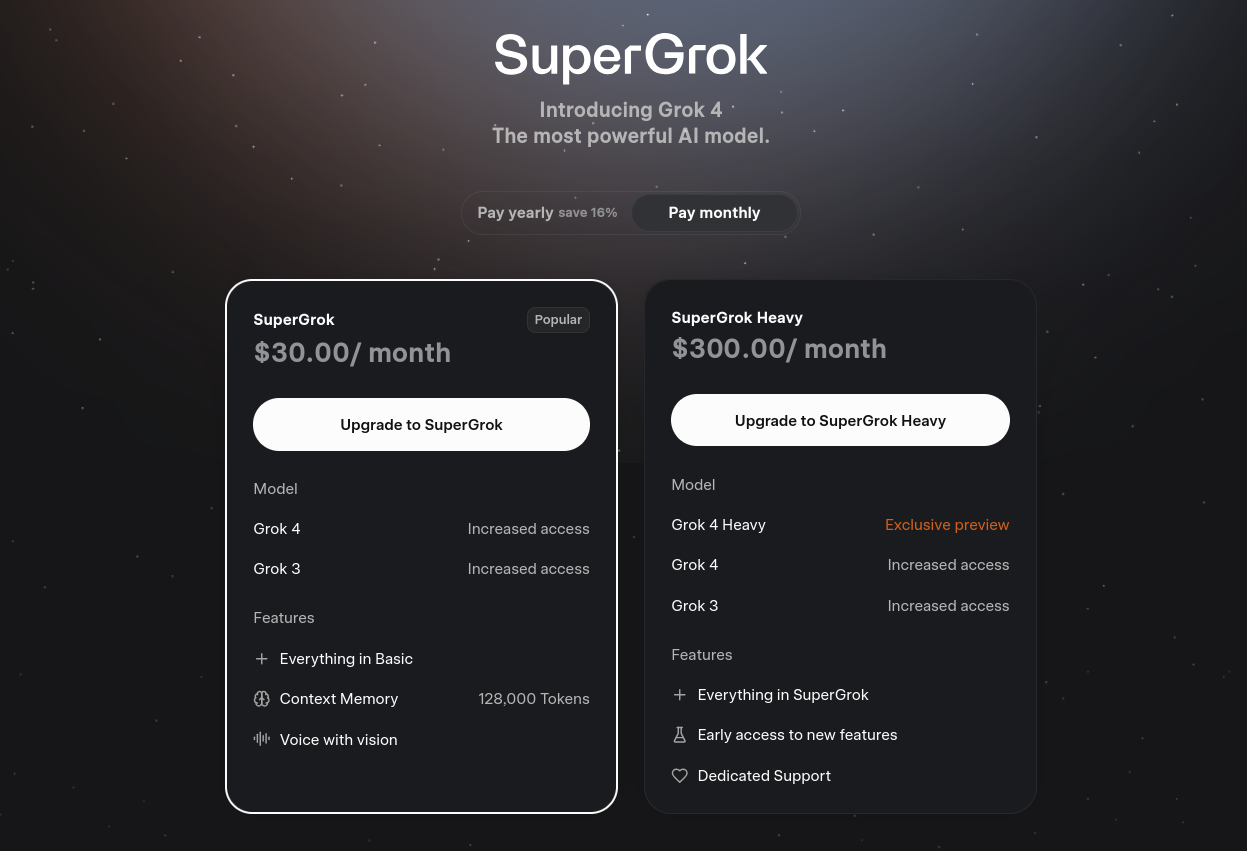
但是如何存取呢?它可以透過 API 和付費訂閱兩種方式存取。您可以在 SuperGrok 上以每月 30 美元或每年 300 美元的價格存取,這樣您就可以存取標準版 Grok 4。但是,要存取Grok 4 Heavy ,您需要訂閱 SuperGrok Heavy 計劃,每月 300 美元或每年 3000 美元。
-
Grok 4:這是標準的通用模型,針對一系列任務進行了微調,例如解決問題、一般對話和寫作。它是 Grok 4 系列中的預設模型。
-
Grok 4 Heavy:這是 Grok 4 系列中的專業版本。它使用多智能體,即並行執行多個 AI 智能體來分析和解決問題,並得出最佳解決方案。這確實有助於提高準確性,主要用於高強度研究、資料分析以及基本上任何需要深入思考的工作。
更好的是,如果您只是想測試模型,它也可以在 OpenRouter 上使用,因此如果您有 API 金鑰,您就可以開始了。
Grok 4 能實現 AGI 嗎?
如果你不清楚什麼是 AGI(通用人工智慧),我來簡單介紹一下。基本上,我們使用的生成式人工智慧,例如 OpenAI 模型、Claude Sonnet 模型等等,都是基於學習到的模式或訓練過的內容來產生內容的。
然而,AGI 有意識地產生內容,其創造力可與人類智慧相媲美。
我的朋友,讓我告訴你,這不是憑空就能造出來的,不是的。我們在這裡討論的是達到與人腦相當的人工智慧,這並非易事。
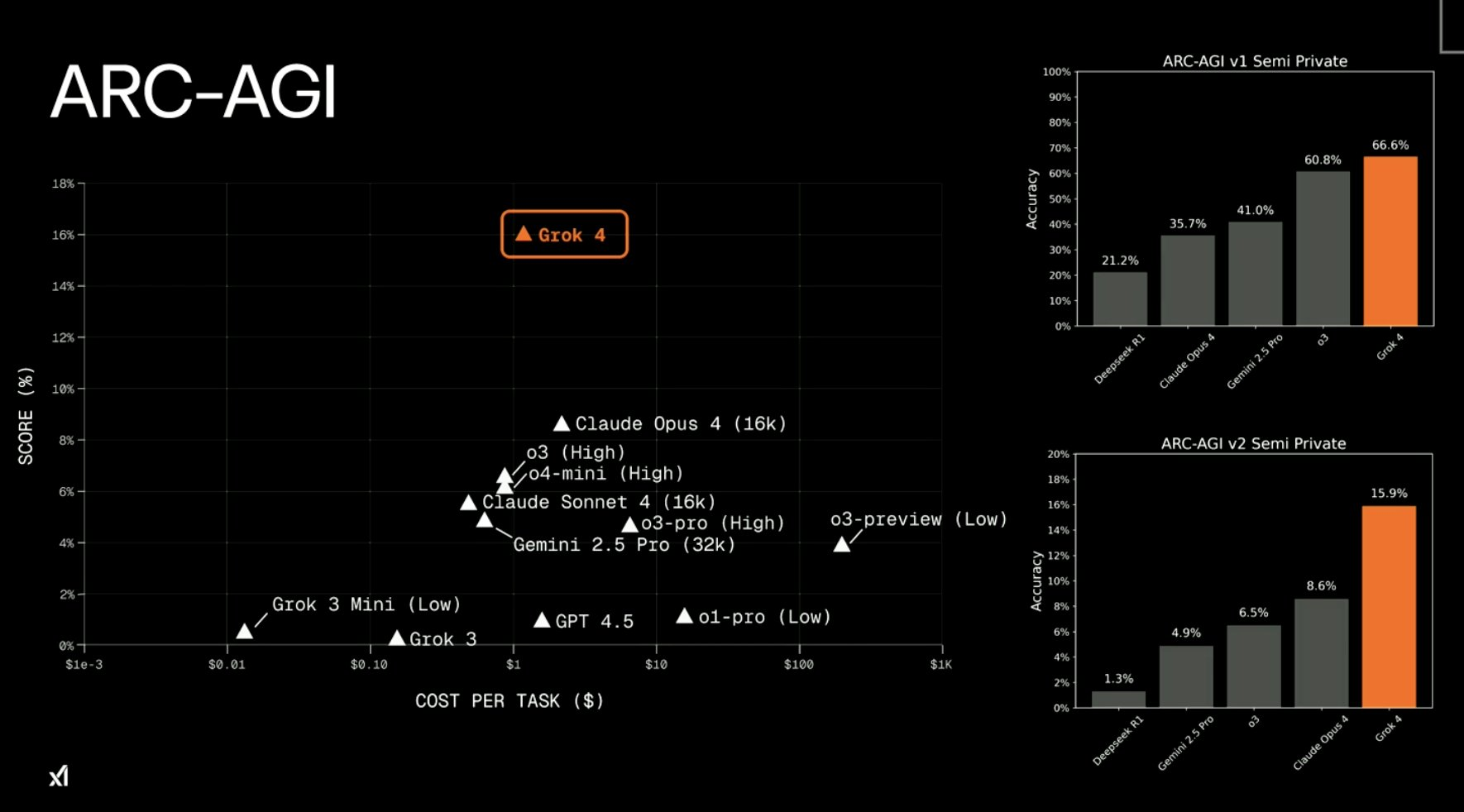
現在回到主題,它尚未實現 AGI,但它是 AGI 競賽中的一次飛躍,也是第一個以較低的成本跨越 ARC-AGI 基準測試中15% 分數的模型。
xAI 也在名為Vending Bench的真實場景模擬中測試了 Grok 4。此基準測試的目的是檢驗模型能否長期管理小型企業,並處理隨之而來的所有事務,例如補充庫存、與供應商合作、調整價格等等。這是一個非常有趣的基準測試,用於在真實場景中測試 AI 模型,而 Grok 4 的表現相當出色。
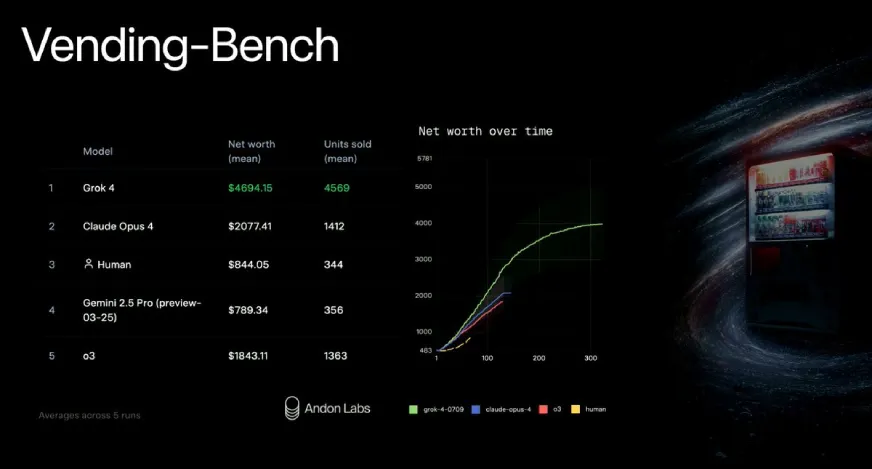
如您所見,Grok 4 的收入和規模是其最大競爭對手 Claude Opus 4 的兩倍多。
Grok 4 與其他 AI 型號相比毫無可比性,而且它的價格更低。所以,這確實是邁向通用人工智慧 (AGI) 的重要一步,但距離真正實現通用人工智慧 (AGI) 還差得遠。
xAI 的社區印象和未來計劃
馬斯克本人聲稱,你可以將整個原始碼複製並貼上到查詢中,它就會幫你修復錯誤或加入功能,一切就這麼簡單。它還聲稱“比 Cursor 更好用” 。
再說一次,這似乎確實如此。自從這個模型發布不到一周以來,社區已經用它建置了很多東西,我們得到的成果令人驚嘆。
https://x.com/mckaywrigley/status/1943385794414334032
它真的一下子就解決了這麼瘋狂的問題,如果這還不夠的話,據說它在每個學科上都比博士水平高。好好想想吧。
🗣️ 「就學術問題而言,Grok 4 在每個學科上都比博士水平要好。無一例外。」——埃隆·馬斯克
https://x.com/AutismCapital/status/1943161993315389554
在發布此模型時,他們簡要介紹了 xAI 的下一步發展,如下所示:

來源:xAI
我們預計未來幾個月將看到以下內容:
-
Grok 程式碼 - 下個月發布
-
Grok 多模式或瀏覽代理商將於 9 月發布
-
十月下旬生成 Grok 影片
因此,如果您使用 AI 模型的主要目的是編碼,那麼可能值得再等一個月,看看這是否更適合您的用例。
Grok 4 的優缺點
Grok 4 幾乎每次都能以大約 99% 的準確率選擇正確的工具並使用適當的參數進行工具呼叫。
它被設計為具有代理功能,這意味著它可以透過單一或多個代理在背景執行,輕鬆處理多項任務。正如您在我們上面討論的基準測試中所見,它是一位學術奇才,也是首批突破 ARC-AGI 基準測試 10% 大關的 AI 模型之一,這使得它能夠做出果斷的決策和計劃,使其成為一個非常強大的模型。
然而,當談到多模式能力時,特別是影像生成和分析,它並沒有比o3、Claude 4等頂級多模式能力AI模型好多少,表現也更差。儘管這種情況在未來幾天會顯著改善。
我非常討厭這個模型的另一點是它在 xAI 之上實現的速率限制。幾乎每 2-3 次連續的請求,就會有幾分鐘的速率限制,這真的很令人沮喪,尤其是考慮到你會在更偏向研究的場景中使用這個模型,在這種情況下,你很可能會多次向模型發出請求才能得到你期望的答案。
結論
如果我必須總結我們目前所讀到的所有內容,那就是它絕對是推理、深度研究和資料分析領域的最佳模型(至少目前如此!)。 Grok 4 並非真正為編碼而設計,因此最好再等一個月左右才能獲得針對編碼進行調優的模型。
這絕對是迄今為止人工智慧領域最大的突破,據稱它是迄今為止最接近通用人工智慧的模型。所以,這個模型確實潛力巨大,所以請謹慎使用。
能力越大,責任越大! 😉
請告訴我你目前對 Grok 4 的評價,如果你親自測試過,請告訴我它的表現如何。請在下方留言處留言!
在 Forge 上試用 Grok 4
我們最近在 Forge 上新增了對 Grok 4 的支援。如果您對此感興趣,一定想在 Forge 上試用一下。您可以建立一個帳戶,只需一分鐘即可開始使用。您可以親自體驗它的性能是否與基準測試結果一致,並決定是否將此模型加入到您的日常工作流程中。
相關文章
註腳
原文出處:https://dev.to/forgecode/everything-you-need-to-know-about-grok-4-5524
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式