

AI 讓撰寫資料分析程式碼的門檻大幅降低了。
只要用自然語言描述你想做的事,不論是 R、Python 還是 SQL,都能生成相當實用的程式碼。
這對資料分析的世界來說,是一個重大的變化。
過去要學習資料分析,不是得使用像 Exploratory 這樣的 UI 工具,就是必須學會 R、Python、SQL 等程式語言。
讀取資料、整理資料、彙總、視覺化、建立模型。
要做這些處理,基本上都需要有寫程式的能力。
但現在,只要對 AI 的提示詞這樣問就可以了。
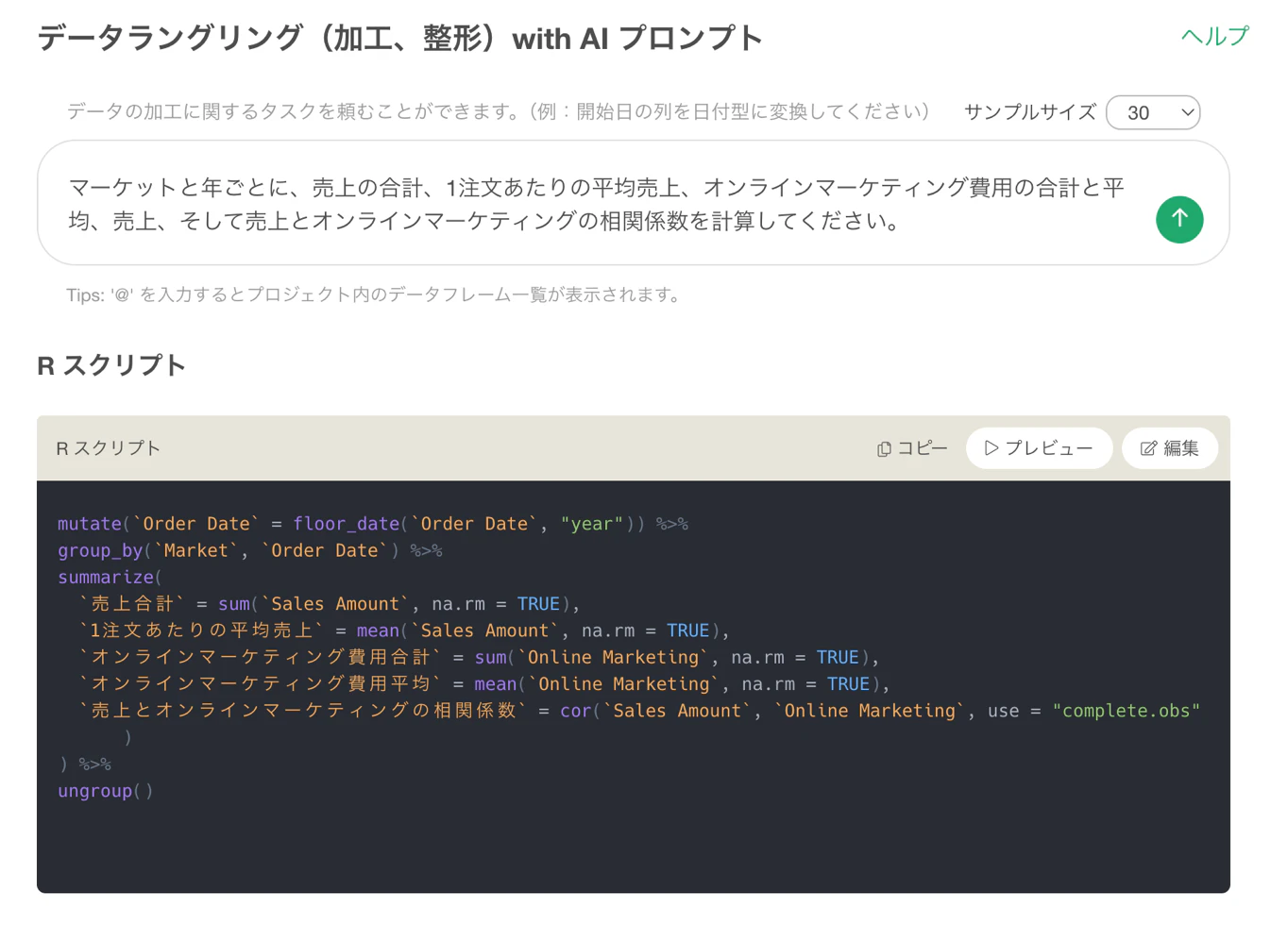
請僅針對 2020 年以後的資料,計算各地區的銷售總額。
於是 AI 就會用指定的程式語言,或依情境而定的語言,生成看起來合理的程式碼。
那麼,在 AI 會幫我們寫程式碼的時代,我們是不是就不需要再學程式語言了呢?
我反而認為正好相反。
在 AI 時代,比起能不能從零寫出程式碼,更重要的是能讀懂、理解並驗證生成出來的程式碼。
尤其在資料分析中,這項能力非常重要。
因為在資料分析裡,「程式碼能跑」與「分析結果可信」並不是同一件事。
這不只是理論上的疑慮。
例如,在 2026 年針對資料相關工作者進行的「State of Analytics Engineering」調查中,將「對資料的信任」列為重要課題的人數比例,從前一年的 66% 上升到 83%。
另外,在針對資深商業領導者的另一項調查中,98% 的受訪者表示曾經遇過與 AI 相關的資料品質問題。
也就是說,在 AI 時代的資料分析中,比起「AI 會不會給答案」,更大的問題是「這個答案能不能信」。
而要信任分析結果,就必須理解它是透過什麼流程產生的。
用了哪些資料。
用什麼條件篩選。
以什麼單位進行彙總。
遺漏值與重複值是怎麼處理的。
和哪一張表、在什麼條件下進行合併。
這些處理,大多都會反映在程式碼中。
也就是說,如果無法理解並驗證 AI 生成的程式碼,就無法真正信任它所產出的分析結果。
而要理解並驗證程式碼,最重要的就是程式碼的可讀性。
這篇文章會整理:在 AI 時代的資料分析中,為什麼可讀性變得重要,以及為什麼 R,特別是 tidyverse 的程式碼,在這方面特別有優勢。
資料分析沒有事先準備好的「正解」
在機器學習的預測模型中,通常都有明確的標準可以評估結果。
例如分類模型,就有正確標籤(實際值)。
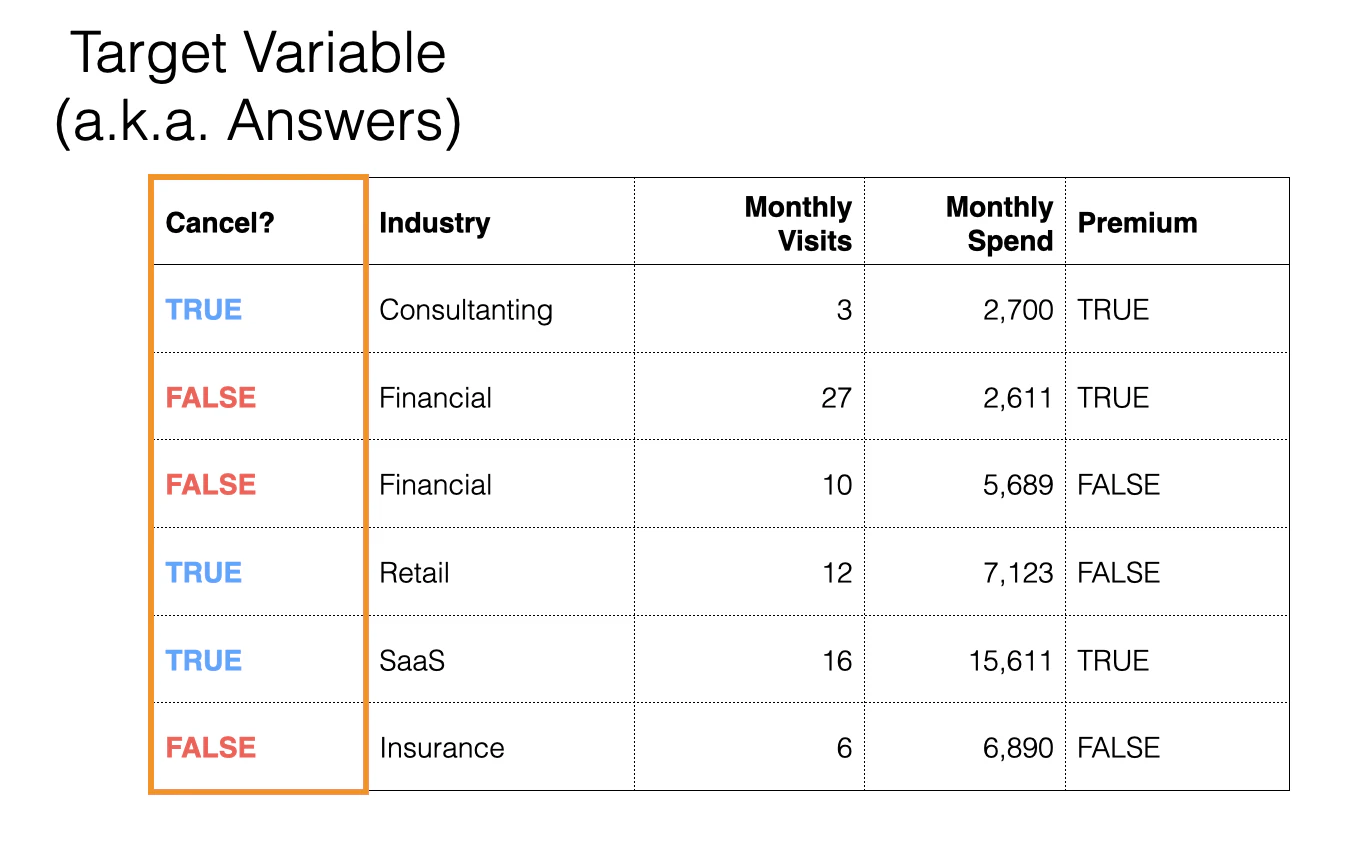
接著可以用準確率、AUC、RMSE 等指標,來評估模型表現得怎麼樣。
但資料分析就稍微不同了。
資料分析一開始並沒有明確的正解。
例如,想一想下面這些問題。
為什麼這個月的業績下滑了?
流失率高的客戶有什麼特徵?
行銷活動真的有帶來成效嗎?
這些問題,沒有預先準備好的正確標籤。
資料分析與其說是在找標準答案,不如說是在探索資料的同時,找出能讓人信服的答案。
因此,重要的不只是結果本身。
而是這個結果,是透過什麼流程產生的。
用了哪些資料?用什麼條件篩選?以什麼單位彙總?遺漏值怎麼處理?和其他哪些資料做了合併?
如果無法理解這些流程,就無法信任最終結果。
即使 AI 已經能生成程式碼,這個問題也不會消失。
相反地,這個問題會變得更重要。
因為之後產生分析結果的,會是你自己沒有親手寫過的程式碼。
看不懂的程式碼是不能信的
AI 生成的程式碼或分析結果,乍看之下通常都像是對的。
但這和它真的有照你想要的方式做分析,是兩回事。
例如,下面這些很小的差異,都可能讓分析結果大幅改變。
- 篩選條件有一點不同
- 分組單位不同
- 遺漏值被自動排除了
- 合併方式是 inner join
- 日期範圍和原本想的不一樣
- 重複資料的處理方式不同
如果看不懂程式碼,就很難發現這些差異。
也就是說,在 AI 會幫你寫程式碼的時代,人類的角色會改變。
以前,人類是寫程式碼的人。
但從現在開始,人類會變成 AI 生成程式碼的閱讀者,以及驗證者。
而這裡最重要的,就是程式碼的可讀性。
如果看不懂程式碼,就無法信任結果。
我認為這是 AI 時代資料分析中非常重要的一點。
R 的程式碼,能以接近問題描述的方式來閱讀
例如,你想做這樣的分析:
僅針對 2020 年以後的資料,計算各地區的銷售總額。
在 R 中,可以這樣寫:
sales %>%
filter(year >= 2020) %>%
group_by(region) %>%
summarize(total_sales = sum(sales))這裡使用的是 R 中廣泛用於資料分析的一組套件寫法:tidyverse。
R 本身也有內建的基本功能,也就是所謂的「Base R」。不過在現今的資料分析實務中,為了讓資料處理、彙總與視覺化寫得更易讀,tidyverse 常常被使用。
本文所說的「R 的程式碼」,若沒有特別註明,指的就是 R + tidyverse 的程式碼。
這段程式碼,就算不是很懂程式的人,只要懂一點英文,也大致能順著理解處理流程。
filter(year >= 2020):篩選出 2020 年以後的資料group_by(region):依地區分組summarize(total_sales = sum(sales)):計算銷售總額
也就是說,程式碼的流程和分析意圖非常接近。
「先篩資料 → 再分組 → 最後彙總」,這正是分析者在腦中思考的順序,並且直接被表達成程式碼。
如果用 Python 的 pandas 來寫,可能會像這樣:
sales[sales['year'] >= 2020] \
.groupby('region') \
.agg(total_sales=('sales', 'sum')) \
.reset_index()當然,這段 Python 程式碼也完全實用。
這並不是在說 Python 或 pandas 不好。Python 作為通用程式語言非常強大,在機器學習與深度學習的生態系中也有很大的優勢。
但如果從「讓人讀懂並驗證資料處理」的角度來看,R 具有它自己的優勢。
Python/pandas 的程式碼裡,除了分析意圖之外,也會看到一些實作上的考量。
例如:
sales['year']這樣的欄位存取agg(total_sales=('sales', 'sum'))這樣的彙總語法.reset_index()這種整理資料結構的處理
這些都不是分析問題本身。
它們是為了執行「僅針對 2020 年以後的資料,計算各地區的銷售總額」這個問題所需的程式手續。
相較之下,R 的程式碼裡,這些手續不會那麼顯眼。
分析邏輯會更直接地浮現出來。
這個差異,在 AI 時代特別重要。
因為要判斷分析結果能不能信,人類必須快速讀懂 AI 生成的程式碼,判斷它是不是照著原本的意圖在做。
為什麼 R 會比較好讀
那麼,為什麼 R 的程式碼會比較好讀呢?
原因有很多,這裡先聚焦在三個最重要的點:
- 邏輯和實作手續是分離的
- 向量化是語言的基本前提
- 透過 NSE,可以自然地處理欄位名稱
下面逐一說明。
1. 邏輯和實作手續是分離的
資料分析程式碼一向都有兩個層次。
一個是邏輯。
也就是「想做什麼」。
例如:
想篩選 2020 年以後的資料。
想依地區分組彙總。
想計算銷售總額與購買次數。
另一個是實作手續。
也就是「要怎麼讓電腦執行」。
例如:
- 怎麼存取欄位
- 怎麼保存中間結果
- 怎麼處理索引
- 怎麼整理輸出格式
資料分析程式碼會變難讀,通常就是因為這些實作手續太過顯眼。
在 R 裡,很多資料操作都會被表達成動詞。
filter()mutate()group_by()summarise()arrange()select()
這些都是很接近分析者腦中操作的詞。
所以讀程式碼時,比起看到一堆實作細節,更容易看見分析流程。
再看一次剛才的程式碼:
sales %>%
filter(year >= 2020) %>%
group_by(region) %>%
summarize(total_sales = sum(sales))這段程式碼可以從上往下直接讀。
- 接收資料
- 用條件篩選
- 分組
- 彙總
這很接近分析者的思考順序。
當 AI 產生這樣的程式碼時,人類也更容易讀懂並確認它是否符合意圖。
2. 向量化是語言的基本前提
R 的一大特色就是向量化。
所謂向量化,是指不是一列一列地處理資料,而是一次對整個欄位或整個向量套用運算。

例如,如果你想把銷售額乘以 1.1:
在 R 裡可以這樣寫:
sales * 1.1這會對 sales 裡的所有值都套用 1.1 倍的計算。
反過來,在 Python 的一般串列中,會寫成:
[s * 1.1 for s in sales]這裡是逐一處理每個值,再移到下一個值的迴圈式寫法。
再想一個有條件的計算。
如果 sales 超過 100,就套用 10% 折扣。
在 R 中,可以使用條件計算函數 ifelse,寫成:
ifelse(sales > 100, sales * 0.9, sales)這裡直接表達了三件事:
- 條件:
sales > 100 - 符合條件時:
sales * 0.9 - 不符合條件時:
sales
這和 Excel 的 IF 函數非常接近。
剛才的 Python 版本則是:
[s * 0.9 if s > 100 else s for s in sales]不過,Python 依照不同函式庫會有很多寫法,例如使用 pandas 和 NumPy 時,也可以做向量化處理:
df['sales'] = np.where(df['sales'] > 100, df['sales'] * 0.9, df['sales'])只是,R 的向量化是語言本身的基本前提,因此不需要因為使用的套件不同,而去學不同的寫法或處理方式。
因此在 R 裡,分析者會自然地從「逐列處理」變成「對整個欄位進行轉換」的思考方式。
這也會大幅影響可讀性。
因為在資料分析裡,我們腦中常常想的不是逐列處理,而是欄位層級的轉換。
例如:轉換銷售額欄位、從日期欄位取出月份、依客戶彙總、依類別計算平均值,等等。
以向量化為前提的 R 程式碼,能夠很自然地表達這種思考方式,因此對人來說通常更容易讀懂。
3. NSE 讓欄位名能自然處理
支撐 R 可讀性的另一個重要機制,就是所謂的 NSE。
NSE 是 Non-Standard Evaluation 的縮寫,中文通常譯作「非標準求值」。
這聽起來有點抽象,但從資料分析的角度來看,可以這樣理解:
讓資料框的欄位名稱,可以像一般變數一樣直接寫出來的機制。
例如,如果你想用銷售額減成本來算利潤,在 R 中可以寫成:
df %>%
mutate(profit = sales - cost)這字面上的意思就是:
profit 等於 sales 減掉 cost。
欄位名稱不需要加引號。
相較之下,在 Python/pandas 中通常會寫成:
df['profit'] = df['sales'] - df['cost']像 df['sales'] 這樣,每次都要寫出資料框名稱,並用引號包住欄位名稱。
這不代表這段程式碼難懂,只是因為 R 的多餘符號和結構比較少,所以更容易看出分析意圖。
而且這個差異在處理越複雜的流程時越明顯。
例如,要依地區計算平均銷售額,在 R 中可以這樣寫:
df %>%
group_by(region) %>%
summarise(avg_sales = mean(sales))這可以直接讀成:
依 region(地區)分組,計算 sales 的 mean(平均值),並命名為 avg_sales。
同樣的處理,在 Python/pandas 中會是:
df.groupby('region')['sales'].mean().reset_index(name='avg_sales')這裡欄位名稱以字串形式指定,還要加上像 reset_index() 這樣的結構整理步驟。
再說一次,這不是在批評 Python 不好。
而是從「讓人讀懂並驗證 AI 生成的程式碼」這個角度來看,R 因為少了許多額外結構,更貼近分析意圖,所以更有優勢。
R 中對 NSE 的支援,讓 R 的程式碼更像是在表達「分析」,而不只是「計算步驟」。
AI 時代更重要的是「讀」,而不是「寫」
在 AI 會幫你寫程式碼的時代,程式設計的角色會改變。
過去談到程式設計,主要是在說寫程式碼。
但當 AI 能夠生成程式碼之後,人對程式碼最重要的能力,就不再只是「寫」。
更重要的是,能夠讀取、理解、驗證,並在需要時修正生成的程式碼。
這在資料分析中特別重要。
因為分析結果永遠伴隨著責任。
如果 AI 生成的程式碼,篩資料時用了和原意略有差異的條件呢?
如果彙總的單位和你原本想的不一樣呢?
如果遺漏值或重複列的處理方式不符合預期呢?
如果看不懂程式碼,就不可能發現這些問題。
但在商業環境裡,人們會根據輸出的數字做決策,根據輸出的圖表進行討論,根據輸出的 KPI 評估策略成效。
所以在 AI 時代,可讀性不只是偏好問題。
它是讓分析結果值得信任的基礎。
可讀性會帶來信賴性、可重現性與互動性
前面提到,程式碼越容易讀,就越能提升對結果的信任。
因為可以追蹤資料處理與分析流程,確認它是否符合自己的意圖。
但可讀性的好處不只如此。
程式碼可讀,對分析的可重現性也有幫助。
當你下週、下個月,或對另一份資料想再跑一次同樣的處理時,只要看得懂程式碼,就可以修改需要的地方並重複使用,而不必每次都請 AI 重新生成新程式碼。
有天天使用 AI 的人應該都知道,同一個問題,不一定每次都會得到完全相同的答案(在這裡就是程式碼)。
此外,可讀性也能讓分析更具互動性。
資料分析不是一次性就結束的。
當你看到一個結果,就會自然產生下一個問題。
- 如果按月份看呢?
- 再依地區看呢?
- 行銷活動前後有變化嗎?
- 如果再分成新客和既有客戶,差異會不會不同?
資料分析本來就是一個在問題與答案之間來回反覆的過程。只要程式碼能讀,就不需要每次都重新請 AI 幫你產出,然後等待回覆。
- 稍微改一下篩選條件。
- 改變分組單位。
- 加上一個計算公式。
你可以直接對程式碼做這些小修改,立即執行、立即確認。
結果就是,分析速度可以更接近思考速度。
我們在 Exploratory 中重視的事
其實,這種由可讀性帶來的「信賴性」、「可重現性」與「互動性」的概念,也是我們在打造 Exploratory 時很重要的前提。
例如,在 Exploratory 中,當你用自然語言輸入資料處理需求時,AI 會生成 R 程式碼。
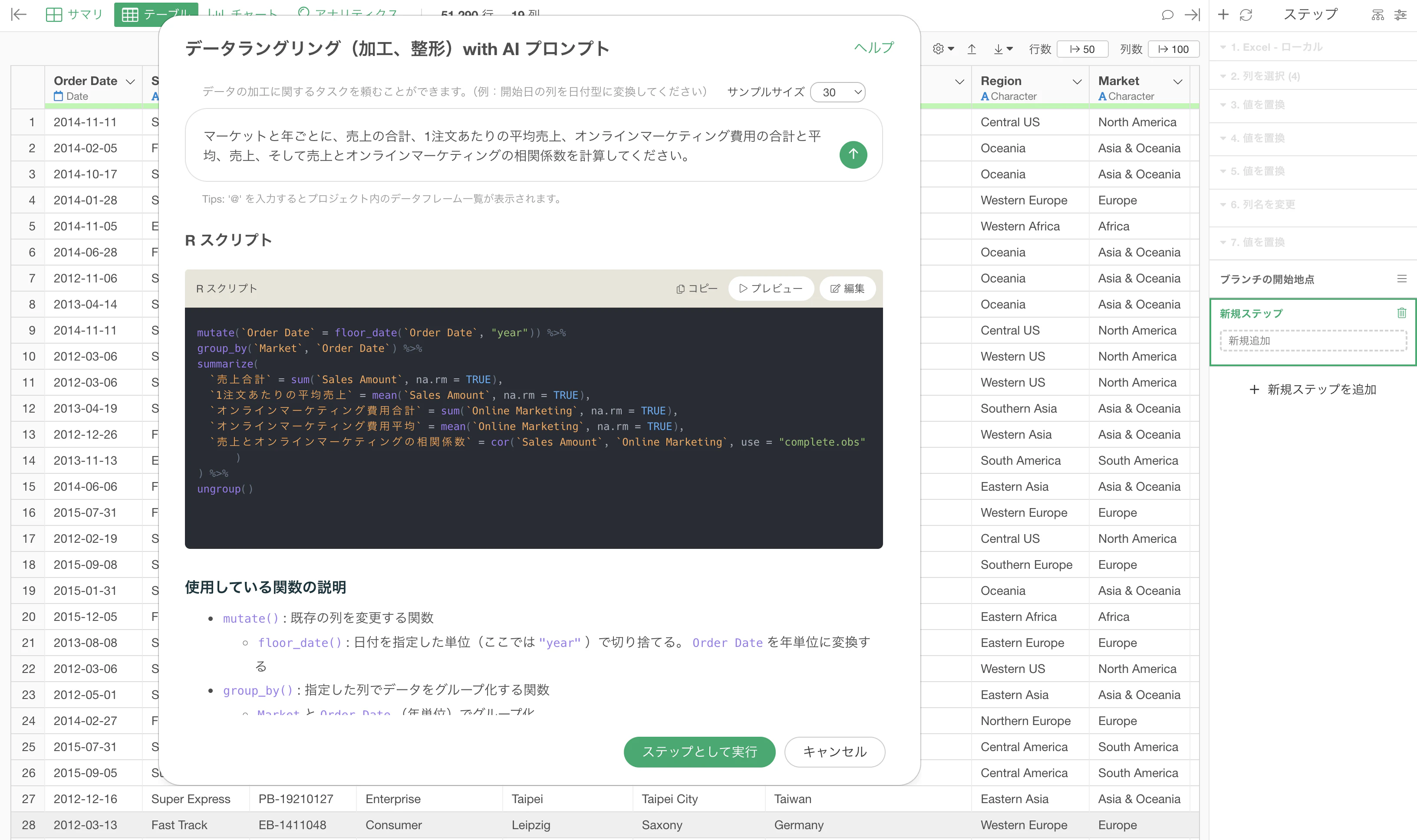
而且這段程式碼不會被藏在背後。
它會以使用者看得到的形式顯示出來,使用者也可以直接編輯。
而執行過的程式碼,也會保留成資料整理(data wrangling)的步驟。
也就是說,一方面可以用 AI 很快產生程式碼,另一方面又能確認、修改並重新執行它。
這是因為我們認為,在 AI 時代的資料分析裡,比起「能不能產生程式碼」,「能不能讀懂並信任這段程式碼」更重要。
總結
AI 讓寫程式碼變得比以往容易許多。
但在資料分析裡,重要的不只是能不能寫,或能不能生成程式碼。
更重要的是,能不能理解它在做什麼、能不能信任結果、以及能不能在需要時修改與重複使用。
在 AI 時代,這些能力會變得越來越重要。
也就是說,程式設計不是不再需要,而是程式設計的角色正在改變。
核心軸心會從「寫程式碼」轉向「閱讀、理解並驗證程式碼」。
而在這個新的世界裡,R 的可讀性會成為資料分析與資料科學的一大優勢。
R 的程式碼將邏輯與實作手續分離,以向量化為前提,並透過 NSE 自然地處理欄位名稱,因此可以用接近資料分析問題本身的方式來閱讀。
結果就是,程式碼不再只是對機器下指令,而更接近人類思考的表達。
正因為 AI 已經能寫程式碼,能夠閱讀的程式碼,才會成為可信賴資料分析的基礎。
透過 Exploratory 體驗 R 的可讀性
如果你也認同「在 AI 時代,比起寫程式碼,更重要的是能讀懂並理解程式碼」,那很推薦你親自試試看。
在 Exploratory 中,只要用自然語言描述你想對資料做的事,AI 就會生成「容易閱讀的 R 程式碼」。
而且你可以直接查看生成出來的程式碼,一邊理解它在做什麼,一邊推進分析。
不是反覆請 AI 重新產生答案,而是自己確認分析內容、修改它、並一點一點地擴展分析。
你可以這樣進行資料分析。
👉 下載 Exploratory
https://exploratory.io/download
如果你還沒有帳號,可以從這裡註冊,開始 30 天免費試用。
https://exploratory.io/
如果有任何問題或回饋,隨時都歡迎與我們聯絡。
[email protected]
原文出處:https://qiita.com/KanNishida/items/74103e76c26b55596f7a
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式