🔧 阿川の電商水電行


前言
這篇文章是「在生產環境中失誤的人 Advent Calendar 2025」的第14天。
我在這裡寫的故事,是關於我在很久之前不經意間使一個批處理變得極慢的經歷。至今仍然記憶猶新,回想起來會不禁想大喊「啊啊啊啊啊啊啊啊! 這傢伙到底在想什麼!」,忍不住會想找個橘子🍊來撞牆。
為了提醒自己要注意這類事情、這類不能做的行為,特地寫下來(對相關人士造成的困擾,真的很抱歉)。希望能對大家有所幫助。
參考)去年的失誤記事
發生了什麼「失誤」
有一個批處理在某位客戶的環境中運行。這個批處理是基於數個資料庫表格生成數據,並調用某個更新類的 API,這是一個非常常見的批處理。重點是:
- 數據量大,執行時需要花費相當的時間。
- 某個更新類的 API 在旁邊的伺服器運行,資料庫以非常快的速度作出響應。
- 因為調用了更新類的 API,所以簡單的重複執行是不可以的。(某個更新類 API 沒有冪等性)
因此,當我不慎地附加了一個字母後,批處理的速度變慢了五倍,完成的時間也超出了預期,給各方造成了困擾。
被「模式」這個詞吸引的糟糕工程師藤田🐱
請看這個 Java5 的 API 文件。這是熟悉的 RandomAccessFile。(當時是在用 Java5 編寫)

這裡有一個名為「模式」的參數。
| 值 | 意義 |
|---|---|
| r | 以讀取模式打開。若調用該物件的任意 write 方法,將拋出 IOException |
| rw | 以讀取和寫入模式打開。如果文件不存在,則會嘗試創建 |
| rws | 同「rw」,以讀取和寫入模式打開。當更新文件內容或元數據時,必須同時應用於基礎記憶體存儲中 |
| rwd | 同「rw」,以讀取和寫入模式打開。當更新文件內容時,必須同時應用於基礎記憶體存儲中 |
模式……某種事物有多種形式。漩渦鳴人九尾查克拉模式 和 JOJO 第二部卡兹的光之模式,我作為一名小小的宅男也對「模式」這一概念有著無法抗拒的誘惑。
此批處理中 RandomAccessFile 的用途
這次提到的批處理使用 RandomAccessFile 作為“指標文件”,以便在 Java 進程中途崩潰或停止時進行恢復,並且記錄處理到何處。這大致如下:
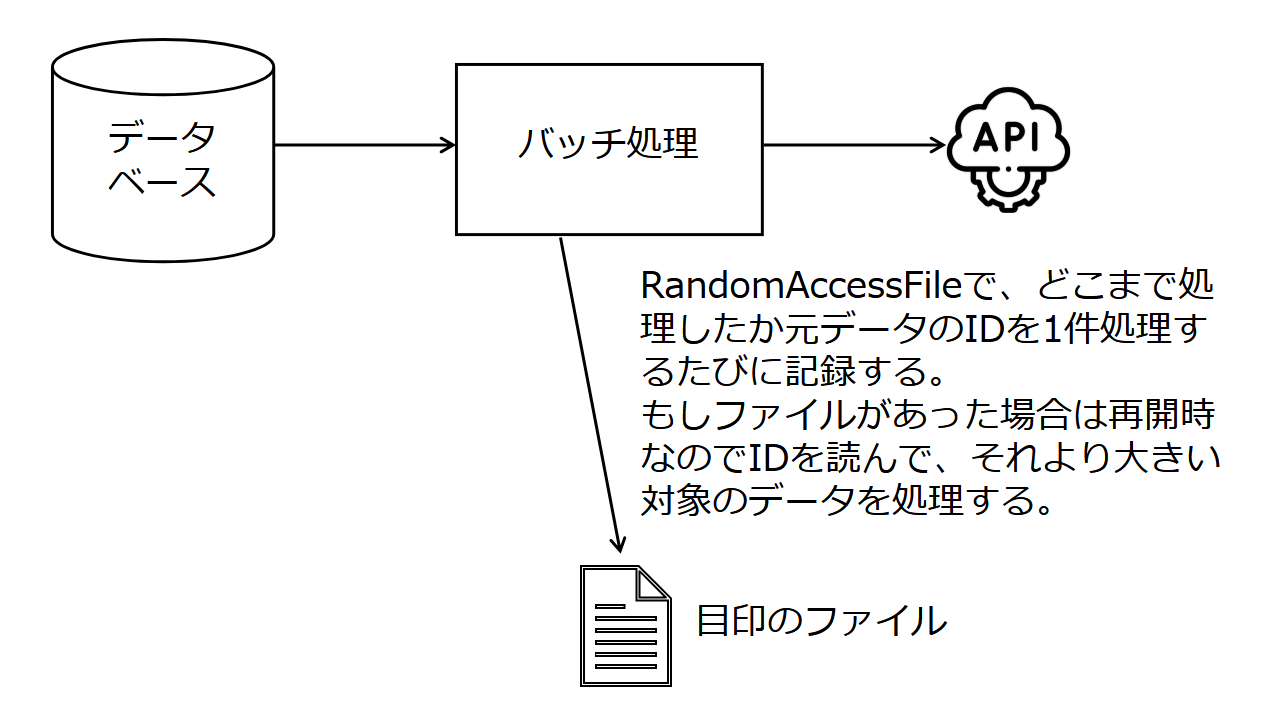
- 在批處理開始時檢查指標文件是否存在。如果存在,則用 RandomAccessFile 讀取文件末尾的 ID。如果不存在,則創建一個新文件。
- 當沒有指標文件時,處理所有數據並調用 API。當有指標文件時,由於是從崩潰後重新啟動,則加載 ID 大於讀到的值的數據並調用 API。無論在哪種情況下,數據都是按 ID 順序獲取的。
- 成功調用一次 API 後,使用 RandomAccessFile 更新指標文件(將 ID 轉為 byte[] 並追加到文件中)。
- 重複步驟 3。
- 在批處理正常結束時刪除指標文件。
那麼,我做了什麼
事情的發展始於某位客戶請求對這個批處理中的 API 進行更改,而由我藤田🐱負責。(這個處理是由當時的前輩們製作的。)
修改必要的部分,整體查看批處理時,當時的我心中不禁想著「這個 RandomAccessFile 是什麼?」。盯著程式碼一小時後,理解了指標文件的設計和目的。於是注意到 RandomAccessFile 的構造函數是:
RandomAccessFile mark = new RandomAccessFile("./mark", "rw")(當時從未使用過)查看 RandomAccessFile 的 API,知道上面有四種模式,並看到了這段說明。
“rws” 模式和 “rwd” 模式的行為,分別類似於對 FileChannel 類的 force(boolean) 方法傳遞 true 或 false 參數。但是,這些模式是適用於所有的輸入輸出操作,因此更有效率。
我藤田🐱「原來 rws 和 rwd 模式似乎更有效率。那很好,效率重要,處理量大……更新文件內容時,基礎記憶體……啊,是指文件,應該要更新rw 變成 rwd。進行測試,好的 OK🎵」於是變更為:
RandomAccessFile mark = new RandomAccessFile("./mark", "rwd")隨便更改後,將代碼提交,並在客戶環境中發布。
隔天早上的電話鈴聲
發布後的隔天早上5點30分,我的手機接到了客戶的電話。我起床應答客戶的電話。
客戶🧑「藤田先生,昨天發布的批處理,平常是4點開始,4點30分前結束,但今天5點30分了還沒結束,之後還有另外一個批處理要執行,這樣有困難。有沒有什麼在發布中發生了變化?」
藤田🐱「哦,能不能發送一下日誌文件的末尾給我?」※因為數據量大,日誌文件也很大
隨後,客戶發來的日誌文件中,記錄著每處理100件的批處理進度。發現進度比之前慢。可能在獲取數據的時候發生了什麼吧?我心中產生疑問,於是電話中請求獲取線程轉儲(*1)。
(*1) Java 的線程轉儲是在處理執行期間,特定瞬間的「所有線程狀態(棧追蹤和鎖定信息)」以文本形式輸出的資料,為了確定死鎖、無響應等性能下降的原因而收集的信息。
之後6點多,又響起了電話
客戶🧑「剛剛發送了線程轉儲。另外,剛才批處理終於結束了,後續處理開始了。請今天查明一下,明天避免再發生。」
藤田🐱「明白了,麻煩您了。」
問題批處理結束後我鬆了一口氣,並查看客戶發來的線程轉儲,隨即發出一聲慨嘆。
"Main":
at java.io.RandomAccessFile.write (RandomAccessFile.java:xxx)
at HogeBatch.java (HogeBatch.java:yyy)
at ……RandomAccessFile?!,咦,難道是因為我更改了那個部分而導致的?我突然想起,測試只是在100件的情況下進行的。
我慌忙趕到公司(當時並沒有遠程工作習慣),進行10000件的測試,果然比之前慢許多。考慮到客戶環境中的數據量,這樣的慢是不可接受的。心中隱約有著不祥的預感,將指標文件的 RandomAccessFile 模式改回 "rwd" 後,速度回到以前的水準。這個變慢的原因就是它。
簡單地恢復也不行
為了在明天之前解決問題,我開始調查 RandomAccessFile 的模式。終於了解到 rwd 是所謂的磁碟 IO 的同步(在 Linux 中,就是將存儲在內核快取中的數據寫入磁碟),這會導致每處理一件事時都會觸發磁碟 IO 的同步操作,從而變慢。
我開始考慮是否可以將 RandomAccessFile 的模式改回原本的 "rw"。但是,這樣做會有疑慮。如果是 "rw",在伺服器處理過程中,若伺服器的電源關閉,或整個 OS 停止,那麼當時指標文件的內容只存在於內存中,並未寫入磁碟。如果發生這種情況,則在恢復處理時,指標文件不能獲取到當時的內容,而是會獲取到較舊的內容,導致會重複調用 API 進行二次執行。
自從這個批處理投入運行以來,運行中的伺服器的電源未曾掉電或整個 OS 停止,所以出現二次執行的風險一直未顯現出來。
對應方案如下所述,但不論怎樣考慮,明天之內進行測試都是不夠的。
- 將指標文件的 RandomAccessFile 模式改回 "rw"。
- 在處理恢復後,調用旁邊伺服器的更新類 API 前,先呼叫參考 API。
- 根據 API 獲得的更新時間判別該批處理是否進行了更新(※這個批處理是唯一用於更新的)。
- 若有更新則跳過調用更新類的 API,接著處理下一個 ID(記錄於日誌)。若沒有更新則調用更新類的 API(之後則不需要檢查步驟 2 和 3)。
因此
- 在處理變慢的當日,只發布了「將指標文件的 RandomAccessFile 模式改回 "rw"」的修正。並告知客戶若伺服器宕機則會有二次執行的風險(客戶同意了)。
- 幾天後,發布了包含「在處理恢復後,調用旁邊伺服器的更新類 API 前,先呼叫參考 API」的修正第二版。
因此我們採取了兩階段的對應措施。
順便提一下,這個批處理約在三年前結束其任務,但「若有更新則跳過調用更新類的 API,接著處理下一個 ID」的幽靈現象從日誌調查中未曾發現過。
為了避免再次發生這種「失誤」,應該怎麼做
這主要是:
- 即便看似沒有問題也要避免隨意更改不必要的部分。進行變更時,必須在充分測試後再進行。
這一點非常重要。說真的就是如此。即便將 RandomAccessFile 的模式從 "rw" 變更為 "rwd",處理結果並未改變,但在當時的環境中,磁碟 IO 的速度相對較慢。因此,這一個字母的變更使得通常在30分鐘內結束的處理卻變為兩小時,速度變慢了四倍。
再加上
- 不要對未充分理解的事情冒然進行
這一點也很重要。「察覺自己是對事情理解不深」是很難的,但那時的我若能理解「效率」這個意義,就不會想隨意進行變更了。
“rws” 模式和 “rwd” 模式的行為,分別類似於對 FileChannel 類的 force(boolean) 方法傳遞 true 或 false 參數。但這些模式是適用於所有的輸入輸出操作,因此更有效率。
僅僅看到這個「有效率」,會讓人誤以為 "rws" 和 "rwd" 模式會更快,具有吸引力。通常,API 文檔中關於 rws 和 rwd 的「必須同時應用於基礎記憶體存儲」的描述,會讓你意識到是磁碟 IO 的同步操作,從而回頭,但我卻沒有這樣做,因而繼續前進了。
這個「有效率」,其實是指:
- 在 RandomAccessFile 寫入磁碟內容後,當強制同步以將其寫入磁碟時
- 使用 "rw" 打開 RandomAccessFile,且每次寫入時通過 FileChannel#force
- 與 "rws" 或 "rwd" 的情況相比,Java 和 OS 能夠自己處理,所以更加有效率
這意味著,並不是說與 rw 比較,某些輸入輸出操作會更有效率。
RandomAccessFile raf = new RandomAccessFile("./foo", "rw")
raf.write(data); //如果數據很大,是否會中途無法強制同步?
raf.getChannel().force(false); //每次都要這樣寫太麻煩,不會忘記嗎?因此,直接這樣寫會更有效率(API 文檔也這麼說):
RandomAccessFile raf = new RandomAccessFile("./bar", "rwd")
raf.write(data); //不會忘記,對於大型數據的同步可以交給 Java 和 OS這並不是說與 rw 相比,某些輸入輸出操作會更有效率。
結語
感謝您的閲讀。如有任何意見,敬請指正。
在現今 SSD 蓬勃發展的時代,我認為「改一個字母使批處理變慢四倍」的情況不太可能再發生,但我相信,隨意的變更仍可能導致災難,即使電腦的性能提升也一樣。我希望這篇文章能成為大家的「他山之石」。
原文出處:https://qiita.com/nfujita55a/items/260750312c565835acaf
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式