
2026年4月16日,Anthropic 發布了 Claude Opus 4.7。
同時,官方部落格「Best Practices for Using Claude Opus 4.7 with Claude Code」也已公開,Claude Code 作者 Boris Cherney 也在 X 上丟出了「6 個新技巧」。
兩者合起來,Anthropic 官方想表達的只有一件事:過去的 Claude Code 用法,今天開始就別再用了。
到 4.6 為止還正確的做法,在 4.7 可能會變成反效果。
「別再像在做 pair programming 一樣細細指示」

到 4.6 為止那種「指示越細,模型就越聰明」的感覺,在 4.7 反而會降低效能。官方部落格開頭就直接寫明了。
"Treat Claude more like a capable engineer you're delegating to than a pair programmer you're guiding line by line."
(與其把 Claude 當成你逐行帶著做的 pair programmer,不如把它當成一位可以放心交辦的工程師)
到 4.6 為止,「送出提示」→「看回傳程式碼再修正」→「再看下一輪回傳」這種來回式流程是標準做法。4.7 則捨棄了這個前提。
官方建議的方式只有一個。
"Specify the task up front, in the first turn."
(在第一輪就把任務完整指定清楚)
在第一次提示中,把 Goal(目標)/Constraints(限制)/Acceptance criteria(驗收條件) 一次放進去。之後盡量減少中途介入,4.7 才能發揮自主執行的能力。
設計思維的變化
官方用 3 點來說明 4.6 與 4.7 的差異:
- 優先推理,而不是工具呼叫
- 對 Subagent 的呼叫更加謹慎(如果自己能完成,就不呼叫)
- 長期自主執行能力提升
到了這一步,「指示越細就會越聰明」的老觀念就反而成了負擔。因為指示越細,自主判斷的空間就越小。可以說,Claude Code 在 4.7 之後,正確的提示詞寫法已經完全反過來了。
「把 Effort Level 常駐設成 max」也別再做了
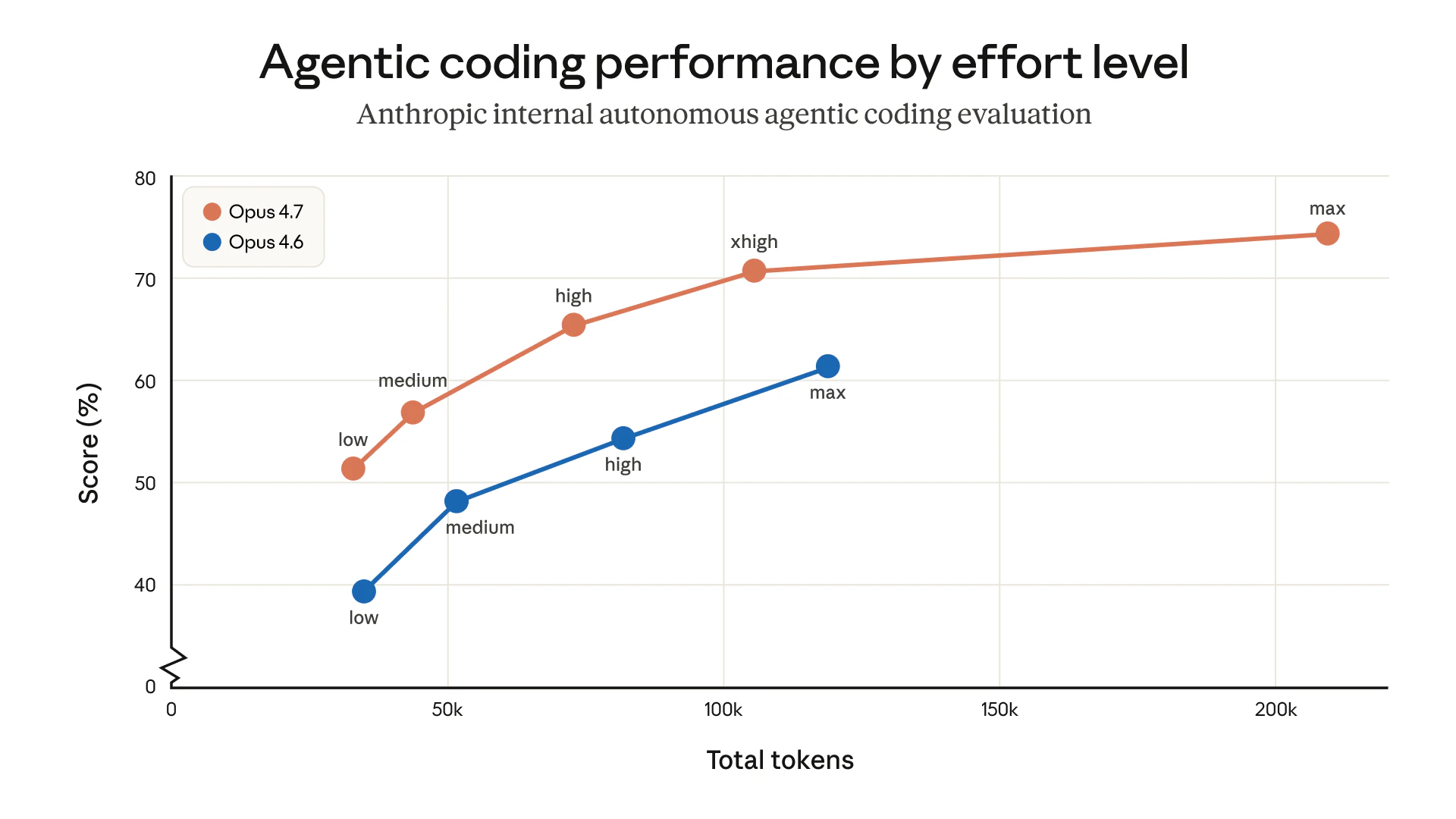
「最高的 max 就是最聰明」這個想法,從今天起請丟掉。Claude Code 的 Effort Level 分成 5 階,官方建議的預設值不是 max,而是 xhigh。
| Level | 官方用途 |
|---|---|
| low | 簡短、重視延遲、不需要太多智能 |
| medium | 重視成本,能接受犧牲一些智能 |
| high | 平衡型(建議 Sonnet) |
| xhigh | Opus 4.7 的建議預設。大多數程式開發任務的最佳選擇 |
| max | 高要求任務使用,容易 overthinking |
官方原文是這樣說的:
"On Opus 4.7, the default effort is
xhighfor all plans and providers."
(在 Opus 4.7 中,所有方案與供應商的預設 effort 都是xhigh)
要特別注意的是 max 的定位。「越高越聰明」並不正確。官方還明講 max 有「overthinking」傾向,也就是想太多,可能導致變慢,甚至反而讓精度下降。Boris 也在 X 上寫到,大多數任務用 xhigh,只有最難的任務才用 max。
規格上的重要變更
以下內容已明載於 Anthropic 官方 API 文件「What's new in Claude Opus 4.7」 的 "Breaking changes" 段落。這些變更只適用於 Messages API,使用 Claude Managed Agents 時不受影響。
- fixed thinking budget 模式不再支援(
thinking: {type: "enabled", budget_tokens: N}會回傳 400 錯誤) - adaptive thinking 預設關閉,需要明確指定
thinking: {type: "adaptive"} temperature/top_p/top_k若設成非預設值也會回傳 400 錯誤(改為以提示詞控制行為)- tokenizer 已更新:相同文字可能變成 1.0~1.35 倍 的 token 數,請為
max_tokens預留空間 - thinking content 預設會省略;若需要可用
display: "summarized"取回
調整手段已收斂為兩條:effort(在 Claude Code 中就是 /effort)與 task_budget(beta)。
Claude Code 的版本需求也改了。必須是 v2.1.111 以上,才能呼叫 Opus 4.7。若版本太舊,就無法享受到新模型的能力,請先確認更新。
claude --version
# 若是 2.1.110 以下,請更新「常用 --dangerously-skip-permissions」也別再做了
把 --dangerously-skip-permissions 當成日常工作流程,到了 2026 年 4 月已經過時。Boris 同一天在 X 上發表的「6 個新技巧」裡,有 2 個就是用來安全取代這種權限提示的。
Auto Mode
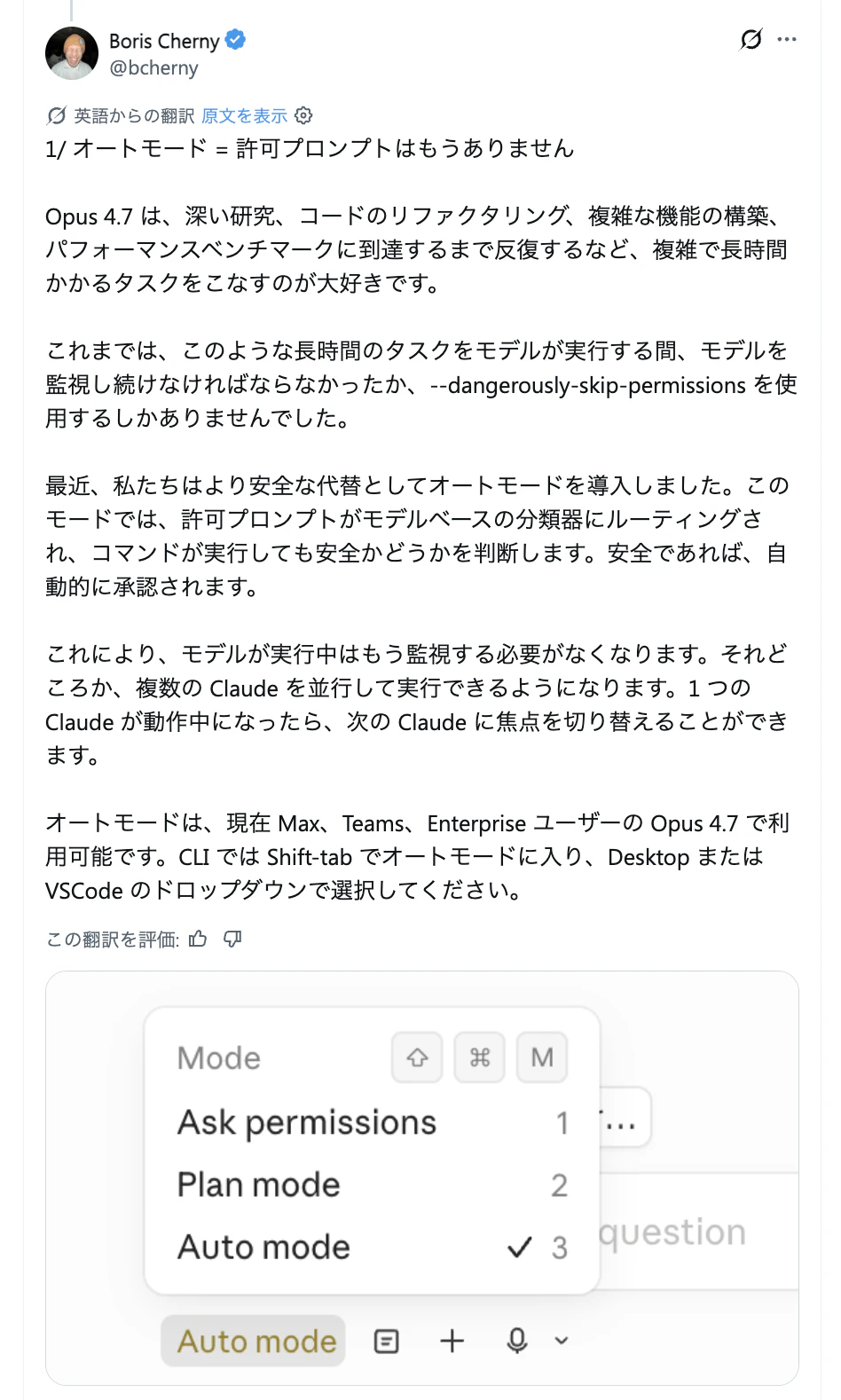
使用 Claude Code 時,最常遇到的就是一直跳出「Allow?」要你按允許。Auto Mode 就是用來解決這個問題的。官方說明如下:
"A classifier model reviews commands and blocks only what looks risky: scope escalation, unknown infrastructure, or hostile-content-driven actions."
(分類模型會審查指令,只阻擋看起來有風險的內容:例如範圍升級、未知基礎架構,或由敵意內容驅動的操作)
啟動方式很簡單:
claude --permission-mode auto -p "fix all lint errors"這是 Max / Team / Enterprise 方案限定的 Research Preview 功能,但官方把它定位成--dangerously-skip-permissions 的正確替代方案。
/fewer-permission-prompts
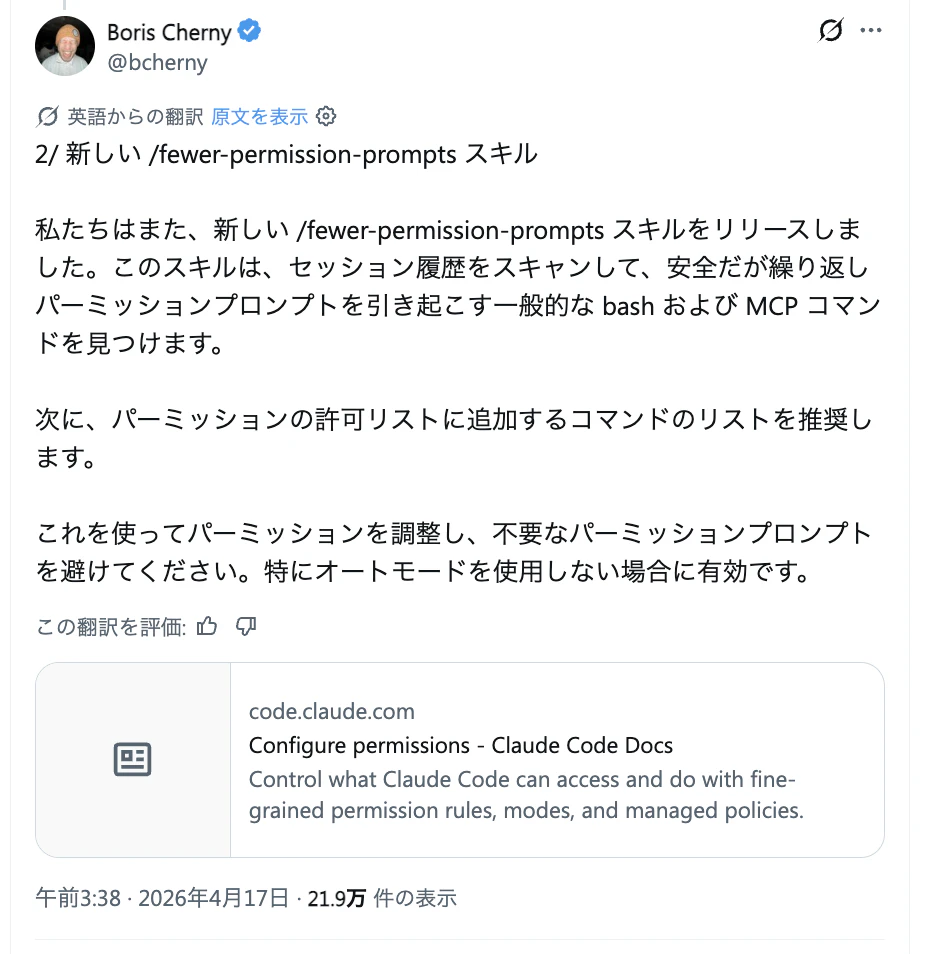
這是同步新增的 Skill。
- 分析工作階段歷史,提議加入允許清單
- 偵測是否反覆批准同一類指令
- 接受提議後,之後就會自動通過
這個功能相當於把原本要在 /permissions 手動加入白名單的工作,做成了半自動化。即使是不能使用 Auto Mode 的 Pro 方案,也可以使用。
方案別可用性
| 功能 | Pro | Max | Team | Enterprise |
|---|---|---|---|---|
| Auto Mode | × | ○ | ○ | ○ |
/fewer-permission-prompts |
○ | ○ | ○ | ○ |
/permissions |
○ | ○ | ○ | ○ |
如上所示,Auto Mode 能提供安全且等效的體驗。
「長時間 session 還一直在旁邊盯著」也別再做了
4.7 的自主執行時間更長了。請停止一行一行盯著看,改成只接收結果的工作方式。Boris 本人在 X 上介紹的兩個 UI 功能,就是用來支援這種模式的。
Focus Mode(/focus)

/focus這個模式只顯示最終結果,會隱藏中途的思考與工具使用紀錄。可以用 /focus off 回到原本模式。它非常適合委派式使用流程,也就是「交出去,最後只看結果」。
Recaps
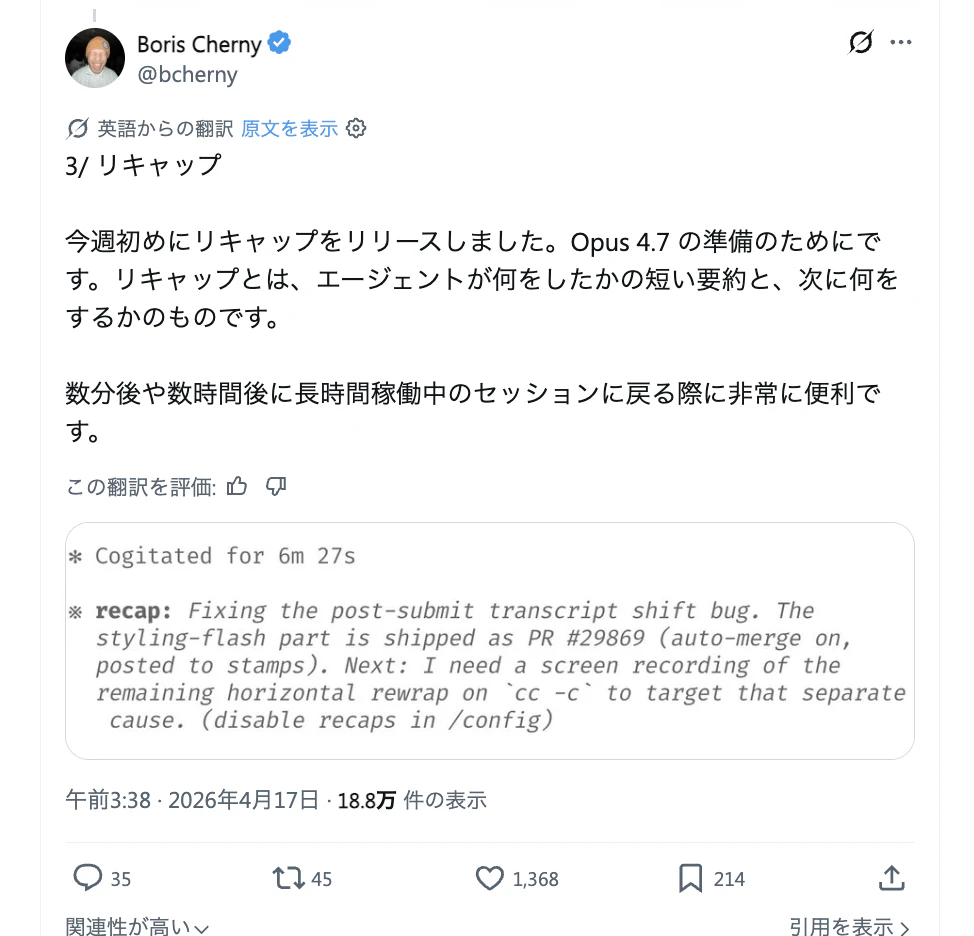
這是用來在長時間 session 結束後回來時,自動顯示摘要的功能。Boris 將它描述為「幫助準備 agent 做了什麼、下一步要做什麼」的 UI。即使你回到一個已經跑了好幾個小時的 /loop 任務,也能立刻掌握「目前做到哪裡、接下來要做什麼」。
這兩個功能都是以 4.7 長期自主執行 為前提設計的 UI。Anthropic 的立場很明確:要讓你透過可視化,感受到「不需要一直盯著看」。
「每次都叫 Subagent」也別再做了

到 4.6 為止那種「積極使用 subagent」的做法,請丟掉。4.7 的官方部落格寫的是完全相反的概念。
"More judicious about when to delegate work to subagents."
(在把工作委派給子代理時,要更審慎)
什麼時候明確呼叫
官方明確列出的條件只有兩個:
- fanning out across files(跨多個檔案並行展開工作)
- independent items(彼此獨立的多個任務)
除此之外,就交給 Claude 自己判斷。像以前那樣每次都加上「請用 subagent」這種指示,有些情況下反而會讓效能下降。因為 4.7 是以自己判斷為前提訓練的。
「沒有驗證機制就直接交辦」也別再做了

6 個「別再做了」的最後一項,也是官方明說最有槓桿效果的做法,就是這個:
"Include tests, screenshots, or expected outputs so Claude can check itself. This is the single highest-leverage thing you can do."
(加入測試、截圖或預期輸出,讓 Claude 可以自行驗證。這是你能做的、槓桿效果最高的一件事)
即使模型變聰明了,只要沒有驗證機制,品質就不會真正提升。
實作模式
後端:把測試套件接到 Stop Hook。讓 Claude 一直自動重跑,直到 npm test 通過為止。可以在 .claude/settings.json 這樣寫:
{
"hooks": {
"Stop": [
{
"hooks": [{ "type": "command", "command": "npm test" }]
}
]
}
}前端:使用 Playwright / Puppeteer 做 E2E,或使用 Chrome 擴充功能。Boris 本人表示他「每次都會用」Chrome 擴充功能。
4.7 特有的狀況
4.7 的自主執行會更長,所以中途沒人看的時間也變多了。如果沒有驗證機制,任務往錯誤方向一路跑下去的風險也會跟著上升。
建議的組合是 xhigh × 長期自主執行 × 驗證機制 這三件事。品質會不會提升,關鍵不在模型差異,而在於你有沒有提供驗證機制。
今天要做的實務設定檢查清單
把以上同日公開的內容整理成設定項目如下。
1. 將 Claude Code 更新到 v2.1.111 以上
claude --version2. 將模型設為 Opus 4.7,Effort 設為 xhigh
/model opus
/effort xhigh3. 整理第一次提示的格式
Goal: <想達成的目標>
Constraints: <必須遵守的限制>
Acceptance criteria: <完成判定標準>4. 建立 Verification Loop
- 後端:把測試接到 Stop Hook
- 前端:使用 Playwright 或 Chrome 擴充功能
5. 試試 Auto Mode(Max 以上方案)
claude --permission-mode auto整理成核取方塊就是這樣:
- 確認 Claude Code 已更新到 v2.1.111 以上
- Opus 1M context 已啟用(Max / Team / Enterprise 會自動套用)
- 將 xhigh 設為 Effort 預設
- 養成在第一次提示中一次提供 Goal / Constraints / Acceptance criteria 的習慣
- 用 Stop Hook 建立驗證機制
- 用
/fewer-permission-prompts整理允許清單
同日登場的其他不能錯過的新功能
除了 Opus 4.7 發布與最佳實踐文章之外,還有 3 個雖然不是本文主軸、但對實務很有幫助的新功能。
/ultrareview 指令(Claude Code)
這是配合 4.7 新增到 Claude Code 的 review 指令。它會從多個角度更嚴格地檢查程式碼,很適合在 PR 前做最後確認。
Task budgets(beta)
這是能把整個 agent loop 的 token 預算,以建議值的方式告訴模型的新功能。max_tokens 是限制單次請求的上限;task budget 則是給 agent 的建議上限,讓它自己分配節奏。
response = client.beta.messages.create(
model="claude-opus-4-7",
output_config={
"effort": "high",
"task_budget": {"type": "tokens", "total": 128000},
},
betas=["task-budgets-2026-03-13"],
...
)最低值是 20k;若是重視品質的探索型任務,通常不建議設定。
高解析度圖片支援
圖片最大解析度擴大到 2576px / 3.75MP(先前是 1568px / 1.15MP)。這對截圖分析、文件理解,以及 computer use 都有幫助。另外,模型座標系統與實際像素已經 1:1 對齊,所以不需要再做座標換算。
總結
2026 年 4 月 16 日,Anthropic 在官方部落格發布的最佳實踐,以及 Claude Code 作者 Boris Cherny 同日在 X 上丟出的 6 個新技巧,結論都指向同一件事:過去的 Claude Code 用法,今天起該畢業了。
pair programming、常駐 max、--dangerously-skip-permissions、每次都叫 Subagent、沒有驗證機制就做自主執行、長時間 session 一路盯著看。到 4.6 還正確的 6 種做法,在 4.7 全部都變成「別再做了」。
4.7 的真正價值,只有在你不去中途介入時才會顯現。把這 6 種舊做法停掉,改成以「交辦」為前提來調整設定吧。
參考
- Best Practices for Using Claude Opus 4.7 with Claude Code(Anthropic 官方,2026-04-16)
- What's new in Claude Opus 4.7(Anthropic 官方 API 文件)
- Introducing Claude Opus 4.7(Anthropic 官方發表,2026-04-16)
- Boris Cherny「6 個新技巧」X 貼文(2026-04-16)
- Boris Cherny 6 tips 存檔(GitHub)
- Claude Code 官方文件
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式