

引言
近來,各種生成AI技術蓄勢待發,筆者每天都在努力追趕。
雖然根本跟不上,,,
因此這次整理了關於「RAG」的學習內容,希望對生成AI初學者們有所幫助。
RAG(檢索擴充生成)是什麼?
RAG(Retrieval-Augmented Generation)在日文中稱為「檢索擴充生成」。
檢索擴充生成??這是什麼呢?
第一次聽到時,很多人可能會有這樣的疑惑。(筆者也是其中之一)
簡單來說,RAG是
在大語言模型(LLM)生成回答之前參考外部知識,並將其內容包含在提示中,以提高回答的精確度的機制。
這裡的「知識」主要是從向量資料庫中參考得來的。
形象圖
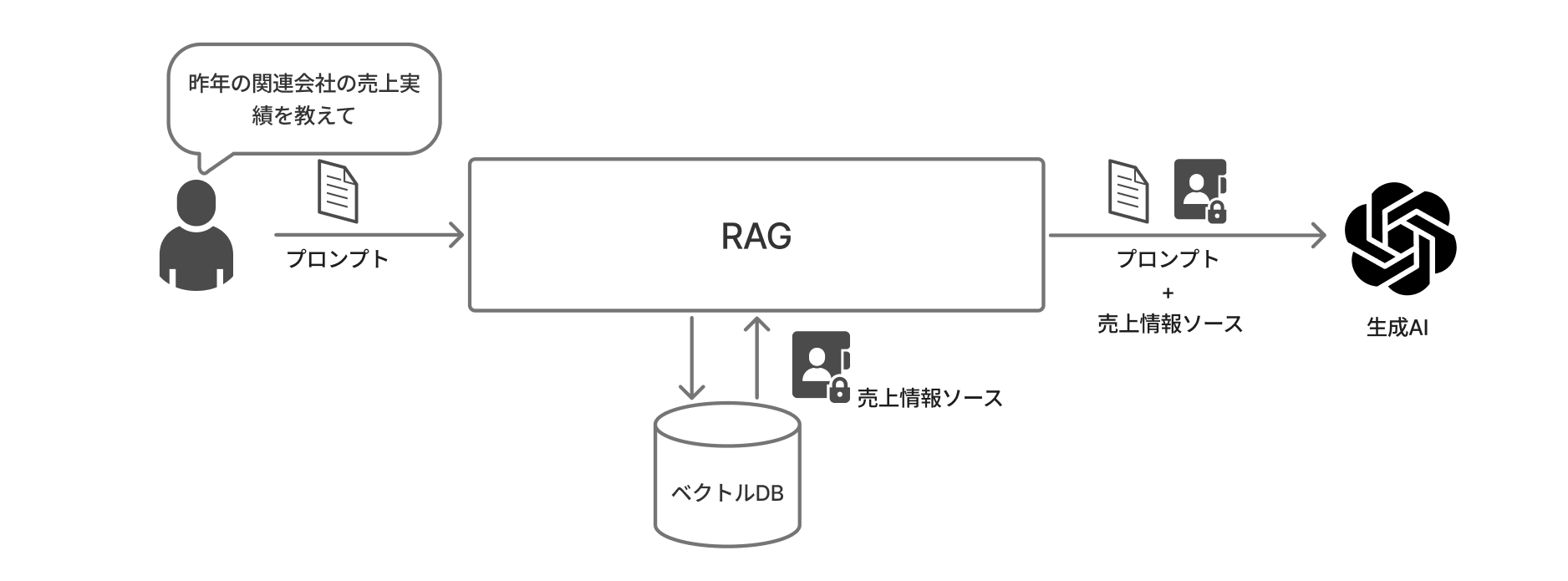
從向量DB獲取與輸入提示內容相似度高的內容,並將其與提示一起傳遞給LLM。
這樣一來,問題內容更容易被納入LLM的上下文窗口,期待能減少不必要的令牌消耗和幻想風險。
上下文窗口
在模型生成響應時,可以參考和記憶的文本或數據量。
幻想
生成AI輸出看似合理的謊言,卻如同真實一樣的現象。
將數據的意義數值化「嵌入」
實現RAG所必不可少的就是嵌入(Embedding)。
這是指將文本或圖像轉換為計算機易於處理的多維數值(向量)。
在向量資料庫中註冊數據時,需要將希望註冊的數據進行向量化。
實作範例
from openai import OpenAI
client = OpenAI()
# 獲取給定文本的向量嵌入
def get_vector_embeddings(text):
response = client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
embeddings = [r.embedding for r in response.data]
return embeddings[0]
display = get_vector_embeddings("有馬紀念")
# 獲取嵌入數據的數量
print(len(display))
# 獲取向量數據
print(display)輸出結果
1536
[-0.04045114293694496, -0.003843134269118309, -0.0005096892127767205
...中略...
-0.01759224757552147, 0.003422629786655307, -0.009237308986485004]解說:
上述實作中對「有馬紀念」這個單詞進行了嵌入處理。
嵌入使用了OpenAI的標準模型text-embedding-ada-002。
這個模型將一個單詞或句子表示為1536維的數值。
因此,能夠更深入地捕捉單詞的意義以及單詞之間的關係。
在上述的輸出結果中,第一行的「1536」表示生成的嵌入向量值的數量。
由於模型有1536維,因此產生了1536個向量值。
第二行到第四行是實際的向量值。(由於1536個太多,這裡只摘取了一部分)
向量資料庫是什麼?
指的是以向量形式保存和管理數據的資料庫。
與傳統資料庫以「關鍵字匹配」進行搜尋不同,向量資料庫的最大特點在於以「意義的相近度(相似性)」進行搜尋。
向量是指在高中數學中學過的「大小」和「方向」的數值表徵。
由於向量資料庫中保存的向量數據同時具有「大小」和「方向」,因此能夠處理高維數據,有效地處理和搜尋大量數據。
搜索與輸入內容距離接近的數據(相似性高的數據)是其最大特色,廣泛應用於機器學習和數據分析等各個領域。
建立向量資料庫的流程
- 切分(Chunking): 將目標數據按合適的長度切分
- 嵌入: 將切分後的數據向量化
- 文檔加載: 將向量化的數據存儲到變數中
- 索引創建: 創建索引並存儲向量數組
- 持久化: 保存第4步,以建立向量資料庫
為向量資料庫附加索引
完成文本的切分、嵌入和文檔加載後,就可以將其保存到向量資料庫中。
不過,如前所述,保存的向量維度很高,要從大量的向量中獲取相似數據將需要大量的計算和時間。
※text-embedding-ada-002為1536維
為了避免這種情況,這裡引入的機制便是索引。
透過附加索引,可以加速相似搜索。
簡單來說,索引就像是「快速尋找特定數據的『索引』」。
這裡不再詳述,但若想進一步了解,可以參考以下頁面。
什麼是索引?淺顯易懂的解說
向量的保存和搜索可使用Faiss(Facebook AI Similarity Search)庫。
RAG的實作:從文檔搜索到回答
考量文本的切分、嵌入、文檔加載和索引的內容,這裡提供向量DB的建立和搜索的實作範例。
實作範例1:數據讀取與向量DB構建
from email import message
import glob
from langchain_community.document_loaders import PDFMinerLoader
from langchain_text_splitters import CharacterTextSplitter
import numpy as np
import faiss
from openai import OpenAI
import os
from dotenv import load_dotenv
# 讀取PDF檔案
# 這裡設置目標檔案(PDF)。
pdf_files = glob.glob("sample.pdf")
for pdf_file in pdf_files:
loader = PDFMinerLoader(pdf_file)
data = loader.load()
# 切分
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=100, separator="\n")
chunks = text_splitter.split_documents(data)
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 嵌入處理
def get_vector_embeddings(text):
text = text.replace("\n", " ")
response = client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
embeddings = [r.embedding for r in response.data]
return embeddings[0]
# 創建嵌入
emb = [get_vector_embeddings(chunk.page_content) for chunk in chunks]
# 文檔加載
vectors = np.array(emb)
# 創建索引
index = faiss.IndexFlatL2(vectors.shape[1])
# 註冊數據到索引
index.add(vectors)
# 數據庫持久化
faiss.write_index(index, "★保存資料庫的路徑★")實作範例2:向量DB搜索與回答生成¹
# 向量DB搜索
def vector_search(query_text, k=1):
query_vector = get_vector_embeddings(query_text)
distance, indices = index.search(np.array([query_vector]), k)
return [(chunks[i], float(dist)) for dist, i in zip(distance[0], indices[0])]
# 聊天響應
def search_and_chat(user_query, k=1):
search_results = vector_search(user_query, k)
prompt_with_context = f"""上下文:{search_results}
問題回答:{user_query}"""
messages = [
{"role": "system", "content": "請回答用戶的問題。回答時僅使用提供的上下文,如果不知道答案請回答「不知道」"},
{"role": "user", "content": prompt_with_context},
]
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
print(f"""響應:{response.choices[0].message.content}""")
# 搜索查詢
user_query = "Redux的內容哪一章最值得閱讀?"
search_and_chat(user_query)最後
通過利用RAG,大語言模型(LLM)將從「只說自己知道的事」轉變為「邊查資料邊準確回答」。
這次使用了在本地運行的Faiss,但在實務中,雲端型的Pinecone或Chroma等更適合大規模資料的向量DB也有很多。
這些文章將在以後的機會中發表。
- import和get_vector_embeddings()將使用與向量DB存儲相同的內容。 ↩
原文出處:https://qiita.com/nAotO01_03/items/cfc2013f38ca95578652
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式