

こんにちは、DeNA 擔任資料科學家的まつけん。
這次我想針對在 Transformer 中扮演重要角色的 Self Attention,特別是 QKV 的機制,做一個能直觀理解的說明。
在 Transformer,尤其是 GPT 這類生成模型中,會透過如下的 Self Attention 計算:
O = \mathrm{softmax}\left(\frac{QK^{\mathrm{T}}}{\sqrt{d_k}} + M\right)\cdot V藉由這樣的計算,模型能夠根據每個詞彙先前的上下文進行語境化,並實現對長篇文字的理解。這篇文章會把重點放在直觀、好理解地說明這個公式到底在做什麼。
概略:
本篇文章中的幾個簡化前提
- 為了方便理解,先假設 token 是以單字為單位。實際上的 GPT 系列模型,輸入並不是單字本身,而是會切分成 token;但本篇會優先考量直觀理解,因此把每個 token 當作「單字」來說明。
- Q、K、V 並不是原始單字 embedding 本身,而是對各 token 表示做線性轉換後得到的向量序列;不過為了讓直觀理解更容易,本投影片會先把每一列當成對應到單字的向量來看。
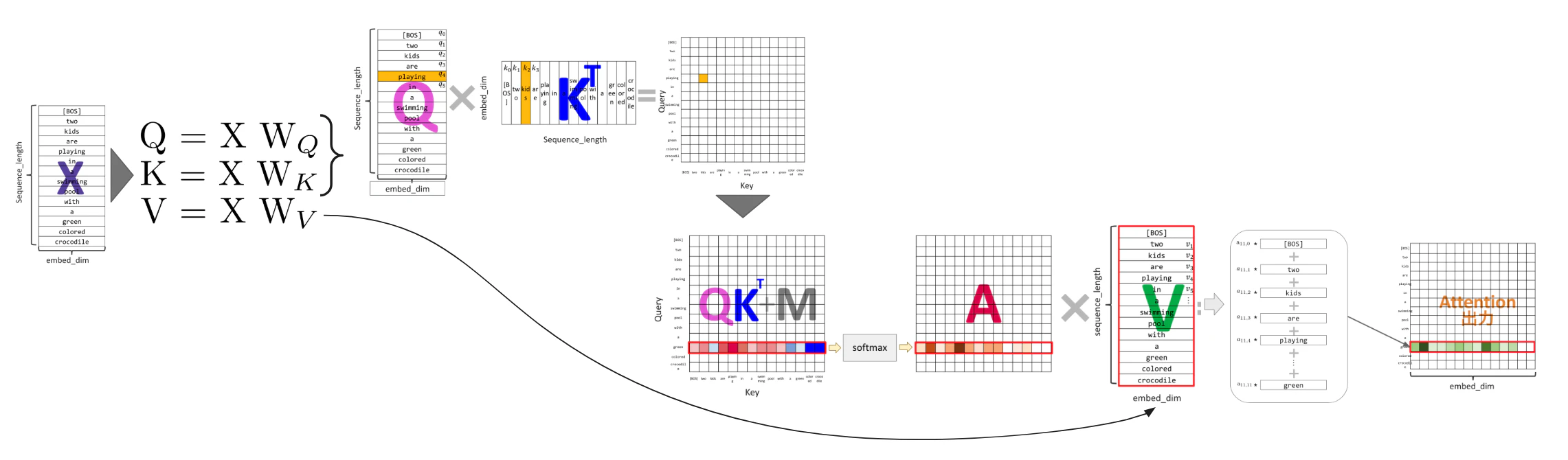
從輸入建立 Query、Key、Value
在 Transformer 的 Self-Attention 中,會從各單字的表示 X 產生三種向量序列:Query:Q、Key:K、Value:V。可以把 Query 理解成「要去找什麼」、Key 理解成「對什麼樣的查詢會有反應」、Value 則是「實際會傳遞到輸出的資訊本體」。
像 GPT 這樣的生成模型,會透過 causal mask 讓模型不能看到未來的 token,同時讓每個單字從自己與過去的單字中,依權重彙整所需資訊。
$Q, K, V$ 會像下面的式子一樣,將輸入文章 X 分別乘上係數($W_Q, W_K, W_V$)後得到 $Q, K, V$。這些是由文章 X 經過轉換後得到的,但本篇為了方便想像,之後會先把它們當成各自對應到單字來看。
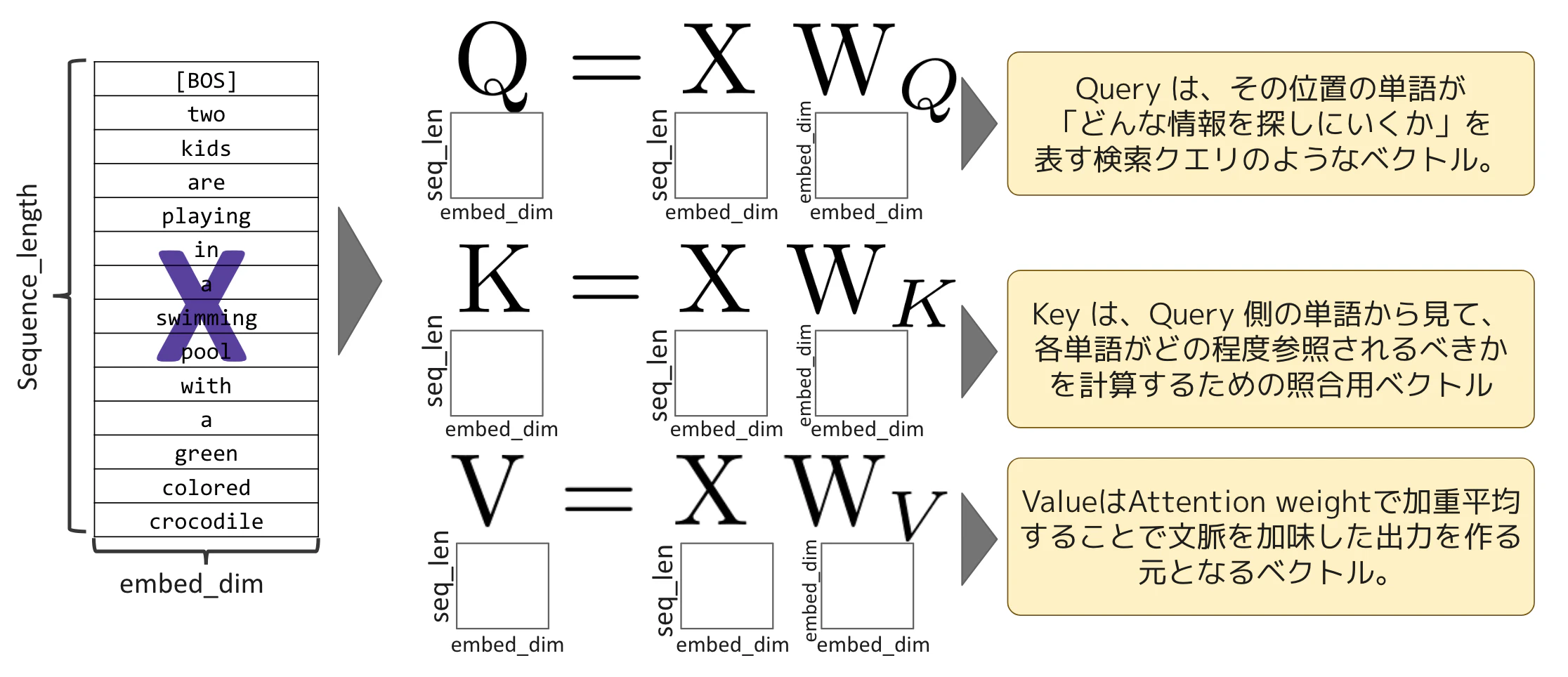
用 Q 和 K 表達單字之間的關係
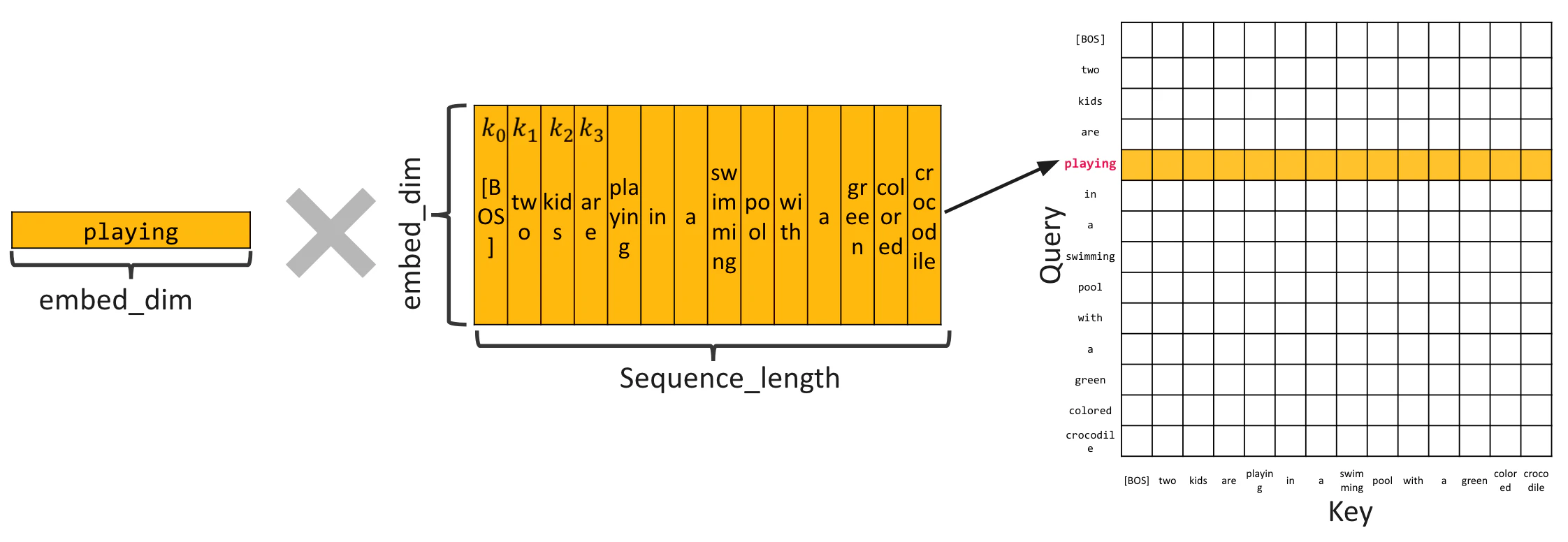
$\frac{QK^{\mathrm{T}}}{\sqrt{d_k}}$ 的分子部分,會對 Q 中每個單字與 K 中每個單字做內積,並把結果填入矩陣中。本文中,我們把這個內積粗略地解讀成單字之間關係強弱的表示。(關於內積的意義,可以參考這篇文章)
若兩個向量都是長度為 1 的單位向量,內積可以視為表示向量方向有多接近的相似度。這次雖然不是單位向量、而是具有長度的向量,但把它當作內積的一種印象來理解,會有助於掌握概念。
在 Self Attention 中使用這種具有意義的內積時,可以解讀為「Query 端的單字,對 Key 端各單字有多想參考的分數」。它有時會接近語意相似度,但實際上是包含上下文、文法關係、指涉關係等因素的、經過學習的配對分數。
本篇為了簡化,將 $d_k$ 視為單字 embedding 的維度1,而分母中的 $\sqrt{d_k}$ 則表示運算上的尺度調整2。
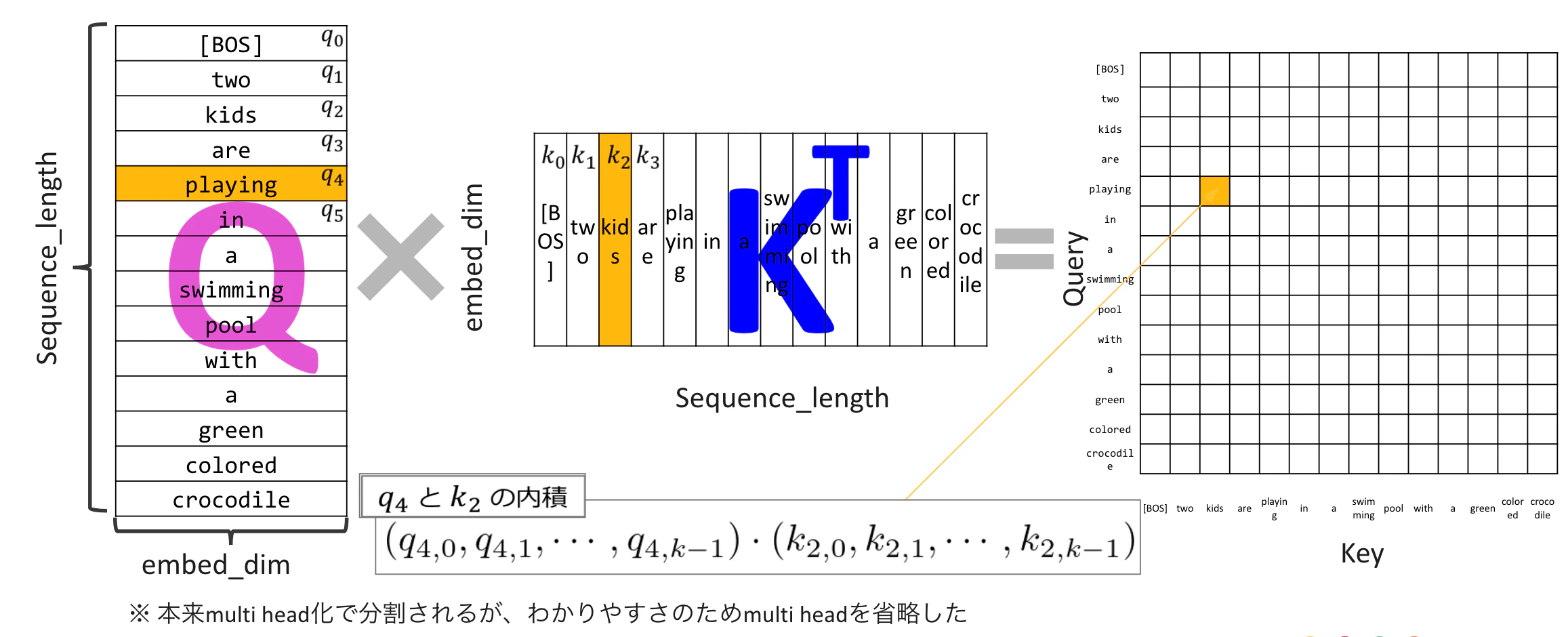
當聚焦在作為 Query 的 "playing" 時,會將 "playing" 分別與 Key 的各個單字做內積,並把結果放到 $QK^T$ 矩陣中對應 "playing" 的那一列。
接著看 $\frac{QK^{\mathrm{T}}}{\sqrt{d_k}} + M$。M 是用來做 mask 的矩陣。這個 mask 的目的,是避免在 next token prediction 時偷看答案,也就是讓 Query 端的單字只能參考自己和過去的單字。把右上角元素設為 -∞ 的矩陣加上去之後,在後續的 softmax 中,對應元素會變成 0,讓這些關係被忽略。
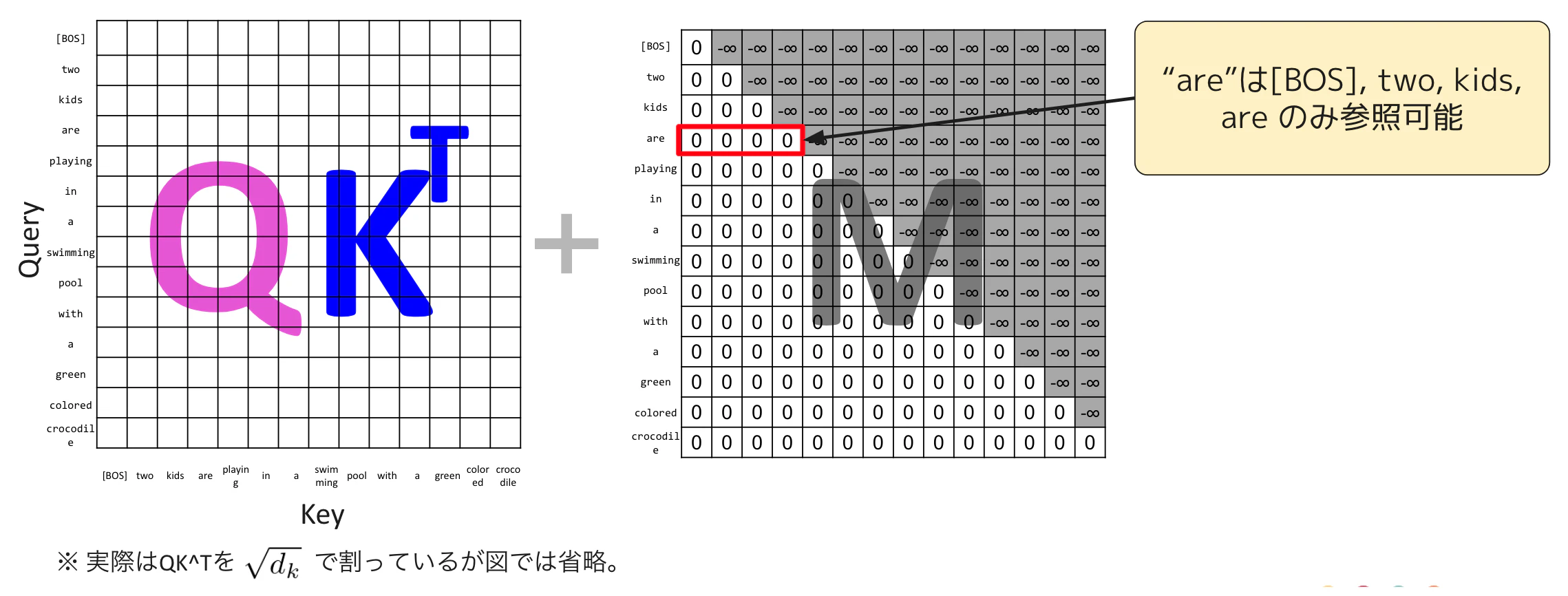
下一步是 Attention:$A = \mathrm{softmax}\left(\frac{QK^{\mathrm{T}}}{\sqrt{d_k}} + M\right)$。
softmax 會沿著橫向套用,將同一列元素的總和正規化為 1,這樣就能把它當作加權平均的權重來使用。被 mask 的位置因為是 -∞,所以 Attention 值幾乎會是 0。對所有 Query 單字都做同樣的處理後,就會得到 Attention 矩陣。
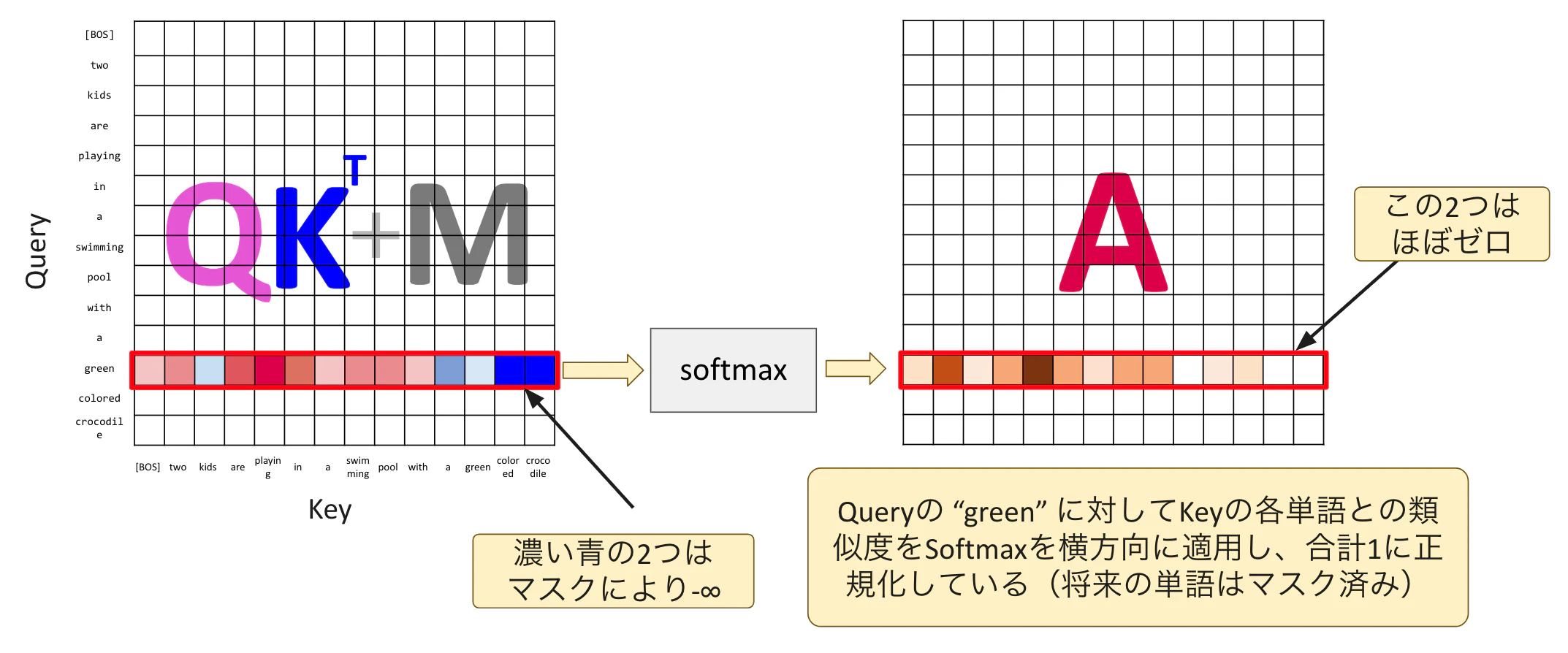
Attention 輸出的計算
將 $A$ 的 Attention 矩陣乘上 Value:$V$,就能得到 Self Attention 的輸出結果。
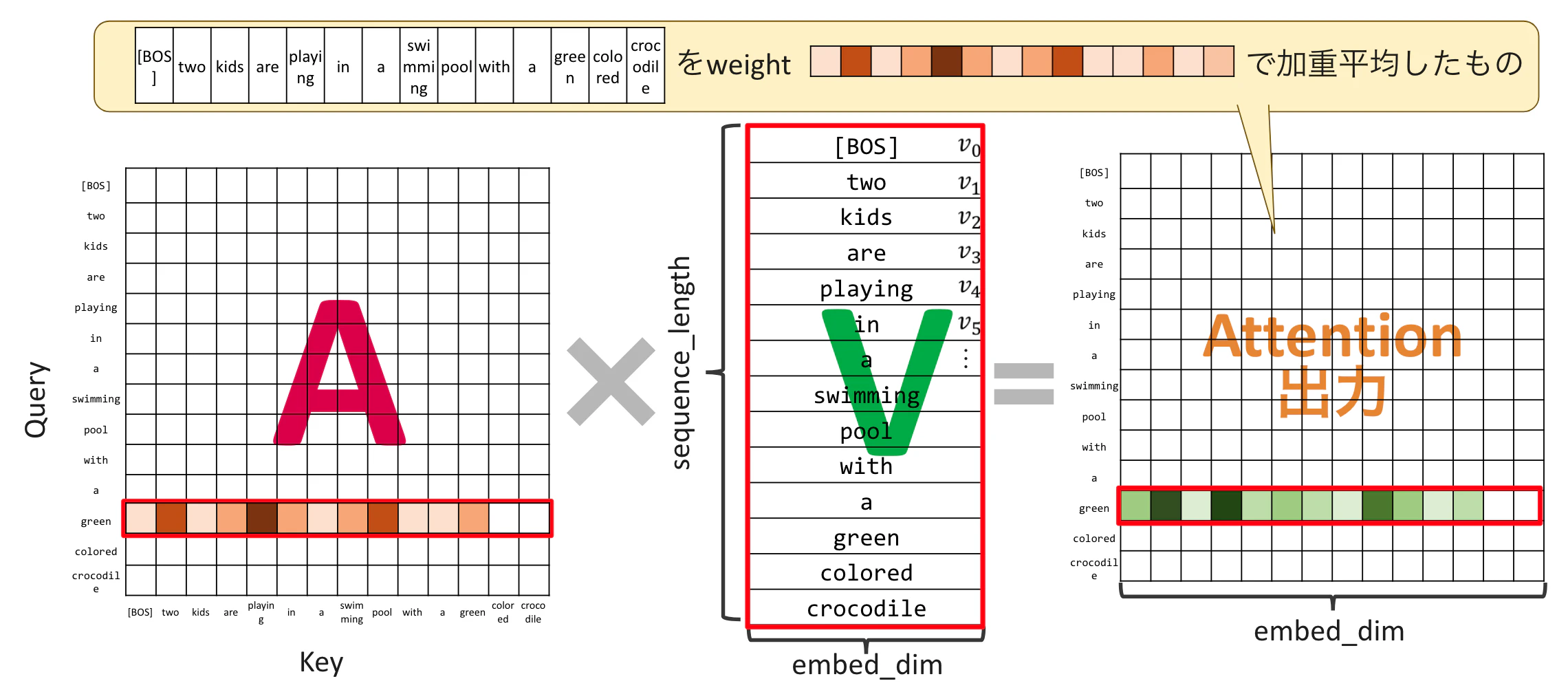
也就是說,由 Attention Weight 加權後的 Value 各單字加總起來形成的向量,就是 Self Attention 的輸出。
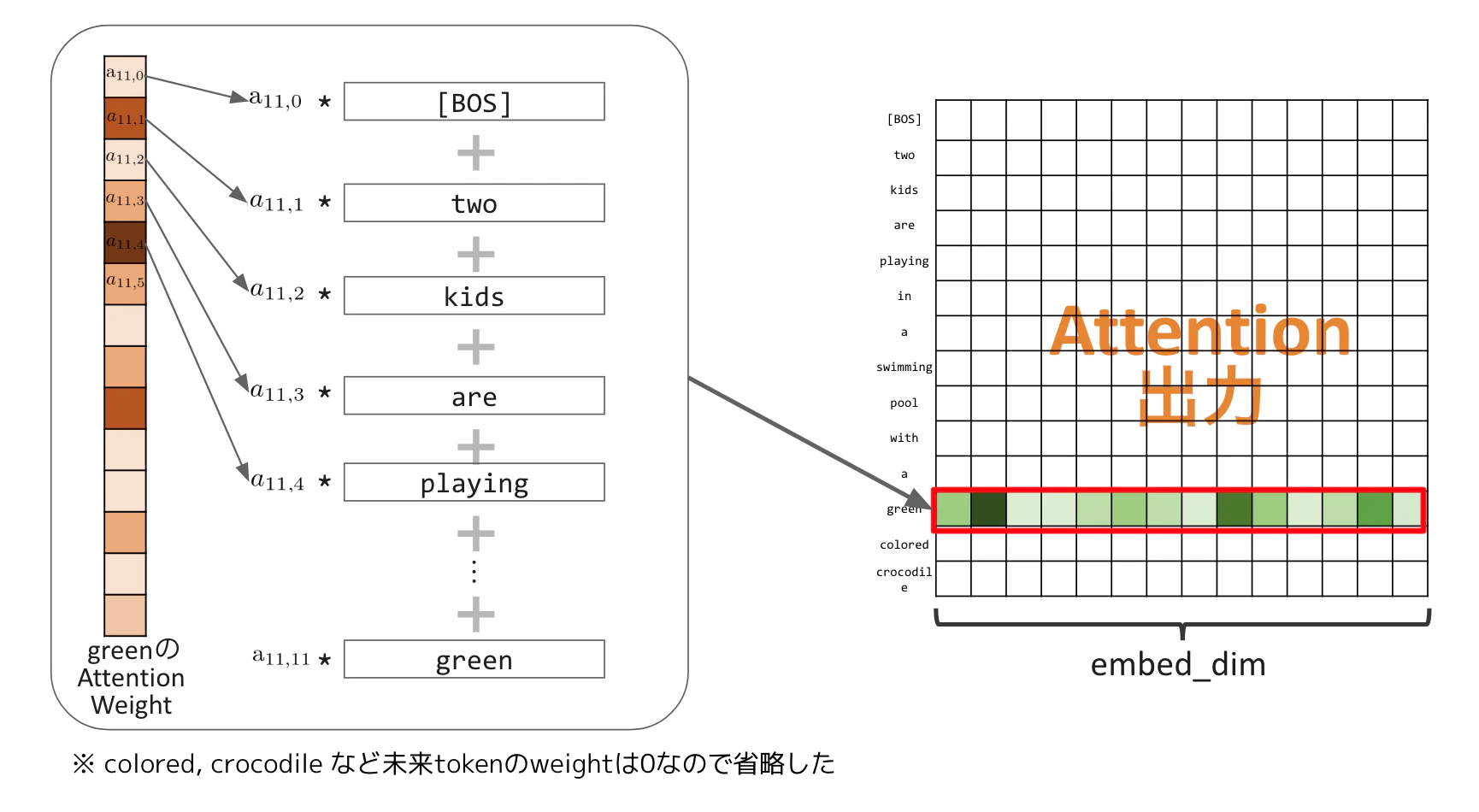
換句話說,若聚焦在 Query 中的一個單字 "green",就會先計算 Query 的 "green" 與 Key 的各單字之間關係強弱作為 Attention Weight,然後用這個 Weight 對 Value 的各單字做加權平均;其結果,就可以視為 "green" 在句子中的、考量了上下文之後的語意向量。
總結
本篇嘗試以直觀的方式,說明 Transformer 的 Self-Attention 中 $Q, K, V$ 的角色,以及其計算的意義。
Self-Attention 是以 Query 的單字為起點,透過 Key 計算與文章中各單字的關係,求出 Attention Weight,再利用這些 Attention Weight 對 Value 中的各單字向量做加權平均,從而產生反映該位置單字上下文的輸出表示。
這樣一來,應該也能直觀地理解:模型是如何參照被關注的單字本身以及它之前的單字,來為該單字賦予意義的。
- 本篇將單字 embedding 的維度視為 Query、Key 向量的維度,因此也把 $d_k$ 視為單字 embedding 的維度。另外,由於本文省略了 Multi-Head Attention,所以把 $d_k$ 視為單字 embedding 的維度。若採用 Multi-Head Attention,則會依 head 數切分,請注意。 ↩
- 因為內積的變異數會隨維度數 $d_k$ 增加而變大,如果不做縮放,softmax 會變得過於尖銳,導致訓練不穩定。因此除以 $\sqrt{d_k}$,用來調整輸入 softmax 的數值尺度。 ↩
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式