

前言
10月14日,「甲骨文 AI 數據平台(AIDP)」的正式提供開始了。(新聞稿)
AIDP是一個統合數據基礎設施,能夠在 OCI 上統一進行數據的收集、管理、分析和 AI 應用。
它配備數據湖、目錄、筆記本、訪問控制等功能,可以整合整個組織的數據。
與甲骨文 AI 數據庫和甲骨文生成 AI 服務的整合,
使其能作為一個 AI 數據基礎來實現 AI 驅動的高度搜索、分析和生成。
這次,我們將嘗試將 自主數據庫(ADB) 的數據作為外部來源創建 AIDP 的外部目錄,並在 AIDP 上將數據合併並使用 SQL/Python 進行參考。
(例如,將訂單明細表放在 ADB,將商品主檔放在 AIDP,然後將它們合併以確認訂單內容。)
參考
-
Qiita:因為甲骨文 AI 數據平台(AIDP)已經發布,所以我嘗試創建它
-
文件:開始使用甲骨文 AI 數據平台
步驟
以下按照以下步驟進行。
| 步驟 | 內容 | 目的 |
|---|---|---|
| 0 | 事前準備 | 準備 ADW(ADB),並準備連接的表 |
| 1 | 建立 AIDP | 在 OCI 上創建 AIDP 實例 |
| 2 | 創建目錄 | 設置數據的邏輯容器 <br>・主目錄 <br>・標準目錄 <br>・外部目錄 |
| 3 | 創建集群 | 為 Spark 處理準備計算環境 |
| 4 | 創建筆記本 | 創建互動分析環境 |
| 5 | 使用 SQL 嘗試 | 合併並查詢 AIDP 和 ADB 的數據 |
| 6 | 使用 Python 嘗試 | 使用 PySpark 實現類似的處理 |
0. 事前準備
這次使用自主數據庫(ADW)的數據作為連結的來源,因此需要提前創建。
請參考以下教程。
https://oracle-japan.github.io/ocitutorials/adb/adb101-provisioning/
這次我們將在 ADB 中放入「orders_items」表。(後面會在 AIDP 中創建「product」表並將數據合併進行參考。)
※測試數據使用了 APEX 的範例數據集「客戶訂單」中的兩張表。
1. 建立 AIDP
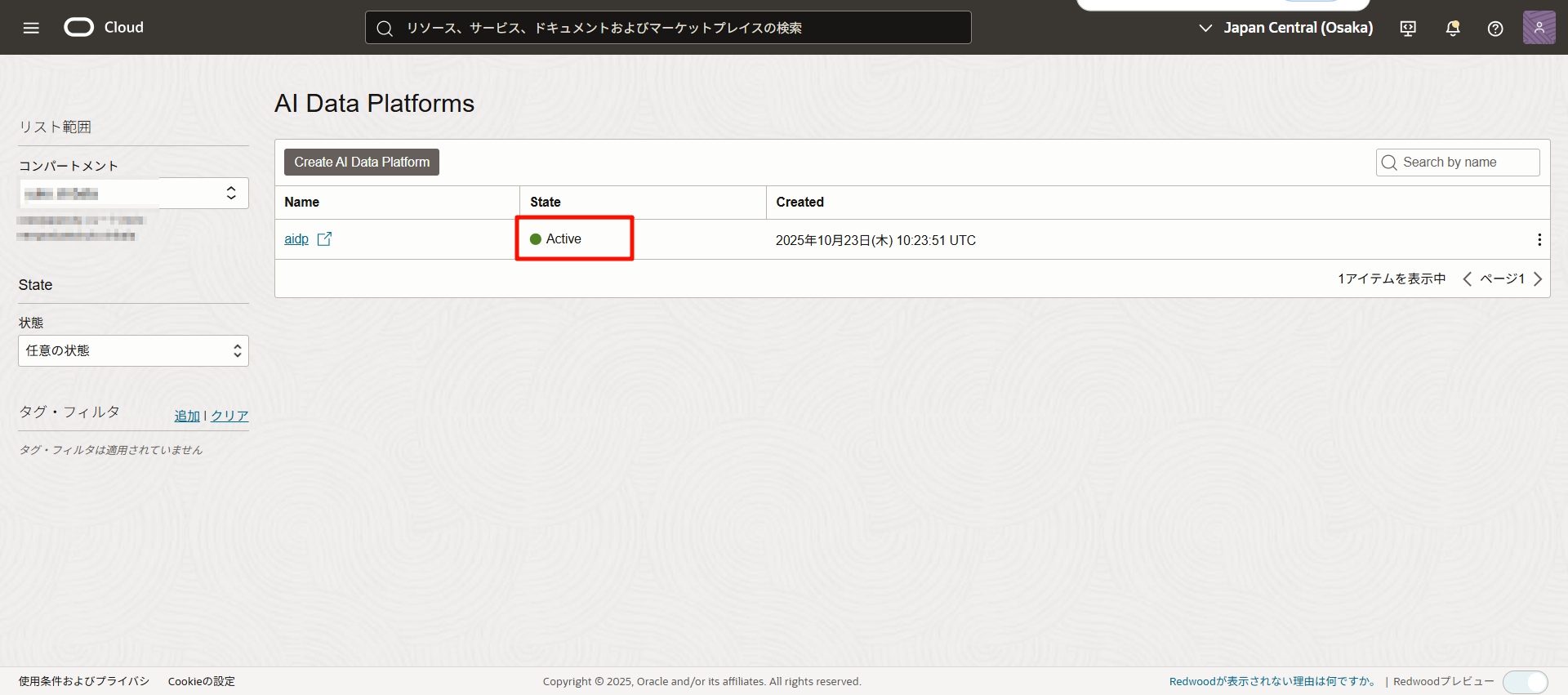
從漢堡菜單選擇「分析和 AI」>「AI 數據平台」。
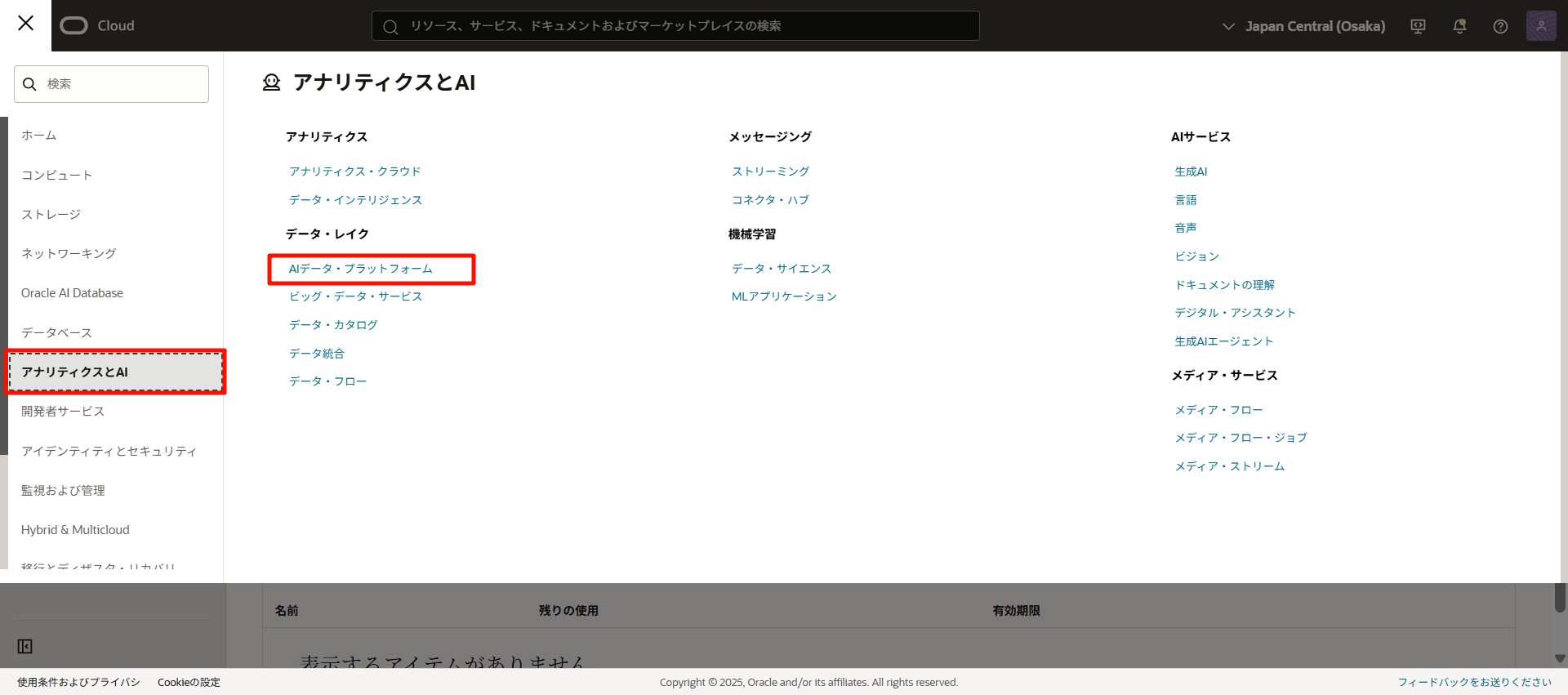
點擊「創建 AI 數據平台」。
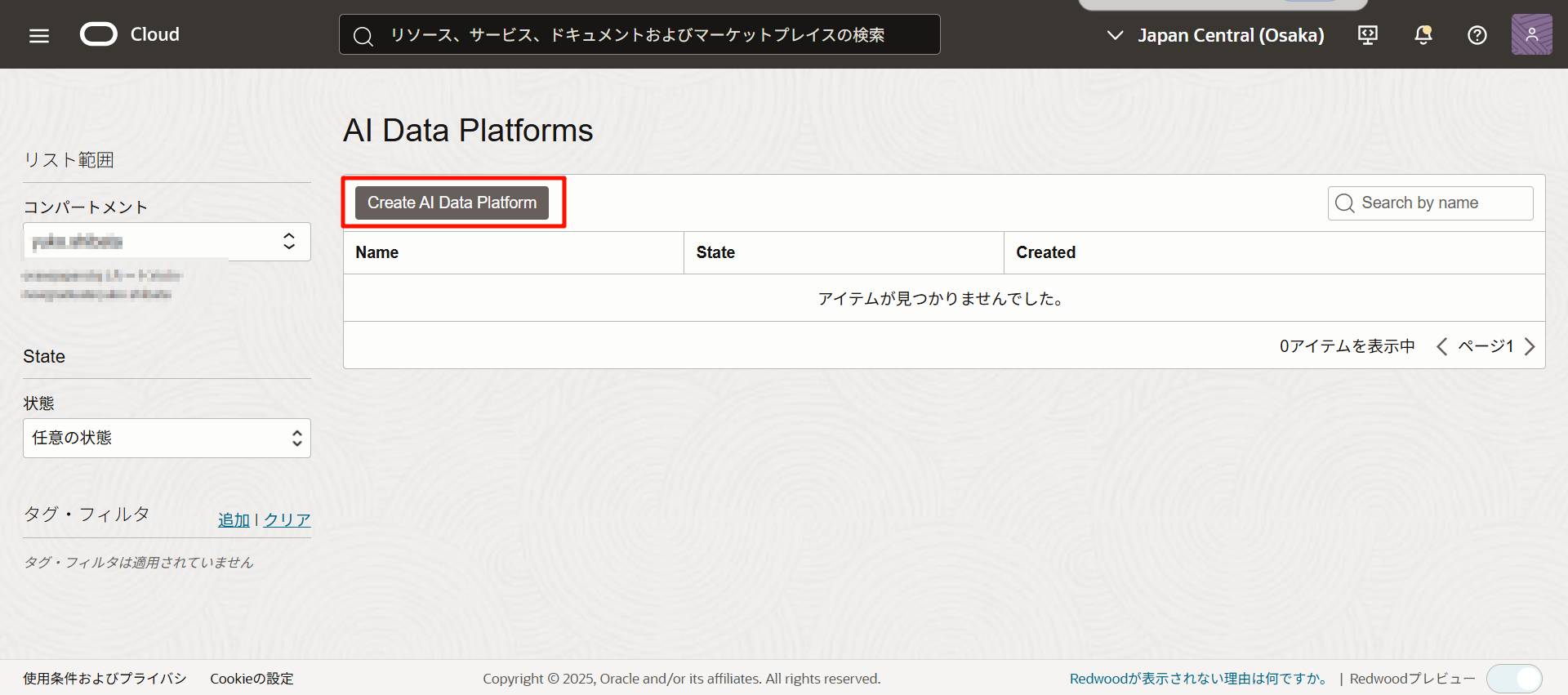
點擊後,將檢查是否設置好所有必要的 IAM 策略。
(當出現 info 標誌時,檢查完成後將轉到創建畫面。)
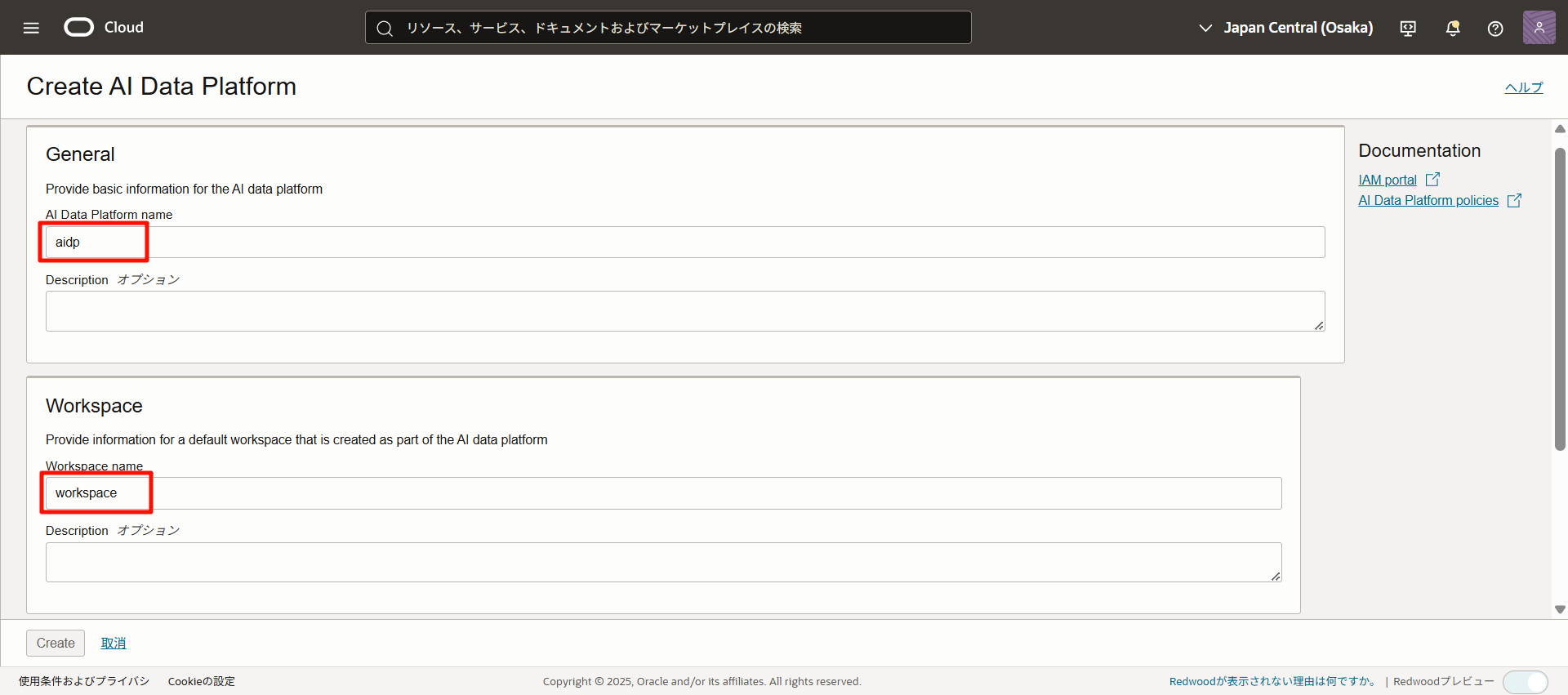
輸入以下內容。
- AIDP 實例的名稱和描述
- AIDP 工作空間的名稱和描述
從「添加策略」中選擇以下其中一項。
- 標準:在租戶層級廣泛應用訪問設置。
- 進階:可以在區域層級配置更精細的訪問。
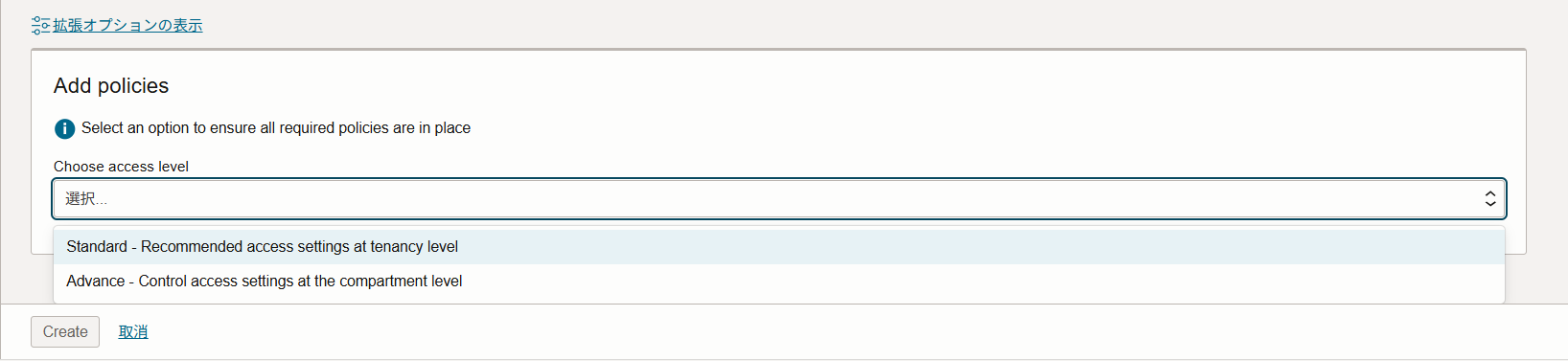
選擇後,如果有缺少的策略,將顯示策略。
請確認內容,然後點擊「添加」。如果成功添加,將顯示「政策已添加」。
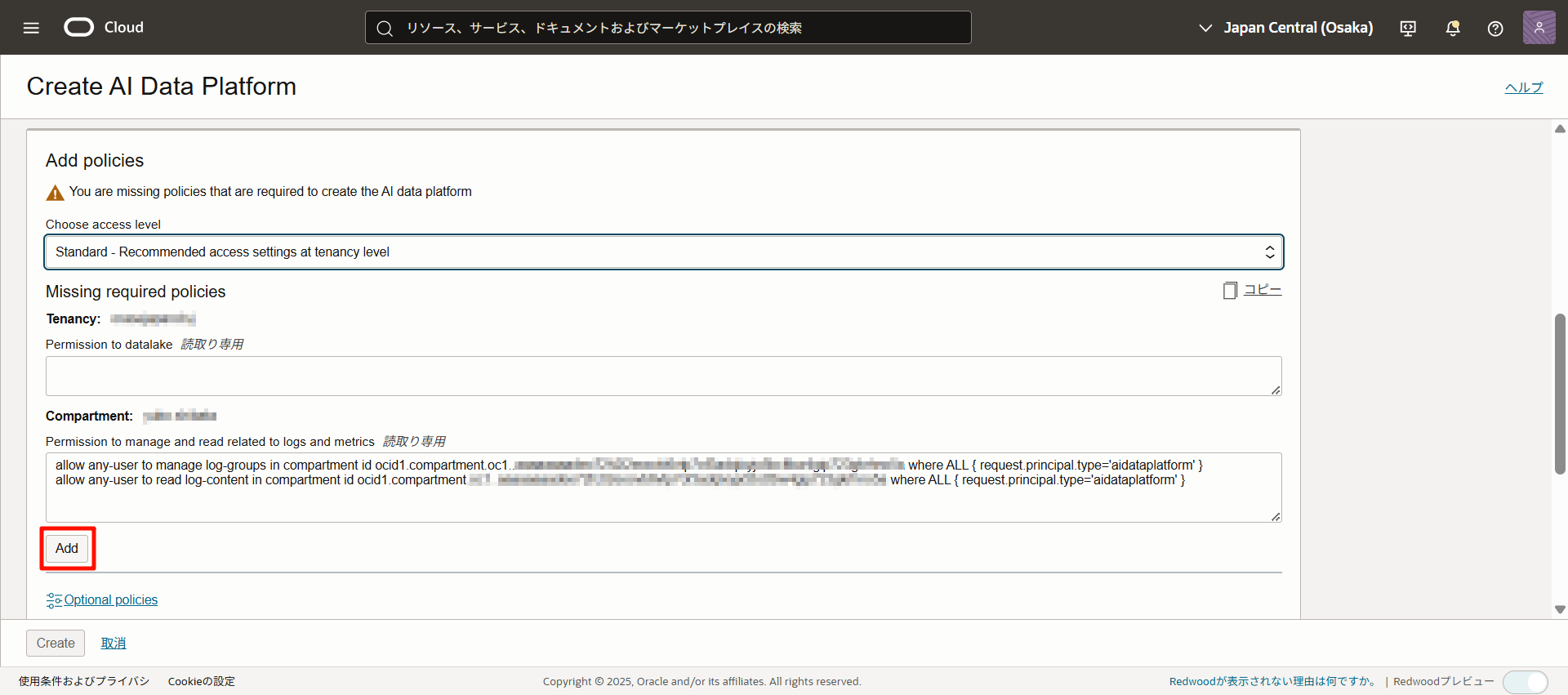
點擊「可選策略」,將顯示可選添加的策略,根據需要添加。
詳細內容請參考:AIDP 的 IAM 策略
確認策略後,點擊「創建」。
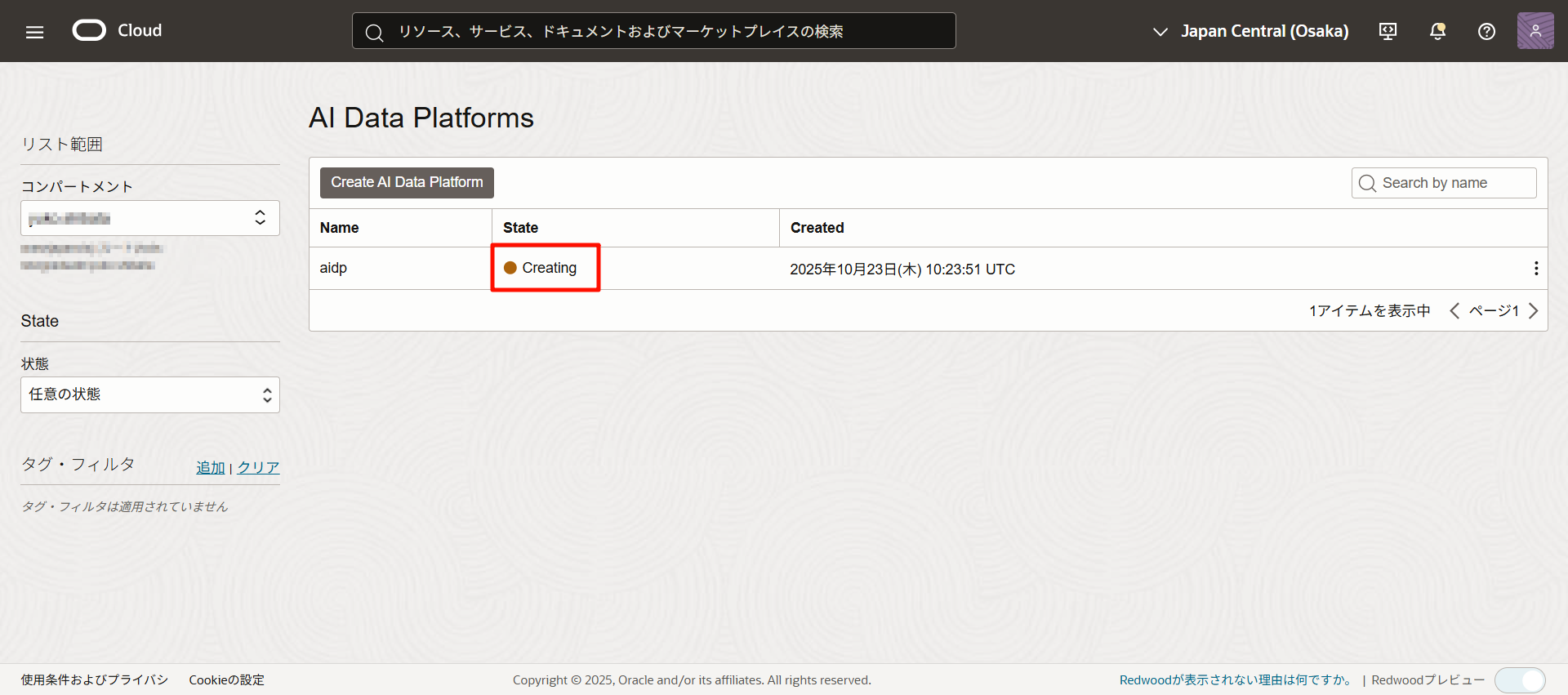
大約在 10 分鐘內創建完成。
訪問 AIDP 的控制台
點擊要訪問的實例名稱。
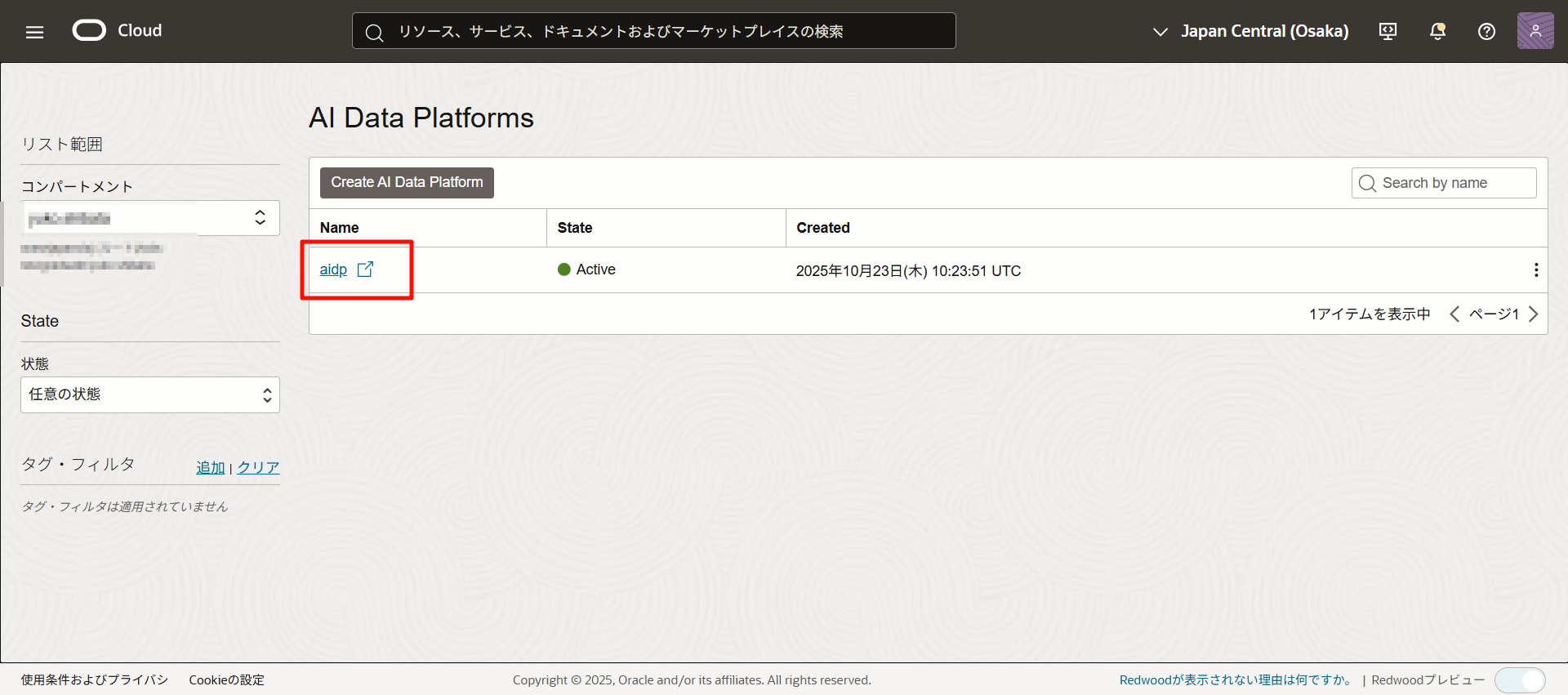
成功訪問!
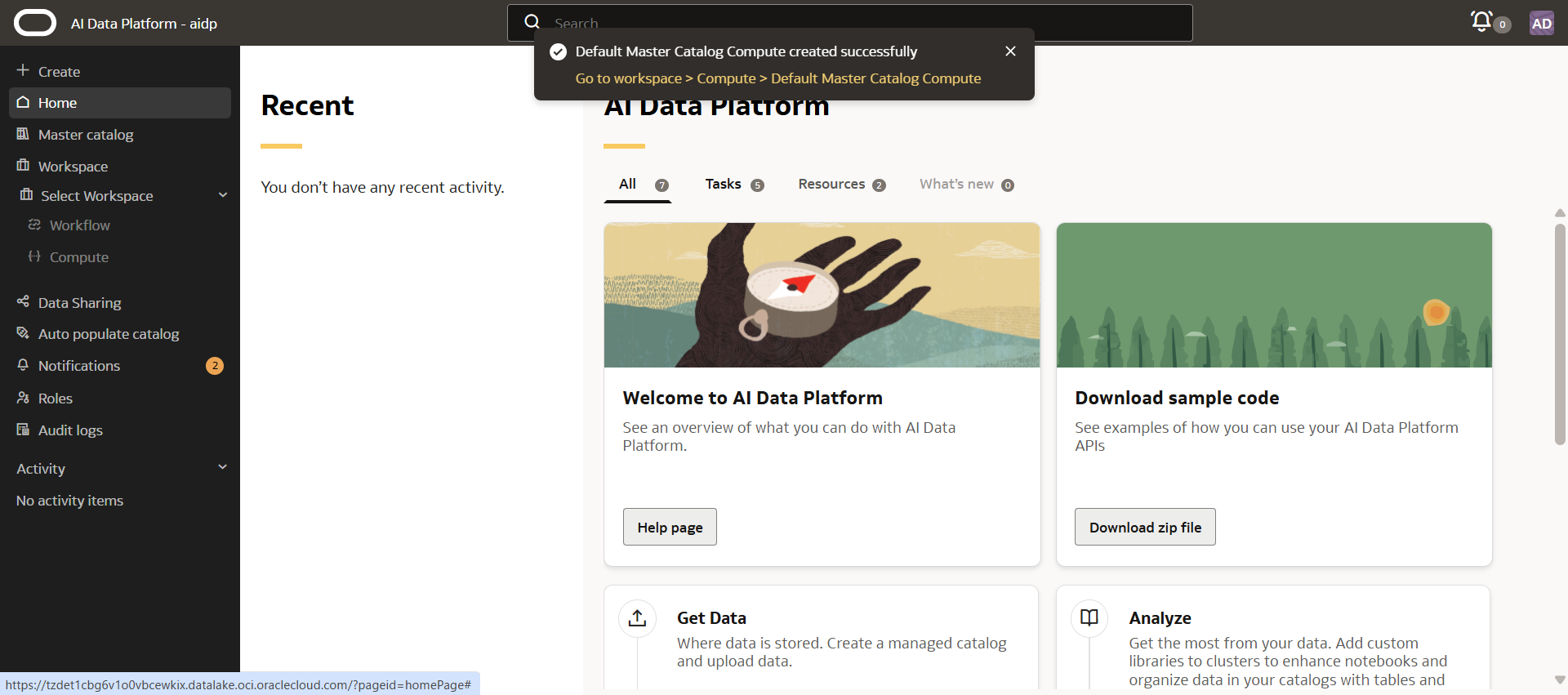
如果通過 URL 訪問,URL 的格式如下所示。
https://<hash>.datalake.oci.oraclecloud.com/#?&tenant=<<tenant_name>>&domain=<<domain_name>>可以與其他用戶共享 AI 數據平台實例的 URL。
訪問需要 AI 數據平台 IAM 策略的 USE 權限以上。
2. 創建目錄
2-1. 主目錄
主目錄(Master Catalog) 是為了集中管理數據和元數據的最高級別實體。它作為接下來要創建的標準目錄(Standard Catalog)和外部目錄(External Catalog)的容器。
可以針對 OCI 對象儲存、自主數據倉庫(ADW)、Kafka 等存在的數據創建目錄。
-
標準目錄(Standard catalog):為 AIDP 內的模式(數據庫)提供的邏輯容器。可以在模式內創建表、視圖和卷。標準目錄管理所有子對象(表、視圖等)的元數據生命周期(創建、更新、刪除等)。
-
外部目錄(External catalog):基於外部數據來源如自主數據倉庫和 Kafka 的目錄。對於外部目錄,元數據從外部來源同步,並且可以使用
catalog_name.schema_name.table_name的形式查詢外部來源的數據。外部目錄的元數據生命周期(創建、更新、刪除等)由外部來源管理,而主目錄(Master Catalog)保留該元數據的副本。
默認情況下提供名為「default」的主目錄。
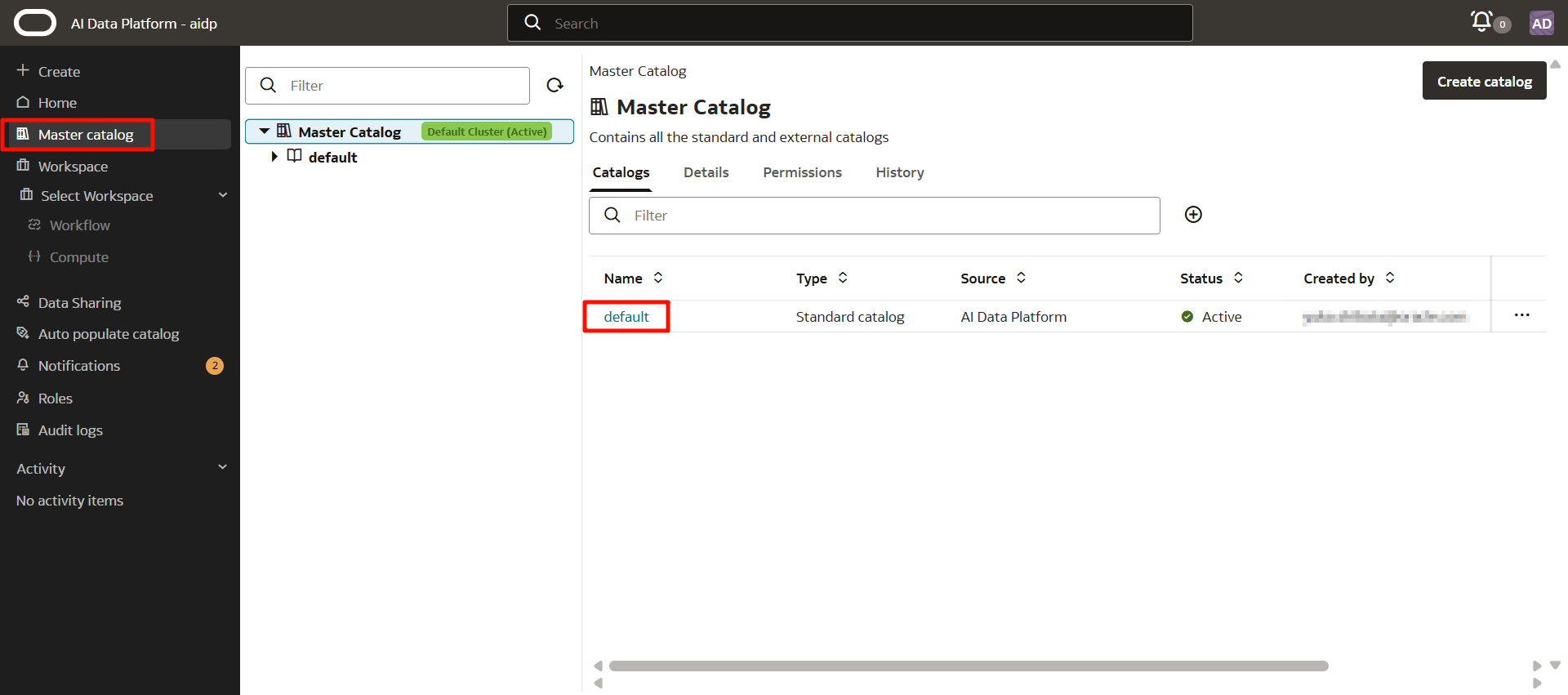
2-2. 創建標準目錄
創建 AIDP 內數據的標準目錄。
點擊「創建目錄」。
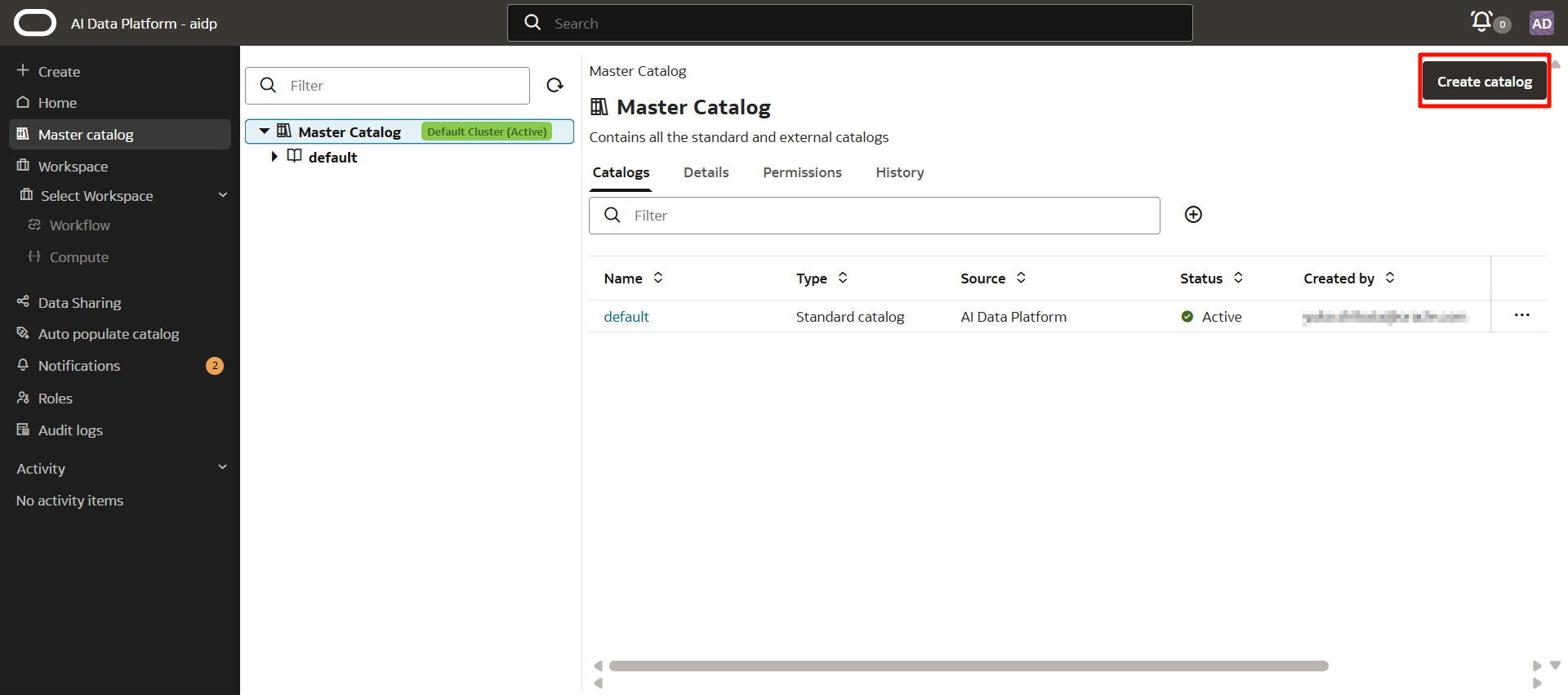
輸入以下內容,然後按「創建」。
- 目錄名稱:自定義(這裡為 standard_catalog)
- 目錄類型:標準目錄
- 容器:自定義
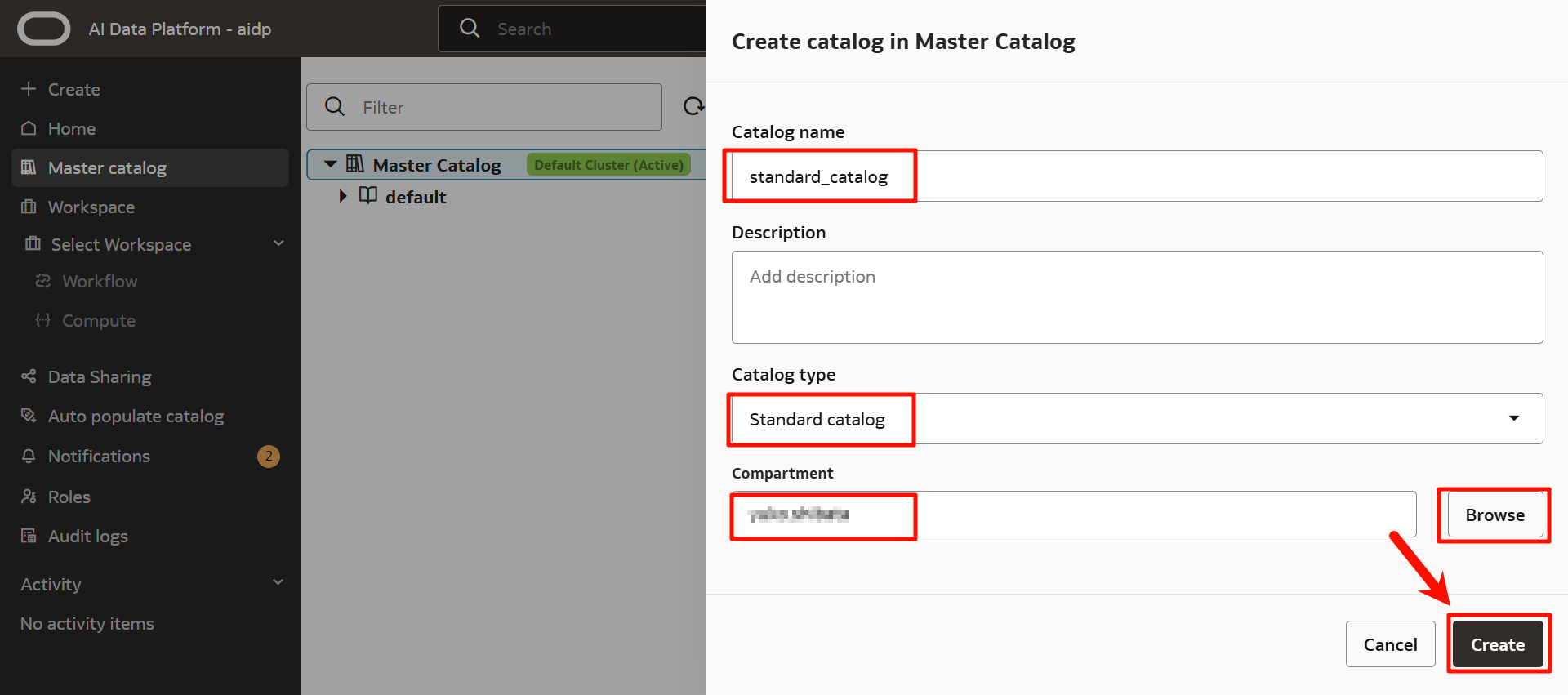
點擊創建的標準目錄。
點擊「創建模式」以創建模式。
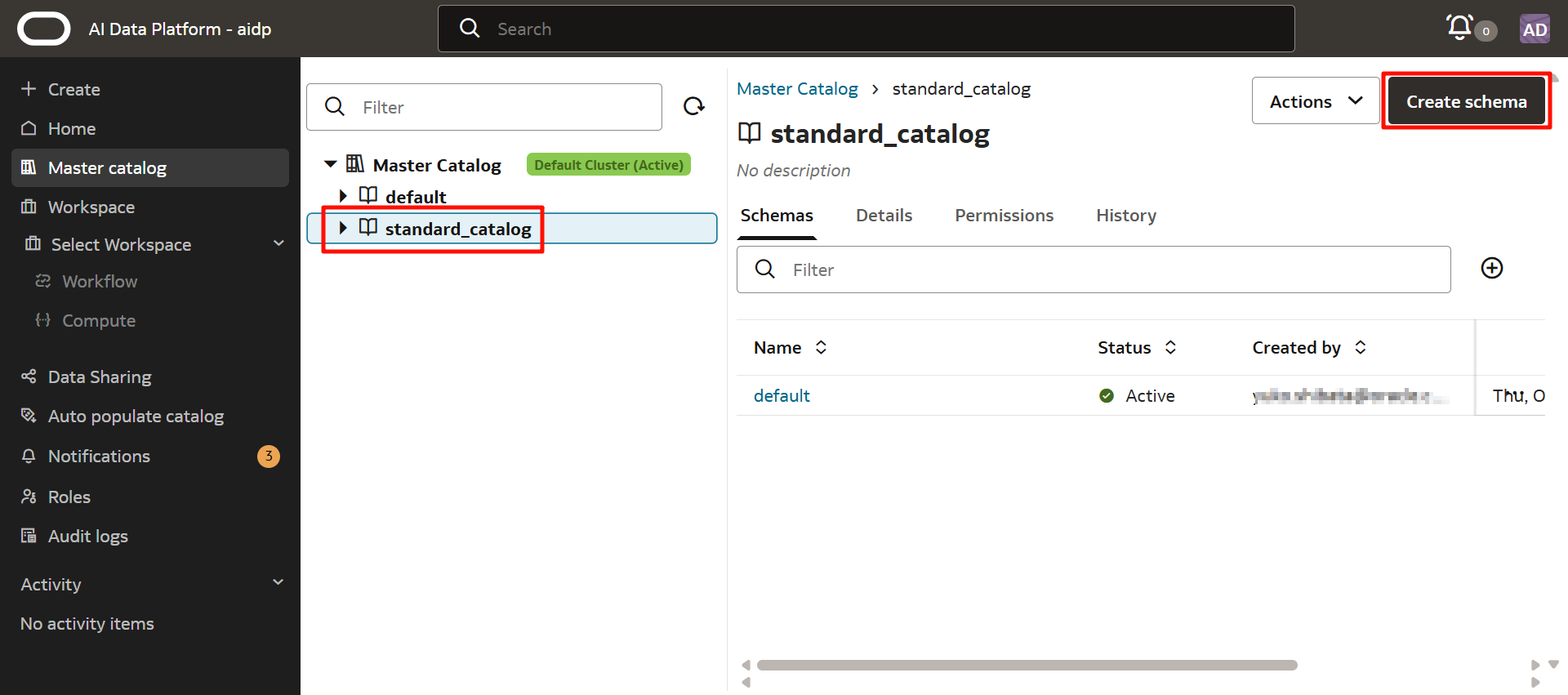
輸入以下內容,然後點擊「創建」。
- 模式名稱:自定義(這裡為 production)
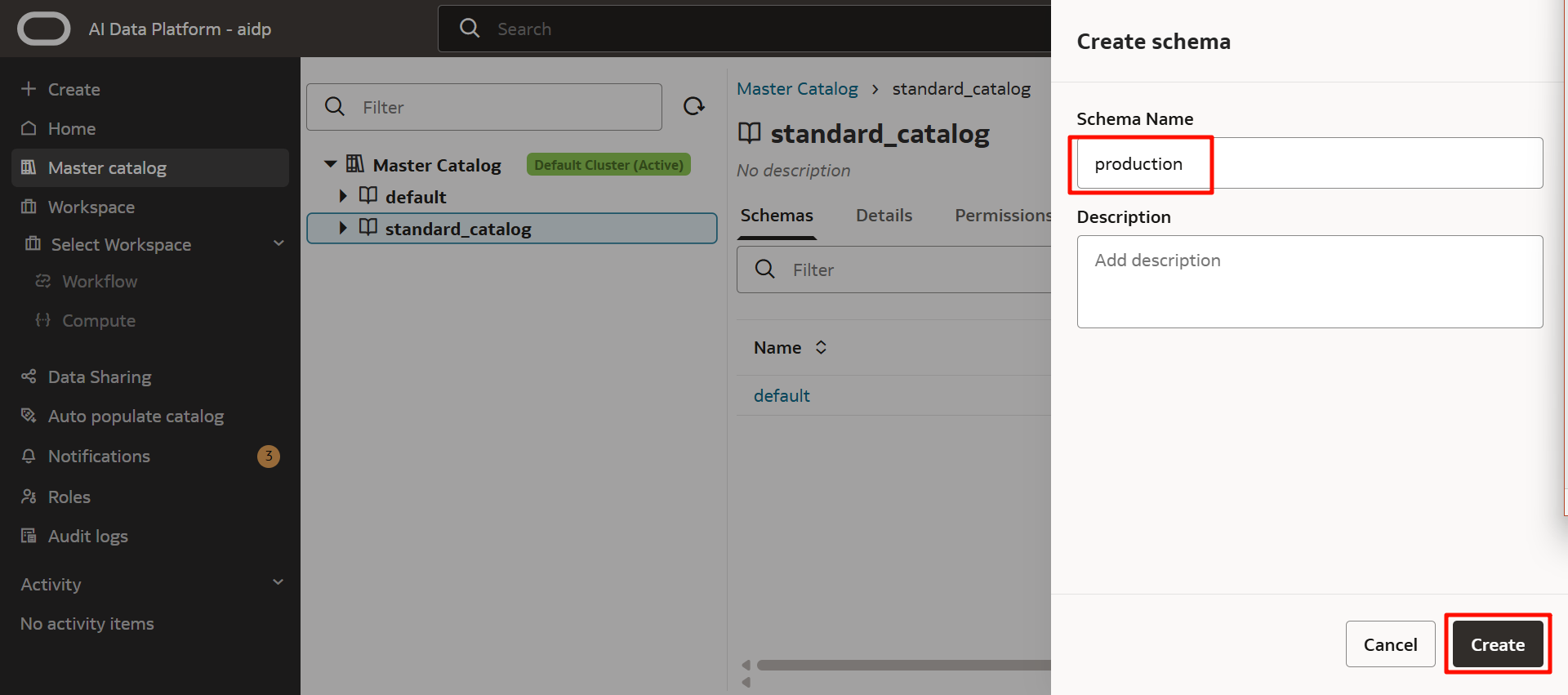
模式已經創建完成。點擊模式名。
點擊「創建表」以創建表。
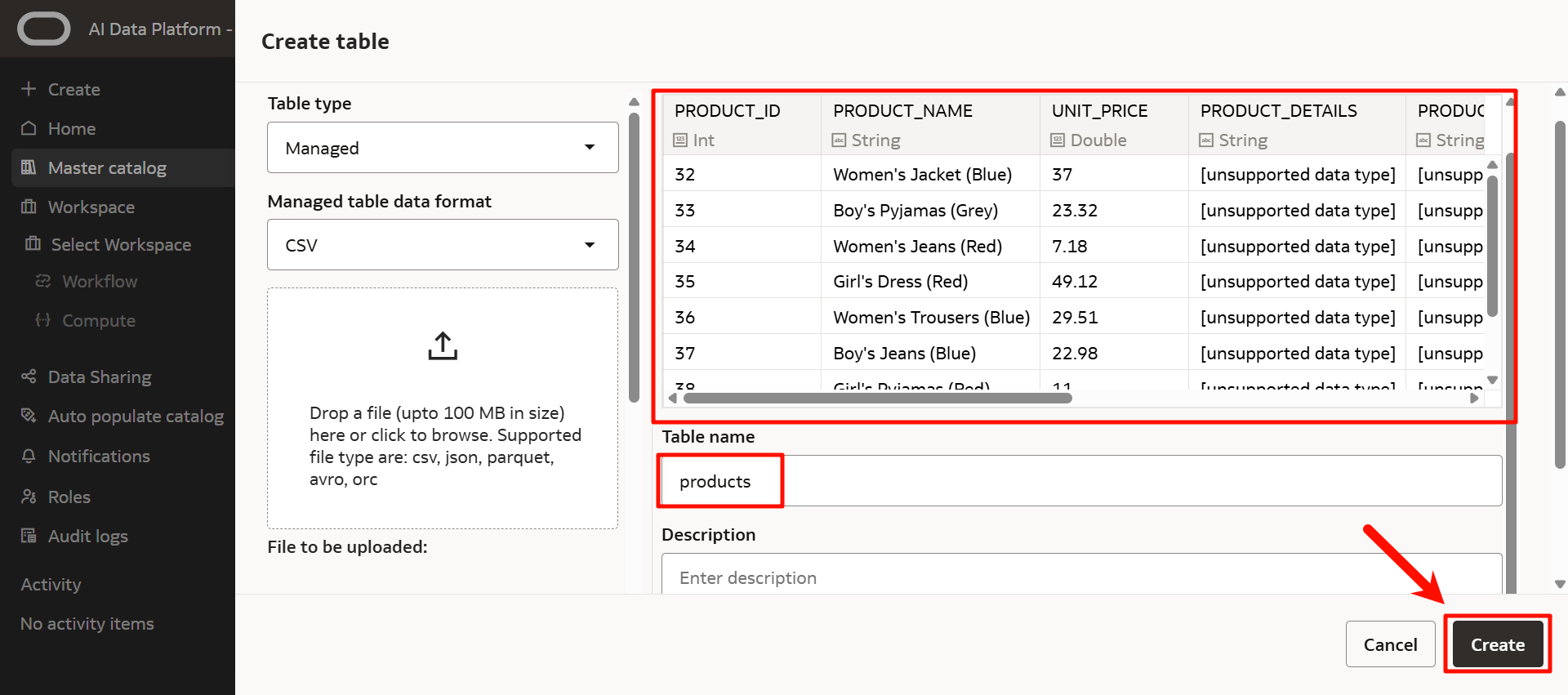
輸入以下內容:
- 表類型 *¹:管理
- 管理表數據格式 *²:自定義(這裡為 CSV)
*¹ 表類型(Table type) 可以選擇 管理(Managed) 或 外部(External)。
-
管理表(Managed Tables)
管理表定義存儲在 AI 數據平台內的數據結構,只有 AI 數據平台的用戶能夠訪問。刪除管理表將刪除不僅是表定義,還有存儲在該表中的數據。 -
外部表(External Tables)
外部表定義存儲在不受甲骨文 AI 數據平台管理位置的數據的結構。
創建外部表後,其元數據的生命週期(創建、更新、刪除)由 AI 數據平台管理。
刪除外部表時,只會刪除表定義,而參考的實際數據不會被刪除。
*² 受管理表(Managed Tables)支持的格式如下:
- CSV
- JSON
- Avro
- Parquet
- ORC
- Delta
將數據上傳到 AIDP 中。
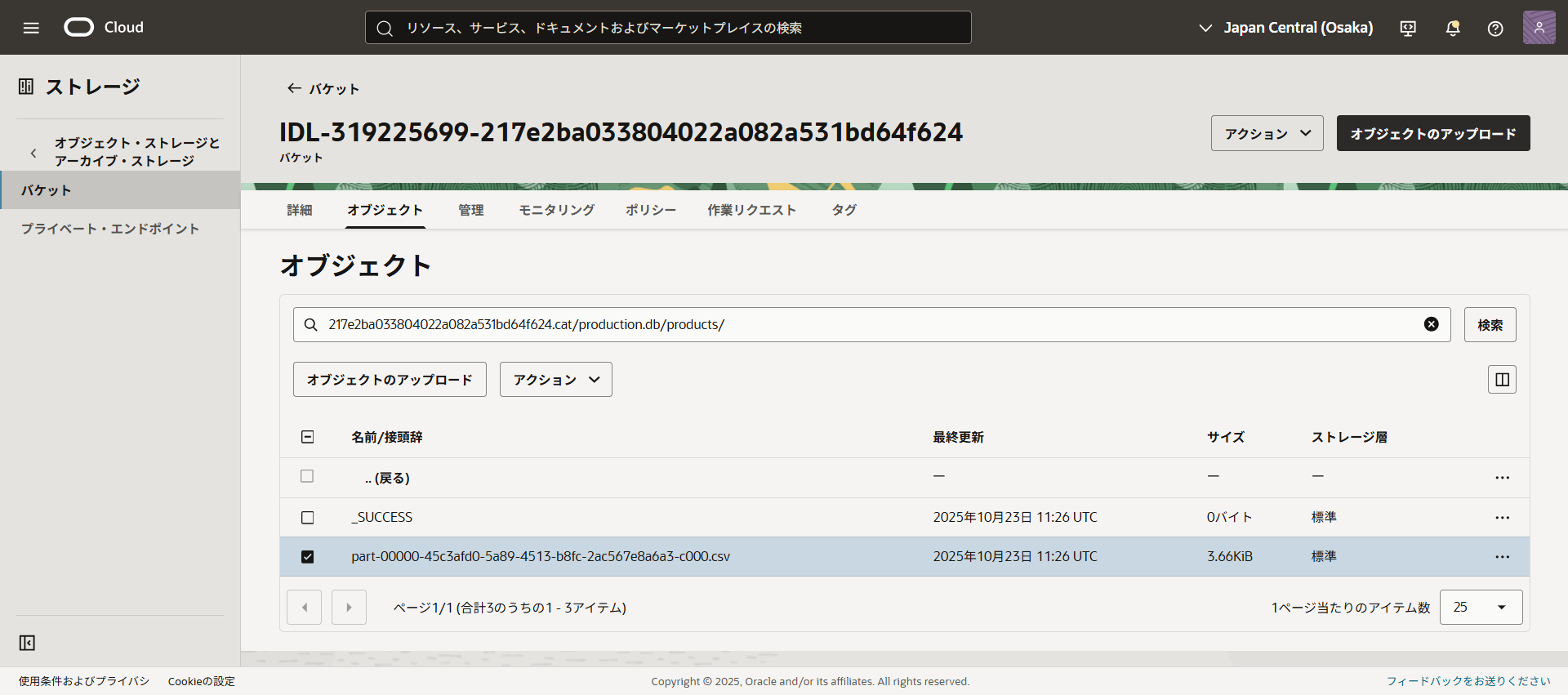
點擊「預覽表」,可以確認要上傳的數據。
確認表名後,點擊「創建」。
表格創建成功。
在對象儲存中確認管理表的數據
創建 AIDP 時,會在創建實例的同一容器中創建幾個桶。
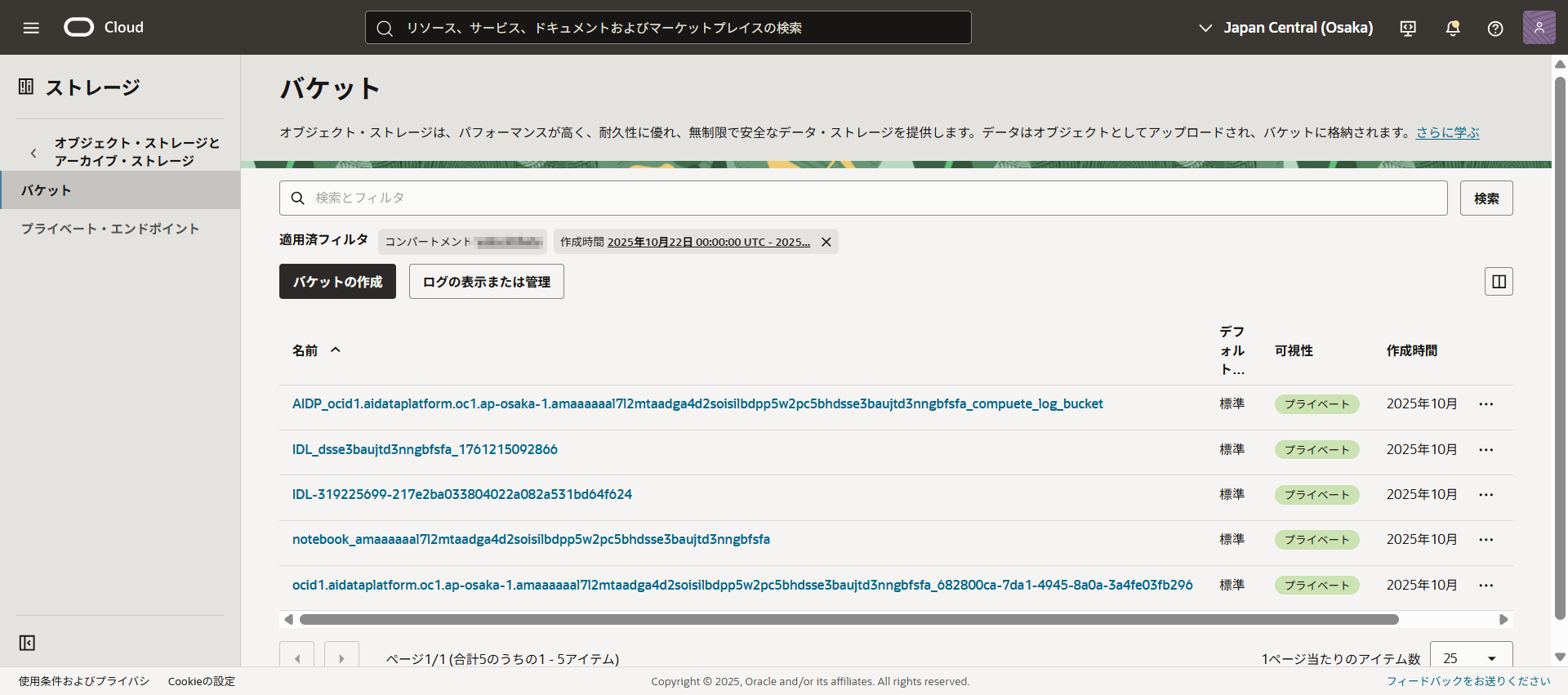
作為管理表上傳的數據則儲存在這裏。
2-3. 創建外部目錄
接下來,針對自主數據庫(ADW)創建外部目錄。
點擊「創建目錄」。
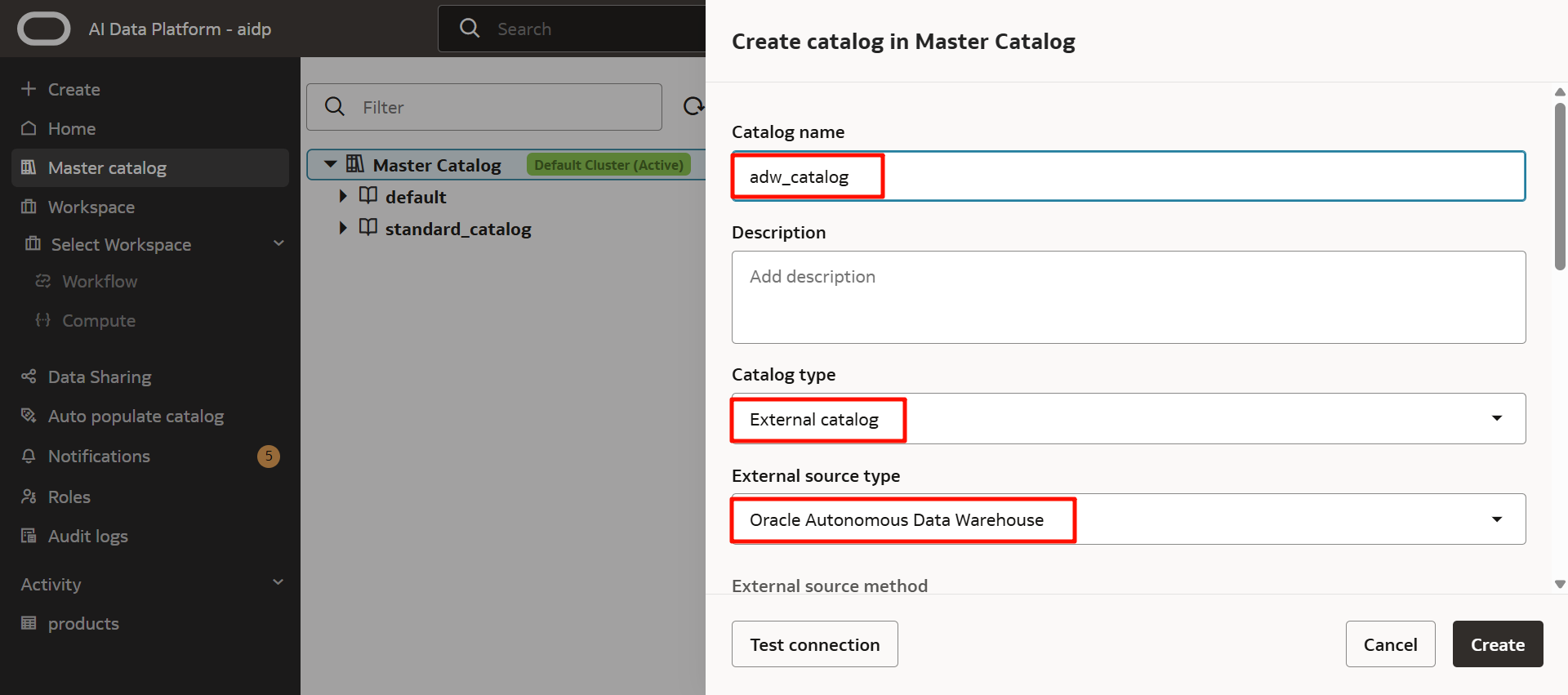
輸入以下內容。
- 目錄名稱:自定義(這裡為 adw_catalog)
- 目錄類型:外部目錄
- 外部來源類型:甲骨文自主數據庫
可選的外部來源包含 自主數據倉庫、自主事務處理、甲骨文數據庫。
(Kafka 預計將於近期發布:截至 2025 年 10 月末)
如果選擇甲骨文數據庫中的三個之一,則可以通過錢包文件或實例選擇進行設置。
選擇事前準備的 ADW。
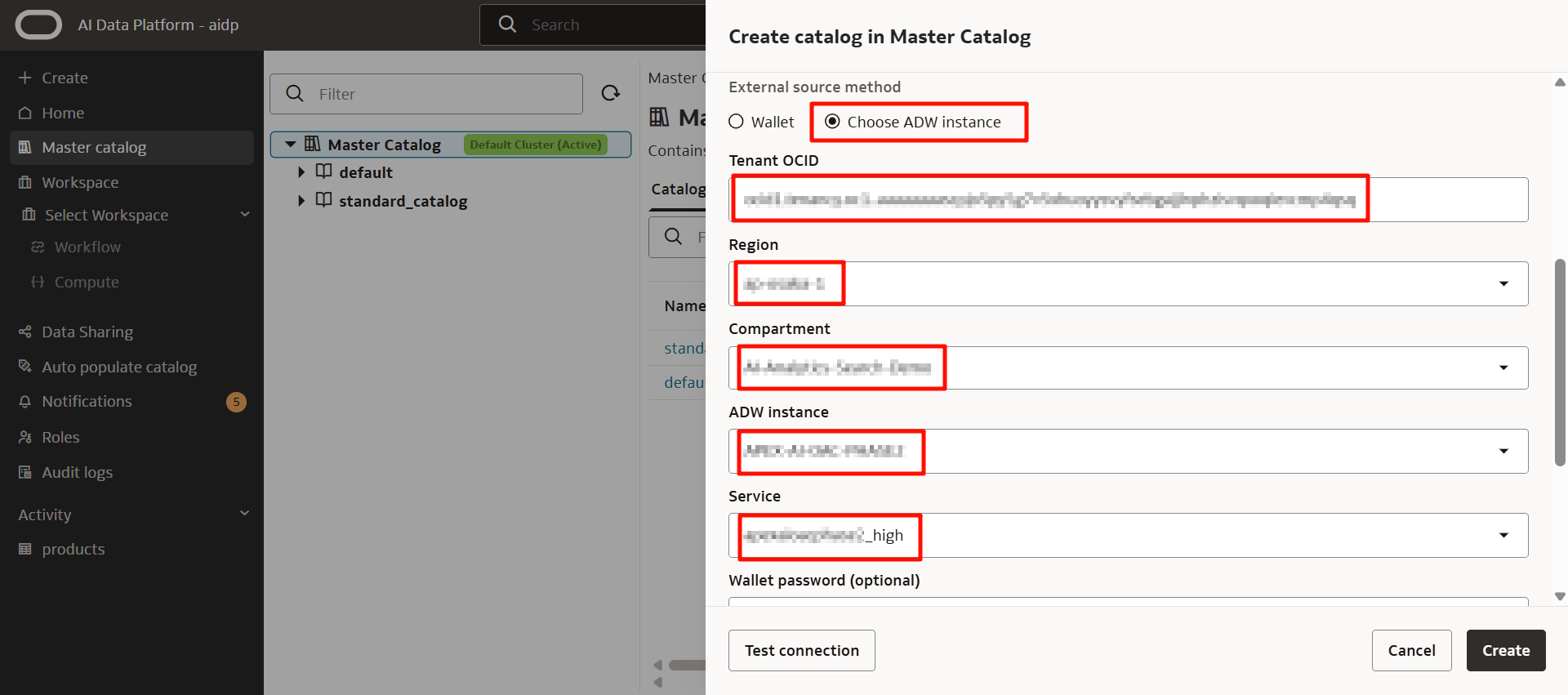
輸入用戶名和密碼後,點擊「創建」。
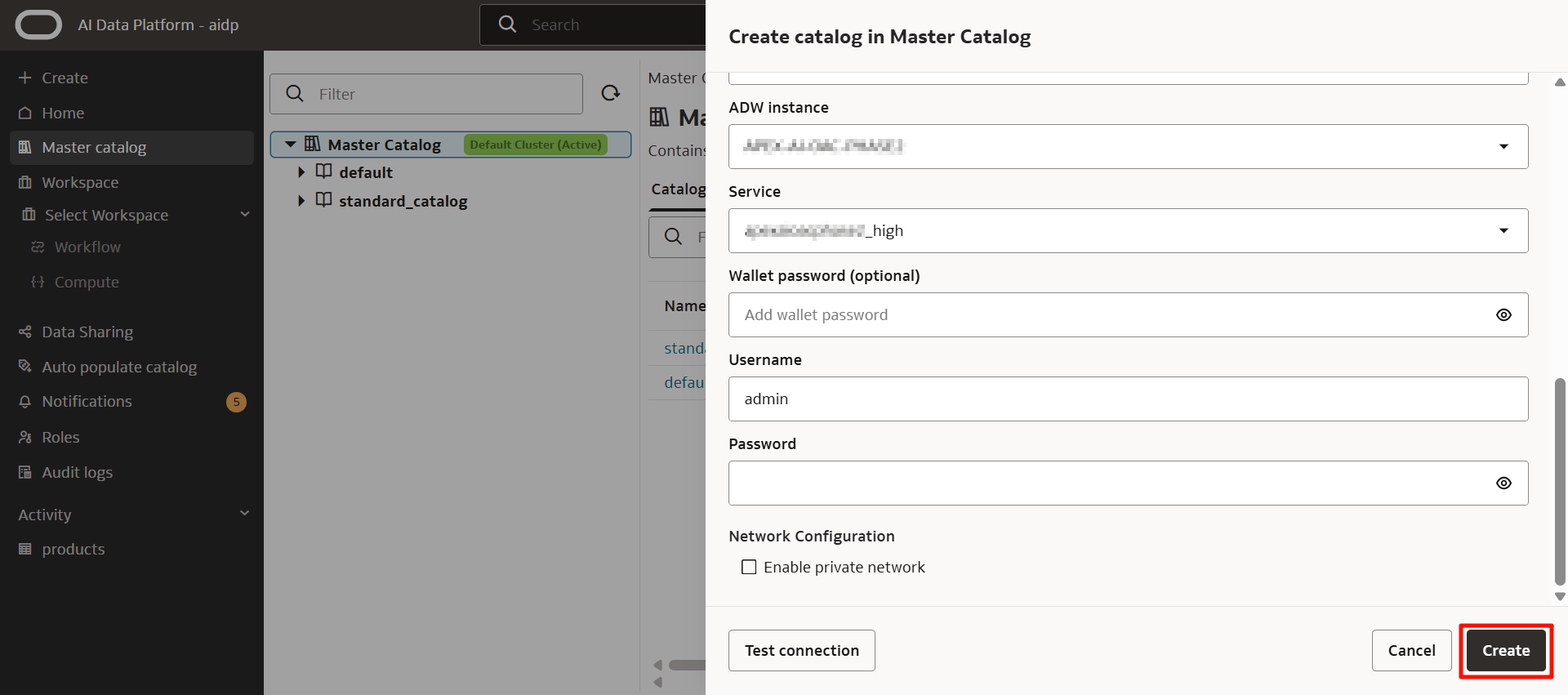
幾秒後,會返回到此畫面,顯示正在創建。
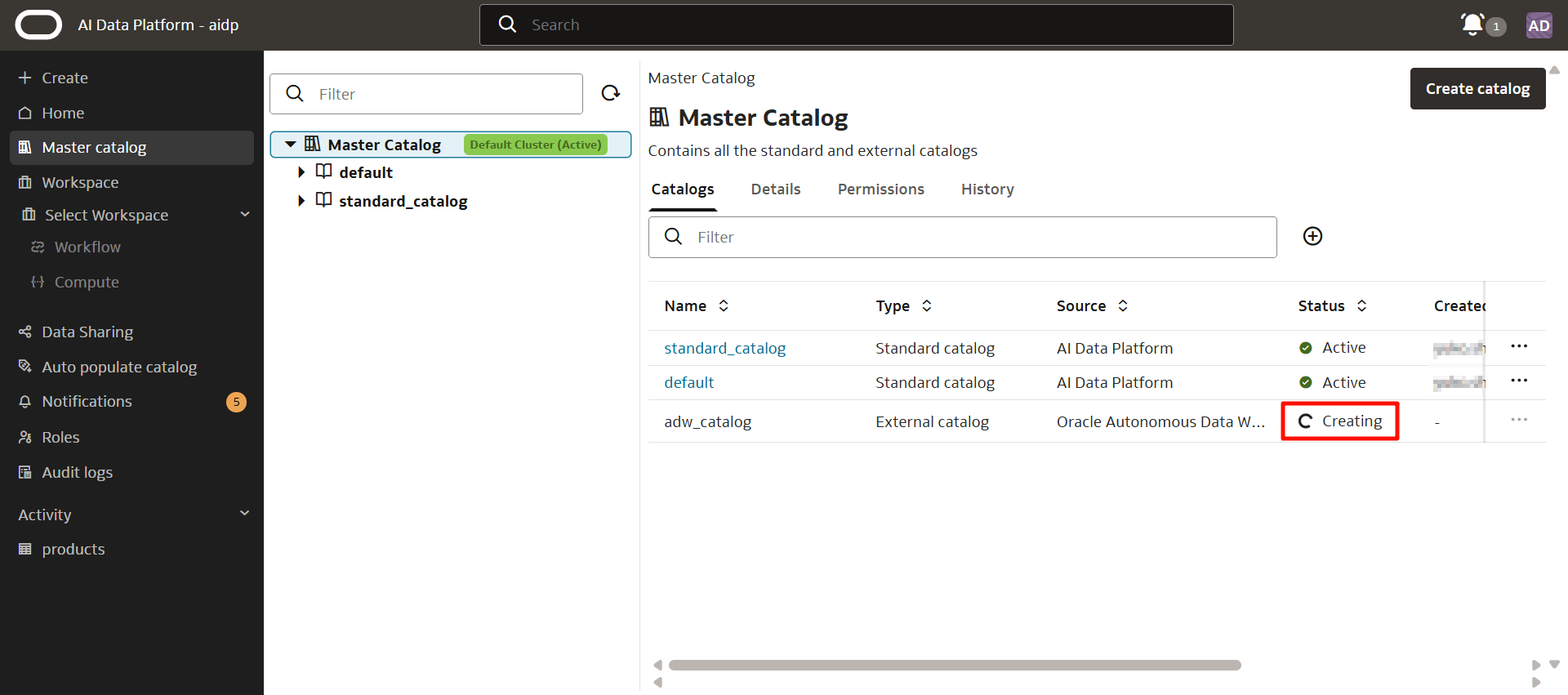
稍等十幾秒後,會顯示成功創建的彈出框,狀態變為「活動(Active)」。
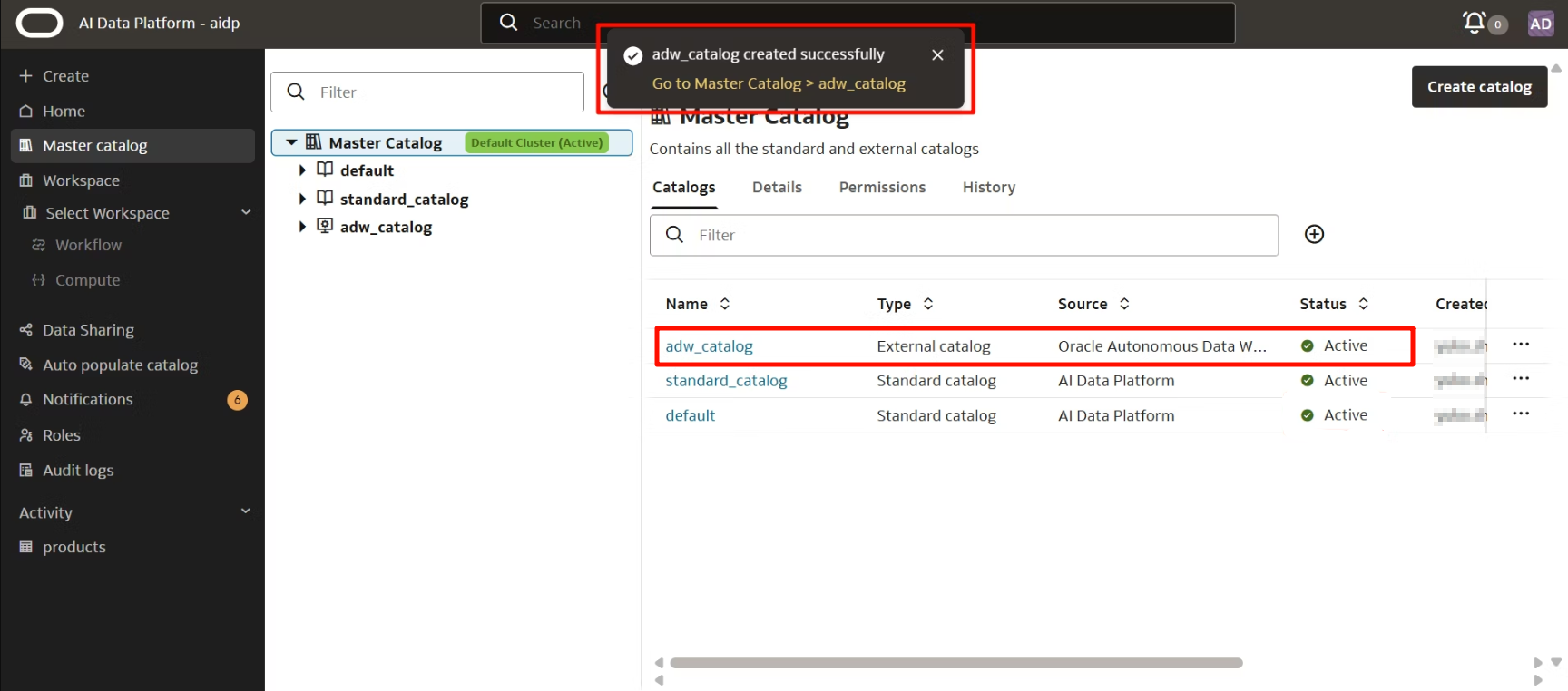
目錄的準備已完成。
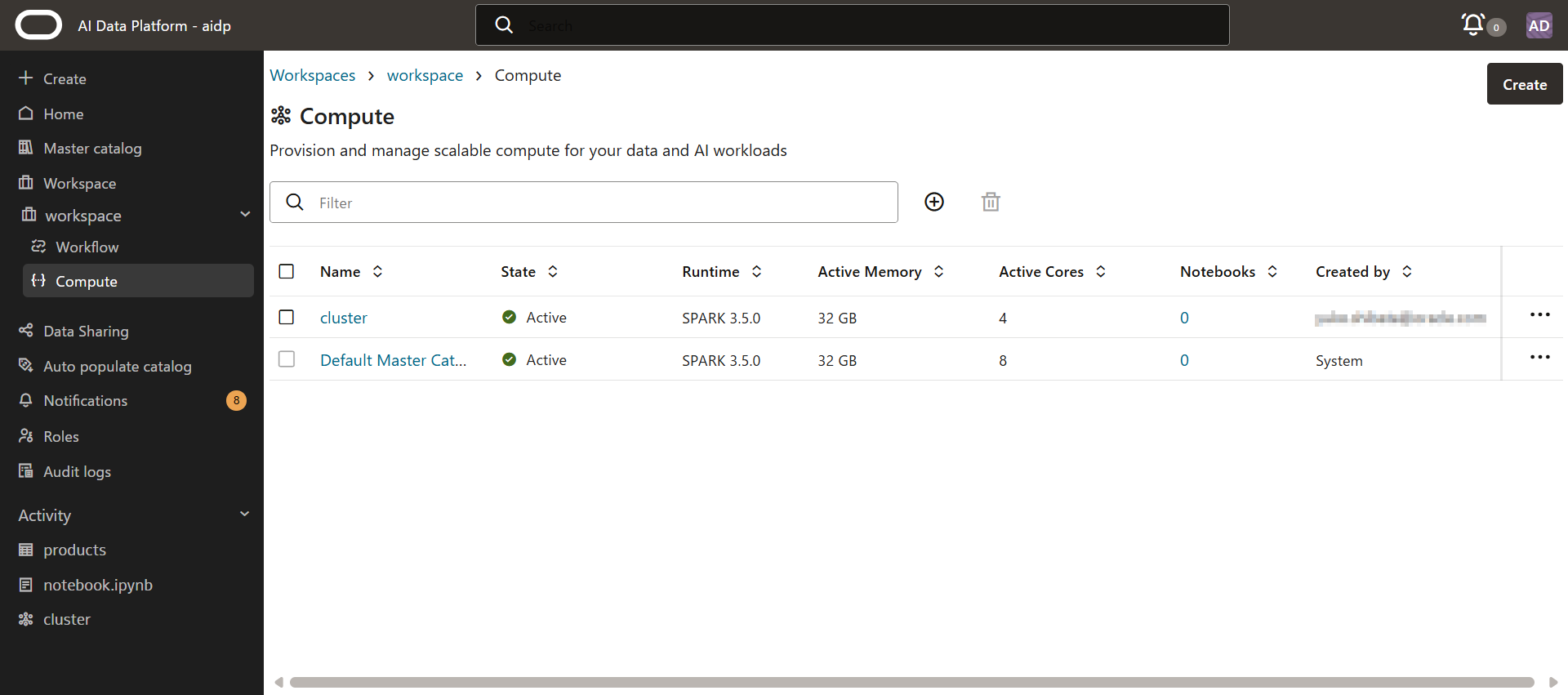
3. 創建集群
從左側菜單中的「工作空間」點擊已創建的工作空間名稱。
點擊「計算」,然後從「創建」選擇創建計算集群。
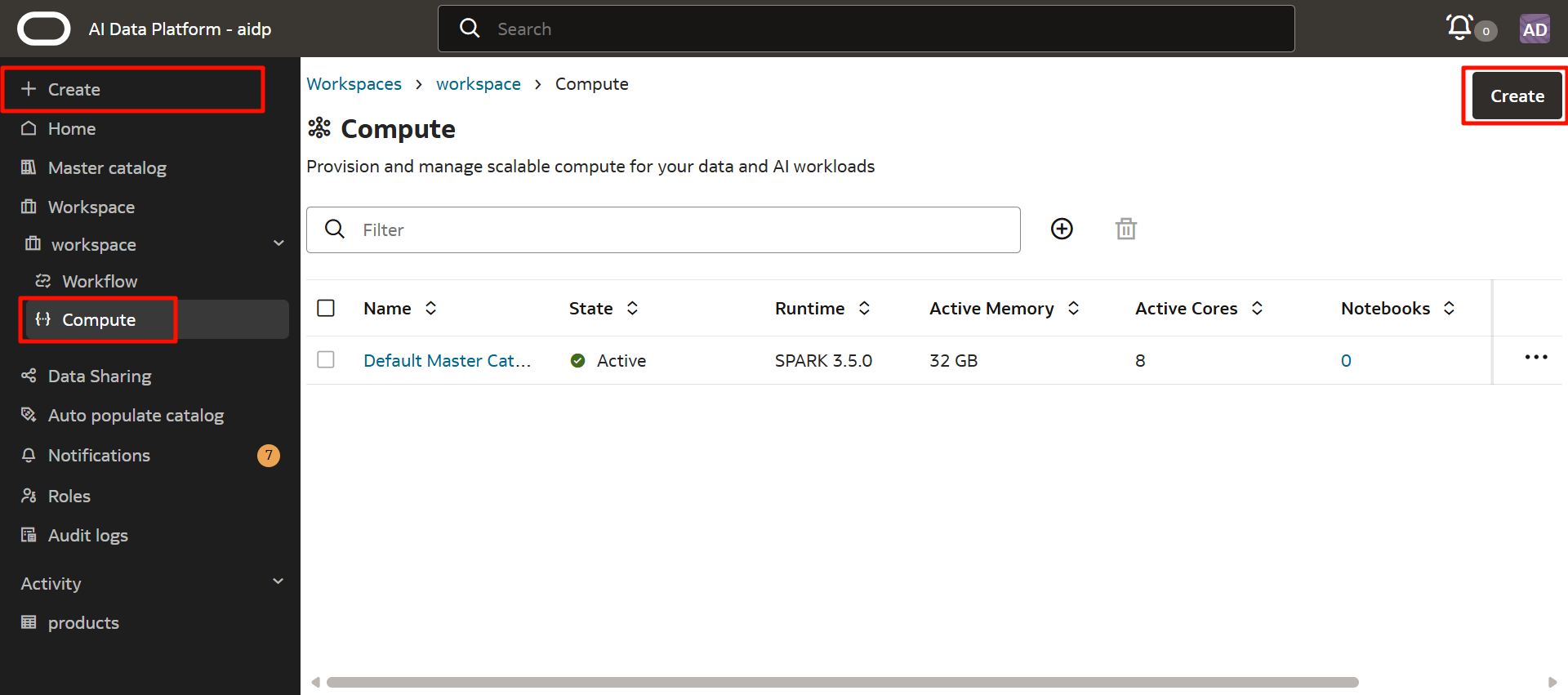
輸入以下內容。
- 集群名稱:自定義(這裡為
cluster) - 運行時版本:
Spark 3.5.0(截至 2025 年 10 月末僅該版本可選) - 驅動器形狀 *³:AMD
- OCPUs:
1(最小) - 記憶體(GB):
16(最小)
*³ 驅動器形狀可選:AMD、INTEL、NVIDIA GPU、ARM。
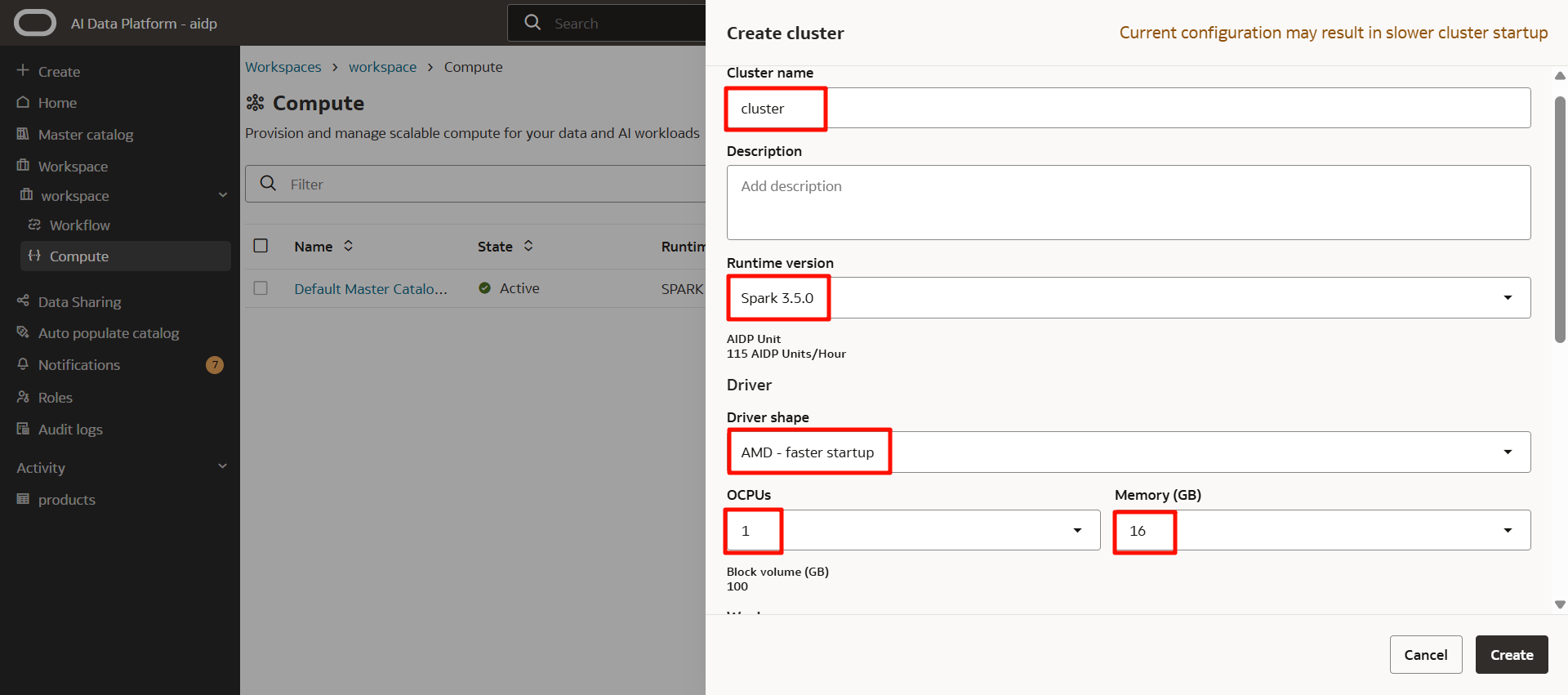
然後輸入以下內容。
- 工作人員形狀
- OCPUs
- 記憶體(GB)
- 設定工作人員數量:靜態(固定值)或自動擴展
- (若為自動擴展)能夠擴展集群的工作人員最小數量與最大數量
- 運行時間:永遠(若在一段時間內無操作會停止集群運行,請輸入閒置時間的分鐘數。)
點擊「創建」。
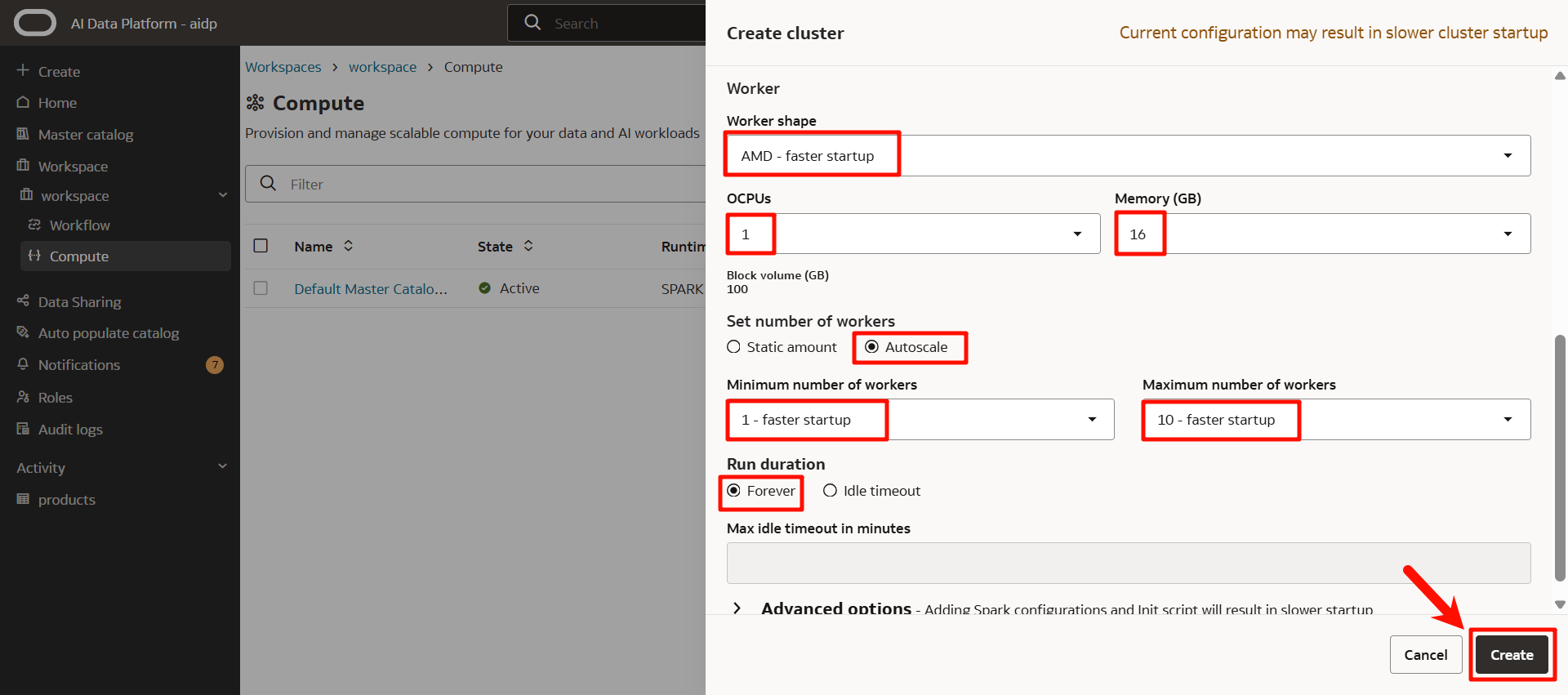
狀態將變為「接受(Accepted)」>「創建(Creating)」。
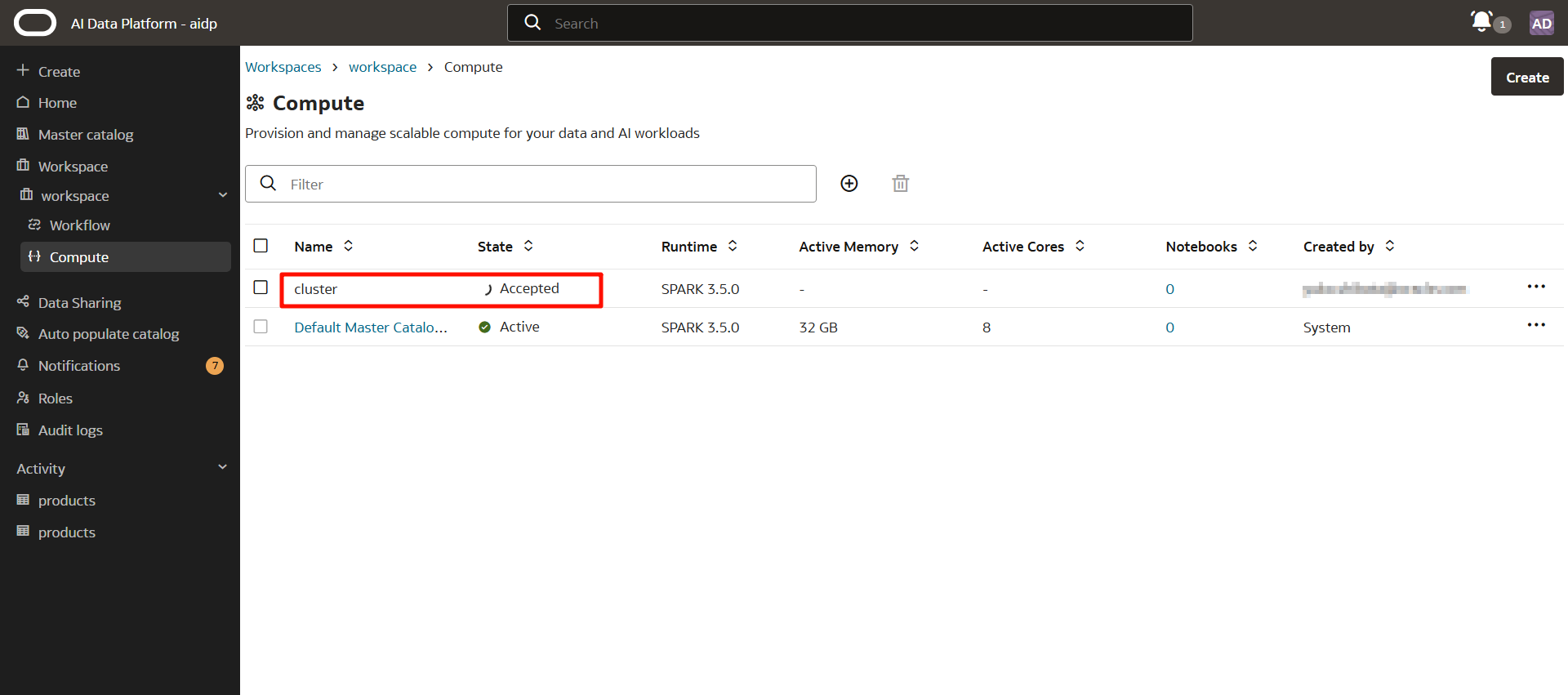
20 分鐘後,集群變為「活動(Active)」,完成創建。
4. 創建筆記本
在 AIDP 中,提供了一個直觀可操作的管理筆記本環境。
創建筆記本,可以將其用作驗證 AIDP 內部數據或進行代碼開發的互動基礎。
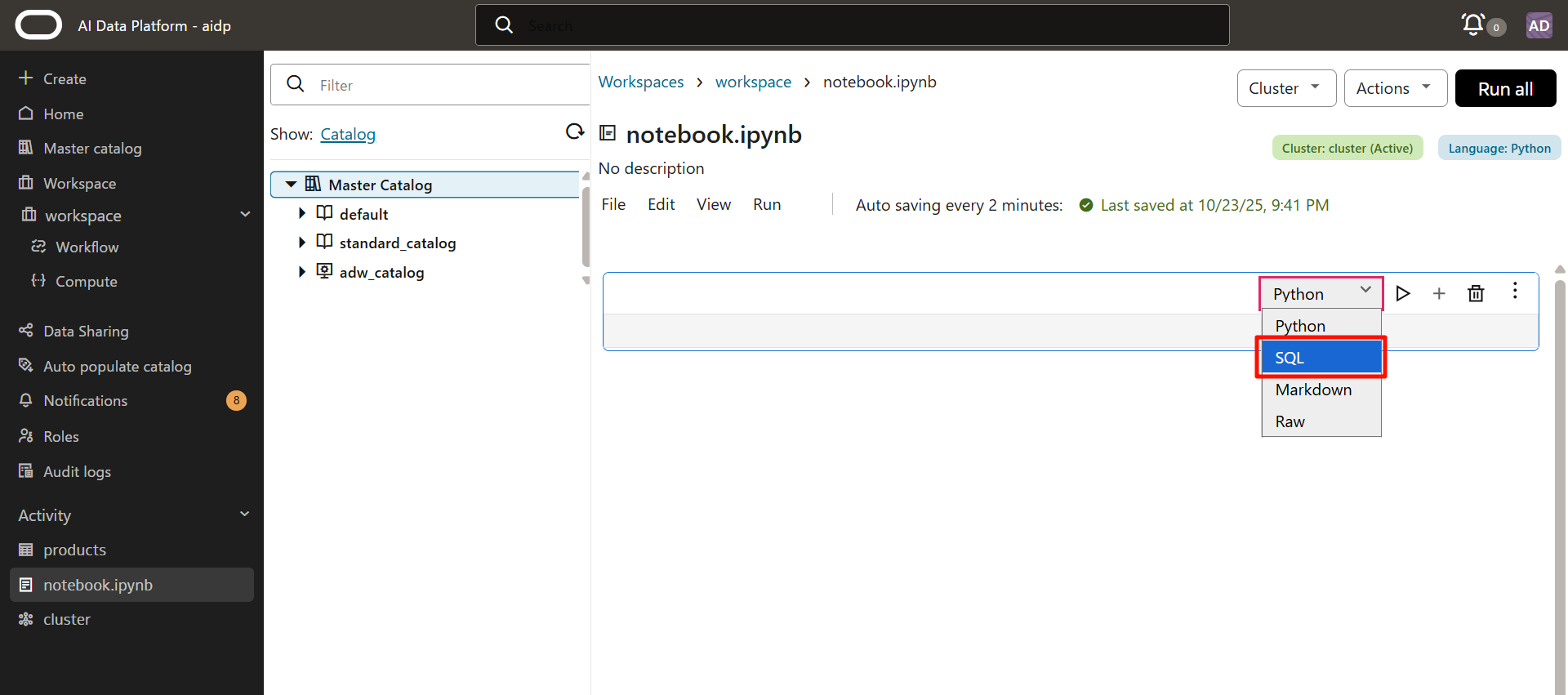
目前(截至 2025 年 10 月末)AIDP 的筆記本支持 Python 和 SQL。
此外,可以將 .ipynb 文件(Jupyter Notebook 形式)導入工作空間。(目前不支持筆記本的導出功能。)
從左側選單選擇「創建」>「筆記本」。
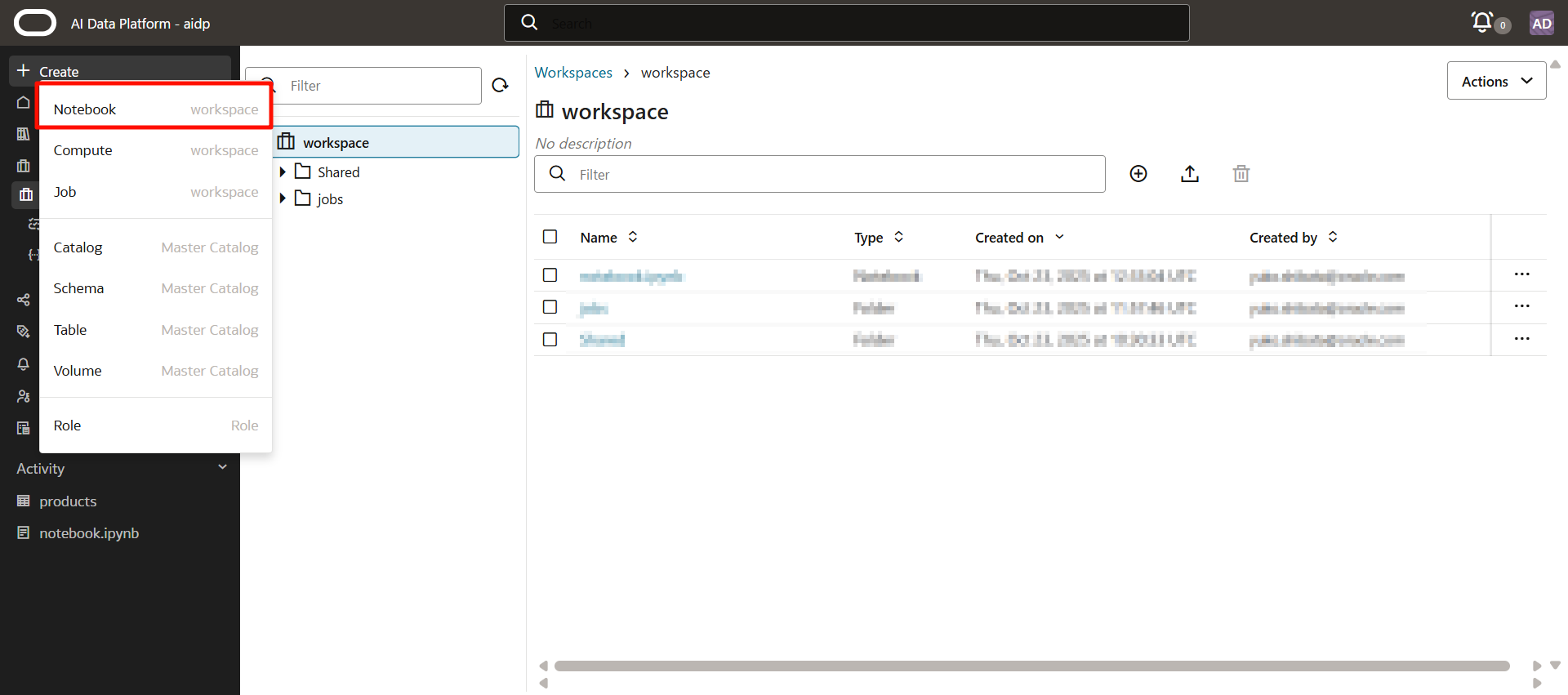
輸入自定義名稱,然後點擊「創建」。
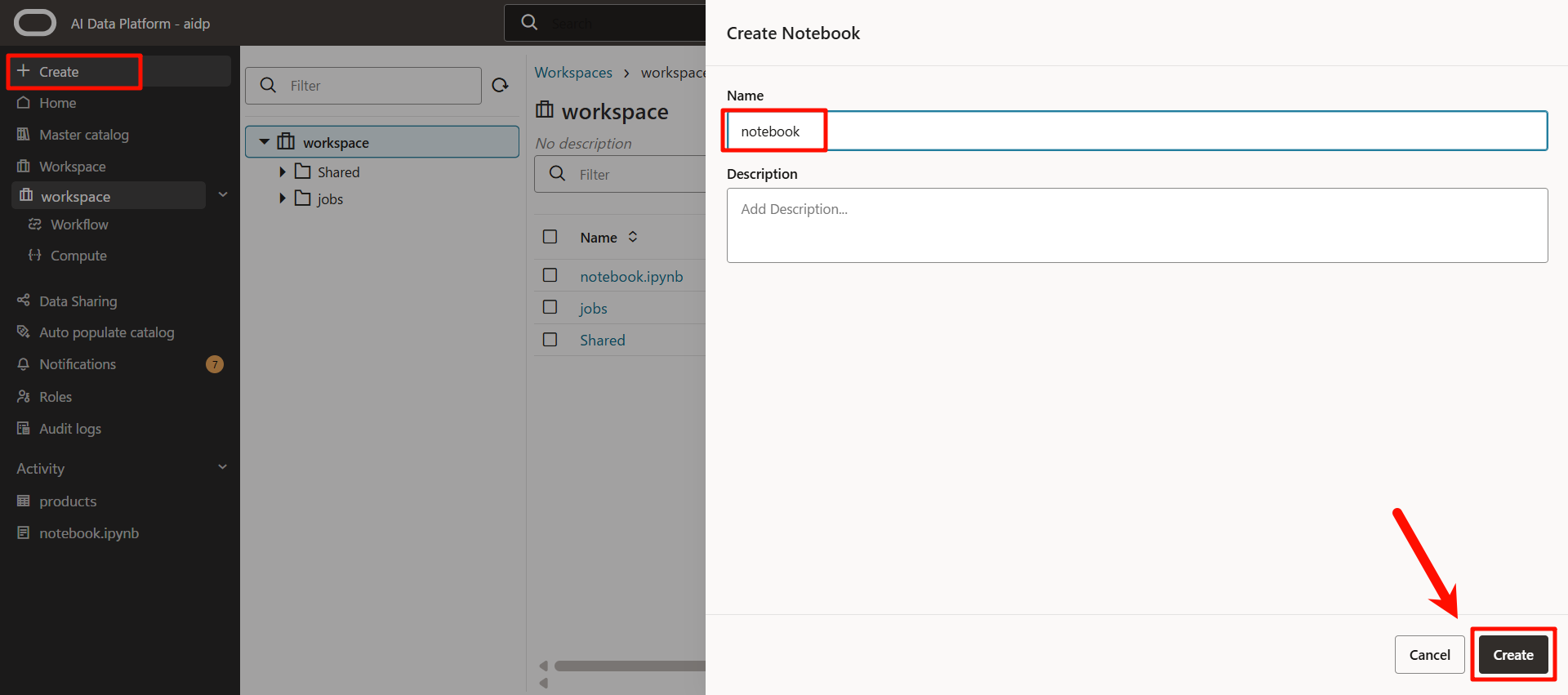
5. 使用 SQL 嘗試
點擊創建的筆記本。
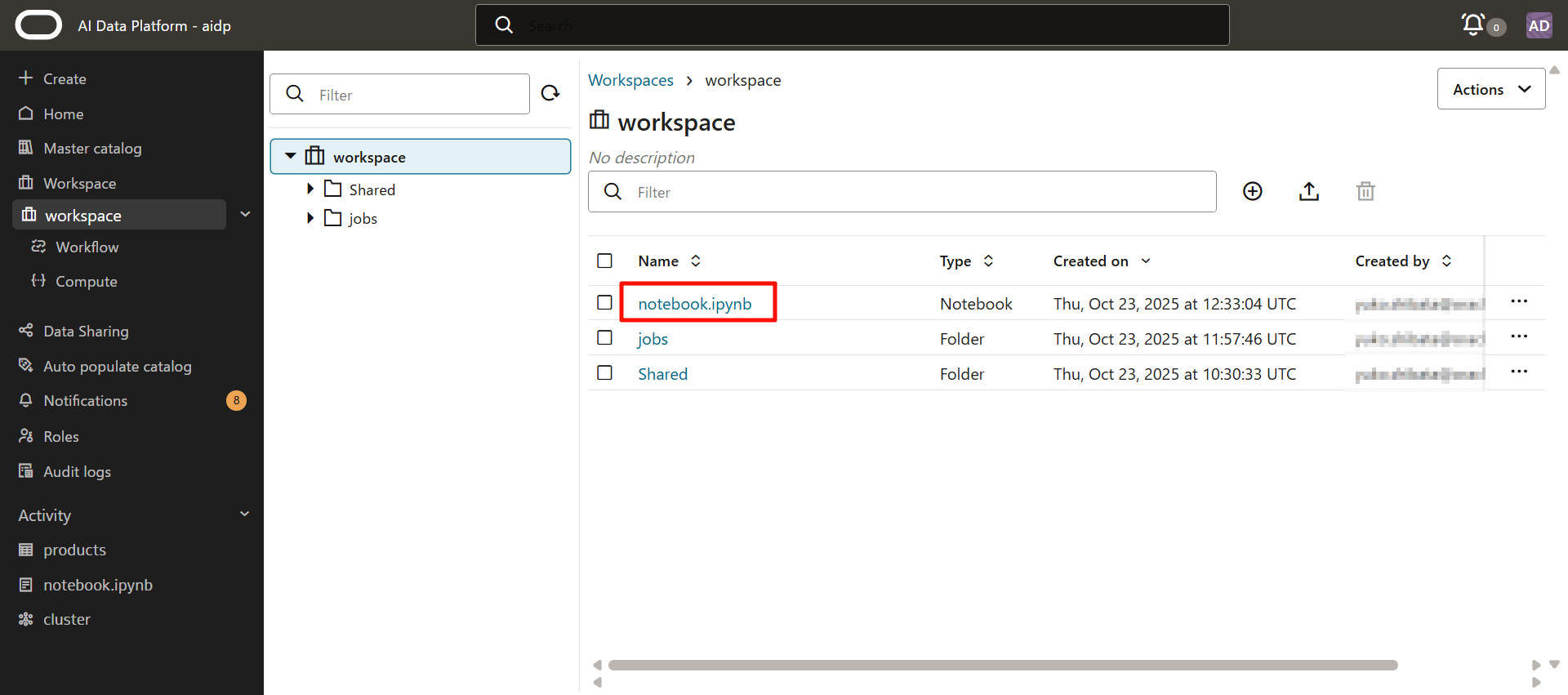
從「集群」中選擇剛剛創建的集群。
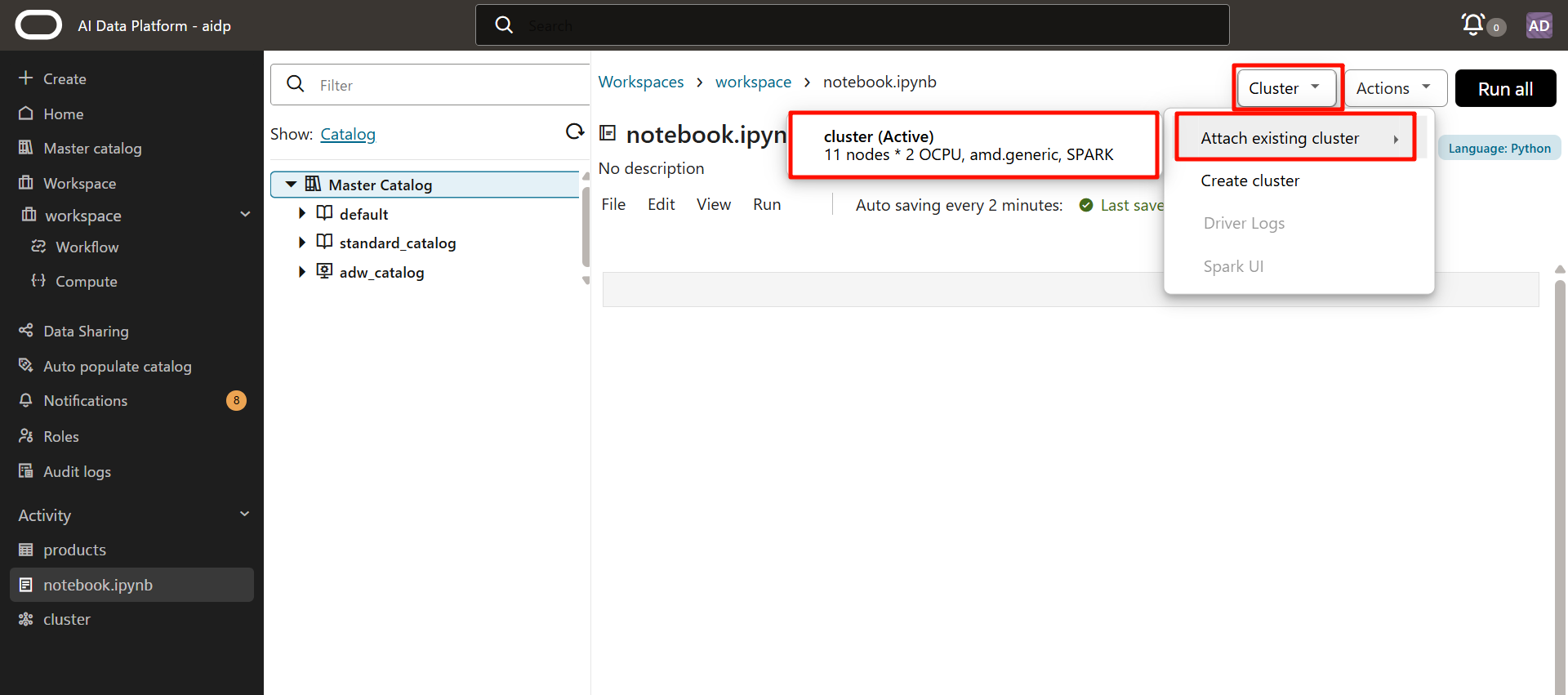
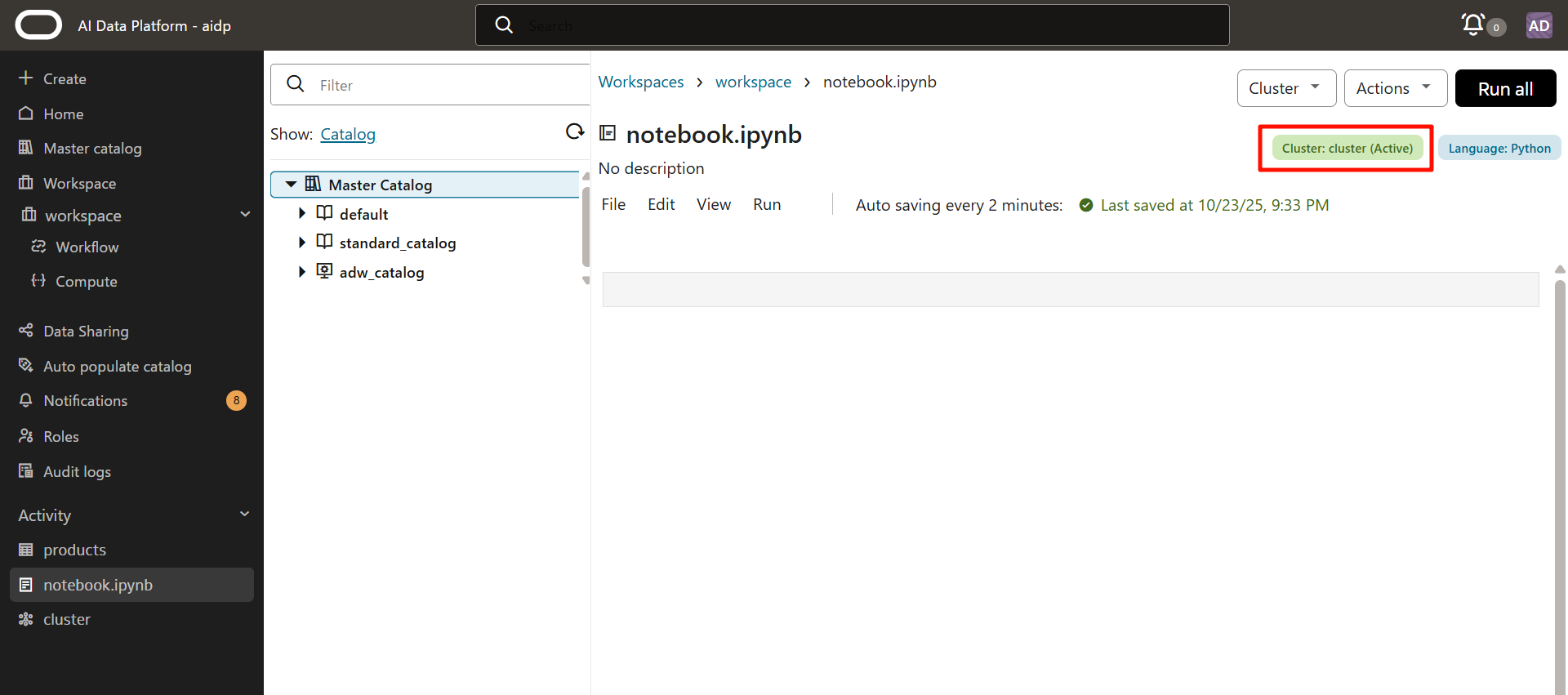
顯示為「附著(Attaching)」> 後變為「活動(Active)」。
選擇 SQL。
首先查看標準目錄的表。
表名按照以下格式指定。
catalog_name.schema_name.table_name
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式