

好的,目前 LMArena 上的WebDev排行榜基本上被三大巨頭壟斷: Anthropic的 Claude Opus 4.5、 OpenAI的 GPT-5.2-codex (high),以及大家最喜歡的Google的 Gemini 3 Pro。
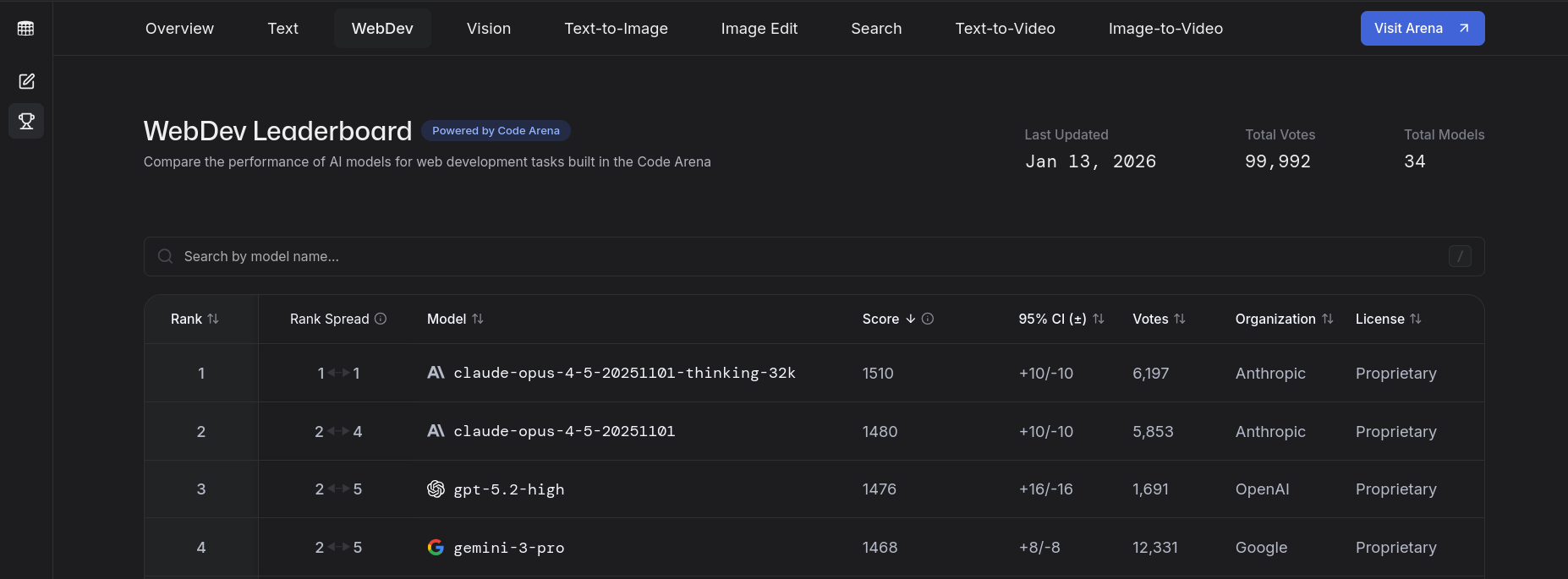
於是,我把這三個人放到同一個現有專案中(超過 8000 個 star 和 50000 多行程式碼),讓他們像普通開發者一樣建立一些真正的功能。
同一個倉庫。同樣的提示。同樣的限制。
為了公平起見,對於每項任務,我取每個模型三次執行中的最佳結果。
然後我比較了他們實際完成的工作:程式碼品質、他們需要多少指導,以及最終該功能是否有效。
⚠️注意:請勿將此測試結果視為絕對標準。這只是一組小型實際程式設計任務,旨在展示每個模型在特定環境下的表現,並讓您大致了解排名前三的模型在相同任務中的表現差異。
太長不看
如果您想快速了解結果,以下是這三款模型在我們測試中的表現:
-
Claude Opus 4.5整體表現最為穩定。它能出色地完成兩項任務,而且使用者介面也是三款中最精緻的。其主要缺點是成本。如果他們能找到在降低成本的同時保持這種性能的方法,那麼其他大多數型號的生存空間將不復存在。
-
GPT-5.2-codex(高難度)是最好的版本之一。但由於推理難度較高,它的速度顯然較慢。程式碼品質和結構都非常出色,但相比本倉庫中的其他兩個版本,它需要更多的耐心。
-
Gemini 3 Pro 的效率最高。兩個任務都能完成,但輸出結果往往感覺像是最低限度可用的版本,尤其是在分析儀表板上。
💡 如果你想找一個最穩健的方案來應對「在大程式碼庫中發布新功能」這類真正的工作,Opus 4.5 在我實際使用中表現最穩定可靠。如果你專注於速度和成本,並且不介意自己打磨 UI,那麼 Gemini 3 Pro 是個不錯的選擇。
測試工作流程
本次測試我們將使用以下 CLI 編碼代理:
-
Claude Opus 4.5: Claude Code(Anthropic 的基於終端的智能體編碼工具)
-
Gemini 3 Pro: Gemini CLI
-
GPT-5.2 High: Codex CLI
這是整個測試所使用的程式碼倉庫: iib0011/omni-tools
我們將用兩個不同的任務來檢驗這些模型:
- 任務 1:新增全域操作面板(Ctrl + K)
每個模型都需要建立一個可透過鍵盤快速鍵開啟的全域操作選單。此功能在現有搜尋功能的基礎上,增加了操作、全域狀態和鍵盤導航。此任務旨在檢驗模型對現有使用者體驗模式的理解程度,以及在不破壞現有功能的前提下避免重複設計的能力。
- 任務 2:工具使用分析 + 洞察儀表板
每個模型都必須在整個應用程式中加入真實的使用情況跟踪,將其保存到本地,然後建立一個分析儀表板,顯示諸如最常用的工具、最近的活動和基本篩選器之類的內容。
我們將比較程式碼品質、令牌使用情況、成本和建置完成時間。
💡注意:我會將每個模型的每個任務的原始程式碼變更整理到一個
.patch檔案中。這樣,您可以透過複製倉庫並使用git apply <path_file_name>` 命令套用修補程式文件,輕鬆地在本機系統上查看這些變更。這種方法讓更改的共享更加便捷。
真實世界的程式設計測試
測試 1:新增全域動作面板(Ctrl + K)
任務很簡單:所有模型都從同一個基礎提交開始,然後按照相同的提示建立提示中要求的內容。
顯然,正如前面提到的,我將評估模型在「三局兩勝」中的反應。
讓我們以一些有趣的內容開始測試:
以下是使用的提示:
This project already has a search input on the home page that lets users find tools. I want to add an improved, global version of this idea that works as an **Action Palette**, similar to what you see in editors like VS Code.
**What to build**
* Pressing **Ctrl + K** (or Cmd + K on macOS) should open a centered action palette overlay from anywhere in the app.
* The palette should support:
* Searching and navigating to tools (reuse existing tool metadata)
* Executing actions, such as:
* Toggle dark mode
* Switch language
* Toggle user type filter (General / Developer)
* Navigate to Home and Bookmarks
* Clear recently used tools
* Fully keyboard-driven experience:
* Type to filter
* Arrow keys to navigate
* Enter to execute
* Escape to close
**Notes**
* This should not replace the existing home page search. Think of it as a more powerful, global version that combines navigation and actions.
* The implementation should follow existing patterns, styling, and state management used in the codebase.GPT-5.2-Codex(高)
GPT-5.2 的表現出乎意料地好。它的實現非常完善,基本上一次性就實現了所有功能,包括國際化支持,無需多次校正。
話雖如此,它的執行時間確實比其他一些模型稍長(約 20 分鐘),這也在意料之中,因為推理難度被明確設置為“高” 。你可以清楚地看到,模型花了更多時間思考架構、命名和邊界情況,而不是急於輸出程式碼。就目前來看,這樣的權衡是值得的。
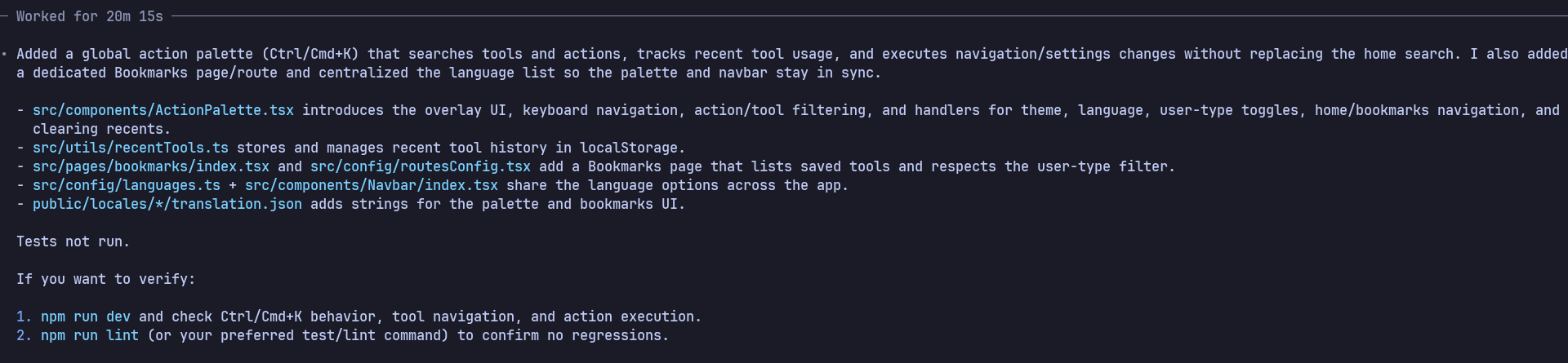
由於推理等級設定為高,令牌使用量明顯更高,但輸出程式碼也反映了這一點。
以下是演示:
https://www.youtube.com/watch?v=https://youtu.be/QCXB5bv4-L4
您可以在這裡找到它產生的程式碼: GPT-5.2 高階程式碼
-
成本:約 0.9-1.0 美元
-
耗時:約20分鐘(API時間)
-
程式碼變更:新增 540 行,僅刪除少量程式碼
-
令牌用途:
-
總計:約20.3萬
-
輸入:約 140k(+ 快取上下文)
-
輸出:約 64k
-
推理標記:約 47k
💡注意:我用相同的模型執行了完全相同的題目,但使用的是預設(中等)推理水平。結果差異巨大。當推理等級設定為高時,程式碼品質、結構以及幾乎所有方面都突飛猛進。這根本無法公平比較。
克勞德作品 4.5
克勞德全力以赴,準備了大量不同的策略。一開始確實遇到了一些建置問題,但他堅持不懈地進行建置,直到修復了所有建置和程式碼檢查問題。

整個運轉過程耗時約7分50秒,是本次測試所有機種中最快的。所有功能都運作正常,使用者介面也非常美觀,完全符合我的預期。
以下是演示:
https://www.youtube.com/watch?v=https://youtu.be/Gki\_kO6o4Qw
您可以在這裡找到它產生的程式碼: Claude Opus 4.5 程式碼
說實話,這超出了我的預期;就連國際化文本都如預期那樣加入到用戶界面並正確顯示。簡直太棒了!
-
費用: 0.94美元
-
持續時間: 7 分 50 秒(API 時間)
-
程式碼變更:新增 540 行,減少 9 行

雙子座3 Pro
Gemini 3 的確能執行,但顯然不如 GPT-5.2 High 或 Claude Opus 4.5 那麼出色。它建置的用戶介面尚可,完全可用,但感覺有點簡陋,而且與其他兩者相比,調色板中的選擇也比較少。
一個明顯的缺點是,語言切換根本沒有顯示在操作面板中,這使得 i18n 支援感覺不完整,即使技術上存在翻譯。
以下是演示:
https://www.youtube.com/watch?v=https://youtu.be/2jxnkna5OmA
您可以在這裡找到它產生的程式碼: Gemini 3 Pro 程式碼
-
成本:低(主要得益於快取讀取)
-
長度:約 10 分 49 秒(API 時間)
-
程式碼變更: +428 行,-65 行
-
令牌用途:
-
輸入:約 79k
-
快取讀取次數:約 536k
-
輸出:約 10.7k
-
節省:約 87% 的輸入令牌來自緩存
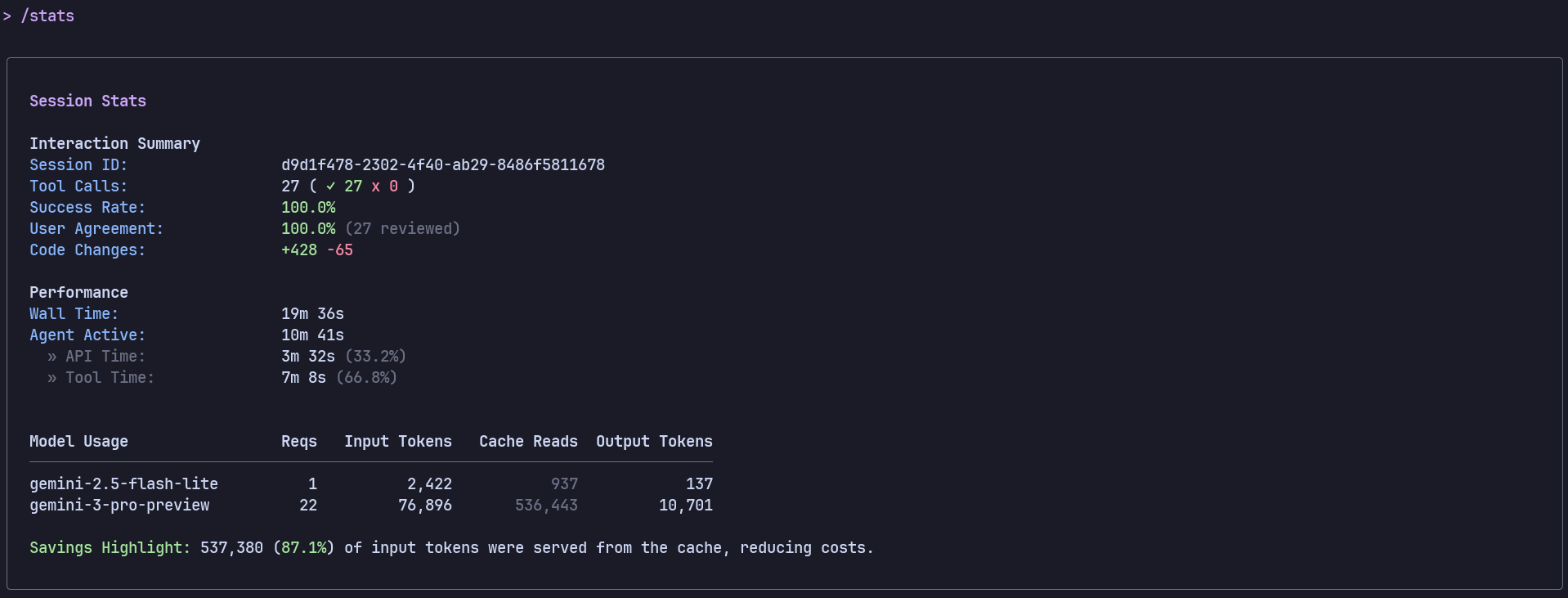
總的來說,Gemini 3 在這裡穩居第三。它能用,使用者介面也不錯,也沒有什麼明顯的缺陷,但與 GPT-5.2 High 和 Claude Opus 4.5 的深度、完整性和完善程度相比,它顯得遜色不少。
測試 2:工具使用分析 + 洞察儀表板
這個測驗比動作面板更進一步。
你可以在這裡找到我使用的提示:提示
GPT-5.2-Codex(高)
GPT-5.2 這次做得太棒了。
最終結果令人驚艷。工具使用情況追蹤功能完全符合預期,資料保存正確,儀錶板也感覺像是一個真正的產品功能。最常用工具、最近使用情況、篩選器,一切都運作良好。
一個非常貼心的設計是,它還將與分析相關的操作整合到了 Test 1 的操作面板中。
這次測試確實比第一次稍長一些,大約花了26分鐘,但這也正是高推理能力帶來的代價。可以看出,模型花了很多時間思考資料建模、程式碼重複使用以及避免邏輯重複。這次的付出完全值得。
以下是演示:
https://www.youtube.com/watch?v=https://youtu.be/8RUeWl\_09nY
您可以在這裡找到它產生的程式碼: GPT-5.2 高階程式碼
-
成本:約1.1-1.2美元
-
耗時:約26分鐘(API時間)
-
程式碼變更:大型多檔案更新,結構清晰
-
令牌用途:
-
總計:約23.6萬
-
輸入:約 162k(+ 大量快取上下文)
-
輸出:約 75k
-
推理標記:約 57k
GPT-5.2 High 的速度仍然很慢,但功能非常強大,對於這樣的任務來說,這是一個非常划算的交易。
克勞德作品 4.5
Claude Opus 4.5 在這裡也表現出色。
最終實現方案運作流暢,說實話,從純粹的介面和功能角度來看,很難看出它與 GPT-5.2 High 的差異。儀錶板簡潔明了,資料清晰易懂,篩選器也運作正常。
以下是演示:
https://www.youtube.com/watch?v=https://youtu.be/-npHfTxicF4
您可以在這裡找到它產生的程式碼: Claude Opus 4.5 程式碼
-
費用: 1.78美元
-
耗時:約 8 分鐘(API 時間)
-
程式碼變更:新增 1279 行,減少 17 行
雙子座3 Pro
Gemini 3 Pro 可以完成這項工作,但與 GPT-5.2 High 和 Claude Opus 4.5 相比,它顯然採用了一種更簡約的方法。
也就是說,整體體驗非常簡陋。使用者介面功能齊全但略顯單調,儀錶板也缺乏其他兩款機型那樣的精緻和深度。
此外,它也沒有像其他兩個模型那樣,在操作面板中直接加入查看分析資料的按鈕。
以下是演示:
https://www.youtube.com/watch?v=https://youtu.be/JuQjYnY-XGE
您可以在這裡找到它產生的程式碼: Gemini 3 Pro 程式碼
-
成本:低,但快取利用率高
-
耗時:約5分鐘(API時間)
-
程式碼變更:新增 351 行,減少 3 行
-
令牌用途:
-
輸入:約 67k
-
輸出:約 7.1k
-
節省:約 85% 以上的輸入令牌來自緩存
總的來說,Gemini 3 Pro 仍然高效可靠,但在這樣的比較中,單憑效率是不夠的。 🤷♂️
結論
至少從這次測試來看,我可以得出結論,這些模型現在基本上能夠一次完成一項相當複雜的任務,至少從我測試的情況來看是如此。
不過,有時模型出錯的程度非常嚴重,如果我要一個一個地修復這些問題,所花費的時間幾乎和從頭開始建造它一樣多。

如果比較不同型號的測試結果,Opus 4.5 無疑是最佳選擇。但我仍然認為,我們距離真正依賴它來完成大型製作專案還很遙遠。雖然最近的改進確實令人驚嘆,但實際結果仍然無法完全體現這些改進。
就目前而言,我認為這些模型非常適合重構、規劃和幫助你加快開發速度。但如果你只依賴它們產生的程式碼,程式碼庫的長期穩定性是無法保證的。
我不認為這些最新的模型中的任何一個可以“直接使用並發布”用於“生產”,尤其是在擁有數百萬行程式碼的專案中,至少不像人們吹捧的那樣。
請在評論區留下您的想法。
原文出處:https://dev.to/tensorlake/claude-opus-45-vs-gpt-52-high-vs-gemini-3-pro-production-coding-test-25of
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式