

Google剛剛宣布發布Gemma 4 !這新一代開放模型帶來了顯著的進步,尤其是在推理能力和架構效率方面。
利用 Gemma 4 連結推理和精確性
在先前的部落格中,我示範如何使用NVIDIA RTX PRO 6000 Blackwell Edition GPU在Cloud Run Jobs上微調 Gemma 3 27B 模型,用於寵物品種分類。隨著 Gemma 4 的發布,我迫不及待地更新了我的流程,看看新模型的性能如何。
在這篇後續文章中,我將解釋 Gemma 4 的獨特之處、它帶來的優勢,以及使用 Cloud Run 上的 PEFT (LoRa) 對其進行微調所需的具體文件修改和變通方案。我們將涵蓋從記憶體需求和動態標籤遮罩到推理模型提示結構等所有內容。無論您是否閱讀過上一篇文章,或者您是第一次接觸此流程,本指南都將為您提供一個完整的、可行的 Gemma 4 解決方案。
如果您更喜歡直接深入程式碼並按照自己的步調進行探索,您可以從這裡克隆儲存庫。
Gemma 4 有哪些新內容?
Gemma 4 相較於 Gemma 3 進行了突破性改進,使其成為谷歌迄今為止最聰明的開放模型系列:
-
Apache 2.0 授權:Gemma 4 採用商業上寬鬆的 Apache 2.0 授權發布,為開發者提供充分的彈性。
-
極具競爭力的基準:31B 模型在 Arena AI 文字排行榜上排名第 3 位,而 26B MoE 模型排名第 6 位,擊敗了規模是其 20 倍的模型!
-
高階推理與智能體:專為多步驟規劃與深度邏輯而設計。它原生支援函數呼叫、結構化 JSON 輸出和原生系統指令。
-
多模態和長上下文:原生支援影像、視訊甚至音訊(在邊緣模型中)。它支援最大 256K 的上下文窗口,適用於更大的模型。
-
多功能架構:包含一個 260 億個專家混合 (MoE) 模型,該模型在推理過程中僅啟動 38 億個參數,以實現快速回應時間。
由於這些變化,直接將 Gemma 4 的程式碼移植到 Gemma 3 的微調腳本中是行不通的。以下是程式碼庫中需要修改的內容,以便使其正常運作。
GPU 記憶體和參數容量
隨著NVIDIA RTX PRO 6000 GPU在Cloud Run上的普及,我們現在可以使用96GB 的記憶體。這對於託管和微調大型模型來說是一項顛覆性的變革。
根據我在部落格文章《解碼高頻寬記憶體》中討論的公式:總 HBM ≈ (模型大小) + (優化器狀態) + (梯度) + (激活值)
使用LoRA (低秩自適應)時,我們會凍結基礎模型的權重,只訓練一小部分參數。這意味著基礎模型的梯度和優化器狀態等記憶體密集型計算可以忽略不計。對於以 16 位元精度載入的Gemma 4 31B資料(bfloat16),基礎模型的大小約為310 億個參數 × 2 位元組/參數 ≈ 62 GB。雖然這款 62GB 的機型可以輕鬆放入 RTX 6000 Pro 的96GB 記憶體中,但我們可以做得更好!
透過 bitsandbytes 函式庫應用4 位元量化 (QLoRA) ,我們將基礎記憶體佔用大幅縮減至約 18–20GB。這使得大量的 VRAM 開銷專門用於多模態處理和長上下文訓練批次所需的高內存激活,從而釋放出無與倫比的無伺服器效率!
Gemma 4 遷移的關鍵程式碼變更
如果您正在更新自己的腳本或從頭開始編寫,以下是對流程進行的關鍵調整:
1. 多模態輸入排序與整合指令
雖然 Gemma 4 支援交錯輸入和原生系統角色,但我們建議採用穩定的慣例,先提供圖像資料,再提供文本,並將指令合併到此流程的使用者提示中。我們發現這種「單輪」結構更能有效地保持指令執行的精確性,並簡化我們自訂的遮罩邏輯。
在以下程式碼中, {"type": "image"}條目用作佔位符,指示處理器將特殊的影像標記注入到聊天模板中。實際的影像張量隨後會在資料整理步驟中單獨傳遞,以確保多模態架構能夠正確適應。
full_user_content = f"{prompt}\n\nIdentify the breed of the animal in this image."
messages = [
{
"role": "user",
"content": [
{"type": "image"}, # Image must come first!
{"type": "text", "text": full_user_content},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": example["caption"]}]
}
]2. 載入正確的多模態架構
Gemma 4 原生支援圖像、視訊甚至音訊(在 E2B 和 E4B 模型中),這改變了模型的載入方式。為了正確處理這些多樣化的輸入,我們明確地使用了AutoModelForMultimodalLM類別。雖然AutoModelForImageTextToText對於純圖像任務仍然有效,但對於 Gemma 4 架構而言,多模態類別是更精確的選擇,它能確保模型原生處理視訊和音訊資料。
from transformers import AutoModelForMultimodalLM
model = AutoModelForMultimodalLM.from_pretrained(model_id, **model_kwargs)3. 多模態資料的標籤遮罩
在 Gemma 3 中,我們可以透過硬編碼特定的標記 ID 來找到助手回應的起始位置,從而屏蔽提示訊息。在 Gemma 4 中,我們最初嘗試單獨對文字提示進行標記化以確定其長度,但遇到了一個重大問題。
Gemma 4 在處理媒體方面效率極高:每張圖片都會獲得與其內容精確匹配的動態數量的軟標記。雖然這些圖片軟標記非常穩定且可預先計算(無論圖片單獨存在還是與文字一起顯示,其數量都不會改變),但標準分詞器在將這些媒體標記之後連接文字和控制標記時,仍然可能會引入一些細微的邊界偏差。如果單獨對提示進行分詞,其長度可能與完整建置的聊天模板略有不同,從而降低模型的準確率。
為了達到最高的精度,我們實作了一個萬無一失的反向搜尋排序器。我們不嘗試計算提示長度,而是搜尋整個_input_ids_陣列,尋找與品種名稱標籤完全匹配的標記。找到後,我們反向搜尋,找到標記<|turn>控制標記,該標記標誌著助手回應的開始,並屏蔽其先前的所有內容。這從數學上保證了模型能夠完全基於所需的模板結構和標籤進行訓練,而不會出現任何屏蔽錯位。
4. 繞過自訂圖層並解鎖視覺塔
這是最關鍵的突破! Gemma 4 的官方 Hugging Face 實作使用名為Gemma4ClippableLinear的自訂神經網路封裝器來封裝其投影層。這個自訂類別封裝了一個標準的nn.Linear層,但加入了特定的邏輯來裁剪最小和最大激活值( input_min 、 output_max等),以穩定訓練過程。
當我們嘗試透過指定層名稱(例如q_proj或v_proj來應用標準 LoRA 時,我們遇到了兩個主要問題:
-
活化值裁切繞過:標準的 PEFT/LoRa 演算法本身並不會辨識
Gemma4ClippableLinear。如果強制將其附加到內部的.linear權重上,則會完全繞過父級包裝器。由於缺少前向傳播期間的關鍵激活值裁剪,模型的激活值會變得不穩定,訓練損失也會急劇增加。 -
凍結的視覺塔:即使我們修復了文字主幹,標準的以文字為中心的 LoRa 配置也常常忽略視覺塔的投影層,導致模型的「眼睛」在訓練期間凍結。
解決方案是使用巨集 `target_modules="all-linear" 。這會指示 PEFT 函式庫遞歸掃描整個模型樹。它能夠安全地辨識並封裝嵌套的線性層,而不會破壞外部Gemma4ClippableLinear裁剪邏輯。至關重要的是,它還可以確保語言模型和視覺塔中的每個線性層都適應您的資料,同時又不會犧牲架構穩定性。
5. 結果
透過結合多模態架構、防彈掩蔽和全塔式 LoRA,我們顯著提高了模型精度。
請注意,Gemma 4 的基準性能(89% 準確率)明顯高於Gemma 3 的基準性能(67% 準確率),因此在這種情況下,準確率的提高較為溫和,但仍然意義重大。
中期結果(700 個樣本,執行時間約 50 分鐘)
即使只使用 700 張訓練影像的一小部分,我們也看到在不到一個小時內,表現比基線有了顯著提升:
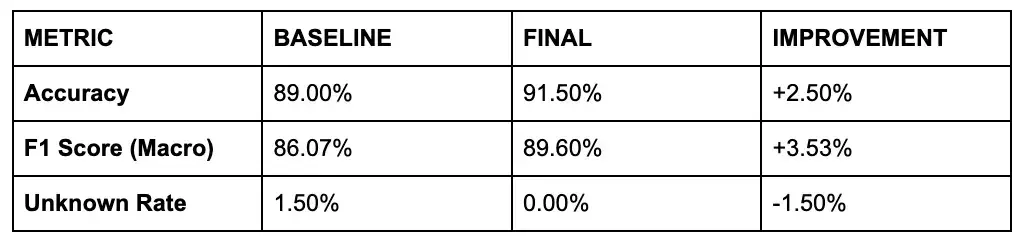
基於700個訓練樣本和200個評估樣本的結果
最終結果(完整資料集,執行時間約 4.25 小時)
執行完整的Oxford-IIIT Pet 資料集(約 4,000 張訓練影像和 3,669 張評估影像)獲得了我們的最佳表現(此資料集的 STOA 準確率為 94%):
{kind=link}
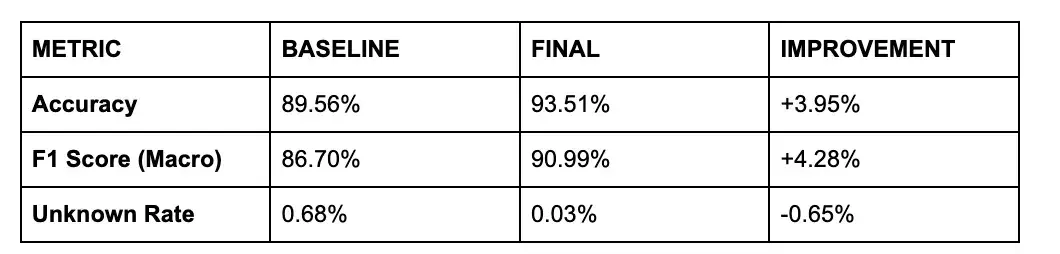
基於 4000 個訓練樣本和 3669 個評估樣本的結果
在本次執行中,我們採用了比典型的純文字執行更為激進的 LoRA 配置: Rank 64 / Alpha 64設置,學習率為 5e-5 。這使得模型擁有足夠的“表面積”,能夠針對寵物資料集的特定細微差別來優化其視覺特徵。
6. 使用 QLoRA 和梯度檢查點管理 VRAM
儘管 RTX 6000 Pro 的 96GB 記憶體容量龐大,但使用 LoRa 訓練一個 310 億參數的模型仍然超出了單 GPU 的效能極限。為了確保絕對穩定性並防止反向傳播過程中出現記憶體溢位 (OOM) 錯誤,我們的腳本採用了雙管齊下的最佳化策略:
-
QLoRA(4 位元量化):利用
BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_quant_type="nf4")大幅減少模型在 CUDA 上載入時的佔用空間。 -
梯度檢查點:專為 31B 型號啟用,它透過重新計算啟動值而不是將它們全部儲存在記憶體中,以略微增加運算時間為代價,大幅減少了 VRAM 使用量。
Cloud Run 上的完整微調工作流程
在開始微調過程之前,請確保已完成以下軟體和環境配置。
先決條件
-
已啟用結算功能並啟動 API 的Google Cloud 專案(Cloud Run、Artifact Registry、Cloud Build、Secret Manager)。
-
NVIDIA RTX PRO 6000在您所在地區(例如
europe-west4)的可用性。 -
Hugging Face Token :具有存取 Gemma 4 模型權重的有效令牌。
步驟0:設定環境變數
設定以下環境變數,使其與以下步驟保持一致:
export PROJECT_ID=[YOUR_PROJECT_ID]
export REGION=europe-west4
export HF_TOKEN=[YOUR_HF_TOKEN]
export SERVICE_ACCOUNT="finetune-gemma-job-sa"
export BUCKET_NAME=$PROJECT_ID-gemma4-finetuning-eu
export AR_REPO=gemma4-finetuning-repo
export SECRET_ID=HF_TOKEN
export IMAGE_NAME=gemma4-finetune
export JOB_NAME=gemma4-finetuning-job第一步:取得程式碼
無論您是在本地執行還是在雲端執行,都需要這段程式碼。克隆程式碼庫並導航到專案目錄:
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/ai-ml/finetune_gemma/步驟二:雲端部署前先進行本地測試
在雲端啟動大量 GPU 之前,最佳實踐始終是在本地使用較小的模型變體(例如 2B IT 模型)在部分資料上驗證您的管道。
若要執行本機 CPU 測試,請先啟動您的虛擬環境:
source .venv/bin/activate然後,使用一個非常小的資料集執行腳本,以確保流程順利完成:
python3 finetune_and_evaluate.py \
--model-id google/gemma-4-e2b-it \
--device cpu \
--train-size 20 \
--eval-size 20 \
--gradient-accumulation-steps 4 \
--num-epochs 1驗證訓練流程成功完成後,即可擴展到 Cloud Run!
步驟 3:在 GCS 中部署模型
為了節省啟動時間並避免訓練期間從網路重複下載,請將模型權重(例如, google/gemma-4-31b-it )暫存在與 Cloud Run 作業位於同一區域的 GCS 儲存桶中。我們在儲存庫中提供了一個實用腳本,可直接執行此傳輸:
# Navigate to the utility directory
cd hf-to-gcs
# Execute the transfer script
python3 hf_to_gcs.py \
--model-id google/gemma-4-31b-it \
--bucket $BUCKET_NAME \
--hf-token $HF_TOKEN此腳本確保將權重儲存在專案的儲存桶中,從而在 Cloud Run 作業執行時透過磁碟區掛載實現高速存取。
步驟 4:建置容器
使用 Cloud Build 將腳本及其相依性打包到與 CUDA 12.8 相容的容器映像中:
gcloud builds submit --tag $REGION-docker.pkg.dev/$PROJECT_ID/$AR_REPO/$IMAGE_NAME:latest .【提示】您可以在雲端建置控制台中追蹤建置的即時進度。
步驟 5:建立並執行 Cloud Run 作業
建立支援 GPU 和磁碟區掛載的作業,用於存放模型的 GCS 儲存桶:
gcloud beta run jobs create gemma4-finetuning-job \
--region $REGION \
--image gcr.io/$PROJECT_ID/gemma4-finetune \
--gpu 1 \
--gpu-type nvidia-rtx-pro-6000 \
--cpu 30.0 \
--memory 120Gi \
--labels dev-tutorial=finetune-gemma \
--add-volume name=model-volume,type=cloud-storage,bucket=$BUCKET_NAME \
--add-volume-mount volume=model-volume,mount-path=/mnt/gcs \
--args="--model-id","/mnt/gcs/google/gemma-4-31b-it/","--output-dir","/mnt/gcs/gemma4-finetuned","--train-size","700","--eval-size","200","--merge"然後執行它:
gcloud beta run jobs execute gemma4-finetuning-job --region $REGION --async結論
遷移到 Gemma 4 需要處理其新的架構和回應格式,但其卓越的推理能力和指令執行力將使一切努力物有所值。透過利用Cloud Run Jobs和Serverless Blackwell GPU ,您可以有效地訓練這些大型模型,而無需管理伺服器。
要開始推理,請探索此程式碼實驗室: 在 Cloud Run 上使用 RTX 6000 Pro GPU 和 vLLM 執行 Gemma 4 模型的推理。
要了解有關生產服務的更多訊息,請參閱Cloud Run Gemma 4 文件。
祝您微調順利! 🎉
特別感謝 Gemma 4 團隊的 Ryan Mullins、Juyeong Ji 和 Gus Martins 對本部落格提供的寶貴意見和回饋。
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式