

軟體工程界一直認為,如果人工智慧能讓我們更快寫程式碼,我們就能建立更多的東西,發展速度也會更快。
這種假設漏掉了一個步驟。
編寫程式碼與整合程式碼、維護程式碼或信任程式碼是兩回事。
我們開始發現,驗證的規模擴張方式與生成方式不同。
我認為,在這種環境下脫穎而出的工程師,並非是能夠編寫出最多程式碼的人,而是能夠審視程式碼輸出並可靠地判斷哪些程式碼應該保留下來的人。
這篇文章探討的是為什麼反駁這種技能即將變得至關重要,以及這對我們建立軟體的方式意味著什麼。
-
成交量不再是價值的訊號。
我們正處於一場真正的人工智慧爆發式成長之中。
程式碼、圖像、影片、文件——所有這些現在都可以以接近零的成本生成,而與歷史上的人力勞動基準相比,成本正在迅速下降。
尤其在軟體工程領域,編寫大量程式碼的能力歷來與生產力甚至創造力連結在一起。
這種聯繫現在正在瓦解。
我們現在可以比以往任何時候都更快地生產更多的產品。
數量本身已經失去了意義。
-
知識是經得起攻擊後仍能存活下來的東西。
要理解正在發生的變化,退後一步,借鏡認識論會有所幫助。
認識論是哲學的一個分支,它區分知識和非知識。
僅僅擁有某方面的經驗並不等於擁有相關知識。
重複所謂權威人士提出的觀點並不等於獲得知識。
根據經驗發表的言論也不等於知識。
只有當陳述內部一致、可公開檢驗且能夠經受對抗性審查時,它們才能成為知識的候選者。

-
價值是在攻擊中體現的,而不是在設計實驗室中體現的。
軍事裝備就是一個恰當的類比。
坦克的價值不是在設計實驗室或行銷手冊中確定的。
它的價值體現在它在實戰中抵禦攻擊的能力。只有經歷過壓力、抵抗和惡劣環境的考驗,我們才能對其效能做出嚴肅的論點。
這同樣適用於創意、設計和程式碼。它們的價值會在遭受攻擊時顯現出來。
-
一個想法的來源並不重要;重要的是它能否存續。
卡爾波普爾明確指出:資訊來源不可信。
聲明的出處是著名科學家、資深工程師或大型語言模型,都無關緊要。
重要的是,這說法能否經得起證偽的考驗。
知識的增長是透過推測和反駁實現的,而不是透過自信的斷言來實現的。
波普寫的是科學與非科學的分野,但這個模式適用範圍更廣:如果沒有被證明是錯的可能性,我們就不能宣稱自己學到了任何東西。
-
GenAI 是一個推測引擎;它產生的一切都是暫時的。
GenAI 的核心是一個推測引擎。
產生的每一段程式碼都是對系統應該如何運作的理論設想。
每個產生的解釋都是一種提出的解釋。
所有這些都必須視為暫定方案。
人工智慧生成的一切都應被視為一種提出的理論,然後接受嚴格的測試和批評,以檢驗其是否經得起考驗。
-
我們已經有了對抗性審查系統(CI/CD、程式碼審查)。
這種情況在人工智慧出現之前就已經存在了。
這就是我們當初發明程式碼審查、程式碼檢查工具和持續整合的原因。我們體認到人會犯錯,初稿往往有缺陷,而結構化的批評也能改善最終成果。
CI/CD 管線、單元測試和整合測試都是對程式碼進行對抗性審查的機制。
從這個意義上講,應用波普爾知識論已經融入我們的工作流程多年了。
-
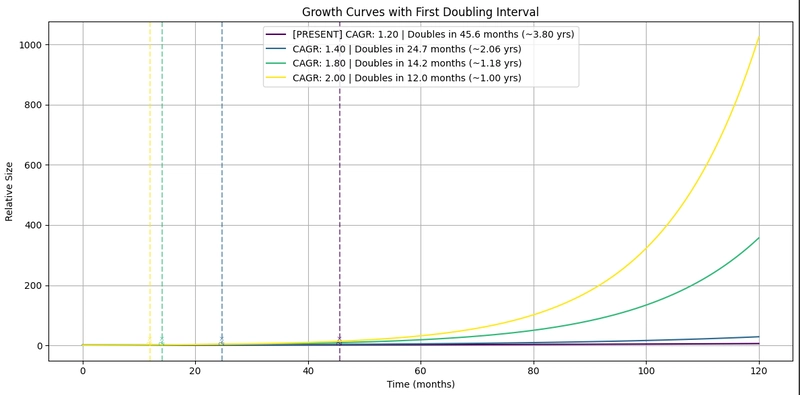
軟體歷史成長率:每年約 20%。
現在改變的是規模。
2016 年,哈頓教授及其團隊發表了《演進軟體的長期成長率》。
早在 GenAI 出現之前,他們就研究了軟體程式碼庫如何隨時間成長。
他們的發現驚人地一致:從歷史上看,軟體專案的複合年增長率 (CAGR) 約為 20%。
照這個速度,程式碼庫的規模大約會在四年內翻倍。
需要注意的是,本文描述的是程式碼庫的實際成長情況,而非理論上的最大值。它代表的是歷史基準,而非物理定律。
-
龐大的程式碼庫是人工智慧驅動生產力的一個可能結果。
現在設想一下,如果人工智慧能夠顯著提高開發人員的生產力,會發生什麼事。
如果生產率翻一番,複合年增長率接近 40%,那麼翻一番所需的時間將縮短到大約兩年。
如果生產力提高五倍,年複合成長率接近 100%,那麼程式碼庫每年都會翻倍。
十年下來,這種複利效應將是爆炸性的。生產力提高5倍並持續十年,最終可能導致程式碼量成長約165倍。
一個中等規模的 10 萬行程式碼庫有可能變成 1 億行程式碼。
作為參考,Linux 核心經過三十年的發展,程式碼量達到了約 4,000 萬行。
我們可能正朝著「巨型程式碼庫」的方向發展。
-
但成長難道不會受到複雜性的限制嗎?是的,但仍然有可能出現顯著增長。
這種預測立即遭到反對。
首先,20% 的複合年增長率來自 LLM 出現之前的世界;用它來預測 LLM 出現之後的世界,在邏輯上是充滿矛盾的。
歷史趨勢為我們提供了一個衡量顛覆性影響的基準。
如果這種趨勢持續下去,一切都不會改變。
如果系統崩潰,我們需要了解新的環境。
其次,軟體發展受限於複雜性,而不僅僅是打字速度。
即使我們編寫程式碼的速度再快,一個包含 1 億行程式碼的程式碼庫也可能無法建置或維護,因為整合複雜性的成長速度並非線性成長。
如果我們產生程式碼的速度超過了我們管理其整合複雜性的能力,我們建構的系統就會因自身過重而崩潰。
問題在於我們的驗證系統能否隨之擴展。
-
編寫程式碼和審查程式碼之間的舊平衡在大規模情況下被打破。
從歷史上看,審查流程可以隨著程式碼庫的成長而發展。
如果程式碼每年成長 20%,人工審查能力大致可以跟上。
但如果程式碼量以倍數而不是百分比的速度成長,那麼舊的平衡就會被打破。
我們從漸進式成長轉向程式碼的大規模生產。
隨著時代變遷,反駁的力量將如何發展?
-
人工智慧必須協助驗證,否則人工審核將崩潰。
此時,注意力就成了稀少資源。
隨著產出增加,價值從生產轉移到選擇。
關鍵問題在於:我們如何將有限的人力集中到機器產生的海量差異中最重要的風險?
我們如何建構更高層次的表徵,將巨大的變化壓縮成可管理的洞察?
如果不利用人工智慧進行驗證,就沒有切實可行的前進方向。
僅靠人工審核無法跟上機器大規模生成的速度。
人工智慧必須有助於吸引人們對有用事物的關注,突出潛在的約束違規行為,檢測行為偏差,並減輕審查負擔。
驗證過程必須部分自動化,否則就會崩潰。
-
但如果人工智慧有缺陷,人工智慧的審查結果是否可信? (無限倒退問題)
最明顯的反對意見就此產生:如果產生程式碼的人工智慧有缺陷並產生幻覺,那麼審查程式碼的人工智慧又怎麼會缺陷更少呢?
這樣做豈不是只會加劇錯誤而不是發現錯誤嗎?這有時被稱為無限倒退問題——如果我們需要一個人工智慧來檢查人工智慧,那麼誰來檢查這個檢查者呢?
-
專業評審人工智慧與通用生成人工智慧不同。
答案在於專業化。
評審型人工智慧不需要具備通用智能。
它需要成為一個專注於檢查特定屬性的工具:類型正確性、是否符合專案風格、是否違反已定義的架構邊界,或是否透過基於屬性的測試來捕捉行為偏差。
用於審查的模型可能與用於生成的模型不同——更小、更保守。
Review AI 不需要對程式碼是否「好」發表意見。
它被要求向人類發現異常情況。
它就像一個不知疲倦、快速但最終會犯錯的初級審閱員,其職責是指出任何異常情況,並讓高級工程師做出最終決定。
目標不是消除人類的判斷,而是引導人類的判斷。
-
護欄屬於驗證範疇,而非僅是生成範疇。
這裡也應該安裝護欄。
防護措施應該主要位於驗證層,而不是生成層。
僅僅限制發電量就像試圖在設計之初就阻止所有糟糕的儲罐設計一樣。
更穩健的做法是對每個設計進行嚴格的批評和壓力測試。
我們不應將審查模型作為主要控制機制,而應升級我們的驗證方法。
這裡還有討論的空間:有些危害發生在產生的時候,而不是執行的時候,而產生層面的防護措施正是為了解決這些問題。
但就工程可靠性而言,驗證才是關鍵。
-
或許我們會寫出更少但更有效率的程式碼。但驗證方式會轉變,不會消失。
另一種反對意見則來自經濟學領域。
或許未來不是龐大的程式碼庫,而是精簡且有效率、資源利用率高的程式碼庫。
如果程式碼成本降低,編寫高效能、可重複使用的抽象層的動力就會增加。
既然人工智慧驅動的十行設定檔就能實現同樣的功能,為什麼還要產生上千行樣板程式碼呢?
這有可能。
但即使是最小的程式碼庫也需要對其最小部分進行驗證,而且槓桿作用會增加任何錯誤的影響範圍。
無論程式碼量增加或減少,驗證負載都會轉移而不是消失。
稀缺資源依然是人類的注意力,而且這種注意力必須放在正確的地方。
如果 GenAI 能夠擴展推測能力,那麼 ReviewAI 就必須能夠擴展反駁能力。
-
市場飽和可能限製成長,但問題空間遠未耗盡。
另一個反對意見是,程式碼量的成長最終會導致市場飽和。
我們真正需要解決的有意義的問題數量是有限的。超過一定限度後,編寫更多程式碼只會增加噪音和技術債。
但這假設問題表面接近飽和。事實並非如此。
以印度這樣的國家為例。大規模的基礎設施缺口、污染治理、物流效率低下、醫療保健服務不足、教育品質低落、城市規劃不完善、農業優化——這些都不是無關緊要的問題。
這些都是系統層面的挑戰,需要大規模的協調、監控、模擬、自動化和最佳化。所有這些都越來越依賴軟體。
即使在已開發經濟體中,軟體對物理系統的滲透仍然不完整:能源網路、水系統、公共交通、製造業、氣候建模、機器人、生物技術。
隨著能力的擴展,軟體不再僅僅滿足現有市場需求;它還能開拓新的領域。
從歷史上看,當產能增加時,需求往往會擴展到以前認為不可能的領域。
限制因素很少是問題不足,而是成本和協調。
-
工程必須適應變化,因為規範的演變太慢了。
工程領域需要將這種轉變內化。
這門學科一直以來都依賴於區分哪些方法真正有效,哪些方法只是看起來有效。
擁有建造某樣東西的經驗並不代表它可靠。
經受住對抗性測試就足夠了。
由於程式碼量可能以前所未有的速度成長,我們沒有時間慢慢制定新的規範。
我們需要易於使用、經濟高效的驗證工具,這些工具可以直接整合到開發工作流程中。
-
具體方向:對每次 Git 提交進行自動審查。
在我自身對 AI 輔助程式碼審查的研究中,我一直在建立工具,當差異提交到 git 儲存庫時,該工具會自動觸發審查。

這個想法很簡單:將每一次變化視為一個假設,並對其進行系統性的檢驗。
從某種意義上說,這是將波普爾的知識論應用於CI/CD(持續改進/持續交付)。其目標並非減緩創作速度,而是促進批判的蓬勃發展。
我並不認為這能解決所有問題。
工具尚處於早期階段,方法尚處於實驗階段,無限倒退的擔憂是真實存在的。
但現在是時候認真對待我們的 ReviewAI 技術堆疊了。
-
未來屬於那些能夠反駁的人,而不僅僅是創造的人。
人工智慧讓推測變得廉價。
複利誤差的風險是真實存在的。
如果我們不能讓反駁同樣有力且廣泛可及,我們就有可能被自己的言論淹沒。
人工智慧時代工程的未來,不在於我們能創造多少,而是我們如何嚴格地決定哪些東西能夠生存。
最後決定哪些東西能夠存續,仍然是人類的責任。
我個人希望,反駁這理念能夠像業界對「代際」這個理念一樣受到重視。
原文出處:https://dev.to/shrsv/the-future-belongs-to-those-who-can-refute-ai-not-just-generate-with-ai-28i0

1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式