🔧 阿川の電商水電行

介紹
歡迎回到我的部落格! 😁 在這裡,我與自己交談,也希望與你交談,談論我在工作中解決的工程問題。我這樣做主要是因為找到解決方案讓我感到興奮。我發現低效率、瓶頸和挑戰的過程使我解決了軟體工程中一個常見但關鍵的問題。
這個問題是需要非同步執行操作——通常需要精確的計時,有時需要重複執行。遵循我解決問題的核心方法(跨空間和時間),我決定建立一個解決方案,該解決方案不僅針對單一操作,而且可以擴展到各種用例。無論是發送通知、處理事務或觸發系統工作流程,許多任務都需要計劃執行。如果沒有強大的調度機制,高效處理這些作業很快就會變得複雜、不可靠且成本高昂。
為了解決這個問題,我著手建立一個可擴展、可靠且經濟高效的事件調度程序,可以無縫管理延遲、即時和重複的操作。
在這篇文章中,我將引導您完成:
-
導致需要事件調度程序的問題
-
理想解決方案的功能和非功能要求
-
實施背後的系統設計與架構決策
最後,您將清楚地了解如何建立無伺服器計劃作業系統,以確保準確性、耐用性和可擴展性,同時控製成本。讓我們深入了解一下吧!

問題:管理跨日曆週期的訂閱更改
訂閱管理面臨獨特的挑戰,尤其是在處理取消或降級時。用戶可以在計費週期內隨時請求這些更改,但由於訂閱的預付費性質,此類修改只能在周期結束時生效。這種延遲引入了對非同步執行的需求——一個可以立即記錄這些請求但將其執行推遲到適當時間的系統。
解決方案:適當的調度機制
如果沒有適當的調度機制,有效管理這些延遲操作就會變得複雜。系統必須確保每個請求都在正確的時間執行,同時防止遺漏或重複操作。此外,頻繁的執行(例如多個計劃變更的批次)必須在不壓垮系統的情況下進行處理。為了解決這個問題,我們需要一個可靠、可擴展且經濟高效的調度程序,能夠無縫處理延遲和重複執行。
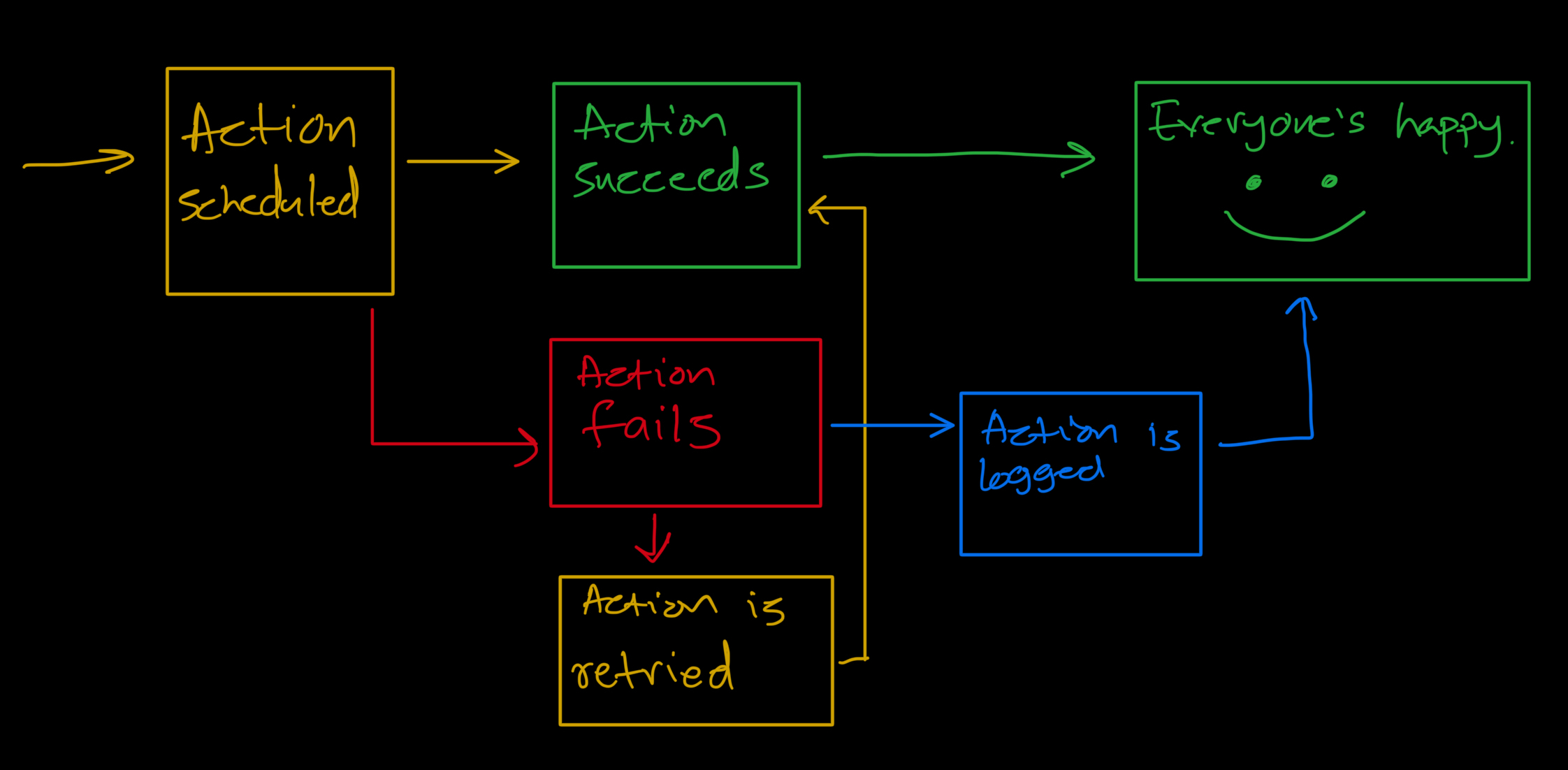
功能需求:定義核心功能
強大且可擴展的計畫作業系統必須能夠有效地規劃、執行、更新、監控和重試操作,同時確保可靠性和靈活性。
1. 安排和建立動作
系統必須允許使用者透過以下方式安排操作:
-
操作類型、執行時間、執行資料和元資料為必填欄位。
-
可選字段,例如重複、頻率和執行餘數。
-
及早驗證以確保行動符合其履行要求。
2. 更新或刪除操作
使用者可以在操作被鎖定之前(執行前 2 分鐘)更新或刪除操作。一旦鎖定,則不允許進行任何外部變更。
3. 動作狀態管理
每個操作都必須具有反映其執行進度的內部管理狀態。狀態轉換和結果必須記錄在元資料中以進行追蹤。
4. 行動履行映射
每個操作都必須對應到負責其執行的特定履行服務。必須標記沒有符合履行服務的操作,以防止執行錯誤。
5. 重試失敗的操作
失敗的操作必須使用指數退避來重試以處理臨時故障。超過最大重試限制的操作必須標記為手動幹預。
6. 處理立即操作、延遲操作、重複操作
系統必須區分立即行動和延遲行動,以確保及時執行:
-
立即行動(2 分鐘內執行)必須即時處理,不得有調度延遲。
-
延遲的操作(2 分鐘後執行)必須在正確的時間安排和處理。
-
重複動作必須以規定的頻率進行規定的次數
非功能性需求 (NFR):確保系統可靠且可擴展
規劃作業系統必須滿足關鍵NFR,以確保可靠性、可擴展性、安全性和可維護性。
1. 可靠性和耐用性
-
行動必須正確且準時(±2 分鐘)執行。
-
重複動作必須完全按照計畫以正確的頻率執行。
-
失敗的操作必須使用指數退避重試,且非重複操作必須僅執行一次。
2. 可擴展性
-
系統必須動態擴展以處理高請求負載。
-
無伺服器架構可確保成本效益和靈活性。
-
基於佇列的方法(例如AWS SQS)必須調節執行頻率以防止下游服務過載。
3. 可用性
- 系統必須始終可用,並且不能冷啟動,確保需要時立即執行。無伺服器架構以合理的成本支持這一點
4. 安全
- 基於簽名的驗證必須保護請求並防止未經授權的執行。
5.可維護性
-
該系統必須是模組化的、封裝的並且組織在單一儲存庫中。
-
基礎設施和資料庫索引規則必須進行編碼。
-
為了獲得更好的可靠性,必須使用類型化語言。
-
必須使用加密的環境變數啟用本地測試。
-
啟動腳本可以自動執行套件安裝和環境設定。
-
全面的測試必須確保安全的變更和整合。
6. 可觀察性
-
API 端點必須公開:
-
所有預定的行動。
-
按狀態過濾的操作。
-
失敗操作的重試功能。
-
集中式日誌系統必須一致地追蹤執行問題。
工具:為計劃好的作業系統提供動力

AWS Lambda:無伺服器執行運算
-
無需管理伺服器即可啟用事件驅動執行。
-
處理動作調度和驗證。
-
使用即時事件流處理即時操作。
-
在預定時間執行延遲的操作。
-
根據操作類型管理履行任務。
Amazon EventBridge:管理計畫執行
-
充當延遲操作的調度程序。
-
每 5 分鐘輪詢一次到期的待處理操作,並將其放入隊列進行處理。
-
確保執行發生在預定時間的 ±2 分鐘內。
Amazon SQS:將操作排隊以實現可擴展性
-
透過非同步處理計劃的操作來解耦執行工作負載。
-
控制履行請求頻率以防止系統過載。
-
使用 FIFO(先進先出)處理來維護執行順序並防止重複執行。
Amazon DynamoDB:儲存計畫操作
-
作為儲存計劃操作的主資料庫。
-
提供快速讀取/寫入操作以處理高工作負載。
-
儲存用於追蹤執行狀態、重試和結果的元資料。
-
使用 DynamoDB Streams 觸發立即執行。
Amazon API Gateway:公開端點以供管理
-
提供用於建立、更新和刪除計劃操作的 HTTP 端點。
-
公開監控端點以依狀態檢索操作並重試失敗的操作。
-
透過身份驗證和授權機制確保安全存取。
系統設計:計劃操作的資料庫架構
|領域|描述 |
|----------------------|-------------|
| id |每個計劃操作的唯一辨識碼。 |
| data |儲存特定於執行的詳細資訊。 |
| action |定義要執行的操作類型。 |
| executionTime |指定操作應運轉的時間。 |
| repeat |指示是否應重複該操作。 |
| frequency |定義重複操作的間隔。 |
| executionRemainder |追蹤剩餘的執行次數。 |
| status |執行狀態(“PENDING”、“IN_PROGRESS”、“COMPLETED”、“FAILED”)。 |
| createdAt |建立操作時的時間戳記。 |
| updatedAt |最後修改時間戳。 |
| retryCount |計算失敗的執行重試次數。 |
| metadata |儲存日誌和其他執行詳細資訊。 |
範例:預定的通知操作
{
"data": {
"mobile": "60123456789",
"subject": "Test",
"name": "Joojo",
"templateType": "USER_LATE_PAYMENT_NOTIFICATION",
"notificationType": "SMS"
},
"repeat": true,
"frequency": "DAILY",
"executionRemainder": 5,
"action": "SEND_NOTIFICATION",
"executionTime": 1736930117120
}專案結構
我使用分層模組化方法來實現可維護性、可擴展性和易於更改。很多時候,不同的團隊可能希望擴展服務中的變更而不引入意外的副作用。我試圖透過將元件組織成不同的模組來實現這一目標。讓我們深入探討一下
1. 模組化設計的單一應用
整個系統建構為單一應用程式,但具有分離關注點的模組化結構。每個模組負責系統的特定方面,使程式碼庫更易於導航和修改。
./src
├── app.ts
├── clients
├── config
├── controllers
├── handlers
├── helpers
├── middleware
├── models
├── routes
├── service
├── types
└── utils2. 用於分散式執行的無伺服器處理程序
該專案是圍繞 AWS Lambda 設計的,匯出並建構不同的處理程序,以允許無縫執行計劃的操作。這些處理程序確保各種任務獨立處理,從而提高容錯能力和可擴展性。
-
操作處理程序:管理建立、規劃、檢索、更新、刪除和處理計劃的操作。這使得所有與操作相關的邏輯集中化,從而可以輕鬆修改而不影響系統的其他部分。
-
延遲操作處理程序:專門處理需要稍後啟動的操作。這種分離可確保有效地調度和處理延遲的操作,而不會幹擾即時執行。
-
立即操作處理程序:觸發必須在 2 分鐘內開始的操作的執行,使用DynamoDB Streams檢測變更並立即啟動執行。這確保了緊急任務的及時處理。
-
履行處理程序:透過與適當的履行服務交互,確保計劃的操作正確執行。這種設計允許履行邏輯獨立於動作調度而發展。
├── handlers
│ ├── fulfillment.ts
│ ├── initiate-scheduled-actions.ts
│ ├── initiate-stream-actions.ts
│ └── process.ts
├── http-apis.ts3. 透過關注點分離實現可維護性
專案中的每個模組都是獨立的,這意味著對一個元件的變更不會直接影響其他元件。這降低了破壞現有功能的風險並簡化了除錯。
-
控制器處理請求路由和執行邏輯。
-
服務管理業務邏輯和資料互動。
-
客戶端與資料庫、佇列和 API 等外部服務互動。
-
模型定義了整個系統所使用的資料結構。
-
中間件確保請求通過驗證和身份驗證層。
-
實用程式為日誌記錄、錯誤處理和重試提供可重複使用的輔助函數。
./src
├── clients
├── controllers
├── middleware
├── models
├── service
└── utils4. 易於擴展
採用模組化設計,無需修改核心元件即可新增功能。例如:
-
可以透過在履行服務中新增操作來引入新類型的計劃操作,而無需修改現有的調度或排隊邏輯。
-
透過擴展客戶端模組,可以實現新的外部服務集成,確保與第三方系統的無縫通訊。
延遲執行:確保及時執行
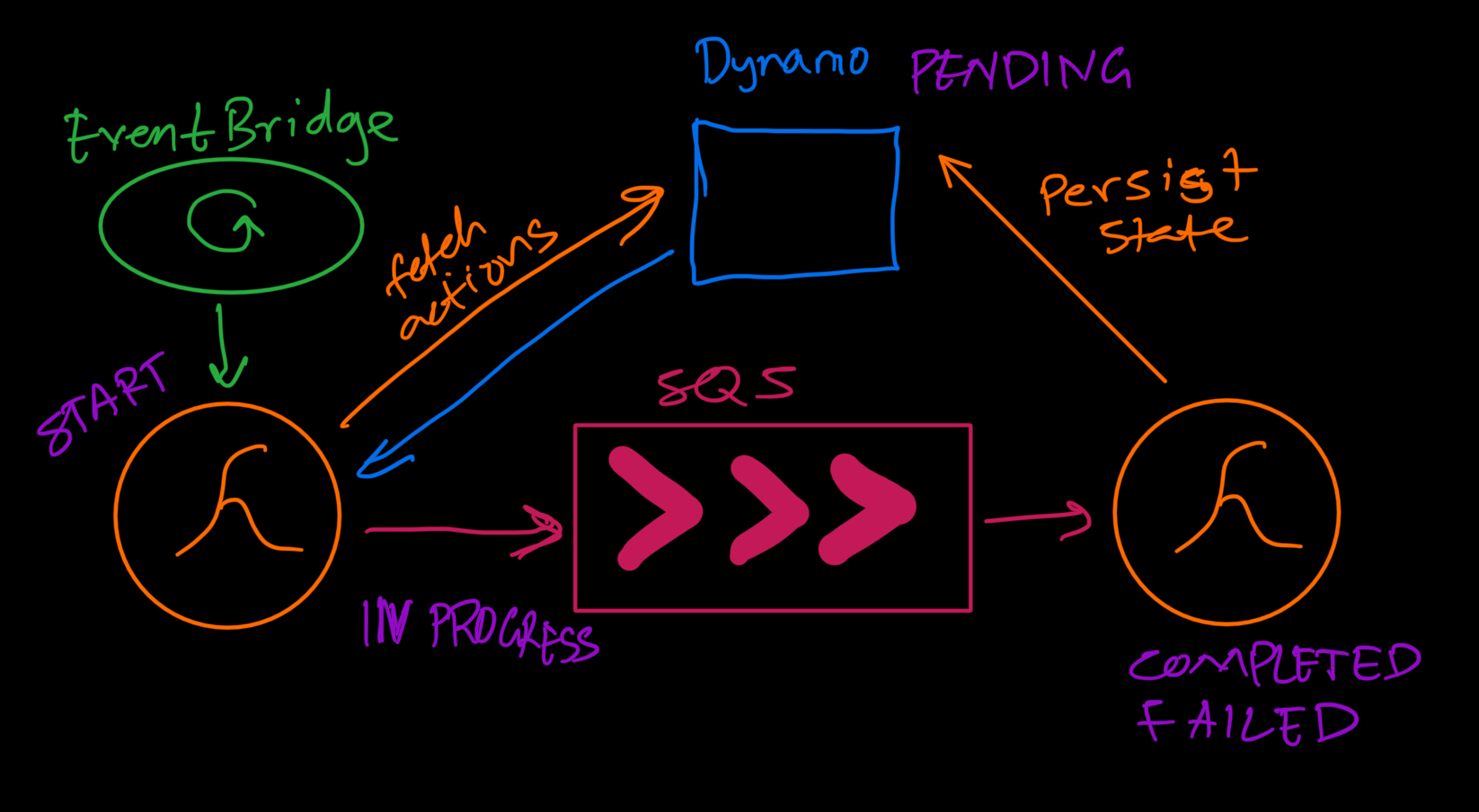
系統透過定期執行來有效率地處理計劃的操作,確保所有待處理的操作都在正確的時間執行,不會出現延遲。
定期執行計劃的操作
-
Lambda 函數會定期掃描資料庫以尋找具有PENDING 狀態和到期執行時間的操作。
-
Amazon EventBridge充當調度程序,每 5 分鐘觸發一次此 Lambda 函數,以確保按時執行操作。
-
此函數將這些待處理操作排隊到 Amazon SQS 中,確保可靠且可擴展的執行管道。
為什麼這種方法有效
-
高效率的批次確保可以同時執行多個操作。
-
透過與SQS解耦執行來保持可擴展性,防止系統過載。隊列對於處理下游系統的負載至關重要。
-
狀態管理:操作遵循生命週期(
PENDING → IN_PROGRESS → COMPLETED/FAILED/NO_ACTION),每個狀態保留在資料庫中以供追蹤和復原。 -
執行處理:成功的執行標記為COMPLETED ,失敗的執行標記為FAILED ,重複操作會在重設為PENDING之前更新其執行剩餘部分。
-
自動重試:失敗的操作使用指數退避重試。如果重試次數超過限制,則該操作將保持失敗狀態,直到手動重置為止。
-
冪等性和資料完整性:執行餘數可防止重複執行,並阻止無效操作(例如負餘數)。
-
可觀察性:元資料儲存日誌、執行時間戳記、API 回應和失敗原因,以便於偵錯。
立即執行:使用 DynamoDB 流程處理時間敏感操作
如果某些計劃操作的執行時間在建立後2 分鐘內,則需要立即執行。為了有效處理這些問題,系統利用DynamoDB Streams和 AWS Lambda 進行即時處理。
1. 立即執行的工作原理
-
插入或修改新作業時, DynamoDB Streams會偵測資料庫中的變更。
-
Lambda 函數會偵聽這些變更、處理新操作並確定它們是否需要立即執行。
-
如果某個操作計劃在 2 分鐘內執行,則 Lambda 函數會將其排入 Amazon SQS 中以供執行。
2. 處理邏輯細分
監聽 DynamoDB 串流事件
每當在 DynamoDB 中插入或修改新記錄時,就會觸發initiateProcessFromDynamoStream函數。
export const initiateProcessFromDynamoStream = async (
event: DynamoDBStreamEvent,
): Promise<void> => {
try {
const { Records } = event;
if (!Records || Records.length === 0) {
console.log("No records to process in DynamoDB stream event.");
return;
}
console.log(`${Records.length} records received.`);-
此函數檢查事件中是否有新記錄。
-
如果不存在記錄,則該函數提前退出。
處理每筆記錄
此函數循環遍歷每筆記錄,提取其詳細訊息,並確定是否需要對其進行處理。
const processingPromises = Records.map(async (record: DynamoDBRecord) => {
const { eventName, dynamodb } = record;
if (!dynamodb?.NewImage) {
console.log("Skipping record: Missing NewImage.");
return Promise.resolve();
}
const cleanedImage = unmarshall(dynamodb.NewImage as Record<string, any>);
console.log(
"Cleaned NewImage object:",
JSON.stringify(cleanedImage, null, 2),
);
if (!["INSERT", "MODIFY"].includes(eventName || "")) {
console.log(`Skipping record with eventName ${eventName}.`);
return Promise.resolve();
}
console.log(`Processing record with eventName: ${eventName}`);-
此函數從 DynamoDB 流中提取新插入或修改的資料。
-
它過濾掉不相關的記錄(即沒有
NewImage或不是新插入/修改的記錄)。
檢查是否立即執行
然後,函數透過計算時間差來檢查該操作是否需要立即執行。
const { status, retryCount, id, executionTime } = cleanedImage;
// Check buffer time logic
const currentTime = Date.now();
const timeUntilExecution = executionTime - currentTime;
if (timeUntilExecution > TWO_MINUTES_IN_MS) {
console.log(
`Skipping record with id ${id}: Execution time is outside the 2-minute buffer window.`,
);
return Promise.resolve();
}-
將目前時間與操作的executionTime進行比較。
-
如果該操作距離時間超過 2 分鐘,則會跳過該操作(稍後將透過定期執行來拾取)。
-
如果該操作需要立即執行,它將繼續處理。
確保有效狀態和重試限制
if (!status || ![STATUSES.PENDING].includes(status)) {
console.log("Skipping record: Missing or invalid status.");
return Promise.resolve();
}
if (retryCount !== undefined && retryCount > CONSTANTS.MAX_RETRY) {
console.log(
`Skipping record with retryCount exceeding limit: ${retryCount}`,
);
return Promise.resolve();
}
if (!id) {
console.log("Skipping record: Missing id.");
return Promise.resolve();
}-
確保操作在處理前具有有效的
PENDING狀態。 -
檢查是否超出重試限制,防止無限重試。
-
確保操作在傳送到佇列之前具有有效的 ID 。
將操作傳送到 SQS 執行
try {
await sendMessage(cleanedImage);
} catch (error: any) {
await fail(id, `Failed to add action to the queue: ${error.message}`);
}-
如果該操作符合立即執行的條件,則會將其傳送至 SQS ,並由履行服務進行處理。
-
如果SQS 失敗,該操作將被標記為 FAILED並記錄下來以供除錯。
3. 為什麼這種方法可靠
-
即時執行: 2 分鐘內規劃的操作立即執行,而不是等待定期輪詢。
-
自動過濾: EventBridge 會在正確的時間跳過並處理計劃稍後執行的操作。
-
錯誤處理:如果操作未能在 SQS 中排隊,則會將其標記為FAILED而不是遺失。
-
可擴充性: Lambda函數可以同時處理多個事件,確保不會延遲任何操作。
重複執行:管理重複操作
一些計劃的操作需要以固定的時間間隔執行多次。系統使用三個關鍵字段處理重複執行:
-
重複– 指示操作是否應執行多次。
-
executionRemainder – 追蹤操作還應執行多少次。
-
頻率– 定義執行之間的時間間隔。
1. 處理重複執行
函數complete(id, notes)負責管理動作的完成。如果某個操作設定為重複,它會更新執行時間並追蹤剩餘的執行次數。
扣除執行餘數
const newExecutionRemainder = repeat && executionRemainder > 0 ? executionRemainder - 1 : 0;
if (newExecutionRemainder < 0) {
throw new Error("Execution remainder cannot be negative.");
}-
如果該動作是重複的,則執行餘數減1 。
-
如果餘數小於 0 ,則會拋出錯誤以防止意外行為。
2. 完成最終執行
if (repeat && newExecutionRemainder === 0) {
await update(id, {
status: STATUSES.COMPLETED,
ttl: calculateTTL(),
executionRemainder: 0,
metadata: {
...metadata,
executionResponses: [...(metadata?.executionResponses || []), notes],
},
});
console.log("Final execution completed successfully:", id);
return;
}-
如果沒有剩餘執行,則該操作標記為「COMPLETED」 。
-
TTL(生存時間)設定為兩週後刪除記錄。
-
更新執行元資料以進行追蹤和可觀察。
3. 安排下一次執行
如果該操作仍有剩餘執行次數,則函數將安排下一次執行。
if (repeat && newExecutionRemainder > 0 && frequency) {
const frequencyInMs = getFrequencyInMilliseconds(frequency);
if (!frequencyInMs) {
throw new Error(`Invalid frequency: ${frequency}`);
}
await update(id, {
status: STATUSES.PENDING,
executionTime: executionTime + frequencyInMs,
executionRemainder: newExecutionRemainder,
metadata: {
...metadata,
executionResponses: [...(metadata?.executionResponses || []), notes],
},
});
console.log("Recurring action updated successfully:", id);
return;
}-
透過新增頻率欄位中的間隔來更新執行時間。
-
操作狀態設定為PENDING ,以便可以再次選擇。
-
元資料已更新以記錄執行歷史記錄。
4.變頻
系統將預先定義的頻率轉換為毫秒以更新執行時間。
const frequencyDurations: Record<string, number> = {
TEN_MINS: 10 * 60 * 1000,
HOURLY: 60 * 60 * 1000,
DAILY: 24 * 60 * 60 * 1000,
WEEKLY: 7 * 24 * 60 * 60 * 1000,
MONTHLY: 30 * 24 * 60 * 60 * 1000, //Not accurate and for demonstration purposes
};這允許基於預定義間隔的靈活調度。
5. 確保冪等性和資料完整性
對於非重複操作,系統確保只執行一次。
await update(id, {
status: STATUSES.COMPLETED,
ttl: calculateTTL(),
metadata: { ...metadata, notes },
});
console.log("Action completed successfully with TTL:", id);-
不重複的操作會立即標記為「已完成」 。
-
TTL 確保資料在刪除之前保留有限的時間。
為什麼這種方法有效
-
自動重新安排– 系統自動設定下一次執行時間。
-
防止過度執行– 當餘數達到零時執行停止。
-
高效追蹤– 每次執行都會更新元資料以進行除錯和可觀察。
-
資料完整性– 確保頻率值有效且執行餘數正確遞減。
操作處理:透過重複資料刪除確保可靠執行
系統使用Amazon SQS FIFO 佇列或基於 Redis 的重複資料刪除來處理計劃操作,以確保每個操作僅執行一次,從而防止重複處理。
1. 使用SQS FIFO處理Action處理
-
訊息被傳送到Amazon SQS FIFO 佇列,確保按照先進先出的順序處理操作。
-
FIFO 佇列保證重複資料刪除,防止相同訊息被處理多次。
-
這種方法非常適合嚴格排序和一次性處理。
2. 使用 Redis 的替代重複資料刪除
如果未使用 FIFO 佇列,系統會在將訊息傳送到標準 SQS 佇列之前利用Redis來管理重複資料刪除。
Redis 重複資料刪除的工作原理
-
每個訊息都會根據以下條件分配一個重複資料刪除 ID :
-
操作的唯一 ID
-
動作的狀態
-
重試次數(如果適用)
const deduplicationId = `${messageBody.id}-${messageBody.status}-${messageBody.retryCount || 0}`;
const redisKey = `sqs-deduplication:${deduplicationId}`;- 在向SQS發送訊息之前,Redis會檢查重複資料刪除ID是否存在。
const redisCheck = await RedisClient.get(redisKey);
if (redisCheck.success && redisCheck.data) {
console.log(
`Duplicate message detected. Skipping send for ID: ${deduplicationId}`,
);
return;
}- 如果偵測到重複訊息,則不會傳送訊息,從而避免冗餘處理。
3. 向SQS發送訊息
如果該操作不是重複的,則將其傳送至SQS 佇列進行處理。
const command = new SendMessageCommand({
QueueUrl: queueUrl,
MessageBody: JSON.stringify(messageBody),
});
await executeSQSCommand(command);
console.log(`Message sent successfully to ${queueUrl}`);-
系統確保訊息的傳遞不會出現不必要的重複。
-
動作進入隊列後進入履行階段。
4.在Redis中儲存去重資料
發送訊息後,重複資料刪除ID將儲存在Redis中, TTL為5分鐘,以確保暫時重複資料刪除。
await RedisClient.set(redisKey, true, 300); // 300 seconds = 5 minutes-
較短的過期時間可確保在需要時仍會處理重試的操作。
-
Redis 有助於管理臨時重複資料刪除,而不會影響長期操作的執行。
5. 優雅地處理錯誤
如果向 SQS 發送訊息失敗,則根據失敗類型處理錯誤:
if (error.name === "TimeoutError") {
throw new AppError({
...CommonErrors.REQUEST_TIMEOUT,
message: "Timeout occurred while sending the message to SQS.",
metadata: { queueUrl, messageBody, error: error.message },
});
}
throw new AppError({
...CommonErrors.INTERNAL_SERVER_ERROR,
message: "Failed to send message to SQS.",
metadata: { queueUrl, messageBody, error: error.message },
});-
超時會觸發特定的重試策略。
-
其他故障日誌元資料可協助診斷問題。
為什麼這種方法有效
-
FIFO 佇列確保時間敏感任務的嚴格排序和重複資料刪除。
-
當 FIFO 佇列不可用時, Redis 重複資料刪除可防止不必要的重複處理。
-
錯誤處理機制確保在必要時重試訊息。
行動履行:處理來自 SQS 的計劃行動
一旦計劃的操作達到其執行時間,它們就會由從Amazon SQS讀取訊息的Lambda 函數進行處理。此函數確保操作正確執行,相應地更新其狀態,並在需要時處理錯誤或重試。
1. 處理來自 SQS 的操作
fulfill函數監聽SQS 事件,其中每筆記錄代表一個需要執行的計畫操作。
export const fulfill = async (event: { Records: SQSRecord[] }): Promise<void> => {
const { Records } = event;
if (!Records || Records.length === 0) {
console.log("No records to process in SQS event.");
return;
}-
此函數檢查是否有新記錄需要處理。
-
如果不存在記錄,則提前退出。
2. 確保行動正確執行
對於佇列中的每個操作:
- 如果該操作超出了最大重試嘗試次數,則會將其標記為「FAILED」 。
if (retryCount >= CONSTANTS.MAX_RETRY) {
await handleFailure(
id,
receiptHandle,
metadata?.retryReason || "Exceeded maximum retry attempts",
);
continue;
}- 如果該操作是第一次執行,其狀態將設定為IN_PROGRESS 。
if (retryCount === 0) {
await start(id);
}3. 處理不同類型的操作
儘管調度程序不允許在沒有有效履行服務的情況下調度操作,但仍存在一種防禦機制 (NO_ACTION)來處理資料庫中手動變更或損壞操作的情況。
- 如果操作類型無法辨識,則將其標記為NO_ACTION並從佇列中刪除。
if (!Object.values(ACTIONS).includes(scheduledAction?.action as Actions)) {
await noAction(id);
await deleteMessage(receiptHandle);
continue;
}- 如果操作有效,則根據其類型進行處理。
處理一般任務
case ACTIONS.EXECUTE_TASK:
result = await taskExecutionService.performTask(scheduledAction.data);
await complete(id, result);
break;-
呼叫外部服務來執行通用任務(例如,處理使用者請求)。
-
完成後將操作標記為「已完成」 。
處理通知
case ACTIONS.SEND_ALERT: {
const { recipient, messageType, ...messageData } = scheduledAction.data;
const processedMessageData = processMessage(messageData);
result = await notificationService.send(
recipient,
messageType,
processedMessageData,
);
await complete(id, result);
break;
}-
使用通知服務發送警報或通知。
-
執行後將操作標記為「已完成」 。
4. 處理失敗和重試
如果操作失敗,系統會套用指數退避並重試執行,然後將其標記為永久失敗。
將操作標記為失敗
const handleFailure = async (id: string, receiptHandle: string, reason: string): Promise<void> => {
console.error(`Action with id: ${id} failed after maximum retries. Reason: ${reason}`);
await fail(id, reason);
await deleteMessage(receiptHandle);
};-
如果某個操作超出重試限制,則會將其標記為「FAILED」 。
-
該訊息將從佇列中刪除以防止進一步處理。
使用退避重試操作
const handleProcessingError = async (
id: string,
receiptHandle: string,
retryCount: number,
error: any,
): Promise<void> => {
console.error(`Error processing message with id: ${id}. Error: ${error.message || error}`);
await applyExponentialBackoff(retryCount, id);
const actionMarkedForRetry = await retry(
id,
error instanceof AppError
? JSON.stringify(error?.metadata) || error?.message || error?.code || error?.name
: `Processing error : ${error}`,
);
await sendMessage(actionMarkedForRetry);
await deleteMessage(receiptHandle);
};-
如果發生錯誤,系統將應用指數退避並增加重試計數。
-
失敗的操作將重新排隊到 SQS 中以進行重試。
5. 完成執行
- 一旦操作成功完成,它就會從 SQS 中刪除。
await deleteMessage(receiptHandle);
console.log(`Message with id: ${id} processed successfully.`);- 如果處理了 SQS 事件中的所有記錄,則會列印摘要日誌。
console.log(`${Records.length} records from the SQS event have been processed.`);為什麼這種方法有效
-
確保操作始終執行– 每個操作都會在永久失敗之前通過退避重試。
-
處理不同的操作類型– 支援通知、任務、訂閱更新和其他排程作業。
-
防止重複執行– 使用SQS FIFO 或 Redis 重複資料刪除以避免重複處理。
-
可靠的狀態管理– 使用IN_PROGRESS、COMPLETED、FAILED 或 NO_ACTION狀態更新資料庫。
-
防禦性處理– NO_ACTION是一種保護措施,以防資料庫中的操作被手動更改。
表示層:公開端點以實現可觀察性
表示層由充當 API 的單一 Lambda 函數組成,透過Amazon API Gateway公開 HTTP 終端節點。這些端點允許用戶觀察、管理計劃的操作並與之交互,確保即時監控和控制。
1.透過API網關公開HTTP端點
無伺服器 API是使用AWS Lambda和API Gateway建置的,提供對與排程操作相關的關鍵功能的存取。
-
按狀態和計數取得操作
-
取得按目前狀態分組的動作(例如,待處理、已完成、失敗)。
-
提供計數摘要以追蹤執行趨勢。
-
啟動失敗的操作
-
允許使用者手動重試失敗的操作。
-
確保可以重新處理失敗的作業,而無需等待自動重試週期。
-
刪除操作
-
提供一個端點來刪除舊的或不必要的操作。
-
透過管理過期記錄來幫助維護乾淨的資料庫。
2. 與監控儀表板集成
這些端點公開的資料可以在儀表板上可視化,以實現即時觀察。

-
按狀態顯示操作計數以追蹤績效。
-
允許使用者透過介面手動重試或刪除操作。
-
提供有關係統健康狀況和執行可靠性的見解。
建立計劃行動系統的挑戰
開發可靠且可擴展的計劃作業系統面臨一些需要仔細解決的挑戰。
-
競賽條件
-
當多個進程嘗試同時更新或執行相同操作時,可能會出現不一致。
-
適當的鎖定機制、重複資料刪除和 FIFO 佇列有助於防止重複執行。
-
在周期的每個點進行負載測試
-
系統必須在高負載下進行測試,以確保調度、執行、重試和履行規模正確。
-
測試包括資料庫效能、SQS 訊息處理、Lambda 執行限制和 API 回應時間。
-
串流和排程程式都會拾取作業
-
執行後 2 分鐘內計劃的操作由DynamoDB Streams處理,而其他操作則依賴EventBridge 。
-
如果沒有適當的協調,可能會發生重複執行。確保操作在待處理、進行中和已完成狀態之間正確轉換可以防止此問題。
-
了解工具的局限性
-
並發處理: AWS Lambda會自動擴展,但高並發可能會導致處理限制和延遲。
-
Lambda 執行時限制:由於Lambda 具有最大執行時間,因此必須將長時間執行的任務分解為較小的執行或卸載到工作服務。
未來的改進
-
用於即時通知的 Webhooks
-
實施Webhooks將允許安排作業的外部服務在操作執行、失敗或重試時接收即時更新。
-
這減少了輪詢的需要並提高了系統回應能力。
-
錯過操作的處理程序
-
專用處理程序,用於偵測和處理仍處於PENDING狀態但執行時間已過的操作。
-
這可確保不會因係統故障、延遲或擴展問題而永久錯過計劃的操作。
這些改進將增強可靠性、可觀察性以及與外部系統的集成,使調度系統更加強大。
結論:調度、擴展和理智🚀
建立可靠、可擴展且容錯的計劃作業系統不僅僅是設定一個 cron 作業並希望得到最好的結果,而是將彈性設計到流程的每個步驟中。從調度和執行到重試和可觀察性,每個元件都必須協同工作,以確保不會丟失任何操作,不會忘記任何通知,並且不會出現訂閱不受管理的情況。
透過這趟旅程,我們解決了:
✅ 使用DynamoDB Streams、EventBridge 和 SQS進行動態調度。
✅ 結合使用立即行動和延遲行動來精確執行。
✅ 透過重複資料刪除、重試和指數退避進行可靠的處理。
✅ 利用無伺服器架構處理高負載的可擴充性。
✅ 透過 API實現可觀察性,以監控、重試和刪除計畫的操作。
當然,每個系統都有其怪癖和挑戰——競爭條件、工具限制和意外故障——但透過正確的設計模式、防禦性編碼和未來的改進(如網路鉤子和錯過的動作恢復) ,這個系統可以演變成一個甚至更強大的系統。
歸根結底,自動化是為了讓生活變得更輕鬆——無論是管理用戶訂閱、發送通知還是處理時間敏感的事務。雖然電腦從不睡覺,但我們當然需要這樣做,這就是為什麼設計一個能夠在凌晨 3 點叫醒我們之前處理自己的問題的系統總是值得付出努力的。
因此,我們要建立可以執行但我們無法執行的系統! 🎉
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式