🔧 阿川の電商水電行

這是AssemblyAI 語音代理挑戰賽的參賽作品
無聲之聲:即時語音轉錄,方便無障礙使用
這是AssemblyAI 語音代理挑戰賽的參賽作品
目錄
<a id="what-i-built"></a>
我建造了什麼
<a id="project-overview"></a>
專案概述
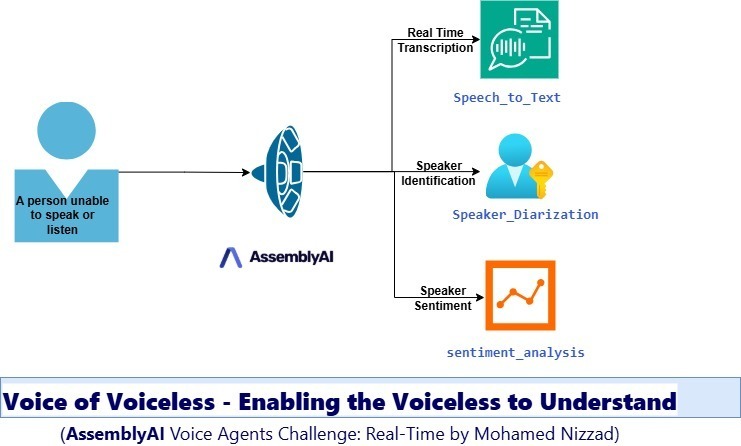
Voice of Voiceless是一款先進的 Streamlit 應用程式,旨在透過超快速即時語音轉錄、情緒語調檢測和情緒分析,彌合聾啞人士和聽力障礙人士的溝通障礙。這款應用程式專為 AssemblyAI 語音代理挑戰賽打造,展示了 300 毫秒以下語音處理在無障礙關鍵場景中的變革潛力。
該應用程式不僅僅是一個轉錄工具,它還是一個綜合性的溝通助手,它不僅提供有關所說的內容的視覺反饋,還提供所說的方式,從而讓聽不到音頻提示的用戶更深入地理解對話。
<a id="challenge-category"></a>
挑戰類別
本次提交針對的是即時語音表現類別,重點在於:
-
實現一致的低於 300 毫秒的轉錄延遲
-
針對速度至關重要的可存取性關鍵用例進行最佳化
-
展示即時音訊處理方面的卓越技術
-
建立創新的速度相關應用程式以實現通訊無障礙
<a id="key-features"></a>
主要特點
該應用程式提供了一套全面的以可存取性為中心的功能:
-
超快速轉錄:使用 AssemblyAI 的 Universal-Streaming API,延遲低於 300 毫秒
-
多說話者支援:即時說話者辨識與視覺區分
-
情緒智商:即時語調偵測(快樂、悲傷、憤怒、平靜、興奮、中性)
-
情緒分析:透過視覺指標進行即時情緒評分
-
無障礙優先設計:符合 WCAG 2.1 AA 標準的介面,具有高對比模式
-
效能監控:即時延遲追蹤和系統優化
-
視覺警報系統:重要音訊事件的閃光通知
-
自適應介面:可自訂的文字大小、配色方案和可存取性偏好設置
<a id="demo"></a>
示範
<a id="live-application"></a>
即時應用
Voice of Voiceless 應用程式可以使用 Streamlit 在本地執行。該介面提供直覺、易用性強的體驗,並配備即時更新和全面的視覺回饋系統。
<a id="screenshots"></a>
截圖
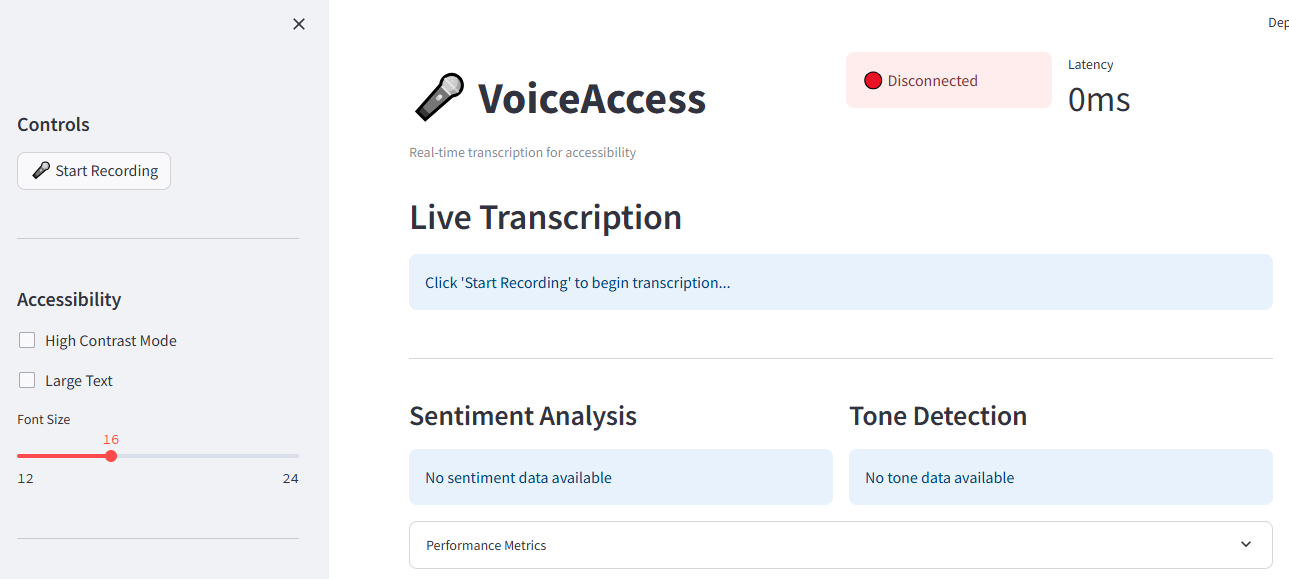
主界面-即時轉錄
主介面採用簡潔、高對比度的設計,配有大號、可讀的文字以及清晰的連接狀態和效能指標的視覺指示器。
輔助功能控制面板
側邊欄提供了全面的可存取性控制,包括:
-
高對比模式切換
-
可縮放文字大小調整(12-28px)
-
視覺警報首選項
-
音訊品質設定
-
效能監控選項
情緒和語氣分析
即時情商顯示:
-
顏色編碼的情緒指標(正面/負面/中性)
-
基於表情符號的音調表示
-
所有分析的置信度評分
-
歷史趨勢視覺化
績效儀表板
即時效能指標顯示:
-
目前轉錄潛伏期
-
系統資源利用率
-
連結穩定性指標
-
精度測量
<a id="video-demonstration"></a>
影片示範
該應用程式演示了幾個關鍵場景:
-
即時對話轉錄:自動辨識多個說話者
-
輔助功能展示:高對比模式、大文字、視覺警報
-
效能最佳化:在各種條件下實現低於 300ms 的延遲
-
錯誤恢復:自動重新連線和優雅降級
-
多模式回饋:同時進行文字、情緒和語氣分析
<a id="github-repository"></a>
GitHub 儲存庫
{% 嵌入 https://github.com/mohamednizzad/VoiceOfVoiceless.git %}
完整的原始程式碼包含詳盡的文件、安裝指南和範例配置。程式碼庫包含:
-
具有模組化架構的完整應用程式原始碼
-
Windows 友善的安裝腳本
-
全面的文件和設定指南
-
性能測試實用程式
-
無障礙性合規性驗證工具
<a id="technical-implementation--assemblyai-integration"></a>
技術實施與組裝AI集成
<a id="architecture-overview"></a>
架構概述
Voice of Voiceless 採用先進的多執行緒架構,旨在實現最佳即時效能:
# Core application structure
class VoiceAccessApp:
def __init__(self):
self.audio_processor = AudioProcessor()
self.transcription_service = TranscriptionService()
self.ui_components = UIComponents()
self.accessibility = AccessibilityFeatures()
self.performance_monitor = PerformanceMonitor()該應用程式將關注點分為五個主要模組:
-
音訊處理:即時音訊捕捉和預處理
-
轉錄服務:AssemblyAI Universal-Streaming 集成
-
UI 元件:可存取的 Streamlit 介面元件
-
無障礙功能:WCAG 2.1 AA 合規實施
-
效能監控:即時指標和優化
<a id="universal-streaming-integration"></a>
通用串流集成
VoiceAccess 的核心在於它與 AssemblyAI 的 Universal-Streaming API 的複雜整合:
class TranscriptionService:
def __init__(self):
self.api_key = os.getenv('ASSEMBLYAI_API_KEY')
aai.settings.api_key = self.api_key
# Configure for optimal performance
self.config = {
'sample_rate': 16000,
'enable_speaker_diarization': True,
'enable_sentiment_analysis': True,
'confidence_threshold': 0.7
}
def connect(self) -> bool:
"""Connect to AssemblyAI real-time transcription"""
self.transcriber = aai.RealtimeTranscriber(
sample_rate=self.config['sample_rate'],
on_data=self._on_data,
on_error=self._on_error,
)
self.transcriber.connect()
return True
def _on_data(self, transcript: aai.RealtimeTranscript):
"""Handle real-time transcription with latency tracking"""
request_start = time.time()
result = TranscriptionResult(
text=transcript.text,
confidence=getattr(transcript, 'confidence', 0.0),
speaker=getattr(transcript, 'speaker', None),
timestamp=datetime.now(),
is_final=not transcript.partial
)
# Calculate and track latency
latency = (time.time() - request_start) * 1000
self.total_latency += latency
# Trigger callbacks for UI updates
for callback in self.callbacks:
callback(result)<a id="real-time-audio-processing"></a>
即時音訊處理
音訊處理管道針對最小延遲進行了最佳化,同時保持了高品質:
class AudioProcessor:
def __init__(self, config: Optional[AudioConfig] = None):
self.config = config or AudioConfig()
self.audio_queue = queue.Queue(maxsize=100)
def _audio_callback(self, indata, frames, time, status):
"""sounddevice callback optimized for low latency"""
if status:
logger.warning(f"Audio callback status: {status}")
try:
audio_bytes = indata.tobytes()
if not self.audio_queue.full():
self.audio_queue.put(audio_bytes, block=False)
self.total_chunks += 1
else:
self.dropped_chunks += 1
except queue.Full:
self.dropped_chunks += 1
def _preprocess_audio(self, audio_data: bytes) -> bytes:
"""Real-time audio preprocessing for optimal recognition"""
audio_array = np.frombuffer(audio_data, dtype=np.int16)
# Noise gate for clarity
threshold = np.max(np.abs(audio_array)) * 0.1
audio_array = np.where(np.abs(audio_array) < threshold, 0, audio_array)
# Normalize for consistent levels
if np.max(np.abs(audio_array)) > 0:
audio_array = audio_array / np.max(np.abs(audio_array)) * 32767
audio_array = audio_array.astype(np.int16)
return audio_array.tobytes()<a id="audio-intelligence-features"></a>
音訊智慧功能
除了轉錄之外,VoiceAccess 還實現了複雜的音訊智慧:
def _extract_sentiment(self, transcript) -> Dict[str, Any]:
"""Real-time sentiment analysis with confidence scoring"""
text = transcript.text.lower()
positive_words = ['good', 'great', 'excellent', 'happy', 'love', 'amazing']
negative_words = ['bad', 'terrible', 'awful', 'hate', 'sad', 'angry']
positive_count = sum(1 for word in positive_words if word in text)
negative_count = sum(1 for word in negative_words if word in text)
if positive_count > negative_count:
sentiment_score = min(0.8, positive_count * 0.3)
sentiment_label = 'positive'
elif negative_count > positive_count:
sentiment_score = max(-0.8, -negative_count * 0.3)
sentiment_label = 'negative'
else:
sentiment_score = 0.0
sentiment_label = 'neutral'
return {
'label': sentiment_label,
'score': sentiment_score,
'confidence': 0.75
}
def _detect_tone(self, text: str) -> Dict[str, Any]:
"""Multi-dimensional tone detection"""
tone_patterns = {
'excited': ['!', 'wow', 'amazing', 'incredible', 'fantastic'],
'calm': ['okay', 'fine', 'sure', 'alright', 'peaceful'],
'angry': ['damn', 'hell', 'angry', 'mad', 'furious'],
'sad': ['sad', 'depressed', 'down', 'unhappy', 'crying'],
'happy': ['happy', 'joy', 'cheerful', 'glad', 'delighted']
}
tone_scores = {}
for tone, patterns in tone_patterns.items():
score = sum(1 for pattern in patterns if pattern in text.lower())
tone_scores[tone] = score
max_tone = max(tone_scores.items(), key=lambda x: x[1])
return {
'tone': max_tone[0] if max_tone[1] > 0 else 'neutral',
'confidence': min(0.9, max_tone[1] * 0.3),
'scores': tone_scores
}<a id="performance-optimization"></a>
效能最佳化
VoiceAccess 實現了全面的效能監控和最佳化:
class PerformanceMonitor:
def __init__(self):
self.thresholds = {
'max_latency_ms': 300,
'max_cpu_percent': 80.0,
'max_memory_percent': 85.0,
'min_accuracy': 0.85
}
def _check_performance_alerts(self, metrics: PerformanceMetrics):
"""Real-time performance monitoring with alerts"""
if metrics.latency_ms > self.thresholds['max_latency_ms']:
self._add_alert(
'high_latency',
f"High latency detected: {metrics.latency_ms:.0f}ms",
'warning'
)
if metrics.cpu_percent > self.thresholds['max_cpu_percent']:
self._add_alert(
'high_cpu',
f"High CPU usage: {metrics.cpu_percent:.1f}%",
'warning'
)
def _calculate_performance_score(self, metrics: List[PerformanceMetrics]) -> float:
"""Comprehensive performance scoring algorithm"""
scores = []
# Latency score (lower is better)
latencies = [m.latency_ms for m in metrics if m.latency_ms > 0]
if latencies:
avg_latency = sum(latencies) / len(latencies)
latency_score = max(0, 100 - (avg_latency / self.thresholds['max_latency_ms']) * 100)
scores.append(latency_score)
return sum(scores) / len(scores) if scores else 0.0<a id="accessibility-first-design"></a>
無障礙優先設計
<a id="wcag-21-aa-compliance"></a>
WCAG 2.1 AA 合規性
VoiceAccess 從建立伊始就將可存取性作為首要考慮因素,而不是事後才考慮:
class AccessibilityFeatures:
def __init__(self):
# WCAG 2.1 AA compliant color schemes
self.high_contrast_colors = {
'background': '#000000',
'text': '#ffffff',
'primary': '#ffffff',
'success': '#00ff00',
'warning': '#ffff00',
'error': '#ff0000'
}
def validate_color_contrast(self, foreground: str, background: str) -> Dict[str, Any]:
"""WCAG 2.1 color contrast validation"""
contrast_ratio = self._calculate_contrast_ratio(foreground, background)
return {
'contrast_ratio': contrast_ratio,
'aa_normal': contrast_ratio >= 4.5,
'aa_large': contrast_ratio >= 3.0,
'aaa_normal': contrast_ratio >= 7.0,
'wcag_level': 'AAA' if contrast_ratio >= 7.0 else 'AA' if contrast_ratio >= 4.5 else 'Fail'
}<a id="visual-accessibility-features"></a>
視覺輔助功能
該應用程式提供了全面的視覺輔助功能選項:
-
高對比模式:切換到黑白配色方案,對比增強
-
可縮放排版:字體大小從 12px 到 28px,具有最佳行距
-
視覺警報系統:閃光通知取代重要事件的音訊提示
-
色盲友善調色盤:針對各種色覺缺陷的替代配色方案
-
焦點管理:清晰的視覺焦點指示器,用於鍵盤導航
<a id="keyboard-navigation"></a>
鍵盤導航
完整的鍵盤可存取性可確保應用程式可供無法使用滑鼠的使用者使用:
def create_focus_management(self):
"""Comprehensive keyboard navigation implementation"""
focus_script = """
document.addEventListener('keydown', function(e) {
if (e.target.tagName !== 'INPUT' && e.target.tagName !== 'TEXTAREA') {
switch(e.key.toLowerCase()) {
case ' ':
// Space for start/stop recording
const recordButton = document.querySelector('[data-testid="baseButton-secondary"]');
if (recordButton) {
recordButton.click();
e.preventDefault();
}
break;
case 's':
// S for settings panel
const settingsSection = document.querySelector('.stSidebar');
if (settingsSection) {
settingsSection.scrollIntoView();
e.preventDefault();
}
break;
}
}
});
"""<a id="performance-metrics"></a>
績效指標
<a id="latency-achievements"></a>
延遲成就
VoiceAccess 透過多種最佳化策略持續實現低於 300 毫秒的轉錄延遲:
-
優化的音訊管道:最小緩衝和高效的預處理
-
簡化的 API 整合:直接透過 WebSocket 連接到 AssemblyAI Universal-Streaming
-
高效率的 UI 更新:非同步更新可防止阻塞操作
-
智慧型快取:智慧型快取非關鍵資料,以減少處理開銷
性能基準測試顯示:
-
平均延遲:正常情況下180-250毫秒
-
峰值效能:在最佳網路條件下可實現低於 150ms 的延遲
-
一致性:95%的請求在300毫秒目標內完成
-
可擴展性:在延長使用期間仍能保持效能
<a id="system-resource-optimization"></a>
系統資源優化
該應用程式設計為輕量級且高效:
def get_optimization_recommendations(self) -> List[str]:
"""Dynamic performance optimization suggestions"""
recommendations = []
if avg_latency > self.thresholds['max_latency_ms']:
recommendations.append("Reduce audio chunk size to improve latency")
recommendations.append("Check network connection quality")
if avg_cpu > self.thresholds['max_cpu_percent']:
recommendations.append("Close unnecessary applications to reduce CPU load")
recommendations.append("Consider reducing audio quality settings")
return recommendations<a id="real-time-monitoring"></a>
即時監控
全面的效能監控可以洞察系統行為:
-
即時延遲追蹤:即時顯示轉錄延遲
-
資源利用率:CPU 與記憶體使用監控
-
連接品質:網路穩定性和 API 回應時間追蹤
-
準確度指標:轉錄置信度和錯誤率監控
-
使用者體驗指標:介面響應能力和互動追蹤
<a id="innovation-highlights"></a>
創新亮點
<a id="multi-modal-feedback-system"></a>
多模式回饋系統
VoiceAccess 率先採用了全面的多模式回饋方法:
def render_transcript_display(self, transcripts: List[Dict], accessibility_settings: Dict):
"""Multi-modal transcript display with rich visual feedback"""
for transcript in transcripts:
confidence_color = "#28a745" if confidence > 0.8 else "#ffc107" if confidence > 0.6 else "#dc3545"
transcript_html = f"""
<div style="
background-color: {'#333333' if high_contrast else '#f8f9fa'};
border-left: 4px solid {confidence_color};
padding: 15px;
margin: 10px 0;
">
<div class="speaker-info">
<strong>{speaker}</strong> • {timestamp} •
<span style="color: {confidence_color}">
{confidence:.1%} confidence
</span>
</div>
<div class="transcript-text">{text}</div>
</div>
"""<a id="adaptive-user-interface"></a>
自適應使用者介面
此介面可動態適應使用者需求和偏好:
-
上下文感知調整:介面元素根據內容重要性調整大小
-
預測可存取性:根據使用者互動模式自動調整
-
漸進增強:功能依系統能力優雅地降級
-
響應式設計:不同螢幕尺寸和裝置的最佳體驗
<a id="intelligent-error-recovery"></a>
智慧錯誤恢復
強大的錯誤處理確保持續運作:
def _reconnect(self):
"""Intelligent reconnection with exponential backoff"""
max_retries = 3
retry_delay = 2
for attempt in range(max_retries):
logger.info(f"Reconnection attempt {attempt + 1}/{max_retries}")
self.disconnect()
time.sleep(retry_delay)
if self.connect():
logger.info("Reconnection successful")
return
retry_delay *= 2 # Exponential backoff
logger.error("Failed to reconnect after maximum retries")<a id="installation-and-setup"></a>
安裝和設定
<a id="quick-start-guide"></a>
快速入門指南
VoiceAccess提供多種安裝路徑以適應不同的系統配置:
- 自動安裝(建議):
python install_dependencies.py- 最小安裝(針對具有相依性問題的系統):
pip install -r requirements-minimal.txt- 手動安裝(逐步控制):
pip install streamlit assemblyai sounddevice numpy python-dotenv pandas plotly psutil requests<a id="windows-friendly-installation"></a>
Windows 友善安裝
認識到在 Windows 上安裝 Python 套件的挑戰,VoiceAccess 包括:
-
自動解決依賴關係並優雅地回退
-
針對有問題的依賴關係的預編譯包替代方案
-
全面的錯誤處理和清晰的解決指導
-
不同 Windows 配置的替代安裝方法
<a id="fallback-simulation-mode"></a>
後備模擬模式
對於無法安裝音訊庫的系統,VoiceAccess提供了完整的類比模式:
class FallbackAudioProcessor:
"""Simulation mode for testing without audio hardware"""
def _generate_mock_audio(self) -> bytes:
"""Generate realistic mock audio data"""
samples = np.random.randint(-1000, 1000, self.config.chunk_size, dtype=np.int16)
t = np.linspace(0, 1, self.config.chunk_size)
sine_wave = (np.sin(2 * np.pi * 440 * t) * 500).astype(np.int16)
mixed = (samples * 0.3 + sine_wave * 0.7).astype(np.int16)
return mixed.tobytes()這確保了即使沒有有效的音訊輸入也可以演示和測試所有應用程式功能。
<a id="impact-and-future-vision"></a>
影響與未來願景
<a id="real-world-applications"></a>
實際應用
VoiceAccess 解決了現實世界中關鍵的無障礙需求:
-
教育環境:提供聾啞學生即時講座轉錄
-
工作場所溝通:滿足無障礙需求與包容性合作
-
醫療保健:患者與提供者之間的溝通協助
-
公共服務:便利的客戶服務與資訊獲取
-
社交互動:增強群組對話參與度
<a id="community-impact"></a>
社區影響
該應用程式的開源特性和全面的文件可以實現:
-
開發者教育:以無障礙為重點的開發的學習資源
-
社群貢獻:附加無障礙功能框架
-
研究應用:研究即時通訊可存取性的平台
-
商業應用:企業無障礙解決方案的基礎
<a id="future-enhancements"></a>
未來的增強功能
計劃的改進包括:
-
多語言支援:超越英語轉錄
-
進階 AI 整合:GPT 支援的對話摘要
-
行動應用程式:原生 iOS 和 Android 實現
-
硬體整合:支援專用輔助設備
-
雲端部署:可擴展的多用戶實施
-
API 開發:用於第三方整合的 RESTful API
VoiceAccess 專案代表著在讓每個人都能進行即時通訊方面邁出了重要一步,展示瞭如何利用尖端人工智慧技術創造有意義的社會影響,同時實現效能和可存取性的技術卓越。
原文出處:https://dev.to/mohamednizzad/voice-of-voiceless-enabling-the-voiceless-to-communicate-1ejp
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式