

AI 驅動開發下,需求定義有什麼改變?
大家好。我是主要在 X 上發表 AI 驅動開發相關內容的熊井悠!
目前擔任 AI 新創公司的 CEO 兼 CTO!
我在前一份工作,也就是 SIer 與 IT 顧問公司時,有很多機會接觸上游工程。
因此,當生成式 AI 出現時,我立刻覺得「這會大幅改變需求定義與上游工程的領域吧」,並馬上在公司內開始驗證。
本文將以時間軸回顧這約 3 年來在需求定義 × 生成式 AI 上的嘗試。先說結論,3 年後得到的答案,多少有點出乎意料。
關於本文
- 由我這位 SIer/顧問出身的人,整理自 2023 年以來投入的「需求定義 × 生成式 AI」變遷記錄
- 依各階段時序追蹤「試了什麼、學到了什麼」
- 希望能成為接下來要投入 AI 需求定義的人的參考
3 年的歷程(整體像)
先來看本文將走過的路線圖。
越到後面,也會稍微談到整個開發流程的內容。
時期 | 嘗試內容 | 得到的學習
---|---|---
2023.7|從文字自動產生流程圖的實驗|事前資訊(術語表、前提)的整理決定精準度
2023.10|利用 Cursor × Markdown 進行需求定義|程式碼基底才是最好的脈絡
2024.3|Cursor、ChatGPT 在公司內部分導入|Know-how 與其說要「展開」,不如說要「累積」
2024.9|在需求定義中全面活用 AI|從單次提示詞走向「機制」
2025.8|以程式碼為骨架,需求放在提示詞|骨架交給程式碼,需求交給提示詞
2025.11|建立「0 日導入」|需求定義從「文件撰寫」轉為「範疇設計」
2025.12|收購「GEAR.indigo」事業並商業化|自家 Know-how × 承接產品的結合
2026.5|以 BYOK 方式免費提供(需求定義民主化)|不要讓工具成本成為「決策」的障礙
從 Email、Slack 驗證自動生成流程圖(2023.7)
最初投入的是大約 3 年前的事情。我們以 Email、Slack 等文字資訊為基礎,利用 OpenAI API(主要是 gpt-3.5),在公司內做了一個用來生成業務需求定義中流程圖的程式,作為實證實驗。
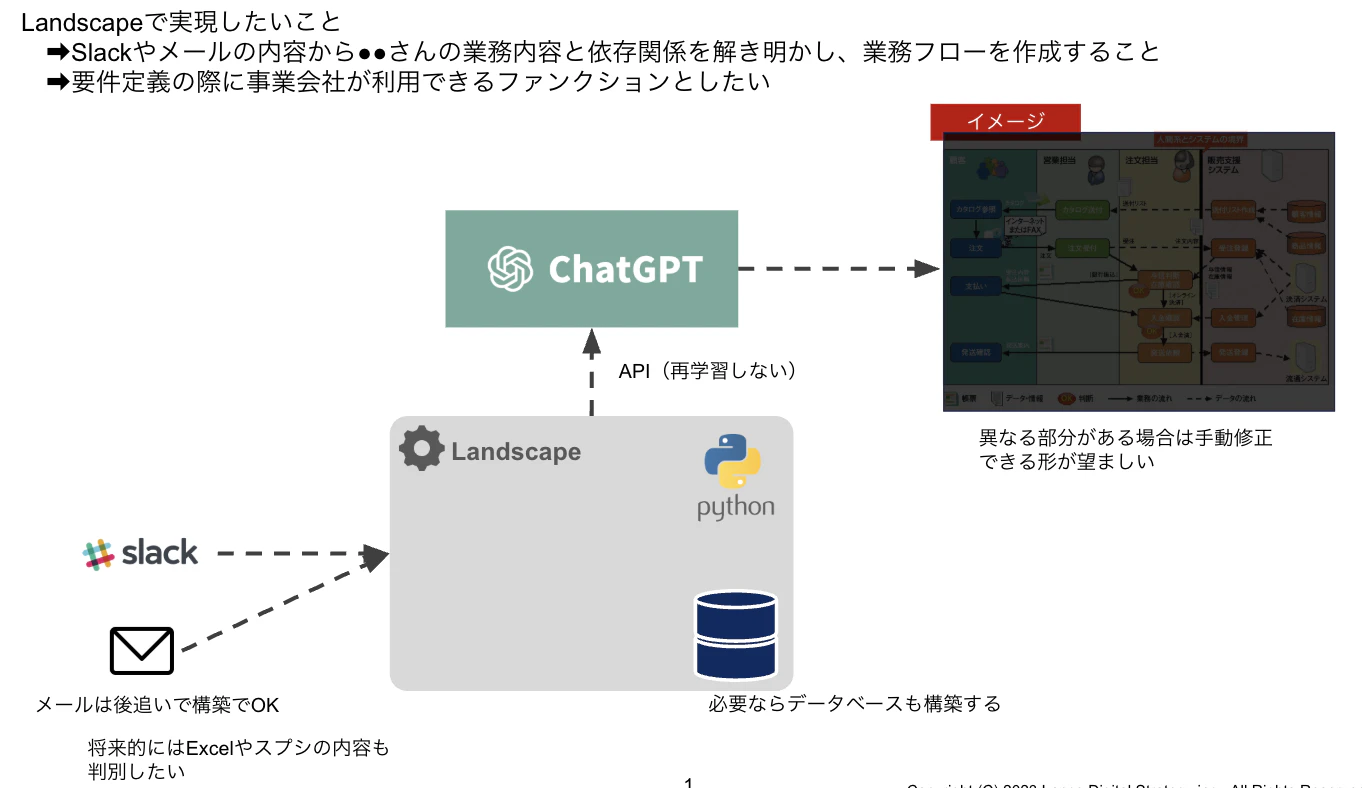
圖:當時的架構概念圖(公司內部資料)
結果是,因為無法仔細辨別閒聊與無關對話,最後只能靠先定義術語表、角色人物,以及一定程度的業務假設,再進行生成,才勉強做出像樣的流程圖。
其實直到現在我仍然非常重視事前資訊的意義,就是因為有這段經驗。即使是定性的資訊,只要也納入脈絡中,生成精準度就會有顯著差異。
這裡的學習
術語表與前提事項的羅列很重要(也連結到後來 Rule 的概念)
使用 Cursor 以 Markdown 形式撰寫需求定義(2023.10)
到了 2023 年 10 月左右,Cursor 已經出現,所以我開始使用。模型以 gpt-3.5 為主,但透過從程式碼取得可參考的脈絡(術語表、需求資訊),在做系統擴充時生成需求文件就變得容易非常多。

圖:當時公司內部的推廣資料(部分對外公開)
另外,當時 Amazon Bedrock 也剛登場,因此連同業務使用在內,也開始看見非常多可能性。

圖:當時公司內部的推廣資料(部分對外公開)
當時我意識到的重點是,要適切取得「程式碼基底」,並將所需資訊以 Markdown 條列出來。如此一來,當有新增需求時,就能非常容易地生成文件。
這裡的學習
善用程式碼基底很重要(也連結到後來的程式碼索引)
在公司內部分導入 Cursor、ChatGPT(2024.3)
由於前面的嘗試讓我感受到生成式 AI 的可能性,所以到了 2024 年春天,我們開始在部分團隊導入。
不過當時也正在摸索如何把「聊天式 AI 使用 + 正確整理脈絡後再交付」這件事組織化,因此還沒能推到全公司,只能先以部分導入的形式進行。
畢竟當時對 AI 持懷疑態度的人也很多,所以我們採取相當保守的方式,沒有直接全面導入。

圖:當時嘗試的回顧資料
當時之後我才造了個詞,將把專案資訊全部用 Markdown 或程式碼來表達這件事稱為「Project as Code」,並持續累積資料。這種把專案資訊以程式碼統一管理的方法,成為後面要介紹的「從程式碼基底反向生成」式需求定義的基礎。
這裡的學習
- 先從以傳道者角色的成員為中心,累積使用 Know-how
- 與其推廣 Know-how,不如先往累積的方向(程式碼化)前進
開始在需求定義中全面活用 AI(2024.9)
2024 年 9 月,在過去累積的 Know-how 基礎上,我們進入在需求定義整個流程中正式活用 AI 的階段。主要並行推進三種方法。
第一種是,透過從程式碼基底反向生成文件。以既有程式碼為起點,生成規格與業務流程文件。比起人工撰寫,不僅更快,也較不容易和實作脫節。
第二種是,活用 UI 生成式 AI,從製作 mock 開始延伸到需求定義文件。先用 v0 等工具做出 mock 來對齊認知,再從那裡把需求逐步定下來。透過先展示可運作的東西,可以更早消除與客戶之間的認知落差。
第三種是,活用 GEAR.indigo,在售前階段就開始需求定義。從商談階段就啟動需求定義,能在簽約前大幅提高需求的清晰度。
這裡的學習
不是靠單次提示詞,而是把脈絡、程式碼基底與 Know-how 整合起來,作為「機制」納入需求定義,才是提升生產力的關鍵
以程式碼為中心思考。「骨架是程式碼脈絡,需求是提示詞」(2025.8)
在 2024 年持續實作之後,接下來我們面對的是「該怎麼推進開發本身」的型態設計。到了能在各個工程階段都活用 AI 之後,下一步就是建立一套能讓團隊從需求定義到實作都穩定運作的方法論。
特別是在讓 AI 需求定義真正落地到組織時,必須回答「如何讓任何人都得到相同的輸出?」這個問題。
在這個過程中確立下來的,就是「骨架是程式碼脈絡,需求是提示詞」這個想法。
比起在什麼都沒有的狀態下,只靠自然語言指令進行開發的完全版 Vibe Coding,以骨架程式碼作為基礎,生成出的程式碼品質與成員的學習效率都更穩定。
骨架由既有程式碼來讀取,需求則透過提示詞來傳達。前面一路累積的學習,在這裡匯聚成一個完整形狀。


圖:AI 驅動敏捷的說明
開發流程本身也演進成我稱為「AI 驅動敏捷」的混合型模式。整體推進方式是敏捷,但個別開發則是偏設計導向的高速瀑布式。為了將因需求、規格不明就直接產碼而造成的返工風險降到最低,重點在於加強需求定義與設計階段。
這裡的學習
讓骨架放在程式碼中,就能建立一個可以專注於需求的流程。
從「0 日導入」完成的系統開始做需求定義(2025.11)
更進一步的是 「0 日導入」 這套方法論。也就是在專案開始時,先將骨架程式碼部署到測試環境,以「系統已經在運作中」為前提,與客戶一起進行需求定義與設計。
文件則只需針對以骨架程式碼為前提的模板做差異修正。
在定期會議中,盡可能實際展示可以運作的東西來對齊認知。把需求定義重新視為「切出範疇(Issue)」的工作,並分解到開發可在 1 小時內完成的粒度。若情況允許,這種粒度的範疇切分最好由商業端人員來負責。

圖:0 日導入的說明
重要的是,需求定義的主角,已經從「撰寫文件」轉變成「切出正確範疇」。AI 讓開發愈來愈快時,上游的「要做什麼、做到什麼粒度」的定義能力就成為瓶頸。
這裡的學習
AI 讓開發越快,瓶頸就越往上游移動。需求定義的角色,從「文件撰寫」變成了「範疇設計」
與「GEAR.indigo」相遇(2025.12)
在花了 3 年打磨需求定義 Know-how 的過程中,我們遇到了一款產品。也就是上面提過的 AI 驅動需求定義工具 「GEAR.indigo」。一開始我們是以使用者身分開始使用,並近距離感受到它的效果。這正是一款把前面提到的方法論完整裝進解決方案中的產品。

圖:GEAR.indigo 的畫面(當時)
接著在 2025 年 12 月,我們從開發商 Stellaps 公司手中接手了 GEAR.indigo 這項業務。這是因為我們想把機制強化,也希望把這份感動傳遞給更多人。
接下來,我們把自家花了 3 年打磨的需求定義 Know-how,與承接來的產品結合,持續將其培育成能加速需求定義・設計階段的「GEAR.indigo Biz」。概念很簡單,就是「只要貼上會議筆記,需求與設計就會自己往前推進」。

圖:GEAR.indigo Biz 的畫面
3 年前,那次從混雜閒聊的文字中生成流程圖、卻苦戰於手工處理的實驗。當時抓到的「事前資訊很重要」「程式碼基底很重要」這些學習,現在都連續不斷地,成為我們打磨 GEAR.indigo Biz 的基礎。
其實即使到了今天,開發流程已經以 Claude Code 為中心,要在需求定義與基本設計中,連同資訊整理與共識形成流程一起透過 Claude 完成,仍然有些困難。
因為像 Markdown 的可視性、審核流程(指示歷程)的可視化等,還是有一些不符合傳統瀑布式流程的地方。基於這樣的背景,我們把這些要素全部整合進了 GEAR.indigo Biz。

圖:目前的開發流程圖
以及,決定把需求定義 AI 「免費提供」(2026.5)
到了 2026 年,我們把 GEAR.indigo Biz 改為 BYOK(Bring Your Own Key/使用者自帶 API 金鑰)的方式,並以免費使用的形式公開。公司內部曾有人反對:「好不容易做出來的產品,為什麼要免費?」即便如此,我們還是決定免費。
原因是,需求定義這個流程本身的意義已經改變了。當 AI 能快速完成整理與文件化後,留給人類的是 「決定要做什麼」。需求定義已從「整理流程」變成 「做出決策的流程」。而這個決策,早已不再只是少數專家的事。業務單位、經營者、公司內部 IT 人員,所有人都被推到必須定義「要做什麼」的場景中。
需求定義與設計,已成為必須民主化的流程。
既然如此,所有阻礙這種民主化的門檻,都應該被移除。
如果一邊談「民主化」,一邊卻保留月費這個入口門檻,那就是矛盾。AI 的 API 費用本來就能由使用者自行控制。
既然如此,那疊加在上面的平台使用費就設為 0。讓說的話與做的事一致。 這就是選擇 BYOK 的原因。
工具應該像空氣一樣自然存在。不要讓人意識到成本或鎖定效應,創造出讓使用者只專注於「要做什麼」這個決策的狀態。3 年後我們得到的答案,不是拼命提供機制與 Know-how,而是把這些視為過去的議論,真正要做的是「打造能面對本質價值創造的土壤」。
這裡的學習(=本文結論)
- 生成式 AI 真正該做的,不是「生成文件」,而是「建立能收集正確脈絡、切出正確範疇的機制」。
- 需求定義已從「整理流程」變成「做決策的流程」。
總結/3 年來看見的事
回顧起來,各階段的學習其實是一條連貫的線。
- 事前資訊(脈絡)是一切的起點:要從混雜閒聊的文字中做出精準結果,整理術語、前提與業務假設不可或缺(後來發展成 Rule 的概念)
- 程式碼基底才是最好的脈絡:比起人工重寫資訊,從既有程式碼反向取得資訊更快也更準確(後來發展成程式碼索引,以及「骨架是程式碼脈絡」)
- Know-how 與其說要展開,不如先累積:在充滿懷疑的氛圍中,以傳道者成員為中心累積提示詞集特別有效
- AI 越快,瓶頸越往上游:當開發速度提升後,需求定義的角色也從「文件撰寫」轉為「範疇設計」
不要把生成式 AI 當成魔法盒,而是要思考如何提供正確的脈絡,並建立能切出正確範疇的機制。
不過,關於機制本身的討論階段早就結束了。現在重要的是,專注在「要做什麼」。透過這 3 年的實證,我深深覺得答案就在這裡。
以上。原本是想寫得更深入一些,但實際上想講的內容比預期多,所以省略了不少。如果有任何想知道的地方,歡迎告訴我!
感謝你讀到這裡。只要能成為一點點參考,我就很開心了!
GEAR.indigo Biz 以 BYOK 方式免費提供
「只要貼上會議筆記,需求與設計就會自己往前推進。」——如果你想親自體驗本文所說的「忘掉工具,專注決策」的狀態,歡迎實際試試看。
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式