

AI 會犯錯、模型會幻覺、模型會亂掰——這些都是眾所周知的抱怨。可是一旦放到代理式工程(agentic engineering)裡,這些說法幾乎就不具備實用性了。既然知道模型會出錯,你最後還能得到什麼?除了不信任任何輸出、或預期每一行都要雙重檢查,結果把所有生產力都扼殺掉之外,還剩下什麼?
我確實很常使用代理式工具,而且對它們在過去半年進步了多少感到非常著迷。與此同時,我也常常對許多大型任務怎麼會那麼嚴重地偏離常識與任務本意而感到火大。
最近,在閱讀大量關於 AI 代理的資料時,我更留意人們點出的失敗模式。很多時候,那些描述都非常能引起我的共鳴。當有人把某種模式提煉成對模型或 AI 代理的簡短特徵時,真的很有價值:例如「鋸齒狀」(jaggedness)。這類知識能幫助你建立自己對 AI 代理能力的直覺,以及思考如何用合理的方式圍繞代理來設計工作流程。它也有助於建立健康的期待,而不是被我們周遭那些過度吹捧的「黑暗工廠」之類、各種憑空捏造的 AI 能力鬼扯說法帶著跑。
以下是我試著根據幾篇部落格文章與演講中提到、而且也與我觀察相符的失敗模式,所做出的分類與整理。
失敗模式
| 失敗模式 | 簡述 | 來源 |
|---|---|---|
| 一口氣做完(One-shotting) | 想要一口吞下整個應用程式,結果上下文用光,留下半成品爛攤子。 | Anthropic 長時間運作代理:「試著一次做太多……一次把應用程式做完。」 |
| 把進度當完成 | 在儲存庫裡看到有活動,就誤以為部分進展等於整個任務已完成。 | Anthropic 長時間運作代理:「看到已有進展,然後宣告任務完成。」 |
| 冷啟動失憶 | 新工作階段既沒有記憶也沒有作業手冊,只會浪費時間猜發生了什麼,以及該如何檢查。 | Anthropic 長時間運作代理:「每個新工作階段一開始都沒有記憶」;「弄清楚要怎麼執行應用程式。」 |
| 願望實現得很難看 | 你把願望講得太模糊,代理就照字面、完整地幫你實現,而且比你根本沒開口還更糟。 | 我的觀察:比較像不是在委派工作,而是對精靈許願,結果拿回來的是被詛咒版。 |
| 規格/交付物混淆 | 把暫時性的計畫或設計文件當成實際交付物的一部分,把支架和真正要做的東西綁在一起。 | 我的觀察:在 plan mode 特別明顯,例如要建立一個 agent skill,結果 skill 裡面直接塞進了規劃產物。 |
| 預設值灌水 | 任務中未明確指定的部分,會被訓練先驗中的平庸預設值填滿:機械式抄樣的程式碼、保守的 UI、通用的產品選擇。 | Mario Zechner:「如果你在規格裡留白……它就會用垃圾把它補上」;Anthropic app harness:「安全、可預測的版面配置。」 |
| 預設過度工程化 | 會加上抽象層、重複設計、向後相容、縱深防禦,因為它從網路形狀的程式碼學到了這些做法。 | Mario Zechner:「agents……學會了複雜性。」 |
| 工作記憶腐蝕 | 重要事實雖然還在上下文裡,但隨著視窗變大,模型卻不再能可靠地取用它們。 | Random Labs Slate:「模型注意力……會隨著上下文長度增加而退化。」 |
| 隱藏式 harness 控制 | 工具會以使用者無法檢視或掌控的方式,改動上下文、提示詞、工具、提醒、可觀測性與可擴充性。 | Mario Zechner:「我的 context 不是我的 context」;「幾乎沒有可觀測性……幾乎沒有可擴充性。」 |
| 有損壓縮 | 壓縮能靠丟棄狀態來讓長流程繼續跑下去,但有時丟掉的偏偏就是你最需要的資訊。 | Random Labs Slate:「我們可能會不可預測地失去重要資訊。」 |
| 局部修補 | 每一步看起來都局部合理,但整個系統卻變得越來越難推理。 | Mario Zechner:「代理的每個決策都是局部的。」 |
| 只靠摘要交接導致資訊流失 | 子代理會把上下文切開,然後只回傳一段乾淨的摘要,而不是足夠的真實狀態來安全整合。 | Random Labs Slate:「無法在上下文邊界之間傳遞資訊。」 |
| 非同步整合失敗 | 平行工作帶來的難題是:什麼時候結果才算定案、哪個分支勝出、哪些東西真的能組合在一起。 | Random Labs Slate:「知道何時以及如何整合結果。」 |
| 盲目的 N 步執行 | 委派出去的片段執行太久都沒有回饋;代理直到最後才發現牆壁就在前面。 | Random Labs Slate:「就像在黑暗中穿越迷宮。」 |
| 計畫拖累 | 計畫與任務樹會阻止提早停下來,直到現實改變之後,結構本身又開始抗拒調整。 | Random Labs Slate:「Markdown 計畫會過時」;「用僵化性換取靈活性……」 |
| 過度拆解 | 規劃者/實作者/審查者這種堆疊雖然技術上可行,但會增加儀式感、延遲與慣性。 | Random Labs Slate:「它大致上會運作,但你會恨死它。」 |
| 驗證中斷 | 在編輯過程中插入診斷,會讓模型在還沒有形成一致修改前就先混亂。 | Mario Zechner:「你先把工作做完,然後再去檢查錯誤。」 |
| 虛假的端到端完成 | 單元測試或 curl 都過了,但真正的使用者流程仍然壞掉。 | Anthropic 長時間運作代理:「沒能辨識出這個功能沒有端到端地正常運作。」 |
| 功能上可用但就是不對 | 結果雖然通過檢查或大致能用,卻仍然笨拙、難用、過度複雜,或違背任務本意。 | 長時間地平線代理:「功能上勉強 OK,但很笨拙、草率,或莫名其妙地過度複雜」;「通過檢查卻仍然感覺不對。」 |
| 自我審查過於寬鬆 | 代理會對自己品質平庸的成果打高分,稱讚很自信,批評卻很薄弱。 | Anthropic app harness:「很自信地稱讚這份工作……明明很平庸。」 |
| 模態盲點 | QA 工具無法發現它看不到、聽不到,或無法像真實使用者那樣操作的 bug。 | Anthropic app harness:「Claude 其實聽不到。」 |
為什麼這會讓人感到疲憊
有兩個相關的問題,雖然不太適合放進失敗模式表格裡,但它們解釋了為什麼整件事會這麼快讓人覺得累。
第一,產出速度超過審查速度。Mario 那句「慢下來,幹」不只是情緒發洩;它其實是操作上的限制。當代理產生程式碼、測試、issue、PR 的速度,已經快到人類來不及閱讀時,瓶頸就會從打字轉移到判斷。審查代理可以抓到一部分問題,但它無法恢復所有權。若沒有人讀程式碼,就沒有人知道什麼是關鍵;等使用者開始哀號時,現場已經沒有任何人類理解了。
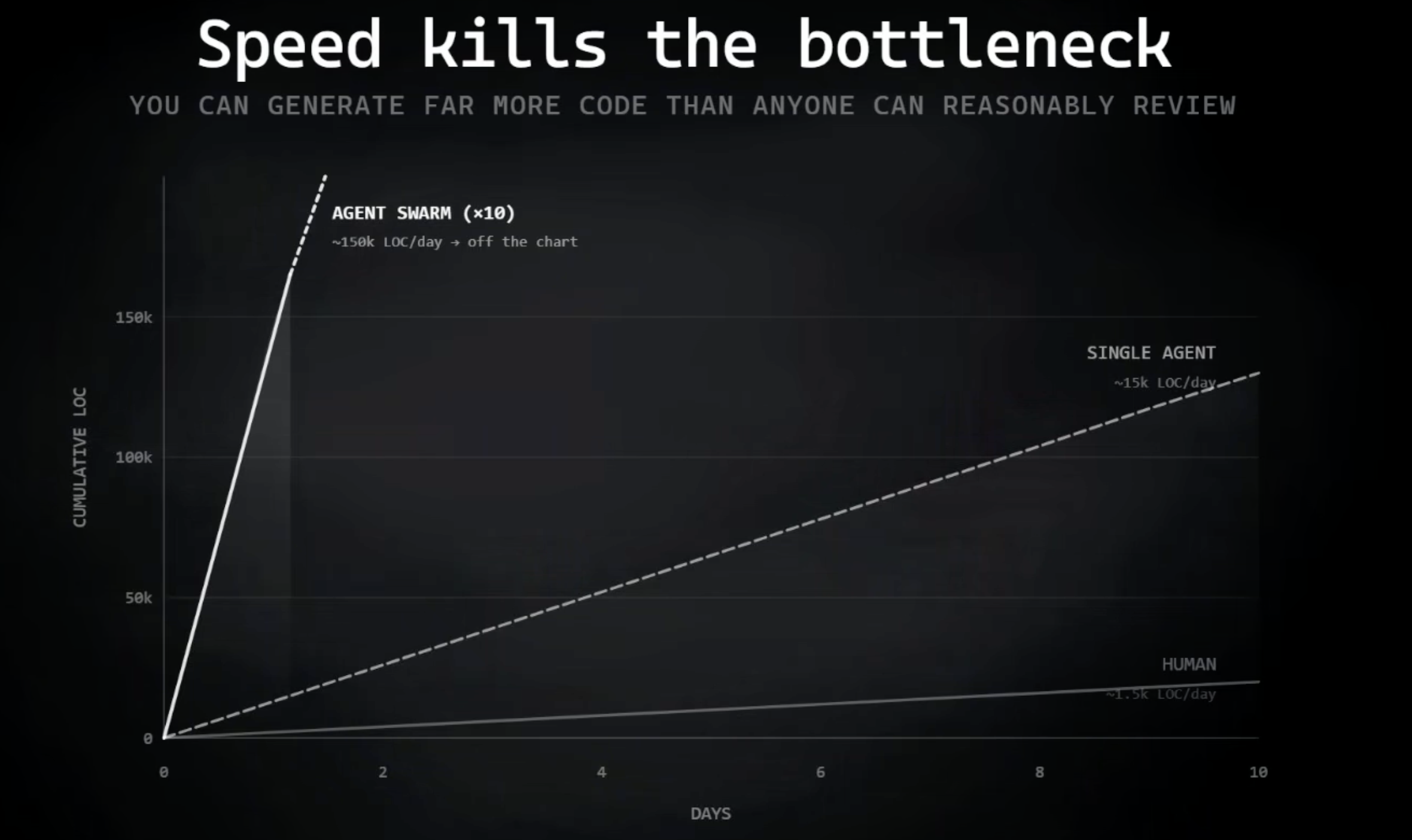
第二,同樣的動態也會滲出你的儲存庫之外。AI issue、AI PR、合成評論、生成文件、制式貼文:其中有些可能有用,但這個頻道會比人們來得及整理更快地被看似合理的文字塞滿。這就是更廣泛的 AI 垃圾問題。認知上留下的是疲憊、犬儒、AI 腦腐,最後甚至會出現全大寫的提示詞,哀求機器不要再賣萌,趕快把真正的工作做完。
所以,「慢下來」不是懷舊,也不是道德訓誡。這是一條實際規則:把生成的工作維持在可審查的範圍內,在驗證成本低的地方使用代理,並保留足夠的人類理解能力,好在需要時能說不。
修補方式與它們的代價
| 修補方式 | 可改善 | 會破壞/造成 |
|---|---|---|
| 重置上下文 | 長任務漂移、上下文焦慮。 | 交接產物變成關鍵狀態。交接不好,下一輪就會很糟。 |
| 壓縮 | 讓長流程能持續跑下去。 | 會不可預期地丟掉重要狀態。 |
| 功能清單/任務清單 | 一口氣做完、過早完成。 | 計畫變僵化、狀態過時、打勾式表演。 |
| 嚴格任務樹 | 及早停止、不完整拆解。 | 表達力低;現實變了就很難調整。 |
| 子代理 | 上下文隔離、平行搜尋。 | 摘要過薄、訊息傳遞限制、整合問題。 |
| 獨立評估器 | 自我稱讚與審查過弱。 | 評估器仍會漏看;標準也可能產生一種規格化的灌水。 |
| 瀏覽器/端到端測試 | 避免只靠本地檢查造成的虛假完成。 | 工具盲點仍在;感知限制仍在。 |
| 使用者自有的最小化 harness | 隱藏的供應商行為、不透明、可擴充性低。 | 安全性、工作流程設計與維護責任回到使用者身上。 |
來源
- Anthropic,"Effective harnesses for long-running agents",2025 年 11 月
- Anthropic,"Harness design for long-running application development",2026 年 3 月
- Random Labs,"Slate: moving beyond ReAct and RLM",2026 年 3 月
- Mario Zechner,"Building Pi in a World of Slop",AI Engineer 研討會演講,2026 年 4 月
- 我先前的文章,"Long-Horizon Agents Are Here. Full Autopilot Isn't.",2026 年 3 月
P.S.>
Pi Agent 的創作者 Mario 在他的演講裡太常講「f.ck」這個字了。我發現自己在提示詞裡也處於類似的狀態:一堆全大寫,還有很多 F.CK。我想,這大概就是 AI 產出太多之後所產生的 AI 疲勞吧 :)
原文出處:https://dev.to/maximsaplin/ai-agent-failure-modes-beyond-hallucination-208g
1) --- 會變成分隔線(上一行必須是空白)
2) # 會變成一級標題
3) ## 會變成二級標題
4) ### 會變成三級標題
5) **粗體文字**會顯示粗體文字
6) ```當第一行與最後一行會顯示程式碼
7) 請搜尋 Markdown 語法,了解各種格式