## 簡介 透過這份備忘清單深入了解 Python,其中包含任何 Pythonista 都需要了解的唯一函式庫。 從資料操作到機器學習和建立 Web 應用程式,這些程式庫在您的 Python 編碼之旅中至關重要。  --- ## 網路應用程式  ### 1. [太皮](https://github.com/Avaiga/taipy) Taipy 是這個街區的新來者。 它專為輕鬆開發前端 (GUI) 和 ML/資料管道而設計。 建立您夢想的應用程式得益於: - 完整的客製化和互動 - 多頁和多用戶應用程式 - 管道圖形編輯器 - 還有更多! ---  您的支持意義重大🌱,並且在許多方面為我們帶來了很大的幫助,例如寫文章! 🙏 --- ### 2. [Streamlit](https://github.com/streamlit/streamlit) Streamlit 是一個完善的函式庫,可用於為飛行員快速建立 Web 應用程式。非常容易使用! --- ## 要點  ### 3. [熊貓](https://github.com/pandas-dev/pandas) 該庫帶來了兩個核心概念:資料幀和系列,使資料清理和準備成為一個輕鬆的過程。 ### 4. [Numpy](https://github.com/numpy/numpy) Pandas 有資料框,而 Numpy 有陣列。 它們以允許快速資料操作而聞名,使 Numpy 成為科學計算的重要工具。 ### 5. [請求](https://github.com/psf/requests) 該程式庫使處理 HTTPS 請求變得輕而易舉。 Requests 提供與 Web API 互動和管理 HTTP 回應的功能。 ### 6. [Scipy](https://github.com/scipy/scipy) Scipy 基於 Numpy,核心功能專注於數學計算,具有最佳化、訊號處理和插值等功能。 --- ## 約會時間  ### 7. [日期時間](https://docs.python.org/3/library/datetime.html) DateTime 是一個標準的 Python 函式庫,對於處理任何 DateTime 格式都是必不可少的。 ### 8. [擺](https://github.com/sdispater/pendulum) Pendulum 具有更高級的日期和時間處理所需的附加功能。 他們有更好的時區支援以及更好的格式選項。 --- ## 機器學習  ### 9. [Scikit-Learn](https://github.com/scikit-learn/scikit-learn) 這個庫不再需要介紹了,這是理所當然的。 Scikit Learn 是機器學習的參考,包含從聚類到分類的演算法。 它還包括從資料驗證到資料選擇的所有功能。 ### 10. [XGboost](https://github.com/dmlc/xgboost) 該庫以其回歸和分類演算法的高效結果而聞名。 ### 11. [Catboost](https://github.com/catboost/catboost) Catboost 是一個機器學習庫,專門設計用於處理主要顯示分類資料的資料集。 --- ## 深度學習  ### 12. [TensorFlow](https://github.com/tensorflow/tensorflow) TensorFlow 是一個成熟的深度學習庫,專門從事自然語言處理和影像分類。 ### 13. [PyTorch](https://github.com/pytorch/pytorch) Pytorch 還是 TensorFlow,這就是問題所在。 最終,您可以選擇自己的團隊,但 PyTorch 的與眾不同之處在於它更注重自然語言處理,並且更具 Python 風格,從而減少了眾所周知的 TensorFlow 陡峭的學習曲線。 ### 14. [Keras](https://github.com/keras-team/keras) Keras 是開始深度學習的好方法,因為它在 TensorFlow 之上執行,但實作過程得到簡化。 ### 15. [OpenCV](https://github.com/opencv/opencv) OpenCV 提供了各種圍繞即時電腦視覺的演算法。 您可以處理多種格式,包括物件、人類,甚至手寫體。 --- ## 自然語言處理  ### 16. [NLTK](https://github.com/nltk/nltk) NLTK 是自然語言處理的首選函式庫。 NLTK 的主要功能包括:處理和操作文本(標記化、詞幹提取等)以及使用 NLP 任務進行分類以進行情緒分析。 ### 17. [SpaCy](https://github.com/explosion/spaCy) 是這個領域的新人,專注於讓 NLP 更容易存取和用戶友好。 該圖書館優化了流程,以確保更高的速度和效率。 --- ## 測試  ### 18. [Pytest](https://github.com/pytest-dev/pytest) Pytest 是一個簡化測試編寫和執行的框架。它的語法簡潔,使用者友善。 ### 19. [Unitest](https://docs.python.org/3/library/unittest.html) Unistest 是 Python 內建的測試框架。 其主要功能是:測試發現、夾具支援、輕鬆組織和測試套件管理。 --- ## 聲音的  ### 20. [AudioFlux](https://github.com/libAudioFlux/audioFlux) Python 中用於音訊訊號處理的首選庫,但很簡單。 AudioFlux 具有大量功能,包括聲音分析,可用於深度學習訓練。 ### 21. [Librosa](https://github.com/librosa/librosa) 此 Python 程式庫允許從音訊來源中分析和提取特徵。 --- ## 程式碼分析  ### 22.[黑色](https://github.com/psf/black) 它是一個自動程式碼格式化程式。 它將自動格式化您的程式碼,以在整個專案中保持一致的風格。 ### 23. [Pylint](https://github.com/pylint-dev/pylint) 顧名思義,Pylint 是一個 linter。 它是一個靜態程式碼分析工具,用於檢查程式碼品質和錯誤。 ### 24. [Flake8](https://github.com/PyCQA/flake8) 這是另一個 linting 函式庫,可以根據 PEP8 編碼約定檢查您的程式碼。 ### 25. [Ruff](https://github.com/astral-sh/ruff) Ruff 是等效 linter 的最快選擇。 它提高了效率和速度,使流程加快了十倍。 --- ## 分散式計算  ### 26. [Dask](https://github.com/dask/dask) Dask 是一個流行的分散式運算 Python 包,因為它在處理大型資料集時特別有用。 Dask 整合了 Pandas、Numpy 和 Scikit-learn API,因此易於使用。 ### 27. [PySpark](https://github.com/apache/spark/tree/master) 顧名思義,PySpark 是 Apache Spark 的 Python API,讓我們可以直接在 Python 中利用 Spark 的功能。 ### 28. [極地](https://github.com/pola-rs/polars) Polars 是一個為處理大型資料集而建立的 DataFrame 函式庫。 它的靈感來自蟒蛇皇室 - 熊貓,但有一個(快速)扭曲,它的速度快了 10 到 100 倍。 --- ## 文件  ### 29. [Mkdocs](https://github.com/mkdocs/mkdocs) Mkdocs 是產生簡單文件的最易於存取的庫。 適合較小的專案,幾乎沒有學習曲線。 ### 30. [獅身人面像](https://github.com/sphinx-doc/sphinx) Sphinx 通常是大型專案的首選。 它包括對多種格式的支援並允許特定的自訂。 ### 31. [Pydoc](https://docs.python.org/3/library/pydoc.html) Pydoc 已整合到 Python 生態系統中。它直接從您的模組產生文件。 --- ## 地理資料  ### 32. [Geopy](https://github.com/geopy/geopy) Geopys 的主要功能是:距離計算、地理編碼和反向地理編碼。 ### 33. [表](https://github.com/python-visualization/sheet) 該庫允許您使用 Python 建立互動式地圖。改變遊戲規則的人。 ### 34. [Geopandas](https://github.com/geopandas/geopandas) 當您擁有地理空間資料時,您應該採取的方法。 如標題所述,Geopandas 是 Pandas,但用於地理空間資料。該庫具有輕鬆操作和分析地理資料的功能。 --- ## 遊戲  ### 35. [Pygame](https://github.com/pygame/pygame) Pygame 是首選、簡單的函式庫,可以輕鬆使用 Python 建立 2D 和互動式視訊遊戲。 ### 36. [街機](https://github.com/pythonarcade/arcade) 就像 PyGame 一樣,Arcade 使 Python 中建立影片遊戲成為一個有趣的過程。 它們對經典 Pygame 進行了更現代的改造,因此選擇實際上取決於個人喜好。 --- ## 網頁抓取  ### 37. [Scrapy](https://github.com/scrapy/scrapy) Scrapy 是一個成熟的函式庫,以網頁抓取而聞名。 一些關鍵功能包括:支援非同步/同步操作、HTTPS 請求處理等。 它具有廣泛的功能,這可能證明該庫具有陡峭的學習曲線。 ### 38. [美麗湯](https://www.crummy.com/software/BeautifulSoup/#Download) Beautiful Soup 是您處理從 XML 和 HTML 檔案中提取資料所需的一切。 由於其 Python 風格,它受到了開發人員的讚賞。 --- ## 視覺化  ### 39. [Matplotlib](https://github.com/matplotlib/matplotlib) Matplotlib 是 Python 中主要的元件庫,這是有充分理由的。 Matplotlib 允許使用多種圖表類型繪製 2D 圖形,並且還允許進行大量自訂。 元素的細粒度控制是該庫的真正優勢。 ### 40. [散景](https://github.com/bokeh/bokeh) 與 Matplotlib 相反,Bokeh 專注於互動式圖表。 ### 41. [Seaborn](https://github.com/mwaskom/seaborn) Seaborn 建構在 Matplotlib 之上。 雖然 Matplolib 強調精確性和簡單性,但 Seaborn 在建立複雜的統計視覺化的同時,其時尚的視覺效果具有真正的附加價值。 ### 42. [Vizzu](https://github.com/vizzuhq/vizzu-lib) Vizzu 在視覺化領域找到了自己的定位,並且做得非常好。 他們將講故事和圖表與高度動畫的視覺化融為一體,這是一種獲得更多動態圖表的好方法。 --- ## 結論 無論您是高級 Python 專家還是正在嘗試 Python,有了這份不可或缺的函式庫列表,您將能夠應對任何挑戰。祝你編碼愉快! --- 我是一名新手作家,歡迎任何改進建議!  如果您有任何疑問,請隨時與我們聯繫。 --- 原文出處:https://dev.to/taipy/top-42-python-libraries-you-need-to-know-1omo
在上一個發布週期間,我們在 Supabase Studio 的 SQL 編輯器中引入了文字到 SQL。這是我們邁向完整人工智慧助理的第一步。 今天,我們將介紹 Supabase Assistant,這是儀表板內的人工智慧助手,以及一些新功能,可幫助您更快地從創意到生產。 https://youtu.be/hu2SQjvCXIw 這是鳥瞰圖: - **行級安全策略:** 透過 AI 輕鬆實現 - **Postgres 角色:** 更改工作室的 Postgres 角色 - **使用者模擬:**視覺化您的安全策略 - **即時檢查器:**檢查和除錯即時請求 - **功能預覽:** 查看 Studio 中的熱門新聞 ## 介紹 Supabase 助手 我們很高興能夠透過新的 **Supabase Assistant 擴展 Studio 的 AI 功能。** 開發人員告訴我們,SQL 編輯器中的文字到 SQL 功能大大提高了他們的速度(以及他們的 SQL 能力)。當人工智慧與基於模式的資料庫(如 Postgres)結合使用時,它的功能非常強大,因為它可以從模式中推斷出大量上下文,並且資料庫為生成的程式碼提供了更嚴格的保證。我們先前的版本堅定了我們的信念,即人工智慧將成為未來資料庫開發的關鍵部分。 今天,我們在行級安全編輯器中推出了 Assistant 支持,並且很快就會擴展到 Studio 中的其他位置:表編輯器、Postgres 函數、無伺服器函數等。 讓我們先進入行級安全性。  ## 透過 AI 實現簡單的 RLS 策略 在我們收到的所有功能請求中(而且我們收到了很多!),編寫[行級安全性](https://supabase.com/docs/guides/auth/row-level-security)策略的更簡單方法是其中之一最頻繁的。 行級安全性 (RLS) 是 Postgres 的一項功能,可提供對資料庫的細粒度存取。雖然 RLS 很強大,但編寫策略可能是一件苦差事。今天,我們發布了一款基於 AI 的 RLS 編輯器,讓編寫安全策略變得簡單。 新的 RLS 編輯器將 SQL 置於中心位置。我們希望讓開發人員能夠充分發揮 Postgres 的潛力,而不是將其抽象化。這個編輯器其實是兩個工具: 1. SQL 編輯器:如果您非常了解 SQL,那麼有一個新的編輯器可以讓您快速編寫策略。 2. 助手:如果您是 RLS 新手並需要幫助,您可以使用助手並透過它進行聊天。  此助手經過調整,可產生用於行級安全性的 SQL,以便快速、輕鬆地按照您需要的方式設定策略。 我們探索了 RLS 編輯器的各種方法和設計。這種 SQL 優先的方法在人工智慧的幫助下,感覺就像我們一直在尋找的解決方案。現在可以透過功能預覽啟用新的 RLS 編輯器(更多資訊請見下文)。我們很樂意[聽到您的回饋。](https://github.com/orgs/supabase/discussions/19594) ## Postgres 角色 您可能從未想過這一點,但 Studio 就像任何其他 Postgres 用戶端一樣連接到您的資料庫。 它使用預設的[Postgres角色](https://supabase.com/docs/guides/database/postgres/roles),`postgres`。 「postgres」角色的功能類似於「服務角色」金鑰,授予它對資料庫的管理權限。它具有管理員讀寫權限,並繞過行級安全性。 如果您使用我們的客戶端程式庫,您將熟悉「anon」和「service_role」 API 金鑰。這些鍵實際上解析為 Postgres 角色,也稱為“anon”和“service_role”。這些密鑰實際上是包含 Postgres 角色的 JWT 令牌: ``` { "role": "service_role", // the Postgres role "iss": "supabase" // the issuer of the JWT "exp": 1445385600, // the time the JWT will expire } ``` 如果您可以使用在應用程式中使用的相同 Postgres 角色在 Studio 中執行查詢會怎麼樣?如果您可以讓 Studio 假裝使用與預設「postgres」角色不同的角色怎麼辦?今天,您可以:  您可以使用新的角色下拉清單為 Studio 中的查詢選擇不同的 Postgres 角色。這是一個強大的工具,用於測試行級安全策略並確定每個角色可以存取哪些資料。 讓我們建立一個 Twitter/X 克隆來進行說明。在 Twitter 克隆中,您: - 有一個包含「user_id」和「content」等欄位的推文表。 - 可以設定行級安全性,以便只有推文的作者才能存取和修改自己的推文。 - 只能查看和編輯您撰寫的推文。 當我們使用“postgres”角色進行查詢時,我們可以看到所有資料。當我們使用“anon”查詢時,不會傳回任何資料。這是有道理的,因為我們尚未建立允許「匿名」存取此表的策略。 角色下拉清單解鎖了另一個方便的功能:與 Supabase Auth 結合使用時,它甚至可以假裝是不同的使用者。 ## 使用者模擬 還記得上面的 API 金鑰嗎?它們可以包含一個附加字段:“sub”。這是用戶的 ID。當您使用「authenticated」角色時,「sub」欄位是登入您的應用程式的使用者的ID: ``` { "sub": "348b-some-user-uuid", // the ID of the user "role": "authenticated", // the Postgres role "iss": "supabase" // the issuer of the JWT "exp": 1445385600, // the time the JWT will expires } ``` 我們可以透過使用使用者 ID「建立」JWT,然後使用該 JWT 執行查詢來模擬 Studio 中的使用者。 在我們編寫 RLS 策略以允許用戶查看自己的推文後,讓我們看看它的實際效果。在這裡,我們可以選擇「已驗證」角色,並選擇特定用戶以僅查看他們的推文。以下是我們所有用戶的推文:  表編輯器現在正在模擬我們的用戶。 您可以模擬專案中的任何用戶,並按照他們的方式查看事物。您的 RLS 政策中的任何條件都會自動反映在表中。 ✨ 魔法 ✨ 您可以直接從 Studio 建立 RLS 策略並測試它們是否完全按照您的預期運作。 表格編輯器的樂趣不止於此。我們還為 SQL 編輯器和 GraphiQL 新增了角色支援。讓我們透過嘗試在 SQL 編輯器中選擇我們自己的推文清單來重複上面所做的事情:  在 GraphiQL 中:  將此功能與新的 RLS 編輯器結合,您可以在幾分鐘內使用真實資料編寫和測試 RLS 策略。這使得編寫 RLS 策略的過程變得更快、更容易。如果您有回饋,[我們很樂意聽到。](https://github.com/orgs/supabase/discussions/19595) ## 即時檢查器 Supabase [Realtime](https://supabase.com/realtime) 非常適合建立協作應用程式。您可以透過 Websocket 接收資料庫更改,儲存和同步有關使用者狀態的資料,以及透過「通道」向客戶端廣播任何資料。 今天,我們發布了 Realtime Inspector:一種直接在 Studio 中進行 Realtime 原型設計、檢查和除錯的簡單方法。您可以使用即時檢查器查看通道中發送和接收的訊息。您可以按類型篩選訊息:狀態、廣播和資料庫變更。  當然,我們也在這裡新增了「角色」下拉清單。您可以按角色查看事件並模擬用戶,就像表和 SQL 編輯器一樣。 如果您使用 Realtime,您會發現新的檢查器非常方便。 ## 功能預覽 今天,我們發布了**功能預覽**,這是我們用於推出新功能的工具。在普遍可用之前,我們會以預覽版的形式發布 Beta 功能。您可以看到可用於預覽的功能清單以及螢幕截圖和簡要說明。每個功能都包含一個指向 Github 討論以獲取反饋的連結。 我們對功能預覽有幾個目標。我們想: - 更快地向您提供功能 - 讓您更輕鬆地向我們提供回饋 - 縮短迭代循環 我們越快地迭代您的回饋,我們就能越快將功能發佈到普遍使用中。 雖然我們認為這些功能是測試版,但請注意,我們非常重視您的安全、隱私和資料完整性。我們發佈到預覽版的任何內容都會考慮到這一點進行測試,並且處於我們正在尋找 UX/UI 回饋的階段。 您可以在左下角的使用者頭像選單下找到我們的功能預覽:  目前我們有兩個預覽功能: 1. 我們之前看到的新 RLS 助手:  2. 以及修改後的 API 側面板:  我們將積極關注 Github 討論並回覆您的回饋。 ## 總結 在此更新中,我們在增強您的 Supabase 體驗方面取得了巨大進展。 1. **行級安全策略:** 在新助理的幫助下,我們比以往任何時候都更容易建立行級安全策略。此功能極大地簡化了定義對資料的細粒度存取的過程。 2. **Postgres 角色和使用者模擬:** 我們的新角色選擇器可讓您直接在 Studio 中視覺化安全策略的影響。這使您可以了解不同角色如何與資料交互,從而為測試存取控制提供強大的工具。 3. **即時檢查器:** 使用即時檢查器,您可以原型設計、檢查和偵錯即時訊息。這個工具對於使用 Supabase Realtime 的人來說非常有用。 4. **功能預覽:** 我們推出了功能預覽,為您帶來測試階段的新工具和功能,讓您更輕鬆地提供回饋並塑造開發流程。 這些更新反映了我們對 SQL 優先方法和以使用者為中心的開發的承諾。我們期待您的回饋,我們將繼續努力讓 Supabase 更快、更輕鬆地讓您的想法付諸實現。 ## 更多發布第 X 週 - [Postgres語言伺服器:實作解析器](https://supabase.com/blog/postgres-language-server-implementing-parser) - [Supabase 設計如何運作](https://supabase.com/blog/how-design-works-at-supabase) - [Supabase 專輯](https://www.youtube.com/watch?v=r1POD-IdG-I) - [Supabase 啟動週 X 黑客松](https://supabase.com/blog/supabase-hackathon-lwx) - [啟動週 X 社群聚會](https://supabase.com/blog/community-meetups-lwx) --- 原文出處:https://dev.to/supabase/supabase-studio-ai-assistant-and-user-impersonation-22mn
## **簡介** 在本教程中,您將學習如何使用**現代工具**和**最佳實踐**來監控您的Javascript應用程式。 探索分散式追蹤的力量,並了解如何無縫整合和利用 Odigos 和 Jaeger 等工具來增強您的監控能力。 **您將學到什麼:✨** - 如何在 Javascript 中建立微服務🐜。 - 為微服務設定 Docker 容器📦。 - 配置 Kubernetes ☸️ 以管理微服務。 - 整合追蹤後端以可視化追蹤🔍。 您準備好成為監控 JS 應用程式的**專家**了嗎? 😍 說**是的,先生!**。 我聽不到你說話。大聲點說。 🙉  *** ## **讓我們設定一下 🦄** > 🚨 在部落格的這一部分中,我們將建立一個虛擬的 JavaScript 微服務應用程式並將其部署在本地 Kubernetes 上。如果您已經有一個並且正在跟進,請隨意跳過這一部分。 為您的應用程式建立初始資料夾結構,如下所示。 👇🏻 ``` mkdir microservices-demo cd microservices-demo mkdir src cd src ``` ### **設定伺服器** 🖥️ > 👀 出於演示目的,我將建立兩個相互通信的微服務,最終我們可以使用它來視覺化分散式追蹤。 - **建置與 Dockerize 微服務 1** 在「/src」資料夾中,建立一個新資料夾「/microservice-1」。在資料夾內初始化 **NodeJS** 專案並安裝所需的依賴項。 ``` mkdir microservice-1 cd microservice-1 npm init -y npm install --save express node-fetch ``` 建立一個新檔案“index.js”並新增以下程式碼: ``` // 👇🏻/src/microservice-1/index.js const express = require("express"); const fetch = require("node-fetch") const app = express(); const PORT = 3001; app.use(express.json()); app.get("/", async (req, res) => { try { const response = await fetch("http://microservice2:8081/api/data"); const data = await response.json(); res.json({ data: "Microservice 2 data received in Microservice 1", microservice2Data: data, }); } catch (error) { console.error(error.message); res.status(500).json({ error: "Internal Server Error" }); } }); app.listen(PORT, () => { console.log(`Microservice 1 listening on port ${PORT}`); }); ``` 伺服器正在偵聽連接埠“3001”,並且在對“/”發出請求時,我們從“microservice2”請求資料並將回應作為 JSON 物件返回。 📦 現在,是時候對這個微服務進行 docker 化了。在“/microservice-1”資料夾中建立一個新的“Dockerfile”並新增以下程式碼: ``` // 👇🏻/src/microservice-1/Dockerfile FROM node:18 # Use /usr/src/app as the working directory WORKDIR /usr/src/app # Copy package files and install production dependencies COPY --chown=node:node package*.json /usr/src/app RUN npm install --production # Copy the rest of the files COPY --chown=node:node . /usr/src/app/ # Switch to the user node with limited permissions USER node # Expose the application port EXPOSE 3001 # Set the default command to run the application CMD ["node", "index.js"] ``` 將我們不想推送到容器的文件加入到“.dockerignore”總是很好。使用我們不想推送的檔案的名稱來建立一個“.dockerignore”檔案。 ``` // 👇🏻/src/microservice-1/.dockerignore node_modules Dockerfile ``` 最後,透過執行以下命令來建構 🏗️ docker 映像: ``` docker build -t microservice1-image:latest . ``` 現在,這就是我們第一個微服務的完整設定。 ✨ - **建置與 Dockerize 微服務 2** 我們將有一個類似於“microservice1”的設置,只是在這裡和那裡進行了一些更改。 在「/src」資料夾中,建立一個新資料夾「/microservice-2」。在該資料夾內,初始化 **NodeJS** 專案並安裝所需的依賴項。 ``` mkdir microservice-2 cd microservice-2 npm init -y npm install --save express node-fetch ``` 建立一個新檔案“index.js”並新增以下程式碼: ``` // 👇🏻/src/microservice-2/index.js const express = require("express"); const fetch = require("node-fetch") const app = express(); const PORT = 3002; app.use(express.json()); app.get("/api/data", async (req, res) => { const url = "https://jsonplaceholder.typicode.com/users"; try { const response = await fetch(url); const data = await response.json(); res.json(data); } catch (error) { console.error(error.message); res.status(500).json({ error: "Internal Server Error" }); } }); app.listen(PORT, () => { console.log(`Microservice 2 listening on port ${PORT}`); }); ``` 伺服器正在偵聽連接埠 3002,根據對“/api/data”的“GET 請求”,我們從“jsonplaceholder”獲取資料並將回應作為 JSON 物件傳回。 📦 現在,是時候對這個微服務進行 docker 化了。複製並貼上「microservice1」的整個「Dockerfile」內容,然後將連接埠從 3001 變更為 3002。 另外,新增一個「.dockerignore」檔案並包含我們在建立「microservice1」時新增的相同檔案。 最後,透過執行以下命令來建構 🏗️ Docker 映像: ``` docker build -t microservice2-image:latest . ``` 現在,這也是我們第二個微服務的完整設定。 ✨ - **設定 Kubernetes** > 確保已安裝 **[Minikube](https://github.com/kubernetes/minikube)** 透過執行以下命令建立新的本機 Kubernetes 叢集。我們在設定 Odigos 和 Jaeger 時將需要它。 **啟動 Minikube:🚀** ``` minikube start ``` 現在我們已經準備好並 Docker 化了兩個微服務,是時候設定 Kubernetes 來管理這些服務了。 在專案的根目錄下,建立一個新資料夾「/k8s/manifests」。在此資料夾中,我們將為兩個微服務新增部署和服務配置。 - **部署設定📜**:用於在 Kubernetes 叢集上實際部署容器。 - **服務配置📄**:將 Pod 暴露給叢集內部和叢集外部。 首先,我們為「microservice1」建立清單。建立一個新檔案「microservice1-deployment-service.yaml」並新增以下內容: ``` // 👇🏻/k8s/manifests/microservice1-deployment-service.yaml apiVersion: apps/v1 kind: Deployment metadata: name: microservice1 spec: selector: matchLabels: app: microservice1 template: metadata: labels: app: microservice1 spec: containers: - name: microservice1 image: microservice1-image # Make sure to set it to Never, or else it will pull from the docker hub and fail. imagePullPolicy: Never resources: limits: memory: "200Mi" cpu: "500m" ports: - containerPort: 3001 --- apiVersion: v1 kind: Service metadata: name: microservice1 labels: app: microservice1 spec: type: NodePort selector: app: microservice1 ports: - port: 8080 targetPort: 3001 nodePort: 30001 ``` 此配置部署了一個名為「microservice1」的微服務,其資源限制為 **200MB 記憶體** 🗃️ 和 **0.5 個 CPU 核心**。它透過部署在連接埠 3001 上公開微服務,並透過服務在 **NodePort** 30001 上公開微服務。 > 🤔 還記得我們用名稱「microservice1-image」建構的「Dockerfile」嗎?我們使用相同的映像來建立容器。 可透過集群內的連接埠 8080 存取它。我們假設「microservice1-image」透過「imagePullPolicy: Never」在本地可用。如果沒有到位,它將嘗試從 Docker Hub 🐋 中提取映像並失敗。 現在,讓我們為「microservice2」建立清單。建立一個名為「microservice2-deployment-service.yaml」的新檔案並新增以下內容: ``` // 👇🏻/k8s/manifests/microservice1-deployment-service.yaml apiVersion: apps/v1 kind: Deployment metadata: name: microservice2 spec: selector: matchLabels: app: microservice2 template: metadata: labels: app: microservice2 spec: containers: - name: microservice2 image: microservice2-image # Make sure to set it to Never, or else it will pull from the docker hub and fail. imagePullPolicy: Never resources: limits: memory: "200Mi" cpu: "500m" ports: - containerPort: 3002 --- apiVersion: v1 kind: Service metadata: name: microservice2 labels: app: microservice2 spec: type: NodePort selector: app: microservice2 ports: - port: 8081 targetPort: 3002 nodePort: 30002 ``` 它與“microservice1”的清單類似,只有一些更改。 👀 此配置部署一個名為「microservice2」的微服務,並透過部署在連接埠 3002 上將其內部公開,並透過服務在 **NodePort** 30002 上將其外部公開。 可透過叢集內的連接埠 8081 進行存取,假設「microservice2-image」可透過「imagePullPolicy: Never」在本地使用。 全部完成後,請確保套用這些設定並使用這些服務啟動 Kubernetes 叢集。將目錄更改為`/manifests`並執行以下命令:👇🏻 ``` kubectl apply -f microservice1-deployment-service.yaml kubectl apply -f microservice2-deployment-service.yaml ``` 執行以下命令檢查我們的兩個部署是否正在**執行**:👇🏻 ``` kubectl get pods ```  最後,我們的應用程式已準備就緒,並使用必要的部署配置部署在 Kubernetes 上。 🎉 *** ## **安裝 Odigos 😍** > 💡 [**Odigos**](https://odigos.io/) 是一個開源可觀察性控制平面,使組織能夠建立和維護其可觀察性管道。  > ℹ️ 如果您在 Mac 上執行,請執行以下命令在本地安裝 Odigos。 ``` brew install keyval-dev/homebrew-odigos-cli/odigos ``` > ℹ️ 如果您使用的是 Linux 計算機,請考慮透過執行以下命令從 GitHub 版本安裝它。確保根據您的 Linux 發行版更改該檔案。 > ℹ️ 如果 Odigos 二進位檔案不可執行,請在執行安裝指令之前執行此指令 `chmod +x odigos` 使其可執行。 ``` curl -LJO https://github.com/keyval-dev/odigos/releases/download/v1.0.9/cli_1.0.9_linux_amd64.tar.gz tar -xvzf cli_1.0.9_linux_amd64.tar.gz ./odigos install ``` 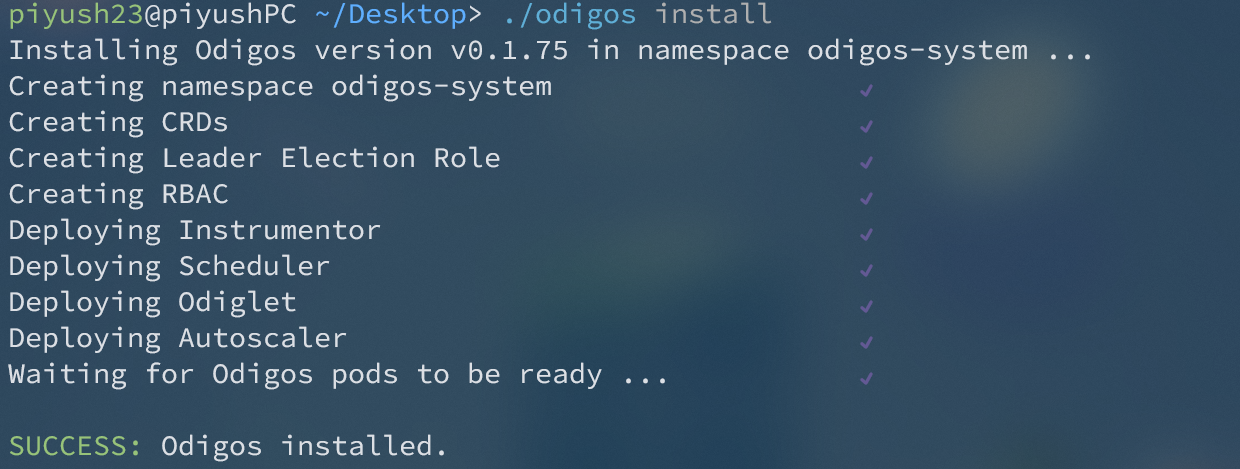 > 如果您需要有關其安裝的更多簡短說明,請按照此[**連結**](https://docs.odigos.io/installation)操作。 現在,Odigos 已準備好執行 🎉。我們可以執行它的 UI,配置追蹤後端,並相應地發送追蹤。 *** ## **將 Odigos 連接到追蹤後端 💫** > 💡 [**Jaeger**](https://github.com/jaegertracing/jaeger) 是一個開源的端對端分散式追蹤系統。  ### **設定 Jaeger!** ✨ 在本教程中,我們將使用 **Jaeger** 🕵️♂️,這是一個流行的開源平台,用於查看微服務應用程式中的分散式追蹤。我們將用它來查看 Odigos 生成的痕跡。 > 有關 Jaeger 安裝說明,請點選此 [**link**](https://www.jaegertracing.io/download/)。 👀 若要在 Kubernetes 叢集上部署 Jaeger,請執行下列命令:👇🏻 ``` kubectl create ns tracing kubectl apply -f https://raw.githubusercontent.com/keyval-dev/opentelemetry-go-instrumentation/master/docs/getting-started/jaeger.yaml -n tracing ``` 在這裡,我們建立一個「tracing」命名空間,並在該命名空間中為 Jaeger 應用部署配置📃。 此命令設定自託管 Jaeger 實例及其服務。 👀 執行以下命令來取得正在執行的 pod 的狀態:👇🏻 ``` kubectl get pods -A -w ``` 等待所有三個 Pod 都 **正在執行**,然後再繼續。 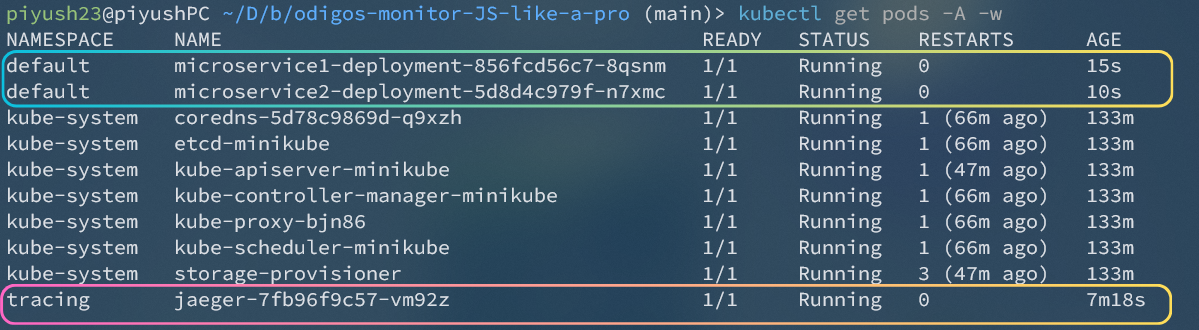 現在,要在本地查看 Jaeger Interface 💻,我們需要進行連接埠轉送。將流量從本機電腦上的連接埠 16686 轉送至 Kubernetes 叢集中選定 pod 上的連接埠 16686。 ``` kubectl port-forward -n tracing svc/jaeger 16686:16686 ``` 此命令在本機電腦和 Jaeger pod 之間建立一條隧道,公開 Jaeger UI,以便您可以與其互動。 最後,在瀏覽器上開啟「 http://localhost:16686 」並查看 Jaeger 實例正在執行。 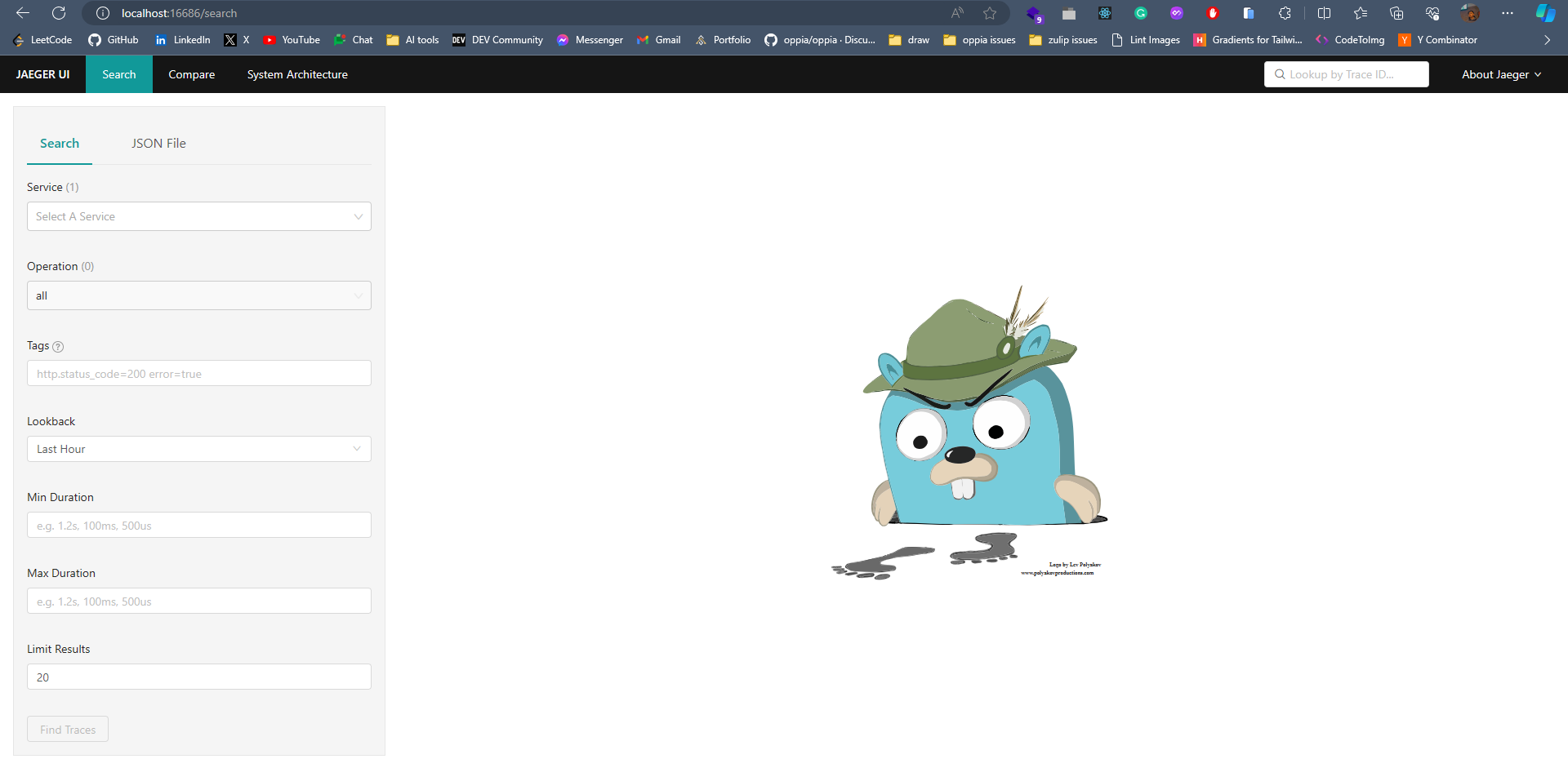 ### **設定 Odigos 與 Jaeger 一起工作!** 🌟 > ℹ️ 對於 Linux 用戶,請前往從 GitHub 版本下載 Odigos 二進位檔案的資料夾,然後執行以下命令來啟動 Odigos UI。 ``` ./odigos ui ``` > ℹ️ 對於 Mac 用戶,只需執行: ``` odigos ui ``` 造訪“ http://localhost:3000 ”,您將看到 Odigos 介面,您將在“default”命名空間中看到您的部署。 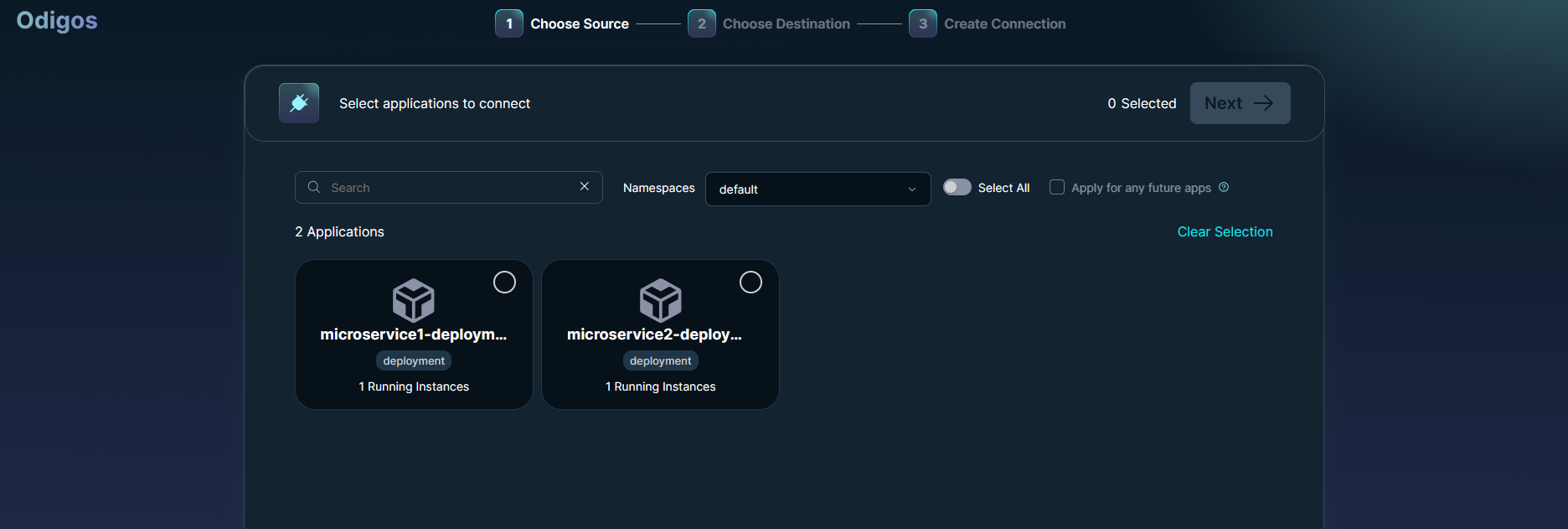 選擇這兩個選項並點擊“下一步”。在下一頁上,選擇 Jaeger 作為後端,並在出現提示時加入以下詳細資訊: - **目的地名稱🛣️**:提供您想要的任何名稱,例如說**快速追蹤**。 - **端點🎯**:為端點加上`jaeger.tracing:4317`。 就是這樣 - Odigos 已準備好向我們的 Jaeger 後端發送痕跡。就是這麼簡單。 🤯 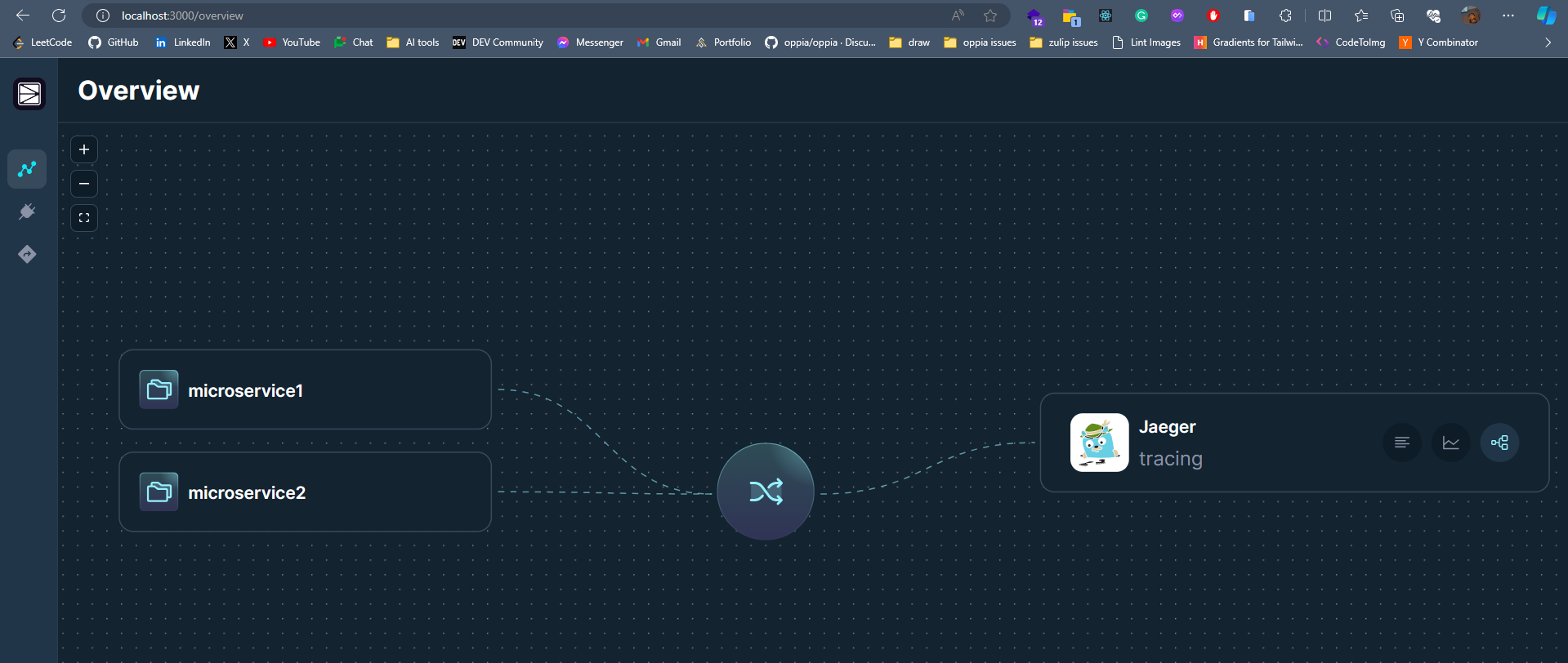 *** ## **查看分散式追蹤 🧐** 設定 Odigos 後,在 Jaeger 主頁「 http://localhost:16686 」上,您將已經看到列出的兩個微服務。 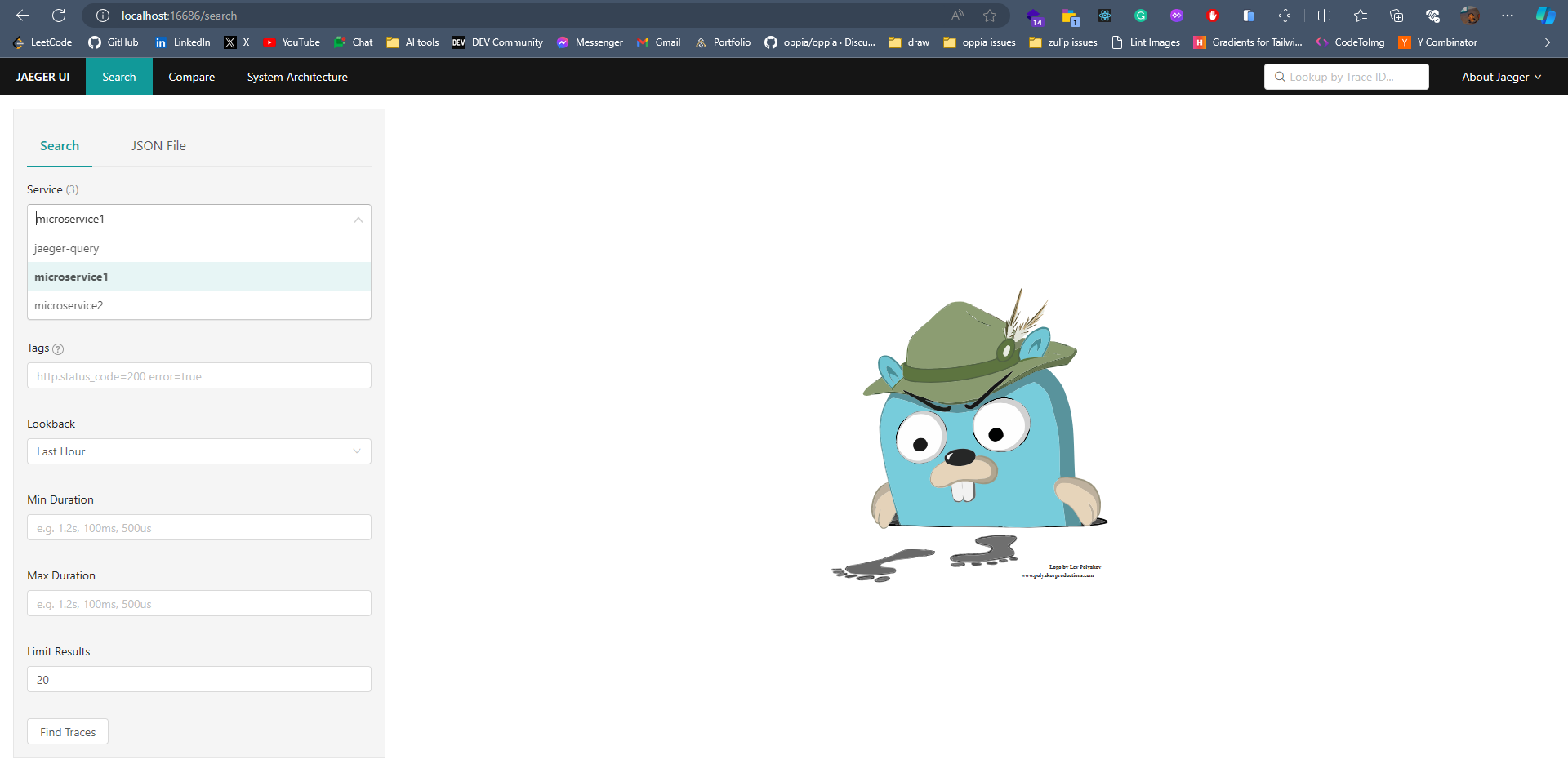 Odigos 已經開始向 Jaeger 發送我們的應用程式痕跡。 😉 請記住,這是我們的微服務應用程式。由於以「microservice1」為起點,因此再向「microservice1」發出一些請求,隨後它將向「microservice2」請求資料並傳回。最終,Jaeger 將開始填滿這些痕跡。 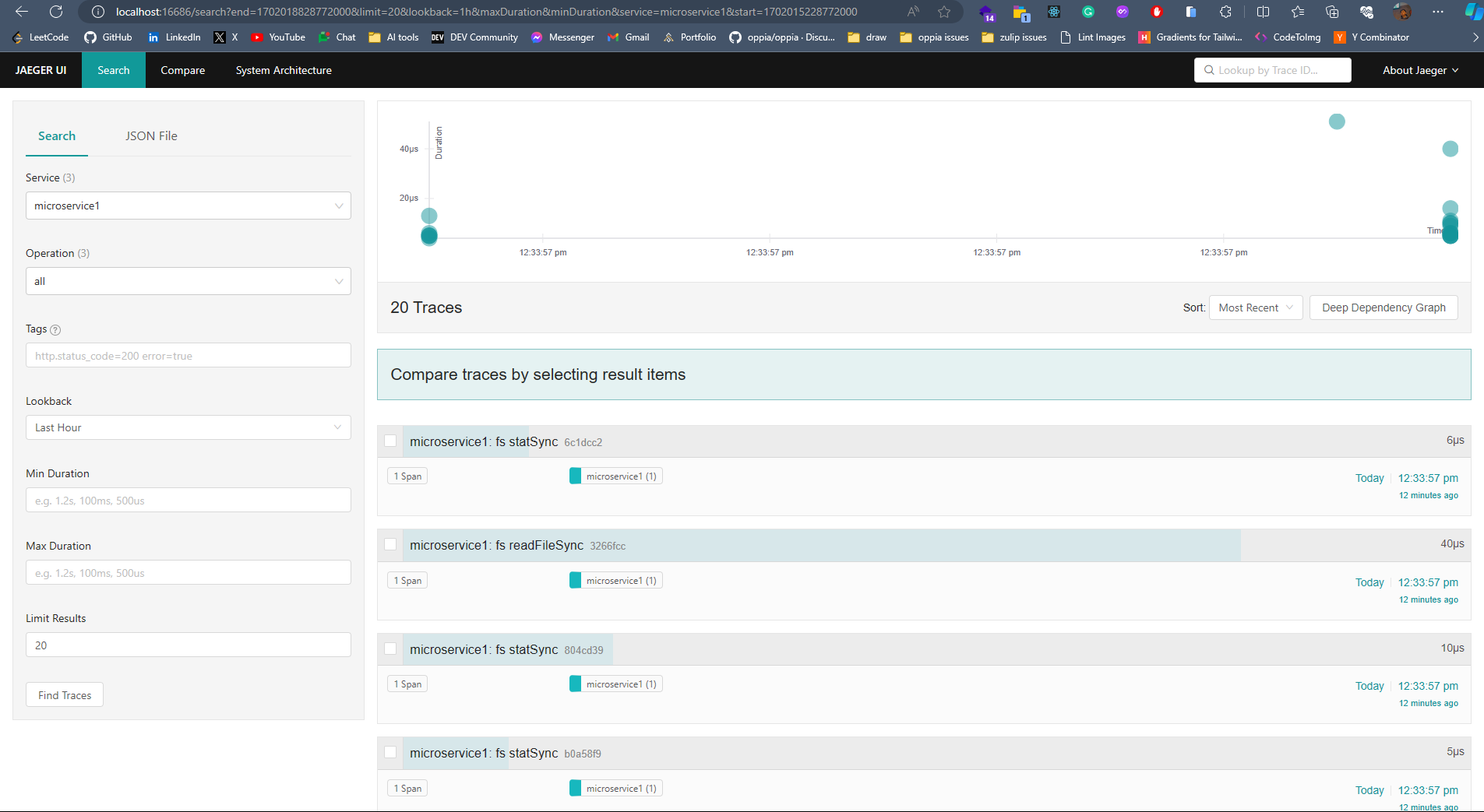 點擊任一請求,您應該能夠觀察請求如何流經您的應用程式以及完成每個請求所需的時間。 這一切都是在沒有更改一行程式碼的情況下完成的。 🤯 一切都感謝 **Odigos**! 🤩  想像一下,這只是一個很小的虛擬應用程式,但對於一個執行著大量微服務並相互交互的更大的應用程式來說,分散式追蹤將非常強大! 💪 透過分散式跟踪,您可以輕鬆辨識應用程式中的瓶頸,並確定哪個服務導致問題或花費更長的時間。 🕒 *** ## **讓我們總結一下! 🥱** 到目前為止,您已經學習如何使用 **Odigos** 作為應用程式和追蹤後端 **Jaeger** 之間的 **中間件**,透過分散式追蹤來密切監控 👀 Javascript 應用程式。 👏 如果您已經做到了這一步,請拍拍自己的背。 🥳你值得擁有! 😉 本教學的源程式碼可在此處取得: https://github.com/keyval-dev/blog/tree/main/odigos-monitor-JS-like-a-pro > 如果您對本文有任何疑問或建議,請在下面的評論部分分享。 👇🏻 那麼,這就是本文的內容。感謝您的閱讀! 🎉🫡 --- 原文出處:https://dev.to/odigos/monitor-your-javascript-application-like-a-pro-581p
想要 **在 2024 年掌握前端 Web 開發?** 無論您是渴望開始前端開發之旅還是希望提升您的技能,我們都能滿足您的需求。 這裡有 9 個令人興奮的專案,它們將使您能夠在 2024 年掌握前端開發。為了加速您的學習過程,每個專案都配有專用資源。 讓我們深入研究並將您的編碼願望變成現實! 🚀 ### 1. 說故事作品集網站 建立一個引人入勝的說故事作品集網站來展示您的技能和專案。使用動畫和過渡來吸引訪客。 **您將學到什麼:** 該專案將提高您建立個人作品集、將動畫與 CSS 和 JavaScript 結合的能力。您還將透過網頁設計深入了解如何有效地講述故事。 **技術堆疊:** HTML、CSS、JavaScript、GSAP(GreenSock 動畫平台)。 **資源:** [說故事作品集教學](https://youtu.be/0fYi8SGA20k?si=lgzXlqL7m2aK3nzg)  ### 2. 電影搜尋應用程式 使用 React Hooks 建立電影搜尋應用程式。用戶可以搜尋電影、查看詳細資訊並發現新上映的電影。 **您將學到什麼:** 透過這個專案,您將掌握使用 React Hooks 進行狀態管理、非同步資料擷取和響應式設計。此外,您還將深入了解如何處理使用者輸入和管理複雜的資料結構。 **技術堆疊:** React Hooks、Axios、CSS(flexbox/grid)和電影資料庫(IMDB)API。 **資源:** [電影搜尋應用程式教學](https://www.freecodecamp.org/news/how-to-build-a-movie-search-app-using-react-hooks-24eb72ddfaf7/)  ### 3. 任務管理應用程式 開發具有任務建立、完成追蹤和類別組織等功能的任務管理應用程式。 **您將學到什麼:** 該專案將加深您對 React 中的狀態管理、CRUD 操作以及用於任務管理的使用者友好介面的實現的理解。 **技術堆疊:** React、useState、useEffect、localStorage、CSS。 **資源:** [任務管理應用教學](https://youtu.be/m4MDt7UUu1w?si=EcCbIMtkmHZIsWPS)  ### 4. 互動式履歷表產生器 建立一個互動式履歷產生器來展示您的職業歷程。包括教育、工作經驗和技能部分。 **您將學到什麼:** 透過這個專案,您將掌握表單處理、動態內容呈現和建立互動式使用者介面的藝術。這是提高你的 React 技能的絕佳機會。 **技術堆疊:** React、表單處理、CSS(樣式元件)。 **資源:** [互動式履歷產生器播放清單](https://youtube.com/playlist?list=PLrL9i_Ka3T0caA37TXSlicITQl1pp_3Ry&si=UhftAkbYr_eYaxJZ)  ### 5.產品落地專案 開發一個產品登陸頁面,重點宣傳特定產品或服務。針對各種螢幕尺寸實施響應式設計。 **您將學到什麼:** 本專案將加深您對響應式網頁設計的理解,包括媒體查詢、Flexbox 和網格佈局。您還將提高建立具有視覺吸引力的登陸頁面的技能。 **技術堆疊:** HTML、CSS(Flexbox/Grid)、響應式設計。 **資源:** [產品登陸頁面教學](https://youtube.com/playlist?list=PL07efmqYWHZ8jroJAkkFB2s4ZKpVNCOQa&si=ZI375j0QMaN7rpdn)  ### 6. 使用 GitHub API 的個人資料頁面 建立一個個人資料頁面,從 GitHub API 取得資料,顯示使用者資訊、儲存庫和貢獻熱圖。 **您將學到什麼:** 該專案將增強您使用 API、處理非同步資料以及建立具有視覺吸引力的使用者設定檔的技能。您還將獲得將第三方 API 整合到應用程式中的經驗。 **技術堆疊:** React、GitHub API、CSS。 **資源:** [GitHub API 設定檔教學](https://dev.to/falanatolu/using-github-api-to-fetch-and-display-a-github-user-profile-26g6) 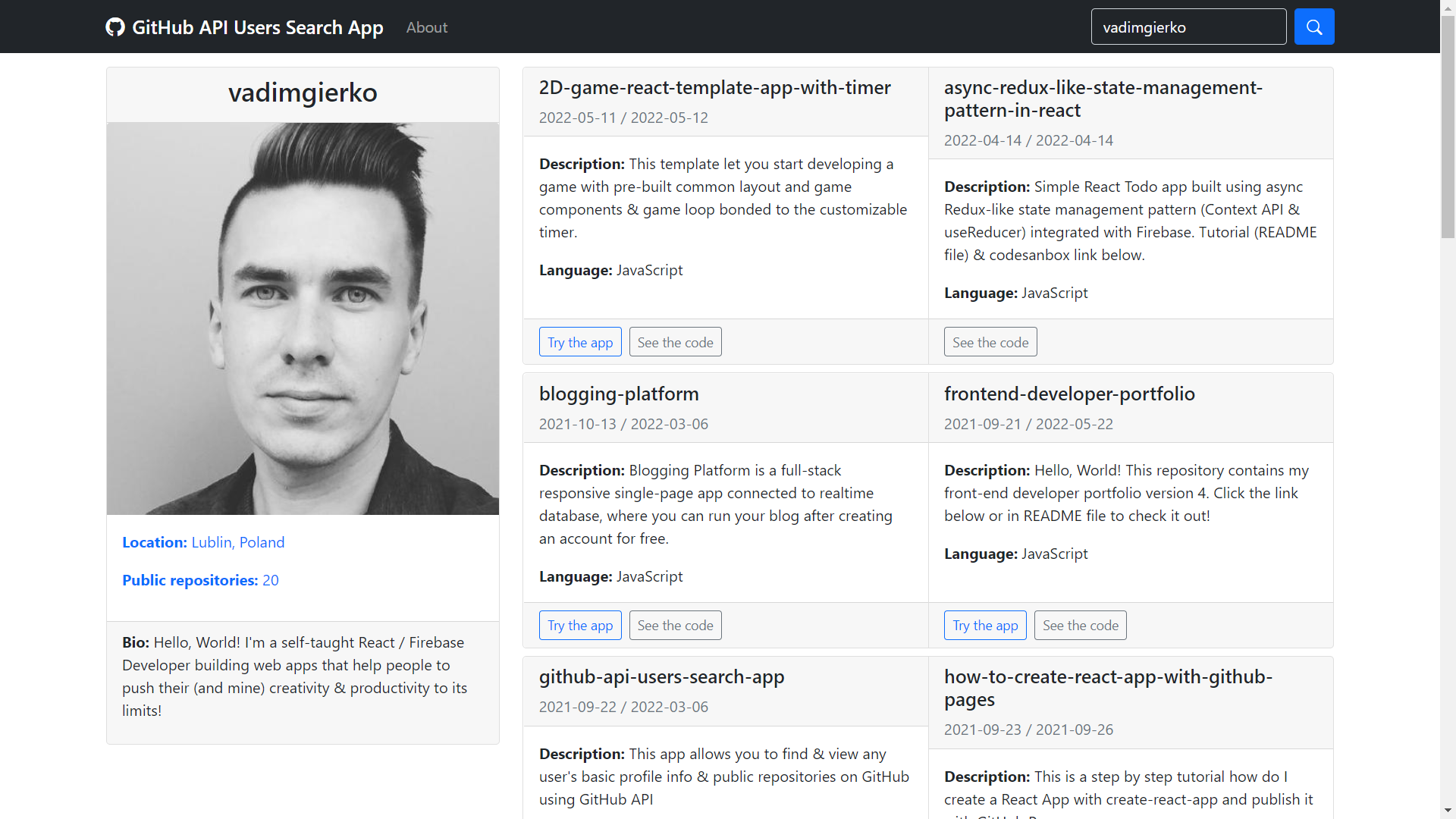 ### 7.響應式部落格網站 開發一個響應式部落格網站,其中包含針對各種裝置優化的文章清單、單一文章頁面和導航選單等功能。 **您將學到什麼:** 該專案將提高您建立複雜佈局的技能,並專注於回應能力。您將獲得建立導航結構和優化不同螢幕尺寸的使用者體驗的經驗。 **技術堆疊:** HTML、CSS (Flexbox/Grid)、JavaScript。 **資源:** [響應式部落格網站教學](https://youtu.be/NNQuhOeM0mI?si=RjNPOIm-otDhMTsE)  ### 8. 使用 Lottie 檔案的動畫天氣應用程式 使用 Lottie 檔案建立帶有動畫天氣圖示的天氣應用程式。提供與當前天氣狀況對應的即時天氣資訊和動畫。 **您將學到什麼:** 該專案將擴展您將外部庫 (Lottie) 整合到專案中的技能。您還將獲得使用即時資料 API 和實現動態動畫的經驗。 **技術堆疊:** React、Lottie、OpenWeatherMap API、CSS。 **資源:** [動畫天氣應用教學](https://youtu.be/pFvWwFua6mw?si=Xut6cKy10rV1DpFd)  ### 9.SaaS 登陸頁面 設計並建置軟體即服務 (SaaS) 產品的登陸頁面。強調簡潔的設計、有效的文案和引人注目的號召性用語元素。 **您將學到什麼:** 該專案將提高您建立以行銷為導向的登陸頁面的技能,並專注於用戶轉換。您還將深入了解有說服力的設計和有效使用配色方案的原則。 **技術堆疊:** React、Tailwind CSS、文案。 **資源:** [SaaS 登陸頁面教學](https://youtube.com/playlist?list=PLz_5rPRIvGEBDvyf-HIIDHjsPppnuXtFG&si=JIpCCIbz4QW8v9o4)  踏上這些令人興奮的專案,在 2024 年掌握前端 Web 開發。每個專案都提供一系列獨特的挑戰和學習機會,讓您具備在動態 Web 開發領域脫穎而出所需的技能。快樂編碼! 🚀 --- 原文出處:https://dev.to/mukeshkuiry/9-projects-to-master-frontend-web-development-in-2024-with-resource-d0k
歡迎來到我的 HTML can do 這個系列,第 1 部分。 為了與我的[GitHub-Can-Do-This](https://dev.to/yuridevat/reference-a-new-issue-3g5h) 系列保持一致,今天我想寫一篇關於HTML 可以做的很酷的事情的文章(很多人顯然不知道)。 我堅信,越多的人理解 HTML 並充分利用它,網路就會自動變得更容易存取。 ## 表中的內容 1. [詳細資訊和摘要 HTML 標籤](#chapter-1) 2. [電子郵件或電話號碼連結](#chapter-2) 3. [自動完成清單](#chapter-3) 4. [文字修改](#chapter-4) --- 由於我不知道接下來還會有多少部分,因此我將透過按字母順序描述出色的標籤及其背後的 HTML 魔力來開始本系列。 ## 1. 詳細資訊和摘要<a name="chapter-1"></a> 開啟/關閉小部件通常使用 JavaScript 建立。很長一段時間以來,有一個預設的 HTML 標籤恰好涵蓋了這種行為。 樣式可以根據需要進行調整。預設情況下,該小部件是關閉的。賦予 `<details>` 屬性 `open`,它會從頭開始顯示其內容。 {% codepen https://codepen.io/YuriDevAT/pen/dyaBQZm %} ## 2. 連結到電子郵件地址或電話號碼<a name="chapter-2"></a> `<a>` 標籤有一個 `href` 屬性,它指示連結的目的地。它可以連結到網頁、文件、電子郵件地址、同一頁面中的位置或 URL 可以尋址的任何其他內容。 `href` 屬性負責使 `<a>` 可聚焦並在按 Enter 鍵時啟動連結。 ### 連結到電子郵件地址 如果您在「href」的 URL 方案中新增「mailto:」和預期收件者的電子郵件地址,則按一下時會開啟新的外寄電子郵件。 ``` <a href="mailto:[email protected]">Send email to nowhere</a> ``` 您還可以在 URL 中加入更多詳細訊息,包括抄送、密件副本、主題和正文 😯。 ``` <a href="mailto:[email protected][email protected]&subject=This%20is%20the%20subject">Send email with subject to nowhere and nobody</a> ``` 詳細了解[連結至電子郵件地址 rfc6068](https://datatracker.ietf.org/doc/html/rfc6068)。 ### 連結到電話號碼 將電話號碼新增至「tel:」之後的「href」時,您也可以連結到電話號碼。 ``` <a href="tel:+18005551239">(800) 555 1239</a> ``` 連結行為可能因設備而異([關於連結到電話號碼的 MDN 官方文件](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/a#linking_to_telephone_numbers)): - 在行動裝置上,系統會自動撥打號碼。 - 大多數作業系統都有可以撥打電話的程序,例如 Skype 或 FaceTime。 - 網站可以使用registerProtocolHandler撥打電話,例如web.skype.com。 - 其他行為包括將號碼儲存到聯絡人,或將號碼傳送到另一台裝置。 詳細了解[連結到電話號碼 rfc3966](https://datatracker.ietf.org/doc/html/rfc3966)。 {% codepen https://codepen.io/YuriDevAT/pen/OJdZLKK %} ## 3. 自動完成清單<a name="chapter-3"></a> 使用“<datalist>”,當使用者開始在輸入欄位中寫入時會出現一個下拉式選單,並使他們可以從清單中的可用選項中進行選擇。 {% codepen https://codepen.io/YuriDevAT/pen/zYeVMbE %} ## 4. 文字修改<a name="chapter-4"></a> 使用特定標籤,可以直接修改文本,無需額外的 CSS。非常便利。 {% codepen https://codepen.io/YuriDevAT/pen/LYqKXwJ %} --- 謝謝閱讀。對此,我真的非常感激! --- 原文出處:https://dev.to/yuridevat/html-can-do-this-part-1-3ab2
## 第 1 部分:將 MongoDB 與 Flask 結合使用 你好!在本系列的最後一個[部分](https://dev.to/paurakhsharma/flask-rest-api-part-0-setup-basic-crud-api-4650)中,我們學習瞭如何建立基本的“ CRUD” ` 使用 python `list` 的 REST API 功能。但這不是現實世界應用程式的建構方式,因為如果您的伺服器重新啟動或上帝禁止崩潰,那麼您將丟失伺服器中儲存的所有資訊。為了解決這些問題(以及許多其他問題),使用了資料庫。所以,這就是我們要做的。我們將使用 [MongoDB](https://docs.mongodb.com/manual/) 作為我們的資料庫。 如果您剛從這部分開始,您可以在[此處]找到我們迄今為止編寫的所有程式碼(https://github.com/paurakhsharma/flask-rest-api-blog-series/tree/master/Part% 20 -%200)。 在開始之前,請確保您已在系統中安裝了 MongoDB。如果您還沒有安裝,可以安裝 [Linux](https://docs.mongodb.com/manual/administration/install-on-linux/)、[Windown](https://docs.mongodb.com/手冊/教學/install-mongodb-on-windows/)和[macOS](https://docs.mongodb.com/manual/tutorial/install-mongodb-on-os-x/)。 主要有一些流行的函式庫可以讓 MongoDB 的使用變得更容易: 1) [Pymongo](https://api.mongodb.com/python/current/) 是 MongoDB 的低階 Python 包裝器,使用 `Pymongo` 類似於直接編寫 MongoDB 查詢。 以下是使用“Pymongo”更新“id”與給定“id”相符的電影名稱的簡單範例。 ``` db['movies'].update({'_id': id}, {'$set': {'name': 'My new title'}}) ``` `Pymongo` 不使用任何預先定義的模式,因此它可以充分利用 MongoDB 的無模式特性。 2) [MongoEngine](http://docs.mongoengine.org/) 是物件文件映射器,它使用文件模式,使 MongoDB 的使用變得清晰、更容易。 這是使用“mongoengine”的相同範例。 ``` Movies.objects(id=id).update(name='My new title') ``` 「Mongoengine」對資料庫中的欄位使用預先定義架構,這限制了它使用 MongoDB 的無架構性質。 正如我們所看到的,雙方都有各自的優點和缺點。因此,請選擇最適合您的專案的一種。在本系列中,我們將學習“Mongoengine”,如果您希望我也介紹“Pymongo”,請在下面的評論部分告訴我。 為了在我們的`Flask` 應用程式中更好地使用`Mongoengine`,有一個很棒的`Flask` 擴展,名為[Flask-Mongengine](http://docs.mongoengine.org/projects/flask- mongoengine/en/latest/)。 那麼,讓我們開始安裝「flask-mongoengine」。 ``` pipenv install flask-mongoengine ``` *注意:由於`flask-mongoengine` 是在`mongoengine` 之上建造的,所以在安裝Flask-mongoengine 時會自動安裝,而且`mongoengine` 是在`pymongo` 之上建造的,所以它也會被安裝* 現在,讓我們在「movie-bag」中建立一個新資料夾。我將其稱為“資料庫”。在「database」資料夾中建立一個名為「db.py」的檔案。另外,建立另一個檔案並將其命名為“models.py” 讓我們看看文件/資料夾現在是什麼樣子。 ``` movie-bag │ app.py | Pipfile | Pipfile.lock └───database │ db.py └───models.py ``` 現在,讓我們深入探討有趣的部分。 首先,讓我們透過將以下程式碼新增至「db.py」來初始化我們的資料庫 ``` #~movie-bag/database/db.py from flask_mongoengine import MongoEngine db = MongoEngine() def initialize_db(app): db.init_app(app) ``` 在這裡,我們導入了“MongoEngine”並建立了“db”物件,並定義了一個函數“initialize_db()”,我們將從“app.py”中呼叫該函數來初始化資料庫。 讓我們在“models”目錄中的“movie.py”中編寫以下程式碼 ``` #~movie-bag/database/models.py from .db import db class Movie(db.Document): name = db.StringField(required=True, unique=True) casts = db.ListField(db.StringField(), required=True) genres = db.ListField(db.StringField(), required=True) ``` 我們剛剛建立的是資料庫的文件。因此,使用者無法新增此處定義的其他欄位。 這裡我們可以看到「Movie」文件有三個欄位: 1)`name`:是一個`String`類型的字段,我們在這個字段上也有兩個約束。 - “必需”,這意味著用戶在不提供標題的情況下無法建立新電影。 - “唯一”,這意味著電影名稱必須是唯一的,不能重複。 2) `casts`:是一個`list`類型的字段,其中包含`String`類型的值 3) `genres`: 與`casts`相同 最後,我們可以在「app.py」中初始化資料庫,並更改「view」函數(處理 API 請求的函數)以使用我們先前定義的「Movie」文件。 ``` #~movie-bag/app.py -from flask import Flask, jsonify, request +from flask import Flask, request, Response +from database.db import initialize_db +from database.models import Movie app = Flask(__name__) -movies = [ - { - "name": "The Shawshank Redemption", - "casts": ["Tim Robbins", "Morgan Freeman", "Bob Gunton", "William Sadler"], - "genres": ["Drama"] - }, - { - "name": "The Godfather ", - "casts": ["Marlon Brando", "Al Pacino", "James Caan", "Diane Keaton"], - "genres": ["Crime", "Drama"] - } -] +app.config['MONGODB_SETTINGS'] = { + 'host': 'mongodb://localhost/movie-bag' +} + +initialize_db(app) [email protected]('/movies') -def hello(): - return jsonify(movies) [email protected]('/movies') +def get_movies(): + movies = Movie.objects().to_json() + return Response(movies, mimetype="application/json", status=200) [email protected]('/movies', methods=['POST']) -def add_movie(): - movie = request.get_json() - movies.append(movie) - return {'id': len(movies)}, 200 [email protected]('/movies', methods=['POST']) + body = request.get_json() + movie = Movie(**body).save() + id = movie.id + return {'id': str(id)}, 200 [email protected]('/movies/<int:index>', methods=['PUT']) -def update_movie(index): - movie = request.get_json() - movies[index] = movie - return jsonify(movies[index]), 200 [email protected]('/movies/<id>', methods=['PUT']) +def update_movie(id): + body = request.get_json() + Movie.objects.get(id=id).update(**body) + return '', 200 [email protected]('/movies/<int:index>', methods=['DELETE']) -def delete_movie(index): - movies.pop(index) - return 'None', 200 [email protected]('/movies/<id>', methods=['DELETE']) +def delete_movie(id): + Movie.objects.get(id=id).delete() + return '', 200 app.run() ``` 哇!變化很多,讓我們一步一步地進行變化。 ``` -from flask import Flask, jsonify, request +from flask import Flask, request, Response +from database.db import initialize_db +from database.models.movie import Movie ``` 這裡我們刪除了“jsonify”,因為我們不再需要,並加入了“Response”,我們用它來設定回應的類型。然後我們從之前定義的「db.py」導入「initialize_db」來初始化資料庫。最後,我們從“movie.py”導入“Movie”文件 ``` +app.config['MONGODB_SETTINGS'] = { + 'host': 'mongodb://localhost/movie-bag' +} + +db = initialize_db(app) ``` 這裡我們設定 mongodb 資料庫的配置。這裡主機的格式為「<host-url>/<database-name>」。由於我們已經在本地安裝了 mongodb,因此我們可以從“mongodb://localhost/”存取它,並且我們將資料庫命名為“movie-bag”。 最後,我們初始化資料庫。 ``` [email protected]('/movies') +def get_movies(): + movies = Movie.objects().to_json() + return Response(movies, mimetype="application/json", status=200) + ``` 在這裡,我們使用“Movies.objects()”從“Movie”文件中獲取所有物件,並使用“to_json()”將它們轉換為“JSON”。最後,我們傳回一個「Response」物件,其中我們將回應類型定義為「application/json」。 ``` [email protected]('/movies', methods=['POST']) + body = request.get_json() + movie = Movie(**body).save() + id = movie.id + return {'id': str(id)}, 200 ``` 在「POST」請求中,我們首先取得發送的「JSON」和一個請求。然後我們使用“Movie(**body)”請求中的欄位來載入“Movie”文件。這裡的「**」稱為擴充運算符,在 JavaScript 中寫為「...」(如果您熟悉的話)。顧名思義,它的作用是傳播「dict」物件。 <br/> 所以,`Movie(**body)` 變成了 ``` Movie(name="Name of the movie", casts=["a caste"], genres=["a genre"]) ``` 最後,我們保存文件並獲取其“id”,我們將其作為回應返回。 ``` [email protected]('/movies/<id>', methods=['PUT']) +def update_movie(id): + body = request.get_json() + Movie.objects.get(id=id).update(**body) + return '', 200 ``` 這裡我們先找到與請求中發送的「id」相符的Movie文件,然後更新它。這裡我們也應用了擴充運算子將值傳遞給「update()」函數。 ``` [email protected]('/movies/<id>', methods=['DELETE']) +def delete_movie(id): + Movie.objects.get(id=id).delete() + return '', 200 ``` 與此處的“update_movie()”類似,我們獲取與給定“id”匹配的電影文件並將其從資料庫中刪除。 哦,**我剛剛想起來**,我們還沒有將 API 端點加入到“GET”,僅從我們的伺服器獲取一個文件。 讓我們加入它: 在 `app.run()` 上方加入以下程式碼 ``` @app.route('/movies/<id>') def get_movie(id): movies = Movie.objects.get(id=id).to_json() return Response(movies, mimetype="application/json", status=200) ``` 現在您可以從 API 端點「/movies/<valid_id>」取得單一影片。 要執行伺服器,請確保您位於“movie-bag”目錄。 然後執行 ``` pipenv shell python app.py ``` 在終端機中啟動虛擬環境並啟動伺服器。 哇!恭喜您已經走到這一步了。要測試API,請使用我們在[上一篇]((https://dev.to/paurakhsharma/flask-rest-api-part-0-setup-basic-crud-api-4650)) 中使用的“ Postman」本系列的一部分。 您可能已經注意到,如果我們向端點發送無效資料,例如:沒有名稱或其他字段,我們會收到“HTML”形式的不友善錯誤。如果我們嘗試取得資料庫中不存在的「id」影片文件,那麼我們也會收到「HTML」回應形式的不友善錯誤。這並不是一個精心建構的 API 的例外行為。我們將在本系列的後面部分中了解如何處理此類錯誤。 ### 我們從本系列的這一部分學到了什麼? - `Pymongo` 和 `Mongoengine` 之間的差異。 - 如何使用「Mongoengine」建立文件架構。 - 如何使用「Mongoengine」執行「CRUD」操作。 - Python 擴充運算子。 您可以在[此處]找到這部分的完整程式碼(https://github.com/paurakhsharma/flask-rest-api-blog-series/tree/master/Part%20-%201) 在下一部分中,我們將學習如何使用「Blueprint」來更好地建立 Flask 應用程式。以及如何使用“flask-restful”以最少的設定遵循最佳實踐,更快地建立 REST API 直到那時快樂編碼😊 --- 原文出處:https://dev.to/paurakhsharma/flask-rest-api-part-1-using-mongodb-with-flask-3g7d
 在過去的十年裡,我一直是一名全端開發人員,建置了像[gitup](https://gitup.dev/) 這樣的較小專案和像[crosspublic](https://github.com/github-20k/) 這樣的更大專案跨公共)。 多年來,我測試了不同的工具: 1. 提高工作效率 2. bug 更少 3. 少寫程式碼 我整理了一系列庫來幫助您開發我每天使用的優秀 NextJS 東西,並解釋了您可以用它們做什麼。 **讓我們深入了解一下。**  --- # 1. [Trigger.dev](https://github.com/triggerdotdev/trigger.dev) 使用 NextJS,我總是需要幫助來處理與後台作業相關的所有事情。 它可以是在背景執行的 cron 作業,用於傳送電子郵件或處理系統中的新使用者管道。 這導致我執行另一台伺服器來處理這些作業,無論是外部 EC2 伺服器還是帶有事件橋的無伺服器功能。 這會導致我支付額外的服務費用(管理更多服務)並自行管理水平擴展(在某些時候)。 [Trigger.dev](http://Trigger.dev) 改變了這一點,在 NextJS(以及許多其他)之上提供後台作業。 他們也知道如何解決 NextJS 無伺服器逾時限制來處理長時間執行的作業。  --- ## 2. [Prisma](https://www.prisma.io) Prisma 不是 NextJS 特有的。它是一個與資料庫一起使用的 ORM。 ORM 是資料庫查詢的統一包裝器。 它保持良好的結構,並允許您在不同的資料庫提供者之間快速更改。 雖然您可以使用很多 ORM,但 Prisma 的獨特之處在於為您的查詢提供 Typescript 支持,使一切速度提高 100 倍。 NextJS 在預設配置中使用了 typescript,使其成為完美的匹配。  --- ## 3. [NextAuth.js](https://next-auth.js.org) 假設您要實現任何服務提供者身份驗證,例如 Facebook / Google / GitHub (oAuth)。 在這種情況下,您必須為每個提供者建立實作或使用外部服務,例如 [Auth0](https://auth0.com/) 或 [Clerk](https://clerk.com/)。 如果您打算自行執行此操作,NextAuth 提供了豐富的實現,以便您只需提供正確的金鑰即可輕鬆新增它們。 一旦您登錄,他們也會處理授權。 *Next.JS auth 可以與 Prisma 開箱即用。*  --- ## 4. [下一個網站地圖](https://github.com/iamvishnusankar/next-sitemap) 在伺服器上部署 NextJS 後,您需要協助 google 索引所有頁面。 如果您可以告訴 Google 您網站上的所有頁面,那就更好了。 為此,您可以建立一個列出所有頁面的 sitemap.xml 檔案。 您可以輕鬆地使用 Next-Sitemap 來實現這一點。  --- ## 5. [下一步 SEO](https://github.com/garmeeh/next-seo) SEO 是透過向您的網站預覽提供關鍵字、描述和圖像,使您的網站出現在 Google Feed 上以進行不同查詢的過程。 如果您使用新的 NextJS 應用程式路由器,則可能不需要使用它。 您可以使用他們的“導出元資料”方法或“生成元資料”, 但如果您使用舊的應用程式路由器,這是為您的網站加入 SEO 的最佳方式。  --- ## 6. [Zod](https://github.com/colinhacks/zod) Zod 是一個物件驗證器(伺服器和客戶端)。 您可以在物件上放置不同的規則並稍後對其進行驗證,例如使用者名稱和密碼,或更複雜的內容(例如陣列長度或其他鍵上的條件)。 *Zod 不是 NextJS 特定的。* 多年來,我看過很多物件驗證器,例如 [Yup](https://github.com/jquense/yup) 和 [class-validator](https://github.com/typestack/class-validator)。 是的,它看起來不像 Zod 那樣維護,並且在使用 NestJS 之類的東西時,類驗證器非常強大 - 所以你最好使用 Zod。  --- ## 7. [React-hook-form](https://github.com/react-hook-form/react-hook-form) 雖然 Zod 可以驗證物件,但如果沒有自訂邏輯,它不會影響您的用戶端和後端。 React-hook-form 是優秀的用戶端驗證專案(顯示輸入錯誤、管理輸入狀態和提交)。 當然,您可以使用 Zod 作為 React-hook-form 的驗證器。  --- ## 8. [tRPC](https://github.com/trpc/trpc) 我承認我以前從未使用過 tRPC,但今天它似乎吸引了許多人的目光。 它與 Prisma 有類似的概念;它們為您的請求和回應產生一個接口,因此當您使用前端呼叫時,您會獲得自動完成功能。 這很好,因為它減少了錯誤的機會 - 假設您修改了後端路由,您將無法編譯專案 - 客戶端將返回不存在的參數或回應鍵的錯誤。  --- ## 9. [SWR](https://swr.vercel.app) 和 [React-Query](https://github.com/TanStack/query) 多年來我一直使用 Axios 和 fetch 作為發送請求的基礎庫。 SWR 和 React-Query 增強了這些函式庫並提供鉤子、快取、轉換等。 強烈推薦用於每個專案。請注意,這些庫適用於客戶端元件(“使用客戶端”),而不是伺服器元件。  --- ## 10. [lodash](https://lodash.com) 這不是 NextJS 特定的函式庫。 它是一個用於改變資料的函式庫,雖然這些年來 JavaScript 憑藉像 flatMap 這樣優秀的原生函數取得了很大的進步,但仍然缺少一些東西,例如按鍵或分塊和陣列的唯一陣列。 我發現自己幾乎在所有專案中都使用 lodash。  --- ## 11. [dayjs](https://day.js.org/) day.js 是一個包含與日期、格式、時區等相關的所有內容的函式庫。 我可能會因為那件事而被烤。我多年來一直在使用“moment.js”。 現在它不再維護了,dayjs 是一個不錯的選擇。 有些人喜歡新的 JS 函數來處理日期,但我仍然覺得 dayjs 選項和原生 JS 日期函數之間存在很大的差距。  --- ## 12. [jsdom](https://github.com/jsdom/jsdom) 這不是必須的,但我最近在許多專案中都使用它作為 [cheerio](https://github.com/cheeriojs/cheerio) 的替代品。 您可以取得整個頁面內容(`<html><body>....</html>)` 並將其轉換為稍後可以使用「本機」javascript dom 函數`querySelector`、`innerHTML` 等來操作的物件… 非常適合需要一些刮擦的專案。  --- 我們在 X 上連接嗎? :) [我在這裡](https://twitter.com/nevodavid) 您是否為 NextJS 使用其他一些很酷的程式庫? 請在評論中讓我了解它們:) --- 原文出處:https://dev.to/nevodavid/top-12-libraries-for-your-nextjs-project-1oob
**開源吞噬軟體** 我建立了 [osssoftware.org](http://osssoftware.org),重點是: - PH 獲獎者 - DevHunt 上最好的開發工具 - 最近在 GitHub 上活躍 - 大多數網路反向連結 - 大多數被提及為“替代......” 👇 **301 個開源替代方案:** - [Supabase](http://supabase.com) - Firebase 的開源替代品 - [Documenso](http://documenso.com) - Docusign 的開源替代方案 - [Cal](http://cal.com) - Calendly 的替代品 - [Plausible](http://plausible.io) - Google Analytics 的開源替代品 - [DevHunt](http://devhunt.org) - ProductHunt 的開源替代品 - [AI.Meta](http://ai.meta.com/llama) - ChatGPT 的開源替代品 - [Papermark](http://papermark.io) - Docsend 的開源替代品 - [Godot Engine](http://godotengine.org) - Unity3D 的開源替代品 - [Ghost](http://ghost.org) - Medium 的開源替代方案 - [Mastodon](http://joinmastodon.org) - Twitter 的開源替代品 - [Rowy](http://rowy.io) - Airtable 的開源替代品 - [Sentry](http://sentry.io) - 錯誤追蹤的開源替代方案 - [N8N](http://n8n.io) - Zapier 的開源替代品 - [Appsmith](http://appsmith.com) - Retool 的開源替代方案 - [ClickHouse](http://clickhouse.com) - BigQuery 的開源替代品 - [GitLab](http://gitlab.com) - GitHub 的開源替代品 - [Penpot](http://penpot.app) - Figma 的開源替代品 - [Jenkins](http://jenkins.io) - DevOps 的開源替代方案 - [Forem](http://forem.com) - Circle 的開源替代品 - [PostHog](http://posthog.com) - Mixpanel 的開源替代品 - [Dub](http://dub.co) - Bitly 的開源替代方案 - [OpenCart](http://opencart.com) - Shopify 的開源替代品 - [類型](http://typesense.org) - Algolia 的開源替代品 - [AppFlowy](http://appflowy.io) - Notion 的開源替代品 - [Webstudio](http://webstudio.is) - Webflow 的開源替代方案 - [Typebot](http://typebot.io) - Typeform 的開源替代品 - [Passbolt](http://passbolt.com) - 1Password 的開源替代品 - shadcn - Tailwind UI 的開源替代方案 **看更多:** - [所有開源替代品](http://osssoftware.org/open-source-alternatives/) - [類別](http://osssoftware.org) **貢獻:** 如果您認為應該加入一個很棒的工具,請在網站上提交它或給我發送 DM 或回复此帖子。 我的推特 [@johnrushx](https://twitter.com/johnrushx) 順便說一句,我們正在進行 Product Hunt 感謝您的支持 →→→ [producthunt.com/osssoftware](https://www.producthunt.com/posts/opensource-alternatives-to-tools-you-pay) --- 原文出處:https://dev.to/johnrushx/open-source-alternatives-to-tools-you-pay-for-1g9c
我們正在開發一個 [React 和 Node.js 的全端 Web 框架](https://github.com/wasp-lang/wasp),它使用簡單的設定語言來擺脫樣板檔案。很多次,我們被問到,*「為什麼你要費心去建立一個新的 Web 應用程式開發框架?無論如何,ChatGPT / LLM X 不是很快就會為開發人員生成所有程式碼嗎?」*。 這是我們對當前情勢的看法,也是我們相信未來的情況。 ## 為什麼我們需要(AI)程式碼產生? 為了讓開發速度更快,我們首先提出了 IDE 自動補全 - 如果您正在使用 React 並開始輸入 `use`,IDE 將自動向 `useState()` 或 `useEffect()` 提供補全。除了節省擊鍵次數之外,也許更有價值的是能夠查看目前範圍內有哪些方法/屬性可供我們使用。 IDE 對專案結構和程式碼層次結構的感知也使重構變得更加容易。 **雖然這已經很棒了,但是我們如何將其提升到一個新的水平?** 傳統的 IDE 支援是基於人類編寫的規則,例如,如果我們想讓 IDE 能夠為我們實現常用功能(例如, *使用API Y* 取得X,或*實現快速排序*),其中的數量太多,無法手動進行分類和維護。 如果有一種方法可以讓電腦分析我們迄今為止編寫的所有程式碼,並自行學習如何自動完成我們的程式碼以及如何對待人類,而不是我們做所有艱苦的工作... [除了美味又濕潤的蛋糕](https://www.youtube.com/watch?v=Y6ljFaKRTrI),我們其實已經做到了!由於機器學習的最新進展,IDE 現在可以做一些非常酷的事情,例如根據函數的名稱和頂部的簡短註釋來建議函數的完整實現: 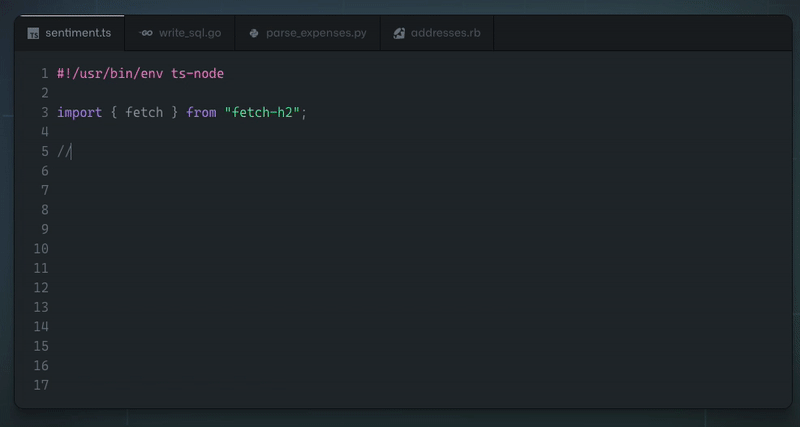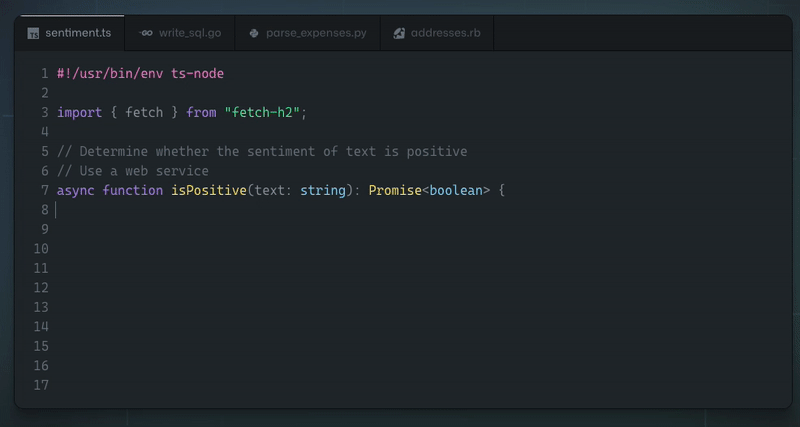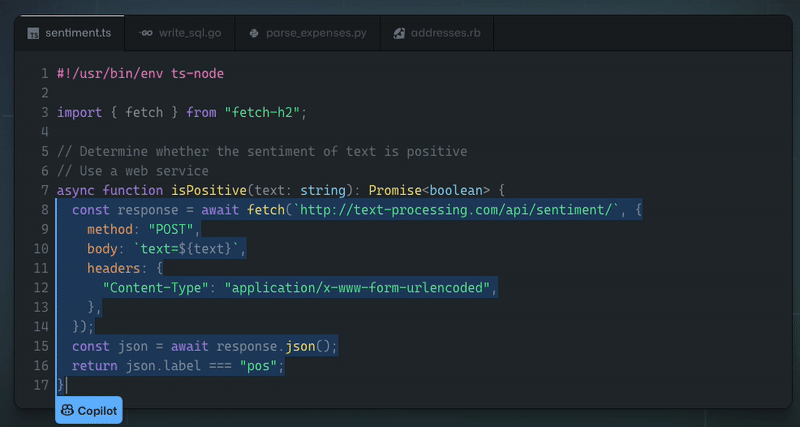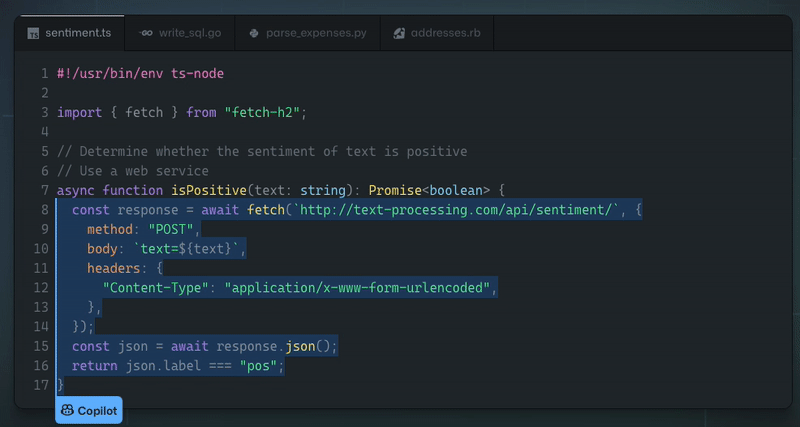 這真是太神奇了!上面的範例由 [Github Copilot](https://copilot.github.com/) 提供支援 - 它本質上是一個在大量公開可用程式碼上訓練的神經網路。我不會深入了解其幕後工作原理的技術細節,但有很多精彩的文章和影片涵蓋了背後的科學知識。 **看到這一點,問題出現了 - 這對程式設計的未來意味著什麼?** 這只是 IDE 自動補全功能還是其他什麼?如果我們只需在註釋中輸入我們想要的內容就可以了,我們還需要繼續手動編寫程式碼嗎? ## 支持我們! 🙏⭐️  如果您想表達對我們正在做的事情的支持,請考慮[在 Github 上給我們一顆星](https://github.com/wasp-lang/wasp)!我們在 Wasp 所做的一切都是開源的,您的支持激勵我們並幫助我們不斷簡化 Web 應用程式開發並減少樣板程式碼。  ## 大問題:程式碼產生後由誰維護? 在思考 ML 程式碼產生如何影響整個開發過程時,有一點需要考慮,但在查看所有令人印象深刻的範例時,通常不會立即想到這一點。 問題是 - **生成程式碼後會發生什麼?誰負責,將來誰來維護和重構?** 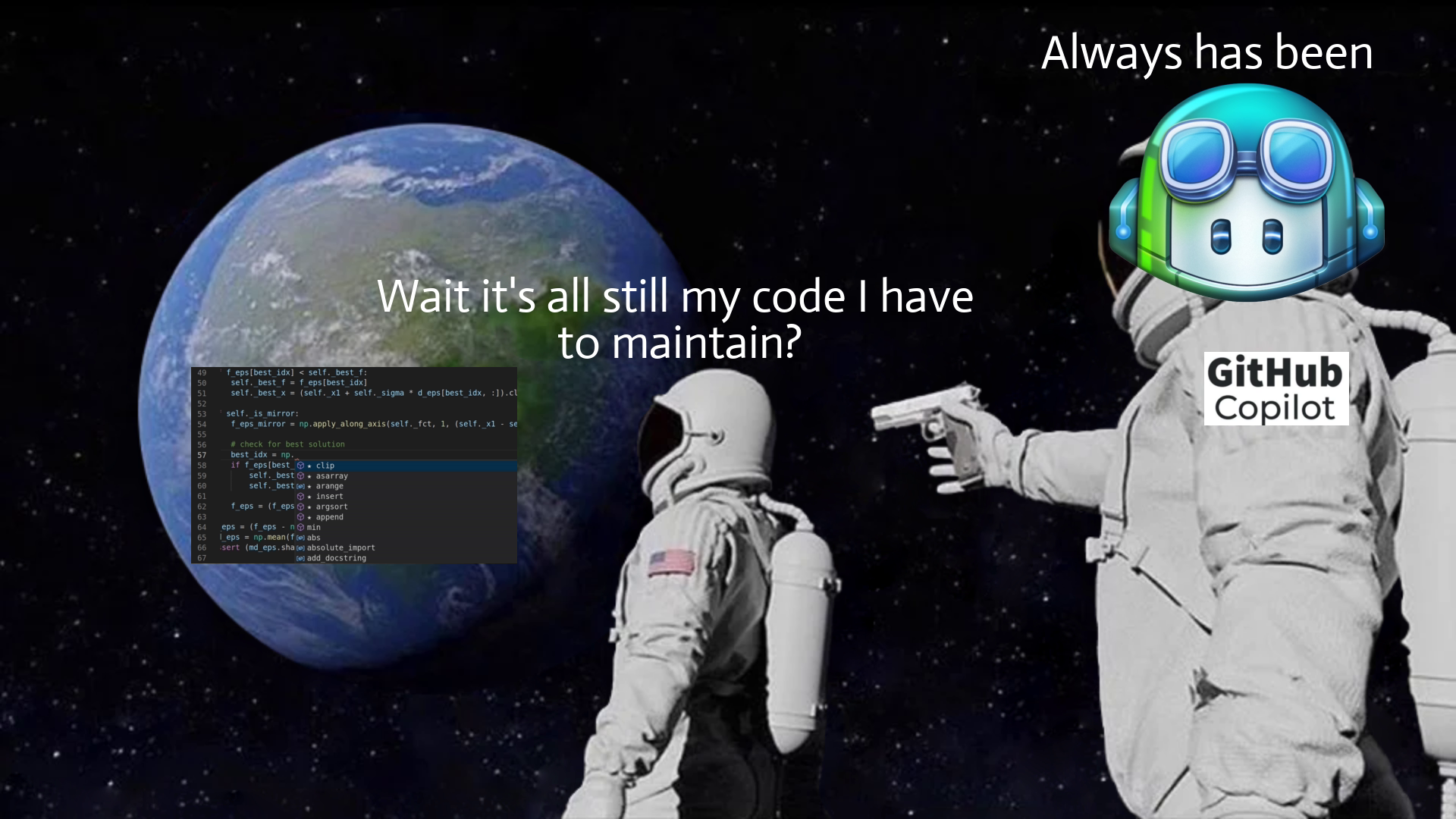 儘管 ML 程式碼產生有助於編寫特定功能的初始程式碼,但它不能做更多的事情 - 如果將來要維護和更改該程式碼(如果有人使用該產品,那麼開發人員仍然會這樣做)需要完全擁有並理解它。你可以再次使用人工智慧來幫助你,但最終,你是負責的人。 想像一下,我們擁有的只是一種彙編語言,但程式碼生成非常適合它,你可以說“實現一個對陣列進行升序排序的函數”,它將完美地生成所需的程式碼。一旦您需要將排序更改為降序,您是否仍想在將來返回該功能? 或者,更貼近我們的日常生活,如果產生的 React 程式碼使用舊的類別語法,或者函數式元件和鉤子,對你來說是否都是一樣的? **換句話說,這意味著GPT 和其他LLM 不會降低程式碼複雜性,也不會降低建置功能所需的知識量**,它們只是幫助更快地編寫初始程式碼並使知識/範例更接近程式碼(其中真的很有幫助)。 **如果開發人員盲目接受生成的程式碼,他們只是在創造技術債並推動其向前發展**。 ## 認識大 A - 抽象 👆 如果 ChatGPT 和這群人無法解決我們學習如何編碼和詳細理解(例如透過 JWT 進行會話管理)工作原理的所有麻煩,還有什麼可以呢? 抽象化——這就是程式設計師幾十年來透過建立庫、框架和語言來處理程式碼重複和降低複雜性的方式。這就是我們從普通 JS 和直接 DOM 操作到 jQuery,最後到 React 和 Vue 等 UI 函式庫的方式。 引入抽像不可避免地意味著放棄一定的功能和靈活性(例如,在 Python 中對數字求和時,您無法準確指定將使用哪些 CPU 寄存器),但重點是,如果如果做得好,在大多數情況下你不需要也不想要這樣的權力。  **不對一段程式碼負責的唯一方法是它從一開始就不存在。** 因為一旦螢幕上的像素改變顏色,你就必須擔心,這就是為什麼所有框架、語言等的主要好處是_更少的程式碼==更少的決策==更少的責任_。 擁有更少程式碼的唯一方法是做出更少的決定,並向計算機提供更少的關於如何完成某項任務的細節- 理想情況下,我們只需要說明我們想要什麼,我們甚至不會關心它是如何完成的,只要它在我們擁有的時間/記憶體/成本邊界內(所以我們可能也需要說明這些)。 讓我們來看看網路應用程式世界中非常常見(也是每個人最喜歡的)功能 - 身份驗證(yaay ☠️ 🔫)!它的典型程式碼如下所示: ``` import jwt from 'jsonwebtoken' import SecurePassword from 'secure-password' import util from 'util' import prisma from '../dbClient.js' import { handleRejection } from '../utils.js' import config from '../config.js' const jwtSign = util.promisify(jwt.sign) const jwtVerify = util.promisify(jwt.verify) const JWT_SECRET = config.auth.jwtSecret export const sign = (id, options) => jwtSign({ id }, JWT_SECRET, options) export const verify = (token) => jwtVerify(token, JWT_SECRET) const auth = handleRejection(async (req, res, next) => { const authHeader = req.get('Authorization') if (!authHeader) { return next() } if (authHeader.startsWith('Bearer ')) { const token = authHeader.substring(7, authHeader.length) let userIdFromToken try { userIdFromToken = (await verify(token)).id } catch (error) { if (['TokenExpiredError', 'JsonWebTokenError', 'NotBeforeError'].includes(error.name)) { return res.status(401).send() } else { throw error } } const user = await prisma.user.findUnique({ where: { id: userIdFromToken } }) if (!user) { return res.status(401).send() } const { password, ...userView } = user req.user = userView } else { return res.status(401).send() } next() }) const SP = new SecurePassword() export const hashPassword = async (password) => { const hashedPwdBuffer = await SP.hash(Buffer.from(password)) return hashedPwdBuffer.toString("base64") } export const verifyPassword = async (hashedPassword, password) => { try { return await SP.verify(Buffer.from(password), Buffer.from(hashedPassword, "base64")) } catch (error) { console.error(error) return false } } ``` 這只是後端程式碼的一部分(僅適用於用戶名和密碼方法)!正如您所看到的,我們在這裡有很大的靈活性,可以執行/指定以下操作: - 選擇身份驗證的實作方法(例如會話或基於 JWT) - 選擇我們想要用於令牌(如果使用 JWT)和密碼管理的確切 npm 套件 - 解析 auth 標頭並指定每個值(授權、承載等)如何回應 - 為每個可能的結果選擇回傳程式碼(例如 401、403) - 選擇密碼的解碼/編碼方式 (base64) 一方面,在我們的程式碼中擁有這種程度的控制和靈活性確實很酷,但另一方面,需要做出很多決定(==錯誤),特別是對於像身份驗證這樣常見的事情! 如果後來有人問“_那麼你到底為什麼選擇secure-password npm 包,或者為什麼到底是base64 編碼?_”,我們可能應該用其他東西來回答,而不是“_好吧,2012 年有一篇看起來相當合法的帖子,它有近 50 票贊成。嗯,不過現在找不到了。另外,它的名字裡有‘安全’,聽起來不錯,對吧?_” 另一件要記住的事情是,我們還應該追蹤事情如何隨著時間的推移而變化,並確保幾年後,我們仍然使用最佳實踐,並且軟體包定期更新。 如果我們嘗試應用上面的原則(更少的程式碼,更少的詳細說明,說明我們想要什麼**而不是需要做什麼**),身份驗證的程式碼可能如下所示: ``` auth: { userEntity: User, externalAuthEntity: SocialLogin, methods: { usernameAndPassword: {}, google: {} }, onAuthFailedRedirectTo: "/login", onAuthSucceededRedirectTo: "/dashboard" } ``` 基於此,計算機/編譯器可以處理上面提到的所有內容,然後根據抽象級別,提供某種接口(例如表單元件或函數)來“掛鉤”我們自己的接口,例如React/Node.js 程式碼(順便說一句,這就是它實際上[在 Wasp 中工作](https://wasp-lang.dev/docs/auth/overview) 的方式)。 我們不需要關心底層使用了什麼確切的套件或加密方法 - 這是我們信任抽象層的作者和維護者的責任,就像我們相信 Python 最了解如何將兩個數字相加一樣裝配水平,並與該領域的最新進展保持同步。當我們依賴內建資料結構或依靠垃圾收集器來很好地管理程式記憶體時,也會發生同樣的情況。 ## 但是我產生的漂亮程式碼😿💻!那麼會發生什麼事呢? 別擔心,一切都還在這裡,您可以產生您想要的所有程式碼!這裡要理解的要點是,人工智慧程式碼生成和框架/語言開發是相互補充而不是替代,並且將繼續存在,這最終對開發人員社群來說是一個巨大的勝利——它們將繼續讓我們的生活更輕鬆,讓我們能夠做更多有趣的事情(而不是第 n 次實作 auth 或 CRUD API)! 我將這裡的演變視為一個循環(或實際上是螺旋式上升,但這超出了我的繪圖能力): 1. **語言/框架:存在**,是主流,很多人使用它 2. **模式開始出現**(例如實作身份驗證,或進行 API 呼叫)→ AI 學習它們,透過自動完成提供 3. **其中一些模式成熟**並變得穩定→抽象的候選者 4. **新的、更抽象的語言/框架**出現 5. **返回步驟 1。** 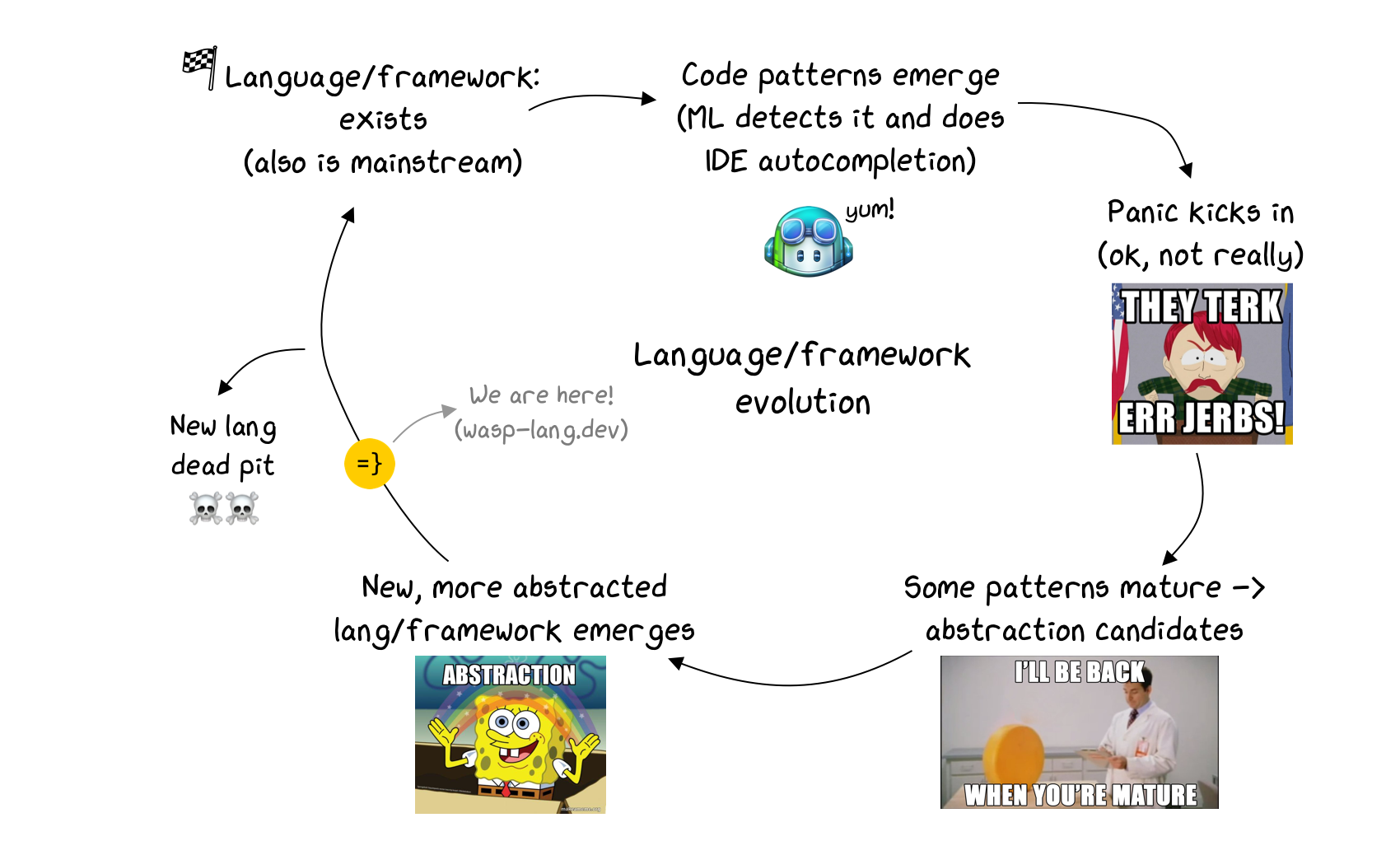 ## 結論 這意味著我們雙贏——當語言成為主流時,我們可以從人工智慧驅動的程式碼產生中受益,幫助我們更快地編寫程式碼。另一方面,當我們不想重複/處理的程式碼模式出現並變得穩定時,我們就得到了一種全新的語言或框架,它允許我們編寫更少的程式碼並關心更少的實作細節!  感謝您的閱讀,並希望您發現這篇文章內容豐富!我很想聽聽您是否同意(或不同意)這一點,以及您如何看待人工智慧工具驅動的程式設計的未來。 --- 原文出處:https://dev.to/wasp/ai-code-generation-vs-coding-by-hand-what-programming-is-going-to-look-like-in-202x-1idh
## **簡介** 在不斷發展的資料工程和自動化領域,Python 已經出現了多種工作流程編排器。在本文中,我將介紹 6 個 Python 函式庫及其一些主要功能。  --- ## 1. [Taipy](https://github.com/Avaiga/taipy) Taipy 是一個開源 Python 庫,用於建立生產就緒的應用程式前端和後端。 對於 Python 開發人員來說,Taipy 是建立管道最簡單的框架之一,這要歸功於它的管道圖形編輯器 (Taipy Studio)。 然後,您可以透過 Python 腳本輕鬆執行和編排管道。一個非常酷的核心功能是每個管道執行都是註冊的。 這可以輕鬆實現假設分析、KPI 監控、資料沿襲等。 🔑特點: - 圖形管道編輯器 - 與 Taipy 前端功能整合以實現端到端部署 - 日程安排 - 管道的版本控制 - 快取等智慧功能  ---  您的支持意義重大🌱,並且在許多方面為我們帶來了很大的幫助,例如寫文章! 🙏 --- ## 2. [Kedro](https://github.com/kedro-org/kedro) Kedro 是一個開源 Python 框架。 它為生產就緒的資料科學管道提供了一個工具箱。 事實上,Kedro 可以輕鬆地與成熟的 Python ML 庫集成,並提供統一的方法來實現端到端框架。 🔑特點: - 資料目錄 - 筆記本集成 - 專案模板 - 有自己的觀點,因為它強制執行特定的約定  --- ## 3. [Airflow](https://github.com/apache/airflow) 十多年來,Airflow 一直是管道領域的知名參與者。 Airbnb 建立了 Airflow 來解決資料處理和工作流程需求的內部挑戰。 眾所周知,這個強大的開源平台具有陡峭的學習曲線,但具有廣泛的功能。 該平台允許您透過建立 DAG(有向無環圖)來建立和管理工作流程。 🔑特點: - 基於DAG的定義 - 豐富的基於 Web 的監控 UI:DAG、故障、重試的可視化… - 各種集成 - 動態任務執行和調度 - 由於其以 Python 為中心的特性而具有靈活性。 - 強大的社區  --- ## 4. [Prefect](https://github.com/PrefectHQ/prefect) Prefect 是一個資料管道開發框架。 Prefect 在策略上將自己定位在與 Airflow 的直接競爭中,以基於簡單性、用戶友好性和靈活性的獨特身份脫穎而出。 如果您想要一個具有各種功能但比 Airflow 更容易學習的成熟產品,Prefect 是一個很好的中間產品。 🔑特點: - 控制面板 - 快取 - 基於流程的結構 - 動態參數化與依賴管理 - 混合執行(本地/雲端)  --- ## 5. [Dagster](https://github.com/dagster-io/dagster) Dagster 是本次編譯中較新的函式庫之一,它是一個雲端原生資料管道編排,旨在統一資料整合、工作流程編排和監控。 與其他工具相比,Dagster 強調工作流程建立和管理的 DataOps 面向。 🔑特點: - 聲明式管道設置 - 固執己見的結構 - 版本控制 - 與 Hadoop 集成 - 全面的元資料跟踪  --- ## 6. [Luigi](https://github.com/spotify/luigi) Luigi 提供了一個資料處理管道框架。 Spotify 與 Airflow 大約在同一時間開發了這個程式庫,以解決其複雜的資料工作流程和管道。 Luigi 專為管理批次作業的複雜通道而設計。如果您正在尋找簡單的東西並且必須快速上手,Luigi 是一個不錯的選擇。 🔑特點: - 內建 Hadoop 支援 - 基於任務的工作流程定義 - 用於依賴管理的中央調度程序 - 任務依賴關係視覺化  --- ##結論 隨著 Python 工作流程編排環境的不斷發展,這些工具展示了主要的共同特徵和特定的差異化因素。 所有這些工具都有不同程度的複雜性,了解您的專案和團隊的需求至關重要。 我建議使用非常簡單的範例來測試一些選項,以獲得對每個框架可用性的第一手了解。 --- 希望您喜歡這篇文章! 我是一名新手作家,歡迎任何改進建議!  如果您有任何疑問,請隨時與我們聯繫。 --- 原文出處:https://dev.to/taipy/the-pipeline-repos-showdown-python-edition-39i5
在這篇部落格中,我想向您解釋 SSH,就好像您是我的 Uber 司機一樣。此練習的目的是假裝您以前沒有 SSH 經驗,甚至沒有太多一般技術知識,並讓您達到以下目標: 1. 不要害怕「SSH」這個模糊的術語,因為你腦子裡有一個具體的形象。 2. 了解業界級開發人員如何使用SSH來測試程式碼變更、進行伺服器設定等。 3. 了解 SSH 的加密/授權協定如何使其優於其他工具。 讓我們開始吧! ## SSH 概念化 什麼是 SSH?讓我用一個類比來幫助您概念化它,而不是從您在 Cloudflare 文章或維基百科頂部看到的傳統技術巨頭開始。  想像一下您剛放學,回到家的臥室。您感到無聊,決定戴上 VR 耳機來存取元宇宙 - 一種沉浸式體驗,將實體世界拒之門外,將您嵌入虛擬環境中。您登入並輸入使用者名稱和密碼以驗證您的身分。完成後,您會看到您的數位化身彈出。它看起來和你一模一樣——身材高大,頭髮漂亮,還有一種奇妙的時尚感。在您面前,您會看到一片森林,或者更確切地說,是森林的數位表示。仍然戴著 VR 耳機站在臥室裡,您可以移動頭部環顧四周,您的化身也會做同樣的事情。你在臥室裡說“你好森林”,你的頭像也在 VR 世界中說“你好森林”。 在現實生活中,這個類比可以翻譯為: - 你==開發者。 - 你的臥室==你的筆記型電腦,或任何你正在打字的本機。 - Metaverse == 您嘗試從本機電腦存取的遠端電腦/伺服器。 - VR 耳機 == SSH 隧道,可讓您從本機(臥室)存取遠端電腦(Metaverse)。 - 登入畫面==確保只有授權方才能使用SSH 隧道的SSH 金鑰對。我將在本部落格的後面部分更徹底地解釋這一點。  這個類比對你有什麼幫助?下次當您聽到有人說「我透過 SSH 連接到伺服器」時,您無需對「SSH」這個模糊的概念感到驚慌。相反,在你的腦海中將其改寫為“我戴上 VR 耳機來存取元宇宙”,這將使它變得更具體。 *通俗地說,SSH 就像一個安全、秘密的隧道,可讓您透過網路連接到另一台電腦。它可以幫助您在計算機上執行操作,就像您坐在計算機前面一樣。* 當然,這只是對SSH的表面、概念性理解。我希望您現在正在思考一些問題來幫助您更深入地了解 SSH。我無法讀懂你的想法,但這裡有一些我自己回答的問題,我認為向你解釋會很有用。 ## 為什麼我需要使用 SSH? SSH 很重要,因為開發人員通常需要存取遠端電腦。例如,在您自己的筆記型電腦上會消耗太多記憶體和運算能力的大型應用程式託管在 AWS、Azure 或 Google Cloud 等雲端平台上,而這些平台都需要遠端存取。其他時候,開發團隊分佈在不同的地點,因此遠端伺服器允許團隊成員在一個一致的位置進行協作和共享程式碼,即使他們實際上不在同一位置。 讓我向您介紹兩個行業級開發人員何時需要透過 SSH 連接到遠端電腦的範例。 **1:部署程式碼** 作為開發人員,您需要將網站的新版本部署到臨時伺服器。這就是它的工作原理,使用 SSH。 在本機上,您可以使用 Git 推送最新的程式碼變更。  然後,您可以透過 SSH 連線到具有臨時環境的遠端伺服器。 (順便說一句,您可能會想為什麼我需要在遠端伺服器而不是本地電腦上建立臨時環境。以下是一些原因。其中之一是最好模擬真實的設置,例如檢查效能瓶頸或可擴展性問題只會發生在伺服器環境中,而不是您的筆記型電腦中。另一個是簡單地確保所有團隊成員都可以在一致的環境中進行測試,而不是他們都在自己的電腦上擁有臨時環境,或者(上帝禁止)使用您的每當他們需要測試某些東西時就在本地機器上。)  最後,您已經透過 SSH 連接到託管臨時環境的遠端伺服器,您可以從該遠端伺服器提取最新的程式碼變更、執行建置並測試您的應用程式(透過導航至 http://staging.example.com)。 **2:更新伺服器設定** 假設您正在建立的 Web 應用程式已經成長,並且您需要調整伺服器配置以適應增加的流量。以下是您可能執行的一些命令的範例: A。透過 SSH 連接到伺服器 `ssh 用戶@您的伺服器 IP` b.找到 Apache 設定檔 `cd /etc/apache2` C。備份設定檔 `cp apache2.conf apache2.conf.bak` d.編輯設定檔。 `vi apache2.conf` e.驗證配置 `apache2ctl 配置測試` **請不要覺得您需要知道這些指令的作用。** 老實說,我要求 ChatGPT 為我產生一個範例,但我自己不太明白。這裡的要點是了解開發人員在透過 SSH 連接到伺服器時可能執行的命令類型。其中很多是移動目錄(cd)、操作文件(cp)和編輯文件(vi)的簡單命令。 ## 為什麼要使用 SSH? 我在學習 SSH 時遇到的一個問題是「SSH 的替代方案是什麼,為什麼 SSH 會勝出」? 我想現在是快速上歷史課的好時機。 在 SSH 被廣泛採用之前,還有其他協定用於兩台機器之間的通訊。一些著名的包括 Telnet、RSH、FTP 和 Rlogin。但它們都缺乏加密和安全功能。 為了描繪一幅圖景,以下是它可能發生的情況。我(惡意駭客)獲得了 Telnet 所經過的網路的存取權限 - 您試圖透過 Telnet 協定將資訊從筆記型電腦發送到另一台電腦的網路。我使用像 Wireshark 這樣的工具來擷取流量。一旦我以下載的“資料包”的形式獲得計算機上的流量,我就可以單擊它們並查找任何登入嘗試。所有資料都是明文形式(這意味著它是人類可讀的,而不是一些亂碼),所以如果我找到它,我實際上可以使用我在我面前看到的登入資訊。正如您所看到的,這些舊工具不是很安全!  1995 年,SSH 被發明。它更好有兩個主要原因。 1. 加密資料 假設從我的機器傳輸到遠端機器的部分資料是字串「用戶名:jesswang 密碼:?IamC00l!」。如果沒有加密(因此使用 Telnet 或 FTP 等舊協定),駭客將能夠像您讀取該字串一樣讀取該字串。透過加密,他們返回的資料可能看起來像「H23kLs*^!d8%PwZx0KsL!9B#N%u@i8」。實際上,加密資料將是遵守加密演算法標準(我不太了解)的不同位元組序列,但這只是為了給您一個想法。 2. 認證 Telnet 等較舊的程式僅依賴基於密碼的身份驗證。當您使用 Telnet 連線到遠端系統時,Telnet 伺服器會提示您輸入使用者名稱和密碼進行登入。然而,Telnet 以明文形式傳輸您的密碼,使駭客很容易讀取。 SSH 主要使用一種不同的(也是更好的)方法,稱為公鑰身份驗證。我將在下面解釋它的工作原理,以便您了解如何更好地保護您的資訊免受駭客攻擊。 首先,您的訊息被放入公文包中,並且您自己給它上鎖。  您將公文包傳送到遠端伺服器。遠端伺服器沒有鑰匙來解鎖您的鎖,因此遠端伺服器將自己的鎖放在公文包上。  遠端伺服器將公文包傳回給您,然後您打開鎖。  您將公文包發送回遠端伺服器,它會用鑰匙解鎖它的鎖。然後它打開公文包,閱讀便條。  這就是公鑰認證的要點!順便說一句,SSH 仍然**支援基於密碼的身份驗證,但即使如此,密碼也是加密的,因此如果駭客攔截它,他們將無法讀取它。 ## 如何使用 SSH? 概念學習已經足夠了。下面是我透過 SSH 執行到伺服器的實際命令。 若要透過 SSH 連線到伺服器,您通常會執行下列命令:`ssh username@server_ip_or_hostname` 您可以將使用者名稱替換為您在伺服器上的實際使用者名稱 您可以將 server_ip_or_hostname 替換為伺服器的 IP 位址或主機名稱。例如,「ssh [email protected]」。 執行該命令後,系統可能會提示您輸入伺服器使用者名稱的密碼。或者,如果您的伺服器使用我們在上一節中介紹的基於金鑰的身份驗證,則可能不會提示您輸入密碼。 進入後,您可以開始執行命令。這些命令將在您連接的遠端伺服器上執行。 我知道,如果您不自己親自輸入內容並看看會發生什麼,就很難充分學習。如果您已經設定了用於工作或個人的遠端伺服器,請隨意嘗試。如果您沒有可連接的遠端伺服器,那也沒關係。您可以按照以下步驟操作: 1. 存取http://sdf.org/ 2. 建立帳戶。您可能會收到一封電子郵件,為您提供為您的帳戶產生的密碼。您可能需要等待 1-2 秒才能收到該電子郵件(至少這是我的經驗)。 3. 您可以透過執行「ssh <your_username>@sdf.org」透過 SSH 存取公共 UNIX 系統。例如,我的用戶名是 poop123。所以我執行了“ssh [email protected]”。 4. 出現提示時,輸入您先前獲得的密碼。 5. 您已成功透過 SSH 連線到伺服器!您可以執行「echo 'hello world'」等指令來列印「hello world」或「ls」來查看目前目錄中的檔案清單。  ## 讀者須知/結論 雖然透過SSH 連接到另一台伺服器相對容易(也許你的同事給你一個命令,你只需將其貼到命令列中),但我發現如果我不理解(至少在高層次上)什麼,則很難使用該命令當我執行它時發生。希望其他人能與我聯繫,這個部落格將有助於解決這個問題。 如果您好奇我是如何想出這個標題的,這個故事位於本系列原始博客的介紹段落中,[“向我的 Uber 司機解釋 Kubernetes”](https://dev.to/therubberduckiee/explaining-kubernetes-to-my-uber-driver-4f60)。 一如既往,我希望收到有關此部落格中的訊息、圖畫或故事講述的任何反饋。請告訴我您還想讓我寫哪些其他主題。 以下是我在撰寫此部落格時參考的一些資源: - 聊天GPT - SSH 初學者指南 [Youtube 影片](https://www.youtube.com/watch?v=qWKK_PNHnnA) - 我對上述影片的 60 秒 [TikTok 影片摘要](https://www.tiktok.com/@therubberduckiee/video/7213401342403005738?lang=en)。 - 我使用 [Charm VHS](https://github.com/charmbracelet/vhs) 來產生您看到的最後一個 gif。非常酷的工具,可讓您建立並輕鬆編輯與 CLI 相關的簡報。 - 我用來拍攝示範的終端,[Warp](https://www.warp.dev/)(這也是我工作的公司。我強烈建議您查看我們)。 --- 原文出處:https://dev.to/therubberduckiee/explaining-ssh-to-my-uber-driver-38a
科技愛好者常有遠大的夢想,渴望實現突破創新和個人發展界限的目標。為了幫助建立這些雄心壯志,我為科技愛好者量身定制了廣泛的願望清單。此清單不僅概述了各種目標,還包括「靈感」、「如何」、「年份」、「狀態」和「紀念品」等附加欄,為您的技術之旅提供全面的路線圖。 ## 清單中有什麼? 該清單涵蓋了廣泛的目標,從培養特定技能(例如達到 150 WPM 的打字速度)到雄心勃勃的專案(例如製作 DIY 電動滑板或自行車)。它包括參加重大活動,例如參加大型技術會議,以及個人發展的里程碑,例如指導初級開發人員。每個目標都經過分類以便於參考,涵蓋 DIY 專案、程式設計、開發、學習等領域。 ## 列表 [我的遺願清單進度](https://syki.dev/bucket-list) |目標|類別|靈感|年份|狀態|紀念品| |---------------------------|----------------|----------------| ----|------|--------| |成為大型專案的貢獻者 |開發 |[如何像專業人士一樣開源](https://www.youtube.com/watch?v=MT6M_sqAuZo) | | | | |建立新聞聚合器 |開發 |[Feedly](https://feedly.com/) | | | | |建立實體引擎 |開發 |[我正在從頭開始編寫整個實體引擎](https://www.youtube.com/watch?v=iSMbRGTBOHU) | | | | |建立推薦系統 |開發 |[推薦系統如何運作 (Netflix/Amazon)](https://www.youtube.com/watch?v=n3RKsY2H-NE) | | | | |建構情緒分析工具 |開發 |【2023 如何掌握人工智慧驅動的情緒分析?】(https://brand24.com/blog/sentiment-analysis/) | | | | |建立擴增實境 (AR) 應用程式 |開發 |[關於如何在 2023 年建立擴增實境應用程式的指南](https://www.tekrevol.com/blogs/how-to-build-an-augmented-reality -應用程式/) | | | | |建置與部署聊天伺服器 |開發 |[IRC](https://en.wikipedia.org/wiki/Internet_Relay_Chat) | | | | |建立網路安全工具|開發|[Kali Tools](https://www.kali.org/tools/) | | | | |建立多人線上遊戲|開發|[Dani](https://www.youtube.com/watch?v=_ze26M_Fm6g) | | | | |建立 PWA(漸進式 Web 應用程式)|開發 |[PWA](https://developer.mozilla.org/en-US/docs/Web/Progressive_web_apps) | | | | |建立 AI 影響者 |開發 |[AI 影響者變得非常富有...讓我們建立一個](https://www.youtube.com/watch?v=ky5ZB-mqZKM&t=11s) | | | | |開發區塊鏈應用程式 |開發 |[使用以太坊智能合約和 Solidity 建置您的第一個區塊鏈應用程式](https://www.youtube.com/watch?v=coQ5dg8wM2o) | | | | |開發一種加密貨幣 |開發 |[您需要立即建立一種加密貨幣!!](https://www.youtube.com/watch?v=befUVytFC80) | | | | |開發VR 應用程式|開發|[教學 - 在Meta Quest 耳機上建立您的第一個VR 應用程式](https://developer.oculus.com/documentation/unity/unity-tutorial-hello-vr/) | | | | |開發一個電子商務網站 |開發 |[Next.js Commerce](https://nextjs.org/commerce) | | | | |開發開源遊戲引擎 |開發 |[C++ 中的 GameDev](https://www.youtube.com/watch?v=LyJkcv_rL9Y&list=PLpM-Dvs8t0Va6RoHkaLuPbRh7Fwpy4nbV) | | | | |開發瀏覽器擴充 |開發 |[Chrome 擴充應該會嚇到你。](https://www.youtube.com/watch?v=xIKwkPWUgOA) | | | | |在 github 上有一個擁有 100 顆星的專案 |開發 |[Linus Torvalds](https://github.com/torvalds?achievement=starstruck&tab=achievements) | | | | |擁有自己的 Tor 頁面 |開發 |[我在 Raspberry Pi 上放置了一個 DARK WEB 網站!!](https://www.youtube.com/watch?v=bllS9tkCkaM) | | | | |發明手勢控制介面 |開發 |[鋼鐵人](https://www.youtube.com/watch?v=P5k-4-OEuTk) | | | | |建立持續整合/持續部署管道|開發|[自動化您的工作流程](https://github.com/features/actions)從想法到生產]| | | | |設定 Kubernetes 叢集 |開發 |[為什麼要建置 Raspberry Pi 叢集?](https://www.youtube.com/watch?v=8zXG4ySy1m8) | | | | |贊助開源專案 |開發 |[投資為您的世界提供動力的軟體](https://github.com/sponsors) | | | | |使用查詢機制編寫自己的資料庫|開發|[製作我們自己的資料庫](https://acmiitr.medium.com/making-our-own-database-part-1-6cd9c49ed924) | | | | |在靜態網站產生器中撰寫頁面 |開發 |[Gatsby](https://www.gatsbyjs.com/) | | | | |編寫單頁應用程式 |開發 |[React](https://react.dev/) | | | | |使用 Raspberry Pi 專案實現家居自動化 |DIY |[我建立了一個更聰明的智慧家庭](https://www.youtube.com/watch?v=0rIvB3LZiKA) | | | | |建立自訂鍵盤 |DIY |[建立自己的機械鍵盤......正確的方式](https://www.youtube.com/watch?v=bBon6WwkdJE) | | | | |DIY電動滑板或自行車 |DIY |[我做了一個電動滑板!](https://www.youtube.com/watch?v=3bcvFzecg2Q) | | | | |以自訂遊戲建立迷你街機 |DIY |[終極 DIY 街機指南](https://www.youtube.com/watch?v=oTydZBIGAuk) | | | | |組裝一台 PC |DIY |[為 Minecraft 組裝一台價值 100,000 美元的 PC](https://www.youtube.com/watch?v=AHR80l7od2Q) | | | | |建立個人雲端儲存系統 |DIY |【這是我的終局之戰 - Mother Vault 伺服器機房更新】(https://www.youtube.com/watch?v=pLC0FUnko-M) | | | | |利用 IoT 建造自動澆水花園系統 |DIY |[Arduino 花園控制器 - 自動澆水和資料記錄](https://www.youtube.com/watch?v=O_Q1WKCtWiA) | | | | |打造小型自動駕駛汽車或機器人 |DIY |[快速巡線機器人](https://www.youtube.com/watch?v=lnP32gzHdvI) | | | | |建造水下ROV |DIY |[建造一艘DIY潛水艇](建造一艘DIY潛水艇) | | | | |搭建並飛行 FPV 無人機 |DIY |[為什麼要以 800mW 功率自由式飛行? | [FPV](https://www.youtube.com/watch?v=bBb_kSO3vTo) | | | | |設計具有互動功能的智慧鏡子|DIY |[DIY智慧鏡子 - 完整教學](https://www.youtube.com/watch?v=OYlloiaBINo) | | | | | 以 3D 方式設計和列印一些東西 |DIY |[我在房間中央製作了一個機器人手臂!](https://www.youtube.com/watch?v=nRsaf16EdNM) | | | | |設計您自己的 PCB |DIY |[PCB 建立初學者 - 10 分鐘內開始完成教程](https://www.youtube.com/watch?v=MsdJgEinb34) | | | | |修復損壞的電子產品 |DIY |[ElectroBOOM](https://www.youtube.com/@ElectroBOOM) | | | | |在本地擁有自己的伺服器 |DIY |[為什麼要建立 Raspberry Pi 叢集?](https://www.youtube.com/watch?v=8zXG4ySy1m8) | | | | |實現智慧家庭|DIY |[我建造了一個更聰明的智慧家庭](https://www.youtube.com/watch?v=0rIvB3LZiKA) | | | | |製作機械手臂 |DIY |[我在房間中央製作了機械手臂!](https://www.youtube.com/watch?v=nRsaf16EdNM) | | | | | 用 Flipper Zero 開啟一些東西 |DIY |[這讓駭客攻擊太容易了 - Flipper Zero](https://www.youtube.com/watch?v=nLIp4wd0oXs) | | | | |成為智慧型手機應用程式的擁有者|創業|[VoidLog](https://www.youtube.com/watch?v=LY4rxYe-jKI&list=PLN3n1USn4xllDDLwgJ4avEqgj4dWynofp) | | | | |開發 SaaS 產品 |創業精神|[我如何在一天內建立一個新的 SaaS 產品](https://www.youtube.com/watch?v=v_3lcqUOaOA) | | | | |在店裡擁有自己的遊戲 |創業|[Dani](https://www.youtube.com/watch?v=_ze26M_Fm6g) | | | | |在新創公司工作 |創業精神|[新創工程師在家工作的一天](https://www.youtube.com/watch?v=TLysAkFM4cA) | | | | |一週多相睡眠|創業|| | | | |參加播客 |創業|[Lex Fridman](https://www.youtube.com/lexfridman) | | | | |完全存取伺服器 - 黑客 |黑客 |[先生。機器人](https://www.youtube.com/watch?v=QqknSms8VVI&t=16s) | | | | |獲得錯誤賞金 |駭客 |[HackerOne](https://www.hackerone.com/) | | | | |在奪旗大賽中進行駭客攻擊 |駭客攻擊 |[Mr.機器人](https://www.youtube.com/watch?v=6MrQ-mN8HM8) | | | | |編寫惡意軟體 |駭客 |[惡意軟體開發:進程、執行緒與句柄](https://www.youtube.com/watch?v=aNEqC-U5tHM) | | | | |150 wpm 速度打字 |程式設計 |[Monkeytype](https://github.com/monkeytypegame/monkeytype) | | | | |使用 Python 腳本自動化您的日常任務 |程式設計 |[開始使用 Python 自動化您的生活! (Python檔案管理教學)](https://www.youtube.com/watch?v=NCvI-K0Gp90) | | | | |建立 Twitter 機器人 |程式設計 |[如何使用人工智慧發布熱門推文 // Twitter 機器人教學](https://www.youtube.com/watch?v=V7LEihbOv3Y) | | | | |編譯您自己的 Linux 核心 |程式設計 |[如何編譯自訂 Linux 核心](https://www.youtube.com/watch?v=APQY0wUbBow) | | | | |建立聊天機器人 |程式設計 |[使用深度學習、Python 和 TensorFlow 建立聊天機器人 p.1](https://www.youtube.com/watch?v=dvOnYLDg8_Y&list=PLQVvvaa0QuDdc2k5dwtDTyT9aCja0on8j) | | | | |使用 D3.js 建立資料視覺化專案 |程式設計 |[使用 D3.js 進行資料視覺化 - 完整教學課程](https://www.youtube.com/watch?v=_8V5o2UHG0E) | | | | |建立照片編輯工具 |程式設計 |[如何製作照片編輯應用程式的完整指南](https://www.cleveroad.com/blog/how-to-build-a-photo-editing-app-like-棱鏡並使其蓬勃發展/) | | | | |開發數位藝術作品產生器 |程式設計 |[如何為初學者產生瘋狂的人工智慧藝術(Midjourney V4)](https://www.youtube.com/watch?v=zf4z8A-OWBY) | | | | |開發檔案加密工具 |程式設計 |[製作您自己的加密程式](https://www.youtube.com/watch?v=TZT7wvTeVyY) | | | | |開發影片編輯軟體|程式設計|[我寫了一個影片編輯器(有點糟糕)](https://www.youtube.com/watch?v=iydG-e1dQGA) | | | | |開發語音助理應用程式 |程式設計 |[建立由 OpenAI 和 Python 驅動的 Jarvis | ChatGPT](https://www.youtube.com/watch?v=BEw5EFqCCEI) | | | | |開發智慧手錶應用程式 |程式設計 |[使用 Android Studio 在 WearOS 上建立並執行穿戴式應用程式](https://www.youtube.com/watch?v=-JO5oHRkybk) | | | | |開發您自己的 Slack/Discord 機器人 |程式設計 |[使用 Python 編寫 Discord 機器人 - 在雲端免費託管](https://www.youtube.com/watch?v=SPTfmiYiuok) | | | | |實現臉部辨識系統 |程式設計 |[從紙張到程式碼建立深度臉部辨識應用程式](https://www.youtube.com/watch?v=bK_k7eebGgc&list=PLgNJO2hghbmhHuhURAGbe6KWpiYZt0AMH) | | | | |學習函數式程式語言 |程式設計 |[函數式程式設計 - 概述](https://www.youtube.com/watch?v=8z_bUIl_uPo) | | | | |學習古老的語言 |程式設計 |[100 秒內的 COBOL](https://www.youtube.com/watch?v=7d7-etf-wNI) | | | | |學習並使用 Docker 進行容器化 |程式設計 |[Docker](https://www.docker.com/) | | | | |學習極快的語言 |程式設計 |[ThePrimeagen](https://www.youtube.com/@ThePrimeagen) | | | | |學習一門不尋常的語言(例如 Brainfuck) |程式設計 |[100 秒內完成 Brainfuck](https://www.youtube.com/watch?v=hdHjjBS4cs8) | | | | |學習量子運算基礎 |程式設計 |[在量子電腦上編碼](https://www.youtube.com/watch?v=q3ecPsMd4tA) | | | | |掌握高階演算法與資料結構(100道LeatCode) |程式設計|【569道 Leetcode 題後的我的大腦】(https://www.youtube.com/watch?v=8wysIxzqgPI) | | | | |對自訂語音控製家庭助理進行程式設計 |程式設計 |[建立由 OpenAI 和 Python 提供支援的 Jarvis | ChatGPT](https://www.youtube.com/watch?v=BEw5EFqCCEI) | | | | |對微控制器進行程式設計 |程式設計 |[微控制器程式設計駭客指南 [教學]](https://www.youtube.com/watch?v=XlFO5Iat178) | | | | |在 Vim 中編程 |程式設計 |[Vim 作為你的編輯器](https://www.youtube.com/watch?v=X6AR2RMB5tE&list=PLm323Lc7iSW_wuxqmKx_xxNtJC_hJbQ7R) | | | | |使用分離式鍵盤|編程|[拆箱新鍵盤!!! (也進行打字測試!)](https://www.youtube.com/watch?v=nh-BAxbithc&t=156s) | | | | |網頁抓取資料 |程式 |[使用 AI 和代理網路進行工業規模的網頁抓取](https://www.youtube.com/watch?v=qo_fUjb02ns) | | | | |用組合語言寫程式 |程式設計 |[Tsoding](https://www.youtube.com/watch?v=WnBXLmKk_qw&t=82s) | | | | |寫一個 NPM 模組 |程式設計 |[NPM](https://www.npmjs.com/) | | | | |編寫伺服器端應用程式 |程式設計 |[Next.js](https://nextjs.org/) | | | | |編寫您自己的人工智慧模型 |程式設計 |[讓我們建立 GPT:從頭開始,用程式碼,拼寫出來。](https://www.youtube.com/watch?v=kCc8FmEb1nY) | | | | |編寫您自己的作業系統 |程式設計 |[Linus Torvalds](https://github.com/torvalds) | | | | |寫你自己的程式語言 |程式設計 |[我製作了自己的程式語言](https://www.youtube.com/watch?v=pgeSGBwtHW8&t=132s) | | | | |擁有私人部落格 |教學 |[Dan Abramov](https://overreacted.io/) | | | | |對學生的講座 |教學 |[馬克·祖克柏的 CS50 講座 - 2005 年 12 月 7 日](https://www.youtube.com/watch?v=xFFs9UgOAlE&t=807s) | | | | |指導初級開發人員 |教學 |[如何正確指導初級開發人員](https://stablekernel.com/article/how-to-properly-mentor-a-junior-developer/) | | | | |寫一篇關於科技主題的論文並發表 |教學 |[兩分鐘論文](https://www.youtube.com/@TwoMinutePapers) | | | | |編寫技術書籍或電子書 |教學 |[編寫技術書籍](https://paulcunningham.me/writing-technical-books/) | | | | |參加大型科技會議 |旅遊 |[CES](https://www.ces.tech/) | | | | |參加黑客松 |旅行 |[我挑戰自己贏得黑客馬拉松](https://www.youtube.com/watch?v=mAJlZUKhOGs) | | | | |參觀電腦歷史博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀 NASA 約翰遜航天中心 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀國家航空暨太空博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀歷史科學儀器收藏 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀大型強子對撞機 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀麻省理工學院博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀國家核科學與歷史博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | ### 下載列表 [下載 CSV](https://syki.dev/uploads/bucket-list.csv) [下載 JSON](https://syki.dev/uploads/bucket-list.json) ## 附加列解釋 ### 靈感 本專欄反映了是什麼激發了追求特定目標的想法或願望。它可以是一個人、一個事件、一本書,甚至一部電影,點燃了人們對特定成就的熱情。例如,DIY 電動滑板的靈感可能是對永續交通的熱情或最喜歡的科技影片部落客的專案。 ### 年 本專欄提出了實現該目標的時間表或目標年份。它有助於規劃和設定現實的時間表。例如,您可能計劃在 2025 年之前參加一次大型技術會議。 ### 地位 狀態追蹤您的進度。它可以是“未開始”“進行中”“已完成”或“暫停”這有助於追蹤您的旅程並保持動力。 ### 紀念品 本專欄是一個獨特的補充,旨在紀念這一成就。它可以是實體、數位徽章、部落格文章,甚至是照片。例如,組裝 PC 的紀念品可能是已完成設定的第一張照片。 ## 結論 技術愛好者的願望清單不僅僅是目標的集合;這是技術領域個人和職業成長的路線圖。透過附加專欄提供靈感、方法、計時、追蹤和紀念成就的框架,此列表對於任何熱衷於技術的人來說都是一個動態工具。 快樂的科技冒險! --- 原文出處:https://dev.to/syki/100-bucket-list-ideas-for-programmers-506m
想像一下,您的任務是在您正在開發的產品中實現一項重要的新功能。這就是您一直在等待的機會 - 每個人都會看到您是多麼出色的 10 倍開發人員!你打開一個你想要嘗試的最酷的新庫和設計模式的列表,然後直接進入它,完整的“地下室”模式。一週後,你勝利地出現並提出了你完美的拉取請求! **但是,團隊中的高級開發人員立即拒絕了** - ***「太複雜了,你應該簡單地使用庫 X 並重用 Y。」***。什麼!?顯然,他們不明白你的解決方案有多天才,很快,你就會看到關於你的 PR 的 100 條評論以及接下來幾天的重構。 如果有一種方法可以在實施一切之前了解 X 和 Y 就好了。是的,它就是 RFC!  我們將透過[關於在 Wasp 中實現身份驗證的 RFC](https://www.notion.so/RFC-Auth-without-user-define-entities-6d2925439627456ab01b74ff4b4cd087?pvs=21) 的範例來了解它。 **[Wasp](https://kdta.io/github-wasp-lang-wasp_4) 是一個建置在 React、Node.js 和 Prisma 之上的全棧框架,提供了大量開箱即用的功能這是建置和部署應用程式的最快方法**。它還附帶一個免費的 GPT 支援的程式碼庫產生器 [MAGE](https://usemage.ai/),已用於建立超過 30,000 個應用程式。 讓我們深入了解一下! ## 支持我們! 🙏⭐️  如果您覺得這篇文章有幫助,請[考慮在 Github 上給我們一顆星](https://github.com/wasp-lang/wasp)!我們在 Wasp 所做的一切都是開源的,您的支援幫助我們使 Web 開發變得更容易,並激勵我們撰寫更多這樣的文章。  ## 那麼,什麼是 RFC?  RFC 代表 *Request For Comments*,簡單地表示 **「**提議更改程式碼庫以解決特定問題的文件。」。 **其主要目的是在實施開始之前找到解決問題的最佳方法。** RFC 最初由開源社群採用,但如今,它們幾乎被用於任何類型的開發者組織。 您在業界可能會遇到此類文件的其他名稱,例如 TDD(*技術設計文件*)或 SDD(*軟體設計文件*)。有些人會爭論它們之間的區別,但我們不會。 **有趣的事實**:RFC 是由 IETF(*網路工程任務組*)發明的,該組織是我們今天使用的一些最重要的網路標準和協議背後的工程組織!不算太寒酸吧? ## 什麼時候該寫 RFC,什麼時候可以跳過?  那麼,為什麼要費勁去寫你最終將要編碼的內容,而不是節省時間並簡單地去做呢? **如果您正在處理錯誤或相對簡單的功能,非常清楚必須做什麼並且不會影響專案結構,那麼就不需要 RFC - 啟動 IDE 並開始破解!** 但是,如果您要引入一個全新的概念(例如,引入基於角色的權限系統)或更改專案的架構(例如,新增對執行後台作業的支援),那麼您可能需要在輸入「git」之前退一步checkout -b my-new-feature` 並深入到那個甜蜜的編碼區域。 綜上所述,有時很難確定是否應該編寫該 RFC。也許這是一個更突出的功能,但你以前做過類似的事情,並且你已經在頭腦中規劃好了一切,而且幾乎沒有任何疑問。為了解決這個問題,我喜歡使用以下一個簡單的啟發式方法:**是否有不只一種明顯的方法來實現此功能?我們是否必須選擇一個新的庫/服務?** 如果這兩個問題的答案都是“否”,那麼您可能不需要 RFC。否則,需要進行討論,而 RFC 是解決問題的方法。做吧。  ## 這對我有什麼好處? 我們已經確定瞭如何決定「何時」編寫 RFC,但這也是您應該這樣做的「原因」: - **你將整理你的想法並變得清晰**。如果您決定編寫 RFC,則表示您正在處理一個不平凡的開放式問題。把事情寫下來將有助於提煉你的想法並客觀地看待它們。 - **與剛開始編碼相比,你會學到更多**。你會給自己空間去探索不同的方法,常常會發現一些你原本沒有想到的東西。 - **您將眾包團隊的知識。** 透過向您的團隊尋求回饋(因此請求評論),您將全面了解您正在解決的問題並填補任何剩餘的空白。 - **您將增進團隊對程式碼庫的理解。** 透過在 RFC 上進行協作,團隊中的每個人都會了解您正在做什麼以及最終是如何做到的。這意味著下次有人必須接觸那部分程式碼時,他們將需要問你更少的問題(===更多不間斷的程式碼時間!)。 - **公關審查將會*更*順利**。還記得本文開頭的情況嗎?當你的 PR 因為「太複雜」而被拒絕時?這是因為審閱者忽略了上下文,並且您在沒有獲得團隊其他成員事先支持的情況下進行了相當大的更改。透過先編寫 RFC,您將永遠不會再遇到這種情況。 - **您的文件已經完成了 50%!** 需要明確的是,RFC 不是最終文件,您不能簡單地指出它,但您可以重複使用很多內容 - 圖像、圖表、段落等。 哇,這聽起來太棒了,我現在就想提出一個新功能,這樣我就可以為其編寫 RFC!開個玩笑,首先瀏覽 RFC 會讓編碼部分變得更加有趣 - 你確切地知道你需要做什麼,並且你不需要質疑你的方法以及建立 PR 後將如何接收它。 ## 好吧,好吧,我被賣了!那麼,我該如何寫一篇呢? 很高興你問了!使用了許多不同的格式,或多或少是正式的,但我更喜歡保持簡單。我們在 Wasp 編寫的 RFC 不遵循嚴格的格式,但有一些共同的部分: - **元資料** - 標題、日期、審稿人等… - **問題/目標** - 你要解決什麼 - **建議的解決方案**(或更多) - **實施概述** - **評論/開放式問題** 這幾乎就是它的要點!其中每一個都可以進一步細分和細化,但這是您可以開始的基本輪廓。 ## 元資料 ⌗  這是非常不言自明的 - 您可能想要追蹤有關 RFC 的一些基本資訊 - 狀態、建立日期等。 一些模板還明確列出了審查者以及他們對RFC 的「批准」狀態- 我們沒有它,因為我們是一個溝通速度很快的小團隊,但對於不是每個人都認識每個人的大型團隊來說,它可以很方便,並且您希望有更多的流程(例如,在指導初級開發人員時)。  ## 問題🤔 這就是事情變得有趣的地方。 **您對問題或需要實現的目標/功能以及為什麼需要這樣做的定義越好,以下所有步驟就會越容易**。因此,即使在開始編寫 RFC 之前,這也是值得投資的事情 - 確保與所有相關方(例如產品所有者、其他開發人員,甚至用戶)進行交談,以加深您對要解決的問題的理解。 透過這樣做,您也很可能獲得有關可能解決方案的初步提示和指示,並對您所處的問題空間有一個粗略的認識。  以下是上面範例中的一些提示: - **從高級摘要開始** - 這樣,讀者可以快速決定這是否與他們相關以及是否應該繼續閱讀。 - **提供一些背景** - 解釋一下世界的現狀。這可以是單一句子或整個章節,這取決於目標受眾。 - **清楚地陳述問題/目標** - 解釋為什麼會出現問題並將其與用戶/公司的痛苦聯繫起來,以便動機明確。 - **如果可能的話,提供額外的細節** - 圖表、程式碼範例… → 任何可以幫助讀者更快到達「頓悟」時刻的內容。使用可折疊部分的額外要點是,RFC 的中心部分保持可消化的長度。 如果您完成了所有這些,那麼您已經踏上了通往優秀 RFC 的道路!由於明確定義問題至關重要,所以不要害怕加入更多問題並進一步分解問題。 ### 非目標🛑 這是“問題”的子部分,有時非常有價值。在此程式碼庫變更中編寫我們不想要或不會做的事情可以幫助設定期望並更好地定義其範圍。 例如,如果我們正在努力為我們的應用程式加入基於角色的身份驗證系統,人們可能會認為我們還將為其建立某種管理面板來管理使用者和新增/刪除角色。透過明確聲明不會完成(並簡要解釋原因 - 不需要,這會花費太長時間,...),審查者將更好地理解您的目標是什麼,並且您將跳過不必要的討論。 ## 解決方案與實作🛠️ 一旦我們知道我們想做什麼,我們就必須找出最好的方法!您可能已經在“問題”部分暗示了可能的解決方案,但現在是更深入研究的時候了 - 研究不同的方法,評估它們的優缺點,並概述它們如何適合現有系統。 這一部分可能是最自由的形式 - 因為它很大程度上取決於您正在做的事情的性質,所以在這裡施加許多限制是沒有意義的。您可能希望停留在更高的水平,例如係統架構,或者您可能需要深入研究程式碼並開始編寫您需要的部分程式碼。因此,我沒有一個確切的格式供您遵循,而是一組指南: ### 寫偽程式碼 RFC 的目的是傳達想法和原則,而不是編譯和涵蓋所有邊緣情況的生產級程式碼。隨意發明/想像/草繪任何您需要的東西(例如,想像您已經有一個發送電子郵件的功能並使用它,即使您沒有),並且不要用實現細節來妨礙您自己或讀者(除非這正是RFC 的內容)。 最好從較高的級別開始,然後當您意識到需要它或其中一位審閱者建議時再深入。 ### 了解其他人是如何做到的  根據您正在開發的產品類型,您發現這一點的方式可能會有所不同,但幾乎總是有一種方法可以做到這一點。如果您正在開發像 [Wasp](https://github.com/wasp-lang/wasp) 這樣的開源工具,您可以簡單地查看其他流行的解決方案(也是開源的)並了解它們是如何做到的它。如果您正在開發 SaaS,並且需要弄清楚是否使用 cookie 還是 JWT 進行身份驗證,您可能有一些朋友以前這樣做過,您可以詢問他們。最後,只需 Google/GPT 即可。 為什麼這麼有幫助? **原因是它讓您(和審閱者)對您的解決方案充滿信心。如果其他人以這種方式成功做到了,這可能是一個有前途的方向。**它還可能幫助您發現以前沒有想到的方法,或者作為您可以建置的基礎。當然,永遠不要認為任何事情都是理所當然的,並考慮到您情況的具體需要,而一定要利用他人的知識和專業知識。 ### 留下未完成的事情並保持骯髒 RFC 的要點是「C」部分,因此協作(是的,我知道它實際上代表「_comments_」)。這不是一個你必須獲得滿分並且不問任何問題的測試 - 如果發生這種情況,你可能一開始就不應該編寫 RFC。 解決問題需要團隊的努力,而你只是第一個嘗試解決問題並推動事情向前發展的人。您的任務是盡可能合理地奠定基礎(完善問題,探索解決問題的多種方法,辨識發現的新子問題),以便審閱者可以快速掌握狀態並提供有效的反饋,指導需要的地方最多。 **RFC 的主要工作是確定最重要的問題並將審閱者的注意力引導到這些問題上,而不是解決它們。** 您正在編寫的 RFC 應該被視為一個討論區和一個正在進行的工作,而不是一件在展示在觀眾面前之前必須完善的藝術品。 ## 評論和開放式問題 🎯 在文件的最後一部分中,您可以總結主要思想並突出顯示最大的未決問題。在瀏覽所有內容之後,提醒讀者他的注意力在哪裡最有價值可能會有所幫助。 ## 現在我知道何時以及如何寫 RFC!您有任何我可以用作起點的模板嗎? 當然!如前所述,我們的格式非常輕量級,但請隨意查看[我們用作示例的 RFC](https://wasp-lang.notion.site/RFC-Auth-without-user-define-entities-6d2925439627456ab01b74ff4b4cd087?pvs=4) 獲得靈感。您的公司也可能已經有他們推薦的現成範本。 以下是您可以使用和/或適應您的需求的一些內容: - [Squarespace RFC 範本](https://engineering.squarespace.com/s/Squarespace-RFC-Template.pdf) - _您有推薦的範本嗎?我很高興將其列在這裡!_ ## 我應該使用什麼工具來寫 RFC?有這麼多選擇! 您使用的確切工具可能是 RFC 中最不重要的部分,但它仍然很重要,因為它圍繞它設置了工作流程。如果您的公司已經選擇了一種工具,那麼當然要堅持使用。如果沒有,以下是我遇到的最常見的選擇,以及快速評論: - **Google 文件** - 經典選擇。超級容易對文件的任何部分進行評論,這是最重要的功能。 - **概念** - 也非常適合協作,此外還提供一些 Markdown 元件,例如可折疊和表格,這可以使您的 RFC 更具可讀性。 - **Github 問題/PR** - 有時會使用它,特別是對於 OSS 專案。缺點是很難對文件的特定部分進行註釋(只能對整行進行註釋),而且插入圖表也相當笨拙。優點是所有內容(程式碼和 RFC)都保留在同一個平台上 我們目前使用 Notion,但以上任何一個都可以是不錯的選擇。 ## 概括  正如在 RFC 末尾編寫摘要是最佳實踐一樣,我們也會在這裡做同樣的事情!這篇文章比我預期的要長,但是有很多東西要提到 - 我希望你會發現它有用! 最後,**能夠清楚地表達你的想法,提出問題,並根據團隊的反饋客觀地分析可能的解決方案,這將幫助你開發正確的東西,這是最終的生產力黑客**。 這就是您成為真正的 10 倍工程師的方法。感謝您的閱讀,下次再見! --- 原文出處:https://dev.to/wasp/develop-the-right-thing-every-time-and-become-a-10x-engineer-the-art-of-writing-rfcs-2mc6
我將提到的七個開源專案不僅是雲端原生創新的重要工具,而且還在當今快節奏的數位世界中提供了策略優勢。 在本文中,我匯總了將這些開源專案設定為 **AWESOME** 層級的關鍵點! 🚀  --- ## 1. [Winglang](https://dub.sh/wing-cloud)  Wing 推出了一種名為 **Winglang** 的程式語言,這是一種以雲端為導向的程式語言,允許開發人員建立分散式系統,以一等公民的身分利用雲端服務。 該語言引入了兩個執行階段:**預檢**和**飛行中**,它們以將 IAM 策略和網路拓撲的建立委託給編譯器的方式連接起來。 這種連結有助於解釋飛行中和飛行前概念的價值,因為它允許開發人員專注於業務邏輯而不是雲端機制,從而加快迭代週期並改進創意流程。 神奇之處在於**預檢**和**飛行中**執行階段: - **預檢:** 在編譯時執行一次的程式碼,並產生雲端應用程式的基礎架構配置。例如,設定資料庫、佇列、儲存桶、API端點等。 - **Inflight:** 在執行時執行並實作應用程式行為的程式碼。例如,處理 API 請求、處理佇列訊息等。Inflight 程式碼可以在雲端中的各種運算平台上執行,例如函數服務(例如 AWS Lambda 或 Azure Functions)、容器(例如 ECS 或 Kubernetes)、VM ,甚至是物理伺服器. 👇 --- ## 2.【裂變】(https://github.com/fission/fission)  Fission 是 Kubernetes 上的無伺服器功能框架。 - 用任何語言編寫短期函數,並將它們對應到 HTTP 請求(或其他事件觸發器)。 - 一個指令即可立即部署功能。無需建置容器,也無需管理 Docker 註冊表。 --- ## 3. [OpenFaaS](https://github.com/openfaas/faas)  在具有相同統一體驗的任何地方執行您的程式碼,並在擁有 Kubernetes 的任何地方部署 OpenFaaS。 - 在幾分鐘內將新功能部署到生產中,並知道它將擴展以滿足需求。 - 透過來自 Apache Kafka、AWS SQS、Postgresql、Cron 和 MQTT 的事件呼叫函數。 --- ## 4.【太空雲】(https://github.com/spacecloud-io/space-cloud)  Space Cloud 是一個基於 kubernetes 的開源平台,可讓您大規模建置、擴充和保護雲端原生應用程式。 - 它為您的資料庫和微服務提供即時 GraphQL 和 REST API,可以安全地直接從前端使用。 - 在 Kubernetes 上部署和擴充 Docker 映像。 --- ## 5. [Pulumi](https://github.com/pulumi/pulumi)  在任何雲端上直觀地管理基礎設施、機密和配置。 - 使用您熟悉且喜愛的程式語言編寫基礎設施程式碼。使用具有自動完成、類型檢查和文件功能的 IDE 編寫語句來定義基礎架構。 - 透過單元測試測試您的程式碼,並透過 CI/CD 管道交付程式碼以進行驗證並部署到任何雲端。 --- ## 6. [Gitpod](https://github.com/gitpod-io/gitpod)  得到啟發,開始建造。 - 環境之間的上下文切換,無需等待,無衝突。 - 分享每個分支的預覽環境,以便開發人員、設計人員和 QA 更快獲得回饋。 --- ## 7. [Knative](https://github.com/knative/serving)  Knative Serving 基於 Kubernetes 建置,支援將應用程式和功能作為無伺服器容器進行部署和服務。 - 無伺服器容器快速部署 - 自動縮放至零 - 路由與網路編程 - 已部署程式碼和配置的時間點快照 --- 感謝您查看這七個強大的開源專案,您在雲端建置時應考慮這些專案。🥇 **支援開源軟體的最佳方式之一就是加一顆星🌟** --- 原文出處:https://dev.to/nathan_tarbert/level-up-your-cloud-experience-with-these-7-open-source-projects-37p8
開發者們大家好👋 今天,我將與您分享 5 個令人驚嘆的網站,它們對您的專案開發有幫助,也可以節省您的寶貴時間⏱。 ## 1️⃣ Flaticon Flaticon 是最大的圖示資料庫。您可以在這裡找到各種圖示、介面圖示、動畫圖示和貼紙,並可以以多種格式免費下載,例如 PNG、SVG、EPS、PSD 和 CSS。您也可以使用 Adobe After Effect 編輯現有圖示。  _造訪此處的網站:[https://www.flaticon.com](https://www.flaticon.com)_ ## 2️⃣ Omatsuri Omatsuri 是一個開源 Web 應用程式,為開發人員提供 12 種不同的工具。它就像“多合一”應用程式。 - **三角形產生器:** 此工具用於為元素和偽元素產生 css 三角形樣式。 - **色調產生器:** 此工具用於產生給定顏色的色調和不同色調。 - **漸層產生器:** 此工具用於產生線性和徑向 css 漸層。 - **頁面分隔線:** 此工具用於使用 css 和 svg 影像產生頁面分隔線。 - **SVG 壓縮器:** 此工具用於使用 SVGO 壓縮 SVG 影像並轉換為 React 元件。 - **SVG -> JSX Converter:** 此工具用於將 SVG 圖示和插圖轉換為 React 元件或其他支援 JSX 的函式庫的元件。 - **base64 編碼器:** 此工具用於將圖像或檔案轉換為 Base64 並產生用作背景圖像的樣式。 - **虛假資料產生器:** 以 JSON Schema 格式產生各種真實的虛假資料,如地址、頭像、姓名、電話等。 - **符號集合:** 此工具包含常用 html 符號的集合:箭頭、標記、貨幣符號等。 - **Lorem ipsum:** 此工具產生不同類型的 lorem ipsum 文字。 - **CSS 遊標:** 這也是所有現有 CSS 遊標屬性值的集合。 - **鍵盤事件程式碼:** 此工具提供 JavaScript 事件鍵盤程式碼值。  _造訪此處的網站:[https://omatsuri.app](https://omatsuri.app/) Github 連結:[https://github.com/rtivital/omatsuri](https://github.com/rtivital/omatsuri)_ ## 3️⃣ RapidAPI RapidAPI 是最大的 API 中心。它提供了大量涵蓋天氣、社交媒體、電子商務、金融等各個類別的 API。您可以輕鬆搜尋 API 並將其整合到您的應用程式中。這裡並非所有 API 金鑰都是免費的,該網站提供免費和付費訂閱。 對於某些 api 金鑰,您需要付費才能使用它們並將其整合到您的應用程式中。  _造訪此處的網站:[https://rapidapi.com/hub](https://rapidapi.com/hub)_ ## 4️⃣ Storyset Storyset 平台為您提供精彩的免費客製化插圖,供您在專案中使用。使用 Storyset,您可以輕鬆自訂、製作動畫和下載插圖,以建立精美的應用程式,尤其是登陸頁面。它還提供了編輯插圖以及以 PNG 和 SVG 格式下載的選項。  _造訪此處的網站:[https://storyset.com](https://storyset.com)_ ## 5️⃣ Transform Transform.tools 是一個開源網站,讓您能夠轉換各種元素,例如 HTML 到 JSX、JavaScript 到 JSON、CSS 到 JS 物件等等。每當您需要快速轉換或轉換任何內容時,它都將真正節省時間。  _造訪網站:[https://transform.tools](https://transform.tools) Github連結:[https://github.com/ritz078/transform](https://github.com/ritz078/transform)_ ⬇ 如果您使用過這些工具,請在下面發表評論並分享您的經驗。另外,提及您最常使用的工具。我會將它們包含在下一篇文章中。 感謝您的閱讀❤ --- 原文出處:https://dev.to/dev_kiran/top-5-killer-websites-for-developers-2knm
這是[使用 Express、Sequelize 和 Postgres 建立 API](https://www.oriechinedu.com/posts/performing-crud-with-sequelize/) 的第三部分。在[第二部分](https://www.oriechinedu.com/posts/performing-crud-with-sequelize/)中,我們建立了簡單的API端點來示範Sequelize中的CRUD操作。在本文中,我們將重點放在為第二部分中建立的 API 端點編寫端到端測試。 ### 術語解釋 - **端對端測試** - 一種測試類型,用於測試應用程式從開始到結束的流程是否如預期運作。這也稱為功能測試。此類測試的一個範例是測試端點或路由,其中涉及測試端點工作所需的所有內容,例如資料庫連接、依賴項等。 - **測試執行器** - 在給定目錄或檔案中取得原始程式碼(測試)、執行測試並將結果寫入控制台或任何指定位置的程式庫或工具,例如 Jest、Mocha。 - **Jest** - [Jest](https://jestjs.io/) 是 Facebook 開發的 JavaScript 測試框架。它以最少的配置開箱即用,並具有內建的測試執行器、斷言庫和模擬支援。 - [**Supertest**](https://www.npmjs.com/package/supertest) - 用於測試 Node.js HTTP 伺服器的函式庫。它使我們能夠以程式設計方式向 HTTP 伺服器發送 HTTP 請求(例如 GET、POST、PATCH、PUT、DELETE)並獲取結果。 現在我們已經解釋了基本術語,讓我們深入了解主要業務。 如果您一直按照先前的[文章](https://www.oriechinedu.com/posts/performing-crud-with-sequelize/)進行操作,那麼請在您最喜歡的文字編輯器中開啟它,否則克隆使用的儲存庫[此處](https://github.com/oriechinedu/sequelize-with-postgres-tutorial)。 **第 1 步 - 安裝 Jest 和 supertest** 打開終端機並“cd”到專案根目錄並執行以下命令: ``` npm install --save-dev jest supertest ``` **步驟 2 - 設定 Jest** 打開“package.json”並將以下程式碼新增至其中。 ``` "jest": { "testEnvironment": "node", "coveragePathIgnorePatterns": [ "/node_modules/" ] }, ``` 這是我們測試 API 時需要設定 jest 的基本配置。您希望 `jest` 忽略的任何檔案都放置在 `"coveragePathIgnorePatterns"` 內。 `"coveragePathIgnorePatterns"` 指定一個與要排除的目錄相符的正規表示式,在我們的例子中,我們希望它忽略 `node_modules` 目錄。 接下來我們新增“test”腳本。在 `package.json` 的 `scripts` 部分中,加入以下腳本: ``` "test": "jest" ``` **步驟 3 - 測試配置** 現在,讓我們確認「jest」已準備好執行我們的測試。在終端機中執行“npm test”。您會注意到控制台上列印如下所示的錯誤,這表示「jest」已設定。  讓我們新增一個簡單的測試來驗證配置。建立一個名為「tests」的新目錄並新增一個新檔案「sample.test.js」。在「sample.test.js」中,加入以下程式碼: ``` describe('Sample Test', () => { it('should test that true === true', () => { expect(true).toBe(true) }) }) ``` 現在,執行“npm test”,您將得到如下所示的輸出: 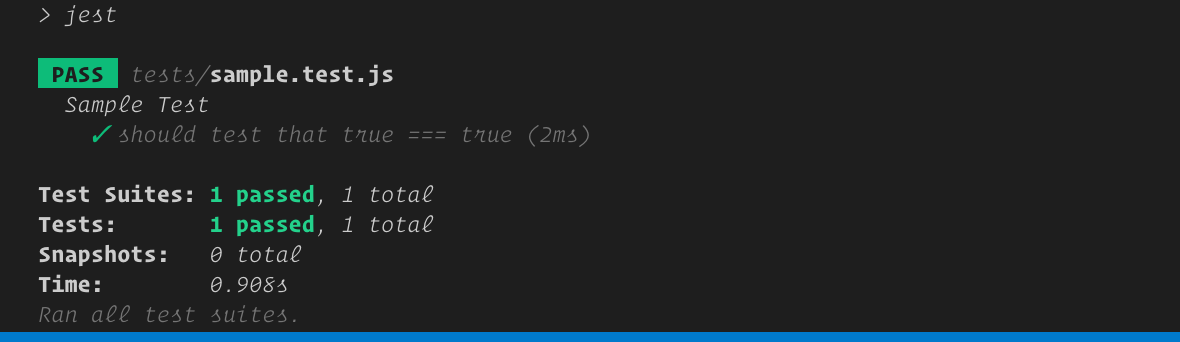 ##### Jest 如何辨識測試檔? Jest 以三種方式辨識測試文件: - 副檔名為「.test.js」的文件 - 副檔名為「.spec.js」的文件 - `__tests__` 資料夾或目錄中的所有檔案。 ## 測試 API 端點 現在我們已經設定了測試環境,是時候開始測試 API 端點了。由於我們的端點需要向資料庫發出請求,因此我們需要設定一個測試資料庫。設定測試資料庫的原因是每次執行測試時我們都會刪除該資料庫。每次執行測試時刪除資料庫可確保測試的完整性。也就是說,如果一個測試是在資料庫中建立一個「post」記錄,我們要確保在測試執行之前資料庫中沒有「post」記錄,這樣,我們就可以確定得到的結果從測試中。 **第 4 步 - 建立測試資料庫** 在本文的[第一部分](https://www.oriechinedu.com/posts/getting-started-with-sequelize-and-postgres/)中,我們建立了兩個資料庫,一個用於開發,另一個用於測試。如果您尚未建立測試資料庫,請依照[連結](https://www.oriechinedu.com/posts/getting-started-with-sequelize-and-postgres/)建立測試資料庫。 **步驟 5 - 設定測試腳本** 我們需要以下腳本: - `pretest` - `pretest` 是一個 npm 腳本,當呼叫 `npm test` 指令時會自動呼叫。我們將掛接命令來更改環境以進行測試,並在每次測試執行之前刷新資料庫。 - `migrate:reset`:此命令將負責在每次測試執行之前刷新資料庫。 現在編輯“package.json”的“scripts”,如下所示: ``` "scripts": { "start-dev": "nodemon index.js", "migrate": "npx sequelize-cli db:migrate", "migrate:reset": "npx sequelize-cli db:migrate:undo:all && npm run migrate", "test": "cross-env NODE_ENV=test jest --testTimeout=10000", "pretest": "cross-env NODE_ENV=test npm run migrate:reset" } ``` 腳本修改需要注意的地方: - [`cross-env`](https://www.npmjs.com/package/cross-env) - 用於設定環境變數的與作業系統無關的套件。我們用它將`NODE_ENV`設為`test`,以便我們的測試可以使用測試資料庫。執行以下命令來安裝跨環境。 ``` npm i -D cross-env ``` - `--testTimeout` 標誌 - 這會增加 Jest 的預設逾時時間,即 5000 毫秒。這很重要,因為測試執行者需要在執行測試之前刷新資料庫。 **第 6 步 - 測試腳本** ``` npm test ``` 如果一切正常,您應該在終端機上看到以下輸出: 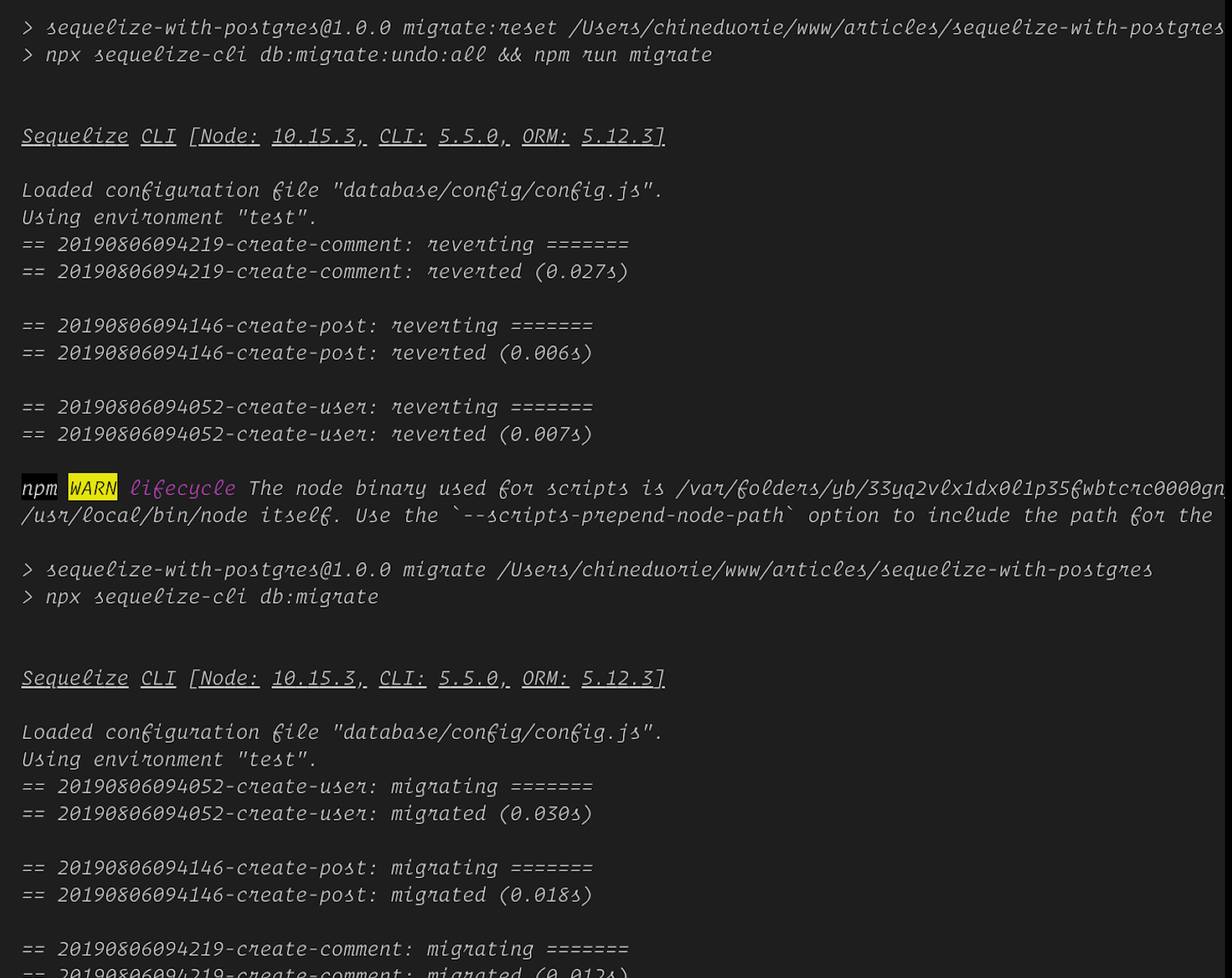 仔細觀察上面的螢幕截圖,您會注意到一行 _`using environment "test"`_ 表示 `cross-env` 已更改了 `NODE_ENV`。 **最後一步 - 測試路由/端點** 現在,讓我們開始為端點編寫測試。在測試目錄中建立一個名為routes.test.js的文件 ``` touch tests/routes.test.js ``` - **測試建立後端點** 將以下程式碼複製到“tests/routes.test.js”中: ``` const request = require('supertest') const app = require('../server') describe('Post Endpoints', () => { it('should create a new post', async () => { const res = await request(app) .post('/api/posts') .send({ userId: 1, title: 'test is cool', }) expect(res.statusCode).toEqual(201) expect(res.body).toHaveProperty('post') }) }) ``` - `describe` 函數用於將相關測試分組在一起 - `it` 是執行實際測試的 `test` 函數的別名。 -“expect”函數使用一組“matcher”函數測試值。 請造訪 [Jest 文件](https://jestjs.io/docs/en/api.html) 以取得 jest 函數的完整清單和詳細資訊。 現在,執行測試 ``` npm test ``` 輸出如下圖所示: 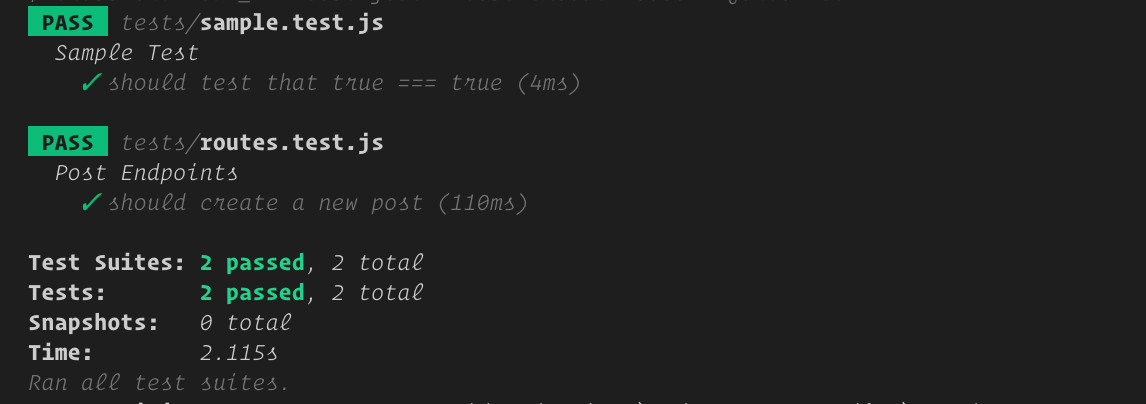 有關所有端點測試的完整程式碼,請檢查[儲存庫](https://github.com/oriechinedu/sequelize-with-postgres-tutorial/blob/master/tests/routes.test.js)。 ### 結論 我們已經能夠完成為與資料庫互動的 API 端點編寫測試的過程。在本文的最後部分,我將撰寫有關將 CI/CD 和程式碼覆蓋工具整合到測試環境的文章。在那之前請繼續關注。 如果您對改進文章有任何疑問或建議,請隨時與我聯繫。您也可以透過下面的評論部分分享您的想法。謝謝! _本文最初發表在我的[部落格](https://www.oriechinedu.com/posts/testing-nodejs-express-api-with-jest-and-supertest/)_ --- 原文出處:https://dev.to/nedsoft/testing-nodejs-express-api-with-jest-and-supertest-1km6
我們很高興地宣布 Supabase Auth 的四項新功能: 1. 身份連結 2. 會話控制 3. 密碼外洩保護 4. 帶有 Postgres 函數的 Auth Hooks {% 嵌入 https://youtu.be/LF8GABnAFyE %} ## 身份連結 當使用者登入時,系統會使用身份驗證方法和登入提供者建立身分。從歷史上看,如果身分與使用者共享相同的經過驗證的電子郵件,[Supabase Auth](https://supabase.com/docs/guides/auth) 會自動將身分連結到使用者。這可以方便地刪除重複的用戶帳戶。然而,一些開發人員還需要靈活地連結不共享相同電子郵件的帳戶。 今天,我們推出身份連結,開發人員可以使用它手動連結兩個單獨的身份。我們為開發人員新增了兩個新端點來管理身分連結流程: 使用者登入後,使用「linkIdentity()」[連結 OAuth 身分:](https://supabase.com/docs/reference/javascript/auth-linkidentity) ``` const { data, error } = await supabase.auth.linkIdentity({ provider: 'google', }) ``` 使用 `unlinkIdentity()` 來[取消連結身分](https://supabase.com/docs/reference/javascript/auth-unlinkidentity): ``` // retrieve all identities linked to a user const { data: { identities }, } = await supabase.auth.getUserIdentities() // find the google identity linked to the user const googleIdentity = identities.find(({ provider }) => provider === 'google') // unlink the google identity from the user const { data, error } = await supabase.auth.unlinkIdentity(googleIdentity) ``` 目前,這些方法支援連結 OAuth 身分。要將電子郵件或電話身分連結到用戶,您可以使用 [updateUser()](https://supabase.com/blog/supabase-auth-identity-linking-hooks#:~:text=can%20use% 20the -,updateUser(),-method.)方法。 預設情況下禁用手動連結。您可以在[儀表板驗證設定](https://supabase.com/dashboard/project/_/settings/auth) 中為您的專案啟用它。 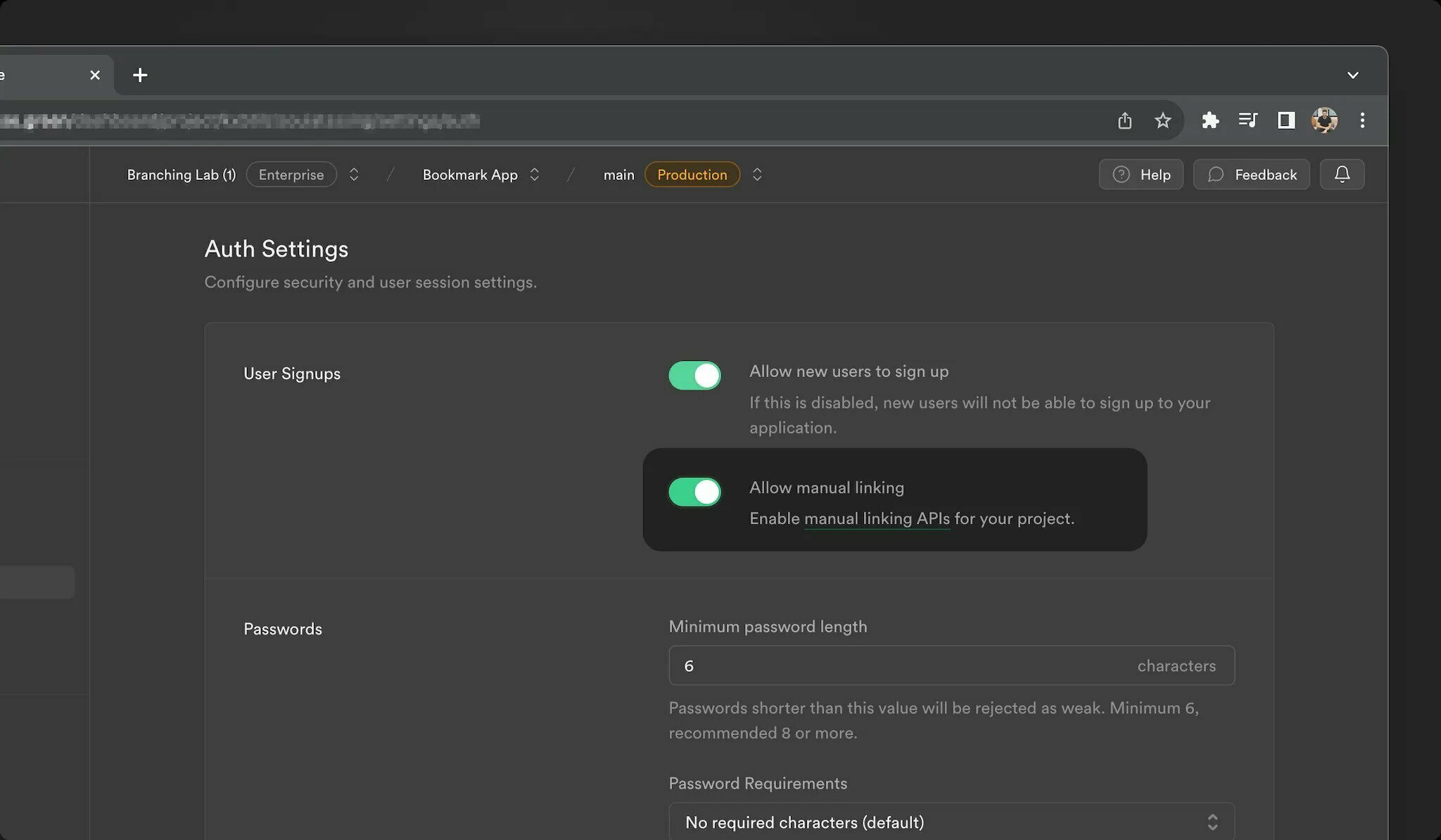 > 有關更多訊息,請參閱[身份連結文件](https://supabase.com/docs/guides/auth/auth-identity-linking)。 ## 會話控制 Supabase Auth 從使用者登入應用程式那一刻起管理整個會話生命週期。這涉及以下步驟: 1. 為使用者建立會話。 2. 刷新會話以使其保持活動狀態。 3. 過期或登出時撤銷會話。 對於想要更好地控制使用者會話的開發人員,我們公開了 3 個新設定: - **時間盒使用者會話:** 強制使用者在一段時間間隔後再次登入。 - **不活動逾時:** 如果使用者在一段時間內不活動,則強制使用者重新登入。 - **每個使用者單一會話:** 將使用者限制為單一會話。保留最近的活動會話,並終止所有其他會話。 這些會話控制設定在專業版及以上版本中可用。 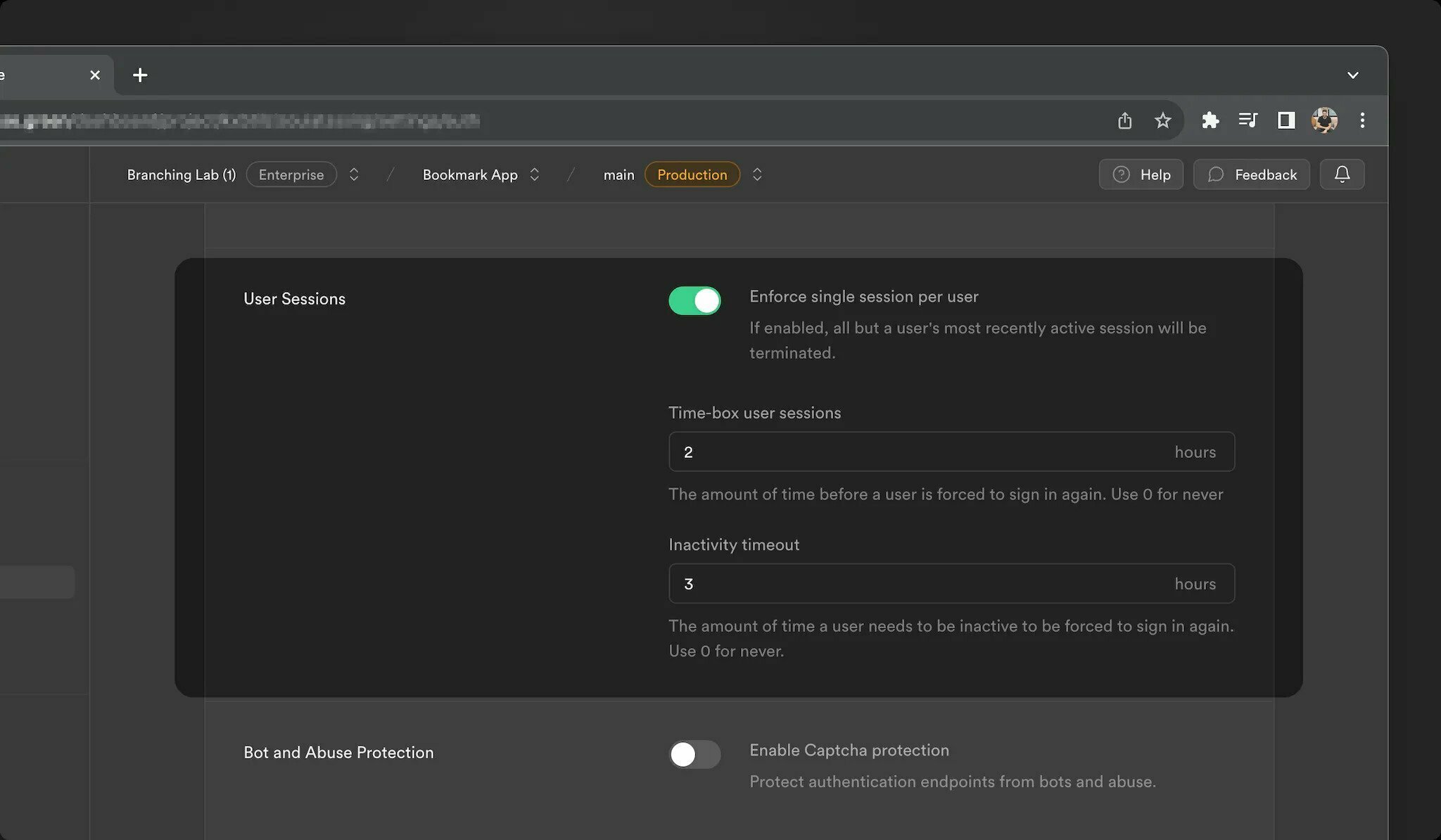 > 有關更多訊息,請參閱[會話管理文件](https://supabase.com/docs/guides/auth/sessions)。 ## 密碼外洩保護 由於常見的使用者行為(例如選擇可猜測的密碼或在不同平台上重複使用密碼),密碼本質上可能是不安全的。 儘管 OAuth 和 magiclinks 更安全,但我們認識到密碼將繼續存在。我們希望讓用戶不易陷入潛在的陷阱。為了實現這一目標,我們在 Supabase Auth 中整合了 [HaveIBeenPwned.org](https://haveibeenpwned.com/) _Pwned Passwords API_,以防止使用者使用洩漏的密碼。 > **去圖書館** ℹ️ 我們開源了一個 Go 函式庫,用於與我們在身分驗證伺服器中使用的 [HaveIBeenPwned.org](http://haveibeenpwned.org/) Pwned 密碼 API 互動。查看 [存儲庫](https://github.com/supabase/hibp) 並隨時貢獻! 作為附加步驟,我們新增了為您的使用者指定密碼要求的功能。這可以透過[儀表板:](https://supabase.com/dashboard/project/_/settings/auth) 中專案的身份驗證設定進行配置 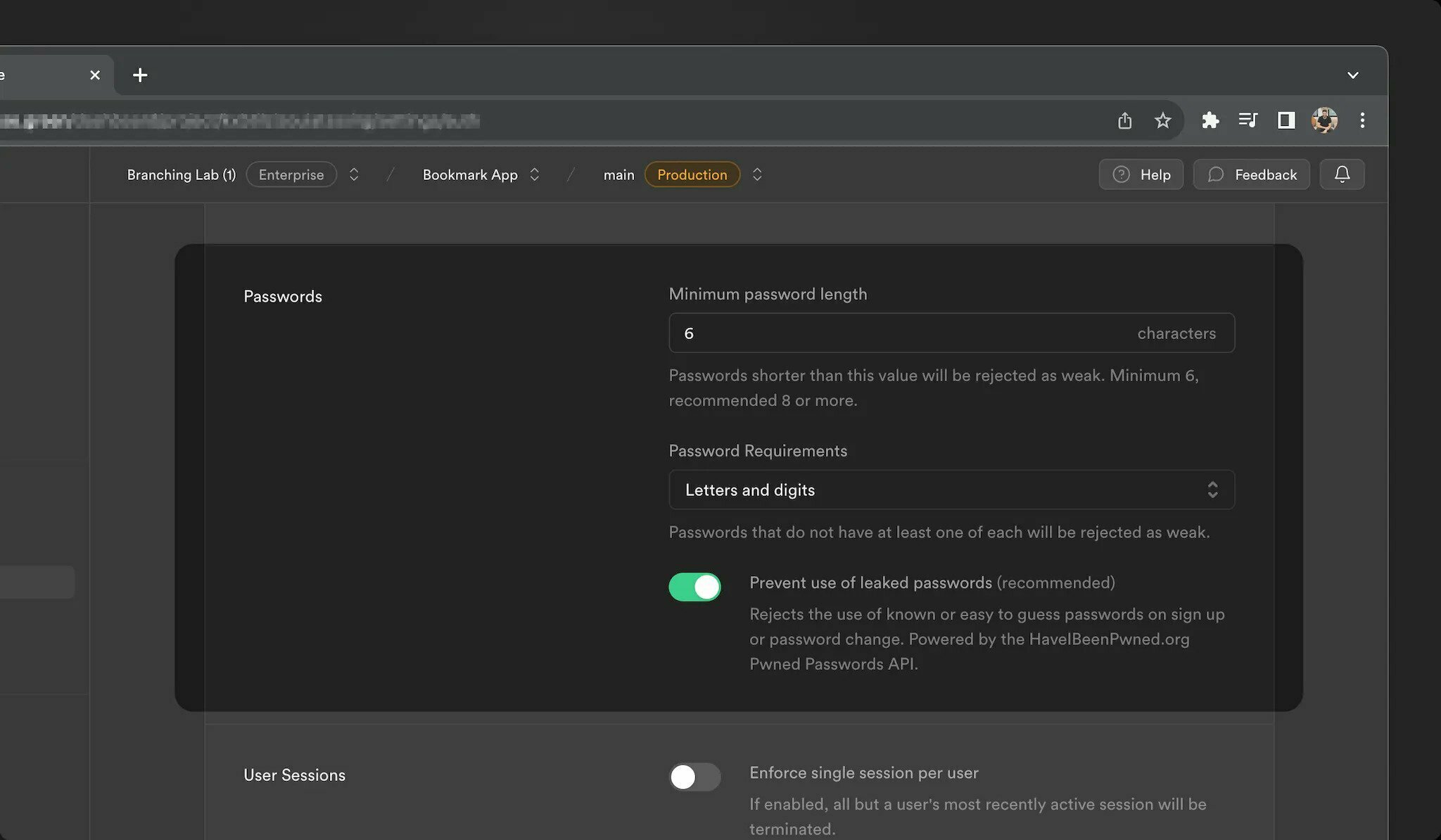 > 請參閱[密碼文件](https://supabase.com/docs/guides/auth/passwords) 以了解更多資訊。 ## 驗證掛鉤 我們收到了大量回饋,詢問如何自訂 Auth,例如: - 將自訂聲明新增至存取權杖 JWT - 多次嘗試 MFA 驗證失敗後註銷用戶 - 對密碼驗證嘗試套用自訂規則 我們的目標是保持簡單、無縫的 Supabase Auth 體驗。對於大多數開發人員來說,它應該可以輕鬆工作,而無需自訂。但是,認識到應用程式的多樣性,您現在可以透過 Auth Hook 擴展標準 Auth 功能。 Auth Hooks 只是 Postgres 函數,它們在 Auth 生命週期的關鍵點同步執行,以更改操作的結果。 例如,要使用 Auth Hooks 自訂 JWT 聲明,您可以建立一個 Postgres 函數,該函數接受第一個參數中的 JWT 聲明並傳回您希望 Supabase Auth 使用的 JWT。 假設您正在建立一個遊戲化應用程式,並且希望將用戶的層級作為自訂聲明附加到 JWT: ``` create function custom_access_token_hook(event jsonb) returns jsonb language plpgsql as $$ declare user_level jsonb; begin -- fetch the current user's level select to_jsonb(level) into user_level from profiles where user_id = event->>'user_id'::uuid; -- change the event.claims.level return jsonb_set( event, '{claims,level}', user_level); end; $$ ``` 在資料庫中建立函數後,您只需使用 Supabase Auth 註冊它: 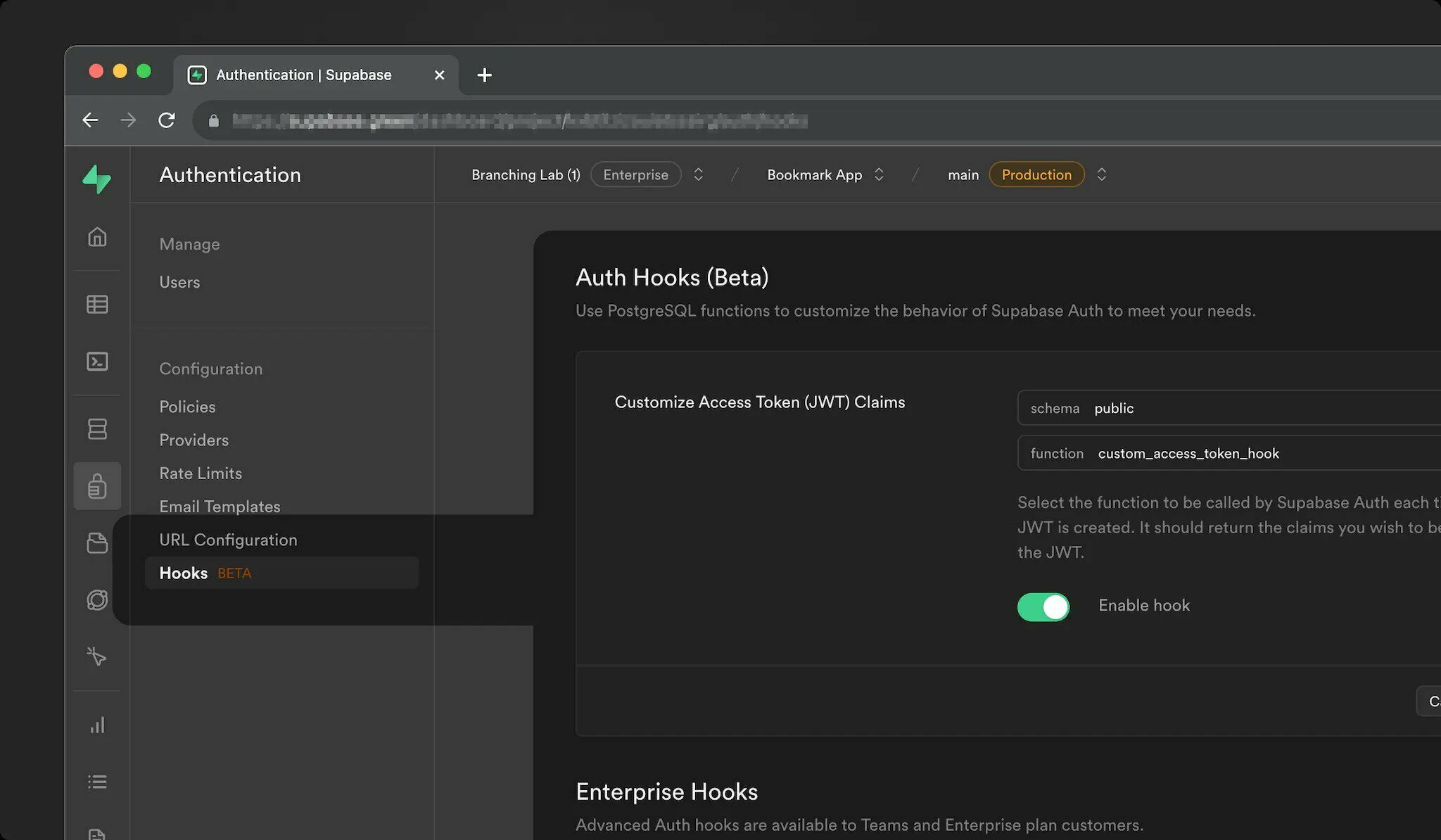 目前,您可以為流程中的以下點註冊 Auth Hook: - **自訂存取權杖:** 每次產生新的 JWT 時都會呼叫。 - **MFA 驗證嘗試:** 每次驗證 MFA 因素時都會呼叫,從而可以更好地控制檢測和阻止嘗試。 - **密碼驗證嘗試:** 每次使用密碼登入使用者時都會呼叫,從而可以更好地控制使用者帳戶的安全性。 如果編寫 PL/pgSQL 函數不是您的強項,您始終可以使用 [pg_net](https://supabase.com/docs/guides/database/extensions/pg_net) 向後端 API 發送請求,或使用[plv8]( https://supabase.com/docs/guides/database/extensions/plv8) 透過用JavaScript 編寫函數來更輕鬆地操作JSON。 Auth Hooks 今天可供自架,並將於下個月推出到該平台。如果您需要盡快存取,請透過[支援](https://supabase.help/)與我們聯繫! 那不是全部! Postgres 函數並不是寫鉤子的唯一方法。 Supabase 是 [Standard Webhooks](https://www.standardwebhooks.com/) 的創始貢獻者,這是一組關於輕鬆、安全、可靠地發送和接收 Webhook 的開源工具和指南。當然,Auth Hooks 將在 2024 年第一季支援 Webhooks。 ## 還有一件事… 如果您從一開始就關注我們(https://supabase.com/blog/supabase-auth),您就會知道Supabase Auth 是透過分叉[Netlify 的GoTrue 伺服器](https://github.com)開始的/netlify/gotrue)。從那時起,發生了很多變化,我們已經偏離了上游儲存庫。在這個階段,將專案重新命名為其他名稱是有意義的(提示鼓聲)-Auth。 這僅僅意味著儲存庫將從使用“gotrue”重新命名為“auth”。但別擔心! Docker 映像和庫(如“@supabase/gotrue-js”)將繼續發布,只要當前 v2 版本受支持,您就可以互換使用“@supabase/auth-js”。所有類別和方法都保持不變。這裡沒有重大變化! ## 結論 感謝您閱讀到最後!我們希望您喜歡第 X 週發布的 Supabase Auth 更新:身分連結、會話控制、洩露密碼保護和帶有 Postgres 功能的 Auth Hooks。 我們期待看到您使用這些新功能建立的內容,當然還有您的回饋意見,以使它們變得更好。 ## 更多發布第 X 週 - [第 1 天 - Supabase Studio 更新:AI 助理與使用者模擬](https://supabase.com/blog/studio-introducing-assistant) - [第 2 天 - Edge Functions:節點和本機 npm 相容性 ](https://supabase.com/blog/edge-functions-node-npm) -[第 3 天 - 介紹 Supabase Branching,這是一個針對每個拉取請求的 Postgres 資料庫](https://supabase.com/blog/supabase-branching) - [Postgres語言伺服器:實作解析器](https://supabase.com/blog/postgres-language-server-implementing-parser) - [Supabase 專輯](https://www.youtube.com/watch?v=r1POD-IdG-I) - [Supabase 啟動週 X 黑客松](https://supabase.com/blog/supabase-hackathon-lwx) - [啟動週 X 社群聚會](https://supabase.com/blog/community-meetups-lwx) --- 原文出處:https://dev.to/supabase/supabase-auth-identity-linking-hooks-and-haveibeenpwned-integration-19e1
我們很高興地宣布,[Edge Functions](https://supabase.com/docs/guides/functions) 現在原生支援 npm 模組和 Node 內建 API。您可以將數百萬個流行、常用的 npm 模組直接匯入 Edge Functions 中。 `從 'npm:drizzle-orm/node-postgres' 導入 { drizzle }` ## 將現有 Node 應用程式遷移到 Edge Functions 您可以透過最少的變更將現有的 Node 應用程式遷移到 Supabase Edge Functions。 我們建立了一個示範來展示如何遷移使用 Express、Node Postgres 和 Drizzle 的 Node 應用程式。有關在 Edge Functions 中使用 npm 模組和 Node 內建程式的更多訊息,請參閱[管理依賴項指南](https://supabase.com/docs/guides/functions/import-maps)。 {% 嵌入 https://youtu.be/eCbiywoDORw %} **npm 模組的底層運作原理** 我們執行一個開源 Deno 伺服器來託管 Edge Functions,稱為 [Supabase Edge Runtime](https://supabase.com/blog/edge-runtime-self-hosted-deno-functions)。此自訂版本可協助我們保持 Edge Functions 以相同的方式運作,無論部署在何處 - 在我們的託管平台上、在本地開發中還是在您的自託管環境中。 加入 npm 支援時最大的挑戰是找到適用於所有環境的方法。我們希望保持工作流程接近 Deno CLI 體驗。應該可以直接在原始程式碼中導入 npm 模組,而無需額外的建置步驟。 部署函數時,我們將其模組圖序列化為單一檔案格式([eszip](https://github.com/denoland/eszip))。在託管環境中,所有模組引用都會從 eszip 中載入。這可以防止獲取模組時出現任何額外的延遲以及模組依賴關係之間的潛在衝突。 我們也在本機和自架環境中使用了 eszip 模組載入器,因此我們只需要為所有環境實作一種模組載入策略。作為本地開發的另一個好處,此方法避免了與使用者係統中安裝的 npm 模組的潛在衝突,因為 Edge Function 的 npm 模組是獨立於 eszip 中的。 [重構模組載入器](https://github.com/supabase/edge-runtime/pull/223)修正了一些其他錯誤,例如[邊緣函數錯誤](https://github.com/supabase/cli /issues/1584#issuecomment-1848799355) 當專案中已存在`deno.lock` 檔案時。 ## 您要求的其他一些東西... **區域呼叫** 現在,您可以選擇在執行邊緣函數時指定區域(也許我們將來應該更改名稱)。通常,邊緣函數在最靠近呼叫函數的使用者的區域中執行。但是,有時您希望在靠近 Postgres 資料庫或其他第 3 方 API 的地方執行它,以獲得最佳效能。 功能仍然部署到所有區域。但是,在呼叫過程中,您可以提供“x-region”標頭以將執行限制在特定區域。 **捲曲** ``` # https://supabase.com/docs/guides/functions/deploy#invoking-remote-functions curl --request POST 'https://<project_ref>.supabase.co/functions/v1/hello-world' \ --header 'Authorization: Bearer ANON_KEY' \ --header 'Content-Type: application/json' \ --header 'x-region: eu-west-3' \ --data '{ "name":"Functions" }' ``` **JavaScript** ``` // https://supabase.com/docs/reference/javascript/installing import { createClient } from '@supabase/supabase-js' // Create a single supabase client for interacting with your database const supabase = createClient('https://xyzcompany.supabase.co', 'public-anon-key') // https://supabase.com/docs/reference/javascript/functions-invoke const { data, error } = await supabase.functions.invoke('hello-world', { body: { name: 'Functions' }, headers: { 'x-region': 'eu-west-3' }, }) ``` > ℹ️查看[區域呼叫指南](https://supabase.com/docs/guides/functions/regional-inspiration)以了解更多詳情。 **更好的指標** 我們在 [Supabase 儀表板](https://supabase.com/dashboard/project/_/functions) 的 Edge Functions 部分中加入了更多指標:它現在顯示 CPU 時間和使用的記憶體。我們也按 HTTP 狀態碼細分了呼叫。 這些變更可協助您發現邊緣功能的任何問題並採取行動。 > ℹ️ 請參閱 Edge Functions 的[日誌記錄和指標指南](https://supabase.com/docs/guides/functions/debugging) 以了解更多資訊。  **使用 Sentry 追蹤錯誤** 我們 Sentry 的朋友最近發布了官方的 [Sentry SDK for Deno](https://deno.land/x/[email protected])。有了這個,現在可以輕鬆追蹤 Sentry 邊緣函數中的錯誤和異常。 以下是一個簡單的範例,說明如何處理函數中的異常並將其傳送到 Sentry。 ``` import * as Sentry from 'https://deno.land/x/sentry/index.mjs' Sentry.init({ dsn: _DSN_, integrations: [], // Performance Monitoring tracesSampleRate: 1.0, // Set sampling rate for profiling - this is relative to tracesSampleRate profilesSampleRate: 1.0, }) // Set region and execution_id as custom tags Sentry.setTag('region', Deno.env.get('SB_REGION')) Sentry.setTag('execution_id', Deno.env.get('SB_EXECUTION_ID')) Deno.serve(async (req) => { try { const { name } = await req.json() const data = { message: `Hello ${name}!`, } return new Response(JSON.stringify(data), { headers: { 'Content-Type': 'application/json' } }) } catch (e) { Sentry.captureException(e) return new Response(JSON.stringify({ msg: 'error' }), { status: 500, headers: { 'Content-Type': 'application/json' }, }) } }) ``` ## 下一步是什麼 NPM 支援是 Edge Functions 最受歡迎的功能之一。如果您之前因缺乏支援而無法使用 Edge Functions,我們希望此更新能夠吸引您[再試一次](https://supabase.com/dashboard/project/_/functions)。如果您遇到任何問題,我們只需[一個支援請求](https://supabase.help/)。 對於現有的 Edge Functions 用戶來說,區域呼叫、更好的指標和錯誤處理只是接下來會發生的事情的一瞥。我們繼續迭代平台穩定性並對邊緣功能可以使用的資源設定自訂限制。請留意新的一年的另一篇文章。 ## 更多發布第 X 週 - [第 1 天 - Supabase Studio 更新:AI 助理與使用者模擬](https://supabase.com/blog/studio-introducing-assistant) - [pg_graphql:現在支援 Postgres 函式](https://supabase.com/blog/pg-graphql-postgres-functions) - [Postgres語言伺服器:實作解析器](https://supabase.com/blog/postgres-language-server-implementing-parser) - [Supabase 設計如何運作](https://supabase.com/blog/how-design-works-at-supabase) - [Supabase 專輯](https://www.youtube.com/watch?v=r1POD-IdG-I) - [Supabase 啟動週 X 黑客松](https://supabase.com/blog/supabase-hackathon-lwx) - [啟動週 X 社群聚會](https://supabase.com/blog/community-meetups-lwx) --- 原文出處:https://dev.to/supabase/edge-functions-node-and-native-npm-compatibility-77f
是的,這篇文章的標題就是一個例子,類似於許多所謂的「Listicles」之一,這些「Listicles」一直在開發人員中亂扔。它們的標題充滿了表情符號和「你必須知道」或「對任何開發人員來說都是必不可少的」之類的詞語,它們吸引了我們人類天生的好奇心。 ## 重要的! ### 並非所有清單都不好! 請遵循以下準則來建立一個好的指南: - 確定目的:明確定義清單的目的和目標。您想提供讀者什麼資訊或價值? - 選擇相關表情符號:選擇與內容相符並有助於您想要傳達的訊息的表情符號。確保它們不會讓人不知所措或分散注意力。 - 提供有意義的內容:專注於建立內容豐富且寫得好的文本,為讀者提供價值。表情符號應該補充內容而不是掩蓋內容。 - 評估整體影響:在發布之前,請檢查清單文章,以確保標題中使用表情符號或潛在的標題誘餌文字可以增強讀者的體驗並支持文章的預期目的。 透過執行這些步驟,您可以建立一個清單文章,該文章可以根據需要有效地包含盡可能多的表情符號和「您必須知道」文本,同時保持內容的品質和實質內容。   本質上,它們是點擊誘餌。這些帖子訴諸了人性中被稱為“FOMO”的東西。 ## 什麼是 FOMO? FOMO 代表「害怕錯過」。這是一種以焦慮或不安的感覺為特徵的現象,這種感覺來自於相信其他人可能擁有自己未參與的有益經驗或機會。 FOMO 通常與社交媒體以及其他人分享的持續更新和活動聯繫在一起。 ## 什麼是「表情符號誘餌」? 這些貼文利用的另一件事是「表情符號誘餌」。這個概念最近才被探索。它涉及使用 🤯、🚨、👿 和 🚀 等表情符號在社交媒體平台上操縱人們的情緒。人工智慧(AI)是這方面的專家。 **為什麼這些貼文不好?** 因為幾乎不可能找到任何好的內容! 作為內容創作者,我們有責任以各種可能的方式支持我們的開發者同行的成長。在下面的評論中,讓我們討論如何在 DEV 這樣的平台上實現這一目標。我很想聽聽您對此事的看法。如何才能提升DEV社群的價值,讓所有開發者不那麼難以承受? 請記住,成為一名出色的開發人員不僅僅需要了解所有可用的工具或資源。這是關於磨練解決問題的能力、培養創造力和擁抱終身學習。讓我們優先考慮這些基本技能,其餘的就自然而然了。 而且,正如所承諾的,這裡有 🚀 🚨 對於 dev.to 🤯 🚨 來說「Listicles」不好的 25 個原因。當您閱讀清單文章時,請考慮它如何反映其內容(畢竟,它本身就是清單文章) {% 可折疊 點選展開並查看清單 %} 1.內容淺薄:清單文章和點擊誘餌通常優先考慮簡潔性而不是深度,導致主題覆蓋膚淺。 2. 缺乏脈絡:它們提供的脈絡或背景資訊有限,使讀者的理解支離破碎。 3. 過度簡化:複雜的主題可能會過度簡化以適應清單格式,導致誤解和誤解。 4.標題誘餌:使用聳人聽聞或誤導性的標題來吸引點擊,損害內容的完整性。 5. 誤導性資訊:清單文章和點擊誘餌可能包含不準確或過時的訊息,導致讀者誤入歧途。 6. 缺乏可信度:有些缺乏可靠的來源或參考資料,導致難以驗證所提供資訊的準確性。 7. 內容重複:類似主題的清單文章經常有重複的內容,對尋求新見解的讀者沒有什麼價值。 8.缺乏深度:由於篇幅限制,清單文章很少深入研究某個主題的複雜或微妙的面向。 9. 阻礙批判性思考:清單文章和標題誘餌提供填鴨式訊息,阻礙讀者進行批判性思考和分析。 10. 忽略替代觀點:他們通常提出單一觀點,排除不同或互相衝突的意見。 11. 貨幣化高於品質:有些人優先考慮透過廣告創造收入,而不是製作高品質、資訊豐富的內容。 12. 不切實際的期望:清單文章和點擊誘餌可能會在沒有適當支持的情況下做出廣泛的主張或承諾,從而造成不切實際的期望。 13.內容研究不足:由於急於快速製作內容,一些內容缺乏徹底的研究和事實查核。 14. 缺乏原創性:許多人重複使用其他來源的內容,但沒有加入任何獨特的價值或見解。 15. 話題過度飽和:熱門話題經常被重複提及,導致社群充斥著冗餘內容。 16. 忽略長篇寫作:清單文章和標題誘餌掩蓋了長篇文章,削弱了深入分析的重要性。 17. 抑制學習:清單文章和點擊誘餌的小規模性質可能會阻礙讀者尋求全面的學習經驗。 18.注意力持續時間縮短:持續閱讀清單文章和點擊誘餌可能會導致注意力持續時間縮短,並減少對詳細內容的關注。 19. 浪費點擊:清單文章和點擊誘餌可能會用誘人的標題來吸引讀者,但結果卻是提供膚淺或無用的內容。 20. 失去細微差別:複雜的主題在簡化為編號列表時就失去了細微差別,從而過度簡化了重要細節。 21. 缺乏參與度:清單文章和點擊誘餌由於其膚淺的性質,經常無法產生有意義的討論或社區參與。 22. 創造力下降:它們可能會扼殺創意表達和原創性,因為作者覺得必須遵守清單格式。 23. 寫作標準下降:對快速清單文章和標題誘餌的需求可能會降低社群內寫作的整體品質和標準。 24. 延續線上瀏覽:清單文章和點擊誘餌助長了瀏覽而不是深度閱讀的文化,影響了整體理解。 25. 專業知識貶值:它們可能削弱主題專家的專業知識,因為他們的見解被濃縮或過度簡化。 {% 結束折疊 %} 我希望您覺得這篇文章很有趣!如果您對我做的其他事情感興趣,請查看我的網站: [https://the-best-codes.github.io/](https://the-best-codes.github.io/?ref=dev.to_post&click=https://dev.to/best_codes/25-原因-你-必須-知道-為什麼-listicles-are-bad-for-devto-1hok/&site=https://dev.to/&reason=best-codes-bad-listicles-post) 謝謝閱讀! _2023年12月13日:_ _更新說明:_ 您可能已經看過我的一些帖子,“面向 Web 開發人員的 11 個令人驚嘆的書籤🔖 🚀(它們是什麼?🤔)”、“6️⃣ 常見瀏覽器:它們到底有多安全? 🔒 😯」和「為無聊的程式設計師提供的 10 個有趣的 Web 開發專案創意 👍」。我相信這些不是“列表文章”或標題誘餌,因為它們並不淺薄,而且它們不僅僅是一個列表。如果您對其中任何一個有不同的意見,請告訴我如何改進它們! --- 原文出處:https://dev.to/best_codes/25-reasons-you-must-know-why-listicles-are-bad-for-devto-1hok
# 傳統搜尋的問題 傳統方法是將資料從一個容器提升並轉移到另一個容器。在很多情況下這是一個大問題。建立倒排索引廣泛應用於傳統搜尋引擎中,以實現快速資訊檢索。然而,這種方法的計算成本可能很高,特別是在辨識新資料並將其整合到這些索引中時。隨著業務的發展和資料變得更加複雜和龐大,這些傳統系統往往難以跟上。 此外,企業現在正以前所未有的速度產生新的資料類型,轉向分散式、基於雲端的資訊池的轉變加劇了這些困難。 傳統的企業資訊存取系統依賴定期更新的倒排索引,較不適合這種動態、異質的資料環境。它們無法輕鬆適應新資料類型的持續湧入或基於雲端的資訊系統的分散性。 這會導致資料檢索效率低下和延遲,從而阻礙組織內的決策和營運工作流程。  _Swirl 3.0 透過連接到各種資料來源並同時搜尋它們,為這個問題提供了一個簡單而優雅的解決方案。_ # 漩渦 3.0 功能 {% 嵌入 https://www.youtube.com/watch?v=nA8e0kMEDxs %} Swirl 建構在 Python Django 堆疊上,並提供了一個名為 Galaxy UI 的使用者友善介面。它可以在 Docker 中執行,也可以作為 Microsoft Azure 中的託管服務執行。 Swirl 使用戶能夠利用人工智慧驅動的重新排名功能,同時維護資料安全和隱私。 Swirl 的搜尋技術改變了企業跨應用程式和資料儲存存取資訊的方式。透過利用先進的大型語言模型,Swirl 可以快速篩選來自多個來源(例如 Salesforce 和 Microsoft365)的資料,為使用者提供最相關的結果和見解。  ## Swirl 方法的好處是顯而易見的: - 使用者收到根據其特定需求量身定制的微調搜尋結果。 - 無需移動資料或重新索引內容的麻煩。 ## 關鍵點:  - Swirl 使用 LLM 技術對來自不同來源(如資料孤島、Salesforce、Microsoft 等)的搜尋結果進行分析和排名。 - 漩渦搜尋增強了近乎即時的相關性排名,並將目標查詢的結果置於上下文中。 - 該系統允許針對特定學科領域定制法學碩士,用戶回饋證實了 Swirl 相關性排名的有效性。 - Swirl 最大限度地減少了重新索引的需要,消除了搜尋基礎設施的內容移動,並有效地管理相關性排名和重複資料刪除。 ## 連接器:  您可以在我們的 GitHub 頁面上找到可用連接器清單的廣泛概述。如果您希望按需並優先建立任何內容,請透過「[email protected]」聯絡 Swirl 支援團隊。 # 內部工作和用例 Swirl 整合了先進的內容處理和分析。它使用 API(應用程式介面)來定位和排名多個來源的內容,並透過控制項來增強某些內容。 Swirl 的框架允許快速尋找資訊並將其串流傳輸到各種基於搜尋的應用程式的資料管道中,例如檢索增強生成 (RAG) 和微調大型語言模型。 它提供對組織資料孤島內的資訊的存取,解決與企業搜尋解決方案相關的傳統成本、複雜性和開發問題。 Swirl 採用 OAuth2 等基於標準的身份驗證機制來消除權限和安全性問題。 隨著組織的發展和數位資產的多樣化,像 Swirl 這樣的工具變得不可或缺。請繼續關注我們探索人工智慧驅動的解決方案如何塑造資訊存取和管理的未來。 # Swirl 是開源的 Swirl 是一個開源搜尋平台。這對您意味著什麼: {% 嵌入 https://github.com/swirlai/swirl-search %} - 它是一個自託管、非限制性軟體,具有寬鬆的 Apache 2.0 授權。 - 軟體開發人員可以為專案的開發做出貢獻,深入了解搜尋生態系統,同時深入了解 Swirl。 - 如果您想了解有關 Swirl 的更多訊息,請加入我們的 Slack 社區,進行更多討論。 {% cta https://join.slack.com/t/swirlmetasearch/shared_invite/zt-1qk7q02eo-kpqFAbiZJGOdqgYVvR1sfw %} 加入 Slack {% endcta %} --- 原文出處:https://dev.to/swirl/adding-ai-to-your-enterprise-with-swirl-search-smarter-better-and-faster-4f9b
你的轉職路上,還缺少一份自學作業包!寫完這幾包,直接拿作品去面試上班!
本論壇另有附設一個 LINE 新手發問&交流群組!歡迎加入討論!



























