## TL;DR 🔍 探索在 Kubernetes 上部署 GitLab 的逐步指南,並專注於 Omnibus 套件配置。了解如何設定 PostgreSQL、SMTP、Container Registry、Sidekiq、Prometheus 指標和備份。使用 Glasskube GitLab Kubernetes Operator 探索替代方案,簡化流程並將設定時間縮短至僅 5 分鐘。 --- ## 我們需要您的回饋! 🫶 在下面的評論中分享您的想法!讓我們知道您想要更多內容的主題。如果本指南有幫助,請點擊貓並留下一顆星,以支持我們建立更多以開發人員為中心的內容。您的回饋很重要! [ ](https://github.com/glasskube/operator) --- ## 讓我們開始吧🏌️ [GitLab](https://glasskube.eu/en/s/kubernetes-operator/gitlab/) 是一個以軟體工程團隊為導向的開源 DevSecOps 平台。 有兩種方式可用於在 Kubernetes 叢集上部署 GitLab: 1.GitLab雲端原生混合 2.GitLab包(綜合) ## GitLab 雲端原生混合 部署 GitLab Cloud 原生混合架構僅在查詢特定用例中才有意義。例如 - 如 [GitLab 決策樹](https://docs.gitlab.com/ee/administration/reference_architectures/#decision-tree) 所示 - 如果 GitLab 實例需要為至少 3,000 個使用者提供服務。對於這種部署,GitLab 元件將單獨安裝在不同的 docker 容器中。最低要求為 10 個節點,總共 19 個 vCPU 和 60 GB 內存,這將導致每月數千美元的雲端成本。 <img width="100%" style="width:100%" src="https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExbHl6eXltNWw0ZDNjbnNqbDdicXBpbzNpdX6e nlfaWQmY 3Q9Zw/2aIZfQdC2V7bBvU5t2/giphy.gif"> 因此,在大多數情況下,GitLab 雲端原生是不需要的,而且過於複雜。 **那麼,如何在 Kubernetes 上部署 GitLab Omnibus?** ## Kubernetes 上的 GitLab Omnibus 使用「omnibus」這個名稱,GitLab 也發布了一體化軟體包,這些軟體包可以作為docker 映像[`hub.docker.com/r/gitlab/gitlab-ce`](https://hub.docker. com /r/gitlab/gitlab-ce),可以透過環境變數輕鬆配置。正確進行設定可以輕鬆在 Kubernetes 上部署 GitLab。 應正確配置以下重要元件,以便歸檔合理的 Kubernetes 設定: 1.PostgreSQL資料庫 2. SMTP配置 3. Kubernetes 上的 GitLab 容器註冊表 4. Sidekiq、Gitaly 和 Puma 配置 5. 普羅米修斯指標 6. Kubernetes 上的 GitLab 備份 ### Kubernetes 上的 GitLab:設定外部 PostgreSQL 資料庫 建立 PostgreSQL 資料庫可以使用 [CloudNativePG PostgreSQL Operator](https://cloudnative-pg.io/) 來完成。安裝完 Operator 後,可以透過套用 Kubernetes CR 來部署新的 Postgres 叢集: ``` kind: Cluster apiVersion: postgresql.cnpg.io/v1 metadata: name: gitlab spec: enableSuperuserAccess: false instances: 2 bootstrap: initdb: database: gitlabhq_production owner: gitlab storage: size: 20Gi ``` 重要的是,資料庫名稱為“gitlabhq_product”,而配置的“gitlab”資料庫使用者是資料庫的擁有者。在本例中,我們建立了一個由兩個 PostgreSQL 副本組成的集群,以確保資料庫保持可用,即使執行主副本的節點發生故障也是如此。這稱為高可用性 (HA)。 現在,我們建立了自己的 PostgreSQL 集群,必須在「gitlab.rb」檔案中停用綜合映像中包含的資料庫。 ``` postgresql['enable'] = false gitlab_rails['db_adapter'] = 'postgresql' gitlab_rails['db_encoding'] = 'unicode' gitlab_rails['db_host'] = 'gitlab-pg-rw' gitlab_rails['db_password'] = '<your-password>' ``` 很好,我們已經為 GitLab 安裝提供了雲端原生資料庫。 <img width="25%" style="width:25%" src="https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExc2VydjJoN3BsN2RycDY5N3prZHhoaW8xdTYxenJoN3BsN2RycDY5N3prZHhoaW8xdTYxenhkbHdtBlcMpm30FmDFt0Fyg n;ipPlcmDMlcM40M400005450000200020025400000 mY3 Q9Zw/SVH9y2LQUVVCRcqD7o/giphy.gif"> #### Kubernetes 上的 GitLab:設定 SMTP 憑證 為了確保您的 GitLab 實例能夠傳送電子郵件,您需要設定 SMTP 伺服器。這也可以在 `gitlab.rb` 檔案中完成。 ``` gitlab_rails['smtp_enable'] = ... gitlab_rails['smtp_address'] = ... gitlab_rails['smtp_port'] = ... gitlab_rails['smtp_user_name'] = ... gitlab_rails['smtp_password'] = ... gitlab_rails['smtp_tls'] = ... gitlab_rails['gitlab_email_from'] = ... ``` 例如,可以在 Brevo 平台上建立用於交易電子郵件的免費 smtp 伺服器。 <img width="25%" style="width:25%" src="https://media.giphy.com/media/0IR3vO2bWY1AQPAsAn/giphy.gif"> #### Kubernetes 上的 GitLab:容器註冊表 在眾多功能中,GitLab 支援充當容器註冊表。這是透過捆綁 docker 容器註冊表的參考實作來實現的,但預設情況下它是禁用的,因為正確設定它相當麻煩。 > **重要** > 重要的是要了解 GitLab 綜合容器中的所有請求將首先由內部 nginx 伺服器處理,然後分發到元件。 容器註冊表僅適用於 TLS 加密連接,因此我們需要透過入口負載平衡器停用 TLS 終止,並將加密流量直接傳送到 GitLab 容器。如果使用 NGINX 入口控制器,可以透過在入口中新增以下註解來完成:「nginx.ingress.kubernetes.io/ssl-passthrough: true」。 之後,必須套用以下`gitlab.rb`配置: ``` registry['enable'] = true gitlab_rails['registry_enabled'] = true registry['token_realm'] = "https://" + ENV['GITLAB_HOST'] gitlab_rails['registry_enabled'] = true gitlab_rails['registry_host'] = ENV['GITLAB_REGISTRY_HOST'] gitlab_rails['registry_api_url'] = "http://localhost:5000" registry_external_url 'https://' + ENV['GITLAB_REGISTRY_HOST'] registry_nginx['redirect_http_to_https'] = true registry_nginx['listen_port'] = 5443 registry_nginx['ssl_certificate'] = "/etc/gitlab/ssl/tls.crt" registry_nginx['ssl_certificate_key'] = "/etc/gitlab/ssl/tls.key" registry_nginx['real_ip_trusted_addresses'] = ['10.0.0.0/8', '172.16.0.0/12', '192.168.0.0/16'] registry_nginx['server_names_hash_bucket_size'] = 128 ``` 此外,可以配置 S3 儲存桶(或相容的雲端儲存端點),以便所有影像層不會儲存在磁碟區內,而是儲存在可擴充的 S3 中 ### Kubernetes 上的 GitLab:Sidekiq、Gitaly 和 Puma 配置 Puma(Ruby 的 HTTP 伺服器)、Sidekiq(作業排程器)和 Gitaly(GitLabs Git 橋接器)都可以使用自訂數量的工作執行緒/執行緒來啟動。最佳配置在很大程度上取決於您的用例和需要支援的使用者數量。合理的最小配置是: ``` puma['worker_processes'] = 2 sidekiq['max_concurrency'] = 9 ``` ### Kubernetes 上的 GitLab:Prometheus 指標 GitLab 綜合包在鏡像中附帶了自己的 prometheus 實例。由於大多數 Kubernetes 叢集中已經存在 Prometheus 實例,因此可以安全地停用包含的 Prometheus。 ``` prometheus_monitoring['enable'] = false ``` ServiceMonitor 可以用來告訴正在執行的 Prometheus 實例在下列連接埠上監視 GitLabs 元件所公開的指標端點: - 8082(sidekiq) - 9168(gitlab) - 9236(義大利) ### Kubernetes 上的 GitLab:備份 嗯,在 Kubernetes 上備份 GitLab 本身就是一個技術指南。最簡單的方法是使用 [Velero](https://velero.io/) 等備份解決方案備份完整的命名空間。 ## 玻璃立方體 GitLab Kubernetes Operator 了解Glasskube GitLab [Kubernetes Operator](https://glasskube.eu/en/r/glossary/kubernetes-operator/) - 我們的開發團隊對繁瑣的配置過程、耗時的設定和不斷的故障排除感到沮喪的產物與 GitLab 部署相關。為了應對這些挑戰,我們精心設計了一個簡化整個體驗的解決方案。 Glasskube GitLab Kubernetes Operator 部署一個完全配置的 GitLab 實例,其所有功能均透過自訂資源定義 (CRD) 巧妙抽象化。感謝操作員,花費過多時間進行設定和更新的日子已經結束。現在,您可以在短短 5 分鐘內輕鬆啟動新的 GitLab 實例。嘗試一下並向我們提供反饋! ### 安裝 Glasskube 運算符 第一步是透過 Helm Chart 安裝 Glasskube: ``` helm repo add glasskube https://charts.glasskube.eu/ helm repo update helm install my-glasskube-operator glasskube/glasskube-operator ``` 完整的文件可以在我們的[入門](https://glasskube.eu/docs/getting-started/install/)文件中找到。 ### 部署 GitLab > **重要** > 必須在「LoadBalancer」或「Ingress Host」上設定 DNS 專案。 SSL 憑證是 > 如果配置了“ClusterIssuer”,則由“LoadBalancer”或“cert-manager”自動產生。 **gitlab.yaml** ``` apiVersion: "v1" kind: "Secret" metadata: name: "gitlab-smtp" stringData: username: "..." password: "..." --- apiVersion: v1 kind: Secret metadata: name: gitlab-registry-secret stringData: accessKey: "..." secretKey: "..." --- apiVersion: "glasskube.eu/v1alpha1" kind: "Gitlab" metadata: name: "gitlab" spec: host: "gitlab.mycompany.eu" sshEnabled: true sshHost: "ssh.gitlab.mycompany.eu" smtp: host: "..." port: 465 fromAddress: "[email protected]" authSecret: name: "gitlab-smtp" tlsEnabled: true registry: host: "registry.gitlab.mycompany.eu" storage: s3: bucket: gitlab-registry accessKeySecret: name: gitlab-registry-secret key: accessKey secretKeySecret: name: gitlab-registry-secret key: secretKey region: ... ``` ``` kubectl apply -f gitlab.yaml ``` <img width="25%" style="width:25%" src="https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExa2RldHpiYnMzOWdlZTgwdWtqOHN3N3eG9I0NjVyd2l4m Y3Q9Zw/YRhUem7n2UaF9EK2PH/giphy.gif"> 就是這樣! 完整的自訂資源文件可以在 Glasskube 文件中找到 關於 [GitLab](https://glasskube.eu/docs/crd-reference/gitlab/) ### 在 Kubernetes 上部署 GitLab Runner <img width="25%" style="width:25%" src="https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExZDJsN2x6NTI0dWdhZW55MjBzMjFobHdtbDRtaHEycXlidWdhZW55MjBzMjFobHdtbDRtaHEycXlidWdhZW55MjBzMjFobHdtbDRtaHEycXlidGt. WQmY 3Q9Zw/945jGDodvZCDe/giphy.gif"> GitLab 上的運作程序是為持續整合和持續交付 (CI/CD) 管道提供支援的執行代理。 他們負責執行作業,即管道中的各個步驟或任務。 Glasskube Gitlab Kubernetes Operator 讓在 Gitlab 中新增執行器變得如此簡單。首先,需要透過「https://{{host}}/admin/runners/new」建立一個新的執行程式。之後,這些執行器令牌只需加入到「gitlab.yaml」規格中,Glasskube Kubernetes Operator 將自動產生並將這些執行器與 Gitlab 實例連接起來。 ``` runners: - token: glrt-xxxxXX-xxxxxXXXXX # can be generated at https://{{host}}/admin/runners/new ``` 完整的自訂資源文件可以在關於 [GitLab runner] 的 Glasskube 文件中找到(https://glasskube.eu/docs/crd-reference/gitlab/runner/) 現在安裝完成了。 Kubernetes Operator 的更新將自動更新 GitLab。 ## 結論 在 Kubernetes 上為少於 1000 個使用者部署 GitLab 實例不應該使用 GitLabs 雲端原生混合 Helm Charts 來完成,而應該使用專門安裝的 GitLab Omnibus 套件與雲端原生基礎架構結合來完成。 Glasskube Kubernetes 操作員負責處理這個問題。 --- [ ](https://github.com/glasskube/operator) --- 星星冰塊: # [`glasskube/operator`](https://github.com/glasskube/operator) --- 原文出處:https://dev.to/glasskube/gitlab-on-kubernetes-the-ultimate-deployment-guide-188b
本文將透過一個簡單的範例來示範如何**將 PySpark 與 Taipy 整合**,以將您的 **大資料處理需求** 與 **智慧作業執行** 結合。 #### 讓我們開始吧!  <小時/> ### 將 PySpark 與 Taipy 結合使用 Taipy 是一個**強大的工作流程編排工具**,具有**易於使用的框架**,可輕鬆應用於您現有的資料應用程式。 Taipy 建立在堅實的概念基礎上: - **場景、任務和資料節點** - 這些概念非常強大,允許開發人員**輕鬆地對其管道進行建模**,即使在沒有明確支援的情況下使用第3 方包也是如此。 <小時/>  {% cta https://github.com/Avaiga/taipy %} Star ⭐ Taipy 儲存庫 {% endcta %} 我們感謝任何幫助我們發展社區的幫助🌱 <小時/> *如果您已經熟悉 PySpark 和 Taipy,則可以跳至「2. Taipy 設定 (*config.py*)」。 *該部分深入探討了為 Taipy 任務定義函數來執行 PySpark 應用程式的本質。否則,請繼續閱讀!* <小時/> ### 一個簡單的例子:*palmerpenguins* 我們以 [palmerpenguins](https://allisonhorst.github.io/palmerpenguins/) 資料集為例: ``` >>> penguin_df ┌───────┬─────────┬───────────┬────────────────┬───────────────┬───────────────────┬─────────────┬────────┬──────┐ │ index │ species │ island │ bill_length_mm │ bill_depth_mm │ flipper_length_mm │ body_mass_g │ sex │ year │ ├───────┼─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼──────┤ │ 0 │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181.0 │ 3750.0 │ male │ 2007 │ │ 1 │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186.0 │ 3800.0 │ female │ 2007 │ │ 2 │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195.0 │ 3250.0 │ female │ 2007 │ │ 3 │ Adelie │ Torgersen │ NaN │ NaN │ NaN │ NaN │ NaN │ 2007 │ │ 4 │ Adelie │ Torgersen │ 36.7 │ 19.3 │ 193.0 │ 3450.0 │ female │ 2007 │ │ ... │ ... │ ... │ ... │ ... │ ... │ ... │ ... │ ... │ └───────┴─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴──────┘ ``` <小時/> 該資料集僅包含 344 筆記錄——幾乎不是一個需要 Spark 處理的資料集。 然而,該資料集是可存取的,且其大小與演示 Spark 與 Taipy 的整合無關。 如果必須使用更大的資料集進行測試,您可以根據需要多次複製資料。 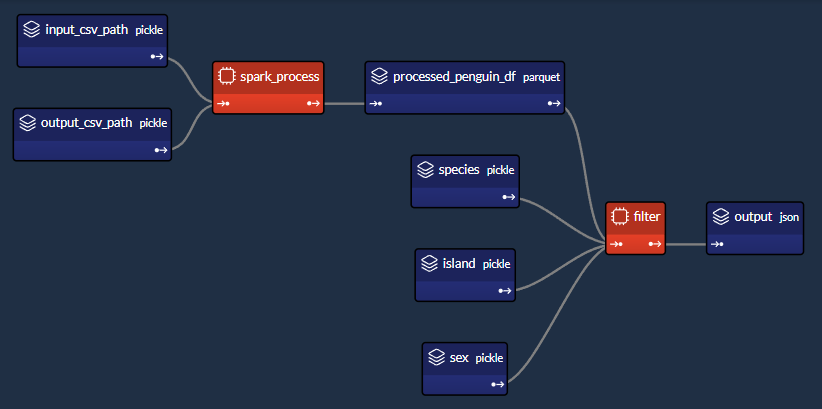 *我們簡單的企鵝應用程式的 DAG* <小時/> 我們將設計一個執行**兩個主要任務**的工作流程: #### 1- Spark 任務(*spark_process*): - 載入資料; - 依「*物種*」、「*島嶼*」和「*性別*」將資料分組; - 求其他欄位的平均值(「*bill_length_mm*」、「*bill_depth_mm*」、「*flipper_length_mm*」、「*body_mass_g*」); - 儲存資料。 #### 2- Python 任務(*過濾器*): - 載入Spark任務之前儲存的輸出資料; - 給定“*物種*”、“*島嶼*”和“*性別*”,傳回聚合值。 我們的小專案將包含 4 個檔案: ``` app/ ├─ penguin_spark_app.py # the spark application ├─ config.py # the configuration for our taipy workflow ├─ main.py # the main script (including our application gui) ├─ penguins.csv # the data as downloaded from the palmerpenguins git repo ``` <小時/> 您可以找到每個檔案的內容(*penguins.csv* 除外,您可以從 [palmerpenguins 儲存庫](https://github.com/allisonhorst/palmerpenguins/blob/main/inst/extdata/penguins.csv 取得) )在本文的程式碼區塊中。 <小時/> ## 1. Spark 應用程式 (*penguin_spark_app.py*) 通常,我們使用 *spark-submit* 命令列實用程式來執行 PySpark 任務。 您可以在他們自己的文件中閱讀有關以這種方式提交Spark 作業的內容和原因的更多資訊[此處](https://spark.apache.org/docs/latest/submitting-applications.html) 。 當使用 Taipy 進行工作流程編排時,我們可以繼續做同樣的事情。 唯一的區別是,我們不是在命令列中執行命令,而是讓工作流程管道產生一個[子進程](https://docs.python.org/3/library/subprocess.html),它使用以下命令執行Spark 應用程式*火花提交*。 在開始討論之前,我們首先**看看我們的 Spark 應用程式**。 只需瀏覽一下程式碼,然後**繼續閱讀有關此腳本功能的簡短說明**: ``` ### app/penguin_spark_app.py import argparse import os import sys parser = argparse.ArgumentParser() parser.add_argument("--input-csv-path", required=True, help="Path to the input penguin CSV file.") parser.add_argument("--output-csv-path", required=True, help="Path to save the output CSV file.") args = parser.parse_args() import pyspark.pandas as ps from pyspark.sql import SparkSession def read_penguin_df(csv_path: str): penguin_df = ps.read_csv(csv_path) return penguin_df def clean(df: ps.DataFrame) -> ps.DataFrame: return df[df.sex.isin(["male", "female"])].dropna() def process(df: ps.DataFrame) -> ps.DataFrame: """The mean of measured penguin values, grouped by island and sex.""" mean_df = df.groupby(by=["species", "island", "sex"]).agg("mean").drop(columns="year").reset_index() return mean_df if __name__ == "__main__": spark = SparkSession.builder.appName("Mean Penguin").getOrCreate() penguin_df = read_penguin_df(args.input_csv_path) cleaned_penguin_df = clean(penguin_df) processed_penguin_df = process(cleaned_penguin_df) processed_penguin_df.to_pandas().to_csv(args.output_csv_path, index=False) sys.exit(os.EX_OK) ``` <小時/> 我們可以透過在終端機中輸入以下命令來提交此 Spark 應用程式以供執行: ``` spark-submit --master local[8] app/penguin_spark_app.py \ --input-csv-path app/penguins.csv \ --output-csv-path app/output.csv ``` <小時/> 它將執行以下操作: 1.提交*penguin_spark_app.py*應用程式在8個CPU核心上本地執行; 2. 從 *app/penguins.csv* CSV 檔案載入資料; 3. 依「*物種*」、「*島嶼*」和「*性別*」分組,然後按平均值聚合其餘欄位; 4. 將產生的 DataFrame 儲存到 *app/output.csv*。 此後,*app/output.csv* 的內容應如下所示: 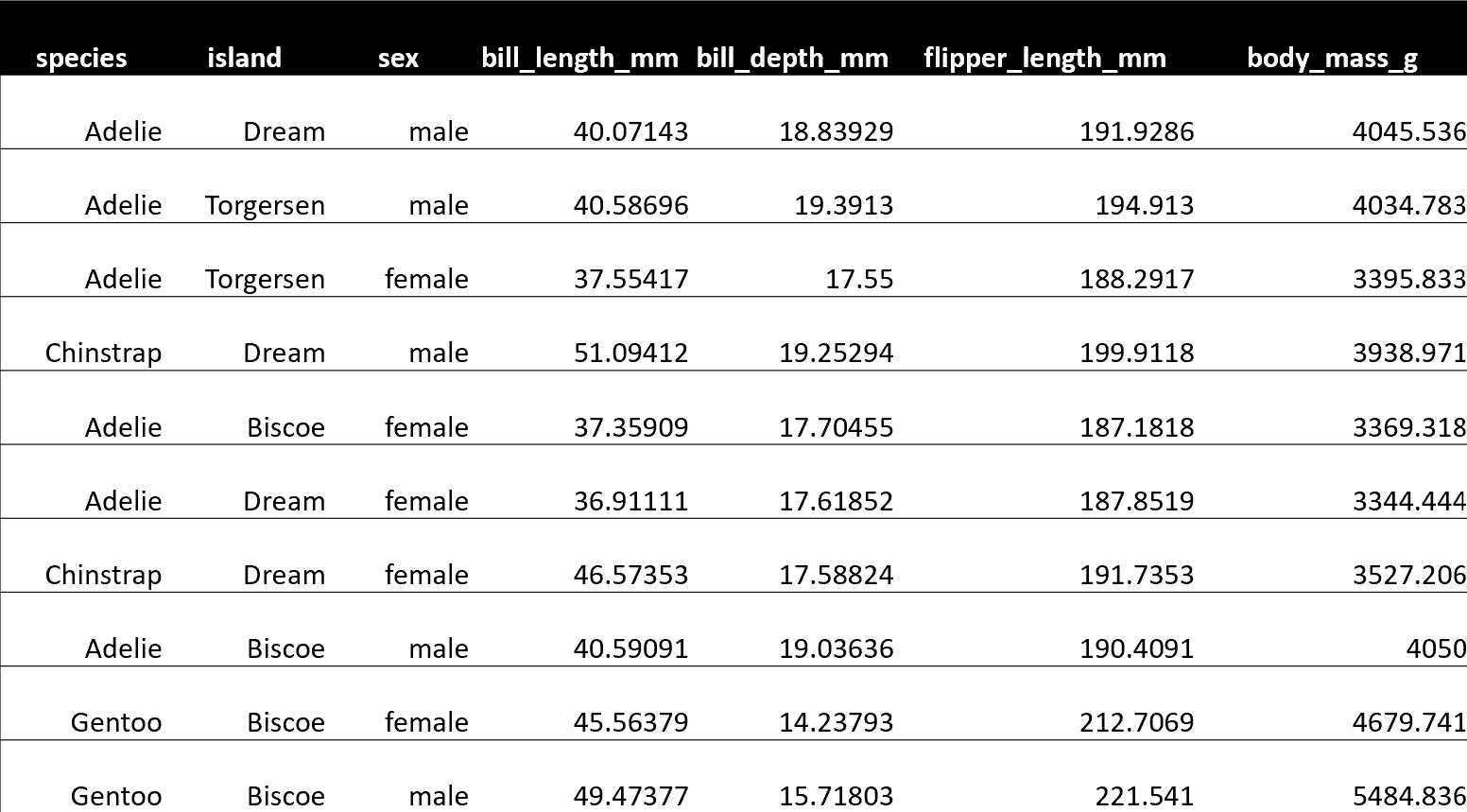 <小時/> 另請注意,我們已對 **Spark 應用程式進行了編碼以接收 2 個命令列參數**: 1. - *input-csv-path* :輸入企鵝 CSV 檔案的路徑;和 2. - *output-csv-path* :Spark 應用程式處理後儲存輸出 CSV 檔案的路徑。 <小時/> ## 2. Taipy 設定 (*config.py*) 此時,我們有了 *penguin_spark_app.py* PySpark 應用程式,並且需要建立一個 **Taipy 任務來執行此 PySpark 應用程式**。 再次快速瀏覽 *app/config.py* 腳本,然後繼續閱讀: ``` ### app/config.py import datetime as dt import os import subprocess import sys from pathlib import Path import pandas as pd import taipy as tp from taipy import Config SCRIPT_DIR = Path(__file__).parent SPARK_APP_PATH = SCRIPT_DIR / "penguin_spark_app.py" input_csv_path = str(SCRIPT_DIR / "penguins.csv") # -------------------- Data Nodes -------------------- input_csv_path_cfg = Config.configure_data_node(id="input_csv_path", default_data=input_csv_path) # Path to save the csv output of the spark app output_csv_path_cfg = Config.configure_data_node(id="output_csv_path") processed_penguin_df_cfg = Config.configure_parquet_data_node( id="processed_penguin_df", validity_period=dt.timedelta(days=1) ) species_cfg = Config.configure_data_node(id="species") # "Adelie", "Chinstrap", "Gentoo" island_cfg = Config.configure_data_node(id="island") # "Biscoe", "Dream", "Torgersen" sex_cfg = Config.configure_data_node(id="sex") # "male", "female" output_cfg = Config.configure_json_data_node( id="output", ) # -------------------- Tasks -------------------- def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame: proc = subprocess.Popen( [ str(Path(sys.executable).with_name("spark-submit")), str(SPARK_APP_PATH), "--input-csv-path", input_csv_path, "--output-csv-path", output_csv_path, ], stdout=subprocess.PIPE, stderr=subprocess.PIPE, ) try: outs, errs = proc.communicate(timeout=15) except subprocess.TimeoutExpired: proc.kill() outs, errs = proc.communicate() if proc.returncode != os.EX_OK: raise Exception("Spark training failed") df = pd.read_csv(output_csv_path) return df def filter(penguin_df: pd.DataFrame, species: str, island: str, sex: str) -> dict: df = penguin_df[(penguin_df.species == species) & (penguin_df.island == island) & (penguin_df.sex == sex)] output = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]].to_dict(orient="records") return output[0] if output else dict() spark_process_task_cfg = Config.configure_task( id="spark_process", function=spark_process, skippable=True, input=[input_csv_path_cfg, output_csv_path_cfg], output=processed_penguin_df_cfg, ) filter_task_cfg = Config.configure_task( id="filter", function=filter, skippable=True, input=[processed_penguin_df_cfg, species_cfg, island_cfg, sex_cfg], output=output_cfg, ) scenario_cfg = Config.configure_scenario( id="scenario", task_configs=[spark_process_task_cfg, filter_task_cfg] ) ``` 您也可以**使用[Taipy Studio](https://docs.taipy.io/en/latest/manuals/studio/config/)** 建立Taipy 配置,這是一個Visual Studio Code 擴展,它提供了圖形編輯器建構 Taipy *.toml* 設定檔。 <小時/> ### Taipy 中的 PySpark 任務 我們對產生這部分 DAG 的程式碼部分特別感興趣: 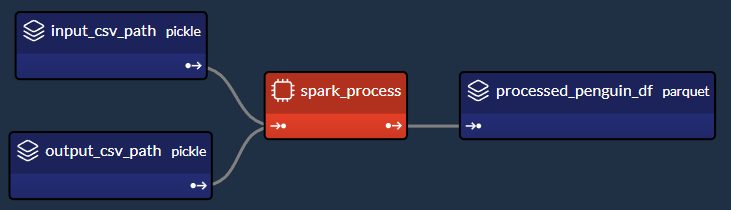 <小時/> 讓我們提取並檢查 *config.py* 腳本的相關部分,該腳本在 Taipy 中建立「*spark_process*」Spark 任務(及其 3 個關聯的資料節點),如上圖所示: ``` ### Code snippet: Spark task in Taipy # -------------------- Data Nodes -------------------- input_csv_path_cfg = Config.configure_data_node(id="input_csv_path", default_data=input_csv_path) # Path to save the csv output of the spark app output_csv_path_cfg = Config.configure_data_node(id="output_csv_path") processed_penguin_df_cfg = Config.configure_parquet_data_node( id="processed_penguin_df", validity_period=dt.timedelta(days=1) ) # -------------------- Tasks -------------------- def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame: proc = subprocess.Popen( [ str(Path(sys.executable).with_name("spark-submit")), str(SPARK_APP_PATH), "--input-csv-path", input_csv_path, "--output-csv-path", output_csv_path, ], stdout=subprocess.PIPE, stderr=subprocess.PIPE, ) try: outs, errs = proc.communicate(timeout=15) except subprocess.TimeoutExpired: proc.kill() outs, errs = proc.communicate() if proc.returncode != os.EX_OK: raise Exception("Spark training failed") df = pd.read_csv(output_csv_path) return df spark_process_task_cfg = Config.configure_task( id="spark_process", function=spark_process, skippable=True, input=[input_csv_path_cfg, output_csv_path_cfg], output=processed_penguin_df_cfg, ) ``` <小時/> 由於我們設計 *penguin_spark_app.py* Spark 應用程式來接收 2 個參數(*input_csv_path* 和 *output_csv_path*),因此我們選擇將這 2 個參數表示為 Taipy 資料節點。 請注意,**您的用例可能有所不同,您可以(並且應該!)根據您的需求修改任務、函數和關聯的資料節點**。 例如,您可以: 1. 有一個 Spark 任務,執行一些例行 ETL 並且不回傳任何內容; 2. 偏好對輸入和輸出路徑進行硬編碼,而不是將它們持久化為資料節點;或者 3. 將其他應用程式參數儲存為資料節點並將其傳遞給 Spark 應用程式。 然後,我們將 *spark-submit* 作為 Python 子進程執行,如下所示: ``` subprocess.Popen( [ str(Path(sys.executable).with_name("spark-submit")), str(SPARK_APP_PATH), "--input-csv-path", input_csv_path, "--output-csv-path", output_csv_path, ], ) ``` <小時/> 回想一下,清單元素的順序應保留以下格式,就像它們在命令列上執行一樣: ``` $ spark-submit [spark-arguments] <pyspark-app-path> [application-arguments] ``` <小時/> 同樣,根據我們的用例,我們可以根據需要指定不同的 Spark-submit 腳本路徑、Spark 參數(我們在範例中未提供任何參數)或不同的應用程式參數。 <小時/> ### 讀取並回傳*output_csv_path* 請注意,*spark_process* 函數的結束如下: ``` def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame: ... df = pd.read_csv(output_csv_path) return df ``` <小時/> 在我們的例子中,我們希望 Taipy 任務在 Spark - 處理資料後輸出資料,以便可以將其寫入 *processed_penguin_df_cfg* [Parquet 資料節點](https://docs.taipy.io/en/latest /手冊/核心/配置/資料節點配置/#parquet)。 我們可以做到這一點的一種方法是手動讀取輸出目標(在本例中為 *output_csv_path*),然後將其作為 Pandas DataFrame 傳回。 但是,如果您不需要 Spark 應用程式的返回資料,您可以簡單地讓 Taipy 任務(透過 *spark_process* 函數)返回 *None*。 <小時/> ### 快取 Spark 任務 由於我們將 *spark_process_task_cfg* 配置為 *True*,當重新執行該場景時,Taipy 將 **跳過 ** ***spark_process 的重新執行*** **任務** 並重複使用持久化任務輸出:* processed_penguin_df_cfg* Pandas DataFrame。 但是,我們也為 *processed_penguin_df_cfg* 資料節點定義了 1 天的 *validity_period*,因此如果 DataFrame 最後一次快取超過一天,Taipy 仍會重新執行任務。 <小時/> ## 3. 建構 GUI (*main.py*) 我們將透過**建立我們在本文開頭看到的 GUI** 來完成我們的應用程式: 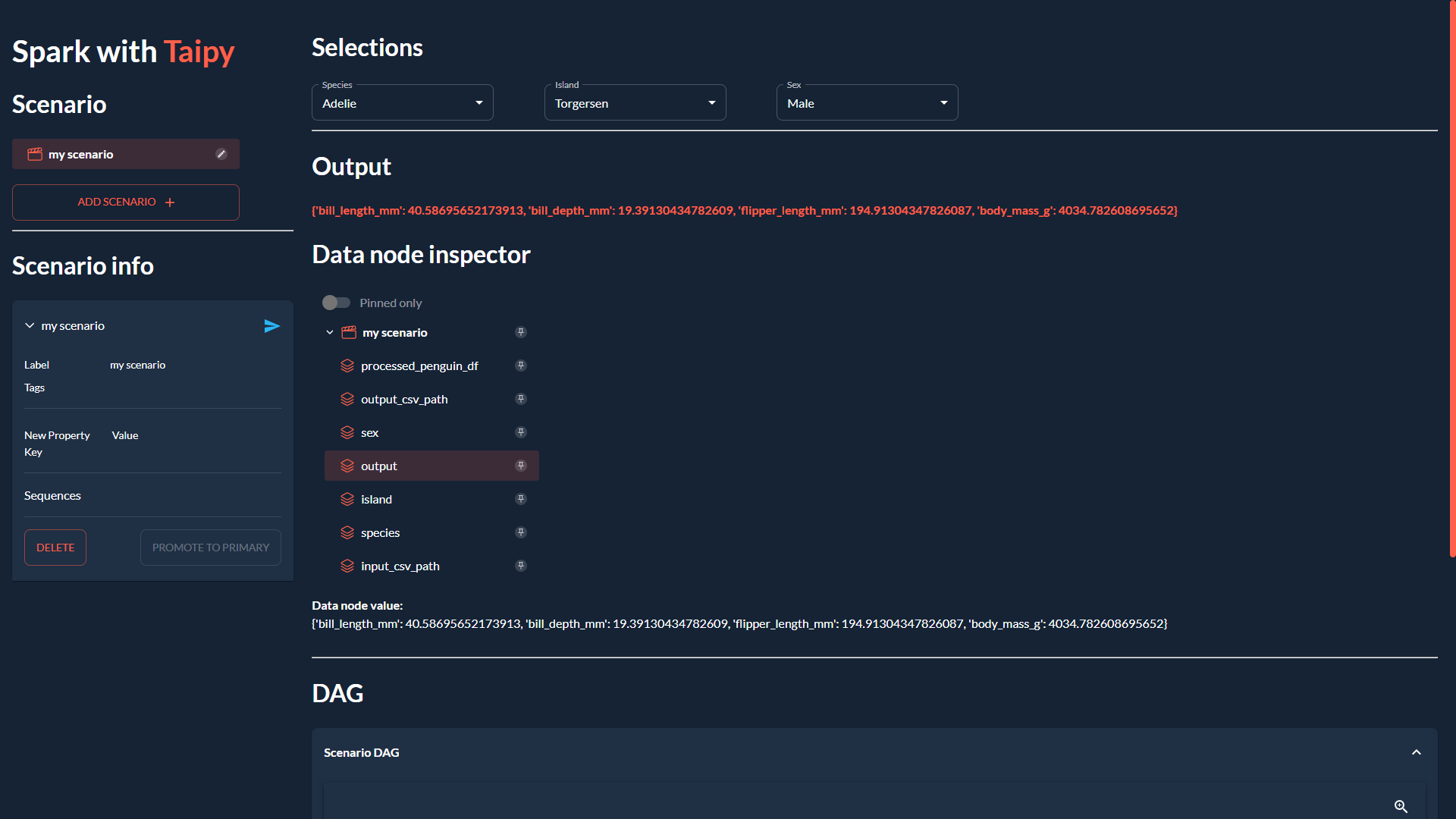 <小時/> 如果您不熟悉 Taipy 的 GUI 功能,可以在此處找到[快速入門](https://docs.taipy.io/en/latest/getting_started/getting-started-gui/)。 無論如何,您只需為 *app/main.py* 複製並貼上以下程式碼,因為它不是我們的重點: ``` ### app/main.py from pathlib import Path from typing import Optional import taipy as tp from config import scenario_cfg from taipy.gui import Gui, notify valid_features: dict[str, list[str]] = { "species": ["Adelie", "Chinstrap", "Gentoo"], "island": ["Torgersen", "Biscoe", "Dream"], "sex": ["Male", "Female"], } selected_species = valid_features["species"][0] selected_island = valid_features["island"][0] selected_sex = valid_features["sex"][0] selected_scenario: Optional[tp.Scenario] = None data_dir = Path(__file__).with_name("data") data_dir.mkdir(exist_ok=True) def scenario_on_creation(state, id, payload): _ = payload["config"] date = payload["date"] label = payload["label"] properties = payload["properties"] # Create scenario with selected configuration scenario = tp.create_scenario(scenario_cfg, creation_date=date, name=label) scenario.properties.update(properties) # Write the selected GUI values to the scenario scenario.species.write(state.selected_species) scenario.island.write(state.selected_island) scenario.sex.write(state.selected_sex.lower()) output_csv_file = data_dir / f"{scenario.id}.csv" scenario.output_csv_path.write(str(output_csv_file)) notify(state, "S", f"Created {scenario.id}") return scenario def scenario_on_submission_change(state, submittable, details): """When the selected_scenario's submission status changes, reassign selected_scenario to force a GUI refresh.""" state.selected_scenario = submittable selected_data_node = None main_md = """ <|layout|columns=1 4|gap=1.5rem| <lhs|part| # Spark with **Taipy**{: .color-primary} ## Scenario <|{selected_scenario}|scenario_selector|on_creation=scenario_on_creation|> ---------- ## Scenario info <|{selected_scenario}|scenario|on_submission_change=scenario_on_submission_change|> |lhs> <rhs|part|render={selected_scenario}| ## Selections <selections|layout|columns=1 1 1 2|gap=1.5rem| <|{selected_species}|selector|lov={valid_features["species"]}|dropdown|label=Species|> <|{selected_island}|selector|lov={valid_features["island"]}|dropdown|label=Island|> <|{selected_sex}|selector|lov={valid_features["sex"]}|dropdown|label=Sex|> |selections> ---------- ## Output **<|{str(selected_scenario.output.read()) if selected_scenario and selected_scenario.output.is_ready_for_reading else 'Submit the scenario using the left panel.'}|text|raw|class_name=color-primary|>** ## Data node inspector <|{selected_data_node}|data_node_selector|display_cycles=False|> **Data node value:** <|{str(selected_data_node.read()) if selected_data_node and selected_data_node.is_ready_for_reading else None}|> <br/> ---------- ## DAG <|Scenario DAG|expandable| <|{selected_scenario}|scenario_dag|> |> |rhs> |> """ def on_change(state, var_name: str, var_value): if var_name == "selected_species": state.selected_scenario.species.write(var_value) elif var_name == "selected_island": state.selected_scenario.island.write(var_value) elif var_name == "selected_sex": state.selected_scenario.sex.write(var_value.lower()) if __name__ == "__main__": tp.Core().run() gui = Gui(main_md) gui.run(title="Spark with Taipy") ``` <小時/> 然後,從專案資料夾中,您可以執行主腳本,如下所示: ``` $ taipy run app/main.py ``` <小時/> ## 結論 現在您已經看到如何將 PySpark 與 Taipy 結合使用的範例,請繼續嘗試使用這兩個工具來**增強您自己的資料應用程式**! 如果您一直在努力應對其他工作流程編排工具減慢您的工作並妨礙您的工作,請不要讓它阻止您嘗試 Taipy。 Taipy 易於使用,並且努力不限制自己可以使用的第 3 方軟體包 - **其強大而靈活的框架使其可以輕鬆適應任何資料應用程式**。 <小時/>  希望您喜歡這篇文章! <小時/> 您可以在此[儲存庫](https://medium.com/r?url=https%3A%2F%2Fgithub.com%2FAvaiga%2Fdemo-pytorch-penguin-app)上找到所有程式碼和資料。 --- 原文出處:https://dev.to/taipy/how-to-master-big-data-pipelines-with-taipy-and-pyspark-14oe
家裡有一台 2018 年的 asus 舊筆電 硬碟大概有 100GB 的閒置空間 剛好最近家裡 中華電信網路升級,想說來用出租硬碟 挖挖看 storj 幣 --- https://www.storj.io/host-a-node 跟著步驟跑 在 `Generate node identity` 這步驟 發現他會狂跑CPU 直到算出一個難度為 36 以上的 key 為止 我筆電大概算到 33 就算不出來了,後面算很久都還是 33 要算到 36 恐怕要一星期吧 --- 上網查了一下報酬 https://www.reddit.com/r/storj/comments/17uk8er/is_it_worth_starting/ 看起來大家都是用 10 - 40 TB 左右的硬碟出租,每個月報酬 10 - 30 美元左右 這個報酬顯然很不划算,可能連電費都付不了? 我就中止嘗試了 分散式的硬碟雲端儲存,所謂的 web3 應用,還要再等等
隨著人工智慧市場的不斷成長。我們即將做出很多改變。 最近,我一直在思考在各個領域取得重大進展的最新新創公司。這些新創公司參與了開創性的工作,從增強資料互動性到探索大型語言模型在營運中的潛力(一種稱為 LLM Ops 的新概念)。此外,我對搜尋引擎和生成人工智慧的進步很著迷,它們正在徹底改變我們與技術互動的方式。 我在 DEV.to 上看到他們中的許多人,然後我想嘗試他們的專案。我對這些公司所付出的努力和創新感到驚訝。 ## [Pezzo:開發者優先的人工智慧平台](https://github.com/pezzolabs/pezzo)  **GitHub 儲存庫**:[GitHub 上的 Pezzo](https://github.com/pezzolabs/pezzo) **網址**:[片段](https://pezzo.ai/) **描述**: Pezzo 是一個為開發人員量身定制的開源雲端原生 LLMOps 平台。它透過提供簡化的提示設計、版本管理、即時交付等,徹底改變了人工智慧操作。該平台能夠有效觀察和監控人工智慧操作、顯著降低成本和延遲、無縫協作以及立即交付人工智慧變更。 **主要特徵**: - **提示管理**:提示的集中管理和版本控制,允許即時部署到生產。 - **可觀察性**:提供有關人工智慧操作的詳細見解,優化支出、速度和品質。 - **故障排除**:即時檢查提示執行,最大限度地減少除錯工作。 - **協作**:促進同步團隊合作,以交付有影響力的 AI 功能。 **加入社群**: 加入他們的 [Discord 社群](https://pezzo.cc),成為 Pezzo 創新之旅的一部分。透過為他們的 GitHub 儲存庫加註星標來為他們的使命做出貢獻並支持他們! [在 GitHub 上給 Pezzo 一顆星](https://github.com/pezzolabs/pezzo) 🌟,加入 AI 維運革命! https://github.com/pezzolabs/pezzo ## [Swirl:人工智慧驅動的多來源搜尋平台](https://github.com/swirlai/swirl-search)  **GitHub 儲存庫**:[GitHub 上的 Swirl](https://github.com/swirlai/swirl-search) **網站**:[Swirl](https://swirl.today/) **描述**: Swirl 是一款創新的開源軟體,它利用人工智慧同時搜尋多個內容和資料來源。它使用人工智慧對結果進行排名,獲取最相關的部分,並使用生成式人工智慧來提供從您自己的資料得出的答案。該工具對於整合和從各種資料來源中提取有價值的見解特別有用。 **主要特徵**: - **人工智慧驅動的搜尋**:同時搜尋多個來源,提供人工智慧排名的結果。 - **生成式人工智慧整合**:使用熱門搜尋結果提示生成式人工智慧提供全面的答案。 - **多樣化資料來源連線**:連接到資料庫(SQL、NoSQL、Google BigQuery)、公共資料服務以及 Microsoft 365、Jira、Miro 等企業來源。 - **可自訂和可擴展**:提供靈活的平台,用於資料豐富、實體分析以及整合各種應用程式的非結構化資料。 **加入社群**: 參與 Swirl 社區並貢獻您的想法!加入 [Swirl Slack 社群](https://join.slack.com/t/swirlmetasearch/shared_invite/zt-1qk7q02eo-kpqFAbiZJGOdqgYVvR1sfw),並透過為他們的儲存庫加入星標來支持他們的成長。 [GitHub 上的 Star Swirl](https://github.com/swirlai/swirl-search) 並成為這令人興奮的人工智慧搜尋演化的一部分! 🌟 https://github.com/swirlai/swirl-search ## [DeepEval:LLM評估架構](https://github.com/confident-ai/deepeval)  **GitHub 儲存庫**:[GitHub 上的 DeepEval](https://github.com/confident-ai/deepeval) **網址**:【Confident AI】(https://www.confident-ai.com/) **描述**: DeepEval 是大型語言模型 (LLM) 的開源評估框架。它簡化了 LLM 應用程式的評估,類似於 Pytest 進行單元測試的操作方式。 DeepEval 因提供一系列專為 LLMs 量身定制的評估指標而脫穎而出,使其成為嚴格績效評估的生產就緒替代方案。 **主要特徵**: - **多樣化的評估指標**:提供由 LLMs 評估或透過統計方法和 NLP 模型計算的多種指標。 - **自訂指標建立**:允許輕鬆建立自訂指標,無縫整合到 DeepEval 的生態系統中。 - **批量資料集評估**:以最少的編碼工作促進整個資料集的評估。 - **與 Confident AI 整合**:能夠即時觀察評估結果並比較不同的超參數。 [在GitHub上Star DeepEval](https://github.com/confident-ai/deepeval)並為LLM評估架構的進步做出貢獻! 🌟 https://github.com/confident-ai/deepeval ## [LiteLLM:通用LLM API介面](https://github.com/BerriAI/litellm)  **GitHub 儲存庫**:[GitHub 上的 LiteLLM](https://github.com/BerriAI/litellm) **網站**:[LiteLLM 文件](https://docs.litellm.ai/docs/#quick-start/) **描述**: LiteLLM是一個開源工具,使用戶能夠使用統一的OpenAI格式呼叫各種LLM API。它支援廣泛的供應商,如 Bedrock、Azure、OpenAI、Cohere、Anthropic、Ollama、Sagemaker、HuggingFace、Replicate 等,提供與 100 多個LLMS合作的簡化方法。該工具對於以一致且高效的方式簡化不同LLMS的整合和利用至關重要。 **主要特徵**: - **通用 API 格式**:方便使用標準化 OpenAI 格式呼叫不同的 LLM API。 - **支援廣泛的LLMS**:與眾多LLMS提供者相容,包括 OpenAI、Azure、Cohere 和 HuggingFace 等主要提供者。 - **一致的輸出和異常映射**:確保統一的輸出結構並將跨提供者的常見異常映射到 OpenAI 異常類型。 - **易於使用**:支援批量操作並簡化與LLMS的交互,使其更適合各種應用程式。 **加入社群**: 參與 LiteLLM 的開發並分享您的改進!克隆存儲庫,進行更改並提交 PR。 [在 GitHub 上星標 LiteLLM](https://github.com/BerriAI/litellm) 並立即簡化您與LLMS的工作! 🌟 https://github.com/BerriAI/litellm ## [Qdrant:人工智慧高效能向量資料庫](https://github.com/qdrant/qdrant)  **GitHub 儲存庫**:[GitHub 上的 Qdrant](https://github.com/qdrant/qdrant) **網址**:[Qdrant](https://qdrant.tech/) **描述**: Qdrant是專為下一代AI應用量身定制的高性能、大規模向量資料庫。它是一個向量相似性搜尋引擎和資料庫,透過易於使用的 API 提供生產就緒的服務。 Qdrant 對於神經網路或基於語義的匹配、分面搜尋以及其他需要有效處理具有相關負載的向量的應用特別有效。 **主要特徵**: - **豐富的資料類型和查詢規劃**:支援多種資料類型和查詢條件,包括字串比對、數值範圍、地理位置等,並利用有效負載資訊進行高效率的查詢規劃。 - **硬體加速和預寫式日誌記錄**:利用現代 CPU 架構實現更快的效能並確保資料持久性和可靠性。 - **分散式部署**:支援水平擴展,多台 Qdrant 機器形成集群,透過 Raft 協定進行協調。 - **集成**:輕鬆與 Cohere、DocArray、LangChain、LlamaIndex 等平台集成,甚至與 OpenAI 的 ChatGPT 檢索插件集成。 **加入社群**: 成為 Qdrant 社區的一部分並為這個創新專案做出貢獻。加入他們的 [Discord](https://qdrant.to/discord)。 [GitHub 上的 Star Qdrant](https://github.com/qdrant/qdrant) 並幫助塑造 AI 中向量資料庫的未來! 🌟 https://github.com/qdrant/qdrant --- ### 衷心的感謝 您有興趣探索和了解這些新創公司正在研究的不同主題。成為他們社群的一部分肯定會幫助您成長並了解不同的軟體和人工智慧領域。 --- 原文出處:https://dev.to/fast/these-5-open-source-ai-startups-are-changing-the-ai-landscape-59dg
## 簡介 在本教程中,您將學習如何在 Kubernetes(容器編排平台)上部署您的第一個 JavaScript 應用程式☸️。 我們將部署一個簡單的 **express** 伺服器,該伺服器使用 **Minikube** ✨ 在本機 Kubernetes 上傳回範例 JSON 物件。 **先決條件📜:** - **Docker**:用於容器化應用程式。 🐋 - **Minikube**:用於在本地執行 Kubernetes。 ☸️  *** ## Odigos - 開源分散式追蹤 **無需編寫任何程式碼即可同時監控所有應用程式!** 利用唯一可以在所有應用程式中產生分散式追蹤的平台來簡化 OpenTelemetry 的複雜性。 我們真的才剛開始。 可以幫我們加個星星嗎?請問? 😽 https://github.com/keyval-dev/odigos [](https://github.com/keyval-dev/odigos) --- ### 讓我們設定一下🚀 我們將首先初始化我們的專案: ``` npm init -y ``` 這會使用 `package.json` 📝 檔案初始化 **NodeJS** 專案,該檔案追蹤我們安裝的依賴項。 安裝 Express.js 框架 ``` npm install express ``` 現在,在 `package.json` 中,依賴項物件應該如下所示。 ✅ ``` "dependencies": { "express": "^4.18.2" } ``` 現在,在專案的根目錄中建立一個「index.js」檔案並新增以下程式碼行。 🚀 ``` // 👇🏻 Initialize express. const express = require("express"); const app = express(); const port = 3000; // 👇🏻 Return a sample JSON object with a message property on the root path. app.get("/", (req, res) => { res.json({ message: "Hello from Odigos!", }); }); // 👇🏻 Listen on port 3000. app.listen(port, () => { console.log(`Server is listening on port ${port}`); }); ``` 我們需要在「package.json」中新增一個腳本來執行應用程式。將其新增至 `package.json` 的腳本物件中。 ``` "scripts": { "dev": "node index.js" }, ``` 現在,要檢查我們的應用程式是否正常執行,請使用「npm run dev」執行伺服器,並透過 CLI 或在瀏覽器中向「localhost:3000」發出 get 請求。 ✨ 如果您使用 CLI,請確保已安裝了 [cURL](https://curl.se/)。 ✅ ``` curl http://localhost:3000 ``` 你應該看到這樣的東西。 👇🏻  現在,您可以使用「Ctrl + C」簡單地停止正在執行的 Express 伺服器🚫 我們的範例應用程式已準備就緒! 🎉 現在,讓我們將其容器化並推送到 Kubernetes。 🐳☸️ *** ### 將應用程式容器化📦 我們將使用 **Docker** 來容器化我們的應用程式。 在專案的根目錄中,建立一個名為「Dockerfile」的新檔案。 > 💡 確保名稱完全相同。否則,您將需要明確傳遞“-f”標誌來指定“Dockerfile”路徑。 ``` # Uses node as the base image FROM node:21-alpine # Sets up our working directory as /app inside the container. WORKDIR /app # Copyies package json files. COPY package.json package-lock.json ./ # Installs the dependencies from the package.json RUN npm install --production # Copies current directory files into the docker environment COPY . . # Expose port 3000 as our server uses it. EXPOSE 3000 # Finally runs the server. CMD ["node", "index.js"] ``` 現在,我們需要建置 ⚒️ 這個容器才能實際使用它並將其推送到 Kubernetes。 執行此命令來建置“Dockerfile”。 > 🚨 如果您在 Windows 上執行它,請確保 Docker Desktop 正在執行。 ``` // 👇🏻 We are tagging our image name to express-server docker build -t express-server . ``` 現在,是時候執行容器了。 🏃🏻♂️💨 ``` docker run -dp 127.0.0.1:3000:3000 express-server ``` > 💡 我們正在後台執行容器,容器連接埠 3000 對應到我們的電腦連接埠 3000。 再次執行以下命令,您應該會看到與之前相同的結果。 ✅ ``` curl http://localhost:3000 ``` > **注意**:這次應用程式沒有像以前一樣在我們的電腦上執行。相反,它在容器內運作。 🤯 *** ### 在 Kubernetes 中部署 ## 如前所述,我們將使用 Minikube 在本機電腦上建立編排環境,並使用 kubectl 命令與 Kubernetes 互動。 😄 **啟動 Minikube:🚀** ``` minikube start ``` 由於我們將使用本機容器而不是從 docker hub 中提取它們,因此請執行這些命令。 ✨ ``` eval $(minikube docker-env) docker build -t express-server . ``` `eval $(minikube docker-env)`:用於將終端機的 `docker-cli` 指向 minikube 內的 Docker 引擎。 > 🚨 注意,我們很多人都使用 Fish 作為 shell,因此對於 Fish 來說,相應的命令是 `eval (minikube docker-env)` 現在,在專案根目錄中,建立一個嵌套資料夾“k8/deployment”,並在部署資料夾中建立一個名為“deployment.yaml”的新文件,其中包含以下內容。 在此文件中,我們將管理容器的部署。 👇🏻 ``` # 👇🏻 /k8/deployment/deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: express-deployment spec: selector: matchLabels: app: express-svr template: metadata: labels: app: express-svr spec: containers: - name: express-svr image: express-server imagePullPolicy: Never # Make sure to set it to Never, or else it will pull from the docker hub and fail. resources: limits: memory: "128Mi" cpu: "500m" ports: - containerPort: 3000 ``` 最後,執行此命令以應用我們剛剛建立的部署配置「deployment.yaml」。 ✨ ``` kubectl apply -f .\k8\deployment\deployment.yaml ``` 現在,如果我們查看正在執行的 Pod,我們可以看到 Pod 已成功建立。 🎉  要查看我們建立的 Pod 的日誌,請執行“kubectl messages <pod_name>”,我們應該會看到以下內容。  至此,我們的「express-server」就成功部署在本地 Kubernetes 上了。 😎 *** 這就是本文的內容,我們成功地將應用程式容器化並將其部署到 Kubernetes。 本文的原始碼可以在這裡找到 https://github.com/keyval-dev/blog/tree/main/js-on-k8s 非常感謝您的閱讀! 🎉🫡 --- 原文出處:https://dev.to/odigos/the-fastest-way-to-deploy-your-javascript-app-to-kubernetes-2j33
 一週前,我參加了在芝加哥舉行的 Kubecon 2023。我讀了一些部落格並參加了會議上的一些101教程,但仍然對這項技術沒有很好的理解。最糟糕的是會議的最後一天——我叫了優步送我回飯店。我的司機問我“大會是關於什麼的?”我回答說“這是關於 Kubernetes 的”,但經過一番解釋後,很明顯我不知道自己在說什麼。 想像一下,參加完為期 3 天的會議後,無法向您的 Uber 司機描述這項技術。 _摀臉_所以,為了挽回自己,這是我重新想像的與我的優步司機的對話。 # 對話開始 我:想像一下,你是一家繁忙餐廳廚房的廚師。你有一組廚師為你工作,每個人都在準備膳食的不同部分——一組負責開胃菜,一組負責主菜,另一組負責甜點。您的工作就是協調這些廚師,確保準時為顧客提供餐點。你腦子裡有畫面嗎?  司機:明白了。 我:在這個場景中,主廚是 Kubernetes。就像主廚需要管理廚房中所有不同的廚師一樣,Kubernetes 可以幫助管理執行軟體所需的所有不同部分。 Kubernetes 的官方定義是“容器編排工具”,但由於“容器”這個詞在這裡非常抽象,因此您可以用“容器”一詞代替“廚師”。所以 Kubernetes 將是一個「廚師編排工具」。這樣,每次聽到這個詞時,您就可以在腦海中形成廚房的畫面。  司機:好的,目前為止是有道理的。但這些容器是什麼?我不能永遠想像他們是廚師。 我:是的,好點。現在您腦海中已經有了 Kubernetes 廚房的圖片,讓我們從最小到最大,深入了解所有不同的廚房角色如何映射到 Kubernetes 概念。 > 貨櫃 這個難題中最小的部分是容器,它基本上是任何軟體。例如,它可以是託管Web 應用程式的Node.js Web 伺服器,也可以是儲存資料的MongoDB 資料庫容器_(這句話更多是針對閱讀此部落格的工程師而言,我不會對我的Uber 司機說這句話😛 )_。在廚房裡,想像一下您正在為開胃菜提供湯和沙拉。湯就是你的容器。沙拉也將是它自己的容器。 我知道這個定義現在看起來有點武斷,但一旦我在即將推出的元件的上下文中解釋它,它就會更有意義。  > 吊艙 在廚房裡,吊艙就是用來盛湯和沙拉的盤子/托盤。在 Kubernetes 中,Pod 是可以容納 1 個或多個容器的東西。原因是 Pod 內的容器可以相互通訊。 給工程師:舉個例子,假設我的 pod 中有一個用於 Web 伺服器的容器和一個用於資料庫的容器。他們可以透過本地主機相互通訊。 至於用廚房來比喻,我真的想不出什麼。想像香腸派對的惡作劇,你的擬人化湯和沙拉開始互相聊天。但是開胃菜盤上的湯和沙拉無法與餐盤上的牛排和土豆通信,因為它們位於不同的盤子上(也就是說,不同的 Pod 不共享相同的網絡命名空間,因此無法相互通信.)  > 主節點 主廚負責管理和監督整個廚房。這就是我們之前談到的「容器編排」或「廚師編排」的概念。這個主節點將執行的編排工作的一些現實範例如下: > 擴展,即根據 CPU 使用率向上或向下調整正在執行的 pod 數量。在繁忙的廚房中,當顧客需求激增時,廚師可能需要透過準備更多菜餚來擴大營運規模。順便說一句,在此視覺化中需要注意的一件事 - 您可能會想像廚房正在招聘新廚師,但我希望您將其想像得更像是當前的廚師正在被克隆。當發生擴展時,Pod 本質上是在被複製。 > 自動部署,又稱為在 YAML 檔案中定義應用程式的依賴項和執行時間指令,以便它可以基於此組態進行部署。在廚房中,此 YAML 檔案類似於書麵食譜,告訴廚師如何製作菜餚以確保一致性和效率並進行準備。 > 負載平衡,又稱在不同 Pod 之間分配網路流量。在廚房中,負載平衡涉及將任務分配給烹飪站的不同廚師。也許甜點站的鮑勃因舀冰淇淋的請求超載,因此主廚克隆了鮑勃,並讓鮑勃 2.0 從鮑勃 1.0 手中接走了一些冰淇淋訂單。  同樣要注意的是:每個工作節點都有一個稱為「kubelet」的東西。在廚房場景中,「kubelet」類似於每張桌子上的廚師。廚師有很多工作,例如確保食物托盤正確組裝、幫助準備食材以及扔掉殘渣。同樣,「kubelet」的作用包括確保 pod 內的容器正在運作、幫助初始化 pod(例如安裝必要的依賴項)、幫助垃圾收集等等。 為工程師提供的一些額外背景資訊:Kubelet 是一個開源的可執行二進位檔案(又稱為包含 CPU 可以直接執行的機器碼指令的檔案),用 Go 程式語言編寫。  讓我們在這裡停一下。如果您理解到目前為止我所說的所有內容,您就了解了 Kubernetes 架構的基礎知識!如果您不想永遠依賴廚房圖像,我已將下圖中的所有廚房圖紙僅替換為 Kubernetes 術語。  司機:其實,這一切都很有道理。所以我明白了 Kubernetes 是什麼。但我還是不明白為什麼它有用。例如擁有它或學習它有什麼意義? 我:是的,難題的最後一部分是了解 Kubernetes 的**如何**使用。人類如何與 Kubernetes 互動? Kubernetes 在科技領域有何相關性/有用性?讓我們回顧一下廚房的類比來解釋更多概念。 - 餐廳/特許經營店的所有者類似於建立應用程式或服務的軟體開發人員。在麥當勞,特許經營權所有者(假設他們的名字是 Francis Cockadoodledoo)希望獲得有關每個麥當勞門市賺多少錢的訊息,並能夠根據需要解僱/僱用員工。為此,Francis Cockadoodledoo 可能會拿起電話打給主廚以獲取資訊並下達命令。在 Kubernetes 中,軟體工程師無法真正拿起電話與他們的 Kubernetes 叢集進行交互,但「主節點」有一個可以呼叫的 API 伺服器,這允許您存取所有任務。例如,工程師可以獲得所有 Pod、節點、服務的訊息,了解執行狀況和指標訊息,並能夠刪除或建立資源。 - 在餐廳吃飯的顧客類似於應用程式或服務的使用者。與麥當勞廚房為我製作巨無霸漢堡類似,Spotify Kubernetes 集群為我提供透過網頁瀏覽器收聽大量音樂的服務。 我已將這些新資訊納入下面的繪圖中。您將看到的實際上與您在谷歌上搜尋“Kubernetes 架構”時看到的圖表非常相似。   當然,我意識到我在解釋中遺漏了一些抽象概念,因為我覺得它們對於形成 Kubernetes 的基本思考模型並不重要。請隨意挖掘更多內容。當我自己深入研究時,我可能會在這個部落格中加入一些我認為有用的資源連結。 # 結論 我之所以選擇這種講故事的方式(透過與 Uber 司機對話的鏡頭來描述技術)是因為我想將 Kubernetes 分解成一種普遍可以理解且平易近人的東西。 感謝您的閱讀!如果您對改進我的寫作(或我糟糕的繪圖)有任何「建設性」回饋,請在評論中留下它們。 請欣賞這張我和我的同事在 #Kubecon 2023 上的照片。順便說一句,我們在那裡推廣我正在開發的產品。 如果您有興趣,您應該檢查一下。這是對過時終端機(命令列)體驗的現代詮釋,讓您成為更好的開發人員。請造訪 https://www.warp.dev/ 以了解更多資訊。  --- 原文出處:https://dev.to/therubberduckiee/explaining-kubernetes-to-my-uber-driver-4f60
想玩一下 stable diffusion 在 macbook 嘗試了一下 不太好安裝 拿出家中的老舊筆電 2018 年買的 asus zenbook 上面有雙系統 ubuntu 18.04 不過顯卡一直沒有順利啟用 不管了先用 cpu 硬跑 https://github.com/AUTOMATIC1111/stable-diffusion-webui 按照 repo 指令照做 然後我有參考這篇文章 亂跑一些 pip 安裝指令之類的 反正亂裝一通 https://zhuanlan.zhihu.com/p/628058158 在執行這個時 會遇到很多錯誤訊息 ``` ./webui.sh ``` 在 terminal 先設定一些環境變數 好像是關閉搜尋顯卡吧 ``` export COMMANDLINE_ARGS="--skip-torch-cuda-test --precision full --no-half" ``` 就可以了 實際跑起來,產生一張圖,大概要 5 分鐘左右
[第1課 ── 學習 Vue 元件基本觀念](https://play.vuejs.org/#eNp1kMsKAjEMRX8ldqOCWNxKEdyILvyD2RQngwP2Qc2IIPPvNm1nfKBQSm56btLkIbbeL28dirVQ11NoPW0q2xrvAsEedY0BmuAMTJcyS4anI3LUrR0BFp/PO+forUKWBQGoLN4TVmOjuwvBg7MnF70WLV3XOQHlI4ssuEsJcz2O+5SpNenZfHAFpC7YQXE7vvuEVzYeJceJoyA0/qIJowJQZXaZVRqzxGUmVkqOJrEQr/3wMj/LnVebA2gD58RMlIyJb/+wvv9uE4nf3tdm/7ubxPzy90/ta6nn) [第2課 ── 學習 Vue 的 props 觀念](https://play.vuejs.org/#eNqNkcGO0zAQhl9l5D0URNOWBVbUhJVYEDdOXHNx60mISGzLcVBLlHdnMolDutWuNoqizD+emW9+d+KLc5s/LQop0uboSxfuM1PWzvoAP84PShcIubc1rDbbKR6OrzIDkBk88UGNuWqrAN2gHi1VGzShkaMAsdF6iHr+ahXUq9cx7zG03sSI+g7fnk9nht50O6NRELB2lQpIEUBan5MDU1bqgNXnTNy8/7a/+36bCSKprF8q9+k2Hn+ieFlmvTIFkhDwFL7GXrvd7iWN9vv9m0Uvj5oib1ujUV9Wp9t5IbEWC48vriQjiGuvAZy37r/Rg/s0UMLP4EtTsNXDM29wlWHeK3UClfBgbYWKXF/eyHPX0ThlQB4r1TS0djc3mn56ckE24VzhkIXVQR1/F5xLmHwlxw3WcZGZnAYLHgHQdUzdMw/B0MhLH5mLp3AFM0W/lNa0qYRbd4I7d/o0yrXyRWkSXxa/goS3uzlxsF6jT7zSZUs+v5sTuTUhacq/KOHjLE7QN3mes8KEm2n3iPCo5Yc4bHR2pA6i/wcEYzAB) [第3課 ── 學習 Vue 的 events 觀念](https://play.vuejs.org/#eNqVVM1u00AQfpWVAblV4yRQUVETqlKuLZdcItU9OPE6sWrvmvW6TYkiIXEAVUgcQEUViB+BxAnEEQSvk6g98QrM7tpru04RRHE2++3MtzPfzHhi3I3j5kGKDdvoJAMWxHzDIUEUU8bRztFWyjklyGc0QmazlQPCwXQIQg7BY2nqYd9NQ44mAh1Q8CeY8MRWANJUDbGdyl/P5e7Scm7AME8ZyXcIJcFDDO67Zq9rNkzx7MCzDU9v29yTBOJDbHR9LdtNJbdD4Ntp6Vxgw3EUhy7HsEOoEx1ZfZVW6PZxeMcxfHeA+5TuOwaEHlIG0JXV9VuutwYIx2N+L0d933eMjU5LcyjKPruMOnmQugyXiClzyVAAFd52uw2QMv4X+gPLl45CJUR9pRYw2PpeAMRerHpbZx5dGvhKWQwVXl0JxGhKPLTpet59AMkKeNUvqZNb/0MeBSRNJL0FfnX6GLLkR6FIc+JTwruQq40IWkFmPDan4KLa4/zn2/mL49nx+7PTd/OnJ/Pvr+HP71/Pzh+dnn38MD95Mvvyav7m8fzlj7Ovx7NPn2ffnkv+VgwEnZZuIqNhlOegMjgOpFGfB4RiRuNiGBwuhbBRl7OADHUzS0lqqFamdqL6xUZblIbYVbOVz07NWKp50VZNIkIR5iPqFRFCLGEw2C/GUwYyCpLmVRwFfMkUFTeXNXn1UFXMXM5P5WAW8/m34cwapaio2XcH+0MZvCX1MW2lUyOXS+sDpS7iQcgehG6SAMfuJBdKrY1cC7lMG0KuvarvpkwffOWqW2gyUS2MplN49Yne0I1YahCZlkxAumUpZUL2KfMwRE3gBXk7aw4QEyoFb7J2PM6wQcoSkVxMA8Ixy1DlbDHXC1Io1k1tHrlsGBCrT+GqCIhqJywYjnjhIUvRVHJUI9Pk7ZKhmkRl5/DDwOMjG60W0Y6woi9BYUCwleOKCyExntZhBq63c/hiWu1rpbt73TxA6a16WyulbBaaVHPdWWByo8qyvcikytJbZKOzVr0tC29M/wBn121P) [第4課 ── 學習 Vue 的 v-model 觀念](https://play.vuejs.org/#eNqNVF1v0zAU/StX2VA3qWm7jSIIYQLeeOAJiRfCg5s4m4VjG8cJ66ry27n+ysc6TSxra1/fc33OuY4PySelVn1HkyzJ21IzZW4LwRoltYGv+y9CdQZqLRtYrNZhbtMXhQAoBH1wiRWtSccNHGy0lIgWVJg28wGIhZZ2dnTfFTHk4jKua2o6LeIMwNAHk4HoOHfJCHLIQuB/vh5o4sTQRnFiKM4A8mafMse4TxtZUf6hSGypIgFOdm5aM85phQE/AFZh0GHSqyK5zdexxP8WlJ3hTLiScTgtev20aL4eKCfLZOLorAEF7nLqLIDSUo22AjhS3wnvaAbfjGbiLhgGnuBJ1MvO4LOUnBIxxCP30xWGsVkR30Bk2DDb4h+LTmE3aTZyWfwM7XqpVxXr3QCH3uLM22adNHtFR6s1/d0xjRYHRviXlZy0LaYcoiD/u5wIiaNjkUyRvWWIyJEubjFJ+OjYYMK5FXjxjLolnNMez/fKEH1HsXk2eomN9r7kznnIaqmDnls4HHw/4HjM127kTVh7FyaHwjnVmj33NuH60HvZMsOkyNAQTGU9fe8XGqTBMLzdqAfYuKB7X7ytAf2HVebe5rwKKEWqCpuawbWFXeFXWKilMGnLHvFIXb0J0bEeyiq7Fv56PcsQRAtYFYNhRyNVBunr7bSE/XgjTkSRXSt5Z6Ioh/ZiEEJrvA8mHEfy14NmxGgiYjnEw2Z104alstOt1BjGIxWzcZg6CHaqyaAkihnU8egpOL6rcE0EtjtS/rrTshNVWkpu651RGhnvpK4ohgRefrNQupPGSNzhBrmiSHTKbauIxlMUUsNpncGnep5ujeK2XtyUaHYve6pfoFu9tc8pznc14ua0rcWe9tlms63LcgIf7rwZFHs1YsrKPs9JcrlPhQwv8FzKad13G/tEJF417qVJjv8AFoE/Hg==) [第5課 ── 學習 Vue 的 slots 觀念](https://play.vuejs.org/#eNrNlE1vnDAQhv/KiBySSAHStLlQulJzb3uJVFXiYmBg3YJt2cM229X+9w7GsB/aNtdIKxaP3xnPeJ5hF302JtkMGGVR7iorDa0KVZDsjbYEX7ZPQim00Fjdw3WSzobR5bpQAIXCFy+tsRFDR7AbrZVmf4WKXDYZYAl1Ny73/lkLEje3s8AiDVb51WTYe2Wh+Jenh9xUTtibThDyCiDvt3E5JVl1wrlPRRSWZRu3VmyLyOsAfugB1mKD0GlHnCKLKpJaAWmgNYJUhFYhJfC8lg6EMcB/umk6qTCZYixnw5XwziE2wPOY/Lev8F02MmjT00TTJVO/fjV5i3URgdWDqrF+izWcbPLS0babdEmoIrTWiLqWqs3g4d68fJxsvbCtVHGpiXSfwbvDTi0dB91m0HQ4234OjmSzjbliYqwycEZUGJdIvxFVEIlOtiqWnBRjV7EMbdipdKdtBldN03iLRysJgMxZlqL61frr5mO8ftw91XNP/i3nzVnNwPrLiO6i45E5m7JLo8O3ZbU5zA0PxkRABk9adyiUn515hl4ZjlpuIJvR2i2Rwst+mY3crHLXaUpXeWpmWzlwb2Y6CvICUKJHjjWRw/58OptXE88jIUdeecrn/xcUM5c54ZDBfehYw42OnfyDjMaHgIbvwhR+dqsG68arN9qTH5wX3o6oKrWtkZWKv0snptiKWg584Y+L9hyXS80mKxRDaBmzoOF2UuzNjbaM9GAM2kq4+bhLJbHX6CDHy8wY4A7uk/fuvNpsrTeHaboAXluKm4fHxzs4PDjO7RynoCR0fIlxufRjcvd/AZMZBoM=) [第6課 ── 學習用外部狀態管理 vue 元件](https://play.vuejs.org/#eNrtVUtvGzcQ/isDpYAdQCs7dYMCW0VogB56aC499BL1QO3OSqz5KjkrSwn83zPkch+SpSQ/IIKw4Azn/fj4efbeucW+xVk5W4bKS0ertZHaWU/w4fiHFMpuofFWw83irmdEhZu1AVgbPCTRGhvRKoLPkVtZ1jdoKJQdAwZT80g+p28tSNy+7gU8UutNTwGEnX16r9DTB1sLVUIjVMCk19/+iUrZC7fPycXa8H95N6TEBKF2ShAyBbDctETWwO+VktXju/Xs1CG8A/ItrmerxFvedeLXVcdoRtXEO1FN6vpY1F1d94W2NaoX3lk3SdMQM7wiSQr7aE5SYZOjWGUNceVXf1mPGqQLrYbaKushSAKhkbg9JmBFseAgaulkkJU0W0AlaQF/o2cVj46DR1O3ISnurWodRQ/5FAD3aCSb4/572+ttlDC1JCkDOPQNejbBZ7Ik9BxQgCCw2jBrjwpMq/9vhQY8oK8km5c8NhpES3Mwgti3ljyMYt45ASU2nNbia/l3xS4ID7Syj2eSy7uh9t9ux9jR6+3IHf7Rju9pR6VswK925OSSyUBHLnKUyyuX4cGJuuYSlfDWHeDNvTv81vGr1gfrSw5Pctl95mrht9IUXm53VI7iHT4kD7P5bAptJ1i45thfQhzH4K1jfPt4k2bmH6EYEv9NEMQaWkbs+3jTOkY5LC+IRIxsCesBIde0jwIDHX9bpBEhu1/GSdrJsBjNjhIdtmaUZPVk9MxGUv4pBnl7IcI5dDoTm/0xHdbU++Dp3dl6BHluQGzxacjfcpage3CWXfUYfh3AeRlruWeHIgReWDYZ95RXOK5ux+hr020vz9pUoRK+Hm74bvcwnJkKyhKPvEaWTJvOohwLc0eNu4nK0l3TzgBwSd+tEgAl4vxJSYWcxMfpTq1O1uqS5cmLE0nOOy9bd7q+ZnGk+AXL7duI6nHrbWvqooqYVYLfbsTt/Rzyf/Hr67xjzjIsMVzwUywPWGcuWVfCfSby/vWkwmZCbSxHrEeaUYoDPLI5hf12/9cGks2RY0klLaHi77DlQsmtKSRnxgM5uUmjtIjtvp7Wq6ZpBrA4FE+yph2Dy/2ILDvM6PF25A0o9PPI+664gxMVFhukJ0SThaI8A6HnlyCVkSNrdX/JMFujLzw/Dy1n9zAiWJ/a7mGeT65P80IWHRKOVR4y6BgTe4MVJQ0WffaTRBtOpgjyEwPWm19exnOK111vAqqmK0zBz9B5CGdQfhrqFKufvwCVGY00) [第7課 ── 學習開發狀態複雜的 vue 元](https://play.vuejs.org/#eNrVWHtv2zYQ/yqEE9T26ncad1DtoMswZAXW/ZECw4AoQGmJtrVIlEBRTrLA333HpyhZtuNuAzYkkMU73uN3d3ycXlo/ZNlgU5CW15rlAYsyfuXTKMlSxtHn5x/TOGVoydIEtQdDPRbT2z5FyKfkSU4MyRIXMUcvghqkIE0J5bmnCMgo6onRVj5DzHGna/iM8IJRM0JoTZ5+w7GH2mfLJR6PRtIaiJbyj5gHa6tf0n0K/7OhBQEDTpIsxpzACKFZ8twPJJ44Wq052vSTNCTx3G8pc37rajY0c2oSIWYPRwVmQ2sPPIJxzp9jZfs74+kifern0Z8RXXnwzkLC+kD6oJgJZquIemikxxkOQzlTERQ8qbPVaznJqORuX1oylmZlRiQSwFAQD33hDKzIsCIVGw9dp2lMMNVEAb9KU1kgSSSyfNcuMkgo8Uqt7fujafY5I6FM8+TyUhtCaMUIoZI6no4tdQEqJXFkSSoHtyQHhE6lWH6ON+S2wYCg3zQaEZzrXUNBwRhU8+3NNZhhq0VHaBNyo66x5hRmQvg6DctABxAy9olmBS/jgBBfR/ngXISv0xC7HsBpd7VqbSJYk+Dhs53zC6ErvjYqfe7zaIk6Um2paBDLWWiG3lvbPj9mW/Ld6EpPhAmAqX+al6HKZ0dE1sEqHBMkdDVHI/TmDZKD2VxkRU4TOsXfjmE0F4F4+2uRLAhTagc8VeXaGU+7A1ggXzhmvDPptUftrpkpFZlCOkFEV9lhCQPreBKbA+nIliUKSCVFRdBM2yIS56SMpBZTk4xIqcSKVSvHBOLfyovj0+ti/T/IitkgTJBNDI9kxkxzc2NU7cmORvefSc43rJ3jM//h7OhN2kRZh/BIbvQsNzVaz57MlH7tS47ZX+dzZ4PdXaYZZjn5RLmUuRvfo7cym3eTezhGLD6dSqeEqnIXVu5dk1wJryp2acWmTWLl4QaSX8Xpdv7ieL/t6aFxyxK0vW33az18+qoi7iFHLmRhtIHzEec5XKnkJaofYBb6LeQZ6ou+jsifnr6HiOcWLl/KXlWLgqOuZEKRvC4JRe0FDh5WLC1oqLhtzznZHXVD0NekOsOUiCufgVthQsU6LGDGeEHiq59/+n02VK8OLxK3AVe0LynC3Y0oNyCWtee3lORHOQdYBxbPOdkAnAEsvBXhA6mrC1oT/KQKFaTfw/hjEEfBg4iWvZsIKmSUCWLTRcPF7QSoFgUon4YooGUq9EI6rm73RoM/ZwI3w3QFkFEUKolStWYkEYXRSKGCN9gO4b28mesDtOJFNd7gZB9Cs19K7KouSBi9GuQKWDcngQSJk0Ha0+hEmDW5vwNUsK5PAgoSJwM1O/uJOKtidZjlu3k70LgpY7Z5Ew2bhyi0t/UW7SIzXVxa8Dii0FfZaXI3HJQ7nNH3GIUcbs+Ty5EVtvomJc20hQ5Jt44Mh1EBvcalw4D+co3D9BFaGPgDDjqbTqeOH6r7NZDsruihM0Jcf9W8hgBYswazmi975Ca1FxcXH2SLLr4NQAyAtFwu65JVQ7XNGkQMiF0lR/yqnAnGwJqogwVaxlqcoR/nPE0q4Q6jHMrj2UPLmBjaH0UOPZfo/ikH9XCawJMwzcUQPdqPoK7AnwrnoK9wGNgOverN+LA3++yVasVDHTTGghAHxVX0MVkClu+tMU6eeJ/Dgs1h4YMfRZYRFuDcrRRYg9/m9U4M8wwHpL8g/BF2qldBA9sebAWQ3nUU25VVc8N+P9HOiofYNWoL8V3prYQtLdfSVwmTheeqFntbc4h3v+doIbWzVp0ZT+qFyUzJlkbt96DtX340SC4=) 作業心得: 製作元件就像在組LEGO一樣,基礎和常用的就那幾個,把他們組一起成為一個新的作品,一開始製作觀念還很模糊,之後就慢慢熟悉,也了解能製作出可以重複使用元件多麼重要
使用 useWorker 在單獨的執行緒中,處理昂貴且阻塞 UI 的任務。 眾所周知,Javascript 是一種單線程語言。所以,做任何昂貴的任務,它都會阻塞 UI 互動。用戶需要等到它完成,才能執行剩餘的其他操作,這會帶來糟糕的用戶體驗。 為了克服和執行這些任務,Javascript 有一個名為 [Web Workers](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Using_web_workers) 的解決方案,它允許在 web 中執行消耗效能的任務時,瀏覽器不會阻塞用戶界面,使用戶體驗非常流暢。 本篇文章簡單介紹這個 hook。 原文出處:https://dev.to/nilanth/multi-threaded-react-app-using-useworker-gf8 --- ## Web Workers Web Worker 是一個在後台執行而不影響用戶界面的腳本,因為它在一個單獨的線程而不是主線程中執行。所以它不會對用戶交互造成任何阻塞。 Web Worker 主要用於在 Web 瀏覽器中執行昂貴的任務,例如對大量資料進行排序、CSV 導出、圖像處理等。 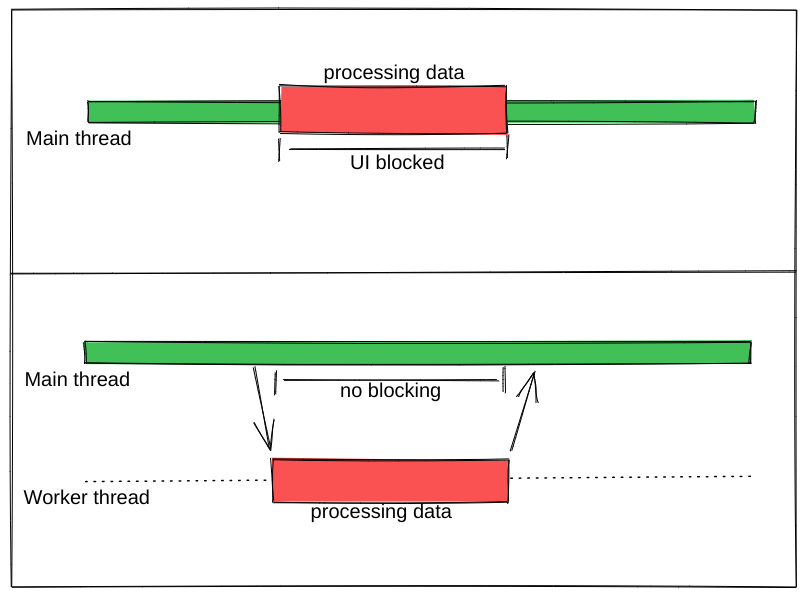 參考上圖,我們可以看到一個昂貴的任務是由一個工作線程並行執行的,而不會阻塞主線程。當我們在主線程中執行相同的操作時,會導致 UI 阻塞。 ## React 中的 Concurrent mode 呢? React [並發模式](https://beta.reactjs.org/reference/react/startTransition) 不會並行執行任務。它將非緊急任務轉移,接著立即執行緊急任務。它使用相同的主線程來處理。 正如我們在下圖中看到的,緊急任務是使用上下文切換來處理的。例如,如果一個表正在呈現一個大型資料集,並且用戶試圖搜尋某些內容,React 會將任務切換為用戶搜尋,並首先處理它,如下所示。 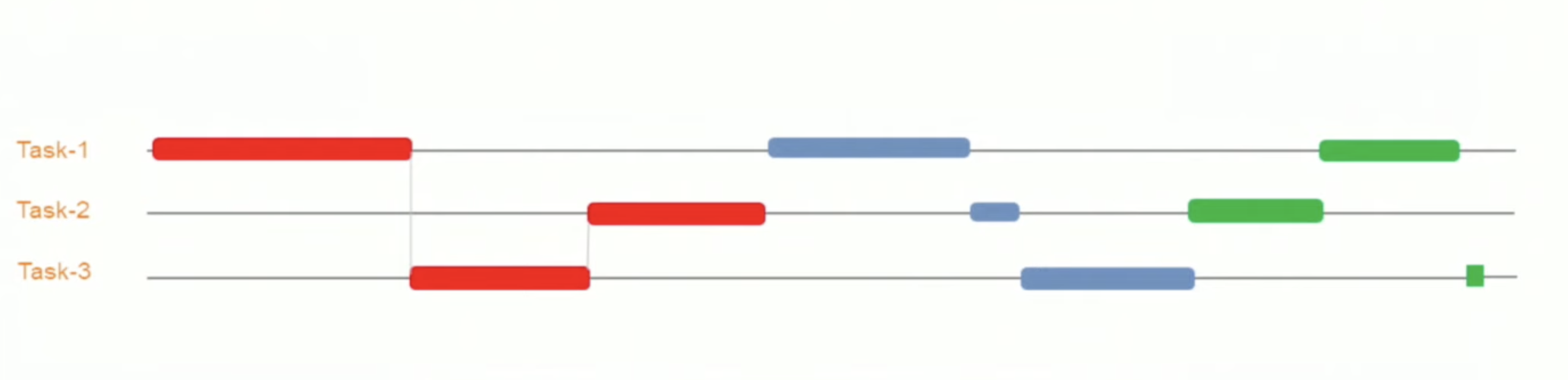 當為同一任務使用 worker 時,表格渲染在一個單獨的線程中並行執行。檢查下圖。  ## useWorker [useWorker](https://github.com/alewin/useWorker) 是一個通過 React Hooks 在簡單配置中使用 Web Worker API 的函式庫。它支持在不阻塞 UI 的情況下執行昂貴任務,支援 promise 而不是事件監聽器,還有一些值得注意的功能: 1. 結束超時 worker 的選項 2. 遠程依賴 3. Transferable 4. Worker status > useWorker 是一個 3KB 的庫 ## 為什麼不用 JavaScript 內置 web worker? 在使用 javascript web worker 時,我們需要加入一些複雜的配置,來設置多行程式碼的 worker。使用 useWorker,我們可以簡化 worker 的設置。讓我們在下面的程式碼中,看看兩者之間的區別。 ## 在 React App 中使用 JS Web Worker 時 ``` // webworker.js self.addEventListener("message", function(event) { var numbers = [...event.data] postMessage(numbers.sort()) }); ``` ``` //index.js var webworker = new Worker("./webworker.js"); webworker.postMessage([3,2,1]); webworker.addEventListener("message", function(event) { console.log("Message from worker:", event.data); // [1,2,3] }); ``` ## 在 React App 中使用 useWorker 時 ``` // index.js const sortNumbers = numbers => ([...numbers].sort()) const [sortWorker] = useWorker(sortNumbers); const result = await sortWorker([1,2,3]) ``` 正如我之前所說,與普通的 javascript worker 相比,`useWorker()` 簡化了配置。 讓我們與 React App 整合並執行高 CPU 密集型任務,來看看 useWorker() 的實際執行情況。 ## Quick Start 要將 useWorker() 加入到 React 專案,請使用以下命令 `yarn add @koale/useworker` 安裝套件後,導入 useWorker()。 `import { useWorker, WORKER_STATUS } from "@koale/useworker";` 我們從函式庫中導入 useWorker 和 WORKER_STATUS。 **useWorker()** 鉤子返回 workerFn 和 controller。 1. `workerFn` 是允許使用 web worker 執行函數的函數。 2.controller 由 status 和 kill 參數組成。 status 參數返回 worker 的狀態和用於終止當前執行的 worker 的 kill 函數。 讓我們用一個例子來看看 **useWorker()**。 使用 **useWorker()** 和主線程對大型陣列進行排序 首先建立一個SortingArray元件,加入如下程式碼 ``` //Sorting.js import React from "react"; import { useWorker, WORKER_STATUS } from "@koale/useworker"; import { useToasts } from "react-toast-notifications"; import bubleSort from "./algorithms/bublesort"; const numbers = [...Array(50000)].map(() => Math.floor(Math.random() * 1000000) ); function SortingArray() { const { addToast } = useToasts(); const [sortStatus, setSortStatus] = React.useState(false); const [sortWorker, { status: sortWorkerStatus }] = useWorker(bubleSort); console.log("WORKER:", sortWorkerStatus); const onSortClick = () => { setSortStatus(true); const result = bubleSort(numbers); setSortStatus(false); addToast("Finished: Sort", { appearance: "success" }); console.log("Buble Sort", result); }; const onWorkerSortClick = () => { sortWorker(numbers).then((result) => { console.log("Buble Sort useWorker()", result); addToast("Finished: Sort using useWorker.", { appearance: "success" }); }); }; return ( <div> <section className="App-section"> <button type="button" disabled={sortStatus} className="App-button" onClick={() => onSortClick()} > {sortStatus ? `Loading...` : `Buble Sort`} </button> <button type="button" disabled={sortWorkerStatus === WORKER_STATUS.RUNNING} className="App-button" onClick={() => onWorkerSortClick()} > {sortWorkerStatus === WORKER_STATUS.RUNNING ? `Loading...` : `Buble Sort useWorker()`} </button> </section> <section className="App-section"> <span style={{ color: "white" }}> Open DevTools console to see the results. </span> </section> </div> ); } export default SortingArray; ``` 這裡我們配置了 useWorker 並傳遞了 bubleSort 函數來使用 worker 執行昂貴的排序。 接下來,將以下程式碼加入到 App.js 元件,並導入 SortingArray 元件。 ``` //App.js import React from "react"; import { ToastProvider } from "react-toast-notifications"; import SortingArray from "./pages/SortingArray"; import logo from "./react.png"; import "./style.css"; let turn = 0; function infiniteLoop() { const lgoo = document.querySelector(".App-logo"); turn += 8; lgoo.style.transform = `rotate(${turn % 360}deg)`; } export default function App() { React.useEffect(() => { const loopInterval = setInterval(infiniteLoop, 100); return () => clearInterval(loopInterval); }, []); return ( <ToastProvider> <div className="App"> <h1 className="App-Title">useWorker</h1> <header className="App-header"> <img src={logo} className="App-logo" alt="logo" /> <ul> <li>Sorting Demo</li> </ul> </header> <hr /> </div> <div> <SortingArray /> </div> </ToastProvider> ); } ``` 我們已將 React 徽標加入到 **App.js** 元件,該組件每 **100ms** 旋轉一次,以直觀地表示執行昂貴任務時的阻塞和非阻塞 UI。 執行上面的程式碼時,我們可以看到兩個按鈕 Normal Sort 和 Sort using **useWorker()**。 接下來,單擊 Normal Sort 按鈕在主線程中對陣列進行排序。我們可以看到 React 徽標停止旋轉幾秒鐘。由於排序任務阻塞了UI渲染,所以排序完成後logo又開始旋轉了。這是因為兩個任務都在主線程中處理。檢查以下gif 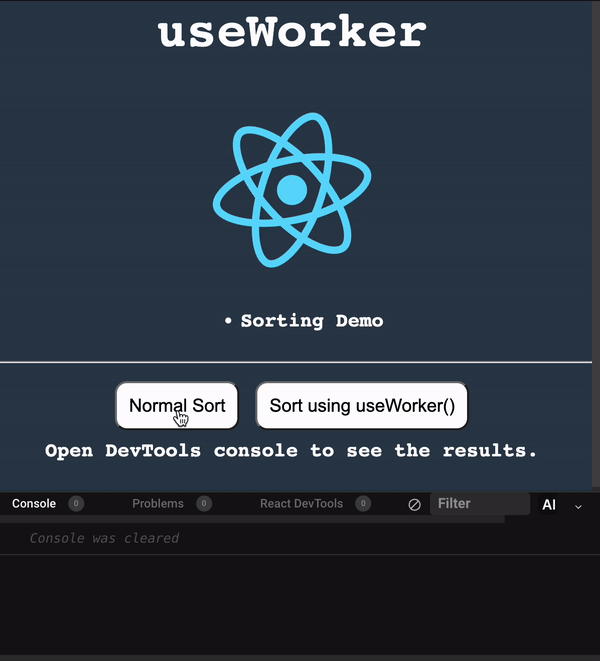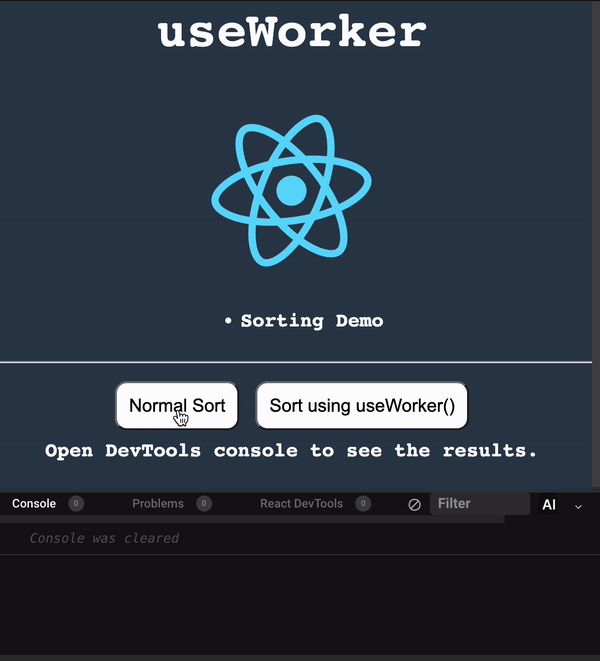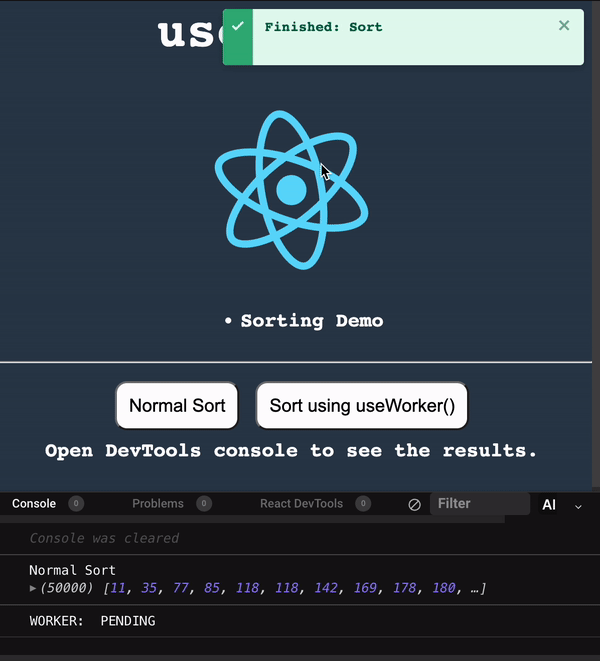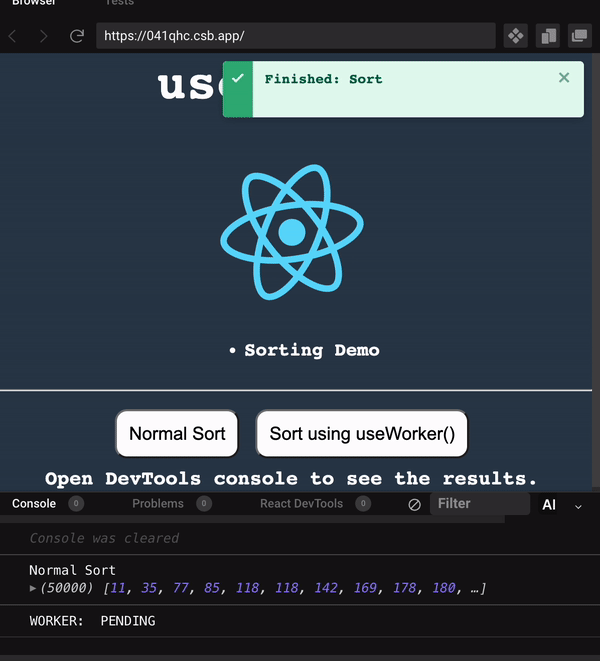 讓我們使用 [chrome 性能記錄](https://developer.chrome.com/docs/devtools/performance/) 檢查其性能分析。  我們可以看到 Event: click 任務用了 **3.86 秒** 來完成這個過程,它阻塞了主線程 3.86 秒。 接下來,讓我們嘗試使用 **useWorker()** 選項進行排序。點擊它的時候我們可以看到 react logo 還在不間斷的旋轉。由於 useWorker 在不阻塞 UI 的情況下在後台執行排序。這使得用戶體驗非常流暢。檢查以下gif 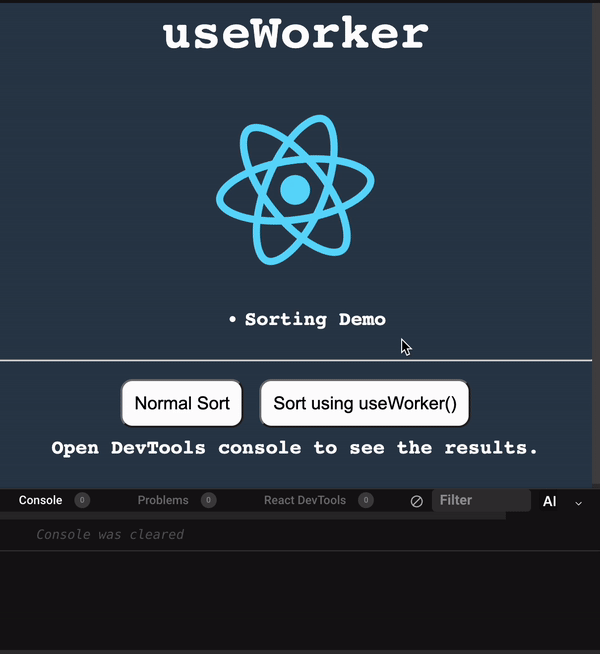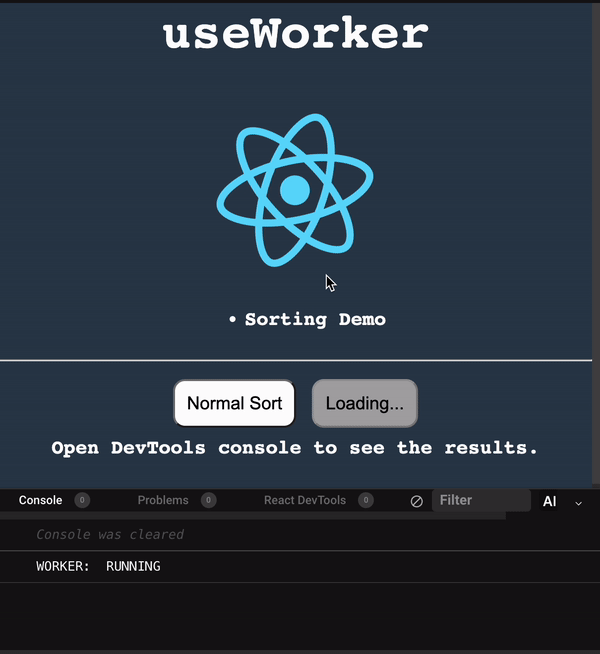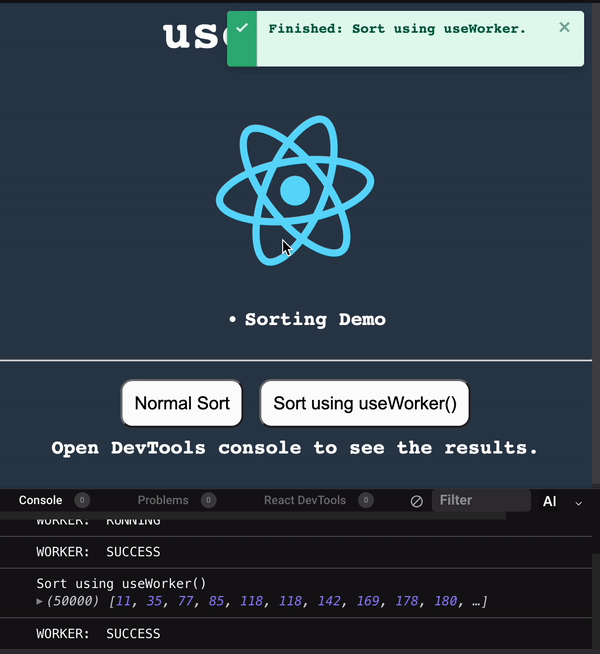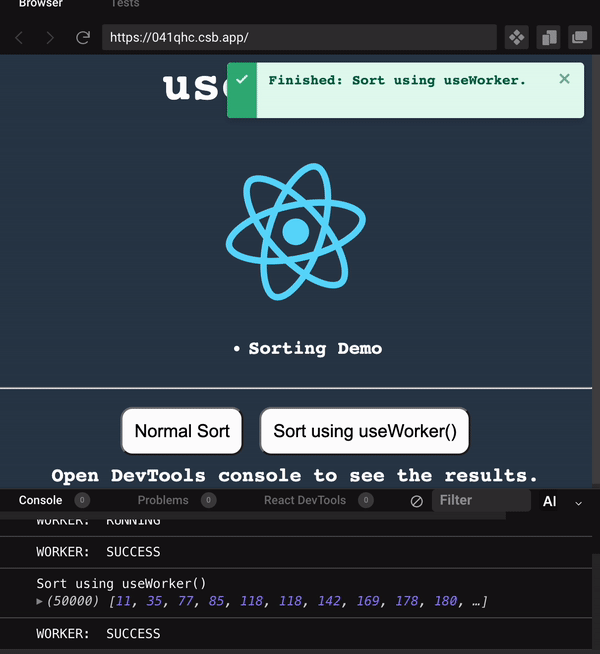 您還可以使用 `sortWorkerStatus` 在控制台中看到 worker 狀態為 **RUNNING**、**SUCCESS**。 讓我們看看這種方法的性能分析結果 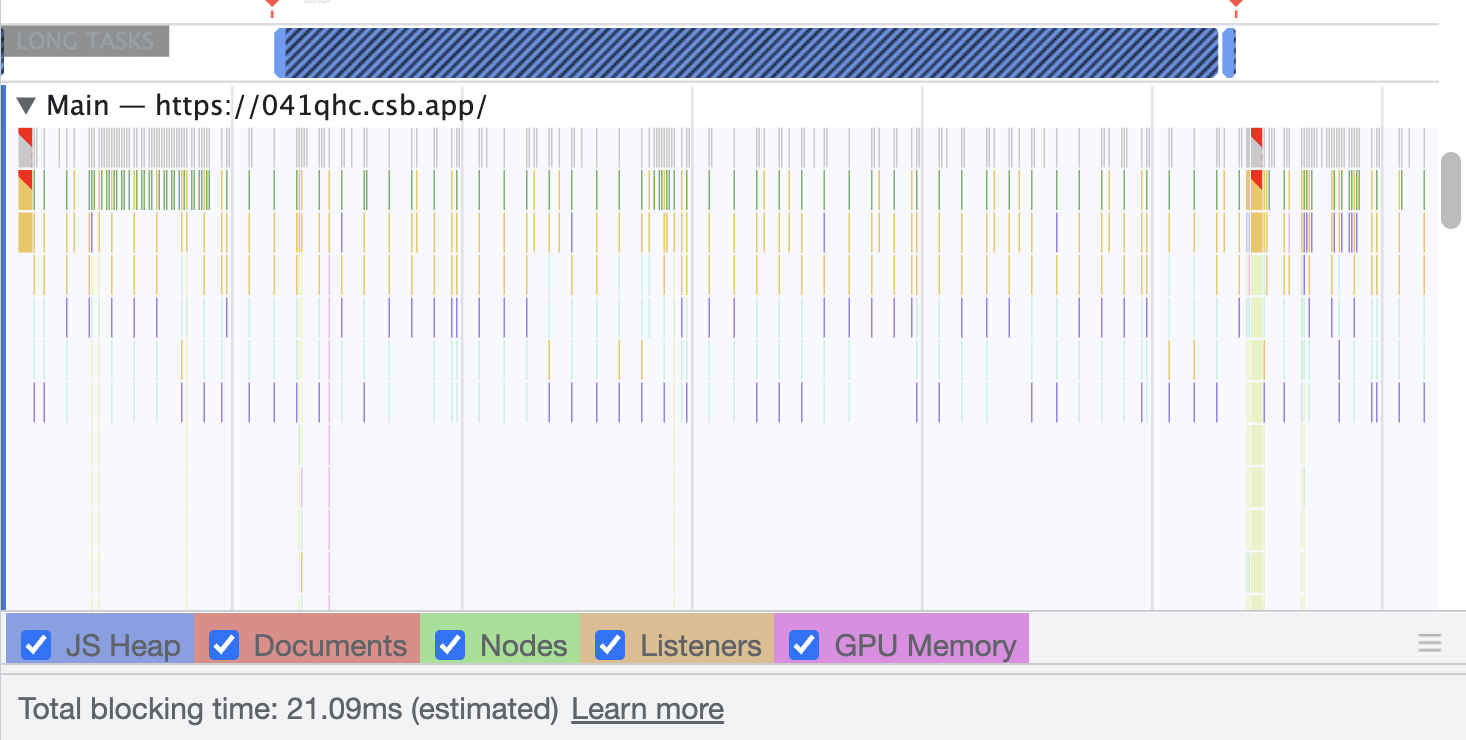 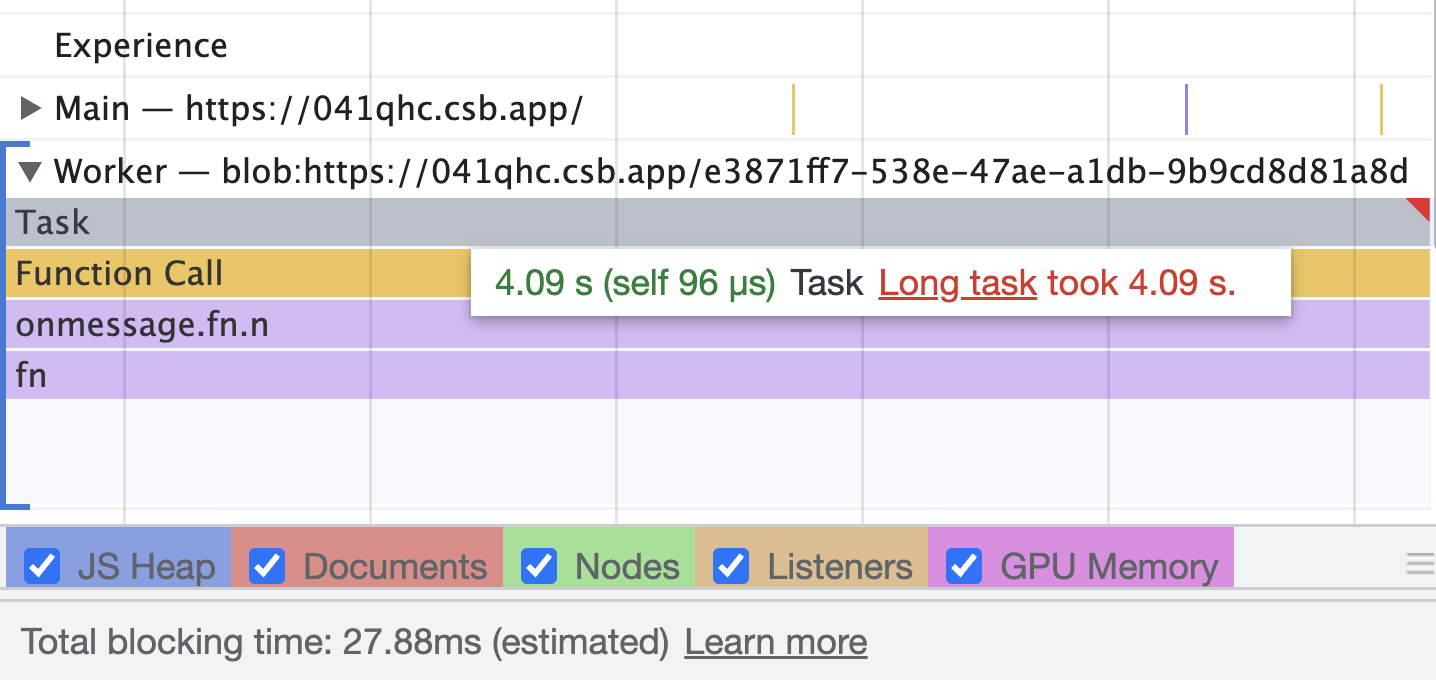 正如我們所看到的,第一張圖片表示主線程中沒有長時間執行的進程。在第二張圖片中,我們可以看到排序任務由一個單獨的工作線程處理。所以主線程沒有阻塞任務。 您可以在以下沙箱中試用整個範例。 https://codesandbox.io/embed/useworker-sorting-example-041qhc?fontsize=14&hidenavigation=1&theme=dark ## 何時使用worker 1.圖像處理 2. 排序或處理大資料集。 3. 大資料CSV或Excel導出。 4. 畫布繪圖 5. 任何 CPU 密集型任務。 ## useWorker 的限制 1. web worker 無權存取 window 物件和 document。 2. 當 worker 正在執行時,我們不能再次呼叫它,直到它完成或被中止。為了解決這個問題,我們可以建立兩個或多個 useWorker() 鉤子實例。 3. Web Worker 無法返回函數,因為響應是序列化的。 4. Web Workers 受限於最終用戶機器的可用 CPU 內核和內存。 ## 結論 Web Worker 允許在 React 應用程式中使用多線程來執行昂貴的任務而不會阻塞 UI。而 useWorker 允許在 React 應用程式中以簡化的掛鉤方法使用 Web Worker API。 Worker 不應該被過度使用,我們應該只在必要時使用它,否則會增加管理 Worker 的複雜性。
作為開發人員,我們在終端機上花費了大量時間。有很多有用的 CLI 工具,它們可以讓您在命令行中的生活更輕鬆、更快速,而且通常更有趣。 這篇文章概述了 50 個必備的好用 CLI 工具。 原文出處:https://dev.to/lissy93/cli-tools-you-cant-live-without-57f6 --- ## 工具 ### [`thefuck`](https://github.com/nvbn/thefuck) - 自動更正錯誤輸入的命令 > `thefuck` 是您一旦嘗試過就離不開的實用程式之一。每當您輸入錯誤的命令並出現錯誤時,只需執行 `fuck`,它就會自動更正它。使用向上/向下選擇一個更正,或者只執行 `fuck --yeah` 立即執行最有可能的。  --- ### [`zoxide`](https://github.com/ajeetdsouza/zoxide) - 輕鬆導航 _(更好的 cd)_ > `z` 讓您可以跳轉到任何目錄,而無需記住或指定其完整路徑。它會記住您存取過的目錄,因此您可以快速跳轉——您甚至不需要鍵入完整的文件夾名稱。它還具有互動式選項,使用“fzf”,因此您可以即時過濾目錄結果  --- ### [`tldr`](https://github.com/tldr-pages/tldr) - 社區維護的文件 _(更好的 `man`)_ > `tldr` 是社區維護的手冊頁的巨大集合。與傳統的手冊頁不同,它們進行了總結,包含有用的用法範例,並且配色良好,便於閱讀  --- ### [`scc`](https://github.com/boyter/scc) - 計算程式碼行數_(更好的`cloc`)_ > `scc` 為您提供了針對特定目錄以每種語言編寫的程式碼行數的細分。它還顯示了一些有趣的統計資料,例如估計的開發成本和復雜性訊息。它的速度非常快,非常準確,並且支持多種語言  --- ### [`exa`](https://github.com/ogham/exa) - 列出文件 _(更好的 `ls`)_ > `exa` 是基於 Rust 的現代替代 `ls` 命令,用於列出文件。它可以顯示文件類型圖標、顏色、文件/文件夾訊息,並有多種輸出格式——樹、網格或列表  --- ### [`duf`](https://github.com/muesli/duf) - 硬碟使用量 _(更好的 `df`)_ > `duf` 非常適合顯示有關已安裝硬碟的訊息和檢查可用空間。它產生清晰多彩的輸出,並包括用於排序和自定義結果的選項。  --- ### [`aria2`](https://github.com/aria2/aria2) - 下載實用程式 _(更好的 `wget`)_ > `aria2` 是一種輕量級、多協議、用於 HTTP/HTTPS、FTP、SFTP、BitTorrent 和 Metalink 的恢復下載實用程序,支持通過 RPC 接口進行控制。它的[功能豐富](https://aria2.github.io/manual/en/html/README.html)令人難以置信,並且有大量的[選項](https://aria2.github.io/manual/en/ html/aria2c.html)。還有 [ziahamza/webui-aria2](https://github.com/ziahamza/webui-aria2) - 一個不錯的網路介面搭配。  --- ### [`bat`](https://github.com/sharkdp/bat) - 讀取文件_(更好的`cat`)_ > `bat` 是 `cat` 的複製品,但具有語法高亮顯示和 git 集成。它是用 Rust 編寫的,性能非常好,並且有多個用於自定義輸出和主題的選項。支持自動管道和文件連接  --- ### [`diff-so-fancy`](https://github.com/so-fancy/diff-so-fancy) - 文件比較_(更好的`diff`)_ > `diff-so-fancy` 為比較字串、文件、目錄和 git 更改提供了更好看的差異。更改突出顯示使發現更改變得更加容易,並且您可以自定義輸出佈局和顏色  --- ### [`entr`](https://github.com/eradman/entr) - 觀察變化 > `entr` 允許您在文件更改時執行任意命令。您可以傳遞一個文件、目錄、符號連結或正則表達式來指定它應該監視哪些文件。它對於自動重建專案、響應日誌、自動化測試等非常有用。與類似專案不同,它使用 kqueue(2) 或 inotify(7) 來避免輪詢,並提高性能  --- ### [`exiftool`](https://github.com/exiftool/exiftool) - 讀取+寫入元資料 > ExifTool 是一個方便的實用程序,用於讀取、寫入、剝離和建立各種文件類型的元訊息。再次分享照片時不要不小心洩露您的位置!  --- ### [`fdupes`](https://github.com/jbruchon/jdupes) - 重複文件查找器 > `jdupes` 用於辨識和/或刪除指定目錄中的重複文件。當您有兩個或更多相同的文件時,它對於釋放硬碟空間很有用  --- ### [`fzf`](https://github.com/junegunn/fzf) - 模糊文件查找器_(更好的`find`)_ > `fzf` 是一個非常強大且易於使用的模糊文件查找器和過濾工具。它允許您跨文件搜尋字串或模式。 fzf 也有可用於大多數 shell 和 IDE 的[插件](https://github.com/junegunn/fzf/wiki/Related-projects),用於在搜尋時顯示即時結果。這篇由 Alexey Samoshkin 撰寫的 [文章](https://www.freecodecamp.org/news/fzf-a-command-line-fuzzy-finder-missing-demo-a7de312403ff/) 重點介紹了它的一些用例。  --- ### [`hyperfine`](https://github.com/sharkdp/hyperfine) - 命令基準測試 > `hyperfine` 可以輕鬆準確地對任意命令或腳本進行基準測試和比較。它負責預熱執行、清除緩存以獲得準確的結果並防止來自其他程序的干擾。它還可以將結果導出為原始資料並生成圖表。  --- ### [`just`](https://github.com/casey/just) - 現代命令執行器_(更好的`make`)_ > `just` 與 `make` 類似,但增加了一些不錯的功能。它讓您可以將專案命令分組到副本中,這些副本可以輕鬆列出和執行。支持別名、位置參數、不同的 shell、dot env 集成、字串插入以及幾乎所有您可能需要的東西 --- ### [`jq`](https://github.com/stedolan/jq) - JSON 處理器 > `jq` 類似於 `sed`,但對於 JSON - 您可以使用它輕鬆地切片、過濾、映射和轉換結構化資料。它可用於編寫複雜的查詢以提取或操作 JSON 資料。還有一個 [jq playground](https://jqplay.org/),您可以用來試用,或通過即時回饋制定查詢 --- ### [`most`](https://www.jedsoft.org/most/) - 多窗口滾動尋呼機_(更好的 less)_ > `most` 是一個尋呼機,用於讀取長文件或命令輸出。 `most` 支持多窗口並且可以選擇不換行 --- ### [`procs`](https://github.com/dalance/procs) - 進程查看器_(更好的 ps)_ > `procs` 是一個易於導航的流程查看器,它具有彩色突出顯示,使流程的排序和搜尋變得容易,具有樹視圖和實時更新  --- ### [`rip`](https://github.com/nivekuil/rip) - 刪除工具_(更好的 rm)_ > `rip` 是一種安全、符合人體工程學且高性能的刪除工具。它讓您直觀地刪除文件和目錄,並輕鬆恢復已刪除的文件  --- ### [`ripgrep`](https://github.com/BurntSushi/ripgrep) - 在文件中搜尋 _(更好的 `grep`)_ > `ripgrep` 是一種面向行的搜尋工具,可遞歸地在當前目錄中搜尋正則表達式模式。它可以忽略 .gitignore 的內容並跳過二進製文件。它能夠在壓縮檔案中搜尋,或只搜尋特定的擴展名,並使用各種編碼方法理解文件  --- ### [`rsync`](https://rsync.samba.org/) - 快速、增量文件傳輸 > `rsync` 讓您可以在本地複制大文件,或將大文件複製到遠程主機或外部驅動器或從遠程主機或外部驅動器複製。它可用於保持多個位置的文件同步,非常適合建立、更新和恢復備份 --- ### [`sd`](https://github.com/chmln/sd) - 查找並替換_(更好的`sed`)_ > `sd` 是一種簡單、快速且直觀的查找和替換工具,基於字串文字。它可以在文件、整個目錄或任何管道文本上執行  --- ### [`tre`](https://github.com/dduan/tre) - 目錄層次結構_(更好的`tree`)_ > `tre` 輸出當前目錄或指定目錄的樹形文件列表,並帶有顏色。使用“-e”選項執行時,它會為每個專案編號,並建立一個臨時別名,您可以使用該別名快速跳轉到該位置  --- ### [`xsel`](https://github.com/kfish/xsel) - 存取剪貼板 > `xsel` 讓您通過命令行讀取和寫入 X 選擇剪貼板。它對於將命令輸出通過管道傳輸到剪貼板或將復制的資料傳輸到命令中很有用 --- ## CLI 監控和性能應用程式 ### [`bandwhich`](https://github.com/imsnif/bandwhich) - 頻寬利用率監視器 > 即時顯示頻寬使用情況、連接訊息、傳出主機和 DNS 查詢  --- ### [`ctop`](https://github.com/bcicen/ctop) - 容器指標和監控 > 類似於 `top`,但用於監控正在執行的(Docker 和 runC)容器的資源使用情況。它顯示實時 CPU、內存和網絡帶寬以及每個容器的名稱、狀態和 ID。還有一個內置的日誌查看器和管理(停止、啟動、執行等)容器的選項  --- ### [`bpytop`](https://github.com/aristocratos/bpytop) - 資源監控_(更好的`htop`)_ > `bpytop` 是一種快速、交互式、可視化的資源監視器。它顯示了最熱門的執行進程、最近的 CPU、內存、磁盤和網絡歷史記錄。您可以從界面中導航、排序和搜尋——還支持自定義顏色主題  --- ### [`glances`](https://github.com/nicolargo/glances) - 資源監視器 + 網絡和 API > `glances` 是另一個資源監視器,但具有不同的功能集。它包括一個完全響應的 Web 視圖、一個 REST API 和歷史監控。它易於擴展,並且可以與其他服務集成  --- ### [`gping`](https://github.com/orf/gping) - 交互式 ping 工具 _(更好的 `ping`)_ > `gping` 可以在多個主機上執行 ping 測試,同時以實時圖形顯示結果。當與 --cmd 標誌一起使用時,它還可以用於監視執行時間  --- ### [`dua-cli`](https://github.com/Byron/dua-cli) - 磁盤使用分析器和監視器 _(更好的 `du`)_ > `dua-cli` 讓您以交互方式查看每個已安裝驅動器的已用和可用磁盤空間,並輕鬆釋放存儲空間  --- ### [`speedtest-cli`](https://github.com/sivel/speedtest-cli) - 命令行速度測試實用程序 > `speedtest-cli` 只是執行網路速度測試,通過 speedtest.net - 但直接從終端 :)  --- ### [`dog`](https://github.com/ogham/dog) - DNS 查找客戶端_(更好的`dig`)_ > `dog` 是一個易於使用的 DNS 查找客戶端,支持 DoT 和 DoH,漂亮的彩色輸出和發出 JSON 的選項  --- ## CLI 生產力應用程式 > 上網衝浪、播放音樂、查看電子郵件、管理日曆、閱讀新聞等等,無需離開終端! ### [`browsh`](https://github.com/browsh-org/browsh) - CLI 網路瀏覽器 > `browsh` 是一個完全交互的、實時的、現代的基於文本的瀏覽器,呈現給 TTY 和瀏覽器。它同時支持鼠標和鍵盤導航,並且對於純基於終端的應用程式來說功能豐富得令人吃驚。它還緩解了困擾現代瀏覽器的電池耗盡問題,並且通過對 MoSH 的支持,由於帶寬減少,您可以體驗更快的加載時間  --- ### [`books`](https://github.com/jarun/books) - 書籤管理器 > `buku` 是一個基於終端的書籤管理器,具有大量的配置、存儲和使用選項。還有一個可選的 [web UI](https://github.com/jarun/buku/tree/master/bukuserver#screenshots) 和 [瀏覽器插件](https://github.com/samhh/bukubrow-webext#installation ), 用於在終端外存取您的書籤  --- ### [`cmus`](https://github.com/cmus/cmus) - 音樂瀏覽器/播放器 > `cmus` 是終端音樂播放器,由鍵盤快捷鍵控制。它支持廣泛的音頻格式和編解碼器,並允許將曲目組織到播放列表中並應用播放設置  --- ### [`cointop`](https://github.com/cointop-sh/cointop) - 跟踪加密價格 > `cointop` 顯示當前的加密貨幣價格,並跟踪您的投資組合的價格歷史。支持價格提醒、歷史圖表、貨幣換算、模糊搜尋等。您可以通過網絡 [cointop.sh](https://cointop.sh/) 或執行 `ssh cointop.sh` 來嘗試演示  --- ### [`ddgr`](https://github.com/jarun/ddgr) - 從終端搜尋網頁 > `ddgr` 類似於 [googler](https://github.com/jarun/googler),但適用於 DuckDuckGo。它快速、乾淨、簡單,支持即時回答、搜尋完成、搜尋 bangs 和高級搜尋。它默認尊重您的隱私,也有 HTTPS 代理支持,並與 Tor 一起工作  --- ### [`micro`](https://github.com/zyedidia/micro) - 程式碼編輯器_(更好的`nano`)_ > `micro` 是一款易於使用、快速且可擴展的程式碼編輯器,支持鼠標。由於它被打包成一個二進製文件,安裝就像`curl https://getmic.ro | 安裝一樣簡單。慶典` --- ### [`khal`](https://github.com/pimutils/khal) - 日曆客戶端 > `khal` 是一個終端日曆應用程式,它顯示即將發生的事件、月份和議程視圖。您可以將它與任何 CalDAV 日曆同步,並直接加入、編輯和刪除事件  --- ### [`mutt`](https://gitlab.com/muttmua/mutt) - 電子郵件客戶端 > `mut` 是一個經典的、基於終端的郵件客戶端,用於發送、閱讀和管理電子郵件。它支持所有主流電子郵件協議和郵箱格式,允許附件、密件抄送/抄送、線程、郵件列表和傳遞狀態通知  --- ### [`newsboat`](https://github.com/newsboat/newsboat) - RSS / ATOM 新聞閱讀器 > `newsboat` 是一個 RSS 提要閱讀器和聚合器,用於直接從終端閱讀新聞、博客和後續更新  --- ### [`rclone`](https://github.com/rclone/rclone) - 管理雲存儲 > `rclone` 是一個方便的實用程序,用於將文件和文件夾同步到各種雲存儲提供商。它可以直接從命令行呼叫,也可以輕鬆集成到腳本中以替代繁重的桌面同步應用程式 --- ### [`taskwarrior`](https://github.com/GothenburgBitFactory/taskwarrior) - Todo + 任務管理 > `task` 是一個 CLI 任務管理/待辦事項應用程式。它既簡單又不引人注目,但也非常強大和可擴展,內置高級組織和查詢功能。還有很多(700+!)額外的[插件](https://taskwarrior.org/tools/) 用於擴展它的功能和與第三方服務的集成  --- ### [`tuir`](https://gitlab.com/ajak/tuir) - Reddit 的終端用戶界面 > `tuir` 是一個很好的選擇,如果你想看起來像在工作,同時實際瀏覽 Reddit!它具有直觀的鍵綁定、自定義主題,還可以呈現圖像和多媒體內容。還有 [haxor](https://github.com/donnemartin/haxor-news) 用於黑客新聞  --- ## CLI 開發套件 ### [`httpie`](https://github.com/httpie/httpie) - HTTP/API測試測試客戶端 > `httpie` 是一個 HTTP 客戶端,用於測試、除錯和使用 API。它支持您所期望的一切——HTTPS、代理、身份驗證、自定義標頭、持久會話、JSON 解析。具有表達語法和彩色輸出的用法很簡單。與其他 HTTP 客戶端(Postman、Hopscotch、Insomnia 等)一樣,HTTPie 也包含一個 Web UI  --- ### [`lazydocker`](https://github.com/jesseduffield/lazydocker) - 完整的 Docker 管理應用程式 > `lazydocker` 是一個 Docker 管理應用程式,可讓您查看所有容器和圖像、管理它們的狀態、讀取日誌、檢查資源使用情況、重新啟動/重建、分析層、修剪未使用的容器、圖像和卷等等。它使您無需記住、鍵入和連結多個 Docker 命令。  --- ### [`lazygit`](https://github.com/jesseduffield/lazygit) - 完整的 Git 管理應用程式 > `lazygit` 是一個可視化的 git 客戶端,在命令行上。輕鬆加入、提交和推送文件、解決衝突、比較差異、管理日誌以及執行壓縮和倒帶等複雜操作。一切都有鍵綁定,顏色,而且很容易配置和擴展  --- ### [`kdash`](https://github.com/kdash-rs/kdash/) - Kubernetes 儀表板應用程式 > `kdash` 是一個一體化的 Kubernetes 管理工具。查看節點指標、觀察資源、流容器日誌、分析上下文和管理節點、pod 和命名空間 --- ### [`gdp-dashboard`](https://github.com/cyrus-and/gdb-dashboard) - 可視化 GDP 除錯器 > `gdp-dashboard` 向 GNU 除錯器加入了一個可視元素,用於除錯 C 和 C++ 程序。輕鬆分析內存、單步執行斷點和查看寄存器  --- ## CLI 外部服務 ### [`ngrok`](https://ngrok.com/) - 共享本地主機的反向代理 > `ngrok` 安全* 將您的本地主機暴露在唯一 URL 後面的網路上。這使您可以與遠程同事實時共享您的工作。使用[非常簡單](https://notes.aliciasykes.com/p/RUi22QSyWe),但它也有很多高級功能,例如身份驗證、webhooks、防火牆、流量檢查、自定義/通配符域等等  --- ### [`tmate`](https://tmate.io/) - 通過網路共享終端會話 > `tmate` 讓您立即與世界其他地方的人分享實時終端會話。跨系統工作,支持存取控制/授權,可自託管,具備Tmux的所有特性 --- ### [`asciinema`](https://asciinema.org/) - 錄製+分享終端會話 > `asciinema` 對於輕鬆記錄、共享和嵌入終端會話非常有用。非常適合展示您建置的內容,或展示教程的命令行步驟。與屏幕錄製視頻不同,用戶可以復制粘貼內容、動態更改主題和控製播放 --- ### [`navi`](https://github.com/denisidoro/navi) - 交互式備忘單 > `navi` 允許您瀏覽備忘單並執行命令。參數的建議值動態顯示在列表中。減少輸入,減少錯誤,讓自己不必記住數千條命令。它集成了 [tldr](https://github.com/tldr-pages/tldr) 和 [cheat.sh](https://github.com/chubin/cheat.sh) 以獲取內容,但您也可以導入其他備忘單,甚至編寫自己的備忘單 --- ### [`transfer.sh`](https://github.com/dutchcoders/transfer.sh/) - 快速文件共享 > `transfer` 使上傳和共享文件變得非常簡單,直接從命令行即可。它是免費的,支持加密,為您提供唯一的 URL,也可以自行託管。 > 我寫了一個 Bash 輔助函數來讓使用更容易一些,你可以[在這裡找到它](https://github.com/Lissy93/dotfiles/blob/master/utils/transfer.sh) 或嘗試一下通過執行`bash <(curl -L -s https://alicia.url.lol/transfer)`  --- ### [`surge`](https://surge.sh/) - 在幾秒鐘內部署一個站點 > `surge` 是一個免費的靜態託管服務提供商,您可以通過一個命令直接從終端部署到它,只需在您的 `dist` 目錄中執行 `surge`!它支持自定義域、自動 SSL 憑證、pushState 支持、跨域資源支持——而且是免費的!  --- ### [`wttr.in`](https://github.com/chubin/wttr.in) - 查看天氣 > `wttr.in` 是一項以命令行中易於理解的格式顯示天氣的服務。只需執行“curl wttr.in”或“curl wttr.in/London”來嘗試一下。有 URL 參數來自定義返回的資料以及格式  --- ## CLI 樂趣 ### [`cowsay`](https://en.wikipedia.org/wiki/Cowsay) - 讓 ASCII 牛說出你的訊息 > `cowsay` 是一個可配置的會說話的奶牛。它基於 Tony Monroe 的[原創](https://github.com/tnalpgge/rank-amateur-cowsay)  --- ### [`figlet`](http://www.figlet.org/) - 將文本輸出為大型 ASCII 藝術文本 > `figlet` 將文本輸出為 ASCII 藝術  --- ### [`lolcat`](https://github.com/busyloop/lolcat) - 使控制台輸出彩虹色 > `lolcat` 使任何傳遞給它的文本變成彩虹色  --- ### [`neofetch`](https://github.com/dylanaraps/neofetch) - 顯示系統資料和 ditstro 訊息 > `neofetch` 打印發行版和系統訊息(這樣你就可以靈活地在 r/unixporn 上使用 Arch btw)  例如,我使用 `cowsay`、`figlet`、`lolcat` 和 `neofetch` 來建立一個自定義的基於時間的 MOTD,在用戶首次登錄時顯示給他們。它以他們的名字問候他們,顯示伺服器訊息和時間、日期、天氣和 IP。 [這裡是源程式碼](https://github.com/Lissy93/dotfiles/blob/master/utils/welcome-banner.sh)。  --- ## 安裝和管理 我們大多數人都有一套核心的 CLI 應用程式和我們所依賴的實用程序。設置一台新機器並單獨安裝每個程序很快就會讓人厭煩。因此,安裝和更新終端應用程式的任務非常適合自動化。 [此處](https://github.com/Lissy93/dotfiles/tree/master/scripts/installs) 是我編寫的一些示例腳本,可以輕鬆將其放入您的點文件或獨立執行以確保您永遠不會錯過一個應用程式。 對於 MacOS 用戶,最簡單的方法是使用 [Homebrew](https://brew.sh/)。只需建立一個 Brewfile(使用 `touch ~/.Brewfile`),然後列出您的每個應用程式,然後執行 `brew bundle`。您可以通過將其放入 Git 存儲庫來備份您的包列表。這是一個示例,讓您入門:https://github.com/Lissy93/Brewfile 在 Linux 上,您通常希望使用本機包管理器(例如 `pacman`、`apt`)。例如,[這裡有一個腳本](https://github.com/Lissy93/dotfiles/blob/master/scripts/installs/arch-pacman.sh) 用於在 Arch Linux 系統上安裝上述應用程式 Linux 上的桌面應用程式可以通過 Flatpak 以類似的方式進行管理。同樣,[這是一個示例腳本](https://github.com/Lissy93/dotfiles/blob/master/scripts/installs/flatpak.sh) :) --- ## 結論 ...就是這樣 - 一個方便的 CLI 應用程式列表,以及一種在您的系統中安裝和保持它們最新的方法。 希望其中一些對你們中的一些人有用:)
你的轉職路上,還缺少一份自學作業包!寫完這幾包,直接拿作品去面試上班!
本論壇另有附設一個 LINE 新手發問&交流群組!歡迎加入討論!


















