毫無疑問,掌握 Web 開發最有效的方法之一就是透過實作。雖然學習理論概念很重要,但將您的知識應用到現實世界的專案中才能真正鞏固您的技能。無論您是想要打下堅實基礎的初學者,還是尋求新挑戰的經驗豐富的開發人員,這裡有 25 個 Web 開發專案可以提高您的能力。 ### 學生成績管理系統 學生成績管理系統旨在為學生和大學提供一種快速且用戶友好的方式來存取和管理考試成績。學生可以登入查看他們的成績,新生可以選擇註冊。該系統旨在以易於理解的方式呈現結果。 **如何做:** 掌握前端、後端和資料庫程式設計的基礎知識後,從建立全端應用程式開始。利用HTML、CSS、JavaScript、PHP和MySQL實現使用者認證、結果顯示和註冊功能。 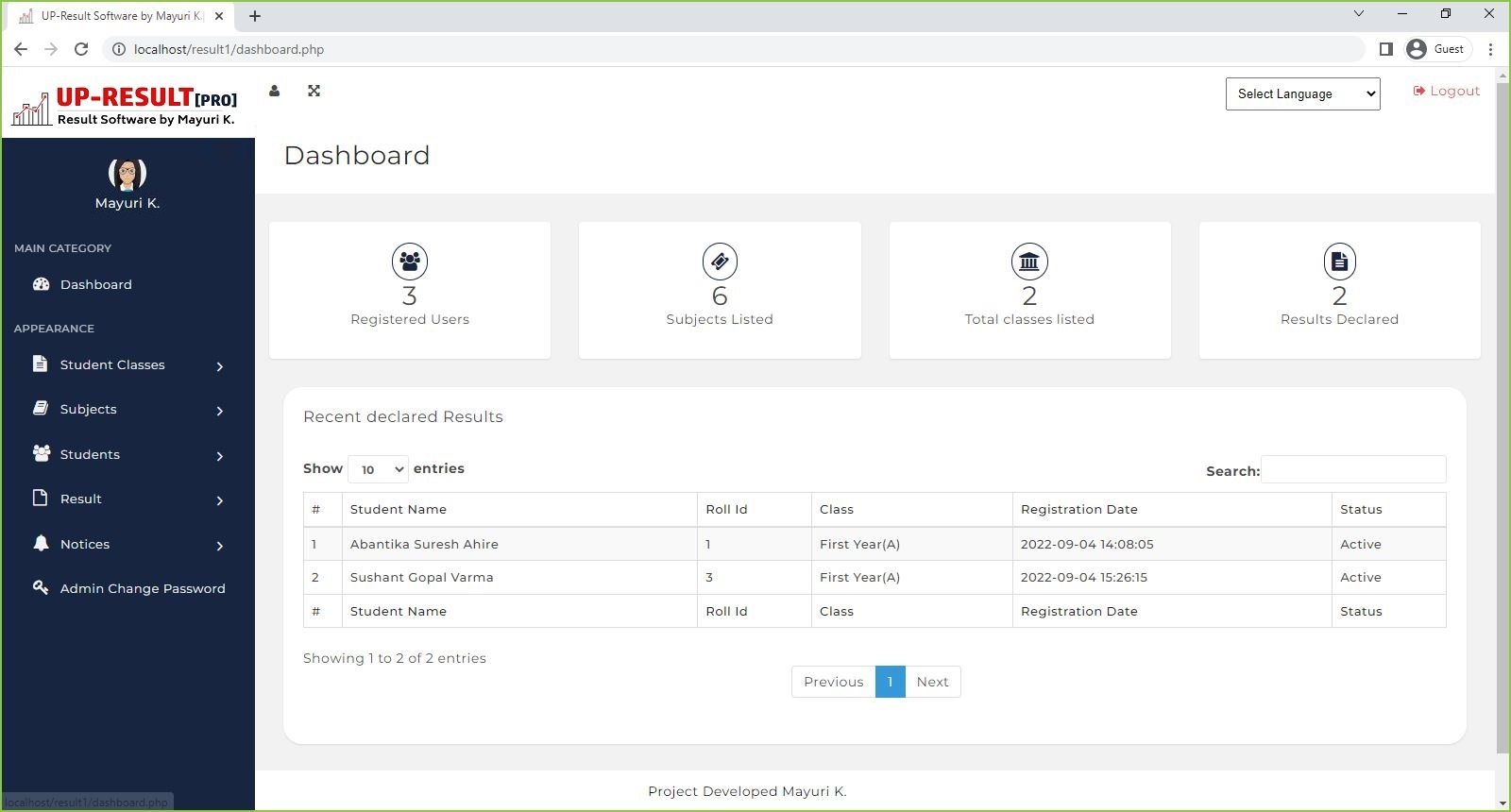 ### 線上程式碼編輯器(React) 該專案涉及使用 React 建立線上程式碼編輯器,允許使用者用各種程式語言編寫和執行程式碼。目標是建立一個用戶可以無縫編輯和測試原始程式碼的平台。 **如何做:** 先使用 HTML、CSS 和 React 進行前端工作。實現程式碼輸入、執行和結果顯示功能。專注於建立用戶友好的介面,以獲得流暢的程式碼編輯體驗。  ### 使用 React 進行 Amazon 克隆 Amazon Clone 專案圍繞著使用 React 建立 Amazon 線上商店的工作副本。該專案將幫助您了解有效的電子商務網站所需的元件並將它們應用到您的應用程式中。 **如何做:** 從 HTML、CSS 和 JavaScript 開始。使用 React 建立電子商務網站的不同部分,例如產品清單、購物車和結帳流程。整合動態資料並增強使用者介面。  ### 客戶關係經理 客戶關係管理器專案涉及建立一個後端 Web 應用程式,該應用程式允許建立、讀取、更新和刪除 (CRUD) 客戶資料。這是了解後端 Web 開發的基礎專案。 **如何做:** 利用 Node.js、Express.js 和 MongoDB 等技術來建立後端基礎架構。實施 CRUD 操作來管理客戶資料。開發一個用戶友好的介面,用於與客戶資料庫互動。 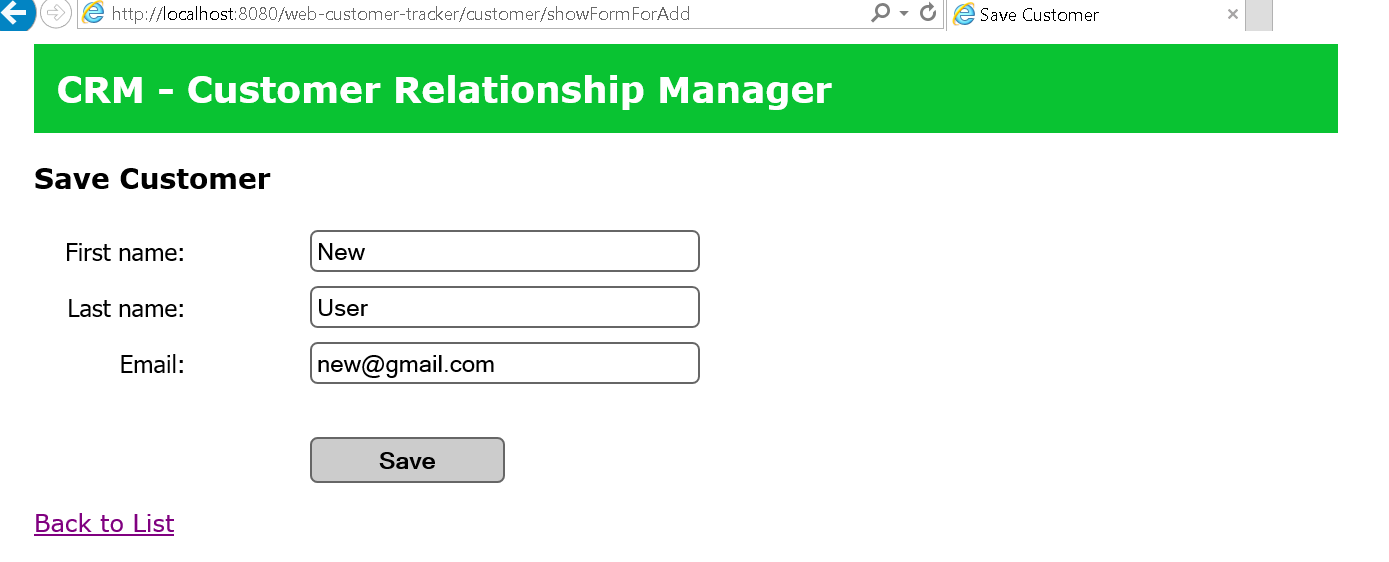 ### 排序展示台 排序可視化器專案旨在提供各種排序演算法的可視化表示。使用者可以觀察不同的演算法如何執行,並更深入地了解 JavaScript 的基本概念。 **具體操作方法:** 使用 HTML、CSS、Bootstrap 和 JavaScript 建立 Web 應用程式。實現冒泡排序、合併排序和快速排序等排序演算法的視覺化。允許用戶與視覺化進行交互,以增強他們的學習體驗。  ### 多人遊戲 – Connect4 多人遊戲 – Connect4 專案專注於建立具有多人遊戲功能的著名 Connect4 遊戲。它提供了學習一些重要的網路和遊戲設計基礎知識的機會。 **如何做:** 如果您想知道多人遊戲是如何開發的,或者您曾經想為週末製作一款遊戲,那麼這個專案適合您。使用 PyGame、Sockets 和遊戲編程為您和您的朋友建立多人 Connect4 遊戲。  ### YouTube 腳本摘要器 投入時間觀看可能比預期更長的電影變得相當具有挑戰性。有時,如果我們不能從他們那裡收集有用的訊息,我們的努力可能會徒勞無功。透過自動總結影片的文字記錄,我們可以輕鬆地發現這些影片中的關鍵主題,這節省了我們再次觀看整個影片的時間和精力。 **如何做到這一點:** 人們每天都會觀看 YouTube 影片,這些影片可以是指導性的、紀錄片的或任何其他持續時間較長的類型;考慮透過提供摘要資訊可以節省多少時間。該專案將是一個 chrome 擴展,它將向後端的 Rest API 發送請求,該 API 將向您發送 YouTube 腳本的摘要。  ### OurApp – NodeJS 中的社交媒體 Web 應用程式 現實應用程式 OurApp 的用戶可以進行交流、相互關注以及發布簡短的推文。掌握 HTML、CSS 和 JS 後,專案最適合想要使用 Nodejs 和 MongoDB 深入研究完整堆疊的人。 **怎麼做:** 你想成為能夠超越 HTML、CSS 和 JS 的全端開發人員嗎?建立這個完整的堆疊應用程式,以了解如何使用 NodeJS、MongoDB 和其他技術來建立現代、快速且可擴展的伺服器端 Web 應用程式。如果您想在磨練 NodeJS 技能的同時開發一些有趣的東西,那麼這個專案就是適合您的。您還可以免費註冊全端 Web 開發課程,這將幫助您成為您所在領域的傑出開發人員。  ### Codechef 通知 CodeChef 經常遇到伺服器過載問題,導致評審難以快速提供提交結果。留給編碼人員的唯一選擇是在一段時間後不斷檢查站點,看看結果是否存在。透過這個專案,我們希望消除審查提交頁面以確定提交結果的額外步驟。我們將自動執行檢索結果的過程並在準備好後立即通知使用者。 **如何操作:** Codechef 是一個流行的編碼實踐平台,但伺服器過載可能會導致結果延遲。此附加元件旨在透過自動化獲取結果並及時通知用戶的流程來節省時間。使用網路抓取或 API 來收集結果資訊並實作通知系統。 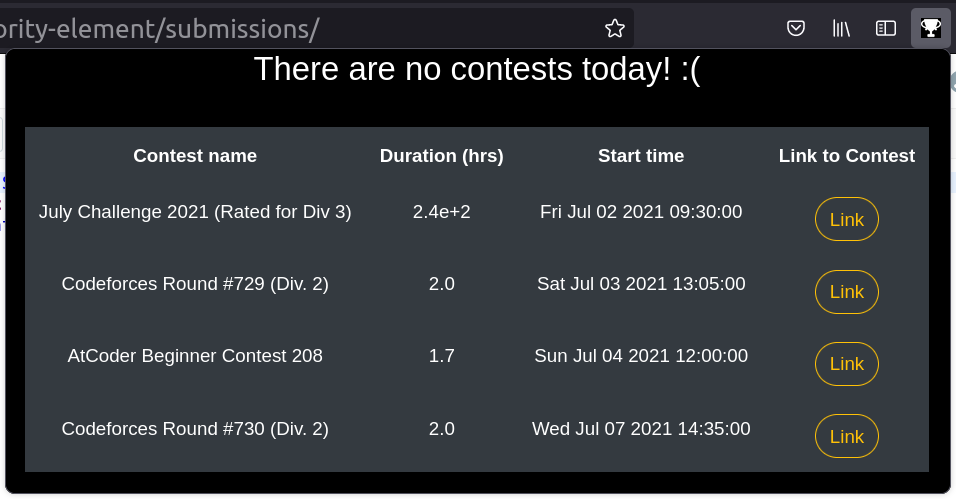 ### 使用 Dash 來視覺化和預測股票 該專案涉及使用 Dash(一種用於建立分析 Web 應用程式的 Python 框架)來視覺化和預測股票資料。它提供了將資料視覺化和機器學習概念應用於金融資料的機會。 **如何操作:** 如果您對股票市場感興趣,該專案將簡化股票資料的可視化。利用Python、Dash和相關函式庫進行資料視覺化。實施基於歷史資料預測股票趨勢的功能。 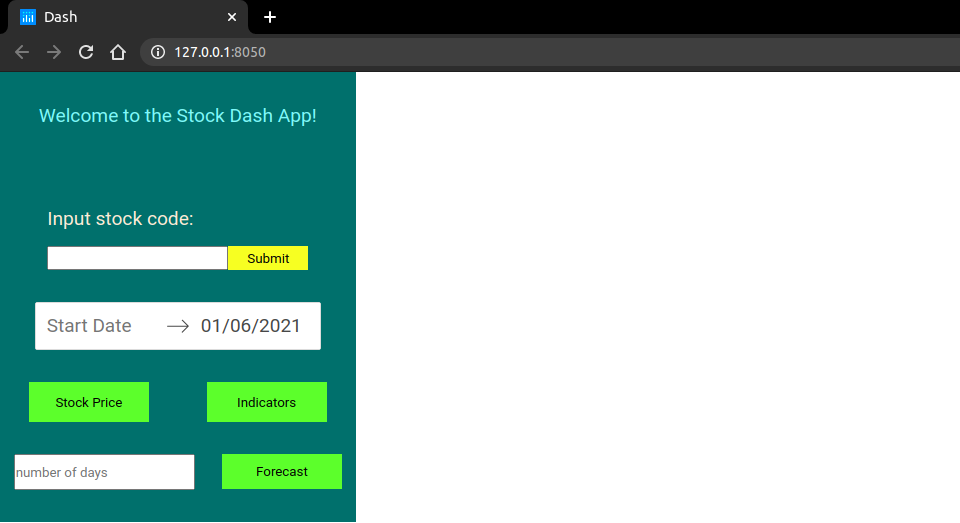 ### 線上程式碼編輯器 (JQuery) 線上程式碼編輯器可透過瀏覽器存取,並位於遠端伺服器上。儘管一些線上程式碼編輯器更像是完整的 IDE,但其他編輯器更像是具有語法突出顯示或程式碼完成等基本功能的文字編輯器。 **如何操作:** 使用 HTML、CSS、JavaScript 和 JQuery 建立線上程式碼編輯器。專注於透過語法突出顯示和程式碼完成等功能來增強使用者體驗。確保程式碼輸入和執行順利。  ### 模糊URL FuzzyURLs 涉及使用 Django(Python 的高級 Web 框架)建立 URL 縮短服務。它提供了建立 Web 應用程式的實務經驗,特別關注 URL 操作。 **如何做:** 從頭開始開發一個基於 Django 的 URL 縮短器。了解 URL 縮短服務的工作流程並實現建立、管理和重新導向短 URL 的功能。  ### 使用 React 進行 Slack 克隆 該專案旨在使用 React 建立 Slack 克隆,提供即時訊息和協作的平台。這是一個中高階專案,強調React-Redux和Firebase。 **如何做:** 應用 React-Redux 原理來建立一個類似 Slack 的 Web 訊息服務。利用 Firebase 實現即時資料庫功能。專注於建立響應靈敏且功能豐富的訊息傳遞應用程式。 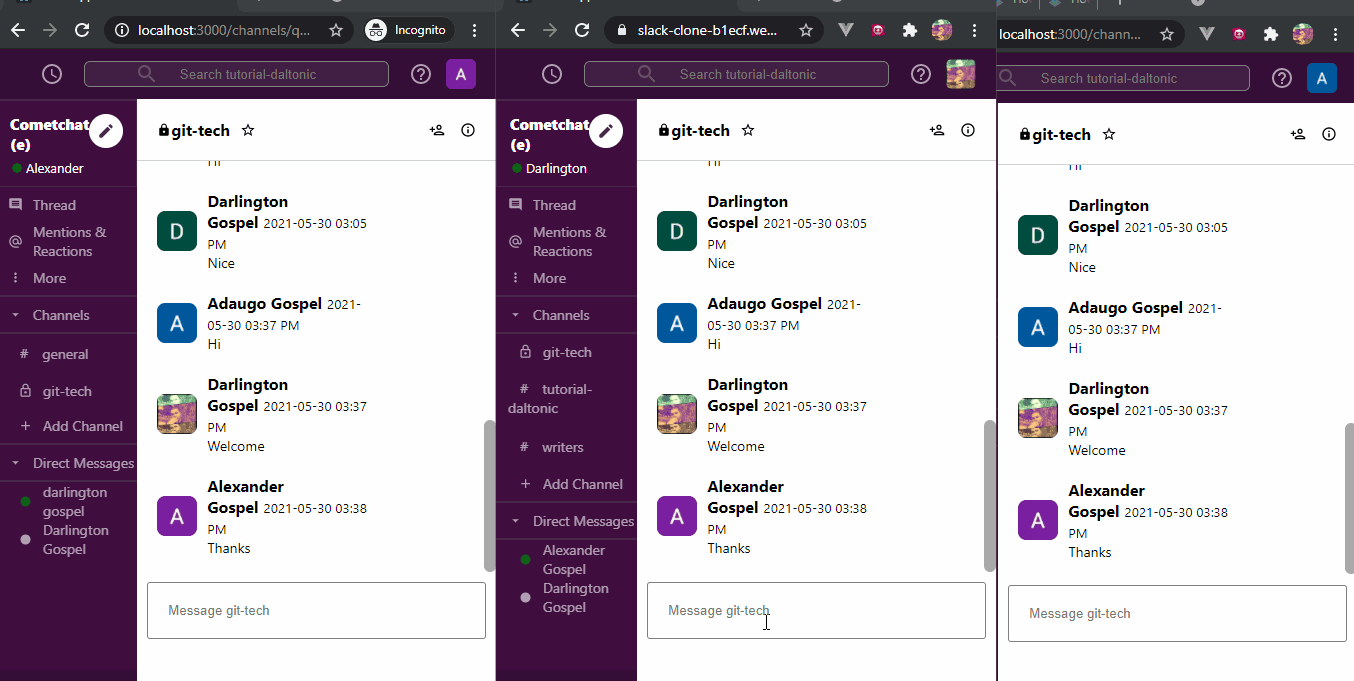 ### Web 應用程式的 Node.js 驗證 了解使用 Node.js 為 Web 應用程式建立驗證系統。探索各種身份驗證技術,評估其優點和缺點,並實施改進。 **如何做:** 對於那些想要深入研究 Node.js 並了解建立安全身份驗證系統的複雜性的人來說,這個專案非常適合。實施使用者身份驗證、會話管理並探索增強安全性的方法。  ### TinyMCE 同義詞插件 為 TinyMCE 富文本編輯器建立一個插件,用於搜尋單字的同義詞並允許使用者將它們插入編輯器中。 **如何做到這一點:** 為 TinyMCE 開發一個自訂插件,整合一項功能,使用戶能夠搜尋同義詞並輕鬆地將它們插入到富文本編輯器中。了解 TinyMCE API 以實現無縫整合。  ### 迷宮裡的老鼠 建立一個基本的 React Web 應用程式,顯示老鼠從帶有預設障礙的方形迷宮的左上角到右下角可以採取的所有可能路徑。 **具體操作方法:** 建立一個簡單的 React Web 應用程式來直觀地呈現經典的 Rat in the Maze 謎題。實施功能來展示老鼠穿過迷宮的所有潛在路徑。 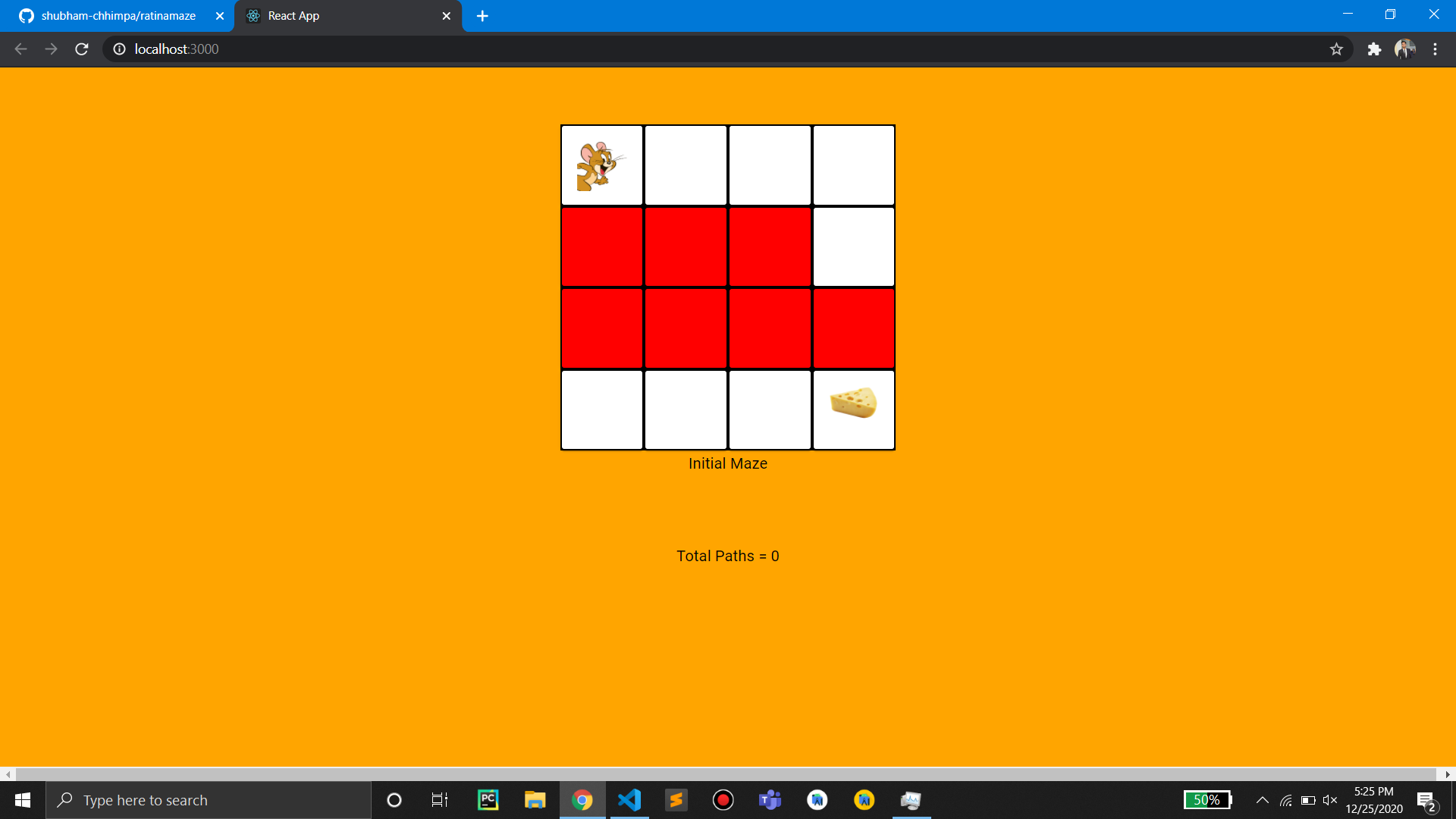 ### 簡歷產生器 Web 應用程式 使用 ReactJS 和 NodeJS 建立一個用於建立履歷的 Web 應用程式。該專案將指導您完成建立簡歷產生器的步驟,並提供一種實用的方法來支援個人製作簡歷。 **如何做:** 深入研究 ReactJS 和 NodeJS 來開發一個用戶友好的簡歷產生器。實施加入個人詳細資訊、教育背景、工作經驗和技能的功能。專注於建立動態且可自訂的履歷模板。  ### Markdown 編輯器 建立一個 Markdown 編輯器,讓使用者編寫 Markdown 並預覽渲染的 HTML。 Markdown 是一種基於網路的文字格式化系統,廣泛用於部落格文章、文件等。 **如何做:** 使用 HTML、CSS 和 JavaScript 開發 Markdown 編輯器。使用戶能夠編寫 Markdown 程式碼並查看渲染的 HTML 的即時預覽。使用粗體文字、圖像和清單等功能增強編輯器。 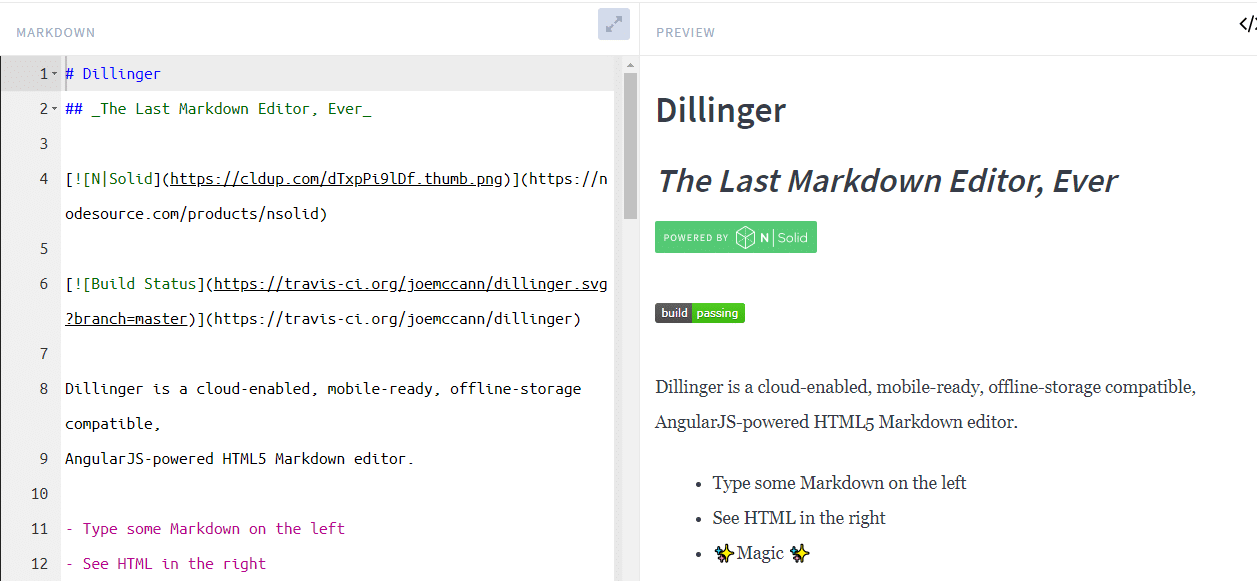 ### 450 DSA 追蹤器 450 DSA Tracker 旨在協助使用者追蹤解決 450 道資料結構和演算法問題的進度。它利用 TypeScript、React.js 的 reducer 和 context API 以及即時瀏覽器 IndexedDB 來快取資訊。 **具體操作方法:** 使用 TypeScript 和 React.js 實作 Web 應用程式,以追蹤解決資料結構和演算法問題的進度。利用reducer 和context API 進行狀態管理,並利用IndexedDB 進行即時瀏覽器快取。 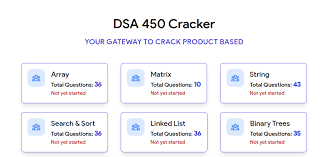 ### 待辦事項網頁應用程式 使用 Node.js 框架 Adonis.js 建立待辦事項 Web 應用程式。了解 HTTP、REST API 和 CRUD 操作,同時建立用於管理待辦事項清單的後端 API。 **如何操作:** 使用 Adonis.js 為待辦事項 Web 應用程式建立 CRUD API。使用 Postman 測試 API 並建立用於新增、更新和刪除任務的後端功能。獲得使用後端框架的經驗。  ### 兩個真相和一個謊言遊戲 Slack 機器人 開發一個 Slack 機器人,用於在 Slack 工作區中玩「兩個真相和一個謊言」遊戲。該專案利用 JavaScript 和 Node.js 為工作區成員建立一個有趣的互動式遊戲。 **如何做:** 建立一個 Slack 機器人,以促進「兩個真相和一個謊言」遊戲。使用 JavaScript 和 Node.js 處理 Slack 工作區中的互動。實現用戶共享陳述並猜測哪一個是錯誤的功能。  ### 使用 Chromakey(綠幕)效果進行即時視訊處理 探索視訊處理中使用的色度(綠幕)效果。使用 HTML、CSS 和 JavaScript 建立 Web 應用程式,以背景影片或圖像取代綠幕。 **具體操作方法:** 開發一個處理即時視訊並應用色鍵效果的 Web 應用程式。使用 HTML、CSS 和 JavaScript 操作影片幀並用背景影片或圖像替換綠幕。 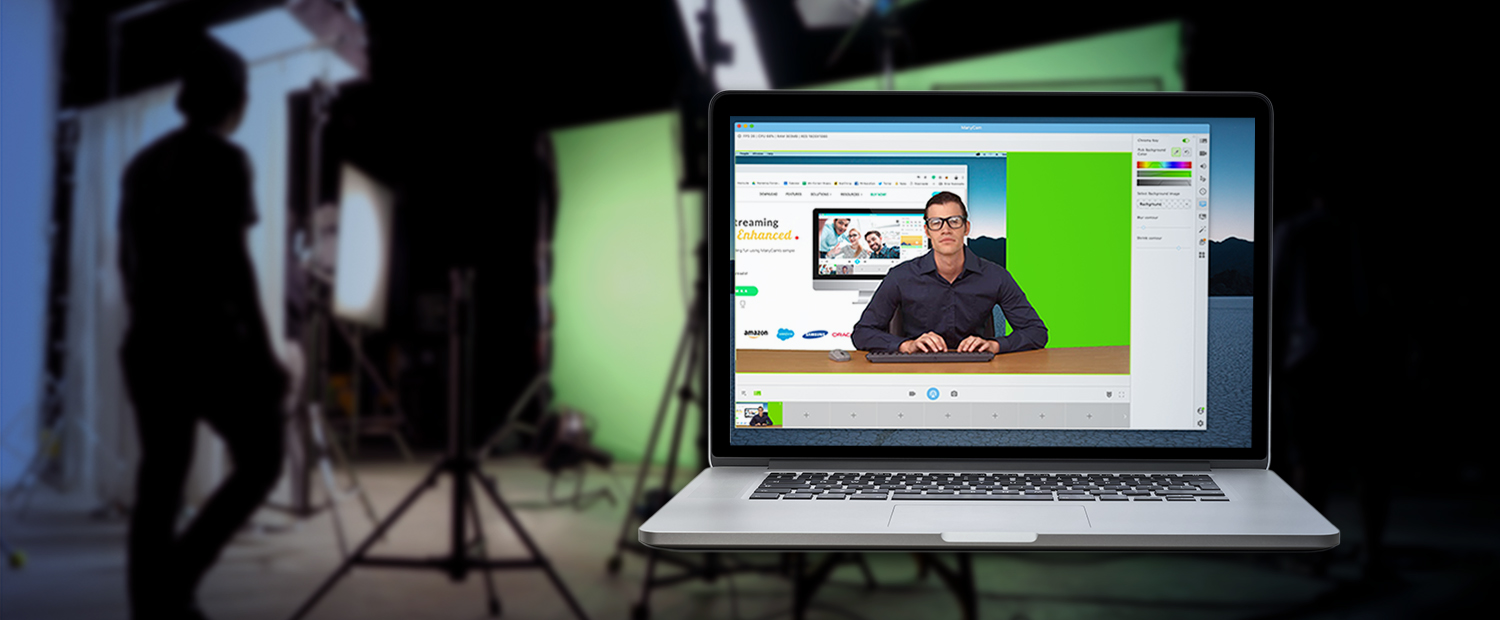 ### WhatsApp 網頁克隆 使用 React 和 Firebase 開發具有即時訊息功能的 WhatsApp Web 克隆。 **如何操作:** 使用 React 建立使用者介面並使用 Firebase 實現即時資料庫功能,打造流暢的訊息體驗。  ### WhatsApp 上的電子郵件提醒 設定新電子郵件的 WhatsApp 提醒以簡化電子郵件管理和通知。 **如何操作:** 使用自動化平台 Twilio 建立一個工具,從收件匣中獲取詳細資訊並在 WhatsApp 上發送警報。  ### 天氣預報應用程式 使用 Streamlit 函式庫和 OpenWeatherMap API 為天氣預報應用程式建立響應式前端。 **如何操作:** 利用 Python 和 Streamlit 可視化天氣資料並與 OpenWeatherMap API 互動以獲取即時天氣資訊。  ### 總結 這個 Web 開發專案的彙編提供了各種各樣的挑戰,使您能夠提高跨不同技術和概念的技能。無論您對全端開發、資料視覺化、遊戲設計還是自動化感興趣,這些專案都可以提供有價值的幫助 --- 原文出處:https://dev.to/mukeshkuiry/25-web-development-projects-you-must-work-on-2024-4onl
嘿嘿👋 在您作為開發人員的旅程中,賺錢的常見方法是**獲得全職工作**。 然而,您可能還沒有找到工作(_又名您仍在學習_),或者您已經開始工作,但您正在尋找賺取額外現金的方法。 現在,您可以嘗試透過多種方式賺取副收入。 “有些比其他更現實。” 在本文中,我們將了解您今天就可以開始的**_可實現的_副業收入工作**。 深吸一口氣,讓我們用這些新知識洗滌我們的靈魂。 🧎  **_免責聲明:_** 我沒有嘗試清單中的每個選項。如果您認為應該在清單中加入一些內容或您想分享個人經歷,請在下面發表評論(我很樂意聽取您的意見!)。 🙇♂️ --- ## ⚔️ 創作者任務 在 Quine,我們目前正在為開發人員提供一種將其技能貨幣化的方法。 _Creator Quests_ 是每兩週發生一次的開源挑戰。 **這就像一場 24/7 的黑客馬拉松,獎勵開發者建立酷炫的應用程式**以及使用未來的開發者工具。 🚀 社區透過對他們喜歡的專案給予榮譽來決定獲勝者。獲得最多榮譽的專案將獲得最多的收益。 🤑 **下一次挑戰將於 12 月 19 日星期二開始。** 要參加,請註冊 [Quine](https://quine.sh/?utm_source=devto&utm_campaign=monetising_dev_skills) 並前往 _Quests_。 PS:測試期間,100%有效參賽者均獲得獎勵💸 目前的獎金池為 1024 美元,隨著更多參與者的加入,獎金池將會增加!點擊下面的並試試看! ⬇️ [](https://quine.sh/?utm_source=devto&utm_campaign=monetising_dev_skills --- # 💃 MaaS - 我即服務 **自由工作者很難開始。** 然而,每個人都可以**實現並獲得**。 我在資料分析方面有一些自由職業經驗。如果我必須重做一次,我會採取以下方法: **1️⃣ 選擇平台:** 了解[Fiverr](https://www. Fiverr.com/)、[Upwork](https://www.upwork.com/en-gb/nx/job)之間的區別-post/instant/welcome) 和 [自由工作者](https://www.freelancer.co.uk/)。選擇一個您喜歡的平台並專注於此。我發現 [Malt](https://www.malt.com/) 是一個有趣的平台,但如果你認為自己非常優秀,你可以隨時關注 [TopTal](https://www.toptal.com) / )。 **2️⃣ 不要成為萬事通先生/女士:** 圍繞非常具體的服務建置配置文件,例如_我專門從事Python 抓取工具的編碼並使用MongoDB 建置資料庫,最終通過Plotly 顯示儀表板_(不完全是這樣)但你明白了🙃)。 **3️⃣ 為您的第一個客戶不收取任何費用:** 獲得您的第一個客戶非常困難,因此請聯繫招聘訊息並說明您很樂意**免費這樣做。** 如果他們對這份工作感到滿意,請詢問他們提供良好的評級。 **4️⃣ 獲得您的第一筆薪水:** 開始為您的工作收費 - 仍然以較低的費率 - 並建立您的聲譽。 **5️⃣ 提高定價:** 一旦您在平台上擁有更強大的地位,您就可以決定提高定價。 我的最後評論是,雖然我相信每個人都可以透過自由工作開始賺錢,但**我不認為每個人都應該這樣做。** 有很多缺點不符合你喜歡的工作方式(難纏的客戶、截止日期) 、平台依賴性等)。 **💁 特別提示:** 在倫敦,我發現了一個吸引一些客戶的小技巧。您可以聯繫一些相關的諮詢/招聘機構,他們可以幫助您找到客戶。如果您在起步時遇到困難,請考慮這樣的機構。 --- ## 🧪 測試一下。獲得報酬。 作為開發人員,您了解網頁或應用程式背後的技術細節。 這意味著您有能力執行出色的品質檢查。 根據您關注的平台,您可以花 10 到 60 分鐘以上嘗試應用程式或網站。 市面上有各種平台,但您可以查看的 3 個已知網站是: - [Trymata](https://trymata.com/) - [使用者測試](https://www.usertesting.com/) - [UserLytics](https://www.userlytics.com/user-experience-research/paid-ux-testing/) PS:還有一個完整的調查選項,在我看來,花費很少。如果您仍然好奇,可以查看[Wynter](https://wynter.com/participants/join)或[SwagBucks](https://www.swagbucks.com/g/paid-surveys)。 --- # 🐛 蟲子獵人 如果您對細節有敏銳的洞察力並且喜歡網路安全,那麼您可以透過這項技能獲利。 如果你有好奇心並且有良好的程式設計技能,你就可以在那裡賺錢。 🥂 一開始你可能會得到 20 美元的報酬,但獎勵可能會增加到天文數字,例如 10 萬英鎊以上。 我要強調的是,這不是你成為百萬富翁的方式。有一些不錯的競爭,你可能不會賺到很高的錢。 您仍然應該嘗試一下,看看它是否適合您。 最知名的平台是: - [HackerOne](https://www.hackerone.com/) - [BugCrowd](https://www.bugcrowd.com/) 如果你在這方面變得擅長,你可以考慮大公司,因為這往往是大公司的地方。 您可以從 [Microsoft](https://www.microsoft.com/en-us/msrc/bounty)、[Apple](https://security.apple.com/bounty/) 和 [Google](https: //bughunters.google.com/about/rules/6625378258649088/google-and-alphabet-vulnerability-reward-program-vrp-rules)。 **最後提示:** 如果您發現自己喜歡使用的網站有漏洞,向他們索取賠償總沒有壞處。 🙃 --- ## 🧑🏫 你學到了什麼嗎?教它回來 輔導是我個人最喜歡的「副業」。 對於某些人來說,這可能看起來“乏味”,但它是非常可以實現的,並且它**增強您圍繞特定主題的知識,同時賺大錢**。 此外,您不一定需要成為專家。 這是正確的! 只要您在特定領域更有知識,您就可以收取教授該知識的服務費用。 您可以透過 3 種方法來解決此問題: ### 📜 老學校方式 1️⃣ **確定合適的學校**:在學校/學院周圍張貼實體廣告,並附上您的課程和聯絡方式。 2️⃣ **辨識社群:** 尋找並參與相關的 Discord、Facebook 和 Linkedin 群組。以尊重的方式讓相關社區了解您的服務。 3️⃣ **不要太貪心:** 以較低的價格開始您的第一堂課,讓一切順利進行。經過一些經驗後,考慮提高價格。 ### 👶 新學校方式 查看以下平台: - [Codementor](https://www.codementor.io/freelance) - [Superprof](https://www.superprof.co.uk/lessons/computer-programming/united-kingdom/) - [導師](https://tutorhouse.co.uk/a/coding) 註冊成為導師並以低於市場價格的價格開始招募您的第一批學生。 ### 📦 數位內容 您可以考慮建立一些視訊課程。 我個人最喜歡的是一個名為 [Stan Store](https://www.stan.store/?ref=bap&utm_source=stan-store-link&utm_medium=redirect&utm_campaign=storefront) 的新工具。 這是數位創作者的全能工具包,不僅僅是建立影片內容。 > 我個人使用這個平台賺了幾百美元。 或者,您可以查看更傳統的平台,例如 [SkillShare](https://www.skillshare.com/en/search?query=Coding) 或 [Udemy](https://www.udemy.com/)。 --- ## 較不容易實現的路徑(但值得一提)👇 <br> <br> - **🚧 黑客馬拉松**:一些黑客馬拉松提供豐厚的現金獎勵。缺點是通常存在相當多的競爭。要尋找合適的黑客馬拉松,迄今為止最好的網站是 [DevPost](https://devpost.com/)。 <br> - **🏷️ 銷售鍋爐模板:** 您可以根據自己的知識建立鍋爐模板。在這種情況下,「稍微少一點」的是你能賺多少錢(至少在最初)。這是因為它需要大量的追隨者(或大量的行銷)。如果你想嘗試一下,可以看看 [Gum Road](https://gumroad.com/) 和 [AppSumo](https://appsumo.com/)。 --- 我希望您喜歡這篇文章,它可以幫助您了解如何利用您的開發技能來從事副業。 上述演出並不是試圖描繪出你將一夜致富的景象。然而,它們是副業,獲得報酬的機會很高。只要保持一定的一致性,隨著時間的推移,您可以期望獲得更多的收入。 🚀 這篇文章的靈感來自 @lissy93 寫的一篇很棒的文章。 如果您有興趣了解將您的開發技能貨幣化的其他方法(特別是如果您更有經驗),請查看他們的[文章](https://dev.to/lissy93/50-ways-to-bring -in- extra-cash-as-a-developer-19b6) 並給它一些愛。 下週見, 您的開發夥伴💚 巴普 --- 如果您想加入開源中自稱「最酷」的伺服器😝,您應該加入我們的[discord伺服器](https://discord.com/invite/ChAuP3SC5H/?utm_source=devto&utm_campaign=9_deep_learning)。我們隨時為您的開源之旅提供協助。 🫶 {% 嵌入 [https://dev.to/quine](https://dev.to/quine) %} --- 原文出處:https://dev.to/quine/5-achievable-side-hustles-for-developers-4bcg
## 第 1 部分:將 MongoDB 與 Flask 結合使用 你好!在本系列的最後一個[部分](https://dev.to/paurakhsharma/flask-rest-api-part-0-setup-basic-crud-api-4650)中,我們學習瞭如何建立基本的“ CRUD” ` 使用 python `list` 的 REST API 功能。但這不是現實世界應用程式的建構方式,因為如果您的伺服器重新啟動或上帝禁止崩潰,那麼您將丟失伺服器中儲存的所有資訊。為了解決這些問題(以及許多其他問題),使用了資料庫。所以,這就是我們要做的。我們將使用 [MongoDB](https://docs.mongodb.com/manual/) 作為我們的資料庫。 如果您剛從這部分開始,您可以在[此處]找到我們迄今為止編寫的所有程式碼(https://github.com/paurakhsharma/flask-rest-api-blog-series/tree/master/Part% 20 -%200)。 在開始之前,請確保您已在系統中安裝了 MongoDB。如果您還沒有安裝,可以安裝 [Linux](https://docs.mongodb.com/manual/administration/install-on-linux/)、[Windown](https://docs.mongodb.com/手冊/教學/install-mongodb-on-windows/)和[macOS](https://docs.mongodb.com/manual/tutorial/install-mongodb-on-os-x/)。 主要有一些流行的函式庫可以讓 MongoDB 的使用變得更容易: 1) [Pymongo](https://api.mongodb.com/python/current/) 是 MongoDB 的低階 Python 包裝器,使用 `Pymongo` 類似於直接編寫 MongoDB 查詢。 以下是使用“Pymongo”更新“id”與給定“id”相符的電影名稱的簡單範例。 ``` db['movies'].update({'_id': id}, {'$set': {'name': 'My new title'}}) ``` `Pymongo` 不使用任何預先定義的模式,因此它可以充分利用 MongoDB 的無模式特性。 2) [MongoEngine](http://docs.mongoengine.org/) 是物件文件映射器,它使用文件模式,使 MongoDB 的使用變得清晰、更容易。 這是使用“mongoengine”的相同範例。 ``` Movies.objects(id=id).update(name='My new title') ``` 「Mongoengine」對資料庫中的欄位使用預先定義架構,這限制了它使用 MongoDB 的無架構性質。 正如我們所看到的,雙方都有各自的優點和缺點。因此,請選擇最適合您的專案的一種。在本系列中,我們將學習“Mongoengine”,如果您希望我也介紹“Pymongo”,請在下面的評論部分告訴我。 為了在我們的`Flask` 應用程式中更好地使用`Mongoengine`,有一個很棒的`Flask` 擴展,名為[Flask-Mongengine](http://docs.mongoengine.org/projects/flask- mongoengine/en/latest/)。 那麼,讓我們開始安裝「flask-mongoengine」。 ``` pipenv install flask-mongoengine ``` *注意:由於`flask-mongoengine` 是在`mongoengine` 之上建造的,所以在安裝Flask-mongoengine 時會自動安裝,而且`mongoengine` 是在`pymongo` 之上建造的,所以它也會被安裝* 現在,讓我們在「movie-bag」中建立一個新資料夾。我將其稱為“資料庫”。在「database」資料夾中建立一個名為「db.py」的檔案。另外,建立另一個檔案並將其命名為“models.py” 讓我們看看文件/資料夾現在是什麼樣子。 ``` movie-bag │ app.py | Pipfile | Pipfile.lock └───database │ db.py └───models.py ``` 現在,讓我們深入探討有趣的部分。 首先,讓我們透過將以下程式碼新增至「db.py」來初始化我們的資料庫 ``` #~movie-bag/database/db.py from flask_mongoengine import MongoEngine db = MongoEngine() def initialize_db(app): db.init_app(app) ``` 在這裡,我們導入了“MongoEngine”並建立了“db”物件,並定義了一個函數“initialize_db()”,我們將從“app.py”中呼叫該函數來初始化資料庫。 讓我們在“models”目錄中的“movie.py”中編寫以下程式碼 ``` #~movie-bag/database/models.py from .db import db class Movie(db.Document): name = db.StringField(required=True, unique=True) casts = db.ListField(db.StringField(), required=True) genres = db.ListField(db.StringField(), required=True) ``` 我們剛剛建立的是資料庫的文件。因此,使用者無法新增此處定義的其他欄位。 這裡我們可以看到「Movie」文件有三個欄位: 1)`name`:是一個`String`類型的字段,我們在這個字段上也有兩個約束。 - “必需”,這意味著用戶在不提供標題的情況下無法建立新電影。 - “唯一”,這意味著電影名稱必須是唯一的,不能重複。 2) `casts`:是一個`list`類型的字段,其中包含`String`類型的值 3) `genres`: 與`casts`相同 最後,我們可以在「app.py」中初始化資料庫,並更改「view」函數(處理 API 請求的函數)以使用我們先前定義的「Movie」文件。 ``` #~movie-bag/app.py -from flask import Flask, jsonify, request +from flask import Flask, request, Response +from database.db import initialize_db +from database.models import Movie app = Flask(__name__) -movies = [ - { - "name": "The Shawshank Redemption", - "casts": ["Tim Robbins", "Morgan Freeman", "Bob Gunton", "William Sadler"], - "genres": ["Drama"] - }, - { - "name": "The Godfather ", - "casts": ["Marlon Brando", "Al Pacino", "James Caan", "Diane Keaton"], - "genres": ["Crime", "Drama"] - } -] +app.config['MONGODB_SETTINGS'] = { + 'host': 'mongodb://localhost/movie-bag' +} + +initialize_db(app) [email protected]('/movies') -def hello(): - return jsonify(movies) [email protected]('/movies') +def get_movies(): + movies = Movie.objects().to_json() + return Response(movies, mimetype="application/json", status=200) [email protected]('/movies', methods=['POST']) -def add_movie(): - movie = request.get_json() - movies.append(movie) - return {'id': len(movies)}, 200 [email protected]('/movies', methods=['POST']) + body = request.get_json() + movie = Movie(**body).save() + id = movie.id + return {'id': str(id)}, 200 [email protected]('/movies/<int:index>', methods=['PUT']) -def update_movie(index): - movie = request.get_json() - movies[index] = movie - return jsonify(movies[index]), 200 [email protected]('/movies/<id>', methods=['PUT']) +def update_movie(id): + body = request.get_json() + Movie.objects.get(id=id).update(**body) + return '', 200 [email protected]('/movies/<int:index>', methods=['DELETE']) -def delete_movie(index): - movies.pop(index) - return 'None', 200 [email protected]('/movies/<id>', methods=['DELETE']) +def delete_movie(id): + Movie.objects.get(id=id).delete() + return '', 200 app.run() ``` 哇!變化很多,讓我們一步一步地進行變化。 ``` -from flask import Flask, jsonify, request +from flask import Flask, request, Response +from database.db import initialize_db +from database.models.movie import Movie ``` 這裡我們刪除了“jsonify”,因為我們不再需要,並加入了“Response”,我們用它來設定回應的類型。然後我們從之前定義的「db.py」導入「initialize_db」來初始化資料庫。最後,我們從“movie.py”導入“Movie”文件 ``` +app.config['MONGODB_SETTINGS'] = { + 'host': 'mongodb://localhost/movie-bag' +} + +db = initialize_db(app) ``` 這裡我們設定 mongodb 資料庫的配置。這裡主機的格式為「<host-url>/<database-name>」。由於我們已經在本地安裝了 mongodb,因此我們可以從“mongodb://localhost/”存取它,並且我們將資料庫命名為“movie-bag”。 最後,我們初始化資料庫。 ``` [email protected]('/movies') +def get_movies(): + movies = Movie.objects().to_json() + return Response(movies, mimetype="application/json", status=200) + ``` 在這裡,我們使用“Movies.objects()”從“Movie”文件中獲取所有物件,並使用“to_json()”將它們轉換為“JSON”。最後,我們傳回一個「Response」物件,其中我們將回應類型定義為「application/json」。 ``` [email protected]('/movies', methods=['POST']) + body = request.get_json() + movie = Movie(**body).save() + id = movie.id + return {'id': str(id)}, 200 ``` 在「POST」請求中,我們首先取得發送的「JSON」和一個請求。然後我們使用“Movie(**body)”請求中的欄位來載入“Movie”文件。這裡的「**」稱為擴充運算符,在 JavaScript 中寫為「...」(如果您熟悉的話)。顧名思義,它的作用是傳播「dict」物件。 <br/> 所以,`Movie(**body)` 變成了 ``` Movie(name="Name of the movie", casts=["a caste"], genres=["a genre"]) ``` 最後,我們保存文件並獲取其“id”,我們將其作為回應返回。 ``` [email protected]('/movies/<id>', methods=['PUT']) +def update_movie(id): + body = request.get_json() + Movie.objects.get(id=id).update(**body) + return '', 200 ``` 這裡我們先找到與請求中發送的「id」相符的Movie文件,然後更新它。這裡我們也應用了擴充運算子將值傳遞給「update()」函數。 ``` [email protected]('/movies/<id>', methods=['DELETE']) +def delete_movie(id): + Movie.objects.get(id=id).delete() + return '', 200 ``` 與此處的“update_movie()”類似,我們獲取與給定“id”匹配的電影文件並將其從資料庫中刪除。 哦,**我剛剛想起來**,我們還沒有將 API 端點加入到“GET”,僅從我們的伺服器獲取一個文件。 讓我們加入它: 在 `app.run()` 上方加入以下程式碼 ``` @app.route('/movies/<id>') def get_movie(id): movies = Movie.objects.get(id=id).to_json() return Response(movies, mimetype="application/json", status=200) ``` 現在您可以從 API 端點「/movies/<valid_id>」取得單一影片。 要執行伺服器,請確保您位於“movie-bag”目錄。 然後執行 ``` pipenv shell python app.py ``` 在終端機中啟動虛擬環境並啟動伺服器。 哇!恭喜您已經走到這一步了。要測試API,請使用我們在[上一篇]((https://dev.to/paurakhsharma/flask-rest-api-part-0-setup-basic-crud-api-4650)) 中使用的“ Postman」本系列的一部分。 您可能已經注意到,如果我們向端點發送無效資料,例如:沒有名稱或其他字段,我們會收到“HTML”形式的不友善錯誤。如果我們嘗試取得資料庫中不存在的「id」影片文件,那麼我們也會收到「HTML」回應形式的不友善錯誤。這並不是一個精心建構的 API 的例外行為。我們將在本系列的後面部分中了解如何處理此類錯誤。 ### 我們從本系列的這一部分學到了什麼? - `Pymongo` 和 `Mongoengine` 之間的差異。 - 如何使用「Mongoengine」建立文件架構。 - 如何使用「Mongoengine」執行「CRUD」操作。 - Python 擴充運算子。 您可以在[此處]找到這部分的完整程式碼(https://github.com/paurakhsharma/flask-rest-api-blog-series/tree/master/Part%20-%201) 在下一部分中,我們將學習如何使用「Blueprint」來更好地建立 Flask 應用程式。以及如何使用“flask-restful”以最少的設定遵循最佳實踐,更快地建立 REST API 直到那時快樂編碼😊 --- 原文出處:https://dev.to/paurakhsharma/flask-rest-api-part-1-using-mongodb-with-flask-3g7d
我們正在開發一個 [React 和 Node.js 的全端 Web 框架](https://github.com/wasp-lang/wasp),它使用簡單的設定語言來擺脫樣板檔案。很多次,我們被問到,*「為什麼你要費心去建立一個新的 Web 應用程式開發框架?無論如何,ChatGPT / LLM X 不是很快就會為開發人員生成所有程式碼嗎?」*。 這是我們對當前情勢的看法,也是我們相信未來的情況。 ## 為什麼我們需要(AI)程式碼產生? 為了讓開發速度更快,我們首先提出了 IDE 自動補全 - 如果您正在使用 React 並開始輸入 `use`,IDE 將自動向 `useState()` 或 `useEffect()` 提供補全。除了節省擊鍵次數之外,也許更有價值的是能夠查看目前範圍內有哪些方法/屬性可供我們使用。 IDE 對專案結構和程式碼層次結構的感知也使重構變得更加容易。 **雖然這已經很棒了,但是我們如何將其提升到一個新的水平?** 傳統的 IDE 支援是基於人類編寫的規則,例如,如果我們想讓 IDE 能夠為我們實現常用功能(例如, *使用API Y* 取得X,或*實現快速排序*),其中的數量太多,無法手動進行分類和維護。 如果有一種方法可以讓電腦分析我們迄今為止編寫的所有程式碼,並自行學習如何自動完成我們的程式碼以及如何對待人類,而不是我們做所有艱苦的工作... [除了美味又濕潤的蛋糕](https://www.youtube.com/watch?v=Y6ljFaKRTrI),我們其實已經做到了!由於機器學習的最新進展,IDE 現在可以做一些非常酷的事情,例如根據函數的名稱和頂部的簡短註釋來建議函數的完整實現: 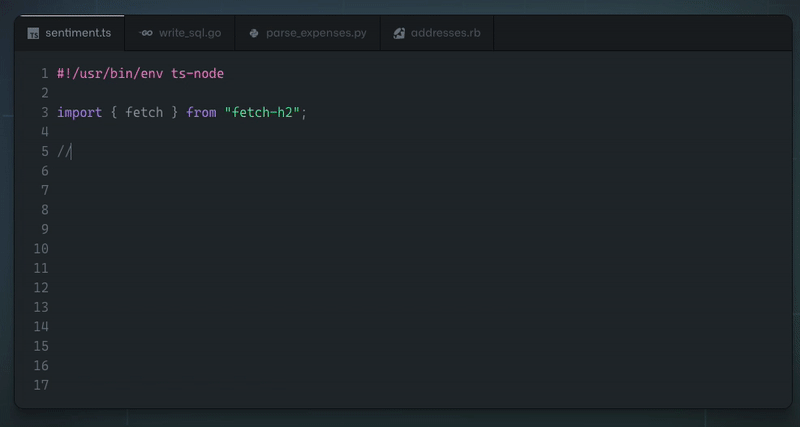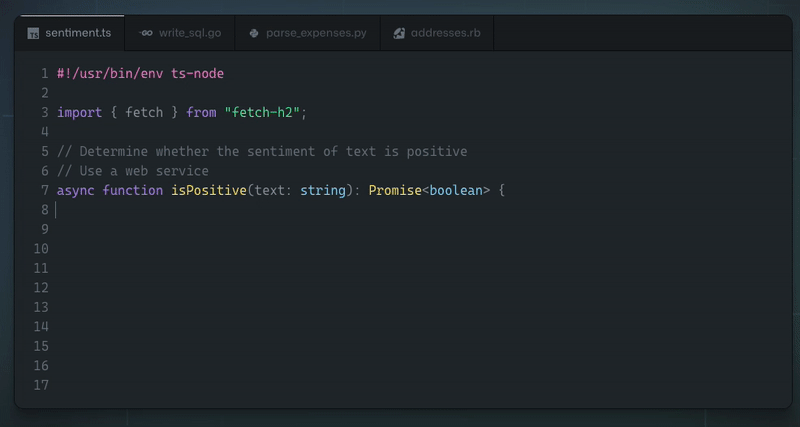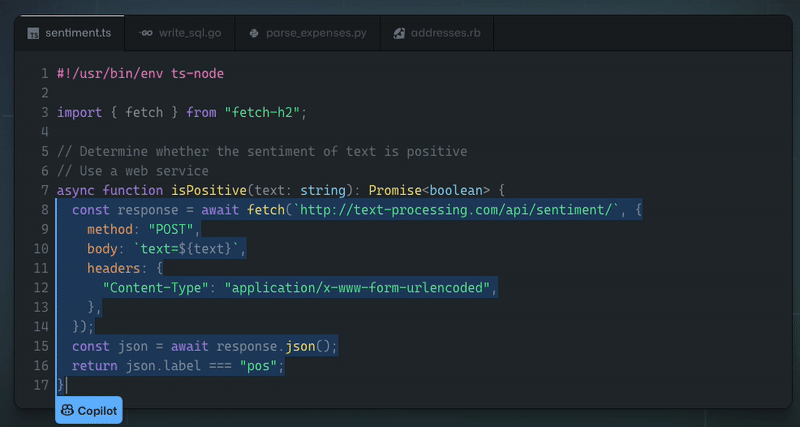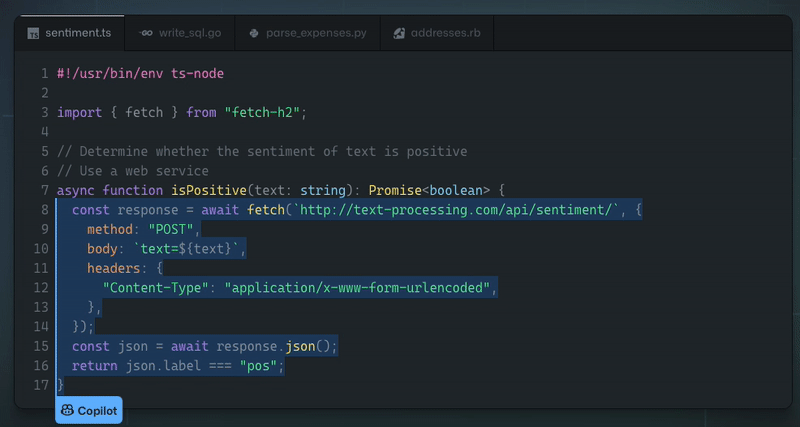 這真是太神奇了!上面的範例由 [Github Copilot](https://copilot.github.com/) 提供支援 - 它本質上是一個在大量公開可用程式碼上訓練的神經網路。我不會深入了解其幕後工作原理的技術細節,但有很多精彩的文章和影片涵蓋了背後的科學知識。 **看到這一點,問題出現了 - 這對程式設計的未來意味著什麼?** 這只是 IDE 自動補全功能還是其他什麼?如果我們只需在註釋中輸入我們想要的內容就可以了,我們還需要繼續手動編寫程式碼嗎? ## 支持我們! 🙏⭐️  如果您想表達對我們正在做的事情的支持,請考慮[在 Github 上給我們一顆星](https://github.com/wasp-lang/wasp)!我們在 Wasp 所做的一切都是開源的,您的支持激勵我們並幫助我們不斷簡化 Web 應用程式開發並減少樣板程式碼。  ## 大問題:程式碼產生後由誰維護? 在思考 ML 程式碼產生如何影響整個開發過程時,有一點需要考慮,但在查看所有令人印象深刻的範例時,通常不會立即想到這一點。 問題是 - **生成程式碼後會發生什麼?誰負責,將來誰來維護和重構?** 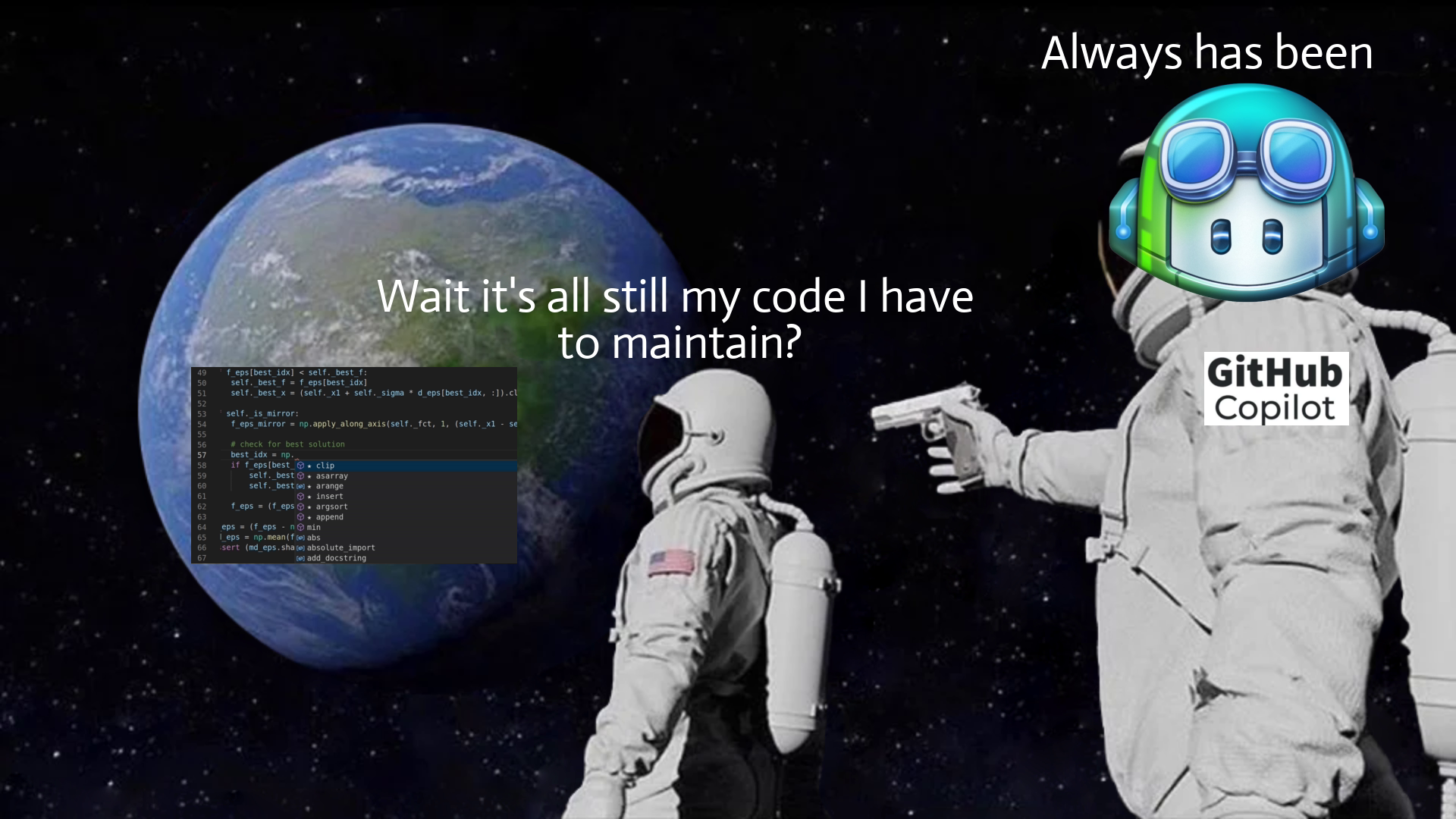 儘管 ML 程式碼產生有助於編寫特定功能的初始程式碼,但它不能做更多的事情 - 如果將來要維護和更改該程式碼(如果有人使用該產品,那麼開發人員仍然會這樣做)需要完全擁有並理解它。你可以再次使用人工智慧來幫助你,但最終,你是負責的人。 想像一下,我們擁有的只是一種彙編語言,但程式碼生成非常適合它,你可以說“實現一個對陣列進行升序排序的函數”,它將完美地生成所需的程式碼。一旦您需要將排序更改為降序,您是否仍想在將來返回該功能? 或者,更貼近我們的日常生活,如果產生的 React 程式碼使用舊的類別語法,或者函數式元件和鉤子,對你來說是否都是一樣的? **換句話說,這意味著GPT 和其他LLM 不會降低程式碼複雜性,也不會降低建置功能所需的知識量**,它們只是幫助更快地編寫初始程式碼並使知識/範例更接近程式碼(其中真的很有幫助)。 **如果開發人員盲目接受生成的程式碼,他們只是在創造技術債並推動其向前發展**。 ## 認識大 A - 抽象 👆 如果 ChatGPT 和這群人無法解決我們學習如何編碼和詳細理解(例如透過 JWT 進行會話管理)工作原理的所有麻煩,還有什麼可以呢? 抽象化——這就是程式設計師幾十年來透過建立庫、框架和語言來處理程式碼重複和降低複雜性的方式。這就是我們從普通 JS 和直接 DOM 操作到 jQuery,最後到 React 和 Vue 等 UI 函式庫的方式。 引入抽像不可避免地意味著放棄一定的功能和靈活性(例如,在 Python 中對數字求和時,您無法準確指定將使用哪些 CPU 寄存器),但重點是,如果如果做得好,在大多數情況下你不需要也不想要這樣的權力。  **不對一段程式碼負責的唯一方法是它從一開始就不存在。** 因為一旦螢幕上的像素改變顏色,你就必須擔心,這就是為什麼所有框架、語言等的主要好處是_更少的程式碼==更少的決策==更少的責任_。 擁有更少程式碼的唯一方法是做出更少的決定,並向計算機提供更少的關於如何完成某項任務的細節- 理想情況下,我們只需要說明我們想要什麼,我們甚至不會關心它是如何完成的,只要它在我們擁有的時間/記憶體/成本邊界內(所以我們可能也需要說明這些)。 讓我們來看看網路應用程式世界中非常常見(也是每個人最喜歡的)功能 - 身份驗證(yaay ☠️ 🔫)!它的典型程式碼如下所示: ``` import jwt from 'jsonwebtoken' import SecurePassword from 'secure-password' import util from 'util' import prisma from '../dbClient.js' import { handleRejection } from '../utils.js' import config from '../config.js' const jwtSign = util.promisify(jwt.sign) const jwtVerify = util.promisify(jwt.verify) const JWT_SECRET = config.auth.jwtSecret export const sign = (id, options) => jwtSign({ id }, JWT_SECRET, options) export const verify = (token) => jwtVerify(token, JWT_SECRET) const auth = handleRejection(async (req, res, next) => { const authHeader = req.get('Authorization') if (!authHeader) { return next() } if (authHeader.startsWith('Bearer ')) { const token = authHeader.substring(7, authHeader.length) let userIdFromToken try { userIdFromToken = (await verify(token)).id } catch (error) { if (['TokenExpiredError', 'JsonWebTokenError', 'NotBeforeError'].includes(error.name)) { return res.status(401).send() } else { throw error } } const user = await prisma.user.findUnique({ where: { id: userIdFromToken } }) if (!user) { return res.status(401).send() } const { password, ...userView } = user req.user = userView } else { return res.status(401).send() } next() }) const SP = new SecurePassword() export const hashPassword = async (password) => { const hashedPwdBuffer = await SP.hash(Buffer.from(password)) return hashedPwdBuffer.toString("base64") } export const verifyPassword = async (hashedPassword, password) => { try { return await SP.verify(Buffer.from(password), Buffer.from(hashedPassword, "base64")) } catch (error) { console.error(error) return false } } ``` 這只是後端程式碼的一部分(僅適用於用戶名和密碼方法)!正如您所看到的,我們在這裡有很大的靈活性,可以執行/指定以下操作: - 選擇身份驗證的實作方法(例如會話或基於 JWT) - 選擇我們想要用於令牌(如果使用 JWT)和密碼管理的確切 npm 套件 - 解析 auth 標頭並指定每個值(授權、承載等)如何回應 - 為每個可能的結果選擇回傳程式碼(例如 401、403) - 選擇密碼的解碼/編碼方式 (base64) 一方面,在我們的程式碼中擁有這種程度的控制和靈活性確實很酷,但另一方面,需要做出很多決定(==錯誤),特別是對於像身份驗證這樣常見的事情! 如果後來有人問“_那麼你到底為什麼選擇secure-password npm 包,或者為什麼到底是base64 編碼?_”,我們可能應該用其他東西來回答,而不是“_好吧,2012 年有一篇看起來相當合法的帖子,它有近 50 票贊成。嗯,不過現在找不到了。另外,它的名字裡有‘安全’,聽起來不錯,對吧?_” 另一件要記住的事情是,我們還應該追蹤事情如何隨著時間的推移而變化,並確保幾年後,我們仍然使用最佳實踐,並且軟體包定期更新。 如果我們嘗試應用上面的原則(更少的程式碼,更少的詳細說明,說明我們想要什麼**而不是需要做什麼**),身份驗證的程式碼可能如下所示: ``` auth: { userEntity: User, externalAuthEntity: SocialLogin, methods: { usernameAndPassword: {}, google: {} }, onAuthFailedRedirectTo: "/login", onAuthSucceededRedirectTo: "/dashboard" } ``` 基於此,計算機/編譯器可以處理上面提到的所有內容,然後根據抽象級別,提供某種接口(例如表單元件或函數)來“掛鉤”我們自己的接口,例如React/Node.js 程式碼(順便說一句,這就是它實際上[在 Wasp 中工作](https://wasp-lang.dev/docs/auth/overview) 的方式)。 我們不需要關心底層使用了什麼確切的套件或加密方法 - 這是我們信任抽象層的作者和維護者的責任,就像我們相信 Python 最了解如何將兩個數字相加一樣裝配水平,並與該領域的最新進展保持同步。當我們依賴內建資料結構或依靠垃圾收集器來很好地管理程式記憶體時,也會發生同樣的情況。 ## 但是我產生的漂亮程式碼😿💻!那麼會發生什麼事呢? 別擔心,一切都還在這裡,您可以產生您想要的所有程式碼!這裡要理解的要點是,人工智慧程式碼生成和框架/語言開發是相互補充而不是替代,並且將繼續存在,這最終對開發人員社群來說是一個巨大的勝利——它們將繼續讓我們的生活更輕鬆,讓我們能夠做更多有趣的事情(而不是第 n 次實作 auth 或 CRUD API)! 我將這裡的演變視為一個循環(或實際上是螺旋式上升,但這超出了我的繪圖能力): 1. **語言/框架:存在**,是主流,很多人使用它 2. **模式開始出現**(例如實作身份驗證,或進行 API 呼叫)→ AI 學習它們,透過自動完成提供 3. **其中一些模式成熟**並變得穩定→抽象的候選者 4. **新的、更抽象的語言/框架**出現 5. **返回步驟 1。** 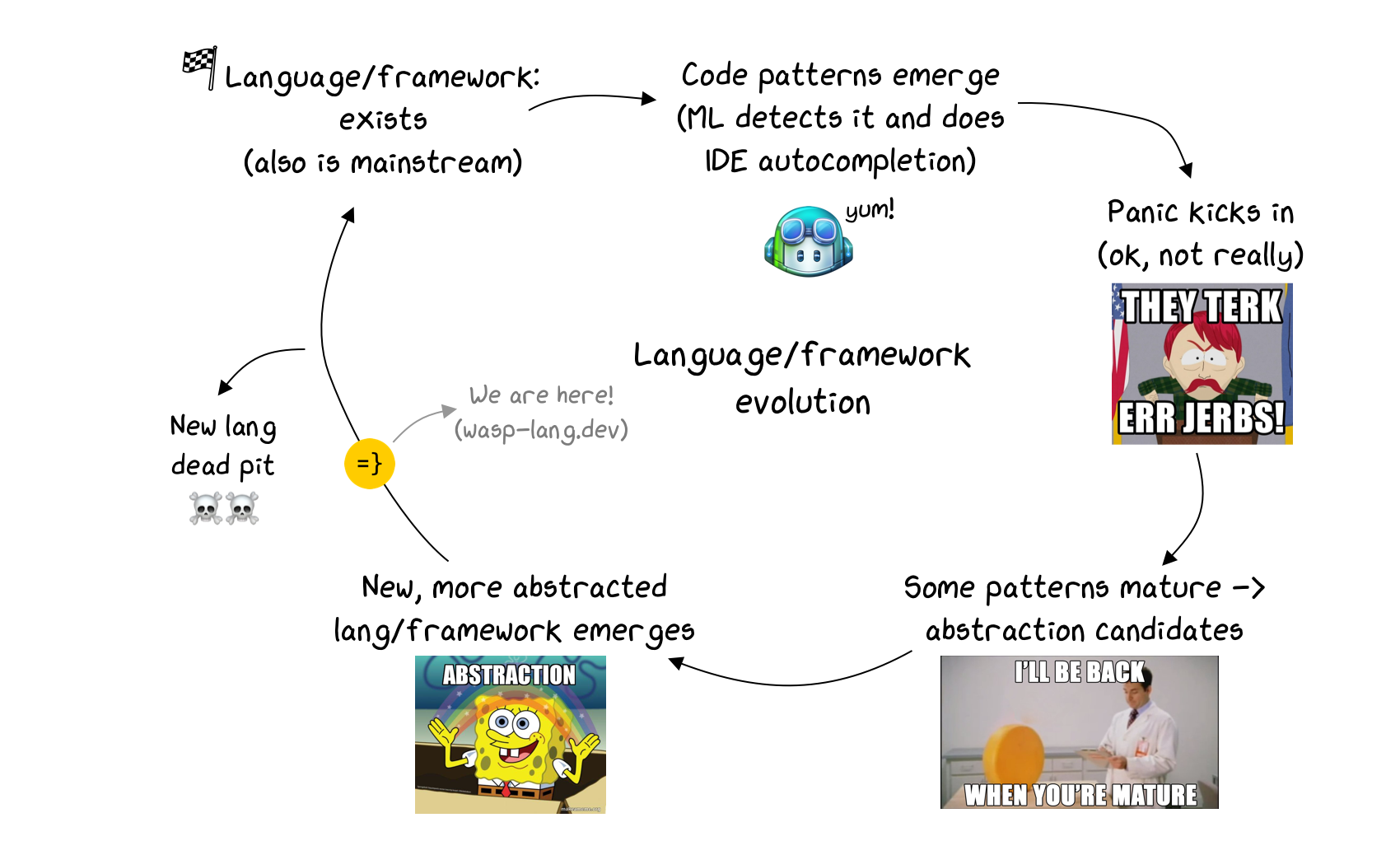 ## 結論 這意味著我們雙贏——當語言成為主流時,我們可以從人工智慧驅動的程式碼產生中受益,幫助我們更快地編寫程式碼。另一方面,當我們不想重複/處理的程式碼模式出現並變得穩定時,我們就得到了一種全新的語言或框架,它允許我們編寫更少的程式碼並關心更少的實作細節!  感謝您的閱讀,並希望您發現這篇文章內容豐富!我很想聽聽您是否同意(或不同意)這一點,以及您如何看待人工智慧工具驅動的程式設計的未來。 --- 原文出處:https://dev.to/wasp/ai-code-generation-vs-coding-by-hand-what-programming-is-going-to-look-like-in-202x-1idh
## **簡介** 在不斷發展的資料工程和自動化領域,Python 已經出現了多種工作流程編排器。在本文中,我將介紹 6 個 Python 函式庫及其一些主要功能。  --- ## 1. [Taipy](https://github.com/Avaiga/taipy) Taipy 是一個開源 Python 庫,用於建立生產就緒的應用程式前端和後端。 對於 Python 開發人員來說,Taipy 是建立管道最簡單的框架之一,這要歸功於它的管道圖形編輯器 (Taipy Studio)。 然後,您可以透過 Python 腳本輕鬆執行和編排管道。一個非常酷的核心功能是每個管道執行都是註冊的。 這可以輕鬆實現假設分析、KPI 監控、資料沿襲等。 🔑特點: - 圖形管道編輯器 - 與 Taipy 前端功能整合以實現端到端部署 - 日程安排 - 管道的版本控制 - 快取等智慧功能  ---  您的支持意義重大🌱,並且在許多方面為我們帶來了很大的幫助,例如寫文章! 🙏 --- ## 2. [Kedro](https://github.com/kedro-org/kedro) Kedro 是一個開源 Python 框架。 它為生產就緒的資料科學管道提供了一個工具箱。 事實上,Kedro 可以輕鬆地與成熟的 Python ML 庫集成,並提供統一的方法來實現端到端框架。 🔑特點: - 資料目錄 - 筆記本集成 - 專案模板 - 有自己的觀點,因為它強制執行特定的約定  --- ## 3. [Airflow](https://github.com/apache/airflow) 十多年來,Airflow 一直是管道領域的知名參與者。 Airbnb 建立了 Airflow 來解決資料處理和工作流程需求的內部挑戰。 眾所周知,這個強大的開源平台具有陡峭的學習曲線,但具有廣泛的功能。 該平台允許您透過建立 DAG(有向無環圖)來建立和管理工作流程。 🔑特點: - 基於DAG的定義 - 豐富的基於 Web 的監控 UI:DAG、故障、重試的可視化… - 各種集成 - 動態任務執行和調度 - 由於其以 Python 為中心的特性而具有靈活性。 - 強大的社區  --- ## 4. [Prefect](https://github.com/PrefectHQ/prefect) Prefect 是一個資料管道開發框架。 Prefect 在策略上將自己定位在與 Airflow 的直接競爭中,以基於簡單性、用戶友好性和靈活性的獨特身份脫穎而出。 如果您想要一個具有各種功能但比 Airflow 更容易學習的成熟產品,Prefect 是一個很好的中間產品。 🔑特點: - 控制面板 - 快取 - 基於流程的結構 - 動態參數化與依賴管理 - 混合執行(本地/雲端)  --- ## 5. [Dagster](https://github.com/dagster-io/dagster) Dagster 是本次編譯中較新的函式庫之一,它是一個雲端原生資料管道編排,旨在統一資料整合、工作流程編排和監控。 與其他工具相比,Dagster 強調工作流程建立和管理的 DataOps 面向。 🔑特點: - 聲明式管道設置 - 固執己見的結構 - 版本控制 - 與 Hadoop 集成 - 全面的元資料跟踪  --- ## 6. [Luigi](https://github.com/spotify/luigi) Luigi 提供了一個資料處理管道框架。 Spotify 與 Airflow 大約在同一時間開發了這個程式庫,以解決其複雜的資料工作流程和管道。 Luigi 專為管理批次作業的複雜通道而設計。如果您正在尋找簡單的東西並且必須快速上手,Luigi 是一個不錯的選擇。 🔑特點: - 內建 Hadoop 支援 - 基於任務的工作流程定義 - 用於依賴管理的中央調度程序 - 任務依賴關係視覺化  --- ##結論 隨著 Python 工作流程編排環境的不斷發展,這些工具展示了主要的共同特徵和特定的差異化因素。 所有這些工具都有不同程度的複雜性,了解您的專案和團隊的需求至關重要。 我建議使用非常簡單的範例來測試一些選項,以獲得對每個框架可用性的第一手了解。 --- 希望您喜歡這篇文章! 我是一名新手作家,歡迎任何改進建議!  如果您有任何疑問,請隨時與我們聯繫。 --- 原文出處:https://dev.to/taipy/the-pipeline-repos-showdown-python-edition-39i5
科技愛好者常有遠大的夢想,渴望實現突破創新和個人發展界限的目標。為了幫助建立這些雄心壯志,我為科技愛好者量身定制了廣泛的願望清單。此清單不僅概述了各種目標,還包括「靈感」、「如何」、「年份」、「狀態」和「紀念品」等附加欄,為您的技術之旅提供全面的路線圖。 ## 清單中有什麼? 該清單涵蓋了廣泛的目標,從培養特定技能(例如達到 150 WPM 的打字速度)到雄心勃勃的專案(例如製作 DIY 電動滑板或自行車)。它包括參加重大活動,例如參加大型技術會議,以及個人發展的里程碑,例如指導初級開發人員。每個目標都經過分類以便於參考,涵蓋 DIY 專案、程式設計、開發、學習等領域。 ## 列表 [我的遺願清單進度](https://syki.dev/bucket-list) |目標|類別|靈感|年份|狀態|紀念品| |---------------------------|----------------|----------------| ----|------|--------| |成為大型專案的貢獻者 |開發 |[如何像專業人士一樣開源](https://www.youtube.com/watch?v=MT6M_sqAuZo) | | | | |建立新聞聚合器 |開發 |[Feedly](https://feedly.com/) | | | | |建立實體引擎 |開發 |[我正在從頭開始編寫整個實體引擎](https://www.youtube.com/watch?v=iSMbRGTBOHU) | | | | |建立推薦系統 |開發 |[推薦系統如何運作 (Netflix/Amazon)](https://www.youtube.com/watch?v=n3RKsY2H-NE) | | | | |建構情緒分析工具 |開發 |【2023 如何掌握人工智慧驅動的情緒分析?】(https://brand24.com/blog/sentiment-analysis/) | | | | |建立擴增實境 (AR) 應用程式 |開發 |[關於如何在 2023 年建立擴增實境應用程式的指南](https://www.tekrevol.com/blogs/how-to-build-an-augmented-reality -應用程式/) | | | | |建置與部署聊天伺服器 |開發 |[IRC](https://en.wikipedia.org/wiki/Internet_Relay_Chat) | | | | |建立網路安全工具|開發|[Kali Tools](https://www.kali.org/tools/) | | | | |建立多人線上遊戲|開發|[Dani](https://www.youtube.com/watch?v=_ze26M_Fm6g) | | | | |建立 PWA(漸進式 Web 應用程式)|開發 |[PWA](https://developer.mozilla.org/en-US/docs/Web/Progressive_web_apps) | | | | |建立 AI 影響者 |開發 |[AI 影響者變得非常富有...讓我們建立一個](https://www.youtube.com/watch?v=ky5ZB-mqZKM&t=11s) | | | | |開發區塊鏈應用程式 |開發 |[使用以太坊智能合約和 Solidity 建置您的第一個區塊鏈應用程式](https://www.youtube.com/watch?v=coQ5dg8wM2o) | | | | |開發一種加密貨幣 |開發 |[您需要立即建立一種加密貨幣!!](https://www.youtube.com/watch?v=befUVytFC80) | | | | |開發VR 應用程式|開發|[教學 - 在Meta Quest 耳機上建立您的第一個VR 應用程式](https://developer.oculus.com/documentation/unity/unity-tutorial-hello-vr/) | | | | |開發一個電子商務網站 |開發 |[Next.js Commerce](https://nextjs.org/commerce) | | | | |開發開源遊戲引擎 |開發 |[C++ 中的 GameDev](https://www.youtube.com/watch?v=LyJkcv_rL9Y&list=PLpM-Dvs8t0Va6RoHkaLuPbRh7Fwpy4nbV) | | | | |開發瀏覽器擴充 |開發 |[Chrome 擴充應該會嚇到你。](https://www.youtube.com/watch?v=xIKwkPWUgOA) | | | | |在 github 上有一個擁有 100 顆星的專案 |開發 |[Linus Torvalds](https://github.com/torvalds?achievement=starstruck&tab=achievements) | | | | |擁有自己的 Tor 頁面 |開發 |[我在 Raspberry Pi 上放置了一個 DARK WEB 網站!!](https://www.youtube.com/watch?v=bllS9tkCkaM) | | | | |發明手勢控制介面 |開發 |[鋼鐵人](https://www.youtube.com/watch?v=P5k-4-OEuTk) | | | | |建立持續整合/持續部署管道|開發|[自動化您的工作流程](https://github.com/features/actions)從想法到生產]| | | | |設定 Kubernetes 叢集 |開發 |[為什麼要建置 Raspberry Pi 叢集?](https://www.youtube.com/watch?v=8zXG4ySy1m8) | | | | |贊助開源專案 |開發 |[投資為您的世界提供動力的軟體](https://github.com/sponsors) | | | | |使用查詢機制編寫自己的資料庫|開發|[製作我們自己的資料庫](https://acmiitr.medium.com/making-our-own-database-part-1-6cd9c49ed924) | | | | |在靜態網站產生器中撰寫頁面 |開發 |[Gatsby](https://www.gatsbyjs.com/) | | | | |編寫單頁應用程式 |開發 |[React](https://react.dev/) | | | | |使用 Raspberry Pi 專案實現家居自動化 |DIY |[我建立了一個更聰明的智慧家庭](https://www.youtube.com/watch?v=0rIvB3LZiKA) | | | | |建立自訂鍵盤 |DIY |[建立自己的機械鍵盤......正確的方式](https://www.youtube.com/watch?v=bBon6WwkdJE) | | | | |DIY電動滑板或自行車 |DIY |[我做了一個電動滑板!](https://www.youtube.com/watch?v=3bcvFzecg2Q) | | | | |以自訂遊戲建立迷你街機 |DIY |[終極 DIY 街機指南](https://www.youtube.com/watch?v=oTydZBIGAuk) | | | | |組裝一台 PC |DIY |[為 Minecraft 組裝一台價值 100,000 美元的 PC](https://www.youtube.com/watch?v=AHR80l7od2Q) | | | | |建立個人雲端儲存系統 |DIY |【這是我的終局之戰 - Mother Vault 伺服器機房更新】(https://www.youtube.com/watch?v=pLC0FUnko-M) | | | | |利用 IoT 建造自動澆水花園系統 |DIY |[Arduino 花園控制器 - 自動澆水和資料記錄](https://www.youtube.com/watch?v=O_Q1WKCtWiA) | | | | |打造小型自動駕駛汽車或機器人 |DIY |[快速巡線機器人](https://www.youtube.com/watch?v=lnP32gzHdvI) | | | | |建造水下ROV |DIY |[建造一艘DIY潛水艇](建造一艘DIY潛水艇) | | | | |搭建並飛行 FPV 無人機 |DIY |[為什麼要以 800mW 功率自由式飛行? | [FPV](https://www.youtube.com/watch?v=bBb_kSO3vTo) | | | | |設計具有互動功能的智慧鏡子|DIY |[DIY智慧鏡子 - 完整教學](https://www.youtube.com/watch?v=OYlloiaBINo) | | | | | 以 3D 方式設計和列印一些東西 |DIY |[我在房間中央製作了一個機器人手臂!](https://www.youtube.com/watch?v=nRsaf16EdNM) | | | | |設計您自己的 PCB |DIY |[PCB 建立初學者 - 10 分鐘內開始完成教程](https://www.youtube.com/watch?v=MsdJgEinb34) | | | | |修復損壞的電子產品 |DIY |[ElectroBOOM](https://www.youtube.com/@ElectroBOOM) | | | | |在本地擁有自己的伺服器 |DIY |[為什麼要建立 Raspberry Pi 叢集?](https://www.youtube.com/watch?v=8zXG4ySy1m8) | | | | |實現智慧家庭|DIY |[我建造了一個更聰明的智慧家庭](https://www.youtube.com/watch?v=0rIvB3LZiKA) | | | | |製作機械手臂 |DIY |[我在房間中央製作了機械手臂!](https://www.youtube.com/watch?v=nRsaf16EdNM) | | | | | 用 Flipper Zero 開啟一些東西 |DIY |[這讓駭客攻擊太容易了 - Flipper Zero](https://www.youtube.com/watch?v=nLIp4wd0oXs) | | | | |成為智慧型手機應用程式的擁有者|創業|[VoidLog](https://www.youtube.com/watch?v=LY4rxYe-jKI&list=PLN3n1USn4xllDDLwgJ4avEqgj4dWynofp) | | | | |開發 SaaS 產品 |創業精神|[我如何在一天內建立一個新的 SaaS 產品](https://www.youtube.com/watch?v=v_3lcqUOaOA) | | | | |在店裡擁有自己的遊戲 |創業|[Dani](https://www.youtube.com/watch?v=_ze26M_Fm6g) | | | | |在新創公司工作 |創業精神|[新創工程師在家工作的一天](https://www.youtube.com/watch?v=TLysAkFM4cA) | | | | |一週多相睡眠|創業|| | | | |參加播客 |創業|[Lex Fridman](https://www.youtube.com/lexfridman) | | | | |完全存取伺服器 - 黑客 |黑客 |[先生。機器人](https://www.youtube.com/watch?v=QqknSms8VVI&t=16s) | | | | |獲得錯誤賞金 |駭客 |[HackerOne](https://www.hackerone.com/) | | | | |在奪旗大賽中進行駭客攻擊 |駭客攻擊 |[Mr.機器人](https://www.youtube.com/watch?v=6MrQ-mN8HM8) | | | | |編寫惡意軟體 |駭客 |[惡意軟體開發:進程、執行緒與句柄](https://www.youtube.com/watch?v=aNEqC-U5tHM) | | | | |150 wpm 速度打字 |程式設計 |[Monkeytype](https://github.com/monkeytypegame/monkeytype) | | | | |使用 Python 腳本自動化您的日常任務 |程式設計 |[開始使用 Python 自動化您的生活! (Python檔案管理教學)](https://www.youtube.com/watch?v=NCvI-K0Gp90) | | | | |建立 Twitter 機器人 |程式設計 |[如何使用人工智慧發布熱門推文 // Twitter 機器人教學](https://www.youtube.com/watch?v=V7LEihbOv3Y) | | | | |編譯您自己的 Linux 核心 |程式設計 |[如何編譯自訂 Linux 核心](https://www.youtube.com/watch?v=APQY0wUbBow) | | | | |建立聊天機器人 |程式設計 |[使用深度學習、Python 和 TensorFlow 建立聊天機器人 p.1](https://www.youtube.com/watch?v=dvOnYLDg8_Y&list=PLQVvvaa0QuDdc2k5dwtDTyT9aCja0on8j) | | | | |使用 D3.js 建立資料視覺化專案 |程式設計 |[使用 D3.js 進行資料視覺化 - 完整教學課程](https://www.youtube.com/watch?v=_8V5o2UHG0E) | | | | |建立照片編輯工具 |程式設計 |[如何製作照片編輯應用程式的完整指南](https://www.cleveroad.com/blog/how-to-build-a-photo-editing-app-like-棱鏡並使其蓬勃發展/) | | | | |開發數位藝術作品產生器 |程式設計 |[如何為初學者產生瘋狂的人工智慧藝術(Midjourney V4)](https://www.youtube.com/watch?v=zf4z8A-OWBY) | | | | |開發檔案加密工具 |程式設計 |[製作您自己的加密程式](https://www.youtube.com/watch?v=TZT7wvTeVyY) | | | | |開發影片編輯軟體|程式設計|[我寫了一個影片編輯器(有點糟糕)](https://www.youtube.com/watch?v=iydG-e1dQGA) | | | | |開發語音助理應用程式 |程式設計 |[建立由 OpenAI 和 Python 驅動的 Jarvis | ChatGPT](https://www.youtube.com/watch?v=BEw5EFqCCEI) | | | | |開發智慧手錶應用程式 |程式設計 |[使用 Android Studio 在 WearOS 上建立並執行穿戴式應用程式](https://www.youtube.com/watch?v=-JO5oHRkybk) | | | | |開發您自己的 Slack/Discord 機器人 |程式設計 |[使用 Python 編寫 Discord 機器人 - 在雲端免費託管](https://www.youtube.com/watch?v=SPTfmiYiuok) | | | | |實現臉部辨識系統 |程式設計 |[從紙張到程式碼建立深度臉部辨識應用程式](https://www.youtube.com/watch?v=bK_k7eebGgc&list=PLgNJO2hghbmhHuhURAGbe6KWpiYZt0AMH) | | | | |學習函數式程式語言 |程式設計 |[函數式程式設計 - 概述](https://www.youtube.com/watch?v=8z_bUIl_uPo) | | | | |學習古老的語言 |程式設計 |[100 秒內的 COBOL](https://www.youtube.com/watch?v=7d7-etf-wNI) | | | | |學習並使用 Docker 進行容器化 |程式設計 |[Docker](https://www.docker.com/) | | | | |學習極快的語言 |程式設計 |[ThePrimeagen](https://www.youtube.com/@ThePrimeagen) | | | | |學習一門不尋常的語言(例如 Brainfuck) |程式設計 |[100 秒內完成 Brainfuck](https://www.youtube.com/watch?v=hdHjjBS4cs8) | | | | |學習量子運算基礎 |程式設計 |[在量子電腦上編碼](https://www.youtube.com/watch?v=q3ecPsMd4tA) | | | | |掌握高階演算法與資料結構(100道LeatCode) |程式設計|【569道 Leetcode 題後的我的大腦】(https://www.youtube.com/watch?v=8wysIxzqgPI) | | | | |對自訂語音控製家庭助理進行程式設計 |程式設計 |[建立由 OpenAI 和 Python 提供支援的 Jarvis | ChatGPT](https://www.youtube.com/watch?v=BEw5EFqCCEI) | | | | |對微控制器進行程式設計 |程式設計 |[微控制器程式設計駭客指南 [教學]](https://www.youtube.com/watch?v=XlFO5Iat178) | | | | |在 Vim 中編程 |程式設計 |[Vim 作為你的編輯器](https://www.youtube.com/watch?v=X6AR2RMB5tE&list=PLm323Lc7iSW_wuxqmKx_xxNtJC_hJbQ7R) | | | | |使用分離式鍵盤|編程|[拆箱新鍵盤!!! (也進行打字測試!)](https://www.youtube.com/watch?v=nh-BAxbithc&t=156s) | | | | |網頁抓取資料 |程式 |[使用 AI 和代理網路進行工業規模的網頁抓取](https://www.youtube.com/watch?v=qo_fUjb02ns) | | | | |用組合語言寫程式 |程式設計 |[Tsoding](https://www.youtube.com/watch?v=WnBXLmKk_qw&t=82s) | | | | |寫一個 NPM 模組 |程式設計 |[NPM](https://www.npmjs.com/) | | | | |編寫伺服器端應用程式 |程式設計 |[Next.js](https://nextjs.org/) | | | | |編寫您自己的人工智慧模型 |程式設計 |[讓我們建立 GPT:從頭開始,用程式碼,拼寫出來。](https://www.youtube.com/watch?v=kCc8FmEb1nY) | | | | |編寫您自己的作業系統 |程式設計 |[Linus Torvalds](https://github.com/torvalds) | | | | |寫你自己的程式語言 |程式設計 |[我製作了自己的程式語言](https://www.youtube.com/watch?v=pgeSGBwtHW8&t=132s) | | | | |擁有私人部落格 |教學 |[Dan Abramov](https://overreacted.io/) | | | | |對學生的講座 |教學 |[馬克·祖克柏的 CS50 講座 - 2005 年 12 月 7 日](https://www.youtube.com/watch?v=xFFs9UgOAlE&t=807s) | | | | |指導初級開發人員 |教學 |[如何正確指導初級開發人員](https://stablekernel.com/article/how-to-properly-mentor-a-junior-developer/) | | | | |寫一篇關於科技主題的論文並發表 |教學 |[兩分鐘論文](https://www.youtube.com/@TwoMinutePapers) | | | | |編寫技術書籍或電子書 |教學 |[編寫技術書籍](https://paulcunningham.me/writing-technical-books/) | | | | |參加大型科技會議 |旅遊 |[CES](https://www.ces.tech/) | | | | |參加黑客松 |旅行 |[我挑戰自己贏得黑客馬拉松](https://www.youtube.com/watch?v=mAJlZUKhOGs) | | | | |參觀電腦歷史博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀 NASA 約翰遜航天中心 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀國家航空暨太空博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀歷史科學儀器收藏 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀大型強子對撞機 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀麻省理工學院博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | |參觀國家核科學與歷史博物館 |旅行 |[工程師的旅行願望清單](https://www.mwrf.com/community/article/21848496/the-engineers-travel-bucket-list) | | | | ### 下載列表 [下載 CSV](https://syki.dev/uploads/bucket-list.csv) [下載 JSON](https://syki.dev/uploads/bucket-list.json) ## 附加列解釋 ### 靈感 本專欄反映了是什麼激發了追求特定目標的想法或願望。它可以是一個人、一個事件、一本書,甚至一部電影,點燃了人們對特定成就的熱情。例如,DIY 電動滑板的靈感可能是對永續交通的熱情或最喜歡的科技影片部落客的專案。 ### 年 本專欄提出了實現該目標的時間表或目標年份。它有助於規劃和設定現實的時間表。例如,您可能計劃在 2025 年之前參加一次大型技術會議。 ### 地位 狀態追蹤您的進度。它可以是“未開始”“進行中”“已完成”或“暫停”這有助於追蹤您的旅程並保持動力。 ### 紀念品 本專欄是一個獨特的補充,旨在紀念這一成就。它可以是實體、數位徽章、部落格文章,甚至是照片。例如,組裝 PC 的紀念品可能是已完成設定的第一張照片。 ## 結論 技術愛好者的願望清單不僅僅是目標的集合;這是技術領域個人和職業成長的路線圖。透過附加專欄提供靈感、方法、計時、追蹤和紀念成就的框架,此列表對於任何熱衷於技術的人來說都是一個動態工具。 快樂的科技冒險! --- 原文出處:https://dev.to/syki/100-bucket-list-ideas-for-programmers-506m
# 傳統搜尋的問題 傳統方法是將資料從一個容器提升並轉移到另一個容器。在很多情況下這是一個大問題。建立倒排索引廣泛應用於傳統搜尋引擎中,以實現快速資訊檢索。然而,這種方法的計算成本可能很高,特別是在辨識新資料並將其整合到這些索引中時。隨著業務的發展和資料變得更加複雜和龐大,這些傳統系統往往難以跟上。 此外,企業現在正以前所未有的速度產生新的資料類型,轉向分散式、基於雲端的資訊池的轉變加劇了這些困難。 傳統的企業資訊存取系統依賴定期更新的倒排索引,較不適合這種動態、異質的資料環境。它們無法輕鬆適應新資料類型的持續湧入或基於雲端的資訊系統的分散性。 這會導致資料檢索效率低下和延遲,從而阻礙組織內的決策和營運工作流程。  _Swirl 3.0 透過連接到各種資料來源並同時搜尋它們,為這個問題提供了一個簡單而優雅的解決方案。_ # 漩渦 3.0 功能 {% 嵌入 https://www.youtube.com/watch?v=nA8e0kMEDxs %} Swirl 建構在 Python Django 堆疊上,並提供了一個名為 Galaxy UI 的使用者友善介面。它可以在 Docker 中執行,也可以作為 Microsoft Azure 中的託管服務執行。 Swirl 使用戶能夠利用人工智慧驅動的重新排名功能,同時維護資料安全和隱私。 Swirl 的搜尋技術改變了企業跨應用程式和資料儲存存取資訊的方式。透過利用先進的大型語言模型,Swirl 可以快速篩選來自多個來源(例如 Salesforce 和 Microsoft365)的資料,為使用者提供最相關的結果和見解。  ## Swirl 方法的好處是顯而易見的: - 使用者收到根據其特定需求量身定制的微調搜尋結果。 - 無需移動資料或重新索引內容的麻煩。 ## 關鍵點:  - Swirl 使用 LLM 技術對來自不同來源(如資料孤島、Salesforce、Microsoft 等)的搜尋結果進行分析和排名。 - 漩渦搜尋增強了近乎即時的相關性排名,並將目標查詢的結果置於上下文中。 - 該系統允許針對特定學科領域定制法學碩士,用戶回饋證實了 Swirl 相關性排名的有效性。 - Swirl 最大限度地減少了重新索引的需要,消除了搜尋基礎設施的內容移動,並有效地管理相關性排名和重複資料刪除。 ## 連接器:  您可以在我們的 GitHub 頁面上找到可用連接器清單的廣泛概述。如果您希望按需並優先建立任何內容,請透過「[email protected]」聯絡 Swirl 支援團隊。 # 內部工作和用例 Swirl 整合了先進的內容處理和分析。它使用 API(應用程式介面)來定位和排名多個來源的內容,並透過控制項來增強某些內容。 Swirl 的框架允許快速尋找資訊並將其串流傳輸到各種基於搜尋的應用程式的資料管道中,例如檢索增強生成 (RAG) 和微調大型語言模型。 它提供對組織資料孤島內的資訊的存取,解決與企業搜尋解決方案相關的傳統成本、複雜性和開發問題。 Swirl 採用 OAuth2 等基於標準的身份驗證機制來消除權限和安全性問題。 隨著組織的發展和數位資產的多樣化,像 Swirl 這樣的工具變得不可或缺。請繼續關注我們探索人工智慧驅動的解決方案如何塑造資訊存取和管理的未來。 # Swirl 是開源的 Swirl 是一個開源搜尋平台。這對您意味著什麼: {% 嵌入 https://github.com/swirlai/swirl-search %} - 它是一個自託管、非限制性軟體,具有寬鬆的 Apache 2.0 授權。 - 軟體開發人員可以為專案的開發做出貢獻,深入了解搜尋生態系統,同時深入了解 Swirl。 - 如果您想了解有關 Swirl 的更多訊息,請加入我們的 Slack 社區,進行更多討論。 {% cta https://join.slack.com/t/swirlmetasearch/shared_invite/zt-1qk7q02eo-kpqFAbiZJGOdqgYVvR1sfw %} 加入 Slack {% endcta %} --- 原文出處:https://dev.to/swirl/adding-ai-to-your-enterprise-with-swirl-search-smarter-better-and-faster-4f9b
_「現在是2021 年了,我的飛行汽車在哪裡?」_ - Joel Spolsky(Stack Overflow 和Trello 的建立者)用這句話來表達他對Web 開發仍然與20 年前幾乎相同的感覺的幻滅。 但今天,有了 GPT,我們就可以再問這個問題了。我們看到了所有這些花哨的推文和演示,但是**當我需要啟動一個新的全端 Web 應用程式時**,這對我作為開發人員意味著什麼?我真的必須經歷“npm create vite my-new-app”,並再次從空白頁面開始嗎? 最後的答案是「否」——你可以使用很多很酷的東西來讓你的生活更輕鬆。它可能還不是超音速德羅寧,但它至少肯定是在地面上盤旋。 讓我們探討一下今天的 AI 場景為我們提供了什麼,以便更輕鬆地啟動和建立全端 Web 應用程式: ## 🐝 🤖 MAGE - 一分鐘內從單一提示到全端、React 和 Node.js 應用程式(免費使用!) 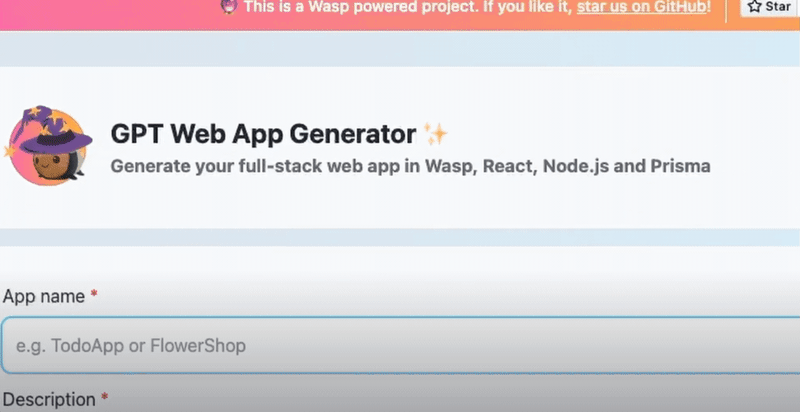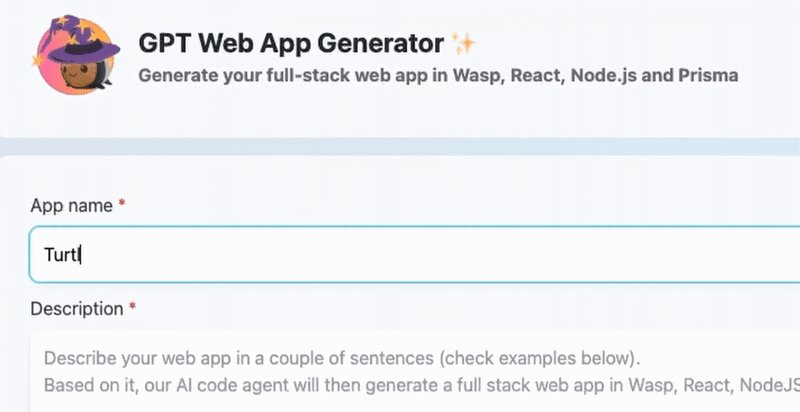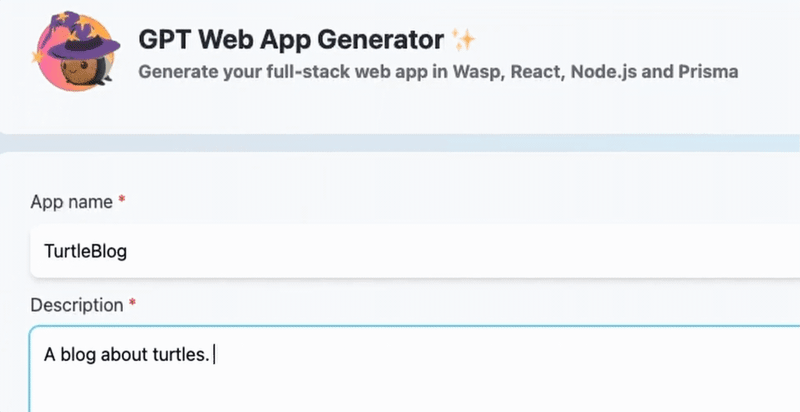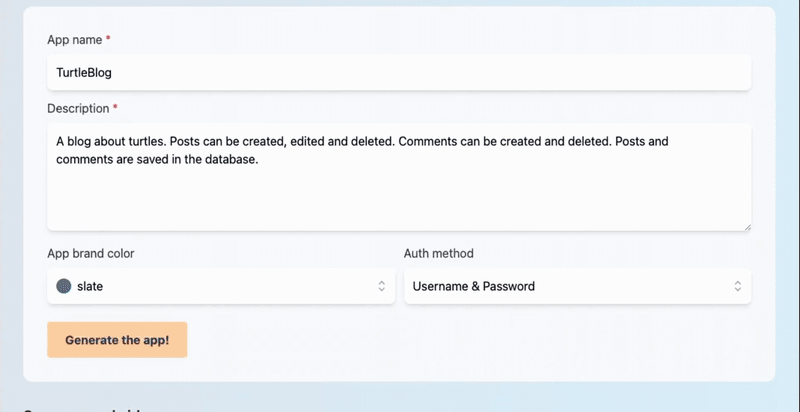 [MAGE](https://usemage.ai/) (*Magic App GEnerator*) 可能是最容易使用的 AI 編碼代理 - 一切都透過 Web 介面進行,**您所要做的就是輸入您要建立的應用程式的簡短描述**。這樣,MAGE 將在由 [Wasp](https://wasp-lang.dev/) 提供支援的 React、Tailwind、Node.js 和 Prisma 中產生完整的全端程式碼庫,您可以免費下載。 MAGE 最好的部分是**它是完全開源且完全免費使用** - 您所需要做的就是[使用您的 GitHub 登入](https://usemage.ai/),然後您就可以開始建立應用程式! MAGE [於7 月在Product Hunt 上推出](https://www.producthunt.com/products/wasp-lang-alpha#gpt-webapp-generator-for-react-node-js),從那時起就被用來建立近 30,000 個應用程式。 ## 📟 Aider - 終端機中的 AI 配對程式設計師 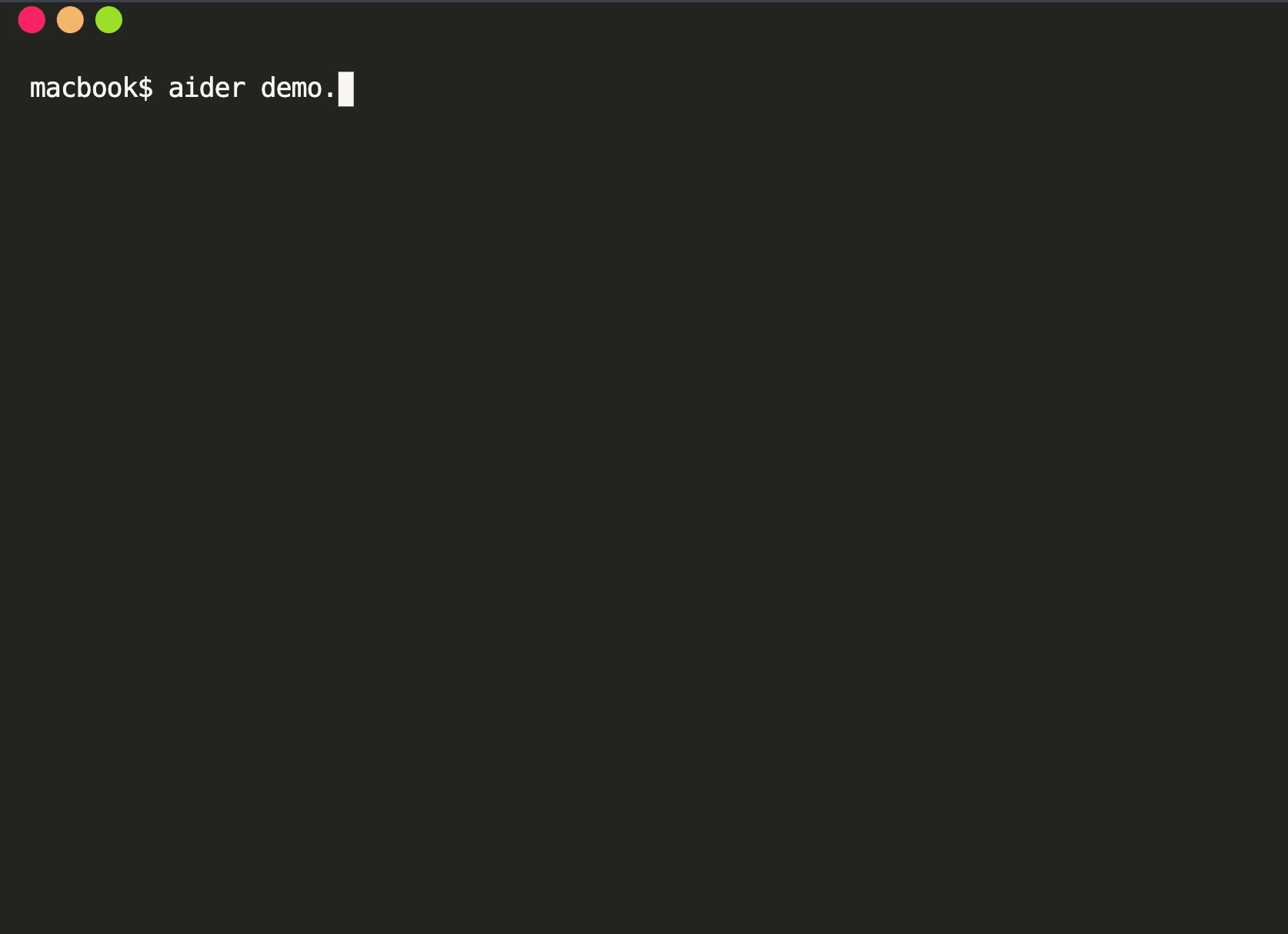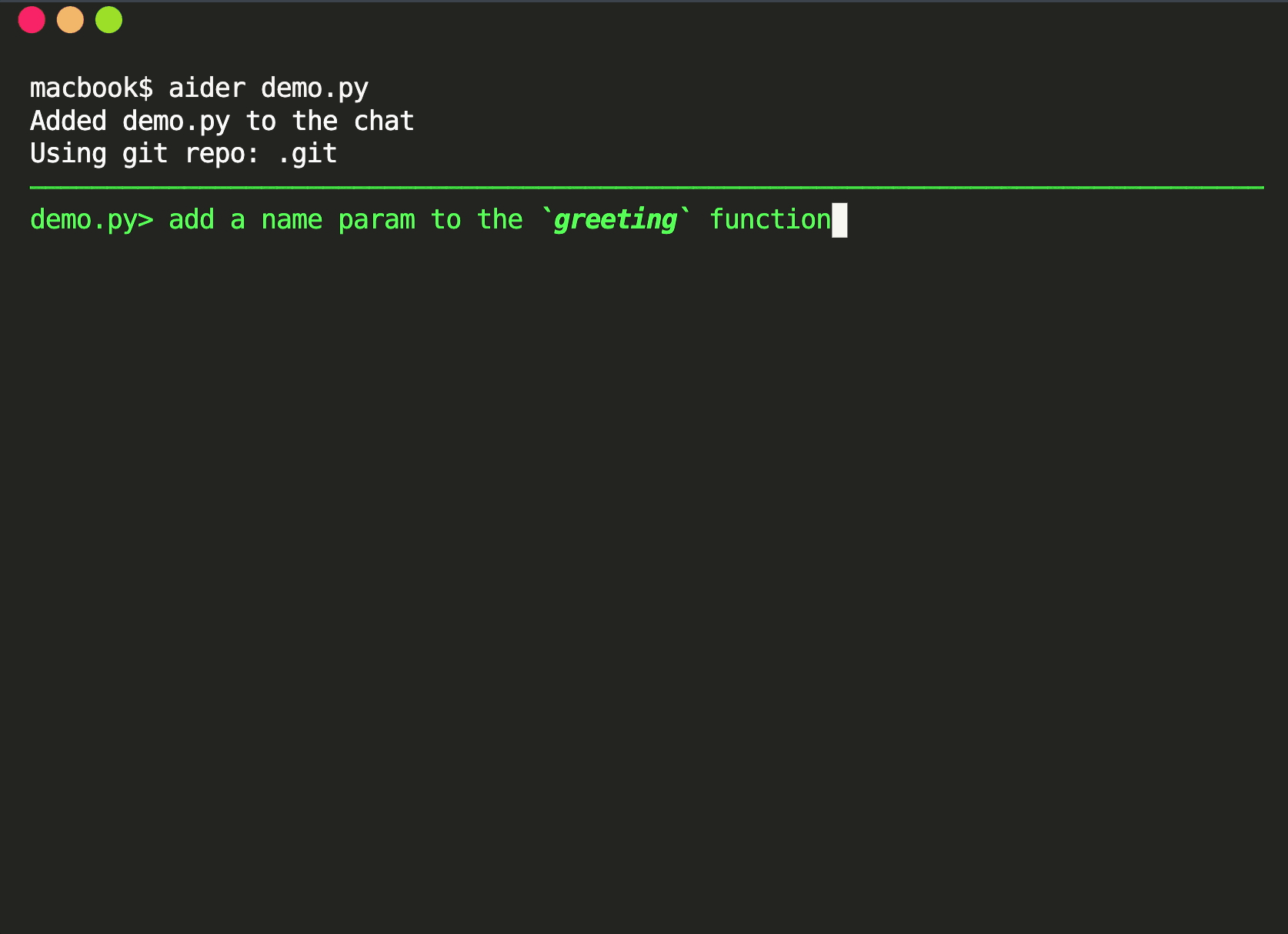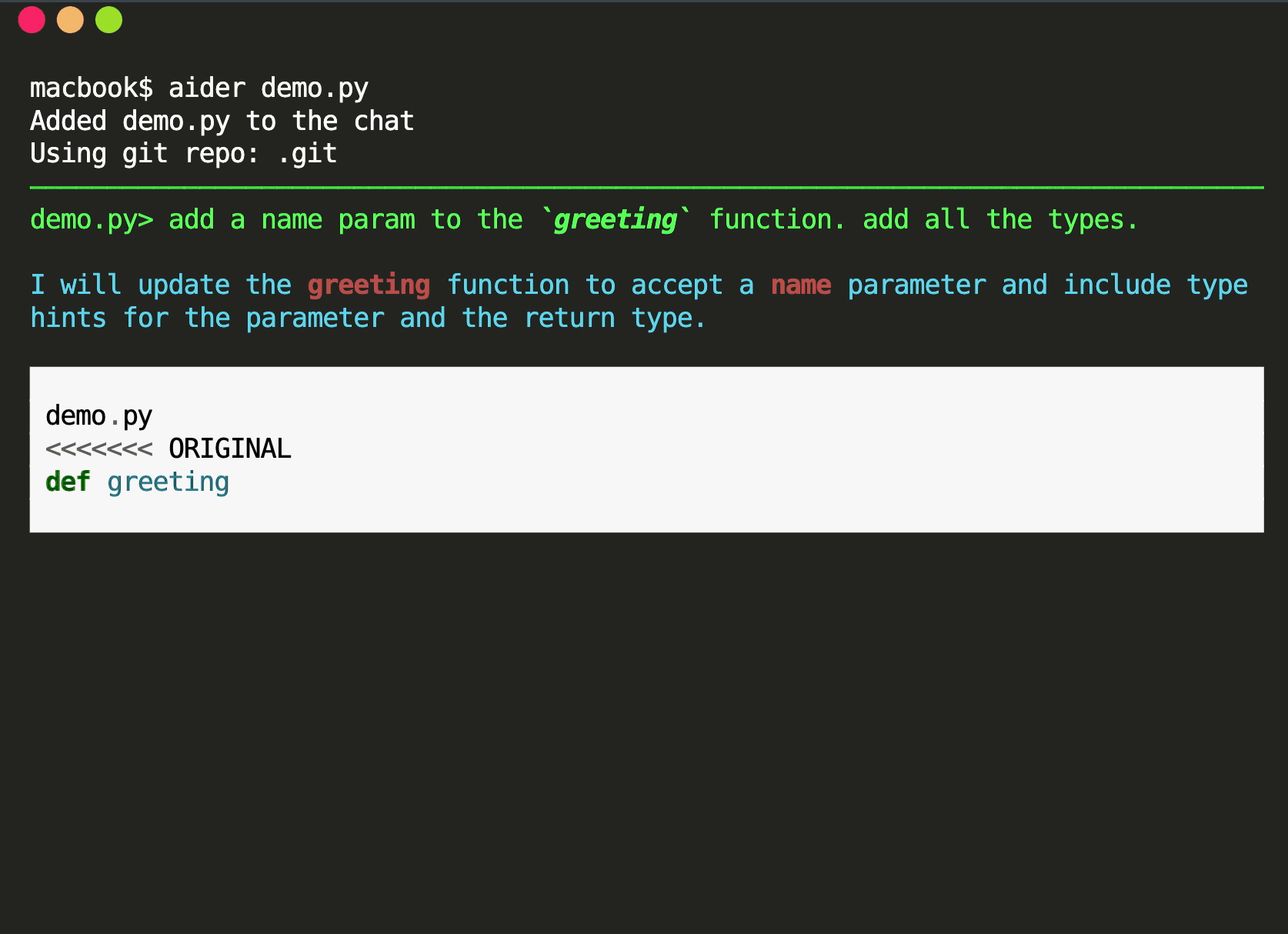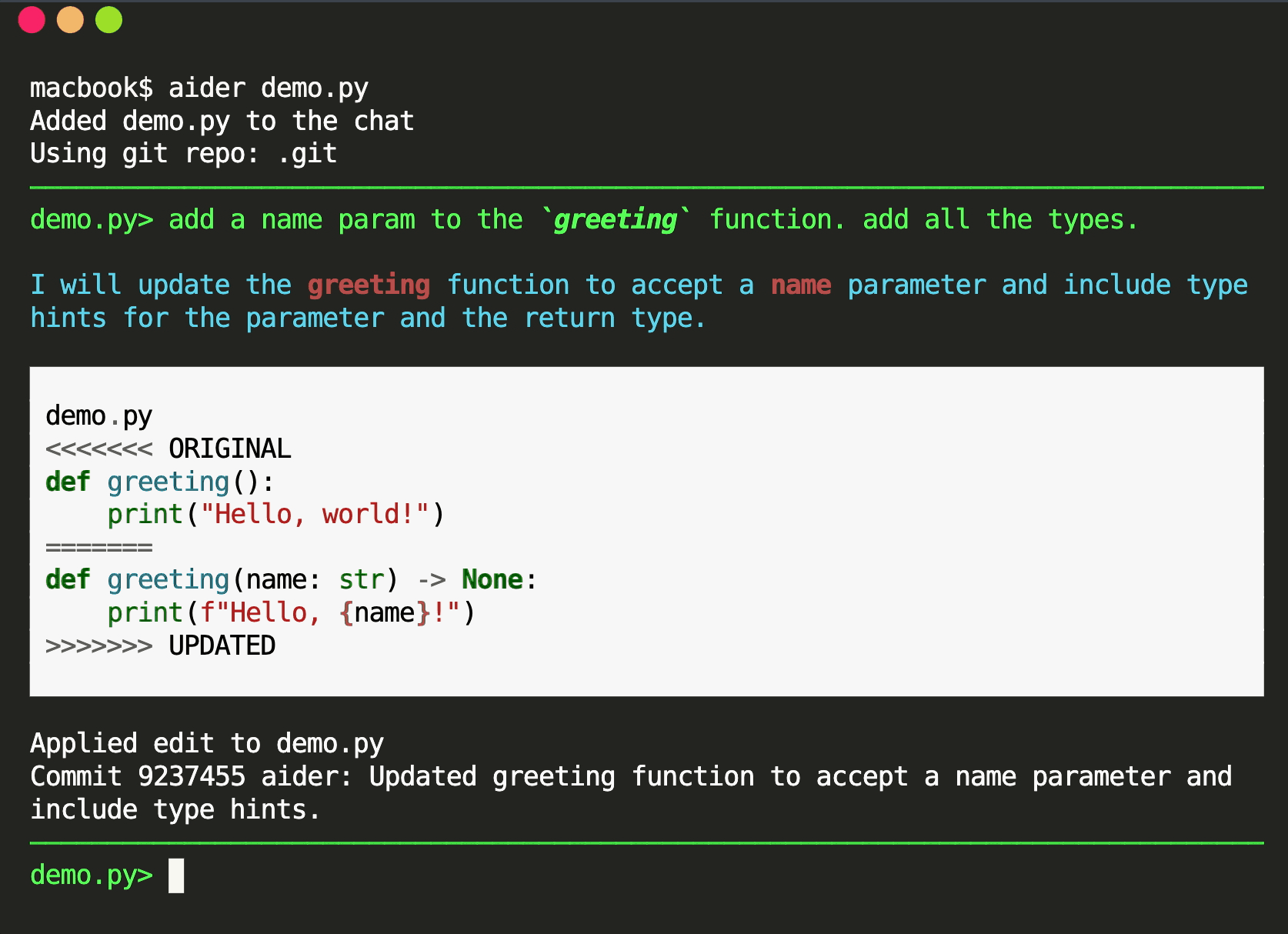 在您使用 MAGE 建立應用程式的 v1 版並獲得基本功能後,您可能會想要加入更多功能。為什麼不使用人工智慧來實現這一點呢?這就是 Aider 發揮作用的地方! Aider 的超能力在於您可以將其插入任何現有專案並開始使用!這感覺就像與坐在您旁邊的開發人員同事聊天 - 只需描述您的下一個功能,Aider 將盡力實現它,同時提供流程的所有詳細訊息,並自動向您的存儲庫加入新的提交!多麼酷啊? 您可以了解更多有關 Aider 的資訊並在這裡嘗試一下:https://github.com/paul-gauthier/aider ## 🦀 🚀 Shuttle AI - 使用 GPT 在 Rust 中建立後端!  當您聽到“網頁應用程式”這個詞時,我們大多數人都會立即想到 JavaScript。雖然對於前端來說這在很大程度上是正確的,但我們可以用我們喜歡的任何技術來建立後端! 除了 Python、Java 和 PHP 等常見的嫌疑犯之外,Rust 又如何呢?它是開發人員最喜愛的語言之一,它不應該只用於低階演算法。 Shuttle AI 讓這一切成為可能 - 他們強大的基於 Rust 的框架已經使建置和部署後端變得容易,而頂部的 AI 使其變得輕而易舉! 在這裡了解更多:https://www.shuttle.rs/ai ## ⚡️📦 Supabase AI - 再見,複雜的 SQL 查詢 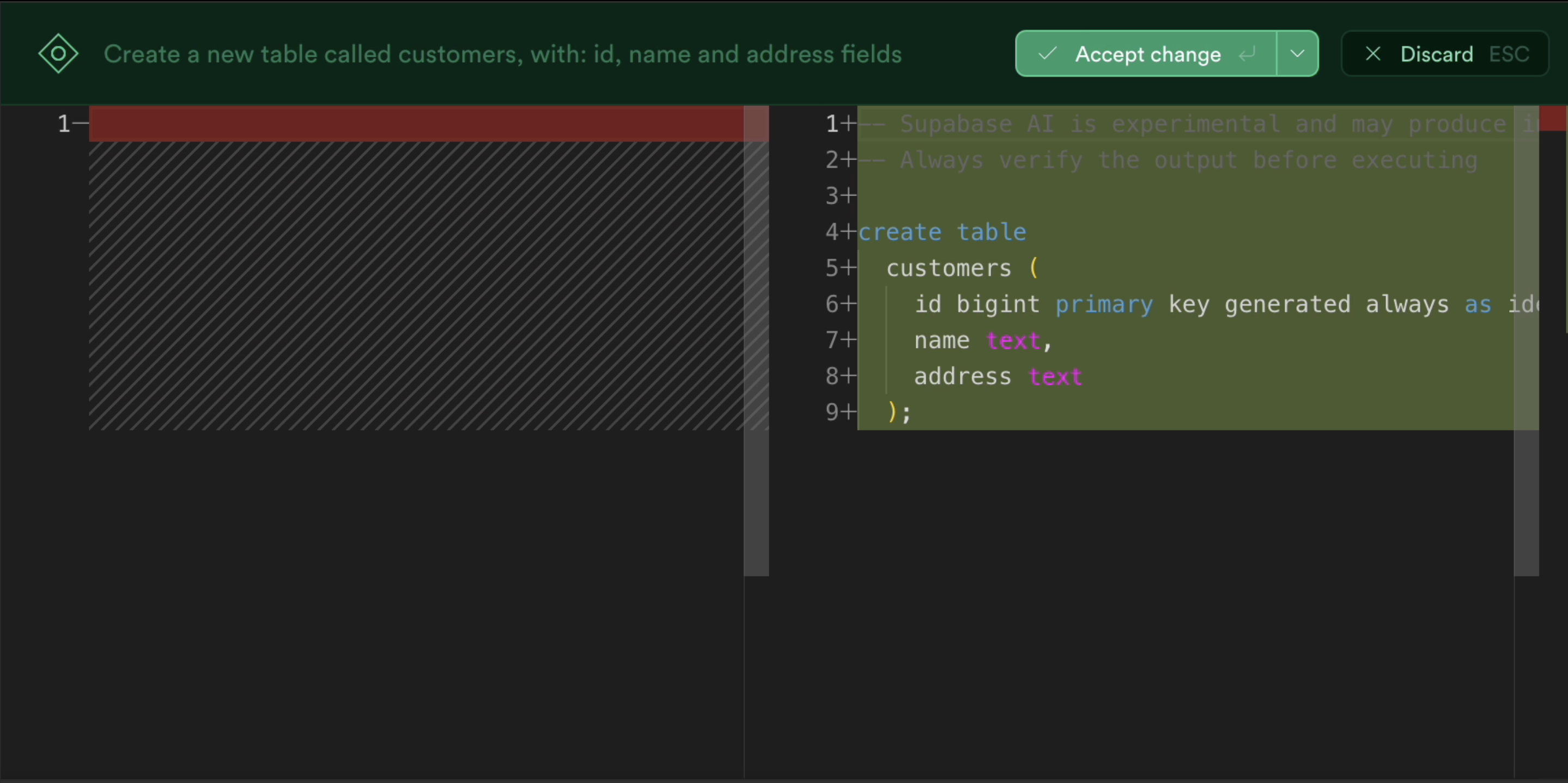 [Supabase](https://supabase.com/) 是為您的全端應用程式啟動和執行資料庫的最佳方法之一,除此之外您還可以獲得大量功能!由於它專門用於 Postgresql,這意味著您偶爾需要編寫一些 SQL。為什麼不從人工智慧得到一些幫助呢? Supabase 因其美觀且用戶友好的儀表板(帶有整合 SQL 編輯器)而聞名,現在他們透過加入自己的 AI 代理使其變得更好。要求它建立新的表和索引,甚至編寫資料庫函數! 在這裡了解更多:https://supabase.com/blog/supabase-studio-3-0 ## 👁️ 🧑✈️Visual Copilot - 將 Figma 設計編碼 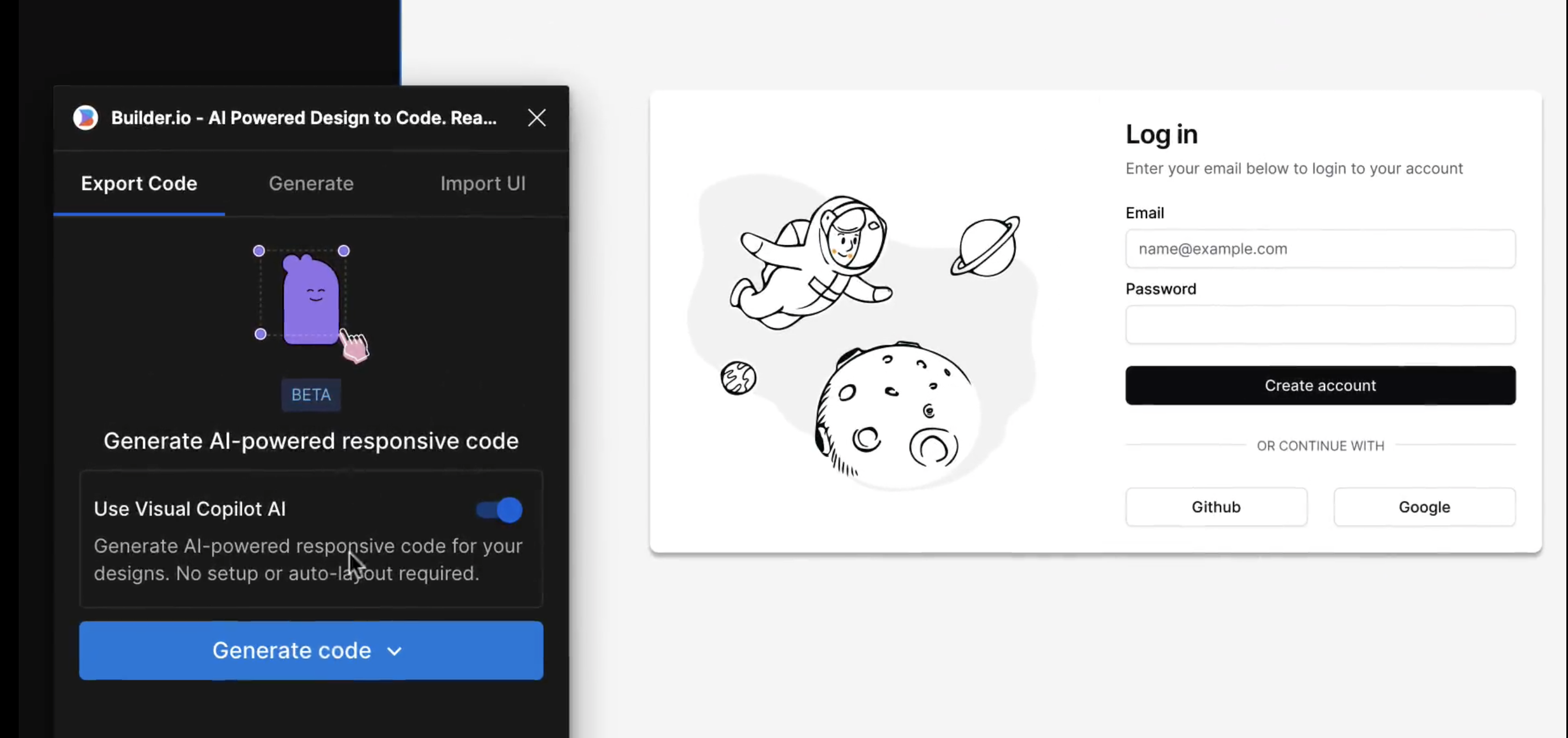 如果您曾經從設計師那裡獲得 Figma 設計講義,然後您的任務是用它來實現 UI,您是否想過是否有一種方法可以自動化此操作?這就是 Visual Copilot 所追求的! 只需點擊一下,並給出 Figma 設計,Visual Copilot 就會為其產生前端程式碼!它將盡最大努力使其具有響應性並保持程式碼整潔和可重複使用。 它目前可作為 [Figma 社群插件](https://www.figma.com/community/plugin/747985167520967365/builder-io-ai-powered-figma-to-code-react-vue-tailwind-more) 。 ## ✈️ 🤖 GPT Pilot - 使用協作 AI 啟動新應用程式 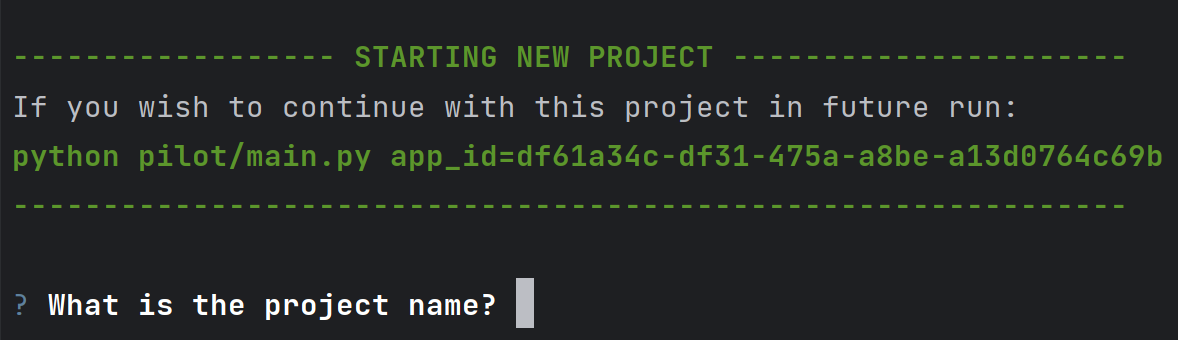 GPT Pilot 是專門用於從頭開始建立新應用程式的編碼代理程式。它獨特的做法是它與開發者合作——每當遇到困難時,它都會尋求你的幫助! 在內部,它由多個代理組成,這些代理一起協作並經歷應用程式開發的不同階段 - 從產品所有者和架構師到 DevOps 和開發人員! 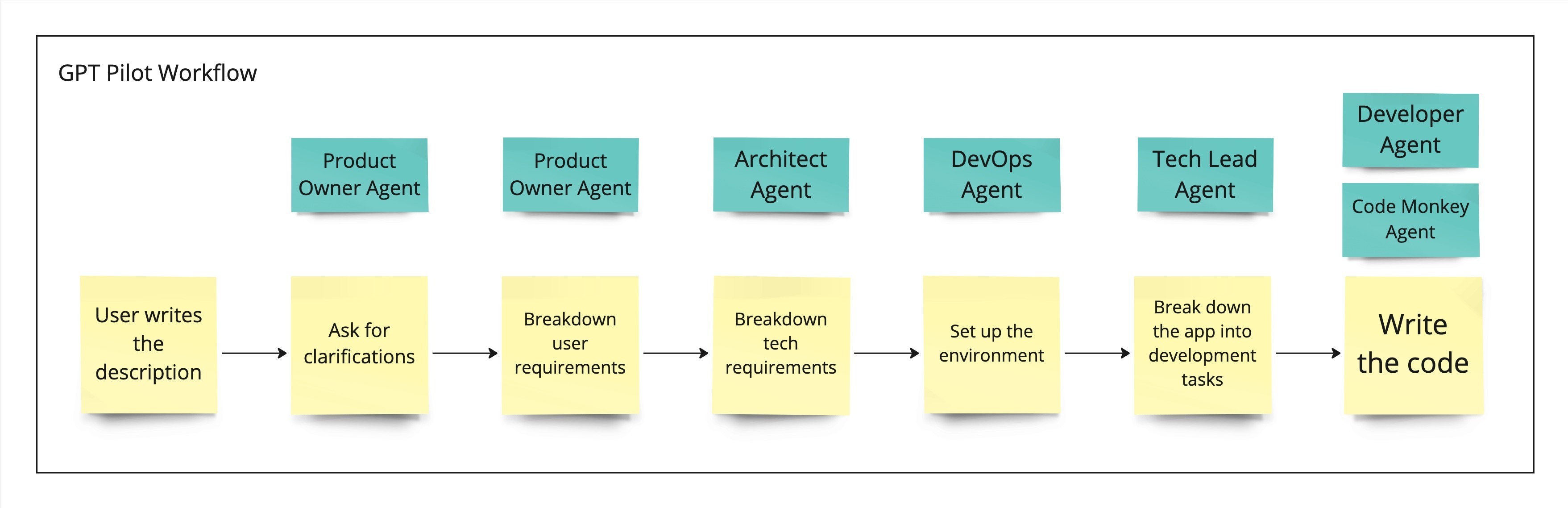 這是另一個完全開源的解決方案,最近受到了開發人員的喜愛,並多次出現在 GitHub 趨勢排行榜上。 了解更多並在這裡嘗試一下:https://github.com/Pythagora-io/gpt-pilot ## 概括  這就是一個包裝!還有更多的人工智慧工具,而且每天都有新的工具出現,但在本概述中,我們試圖專注於您今天可以用來啟動新的網路應用程式的工具。 希望您發現這很有幫助,並學到了一些可能派上用場的新東西!我也很想在評論中聽到您的意見 - 您最喜歡的 Web 開發人工智慧工具是什麼,無論是您每天使用的工具還是只是感到興奮的工具,接下來我們應該介紹什麼? --- 原文出處:https://dev.to/matijasos/6-tools-to-kickstart-your-full-stack-app-with-ai-4oh3
## **簡介** 在本文中,我提供了主流 Python 函式庫的替代方案。 儘管主流函式庫得到了更強大的活躍社群的支持,但這些替代方案為 Python 領域增加了一些價值。 選擇您的庫取決於您的用例和個人喜好。  --- ## 1.[Taipy](https://github.com/Avaiga/taipy) 而非 Streamlit Taipy 是這個街區的新來者。就像 Streamlit 一樣,Taipy 提供了一種建立互動式 GUI 的簡單方法; 然而,Taipy 解決了 Streamlit 的大部分限制/低效率: - 管理同步/非同步呼叫 - 完全筆記型電腦相容性 - 多用戶 - 為您的佈局、樣式等提供更多自訂功能(無需 CSS) - 大資料支持 - 更好的性能  ---  我們感謝任何幫助我們發展社區的幫助🌱 --- ## 2.[Polars](https://github.com/pola-rs/polars)取代Pandas Polars 的靈感來自於 Python 的皇室成員:Pandas。就像它一樣,它是一個為處理資料而建立的 DataFrame 庫,但在處理大型資料集時它確實表現出色。 Polars 的速度比 Pandas 快 10 到 100 倍,主要原因有二: - Polars 內建平行處理 - 用 Rust 寫 北極熊會取代熊貓嗎?只有時間會給出答案。  --- ## 3.[Dask](https://github.com/dask/dask)取代PySpark Dask 可以結合平行計算來處理大於記憶體的計算。 當您希望擴展計算時,它是一個很好的工具。它是用 Python 原生編寫的,使得學習/使用變得輕而易舉(對於 Python 開發人員來說)。 它不是為超大資料(超過 2 TB)而設計的,如果您正在處理類似 SQL 的查詢,它也沒有競爭力(與 Spark)。 非常適合筆記型電腦執行。  --- ## 4.[LightGBM](https://github.com/microsoft/LightGBM)而不是XGBoost XGBoost 和 LightGBM 都是梯度增強函式庫。 XGBoost 是 Kaggle 的最愛,但在處理大型資料集時,LightGBM 針對具有平行計算的大資料進行了最佳化。  --- ## 5.[PyCaret](https://github.com/pycaret/pycaret)取代Scikit-learn 與 Scikit-learn 一樣,您可以使用 PyCaret 執行機器學習任務。 PyCaret 透過更簡單的程式碼來展示其功能,這是開始 ML 學習專案的好方法。 PyCaret 簡單易學。它的一些高級功能是: - EDA 和資料處理 - 建模/培訓 - 模型可解釋性 - 模型部署 它對各種機器學習步驟的端到端覆蓋使得 PyCaret 成為 ML 愛好者甚至是沒有時間進行更深入分析的高級資料科學家的絕佳工具!  --- ## 6.[Darts](https://github.com/unit8co/darts) 而非 tsfresh 這兩個庫都致力於時間序列。然而,它們有不同的目的。 Darts 是時間序列的「sklearn」。它涵蓋了 DS 在處理時間序列時所需的所有不同功能: - 資料發現 - 資料預處理 - 預測 - 模型評估/選擇 不再需要使用多個庫;這一切都可以在 Darts 中找到。 tsfresh 旨在自動化為 ML 訓練步驟準備時間序列時最具挑戰性的步驟之一:特徵提取和選擇。 tsfresh 可以從您的時間序列中提取大量特徵,並幫助您辨識相關特徵。  --- ## 7.[PyTorch](https://github.com/pytorch/pytorch) 而非 TensorFlow 兩者都是參與深度學習的資料科學家和研究人員的首選庫。 幾年前,TensorFlow 是一個受歡迎的庫,但從 2020 年到 2021 年,PyTorch 已經趕上了 TensorFlow。 您如何在這兩個令人難以置信的庫之間做出選擇? PyTorch 似乎在研究方面具有優勢,更專注於 NLP。 此外,PyTorch 更具 Python 風格,學習曲線也更容易。 如果您是深度學習遊戲的新手,我建議您嘗試一下 PyTorch;否則,兩個庫都是不相上下的。  --- ## 8.[Arcade](https://github.com/pythonarcade/arcade) 而非 Pygame 在 Python 2D 遊戲領域,Pygame 獲得了良好的聲譽,而 Arcade 作為一個較新但完善的庫,在以下屬性上脫穎而出: - 內建遊戲循環 - 高效率的事件模型 - 更多功能 - 更人性化 兩個庫都有自己的優點;然而,Arcade 是更適合初學者的選擇。 Pygame 確實提供了一種教育替代方案 Pygame Zero,對於新開發人員來說是一個更好的選擇。  --- ## 9.[spaCy](https://github.com/explosion/spaCy)取代NLTK NLTK 是自然語言處理的主流函式庫,具有豐富的功能。 然而,隨著複雜性的增加,學習曲線也會變得更加陡峭。 SpaCy 是開始該領域的一個不錯的選擇。 SpaCy 的另一個優點是它是為了優化 NLP 應用程式而建構的,專注於更高的速度和效率。  --- ## 10.[Ruff](https://github.com/astral-sh/ruff) 而非 Pylint Linters 是任何編碼之旅的重要組成部分。 Pylint 被廣泛使用,但 Ruff 提高了過程的有效性和速度。 眾所周知,它比同等的 linter 快 10-100 倍,Ruff 絕對是一個很好的庫,可以作為 Pylint 的替代品。  --- 我希望你喜歡這篇文章!🙂 我是一名新手作家,歡迎任何改進建議! 如果您有最喜歡的庫而不是更主流的庫,請隨時分享。  --- 原文出處:https://dev.to/taipy/new-open-source-vs-old-open-source-33k7
## **TL;博士** 對於使用 VSCode 的 Python 開發人員、資料科學家和分析師來說,此編譯提供了一些擴展,可以提高 Python 和一般編碼需求的編碼生產力和效率。  <小時/> ## 1. [Taipy Studio](https://marketplace.visualstudio.com/items?itemName=Taipy.taipy-studio) Taipy 是一個開源 Python 庫,用於建立 Web 應用程式前端和後端。 您只需使用 Python 即可為您的資料/機器學習用例建立多頁面、多用戶和可自訂的 GUI。 但它不止於此。 Taipy 還可以處理您的後端,因為它允許管道編排和管理。 現在,回到 Taipy Studio 的 VSCode 擴充功能。此擴充功能是兩個工具的包裝器,旨在加速 Taipy 應用程式的建立。 - Taipy Studio Configuration Builder:圖形管道編輯器,全部在點擊環境中; - Taipy Studio GUI 助手:在編寫 GUI 時包括 IntelliSense。 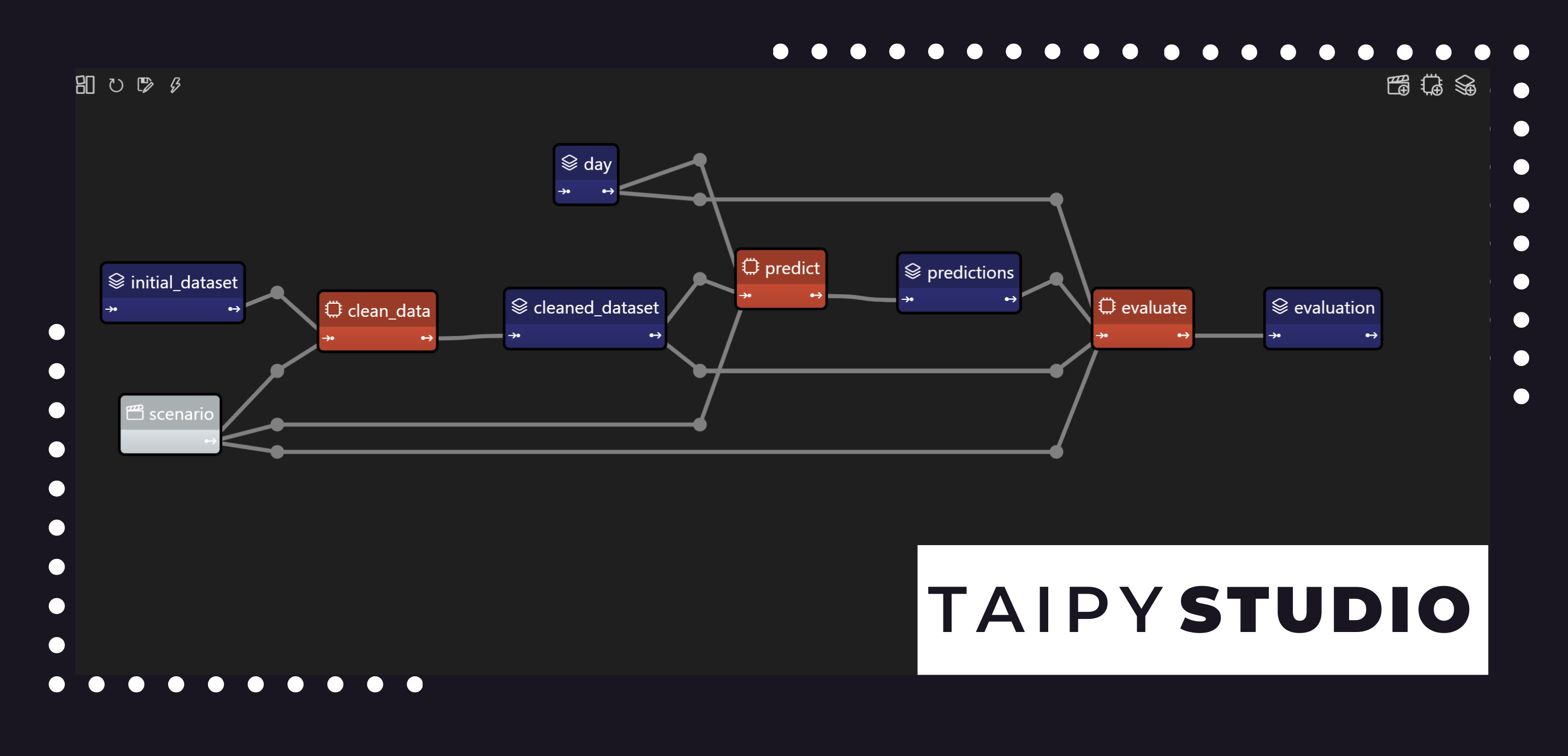 <小時/>  {% cta https://github.com/Avaiga/taipy %} Star ⭐ Taipy 儲存庫 {% endcta %} 我們已經快有 2000 顆星了,沒有你我們無法做到這一點🙏 <小時/> ## 2. [Github Copilot](https://marketplace.visualstudio.com/items?itemName=GitHub.copilot) 還需要出示副駕駛嗎?這個工具就是您自己的程式碼助手。 利用人工智慧,Copilot 可以無縫地自動完成您的程式碼。 另一個主要功能是能夠提供上下文感知建議。 對於開發人員來說,這是一個偉大的遊戲規則改變者,可以節省時間和提高效率,並且將其直接作為 VSCode 擴展使用是完全有意義的。  <小時/> ## 3. [Rainbow CSV](https://marketplace.visualstudio.com/items?itemName=mechatroner.rainbow-csv) 光看名字,你就差不多能猜到這個工具的功能了。 Rainbow CSV 將透過以不同顏色突出顯示列來讓您的 CSV 檔案易於閱讀。 就這麼簡單,但對任何處理資料的人來說都很有幫助。真正改變使用者視覺體驗的遊戲規則。  <小時/> ## 4. [待辦事項樹](https://marketplace.visualstudio.com/items?itemName=Gruntfuggly.todo-tree) 對於需要在程式碼的待辦事項清單中進行組織的人來說,這個工具非常有用。使用此擴展,只需在需要時在程式碼中加入 TODO 或 FIXME 標記即可。 ToDo Tree 將會尋找這些標籤並將它們組織成樹狀結構。 現在您可以輕鬆返回標籤。  <小時/> ## 5. [Jupyter](https://marketplace.visualstudio.com/items?itemName=ms-toolsai.jupyter) 如果您想使用類似筆記本的 IDE 來啟動資料/ML 專案以促進探索和實驗,VSCode 透過 Jupyter 擴充功能提供此功能。 當筆記型電腦的限制(例如擴展、部署、測試和維護)使得有必要轉向更傳統的編碼實踐時,在 VSCode 上進行所有設定只會讓事情變得更容易。  <小時/> ## 6. [Markdown 表情符號](https://marketplace.visualstudio.com/items?itemName=bierner.markdown-emoji) 這裡並沒有什麼真正令人驚訝的地方。此 VSCode 擴展為 VSCode Markdown 預覽提供表情符號支持,這是為任何 Markdown 專案加入表現和可讀性的好方法。  <小時/> ## 7. [Pylint](https://marketplace.visualstudio.com/items?itemName=ms-python.pylint) Pylint 與 Python linter 同名,是其在 VSCode 中的擴充。它透過分析程式碼、檢查錯誤並為您提供改進建議來幫助您提高效率。 確保您的腳本遵循所有編碼標準是必須的。  <小時/> ## 8. [Pylance](https://marketplace.visualstudio.com/items?itemName=ms-python.vscode-pylance) Pylance 是 Python 語言的支援。 它最初作為 Python 庫存在,但透過此擴充整合到 VSCode 中。 一些主要特點: - 程式碼完成 - 自動導入 - 與 Juypter 筆記本相容 - 語意突出顯示  <小時/> ## 9. [Liveshare](https://marketplace.visualstudio.com/items?itemName=MS-vsliveshare.vsliveshare) 使用此 VSCode 擴充功能可以輕鬆進行協作。無需配置任何東西;只需啟動 Liveshare 會話並繼續除錯會話即可。 Liveshare 也保留您所有的個人 IDE 首選項,讓協作更加輕鬆。  <小時/> ## 10. [Markdown 多合一](https://marketplace.visualstudio.com/items?itemName=yzhang.markdown-all-in-one) 此擴充增強了 VSCode 中 Markdown 的使用,並具有各種不同的功能: - 內容表生成 - 鍵盤快速鍵 - 程式碼區塊插入 - 預覽功能 該工具非常適合編寫“README.md”檔案。  <小時/> 由於各種原因,VSCode 已成為開發人員最常使用的 IDE 之一。 它的主要功能包括強大的 git 整合和跨平台支持,但擴展是一個突出的功能。 它們支援自訂您的環境,促進與各種工具的無縫整合。 <小時/> 希望您喜歡這篇文章! 我是一名新手作家,歡迎任何改進建議!  如果您有任何疑問,請隨時與我們聯繫。 --- 原文出處:https://dev.to/taipy/top-10-must-have-vscode-extensions-forpythonistas-561a
本文將透過一個簡單的範例來示範如何**將 PySpark 與 Taipy 整合**,以將您的 **大資料處理需求** 與 **智慧作業執行** 結合。 #### 讓我們開始吧!  <小時/> ### 將 PySpark 與 Taipy 結合使用 Taipy 是一個**強大的工作流程編排工具**,具有**易於使用的框架**,可輕鬆應用於您現有的資料應用程式。 Taipy 建立在堅實的概念基礎上: - **場景、任務和資料節點** - 這些概念非常強大,允許開發人員**輕鬆地對其管道進行建模**,即使在沒有明確支援的情況下使用第3 方包也是如此。 <小時/>  {% cta https://github.com/Avaiga/taipy %} Star ⭐ Taipy 儲存庫 {% endcta %} 我們感謝任何幫助我們發展社區的幫助🌱 <小時/> *如果您已經熟悉 PySpark 和 Taipy,則可以跳至「2. Taipy 設定 (*config.py*)」。 *該部分深入探討了為 Taipy 任務定義函數來執行 PySpark 應用程式的本質。否則,請繼續閱讀!* <小時/> ### 一個簡單的例子:*palmerpenguins* 我們以 [palmerpenguins](https://allisonhorst.github.io/palmerpenguins/) 資料集為例: ``` >>> penguin_df ┌───────┬─────────┬───────────┬────────────────┬───────────────┬───────────────────┬─────────────┬────────┬──────┐ │ index │ species │ island │ bill_length_mm │ bill_depth_mm │ flipper_length_mm │ body_mass_g │ sex │ year │ ├───────┼─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼──────┤ │ 0 │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181.0 │ 3750.0 │ male │ 2007 │ │ 1 │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186.0 │ 3800.0 │ female │ 2007 │ │ 2 │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195.0 │ 3250.0 │ female │ 2007 │ │ 3 │ Adelie │ Torgersen │ NaN │ NaN │ NaN │ NaN │ NaN │ 2007 │ │ 4 │ Adelie │ Torgersen │ 36.7 │ 19.3 │ 193.0 │ 3450.0 │ female │ 2007 │ │ ... │ ... │ ... │ ... │ ... │ ... │ ... │ ... │ ... │ └───────┴─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴──────┘ ``` <小時/> 該資料集僅包含 344 筆記錄——幾乎不是一個需要 Spark 處理的資料集。 然而,該資料集是可存取的,且其大小與演示 Spark 與 Taipy 的整合無關。 如果必須使用更大的資料集進行測試,您可以根據需要多次複製資料。 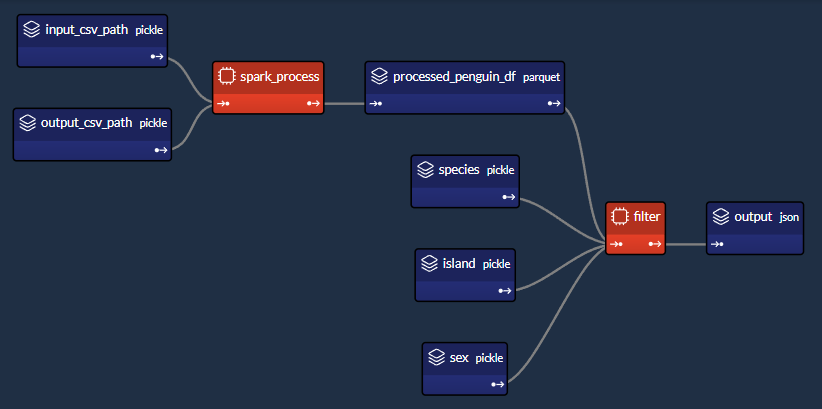 *我們簡單的企鵝應用程式的 DAG* <小時/> 我們將設計一個執行**兩個主要任務**的工作流程: #### 1- Spark 任務(*spark_process*): - 載入資料; - 依「*物種*」、「*島嶼*」和「*性別*」將資料分組; - 求其他欄位的平均值(「*bill_length_mm*」、「*bill_depth_mm*」、「*flipper_length_mm*」、「*body_mass_g*」); - 儲存資料。 #### 2- Python 任務(*過濾器*): - 載入Spark任務之前儲存的輸出資料; - 給定“*物種*”、“*島嶼*”和“*性別*”,傳回聚合值。 我們的小專案將包含 4 個檔案: ``` app/ ├─ penguin_spark_app.py # the spark application ├─ config.py # the configuration for our taipy workflow ├─ main.py # the main script (including our application gui) ├─ penguins.csv # the data as downloaded from the palmerpenguins git repo ``` <小時/> 您可以找到每個檔案的內容(*penguins.csv* 除外,您可以從 [palmerpenguins 儲存庫](https://github.com/allisonhorst/palmerpenguins/blob/main/inst/extdata/penguins.csv 取得) )在本文的程式碼區塊中。 <小時/> ## 1. Spark 應用程式 (*penguin_spark_app.py*) 通常,我們使用 *spark-submit* 命令列實用程式來執行 PySpark 任務。 您可以在他們自己的文件中閱讀有關以這種方式提交Spark 作業的內容和原因的更多資訊[此處](https://spark.apache.org/docs/latest/submitting-applications.html) 。 當使用 Taipy 進行工作流程編排時,我們可以繼續做同樣的事情。 唯一的區別是,我們不是在命令列中執行命令,而是讓工作流程管道產生一個[子進程](https://docs.python.org/3/library/subprocess.html),它使用以下命令執行Spark 應用程式*火花提交*。 在開始討論之前,我們首先**看看我們的 Spark 應用程式**。 只需瀏覽一下程式碼,然後**繼續閱讀有關此腳本功能的簡短說明**: ``` ### app/penguin_spark_app.py import argparse import os import sys parser = argparse.ArgumentParser() parser.add_argument("--input-csv-path", required=True, help="Path to the input penguin CSV file.") parser.add_argument("--output-csv-path", required=True, help="Path to save the output CSV file.") args = parser.parse_args() import pyspark.pandas as ps from pyspark.sql import SparkSession def read_penguin_df(csv_path: str): penguin_df = ps.read_csv(csv_path) return penguin_df def clean(df: ps.DataFrame) -> ps.DataFrame: return df[df.sex.isin(["male", "female"])].dropna() def process(df: ps.DataFrame) -> ps.DataFrame: """The mean of measured penguin values, grouped by island and sex.""" mean_df = df.groupby(by=["species", "island", "sex"]).agg("mean").drop(columns="year").reset_index() return mean_df if __name__ == "__main__": spark = SparkSession.builder.appName("Mean Penguin").getOrCreate() penguin_df = read_penguin_df(args.input_csv_path) cleaned_penguin_df = clean(penguin_df) processed_penguin_df = process(cleaned_penguin_df) processed_penguin_df.to_pandas().to_csv(args.output_csv_path, index=False) sys.exit(os.EX_OK) ``` <小時/> 我們可以透過在終端機中輸入以下命令來提交此 Spark 應用程式以供執行: ``` spark-submit --master local[8] app/penguin_spark_app.py \ --input-csv-path app/penguins.csv \ --output-csv-path app/output.csv ``` <小時/> 它將執行以下操作: 1.提交*penguin_spark_app.py*應用程式在8個CPU核心上本地執行; 2. 從 *app/penguins.csv* CSV 檔案載入資料; 3. 依「*物種*」、「*島嶼*」和「*性別*」分組,然後按平均值聚合其餘欄位; 4. 將產生的 DataFrame 儲存到 *app/output.csv*。 此後,*app/output.csv* 的內容應如下所示: 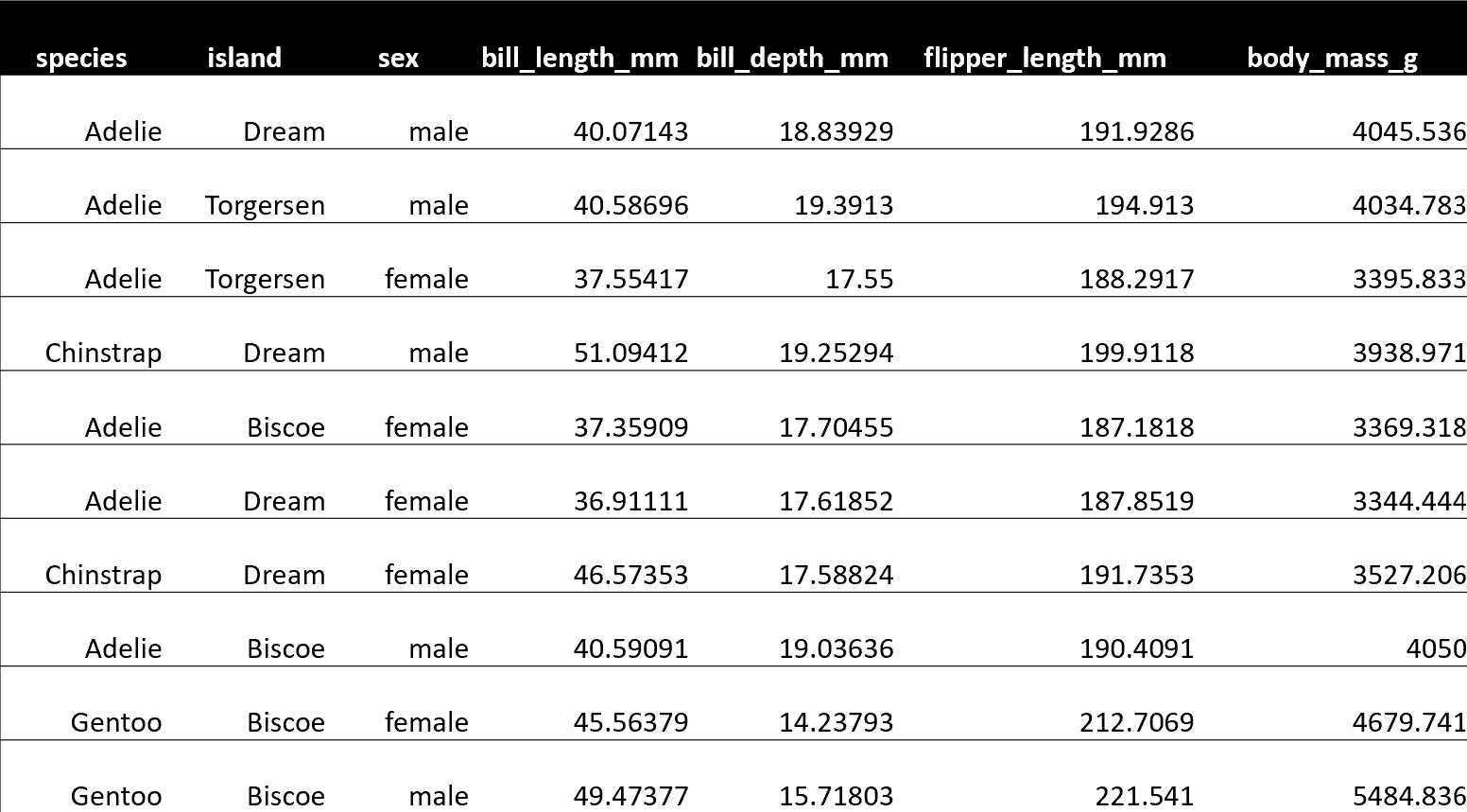 <小時/> 另請注意,我們已對 **Spark 應用程式進行了編碼以接收 2 個命令列參數**: 1. - *input-csv-path* :輸入企鵝 CSV 檔案的路徑;和 2. - *output-csv-path* :Spark 應用程式處理後儲存輸出 CSV 檔案的路徑。 <小時/> ## 2. Taipy 設定 (*config.py*) 此時,我們有了 *penguin_spark_app.py* PySpark 應用程式,並且需要建立一個 **Taipy 任務來執行此 PySpark 應用程式**。 再次快速瀏覽 *app/config.py* 腳本,然後繼續閱讀: ``` ### app/config.py import datetime as dt import os import subprocess import sys from pathlib import Path import pandas as pd import taipy as tp from taipy import Config SCRIPT_DIR = Path(__file__).parent SPARK_APP_PATH = SCRIPT_DIR / "penguin_spark_app.py" input_csv_path = str(SCRIPT_DIR / "penguins.csv") # -------------------- Data Nodes -------------------- input_csv_path_cfg = Config.configure_data_node(id="input_csv_path", default_data=input_csv_path) # Path to save the csv output of the spark app output_csv_path_cfg = Config.configure_data_node(id="output_csv_path") processed_penguin_df_cfg = Config.configure_parquet_data_node( id="processed_penguin_df", validity_period=dt.timedelta(days=1) ) species_cfg = Config.configure_data_node(id="species") # "Adelie", "Chinstrap", "Gentoo" island_cfg = Config.configure_data_node(id="island") # "Biscoe", "Dream", "Torgersen" sex_cfg = Config.configure_data_node(id="sex") # "male", "female" output_cfg = Config.configure_json_data_node( id="output", ) # -------------------- Tasks -------------------- def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame: proc = subprocess.Popen( [ str(Path(sys.executable).with_name("spark-submit")), str(SPARK_APP_PATH), "--input-csv-path", input_csv_path, "--output-csv-path", output_csv_path, ], stdout=subprocess.PIPE, stderr=subprocess.PIPE, ) try: outs, errs = proc.communicate(timeout=15) except subprocess.TimeoutExpired: proc.kill() outs, errs = proc.communicate() if proc.returncode != os.EX_OK: raise Exception("Spark training failed") df = pd.read_csv(output_csv_path) return df def filter(penguin_df: pd.DataFrame, species: str, island: str, sex: str) -> dict: df = penguin_df[(penguin_df.species == species) & (penguin_df.island == island) & (penguin_df.sex == sex)] output = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]].to_dict(orient="records") return output[0] if output else dict() spark_process_task_cfg = Config.configure_task( id="spark_process", function=spark_process, skippable=True, input=[input_csv_path_cfg, output_csv_path_cfg], output=processed_penguin_df_cfg, ) filter_task_cfg = Config.configure_task( id="filter", function=filter, skippable=True, input=[processed_penguin_df_cfg, species_cfg, island_cfg, sex_cfg], output=output_cfg, ) scenario_cfg = Config.configure_scenario( id="scenario", task_configs=[spark_process_task_cfg, filter_task_cfg] ) ``` 您也可以**使用[Taipy Studio](https://docs.taipy.io/en/latest/manuals/studio/config/)** 建立Taipy 配置,這是一個Visual Studio Code 擴展,它提供了圖形編輯器建構 Taipy *.toml* 設定檔。 <小時/> ### Taipy 中的 PySpark 任務 我們對產生這部分 DAG 的程式碼部分特別感興趣: 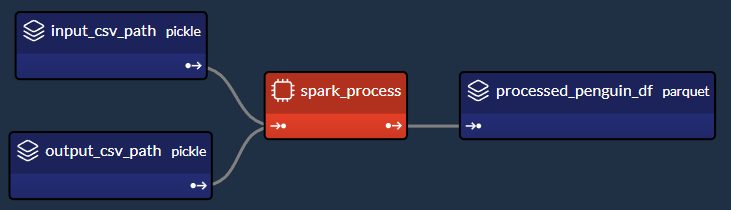 <小時/> 讓我們提取並檢查 *config.py* 腳本的相關部分,該腳本在 Taipy 中建立「*spark_process*」Spark 任務(及其 3 個關聯的資料節點),如上圖所示: ``` ### Code snippet: Spark task in Taipy # -------------------- Data Nodes -------------------- input_csv_path_cfg = Config.configure_data_node(id="input_csv_path", default_data=input_csv_path) # Path to save the csv output of the spark app output_csv_path_cfg = Config.configure_data_node(id="output_csv_path") processed_penguin_df_cfg = Config.configure_parquet_data_node( id="processed_penguin_df", validity_period=dt.timedelta(days=1) ) # -------------------- Tasks -------------------- def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame: proc = subprocess.Popen( [ str(Path(sys.executable).with_name("spark-submit")), str(SPARK_APP_PATH), "--input-csv-path", input_csv_path, "--output-csv-path", output_csv_path, ], stdout=subprocess.PIPE, stderr=subprocess.PIPE, ) try: outs, errs = proc.communicate(timeout=15) except subprocess.TimeoutExpired: proc.kill() outs, errs = proc.communicate() if proc.returncode != os.EX_OK: raise Exception("Spark training failed") df = pd.read_csv(output_csv_path) return df spark_process_task_cfg = Config.configure_task( id="spark_process", function=spark_process, skippable=True, input=[input_csv_path_cfg, output_csv_path_cfg], output=processed_penguin_df_cfg, ) ``` <小時/> 由於我們設計 *penguin_spark_app.py* Spark 應用程式來接收 2 個參數(*input_csv_path* 和 *output_csv_path*),因此我們選擇將這 2 個參數表示為 Taipy 資料節點。 請注意,**您的用例可能有所不同,您可以(並且應該!)根據您的需求修改任務、函數和關聯的資料節點**。 例如,您可以: 1. 有一個 Spark 任務,執行一些例行 ETL 並且不回傳任何內容; 2. 偏好對輸入和輸出路徑進行硬編碼,而不是將它們持久化為資料節點;或者 3. 將其他應用程式參數儲存為資料節點並將其傳遞給 Spark 應用程式。 然後,我們將 *spark-submit* 作為 Python 子進程執行,如下所示: ``` subprocess.Popen( [ str(Path(sys.executable).with_name("spark-submit")), str(SPARK_APP_PATH), "--input-csv-path", input_csv_path, "--output-csv-path", output_csv_path, ], ) ``` <小時/> 回想一下,清單元素的順序應保留以下格式,就像它們在命令列上執行一樣: ``` $ spark-submit [spark-arguments] <pyspark-app-path> [application-arguments] ``` <小時/> 同樣,根據我們的用例,我們可以根據需要指定不同的 Spark-submit 腳本路徑、Spark 參數(我們在範例中未提供任何參數)或不同的應用程式參數。 <小時/> ### 讀取並回傳*output_csv_path* 請注意,*spark_process* 函數的結束如下: ``` def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame: ... df = pd.read_csv(output_csv_path) return df ``` <小時/> 在我們的例子中,我們希望 Taipy 任務在 Spark - 處理資料後輸出資料,以便可以將其寫入 *processed_penguin_df_cfg* [Parquet 資料節點](https://docs.taipy.io/en/latest /手冊/核心/配置/資料節點配置/#parquet)。 我們可以做到這一點的一種方法是手動讀取輸出目標(在本例中為 *output_csv_path*),然後將其作為 Pandas DataFrame 傳回。 但是,如果您不需要 Spark 應用程式的返回資料,您可以簡單地讓 Taipy 任務(透過 *spark_process* 函數)返回 *None*。 <小時/> ### 快取 Spark 任務 由於我們將 *spark_process_task_cfg* 配置為 *True*,當重新執行該場景時,Taipy 將 **跳過 ** ***spark_process 的重新執行*** **任務** 並重複使用持久化任務輸出:* processed_penguin_df_cfg* Pandas DataFrame。 但是,我們也為 *processed_penguin_df_cfg* 資料節點定義了 1 天的 *validity_period*,因此如果 DataFrame 最後一次快取超過一天,Taipy 仍會重新執行任務。 <小時/> ## 3. 建構 GUI (*main.py*) 我們將透過**建立我們在本文開頭看到的 GUI** 來完成我們的應用程式: 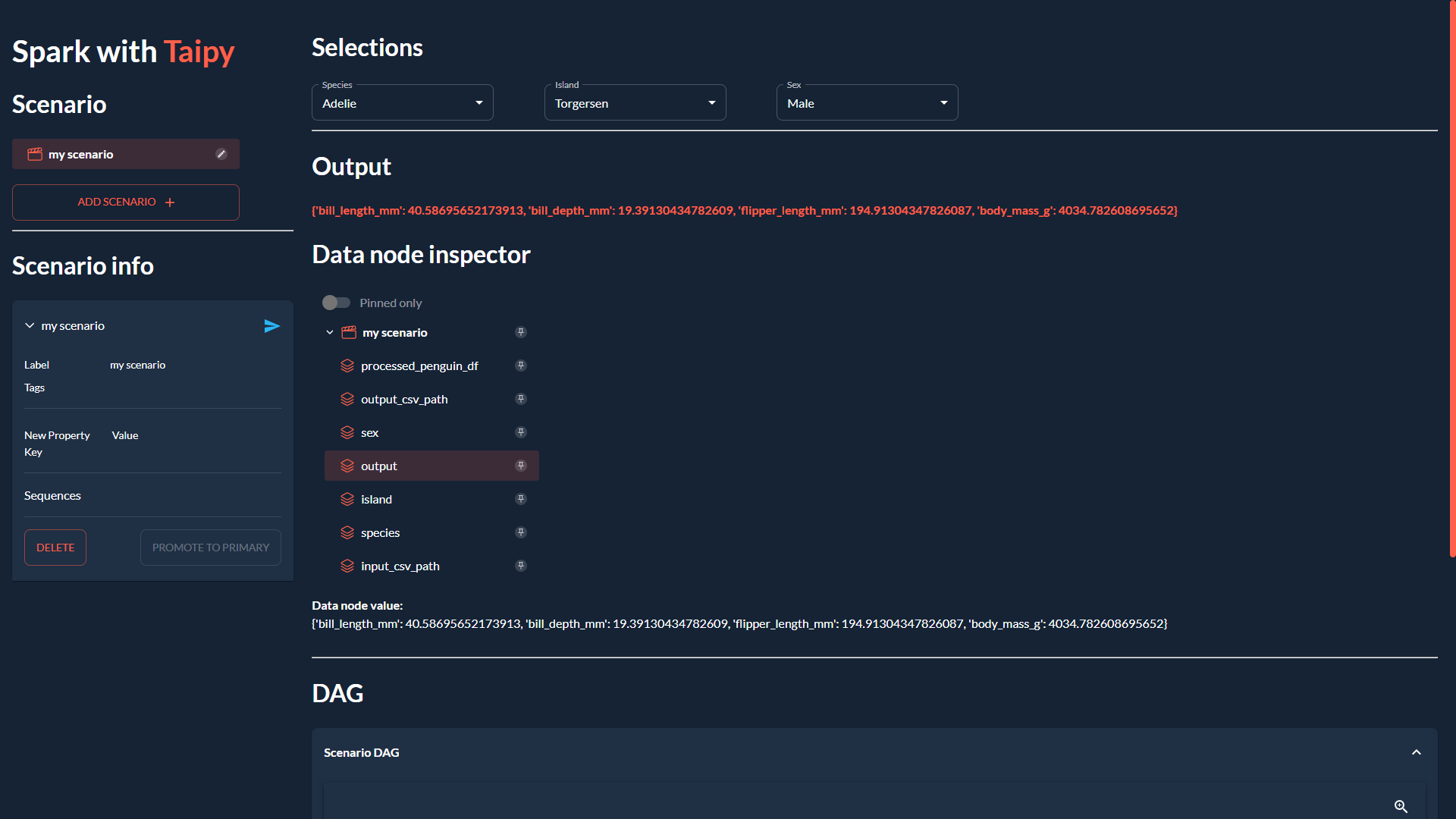 <小時/> 如果您不熟悉 Taipy 的 GUI 功能,可以在此處找到[快速入門](https://docs.taipy.io/en/latest/getting_started/getting-started-gui/)。 無論如何,您只需為 *app/main.py* 複製並貼上以下程式碼,因為它不是我們的重點: ``` ### app/main.py from pathlib import Path from typing import Optional import taipy as tp from config import scenario_cfg from taipy.gui import Gui, notify valid_features: dict[str, list[str]] = { "species": ["Adelie", "Chinstrap", "Gentoo"], "island": ["Torgersen", "Biscoe", "Dream"], "sex": ["Male", "Female"], } selected_species = valid_features["species"][0] selected_island = valid_features["island"][0] selected_sex = valid_features["sex"][0] selected_scenario: Optional[tp.Scenario] = None data_dir = Path(__file__).with_name("data") data_dir.mkdir(exist_ok=True) def scenario_on_creation(state, id, payload): _ = payload["config"] date = payload["date"] label = payload["label"] properties = payload["properties"] # Create scenario with selected configuration scenario = tp.create_scenario(scenario_cfg, creation_date=date, name=label) scenario.properties.update(properties) # Write the selected GUI values to the scenario scenario.species.write(state.selected_species) scenario.island.write(state.selected_island) scenario.sex.write(state.selected_sex.lower()) output_csv_file = data_dir / f"{scenario.id}.csv" scenario.output_csv_path.write(str(output_csv_file)) notify(state, "S", f"Created {scenario.id}") return scenario def scenario_on_submission_change(state, submittable, details): """When the selected_scenario's submission status changes, reassign selected_scenario to force a GUI refresh.""" state.selected_scenario = submittable selected_data_node = None main_md = """ <|layout|columns=1 4|gap=1.5rem| <lhs|part| # Spark with **Taipy**{: .color-primary} ## Scenario <|{selected_scenario}|scenario_selector|on_creation=scenario_on_creation|> ---------- ## Scenario info <|{selected_scenario}|scenario|on_submission_change=scenario_on_submission_change|> |lhs> <rhs|part|render={selected_scenario}| ## Selections <selections|layout|columns=1 1 1 2|gap=1.5rem| <|{selected_species}|selector|lov={valid_features["species"]}|dropdown|label=Species|> <|{selected_island}|selector|lov={valid_features["island"]}|dropdown|label=Island|> <|{selected_sex}|selector|lov={valid_features["sex"]}|dropdown|label=Sex|> |selections> ---------- ## Output **<|{str(selected_scenario.output.read()) if selected_scenario and selected_scenario.output.is_ready_for_reading else 'Submit the scenario using the left panel.'}|text|raw|class_name=color-primary|>** ## Data node inspector <|{selected_data_node}|data_node_selector|display_cycles=False|> **Data node value:** <|{str(selected_data_node.read()) if selected_data_node and selected_data_node.is_ready_for_reading else None}|> <br/> ---------- ## DAG <|Scenario DAG|expandable| <|{selected_scenario}|scenario_dag|> |> |rhs> |> """ def on_change(state, var_name: str, var_value): if var_name == "selected_species": state.selected_scenario.species.write(var_value) elif var_name == "selected_island": state.selected_scenario.island.write(var_value) elif var_name == "selected_sex": state.selected_scenario.sex.write(var_value.lower()) if __name__ == "__main__": tp.Core().run() gui = Gui(main_md) gui.run(title="Spark with Taipy") ``` <小時/> 然後,從專案資料夾中,您可以執行主腳本,如下所示: ``` $ taipy run app/main.py ``` <小時/> ## 結論 現在您已經看到如何將 PySpark 與 Taipy 結合使用的範例,請繼續嘗試使用這兩個工具來**增強您自己的資料應用程式**! 如果您一直在努力應對其他工作流程編排工具減慢您的工作並妨礙您的工作,請不要讓它阻止您嘗試 Taipy。 Taipy 易於使用,並且努力不限制自己可以使用的第 3 方軟體包 - **其強大而靈活的框架使其可以輕鬆適應任何資料應用程式**。 <小時/>  希望您喜歡這篇文章! <小時/> 您可以在此[儲存庫](https://medium.com/r?url=https%3A%2F%2Fgithub.com%2FAvaiga%2Fdemo-pytorch-penguin-app)上找到所有程式碼和資料。 --- 原文出處:https://dev.to/taipy/how-to-master-big-data-pipelines-with-taipy-and-pyspark-14oe
資料管道是任何資料密集型專案的支柱。 **隨著資料集的成長**超出記憶體大小(「核心外」),**有效處理它們變得具有挑戰性**。 Dask 可以輕鬆管理大型資料集(核心外),提供與 Numpy 和 Pandas 的良好相容性。  --- 本文重點介紹 **Dask(用於處理核心外資料)與 Taipy** 的無縫集成,Taipy** 是一個用於 **管道編排和場景管理** 的 Python 庫。 --- ## Taipy - 您的 Web 應用程式建構器 關於我們的一些資訊。 **Taipy** 是一個開源程式庫,旨在輕鬆開發前端 (GUI) 和 ML/資料管道。 不需要其他知識(沒有 CSS,什麼都不需要!)。 它旨在加快應用程式開發,從最初的原型到生產就緒的應用程式。  https://github.com/Avaiga/taipy 我們已經快有 1000 顆星了,沒有你就無法做到這一點🙏 --- ## 1. 範例應用程式 透過範例最好地演示了 Dask 和 Taipy 的整合。在本文中,我們將考慮包含 4 個任務的資料工作流程: - **資料預處理與客戶評分** 使用 Dask 讀取和處理大型資料集。 - **特徵工程和分割** 根據購買行為對客戶進行評分。 - **細分分析** 根據這些分數和其他因素將客戶分為不同的類別。 - **高價值客戶的總統計** 分析每個客戶群以獲得見解 我們將更詳細地探討這 4 個任務的程式碼。 請注意,此程式碼是您的 Python 程式碼,並未使用 Taipy。 在後面的部分中,我們將展示如何使用 Taipy 對現有資料應用程式進行建模,並輕鬆獲得其工作流程編排的好處。 --- 該應用程式將包含以下 5 個檔案: ``` algos/ ├─ algo.py # Our existing code with 4 tasks data/ ├─ SMALL_amazon_customers_data.csv # A sample dataset app.ipynb # Jupyter Notebook for running our sample data application config.py # Taipy configuration which models our data workflow config.toml # (Optional) Taipy configuration in TOML made using Taipy Studio ``` --- ## 2. Taipy 簡介 - 綜合解決方案 [Taipy](https://docs.taipy.io/) **不只是另一個編排工具**。 Taipy 專為 ML 工程師、資料科學家和 Python 開發人員設計,帶來了幾個基本且簡單的功能。 以下是**一些關鍵要素**,使 Taipy 成為令人信服的選擇: 1. **管道執行註冊表** 此功能使開發人員和最終用戶能夠: - 將每個管道執行註冊為「*場景*」(任務和資料節點圖); - 精確追蹤每個管道執行的沿襲;和 - 輕鬆比較場景、監控 KPI 並為故障排除和微調參數提供寶貴的見解。 2. **管道版本控制** Taipy 強大的場景管理使您能夠輕鬆調整管道以適應不斷變化的專案需求。 3. **智能任務編排** Taipy 讓開發人員可以輕鬆地對任務和資料來源網路進行建模。 此功能透過以下方式提供對任務執行的內建控制: - 並行執行您的任務;和 - 任務“跳過”,即選擇要執行的任務並 要繞過哪個。 4. **任務編排的模組化方法** 模組化不僅僅是 Taipy 的一個流行詞;這是一個核心原則。 設定可以互換使用的任務和資料來源,從而產生更乾淨、更易於維護的程式碼庫。 --- ## 3. Dask 簡介 Dask 是一個流行的分散式運算 Python 套件。 Dask API 實作了熟悉的 Pandas、Numpy 和 Scikit-learn API - ,這使得許多已經熟悉這些 API 的資料科學家更愉快地學習和使用 Dask。 如果您是 Dask 新手,請查看 Dask 團隊撰寫的精彩 Dask [10 分鐘簡介](https://docs.dask.org/en/stable/10-minutes-to-dask.html)。 --- ## 4. 應用:顧客分析 (*algos/algo.py*) 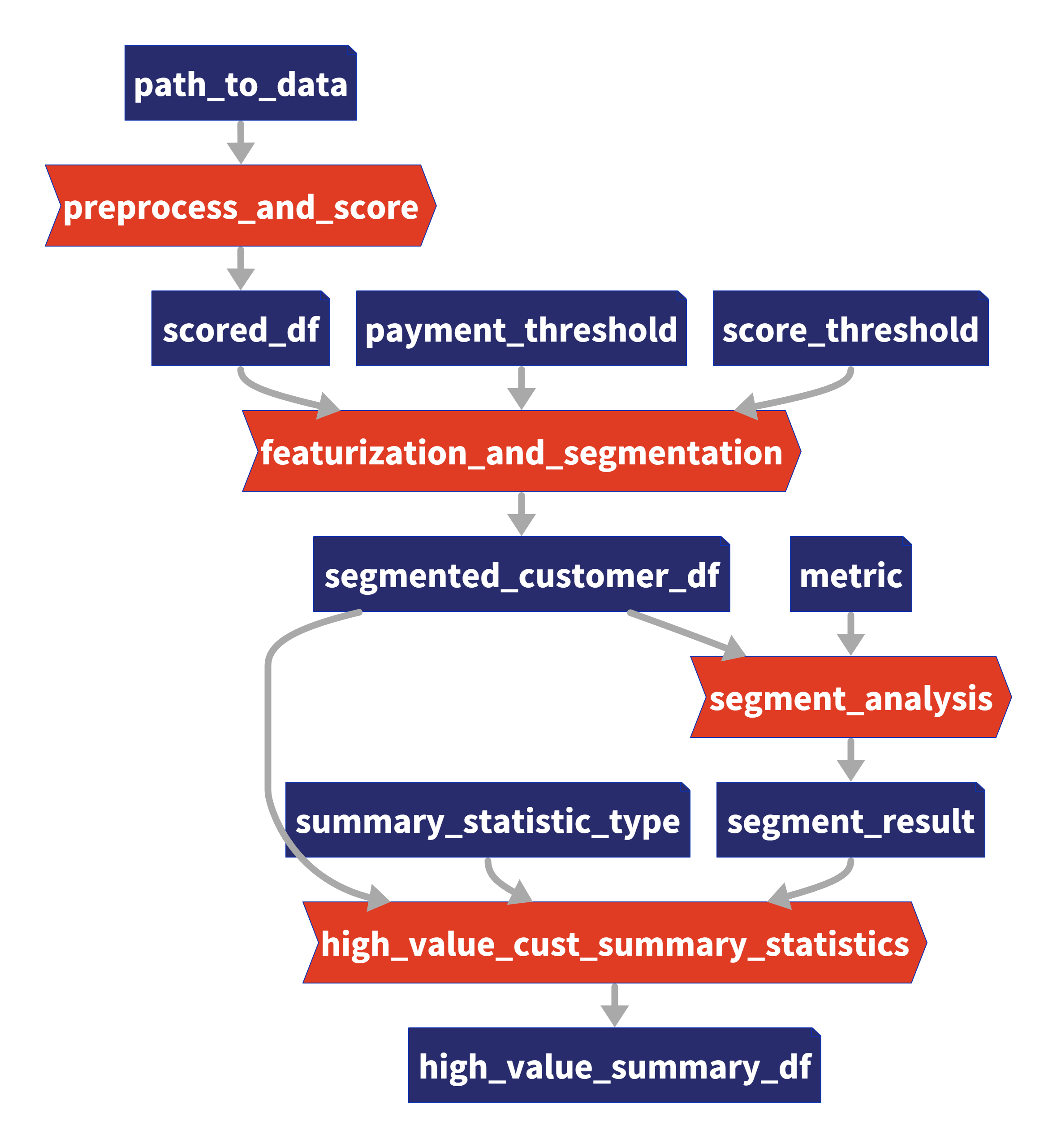 *我們的 4 項任務的圖表(在 Taipy 中可視化),我們將在下一節中對其進行建模。* 我們現有的程式碼(不含 Taipy)包含 4 個函數,您也可以在上圖中看到: - 任務 1:*預處理和評分* - 任務 2:*特徵化與細分* - 任務 3:*分段分析* - 任務 4:*high_value_cust_summary_statistics* 您可以瀏覽以下定義了 4 個函數的 *algos/algo.py* 腳本,然後繼續閱讀每個函數的簡要說明: ``` ### algos/algo.py import time import dask.dataframe as dd import pandas as pd def preprocess_and_score(path_to_original_data: str): print("__________________________________________________________") print("1. TASK 1: DATA PREPROCESSING AND CUSTOMER SCORING ...") start_time = time.perf_counter() # Start the timer # Step 1: Read data using Dask df = dd.read_csv(path_to_original_data) # Step 2: Simplify the customer scoring formula df["CUSTOMER_SCORE"] = ( 0.5 * df["TotalPurchaseAmount"] / 1000 + 0.3 * df["NumberOfPurchases"] / 10 + 0.2 * df["AverageReviewScore"] ) # Save all customers to a new CSV file scored_df = df[["CUSTOMER_SCORE", "TotalPurchaseAmount", "NumberOfPurchases", "TotalPurchaseTime"]] pd_df = scored_df.compute() end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return pd_df def featurization_and_segmentation(scored_df, payment_threshold, score_threshold): print("__________________________________________________________") print("2. TASK 2: FEATURE ENGINEERING AND SEGMENTATION ...") # payment_threshold, score_threshold = float(payment_threshold), float(score_threshold) start_time = time.perf_counter() # Start the timer df = scored_df # Feature: Indicator if customer's total purchase is above the payment threshold df["HighSpender"] = (df["TotalPurchaseAmount"] > payment_threshold).astype(int) # Feature: Average time between purchases df["AverageTimeBetweenPurchases"] = df["TotalPurchaseTime"] / df["NumberOfPurchases"] # Additional computationally intensive features df["Interaction1"] = df["TotalPurchaseAmount"] * df["NumberOfPurchases"] df["Interaction2"] = df["TotalPurchaseTime"] * df["CUSTOMER_SCORE"] df["PolynomialFeature"] = df["TotalPurchaseAmount"] ** 2 # Segment customers based on the score_threshold df["ValueSegment"] = ["High Value" if score > score_threshold else "Low Value" for score in df["CUSTOMER_SCORE"]] end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return df def segment_analysis(df: pd.DataFrame, metric): print("__________________________________________________________") print("3. TASK 3: SEGMENT ANALYSIS ...") start_time = time.perf_counter() # Start the timer # Detailed analysis for each segment: mean/median of various metrics segment_analysis = ( df.groupby("ValueSegment") .agg( { "CUSTOMER_SCORE": metric, "TotalPurchaseAmount": metric, "NumberOfPurchases": metric, "TotalPurchaseTime": metric, "HighSpender": "sum", # Total number of high spenders in each segment "AverageTimeBetweenPurchases": metric, } ) .reset_index() ) end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return segment_analysis def high_value_cust_summary_statistics(df: pd.DataFrame, segment_analysis: pd.DataFrame, summary_statistic_type: str): print("__________________________________________________________") print("4. TASK 4: ADDITIONAL ANALYSIS BASED ON SEGMENT ANALYSIS ...") start_time = time.perf_counter() # Start the timer # Filter out the High Value customers high_value_customers = df[df["ValueSegment"] == "High Value"] # Use summary_statistic_type to calculate different types of summary statistics if summary_statistic_type == "mean": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].mean() elif summary_statistic_type == "median": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].median() elif summary_statistic_type == "max": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].max() elif summary_statistic_type == "min": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].min() median_score_high_value = high_value_customers["CUSTOMER_SCORE"].median() # Fetch the summary statistic for 'TotalPurchaseAmount' for High Value customers from segment_analysis segment_statistic_high_value = segment_analysis.loc[ segment_analysis["ValueSegment"] == "High Value", "TotalPurchaseAmount" ].values[0] # Create a DataFrame to hold the results result_df = pd.DataFrame( { "SummaryStatisticType": [summary_statistic_type], "AveragePurchaseHighValue": [average_purchase_high_value], "MedianScoreHighValue": [median_score_high_value], "SegmentAnalysisHighValue": [segment_statistic_high_value], } ) end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return result_df ``` --- ### 任務 1 - 資料預處理與客戶評分 Python 函數:*preprocess_and_score* 這是管道中的第一步,也許也是最關鍵的一步。 它使用 **Dask** 讀取大型資料集,專為大於記憶體的計算而設計。 然後,它根據“*TotalPurchaseAmount*”、“*NumberOfPurchases*”和“*AverageReviewScore*”等各種指標,在名為 *scored_df* 的 DataFrame 中計算“*Customer Score*”。 使用 Dask 讀取和處理資料集後,此任務將輸出一個 Pandas DataFrame,以供其餘 3 個任務進一步使用。 --- ### 任務 2 - 特徵工程與分割 Python 函數:*featureization_and_segmentation* 此任務採用評分的 DataFrame 並新增功能,例如高支出指標。 它還根據客戶的分數對客戶進行細分。 --- ### 任務 3 - 細分分析 Python 函數:*segment_analysis* 此任務採用分段的 DataFrame 並根據客戶細分執行分組分析以計算各種指標。 --- ### 任務 4 - 高價值客戶的總統計 Python 函數:*high_value_cust_summary_statistics* 此任務對高價值客戶群進行深入分析並傳回匯總統計資料。 --- ## 5. 在 Taipy 中建模工作流程 (*config.py*) 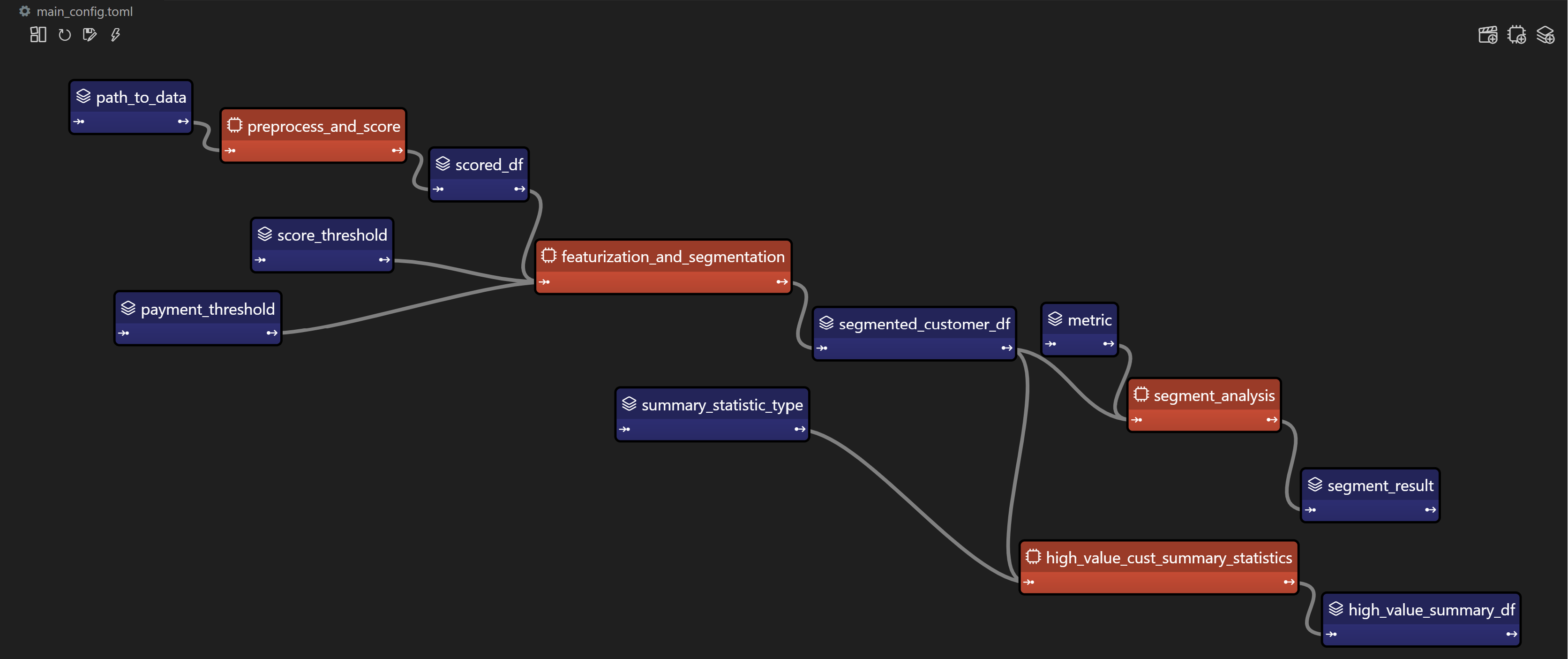 *Taipy DAG — Taipy「任務」為橘色,「資料節點」為藍色。* 在本節中,我們將建立對變數/參數進行建模的Taipy 配置(表示為[“資料節點”](https://docs.taipy.io/en/latest/manuals/core/concepts/data-node/ ))和 Taipy 中的函數(表示為 [“Tasks”](https://docs.taipy.io/en/latest/manuals/core/concepts/task/))。 --- 請注意,以下 *config.py* 腳本中的此配置類似於定義變數和函數 - 只不過我們定義的是「藍圖變數」(資料節點)和「藍圖函數」(任務)。 我們通知 Taipy 如何呼叫我們之前定義的函數、資料節點的預設值(我們可能會在執行時覆蓋)以及是否可以跳過任務: ``` ### config.py from taipy import Config from algos.algo import ( preprocess_and_score, featurization_and_segmentation, segment_analysis, high_value_cust_summary_statistics, ) # -------------------- Data Nodes -------------------- path_to_data_cfg = Config.configure_data_node(id="path_to_data", default_data="data/customers_data.csv") scored_df_cfg = Config.configure_data_node(id="scored_df") payment_threshold_cfg = Config.configure_data_node(id="payment_threshold", default_data=1000) score_threshold_cfg = Config.configure_data_node(id="score_threshold", default_data=1.5) segmented_customer_df_cfg = Config.configure_data_node(id="segmented_customer_df") metric_cfg = Config.configure_data_node(id="metric", default_data="mean") segment_result_cfg = Config.configure_data_node(id="segment_result") summary_statistic_type_cfg = Config.configure_data_node(id="summary_statistic_type", default_data="median") high_value_summary_df_cfg = Config.configure_data_node(id="high_value_summary_df") # -------------------- Tasks -------------------- preprocess_and_score_task_cfg = Config.configure_task( id="preprocess_and_score", function=preprocess_and_score, skippable=True, input=[path_to_data_cfg], output=[scored_df_cfg], ) featurization_and_segmentation_task_cfg = Config.configure_task( id="featurization_and_segmentation", function=featurization_and_segmentation, skippable=True, input=[scored_df_cfg, payment_threshold_cfg, score_threshold_cfg], output=[segmented_customer_df_cfg], ) segment_analysis_task_cfg = Config.configure_task( id="segment_analysis", function=segment_analysis, skippable=True, input=[segmented_customer_df_cfg, metric_cfg], output=[segment_result_cfg], ) high_value_cust_summary_statistics_task_cfg = Config.configure_task( id="high_value_cust_summary_statistics", function=high_value_cust_summary_statistics, skippable=True, input=[segment_result_cfg, segmented_customer_df_cfg, summary_statistic_type_cfg], output=[high_value_summary_df_cfg], ) scenario_cfg = Config.configure_scenario( id="scenario_1", task_configs=[ preprocess_and_score_task_cfg, featurization_and_segmentation_task_cfg, segment_analysis_task_cfg, high_value_cust_summary_statistics_task_cfg, ], ) ``` 號 您可以在[此處的文件](https://docs.taipy.io/en/latest/manuals/core/config/)中閱讀有關配置場景、任務和資料節點的更多資訊。 --- ### Taipy Studio [Taipy Studio](https://docs.taipy.io/en/latest/manuals/studio/config/) **是來自Taipy 的VS Code 擴充功能**,讓您**透過簡單的方式建置和視覺化您的管道拖放互動**。 Taipy Studio 提供了一個圖形編輯器,您可以在其中建立 Taipy 配置**存儲在 TOML 文件中**,您的 Taipy 應用程式可以加載並執行這些配置。 編輯器將場景表示為圖形,其中節點是資料節點和任務。 --- *作為本節中 config.py 腳本的替代方案,您可以使用 Taipy Studio 產生 config.toml 設定檔。 本文的倒數第二部分將提供有關如何使用 Taipy Studio 建立 config.toml 設定檔的指南。* --- ## 6. 場景建立與執行 執行 Taipy 場景涉及: - 載入配置; - 執行 Taipy Core 服務;和 - 建立並提交場景以供執行。 這是基本的程式碼模板: ``` import taipy as tp from config import scenario_cfg # Import the Scenario configuration tp.Core().run() # Start the Core service scenario_1 = tp.create_scenario(scenario_cfg) # Create a Scenario instance scenario_1.submit() # Submit the Scenario for execution # Total runtime: 74.49s ``` --- ### 跳過不必要的任務執行 Taipy 最實用的功能之一是,如果任務的輸出已經計算出來,它能夠跳過任務執行。 讓我們透過一些場景來探討這一點: --- #### 更改付款閾值 ``` # Changing Payment Threshold to 1600 scenario_1.payment_threshold.write(1600) scenario_1.submit() # Total runtime: 31.499s ``` *發生了什麼事*:Taipy 夠聰明,可以跳過任務 1,因為付款閾值只影響任務 2。 在這種情況下,透過使用 Taipy 執行管道,我們發現執行時間減少了 50% 以上。 --- #### 更改細分分析指標 ``` # Changing metric to median scenario_1.metric.write("median") scenario_1.submit() # Total runtime: 23.839s ``` *會發生什麼事*:在這種情況下,只有任務 3 和任務 4 受到影響。 Taipy 巧妙地跳過任務 1 和任務 2。 --- #### 更改總計統計類型 ``` # Changing summary_statistic_type to max scenario_1.summary_statistic_type.write("max") scenario_1.submit() # Total runtime: 5.084s ``` *發生了什麼事*:這裡,只有任務 4 受到影響,Taipy 僅執行此任務,跳過其餘任務。 Taipy 的智慧任務跳過功能不僅能節省時間,還能節省時間。它是一個資源優化器,在處理大型資料集時變得非常有用。 --- ## 7. Taipy Studio 您可以使用 Taipy Studio 建置 Taipy *config.toml* 設定檔來取代定義 *config.py* 腳本。 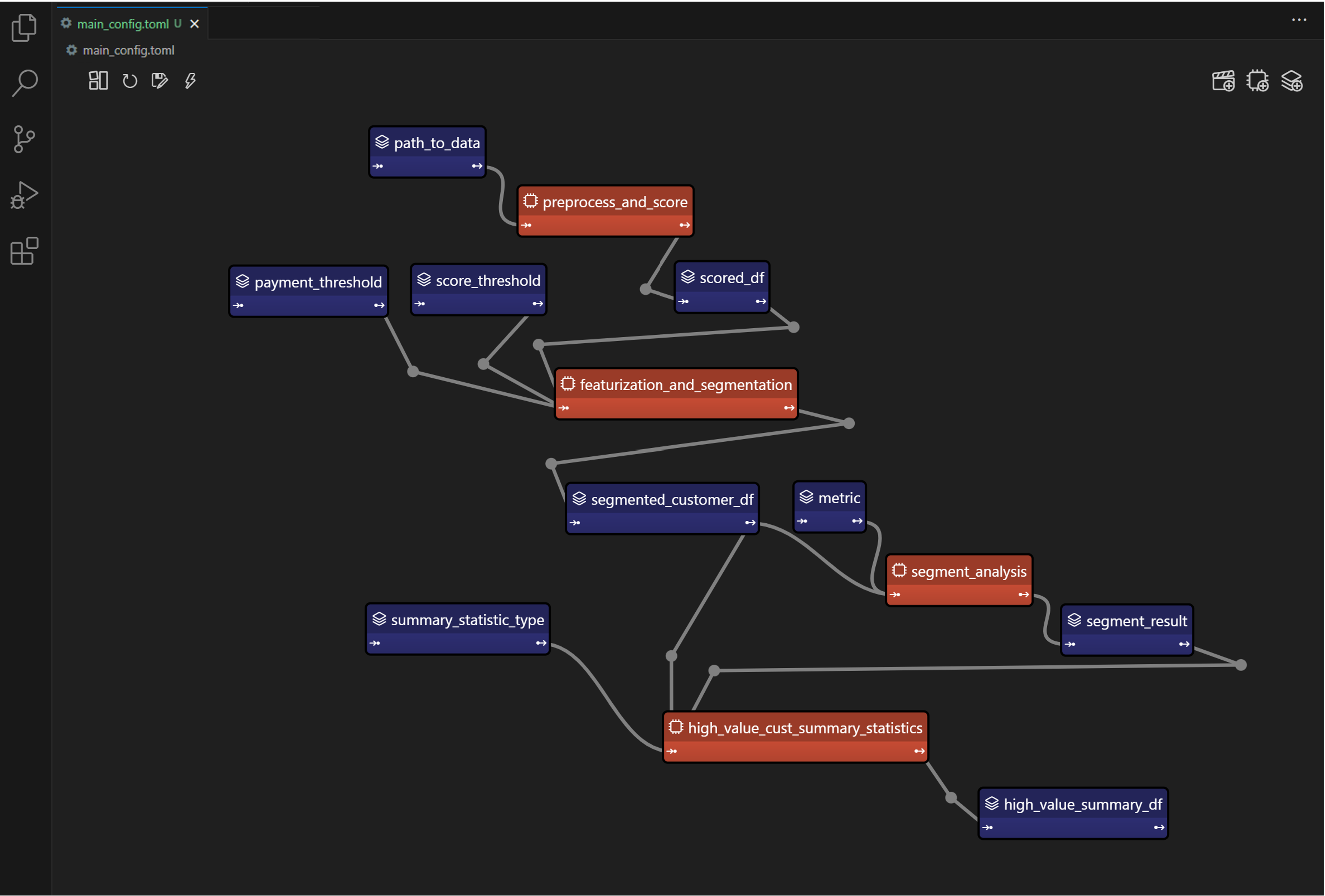 首先,使用擴展市場安裝 [Taipy Studio ](https://marketplace.visualstudio.com/items?itemName=Taipy.taipy-studio)擴充。 --- ### 建立配置 - **建立設定檔**:在 VS Code 中,導覽至 Taipy Studio,然後透過點擊參數視窗上的 + 按鈕啟動新的 TOML 設定檔。 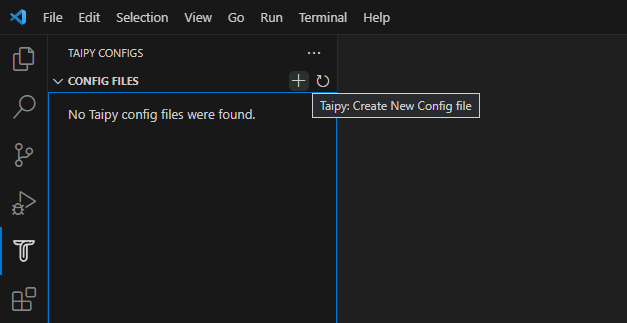 - 然後右鍵單擊它並選擇 **Taipy:顯示視圖**。 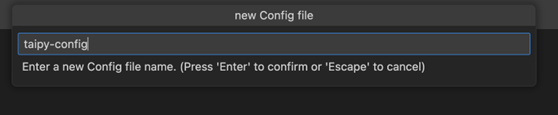 - **新增實體**到您的 Taipy 配置: 在 Taipy Studio 的右側,您應該會看到一個包含 3 個圖示的列表,可用於設定管道。  1. 第一項是新增資料節點。您可以將任何 Python 物件連結到 Taipy 的資料節點。 2. 第二項用於新增任務。任務可以連結到預先定義的 Python 函數。 3. 第三項是新增場景。 Taipy 讓您在一個配置中擁有多個場景。 --- #### - 資料節點 **輸入資料節點**:建立一個名為“*path_to_data*”的資料節點,然後導航到“詳細資料”選項卡,新增屬性“*default_data*”,並將“*SMALL_amazon_customers_data.csv*”貼上為您的資料的路徑資料集。 --- **中間資料節點**:我們需要再增加四個資料節點:「*scored_df*」、「*segmented_customer_df*」、「*segment_result*」、「*high_value_summary_df*」。透過 Taipy 的智慧設計,您無需為這些中間資料節點進行任何配置;系統會巧妙地處理它們。 --- **具有預設值的中間資料節點**:我們最終定義了另外四個中間資料節點,並將「*default_data*」屬性設為以下內容: - payment_threshold: “1000:int” 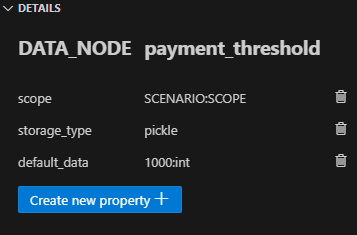 - 分數閾值:“1.5:浮動” - 測量:“平均值” -summary_statistic_type:“中位數” --- #### - 任務 點擊新增任務按鈕,您可以配置新任務。 新增四個任務,然後**將每個任務連結到「詳細資料」標籤下的對應函數**。 Taipy Studio 將掃描您的專案資料夾並提供可供選擇的分類函數列表,並按 Python 檔案排序。 --- **任務 1** (*preprocess_and_score*):在 Taipy studio 中,您可以按一下「任務」圖示以新增任務。 您可以將輸入指定為“*path_to_data*”,將輸出指定為“*scored_df*”。 然後,在「詳細資料」標籤下,您可以將此任務連結到 *algos.algo.preprocess_and_score* 函數。 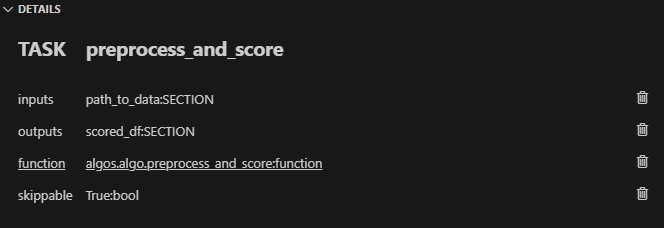 --- **任務 2** (*featurization_and_segmentation*):與任務 1 類似,您需要指定輸入 (“*scored_df*”、“* payment_threshold*”、“*score_threshold*”) 和輸出 (“*segmented_customer_df*”) ” )。將此任務連結到 *algos.algo.featurization_and_segmentation* 函數。 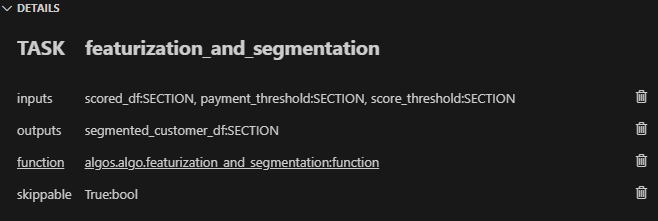 --- **任務 3** (*segment_analysis*):輸入為“*segmented_customer_df*”和“*metric*”,輸出為“*segment_result*”。 連結到 *algos.algo.segment_analysis* 函數。  --- **任務 4** (high_value_cust_summary_statistics):輸入包含「*segment_result*」、「*segmented_customer_df*」和「*summary_statistic_type*」。輸出為“*high_value_summary_df*”。連結到 *algos.algo.high_value_cust_summary_statistics* 函數。 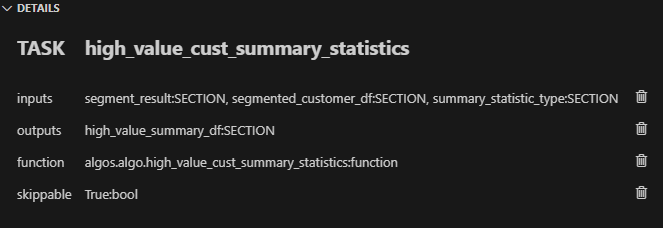 --- ## 結論 Taipy 提供了一種**智慧方式來建立和管理資料管道**。 特別是可跳過的功能使其成為優化運算資源和時間的強大工具,在涉及大型資料集的場景中特別有用。 Dask 提供了資料操作的原始能力,而 Taipy 增加了一層智能,使您的管道不僅強大而且智能。 --- 其他資源 如需完整程式碼和 TOML 配置,您可以存取此 [GitHub 儲存庫](https://github.com/Avaiga/demo-dask-customer-analysis/tree/develop)。若要深入了解 Taipy,請參閱[官方文件](https://docs.taipy.io/en/latest/)。 一旦您了解 Taipy 場景管理,您就可以更有效率地為最終用戶建立資料驅動的應用程式。只需專注於您的演算法,Taipy 就會處理剩下的事情。 ---  希望您喜歡這篇文章! --- 原文出處:https://dev.to/taipy/big-data-models-vs-computer-memory-4po6
目前大環境不好,但作為開發人員,我們擁有一套獨特的技能,如果您知道在哪裡尋找,這些技能的需求量很大! 這篇文章簡要概述了 50 個作為開發人員可以用來賺取額外收入的副業 --- ### 1. 銷售注意力 基於參與度的收入是指您將根據使用者在您的網站、個人資料或消費您的內容上花費的時間來獲得收入分成。它通常很小,至少對於較小的網站或創作者來說是這樣,但隨著時間的推移,它會增加,任何人都可以啟用它 - 所以你不會有任何損失。 - [Brave](https://creators.brave.com/) - 為使用 Brave 瀏覽器造訪您的網站、個人資料或查看您的內容的使用者付費。資金以 [BAT](https://basicattentiontoken.org/) 形式存入您的 Uphold 帳戶,然後可以以美元、英鎊或歐元形式提取至您的銀行帳戶 - [Flattr](https://flattr.com/) - 付費使用 Flattr 的用戶將其資金分配給用戶存取過其內容的創作者 > 幾年前,我親自報名了 Brave Rewards。在驗證了我的網域和個人資料的所有權後,我每月一直賺幾英鎊 - 到目前為止大約 200 英鎊以上(儘管我是 Firefox 用戶!)。雖然不多,但只需付出很少的努力,就值得了。 有關其工作原理的更多訊息,請查看 [webmonetization.org](https://webmonetization.org/) 規範,該規範利用了 [付款指針](https://paymentpointers.org/)通過[ILP](https://interledger.org/) 透過使用簡單的`<link rel="monetization" href="your-pointer-here" />` 標籤來串流來自支援WM 的訪客的收入。 --- ### 2. API 即服務 RapidAPI 等平台可讓您從 API 中[賺取被動收入](https://rapidapi.com/guides/earn-a-passive-venue-by-monetizing-apis-as-a-developer)。 建置並部署簡單的 API 後,您可以將其匯入 RapidAPI Hub,選擇使用和定價計劃,然後點擊發布。您的 API 可大可小,如您所願。 如果您正在為一個簡單的第一個專案尋找靈感,請考慮將開放資料集轉換為 API。對於初學者,RapidAPI 有一個關於如何入門的[影片系列](https://rapidapi.com/courses/build-and-sell-your-own-api)。其他想法可能包括將現有套件包裝為 API、向其他服務(如 OpenAI)加入功能或建置執行一些簡單計算的端點。 --- ### 3. 發放賞金 這些是開源專案的熱門功能請求。用戶可以在承諾一定金額的情況下提供“賞金”,然後將其支付給第一個完成並合併該功能的開發人員。 - [BOSS.dev](https://www.boss.dev/) - 完成功能請求和錯誤修復,獎金從 30 美元到 1000 美元不等。 --- ### 4. 贊助商 如果您在 GitHub 或其他平台上有業務,那麼啟用贊助是一種為您的工作帶來收入的有益方式。 不要忘記啟用贊助商按鈕。這適用於各種平台以及 GitHub 贊助商 - [GitHub Sponsors](https://github.com/sponsors) - 對於開發人員(無論規模大小)來說都是一個不錯的選擇。如果支持者已經在 GitHub 上,則零費用且進入門檻低 - [Patreon](https://www.patreon.com/) - 允許向您的支持者提供福利和獨家內容。如果您在 GitHub 以外的其他平台上有業務,這是一個不錯的選擇 - [LibrePay](https://liberapay.com/) - 針對那些建立開源內容的人 - [Open Collective](https://opencollective.com/) - 如果您正在為特定專案籌集資金,並使用收益來支持該專案(而不是個人),那麼這是一個不錯的選擇 - [Steday](https://steadyhq.com/en) - [TideLift](https://tidelift.com) - 更針對那些開發企業級開源專案的人,潛在收入更大,但僅限於最大的專案 - [LFX](https://lfx.linuxfoundation.org/) - 由 Linux 基金會提供 > 贊助(特別是GitHub 贊助商)是我個人最喜歡的方法之一,因為付費是可選的,所以你不會阻止那些無力承擔費用的人存取,而且那些支持你的人已經知道他們會預先得到什麼,所以您永遠不會讓客戶失望。 --- ### 5. 小費 您可能遇到過這樣的情況,您發現某個部落格文章、SO 答案、GitHub 儲存庫或論壇回應非常有幫助,以至於您希望可以為作者買一杯啤酒來表示感謝。 支援這些小額一次性付款的平台可以免費註冊,並且在您的個人資料中或在部落格文章末尾加入「提示」按鈕不會有任何損失。 - [Ko-fi](https://ko-fi.com/) - [請我喝杯咖啡](https://www.buymeacoffee.com/) - [Tipeee](https://en.tipeee.com/) - [PayPal Me](https://www.paypal.com/paypalme/) 提示:不要乞求。建立一些有用的內容,然後將提示連結放在底部。 --- ### 6. 企業贊助 許多具有一定下載量/經常性用戶的開源專案將開始被希望贊助創作者作品的公司接洽,以換取他們的公司徽標+連結包含在自述文件頂部附近。與個人贊助不同,這些贊助通常起價為 100-500 美元/月,專案使用量越大,贊助金額就越多。 --- ### 7. 黑客松 編碼競賽一直在遠端進行。這些通常由公司贊助,並向獲獎者支付現金獎勵。 - [程式碼之夏](https://summerofcode.withgoogle.com/) - 由 Google 執行,您將收到[貢獻者津貼](https://developers.google.com/open-source/gsoc/help/student-stipends) 成功接受後,金額從750 美元到6000 美元不等,金額取決於您所在的國家/地區和專案規模 - [CodeHeat](https://codeheat.org/) - 由 FOSS Asia 運營,每兩週 100 新元,外加較小的獎品 - [HackerEarth](https://www.hackerearth.com/challenges/hackathon/) - [Hackathon.com](https://www.hackathon.com/online) - [Devfolio 黑客松](https://devfolio.co/hackathons/upcoming) > 當我還是學生時,我[曾經參加過很多](https://alicia.omg.lol/hackathons) 黑客馬拉松(大部分是面對面的),並且經常能夠通過參加各種活動來資助我的暑假活動!這也是認識新朋友、學習新事物的好方法,而且非常有趣! --- ### 8. 依賴套件的贊助 如果您有一個軟體包(例如 NPM 模組),那麼在您的設定檔中啟用贊助將允許您的程式碼的使用者在財務上做出貢獻。 - NPM 資金 - 您可能熟悉執行“npm 基金”,並查看您正在使用的正在尋求資金的軟體包清單。新增了 [npm 基金](https://docs.npmjs.com/cli/v6/commands/npm-fund),以便更輕鬆地向專案所依賴的依賴項的維護者捐款。如果您維護 NPM 包,只需在 package.json 中包含「funding」字段,用戶將能夠更輕鬆地支援您。 - [StackAid](https://www.stackaid.us/) - 只需安裝 StackAid GitHub 應用程式並連結您的 Stripe 帳戶,直接或間接使用您專案的支持者捐贈的部分資金將分配給您每個月 - GitHub Sponsors - GitHub Sponsors 再次出現,因為它[讓用戶提供他們最常用的依賴項](https://github.com/sponsors/explore) - 儘管這是一個手動過程,而不是自動的。 --- ### 9. 回報問題 如果您注重安全性,或喜歡在應用程式中尋找錯誤和漏洞,那麼這款就適合您。最受歡迎的平台是[HackerOne](https://hackerone.com/opportunities/all/search?ordering=Highest+bounties),每個負責任地披露的錯誤都可以在其中賺取20 到200,000 美元的收入。 許多其他網站也直接提供負責任的揭露政策,他們會獎勵您的工作。如果您對此感興趣,我在以下位置保留了 1000 多個賞金計劃的清單:[https://bug-bounties.as93.net](https://bug-bounties.as93.net) > 我個人透過這種方法取得了很大的成功,而且也很有趣 - 所以我強烈推薦它! 其他值得查看的平台包括: - [HackerOne](https://www.hackerone.com/) - 排名第一的平台,最多的賞金以及良好的保護和支付率 - [Immunefi](https://immunefi.com/) - 專門針對 Web3 - [BugCrowd](https://www.bugcrowd.com/bug-bounty-list/) - [Intigriti](https://www.intigriti.com/) - [issuehunt](https://issuehunt.io/) --- ### 10.開放核心模型 這是您的大部分程式碼都是開源的,但某些擴充功能或附加元件(特別是針對企業客戶的擴充或附加元件)被授權為專有的。 因此,開發者可以在其他開源專案中自由使用該軟體。然而,公司必須為使用企業特定的模組或整合付費。 請記住,這通常說起來容易做起來難。您需要能夠分離專有功能,而大公司通常會採取一切措施(包括違反許可限制)來避免付費。 --- ### 11. 付費升級套件 這些服務可以輕鬆為常見註冊管理機構提供高級/付費方案。例如,如果您希望分發 NPM 模組的高級版本,或對特定軟體包功能收費,這可能是個不錯的選擇。 - [PrivJS](https://www.privjs.com/) - 分發 Node 套件的進階版本 - [CodeShip](https://codecodeship.com/) - 私人註冊中心,用戶需要付費才能使用你的包 --- ### 12.贊助支持 在開源專案中加入專業支援計劃選項使客戶能夠支付一次性或持續的幫助和支援費用,以啟動和執行。 這可以透過您自己的系統啟用,也可以使用現有的贊助平台(例如Patreon 和GitHub Sponsors),或使用專門的服務(例如[Otechie](https://otechie.com/))來啟用,該服務加入了付費功能+ 支援通過嵌入的聊天對話框。 [Calendly](https://calendly.com/) 等工具可以讓客戶將時間放入日曆中,或者對於較大的專案,投資專用的客戶支援平台,例如[HelpScout](https://www.helpscout.com/) 可能會讓這件事變得更容易。 --- ### 13. 寫文件 - [撰寫文件](https://www.writethedocs.org/) 是所有文件的首選位置。 - [文件季節](https://developers.google.com/season-of-docs) - 在 Google 的支持下,每年都有技術作家為開源專案做出貢獻。參與專案將獲得 5,000 至 15,000 美元的贈款,然後通常透過 Open Collective 分發給貢獻者。 - 如果你環顧四周,你會發現還有很多產品正在尋找技術作家。 Julia 列出了一份[好名單](https://dev.to/juliafmorgado/get-paid-to-write-technical-articles-16cl),列出了願意付費讓你撰寫技術內容的公司 - 版權也屬於這一類。 [scripted](https://www.scripted.com/) 等服務可讓您透過校對或編輯其他文字內容來賺錢。 即使只是記錄您自己的和其他開發人員的儲存庫也是一個不錯的起點。 如果專案被記錄下來,它的價值就會大幅增加。如果沒有文件,潛在使用者、客戶或開發人員將不知道它的用途、如何使用它、如何在其基礎上建立或如何做出貢獻。 > 我可能是唯一的一個,但我個人喜歡寫文件。 [我的所有專案](https://github.com/Lissy93?tab=repositories) 包括完整的使用、開發和貢獻文件。這促進了它們的成功和採用。我覺得如果你不花一點時間向人們展示如何使用它,那麼花幾個小時建立一些很棒的東西是沒有意義的。 --- ### 14. 廣告 在你跳過這一點之前——我也討厭廣告。它們很煩人,並且經常涉及某種形式的跟踪,從而損害用戶的隱私。但是,對於開源專案,還有一些其他選項沒有這些缺點。 - [Ethical Ads](https://www.ethicalads.io/) - [Carbon Ads](https://www.carbonads.net/open-source) 如果您正在維護獲得穩定流量的 GitHub 儲存庫、網站、部落格或服務,那麼這是一個不錯的選擇。通常每月至少需要約 10,000 個用戶,但如果您每月獲得 50,000 以上的用戶,您將獲得更好的回報。 --- ### 15. 出售你的程式碼 > 我個人不同意這種方法,只是因為出售的許多程式碼都是開源軟體的糟糕的重新設計版本,並且並不總是給予原始作者適當的榮譽。也就是說,一些開發商確實設法讓它發揮作用,建造簡單的專案然後將其出售。 - [IndieMaker](https://indiemaker.co/) - 出售您的整個專案 - [PieceX](https://www.piecex.com/) - 出售現成的原始碼 - [Codester](https://www.codester.com/info/seller) - 針對 PHP 和 Wordpress --- ### 16.銷售內容 當您查看開發人員的副業時,這是一個常見的建議。但有充分的理由 - 如果您能夠建立高品質的內容,您可以賺到很多錢。特別是如果您對新興領域有深入的了解。 銷售內容的熱門網站包括: - [GumRoad](https://gumroad.com/) - 程式碼、課程、貼文、藝術、設計、媒體(10% 費用) - [AppSumo](https://sell.appsumo.com/) - 程式碼、應用程式、擴充功能、課程、範本等 --- ### 17.寫作 這是一套獨特的技能。要么您非常擅長編寫引人入勝的內容,要么您對特定的熱門領域有深入的了解。否則,如果您對此感興趣,請考慮電子書出版,如果您的書不成功,也不會造成任何損失。 - [LeanPub](https://leanpub.com/) - 一個自助出版技術/開發電子書和課程的平台,具有豐厚的收入模式(您可以保留 70%) - [Amazon KDP](https://kdp.amazon.com/en_US/) - 發佈至 Amazon Kindle,並立即向全球數百萬用戶提供(亞馬遜將收取至少 30% 的佣金,可能會更多)小出版商) - [SmashWords](https://www.smashwords.com/) 和 [Draft2Digital](https://draft2digital.com/sw/) - 分發給全球其他電子書賣家,這是一種簡單的開始出版。他們收取的佣金比亞馬遜少,但比 LeanPub 多。 --- ### 18.補助金 補助金和企業贊助涉及多個領域,包括開源、創新、DeFi、人工智慧等。它們通常是為了幫助您在從事特定工作時支付短期生活費用。 - [GitHub Sponsors](https://github.com/sponsors) - 為個人和組織提供經濟支援開源開發者的平台。金額依贊助情況而有所不同。 - [Google Summer of Code (GSoC)](https://summerofcode.withgoogle.com/) - 學生開發者為開源專案做出貢獻的全球計劃,津貼通常為 1500 美元到 3300 美元不等。 - [Mozilla 開源支援 (MOSS)](https://www.mozilla.org/en-US/moss/) - 為開源軟體開發提供資助,特別是與 Mozilla 使命相符的專案。 - [Linux 基金會資助](https://www.linuxfoundation.org/) - 為從事 Linux 基金會專案的開發人員提供各種資助和獎學金。 - [NumFOCUS 小額發展補助金](https://numfocus.org/programs/small-development-grants) - 支援資料科學和科學計算的小型專案。資助金額各不相同(所有申請人均分配 285,000 美元)。 - [Apache 軟體基金會贊助](https://www.apache.org/foundation/sponsorship.html) - 對 Apache 軟體專案的財務支持,重點關注 Apache 軟體生態系統。 - [Outreachy](https://www.outreachy.org/) - 為技術領域代表性不足的群體提供為期三個月的實習機會,津貼通常約為 5,500 美元。 - [奈特基金會](https://knightfoundation.org/grants/) - 為促進優質新聞業的技術專案提供資助。根據專案範圍的不同,贈款金額差異很大。 - [原型基金](https://prototypefund.de/) - 在六個月內提供高達 47,500 歐元的開源原型支持,重點支持德國的軟體開發人員。 - [斯隆基金會](https://sloan.org/programs/digital-technology) - 為開放科學社群計畫提供資助,特別是那些增強研究中的開源軟體的計畫。 - [Chan Zuckerberg Initiative 開源軟體專案](https://chanzuckerberg.com/rfa/) - 專注於支援對生物醫學研究至關重要的開源軟體。資助金額各不相同。 - [Raspberry Pi 基金會](https://www.raspberrypi.org/grants/) - 為涉及 Raspberry Pi 和計算教育的教育計畫提供補助。 - [GitCoin](https://gitcoin.co/) - 一個為開源專案提供資金的眾籌平台,特別是在以太坊和 Web3 領域。資金根據社區支持而有所不同。 - [NLnet 基金會](https://nlnet.nl/foundation/) - 支援網路科技與網路研究計畫。補助金額各不相同。 - [開放技術基金](https://www.opentech.fund/) - 支持開發促進人權和開放社會的開放技術的專案。資金各不相同。 --- ### 19. 舉辦活動 活動空間是一個利潤豐厚的行業,尤其是如果您能夠舉辦一場精彩的活動並為自己贏得大型贊助商的話。雖然不適合所有人,但舉辦活動可以帶來以下 10 個潛在收入來源: - **門票銷售**:透過收取入場費來產生收入。使用 [Eventbrite](https://www.eventbrite.co.uk/)、[Meetup](https://meetup.com/) 或 [Ticketmaster](https://ticketmaster.com) 等平台取得門票管理。 - **贊助**:確保科技公司的財務捐助,以換取活動中的促銷機會。 - **研討會和培訓課程**:提供特定技術或程式語言的專業實務學習經驗,收取額外費用。 - **虛擬活動**:使用[Zoom](https://zoom.us/)、[WebEx](https://www.webex.com/) 或 [Hopin](https://hopin.com/)。 - **黑客馬拉松**:舉辦收取報名費的程式設計競賽,或尋找贊助商來支付費用並提供獎金。 - **社交活動**:針對技術專業人士的社交活動收費,可能會吸引招聘公司的贊助。 - **演講活動**:利用您在特定技術領域的專業知識,組織並負責演講活動或小組討論。 - **企業培訓及靜修**:為企業內部培訓或團隊建立活動提供活動組織服務。 - **聯盟行銷**:在活動期間利用科技產品或服務的聯盟行銷來獲取額外收入。 - **產品發布**:與科技公司合作舉辦產品發布活動,為您提供收費的組織服務。 --- ### 20.研究 您的意見很有價值,尤其是作為開發人員。有些研究人員會付錢給你參加他們的研究、調查或智庫。通常,好的研究機會很少而且相距甚遠,或者報酬相當低。 這類工作的熱門平台包括:[Testable Minds](https://minds.testable.org/)、[Respondent](https://app.respondent.io/signup) --- ### 21. 建立課程 - [Skillshare](https://www.skillshare.com/teach) - 根據課程觀看分鐘數提供付款以及推薦獎金。 - [Coursera](https://www.coursera.org/for-universities) - 與機構合作提供課程;付款通常基於收入分享協議。 - [LinkedIn Learning](https://www.linkedin.com/learning/instructors) - 講師可以為專業人士建立課程;薪酬詳細資訊由 LinkedIn 安排。 - [Thinkific](https://www.thinkific.com/) - 提供建立、行銷和銷售線上課程的工具,具有各種定價計劃,包括免費選項。 - [Kajabi](https://kajabi.com/) - 線上課程、行銷、支付和網站建立的一體化平台。 - [Podia](https://www.podia.com/) - 提供一個用於舉辦課程、網路研討會和數位下載的平台,並直接向觀眾銷售。 - [Pluralsight](https://www.pluralsight.com/teach) - 專注於科技與創意課程;根據課程的受歡迎程度向教師支付版稅。 - [MasterClass](https://www.masterclass.com/teach) - 高品質、名人主導的課程;講師通常是各自領域的知名專家或名人。 - [uTeach](https://ueach.io/) - [NewLine](https://www.newline.co/) --- ### 22.時事通訊 隨著流行的社群媒體管道變得更加集中和受控,電子郵件通訊和基於訂閱的 RSS 來源正在慢慢捲土重來。 這種模式的工作方式要么是提供對技術主題或新聞的有價值的見解,並建立一個龐大的(因此有價值的)訂閱者基礎,要么是向少數用戶收取更新費用。 提供此功能的流行平台包括: - [子堆疊](https://substack.com) - [ButtonDown](https://buttondown.email/) - [ConvertKit](https://convertkit.com/) - [穩定](https://steadyhq.com) - [幽靈](https://ghost.org/) --- ### 23. 僅限會員的網站 - [MemberSpace](https://www.memberspace.com/) - 讓您能夠為網站的某些部分付費,僅供會員使用 - [Patreon](https://www.patreon.com/) - 因設定具有獨家內容和福利的會員等級而廣受歡迎。 - [Substack](https://substack.com/) - 新聞通訊的理想選擇;提供付費訂閱獨家內容的能力。 - [Ghost](https://ghost.org/) - 內建會員和訂閱功能的專業發布平台。 - [Podia](https://www.podia.com/) - 允許銷售會員資格、線上課程和數位下載。 - WordPress 與 [MemberPress 外掛程式](https://memberpress.com/) - 供 WP 使用者建立會員網站的外掛程式。 - [Wild Apricot](https://www.wildapricot.com/) - 與您的網站整合的會員管理軟體。 - [Kajabi](https://kajabi.com/) - 提供用於建立線上課程、會員網站等的工具,重點是行銷。 - [Mighty Networks](https://www.mightynetworks.com/) - 建立一個包含會員資格、訂閱和課程的社群。 --- ### 24. VIP 貼文 還有許多公司會為您在其平台上分享的優質貼文付費。這既可以提高您的知名度(幫助您擴大人脈並獲得未來的工作),也可以帶來一些短期收入。 如果您正在努力獲得這些計劃的錄取,請先編寫自己的帖子並將其發佈到流行的基於開發的社交網絡(例如 DEV.to!)。這將增強您的寫作技巧,並幫助您向潛在公司展示您的知識。 例如,以下網站將為高品質的訪客貼文付費: - [Linode](https://www.linode.com/lp/write-for-linode/) - [日誌火箭](https://blog.logrocket.com/become-a-logrocket-guest-author/) - [Smashing 雜誌](https://www.smashingmagazine.com/contact/?Becoming%20an%20Author/Reviewer%20(自動回覆)) - [Auth0](https://auth0.com/apollo-program) - [CSS 技巧](https://css-tricks.com/guest-writing-for-css-tricks/) - [DelftStack](https://www.delftstack.com/write-for-us/) - [DigitalOcean](https://www.digitalocean.com/community/pages/write-for-digitalocean) - [Infatica](https://infatica.io/contribute/) - [蜜罐](https://blog.honeypot.io/write-for-honeypot/) - [進階編碼](https://premiumcoding.com/write-for-us-premiumcoding/) - [反思](https://reflectoring.io/contribute/become-an-author/) - [Strapi](https://strapi.io/write-for-the-community) - [Android 權威](https://www.authoritymedia.com/jobs) - [SitePoint](https://www.sitepoint.com/write-for-us/) - [TutorialsPoint](https://www.tutorialspoint.com/about/tutorials_writing.htm) - [真正的Python](https://realpython.com/jobs/tutorial-writer/) - [Dart Creations](https://www.dart-creations.com/about-us/write-for-us.html) Dmytro Spilka 編制了一份包含 300 多個[接受訪客貼文的網站](https://solvid.co.uk/180-websites-that-accept-guest-posts/) 的清單。另一個很棒的清單[由 Julia 在 Dev.to 上整理](https://dev.to/juliafmorgado/get-paid-to-write-technical-articles-16cl)。 --- ### 25. 諮詢 您可能沒有意識到,您從日常工作中累積的技能和經驗對許多公司來說可能非常有價值。尤其是尚無法聘請全職專家的新創公司和小型企業。對能夠提供最新趨勢、工具和最佳實踐見解的專業人士的需求非常高。 尖端: - 以適當的速度開始的最佳方式是透過網路和口碑。但如果做不到這一點,總有自由工作網站可以幫助您累積經驗。 - 記錄你所獲得的經驗,或在你工作的過程中建立一個投資組合,因為這將幫助你在未來獲得更好的工作。 - 在開始任何專案之前,請先明確您的空閒時間、條款、日薪和工作範圍。 - 切勿拒絕潛在的聯絡人。您會驚訝地發現,即使多年後,誰可能會重新與您聯繫並尋求諮詢支援。 --- ### 26. 指導 無論您的級別如何,您作為開發人員的經驗都可以真正幫助經驗不足的其他人。指導是一種非常有益的方式,可以幫助他人,同時也能帶來一些額外的收入。 - [MentorCruise](https://mentorcruise.com/) - 主要是長期的,按月付費,非常適合建立專業關係(每個學員每月賺取 50-500 美元) - [CodeMentor](https://www.codementor.io/) - 更適合短期,按小時收費,非常適合解決特定問題(每小時賺取 60-300 美元) --- ### 27.輔導 隨著 CompSci 現在成為國家課程的一部分(至少在英國和大部分歐洲),大量學生(11 歲至 18 歲以上)正在尋找導師來幫助他們獲得編碼技能並準備考試。收入範圍為每小時 15 美元到 150 美元以上,具體取決於級別、經驗和背景。 - [Super Prof](https://www.superprof.co.uk/) - 列出您的全球服務(30-300 美元/小時) - [The Profs](https://www.theprofs.co.uk/become-a-private-tutor/) - 經過驗證的導師(收入未知) - [我的導師](https://www.mytutor.co.uk/) - 僅限英國,(22-55 英鎊/小時) - [Tutor.com](https://www.tutor.com/) - 美國高中學費($75-$100/小時) --- ### 28.社群媒體 市場存在巨大空白,等待主流社群媒體平台上真正優秀的、注重發展的影響者來填補。 許多社群媒體平台允許您透過內容貨幣化,您通常會按觀看次數付費,金額根據內容類別、地區和聲譽而有所不同。但請注意,您通常必須擁有一定數量的追蹤者才有資格,而且您還將受到「演算法」的支配。 - YouTube - 每年至少需要 1,000 訂閱者 + 4,000 小時觀看時間 - X - 需要 Twitter Blue 訂閱,無最低追蹤人數 - TikTok - 需要至少 10k 追蹤者 + 100k 瀏覽量/月 - Instagram - 需要至少 10k 追蹤者 - Snap - 1,000 名追蹤者,1,000 次瀏覽/月,10 多個每月貼文 - Facebook - 10k 追蹤者或 600k 影片觀看分鐘 - Twitch - 350 位每月付費訂閱者 --- ### 29.品牌優惠 繼上面的社群媒體部分之後,一旦您成功突破了數百名訂閱者,您可能還可以開始考慮品牌交易,這有助於帶來額外收入。同樣,這些需要您的受眾達到一定程度的參與度,您可能還需要同意提供贊助的公司的條款。 --- ### 30.串流媒體 開發串流是一個快速成長的利基市場,不要指望立即[加入排行榜](https://twitch.pages.dev/),但它可能是一個很好的起點,特別是如果您已經有串流媒體經驗(例如影片遊戲)。 Nick Taylor 寫了一篇關於 [開發串流媒體入門的精彩文章](https://dev.to/nickytonline/getting-started-with-streaming-on-twitch-4im7)。 --- ### 31.SaaS 如果您能夠做到這一點,那麼它就是開源專案的最佳收入模式之一。您的程式碼仍然是 100% 免費和開源的,用戶仍然可以免費下載和自行託管它,但您還提供付費/託管計劃,您可以在其中託管應用程式並負責小型伺服器的所有伺服器管理經常性費用。 此模型符合開源精神,同時也使您的應用程式可供更廣泛的用戶使用。 [Stripe](https://stripe.com/docs/payments) 等服務讓您的應用程式接受付款和新增訂閱功能變得非常簡單。 --- ### 32.微型 SaaS 如果從頭開始建立一個生產就緒的應用程式聽起來像是一項艱鉅的任務(因為它確實如此!),那麼另一種方法就是 Micro-SaaS 應用程式。這些是較小的應用程式,它們執行一項非常具體的任務,例如: - 自動執行重複和/或乏味的任務。 - 執行目前手動計算的計算。 - 連接不同的系統。 - 取代 Excel 電子表格解決方法。 - 填補宿主生態系中缺失功能的空白 - 加強報告 --- ### 33. 寫外掛 與 SaaS 應用程式不同,一旦建置並發布了擴展,通常不需要太多的持續管理。您也可能會發現,如果您的專案為已經完善的網站加入功能,那麼您的專案會更容易快速獲得關注。 儘管網路擴展似乎是一個過時的或完全飽和的市場,但仍然有很多可以做的事情,而且這些對於新開發人員來說都是很棒的專案。 以下是一些可以幫助您入門的想法: - [WA Web Plus](https://chrome.google.com/webstore/detail/wa-web-plus-by-elbruz-tec/ekcgkejcjdcmonfpmnljobemcbpnkamh) 已下載 200 萬次(22k 評級),收費 12 美元/每個用戶的月。為什麼不為 Telegram、Threema、Wire、Messenger 等建立類似的東西呢? - Runkeeper擁有4500萬用戶,但UI在資料顯示方式方面有所欠缺。為什麼不建立一個擴充功能來加入更好的報告、過濾以及與相關外部資料的組合? (與 [Elevate for Strava](https://chrome.google.com/webstore/detail/elevate-for-strava/dhiaggccakkgdfcadnklkbljcgicpckn) 類似,但適用於 RunKeeper) - 選擇一個提供基本服務但 UI 過於不切實際的網站(也許是 Microsoft Azure?),然後建立一個擴充功能以簡化導覽、顯示關鍵指標或提供不那麼難看的使用者體驗 - 使用人工智慧增強任何現有網站。這比聽起來容易得多,您的擴充功能可以利用 OpenAI 的 API 等服務來總結網頁,或重新措辭選定的內容(用於複製/貼上到作業中!?) - 如果您知道某個網站的使用者數量很高,但 UI 很糟糕,那麼一個簡單的擴充想法可以是應用 CSS 覆蓋來重新設計它的樣式。例如亞馬遜、雅虎、Instagram 都是高流量網站,設計改善空間巨大(深色模式?!) - 即使是簡單的獨立擴展應用程式也可能具有很大的潛力。就像番茄計時器、貨幣轉換器、IP 位址小部件或只是一個網路應用程式快捷方式。 --- ### 34. 發布應用程式 建立簡單的應用程式或遊戲,並將其在平台應用程式商店上提供,使您能夠透過簡單的盈利模型來瞄準數百萬客戶。所有主流應用程式商店 - Google Play、Apple App Store、Windows Store、Steam 等都提供對付費應用程式、進階功能和應用程式內購買的支援。 請記住,在發布第一個應用程式之前通常需要支付安裝費,應用程式商店也會從您的收入中抽取一部分,並且小型創作者獲得單次或雙次下載的情況並不罕見。人物。 --- ### 35. 為小型企業開發網站 許多小型企業都專注於自己的業務,沒有時間或專業知識建立自己的網站。作為開發人員,這是我們能夠很快完成的事情,如果您也託管他們的網站,您將能夠收取定期付款。 一旦您開始進行網頁設計和開發,並為一些客戶提供服務,您就會發現透過口碑和展示您的作品集來找到未來的工作要容易得多。 為了在這方面取得成功,您可能還需要設計、溝通和銷售方面的技能。 --- ### 36. 兜售網域 隨著新 TLD 的湧入,域名經銷商市場正在迎來第二波受歡迎。域名翻轉涉及註冊未來可能有價值的域名,然後將其轉售給想要將該名稱用於企業或專案的買家。 雖然這可能有利可圖,但它確實涉及高風險,並且需要對市場有充分的了解。 尖端: - 研究簡短或令人難忘的域名,或者可能具有較高關鍵字潛力的域名(您可以使用諸如使用 Google 關鍵字規劃師等工具來幫助進行這項研究) - 停放您目前未使用的域名,以便您同時獲得一些廣告收入 - 查看最近過期的域名,特別是那些正在使用的域名,因為這些域名可能會收到流量 - 接收流量的網域更有價值。因此,請考慮在您持有網域時為其建立網站、應用程式或登入頁面 --- ### 37. 使用者測試 開發應用程式的公司通常需要獲得用戶的回饋。這就是用戶測試服務的用武之地。您花 10-30 分鐘嘗試給定的網站或應用程式,然後提供反饋或填寫調查,並獲得報酬! 儘管並非特定於開發人員,但憑藉您的技術背景,您會發現自己具有獨特的優勢,可以快速完成這些工作並提供良好的反饋,從而使您比普通用戶更快地賺錢。您還將獲得有關用戶測試流程如何運作的寶貴見解,這可能對您在自己的應用程式上進行委託測試時有用。 - [嘗試我的 UI](https://www.trymyui.com/) - 每個網站或應用程式測試平均費用為 10 美元 - [Userlytics](https://www.userlytics.com/user-experience-research/paid-ux-testing/) - 根據測試的複雜程度和長度,賺取 5 至 50 美元之間 - [使用者測試](https://www.usertesting.com/get-paid-to-test) - 透過 PayPal 付款,在測試會話期間需要螢幕共用和/或網路攝影機存取。每次測試賺取約 10 美元,較長時間或現場會議的某些測試最高可支付 50 美元 - [TestingTime](https://www.testingtime.com/en/become-a-paid-testuser/) - 面對面或視訊通話測試的選項。不太定期,但測試時間更長。當您考慮到會話之間的延遲時,報酬比其他選擇更低 - [IntelliZoom](https://www.intellizoom.com/) - 每 10 分鐘學習可賺取 2 至 10 美元。透過 PayPal 付款,延遲 3-5 天 --- ### 38.微任務 與開發人員的具體關係不大,但如果您來自技術背景,您可能會發現這些工作比那些沒有開發技能的工作更有利可圖。 - [Amazon Mechanical Turk](https://www.mturk.com/) - 外包虛擬微任務的眾包市場 - [Sequence Works](https://sequence.work/contributors/) - 影像標註、資料標記與分類 - [App Jobber](https://en.appjobber.com/) - 市場調查,去商店拍攝特定植入式廣告的照片 - [GigWalk](https://www.gigwalk.com/gigwalkers/) - 應用程式為基礎的行動微任務 - 請造訪 [GigWorker.com](https://gigworker.com/) 以了解更多微任務和零工工作 --- ### 39. 調查 儘管對具有某些技能(如軟體工程)的參與者的需求較高,但調查的報酬往往很低,因此可以賺更多一點。即便如此,除非您有大量時間,或使用比美元弱得多的貨幣,否則這可能不是一個好的選擇。 這些通常涉及測試新產品或服務,並提供回饋 - 或回答問題以協助市場研究活動。 有很多不同的基於調查的公司,所以我不會全部連結到它們。但 [Swagbucks](https://www.swagbucks.com/)、[20Cogs](https://20cogs.co.uk/)、[TestingTime](https://www.testingtime.com/en/become-a-paid-testuser) 是一些著名的。 --- ### 40.去中心化節點 這可能不適合所有人,因為收益通常以加密貨幣形式支付,而加密貨幣的波動性非常大。但是,您可以自願為許多 Web3 專案執行節點(通常在 Rasperry Pi、雲端伺服器或備用筆記型電腦上),這將為您支付正常執行時間、頻寬、磁碟空間、運算、IP/代理或其他一些費用。計算資源。 作為開發人員,管理基礎設施是我們所擅長的,因此,如果您有任何閒置資源,您也許可以將它們投入使用,並在睡覺時賺取一些額外的現金。 - [Storj](https://www.storj.io/node):執行Storj節點,用於去中心化雲端運算 - [Network3](https://network3.io/):用於訓練和驗證模型的 AIoT 第 2 層 - [Flux](https://runonflux.io/):去中心化基礎設施 - [Mysterium](https://mystnodes.com/): P2P VPN 節點 - [Koii](https://www.koii.network/node): 分散式雲 - [Helium](https://www.helium.com/mine):提供遠端物聯網設備無線連接 - [Filecoin](https://filecoin.io/):它是一個去中心化儲存網絡,將雲端儲存轉變為演算法市場。用戶可以出租閒置的儲存空間並賺取 Filecoin 代幣。 - [Sia Network](https://sia.tech/host):這是一個由區塊鏈技術所保障的去中心化儲存平台。 Sia 透過去中心化網路儲存和加密您的檔案。您可以透過出租未使用的硬碟空間來賺取 Siacoins。 - [Crust Network](https://wiki.crust.network/docs/en/nodeOverview):與 Filecoin、Sia 類似,Crust 支援 IPFS 等多種儲存層協議,並為應用層提供儲存介面。 - [Arweave](https://www.arweave.org/):一個基於區塊鏈的平台,以永久和去中心化的方式提供資料儲存。透過託管資料,用戶可以獲得 Arweave 代幣獎勵。 - [BitTorrent](https://docs.btfs.io/v2.0/docs/install-run-btfs20-node):該平台標記了世界上最大的文件共享協議,使用戶能夠通過在網路上。 - [HOLO](https://holo.host/):Holochain 應用程式 (hApps) 的點對點託管平台。在電腦上託管 hApp 的用戶將獲得 HOT 代幣獎勵。 --- ### 41.其他 Web3 方法 加密產業還有許多其他賺取被動收入的方式,從PoS 質押、持有生息數位資產、借貸、流動性挖礦、雲端挖礦、賺取股息的代幣、流動性挖礦、交易、本地/ PoW 思維、NFT 等等。很少。 我不會在這裡連結到任何具體細節,因為這是一個風險非常高的行業,因此您自己進行研究很重要。但作為技術專家,我們能夠理解任何給定協議或 Web3 資產背後的基本概念,並確定其可行性。 我的建議是閱讀白皮書,如果你不能立即理解它,那就遠離它!這是狂野的西部,所以除非一個專案的基本面是堅實的,否則你應該做好失去投資的任何資金的準備。 --- ### 42. 聯盟行銷 聯盟行銷對於那些剛開始的人來說是眾所周知的無利可圖,但我將其包含在此處是因為作為開發人員,有一定的空間來自動化許多過程。此外,您行銷的服務越細分,支付的佣金通常就越高。因此,如果您融入了技術社區,您可能處於銷售小批量高回報服務的有利位置。 同樣,如果您已經有了追蹤者(社交、部落格、YouTube 頻道...),那麼聯盟行銷可能更有意義,因為如果您獲得了大量點擊。 值得注意的是,您可能不應該在未透露它是附屬連結的情況下共享附屬連結。並儘量避免宣傳您自己沒有使用過或不會推薦給朋友的產品。 > 作為範例,[此處](https://notes.aliciasykes.com/p/3Ia4JzPw43) 是我使用過且擁有附屬帳戶的一些服務。我從未從其中任何一個身上賺過任何有意義的錢。 --- ### 43.經銷商 這涉及建立一個應用程式來包裝現有服務,同時加入 USP - 技術、客戶支援、UI 或其他功能。如果您有行銷或銷售背景,這可能適合您。如果您想加入功能或使流程自動化,那麼將需要大量的前期工作,但您將能夠更好地獲得收入。 您可以在大多數主要行業中找到提供經銷商計劃的服務提供者。 一些例子包括: - [Supermetrics](https://supermetrics.com/):行銷報告、分析、資料整合、20% 經常性佣金。 - [Keap](https://keap.com/):CRM、銷售與行銷自動化、20-30% 經常性佣金。 - [Klaviyo](https://www.klaviyo.com/):電子郵件與簡訊行銷,5–15% 一次性付款,10–20% 收入分成。 - [Drift](https://www.drift.com/):即時聊天軟體,20%收益分成。 - [ActiveCampaign](https://www.activecampaign.com/):電子郵件行銷、CRM、20–30% 佣金或折扣模式。 - [HubSpot](https://www.hubspot.com/):CRM、入站行銷、銷售、20% 營收分成。 - [Gorgias](https://www.gorgias.com/):電子商務幫助台,20% 收入分成。 - [Shopify](https://www.shopify.com/):電子商務平台,佣金20%,Shopify Plus 10%。 - [LiveChat](https://partners.livechat.com/):客戶服務平台,即時聊天,委託20%。 - [GetResponse](https://www.getresponse.com/):電子郵件行銷、線上活動管理、子帳號 35% 折扣、35% 經常性佣金。 --- ### 44. 人體實驗 這與技術根本無關。但作為程式設計師,我們通常可以在任何地方工作 - 那麼為什麼不在有報酬的地方編寫程式碼呢? 通常,您的收入在 2,000 美元到 10,000 美元之間,具體取決於試用期、持續時間、是否為住宅和具體情況。 像[流感營](https://flucamp.com/) 這樣的地方將支付您 4,000 英鎊,讓您在舒適的酒店式套房中入住兩週,同時他們會測試新的治療方法。那些患有氣喘等特定疾病的人可能可以透過參加更專業的試驗來賺取更多收入 --- ### 45.自由職業 自由職業可能會根據您的技能、經驗和您所在的領域而有所不同。對於新自由工作者來說,某些領域(例如網頁開發)的費率往往非常低,但您擁有的經驗和客戶滿意度越高,您就越能夠充電。 開發人員零工工作的三個主要平台是: - [Fiverr](https://www.Fiverr.com/):Fiverr 以其多元化的市場而聞名,非常適合剛開始從事自由職業的開發人員 - [Upwork](https://www.upwork.com/work):Upwork 迎合了廣泛的專業人士,但它對經驗豐富的開發人員特別有利。它提供了長期合約和高薪工作的潛力。該平台適合喜歡從事更實質專案的人。 - [People per Hour](https://www.peopleperhour.com/):這個平台對歐洲市場的開發者有好處。它強調當地的商業聯繫,並在短期和長期專案之間提供良好的平衡。 --- ### 46. 說話 面對面的和移除的開發者聚會和活動在全球各地不斷發生。這些活動需要演講者,許多人願意付費以獲得良好的演講。支付的金額根據規模、觀眾、主題、演講者(你!)和其他因素而有很大差異。通常,您必須先自願在當地的小型技術聚會上發表演講,然後逐步提高。 --- ### 47. 遠端技術支持 這不是最迷人的角色,但較小的公司通常無法聘請全職的專門技術支援人員,因此您可以找到很多兼職工作。如果您擁有雲端經驗或認證,這些的薪資等級會大幅提高。只需查看任何求職板(例如 [WeWorkRemotley](https://weworkremotely.com/)),您就會看到大量職位。 請注意,您通常需要在特定時間內有空,並期望您可以在給定的時間內回覆。在申請之前,請確保這是您可以解決的問題。 --- ### 49. 投資 是的,這不是副業——但聽我說完… 如果您每年的收入為 6 萬美元,生活成本為 4 萬美元,那麼 5 年後您可能會有 10 萬美元的儲蓄。如果您將其投資於年平均回報率為10 - 15% 的標準普爾500 指數- 您每月可能會從您的投資中獲得超過1,000 美元的額外收入,並且您的投資能力越強,收入就會不斷增加儲蓄(當然,投資可以減少也可以增加)。這已經比這裡列出的許多副業更好的回報了! --- ### 50. 就業 我們不要忘記,儘管目前情況看起來很艱難,但身為開發人員,即使只有一兩年的經驗,我們也處於非常幸運的地位,與平均收入者相比,我們的薪水很高。 如果你的工作不適合你——換公司通常是提高薪資的可靠方法,如果你不喜歡目前的工作,這可能是值得考慮的事情。 也許經歷了這一切之後,你所追求的不是副業,而是更好的「主業」? --- ## 真實的說話 儘管您可能會在 IndieHackers 和 Instagram 上看到一些內容,但副業並不是全部。這通常需要大量的工作,但回報卻非常有限。因此,在在這裡或其他地方進行任何事情之前,請退後一步,思考「我為什麼要這樣做?」。如果您這樣做是為了累積經驗、學習新技能並享受樂趣——那就太好了。如果你這樣做是為了快速致富 - 你可能會非常失望。 還有一點要注意的是,儘管看起來不公平,但與那些剛起步的人相比,那些已經擁有強大追隨者或幾個成功的開源專案的人將處於更好的位置來利用機會。 因此,從短期來看,作為一名開發人員,您的時間可能會更好地花在提升自己身上。如果您不確定從哪裡開始,這裡有 5 個關鍵提示: - **網絡** - 建立你的網絡,參加聚會、黑客馬拉松和開發活動,加入社區,結交朋友 - **開源** - 將您的工作放在那裡,公開學習,建立您感興趣的迷你專案,並且不要害怕失敗 - **經驗** - 獲得實務經驗,申請實習機會,作為自由開發人員提供服務 - **基礎知識** - 確保您對電腦科學基礎知識有深入的了解,其餘的就會容易得多 - **玩得開心!** - 你自然會在你真正熱愛的領域做得更好。如果你不喜歡你正在做的事情,請退一步,考慮不同的方法是否更適合你 --- ## 免責聲明 - 以上列表僅供您參考。 - 我沒有親自測試過這裡列出的所有服務。 - 如果您有 - 我很想聽聽您的回饋。同樣,如果有任何需要加入或刪除的內容,請在下面告訴我。 - 並非所有服務都在所有國家/地區提供(此清單主要針對英國/歐洲和美國🇬🇧🇪🇺🇺🇸) - 有些平台會抽取您的收入。這通常是一個很小的數額,但重要的是你要考慮到 - 如果您已經擁有大量追隨者或流行的開源專案,賺錢通常會容易得多 - 有些方法涉及風險。儘管我已盡力強調這一點,但請記住,您的投資可能會下降而不是上升 - 您的結果可能會有所不同 - 沒有保證 --- 原文出處:https://dev.to/lissy93/50-ways-to-bring-in-extra-cash-as-a-developer-19b6
## **簡介** 在這篇文章中,我將介紹 11 個我玩得很開心並想與您分享的函式庫。  --- ## 1. [Taipy](https://github.com/Avaiga/taipy) Taipy 是一個開源程式庫,旨在輕鬆開發前端 (GUI) 和 ML/資料管道。 不需要其他知識(不需要 CSS,不需要 JS,什麼都不需要!)。 建立您夢想的應用程式得益於: - 完整的客製化和互動 - 多頁和多用戶 - 管道圖形編輯器 - ...還有更多。 您甚至可以將以下所有庫與 Taipy 一起使用,並使其更加有趣。 你的想像力是極限!  ---  https://github.com/Avaiga/taipy 我們已經快有 1000 顆星了,沒有你就無法做到這一點🙏 --- ## 2.[Asciimatics](https://github.com/peterbrittain/asciimatics) Asciimatics 是一個可讓您建立全螢幕文字 UI 的程式庫。這個圖書館是出於對 80 年代的懷舊之情而建造的。 以下是它們的一些主要功能: - 彩色/樣式文字 - 遊標定位 - 鍵盤輸入(無阻塞或迴聲)  --- ## 3.[Arcade](https://github.com/pythonarcade/arcade) 沒有遊戲,樂趣怎麼可能有意義呢?正如庫名稱所暗示的,它允許建立 2D 影片遊戲。是的,這看起來確實很難,但 Arcade 讓它變得容易。因此,「pip install arcade」並開始遊戲或從一些[現有遊戲](https://api.arcade.academy/en/latest/sample_games.html)中汲取靈感!  --- ## 4.[Rich](https://github.com/Textualize/rich) Rich 將為您的生活增添色彩! Rich 在您的終端機中寫入豐富的文字(顏色+樣式),因此它們最終可以反映您是誰。 豐富包括: - 不同的風格 - 降價 - 進度條 - 亞洲語言支持 - ... 和更多!  --- ## 5.[PyEphem](https://github.com/brandon-rhodes/pyephem) PyEphem 是一個在天空中迷失的好工具。該庫允許進行天文學計算;以下是一些有趣的用例: - 尋找行星在天空中的位置 - 確定春分和至日的日期 - 計算月相的日期 - ... 還有很多! 這個圖書館一定會激發您的好奇心。  --- ## 6.[tqdm](https://github.com/tqdm/tqdm) 光是這個圖書館的名字就已經很有趣了。 Tqdm 表示兩件事: - 是西班牙文「我非常愛你」的縮寫 (*te quiero demasiado)* - 源自阿拉伯語單字“*taqaddum* ()”,意思是進步,這實際上是對該庫所做工作的一個很好的介紹。 Tqdm 是任何循環的包裝器,它將透過進度條追蹤進度。您可以自訂它,讓等待任務完成不再那麼無聊!  --- ## 7. [Pygame](https://github.com/pygame/pygame) Pygame 讓編寫視訊遊戲變得容易。該庫將使您可以存取多種多媒體元素,例如: - 圖形 - 聲音 - 輸入設備 現在,發揮您的創造力,建立您自己的 2D 互動遊戲或探索一些[可用遊戲](https://www.pygame.org/tags/all)。  --- ## 8.[Turtle](https://docs.python.org/3/library/turtle.html) 這個函式庫有所不同,因為它是 Python 語言的一部分,因此不需要 *pip install*。 Turtle 是為了教育目的而建立的,幫助新程式設計師透過在畫布上設計圖形來使用 Python 進行編碼。一種進入 Python 或享受一點創意樂趣的有趣方式。  --- ## 9.[MoviePy](https://github.com/Zulko/moviepy) MoviePy 是用 Python 編輯影片的便利工具。其功能包括: - 切割 - 連接 - 過濾 - 和轉變。 您可以閱讀許多不同的格式,包括 GIF。  --- ## 10. [Emoji](https://github.com/carpedm20/emoji) 透過此庫在 Python 程式中使用表情符號。它只是使用 *emojize()* 函數將 unicode 表情符號轉換為表情符號名稱。其他功能包括加入表情符號、計算表情符號等…  --- ## 11.[Pyjokes](https://github.com/pyjokes/pyjokes) 有了 pyjokes,您只需安裝一點就能獲得點播笑聲。這個圖書館會給你一些俏皮的笑話;您甚至可以選擇語言和類別。 玩得開心!  --- 希望您喜歡這篇文章! 我是一名新手作家,歡迎任何改進建議!  如果您有任何疑問,請隨時與我們聯繫。 --- 原文出處:https://dev.to/taipy/11-fun-python-libraries-to-make-your-day-better-4gpc
哈囉大家好,我加入這平台有九個多月,後來神隱一段時間,趁現在的我有空閒時間,趕緊與大家分享我的轉職之路。 神隱的這段時間想當然是成功轉職,跑去上班,才有辦法與大家分享我的轉職心得XDD。開始上班後,因為有太多東西都是第一次接觸到,忙得不可開交,所以拖到現在才上來分享,抱歉><" ! 那麼就進入正文吧! 我大學是有接觸過程式的經驗的,正確來說,應該是這科系本來就會接觸到( C、C++、Java、Python等),但因為學校的特殊性,也有碰到硬體,當時我是比較傾向於硬體,所以程式沒甚麼太專研,成績有過就好,後來畢業後也是從事硬體職位,程式幾乎只記得超基礎的東西。後來的職涯目標轉變,所以重新開始寫程式,跟別人不太一樣的地方大概就是有一點程式的基礎,但我也沒接觸過網頁,所以是從大概距離起跑點十的位置前進吧 ? 哈哈哈 ~ 確定目標後就果斷離職,離職後開始全力進修學網頁(3月開始),也設定了進度: 三月 ~ 六月 : 學會HTML、 CSS、JS最基本語法。 六月 : 開始準備履歷作品、學 Vue 及投履歷 七月 : 邊面試、邊修履歷及作品 八月 : 開始上班。 一開始在找資源時,因緣際會下,發現到這平台,就跟著站長的那些課程進度走。我就真的只有上站長這裡的課程,完全沒去其他地方,例如udemy、Hahow 好學校等。沒錯......因為我想省錢,當時是想說先上看看,真的不行再去買那些課程,結果就一路到現在都還沒買其他課程......。 跟了這平台的課程後,也認識到了一些學習前端的免費資源,像是W3Schools等,所以雖然是跟著進度上,但我是搭配著上。甚麼意思呢 ? 舉例來說,在學HTML時,站長在文內可能只說學第幾個(A)跟第幾個(B)即可完成這作業,但在W3Schools,A跟B之間可能還有其他的部分,所以我是照W3Schools裡的HTML的順序學下來,學到課程內要學的A跟B,就先去完成作業,再接下去學。因為也有提供中文的W3Schools,所以也是這樣喔 ! 寫過的就當作複習,加深印象,打好基礎~ 而在自學中,最難的事之一就是自律這件事,所以我每天都一定強迫自己最晚十點到圖書館,午休一個小時,因為有找個兼職,要維持生活開銷,所以到六點就會離開圖書館。除了休息那一個小時外,我都是在學習,沒有中途玩手機還是做其他事喔 ! (有時覺得用眼過度,抬頭看窗外,那不到三分鐘的事不算~),一周有六天都是如此,禮拜天就會給自己放鬆一下,只到下午兩、三點。 一直這狀態直到六月,開始準備作品,當時也是爬文、看別人都是怎麼準備、展示自己的作品的,就發現大多的人都會做個人網頁。而要怎麼做個人網頁呢?就繼續爬爬爬...,就認識到GitHub有提供GitHub Pages,能把自己的作品上傳到這後,別人就可以看到你的作品。真的是非常方便,而且又是免費的阿 ! 剛好課程也有教到Git指令,所以就架了一個自己的履歷網頁~ 準備得差不多後,就照著站長建議的,把工作經驗一年以下、無經驗的、可以應屆畢業生(雖然我不是),全都投了一遍,只留自己夢想公司,這樣就能先累積面試經驗,並依面試得到的反應去修改自己的作品,再最後投夢想公司。能投得都投後,就開始照課程學框架Vue,若有做出作品就隨時更新到我的個人履歷網頁上。 面試時,大多都是看履歷問問題,有些有筆試,但都是像網路上大家說的那樣,前端必學觀念,沒遇過上機coding的。有些有手寫code,通常只有1-2題,印象中,有個題目是要你把字串反過來,怎麼寫 ? 只要把網路上大家說的必考題目弄熟,基本沒有太大問題。 而個人面試時有遇到的幾個問題,第一個是作品有點陽春Q,本身也沒有UI/UX的經驗等,所以是這職位轉過來的在這點上就會很加分呢 ! 我只能靠時間一點點的累積、培養了QQ。再來就是很常被問自學的困難點,又加上我只在這平台學習(雖然他們不知道),但我認為最重要的還是有沒有決心想學前端,如果有就一定會去找資源,遇到問題,也不會那麼容易就挫折、放棄,畢竟已經下定決心自學的人都早就帶有這覺悟了吧 ? 就像在學Vue時,可能在這課程學到的不完善,但我認為這裏只是給一個學習的方向,那麼就可以朝這方向去找更多資訊,也能知道哪邊需要在著重釐清概念,就可以去看這部分的影片! 之後,運氣非常好的收到幾個offer,並在八月如預期開始上班,真是太開心了( 灑花~ 最後就說一些建議,雖然還是菜鳥,但應該可以多少能給一些方向 ? 這些建議是,若我今天還沒開始上班,我還會做甚麼事,大家就當作參考吧~ 假如我能帶著上班後遇到問題的記憶回到還沒就職時,我會: 1. 把JS基礎打好,多找題目做! 2. (假如學的框架是Vue),慢慢開始從API換成CLI,並多做作品,熟悉框架物件等等之間的傳遞。 3. 認識更多套件,並學會使用,可以的話套看看在框架上,並把每個套件組合成一個流暢性的作品。 4. Code Review : 會打程式固然重要,但專案的架構、流程設計的好,真是輕鬆一半,也會更清楚程式間是如何傳遞的! 5. 課程的每個作業能把它做到最好就做到最好~ 就先大概這樣吧,真的是有太多東西等著我去學,希望未來的我不要菜味這麼重,也能為大家提出更實質性的建議或幫助,不管是自學的還是轉職的,大家一起加油吧 ! ( 我可能又會神隱一段時間,但有時間,一定會繼續完成站長的課程 & 與大家分享工作心得的 !
你有沒有想過... **如果軟體開發人員的需求如此之大,為什麼現在找到開發人員的工作這麼難?** 為什麼面試過程這麼長?為什麼會有數百次拒絕? 為什麼提供的工資低? 今天,您將了解混亂背後的原因。 我們是如何來到這裡的。以及為什麼。 我還將向您展示為什麼事情並不像大多數開發人員想像的那麼糟糕。以及您需要採取的 5 個步驟來利用這種情況為您帶來優勢。 因此,當大多數開發人員都在倒退時,您可以快速發展您的職業生涯。 如果您是一位雄心勃勃的開發人員,想要更上一層樓並增加薪水,那麼這就是適合您的。 **因為有一件事是真的,我們所知道的軟體開發在 2023 年已經發生了永遠的變化。** 「美好的舊時光」已經一去不復返了。 知道如何建立 React 應用程式將不再讓你獲得這份工作。我們不會很快回到那個狀態。 我們走吧。 這一切都要追溯到 2022 年,當時從谷歌到 Meta 和微軟等大型科技公司開始宣布裁員。不是各種裁員,是裁員開發者。 起初,大多數開發人員都很有信心。 他們說,_「軟體開發總是在成長並且需求旺盛,我們將會復甦」_。 現在,12 個多月過去了,許多程式設計師已經失去了樂觀情緒(免責聲明:我仍然對開發人員的未來非常樂觀,稍後會詳細介紹)。 許多開發者正在失去耐心等待就業市場的復甦。如果它永遠不會發生怎麼辦? 一些開發人員正在懷疑他們的職業選擇。正在考慮 B 計劃或已經轉向做其他事情。 其他人則被迫回到編寫程式碼之前的低薪工作。  最初的樂觀很快就變成了悲觀,許多開發者都在尋找 B 計畫。 **最好的情況是資料輸入或客戶服務工作。在最壞的情況下,它會回到咖啡店或倉庫。** 我認為這是一件非常悲傷的事情。僅僅因為你找不到擺脫困境的有效策略,就拋棄了你的夢想和多年的努力。 我相信,如果你進入軟體開發,那是有原因的。您可能工作勤奮、雄心勃勃且富有創造力。你至少應該有機會證明自己的價值。 在這篇文章中,我將向您展示該怎麼做。具體來說,無論市場表現如何,如何使用經過驗證的軟體工程原理來度過這場風暴,並將您的開發人員職業生涯提升到一個新的水平。 我是誰可以給你這方面的建議? 我叫 Dragos,在過去 3 年裡,我幫助超過 230 多名軟體開發人員提升了技能,快速晉升到高級級別,並獲得了他們應得的認可和報酬。  我不是大師或技術影響者。我並不打算成為其中之一。 但是,在作為自學成才的開發人員編寫程式碼期間,我一直在戰壕里工作,現在幫助其他開發人員升級,這使我很有資格為您提供這方面的建議。 首先,讓我們先了解一下軟體開發行業目前正在發生什麼… **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ## 現在的情況 像任何好醫生一樣,為了治療症狀,我們必須了解背後的問題。 開發人員就業市場就像任何市場一樣,受簡單的供需機制控制。對開發者的需求越大,開發者的議價能力就越大。 對開發者的需求越少,我們的談判能力就越小。 如果你不斷地感覺自己與其他開發者比較,無法要求高薪,並且很難找到工作,這意味著你在市場上的力量很小。  供需關係決定開發者就業市場。 傳統上,開發者在市場上擁有大部分權力,公司會不遺餘力地獲得最好的工程人才。 這就是為什麼開發人員的薪水不斷增長以及每個人都想學習如何編碼的原因。 **但是,在過去 12 個月裡,權力已經從開發者轉移到了公司(除了頂層的開發者,稍後會詳細介紹)。** 為什麼? 很多原因。讓我們一一回顧一下… ## 1.“效率時代” 戰爭、通貨膨脹和經濟衰退迫使世界各地的公司最大限度地利用資金。包括軟體公司。 企業需要找到更有效的做事方式——如果您正在建立軟體,這意味著擺脫一些開發人員並自動化盡可能多的任務。  糟糕的經濟狀況迫使科技公司的執行長提高公司的效率。 正如馬克·祖克柏在他關於 Meta 的「效率年」的文章中提到的那樣,公司希望提高開發人員的生產力和工具並減少員工人數。 **一言以蔽之:科技公司希望盡可能精簡。** 這意味著軟體開發團隊不能再龐大了。他們需要一些高技能的開發人員以及大量的自動化設備。  這意味著縮小團隊規模(即:解僱表現不佳的員工)、取消優先順序較低的專案並降低招募率。用更少的軟體開發人員完成更多的工作。 對於開發人員就業市場來說,這可不是好訊息… **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ## 2.人才海嘯 開發人員就業市場變得非常非常擁擠,有數百名候選人瞄準同一職位。 這是因為編碼技能變得越來越普遍。 在過去的十年中,訓練營和電腦科學學位一直在將軟體開發人員吸引到一個已經擁擠的市場中。尤其是訓練營,經過六週的編碼後,他們實現了六位數薪資的夢想。  這引發了一場「人才海嘯」。開發人員的工作被當作中產階級的金票出售。成千上萬的人放棄了學習編碼的希望。 然而,正如許多初級開發人員所看到的那樣,這主要是一種行銷承諾。 事實上,開發人員職位的競爭非常激烈,你在 3 個月的 Bootcamp 中學到的技能已經不足以脫穎而出。  由於大量開發者在尋找黃金,就業市場很快就飽和了。 2020 年的情況就已經如此,但後來情況變得更糟… ## 3.遠距工作 Covid-19 大流行推動全世界轉向遠距工作。鑑於編碼基本上可以在任何地方完成,開發人員的工作是適應速度最快的工作之一。 對許多開發人員來說,在家工作聽起來像是個夢想。 無需通勤,擁有更多屬於自己的時間,並以相同的薪水在舒適的家中進行編碼,這是大多數人在任何給定時間都需要的交易。 但事實證明,遠距工作是一把雙面刃。 因為最終,公司透過增加招募人數而受益最多。  遠距工作意味著軟體公司現在可以僱用來自世界各地的開發人員。 本地職缺吸引了數十名遠距求職者,他們願意以少得多的錢做同樣的工作。正如《紐約時報》所說: **“遠距工作者普遍面臨更多競爭,並且更加依賴運氣。” - 紐約時報** 如果您想知道為什麼現在有數百甚至數千名求職者,那麼答案就是:遠端候選人。 大多數職缺現在都在收到來自世界各地的申請。  隨著遠距工作的興起,本地工作現在面臨國際競爭。 當我可以在中西部找到具有相同技能且至少少兩倍的錢的人時,為什麼還要雇用矽谷的開發人員呢? 在歐洲也一樣。 一家位於柏林的公司可以聘請一位位於德國中部小村莊的開發者。讓他們每個月來辦公室兩次。並少付給他們幾十萬歐元。 當然,一些公司採取了重返辦公室政策。 但從長遠來看,我們將看到越來越多的公司採用完全遠端的思維方式。從經濟學的角度來看,遠距工作很有意義。 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ## 4. 人工智慧與自動化 人工智慧已經存在很多年了,但從未像現在這樣出現在我們的生活中。 2023 年 10 月,OpenAI 發布了 ChatGPT。 近年來人工智慧創新的巔峰和迄今為止最好的人工智慧模型。它可以與您談論您的一天,也可以為您撰寫論文。 更糟的是,它可以編碼。  隨著人工智慧能夠編寫功能齊全的程式碼,許多開發人員都會問自己:“現在怎麼辦?” 如果有足夠好的提示,它可以比大多數人類開發人員更好、更快、更便宜地編寫程式碼。 當然,ChatGPT 無法自行思考。 這是一個巨大的統計機器。它會犯很多錯誤並且陷入循環。但是,這足以讓事情順利進行。而且情況只會變得更好。 GitHub 很快就做出了調整,將其整合到 GitHub Copilot 中,後者已直接在 VS Code 中可用。 從長遠來看,沒有人知道人工智慧將對就業市場產生什麼影響。 它會像某些人聲稱的那樣導致我們所知的編碼的終結嗎?或者它只是人類開發人員完成工作的工具? 我們所知道的是,在短期內,人工智慧透過自動化任務或完全取代一些工作,給就業市場帶來了更大的壓力。  高盛估計,大約 29% 的電腦相關任務可以透過人工智慧自動化。 結果? **找到一份體面的開發人員工作變得越來越難。** 回到報價和供應曲線,開發者數量增加,但就業機會數量保持不變。 隨著市場上數百名開發人員尋找職位,軟體開發產業正遭受「Tinder 效應」的困擾。類似網路約會的現象。 就像約會應用程式中的熱門個人資料一樣,軟體公司現在面臨著數百種不同的選擇。數百名候選人和簡歷。 整理噪音並不容易。 你必須更快地放棄候選人。即使你拒絕了一個合適的開發者,總會有其他人在門口等著。 好吧,現在對於開發者來說情況並不好。 忍住眼淚,因為我會告訴你為什麼事情並不像大多數開發人員想像的那麼糟糕... # 好訊息 這場「完美風暴」讓大多數開發者感到驚訝。許多人覺得薪水過低,但同時又沒有勇氣去市場。 這創造了一個“技能差距”,你可以利用它來跑得更快。  「在陽光明媚的天氣裡你無法超越 15 輛汽車…但在下雨天你可以。」- Ayrton Senna **風雨飄搖的就業市場實際上可能是您將開發人員職業提升到全新水平的完美時刻。** 首先,不要像其他人一樣屈服於恐懼。恐懼會讓你癱瘓,擾亂你的思考。不要驚慌失措,而是要超越噪音。 裁員開始一年後,公司意識到消除成本實際上會阻礙他們的成長。 在資本主義中,一家不成長的公司就是一家正在消亡的公司。 公司需要重新開始創造價值。緊急。 更多價值,因為我們正處於經濟衰退之中,消費者只想要最優惠的價格。而且速度更快,因為競爭是全球性的。 **在軟體開發中,價值意味著功能。這意味著高品質的程式碼。** 那麼人工智慧呢? AI實際上刺激了市場。軟體公司別無選擇,只能將人工智慧模型整合到現有的軟體中。否則就有倒閉的風險。 你需要什麼? 開發者、開發者、開發者… 好吧,這就是為什麼這可能是您作為一個雄心勃勃的開發人員超越競爭對手的最佳時機: ## 1. 質量重於數量 是的,市場上的開發者總數有所增加。但他們的技術技能品質卻沒有。 經濟衰退可能在一夜之間發生,但技術掌握需要時間。 即使在這樣的市場條件下,大多數公司仍然抱怨很難找到符合其工作要求的合格開發人員。 企業的要求是否過高? 或許。 但是,這正是您可以利用的差距來保持競爭優勢。  市場上有如此多的噪音,這與您發送的申請數量無關。追求數量只會產生更多垃圾郵件。 重要的是您的簡歷和申請的品質。 這並不意味著您應該成為完美主義者。數字仍然很重要。在開始找工作之前,只需在[您的簡歷和LinkedIn 個人資料上做更多工作](https://dev.to/dragosnedelcu/how-to-find-a-developer-job-in-2023-with-little-or-no-experience-27h7)。 並專注於技術掌握而不是數字! ## 2. 人工智慧作為補充 正如我所提到的,人工智慧模型無法思考,至少目前還不能。事實證明,它們更多的是對開發人員工作的補充,而不是替代品。 人工智慧帶來的是更多透過人工智慧整合進行的軟體開發。對正在開發的軟體的需求不斷增加。 這似乎有悖常理,但事實證明,人工智慧和自動化對軟體產業的影響與 70 年代修建高速公路對汽車交通的影響類似。 更多的高速公路意味著更多的汽車空間,因此更多的人使用汽車。導致汽車流量增加,而不是減少!  更多的高速公路,更多的汽車。更多人工智慧,更多程式碼。 人工智慧編碼工具將使產生的程式碼量倍增。 最終,這意味著更多的程式碼需要由人類檢查、驗證和維護。整體而言,需要更多的開發人員。 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ## 3. 現金仍為王 $$$ 有趣的是,開發人員的薪資仍在增加。但它們的成長並不相同。 事實上,大多數開發者都無法跟上通貨膨脹的腳步。許多人根本沒有加薪,儘管在市場上待了很久卻找不到職位。 其他人則獲得小幅加薪,例如 3%。由於去年通膨率約為 10%,這並不是加薪。又是減薪! 但是,一小群幸運的程式設計師的薪酬正在打破記錄。 事實上,我們在 theSeniorDev.com 上看到了這一點。許多高級開發人員的薪資創下歷史新高,即使在歐盟市場也超過 6 位數。 幾年前,如此高的報價是非常不尋常的。 但是,如果你仔細想想,更高的薪水是有道理的。 一家公司面臨著交付一款可以為他們帶來數百萬美元收入的軟體的壓力,他們不會介意為能夠交付該軟體的開發人員額外花費數千美元。 這樣想吧,熟練勞力不是商品。 公司不會購買一雙一模一樣的鞋子並尋求優惠。有些鞋子會讓他們走得更快。為他們支付更多費用是有道理的。 **無論是矽谷或歐洲科技中心,趨勢都很明顯:熟練的開發人員需求量很大,公司願意為他們支付大量資金。** 正如您所看到的,事情並不像大多數開發人員想像的那麼糟糕。 至少不適合所有開發人員... 因為如果你和你的資深朋友交談過,你可能會發現有一群開發者做得併不差…。 ## 僅限資深開發人員的就業市場 儘管發生了一切,但高階開發人員的需求仍然非常大。您可以在招聘板上看到它,其中指定:僅限高級。 或查看誰正在被雇用並立即簽署工作合約。 Hired.com 的一份報告顯示,目前簽署工作合約的軟體開發人員中有超過 73% 擁有 7 到 5 年(或更長)的經驗。  高級開發人員受最近科技業裁員的影響最小。 感覺無論經濟如何發展,成為高級開發人員都會有回報。或多少程式碼 A.I.可以生成。  如果就業市場是動物農場。所有開發人員都是平等的,但高級開發人員比其他人更平等。 如果市場如此糟糕,為什麼高級開發人員仍然受歡迎? 從公司的角度來看,高階開發人員從第一天起就可以創造價值。 公司知道,他們比以往任何時候都更需要快速、優質的交付,才能在當前經濟狀況下保持競爭力。通貨膨脹,記住。 所有這些因素意味著整個軟體開發團隊將崩潰為少數開發人員利用兩個要素: 1. **高級開發人員** 2. **人工智慧工具和自動化** 儘管發生了這一切,但也不全然是壞訊息。堅持幾秒鐘,我會告訴你原因。 **事實是,您可以利用當前的情況來發揮自己的優勢。** **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** # 真相 為了在這個充滿活力的就業市場中取得成功,您將需要比與您競爭的其他數千名開發人員更可靠的策略和更有效率的流程。 您需要立即採取行動,因為… 提供高薪、酷炫技術堆疊、良好福利和遠距工作的開發人員工作每天都變得越來越有競爭力。 這並不意味著他們不可能到達。簡而言之,獲得開發人員工作的舊方法不再有效。 如果您需要其他 5 名開發人員的幫助才能將程式碼投入生產,那麼您的日子就很寶貴了。還有另一個開發人員可以提供端到端的服務,他們將取代您的位置。 所以你會怎麼做? 正如我的一位招募人員朋友所說: **「你最好的選擇是盡快成為高級開發人員」。** 盡快達到高級水平是目前在軟體開發市場中生存的唯一途徑。 成為高級開發人員將使您從眾多編碼人員中脫穎而出,提供端到端的價值,並被視為對公司的投資,而不僅僅是另一個昂貴的開發人員。  聰明的開發人員正在尋找提供更多服務並脫穎而出的方法。他們正在尋找快速實現這一目標的方法。 他們首先需要解決的是如何提升自己的技術能力。 好訊息是,您不需要在周末花費無數時間或編碼來實現這一目標。您不需要啟動數百個線上課程和副專案。 而且您不需要等待數年才能做到這一點。因為有更好的方法可以做到這一點。 你只需要專注在那些不會改變的事情上。 **那麼,如何獲得對自己技能的完全信心、端到端交付並釋放高級信心?** 您遵循基於經過驗證的軟體開發原則的逐步過程。就像高級開發人員每天使用的那樣。我們稱之為技術掌握藍圖。 在接下來的幾行中,我將更深入地討論具體步驟,但這不是本文的目標。 如果您有興趣了解更多訊息,可以單擊下面的連結並觀看我為您準備的免費培訓。 [這是免費培訓的連結。](https://bit.ly/3udWD0m) **免責聲明**:您必須加入您最好的電子郵件才能存取它。別擔心我不會寄垃圾郵件給你。我只會與您分享有關如何快速晉升高級開發人員並讓您的開發人員職業生涯提升到一個全新水平的相關資訊。您可以隨時取消訂閱。 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ### 1. 首先,你要採取資深開發人員的心態🧠 成為高級開發人員的第一步是改變您對軟體開發職業和整個生活的看法。 這意味著要以更高的標準要求自己。對您目前的開發者職業生涯承擔全部責任。並掌控你的職涯道路。 你也必須擺脫限制性信念或任何內在的關於自己的負面情緒。你必須養成新的習慣並培養紀律技能。 這意味著設定明確的重點目標,為自己定義一個在情感上令人信服的願景,並在執行這些目標時對自己負責。 **🚀[行動專案]**:準確定義您想要在未來 12 個月內實現的目標。為什麼想實現它?到達那裡需要採取哪些步驟?你是否缺乏任何知識和技能?你需要做一些與現在不同的事情才能到達那裡嗎?寫下來。 當你走向高級開發的旅程時,這將是讓你的火焰保持活力的燃料。大多數開發人員從未到達那裡,因為他們退出得太早。他們忘記了過程就是目標。 ### 2. 其次,你掌握了「基礎知識」📚 大多數開發人員,特別是 JavaScript 開發人員已經習慣相信軟體開發中的資歷就像一個購物袋。 新增的庫和框架越多,其等級就越高。 事實上,情況完全相反。高級開發人員平均編寫的程式碼比初級開發人員少。他們使用不太閃亮的庫和框架來解決問題。 沉迷於框架和庫會讓你成為炒作列車的受害者。當一個圖書館失寵時,另一個圖書館就會出現,需要您投入時間和注意力。這是一場你無法獲勝的遊戲。 如何才能逃脫炒作機器? 透過專注於**「不會改變的事情」**。我們所說的基礎知識。 模式和原則是大多數框架和函式庫的核心。對基礎知識的深入理解將確保您無論情況如何變化都能掌握最新資訊。 它還可以保護您免受人工智慧和自動化的影響。在程式碼在幾秒鐘內產生的世界中,清晰的思維變得越來越有價值。雙贏。 基礎知識取決於您的技術堆疊。 如果您是 JavaScript 開發人員,您主要需要掌握 2 組基礎知識。電腦科學基礎知識和 JavaScript 基礎知識。 這不是本文的範圍,但我整理了一個路線圖,供您準確了解這些內容,請參見下文。 🚨 PS有關“計算機科學基礎知識”的詳細列表,請查看[計算機科學基礎知識掌握路線圖](https://mm.tt/app/map/2980765378?t=LsjjpEBYky)。🚨 🚨附言有關「JavaScript 基礎知識」的詳細列表,請查看我們的 2023 年 [JavaScript 基礎知識掌握路線圖](https://mm.tt/app/map/2962635113?t=ILeYm71vU3)。🚨 順便說一句,我們免費社群的開發人員可以存取獨家內容和針對基礎知識的客製化練習。請在下面註冊! **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ### 3. 第三,您學習如何端到端交付🎯 任何科技公司執行長現在最不想做的就是僱用更多的開發人員。但他們確實想解決問題。很多問題。 但是,你無法真正解決問題,我的意思是,當你只建構孤立的功能時,會出現有價值的問題。或者當您需要另外 5 名開發人員的幫助才能將您的東西投入生產時。 **高級開發人員之所以需求如此巨大,是因為他們可以提供端到端的服務。** 他們可以與產品經理或其他利害關係人獨立工作,並從第一天起就交付價值。掌握了這一點,你的價值就會增加10倍。 端到端交付並不意味著您必須了解一切。 這意味著您需要了解後端以及基礎設施方面的情況。目前無需深入研究各個元件。但從大局來看是的。 **[進階開發提示]**:學習如何端到端交付的最快方法不是 100 小時的雲端憑證課程(這些課程的重點是向您推銷品牌,而不是教您東西) )。 相反,請嘗試規劃您公司的 CI/CD 流程。 找出他們擁有的任何架構圖,然後自己參與其中。如果他們沒有,請自己建造一些。這已經可以給你一個良好的開始,並在你的下一次技術面試中談論很多事情。 🚨附言要確切了解您需要掌握哪些端對端交付心理模型,請查看我們的[JavaScript 開發人員的「端對端交付」路線圖](https://mm.tt/app/map/2974013323?t=pqAIdWZ7W2 ).🚨 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ### 4.第四,成為「AI驅動」🚀 當我接到想要加入我們專案的開發人員的電話時,最令我驚訝的事情之一是他們每天很少使用人工智慧。 有些人多次使用 ChatGPT 來執行日常任務(樣板檔案、測試)。真正使用過 GitHub Copilot 的人就更少了。 他們告訴我他們不相信它的未來。或者他們的公司並沒有真正使用它。 如果你在飛機上,氧氣會耗盡,我敢打賭,即使機組人員沒有給你,你也會尋找氧氣面罩。 ChatGPT 和 GitHub Copilot 不只是更好的自動完成工具。自動完成無法重構、尋找程式碼中的錯誤或擴充功能。 人工智慧模型可以優化、重構,甚至可以比許多開發人員提出更好的程式碼。事實上,到 2023 年,在人工智慧工具的幫助下,初級開發人員可以完成與沒有人工智慧工具的高級開發人員一樣多的工作。 重點很明確:如果您是願意轉為高級的 JavaScript 開發人員,您需要成為「人工智慧驅動」。 如果您已經是大四學生並希望在未來幾年保持相關性,情況也是如此。潮流正在改變。透過升級這些技能來確保您處於正確的位置。 您是否必須學習 Python、Numpy、深度學習以及 AI 堆疊中的十幾種工具?並不真地。這是一項完全不同的工作。 **這意味著你應該將人工智慧工具整合到你所做的一切中。** 從建置功能到程式碼審查,再到測試和效能優化。如果您希望我寫一篇有關如何做到這一點的文章,請在評論中告訴我。 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ### 5.第五,有效推銷自己🏆 如果你找不到一家公司來支付你的技能費用,那麼無論你是多麼優秀的開發人員,也沒有用。由於開發人員就業市場已經過度飽和,這一點更加正確。 為了脫穎而出並獲得頂級軟體開發人員的職位,您必須以盡可能最好的方式將自己推向市場。 作為一名員工,這一點更為重要,因為您應該始終擔心的一件事是您的就業能力。 **如果你明天被解僱,你找到另一個職位有多容易?** 你越有就業能力就越好。 您的就業能力取決於兩件事。您的產品(在這種情況下,您的開發技能和支持這些技能的過去經驗)。 其次,你如何推銷自己和你的人脈。有多少人認識你?如果你現在被解僱,明天有人可以提供你工作嗎? 要改進您的產品,請提高您的開發技能。我們在前面的幾點中討論過這一點。但如何改進自我推銷的方式呢? **好吧,如果你想要高級開發人員的薪水,你首先必須看起來像高級開發人員。** 這意味著建立一份相關的履歷,以最好的方式量化以展示您為市場帶來的東西。 如果您想讓我寫一篇關於如何打造一流開發人員履歷表的文章,請在評論中告訴我! ## 總結與後續步驟 好吧,現在你知道了。 下次當你問自己為什麼現在找到開發人員的工作如此困難時,請考慮這些原因。您還了解如何透過盡快成為高級開發人員來解決這個問題。 能夠落實這 5 個支柱並以最快的速度適應這個新市場範式的開發人員將獲得工作保障、對自己的技能充滿信心並獲得最高的薪水。 無法適應的開發者將慢慢被淘汰,並面臨被完全擠出市場的風險。 按照我在本文中概述的步驟操作,您不僅可以輕鬆找到開發人員工作,而且可以「快速」晉升到高級開發人員級別,並將您的開發人員職業生涯提升到一個全新的水平。 他們為我和世界各地 230 多名其他開發人員工作,他們也將為您工作! 我們下一篇再見 德拉戈斯 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** --- 原文出處:https://dev.to/dragosnedelcu/why-is-it-so-hard-to-find-a-developer-job-in-2023-and-how-to-fix-it-2d13
嘿朋友們👋 曾經造訪過某人的 Github 個人資料並思考過:  在本文中,我將嘗試向您展示建立專業的 GitHub 個人資料比您想像的要容易得多。 沒錯,即使您不是經驗豐富的專家,您也可以讓您的個人資料看起來可靠。 這是我的 GitHub 個人資料的範例。讓我們深入探討如何在接下來的 10 分鐘內讓您的個人資料看起來同樣完美。 😉** [](https://github.com/fernandezbaptiste) 準備好了,出發吧⏰ --- # 1. 建立您的 GitHub 設定檔:新增 `README` 如果您還沒有這樣做,則必須建立自己的 GitHub「自述文件」來建立您的個人資料頁面。 為此,請轉到您的個人資料並點擊“您的儲存庫”。 之後,建立一個「New」儲存庫: - 儲存庫的名稱需要與您的使用者名稱相同。 - 確保將儲存庫設為“公開” - 點擊“新增自述文件”  --- # 2. 為您的儲存庫建立一個開源儲存庫 🤫 不久前我發現了這個[repo](https://github.com/rahuldkjain/github-profile-readme-generator),我愛上了它。❤️ 這個很酷的專案可以幫助您立即建立自己的 GitHub 個人資料! 前往 [GitHub Profile README Generator](https://rahuldkjain.github.io/gh-profile-readme-generator/) 並填寫您的資料。 [](https://rahuldkjain.github.io/gh-profile-readme-generator/) **注意:** 您不需要完成每個部分;僅相關的。 完成後: - 點擊“生成自述文件” - 然後點選“複製markdown” - 前往您新建立的 GitHub 個人資料並將程式碼貼到您的「自述文件」中 💪 --- # 3. 使用小工具提升您的個人資料設計水平 您現在應該擁有一個看起來非常漂亮的個人資料! 為了提高您的遊戲水平,您可以加入一些優雅的小部件,這些小部件提供有價值的統計資料來展示您的技能和成就。 🚀⭐️ 就我而言,我已將這些加入到我的[個人資料](https://github.com/fernandezbaptiste): [](www.quine.sh/?utm_source=devto&utm_campaign=beautify_github_profile) 您也可以加入一些小工具來展示您的 _Web3_ 或 _StackOverflow_ 體驗: [](www.quine.sh/?utm_source=devto&utm_campaign=beautify_github_profile) 這些小工具_完全免費_,您可以透過註冊 [quine.sh](www.quine.sh/?utm_source=devto&utm_campaign=beautify_github_profile) 來取得它們。 只需前往您的 Quine 個人資料上的_“Widgets”_,然後將複製的 Wiget 程式碼貼到您的「自述文件」頁面中即可。 [](www.quine.sh/?utm_source=devto&utm_campaign=beautify_github_profile) --- # 4.「美化」你的聯絡資訊💄 您可能不喜歡 GitHub README 產生器中的某些設計。 🙃 有些人喜歡不同的風格,尤其是與他們的_社交連結/連結輸出相關的風格。_ 您可以使用以下替代樣式: [](https://github.com/fernandezbaptiste) 如果您喜歡這種風格,您可以使用此合成器建立自己的徽章: ```  ``` 例如,如果您想新增 **GitHub 徽章**,則為: ``` ] ``` 根據您想要顯示的橫幅圖示的類型,您可以在此清單中找到許多簡潔的圖示[此處](https://simpleicons.org)。 🙌 --- # 5.利用 PIN 儲存庫功能 如果您已經建立了幾個專案,那麼這是展示您最引以為傲的專案的好機會! 在您的個人資料上,只需點擊“自訂您的 pin”,然後選擇最多 6 個您想要固定的專案。  --- # 6. 貢獻並升級你的遊戲! 在您的 PIN 儲存庫之後,您的個人資料將顯示以下網格。  這代表您**在 GitHub 上的貢獻和活動水平。** 需要強調的是,儘管您應該嘗試透過經常貢獻來展示您的一致性,但此欄上的「綠色度」百分比並不是最重要的方面。 👀 許多人專注於試圖建立完美的連勝,但實際上,他們的工作沒有影響力,他們的貢獻也沒有什麼價值。 在我看來(我相信很多人都有同樣的看法),貢獻應該集中在: **品質 > 數量** ❤️ 話雖如此,定期建立幾個專案或為其他人的專案做出貢獻符合您的利益。 現在,為了嘗試為專案做出貢獻,您可以使用多種工具。 🔎 這裡有 3 個免費網站,可以幫助您找到下一個要從事的專案: - [GitHub 探索](https://github.com/explore) - [UpForGrabs](https://up-for-grabs.net/#/filters?tags=python&date=1month) - [Quine.sh](https://quine.sh/?&utm_source=devto&utm_campaign=beautify_github_profile) 或者,如果這是您第一次貢獻,我已經建立了這篇逐步[文章](https://dev.to/quine/contribute-to-open-source-in-the-next-10-min-step-by-step-beginner-edition-4aia)適合初學者。您將學習在 GitHub 上做出貢獻的機制,並能夠在接下來的 10 分鐘內做出貢獻! --- # 7. 新增個人簡介 我們已準備好進行最後的潤色... 現在你的個人資料看起來應該會很火。 🔥 我建議您做的最後一件事就是完成您的“簡歷”。 當您進入個人資料頁面時,請轉到照片下方的左側,然後按一下「編輯個人資料」。  加入您自己的簡短描述,然後您就可以開始了! --- 現在就這樣。 😄 我希望您對**您精美的 GitHub 個人資料**感到滿意! 💅 我必須強調,我的個人資料還遠遠不是世界上最好的... 然而,有了這些免費工具,您將能夠自訂一個奇妙的新設定檔! 這就是為什麼我想先睹為快,並從您將建立的酷炫設定檔中獲得靈感! 👀 `在評論部分分享您全新的個人資料! 🙌` 下週見。 你的開發夥伴, 巴巴💚 --- 如果您想加入開源中自稱「最酷」的伺服器😝,您應該加入我們的[discord伺服器](https://discord.com/invite/ChAuP3SC5H/?utm_source=devto&utm_campaign=beautify_github_profile)。我們隨時為您的開源之旅提供協助。 🫶 [https://dev.to/quine](https://dev.to/quine) --- 原文出處:https://dev.to/quine/7-tips-to-build-your-github-profile-like-a-pro-38bg
我是播客的忠實粉絲,這是最被低估的純粹知識資源。播客已成為學習和娛樂領域的革命性媒介。近年來,它們從小眾聽眾的愛好轉變為主流媒體形式。 向兩個或更多經驗豐富的人學習談論特定主題,討論他們在做某事時面臨的挑戰,並分享他們的旅程是很有趣的。 它為解決特定問題和建立獨特的解決方案提供了令人難以置信的見解。您將了解: - 不同的心態以及其他人如何看待事物。 - 人們用來解決問題的各種工具。 - 傑出人物和他們的故事以及他們如何解決特定問題。 - 走出精神泡泡並開始以不同的方式看待事物。 另一個好處是,你透過聽這些播客所獲得的知識會成為你的潛在知識或隱性知識庫。 因此,當您面臨類似領域的挑戰時,從播客中獲得的知識可以為您提供一些時間或路線圖來建立應對挑戰的解決方案。 身為人工智慧愛好者,在知識和資料領域工作。我選擇了 [Vector Podcast](https://www.youtube.com/@VectorPodcast),因為我對向量資料庫和向量搜尋、它們如何幫助公司建立基於人工智慧的產品等感到好奇。 以下是我推薦的 8 個最佳播客,您可以收聽。 _我正在提供他們的 YouTube 頻道,假設每個人都知道並使用 YouTube。其中大多數也出現在 Apple Podcast、Spotify 等上_ ## [向量播客](https://www.youtube.com/@VectorPodcast)  Vector Podcast 是 Dmitry Kan 博士的創意。研究生研究科學家涉足產品管理和創業。他也曾在赫爾辛基大學講課。 他在搜尋引擎領域、人工智慧和軟體開發領域擁有超過 15 年的經驗,並採訪了人工智慧領域的專業人士和執行長。 一些值得注意的情節是: - 與 Swirl 執行長 Sid Probstein 一起進行搜尋。 - 向量資料庫以及 Weviate 執行長 Bob van Luijt。 - 康納肖頓的搜尋未來。 https://www.youtube.com/@VectorPodcast ## [萊克斯‧弗里德曼](https://www.youtube.com/c/lexfridman)  萊克斯·弗里德曼(Lex Fridman)是一位受歡迎的人物,正因為如此,他可以接待許多著名人物、首席執行官、領導人和頂尖研究人員。把他們帶到麥克風桌前問他們問題(他很擅長這一點。) 他採訪過的一些著名人士包括 Sam Altman、Elon Musk、Guido van Rossum(Python 語言的建立者)、Stephen Wolfram 和 [Goose](https://www.youtube.com/watch?v=QqRV5FD8ob4)。 他也是機器學習講師,您可以在此[播放清單](https://www.youtube.com/playlist?list=PLe8HThjUpqadLD-AewSKkhAyW5Nr4Yq4Z)中查看他們。 ## [知識專案](https://www.youtube.com/@tkppodcast)  知識專案播客由法納姆街的 Shane Parrish 主持,揭示了其他人已經發現的最好的東西,以便您可以將他們的見解應用到您的生活中。 肖恩·帕里什 (Shane Parrish) 的播客和見解無疑令人驚嘆。你必須經歷知識專案才能很好地理解它。 ## [語法](https://www.youtube.com/@syntaxfm)  來自 30 Days of JavaScript 的 Wes Bos。該播客討論 JavaScript 和 Web 開發。 它涵蓋了一些有趣的主題,從 Web 開發的新功能到 JavaScript 測試和其他主題。 ## [本週機器學習 (TWIML)](https://www.youtube.com/@twimlai)  與 Sam 一起探索人工智慧的最新趨勢和突破,討論將人工智慧驅動的產品推向市場的實際挑戰,並研究人工智慧技術與商業和消費者應用的交叉點。 這個播客不只是一次對話;更是一次對話。它是理解和利用機器學習和人工智慧的全部潛力來改善我們的生活和社區的門戶。我非常喜歡這個播客! ## [變更日誌](https://www.youtube.com/@Changelog)  變更日誌不只是播客的集合;這是一個充滿活力的社區,為處於各個階段的開發者提供豐富的資源。 無論您是經驗豐富的專業人士、好奇的初學者,還是介於兩者之間,我們的節目和資源都會提供與開發人員體驗產生共鳴的寶貴見解、討論和故事。 ## [談 Python](https://www.youtube.com/@talkpython)  Talk Python to Me 是由 Michael Kennedy 主持的每周播客。本節目涵蓋各種 Python 和相關主題(例如 MongoDB、AngularJS、DevOps)。 ## [超越編碼](https://www.youtube.com/@BeyondCoding)  帕特里克·阿基爾 (Patrick Akil) 和他的客人分享了他們的旅程和觀點,供您隨身攜帶並形成自己的旅程和觀點。 Beyond Coding 是一個每周播客,以爐邊聊天的形式進行「超越編碼」的對話。典型的主題是軟體工程、領導力、溝通、自我提升和幸福。 --- 💡***有趣的事實:*** 您知道「播客」來自 iPod 和廣播的融合嗎? ## 結論 我希望您喜歡本文中介紹的播客清單。如果您有任何建議,請隨時在評論中分享。 **在 YouTube 上查看向量播客** 我們致力於為您提供有關人工智慧、大型語言模型等方面的一流內容。 嵌入 https://www.youtube.com/watch?v=vhQ5LM5pK_Y https://www.youtube.com/@VectorPodcast 謝謝閱讀。 --- 原文出處:https://dev.to/vectorpodcast/these-8-podcasts-will-help-increase-your-knowledge-and-expand-your-mindset-5lb
您是否想過如何使用 python 測試您的 API?在本文中,我們將學習如何使用 Python 和 pytest 框架來測試我們的 API。 對於本教程,您需要安裝 python,您可以在[此處](https://www.python.org/downloads/)下載它 --- ### 簡介: - [什麼是 Python 和 Pytest 框架](#what-is-python-and-pytest-framework) - [我們專案的設定](#configuration-of-our-project) - [使用python建立虛擬環境](#creation-of-virtual-environment-with-python) - [測試的依賴關係設定](#setup-of-dependency-for-the-tests) - [建立我們的第一個測試](#creating-our-first-test) - [將被測試的 API 的定義](#definition-of-the-api-that-will-be-tested) - [建立我們的測試](#creating-our-test) - [重建我們的測試](#refactoring-our-tests) - [產生 html 報告結果](#generate-html-report-result) - [結論](#conclusion) --- ## 什麼是 Python 和 Pytest 框架 「Python」是一種高級通用程式語言,以其簡單性和可讀性而聞名。它由 Guido van Rossum 建立,於 1991 年首次發布。 Python 的設計易於學習,並且具有乾淨簡潔的語法,這使其成為初學者和經驗豐富的程式設計師的流行選擇。 「pytest」框架可以輕鬆編寫小型、可讀的測試,並且可以擴展以支援應用程式和程式庫的複雜功能測試。 --- ## 我們專案的配置 ### 用python建立虛擬環境 在開始建立之前,我們先來了解一下什麼是Python上的虛擬環境。 Python 中的虛擬環境是一個獨立的目錄或資料夾,可讓您為專案建立和管理隔離的 Python 環境。透過環境,您可以輕鬆管理依賴項,避免與不同版本的 python 發生衝突。 虛擬環境(除其他外)是: - 用於包含支援專案(庫或應用程式)所需的特定 Python 解釋器以及軟體庫和二進位檔案。預設情況下,它們與其他虛擬環境中的軟體以及作業系統中安裝的 Python 解釋器和庫隔離。 - 包含在專案目錄中的目錄中,通常名為“venv”或“.venv”,或在許多虛擬環境的容器目錄下,例如“~/.virtualenvs”。 - 未簽入原始碼控制系統(例如 Git)。 - 被認為是一次性的 - 應該很容易刪除並從頭開始重新建立它。您沒有在環境中放置任何專案程式碼 - 不被視為可移動或可複製 - 您只需在目標位置重新建立相同的環境。 您可以在[此處](https://docs.python.org/3/library/venv.html#venv-def)閱讀有關 python 環境的更多資訊。 #### 視窗 首先,為您的專案建立一個資料夾,然後打開 cmd 並使用命令 cd 導航到該資料夾: ``` cd tests_with_python ``` 如果您不知道資料夾在哪裡,可以執行命令“ls”,您將看到資料夾列表,並且可以瀏覽它們。在我們的專案資料夾中,執行以下命令: ``` python -m venv name_of_environment ``` 您的環境名稱可以是任何人,只需記住python 區分大小寫,請查看[PEP 8 風格指南](https://peps.python.org/pep-0008/) 以了解有關Python 約定的更多資訊. 要啟動我們的環境,我們使用以下命令: ``` name_of_environment\Scripts\Activate ``` 如果一切正確,您的環境將被激活,並且在 cmd 上您將看到如下所示: ``` (name_of_environment) C:\User\tests ``` 要停用您的環境,只需執行: ``` deactivate ``` #### Linux 或 MacOS 為您的專案建立一個資料夾,然後打開 cmd 並使用命令 cd 導航到該資料夾: ``` cd tests_with_python ``` 要啟動我們的環境,我們使用以下命令: ``` source name_of_environment/bin/activate ``` 如果一切正確,您的環境將被激活,並且在 cmd 上您將看到如下所示: ``` (name_of_environment) your_user_name tests % ``` 要停用您的環境,只需執行: ``` deactivate ``` ### 設定測試的依賴關係 當我們要測試 API 時,我們需要安裝依賴項來幫助我們進行測試,首先我們將安裝「requests」函式庫來幫助我們發出請求: PS:在執行此命令之前請確保您的環境已激活 ``` pip install requests ``` 為了進行測試,我們將安裝「pytests」框架: ``` pip install pytest ``` --- ## 建立我們的第一個測試 ### 將要測試的 API 的定義 在本教程中,我們將使用返回小行星列表的 Nasa API:[Asteroids - NeoWs](https://api.nasa.gov/#donkiGST),我們將測試檢索基於小行星列表的端點在他們最接近地球的日期。 關於API: - 基本網址:`https://api.nasa.gov/neo/rest/v1/feed` - 查詢參數: |參數|類型|預設|描述| | --------|---------|--------|--------------------| |start_date|YYYY-MM-DD|無|小行星搜尋的開始日期| |end_date|YYYY-MM-DD|start_date後7天|小行星搜尋的結束日期| |api_key|字串|DEMO_KEY|用於擴展用途的 api.nasa.gov 密鑰| 在本教程中,我們將重點放在三種類型的測試: - 合約:如果 API 能夠驗證傳送的查詢參數 - 狀態:狀態程式碼是否正確 - 身份驗證:即使這個API不需要令牌,我們也可以用它來做測試 我們的場景: |方法|測試|預期結果 | | --------|--------|--------------------| |獲取 |搜尋成功 | - 傳回狀態程式碼 200<br/> 正文回應包含小行星清單| |獲取 |無需任何查詢參數即可搜尋 | - 返回狀態碼403<br/>| |獲取 |僅搜尋開始日期| - 傳回狀態程式碼 200 <br/> 主體回應包含小行星清單| |獲取 |僅搜尋結束日期| - 傳回狀態程式碼 200 <br/> 主體回應包含小行星清單| |獲取 |在有效日期範圍內搜尋| - 傳回狀態碼 200<br/> - 正文回應包含所有非空白欄位| |獲取 |當開始日期大於結束日期時進行搜尋| - 傳回狀態程式碼 400 <br/>| |獲取 |使用無效的 API 令牌進行搜尋| - 傳回狀態程式碼 403 <br/> 主體回應包含小行星清單| ### 建立我們的測試 首先,我們將建立一個名為「tests.py」的文件,我們將在該文件中編寫測試。為了幫助我們使用良好的實踐並編寫良好的自動化測試,讓我們使用 [TDD(測試驅動開發)](https://www.browserstack.com/guide/what-is-test-driven-development?psafe_param=1?keyword=&campaignid=&adgroupid=&adid=8784011037660164696&utm_source=google&utm_medium=cpc&utm_platform=paidads&utm_content=602353912717&utm_campapaidads&utm_content=602353912717&utm_campa.utm_term=+&gad_source=1&gclid=CjwKCAiAxreqBhAxEiwAfGfndN8P705lwnkvEFnCz_lueR2hnhmZXgboBQEtKTaCIRbhcb1SXOxBYhoC-WoQAD_BwwE)技術。 該技術包括: - 紅色 - 進行失敗的測試 - 綠色 - 使此測試通過 - 重構 - 重構所做的事情,刪除重複的內容 為了編寫一套好的測試,我們將使用 3A 技術: - 安排:準備上下文。 - 行動:執行我們想要示範的行動。 - 斷言:表明我們預期的結果確實發生了。 從紅色開始,使用 3A 技術,我們將編寫第一個測試「成功搜尋小行星」: ``` import pytest def test_search_asteroids_with_sucess(): # Arrange: api_key = "DEMO_KEY" #Act: response = make_request(api_key) #Assertion: assert response.status_code == 200 # Validation of status code data = response.json() # Assertion of body response content: assert len(data) > 0 assert data["element_count"] > 0 ``` - 安排:我們建立一個變數來插入 api_key,在此步驟中,您可以插入執行測試所需的任何資料。通常,在這一步驟我們會建立模擬資料。 - Act:在這一步驟中我們呼叫了負責發出請求的方法 - 斷言:我們驗證回應 `方法或類別的名稱應以 test 開頭` 若要執行我們的測試,請在命令提示字元中執行: ``` pytest test.py ``` 我們將收到一個錯誤,因為我們沒有建立執行請求的方法: ``` test.py F [100%] ====================================================================== FAILURES ====================================================================== _________________________________________________________ test_search_asteroids_with_sucess __________________________________________________________ def test_search_asteroids_with_sucess(): > response = make_request() E NameError: name 'make_request' is not defined test.py:5: NameError ============================================================== short test summary info =============================================================== FAILED test.py::test_search_asteroids_with_sucess - NameError: name 'make_request' is not defined ================================================================= 1 failed in 0.01s ================================================================== ``` 現在,讓我們建立方法來執行請求: ``` import requests def make_request(api_key): base_url = "https://api.nasa.gov/neo/rest/v1/feed/" response = requests.get(f'{base_url}?api_key={api_key}') return response ``` 現在,再次執行我們的測試: ``` ================================================================ test session starts ================================================================= platform darwin -- Python 3.11.5, pytest-7.4.3, pluggy-1.3.0 rootdir: /Users/Documents/tests_python collected 1 item test.py . [100%] ================================================================= 1 passed in 20.22s ================================================================= ``` --- ## 重構我們的測試 現在我們已經了解如何使用 pytest 建立測試以及如何建立請求,我們可以編寫其他測試並開始重構測試。我們要做的第一個重構是從測試文件中刪除請求方法。我們將建立一個名為「make_requests.py」的新文件,其中將包含我們的請求,並將我們所做的請求移至此文件: ``` import requests def make_request(api_key): base_url = "https://api.nasa.gov/neo/rest/v1/feed/" response = requests.get(f'{base_url}?api_key={api_key}') return response ``` 現在,我們需要考慮在其他測試中重複使用此方法,因為我們需要為不同的測試傳遞不同的參數。我們可以透過很多方法來做到這一點,在本教程中,我們將參數的名稱從“api_key”更改為“query_parameters”。我們這樣做是為了讓我們的方法更加靈活,我們可以一次傳遞參數進行測試: ``` import requests def make_request(query_parameters): base_url = "https://api.nasa.gov/neo/rest/v1/feed/" response = requests.get(f'{base_url}?{query_parameters}') return response ``` 之後,我們需要更改我們的測試文件。我們將導入我們建立的這個方法: ``` from make_requests import make_request ``` 為了以更好的方式組織我們的測試,並遵循 pytest 文件的建議,我們將測試移至類別「TestClass」: 再次執行我們的測試: ``` ============================= test session starts ============================== collecting ... collected 7 items test.py::TestClass::test_search_asteroids_with_sucess test.py::TestClass::test_search_asteroids_with_query_parameters_empty test.py::TestClass::test_search_asteroids_with_start_date test.py::TestClass::test_search_asteroids_with_end_date test.py::TestClass::test_search_asteroids_in_valid_range test.py::TestClass::test_search_asteroids_in_invalid_range test.py::TestClass::test_search_asteroids_in_invalid_token ============================== 7 passed in 5.85s =============================== PASSED [ 14%]PASSED [ 28%]PASSED [ 42%]PASSED [ 57%]PASSED [ 71%]PASSED [ 85%]PASSED [100%] Process finished with exit code 0 ``` ### 產生 html 報告結果 為了更好地視覺化您的測試結果,我們可以使用 pytest-html-reporter 庫產生報告 html,為此,我們首先需要安裝該套件: ``` pip install pytest-html ``` 若要產生報告,請在執行測試時新增: ``` pytest test.py --html-report=./report/report.html ``` 將產生一個包含測試結果的 .html 文件,如下所示:  ## 結論 本文是一篇教程,介紹如何開始使用 python 和 pytest 框架為 API 編寫自動化測試以及如何產生一個報告 html。 您可以在[此處](https://github.com/aliciamarianne1507/tests_python)存取本教學中使用的專案。 我希望這些內容對您有用。 如果您有任何疑問,請隨時與我聯繫! 親親,下週見💅🏼 --- 原文出處:https://dev.to/m4rri4nne/automating-your-api-tests-using-python-and-pytest-23cc
## **簡介** 在本文中,我將為您提供適用於任何機器學習專案的終極 Python 庫: - 機器學習週期每個步驟必須了解的函式庫 - EDA、資料清理、資料工程、建模等… - 全部開源 - 所有蟒蛇  --- ## 完整的應用程式 ### 1. 🚀[Taipy](https://github.com/Avaiga/taipy) 讓我們先討論一些經常被忽視的事情——實際上讓你的模型易於存取和有用。 Taipy 將會做到這一點,並將您的機器學習模型提升到一個新的水平。 它是一個開源程式庫,旨在輕鬆開發前端 (GUI) 和 ML/資料管道。不需要其他知識(沒有 CSS,什麼都不需要!)。它旨在加快應用程式開發,從最初的原型到生產就緒的應用程式。  Taipy 確保您的 ML 模型可以進入成熟的試點和應用程式,給您的最終用戶留下深刻的印象。 ---  https://github.com/Avaiga/taipy 我們已經快有 1000 顆星了,沒有你就無法做到這一點🙏 --- ## EDA、資料清理和資料工程 ### 2.🐼[Pandas](https://github.com/pandas-dev/pandas) 如何在不了解 Pandas 的情況下使用 Python 進行編碼? 該庫有兩個核心資料結構:資料幀和系列,允許快速靈活的資料清理和準備。基本功能包括: - 載入資料中 - 重塑資料框 - 基本統計 Pandas 是啟動資料科學計畫的工具。 其他並發試圖超越 Pandas,但沒有像 Dask 或 Polars 那樣廣泛使用。 *這是未來文章的好主題!*  --- ### 3.🌱[Numpy](https://github.com/numpy/numpy) Numpy 雖然等級比 Pandas 低,但它是科學計算和資料預處理的必備工具。 它圍繞著陣列發展,並允許快速資料操作和數學函數。 該函式庫是另一個必須了解的 Python 函式庫,與 Pandas 一樣,也是以資料為中心的任務的必備函式庫。  --- ### 4.🔢[統計模型](https://github.com/statsmodels/statsmodels) 顧名思義,該函式庫提供了統計分析函數。 一系列功能涵蓋從描述性分析到統計測試;它也是一個處理時間序列資料、單變數和多元統計資料等的優秀函式庫。  --- ### 5.👓[YData Profiling](https://github.com/ydataai/ydata-profiling) YData Profiling 透過一行程式碼徹底分析資料來促進 EDA 步驟。 分析包括缺失值檢測、相關性、分佈分析等。 該工具非常用戶友好且簡單,可以輕鬆加入到您的資料科學工具箱中。  --- ## 機器學習/深度學習演算法 ### 6.💼 [Scikit-learn](https://github.com/scikit-learn/scikit-learn) 這可能是 Python 最著名的 3 個函式庫,這是理所當然的。 Sklearn 是機器學習領域的參考書。它包括不同的模型,例如 K 均值聚類、回歸和分類演算法。 它在降維技術方面也很出色。 Sklearn也提供資料選擇和驗證功能。它易於學習/使用,應該成為您資料科學之旅中的首選 ML 庫。  --- ### 7.🧠 [Keras](https://github.com/keras-team/keras) Keras 是一個高階 API,運作在 TensorFlow 等框架之上。如果從神經網路開始,請從 Keras 開始。它非常適合快速實施,因為它簡化了實施過程,使其成為神經網路實施的最佳初學者友善選項。  --- ### 8.🧠💪[TensorFlow](https://github.com/tensorflow/tensorflow) 這個庫是神經網路建模必須知道的。非常適合處理影像分類或 NLP(自然語言處理)等非結構化資料。 TensorFlow 廣泛應用於研究和工業領域,因為它為神經網路的設計和操作提供了完整的 API。 Keras(上面提到的)提供了一個更高層級(更簡單)的 API(它是建構在 TensorFlow 之上)。  --- ### 9.🌴[XGBoost](https://github.com/dmlc/xgboost) XGBoost 是有關機器學習演算法的最受歡迎的函式庫之一。 這個梯度提升庫廣泛用於現實生活中的用例,特別是表格資料。 它是 Kaggle 競賽獲勝者的最愛。 該庫包括回歸和分類演算法,但也提供特徵選擇工具。  --- ### 10.🐈[CatBoost](https://github.com/catboost/catboost) 如果您的資料集主要由分類資料組成,那麼這個函式庫代表分類提升(Categorical Boosting),它是您的最佳選擇。該庫將規避一種熱編碼的複雜性,從而無需預處理分類資料。當使用預設參數執行時,它可以提供比 XGBoost 更好的精度。  --- 希望您喜歡這篇文章! 我是一名新手作家,歡迎任何改進建議!  如果您有任何疑問,請隨時與我們聯繫。 --- 原文出處:https://dev.to/taipy/top-10-python-libraries-for-any-ml-projects-3gfp
你的轉職路上,還缺少一份自學作業包!寫完這幾包,直接拿作品去面試上班!
本論壇另有附設一個 LINE 新手發問&交流群組!歡迎加入討論!


























