本文將透過一個簡單的範例來示範如何**將 PySpark 與 Taipy 整合**,以將您的 **大資料處理需求** 與 **智慧作業執行** 結合。 #### 讓我們開始吧!  <小時/> ### 將 PySpark 與 Taipy 結合使用 Taipy 是一個**強大的工作流程編排工具**,具有**易於使用的框架**,可輕鬆應用於您現有的資料應用程式。 Taipy 建立在堅實的概念基礎上: - **場景、任務和資料節點** - 這些概念非常強大,允許開發人員**輕鬆地對其管道進行建模**,即使在沒有明確支援的情況下使用第3 方包也是如此。 <小時/>  {% cta https://github.com/Avaiga/taipy %} Star ⭐ Taipy 儲存庫 {% endcta %} 我們感謝任何幫助我們發展社區的幫助🌱 <小時/> *如果您已經熟悉 PySpark 和 Taipy,則可以跳至「2. Taipy 設定 (*config.py*)」。 *該部分深入探討了為 Taipy 任務定義函數來執行 PySpark 應用程式的本質。否則,請繼續閱讀!* <小時/> ### 一個簡單的例子:*palmerpenguins* 我們以 [palmerpenguins](https://allisonhorst.github.io/palmerpenguins/) 資料集為例: ``` >>> penguin_df ┌───────┬─────────┬───────────┬────────────────┬───────────────┬───────────────────┬─────────────┬────────┬──────┐ │ index │ species │ island │ bill_length_mm │ bill_depth_mm │ flipper_length_mm │ body_mass_g │ sex │ year │ ├───────┼─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼──────┤ │ 0 │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181.0 │ 3750.0 │ male │ 2007 │ │ 1 │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186.0 │ 3800.0 │ female │ 2007 │ │ 2 │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195.0 │ 3250.0 │ female │ 2007 │ │ 3 │ Adelie │ Torgersen │ NaN │ NaN │ NaN │ NaN │ NaN │ 2007 │ │ 4 │ Adelie │ Torgersen │ 36.7 │ 19.3 │ 193.0 │ 3450.0 │ female │ 2007 │ │ ... │ ... │ ... │ ... │ ... │ ... │ ... │ ... │ ... │ └───────┴─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴──────┘ ``` <小時/> 該資料集僅包含 344 筆記錄——幾乎不是一個需要 Spark 處理的資料集。 然而,該資料集是可存取的,且其大小與演示 Spark 與 Taipy 的整合無關。 如果必須使用更大的資料集進行測試,您可以根據需要多次複製資料。 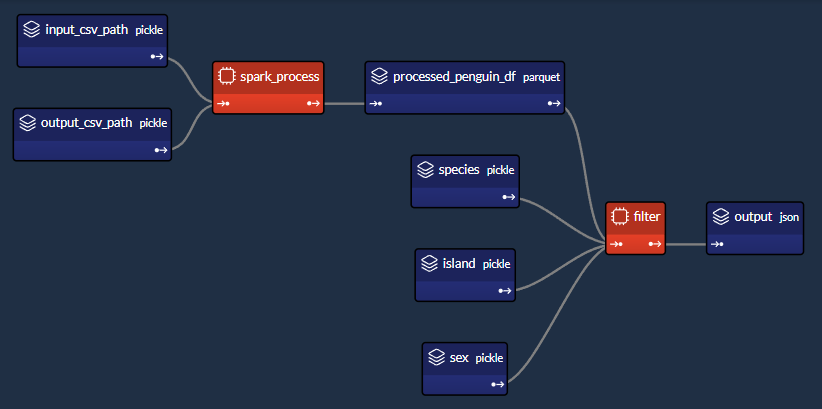 *我們簡單的企鵝應用程式的 DAG* <小時/> 我們將設計一個執行**兩個主要任務**的工作流程: #### 1- Spark 任務(*spark_process*): - 載入資料; - 依「*物種*」、「*島嶼*」和「*性別*」將資料分組; - 求其他欄位的平均值(「*bill_length_mm*」、「*bill_depth_mm*」、「*flipper_length_mm*」、「*body_mass_g*」); - 儲存資料。 #### 2- Python 任務(*過濾器*): - 載入Spark任務之前儲存的輸出資料; - 給定“*物種*”、“*島嶼*”和“*性別*”,傳回聚合值。 我們的小專案將包含 4 個檔案: ``` app/ ├─ penguin_spark_app.py # the spark application ├─ config.py # the configuration for our taipy workflow ├─ main.py # the main script (including our application gui) ├─ penguins.csv # the data as downloaded from the palmerpenguins git repo ``` <小時/> 您可以找到每個檔案的內容(*penguins.csv* 除外,您可以從 [palmerpenguins 儲存庫](https://github.com/allisonhorst/palmerpenguins/blob/main/inst/extdata/penguins.csv 取得) )在本文的程式碼區塊中。 <小時/> ## 1. Spark 應用程式 (*penguin_spark_app.py*) 通常,我們使用 *spark-submit* 命令列實用程式來執行 PySpark 任務。 您可以在他們自己的文件中閱讀有關以這種方式提交Spark 作業的內容和原因的更多資訊[此處](https://spark.apache.org/docs/latest/submitting-applications.html) 。 當使用 Taipy 進行工作流程編排時,我們可以繼續做同樣的事情。 唯一的區別是,我們不是在命令列中執行命令,而是讓工作流程管道產生一個[子進程](https://docs.python.org/3/library/subprocess.html),它使用以下命令執行Spark 應用程式*火花提交*。 在開始討論之前,我們首先**看看我們的 Spark 應用程式**。 只需瀏覽一下程式碼,然後**繼續閱讀有關此腳本功能的簡短說明**: ``` ### app/penguin_spark_app.py import argparse import os import sys parser = argparse.ArgumentParser() parser.add_argument("--input-csv-path", required=True, help="Path to the input penguin CSV file.") parser.add_argument("--output-csv-path", required=True, help="Path to save the output CSV file.") args = parser.parse_args() import pyspark.pandas as ps from pyspark.sql import SparkSession def read_penguin_df(csv_path: str): penguin_df = ps.read_csv(csv_path) return penguin_df def clean(df: ps.DataFrame) -> ps.DataFrame: return df[df.sex.isin(["male", "female"])].dropna() def process(df: ps.DataFrame) -> ps.DataFrame: """The mean of measured penguin values, grouped by island and sex.""" mean_df = df.groupby(by=["species", "island", "sex"]).agg("mean").drop(columns="year").reset_index() return mean_df if __name__ == "__main__": spark = SparkSession.builder.appName("Mean Penguin").getOrCreate() penguin_df = read_penguin_df(args.input_csv_path) cleaned_penguin_df = clean(penguin_df) processed_penguin_df = process(cleaned_penguin_df) processed_penguin_df.to_pandas().to_csv(args.output_csv_path, index=False) sys.exit(os.EX_OK) ``` <小時/> 我們可以透過在終端機中輸入以下命令來提交此 Spark 應用程式以供執行: ``` spark-submit --master local[8] app/penguin_spark_app.py \ --input-csv-path app/penguins.csv \ --output-csv-path app/output.csv ``` <小時/> 它將執行以下操作: 1.提交*penguin_spark_app.py*應用程式在8個CPU核心上本地執行; 2. 從 *app/penguins.csv* CSV 檔案載入資料; 3. 依「*物種*」、「*島嶼*」和「*性別*」分組,然後按平均值聚合其餘欄位; 4. 將產生的 DataFrame 儲存到 *app/output.csv*。 此後,*app/output.csv* 的內容應如下所示: 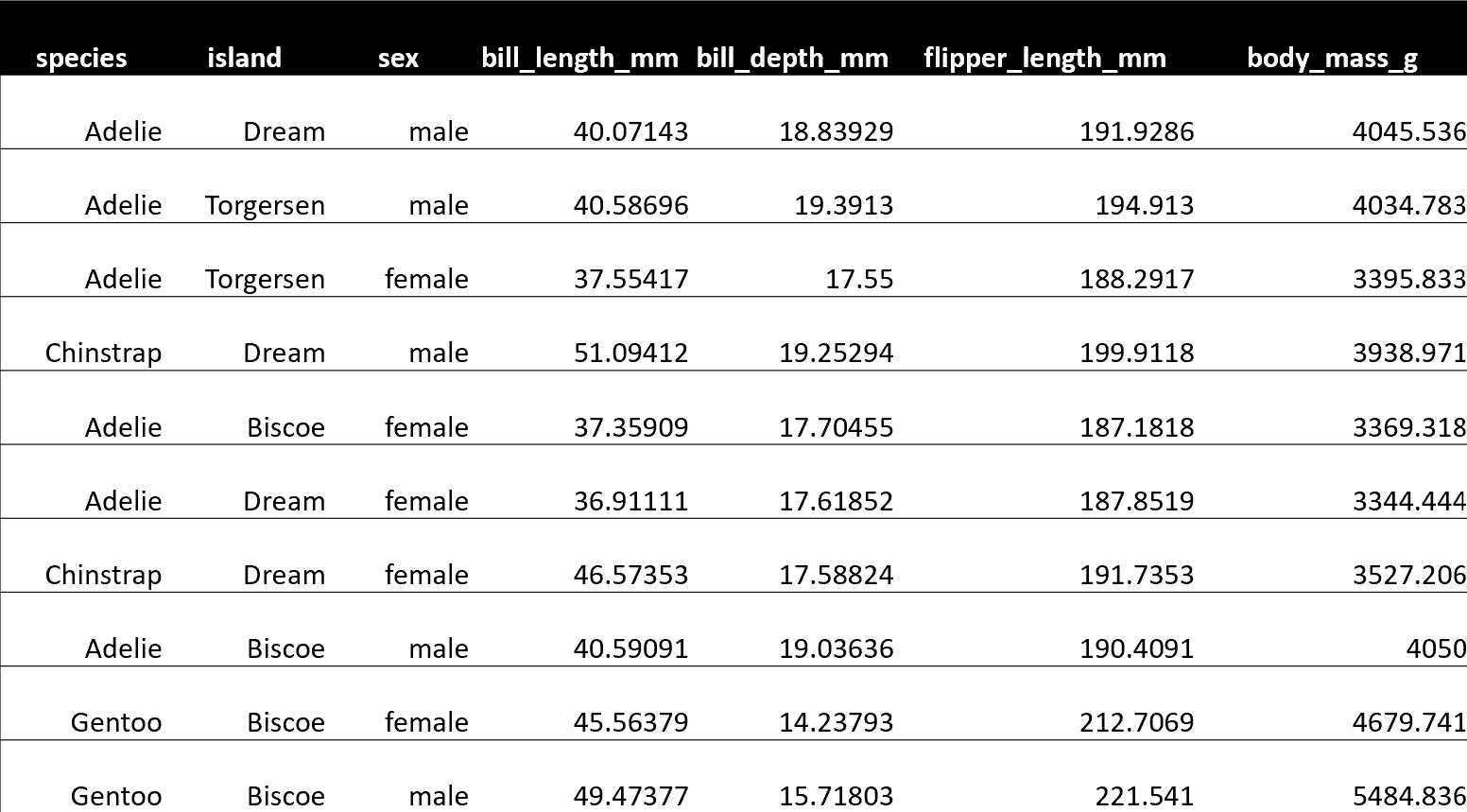 <小時/> 另請注意,我們已對 **Spark 應用程式進行了編碼以接收 2 個命令列參數**: 1. - *input-csv-path* :輸入企鵝 CSV 檔案的路徑;和 2. - *output-csv-path* :Spark 應用程式處理後儲存輸出 CSV 檔案的路徑。 <小時/> ## 2. Taipy 設定 (*config.py*) 此時,我們有了 *penguin_spark_app.py* PySpark 應用程式,並且需要建立一個 **Taipy 任務來執行此 PySpark 應用程式**。 再次快速瀏覽 *app/config.py* 腳本,然後繼續閱讀: ``` ### app/config.py import datetime as dt import os import subprocess import sys from pathlib import Path import pandas as pd import taipy as tp from taipy import Config SCRIPT_DIR = Path(__file__).parent SPARK_APP_PATH = SCRIPT_DIR / "penguin_spark_app.py" input_csv_path = str(SCRIPT_DIR / "penguins.csv") # -------------------- Data Nodes -------------------- input_csv_path_cfg = Config.configure_data_node(id="input_csv_path", default_data=input_csv_path) # Path to save the csv output of the spark app output_csv_path_cfg = Config.configure_data_node(id="output_csv_path") processed_penguin_df_cfg = Config.configure_parquet_data_node( id="processed_penguin_df", validity_period=dt.timedelta(days=1) ) species_cfg = Config.configure_data_node(id="species") # "Adelie", "Chinstrap", "Gentoo" island_cfg = Config.configure_data_node(id="island") # "Biscoe", "Dream", "Torgersen" sex_cfg = Config.configure_data_node(id="sex") # "male", "female" output_cfg = Config.configure_json_data_node( id="output", ) # -------------------- Tasks -------------------- def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame: proc = subprocess.Popen( [ str(Path(sys.executable).with_name("spark-submit")), str(SPARK_APP_PATH), "--input-csv-path", input_csv_path, "--output-csv-path", output_csv_path, ], stdout=subprocess.PIPE, stderr=subprocess.PIPE, ) try: outs, errs = proc.communicate(timeout=15) except subprocess.TimeoutExpired: proc.kill() outs, errs = proc.communicate() if proc.returncode != os.EX_OK: raise Exception("Spark training failed") df = pd.read_csv(output_csv_path) return df def filter(penguin_df: pd.DataFrame, species: str, island: str, sex: str) -> dict: df = penguin_df[(penguin_df.species == species) & (penguin_df.island == island) & (penguin_df.sex == sex)] output = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]].to_dict(orient="records") return output[0] if output else dict() spark_process_task_cfg = Config.configure_task( id="spark_process", function=spark_process, skippable=True, input=[input_csv_path_cfg, output_csv_path_cfg], output=processed_penguin_df_cfg, ) filter_task_cfg = Config.configure_task( id="filter", function=filter, skippable=True, input=[processed_penguin_df_cfg, species_cfg, island_cfg, sex_cfg], output=output_cfg, ) scenario_cfg = Config.configure_scenario( id="scenario", task_configs=[spark_process_task_cfg, filter_task_cfg] ) ``` 您也可以**使用[Taipy Studio](https://docs.taipy.io/en/latest/manuals/studio/config/)** 建立Taipy 配置,這是一個Visual Studio Code 擴展,它提供了圖形編輯器建構 Taipy *.toml* 設定檔。 <小時/> ### Taipy 中的 PySpark 任務 我們對產生這部分 DAG 的程式碼部分特別感興趣: 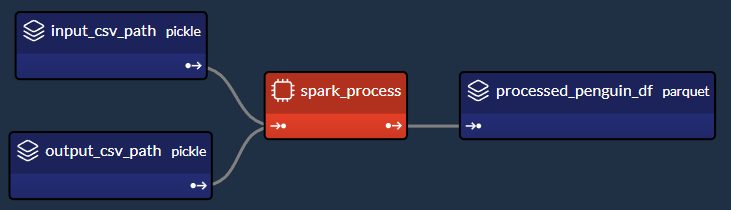 <小時/> 讓我們提取並檢查 *config.py* 腳本的相關部分,該腳本在 Taipy 中建立「*spark_process*」Spark 任務(及其 3 個關聯的資料節點),如上圖所示: ``` ### Code snippet: Spark task in Taipy # -------------------- Data Nodes -------------------- input_csv_path_cfg = Config.configure_data_node(id="input_csv_path", default_data=input_csv_path) # Path to save the csv output of the spark app output_csv_path_cfg = Config.configure_data_node(id="output_csv_path") processed_penguin_df_cfg = Config.configure_parquet_data_node( id="processed_penguin_df", validity_period=dt.timedelta(days=1) ) # -------------------- Tasks -------------------- def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame: proc = subprocess.Popen( [ str(Path(sys.executable).with_name("spark-submit")), str(SPARK_APP_PATH), "--input-csv-path", input_csv_path, "--output-csv-path", output_csv_path, ], stdout=subprocess.PIPE, stderr=subprocess.PIPE, ) try: outs, errs = proc.communicate(timeout=15) except subprocess.TimeoutExpired: proc.kill() outs, errs = proc.communicate() if proc.returncode != os.EX_OK: raise Exception("Spark training failed") df = pd.read_csv(output_csv_path) return df spark_process_task_cfg = Config.configure_task( id="spark_process", function=spark_process, skippable=True, input=[input_csv_path_cfg, output_csv_path_cfg], output=processed_penguin_df_cfg, ) ``` <小時/> 由於我們設計 *penguin_spark_app.py* Spark 應用程式來接收 2 個參數(*input_csv_path* 和 *output_csv_path*),因此我們選擇將這 2 個參數表示為 Taipy 資料節點。 請注意,**您的用例可能有所不同,您可以(並且應該!)根據您的需求修改任務、函數和關聯的資料節點**。 例如,您可以: 1. 有一個 Spark 任務,執行一些例行 ETL 並且不回傳任何內容; 2. 偏好對輸入和輸出路徑進行硬編碼,而不是將它們持久化為資料節點;或者 3. 將其他應用程式參數儲存為資料節點並將其傳遞給 Spark 應用程式。 然後,我們將 *spark-submit* 作為 Python 子進程執行,如下所示: ``` subprocess.Popen( [ str(Path(sys.executable).with_name("spark-submit")), str(SPARK_APP_PATH), "--input-csv-path", input_csv_path, "--output-csv-path", output_csv_path, ], ) ``` <小時/> 回想一下,清單元素的順序應保留以下格式,就像它們在命令列上執行一樣: ``` $ spark-submit [spark-arguments] <pyspark-app-path> [application-arguments] ``` <小時/> 同樣,根據我們的用例,我們可以根據需要指定不同的 Spark-submit 腳本路徑、Spark 參數(我們在範例中未提供任何參數)或不同的應用程式參數。 <小時/> ### 讀取並回傳*output_csv_path* 請注意,*spark_process* 函數的結束如下: ``` def spark_process(input_csv_path: str, output_csv_path: str) -> pd.DataFrame: ... df = pd.read_csv(output_csv_path) return df ``` <小時/> 在我們的例子中,我們希望 Taipy 任務在 Spark - 處理資料後輸出資料,以便可以將其寫入 *processed_penguin_df_cfg* [Parquet 資料節點](https://docs.taipy.io/en/latest /手冊/核心/配置/資料節點配置/#parquet)。 我們可以做到這一點的一種方法是手動讀取輸出目標(在本例中為 *output_csv_path*),然後將其作為 Pandas DataFrame 傳回。 但是,如果您不需要 Spark 應用程式的返回資料,您可以簡單地讓 Taipy 任務(透過 *spark_process* 函數)返回 *None*。 <小時/> ### 快取 Spark 任務 由於我們將 *spark_process_task_cfg* 配置為 *True*,當重新執行該場景時,Taipy 將 **跳過 ** ***spark_process 的重新執行*** **任務** 並重複使用持久化任務輸出:* processed_penguin_df_cfg* Pandas DataFrame。 但是,我們也為 *processed_penguin_df_cfg* 資料節點定義了 1 天的 *validity_period*,因此如果 DataFrame 最後一次快取超過一天,Taipy 仍會重新執行任務。 <小時/> ## 3. 建構 GUI (*main.py*) 我們將透過**建立我們在本文開頭看到的 GUI** 來完成我們的應用程式: 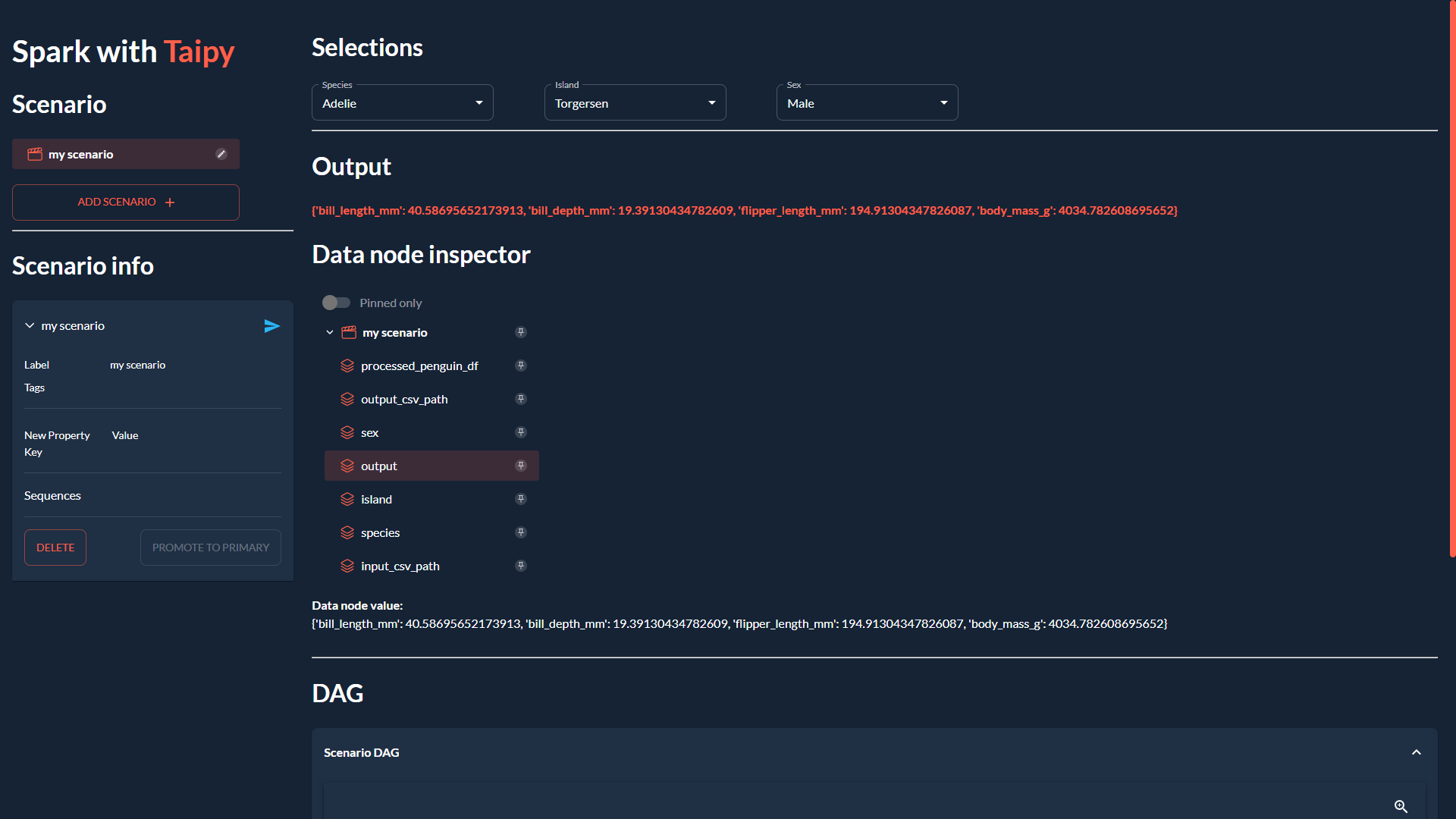 <小時/> 如果您不熟悉 Taipy 的 GUI 功能,可以在此處找到[快速入門](https://docs.taipy.io/en/latest/getting_started/getting-started-gui/)。 無論如何,您只需為 *app/main.py* 複製並貼上以下程式碼,因為它不是我們的重點: ``` ### app/main.py from pathlib import Path from typing import Optional import taipy as tp from config import scenario_cfg from taipy.gui import Gui, notify valid_features: dict[str, list[str]] = { "species": ["Adelie", "Chinstrap", "Gentoo"], "island": ["Torgersen", "Biscoe", "Dream"], "sex": ["Male", "Female"], } selected_species = valid_features["species"][0] selected_island = valid_features["island"][0] selected_sex = valid_features["sex"][0] selected_scenario: Optional[tp.Scenario] = None data_dir = Path(__file__).with_name("data") data_dir.mkdir(exist_ok=True) def scenario_on_creation(state, id, payload): _ = payload["config"] date = payload["date"] label = payload["label"] properties = payload["properties"] # Create scenario with selected configuration scenario = tp.create_scenario(scenario_cfg, creation_date=date, name=label) scenario.properties.update(properties) # Write the selected GUI values to the scenario scenario.species.write(state.selected_species) scenario.island.write(state.selected_island) scenario.sex.write(state.selected_sex.lower()) output_csv_file = data_dir / f"{scenario.id}.csv" scenario.output_csv_path.write(str(output_csv_file)) notify(state, "S", f"Created {scenario.id}") return scenario def scenario_on_submission_change(state, submittable, details): """When the selected_scenario's submission status changes, reassign selected_scenario to force a GUI refresh.""" state.selected_scenario = submittable selected_data_node = None main_md = """ <|layout|columns=1 4|gap=1.5rem| <lhs|part| # Spark with **Taipy**{: .color-primary} ## Scenario <|{selected_scenario}|scenario_selector|on_creation=scenario_on_creation|> ---------- ## Scenario info <|{selected_scenario}|scenario|on_submission_change=scenario_on_submission_change|> |lhs> <rhs|part|render={selected_scenario}| ## Selections <selections|layout|columns=1 1 1 2|gap=1.5rem| <|{selected_species}|selector|lov={valid_features["species"]}|dropdown|label=Species|> <|{selected_island}|selector|lov={valid_features["island"]}|dropdown|label=Island|> <|{selected_sex}|selector|lov={valid_features["sex"]}|dropdown|label=Sex|> |selections> ---------- ## Output **<|{str(selected_scenario.output.read()) if selected_scenario and selected_scenario.output.is_ready_for_reading else 'Submit the scenario using the left panel.'}|text|raw|class_name=color-primary|>** ## Data node inspector <|{selected_data_node}|data_node_selector|display_cycles=False|> **Data node value:** <|{str(selected_data_node.read()) if selected_data_node and selected_data_node.is_ready_for_reading else None}|> <br/> ---------- ## DAG <|Scenario DAG|expandable| <|{selected_scenario}|scenario_dag|> |> |rhs> |> """ def on_change(state, var_name: str, var_value): if var_name == "selected_species": state.selected_scenario.species.write(var_value) elif var_name == "selected_island": state.selected_scenario.island.write(var_value) elif var_name == "selected_sex": state.selected_scenario.sex.write(var_value.lower()) if __name__ == "__main__": tp.Core().run() gui = Gui(main_md) gui.run(title="Spark with Taipy") ``` <小時/> 然後,從專案資料夾中,您可以執行主腳本,如下所示: ``` $ taipy run app/main.py ``` <小時/> ## 結論 現在您已經看到如何將 PySpark 與 Taipy 結合使用的範例,請繼續嘗試使用這兩個工具來**增強您自己的資料應用程式**! 如果您一直在努力應對其他工作流程編排工具減慢您的工作並妨礙您的工作,請不要讓它阻止您嘗試 Taipy。 Taipy 易於使用,並且努力不限制自己可以使用的第 3 方軟體包 - **其強大而靈活的框架使其可以輕鬆適應任何資料應用程式**。 <小時/>  希望您喜歡這篇文章! <小時/> 您可以在此[儲存庫](https://medium.com/r?url=https%3A%2F%2Fgithub.com%2FAvaiga%2Fdemo-pytorch-penguin-app)上找到所有程式碼和資料。 --- 原文出處:https://dev.to/taipy/how-to-master-big-data-pipelines-with-taipy-and-pyspark-14oe
資料管道是任何資料密集型專案的支柱。 **隨著資料集的成長**超出記憶體大小(「核心外」),**有效處理它們變得具有挑戰性**。 Dask 可以輕鬆管理大型資料集(核心外),提供與 Numpy 和 Pandas 的良好相容性。  --- 本文重點介紹 **Dask(用於處理核心外資料)與 Taipy** 的無縫集成,Taipy** 是一個用於 **管道編排和場景管理** 的 Python 庫。 --- ## Taipy - 您的 Web 應用程式建構器 關於我們的一些資訊。 **Taipy** 是一個開源程式庫,旨在輕鬆開發前端 (GUI) 和 ML/資料管道。 不需要其他知識(沒有 CSS,什麼都不需要!)。 它旨在加快應用程式開發,從最初的原型到生產就緒的應用程式。  https://github.com/Avaiga/taipy 我們已經快有 1000 顆星了,沒有你就無法做到這一點🙏 --- ## 1. 範例應用程式 透過範例最好地演示了 Dask 和 Taipy 的整合。在本文中,我們將考慮包含 4 個任務的資料工作流程: - **資料預處理與客戶評分** 使用 Dask 讀取和處理大型資料集。 - **特徵工程和分割** 根據購買行為對客戶進行評分。 - **細分分析** 根據這些分數和其他因素將客戶分為不同的類別。 - **高價值客戶的總統計** 分析每個客戶群以獲得見解 我們將更詳細地探討這 4 個任務的程式碼。 請注意,此程式碼是您的 Python 程式碼,並未使用 Taipy。 在後面的部分中,我們將展示如何使用 Taipy 對現有資料應用程式進行建模,並輕鬆獲得其工作流程編排的好處。 --- 該應用程式將包含以下 5 個檔案: ``` algos/ ├─ algo.py # Our existing code with 4 tasks data/ ├─ SMALL_amazon_customers_data.csv # A sample dataset app.ipynb # Jupyter Notebook for running our sample data application config.py # Taipy configuration which models our data workflow config.toml # (Optional) Taipy configuration in TOML made using Taipy Studio ``` --- ## 2. Taipy 簡介 - 綜合解決方案 [Taipy](https://docs.taipy.io/) **不只是另一個編排工具**。 Taipy 專為 ML 工程師、資料科學家和 Python 開發人員設計,帶來了幾個基本且簡單的功能。 以下是**一些關鍵要素**,使 Taipy 成為令人信服的選擇: 1. **管道執行註冊表** 此功能使開發人員和最終用戶能夠: - 將每個管道執行註冊為「*場景*」(任務和資料節點圖); - 精確追蹤每個管道執行的沿襲;和 - 輕鬆比較場景、監控 KPI 並為故障排除和微調參數提供寶貴的見解。 2. **管道版本控制** Taipy 強大的場景管理使您能夠輕鬆調整管道以適應不斷變化的專案需求。 3. **智能任務編排** Taipy 讓開發人員可以輕鬆地對任務和資料來源網路進行建模。 此功能透過以下方式提供對任務執行的內建控制: - 並行執行您的任務;和 - 任務“跳過”,即選擇要執行的任務並 要繞過哪個。 4. **任務編排的模組化方法** 模組化不僅僅是 Taipy 的一個流行詞;這是一個核心原則。 設定可以互換使用的任務和資料來源,從而產生更乾淨、更易於維護的程式碼庫。 --- ## 3. Dask 簡介 Dask 是一個流行的分散式運算 Python 套件。 Dask API 實作了熟悉的 Pandas、Numpy 和 Scikit-learn API - ,這使得許多已經熟悉這些 API 的資料科學家更愉快地學習和使用 Dask。 如果您是 Dask 新手,請查看 Dask 團隊撰寫的精彩 Dask [10 分鐘簡介](https://docs.dask.org/en/stable/10-minutes-to-dask.html)。 --- ## 4. 應用:顧客分析 (*algos/algo.py*) 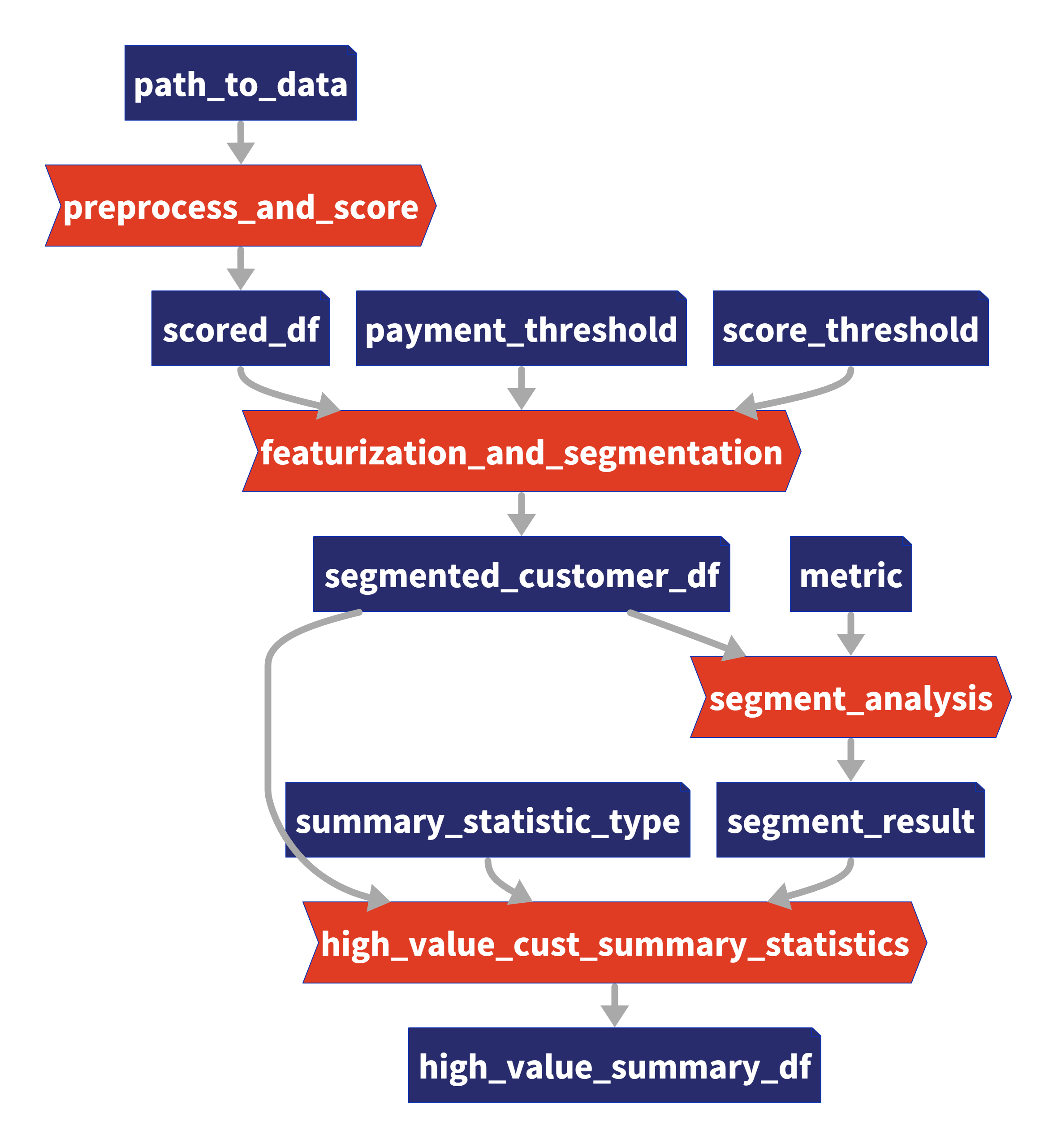 *我們的 4 項任務的圖表(在 Taipy 中可視化),我們將在下一節中對其進行建模。* 我們現有的程式碼(不含 Taipy)包含 4 個函數,您也可以在上圖中看到: - 任務 1:*預處理和評分* - 任務 2:*特徵化與細分* - 任務 3:*分段分析* - 任務 4:*high_value_cust_summary_statistics* 您可以瀏覽以下定義了 4 個函數的 *algos/algo.py* 腳本,然後繼續閱讀每個函數的簡要說明: ``` ### algos/algo.py import time import dask.dataframe as dd import pandas as pd def preprocess_and_score(path_to_original_data: str): print("__________________________________________________________") print("1. TASK 1: DATA PREPROCESSING AND CUSTOMER SCORING ...") start_time = time.perf_counter() # Start the timer # Step 1: Read data using Dask df = dd.read_csv(path_to_original_data) # Step 2: Simplify the customer scoring formula df["CUSTOMER_SCORE"] = ( 0.5 * df["TotalPurchaseAmount"] / 1000 + 0.3 * df["NumberOfPurchases"] / 10 + 0.2 * df["AverageReviewScore"] ) # Save all customers to a new CSV file scored_df = df[["CUSTOMER_SCORE", "TotalPurchaseAmount", "NumberOfPurchases", "TotalPurchaseTime"]] pd_df = scored_df.compute() end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return pd_df def featurization_and_segmentation(scored_df, payment_threshold, score_threshold): print("__________________________________________________________") print("2. TASK 2: FEATURE ENGINEERING AND SEGMENTATION ...") # payment_threshold, score_threshold = float(payment_threshold), float(score_threshold) start_time = time.perf_counter() # Start the timer df = scored_df # Feature: Indicator if customer's total purchase is above the payment threshold df["HighSpender"] = (df["TotalPurchaseAmount"] > payment_threshold).astype(int) # Feature: Average time between purchases df["AverageTimeBetweenPurchases"] = df["TotalPurchaseTime"] / df["NumberOfPurchases"] # Additional computationally intensive features df["Interaction1"] = df["TotalPurchaseAmount"] * df["NumberOfPurchases"] df["Interaction2"] = df["TotalPurchaseTime"] * df["CUSTOMER_SCORE"] df["PolynomialFeature"] = df["TotalPurchaseAmount"] ** 2 # Segment customers based on the score_threshold df["ValueSegment"] = ["High Value" if score > score_threshold else "Low Value" for score in df["CUSTOMER_SCORE"]] end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return df def segment_analysis(df: pd.DataFrame, metric): print("__________________________________________________________") print("3. TASK 3: SEGMENT ANALYSIS ...") start_time = time.perf_counter() # Start the timer # Detailed analysis for each segment: mean/median of various metrics segment_analysis = ( df.groupby("ValueSegment") .agg( { "CUSTOMER_SCORE": metric, "TotalPurchaseAmount": metric, "NumberOfPurchases": metric, "TotalPurchaseTime": metric, "HighSpender": "sum", # Total number of high spenders in each segment "AverageTimeBetweenPurchases": metric, } ) .reset_index() ) end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return segment_analysis def high_value_cust_summary_statistics(df: pd.DataFrame, segment_analysis: pd.DataFrame, summary_statistic_type: str): print("__________________________________________________________") print("4. TASK 4: ADDITIONAL ANALYSIS BASED ON SEGMENT ANALYSIS ...") start_time = time.perf_counter() # Start the timer # Filter out the High Value customers high_value_customers = df[df["ValueSegment"] == "High Value"] # Use summary_statistic_type to calculate different types of summary statistics if summary_statistic_type == "mean": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].mean() elif summary_statistic_type == "median": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].median() elif summary_statistic_type == "max": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].max() elif summary_statistic_type == "min": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].min() median_score_high_value = high_value_customers["CUSTOMER_SCORE"].median() # Fetch the summary statistic for 'TotalPurchaseAmount' for High Value customers from segment_analysis segment_statistic_high_value = segment_analysis.loc[ segment_analysis["ValueSegment"] == "High Value", "TotalPurchaseAmount" ].values[0] # Create a DataFrame to hold the results result_df = pd.DataFrame( { "SummaryStatisticType": [summary_statistic_type], "AveragePurchaseHighValue": [average_purchase_high_value], "MedianScoreHighValue": [median_score_high_value], "SegmentAnalysisHighValue": [segment_statistic_high_value], } ) end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return result_df ``` --- ### 任務 1 - 資料預處理與客戶評分 Python 函數:*preprocess_and_score* 這是管道中的第一步,也許也是最關鍵的一步。 它使用 **Dask** 讀取大型資料集,專為大於記憶體的計算而設計。 然後,它根據“*TotalPurchaseAmount*”、“*NumberOfPurchases*”和“*AverageReviewScore*”等各種指標,在名為 *scored_df* 的 DataFrame 中計算“*Customer Score*”。 使用 Dask 讀取和處理資料集後,此任務將輸出一個 Pandas DataFrame,以供其餘 3 個任務進一步使用。 --- ### 任務 2 - 特徵工程與分割 Python 函數:*featureization_and_segmentation* 此任務採用評分的 DataFrame 並新增功能,例如高支出指標。 它還根據客戶的分數對客戶進行細分。 --- ### 任務 3 - 細分分析 Python 函數:*segment_analysis* 此任務採用分段的 DataFrame 並根據客戶細分執行分組分析以計算各種指標。 --- ### 任務 4 - 高價值客戶的總統計 Python 函數:*high_value_cust_summary_statistics* 此任務對高價值客戶群進行深入分析並傳回匯總統計資料。 --- ## 5. 在 Taipy 中建模工作流程 (*config.py*) 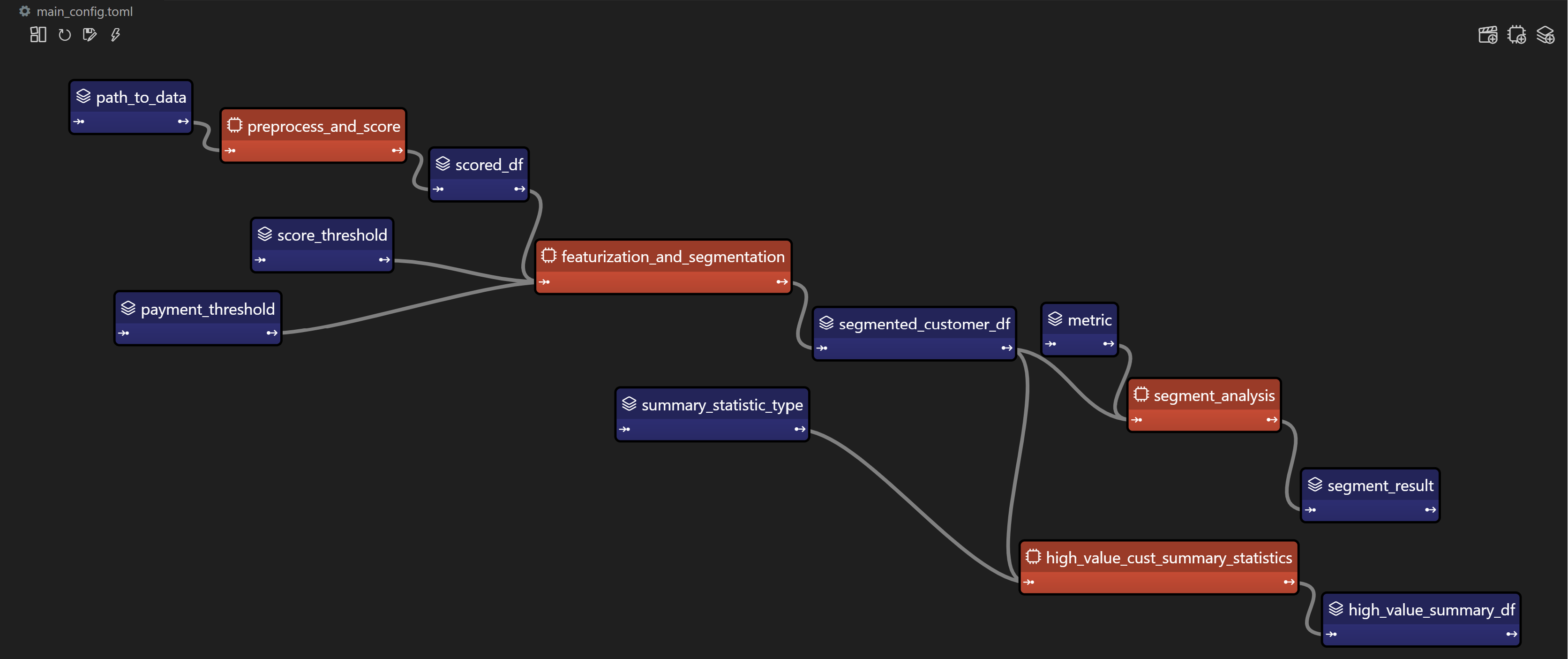 *Taipy DAG — Taipy「任務」為橘色,「資料節點」為藍色。* 在本節中,我們將建立對變數/參數進行建模的Taipy 配置(表示為[“資料節點”](https://docs.taipy.io/en/latest/manuals/core/concepts/data-node/ ))和 Taipy 中的函數(表示為 [“Tasks”](https://docs.taipy.io/en/latest/manuals/core/concepts/task/))。 --- 請注意,以下 *config.py* 腳本中的此配置類似於定義變數和函數 - 只不過我們定義的是「藍圖變數」(資料節點)和「藍圖函數」(任務)。 我們通知 Taipy 如何呼叫我們之前定義的函數、資料節點的預設值(我們可能會在執行時覆蓋)以及是否可以跳過任務: ``` ### config.py from taipy import Config from algos.algo import ( preprocess_and_score, featurization_and_segmentation, segment_analysis, high_value_cust_summary_statistics, ) # -------------------- Data Nodes -------------------- path_to_data_cfg = Config.configure_data_node(id="path_to_data", default_data="data/customers_data.csv") scored_df_cfg = Config.configure_data_node(id="scored_df") payment_threshold_cfg = Config.configure_data_node(id="payment_threshold", default_data=1000) score_threshold_cfg = Config.configure_data_node(id="score_threshold", default_data=1.5) segmented_customer_df_cfg = Config.configure_data_node(id="segmented_customer_df") metric_cfg = Config.configure_data_node(id="metric", default_data="mean") segment_result_cfg = Config.configure_data_node(id="segment_result") summary_statistic_type_cfg = Config.configure_data_node(id="summary_statistic_type", default_data="median") high_value_summary_df_cfg = Config.configure_data_node(id="high_value_summary_df") # -------------------- Tasks -------------------- preprocess_and_score_task_cfg = Config.configure_task( id="preprocess_and_score", function=preprocess_and_score, skippable=True, input=[path_to_data_cfg], output=[scored_df_cfg], ) featurization_and_segmentation_task_cfg = Config.configure_task( id="featurization_and_segmentation", function=featurization_and_segmentation, skippable=True, input=[scored_df_cfg, payment_threshold_cfg, score_threshold_cfg], output=[segmented_customer_df_cfg], ) segment_analysis_task_cfg = Config.configure_task( id="segment_analysis", function=segment_analysis, skippable=True, input=[segmented_customer_df_cfg, metric_cfg], output=[segment_result_cfg], ) high_value_cust_summary_statistics_task_cfg = Config.configure_task( id="high_value_cust_summary_statistics", function=high_value_cust_summary_statistics, skippable=True, input=[segment_result_cfg, segmented_customer_df_cfg, summary_statistic_type_cfg], output=[high_value_summary_df_cfg], ) scenario_cfg = Config.configure_scenario( id="scenario_1", task_configs=[ preprocess_and_score_task_cfg, featurization_and_segmentation_task_cfg, segment_analysis_task_cfg, high_value_cust_summary_statistics_task_cfg, ], ) ``` 號 您可以在[此處的文件](https://docs.taipy.io/en/latest/manuals/core/config/)中閱讀有關配置場景、任務和資料節點的更多資訊。 --- ### Taipy Studio [Taipy Studio](https://docs.taipy.io/en/latest/manuals/studio/config/) **是來自Taipy 的VS Code 擴充功能**,讓您**透過簡單的方式建置和視覺化您的管道拖放互動**。 Taipy Studio 提供了一個圖形編輯器,您可以在其中建立 Taipy 配置**存儲在 TOML 文件中**,您的 Taipy 應用程式可以加載並執行這些配置。 編輯器將場景表示為圖形,其中節點是資料節點和任務。 --- *作為本節中 config.py 腳本的替代方案,您可以使用 Taipy Studio 產生 config.toml 設定檔。 本文的倒數第二部分將提供有關如何使用 Taipy Studio 建立 config.toml 設定檔的指南。* --- ## 6. 場景建立與執行 執行 Taipy 場景涉及: - 載入配置; - 執行 Taipy Core 服務;和 - 建立並提交場景以供執行。 這是基本的程式碼模板: ``` import taipy as tp from config import scenario_cfg # Import the Scenario configuration tp.Core().run() # Start the Core service scenario_1 = tp.create_scenario(scenario_cfg) # Create a Scenario instance scenario_1.submit() # Submit the Scenario for execution # Total runtime: 74.49s ``` --- ### 跳過不必要的任務執行 Taipy 最實用的功能之一是,如果任務的輸出已經計算出來,它能夠跳過任務執行。 讓我們透過一些場景來探討這一點: --- #### 更改付款閾值 ``` # Changing Payment Threshold to 1600 scenario_1.payment_threshold.write(1600) scenario_1.submit() # Total runtime: 31.499s ``` *發生了什麼事*:Taipy 夠聰明,可以跳過任務 1,因為付款閾值只影響任務 2。 在這種情況下,透過使用 Taipy 執行管道,我們發現執行時間減少了 50% 以上。 --- #### 更改細分分析指標 ``` # Changing metric to median scenario_1.metric.write("median") scenario_1.submit() # Total runtime: 23.839s ``` *會發生什麼事*:在這種情況下,只有任務 3 和任務 4 受到影響。 Taipy 巧妙地跳過任務 1 和任務 2。 --- #### 更改總計統計類型 ``` # Changing summary_statistic_type to max scenario_1.summary_statistic_type.write("max") scenario_1.submit() # Total runtime: 5.084s ``` *發生了什麼事*:這裡,只有任務 4 受到影響,Taipy 僅執行此任務,跳過其餘任務。 Taipy 的智慧任務跳過功能不僅能節省時間,還能節省時間。它是一個資源優化器,在處理大型資料集時變得非常有用。 --- ## 7. Taipy Studio 您可以使用 Taipy Studio 建置 Taipy *config.toml* 設定檔來取代定義 *config.py* 腳本。 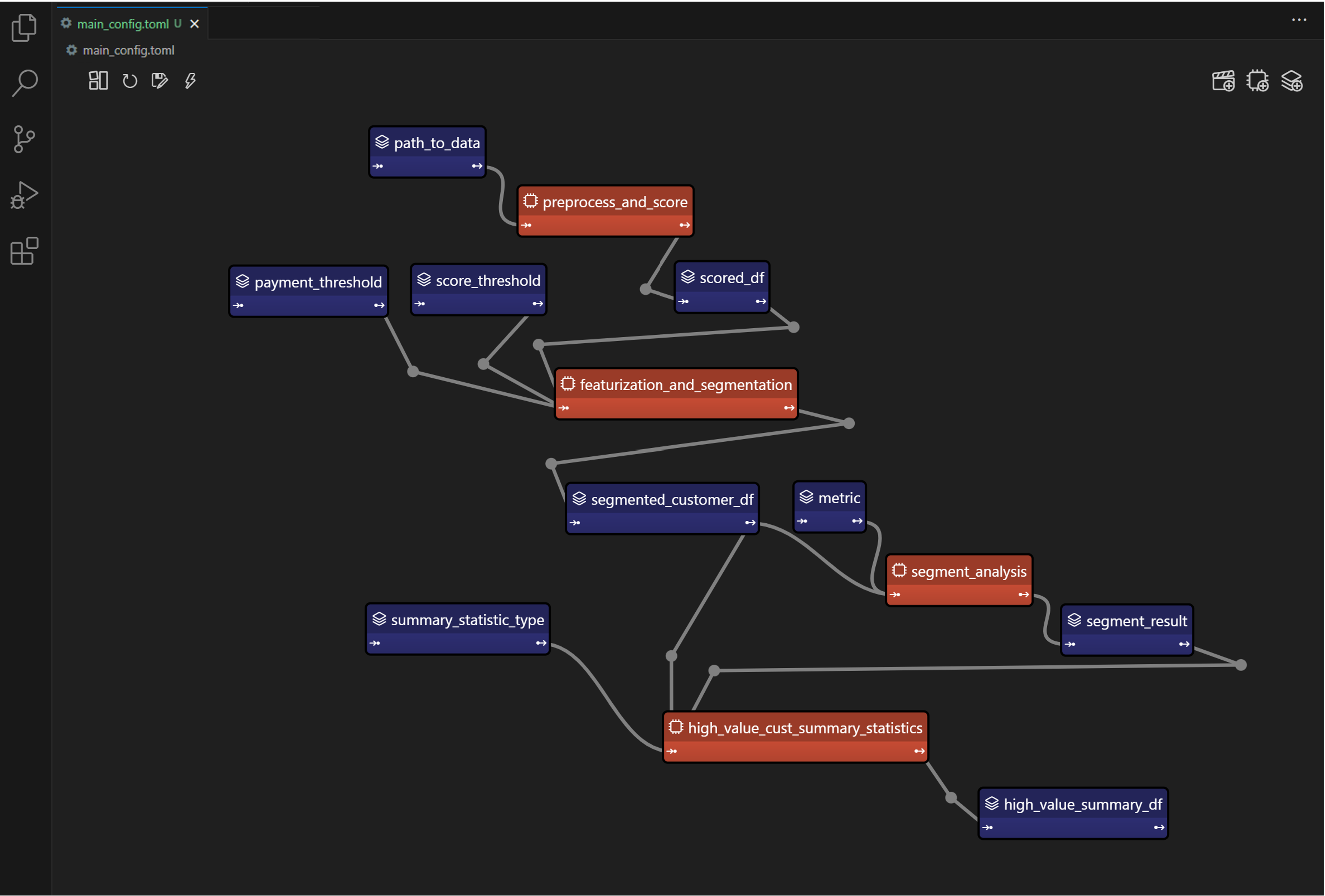 首先,使用擴展市場安裝 [Taipy Studio ](https://marketplace.visualstudio.com/items?itemName=Taipy.taipy-studio)擴充。 --- ### 建立配置 - **建立設定檔**:在 VS Code 中,導覽至 Taipy Studio,然後透過點擊參數視窗上的 + 按鈕啟動新的 TOML 設定檔。  - 然後右鍵單擊它並選擇 **Taipy:顯示視圖**。 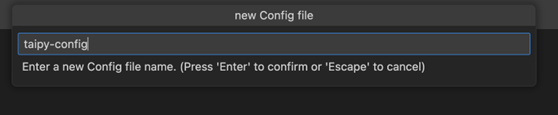 - **新增實體**到您的 Taipy 配置: 在 Taipy Studio 的右側,您應該會看到一個包含 3 個圖示的列表,可用於設定管道。  1. 第一項是新增資料節點。您可以將任何 Python 物件連結到 Taipy 的資料節點。 2. 第二項用於新增任務。任務可以連結到預先定義的 Python 函數。 3. 第三項是新增場景。 Taipy 讓您在一個配置中擁有多個場景。 --- #### - 資料節點 **輸入資料節點**:建立一個名為“*path_to_data*”的資料節點,然後導航到“詳細資料”選項卡,新增屬性“*default_data*”,並將“*SMALL_amazon_customers_data.csv*”貼上為您的資料的路徑資料集。 --- **中間資料節點**:我們需要再增加四個資料節點:「*scored_df*」、「*segmented_customer_df*」、「*segment_result*」、「*high_value_summary_df*」。透過 Taipy 的智慧設計,您無需為這些中間資料節點進行任何配置;系統會巧妙地處理它們。 --- **具有預設值的中間資料節點**:我們最終定義了另外四個中間資料節點,並將「*default_data*」屬性設為以下內容: - payment_threshold: “1000:int” 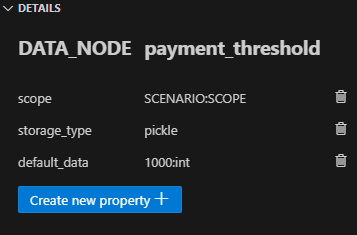 - 分數閾值:“1.5:浮動” - 測量:“平均值” -summary_statistic_type:“中位數” --- #### - 任務 點擊新增任務按鈕,您可以配置新任務。 新增四個任務,然後**將每個任務連結到「詳細資料」標籤下的對應函數**。 Taipy Studio 將掃描您的專案資料夾並提供可供選擇的分類函數列表,並按 Python 檔案排序。 --- **任務 1** (*preprocess_and_score*):在 Taipy studio 中,您可以按一下「任務」圖示以新增任務。 您可以將輸入指定為“*path_to_data*”,將輸出指定為“*scored_df*”。 然後,在「詳細資料」標籤下,您可以將此任務連結到 *algos.algo.preprocess_and_score* 函數。 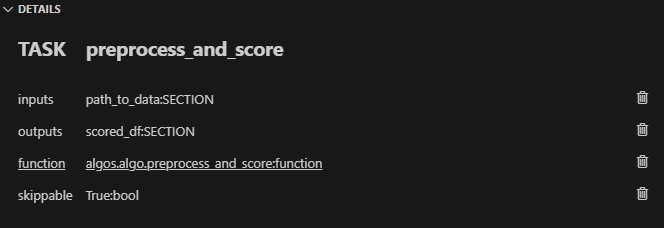 --- **任務 2** (*featurization_and_segmentation*):與任務 1 類似,您需要指定輸入 (“*scored_df*”、“* payment_threshold*”、“*score_threshold*”) 和輸出 (“*segmented_customer_df*”) ” )。將此任務連結到 *algos.algo.featurization_and_segmentation* 函數。 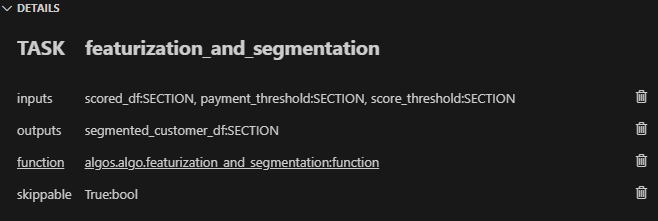 --- **任務 3** (*segment_analysis*):輸入為“*segmented_customer_df*”和“*metric*”,輸出為“*segment_result*”。 連結到 *algos.algo.segment_analysis* 函數。  --- **任務 4** (high_value_cust_summary_statistics):輸入包含「*segment_result*」、「*segmented_customer_df*」和「*summary_statistic_type*」。輸出為“*high_value_summary_df*”。連結到 *algos.algo.high_value_cust_summary_statistics* 函數。 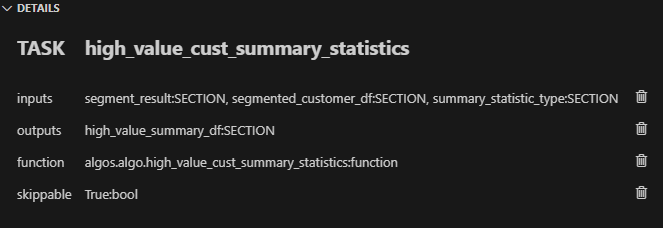 --- ## 結論 Taipy 提供了一種**智慧方式來建立和管理資料管道**。 特別是可跳過的功能使其成為優化運算資源和時間的強大工具,在涉及大型資料集的場景中特別有用。 Dask 提供了資料操作的原始能力,而 Taipy 增加了一層智能,使您的管道不僅強大而且智能。 --- 其他資源 如需完整程式碼和 TOML 配置,您可以存取此 [GitHub 儲存庫](https://github.com/Avaiga/demo-dask-customer-analysis/tree/develop)。若要深入了解 Taipy,請參閱[官方文件](https://docs.taipy.io/en/latest/)。 一旦您了解 Taipy 場景管理,您就可以更有效率地為最終用戶建立資料驅動的應用程式。只需專注於您的演算法,Taipy 就會處理剩下的事情。 ---  希望您喜歡這篇文章! --- 原文出處:https://dev.to/taipy/big-data-models-vs-computer-memory-4po6
## **簡介** 在這篇文章中,我將介紹 11 個我玩得很開心並想與您分享的函式庫。  --- ## 1. [Taipy](https://github.com/Avaiga/taipy) Taipy 是一個開源程式庫,旨在輕鬆開發前端 (GUI) 和 ML/資料管道。 不需要其他知識(不需要 CSS,不需要 JS,什麼都不需要!)。 建立您夢想的應用程式得益於: - 完整的客製化和互動 - 多頁和多用戶 - 管道圖形編輯器 - ...還有更多。 您甚至可以將以下所有庫與 Taipy 一起使用,並使其更加有趣。 你的想像力是極限!  ---  https://github.com/Avaiga/taipy 我們已經快有 1000 顆星了,沒有你就無法做到這一點🙏 --- ## 2.[Asciimatics](https://github.com/peterbrittain/asciimatics) Asciimatics 是一個可讓您建立全螢幕文字 UI 的程式庫。這個圖書館是出於對 80 年代的懷舊之情而建造的。 以下是它們的一些主要功能: - 彩色/樣式文字 - 遊標定位 - 鍵盤輸入(無阻塞或迴聲)  --- ## 3.[Arcade](https://github.com/pythonarcade/arcade) 沒有遊戲,樂趣怎麼可能有意義呢?正如庫名稱所暗示的,它允許建立 2D 影片遊戲。是的,這看起來確實很難,但 Arcade 讓它變得容易。因此,「pip install arcade」並開始遊戲或從一些[現有遊戲](https://api.arcade.academy/en/latest/sample_games.html)中汲取靈感!  --- ## 4.[Rich](https://github.com/Textualize/rich) Rich 將為您的生活增添色彩! Rich 在您的終端機中寫入豐富的文字(顏色+樣式),因此它們最終可以反映您是誰。 豐富包括: - 不同的風格 - 降價 - 進度條 - 亞洲語言支持 - ... 和更多!  --- ## 5.[PyEphem](https://github.com/brandon-rhodes/pyephem) PyEphem 是一個在天空中迷失的好工具。該庫允許進行天文學計算;以下是一些有趣的用例: - 尋找行星在天空中的位置 - 確定春分和至日的日期 - 計算月相的日期 - ... 還有很多! 這個圖書館一定會激發您的好奇心。  --- ## 6.[tqdm](https://github.com/tqdm/tqdm) 光是這個圖書館的名字就已經很有趣了。 Tqdm 表示兩件事: - 是西班牙文「我非常愛你」的縮寫 (*te quiero demasiado)* - 源自阿拉伯語單字“*taqaddum* ()”,意思是進步,這實際上是對該庫所做工作的一個很好的介紹。 Tqdm 是任何循環的包裝器,它將透過進度條追蹤進度。您可以自訂它,讓等待任務完成不再那麼無聊!  --- ## 7. [Pygame](https://github.com/pygame/pygame) Pygame 讓編寫視訊遊戲變得容易。該庫將使您可以存取多種多媒體元素,例如: - 圖形 - 聲音 - 輸入設備 現在,發揮您的創造力,建立您自己的 2D 互動遊戲或探索一些[可用遊戲](https://www.pygame.org/tags/all)。  --- ## 8.[Turtle](https://docs.python.org/3/library/turtle.html) 這個函式庫有所不同,因為它是 Python 語言的一部分,因此不需要 *pip install*。 Turtle 是為了教育目的而建立的,幫助新程式設計師透過在畫布上設計圖形來使用 Python 進行編碼。一種進入 Python 或享受一點創意樂趣的有趣方式。  --- ## 9.[MoviePy](https://github.com/Zulko/moviepy) MoviePy 是用 Python 編輯影片的便利工具。其功能包括: - 切割 - 連接 - 過濾 - 和轉變。 您可以閱讀許多不同的格式,包括 GIF。  --- ## 10. [Emoji](https://github.com/carpedm20/emoji) 透過此庫在 Python 程式中使用表情符號。它只是使用 *emojize()* 函數將 unicode 表情符號轉換為表情符號名稱。其他功能包括加入表情符號、計算表情符號等…  --- ## 11.[Pyjokes](https://github.com/pyjokes/pyjokes) 有了 pyjokes,您只需安裝一點就能獲得點播笑聲。這個圖書館會給你一些俏皮的笑話;您甚至可以選擇語言和類別。 玩得開心!  --- 希望您喜歡這篇文章! 我是一名新手作家,歡迎任何改進建議!  如果您有任何疑問,請隨時與我們聯繫。 --- 原文出處:https://dev.to/taipy/11-fun-python-libraries-to-make-your-day-better-4gpc
## **簡介** 在本文中,我將為您提供適用於任何機器學習專案的終極 Python 庫: - 機器學習週期每個步驟必須了解的函式庫 - EDA、資料清理、資料工程、建模等… - 全部開源 - 所有蟒蛇  --- ## 完整的應用程式 ### 1. 🚀[Taipy](https://github.com/Avaiga/taipy) 讓我們先討論一些經常被忽視的事情——實際上讓你的模型易於存取和有用。 Taipy 將會做到這一點,並將您的機器學習模型提升到一個新的水平。 它是一個開源程式庫,旨在輕鬆開發前端 (GUI) 和 ML/資料管道。不需要其他知識(沒有 CSS,什麼都不需要!)。它旨在加快應用程式開發,從最初的原型到生產就緒的應用程式。  Taipy 確保您的 ML 模型可以進入成熟的試點和應用程式,給您的最終用戶留下深刻的印象。 ---  https://github.com/Avaiga/taipy 我們已經快有 1000 顆星了,沒有你就無法做到這一點🙏 --- ## EDA、資料清理和資料工程 ### 2.🐼[Pandas](https://github.com/pandas-dev/pandas) 如何在不了解 Pandas 的情況下使用 Python 進行編碼? 該庫有兩個核心資料結構:資料幀和系列,允許快速靈活的資料清理和準備。基本功能包括: - 載入資料中 - 重塑資料框 - 基本統計 Pandas 是啟動資料科學計畫的工具。 其他並發試圖超越 Pandas,但沒有像 Dask 或 Polars 那樣廣泛使用。 *這是未來文章的好主題!*  --- ### 3.🌱[Numpy](https://github.com/numpy/numpy) Numpy 雖然等級比 Pandas 低,但它是科學計算和資料預處理的必備工具。 它圍繞著陣列發展,並允許快速資料操作和數學函數。 該函式庫是另一個必須了解的 Python 函式庫,與 Pandas 一樣,也是以資料為中心的任務的必備函式庫。  --- ### 4.🔢[統計模型](https://github.com/statsmodels/statsmodels) 顧名思義,該函式庫提供了統計分析函數。 一系列功能涵蓋從描述性分析到統計測試;它也是一個處理時間序列資料、單變數和多元統計資料等的優秀函式庫。  --- ### 5.👓[YData Profiling](https://github.com/ydataai/ydata-profiling) YData Profiling 透過一行程式碼徹底分析資料來促進 EDA 步驟。 分析包括缺失值檢測、相關性、分佈分析等。 該工具非常用戶友好且簡單,可以輕鬆加入到您的資料科學工具箱中。  --- ## 機器學習/深度學習演算法 ### 6.💼 [Scikit-learn](https://github.com/scikit-learn/scikit-learn) 這可能是 Python 最著名的 3 個函式庫,這是理所當然的。 Sklearn 是機器學習領域的參考書。它包括不同的模型,例如 K 均值聚類、回歸和分類演算法。 它在降維技術方面也很出色。 Sklearn也提供資料選擇和驗證功能。它易於學習/使用,應該成為您資料科學之旅中的首選 ML 庫。  --- ### 7.🧠 [Keras](https://github.com/keras-team/keras) Keras 是一個高階 API,運作在 TensorFlow 等框架之上。如果從神經網路開始,請從 Keras 開始。它非常適合快速實施,因為它簡化了實施過程,使其成為神經網路實施的最佳初學者友善選項。  --- ### 8.🧠💪[TensorFlow](https://github.com/tensorflow/tensorflow) 這個庫是神經網路建模必須知道的。非常適合處理影像分類或 NLP(自然語言處理)等非結構化資料。 TensorFlow 廣泛應用於研究和工業領域,因為它為神經網路的設計和操作提供了完整的 API。 Keras(上面提到的)提供了一個更高層級(更簡單)的 API(它是建構在 TensorFlow 之上)。  --- ### 9.🌴[XGBoost](https://github.com/dmlc/xgboost) XGBoost 是有關機器學習演算法的最受歡迎的函式庫之一。 這個梯度提升庫廣泛用於現實生活中的用例,特別是表格資料。 它是 Kaggle 競賽獲勝者的最愛。 該庫包括回歸和分類演算法,但也提供特徵選擇工具。  --- ### 10.🐈[CatBoost](https://github.com/catboost/catboost) 如果您的資料集主要由分類資料組成,那麼這個函式庫代表分類提升(Categorical Boosting),它是您的最佳選擇。該庫將規避一種熱編碼的複雜性,從而無需預處理分類資料。當使用預設參數執行時,它可以提供比 XGBoost 更好的精度。  --- 希望您喜歡這篇文章! 我是一名新手作家,歡迎任何改進建議!  如果您有任何疑問,請隨時與我們聯繫。 --- 原文出處:https://dev.to/taipy/top-10-python-libraries-for-any-ml-projects-3gfp
你的轉職路上,還缺少一份自學作業包!寫完這幾包,直接拿作品去面試上班!
本論壇另有附設一個 LINE 新手發問&交流群組!歡迎加入討論!















