您是否嘗試過實際建立神經網路?不,我也沒有……直到今天! 在這篇文章中,我們將介紹我學到的一些東西,以及一些用 vanilla JS 編寫的非常簡單的神經網路的 2 個演示。 ## 介紹 今天早些時候,我正在閱讀 @supabase_io [“AI 內容風暴”](https://supabase.com/blog/supabase-ai-content-storm) 文章。 我突然意識到一件事。我得到了神經網路......但我實際上根本沒有得到它們! 就像,我得到了神經元的概念。但數學是如何運作的呢? 特別是如何使用「反向傳播」來訓練神經網路?偏差和權重如何發揮作用?什麼或誰是 sigmoid? ETC。 現在,明智的做法是閱讀大量文章,獲取一個庫並使用它。 **但我不懂事。** 因此,我閱讀了大量文章……然後決定建立我的第一個神經網路。 但這還不夠難,所以我決定用 JavaScript 來做(因為每個人似乎都使用 Python...)。哦,我決定在沒有任何庫的情況下完成它。哦,我也想在其中建立一個視覺化工具。 我有些不對勁……我似乎在痛苦中茁壯成長。 無論如何,我做到了,這就是我學到的東西。 ## 注意:這不是教學課程 聽著,我想澄清一下,這不是教學! 這只是我分享一些我在學習和我的**第一個**神經網路時發現有趣的事情。 請注意,這裡強調**第一**,所以請不要將其視為除了有趣的東西之外的任何東西。 我也盡力解釋每個部分及其作用,但與所有事情一樣,你對某些東西越熟練,你就越能更好地解釋它......所以我的一些解釋可能有點“偏離” ! 無論如何,既然所有這些都已經解決了,讓我們繼續吧! 如果您想直接跳到[最終演示](#the-demo),請繼續! ## 第一步 好的,首先,我可以建立的最基本的神經網路是什麼? 經過一番閱讀後,我發現神經網路可以像一些輸入神經元和一些輸出神經元一樣簡單。 每個輸入神經元都連接到一個輸出神經元,然後我們可以為每個連接加入權重。 考慮到這一點,我必須想出一個易於理解的問題來解決,但又足夠複雜以確保我的網路正常運作。 我決定建立一個神經網絡,它獲取圖表上某個點的 X 和 Y 座標,然後根據它們是正還是負為它們分配一個「團隊」(顏色)。 這樣我們就有了 2 個輸入(X 和 Y 位置),然後有 4 個輸出: 1. X > 0 且 Y > 0 2. X < 0 且 Y > 0 3. X > 0 且 Y < 0 4. X < 0 且 Y < 0 由於這裡的要求非常簡單,我們可以擺脫一些「隱藏」神經元(這是我稍後將介紹的內容)並讓事情變得超級簡單! 所以本質上我們必須建構一個看起來像這樣的神經網路: 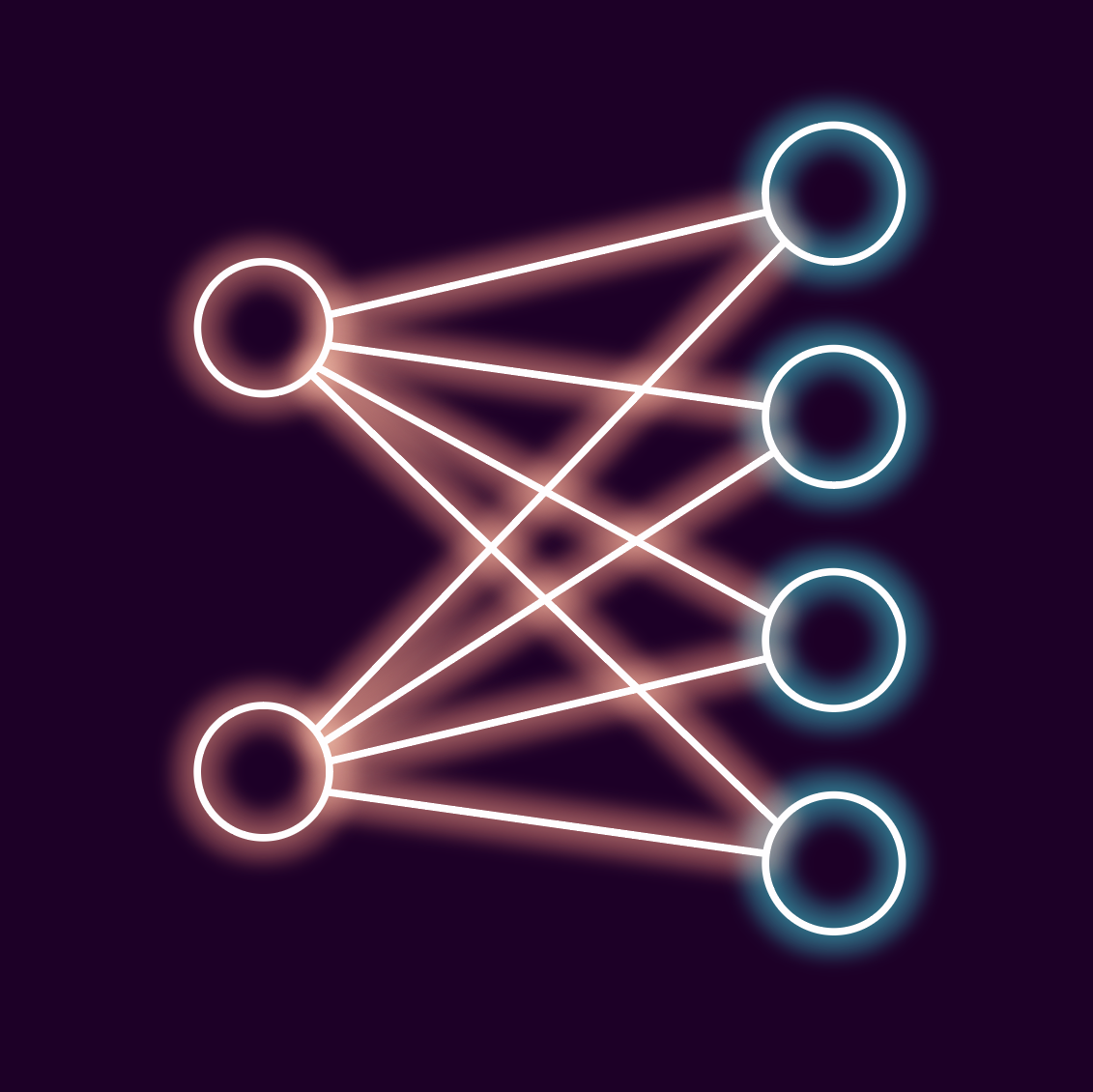 左邊的圓圈是我們的輸入(X 和 Y 位置),右邊的圓圈是我們之前討論的輸出。 ### 我們的第一個神經元 好的,現在我們可以真正開始了。 現在我實際上並沒有先建置神經元。事實上,我實際上首先建立了一個視覺化工具,因為這是查看事情是否正常運作的最簡單方法,但我稍後會介紹這一點。 因此,讓我們建立一個神經元(或更具體地說,一些神經元及其連接)。 幸運的是,神經元其實非常簡單! (或者我應該說,它們*可以*非常簡單......它們在大型語言模型(LLM)等中變得更加複雜。) 簡單神經元具有偏差(將其視為內部權重,我們將加入到最終計算中以對每個神經元進行加權的數字),並透過每個連接之間的權重連接到其他神經元。 現在回想起來,單獨加入到每個神經元的連接可能是一個更好的主意,但我決定將每層神經元和每層連接作為單獨的專案加入,因為這樣更容易理解。 所以建構我的第一個神經網路的程式碼如下所示: ``` class NeuralNetwork { constructor(inputLen, outputLen) { this.inputLen = inputLen; this.outputLen = outputLen; this.weights = Array.from({ length: this.outputLen }, () => Array.from({ length: this.inputLen }, () => Math.random()) ); this.bias = Array(this.outputLen).fill(0); } } const neuralNetwork = new NeuralNetwork(2, 4); ``` 好的,我跳過了一些步驟,所以讓我們簡要介紹一下每個部分。 `this.inputLen = inputLen;` 和 `this.outputLen = outputLen;` 只是為了讓我們可以引用輸入和輸出的數量。 `this.weights = [...]` 是連線。現在看起來可能有點嚇人,但這就是我們正在做的事情: - 建立輸出神經元陣列(`outputLen`) - 將長度為“inputLen”的陣列加入到每個陣列條目,並用 0 到 1 之間的一些隨機值填充它以開始我們的工作。 該程式碼的輸出範例如下所示: ``` this.weights = [ [0.7583747881712366,0.4306037998314902], [0.40553698492617807,0.4419651593960727], [0.852978801662627,0.9762509253699836], [0.8701610553353811,0.5583309725764114] ] ``` 它們本質上代表以下內容: ``` [input 1 to output 1, input 2 to output 1], [input 1 to output 2, input 2 to output 2], [input 1 to output 3, input 2 to output 3], [input 1 to output 4, input 2 to output 4], ``` 然後我們還有「this.bias」。 這適用於輸出層中的每個神經元。我們稍後用它來加入輸出值,使一些神經元更強,一些神經元更弱。 它只是一個由 4 個 0 組成的陣列來讓我們開始,因為我們不想要初始偏差! 現在,雖然這是一個神經網絡,但它完全沒有用。 我們無法實際使用它......如果我們確實使用它,它產生的結果將是完全隨機的! 所以我們需要解決這些問題! ### 使用我們的網路! 我們需要做的第一件事是實際獲取一些輸入,透過我們的網路執行它們並收集輸出。 這是我想出來的: ``` propagate(inputs) { const output = new Array(this.outputLen); for (let i = 0; i < this.outputLen; i++) { output[i] = 0; for (let j = 0; j < this.inputLen; j++) { output[i] += this.weights[i][j] * inputs[j]; } output[i] += this.bias[i]; output[i] = this.sigmoid(output[i]); } return output; } sigmoid(x) { return 1 / (1 + Math.exp(-x)); } ``` 現在這裡有兩件有趣的事情。 ####乙狀結腸 首先,一件有趣的事情是我們的“sigmoid”函數。它所做的只是沿著「S 形」曲線將我們輸入的值(例如 12)轉換為 0 到 1 之間的值。 這是我們將價值觀從極端標準化為更統一的**且始終為正值的方式。** 進一步閱讀後,這裡還有其他關於如何將值更改為 0 到 1 之間的選項,但我還沒有完全探索它們(例如 [ReLU](https://en.wikipedia.org/wiki/Rectifier_(neural_networks)) 如果你想閱讀相關內容)。 我確信有一些很好的解釋為什麼需要這樣做,但在我的猴腦中,這只是將值保持在 0 和 1 之間的方法,以便乘法保持在一定範圍內並且值被「展平」。 這樣你就不會在過於強大的神經元之間出現「失控」的路徑。 例如,假設您有一個權重為 16 的連接和一個權重為 1 的連接,使用我們的 sigmoid 函數,我們可以將其從 16 倍的差異減少到大約 35% 的差異(「sigmoid(1)」為0.73 ,執行我們的函數後,`sigmoid(16)` 為0.99)。 這也意味著負值變成正值。 因此,透過 sigmoid 函數執行值意味著負數會轉換為 0 到 0.5 之間的值,0 的值恰好變成 0.5,大於 0 的值變成 0.5 到 1 之間的值。  如果你考慮一下,這是有道理的,因為當我們開始將負數和正數相乘時,我們可以極大地改變我們的輸出。 例如,如果我們在 100 的路徑中有一個負神經元,而其餘的都是正神經元,這會將強值更改為弱值,並且可能會導致問題。 不管怎樣,隨著我閱讀更多和實驗更多,我相信我會更好地理解這一部分! #### 我需要偏見嗎? 第二個有趣的是「output[i] += this.bias[i];」。 好吧,在這個神經網路中,所有 4 個輸出都同樣重要,而且我們沒有隱藏神經元,所以我後來刪除了它以簡化程式碼! 但諷刺的是,在我們更複雜的神經網路上,由於網路反向傳播的工作方式,我需要重新加入輸出神經元的偏差。否則,一個輸出神經元會一直啟動。 我無法弄清楚這是否是必要的步驟,或者我的神經網路是否犯了一個錯誤,而這是為了彌補它。 再次提醒大家,我還在學習中,只是掌握了基礎知識,所以我不知道它是什麼! 🤣 #### 我們快到了 上面的其餘程式碼相當簡單。我們只是將每個輸入乘以與每個輸出相關的權重(並加入不必要的偏差!)。 事實上,我們現在就可以執行它,但結果會很糟糕!讓我們來解決這個問題! ### 訓練時間到了! 好吧,神經網路的最後一個重要部分是訓練它! 現在,隨著這篇文章越來越長,我將只介紹以下訓練程式碼的要點(順便說一下,我花了將近一個小時來編寫......我告訴過你我對此是個菜鳥! ) ``` train(inputs, target) { const output = this.propagate(inputs); const errors = new Array(this.outputLen); for (let i = 0; i < this.outputLen; i++) { errors[i] = target[i] - output[i]; for (let j = 0; j < this.inputLen; j++) { this.weights[i][j] += this.learningRate * errors[i] * output[i] * (1 - output[i]) * inputs[j]; } this.bias[i] += this.learningRate * errors[i]; } } ``` “為什麼花了這麼長時間?”我聽到你問了!好吧,它讓我思考了所有需要相乘才能更新每個權重的位元。 另外 `this.learningRate` 也需要一點時間來適應。這只是降低我們改變權重的速率,這樣我們就不會“超過”每個權重的目標值,但是將其調整到合理的值需要經驗......我沒有經驗並且設置得太低,所以我的程式碼看起來被破壞了! 經過一番擺弄後,我將數值定為 0.1(而不是 0.01 🤦🏼♂️),突然間事情開始變得更好了! 是的,所以我們有一個訓練函數。但請記住,此訓練功能僅進行一次訓練。 我們需要對我們的網路進行多次訓練,希望每次訓練都能使其更加準確。 我們將在一秒鐘內討論這一點,但我想分享一個快速的側面/我學到的東西。 #### 訓練資料調整 我知道我們甚至還沒有涵蓋最終的訓練資料,但這是我學到的一個有趣的觀點,適合這裡(因為它解釋了為什麼我花了這麼長時間來編寫這個訓練函數)。 最初我產生了數百個不同的訓練 X 和 Y 座標,全部都是隨機的。 但經過進一步閱讀後,我只產生 4 個靜態訓練點,得到了更好的結果: ``` const trainingData = [ { x: -0.5, y: -0.5, label: "blue" }, { x: 0.5, y: -0.5, label: "red" }, { x: -0.5, y: 0.5, label: "green" }, { x: 0.5, y: 0.5, label: "purple" } ]; ``` 一旦你明白了,就很有意義了! 我們希望「拉」值更接近目標,上述值是我們每個區域的確切「中心點」。 因此,對於給定的距離,我們的錯誤率將始終保持一致。 這意味著我們的神經網路學習得更快,因為我們的錯誤率更大,這取決於它們距離 X 更遠還是距離 Y 更遠。 我可以更好地解釋這一點,但這超出了本文的範圍。希望如果您仔細考慮一下,那麼它也會像對我一樣為您「點擊」! 諷刺的是,我回到了更大模型的更隨機的資料集,因為我想真正測試我對學習率、過度訓練等的理解。 ## 我們有一個有效且有用的神經網路! 實際上,這就是我們的整個神經網路。 不過,我們需要做一件事。 我們的訓練函數需要執行很多次! 因此,我們需要最後一個函數來做到這一點,它獲取我們的訓練資料並執行我們的訓練函數數百次: ``` function train() { for (let i = 0; i < 10000; i++) { const data = trainingData[Math.floor(Math.random() * trainingData.length)]; neuralNetwork.train([data.x, data.y], encode(data.label)); } console.log("Training complete"); } ``` ### 金髮女孩迭代 請注意,我們在「for」循環中訓練網路 10,000 次。 10,000 次迭代足以訓練這個特定的神經網路。但對於我們稍後將介紹的更複雜的問題,我需要更多的迭代(並降低學習率)。 這是機器學習有趣的部分之一,您需要足夠地訓練神經網路(這很難做到正確),但如果訓練太多,就會發生“過度擬合”,並且實際上開始得到更糟糕的結果。因此,為了獲得最佳結果,需要完美平衡! 不管怎樣,已經很多了,我們終於迎來了第一個示範! ## 簡單的普通 JS 神經網路演示 雖然有點亂,但我們的神經網路和所有訓練部分都在下面 CodePen 的前 67 行。 其餘程式碼行實際上執行我們的網路(“neuralNetwork.propagate([x, y]);”大約第 85 行),然後將點及其預測顏色輸出到“<canvas>”上。 「encode」和「decode」純粹是為了獲取我們的輸出神經元,找到哪個神經元具有最高的激活,然後將其映射到我們可視化的顏色。 這是最後要理解的事。我們的輸出神經元都會有一個值。神經網路不僅僅輸出 1, 0, 0, 0。 相反,它會輸出每個輸出神經元的「確定性」或猜測。因此我們將得到類似「0.92,0.76,0.55,0.87」的輸出。 這就是為什麼我們有“解碼”函數,它找到最高輸出的神經元並將其作為我們的最終猜測! ``` // this line finds the max value of all of our output neurons and then returns its index so we can use that to classify our X and Y coordinates. const maxIndex = output.indexOf(Math.max(...output)); ``` ### 用法和實際演示 要使用該範例,您有 3 個按鈕: - **訓練** - 在我們的神經網路開始未經訓練和隨機化時對其進行訓練。 - **分類點** - 這是為了執行我們的神經網路。它將在圖表上繪製點並為它們分配顏色。我建議在訓練之前和之後執行這個。 - **重設** - 這將建立一個未經訓練的新神經網路。非常適合在訓練前後測試點的分類。 另請注意,每個區域都根據該區域應顯示的顏色進行著色。它真的可以讓您看到隨機且未經訓練的神經網路距離成功還有多遠(重置然後對測試點進行分類)! 玩吧! https://codepen.io/GrahamTheDev/pen/abPxoqb ### 我們最基本的神經網路結束 這樣我們就有了最基本的神經網路! 它可以很好地滿足我們的需求,並且我們設法了解了一些關於反向傳播(我們在主類別中的“train”函數)以及權重和偏差的知識。 但這是非常有限的。如果我們將來想做更高級的事情,我們需要加入一些隱藏神經元! ## 版本 2 - 隱藏神經元 好的,那為什麼要隱藏神經元呢?他們的目的是什麼? 在更複雜的範例中,它們充當獲取輸入並為它們的分類方式加入更多維度的方式。 我們仍然使用 2 個輸入神經元和 4 個輸出神經元,但這次我們在中間加入了一個附加層(我們可以更改和調整其中神經元的數量)。 所以我們的神經網路看起來像這樣:  由於神經網路需要處理更多的輸入並進行更複雜的計算,隱藏層中的額外神經元使它們能夠更好地對輸入進行分類並提供更好的結果。 隱藏層也可以是不同的「深度」。 假設我們有 2 個輸入神經元。我們可以將它們連接到 6 個「隱藏」神經元,然後將它們連接到 4 個輸出神經元。 但我們也可以將第一層的 6 個神經元連結到第二層隱藏神經元。第二層可能有 8 個神經元,然後連接到我們的 4 個輸出神經元。 但要遵循的內容還有很多,這是為了讓我學習基礎知識,所以我選擇加入一個隱藏層。這也意味著我可以將每個連接層保留為單獨的陣列,這在現階段更容易理解! ### 那麼有什麼新內容呢? 沒有太大變化,只是我們有了更多的連結和更多的神經元! 您可以將其視為串聯加入 2 個原始神經網絡,只是第一個神經網路的輸出現在充當第二個神經網路的輸入。 雖然程式碼可能更加複雜,但我們的神經網路遵循相同的原則。 這是程式碼: ``` class NeuralNetwork { constructor(inputSize, hiddenSize, outputSize) { this.inputSize = inputSize; this.hiddenSize = hiddenSize; this.outputSize = outputSize; this.weightsInputToHidden = Array.from({ length: hiddenSize }, () => Array.from({ length: inputSize }, () => Math.random() * 2 - 1) ); this.biasHidden = Array(hiddenSize).fill(0); this.weightsHiddenToOutput = Array.from({ length: outputSize }, () => Array.from({ length: hiddenSize }, () => Math.random() * 2 - 1) ); this.biasOutput = Array(outputSize).fill(0); this.learningRate = document.querySelector('#learningRate').value; // Adjusted learning rate this.hiddenLayer = new Array(this.hiddenSize); } feedForward(inputs) { for (let i = 0; i < this.hiddenSize; i++) { this.hiddenLayer[i] = 0; for (let j = 0; j < this.inputSize; j++) { this.hiddenLayer[i] += this.weightsInputToHidden[i][j] * inputs[j]; } this.hiddenLayer[i] += this.biasHidden[i]; this.hiddenLayer[i] = sigmoid(this.hiddenLayer[i]); } const output = new Array(this.outputSize); for (let i = 0; i < this.outputSize; i++) { output[i] = 0; for (let j = 0; j < this.hiddenSize; j++) { output[i] += this.weightsHiddenToOutput[i][j] * this.hiddenLayer[j]; } output[i] += this.biasOutput[i]; output[i] = sigmoid(output[i]); } return output; } train(inputs, target) { for (let i = 0; i < this.hiddenSize; i++) { this.hiddenLayer[i] = 0; for (let j = 0; j < this.inputSize; j++) { this.hiddenLayer[i] += this.weightsInputToHidden[i][j] * inputs[j]; } this.hiddenLayer[i] += this.biasHidden[i]; this.hiddenLayer[i] = sigmoid(this.hiddenLayer[i]); } const output = new Array(this.outputSize); for (let i = 0; i < this.outputSize; i++) { output[i] = 0; for (let j = 0; j < this.hiddenSize; j++) { output[i] += this.weightsHiddenToOutput[i][j] * this.hiddenLayer[j]; } output[i] += this.biasOutput[i]; output[i] = sigmoid(output[i]); } const errorsOutput = new Array(this.outputSize); const errorsHidden = new Array(this.hiddenSize); for (let i = 0; i < this.outputSize; i++) { errorsOutput[i] = target[i] - output[i]; for (let j = 0; j < this.hiddenSize; j++) { this.weightsHiddenToOutput[i][j] += this.learningRate * errorsOutput[i] * output[i] * (1 - output[i]) * this.hiddenLayer[j]; } this.biasOutput[i] += this.learningRate * errorsOutput[i]; } for (let i = 0; i < this.hiddenSize; i++) { errorsHidden[i] = 0; for (let j = 0; j < this.outputSize; j++) { errorsHidden[i] += this.weightsHiddenToOutput[j][i] * errorsOutput[j]; } this.biasHidden[i] += this.learningRate * errorsHidden[i]; for (let j = 0; j < this.inputSize; j++) { this.weightsInputToHidden[i][j] += this.learningRate * errorsHidden[i] * this.hiddenLayer[i] * (1 - this.hiddenLayer[i]) * inputs[j]; } } } } ``` 現在,不要被嚇倒,我剛剛複製了幾個循環,其中要操作的目標資料集略有不同。 我們加入了一組額外的偏差(對於我們的隱藏層)和一組額外的連接:我們的輸入層到我們的隱藏層,然後我們的隱藏層現在連接到我們的輸出層。 最後,我們的「train」函數有一些額外的循環,只是為了透過每個步驟進行反向傳播。 唯一值得一提的其他變化是我們現在有第三個輸入參數(中間),用於隱藏神經元的數量。 ### 醜陋,但似乎有用 看,我想再說一遍,這是我一邊學習一邊學習,所以程式碼反映了這一點。 這裡有很多重複,可擴展性不太好。 然而,據我所知,它是有效的。 話雖如此,雖然它有效,但它的性能似乎比我們原來的、簡單得多的神經網路要差。 這要么意味著我犯了一個錯誤(可能),要么是我沒有「撥入」正確的訓練設定。 說到這裡... ### 加入一些變數來玩 由於這更複雜,我在一些快速設定中「迴避」了。 現在我們可以更新: - **訓練資料大小** - 我們產生的不同隨機點的數量 - **訓練迭代** - 我們從訓練集中選擇隨機資料點並將其輸入神經網路上的「訓練」函數的次數。 - **學習率** - 我們根據錯誤調整速度的乘數。 - **隱藏節點(超過2個!)** - 調整第二層有多少個隱藏節點(需要您再次初始化網絡,否則會損壞!) - **要分類的點** - 傳遞給我們訓練過的神經網路並繪製在圖表上的點數。 這意味著我們可以更快地處理這些值,看看它們對我們的神經網路及其準確性有什麼影響! ### 最後一件事 哦,我加入了一個按鈕來視覺化神經網路的樣子。 無論如何按“可視化神經元和權重”,但它還沒有完成。我也沒有立即完成它的打算,因為我想完全重新設計建構神經網路的方法,使其更具可擴展性。 不過,按鈕就在那裡,請隨意按下。更好的是,請隨時為我修復它! 🤣💗 ## 演示 控制項與以前相同,加上前面 2 個小節中提到的輸入。 試試一下,看看是否可以微調學習率、神經元數量和訓練設定以獲得真正準確的結果! https://codepen.io/GrahamTheDev/pen/qBLwBxP 請務必更新一些值,重新初始化神經網絡,嘗試使用不同數量的隱藏神經元等。 如果您像我一樣是初學者,希望您能開始理解一些事情! ## 結論 用 vanilla JS 建立神經網路真的很有趣。 我沒有見過很多人這樣做,所以我希望它對你或至少對某人有用! 我學到了很多關於偏差、反向傳播(神經網路的關鍵)等的知識。 顯然這個例子和這裡學到的東西只是機器學習的1%。但對於像我這樣的微小的、未優化的神經網路和巨大的數十億參數模型來說,核心原理是相同的。 這個例子就像機器學習 (ML) 和神經網路的「hello world」。 接下來,我真的想嘗試建立一個更大的、結構更好、更容易擴展的神經網絡,看看我們是否可以進行一些光學字元辨識(OCR)。您可以將其視為機器學習和神經網路的“待辦事項清單”! ### 發表評論。 您是神經網路專家嗎?告訴我我哪裡錯了! 你是像我一樣的初學者嗎?那麼請告訴我這是否有助於您理解,至少一點點!或者,如果這實際上讓事情變得更加混亂! 😱 最重要的是,如果這篇文章激發了您對我糟糕的編碼做鬼臉,或者想要建置您自己的神經網絡......那麼我很高興它對您產生了一些影響,並且很樂意聽到它! 💗 --- 原文出處:https://dev.to/grahamthedev/a-noob-learns-ai-my-first-neural-networkin-vanilla-jswith-no-libraries-1f92
原文出處:https://dev.to/jamesliudotcc/how-to-use-async-await-with-map-and-promise-all-1gb5 我發現自己一直在使用帶有 async 和 await 的 map 函數。我需要重新學習如何使用 Promise 來解決這個問題,但是一旦我解決了這個問題,語法就變得非常漂亮且可讀。 JavaScript 的 async 和 wait 語法是 ES2017 中的新語法。我認為語法非常簡潔,因為它允許我編寫比承諾金字塔更短、更容易理解的程式碼,類似於承諾是回調地獄的改進。 但是當你想從一堆請求中取回一堆資料時會發生什麼? JavaScript 中沒有「await all」。這就是 `Promises.all()` 的用武之地。Promises.all() 收集一堆 Promise,並將它們匯總成一個 Promise。一旦所有內部承諾成功解決,Promise.all() 將返回已解決的承諾,其中所有內部承諾都已解決。為了讓事情變得更快,一旦任何內部 Promise 被拒絕,Promise.all() 就會拒絕。 重點是 Promise.all() 將一系列 Promise 轉換為單一 Promise,如果正常的話,它會解析為您想要的陣列。其他一切都只是細節。 不知何故,我花了很長時間才擺脫困境。這是我最終開始工作的程式碼,希望這有助於解釋。 假設您點擊一個 REST 端點並取得 REST 端點的 URL 陣列,其中包含您最終想要的內容。例如,您想從 Star Wars API 中找到有關電影 R2-D2 的一些資訊。無論出於何種原因,您都不能使用 SWAPI GraphQL。我們知道從網路取得是一個非同步操作,因此我們必須使用回呼、promise 或 async 和await 關鍵字。由於 R2-D2 出現在多部電影中,因此需要多次網路呼叫才能獲取所有電影。 首先,讓我們進行設定。讓我們只專注於我們正在開發的最小功能,因此我們將在命令列上使用 Node.js。 Node.js 沒有附帶 fetch,所以讓我們使用 npm 或 YARN 來安裝它。 ``` npm install node-fetch --save-dev ``` 或者 ``` yarn add node-fetch --dev ``` async/await 的一個問題是,await 關鍵字只允許在 async 函數內部使用。在真實的程式中,您可能已經進行了足夠的封裝,以便您可以在使用await關鍵字的函數上新增async關鍵字,但在臨時檔案中,我們希望從封閉的上下文中抽像出來。但作為 Javascript 程式設計師,我們知道如何透過將我們想要的內容包裝在即時呼叫的函數表達式中來解決這個問題。 ``` // prettier-ignore const fetch = require('node-fetch') // prettier-ignore (async () => { try { let characterResponse = await fetch('http://swapi.co/api/people/2/') let characterResponseJson = await characterResponse.json() console.log(characterResponseJson) } catch (err) { console.log(err) } } )() ``` 現在我們已經有了基本的 async/await 語法,我們可以檢查回應以查看我們想要的電影欄位。它是一個 URL 陣列。 ``` let films = characterResponseJson.films.map(async filmUrl => { let filmResponse = await fetch(filmUrl) let filmResponseJSON = filmResponse.json() return filmResponseJSON }) console.log(films) ``` 當您執行此程式碼時,您會得到一組待處理的承諾。您需要新的“async”,否則箭頭函數內的等待將無法工作。如果你不「等待」獲取,你會得到一堆被拒絕的承諾,並且錯誤告訴你處理你的承諾拒絕。 但回想一下,「Promise.all()」接受一組 Promise 並將它們包裝成一個 Promise。所以我們包裝我們的“map”函數。我們已經知道一些處理單一 Promise 的好語法。我們可以‘等待’。 ``` let characterResponse = await fetch('http://swapi.co/api/people/2/') let characterResponseJson = await characterResponse.json() let films = await Promise.all( characterResponseJson.films.map(async filmUrl => { let filmResponse = await fetch(filmUrl) return filmResponse.json() }) ) console.log(films) ``` 為了進行比較,promise 中的等效程式碼如下所示: ``` fetch('http://swapi.co/api/people/2/') .then(characterResponse => characterResponse.json()) .then(characterResponseJson => { Promise.all( characterResponseJson.films.map(filmUrl => fetch(filmUrl).then(filmResponse => filmResponse.json()) ) ).then(films => { console.log(films) }) }) ``` 對我來說,第一組 `.then().then()` 非常語意化,我幾乎可以遵循 async/await 文法。但是一旦我們進入“Promise.all()”,僅使用 Promise 語法事情就開始變得難以遵循。無論我們要對影片執行什麼操作,都將取代“console.log”,並且在“.then”連結語法中,它已經埋藏了 3 級縮排。淺層程式碼是易於理解的程式碼。
原文出處:https://dev.to/antonmelnyk/how-to-configure-webpack-from-scratch-for-a-basic-website-46a5 #簡介 你好,讀者! 如您所知,設定 [Webpack](https://webpack.js.org/) 可能是一項令人沮喪的任務。儘管有很好的文件,但由於一些原因,這個捆綁器並不是一匹舒服的馬。 Webpack 團隊正在非常努力且相對快速地開發它,這是一件好事。然而,對於新開發人員來說,一次性學習所有內容是難以承受的。教程已經過時,一些插件損壞,發現的範例可能會令人困惑。有時,您可能會陷入一些瑣碎的事情,並透過 Google 進行大量搜尋,以在 GitHub issues 中找到一些最終有幫助的簡訊。 缺乏關於 Webpack 及其工作原理的介紹性文章,人們直接奔向 *create-react-app* 或 *vue-cli* 等工具,但有時需要編寫一些簡單的純 JavaScript 和 SASS,無需框架或任何奇特的東西。 本指南將逐步介紹 ES6、SASS 和圖片/字體的 Webpack 配置,無需任何框架。對於大多數簡單的網站開始使用 Webpack 或將其用作進一步學習的平台應該足夠了。儘管本指南需要一些有關 Web 開發和 JavaScript 的先驗知識,但它可能對某些人有用。至少當我開始使用 Webpack 時,我會很高興遇到這樣的事情! #我們的目標 我們將使用 Webpack 將 JavaScript、樣式、圖像和字體檔案捆綁到一個 *dist* 資料夾中。 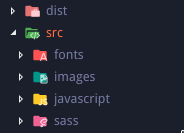 Webpack 將產生 1 個捆綁的 JavaScript 檔案和 1 個捆綁的 CSS 檔案。您可以像這樣簡單地將它們加入到 HTML 文件中(當然,如果需要,您應該更改 dist 資料夾的路徑): ``` <link rel="stylesheet" href="dist/bundle.css"> <script src="dist/bundle.js"></script> ``` 你就可以走了:tropical_drink: 您可以查看本指南中完成的範例::link:[link](https://github.com/heyanton/simple_webpack_boilerplate)。 注意:我最近更新了依賴項。本指南適用於最新的 Webpack 5,但設定仍適用於 Webpack 4,以防您需要! #開始 ####1。安裝Webpack 我們使用 [npm](https://www.npmjs.com/): `$ npm init` 命令在專案資料夾中建立一個 *package.json* 文件,我們將在其中放置 JavaScript 依賴項。然後我們可以使用 $ npm i --save-dev webpack webpack-cli 來安裝 Webpack 本身。 ####2。建立入口點文件 Webpack 從單一 JavaScript 檔案開始運作,該檔案稱為入口點。在 *javascript* 資料夾中建立 *index.js*。您可以在這裡編寫一些簡單的程式碼,例如 `console.log('Hi')` 以確保其正常運作。 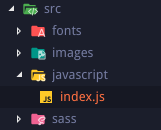 ####3。建立 webpack.config.js ....在專案資料夾中。這裡是所有:sparkles:魔法發生的地方。 ``` // Webpack uses this to work with directories const path = require('path'); // This is the main configuration object. // Here, you write different options and tell Webpack what to do module.exports = { // Path to your entry point. From this file Webpack will begin its work entry: './src/javascript/index.js', // Path and filename of your result bundle. // Webpack will bundle all JavaScript into this file output: { path: path.resolve(__dirname, 'dist'), publicPath: '', filename: 'bundle.js' }, // Default mode for Webpack is production. // Depending on mode Webpack will apply different things // on the final bundle. For now, we don't need production's JavaScript // minifying and other things, so let's set mode to development mode: 'development' }; ``` ####4。在 *package.json* 中新增 npm 腳本來執行 Webpack 要執行 Webpack,我們必須使用 npm 腳本和簡單的命令「webpack」以及我們的設定檔作為 *config* 選項。我們的 *package.json* 現在應該如下所示: ``` { "scripts": { "build": "webpack --config webpack.config.js" }, "devDependencies": { "webpack": "^4.29.6", "webpack-cli": "^3.2.3" } } ``` ####5。執行Webpack 透過基本設置,您可以執行“$ npm run build”命令。 Webpack 將尋找我們的入口文件,解析其中的所有[*import*](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/import) 模組相依性並將其捆綁到*dist* 資料夾中的單一 *.js* 檔案。在控制台中,您應該看到如下內容: 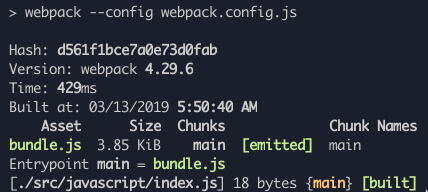 如果您將 `<script src="dist/bundle.js"></script>` 加入到 HTML 檔案中,您應該在瀏覽器控制台中看到「Hi」! #:顯微鏡:裝載機 偉大的!我們捆綁了標準 JavaScript。但是,如果我們想使用 ES6(及更高版本)的所有酷炫功能並保持瀏覽器相容性怎麼辦?我們應該如何告訴 Webpack 將我們的 ES6 程式碼轉換(*transpile*)相容於瀏覽器的程式碼? 這就是 Webpack **loaders** 發揮作用的地方。 Loader 是 Webpack 的主要功能之一。他們對我們的程式碼進行某些轉換。 讓我們在 *webpack.config.js* 檔案中新增選項 *module.rules*。在此選項中,我們將介紹 Webpack 如何準確地轉換不同類型的檔案。 ``` entry: /* ... */, output: /* ... */, module: { rules: [ ] } ``` 對於 JavaScript 文件,我們將使用: ###1。 [babel-loader](https://github.com/babel/babel-loader) [Babel](https://babeljs.io/) 是目前最好的 JavaScript 轉譯器。我們將告訴 Webpack 在捆綁之前使用它將現代 JavaScript 程式碼轉換為與瀏覽器相容的 JavaScript 程式碼。 Babel-loader 正是這樣做的。讓我們安裝它: `$ npm i --save-dev babel-loader @babel/core @babel/preset-env` 現在我們要新增有關 JavaScript 檔案的規則: ``` rules: [ { test: /\.js$/, exclude: /(node_modules)/, use: { loader: 'babel-loader', options: { presets: ['@babel/preset-env'] } } } ] ``` * `test` 是我們要轉換的檔案副檔名的[正規表示式](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions)。在我們的例子中,它是 JavaScript 檔案。 * `exclude` 是一個正規表示式,它告訴 Webpack 在轉換模組時應該忽略哪個路徑。這意味著如果我們將來導入它們,我們將不會轉換從 npm 匯入的供應商庫。 * `use` 是主要規則的選項。這裡我們設定 loader,它將應用於與「test」正規表示式相對應的檔案(在本例中為 JavaScript 檔案) * “選項”可能因載入程式而異。在這種情況下,我們為 Babel 設定預設預設,以考慮應該轉換哪些 ES6 功能,哪些不應該轉換。它本身是一個單獨的主題,如果您感興趣,可以深入研究它,但目前保持這樣是安全的。 現在您可以將 ES6 程式碼安全地放置在 JavaScript 模組中! ###2。 [sass-loader](https://github.com/webpack-contrib/sass-loader) 是時候處理樣式了。通常,我們不想寫純 CSS。我們經常使用 [SASS](https://sass-lang.com/) 預處理器。我們將 SASS 轉換為 CSS,然後應用自動前綴和縮小。這是 CSS 的一種「預設」方法。讓我們告訴 Webpack 要這樣做。 假設我們在 *javascripts/index.js* 入口點導入主 SASS 檔案 *sass/styles.scss*。 ``` import '../sass/styles.scss'; ``` 但目前,Webpack 不知道如何處理 *.scss* 檔案或除 *.js* 之外的任何檔案。我們需要新增適當的載入器,以便 Webpack 可以解析這些檔案: `$ npm i --save-dev sass sass-loader postcss-loader css-loader` 我們可以為 SASS 檔案新增規則並告訴 Webpack 如何處理它們: ``` rules: [ { test: /\.js$/, /* ... */ }, { // Apply rule for .sass, .scss or .css files test: /\.(sa|sc|c)ss$/, // Set loaders to transform files. // Loaders are applying from right to left(!) // The first loader will be applied after others use: [ { // This loader resolves url() and @imports inside CSS loader: "css-loader", }, { // Then we apply postCSS fixes like autoprefixer and minifying loader: "postcss-loader" }, { // First we transform SASS to standard CSS loader: "sass-loader" options: { implementation: require("sass") } } ] } ] ``` 請注意此處有關 Webpack 的重要事項。可連結多個裝載機;它們將從“use”陣列中的最後一個到第一個逐個應用。 現在,當 Webpack 在程式碼中遇到“import 'file.scss';”時,它知道該怎麼做! ####PostCSS 我們應該如何告訴 *postcss-loader* 它必須應用哪些轉換?我們建立一個單獨的設定檔 `postcss.config.js` 並使用我們的樣式所需的 postcss 外掛程式。您可能會發現對最基本和有用的插件進行縮小和自動加入前綴,以確保 CSS 為您的真實網站做好準備。 首先,安裝這些 postcss 外掛:`$ npm i --save-dev autoprefixer cssnano`。 其次,將它們加入到 *postcss.config.js* 檔案中,如下所示: ``` module.exports = { plugins: [ require('autoprefixer'), require('cssnano'), // More postCSS modules here if needed ] } ``` 您可以更深入地研究 [PostCSS](https://github.com/postcss/postcss),找到更多適合您的工作流程或專案需求的插件。 在完成所有 CSS 設定之後,只剩下一件事了。 Webpack 將解析您的 *.scss* 導入,對其進行轉換,然後...下一步是什麼?它不會神奇地建立一個與您的樣式捆綁在一起的單一 *.css* 檔案;我們必須告訴 Webpack 要這樣做。但這個任務超出了裝載機的能力範圍。為此,我們必須使用 Webpack 的 **插件**。 #:electric_plug: 插件 他們的目的是做裝載機做不到的任何事。如果我們需要將所有轉換後的 CSS 提取到一個單獨的「捆綁」檔案中,我們必須使用插件。我們的案例有一個特殊的插件:*MiniCssExtractPlugin*: `$ npm i --save-dev mini-css-extract-plugin` 我們可以在 *webpack.config.js* 檔案的開頭單獨導入外掛: ``` const MiniCssExtractPlugin = require("mini-css-extract-plugin"); ``` 在我們設定載入器的“module.rules”陣列之後加入新的“plugins”程式碼,我們用選項啟動我們的插件: ``` module: { rules: [ /* ... */ ] }, plugins: [ new MiniCssExtractPlugin({ filename: "bundle.css" }) ] ``` 現在我們可以將此插件連結到我們的 CSS 載入器中: ``` { test: /\.(sa|sc|c)ss$/, use: [ { // After all CSS loaders, we use a plugin to do its work. // It gets all transformed CSS and extracts it into separate // single bundled file loader: MiniCssExtractPlugin.loader }, { loader: "css-loader", }, /* ... Other loaders ... */ ] } ``` 完畢!如果您按照步驟操作,則可以執行「$ npm run build」命令並在 *dist* 資料夾中找到 *bundle.css* 檔案。現在的一般設定應如下所示:  Webpack 有大量用於不同目的的插件。您可以根據需要在[官方文件](https://webpack.js.org/plugins/)中探索它們。 # 更多載入器:圖像和字體 此時,您應該了解 Webpack 工作原理的基礎知識。但我們還沒完成。大多數網站都需要一些資源:我們透過 CSS 設定的圖像和字體。由於 *css-loader*,Webpack 可以解析 `background-image: url(...)` 行,但它不知道如果將 URL 設為 *.png* 或 *jpg* 檔案該怎麼辦。 我們需要一個新的載入器來處理 CSS 內的檔案或能夠直接在 JavaScript 中匯入它們。這是: ### [檔案載入器](https://github.com/webpack-contrib/file-loader) 使用 `$ npm i --save-dev file-loader` 安裝它,並在我們的 *webpack.config.js* 新增規則: ``` rules: [ { test: /\.js$/, /* ... */ }, { test: /\.(sa|sc|c)ss$/, /* ... */ }, { // Now we apply rule for images test: /\.(png|jpe?g|gif|svg)$/, use: [ { // Using file-loader for these files loader: "file-loader", // In options we can set different things like format // and directory to save options: { outputPath: 'images' } } ] } ] ``` 現在,如果你在 CSS 中使用一些像這樣的圖像: ``` body { background-image: url('../images/cat.jpg'); } ``` Webpack 將成功解決它。您將在 *dist/images* 資料夾中找到帶有雜湊名稱的圖像。在 *bundle.css* 會發現類似這樣的內容: ``` body { background-image: url(images/e1d5874c81ec7d690e1de0cadb0d3b8b.jpg); } ``` 正如你所看到的,Webpack 非常聰明——它正確解析了你的 url 相對於 *dist* 資料夾的路徑! 您也可以為字體加入規則並以與圖像類似的方式解析它們;將 outputPath 變更為 *fonts* 資料夾以保持一致性: ``` rules: [ { test: /\.js$/, /* ... */ }, { test: /\.(sa|sc|c)ss$/, /* ... */ }, { test: /\.(png|jpe?g|gif|svg)$/, /* ... */ }, { // Apply rule for fonts files test: /\.(woff|woff2|ttf|otf|eot)$/, use: [ { // Using file-loader too loader: "file-loader", options: { outputPath: 'fonts' } } ] } ] ``` #總結 就是這樣!經典網站的簡單 Webpack 設定。我們介紹了 **入口點**、**載入器** 和 **插件** 的概念以及 Webpack 如何轉換和捆綁檔案。 當然,這是一個非常簡單的配置,旨在了解 Webpack 的一般概念。如果您需要的話,還有很多事情可以加入:來源映射、熱重載、設定 JavaScript 框架以及 Webpack 可以做的所有其他事情,但我覺得這些事情超出了本指南的範圍。 如果您遇到困難或想了解更多訊息,我鼓勵您查看 Webpack [官方文件](https://webpack.js.org/concepts)。快樂捆綁!
原文出處:https://dev.to/gfish94/brainjs-for-beginners-1g77 ## Brain.js Brain.js 是一個用於建立神經網路的 JavaScript 函式庫,非常容易學習和實作。神經網路是一種受人腦啟發並以人腦命名的資料結構。神經網路由節點層組成,每個節點都有相關的權重閾值。如果節點輸出高於閾值,則啟動該神經元並將資料傳送到下一層中的連接節點。在 Brain.js 中,初始化該資料結構的過程就像載入到模組中並呼叫建構函數一樣簡單。 ``` const brain = require('brain.js'); //initialize neural network const net = new brain.NeuralNetwork(); ``` ## 訓練  這個新建構的物件需要提供一個資料集才能進行預測。 Brain.js 讓這個過程變得非常簡單,您所需要做的就是呼叫「.train」方法並傳入一個物件陣列——每個物件都帶有輸入和輸出的鍵值對。基本網路建構函數僅支援 0 和 1 的陣列,或 0 和 1 的雜湊;然而,還有其他更複雜的模型,允許在資料集中輸入其他資料類型。 ``` //input training dataset net.train([ { input: [0, 0], output: [0] }, { input: [0, 1], output: [1] }, { input: [1, 0], output: [1] }, { input: [1, 1], output: [0] }, ]); ``` ## Run  現在您已經輸入了資料集並訓練了您的人工大腦,您需要在神經網路上呼叫“.run”方法。這將傳回一個陣列,其十進制值對應於您的預期輸出等於 1 的機率。小數點值越高,神經網路認為輸出應該為 1 的可能性越大。 ``` //outputs a probability const output1 = net.run([1, 0]);// [ 0.9327429533004761 ] const output2 = net.run([0, 0]);//) [ 0.05645085498690605 ] const output3 = net.run([1, 1]);// [ 0.08839469403028488 ] console.log('output 1:', output1); console.log('output 2:', output2); console.log('output 3:', output3); console.log(Math.round(output1[0]));// => 1 console.log(Math.round(output2[0]));// => 0 console.log(Math.round(output3[0]));// => 0 ``` ## 儲存你訓練過的網絡  透過提供更大的資料集,網路預測預期輸出的能力變得更加準確;然而,對於更大的資料集,或者如果您正在實現一個更複雜的網路模型(這需要在資料集上迭代一定次數才能進行訓練),程式碼執行所需的時間也會增加。可以透過利用 Brain.js 的「.toJSON」和「.fromJSON」將預訓練網路儲存為 JSON 來規避此問題。以下是如何使用 Node.js 的檔案系統模組來儲存和載入網路的範例。 ``` const brain = require('brain.js'); const data = require('./data.json'); const fs = require('fs'); //init neural network const net = new brain.recurrent.LSTM(); const trainingData = data.map(item => ({ input: item.message, output: item.response })); //input training data and configuration object net.train(trainingData, { log: (err) => console.log(err), iterations: 500 }); //save trained network to json const networkState = net.toJSON(); fs.writeFileSync('network_state.json', JSON.stringify(networkState), 'utf-8'); ``` ``` const brain = require('brain.js'); const fs = require('fs'); //init neural network const net = new brain.recurrent.LSTM(); //load trained network to json const networkState = JSON.parse( fs.readFileSync('network_state.json', 'utf-8')); net.fromJSON(networkState); ``` ## 結論 Brain.js 是一種用 JavaScript 學習和實作神經網路的有趣且簡單的方法。我希望這能激勵更多的人走出去,用 JavaScript 實作機器學習演算法。
原文出處:https://dev.to/nikl/json-is-slower-here-are-its-4-faster-alternatives-2g30 --- ## 介紹 在快節奏的 Web 開發世界中,速度和反應能力是不容妥協的。您的用戶希望即時存取資訊、快速互動和無縫體驗。 JSON 是 JavaScript 物件表示法的縮寫,一直是 Web 開發中資料交換的忠實夥伴,但它會減慢您的應用程式速度嗎?讓我們深入探討 JSON 的世界,探索其潛在瓶頸,並發現更快的替代方案和優化技術,讓您的應用程式像獵豹一樣衝刺。 --- 您可能還想查看本教學:[使用 Golang 建立即時通知系統 - 逐步通知系統設計指南](https://dev.to/nikl/using-golang-to-build -即時通知系統逐步通知系統設計指南-50l7) --- ### 什麼是 JSON 以及為什麼您應該關心? 在開始 JSON 優化之旅之前,讓我們先了解 JSON 是什麼以及它為何重要。 JSON 是將應用程式中的資料黏合在一起的黏合劑。它是伺服器和客戶端之間通訊資料的語言,也是資料儲存在資料庫和設定檔中的格式。從本質上講,JSON 在現代 Web 開發中發揮關鍵作用。 了解 JSON 及其細微差別不僅是任何 Web 開發人員的基本技能,而且對於優化應用程式也至關重要。隨著我們深入研究此博客,您將發現為什麼 JSON 在性能方面可以成為一把雙刃劍,以及這些知識如何對您的開發之旅產生重大影響。 ## JSON 的受歡迎程度以及人們使用它的原因 JSON 在 Web 開發領域的受歡迎程度怎麼強調都不為過。由於以下幾個令人信服的原因,它已成為資料交換的事實上的標準: 1. **人類可讀格式**:JSON 使用簡單的、基於文字的結構,開發人員和非開發人員都可以輕鬆閱讀和理解。這種人類可讀的格式增強了協作並簡化了調試。 ``` // Inefficient { "customer_name_with_spaces": "John Doe" } // Efficient { "customerName": "John Doe" } ``` 2. **與語言無關**:JSON 不依賴任何特定的程式語言。它是一種通用資料格式,幾乎可以由所有現代程式語言解析和生成,因此具有高度通用性。 3. **資料結構一致性**:JSON 使用鍵值對、陣列和巢狀物件強制資料結構一致。這種一致性使其在各種程式設計場景中都可預測且易於使用。 ``` // Inefficient { "order": { "items": { "item1": "Product A", "item2": "Product B" } } } // Efficient { "orderItems": ["Product A", "Product B"] } ``` 4. **瀏覽器支援**:Web 瀏覽器原生支援 JSON,允許 Web 應用程式與伺服器無縫通訊。這種原生支援對其在 Web 開發中的採用做出了重大貢獻。 5. **JSON API**:許多Web服務和API預設提供JSON格式的資料。這進一步鞏固了 JSON 作為 Web 開發中資料交換首選的角色。 6. **JSON Schema**:開發人員可以使用 JSON Schema 來定義和驗證 JSON 資料的結構,為其應用程式添加額外的清晰度和可靠性。 有鑑於這些優勢,全球開發人員依賴 JSON 來滿足資料交換需求也就不足為奇了。然而,當我們更深入地探索部落格時,我們將發現與 JSON 相關的潛在性能挑戰以及如何有效解決這些挑戰。 ## 對速度的極品 在當今快節奏的數位環境中,應用程式速度和回應能力是不容談判的。用戶期望跨網路和行動應用程式即時存取資訊、快速互動以及無縫體驗。這種對速度的需求是由以下幾個因素所驅動的: ### 用戶期望 使用者已經習慣了數位互動中閃電般的快速回應。他們不想等待網頁加載或應用程式回應。即使是幾秒鐘的延遲也會導致沮喪和放棄。 ### 競爭優勢 速度可以成為顯著的競爭優勢。快速回應的應用程式往往比反應遲緩的應用程式更有效地吸引和留住用戶。 ### 搜尋引擎排名 像 Google 這樣的搜尋引擎將頁面速度視為排名因素。載入速度更快的網站往往在搜尋結果中排名更高,從而提高可見度和流量。 ### 轉換率 尤其是電子商務網站,他們敏銳地意識到速度對轉換率的影響。更快的網站可以帶來更高的轉換率,從而增加收入。 ### 移動效能 隨著行動裝置的普及,對速度的需求變得更加重要。行動用戶的頻寬和處理能力通常有限,因此需要快速的應用程式效能。 ### JSON 會減慢我們的應用程式速度嗎? 現在,讓我們解決核心問題:JSON 是否會減慢我們的應用程式速度? 如同前面提到的,JSON 是一種非常流行的資料交換格式。它靈活、易於使用且廣受支援。然而,這種廣泛的採用並不能使其免受性能挑戰。 在某些情況下,JSON 可能是降低應用程式速度的罪魁禍首。解析 JSON 資料的過程,尤其是在處理大型或複雜結構時,可能會消耗寶貴的毫秒時間。此外,低效率的序列化和反序列化可能會影響應用程式的整體效能。 ### 解析開銷 當 JSON 資料到達您的應用程式時,它必須經過解析過程才能將其轉換為可用的資料結構。解析可能相對較慢,尤其是在處理大量或深層巢狀的 JSON 資料時。 ``` // JavaScript example using JSON.parse for parsing const jsonData = '{"key": "value"}'; const parsedData = JSON.parse(jsonData); ``` ### 序列化與反序列化 JSON 要求資料從用戶端傳送到伺服器時進行序列化(將物件編碼為字串),並在接收時進行反序列化(將字串轉換回可用物件)。這些步驟可能會帶來開銷並影響應用程式的整體速度。 ``` // Node.js example using JSON.stringify for serialization const data = { key: 'value' }; const jsonString = JSON.stringify(data); ``` ### 字串操作 JSON 是基於文字的,嚴重依賴字串操作來進行連接和解析等操作。與處理二進位資料相比,字串處理可能會慢一些。 ### 缺乏資料類型 JSON 具有一組有限的資料類型(例如字串、數字、布林值)。複雜的資料結構可能需要效率較低的表示,導致記憶體使用量增加和處理速度變慢。 ``` { "quantity": 1.0 } ``` ### 冗長 JSON 的人類可讀設計可能會導致冗長。冗餘金鑰和重複結構會增加有效負載大小,導致資料傳輸時間更長。 ``` // Inefficient { "product1": { "name": "Product A", "price": 10 }, "product2": { "name": "Product A", "price": 10 } } ``` ### 沒有二進位支持 JSON 缺乏對二進位資料的本機支援。在處理二進位資料時,開發人員通常需要將其編碼和解碼為文本,這可能會降低效率。 ### 深度嵌套 在某些場景下,JSON資料可能會深度嵌套,需要遞歸解析和遍歷。這種計算複雜性可能會減慢您的應用程式的速度,尤其是在沒有最佳化的情況下。 --- > **與此類似,我與其他熱愛開源的開發人員一起在 Slack 上運行一個以開發人員為中心的社群。我們討論這些類型的主題、實現、整合、一些真相炸彈、奇怪的聊天、虛擬會議、為開源做出貢獻以及一切有助於開發人員保持理智的事情;)畢竟,太多的知識也可能是危險的。* * > **我邀請您加入我們的免費社區(_沒有廣告,我保證,並且我打算保持這種方式_),參與討論,並分享您的經驗和專業知識。您可以填寫此表格,Slack 邀請將在幾天後收到您的電子郵件。我們有來自一些偉大公司(Atlassian、Gong、Scaler)的優秀人員,您一定不想錯過與他們的互動。 [邀請表](https://forms.gle/VzA3ST8tCFrxt39U9)** 讓我們繼續... --- ## JSON 的替代方案 雖然 JSON 是一種通用的資料交換格式,但其在某些場景下的效能限制導致人們探索更快的替代方案。讓我們深入研究其中一些替代方案,並了解您何時以及為何選擇它們: ### 協定緩衝區 Protocol Buffers,也稱為 protobuf,是 Google 開發的二元序列化格式。它在速度和效率方面表現出色。這就是您可能考慮使用 Protocol Buffer 的原因: 1. **二進位編碼**:Protocol Buffers 使用二進位編碼,與 JSON 基於文字的編碼相比,它更緊湊,編碼和解碼速度更快。 2. **高效的資料結構**:Protocol Buffers 可讓您透過精確的類型定義高效的資料結構,從而實現更快的序列化和反序列化。 3. **架構演化**:Protocol Buffers 支援架構演化,這表示您可以在不破壞向後相容性的情況下更新資料結構。 ``` syntax = "proto3"; message Person { string name = 1; int32 age = 2; } ``` ### 訊息包 MessagePack 是另一種專為提高效率和速度而設計的二元序列化格式。以下是您可能考慮使用 MessagePack 的原因: 1. **緊湊性**:MessagePack 產生高度緊湊的資料表示形式,從而減少資料傳輸大小。 2. **二進位資料**:MessagePack 提供了對二進位資料的原生支持,非常適合涉及二進位資訊的場景。 3. **速度**:MessagePack 的二進位性質允許快速編碼和解碼。 ``` // JavaScript example using MessagePack for serialization const msgpack = require('msgpack-lite'); const data = { key: 'value' }; const packedData = msgpack.encode(data); ``` ### BSON(二進位 JSON) BSON,通常發音為“bee-son”或“bi-son”,是一種二進位序列化格式,主要用於 MongoDB 等資料庫。以下是您可能考慮使用 BSON 的原因: 1. **類似 JSON 的結構**:BSON 維護了類似 JSON 的結構,並添加了二進位資料類型,在效率和可讀性之間提供了平衡。 2. **二進位資料支援**:BSON 提供對二進位資料類型的原生支持,這有利於處理映像或多媒體等資料。 3. **資料庫集成**:BSON 與 MongoDB 等資料庫無縫集成,使其成為此類環境的自然選擇。 ``` { "_id": ObjectId("60c06fe9479e1a1280e6bfa7"), "name": "John Doe", "age": 30 } ``` ### 歐元 Avro 是在 Apache Hadoop 專案中開發的資料序列化框架。它強調模式相容性和效能。以下是您可能考慮使用 Avro 的原因: 1. **架構相容性**:Avro 優先考慮架構相容性,讓您在不破壞相容性的情況下發展資料結構。 2. **二進位資料**:Avro 使用緊湊的二進位編碼格式進行資料傳輸,從而產生更小的有效負載。 3. **語言中立**:Avro 支援多種程式語言,使其適合不同的應用程式生態系統。 ``` { "type": "record", "name": "Person", "fields": [ { "name": "name", "type": "string" }, { "name": "age", "type": "int" } ] } ``` JSON 及其替代方案之間的選擇取決於您的特定用例和要求。如果架構相容性至關重要,Avro 可能是最佳選擇。如果您需要緊湊性和效率,MessagePack 和 Protocol Buffers 是強有力的競爭者。在處理二進位資料時,MessagePack 和 BSON 可以滿足您的需求。每種格式都有其優點和缺點,因此請選擇適合您專案需求的格式。 ### 最佳化 JSON 效能 但是,如果您決心使用 JSON,儘管它有潛在的速度障礙,該怎麼辦?如何讓 JSON 運作得更快、更有效率?好消息是,有一些實用的策略和最佳化可以幫助您實現這一目標。讓我們透過程式碼範例和最佳實踐來探索這些策略。 **1.最小化資料大小** A。 **使用簡短的描述性鍵**:選擇簡潔但有意義的鍵名稱以減少 JSON 物件的大小。 ``` // Inefficient { "customer_name_with_spaces": "John Doe" } // Efficient { "customerName": "John Doe" } ``` b. **盡可能縮寫**:在不犧牲清晰度的情況下,考慮使用鍵或值的縮寫。 ``` // Inefficient { "transaction_type": "purchase" } // Efficient { "txnType": "purchase" } ``` **2.明智地使用數組** A。 **最小化巢狀**:避免深度巢狀數組,因為它們會增加解析和遍歷 JSON 的複雜度。 ``` // Inefficient { "order": { "items": { "item1": "Product A", "item2": "Product B" } } } // Efficient { "orderItems": ["Product A", "Product B"] } ``` **3.優化數位表示** A。 **盡可能使用整數**:如果一個值可以表示為整數,請使用它而不是浮點數。 ``` // Inefficient { "quantity": 1.0 } // Efficient { "quantity": 1 } ``` **4.刪除冗餘** A。 **避免重複資料**:透過引用共享值來消除冗餘資料。 ``` // Inefficient { "product1": { "name": "Product A", "price": 10 }, "product2": { "name": "Product A", "price": 10 } } // Efficient { "products": [ { "name": "Product A", "price": 10 }, { "name": "Product B", "price": 15 } ] } ``` **5.使用壓縮** A。 **套用壓縮演算法**:如果適用,請使用 Gzip 或 Brotli 等壓縮演算法來減少傳輸過程中 JSON 有效負載的大小。 ``` // Node.js example using zlib for Gzip compression const zlib = require('zlib'); const jsonData = { // Your JSON data here }; zlib.gzip(JSON.stringify(jsonData), (err, compressedData) => { if (!err) { // Send compressedData over the network } }); ``` 根據塞繆爾的評論,我添加了一個編輯。 {% devcomment 2adn4 %} ``` As Samuel rightly observes, the adoption of HTTP/2 has brought significant advancements, particularly in optimizing data interchange formats like JSON. HTTP/2's multiplexing capabilities efficiently manage multiple requests over a single connection, enhancing responsiveness and reducing overhead. In practical terms, a comprehensive optimization strategy may involve both embracing HTTP/2 and utilizing compression techniques per your use-case, recognizing that each approach addresses specific aspects of network efficiency and performance. HTTP/2 excels in network-level optimization, while compression strategies enhance application-level efficiency, and the synergy between them can lead to substantial gains in data handling speed and resource utilization. ``` **6。使用伺服器端快取** A。 **快取 JSON 回應**:實作伺服器端快取以有效儲存和提供 JSON 回應,減少重複資料處理的需要。 **7.設定檔和優化** A。 **分析效能**:使用分析工具來識別 JSON 處理程式碼中的瓶頸,然後最佳化這些部分。 請記住,您實施的具體優化應符合應用程式的要求和約束。 ### 實際最佳化:在實作中加速 JSON 現在您已經探索了優化 JSON 的理論方面,現在是時候深入研究遇到 JSON 效能瓶頸並巧妙克服它們的實際應用程式和專案了。這些範例提供了有關用於提高速度和回應能力的策略的寶貴見解,同時仍利用 JSON 的多功能性。 **1. LinkedIn 的協定緩衝區整合** *挑戰:LinkedIn 與 JSON 冗長和網路頻寬使用的鬥爭* 全球最大的職業社交平台LinkedIn面臨嚴峻的挑戰。他們對 JSON 進行微服務通訊的依賴導致了冗長和網路頻寬使用量的增加,最終導致更高的延遲。在每一毫秒都至關重要的數位世界中,這是一個需要解決方案的挑戰。 **解決方案:協定緩衝區的力量** LinkedIn 轉向了 [Protocol Buffers](https://engineering.linkedin.com/blog/2023/linkedin-integrates-protocol-buffers-with-rest-li-for-improved-m),通常稱為 protobuf,由Google開發的二進位序列化格式。 Protocol Buffers 的主要優勢在於其效率、緊湊性和速度,使其在序列化和反序列化方面比 JSON 快得多。 **影響:延遲減少高達 60%** Protocol Buffers 的採用顯著降低了延遲,報告顯示延遲可提高高達 60%。此次優化顯著提高了 LinkedIn 服務的速度和回應能力,為全球數百萬用戶提供了更流暢的體驗。 **2. Uber 的 H3 地理索引** *挑戰:Uber 在地理空間資料方面的 JSON 困境* 叫車巨頭優步的營運嚴重依賴地理空間數據。 JSON 是表示地理空間資料的預設選擇,但解析大型資料集的 JSON 被證明是一個瓶頸,減慢了演算法的速度。 **解決方案:引入 H3 地理索引** Uber 推出了 [H3 Geo-Index](https://www.uber.com/en-IN/blog/h3/),這是一種用於地理空間資料的高效能六邊形網格系統。透過從 JSON 轉向這種創新解決方案,他們成功地大幅減少了 JSON 解析開銷。 **影響:加速地理空間操作** 這種優化大大加速了地理空間操作,提高了 Uber 乘車服務和地圖系統的效率。使用者體驗到更快的回應時間和更可靠的服務。 **3. Slack 的訊息格式最佳化** *挑戰:Slack 與即時訊息渲染的戰鬥* Slack 是團隊的訊息平台,需要在即時聊天中傳輸和呈現大量 JSON 格式的訊息。然而,這導致了效能瓶頸和訊息渲染緩慢。 **解決方案:簡化 JSON 結構** Slack 優化了 JSON 結構以減少不必要的資料。他們開始在每個訊息中只包含基本訊息,從而減少有效負載的大小。 **影響:更快的訊息渲染和增強的聊天效能** 此優化顯著提高了訊息渲染速度。 Slack 用戶享受到更靈敏、更有效率的聊天體驗,尤其是在繁忙的群組聊天中。 **4. Auth0 的協定緩衝區實作** *挑戰:Auth0的身份驗證和授權資料效能* Auth0 是一個著名的身份和存取管理平台,在處理身份驗證和授權資料時面臨 JSON 的效能挑戰。這些數據需要在不影響安全性的情況下有效處理。 **解決方案:採用協定緩衝區進行資料序列化** [Auth0 也轉向Protocol Buffers](https://auth0.com/blog/beating-json-performance-with-protobuf/#How-Do-We-Use-Protobuf),利用其高效的資料序列化和反序列化功能。此交換器顯著提高了資料處理速度,使身份驗證過程更快並增強了整體效能。 **影響:加速身份驗證和授權** Protocol Buffers 的採用增強了身分驗證和授權流程,確保 Auth0 的服務提供一流的效能,同時保持最高的安全標準。 這些現實世界的例子強調了優化在克服 JSON 相關的速度下降方面的力量。這些案例中採用的策略證明了 JSON 和替代格式在滿足現代數位環境的需求方面的適應性和多功能性。 請繼續關注結論部分,我們總結了關鍵要點,並為您提供了在您自己的專案中優化 JSON 效能的路線圖。 ## 結束語 在開發領域,JSON 是一種多功能且不可或缺的資料交換工具。其人類可讀的結構和跨語言適應性使其成為當代應用程式的基石。然而,正如我們在本指南中的探索所揭示的那樣,JSON 的普遍使用並不能使其免受性能挑戰。 我們在增強 JSON 效能的過程中獲得的重要收穫是顯而易見的: - 1. **效能至關重要:** 速度和反應能力在當今的數位環境中至關重要。用戶要求應用程式以閃電般的速度運行,即使是輕微的延遲也會導致不滿意並錯失機會。 - 2. **大小很重要:** 資料有效負載的大小直接影響網路頻寬使用和回應時間。減少資料大小通常是優化 JSON 效能的第一步。 - 3. **探索替代格式:** 當效率和速度至關重要時,探索替代資料序列化格式(如 Protocol Buffers、MessagePack、BSON 或 Avro)是有益的。 - 4. **真實世界範例:** 從組織有效解決 JSON 相關減速問題的真實實例中學習,表明最佳化工作可以顯著提高應用程式效能。 當您繼續開發和增強 Web 應用程式時,請務必牢記 JSON 對效能的影響。精心設計資料結構,選擇有意義的鍵名稱,並在情況需要時開放探索替代序列化格式。透過這樣做,您可以確保您的應用程式在速度和效率方面不僅滿足而且超越用戶的期望。 在不斷發展的 Web 開發環境中,優化 JSON 效能成為一項寶貴的資產,使您的專案與眾不同,並確保您的應用程式在即時數位體驗時代蓬勃發展。 --- > **與此類似,我與其他熱愛開源的開發人員一起在 Slack 上運行一個以開發人員為中心的社群。我們討論這些類型的主題、實現、整合、一些真相炸彈、奇怪的聊天、虛擬會議、為開源做出貢獻以及一切有助於開發人員保持理智的事情;)畢竟,太多的知識也可能是危險的。* * > **我邀請您加入我們的免費社區(_沒有廣告,我保證,並且我打算保持這種方式_),參與討論,並分享您的經驗和專業知識。您可以填寫此表格,Slack 邀請將在幾天後收到您的電子郵件。我們有來自一些偉大公司(Atlassian、Gong、Scaler)的優秀人員,您一定不想錯過與他們的互動。 [邀請表](https://forms.gle/VzA3ST8tCFrxt39U9)** > _如果您能與您的開發朋友(他們是奉獻者)分享該表格,我將不勝感激。_
原文出處:https://dev.to/turculaurentiu91/why-you-should-choose-htmx-for-your-next-project-o7j 在本文中,我們將旨在了解為什麼您下次為 Web 應用程式選擇技術堆疊時應該考慮 HTMX 作為 React 的替代品。我們將研究傳統 HTTP JSON API + React 帶來的複雜性和挑戰,以及如何透過使用 HTMX 輕鬆避免它們。 **注意**:在本文中,我將討論 React,但它可以替換為任何其他前端框架,如 Angular、Vue、Svelte 或 Solid,但我談論 React 是因為它是大多數 Web 的預設技術開發人員預設為。 ### HTMX 到底是什麼 如果您還不知道,[HTMX](https://htmx.org/) 是一個小型瀏覽器 (JS) 庫,它使用一些屬性擴展了 HTML,允許您使用來自伺服器。它還使 HTML 能夠對所有動詞發出 HTTP 請求,而不僅僅是 GET 和 POST。 ## React 解決了什麼問題 React 是一個 JavaScript 程式庫,可協助您透過保持使用者介面與狀態同步來編寫高度互動的應用程式。您告訴它如何渲染給定的狀態,每次更新狀態時,它都會重新渲染(盡可能有效率)UI 以反映狀態變更。 每次狀態發生變化時,您都會通知庫它發生了變化,並提供新的狀態,它將處理 UI 更新。 需要本地記憶體狀態的高互動應用程式的範例可以是您可以在網路上找到的各種文字編輯器(VSCode)之一、拖放看板(如 Trello 或 JIRA)、視訊播放器或聊天室。 什麼不是此類應用程式的範例?您正在建立的待辦事項清單、您正在閱讀的新聞網站、您發布的部落格以及周圍的大多數網站。如果我們看一下 [80/20 規則](https://en.wikipedia.org/wiki/Pareto_principle) >80% 的結果來自 20% 的原因,80% 的結果來自 20% 的努力。 你可以說 80% 使用 React 的 Web 應用程式不需要本地狀態。對於那 20% 需要它的人來說,你可以說它只是應用程式的一小部分(大約 20%),其餘部分只能用 HTML 來表達。 **這些數字是編造的,我沒有任何研究來支持這一點** ## React 也解決了哪些問題,使其被現代網站廣泛採用 HTML 已經過時了。使用 HTML 製作應用程式的舊方法涉及頁面、連結和表單的集合,這些頁面、連結和表單向使用者描述給定資源的當前狀態以及他們可以執行哪些操作來更改它。 每次使用者與資源互動時,應用程式只能重新載入整個頁面以顯示資源的新狀態。 幾年後,FaceBook 推出了 React,這是一個 JS 程式庫,可讓開發人員建立單頁應用程式 (SPA)。導航時不再需要重新加載整個頁面,狀態更新的酷過渡、對用戶的有趣反饋以及其他使 Web 開發人員在其網站中採用 SPA 框架的細節。 ## 複雜性問題  如果你不理解上面的架構,不用擔心,沒有什麼好理解的。我要求 ChantGPT 為我生成它,由於它過於複雜且沒有任何意義,它完美地反映了現代 Web 應用程式目前的預設基礎架構。 一個很酷的程式設計原則是**KISS**,它代表“保持簡單,愚蠢”,或者有些人可能喜歡開玩笑,“保持簡單,愚蠢!” 現代開發人員預設建立 Web 應用程式的當前基礎設施和技術堆疊極其複雜,做了很多不必要的事情,只是因為它很酷! 當您自己建立第一個 POC 時,效果很好,但下一刻您加入了更多團隊成員,並且使用多次迭代和「擁抱」更改的敏捷方式,它有點崩潰,原因是我們將往下看一下。 ## 傳統 HTTP JSON API + React 的狀態管理問題 在 Web 應用程式中,您經常要做的就是從資料庫中獲取資源的狀態並將其呈現給使用者。讓我們以任務管理應用程式為例。使用者有一個任務列表,每個任務都有一個狀態: - 任務的標題 - 說明 - 任務完成時的標誌 - 截止日期(可選) 我們通常將此狀態儲存在資料庫中,並將此資訊呈現給用戶,您必須: - 從使用者有權存取的資料庫中取得所有任務。 - 可以選擇轉換資料(也許您儲存完成的日期並從中計算「is_completed」標誌)。 - 將資料序列化為 JSON。 - 透過 HTTP 請求取得資料。 - (可選但通常)根據模式驗證資料,可能使用 YUP 或 ZOD。 - 使用 Redux、Zustand、react-query 或其他狀態管理庫將 JSON 轉換為狀態並將其儲存在快取中。 - 轉換 HTML 中的狀態,通常會決定使用者可以使用資料做什麼。 簡而言之,我們正在描述如何在 JavaScript 中渲染所有資源的所有可能狀態,在瀏覽器中下載所述 JavaScript,然後 JavaScript 下載一堆 JSON 格式的資料並將其渲染(如果它知道如何)瀏覽器顯示為HTML! 向使用者顯示任務清單需要做大量工作,特別是當任務僅在使用者變更時才更改時,應用程式必須將應用程式置於載入狀態,發出另一個 HTTP 請求(以PUT 或PATCH 或DELETE)使快取值(狀態)無效並重新獲取它以顯示更改的任務。 或者更糟的是,當用戶更改某些任務時,樂觀地更新本地狀態並立即顯示更改,並在幕後執行更新請求,僅在他們成功更新後通知用戶更新失敗。 這是非常容易出錯的。對於這個待辦事項應用程式來說,它可能會很有效,因為您是唯一的開發人員,並且該應用程式足夠大,您可以在腦海中保留正在發生的所有事情的地圖。但是當你的團隊規模更大時,尤其是當你將團隊分成前端和後端時,溝通不良可能會導致很多問題。 後端可能使用“is_completed”標誌,而前端可能需要“is_active”標誌。後端可能會將經過 Markdown 處理的「描述」傳送到 HTML,而前端可能希望它不被處理。後端可能會將“描述”設為可選,以允許使用者在前端不同步時保存草稿,並且您會看到許多“未捕獲的類型錯誤:無法讀取未定義的屬性(讀取“toLowerCase” )” 另一方面,在 HTMX 上,您可以直接在範本上呈現 HTML,只要後端語言允許,就可以確保類型安全。您僅向瀏覽器發送相關訊息,向使用者提供對資源的適當控制,並指示瀏覽器或 HTMX 如何解釋使用者操作以及後端對這些操作的回應。所有應用程式狀態都是 HTML,這個概念稱為 [HATEOAS](https://htmx.org/essays/hateoas/) ## 傳統 HTTP JSON API + React 對文件的需求 為了讓兩個團隊(後端和前端)獨立工作並透過 HTTP JSON API 進行通信,您需要擁有適當的 API 文件。您還需要記錄如何計算使用者可以對給定資源執行哪些操作以顯示控制項。 大多數此類文件寫起來都很痛苦,特別是因為通常需要在實作之前編寫,而開發人員尚未完全理解問題的範圍,因此前端可以並行開發。這通常會在開發過程中進行許多更新,以適應開發過程中出現的問題,並可能導致團隊之間的版本不一致。 您還需要對 API 進行版本控制,並注意不要在非主要版本變更中引入重大變更。您無法再在不變更主要版本的情況下變更欄位名稱。您還需要保持 API 的多個版本運作或強制前端團隊進行調整。 大多數時候,文件已經過時了。有些必須緊急修復,有些新要求是在發布前一天提出的,現在您的文件已經過時,即使在很短的時間內。而且您必須記住更新它,或者更糟的是,您建立了一張票來記住它,而其他人拿起它,但沒有完整的圖片並記錄了錯誤! ## 重複的邏輯問題 對於每個資源,您必須實施授權策略。您必須確定目前使用者是否可以將任務 **46234** 標記為已完成。您必須在後端程式碼的某個位置編寫此檢查。否則,您的應用程式將開放給_不安全的直接物件參考_,或任何使用 Postman 的人都可以將您的任務標記為已完成。 您還必須在前端實現相同的邏輯,僅當用戶有權標記已完成時才顯示標記按鈕(讓我們假設您可以與其他用戶共享您的任務,但只有您可以更改它們)。 現在每次這個邏輯改變時,你都必須在兩個應用程式中實作它,並同時發布它或擁有多個版本的API。 ## 效能問題 為了使用 React 在瀏覽器中呈現網站,您需要將佔用大量內存和解析/處理影響的 React 程式碼、狀態管理庫程式碼、腳趾 UI 庫程式碼、CSS-IN- 捆綁在一起。JS 庫程式碼、應用程式程式碼以及我們透過NPM 安裝和使用的任何js 程式庫(我們並不羞於安裝新套件,請參閱[leftpad 問題](https://www.theregister.com/2016/03/23/npm_left_pad_chaos/))。這通常會導致透過網路傳送大塊的 JavaScript 資源。當然,您可以在瀏覽器中緩存,但在現代敏捷開發中,每個衝刺至少部署一次,因此這無法解決任何問題。這會消耗網路流量和電池,這對行動裝置來說是一個經常被忽視的問題。 上述JavaScript需要由瀏覽器來解釋,消耗處理能力和電池。 JavaScript,尤其是 ReactDOM,需要追蹤 DOM 的鏡像。在其之上加入普通 DOM 和本地狀態緩存,以及所有渲染函數,以及所有“useMemo”、“useCallback”和“useState”。也要加入需要在記憶體中保存所有上下文變數的所有閉包。 JavaScript 引擎並不以其記憶體效率而聞名!您會聽到人們抱怨瀏覽器消耗了多少內存,但他們低估了他們存取的網站所消耗的內存量。 所有這些加起來,最終會耗盡用戶的電池和記憶體。當然,您可以付出努力並優化所有這些,或使用其他程式庫(如 Svelte),但所有這些努力都可以用於為您的用戶提供更有意義的功能。 ## 服務端渲染的需要 近年來,我們播種了伺服器端渲染專用框架(如「Next.js」)的興起。它們的流行凸顯了對以 HTML 格式交付內容的需求,特別是出於可存取性優化、效能和搜尋引擎優化的原因。 你不想等待瀏覽器下載 JavaScript 來渲染頁面,然後等待 JavaScript 發出 HTTP 請求來獲取內容然後渲染它,你希望它立即渲染,特別是對於上面的情況折疊內容。 這又增加了一層複雜性,包括: - 基礎設施,現在您還需要另一台伺服器用於前端應用程式 - 程式碼更複雜,包括什麼程式碼在伺服器上執行以及什麼在瀏覽器上執行的思維導圖 - 部署管道現在更加複雜 - 測試基礎設施現在更加複雜 - 現在解決問題變得更加困難,您需要了解問題是在瀏覽器上、在客戶端應用程式伺服器上還是在 API 伺服器上 ## 解決這些問題 Web 開發社群各自使用自己的語言或開發技術,以不同的方式解決這些問題: - Next.js(以及 Nuxt 等) - 反應伺服器元件 - 拉維爾 - 慣性.JS - 活線 - 點網 - Blazor 頁面 - 靈藥 - 鳳凰即時查看 - 鐵鏽 - 樂浦伺服器功能 還有許多我忘記或從未聽說過的其他解決方案! 無論如何,此類解決方案的存在和流行證明了這些問題是有效的並且在 Web 開發人員的日常生活中遇到過。否則他們不會不遺餘力地解決這些問題,尤其是以開源的方式! 還有 [Turbo](https://turbo.hotwired.dev/) 以及採用它們的框架、Ruby on Rails、PHP Symphony 以及其他可能以與 HTMX 相同的方式解決相同問題的框架。選擇 HTMX 只是個人喜好,但你絕對應該了解這一點,這和 HTMX 一樣酷! 在所有這些中,HTMX 脫穎而出,不僅因為它不會將您鎖定到特定技術,您可以透過對模板進行微小更改來從 PHP 切換到 Rust,而且還因為它完全消除了對有狀態元件的需求,或者需要追蹤與資源無關的應用程式的某種狀態。 例如,讓我們採用確認對話方塊模式。您通常最終要做的是,您有一個本地記憶體狀態(如果它是開啟的),並根據該狀態將其顯示給使用者。在 HTMX 中,狀態 **IS THE HTML** 意味著當您按一下開啟模式時,您 **GET** `tasks/{taskId}/confirm-delete` 並將回應 HTML 嵌入到 DOM 中。當它被刪除時,您就完全刪除了模式和任務!這以一種獨特且極其簡單的方式解決了上述所有問題,您不需要: - 追蹤狀態 - 知道如何渲染對話框 - 記錄API - 檢查使用者是否可以刪除任務(在前端) - 您的後端應用程式始終負責 - 您可以獲得更好的安全性,因為您不會向瀏覽器發送不相關的資料並竊取敏感資訊 - 你會得到更好的表現 __*最重要的是,您可以讓您的應用程式保持簡單,只有在解決使用者問題時才允許複雜性!*__ 您只需指示 HTMX 從何處獲取對話框以及將其放置在何處,一切就完成了! ``` <!-- the delete button --> @if ($chirp->user->is(auth()->user())) <form> @csrf @method('delete') <x-dropdown-link :component="'button'" type="submit" hx-get="{{ route('chirps.confirm-destroy', $chirp) }}" hx-swap="beforeend" hx-target="closest .chirp" > {{ __('Delete') }} </x-dropdown-link> </form> @endif <!-- the dialog template --> <div class="modal fixed z-10 inset-0 overflow-y-auto flex justify-center items-center bg-black bg-opacity-50" style="backdrop-filter: blur(14px);"> <div class="bg-white rounded p-6"> <h2 class="text-xl border-b pb-2 mb-2">Confirm Action</h2> <p>Are you sure you want to delete this chirp?</p> <div class="flex justify-end mt-4 gap-4"> <x-secondary-button _="on click remove closest .modal" > Cancel </x-secondary-button> <form> @csrf <x-danger-button hx-delete="{{route('chirps.destroy', $chirp)}}" hx-target="closest .chirp" hx-swap="delete"> Delete </x-danger-button> </form> </div> </div> </div> ``` _這個範例來自我的 [HTMX with Laravel] 教學(https://dev.to/turculaurentiu91/laravel-htmx--g0n) ,請看!_ 就像這樣,當我們單擊刪除按鈕時,我們指示 HTMX 對 `chirps/{chirp}/confirm-destroy` 執行 **GET** 請求,並將結果 HTML 放在最接近的父級 `< 之前div class="chirp">` 結束(在底部)。在刪除對話方塊中,當使用者確認時,我們指示 HTMX 對 `chirps/{chirp}` 端點執行 **DELETE** 請求,成功後,我們刪除具有 `chirp` 類別的最接近的父級。 ## 結論 在不斷發展的 Web 開發領域,看到 HTMX 等倡導簡單性和回歸基礎的工具令人耳目一新。透過利用 HTML 和 HTTP 的強大功能,HTMX 允許開發人員建立動態 Web 應用程式,而無需傳統 JavaScript 框架的複雜性和開銷。 因此,下次您開始新專案或考慮重構現有專案時,請嘗試 HTMX。您可能會驚訝於用這麼少的錢就能取得如此大的成就。
原文出處:https://dev.to/m_midas/44-react-frontend-interview-questions-2o63 ## 介紹 在面試 React 前端開發人員職位時,為技術問題做好充分準備至關重要。 React 已經成為建立使用者介面最受歡迎的 JavaScript 程式庫之一,雇主通常專注於評估候選人對 React 核心概念、最佳實踐和相關技術的理解。在本文中,我們將探討 React 前端開發人員面試期間常見問題的完整清單。透過熟悉這些問題及其答案,您可以增加成功的機會並展示您在 React 開發方面的熟練程度。因此,讓我們深入探討您應該準備好在 React 前端開發人員面試中解決的關鍵主題。  ### 1.你知道哪些React hooks? - `useState`:用於管理功能元件中的狀態。 - `useEffect`:用於在功能元件中執行副作用,例如取得資料或訂閱事件。 - `useContext`:用於存取功能元件內的 React 上下文的值。 - `useRef`:用於建立對跨渲染持續存在的元素或值的可變引用。 - `useCallback`:用於記憶函數以防止不必要的重新渲染。 - `useMemo`:用於記憶值,透過快取昂貴的計算來提高效能。 - `useReducer`:用於使用reducer函數管理狀態,類似於Redux的工作方式。 - `useLayoutEffect`:與 useEffect 類似,但效果在所有 DOM 變更後同步運作。 這些鉤子提供了強大的工具來管理狀態、處理副作用以及重複使用 React 功能元件中的邏輯。 [了解更多](https://react.dev/reference/react) ### 2.什麼是虛擬 DOM? 虛擬 DOM 是 React 中的一個概念,其中建立實際 DOM(文件物件模型)的輕量級虛擬表示並將其儲存在記憶體中。它是一種用於優化 Web 應用程式效能的程式設計技術。 當 React 元件的資料或狀態發生變更時,虛擬 DOM 會被更新,而不是直接操作真實 DOM。然後,虛擬 DOM 計算元件的先前狀態和更新狀態之間的差異,稱為「比較」過程。 一旦辨識出差異,React 就會有效地僅更新真實 DOM 的必要部分以反映變更。這種方法最大限度地減少了實際 DOM 操作的數量,並提高了應用程式的整體效能。 透過使用虛擬 DOM,React 提供了一種建立動態和互動式使用者介面的方法,同時確保最佳效率和渲染速度。 ### 3. 如何渲染元素陣列? 要渲染元素陣列,可以使用“map()”方法迭代該陣列並傳回一個新的 React 元素陣列。 ``` const languages = [ "JavaScript", "TypeScript", "Python", ]; function App() { return ( <div> <ul>{languages.map((language) => <li>{language}</li>)}</ul> </div> ); } ``` [了解更多](https://react.dev/learn/rendering-lists) ### 4. 受控元件和非受控元件有什麼不同? 受控元件和非受控元件之間的區別在於**它們如何管理和更新其狀態**。 受控元件是狀態由 React 控制的元件。元件接收其當前值並透過 props 更新它。當值改變時它也會觸發回調函數。這意味著該元件不儲存其自己的內部狀態。相反,父元件管理該值並將其傳遞給受控元件。 ``` import { useState } from 'react'; function App() { const [value, setValue] = useState(''); return ( <div> <h3>Controlled Component</h3> <input name="name" value={name} onChange={(e) => setValue(e.target.value)} /> <button onClick={() => console.log(value)}>Get Value</button> </div> ); } ``` 另一方面,不受控制的元件使用 refs 或其他方法在內部管理自己的狀態。它們獨立儲存和更新狀態,不依賴 props 或回呼。父元件對不受控元件的狀態控制較少。 ``` import { useRef } from 'react'; function App() { const inputRef = useRef(null); return ( <div className="App"> <h3>Uncontrolled Component</h3> <input type="text" name="name" ref={inputRef} /> <button onClick={() => console.log(inputRef.current.value)}>Get Value</button> </div> ); } ``` [了解更多](https://react.dev/learn/sharing-state- Between-components#driven-and-uncontrol-components) ### 5. 基於類別的 React 元件和函數式 React 元件有什麼不同? 基於類別的元件和函數式元件之間的主要區別在於**它們的定義方式以及它們使用的語法。** 基於類別的元件被定義為 ES6 類別並擴展了 `React.Component` 類別。他們使用「render」方法傳回定義元件輸出的 JSX (JavaScript XML)。類別元件可以透過「this.state」和「this.setState()」存取元件生命週期方法和狀態管理。 ``` class App extends React.Component { state = { value: 0, }; handleAgeChange = () => { this.setState({ value: this.state.value + 1 }); }; render() { return ( <> <p>Value is {this.state.value}</p> <button onClick={this.handleAgeChange}> Increment value </button> </> ); } } ``` 另一方面,函數元件被定義為簡單的 JavaScript 函數。他們接受 props 作為參數並直接返回 JSX。功能元件無權存取生命週期方法或狀態。然而,隨著 React 16.8 中 React Hooks 的引入,功能元件現在可以管理狀態並使用其他功能,例如上下文和效果。 ``` import { useState } from 'react'; const App = () => { const [value, setValue] = useState(0); const handleAgeChange = () => { setValue(value + 1); }; return ( <> <p>Value is {value}</p> <button onClick={handleAgeChange}> Increment value </button> </> ); } ``` 一般來說,功能元件被認為更簡單、更容易閱讀和測試。建議盡可能使用函數式元件,除非有特定需要基於類別的元件。 ### 6. 元件的生命週期方法有哪些? 生命週期方法是一種掛鉤元件生命週期不同階段的方法,可讓您在特定時間執行特定程式碼。 以下是主要生命週期方法的清單: 1. `constructor`:這是建立元件時呼叫的第一個方法。它用於初始化狀態和綁定事件處理程序。在功能元件中,您可以使用“useState”鉤子來實現類似的目的。 2. `render`:此方法負責渲染 JSX 標記並傳回螢幕上要顯示的內容。 3. `componentDidMount`:元件在 DOM 中渲染後立即呼叫該方法。它通常用於初始化任務,例如 API 呼叫或設定事件偵聽器。 4. `componentDidUpdate`:當元件的 props 或 state 改變時呼叫該方法。它允許您執行副作用、根據更改更新元件或觸發其他 API 呼叫。 5. `componentWillUnmount`:在元件從 DOM 刪除之前呼叫此方法。它用於清理在`componentDidMount`中設定的任何資源,例如刪除事件偵聽器或取消計時器。 一些生命週期方法,例如“componentWillMount”、“componentWillReceiveProps”和“componentWillUpdate”,已被棄用或替換為替代方法或掛鉤。 至於“this”,它指的是類別元件的當前實例。它允許您存取元件內的屬性和方法。在函數式元件中,不使用“this”,因為函數未綁定到特定實例。 ### 7. 使用 useState 有什麼特色? `useState` 傳回一個狀態值和一個更新它的函數。 ``` const [value, setValue] = useState('Some state'); ``` 在初始渲染期間,傳回的狀態與作為第一個參數傳遞的值相符。 `setState` 函數用於更新狀態。它採用新的狀態值作為參數,並**對元件的重新渲染進行排隊**。 `setState` 函數也可以接受回呼函數作為參數,該函數將先前的狀態值作為參數。 [了解更多](https://react.dev/reference/react/useState) ### 8. 使用 useEffect 有什麼特別之處? `useEffect` 鉤子可讓您在功能元件中執行副作用。 稱為 React 渲染階段的功能元件的主體內部不允許突變、訂閱、計時器、日誌記錄和其他副作用。這可能會導致用戶介面中出現令人困惑的錯誤和不一致。 相反,建議使用 useEffect。傳遞給 useEffect 的函數將在渲染提交到螢幕後執行,或者如果您傳遞一組依賴項作為第二個參數,則每次依賴項之一發生變更時都會呼叫該函數。 ``` useEffect(() => { console.log('Logging something'); }, []) ``` [了解更多](https://react.dev/reference/react/useEffect) ### 9. 如何追蹤功能元件的卸載? 通常,「useEffect」會建立在元件離開畫面之前需要清理或重設的資源,例如訂閱或計時器辨識碼。 為了做到這一點,傳遞給`useEffect`的函數可以傳回一個**清理函數**。清理函數在元件從使用者介面刪除之前執行,以防止記憶體洩漏。此外,如果元件渲染多次(通常是這種情況),則在執行下一個效果之前會清除上一個效果。 ``` useEffect(() => { function handleChange(value) { setValue(value); } SomeAPI.doFunction(id, handleChange); return function cleanup() { SomeAPI.undoFunction(id, handleChange); }; }) ``` ### 10. React 中的 props 是什麼? Props 是從父元件傳遞給元件的資料。道具 是唯讀的,無法更改。 ``` // Parent component const Parent = () => { const data = "Hello, World!"; return ( <div> <Child data={data} /> </div> ); }; // Child component const Child = ({ data }) => { return <div>{data}</div>; }; ``` [了解更多](https://react.dev/learn/passing-props-to-a-component) ### 11. 什麼是狀態管理器?您曾與哪些狀態管理器合作過或認識哪些狀態管理器? 狀態管理器是幫助管理應用程式狀態的工具或程式庫。它提供了一個集中式儲存或容器來儲存和管理可由應用程式中的不同元件存取和更新的資料。 狀態管理器可以解決幾個問題。首先,將資料和與其相關的邏輯與元件分開是一個很好的做法。其次,當使用本機狀態並在元件之間傳遞它時,由於元件可能存在深層嵌套,程式碼可能會變得複雜。透過擁有全域存儲,我們可以存取和修改來自任何元件的資料。 除了 React Context,Redux 或 MobX 通常用作狀態管理庫。 [了解更多](https://mobx.js.org/README.html) [了解更多](https://redux-toolkit.js.org/) ### 12. 在什麼情況下可以使用本地狀態,什麼時候應該使用全域狀態? 如果本機狀態僅在一個元件中使用且不打算將其傳遞給其他元件,則建議使用本機狀態。本地狀態也用在表示清單中單一專案的元件中。但是,如果元件分解涉及嵌套元件且資料沿層次結構傳遞,則最好使用全域狀態。 ### 13. Redux中的reducer是什麼,它需要哪些參數? 減速器是一個純函數,它將狀態和操作作為參數。在減速器內部,我們追蹤接收到的操作的類型,並根據它修改狀態並傳回一個新的狀態物件。 ``` export default function appReducer(state = initialState, action) { // The reducer normally looks at the action type field to decide what happens switch (action.type) { // Do something here based on the different types of actions default: // If this reducer doesn't recognize the action type, or doesn't // care about this specific action, return the existing state unchanged return state } } ``` [了解更多](https://redux.js.org/tutorials/fundamentals/part-3-state-actions-reducers) ### 14. 什麼是操作以及如何更改 Redux 中的狀態? Action 是一個簡單的 JavaScript 物件,必須有一個字段 一種。 ``` { type: "SOME_TYPE" } ``` 您也可以選擇新增一些資料作為**有效負載**。為了 改變狀態,需要呼叫我們傳遞給它的調度函數 行動 ``` { type: "SOME_TYPE", payload: "Any payload", } ``` [了解更多](https://redux.js.org/tutorials/fundamentals/part-3-state-actions-reducers) ### 15. Redux 實作了哪一種模式? Redux 實作了 **Flux 模式**,這是應用程式可預測的狀態管理模式。它透過引入單向資料流和應用程式狀態的集中儲存來幫助管理應用程式的狀態。 [了解更多](https://www.newline.co/fullstack-react/30-days-of-react/day-18/#:~:text=Flux%20is%20a%20pattern%20for,default% 20method %20用於%20處理%20資料。) ### 16. Mobx 實作哪一種模式? Mobx 實作了**觀察者模式**,也稱為發布-訂閱模式。 [了解更多](https://www.patterns.dev/posts/observer-pattern) ### 17. 使用 Mobx 的特徵是什麼? Mobx 提供了「observable」和「compulated」等裝飾器來定義可觀察狀態和反應函數。以action修飾的動作用於修改狀態,確保追蹤所有變更。 Mobx 還提供自動依賴追蹤、不同類型的反應、對反應性的細粒度控制,以及透過 mobx-react 套件與 React 無縫整合。總體而言,Mobx 透過根據可觀察狀態的變化自動執行更新過程來簡化狀態管理。 ### 18.如何存取Mobx狀態下的變數? 您可以透過使用「observable」裝飾器將變數定義為可觀察來存取狀態中的變數。這是一個例子: ``` import { observable, computed } from 'mobx'; class MyStore { @observable myVariable = 'Hello Mobx'; @computed get capitalizedVariable() { return this.myVariable.toUpperCase(); } } const store = new MyStore(); console.log(store.capitalizedVariable); // Output: HELLO MOBX store.myVariable = 'Hi Mobx'; console.log(store.capitalizedVariable); // Output: HI MOBX ``` 在此範例中,使用“observable”裝飾器將“myVariable”定義為可觀察物件。然後,您可以使用“store.myVariable”存取該變數。對「myVariable」所做的任何變更都會自動觸發相關元件或反應的更新。 [了解更多](https://mobx.js.org/actions.html) ### 19.Redux 和 Mobx 有什麼差別? Redux 是一個更簡單、更固執己見的狀態管理庫,遵循嚴格的單向資料流並促進不變性。它需要更多的樣板程式碼和顯式更新,但與 React 具有出色的整合。 另一方面,Mobx 提供了更靈活、更直觀的 API,且樣板程式碼更少。它允許您直接修改狀態並自動追蹤更改以獲得更好的性能。 Redux 和 Mobx 之間的選擇取決於您的特定需求和偏好。 ### 20.什麼是 JSX? 預設情況下,以下語法用於在 React 中建立元素。 ``` const someElement = React.createElement( 'h3', {className: 'title__value'}, 'Some Title Value' ); ``` 但我們已經習慣這樣看 ``` const someElement = ( <h3 className='title__value'>Some Title Value</h3> ); ``` 這正是標記所謂的 jsx。這是一種語言的擴展 簡化對程式碼和開發的認知 [了解更多](https://react.dev/learn/writing-markup-with-jsx#jsx-putting-markup-into-javascript) ### 21.什麼是道具鑽探? Props 鑽取是指透過多層嵌套元件傳遞 props 的過程,即使某些中間元件不直接使用這些 props。這可能會導致程式碼結構複雜且繁瑣。 ``` // Parent component const Parent = () => { const data = "Hello, World!"; return ( <div> <ChildA data={data} /> </div> ); }; // Intermediate ChildA component const ChildA = ({ data }) => { return ( <div> <ChildB data={data} /> </div> ); }; // Leaf ChildB component const ChildB = ({ data }) => { return <div>{data}</div>; }; ``` 在此範例中,「data」屬性從 Parent 元件傳遞到 ChildA,然後從 ChildA 傳遞到 ChildB,即使 ChildA 不會直接使用該屬性。當存在許多層級的嵌套或當元件樹中更靠下的元件需要存取資料時,這可能會成為問題。它會使程式碼更難維護和理解。 可以透過使用其他模式(如上下文或狀態管理庫(如 Redux 或 MobX))來緩解 Props 鑽探。這些方法允許元件存取資料,而不需要透過每個中間元件傳遞 props。 ### 22. 如何有條件地渲染元素? 您可以使用任何條件運算符,包括三元。 ``` return ( <div> {isVisible && <span>I'm visible!</span>} </div> ); ``` ``` return ( <div> {isOnline ? <span>I'm online!</span> : <span>I'm offline</span>} </div> ); ``` ``` if (isOnline) { element = <span>I'm online!</span>; } else { element = <span>I'm offline</span>; } return ( <div> {element} </div> ); ``` [了解更多](https://react.dev/learn/conditional-rendering) ### 23. useMemo 的用途是什麼?它是如何運作的? `useMemo` 用於緩存和記憶 計算結果。 傳遞建立函數和依賴項陣列。只有當任何依賴項的值發生變更時,`useMemo` 才會重新計算記憶值。此優化有助於避免 每次渲染都需要昂貴的計算。 使用第一個參數,函數接受執行計算的回調,使用第二個依賴項陣列,僅當至少一個依賴項發生變更時,該函數才會重新執行計算。 ``` const memoValue = useMemo(() => computeFunc(paramA, paramB), [paramA, paramB]); ``` [了解更多](https://react.dev/reference/react/useMemo) ### 24. useCallback 的用途是什麼?它是如何運作的? `useCallback` 掛鉤將傳回回呼的記憶版本,僅當依賴項之一的值發生變更時,該版本才會變更。 當將回調傳遞給依賴連結相等性來防止不必要的渲染的最佳化子元件時,這非常有用。 ``` const callbackValue = useCallback(() => computeFunc(paramA, paramB), [paramA, paramB]); ``` [了解更多](https://react.dev/reference/react/useCallback) ### 25. useMemo 和 useCallback 有什麼不同? 1. `useMemo` 用於儲存計算結果,而 `useCallback` 用於儲存函數本身。 2. `useMemo` 快取計算值,如果依賴項沒有改變,則在後續渲染時傳回它。 3. `useCallback` 快取函數本身並傳回相同的實例,除非相依性發生變更。 ### 26.什麼是 React Context? React Context 是一項功能,它提供了一種透過元件樹傳遞資料的方法,而無需在每個層級手動傳遞 props。它允許您建立一個全域狀態,樹中的任何元件都可以存取該狀態,無論其位置如何。當您需要在未透過 props 直接連接的多個元件之間共用資料時,上下文就非常有用。 React Context API 由三個主要部分組成: 1. `createContext`:此函數用於建立一個新的上下文物件。 2. `Context.Provider`:該元件用於向上下文提供值。它包裝了需要存取該值的元件。 3. `Context.Consumer` 或 `useContext` 鉤子:此元件或鉤子用於使用上下文中的值。它可以在上下文提供者內的任何元件中使用。 透過使用 React Context,您可以避免道具鑽探(透過多個層級的元件傳遞道具)並輕鬆管理更高層級的狀態,使您的程式碼更有組織性和效率。 [了解更多](https://react.dev/learn/passing-data-deeply-with-context) ### 27. useContext 的用途是什麼?它是如何運作的? 在典型的 React 應用程式中,資料使用 props 從上到下(從父元件到子元件)傳遞。但這樣的使用方法對於某些類型的道具來說可能過於繁瑣 (例如,所選語言、UI 主題),必須傳遞給應用程式中的許多元件。上下文提供了一種在元件之間共享此類資料的方法,而無需明確傳遞 props 樹的每一層。 呼叫 useContext 的元件將始終在以下情況下重新渲染: 上下文值發生變化。如果重新渲染元件的成本很高,您可以使用記憶來優化它。 ``` const App = () => { const theme = useContext(ThemeContext); return ( <div style={{ color: theme.palette.primary.main }}> Some div </div> ); } ``` [了解更多](https://react.dev/reference/react/useContext) ### 28. useRef 的用途是什麼?它是如何運作的? `useRef` 傳回一個可修改的 ref 物件,一個屬性。其中的當前值由傳遞的參數初始化。傳回的物件將在元件的整個生命週期內持續存在,並且不會因渲染而改變。 通常的用例是以命令式存取後代 風格。 IE。使用 ref,我們可以明確引用 DOM 元素。 ``` const App = () => { const inputRef = useRef(null); const buttonClick = () => { inputRef.current.focus(); } return ( <> <input ref={inputRef} type="text" /> <button onClick={buttonClick}>Focus on input tag</button> </> ) } ``` [了解更多](https://react.dev/reference/react/useRef) ### 29. 什麼是 React.memo()? `React.memo()` 是一個高階元件。如果您的元件始終使用不變的 props 渲染相同的內容,您可以將其包裝在「React.memo()」呼叫中,以在某些情況下提高效能,從而記住結果。這意味著 React 將使用上次渲染的結果,避免重新渲染。 `React.memo()` 只影響 props 的變更。如果一個功能元件被包裝在 React.memo 中並使用 useState、useReducer 或 useContext,那麼當狀態或上下文發生變化時,它將重新渲染。 ``` import { memo } from 'react'; const MemoComponent = memo(MemoComponent = (props) => { // ... }); ``` [了解更多](https://react.dev/reference/react/memo) ### 30.React Fragment是什麼? 從元件傳回多個元素是 React 中的常見做法。片段可讓您形成子元素列表,而無需在 DOM 中建立不必要的節點。 ``` <> <OneChild /> <AnotherChild /> </> // or <React.Fragment> <OneChild /> <AnotherChild /> </React.Fragment> ``` [了解更多](https://react.dev/reference/react/Fragment) ### 31.什麼是 React Reconciliation? 協調是一種 React 演算法,用於區分一棵元素樹與另一棵元素樹,以確定需要替換的部分。 協調是我們過去所說的虛擬 DOM 背後的演算法。這個定義聽起來是這樣的:當你渲染一個 React 應用程式時,描述該應用程式的元素樹是在保留的記憶體中產生的。然後這棵樹被包含在渲染環境中——例如,瀏覽器應用程式,它被翻譯成一組 DOM 操作。當應用程式狀態更新時,會產生一棵新樹。將新樹與前一棵樹進行比較,以便準確計算並啟用重繪更新的應用程式所需的操作。 [了解更多](https://react.dev/learn/preserving-and-resetting-state) ### 32.為什麼使用map()時需要列表中的鍵? 這些鍵可幫助 React 確定哪些元素已更改, 新增或刪除。必須指定它們以便 React 可以匹配 隨著時間的推移陣列元素。選擇鍵的最佳方法是使用能夠清楚區分清單專案與其鄰居的字串。大多數情況下,您將使用資料中的 ID 作為金鑰。 ``` const languages = [ { id: 1, lang: "JavaScript", }, { id: 2, lang: "TypeScript", }, { id: 3, lang: "Python", }, ]; const App = () => { return ( <div> <ul>{languages.map((language) => ( <li key={`${language.id}_${language.lang}`}>{language.lang}</li> ))} </ul> </div> ); } ``` [了解更多](https://react.dev/learn/rendering-lists#keeping-list-items-in-order-with-key) ### 33. 如何在 Redux Thunk 中處理非同步操作? 要使用 Redux Thunk,您需要將其作為中間件導入。動作建立者不僅應該傳回一個物件,還應該傳回以調度為參數的函數。 ``` export const addUser = ({ firstName, lastName }) => { return dispatch => { dispatch(addUserStart()); } axios.post('https://jsonplaceholder.typicode.com/users', { firstName, lastName, completed: false }) .then(res => { dispatch(addUserSuccess(res.data)); }) .catch(error => { dispatch(addUserError(error.message)); }) } ``` [了解更多](https://redux.js.org/usage/writing-logic-thunks) ### 34.如何追蹤功能元件中物件欄位的變化? 為此,您需要使用“useEffect”掛鉤並將物件的欄位作為依賴項陣列傳遞。 ``` useEffect(() => { console.log('Changed!') }, [obj.someField]) ``` ### 35.如何存取DOM元素? 引用是使用 React.createRef() 或 useRef() 鉤子建立的,並透過 ref 屬性附加到 React 元素。透過存取已建立的引用,我們可以使用「ref.current」來存取 DOM 元素。 ``` const App = () => { const myRef = useRef(null); const handleClick = () => { console.log(myRef.current); // Accessing the DOM element }; return ( <div> <input type="text" ref={myRef} /> <button onClick={handleClick}>Click Me</button> </div> ); } export default App; ``` ### 36.什麼是自訂鉤子? 自訂鉤子是一個允許您在不同元件之間重複使用邏輯的功能。它是一種封裝可重複使用邏輯的方法,以便可以在多個元件之間輕鬆共用和重複使用。自訂掛鉤是通常以 **use ** 開頭的函數,並且可以根據需要呼叫其他掛鉤。 [了解更多](https://react.dev/learn/reusing-logic-with-custom-hooks) ### 37.什麼是公共API? 在索引檔案的上下文中,公共 API 通常是指向外部模組或元件公開並可存取的介面或函數。 以下是表示公共 API 的索引檔案的程式碼範例: ``` // index.js export function greet(name) { return `Hello, ${name}!`; } export function calculateSum(a, b) { return a + b; } ``` 在此範例中,index.js 檔案充當公共 API,其中導出函數“greet()”和“calculateSum()”,並且可以透過匯入它們從其他模組存取它們。其他模組可以導入並使用這些函數作為其實現的一部分: ``` // main.js import { greet, calculateSum } from './index.js'; console.log(greet('John')); // Hello, John! console.log(calculateSum(5, 3)); // 8 ``` 透過從索引檔案匯出特定函數,我們定義了模組的公共 API,允許其他模組使用這些函數。 ### 38. 建立自訂鉤子的規則是什麼? 1. 鉤子名稱以「use」開頭。 2. 如果需要,使用現有的鉤子。 3. 不要有條件地呼叫鉤子。 4. 將可重複使用邏輯提取到自訂掛鉤中。 5. 自訂hook必須是純函數。 6. 自訂鉤子可以傳回值或其他鉤子。 7. 描述性地命名自訂掛鉤。 [了解更多](https://react.dev/learn/reusing-logic-with-custom-hooks) ### 39.什麼是SSR(伺服器端渲染)? 伺服器端渲染(SSR)是一種用於在伺服器上渲染頁面並將完整渲染的頁面傳送到客戶端進行顯示的技術。它允許伺服器產生網頁的完整 HTML 標記(包括其動態內容),並將其作為對請求的回應傳送到客戶端。 在傳統的用戶端渲染方法中,用戶端接收最小的 HTML 頁面,然後向伺服器發出額外的資料和資源請求,這些資料和資源用於在客戶端渲染頁面。這可能會導致初始頁面載入時間變慢,並對搜尋引擎優化 (SEO) 產生負面影響,因為搜尋引擎爬蟲很難對 JavaScript 驅動的內容建立索引。 透過 SSR,伺服器透過執行必要的 JavaScript 程式碼來產生最終的 HTML 來負責渲染網頁。這意味著客戶端從伺服器接收完全呈現的頁面,從而減少了額外資源請求的需要。 SSR 縮短了初始頁面載入時間,並允許搜尋引擎輕鬆索引內容,從而實現更好的 SEO。 SSR 通常用於框架和函式庫中,例如用於 React 的 Next.js 和用於 Vue.js 的 Nuxt.js,以啟用伺服器端渲染功能。這些框架為您處理伺服器端渲染邏輯,讓實作 SSR 變得更加容易。 ### 40.使用SSR有什麼好處? 1. **改進初始載入時間**:SSR 允許伺服器將完全渲染的 HTML 頁面傳送到客戶端,從而減少客戶端所需的處理量。這可以縮短初始載入時間,因為使用者可以更快地看到完整的頁面。 2. **SEO友善**:搜尋引擎可以有效地抓取和索引SSR頁面的內容,因為完全渲染的HTML在初始回應中可用。這提高了搜尋引擎的可見度並有助於更好的搜尋排名。 3. **可存取性**:SSR 確保禁用 JavaScript 或使用輔助技術的使用者可以存取內容。透過在伺服器上產生 HTML,SSR 為所有使用者提供可靠且易於存取的使用者體驗。 4. **低頻寬環境下的效能**:SSR減少了客戶端需要下載的資料量,有利於低頻寬或高延遲環境下的使用者。這對於行動用戶或網路連線速度較慢的用戶尤其重要。 雖然 SSR 提供了這些優勢,但值得注意的是,與客戶端渲染方法相比,它可能會帶來更多的伺服器負載和維護複雜性。應仔細考慮快取、可擴展性和伺服器端渲染效能最佳化等因素。 ### 41.你知道Next.js的主要功能有哪些? 1. `getStaticProps`:此方法用於在建置時取得資料並將頁面預先渲染為靜態 HTML。它確保資料在建置時可用,並且不會因後續請求而更改。 ``` export async function getStaticProps() { const res = await fetch('https://api.example.com/data'); const data = await res.json(); return { props: { data } }; } ``` 2. `getServerSideProps`:此方法用於在每個請求上取得資料並在伺服器上預先渲染頁面。當您需要取得可能經常變更或特定於使用者的資料時,可以使用它。 ``` export async function getServerSideProps() { const res = await fetch('https://api.example.com/data'); const data = await res.json(); return { props: { data } }; } ``` 3. `getStaticPaths`:此方法在動態路由中使用,用於指定建置時應預先渲染的路徑清單。它通常用於獲取帶有參數的動態路由的資料。 ``` export async function getStaticPaths() { const res = await fetch('https://api.example.com/posts'); const posts = await res.json(); const paths = posts.map((post) => ({ params: { id: post.id } })); return { paths, fallback: false }; } ``` [了解更多](https://nextjs.org/docs/app/building-your-application/data-fetching/fetching-caching-and-revalidating) ### 42.什麼是 Linters? Linters 是用來檢查原始程式碼是否有潛在錯誤、錯誤、風格不一致和可維護性問題的工具。它們可幫助執行編碼標準並確保整個程式碼庫的程式碼品質和一致性。 Linters 的工作原理是掃描原始程式碼並將其與一組預先定義的規則或指南進行比較。這些規則可以包括語法和格式約定、最佳實踐、潛在錯誤和程式碼異味。當 linter 發現違反規則時,它會產生警告或錯誤,突出顯示需要注意的特定行或多行程式碼。 使用 linter 可以帶來幾個好處: 1. **程式碼品質**:Linter 有助於辨識和防止潛在的錯誤、程式碼異味和反模式,從而提高程式碼品質。 2. **一致性**:Linter 強制執行編碼約定和風格指南,確保整個程式碼庫的格式和程式碼結構一致,即使多個開發人員正在處理同一個專案時也是如此。 3. **可維護性**:透過儘早發現問題並促進良好的編碼實踐,linter 有助於程式碼的可維護性,使程式碼庫更容易理解、修改和擴展。 4. **效率**:Linter 可以透過自動化程式碼審查流程並在常見錯誤在開發或生產過程中引起問題之前捕獲它們來節省開發人員的時間。 一些流行的 linter 包括用於 JavaScript 的 ESLint 以及用於 CSS 和 Sass 的 Stylelint。 [了解更多](https://eslint.org/docs/latest/use/getting-started) ### 43.你知道哪些 React 架構解決方案? 有多種用於建立 React 專案的架構解決方案和模式。一些受歡迎的包括: 1. **MVC(模型-視圖-控制器)**:MVC 是一種傳統的架構模式,它將應用程式分為三個主要元件 - 模型、視圖和控制器。 React 可以在 View 層中使用來渲染 UI,而其他程式庫或框架可以用於 Model 和 Controller 層。 2. **Flux**:Flux是Facebook專門針對React應用程式所推出的應用架構。它遵循單向資料流,其中資料沿著單一方向流動,從而更容易理解和除錯應用程式的狀態變更。 3. **原子設計**:原子設計並不是React特有的,而是將UI分割成更小、可重複使用元件的設計方法。它鼓勵建立小型、獨立且可以組合以建立更複雜的 UI 的元件。 4. **容器和元件模式**:此模式將表示(元件)與邏輯和狀態管理(容器)分開。元件負責渲染 UI,而容器則處理業務邏輯和狀態管理。 5. **功能切片設計**:它是一種用於組織和建構 React 應用程式的現代架構方法。它旨在透過根據功能或模組劃分應用程式程式碼庫來解決可擴展性、可維護性和可重用性的挑戰。 ### 44.什麼是特徵切片設計? 它是一種用於組織和建立 React 應用程式的現代架構方法。它旨在透過根據功能或模組劃分應用程式程式碼庫來解決可擴展性、可維護性和可重用性的挑戰。 在功能切片設計中,應用程式的每個功能或模組都組織到一個單獨的目錄中,其中包含所有必要的元件、操作、reducers 和其他相關檔案。這有助於保持程式碼庫的模組化和隔離性,使其更易於開發、測試和維護。 功能切片設計促進了關注點的清晰分離,並將功能封裝在各個功能中。這允許不同的團隊或開發人員獨立地處理不同的功能,而不必擔心衝突或依賴性。 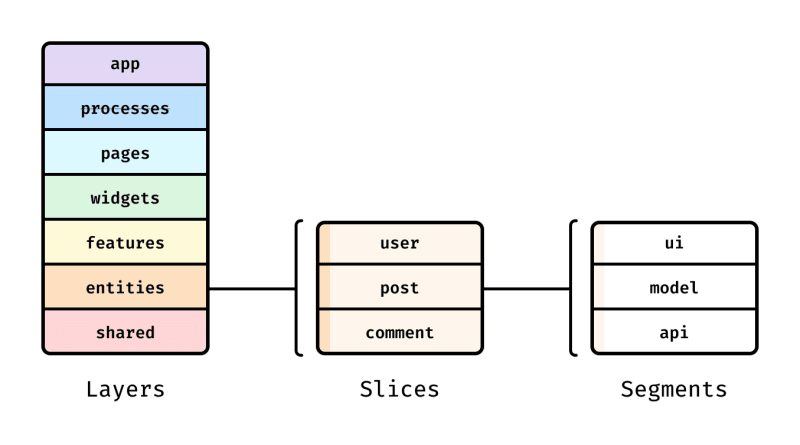 **我強烈建議點擊“了解更多”按鈕以了解功能切片設計** [了解更多](https://dev.to/m_midas/feature-sliced-design-the-best-frontend-architecture-4noj) ## 了解更多 如果您還沒有閱讀過,我強烈建議您閱讀我關於前端面試問題的其餘文章。 https://dev.to/m_midas/52-frontend-interview-questions-javascript-59h6 https://dev.to/m_midas/41-frontend-interview-questions-css-4imc https://dev.to/m_midas/15-most-common-frontend-interview-questions-4njp ## 結論 總之,面試 React 前端開發人員職位需要對框架的核心概念、原理和相關技術有深入的了解。透過準備本文中討論的問題,您可以展示您的 React 知識並展示您建立高效且可維護的使用者介面的能力。請記住,不僅要專注於記住答案,還要理解基本概念並能夠清楚地解釋它們。 此外,請記住,面試不僅涉及技術方面,還旨在展示您解決問題的能力、溝通能力以及團隊合作能力。透過將技術專業知識與強大的整體技能相結合,您將具備在 React 前端開發人員面試中脫穎而出的能力,並在這個令人興奮且快速發展的領域找到您夢想的工作。 祝你好運!
## 前情提要 常常寫文章的時候都會運用到圖文並茂, 如果可以設定文章的圖片封面就是一個很棒的設計。 今天的JS腳本教學已經夢幻連動! 原本IT幫的文章與codeLove像是平行宇宙,只有偶爾轉載,現在, 教學內容直接來針對codelove來寫一個小小有趣小功能XD ## 目標設計 今天以codelove這個論壇為例, 讓我們來手動創造一個小腳本:分析文章內容,以正則去匹配圖片網址, 然後透過create的API寫出div,並且監聽事件, 當點擊圖片的時候,把圖片網址放到封面圖片的input欄位。 ## 效果 會根據textArea change的時候來匹配出網址。 並且創建div與img元素去放入網頁。  點圖片後會把圖片網址丟入。  ## 程式碼內容 ``` // 獲取textarea元素 var textarea = document.querySelector("body > div.container.px-0 > div > div.col-12.col-lg-9 > div > div > form > textarea"); var featuredImageInput = document.querySelector('input[name="featured_image"]'); textarea.addEventListener('change', function(event) { // 檢查是否存在imgBox元素 let imgBoxCheck = document.querySelector('.imgBox'); if (imgBoxCheck) { // 如果存在,則刪除imgBox元素 imgBoxCheck.parentNode.removeChild(imgBoxCheck); } // 獲取文本框的內容 var ContentText = textarea.value; // 創建一個空數組來存儲圖片鏈接 var imgArray = []; // 使用正則表達式查找圖片鏈接 var urlRegex = /https?:\/\/[^\s/$.?#].[^\s]*/gi; // 匹配以http或https開頭的鏈接 var matches = ContentText.match(urlRegex); if (matches) { // 疊代所有匹配項並篩選出以.png或.jpg結尾的鏈接 for (var i = 0; i < matches.length; i++) { if (matches[i].match(/\.(png|jpg)$/i)) { imgArray.push(matches[i]); } } } // 使用正則表達式匹配鏈接部分 var regex = /!\[\]\(([^)]+)\)/g; var match; while ((match = regex.exec(ContentText)) !== null) { imgArray.push(match[1]); } // 創建一個包含圖片的容器div(imgBox)並設置為display: flex let imgBox = document.createElement('div'); imgBox.className = 'imgBox'; // 添加類名 imgBox.style.display = 'flex'; // 平均分配圖片大小 var imageSize = 100 / imgArray.length; // 假設100%寬度,根據圖片數量計算每張圖片的寬度 // 將圖片鏈接轉換為img元素並插入到imgBox imgArray.forEach(function (imgUrl) { var imgDiv = document.createElement('div'); var img = document.createElement('img'); img.src = imgUrl; img.className = 'imgCover'; img.addEventListener('click', function () { // 設置name="featured_image"的輸入框的值為被點擊圖片的src屬性 featuredImageInput.value = img.src; }); // 設置img的寬度為100% img.style.width = '100%'; img.style.height = '100%'; imgDiv.appendChild(img); imgBox.appendChild(imgDiv); }); // 將imgBox插入到textarea後面 h5.insertAdjacentElement('afterend', imgBox); textarea.style.overflow = 'auto'; imgBox.style.border="5px solid gray" imgBox.style.marginTop="5px" }); // 創建一個包含CSS規則的<style>元素 var style = document.createElement('style'); style.type = 'text/css'; style.textContent = '.imgBox:hover .imgCover:not(:hover) { filter: grayscale(100%); opacity: 0.75; }'; // 將<style>元素添加到<head>中 document.head.appendChild(style); h5= document.createElement('h5') h5.innerText='請選擇你的文章縮圖:' h5.style.marginTop="50px" h5.style.fontSize="16px" textarea.insertAdjacentElement('afterend', h5); ``` ## 觀念筆記 這次的腳本內容其實沒有太多新的知識點,算是一個很好的複習。 querySelector addEventListener insertAdjacentElement forEach 以及正則表達式的使用。 ## 心得後記 網頁上的功能,其實就是這些基礎的運用配合起來!(°ཀ°) 所以不用擔心前端沒有東西練習,其實點子四處都有,練習也都很實用。 而不是每次都在重複輪迴相同的東西、感到疲倦! 這次的前端小試身手就帶來一個回鍋菜,下次敬請期待更有趣的變化。 喜歡記得追蹤或留言唷。 還沒挑戰過此系列其他內容的,可以試著去挑戰看看◑ω◐
最近跟一些年輕的工程師合作,發現系統上線之後 bug 有點多 這當然很正常,不過,如果適度的留意自己的當下的「寫作風格」 其實可以減少很多 bug,或者是可以減少 debug 的時間 這些年工作下來,我發現在開發不同元件的時候,我基本上會在兩種風格中選擇,簡單跟大家分享 # 嚴格風 在寫一些基礎重要元件、或者呼叫第三方 API 時,我認為把「可能的狀態」通通清楚列出來比較好 也就是像這樣 ``` function doTask($arg1) { if ($arg1 === 'val1') { // ... } else if ($arg1 === 'val2') { // ... } else if ($arg1 === 'val3') { // ... } else { throw new Exception("Impossible state."); } } ``` 只要出現預期之外的值,就直接丟出例外,這樣可以大幅改善 developer experience 也就是在當下就提醒同事:「我這元件當初設計不是這樣用的,請檢查」 很多人不會把「可能的狀態」寫完,而是放在 else 底下,比如說 ``` function doTask($arg1) { if ($arg1 === 'val1') { // ... } else if ($arg1 === 'val2') { // ... } else { // handle `val3` here } } ``` 雖然程式課本都是這樣教的,但實務上這會導致很多可能的 bug 比方說有同事在使用這元件時,參數傳入 `val4` 結果程式繼續運行 這會導致一些錯誤的理解、讓錯誤的假設在團隊中持續蔓延 所以,在重要的元件,比如金流相關時,採用這種「嚴格風」去寫會比較好 也就是強迫大家搞清楚這個元件的用法,不准許憑感覺隨意呼叫 # 隨興風 在一些寬鬆的元件,通常是 search 相關的元件、抓資料相關的元件時,可以預期,呼叫方會隨意嘗試各種參數 甚至會有一些參數傳都不傳,覺得元件要有預設才合理 這種元件,就寫得盡量寬鬆、盡量多給預設值,會比較好 也就是呼叫方,參數要傳不傳,都可以,傳錯的時候,就當作是跟沒傳一樣,就用預設值就好 這種元件就是用起來很寬鬆,主要目的是希望不要因為這些小事,讓程式爛掉、故障在那邊 寫起來就是多檢查變數有沒有存在,沒有就給預設值 然後 if else 的時候也比較隨興,基本上不會丟例外,不管怎麼傳都盡量讓你跑 --- 不同的元件,適合採用不同的風格來寫 雖然這是一個主觀的問題,但適當的分辨當下應該採用哪種風格 會讓你的同事非常喜歡跟你工作,覺得你寫的元件「總是很好用」、「用錯的時候都會提醒」、「在不需要拘泥小節的時候,也不會囉唆」 話雖如此,要能知道當下適用的風格,其實需要許多年的經驗累積。 嚴格風、隨興風,只是一個概念,實際上的 coding style 有很多寫法,大家可以慢慢實驗&嘗試 簡單給個方向,跟大家簡單分享
本文轉自:https://ithelp.ithome.com.tw/articles/10338948 ## 前情提要 資訊大爆炸。 有時候我們瀏覽技術文章,不一定真的是想學深奧的高級技術。 然而劣質低端的文章充斥著,則會降低我們學習的效率、甚至變成噪音與雜訊,干擾我們的思緒。 因此針對某些洗文或是質量很低的作者,我們必須列為思想犯, 否則會降低閱讀質量,平白浪費自己的時間、平台的版面、上網的電力、看到垃圾資訊的副作用等等.... ## 構思來源 如果有個思想審查警衛可以:**去除那些垃圾低端,稱不上技術文章的雜訊。** 以確保未來瀏覽文章的時候,不會再被洗文打擾, 也可以針對不喜歡的主題去封鎖,讓時間與精神更能專注於自己想要學的資訊。 阻止一些垃圾就是喜歡把自己尚未整理的白痴內容一直丟上來, 什麼都還不懂,把技術文章當成個人日記簿,寫一堆自我囈語、無病呻吟, 每天大量狂發文章,昭告天下以為這就是努力,欺騙自己也浪費別人的人生。 ## 「思想審查警衛」出動! ## 功能 1. 把頭像屏蔽 2. 加上思想通緝犯、紅字與刪除線 3. 新增封殺按鈕 4. 版面通知封殺名單與文章數 5. 透過ajax確認某id的最新ID ## 效果截圖  此截圖僅是腳本示範,跟其使用者無關, 本人沒有任何覺得此使用者發的文章是差勁的意味,我認為非常上進、值得學習。  此圖也只是隨機挑user使用,純粹作為範例用途,不代表我個人意見。 ## 腳本下載 https://greasyfork.org/zh-TW/scripts/477283-%E6%80%9D%E6%83%B3%E7%8A%AF%E5%B0%81%E6%AE%BA ## 原理說明 鄭重聲明,這個示範真的毫無任何私人意味,此腳本也只是針對不同的主題去隱藏, 例如我想學python就不想看到JS的文章,因此使用此工具幫忙隱藏罷了。 取名做思想警察、比喻成清除垃圾等都只是文學上的趣味。 請勿當真Ꮚ・ꈊ・Ꮚ 這次的技術可說比較難,認真難很多!但是趣味性以及功能性是無比的超越! 可以說幾乎是我寫系列文以來,最頂、最派的一篇! 不過很多觀念已經出現過,在【前端小試身手】系列裡面,每次的腳本都是主打實用, 因此cookie或localstorage這種技術當然都會運用到。 ## JS原始碼 ``` // ==UserScript== // @license MIT // @name 👮思想犯封殺 // @namespace http://tampermonkey.net/ // @version 0.1 // @description 把廢文製造機轟出去 // @author You // @match https://ithelp.ithome.com.tw/articles* // @match https://ithelp.ithome.com.tw/users/* // @icon https://www.google.com/s2/favicons?sz=64&domain=ithome.com.tw // @grant none // @run-at document-end // ==/UserScript== let URL = window.location.href; let ArticleSite = "https://ithelp.ithome.com.tw/articles?tab=tech" let UserSite = "https://ithelp.ithome.com.tw/users/" // 判斷URL的開頭部分 if (URL.startsWith(ArticleSite)) { //文章頁執行清理垃圾程序 CleanGarbage(); } else if (URL.startsWith(UserSite)) { UserCheck(); } else { console.log("這邊不執行腳本"); } // 餅乾儲存的機制函數------------------------------------------------- function setListInCookie(list) { document.cookie = 'myList=' + JSON.stringify(list) + '; expires=Wed, 31 Dec 2099 23:59:59 GMT;'; } // 從 Cookie 中獲取 list function getListFromCookie() { var cookieValue = document.cookie.replace(/(?:(?:^|.*;\s*)myList\s*\=\s*([^;]*).*$)|^.*$/, "$1"); return JSON.parse(cookieValue) || []; } function CleanGarbage(){ // 從本地存儲中獲取數據 var myListData = localStorage.getItem("myList"); // 解析數據到變量 list var list = myListData ? JSON.parse(myListData) : []; //list = getListFromCookie()||[]; // 儲存要刪除的字符串名單 // 找到所有CLASS是"qa-list__info-link"的<a>元素 var linkElements = document.querySelectorAll('.qa-list__info-link'); var removedCount = 0; // 初始化已清除的垃圾數量 for (var j = 0; j < list.length; j++) { // 遍歷這些<a>元素,確保文本內容包含"伍貳捌",然後刪除其父元素 for (var i = 0; i < linkElements.length; i++) { if (linkElements[i].textContent.includes(list[j])) { // 開始向上查找父元素 var parentElement = linkElements[i].parentElement; while (parentElement) { // 如果找到具有"classname"為"qa-list"的<div>元素,則刪除它 if (parentElement.classList.contains('qa-list')) { parentElement.remove(); removedCount++; // 增加清除的數量 console.warn('抓到"'+list[j]+'"這位思想犯'); break; // 找到並刪除後,結束循環 } parentElement = parentElement.parentElement; } } } if (removedCount>0){ // 顯示已清除的垃圾數量 console.log('已清除他的 ' + removedCount + ' 篇垃圾');} removedCount=0; } } //------------------------------------------------------- // 為了防止五百八改名,我們針對他的ID去ajax得到他最新的名稱 function FindBitch() { // 使用 Fetch API 獲取指定 URL 的內容 return fetch("https://ithelp.ithome.com.tw/users/20163468") .then(response => response.text()) .then(data => { // 創建一個臨時 div 元素以容納頁面內容 var tempDiv = document.createElement("div"); tempDiv.innerHTML = data; // 查找 class 為 "profile-header__name" 的元素 var profileNameElement = tempDiv.querySelector(".profile-header__name"); if (profileNameElement) { // 刪除元素內的所有 <span> 元素 var spanElements = profileNameElement.querySelectorAll("span"); spanElements.forEach(function(span) { span.remove(); }); // 讀取元素的文本內容,去掉前導和尾隨空格 var text = profileNameElement.textContent.trim(); // 返回處理後的文本內容 return text; } else { return "未找到元素"; } }) .catch(error => { console.error("發生錯誤: " + error); return "發生錯誤"; }); } //------------------------------------------------------- function UserCheck(){ //轉換資料從餅乾到localstorage var currentCookieValue = getCookie("myList"); // 2. 存儲數據到本地存儲 if (currentCookieValue) { var list = JSON.parse(currentCookieValue); // 存儲到本地存儲 localStorage.setItem("myList", JSON.stringify(list)); }else{ FindBitch() .then(text => { let FirstKill = [text]; setListInCookie(FirstKill); }) .catch(error => { console.error("找不到五百八:", error); }); } // 刪除不需要的ID document.querySelector('.profile-header__account').remove(); //封殺按鈕------------------------------------------------- // 找到具有class為"profile-header__right"的元素 var profileRightElement = document.querySelector('.profile-header__right'); var pullRightElement = profileRightElement.querySelector('.pull-right'); // 創建一個新按鈕元素 var BlockBtn = document.createElement('button'); BlockBtn.textContent = '封殺'; // 添加樣式和類名到按鈕 BlockBtn.style.marginTop = '10px'; BlockBtn.style.width = '100%'; BlockBtn.className = 'btn btn-trace trace_btn_border BlockBtn'; // 將按鈕元素添加到"pull-right"元素內部 pullRightElement.appendChild(BlockBtn); // 通緝犯名單的cookie------------------------------------------------ // 從 Cookie 中加載 list(例如,頁面加載時) list = getListFromCookie()||[]; let UserBlock = document.querySelector('.profile-header__name'); let text = UserBlock.textContent.trim(); // 如果使用者已經在封殺名單內的判斷,已存在或不存在 if (list.includes(text)) { BlockStart(BlockBtn); } else { // 針對封殺按鈕進行監聽事件 BlockBtn.addEventListener('click', function() { list.push(text); setListInCookie(list); //先加入到名單內,然後再執行封殺事件 BlockStart(); // 輸出到控制台 console.log('黑名單新增:' + text); //本地儲存機制----------------------------- let currentCookieValue = getCookie("myList"); let list2 = JSON.parse(currentCookieValue); // 存儲到本地存儲 localStorage.setItem("myList", JSON.stringify(list2)); }); } } // ------------------------------------------------ //封殺事件的函數 function BlockStart(){ let BlockBtn = document.querySelector('.BlockBtn'); BlockBtn.textContent = '已封殺'; BlockBtn.disabled = true; BadText(); BadImg(); } //封殺事件函數裡面的細項函數 function BadText(){ // 標記這傢夥是垃圾------------------------------------------------- let UserBlock = document.querySelector('.profile-header__name'); let newHeading = document.createElement('h1'); newHeading.textContent = '思想通緝犯'; // 把思想通緝犯這幾個大字加上去 UserBlock.parentElement.insertBefore(newHeading, UserBlock); UserBlock.style.textDecoration = "line-through"; UserBlock.style.color = "red"; } function BadImg(){ //圖片進行網點作業XD------------------------------------------------- var originalImage = document.querySelector('.profile-header__avatar'); // 創建一個包含交叉紅線的覆蓋層 <div> 元素 var overlayDiv = document.createElement('div'); overlayDiv.style.position = 'absolute'; overlayDiv.style.width = '150px'; overlayDiv.style.height = '150px'; overlayDiv.style.background = 'linear-gradient(45deg, black 50%, transparent 50%), linear-gradient(-45deg, black 50%, transparent 50%)'; overlayDiv.style.backgroundSize = '5px 5px, 5px 5px'; overlayDiv.style.backgroundPosition = '0 0, 0 2px'; // 將覆蓋層疊加到圖片上 originalImage.parentNode.appendChild(overlayDiv); // 設置覆蓋層的位置,以與原始圖像對齊 overlayDiv.style.top = originalImage.offsetTop + 'px'; overlayDiv.style.left = originalImage.offsetLeft + 'px'; // 設置覆蓋層的z-index,以確保它在圖片上方 overlayDiv.style.zIndex = '2'; } ``` ## 觀念筆記 這個腳本開發足足花了我一整個晚上,將近八小時之久。 有趣的是,其中為了進行測試才選某些user當作隱藏對象,否則腳本執行上會出錯。 細心的人若觀察原始碼,也會發現裡面有個firstKill, 那是必須要的段落,先設置好cookie的首要內容物,才有辦法繼續操作下去( ิ◕㉨◕ ิ) 也就是初始化的概念XD 另一個有趣的點是,為了防止使用者改名導致腳本出錯,我甚至不惜再寫一段ajax, 去更新一下ID,這樣不管人家怎麼改,都逃不了, 要改成「別抓我」也沒用,這個腳本都還是可以run。 ## 心得後記 我只能說這篇是自從「備份IT幫發文、一眼全覽」最強的JS教學文章! 超派,真的不騙( メ∀・) 有些人喜歡看前端小試身手,有些人喜歡前端動手玩創意; 其實這兩個系列的本質都是JS的教學,是可以互相連接的,但也有很多不同的重心。 這個系列就是以腳本為主,重點在於創意與發想,打到使用者痛點。 【前端動手玩創意】則是以建構網站為起點, 任何元素與概念都會變成網頁上的一部分,算是比較基礎工的建立。 如果對JS的強大感興趣,那麼可以把這兩個系列交互看,反覆的閱讀、實際動手操作, 這樣一來的學習非常踏實,甚至比YT學習都來的高效率、實際。 尤其此系列都是原創發想的腳本,當然超強! 喜歡記得關注,未來還有更多超酷的前端內容可以玩,下課⧸⎩⎠⎞͏(・∀・)⎛͏⎝⎭⧹
本文轉載自:https://ithelp.ithome.com.tw/articles/10338469 ## 前情提要 有時候,夜深人靜,總是會想要沉思人生的意義。 於是打開某個網站, 開始看一些只有長大了才能看的大人動作愛情學,必須好好鑽研, 此刻電影裡的聲響徹雲霄,你感覺無比尷尬..... 這時候就需要靜音神隊友。 可以自己加入網頁名單,讓小電影們先保持靜音,自己再手動開啟。 如此一來非常保險,絕對不讓你不小心爆音。 非常的有禮貌,人生的哲理更奧妙了。 ## 腳本下載  https://greasyfork.org/zh-TW/scripts/477196-%E9%9D%9C%E9%9F%B3%E5%B0%8F%E5%8A%A9%E6%89%8B ## JS程式碼 ``` // ==UserScript== // @name 靜音小助手 // @namespace http://tampermonkey.net/ // @version 0.1 // @description try to take over the world! // @author You // @match https://*/* // @icon https://www.google.com/s2/favicons?sz=64&domain=xvideos.com // @grant none // ==/UserScript== // 定義 JSON 資料,包含網址開頭 var jsonUrls = [ "https://www.xvideos.com/", "https://example.com/json2", // 添加更多的網址開頭 ]; // 取得當前網址 var currentUrl = window.location.href; // 檢查當前網址是否以 JSON 中的某些開頭開始 var isJsonUrl = jsonUrls.some(function(jsonUrl) { return currentUrl.startsWith(jsonUrl); }); // 如果當前網址符合 JSON 的某些開頭,執行程式碼 if (isJsonUrl) { // 在這裡放置你想要執行的程式碼 console.log("當前網址符合 JSON 開頭"); Mute(); } else { console.log("當前網址不符合 JSON 開頭"); } function Mute(){ // 取得網頁上所有的 <video> 元素 var videoElements = document.getElementsByTagName('video'); // 迭代所有的 <video> 元素並將其靜音 for (var i = 0; i < videoElements.length; i++) { videoElements[i].muted = true; } } ``` ## 觀念筆記 只能說,前端的東西往往越簡單,越強。 這次只是使用三個小觀念,都是超級基本的小小觀念,幼稚園等級。 ### 第一部分:使用陣列儲存網址 ``` // 定義 JSON 資料,包含網址開頭 var jsonUrls = [ "https://www.xvideos.com/", "https://example.com/json2", // 添加更多的網址開頭 ]; ``` 這部分就是把我們的資料儲存起來,可以自己新增訂義哪些網址要被匹配。 ### 第二部分:location的API 使用網址要確認網址,就是用location,這已經屢見不鮮。 另外字串的搜查,startsWith非常老舊卻也很無敵。 ### 第三部分:影片靜音API 很簡單,針對video元素muted就可以了,非常輕鬆! 簡直就像早餐吃鬆餅一樣,鬆。 ## 心得 很多人常常說前端,好難,JS好基八 我是覺得,關你屁事?/ᐠ。ꞈ。ᐟ\ 你會罵蛋餅為什麼要這麼蛋餅嗎,蛋餅之所以好吃就是因為它是蛋餅,不好吃也因為它是蛋餅。 JS的奇怪或是難懂,只是它的本質,在那邊靠北靠母的風氣真的很無聊。 要玩梗也可以多一點新的梗,而不是表面嘴皮耍耍。 它很機八,但也很強,這就是JS的厲害之處。 因此這個簡單實用的小腳本,又再次被我們秒殺了! 喜歡可以關注,未來還會有更多JS的小試身手、前端動手玩創意也還有一堆素材呢⁽⁽٩(๑˃̶͈̀ ᗨ ˂̶͈́)۶⁾⁾
## 轉載自 https://ithelp.ithome.com.tw/articles/10338052 ## 前情提要 有時候我們需要使用一些圖片,勢必需要圖片的網址,這時候, 也許你可以本機上傳,然後去把網址抓好, 又或者你可以找到網路上別人的圖片,右鍵開啟新分頁,再複製網址; 又或者直接打開檢查(F12)找到src的網址去複製。 光聽這個流程我就覺得,心累。 這時候前端大師,就會寫一套簡單的小腳本來完成這個白爛的工作。 ## 腳本下載  https://greasyfork.org/zh-TW/scripts/477141-img%E8%A4%87%E8%A3%BD%E5%A4%A7%E5%B8%AB ## JS程式碼 ``` // ==UserScript== // @name IMG複製大師 // @namespace http://tampermonkey.net/ // @version 0.1 // @description 針對網頁上圖片,點擊就複製其網址 // @author You // @match *://*/* // @icon https://www.highcharts.com/demo/highcharts/spline-plot-bands // @grant none // ==/UserScript== let isEventActive = false; // 用於跟蹤事件的狀態 // 創建一個鏈接元素並設置其屬性 const toastrCssLink = document.createElement('link'); toastrCssLink.rel = 'stylesheet'; toastrCssLink.href = 'https://cdnjs.cloudflare.com/ajax/libs/toastr.js/latest/css/toastr.min.css'; // 創建一個腳本元素並設置其屬性 const toastrScript = document.createElement('script'); toastrScript.src = 'https://cdnjs.cloudflare.com/ajax/libs/jquery/3.6.0/jquery.min.js'; // 創建另一個腳本元素並設置其屬性 const toastrScript2 = document.createElement('script'); toastrScript2.src = 'https://cdnjs.cloudflare.com/ajax/libs/toastr.js/latest/js/toastr.min.js'; // 將鏈接元素和腳本元素添加到文檔頭部 document.head.appendChild(toastrCssLink); document.head.appendChild(toastrScript); document.head.appendChild(toastrScript2); // 獲取頁面上的所有img元素 const images = document.querySelectorAll('img'); function removeClickHandler(image) { image.removeEventListener('click', clickHandler); } function toggleEvent() { if (isEventActive) { // 如果事件已經激活,則關閉事件 console.log('IMG複製大師關閉ꐦ°᷄д°᷅'); // 解除事件監聽 images.forEach(removeClickHandler); isEventActive = false; } else { // 如果事件尚未激活,則打開事件 console.log('IMG複製大師啟動ฅ^•ﻌ•^ฅ'); // 遍歷所有img元素 images.forEach((image) => { // 檢查圖像是否已加載 if (image.complete) { // 圖像已加載,直接添加點擊事件處理程序 addClickHandler(image); } else { // 圖像尚未加載,等待加載完成後再添加點擊事件處理程序 image.addEventListener('load', () => { addClickHandler(image); }); } }); isEventActive = true; } } document.addEventListener('keydown', (event) => { if ((event.key === 'q' && event.ctrlKey) || event.key === 'F8') { toggleEvent(); // 切換事件的狀態 } }); function transformImageUrl(url) { // 使用正則表達式匹配URL中的目標部分 const regex = /https:\/\/cache.ptt.cc\/c\/https\/i.imgur.com\/([^?]+)/; const match = url.match(regex); if (match) { // 如果匹配成功,構建新的URL const imgurId = match[1]; return `https://i.imgur.com/${imgurId}`; } else { // 如果沒有匹配到目標部分,返回原始URL return url; } } // 創建一個函數,用於添加點擊事件處理程序並處理圖像的src function addClickHandler(image) { image.addEventListener('click', clickHandler); } // 創建一個函數,用於處理點擊事件 function clickHandler() { let src = this.src; src = transformImageUrl(src); const textArea = document.createElement('textarea'); textArea.value = src; document.body.appendChild(textArea); textArea.select(); document.execCommand('copy'); document.body.removeChild(textArea); // 使用 toastr 進行通知 toastr.success('網址複製完成: ' + src); } ``` ## 觀念筆記 這個小腳本總共使用了大概三種觀念, 第一種就是toast的套件使用, 第二個是監聽鍵盤做開關, 第三個則是程式本身對於img的監聽,把src複製到剪貼簿。 ### 第一部分:套件 使用套件在於腳本,必須利用appendChild,先使用create的API製作出放置CDN的link元素, 再把它append到網頁上,則可以使用其套件。 ### 第二部分:監聽鍵盤 這腳本啟動與關閉是透過監聽鍵盤的,ctrl+q或F8這部分就是純粹監聽。 ``` document.addEventListener('keydown', (event) => { if ((event.key === 'q' && event.ctrlKey) || event.key === 'F8') { toggleEvent(); // 切換事件的狀態 } }); ``` 裡面寫了一個toggleEvent是因為想要設定可以開開關關。 ### 第三部分:程式本身 這邊有一點小技巧是複製到剪貼簿,其實以前文章也有寫過教學,是個常見實用的招數: ``` const textArea = document.createElement('textarea'); textArea.value = src; document.body.appendChild(textArea); textArea.select(); document.execCommand('copy'); ``` 再來就是針對網頁上全部的img元素,去監聽點擊事件、移除事件這兩個。 ``` const images = document.querySelectorAll('img'); function addClickHandler(image) { image.addEventListener('click', clickHandler); } function removeClickHandler(image) { image.removeEventListener('click', clickHandler); } ``` 之後這兩個事件要寫在toggle裡面,當開啟的條件就執行新增事件;關閉就執行解除綁定 開啟也就是: ``` images.forEach((image) => { // 檢查圖像是否已加載 if (image.complete) { // 圖像已加載,直接添加點擊事件處理程序 addClickHandler(image); } else { // 圖像尚未加載,等待加載完成後再添加點擊事件處理程序 image.addEventListener('load', () => { addClickHandler(image); }); ``` 關閉則是: `images.forEach(removeClickHandler);` ## 心得 這次的小腳本功能非常簡單,寫起來邏輯也是很清晰透明,沒有什麼彎曲。 雖然簡單,但是寫起來功能非常實用! 這就是針對懶人專用的! 其實沒有人規定前端這種東西要寫得多大,多了不起/ᐠ。ꞈ。ᐟ\ 好像你很屌、很懂前端、框架,那個是一回事,能夠完成自己的需求也很美好。 很久沒更新了,這次的酷酷小腳本應該很爽⁽⁽٩(๑˃̶͈̀ ᗨ ˂̶͈́)۶⁾⁾ 好好的來玩前端吧,未來還有更大的宇宙!
測試程式碼是軟體開發最重要的方面之一,因為它可以確保產品的品質、可擴展性和可靠性。 但是,如果沒有任何指導,編寫有效的測試可能會很困難。測試程式碼可能比實際功能的程式碼更複雜、更難維護! 原文出處:https://dev.to/one-beyond/the-5-principles-of-unit-testing-1p5f ## 1.精簡和準確的測試 測試程式碼必須**簡單且易於使用**。任何查看測試的人都應該立即知道測試的內容及其目的是什麼。開發測試應該以很少的精力和時間投入帶來巨大的價值。 > _您是否需要超過 30 秒的時間來閱讀和理解您的測試?重寫它!_ 測試“覆蓋率”是重點嗎?不! **僅測試必要的部份就好**。為了敏捷性和簡單性,最好放棄一些測試,**只測試主要業務邏輯和主要邊緣情況就好**。 ## 2.測試行為,而不是元件實作 不要檢查程式碼中的每一行和內部變數。測試時,您應該**專注於結果**。即使方法內的程式碼被重構,結果也應該永遠保持不變! 這樣,如果程式碼庫發生更改,您**不需要重寫測試**。 ``` // Wrong ❌ - Test behaviour describe('Evaluation Service', () => { describe('Register Students', () => { it('Should add new students to the evaluation service', () => { const studentJosh = { id: 1, name: 'Josh McLovin', average: 6.98, } evaluationService.addStudent(studentJosh) expect(evaluationService._students[0].name).toBe('Josh') expect(evaluationService._students[0].average).toBe(6.98) }) }) }) ``` ``` // Right ✅ - Test behaviour describe('Evaluation Service', () => { describe('Register Students', () => { it('Should add new students to the evaluation service', () => { const studentJosh = { id: 1, name: 'Josh McLovin', average: 6.98, } evaluationService.addStudent(studentJosh) expect(evaluationService.getStudentAverage('Josh')).toBe(6.98) }) }) }) ``` ## 3. 關於命名和結構:AAA 模式 您是否曾經遇到過名為“_它應該[...]正確_”的失敗測試,但花了幾分鐘才找到問題所在? 良好命名和結構可以讓您快速且準確地找到任何失敗的測試,最終節省您的寶貴時間。因此,讓我們深入探討兩個關鍵原則,以便在下次測試時牢記: ### 3.1 經過深思熟慮的測試命名: 在命名您的測試時,請嘗試合併以下資訊: - **正在測試什麼**? - **什麼情況**? - **預期結果**是什麼? ``` // Right ✅ - Test naming // 1. What is being tested: describe('Evaluation Service', () => { describe('Evaluate Students', () => { // 2 & 3. Context and expected result it('If the student grade is below the minimum grade, student should be suspended', () => { const students = [ { name: 'Mark', grade: 4.25 }, { name: 'Colin', grade: 6.7 }, { name: 'Ben', grade: 5.3 }, ] const result = evaluationService.evaluateStudents({ students, minGrade: 5 }) expect(result['Mark']).toBe('suspended') }) }) }) ``` ### 3.2 測試程式碼結構的AAA模式: 如果您想維護一個可讀且易於理解的測試套件,請按如下方式建立測試: - **安排**:設定模擬所需情況所需的所有程式碼。這可以包括初始化變數、模擬響應、實例化被測單元等。 - **行為**:執行正在測試的內容,通常在一行程式碼中。 - **斷言**:檢查得到的結果是否為預期的結果。與上面的一樣,這應該只需要一行。 ``` // Right - AAA Testing Pattern describe('Evaluation Service', () => { describe('Average Calculation', () => { it('Should calculate the average grade of all the students', () => { // Arrange: create an object with the student names and their grades const students = [ { name: 'Mark', grade: 4 }, { name: 'Colin', grade: 10 }, { name: 'Ben', grade: 7 }, { name: 'Tim', grade: 3 }, ] // Act: execute the getAverage method const avg = evaluationService.getAverage(students) // Assert: check if the result is the expected one -> (4+10+7+3)/4 = 6 expect(avg).toEqual(6) }) }) }) ``` ##4。確定性和隔離測試 如果一個失敗的測試使您的整個套件變紅,那麼您可能沒有以正確的方式處理它! 測試應該**獨立和隔離**,一次針對並處理一個特定邏輯,從而完成更快、更穩定的測試套件。 **如果您不**獨立編寫測試會發生什麼? - 您將無法找出錯誤和問題的**確切原因和位置**。 - 重構測試時,您必須**更新和同步多個測試**。 - 您將無法以任何順序執行測試,這可能會導致**破壞或跳過某些斷言或期望**。 ## 5。基於屬性的測試和真實資料 厭倦了在測試中編寫大量可能的輸入?基於屬性的測試可以為您做到這一點!……那是什麼? 基於屬性的測試建立了數百種可能的組合,強調了測試並**增加了發現以前未被注意到的錯誤的機會**。這種方法甚至可以傳回可能導致意外結果的輸入。 [JSVerify](https://github.com/jsverify/jsverify) 或 [Fast-Check](https://github.com/dubzzz/fast-check) 等函式庫提供了促進基於屬性的測試的基本工具。 但是,如果您不想深入進行如此廣泛的測試,那麼盡可能利用**真實資料**至關重要。像“abc”或“1234”這樣的輸入可能會在實際失敗時錯誤地通過測試。 ``` // Wrong ❌ - False Positive - Test that passes even though it shouldn't class EvaluationService { _students = []; addStudent(student) { // Add the student if the name has no numbers if(!student.name.matches(/^([^0-9]*)$/)){ this._students.push(student); } } } describe('Evaluation Service', () => { describe('Register Students', () => { it('Should add students to the Evaluation service', () => { const mockStudent = { id: 2, name: 'username', average: 7 } // Won't fail because the name is a string without number -> We are not checking what happens if the user // inputs a name with a number. evaluationService.addStudent(mockStudent) expect(evaluationService.getStudentAverage('username')).toBe(7) }) }) }) // In the example above, we are making a test so the test passes, instead of looking for edge cases with realistic data ``` ##額外提示! 如果您在測試元件中的任何邏輯時遇到困難,這可能反映出您也許應該將元件邏輯分解為更小、更容易且可測試的程式碼片段! 總而言之,遵循此最佳實踐可能會帶來一種新的、可讀且可維護的方法來測試您喜愛的生產程式碼。 > 經過測試的應用程式才是可靠的應用程式!
## 課程目標 - 認識 async/await 語法與收尾處理 ## 課程內容 接著來學 async/await 的收尾處理吧! 說起來也神奇,只要加上 `finally` 區塊就可以了! ``` try { const data1 = await $.get(url, params); // do something with data to get params2 const data2 = await $.get(url2, params2); // do something with data to get params3 const data3 = await $.get(url3, params3); // do the final task with data } catch (err) { alert('Something went wrong.'); } finally { // hide the loading icon } ``` 因為 `try/catch/finally` 本來就是一般同步程式設計語言會用到的錯誤處理語法 所以這整段程式碼,看起來跟一般的同步程式設計,幾乎一模一樣! 就是這麼奇妙!應該不用我多解釋什麼了! --- 多補充一句,我個人開發比較複雜的前端應用時,最常用的語法就是這種! 我認為 `async/await` 加上 `try/catch/finally` 是最簡潔有力的! 錯誤訊息提示、忙碌狀態提示,通通都有了,很輕易就做出 UX 很棒的應用程式! ## 課後作業 請拿出第三課的作業,我們來改善這個頁面的 UX(使用者體驗),明確提示「忙碌中」這個狀態 --- - 請用 html 元素,在頁面中加入一段 `讀取中,請稍等...` 的訊息,這個元素預設不顯示 - 在開始呼叫 API 的地方,用 js 操作來讓那個 html 元素顯示 - 在結束呼叫 API 的地方,使用 `finally` 語法,用 js 操作來讓那個 html 元素隱藏 做出以上功能,你就完成這次的課程目標了!
## 課程目標 - 認識 promise chain 鏈接與收尾處理 ## 課程內容 接著來學 promise chain 的收尾處理吧! 繼續拿 jquery 當範例,只要在上次的 promise chain 最後,加上 `.always()` 就可以了! ``` $.get(url, params).then((data) => { // do something with data to get params2 return $.get(url2, params2); }).then((data) => { // do something with data to get params3 return $.get(url3, params3); }).then((data) => { // do the final task with data }).catch((err) => { alert('Something went wrong.'); }).always(() => { // hide the loading icon }); ``` 很簡潔有力吧! ### ⚠️特別注意事項⚠️ 因為某些歷史因素,jquery 包裝的 promise 跟現在瀏覽器原生的 promise 有點不太一樣! 原生的 promise 是 `.finally()`,而不像 jquery 是 `.always()`! 為了教學方便,本課&作業都用 jquery 示範,實務上如果看到 `.finally()` 請不要意外! 都是類似東西,知道這樣就好! ## 課後作業 請拿出第二課的作業,我們來改善這個頁面的 UX(使用者體驗),明確提示「忙碌中」這個狀態 --- - 請用 html 元素,在頁面中加入一段 `讀取中,請稍等...` 的訊息,這個元素預設不顯示 - 在開始呼叫 API 的地方,用 js 操作來讓那個 html 元素顯示 - 在結束呼叫 API 的地方,使用 `always()`,用 js 操作來讓那個 html 元素隱藏 寫完之後,你應該會發現不但 callback hell 改善了、錯誤處理有了、連 UX 都改善了! 做出以上功能,你就完成這次的課程目標了!
## 課程目標 - 認識 async/await 語法與錯誤處理 ## 課程內容 在非同步訓練一的課程,我們初步體驗到 async/await 寫起來的感覺,效果不錯! 這次來試著加上錯誤處理! 說起來也神奇,只要使用 `try/catch` 語法包起來就可以了! ``` try { const data1 = await $.get(url, params); // do something with data to get params2 const data2 = await $.get(url2, params2); // do something with data to get params3 const data3 = await $.get(url3, params3); // do the final task with data } catch (err) { alert('Something went wrong.'); } ``` 因為 `try/catch` 本來就是一般同步程式設計語言會用到的錯誤處理語法 所以這整段程式碼,看起來跟一般的同步程式設計,幾乎一模一樣! --- 上次我們說過:每次只要看到 await,就要去想「現在是去剝開 promise 的 then 裡面,拿出最後回傳的內容!」 現在可以多補充一句:「如果 await 後面的非同步任務跑失敗,就會直接 throw exception(拋出例外)」 有點看不懂沒關係,就先跟著使用方式,照做即可! 工作上多用幾次之後,會逐漸抓到感覺! ## 課後作業 這一次的作業,我們要延續「非同步 JS 訓練一:第3課」的內容,並且加上錯誤處理 https://codelove.tw/@howtomakeaturn/post/bapzbx 請找出你上次寫的作業,把上次的三組 API,換成以下這三組 ``` https://codelove.tw/fake-api/get-current-user-unstable ``` ``` https://codelove.tw/fake-api/get-orders-unstable ``` ``` https://codelove.tw/fake-api/get-order-details-unstable ``` --- 幾點注意事項如下: - 繼續用 `$.get()` 來呼叫 API 即可 - 寫一個 `try/catch` 就好了,不要寫成多個 `try/catch` - 任何一個 API 失敗時,請 `alert('抱歉,系統出了點問題,請稍後再試一次。');` 寫完之後,你會發現,整段程式碼看起來很像「一般程式語言中,同步程式設計」的寫法! 連 `try/catch` 看起來都跟常見程式語言的錯誤處理,一模一樣! 做出以上功能,你就完成這次的課程目標了!
## 課程目標 - 認識 promise chain 鏈接與錯誤處理 ## 課程內容 在非同步訓練一的課程,我們初步體驗到 promise chain 寫起來的感覺,效果不錯! 這次來試著加上錯誤處理! 只要在上次的 promise chain 最後,加上 `.catch()` 就可以了! ``` $.get(url, params).then((data) => { // do something with data to get params2 return $.get(url2, params2); }).then((data) => { // do something with data to get params3 return $.get(url3, params3); }).then((data) => { // do the final task with data }).catch((err) => { alert('Something went wrong.'); }); ``` 上面這段程式碼,總共發了三次 ajax,不論是哪一次失敗,都會被最後的 `.catch()` 捕捉到喔! 很簡潔有力吧! --- 看到這邊,你可能會心想,可是上次 callback hell 的寫法,我可以針對三個 api 分別寫不同的 callback,顯示不同的錯誤訊息耶! 這次只能寫一個 callback,給一個籠統的系統錯誤,好像 UX 不夠好呀? 其實你說的沒錯!這樣寫的確會有這問題! 但我個人經驗是,系統跑 ajax 失敗,其實整體 UX 已經很不好了,用戶已經覺得這網站很難用了 明確顯示哪個步驟失敗,其實幫助不大。就一律在訊息中「道歉&懇請用戶再試一次&告知可以回報客服」就好了! (如果真的要顯示不同錯誤訊息,是有其他 promise 比較複雜的寫法,這一課先不談論) ## 課後作業 這一次的作業,我們要延續「非同步 JS 訓練一:第2課」的內容,並且加上錯誤處理 https://codelove.tw/@howtomakeaturn/post/8aAPD3 請找出你上次寫的作業,把上次的三組 API,換成以下這三組 ``` https://codelove.tw/fake-api/get-current-user-unstable ``` ``` https://codelove.tw/fake-api/get-orders-unstable ``` ``` https://codelove.tw/fake-api/get-order-details-unstable ``` --- 幾點注意事項如下: - 繼續用 `$.get()` 來呼叫 API 即可 - 寫一個 `.catch()` 就好了,不用特別寫三種錯誤訊息 - 任何一個 API 失敗時,請 `alert('抱歉,系統出了點問題,請稍後再試一次。');` 寫完之後,你應該會看到多個 `.then()` 串接在一起,不再出現多層深度的巢狀 callback 傳遞了! 而且錯誤處理的部份,也比之前改善很多,簡單又清楚! 做出以上功能,你就完成這次的課程目標了!
## 課程目標 - 認識 callback hell 與錯誤處理 ## 課程內容 在非同步訓練一的課程,我們初步體驗到 callback hell 寫起來的感覺 其實,當年的工程師,面對的真正痛苦,比上次體驗到的更嚴重! 非同步任務,常常需要處理「任務失敗」的情況 比方說「主機回應超時」、「資料庫連線失敗」、「主機斷線」等等情況 按照 javascript 的慣例,就是多寫一個 callback function 處理這種情況 比方說函式可以設計成這樣 ``` runAsyncTask(success, error) ``` 使用者只要分別傳進「成功後的處理」以及「失敗後的處理」即可 ``` runAsyncTask(() => { alert('執行成功!'); }, () => { alert('執行失敗,請等等重新嘗試!'); }); ``` 如果繼續拿 jquery 做範例,看起來會像這樣: ``` $.ajax({ url: url, data: params, success: (res) => {}, error: (res) => {}, }); ``` 註1:他不是設計成兩個參數,而是物件的兩個屬性,但意思一樣 註2:沒辦法繼續用上次的 `$.get()`,他沒有設計錯誤處理的 callback。所以改用 `$.ajax()` 光看這樣可能還好,畢竟寫 javascript 就是很常到處寫 callback 傳來傳去 可是,你能想像連續呼叫多個 ajax 時,再加上錯誤處理機制,callback hell 會有多嚴重嗎! 來跟著作業,體驗一下,試著用當年的方式開發看看吧! ## 課後作業 這一次的作業,我們要延續「非同步 JS 訓練一:第1課」的內容,並且加上錯誤處理 https://codelove.tw/@howtomakeaturn/post/lqOkWq 請找出你上次寫的作業,把上次的三組 API,換成以下這三組 ``` https://codelove.tw/fake-api/get-current-user-unstable ``` ``` https://codelove.tw/fake-api/get-orders-unstable ``` ``` https://codelove.tw/fake-api/get-order-details-unstable ``` 這三組 API 很不穩定,每組 API 都有 1/3 的機率會抓資料失敗! 實務上不可能有 API 爛成這樣,通常失敗率會在 1% 以下,這次是方便測試,我故意寫的 API --- 幾點注意事項如下: - 不要使用現代的非同步寫法,請使用 callback hell 的寫法 - 使用 `$.ajax()` 來呼叫 API - 使用 `$.ajax()` 的 `success` 參數來處理成功的情況 - 使用 `$.ajax()` 的 `error` 參數來處理失敗的情況 - 第一個 API 失敗時,請 `alert('讀取用戶失敗,請稍後再試一次。');` - 第二個 API 失敗時,請 `alert('讀取訂單列表失敗,請稍後再試一次。');` - 第三個 API 失敗時,請 `alert('讀取訂單細節失敗,請稍後再試一次。');` 寫完之後,你應該會看到有三層深度的巢狀 callback 傳遞! 而且比上次的情況還離譜!加上錯誤處理之後,整段 code 更加難以閱讀、維護! 這就是當年前端工程師,每天工作面臨的狀況!很悲慘吧! 做出以上功能,你就完成這次的課程目標了!
## 課程目標 - 認識 callback hell ## 課程內容 在一般「同步程式設計語言」中,程式碼執行的順序,就是一行一行跑下來,很容易理解 但 JavaScript 是「非同步程式設計語言」,很多時候,執行順序不是一行一行跑下來 為了讓用戶能持續流暢操作瀏覽器介面,工程師需要在會用到「非同步」的地方使用特殊寫法 最原始、也最單純的做法是使用 callback function,也就是把要在非同步任務結束後才跑的任務,寫在 callback function 傳進去 以 jquery 最原始的 ajax 處理為例 ``` $.get(url, params, (data) => { // do something with data }) ``` 第三個參數,也就是箭頭函式的部份,就是所謂的 callback function --- 當年的前端工程師,在一開始覺得這樣寫沒問題,但是當網頁應用程式越來越複雜之後 發現在需要連續執行多個非同步任務時,會需要不斷傳 callback function 進去更深層 最後導致的結果,就是所謂的「callback hell」!這讓程式碼很難讀、很難維護! ``` $.get(url, params, (data) => { // do something with data to get params2 $.get(url2, params2, (data) => { // do something with data to get params3 $.get(url3, params3, (data) => { // do the final task with data }); }); }); ``` 這樣描述比較抽象,來跟著作業,試著用當年的方式開發看看吧! ## 課後作業 讓我們時光倒轉,回到 2000 年代,體驗一下當時的開發方式 請使用 https://jsfiddle.net/ 寫作業 請載入 jquery 套件,並且用 `jQuery.get()` 來處理 ajax ``` <script src="https://code.jquery.com/jquery-3.7.1.min.js" integrity="sha256-/JqT3SQfawRcv/BIHPThkBvs0OEvtFFmqPF/lYI/Cxo=" crossorigin="anonymous"></script> ``` --- 假設你身為前端工程師,正在開發電商網站 今天,產品經理跟你說,為了提升 UX(用戶體驗) 希望能在網頁上顯示「最近一次的訂單內容」,就像這樣: ``` 尊貴的客戶您好,您上次的消費內容是: 訂單編號:XXX 訂單內容:XXX 訂單金額:XXX 希望這次也能有機會服務您! ``` --- 目前後端工程師提供了三組 API 給你使用 使用當年的 jquery 寫法會像是下面這樣: ### 取得當前登入用戶的資料 為了簡化起見,你不用實作「登入、驗證」等等功能 就當作用戶已經登入了,請直接呼叫這個 API 即可 ``` $.get("https://codelove.tw/fake-api/get-current-user", {}, (res) => { console.log('the current user id is:' + res.data.user.id) }); ``` ### 取得指定用戶的全部訂單 ``` $.get("https://codelove.tw/fake-api/get-orders", { user_id: 1 }, (res) => { console.log('get ' + res.data.orders.length + ' orders'); }); ``` ### 取得指定訂單的內容細節 ``` $.get("https://codelove.tw/fake-api/get-order-details", { order_id: 1 }, (res) => { console.log('the order id is #' + res.data.order.id); console.log('the order content is ' + res.data.order.content); console.log('the order amount is $' + res.data.order.amount); }); ``` - 請依序呼叫這三個 API,來完成這次需要的功能 - 把第一個 API 拿到的 user id 放進第二個 API 呼叫 - 把第二個 API 拿到的最後一個 order id 放進第三個 API 呼叫 - 把第三個 API 拿到的資料,顯示在網頁上 請注意,不要使用現代的非同步寫法,請使用 callback hell 的寫法,也就是: - 在第一個 API 的 callback function 裡面呼叫第二個 API - 在第二個 API 的 callback function 裡面呼叫第三個 API - 在第三個 API 的 callback function 裡面完成最終需要的功能 寫完之後,你應該會看到有三層深度的巢狀 callback 傳遞! 這就有一點悲慘了,有點 callback hell 的感覺! 做出以上功能,你就完成這次的課程目標了!
https://youtu.be/I7dwJxGuGYQ ## TL;DR - 在使用 useContext 時,一定要將其包裝成 custom hook - [好讀版本](https://hackmd.io/@jason60810/rklVqNUh2) - [React 官方文件新增了 TypeScript 使用專文](https://react.dev/learn/typescript?fbclid=IwAR3Pgkr8xpS48Vwa0ADo3oagaAPKX1q05jHhtbXH8ltV8MKwa8FAvePoXPU) - [英文版本](https://jason60810.hashnode.dev/always-use-a-custom-hook-for-context-api-not-usecontext-react-context-api-typescript) ## 資料夾結構 ( 使用 next app route )  ### theme-context.tsx 一定要加上 `use client`,因為 useState 只能在 client component 運作 , **特別注意,就算這裡加了`use client`,所有的子層還是 server component (預設)**  ### layout.tsx 加上 provider 之後,下面所有的子層都可以拿到值,不用用 prop 一個一個傳下去  ### page.tsx  ### logo.tsx 1. 因為 useContext 要在 client component 運作,所以要加上 `use client`。 2. 當使用 useContext 時,一定要引入 ThemeContext,用起來很麻煩 3. 因為 ThemeContext 預設是 null,所以當不是在 provider 裡使用 `useContext` 時 ( Logo component ),會發生錯誤,因此需要先確認有 context  舉例:不是在 provider 裡使用 `useContext`  ### 創建 custom hook  ### 使用 custom hook 現在引入 ThemeContext 和處理錯誤的問題,已經抽離到 custom hook 中  ### 加上型別 1. React.ReactNode,可以接受 JavaScript primitives ,如果只想要是 jsx 可以使用 React.ReactElement ( [react 官方文件](https://react.dev/learn/typescript#typing-children) ) 2. `type Theme` 可以讓 `useState` 在 get 和 set 時,可以使用正確的型別,例如:當想要 `setTheme('blue')` 時,會報錯,因為 `type Theme` 只有 'dark' 和 'light' 3. 在給予 createContext 型別時,可以利用 ts 的 union 讓 createContext 知道可能有 null 這個型別 ( [react 官方文件](https://react.dev/learn/typescript#typing-usecontext) ) 
你的轉職路上,還缺少一份自學作業包!寫完這幾包,直接拿作品去面試上班!
本論壇另有附設一個 LINE 新手發問&交流群組!歡迎加入討論!




























