所以我現在已經進入 Web 開發大約 3 年了,專業也有一年多了,這是我處理一個與資料庫查詢最佳化相關的問題的時候,我不是 SQL 專家,我可以得到這份工作完成。沒有花哨的查詢、觸發器、預存程序等。無論如何,我不得不穀歌搜尋最後一個。 長話短說..我們的 ORM (TypeORM) 把我們搞砸了.. ## 免責聲明: 這並不是要誹謗 TypeORM 或任何 ORM。它們是為其建置目的而設計的特殊工具。我在最後附加了一些參考連結,這些連結是人們面臨類似問題的公開討論。無論如何,讓我們繼續這篇文章。 ## 問題! 我們的提交表有超過 70 萬筆記錄,表現非常糟糕。從表中取得資料的最長時間超過 6 秒。  查詢相當簡單。我們所擁有的只是 4 個連接、幾個 where 子句(大約 4 個)、排序(在created_at time 字段上的 DESC)、限制和跳過。 ## 根本原因分析.. 導致我們的提交表大幅放緩的幾個因素如下:- - **索引** - 對用於連接表的欄位進行不正確的索引或未進行索引。 - **不必要的連接** - 我們的查詢中有一些不必要的連接,可以將其刪除以獲得更多效能。 - **空字串錯誤** - 我們程式碼中的一個錯誤,如果沒有為這些列提供使用者輸入,我們將與作為查詢的 where 條件一部分的所有列的空字串 (“”) 進行比較。 - **ORM** - ORM 正在執行一個超級愚蠢的查詢來獲取資料。 這些是我在檢查程式碼和資料庫模式以及分析正在執行以獲取所需資料的查詢時發現的精確點。 ## 對提到的每個問題進行分析和測試。 ###<u>原因 1:索引</u> 在進行了一些谷歌搜尋並閱讀了人們的類似問題後,我發現我們的問題並不是那麼大。人們正在為數百萬行而苦苦掙扎,而我們的只是其中的一小部分,所以一定是我們做錯了什麼。 早期解決這些問題的社區提出了許多建議。我發現進行適當的索引會有很大幫助。 因此,為了進行測試,我從 beta 資料庫中獲取了提交內容,該資料庫擁有大約超過 **100k 記錄**。 在沒有任何最佳化的情況下,執行整個過程平均需要 **2.3 秒**。 (當然,這個時間不僅包括在資料庫上執行查詢的時間,還包括透過網路傳播資料的時間)  在向列加入索引後,我確實發現它縮短了幾毫秒的時間,但這還不夠。它仍然在 **2 秒** 左右,而且往往不止於此。 所以有點令人失望!無論如何,繼續下一個目標。 ### <u>原因 2:空字串錯誤</u> 因此,我們的時間從 **2.3** 秒縮短到了大約 2 秒,這對於索引來說並不算多。但後來我在我們的程式碼中發現了一個小錯誤,假設有四個輸入欄位供使用者根據四個不同的列鍵入和過濾結果。如果使用者沒有在任何輸入上鍵入任何內容(主要是在頁面首次載入時),且 API 呼叫會直接取得最新資料,而不進行任何過濾,僅進行連接和排序。 因此,在那一刻,我們為資料庫中的所有列傳遞了“”字串,這似乎無害,但實際上發生的情況是,資料庫正在對所有四列進行查找,您猜對了“”字串。所以進行了大量的查找,實際上什麼都沒有。 因此,當我將其更改為空(如empty/null)時(相當於從查詢中刪除where子句),查詢時間從**2.3秒變為1.3秒**。 如果您想知道使用使用者提供的實際輸入進行過濾需要多長時間。大約**500ms**(這是可以接受的)。 結論 - 即使您的資料庫使用所有可搜尋列進行索引,“”字串也不能很好地發揮作用。 好的,我們正朝著正確的方向前進。我們整整縮短了 1 秒,但我們仍然必須將其控制在 **200/150ms** 以下,所以還有很長的路要走。 ### <u>原因 3:不必要的連接</u> 在查詢提交時,我們正在與不需要的比賽和課程表進行連接。因此,當所有內容都加入到程式碼中時,我們只是刪除了它,但這表明審閱者並沒有給予太多關注(我是其中之一)。 ### <u>原因 4:ORM</u> 這是造成最多的問題.. 好.. 問題!!. 所以有一種叫做 **主動記錄模式** 的東西,TypeORM 為我們提供了使用類似 JSON 的物件產生 SQL 查詢的東西,一個例子就是。 ``` model.find({ select: { userName : true, firstName : true }, where: { userName : “SomeUsername” }, relations: { user : true, contest: true, problem: true }, order: { created_at : “ASC/DESC” , skip: 0, take: 10, }) ``` 因此,這使得開發變得快速、簡單,對於不擅長編寫原始 SQL 查詢的開發人員來說,感覺非常直觀,因為這是最抽象的版本,您實際上是在建立 JSON 物件來產生 SQL 查詢。 這種方法看起來不錯,而且大多數時候都有效,但在我們的例子中,它做了一些非常愚蠢的事情,我不會輸入它在做什麼,這樣你就可以自己看到查詢。 簡而言之,它正在執行兩個查詢,首先對於這種情況根本不需要,它可以通過我稍後編寫並測試的一個簡單的單個查詢輕鬆完成。 它不僅執行兩個單獨的查詢(原因尚不清楚,因為這是一個已知問題,有時在使用typeorm 的活動記錄模式時發生),它還將四個表連接兩次,每個查詢一次,然後還排序兩次各一次。 (這實際上沒有任何意義) 這也是表演受到最大打擊的地方。自己看看下面的查詢。 ``` SELECT DISTINCT `distinctAlias`.`Submission_id` AS `ids_Submission_id`, `distinctAlias`.`Submission_created_at` FROM (SELECT `Submission`.`id` AS `Submission_id`, ... more selects FROM `submission` `Submission` LEFT JOIN `problem` `SubmissionSubmission_problem` ON `SubmissionSubmission_problem`.`id`=`Submission`.`problemId` LEFT JOIN `user` `SubmissionSubmission_user` ON `Submission_Submission_user`.`id`=`Submission`.`userId`) `distinctAlias` ORDER BY `distinctAlias`.`Submission_created_at` DESC, `Submission_id` ASC LIMIT 10 ``` ``` SELECT `Submission`.`id` AS `Submission_id`, `Submission`.`language` AS `Submission_language`, `Submission`.`verdictCode` AS `Submission_verdictCode`, `Submission`.`tokens` ... shit ton of selects FROM `submission` `Submission` LEFT JOIN `problem` `SubmissionSubmission_problem` ON `SubmissionSubmission_problem`.`id`=`Submission`.`problemId` LEFT JOIN `user` `SubmissionSubmission_user` ON `Submission_Submission_user`.`id`=`Submission`.`userId` WHERE `Submission`.`id` IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?) ORDER BY `Submission`.`created_at` DESC ``` 所以這兩個查詢是問題的主要原因,也是主要原因之一。 因此,我編寫了一個簡單的原始 SQL 查詢來執行與它嘗試使用 2 個單獨的查詢執行的完全相同的操作,查詢如下:- ``` SELECT Submission.id, Submission.language, Submission.verdictCode, ... FROM submission AS Submission LEFT JOIN problem ... LEFT JOIN user ... ORDER BY Submission.created_at DESC LIMIT 10 ``` 當我們執行這個查詢時,它的執行時間僅為 **100ms!!!** 因此,我們現在從 **1.3** 秒移至 **100ms**,總體從 **2.3** 秒移至 **100ms** 效能提升超過 **23 倍。** 之後我就去睡覺了。仍然需要做更多的測試,並嘗試找出邊緣情況(如果有),並提出為此編寫查詢的最佳方法。目前,我正在考慮使用 TypeORM 提供的儲存庫模式或查詢建構器模式。 第二天: 又來了.. ### <u>全文索引</u> **全文索引**可以提高從這些索引列中搜尋單字和短語的效率,我們也可以嘗試一下。 (這是我的同事 Jay 提出的一個非常好的觀點,它進一步提高了表現)。 ###<u>發現了一些更重要的點。</u> 在 MySQL 中最佳化具有唯一索引的資料列上的「LIKE」查詢時,可以採用一些策略來提高效能。以下是一些建議: 1. **索引優化:** - **使用全文索引:** 如果您的「LIKE」查詢涉及在列中搜尋單字或片語,請考慮使用全文索引而不是常規唯一索引。全文索引是專門為基於文字的搜尋而設計的,可以提供更快、更準確的結果。 - **使用排序規則:** 確保列的排序規則不區分大小寫和重音。這可以透過使用「utf8_general_ci」或「utf8mb4_general_ci」等排序規則來實現。它允許更有效地利用索引,因為搜尋變得不區分大小寫和重音。 2. **查詢最佳化:** - **前綴搜尋:**如果您的`LIKE`查詢在末尾使用通配符(例如,`column LIKE 'prefix%'`),索引仍然可以有效地使用。但是,如果通配符位於開頭(例如“column LIKE '%suffix'”),則不會使用索引。在這種情況下,請考慮使用替代技術,例如全文搜尋或儲存列的反向值以實現高效的後綴搜尋。 - **最小化通配符:** 模式開頭的通配符(`'%suffix'`)會使查詢速度明顯變慢。如果可能,請嘗試建立查詢,使通配符僅出現在模式的末尾(「前綴%」)。 - **參數綁定:** 如果您從應用程式內執行「LIKE」查詢,請使用參數綁定或準備好的語句,而不是直接連接查詢字串。這有助於防止SQL注入並允許資料庫更有效地快取執行計劃。 3. **快取和查詢結果:** - **快取查詢結果:** 如果`LIKE`查詢結果相對靜態或不需要即時,可以考慮實作像memcached或Redis這樣的快取機制。快取可以透過直接從記憶體提供結果來顯著縮短反應時間。 - **物化視圖:** 如果經常執行「LIKE」查詢且資料列的資料相對靜態,請考慮建立物化視圖來預先計算並儲存「LIKE」查詢的結果。如果查詢物化視圖所帶來的效能提升超過了額外的儲存和維護需求,則此方法可能會很有用。 值得注意的是,這些優化策略的有效性可能會根據您的特定用例而有所不同。 ### 經過所有測試後建議的改進點。 1. 修正將空字串傳遞到 where/過濾條件的問題。 2. 在效能至關重要的讀取操作中,轉而使用查詢建構器而不是活動記錄模式。 3. 在用於搜尋和過濾的欄位中新增索引。另外,在不唯一且用於搜尋的列上新增全文索引。 4. 刪除/避免不必要的連線。如果可能的話,重組架構以在必要時複製資料。 5. 使用 LIKE 運算子搜尋時,使用「prefix%」模式,而不是我們使用的預設模式「%suff+pref%」。使用前綴模式有助於資料庫使用索引並提供更好的結果。 儘管如此,我們成功地將查詢時間從 **7 秒** 降低到 **<=150 毫秒**,這樣做後感覺很好,因為這是我第一次涉足性能和優化並尋找從我們已有的資源中榨取更多資源的方法。 特別感謝[Mitesh Sir](https://www.linkedin.com/in/miteshskj/) 在這次調查期間指出了潛在的原因並引導我走向正確的方向,並一遍又一遍地重新啟動測試伺服器😂因為由於記憶體限制,在多次執行測試後,資料庫會變得非常慢。 如果您想更多地談論與這一切相關的內容,請在 X 上關注我,https://twitter.com/RishiNavneet ### 參考 1. https://github.com/typeorm/typeorm/issues/3857#issuecomment-714758799 2. https://github.com/typeorm/typeorm/issues/3857 3. https://stackoverflow.com/questions/714950/mysql-performance-optimization-order-by-datetime-field 4. https://stackoverflow.com/questions/22411979/mysql-select-millions-of-rows 5. https://dba.stackexchange.com/questions/20335/can-mysql-reasonously-perform-queries-on-billions-of-rows 6. https://stackoverflow.com/questions/38346613/mysql-and-a-table-with-100-millions-of-rows 7. https://github.com/typeorm/typeorm/issues/3191 PS - 這些改進很久以前就完成了,我只是懶得發布它😬。 --- 原文出處:https://dev.to/navneet7716/optimizing-sql-queries-h9j
喜歡這些文章嗎?買書吧! [***Jason C. McDonald 的《Dead Simple Python》可從 No Starch Press 取得。](https://nostarch.com/dead-simple-python) --- 教程最糟糕的部分始終是它們的簡單性,不是嗎?您很少會發現一個包含多個文件的文件,更罕見的是包含多個目錄的文件。 我發現**建立 Python 專案**是語言教學中最常被忽略的部分之一。更糟的是,許多開發人員都會犯錯,在一堆常見錯誤中跌跌撞撞,直到他們得到至少「有效」的東西。 好訊息是:您不必成為他們中的一員! 在《Dead Simple Python》系列的本期中,我們將探索「import」語句、模組、包,以及如何將所有內容組合在一起而不費力氣。我們甚至會涉及 VCS、PEP 和 Python 之禪。係好安全帶! # 設定儲存庫 在我們深入研究實際的專案結構之前,讓我們先討論一下它如何適合我們的版本控制系統 [VCS]…從您*需要* VCS 的事實開始!有幾個原因是... * 追蹤您所做的每一個更改, * 弄清楚你什麼時候弄壞了東西, * 能夠查看舊版的程式碼, * 備份您的程式碼,以及 * 與他人合作。 您有很多選擇。 **Git** 是最明顯的,尤其是當您不知道還可以使用什麼時。您可以在 GitHub、GitLab、Bitbucket 或 Gitote 等上免費託管 Git 儲存庫。如果您想要 Git 以外的東西,還有許多其他選擇,包括 Mercurial、Bazaar、Subversion(儘管如果您使用最後一個,您可能會被同行視為恐龍。) 我將悄悄假設您在本指南的其餘部分中使用 Git,因為這是我專門使用的。 建立儲存庫並將「本機副本」複製到電腦後,您就可以開始設定專案了。您至少需要建立以下內容: - `README.md`:您的專案及其目標的描述。 - `LICENSE.md`:您的專案的許可證(如果它是開源的)。 (有關選擇一個的更多訊息,請參閱 [opensource.org](https://opensource.org/)。) - `.gitignore`:一個特殊文件,告訴 Git 要忽略哪些文件和目錄。 (如果您使用其他 VCS,則該檔案具有不同的名稱。請尋找。) - 包含您的專案名稱的目錄。 沒錯...**我們的Python 程式碼檔案實際上屬於一個單獨的子目錄!** 這非常重要,因為我們的儲存庫的根目錄將變得非常混亂,其中包含建置檔案、打包腳本、虛擬環境以及各種方式其他實際上不屬於原始碼的內容。 僅為了舉例,我們將虛構的專案稱為「awesomething」。 # PEP 8 和命名 Python 風格主要由一組稱為 **Python 增強提案**(縮寫為 **PEP**)的文件管轄。當然,並非所有 PEP 都被實際採納——這就是它們被稱為「提案」的原因——但有些是被採納的。您可以在Python官方網站上瀏覽主PEP索引。此索引的正式名稱為 [PEP 0](https://www.python.org/dev/peps/)。 現在,我們主要關注 [**PEP 8**](https://www.python.org/dev/peps/pep-0008/),它最初由 Python 語言建立者 Guido van Rossum 於2001 年。該文件正式概述了所有Python 開發人員應普遍遵循的程式設計風格。把它放在枕頭下!學習它,遵循它,鼓勵其他人也這樣做。 (附註:PEP 8 指出樣式規則總是有例外。它是*指南*,而不是*命令*。) 現在,我們主要關注標題為 [“包和模組名稱”](https://www.python.org/dev/peps/pep-0008/#package-and-module-names)的部分。。 > 模組應該有簡短的、全小寫的名稱。如果可以提高可讀性,可以在模組名稱中使用下劃線。 Python 套件也應該有短的、全小寫的名稱,儘管不鼓勵使用底線。 我們稍後會了解*模組*和*包*到底是什麼,但現在,請了解**模組由檔案名稱命名**,而**套件由其目錄名稱命名**。 換句話說,**檔案名稱應全部小寫,如果可以提高可讀性,則使用下劃線。**同樣,**目錄名稱應全部小寫,如果可以避免,則不使用下劃線**。換句話說... + 執行此動作:`awesomething/data/load_settings.py` + 不是這個:`awesomething/Data/LoadSettings.py` 我知道,我知道,這是一種冗長的表達方式,但至少我在你的步驟中加入了一點 PEP。 (*你好?這個東西開著嗎?*) # 套件和模組 這會讓人感覺虎頭蛇尾,但這裡是那些承諾的定義: **任何Python(`.py`)檔案都是一個*模組*,目錄中的一堆模組是一個*套件*。** 嗯……差不多了。要讓目錄成為包,您還必須做另一件事,那就是將名為「__init__.py」的檔案貼到其中。實際上,您不必將任何內容*放入*該文件中。它必須在那裡。 您也可以使用`__init__.py` 做其他很酷的事情,但這超出了本指南的範圍,因此[請閱讀文件以了解更多資訊](https://docs.python.org/3/tutorial/modules.html#packages)。 如果你*確實*忘記了套件中的`__init__.py`,它會做一些比失敗更奇怪的事情,因為這使它成為一個**隱式命名空間包**。您可以使用這種特殊類型的套件做一些有趣的事情,但我不會在這裡討論。像往常一樣,您可以透過閱讀文件來了解更多:[PEP 420:隱式命名空間包](https://www.python.org/dev/peps/pep-0420/)。 所以,如果我們看看我們的專案結構,`awesomething` 實際上是一個包,它可以包含其他包。因此,我們可以將「awesomething」稱為我們的*頂級包*,以及其*子包*下的所有包。一旦我們開始進口東西,這將非常重要。 讓我們看一下我的現實專案“遺漏”的快照,以了解我們如何建置東西... ``` omission-git ├── LICENSE.md ├── omission │ ├── app.py │ ├── common │ │ ├── classproperty.py │ │ ├── constants.py │ │ ├── game_enums.py │ │ └── __init__.py │ ├── data │ │ ├── data_loader.py │ │ ├── game_round_settings.py │ │ ├── __init__.py │ │ ├── scoreboard.py │ │ └── settings.py │ ├── game │ │ ├── content_loader.py │ │ ├── game_item.py │ │ ├── game_round.py │ │ ├── __init__.py │ │ └── timer.py │ ├── __init__.py │ ├── __main__.py │ ├── resources │ └── tests │ ├── __init__.py │ ├── test_game_item.py │ ├── test_game_round_settings.py │ ├── test_scoreboard.py │ ├── test_settings.py │ ├── test_test.py │ └── test_timer.py ├── pylintrc ├── README.md └── .gitignore ``` (如果您想知道的話,我使用 UNIX 程式“tree”來製作上面的小圖。) 您會看到我有一個名為“omission”的頂級包,它有四個子包:“common”、“data”、“game”和“tests”。我還有“resources”目錄,但只包含遊戲音訊、圖像等(為簡潔起見,此處省略)。 `resources` 不是一個包,因為它不包含 `__init__.py`。 我的頂層包中還有另一個特殊檔案:`__main__.py`。這是當我們直接透過「python -m omission」執行頂級套件時執行的檔案。我們稍後會討論「__main__.py」中的內容。 # 導入如何進行 如果您以前編寫過任何有意義的 Python 程式碼,那麼您幾乎肯定熟悉「import」語句。例如... ``` import re ``` 知道當我們導入模組時,我們實際上是在執行它是有幫助的。這意味著模組中的任何“import”語句也正在執行。 例如,[`re.py`](https://github.com/python/cpython/blob/3.7/Lib/re.py#L122) 有幾個自己的 import 語句,當我們說 `導入重新`。這並不意味著它們可用於我們從*導入“re”的文件,但這確實意味著這些文件必須存在。如果(由於某種不太可能的原因)“enum.py”在您的環境中被刪除,並且您執行了“import re”,它將失敗並出現錯誤... > 回溯(最近一次呼叫最後一次): > 檔案“weird.py”,第 1 行,位於 <module> 中 > 進口再 > 檔案“re.py”,第 122 行,位於 <module> 中 > 導入枚舉 > ModuleNotFoundError:沒有名為「enum」的模組 當然,讀到這裡,你可能會有點困惑。有人問我為什麼找不到外部模組(在本例中為“re”)。其他人想知道為什麼要導入內部模組(此處為“enum”),因為他們沒有直接在程式碼中請求它。答案很簡單:我們導入了 `re`,然後導入了 `enum`。 當然,上面的場景是虛構的:「import enum」和「import re」在正常情況下永遠不會失敗,因為這兩個模組都是Python核心庫的一部分。這只是一個愚蠢的例子。 ;) # 匯入註意事項 實際上有多種導入方式,但其中大多數應該很少使用(如果有的話)。 對於下面的所有範例,我們假設有一個名為「smart_door.py」的檔案: ``` # smart_door.py def close(): print("Ahhhhhhhhhhhh.") def open(): print("Thank you for making a simple door very happy.") ``` 例如,我們將在 Python 互動式 shell 中執行本節中的其餘程式碼,執行位置與「smart_door.py」相同。 如果我們想執行`open()`函數,我們必須先導入模組`smart_door`。最簡單的方法是...... ``` import smart_door smart_door.open() smart_door.close() ``` 我們實際上會說“smart_door”是“open()”和“close()”的**命名空間**。 Python 開發人員非常喜歡命名空間,因為它們讓函數和其他內容的來源一目了然。 (順便說一句,不要將 *命名空間* 與 *隱式命名空間包* 混淆。它們是兩個不同的東西。) **Python 之禪**,也稱為 [PEP 20](https://www.python.org/dev/peps/pep-0020/),定義了 Python 語言背後的哲學。最後一行有一個聲明解決了這個問題: > 命名空間是一個非常棒的想法——讓我們做更多這樣的事情! 然而,在某種程度上,命名空間可能會變得很痛苦,尤其是對於嵌套包來說。 `foo.bar.baz.whatever.doThing()` 太醜了。值得慶幸的是,我們確實有辦法避免*每次*呼叫函數時都必須使用命名空間。 如果我們希望能夠使用 `open()` 函數,而不必總是在其前面加上模組名稱,我們可以這樣做... ``` from smart_door import open open() ``` 但請注意,「close()」和「smart_door.close()」在最後一個場景中都不起作用,因為我們沒有直接匯入該函數。要使用它,我們必須將程式碼更改為這樣... ``` from smart_door import open, close open() close() ``` 在之前可怕的嵌套包噩夢中,我們現在可以說“from foo.bar.baz.whatever import doThing”,然後直接使用“doThing()”。或者,如果我們想要一點命名空間,我們可以說“from foo.bar.baz importwhatever”,然後說“whatever.doThing()”。 “導入”系統非常靈活。 但不久之後,您可能會發現自己說“但是我的模組中有數百個函數,我想全部使用它們!”這是許多開發人員偏離軌道的地方,這樣做... ``` from smart_door import * ``` **這非常非常糟糕!** 簡而言之,它直接導入模組中的所有內容,這是一個問題。想像一下下面的程式碼... ``` from smart_door import * from gzip import * open() ``` 你認為會發生什麼事?答案是,「gzip.open()」將是被呼叫的函數,因為這是在我們的程式碼中導入並定義的「open()」的最後一個版本。 `smart_door.open()` 已被 **shadowed** - 我們不能稱之為 `open()`,這意味著我們實際上根本無法呼叫它。 當然,由於我們通常不知道,或者至少不記得每個導入的模組中的*每個*函數、類別和變數,所以我們很容易陷入一堆混亂。 *Python 之禪* 也解決了這個情況... > 顯式優於隱式。 您永遠不必“猜測”函數或變數來自何處。文件中的某個位置應該有程式碼“明確”告訴我們它來自哪裡。前兩個場景證明了這一點。 我還應該提到,早期的 `foo.bar.baz.whatever.doThing()` 場景是 Python 開發人員不喜歡看到的。也來自 *Python 之禪*... > 扁平比嵌套更好。 一些包的嵌套是可以的,但是當你的專案開始看起來像一套精緻的俄羅斯娃娃時,你就做錯了。將模組組織到包中,但保持相當簡單。 # 在您的專案中匯入 我們之前建立的專案文件結構即將「非常方便」。回想一下我的「遺漏」專案... ``` omission-git ├── LICENSE.md ├── omission │ ├── app.py │ ├── common │ │ ├── classproperty.py │ │ ├── constants.py │ │ ├── game_enums.py │ │ └── __init__.py │ ├── data │ │ ├── data_loader.py │ │ ├── game_round_settings.py │ │ ├── __init__.py │ │ ├── scoreboard.py │ │ └── settings.py │ ├── game │ │ ├── content_loader.py │ │ ├── game_item.py │ │ ├── game_round.py │ │ ├── __init__.py │ │ └── timer.py │ ├── __init__.py │ ├── __main__.py │ ├── resources │ └── tests │ ├── __init__.py │ ├── test_game_item.py │ ├── test_game_round_settings.py │ ├── test_scoreboard.py │ ├── test_settings.py │ ├── test_test.py │ └── test_timer.py ├── pylintrc ├── README.md └── .gitignore ``` 在我的“game_round_settings”模組中,由“omission/data/game_round_settings.py”定義,我想使用“GameMode”類別。類別在「omission/common/game_enums.py」中定義。我怎樣才能到達它? 因為我將“omission”定義為包,並將模組組織到子包中,所以實際上非常簡單。在“game_round_settings.py”中,我說...... ``` from omission.common.game_enums import GameMode ``` 這稱為**絕對導入**。它從頂級包“omission”開始,然後進入“common”包,在其中查找“game_enums.py”。 一些開發人員向我提供更像「from common.game_enums import GameMode」的導入語句,並想知道為什麼它不起作用。簡而言之,「data」套件(「game_round_settings.py」所在的位置)不知道其兄弟包。 然而,它確實知道它的父母。正因為如此,Python 有一種叫做「相對導入」的東西,它可以讓我們做同樣的事情,就像這樣... ``` from ..common.game_enums import GameMode ``` `..` 表示“此套件的直接父包”,在本例中為“omission”。因此,導入後退一級,進入“common”,並找到“game_enums.py”。 關於是否使用絕對導入或相對導入有許多爭論。就我個人而言,我更喜歡盡可能使用絕對導入,因為它使程式碼更具可讀性。不過,您可以自己做決定。唯一重要的部分是結果是「顯而易見的」——任何東西的來源都不應該是神秘的。 (繼續閱讀:[Real Python - Python 中的絕對導入與相對導入](https://realpython.com/absolute-vs-relative-python-imports/) 這裡還隱藏著另一個陷阱!在 `omission/data/settings.py` 中,我有這一行: ``` from omission.data.game_round_settings import GameRoundSettings ``` 當然,由於這兩個模組都在同一個包中,我們應該可以直接說“from game_round_settings import GameRoundSettings”,對嗎? *錯誤!* 它實際上無法找到“game_round_settings.py”。這是因為我們正在執行頂級包“omission”,這意味著**搜尋路徑**(Python 查找模組的位置以及順序)的工作方式不同。 但是,我們可以使用相對導入來代替: ``` from .game_round_settings import GameRoundSettings ``` 在這種情況下,單一“.”表示“這個包”。 如果您熟悉典型的 UNIX 檔案系統,這應該開始有意義。 `..` 表示“後一級”,“.` 表示“目前位置”。當然,Python 更進一步:`...` 表示“後兩級”,`....` 表示“後三級”,依此類推。 但是,請記住,這些「等級」不僅僅是簡單的目錄。他們是包裹。如果在一個不是包的普通目錄中有兩個不同的包,則不能使用相對導入從一個包跳到另一個包。為此,您必須使用 Python 搜尋路徑,但這超出了本指南的範圍。 (請參閱本文末尾的文件。) # `__main__.py` 還記得我提到在我們的頂級包中建立一個 `__main__.py` 嗎?這是一個特殊的文件,當我們直接使用 Python 執行套件時會執行該文件。我的“omission”包可以使用“python -m omission”從我的存儲庫的根目錄執行。 這是該文件的內容: ``` from omission import app if __name__ == '__main__': app.run() ``` 是的,實際上就是這樣!我正在從頂級包“omission”導入我的模組“app”。 請記住,我也可以說「來自…」。改為導入應用程式。或者,如果我只想說“run()”而不是“app.run()”,我可以執行“from omission.app import run”或“from .app import run”。最後,只要程式碼可讀,我如何進行導入並沒有太大的技術差異。 (附註:我們可以爭論為我的主要`run()` 函數設定一個單獨的`app.py` 對我來說是否合乎邏輯,但我有我的理由......而且它們超出了本指南的範圍。 ) 首先讓大多數人感到困惑的部分是整個「if __name__ == '__main__'」語句。 Python 沒有太多**樣板** - 必須非常普遍地使用且幾乎不需要修改的程式碼 - 但這是那些罕見的位元之一。 `__name__` 是每個 Python 模組的特殊字串屬性。如果我將“print(__name__)”行貼在“omission/data/settings.py”的頂部,當該模組被導入(並因此執行)時,我們會看到“omission.data.settings”被打印出去。 當模組直接透過「python -m some_module」運作時,模組會被指派一個特殊值「__name__」:「__main__」。 因此,「if __name__ == '__main__':」實際上是在檢查該模組是否以 *main* 模組執行。如果是,它將在條件下執行程式碼。 您可以透過另一種方式看到這一點。如果我將以下內容加入到“app.py”的底部... ``` if __name__ == '__main__': run() ``` ……然後我可以直接透過 `python -m omission.app` 執行該模組,結果與 `python -m omission` 相同。現在`__main__.py`被完全忽略,`omission/app.py`的`__name__`是`"__main__.py"`。 同時,如果我只是執行“python -m omission”,“app.py”中的特殊程式碼將被忽略,因為它的“__name__”現在又是“omission.app”。 看看效果如何? # 總結 我們來複習。 * 每個專案都應該使用 VCS,例如 Git。有很多選項可供選擇。 * 每個 Python 程式碼檔案 (`.py`) 都是一個 **模組**。 * 將您的模組組織到**包**中。每個包必須包含一個特殊的「__init__.py」檔案。 * 您的專案通常應由一個頂級包組成,通常包含子包。該頂級包通常共享您的專案的名稱,並作為專案存儲庫根目錄中的目錄存在。 * **永遠不要**在導入語句中使用「*」。在考慮可能的例外之前,Python 之禪指出「特殊情況並沒有特殊到足以違反規則」。 * 使用絕對或相對導入來引用專案中的其他模組。 * 可執行專案的頂層套件中應該有一個`__main__.py`。然後,您可以使用「python -m myproject」直接執行該套件。 當然,我們可以在建立 Python 專案時使用許多更高級的概念和技巧,但我們不會在這裡討論。我強烈建議閱讀文件: + [Python 參考:導入系統](https://docs.python.org/3/reference/import.html) + [Python 教學:模組](https://docs.python.org/3/tutorial/modules.html) + [PEP 8:Python 風格指南](https://www.python.org/dev/peps/pep-0008/) + [PEP 20:Python 之禪](https://www.python.org/dev/peps/pep-0020/) + [PEP 240:隱式命名空間套件](https://www.python.org/dev/peps/pep-0420/) --- *感謝 `grym`、`deniska` (Freenode IRC `#python`)、@cbrintnall 和 @rhymes (Dev) 提出的修改建議。* --- 原文出處:https://dev.to/codemouse92/dead-simple-python-project-structure-and-imports-38c6
如果你錯過了,Node 的建立者 Ryan Dahl 的新 Javascript 和 Typescript runtime[已發布](https://deno.land/)!它有一些非常酷的功能,可供公眾使用!讓我們來看看一些簡潔的功能,並開始建立一個簡單的 hello world! ## 什麼是 Deno? Deno 是 Typescript(和 Javascript)的新runtime,主要用 Rust 寫。它有一些[偉大的目標](https://deno.land/manual.html#goals)和一些非常有趣的“非目標”,例如不使用`npm`並且沒有package.json。 ## 安裝 安裝 deno 就像執行以下命令一樣簡單: `curl -fsSL https://deno.land/x/install/install.sh |噓` 然後複製“export”行並將其新增至“~/bashrc”或“~/bash_profile”中。 打開一個新終端並執行“deno”。您應該會收到“>”提示。輸入“exit”,讓我們深入研究一些功能! ## Deno 中的酷功能 ### 預設打字稿 預設情況下,整合 Deno 來執行 Typescript 檔案。它基本上使 Javascript 中的類型成為一等公民。不再需要透過 Babel 編譯來在伺服器端 Javascript 中使用 Typescript。 ### 從 URL 導入 Deno 允許您從網頁匯入,就像在瀏覽器中一樣。只需在您通常命名模組的位置新增一個 URL: ``` import { bgBlue, red, bold } from "https://deno.land/std/colors/mod.ts"; ``` ### 標準庫 此外,Deno 有一個易於導入和使用的標準函式庫。有些模組可以執行多種不同的操作,例如 HTTP 處理、日期時間工作和檔案系統工作。您可以在[此處](https://github.com/denoland/deno_std)查看。 ### 使用 ES 模組 最後,Deno 僅支援 ES 模組語法,這表示不再需要 `require()` 語句,只需良好的 ole' `import x from "y"`。 ## 你好世界範例 讓我們快速看一下 Hello World,其中重點介紹了其中一些功能! 將其複製到“hello-world.ts”檔案中。 ``` import { bgBlue, red, bold } from "https://deno.land/std/colors/mod.ts"; const sayHello = (name: string = "world") => { console.log(bgBlue(red(bold(`Hello ${name}!`)))); } sayHello(); sayHello("Conlin"); ``` 現在您可以使用“deno hello-world.ts”執行它,它應該會列印出一些內容。 將“sayHello”呼叫之一更改為“sayHello(15);”並重新執行它。您應該看到類型錯誤,因為 15 不是字串!太酷了! 您還會注意到如何從 URL 導入 - 它從標準庫中獲取一些控制台顏色內容! # 最後的想法 Deno 還沒有完全準備好用於生產 - 有幾個 [bug](https://deno.land/benchmarks.html#req-per-sec),但開發正在快速推進!這絕對是一個很酷的新開源專案,值得關注! --- 原文出處:https://dev.to/wuz/getting-started-with-deno-e1m
> 本文主要讲解脚本文件加载失败时的处理,对于其他类型的文件加载错误时,解决方向大致一样 ## 背景 在我们开发网站应用时,我们可能会遇到脚本加载失败的情况,导致脚本加载失败的原因有很多,比如用户的网络问题、终端设备问题、用户浏览器版本等诸多因素。 ## 解决方案 在 JavaScript 中,我们可以创建一个监听来监听脚本加载失败的情况,然后针对加载失败的脚本进行重新加载。 重新加载的方案,一般是通过更换域名来解决。我们给每个脚本添加一个映射关系表,用来在加载失败时匹配新的域名进行重试。 具体的解决方案,下面我一步一步讲解,另外希望大家可以仔细阅读注释中的内容 ```html <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>脚本加载失败如何重试</title> <script> window.addEventListener( "error", // 监听全局错误 function (e) { console.log(e); }, true // 由于脚本加载失败不会冒泡,所以我们要在捕获阶段进行监听 ); </script> </head> <body> <script src="https://www.zowlsat.com/api/1.js"></script> <script src="https://www.qqqqqqq.com/api/2.js"></script> <script src="https://www.zowlsat.com/api/3.js"></script> </body> </html> ``` 此时我们可以在浏览器控制台看到以下效果 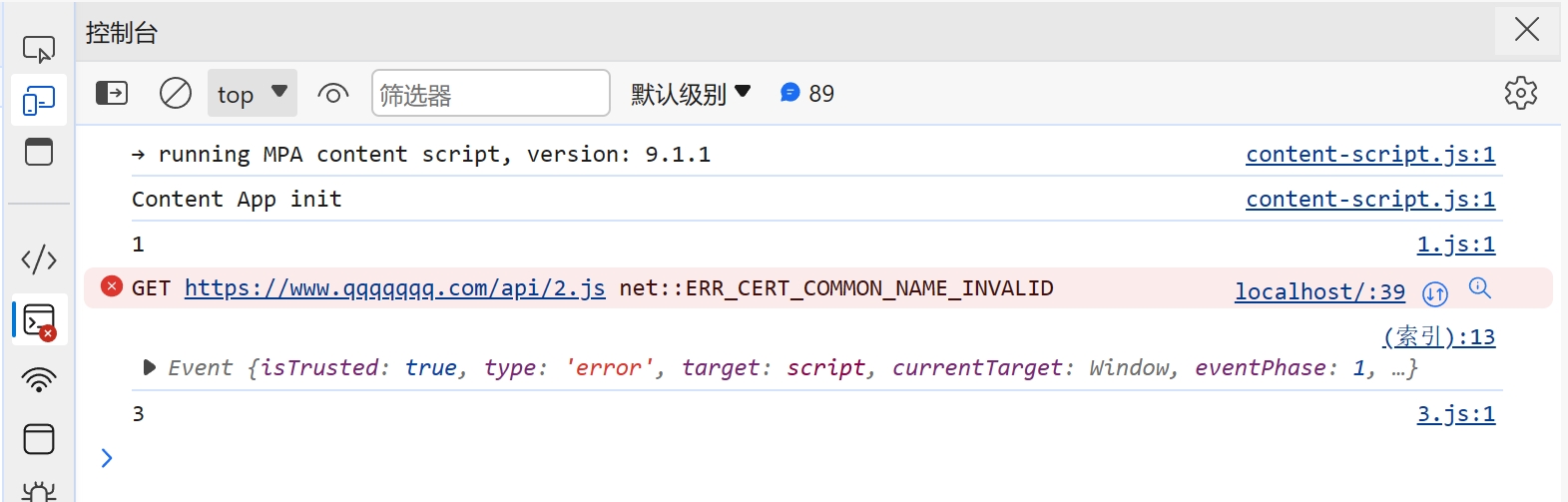 但是这个监听方法会监听到很多其他的错误,我们只需要监听脚本加载失败的错误,所以我们要通过这个监听事件的参数 e 来判断了 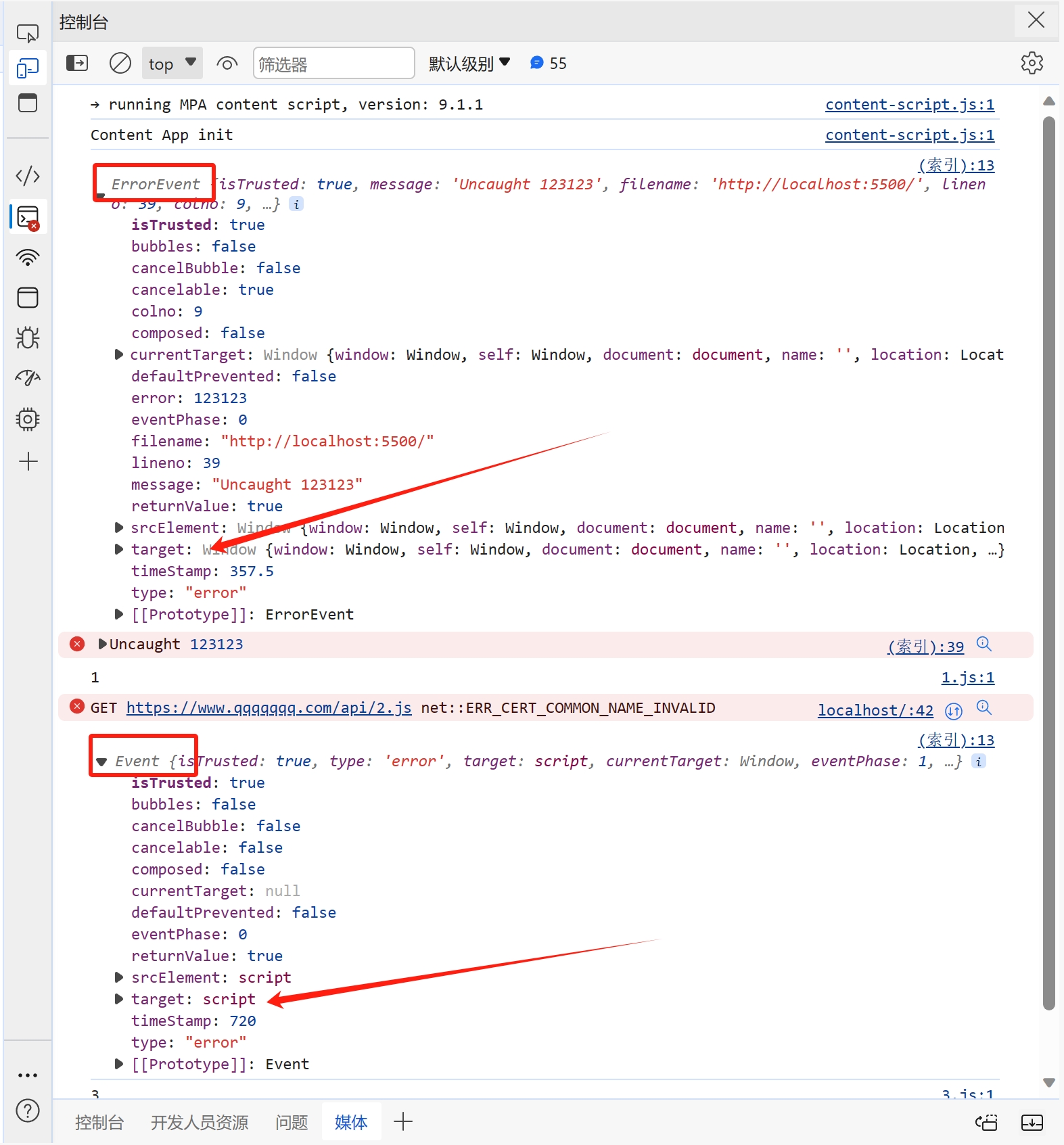 根据上图我们可以发现,普通错误的类型是 ErrorEvent,而脚本加载失败的类型是 Event,并且他的 target 会指向 script 标签,所以我们根据这个区别过滤掉其他的错误,这样剩下的情况才是我们需要处理的。 ```js window.addEventListener( "error", function (e) { if (e.target.tagName !== "SCRIPT" || e instanceof ErrorEvent) return; console.log(e); }, true ); ``` 接下来就是如何来实现重新加载,我们先给需要重新加载的域名建立一个映射关系,用于替换映射关系表中的域名。然后就是挨个匹配,当还是加载失败时继续匹配下一个,直到成功为止。 ```js const domainList = ["www.aaaaa.com", "www.bbbbb.com", "www.zowlsat.com"]; const retry = {}; window.addEventListener( "error", function (e) { if (e.target.tagName !== "SCRIPT" || e instanceof ErrorEvent) return; // 创建一个URL对象 const url = new URL(e.target.src); // 获取文件路径 const key = url.pathname; // 假如映射表中没有这个文件路径,那么就初始化一个映射键 if (!(key in retry)) { retry[key] = 0; } // 假如匹配完整个映射表都没重新加载成功,则放弃 const index = retry[key]; if (index >= domainList.length) { return; } // 获取新的完整路径 const domain = domainList[index]; // 替换域名 url.host = domain; // 创建新的script标签 const script = document.createElement("script"); script.src = url.toString(); // 将新的script标签追加到加载失败的script标签之前 document.body.insertBefore(script, e.target); retry[key]++; }, true // 由于脚本加载失败不会冒泡,所以我们要在捕获阶段进行监听 ); ``` 到此为止,我们功能已经基本实现,效果如下图 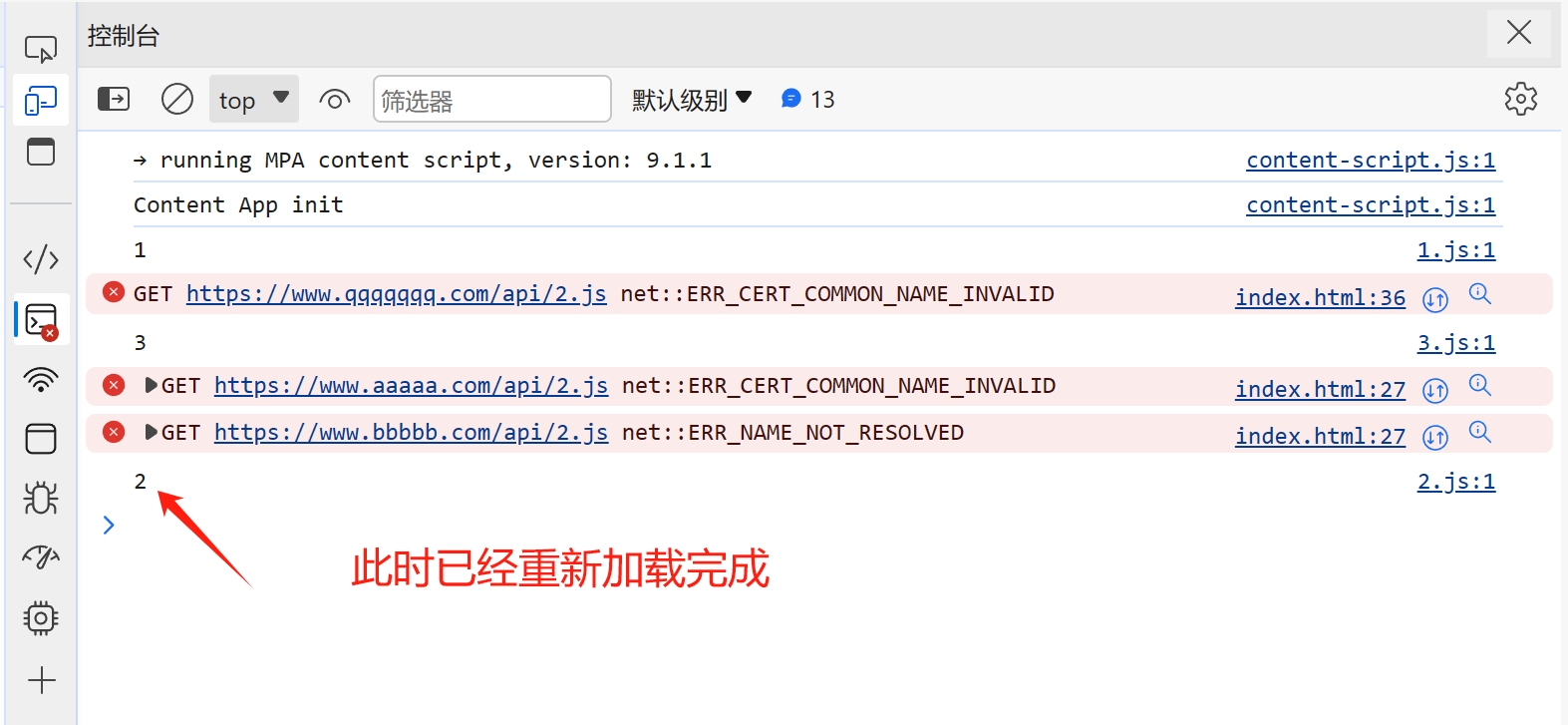 但是有一个很关键的问题,就是假如我 2.js 这个文件中的内容,在 3.js 中要使用,那这样的话,2.js 就必须加载到 3.js 之前,否则就会报错。此时,我们就需要在 2.js 加载失败时,阻塞浏览器的解析,知道重新加载完成或者放弃重新加载时,再继续渲染之后的内容。 那这样的话我们该怎么做呢?🤔 其实很简单,在我们入门 js 时就学到过一个知识点,就是使用`document.write` `document.write`这个方法在解析期间使用的话,会阻塞浏览器的解析,而我们现在就是需要阻塞浏览器解析,那此时我们只需要将创建 script 标签的方法更换为`document.write`方法即可。 修改之后的代码如下: ```js const domainList = ["www.aaaaa.com", "www.bbbbb.com", "www.zowlsat.com"]; const retry = {}; window.addEventListener( "error", function (e) { if (e.target.tagName !== "SCRIPT" || e instanceof ErrorEvent) return; const url = new URL(e.target.src); const key = url.pathname; if (!(key in retry)) { retry[key] = 0; } const index = retry[key]; if (index >= domainList.length) { return; } const domain = domainList[index]; url.host = domain; // 此处加上转译是因为防止编译器识别script标签为结束标签报错 document.write(`\<script src="${url.toString()}">\<\/script>`); // const script = document.createElement("script"); // script.src = url.toString(); // document.body.insertBefore(script, e.target); retry[key]++; }, true ); ``` 现在我们再打开控制台查看,现在js文件按它原来的顺序执行了,这样既不会改变原有的代码逻辑,又可以在可控范围内进行重新加载。 效果如下图: 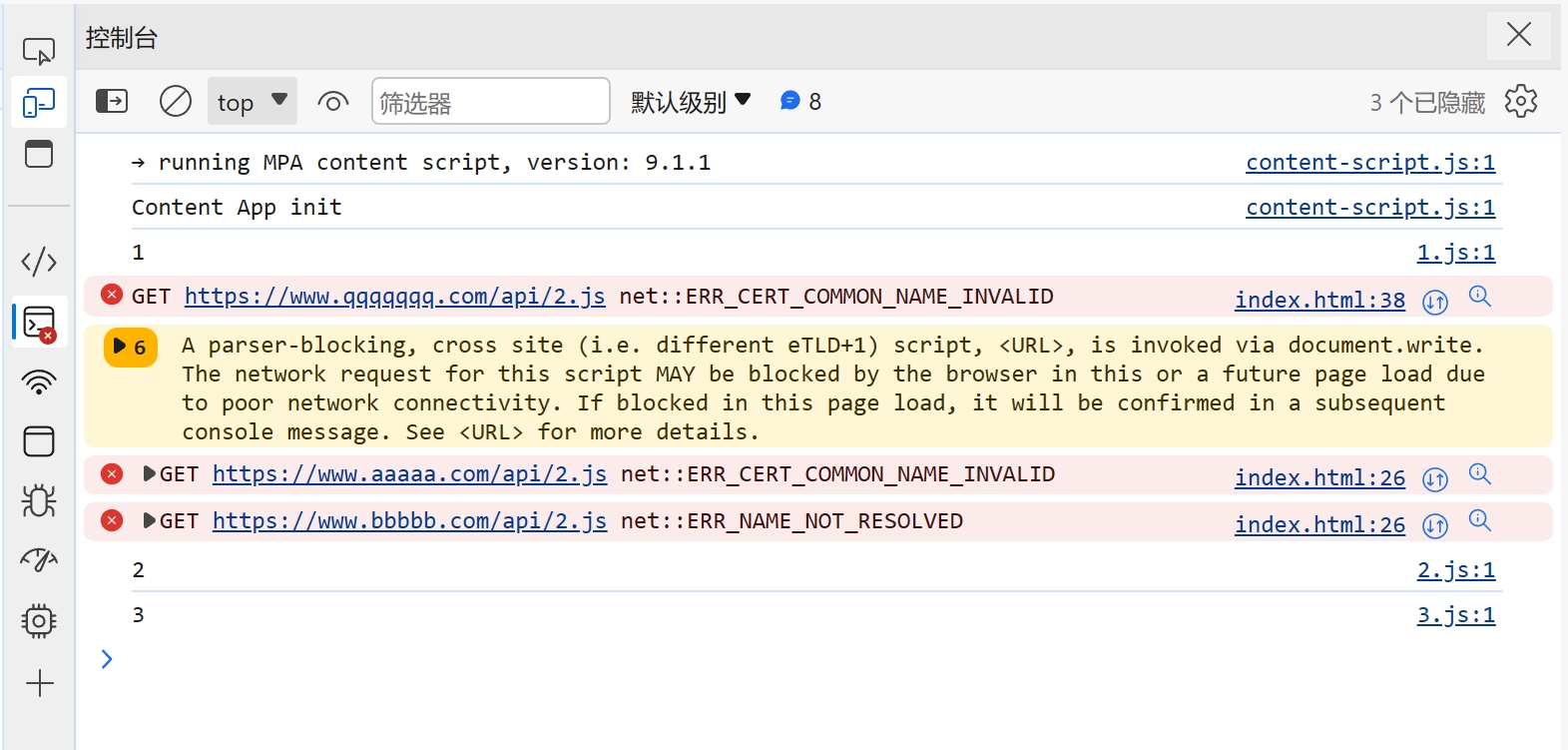 以上是简单实现了一个js文件重新加载错误的方案,其实这个方案也可以运用到其他很多类型的文件,不限于js文件。 然后我们还需要更加细化这个方法的话,我们可能还需要考虑到这个script标签是否带有`async`、`defer`等属性,还有诸多需要考虑的点,但是沿着这个方向解决的话,大体是没有问题的。
剛開始**物件導向程式設計**,不知道**SOLID**?別擔心,在本文中我將向您解釋它並舉例說明如何在開發程式碼時使用它。 - [什麼是 SOLID?](#什麼是 SOLID) - [S - 單一責任原則](#s-single-responsibility-principle) - [開閉原則](#the-開閉原則) - [L - 里氏替換原理](#l-里氏替換原理) - [I - 介面隔離原則](#i-interface-segregation-principle) - [D - 依賴倒置原則](#d-dependency-inversion-principle) - [結論](#conclusion) ##什麼是實體? 在物件導向程式設計中,術語 SOLID 是五個設計假設的縮寫,旨在促進理解、開發和維護軟體。 當使用這套原則時,可以顯著減少錯誤的產生,提高程式碼質量,產生更有組織的程式碼,減少耦合,改進重構並鼓勵程式碼重複使用。 ## S - 單一職責原則  >*SRP - 單一職責原則* 這原則說**一個類別必須有一個且只有一個改變的理由** 就是這樣,不要建立具有多種功能和職責的類別。您可能已經完成或遇到一個可以做所有事情的類,例如“God Class”。在那一刻看起來一切都很好,但是當需要對這個類別的邏輯進行任何更改時,問題肯定會開始出現。 >**God Class - God Class:** 在物件導向程式設計中,它是一個知道太多或做太多事情的類別。 ``` class Task { createTask(){/*...*/} updateTask(){/*...*/} deleteTask(){/*...*/} showAllTasks(){/*...*/} existsTask(){/*...*/} TaskCompleter(){/*...*/} } ``` 這個 **Task** 類別透過執行 **四個** 不同的任務來打破 **SRP** 原則。它正在處理**任務**的資料、顯示、驗證和驗證。 ### 這可能導致的問題: - 「缺乏連結」-一個類別不應該承擔不屬於它自己的責任; - 「太多的資訊在一起」 - 你的類別將有很多依賴項並且很難進行更改; - 「實現自動化測試的困難」 - 很難[“mock”](https://pt.wikipedia.org/wiki/Objeto_Mock)這種類型的類別; 現在將 **SRP** 應用於 *Task* 類,讓我們看看這個原則可以帶來的改進: ``` class TaskHandler{ createTask() {/*...*/} updateTask() {/*...*/} deleteTask() {/*...*/} } class TaskViewer{ showAllTasks() {/*...*/} } class TaskChecker { existsTask() {/*...*/} } class TaskCompleter { completeTask() {/*...*/} } ``` >您可以將建立、更新和刪除放在單獨的類別中,但根據專案的上下文和大小,最好避免不必要的複雜性。 也許您問過自己「我只能將其應用於類別嗎?」不,相反,您也可以將其應用於方法和函數。 ``` //❌ function emailClients(clients: IClient[]) { clients.forEach((client)=>{ const clientRecord = db.find(client); if(clientRecord){ sendEmail(client); } }) } //✅ function isClientActive(client: IClient):boolean { const clientRecord = db.find(client); return !!clientRecord; } function getActiveClients(clients: IClient[]):<IClient | undefined> { return clients.filter(isClientActive); } function emailClients(clients: IClient[]):void { const activeClients = getActiveClients(clients); activeClients?.forEach(sandEmail); } ``` 更美觀、優雅、更有組織的程式碼。這個原則是其他原則的基礎,透過應用它,您將建立優質、易於閱讀和易於維護的程式碼。 ## O - 開閉原則  >*OCP - 開閉原則* 這個原則說的是**物件或實體必須對擴充功能開放,但對修改關閉**,如果需要加入功能,最好對其進行擴展而不是更改其原始程式碼。 想像一個學校辦公室的小型系統,其中有兩個班級代表學生的課程表:小學和高中。另外還有一個班級,定義了學生的班級。 ``` class EnsinoFundamental { gradeCurricularFundamental(){} } class EnsinoMedio { gradeCurricularMedio(){} } class SecretariaEscola { aulasDoAluno: string; cadastrarAula(aulasAluno){ if(aulasAluno instanceof EnsinoFundamental){ this.aulasDoAluno = aulasAluno.gradeCurricularFundamental(); } else if(aulasAluno.ensino instanceof EnsinoMedio){ this.aulasDoAluno = aulasAluno.gradeCurricularMedio(); } } } ``` `SecretariaEscola` 類別負責檢查學生的教育程度,以便在註冊課程時應用正確的業務規則。現在想像一下,這所學校在系統中加入了技術教育和課程表,那麼就需要修改這個課程,對吧?但是,這樣你就會遇到一個問題,那就是違反了*SOLID 的「開閉原則” *。 我想到了什麼解決方案?可能在類別中加入一個“else if”,就這樣,問題解決了。不是小學徒😐,這就是問題所在! **透過更改現有類別以加入新行為,我們面臨著將錯誤引入到已經執行的內容中的嚴重風險。** >**記住:** **OCP** 認為課程必須針對更改關閉並針對擴充功能開放。 看看重構程式碼所帶來的美妙之處: ``` interface gradeCurricular { gradeDeAulas(); } class EnsinoFundamental implements gradeCurricular { gradeDeAulas(){} } class EnsinoMedio implements gradeCurricular { gradeDeAulas(){} } class EnsinoTecnico implements gradeCurricular { gradeDeAulas(){} } class SecretariaEscola { aulasDoAluno: string; cadastrarAula(aulasAluno: gradeCurricular) { this.aulasDoAluno = aulasAluno.gradeDeAulas(); } } ``` 看到 `SecretariaEscola` 類,它不再需要知道要呼叫哪些方法來註冊該類別。它將能夠為建立的任何新型教學模式正確註冊課程表,請注意,我加入了“EnsinoTecnico”,無需更改原始程式碼。 >*自從我實作了 `gradeCurrarily` 介面以來。* >介面背後的獨立可擴展行為和反向依賴關係。 >鮑伯叔叔 - `開放擴充`:您可以為類別加入一些新功能或行為,而無需更改其原始程式碼。 -「修改關閉」:如果您的類別已經具有不存在任何問題的功能或行為,請勿變更其原始程式碼以新增內容。 ## L - 里氏替換原則  >*LSP - 里氏替換原理* 里氏替換原則 — **A** **衍生類別必須可以被其基底類別取代**。 *兄弟* Liskov 在 1987 年的一次會議上介紹的這個原理在閱讀他的解釋時有點難以理解,但是不用擔心,我將向您展示另一個解釋和一個示例來幫助您理解。 > 如果對於 S 類型的每個物件 o1 都有一個 T 類型的物件 o2,這樣,對於用 T 定義的所有程式 P,當 o1 被 o2 取代時 P 的行為不變,那麼 S 是 T 的子類型 你明白了嗎?不,我第一次讀它時(或其他十次)也不明白它,但等等,還有另一種解釋: > 如果 S 是 T 的子類型,則程式中類型 T 的物件可以用類型 S 的物件替換,而不必變更該程式的屬性。 - [維基百科](https://pt.wikipedia.org/wiki/Princ%C3%ADpio_da_substitui%C3%A7%C3%A3o_de_Liskov)。 如果您更直觀,我有一個程式碼範例: ``` class Fulano { falarNome() { return "sou fulano!"; } } class Sicrano extends Fulano { falarNome() { return "sou sicrano!"; } } const a = new Fulano(); const b = new Sicrano(); function imprimirNome(msg: string) { console.log(msg); } imprimirNome(a.falarNome()); // sou fulano! imprimirNome(b.falarNome()); // sou sicrano! ``` 父類別和衍生類別作為參數傳遞,並且程式碼繼續按預期工作,神奇嗎?沒什麼,這就是我們利斯科夫兄弟的原則。 ### 違規範例: - 覆蓋/實作一個不執行任何操作的方法; - 拋出意外的異常; - 從基底類別傳回不同類型的值; ## I - 介面隔離原則  >*ISP - 介面隔離原則* 介面隔離原則 — **不應強迫類別實作它不會使用的介面和方法。** 該原則表明,建立更具體的介面比建立通用介面更好。 在下面的範例中,建立了一個「Animal」接口來抽象化動物行為,然後類別實作該接口,請參閱: ``` interface Animal { comer(); dormir(); voar(); } class Pato implements Animal{ comer(){/*faz algo*/}; dormir(){/*faz algo*/}; voar(){/*faz algo*/}; } class Peixe implements Animal{ comer(){/*faz algo*/}; dormir(){/*faz algo*/}; voar(){/*faz algo*/}; // Esta implementação não faz sentido para um peixe // ela viola o Princípio da Segregação da Interface } ``` 通用介面「Animal」強制「Peixe」類別具有有意義的行為,最終違反了 **ISP** 原則和 **LSP** 原則。 使用 **ISP** 解決此問題: ``` interface Animal { comer(); dormir(); } interface AnimalQueVoa extends Animal { voar(); } class Peixe implements Animal{ comer(){/*faz algo*/}; dormir(){/*faz algo*/}; } class Pato implements AnimalQueVoa { comer(){/*faz algo*/}; dormir(){/*faz algo*/}; voar(){/*faz algo*/}; } ``` 現在更好了,“voar()”方法已從“Animal”介面中刪除,我們將其加入到派生介面“AnimalQueVoa”中。這樣,行為就在我們的上下文中被正確隔離,並且我們仍然尊重介面隔離的原則。 ## D - 依賴倒置原則  > *DIP — 依賴倒置原理* 依賴倒置原則 — **依賴抽象,而不是實現。** > 1. 高層模組不應該依賴低層模組。兩者都必須依賴抽象。 > > 2. 抽像不應該依賴細節。細節必須依賴抽象。 > > - *叔叔鮑伯* 在下面的範例中,我將展示一個簡單的程式碼來說明**DIP**。在此範例中,我們有一個透過不同方式(例如電子郵件和簡訊)發送訊息的通知系統。首先讓我們為這些通知方式建立具體的類別: ``` class EmailNotification { send(message) { console.log(`Enviando e-mail: ${message}`); } } class SMSNotification { send(message) { console.log(`Enviando SMS: ${message}`); } } ``` 現在,讓我們建立一個依賴這些具體實作的服務類別: ``` class NotificationService { constructor() { this.emailNotification = new EmailNotification(); this.smsNotification = new SMSNotification(); } sendNotifications(message) { this.emailNotification.send(message); this.smsNotification.send(message); } } ``` 在上面的例子中,`NotificationService`直接依賴`EmailNotification`和`SMSNotification`的具體實作。這違反了 DIP,因為高級 `NotificationService` 類別直接依賴低階類別。 讓我們使用 **DIP** 修復此程式碼。高級“NotificationService”類別不應依賴具體實現,而應依賴抽象。讓我們建立一個「Notification」介面作為抽象: ``` // Abstração para o envio de notificações interface Notification { send(message) {} } ``` 現在,具體的「EmailNotification」和「SMSNotification」實作必須實作此介面: ``` class EmailNotification implements Notification { send(message) { console.log(`Enviando e-mail: ${message}`); } } class SMSNotification implements Notification { send(message) { console.log(`Enviando SMS: ${message}`); } } ``` 最後,通知服務類別可以依賴「Notification」抽象: ``` class NotificationService { constructor(notificationMethod: Notification) { this.notificationMethod = notificationMethod; } sendNotification(message) { this.notificationMethod.send(message); } } ``` 這樣,「NotificationService」服務類別依賴「Notification」抽象,而不是具體實現,從而滿足**依賴倒置原則**。 ## 結論 透過採用這些原則,開發人員可以建立更能適應變化的系統,使維護變得更容易,並隨著時間的推移提高程式碼品質。 所有這些內容都是基於我學習 OOP 期間在網上找到的筆記、其他文章和影片,其中的解釋接近原理的作者,而示例中使用的程式碼是我根據自己對 OOP 的理解建立的。原則。讀者,我希望我對您的學習進程有所幫助。 --- 原文出處:https://dev.to/clintonrocha98/era-solid-o-que-me-faltava-bhp
Docker 是一個工具,允許開發人員將他們的應用程式及其所有依賴項打包到一個容器中。然後,這個容器就可以輕鬆地在任何安裝了 Docker 的機器上傳輸和執行,而不必擔心環境的差異。這就像是打包和執行軟體的標準化方式。 **容器是什麼?**  容器就像一個小包,其中包含程式執行所需的一切,可以輕鬆地在不同電腦上移動和執行,而不會造成任何麻煩。 最酷的部分是這個迷你電腦(容器)就像一個披著斗篷的超級英雄。它可以在任何電腦上執行,無論它們有多麼不同,因為它自帶特殊的環境。這是一種保持軟體井然有序的方式,並確保它無論在哪裡都能以相同的方式運作。 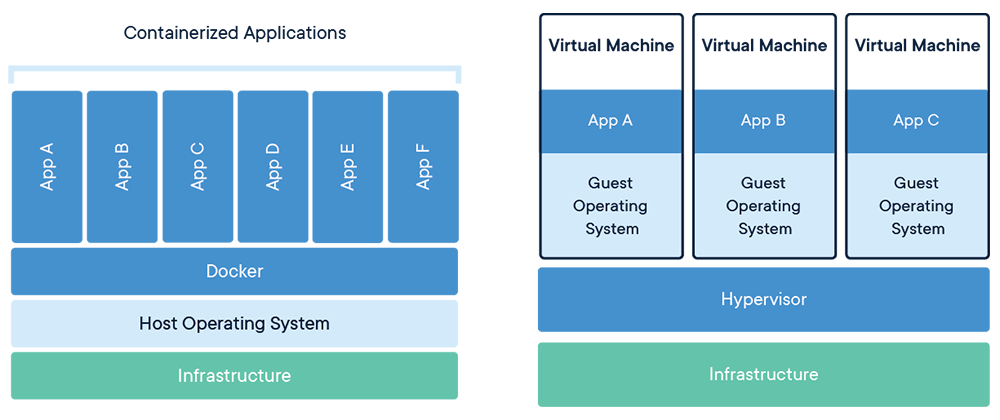 **為什麼我們需要 Docker?** 1. **一致性:** Docker 確保軟體在您的電腦、您朋友的電腦或任何電腦上以相同的方式運作。它使事情保持一致。 2. **可移植性:** 您可以將您的軟體及其朋友打包到 Docker 容器中,並且它可以移動到任何地方。這就像將您的遊戲及其所有規則放在手提箱中並在朋友家中玩。 3. **隔離:** Docker 容器就像小氣泡。氣泡內發生的事只會留在氣泡內。這意味著容器中的一個程式不會幹擾容器外的另一個程式。 4. **效率:** Docker有助於節省電腦資源。您可以讓許多容器在同一台電腦上執行,而不會相互妨礙,而不是讓一整台電腦只用於一個程式。 5. **速度:** Docker 讓啟動、停止和共享軟體變得快速、輕鬆。這就像打開和關閉遊戲機一樣 - 快速而簡單。 **什麼是 Docker 映像?** 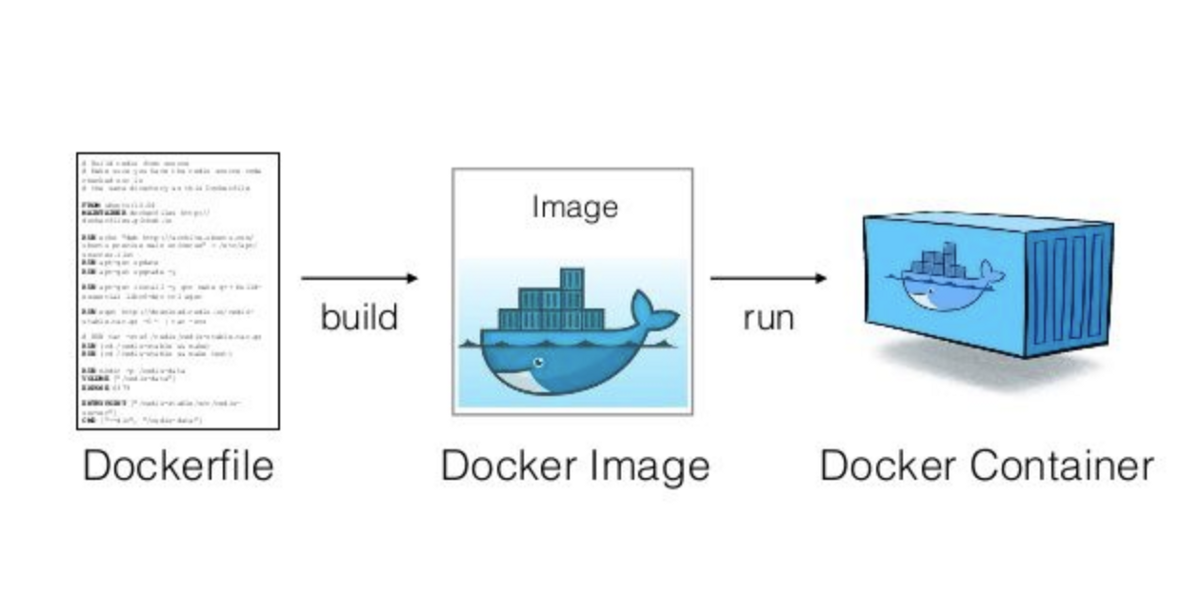 Docker 映像像是程式及其運作所需的所有內容的快照。它是一個打包版本,包括程式碼、工具和設置,就像包含所有成分的餅乾食譜的快照一樣。 **圖像是配方,容器是當您按照該配方實際製作和執行程序時所得到的。** **一些基本的 Docker 命令。**  1. **`docker執行nginx`** - 此命令告訴 Docker 使用「nginx」映像執行容器。這就像告訴 Docker 啟動一個預製程式的新實例(nginx,它是一個 Web 伺服器)。 2. **`docker ps`** - 顯示正在執行的容器的清單。這就像檢查當前正在執行哪些程式。 3. **`docker ps -a`** - 顯示所有容器的列表,包括已停止的容器。這就像檢查您執行過的所有程式的歷史記錄。 4. **`docker stopsilly_sammet'** - 停止名為「silly_sammet」的正在運作的容器。這就像關閉當前正在執行的程式。 5. **`docker rmsilly_sammet'** - 刪除名為「silly_sammet」的已停止容器。這就像丟掉你不再需要的程式的指令一樣。 6. **`docker 映像`** - 列出您擁有的所有 Docker 映像。這就像查看您可以執行的所有不同程式的選單一樣。 7. **`docker rmi nginx`** - 刪除“nginx”圖像。這就像刪除您不想再使用的程式的配方。 8. **`docker拉nginx`** - 從網路下載「nginx」映像。這就像從食譜中獲取新食譜一樣。 9. **`docker 執行 ubuntu sleep 5`** - 使用「ubuntu」映像檔執行容器並使其休眠 5 秒。這就像啟動一個程序,只是等待一小會兒,然後就停止了。 10. **`docker exectracted_mcclintock cat /etc/hosts`** - 在名為「distracted_mcclintock」的正在執行的容器內執行命令。這就像在食譜書中偷看特定頁面一樣。 11. **`docker run -d kodekloud/simple-webapp`** - 從「kodekloud/simple-webapp」鏡像以分離模式執行容器。這就像啟動一個程式並讓它在背景執行。 12. **`docker Attach a043d`** - 將您的終端附加到 ID 為「a043d」的正在執行的容器。這就像跳入正在執行的程式來查看發生了什麼。 **一些 Docker 概念:** 1. **使用標籤執行:** - 標籤就像程式的版本。它指定您要執行哪個版本。 - 範例程式碼:`docker run nginx:latest` - 這將執行最新版本的 Nginx 程式。 2. **使用標準輸入執行:** - STDIN 就像在鍵盤上打字一樣。有些程式需要您的輸入。 - 範例程式碼:`docker run -i -t ubuntu` - 這會在 Ubuntu 容器內執行互動終端,讓您可以鍵入命令。 3. **使用連接埠映射執行:** - 連接埠就像門。程式使用它們與外界進行通訊。 - 範例程式碼:`docker run -p 8080:80 nginx` - 這將執行 Nginx,並打開電腦連接埠 8080 上的門,將其連接到容器的連接埠 80。 4. **使用磁碟區映射執行:** - 磁碟區就像共用資料夾。它們讓您可以將東西存放在容器之外。 - 範例程式碼:`docker run -v /your/local/folder:/container/folder nginx` - 這將執行 Nginx 並將電腦上的資料夾連接到容器內的資料夾。 5. **檢查容器:** - 檢查就像仔細檢查正在執行的程式。 - 範例程式碼:`docker檢查container_name` - 這為您提供有關正在執行或已停止的容器的詳細資訊。 6. **容器日誌:** - 日誌就像日記。他們記錄程式正在做什麼。 - 範例程式碼:“docker 日誌容器名稱” - 這會向您顯示特定容器的日誌或活動。 ##環境變數 環境變數就像程式用來尋找重要資訊的便利筆記,有點像是程式可以理解和更好工作的秘密訊息! 1. **Python腳本(app.py)中的環境變數:** - 假設您有一個用 Python 寫的程式 (app.py)。您可能想要在不更改程式碼的情況下自訂它。您可以使用環境變數。 - 範例程式碼(app.py): ``` import os app_color = os.getenv("APP_COLOR", "default_color") print(f"The app color is {app_color}") ``` - 正常運作腳本:`python app.py` - 以特定顏色執行:`export APP_COLOR=blue; python 應用程式.py` 2. **在 Docker 中使用 ENV 變數:** - Docker 容器也可以使用環境變數。這就像是向容器內的程式發出指令。 - 範例程式碼: - `docker run -e APP_COLOR=green simple-webapp-color` - 這會執行 Docker 容器(`simple-webapp-color`)並將環境變數 `APP_COLOR` 設為「綠色」。 3. **檢查環境變數:** - 有時,您會想要檢查正在執行的容器正在使用哪些環境變數。 - 範例程式碼:`docker檢查blissful_hopper` - 此命令提供有關名為“blissful_hopper”的容器的詳細訊息,包括其環境變數。 簡單來說,環境變數就像程式(或 Docker 容器)可以讀取以了解如何行為的小註釋。您可以在執行程式之前設定這些註釋,程式將使用它們來自訂自身。第二個範例中的「export」指令就像在執行程式之前寫一條註釋,告訴它如何運作。 “docker Inspect”指令就像是在容器內部查看它有什麼註解。 ## Docker 映像 **Docker 檔案:** Dockerfile 就像是 Docker 建立映像的一組指令。這就像是烤蛋糕的食譜。 ``` # Use the Ubuntu base image FROM Ubuntu # Update apt repository RUN apt-get update # Install dependencies using apt RUN apt-get install -y python # Install Python dependencies using pip RUN pip install flask RUN pip install flask-mysql # Copy source code to /opt folder COPY . /opt/source-code # Set the working directory WORKDIR /opt/source-code # Specify entry point to run the web server ENTRYPOINT ["flask", "run"] ``` **建立自己的圖像的步驟:** 1. 使用上述內容建立一個名為「Dockerfile」的檔案。 2. 將其保存在與原始碼相同的目錄中。 **建置 Docker 映像:** 在終端機中執行以下命令: ``` docker build -t your-image-name . ``` 此命令告訴 Docker 使用目前目錄中的 Dockerfile (`.`) 建置映像,並使用您選擇的名稱對其進行標記 (`-t your-image-name`)。 **分層架構:** 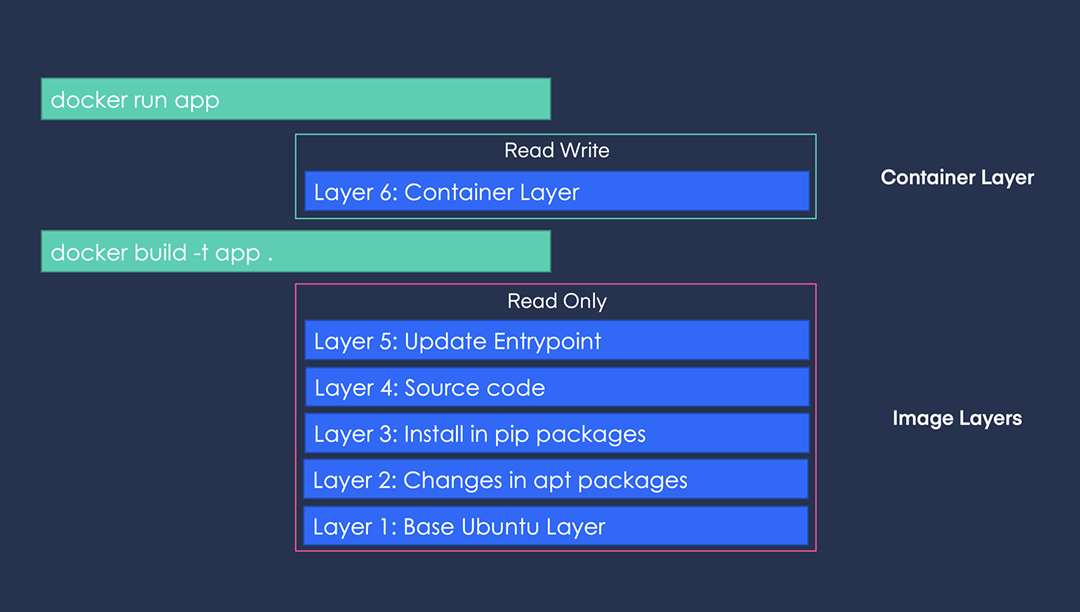 - 將 Docker 映像視為一個分層蛋糕。 Dockerfile 中的每個指令都會在映像上新增一層。 - 圖層可重複使用。如果您變更程式碼中的某些內容,Docker 只會重建受影響的層,從而提高效率。 **Docker 建置輸出:** - 當您建置映像檔時,Docker 會顯示流程中的每個步驟。如果發生故障,它會給您錯誤訊息。 **你可以容器化什麼?** - 幾乎所有東西!應用程式、服務、資料庫、網站,基本上任何軟體都可以容器化。 - 這就像將您的軟體放入一個盒子中,以便它可以在任何地方執行而不會造成麻煩。 ## 什麼是 Docker CMD 與 ENTRYPOINT **Docker 中的`CMD`:** - 將 CMD 視為啟動容器時程式執行的預設操作。 - 這就像說,“嘿,當你執行這個容器時,默認執行此操作。” - 範例:`CMD ["flask", "run"]` 表示當容器啟動時,它會自動執行 Flask Web 伺服器。 **CMD 範例:** ``` FROM alpine CMD ["sleep", "5"] ``` 在此範例中,當您使用此映像執行容器時,它會自動休眠 5 秒。 **Docker 中的`ENTRYPOINT`:** - 將 ENTRYPOINT 視為容器所做的主要事情。就好像boss的命令一樣。 - 它設定一個預設應用程式在容器啟動時執行,但您仍然可以根據需要覆蓋它。 - 範例:`ENTRYPOINT ["flask", "run"]` 表示容器主要用於執行 Flask Web 伺服器,但如果需要,您仍可新增更多指令。 **入口點範例:** ``` FROM alpine ENTRYPOINT ["sleep"] CMD ["5"] ``` 在這裡,主要目的是睡眠,如果您願意,您仍然可以覆蓋睡眠持續時間。 在這兩種情況下,容器在啟動時只會休眠幾秒鐘。主要區別在於如何提供參數以及它們是否可以輕鬆覆蓋。 CMD 就像在說,“這是默認要做的事情”,而 ENTRYPOINT 就像在說,“這是主要要做的事情,但如果你願意,你可以稍微調整一下。”它們都有助於定義容器啟動時執行的操作。 ## Docker 中的網路: Docker 網路幫助容器(程式)相互通信,確保它們可以順利地協同工作。 **預設網路:** - Docker 建立預設網路供容器通訊。 - 範例程式碼:`docker run ubuntu --network=host` - 這使用主機網路執行 Ubuntu 容器,這意味著它與主機共享網路命名空間。 **使用者定義的網路:** - 您可以建立自己的網路以更好地組織和控制。 - 範例程式碼: ``` docker network create --driver=bridge --subnet=182.18.0.0/16 custom-isolated-network ``` - 這將建立一個名為「custom-isolated-network」的使用者定義的橋接網絡,具有特定的子網。 **上市網路:** - 您可以查看您擁有的所有網路。 - 範例程式碼:`docker network ls` **檢查網路:** - 您可以檢查特定網路的詳細資訊。 - 範例程式碼:`docker網路檢查blissful_hopper` - 這顯示有關名為「blissful_hopper」的網路的詳細資訊。 **嵌入式 DNS:** - Docker 有一個內建的 DNS 系統,供容器透過名稱相互查找。 - 範例程式碼:`mysql.connect(mysql)` - 這可能是程式碼中的一行,其中名為「mysql」的服務使用 Docker 的 DNS 連接到另一個名為「mysql」的服務。 ## Docker 儲存: 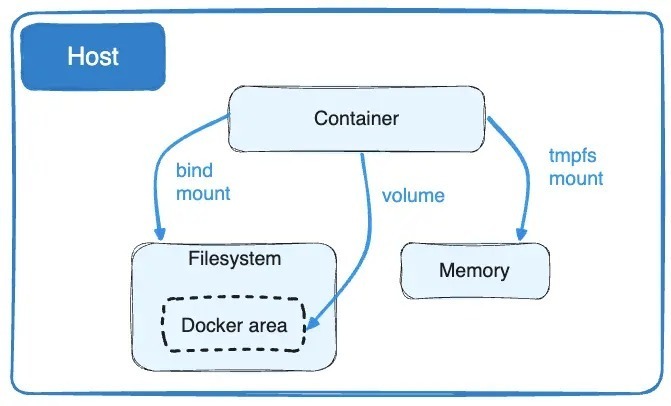 Docker 儲存就像使用容器時決定將資料保存在哪裡一樣。您可以將它們保留在容器內,使用磁碟區在容器之間共用它們,或將它們儲存在容器外部以妥善保管。 **Docker中的檔案系統:** - Docker 使用分層架構來建立映像。 Dockerfile 中的每個指令都會在檔案系統中新增一個新圖層。 ``` # Dockerfile FROM Ubuntu RUN apt-get update && apt-get install -y python RUN pip install flask flask-mysql COPY . /opt/source-code WORKDIR /opt/source-code ENTRYPOINT ["flask", "run"] ``` - Dockerfile 中的層: - 第 1 層:Ubuntu 基礎層 - 第 2 層:apt 軟體包的更改 - 第 3 層:pip 套件的變化 - 第 4 層:原始碼 - 第 5 層:使用「flask」指令更新入口點 - 第 6 層:容器層 **影像圖層:** - 當您建立 Docker 映像時,它由唯讀層組成。每一層代表影像的變化或加入。 - 第 1 層:Ubuntu 基礎層 - 第 2 層:apt 軟體包的更改 - 第 3 層:pip 套件的變化 - 第 4 層:原始碼 - 第 5 層:使用「flask」指令更新入口點 ``` # Build the Docker image docker build -t mmumshad/my-custom-app . ``` **容器層:** - 當您執行 Docker 容器時,會在唯讀映像層上方新增一個讀寫層。該層特定於正在執行的容器。 - 第 6 層. 容器層 ``` # Run the Docker container docker run mmumshad/my-custom-app ``` **數量:** - 卷是一種在容器外部保存資料的方法。它們就像外部記憶體。 ``` # Create a Docker volume docker volume create data_volume # Use the volume in a container docker run -v data_volume:/var/mysql mysql ``` - 您也可以使用「-v」將特定目錄從主機掛載到容器: ``` # Mount a host directory to a container directory docker run -v /path/on/host:/var/mysql/mysql -d mysql ``` - docker run --mount 指令用於將主機上的特定目錄或檔案掛載到正在執行的 Docker 容器中。 ``` docker run --mount type=bind,source=/mysql,target=/var/mysql mysql ``` **儲存驅動程式:** - Docker 使用儲存驅動程式來管理資料的儲存和存取方式。一些常見的儲存驅動程式包括 AUFS、ZFS、BTRFS、Device Mapper、Overlay 和 Overlay2。 [在 Docker 管理資料](https://docs.docker.com/storage/) [關於儲存驅動程式](https://docs.docker.com/storage/storagedriver/) [卷](https://docs.docker.com/storage/volumes/) ## Docker 組合  Docker Compose 是一個方便的工具,可幫助您輕鬆執行和連接不同的軟體服務,就好像它們都是同一事件的一部分一樣。 **Docker Compose 基礎:** 1. **執行單一容器:** - 通常,您可以像這樣執行單獨的 Docker 容器: ``` docker run mmumshad/simple-webapp docker run mongodb docker run redis:alpine docker run ansible ``` 2. **Docker 撰寫文件(`docker-compose.yml`):** - Docker Compose 允許您在一個簡單的檔案中定義所有這些服務: ``` # docker-compose.yml version: '3' services: web: image: 'mmumshad/simple-webapp' database: image: 'mongodb' messaging: image: 'redis:alpine' orchestration: image: 'ansible' ``` - 此檔案描述您要執行的服務(「web」、「database」、「messaging」、「orchestration」)、它們各自的映像以及任何其他配置。 3. **使用 Docker Compose 執行:** - 要一起啟動所有這些服務: ``` docker-compose up ``` - Docker Compose 負責啟動「docker-compose.yml」檔案中定義的所有容器。 4. **使用 Docker Compose 建置:** - 您也可以使用 Docker Compose 建置映像: ``` docker-compose build ``` - 此指令建置「docker-compose.yml」檔案中指定的映像。 **執行連結容器:** - 如果您要透過連結執行單一容器: ``` docker run -d --name redis redis docker run --name voting-app -p 5000:80 --link redis:redis voting-app docker run --name result-app -p 5001:80 --link db:db result-app docker run -d --name worker --link db:db --link redis:redis worker ``` - 在 Docker 中撰寫: ``` # docker-compose.yml version: '3' services: vote: image: 'voting-app' ports: - '5000:80' links: - 'redis:redis' result: image: 'result-app' ports: - '5001:80' links: - 'db:db' worker: image: 'worker' links: - 'db:db' - 'redis:redis' db: image: 'db' redis: image: 'redis' ``` Docker Compose 可讓您在單一檔案中描述整個應用程式堆疊,從而輕鬆管理、執行和連接不同的服務。這就像在一份計劃中寫下活動的所有任務,然後 Docker Compose 為您處理設定。 [Docker Compose 概述](https://docs.docker.com/compose/) [Docker 撰寫文件](https://docs.docker.com/engine/reference/commandline/compose/) ## Docker 註冊表 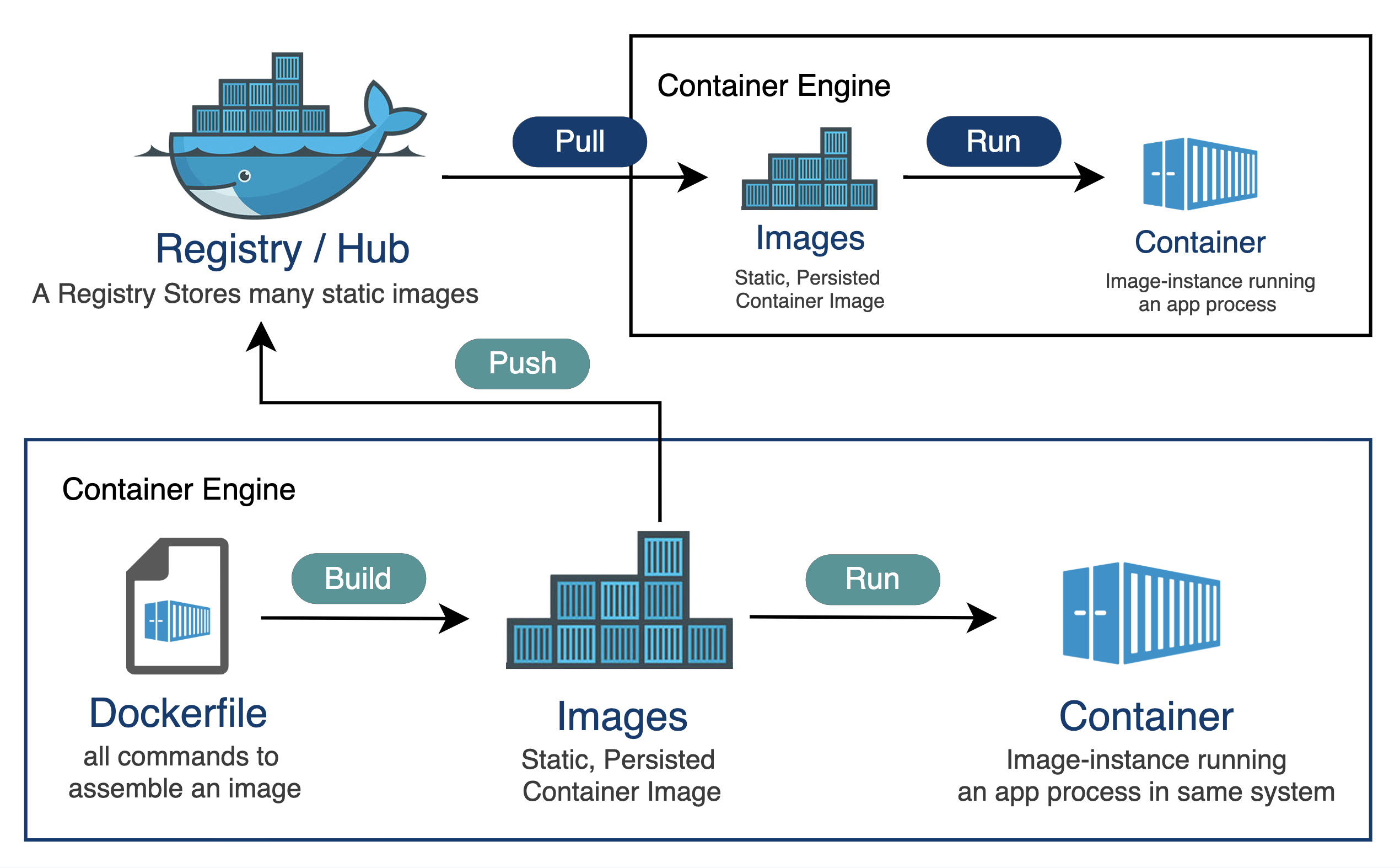 Docker 註冊表是人們儲存和分享 Docker 映像的地方,使其他人可以輕鬆使用和執行他們的軟體。它就像一個大型線上程式庫,可以輕鬆下載並在不同電腦上使用。 **Docker 註冊表基礎知識:** 1. **公共登記處:** - Docker 映像可以在 Docker Hub 等公共註冊表中儲存和共用。 - 例: ``` docker pull nginx ``` 2. **私人登記處:** - 有時,您可能希望將圖像保存在您自己的私人註冊表中。 - 例: - 登入私人註冊表: ``` bash docker login private-registry.io ``` - 從私有註冊表中的映像執行容器: ``` docker run private-registry.io/apps/internal-app ``` 3. **部署您自己的私有註冊表:** - 您可以為您的團隊或公司部署自己的私人註冊表。 - 例: - 在您的電腦上執行私有註冊表: ``` docker run -d -p 5000:5000 --name registry registry:2 ``` - 為私人註冊表標記您的圖像: ``` bash docker image tag my-image localhost:5000/my-image ``` - 將映像推送到您的私人註冊表: ``` bash docker push localhost:5000/my-image ``` - 從您的私人註冊表中提取映像: ``` bash docker pull localhost:5000/my-image ``` 4. **從遠端私有註冊表中提取:** - 您也可以使用 IP 位址或網域從遠端私有註冊表中提取映像。 - 例: ``` docker pull 192.168.56.100:5000/my-image ``` Docker 註冊表就像一個儲存空間,人們在其中保存和共享 Docker 映像。您可以將公用註冊表用於廣泛使用的映像,也可以根據您的特定需求設定自己的私人註冊表。它就像一個用於共享和儲存軟體藍圖(圖像)的特殊庫。 ## Docker 引擎 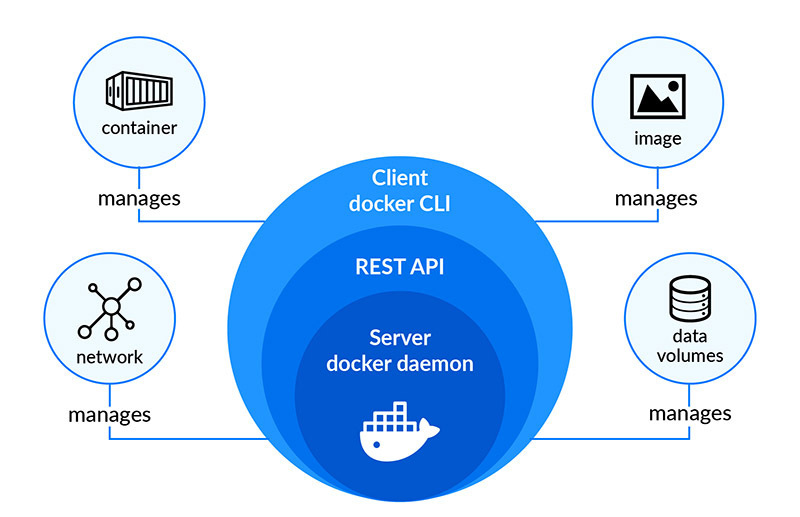 想像一下,你有一個魔盒(Docker Engine),可以為你執行和管理各種程式(容器)。 Docker Engine 就像是這個魔盒的大腦。 1. **Docker 守護程式:** - 守護程式就像魔法盒的看門人。它始終在那裡,隨時準備接受指示並確保一切順利進行。 2. **REST API:** - 將 REST API 視為一組允許您與魔盒對話的規則。它就像你和守護程式用來溝通的語言。你告訴守護程式要做什麼,它會理解,因為你們說的是同一種語言。 3. **Docker CLI(命令列介面):** - Docker CLI 就像是用來命令守護程式的魔杖。您輸入指令,守護程式就會按照您的指示進行操作。這就像說「Abracadabra」就能讓事情發生。 **連線到遠端 Docker 引擎:** 連接到遠端 Docker 引擎可讓您控制另一台機器上的容器,且設定約束可確保容器僅使用指定的資源。 1. **Docker主機IP:** - 您可以使用 IP 位址和連接埠連接到不同電腦上的 Docker 引擎。 - 例: ``` docker -H=remote-docker-engine:2375 run nginx ``` - 這告訴您的本機 Docker CLI 與遠端 Docker 引擎進行通訊。 2. **有約束地執行容器:** - Docker 允許您設定容器的資源限制,例如 CPU 和記憶體限制。 - 例: ``` docker run --cpus=0.5 ubuntu docker run --memory=100m ubuntu ``` - 這些指令限制容器僅使用半個 CPU 核心和 100 MB 記憶體。 當然,讓我們簡化一下PID命名空間的概念: **命名空間PID:** PID 命名空間可讓您為容器中的進程(如程式或任務)建立單獨的區域,因此它們有自己的一組「票號」(進程 ID),不會與容器外的進程發生衝突。 **範例程式碼:** 1. **使用主機 PID 命名空間執行容器:** - 這表示容器與主機共用相同的「票號」。 ``` docker run --pid=host ubuntu ``` 2. **執行具有隔離 PID 命名空間的容器:** - 這表示容器有自己的一組獨立於主機的「票號」。 ``` docker run --pid=container ubuntu ``` 在第一個範例中,容器與進程交互,就好像它與主機位於同一空間中一樣。在第二個範例中,容器有自己的進程隔離空間。這就像在大型活動中擁有一個私人區域,您的團隊有自己的一套票號,讓您可以獨立於活動的其餘部分進行操作。 **容器化概念:** 1. **進程 ID 命名空間:** - 容器有自己獨立的流程 ID (PID) 空間,因此容器內的流程與容器外的流程是分開的。 - 例: ``` docker run --pid=host ubuntu ``` - 此指令使用主機的 PID 命名空間來執行容器,因此它共用相同的程序。 2. **網路命名空間:** - 容器也有自己獨立的網路命名空間,這意味著它們可以有自己的網路配置。 - 例: ``` docker run --net=host nginx ``` - 此指令使用主機的網路命名空間來執行容器。 3. **Unix分時命名空間:** - 此命名空間允許容器擁有自己的時間視圖,與主機和其他容器分開。 - 例: ``` docker run --uts=host ubuntu ``` - 此指令使用主機的 Unix 時間共用命名空間來執行容器。 4. **進程間掛載命名空間:** - Mount命名空間隔離檔案系統,讓容器擁有自己的檔案系統視圖。 - 例: ``` docker run --mount=type=bind,source=/host/folder,target=/container/folder ubuntu ``` - 此指令將主機中的資料夾安裝到容器中。 當然!我們來簡化一下cgroup的概念: **C組:** cgroup(控制組的縮寫)可協助在不同進程或容器之間管理和分配系統資源,例如 CPU 和記憶體。它們確保沒有任何一個進程或容器耗盡所有可用資源,從而保持一切平衡。 **範例程式碼:** 1. **使用 Cgroup 設定 CPU 限制:** - 這就像說聚會上的每位客人只能吃一定數量的食物。 ``` docker run --cpus=0.5 ubuntu ``` - 這限制容器僅使用一半的 CPU 核心。 2. **使用 Cgroup 設定記憶體限制:** - 這就像說每位客人只能在舞池上佔據一定的空間。 ``` docker run --memory=100m ubuntu ``` - 這限制容器僅使用 100 MB 記憶體。 [Docker 引擎概述](https://docs.docker.com/engine/) [使用 Docker Engine API 進行開發](https://docs.docker.com/engine/api/) [執行時指標](https://docs.docker.com/config/containers/runmetrics/#control-groups) ## Linux容器與Windows容器的概念: **Linux 容器(預設):** Linux 容器是一種打包和執行軟體及其所需一切的方法,它們最適合執行 Linux 的電腦。 **Windows 容器:** Windows 容器是一種打包和執行軟體的方式,就像 Linux 容器一樣,但它們設計用於執行 Windows 的電腦。 **Windows 容器基礎:** 1. **集裝箱類型:** - Windows 容器有兩種主要類型:Windows Server Core 和 Nano Server。 - **Windows Server Core:** 將其視為功能更齊全的容器,適合各種應用程式。 - **Nano Server:** 將其視為一個輕量級容器,專為特定的、簡約的用例而設計。 2. **基礎鏡像:** - 基礎映像就像是建立容器時開始使用的空白畫布。 - 例: ``` docker pull mcr.microsoft.com/windows/servercore:ltsc2019 ``` - 此指令擷取 Windows Server Core 基礎映像。 - 例: ``` docker pull mcr.microsoft.com/windows/nanoserver:ltsc2019 ``` - 此命令提取 Nano Server 基礎映像。 3. **支援的環境:** - Windows 容器可以在特定版本的 Windows 作業系統上運作。 - 例: - 您可以在 Windows Server 2016 上執行 Windows 容器。 - 例: - 您可以在 Windows 10 專業版和企業版上執行 Windows 容器,並使用 Hyper-V 隔離容器進行額外隔離。 ## 容器編排 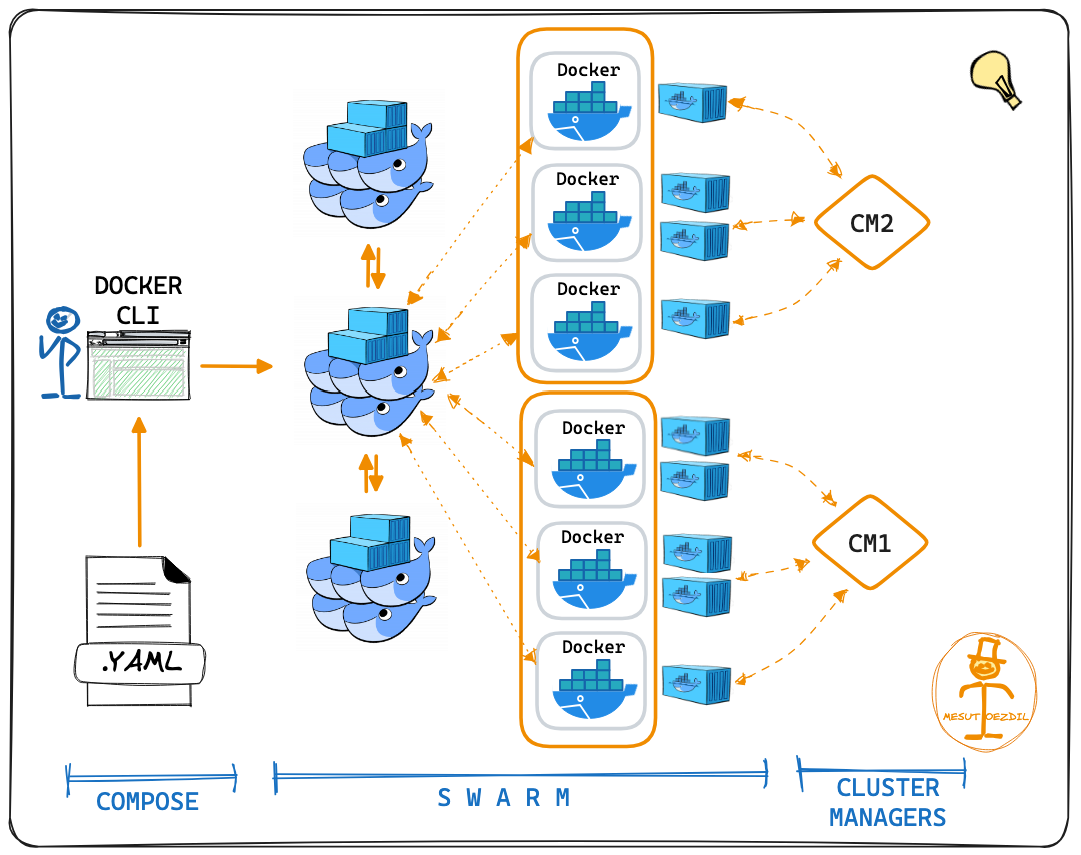 容器編排是一種管理和協調多個容器的方法,確保它們無縫協作來執行應用程式,就像一個超級智能的管理器確保所有機器人一起工作來建置完美的塔一樣。 **為什麼要編曲?** 1. **多項任務,一名經理:** - 想像一下您有許多機器人(容器)執行不同的工作。編排就像有一位超級聰明的經理(編排者),他告訴每個機器人該做什麼,並確保一切順利進行。 2. **一致性:** - 編排確保所有任務每次都以相同的方式完成。這就像為您的機器人提供了一套要遵循的指令,以確保其行為的一致性。 3. **效率:** - 編排有助於優化任務,確保資源(如時間和材料)有效利用。這就像經理確保所有機器人一起工作而不浪費能源。 4. **縮放比例:** - 當您需要完成更多工作時,編排可以輕鬆建立額外的機器人(容器)。這就像當有很多事情需要完成時神奇地召喚更多機器人來提供幫助。 5. **可靠性:** - 編排確保任務可靠地完成,即使機器人(容器)出現故障。這就像製定備份計劃來確保無論如何都能完成工作。 6. **協調:** - 編排協調任務,確保機器人無縫協作。這就像經理確保每個機器人都知道自己的角色並協作以實現總體目標。 **容器編排程式碼:** ``` # Create a Docker service with 100 replicas (instances) of a Node.js application docker service create --replicas 100 --name my-nodejs-app nodejs ``` 在這個例子中: - `docker service create`:該指令告訴 Docker 建立一個服務,該服務是一組正在執行的容器。 - `--replicas 100`:此標誌指定您需要 100 個服務實例(副本)。 - `--name my-nodejs-app`:此標誌為您的服務提供名稱,在本例中為「my-nodejs-app」。 - `nodejs`:這是 Node.js 應用程式的圖片或配方。這就像是烘焙紙杯蛋糕的藍圖。 因此,這段簡單的程式碼就像告訴您神奇的廚師助手 (Docker Swarm) 建立 Node.js 應用程式的 100 個副本,確保您有大量容器正在執行並準備好提供服務。 ## Docker 群  Docker Swarm 是一個工具,可以幫助協調和管理一組電腦(節點)作為一個機器人團隊一起工作,使它們能夠以協調的方式部署和執行多個容器。這就像有一個首席機器人經理,確保所有單一機器人一起建造出偉大而令人驚嘆的東西。 **設定 Docker Swarm:** 1. **群組管理器:** - 想像你有一個首席機器人(Swarm Manager)來領導團隊。主機器人決定需要做什麼,並指導其他機器人(節點)如何協同工作。 ``` # Initiate Docker Swarm on the Swarm Manager docker swarm init ``` 2. **節點工作人員:** - 現在,您的工作機器人(節點工作人員)已準備好加入團隊。 Swarm Manager 共享一個特殊的程式碼(令牌)來邀請他們一起工作。 ``` # Join a Node Worker to the Docker Swarm docker swarm join --token <token> <Swarm Manager IP> ``` **Docker Swarm 服務:** 現在您已經有了一個協調的團隊,您想要建立一項服務,例如與您的機器人團隊一起建造塔: ``` # Create a Docker service (a group of containers) with 3 replicas (instances) docker service create --replicas 3 --network frontend --name my-web-server my-web-image ``` - `--replicas 3`:此標誌告訴 Docker 建立服務的三個實例(副本)。 - `--network frontend`:此標誌指定您的服務屬於名為「frontend」的網路。 - `--name my-web-server`:這會為您的服務命名,在本例中為「my-web-server」。 - `my-web-image`:這是您的網頁伺服器的圖片或藍圖。這就像建造塔樓的配方。 您建立了一個由隊長(Swarm Manager)和工作機器人(Node Workers)組成的機器人團隊。然後,您指示他們建立一個執行您的 Web 伺服器應用程式的服務(容器群組)。主機器人確保建立 Web 伺服器的三個副本並將其連接到「前端」網路。這就像有一個首席機器人經理在工作機器人的幫助下監督多個塔(貨櫃)的建造。  **好的,這就是本文的內容。** 另外,如果您對此或其他任何問題有任何疑問,請隨時在下面的評論中或在 [Instagram](https://www.instagram.com/_abhixsh/) 、[Facebook](https://www.facebook.com/abhi.haththakage/) 或[Twitter](https://twitter.com/abhixsh)。 感謝您閱讀這篇文章,我們下一篇再見! ❤️ --- 原文出處:https://dev.to/abhixsh/docker-for-the-absolute-beginner-3h1p
 JavaScript 以其廣泛的採用和多功能性,已成為現代 Web 開發的基石。隨著您深入研究 JavaScript 開發,理解和利用模式變得至關重要。在本文中,我們將踏上揭開 JavaScript 模式神秘面紗的旅程,並探索它們如何增強您的程式設計實踐。 ## 先決條件 要理解本文中討論的概念和技術,您需要了解 JavaScript 的基礎知識。熟悉變數、函數、資料類型、物件導向程式設計等概念至關重要。 在繼續之前,讓我們花點時間了解 JavaScript 作為程式語言的重要性。 ### JavaScript 作為程式語言 JavaScript 通常被稱為“網路語言”,是一種動態的高階程式語言。它主要用於 Web 瀏覽器中的客戶端腳本編寫,但隨著 Node.js 的出現,它也在伺服器端獲得了關注。 JavaScript 的主要功能包括操作 DOM、處理事件、為網頁提供互動性等的能力。 話雖這麼說,讓我們簡單討論一下 JavaScript 中模式的重要性和用途。 ### JavaScript 開發中模式的重要性 JavaScript 中的模式可以作為軟體開發過程中遇到的重複問題的經過驗證的解決方案。它們提供結構、改進程式碼組織、增強可維護性並促進可重複使用性。透過理解和應用模式,開發人員可以編寫更清晰、更有效率的程式碼並有效應對複雜的挑戰。 ### 理解 JavaScript 模式的目的 理解 JavaScript 模式不僅僅是記住文法或遵循最佳實踐。它使開發人員能夠批判性地思考軟體設計、選擇適當的解決方案並建立可擴展的應用程式。透過掌握 JavaScript 模式,您可以深入了解該語言及其生態系統,從而能夠編寫健全且可維護的程式碼。 現在我們知道了 JavaScript 模式的重要性和用途,讓我們深入研究 JS 設計模式的基礎知識。 ## 設計模式的基礎知識 在本節中,我們為理解 JavaScript 開發背景下的設計模式奠定了基礎。 ###設計模式的定義與特點 設計模式是可重複使用的模板,封裝了解決重複出現的軟體設計問題的最佳實踐。它們提供了一種結構化的方法來設計軟體系統,並促進模組化、靈活和可維護的程式碼。設計模式的共同特徵包括其目的、結構、參與者和協作。 ###設計模式的類型 設計模式可分為三種主要類型: - 創意 - 結構性 - 行為的 了解這些類別有助於確定給定問題的適當模式。 - **創作模式** 建立模式專注於物件建立機制,提供以靈活且受控的方式實例化物件的方法。 JavaScript 中一些常用的建立模式包括: - 辛格頓 - 工廠 - 建構函數 - 原型 - 建造者 - 模組 **單例模式** 單例模式確保一個類別只有一個實例,並提供對其的全域存取點。當您想要限制類別的實例數量並確保在整個應用程式中可以存取單一共用實例時,此模式非常有用。 ``` // Implementation example of the Singleton Pattern class Singleton { constructor() { if (!Singleton.instance) { // Initialize the instance Singleton.instance = this; } return Singleton.instance; } } const instance1 = new Singleton(); const instance2 = new Singleton(); console.log(instance1 === instance2); // Output: true ``` 在此範例中,Singleton 類別有一個建構函數,用於檢查該類別的實例是否已存在。如果實例不存在(“!Singleton.instance”條件),它將透過將其指派給「Singleton.instance」來初始化該實例。這確保了對建構函數的後續呼叫將傳回相同的實例。 當使用新的 Singleton() 語法建立實例 1 和實例 2 時,這兩個變數都會引用 Singleton 類別的同一個實例。因此,當使用嚴格相等運算子比較實例 1 === 實例 2 時,其計算結果為 true。 **工廠模式** 工廠模式提供了一種建立物件而無需指定其特定類別的方法。它將物件建立邏輯封裝在一個單獨的工廠方法中,允許建立者和建立的物件之間的靈活性和解耦。 ``` // Implementation example of the Factory Pattern class Car { constructor(make, model) { this.make = make; this.model = model; } } class CarFactory { createCar(make, model) { return new Car(make, model); } } const factory = new CarFactory(); const myCar = factory.createCar("Tope", "Model 1"); ``` 在此範例中,使用 new CarFactory() 建立了一個 CarFactory 實例,然後使用參數「Tope」和「Model 1」在工廠上呼叫「createCar」方法。這將建立一個新的 Car 物件,其品牌為“Tope”,型號為“Model 1”,並分配給 `myCar` 變數。 **建構函式模式** 建構函式模式使用“new”關鍵字從建構函式建立物件。它允許您在建構函數中定義和初始化物件屬性。 ``` // Implementation example of the Constructor Pattern function Person(name, age) { this.name = name; this.age = age; } const tope = new Person("Tope", 24); ``` 上面的程式碼定義了一個名為 Person 的建構函數,它帶有兩個參數:姓名和年齡。在函數內部,使用 this 關鍵字將名稱和年齡值指派給新建立的物件的對應屬性。 稍後,透過使用參數“Tope”和 24 呼叫 Person 函數來建立 Person 物件的新實例。這將建立一個新物件,其 name 屬性設為“Tope”,age 屬性設為 24,然後指派給變數top。這段程式碼的輸出是 Tope 持有一個物件,代表一個名為「Tope」、年齡為 24 歲的人。 **原型模式** JavaScript 中的原型模式專注於透過複製或擴展現有物件作為原型來建立物件。它允許我們建立新實例而無需明確定義它們的類別。在此模式中,物件充當建立新物件的原型,從而實現繼承以及在多個物件之間共享屬性和方法。 ``` // Prototype object const carPrototype = { wheels: 4, startEngine() { console.log("Engine started."); }, stopEngine() { console.log("Engine stopped."); } }; // Create new car instance using the prototype const car1 = Object.create(carPrototype); car1.make = "Toyota"; car1.model = "Camry"; // Create another car instance using the same prototype const car2 = Object.create(carPrototype); car2.make = "Honda"; car2.model = "Accord"; car1.startEngine(); // Output: "Engine started." car2.stopEngine(); // Output: "Engine stopped." ``` 在此範例中,汽車實例 car1 和 car2 是使用原型物件 carPrototype 建立的。 car1 的品牌為“Toyota”,型號為“Camry”,而 car2 的品牌為“Honda”,型號為“Accord”。當呼叫 `car1.startEngine()` 時,輸出“Engine started.”,當呼叫 `car2.stopEngine()` 時,輸出“Engine waiting.”。這示範如何利用原型物件在多個實例之間共用屬性和方法。 **建造者模式** 在建構器模式中,建構器類別或物件負責建構最終物件。它提供了一組方法來配置和設定正在建置的物件的屬性。建置過程通常涉及按特定順序呼叫這些方法來逐步建立物件。 ``` class CarBuilder { constructor() { this.car = new Car(); } setMake(make) { this.car.make = make; return this; } setModel(model) { this.car.model = model; return this; } setEngine(engine) { this.car.engine = engine; return this; } setWheels(wheels) { this.car.wheels = wheels; return this; } build() { return this.car; } } class Car { constructor() { this.make = ""; this.model = ""; this.engine = ""; this.wheels = 0; } displayInfo() { console.log(`Make: ${this.make}, Model: ${this.model}, Engine: ${this.engine}, Wheels: ${this.wheels}`); } } // Usage const carBuilder = new CarBuilder(); const car = carBuilder.setMake("Toyota").setModel("Camry").setEngine("V6").setWheels(4).build(); car.displayInfo(); // Output: Make: Toyota, Model: Camry, Engine: V6, Wheels: 4 ``` 在此範例中,「CarBuilder」類別允許建構具有不同屬性的 Car 物件。透過呼叫`setMake`、`setModel`、`setEngine`、`setWheels`方法,設定Car物件的屬性。 build 方法完成建置並傳回完全建置的 Car 物件。 Car 類別代表一輛汽車,並包含一個「displayInfo」方法來記錄其詳細資訊。透過建立「carBuilder」實例並連結屬性設定方法,可以使用特定的品牌、型號、引擎和車輪值來建構汽車物件。呼叫“car.displayInfo()”顯示汽車的資訊。 **模組模式** 模組模式將相關的方法和屬性封裝到單一模組中,提供了一種乾淨的方式來組織和保護程式碼。它允許私有和公共成員,從而實現資訊隱藏並防止全域名稱空間污染。 ``` const MyModule = (function() { // Private members let privateVariable = "I am private"; function privateMethod() { console.log("This is a private method"); } // Public members return { publicVariable: "I am public", publicMethod() { console.log("This is a public method"); // Accessing private members within the module console.log(privateVariable); privateMethod(); } }; })(); // Usage console.log(MyModule.publicVariable); // Output: "I am public" MyModule.publicMethod(); // Output: "This is a public method" "I am private" "This is a private method" ``` 在此範例中,程式碼使用立即呼叫的函數表達式來封裝私人和公共成員。該模組具有私有變數和方法,以及公共變數和方法。存取時,公共成員提供預期的輸出。此模式允許對封裝的私有成員進行受控存取,同時公開選定的公共成員。 - **結構模式** 結構模式著重於組織和組合物件以形成更大的結構。它們促進物件的組合,定義物件之間的關係並提供靈活的方法來操縱其結構。 JavaScript 中一些常用的結構模式包括: - 裝飾模式 - 立面圖案 - 適配器 - 橋 - 合成的 **裝飾器模式** 裝飾器模式可讓您動態新增行為或修改物件的現有行為。它透過用一個或多個裝飾器包裝物件來增強物件的功能,而無需修改其結構。 ``` // Implementation example of the Decorator Pattern class Coffee { getCost() { return 1; } } class CoffeeDecorator { constructor(coffee) { this.coffee = coffee; } getCost() { return this.coffee.getCost() + 0.5; } } const myCoffee = new Coffee(); const coffeeWithMilk = new CoffeeDecorator(myCoffee); console.log(coffeeWithMilk.getCost()); // Output: 1.5 ``` 在此範例中,「CoffeeDecorator」類別包裝了基本「Coffee」物件並新增了附加功能。它有一個「getCost」方法,透過將基礎咖啡的成本與 0.5 的附加成本相結合來計算總成本。 在使用部分,建立了「Coffee」類別的「myCoffee」實例。然後,實例化「CoffeeDecorator」類別的「coffeeWithMilk」實例,並將「myCoffee」作為參數傳遞。當呼叫“coffeeWithMilk.getCost()”時,它會返回咖啡的總成本以及裝飾器加入的成本,從而得到 1.5 的輸出。此範例說明了裝飾器模式如何透過動態新增或修改物件的屬性或方法來擴展物件的功能。 **立面圖案** 外觀模式為複雜子系統提供了一個簡化的接口,充當隱藏底層實現細節的前端接口。它透過提供高級接口,提供了一種與複雜系統互動的便捷方式。 ``` // Implementation example of the Facade Pattern class SubsystemA { operationA() { console.log("Subsystem A operation."); } } class SubsystemB { operationB() { console.log("Subsystem B operation."); } } class Facade { constructor() { this.subsystemA = new SubsystemA(); this.subsystemB = new SubsystemB(); } operation() { this.subsystemA.operationA(); this.subsystemB.operationB(); } } const facade = new Facade(); facade.operation(); // Output: "Subsystem A operation." "Subsystem B operation." ``` 在此範例中,程式碼由三個類別組成:「SubsystemA」、「SubsystemB」和「Facade」。 `SubsystemA` 和 `SubsystemB` 類別代表獨立的子系統,並具有各自的 `operationA` 和 `operationB` 方法。 「Facade」類別作為一個簡化的接口,聚合了子系統的功能。 在使用部分,建立了“Facade”類別的“facade”實例。呼叫「facade.operation()」會觸發「SubsystemA」中的「operationA」和「SubsystemB」中的「operationB」的執行。結果,輸出顯示“子系統 A 操作”。接下來是「子系統 B 操作」。這展示了外觀模式如何提供統一且簡化的介面來與複雜的子系統交互,抽像出它們的複雜性並使它們更易於使用。 **適配器模式** 適配器模式是一種結構設計模式,它允許具有不相容介面的物件透過充當它們之間的橋樑來進行協作。它提供了一種將一個物件的介面轉換為客戶期望的另一個介面的方法。 ``` // Implementation class LegacyPrinter { printLegacy(text) { console.log(`Legacy Printing: ${text}`); } } // Target interface class Printer { print(text) {} } // Adapter class PrinterAdapter extends Printer { constructor() { super(); this.legacyPrinter = new LegacyPrinter(); } print(text) { this.legacyPrinter.printLegacy(text); } } // Usage const printer = new PrinterAdapter(); printer.print("Hello, World!"); // Output: "Legacy Printing: Hello, World!" ``` 在此程式碼中,適配器模式用於彌合「LegacyPrinter」類別和所需的「Printer」介面之間的差距。 `PrinterAdapter` 擴展了 `Printer` 類,並在內部利用 `LegacyPrinter` 來適配 `print` 方法。當呼叫 printer.print("Hello, World!")` 時,它會有效地觸發舊版列印功能,並輸出「Legacy Printing: Hello, World!」。這展示了適配器模式如何透過提供標準化介面來整合不相容的元件。 **橋樑圖案** 橋接模式是一種結構設計模式,它將系統的抽象和實現分開,允許系統獨立發展。它透過使用介面或抽象類別在兩者之間引入了橋樑。下面是一個範例程式碼片段來說明橋接模式: ``` // Example class Shape { constructor(color) { this.color = color; } draw() {} } // Concrete Abstractions class Circle extends Shape { draw() { console.log(`Drawing a ${this.color} circle`); } } class Square extends Shape { draw() { console.log(`Drawing a ${this.color} square`); } } // Implementor class Color { getColor() {} } // Concrete Implementors class RedColor extends Color { getColor() { return "red"; } } class BlueColor extends Color { getColor() { return "blue"; } } // Usage const redCircle = new Circle(new RedColor()); redCircle.draw(); // Output: "Drawing a red circle" const blueSquare = new Square(new BlueColor()); blueSquare.draw(); // Output: "Drawing a blue square" ``` 在此範例中,我們有由 Shape 類別表示的抽象,它具有顏色屬性和繪製方法。具體抽象(圓形和方形)繼承自 Shape 類別並實現其特定的繪製行為。 「Implementor」由 Color 類別表示,該類別聲明了「getColor」方法。具體的「Implementors」、「RedColor」和「BlueColor」繼承自 Color 類別並提供各自的顏色實作。 在使用部分,我們建立具體抽象的實例,傳遞適當的具體實現者物件。這允許抽象化將與顏色相關的功能委託給實現者。當我們呼叫draw方法時,它會從Implementor存取顏色並相應地執行繪圖操作。 **複合模式** 組合模式是一種結構設計模式,可讓您統一處理單一物件和物件組合。它使您能夠建立層次結構,其中每個元素都可以被視為單個物件或物件集合。此模式使用通用介面來表示單一物件(葉節點)和組合(複合節點),允許客戶端與它們統一互動。 ``` // Implementation class Employee { constructor(name) { this.name = name; } print() { console.log(`Employee: ${this.name}`); } } // Composite class Manager extends Employee { constructor(name) { super(name); this.employees = []; } add(employee) { this.employees.push(employee); } remove(employee) { const index = this.employees.indexOf(employee); if (index !== -1) { this.employees.splice(index, 1); } } print() { console.log(`Manager: ${this.name}`); for (const employee of this.employees) { employee.print(); } } } // Usage const john = new Employee("John Doe"); const jane = new Employee("Jane Smith"); const mary = new Manager("Mary Johnson"); mary.add(john); mary.add(jane); const peter = new Employee("Peter Brown"); const bob = new Manager("Bob Williams"); bob.add(peter); bob.add(mary); bob.print(); ``` 在此範例中,我們有 Component 類別 Employee,它代表個別員工。 Composite 類 Manager 擴展了 Employee 類,並且可以包含員工的集合。它提供了在集合中新增和刪除員工的方法,並重寫 print 方法以顯示經理的姓名及其下的員工。 在使用部分,我們建立一個複合層次結構,其中 Manager 物件可以包含單一員工 (Employee) 和其他經理 (Manager)。我們將員工加入經理中,建構了一個層次結構。最後,我們呼叫頂級經理的 print 方法,該方法遞歸地列印層次結構,顯示經理及其各自的員工。 - **行為模式** 行為模式關注物件之間的互動和職責分配。它們為物件之間的通訊、協調和協作提供解決方案。以下是行為模式的類型。 - 觀察者模式 - 策略模式 - 命令模式 - 迭代器模式 - 調解者模式 **觀察者模式** 觀察者模式在物件之間建立一對多關係,其中多個觀察者會收到主體狀態變化的通知。它支援物件之間的鬆散耦合並促進事件驅動的通訊。 ``` // Implementation example of the Observer Pattern class Subject { constructor() { this.observers = []; } addObserver(observer) { this.observers.push(observer); } removeObserver(observer) { const index = this.observers.indexOf(observer); if (index !== -1) { this.observers.splice(index, 1); } } notifyObservers() { this.observers.forEach((observer) => observer.update()); } } class Observer { update() { console.log("Observer is notified of changes."); } } const subject = new Subject(); const observer1 = new Observer(); const observer2 = new Observer(); subject.addObserver(observer1); subject.addObserver(observer2); subject.notifyObservers(); // Output: "Observer is notified of changes." "Observer is notified of changes." ``` 在此範例中,「Subject」類別表示一個主題,它維護觀察者清單並提供新增、刪除和通知觀察者的方法。 「Observer」類別透過其「update」方法定義觀察者的行為。在使用部分,建立了「Subject」類別的「subject」實例。也使用“addObserver”方法建立兩個“observer”實例並將其新增至主題。 當呼叫“subject.notifyObservers()”時,它會觸發每個觀察者的“update”方法。結果,輸出「觀察者收到更改通知」。被記錄兩次,顯示觀察者已被告知主題的變化。 **策略模式** 策略模式可讓您將可互換的演算法封裝在單獨的策略物件中。它支援在執行時動態選擇演算法,從而提高靈活性和可擴展性。 ``` // Implementation example of the Strategy Pattern class Context { constructor(strategy) { this.strategy = strategy; } executeStrategy() { this.strategy.execute(); } } class ConcreteStrategyA { execute() { console.log("Strategy A is executed."); } } class ConcreteStrategyB { execute() { console.log("Strategy B is executed."); } } const contextA = new Context(new ConcreteStrategyA()); contextA.executeStrategy(); // Output: "Strategy A is executed." const contextB = new Context(new ConcreteStrategyB()); contextB.executeStrategy(); // Output: "Strategy B is executed." ``` 在此範例中,「Context」類別表示封裝不同策略的上下文,具有「strategy」屬性和「executeStrategy」方法。有兩個特定策略類,“ConcreteStrategyA”和“ConcreteStrategyB”,每個類別都有自己的“execute”方法來輸出特定訊息。 在使用部分,使用“ConcreteStrategyA”作為策略來建立“Context”類別的“contextA”實例。呼叫 `contextA.executeStrategy()` 會呼叫 `ConcreteStrategyA` 的 `execute` 方法,導致輸出「策略 A 已執行」。類似地,以「ConcreteStrategyB」為策略建立「contextB」實例,呼叫「contextB.executeStrategy()」會觸發「ConcreteStrategyB」的「execute」方法,從而輸出「策略 B 已執行」。這演示了策略模式如何透過將行為封裝在不同的策略物件中來允許在執行時動態選擇行為。 **命令模式** 命令模式將請求封裝為物件,允許您使用不同的請求對客戶端進行參數化、對請求進行排隊或記錄請求,並支援撤銷操作。它將請求的發送者與接收者解耦,從而促進鬆散耦合和靈活性。 ``` // Implementation class Receiver { execute() { console.log("Receiver executes the command."); } } class Command { constructor(receiver) { this.receiver = receiver; } execute() { this.receiver.execute(); } } class Invoker { setCommand(command) { this.command = command; } executeCommand() { this.command.execute(); } } const receiver = new Receiver(); const command = new Command(receiver); const invoker = new Invoker(); invoker.setCommand(command); invoker.executeCommand(); // Output: "Receiver executes the command." ``` 在此範例中,「Receiver」類別在呼叫時執行命令,「Command」類別封裝命令並將執行委託給接收者。 `Invoker` 類別設定並執行命令。在使用部分,建立了接收者、命令和呼叫者。此指令是為呼叫者設定的,呼叫「invoker.executeCommand()」會執行該指令,從而產生輸出「接收者執行該指令」。 **迭代器模式** 迭代器模式是一種行為設計模式,它提供了一種順序存取聚合物件的元素而不暴露其底層表示的方法。它允許您以統一的方式遍歷物件集合,而不管集合的具體實現如何。該模式將遍歷邏輯與集合分開,從而促進了一種乾淨而靈活的方法來迭代元素。 ``` // Implementation class Collection { constructor() { this.items = []; } addItem(item) { this.items.push(item); } createIterator() {} } // Concrete Aggregate class ConcreteCollection extends Collection { createIterator() { return new ConcreteIterator(this); } } // Iterator class Iterator { constructor(collection) { this.collection = collection; this.index = 0; } hasNext() {} next() {} } // Concrete Iterator class ConcreteIterator extends Iterator { hasNext() { return this.index < this.collection.items.length; } next() { return this.collection.items[this.index++]; } } // Usage const collection = new ConcreteCollection(); collection.addItem("Item 1"); collection.addItem("Item 2"); collection.addItem("Item 3"); const iterator = collection.createIterator(); while (iterator.hasNext()) { console.log(iterator.next()); } ``` 在此程式碼中,我們有由 Collection 類別表示的 Aggregate,它定義了用於建立迭代器物件的介面。具體聚合「ConcreteCollection」擴展了 Collection 類別並提供了迭代器建立的具體實作。 Iterator 由 Iterator 類別表示,它定義了存取和遍歷元素的介面。具體迭代器“ConcreteIterator”擴展了迭代器類別並提供了迭代邏輯的具體實作。在使用部分,我們建立一個 Concrete Aggregate 的實例“ConcreteCollection”,並向其中新增專案。然後我們使用 createIterator 方法建立一個迭代器。透過使用迭代器的“hasNext”和 next 方法,我們迭代集合併列印每個專案。 **調解者模式** 中介者模式透過引入充當協調物件之間互動的中心樞紐的中介者物件來簡化物件溝通。它封裝了通訊邏輯,並為物件提供了註冊、發送和接收訊息的方法。 ``` // Implementation class Mediator { constructor() { this.colleague1 = null; this.colleague2 = null; } setColleague1(colleague) { this.colleague1 = colleague; } setColleague2(colleague) { this.colleague2 = colleague; } notifyColleague1(message) { this.colleague1.receive(message); } notifyColleague2(message) { this.colleague2.receive(message); } } class Colleague { constructor(mediator) { this.mediator = mediator; } send(message) { // Send a message to the mediator this.mediator.notifyColleague2(message); } receive(message) { console.log(`Received message: ${message}`); } } // Usage const mediator = new Mediator(); const colleague1 = new Colleague(mediator); const colleague2 = new Colleague(mediator); mediator.setColleague1(colleague1); mediator.setColleague2(colleague2); colleague1.send("Hello Colleague 2!"); // Output: "Received message: Hello Colleague 2!" ``` 在此範例中,我們有一個 Mediator 類,它充當兩個 Colleague 物件之間的中介。中介者保存對同事的引用並提供在他們之間發送訊息的方法。 每個Colleague物件都有一個對中介者的引用,並且可以透過通知中介者來發送訊息。調解員又將訊息轉發給適當的同事。在這種情況下,同事 1 會向同事 2 發送訊息,後者接收並記錄該訊息。 ### 結論 我們探索了 JavaScript 中的一系列基本設計模式,包括建立模式、結構模式和行為模式。建立模式使我們能夠以靈活且高效的方式建立物件。結構模式有助於器官的靈活性和可擴展性。行為模式支援 JavaScript 物件之間的有效溝通和互動。透過利用這些設計模式,JavaScript 開發人員可以提高程式碼的可重複使用性、可維護性和整體系統效能。有了這些知識,我們就可以建立健壯且高效的 JavaScript 應用程式,以滿足現代軟體開發的需求。 --- 原文出處:https://dev.to/topefasasi/js-design-patterns-a-comprehensive-guide-h3m
我不是第一個這麼說的人,但我還是要說,2023 年對 JavaScript 框架來說是個不平凡的一年。我們一直在關注的新技術最終顯示出它們可以交付,而舊框架正在復興,如果您不注意,您可能會錯過一個相當重大的轉變。 我預計 2024 年將繼續出現更大的全面變化。這次不是新技術,而是精細化。既然基礎已經存在,那麼還有很多事情要做。 -------------------- ## 伺服器優先 如果讓我為過去幾年選擇一個主題,那就是這個。這一直是爭論的焦點,但不可否認。幾年前,每個人都在談論漸進式 Web 應用程式和離線應用程式。但那個對話框幾乎消失了。 相反,我們會受到 HTMX 的敏銳智慧的影響,解釋為什麼 JavaScript 只是一個錯誤。 Astro 毫無歉意地接管了內容網站的開發。甚至 React Core 團隊也接受了 React Server Components 的伺服器簡單性,Dan Abramov 的演講令人信服地表達了這一點,該演講探討瞭如果 React 始終是伺服器優先會怎樣。 https://www.youtube.com/watch?v=zMf_xeGPn6s 那麼我們的單頁應用程式親愛的在這麼短的時間內發生了什麼?它是否仍然存在,還是我們生活在多頁面應用程式和僅伺服器渲染 HTML 的時代? ------------------ ## 回顧 2023 年 去年,我寫了一篇非常類似的文章,探討了新的一年 JavaScript 框架的趨勢,我認為這是一個很好的起點。 https://dev.to/this-is-learning/javascript-frameworks-heading-into-2023-nln 該文章中確定的三大技術趨勢成為去年討論的重要組成部分。 ### 訊號無所不在 從 2022 年底開始,Preact 和 Qwik 緊跟著 SolidJS 和 Vue 的腳步,採用這些 Reactive 原語,這種勢頭只會持續到 2023 年。 二月份,Angular 團隊宣布採用。這一訊息震驚了社群媒體。不僅。這是 Angular 的存在發生非常顯著變化的幾個因素之一。有人甚至稱之為「角度復興」。這是過去幾年我們第一次看到 React 團隊加入這場爭論,因為真正被問到的問題是「訊號什麼時候出現在 React 中?」。 我在下面的文章中寫了這個問題的更長的答案(以及在評論中與丹·阿布拉莫夫的討論)。 https://dev.to/this-is-learning/react-vs-signals-10-years-later-3k71 但簡短的回答是,訊號(至少作為 API)並不是他們感興趣的東西,而他們備受期待的「忘記」編譯器將扮演類似的角色。 但訊號傳播並沒有就此結束。 Lit 是 Google 的 Web 元件框架,推出了[Lit 3,具有第一方訊號支援](https://lit.dev/blog/2023-10-10-lit-3.0/#preact-signals-integration)。 Rich Harris 公佈了 Svelte 的未來,[他們新的基於訊號的「Runes」](https://svelte.dev/blog/runes),將成為即將推出的 Svelte 5 中反應性的主要來源。 2023 年結束訊號是大多數前端 JavaScript 框架的主要部分。 ### 混合路由  去年,基於伺服器的路由得到了加強並發揮了新的作用。從 2022 年底開始,到今年,我們看到人們已經習慣了這種範式轉變,例如 React Server Components 和 Astro 的 View Transition API 整合。 前提是初始頁面載入後的伺服器渲染不應阻止客戶端導航,且客戶端導航不應意味著我們需要發送所有 JavaScript 來渲染可以靜態伺服器渲染的頁面部分。 值得注意的是,並非所有解決方案都是等效的,而且這個領域仍在建設中。我們正在進入一個新的空間,它不完全是單頁應用程式,也不完全是傳統的多頁面網站。需要進行新的權衡和新的理解。我們還沒有完成對陷阱的探索。 ### 邊緣網路:最後的前沿  邊緣功能似乎是那些明顯的勝利之一。將伺服器移至更靠近最終用戶的位置,可以大幅減少延遲。使用更輕的執行時間可以大幅減少冷啟動時間。我們終於可以提供我們一直夢想的網路體驗。以靜態的速度實現動態。 好吧,如果有什麼不同的話,2023 年是成長的陣痛和邊緣的一年。我們開始非常熱情。畢竟,Cloudflare 發布了邊緣資料庫,我們最喜歡的所有提供者都開始提供邊緣功能,而我們最喜歡的框架正在加入開箱即用的支援。提供者成立了一個 WinterCG 委員會來討論平台標準化問題。未來就在這裡。 我們最終認識到,即使在這些邊緣功能中,某些 Node API 也是必不可少的。您可以感謝或討厭 Next 和 Vercel 將“AsyncLocalStorage”推送到每個執行時,但我們需要它。 我們也意識到邊緣資料庫永遠無法滿足所有應用程式。即使使用串流媒體,伺服器瀑布也是真實且有影響力的。是的,即使使用 React Server 元件也是如此。 但這確實實現了我去年提出的目標,透過分散式部署進行整體創作。我們看到伺服器函數(`server$`、`use server`),甚至像 Worker Functions 這樣的變體在今年年初出現,表明我們可以分發我們部署 API 的方式,並被 Solid、Qwik 和 Next 採用。 到年底 [Next 14 發布了新的實驗性部分預渲染](https://nextjs.org/blog/next-14),它允許單一請求從邊緣提供靜態內容,同時代理到伺服器-less 靠近資料庫的函數全部被串流傳輸,以提供類似Edge 的體驗,而無需在那裡部署整個應用程式。看到一些獨創性提供了兩全其美的解決方案真是太棒了。 ---------------- ## 展望 2024 年 ### 訊號年 我知道我已經在一篇文章中充分討論了信號,但真正的回報還沒有發生。我們在 JavaScript 中使用細粒度的類似 Signal 的原語已有 15 年了,那麼為什麼現在呢? 這不僅僅是關於擁有它們,而是關於你如何使用它們。 Vue 多年來一直在隱藏這些原語,React 和 MobX 也是如此,但這幾乎沒有觸及事情的發展方向。那就是細粒度渲染。 SolidJS 所普及的內容,現在以 Vue Vapor 的形式進入 Vue,以及 Svelte 5 中的 Svelte。這些只是已經宣布的內容。 我希望其他採用訊號的人能夠更自然地將它們融入框架中,以便更好地從中受益。 這個領域的潛力令人興奮,致力於將 Signals 引入瀏覽器的 TC-39 提案的小組包括來自每個主要 JavaScript 框架的代表,而這個小組並不總是與標準密切相關。 ### 基礎設施主導的發展 既然伺服器端渲染框架已經打了一針強心劑,那麼下一個合乎邏輯的地方就是繼續考慮最大限度地利用這項新功能為我們提供的功能。標準的製定很慢,WinterCG 也需要一些時間,但這不會阻止這裡的發展。 為了實現差異化,我預期框架和基礎設施供應商都會面臨壓力,要求他們提供只能在特定平台上運作的獨特功能。雖然 2023 年各個提供者都在推動平等,以提供超出其基本靜態和功能託管的類似功能(例如鍵值存儲 Blob),但我只看到這裡提供獨特價值的競爭正在升溫。 框架在這方面的作用是保持一致的創作體驗和思考模型,同時找到利用呈現給我們的新能力的方法。這與 2000 年代末的瀏覽器戰爭沒有什麼不同,而且未來還會有很多事情發生。 ### 人工智慧  去年從框架的角度談論人工智慧還為時過早。明年也可能如此。但它就在眼前。程式碼遷移和生成工具都是很棒的想法,但它們遇到了我們多年來使用視覺化無程式碼或低程式碼編輯器所遇到的相同問題。人機界麵點仍然至關重要。畢竟,程式碼是有生命的東西。它會隨著時間的推移而增長和維持。 在過去的一年裡,與其他框架作者交談時,我們發現它吸引了我們周圍的人,但還沒有達到明確我們在其中的角色的程度。但這種情況正在改變。 是的,人工智慧正在回答一個永恆的問題:為什麼你的應用程式速度很慢。 對開發人員工具的影響是一回事。但我們也看到我們的框架中內建即時性的潛力越來越大。我也不僅僅指用於持久後端的 Websockets。元框架中的 API 已經從簡單的 JSON 發展到使用 SolidStart、Qwik 和 Next 中的「伺服器功能」完全流式跨網路 JavaScript 執行。不難想像生成技術即時建立使用者介面。 -------------------------- ## 結論  2024 年可能會繼續我們過去幾年看到的成熟趨勢。從 2020-22 年,我們看到了許多新的 JavaScript(和 WASM)框架(Qwik、Million.js、Astro、Next 13、Remix、Hydrogen、SvelteKit、SolidStart、Leptos、Dioxus、HTMX),但這還不是去年的案例。我們已經找到了方法,現在我們需要充分發揮它們的潛力。 我不確定我們是否已經成功地解決了複雜性,這對像 Astro 或 HTMX 這樣的簡化解決方案給予了大力支持。但我仍然充滿希望。 期望每個人都就「單頁應用程式」到底是什麼或何時應該使用擺在我們面前的各種選項達成一致可能有點太過分了,但這些解決方案每天都在變得更有能力實現他們設定的目標出去做。 我們所知道的網頁開發是否會改變已經不再是一個問題。即使方向還不完全明確,革命已經來臨。期望在那裡見到你。 --- 原文出處:https://dev.to/this-is-learning/javascript-frameworks-heading-into-2024-i3l
在学习 JavaScript中,变量、函数、类、循环、异步这些都是基础知识。这些基础知识是我们使用 JavaScript 的基础。但是,在日常的业务开发中,我们需要一些更高级的技巧来更好地解决问题。 > 通过本文你将了解到 JS 的高级知识点以及实际应用技巧,如高级数据结构和算法、函数式编程、异步编程和面向对象编程。我们会利用代码实例来让大家更好地理解这些知识点。同时,我们也会提供一些实战案例的示范和使用技巧,让你更好地将这些技术应用到实际业务中。 ## 高级数据结构和算法 ### Map 和 Set 数据结构 在 JavaScript 中,Map 数据结构通常用于存储键值对,它可以使用任意类型作为键和值。Set 数据结构用于存储唯一值的集合。 ```js // 创建Map对象 const map = new Map(); // 设置键值对 map.set("name", "Tom"); map.set("age", 20); // 获取键值对 console.log(map.get("name")); // 'Tom' console.log(map.get("age")); // 20 // 创建Set对象 const set = new Set(); // 添加元素 set.add(10); set.add(20); set.add(30); // 删除元素 set.delete(20); // 判断元素是否存在 console.log(set.has(10)); // true console.log(set.has(20)); // false ``` ### 堆、栈和队列 堆和栈是常用的内存分配方式。栈是一种后进先出的数据结构,堆是一种动态分配的内存结构。队列是一种先进先出的数据结构,它通常用于缓存和并发编程中。 ```js // 使用数组模拟堆 const arr = [1, 2, 3, 4]; arr.push(5); // 入堆 console.log(arr.pop()); // 出堆 // 使用数组模拟栈 const stack = [1, 2, 3, 4]; stack.push(5); // 入栈 console.log(stack.pop()); // 出栈 // 使用数组模拟队列 const queue = [1, 2, 3, 4]; queue.push(5); // 入队 console.log(queue.shift()); // 出队 ``` ### 深度优先搜索和广度优先搜索 深度优先搜索(DFS)和广度优先搜索(BFS)是常用的遍历算法。DFS 通常用于解决深度问题,BFS 适用于宽度问题。 ```js // 深度优先遍历 function dfs(node) { if (node == null) return; console.log(node.value); dfs(node.left); dfs(node.right); } // 广度优先遍历 function bfs(node) { const queue = [node]; while (queue.length) { const curr = queue.shift(); console.log(curr.value); if (curr.left) queue.push(curr.left); if (curr.right) queue.push(curr.right); } } ``` ### 常用算法 常用的算法有排序、搜索、查找等。 ```js // 排序算法:快速排序使用分治思想,通过把数组分成较小的块来排序。 function quickSort(arr) { if (arr.length < 2) { return arr; } let pivot = arr[0]; let left = []; let right = []; for (let i = 1; i < arr.length; i++) { if (arr[i] < pivot) { left.push(arr[i]); } else { right.push(arr[i]); } } return [...quickSort(left), pivot, ...quickSort(right)]; } // 查找算法: function binarySearch(arr, target) { let left = 0; let right = arr.length - 1; while (left <= right) { const mid = Math.floor((left + right) / 2); if (arr[mid] === target) { return mid; } else if (arr[mid] < target) { left = mid + 1; } else { right = mid - 1; } } return -1; } ``` ## 函数式编程 ### 高阶函数和柯里化 高阶函数和柯里化是函数式编程中的常见概念,它们可以让我们创建更加抽象、灵活的函数。 ```js // 高阶函数 function higherOrderFunction(func) { return function (num) { return func(num); }; } function double(num) { return num * 2; } const doubleFunc = higherOrderFunction(double); console.log(doubleFunc(10)); // 20 // 柯里化 function curry(func) { return function curried(...args) { if (args.length >= func.length) { return func.apply(this, args); } else { return function (...args2) { return curried.apply(this, [...args, ...args2]); }; } }; } function sum(a, b, c) { return a + b + c; } const curriedSum = curry(sum); console.log(curriedSum(1)(2)(3)); // 6 ``` ### 闭包和作用域 闭包和作用域是 JavaScript 中比较常见的概念。闭包可以让我们维护函数内的状态,作用域则决定了变量的可见范围。 ```js // 闭包 function closure() { let i = 0; return function () { return ++i; }; } const func = closure(); console.log(func()); // 1 console.log(func()); // 2 // 作用域 let a = 10; function foo() { let a = 20; console.log(a); // 20 } foo(); console.log(a); // 10 ``` ### 函数式编程中的常见模式 函数式编程中有很多常见的模式,如 map、filter、reduce 等。 ```js // map const arr = [1, 2, 3]; const mapArr = arr.map((item) => item * 2); console.log(mapArr); // [2, 4, 6] // filter const filterArr = arr.filter((item) => item > 1); console.log(filterArr); // [2, 3] // reduce const reduceArr = arr.reduce((sum, curr) => sum + curr, 0); console.log(reduceArr); // 6 异步编程 Promise和async/await Promise和async/await是常见的异步编程方式,它们可以让我们更好地处理异步编程中的问题。 // Promise function promise() { return new Promise((resolve, reject) => { setTimeout(() => { resolve('done'); }, 1000); }); } promise().then((result) => console.log(result)); // 'done' // async/await async function asyncFunc() { const result = await promise(); console.log(result); } asyncFunc(); // 'done' ``` ### 事件循环和 EventEmitter 事件循环和 EventEmitter 用于处理异步事件,它们可以让我们更好地处理事件流。 ```js // 事件循环 console.log("start"); setTimeout(() => { console.log("setTimeout"); }, 0); Promise.resolve().then(() => console.log("promise")); console.log("end"); // EventEmitter const { EventEmitter } = require("events"); const emitter = new EventEmitter(); emitter.on("doSomething", (arg1, arg2) => { console.log(`${arg1} ${arg2}`); }); emitter.emit("doSomething", "Hello", "World"); // 'Hello World' ``` ### Web Worker Web Worker 可以让我们将长时间运行的任务移出主线程,以避免阻塞 UI。 ```js // 主线程 const worker = new Worker("worker.js"); worker.onmessage = (event) => { console.log(event.data); }; worker.postMessage("start"); // worker.js self.onmessage = (event) => { const result = longCalculation(event.data); self.postMessage(result); }; ``` ## 面向对象编程 ### 类和继承 JavaScript 中的类和继承与其他面向对象编程语言类似。 ```js // 类 class Animal { constructor(name) { this.name = name; } speak() { console.log(`${this.name} makes a noise.`); } } class Cat extends Animal { constructor(name, breed) { super(name); this.breed = breed; } speak() { console.log(`${this.name} meows.`); } get description() { return `${this.name} is a ${this.breed} cat.`; } set nickname(nick) { this.name = nick; } } const cat = new Cat("Fluffy", "Persian"); cat.speak(); // 'Fluffy meows.' console.log(cat.description); // 'Fluffy is a Persian cat.' cat.nickname = "Fuffy"; console.log(cat.name); // 'Fuffy' ``` ### Encapsulation、Inheritance、Polymorphism(封装、继承、多态) 封装、继承、多态是面向对象编程中的重要概念。 ```js // 封装 class Person { constructor(name) { this._name = name; } get name() { return this._name.toUpperCase(); } set name(newName) { this._name = newName; } } const person = new Person("John"); console.log(person.name); // 'JOHN' person.name = "Lisa"; console.log(person.name); // 'LISA' // 继承 class Shape { constructor(color) { this.color = color; } draw() { console.log("Drawing a shape..."); } } class Circle extends Shape { constructor(color, radius) { super(color); this.radius = radius; } draw() { console.log(`Drawing a ${this.color} circle with radius ${this.radius}.`); } } const circle = new Circle("red", 10); circle.draw(); // 'Drawing a red circle with radius 10.' // 多态 function drawShape(shape) { shape.draw(); } drawShape(new Shape("blue")); // 'Drawing a shape...' drawShape(new Circle("green", 20)); // 'Drawing a green circle with radius 20.' ``` ## 总结和实战 在本文中,我们介绍了一些 JavaScript 的高级知识点,如高级数据结构和算法、函数式编程、异步编程和面向对象编程。我们还提供了一些代码示例和实战案例,让大家更好地理解和掌握这些技术。 ### 通过 Promise.all 实现并发请求 ```js function fetchData(urls) { const promises = urls.map((url) => fetch(url)); return Promise.all(promises).then((responses) => Promise.all( responses.map((response) => { if (!response.ok) throw new Error(response.statusText); return response.json(); }) ) ); } ``` ### 使用 async/await 实现异步调用 ```js async function getData(url) { const response = await fetch(url); if (!response.ok) throw new Error(response.statusText); const data = await response.json(); return data; } ``` ### 在面向对象编程中使用工厂模式 ```js class Product { constructor(name, price) { this.name = name; this.price = price; } } class ProductFactory { createProduct(name, price) { return new Product(name, price); } } const productFactory = new ProductFactory(); const product = productFactory.createProduct("Apple", 1); console.log(product.name); // 'Apple' console.log(product.price); // 1 ``` 本文结束,感谢阅读
## **簡介** 在本教程中,您將學習如何使用**現代工具**和**最佳實踐**來監控您的Javascript應用程式。 探索分散式追蹤的力量,並了解如何無縫整合和利用 Odigos 和 Jaeger 等工具來增強您的監控能力。 **您將學到什麼:✨** - 如何在 Javascript 中建立微服務🐜。 - 為微服務設定 Docker 容器📦。 - 配置 Kubernetes ☸️ 以管理微服務。 - 整合追蹤後端以可視化追蹤🔍。 您準備好成為監控 JS 應用程式的**專家**了嗎? 😍 說**是的,先生!**。 我聽不到你說話。大聲點說。 🙉  *** ## **讓我們設定一下 🦄** > 🚨 在部落格的這一部分中,我們將建立一個虛擬的 JavaScript 微服務應用程式並將其部署在本地 Kubernetes 上。如果您已經有一個並且正在跟進,請隨意跳過這一部分。 為您的應用程式建立初始資料夾結構,如下所示。 👇🏻 ``` mkdir microservices-demo cd microservices-demo mkdir src cd src ``` ### **設定伺服器** 🖥️ > 👀 出於演示目的,我將建立兩個相互通信的微服務,最終我們可以使用它來視覺化分散式追蹤。 - **建置與 Dockerize 微服務 1** 在「/src」資料夾中,建立一個新資料夾「/microservice-1」。在資料夾內初始化 **NodeJS** 專案並安裝所需的依賴項。 ``` mkdir microservice-1 cd microservice-1 npm init -y npm install --save express node-fetch ``` 建立一個新檔案“index.js”並新增以下程式碼: ``` // 👇🏻/src/microservice-1/index.js const express = require("express"); const fetch = require("node-fetch") const app = express(); const PORT = 3001; app.use(express.json()); app.get("/", async (req, res) => { try { const response = await fetch("http://microservice2:8081/api/data"); const data = await response.json(); res.json({ data: "Microservice 2 data received in Microservice 1", microservice2Data: data, }); } catch (error) { console.error(error.message); res.status(500).json({ error: "Internal Server Error" }); } }); app.listen(PORT, () => { console.log(`Microservice 1 listening on port ${PORT}`); }); ``` 伺服器正在偵聽連接埠“3001”,並且在對“/”發出請求時,我們從“microservice2”請求資料並將回應作為 JSON 物件返回。 📦 現在,是時候對這個微服務進行 docker 化了。在“/microservice-1”資料夾中建立一個新的“Dockerfile”並新增以下程式碼: ``` // 👇🏻/src/microservice-1/Dockerfile FROM node:18 # Use /usr/src/app as the working directory WORKDIR /usr/src/app # Copy package files and install production dependencies COPY --chown=node:node package*.json /usr/src/app RUN npm install --production # Copy the rest of the files COPY --chown=node:node . /usr/src/app/ # Switch to the user node with limited permissions USER node # Expose the application port EXPOSE 3001 # Set the default command to run the application CMD ["node", "index.js"] ``` 將我們不想推送到容器的文件加入到“.dockerignore”總是很好。使用我們不想推送的檔案的名稱來建立一個“.dockerignore”檔案。 ``` // 👇🏻/src/microservice-1/.dockerignore node_modules Dockerfile ``` 最後,透過執行以下命令來建構 🏗️ docker 映像: ``` docker build -t microservice1-image:latest . ``` 現在,這就是我們第一個微服務的完整設定。 ✨ - **建置與 Dockerize 微服務 2** 我們將有一個類似於“microservice1”的設置,只是在這裡和那裡進行了一些更改。 在「/src」資料夾中,建立一個新資料夾「/microservice-2」。在該資料夾內,初始化 **NodeJS** 專案並安裝所需的依賴項。 ``` mkdir microservice-2 cd microservice-2 npm init -y npm install --save express node-fetch ``` 建立一個新檔案“index.js”並新增以下程式碼: ``` // 👇🏻/src/microservice-2/index.js const express = require("express"); const fetch = require("node-fetch") const app = express(); const PORT = 3002; app.use(express.json()); app.get("/api/data", async (req, res) => { const url = "https://jsonplaceholder.typicode.com/users"; try { const response = await fetch(url); const data = await response.json(); res.json(data); } catch (error) { console.error(error.message); res.status(500).json({ error: "Internal Server Error" }); } }); app.listen(PORT, () => { console.log(`Microservice 2 listening on port ${PORT}`); }); ``` 伺服器正在偵聽連接埠 3002,根據對“/api/data”的“GET 請求”,我們從“jsonplaceholder”獲取資料並將回應作為 JSON 物件傳回。 📦 現在,是時候對這個微服務進行 docker 化了。複製並貼上「microservice1」的整個「Dockerfile」內容,然後將連接埠從 3001 變更為 3002。 另外,新增一個「.dockerignore」檔案並包含我們在建立「microservice1」時新增的相同檔案。 最後,透過執行以下命令來建構 🏗️ Docker 映像: ``` docker build -t microservice2-image:latest . ``` 現在,這也是我們第二個微服務的完整設定。 ✨ - **設定 Kubernetes** > 確保已安裝 **[Minikube](https://github.com/kubernetes/minikube)** 透過執行以下命令建立新的本機 Kubernetes 叢集。我們在設定 Odigos 和 Jaeger 時將需要它。 **啟動 Minikube:🚀** ``` minikube start ``` 現在我們已經準備好並 Docker 化了兩個微服務,是時候設定 Kubernetes 來管理這些服務了。 在專案的根目錄下,建立一個新資料夾「/k8s/manifests」。在此資料夾中,我們將為兩個微服務新增部署和服務配置。 - **部署設定📜**:用於在 Kubernetes 叢集上實際部署容器。 - **服務配置📄**:將 Pod 暴露給叢集內部和叢集外部。 首先,我們為「microservice1」建立清單。建立一個新檔案「microservice1-deployment-service.yaml」並新增以下內容: ``` // 👇🏻/k8s/manifests/microservice1-deployment-service.yaml apiVersion: apps/v1 kind: Deployment metadata: name: microservice1 spec: selector: matchLabels: app: microservice1 template: metadata: labels: app: microservice1 spec: containers: - name: microservice1 image: microservice1-image # Make sure to set it to Never, or else it will pull from the docker hub and fail. imagePullPolicy: Never resources: limits: memory: "200Mi" cpu: "500m" ports: - containerPort: 3001 --- apiVersion: v1 kind: Service metadata: name: microservice1 labels: app: microservice1 spec: type: NodePort selector: app: microservice1 ports: - port: 8080 targetPort: 3001 nodePort: 30001 ``` 此配置部署了一個名為「microservice1」的微服務,其資源限制為 **200MB 記憶體** 🗃️ 和 **0.5 個 CPU 核心**。它透過部署在連接埠 3001 上公開微服務,並透過服務在 **NodePort** 30001 上公開微服務。 > 🤔 還記得我們用名稱「microservice1-image」建構的「Dockerfile」嗎?我們使用相同的映像來建立容器。 可透過集群內的連接埠 8080 存取它。我們假設「microservice1-image」透過「imagePullPolicy: Never」在本地可用。如果沒有到位,它將嘗試從 Docker Hub 🐋 中提取映像並失敗。 現在,讓我們為「microservice2」建立清單。建立一個名為「microservice2-deployment-service.yaml」的新檔案並新增以下內容: ``` // 👇🏻/k8s/manifests/microservice1-deployment-service.yaml apiVersion: apps/v1 kind: Deployment metadata: name: microservice2 spec: selector: matchLabels: app: microservice2 template: metadata: labels: app: microservice2 spec: containers: - name: microservice2 image: microservice2-image # Make sure to set it to Never, or else it will pull from the docker hub and fail. imagePullPolicy: Never resources: limits: memory: "200Mi" cpu: "500m" ports: - containerPort: 3002 --- apiVersion: v1 kind: Service metadata: name: microservice2 labels: app: microservice2 spec: type: NodePort selector: app: microservice2 ports: - port: 8081 targetPort: 3002 nodePort: 30002 ``` 它與“microservice1”的清單類似,只有一些更改。 👀 此配置部署一個名為「microservice2」的微服務,並透過部署在連接埠 3002 上將其內部公開,並透過服務在 **NodePort** 30002 上將其外部公開。 可透過叢集內的連接埠 8081 進行存取,假設「microservice2-image」可透過「imagePullPolicy: Never」在本地使用。 全部完成後,請確保套用這些設定並使用這些服務啟動 Kubernetes 叢集。將目錄更改為`/manifests`並執行以下命令:👇🏻 ``` kubectl apply -f microservice1-deployment-service.yaml kubectl apply -f microservice2-deployment-service.yaml ``` 執行以下命令檢查我們的兩個部署是否正在**執行**:👇🏻 ``` kubectl get pods ```  最後,我們的應用程式已準備就緒,並使用必要的部署配置部署在 Kubernetes 上。 🎉 *** ## **安裝 Odigos 😍** > 💡 [**Odigos**](https://odigos.io/) 是一個開源可觀察性控制平面,使組織能夠建立和維護其可觀察性管道。  > ℹ️ 如果您在 Mac 上執行,請執行以下命令在本地安裝 Odigos。 ``` brew install keyval-dev/homebrew-odigos-cli/odigos ``` > ℹ️ 如果您使用的是 Linux 計算機,請考慮透過執行以下命令從 GitHub 版本安裝它。確保根據您的 Linux 發行版更改該檔案。 > ℹ️ 如果 Odigos 二進位檔案不可執行,請在執行安裝指令之前執行此指令 `chmod +x odigos` 使其可執行。 ``` curl -LJO https://github.com/keyval-dev/odigos/releases/download/v1.0.9/cli_1.0.9_linux_amd64.tar.gz tar -xvzf cli_1.0.9_linux_amd64.tar.gz ./odigos install ```  > 如果您需要有關其安裝的更多簡短說明,請按照此[**連結**](https://docs.odigos.io/installation)操作。 現在,Odigos 已準備好執行 🎉。我們可以執行它的 UI,配置追蹤後端,並相應地發送追蹤。 *** ## **將 Odigos 連接到追蹤後端 💫** > 💡 [**Jaeger**](https://github.com/jaegertracing/jaeger) 是一個開源的端對端分散式追蹤系統。  ### **設定 Jaeger!** ✨ 在本教程中,我們將使用 **Jaeger** 🕵️♂️,這是一個流行的開源平台,用於查看微服務應用程式中的分散式追蹤。我們將用它來查看 Odigos 生成的痕跡。 > 有關 Jaeger 安裝說明,請點選此 [**link**](https://www.jaegertracing.io/download/)。 👀 若要在 Kubernetes 叢集上部署 Jaeger,請執行下列命令:👇🏻 ``` kubectl create ns tracing kubectl apply -f https://raw.githubusercontent.com/keyval-dev/opentelemetry-go-instrumentation/master/docs/getting-started/jaeger.yaml -n tracing ``` 在這裡,我們建立一個「tracing」命名空間,並在該命名空間中為 Jaeger 應用部署配置📃。 此命令設定自託管 Jaeger 實例及其服務。 👀 執行以下命令來取得正在執行的 pod 的狀態:👇🏻 ``` kubectl get pods -A -w ``` 等待所有三個 Pod 都 **正在執行**,然後再繼續。 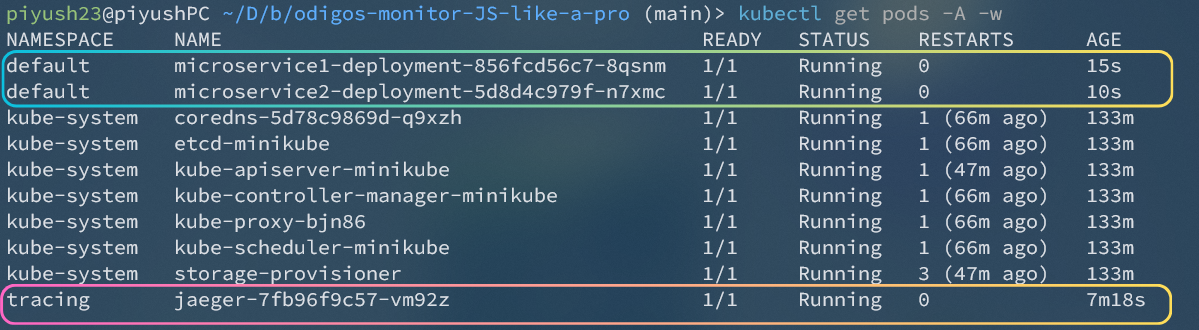 現在,要在本地查看 Jaeger Interface 💻,我們需要進行連接埠轉送。將流量從本機電腦上的連接埠 16686 轉送至 Kubernetes 叢集中選定 pod 上的連接埠 16686。 ``` kubectl port-forward -n tracing svc/jaeger 16686:16686 ``` 此命令在本機電腦和 Jaeger pod 之間建立一條隧道,公開 Jaeger UI,以便您可以與其互動。 最後,在瀏覽器上開啟「 http://localhost:16686 」並查看 Jaeger 實例正在執行。 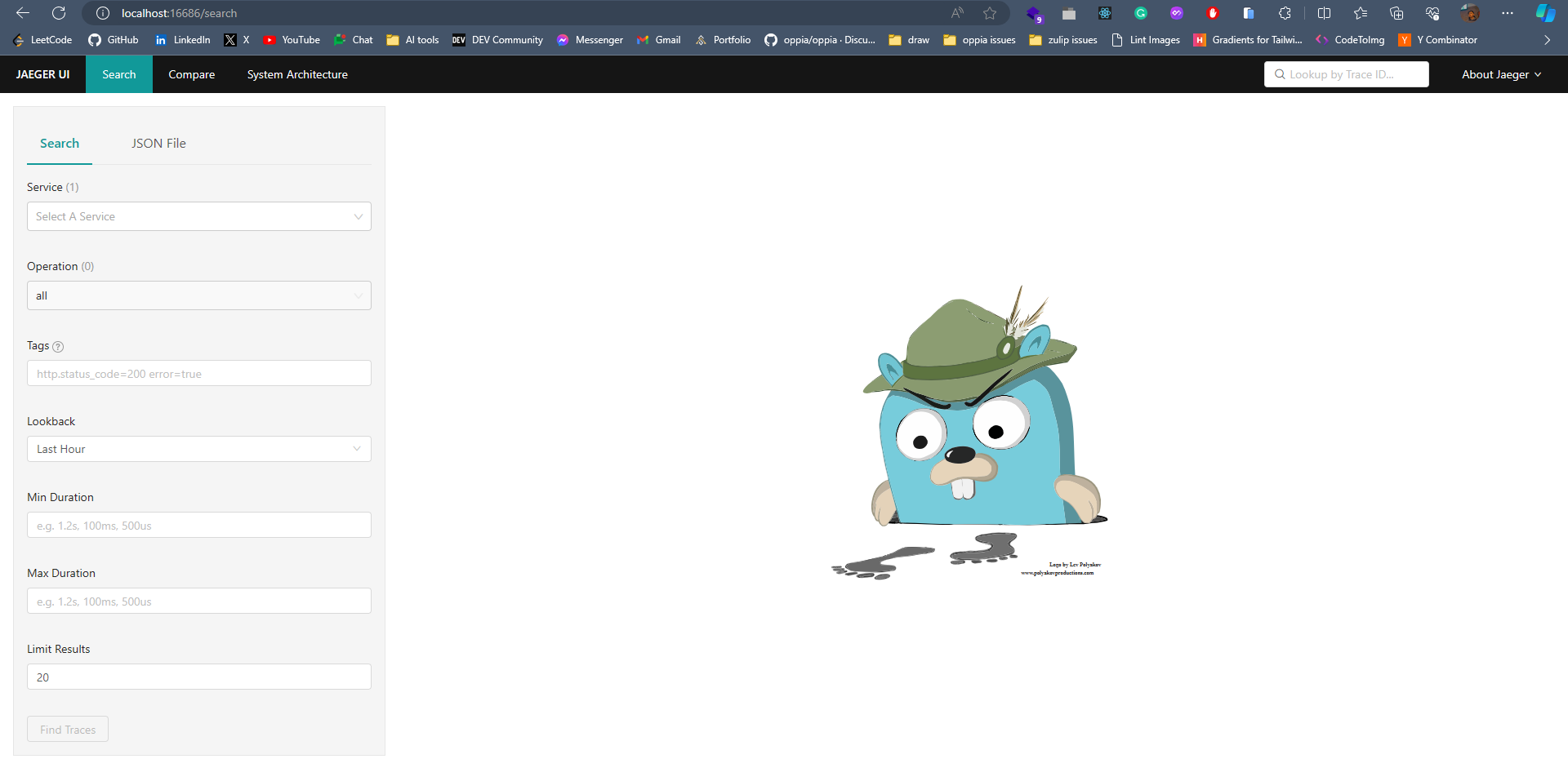 ### **設定 Odigos 與 Jaeger 一起工作!** 🌟 > ℹ️ 對於 Linux 用戶,請前往從 GitHub 版本下載 Odigos 二進位檔案的資料夾,然後執行以下命令來啟動 Odigos UI。 ``` ./odigos ui ``` > ℹ️ 對於 Mac 用戶,只需執行: ``` odigos ui ``` 造訪“ http://localhost:3000 ”,您將看到 Odigos 介面,您將在“default”命名空間中看到您的部署。 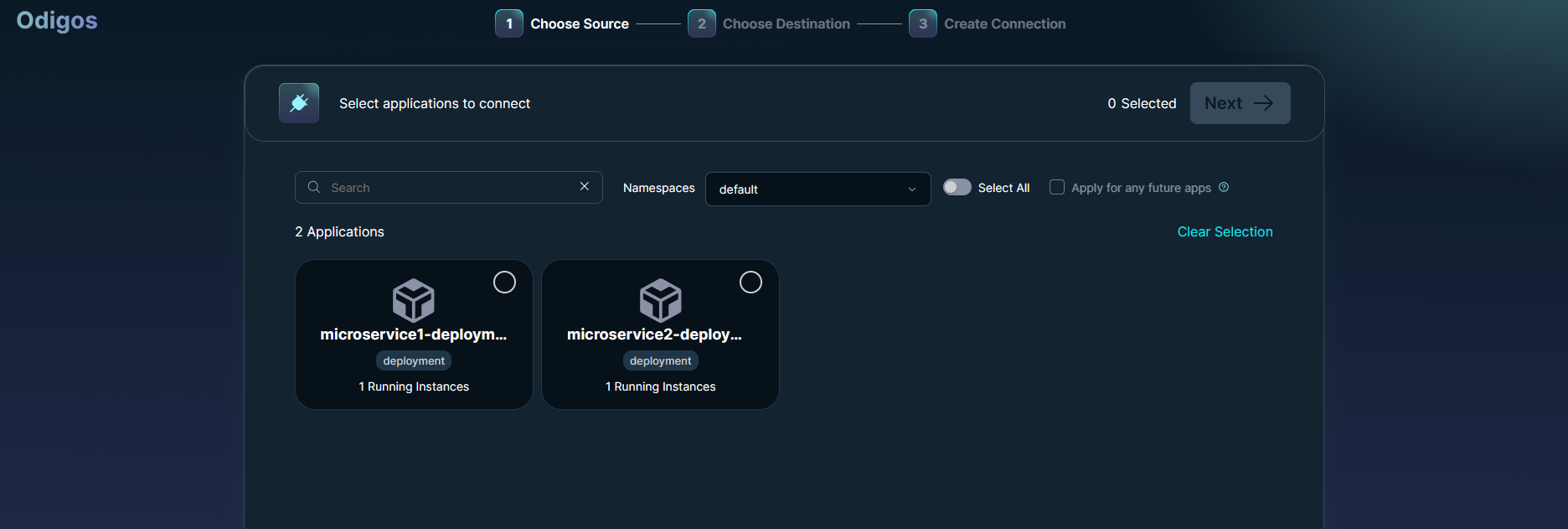 選擇這兩個選項並點擊“下一步”。在下一頁上,選擇 Jaeger 作為後端,並在出現提示時加入以下詳細資訊: - **目的地名稱🛣️**:提供您想要的任何名稱,例如說**快速追蹤**。 - **端點🎯**:為端點加上`jaeger.tracing:4317`。 就是這樣 - Odigos 已準備好向我們的 Jaeger 後端發送痕跡。就是這麼簡單。 🤯 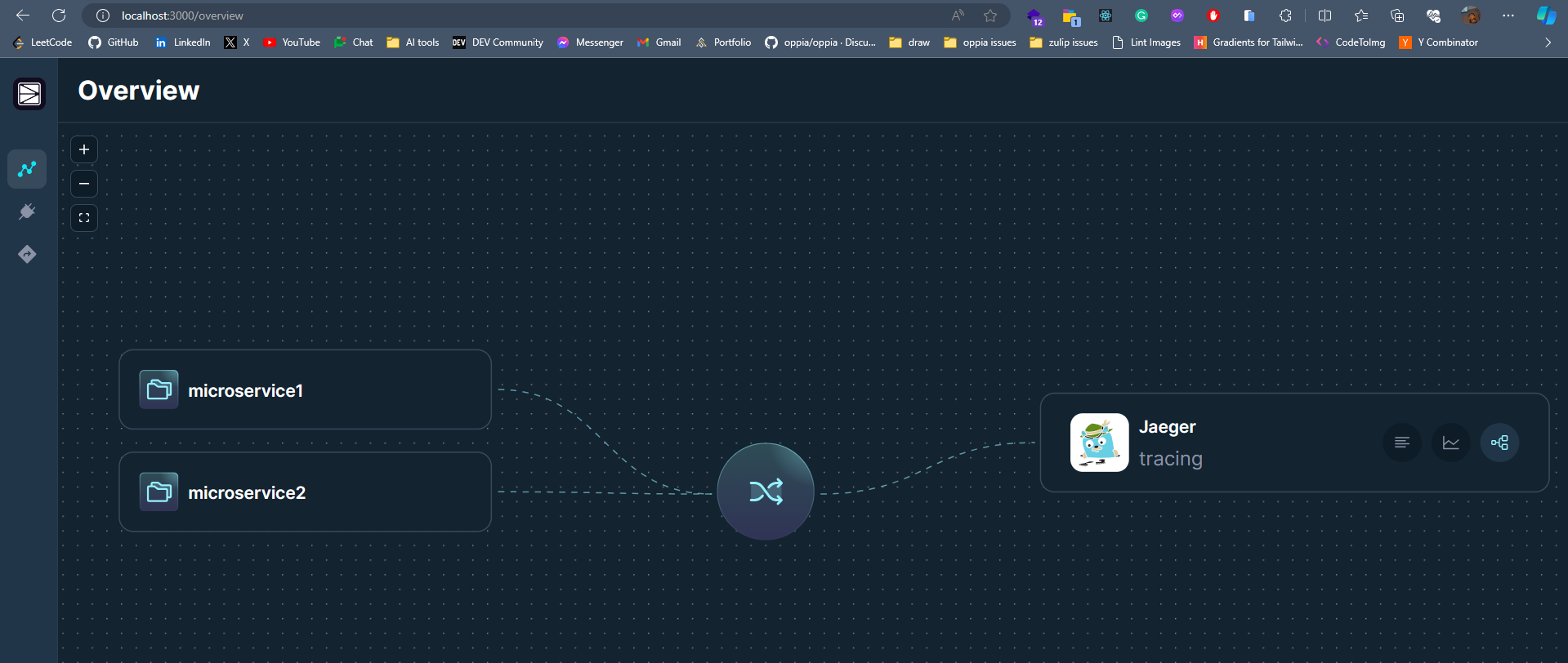 *** ## **查看分散式追蹤 🧐** 設定 Odigos 後,在 Jaeger 主頁「 http://localhost:16686 」上,您將已經看到列出的兩個微服務。 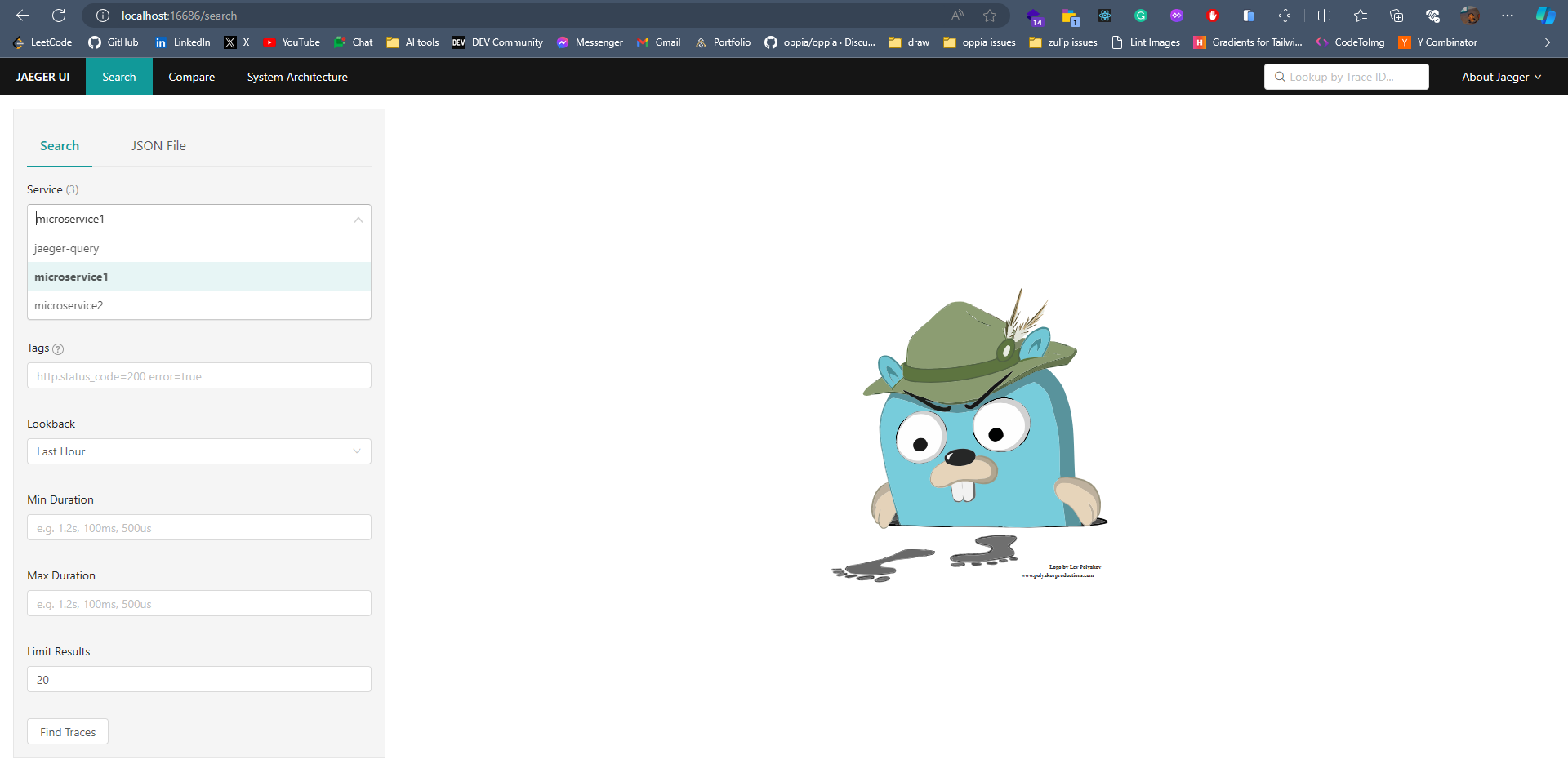 Odigos 已經開始向 Jaeger 發送我們的應用程式痕跡。 😉 請記住,這是我們的微服務應用程式。由於以「microservice1」為起點,因此再向「microservice1」發出一些請求,隨後它將向「microservice2」請求資料並傳回。最終,Jaeger 將開始填滿這些痕跡。 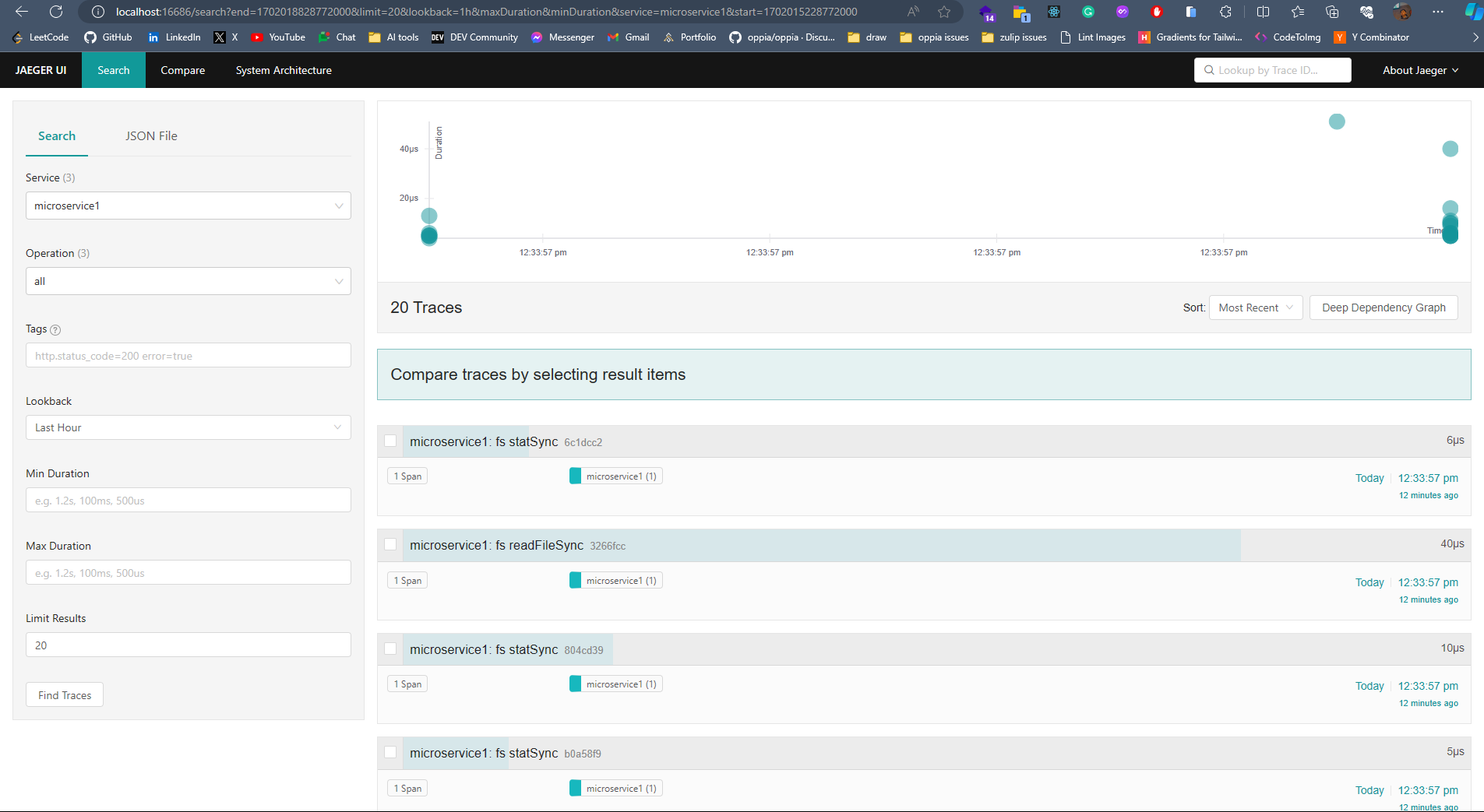 點擊任一請求,您應該能夠觀察請求如何流經您的應用程式以及完成每個請求所需的時間。 這一切都是在沒有更改一行程式碼的情況下完成的。 🤯 一切都感謝 **Odigos**! 🤩  想像一下,這只是一個很小的虛擬應用程式,但對於一個執行著大量微服務並相互交互的更大的應用程式來說,分散式追蹤將非常強大! 💪 透過分散式跟踪,您可以輕鬆辨識應用程式中的瓶頸,並確定哪個服務導致問題或花費更長的時間。 🕒 *** ## **讓我們總結一下! 🥱** 到目前為止,您已經學習如何使用 **Odigos** 作為應用程式和追蹤後端 **Jaeger** 之間的 **中間件**,透過分散式追蹤來密切監控 👀 Javascript 應用程式。 👏 如果您已經做到了這一步,請拍拍自己的背。 🥳你值得擁有! 😉 本教學的源程式碼可在此處取得: https://github.com/keyval-dev/blog/tree/main/odigos-monitor-JS-like-a-pro > 如果您對本文有任何疑問或建議,請在下面的評論部分分享。 👇🏻 那麼,這就是本文的內容。感謝您的閱讀! 🎉🫡 --- 原文出處:https://dev.to/odigos/monitor-your-javascript-application-like-a-pro-581p
#我要做一個自動解方程 主控臺 --- "Error solving equation: Invalid left hand side of assignment operator = (char 5) Return:a + 27 = 0" --- ```<!DOCTYPE html> <html> <head> <meta name="description" content="math.js | basic usage"> <title>math.js | basic usage</title> <script src="https://unpkg.com/mathjs/lib/browser/math.js"></script> </head> <body> <script> function solveEquation(equationString, variableRange = { start: -10, end: 10, step: 0.1 }) { if (typeof equationString !== 'string') { throw new Error('Equation must be a string'); } const equation = equationString.replace(/\s/g, ''); const variables = equation.match(/[a-zA-Z]+/g); if (!variables) { throw new Error('No variables found in equation'); } const parser = math.parser(); variables.forEach(variable => { parser.evaluate(`${variable} = ${variableRange.start}:${variableRange.step}:${variableRange.end}`); }); let result; try { result = parser.evaluate(equation); } catch (error) { throw new Error('Error solving equation: ' + error.message + "\nReturn:" + equationString); } return result; } const equationString = "a + 27 = 0"; try { const result = solveEquation(equationString); console.log("方程的解为:", result); } catch (error) { console.error(error.message); } </script> </body> </html>
# 長話短說;博士 我們都已經看到了 ChatGPT 的功能(這對任何人來說都不陌生)。 很多文章都是使用 ChatGPT 一遍又一遍地寫的。 **實際上**,DEV 上的文章有一半是用 ChatGPT 寫的。 你可以使用一些[AI內容偵測器](https://copyleaks.com/ai-content- detector)來檢視。 問題是,ChatGPT 永遠不會產生一些非凡的內容,除了它內部已經有(經過訓練/微調)的內容。 但有一種方法可以超越目前使用 RAG(OpenAI 助理)訓練的內容。 [上一篇](https://dev.to/triggerdotdev/train-chatgpt-on-your-documentation-1a9g),我們討論了在您的文件上「訓練」ChatGPT;今天,讓我們看看如何從中製作出很多內容。我們將: - 使用 Docusaurus 建立新的部落格系統。 - 詢問 ChatGPT,為我們寫一篇與文件相關的部落格文章。  --- ## 你的後台工作平台🔌 [Trigger.dev](https://trigger.dev/) 是一個開源程式庫,可讓您使用 NextJS、Remix、Astro 等為您的應用程式建立和監控長時間執行的作業! [](https://github.com/triggerdotdev/trigger.dev) 請幫我們一顆星🥹。 這將幫助我們建立更多這樣的文章💖 {% cta https://github.com/triggerdotdev/trigger.dev %} 為 Trigger.dev 儲存庫加註星標 ⭐️ {% endcta %} --- ## 上次回顧 ⏰ - 我們建立了一個作業來取得文件 XML 並提取所有 URL。 - 我們抓取了每個網站的 URL 並提取了標題和內容。 - 我們將所有內容儲存到文件中並將其發送給 ChatGPT 助手。 - 我們建立了一個 ChatBot 畫面來詢問 ChatGPT 有關文件的資訊。 您可以在此處找到上一個[教學]的完整原始程式碼(https://github.com/triggerdotdev/blog/tree/main/openai-assistant)。 ---  ## 稍作修改⚙️ 上次,我們建立了一個文件助理。我們寫: ``` You are a documentation assistant, loaded with documentation from ' + payload.url + ', return everything in an MD format. ``` 讓我們將其更改為部落格作者,請轉到“jobs/process.documentation.ts”第 92 行,並將其替換為以下內容: ``` You are a content writer assistant. You have been loaded with documentation from ${payload.url}, you write blog posts based on the documentation and return everything in the following MD format: --- slug: [post-slug] title: [post-title] --- [post-content] ``` 使用“slug”和“title”非常重要,因為這是 Docusaurus 的格式 - 我們的部落格系統可以接受(當然,我們也以 MD 格式發送所有輸出) ---  ## 多庫龍🦖 您可以使用多種類型的部落格系統! 對於我們的用例,我們將使用 Docusaurus,它可以讀取基於 MD 的格式(我們從 ChatGPT 請求的輸出)。 **我們可以透過執行來安裝 Docusaurus:** ``` npx create-docusaurus@latest blog classic --typescript ``` 接下來,我們可以進入已建立的目錄並執行以下命令: ``` npm run start ``` 這將啟動 Docusaurus。你可以關註一下。還有一個名為“blog”的附加目錄,其中包含所有部落格文章;這是我們保存 ChatGPT 產生的部落格文章的地方。  ---  ## 產生部落格 📨 我們需要創造一個就業機會 - 取得部落格標題 - 使用 ChatGPT 產生完整的部落格文章 - 將其保存到我們部落格上的 MD 文件中 我們可以輕鬆地使用 ChatGPT 來實現這一點! 前往“jobs”資料夾並新增一個名為“process.blog.ts”的新檔案。新增以下程式碼: ``` import { eventTrigger } from "@trigger.dev/sdk"; import { client } from "@openai-assistant/trigger"; import {object, string} from "zod"; import {openai} from "@openai-assistant/helper/open.ai"; import {writeFileSync} from "fs"; import slugify from "slugify"; client.defineJob({ // This is the unique identifier for your Job, it must be unique across all Jobs in your project. id: "process-blog", name: "Process Blog", version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction trigger: eventTrigger({ name: "process.blog.event", schema: object({ title: string(), aId: string(), }) }), integrations: { openai }, run: async (payload, io, ctx) => { const {title, aId} = payload; const thread = await io.openai.beta.threads.create('create-thread'); await io.openai.beta.threads.messages.create('create-message', thread.id, { content: ` title: ${title} `, role: 'user', }); const run = await io.openai.beta.threads.runs.createAndWaitForCompletion('run-thread', thread.id, { model: 'gpt-4-1106-preview', assistant_id: payload.aId, }); if (run.status !== "completed") { console.log('not completed'); throw new Error(`Run finished with status ${run.status}: ${JSON.stringify(run.last_error)}`); } const messages = await io.openai.beta.threads.messages.list("list-messages", run.thread_id, { query: { limit: "1" } }); return io.runTask('save-blog', async () => { const content = messages[0].content[0]; if (content.type === 'text') { const fileName = slugify(title, {lower: true, strict: true, trim: true}); writeFileSync(`./blog/blog/${fileName}.md`, content.text.value) return {fileName}; } }); }, }); ``` - 我們加入了一些必要的變數: - `title` 部落格文章標題 - `aId` 上一篇文章中新增的助手 ID。 - 我們為助手建立了一個新線程(`io.openai.beta.threads.create`) - 我們無法在沒有任何線程的情況下質疑它。與之前的教程不同,在這裡,我們對每個請求建立一個新線程。我們不需要對話中最後一條訊息的上下文。 - 然後,我們使用部落格標題為線程(`io.openai.beta.threads.messages.create`)新增訊息。我們不需要提供額外的說明 - 我們已經在第一部分完成了該部分😀 - 我們執行 `io.openai.beta.threads.runs.createAndWaitForCompletion` 來啟動進程 - 通常,您需要某種每分鐘執行一次的遞歸來檢查作業是否完成,但是 [Trigger.dev]( http://Trigger .dev)已經加入了一種執行進程並同時等待它的方法🥳 - 我們在查詢正文中執行帶有“limit: 1”的“io.openai.beta.threads.messages.list”,以從對話中獲取第一則訊息(在ChatGPT 結果中,第一則訊息是最後一條訊息) 。 - 然後,我們使用「writeFileSync」從 ChatGPT 取得的值來儲存新建立的部落格 - 確保您擁有正確的部落格路徑。 轉到“jobs/index.ts”並加入以下行: ``` export * from "./process.blog"; ``` 現在,讓我們建立一個新的路由來觸發該作業。 前往“app/api”,建立一個名為“blog”的新資料夾,並在一個名為“route.tsx”的新檔案中 新增以下程式碼: ``` import {client} from "@openai-assistant/trigger"; export async function POST(request: Request) { const payload = await request.json(); if (!payload.title || !payload.aId) { return new Response(JSON.stringify({error: 'Missing parameters'}), {status: 400}); } // We send an event to the trigger to process the documentation const {id: eventId} = await client.sendEvent({ name: "process.blog.event", payload }); return new Response(JSON.stringify({eventId}), {status: 200}); } ``` - 我們檢查標題和助理 ID 是否存在。 - 我們在 [Trigger.dev](http://Trigger.dev) 中觸發事件並發送訊息。 - 我們將事件 ID 傳送回客戶端,以便我們可以追蹤作業的進度。 ---  ## 前端🎩 沒什麼好做的! 在我們的「components」目錄中,建立一個名為「blog.component.tsx」的新檔案和以下程式碼: ``` "use client"; import {FC, useCallback, useEffect, useState} from "react"; import {ExtendedAssistant} from "@openai-assistant/components/main"; import {SubmitHandler, useForm} from "react-hook-form"; import {useEventRunDetails} from "@trigger.dev/react"; interface Blog { title: string, aId: string; } export const BlogComponent: FC<{list: ExtendedAssistant[]}> = (props) => { const {list} = props; const {register, formState, handleSubmit} = useForm<Blog>(); const [event, setEvent] = useState<string | undefined>(undefined); const addBlog: SubmitHandler<Blog> = useCallback(async (param) => { const {eventId} = await (await fetch('/api/blog', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(param) })).json(); setEvent(eventId); }, []); return ( <> <form className="flex flex-col gap-3 mt-5" onSubmit={handleSubmit(addBlog)}> <div className="flex flex-col gap-1"> <div className="font-bold">Assistant</div> <select className="border border-gray-200 rounded-xl py-2 px-3" {...register('aId', {required: true})}> {list.map(val => ( <option key={val.id} value={val.aId}>{val.url}</option> ))} </select> </div> <div className="flex flex-col gap-1"> <div className="font-bold">Title</div> <input className="border border-gray-200 rounded-xl py-2 px-3" placeholder="Blog title" {...register('title', {required: true})} /> </div> <button className="border border-gray-200 rounded-xl py-2 px-3 bg-gray-100 hover:bg-gray-200" disabled={formState.isSubmitting}>Create blog</button> </form> {!!event && ( <Blog eventId={event} /> )} </> ) } export const Blog: FC<{eventId: string}> = (props) => { const {eventId} = props; const { data, error } = useEventRunDetails(eventId); if (data?.status !== 'SUCCESS') { return <div className="pointer bg-yellow-300 border-yellow-500 p-1 px-3 text-yellow-950 border rounded-2xl">Loading</div> } return ( <div> <a href={`http://localhost:3000/blog/${data.output.fileName}`}>Check blog post</a> </div> ) }; ``` - 我們使用「react-hook-form」來輕鬆控制我們的輸入。 - 我們讓使用者選擇他們想要使用的助手。 - 我們建立一個包含文章標題的新輸入。 - 我們將所有內容傳送到先前建立的路由並傳回作業的「eventId」。 - 我們建立一個新的「<Blog />」元件,該元件顯示載入直到事件完成,並使用新建立的教程新增指向我們部落格的連結。 將元件加入我們的“components/main.tsx”檔案中: ``` {assistantState.filter(f => !f.pending).length > 0 && <BlogComponent list={assistantState} />} ``` 我們完成了!  現在,讓我們新增部落格標題並點擊「生成」。  ---  ## 讓我們聯絡吧! 🔌 作為開源開發者,您可以加入我們的[社群](https://discord.gg/nkqV9xBYWy) 做出貢獻並與維護者互動。請隨時造訪我們的 [GitHub 儲存庫](https://github.com/triggerdotdev/trigger.dev),貢獻並建立與 Trigger.dev 相關的問題。 本教學的源程式碼可在此處取得: https://github.com/triggerdotdev/blog/tree/main/openai-blog-writer 感謝您的閱讀! --- 原文出處:https://dev.to/triggerdotdev/generate-blogs-with-chatgpt-assistant-1894
# 簡介 ChatGPT 訓練至 2022 年。 但是,如果您希望它專門為您提供有關您網站的資訊怎麼辦?最有可能的是,這是不可能的,**但不再是了!** OpenAI 推出了他們的新功能 - [助手](https://platform.openai.com/docs/assistants/how-it-works)。 現在您可以輕鬆地為您的網站建立索引,然後向 ChatGPT 詢問有關該網站的問題。在本教程中,我們將建立一個系統來索引您的網站並讓您查詢它。我們將: - 抓取文件網站地圖。 - 從網站上的所有頁面中提取資訊。 - 使用新資訊建立新助理。 - 建立一個簡單的ChatGPT前端介面並查詢助手。  --- ## 你的後台工作平台🔌 [Trigger.dev](https://trigger.dev/) 是一個開源程式庫,可讓您使用 NextJS、Remix、Astro 等為您的應用程式建立和監控長時間執行的作業! [](https://github.com/triggerdotdev/trigger.dev) 請幫我們一顆星🥹。 這將幫助我們建立更多這樣的文章💖 --- ## 讓我們開始吧🔥 讓我們建立一個新的 NextJS 專案。 ``` npx create-next-app@latest ``` >💡 我們使用 NextJS 新的應用程式路由器。安裝專案之前請確保您的節點版本為 18+ 讓我們建立一個新的資料庫來保存助手和抓取的頁面。 對於我們的範例,我們將使用 [Prisma](https://www.prisma.io/) 和 SQLite。 安裝非常簡單,只需執行: ``` npm install prisma @prisma/client --save ``` 然後加入架構和資料庫 ``` npx prisma init --datasource-provider sqlite ``` 轉到“prisma/schema.prisma”並將其替換為以下架構: ``` // This is your Prisma schema file, // learn more about it in the docs: https://pris.ly/d/prisma-schema generator client { provider = "prisma-client-js" } datasource db { provider = "sqlite" url = env("DATABASE_URL") } model Docs { id Int @id @default(autoincrement()) content String url String @unique identifier String @@index([identifier]) } model Assistant { id Int @id @default(autoincrement()) aId String url String @unique } ``` 然後執行 ``` npx prisma db push ``` 這將建立一個新的 SQLite 資料庫(本機檔案),其中包含兩個主表:“Docs”和“Assistant” - 「Docs」包含所有抓取的頁面 - `Assistant` 包含文件的 URL 和內部 ChatGPT 助理 ID。 讓我們新增 Prisma 客戶端。 建立一個名為「helper」的新資料夾,並新增一個名為「prisma.ts」的新文件,並在其中新增以下程式碼: ``` import {PrismaClient} from '@prisma/client'; export const prisma = new PrismaClient(); ``` 我們稍後可以使用“prisma”變數來查詢我們的資料庫。 ---  ## 刮擦和索引 ### 建立 Trigger.dev 帳戶 抓取頁面並為其建立索引是一項長期執行的任務。 **我們需要:** - 抓取網站地圖的主網站元 URL。 - 擷取網站地圖內的所有頁面。 - 前往每個頁面並提取內容。 - 將所有內容儲存到 ChatGPT 助手中。 為此,我們使用 Trigger.dev! 註冊 [Trigger.dev 帳號](https://trigger.dev/)。 註冊後,建立一個組織並為您的工作選擇一個專案名稱。  選擇 Next.js 作為您的框架,並按照將 Trigger.dev 新增至現有 Next.js 專案的流程進行操作。  否則,請點選專案儀表板側邊欄選單上的「環境和 API 金鑰」。  複製您的 DEV 伺服器 API 金鑰並執行下面的程式碼片段來安裝 Trigger.dev。 仔細按照說明進行操作。 ``` npx @trigger.dev/cli@latest init ``` 在另一個終端中執行以下程式碼片段,在 Trigger.dev 和您的 Next.js 專案之間建立隧道。 ``` npx @trigger.dev/cli@latest dev ``` ### 安裝 ChatGPT (OpenAI) 我們將使用OpenAI助手,因此我們必須將其安裝到我們的專案中。 [建立新的 OpenAI 帳戶](https://platform.openai.com/) 並產生 API 金鑰。  點擊下拉清單中的「檢視 API 金鑰」以建立 API 金鑰。  接下來,透過執行下面的程式碼片段來安裝 OpenAI 套件。 ``` npm install @trigger.dev/openai ``` 將您的 OpenAI API 金鑰新增至「.env.local」檔案。 ``` OPENAI_API_KEY=<your_api_key> ``` 建立一個新目錄“helper”並新增一個新檔案“open.ai.tsx”,其中包含以下內容: ``` import {OpenAI} from "@trigger.dev/openai"; export const openai = new OpenAI({ id: "openai", apiKey: process.env.OPENAI_API_KEY!, }); ``` 這是我們透過 Trigger.dev 整合封裝的 OpenAI 用戶端。 ### 建立後台作業 讓我們繼續建立一個新的後台作業! 前往“jobs”並建立一個名為“process.documentation.ts”的新檔案。 **新增以下程式碼:** ``` import { eventTrigger } from "@trigger.dev/sdk"; import { client } from "@openai-assistant/trigger"; import {object, string} from "zod"; import {JSDOM} from "jsdom"; import {openai} from "@openai-assistant/helper/open.ai"; client.defineJob({ // This is the unique identifier for your Job; it must be unique across all Jobs in your project. id: "process-documentation", name: "Process Documentation", version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction trigger: eventTrigger({ name: "process.documentation.event", schema: object({ url: string(), }) }), integrations: { openai }, run: async (payload, io, ctx) => { } }); ``` 我們定義了一個名為「process.documentation.event」的新作業,並新增了一個名為 URL 的必要參數 - 這是我們稍後要傳送的文件 URL。 正如您所看到的,該作業是空的,所以讓我們向其中加入第一個任務。 我們需要獲取網站網站地圖並將其返回。 抓取網站將返回我們需要解析的 HTML。 為此,我們需要安裝 JSDOM。 ``` npm install jsdom --save ``` 並將其導入到我們文件的頂部: ``` import {JSDOM} from "jsdom"; ``` 現在,我們可以新增第一個任務。 用「runTask」包裝我們的程式碼很重要,這可以讓 Trigger.dev 將其與其他任務分開。觸發特殊架構將任務拆分為不同的進程,因此 Vercel 無伺服器逾時不會影響它們。 **這是第一個任務的程式碼:** ``` const getSiteMap = await io.runTask("grab-sitemap", async () => { const data = await (await fetch(payload.url)).text(); const dom = new JSDOM(data); const sitemap = dom.window.document.querySelector('[rel="sitemap"]')?.getAttribute('href'); return new URL(sitemap!, payload.url).toString(); }); ``` - 我們透過 HTTP 請求從 URL 取得整個 HTML。 - 我們將其轉換為 JS 物件。 - 我們找到網站地圖 URL。 - 我們解析它並返回它。 接下來,我們需要抓取網站地圖,提取所有 URL 並返回它們。 讓我們安裝“Lodash”——陣列結構的特殊函數。 ``` npm install lodash @types/lodash --save ``` 這是任務的程式碼: ``` export const makeId = (length: number) => { let text = ''; const possible = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789'; for (let i = 0; i < length; i += 1) { text += possible.charAt(Math.floor(Math.random() * possible.length)); } return text; }; const {identifier, list} = await io.runTask("load-and-parse-sitemap", async () => { const urls = /(http|ftp|https):\/\/([\w_-]+(?:(?:\.[\w_-]+)+))([\w.,@?^=%&:\/~+#-]*[\w@?^=%&\/~+#-])/g; const identifier = makeId(5); const data = await (await fetch(getSiteMap)).text(); // @ts-ignore return {identifier, list: chunk(([...new Set(data.match(urls))] as string[]).filter(f => f.includes(payload.url)).map(p => ({identifier, url: p})), 25)}; }); ``` - 我們建立一個名為 makeId 的新函數來為所有頁面產生隨機辨識碼。 - 我們建立一個新任務並加入正規表示式來提取每個可能的 URL - 我們發送一個 HTTP 請求來載入網站地圖並提取其所有 URL。 - 我們將 URL「分塊」為 25 個元素的陣列(如果有 100 個元素,則會有四個 25 個元素的陣列) 接下來,讓我們建立一個新作業來處理每個 URL。 **這是完整的程式碼:** ``` function getElementsBetween(startElement: Element, endElement: Element) { let currentElement = startElement; const elements = []; // Traverse the DOM until the endElement is reached while (currentElement && currentElement !== endElement) { currentElement = currentElement.nextElementSibling!; // If there's no next sibling, go up a level and continue if (!currentElement) { // @ts-ignore currentElement = startElement.parentNode!; startElement = currentElement; if (currentElement === endElement) break; continue; } // Add the current element to the list if (currentElement && currentElement !== endElement) { elements.push(currentElement); } } return elements; } const processContent = client.defineJob({ // This is the unique identifier for your Job; it must be unique across all Jobs in your project. id: "process-content", name: "Process Content", version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction trigger: eventTrigger({ name: "process.content.event", schema: object({ url: string(), identifier: string(), }) }), run: async (payload, io, ctx) => { return io.runTask('grab-content', async () => { // We first grab a raw html of the content from the website const data = await (await fetch(payload.url)).text(); // We load it with JSDOM so we can manipulate it const dom = new JSDOM(data); // We remove all the scripts and styles from the page dom.window.document.querySelectorAll('script, style').forEach((el) => el.remove()); // We grab all the titles from the page const content = Array.from(dom.window.document.querySelectorAll('h1, h2, h3, h4, h5, h6')); // We grab the last element so we can get the content between the last element and the next element const lastElement = content[content.length - 1]?.parentElement?.nextElementSibling!; const elements = []; // We loop through all the elements and grab the content between each title for (let i = 0; i < content.length; i++) { const element = content[i]; const nextElement = content?.[i + 1] || lastElement; const elementsBetween = getElementsBetween(element, nextElement); elements.push({ title: element.textContent, content: elementsBetween.map((el) => el.textContent).join('\n') }); } // We create a raw text format of all the content const page = ` ---------------------------------- url: ${payload.url}\n ${elements.map((el) => `${el.title}\n${el.content}`).join('\n')} ---------------------------------- `; // We save it to our database await prisma.docs.upsert({ where: { url: payload.url }, update: { content: page, identifier: payload.identifier }, create: { url: payload.url, content: page, identifier: payload.identifier } }); }); }, }); ``` - 我們從 URL 中獲取內容(之前從網站地圖中提取) - 我們用`JSDOM`解析它 - 我們刪除頁面上存在的所有可能的“<script>”或“<style>”。 - 我們抓取頁面上的所有標題(`h1`、`h2`、`h3`、`h4`、`h5`、`h6`) - 我們迭代標題並獲取它們之間的內容。我們不想取得整個頁面內容,因為它可能包含不相關的內容。 - 我們建立頁面原始文字的版本並將其保存到我們的資料庫中。 現在,讓我們為每個網站地圖 URL 執行此任務。 觸發器引入了名為“batchInvokeAndWaitForCompletion”的東西。 它允許我們批量發送 25 個專案進行處理,並且它將同時處理所有這些專案。下面是接下來的幾行程式碼: ``` let i = 0; for (const item of list) { await processContent.batchInvokeAndWaitForCompletion( 'process-list-' + i, item.map( payload => ({ payload, }), 86_400), ); i++; } ``` 我們以 25 個為一組[手動觸發](https://trigger.dev/docs/documentation/concepts/triggers/invoke)之前建立的作業。 完成後,讓我們將保存到資料庫的所有內容並連接它: ``` const data = await io.runTask("get-extracted-data", async () => { return (await prisma.docs.findMany({ where: { identifier }, select: { content: true } })).map((d) => d.content).join('\n\n'); }); ``` 我們使用之前指定的標識符。 現在,讓我們在 ChatGPT 中使用新資料建立一個新檔案: ``` const file = await io.openai.files.createAndWaitForProcessing("upload-file", { purpose: "assistants", file: data }); ``` `createAndWaitForProcessing` 是 Trigger.dev 建立的任務,用於將檔案上傳到助手。如果您在沒有整合的情況下手動使用“openai”,則必須串流傳輸檔案。 現在讓我們建立或更新我們的助手: ``` const assistant = await io.openai.runTask("create-or-update-assistant", async (openai) => { const currentAssistant = await prisma.assistant.findFirst({ where: { url: payload.url } }); if (currentAssistant) { return openai.beta.assistants.update(currentAssistant.aId, { file_ids: [file.id] }); } return openai.beta.assistants.create({ name: identifier, description: 'Documentation', instructions: 'You are a documentation assistant, you have been loaded with documentation from ' + payload.url + ', return everything in an MD format.', model: 'gpt-4-1106-preview', tools: [{ type: "code_interpreter" }, {type: 'retrieval'}], file_ids: [file.id], }); }); ``` - 我們首先檢查是否有針對該特定 URL 的助手。 - 如果我們有的話,讓我們用新文件更新助手。 - 如果沒有,讓我們建立一個新的助手。 - 我們傳遞「你是文件助理」的指令,需要注意的是,我們希望最終輸出為「MD」格式,以便稍後更好地顯示。 對於拼圖的最後一塊,讓我們將新助手儲存到我們的資料庫中。 **這是程式碼:** ``` await io.runTask("save-assistant", async () => { await prisma.assistant.upsert({ where: { url: payload.url }, update: { aId: assistant.id, }, create: { aId: assistant.id, url: payload.url, } }); }); ``` 如果該 URL 已經存在,我們可以嘗試使用新的助手 ID 來更新它。 這是該頁面的完整程式碼: ``` import { eventTrigger } from "@trigger.dev/sdk"; import { client } from "@openai-assistant/trigger"; import {object, string} from "zod"; import {JSDOM} from "jsdom"; import {chunk} from "lodash"; import {prisma} from "@openai-assistant/helper/prisma.client"; import {openai} from "@openai-assistant/helper/open.ai"; const makeId = (length: number) => { let text = ''; const possible = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789'; for (let i = 0; i < length; i += 1) { text += possible.charAt(Math.floor(Math.random() * possible.length)); } return text; }; client.defineJob({ // This is the unique identifier for your Job; it must be unique across all Jobs in your project. id: "process-documentation", name: "Process Documentation", version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction trigger: eventTrigger({ name: "process.documentation.event", schema: object({ url: string(), }) }), integrations: { openai }, run: async (payload, io, ctx) => { // The first task to get the sitemap URL from the website const getSiteMap = await io.runTask("grab-sitemap", async () => { const data = await (await fetch(payload.url)).text(); const dom = new JSDOM(data); const sitemap = dom.window.document.querySelector('[rel="sitemap"]')?.getAttribute('href'); return new URL(sitemap!, payload.url).toString(); }); // We parse the sitemap; instead of using some XML parser, we just use regex to get the URLs and we return it in chunks of 25 const {identifier, list} = await io.runTask("load-and-parse-sitemap", async () => { const urls = /(http|ftp|https):\/\/([\w_-]+(?:(?:\.[\w_-]+)+))([\w.,@?^=%&:\/~+#-]*[\w@?^=%&\/~+#-])/g; const identifier = makeId(5); const data = await (await fetch(getSiteMap)).text(); // @ts-ignore return {identifier, list: chunk(([...new Set(data.match(urls))] as string[]).filter(f => f.includes(payload.url)).map(p => ({identifier, url: p})), 25)}; }); // We go into each page and grab the content; we do this in batches of 25 and save it to the DB let i = 0; for (const item of list) { await processContent.batchInvokeAndWaitForCompletion( 'process-list-' + i, item.map( payload => ({ payload, }), 86_400), ); i++; } // We get the data that we saved in batches from the DB const data = await io.runTask("get-extracted-data", async () => { return (await prisma.docs.findMany({ where: { identifier }, select: { content: true } })).map((d) => d.content).join('\n\n'); }); // We upload the data to OpenAI with all the content const file = await io.openai.files.createAndWaitForProcessing("upload-file", { purpose: "assistants", file: data }); // We create a new assistant or update the old one with the new file const assistant = await io.openai.runTask("create-or-update-assistant", async (openai) => { const currentAssistant = await prisma.assistant.findFirst({ where: { url: payload.url } }); if (currentAssistant) { return openai.beta.assistants.update(currentAssistant.aId, { file_ids: [file.id] }); } return openai.beta.assistants.create({ name: identifier, description: 'Documentation', instructions: 'You are a documentation assistant, you have been loaded with documentation from ' + payload.url + ', return everything in an MD format.', model: 'gpt-4-1106-preview', tools: [{ type: "code_interpreter" }, {type: 'retrieval'}], file_ids: [file.id], }); }); // We update our internal database with the assistant await io.runTask("save-assistant", async () => { await prisma.assistant.upsert({ where: { url: payload.url }, update: { aId: assistant.id, }, create: { aId: assistant.id, url: payload.url, } }); }); }, }); export function getElementsBetween(startElement: Element, endElement: Element) { let currentElement = startElement; const elements = []; // Traverse the DOM until the endElement is reached while (currentElement && currentElement !== endElement) { currentElement = currentElement.nextElementSibling!; // If there's no next sibling, go up a level and continue if (!currentElement) { // @ts-ignore currentElement = startElement.parentNode!; startElement = currentElement; if (currentElement === endElement) break; continue; } // Add the current element to the list if (currentElement && currentElement !== endElement) { elements.push(currentElement); } } return elements; } // This job will grab the content from the website const processContent = client.defineJob({ // This is the unique identifier for your Job; it must be unique across all Jobs in your project. id: "process-content", name: "Process Content", version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction trigger: eventTrigger({ name: "process.content.event", schema: object({ url: string(), identifier: string(), }) }), run: async (payload, io, ctx) => { return io.runTask('grab-content', async () => { try { // We first grab a raw HTML of the content from the website const data = await (await fetch(payload.url)).text(); // We load it with JSDOM so we can manipulate it const dom = new JSDOM(data); // We remove all the scripts and styles from the page dom.window.document.querySelectorAll('script, style').forEach((el) => el.remove()); // We grab all the titles from the page const content = Array.from(dom.window.document.querySelectorAll('h1, h2, h3, h4, h5, h6')); // We grab the last element so we can get the content between the last element and the next element const lastElement = content[content.length - 1]?.parentElement?.nextElementSibling!; const elements = []; // We loop through all the elements and grab the content between each title for (let i = 0; i < content.length; i++) { const element = content[i]; const nextElement = content?.[i + 1] || lastElement; const elementsBetween = getElementsBetween(element, nextElement); elements.push({ title: element.textContent, content: elementsBetween.map((el) => el.textContent).join('\n') }); } // We create a raw text format of all the content const page = ` ---------------------------------- url: ${payload.url}\n ${elements.map((el) => `${el.title}\n${el.content}`).join('\n')} ---------------------------------- `; // We save it to our database await prisma.docs.upsert({ where: { url: payload.url }, update: { content: page, identifier: payload.identifier }, create: { url: payload.url, content: page, identifier: payload.identifier } }); } catch (e) { console.log(e); } }); }, }); ``` 我們已經完成建立後台作業來抓取和索引文件🎉 ### 詢問助理 現在,讓我們建立一個任務來詢問我們的助手。 前往“jobs”並建立一個新檔案“question.assistant.ts”。 **新增以下程式碼:** ``` import {eventTrigger} from "@trigger.dev/sdk"; import {client} from "@openai-assistant/trigger"; import {object, string} from "zod"; import {openai} from "@openai-assistant/helper/open.ai"; client.defineJob({ // This is the unique identifier for your Job; it must be unique across all Jobs in your project. id: "question-assistant", name: "Question Assistant", version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction trigger: eventTrigger({ name: "question.assistant.event", schema: object({ content: string(), aId: string(), threadId: string().optional(), }) }), integrations: { openai }, run: async (payload, io, ctx) => { // Create or use an existing thread const thread = payload.threadId ? await io.openai.beta.threads.retrieve('get-thread', payload.threadId) : await io.openai.beta.threads.create('create-thread'); // Create a message in the thread await io.openai.beta.threads.messages.create('create-message', thread.id, { content: payload.content, role: 'user', }); // Run the thread const run = await io.openai.beta.threads.runs.createAndWaitForCompletion('run-thread', thread.id, { model: 'gpt-4-1106-preview', assistant_id: payload.aId, }); // Check the status of the thread if (run.status !== "completed") { console.log('not completed'); throw new Error(`Run finished with status ${run.status}: ${JSON.stringify(run.last_error)}`); } // Get the messages from the thread const messages = await io.openai.beta.threads.messages.list("list-messages", run.thread_id, { query: { limit: "1" } }); const content = messages[0].content[0]; if (content.type === 'text') { return {content: content.text.value, threadId: thread.id}; } } }); ``` - 該事件需要三個參數 - `content` - 我們想要傳送給助理的訊息。 - `aId` - 我們先前建立的助手的內部 ID。 - `threadId` - 對話的執行緒 ID。正如您所看到的,這是一個可選參數,因為在第一個訊息中,我們還沒有線程 ID。 - 然後,我們建立或取得前一個執行緒的執行緒。 - 我們在助理提出的問題的線索中加入一條新訊息。 - 我們執行線程並等待它完成。 - 我們取得訊息清單(並將其限制為 1),因為第一則訊息是對話中的最後一則訊息。 - 我們返回訊息內容和我們剛剛建立的線程ID。 ### 新增路由 我們需要為我們的應用程式建立 3 個 API 路由: 1、派新助理進行處理。 2. 透過URL獲取特定助手。 3. 新增訊息給助手。 在「app/api」中建立一個名為assistant的新資料夾,並在其中建立一個名為「route.ts」的新檔案。裡面加入如下程式碼: ``` import {client} from "@openai-assistant/trigger"; import {prisma} from "@openai-assistant/helper/prisma.client"; export async function POST(request: Request) { const body = await request.json(); if (!body.url) { return new Response(JSON.stringify({error: 'URL is required'}), {status: 400}); } // We send an event to the trigger to process the documentation const {id: eventId} = await client.sendEvent({ name: "process.documentation.event", payload: {url: body.url}, }); return new Response(JSON.stringify({eventId}), {status: 200}); } export async function GET(request: Request) { const url = new URL(request.url).searchParams.get('url'); if (!url) { return new Response(JSON.stringify({error: 'URL is required'}), {status: 400}); } const assistant = await prisma.assistant.findFirst({ where: { url: url } }); return new Response(JSON.stringify(assistant), {status: 200}); } ``` 第一個「POST」方法取得一個 URL,並使用用戶端傳送的 URL 觸發「process.documentation.event」作業。 第二個「GET」方法從我們的資料庫中透過客戶端發送的 URL 取得助手。 現在,讓我們建立向助手新增訊息的路由。 在「app/api」內部建立一個新資料夾「message」並新增一個名為「route.ts」的新文件,然後新增以下程式碼: ``` import {prisma} from "@openai-assistant/helper/prisma.client"; import {client} from "@openai-assistant/trigger"; export async function POST(request: Request) { const body = await request.json(); // Check that we have the assistant id and the message if (!body.id || !body.message) { return new Response(JSON.stringify({error: 'Id and Message are required'}), {status: 400}); } // get the assistant id in OpenAI from the id in the database const assistant = await prisma.assistant.findUnique({ where: { id: +body.id } }); // We send an event to the trigger to process the documentation const {id: eventId} = await client.sendEvent({ name: "question.assistant.event", payload: { content: body.message, aId: assistant?.aId, threadId: body.threadId }, }); return new Response(JSON.stringify({eventId}), {status: 200}); } ``` 這是一個非常基本的程式碼。我們從客戶端獲取訊息、助手 ID 和線程 ID,並將其發送到我們之前建立的「question.assistant.event」。 最後要做的事情是建立一個函數來獲取我們所有的助手。 在「helpers」內部建立一個名為「get.list.ts」的新函數並新增以下程式碼: ``` import {prisma} from "@openai-assistant/helper/prisma.client"; // Get the list of all the available assistants export const getList = () => { return prisma.assistant.findMany({ }); } ``` 非常簡單的程式碼即可獲得所有助手。 我們已經完成了後端🥳 讓我們轉到前面。 ---  ## 建立前端 我們將建立一個基本介面來新增 URL 並顯示已新增 URL 的清單:  ### 首頁 將 `app/page.tsx` 的內容替換為以下程式碼: ``` import {getList} from "@openai-assistant/helper/get.list"; import Main from "@openai-assistant/components/main"; export default async function Home() { const list = await getList(); return ( <Main list={list} /> ) } ``` 這是一個簡單的程式碼,它從資料庫中取得清單並將其傳遞給我們的 Main 元件。 接下來,讓我們建立“Main”元件。 在「app」內建立一個新資料夾「components」並新增一個名為「main.tsx」的新檔案。 **新增以下程式碼:** ``` "use client"; import {Assistant} from '@prisma/client'; import {useCallback, useState} from "react"; import {FieldValues, SubmitHandler, useForm} from "react-hook-form"; import {ChatgptComponent} from "@openai-assistant/components/chatgpt.component"; import {AssistantList} from "@openai-assistant/components/assistant.list"; import {TriggerProvider} from "@trigger.dev/react"; export interface ExtendedAssistant extends Assistant { pending?: boolean; eventId?: string; } export default function Main({list}: {list: ExtendedAssistant[]}) { const [assistantState, setAssistantState] = useState(list); const {register, handleSubmit} = useForm(); const submit: SubmitHandler<FieldValues> = useCallback(async (data) => { const assistantResponse = await (await fetch('/api/assistant', { body: JSON.stringify({url: data.url}), method: 'POST', headers: { 'Content-Type': 'application/json' } })).json(); setAssistantState([...assistantState, {...assistantResponse, url: data.url, pending: true}]); }, [assistantState]) const changeStatus = useCallback((val: ExtendedAssistant) => async () => { const assistantResponse = await (await fetch(`/api/assistant?url=${val.url}`, { method: 'GET', headers: { 'Content-Type': 'application/json' } })).json(); setAssistantState([...assistantState.filter((v) => v.id), assistantResponse]); }, [assistantState]) return ( <TriggerProvider publicApiKey={process.env.NEXT_PUBLIC_TRIGGER_PUBLIC_API_KEY!}> <div className="w-full max-w-2xl mx-auto p-6 flex flex-col gap-4"> <form className="flex items-center space-x-4" onSubmit={handleSubmit(submit)}> <input className="flex-grow p-3 border border-black/20 rounded-xl" placeholder="Add documentation link" type="text" {...register('url', {required: 'true'})} /> <button className="flex-shrink p-3 border border-black/20 rounded-xl" type="submit"> Add </button> </form> <div className="divide-y-2 divide-gray-300 flex gap-2 flex-wrap"> {assistantState.map(val => ( <AssistantList key={val.url} val={val} onFinish={changeStatus(val)} /> ))} </div> {assistantState.filter(f => !f.pending).length > 0 && <ChatgptComponent list={assistantState} />} </div> </TriggerProvider> ) } ``` 讓我們看看這裡發生了什麼: - 我們建立了一個名為「ExtendedAssistant」的新接口,其中包含兩個參數「pending」和「eventId」。當我們建立一個新的助理時,我們沒有最終的值,我們將只儲存`eventId`並監聽作業處理直到完成。 - 我們從伺服器元件取得清單並將其設定為新狀態(以便我們稍後可以修改它) - 我們新增了「TriggerProvider」來幫助我們監聽事件完成並用資料更新它。 - 我們使用「react-hook-form」建立一個新表單來新增助手。 - 我們新增了一個帶有一個輸入「URL」的表單來提交新的助理進行處理。 - 我們迭代並顯示所有現有的助手。 - 在提交表單時,我們將資訊傳送到先前建立的「路由」以新增助理。 - 事件完成後,我們觸發「changeStatus」以從資料庫載入助手。 - 最後,我們有了 ChatGPT 元件,只有在沒有等待處理的助手時才會顯示(`!f.pending`) 讓我們建立 `AssistantList` 元件。 在「components」內,建立一個新檔案「assistant.list.tsx」並在其中加入以下內容: ``` "use client"; import {FC, useEffect} from "react"; import {ExtendedAssistant} from "@openai-assistant/components/main"; import {useEventRunDetails} from "@trigger.dev/react"; export const Loading: FC<{eventId: string, onFinish: () => void}> = (props) => { const {eventId} = props; const { data, error } = useEventRunDetails(eventId); useEffect(() => { if (!data || error) { return ; } if (data.status === 'SUCCESS') { props.onFinish(); } }, [data]); return <div className="pointer bg-yellow-300 border-yellow-500 p-1 px-3 text-yellow-950 border rounded-2xl">Loading</div> }; export const AssistantList: FC<{val: ExtendedAssistant, onFinish: () => void}> = (props) => { const {val, onFinish} = props; if (val.pending) { return <Loading eventId={val.eventId!} onFinish={onFinish} /> } return ( <div key={val.url} className="pointer relative bg-green-300 border-green-500 p-1 px-3 text-green-950 border rounded-2xl hover:bg-red-300 hover:border-red-500 hover:text-red-950 before:content-[attr(data-content)]" data-content={val.url} /> ) } ``` 我們迭代我們建立的所有助手。如果助手已經建立,我們只顯示名稱。如果沒有,我們渲染`<Loading />`元件。 載入元件在螢幕上顯示“正在載入”,並長時間輪詢伺服器直到事件完成。 我們使用 Trigger.dev 建立的 useEventRunDetails 函數來了解事件何時完成。 事件完成後,它會觸發「onFinish」函數,用新建立的助手更新我們的客戶端。 ### 聊天介面  現在,讓我們加入 ChatGPT 元件並向我們的助手提問! - 選擇我們想要使用的助手 - 顯示訊息列表 - 新增我們要傳送的訊息的輸入和提交按鈕。 在「components」內部新增一個名為「chatgpt.component.tsx」的新文件 讓我們繪製 ChatGPT 聊天框: ``` "use client"; import {FC, useCallback, useEffect, useRef, useState} from "react"; import {ExtendedAssistant} from "@openai-assistant/components/main"; import Markdown from 'react-markdown' import {useEventRunDetails} from "@trigger.dev/react"; interface Messages { message?: string eventId?: string } export const ChatgptComponent = ({list}: {list: ExtendedAssistant[]}) => { const url = useRef<HTMLSelectElement>(null); const [message, setMessage] = useState(''); const [messagesList, setMessagesList] = useState([] as Messages[]); const [threadId, setThreadId] = useState<string>('' as string); const submitForm = useCallback(async (e: any) => { e.preventDefault(); setMessagesList((messages) => [...messages, {message: `**[ME]** ${message}`}]); setMessage(''); const messageResponse = await (await fetch('/api/message', { method: 'POST', body: JSON.stringify({message, id: url.current?.value, threadId}), })).json(); if (!threadId) { setThreadId(messageResponse.threadId); } setMessagesList((messages) => [...messages, {eventId: messageResponse.eventId}]); }, [message, messagesList, url, threadId]); return ( <div className="border border-black/50 rounded-2xl flex flex-col"> <div className="border-b border-b-black/50 h-[60px] gap-3 px-3 flex items-center"> <div>Assistant:</div> <div> <select ref={url} className="border border-black/20 rounded-xl p-2"> {list.filter(f => !f.pending).map(val => ( <option key={val.id} value={val.id}>{val.url}</option> ))} </select> </div> </div> <div className="flex-1 flex flex-col gap-3 py-3 w-full min-h-[500px] max-h-[1000px] overflow-y-auto overflow-x-hidden messages-list"> {messagesList.map((val, index) => ( <div key={index} className={`flex border-b border-b-black/20 pb-3 px-3`}> <div className="w-full"> {val.message ? <Markdown>{val.message}</Markdown> : <MessageComponent eventId={val.eventId!} onFinish={setThreadId} />} </div> </div> ))} </div> <form onSubmit={submitForm}> <div className="border-t border-t-black/50 h-[60px] gap-3 px-3 flex items-center"> <div className="flex-1"> <input value={message} onChange={(e) => setMessage(e.target.value)} className="read-only:opacity-20 outline-none border border-black/20 rounded-xl p-2 w-full" placeholder="Type your message here" /> </div> <div> <button className="border border-black/20 rounded-xl p-2 disabled:opacity-20" disabled={message.length < 3}>Send</button> </div> </div> </form> </div> ) } export const MessageComponent: FC<{eventId: string, onFinish: (threadId: string) => void}> = (props) => { const {eventId} = props; const { data, error } = useEventRunDetails(eventId); useEffect(() => { if (!data || error) { return ; } if (data.status === 'SUCCESS') { props.onFinish(data.output.threadId); } }, [data]); if (!data || error || data.status !== 'SUCCESS') { return ( <div className="flex justify-end items-center pb-3 px-3"> <div className="animate-spin rounded-full h-3 w-3 border-t-2 border-b-2 border-blue-500" /> </div> } return <Markdown>{data.output.content}</Markdown>; }; ``` 這裡正在發生一些令人興奮的事情: - 當我們建立新訊息時,我們會自動將其呈現在螢幕上作為「我們的」訊息,但是當我們將其發送到伺服器時,我們需要推送事件 ID,因為我們還沒有訊息。這就是我們使用 `{val.message ? <Markdown>{val.message}</Markdown> : <MessageComponent eventId={val.eventId!} onFinish={setThreadId} />}` - 我們用「Markdown」元件包裝訊息。如果您還記得,我們在前面的步驟中告訴 ChatGPT 以 MD 格式輸出所有內容,以便我們可以正確渲染它。 - 事件處理完成後,我們會更新線程 ID,以便我們從以下訊息中獲得相同對話的上下文。 我們就完成了🎉 ---  ## 讓我們聯絡吧! 🔌 作為開源開發者,您可以加入我們的[社群](https://discord.gg/nkqV9xBYWy) 做出貢獻並與維護者互動。請隨時造訪我們的 [GitHub 儲存庫](https://github.com/triggerdotdev/trigger.dev),貢獻並建立與 Trigger.dev 相關的問題。 本教學的源程式碼可在此處取得: [https://github.com/triggerdotdev/blog/tree/main/openai-assistant](https://github.com/triggerdotdev/blog/tree/main/openai-assistant) 感謝您的閱讀! --- 原文出處:https://dev.to/triggerdotdev/train-chatgpt-on-your-documentation-1a9g
曾經嘗試過在 Web 應用程式中使用 Docker 磁碟區進行熱重載嗎?如果你有跟我一樣可怕的經歷,你會喜歡 Docker 剛剛發布的最新功能:**docker-compose watch**!讓我向您展示如何升級現有專案以獲得出色的 Docker 開發設置,您的團隊*實際上*會喜歡使用它 🤩 TL;DR:看看這個 [docker-compose](https://github.com/Code42Cate/hackathon-starter/blob/main/docker-compose.yml) 檔案和 [官方文件](https://docs.docker.com/compose/file-watch/) 讓我們開始吧!  ## 介紹 Docker 剛剛發布了[Docker Compose Watch](https://docs.docker.com/compose/file-watch/) 和[Docker Compose Version 2.22](https://docs.docker.com/compose/release-notes/) #2220).有了這個新功能,您可以使用“docker-compose watch”代替“docker-compose up”,並自動將本機原始程式碼與 Docker 容器中的程式碼同步,而無需使用磁碟區! 讓我們透過使用我[之前寫過的](https://dev.project) 來看看它在實際專案中的工作原理。 在這個專案中,我有一個帶有前端、後端以及一些用於 UI 和資料庫的附加庫的 monorepo。 ``` ├── apps │ ├── api │ └── web └── packages ├── database ├── eslint-config-custom ├── tsconfig └── ui ``` 兩個應用程式(「api」和「web」)都已經進行了docker 化,而Dockerfile 位於專案的根目錄中([1](https://github.com/Code42Cate/hackathon-starter/blob/main/api.Dockerfile ), [2](https://github.com/Code42Cate/hackathon-starter/blob/main/web.Dockerfile)) `docker-compose.yml` 檔案如下所示: ``` services: web: build: dockerfile: web.Dockerfile ports: - "3000:3000" depends_on: - api api: build: dockerfile: api.Dockerfile ports: - "3001:3000"from within the Docker network ``` 這已經相當不錯了,但如您所知,在開發過程中使用它是一個 PITA。每當您更改程式碼時,您都必須重建 Docker 映像,即使您的應用程式可能支援開箱即用的熱重載(或使用 [Nodemon](https://www.npmjs.com/package/nodemon) 如果不)。 為了改善這一點,Docker Compose Watch [引入了一個新屬性](https://docs.docker.com/compose/file-watch/#configuration),稱為「watch」。 watch 屬性包含一個所謂的 **rules** 列表,每個規則都包含它們正在監視的 **path** 以及一旦路徑中的文件發生更改就會執行的 **action**。 ## 同步 如果您希望在主機和容器之間同步資料夾,您可以新增: ``` services: web: # shortened for clarity build: dockerfile: web.Dockerfile develop: watch: - action: sync path: ./apps/web target: /app/apps/web ``` 每當主機上的路徑“./apps/web/”中的檔案發生變更時,它將同步(複製)到容器的“/app/apps/web”。目標路徑中的附加應用程式是必要的,因為這是我們在 [Dockerfile](https://github.com/Code42Cate/hackathon-starter/blob/main/web.Dockerfile) 中定義的「WORKDIR」。如果您有可熱重新加載的應用程式,這可能是您可能會使用的主要內容。 ## 重建 如果您有需要編譯的應用程式或需要重新安裝的依賴項,還有一個名為 **rebuild** 的操作。它將重建並重新啟動容器,而不是簡單地在主機和容器之間複製檔案。這對你的 npm 依賴關係非常有幫助!讓我們補充一下: ``` services: web: # shortened for clarity build: dockerfile: web.Dockerfile develop: watch: - action: sync path: ./apps/web target: /app/apps/web - action: rebuild path: ./package.json target: /app/package.json ``` 每當我們的 package.json 發生變化時,我們都會重建整個 Dockerfile 以安裝新的依賴項。 ## 同步+重啟 除了同步和重建之外,中間還有一些稱為同步+重新啟動的操作。此操作將首先同步目錄,然後立即重新啟動容器而不重建。大多數框架通常都有無法熱重載的設定檔(例如「next.config.js」)(僅同步是不夠的),但也不需要緩慢重建。 這會將您的撰寫文件更改為: ``` services: web: # shortened for clarity build: dockerfile: web.Dockerfile develop: watch: - action: sync path: ./apps/web target: /app/apps/web - action: rebuild path: ./package.json target: /app/package.json - action: sync+restart path: ./apps/web/next.config.js target: /app/apps/web/next.config.js ``` ## 注意事項 一如既往,沒有[免費午餐](https://en.wikipedia.org/wiki/No_free_lunch_in_search_and_optimization)和一些警告😬 新的“watch”屬性的最大問題是路徑仍然非常基本。文件指出,尚不支援 Glob 模式,如果您想具體說明,這可能會導致「大量」規則。 以下是一些有效和無效的範例: ✅ `應用程式/網路` 這將會符合`./apps/web`中的*所有*檔案(例如`./apps/web/README.md`,還有`./apps/web/src/index.tsx`) ❌ `build/**/!(*.spec|*.bundle|*.min).js` 遺憾的是(還沒?) 支持 Glob ❌ `~/下載` 所有路徑都是相對於專案根目錄的! ## 下一步 如果您對 Docker 設定仍然不滿意,還有很多方法可以改進它! 協作是軟體開發的重要組成部分,[孤島工作](https://www.personio.com/hr-lexicon/working-in-silos/)可能會嚴重損害您的團隊。緩慢的 Docker 建置和複雜的設定沒有幫助!為了解決這個問題並促進協作文化,您可以使用 Docker 擴展,例如 [Livecycle](https://hub.docker.com/extensions/livecycle/docker-extension?utm_source=github&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm)立即與您的隊友分享您本地的docker-compose 應用程式。由於您已經在使用 Docker 和 docker-compose,因此您需要做的就是安裝 [Docker 桌面擴充](https://hub.docker.com/extensions/livecycle/docker-extension?utm_source=github&utm_medium=code42cate&utm_campaign=hackathonstarter )並點擊共享切換按鈕。然後,您的應用程式將透過隧道連接到網路,您可以與您的團隊分享您的唯一 URL 以獲取回饋!如果您想查看 Livecycle 的更多用例,我在[這篇文章](https://dev.to/code42cate/how-to-win-any-hackathon-3i99)中寫了更多相關內容:) 像往常一樣,確保您的 Dockerfile 遵循最佳實踐,尤其是在多階段建置和快取方面。雖然這可能會使編寫初始 Dockerfile 變得更加困難,但它將使您的 Docker 應用程式在開發過程中使用起來更加愉快。 建立一個基本的“.dockerignore”檔案並將依賴項安裝與程式碼建置分開還有很長的路要走! ## 結論 一如既往,我希望你今天學到新東西了!如果您在設定 Docker 專案時需要任何協助,或者您有任何其他回饋,請告訴我 乾杯,喬納斯:D --- 原文出處:https://dev.to/code42cate/say-goodbye-to-docker-volumes-j9l
VSCode 寫程式技巧分享! ## 更聰明地複製、貼上 我見過人們透過執行以下操作來複製貼上程式碼: 1. 將滑鼠遊標移至單字開頭。 2. 按住左鍵點選。 3. 一直拖曳到單字最後。 4. 釋放左鍵點選。 5. 右鍵點選所選內容。 6. 按一下「複製」。 7. 在 VS Code 的檔案總管中捲動以尋找目標檔案。 8. 點選目標檔案。 9. 將遊標移到檔案中的所需位置。 8. 右鍵點選目標位置。 9. 按一下「貼上」。 這是一個有點慢的過程。特別是如果您需要多次應用此操作...改進複製貼上的一些方法是: - 使用“CTRL + C”進行**複製**,使用“CTRL + V”進行**貼上**。 - 使用“CTRL + SHIFT + 左/右箭頭”**增加/減少單字選擇**。 - 使用“SHIFT + 左/右”箭頭**按字元增加/減少選擇**。 - 點擊 VS Code 中的一行程式碼並按下「CTRL + X」將**將該行放入剪貼簿**。在任何地方使用“CTRL + V”都會**在其中插入該行程式碼**。 - 使用「ALT + 向上/向下箭頭」**將一行程式碼向上/向下移動**一個位置。 更聰明地複製貼上也意味著更聰明地導航。 ## 更聰明地導航 使用組合鍵“CTRL + P”,而不是手動瀏覽資源管理器窗格。這樣,您可以按名稱搜尋文件。這是一個“智能”搜尋,意味著它不僅會查找包含搜尋文本的單詞,還會查找組合,例如“prodetcon”還將查找“project-details-container.component.ts”。使用「CTRL + P」比看到有人在檔案總管窗格中掙扎要快得多,這本身就是一種痛苦(雙關語)。  不要透過捲動來尋找文件內的某些程式碼,而是使用以下組合鍵: - `CTRL + G`:轉到行 - `CTRL + F`:在檔案中搜尋(使用`ENTER`鍵導航到下一個符合專案) - `CTRL + 點選類別/函數/等`:轉到所述類別/函數/等的定義。 使用“CTRL + TAB”在上次開啟的檔案和目前開啟的檔案之間切換(或使用“TAB”進一步切換到其他開啟的檔案)。這比將遊標移到工作列、查找正確的標籤並點擊它打開要快得多。 > 注意:在 VS Code 中,以這種方式在開啟的檔案之間進行切換非常有效率。另外,在 Windows 中使用「ALT + TAB」在開啟的視窗之間切換。 ## 更聰明地重新命名 不要自己重命名變數的每一次出現。它既耗時又容易出錯。相反,請轉到該變數的定義並按“F2”,重命名它,然後按“ENTER”。這將改變每一次發生的情況。這不僅適用於變數,也適用於函數、類別、介面等。這也適用於跨文件。  ## 使用 Emmet [Emmet](https://emmet.io/) 是一個內容/程式碼輔助工具,可以更快、更有效率地編寫程式碼。它是[VS Code 的標準](https://code.visualstudio.com/docs/editor/emmet),因此不需要任何插件。這個概念很簡單:您開始輸入 Emmet 縮寫,按下“TAB”或“ENTER”,就會出現該縮寫的完整 Emmet 片段。 Emmet 縮寫的範例可以是「.grid>.col*3」。當您按下「TAB」或「ENTER」時,VS Code 會為您填寫整段程式碼:  Emmet 的一大優點是您也可以產生 [“lorem ipsum” 文字](https://docs.emmet.io/abbreviations/lorem-ipsum/)。例如,`ul>li*4>lorem4`將產生一個包含 4 個元素的無序列表,每個清單專案包含 4 個隨機單字。  ## 使用格式化程式 使用 VS Code 中的程式碼格式化程式來格式化程式碼。我強烈推薦[Prettier](https://prettier.io/docs/en/)。 使用程式碼格式化程式的好處之一是它還可以「美化」您的程式碼。因此,如果您從根本沒有佈局的地方複製貼上程式碼,您可以點擊格式組合鍵(“CTRL + ALT + F”)等等,您的程式碼現在“美化”了,更重要的是,可讀了。 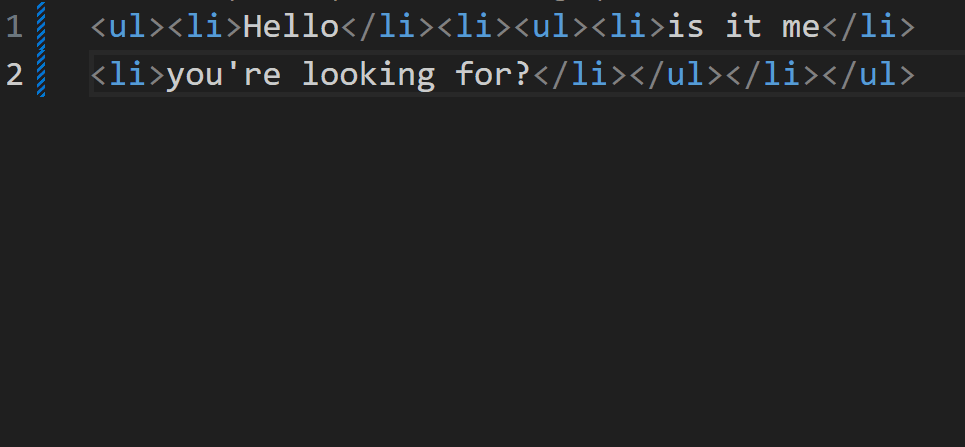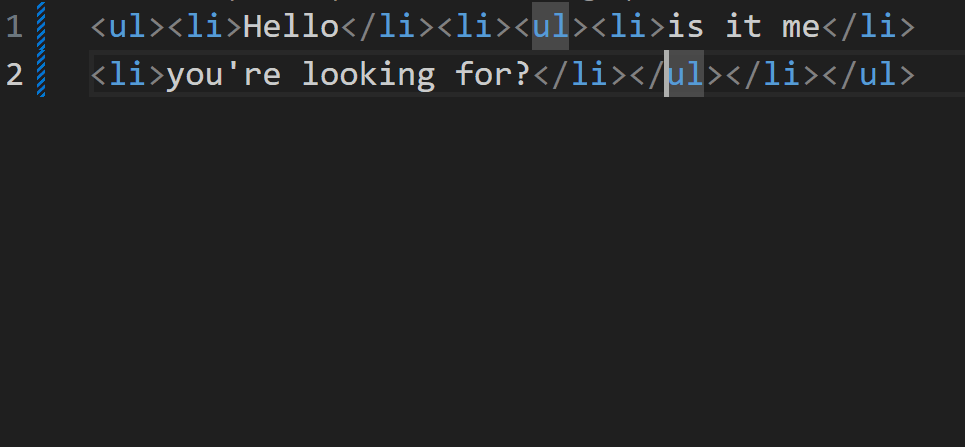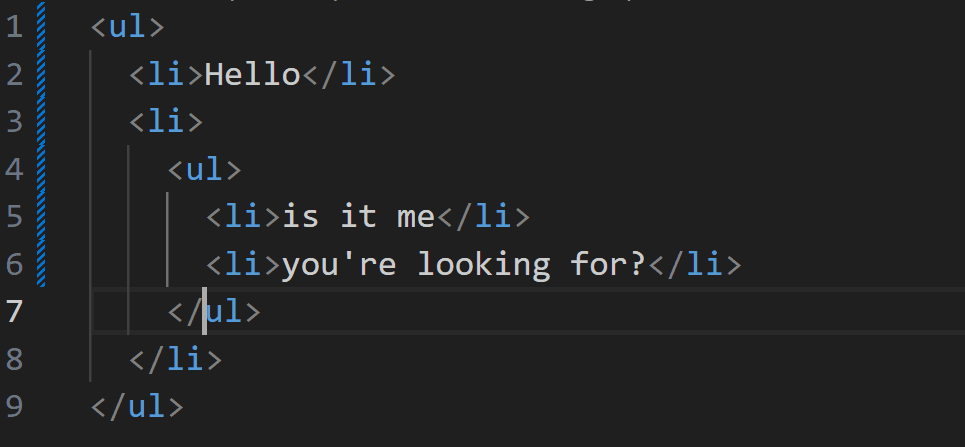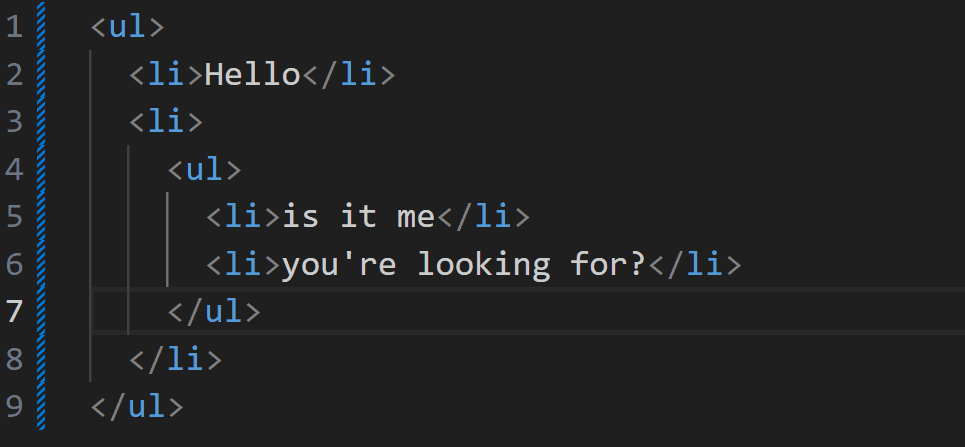 > 注意:一個好的提示是在儲存時套用格式。您可以在設定中變更此設定(尋找「儲存時格式」)。 格式化不僅對你自己有用,而且對整個團隊有用,因為它強制團隊的程式碼更加一致。看看我的另一篇文章[在Angular 專案中強制執行前端指南](https://dev.to/kinginit/enforcing-front-end-guidelines-in-an-angular-project-4199) 了解更多資訊關於它。 ## 使用程式碼片段 程式碼片段是模板,可以更輕鬆地編寫重複的程式碼片段,例如 for 迴圈、while 語句等。  透過使用程式碼片段,您可以透過輸入最少的內容輕鬆建立程式碼區塊。您可以使用內建的程式碼片段,使用提供程式碼片段的擴展,甚至建立您自己的程式碼片段! 內建程式碼片段提供了多種語言的模板,例如 TypeScript、JavaScript、HTML、CSS 等。例如,您可以使用它輕鬆建立「switch」語句,如上所示。 VS Code Marketplace 有多個擴充功能可以提供您程式碼片段。例如 [Angular 片段](https://marketplace.visualstudio.com/items?itemName=johnpapa.Angular2)、[Tailwind UI 片段](https://marketplace.visualstudio.com/items?itemName=evondev.tailwindui-marketplace.visualstudio.com/items?itemName=evondev.tailwindui-evondev.tailwindui-片段)、[Bootstrap 片段](https://marketplace.visualstudio.com/items?itemName=thekalinga.bootstrap4-vscode) 等。 最後,您可以建立自己的片段。您可以為特定語言建立全域程式碼片段,也可以建立特定於專案的程式碼片段。我不會在這裡詳細介紹任何細節,但請查看有關[如何建立自己的片段](https://code.visualstudio.com/docs/editor/userdefinesnippets#_create-your-own-snippets)。 ## 利用“量子打字” 我將其稱為“量子輸入”,因為這確實加快了您在 VS Code 中輸入程式碼的速度。這都是關於多重選擇的。當您需要更改或新增文字到多行時,VS Code 允許您透過選擇這些多行並同時開始在這些行上鍵入來完成此操作。 按住“SHIFT + ALT”並拖曳多條線以進行選擇。您將看到這些行上出現多個鍵入遊標。只需開始輸入,文字就會同時加入。  如果您想將相同的文字新增至多個位置但它們不對齊,您可以按住「ALT」同時按一下您要鍵入相同文字的所有位置。  您也可以按住“ALT”並同時選擇多個單字。無需單擊某個位置,只需拖曳進行選擇,然後釋放左鍵單擊或雙擊即可選擇單個單字,同時按住“ALT”鍵。  ## 快速環繞選擇 程式碼通常必須用方括號、圓括號或大括號括起來。或某些內容需要用引號(單引號或雙引號)引起來。為此,人們通常會轉到起始位置,輸入起始括號,將遊標移到結束位置,然後輸入結束括號。更有效的方法是選擇需要包圍的零件,然後簡單地鍵入起始括號。 VS Code 會夠聰明,知道整個部分需要被包圍。  這適用於 `(`、`{`、`[`、`<`、`'` 和 `"`。 ## 利用 VS Code 重構技巧 您可以使用 VS Code 自動重構程式碼片段。例如,您可以讓 VS Code 為您產生它們,而不是編寫自己的 getter 和 setter。 要重構某些內容,只需選擇需要重構的內容,右鍵單擊,然後單擊“重構...”,甚至更快:使用“CTRL + SHIFT + R”。 根據您所在的文件,VS Code 可以為您提供多種重構。例如,對於 TypeScript,您可以使用「提取函數」、「提取常數」或「產生 get 和 set 存取器」。請參閱 [此處](https://code.visualstudio.com/docs/typescript/typescript-refactoring) 的 TypeScript 完整清單。 ## 使用正規表示式搜尋和替換 正規表示式 (RegEx) 可能是開發人員工具包中非常強大的工具,值得您花時間更好地熟悉它們。您不僅可以在自己的程式碼中使用它(例如,驗證模式、字串替換等),還可以在 VS Code 中使用它進行高級搜尋和替換。 ### 例子 在您所在的專案中,一些 CSS 選擇器以 `app-` 開頭並以 `-container` 結尾。由於新的指導方針,他們希望您將後綴“-container”更改為“-wrapper”。您可以嘗試進行簡單的搜尋和替換,方法是尋找“-container”並將其替換為“-page”,但是當您進行替換時,您會看到某些出現的內容已被替換,而這本不應該是這樣的(例如,名為“.unit-container-highlight”的 CSS 選擇器變成“.unit-wrapper-highlight”)。 透過RegEx,我們可以進行更細粒度的搜尋。使用捕獲組,我們可以提取我們想要保留的單詞,同時替換其餘的單詞。正規表示式看起來像是「app-([a-z\-]+)-container」。我們想要替換結果,使其以“-page”結尾。替換字串將類似於“app-$1-wrapper”。只要確保您選取了“使用正規表示式”即可。 > 注意:儘管正則表達式允許更細粒度的搜尋,但在進行實際替換之前請檢查搜尋窗格中的結果!  您可以透過允許搜尋僅應用於某些文件來獲得更多控制。範例可以只是 HTML 檔案(`*.html`),甚至只是整個資料夾(`src/app/modules`)。  如果您想在搜尋之前嘗試 RegEx 以確保它是正確的,請使用線上 RegEx 測試器,例如 [Regex101](https://regex101.com/)。如果您沒有或很少有 RegEx 經驗,請查看 [https://regexlearn.com/](https://regexlearn.com/learn/regex101)。 ## 使用工具自動化單調的工作 有時我們必須做一些單調的工作,例如建立模擬資料、為類別中的每個欄位建立函數、根據介面的屬性建立 HTML 清單專案等。俗話說: > 更聰明地工作,而不是更努力工作! 使用工具來自動化此類單調的工作,而不是自己完成所有繁瑣的工作。我常用的工具有: - [NimbleText](https://nimbletext.com/live):根據給定格式將行輸入轉換為特定輸出。 - [Mockaroo](https://www.mockaroo.com/):產生模擬資料並以多種格式(JSON、CSV、XML 等)輸出。 - [JSON Generator](https://json-generator.com/):也產生模擬資料,但專門針對 JSON。它有點複雜,但它允許定制結果。 使用 NimbleText 的一個很好的例子是基於幾個欄位在 HTML 中建立整個表單。我們有一個要在表單中顯示的欄位清單。每個欄位都有一個標籤和一個輸入。讓我們建立一些資料供 NimbleText 進行轉換: ``` first name, text last name, text email, email street, text number, number city, text postal code, text ``` 這裡我們有 7 行和 2 列。每行代表表單欄位。第一列是標籤的名稱,第二列是 HTML 輸入的類型。 在 NimbleText 中,我們保留設定不變(列分隔符號“,”和行分隔符號“\n”)。 每個表單欄位都應該位於類別為「.form-field」的「div」中,其中包含帶有文字的「label」和表單欄位的「input」。 NimbleText 的模式如下: ``` <div class="form-field"> <label for="<% $0.toCamelCase() %>"><% $0.toSentenceCase() %>:</label> <input id="<% $0.toCamelCase() %>" type="$1"/> </div> ``` 當我們查看輸出時,我們發現**大量**工作已經為我們完成: ``` <div class="form-field"> <label for="firstName">First name:</label> <input id="firstName" type="text"/> </div> <div class="form-field"> <label for="lastName">Last name:</label> <input id="lastName" type="text"/> </div> <div class="form-field"> <label for="email">Email:</label> <input id="email" type="email"/> </div> <div class="form-field"> <label for="street">Street:</label> <input id="street" type="text"/> </div> <div class="form-field"> <label for="number">Number:</label> <input id="number" type="number"/> </div> <div class="form-field"> <label for="city">City:</label> <input id="city" type="text"/> </div> <div class="form-field"> <label for="postalCode">Postal code:</label> <input id="postalCode" type="text"/> </div> ``` 因此,盡可能發揮創意並使用這些工具。 ## 結論 在 VS Code 中更快編碼取決於了解快捷鍵並充分利用 IDE 的強大功能。以下是所提及內容的快速總結: 1. 使用快捷鍵進行複製貼上。 2. 透過搜尋取代手動導航,導航更有效率。 3. 使用“F2”重新命名,而不是手動執行。 4. 使用 Emmet。 5. 使用格式化程式來獲得整潔的大綱(以及其他優點)。 6. 使用程式碼片段。 7. 量子型。 8. 使用VS Code重構。 9. RegEx 可以幫助您進行搜尋和取代。 10. 使用NimbleText等工具將單調的工作自動化。 我希望您喜歡閱讀本文。如果您知道有人可能需要一些幫助來更快地編碼,請隨時分享這篇文章! 如果您有任何疑問,請隨時與我們聯繫!謝謝! --- 原文出處:https://dev.to/kinginit/how-to-code-faster-vs-code-edition-4pa
--- 標題:我如何教 Git 發表:真實 描述: 標籤: git, 學習 canonical_url:https://blog.ltgt.net/teaching-git/ 封面圖片:https://marklodato.github.io/visual-git-guide/conventions.svg.png # 使用 100:42 的比例以獲得最佳效果。 # 發佈時間: 2023-11-26 19:17 +0000 --- 我使用 Git 已經十幾年了。八年前,我必須為一家即將建立開源專案的合作夥伴公司舉辦有關 Git(和 GitHub)的培訓課程,我將在這裡向您介紹我的教學方式。順便說一句,從那時起,我們在工作中建立了使用相同(或類似)方法的內部培訓課程。話雖如此,我並沒有發明任何東西:這很大程度上受到了其他人之前寫的內容的啟發,包括[the <cite>Pro Git</cite> book](https://git-scm. com/book/),儘管順序不同,但 <abbr title="in my view">IMO</abbr> 可以有所作為。 我寫這篇文章的原因是,多年來,我不斷看到人們實際上使用 Git,但沒有真正理解他們在做什麼;他們正在使用 Git。他們要么被鎖定在一個非常具體的工作流程中,他們被告知要遵循,並且無法適應另一個開源專案正在使用的工作流程(這也適用於開源維護人員並不真正了解外部貢獻者如何使用 Git) ),或者如果任何事情沒有按照他們想像的方式執行,或者他們在呼叫Git 命令時犯了錯誤,他們就會完全迷失。我受到 [Julia Evans](https://jvns.ca) 對 Git 的(更新)興趣的啟發而寫下來,因為她有時會在社交網絡上徵求評論。 我的目標不是真正教你有關 Git 的知識,而是更多地分享我教授 Git 的方法,以便其他可能會教導的人從中獲得靈感。因此,如果您正在學習 Git,那麼這篇文章並不是專門為您而寫的(抱歉),因此可能不是自給自足的,但希望其他學習資源的連結足以填補空白,使其成為也是有用的學習資源。如果您是視覺學習者,這些外部學習資源都是有插圖的,甚至是視覺學習的。 ## 心理模型 一旦我們清楚了為什麼我們使用VCS(版本控制系統)來記錄_commits_ 中的更改(或者換句話說,我們_將我們的更改_提交到歷史記錄;我假設你對這個術語有一定的熟悉),讓我們多了解一下Git具體來說。 我認為理解 Git 至關重要的一件事是獲得其背後概念的準確心理模型。 首先,這並不是很重要,但Git 實際上並沒有記錄_changes_,而是記錄我們文件的_snapshots_(至少在概念上是這樣;它將使用_packfiles_ 來有效地儲存內容,並且在某些情況下方實際上會儲存_changes_ –diffs–),並且會按需產生差異。不過,這有時會顯示在某些命令的結果中(例如為什麼某些命令顯示一個檔案被刪除而另一個檔案被加入,而其他命令顯示一個檔案被重新命名)。 現在讓我們深入探討一些 Git 概念,或是 Git 如何實現一些常見的 VCS 概念。 ### 犯罪 Git _commit_ 是: * 一個或多個父親提交,或第一次提交沒有父親提交 (_root_) * 提交訊息 * 作者和作者日期(實際上是帶有時區偏移的時間戳) * 提交者和提交日期 * 和我們的檔案:相對於儲存庫根的路徑名、_mode_(UNIX 檔案系統權限)及其內容 每次提交都會獲得一個標識符,該標識符是透過計算該資訊的 SHA1 雜湊值確定的:更改逗號,您將獲得不同的 SHA1,即不同的_提交物件_。 (<abbr title="For What it's value">Fwiw</abbr>,Git 正在慢慢[轉向 SHA-256](https://git-scm.com/docs/hash-function-transition) 作為哈希功能)。 #### 旁白:SHA1 是如何計算的? Git 的儲存是_內容尋址_,這表示每個_物件_都使用直接從其內容派生的名稱進行存儲,並採用 SHA1 雜湊的形式。 從歷史上看,Git 將所有內容儲存在文件中,我們仍然可以這樣推理。文件的內容儲存為 _blob_,目錄儲存為 _tree_(一個文字文件,列出目錄中的文件及其名稱、模式和表示其內容的 _blob_ 的 SHA1,以及其子目錄及其名稱和 SHA1他們的_樹_) 如果您想了解詳細訊息,Julia Evans(再次)寫了一篇令人驚嘆的[博客文章](https://jvns.ca/blog/2023/09/14/in-a-git-repository-- where-do-your-檔案-即時-/);或者您可以[從 <cite>Pro Git</cite> 書中閱讀](https://git-scm.com/book/en/v2/Git-Internals-Git-Objects)。 <圖> <img src=https://git-scm.com/book/en/v2/images/commit-and-tree.png width=800 height=443 alt='包含5 個框的圖表,分為3 列,每個框標有 5 位 SHA1 前綴;左邊的子標籤為“commit”,包含元資料“tree”,中間是框的 SHA1,“author”和“committer”的值均為“Scott”,文字為“The initial commit of我的專案”;中間的框被子標記為“tree”,包括三行,每行標記為“blob”,其餘 3 個框的 SHA1 以及看起來像文件名的內容:“README”、“LICENSE”和“test.rb” ”;最後 3 個框,在右側垂直對齊,都是子標籤為「blob」的內容,包含看起來像是 README、LICENSE 和 Ruby 原始檔內容開頭的內容;有箭頭連結框:提交指向樹,樹指向 blob。'> <figcaption>提交及其樹(來源:<a src=https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell><cite>Pro Git</引用></a>)</figcaption> </圖> _commit_ 中的_父親提交_ 建立一個代表我們歷史的[有向無環圖](https://en.wikipedia.org/wiki/Directed_acirclic_graph):_有向無環圖_ 由連結的節點(我們的提交)組成與有向邊一起(每個提交連結到其父提交,有一個方向,因此_directed_)並且不能有循環/循環(提交永遠不會是它自己的祖先,它的祖先提交都不會連結到它作為父提交)。 <圖> <img src=https://git-scm.com/book/en/v2/images/commits-and-parents.png width=800 height=265 alt='包含 6 個框排列成 2 行 3 列的圖表;第一行的每個框都標有 5 位 SHA1 前綴,子標籤為“commit”,元資料“tree”和“parent”均帶有 5 位 SHA1 前綴(每次都不同)、“author”和“ committer」的值都是“Scott”,以及一些代表提交訊息的文字;左邊的盒子沒有「父」值,另外兩個盒子將左邊的盒子的 SHA1 作為「父」;這些框之間有一個箭頭,指向代表「父」的左側;順便說一句,左邊的框與上圖中的提交框具有相同的 SHA1 和相同的內容;最後,每個提交框也指向其下方的一個框,每個框都標記為「快照 A」、「快照 B」等,並且可能代表從每個提交連結的「樹」物件。'> <figcaption>提交及其父級(來源:<a src=https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell><cite>Pro Git</ cite ></a>)</figcaption> </圖> ### 參考文獻、分支和標籤 現在 SHA1 哈希對於人類來說是不切實際的,雖然 Git 允許我們使用唯一的 SHA1 前綴而不是完整的 SHA1 哈希,但我們需要更簡單的名稱來引用我們的提交:輸入 _references_。這些是我們選擇的提交的_標籤_(而不是 Git)。 有幾種_參考_: * _branches_ 是_moving_ 引用(請注意,`main` 或`master` 並不特殊,它們的名稱只是一個約定) *_標籤_是_不可變_引用 * `HEAD` 是一個特殊的引用,指向_當前提交_。它通常指向一個分支而不是直接指向一個提交(稍後我們會看到原因)。當一個引用指向另一個引用時,這稱為[_符號引用_](https://blog.ltgt.net/confusing-git-terminology/#reference-symbolic-reference)。 * Git 會在某些操作期間為您設定其他特殊參考(`FETCH_HEAD`、`ORIG_HEAD` 等) <圖> <img src=https://git-scm.com/book/en/v2/images/branch-and-history.png width=800 height=430 alt='帶有 9 個框的圖; 6 個盒子的排列方式與上圖相同,並且標記相同(三個提交及其 3 個樹);最右邊(最新)提交上方的兩個框,箭頭指向它,分別標記為“v1.0”和“master”;最後一個框位於“master”框上方,有一個箭頭指向它,並標記為“HEAD”。'> <figcaption>分支及其提交歷史記錄(來源:<a src=https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell><cite>Pro Git< /引用></a>)</figcaption> </圖> ### 三個狀態 當您在 Git 儲存庫中工作時,您在 Git 歷史記錄中操作和記錄的檔案位於您的_工作目錄_中。要建立提交,您需要在 [_index_](https://blog.ltgt.net/confusing-git-terminology/#index-staged-cached) 或_暫存區域_中_暫存_檔案。完成後,您附加一則提交訊息並將您的_staged_檔案移至_history_。 為了關閉循環,_工作目錄_是根據_歷史記錄_中的給定提交進行初始化的。 <圖> <img src=https://git-scm.com/book/en/v2/images/areas.png width=800 height=441 alt='包含3 位參與者的序列圖:「工作目錄」、「暫存區域」和「.git directpry(儲存庫)」;有一條“簽出專案”訊息從“.git 目錄”到“工作目錄”,然後從“工作目錄”到“暫存區域”進行“階段修復”,最後從“暫存區域”進行“提交”區域」到「.git 目錄」。'> <figcaption>工作樹、暫存區域和 Git 目錄(來源:<a href="https://git-scm.com/book/en/v2/Getting-Started-What-is-Git%3F#_the_third_states" ><cite>Pro Git</cite></a>)</figcaption> </圖> ### 旁白:忽略文件 並非所有檔案都需要_追蹤_歷史記錄:由建置系統(如果有)產生的檔案、特定於您的編輯器的檔案以及特定於您的作業系統或其他工作環境的檔案。 Git 允許定義要忽略的檔案或目錄的命名模式。這實際上並不意味著Git 會忽略它們並且無法_跟踪_,但如果不跟踪它們,多個Git 操作將不會向您顯示它們或操縱它們(但您可以手動將它們加入到歷史記錄中,並且從那時起,他們將不再被_忽略_)。 忽略檔案是透過將路徑名稱(可能使用 glob)放入忽略檔案中來完成的: * 儲存庫中任何位置的 `.gitignore` 檔案定義了包含目錄的忽略模式;這些忽略文件會在歷史記錄中被跟踪,作為開發人員之間共享它們的一種方式;在這裡,您將忽略建置系統產生的那些檔案(Gradle 專案的“build/”,Eleventy 網站的“_site/”等) * `.git/info/excludes` 是您機器上的本機儲存庫;很少使用,但有時很有用,所以很高興了解一下 * 最後 `~/.config/git/ignore` 對機器來說是全域的(對你的使用者);在這裡,您將忽略特定於您的電腦的文件,例如特定於您使用的編輯器的文件,或特定於您的作業系統的文件(例如macOS 上的“.DS_Store”或Windows 上的“Thumbs. db”) ) ### 加起來 這是所有這些概念的另一種表示: <圖> <img src=https://marklodato.github.io/visual-git-guide/conventions.svg width=907 height=529 alt='有 10 個框的圖; 5 個框在中心排成一行,標有 5 位 SHA1 前綴,它們之間有從右向左指向的箭頭;一條註釋將它們描述為“提交物件,由 SHA-1 哈希標識”,另一條註釋將其中一個箭頭描述為“子項指向父項”;一對框(看起來像一個水平分割成兩個框的單一框)位於最右邊(最新)提交的上方,有一個向下指向它的箭頭,該對的上面的框被標記為“HEAD”並描述為“引用當前分支”;下面的框被標記為“main”並被描述為“目前分支”;第七個框位於另一個提交上方,有一個向下指向它的箭頭;它被標記為“穩定”並被描述為“另一個分支”;最後兩個框位於提交歷史記錄下,一個在另一個之上;最底部的框標記為“工作目錄”並描述為“您'看到'的文件”,它和提交歷史記錄之間的另一個框標記為“階段(索引)”並描述為“要存取的文件”在下次提交中”。'> <figcaption>提交、引用和區域(來源:<a href=https://marklodato.github.io/visual-git-guide/index-en.html#conventions><cite>可視化 Git 參考</cite >< /a>,馬克‧洛達托)</figcaption> </圖> ## 基本操作 這就是我們開始討論 Git 指令以及它們如何與圖表互動的地方: * `git init` 初始化一個新的儲存庫 * `git status` 取得檔案狀態的摘要 * `git diff` 顯示任意兩個工作目錄、索引、`HEAD` 之間的更改,或實際上任何提交之間的更改 * `git log` 顯示並搜尋您的歷史記錄 * 建立提交 * `git add` 將檔案加入_index_ * `git commit` 將_index_ 轉換為_commit_ (帶有新增的_commit 訊息_) * `git add -p` 以互動方式將檔案新增至 _index_:選擇要新增的變更以及僅將哪些變更保留在工作目錄中,逐一檔案、逐個部分(稱為 _hunk_) * 管理分支機構 * `gitbranch` 顯示分支,或建立分支 *`git switch`(也稱為`git checkout`)將分支(或任何提交,實際上是任何_樹_)簽出到您的工作目錄 * `git switch -b` (也稱為 `git checkout -b`)作為 `gitbranch` 和 `gitswitch` 的捷徑 * `git grep` 搜尋您的工作目錄、索引或任何提交;這是一種增強的“grep -R”,它支援 Git * `gitblame` 來了解更改給定文件每一行的最後一次提交(因此,誰應該為錯誤負責) * `git stash` 將未提交的更改放在一邊(這包括_staged_文件,以及工作目錄中的_tracked_文件),然後_unstash_它們。 ### 提交、分支切換和 HEAD 當您建立提交(使用「git commit」)時,Git 不僅建立_提交物件_,還移動「HEAD」以指向它。如果「HEAD」實際上指向一個分支(通常是這種情況),Git 會將該分支移動到新的提交(並且「HEAD」將繼續指向該分支)。每當當前分支是另一個分支的祖先(該分支指向的提交也是另一個分支的一部分)時,提交將使“HEAD”移動相同,並且分支將_發散_。 當您切換到另一個分支(使用“git switch”或“git checkout”)時,“HEAD”會移至新的目前分支,並且您的工作目錄和索引將設定為重新組合該提交的狀態(未提交的更改將暫時保留;如果 Git 無法做到這一點,它將拒絕切換)。 如需更多詳細資訊和視覺表示,請參閱[commit](https://marklodato.github.io/visual-git-guide/index-en.html#commit) 和[checkout](https://marklodato. github .io/visual-git-guide/index-en.html#checkout)Mark Lotato 的<cite>可視化Git 參考</cite>的部分(請注意,該參考是幾年前寫的,當時`git switch ` 和 ` git Restore` 不存在,而 `git checkout` 是我們所擁有的一切;因此 _checkout_ 部分涵蓋的內容比 `git switch` 多一點)。 當然,<cite>Pro Git</cite> 這本書也是一個很好的視覺表示參考; [<cite>Branches in a Nutshell</cite> 子章節](https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell) 涵蓋了所有內容的很大一部分上述的。 ### 旁白:Git 是保守的 正如我們在上面所看到的,由於其_內容尋址存儲_,對提交的任何“更改”(例如使用“git commit --amend”)實際上都會導致不同的提交(不同的 SHA1)。 _舊提交_不會立即消失:Git 使用_垃圾收集_最終刪除無法從任何_引用_存取的提交。這意味著,如果您設法找回提交SHA1,則可以恢復許多錯誤(“git reflog”可以在此處提供幫助,或者符號“<branch-name>@{<n>}”,例如“main@{ 1}”) ` main` 在更改之前指向的最後一次提交)。 ### 使用分支機構 我們在上面已經看到了分支是如何發散的。 但分歧要求最終_合併_變回來(使用“git merge”)。 Git 在這方面非常擅長(我們稍後會看到)。 合併的一個特殊情況是目前分支是要合併到的分支的祖先。在這種情況下,Git 可以執行 [_fast-forward merge_](https://blog.ltgt.net/confusing-git-terminology/#can-be-fast-forwarded)。 由於兩個分支之間的操作可能始終針對同一對分支,因此 Git 允許您設定一個分支來追蹤另一個分支。另一個分支被稱為_追蹤_它的分支的_上游_。例如,設定時,「git status」將告訴您兩個分支彼此之間有多少分歧:目前分支是[_最新_](https://blog.ltgt.net/confusing-git-terminology /#your- branch-is-up-to-date-with-originmain) 及其上游分支,_後面_和[可以快轉](https://blog.ltgt.net/confusing-git-terminology/ #can-be- fast-forwarded),_超前_許多提交,或它們有分歧,每個提交都有一定數量。其他命令將使用該資訊為參數提供良好的預設值,以便可以省略它們。 要整合來自另一個分支的更改,而不是合併,另一種選擇是_cherry-pick_(使用同名命令)單一提交,而不包含其歷史記錄:Git 將計算該提交帶來的更改並將相同的更改應用於當前分支,建立一個與原始分支類似的新提交(如果您想了解更多有關Git 實際操作方式的訊息,請參閱Julia Evans 的[<cite>如何gitcherry-pick 和revert 使用3 路合併< /cite> ](https://jvns.ca/blog/2023/11/10/how-cherry-pick-and-revert-work/))。 最後,工具帶中的另一個指令是「rebase」。 您可以將其視為一次進行許多選擇的方法,但它實際上更強大(正如我們將在下面看到的)。但在其基本用途中,它只是這樣:您給它一系列提交(在作為起點的任何提交和作為終點的現有分支之間,預設為當前分支)和一個目標,並且它會挑選所有這些提交位於目標之上,並最終更新用作終點的分支。這裡的指令的形式是`git rebase --onto=<target> <start> <end>`。與許多 Git 命令一樣,參數可以省略,並且具有預設值和/或特定含義:因此,`git rebase` 是 `git rebase --fork-point upper` 的簡寫,其中 `upstream` 是 [upstream]當前分支的(https://blog.ltgt.net/confusing-git-terminology/#untracked-files-remote-tracking-branch-track-remote-branch)(我會忽略`--fork-point`這裡,它的作用很微妙,在日常使用上並不那麼重要),它本身就是`git rebase upper HEAD` 的簡寫(其中`HEAD` 必須指向一個分支),它本身就是`git rebase 的簡寫-- on=upstream uploaded `,`git rebase --onto=upstream $(git merge-baseupstream HEAD) HEAD` 的簡寫,並將rebase `upstream` 的最後一個共同祖先與當前分支之間的所有提交另一方面,手和當前分支(即自從它們分歧以來的所有提交),並將它們重新應用到“上游”之上,然後更新當前分支以指向新的提交。明確使用`--onto` (其值與起始點不同)實際上很少見,請參閱[我之前的文章](https://blog.ltgt.net/confusing-git-terminology/#git- rebase- --onto) 對於一個用例。 我們無法在沒有互動式變體「git rebase -i」的情況下呈現「git rebase」:它以與非互動式變體完全相同的行為開始,但在計算需要完成的操作之後,它將允許您對其進行編輯(作為編輯器中的文字文件,每行一個操作)。預設情況下,所有選定的提交都是精心挑選的,但您可以對它們重新排序,跳過某些提交,甚至將某些提交合併到單一提交中。實際上,您可以挑選最初未選擇的提交,甚至建立合併提交,從而完全重寫整個歷史記錄!最後,您還可以停止對其進行編輯(然後使用“git commit --amend”,和/或可能在繼續變基之前建立新的提交),和/或在兩次提交之間執行給定的命令。最後一個選項非常有用(例如,驗證您沒有在歷史記錄的每個點上破壞您的專案),您可以在`--exec` 選項中傳遞該命令,Git 將在每個重新基底提交之間執行它(這也適用於非互動式變基;在互動模式下,當能夠編輯變基場景時,您將看到在每個櫻桃選擇行之間插入執行行)。 更多詳細資訊和視覺表示,請參閱[merge](https://marklodato.github.io/visual-git-guide/index-en.html#merge)、[cherry pick](https://marklodato . github.io/visual-git-guide/index-en.html#cherry-pick) 和 [rebase](https://marklodato.github.io/visual-git-guide/index-en.html#rebase) Mark Lodato 的<cite>視覺化Git 參考</cite> 部分,以及[<cite>基本分支和合併</cite>](https://git-scm.com/book/en/v2/Git-分支-基本-分支和合併),[<cite>變基</cite>](https://git-scm.com/book/en/v2/Git-Branching-Rebasing)和[<cite>重寫歷史< /cite>](https://git-scm.com/book/en/v2/Git-Tools-Rewriting-History) <cite>Pro Git</cite> 書的子章節。 您也可以查看 David Drysdale 的 [<cite>Git Visual Reference</cite>](https://lurklurk.org/gitpix/gitpix.html) 中的「分支和合併」圖。 ## 與他人合作 目前,我們只在我們的儲存庫中進行本地工作。 但 Git 是專門為與他人合作而建構的。 讓我介紹一下_遙控器_。 ### 遙控器 當您_複製_儲存庫時,該儲存庫將成為本機儲存庫的_遠端_,名為「origin」(就像「main」分支一樣,這只是預設值,名稱本身沒有什麼特別的,除了有時用作省略命令參數時的預設值)。然後,您將開始工作,建立本地提交和分支(因此從遠端_forking_),同時遠端可能會從其作者那裡獲得更多提交和分支。因此,您需要將這些遠端變更同步到本機儲存庫,並希望快速了解與遠端相比您在本機所做的變更。 Git 處理這個問題的方式是在一個特殊的命名空間中記錄它所知道的遠端(主要是分支)的狀態:「refs/remote/」。這些被稱為[_遠端追蹤分支_](https://blog.ltgt.net/confusing-git-terminology/#untracked-files-remote-tracking-branch-track-remote-branch)。 Fwiw,本機分支儲存在「refs/heads/」命名空間中,標籤儲存在「refs/tags/」中(來自遠端的標籤通常直接「匯入」到「refs/tags/」中,因此例如您會遺失位置資訊他們來自)。您可以根據需要擁有任意多個遙控器,每個遙控器都有一個名稱。 (請注意,遙控器不一定位於其他電腦上,它們實際上可以位於同一台電腦上,直接從檔案系統存取,因此您無需進行任何設定即可使用遙控器。) ### 取得 每當你從遠端 _fetch_ 時(使用 `git fetch`、`git pull` 或 `git Remote update`),Git 都會與它對話以下載它還不知道的提交,並更新 _remote-tracking遠端分支_ 。要取得的確切引用集以及取得它們的位置將傳遞給 `git fetch` 命令(如 [refspecs](https://blog.ltgt.net/confusing-git-terminology/#refspecs) )以及儲存庫的` .git/config` 中定義的預設值,預設由`git clone` 或`git remote add` 配置以取得所有分支(遠端上的`refs/heads/` 中的所有內容)並放置它們位於` refs/remote/<remote>` 中(因此`origin` 遙控器的`refs/remote/origin/` )具有相同的名稱(因此遙控器上的`refs/heads/main` 變成`refs/remote / origin/main` 本地)。 <圖> <img src=https://git-scm.com/book/en/v2/images/remote-branches-5.png width=800 height=577 alt='帶有3 個大方框的圖表,代表機器或儲存庫,包含代表提交歷史的較小框和箭頭;一個框標記為“git.outcompany.com”,子標記為“origin”,並包含名為“master”的分支中的提交;另一個框標記為“git.team1.outcompany.com”,子標記為“teamone”,並包含名為“master”的分支中的提交; 「origin」和「teamone」中的提交 SHA1 雜湊值相同,除了「origin」在其「master」分支上多了一個提交,即「teamone」在「後面」;第三個框標記為“我的電腦”,它包含與其他兩個框相同的提交,但這次分支被命名為“origin/master”和“teamone/master”;它還在名為“master”的分支中包含另外兩個提交,與遠端分支的較早點不同。'> <figcaption>遠端和遠端追蹤分支(來源:<a href=https://git-scm.com/book/en/v2/Git-Branching-Remote-Branches><cite>Pro Git</cite>< / a>)</figcaption> </圖> 然後,您將使用與分支相關的命令來獲取從_遠端追蹤分支_到本地分支的更改(“git merge”或“git rebase”),或“git pull”,這只不過是“git fetch”的簡寫` 後面跟著 `git merge` 或 `git rebase`。 <abbr title="By the way">順便說一句</abbr>,在很多情況下,當你建立本地分支時,Git 會自動將_遠端追蹤分支_設定為本地分支的_上游_(它會告訴你相關資訊)當這種情況發生時)。 ### 推 要與其他人共用您的更改,他們可以將您的儲存庫新增為遠端儲存庫並從中_pull_(意味著透過網路存取您的電腦),或者您可以_push_到遠端儲存庫。 (如果您要求某人從您的遙控器中提取更改,這稱為..._拉請求_,您可能在 GitHub 或類似服務中聽說過這個術語。) 推送與提取類似,相反:您將提交發送到遠端並更新其分支以指向新提交。作為安全措施,Git 只允許遠端分支_快速轉送_;如果您想推送以非快轉方式更新遠端分支的更改,則必須使用「git push --force-with-lease」(或「git push --force」)_force_它,但要小心:`-- force-with-lease`將首先確保您的_遠端追蹤分支_與遠端分支是最新的,以確保自上次_fetched_以來沒有人將變更推送到分支;` --force` 不會執行該檢查,而是按照您的指示執行操作,風險由您自己承擔)。 與「git fetch」一樣,您可以將要更新的分支傳遞給「git push」命令,但如果您不這樣做,Git 會提供良好的預設行為。如果你不指定任何東西,Git 會從目前分支的上游推斷遠程,所以大多數時候 `git push` 相當於 `git push origin`。這實際上是“git Push origin main”的簡寫(假設當前分支是“main”),它本身是“git Push origin main:main”的簡寫,是“git Push origin refs/heads/main:refs/”的簡寫heads/main`,意思是將本地的`refs/heads/main`推送到`origin`遠端的`refs/heads/main`。有關使用不同來源和目標指定 _refspecs_ 的一些用例,請參閱[我之前的文章](https://blog.ltgt.net/confusing-git-terminology/#refspecs)。 <圖> <img src=https://lurklurk.org/gitpix/push2.svg width=1052 height=744 alt='代表「git push」指令的圖表,有四個 git 圖表(點,有些有標籤,用線連接) 排列成兩行兩列;列之間的箭頭表示左列是「之前」狀態,右列是「之後」狀態;上面一行中的圖位於雲內部,代表遠端儲存庫,並且有兩個分支,“master”和“other”,它們偏離了共同的祖先;左下圖與上面的圖形狀相同,只是標籤更改為“origin/master”和“origin/other”,並且每個分支有更多提交:與“origin”分支相比,“master”分支有兩個額外的提交/master”,而“other”比“origin/other”多了一個提交;與左上圖相比,右上圖在其「master」分支中多了兩次提交;右下圖與左下圖相同,除了「origin/master」現在指向與「master」相同的提交;換句話說,在「之前」狀態下,遠端缺少三個提交,而在「git Push」之後,本地「master」分支的兩個提交被複製到遠端,而「其他」保持不變。'> <figcaption><code>git Push</code>(資料來源:<a href=https://lurklurk.org/gitpix/gitpix.html><cite>Git 視覺參考</cite></a>,David Drysdale )</圖標題> </圖> 更多詳細資訊和視覺表示,請參閱[<cite>遠端分支</cite>](https://git-scm.com/book/en/v2/Git-Branching-Remote-Branches),[< cite >使用遙控器</cite>](https://git-scm.com/book/en/v2/Git-Basics-Working-with-Remotes),以及[<cite>為專案做出貢獻</ cite> ](https://git-scm.com/book/en/v2/Distributed-Git-Contributing-to-a-Project) <cite>Pro Git</cite> 書的子章節,以及「處理遠程來自David Drysdale 的[<cite>Git Visual Reference</cite>](https://lurklurk.org/gitpix/gitpix.html) 的「儲存庫」圖表。 <cite>Pro Git</cite> 的<cite>為專案做出貢獻</cite>一章也涉及在GitHub 等平台上為開源專案做出貢獻,您必須先_fork_儲存庫,然後透過_pull requests_進行貢獻(或_合併請求_)。 ## 最佳實踐 這些是針對初學者的,希望不會引起太多爭議。 嘗試保留_clean_歷史記錄: * 明智地使用合併提交 * 清晰且高品質的提交訊息(請參閱[<cite>提交指南</cite>](https://git-scm.com/book/en/v2/Distributed-Git-Contributing-to-a-Project #_commit_guidelines)在<cite>Pro Git</cite> 中) * make _atomic_ commits:每個提交應該獨立於歷史記錄中跟隨它的提交進行編譯和執行 這僅適用於您與他人分享的歷史記錄。 在本地,想怎麼做就怎麼做。對於初學者,我會給以下建議: * 不要直接在“main”(或“master”,或您在遠端上沒有專門擁有的任何分支)上工作,而是建立本機分支;它有助於解耦不同任務的工作:即將開始處理另一個錯誤或功能,同時等待有關當前任務的說明的更多詳細資訊?切換到另一個分支,稍後您可以透過切換回來回到該分支;它還使從遠端更新變得更容易,因為如果您的本地分支只是同名遠端分支的副本,沒有任何本地更改(除非您想推送這些更改),您確信不會發生衝突到該分支) * 毫不猶豫地重寫你的提交歷史記錄(`git commit --amend` 和/或 `git rebase -i`),但不要太早這樣做;在工作時堆疊許多小提交是完全可以的,並且只在共享之前重寫/清理歷史記錄 * 同樣,請毫不猶豫地重新調整本機分支以整合上游變更(直到您共用該分支,此時您將遵循專案的分支工作流程) 如果出現任何問題並且您迷路了,我的建議是使用 `gitk` 或 `gitk HEAD @{1}`,也可能使用 `gitk --all` (我在這裡使用 `gitk` 但使用任何工具你喜歡),可視化你的Git 歷史並嘗試了解發生了什麼。由此,您可以回滾到先前的狀態(`git reset @{1}`)或嘗試修復問題(擇優選擇提交等)。合併失敗,您可以使用“git rebase --abort”或“git merge - -abort」等命令中止並回滾到先前的狀態。 為了讓事情變得更簡單,請不要猶豫,在任何可能具有破壞性的命令(`git rebase`)之前,建立一個分支或標籤作為“書籤”,如果事情沒有按預期進行,您可以輕鬆重置。當然,在執行這樣的命令後,請檢查歷史記錄和文件,以確保結果是您所期望的。 ## 進階概念 這只是其中的一小部分,還有更多值得探索! * 分離的「HEAD」:[`git checkout` 手冊頁](https://git-scm.com/docs/git-checkout#_detached_head) 有一個關於該主題的很好的部分,另請參閱[我之前的帖子](https ://blog.ltgt.net/confusing-git-terminology/#detached-head-state),要獲得良好的視覺表示,請參閱[<cite>使用分離的HEAD 進行提交</ cite>](https:// /marklodato.github.io/visual-git-guide/index-en.html#detached) Mark Lodato 的 <cite>視覺化 Git 參考</cite> 部分。 * Hooks:這些是可執行檔(大多數情況下是 shell 腳本),Git 將執行它們來回應儲存庫上的操作;人們使用它們在每次提交之前檢查程式碼(如果失敗則中止提交),產生或後處理提交訊息,或在有人推送到儲存庫後觸發伺服器上的操作(觸發建置和/或部署)。 * 一些很少需要的命令可以在您真正需要時節省您的時間: * `git bisect`:一個進階命令,透過測試多個提交(手動或透過腳本)來幫助您找出哪個提交引入了錯誤;對於線性歷史,這是使用二分法並且可以手動完成,但是一旦您有許多合併提交,這就會變得更加複雜,並且最好讓 git bisect 來完成繁重的工作。 * `git filter-repo`:實際上是一個[第三方命令](https://github.com/newren/git-filter-repo),作為Git 自己的`filter-branch` 的替代品,它允許重寫儲存庫的整個歷史記錄,以刪除錯誤新增的文件,或協助將儲存庫的一部分提取到另一個儲存庫。 我們完成了。 有了這些知識,人們應該能夠將任何 Git 命令映射到如何修改提交的_有向無環圖_,並了解如何修復錯誤(在錯誤的分支上執行合併?基於錯誤的分支重新建置?)並不是說理解這些事情會很容易,但至少應該是可能的。 --- 原文出處:https://dev.to/tbroyer/how-i-teach-git-3nj3
# 簡介 在上一篇文章中,我討論了建立一個[GitHub stars 監視器](https://dev.to/triggerdotdev/take-nextjs-to-the-next-level-create-a-github-stars-monitor-130a)。 在這篇文章中,我想向您展示如何每天了解新星的資訊。 我們將學習: - 如何建立通用系統來建立和使用提供者。 - 如何使用提供者發送通知。 - 使用不同提供者的不同用例。  --- ## 你的後台工作平台🔌 [Trigger.dev](https://trigger.dev/) 是一個開源程式庫,可讓您使用 NextJS、Remix、Astro 等為您的應用程式建立和監控長時間執行的作業! [](https://github.com/triggerdotdev/trigger.dev) 請幫我們一顆星🥹。 這將幫助我們建立更多這樣的文章💖 https://github.com/triggerdotdev/trigger.dev --- ## 讓我們來設定一下 🔥 我們將建立不同的提供者來通知我們何時有新的明星。我們將設定「電子郵件」、「簡訊」、「Slack」和「Discord」通知。 我們的目標是讓每個貢獻者都足夠簡單,以便在未來貢獻更多的提供者。 每個提供者都會有一組不同的參數,有些只有“API 金鑰”,有些則有電話號碼,具體取決於提供者。 為了驗證這些金鑰,讓我們安裝“zod”;它是一個很棒的庫,可以定義模式並根據模式檢查資料。 您可以透過執行以下命令開始: ``` npm install zod --save ``` 完成後,建立一個名為「providers」的新資料夾,然後在其中建立一個名為「register.provider.ts」的新檔案。 這是文件的程式碼: ``` import {Schema} from "zod"; export function registerProvider<T>( name: string, options: {active: boolean}, validation: Schema<T>, run: (libName: string, stars: number, values: T) => Promise<void> ) { // if not active, we can just pass an empty function, nothing will run if (!options.active) { return () => {}; } // will validate and remove unnecessary values (Security wise) const env = validation.parse(process.env); // return the function we will run at the end of the job return async (libName: string, stars: number) => { console.log(`Running provider ${name}`); await run(libName, stars, env as T); console.log(`Finished running provider ${name}`); } } ``` 程式碼不多,但可能有點複雜。 我們首先建立一個名為「registerProvider」的新函數。該函數獲得一個通用類型“T”,基本上是我們所需的環境變數。 然後我們還有 4 個參數: - 名稱 - 可以是「Twilio」、「Discord」、「Slack」或「Resend」中的任何一個。 - 選項 - 目前,一個參數是提供者是否處於活動狀態? - 驗證 - 在這裡,我們在 .env 檔案中傳遞所需參數的「zod」模式。 - run - 實際上用於發送通知。請注意,傳入其中的參數是庫名稱、星星數量以及我們在「validation」中指定的環境變數 **然後我們就有了實際的功能:** 首先,我們檢查提供者是否處於活動狀態。如果沒有,我們發送一個空函數。 然後,我們驗證並提取我們在模式中指定的變數。如果變數缺少 `zod` 將發送錯誤並且不會讓應用程式執行。 最後,我們傳回一個函數,該函數會取得庫名稱和星星數量並觸發通知。 在我們的「providers」資料夾中,建立一個名為「providers.ts」的新文件,並在其中新增以下程式碼: ``` export const Providers = []; ``` 稍後,我們將在那裡加入所有提供者。 --- ## 修改 TriggerDev 作業 本文是上一篇關於建立 [GitHub stars 監視器](https://dev.to/triggerdotdev/take-nextjs-to-the-next-level-create-a-github-stars-monitor-130a)。 編輯檔案 `jobs/sync.stars.ts` 並將以下程式碼加入檔案底部: ``` const triggerNotification = client.defineJob({ id: "trigger-notification", name: "Trigger Notification", version: "0.0.1", trigger: invokeTrigger({ schema: z.object({ stars: z.number(), library: z.string(), providerNumber: z.number(), }) }), run: async (payload, io, ctx) => { await io.runTask("trigger-notification", async () => { return Providers[payload.providerNumber](payload.library, payload.stars); }); } }); ``` 此作業取得星星數量、圖書館名稱和提供者編號,並從先前定義的提供者觸發特定提供者的通知。 現在,我們繼續修改“getStars”,在函數末尾加入以下程式碼: ``` for (let i = 0; i < Providers.length; i++) { await triggerNotification.invoke(payload.name + '-' + i, { library: payload.name, stars: stargazers_count - payload.previousStarCount, providerNumber: i, }); } ``` 這將觸發每個圖書館的通知。 完整頁面程式碼: ``` import { cronTrigger, invokeTrigger } from "@trigger.dev/sdk"; import { client } from "@/trigger"; import { prisma } from "../../helper/prisma"; import axios from "axios"; import { z } from "zod"; import {Providers} from "@/providers/providers"; // Your first job // This Job will be triggered by an event, log a joke to the console, and then wait 5 seconds before logging the punchline. client.defineJob({ id: "sync-stars", name: "Sync Stars Daily", version: "0.0.1", // Run a cron every day at 23:00 AM trigger: cronTrigger({ cron: "0 23 * * *", }), run: async (payload, io, ctx) => { const repos = await io.runTask("get-stars", async () => { // get all libraries and current amount of stars return await prisma.repository.groupBy({ by: ["name"], _sum: { stars: true, }, }); }); //loop through all repos and invoke the Job that gets the latest stars for (const repo of repos) { await getStars.invoke(repo.name, { name: repo.name, previousStarCount: repo?._sum?.stars || 0, }); } }, }); const getStars = client.defineJob({ id: "get-latest-stars", name: "Get latest stars", version: "0.0.1", // Run a cron every day at 23:00 AM trigger: invokeTrigger({ schema: z.object({ name: z.string(), previousStarCount: z.number(), }), }), run: async (payload, io, ctx) => { const stargazers_count = await io.runTask("get-stars", async () => { const {data} = await axios.get(`https://api.github.com/repos/${payload.name}`, { headers: { authorization: `token ${process.env.TOKEN}`, }, }); return data.stargazers_count as number; }); await io.runTask("upsert-stars", async () => { await prisma.repository.upsert({ where: { name_day_month_year: { name: payload.name, month: new Date().getMonth() + 1, year: new Date().getFullYear(), day: new Date().getDate(), }, }, update: { stars: stargazers_count - payload.previousStarCount, }, create: { name: payload.name, stars: stargazers_count - payload.previousStarCount, month: new Date().getMonth() + 1, year: new Date().getFullYear(), day: new Date().getDate(), }, }); }); for (let i = 0; i < Providers.length; i++) { await triggerNotification.invoke(payload.name + '-' + i, { library: payload.name, stars: stargazers_count - payload.previousStarCount, providerNumber: i, }); } }, }); const triggerNotification = client.defineJob({ id: "trigger-notification", name: "Trigger Notification", version: "0.0.1", trigger: invokeTrigger({ schema: z.object({ stars: z.number(), library: z.string(), providerNumber: z.number(), }) }), run: async (payload, io, ctx) => { await io.runTask("trigger-notification", async () => { return Providers[payload.providerNumber](payload.library, payload.stars); }); } }); ``` 現在,有趣的部分🎉 讓我們繼續建立我們的提供者! 首先建立一個名為「providers/lists」的新資料夾 --- ## 1. Discord  建立一個名為「discord.provider.ts」的新檔案並新增以下程式碼: ``` import {object, string} from "zod"; import {registerProvider} from "@/providers/register.provider"; import axios from "axios"; export const DiscordProvider = registerProvider( "discord", {active: true}, object({ DISCORD_WEBHOOK_URL: string(), }), async (libName, stars, values) => { await axios.post(values.DISCORD_WEBHOOK_URL, {content: `The library ${libName} has ${stars} new stars!`}); } ); ``` 如您所見,我們正在使用 `registerProvider` 建立一個名為 DiscordProvider 的新提供程序 - 我們將名稱設定為“discord” - 我們將其設定為活動狀態 - 我們指定需要一個名為「DISCORD_WEBHOOK_URL」的環境變數。 - 我們使用 Axios 的簡單 post 指令將資訊加入支票中。 若要取得“DISCORD_WEBHOOK_URL”: 1. 前往您的 Discord 伺服器 2. 點選其中一個頻道的“編輯” 3. 轉到“整合” 4. 點選“建立 Webhook” 5. 點選建立的 webhook,然後點選“複製 webhook URL” 在根專案上編輯“.env”檔案並加入 ``` SLACK_WEBHOOK_URL=<your copied url> ```  --- ## 2. Slack  建立一個名為「slack.provider.ts」的新檔案並新增以下程式碼: ``` import {object, string} from "zod"; import {registerProvider} from "@/providers/register.provider"; import axios from "axios"; export const SlackProvider = registerProvider( "slack", {active: true}, object({ SLACK_WEBHOOK_URL: string(), }), async (libName, stars, values) => { await axios.post(values.SLACK_WEBHOOK_URL, {text: `The library ${libName} has ${stars} new stars!`}); } ); ``` 如您所見,我們正在使用 `registerProvider` 建立一個名為 SlackProvider 的新提供者 - 我們將名稱設定為“slack” - 我們將其設定為活動狀態 - 我們指定需要一個名為「SLACK_WEBHOOK_URL」的環境變數。 - 我們使用 Axios 的簡單 post 指令將資訊加入支票中。 要取得“SLACK_WEBHOOK_URL”: 1. 使用下列 URL 建立新的 Slack 應用程式:https://api.slack.com/apps?new_app=1 2. 選擇第一個選項:“從頭開始” 3. 指定應用程式名稱(任意)以及您想要新增通知的 Slack 工作區。點擊“建立應用程式”。 4. 在“新增特性和功能”中,按一下“傳入掛鉤” 5. 在啟動傳入 Webhooks 中,將其變更為「開啟」。 6. 按一下「將新 Webhook 新增至工作區」。 7. 選擇您想要的頻道並點選「允許」。 8. 複製 Webhook URL。 在根專案上編輯“.env”檔案並加入 ``` SLACK_WEBHOOK_URL=<your copied url> ```  --- ## 3. 電子郵件  您可以使用不同類型的電子郵件提供者。例如,我們將使用**Resend**來傳送電子郵件。 為此,讓我們在我們的專案上安裝重新發送: ``` npm install resend --save ``` 建立一個名為「resend.provider.ts」的新檔案並新增以下程式碼: ``` import {object, string} from "zod"; import {registerProvider} from "@/providers/register.provider"; import axios from "axios"; import { Resend } from 'resend'; export const ResendProvider = registerProvider( "resend", {active: true}, object({ RESEND_API_KEY: string(), }), async (libName, stars, values) => { const resend = new Resend(values.RESEND_API_KEY); await resend.emails.send({ from: "Eric Allam <[email protected]>", to: ['[email protected]'], subject: 'New GitHub stars', html: `The library ${libName} has ${stars} new stars!`, }); } ); ``` 如您所見,我們正在使用 `registerProvider` 建立一個名為 ResendProvider 的新提供程序 - 我們將名稱設定為“重新發送” - 我們將其設定為活動狀態 - 我們指定需要一個名為「RESEND_API_KEY」的環境變數。 - 我們使用重新發送庫向自己發送一封包含新星數的電子郵件。 若要取得“RESEND_API_KEY”: 1. 建立一個新帳戶:https://resend.com 2. 前往「API 金鑰」或使用此 URL https://resend.com/api-keys 3. 按一下“+ 建立 API 金鑰”,新增金鑰名稱,選擇“傳送存取”並使用預設的“所有網域”。單擊新增。 4. 複製 API 金鑰。 在根專案上編輯“.env”檔案並加入 ``` RESEND_API_KEY=<your API key> ```  --- ## 4.簡訊  SMS 有點複雜,因為它們需要多個變數。 為此,我們在專案中安裝 Twilio: ``` npm install twilio --save ``` 建立一個名為「twilio.provider.ts」的新檔案並新增以下程式碼: ``` import {object, string} from "zod"; import {registerProvider} from "@/providers/register.provider"; import axios from "axios"; import client from 'twilio'; export const TwilioProvider = registerProvider( "twilio", {active: true}, object({ TWILIO_SID: string(), TWILIO_AUTH_TOKEN: string(), TWILIO_FROM_NUMBER: string(), TWILIO_TO_NUMBER: string(), }), async (libName, stars, values) => { const twilio = client(values.TWILIO_SID, values.TWILIO_AUTH_TOKEN); await twilio.messages.create({ body: `The library ${libName} has ${stars} new stars!`, from: values.TWILIO_FROM_NUMBER, to: values.TWILIO_TO_NUMBER, }); } ); ``` 如您所見,我們正在使用 `registerProvider` 建立一個名為 TwilioProvider 的新提供者 - 我們將名稱設定為“twilio” - 我們將其設定為活動狀態 - 我們指定需要環境變數:`TWILIO_SID`、`TWILIO_AUTH_TOKEN`、`TWILIO_FROM_NUMBER` 和 `TWILIO_TO_NUMBER` - 我們使用 Twilio「建立」功能發送簡訊。 取得“TWILIO_SID”、“TWILIO_AUTH_TOKEN”、“TWILIO_FROM_NUMBER”和“TWILIO_TO_NUMBER” 1. 在 https://twilio.com 建立一個新帳戶 2. 標記您要使用它來發送簡訊。 3. 點選“取得電話號碼” 4. 複製“帳戶 SID”、“身份驗證令牌”和“我的 Twilio 電話號碼” 在根專案上編輯“.env”檔案並加入 ``` TWILIO_SID=<your SID key> TWILIO_AUTH_TOKEN=<your AUTH TOKEN key> TWILIO_FROM_NUMBER=<your FROM number> TWILIO_TO_NUMBER=<your TO number> ```  --- ## 建立新的提供者 正如您所看到的,現在建立提供者非常容易。 您也可以使用開源社群來建立新的提供程序,因為他們只需要在「providers/list」目錄中建立一個新檔案。 最後要做的事情是編輯“providers.ts”檔案並加入所有提供程序。 ``` import {DiscordProvider} from "@/providers/list/discord.provider"; import {ResendProvider} from "@/providers/list/resend.provider"; import {SlackProvider} from "@/providers/list/slack.provider"; import {TwilioProvider} from "@/providers/list/twilio.provider"; export const Providers = [ DiscordProvider, ResendProvider, SlackProvider, TwilioProvider, ]; ``` 請隨意建立更多推播通知、網路推播通知、應用程式內通知等提供者。 你就完成了🥳 --- ## 讓我們聯絡吧! 🔌 作為開源開發者,我們邀請您加入我們的[社群](https://discord.gg/nkqV9xBYWy),以做出貢獻並與維護者互動。請隨時造訪我們的 [GitHub 儲存庫](https://github.com/triggerdotdev/trigger.dev),貢獻並建立與 Trigger.dev 相關的問題。 本教學的源程式碼可在此處取得: [https://github.com/triggerdotdev/blog/tree/main/stars-monitor-notifications](https://github.com/triggerdotdev/blog/tree/main/stars-monitor-notifications) 感謝您的閱讀! --- 原文出處:https://dev.to/triggerdotdev/top-4-ways-to-send-notifications-about-new-stars-1cgb
狀態管理器到底是什麼?狀態管理器是一個智慧模組,能夠保留(應用程式或 Web 應用程式的)會話資料並對資料的變更做出反應。 您是網頁開發人員嗎?使用過 Redux、Mobx 或 Zustand 等函式庫嗎?恭喜!您已經使用了狀態管理器。 我記得我第一天嘗試為 React 設定(舊的)Redux。只要想到所有不必要的複雜性——調度程序、減速器、中間件,我就會患上創傷後壓力症候群(PTSD)!我只是想聲明一些變數,_請讓它停止_。  這是一個過度設計、臃腫的庫,每個人都在使用!由於某種瘋狂的、未知的原因,它成為了當時的行業標準。 ###一些背景故事 2021 年的一個晚上,當我無法入睡時,我漫無目的地打開 GitHub,注意到我以前的大學課程老師(我在 GH 上關注過他)為他現在的學生上傳了一份作業。該作業要求學生使用公共 Pokemon API 建立一個 Pokedex 網站。目標是用 Javascript 實現它(沒有框架或函式庫,因為他目前的學生是 Web 開發初學者,仍在學習 Javascript 和開發的基礎知識)。 作為一個笑話,主要是因為我睡不著,我開始在我的神奇寶貝網站上工作。最終,我能夠建立一些可行的東西,而無需使用任何外部庫。 ### 但一路走來,我很掙扎...... 你看,我已經習慣了擁有一個狀態管理器,以至於在不使用外部框架或庫的情況下建置一個簡單的兩頁應用程式的要求讓我開始思考 - _為什麼狀態管理器必須如此復雜?這只是變數和事件._ 長話短說,我發現自己在凌晨 2 點組裝了一個超級簡單的狀態管理器模組,只是為了管理我的 Pokemon Web 應用程式的狀態。我將我的網站部署到了 GitHub 頁面,然後就忘記了這一切。 幾個月過去了,但出於某種原因,我時不時地思考我的狀態管理解決方案...你看,它有其他庫沒有的東西 - _它太簡單了。_ _“嘿!”我心想,「我應該將它重寫為 NPM 套件」。_ 當天晚上,我就這麼做了——我把它寫成了一個獨立的 NPM 包。最後,它的重量為 2kB(相比之下 Redux 的 150kB),具有零依賴性,並且使用起來非常簡單,您只需 3 行程式碼即可完成設定。 ### 我稱之為 VSSM 代表**_非常小的狀態管理器_**。 您可以在[GitHub](https://github.com/lnahrf/Vssm)上查看原始程式碼。另外,請查看使用 React 和 VSSM 建立的[文件網站](https://lnahrf.github.io/Vssm-docs/)。 第二天,我發布了我的 NPM 包,然後又忘記了這件事。 同年晚些時候,我面試了兩家不同公司的全端開發人員職位。我在第一家公司的面試中取得了優異的成績,這是一家非常成熟的科技公司。作為面試過程的一部分,他們要求我告訴他們我是否在空閒時間編碼,或者是否有我貢獻過的任何開源專案等等。 當時我做的唯一很酷的事情就是 VSSM,所以我告訴了他們。他們對我自己建立一個「Redux 替代方案」的想法印象深刻。 另一方面,我在第二家公司的面試中慘敗。我的大腦一片空白,我很緊張,無法回答簡單的問題,例如 > “React 會在狀態變更時重新渲染整個應用程式,還是在使用 Redux 時僅更新受影響的元件及其子元件?” “每次狀態更新時,它都會重新渲染整個應用程式”,我說。  我很緊張,哈哈,顯然我知道正確的答案是「它只渲染註冊的元件以及可能受影響的子元件」。 直到今天我也不明白為什麼二號公司決定給我第二次機會。他們邀請我再次接受採訪(是的!)。 在我的第二次面試中,他們要求我告訴他們我是否在空閒時間編碼、開源貢獻,你知道該怎麼做。當我告訴面試官我的小副專案時,他看起來很高興,似乎他喜歡我只是因為我從頭開始編寫了一個狀態管理器。 我想情況確實如此,因為我第二次面試也失敗了(在程式設計挑戰期間耗盡了時間),但仍然得到了一份工作機會。 1 號公司打算向我發送報價,但我已經與 2 號公司簽署了報價。 我的底線是——我建立 VSSM 幫助我獲得了這兩個機會。  ### 我是怎麼做到的? 您是否知道 Javascript 內建了監視變數變更所需的所有功能? 它被稱為代理(它很神奇)。 Javascript 代理程式是程式碼和變數分配之間的附加邏輯層。 如果您要將物件包裝在代理程式中,您可以決定在每次更新時將其值記錄到控制台,除了為該物件指派新值之外,無需執行任何操作。 ``` const target = { v: "hello" } const proxyTarget = new Proxy(target, { set: (target, property, value) => { console.log(`${property} is now ${value}`); target[property] = value; return target[property]; } }); proxyTarget.v = "world!" // v is now world! ``` VSSM 是基於代理建置,它在變數賦值和其餘程式碼之間建立了一個層。使用代理,您可以設定 setter、getter,並在操作或請求目標值時實現任何類型的邏輯。 VSSM 不僅僅是一個代理,它是各種智慧代理,它們知道分配給變數的值是它的新值還是回調方法。 例如,使用 VSSM,您只需幾行程式碼即可設定狀態、監聽變更並發出事件。 ``` import { createVSSM, createState } from 'vssm'; import { getVSSM } from 'vssm'; // Create the initial state createVSSM({ user: createState('user', { address: '' }) }); // Get the user proxy reference const { user } = getVSSM(); // Listen to events on user.address user.address = () => { console.log(`Address updated! the new address is ${user.address}`); }; // Emit the mutation event user.address = 'P.Sherman 42 Wallaby Way, Sydney' ``` 正如您所看到的,我確保我的狀態管理器盡可能簡單。我的目標是擺脫僅僅為了分配一些變數而陷入減速器、中間件和極其複雜的配置的困境。 現在,一切都透過分配變數來進行!想要設定監聽器嗎?將回調函數指派給變數。想要編輯值並發出事件嗎?只需指派一個新值即可。 直到今天我仍然不明白為什麼流行的狀態管理器必須如此複雜,也許我永遠不會。 我鼓勵您繼續閱讀 [MDN Web Docs](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Proxy) 上有關 Javascript 代理的所有內容。 ### 這一切的結論是什麼? 我認為,對自己所做的事情充滿熱情是關鍵。 我建立 VSSM 只是為了突破自己的極限並發布合理的 NPM 包。它成功地給面試官和同事留下了深刻的印象,並讓我從那時起就進入了不同的職位。 沒有人會使用 VSSM,它不會流行。當我將其發佈到 NPM 時,我就意識到了這一事實。但我仍然選擇盡我所能,因為我熱衷於做一些我認為比行業標準更好的事情。我知道我可以做出一些必須更好的東西,即使這意味著它對我更好。 儘管 VSSM 已經死在 NPM 墓地裡,但它給我帶來了很多價值,並且因為這篇文章而繼續這樣做。 獲得開發工作的最佳方法是建立令人驚嘆的東西,即使您認為這一切以前都已經完成了 - 建置得更好。即使您認為沒有人會使用它,那又有什麼意義呢? - 現在建置,價值稍後顯現。 不要低估你的能力,如果你認為自己有不足,請知道你會進步。走出去,建構能夠帶來價值的專案,一次一小步。 祝您工程之旅順利。 --- 原文出處:https://dev.to/lnahrf/javascript-proxy-magic-how-i-built-a-2kb-state-manager-with-zero-dependencies-and-how-it-got-me-two-different-job-offers-2539
在本文中,您將學習如何建立 **GitHub 星數監視器** 來檢查您幾個月內的星數以及每天獲得的星數。 - 使用 GitHub API 取得目前每天收到的星星數量。 - 在螢幕上每天繪製美麗的星星圖表。 - 創造一個工作來每天收集新星星。  --- ## 你的後台工作平台🔌 [Trigger.dev](https://trigger.dev/) 是一個開源程式庫,可讓您使用 NextJS、Remix、Astro 等為您的應用程式建立和監控長時間執行的作業! [](https://github.com/triggerdotdev/trigger.dev) 請幫我們一顆星🥹。 這將幫助我們建立更多這樣的文章💖 https://github.com/triggerdotdev/trigger.dev --- ## 這是你需要知道的 😻 取得 GitHub 上星星數量的大部分工作將透過 GitHub API 完成。 GitHub API 有一些限制: - 每個請求最多 100 名觀星者 - 最多 100 個同時請求 - 每小時最多 60 個請求 [TriggerDev](https://github.com/triggerdotdev/trigger.dev) 儲存庫擁有超過 5000 顆星,實際上不可能在合理的時間內(即時)計算所有星數。 因此,我們將採用與 [GitHub Stars History](https://star-history.com/) 相同的技巧。 - 取得星星總數 (**5,715**) 除以每頁 **100** 結果 = **58 頁** - 設定我們想要的最大請求量(**20 頁最大**)除以 **58 頁** = 跳過 3 頁。 - 從這些頁面中獲取星星**(2000 顆星)**,然後獲取剩餘的星星,我們將按比例加入到其他日期(**3715 顆星**)。 它會為我們繪製一個漂亮的圖表,並在需要的地方用星星凸起。 當我們每天獲取新數量的星星時,事情就會變得容易得多。 我們將用目前擁有的星星總數減去 GitHub 上的新星星數量。 **我們不再需要迭代觀星者。** --- ## 讓我們來設定一下 🔥 我們的申請將包含一頁: - 新增您想要監控的儲存庫。 - 查看儲存庫清單及其 GitHub 星圖。 - 刪除那些你不再想要的。  > 💡 我們將使用 NextJS 新的應用程式路由器,在安裝專案之前請確保您的節點版本為 18+。 > 使用 NextJS 設定一個新專案 ``` npx create-next-app@latest ``` 我們必須將所有星星保存到我們的資料庫中! 在我們的示範中,我們將使用 SQLite 和 `Prisma`。 它非常容易安裝,但可以隨意使用任何其他資料庫。 ``` npm install prisma @prisma/client --save ``` 在我們的專案中安裝 Prisma ``` npx prisma init --datasource-provider sqlite ``` 轉到“prisma/schema.prisma”並將其替換為以下模式: ``` generator client { provider = "prisma-client-js" } datasource db { provider = "sqlite" url = env("DATABASE_URL") } model Repository { id String @id @default(uuid()) month Int year Int day Int name String stars Int @@unique([name, day, month, year]) } ``` 然後執行 ``` npx prisma db push ``` 我們基本上已經在 SQLite 資料庫中建立了一個名為「Repository」的新表: - 「月」、「年」、「日」是日期。 - `name` 儲存庫的名稱 - 「星星」以及該特定日期的星星數量。 你還可以看到我們在底部加入了一個`@@unique`,這意味著我們可以將`name`,`month`,`year`,`day`一起重複記錄。它會拋出一個錯誤。 讓我們新增 Prisma 客戶端。 建立一個名為「helper」的新資料夾,並新增一個名為「prisma.ts」的新文件,並在其中新增以下程式碼: ``` import {PrismaClient} from '@prisma/client'; export const prisma = new PrismaClient(); ``` 我們稍後可以使用該「prisma」變數來查詢我們的資料庫。 --- ## 應用程式 UI 骨架 💀 我們需要一些函式庫來完成本教學: - **Axios** - 向伺服器發送請求(如果您覺得更舒服,可以隨意使用 fetch) - **Dayjs -** 很棒的處理日期的函式庫。它是 moment.js 的替代品,但不再完全維護。 - **Lodash -** 很酷的資料結構庫。 - **react-hook-form -** 處理表單的最佳函式庫(驗證/值/等) - **chart.js** - 我選擇繪製 GitHub 星圖的函式庫。 讓我們安裝它們: ``` npm install axios dayjs lodash @types/lodash chart.js react-hook-form react-chartjs-2 --save ``` 建立一個名為“components”的新資料夾並新增一個名為“main.tsx”的新文件 新增以下程式碼: ``` "use client"; import {useForm} from "react-hook-form"; import axios from "axios"; import {Repository} from "@prisma/client"; import {useCallback, useState} from "react"; export default function Main() { const [repositoryState, setRepositoryState] = useState([]); const {register, handleSubmit} = useForm(); const submit = useCallback(async (data: any) => { const {data: repositoryResponse} = await axios.post('/api/repository', {todo: 'add', repository: data.name}); setRepositoryState([...repositoryState, ...repositoryResponse]); }, [repositoryState]) const deleteFromList = useCallback((val: List) => () => { axios.post('/api/repository', {todo: 'delete', repository: `https://github.com/${val.name}`}); setRepositoryState(repositoryState.filter(v => v.name !== val.name)); }, [repositoryState]) return ( <div className="w-full max-w-2xl mx-auto p-6 space-y-12"> <form className="flex items-center space-x-4" onSubmit={handleSubmit(submit)}> <input className="flex-grow p-3 border border-black/20 rounded-xl" placeholder="Add Git repository" type="text" {...register('name', {required: 'true'})} /> <button className="flex-shrink p-3 border border-black/20 rounded-xl" type="submit"> Add </button> </form> <div className="divide-y-2 divide-gray-300"> {repositoryState.map(val => ( <div key={val.name} className="space-y-4"> <div className="flex justify-between items-center py-10"> <h2 className="text-xl font-bold">{val.name}</h2> <button className="p-3 border border-black/20 rounded-xl bg-red-400" onClick={deleteFromList(val)}>Delete</button> </div> <div className="bg-white rounded-lg border p-10"> <div className="h-[300px]]"> {/* Charts Component */} </div> </div> </div> ))} </div> </div> ) } ``` **超簡單的React元件** - 允許我們新增新的 GitHub 庫並將其發送到伺服器 POST 的表單 - `/api/repository` `{todo: 'add'}` - 刪除我們不需要 POST 的儲存庫 - `/api/repository` `{todo: 'delete'}` - 所有新增的庫及其圖表的清單。 讓我們轉到本文的複雜部分,新增儲存庫。 --- ## 數星星  在「helper」內部建立一個名為「all.stars.ts」的新檔案並新增以下程式碼: ``` import axios from "axios"; import dayjs from "dayjs"; import utc from 'dayjs/plugin/utc'; dayjs.extend(utc); const requestAmount = 20; export const getAllGithubStars = async (owner: string, name: string) => { // Get the amount of stars from GitHub const totalStars = (await axios.get(`https://api.github.com/repos/${owner}/${name}`)).data.stargazers_count; // get total pages const totalPages = Math.ceil(totalStars / 100); // How many pages to skip? We don't want to spam requests const pageSkips = totalPages < requestAmount ? requestAmount : Math.ceil(totalPages / requestAmount); // Send all the requests at the same time const starsDates = (await Promise.all([...new Array(requestAmount)].map(async (_, index) => { const getPage = (index * pageSkips) || 1; return (await axios.get(`https://api.github.com/repos/${owner}/${name}/stargazers?per_page=100&page=${getPage}`, { headers: { Accept: "application/vnd.github.v3.star+json", }, })).data; }))).flatMap(p => p).reduce((acc: any, stars: any) => { const yearMonth = stars.starred_at.split('T')[0]; acc[yearMonth] = (acc[yearMonth] || 0) + 1; return acc; }, {}); // how many stars did we find from a total of `requestAmount` requests? const foundStars = Object.keys(starsDates).reduce((all, current) => all + starsDates[current], 0); // Find the earliest date const lowestMonthYear = Object.keys(starsDates).reduce((lowest, current) => { if (lowest.isAfter(dayjs.utc(current.split('T')[0]))) { return dayjs.utc(current.split('T')[0]); } return lowest; }, dayjs.utc()); // Count dates until today const splitDate = dayjs.utc().diff(lowestMonthYear, 'day') + 1; // Create an array with the amount of stars we didn't find const array = [...new Array(totalStars - foundStars)]; // Set the amount of value to add proportionally for each day let splitStars: any[][] = []; for (let i = splitDate; i > 0; i--) { splitStars.push(array.splice(0, Math.ceil(array.length / i))); } // Calculate the amount of stars for each day return [...new Array(splitDate)].map((_, index, arr) => { const yearMonthDay = lowestMonthYear.add(index, 'day').format('YYYY-MM-DD'); const value = starsDates[yearMonthDay] || 0; return { stars: value + splitStars[index].length, date: { month: +dayjs.utc(yearMonthDay).format('M'), year: +dayjs.utc(yearMonthDay).format('YYYY'), day: +dayjs.utc(yearMonthDay).format('D'), } }; }); } ``` 那麼這裡發生了什麼事: - `totalStars` - 我們計算圖書館擁有的星星總數。 - `totalPages` - 我們計算頁數 **(每頁 100 筆記錄)** - `pageSkips` - 由於我們最多需要 20 個請求,因此我們檢查每次必須跳過多少頁。 - `starsDates` - 我們填充每個日期的星星數量。 - `foundStars` - 由於我們跳過日期,我們需要計算實際找到的星星總數。 - `lowestMonthYear` - 尋找我們擁有的恆星的最早日期。 - `splitDate` - 最早的日期和今天之間有多少個日期? - `array` - 一個包含 `splitDate` 專案數量的空陣列。 - `splitStars` - 我們缺少的星星數量,需要按比例加入每個日期。 - 最終返回 - 新陣列包含自開始以來每天的星星數量。 所以,我們已經成功建立了一個每天可以給我們星星的函數。 我嘗試過這樣顯示,結果很混亂。 您可能想要顯示每個月的星星數量。 此外,您可能想要累積星星**而不是:** - 二月 - 300 顆星 - 三月 - 200 顆星 - 四月 - 400 顆星 **如果有這樣的就更好了:** - 二月 - 300 顆星 - 三月 - 500 顆星 - 四月 - 900 顆星 兩個選項都有效。 **這取決於你想展示什麼!** 因此,讓我們轉到 helper 資料夾並建立一個名為「get.list.ts」的新檔案。 這是文件的內容: ``` import {prisma} from "./prisma"; import {groupBy, sortBy} from "lodash"; import {Repository} from "@prisma/client"; function fixStars (arr: any[]): Array<{name: string, stars: number, month: number, year: number}> { return arr.map((current, index) => { return { ...current, stars: current.stars + arr.slice(index + 1, arr.length).reduce((acc, current) => acc + current.stars, 0), } }).reverse(); } export const getList = async (data?: Repository[]) => { const repo = data || await prisma.repository.findMany(); const uniqMonth = Object.values( groupBy( sortBy( Object.values( groupBy(repo, (p) => p.name + '-' + p.year + '-' + p.month)) .map(current => { const stars = current.reduce((acc, current) => acc + current.stars, 0); return { name: current[0].name, stars, month: current[0].month, year: current[0].year } }), [(p: any) => -p.year, (p: any) => -p.month] ),p => p.name) ); const fixMonthDesc = uniqMonth.map(p => fixStars(p)); return fixMonthDesc.map(p => ({ name: p[0].name, list: p })); } ``` 首先,它將所有按日的星星轉換為按月的星星。 稍後我們會累積每個月的星星數量。 這裡要注意的一件主要事情是 `data?: Repository[]` 是可選的。 我們制定了一個簡單的邏輯:如果我們不傳遞資料,它將為我們資料庫中的所有儲存庫傳遞資料。 如果我們傳遞資料,它只會對其起作用。 為什麼問? - 當我們建立一個新的儲存庫時,我們需要在將其新增至資料庫後處理特定的儲存庫資料。 - 當我們重新載入頁面時,我們需要取得所有資料。 現在,讓我們來處理我們的星星建立/刪除路線。 轉到“src/app/api”並建立一個名為“repository”的新資料夾。在該資料夾中,建立一個名為「route.tsx」的新檔案。 在那裡加入以下程式碼: ``` import {getAllGithubStars} from "../../../../helper/all.stars"; import {prisma} from "../../../../helper/prisma"; import {Repository} from "@prisma/client"; import {getList} from "../../../../helper/get.list"; export async function POST(request: Request) { const body = await request.json(); if (!body.repository) { return new Response(JSON.stringify({error: 'Repository is required'}), {status: 400}); } const {owner, name} = body.repository.match(/github.com\/(?<owner>.*)\/(?<name>.*)/).groups; if (!owner || !name) { return new Response(JSON.stringify({error: 'Repository is invalid'}), {status: 400}); } if (body.todo === 'delete') { await prisma.repository.deleteMany({ where: { name: `${owner}/${name}` } }); return new Response(JSON.stringify({deleted: true}), {status: 200}); } const starsMonth = await getAllGithubStars(owner, name); const repo: Repository[] = []; for (const stars of starsMonth) { repo.push( await prisma.repository.upsert({ where: { name_day_month_year: { name: `${owner}/${name}`, month: stars.date.month, year: stars.date.year, day: stars.date.day, }, }, update: { stars: stars.stars, }, create: { name: `${owner}/${name}`, month: stars.date.month, year: stars.date.year, day: stars.date.day, stars: stars.stars, } }) ); } return new Response(JSON.stringify(await getList(repo)), {status: 200}); } ``` 我們共享 DELETE 和 CREATE 路由,這些路由通常不應在生產中使用,但我們在本文中這樣做是為了讓您更輕鬆。 我們從請求中取得 JSON,檢查「repository」欄位是否存在,並且它是 GitHub 儲存庫的有效路徑。 如果是刪除請求,我們使用 prisma 根據儲存庫名稱從資料庫中刪除儲存庫並傳回請求。 如果是建立,我們使用 getAllGithubStars 來獲取資料以保存到我們的資料庫中。 > 💡 由於我們已經在 `name`、`month`、`year` 和 `day` 上放置了唯一索引,如果記錄已經存在,我們可以使用 `prisma` `upsert` 來更新資料 最後,我們將新累積的資料回傳給客戶端。 最困難的部分完成了🍾 --- ## 主頁人口 💽 我們還沒有建立我們的主頁元件。 **我們開始做吧。** 前往“app”資料夾建立或編輯“page.tsx”並新增以下程式碼: ``` "use server"; import Main from "@/components/main"; import {getList} from "../../helper/get.list"; export default async function Home() { const list: any[] = await getList(); return ( <Main list={list} /> ) } ``` 我們使用與 getList 相同的函數來取得累積的所有儲存庫的所有資料。 我們還修改主要元件以支援它。 編輯 `components/main.tsx` 並將其替換為: ``` "use client"; import {useForm} from "react-hook-form"; import axios from "axios"; import {Repository} from "@prisma/client"; import {useCallback, useState} from "react"; interface List { name: string, list: Repository[] } export default function Main({list}: {list: List[]}) { const [repositoryState, setRepositoryState] = useState(list); const {register, handleSubmit} = useForm(); const submit = useCallback(async (data: any) => { const {data: repositoryResponse} = await axios.post('/api/repository', {todo: 'add', repository: data.name}); setRepositoryState([...repositoryState, ...repositoryResponse]); }, [repositoryState]) const deleteFromList = useCallback((val: List) => () => { axios.post('/api/repository', {todo: 'delete', repository: `https://github.com/${val.name}`}); setRepositoryState(repositoryState.filter(v => v.name !== val.name)); }, [repositoryState]) return ( <div className="w-full max-w-2xl mx-auto p-6 space-y-12"> <form className="flex items-center space-x-4" onSubmit={handleSubmit(submit)}> <input className="flex-grow p-3 border border-black/20 rounded-xl" placeholder="Add Git repository" type="text" {...register('name', {required: 'true'})} /> <button className="flex-shrink p-3 border border-black/20 rounded-xl" type="submit"> Add </button> </form> <div className="divide-y-2 divide-gray-300"> {repositoryState.map(val => ( <div key={val.name} className="space-y-4"> <div className="flex justify-between items-center py-10"> <h2 className="text-xl font-bold">{val.name}</h2> <button className="p-3 border border-black/20 rounded-xl bg-red-400" onClick={deleteFromList(val)}>Delete</button> </div> <div className="bg-white rounded-lg border p-10"> <div className="h-[300px]]"> {/* Charts Components */} </div> </div> </div> ))} </div> </div> ) } ``` --- ## 顯示圖表! 📈 前往“components”資料夾並新增一個名為“chart.tsx”的新檔案。 新增以下程式碼: ``` "use client"; import {Repository} from "@prisma/client"; import {useMemo} from "react"; import React from 'react'; import { Chart as ChartJS, CategoryScale, LinearScale, PointElement, LineElement, Title, Tooltip, Legend, } from 'chart.js'; import { Line } from 'react-chartjs-2'; ChartJS.register( CategoryScale, LinearScale, PointElement, LineElement, Title, Tooltip, Legend ); export default function ChartComponent({repository}: {repository: Repository[]}) { const labels = useMemo(() => { return repository.map(r => `${r.year}/${r.month}`); }, [repository]); const data = useMemo(() => ({ labels, datasets: [ { label: repository[0].name, data: repository.map(p => p.stars), borderColor: 'rgb(255, 99, 132)', backgroundColor: 'rgba(255, 99, 132, 0.5)', tension: 0.2, }, ], }), [repository]); return ( <Line options={{ responsive: true, }} data={data} /> ); } ``` 我們使用“chart.js”函式庫來繪製“Line”類型的圖表。 這非常簡單,因為我們在伺服器端完成了所有資料結構。 這裡需要注意的一件大事是我們「匯出預設值」我們的 ChartComponent。那是因為它使用了「Canvas」。這在伺服器端不可用,我們需要延遲載入該元件。 讓我們修改“main.tsx”: ``` "use client"; import {useForm} from "react-hook-form"; import axios from "axios"; import {Repository} from "@prisma/client"; import dynamic from "next/dynamic"; import {useCallback, useState} from "react"; const ChartComponent = dynamic(() => import('@/components/chart'), { ssr: false, }) interface List { name: string, list: Repository[] } export default function Main({list}: {list: List[]}) { const [repositoryState, setRepositoryState] = useState(list); const {register, handleSubmit} = useForm(); const submit = useCallback(async (data: any) => { const {data: repositoryResponse} = await axios.post('/api/repository', {todo: 'add', repository: data.name}); setRepositoryState([...repositoryState, ...repositoryResponse]); }, [repositoryState]) const deleteFromList = useCallback((val: List) => () => { axios.post('/api/repository', {todo: 'delete', repository: `https://github.com/${val.name}`}); setRepositoryState(repositoryState.filter(v => v.name !== val.name)); }, [repositoryState]) return ( <div className="w-full max-w-2xl mx-auto p-6 space-y-12"> <form className="flex items-center space-x-4" onSubmit={handleSubmit(submit)}> <input className="flex-grow p-3 border border-black/20 rounded-xl" placeholder="Add Git repository" type="text" {...register('name', {required: 'true'})} /> <button className="flex-shrink p-3 border border-black/20 rounded-xl" type="submit"> Add </button> </form> <div className="divide-y-2 divide-gray-300"> {repositoryState.map(val => ( <div key={val.name} className="space-y-4"> <div className="flex justify-between items-center py-10"> <h2 className="text-xl font-bold">{val.name}</h2> <button className="p-3 border border-black/20 rounded-xl bg-red-400" onClick={deleteFromList(val)}>Delete</button> </div> <div className="bg-white rounded-lg border p-10"> <div className="h-[300px]]"> <ChartComponent repository={val.list} /> </div> </div> </div> ))} </div> </div> ) } ``` 您可以看到我們使用“nextjs/dynamic”來延遲載入元件。 我希望將來 NextJS 能為客戶端元件加入類似「使用延遲載入」的內容 😺 --- ## 但是新星呢?來認識一下 Trigger.Dev! 每天加入新星星的最佳方法是執行 cron 請求來檢查新加入的星星並將其加入到我們的資料庫中。 不要使用 Vercel cron / GitHub 操作,或(上帝禁止)為此建立一個新伺服器。 我們可以使用 [Trigger.DEV](http://Trigger.DEV) 直接與我們的 NextJS 應用程式搭配使用。 那麼就讓我們來設定一下吧! 註冊 [Trigger.dev 帳號](https://trigger.dev/)。 註冊後,建立一個組織並為您的工作選擇一個專案名稱。  選擇 Next.js 作為您的框架,並按照將 Trigger.dev 新增至現有 Next.js 專案的流程進行操作。  否則,請點選專案儀表板側邊欄選單上的「環境和 API 金鑰」。  複製您的 DEV 伺服器 API 金鑰並執行下面的程式碼片段以安裝 Trigger.dev。 仔細按照說明進行操作。 ``` npx @trigger.dev/cli@latest init ``` 在另一個終端中執行以下程式碼片段,在 Trigger.dev 和您的 Next.js 專案之間建立隧道。 ``` npx @trigger.dev/cli@latest dev ``` 讓我們建立 TriggerDev 作業! 您將看到一個新建立的資料夾,名為“jobs”。 在那裡建立一個名為“sync.stars.ts”的新文件 新增以下程式碼: ``` import { cronTrigger, invokeTrigger } from "@trigger.dev/sdk"; import { client } from "@/trigger"; import { prisma } from "../../helper/prisma"; import axios from "axios"; import { z } from "zod"; // Your first job // This Job will be triggered by an event, log a joke to the console, and then wait 5 seconds before logging the punchline. client.defineJob({ id: "sync-stars", name: "Sync Stars Daily", version: "0.0.1", // Run a cron every day at 23:00 AM trigger: cronTrigger({ cron: "0 23 * * *", }), run: async (payload, io, ctx) => { const repos = await io.runTask("get-stars", async () => { // get all libraries and current amount of stars return await prisma.repository.groupBy({ by: ["name"], _sum: { stars: true, }, }); }); //loop through all repos and invoke the Job that gets the latest stars for (const repo of repos) { getStars.invoke(repo.name, { name: repo.name, previousStarCount: repo?._sum?.stars || 0, }); } }, }); const getStars = client.defineJob({ id: "get-latest-stars", name: "Get latest stars", version: "0.0.1", // Run a cron every day at 23:00 AM trigger: invokeTrigger({ schema: z.object({ name: z.string(), previousStarCount: z.number(), }), }), run: async (payload, io, ctx) => { const stargazers_count = await io.runTask("get-stars", async () => { const { data } = await axios.get( `https://api.github.com/repos/${payload.name}`, { headers: { authorization: `token ${process.env.TOKEN}`, }, } ); return data.stargazers_count as number; }); await prisma.repository.upsert({ where: { name_day_month_year: { name: payload.name, month: new Date().getMonth() + 1, year: new Date().getFullYear(), day: new Date().getDate(), }, }, update: { stars: stargazers_count - payload.previousStarCount, }, create: { name: payload.name, stars: stargazers_count - payload.previousStarCount, month: new Date().getMonth() + 1, year: new Date().getFullYear(), day: new Date().getDate(), }, }); }, }); ``` 我們建立了一個名為“Sync Stars Daily”的新作業,該作業將在每天下午 23:00 執行 - 它在 cron 文本中的表示為:`0 23 * * *` 我們在資料庫中取得所有目前儲存庫,按名稱將它們分組,並對星星進行求和。 由於一切都在 Vercel 無伺服器上執行,因此我們可能會在檢查所有儲存庫時遇到逾時。 為此,我們將每個儲存庫傳送到不同的作業。 我們使用“invoke”建立新作業,然後在“獲取最新的星星”中處理它們 我們迭代所有新儲存庫並獲取當前的星星數量。 我們用舊的星星數量去除新的星星數量,得到今天的星星數量。 我們使用“prisma”將其新增至資料庫。沒有比這更簡單的了! 最後一件事是編輯“jobs/index.ts”並將內容替換為: ``` export * from "./sync.stars"; ``` 你就完成了🥳 --- ## 讓我們聯絡吧! 🔌 作為開源開發者,我們邀請您加入我們的[社群](https://discord.gg/nkqV9xBYWy),以做出貢獻並與維護者互動。請隨時造訪我們的 [GitHub 儲存庫](https://github.com/triggerdotdev/trigger.dev),貢獻並建立與 Trigger.dev 相關的問題。 本教學的源程式碼可在此處取得: [https://github.com/triggerdotdev/blog/tree/main/stars-monitor](https://github.com/triggerdotdev/blog/tree/main/stars-monitor) 感謝您的閱讀! --- 原文出處:https://dev.to/triggerdotdev/take-nextjs-to-the-next-level-create-a-github-stars-monitor-130a
## 簡介 在本教程中,您將學習如何在 Kubernetes(容器編排平台)上部署您的第一個 JavaScript 應用程式☸️。 我們將部署一個簡單的 **express** 伺服器,該伺服器使用 **Minikube** ✨ 在本機 Kubernetes 上傳回範例 JSON 物件。 **先決條件📜:** - **Docker**:用於容器化應用程式。 🐋 - **Minikube**:用於在本地執行 Kubernetes。 ☸️  *** ## Odigos - 開源分散式追蹤 **無需編寫任何程式碼即可同時監控所有應用程式!** 利用唯一可以在所有應用程式中產生分散式追蹤的平台來簡化 OpenTelemetry 的複雜性。 我們真的才剛開始。 可以幫我們加個星星嗎?請問? 😽 https://github.com/keyval-dev/odigos [](https://github.com/keyval-dev/odigos) --- ### 讓我們設定一下🚀 我們將首先初始化我們的專案: ``` npm init -y ``` 這會使用 `package.json` 📝 檔案初始化 **NodeJS** 專案,該檔案追蹤我們安裝的依賴項。 安裝 Express.js 框架 ``` npm install express ``` 現在,在 `package.json` 中,依賴項物件應該如下所示。 ✅ ``` "dependencies": { "express": "^4.18.2" } ``` 現在,在專案的根目錄中建立一個「index.js」檔案並新增以下程式碼行。 🚀 ``` // 👇🏻 Initialize express. const express = require("express"); const app = express(); const port = 3000; // 👇🏻 Return a sample JSON object with a message property on the root path. app.get("/", (req, res) => { res.json({ message: "Hello from Odigos!", }); }); // 👇🏻 Listen on port 3000. app.listen(port, () => { console.log(`Server is listening on port ${port}`); }); ``` 我們需要在「package.json」中新增一個腳本來執行應用程式。將其新增至 `package.json` 的腳本物件中。 ``` "scripts": { "dev": "node index.js" }, ``` 現在,要檢查我們的應用程式是否正常執行,請使用「npm run dev」執行伺服器,並透過 CLI 或在瀏覽器中向「localhost:3000」發出 get 請求。 ✨ 如果您使用 CLI,請確保已安裝了 [cURL](https://curl.se/)。 ✅ ``` curl http://localhost:3000 ``` 你應該看到這樣的東西。 👇🏻  現在,您可以使用「Ctrl + C」簡單地停止正在執行的 Express 伺服器🚫 我們的範例應用程式已準備就緒! 🎉 現在,讓我們將其容器化並推送到 Kubernetes。 🐳☸️ *** ### 將應用程式容器化📦 我們將使用 **Docker** 來容器化我們的應用程式。 在專案的根目錄中,建立一個名為「Dockerfile」的新檔案。 > 💡 確保名稱完全相同。否則,您將需要明確傳遞“-f”標誌來指定“Dockerfile”路徑。 ``` # Uses node as the base image FROM node:21-alpine # Sets up our working directory as /app inside the container. WORKDIR /app # Copyies package json files. COPY package.json package-lock.json ./ # Installs the dependencies from the package.json RUN npm install --production # Copies current directory files into the docker environment COPY . . # Expose port 3000 as our server uses it. EXPOSE 3000 # Finally runs the server. CMD ["node", "index.js"] ``` 現在,我們需要建置 ⚒️ 這個容器才能實際使用它並將其推送到 Kubernetes。 執行此命令來建置“Dockerfile”。 > 🚨 如果您在 Windows 上執行它,請確保 Docker Desktop 正在執行。 ``` // 👇🏻 We are tagging our image name to express-server docker build -t express-server . ``` 現在,是時候執行容器了。 🏃🏻♂️💨 ``` docker run -dp 127.0.0.1:3000:3000 express-server ``` > 💡 我們正在後台執行容器,容器連接埠 3000 對應到我們的電腦連接埠 3000。 再次執行以下命令,您應該會看到與之前相同的結果。 ✅ ``` curl http://localhost:3000 ``` > **注意**:這次應用程式沒有像以前一樣在我們的電腦上執行。相反,它在容器內運作。 🤯 *** ### 在 Kubernetes 中部署 ## 如前所述,我們將使用 Minikube 在本機電腦上建立編排環境,並使用 kubectl 命令與 Kubernetes 互動。 😄 **啟動 Minikube:🚀** ``` minikube start ``` 由於我們將使用本機容器而不是從 docker hub 中提取它們,因此請執行這些命令。 ✨ ``` eval $(minikube docker-env) docker build -t express-server . ``` `eval $(minikube docker-env)`:用於將終端機的 `docker-cli` 指向 minikube 內的 Docker 引擎。 > 🚨 注意,我們很多人都使用 Fish 作為 shell,因此對於 Fish 來說,相應的命令是 `eval (minikube docker-env)` 現在,在專案根目錄中,建立一個嵌套資料夾“k8/deployment”,並在部署資料夾中建立一個名為“deployment.yaml”的新文件,其中包含以下內容。 在此文件中,我們將管理容器的部署。 👇🏻 ``` # 👇🏻 /k8/deployment/deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: express-deployment spec: selector: matchLabels: app: express-svr template: metadata: labels: app: express-svr spec: containers: - name: express-svr image: express-server imagePullPolicy: Never # Make sure to set it to Never, or else it will pull from the docker hub and fail. resources: limits: memory: "128Mi" cpu: "500m" ports: - containerPort: 3000 ``` 最後,執行此命令以應用我們剛剛建立的部署配置「deployment.yaml」。 ✨ ``` kubectl apply -f .\k8\deployment\deployment.yaml ``` 現在,如果我們查看正在執行的 Pod,我們可以看到 Pod 已成功建立。 🎉  要查看我們建立的 Pod 的日誌,請執行“kubectl messages <pod_name>”,我們應該會看到以下內容。  至此,我們的「express-server」就成功部署在本地 Kubernetes 上了。 😎 *** 這就是本文的內容,我們成功地將應用程式容器化並將其部署到 Kubernetes。 本文的原始碼可以在這裡找到 https://github.com/keyval-dev/blog/tree/main/js-on-k8s 非常感謝您的閱讀! 🎉🫡 --- 原文出處:https://dev.to/odigos/the-fastest-way-to-deploy-your-javascript-app-to-kubernetes-2j33
你的轉職路上,還缺少一份自學作業包!寫完這幾包,直接拿作品去面試上班!
本論壇另有附設一個 LINE 新手發問&交流群組!歡迎加入討論!





























