以下是一些重要的快捷方式,可以幫助我全天提高工作效率: - 為指令建立別名。 - 使用 pbcopy。 - 在終端機中使用反向搜尋。 - 獎勵技巧和技巧。 --- ## 指令的別名 Alias可以是我們手中最強大的工具之一,它為我們提供了編寫自己的快捷方式的能力。讓我們透過一個例子來看看我的意思。 ``` alias dev="cd ~/Project/development" ``` 每當我輸入 dev 並按 Enter 鍵時,它都會執行此命令。當導航到不同的資料夾時,這變得非常有用。我們可以執行別名中的幾乎所有命令。以下是我最常用的一些指令的清單: ``` alias ..="cd .." alias gs="git status" alias gp="git pull" alias gb="git branch" alias ga="git add ." ``` 因此,使用這些別名,我可以在白天節省大量時間來建立我鍵入的目錄,而不是 cd...我認為其餘的都是不言自明的。我們也可以使用 $1、$2 等參數來提高可擴展性,如下例所示: ``` alias gc="git commit -m $1" ``` 現在,我只需輸入 gc“Commit message”,它就會使用提供的訊息提交我的更改。您所要做的就是找到最常用的命令,並嘗試使用別名來縮短它們,從而提高工作效率。 現在我們知道別名可以做什麼,讓我們看看如何設定它們。我們可以透過兩種方法來實現這一點,第一種是臨時的,可以透過執行命令來設定: ``` alias dev="cd ~/Project/development" ``` 這將一直有效,直到會話結束。另一種方法是永久設定這些別名。為此,我們需要在 shell 中進行設置,我使用 Zsh,所以我將更新我的 ~/.zshrc 檔案。 如果您使用的是 Bash,請使用 ~/.bashrc 檔案。將命令新增至文件中,您的文件應如下所示:  更改此文件後,您需要執行命令: ``` source ~/.zshrc ``` 然後,您的所有別名都可供您使用。 --- ## pbcopy 該命令在 Mac 上可用,如果您想在 Linux 發行版上使用它,可以按照本指南進行操作。 pbcopy 是類固醇複製。您可以使用此命令將文件的內容複製到剪貼簿。讓我舉一個例子。假設您必須將 SSH 身分複製到剪貼簿,可以使用以下命令來完成: ``` pbcopy < ~/.ssh/id_rsa.pub ``` 您可以將其他密碼保存在不同的檔案中,並在登入時使用它。 假設您正在使用和存取遠端伺服器,並且您必須提供密碼,您可以將其 pbcopy 到剪貼簿,而不是打開文件,而無需打開和關閉文件的所有麻煩,您將獲得密碼。 當它與 grep 等其他命令一起通過管道傳輸時,它會變得更有用。它將把 grep 結果複製到剪貼簿。讓我們來看一個例子: ``` grep "<keyword>" | pbcopy ``` 我在偵錯日誌檔案時使用此命令,並提供要搜尋的關鍵字(例如時間戳記),並將所有行複製到剪貼簿中。 我可以將其貼到文件中以查看所需的日誌而不是整個文件。如果您使用 tee 命令作為 grep 的管道,它會更有用,它會將結果寫入檔案。 它具有以下語法: ``` grep "<keyword>" | tee myfile.txt ``` --- ## 使用反向搜尋 反向搜尋是 Unix 系統上最酷的功能之一。 假設你忘記了完整的命令,只記住了一部分,你能做的就是去反向搜尋並輸入你記住的單字。讓我們來看一個例子。 我必須重新啟動在臨時環境中執行的伺服器,我只記得臨時關鍵字,而忘記了命令的其餘部分。因此,我輸入 ctrl + r 進入反向搜尋模式並輸入: ``` (reverse-i-search)`stag': cd /home/ubuntu/server; pm2 stop app.js && export NODE_ENV="staging" && pm2 start app.js && pm2 logs ``` 它會記住之前輸入的命令並找到您正在尋找的正確匹配項。 --- ## 獎勵技巧和技巧 ### 卡爾 它在終端上列印當前月份。它有許多不同的可用選項,可以使用 man cal 進行檢查。  ### 使用 vim 加密文件 您可以使用 vim 加密文件,只需輸入 :X 即可。它會要求您設定密碼,如下所示:  當您再次造訪該文件時,它會要求您輸入密碼。  --- ## 結論 請提及您最常用的命令並將其加入到清單中。 --- 原文出處:https://dev.to/pankajgupta221b/3-terminal-commands-to-increase-your-productivity-57dm
Docker 是一個工具,允許開發人員將他們的應用程式及其所有依賴項打包到一個容器中。然後,這個容器就可以輕鬆地在任何安裝了 Docker 的機器上傳輸和執行,而不必擔心環境的差異。這就像是打包和執行軟體的標準化方式。 **容器是什麼?**  容器就像一個小包,其中包含程式執行所需的一切,可以輕鬆地在不同電腦上移動和執行,而不會造成任何麻煩。 最酷的部分是這個迷你電腦(容器)就像一個披著斗篷的超級英雄。它可以在任何電腦上執行,無論它們有多麼不同,因為它自帶特殊的環境。這是一種保持軟體井然有序的方式,並確保它無論在哪裡都能以相同的方式運作。 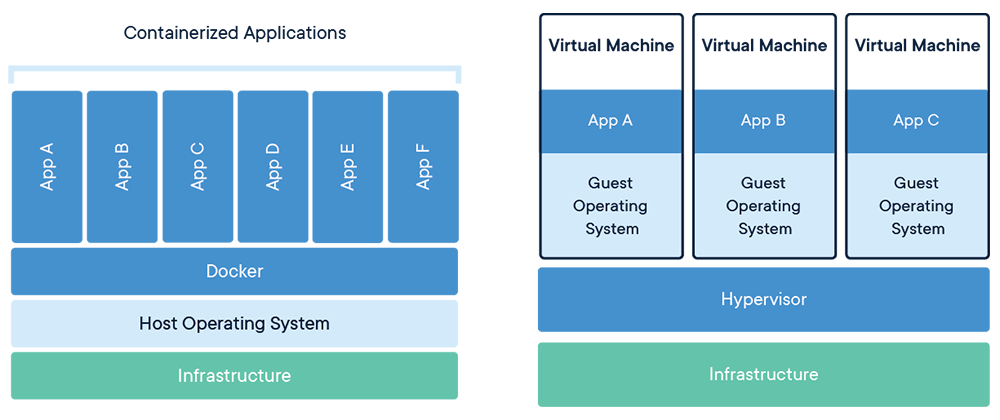 **為什麼我們需要 Docker?** 1. **一致性:** Docker 確保軟體在您的電腦、您朋友的電腦或任何電腦上以相同的方式運作。它使事情保持一致。 2. **可移植性:** 您可以將您的軟體及其朋友打包到 Docker 容器中,並且它可以移動到任何地方。這就像將您的遊戲及其所有規則放在手提箱中並在朋友家中玩。 3. **隔離:** Docker 容器就像小氣泡。氣泡內發生的事只會留在氣泡內。這意味著容器中的一個程式不會幹擾容器外的另一個程式。 4. **效率:** Docker有助於節省電腦資源。您可以讓許多容器在同一台電腦上執行,而不會相互妨礙,而不是讓一整台電腦只用於一個程式。 5. **速度:** Docker 讓啟動、停止和共享軟體變得快速、輕鬆。這就像打開和關閉遊戲機一樣 - 快速而簡單。 **什麼是 Docker 映像?** 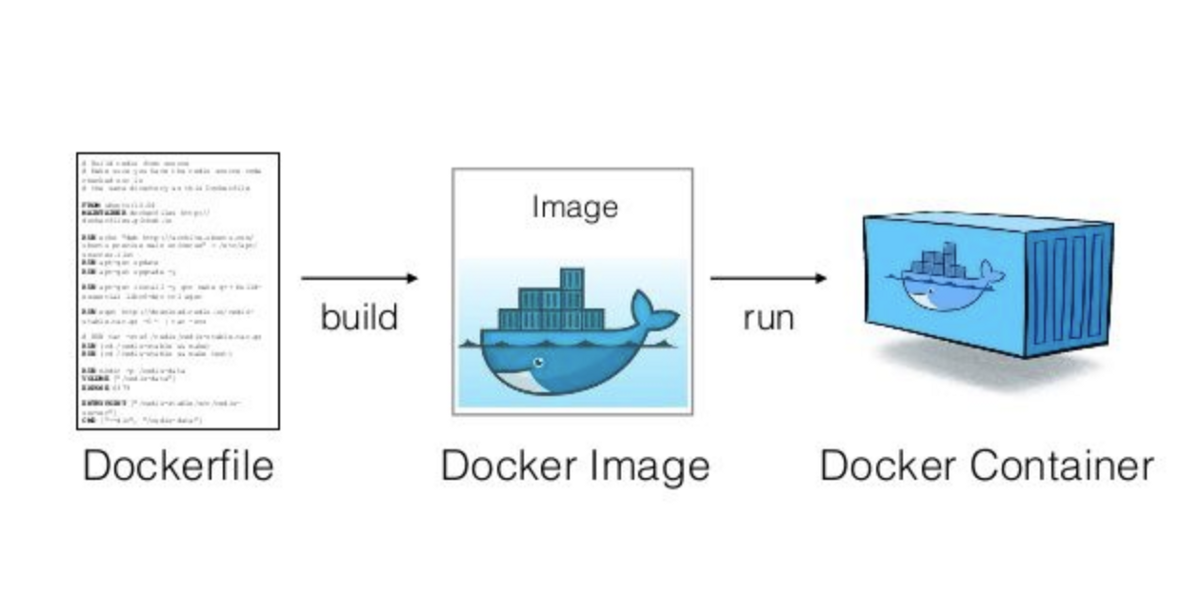 Docker 映像像是程式及其運作所需的所有內容的快照。它是一個打包版本,包括程式碼、工具和設置,就像包含所有成分的餅乾食譜的快照一樣。 **圖像是配方,容器是當您按照該配方實際製作和執行程序時所得到的。** **一些基本的 Docker 命令。**  1. **`docker執行nginx`** - 此命令告訴 Docker 使用「nginx」映像執行容器。這就像告訴 Docker 啟動一個預製程式的新實例(nginx,它是一個 Web 伺服器)。 2. **`docker ps`** - 顯示正在執行的容器的清單。這就像檢查當前正在執行哪些程式。 3. **`docker ps -a`** - 顯示所有容器的列表,包括已停止的容器。這就像檢查您執行過的所有程式的歷史記錄。 4. **`docker stopsilly_sammet'** - 停止名為「silly_sammet」的正在運作的容器。這就像關閉當前正在執行的程式。 5. **`docker rmsilly_sammet'** - 刪除名為「silly_sammet」的已停止容器。這就像丟掉你不再需要的程式的指令一樣。 6. **`docker 映像`** - 列出您擁有的所有 Docker 映像。這就像查看您可以執行的所有不同程式的選單一樣。 7. **`docker rmi nginx`** - 刪除“nginx”圖像。這就像刪除您不想再使用的程式的配方。 8. **`docker拉nginx`** - 從網路下載「nginx」映像。這就像從食譜中獲取新食譜一樣。 9. **`docker 執行 ubuntu sleep 5`** - 使用「ubuntu」映像檔執行容器並使其休眠 5 秒。這就像啟動一個程序,只是等待一小會兒,然後就停止了。 10. **`docker exectracted_mcclintock cat /etc/hosts`** - 在名為「distracted_mcclintock」的正在執行的容器內執行命令。這就像在食譜書中偷看特定頁面一樣。 11. **`docker run -d kodekloud/simple-webapp`** - 從「kodekloud/simple-webapp」鏡像以分離模式執行容器。這就像啟動一個程式並讓它在背景執行。 12. **`docker Attach a043d`** - 將您的終端附加到 ID 為「a043d」的正在執行的容器。這就像跳入正在執行的程式來查看發生了什麼。 **一些 Docker 概念:** 1. **使用標籤執行:** - 標籤就像程式的版本。它指定您要執行哪個版本。 - 範例程式碼:`docker run nginx:latest` - 這將執行最新版本的 Nginx 程式。 2. **使用標準輸入執行:** - STDIN 就像在鍵盤上打字一樣。有些程式需要您的輸入。 - 範例程式碼:`docker run -i -t ubuntu` - 這會在 Ubuntu 容器內執行互動終端,讓您可以鍵入命令。 3. **使用連接埠映射執行:** - 連接埠就像門。程式使用它們與外界進行通訊。 - 範例程式碼:`docker run -p 8080:80 nginx` - 這將執行 Nginx,並打開電腦連接埠 8080 上的門,將其連接到容器的連接埠 80。 4. **使用磁碟區映射執行:** - 磁碟區就像共用資料夾。它們讓您可以將東西存放在容器之外。 - 範例程式碼:`docker run -v /your/local/folder:/container/folder nginx` - 這將執行 Nginx 並將電腦上的資料夾連接到容器內的資料夾。 5. **檢查容器:** - 檢查就像仔細檢查正在執行的程式。 - 範例程式碼:`docker檢查container_name` - 這為您提供有關正在執行或已停止的容器的詳細資訊。 6. **容器日誌:** - 日誌就像日記。他們記錄程式正在做什麼。 - 範例程式碼:“docker 日誌容器名稱” - 這會向您顯示特定容器的日誌或活動。 ##環境變數 環境變數就像程式用來尋找重要資訊的便利筆記,有點像是程式可以理解和更好工作的秘密訊息! 1. **Python腳本(app.py)中的環境變數:** - 假設您有一個用 Python 寫的程式 (app.py)。您可能想要在不更改程式碼的情況下自訂它。您可以使用環境變數。 - 範例程式碼(app.py): ``` import os app_color = os.getenv("APP_COLOR", "default_color") print(f"The app color is {app_color}") ``` - 正常運作腳本:`python app.py` - 以特定顏色執行:`export APP_COLOR=blue; python 應用程式.py` 2. **在 Docker 中使用 ENV 變數:** - Docker 容器也可以使用環境變數。這就像是向容器內的程式發出指令。 - 範例程式碼: - `docker run -e APP_COLOR=green simple-webapp-color` - 這會執行 Docker 容器(`simple-webapp-color`)並將環境變數 `APP_COLOR` 設為「綠色」。 3. **檢查環境變數:** - 有時,您會想要檢查正在執行的容器正在使用哪些環境變數。 - 範例程式碼:`docker檢查blissful_hopper` - 此命令提供有關名為“blissful_hopper”的容器的詳細訊息,包括其環境變數。 簡單來說,環境變數就像程式(或 Docker 容器)可以讀取以了解如何行為的小註釋。您可以在執行程式之前設定這些註釋,程式將使用它們來自訂自身。第二個範例中的「export」指令就像在執行程式之前寫一條註釋,告訴它如何運作。 “docker Inspect”指令就像是在容器內部查看它有什麼註解。 ## Docker 映像 **Docker 檔案:** Dockerfile 就像是 Docker 建立映像的一組指令。這就像是烤蛋糕的食譜。 ``` # Use the Ubuntu base image FROM Ubuntu # Update apt repository RUN apt-get update # Install dependencies using apt RUN apt-get install -y python # Install Python dependencies using pip RUN pip install flask RUN pip install flask-mysql # Copy source code to /opt folder COPY . /opt/source-code # Set the working directory WORKDIR /opt/source-code # Specify entry point to run the web server ENTRYPOINT ["flask", "run"] ``` **建立自己的圖像的步驟:** 1. 使用上述內容建立一個名為「Dockerfile」的檔案。 2. 將其保存在與原始碼相同的目錄中。 **建置 Docker 映像:** 在終端機中執行以下命令: ``` docker build -t your-image-name . ``` 此命令告訴 Docker 使用目前目錄中的 Dockerfile (`.`) 建置映像,並使用您選擇的名稱對其進行標記 (`-t your-image-name`)。 **分層架構:** 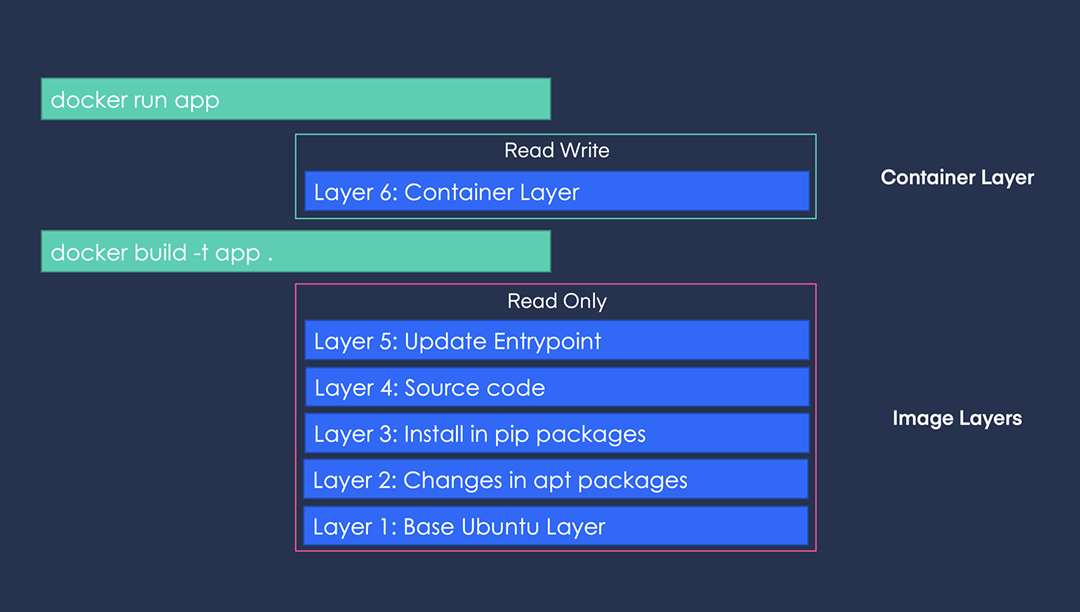 - 將 Docker 映像視為一個分層蛋糕。 Dockerfile 中的每個指令都會在映像上新增一層。 - 圖層可重複使用。如果您變更程式碼中的某些內容,Docker 只會重建受影響的層,從而提高效率。 **Docker 建置輸出:** - 當您建置映像檔時,Docker 會顯示流程中的每個步驟。如果發生故障,它會給您錯誤訊息。 **你可以容器化什麼?** - 幾乎所有東西!應用程式、服務、資料庫、網站,基本上任何軟體都可以容器化。 - 這就像將您的軟體放入一個盒子中,以便它可以在任何地方執行而不會造成麻煩。 ## 什麼是 Docker CMD 與 ENTRYPOINT **Docker 中的`CMD`:** - 將 CMD 視為啟動容器時程式執行的預設操作。 - 這就像說,“嘿,當你執行這個容器時,默認執行此操作。” - 範例:`CMD ["flask", "run"]` 表示當容器啟動時,它會自動執行 Flask Web 伺服器。 **CMD 範例:** ``` FROM alpine CMD ["sleep", "5"] ``` 在此範例中,當您使用此映像執行容器時,它會自動休眠 5 秒。 **Docker 中的`ENTRYPOINT`:** - 將 ENTRYPOINT 視為容器所做的主要事情。就好像boss的命令一樣。 - 它設定一個預設應用程式在容器啟動時執行,但您仍然可以根據需要覆蓋它。 - 範例:`ENTRYPOINT ["flask", "run"]` 表示容器主要用於執行 Flask Web 伺服器,但如果需要,您仍可新增更多指令。 **入口點範例:** ``` FROM alpine ENTRYPOINT ["sleep"] CMD ["5"] ``` 在這裡,主要目的是睡眠,如果您願意,您仍然可以覆蓋睡眠持續時間。 在這兩種情況下,容器在啟動時只會休眠幾秒鐘。主要區別在於如何提供參數以及它們是否可以輕鬆覆蓋。 CMD 就像在說,“這是默認要做的事情”,而 ENTRYPOINT 就像在說,“這是主要要做的事情,但如果你願意,你可以稍微調整一下。”它們都有助於定義容器啟動時執行的操作。 ## Docker 中的網路: Docker 網路幫助容器(程式)相互通信,確保它們可以順利地協同工作。 **預設網路:** - Docker 建立預設網路供容器通訊。 - 範例程式碼:`docker run ubuntu --network=host` - 這使用主機網路執行 Ubuntu 容器,這意味著它與主機共享網路命名空間。 **使用者定義的網路:** - 您可以建立自己的網路以更好地組織和控制。 - 範例程式碼: ``` docker network create --driver=bridge --subnet=182.18.0.0/16 custom-isolated-network ``` - 這將建立一個名為「custom-isolated-network」的使用者定義的橋接網絡,具有特定的子網。 **上市網路:** - 您可以查看您擁有的所有網路。 - 範例程式碼:`docker network ls` **檢查網路:** - 您可以檢查特定網路的詳細資訊。 - 範例程式碼:`docker網路檢查blissful_hopper` - 這顯示有關名為「blissful_hopper」的網路的詳細資訊。 **嵌入式 DNS:** - Docker 有一個內建的 DNS 系統,供容器透過名稱相互查找。 - 範例程式碼:`mysql.connect(mysql)` - 這可能是程式碼中的一行,其中名為「mysql」的服務使用 Docker 的 DNS 連接到另一個名為「mysql」的服務。 ## Docker 儲存: 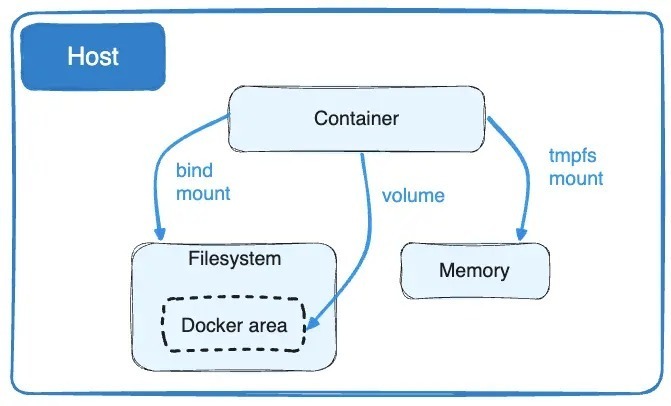 Docker 儲存就像使用容器時決定將資料保存在哪裡一樣。您可以將它們保留在容器內,使用磁碟區在容器之間共用它們,或將它們儲存在容器外部以妥善保管。 **Docker中的檔案系統:** - Docker 使用分層架構來建立映像。 Dockerfile 中的每個指令都會在檔案系統中新增一個新圖層。 ``` # Dockerfile FROM Ubuntu RUN apt-get update && apt-get install -y python RUN pip install flask flask-mysql COPY . /opt/source-code WORKDIR /opt/source-code ENTRYPOINT ["flask", "run"] ``` - Dockerfile 中的層: - 第 1 層:Ubuntu 基礎層 - 第 2 層:apt 軟體包的更改 - 第 3 層:pip 套件的變化 - 第 4 層:原始碼 - 第 5 層:使用「flask」指令更新入口點 - 第 6 層:容器層 **影像圖層:** - 當您建立 Docker 映像時,它由唯讀層組成。每一層代表影像的變化或加入。 - 第 1 層:Ubuntu 基礎層 - 第 2 層:apt 軟體包的更改 - 第 3 層:pip 套件的變化 - 第 4 層:原始碼 - 第 5 層:使用「flask」指令更新入口點 ``` # Build the Docker image docker build -t mmumshad/my-custom-app . ``` **容器層:** - 當您執行 Docker 容器時,會在唯讀映像層上方新增一個讀寫層。該層特定於正在執行的容器。 - 第 6 層. 容器層 ``` # Run the Docker container docker run mmumshad/my-custom-app ``` **數量:** - 卷是一種在容器外部保存資料的方法。它們就像外部記憶體。 ``` # Create a Docker volume docker volume create data_volume # Use the volume in a container docker run -v data_volume:/var/mysql mysql ``` - 您也可以使用「-v」將特定目錄從主機掛載到容器: ``` # Mount a host directory to a container directory docker run -v /path/on/host:/var/mysql/mysql -d mysql ``` - docker run --mount 指令用於將主機上的特定目錄或檔案掛載到正在執行的 Docker 容器中。 ``` docker run --mount type=bind,source=/mysql,target=/var/mysql mysql ``` **儲存驅動程式:** - Docker 使用儲存驅動程式來管理資料的儲存和存取方式。一些常見的儲存驅動程式包括 AUFS、ZFS、BTRFS、Device Mapper、Overlay 和 Overlay2。 [在 Docker 管理資料](https://docs.docker.com/storage/) [關於儲存驅動程式](https://docs.docker.com/storage/storagedriver/) [卷](https://docs.docker.com/storage/volumes/) ## Docker 組合  Docker Compose 是一個方便的工具,可幫助您輕鬆執行和連接不同的軟體服務,就好像它們都是同一事件的一部分一樣。 **Docker Compose 基礎:** 1. **執行單一容器:** - 通常,您可以像這樣執行單獨的 Docker 容器: ``` docker run mmumshad/simple-webapp docker run mongodb docker run redis:alpine docker run ansible ``` 2. **Docker 撰寫文件(`docker-compose.yml`):** - Docker Compose 允許您在一個簡單的檔案中定義所有這些服務: ``` # docker-compose.yml version: '3' services: web: image: 'mmumshad/simple-webapp' database: image: 'mongodb' messaging: image: 'redis:alpine' orchestration: image: 'ansible' ``` - 此檔案描述您要執行的服務(「web」、「database」、「messaging」、「orchestration」)、它們各自的映像以及任何其他配置。 3. **使用 Docker Compose 執行:** - 要一起啟動所有這些服務: ``` docker-compose up ``` - Docker Compose 負責啟動「docker-compose.yml」檔案中定義的所有容器。 4. **使用 Docker Compose 建置:** - 您也可以使用 Docker Compose 建置映像: ``` docker-compose build ``` - 此指令建置「docker-compose.yml」檔案中指定的映像。 **執行連結容器:** - 如果您要透過連結執行單一容器: ``` docker run -d --name redis redis docker run --name voting-app -p 5000:80 --link redis:redis voting-app docker run --name result-app -p 5001:80 --link db:db result-app docker run -d --name worker --link db:db --link redis:redis worker ``` - 在 Docker 中撰寫: ``` # docker-compose.yml version: '3' services: vote: image: 'voting-app' ports: - '5000:80' links: - 'redis:redis' result: image: 'result-app' ports: - '5001:80' links: - 'db:db' worker: image: 'worker' links: - 'db:db' - 'redis:redis' db: image: 'db' redis: image: 'redis' ``` Docker Compose 可讓您在單一檔案中描述整個應用程式堆疊,從而輕鬆管理、執行和連接不同的服務。這就像在一份計劃中寫下活動的所有任務,然後 Docker Compose 為您處理設定。 [Docker Compose 概述](https://docs.docker.com/compose/) [Docker 撰寫文件](https://docs.docker.com/engine/reference/commandline/compose/) ## Docker 註冊表 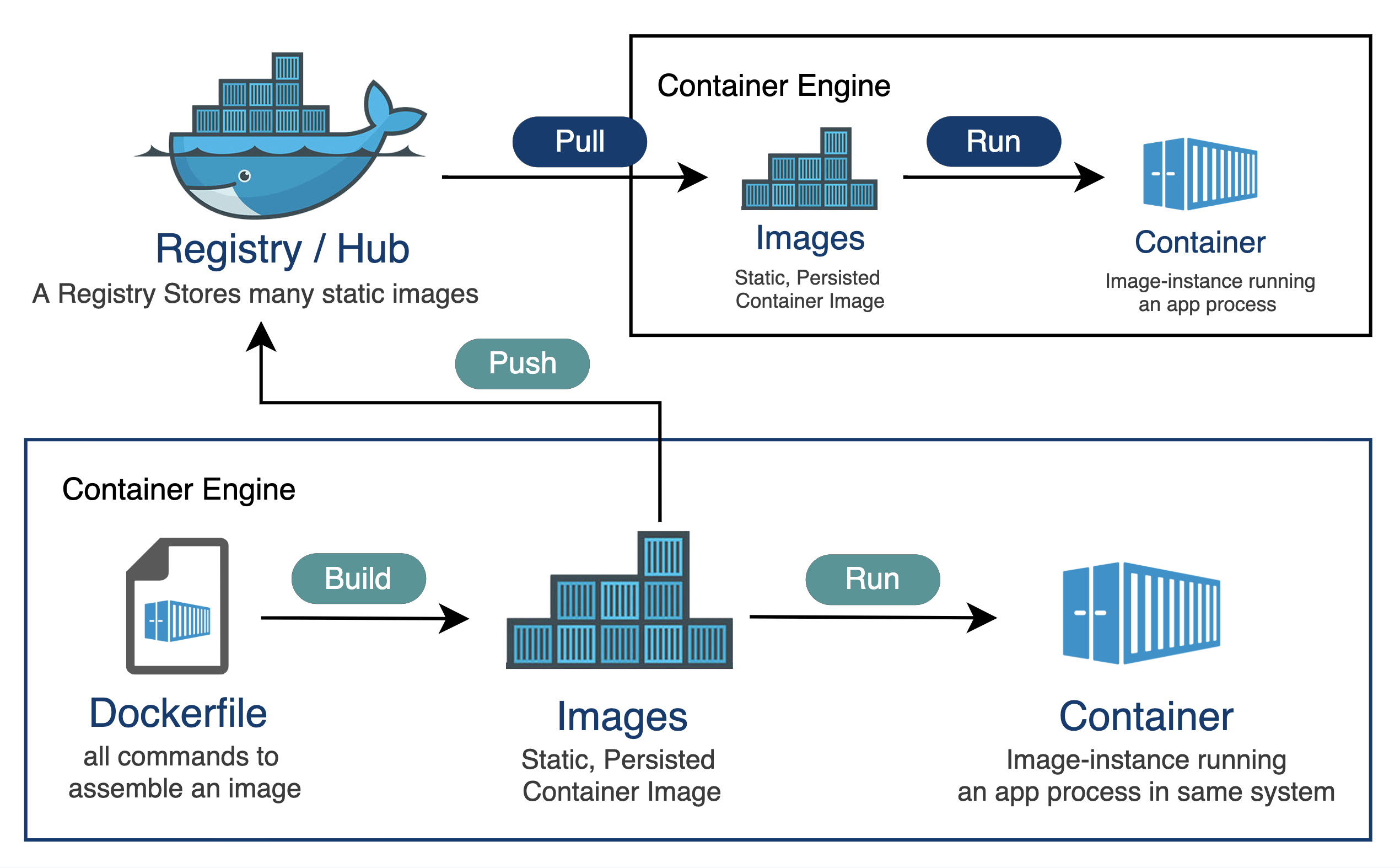 Docker 註冊表是人們儲存和分享 Docker 映像的地方,使其他人可以輕鬆使用和執行他們的軟體。它就像一個大型線上程式庫,可以輕鬆下載並在不同電腦上使用。 **Docker 註冊表基礎知識:** 1. **公共登記處:** - Docker 映像可以在 Docker Hub 等公共註冊表中儲存和共用。 - 例: ``` docker pull nginx ``` 2. **私人登記處:** - 有時,您可能希望將圖像保存在您自己的私人註冊表中。 - 例: - 登入私人註冊表: ``` bash docker login private-registry.io ``` - 從私有註冊表中的映像執行容器: ``` docker run private-registry.io/apps/internal-app ``` 3. **部署您自己的私有註冊表:** - 您可以為您的團隊或公司部署自己的私人註冊表。 - 例: - 在您的電腦上執行私有註冊表: ``` docker run -d -p 5000:5000 --name registry registry:2 ``` - 為私人註冊表標記您的圖像: ``` bash docker image tag my-image localhost:5000/my-image ``` - 將映像推送到您的私人註冊表: ``` bash docker push localhost:5000/my-image ``` - 從您的私人註冊表中提取映像: ``` bash docker pull localhost:5000/my-image ``` 4. **從遠端私有註冊表中提取:** - 您也可以使用 IP 位址或網域從遠端私有註冊表中提取映像。 - 例: ``` docker pull 192.168.56.100:5000/my-image ``` Docker 註冊表就像一個儲存空間,人們在其中保存和共享 Docker 映像。您可以將公用註冊表用於廣泛使用的映像,也可以根據您的特定需求設定自己的私人註冊表。它就像一個用於共享和儲存軟體藍圖(圖像)的特殊庫。 ## Docker 引擎 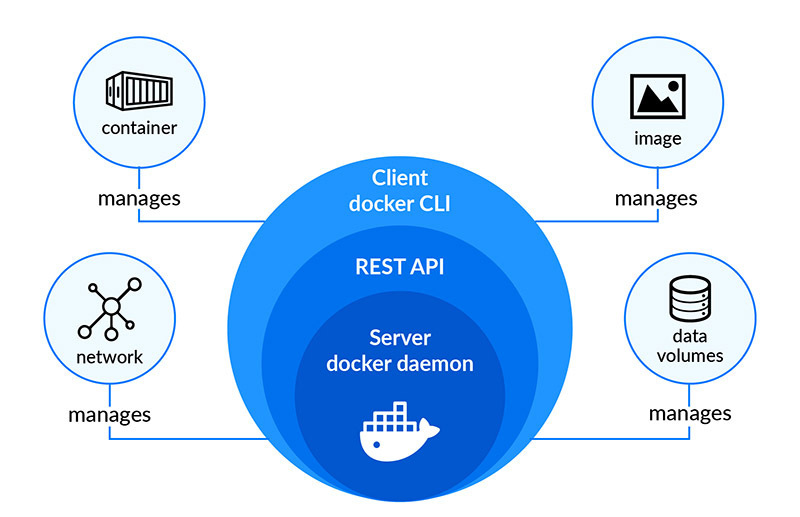 想像一下,你有一個魔盒(Docker Engine),可以為你執行和管理各種程式(容器)。 Docker Engine 就像是這個魔盒的大腦。 1. **Docker 守護程式:** - 守護程式就像魔法盒的看門人。它始終在那裡,隨時準備接受指示並確保一切順利進行。 2. **REST API:** - 將 REST API 視為一組允許您與魔盒對話的規則。它就像你和守護程式用來溝通的語言。你告訴守護程式要做什麼,它會理解,因為你們說的是同一種語言。 3. **Docker CLI(命令列介面):** - Docker CLI 就像是用來命令守護程式的魔杖。您輸入指令,守護程式就會按照您的指示進行操作。這就像說「Abracadabra」就能讓事情發生。 **連線到遠端 Docker 引擎:** 連接到遠端 Docker 引擎可讓您控制另一台機器上的容器,且設定約束可確保容器僅使用指定的資源。 1. **Docker主機IP:** - 您可以使用 IP 位址和連接埠連接到不同電腦上的 Docker 引擎。 - 例: ``` docker -H=remote-docker-engine:2375 run nginx ``` - 這告訴您的本機 Docker CLI 與遠端 Docker 引擎進行通訊。 2. **有約束地執行容器:** - Docker 允許您設定容器的資源限制,例如 CPU 和記憶體限制。 - 例: ``` docker run --cpus=0.5 ubuntu docker run --memory=100m ubuntu ``` - 這些指令限制容器僅使用半個 CPU 核心和 100 MB 記憶體。 當然,讓我們簡化一下PID命名空間的概念: **命名空間PID:** PID 命名空間可讓您為容器中的進程(如程式或任務)建立單獨的區域,因此它們有自己的一組「票號」(進程 ID),不會與容器外的進程發生衝突。 **範例程式碼:** 1. **使用主機 PID 命名空間執行容器:** - 這表示容器與主機共用相同的「票號」。 ``` docker run --pid=host ubuntu ``` 2. **執行具有隔離 PID 命名空間的容器:** - 這表示容器有自己的一組獨立於主機的「票號」。 ``` docker run --pid=container ubuntu ``` 在第一個範例中,容器與進程交互,就好像它與主機位於同一空間中一樣。在第二個範例中,容器有自己的進程隔離空間。這就像在大型活動中擁有一個私人區域,您的團隊有自己的一套票號,讓您可以獨立於活動的其餘部分進行操作。 **容器化概念:** 1. **進程 ID 命名空間:** - 容器有自己獨立的流程 ID (PID) 空間,因此容器內的流程與容器外的流程是分開的。 - 例: ``` docker run --pid=host ubuntu ``` - 此指令使用主機的 PID 命名空間來執行容器,因此它共用相同的程序。 2. **網路命名空間:** - 容器也有自己獨立的網路命名空間,這意味著它們可以有自己的網路配置。 - 例: ``` docker run --net=host nginx ``` - 此指令使用主機的網路命名空間來執行容器。 3. **Unix分時命名空間:** - 此命名空間允許容器擁有自己的時間視圖,與主機和其他容器分開。 - 例: ``` docker run --uts=host ubuntu ``` - 此指令使用主機的 Unix 時間共用命名空間來執行容器。 4. **進程間掛載命名空間:** - Mount命名空間隔離檔案系統,讓容器擁有自己的檔案系統視圖。 - 例: ``` docker run --mount=type=bind,source=/host/folder,target=/container/folder ubuntu ``` - 此指令將主機中的資料夾安裝到容器中。 當然!我們來簡化一下cgroup的概念: **C組:** cgroup(控制組的縮寫)可協助在不同進程或容器之間管理和分配系統資源,例如 CPU 和記憶體。它們確保沒有任何一個進程或容器耗盡所有可用資源,從而保持一切平衡。 **範例程式碼:** 1. **使用 Cgroup 設定 CPU 限制:** - 這就像說聚會上的每位客人只能吃一定數量的食物。 ``` docker run --cpus=0.5 ubuntu ``` - 這限制容器僅使用一半的 CPU 核心。 2. **使用 Cgroup 設定記憶體限制:** - 這就像說每位客人只能在舞池上佔據一定的空間。 ``` docker run --memory=100m ubuntu ``` - 這限制容器僅使用 100 MB 記憶體。 [Docker 引擎概述](https://docs.docker.com/engine/) [使用 Docker Engine API 進行開發](https://docs.docker.com/engine/api/) [執行時指標](https://docs.docker.com/config/containers/runmetrics/#control-groups) ## Linux容器與Windows容器的概念: **Linux 容器(預設):** Linux 容器是一種打包和執行軟體及其所需一切的方法,它們最適合執行 Linux 的電腦。 **Windows 容器:** Windows 容器是一種打包和執行軟體的方式,就像 Linux 容器一樣,但它們設計用於執行 Windows 的電腦。 **Windows 容器基礎:** 1. **集裝箱類型:** - Windows 容器有兩種主要類型:Windows Server Core 和 Nano Server。 - **Windows Server Core:** 將其視為功能更齊全的容器,適合各種應用程式。 - **Nano Server:** 將其視為一個輕量級容器,專為特定的、簡約的用例而設計。 2. **基礎鏡像:** - 基礎映像就像是建立容器時開始使用的空白畫布。 - 例: ``` docker pull mcr.microsoft.com/windows/servercore:ltsc2019 ``` - 此指令擷取 Windows Server Core 基礎映像。 - 例: ``` docker pull mcr.microsoft.com/windows/nanoserver:ltsc2019 ``` - 此命令提取 Nano Server 基礎映像。 3. **支援的環境:** - Windows 容器可以在特定版本的 Windows 作業系統上運作。 - 例: - 您可以在 Windows Server 2016 上執行 Windows 容器。 - 例: - 您可以在 Windows 10 專業版和企業版上執行 Windows 容器,並使用 Hyper-V 隔離容器進行額外隔離。 ## 容器編排 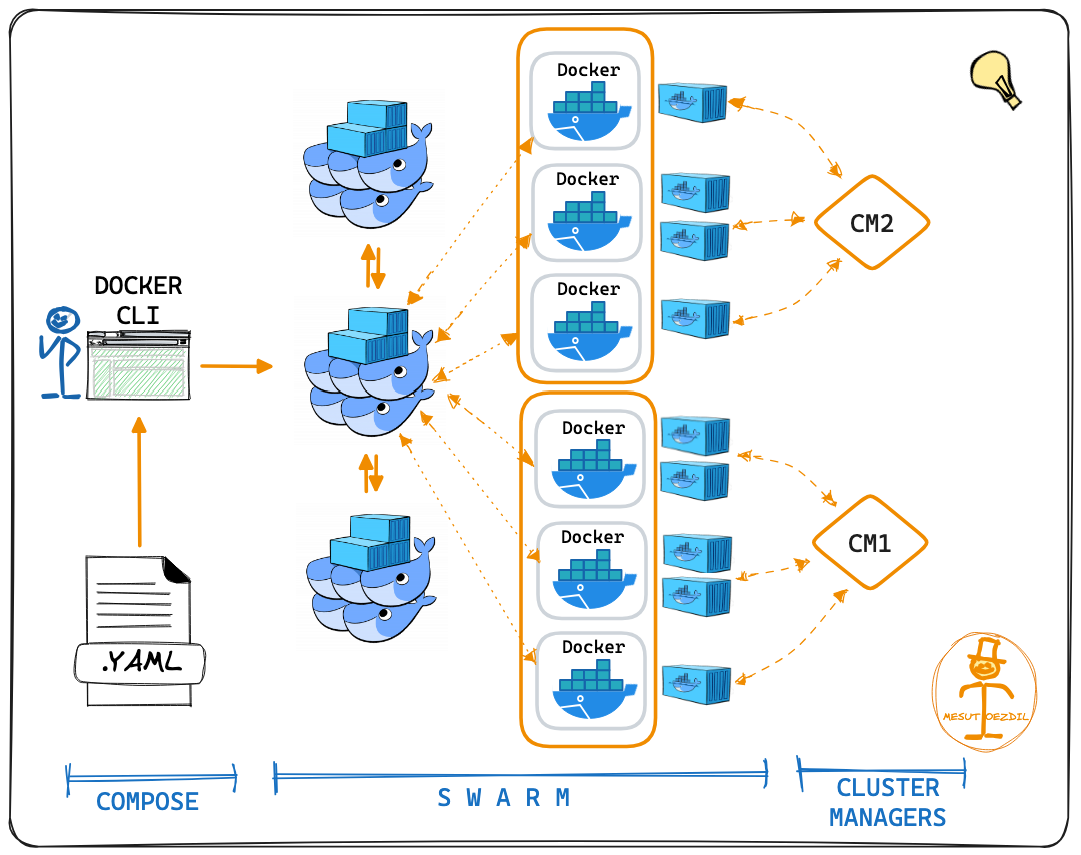 容器編排是一種管理和協調多個容器的方法,確保它們無縫協作來執行應用程式,就像一個超級智能的管理器確保所有機器人一起工作來建置完美的塔一樣。 **為什麼要編曲?** 1. **多項任務,一名經理:** - 想像一下您有許多機器人(容器)執行不同的工作。編排就像有一位超級聰明的經理(編排者),他告訴每個機器人該做什麼,並確保一切順利進行。 2. **一致性:** - 編排確保所有任務每次都以相同的方式完成。這就像為您的機器人提供了一套要遵循的指令,以確保其行為的一致性。 3. **效率:** - 編排有助於優化任務,確保資源(如時間和材料)有效利用。這就像經理確保所有機器人一起工作而不浪費能源。 4. **縮放比例:** - 當您需要完成更多工作時,編排可以輕鬆建立額外的機器人(容器)。這就像當有很多事情需要完成時神奇地召喚更多機器人來提供幫助。 5. **可靠性:** - 編排確保任務可靠地完成,即使機器人(容器)出現故障。這就像製定備份計劃來確保無論如何都能完成工作。 6. **協調:** - 編排協調任務,確保機器人無縫協作。這就像經理確保每個機器人都知道自己的角色並協作以實現總體目標。 **容器編排程式碼:** ``` # Create a Docker service with 100 replicas (instances) of a Node.js application docker service create --replicas 100 --name my-nodejs-app nodejs ``` 在這個例子中: - `docker service create`:該指令告訴 Docker 建立一個服務,該服務是一組正在執行的容器。 - `--replicas 100`:此標誌指定您需要 100 個服務實例(副本)。 - `--name my-nodejs-app`:此標誌為您的服務提供名稱,在本例中為「my-nodejs-app」。 - `nodejs`:這是 Node.js 應用程式的圖片或配方。這就像是烘焙紙杯蛋糕的藍圖。 因此,這段簡單的程式碼就像告訴您神奇的廚師助手 (Docker Swarm) 建立 Node.js 應用程式的 100 個副本,確保您有大量容器正在執行並準備好提供服務。 ## Docker 群  Docker Swarm 是一個工具,可以幫助協調和管理一組電腦(節點)作為一個機器人團隊一起工作,使它們能夠以協調的方式部署和執行多個容器。這就像有一個首席機器人經理,確保所有單一機器人一起建造出偉大而令人驚嘆的東西。 **設定 Docker Swarm:** 1. **群組管理器:** - 想像你有一個首席機器人(Swarm Manager)來領導團隊。主機器人決定需要做什麼,並指導其他機器人(節點)如何協同工作。 ``` # Initiate Docker Swarm on the Swarm Manager docker swarm init ``` 2. **節點工作人員:** - 現在,您的工作機器人(節點工作人員)已準備好加入團隊。 Swarm Manager 共享一個特殊的程式碼(令牌)來邀請他們一起工作。 ``` # Join a Node Worker to the Docker Swarm docker swarm join --token <token> <Swarm Manager IP> ``` **Docker Swarm 服務:** 現在您已經有了一個協調的團隊,您想要建立一項服務,例如與您的機器人團隊一起建造塔: ``` # Create a Docker service (a group of containers) with 3 replicas (instances) docker service create --replicas 3 --network frontend --name my-web-server my-web-image ``` - `--replicas 3`:此標誌告訴 Docker 建立服務的三個實例(副本)。 - `--network frontend`:此標誌指定您的服務屬於名為「frontend」的網路。 - `--name my-web-server`:這會為您的服務命名,在本例中為「my-web-server」。 - `my-web-image`:這是您的網頁伺服器的圖片或藍圖。這就像建造塔樓的配方。 您建立了一個由隊長(Swarm Manager)和工作機器人(Node Workers)組成的機器人團隊。然後,您指示他們建立一個執行您的 Web 伺服器應用程式的服務(容器群組)。主機器人確保建立 Web 伺服器的三個副本並將其連接到「前端」網路。這就像有一個首席機器人經理在工作機器人的幫助下監督多個塔(貨櫃)的建造。  **好的,這就是本文的內容。** 另外,如果您對此或其他任何問題有任何疑問,請隨時在下面的評論中或在 [Instagram](https://www.instagram.com/_abhixsh/) 、[Facebook](https://www.facebook.com/abhi.haththakage/) 或[Twitter](https://twitter.com/abhixsh)。 感謝您閱讀這篇文章,我們下一篇再見! ❤️ --- 原文出處:https://dev.to/abhixsh/docker-for-the-absolute-beginner-3h1p
 JavaScript 以其廣泛的採用和多功能性,已成為現代 Web 開發的基石。隨著您深入研究 JavaScript 開發,理解和利用模式變得至關重要。在本文中,我們將踏上揭開 JavaScript 模式神秘面紗的旅程,並探索它們如何增強您的程式設計實踐。 ## 先決條件 要理解本文中討論的概念和技術,您需要了解 JavaScript 的基礎知識。熟悉變數、函數、資料類型、物件導向程式設計等概念至關重要。 在繼續之前,讓我們花點時間了解 JavaScript 作為程式語言的重要性。 ### JavaScript 作為程式語言 JavaScript 通常被稱為“網路語言”,是一種動態的高階程式語言。它主要用於 Web 瀏覽器中的客戶端腳本編寫,但隨著 Node.js 的出現,它也在伺服器端獲得了關注。 JavaScript 的主要功能包括操作 DOM、處理事件、為網頁提供互動性等的能力。 話雖這麼說,讓我們簡單討論一下 JavaScript 中模式的重要性和用途。 ### JavaScript 開發中模式的重要性 JavaScript 中的模式可以作為軟體開發過程中遇到的重複問題的經過驗證的解決方案。它們提供結構、改進程式碼組織、增強可維護性並促進可重複使用性。透過理解和應用模式,開發人員可以編寫更清晰、更有效率的程式碼並有效應對複雜的挑戰。 ### 理解 JavaScript 模式的目的 理解 JavaScript 模式不僅僅是記住文法或遵循最佳實踐。它使開發人員能夠批判性地思考軟體設計、選擇適當的解決方案並建立可擴展的應用程式。透過掌握 JavaScript 模式,您可以深入了解該語言及其生態系統,從而能夠編寫健全且可維護的程式碼。 現在我們知道了 JavaScript 模式的重要性和用途,讓我們深入研究 JS 設計模式的基礎知識。 ## 設計模式的基礎知識 在本節中,我們為理解 JavaScript 開發背景下的設計模式奠定了基礎。 ###設計模式的定義與特點 設計模式是可重複使用的模板,封裝了解決重複出現的軟體設計問題的最佳實踐。它們提供了一種結構化的方法來設計軟體系統,並促進模組化、靈活和可維護的程式碼。設計模式的共同特徵包括其目的、結構、參與者和協作。 ###設計模式的類型 設計模式可分為三種主要類型: - 創意 - 結構性 - 行為的 了解這些類別有助於確定給定問題的適當模式。 - **創作模式** 建立模式專注於物件建立機制,提供以靈活且受控的方式實例化物件的方法。 JavaScript 中一些常用的建立模式包括: - 辛格頓 - 工廠 - 建構函數 - 原型 - 建造者 - 模組 **單例模式** 單例模式確保一個類別只有一個實例,並提供對其的全域存取點。當您想要限制類別的實例數量並確保在整個應用程式中可以存取單一共用實例時,此模式非常有用。 ``` // Implementation example of the Singleton Pattern class Singleton { constructor() { if (!Singleton.instance) { // Initialize the instance Singleton.instance = this; } return Singleton.instance; } } const instance1 = new Singleton(); const instance2 = new Singleton(); console.log(instance1 === instance2); // Output: true ``` 在此範例中,Singleton 類別有一個建構函數,用於檢查該類別的實例是否已存在。如果實例不存在(“!Singleton.instance”條件),它將透過將其指派給「Singleton.instance」來初始化該實例。這確保了對建構函數的後續呼叫將傳回相同的實例。 當使用新的 Singleton() 語法建立實例 1 和實例 2 時,這兩個變數都會引用 Singleton 類別的同一個實例。因此,當使用嚴格相等運算子比較實例 1 === 實例 2 時,其計算結果為 true。 **工廠模式** 工廠模式提供了一種建立物件而無需指定其特定類別的方法。它將物件建立邏輯封裝在一個單獨的工廠方法中,允許建立者和建立的物件之間的靈活性和解耦。 ``` // Implementation example of the Factory Pattern class Car { constructor(make, model) { this.make = make; this.model = model; } } class CarFactory { createCar(make, model) { return new Car(make, model); } } const factory = new CarFactory(); const myCar = factory.createCar("Tope", "Model 1"); ``` 在此範例中,使用 new CarFactory() 建立了一個 CarFactory 實例,然後使用參數「Tope」和「Model 1」在工廠上呼叫「createCar」方法。這將建立一個新的 Car 物件,其品牌為“Tope”,型號為“Model 1”,並分配給 `myCar` 變數。 **建構函式模式** 建構函式模式使用“new”關鍵字從建構函式建立物件。它允許您在建構函數中定義和初始化物件屬性。 ``` // Implementation example of the Constructor Pattern function Person(name, age) { this.name = name; this.age = age; } const tope = new Person("Tope", 24); ``` 上面的程式碼定義了一個名為 Person 的建構函數,它帶有兩個參數:姓名和年齡。在函數內部,使用 this 關鍵字將名稱和年齡值指派給新建立的物件的對應屬性。 稍後,透過使用參數“Tope”和 24 呼叫 Person 函數來建立 Person 物件的新實例。這將建立一個新物件,其 name 屬性設為“Tope”,age 屬性設為 24,然後指派給變數top。這段程式碼的輸出是 Tope 持有一個物件,代表一個名為「Tope」、年齡為 24 歲的人。 **原型模式** JavaScript 中的原型模式專注於透過複製或擴展現有物件作為原型來建立物件。它允許我們建立新實例而無需明確定義它們的類別。在此模式中,物件充當建立新物件的原型,從而實現繼承以及在多個物件之間共享屬性和方法。 ``` // Prototype object const carPrototype = { wheels: 4, startEngine() { console.log("Engine started."); }, stopEngine() { console.log("Engine stopped."); } }; // Create new car instance using the prototype const car1 = Object.create(carPrototype); car1.make = "Toyota"; car1.model = "Camry"; // Create another car instance using the same prototype const car2 = Object.create(carPrototype); car2.make = "Honda"; car2.model = "Accord"; car1.startEngine(); // Output: "Engine started." car2.stopEngine(); // Output: "Engine stopped." ``` 在此範例中,汽車實例 car1 和 car2 是使用原型物件 carPrototype 建立的。 car1 的品牌為“Toyota”,型號為“Camry”,而 car2 的品牌為“Honda”,型號為“Accord”。當呼叫 `car1.startEngine()` 時,輸出“Engine started.”,當呼叫 `car2.stopEngine()` 時,輸出“Engine waiting.”。這示範如何利用原型物件在多個實例之間共用屬性和方法。 **建造者模式** 在建構器模式中,建構器類別或物件負責建構最終物件。它提供了一組方法來配置和設定正在建置的物件的屬性。建置過程通常涉及按特定順序呼叫這些方法來逐步建立物件。 ``` class CarBuilder { constructor() { this.car = new Car(); } setMake(make) { this.car.make = make; return this; } setModel(model) { this.car.model = model; return this; } setEngine(engine) { this.car.engine = engine; return this; } setWheels(wheels) { this.car.wheels = wheels; return this; } build() { return this.car; } } class Car { constructor() { this.make = ""; this.model = ""; this.engine = ""; this.wheels = 0; } displayInfo() { console.log(`Make: ${this.make}, Model: ${this.model}, Engine: ${this.engine}, Wheels: ${this.wheels}`); } } // Usage const carBuilder = new CarBuilder(); const car = carBuilder.setMake("Toyota").setModel("Camry").setEngine("V6").setWheels(4).build(); car.displayInfo(); // Output: Make: Toyota, Model: Camry, Engine: V6, Wheels: 4 ``` 在此範例中,「CarBuilder」類別允許建構具有不同屬性的 Car 物件。透過呼叫`setMake`、`setModel`、`setEngine`、`setWheels`方法,設定Car物件的屬性。 build 方法完成建置並傳回完全建置的 Car 物件。 Car 類別代表一輛汽車,並包含一個「displayInfo」方法來記錄其詳細資訊。透過建立「carBuilder」實例並連結屬性設定方法,可以使用特定的品牌、型號、引擎和車輪值來建構汽車物件。呼叫“car.displayInfo()”顯示汽車的資訊。 **模組模式** 模組模式將相關的方法和屬性封裝到單一模組中,提供了一種乾淨的方式來組織和保護程式碼。它允許私有和公共成員,從而實現資訊隱藏並防止全域名稱空間污染。 ``` const MyModule = (function() { // Private members let privateVariable = "I am private"; function privateMethod() { console.log("This is a private method"); } // Public members return { publicVariable: "I am public", publicMethod() { console.log("This is a public method"); // Accessing private members within the module console.log(privateVariable); privateMethod(); } }; })(); // Usage console.log(MyModule.publicVariable); // Output: "I am public" MyModule.publicMethod(); // Output: "This is a public method" "I am private" "This is a private method" ``` 在此範例中,程式碼使用立即呼叫的函數表達式來封裝私人和公共成員。該模組具有私有變數和方法,以及公共變數和方法。存取時,公共成員提供預期的輸出。此模式允許對封裝的私有成員進行受控存取,同時公開選定的公共成員。 - **結構模式** 結構模式著重於組織和組合物件以形成更大的結構。它們促進物件的組合,定義物件之間的關係並提供靈活的方法來操縱其結構。 JavaScript 中一些常用的結構模式包括: - 裝飾模式 - 立面圖案 - 適配器 - 橋 - 合成的 **裝飾器模式** 裝飾器模式可讓您動態新增行為或修改物件的現有行為。它透過用一個或多個裝飾器包裝物件來增強物件的功能,而無需修改其結構。 ``` // Implementation example of the Decorator Pattern class Coffee { getCost() { return 1; } } class CoffeeDecorator { constructor(coffee) { this.coffee = coffee; } getCost() { return this.coffee.getCost() + 0.5; } } const myCoffee = new Coffee(); const coffeeWithMilk = new CoffeeDecorator(myCoffee); console.log(coffeeWithMilk.getCost()); // Output: 1.5 ``` 在此範例中,「CoffeeDecorator」類別包裝了基本「Coffee」物件並新增了附加功能。它有一個「getCost」方法,透過將基礎咖啡的成本與 0.5 的附加成本相結合來計算總成本。 在使用部分,建立了「Coffee」類別的「myCoffee」實例。然後,實例化「CoffeeDecorator」類別的「coffeeWithMilk」實例,並將「myCoffee」作為參數傳遞。當呼叫“coffeeWithMilk.getCost()”時,它會返回咖啡的總成本以及裝飾器加入的成本,從而得到 1.5 的輸出。此範例說明了裝飾器模式如何透過動態新增或修改物件的屬性或方法來擴展物件的功能。 **立面圖案** 外觀模式為複雜子系統提供了一個簡化的接口,充當隱藏底層實現細節的前端接口。它透過提供高級接口,提供了一種與複雜系統互動的便捷方式。 ``` // Implementation example of the Facade Pattern class SubsystemA { operationA() { console.log("Subsystem A operation."); } } class SubsystemB { operationB() { console.log("Subsystem B operation."); } } class Facade { constructor() { this.subsystemA = new SubsystemA(); this.subsystemB = new SubsystemB(); } operation() { this.subsystemA.operationA(); this.subsystemB.operationB(); } } const facade = new Facade(); facade.operation(); // Output: "Subsystem A operation." "Subsystem B operation." ``` 在此範例中,程式碼由三個類別組成:「SubsystemA」、「SubsystemB」和「Facade」。 `SubsystemA` 和 `SubsystemB` 類別代表獨立的子系統,並具有各自的 `operationA` 和 `operationB` 方法。 「Facade」類別作為一個簡化的接口,聚合了子系統的功能。 在使用部分,建立了“Facade”類別的“facade”實例。呼叫「facade.operation()」會觸發「SubsystemA」中的「operationA」和「SubsystemB」中的「operationB」的執行。結果,輸出顯示“子系統 A 操作”。接下來是「子系統 B 操作」。這展示了外觀模式如何提供統一且簡化的介面來與複雜的子系統交互,抽像出它們的複雜性並使它們更易於使用。 **適配器模式** 適配器模式是一種結構設計模式,它允許具有不相容介面的物件透過充當它們之間的橋樑來進行協作。它提供了一種將一個物件的介面轉換為客戶期望的另一個介面的方法。 ``` // Implementation class LegacyPrinter { printLegacy(text) { console.log(`Legacy Printing: ${text}`); } } // Target interface class Printer { print(text) {} } // Adapter class PrinterAdapter extends Printer { constructor() { super(); this.legacyPrinter = new LegacyPrinter(); } print(text) { this.legacyPrinter.printLegacy(text); } } // Usage const printer = new PrinterAdapter(); printer.print("Hello, World!"); // Output: "Legacy Printing: Hello, World!" ``` 在此程式碼中,適配器模式用於彌合「LegacyPrinter」類別和所需的「Printer」介面之間的差距。 `PrinterAdapter` 擴展了 `Printer` 類,並在內部利用 `LegacyPrinter` 來適配 `print` 方法。當呼叫 printer.print("Hello, World!")` 時,它會有效地觸發舊版列印功能,並輸出「Legacy Printing: Hello, World!」。這展示了適配器模式如何透過提供標準化介面來整合不相容的元件。 **橋樑圖案** 橋接模式是一種結構設計模式,它將系統的抽象和實現分開,允許系統獨立發展。它透過使用介面或抽象類別在兩者之間引入了橋樑。下面是一個範例程式碼片段來說明橋接模式: ``` // Example class Shape { constructor(color) { this.color = color; } draw() {} } // Concrete Abstractions class Circle extends Shape { draw() { console.log(`Drawing a ${this.color} circle`); } } class Square extends Shape { draw() { console.log(`Drawing a ${this.color} square`); } } // Implementor class Color { getColor() {} } // Concrete Implementors class RedColor extends Color { getColor() { return "red"; } } class BlueColor extends Color { getColor() { return "blue"; } } // Usage const redCircle = new Circle(new RedColor()); redCircle.draw(); // Output: "Drawing a red circle" const blueSquare = new Square(new BlueColor()); blueSquare.draw(); // Output: "Drawing a blue square" ``` 在此範例中,我們有由 Shape 類別表示的抽象,它具有顏色屬性和繪製方法。具體抽象(圓形和方形)繼承自 Shape 類別並實現其特定的繪製行為。 「Implementor」由 Color 類別表示,該類別聲明了「getColor」方法。具體的「Implementors」、「RedColor」和「BlueColor」繼承自 Color 類別並提供各自的顏色實作。 在使用部分,我們建立具體抽象的實例,傳遞適當的具體實現者物件。這允許抽象化將與顏色相關的功能委託給實現者。當我們呼叫draw方法時,它會從Implementor存取顏色並相應地執行繪圖操作。 **複合模式** 組合模式是一種結構設計模式,可讓您統一處理單一物件和物件組合。它使您能夠建立層次結構,其中每個元素都可以被視為單個物件或物件集合。此模式使用通用介面來表示單一物件(葉節點)和組合(複合節點),允許客戶端與它們統一互動。 ``` // Implementation class Employee { constructor(name) { this.name = name; } print() { console.log(`Employee: ${this.name}`); } } // Composite class Manager extends Employee { constructor(name) { super(name); this.employees = []; } add(employee) { this.employees.push(employee); } remove(employee) { const index = this.employees.indexOf(employee); if (index !== -1) { this.employees.splice(index, 1); } } print() { console.log(`Manager: ${this.name}`); for (const employee of this.employees) { employee.print(); } } } // Usage const john = new Employee("John Doe"); const jane = new Employee("Jane Smith"); const mary = new Manager("Mary Johnson"); mary.add(john); mary.add(jane); const peter = new Employee("Peter Brown"); const bob = new Manager("Bob Williams"); bob.add(peter); bob.add(mary); bob.print(); ``` 在此範例中,我們有 Component 類別 Employee,它代表個別員工。 Composite 類 Manager 擴展了 Employee 類,並且可以包含員工的集合。它提供了在集合中新增和刪除員工的方法,並重寫 print 方法以顯示經理的姓名及其下的員工。 在使用部分,我們建立一個複合層次結構,其中 Manager 物件可以包含單一員工 (Employee) 和其他經理 (Manager)。我們將員工加入經理中,建構了一個層次結構。最後,我們呼叫頂級經理的 print 方法,該方法遞歸地列印層次結構,顯示經理及其各自的員工。 - **行為模式** 行為模式關注物件之間的互動和職責分配。它們為物件之間的通訊、協調和協作提供解決方案。以下是行為模式的類型。 - 觀察者模式 - 策略模式 - 命令模式 - 迭代器模式 - 調解者模式 **觀察者模式** 觀察者模式在物件之間建立一對多關係,其中多個觀察者會收到主體狀態變化的通知。它支援物件之間的鬆散耦合並促進事件驅動的通訊。 ``` // Implementation example of the Observer Pattern class Subject { constructor() { this.observers = []; } addObserver(observer) { this.observers.push(observer); } removeObserver(observer) { const index = this.observers.indexOf(observer); if (index !== -1) { this.observers.splice(index, 1); } } notifyObservers() { this.observers.forEach((observer) => observer.update()); } } class Observer { update() { console.log("Observer is notified of changes."); } } const subject = new Subject(); const observer1 = new Observer(); const observer2 = new Observer(); subject.addObserver(observer1); subject.addObserver(observer2); subject.notifyObservers(); // Output: "Observer is notified of changes." "Observer is notified of changes." ``` 在此範例中,「Subject」類別表示一個主題,它維護觀察者清單並提供新增、刪除和通知觀察者的方法。 「Observer」類別透過其「update」方法定義觀察者的行為。在使用部分,建立了「Subject」類別的「subject」實例。也使用“addObserver”方法建立兩個“observer”實例並將其新增至主題。 當呼叫“subject.notifyObservers()”時,它會觸發每個觀察者的“update”方法。結果,輸出「觀察者收到更改通知」。被記錄兩次,顯示觀察者已被告知主題的變化。 **策略模式** 策略模式可讓您將可互換的演算法封裝在單獨的策略物件中。它支援在執行時動態選擇演算法,從而提高靈活性和可擴展性。 ``` // Implementation example of the Strategy Pattern class Context { constructor(strategy) { this.strategy = strategy; } executeStrategy() { this.strategy.execute(); } } class ConcreteStrategyA { execute() { console.log("Strategy A is executed."); } } class ConcreteStrategyB { execute() { console.log("Strategy B is executed."); } } const contextA = new Context(new ConcreteStrategyA()); contextA.executeStrategy(); // Output: "Strategy A is executed." const contextB = new Context(new ConcreteStrategyB()); contextB.executeStrategy(); // Output: "Strategy B is executed." ``` 在此範例中,「Context」類別表示封裝不同策略的上下文,具有「strategy」屬性和「executeStrategy」方法。有兩個特定策略類,“ConcreteStrategyA”和“ConcreteStrategyB”,每個類別都有自己的“execute”方法來輸出特定訊息。 在使用部分,使用“ConcreteStrategyA”作為策略來建立“Context”類別的“contextA”實例。呼叫 `contextA.executeStrategy()` 會呼叫 `ConcreteStrategyA` 的 `execute` 方法,導致輸出「策略 A 已執行」。類似地,以「ConcreteStrategyB」為策略建立「contextB」實例,呼叫「contextB.executeStrategy()」會觸發「ConcreteStrategyB」的「execute」方法,從而輸出「策略 B 已執行」。這演示了策略模式如何透過將行為封裝在不同的策略物件中來允許在執行時動態選擇行為。 **命令模式** 命令模式將請求封裝為物件,允許您使用不同的請求對客戶端進行參數化、對請求進行排隊或記錄請求,並支援撤銷操作。它將請求的發送者與接收者解耦,從而促進鬆散耦合和靈活性。 ``` // Implementation class Receiver { execute() { console.log("Receiver executes the command."); } } class Command { constructor(receiver) { this.receiver = receiver; } execute() { this.receiver.execute(); } } class Invoker { setCommand(command) { this.command = command; } executeCommand() { this.command.execute(); } } const receiver = new Receiver(); const command = new Command(receiver); const invoker = new Invoker(); invoker.setCommand(command); invoker.executeCommand(); // Output: "Receiver executes the command." ``` 在此範例中,「Receiver」類別在呼叫時執行命令,「Command」類別封裝命令並將執行委託給接收者。 `Invoker` 類別設定並執行命令。在使用部分,建立了接收者、命令和呼叫者。此指令是為呼叫者設定的,呼叫「invoker.executeCommand()」會執行該指令,從而產生輸出「接收者執行該指令」。 **迭代器模式** 迭代器模式是一種行為設計模式,它提供了一種順序存取聚合物件的元素而不暴露其底層表示的方法。它允許您以統一的方式遍歷物件集合,而不管集合的具體實現如何。該模式將遍歷邏輯與集合分開,從而促進了一種乾淨而靈活的方法來迭代元素。 ``` // Implementation class Collection { constructor() { this.items = []; } addItem(item) { this.items.push(item); } createIterator() {} } // Concrete Aggregate class ConcreteCollection extends Collection { createIterator() { return new ConcreteIterator(this); } } // Iterator class Iterator { constructor(collection) { this.collection = collection; this.index = 0; } hasNext() {} next() {} } // Concrete Iterator class ConcreteIterator extends Iterator { hasNext() { return this.index < this.collection.items.length; } next() { return this.collection.items[this.index++]; } } // Usage const collection = new ConcreteCollection(); collection.addItem("Item 1"); collection.addItem("Item 2"); collection.addItem("Item 3"); const iterator = collection.createIterator(); while (iterator.hasNext()) { console.log(iterator.next()); } ``` 在此程式碼中,我們有由 Collection 類別表示的 Aggregate,它定義了用於建立迭代器物件的介面。具體聚合「ConcreteCollection」擴展了 Collection 類別並提供了迭代器建立的具體實作。 Iterator 由 Iterator 類別表示,它定義了存取和遍歷元素的介面。具體迭代器“ConcreteIterator”擴展了迭代器類別並提供了迭代邏輯的具體實作。在使用部分,我們建立一個 Concrete Aggregate 的實例“ConcreteCollection”,並向其中新增專案。然後我們使用 createIterator 方法建立一個迭代器。透過使用迭代器的“hasNext”和 next 方法,我們迭代集合併列印每個專案。 **調解者模式** 中介者模式透過引入充當協調物件之間互動的中心樞紐的中介者物件來簡化物件溝通。它封裝了通訊邏輯,並為物件提供了註冊、發送和接收訊息的方法。 ``` // Implementation class Mediator { constructor() { this.colleague1 = null; this.colleague2 = null; } setColleague1(colleague) { this.colleague1 = colleague; } setColleague2(colleague) { this.colleague2 = colleague; } notifyColleague1(message) { this.colleague1.receive(message); } notifyColleague2(message) { this.colleague2.receive(message); } } class Colleague { constructor(mediator) { this.mediator = mediator; } send(message) { // Send a message to the mediator this.mediator.notifyColleague2(message); } receive(message) { console.log(`Received message: ${message}`); } } // Usage const mediator = new Mediator(); const colleague1 = new Colleague(mediator); const colleague2 = new Colleague(mediator); mediator.setColleague1(colleague1); mediator.setColleague2(colleague2); colleague1.send("Hello Colleague 2!"); // Output: "Received message: Hello Colleague 2!" ``` 在此範例中,我們有一個 Mediator 類,它充當兩個 Colleague 物件之間的中介。中介者保存對同事的引用並提供在他們之間發送訊息的方法。 每個Colleague物件都有一個對中介者的引用,並且可以透過通知中介者來發送訊息。調解員又將訊息轉發給適當的同事。在這種情況下,同事 1 會向同事 2 發送訊息,後者接收並記錄該訊息。 ### 結論 我們探索了 JavaScript 中的一系列基本設計模式,包括建立模式、結構模式和行為模式。建立模式使我們能夠以靈活且高效的方式建立物件。結構模式有助於器官的靈活性和可擴展性。行為模式支援 JavaScript 物件之間的有效溝通和互動。透過利用這些設計模式,JavaScript 開發人員可以提高程式碼的可重複使用性、可維護性和整體系統效能。有了這些知識,我們就可以建立健壯且高效的 JavaScript 應用程式,以滿足現代軟體開發的需求。 --- 原文出處:https://dev.to/topefasasi/js-design-patterns-a-comprehensive-guide-h3m
為優秀的開源庫做出貢獻是建立您的作品集並加入令人驚嘆的社群的最佳方式。 我編譯了 31 個開源程式庫和一些好的第一期,以幫助推動您的旅程。 不要忘記加星號並支持這些🌟  --- #AI最愛🦾: ### 1. [CopilotKit](https://github.com/CopilotKit/CopilotKit) - 應用內 AI 聊天機器人與 AI 文字區域 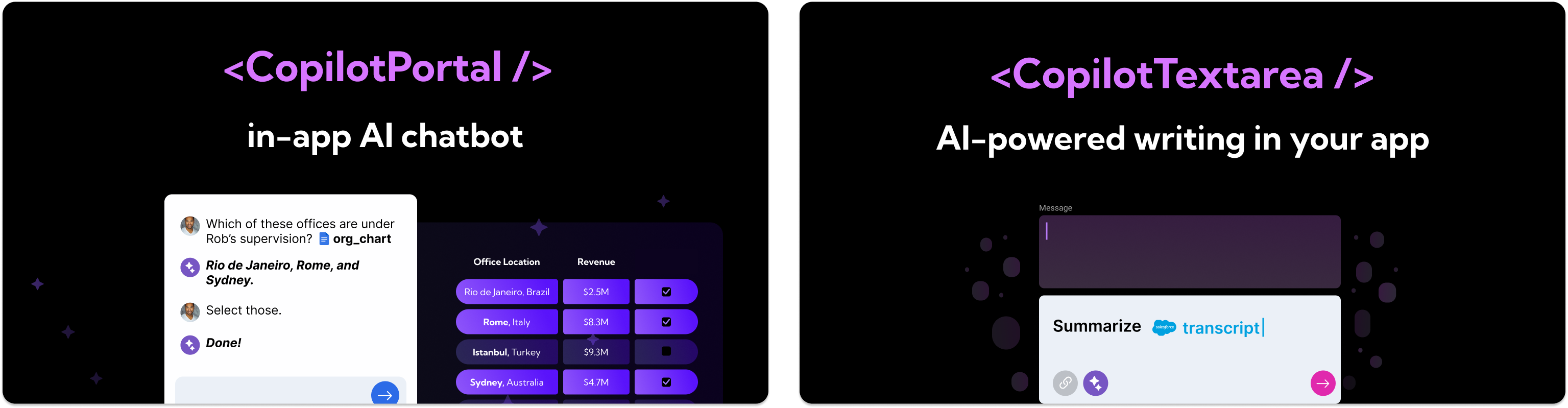 開源平台,用於使用兩個 React 元件將關鍵 AI 功能整合到 React 應用程式中。 CopilotPortal:應用程式內人工智慧聊天機器人,可以「查看」當前應用程式狀態並採取行動。 CopilotTextarea:AI 驅動的 <textarea /'> 替換。具有自動完成、插入和生成功能。 ###[好第一期:](https://github.com/CopilotKit/CopilotKit/issues/62) ``` Gracefully fail if CopilotProvider is omitted The bug: Virtually every CopilotKit functionality depends on a CopilotContext provided by the CopilotProvider. e.g. CopilotTextarea autocompletions, chatbot, etc. However when a CopilotProvider does not wrap the component, functionality fails silently. To Reproduce 1. Omit <CopilotProvider>...</CopilotProvider> 2. trigger useMakeCopilotReadable, useMakeCopilotActionable, CopilotTextarea, CopilotSidebarUIProvider 3. See how functionality does not work, but no error is emitted Expected behavior An error is emitted, with clear description of the likely core issue and how to resolve it (namely, wrap the app in a CopilotProvider). Point to docs. ``` {% cta https://github.com/CopilotKit/CopilotKit %} Star CopilotKit ⭐️ {% endcta %} --- ###2.[PortKeyAI](https://github.com/Portkey-AI/gateway){% embed https://github.com/Portkey-AI/gateway no-readme %} ###3.[Pezzo.ai](https://github.com/pezzolabs/pezzo){% 嵌入 https://github.com/pezzolabs/pezzo no-readme %} ###4.[OpenVoice](https://github.com/myshell-ai/OpenVoice){% 嵌入 https://github.com/myshell-ai/OpenVoice no-readme %} ###5.[LLMCourse](https://github.com/mlabonne/llm-course){% 嵌入 https://github.com/mlabonne/llm-course no-readme %} --- #雲端和資料庫☁️ ### 6. [Winglang](https://github.com/winglang/wing) - 雲端導向的程式語言  Wing 是一種用於雲端應用程式的程式語言。 它結合了雲端基礎設施和應用程式的程式碼,使雲端服務開發變得更加容易。 Wing 獨特的執行模型和測試模擬器有助於高效建置和部署雲端應用程式。 ###[第一期好:](https://github.com/winglang/wing/issues/4998) ``` Support Array.sort() method Feature Spec: let arr: MutArray<num>=[2, 1, 3, 9, 6, 4]; arr.sort(); log("${arr}"); // it should print sorted array in ascending order, eg: [1, 2, 3, 4, 6, 9] Component: Wing SDK Community Notes: If you are interested to work on this issue, please leave a comment. If this issue is labeled needs-discussion, it means the spec has not been finalized yet. Please reach out on the #dev channel in the Wing Slack. ``` {% cta https://github.com/winglang/wing %} 星翼朗 ⭐️ {% endcta %} --- ### 7. [StackQL](https://github.com/stackql/stackql) - 以 SQL 為基礎的雲端資源管理  StackQL 提供了一個獨特的 SQL 為基礎的框架來管理和查詢跨不同提供者(例如 Google、AWS、Azure 等)的雲端資源和 API。 它允許使用類似 SQL 的命令來配置和操作雲端服務,從而簡化了雲端操作。 這使得 StackQL 成為雲端資源管理和互動的多功能工具,特別是對於熟悉 SQL 的人來說。 ###[好第一期:](https://github.com/stackql/stackql/issues/280) ``` Add unit testing to package writer Add unit testing for internal/stackql/writer . Description: add implementation for testing sql_writer.go modify sql_writer.go by adding function for dependency injection add implementation for testing generic.go modify generic.go by adding variable for patching GetDB function modify entryutil.go to adjust sql_writer.go ``` {% cta https://github.com/stackql/stackql/ %} Star StackSQL ⭐️ {% endcta %} --- ###8.[Appwrite](https://github.com/appwrite/appwrite){% 嵌入 https://github.com/appwrite/appwrite no-readme %} ###9.[Supabase](https://github.com/supabase/supabase){% 嵌入 https://github.com/supabase/supabase no-readme %} ###10.[SuperDuperDB](https://github.com/SuperDuperDB/superduperdb){% 嵌入 https://github.com/SuperDuperDB/superduperdb no-readme %} --- #開發實用程式🛠️ ### 11. [Firecamp](https://github.com/firecamp-dev/firecamp) - 多協定 API 協作工具  Firecamp 是一款多功能 API 開發工具,支援 Rest、GraphQL 和 WebSockets 等協定。 它簡化了 API 的設計、測試和記錄,並增強了 API 專案的團隊協作。 ###[好第一期:](https://github.com/firecamp-dev/firecamp/issues/137) ``` Help out with Manual Testing of Firecamp Responsibilities: Executing test cases and reporting results Logging bugs and issues in the Github issue tracker Providing feedback on usability and the testing process Suggesting improvements to tests and expanding test coverage. Benefits Benefits for your testing profile and career: Experience testing a real-world open source application Each release will include your name with bugs fixes. Exposure to different types of testing such as UI, API, integration, etc Opportunity to have your contributions and feedback incorporated into the product Collaborating with an open source community Having your testing work visible to potential employers Firecamp Swags (T-shirts and stickers) Community shoutout and promotion ``` {% cta https://github.com/firecamp-dev/firecamp %} 星際火營 ⭐️ {% endcta %} --- ###12.[Odigos](https://github.com/keyval-dev/odigos){% 嵌入 https://github.com/keyval-dev/odigos no-readme %} ###13.[Digger](https://github.com/diggerhq/digger){% 嵌入 https://github.com/diggerhq/digger no-readme %} ###14.[鏡像](https://github.com/metalbear-co/mirrord){% 嵌入 https://github.com/metalbear-co/mirrord no-readme %} --- #後端⚙️ ### 15. [Cerbos](https://github.com/cerbos/cerbos) - 可擴充、與語言無關的授權  Cerbos 提供獨特、可擴展的解決方案,用於在應用程式中實施特定於上下文的使用者權限。 其靈活的、與語言無關的方法可以輕鬆整合和管理複雜的授權結構。 與眾不同的是,Cerbos 簡化了存取控制策略的開發,使其更能適應各種應用需求。 ###[第一期好:](https://github.com/cerbos/cerbos/issues/1920) ``` Produce output when the rule condition is not satisfied Currently the output block is only evaluated if the rule is actually activated (action, roles and conditions are satisfied). In certain situations, it's desirable to produce output when the rule is nearly activated (action and roles match but the condition is not satisfied). In order to maintain backward compatibility, reduce noise, and to keep policy execution as fast as possible (outputs incur a tiny overhead), the proposal is to let users add an optional when section to the output block to opt into this behaviour. - actions: ['view'] effect: EFFECT_ALLOW roles: ['user'] condition: match: expr: timestamp(R.expiry_date) > now() output: expr: > format("%d hours until expiry", (timestamp(R.expiry_date) - now()).getHours()) when: cond_fail: > format("expired on %s", R.expiry_date) When evaluating the above rule, if the action, roles and condition match, output will be the result of evaluating output.expr If the condition is not satisfied, output will be the result of evaluating output. when.cond_fail if it exists. Otherwise no output will be produced. ``` {% cta https://github.com/cerbos/cerbos %} 明星 Cerbos ⭐️ {% endcta %} --- ###16.[Novu](https://github.com/novuhq/novu){% 嵌入 https://github.com/novuhq/novu no-readme %} ###17.[Trigger.dev](https://github.com/triggerdotdev/trigger.dev){% 嵌入 https://github.com/triggerdotdev/trigger.dev no-readme %} ###18.[SuperTokens](https://github.com/supertokens/supertokens-core){% 嵌入 https://github.com/supertokens/supertokens-core no-readme %} ###19.[Wazuh](https://github.com/wazuh/wazuh){% 嵌入 https://github.com/wazuh/wazuh no-readme %} --- #UI/UX🦋: ### 20. [Flowbite](https://github.com/themesberg/flowbite) - 頂級 CSS 元件庫  最好、最受尊敬的 UI 元件庫之一。 基於實用優先的 CSS 框架。 易於使用,充滿重要的支援和模板。 {% cta https://github.com/themesberg/flowbite %} 明星 Flowbite ⭐️ {% endcta %} ###21.[MaterialUI](https://github.com/mui/material-ui) - 使用 Google 的 Material Design 實現的基礎 React 元件 {% 嵌入 https://github.com/mui/material-ui no-readme %} ###22。 [SwiperUI](https://github.com/nolimits4web/swiper) - 用於實現行動滑動 UI 的受人尊敬的庫 {% 嵌入 https://github.com/nolimits4web/swiper no-readme %} ###23.[ReactSpring](https://github.com/pmndrs/react-spring) - 在 React 中實現具有真實物理效果的動畫 {% 嵌入 https://github.com/pmndrs/react-spring no-readme %} --- #雜項🎨 ### 24. [SwirlSearch](https://github.com/swirlai/swirl-search) - 多源人工智慧資料搜尋器  Swirl 是一款由人工智慧驅動的搜尋工具,可同時查詢多個資料來源,包括資料庫和公用資料服務。 它使用人工智慧對結果進行排名並產生見解,從而可以跨不同的資料儲存庫進行全面搜尋。 Swirl 一次簡化了對各種來源的資料的搜尋和分析,使其成為資料驅動洞察的獨特工具。 ###[第一期好:](https://github.com/swirlai/swirl-search/issues/789) ``` Add a Connector: Yahoo search It would help to search anything with Swirl on Yahoo effectively. Locate and read a bit in their search API first. You might just need to make a new SearchProvider configration vs. a new Connector. Their docs should help guide you a bit in which way you might need to go. ``` {% cta https://github.com/swirlai/swirl-search/ %} Star SwirlSearch ⭐️ {% endcta %} --- ### 25. [Wasp](https://github.com/wasp-lang/wasp) - 使用 React 和 Node.js 開發全端 Web 應用程式  使用 React 和 Node.js 進行快速全端 Web 應用程式開發。 Wasp 提供了一種建立現代 Web 應用程式的簡化方法,將前端的 React 和後端的 Node.js 結合在一個緊密結合的框架中。 ###[好第一期:](https://github.com/wasp-lang/wasp/issues/874) ``` Add images (or link to the example app) of auth UI helpers Wasp provides At this point in docs (also in the tutorial if we're using it), it would be nice to add an image of UI helpers for Auth (login/signup form, Google/GitHub button, ...) so developers can immediately see what they are getting and how nice it looks. ``` {% cta https://github.com/wasp-lang/wasp %} 星黃蜂 ⭐️ {% endcta %} ###26.[Logstash](https://github.com/elastic/logstash) {% 嵌入 https://github.com/elastic/logstash 無自述文件 %} ###27.[Snapify](https://github.com/MarconLP/snapify) {% 嵌入 https://github.com/MarconLP/snapify 無自述文件 %} --- #為了好玩🎭 ###28.[Twitter 的演算法](https://github.com/twitter/the-algorithm){% embed https://github.com/twitter/the-algorithm no-readme %} ###29.[十億行挑戰](https://github.com/gunnarmorling/1brc){% embed https://github.com/gunnarmorling/1brc no-readme %} ###30.【秘密知識之書】(https://github.com/trimstray/the-book-of-secret-knowledge){% embed https://github.com/trimstray/the-book-of -秘密知識無自述文件%} ###31.[GenAI 初學者](https://github.com/microsoft/generative-ai-for-beginners){% 嵌入 https://github.com/microsoft/generative-ai-for-beginners no -自述文件%} --- 原文出處:https://dev.to/copilotkit/31-open-source-libraries-to-kickstart-your-journey-4hhd
在学习 JavaScript中,变量、函数、类、循环、异步这些都是基础知识。这些基础知识是我们使用 JavaScript 的基础。但是,在日常的业务开发中,我们需要一些更高级的技巧来更好地解决问题。 > 通过本文你将了解到 JS 的高级知识点以及实际应用技巧,如高级数据结构和算法、函数式编程、异步编程和面向对象编程。我们会利用代码实例来让大家更好地理解这些知识点。同时,我们也会提供一些实战案例的示范和使用技巧,让你更好地将这些技术应用到实际业务中。 ## 高级数据结构和算法 ### Map 和 Set 数据结构 在 JavaScript 中,Map 数据结构通常用于存储键值对,它可以使用任意类型作为键和值。Set 数据结构用于存储唯一值的集合。 ```js // 创建Map对象 const map = new Map(); // 设置键值对 map.set("name", "Tom"); map.set("age", 20); // 获取键值对 console.log(map.get("name")); // 'Tom' console.log(map.get("age")); // 20 // 创建Set对象 const set = new Set(); // 添加元素 set.add(10); set.add(20); set.add(30); // 删除元素 set.delete(20); // 判断元素是否存在 console.log(set.has(10)); // true console.log(set.has(20)); // false ``` ### 堆、栈和队列 堆和栈是常用的内存分配方式。栈是一种后进先出的数据结构,堆是一种动态分配的内存结构。队列是一种先进先出的数据结构,它通常用于缓存和并发编程中。 ```js // 使用数组模拟堆 const arr = [1, 2, 3, 4]; arr.push(5); // 入堆 console.log(arr.pop()); // 出堆 // 使用数组模拟栈 const stack = [1, 2, 3, 4]; stack.push(5); // 入栈 console.log(stack.pop()); // 出栈 // 使用数组模拟队列 const queue = [1, 2, 3, 4]; queue.push(5); // 入队 console.log(queue.shift()); // 出队 ``` ### 深度优先搜索和广度优先搜索 深度优先搜索(DFS)和广度优先搜索(BFS)是常用的遍历算法。DFS 通常用于解决深度问题,BFS 适用于宽度问题。 ```js // 深度优先遍历 function dfs(node) { if (node == null) return; console.log(node.value); dfs(node.left); dfs(node.right); } // 广度优先遍历 function bfs(node) { const queue = [node]; while (queue.length) { const curr = queue.shift(); console.log(curr.value); if (curr.left) queue.push(curr.left); if (curr.right) queue.push(curr.right); } } ``` ### 常用算法 常用的算法有排序、搜索、查找等。 ```js // 排序算法:快速排序使用分治思想,通过把数组分成较小的块来排序。 function quickSort(arr) { if (arr.length < 2) { return arr; } let pivot = arr[0]; let left = []; let right = []; for (let i = 1; i < arr.length; i++) { if (arr[i] < pivot) { left.push(arr[i]); } else { right.push(arr[i]); } } return [...quickSort(left), pivot, ...quickSort(right)]; } // 查找算法: function binarySearch(arr, target) { let left = 0; let right = arr.length - 1; while (left <= right) { const mid = Math.floor((left + right) / 2); if (arr[mid] === target) { return mid; } else if (arr[mid] < target) { left = mid + 1; } else { right = mid - 1; } } return -1; } ``` ## 函数式编程 ### 高阶函数和柯里化 高阶函数和柯里化是函数式编程中的常见概念,它们可以让我们创建更加抽象、灵活的函数。 ```js // 高阶函数 function higherOrderFunction(func) { return function (num) { return func(num); }; } function double(num) { return num * 2; } const doubleFunc = higherOrderFunction(double); console.log(doubleFunc(10)); // 20 // 柯里化 function curry(func) { return function curried(...args) { if (args.length >= func.length) { return func.apply(this, args); } else { return function (...args2) { return curried.apply(this, [...args, ...args2]); }; } }; } function sum(a, b, c) { return a + b + c; } const curriedSum = curry(sum); console.log(curriedSum(1)(2)(3)); // 6 ``` ### 闭包和作用域 闭包和作用域是 JavaScript 中比较常见的概念。闭包可以让我们维护函数内的状态,作用域则决定了变量的可见范围。 ```js // 闭包 function closure() { let i = 0; return function () { return ++i; }; } const func = closure(); console.log(func()); // 1 console.log(func()); // 2 // 作用域 let a = 10; function foo() { let a = 20; console.log(a); // 20 } foo(); console.log(a); // 10 ``` ### 函数式编程中的常见模式 函数式编程中有很多常见的模式,如 map、filter、reduce 等。 ```js // map const arr = [1, 2, 3]; const mapArr = arr.map((item) => item * 2); console.log(mapArr); // [2, 4, 6] // filter const filterArr = arr.filter((item) => item > 1); console.log(filterArr); // [2, 3] // reduce const reduceArr = arr.reduce((sum, curr) => sum + curr, 0); console.log(reduceArr); // 6 异步编程 Promise和async/await Promise和async/await是常见的异步编程方式,它们可以让我们更好地处理异步编程中的问题。 // Promise function promise() { return new Promise((resolve, reject) => { setTimeout(() => { resolve('done'); }, 1000); }); } promise().then((result) => console.log(result)); // 'done' // async/await async function asyncFunc() { const result = await promise(); console.log(result); } asyncFunc(); // 'done' ``` ### 事件循环和 EventEmitter 事件循环和 EventEmitter 用于处理异步事件,它们可以让我们更好地处理事件流。 ```js // 事件循环 console.log("start"); setTimeout(() => { console.log("setTimeout"); }, 0); Promise.resolve().then(() => console.log("promise")); console.log("end"); // EventEmitter const { EventEmitter } = require("events"); const emitter = new EventEmitter(); emitter.on("doSomething", (arg1, arg2) => { console.log(`${arg1} ${arg2}`); }); emitter.emit("doSomething", "Hello", "World"); // 'Hello World' ``` ### Web Worker Web Worker 可以让我们将长时间运行的任务移出主线程,以避免阻塞 UI。 ```js // 主线程 const worker = new Worker("worker.js"); worker.onmessage = (event) => { console.log(event.data); }; worker.postMessage("start"); // worker.js self.onmessage = (event) => { const result = longCalculation(event.data); self.postMessage(result); }; ``` ## 面向对象编程 ### 类和继承 JavaScript 中的类和继承与其他面向对象编程语言类似。 ```js // 类 class Animal { constructor(name) { this.name = name; } speak() { console.log(`${this.name} makes a noise.`); } } class Cat extends Animal { constructor(name, breed) { super(name); this.breed = breed; } speak() { console.log(`${this.name} meows.`); } get description() { return `${this.name} is a ${this.breed} cat.`; } set nickname(nick) { this.name = nick; } } const cat = new Cat("Fluffy", "Persian"); cat.speak(); // 'Fluffy meows.' console.log(cat.description); // 'Fluffy is a Persian cat.' cat.nickname = "Fuffy"; console.log(cat.name); // 'Fuffy' ``` ### Encapsulation、Inheritance、Polymorphism(封装、继承、多态) 封装、继承、多态是面向对象编程中的重要概念。 ```js // 封装 class Person { constructor(name) { this._name = name; } get name() { return this._name.toUpperCase(); } set name(newName) { this._name = newName; } } const person = new Person("John"); console.log(person.name); // 'JOHN' person.name = "Lisa"; console.log(person.name); // 'LISA' // 继承 class Shape { constructor(color) { this.color = color; } draw() { console.log("Drawing a shape..."); } } class Circle extends Shape { constructor(color, radius) { super(color); this.radius = radius; } draw() { console.log(`Drawing a ${this.color} circle with radius ${this.radius}.`); } } const circle = new Circle("red", 10); circle.draw(); // 'Drawing a red circle with radius 10.' // 多态 function drawShape(shape) { shape.draw(); } drawShape(new Shape("blue")); // 'Drawing a shape...' drawShape(new Circle("green", 20)); // 'Drawing a green circle with radius 20.' ``` ## 总结和实战 在本文中,我们介绍了一些 JavaScript 的高级知识点,如高级数据结构和算法、函数式编程、异步编程和面向对象编程。我们还提供了一些代码示例和实战案例,让大家更好地理解和掌握这些技术。 ### 通过 Promise.all 实现并发请求 ```js function fetchData(urls) { const promises = urls.map((url) => fetch(url)); return Promise.all(promises).then((responses) => Promise.all( responses.map((response) => { if (!response.ok) throw new Error(response.statusText); return response.json(); }) ) ); } ``` ### 使用 async/await 实现异步调用 ```js async function getData(url) { const response = await fetch(url); if (!response.ok) throw new Error(response.statusText); const data = await response.json(); return data; } ``` ### 在面向对象编程中使用工厂模式 ```js class Product { constructor(name, price) { this.name = name; this.price = price; } } class ProductFactory { createProduct(name, price) { return new Product(name, price); } } const productFactory = new ProductFactory(); const product = productFactory.createProduct("Apple", 1); console.log(product.name); // 'Apple' console.log(product.price); // 1 ``` 本文结束,感谢阅读
問題描述: 在testfn函數中,switch imbue的部分會被filestr.imbue(std::cout.getloc());觸發, 接下來理論上會cout, 接著LOG(我自己寫的輸出封裝函數), 但是cout後就離開switch, 觸發流刪除事件了,LOG沒有觸發。 如果先LOG再cout則沒問題, LOG和cout都會被輸出到console。 像這樣,提供出stream.imbue_event非常多的信息。 ``` LOG [enum std::ios_base::event] stream.imbue_event = 1At testfn ,line 00219 imbue_event erase_event ``` 出事代碼 C++ ``` #include <iostream> //std::ios, std::cout, std::cerr, std::clog, std::left #include <iomanip> #include <fstream> // ofstream #include <locale> // std::locale #include <typeinfo> #include <chrono> #include <thread> #include <ctime> #include <sstream> template <typename T> void Log(const char* varName, T var, int line, const char* functionName) { std::stringstream ss; ss << "[" << typeid(var).name() << "] " << varName << " = " << var; std::ios_base::fmtflags originalFlags = std::cout.flags();/*FORMAT FLAG*/\ /*auto now = std::chrono::system_clock::now();*//*TIME*/\ /*std::time_t timestamp = std::chrono::system_clock::to_time_t(now);*//*TIME*/\ /* std::cout << "\nTime taken at Total : " << duration.count() / 1000.0 << " millisecond" << std::endl;*//*TIME*/ std::cout.width(0); std::cout << std::setfill(' ') << std::left << "LOG "\ << std::setw(50) << ss.str()/*TYPE*//*VARIABLE*//*VALUE*/\ << "At " << std::setw(15) << functionName /*FUNCTION*/\ << std::dec << ",line " << std::setw(5) << std::setfill('0') << std::right << line /*LINE*/\ /*<< "File: " << __FILE__ */ /*FILE*/\ /*<< ", Thread ID: " << std::this_thread::get_id() << ", "*//*THREAD*/\ << std::endl; \ std::cout.flags(originalFlags); } //register_callback, imbue_event, erase_event void testfn(std::ios::event ev, std::ios_base& stream, int index) { switch (ev) { case stream.copyfmt_event: std::cout << "copyfmt_event\n"; break; case stream.imbue_event: std::cout << "imbue_event\n"; break; Log("stream.imbue_event", stream.imbue_event, 219, __FUNCTION__); case stream.erase_event: std::cout << "erase_event\n"; break; } } void funcPart6() { /*register_callback*/std::cout << "//---//\n"; std::ofstream filestr; filestr.register_callback(testfn, 0);/*imbue_event*//*erase_event*/ filestr.imbue(std::cout.getloc()); /* * 使用register_callback來設定事件 如 copyfmt_event imbue_event erase_event * filestr.register_callback(testfn, 0); * /* * 筆記: * 試圖複製或複製但是構造了一個 std::basic_ofstream 對象,該類的複製構造函數是被刪除的(deleted)。 * 這是因為 std::basic_ofstream 對象通常代表一個文件流,而文件流的複製構造函數不是允許的, * 因為一個檔案流在複製時可能會引起一些不可預測的行為。在這種情況下,應該避免直接複製 std::basic_ofstream 物件。 */ } ```
最近,社群網路上流行一張 gif 動圖,展示了一件 [Bjorn Staal 製作的令人驚嘆的藝術品](https://twitter.com/_nonfigurativ_/status/1727322594570027343)。 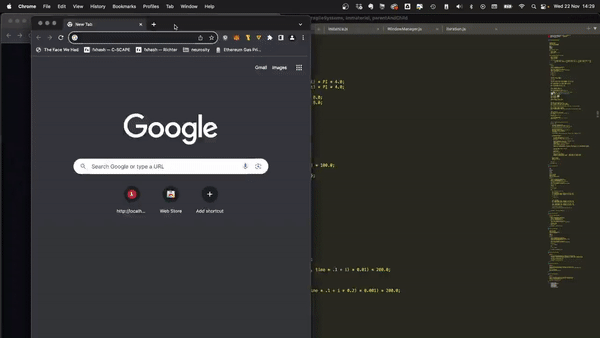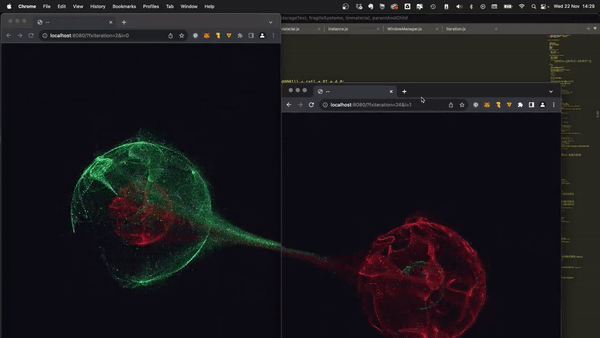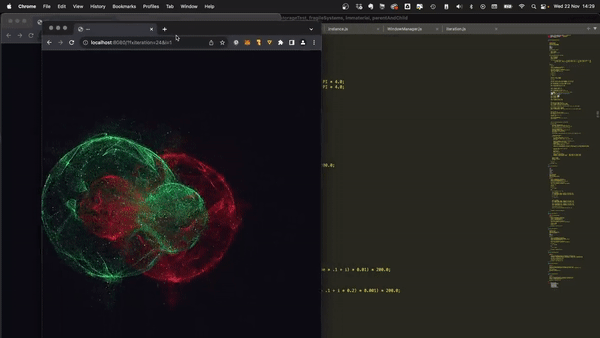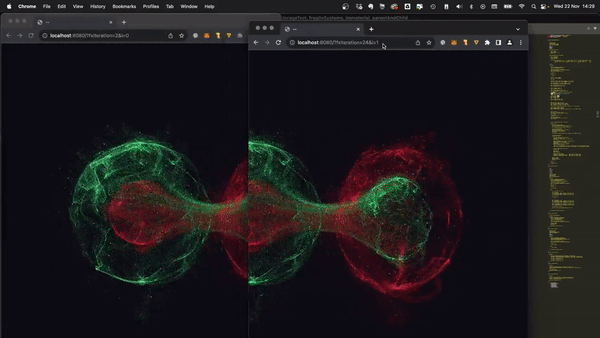 我想重新建立它,但缺乏球體、粒子和物理的 3D 技能,我的目標是了解如何讓一個視窗對另一個視窗的位置做出反應。 本質上,在多個視窗之間共享狀態,我發現這是 Bjorn 專案中最酷的方面之一! 由於無法找到有關該主題的好文章或教程,我決定與您分享我的發現。 > 讓我們嘗試根據 Bjorn 的工作建立一個簡化的概念驗證 (POC)! 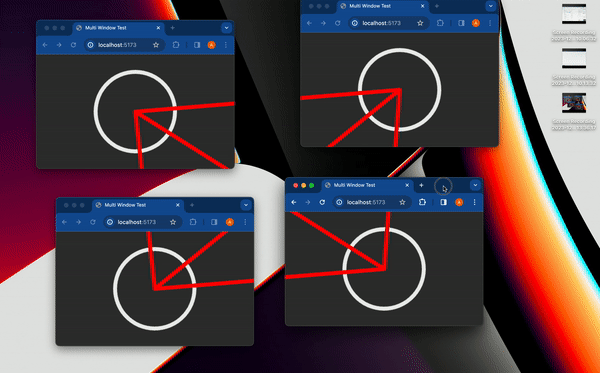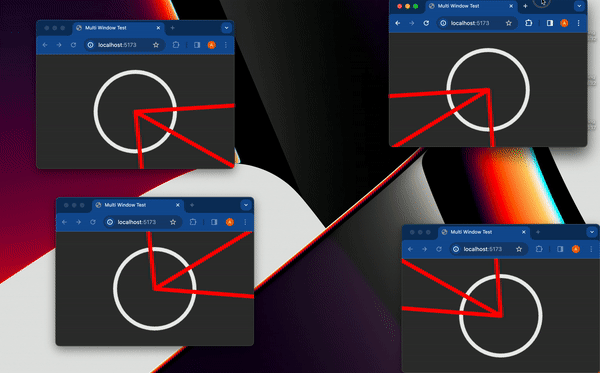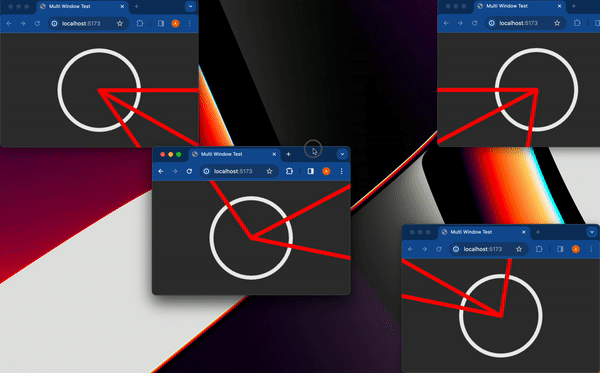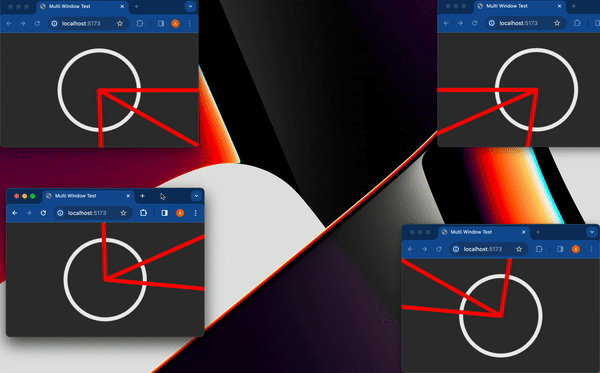 我做的第一件事就是列出我所知道的在多個客戶端之間共享資訊的所有方法: ## 呃:伺服器 顯然,擁有伺服器(帶有輪詢或 Websocket)可以簡化問題。然而,由於 Bjorn 在沒有使用伺服器的情況下實現了他的結果,所以這是不可能的。 ## 本機存儲 本地存儲本質上是瀏覽器鍵值存儲,通常用於在瀏覽器會話之間保存資訊。雖然通常用於儲存身份驗證令牌或重定向 URL,但它可以儲存任何可序列化的內容。 [您可以在這裡了解更多](https://developer.mozilla.org/en-US/docs/Web/API/Window/localStorage)。 我最近發現了一些有趣的本地儲存 API,包括 *`storage`* 事件,每當同一網站的另一個會話更改本地儲存時就會觸發該事件。 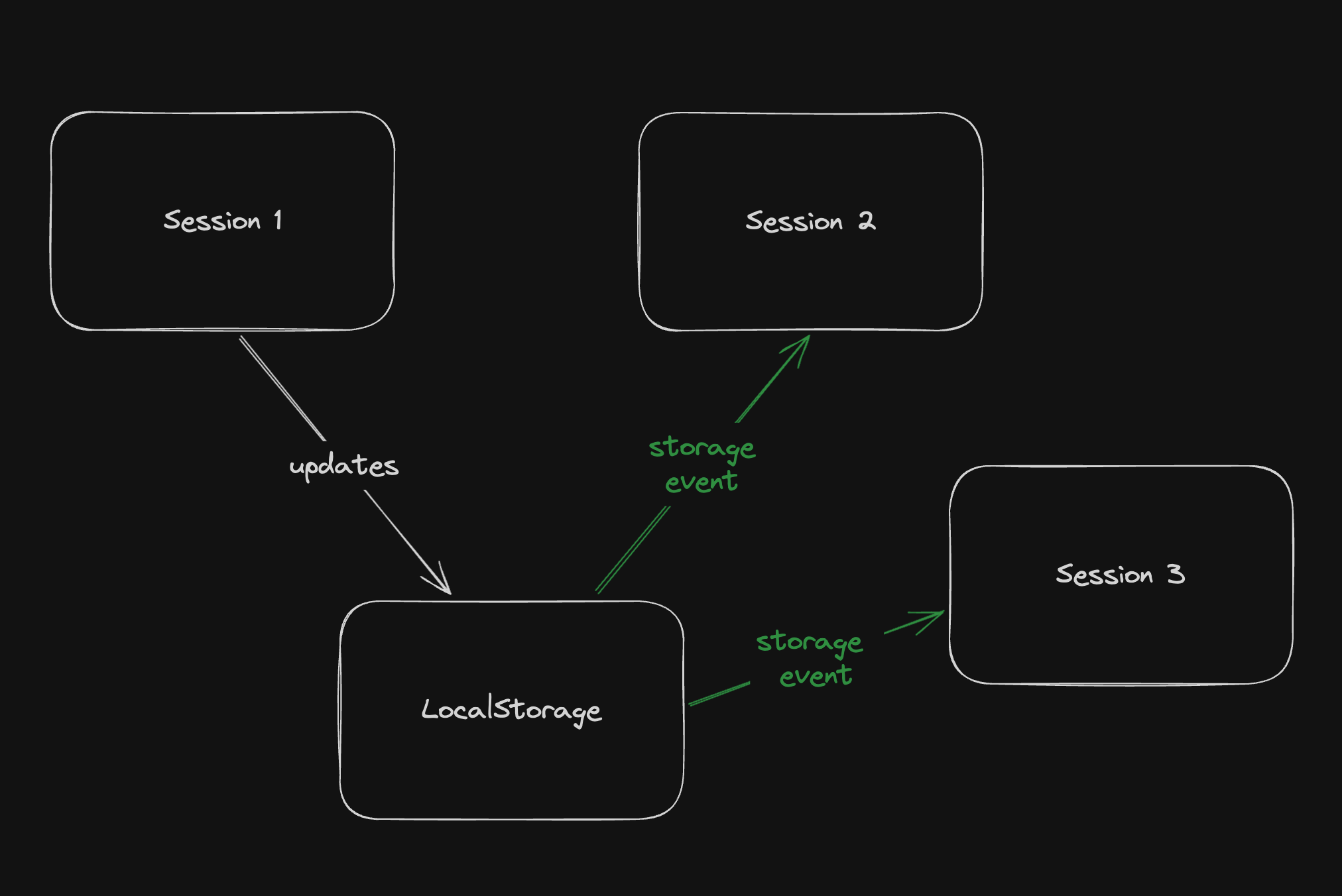 我們可以透過將每個視窗的狀態儲存在本地儲存中來利用這一點。每當一個視窗改變其狀態時,其他視窗將透過儲存事件進行更新。 這是我最初的想法,這似乎是Bjorn 選擇的解決方案,因為他分享了他的LocalStorage 管理器程式碼以及與ThreeJs 一起使用的範例[此處](https://github.com/bgstaal/multipleWindow3dScene) 。 但是當我發現有程式碼可以解決這個問題時,我想看看是否有其他方法…劇透警告:是的,有! ## 共享工作者 這個華而不實的術語背後是一個令人著迷的概念——WebWorkers 的概念。 簡單來說,工作執行緒本質上是在另一個執行緒上執行的第二個腳本。雖然它們無法存取 DOM(因為它們存在於 HTML 文件之外),但它們仍然可以與您的主腳本進行通訊。 它們主要用於透過處理背景作業來卸載主腳本,例如預取資訊或處理不太關鍵的任務(例如流日誌和輪詢)。 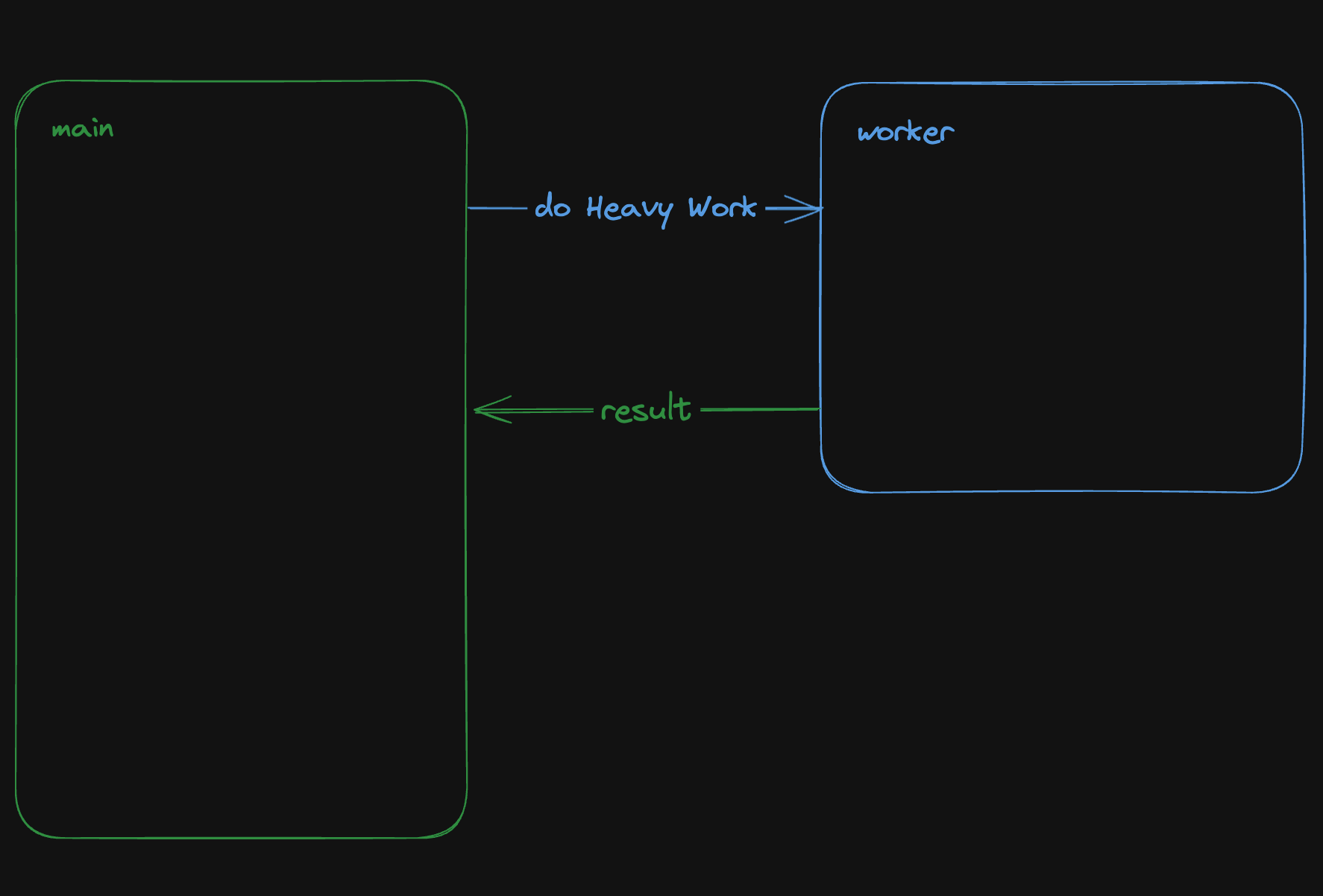 共享工作線程是一種特殊類型的 WebWorkers,它可以與同一腳本的多個實例進行通信,這使得它們對我們的用例很有趣!好吧,讓我們直接進入程式碼! 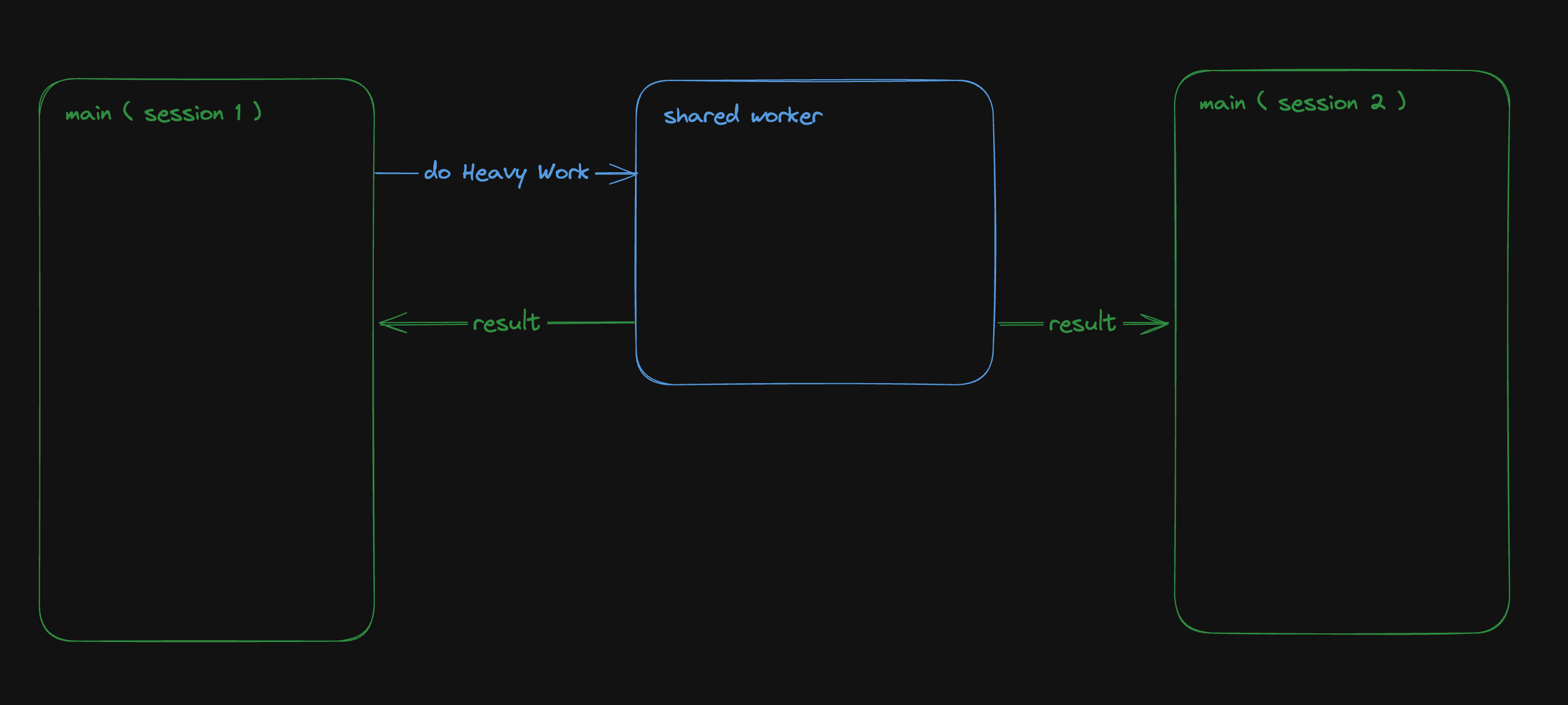 ### 設定工人 如前所述,工作人員是具有自己的入口點的「第二腳本」。根據您的設定(TypeScript、捆綁程式、開發伺服器),您可能需要調整 tsconfig、新增指令或使用特定的匯入語法。 我無法涵蓋所有使用 Web Worker 的可能方法,但您可以在 MDN 或網路上找到資訊。 如果需要,我很樂意為本文撰寫前傳,詳細介紹設定它們的所有方法! 就我而言,我使用的是 Vite 和 TypeScript,因此我需要一個「worker.ts」檔案並將「@types/sharedworker」安裝為開發依賴項。我們可以使用以下語法在主腳本中建立連結: ``` new SharedWorker(new URL("worker.ts", import.meta.url)); ``` 基本上,我們需要: * 辨識每個視窗 * 追蹤所有視窗狀態 * 一旦視窗改變狀態,提醒其他視窗重繪 我們的狀態將非常簡單: ``` type WindowState = { screenX: number; // window.screenX screenY: number; // window.screenY width: number; // window.innerWidth height: number; // window.innerHeight }; ``` 當然,最重要的訊息是“window.screenX”和“window.screenY”,因為它們告訴我們視窗相對於顯示器左上角的位置。 我們將有兩種類型的訊息: * 每個窗口,無論何時改變其狀態,都會發布一個帶有新狀態的“windowStateChangedmessage”。 * 工作人員將向所有其他視窗發送更新,以提醒他們其中一個視窗已更改。工作人員將發送包含所有視窗狀態的「syncmessage」。 我們可以從一個看起來有點像這樣的普通工人開始: ``` // worker.ts let windows: { windowState: WindowState; id: number; port: MessagePort }[] = []; onconnect = ({ ports }) => { const port = ports[0]; port.onmessage = function (event: MessageEvent<WorkerMessage>) { console.log("We'll do something"); }; }; ``` 我們與 SharedWorker 的基本連結如下所示。我有一些基本函數可以產生 id,並計算當前視窗狀態,我還對我們可以使用的稱為 WorkerMessage 的訊息類型進行了一些輸入: ``` // main.ts import { WorkerMessage } from "./types"; import { generateId, getCurrentWindowState, } from "./windowState"; const sharedWorker = new SharedWorker(new URL("worker.ts", import.meta.url)); let currentWindow = getCurrentWindowState(); let id = generateId(); ``` 一旦我們啟動應用程式,我們應該提醒工作人員有一個新窗口,因此我們立即發送一條訊息: ``` // main.ts sharedWorker.port.postMessage({ action: "windowStateChanged", payload: { id, newWindow: currentWindow, }, } satisfies WorkerMessage); ``` 我們可以在工作端監聽此訊息並相應地更改 onmessage。基本上,一旦工作人員收到 windowStateChanged 訊息,要么它是一個新窗口,我們將其附加到狀態,要么它是一個已更改的舊窗口。然後我們應該提醒大家狀態已經改變: ``` // worker.ts port.onmessage = function (event: MessageEvent<WorkerMessage>) { const msg = event.data; switch (msg.action) { case "windowStateChanged": { const { id, newWindow } = msg.payload; const oldWindowIndex = windows.findIndex((w) => w.id === id); if (oldWindowIndex !== -1) { // old one changed windows[oldWindowIndex].windowState = newWindow; } else { // new window windows.push({ id, windowState: newWindow, port }); } windows.forEach((w) => // send sync here ); break; } } }; ``` 為了發送同步,我實際上需要一些技巧,因為“port”屬性無法序列化,所以我將其字串化並解析回來。因為我很懶,所以我不只是將視窗映射到更可序列化的陣列: ``` w.port.postMessage({ action: "sync", payload: { allWindows: JSON.parse(JSON.stringify(windows)) }, } satisfies WorkerMessage); ``` 現在是時候畫東西了! ## 有趣的部分:繪畫! 當然,我們不會做複雜的 3D 球體:我們只會在每個視窗的中心畫一個圓,並在球體之間畫一條線! 我將使用 HTML Canvas 的基本 2D 上下文進行繪製,但您可以使用任何您想要的內容。畫一個圓,非常簡單: ``` const drawCenterCircle = (ctx: CanvasRenderingContext2D, center: Coordinates) => { const { x, y } = center; ctx.strokeStyle = "#eeeeee"; ctx.lineWidth = 10; ctx.beginPath(); ctx.arc(x, y, 100, 0, Math.PI * 2, false); ctx.stroke(); ctx.closePath(); }; ``` 為了繪製線條,我們需要做一些數學運算(我保證,這不是很多🤓),並將另一個視窗中心的相對位置轉換為目前視窗上的座標。 基本上,我們正在改變基地。我用一點數學來做到這一點。首先,我們將更改底座以在顯示器上具有座標,並透過目前視窗 screenX/screenY 進行偏移 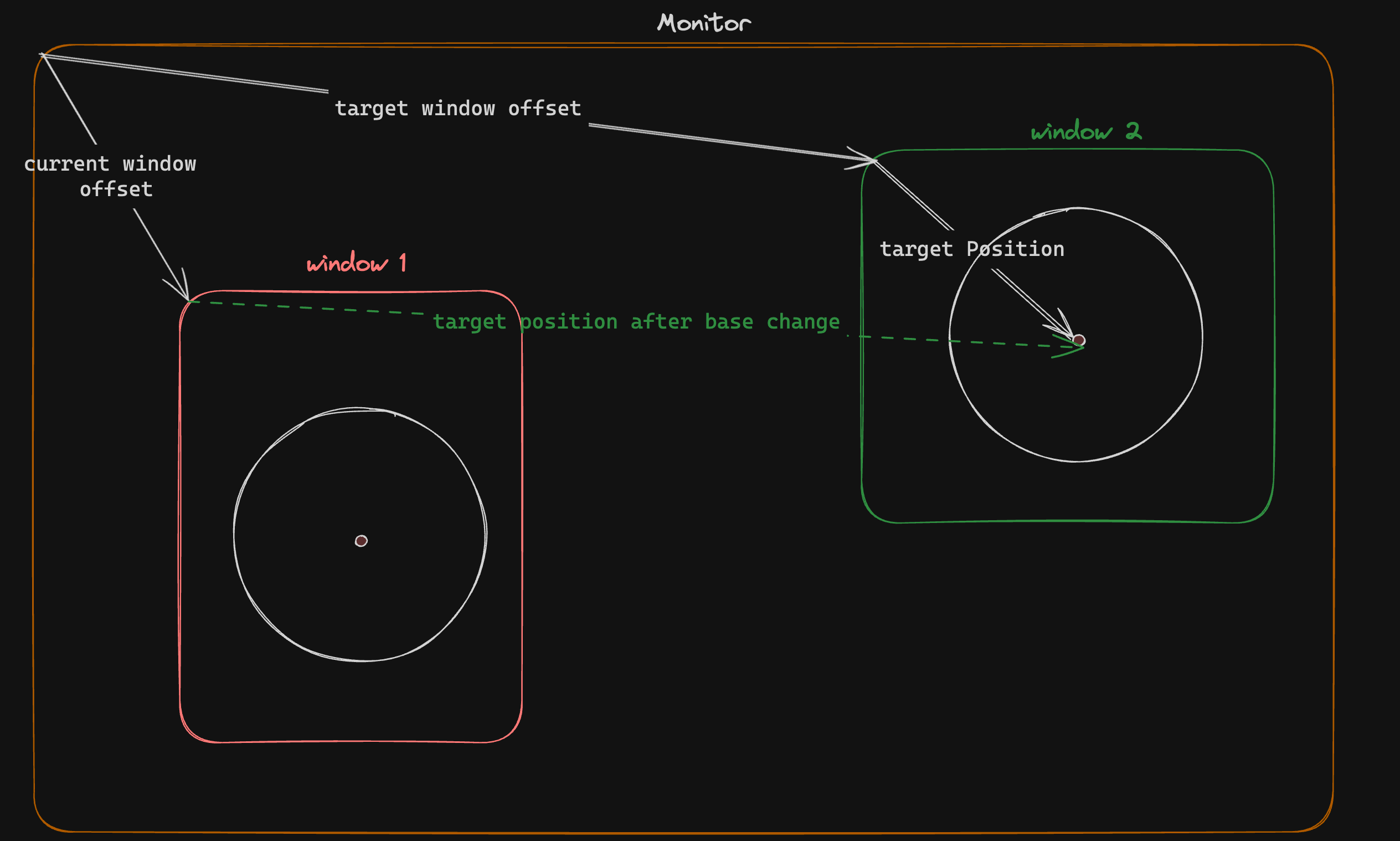 ``` const baseChange = ({ currentWindowOffset, targetWindowOffset, targetPosition, }: { currentWindowOffset: Coordinates; targetWindowOffset: Coordinates; targetPosition: Coordinates; }) => { const monitorCoordinate = { x: targetPosition.x + targetWindowOffset.x, y: targetPosition.y + targetWindowOffset.y, }; const currentWindowCoordinate = { x: monitorCoordinate.x - currentWindowOffset.x, y: monitorCoordinate.y - currentWindowOffset.y, }; return currentWindowCoordinate; }; ``` 如您所知,現在我們在同一相對座標系上有兩個點,我們現在可以畫線了! ``` const drawConnectingLine = ({ ctx, hostWindow, targetWindow, }: { ctx: CanvasRenderingContext2D; hostWindow: WindowState; targetWindow: WindowState; }) => { ctx.strokeStyle = "#ff0000"; ctx.lineCap = "round"; const currentWindowOffset: Coordinates = { x: hostWindow.screenX, y: hostWindow.screenY, }; const targetWindowOffset: Coordinates = { x: targetWindow.screenX, y: targetWindow.screenY, }; const origin = getWindowCenter(hostWindow); const target = getWindowCenter(targetWindow); const targetWithBaseChange = baseChange({ currentWindowOffset, targetWindowOffset, targetPosition: target, }); ctx.strokeStyle = "#ff0000"; ctx.lineCap = "round"; ctx.beginPath(); ctx.moveTo(origin.x, origin.y); ctx.lineTo(targetWithBaseChange.x, targetWithBaseChange.y); ctx.stroke(); ctx.closePath(); }; ``` 現在,我們只需要對狀態變化做出反應。 ``` // main.ts sharedWorker.port.onmessage = (event: MessageEvent<WorkerMessage>) => { const msg = event.data; switch (msg.action) { case "sync": { const windows = msg.payload.allWindows; ctx.reset(); drawMainCircle(ctx, center); windows .forEach(({ windowState: targetWindow }) => { drawConnectingLine({ ctx, hostWindow: currentWindow, targetWindow, }); }); } } }; ``` 最後一步,我們只需要定期檢查視窗是否發生變化,如果發生變化則發送訊息 ``` setInterval(() => { const newWindow = getCurrentWindowState(); if ( didWindowChange({ newWindow, oldWindow: currentWindow, }) ) { sharedWorker.port.postMessage({ action: "windowStateChanged", payload: { id, newWindow, }, } satisfies WorkerMessage); currentWindow = newWindow; } }, 100); ``` [您可以在此儲存庫中找到完整的程式碼](https://github.com/achrafl0/multi-window-article)。實際上,我用它做了很多實驗,使它變得更加抽象,但其要點是相同的。 如果您在多個視窗上執行它,希望您能得到與此相同的結果!  謝謝閱讀 ! 如果您發現這篇文章有幫助、有趣或只是有趣,您可以將其分享給您的朋友/同事/社區 [您也可以訂閱我的電子報](https://notachraf.substack.com/)它是免費的! --- 原文出處:https://dev.to/notachraf/sharing-a-state-between-windows-without-a-serve-23an
你好👋 今天,讓我們來看看**前 1% 的開發人員使用**的 8 個 React 儲存庫(以及那些您可能從未聽說過的儲存庫)。 準備好?  --- # 我們如何找到前 1% 的開發人員使用的儲存庫? 🔦 我們如何找到最好的開發人員使用的東西背後的故事植根於大量的資料探勘和一些重要的建模。 現在,在 Quine,我們根據開發人員的**[DevRank](https://docs.quine.sh/for-developers/devrank)** 對開發人員進行排名。 簡單來說,DevRank 使用 [Google 的 PageRank 演算法](https://en.wikipedia.org/wiki/PageRank) 根據開發人員對開源儲存庫的貢獻來衡量開發人員在開源領域的重要性。 為了建立此列表,我們查看了前 1% 已加星號的儲存庫。 🌟 然後,我們計算了前 1% 的開發者會為回購加註星標的可能性,與後 50% 的開發者不支持的可能性進行比較。 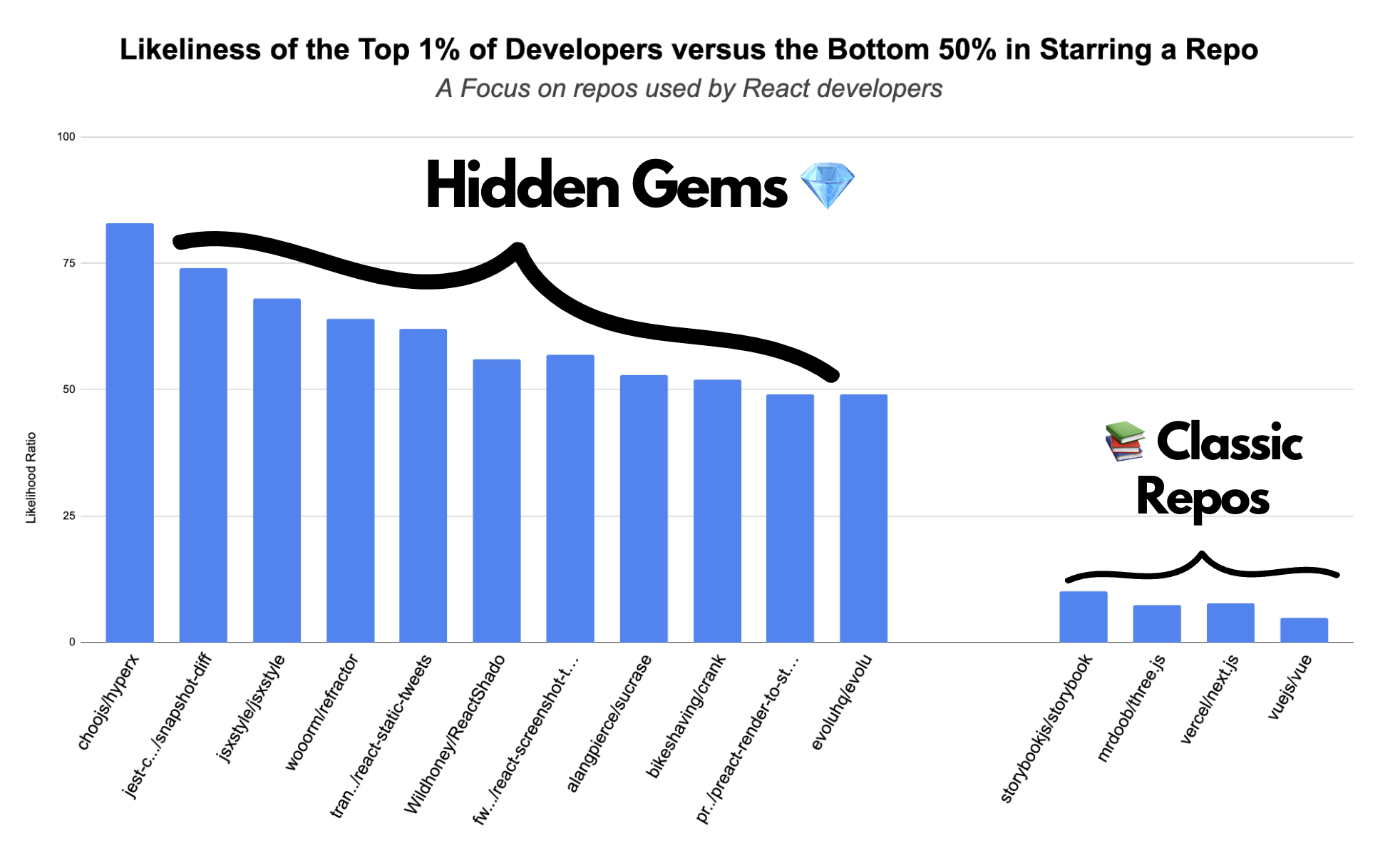 最後,經過一番挑選,我們找到了以下 8 個儲存庫。 :向下點: 當您想要建立很酷的網頁應用程式時,這些儲存庫將特別有用。** 如果您有興趣建立小型應用程式,並且喜歡應用人工智慧方面,我們建議您查看 Creator Quests,這是一項**開源挑戰,獎勵開發人員使用 ChatGPT、Claude、Gemini 建立酷炫的 GenerativeAI 應用程式**和更多。 :upside_down_face: 💰 最新的 Creator Quest 挑戰您使用生成式 AI 建立開發人員工具。要參與,只需註冊 [Quine](https://quine.sh/?utm_source=devto&utm_campaign=best_react_repos) 並前往 _Quests_。 **目前獎金池為$2028**,並且隨著更多參與者的加入,獎金池將會增加!點擊下面的圖片並嘗試! ⬇️ [](https://quine.sh/?utm_source=devto&utm_campaign=best_react_repos) --- # jsxstyle/jsxstyle **不再有 JS 到 CSS 的跳躍** [](https://github.com/jsxstyle/jsxstyle) **為什麼要關心?** 在 Web 開發中,使用 React 或 Preact,您必須設定元件的樣式(如按鈕、選單等)。傳統上,這是使用單獨的 CSS 檔案或複雜的樣式系統來完成的,這可能非常耗時且管理起來很麻煩。 jsxstyle 可讓您直接在 JavaScript 程式碼中以及元件中定義樣式,從而簡化了此過程。換句話說,這意味著您不再需要在 JS 和 CSS 檔案之間跳躍。 **設定**:`npm install jsxstyle` **範例用例**:您的程式碼可以如下所示。 👇 ``` <Row padding={15}> <Block backgroundColor="#EEE" boxShadow="inset 0 0 0 1px rgba(0,0,0,0.15)" borderRadius={5} height={64} width={64} marginRight={15} backgroundSize="contain" backgroundImage="url(http://graph.facebook.com/justinbieber/picture?type=large)" /> <Col fontFamily="sans-serif" fontSize={16} lineHeight="24px"> <Block fontWeight={600}>Justin Bieber</Block> <Block fontStyle="italic">Canadian</Block> </Col> </Row> ``` [https://github.com/jsxstyle/jsxstyle](https://github.com/jsxstyle/jsxstyle) --- # 💨 alangpierce/蔗糖酶 **Babel 的超快替代品** [](https://github.com/alangpierce/sucrase) **為什麼你應該關心?** Babel 是 Web 開發中廣泛使用的工具,可將現代 JavaScript 程式碼轉換為舊瀏覽器可以理解的格式。 Sucrase 是 Babel 更快的替代品。 **設定**: ``` yarn add --dev sucrase # Or npm install --save-dev sucrase node -r sucrase/register main.ts ``` **用例範例**:Sucrase 可以直接從 JS 呼叫: ``` import {transform} from "sucrase"; const compiledCode = transform(code, {transforms: ["typescript", "imports"]}).code; ``` [https://github.com/alangpierce/sucrase](https://github.com/alangpierce/sucrase) --- # 🎨 woorm/折射鏡 **我為您的網頁程式碼著色,讓您的生活更輕鬆** [](https://github.com/wooorm/refractor) **為什麼你應該關心?** Refractor 很重要,因為它允許您加入突出顯示,從而增強專案的可讀性;尤其是當您將程式碼片段新增至 Web 應用程式時。它允許您用 270 多種程式語言表達程式碼,並且在傳統的基於 HTML 的突出顯示不理想的領域(例如 CLI 表單)特別有用。 **設定**:`npm install refractor` **用例範例**: ``` import {refractor} from 'refractor' const tree = refractor.highlight('"use strict";', 'js') console.log(tree) ``` **產量**: ``` { type: 'root', children: [ { type: 'element', tagName: 'span', properties: {className: ['token', 'string']}, children: [{type: 'text', value: '"use strict"'}] }, { type: 'element', tagName: 'span', properties: {className: ['token', 'punctuation']}, children: [{type: 'text', value: ';'}] } ] } ``` [https://github.com/wooorm/refractor](https://github.com/wooorm/refractor) --- # 🐦 react-static-tweets **您在網站上加入推文的最佳選擇。** [](https://github.com/transitive-bullshit/react-static-tweets) **為什麼你應該關心?** 將推文加入到您的網站是您在許多登陸頁面上看到的一項很酷的功能。 React Static Tweets 很重要,因為它提供了一種在 Web 專案中嵌入推文的高效方法,與 Twitter 的標準嵌入方法相比,提供更快的載入時間和更好的效能。 **設定**: ``` npm install react-static-tweets static-tweets date-fns # or yarn add react-static-tweets static-tweets date-fns ``` **用例範例:** ``` import React from 'react' import { fetchTweetAst } from 'static-tweets' import { Tweet } from 'react-static-tweets' const tweetId = '1358199505280262150' export const getStaticProps = async () => { try { const tweetAst = await fetchTweetAst(tweetId) return { props: { tweetAst }, revalidate: 10 } } catch (err) { console.error('error fetching tweet', err) throw err } } export default function Example({ tweetAst }) { return <Tweet ast={tweetAst} /> } ``` [https://github.com/transitive-bullshit/react-static-tweets](https://github.com/transitive-bullshit/react-static-tweets) --- # 🖨️ preactjs/preact-render-to-string **以 HTML 形式呈現您的元件** [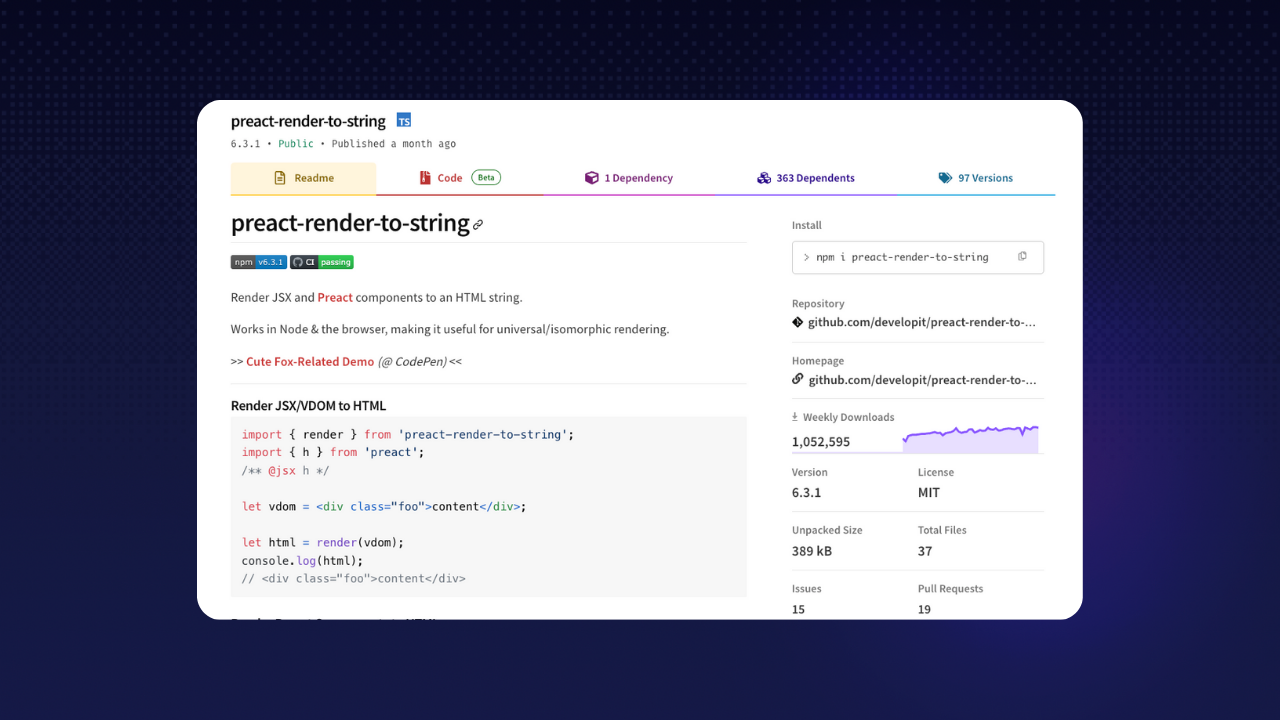](https://github.com/preactjs/preact-render-to-string) **為什麼要關心?** 「preact-render-to-string」是一個工具,可以幫助網站更快地載入並在搜尋引擎中更好地顯示。使用 Preact 等 JS 框架建立的網站需要一段時間才能顯示內容,因為瀏覽器必須先執行 JavaScript。此儲存庫透過將元件轉換為現成的 HTML 來完成伺服器端的繁重工作。因此,當有人造訪該網站時,即使網路速度很慢,他們也會立即看到內容。 **設定**:`npm install preact-render-to-string` **用例範例:** ``` import { render } from 'preact-render-to-string'; import { h, Component } from 'preact'; /** @jsx h */ // Classical components work class Fox extends Component { render({ name }) { return <span class="fox">{name}</span>; } } // ... and so do pure functional components: const Box = ({ type, children }) => ( <div class={`box box-${type}`}>{children}</div> ); let html = render( <Box type="open"> <Fox name="Finn" /> </Box> ); console.log(html); // <div class="box box-open"><span class="fox">Finn</span></div> ``` [https://github.com/preactjs/preact-render-to-string](https://github.com/preactjs/preact-render-to-string) --- # 🏆 自行車刮鬍/曲柄 **唯一的 JavaScript 框架** [](https://github.com/bikeshaving/crank) **為什麼要關心?** 在像 React 這樣的傳統 Web 框架中,Web 元件配置一次,僅在明確指定時才更改。它們看起來像是需要手動更新的靜態影像。 Crank.js 透過允許小部件更新自身以回應新資料來改變這一點,類似於用新新聞刷新的新聞收報機。這對於管理即時資料(例如即時體育賽事比分或產品更新)的 Web 應用程式尤其有用。 這個倉庫需要更多的人遷移到這裡才能獲得關注,但它仍然是一個非常酷的倉庫,值得關注。 👀 **設定**:`$ npm i @b9g/crank` **用例範例**: ``` import {renderer} from "@b9g/crank/dom"; function Greeting({name = "World"}) { return ( <div>Hello {name}</div> ); } renderer.render(<Greeting />, document.body); ``` [https://github.com/bikeshaving/crank](https://github.com/bikeshaving/crank) --- # 🎯 evoluhq/evolu **我是一個本地第一的人** [](https://github.com/evoluhq/evolu) **為什麼要關心?** Web 應用程式通常依賴在伺服器上儲存使用者資料,這需要持續的網路連接,並引起對隱私和資料安全的擔憂。這種基於伺服器的方法也意味著如果伺服器發生故障或公司停止運營,效能會降低,並且可能會遺失資料。 Evolu 引入了「本地優先」方法,其中資料直接儲存在使用者的裝置上。這意味著您的應用程式可以離線工作,更快地存取資料,並提供增強的隱私和安全性。如果您正在建立離線 Chrome/瀏覽器應用程式,這將非常有用。 **設定**:` npm install @evolu/react` 要開始使用它,您可以在[此處](https://www.evolu.dev/docs/quickstart)找到這個很棒的指南。 [https://github.com/evoluhq/evolu](https://github.com/evoluhq/evolu) --- # 📸 笑話社群/快照差異 **我比較你們的元件並突出顯示差異** [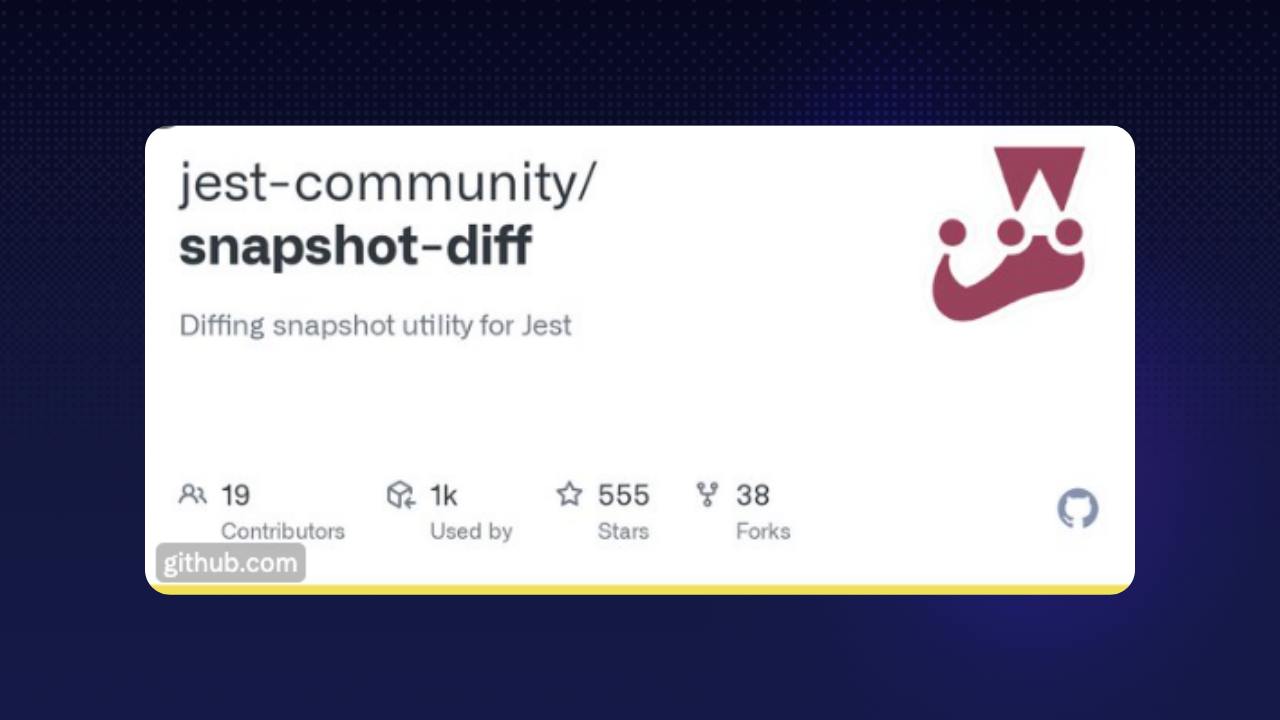](https://github.com/jest-community/snapshot-diff) **為什麼要關心?** 在測試 React 元件或其他 JavaScript 值時,開發人員通常會比較整個狀態或輸出。這意味著處理大量資料,查找特定變更就像大海撈針一樣。 Snapshot-diff 是重點比較工具,可讓您取得元件的兩種不同狀態(或任兩個 JavaScript 值)並直接比較它們,僅將差異突出顯示。 這對於測試 React 元件特別有幫助,因為它可以準確指出兩種狀態之間發生的變化,從而更容易辨識和理解程式碼變更的影響。 **設定**:`yarn add --dev snapshot-diff` **範例用例:** 預設笑話匹配器 ``` const snapshotDiff = require('snapshot-diff'); test('snapshot difference between 2 strings', () => { expect(snapshotDiff(a, b)).toMatchSnapshot(); }); const React = require('react'); const Component = require('./Component'); test('snapshot difference between 2 React components state', () => { expect( snapshotDiff(<Component test="say" />, <Component test="my name" />) ).toMatchSnapshot(); }); ``` [https://github.com/jest-community/snapshot-diff](https://github.com/jest-community/snapshot-diff) --- **我希望這些發現對您有價值,並將有助於建立更強大的 React 工具包!⚒️** 如果您今天想利用這些工具來獲得獎勵,我們剛剛發起了一項使用生成式人工智慧建立開發人員工具的挑戰。 如果對此有興趣,請登入 [Quine](https://quine.sh/?utm_source=devto&utm_campaign=best_react_repos) 並發現任務! 💰  最後,請**考慮透過加星號來支持這些專案。 ⭐️** PS:我們與他們沒有任何關係。我們只是認為偉大的專案值得高度認可。 下週見, 您的開發夥伴💚 巴普 --- 原文出處:https://dev.to/quine/8-repos-used-by-the-top-1-of-react-devs-2758
在上一個發布週期間,我們在 Supabase Studio 的 SQL 編輯器中引入了文字到 SQL。這是我們邁向完整人工智慧助理的第一步。 今天,我們將介紹 Supabase Assistant,這是儀表板內的人工智慧助手,以及一些新功能,可幫助您更快地從創意到生產。 https://youtu.be/hu2SQjvCXIw 這是鳥瞰圖: - **行級安全策略:** 透過 AI 輕鬆實現 - **Postgres 角色:** 更改工作室的 Postgres 角色 - **使用者模擬:**視覺化您的安全策略 - **即時檢查器:**檢查和除錯即時請求 - **功能預覽:** 查看 Studio 中的熱門新聞 ## 介紹 Supabase 助手 我們很高興能夠透過新的 **Supabase Assistant 擴展 Studio 的 AI 功能。** 開發人員告訴我們,SQL 編輯器中的文字到 SQL 功能大大提高了他們的速度(以及他們的 SQL 能力)。當人工智慧與基於模式的資料庫(如 Postgres)結合使用時,它的功能非常強大,因為它可以從模式中推斷出大量上下文,並且資料庫為生成的程式碼提供了更嚴格的保證。我們先前的版本堅定了我們的信念,即人工智慧將成為未來資料庫開發的關鍵部分。 今天,我們在行級安全編輯器中推出了 Assistant 支持,並且很快就會擴展到 Studio 中的其他位置:表編輯器、Postgres 函數、無伺服器函數等。 讓我們先進入行級安全性。  ## 透過 AI 實現簡單的 RLS 策略 在我們收到的所有功能請求中(而且我們收到了很多!),編寫[行級安全性](https://supabase.com/docs/guides/auth/row-level-security)策略的更簡單方法是其中之一最頻繁的。 行級安全性 (RLS) 是 Postgres 的一項功能,可提供對資料庫的細粒度存取。雖然 RLS 很強大,但編寫策略可能是一件苦差事。今天,我們發布了一款基於 AI 的 RLS 編輯器,讓編寫安全策略變得簡單。 新的 RLS 編輯器將 SQL 置於中心位置。我們希望讓開發人員能夠充分發揮 Postgres 的潛力,而不是將其抽象化。這個編輯器其實是兩個工具: 1. SQL 編輯器:如果您非常了解 SQL,那麼有一個新的編輯器可以讓您快速編寫策略。 2. 助手:如果您是 RLS 新手並需要幫助,您可以使用助手並透過它進行聊天。  此助手經過調整,可產生用於行級安全性的 SQL,以便快速、輕鬆地按照您需要的方式設定策略。 我們探索了 RLS 編輯器的各種方法和設計。這種 SQL 優先的方法在人工智慧的幫助下,感覺就像我們一直在尋找的解決方案。現在可以透過功能預覽啟用新的 RLS 編輯器(更多資訊請見下文)。我們很樂意[聽到您的回饋。](https://github.com/orgs/supabase/discussions/19594) ## Postgres 角色 您可能從未想過這一點,但 Studio 就像任何其他 Postgres 用戶端一樣連接到您的資料庫。 它使用預設的[Postgres角色](https://supabase.com/docs/guides/database/postgres/roles),`postgres`。 「postgres」角色的功能類似於「服務角色」金鑰,授予它對資料庫的管理權限。它具有管理員讀寫權限,並繞過行級安全性。 如果您使用我們的客戶端程式庫,您將熟悉「anon」和「service_role」 API 金鑰。這些鍵實際上解析為 Postgres 角色,也稱為“anon”和“service_role”。這些密鑰實際上是包含 Postgres 角色的 JWT 令牌: ``` { "role": "service_role", // the Postgres role "iss": "supabase" // the issuer of the JWT "exp": 1445385600, // the time the JWT will expire } ``` 如果您可以使用在應用程式中使用的相同 Postgres 角色在 Studio 中執行查詢會怎麼樣?如果您可以讓 Studio 假裝使用與預設「postgres」角色不同的角色怎麼辦?今天,您可以:  您可以使用新的角色下拉清單為 Studio 中的查詢選擇不同的 Postgres 角色。這是一個強大的工具,用於測試行級安全策略並確定每個角色可以存取哪些資料。 讓我們建立一個 Twitter/X 克隆來進行說明。在 Twitter 克隆中,您: - 有一個包含「user_id」和「content」等欄位的推文表。 - 可以設定行級安全性,以便只有推文的作者才能存取和修改自己的推文。 - 只能查看和編輯您撰寫的推文。 當我們使用“postgres”角色進行查詢時,我們可以看到所有資料。當我們使用“anon”查詢時,不會傳回任何資料。這是有道理的,因為我們尚未建立允許「匿名」存取此表的策略。 角色下拉清單解鎖了另一個方便的功能:與 Supabase Auth 結合使用時,它甚至可以假裝是不同的使用者。 ## 使用者模擬 還記得上面的 API 金鑰嗎?它們可以包含一個附加字段:“sub”。這是用戶的 ID。當您使用「authenticated」角色時,「sub」欄位是登入您的應用程式的使用者的ID: ``` { "sub": "348b-some-user-uuid", // the ID of the user "role": "authenticated", // the Postgres role "iss": "supabase" // the issuer of the JWT "exp": 1445385600, // the time the JWT will expires } ``` 我們可以透過使用使用者 ID「建立」JWT,然後使用該 JWT 執行查詢來模擬 Studio 中的使用者。 在我們編寫 RLS 策略以允許用戶查看自己的推文後,讓我們看看它的實際效果。在這裡,我們可以選擇「已驗證」角色,並選擇特定用戶以僅查看他們的推文。以下是我們所有用戶的推文:  表編輯器現在正在模擬我們的用戶。 您可以模擬專案中的任何用戶,並按照他們的方式查看事物。您的 RLS 政策中的任何條件都會自動反映在表中。 ✨ 魔法 ✨ 您可以直接從 Studio 建立 RLS 策略並測試它們是否完全按照您的預期運作。 表格編輯器的樂趣不止於此。我們還為 SQL 編輯器和 GraphiQL 新增了角色支援。讓我們透過嘗試在 SQL 編輯器中選擇我們自己的推文清單來重複上面所做的事情:  在 GraphiQL 中:  將此功能與新的 RLS 編輯器結合,您可以在幾分鐘內使用真實資料編寫和測試 RLS 策略。這使得編寫 RLS 策略的過程變得更快、更容易。如果您有回饋,[我們很樂意聽到。](https://github.com/orgs/supabase/discussions/19595) ## 即時檢查器 Supabase [Realtime](https://supabase.com/realtime) 非常適合建立協作應用程式。您可以透過 Websocket 接收資料庫更改,儲存和同步有關使用者狀態的資料,以及透過「通道」向客戶端廣播任何資料。 今天,我們發布了 Realtime Inspector:一種直接在 Studio 中進行 Realtime 原型設計、檢查和除錯的簡單方法。您可以使用即時檢查器查看通道中發送和接收的訊息。您可以按類型篩選訊息:狀態、廣播和資料庫變更。  當然,我們也在這裡新增了「角色」下拉清單。您可以按角色查看事件並模擬用戶,就像表和 SQL 編輯器一樣。 如果您使用 Realtime,您會發現新的檢查器非常方便。 ## 功能預覽 今天,我們發布了**功能預覽**,這是我們用於推出新功能的工具。在普遍可用之前,我們會以預覽版的形式發布 Beta 功能。您可以看到可用於預覽的功能清單以及螢幕截圖和簡要說明。每個功能都包含一個指向 Github 討論以獲取反饋的連結。 我們對功能預覽有幾個目標。我們想: - 更快地向您提供功能 - 讓您更輕鬆地向我們提供回饋 - 縮短迭代循環 我們越快地迭代您的回饋,我們就能越快將功能發佈到普遍使用中。 雖然我們認為這些功能是測試版,但請注意,我們非常重視您的安全、隱私和資料完整性。我們發佈到預覽版的任何內容都會考慮到這一點進行測試,並且處於我們正在尋找 UX/UI 回饋的階段。 您可以在左下角的使用者頭像選單下找到我們的功能預覽:  目前我們有兩個預覽功能: 1. 我們之前看到的新 RLS 助手:  2. 以及修改後的 API 側面板:  我們將積極關注 Github 討論並回覆您的回饋。 ## 總結 在此更新中,我們在增強您的 Supabase 體驗方面取得了巨大進展。 1. **行級安全策略:** 在新助理的幫助下,我們比以往任何時候都更容易建立行級安全策略。此功能極大地簡化了定義對資料的細粒度存取的過程。 2. **Postgres 角色和使用者模擬:** 我們的新角色選擇器可讓您直接在 Studio 中視覺化安全策略的影響。這使您可以了解不同角色如何與資料交互,從而為測試存取控制提供強大的工具。 3. **即時檢查器:** 使用即時檢查器,您可以原型設計、檢查和偵錯即時訊息。這個工具對於使用 Supabase Realtime 的人來說非常有用。 4. **功能預覽:** 我們推出了功能預覽,為您帶來測試階段的新工具和功能,讓您更輕鬆地提供回饋並塑造開發流程。 這些更新反映了我們對 SQL 優先方法和以使用者為中心的開發的承諾。我們期待您的回饋,我們將繼續努力讓 Supabase 更快、更輕鬆地讓您的想法付諸實現。 ## 更多發布第 X 週 - [Postgres語言伺服器:實作解析器](https://supabase.com/blog/postgres-language-server-implementing-parser) - [Supabase 設計如何運作](https://supabase.com/blog/how-design-works-at-supabase) - [Supabase 專輯](https://www.youtube.com/watch?v=r1POD-IdG-I) - [Supabase 啟動週 X 黑客松](https://supabase.com/blog/supabase-hackathon-lwx) - [啟動週 X 社群聚會](https://supabase.com/blog/community-meetups-lwx) --- 原文出處:https://dev.to/supabase/supabase-studio-ai-assistant-and-user-impersonation-22mn
## **簡介** 在本教程中,您將學習如何使用**現代工具**和**最佳實踐**來監控您的Javascript應用程式。 探索分散式追蹤的力量,並了解如何無縫整合和利用 Odigos 和 Jaeger 等工具來增強您的監控能力。 **您將學到什麼:✨** - 如何在 Javascript 中建立微服務🐜。 - 為微服務設定 Docker 容器📦。 - 配置 Kubernetes ☸️ 以管理微服務。 - 整合追蹤後端以可視化追蹤🔍。 您準備好成為監控 JS 應用程式的**專家**了嗎? 😍 說**是的,先生!**。 我聽不到你說話。大聲點說。 🙉  *** ## **讓我們設定一下 🦄** > 🚨 在部落格的這一部分中,我們將建立一個虛擬的 JavaScript 微服務應用程式並將其部署在本地 Kubernetes 上。如果您已經有一個並且正在跟進,請隨意跳過這一部分。 為您的應用程式建立初始資料夾結構,如下所示。 👇🏻 ``` mkdir microservices-demo cd microservices-demo mkdir src cd src ``` ### **設定伺服器** 🖥️ > 👀 出於演示目的,我將建立兩個相互通信的微服務,最終我們可以使用它來視覺化分散式追蹤。 - **建置與 Dockerize 微服務 1** 在「/src」資料夾中,建立一個新資料夾「/microservice-1」。在資料夾內初始化 **NodeJS** 專案並安裝所需的依賴項。 ``` mkdir microservice-1 cd microservice-1 npm init -y npm install --save express node-fetch ``` 建立一個新檔案“index.js”並新增以下程式碼: ``` // 👇🏻/src/microservice-1/index.js const express = require("express"); const fetch = require("node-fetch") const app = express(); const PORT = 3001; app.use(express.json()); app.get("/", async (req, res) => { try { const response = await fetch("http://microservice2:8081/api/data"); const data = await response.json(); res.json({ data: "Microservice 2 data received in Microservice 1", microservice2Data: data, }); } catch (error) { console.error(error.message); res.status(500).json({ error: "Internal Server Error" }); } }); app.listen(PORT, () => { console.log(`Microservice 1 listening on port ${PORT}`); }); ``` 伺服器正在偵聽連接埠“3001”,並且在對“/”發出請求時,我們從“microservice2”請求資料並將回應作為 JSON 物件返回。 📦 現在,是時候對這個微服務進行 docker 化了。在“/microservice-1”資料夾中建立一個新的“Dockerfile”並新增以下程式碼: ``` // 👇🏻/src/microservice-1/Dockerfile FROM node:18 # Use /usr/src/app as the working directory WORKDIR /usr/src/app # Copy package files and install production dependencies COPY --chown=node:node package*.json /usr/src/app RUN npm install --production # Copy the rest of the files COPY --chown=node:node . /usr/src/app/ # Switch to the user node with limited permissions USER node # Expose the application port EXPOSE 3001 # Set the default command to run the application CMD ["node", "index.js"] ``` 將我們不想推送到容器的文件加入到“.dockerignore”總是很好。使用我們不想推送的檔案的名稱來建立一個“.dockerignore”檔案。 ``` // 👇🏻/src/microservice-1/.dockerignore node_modules Dockerfile ``` 最後,透過執行以下命令來建構 🏗️ docker 映像: ``` docker build -t microservice1-image:latest . ``` 現在,這就是我們第一個微服務的完整設定。 ✨ - **建置與 Dockerize 微服務 2** 我們將有一個類似於“microservice1”的設置,只是在這裡和那裡進行了一些更改。 在「/src」資料夾中,建立一個新資料夾「/microservice-2」。在該資料夾內,初始化 **NodeJS** 專案並安裝所需的依賴項。 ``` mkdir microservice-2 cd microservice-2 npm init -y npm install --save express node-fetch ``` 建立一個新檔案“index.js”並新增以下程式碼: ``` // 👇🏻/src/microservice-2/index.js const express = require("express"); const fetch = require("node-fetch") const app = express(); const PORT = 3002; app.use(express.json()); app.get("/api/data", async (req, res) => { const url = "https://jsonplaceholder.typicode.com/users"; try { const response = await fetch(url); const data = await response.json(); res.json(data); } catch (error) { console.error(error.message); res.status(500).json({ error: "Internal Server Error" }); } }); app.listen(PORT, () => { console.log(`Microservice 2 listening on port ${PORT}`); }); ``` 伺服器正在偵聽連接埠 3002,根據對“/api/data”的“GET 請求”,我們從“jsonplaceholder”獲取資料並將回應作為 JSON 物件傳回。 📦 現在,是時候對這個微服務進行 docker 化了。複製並貼上「microservice1」的整個「Dockerfile」內容,然後將連接埠從 3001 變更為 3002。 另外,新增一個「.dockerignore」檔案並包含我們在建立「microservice1」時新增的相同檔案。 最後,透過執行以下命令來建構 🏗️ Docker 映像: ``` docker build -t microservice2-image:latest . ``` 現在,這也是我們第二個微服務的完整設定。 ✨ - **設定 Kubernetes** > 確保已安裝 **[Minikube](https://github.com/kubernetes/minikube)** 透過執行以下命令建立新的本機 Kubernetes 叢集。我們在設定 Odigos 和 Jaeger 時將需要它。 **啟動 Minikube:🚀** ``` minikube start ``` 現在我們已經準備好並 Docker 化了兩個微服務,是時候設定 Kubernetes 來管理這些服務了。 在專案的根目錄下,建立一個新資料夾「/k8s/manifests」。在此資料夾中,我們將為兩個微服務新增部署和服務配置。 - **部署設定📜**:用於在 Kubernetes 叢集上實際部署容器。 - **服務配置📄**:將 Pod 暴露給叢集內部和叢集外部。 首先,我們為「microservice1」建立清單。建立一個新檔案「microservice1-deployment-service.yaml」並新增以下內容: ``` // 👇🏻/k8s/manifests/microservice1-deployment-service.yaml apiVersion: apps/v1 kind: Deployment metadata: name: microservice1 spec: selector: matchLabels: app: microservice1 template: metadata: labels: app: microservice1 spec: containers: - name: microservice1 image: microservice1-image # Make sure to set it to Never, or else it will pull from the docker hub and fail. imagePullPolicy: Never resources: limits: memory: "200Mi" cpu: "500m" ports: - containerPort: 3001 --- apiVersion: v1 kind: Service metadata: name: microservice1 labels: app: microservice1 spec: type: NodePort selector: app: microservice1 ports: - port: 8080 targetPort: 3001 nodePort: 30001 ``` 此配置部署了一個名為「microservice1」的微服務,其資源限制為 **200MB 記憶體** 🗃️ 和 **0.5 個 CPU 核心**。它透過部署在連接埠 3001 上公開微服務,並透過服務在 **NodePort** 30001 上公開微服務。 > 🤔 還記得我們用名稱「microservice1-image」建構的「Dockerfile」嗎?我們使用相同的映像來建立容器。 可透過集群內的連接埠 8080 存取它。我們假設「microservice1-image」透過「imagePullPolicy: Never」在本地可用。如果沒有到位,它將嘗試從 Docker Hub 🐋 中提取映像並失敗。 現在,讓我們為「microservice2」建立清單。建立一個名為「microservice2-deployment-service.yaml」的新檔案並新增以下內容: ``` // 👇🏻/k8s/manifests/microservice1-deployment-service.yaml apiVersion: apps/v1 kind: Deployment metadata: name: microservice2 spec: selector: matchLabels: app: microservice2 template: metadata: labels: app: microservice2 spec: containers: - name: microservice2 image: microservice2-image # Make sure to set it to Never, or else it will pull from the docker hub and fail. imagePullPolicy: Never resources: limits: memory: "200Mi" cpu: "500m" ports: - containerPort: 3002 --- apiVersion: v1 kind: Service metadata: name: microservice2 labels: app: microservice2 spec: type: NodePort selector: app: microservice2 ports: - port: 8081 targetPort: 3002 nodePort: 30002 ``` 它與“microservice1”的清單類似,只有一些更改。 👀 此配置部署一個名為「microservice2」的微服務,並透過部署在連接埠 3002 上將其內部公開,並透過服務在 **NodePort** 30002 上將其外部公開。 可透過叢集內的連接埠 8081 進行存取,假設「microservice2-image」可透過「imagePullPolicy: Never」在本地使用。 全部完成後,請確保套用這些設定並使用這些服務啟動 Kubernetes 叢集。將目錄更改為`/manifests`並執行以下命令:👇🏻 ``` kubectl apply -f microservice1-deployment-service.yaml kubectl apply -f microservice2-deployment-service.yaml ``` 執行以下命令檢查我們的兩個部署是否正在**執行**:👇🏻 ``` kubectl get pods ```  最後,我們的應用程式已準備就緒,並使用必要的部署配置部署在 Kubernetes 上。 🎉 *** ## **安裝 Odigos 😍** > 💡 [**Odigos**](https://odigos.io/) 是一個開源可觀察性控制平面,使組織能夠建立和維護其可觀察性管道。  > ℹ️ 如果您在 Mac 上執行,請執行以下命令在本地安裝 Odigos。 ``` brew install keyval-dev/homebrew-odigos-cli/odigos ``` > ℹ️ 如果您使用的是 Linux 計算機,請考慮透過執行以下命令從 GitHub 版本安裝它。確保根據您的 Linux 發行版更改該檔案。 > ℹ️ 如果 Odigos 二進位檔案不可執行,請在執行安裝指令之前執行此指令 `chmod +x odigos` 使其可執行。 ``` curl -LJO https://github.com/keyval-dev/odigos/releases/download/v1.0.9/cli_1.0.9_linux_amd64.tar.gz tar -xvzf cli_1.0.9_linux_amd64.tar.gz ./odigos install ``` 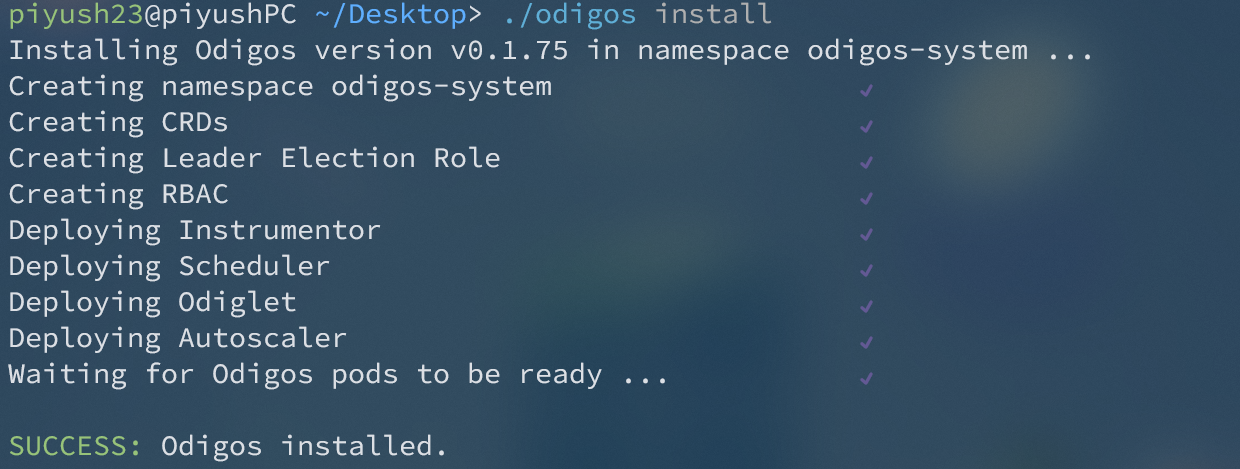 > 如果您需要有關其安裝的更多簡短說明,請按照此[**連結**](https://docs.odigos.io/installation)操作。 現在,Odigos 已準備好執行 🎉。我們可以執行它的 UI,配置追蹤後端,並相應地發送追蹤。 *** ## **將 Odigos 連接到追蹤後端 💫** > 💡 [**Jaeger**](https://github.com/jaegertracing/jaeger) 是一個開源的端對端分散式追蹤系統。  ### **設定 Jaeger!** ✨ 在本教程中,我們將使用 **Jaeger** 🕵️♂️,這是一個流行的開源平台,用於查看微服務應用程式中的分散式追蹤。我們將用它來查看 Odigos 生成的痕跡。 > 有關 Jaeger 安裝說明,請點選此 [**link**](https://www.jaegertracing.io/download/)。 👀 若要在 Kubernetes 叢集上部署 Jaeger,請執行下列命令:👇🏻 ``` kubectl create ns tracing kubectl apply -f https://raw.githubusercontent.com/keyval-dev/opentelemetry-go-instrumentation/master/docs/getting-started/jaeger.yaml -n tracing ``` 在這裡,我們建立一個「tracing」命名空間,並在該命名空間中為 Jaeger 應用部署配置📃。 此命令設定自託管 Jaeger 實例及其服務。 👀 執行以下命令來取得正在執行的 pod 的狀態:👇🏻 ``` kubectl get pods -A -w ``` 等待所有三個 Pod 都 **正在執行**,然後再繼續。 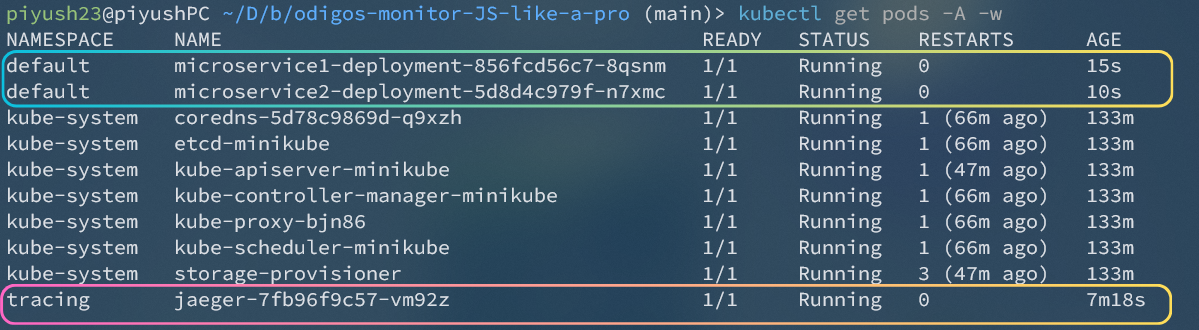 現在,要在本地查看 Jaeger Interface 💻,我們需要進行連接埠轉送。將流量從本機電腦上的連接埠 16686 轉送至 Kubernetes 叢集中選定 pod 上的連接埠 16686。 ``` kubectl port-forward -n tracing svc/jaeger 16686:16686 ``` 此命令在本機電腦和 Jaeger pod 之間建立一條隧道,公開 Jaeger UI,以便您可以與其互動。 最後,在瀏覽器上開啟「 http://localhost:16686 」並查看 Jaeger 實例正在執行。 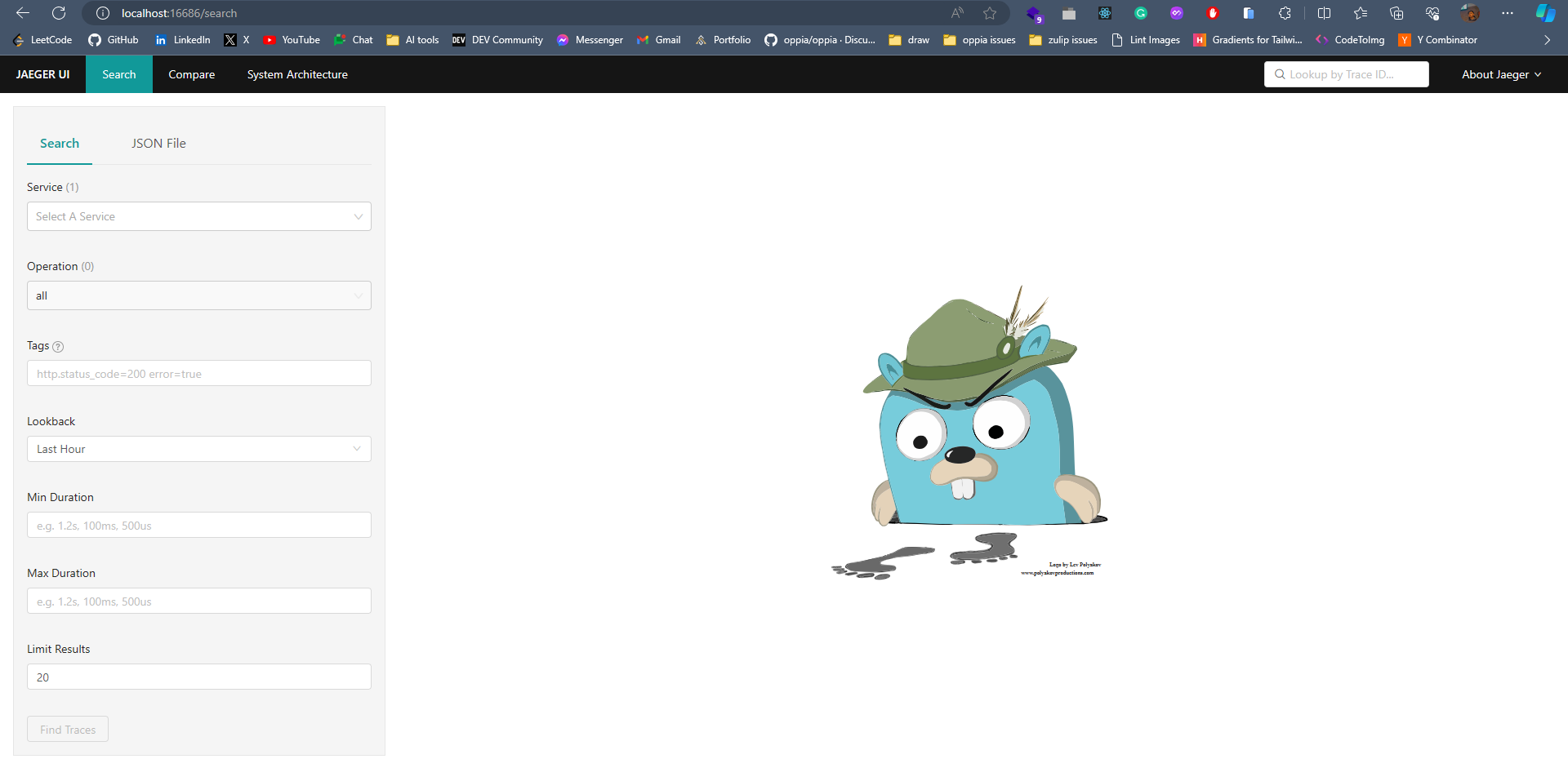 ### **設定 Odigos 與 Jaeger 一起工作!** 🌟 > ℹ️ 對於 Linux 用戶,請前往從 GitHub 版本下載 Odigos 二進位檔案的資料夾,然後執行以下命令來啟動 Odigos UI。 ``` ./odigos ui ``` > ℹ️ 對於 Mac 用戶,只需執行: ``` odigos ui ``` 造訪“ http://localhost:3000 ”,您將看到 Odigos 介面,您將在“default”命名空間中看到您的部署。  選擇這兩個選項並點擊“下一步”。在下一頁上,選擇 Jaeger 作為後端,並在出現提示時加入以下詳細資訊: - **目的地名稱🛣️**:提供您想要的任何名稱,例如說**快速追蹤**。 - **端點🎯**:為端點加上`jaeger.tracing:4317`。 就是這樣 - Odigos 已準備好向我們的 Jaeger 後端發送痕跡。就是這麼簡單。 🤯 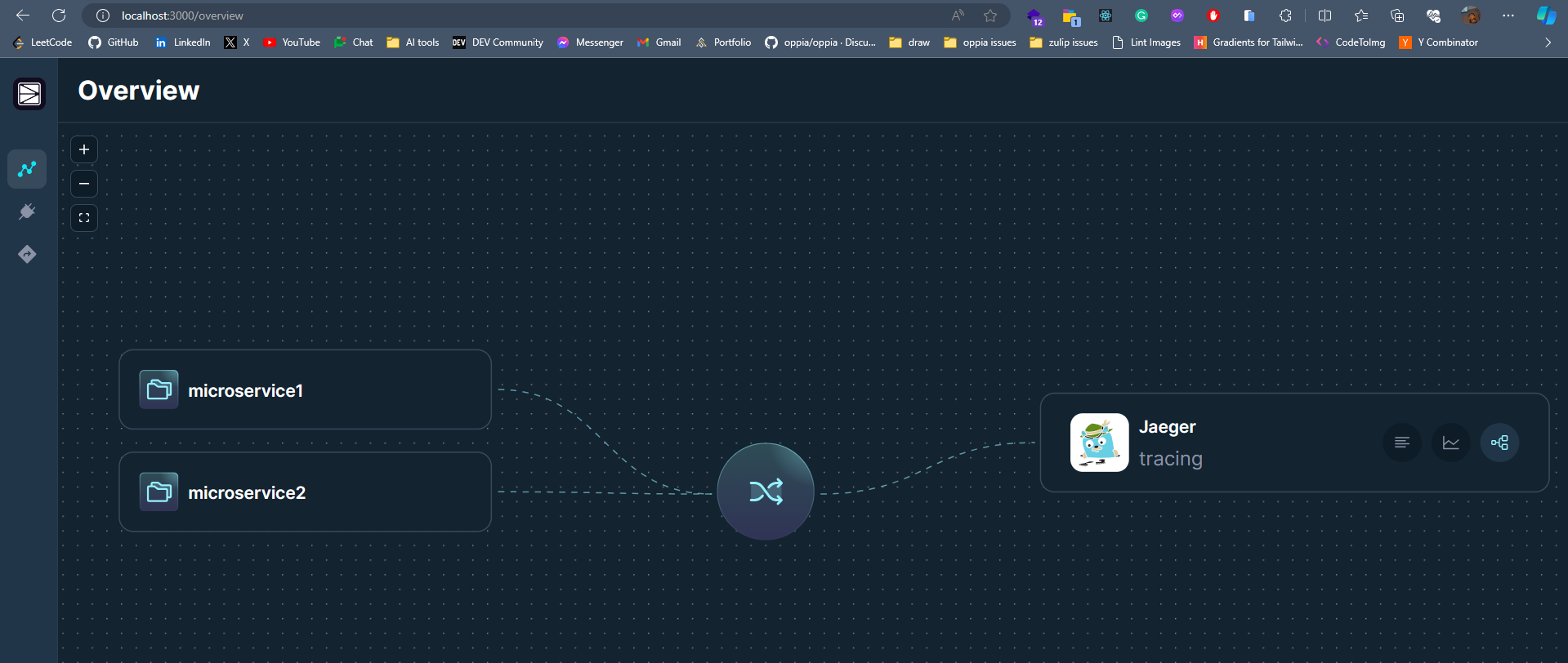 *** ## **查看分散式追蹤 🧐** 設定 Odigos 後,在 Jaeger 主頁「 http://localhost:16686 」上,您將已經看到列出的兩個微服務。 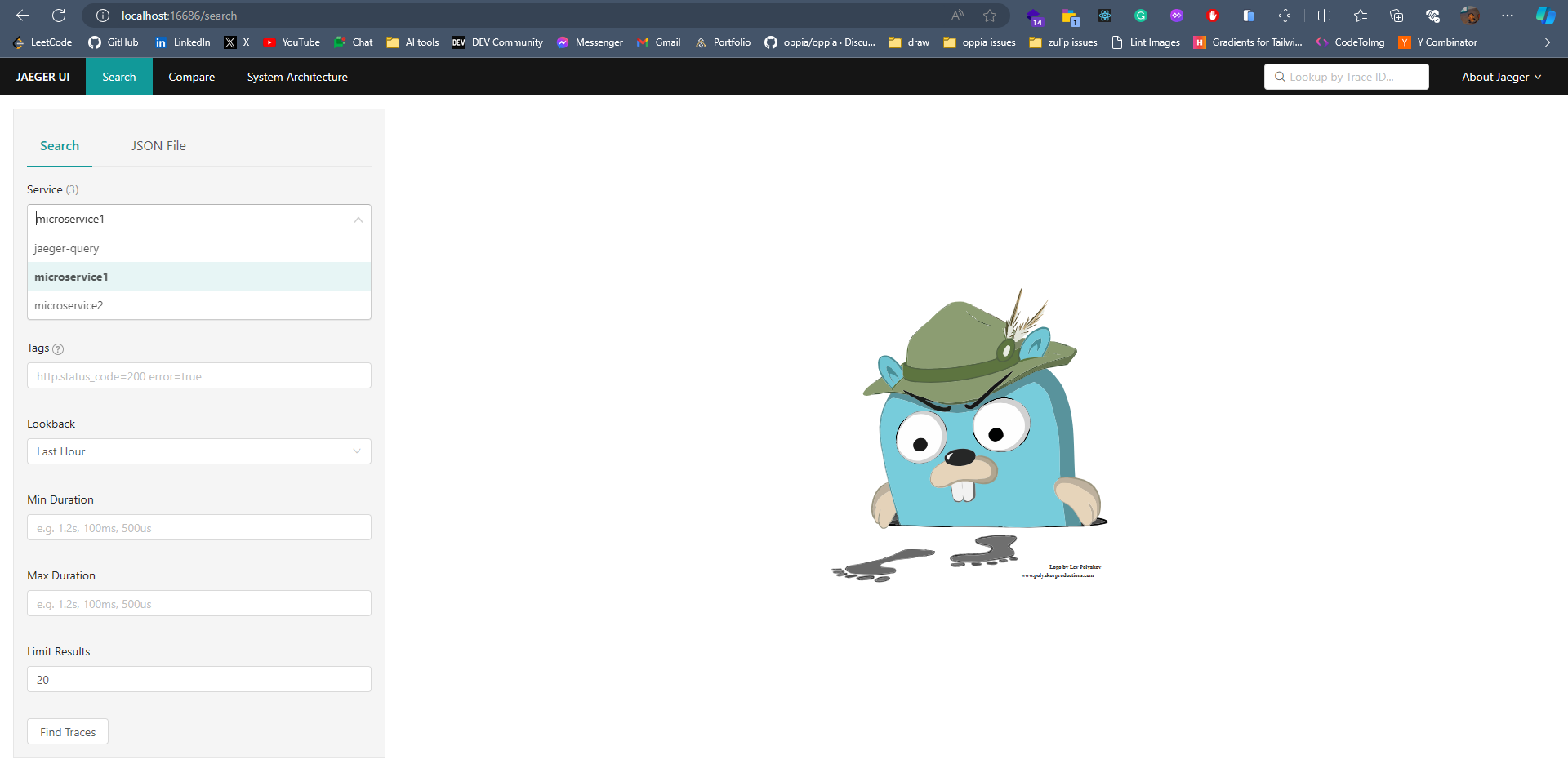 Odigos 已經開始向 Jaeger 發送我們的應用程式痕跡。 😉 請記住,這是我們的微服務應用程式。由於以「microservice1」為起點,因此再向「microservice1」發出一些請求,隨後它將向「microservice2」請求資料並傳回。最終,Jaeger 將開始填滿這些痕跡。 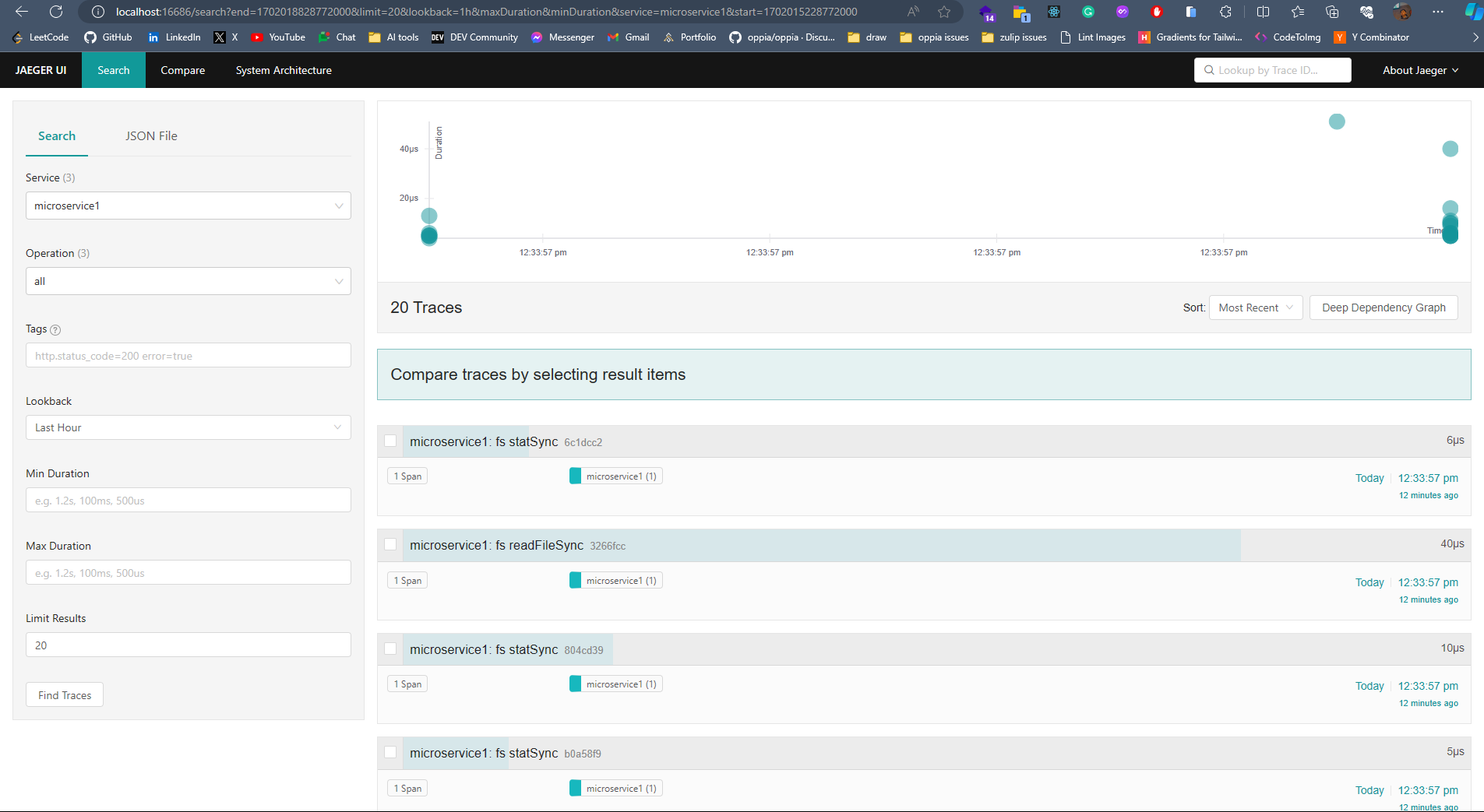 點擊任一請求,您應該能夠觀察請求如何流經您的應用程式以及完成每個請求所需的時間。 這一切都是在沒有更改一行程式碼的情況下完成的。 🤯 一切都感謝 **Odigos**! 🤩  想像一下,這只是一個很小的虛擬應用程式,但對於一個執行著大量微服務並相互交互的更大的應用程式來說,分散式追蹤將非常強大! 💪 透過分散式跟踪,您可以輕鬆辨識應用程式中的瓶頸,並確定哪個服務導致問題或花費更長的時間。 🕒 *** ## **讓我們總結一下! 🥱** 到目前為止,您已經學習如何使用 **Odigos** 作為應用程式和追蹤後端 **Jaeger** 之間的 **中間件**,透過分散式追蹤來密切監控 👀 Javascript 應用程式。 👏 如果您已經做到了這一步,請拍拍自己的背。 🥳你值得擁有! 😉 本教學的源程式碼可在此處取得: https://github.com/keyval-dev/blog/tree/main/odigos-monitor-JS-like-a-pro > 如果您對本文有任何疑問或建議,請在下面的評論部分分享。 👇🏻 那麼,這就是本文的內容。感謝您的閱讀! 🎉🫡 --- 原文出處:https://dev.to/odigos/monitor-your-javascript-application-like-a-pro-581p
假設你有一個段落。 ``` <p id="target">rainbow 🌈</p> ``` 你需要用JS改變它的顏色。你有什麼選擇? ## 1. 內聯樣式 最直接的路徑。從 DOM 查詢元素並變更其內聯樣式。 ``` document.getElementById('target').style.color = 'tomato'; ```  簡短而簡單。 ## 2. 全域樣式 另一種選擇是建立 `<style>` 標籤,用 CSS 規則填充它並將標籤附加到 DOM。 ``` var style = document.createElement('style'); style.innerHTML = ` #target { color: blueviolet; } `; document.head.appendChild(style); ``` 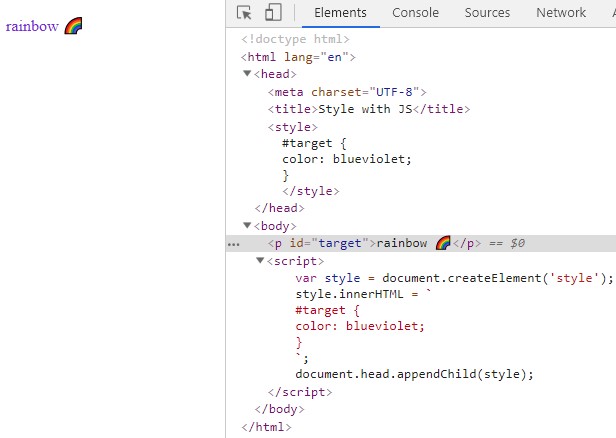 ## 3. CSSOM 插入規則 第三種選擇鮮為人知。我們將使用 [CSSStyleSheet](https://developer.mozilla.org/en-US/docs/Web/API/CSSStyleSheet) `insertRule` 方法。 ``` var style = document.createElement('style'); document.head.appendChild(style); style.sheet.insertRule('#target {color: darkseagreen}'); ``` 雖然它可能看起來與第二個選項相似,但它絕對不同。 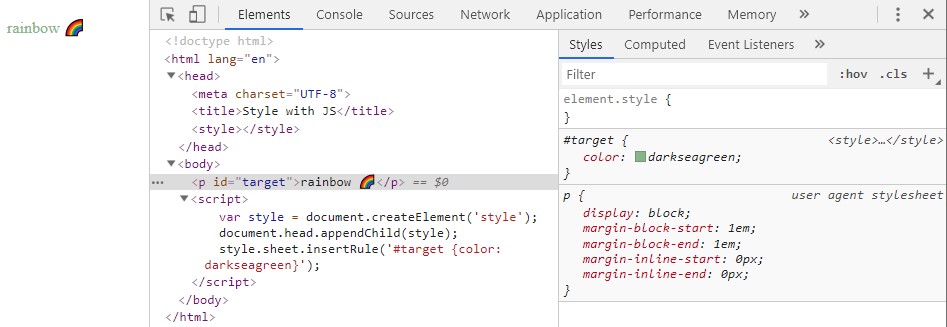 正如您在 Chrome 開發工具中看到的那樣,“<style>”標籤為空,但樣式(深海綠顏色)已應用於該元素。此外,顏色無法透過開發工具更改,因為 Chrome 不允許[編輯動態 CSS 樣式](https://bugs.chromium.org/p/chromium/issues/detail?id=387952)。 其實這樣的行為才是寫這篇文章的動機。由於性能原因,流行的 CSS-in-JS 庫 [Styled Components](https://www.styled-components.com/) 使用此功能在生產模式下注入樣式。在特定專案或環境中,此功能可能不受歡迎,有些人在專案問題中抱怨它。 ## 4.可建構樣式表(2019 年 7 月更新) 現在可以從 JavaScript 建立 `CSSStyleSheet` 物件。 ``` // Create our shared stylesheet: const sheet = new CSSStyleSheet(); sheet.replaceSync('#target {color: darkseagreen}'); // Apply the stylesheet to a document: document.adoptedStyleSheets = [sheet]; ``` 更多詳細資訊請參閱[此處](https://developers.google.com/web/updates/2019/02/constructable-stylesheets)。 此選項僅對 Chrome 有效,因此請謹慎使用。 您知道使用 javascript 新增樣式的其他選項嗎?這些天你的首選選擇是什麼? 謝謝閱讀! --- 原文出處:https://dev.to/karataev/set-css-styles-with-javascript-3nl5
碰巧有些 Linux 終端機命令很難記住,將它們作為備忘單保存在電腦或紙上是一個很好的做法。此列表並不詳盡,但包含最常用的命令。請隨意在下面的評論中加入您最常用的命令並分享此列表✌️。 ## 用戶 - **Id** – 有關使用者的詳細資訊(uid、gid 和群組)。 - **last** – 列出有關最近登入的訊息,包括時間、使用者名稱、IP 位址和會話持續時間。 - **who** – 顯示授權使用者。 - **groupadd "testgroup"** – 建立一個名為「testgroup」的群組。 - **adduser NewUser** – 新增名為「NewUser」的使用者。 - **userdel NewUser** – 刪除名為「NewUser」的使用者。 - **usermod NewUser** – 修改使用者「NewUser」的資訊。 ## 目錄導航 - **cd /**- 導覽至根目錄。 - **cd** - 導航到主目錄(使用 $HOME 變數)。 - **cd /root** - 導覽至 /root 目錄。 - **cd ..** - 向上移動一級。 - **cd /root/.ssh** - 導航到隱藏資料夾 .ssh。 ## 使用文件 - **ls -al** – 顯示目前資料夾中的檔案和目錄。 - **pwd** – 顯示目前工作目錄。 - **mkdir NewFolder** – 建立一個名為「NewFolder」的新目錄。 - **rm NewFile** – 刪除名為「NewFile」的檔案。 - **rm -f NewFile** – 強制刪除名為「NewFile」的檔案。 - **rm -r NewFolder** – 遞歸刪除名為「NewFolder」的目錄。 - **rm -rf NewFolder** – 強制遞歸刪除名為「NewFolder」的目錄。 - **cp oldfile1 newfile2** – 將「oldfile1」的內容複製到「newfile2」。 - **cp -r olddir1 newdir2** – 遞歸地將目錄「olddir1」複製到「newdir2」。如果 Dir2 不存在,則會建立它。 - **mv oldfile1 newfile2** – 將「oldfile1」重新命名為「newfile2」。 - **ln -s /etc/log/file logfile** – 建立到檔案的符號連結。 - **touch newfile** – 建立一個名為「newfile」的空白檔案。 - **cat > newfile** – 取得 STDIN 並將其放入「newfile」中。 - **head newfile** – 輸出檔案「newfile」的前 10 行。 - **tail newfile** – 輸出「newfile」的最後 10 行。 - **gpg -c newfile** – 使用密碼以 gpg 格式加密「newfile」並將其儲存在同一目錄中。 - **gpg newfile.gpg** – 解密 gpg 檔案。 - **wc newfile** – 顯示新檔案中的位元組數、字數和行數。 ## 檔案/目錄權限 - **chmod 777 /root/ssh** – 為有權存取伺服器的每個人(擁有者、群組、其他人)設定讀取、寫入和執行權限。 - **chmod 755 /root/ssh** – 將擁有者的權限配置為 rwx,將群組和其他人的權限配置為 r_x。 - **chmod 766 /root/ssh** – 設定擁有者的 rwx 以及群組和其他人的 rw。 - **chown newuser newfile** – 將 newfile 的擁有者改為 newuser。 - **chown newuser:newgroup newfile** – 將 newfile 的擁有者和群組擁有者變更為 newuser 和 newgroup。 - **chown newuser:newgroup newfolder** – 將目錄 newfolder 的擁有者和群組擁有者變更為 newuser 和 newgroup。 - **stat -c “%U %G” newfile** – 顯示 newfile 的使用者和群組擁有者。 ## 搜尋 - **grep searchargument newfile** – 在 newfile 中搜尋 searchargument。 - **grep -r searchargument newfolder** – 遞歸搜尋 newfolder 中所有檔案中的 searchargument。 - **定位新檔案** – 顯示新檔案的所有位置。 - **find /etc/ -name "searchargument"** – 在 /etc 目錄中尋找名稱以 searchargument 開頭的檔案。 - **find /etc/ -size +50000k** – 在 /etc 目錄中尋找大小大於 50000k 的檔案。 ## 檔案 - **tar -cf archive.tar newfile** – 從檔案「newfile」建立檔案「archive.tar」。 - **tar -xf archive.tar** – 提取檔案「archive.tar」的內容。 - **tar -zcvf archive.tar.gz /var/log/** – 從 /var/log/ 目錄建立檔案並使用 gzip 對其進行壓縮。 - **gzip newfile** – 壓縮新檔案(副檔名為 .gz)。 ## 從套件中安裝程式 - **rpm -i pkg_program.rpm** – 在 CentOS、RHEL 等上安裝 RPM 軟體包。 - **rpm -e pkg_name** – 刪除 CentOS、RHEL 等上的 RPM 軟體包。 - **dnf install pkg_name** – 在 CentOS、RHEL 等上使用 DNF 從儲存庫安裝軟體包。以前使用 YUM,但最近已被 DNF 取代。 - **dpkg -i pkg_name** – 從 Debian、Ubuntu、Mint 等上的 DEB 軟體包安裝。 - **dpkg -r pkg_name** – 刪除 Debian、Ubuntu、Mint 等上的 DEB 軟體包。 - **apt install pkg_name** – 在 Debian、Ubuntu、Mint 等上從儲存庫安裝軟體套件。 - **apt remove pkg_name** – 移除 Debian、Ubuntu、Mint 等上的軟體套件。 - **apt update && apt update** – 更新系統中的軟體包(Debian、Ubuntu、Mint 等)並更新儲存庫。 ## 流程 - **ps** – 顯示目前正在執行的進程。 - **ps aux | grep 'bash'** – 尋找 'bash' 的程序 ID (PID)。 - **pmap -x 11** – 在進程記憶體中映射 PID 11 的進程。 - **top** – 顯示所有正在執行的進程。 - **kill pid** – 透過 PID 終止進程。 - **killall process** – 終止名為「process」的所有程序。 - **pkill process-name** – 按名稱向程序發送訊號。 - **bg** – 將掛起的程序傳送到背景。 - **fg** – 將正在執行的進程帶到前台。 - **fg process** – 將名為「process」的進程帶到前台。 - **lsof** – 列出進程開啟的檔案。 - **renice 19 PID** – 設定進程的最低優先權。 - **pgrep bash** – 尋找「bash」的進程 ID。 - **pstree** – 顯示進程的樹狀表示。 ## 系統 - **uname** – 顯示系統資訊。 - **uname -r** – 顯示有關 Linux 核心的資訊。 - **hostname** – 顯示主機名稱。 - **hostname -i** – 顯示主機的 IP 位址。 - **date** – 顯示日期和時間。 - **timedatectl** – 輸出和修改日期和時間設定。 - **cal** – 顯示日曆。 - **w** – 顯示目前登入的使用者。 - **whoami** – 顯示您的使用者名稱。 - **finger root** – 顯示有關 root 使用者(需要使用「apt-get install Finger」的資訊進行安裝)。 ## 硬體指令 - **dmesg** – 在啟動期間顯示系統訊息。 - **cat /proc/cpuinfo** – 顯示有關處理器的資訊。 - **cat /proc/meminfo** – 顯示有關記憶體的資訊。 - **lshw** – 顯示有關裝置的詳細資訊。 - **lsblk** – 顯示有關區塊裝置的資訊。 - **free -m** – 釋放記憶體:RAM 和交換(切換 -m 表示 MB)。 - **lspci -tv** – 在樹狀圖視圖中顯示 PCI 裝置資訊。 - **lsusb -tv** – 在樹狀圖視圖中顯示 USB 裝置。 - **dmidecode** – 顯示有關 BIOS 設備的資訊。 - **hdparm -i /dev/xda** – 顯示有關磁碟的資訊。 - **hdparm -tT /dev/xda** – 顯示 xda 的讀寫速度。 - **badblocks -s /dev/xda** – 執行壞扇區測試。 ## 光碟管理指令 - **df -h** – 顯示已安裝分割區上的可用空間(以位元組為單位)。 - **df -i** – 顯示檔案系統中的空閒 inode。 - **fdisk -l** – 提供有關磁碟、分割區和檔案系統的資訊。 - **du -sh** – 顯示已安裝分割區上的未分配空間(以 MB、GB、TB 為單位)。 - **findmnt** – 顯示所有安裝點。 - **mount /dev/sdb1 /mnt** – 將 sdb 磁碟的分割區 1 掛載到 /mnt 目錄。 ## 網絡 - **ip addr show** – 顯示所有可用網路介面的 IP 位址。 - **ip address add 192.168.0.1/24 dev eth0** – 將位址 192.168.0.1 指派給 eth0 介面。 - **ifconfig** – 顯示所有可用網路介面的 IP 位址。 - **ping 192.168.0.1** – 發送 ICMP 協定請求以連接到 192.168.0.1 處的節點。 - **whois 網域** – 顯示有關網域的資訊。 - **dig 網域 **– 檢索有關網域的 DNS 資訊。 - **dig -x 192.168.0.1 ** – 執行反向 DNS 解析。 - **host serverspace.us** – 解析主機位址。 - **hostname -I ** – 顯示本機位址。 - **wget file_name(連結到檔案)** – 下載檔案。 - **netstat -pnltu ** – 顯示主機上正在偵聽的所有連接埠(需要「apt-get install net-tools」)。 ## 遠端連線 - **ssh root@host** – 以 root 使用者身分透過 ssh 連線到遠端主機。 - **ssh -p port_number user@host** – 使用非預設 ssh 連接埠連接到遠端主機,指定使用者。 - **ssh host** – 使用目前使用者的預設連線。 - **telnet host** – 使用 telnet 連線(連接埠 23)。 --- 原文出處:https://dev.to/serverspace/linux-commands-cheat-sheet-aif
歡迎來到我的 HTML can do 這個系列,第 1 部分。 為了與我的[GitHub-Can-Do-This](https://dev.to/yuridevat/reference-a-new-issue-3g5h) 系列保持一致,今天我想寫一篇關於HTML 可以做的很酷的事情的文章(很多人顯然不知道)。 我堅信,越多的人理解 HTML 並充分利用它,網路就會自動變得更容易存取。 ## 表中的內容 1. [詳細資訊和摘要 HTML 標籤](#chapter-1) 2. [電子郵件或電話號碼連結](#chapter-2) 3. [自動完成清單](#chapter-3) 4. [文字修改](#chapter-4) --- 由於我不知道接下來還會有多少部分,因此我將透過按字母順序描述出色的標籤及其背後的 HTML 魔力來開始本系列。 ## 1. 詳細資訊和摘要<a name="chapter-1"></a> 開啟/關閉小部件通常使用 JavaScript 建立。很長一段時間以來,有一個預設的 HTML 標籤恰好涵蓋了這種行為。 樣式可以根據需要進行調整。預設情況下,該小部件是關閉的。賦予 `<details>` 屬性 `open`,它會從頭開始顯示其內容。 {% codepen https://codepen.io/YuriDevAT/pen/dyaBQZm %} ## 2. 連結到電子郵件地址或電話號碼<a name="chapter-2"></a> `<a>` 標籤有一個 `href` 屬性,它指示連結的目的地。它可以連結到網頁、文件、電子郵件地址、同一頁面中的位置或 URL 可以尋址的任何其他內容。 `href` 屬性負責使 `<a>` 可聚焦並在按 Enter 鍵時啟動連結。 ### 連結到電子郵件地址 如果您在「href」的 URL 方案中新增「mailto:」和預期收件者的電子郵件地址,則按一下時會開啟新的外寄電子郵件。 ``` <a href="mailto:[email protected]">Send email to nowhere</a> ``` 您還可以在 URL 中加入更多詳細訊息,包括抄送、密件副本、主題和正文 😯。 ``` <a href="mailto:[email protected][email protected]&subject=This%20is%20the%20subject">Send email with subject to nowhere and nobody</a> ``` 詳細了解[連結至電子郵件地址 rfc6068](https://datatracker.ietf.org/doc/html/rfc6068)。 ### 連結到電話號碼 將電話號碼新增至「tel:」之後的「href」時,您也可以連結到電話號碼。 ``` <a href="tel:+18005551239">(800) 555 1239</a> ``` 連結行為可能因設備而異([關於連結到電話號碼的 MDN 官方文件](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/a#linking_to_telephone_numbers)): - 在行動裝置上,系統會自動撥打號碼。 - 大多數作業系統都有可以撥打電話的程序,例如 Skype 或 FaceTime。 - 網站可以使用registerProtocolHandler撥打電話,例如web.skype.com。 - 其他行為包括將號碼儲存到聯絡人,或將號碼傳送到另一台裝置。 詳細了解[連結到電話號碼 rfc3966](https://datatracker.ietf.org/doc/html/rfc3966)。 {% codepen https://codepen.io/YuriDevAT/pen/OJdZLKK %} ## 3. 自動完成清單<a name="chapter-3"></a> 使用“<datalist>”,當使用者開始在輸入欄位中寫入時會出現一個下拉式選單,並使他們可以從清單中的可用選項中進行選擇。 {% codepen https://codepen.io/YuriDevAT/pen/zYeVMbE %} ## 4. 文字修改<a name="chapter-4"></a> 使用特定標籤,可以直接修改文本,無需額外的 CSS。非常便利。 {% codepen https://codepen.io/YuriDevAT/pen/LYqKXwJ %} --- 謝謝閱讀。對此,我真的非常感激! --- 原文出處:https://dev.to/yuridevat/html-can-do-this-part-1-3ab2
## 第 1 部分:將 MongoDB 與 Flask 結合使用 你好!在本系列的最後一個[部分](https://dev.to/paurakhsharma/flask-rest-api-part-0-setup-basic-crud-api-4650)中,我們學習瞭如何建立基本的“ CRUD” ` 使用 python `list` 的 REST API 功能。但這不是現實世界應用程式的建構方式,因為如果您的伺服器重新啟動或上帝禁止崩潰,那麼您將丟失伺服器中儲存的所有資訊。為了解決這些問題(以及許多其他問題),使用了資料庫。所以,這就是我們要做的。我們將使用 [MongoDB](https://docs.mongodb.com/manual/) 作為我們的資料庫。 如果您剛從這部分開始,您可以在[此處]找到我們迄今為止編寫的所有程式碼(https://github.com/paurakhsharma/flask-rest-api-blog-series/tree/master/Part% 20 -%200)。 在開始之前,請確保您已在系統中安裝了 MongoDB。如果您還沒有安裝,可以安裝 [Linux](https://docs.mongodb.com/manual/administration/install-on-linux/)、[Windown](https://docs.mongodb.com/手冊/教學/install-mongodb-on-windows/)和[macOS](https://docs.mongodb.com/manual/tutorial/install-mongodb-on-os-x/)。 主要有一些流行的函式庫可以讓 MongoDB 的使用變得更容易: 1) [Pymongo](https://api.mongodb.com/python/current/) 是 MongoDB 的低階 Python 包裝器,使用 `Pymongo` 類似於直接編寫 MongoDB 查詢。 以下是使用“Pymongo”更新“id”與給定“id”相符的電影名稱的簡單範例。 ``` db['movies'].update({'_id': id}, {'$set': {'name': 'My new title'}}) ``` `Pymongo` 不使用任何預先定義的模式,因此它可以充分利用 MongoDB 的無模式特性。 2) [MongoEngine](http://docs.mongoengine.org/) 是物件文件映射器,它使用文件模式,使 MongoDB 的使用變得清晰、更容易。 這是使用“mongoengine”的相同範例。 ``` Movies.objects(id=id).update(name='My new title') ``` 「Mongoengine」對資料庫中的欄位使用預先定義架構,這限制了它使用 MongoDB 的無架構性質。 正如我們所看到的,雙方都有各自的優點和缺點。因此,請選擇最適合您的專案的一種。在本系列中,我們將學習“Mongoengine”,如果您希望我也介紹“Pymongo”,請在下面的評論部分告訴我。 為了在我們的`Flask` 應用程式中更好地使用`Mongoengine`,有一個很棒的`Flask` 擴展,名為[Flask-Mongengine](http://docs.mongoengine.org/projects/flask- mongoengine/en/latest/)。 那麼,讓我們開始安裝「flask-mongoengine」。 ``` pipenv install flask-mongoengine ``` *注意:由於`flask-mongoengine` 是在`mongoengine` 之上建造的,所以在安裝Flask-mongoengine 時會自動安裝,而且`mongoengine` 是在`pymongo` 之上建造的,所以它也會被安裝* 現在,讓我們在「movie-bag」中建立一個新資料夾。我將其稱為“資料庫”。在「database」資料夾中建立一個名為「db.py」的檔案。另外,建立另一個檔案並將其命名為“models.py” 讓我們看看文件/資料夾現在是什麼樣子。 ``` movie-bag │ app.py | Pipfile | Pipfile.lock └───database │ db.py └───models.py ``` 現在,讓我們深入探討有趣的部分。 首先,讓我們透過將以下程式碼新增至「db.py」來初始化我們的資料庫 ``` #~movie-bag/database/db.py from flask_mongoengine import MongoEngine db = MongoEngine() def initialize_db(app): db.init_app(app) ``` 在這裡,我們導入了“MongoEngine”並建立了“db”物件,並定義了一個函數“initialize_db()”,我們將從“app.py”中呼叫該函數來初始化資料庫。 讓我們在“models”目錄中的“movie.py”中編寫以下程式碼 ``` #~movie-bag/database/models.py from .db import db class Movie(db.Document): name = db.StringField(required=True, unique=True) casts = db.ListField(db.StringField(), required=True) genres = db.ListField(db.StringField(), required=True) ``` 我們剛剛建立的是資料庫的文件。因此,使用者無法新增此處定義的其他欄位。 這裡我們可以看到「Movie」文件有三個欄位: 1)`name`:是一個`String`類型的字段,我們在這個字段上也有兩個約束。 - “必需”,這意味著用戶在不提供標題的情況下無法建立新電影。 - “唯一”,這意味著電影名稱必須是唯一的,不能重複。 2) `casts`:是一個`list`類型的字段,其中包含`String`類型的值 3) `genres`: 與`casts`相同 最後,我們可以在「app.py」中初始化資料庫,並更改「view」函數(處理 API 請求的函數)以使用我們先前定義的「Movie」文件。 ``` #~movie-bag/app.py -from flask import Flask, jsonify, request +from flask import Flask, request, Response +from database.db import initialize_db +from database.models import Movie app = Flask(__name__) -movies = [ - { - "name": "The Shawshank Redemption", - "casts": ["Tim Robbins", "Morgan Freeman", "Bob Gunton", "William Sadler"], - "genres": ["Drama"] - }, - { - "name": "The Godfather ", - "casts": ["Marlon Brando", "Al Pacino", "James Caan", "Diane Keaton"], - "genres": ["Crime", "Drama"] - } -] +app.config['MONGODB_SETTINGS'] = { + 'host': 'mongodb://localhost/movie-bag' +} + +initialize_db(app) [email protected]('/movies') -def hello(): - return jsonify(movies) [email protected]('/movies') +def get_movies(): + movies = Movie.objects().to_json() + return Response(movies, mimetype="application/json", status=200) [email protected]('/movies', methods=['POST']) -def add_movie(): - movie = request.get_json() - movies.append(movie) - return {'id': len(movies)}, 200 [email protected]('/movies', methods=['POST']) + body = request.get_json() + movie = Movie(**body).save() + id = movie.id + return {'id': str(id)}, 200 [email protected]('/movies/<int:index>', methods=['PUT']) -def update_movie(index): - movie = request.get_json() - movies[index] = movie - return jsonify(movies[index]), 200 [email protected]('/movies/<id>', methods=['PUT']) +def update_movie(id): + body = request.get_json() + Movie.objects.get(id=id).update(**body) + return '', 200 [email protected]('/movies/<int:index>', methods=['DELETE']) -def delete_movie(index): - movies.pop(index) - return 'None', 200 [email protected]('/movies/<id>', methods=['DELETE']) +def delete_movie(id): + Movie.objects.get(id=id).delete() + return '', 200 app.run() ``` 哇!變化很多,讓我們一步一步地進行變化。 ``` -from flask import Flask, jsonify, request +from flask import Flask, request, Response +from database.db import initialize_db +from database.models.movie import Movie ``` 這裡我們刪除了“jsonify”,因為我們不再需要,並加入了“Response”,我們用它來設定回應的類型。然後我們從之前定義的「db.py」導入「initialize_db」來初始化資料庫。最後,我們從“movie.py”導入“Movie”文件 ``` +app.config['MONGODB_SETTINGS'] = { + 'host': 'mongodb://localhost/movie-bag' +} + +db = initialize_db(app) ``` 這裡我們設定 mongodb 資料庫的配置。這裡主機的格式為「<host-url>/<database-name>」。由於我們已經在本地安裝了 mongodb,因此我們可以從“mongodb://localhost/”存取它,並且我們將資料庫命名為“movie-bag”。 最後,我們初始化資料庫。 ``` [email protected]('/movies') +def get_movies(): + movies = Movie.objects().to_json() + return Response(movies, mimetype="application/json", status=200) + ``` 在這裡,我們使用“Movies.objects()”從“Movie”文件中獲取所有物件,並使用“to_json()”將它們轉換為“JSON”。最後,我們傳回一個「Response」物件,其中我們將回應類型定義為「application/json」。 ``` [email protected]('/movies', methods=['POST']) + body = request.get_json() + movie = Movie(**body).save() + id = movie.id + return {'id': str(id)}, 200 ``` 在「POST」請求中,我們首先取得發送的「JSON」和一個請求。然後我們使用“Movie(**body)”請求中的欄位來載入“Movie”文件。這裡的「**」稱為擴充運算符,在 JavaScript 中寫為「...」(如果您熟悉的話)。顧名思義,它的作用是傳播「dict」物件。 <br/> 所以,`Movie(**body)` 變成了 ``` Movie(name="Name of the movie", casts=["a caste"], genres=["a genre"]) ``` 最後,我們保存文件並獲取其“id”,我們將其作為回應返回。 ``` [email protected]('/movies/<id>', methods=['PUT']) +def update_movie(id): + body = request.get_json() + Movie.objects.get(id=id).update(**body) + return '', 200 ``` 這裡我們先找到與請求中發送的「id」相符的Movie文件,然後更新它。這裡我們也應用了擴充運算子將值傳遞給「update()」函數。 ``` [email protected]('/movies/<id>', methods=['DELETE']) +def delete_movie(id): + Movie.objects.get(id=id).delete() + return '', 200 ``` 與此處的“update_movie()”類似,我們獲取與給定“id”匹配的電影文件並將其從資料庫中刪除。 哦,**我剛剛想起來**,我們還沒有將 API 端點加入到“GET”,僅從我們的伺服器獲取一個文件。 讓我們加入它: 在 `app.run()` 上方加入以下程式碼 ``` @app.route('/movies/<id>') def get_movie(id): movies = Movie.objects.get(id=id).to_json() return Response(movies, mimetype="application/json", status=200) ``` 現在您可以從 API 端點「/movies/<valid_id>」取得單一影片。 要執行伺服器,請確保您位於“movie-bag”目錄。 然後執行 ``` pipenv shell python app.py ``` 在終端機中啟動虛擬環境並啟動伺服器。 哇!恭喜您已經走到這一步了。要測試API,請使用我們在[上一篇]((https://dev.to/paurakhsharma/flask-rest-api-part-0-setup-basic-crud-api-4650)) 中使用的“ Postman」本系列的一部分。 您可能已經注意到,如果我們向端點發送無效資料,例如:沒有名稱或其他字段,我們會收到“HTML”形式的不友善錯誤。如果我們嘗試取得資料庫中不存在的「id」影片文件,那麼我們也會收到「HTML」回應形式的不友善錯誤。這並不是一個精心建構的 API 的例外行為。我們將在本系列的後面部分中了解如何處理此類錯誤。 ### 我們從本系列的這一部分學到了什麼? - `Pymongo` 和 `Mongoengine` 之間的差異。 - 如何使用「Mongoengine」建立文件架構。 - 如何使用「Mongoengine」執行「CRUD」操作。 - Python 擴充運算子。 您可以在[此處]找到這部分的完整程式碼(https://github.com/paurakhsharma/flask-rest-api-blog-series/tree/master/Part%20-%201) 在下一部分中,我們將學習如何使用「Blueprint」來更好地建立 Flask 應用程式。以及如何使用“flask-restful”以最少的設定遵循最佳實踐,更快地建立 REST API 直到那時快樂編碼😊 --- 原文出處:https://dev.to/paurakhsharma/flask-rest-api-part-1-using-mongodb-with-flask-3g7d
我們正在開發一個 [React 和 Node.js 的全端 Web 框架](https://github.com/wasp-lang/wasp),它使用簡單的設定語言來擺脫樣板檔案。很多次,我們被問到,*「為什麼你要費心去建立一個新的 Web 應用程式開發框架?無論如何,ChatGPT / LLM X 不是很快就會為開發人員生成所有程式碼嗎?」*。 這是我們對當前情勢的看法,也是我們相信未來的情況。 ## 為什麼我們需要(AI)程式碼產生? 為了讓開發速度更快,我們首先提出了 IDE 自動補全 - 如果您正在使用 React 並開始輸入 `use`,IDE 將自動向 `useState()` 或 `useEffect()` 提供補全。除了節省擊鍵次數之外,也許更有價值的是能夠查看目前範圍內有哪些方法/屬性可供我們使用。 IDE 對專案結構和程式碼層次結構的感知也使重構變得更加容易。 **雖然這已經很棒了,但是我們如何將其提升到一個新的水平?** 傳統的 IDE 支援是基於人類編寫的規則,例如,如果我們想讓 IDE 能夠為我們實現常用功能(例如, *使用API Y* 取得X,或*實現快速排序*),其中的數量太多,無法手動進行分類和維護。 如果有一種方法可以讓電腦分析我們迄今為止編寫的所有程式碼,並自行學習如何自動完成我們的程式碼以及如何對待人類,而不是我們做所有艱苦的工作... [除了美味又濕潤的蛋糕](https://www.youtube.com/watch?v=Y6ljFaKRTrI),我們其實已經做到了!由於機器學習的最新進展,IDE 現在可以做一些非常酷的事情,例如根據函數的名稱和頂部的簡短註釋來建議函數的完整實現: 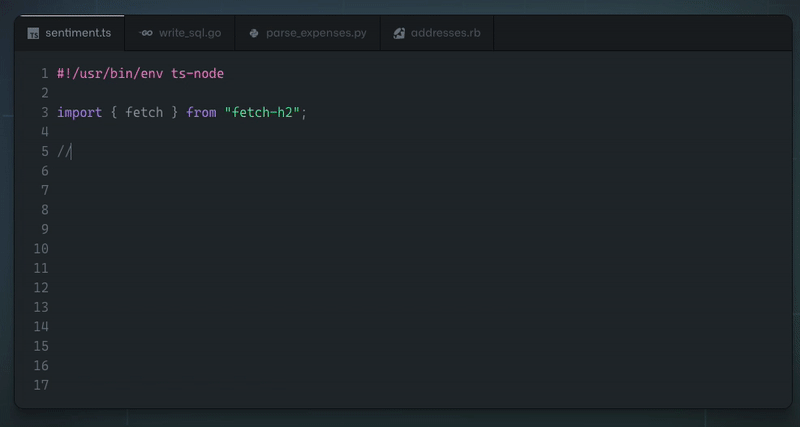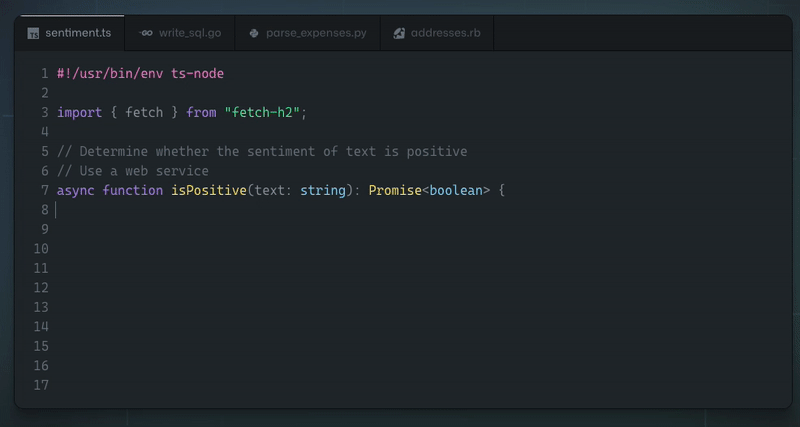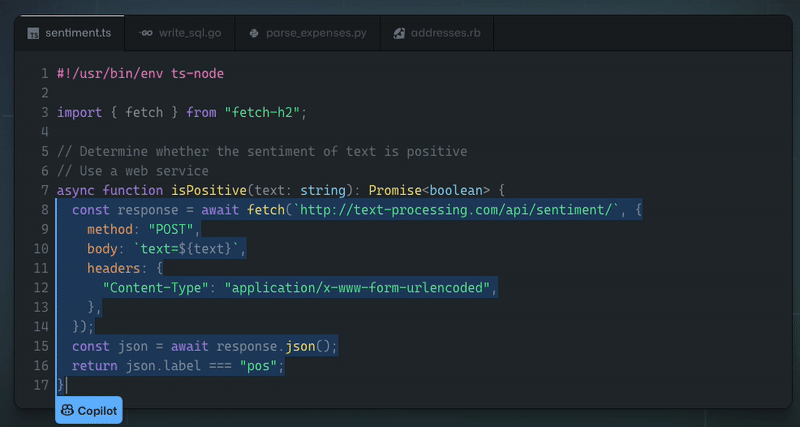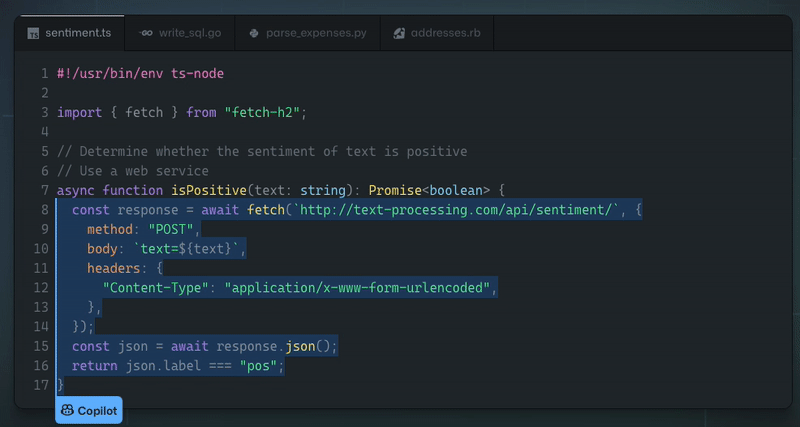 這真是太神奇了!上面的範例由 [Github Copilot](https://copilot.github.com/) 提供支援 - 它本質上是一個在大量公開可用程式碼上訓練的神經網路。我不會深入了解其幕後工作原理的技術細節,但有很多精彩的文章和影片涵蓋了背後的科學知識。 **看到這一點,問題出現了 - 這對程式設計的未來意味著什麼?** 這只是 IDE 自動補全功能還是其他什麼?如果我們只需在註釋中輸入我們想要的內容就可以了,我們還需要繼續手動編寫程式碼嗎? ## 支持我們! 🙏⭐️  如果您想表達對我們正在做的事情的支持,請考慮[在 Github 上給我們一顆星](https://github.com/wasp-lang/wasp)!我們在 Wasp 所做的一切都是開源的,您的支持激勵我們並幫助我們不斷簡化 Web 應用程式開發並減少樣板程式碼。  ## 大問題:程式碼產生後由誰維護? 在思考 ML 程式碼產生如何影響整個開發過程時,有一點需要考慮,但在查看所有令人印象深刻的範例時,通常不會立即想到這一點。 問題是 - **生成程式碼後會發生什麼?誰負責,將來誰來維護和重構?**  儘管 ML 程式碼產生有助於編寫特定功能的初始程式碼,但它不能做更多的事情 - 如果將來要維護和更改該程式碼(如果有人使用該產品,那麼開發人員仍然會這樣做)需要完全擁有並理解它。你可以再次使用人工智慧來幫助你,但最終,你是負責的人。 想像一下,我們擁有的只是一種彙編語言,但程式碼生成非常適合它,你可以說“實現一個對陣列進行升序排序的函數”,它將完美地生成所需的程式碼。一旦您需要將排序更改為降序,您是否仍想在將來返回該功能? 或者,更貼近我們的日常生活,如果產生的 React 程式碼使用舊的類別語法,或者函數式元件和鉤子,對你來說是否都是一樣的? **換句話說,這意味著GPT 和其他LLM 不會降低程式碼複雜性,也不會降低建置功能所需的知識量**,它們只是幫助更快地編寫初始程式碼並使知識/範例更接近程式碼(其中真的很有幫助)。 **如果開發人員盲目接受生成的程式碼,他們只是在創造技術債並推動其向前發展**。 ## 認識大 A - 抽象 👆 如果 ChatGPT 和這群人無法解決我們學習如何編碼和詳細理解(例如透過 JWT 進行會話管理)工作原理的所有麻煩,還有什麼可以呢? 抽象化——這就是程式設計師幾十年來透過建立庫、框架和語言來處理程式碼重複和降低複雜性的方式。這就是我們從普通 JS 和直接 DOM 操作到 jQuery,最後到 React 和 Vue 等 UI 函式庫的方式。 引入抽像不可避免地意味著放棄一定的功能和靈活性(例如,在 Python 中對數字求和時,您無法準確指定將使用哪些 CPU 寄存器),但重點是,如果如果做得好,在大多數情況下你不需要也不想要這樣的權力。  **不對一段程式碼負責的唯一方法是它從一開始就不存在。** 因為一旦螢幕上的像素改變顏色,你就必須擔心,這就是為什麼所有框架、語言等的主要好處是_更少的程式碼==更少的決策==更少的責任_。 擁有更少程式碼的唯一方法是做出更少的決定,並向計算機提供更少的關於如何完成某項任務的細節- 理想情況下,我們只需要說明我們想要什麼,我們甚至不會關心它是如何完成的,只要它在我們擁有的時間/記憶體/成本邊界內(所以我們可能也需要說明這些)。 讓我們來看看網路應用程式世界中非常常見(也是每個人最喜歡的)功能 - 身份驗證(yaay ☠️ 🔫)!它的典型程式碼如下所示: ``` import jwt from 'jsonwebtoken' import SecurePassword from 'secure-password' import util from 'util' import prisma from '../dbClient.js' import { handleRejection } from '../utils.js' import config from '../config.js' const jwtSign = util.promisify(jwt.sign) const jwtVerify = util.promisify(jwt.verify) const JWT_SECRET = config.auth.jwtSecret export const sign = (id, options) => jwtSign({ id }, JWT_SECRET, options) export const verify = (token) => jwtVerify(token, JWT_SECRET) const auth = handleRejection(async (req, res, next) => { const authHeader = req.get('Authorization') if (!authHeader) { return next() } if (authHeader.startsWith('Bearer ')) { const token = authHeader.substring(7, authHeader.length) let userIdFromToken try { userIdFromToken = (await verify(token)).id } catch (error) { if (['TokenExpiredError', 'JsonWebTokenError', 'NotBeforeError'].includes(error.name)) { return res.status(401).send() } else { throw error } } const user = await prisma.user.findUnique({ where: { id: userIdFromToken } }) if (!user) { return res.status(401).send() } const { password, ...userView } = user req.user = userView } else { return res.status(401).send() } next() }) const SP = new SecurePassword() export const hashPassword = async (password) => { const hashedPwdBuffer = await SP.hash(Buffer.from(password)) return hashedPwdBuffer.toString("base64") } export const verifyPassword = async (hashedPassword, password) => { try { return await SP.verify(Buffer.from(password), Buffer.from(hashedPassword, "base64")) } catch (error) { console.error(error) return false } } ``` 這只是後端程式碼的一部分(僅適用於用戶名和密碼方法)!正如您所看到的,我們在這裡有很大的靈活性,可以執行/指定以下操作: - 選擇身份驗證的實作方法(例如會話或基於 JWT) - 選擇我們想要用於令牌(如果使用 JWT)和密碼管理的確切 npm 套件 - 解析 auth 標頭並指定每個值(授權、承載等)如何回應 - 為每個可能的結果選擇回傳程式碼(例如 401、403) - 選擇密碼的解碼/編碼方式 (base64) 一方面,在我們的程式碼中擁有這種程度的控制和靈活性確實很酷,但另一方面,需要做出很多決定(==錯誤),特別是對於像身份驗證這樣常見的事情! 如果後來有人問“_那麼你到底為什麼選擇secure-password npm 包,或者為什麼到底是base64 編碼?_”,我們可能應該用其他東西來回答,而不是“_好吧,2012 年有一篇看起來相當合法的帖子,它有近 50 票贊成。嗯,不過現在找不到了。另外,它的名字裡有‘安全’,聽起來不錯,對吧?_” 另一件要記住的事情是,我們還應該追蹤事情如何隨著時間的推移而變化,並確保幾年後,我們仍然使用最佳實踐,並且軟體包定期更新。 如果我們嘗試應用上面的原則(更少的程式碼,更少的詳細說明,說明我們想要什麼**而不是需要做什麼**),身份驗證的程式碼可能如下所示: ``` auth: { userEntity: User, externalAuthEntity: SocialLogin, methods: { usernameAndPassword: {}, google: {} }, onAuthFailedRedirectTo: "/login", onAuthSucceededRedirectTo: "/dashboard" } ``` 基於此,計算機/編譯器可以處理上面提到的所有內容,然後根據抽象級別,提供某種接口(例如表單元件或函數)來“掛鉤”我們自己的接口,例如React/Node.js 程式碼(順便說一句,這就是它實際上[在 Wasp 中工作](https://wasp-lang.dev/docs/auth/overview) 的方式)。 我們不需要關心底層使用了什麼確切的套件或加密方法 - 這是我們信任抽象層的作者和維護者的責任,就像我們相信 Python 最了解如何將兩個數字相加一樣裝配水平,並與該領域的最新進展保持同步。當我們依賴內建資料結構或依靠垃圾收集器來很好地管理程式記憶體時,也會發生同樣的情況。 ## 但是我產生的漂亮程式碼😿💻!那麼會發生什麼事呢? 別擔心,一切都還在這裡,您可以產生您想要的所有程式碼!這裡要理解的要點是,人工智慧程式碼生成和框架/語言開發是相互補充而不是替代,並且將繼續存在,這最終對開發人員社群來說是一個巨大的勝利——它們將繼續讓我們的生活更輕鬆,讓我們能夠做更多有趣的事情(而不是第 n 次實作 auth 或 CRUD API)! 我將這裡的演變視為一個循環(或實際上是螺旋式上升,但這超出了我的繪圖能力): 1. **語言/框架:存在**,是主流,很多人使用它 2. **模式開始出現**(例如實作身份驗證,或進行 API 呼叫)→ AI 學習它們,透過自動完成提供 3. **其中一些模式成熟**並變得穩定→抽象的候選者 4. **新的、更抽象的語言/框架**出現 5. **返回步驟 1。**  ## 結論 這意味著我們雙贏——當語言成為主流時,我們可以從人工智慧驅動的程式碼產生中受益,幫助我們更快地編寫程式碼。另一方面,當我們不想重複/處理的程式碼模式出現並變得穩定時,我們就得到了一種全新的語言或框架,它允許我們編寫更少的程式碼並關心更少的實作細節!  感謝您的閱讀,並希望您發現這篇文章內容豐富!我很想聽聽您是否同意(或不同意)這一點,以及您如何看待人工智慧工具驅動的程式設計的未來。 --- 原文出處:https://dev.to/wasp/ai-code-generation-vs-coding-by-hand-what-programming-is-going-to-look-like-in-202x-1idh
這是[使用 Express、Sequelize 和 Postgres 建立 API](https://www.oriechinedu.com/posts/performing-crud-with-sequelize/) 的第三部分。在[第二部分](https://www.oriechinedu.com/posts/performing-crud-with-sequelize/)中,我們建立了簡單的API端點來示範Sequelize中的CRUD操作。在本文中,我們將重點放在為第二部分中建立的 API 端點編寫端到端測試。 ### 術語解釋 - **端對端測試** - 一種測試類型,用於測試應用程式從開始到結束的流程是否如預期運作。這也稱為功能測試。此類測試的一個範例是測試端點或路由,其中涉及測試端點工作所需的所有內容,例如資料庫連接、依賴項等。 - **測試執行器** - 在給定目錄或檔案中取得原始程式碼(測試)、執行測試並將結果寫入控制台或任何指定位置的程式庫或工具,例如 Jest、Mocha。 - **Jest** - [Jest](https://jestjs.io/) 是 Facebook 開發的 JavaScript 測試框架。它以最少的配置開箱即用,並具有內建的測試執行器、斷言庫和模擬支援。 - [**Supertest**](https://www.npmjs.com/package/supertest) - 用於測試 Node.js HTTP 伺服器的函式庫。它使我們能夠以程式設計方式向 HTTP 伺服器發送 HTTP 請求(例如 GET、POST、PATCH、PUT、DELETE)並獲取結果。 現在我們已經解釋了基本術語,讓我們深入了解主要業務。 如果您一直按照先前的[文章](https://www.oriechinedu.com/posts/performing-crud-with-sequelize/)進行操作,那麼請在您最喜歡的文字編輯器中開啟它,否則克隆使用的儲存庫[此處](https://github.com/oriechinedu/sequelize-with-postgres-tutorial)。 **第 1 步 - 安裝 Jest 和 supertest** 打開終端機並“cd”到專案根目錄並執行以下命令: ``` npm install --save-dev jest supertest ``` **步驟 2 - 設定 Jest** 打開“package.json”並將以下程式碼新增至其中。 ``` "jest": { "testEnvironment": "node", "coveragePathIgnorePatterns": [ "/node_modules/" ] }, ``` 這是我們測試 API 時需要設定 jest 的基本配置。您希望 `jest` 忽略的任何檔案都放置在 `"coveragePathIgnorePatterns"` 內。 `"coveragePathIgnorePatterns"` 指定一個與要排除的目錄相符的正規表示式,在我們的例子中,我們希望它忽略 `node_modules` 目錄。 接下來我們新增“test”腳本。在 `package.json` 的 `scripts` 部分中,加入以下腳本: ``` "test": "jest" ``` **步驟 3 - 測試配置** 現在,讓我們確認「jest」已準備好執行我們的測試。在終端機中執行“npm test”。您會注意到控制台上列印如下所示的錯誤,這表示「jest」已設定。  讓我們新增一個簡單的測試來驗證配置。建立一個名為「tests」的新目錄並新增一個新檔案「sample.test.js」。在「sample.test.js」中,加入以下程式碼: ``` describe('Sample Test', () => { it('should test that true === true', () => { expect(true).toBe(true) }) }) ``` 現在,執行“npm test”,您將得到如下所示的輸出:  ##### Jest 如何辨識測試檔? Jest 以三種方式辨識測試文件: - 副檔名為「.test.js」的文件 - 副檔名為「.spec.js」的文件 - `__tests__` 資料夾或目錄中的所有檔案。 ## 測試 API 端點 現在我們已經設定了測試環境,是時候開始測試 API 端點了。由於我們的端點需要向資料庫發出請求,因此我們需要設定一個測試資料庫。設定測試資料庫的原因是每次執行測試時我們都會刪除該資料庫。每次執行測試時刪除資料庫可確保測試的完整性。也就是說,如果一個測試是在資料庫中建立一個「post」記錄,我們要確保在測試執行之前資料庫中沒有「post」記錄,這樣,我們就可以確定得到的結果從測試中。 **第 4 步 - 建立測試資料庫** 在本文的[第一部分](https://www.oriechinedu.com/posts/getting-started-with-sequelize-and-postgres/)中,我們建立了兩個資料庫,一個用於開發,另一個用於測試。如果您尚未建立測試資料庫,請依照[連結](https://www.oriechinedu.com/posts/getting-started-with-sequelize-and-postgres/)建立測試資料庫。 **步驟 5 - 設定測試腳本** 我們需要以下腳本: - `pretest` - `pretest` 是一個 npm 腳本,當呼叫 `npm test` 指令時會自動呼叫。我們將掛接命令來更改環境以進行測試,並在每次測試執行之前刷新資料庫。 - `migrate:reset`:此命令將負責在每次測試執行之前刷新資料庫。 現在編輯“package.json”的“scripts”,如下所示: ``` "scripts": { "start-dev": "nodemon index.js", "migrate": "npx sequelize-cli db:migrate", "migrate:reset": "npx sequelize-cli db:migrate:undo:all && npm run migrate", "test": "cross-env NODE_ENV=test jest --testTimeout=10000", "pretest": "cross-env NODE_ENV=test npm run migrate:reset" } ``` 腳本修改需要注意的地方: - [`cross-env`](https://www.npmjs.com/package/cross-env) - 用於設定環境變數的與作業系統無關的套件。我們用它將`NODE_ENV`設為`test`,以便我們的測試可以使用測試資料庫。執行以下命令來安裝跨環境。 ``` npm i -D cross-env ``` - `--testTimeout` 標誌 - 這會增加 Jest 的預設逾時時間,即 5000 毫秒。這很重要,因為測試執行者需要在執行測試之前刷新資料庫。 **第 6 步 - 測試腳本** ``` npm test ``` 如果一切正常,您應該在終端機上看到以下輸出:  仔細觀察上面的螢幕截圖,您會注意到一行 _`using environment "test"`_ 表示 `cross-env` 已更改了 `NODE_ENV`。 **最後一步 - 測試路由/端點** 現在,讓我們開始為端點編寫測試。在測試目錄中建立一個名為routes.test.js的文件 ``` touch tests/routes.test.js ``` - **測試建立後端點** 將以下程式碼複製到“tests/routes.test.js”中: ``` const request = require('supertest') const app = require('../server') describe('Post Endpoints', () => { it('should create a new post', async () => { const res = await request(app) .post('/api/posts') .send({ userId: 1, title: 'test is cool', }) expect(res.statusCode).toEqual(201) expect(res.body).toHaveProperty('post') }) }) ``` - `describe` 函數用於將相關測試分組在一起 - `it` 是執行實際測試的 `test` 函數的別名。 -“expect”函數使用一組“matcher”函數測試值。 請造訪 [Jest 文件](https://jestjs.io/docs/en/api.html) 以取得 jest 函數的完整清單和詳細資訊。 現在,執行測試 ``` npm test ``` 輸出如下圖所示:  有關所有端點測試的完整程式碼,請檢查[儲存庫](https://github.com/oriechinedu/sequelize-with-postgres-tutorial/blob/master/tests/routes.test.js)。 ### 結論 我們已經能夠完成為與資料庫互動的 API 端點編寫測試的過程。在本文的最後部分,我將撰寫有關將 CI/CD 和程式碼覆蓋工具整合到測試環境的文章。在那之前請繼續關注。 如果您對改進文章有任何疑問或建議,請隨時與我聯繫。您也可以透過下面的評論部分分享您的想法。謝謝! _本文最初發表在我的[部落格](https://www.oriechinedu.com/posts/testing-nodejs-express-api-with-jest-and-supertest/)_ --- 原文出處:https://dev.to/nedsoft/testing-nodejs-express-api-with-jest-and-supertest-1km6
## 設定 Next.js 先執行以下指令,使用supabase、typescript和tailwind初始化下一個js專案:`npx create-next-app@latest`。選擇所有預設選項: ## 設定 Prisma 執行以下命令安裝 prisma: `npm install prisma --save-dev` 安裝 prisma 後,執行以下命令來初始化架構檔案和 .env 檔案: `npx 棱鏡熱` 現在應該有一個 .env 檔案。您應該加入您的database_url 將 prisma 連接到您的資料庫。應該看起來像這樣: ``` // .env DATABASE_URL=url ``` 在你的 schema.prisma 中你應該要加入你的模型,我現在只是使用一些隨機模型: ``` generator client { provider = "prisma-client-js" } datasource db { provider = "postgresql" url = env("DATABASE_URL") } model Post { id String @default(cuid()) @id title String content String? published Boolean @default(false) author User? @relation(fields: [authorId], references: [id]) authorId String? } model User { id String @default(cuid()) @id name String? email String? @unique createdAt DateTime @default(now()) @map(name: "created_at") updatedAt DateTime @updatedAt @map(name: "updated_at") posts Post[] @@map(name: "users") } ``` 現在您可以執行以下命令將資料庫與架構同步: `npx prisma 資料庫推送` 為了在客戶端存取 prisma,您需要安裝 prisma 用戶端。您可以透過執行以下命令來執行此操作: `npm 安裝@prisma/client` 您的客戶端也必須與您的架構同步,您可以透過執行以下命令來做到這一點: `npx prisma 生成` 當您執行“npx prisma db push”時,會自動呼叫產生指令。 為了存取 prisma 用戶端,您需要建立它的一個實例,因此在 src 目錄中建立一個名為 lib 的新資料夾,並在其中新增一個名為 prisma.ts 的新檔案。 ``` // prisma.ts import { PrismaClient } from "@prisma/client"; const prisma = new PrismaClient(); export default prisma; ``` 現在您可以在任何檔案中匯入相同的 Prisma 實例。 ## 設定 Shadcn 首先執行以下命令開始設定 shadcn: `npx shadcn-ui@latest init` 我選擇了以下選項: 打字稿:是的 風格:預設 底色: 板岩色 全域 CSS:src/app/globals.css CSS 變數:是 順風配置:tailwind.config.ts 元件:@/元件(預設) utils:@/lib/utils(預設) 反應伺服器元件:是 寫入 Components.json:是 接下來執行以下命令來設定下一個主題: `npm 安裝下一個主題` 然後將一個名為 theme-provider.tsx 的檔案加入到您的元件庫中並新增以下程式碼: ``` // theme-provider.tsx "use client" import * as React from "react" import { ThemeProvider as NextThemesProvider } from "next-themes" import { type ThemeProviderProps } from "next-themes/dist/types" export function ThemeProvider({ children, ...props }: ThemeProviderProps) { return <NextThemesProvider {...props}>{children}</NextThemesProvider> } ``` 設定完提供者後,您需要將其新增至 layout.tsx 中,以便在整個應用程式上實現它。使用主題提供者包裝 {children},如下所示: ``` // layout.tsx return ( <html lang="en" suppressHydrationWarning> <body className={inter.className}> <ThemeProvider attribute="class" defaultTheme="system" enableSystem disableTransitionOnChange > {children} </ThemeProvider> </body> </html> ); ``` 現在前往 shadcn [主題頁](https://ui.shadcn.com/themes)。然後選擇您要使用的主題並按複製程式碼。然後將複製的程式碼加入您的 globals.css 中,如下所示: ``` // globals.css @tailwind base; @tailwind components; @tailwind utilities; @layer base { :root { --background: 0 0% 100%; --foreground: 224 71.4% 4.1%; --card: 0 0% 100%; --card-foreground: 224 71.4% 4.1%; --popover: 0 0% 100%; --popover-foreground: 224 71.4% 4.1%; --primary: 262.1 83.3% 57.8%; --primary-foreground: 210 20% 98%; --secondary: 220 14.3% 95.9%; --secondary-foreground: 220.9 39.3% 11%; --muted: 220 14.3% 95.9%; --muted-foreground: 220 8.9% 46.1%; --accent: 220 14.3% 95.9%; --accent-foreground: 220.9 39.3% 11%; --destructive: 0 84.2% 60.2%; --destructive-foreground: 210 20% 98%; --border: 220 13% 91%; --input: 220 13% 91%; --ring: 262.1 83.3% 57.8%; --radius: 0.5rem; } .dark { --background: 224 71.4% 4.1%; --foreground: 210 20% 98%; --card: 224 71.4% 4.1%; --card-foreground: 210 20% 98%; --popover: 224 71.4% 4.1%; --popover-foreground: 210 20% 98%; --primary: 263.4 70% 50.4%; --primary-foreground: 210 20% 98%; --secondary: 215 27.9% 16.9%; --secondary-foreground: 210 20% 98%; --muted: 215 27.9% 16.9%; --muted-foreground: 217.9 10.6% 64.9%; --accent: 215 27.9% 16.9%; --accent-foreground: 210 20% 98%; --destructive: 0 62.8% 30.6%; --destructive-foreground: 210 20% 98%; --border: 215 27.9% 16.9%; --input: 215 27.9% 16.9%; --ring: 263.4 70% 50.4%; } } ``` 現在您應該能夠在專案中使用 shadcn 元件和主題。 ## 設定 Supabase 第一步是建立一個新的 SUPABASE 專案。接下來,安裝 next.js 驗證幫助程式庫: `npm install @supabase/auth-helpers-nextjs @supabase/supabase-js` 現在您必須將您的 supabase url 和您的匿名金鑰新增至您的 .env 檔案中。您的 .env 檔案現在應如下所示: ``` // .env DATABASE_URL=url NEXT_PUBLIC_SUPABASE_URL=your-supabase-url NEXT_PUBLIC_SUPABASE_ANON_KEY=your-supabase-anon-key ``` 我們將使用 supabase cli 根據我們的架構產生類型。使用以下命令安裝 cli: `npm install supabase --save-dev` 為了登入 supabase,請執行“npx supabase login”,它會自動讓您登入。 現在我們可以透過執行以下命令來產生我們的類型: `npx supabase gen types typescript --project-id YOUR_PROJECT_ID > src/lib/database.types.ts` 應該在您的 lib 資料夾中新增文件,其中包含基於您的架構的類型。 現在在專案的根目錄中建立一個 middleware.ts 檔案並新增以下程式碼: ``` import { createMiddlewareClient } from "@supabase/auth-helpers-nextjs"; import { NextResponse } from "next/server"; import type { NextRequest } from "next/server"; import type { Database } from "@/lib/database.types"; export async function middleware(req: NextRequest) { const res = NextResponse.next(); const supabase = createMiddlewareClient<Database>({ req, res }); await supabase.auth.getSession(); return res; } ``` 現在,在應用程式目錄中建立一個名為 auth 的新資料夾,然後在 auth 中建立另一個名為callback 的資料夾,最後建立一個名為route.ts 的檔案。在該文件中加入以下程式碼: ``` // app/auth/callback/route.ts import { createRouteHandlerClient } from "@supabase/auth-helpers-nextjs"; import { cookies } from "next/headers"; import { NextResponse } from "next/server"; import type { NextRequest } from "next/server"; import type { Database } from "@/lib/database.types"; export async function GET(request: NextRequest) { const requestUrl = new URL(request.url); const code = requestUrl.searchParams.get("code"); if (code) { const cookieStore = cookies(); const supabase = createRouteHandlerClient<Database>({ cookies: () => cookieStore, }); await supabase.auth.exchangeCodeForSession(code); } // URL to redirect to after sign in process completes return NextResponse.redirect(requestUrl.origin); } ``` 透過該設置,我們可以建立一個登入頁面。在應用程式目錄中建立一個名為「login with page.tsx」的新資料夾。 ``` // app/login/page.tsx "use client"; import { createClientComponentClient } from "@supabase/auth-helpers-nextjs"; import { useRouter } from "next/navigation"; import { useState } from "react"; import type { Database } from "@/lib/database.types"; export default function Login() { const [email, setEmail] = useState(""); const [password, setPassword] = useState(""); const router = useRouter(); const supabase = createClientComponentClient<Database>(); const handleSignUp = async () => { await supabase.auth.signUp({ email, password, options: { emailRedirectTo: `${location.origin}/auth/callback`, }, }); router.refresh(); }; const handleSignIn = async () => { await supabase.auth.signInWithPassword({ email, password, }); router.refresh(); }; const handleSignOut = async () => { await supabase.auth.signOut(); router.refresh(); }; return ( <> <input name="email" onChange={(e) => setEmail(e.target.value)} value={email} /> <input type="password" name="password" onChange={(e) => setPassword(e.target.value)} value={password} /> <button onClick={handleSignUp}>Sign up</button> <button onClick={handleSignIn}>Sign in</button> <button onClick={handleSignOut}>Sign out</button> </> ); } ``` 現在,在 auth 目錄中建立一個名為「sign-up」的新資料夾,並在該檔案中建立一個「route.ts」。新增以下程式碼: ``` // app/auth/sign-up/route.ts import { createRouteHandlerClient } from "@supabase/auth-helpers-nextjs"; import { cookies } from "next/headers"; import { NextResponse } from "next/server"; import type { Database } from "@/lib/database.types"; export async function POST(request: Request) { const requestUrl = new URL(request.url); const formData = await request.formData(); const email = String(formData.get("email")); const password = String(formData.get("password")); const cookieStore = cookies(); const supabase = createRouteHandlerClient<Database>({ cookies: () => cookieStore, }); await supabase.auth.signUp({ email, password, options: { emailRedirectTo: `${requestUrl.origin}/auth/callback`, }, }); return NextResponse.redirect(requestUrl.origin, { status: 301, }); } ``` 在同一位置建立另一個名為「登入」的資料夾。 ``` // app/auth/login/route.ts import { createRouteHandlerClient } from "@supabase/auth-helpers-nextjs"; import { cookies } from "next/headers"; import { NextResponse } from "next/server"; import type { Database } from "@/lib/database.types"; export async function POST(request: Request) { const requestUrl = new URL(request.url); const formData = await request.formData(); const email = String(formData.get("email")); const password = String(formData.get("password")); const cookieStore = cookies(); const supabase = createRouteHandlerClient<Database>({ cookies: () => cookieStore, }); await supabase.auth.signInWithPassword({ email, password, }); return NextResponse.redirect(requestUrl.origin, { status: 301, }); } ``` 最後在同一位置新增註銷路由。 ``` // app/auth/logout/route.ts import { createRouteHandlerClient } from '@supabase/auth-helpers-nextjs' import { cookies } from 'next/headers' import { NextResponse } from 'next/server' import type { Database } from '@/lib/database.types' export async function POST(request: Request) { const requestUrl = new URL(request.url) const cookieStore = cookies() const supabase = createRouteHandlerClient<Database>({ cookies: () => cookieStore }) await supabase.auth.signOut() return NextResponse.redirect(`${requestUrl.origin}/login`, { status: 301, }) } ``` 現在,當您導航至 localhost http://localhost:3000/login 時,應該有基本的登入登出註冊功能。 現在我們有了一些帶有 prisma shadcn 和 supabase auth 設定的下一個 js 應用程式的基本樣板。 --- 原文出處:https://dev.to/isaacdyor/setting-up-nextjs-project-with-prisma-200j
我們很高興地宣布,[Edge Functions](https://supabase.com/docs/guides/functions) 現在原生支援 npm 模組和 Node 內建 API。您可以將數百萬個流行、常用的 npm 模組直接匯入 Edge Functions 中。 `從 'npm:drizzle-orm/node-postgres' 導入 { drizzle }` ## 將現有 Node 應用程式遷移到 Edge Functions 您可以透過最少的變更將現有的 Node 應用程式遷移到 Supabase Edge Functions。 我們建立了一個示範來展示如何遷移使用 Express、Node Postgres 和 Drizzle 的 Node 應用程式。有關在 Edge Functions 中使用 npm 模組和 Node 內建程式的更多訊息,請參閱[管理依賴項指南](https://supabase.com/docs/guides/functions/import-maps)。 {% 嵌入 https://youtu.be/eCbiywoDORw %} **npm 模組的底層運作原理** 我們執行一個開源 Deno 伺服器來託管 Edge Functions,稱為 [Supabase Edge Runtime](https://supabase.com/blog/edge-runtime-self-hosted-deno-functions)。此自訂版本可協助我們保持 Edge Functions 以相同的方式運作,無論部署在何處 - 在我們的託管平台上、在本地開發中還是在您的自託管環境中。 加入 npm 支援時最大的挑戰是找到適用於所有環境的方法。我們希望保持工作流程接近 Deno CLI 體驗。應該可以直接在原始程式碼中導入 npm 模組,而無需額外的建置步驟。 部署函數時,我們將其模組圖序列化為單一檔案格式([eszip](https://github.com/denoland/eszip))。在託管環境中,所有模組引用都會從 eszip 中載入。這可以防止獲取模組時出現任何額外的延遲以及模組依賴關係之間的潛在衝突。 我們也在本機和自架環境中使用了 eszip 模組載入器,因此我們只需要為所有環境實作一種模組載入策略。作為本地開發的另一個好處,此方法避免了與使用者係統中安裝的 npm 模組的潛在衝突,因為 Edge Function 的 npm 模組是獨立於 eszip 中的。 [重構模組載入器](https://github.com/supabase/edge-runtime/pull/223)修正了一些其他錯誤,例如[邊緣函數錯誤](https://github.com/supabase/cli /issues/1584#issuecomment-1848799355) 當專案中已存在`deno.lock` 檔案時。 ## 您要求的其他一些東西... **區域呼叫** 現在,您可以選擇在執行邊緣函數時指定區域(也許我們將來應該更改名稱)。通常,邊緣函數在最靠近呼叫函數的使用者的區域中執行。但是,有時您希望在靠近 Postgres 資料庫或其他第 3 方 API 的地方執行它,以獲得最佳效能。 功能仍然部署到所有區域。但是,在呼叫過程中,您可以提供“x-region”標頭以將執行限制在特定區域。 **捲曲** ``` # https://supabase.com/docs/guides/functions/deploy#invoking-remote-functions curl --request POST 'https://<project_ref>.supabase.co/functions/v1/hello-world' \ --header 'Authorization: Bearer ANON_KEY' \ --header 'Content-Type: application/json' \ --header 'x-region: eu-west-3' \ --data '{ "name":"Functions" }' ``` **JavaScript** ``` // https://supabase.com/docs/reference/javascript/installing import { createClient } from '@supabase/supabase-js' // Create a single supabase client for interacting with your database const supabase = createClient('https://xyzcompany.supabase.co', 'public-anon-key') // https://supabase.com/docs/reference/javascript/functions-invoke const { data, error } = await supabase.functions.invoke('hello-world', { body: { name: 'Functions' }, headers: { 'x-region': 'eu-west-3' }, }) ``` > ℹ️查看[區域呼叫指南](https://supabase.com/docs/guides/functions/regional-inspiration)以了解更多詳情。 **更好的指標** 我們在 [Supabase 儀表板](https://supabase.com/dashboard/project/_/functions) 的 Edge Functions 部分中加入了更多指標:它現在顯示 CPU 時間和使用的記憶體。我們也按 HTTP 狀態碼細分了呼叫。 這些變更可協助您發現邊緣功能的任何問題並採取行動。 > ℹ️ 請參閱 Edge Functions 的[日誌記錄和指標指南](https://supabase.com/docs/guides/functions/debugging) 以了解更多資訊。  **使用 Sentry 追蹤錯誤** 我們 Sentry 的朋友最近發布了官方的 [Sentry SDK for Deno](https://deno.land/x/[email protected])。有了這個,現在可以輕鬆追蹤 Sentry 邊緣函數中的錯誤和異常。 以下是一個簡單的範例,說明如何處理函數中的異常並將其傳送到 Sentry。 ``` import * as Sentry from 'https://deno.land/x/sentry/index.mjs' Sentry.init({ dsn: _DSN_, integrations: [], // Performance Monitoring tracesSampleRate: 1.0, // Set sampling rate for profiling - this is relative to tracesSampleRate profilesSampleRate: 1.0, }) // Set region and execution_id as custom tags Sentry.setTag('region', Deno.env.get('SB_REGION')) Sentry.setTag('execution_id', Deno.env.get('SB_EXECUTION_ID')) Deno.serve(async (req) => { try { const { name } = await req.json() const data = { message: `Hello ${name}!`, } return new Response(JSON.stringify(data), { headers: { 'Content-Type': 'application/json' } }) } catch (e) { Sentry.captureException(e) return new Response(JSON.stringify({ msg: 'error' }), { status: 500, headers: { 'Content-Type': 'application/json' }, }) } }) ``` ## 下一步是什麼 NPM 支援是 Edge Functions 最受歡迎的功能之一。如果您之前因缺乏支援而無法使用 Edge Functions,我們希望此更新能夠吸引您[再試一次](https://supabase.com/dashboard/project/_/functions)。如果您遇到任何問題,我們只需[一個支援請求](https://supabase.help/)。 對於現有的 Edge Functions 用戶來說,區域呼叫、更好的指標和錯誤處理只是接下來會發生的事情的一瞥。我們繼續迭代平台穩定性並對邊緣功能可以使用的資源設定自訂限制。請留意新的一年的另一篇文章。 ## 更多發布第 X 週 - [第 1 天 - Supabase Studio 更新:AI 助理與使用者模擬](https://supabase.com/blog/studio-introducing-assistant) - [pg_graphql:現在支援 Postgres 函式](https://supabase.com/blog/pg-graphql-postgres-functions) - [Postgres語言伺服器:實作解析器](https://supabase.com/blog/postgres-language-server-implementing-parser) - [Supabase 設計如何運作](https://supabase.com/blog/how-design-works-at-supabase) - [Supabase 專輯](https://www.youtube.com/watch?v=r1POD-IdG-I) - [Supabase 啟動週 X 黑客松](https://supabase.com/blog/supabase-hackathon-lwx) - [啟動週 X 社群聚會](https://supabase.com/blog/community-meetups-lwx) --- 原文出處:https://dev.to/supabase/edge-functions-node-and-native-npm-compatibility-77f
隨著每個人和他們的貓為他們的應用程式建立一個“2023 Wrapped”,我無法阻止,不得不為這個很棒的 dev.to 社區建立一個小型開源應用程式 🥰 造訪[devto-wrapped.sliplane.app](https://devto-wrapped.sliplane.app/?username=code42cate),輸入您的用戶名,看看您作為dev.to 的作者在2023 年取得了什麼成就! **無需 API 金鑰或登入!** 這是我在 dev.to 的第一年的經驗: 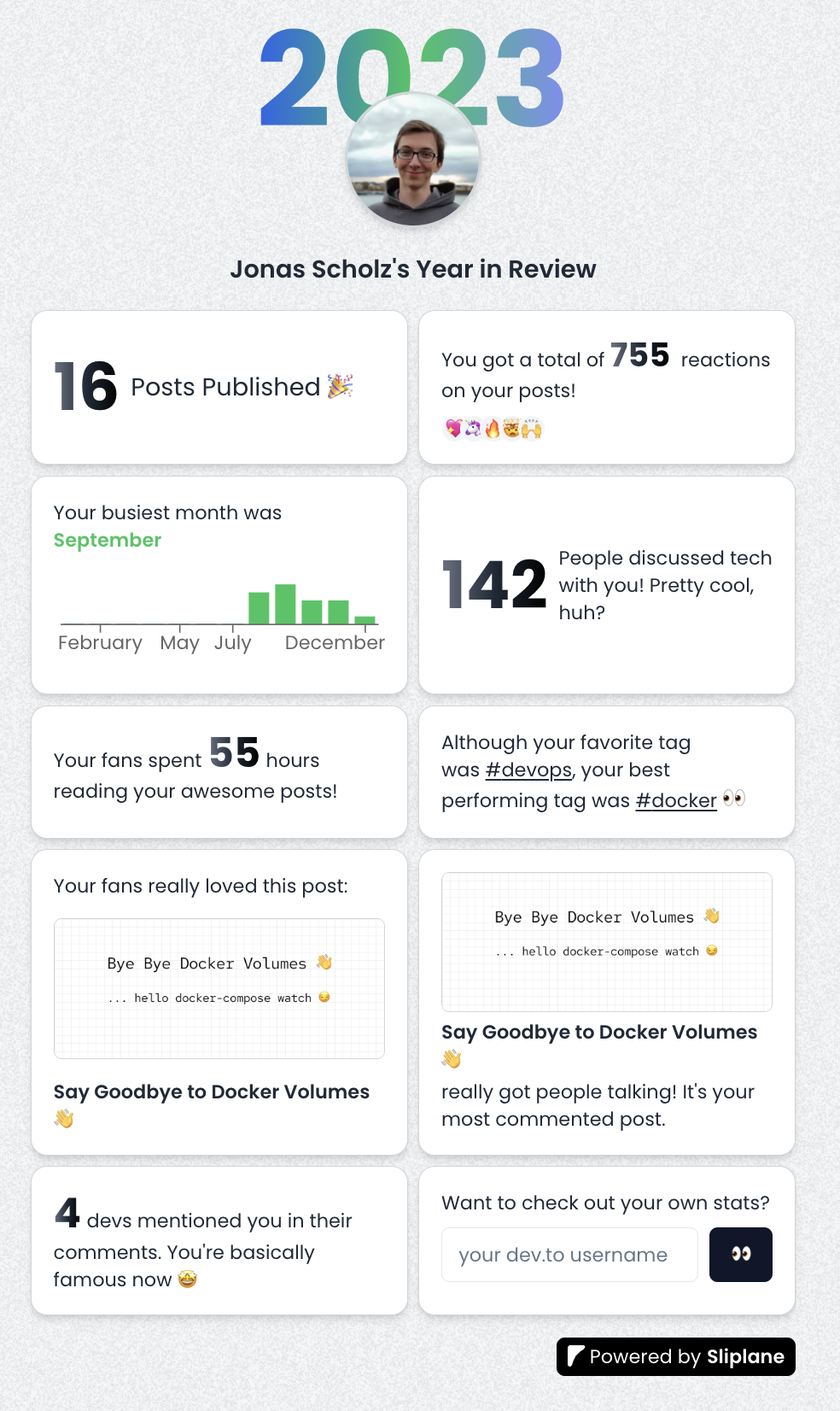 PS:在評論中分享你的截圖,我會隨機挑選一個人,給他們發送一些免費的開發者貼紙作為提前的聖誕禮物🎅🎁 不管怎樣,你來這裡是為了學習一些東西,所以讓我們深入研究程式碼吧! ## 教程 建立這個小應用程式的速度對我來說至關重要,因此我決定使用我最近使用的自己的[Hackathon Starter Template](https://dev.to/code42cate/how-to-win-any-hackathon -3i99)寫了關於。我剝離了一些我不需要的功能,從而產生了一個非常精簡的 monorepo: 1.Next.js + Tailwind 2. ShadcnUI 你可以在這個[Github儲存庫](https://github.com/Code42Cate/devto-wrapped)中看到所有內容 ### 設定 如果您想長期關注並親自嘗試一下,請按照以下步驟操作: ``` # Clone repository git clone https://github.com/Code42Cate/devto-wrapped.git # Install dependencies pnpm install # Start app pnpm run dev --filter web ``` 該應用程式現在應該從 http://localhost:3000 啟動。如果它不起作用,請在評論中告訴我! ### 存取 dev.to 資料 這個小應用程式最有趣的部分可能是我們如何存取 dev.to 資料。雖然有幾種方法可以解決這個問題,但我有一些要求幫助我決定前進的方向: 1. 不抓取 - 花費太長時間,我希望資料可用 <1 秒 2. 僅公開資料 - 我不想向使用者詢問 API 金鑰或使用我自己的 3.不需要資料庫-我很懶,想避免無用的複雜性 這為我們提供了兩種可能的獲取資料的方式: 1. [記錄和未經驗證的 API 呼叫](https://developers.forem.com/api/v1) 2. 即使您未登錄,dev.to 網站也會進行未記錄的公開 API 呼叫 考慮到這兩種獲取資料的方式,我們基本上可以獲得 3 類資料: 1.使用API公開使用者資訊:`dev.to/api/users/by_username` 2. 使用 `dev.to/search/feed_content` API 和 `class_name=Article` 發布帖子 3. 包含 `dev.to/search/feed_content` 和 `class_name=Comment&search_fields=xyz` 的搜尋查詢的評論 這些 API 呼叫都是在伺服器端進行的,以加快請求速度,可以在「/apps/web/actions/api.ts」中找到。由於這只是組合在一起,因此功能相當簡單,錯誤處理也非常少: ``` export async function getUserdata(username: string): Promise<User | undefined> { const res = await fetch( `https://dev.to/api/users/by_username?url=${username}`, ); if (!res.ok) { return undefined; } const data = await res.json(); return data as User; } ``` 對於這個用例來說,這很好,但如果您不希望用戶發生意外崩潰,請記住正確捕獲異常並驗證您的類型😵 ### 計算統計資料 計算統計資料出奇地容易,主要是因為我們的資料非常小。即使你每天發帖,我們只會瀏覽 365 個帖子。迭代 365 個專案的陣列幾乎不需要時間,這給了我們很大的空間來完成工作,而無需關心效能!您在頁面上看到的每個統計資料都是在單一函數中計算的。以「總反應」為例: ``` const reactionsCount = posts?.reduce( (acc: number, post: Article) => acc + post.public_reactions_count, 0, ); ``` 我們需要做的就是檢查帖子陣列並總結每個帖子的“public_reactions_count”數量。田田,完成! 即使對於更複雜的,它也只不過是一個嵌套循環: ``` const postsPerTag: Record<string, number> = posts?.reduce( (acc: Record<string, number>, post: Article) => { post.tag_list.forEach((tag) => { acc[tag] = acc[tag] ? acc[tag] + 1 : 1; }); return acc; }, {} as Record<string, number>, ); ``` ### 前端 由於這是使用 Next.js 建構的,因此所有內容都可以在「/apps/web/app/page.tsx」檔案中找到。 在元件的頂部,您可以先看到我們如何取得資料並檢查使用者是否存在或是否有足夠的資料來顯示任何內容: ``` const user = await getUserdata(username); if (!user) { return <EmptyUser message="This user could not be found 🫠" />; } const stats = await getStats(user.id.toString()); const mentionsCount = await getMentionedCommentCount(user.username); if (stats.postCount === 0) { return <EmptyUser message="This user has no posts 🫠" />; } ``` 不同的統計資料都是它們自己的元件,它們是 CSS 網格的一部分,看起來像這樣(縮短) ``` <div className="grid grid-cols-2 gap-2 w-full text-sm text-gray-800"> <PublishedPostsCard count={stats.postCount} /> <ReactionsCard count={stats.reactionsCount} /> <BusiestMonthCard busiestMonth={stats.busiestMonth} postsPerMonth={stats.postsPerMonth} /> <CommentsCard count={stats.commentsCount} /> <ReadingTimeCard readingTime={stats.readingTime} totalEstimatedReadingTime={stats.totalEstimatedReadingTime} /> </div> ``` 這些元件都是「啞」的,這意味著它們只負責顯示資料。他們不獲取或計算任何東西。其中大多數都非常簡單,就像這張「最佳貼文」卡: ``` import Image from "next/image"; import { Article } from "@/actions/api"; export default function BestPostCard({ post, coverImage, }: { post: Article; coverImage: string; }) { return ( <div className="flex w-full flex-col justify-between gap-2 rounded-xl border border-gray-300 bg-white p-4 shadow-md"> Your fans really loved this post: <br /> <Image src={coverImage} alt={post.title} width={500} height={500} className="rounded-md border border-gray-300" /> <a className="font-semibold underline-offset-2" href={`https://dev.to${post.path}`} > {post.title} </a> </div> ); } ``` ### 部署 為了部署我們的應用程式,我們將對其進行dockerize,然後使用Sliplane(稍微有偏見,我是聯合創始人!)將其託管在我們自己的[Hetzner Cloud](https://www.hetzner.com /cloud) 伺服器上。我在[上一篇部落格文章](https://dev.to/sliplane/understanding-nextjs-docker-images-2g08)中介紹瞭如何對Next.js 應用程式進行docker 化,這基本上是相同的,只是做了一些小的更改適應我的 Turborepo 設定:) ``` # src Dockerfile: https://github.com/vercel/turbo/blob/main/examples/with-docker/apps/web/Dockerfile FROM node:18-alpine AS alpine # setup pnpm on the alpine base FROM alpine as base ENV PNPM_HOME="/pnpm" ENV PATH="$PNPM_HOME:$PATH" RUN corepack enable RUN pnpm install turbo --global FROM base AS builder # Check https://github.com/nodejs/docker-node/tree/b4117f9333da4138b03a546ec926ef50a31506c3#nodealpine to understand why libc6-compat might be needed. RUN apk add --no-cache libc6-compat RUN apk update # Set working directory WORKDIR /app COPY . . RUN turbo prune --scope=web --docker # Add lockfile and package.json's of isolated subworkspace FROM base AS installer RUN apk add --no-cache libc6-compat RUN apk update WORKDIR /app # First install the dependencies (as they change less often) COPY .gitignore .gitignore COPY --from=builder /app/out/json/ . COPY --from=builder /app/out/pnpm-lock.yaml ./pnpm-lock.yaml COPY --from=builder /app/out/pnpm-workspace.yaml ./pnpm-workspace.yaml RUN pnpm install # Build the project COPY --from=builder /app/out/full/ . COPY turbo.json turbo.json RUN turbo run build --filter=web # use alpine as the thinest image FROM alpine AS runner WORKDIR /app # Don't run production as root RUN addgroup --system --gid 1001 nodejs RUN adduser --system --uid 1001 nextjs USER nextjs COPY --from=installer /app/apps/web/next.config.js . COPY --from=installer /app/apps/web/package.json . # Automatically leverage output traces to reduce image size # https://nextjs.org/docs/advanced-features/output-file-tracing COPY --from=installer --chown=nextjs:nodejs /app/apps/web/.next/standalone ./ COPY --from=installer --chown=nextjs:nodejs /app/apps/web/.next/static ./apps/web/.next/static COPY --from=installer --chown=nextjs:nodejs /app/apps/web/public ./apps/web/public CMD node apps/web/server.js ``` 在 Docker 化並推送到 Github 儲存庫後,我們需要做的就是在 Sliplane 中建立一個新服務並選擇我們想要託管的伺服器。我已經有一台伺服器,在上面執行一些小型專案,所以我只使用該伺服器: 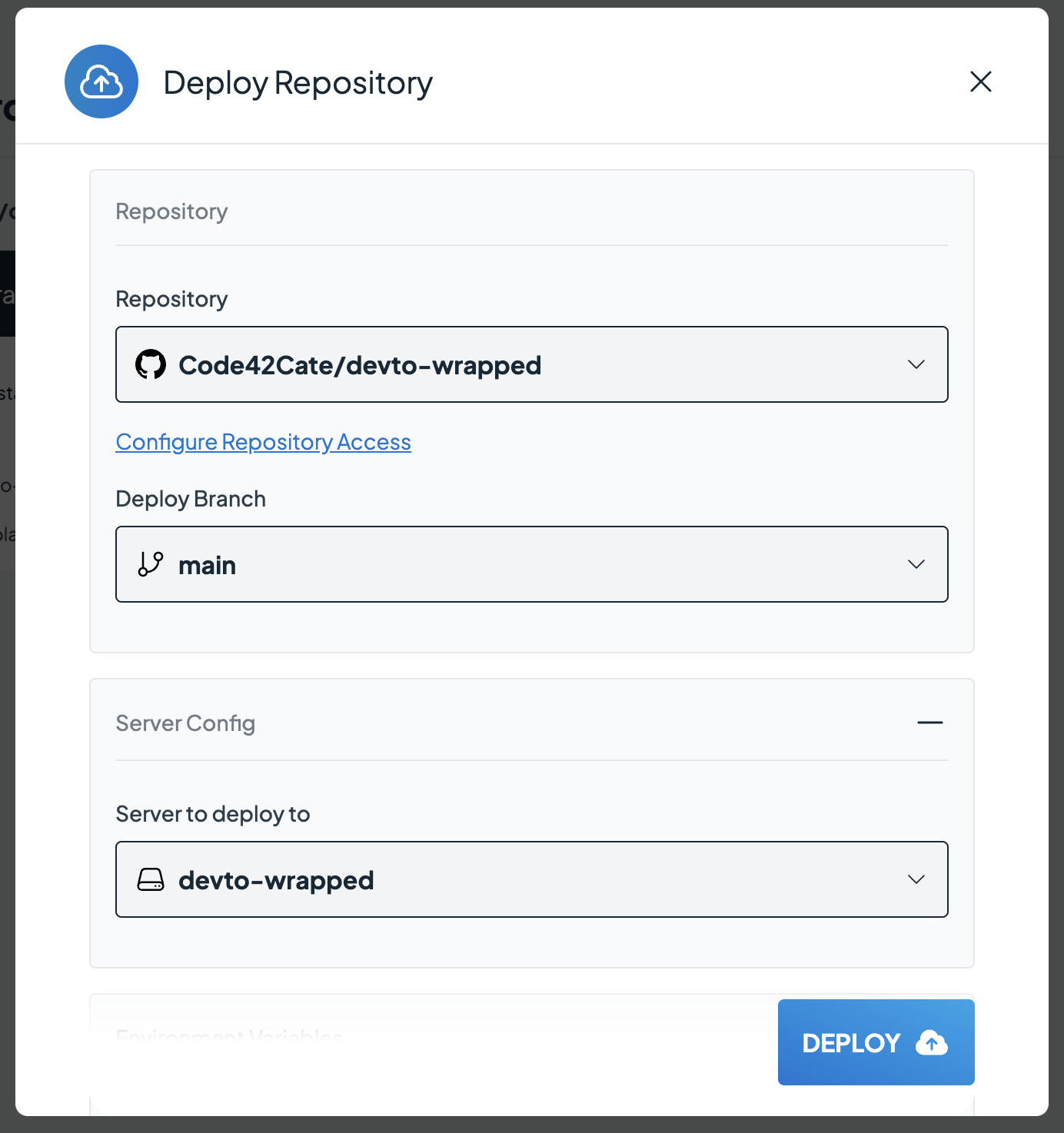 點擊「部署」後,需要幾分鐘時間來建置並啟動我們的 Docker 映像。可以在日誌檢視器中監視進度:  第一次成功部署後,我們將獲得一個可以存取我們的應用程式的免費子網域,或者我們可以加入自己的自訂網域: 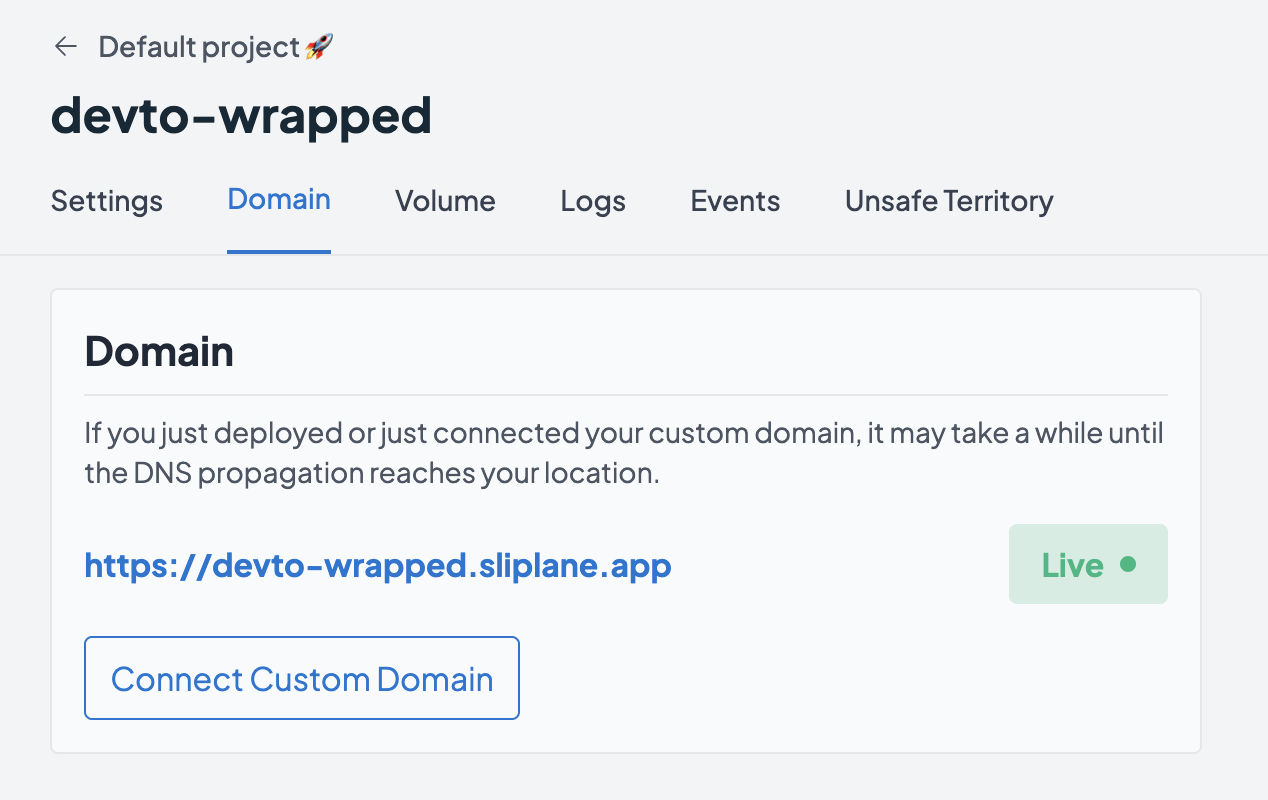 就是這樣!我們的應用程式在線,世界上每個人都可以存取,並且不會產生令人驚訝的無伺服器帳單 🤑 感謝您到目前為止的閱讀,不要忘記用您的截圖進行評論,以_可能_贏得一些貼紙😊 乾杯,喬納斯 --- 原文出處:https://dev.to/code42cate/devto-wrapped-2023-13o
#我要做一個自動解方程 主控臺 --- "Error solving equation: Invalid left hand side of assignment operator = (char 5) Return:a + 27 = 0" --- ```<!DOCTYPE html> <html> <head> <meta name="description" content="math.js | basic usage"> <title>math.js | basic usage</title> <script src="https://unpkg.com/mathjs/lib/browser/math.js"></script> </head> <body> <script> function solveEquation(equationString, variableRange = { start: -10, end: 10, step: 0.1 }) { if (typeof equationString !== 'string') { throw new Error('Equation must be a string'); } const equation = equationString.replace(/\s/g, ''); const variables = equation.match(/[a-zA-Z]+/g); if (!variables) { throw new Error('No variables found in equation'); } const parser = math.parser(); variables.forEach(variable => { parser.evaluate(`${variable} = ${variableRange.start}:${variableRange.step}:${variableRange.end}`); }); let result; try { result = parser.evaluate(equation); } catch (error) { throw new Error('Error solving equation: ' + error.message + "\nReturn:" + equationString); } return result; } const equationString = "a + 27 = 0"; try { const result = solveEquation(equationString); console.log("方程的解为:", result); } catch (error) { console.error(error.message); } </script> </body> </html>
你的轉職路上,還缺少一份自學作業包!寫完這幾包,直接拿作品去面試上班!
本論壇另有附設一個 LINE 新手發問&交流群組!歡迎加入討論!



























