# 簡介 ChatGPT 訓練至 2022 年。 但是,如果您希望它專門為您提供有關您網站的資訊怎麼辦?最有可能的是,這是不可能的,**但不再是了!** OpenAI 推出了他們的新功能 - [助手](https://platform.openai.com/docs/assistants/how-it-works)。 現在您可以輕鬆地為您的網站建立索引,然後向 ChatGPT 詢問有關該網站的問題。在本教程中,我們將建立一個系統來索引您的網站並讓您查詢它。我們將: - 抓取文件網站地圖。 - 從網站上的所有頁面中提取資訊。 - 使用新資訊建立新助理。 - 建立一個簡單的ChatGPT前端介面並查詢助手。  --- ## 你的後台工作平台🔌 [Trigger.dev](https://trigger.dev/) 是一個開源程式庫,可讓您使用 NextJS、Remix、Astro 等為您的應用程式建立和監控長時間執行的作業! [](https://github.com/triggerdotdev/trigger.dev) 請幫我們一顆星🥹。 這將幫助我們建立更多這樣的文章💖 --- ## 讓我們開始吧🔥 讓我們建立一個新的 NextJS 專案。 ``` npx create-next-app@latest ``` >💡 我們使用 NextJS 新的應用程式路由器。安裝專案之前請確保您的節點版本為 18+ 讓我們建立一個新的資料庫來保存助手和抓取的頁面。 對於我們的範例,我們將使用 [Prisma](https://www.prisma.io/) 和 SQLite。 安裝非常簡單,只需執行: ``` npm install prisma @prisma/client --save ``` 然後加入架構和資料庫 ``` npx prisma init --datasource-provider sqlite ``` 轉到“prisma/schema.prisma”並將其替換為以下架構: ``` // This is your Prisma schema file, // learn more about it in the docs: https://pris.ly/d/prisma-schema generator client { provider = "prisma-client-js" } datasource db { provider = "sqlite" url = env("DATABASE_URL") } model Docs { id Int @id @default(autoincrement()) content String url String @unique identifier String @@index([identifier]) } model Assistant { id Int @id @default(autoincrement()) aId String url String @unique } ``` 然後執行 ``` npx prisma db push ``` 這將建立一個新的 SQLite 資料庫(本機檔案),其中包含兩個主表:“Docs”和“Assistant” - 「Docs」包含所有抓取的頁面 - `Assistant` 包含文件的 URL 和內部 ChatGPT 助理 ID。 讓我們新增 Prisma 客戶端。 建立一個名為「helper」的新資料夾,並新增一個名為「prisma.ts」的新文件,並在其中新增以下程式碼: ``` import {PrismaClient} from '@prisma/client'; export const prisma = new PrismaClient(); ``` 我們稍後可以使用“prisma”變數來查詢我們的資料庫。 ---  ## 刮擦和索引 ### 建立 Trigger.dev 帳戶 抓取頁面並為其建立索引是一項長期執行的任務。 **我們需要:** - 抓取網站地圖的主網站元 URL。 - 擷取網站地圖內的所有頁面。 - 前往每個頁面並提取內容。 - 將所有內容儲存到 ChatGPT 助手中。 為此,我們使用 Trigger.dev! 註冊 [Trigger.dev 帳號](https://trigger.dev/)。 註冊後,建立一個組織並為您的工作選擇一個專案名稱。 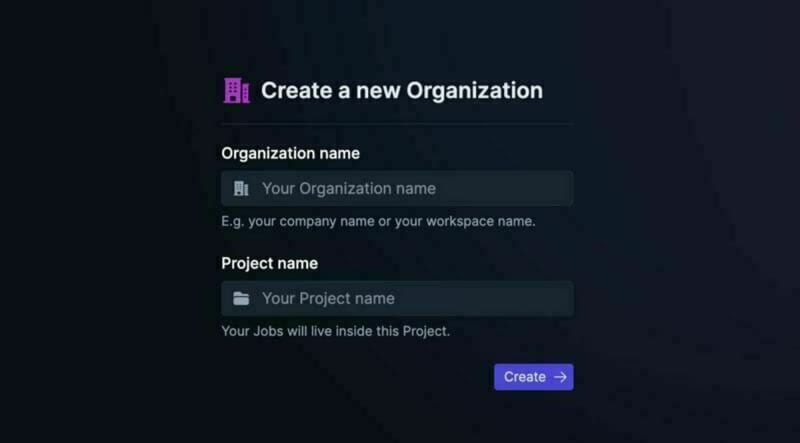 選擇 Next.js 作為您的框架,並按照將 Trigger.dev 新增至現有 Next.js 專案的流程進行操作。  否則,請點選專案儀表板側邊欄選單上的「環境和 API 金鑰」。  複製您的 DEV 伺服器 API 金鑰並執行下面的程式碼片段來安裝 Trigger.dev。 仔細按照說明進行操作。 ``` npx @trigger.dev/cli@latest init ``` 在另一個終端中執行以下程式碼片段,在 Trigger.dev 和您的 Next.js 專案之間建立隧道。 ``` npx @trigger.dev/cli@latest dev ``` ### 安裝 ChatGPT (OpenAI) 我們將使用OpenAI助手,因此我們必須將其安裝到我們的專案中。 [建立新的 OpenAI 帳戶](https://platform.openai.com/) 並產生 API 金鑰。 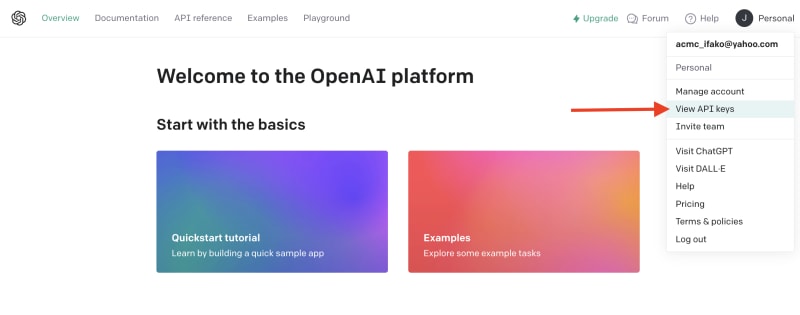 點擊下拉清單中的「檢視 API 金鑰」以建立 API 金鑰。 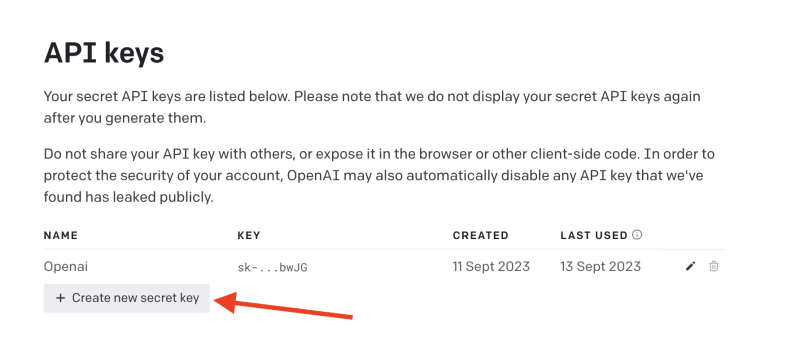 接下來,透過執行下面的程式碼片段來安裝 OpenAI 套件。 ``` npm install @trigger.dev/openai ``` 將您的 OpenAI API 金鑰新增至「.env.local」檔案。 ``` OPENAI_API_KEY=<your_api_key> ``` 建立一個新目錄“helper”並新增一個新檔案“open.ai.tsx”,其中包含以下內容: ``` import {OpenAI} from "@trigger.dev/openai"; export const openai = new OpenAI({ id: "openai", apiKey: process.env.OPENAI_API_KEY!, }); ``` 這是我們透過 Trigger.dev 整合封裝的 OpenAI 用戶端。 ### 建立後台作業 讓我們繼續建立一個新的後台作業! 前往“jobs”並建立一個名為“process.documentation.ts”的新檔案。 **新增以下程式碼:** ``` import { eventTrigger } from "@trigger.dev/sdk"; import { client } from "@openai-assistant/trigger"; import {object, string} from "zod"; import {JSDOM} from "jsdom"; import {openai} from "@openai-assistant/helper/open.ai"; client.defineJob({ // This is the unique identifier for your Job; it must be unique across all Jobs in your project. id: "process-documentation", name: "Process Documentation", version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction trigger: eventTrigger({ name: "process.documentation.event", schema: object({ url: string(), }) }), integrations: { openai }, run: async (payload, io, ctx) => { } }); ``` 我們定義了一個名為「process.documentation.event」的新作業,並新增了一個名為 URL 的必要參數 - 這是我們稍後要傳送的文件 URL。 正如您所看到的,該作業是空的,所以讓我們向其中加入第一個任務。 我們需要獲取網站網站地圖並將其返回。 抓取網站將返回我們需要解析的 HTML。 為此,我們需要安裝 JSDOM。 ``` npm install jsdom --save ``` 並將其導入到我們文件的頂部: ``` import {JSDOM} from "jsdom"; ``` 現在,我們可以新增第一個任務。 用「runTask」包裝我們的程式碼很重要,這可以讓 Trigger.dev 將其與其他任務分開。觸發特殊架構將任務拆分為不同的進程,因此 Vercel 無伺服器逾時不會影響它們。 **這是第一個任務的程式碼:** ``` const getSiteMap = await io.runTask("grab-sitemap", async () => { const data = await (await fetch(payload.url)).text(); const dom = new JSDOM(data); const sitemap = dom.window.document.querySelector('[rel="sitemap"]')?.getAttribute('href'); return new URL(sitemap!, payload.url).toString(); }); ``` - 我們透過 HTTP 請求從 URL 取得整個 HTML。 - 我們將其轉換為 JS 物件。 - 我們找到網站地圖 URL。 - 我們解析它並返回它。 接下來,我們需要抓取網站地圖,提取所有 URL 並返回它們。 讓我們安裝“Lodash”——陣列結構的特殊函數。 ``` npm install lodash @types/lodash --save ``` 這是任務的程式碼: ``` export const makeId = (length: number) => { let text = ''; const possible = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789'; for (let i = 0; i < length; i += 1) { text += possible.charAt(Math.floor(Math.random() * possible.length)); } return text; }; const {identifier, list} = await io.runTask("load-and-parse-sitemap", async () => { const urls = /(http|ftp|https):\/\/([\w_-]+(?:(?:\.[\w_-]+)+))([\w.,@?^=%&:\/~+#-]*[\w@?^=%&\/~+#-])/g; const identifier = makeId(5); const data = await (await fetch(getSiteMap)).text(); // @ts-ignore return {identifier, list: chunk(([...new Set(data.match(urls))] as string[]).filter(f => f.includes(payload.url)).map(p => ({identifier, url: p})), 25)}; }); ``` - 我們建立一個名為 makeId 的新函數來為所有頁面產生隨機辨識碼。 - 我們建立一個新任務並加入正規表示式來提取每個可能的 URL - 我們發送一個 HTTP 請求來載入網站地圖並提取其所有 URL。 - 我們將 URL「分塊」為 25 個元素的陣列(如果有 100 個元素,則會有四個 25 個元素的陣列) 接下來,讓我們建立一個新作業來處理每個 URL。 **這是完整的程式碼:** ``` function getElementsBetween(startElement: Element, endElement: Element) { let currentElement = startElement; const elements = []; // Traverse the DOM until the endElement is reached while (currentElement && currentElement !== endElement) { currentElement = currentElement.nextElementSibling!; // If there's no next sibling, go up a level and continue if (!currentElement) { // @ts-ignore currentElement = startElement.parentNode!; startElement = currentElement; if (currentElement === endElement) break; continue; } // Add the current element to the list if (currentElement && currentElement !== endElement) { elements.push(currentElement); } } return elements; } const processContent = client.defineJob({ // This is the unique identifier for your Job; it must be unique across all Jobs in your project. id: "process-content", name: "Process Content", version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction trigger: eventTrigger({ name: "process.content.event", schema: object({ url: string(), identifier: string(), }) }), run: async (payload, io, ctx) => { return io.runTask('grab-content', async () => { // We first grab a raw html of the content from the website const data = await (await fetch(payload.url)).text(); // We load it with JSDOM so we can manipulate it const dom = new JSDOM(data); // We remove all the scripts and styles from the page dom.window.document.querySelectorAll('script, style').forEach((el) => el.remove()); // We grab all the titles from the page const content = Array.from(dom.window.document.querySelectorAll('h1, h2, h3, h4, h5, h6')); // We grab the last element so we can get the content between the last element and the next element const lastElement = content[content.length - 1]?.parentElement?.nextElementSibling!; const elements = []; // We loop through all the elements and grab the content between each title for (let i = 0; i < content.length; i++) { const element = content[i]; const nextElement = content?.[i + 1] || lastElement; const elementsBetween = getElementsBetween(element, nextElement); elements.push({ title: element.textContent, content: elementsBetween.map((el) => el.textContent).join('\n') }); } // We create a raw text format of all the content const page = ` ---------------------------------- url: ${payload.url}\n ${elements.map((el) => `${el.title}\n${el.content}`).join('\n')} ---------------------------------- `; // We save it to our database await prisma.docs.upsert({ where: { url: payload.url }, update: { content: page, identifier: payload.identifier }, create: { url: payload.url, content: page, identifier: payload.identifier } }); }); }, }); ``` - 我們從 URL 中獲取內容(之前從網站地圖中提取) - 我們用`JSDOM`解析它 - 我們刪除頁面上存在的所有可能的“<script>”或“<style>”。 - 我們抓取頁面上的所有標題(`h1`、`h2`、`h3`、`h4`、`h5`、`h6`) - 我們迭代標題並獲取它們之間的內容。我們不想取得整個頁面內容,因為它可能包含不相關的內容。 - 我們建立頁面原始文字的版本並將其保存到我們的資料庫中。 現在,讓我們為每個網站地圖 URL 執行此任務。 觸發器引入了名為“batchInvokeAndWaitForCompletion”的東西。 它允許我們批量發送 25 個專案進行處理,並且它將同時處理所有這些專案。下面是接下來的幾行程式碼: ``` let i = 0; for (const item of list) { await processContent.batchInvokeAndWaitForCompletion( 'process-list-' + i, item.map( payload => ({ payload, }), 86_400), ); i++; } ``` 我們以 25 個為一組[手動觸發](https://trigger.dev/docs/documentation/concepts/triggers/invoke)之前建立的作業。 完成後,讓我們將保存到資料庫的所有內容並連接它: ``` const data = await io.runTask("get-extracted-data", async () => { return (await prisma.docs.findMany({ where: { identifier }, select: { content: true } })).map((d) => d.content).join('\n\n'); }); ``` 我們使用之前指定的標識符。 現在,讓我們在 ChatGPT 中使用新資料建立一個新檔案: ``` const file = await io.openai.files.createAndWaitForProcessing("upload-file", { purpose: "assistants", file: data }); ``` `createAndWaitForProcessing` 是 Trigger.dev 建立的任務,用於將檔案上傳到助手。如果您在沒有整合的情況下手動使用“openai”,則必須串流傳輸檔案。 現在讓我們建立或更新我們的助手: ``` const assistant = await io.openai.runTask("create-or-update-assistant", async (openai) => { const currentAssistant = await prisma.assistant.findFirst({ where: { url: payload.url } }); if (currentAssistant) { return openai.beta.assistants.update(currentAssistant.aId, { file_ids: [file.id] }); } return openai.beta.assistants.create({ name: identifier, description: 'Documentation', instructions: 'You are a documentation assistant, you have been loaded with documentation from ' + payload.url + ', return everything in an MD format.', model: 'gpt-4-1106-preview', tools: [{ type: "code_interpreter" }, {type: 'retrieval'}], file_ids: [file.id], }); }); ``` - 我們首先檢查是否有針對該特定 URL 的助手。 - 如果我們有的話,讓我們用新文件更新助手。 - 如果沒有,讓我們建立一個新的助手。 - 我們傳遞「你是文件助理」的指令,需要注意的是,我們希望最終輸出為「MD」格式,以便稍後更好地顯示。 對於拼圖的最後一塊,讓我們將新助手儲存到我們的資料庫中。 **這是程式碼:** ``` await io.runTask("save-assistant", async () => { await prisma.assistant.upsert({ where: { url: payload.url }, update: { aId: assistant.id, }, create: { aId: assistant.id, url: payload.url, } }); }); ``` 如果該 URL 已經存在,我們可以嘗試使用新的助手 ID 來更新它。 這是該頁面的完整程式碼: ``` import { eventTrigger } from "@trigger.dev/sdk"; import { client } from "@openai-assistant/trigger"; import {object, string} from "zod"; import {JSDOM} from "jsdom"; import {chunk} from "lodash"; import {prisma} from "@openai-assistant/helper/prisma.client"; import {openai} from "@openai-assistant/helper/open.ai"; const makeId = (length: number) => { let text = ''; const possible = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789'; for (let i = 0; i < length; i += 1) { text += possible.charAt(Math.floor(Math.random() * possible.length)); } return text; }; client.defineJob({ // This is the unique identifier for your Job; it must be unique across all Jobs in your project. id: "process-documentation", name: "Process Documentation", version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction trigger: eventTrigger({ name: "process.documentation.event", schema: object({ url: string(), }) }), integrations: { openai }, run: async (payload, io, ctx) => { // The first task to get the sitemap URL from the website const getSiteMap = await io.runTask("grab-sitemap", async () => { const data = await (await fetch(payload.url)).text(); const dom = new JSDOM(data); const sitemap = dom.window.document.querySelector('[rel="sitemap"]')?.getAttribute('href'); return new URL(sitemap!, payload.url).toString(); }); // We parse the sitemap; instead of using some XML parser, we just use regex to get the URLs and we return it in chunks of 25 const {identifier, list} = await io.runTask("load-and-parse-sitemap", async () => { const urls = /(http|ftp|https):\/\/([\w_-]+(?:(?:\.[\w_-]+)+))([\w.,@?^=%&:\/~+#-]*[\w@?^=%&\/~+#-])/g; const identifier = makeId(5); const data = await (await fetch(getSiteMap)).text(); // @ts-ignore return {identifier, list: chunk(([...new Set(data.match(urls))] as string[]).filter(f => f.includes(payload.url)).map(p => ({identifier, url: p})), 25)}; }); // We go into each page and grab the content; we do this in batches of 25 and save it to the DB let i = 0; for (const item of list) { await processContent.batchInvokeAndWaitForCompletion( 'process-list-' + i, item.map( payload => ({ payload, }), 86_400), ); i++; } // We get the data that we saved in batches from the DB const data = await io.runTask("get-extracted-data", async () => { return (await prisma.docs.findMany({ where: { identifier }, select: { content: true } })).map((d) => d.content).join('\n\n'); }); // We upload the data to OpenAI with all the content const file = await io.openai.files.createAndWaitForProcessing("upload-file", { purpose: "assistants", file: data }); // We create a new assistant or update the old one with the new file const assistant = await io.openai.runTask("create-or-update-assistant", async (openai) => { const currentAssistant = await prisma.assistant.findFirst({ where: { url: payload.url } }); if (currentAssistant) { return openai.beta.assistants.update(currentAssistant.aId, { file_ids: [file.id] }); } return openai.beta.assistants.create({ name: identifier, description: 'Documentation', instructions: 'You are a documentation assistant, you have been loaded with documentation from ' + payload.url + ', return everything in an MD format.', model: 'gpt-4-1106-preview', tools: [{ type: "code_interpreter" }, {type: 'retrieval'}], file_ids: [file.id], }); }); // We update our internal database with the assistant await io.runTask("save-assistant", async () => { await prisma.assistant.upsert({ where: { url: payload.url }, update: { aId: assistant.id, }, create: { aId: assistant.id, url: payload.url, } }); }); }, }); export function getElementsBetween(startElement: Element, endElement: Element) { let currentElement = startElement; const elements = []; // Traverse the DOM until the endElement is reached while (currentElement && currentElement !== endElement) { currentElement = currentElement.nextElementSibling!; // If there's no next sibling, go up a level and continue if (!currentElement) { // @ts-ignore currentElement = startElement.parentNode!; startElement = currentElement; if (currentElement === endElement) break; continue; } // Add the current element to the list if (currentElement && currentElement !== endElement) { elements.push(currentElement); } } return elements; } // This job will grab the content from the website const processContent = client.defineJob({ // This is the unique identifier for your Job; it must be unique across all Jobs in your project. id: "process-content", name: "Process Content", version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction trigger: eventTrigger({ name: "process.content.event", schema: object({ url: string(), identifier: string(), }) }), run: async (payload, io, ctx) => { return io.runTask('grab-content', async () => { try { // We first grab a raw HTML of the content from the website const data = await (await fetch(payload.url)).text(); // We load it with JSDOM so we can manipulate it const dom = new JSDOM(data); // We remove all the scripts and styles from the page dom.window.document.querySelectorAll('script, style').forEach((el) => el.remove()); // We grab all the titles from the page const content = Array.from(dom.window.document.querySelectorAll('h1, h2, h3, h4, h5, h6')); // We grab the last element so we can get the content between the last element and the next element const lastElement = content[content.length - 1]?.parentElement?.nextElementSibling!; const elements = []; // We loop through all the elements and grab the content between each title for (let i = 0; i < content.length; i++) { const element = content[i]; const nextElement = content?.[i + 1] || lastElement; const elementsBetween = getElementsBetween(element, nextElement); elements.push({ title: element.textContent, content: elementsBetween.map((el) => el.textContent).join('\n') }); } // We create a raw text format of all the content const page = ` ---------------------------------- url: ${payload.url}\n ${elements.map((el) => `${el.title}\n${el.content}`).join('\n')} ---------------------------------- `; // We save it to our database await prisma.docs.upsert({ where: { url: payload.url }, update: { content: page, identifier: payload.identifier }, create: { url: payload.url, content: page, identifier: payload.identifier } }); } catch (e) { console.log(e); } }); }, }); ``` 我們已經完成建立後台作業來抓取和索引文件🎉 ### 詢問助理 現在,讓我們建立一個任務來詢問我們的助手。 前往“jobs”並建立一個新檔案“question.assistant.ts”。 **新增以下程式碼:** ``` import {eventTrigger} from "@trigger.dev/sdk"; import {client} from "@openai-assistant/trigger"; import {object, string} from "zod"; import {openai} from "@openai-assistant/helper/open.ai"; client.defineJob({ // This is the unique identifier for your Job; it must be unique across all Jobs in your project. id: "question-assistant", name: "Question Assistant", version: "0.0.1", // This is triggered by an event using eventTrigger. You can also trigger Jobs with webhooks, on schedules, and more: https://trigger.dev/docs/documentation/concepts/triggers/introduction trigger: eventTrigger({ name: "question.assistant.event", schema: object({ content: string(), aId: string(), threadId: string().optional(), }) }), integrations: { openai }, run: async (payload, io, ctx) => { // Create or use an existing thread const thread = payload.threadId ? await io.openai.beta.threads.retrieve('get-thread', payload.threadId) : await io.openai.beta.threads.create('create-thread'); // Create a message in the thread await io.openai.beta.threads.messages.create('create-message', thread.id, { content: payload.content, role: 'user', }); // Run the thread const run = await io.openai.beta.threads.runs.createAndWaitForCompletion('run-thread', thread.id, { model: 'gpt-4-1106-preview', assistant_id: payload.aId, }); // Check the status of the thread if (run.status !== "completed") { console.log('not completed'); throw new Error(`Run finished with status ${run.status}: ${JSON.stringify(run.last_error)}`); } // Get the messages from the thread const messages = await io.openai.beta.threads.messages.list("list-messages", run.thread_id, { query: { limit: "1" } }); const content = messages[0].content[0]; if (content.type === 'text') { return {content: content.text.value, threadId: thread.id}; } } }); ``` - 該事件需要三個參數 - `content` - 我們想要傳送給助理的訊息。 - `aId` - 我們先前建立的助手的內部 ID。 - `threadId` - 對話的執行緒 ID。正如您所看到的,這是一個可選參數,因為在第一個訊息中,我們還沒有線程 ID。 - 然後,我們建立或取得前一個執行緒的執行緒。 - 我們在助理提出的問題的線索中加入一條新訊息。 - 我們執行線程並等待它完成。 - 我們取得訊息清單(並將其限制為 1),因為第一則訊息是對話中的最後一則訊息。 - 我們返回訊息內容和我們剛剛建立的線程ID。 ### 新增路由 我們需要為我們的應用程式建立 3 個 API 路由: 1、派新助理進行處理。 2. 透過URL獲取特定助手。 3. 新增訊息給助手。 在「app/api」中建立一個名為assistant的新資料夾,並在其中建立一個名為「route.ts」的新檔案。裡面加入如下程式碼: ``` import {client} from "@openai-assistant/trigger"; import {prisma} from "@openai-assistant/helper/prisma.client"; export async function POST(request: Request) { const body = await request.json(); if (!body.url) { return new Response(JSON.stringify({error: 'URL is required'}), {status: 400}); } // We send an event to the trigger to process the documentation const {id: eventId} = await client.sendEvent({ name: "process.documentation.event", payload: {url: body.url}, }); return new Response(JSON.stringify({eventId}), {status: 200}); } export async function GET(request: Request) { const url = new URL(request.url).searchParams.get('url'); if (!url) { return new Response(JSON.stringify({error: 'URL is required'}), {status: 400}); } const assistant = await prisma.assistant.findFirst({ where: { url: url } }); return new Response(JSON.stringify(assistant), {status: 200}); } ``` 第一個「POST」方法取得一個 URL,並使用用戶端傳送的 URL 觸發「process.documentation.event」作業。 第二個「GET」方法從我們的資料庫中透過客戶端發送的 URL 取得助手。 現在,讓我們建立向助手新增訊息的路由。 在「app/api」內部建立一個新資料夾「message」並新增一個名為「route.ts」的新文件,然後新增以下程式碼: ``` import {prisma} from "@openai-assistant/helper/prisma.client"; import {client} from "@openai-assistant/trigger"; export async function POST(request: Request) { const body = await request.json(); // Check that we have the assistant id and the message if (!body.id || !body.message) { return new Response(JSON.stringify({error: 'Id and Message are required'}), {status: 400}); } // get the assistant id in OpenAI from the id in the database const assistant = await prisma.assistant.findUnique({ where: { id: +body.id } }); // We send an event to the trigger to process the documentation const {id: eventId} = await client.sendEvent({ name: "question.assistant.event", payload: { content: body.message, aId: assistant?.aId, threadId: body.threadId }, }); return new Response(JSON.stringify({eventId}), {status: 200}); } ``` 這是一個非常基本的程式碼。我們從客戶端獲取訊息、助手 ID 和線程 ID,並將其發送到我們之前建立的「question.assistant.event」。 最後要做的事情是建立一個函數來獲取我們所有的助手。 在「helpers」內部建立一個名為「get.list.ts」的新函數並新增以下程式碼: ``` import {prisma} from "@openai-assistant/helper/prisma.client"; // Get the list of all the available assistants export const getList = () => { return prisma.assistant.findMany({ }); } ``` 非常簡單的程式碼即可獲得所有助手。 我們已經完成了後端🥳 讓我們轉到前面。 ---  ## 建立前端 我們將建立一個基本介面來新增 URL 並顯示已新增 URL 的清單: 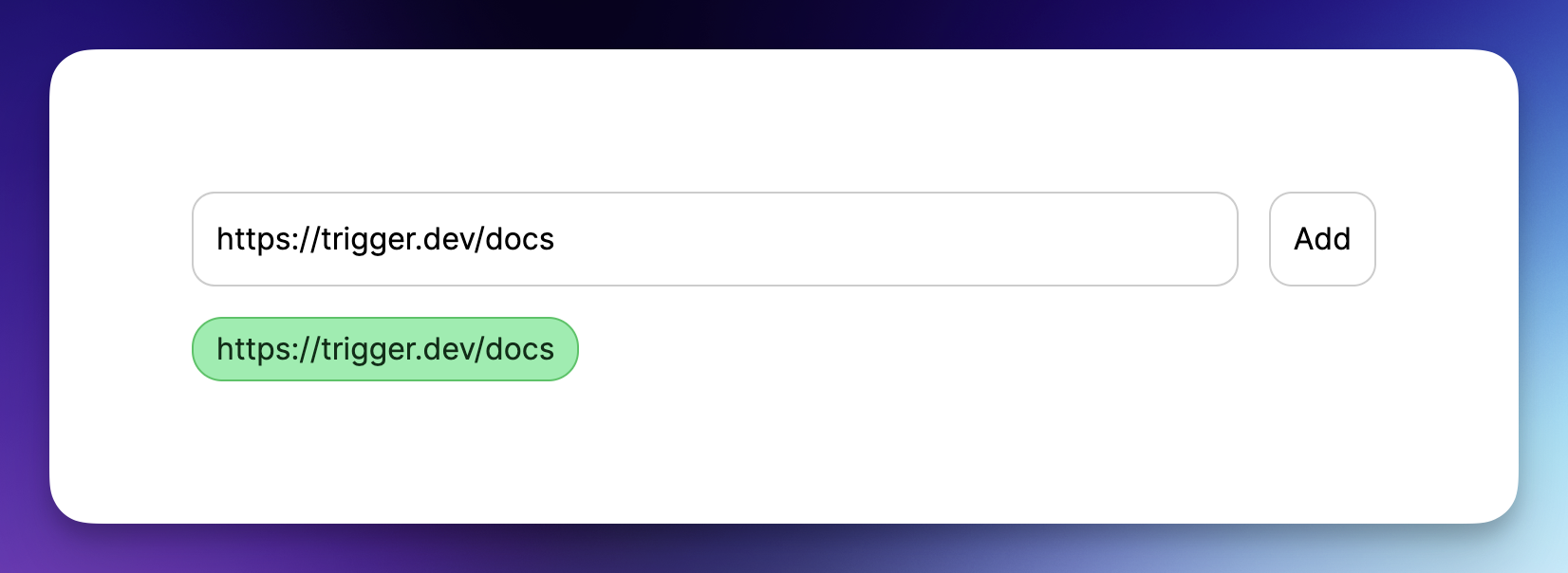 ### 首頁 將 `app/page.tsx` 的內容替換為以下程式碼: ``` import {getList} from "@openai-assistant/helper/get.list"; import Main from "@openai-assistant/components/main"; export default async function Home() { const list = await getList(); return ( <Main list={list} /> ) } ``` 這是一個簡單的程式碼,它從資料庫中取得清單並將其傳遞給我們的 Main 元件。 接下來,讓我們建立“Main”元件。 在「app」內建立一個新資料夾「components」並新增一個名為「main.tsx」的新檔案。 **新增以下程式碼:** ``` "use client"; import {Assistant} from '@prisma/client'; import {useCallback, useState} from "react"; import {FieldValues, SubmitHandler, useForm} from "react-hook-form"; import {ChatgptComponent} from "@openai-assistant/components/chatgpt.component"; import {AssistantList} from "@openai-assistant/components/assistant.list"; import {TriggerProvider} from "@trigger.dev/react"; export interface ExtendedAssistant extends Assistant { pending?: boolean; eventId?: string; } export default function Main({list}: {list: ExtendedAssistant[]}) { const [assistantState, setAssistantState] = useState(list); const {register, handleSubmit} = useForm(); const submit: SubmitHandler<FieldValues> = useCallback(async (data) => { const assistantResponse = await (await fetch('/api/assistant', { body: JSON.stringify({url: data.url}), method: 'POST', headers: { 'Content-Type': 'application/json' } })).json(); setAssistantState([...assistantState, {...assistantResponse, url: data.url, pending: true}]); }, [assistantState]) const changeStatus = useCallback((val: ExtendedAssistant) => async () => { const assistantResponse = await (await fetch(`/api/assistant?url=${val.url}`, { method: 'GET', headers: { 'Content-Type': 'application/json' } })).json(); setAssistantState([...assistantState.filter((v) => v.id), assistantResponse]); }, [assistantState]) return ( <TriggerProvider publicApiKey={process.env.NEXT_PUBLIC_TRIGGER_PUBLIC_API_KEY!}> <div className="w-full max-w-2xl mx-auto p-6 flex flex-col gap-4"> <form className="flex items-center space-x-4" onSubmit={handleSubmit(submit)}> <input className="flex-grow p-3 border border-black/20 rounded-xl" placeholder="Add documentation link" type="text" {...register('url', {required: 'true'})} /> <button className="flex-shrink p-3 border border-black/20 rounded-xl" type="submit"> Add </button> </form> <div className="divide-y-2 divide-gray-300 flex gap-2 flex-wrap"> {assistantState.map(val => ( <AssistantList key={val.url} val={val} onFinish={changeStatus(val)} /> ))} </div> {assistantState.filter(f => !f.pending).length > 0 && <ChatgptComponent list={assistantState} />} </div> </TriggerProvider> ) } ``` 讓我們看看這裡發生了什麼: - 我們建立了一個名為「ExtendedAssistant」的新接口,其中包含兩個參數「pending」和「eventId」。當我們建立一個新的助理時,我們沒有最終的值,我們將只儲存`eventId`並監聽作業處理直到完成。 - 我們從伺服器元件取得清單並將其設定為新狀態(以便我們稍後可以修改它) - 我們新增了「TriggerProvider」來幫助我們監聽事件完成並用資料更新它。 - 我們使用「react-hook-form」建立一個新表單來新增助手。 - 我們新增了一個帶有一個輸入「URL」的表單來提交新的助理進行處理。 - 我們迭代並顯示所有現有的助手。 - 在提交表單時,我們將資訊傳送到先前建立的「路由」以新增助理。 - 事件完成後,我們觸發「changeStatus」以從資料庫載入助手。 - 最後,我們有了 ChatGPT 元件,只有在沒有等待處理的助手時才會顯示(`!f.pending`) 讓我們建立 `AssistantList` 元件。 在「components」內,建立一個新檔案「assistant.list.tsx」並在其中加入以下內容: ``` "use client"; import {FC, useEffect} from "react"; import {ExtendedAssistant} from "@openai-assistant/components/main"; import {useEventRunDetails} from "@trigger.dev/react"; export const Loading: FC<{eventId: string, onFinish: () => void}> = (props) => { const {eventId} = props; const { data, error } = useEventRunDetails(eventId); useEffect(() => { if (!data || error) { return ; } if (data.status === 'SUCCESS') { props.onFinish(); } }, [data]); return <div className="pointer bg-yellow-300 border-yellow-500 p-1 px-3 text-yellow-950 border rounded-2xl">Loading</div> }; export const AssistantList: FC<{val: ExtendedAssistant, onFinish: () => void}> = (props) => { const {val, onFinish} = props; if (val.pending) { return <Loading eventId={val.eventId!} onFinish={onFinish} /> } return ( <div key={val.url} className="pointer relative bg-green-300 border-green-500 p-1 px-3 text-green-950 border rounded-2xl hover:bg-red-300 hover:border-red-500 hover:text-red-950 before:content-[attr(data-content)]" data-content={val.url} /> ) } ``` 我們迭代我們建立的所有助手。如果助手已經建立,我們只顯示名稱。如果沒有,我們渲染`<Loading />`元件。 載入元件在螢幕上顯示“正在載入”,並長時間輪詢伺服器直到事件完成。 我們使用 Trigger.dev 建立的 useEventRunDetails 函數來了解事件何時完成。 事件完成後,它會觸發「onFinish」函數,用新建立的助手更新我們的客戶端。 ### 聊天介面  現在,讓我們加入 ChatGPT 元件並向我們的助手提問! - 選擇我們想要使用的助手 - 顯示訊息列表 - 新增我們要傳送的訊息的輸入和提交按鈕。 在「components」內部新增一個名為「chatgpt.component.tsx」的新文件 讓我們繪製 ChatGPT 聊天框: ``` "use client"; import {FC, useCallback, useEffect, useRef, useState} from "react"; import {ExtendedAssistant} from "@openai-assistant/components/main"; import Markdown from 'react-markdown' import {useEventRunDetails} from "@trigger.dev/react"; interface Messages { message?: string eventId?: string } export const ChatgptComponent = ({list}: {list: ExtendedAssistant[]}) => { const url = useRef<HTMLSelectElement>(null); const [message, setMessage] = useState(''); const [messagesList, setMessagesList] = useState([] as Messages[]); const [threadId, setThreadId] = useState<string>('' as string); const submitForm = useCallback(async (e: any) => { e.preventDefault(); setMessagesList((messages) => [...messages, {message: `**[ME]** ${message}`}]); setMessage(''); const messageResponse = await (await fetch('/api/message', { method: 'POST', body: JSON.stringify({message, id: url.current?.value, threadId}), })).json(); if (!threadId) { setThreadId(messageResponse.threadId); } setMessagesList((messages) => [...messages, {eventId: messageResponse.eventId}]); }, [message, messagesList, url, threadId]); return ( <div className="border border-black/50 rounded-2xl flex flex-col"> <div className="border-b border-b-black/50 h-[60px] gap-3 px-3 flex items-center"> <div>Assistant:</div> <div> <select ref={url} className="border border-black/20 rounded-xl p-2"> {list.filter(f => !f.pending).map(val => ( <option key={val.id} value={val.id}>{val.url}</option> ))} </select> </div> </div> <div className="flex-1 flex flex-col gap-3 py-3 w-full min-h-[500px] max-h-[1000px] overflow-y-auto overflow-x-hidden messages-list"> {messagesList.map((val, index) => ( <div key={index} className={`flex border-b border-b-black/20 pb-3 px-3`}> <div className="w-full"> {val.message ? <Markdown>{val.message}</Markdown> : <MessageComponent eventId={val.eventId!} onFinish={setThreadId} />} </div> </div> ))} </div> <form onSubmit={submitForm}> <div className="border-t border-t-black/50 h-[60px] gap-3 px-3 flex items-center"> <div className="flex-1"> <input value={message} onChange={(e) => setMessage(e.target.value)} className="read-only:opacity-20 outline-none border border-black/20 rounded-xl p-2 w-full" placeholder="Type your message here" /> </div> <div> <button className="border border-black/20 rounded-xl p-2 disabled:opacity-20" disabled={message.length < 3}>Send</button> </div> </div> </form> </div> ) } export const MessageComponent: FC<{eventId: string, onFinish: (threadId: string) => void}> = (props) => { const {eventId} = props; const { data, error } = useEventRunDetails(eventId); useEffect(() => { if (!data || error) { return ; } if (data.status === 'SUCCESS') { props.onFinish(data.output.threadId); } }, [data]); if (!data || error || data.status !== 'SUCCESS') { return ( <div className="flex justify-end items-center pb-3 px-3"> <div className="animate-spin rounded-full h-3 w-3 border-t-2 border-b-2 border-blue-500" /> </div> } return <Markdown>{data.output.content}</Markdown>; }; ``` 這裡正在發生一些令人興奮的事情: - 當我們建立新訊息時,我們會自動將其呈現在螢幕上作為「我們的」訊息,但是當我們將其發送到伺服器時,我們需要推送事件 ID,因為我們還沒有訊息。這就是我們使用 `{val.message ? <Markdown>{val.message}</Markdown> : <MessageComponent eventId={val.eventId!} onFinish={setThreadId} />}` - 我們用「Markdown」元件包裝訊息。如果您還記得,我們在前面的步驟中告訴 ChatGPT 以 MD 格式輸出所有內容,以便我們可以正確渲染它。 - 事件處理完成後,我們會更新線程 ID,以便我們從以下訊息中獲得相同對話的上下文。 我們就完成了🎉 ---  ## 讓我們聯絡吧! 🔌 作為開源開發者,您可以加入我們的[社群](https://discord.gg/nkqV9xBYWy) 做出貢獻並與維護者互動。請隨時造訪我們的 [GitHub 儲存庫](https://github.com/triggerdotdev/trigger.dev),貢獻並建立與 Trigger.dev 相關的問題。 本教學的源程式碼可在此處取得: [https://github.com/triggerdotdev/blog/tree/main/openai-assistant](https://github.com/triggerdotdev/blog/tree/main/openai-assistant) 感謝您的閱讀! --- 原文出處:https://dev.to/triggerdotdev/train-chatgpt-on-your-documentation-1a9g
曾經嘗試過在 Web 應用程式中使用 Docker 磁碟區進行熱重載嗎?如果你有跟我一樣可怕的經歷,你會喜歡 Docker 剛剛發布的最新功能:**docker-compose watch**!讓我向您展示如何升級現有專案以獲得出色的 Docker 開發設置,您的團隊*實際上*會喜歡使用它 🤩 TL;DR:看看這個 [docker-compose](https://github.com/Code42Cate/hackathon-starter/blob/main/docker-compose.yml) 檔案和 [官方文件](https://docs.docker.com/compose/file-watch/) 讓我們開始吧!  ## 介紹 Docker 剛剛發布了[Docker Compose Watch](https://docs.docker.com/compose/file-watch/) 和[Docker Compose Version 2.22](https://docs.docker.com/compose/release-notes/) #2220).有了這個新功能,您可以使用“docker-compose watch”代替“docker-compose up”,並自動將本機原始程式碼與 Docker 容器中的程式碼同步,而無需使用磁碟區! 讓我們透過使用我[之前寫過的](https://dev.project) 來看看它在實際專案中的工作原理。 在這個專案中,我有一個帶有前端、後端以及一些用於 UI 和資料庫的附加庫的 monorepo。 ``` ├── apps │ ├── api │ └── web └── packages ├── database ├── eslint-config-custom ├── tsconfig └── ui ``` 兩個應用程式(「api」和「web」)都已經進行了docker 化,而Dockerfile 位於專案的根目錄中([1](https://github.com/Code42Cate/hackathon-starter/blob/main/api.Dockerfile ), [2](https://github.com/Code42Cate/hackathon-starter/blob/main/web.Dockerfile)) `docker-compose.yml` 檔案如下所示: ``` services: web: build: dockerfile: web.Dockerfile ports: - "3000:3000" depends_on: - api api: build: dockerfile: api.Dockerfile ports: - "3001:3000"from within the Docker network ``` 這已經相當不錯了,但如您所知,在開發過程中使用它是一個 PITA。每當您更改程式碼時,您都必須重建 Docker 映像,即使您的應用程式可能支援開箱即用的熱重載(或使用 [Nodemon](https://www.npmjs.com/package/nodemon) 如果不)。 為了改善這一點,Docker Compose Watch [引入了一個新屬性](https://docs.docker.com/compose/file-watch/#configuration),稱為「watch」。 watch 屬性包含一個所謂的 **rules** 列表,每個規則都包含它們正在監視的 **path** 以及一旦路徑中的文件發生更改就會執行的 **action**。 ## 同步 如果您希望在主機和容器之間同步資料夾,您可以新增: ``` services: web: # shortened for clarity build: dockerfile: web.Dockerfile develop: watch: - action: sync path: ./apps/web target: /app/apps/web ``` 每當主機上的路徑“./apps/web/”中的檔案發生變更時,它將同步(複製)到容器的“/app/apps/web”。目標路徑中的附加應用程式是必要的,因為這是我們在 [Dockerfile](https://github.com/Code42Cate/hackathon-starter/blob/main/web.Dockerfile) 中定義的「WORKDIR」。如果您有可熱重新加載的應用程式,這可能是您可能會使用的主要內容。 ## 重建 如果您有需要編譯的應用程式或需要重新安裝的依賴項,還有一個名為 **rebuild** 的操作。它將重建並重新啟動容器,而不是簡單地在主機和容器之間複製檔案。這對你的 npm 依賴關係非常有幫助!讓我們補充一下: ``` services: web: # shortened for clarity build: dockerfile: web.Dockerfile develop: watch: - action: sync path: ./apps/web target: /app/apps/web - action: rebuild path: ./package.json target: /app/package.json ``` 每當我們的 package.json 發生變化時,我們都會重建整個 Dockerfile 以安裝新的依賴項。 ## 同步+重啟 除了同步和重建之外,中間還有一些稱為同步+重新啟動的操作。此操作將首先同步目錄,然後立即重新啟動容器而不重建。大多數框架通常都有無法熱重載的設定檔(例如「next.config.js」)(僅同步是不夠的),但也不需要緩慢重建。 這會將您的撰寫文件更改為: ``` services: web: # shortened for clarity build: dockerfile: web.Dockerfile develop: watch: - action: sync path: ./apps/web target: /app/apps/web - action: rebuild path: ./package.json target: /app/package.json - action: sync+restart path: ./apps/web/next.config.js target: /app/apps/web/next.config.js ``` ## 注意事項 一如既往,沒有[免費午餐](https://en.wikipedia.org/wiki/No_free_lunch_in_search_and_optimization)和一些警告😬 新的“watch”屬性的最大問題是路徑仍然非常基本。文件指出,尚不支援 Glob 模式,如果您想具體說明,這可能會導致「大量」規則。 以下是一些有效和無效的範例: ✅ `應用程式/網路` 這將會符合`./apps/web`中的*所有*檔案(例如`./apps/web/README.md`,還有`./apps/web/src/index.tsx`) ❌ `build/**/!(*.spec|*.bundle|*.min).js` 遺憾的是(還沒?) 支持 Glob ❌ `~/下載` 所有路徑都是相對於專案根目錄的! ## 下一步 如果您對 Docker 設定仍然不滿意,還有很多方法可以改進它! 協作是軟體開發的重要組成部分,[孤島工作](https://www.personio.com/hr-lexicon/working-in-silos/)可能會嚴重損害您的團隊。緩慢的 Docker 建置和複雜的設定沒有幫助!為了解決這個問題並促進協作文化,您可以使用 Docker 擴展,例如 [Livecycle](https://hub.docker.com/extensions/livecycle/docker-extension?utm_source=github&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm_medium=code42cate&utm_campaign=docker-composeub&utm)立即與您的隊友分享您本地的docker-compose 應用程式。由於您已經在使用 Docker 和 docker-compose,因此您需要做的就是安裝 [Docker 桌面擴充](https://hub.docker.com/extensions/livecycle/docker-extension?utm_source=github&utm_medium=code42cate&utm_campaign=hackathonstarter )並點擊共享切換按鈕。然後,您的應用程式將透過隧道連接到網路,您可以與您的團隊分享您的唯一 URL 以獲取回饋!如果您想查看 Livecycle 的更多用例,我在[這篇文章](https://dev.to/code42cate/how-to-win-any-hackathon-3i99)中寫了更多相關內容:) 像往常一樣,確保您的 Dockerfile 遵循最佳實踐,尤其是在多階段建置和快取方面。雖然這可能會使編寫初始 Dockerfile 變得更加困難,但它將使您的 Docker 應用程式在開發過程中使用起來更加愉快。 建立一個基本的“.dockerignore”檔案並將依賴項安裝與程式碼建置分開還有很長的路要走! ## 結論 一如既往,我希望你今天學到新東西了!如果您在設定 Docker 專案時需要任何協助,或者您有任何其他回饋,請告訴我 乾杯,喬納斯:D --- 原文出處:https://dev.to/code42cate/say-goodbye-to-docker-volumes-j9l
本文列出了開發人員在 Kubernetes 叢集上安裝的五個必備工具。 🎉 請隨意探索這些專案,為儲存庫加註星標,並為您最喜歡的專案做出貢獻。 😉 事不宜遲,讓我們開始吧。 🏃♂️💨  ** ** ## **1\. [Odigos](https://odigos.io)** > 💡 分散式跟踪,無需更改程式碼。  Odigos 是一個開源可觀測性控制平面,使組織能夠建立和維護其可觀測性管道。 Odigos 自動產生 OpenTelemetry 格式的遙測資料到任何 Observability 後端,無需更改任何程式碼。 😻。 它會自動檢測我們的應用程式,從而無需我們自己設定 OpenTelemetry 或任何其他內容。奧迪戈斯處理這一切。 🤯 這一切之所以成為可能,是因為: * **自動化檢測👾:** Odigos 支援使用 OpenTelemetry 和 eBPF 對應用程式進行自動化檢測,無需修改程式碼。 * **通用觀測工具相容性🤝:** 與各種觀測工具平滑集成,提供全面的支援和高效的收集器管理。 ** ** ## **2\. [Argo CD](https://argoproj.github.io/cd/)** 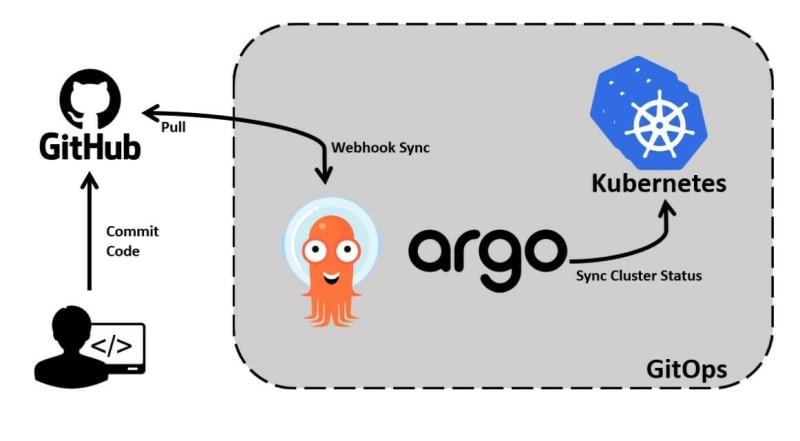 Argo CD 是一款功能強大的 GitOps CD 工具,可協助自動化和簡化 Kubernetes 應用程式的部署和管理🚀。 Argo CD 主要功能包括 Web UI 💻、CLI、回滾功能和簡化的監控。 > **為什麼要使用 Argo CD 而不是傳統的 CD 工具?** 🤔 * **Git 作為單一事實來源 🤫:** Argo CD 使用 Git 作為應用程式和基礎設施配置的單一事實來源。如果出現問題,它可以輕鬆追蹤變更並回滾部署。 * **友善的 Web UI 💻:** Argo CD 提供了一個儀表板來管理和取得所有已部署應用程式的狀態。 * **輕鬆回滾 🔄:** 叢集與單獨的 git 儲存庫同步,因此我們只需要恢復 git 中的更改,叢集就會自動與 git 儲存庫同步。 * **災難復原 🌋:** 如果發生災難,只需將 git 儲存庫指向新建立的集群,它將擁有先前集群的所有配置。 這些功能使初學者和經驗豐富的 Kubernetes 用戶都可以使用它。 > 簡而言之,Argo CD 是 Kubernetes ☸️ 的 GitOps CD 工具,它使用 Git 作為應用程式和基礎設施配置的單一來源,並提供輕鬆的回滾、儀表板和災難復原功能。 ** ** ## **3\. [Nginx 入口控制器](https://docs.nginx.com/nginx-ingress-controller/)** > 💡 適用於 Kubernetes 環境的專用負載平衡器。 它是 Kubernetes 使用最廣泛的入口控制器。 ☸️ 它使用 Nginx 作為反向代理和負載平衡器。 它在具有 Nginx Plus 或 Nginx 開源實例的 Kubernetes 環境中執行 🏃♂️。 Nginx Ingress Controller 的主要職責是👇: * 負載平衡 Kubernetes 叢集中容器📦的流量。它監視 Kubernetes 入口資源並將流量路由到適當的 Kubernetes 服務和 Pod。 * 處理網路、流量管理👮♂️、通訊和安全性🔒。 * 根據其配置部署資源並根據入口資源定義自動更新規則。 > 簡而言之,它管理流量、安全性並根據 Kubernetes 入口資源和配置動態調整路由。 ** ** ## **4\. [適用於 Kubernetes 的 AWS 控制器](https://aws-controllers-k8s.github.io/community/)** > 💡 使用 Kubernetes 管理 AWS 服務。 **ACK** 是 AWS Controllers for Kubernetes 的縮寫,是一組自訂控制器,可實現 AWS 服務和 Kubernetes 叢集之間的集成,讓您可以直接從 Kubernetes 管理 AWS 服務。 ACK 讓您可以輕鬆建立利用 AWS 服務的可擴充且高度可用的 Kubernetes 應用程式。它提供了一種統一的方式來管理我們的應用程式及其相依性✨️。 適用於 Kubernetes 的 AWS 控制器的一些主要功能包括: * 直接從 Kubernetes 定義和使用 AWS 服務資源。 * 利用 AWS 託管服務來管理 Kubernetes 應用程式,無需在叢集外部定義資源或執行提供資料庫或訊息佇列等支援功能的服務。 > 簡而言之,ACK 使我們能夠直接從 Kubernetes 管理 AWS 服務,並提供一種在 Kubernetes 叢集內定義和使用 AWS 服務的統一方法。 ** ** ## **5\. [Kyverno](https://kyverno.io)** > 💡 為 Kubernetes 設計的策略引擎。 在 Kubernetes 中部署事物(例如 Pod 或 ConfigMap)時,設定規則/策略非常重要。 一個關鍵的做法是避免在生產中使用容器鏡像的“最新”標籤,因為它通常是正在進行的開發建置。 > **Kyverno 實際上做了什麼?** 🧐 在 Kubernetes 中,安全性問題是一個大問題,主要原因之一是**配置錯誤**。當沒有良好的規則(政策)時,就會出現這些安全問題。 這就是像 **Kyverno** 這樣的策略管理器發揮作用的地方。 😎 > 🚨 **注意:** Kyverno 不適用於 Kubernetes 以外的任何其他環境。如果您正在尋找與供應商無關的策略管理,您可以考慮使用諸如[開放策略代理程式](https://www.openpolicyagent.org/)之類的東西。 Kyverno 在我們的 Kubernetes 設定中管理策略,無論它們是關於安全還是只是良好實踐。 我們可以為前面提到的「最新」標籤問題等建立規則,或專注於安全性,例如確保您的容器映像在軟體供應鏈中是安全的。 > 簡而言之,Kyverno 是一個策略引擎,它允許使用者管理部署策略、解決錯誤配置等問題並推廣良好實踐,從而幫助管理安全性和最佳實踐。 ** ** > 如果您認為本文中未提及的任何其他有用的專案,請在下面的評論部分分享。 👇🏻 那麼,這就是本文的內容。非常感謝您的閱讀! 🎉 --- 原文出處:https://dev.to/odigos/5-must-have-tools-to-install-on-your-kubernetes-cluster-489k
嗨朋友👋 今天,我們來看看如何編寫一個**KILLER GitHub README 文件。**  自述文件是任何剛接觸您的儲存庫的人的第一個接觸點。 **完善的自述文件可以提供資訊、吸引並邀請參與**。 當您啟動新專案或開發人員參與您的儲存庫至關重要時,這特別有用。 一個很好的例子是,當您向[Quine's Creator Quests](https://www.quine.sh/?utm_source=devto&utm_campaign=killer_github_profile) 提交儲存庫時,這是一種獎勵開發人員的新型開源「賞金」創造社區喜愛的酷炫新倉庫。 在創作者任務中,擁有一份寫得好的自述文件確實可以幫助您將獎品帶回家。 :錢_帶_翅膀: 如果您想參與,請在 [Quine](https://www.quine.sh/?utm_source=devto&utm_campaign=killer_github_profile) 免費註冊並前往 _Quests_。 --- ## 1️⃣ 自述文件...這是什麼? 🔮 README 文件,通常是“.txt”或“.md”文件,是專案中最重要的文件。它是開源專案的登陸頁面,也是最明顯的文件部分。 _這是 Hoppscotch 專案的自述文件範例。_ [](https://github.com/hoppscotch/hoppscotch) 您的自述文件是**您為專案定調的地方**。 這就是為什麼應該包含幾個元素的原因。 ⬇️ --- ## 2️⃣ 10 個建置模組🧱 自述文件可以透過多種方式編寫;有些比其他更好。 以下是您應該能夠在專業自述文件中找到的主要部分類型。 如果以下內容與您的專案相關,我建議您嘗試將它們加入到您的自述文件中。 👇 **1.想出一個名字** 大量的儲存庫沒有好名字。花點時間想一個令人難忘的名字總是一個好的開始。 **2.寫一個介紹** 解釋專案目的和目標受眾的摘要。 **3.目錄** 許多存儲庫未能加入此部分。組織良好的目錄有助於使您的儲存庫清晰易懂。 **4.先決條件和安裝說明** 列出各種逐步安裝說明。 _這裡的清晰度至關重要。_ ✨ **5.使用者指南/示範** 本節重點介紹如何透過範例和可選命令使用您的專案。我喜歡的一種方法是加入_如何執行專案_以及用戶如何使用它的螢幕記錄。 **6。文件/幫助中心** 如果您編寫了文件、常見問題或可以充當_幫助中心_的空間,請在此處寫下它或加入其連結。 **7.貢獻** 簡要解釋如何為您的文件做出貢獻並加入指向您的 CONTRIBUTING.md 文件的連結。在這裡或在單獨的部分中,您還可以藉此機會列出您的貢獻者並感謝他們。 **8.致謝** 使用或協助取得外部資源。僅當與您的儲存庫相關時才需要此部分。 **9.聯絡資訊** 如果您正在嘗試發展專案並建立協作,本節非常有用。 **10.權限資訊** 這是指您為專案選擇的許可證類型。澄清其他人如何使用您的內容至關重要。 👍 --- ## 3️⃣ 美化它💄 自述文件可以用各種文字格式編寫,其中 Markdown 是最常見的一種。 Markdown 可讓您使用簡單的純文字語法,支援建立標題、清單、連結和其他元素,使文件更具可讀性和組織性。 **Markdown 也支援 HTML 程式碼**,這拓寬了您可以做的事情的範圍。 👇 --- ### 標識 如果您已經為專案建立了徽標,則將其新增至自述文件的開頭是標準做法。 為此,請在自述文件中新增並修改以下程式碼: ``` <p align="center"> <!-- You can add your logo in the _src_ below --> <img src="https://www.amug.com/wp-content/uploads/2016/09/you-logo-here-300x106.png" /> </p> ``` --- ### 徽章 您經常會發現好的自述文件在其介紹部分中提供了徽章。 這些可以看起來像這樣: <p對齊=“中心”> <!-- 您可以在此處新增您的徽章 --> <!-- 如果您從未加入過徽章,請前往 https://img.shields.io/badges/static-badge --> <!-- 按照說明產生 URL 連結加入到下面 --> <img src="https://img.shields.io/badge/STARS-20K-green" /> <img src="https://img.shields.io/badge/FORKS-15K-blue" /> <img src="https://img.shields.io/badge/npm-v.0.21.0-red" /> <img src="https://img.shields.io/badge/LICENSE-MIT-green" /> </p> 正如您所看到的,這些突出顯示了維護人員想要闡明的一些領域。 以下是將 _static_ 徽章新增至自述文件的方法: ``` <p align="center"> <!-- You can add your badges here --> <!-- If you have never added badges, head over to https://img.shields.io/badges/static-badge, follow the instructions and generate URL links to add below --> <img src="https://img.shields.io/badge/STARS-20K-green" /> <img src="https://img.shields.io/badge/FORKS-15K-blue" /> <img src="https://img.shields.io/badge/npm-v.0.21.0-red" /> <img src="https://img.shields.io/badge/LICENSE-MIT-green" /> </p> ``` **注意**:_有一些高級動態選項我們不會在這裡討論。_ --- ### 圖示 近年來,圖標變得相當突出。 您可以將它們新增至您的_聯絡資訊_或您的_技術堆疊_部分。您可以找到 X(_以前的 Twitter_)和 Linkedin 的圖示範例。 <p對齊=“左”> <a href="https://twitter.com/fernandezbap" target="blank"><imgalign="center" src="https://img.shields.io/badge/X-000000?style=for - the-badge&logo=x&logoColor=white" alt="fernandezbap" /></a> </p> <p對齊=“左”> <a href="https://www.linkedin.com/in/baptiste-fernandez-%E5%B0%8F%E7%99%BD-0a958630/" target="blank"><img src="https: //img.shields.io/badge/LinkedIn-0077B5?style=for-the-badge&logo=linkedin&logoColor=white" alt="https://img.shields.io/badge/LinkedIn-0077B5?style=for-the -badge&logo=linkedin&logoColor=white" /></a> </p> 建立您自己的: 1️⃣ 前往此儲存庫[此處](https://github.com/alexandresanlim/Badges4-README.md-Profile#-social-) 2️⃣ 找到_社交_和/或_技術堆疊_,然後“複製”其連結 3️⃣ 將連結「貼上」到如下所示的「href」中 ``` <p align="left"> <!-- Add your own socials inside "href" --> <a href="https://twitter.com/fernandezbap" target="blank"><img align="center" src="https://img.shields.io/badge/X-000000?style=for-the-badge&logo=x&logoColor=white" alt="fernandezbap" /></a> </p> <p align="left"> <a href="https://www.linkedin.com/in/baptiste-fernandez-%E5%B0%8F%E7%99%BD-0a958630/" target="blank"><img src="https://img.shields.io/badge/LinkedIn-0077B5?style=for-the-badge&logo=linkedin&logoColor=white" alt="https://img.shields.io/badge/LinkedIn-0077B5?style=for-the-badge&logo=linkedin&logoColor=white" /></a> </p> ``` --- ## 4️⃣ 進階技巧🛠️ ### 互動內容🎥 您可以考慮嵌入影片或小部件來獲取互動式內容。 在自述文件的_演示_部分中,您可以嵌入影片。 **⭐️提示:** 有時,影片的尺寸太大,將影片上傳到 YouTube 然後連結出來更有意義。 如果您想讓它更加直觀,這裡有加入圖片/影片縮圖的程式碼,一旦您點擊它,該縮圖就會重定向到您的 YouTube 影片。 ``` <p align="center"> <a href="THE LINK TO YOUR YOUTUBE VIDEO HERE"> <img src="YOUR IMAGE/VIDEO THUMBNAIL SOURCE HERE"/> </a> </p> ``` --- ### Markdown 掌握 ✨ 有許多進階 Markdown 功能可以讓你的 README 看起來更漂亮。 您可以查看這個很酷的[repo](https://github.com/DavidWells/advanced-markdown),其中列出了其中一些功能。 我特別喜歡的一個是 **_切換列表_** 或更常見的名稱是_可折疊部分。_ 它們對於使您的自述文件看起來簡潔明了特別有用。這是一個例子:  以下是用於建立您自己的切換清單的 MARKDOWN 模板: ``` <details> <summary>Toggle List Example</summary> ### Heading 1. ABC 2. DEF * Hello </details> ``` --- ### 額外提示🎖️ 如果您想在_貢獻者部分_中表彰您的貢獻者,您應該查看 [AllContributors](https://allcontributors.org/)。 您可以利用其機器人自動將所有最新貢獻者新增至您的自述文件。 以下是您可以獲得的內容的範例: [](https://allcontributors.org/) 您還應該查看[表情符號關鍵文件](https://allcontributors.org/docs/en/emoji-key),它使您能夠對不同類型的貢獻進行分類。 ⚡️ ---- ## 5️⃣ 利用預製模板📝 ### 有沒有為您建立自述文件的網站? 🤔 絕對地! 您可以**在那裡找到大量自述文件生成器。** 我掃描並挑選了我最喜歡的三個給你: 1️⃣ [自述文件範本](https://www.readme-templates.com/) 2️⃣ [Readme.so](https://readme.so/editor) 3️⃣ [Vercel 的 ReadME 產生器](https://readme-gen.vercel.app/) 我對這些的建議是使用它們作為基礎,然後自訂它們。 ⭐️ --- ### 你有給我一個自述文件範本嗎? 👀 我找到你了,朋友。 🫶 您可以在[此處](https://github.com/quine-sh/README-Template)找到我現成的範本。 [](https://github.com/quine-sh/README-Template) 要開始使用它: 1️⃣ `Fork` 倉庫 2️⃣ 將滑鼠停留在自述文件的「編輯」部分 3️⃣開始填寫您的資料✍️ 如果您發現此模板有用,如果您能通過**加星標**_給予它一些愛_,我將不勝感激。 🌟 --- 建立良好的自述文件是一項重要技能。 🛠️ 如何建構它可能是_存儲庫成功的決定因素。_ 請務必在評論部分分享您的專案及其完善的新自述文件! 您還可以利用這項新技能來建立很酷的編碼專案並競爭以獲得報酬。 🙌 如果您對此感興趣,請登入 Quine 並探索[任務](https://www.quine.sh/?utm_source=devto&utm_campaign=killer_github_profile),這是一個編碼、享受樂趣並獲得一些超棒獎勵的地方! 💰  下週見。 你的開發夥伴, 巴巴💚 --- 原文出處:https://dev.to/quine/5-pro-tips-for-an-unbeatable-readme-143i
資料管道是任何資料密集型專案的支柱。 **隨著資料集的成長**超出記憶體大小(「核心外」),**有效處理它們變得具有挑戰性**。 Dask 可以輕鬆管理大型資料集(核心外),提供與 Numpy 和 Pandas 的良好相容性。  --- 本文重點介紹 **Dask(用於處理核心外資料)與 Taipy** 的無縫集成,Taipy** 是一個用於 **管道編排和場景管理** 的 Python 庫。 --- ## Taipy - 您的 Web 應用程式建構器 關於我們的一些資訊。 **Taipy** 是一個開源程式庫,旨在輕鬆開發前端 (GUI) 和 ML/資料管道。 不需要其他知識(沒有 CSS,什麼都不需要!)。 它旨在加快應用程式開發,從最初的原型到生產就緒的應用程式。  https://github.com/Avaiga/taipy 我們已經快有 1000 顆星了,沒有你就無法做到這一點🙏 --- ## 1. 範例應用程式 透過範例最好地演示了 Dask 和 Taipy 的整合。在本文中,我們將考慮包含 4 個任務的資料工作流程: - **資料預處理與客戶評分** 使用 Dask 讀取和處理大型資料集。 - **特徵工程和分割** 根據購買行為對客戶進行評分。 - **細分分析** 根據這些分數和其他因素將客戶分為不同的類別。 - **高價值客戶的總統計** 分析每個客戶群以獲得見解 我們將更詳細地探討這 4 個任務的程式碼。 請注意,此程式碼是您的 Python 程式碼,並未使用 Taipy。 在後面的部分中,我們將展示如何使用 Taipy 對現有資料應用程式進行建模,並輕鬆獲得其工作流程編排的好處。 --- 該應用程式將包含以下 5 個檔案: ``` algos/ ├─ algo.py # Our existing code with 4 tasks data/ ├─ SMALL_amazon_customers_data.csv # A sample dataset app.ipynb # Jupyter Notebook for running our sample data application config.py # Taipy configuration which models our data workflow config.toml # (Optional) Taipy configuration in TOML made using Taipy Studio ``` --- ## 2. Taipy 簡介 - 綜合解決方案 [Taipy](https://docs.taipy.io/) **不只是另一個編排工具**。 Taipy 專為 ML 工程師、資料科學家和 Python 開發人員設計,帶來了幾個基本且簡單的功能。 以下是**一些關鍵要素**,使 Taipy 成為令人信服的選擇: 1. **管道執行註冊表** 此功能使開發人員和最終用戶能夠: - 將每個管道執行註冊為「*場景*」(任務和資料節點圖); - 精確追蹤每個管道執行的沿襲;和 - 輕鬆比較場景、監控 KPI 並為故障排除和微調參數提供寶貴的見解。 2. **管道版本控制** Taipy 強大的場景管理使您能夠輕鬆調整管道以適應不斷變化的專案需求。 3. **智能任務編排** Taipy 讓開發人員可以輕鬆地對任務和資料來源網路進行建模。 此功能透過以下方式提供對任務執行的內建控制: - 並行執行您的任務;和 - 任務“跳過”,即選擇要執行的任務並 要繞過哪個。 4. **任務編排的模組化方法** 模組化不僅僅是 Taipy 的一個流行詞;這是一個核心原則。 設定可以互換使用的任務和資料來源,從而產生更乾淨、更易於維護的程式碼庫。 --- ## 3. Dask 簡介 Dask 是一個流行的分散式運算 Python 套件。 Dask API 實作了熟悉的 Pandas、Numpy 和 Scikit-learn API - ,這使得許多已經熟悉這些 API 的資料科學家更愉快地學習和使用 Dask。 如果您是 Dask 新手,請查看 Dask 團隊撰寫的精彩 Dask [10 分鐘簡介](https://docs.dask.org/en/stable/10-minutes-to-dask.html)。 --- ## 4. 應用:顧客分析 (*algos/algo.py*) 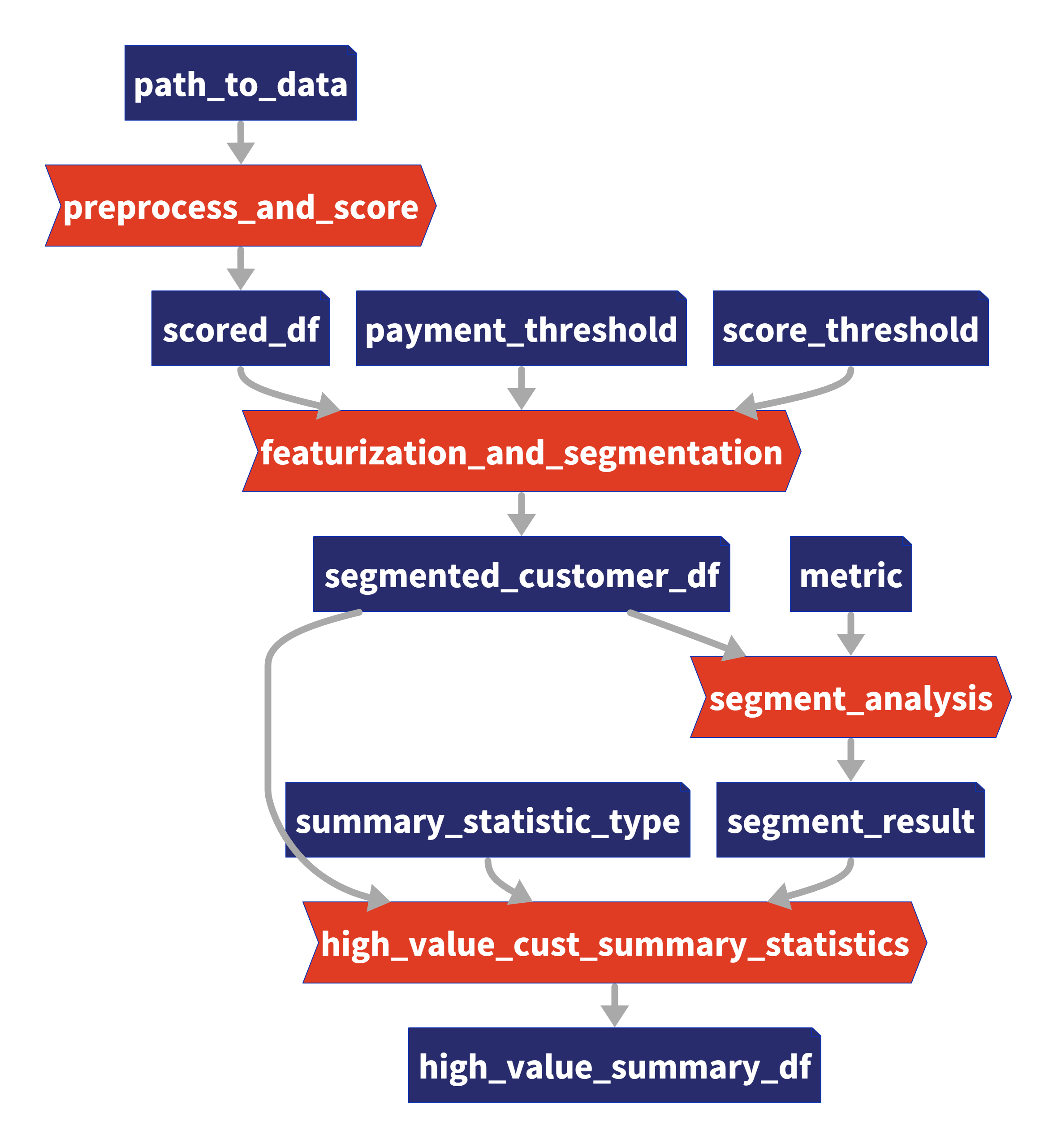 *我們的 4 項任務的圖表(在 Taipy 中可視化),我們將在下一節中對其進行建模。* 我們現有的程式碼(不含 Taipy)包含 4 個函數,您也可以在上圖中看到: - 任務 1:*預處理和評分* - 任務 2:*特徵化與細分* - 任務 3:*分段分析* - 任務 4:*high_value_cust_summary_statistics* 您可以瀏覽以下定義了 4 個函數的 *algos/algo.py* 腳本,然後繼續閱讀每個函數的簡要說明: ``` ### algos/algo.py import time import dask.dataframe as dd import pandas as pd def preprocess_and_score(path_to_original_data: str): print("__________________________________________________________") print("1. TASK 1: DATA PREPROCESSING AND CUSTOMER SCORING ...") start_time = time.perf_counter() # Start the timer # Step 1: Read data using Dask df = dd.read_csv(path_to_original_data) # Step 2: Simplify the customer scoring formula df["CUSTOMER_SCORE"] = ( 0.5 * df["TotalPurchaseAmount"] / 1000 + 0.3 * df["NumberOfPurchases"] / 10 + 0.2 * df["AverageReviewScore"] ) # Save all customers to a new CSV file scored_df = df[["CUSTOMER_SCORE", "TotalPurchaseAmount", "NumberOfPurchases", "TotalPurchaseTime"]] pd_df = scored_df.compute() end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return pd_df def featurization_and_segmentation(scored_df, payment_threshold, score_threshold): print("__________________________________________________________") print("2. TASK 2: FEATURE ENGINEERING AND SEGMENTATION ...") # payment_threshold, score_threshold = float(payment_threshold), float(score_threshold) start_time = time.perf_counter() # Start the timer df = scored_df # Feature: Indicator if customer's total purchase is above the payment threshold df["HighSpender"] = (df["TotalPurchaseAmount"] > payment_threshold).astype(int) # Feature: Average time between purchases df["AverageTimeBetweenPurchases"] = df["TotalPurchaseTime"] / df["NumberOfPurchases"] # Additional computationally intensive features df["Interaction1"] = df["TotalPurchaseAmount"] * df["NumberOfPurchases"] df["Interaction2"] = df["TotalPurchaseTime"] * df["CUSTOMER_SCORE"] df["PolynomialFeature"] = df["TotalPurchaseAmount"] ** 2 # Segment customers based on the score_threshold df["ValueSegment"] = ["High Value" if score > score_threshold else "Low Value" for score in df["CUSTOMER_SCORE"]] end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return df def segment_analysis(df: pd.DataFrame, metric): print("__________________________________________________________") print("3. TASK 3: SEGMENT ANALYSIS ...") start_time = time.perf_counter() # Start the timer # Detailed analysis for each segment: mean/median of various metrics segment_analysis = ( df.groupby("ValueSegment") .agg( { "CUSTOMER_SCORE": metric, "TotalPurchaseAmount": metric, "NumberOfPurchases": metric, "TotalPurchaseTime": metric, "HighSpender": "sum", # Total number of high spenders in each segment "AverageTimeBetweenPurchases": metric, } ) .reset_index() ) end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return segment_analysis def high_value_cust_summary_statistics(df: pd.DataFrame, segment_analysis: pd.DataFrame, summary_statistic_type: str): print("__________________________________________________________") print("4. TASK 4: ADDITIONAL ANALYSIS BASED ON SEGMENT ANALYSIS ...") start_time = time.perf_counter() # Start the timer # Filter out the High Value customers high_value_customers = df[df["ValueSegment"] == "High Value"] # Use summary_statistic_type to calculate different types of summary statistics if summary_statistic_type == "mean": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].mean() elif summary_statistic_type == "median": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].median() elif summary_statistic_type == "max": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].max() elif summary_statistic_type == "min": average_purchase_high_value = high_value_customers["TotalPurchaseAmount"].min() median_score_high_value = high_value_customers["CUSTOMER_SCORE"].median() # Fetch the summary statistic for 'TotalPurchaseAmount' for High Value customers from segment_analysis segment_statistic_high_value = segment_analysis.loc[ segment_analysis["ValueSegment"] == "High Value", "TotalPurchaseAmount" ].values[0] # Create a DataFrame to hold the results result_df = pd.DataFrame( { "SummaryStatisticType": [summary_statistic_type], "AveragePurchaseHighValue": [average_purchase_high_value], "MedianScoreHighValue": [median_score_high_value], "SegmentAnalysisHighValue": [segment_statistic_high_value], } ) end_time = time.perf_counter() # Stop the timer execution_time = (end_time - start_time) * 1000 # Calculate the time in milliseconds print(f"Time of Execution: {execution_time:.4f} ms") return result_df ``` --- ### 任務 1 - 資料預處理與客戶評分 Python 函數:*preprocess_and_score* 這是管道中的第一步,也許也是最關鍵的一步。 它使用 **Dask** 讀取大型資料集,專為大於記憶體的計算而設計。 然後,它根據“*TotalPurchaseAmount*”、“*NumberOfPurchases*”和“*AverageReviewScore*”等各種指標,在名為 *scored_df* 的 DataFrame 中計算“*Customer Score*”。 使用 Dask 讀取和處理資料集後,此任務將輸出一個 Pandas DataFrame,以供其餘 3 個任務進一步使用。 --- ### 任務 2 - 特徵工程與分割 Python 函數:*featureization_and_segmentation* 此任務採用評分的 DataFrame 並新增功能,例如高支出指標。 它還根據客戶的分數對客戶進行細分。 --- ### 任務 3 - 細分分析 Python 函數:*segment_analysis* 此任務採用分段的 DataFrame 並根據客戶細分執行分組分析以計算各種指標。 --- ### 任務 4 - 高價值客戶的總統計 Python 函數:*high_value_cust_summary_statistics* 此任務對高價值客戶群進行深入分析並傳回匯總統計資料。 --- ## 5. 在 Taipy 中建模工作流程 (*config.py*) 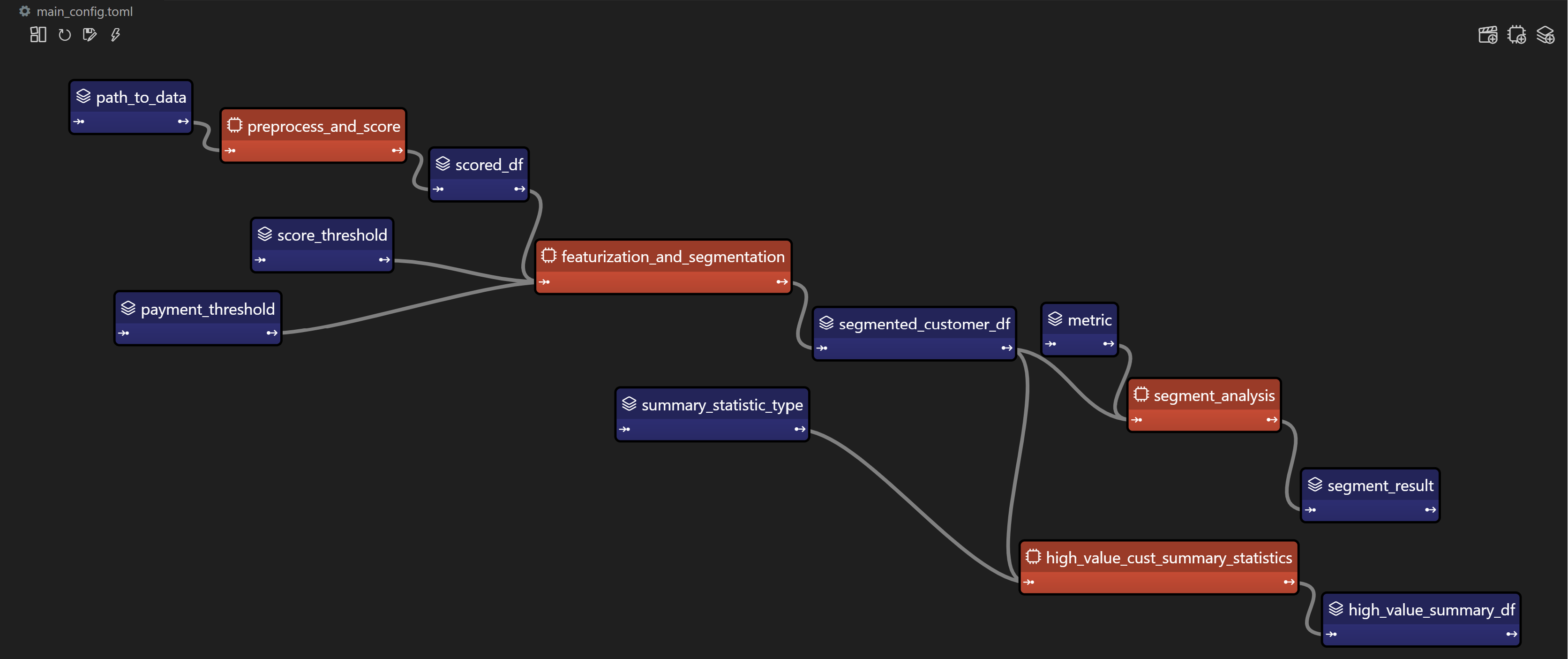 *Taipy DAG — Taipy「任務」為橘色,「資料節點」為藍色。* 在本節中,我們將建立對變數/參數進行建模的Taipy 配置(表示為[“資料節點”](https://docs.taipy.io/en/latest/manuals/core/concepts/data-node/ ))和 Taipy 中的函數(表示為 [“Tasks”](https://docs.taipy.io/en/latest/manuals/core/concepts/task/))。 --- 請注意,以下 *config.py* 腳本中的此配置類似於定義變數和函數 - 只不過我們定義的是「藍圖變數」(資料節點)和「藍圖函數」(任務)。 我們通知 Taipy 如何呼叫我們之前定義的函數、資料節點的預設值(我們可能會在執行時覆蓋)以及是否可以跳過任務: ``` ### config.py from taipy import Config from algos.algo import ( preprocess_and_score, featurization_and_segmentation, segment_analysis, high_value_cust_summary_statistics, ) # -------------------- Data Nodes -------------------- path_to_data_cfg = Config.configure_data_node(id="path_to_data", default_data="data/customers_data.csv") scored_df_cfg = Config.configure_data_node(id="scored_df") payment_threshold_cfg = Config.configure_data_node(id="payment_threshold", default_data=1000) score_threshold_cfg = Config.configure_data_node(id="score_threshold", default_data=1.5) segmented_customer_df_cfg = Config.configure_data_node(id="segmented_customer_df") metric_cfg = Config.configure_data_node(id="metric", default_data="mean") segment_result_cfg = Config.configure_data_node(id="segment_result") summary_statistic_type_cfg = Config.configure_data_node(id="summary_statistic_type", default_data="median") high_value_summary_df_cfg = Config.configure_data_node(id="high_value_summary_df") # -------------------- Tasks -------------------- preprocess_and_score_task_cfg = Config.configure_task( id="preprocess_and_score", function=preprocess_and_score, skippable=True, input=[path_to_data_cfg], output=[scored_df_cfg], ) featurization_and_segmentation_task_cfg = Config.configure_task( id="featurization_and_segmentation", function=featurization_and_segmentation, skippable=True, input=[scored_df_cfg, payment_threshold_cfg, score_threshold_cfg], output=[segmented_customer_df_cfg], ) segment_analysis_task_cfg = Config.configure_task( id="segment_analysis", function=segment_analysis, skippable=True, input=[segmented_customer_df_cfg, metric_cfg], output=[segment_result_cfg], ) high_value_cust_summary_statistics_task_cfg = Config.configure_task( id="high_value_cust_summary_statistics", function=high_value_cust_summary_statistics, skippable=True, input=[segment_result_cfg, segmented_customer_df_cfg, summary_statistic_type_cfg], output=[high_value_summary_df_cfg], ) scenario_cfg = Config.configure_scenario( id="scenario_1", task_configs=[ preprocess_and_score_task_cfg, featurization_and_segmentation_task_cfg, segment_analysis_task_cfg, high_value_cust_summary_statistics_task_cfg, ], ) ``` 號 您可以在[此處的文件](https://docs.taipy.io/en/latest/manuals/core/config/)中閱讀有關配置場景、任務和資料節點的更多資訊。 --- ### Taipy Studio [Taipy Studio](https://docs.taipy.io/en/latest/manuals/studio/config/) **是來自Taipy 的VS Code 擴充功能**,讓您**透過簡單的方式建置和視覺化您的管道拖放互動**。 Taipy Studio 提供了一個圖形編輯器,您可以在其中建立 Taipy 配置**存儲在 TOML 文件中**,您的 Taipy 應用程式可以加載並執行這些配置。 編輯器將場景表示為圖形,其中節點是資料節點和任務。 --- *作為本節中 config.py 腳本的替代方案,您可以使用 Taipy Studio 產生 config.toml 設定檔。 本文的倒數第二部分將提供有關如何使用 Taipy Studio 建立 config.toml 設定檔的指南。* --- ## 6. 場景建立與執行 執行 Taipy 場景涉及: - 載入配置; - 執行 Taipy Core 服務;和 - 建立並提交場景以供執行。 這是基本的程式碼模板: ``` import taipy as tp from config import scenario_cfg # Import the Scenario configuration tp.Core().run() # Start the Core service scenario_1 = tp.create_scenario(scenario_cfg) # Create a Scenario instance scenario_1.submit() # Submit the Scenario for execution # Total runtime: 74.49s ``` --- ### 跳過不必要的任務執行 Taipy 最實用的功能之一是,如果任務的輸出已經計算出來,它能夠跳過任務執行。 讓我們透過一些場景來探討這一點: --- #### 更改付款閾值 ``` # Changing Payment Threshold to 1600 scenario_1.payment_threshold.write(1600) scenario_1.submit() # Total runtime: 31.499s ``` *發生了什麼事*:Taipy 夠聰明,可以跳過任務 1,因為付款閾值只影響任務 2。 在這種情況下,透過使用 Taipy 執行管道,我們發現執行時間減少了 50% 以上。 --- #### 更改細分分析指標 ``` # Changing metric to median scenario_1.metric.write("median") scenario_1.submit() # Total runtime: 23.839s ``` *會發生什麼事*:在這種情況下,只有任務 3 和任務 4 受到影響。 Taipy 巧妙地跳過任務 1 和任務 2。 --- #### 更改總計統計類型 ``` # Changing summary_statistic_type to max scenario_1.summary_statistic_type.write("max") scenario_1.submit() # Total runtime: 5.084s ``` *發生了什麼事*:這裡,只有任務 4 受到影響,Taipy 僅執行此任務,跳過其餘任務。 Taipy 的智慧任務跳過功能不僅能節省時間,還能節省時間。它是一個資源優化器,在處理大型資料集時變得非常有用。 --- ## 7. Taipy Studio 您可以使用 Taipy Studio 建置 Taipy *config.toml* 設定檔來取代定義 *config.py* 腳本。 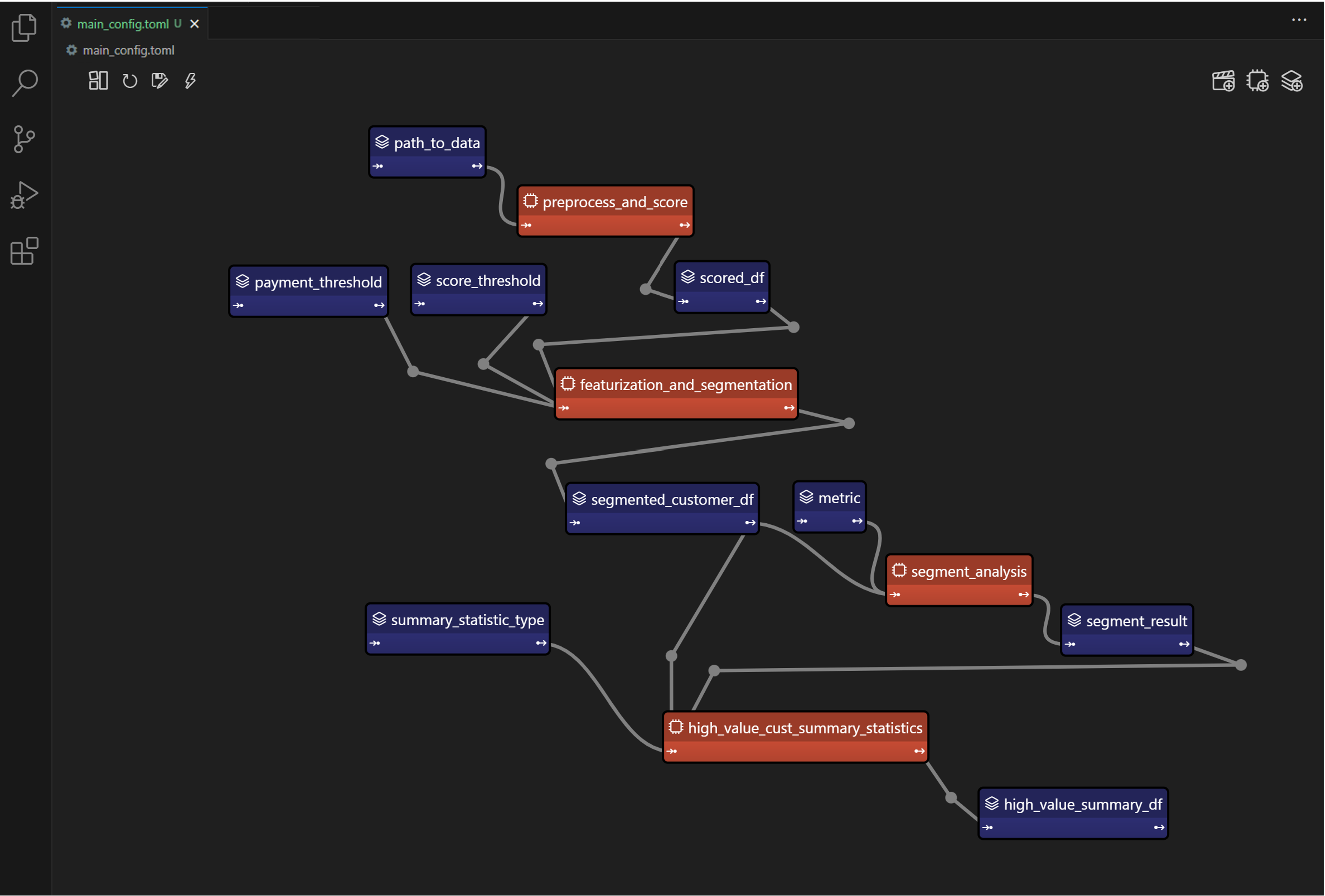 首先,使用擴展市場安裝 [Taipy Studio ](https://marketplace.visualstudio.com/items?itemName=Taipy.taipy-studio)擴充。 --- ### 建立配置 - **建立設定檔**:在 VS Code 中,導覽至 Taipy Studio,然後透過點擊參數視窗上的 + 按鈕啟動新的 TOML 設定檔。  - 然後右鍵單擊它並選擇 **Taipy:顯示視圖**。  - **新增實體**到您的 Taipy 配置: 在 Taipy Studio 的右側,您應該會看到一個包含 3 個圖示的列表,可用於設定管道。  1. 第一項是新增資料節點。您可以將任何 Python 物件連結到 Taipy 的資料節點。 2. 第二項用於新增任務。任務可以連結到預先定義的 Python 函數。 3. 第三項是新增場景。 Taipy 讓您在一個配置中擁有多個場景。 --- #### - 資料節點 **輸入資料節點**:建立一個名為“*path_to_data*”的資料節點,然後導航到“詳細資料”選項卡,新增屬性“*default_data*”,並將“*SMALL_amazon_customers_data.csv*”貼上為您的資料的路徑資料集。 --- **中間資料節點**:我們需要再增加四個資料節點:「*scored_df*」、「*segmented_customer_df*」、「*segment_result*」、「*high_value_summary_df*」。透過 Taipy 的智慧設計,您無需為這些中間資料節點進行任何配置;系統會巧妙地處理它們。 --- **具有預設值的中間資料節點**:我們最終定義了另外四個中間資料節點,並將「*default_data*」屬性設為以下內容: - payment_threshold: “1000:int” 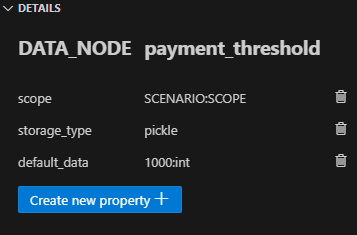 - 分數閾值:“1.5:浮動” - 測量:“平均值” -summary_statistic_type:“中位數” --- #### - 任務 點擊新增任務按鈕,您可以配置新任務。 新增四個任務,然後**將每個任務連結到「詳細資料」標籤下的對應函數**。 Taipy Studio 將掃描您的專案資料夾並提供可供選擇的分類函數列表,並按 Python 檔案排序。 --- **任務 1** (*preprocess_and_score*):在 Taipy studio 中,您可以按一下「任務」圖示以新增任務。 您可以將輸入指定為“*path_to_data*”,將輸出指定為“*scored_df*”。 然後,在「詳細資料」標籤下,您可以將此任務連結到 *algos.algo.preprocess_and_score* 函數。 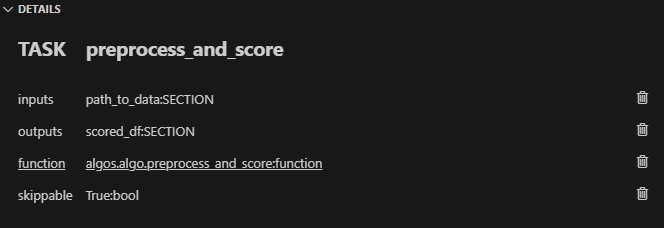 --- **任務 2** (*featurization_and_segmentation*):與任務 1 類似,您需要指定輸入 (“*scored_df*”、“* payment_threshold*”、“*score_threshold*”) 和輸出 (“*segmented_customer_df*”) ” )。將此任務連結到 *algos.algo.featurization_and_segmentation* 函數。 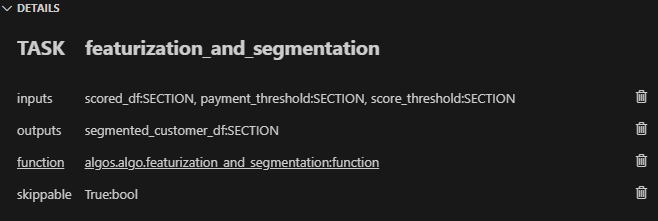 --- **任務 3** (*segment_analysis*):輸入為“*segmented_customer_df*”和“*metric*”,輸出為“*segment_result*”。 連結到 *algos.algo.segment_analysis* 函數。  --- **任務 4** (high_value_cust_summary_statistics):輸入包含「*segment_result*」、「*segmented_customer_df*」和「*summary_statistic_type*」。輸出為“*high_value_summary_df*”。連結到 *algos.algo.high_value_cust_summary_statistics* 函數。 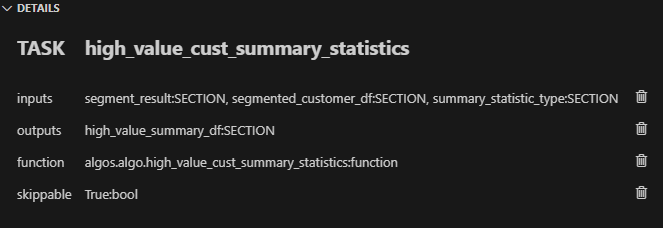 --- ## 結論 Taipy 提供了一種**智慧方式來建立和管理資料管道**。 特別是可跳過的功能使其成為優化運算資源和時間的強大工具,在涉及大型資料集的場景中特別有用。 Dask 提供了資料操作的原始能力,而 Taipy 增加了一層智能,使您的管道不僅強大而且智能。 --- 其他資源 如需完整程式碼和 TOML 配置,您可以存取此 [GitHub 儲存庫](https://github.com/Avaiga/demo-dask-customer-analysis/tree/develop)。若要深入了解 Taipy,請參閱[官方文件](https://docs.taipy.io/en/latest/)。 一旦您了解 Taipy 場景管理,您就可以更有效率地為最終用戶建立資料驅動的應用程式。只需專注於您的演算法,Taipy 就會處理剩下的事情。 ---  希望您喜歡這篇文章! --- 原文出處:https://dev.to/taipy/big-data-models-vs-computer-memory-4po6
警告:所表達的觀點可能不適合所有受眾! 😂 ## 簡介 在本文結束時,您將了解並能夠根據使用者偏好 - **深色**或**淺色**模式展示您的 Markdown 影像。 1. 我將介紹如何在 GitHub README.md 中加入兩個圖像 - 根據所選的“主題”,您的圖像將正確回應。 2. 我將引導您在 Markdown 中合併影像的過程,並示範如何使用 React 使它們回應。 😎 ___ ## 你使用淺色還是深色? 我不了解你的情況,但無論平台如何,如果他們可以選擇在淺色和深色模式之間切換,那就沒有競爭了。 淺色主題正在切換為深色,事實上,當然在我寫這篇文章的時候!  話雖如此,在軟體開發的快速發展中,創造無縫的使用者體驗至關重要。 這種體驗的一部分涉及適應使用者偏好,例如淺色和深色模式。 我還記得幾年前,Github 宣布了用戶可以切換到「深色模式」的選項,這是一件非常大的事情。  【Github揭曉黑暗主題的重要時刻】(https://t.co/HEotvXVJ7R) 🤩 2020 年 12 月 8 日🎆 近年來,使用者介面中深色和淺色模式選項的出現已成為一種流行趨勢。 我絕對不是唯一一個喜歡使用深色主題選項的人,根據 Android 用戶的說法,[91.8% 的用戶更喜歡深色模式](https://www.androidauthority.com/dark-mode-poll-results-1090716/) 所以我們可以猜測這個數字在所有作業系統中都相當高。 這當然可能會引起激烈的爭論,所以我會盡力將自己的觀點降到最低。  ## 改善使用者體驗 主要目標是透過在應用程式中提供選項來改善用戶體驗。 有多種方法可以建立每個圖像的多個版本,在本教程中我們不會深入討論細節。 只要確保您的圖像在兩個主題中脫穎而出並具有透明背景,您就會獲得成功。 **_讓我們開始派對吧!_** ## GitHub 自述文件中的響應式圖像 您有一個專案並想讓您的 GitHub 專案 README.md 真正流行嗎? 無論使用者使用什麼淺色主題,我們都需要一種方法來指定圖像應在 Markdown 中顯示哪種主題(淺色或深色)。 當您想要根據使用者選擇的配色方案優化圖片的顯示時,這特別有用,並且它涉及將 **HTML `<picture>`** 元素與 `prefers-color-scheme` 媒體功能結合使用如下所示。 繼續將圖片檔案直接拖曳到 GitHub 中並放在“srcset=”後面。 ``` <picture> <source media="(prefers-color-scheme: dark)" srcset="https://github.com/boxyhq/.github/assets/66887028/df1c9904-df2f-4515-b403-58b14a0e9093"> <source media="(prefers-color-scheme: light)" srcset="https://github.com/boxyhq/.github/assets/66887028/e093a466-72ea-41c6-a292-4c39a150facd"> <img alt="BoxyHQ Banner" src="https://github.com/boxyhq/jackson/assets/66887028/b40520b7-dbce-400b-88d3-400d1c215ea1"> </picture> ``` 瞧!   太好了,你有 5 秒嗎? https://github.com/boxyhq/jackson --- ## 使用 React 在 Markdown 中回應影像 假設今天我將像平常一樣用 Markdown 編寫博客,並將其發佈到我的網站上。 我使用的圖像需要根據使用者偏好做出回應,但在 Markdown 中不可能偵聽本地儲存和設定狀態中的「主題」變更。  值得慶幸的是,如果我們將 React 匯入到 Markdown 檔案中,但先建立一個元件,就有一種方法可以解決這個困境。 ## 反應文件 ``` src/components/LightDarkToggle.js import React, { useEffect, useState } from 'react'; function ToggleImages() { // Define a state variable to track the user's login status const [currentTheme, setcurrentTheme] = useState(localStorage.getItem('theme')); // Add an event listener for the 'storage' event inside a useEffect useEffect(() => { const handleStorageChange = (event) => { console.log('Storage event detected:', event); // Check the changed key and update the state accordingly console.log("event", event.key) if (event.key === 'theme') { setcurrentTheme(event.newValue); } }; window.addEventListener('storage', handleStorageChange); // Clean up the event listener when the component unmounts return () => { window.removeEventListener('storage', handleStorageChange); }; }, []); // The empty dependency array ensures that this effect runs once when the component mounts return ( <div className="image-container"> {currentTheme == 'light'? ( <img id="light-mode-image" src="/img/blog/boxyhq-banner-light-bg.png" alt="Light Mode Image" ></img> ):( <img id="dark-mode-image" src="/img/blog/boxyhq-banner-dark-bg.png" alt="Dark Mode Image" ></img> )} </div> ); } export default ToggleImages; ``` 我在程式碼中加入了註釋和一些控制台日誌,以幫助了解正在發生的事情,但讓我們快速分解它。 - React useState 鉤子管理 `currentTheme` 的狀態,它代表使用者選擇的儲存在本機儲存中的主題。 - useEffect 掛鉤用於為「儲存」事件新增事件偵聽器。當儲存事件發生時(表示本機儲存發生變化),元件會檢查變更的鍵是否為“theme”,並相應地更新“currentTheme”狀態。 - 此元件根據使用者選擇的主題呈現不同的影像,如果主題是“淺色”,則顯示淺色模式影像;如果主題是其他主題,則顯示深色模式影像。 酷,讓我們繼續吧! ## 降價文件 讓我們為新部落格建立一個 .md 檔案。 ``` --- slug: light-and-dark-mode-responsive-images title: 'Light and Dark Mode Responsive Images' tags_disabled: [ developer, react, javascript, open-source, ] image: /img/blog/light-dark.png author: Nathan Tarbert author_title: Community Engineer @BoxyHQ author_url: https://github.com/NathanTarbert author_image_url: https://boxyhq.com/img/team/nathan.jpg --- import ToggleImages from '../src/components/LightDarkToggle.js'; ## 🤩 Let's start this blog off with a bang! Our business logo is now responsive with each user's preference, whether it's **light** or **dark** mode! <div> <ToggleImages /> </div> More blog words... ``` 此時,我們只需匯入 React 元件並將其呈現在 Markdown 檔案中。 由於這是一個 Next.js 應用程式,讓我們啟動伺服器“npm run dev”並查看結果。  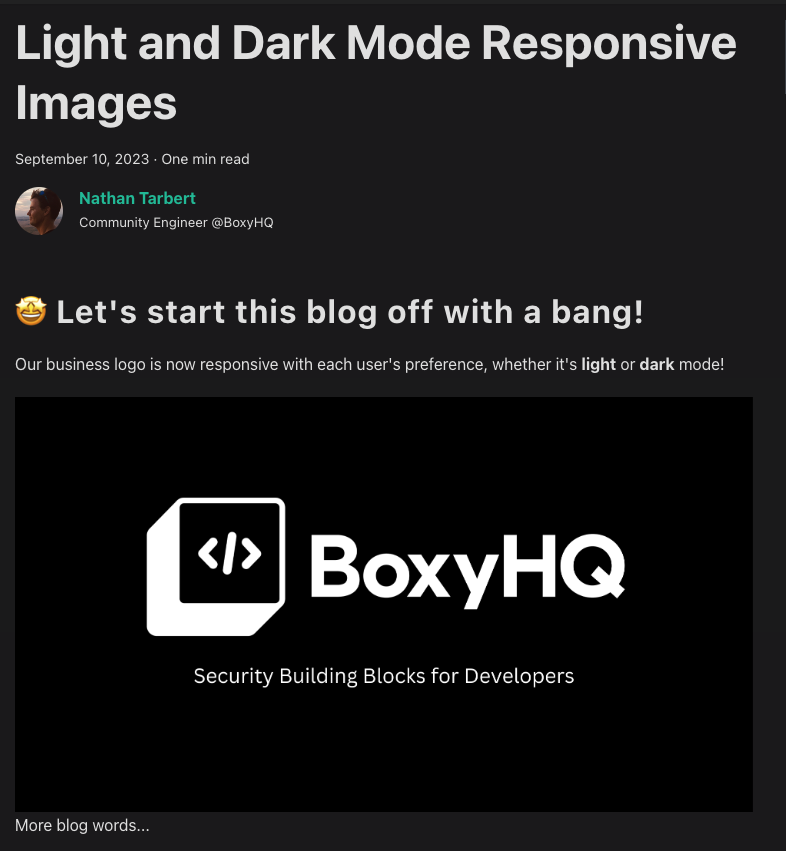 並切換到淺色主題 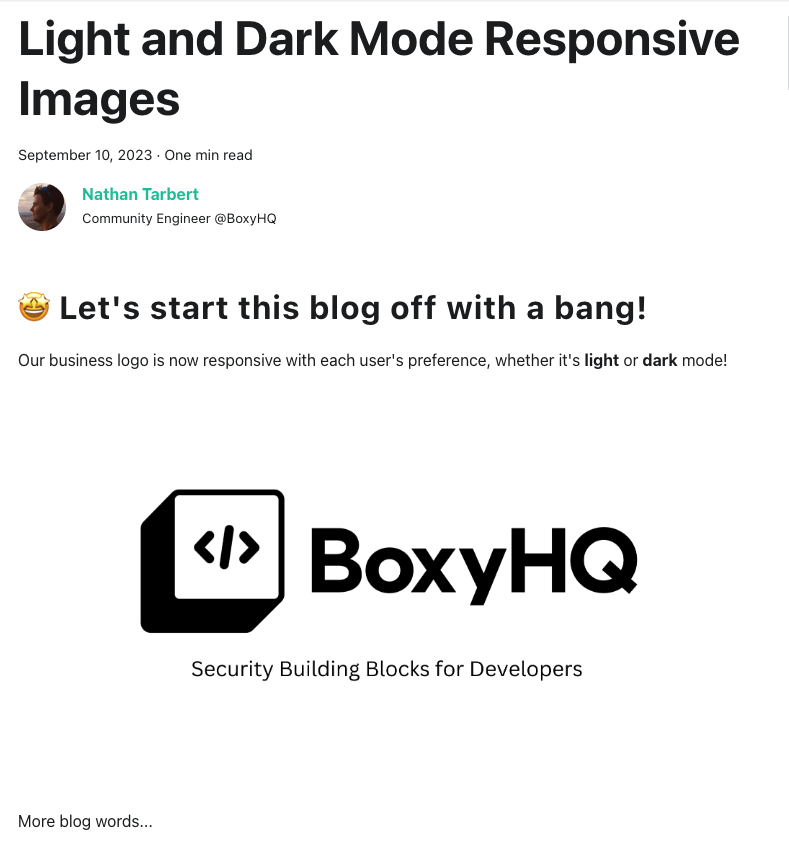 讓我們打開控制台來查看我們的事件 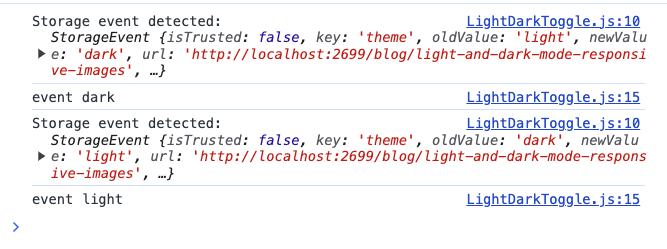 你有它! 這些是在 Markdown 中展示響應式映像的幾種方法,其中一個範例使用 React 來幫助我們在本地儲存中設定狀態。 我希望您喜歡這篇文章,如果您喜歡開發,請在 [X (Twitter)](https://twitter.com/nathan_tarbert) 上關注我,我們下次再見! --- 原文出處:https://dev.to/nathan_tarbert/the-zebras-guide-to-showcase-your-images-in-light-dark-17f5
## 你好!我是[鮑里斯](https://www.martinovic.dev/)! 我是一名軟體工程師,專門從事保險工作,教授其他開發人員,並在會議上發言。多年來,我使用了相當多的不同開發環境和作業系統,除了 .Net 開發之外,我個人從來不喜歡在 Windows 中進行開發。這是為什麼?讓我們更深入地研究一下。 好吧,我的大部分問題都可以歸結為一個詞:**麻煩**。無論是在日常使用中處理Windows,您都會經常遇到作業系統本身的不同方式帶給您的困擾。這樣的例子很多,無論是登錄問題、套件管理、切換節點版本或 Windows 更新,這些問題本身就可以讓人們放棄作業系統。 所以你可以明白為什麼我開始與下圖的烏鴉產生連結。  我並沒有放棄尋找可行的解決方案。而且,我(有點)找到了它。 ## 什麼是 WSL?我為什麼要對它感興趣? Windows Subsystem for Linux(或 WSL)讓開發人員可以直接在 Windows 上執行功能齊全的本機 GNU/Linux 環境。換句話說,我們可以直接執行Linux,而無需使用虛擬機器或雙重開機系統。 **第一個很酷的事情是 WSL 允許您永遠不用切換作業系統,但仍然可以在作業系統中擁有兩全其美的優點。** 這對我們普通用戶意味著什麼?當您查看WSL 在實踐中的工作方式時,它可以被視為一項Windows 功能,直接在Windows 10 或11 內執行Linux 作業系統,具有功能齊全的Linux 檔案系統、Linux 命令列工具、*** *** 和****** Linux GUI 應用程式(*真的很酷,順便說一句*)。除此之外,與虛擬機器相比,它使用的運作資源要少得多,並且不需要單獨的工具來建立和管理這些虛擬機器。 WSL 主要針對開發人員,因此本文將重點放在開發人員的使用以及如何使用 VS Code 設定完全工作的開發環境。在本文中,我們將介紹一些很酷的功能以及如何在實踐中使用它們。另外,理解新事物的最好方法就是實際開始使用它們。 ### 覺得這篇文章有用嗎? 我們正在 [Wasp](https://wasp-lang.dev/) 努力建立這樣的內容,更不用說建立一個現代的開源 React/NodeJS 框架了。 表達您支援的最簡單方法就是為 Wasp 儲存庫加註星標! 🐝 但如果您可以查看[存儲庫](https://github.com/wasp-lang/wasp)(用於貢獻,或只是測試產品),我們將不勝感激。點擊下面的按鈕給黃蜂星一顆星並表示您的支持!  https://github.com/wasp-lang/wasp ## 在 Windows 作業系統上安裝 WSL 為了在 Windows 上安裝 WSL,請先啟用 [Hyper-V](https://learn.microsoft.com/en-us/virtualization/hyper-v-on-windows/quick-start/enable-hyper-v )架構是微軟的硬體虛擬化解決方案。要安裝它,請右鍵單擊 Windows 終端機/Powershell 並以管理員模式開啟它。  然後,執行以下命令: ``` Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Hyper-V -All ``` 這將確保您具備安裝的所有先決條件。然後,在管理員模式下開啟 Powershell(最好在 Windows 終端機中完成)。然後,執行 ``` wsl —install ``` 有大量的 Linux 發行版需要安裝,但 Ubuntu 是預設安裝的。本指南將介紹許多控制台命令,但其中大多數將是複製貼上過程。 如果您之前安裝過 Docker,那麼您的系統上很可能已經安裝了 WSL 2。在這種情況下,您將收到安裝所選發行版的提示。由於本教程將使用 Ubuntu,因此我建議執行。 ``` wsl --install -d Ubuntu ``` 安裝 Ubuntu(或您選擇的其他發行版)後,您將進入 Linux 作業系統並出現歡迎畫面提示。在那裡,您將輸入一些基本資訊。首先,您將輸入您的用戶名,然後輸入密碼。這兩個都是 Linux 特定的,因此您不必重複您的 Windows 憑證。完成此操作後,安裝部分就結束了!您已經在 Windows 電腦上成功安裝了 Ubuntu!說起來還是感覺很奇怪吧? ### 等一下! 但在我們開始討論開發環境設定之前,我想向您展示一些很酷的技巧,這些技巧將使您的生活更輕鬆,並幫助您了解為什麼 WSL 實際上是 Windows 用戶的遊戲規則改變者。 WSL 的第一個很酷的事情是您不必放棄目前透過 Windows 資源管理器管理檔案的方式。在 Windows 資源管理器的側邊欄中,您現在可以在網路標籤下找到 Linux 選項。  從那裡,您可以直接從 Windows 資源管理器存取和管理 Linux 作業系統的檔案系統。這個功能真正酷的是,你基本上可以在不同的作業系統之間複製、貼上和移動文件,沒有任何問題,這開啟了一個充滿可能性的世界。實際上,您不必對文件工作流程進行太多更改,並且可以輕鬆地將許多專案和文件從一個作業系統移動到另一個作業系統。如果您在 Windows 瀏覽器上下載 Web 應用程式的映像,只需將其複製並貼上到您的 Linux 作業系統中即可。  我們將在範例中使用的另一個非常重要的事情是 WSL2 虛擬路由。由於您的作業系統中現在有作業系統,因此它們有一種通訊方式。當您想要存取 Linux 作業系統的網路時(例如,當您想要存取在 Linux 中本機執行的 Web 應用程式時),您可以使用 *${PC-name}.local*。對我來說,由於我的電腦名稱是 Boris-PC,所以我的網路位址是 boris-pc.local。這樣你就不必記住不同的 IP 位址,這真的很酷。如果您出於某種原因需要您的位址,您可以前往 Linux 發行版的終端,然後輸入 ipconfig。然後,您可以看到您的 Windows IP 和 Linux 的 IP 位址。這樣,您就可以毫無摩擦地與兩個作業系統進行通訊。 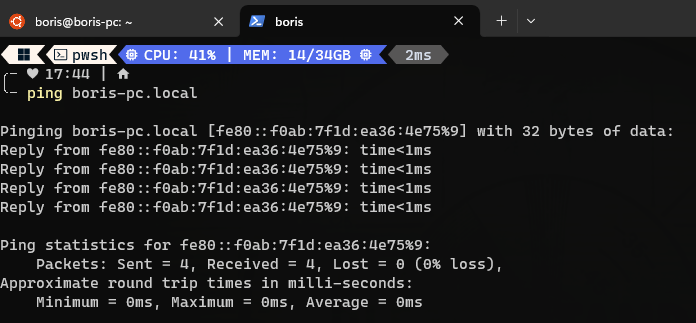 我想強調的最後一件很酷的事情是 Linux GUI 應用程式。這是一項非常酷的功能,有助於使 WSL 對普通用戶更具吸引力。您可以使用流行的套件管理器(例如 apt(Ubuntu 上的預設值)或 flatpak)在 Linux 系統上安裝任何您想要的應用程式。然後,您也可以從命令列啟動它們,應用程式將啟動並在 Windows 作業系統中可見。但這可能會引起一些摩擦並且不方便用戶使用。此功能真正具有突破性的部分是,您可以直接從 Windows 作業系統啟動它們,甚至無需親自啟動 WSL。因此,您可以建立捷徑並將它們固定到「開始」功能表或任務欄,沒有任何摩擦,並且實際上不需要考慮您的應用程式來自哪裡。為了演示,我安裝了 Dolphin 檔案管理器並透過 Windows 作業系統執行它。您可以在下面看到它與 Windows 資源管理器並排的操作。 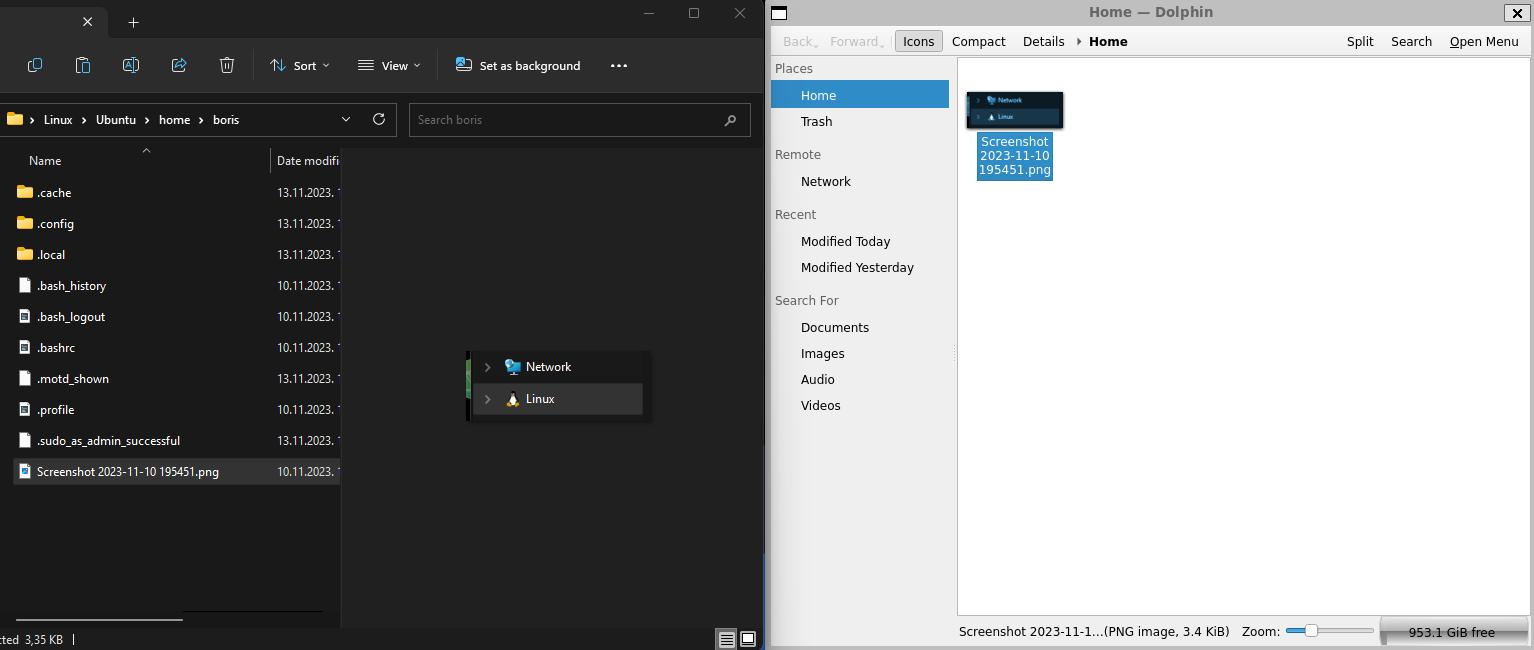 ## WSL 開發入門 在了解了 WSL 的所有酷炫功能後,讓我們慢慢回到教學的正軌。接下來是設定我們的開發環境並啟動我們的第一個應用程式。我將設定一個 Web 開發環境,我們將使用 [Wasp](https://wasp-lang.dev/) 作為範例。 如果你不熟悉的話,Wasp 是一個類似 Rails 的 React、Node.js 和 Prisma 框架。這是開發和部署全端 Web 應用程式的快速、簡單的方法。對於我們的教程,Wasp 是一個完美的候選者,因為它本身不支援 Windows 開發,而只能透過 WSL 來支持,因為它需要 Unix 環境。 讓我們先開始安裝 Node.js。目前,Wasp 要求使用者使用 Node v18(版本要求很快就會放寬),因此我們希望從 Node.js 和 NVM 的安裝開始。 但首先,讓我們先從 Node.js 開始。在 WSL 中,執行: ``` sudo apt install nodejs ``` 為了在您的 Linux 環境中安裝 Node。接下來是 NVM。我建議存取 https://github.com/nvm-sh/nvm 並從那裡獲取最新的安裝腳本。目前下載的是: ``` curl -o- [https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh](https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh) | bash ``` 之後,我們在系統中設定了 Node.js 和 NVM。 接下來是在我們的 Linux 環境中安裝 Wasp。 Wasp 安裝也非常簡單。因此,只需複製並貼上此命令: ``` curl -sSL [https://get.wasp-lang.dev/installer.sh](https://get.wasp-lang.dev/installer.sh) | sh ``` 並等待安裝程序完成它的事情。偉大的!但是,如果您從 0 開始進行 WSL 設置,您會注意到下面有以下警告:看起來“/home/boris/.local/bin”不在您的 PATH 上!您將無法透過終端名稱呼叫 wasp。 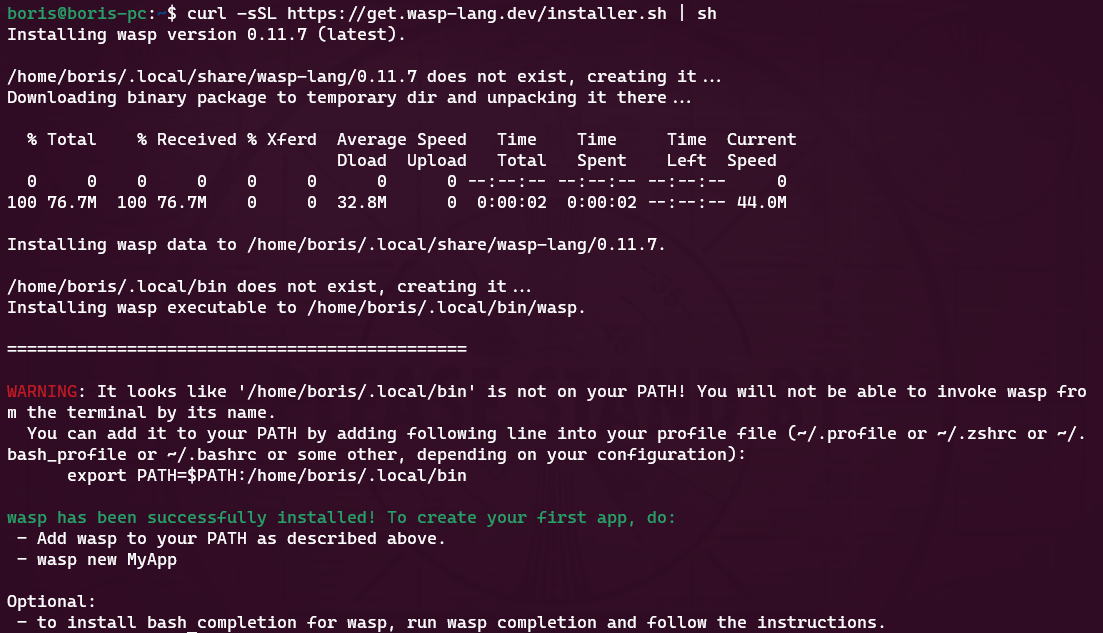 讓我們快速解決這個問題。為了做到這一點,讓我們執行 ``` code ~/.profile ``` 如果我們還沒有 VS Code,它會自動設定所需的一切並啟動,以便您可以將命令新增至檔案末端。每個人的系統名稱都會有所不同。例如我的是: ``` export PATH=$PATH:/home/boris/.local/bin ``` 偉大的!現在我們只需要將節點版本切換到 v18.14.2 即可確保與 Wasp 完全相容。我們將一次性安裝並切換到 Node 18!為此,只需執行: ``` nvm install v18.14.2 && nvm use v18.14.2 ``` 設定 Wasp 後,我們希望了解如何執行應用程式並從 VS Code 存取它。在幕後,您仍將使用 WSL 進行開發,但我們將能夠使用主機作業系統 (Windows) 中的 VS Code 來完成大多數事情。 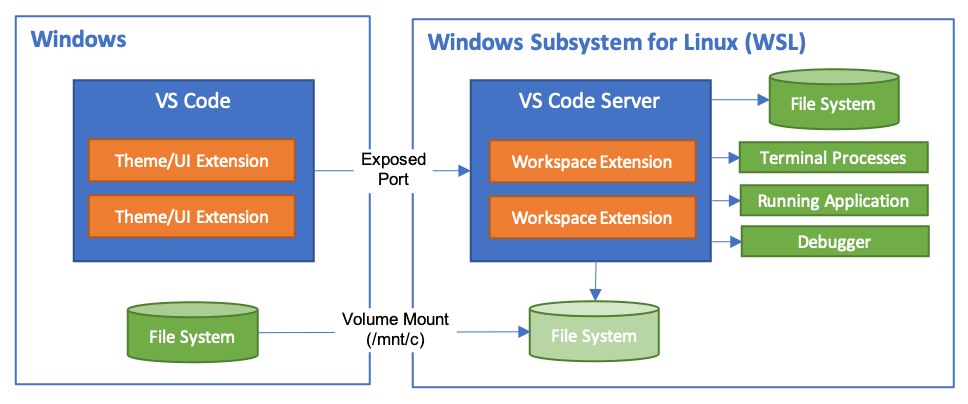 首先,將 [WSL 擴充功能](https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.remote-wsl) 下載到 Windows 中的 VS Code。然後,讓我們啟動一個新的 Wasp 專案來看看它是如何運作的。開啟 VS Code 命令面板(ctrl + shift + P)並選擇「在 WSL 中開啟資料夾」選項。 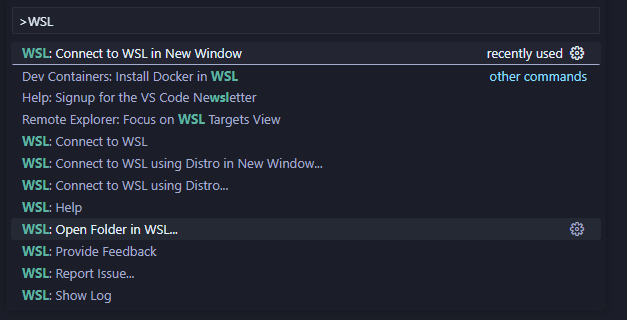 我打開的資料夾是 ``` \\wsl.localhost\Ubuntu\home\boris\Projects ``` 這是我在 WSL 中的主資料夾中的「Projects」資料夾。我們可以透過兩種方式知道我們處於 WSL 中:頂部欄和 VS Code 的左下角。在這兩個地方,我們都編寫了 WSL: Ubuntu,如螢幕截圖所示。  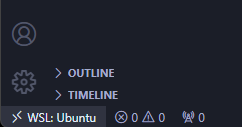 進入該資料夾後,我將打開一個終端。它還將已經連接到 WSL 中的正確資料夾,因此我們可以開始工作了!讓我們執行 ``` wasp new ``` 命令建立一個新的 Wasp 應用程式。我選擇了基本模板,但您可以自由建立您選擇的專案,例如[SaaS 入門](https://github.com/wasp-lang/SaaS-Template-GPT) 具有 GPT、Stripe 等預先配置。如螢幕截圖所示,我們應該將專案的當前目錄變更為正確的目錄,然後用它來執行我們的專案。 ``` wasp start ``` 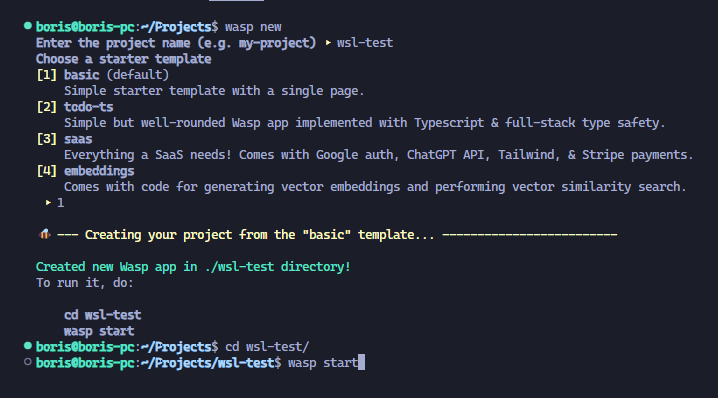 就像這樣,我的 Windows 電腦上將打開一個新螢幕,顯示我的 Wasp 應用程式已開啟。涼爽的!我的位址仍然是預設的 localhost:3000,但它是從 WSL 執行的。恭喜,您已透過 WSL 成功啟動了您的第一個 Wasp 應用程式。這並不難,不是嗎?  對於我們的最後一個主題,我想重點介紹使用 WSL 的 Git 工作流程,因為它的設定相對輕鬆。您始終可以手動進行 git config 設置,但我為您提供了一些更酷的東西:在 Windows 和 WSL 之間共享憑證。要設定共享 Git 憑證,我們必須執行以下操作。在 Powershell(在 Windows 上)中,設定 Windows 上的憑證管理員。 ``` git config --global credential.helper wincred ``` 讓我們在 WSL 中做同樣的事情。 ``` git config --global credential.helper "/mnt/c/Program\ Files/Git/mingw64/bin/git-credential-manager.exe" ``` 這使我們能夠共享 Git 使用者名稱和密碼。 Windows 中設定的任何內容都可以在 WSL 中運作(反之亦然),我們可以根據需要在 WSL 中使用 Git(透過 VS Code GUI 或透過 shell)。 ## 結論 透過我們在這裡的旅程,我們了解了 WSL 是什麼、它如何有助於增強 Windows PC 的工作流程,以及如何在其上設定初始開發環境。 Microsoft 在這個工具方面做得非常出色,並且確實使 Windows 作業系統成為所有開發人員更容易使用和可行的選擇。我們了解如何安裝啟動開發所需的開發工具以及如何掌握基本的開發工作流程。如果您想深入了解該主題,這裡有一些重要的連結: - [https://wasp-lang.dev/](https://wasp-lang.dev/) - [https://github.com/microsoft/WSL](https://github.com/microsoft/WSL) - [https://learn.microsoft.com/en-us/windows/wsl/install](https://learn.microsoft.com/en-us/windows/wsl/install) - [https://code.visualstudio.com/docs/remote/wsl](https://code.visualstudio.com/docs/remote/wsl) --- 原文出處:https://dev.to/wasp/supercharge-your-windows-development-the-ultimate-guide-to-wsl-195m
## 簡介 我收集了最好的 React 元件,您可以使用它來建立強大的 Web 應用程式。 每個都有自己的味道。 別忘了表達你的支持🌟 現在,讓我們仔細閱讀這段程式碼! 🍽️  --- ## 1. [CopilotPortal](https://github.com/RecursivelyAI/CopilotKit):將可操作的 GPT 聊天機器人嵌入您的網路應用程式中。 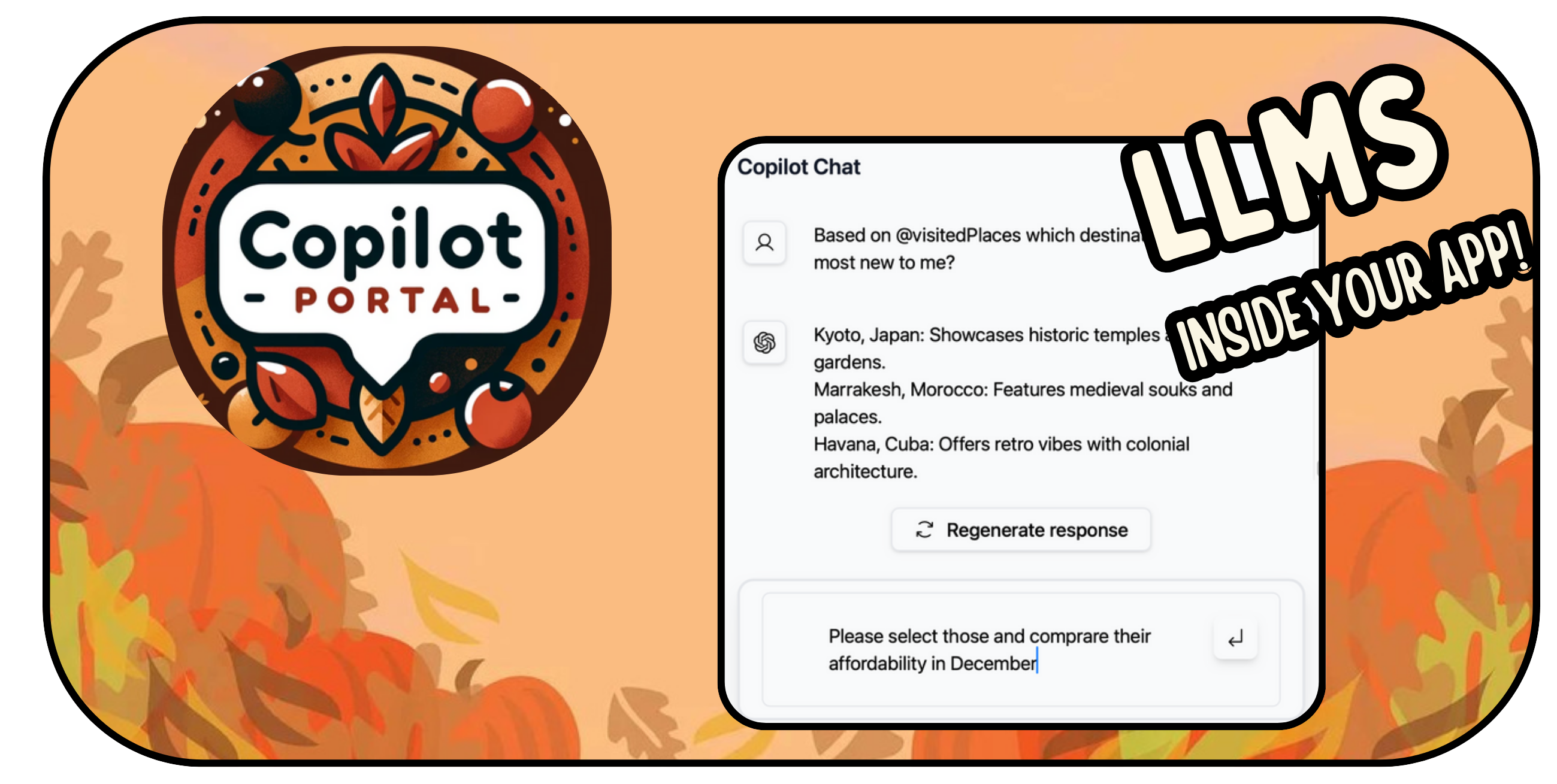 將 GPT 支援的聊天機器人插入您的 React 應用程式中。 可以將 RAG 與雲端和應用程式狀態即時整合。 需要幾行程式碼才能嵌入。 ``` import "@copilotkit/react-ui/styles.css"; import { CopilotProvider } from "@copilotkit/react-core"; import { CopilotSidebarUIProvider } from "@copilotkit/react-ui"; export default function App(): JSX.Element { return ( <CopilotProvider chatApiEndpoint="/api/copilotkit/chat"> <CopilotSidebarUIProvider> <YourContent /> </CopilotSidebarUIProvider> </CopilotProvider> ); } ``` https://github.com/RecursivelyAI/CopilotKit --- ## 2. [ClickVote](https://github.com/clickvote/clickvote) - 按讚、投票並查看任何上下文  輕鬆將點讚、按讚和評論加入到您的網路應用程式中。 用於加入這些元件的簡單反應程式碼。 ``` import { ClickVoteProvider } from '@clickvote/react'; import { ClickVoteComponent } from '@clickvote/react'; import { LikeStyle } from '@clickvote/react'; <ClickVoteProvider> <ClickVoteComponent id={CONTEXT} voteTo={ID}> {(props) => <LikeStyle {...props} />} </ClickVoteComponent> </ClickVoteProvider> ``` https://github.com/clickvote/clickvote --- ## 3. [React Flow](https://github.com/xyflow/xyflow) - 建立可拖曳工作流程的最佳方式!  專為建立基於節點的編輯器和互動式圖表而客製化的 React 元件。 它具有高度可自訂性,提供拖放功能以實現高效的工作流程建立。 ``` import ReactFlow, { MiniMap, Controls, Background, useNodesState, useEdgesState, addEdge, } from 'reactflow'; <ReactFlow nodes={nodes} edges={edges} onNodesChange={onNodesChange} onEdgesChange={onEdgesChange} onConnect={onConnect} > <MiniMap /> <Controls /> <Background /> </ReactFlow> ``` https://github.com/xyflow/xyflow --- ## 4. [CopilotTextarea](https://github.com/RecursivelyAI/CopilotKit/tree/main/CopilotKit/packages/react-textarea) - React 應用程式中的 AI 驅動寫作 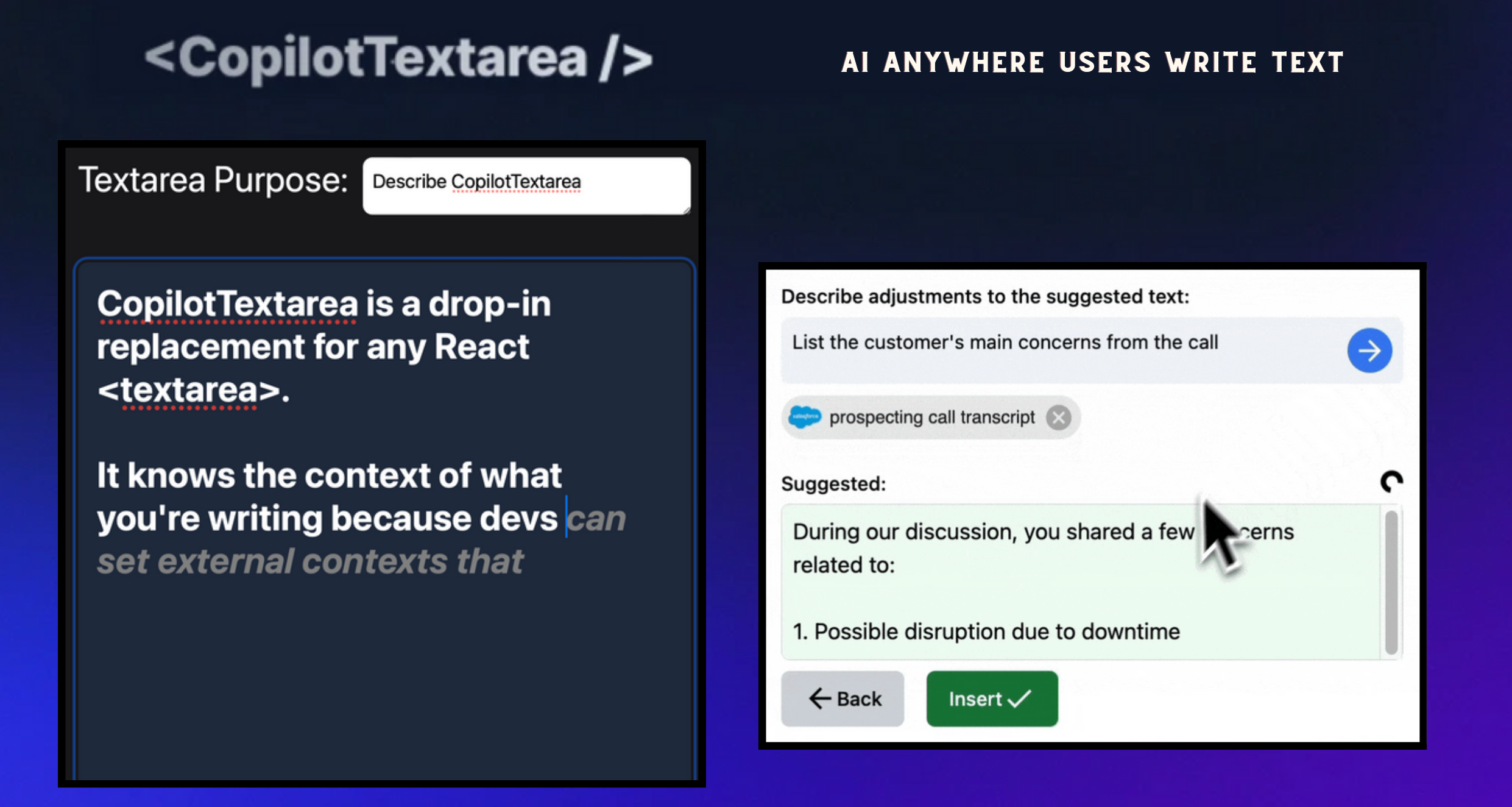 具有 Github CopilotX 功能的任何 React `<textarea>` 的直接替代品。 自動完成、插入、編輯。 可以即時或由開發人員提前提供任何上下文。 ``` import { CopilotTextarea } from "@copilotkit/react-textarea"; import { CopilotProvider } from "@copilotkit/react-core"; // Provide context... useMakeCopilotReadable(...) // in your component... <CopilotProvider> <CopilotTextarea/> </CopilotProvider>` ``` https://github.com/RecursivelyAI/CopilotKit --- ## 5. [Novu](https://github.com/novuhq/novu) - 將應用程式內通知新增至您的應用程式!  用於在一個地方管理所有通訊管道的簡單元件和 API:電子郵件、SMS、Direct 和 Push 您可以使用此 React 元件為您的應用程式新增應用程式內通知。 ``` import { NovuProvider, PopoverNotificationCenter, NotificationBell, IMessage, } from "@novu/notification-center"; <NovuProvider subscriberId={"SUBSCRIBER_ID"} applicationIdentifier={"APPLICATION_IDENTIFIER"} > <PopoverNotificationCenter colorScheme="dark"> {({ unseenCount }) => <NotificationBell unseenCount={unseenCount} />} </PopoverNotificationCenter> </NovuProvider> ``` https://github.com/novuhq/novu --- ## 6. [ReactIcons](https://github.com/react-icons/react-icons) - 最受歡迎的反應圖示集合  輕鬆將 Font Awesome、Material Design 等中的流行圖標加入到您的 React 應用程式中。 為開發人員提供簡單、廣泛的選擇。 ``` import { FaBeer } from "react-icons/fa"; function Question() { return ( <h3> Lets go for a <FaBeer />? </h3> ); } ``` https://github.com/react-icons/react-icons --- ## 7. [React-dropzone](https://github.com/react-dropzone/react-dropzone) - 新增 HTML5 拖放 UI。  用於實作 HTML5 拖放區域的簡單 React 鉤子,重點放在檔案互動。 它提供了一個易於使用的介面,用於向 React 應用程式加入檔案拖放功能。 ``` import React from 'react'; import {useDropzone} from 'react-dropzone'; const Basic = (props)=>{ const {acceptedFiles, getRootProps, getInputProps} = useDropzone(); const files = acceptedFiles.map(file => ( <li key={file.path}> {file.path} - {file.size} bytes </li> )); return ( <section className="container"> <div {...getRootProps({className: 'dropzone'})}> <input {...getInputProps()} /> <p>Drag 'n' drop some files here, or click to select files</p> </div> <aside> <h4>Files</h4> <ul>{files}</ul> </aside> </section> ); } export default Basic; ``` https://github.com/react-dropzone/react-dropzone --- ## 8. [React ChartJS 2](https://github.com/reactchartjs/react-chartjs-2) - 建立和整合各種圖表。  用於在 React 應用程式中繪製圖表的即插即用解決方案,類似於 Chart.js 功能。 啟用動態、互動式圖表。 適用於即時資料或預定義資料集。 ``` import React from 'react'; import { Chart as ChartJS, ArcElement, Tooltip, Legend } from 'chart.js'; import { Doughnut } from 'react-chartjs-2'; ChartJS.register(ArcElement, Tooltip, Legend); const data = { labels: ['Red', 'Blue', 'Yellow', 'Green', 'Purple', 'Orange'], datasets: [ { label: '# of Votes', data: [12, 19, 3, 5, 2, 3], backgroundColor: [ 'rgba(255, 99, 132, 0.2)', ], borderColor: [ 'rgba(255, 99, 132, 1)', ], borderWidth: 1, }, ], }; export default function ShowChart() { return <Doughnut data={data} />; } ``` https://github.com/reactchartjs/react-chartjs-2 ## 9. [Redux](https://github.com/reduxjs/redux) - 可預測的狀態容器庫  JavaScript 應用程式中 Redux 的無縫補充,提供可靠的狀態管理。 確保一致的應用程式行為。 便於輕鬆除錯和測試。 與各種庫整合。 https://github.com/reduxjs/redux --- ## 10. [Blueprint](https://github.com/palantir/blueprint) - Palantir 的密集 UI 庫  提供一組用於建立複雜且資料豐富的介面的元件和樣式。 設計和開發具有現代外觀和感覺的類似桌面的 Web 應用程式。 由 Palantir 開發 ``` import React from 'react'; import '@blueprintjs/core/lib/css/blueprint.css'; import { H3, H4, OL, Pre } from "@blueprintjs/core"; function App() { return ( <div style={{ display: 'block', width: 500, padding: 30 }}> <h4>ReactJS Blueprint HTML Elements Component</h4> Heading Component: <H4>H4 Size Heading</H4> <H3>H3 Size Heading</H3> <br></br> OrderList Component: <OL> <li>1st item</li> <li>2nd item</li> </OL> Pre Component: <Pre>Sample Pre</Pre> </div> ); } ``` https://github.com/palantir/blueprint --- ## 11. [Headless UI](https://github.com/tailwindlabs/headlessui) - 可存取的 Tailwind 整合 UI 元件。  在 React 和 Vue 應用程式中建立可存取的 UI 元件。 適用於即時資料或預定義資料集,使其成為現代 Web 開發專案的寶貴補充 ``` import React, { useState } from 'react'; import { Dialog } from '@headlessui/react'; function MyDialog() { let [isOpen, setIsOpen] = useState(true); return ( <Dialog open={isOpen} onClose={() => setIsOpen(false)} className="relative z-50"> {/* The backdrop, rendered as a fixed sibling to the panel container */} <div className="fixed inset-0 bg-black/30" aria-hidden="true" /> {/* Full-screen container to center the panel */} <div className="fixed inset-0 flex w-screen items-center justify-center p-4"> {/* Your dialog content goes here */} </div> </Dialog> ); } ``` https://github.com/tailwindlabs/headlessui --- 保存這些元件,以便像朝聖者一樣專業地建造。 謝謝大家,節日快樂! --- 原文出處:https://dev.to/copilotkit/reacts-giving-11-react-components-for-aspiring-pros-eck
目前大環境不好,但作為開發人員,我們擁有一套獨特的技能,如果您知道在哪裡尋找,這些技能的需求量很大! 這篇文章簡要概述了 50 個作為開發人員可以用來賺取額外收入的副業 --- ### 1. 銷售注意力 基於參與度的收入是指您將根據使用者在您的網站、個人資料或消費您的內容上花費的時間來獲得收入分成。它通常很小,至少對於較小的網站或創作者來說是這樣,但隨著時間的推移,它會增加,任何人都可以啟用它 - 所以你不會有任何損失。 - [Brave](https://creators.brave.com/) - 為使用 Brave 瀏覽器造訪您的網站、個人資料或查看您的內容的使用者付費。資金以 [BAT](https://basicattentiontoken.org/) 形式存入您的 Uphold 帳戶,然後可以以美元、英鎊或歐元形式提取至您的銀行帳戶 - [Flattr](https://flattr.com/) - 付費使用 Flattr 的用戶將其資金分配給用戶存取過其內容的創作者 > 幾年前,我親自報名了 Brave Rewards。在驗證了我的網域和個人資料的所有權後,我每月一直賺幾英鎊 - 到目前為止大約 200 英鎊以上(儘管我是 Firefox 用戶!)。雖然不多,但只需付出很少的努力,就值得了。 有關其工作原理的更多訊息,請查看 [webmonetization.org](https://webmonetization.org/) 規範,該規範利用了 [付款指針](https://paymentpointers.org/)通過[ILP](https://interledger.org/) 透過使用簡單的`<link rel="monetization" href="your-pointer-here" />` 標籤來串流來自支援WM 的訪客的收入。 --- ### 2. API 即服務 RapidAPI 等平台可讓您從 API 中[賺取被動收入](https://rapidapi.com/guides/earn-a-passive-venue-by-monetizing-apis-as-a-developer)。 建置並部署簡單的 API 後,您可以將其匯入 RapidAPI Hub,選擇使用和定價計劃,然後點擊發布。您的 API 可大可小,如您所願。 如果您正在為一個簡單的第一個專案尋找靈感,請考慮將開放資料集轉換為 API。對於初學者,RapidAPI 有一個關於如何入門的[影片系列](https://rapidapi.com/courses/build-and-sell-your-own-api)。其他想法可能包括將現有套件包裝為 API、向其他服務(如 OpenAI)加入功能或建置執行一些簡單計算的端點。 --- ### 3. 發放賞金 這些是開源專案的熱門功能請求。用戶可以在承諾一定金額的情況下提供“賞金”,然後將其支付給第一個完成並合併該功能的開發人員。 - [BOSS.dev](https://www.boss.dev/) - 完成功能請求和錯誤修復,獎金從 30 美元到 1000 美元不等。 --- ### 4. 贊助商 如果您在 GitHub 或其他平台上有業務,那麼啟用贊助是一種為您的工作帶來收入的有益方式。 不要忘記啟用贊助商按鈕。這適用於各種平台以及 GitHub 贊助商 - [GitHub Sponsors](https://github.com/sponsors) - 對於開發人員(無論規模大小)來說都是一個不錯的選擇。如果支持者已經在 GitHub 上,則零費用且進入門檻低 - [Patreon](https://www.patreon.com/) - 允許向您的支持者提供福利和獨家內容。如果您在 GitHub 以外的其他平台上有業務,這是一個不錯的選擇 - [LibrePay](https://liberapay.com/) - 針對那些建立開源內容的人 - [Open Collective](https://opencollective.com/) - 如果您正在為特定專案籌集資金,並使用收益來支持該專案(而不是個人),那麼這是一個不錯的選擇 - [Steday](https://steadyhq.com/en) - [TideLift](https://tidelift.com) - 更針對那些開發企業級開源專案的人,潛在收入更大,但僅限於最大的專案 - [LFX](https://lfx.linuxfoundation.org/) - 由 Linux 基金會提供 > 贊助(特別是GitHub 贊助商)是我個人最喜歡的方法之一,因為付費是可選的,所以你不會阻止那些無力承擔費用的人存取,而且那些支持你的人已經知道他們會預先得到什麼,所以您永遠不會讓客戶失望。 --- ### 5. 小費 您可能遇到過這樣的情況,您發現某個部落格文章、SO 答案、GitHub 儲存庫或論壇回應非常有幫助,以至於您希望可以為作者買一杯啤酒來表示感謝。 支援這些小額一次性付款的平台可以免費註冊,並且在您的個人資料中或在部落格文章末尾加入「提示」按鈕不會有任何損失。 - [Ko-fi](https://ko-fi.com/) - [請我喝杯咖啡](https://www.buymeacoffee.com/) - [Tipeee](https://en.tipeee.com/) - [PayPal Me](https://www.paypal.com/paypalme/) 提示:不要乞求。建立一些有用的內容,然後將提示連結放在底部。 --- ### 6. 企業贊助 許多具有一定下載量/經常性用戶的開源專案將開始被希望贊助創作者作品的公司接洽,以換取他們的公司徽標+連結包含在自述文件頂部附近。與個人贊助不同,這些贊助通常起價為 100-500 美元/月,專案使用量越大,贊助金額就越多。 --- ### 7. 黑客松 編碼競賽一直在遠端進行。這些通常由公司贊助,並向獲獎者支付現金獎勵。 - [程式碼之夏](https://summerofcode.withgoogle.com/) - 由 Google 執行,您將收到[貢獻者津貼](https://developers.google.com/open-source/gsoc/help/student-stipends) 成功接受後,金額從750 美元到6000 美元不等,金額取決於您所在的國家/地區和專案規模 - [CodeHeat](https://codeheat.org/) - 由 FOSS Asia 運營,每兩週 100 新元,外加較小的獎品 - [HackerEarth](https://www.hackerearth.com/challenges/hackathon/) - [Hackathon.com](https://www.hackathon.com/online) - [Devfolio 黑客松](https://devfolio.co/hackathons/upcoming) > 當我還是學生時,我[曾經參加過很多](https://alicia.omg.lol/hackathons) 黑客馬拉松(大部分是面對面的),並且經常能夠通過參加各種活動來資助我的暑假活動!這也是認識新朋友、學習新事物的好方法,而且非常有趣! --- ### 8. 依賴套件的贊助 如果您有一個軟體包(例如 NPM 模組),那麼在您的設定檔中啟用贊助將允許您的程式碼的使用者在財務上做出貢獻。 - NPM 資金 - 您可能熟悉執行“npm 基金”,並查看您正在使用的正在尋求資金的軟體包清單。新增了 [npm 基金](https://docs.npmjs.com/cli/v6/commands/npm-fund),以便更輕鬆地向專案所依賴的依賴項的維護者捐款。如果您維護 NPM 包,只需在 package.json 中包含「funding」字段,用戶將能夠更輕鬆地支援您。 - [StackAid](https://www.stackaid.us/) - 只需安裝 StackAid GitHub 應用程式並連結您的 Stripe 帳戶,直接或間接使用您專案的支持者捐贈的部分資金將分配給您每個月 - GitHub Sponsors - GitHub Sponsors 再次出現,因為它[讓用戶提供他們最常用的依賴項](https://github.com/sponsors/explore) - 儘管這是一個手動過程,而不是自動的。 --- ### 9. 回報問題 如果您注重安全性,或喜歡在應用程式中尋找錯誤和漏洞,那麼這款就適合您。最受歡迎的平台是[HackerOne](https://hackerone.com/opportunities/all/search?ordering=Highest+bounties),每個負責任地披露的錯誤都可以在其中賺取20 到200,000 美元的收入。 許多其他網站也直接提供負責任的揭露政策,他們會獎勵您的工作。如果您對此感興趣,我在以下位置保留了 1000 多個賞金計劃的清單:[https://bug-bounties.as93.net](https://bug-bounties.as93.net) > 我個人透過這種方法取得了很大的成功,而且也很有趣 - 所以我強烈推薦它! 其他值得查看的平台包括: - [HackerOne](https://www.hackerone.com/) - 排名第一的平台,最多的賞金以及良好的保護和支付率 - [Immunefi](https://immunefi.com/) - 專門針對 Web3 - [BugCrowd](https://www.bugcrowd.com/bug-bounty-list/) - [Intigriti](https://www.intigriti.com/) - [issuehunt](https://issuehunt.io/) --- ### 10.開放核心模型 這是您的大部分程式碼都是開源的,但某些擴充功能或附加元件(特別是針對企業客戶的擴充或附加元件)被授權為專有的。 因此,開發者可以在其他開源專案中自由使用該軟體。然而,公司必須為使用企業特定的模組或整合付費。 請記住,這通常說起來容易做起來難。您需要能夠分離專有功能,而大公司通常會採取一切措施(包括違反許可限制)來避免付費。 --- ### 11. 付費升級套件 這些服務可以輕鬆為常見註冊管理機構提供高級/付費方案。例如,如果您希望分發 NPM 模組的高級版本,或對特定軟體包功能收費,這可能是個不錯的選擇。 - [PrivJS](https://www.privjs.com/) - 分發 Node 套件的進階版本 - [CodeShip](https://codecodeship.com/) - 私人註冊中心,用戶需要付費才能使用你的包 --- ### 12.贊助支持 在開源專案中加入專業支援計劃選項使客戶能夠支付一次性或持續的幫助和支援費用,以啟動和執行。 這可以透過您自己的系統啟用,也可以使用現有的贊助平台(例如Patreon 和GitHub Sponsors),或使用專門的服務(例如[Otechie](https://otechie.com/))來啟用,該服務加入了付費功能+ 支援通過嵌入的聊天對話框。 [Calendly](https://calendly.com/) 等工具可以讓客戶將時間放入日曆中,或者對於較大的專案,投資專用的客戶支援平台,例如[HelpScout](https://www.helpscout.com/) 可能會讓這件事變得更容易。 --- ### 13. 寫文件 - [撰寫文件](https://www.writethedocs.org/) 是所有文件的首選位置。 - [文件季節](https://developers.google.com/season-of-docs) - 在 Google 的支持下,每年都有技術作家為開源專案做出貢獻。參與專案將獲得 5,000 至 15,000 美元的贈款,然後通常透過 Open Collective 分發給貢獻者。 - 如果你環顧四周,你會發現還有很多產品正在尋找技術作家。 Julia 列出了一份[好名單](https://dev.to/juliafmorgado/get-paid-to-write-technical-articles-16cl),列出了願意付費讓你撰寫技術內容的公司 - 版權也屬於這一類。 [scripted](https://www.scripted.com/) 等服務可讓您透過校對或編輯其他文字內容來賺錢。 即使只是記錄您自己的和其他開發人員的儲存庫也是一個不錯的起點。 如果專案被記錄下來,它的價值就會大幅增加。如果沒有文件,潛在使用者、客戶或開發人員將不知道它的用途、如何使用它、如何在其基礎上建立或如何做出貢獻。 > 我可能是唯一的一個,但我個人喜歡寫文件。 [我的所有專案](https://github.com/Lissy93?tab=repositories) 包括完整的使用、開發和貢獻文件。這促進了它們的成功和採用。我覺得如果你不花一點時間向人們展示如何使用它,那麼花幾個小時建立一些很棒的東西是沒有意義的。 --- ### 14. 廣告 在你跳過這一點之前——我也討厭廣告。它們很煩人,並且經常涉及某種形式的跟踪,從而損害用戶的隱私。但是,對於開源專案,還有一些其他選項沒有這些缺點。 - [Ethical Ads](https://www.ethicalads.io/) - [Carbon Ads](https://www.carbonads.net/open-source) 如果您正在維護獲得穩定流量的 GitHub 儲存庫、網站、部落格或服務,那麼這是一個不錯的選擇。通常每月至少需要約 10,000 個用戶,但如果您每月獲得 50,000 以上的用戶,您將獲得更好的回報。 --- ### 15. 出售你的程式碼 > 我個人不同意這種方法,只是因為出售的許多程式碼都是開源軟體的糟糕的重新設計版本,並且並不總是給予原始作者適當的榮譽。也就是說,一些開發商確實設法讓它發揮作用,建造簡單的專案然後將其出售。 - [IndieMaker](https://indiemaker.co/) - 出售您的整個專案 - [PieceX](https://www.piecex.com/) - 出售現成的原始碼 - [Codester](https://www.codester.com/info/seller) - 針對 PHP 和 Wordpress --- ### 16.銷售內容 當您查看開發人員的副業時,這是一個常見的建議。但有充分的理由 - 如果您能夠建立高品質的內容,您可以賺到很多錢。特別是如果您對新興領域有深入的了解。 銷售內容的熱門網站包括: - [GumRoad](https://gumroad.com/) - 程式碼、課程、貼文、藝術、設計、媒體(10% 費用) - [AppSumo](https://sell.appsumo.com/) - 程式碼、應用程式、擴充功能、課程、範本等 --- ### 17.寫作 這是一套獨特的技能。要么您非常擅長編寫引人入勝的內容,要么您對特定的熱門領域有深入的了解。否則,如果您對此感興趣,請考慮電子書出版,如果您的書不成功,也不會造成任何損失。 - [LeanPub](https://leanpub.com/) - 一個自助出版技術/開發電子書和課程的平台,具有豐厚的收入模式(您可以保留 70%) - [Amazon KDP](https://kdp.amazon.com/en_US/) - 發佈至 Amazon Kindle,並立即向全球數百萬用戶提供(亞馬遜將收取至少 30% 的佣金,可能會更多)小出版商) - [SmashWords](https://www.smashwords.com/) 和 [Draft2Digital](https://draft2digital.com/sw/) - 分發給全球其他電子書賣家,這是一種簡單的開始出版。他們收取的佣金比亞馬遜少,但比 LeanPub 多。 --- ### 18.補助金 補助金和企業贊助涉及多個領域,包括開源、創新、DeFi、人工智慧等。它們通常是為了幫助您在從事特定工作時支付短期生活費用。 - [GitHub Sponsors](https://github.com/sponsors) - 為個人和組織提供經濟支援開源開發者的平台。金額依贊助情況而有所不同。 - [Google Summer of Code (GSoC)](https://summerofcode.withgoogle.com/) - 學生開發者為開源專案做出貢獻的全球計劃,津貼通常為 1500 美元到 3300 美元不等。 - [Mozilla 開源支援 (MOSS)](https://www.mozilla.org/en-US/moss/) - 為開源軟體開發提供資助,特別是與 Mozilla 使命相符的專案。 - [Linux 基金會資助](https://www.linuxfoundation.org/) - 為從事 Linux 基金會專案的開發人員提供各種資助和獎學金。 - [NumFOCUS 小額發展補助金](https://numfocus.org/programs/small-development-grants) - 支援資料科學和科學計算的小型專案。資助金額各不相同(所有申請人均分配 285,000 美元)。 - [Apache 軟體基金會贊助](https://www.apache.org/foundation/sponsorship.html) - 對 Apache 軟體專案的財務支持,重點關注 Apache 軟體生態系統。 - [Outreachy](https://www.outreachy.org/) - 為技術領域代表性不足的群體提供為期三個月的實習機會,津貼通常約為 5,500 美元。 - [奈特基金會](https://knightfoundation.org/grants/) - 為促進優質新聞業的技術專案提供資助。根據專案範圍的不同,贈款金額差異很大。 - [原型基金](https://prototypefund.de/) - 在六個月內提供高達 47,500 歐元的開源原型支持,重點支持德國的軟體開發人員。 - [斯隆基金會](https://sloan.org/programs/digital-technology) - 為開放科學社群計畫提供資助,特別是那些增強研究中的開源軟體的計畫。 - [Chan Zuckerberg Initiative 開源軟體專案](https://chanzuckerberg.com/rfa/) - 專注於支援對生物醫學研究至關重要的開源軟體。資助金額各不相同。 - [Raspberry Pi 基金會](https://www.raspberrypi.org/grants/) - 為涉及 Raspberry Pi 和計算教育的教育計畫提供補助。 - [GitCoin](https://gitcoin.co/) - 一個為開源專案提供資金的眾籌平台,特別是在以太坊和 Web3 領域。資金根據社區支持而有所不同。 - [NLnet 基金會](https://nlnet.nl/foundation/) - 支援網路科技與網路研究計畫。補助金額各不相同。 - [開放技術基金](https://www.opentech.fund/) - 支持開發促進人權和開放社會的開放技術的專案。資金各不相同。 --- ### 19. 舉辦活動 活動空間是一個利潤豐厚的行業,尤其是如果您能夠舉辦一場精彩的活動並為自己贏得大型贊助商的話。雖然不適合所有人,但舉辦活動可以帶來以下 10 個潛在收入來源: - **門票銷售**:透過收取入場費來產生收入。使用 [Eventbrite](https://www.eventbrite.co.uk/)、[Meetup](https://meetup.com/) 或 [Ticketmaster](https://ticketmaster.com) 等平台取得門票管理。 - **贊助**:確保科技公司的財務捐助,以換取活動中的促銷機會。 - **研討會和培訓課程**:提供特定技術或程式語言的專業實務學習經驗,收取額外費用。 - **虛擬活動**:使用[Zoom](https://zoom.us/)、[WebEx](https://www.webex.com/) 或 [Hopin](https://hopin.com/)。 - **黑客馬拉松**:舉辦收取報名費的程式設計競賽,或尋找贊助商來支付費用並提供獎金。 - **社交活動**:針對技術專業人士的社交活動收費,可能會吸引招聘公司的贊助。 - **演講活動**:利用您在特定技術領域的專業知識,組織並負責演講活動或小組討論。 - **企業培訓及靜修**:為企業內部培訓或團隊建立活動提供活動組織服務。 - **聯盟行銷**:在活動期間利用科技產品或服務的聯盟行銷來獲取額外收入。 - **產品發布**:與科技公司合作舉辦產品發布活動,為您提供收費的組織服務。 --- ### 20.研究 您的意見很有價值,尤其是作為開發人員。有些研究人員會付錢給你參加他們的研究、調查或智庫。通常,好的研究機會很少而且相距甚遠,或者報酬相當低。 這類工作的熱門平台包括:[Testable Minds](https://minds.testable.org/)、[Respondent](https://app.respondent.io/signup) --- ### 21. 建立課程 - [Skillshare](https://www.skillshare.com/teach) - 根據課程觀看分鐘數提供付款以及推薦獎金。 - [Coursera](https://www.coursera.org/for-universities) - 與機構合作提供課程;付款通常基於收入分享協議。 - [LinkedIn Learning](https://www.linkedin.com/learning/instructors) - 講師可以為專業人士建立課程;薪酬詳細資訊由 LinkedIn 安排。 - [Thinkific](https://www.thinkific.com/) - 提供建立、行銷和銷售線上課程的工具,具有各種定價計劃,包括免費選項。 - [Kajabi](https://kajabi.com/) - 線上課程、行銷、支付和網站建立的一體化平台。 - [Podia](https://www.podia.com/) - 提供一個用於舉辦課程、網路研討會和數位下載的平台,並直接向觀眾銷售。 - [Pluralsight](https://www.pluralsight.com/teach) - 專注於科技與創意課程;根據課程的受歡迎程度向教師支付版稅。 - [MasterClass](https://www.masterclass.com/teach) - 高品質、名人主導的課程;講師通常是各自領域的知名專家或名人。 - [uTeach](https://ueach.io/) - [NewLine](https://www.newline.co/) --- ### 22.時事通訊 隨著流行的社群媒體管道變得更加集中和受控,電子郵件通訊和基於訂閱的 RSS 來源正在慢慢捲土重來。 這種模式的工作方式要么是提供對技術主題或新聞的有價值的見解,並建立一個龐大的(因此有價值的)訂閱者基礎,要么是向少數用戶收取更新費用。 提供此功能的流行平台包括: - [子堆疊](https://substack.com) - [ButtonDown](https://buttondown.email/) - [ConvertKit](https://convertkit.com/) - [穩定](https://steadyhq.com) - [幽靈](https://ghost.org/) --- ### 23. 僅限會員的網站 - [MemberSpace](https://www.memberspace.com/) - 讓您能夠為網站的某些部分付費,僅供會員使用 - [Patreon](https://www.patreon.com/) - 因設定具有獨家內容和福利的會員等級而廣受歡迎。 - [Substack](https://substack.com/) - 新聞通訊的理想選擇;提供付費訂閱獨家內容的能力。 - [Ghost](https://ghost.org/) - 內建會員和訂閱功能的專業發布平台。 - [Podia](https://www.podia.com/) - 允許銷售會員資格、線上課程和數位下載。 - WordPress 與 [MemberPress 外掛程式](https://memberpress.com/) - 供 WP 使用者建立會員網站的外掛程式。 - [Wild Apricot](https://www.wildapricot.com/) - 與您的網站整合的會員管理軟體。 - [Kajabi](https://kajabi.com/) - 提供用於建立線上課程、會員網站等的工具,重點是行銷。 - [Mighty Networks](https://www.mightynetworks.com/) - 建立一個包含會員資格、訂閱和課程的社群。 --- ### 24. VIP 貼文 還有許多公司會為您在其平台上分享的優質貼文付費。這既可以提高您的知名度(幫助您擴大人脈並獲得未來的工作),也可以帶來一些短期收入。 如果您正在努力獲得這些計劃的錄取,請先編寫自己的帖子並將其發佈到流行的基於開發的社交網絡(例如 DEV.to!)。這將增強您的寫作技巧,並幫助您向潛在公司展示您的知識。 例如,以下網站將為高品質的訪客貼文付費: - [Linode](https://www.linode.com/lp/write-for-linode/) - [日誌火箭](https://blog.logrocket.com/become-a-logrocket-guest-author/) - [Smashing 雜誌](https://www.smashingmagazine.com/contact/?Becoming%20an%20Author/Reviewer%20(自動回覆)) - [Auth0](https://auth0.com/apollo-program) - [CSS 技巧](https://css-tricks.com/guest-writing-for-css-tricks/) - [DelftStack](https://www.delftstack.com/write-for-us/) - [DigitalOcean](https://www.digitalocean.com/community/pages/write-for-digitalocean) - [Infatica](https://infatica.io/contribute/) - [蜜罐](https://blog.honeypot.io/write-for-honeypot/) - [進階編碼](https://premiumcoding.com/write-for-us-premiumcoding/) - [反思](https://reflectoring.io/contribute/become-an-author/) - [Strapi](https://strapi.io/write-for-the-community) - [Android 權威](https://www.authoritymedia.com/jobs) - [SitePoint](https://www.sitepoint.com/write-for-us/) - [TutorialsPoint](https://www.tutorialspoint.com/about/tutorials_writing.htm) - [真正的Python](https://realpython.com/jobs/tutorial-writer/) - [Dart Creations](https://www.dart-creations.com/about-us/write-for-us.html) Dmytro Spilka 編制了一份包含 300 多個[接受訪客貼文的網站](https://solvid.co.uk/180-websites-that-accept-guest-posts/) 的清單。另一個很棒的清單[由 Julia 在 Dev.to 上整理](https://dev.to/juliafmorgado/get-paid-to-write-technical-articles-16cl)。 --- ### 25. 諮詢 您可能沒有意識到,您從日常工作中累積的技能和經驗對許多公司來說可能非常有價值。尤其是尚無法聘請全職專家的新創公司和小型企業。對能夠提供最新趨勢、工具和最佳實踐見解的專業人士的需求非常高。 尖端: - 以適當的速度開始的最佳方式是透過網路和口碑。但如果做不到這一點,總有自由工作網站可以幫助您累積經驗。 - 記錄你所獲得的經驗,或在你工作的過程中建立一個投資組合,因為這將幫助你在未來獲得更好的工作。 - 在開始任何專案之前,請先明確您的空閒時間、條款、日薪和工作範圍。 - 切勿拒絕潛在的聯絡人。您會驚訝地發現,即使多年後,誰可能會重新與您聯繫並尋求諮詢支援。 --- ### 26. 指導 無論您的級別如何,您作為開發人員的經驗都可以真正幫助經驗不足的其他人。指導是一種非常有益的方式,可以幫助他人,同時也能帶來一些額外的收入。 - [MentorCruise](https://mentorcruise.com/) - 主要是長期的,按月付費,非常適合建立專業關係(每個學員每月賺取 50-500 美元) - [CodeMentor](https://www.codementor.io/) - 更適合短期,按小時收費,非常適合解決特定問題(每小時賺取 60-300 美元) --- ### 27.輔導 隨著 CompSci 現在成為國家課程的一部分(至少在英國和大部分歐洲),大量學生(11 歲至 18 歲以上)正在尋找導師來幫助他們獲得編碼技能並準備考試。收入範圍為每小時 15 美元到 150 美元以上,具體取決於級別、經驗和背景。 - [Super Prof](https://www.superprof.co.uk/) - 列出您的全球服務(30-300 美元/小時) - [The Profs](https://www.theprofs.co.uk/become-a-private-tutor/) - 經過驗證的導師(收入未知) - [我的導師](https://www.mytutor.co.uk/) - 僅限英國,(22-55 英鎊/小時) - [Tutor.com](https://www.tutor.com/) - 美國高中學費($75-$100/小時) --- ### 28.社群媒體 市場存在巨大空白,等待主流社群媒體平台上真正優秀的、注重發展的影響者來填補。 許多社群媒體平台允許您透過內容貨幣化,您通常會按觀看次數付費,金額根據內容類別、地區和聲譽而有所不同。但請注意,您通常必須擁有一定數量的追蹤者才有資格,而且您還將受到「演算法」的支配。 - YouTube - 每年至少需要 1,000 訂閱者 + 4,000 小時觀看時間 - X - 需要 Twitter Blue 訂閱,無最低追蹤人數 - TikTok - 需要至少 10k 追蹤者 + 100k 瀏覽量/月 - Instagram - 需要至少 10k 追蹤者 - Snap - 1,000 名追蹤者,1,000 次瀏覽/月,10 多個每月貼文 - Facebook - 10k 追蹤者或 600k 影片觀看分鐘 - Twitch - 350 位每月付費訂閱者 --- ### 29.品牌優惠 繼上面的社群媒體部分之後,一旦您成功突破了數百名訂閱者,您可能還可以開始考慮品牌交易,這有助於帶來額外收入。同樣,這些需要您的受眾達到一定程度的參與度,您可能還需要同意提供贊助的公司的條款。 --- ### 30.串流媒體 開發串流是一個快速成長的利基市場,不要指望立即[加入排行榜](https://twitch.pages.dev/),但它可能是一個很好的起點,特別是如果您已經有串流媒體經驗(例如影片遊戲)。 Nick Taylor 寫了一篇關於 [開發串流媒體入門的精彩文章](https://dev.to/nickytonline/getting-started-with-streaming-on-twitch-4im7)。 --- ### 31.SaaS 如果您能夠做到這一點,那麼它就是開源專案的最佳收入模式之一。您的程式碼仍然是 100% 免費和開源的,用戶仍然可以免費下載和自行託管它,但您還提供付費/託管計劃,您可以在其中託管應用程式並負責小型伺服器的所有伺服器管理經常性費用。 此模型符合開源精神,同時也使您的應用程式可供更廣泛的用戶使用。 [Stripe](https://stripe.com/docs/payments) 等服務讓您的應用程式接受付款和新增訂閱功能變得非常簡單。 --- ### 32.微型 SaaS 如果從頭開始建立一個生產就緒的應用程式聽起來像是一項艱鉅的任務(因為它確實如此!),那麼另一種方法就是 Micro-SaaS 應用程式。這些是較小的應用程式,它們執行一項非常具體的任務,例如: - 自動執行重複和/或乏味的任務。 - 執行目前手動計算的計算。 - 連接不同的系統。 - 取代 Excel 電子表格解決方法。 - 填補宿主生態系中缺失功能的空白 - 加強報告 --- ### 33. 寫外掛 與 SaaS 應用程式不同,一旦建置並發布了擴展,通常不需要太多的持續管理。您也可能會發現,如果您的專案為已經完善的網站加入功能,那麼您的專案會更容易快速獲得關注。 儘管網路擴展似乎是一個過時的或完全飽和的市場,但仍然有很多可以做的事情,而且這些對於新開發人員來說都是很棒的專案。 以下是一些可以幫助您入門的想法: - [WA Web Plus](https://chrome.google.com/webstore/detail/wa-web-plus-by-elbruz-tec/ekcgkejcjdcmonfpmnljobemcbpnkamh) 已下載 200 萬次(22k 評級),收費 12 美元/每個用戶的月。為什麼不為 Telegram、Threema、Wire、Messenger 等建立類似的東西呢? - Runkeeper擁有4500萬用戶,但UI在資料顯示方式方面有所欠缺。為什麼不建立一個擴充功能來加入更好的報告、過濾以及與相關外部資料的組合? (與 [Elevate for Strava](https://chrome.google.com/webstore/detail/elevate-for-strava/dhiaggccakkgdfcadnklkbljcgicpckn) 類似,但適用於 RunKeeper) - 選擇一個提供基本服務但 UI 過於不切實際的網站(也許是 Microsoft Azure?),然後建立一個擴充功能以簡化導覽、顯示關鍵指標或提供不那麼難看的使用者體驗 - 使用人工智慧增強任何現有網站。這比聽起來容易得多,您的擴充功能可以利用 OpenAI 的 API 等服務來總結網頁,或重新措辭選定的內容(用於複製/貼上到作業中!?) - 如果您知道某個網站的使用者數量很高,但 UI 很糟糕,那麼一個簡單的擴充想法可以是應用 CSS 覆蓋來重新設計它的樣式。例如亞馬遜、雅虎、Instagram 都是高流量網站,設計改善空間巨大(深色模式?!) - 即使是簡單的獨立擴展應用程式也可能具有很大的潛力。就像番茄計時器、貨幣轉換器、IP 位址小部件或只是一個網路應用程式快捷方式。 --- ### 34. 發布應用程式 建立簡單的應用程式或遊戲,並將其在平台應用程式商店上提供,使您能夠透過簡單的盈利模型來瞄準數百萬客戶。所有主流應用程式商店 - Google Play、Apple App Store、Windows Store、Steam 等都提供對付費應用程式、進階功能和應用程式內購買的支援。 請記住,在發布第一個應用程式之前通常需要支付安裝費,應用程式商店也會從您的收入中抽取一部分,並且小型創作者獲得單次或雙次下載的情況並不罕見。人物。 --- ### 35. 為小型企業開發網站 許多小型企業都專注於自己的業務,沒有時間或專業知識建立自己的網站。作為開發人員,這是我們能夠很快完成的事情,如果您也託管他們的網站,您將能夠收取定期付款。 一旦您開始進行網頁設計和開發,並為一些客戶提供服務,您就會發現透過口碑和展示您的作品集來找到未來的工作要容易得多。 為了在這方面取得成功,您可能還需要設計、溝通和銷售方面的技能。 --- ### 36. 兜售網域 隨著新 TLD 的湧入,域名經銷商市場正在迎來第二波受歡迎。域名翻轉涉及註冊未來可能有價值的域名,然後將其轉售給想要將該名稱用於企業或專案的買家。 雖然這可能有利可圖,但它確實涉及高風險,並且需要對市場有充分的了解。 尖端: - 研究簡短或令人難忘的域名,或者可能具有較高關鍵字潛力的域名(您可以使用諸如使用 Google 關鍵字規劃師等工具來幫助進行這項研究) - 停放您目前未使用的域名,以便您同時獲得一些廣告收入 - 查看最近過期的域名,特別是那些正在使用的域名,因為這些域名可能會收到流量 - 接收流量的網域更有價值。因此,請考慮在您持有網域時為其建立網站、應用程式或登入頁面 --- ### 37. 使用者測試 開發應用程式的公司通常需要獲得用戶的回饋。這就是用戶測試服務的用武之地。您花 10-30 分鐘嘗試給定的網站或應用程式,然後提供反饋或填寫調查,並獲得報酬! 儘管並非特定於開發人員,但憑藉您的技術背景,您會發現自己具有獨特的優勢,可以快速完成這些工作並提供良好的反饋,從而使您比普通用戶更快地賺錢。您還將獲得有關用戶測試流程如何運作的寶貴見解,這可能對您在自己的應用程式上進行委託測試時有用。 - [嘗試我的 UI](https://www.trymyui.com/) - 每個網站或應用程式測試平均費用為 10 美元 - [Userlytics](https://www.userlytics.com/user-experience-research/paid-ux-testing/) - 根據測試的複雜程度和長度,賺取 5 至 50 美元之間 - [使用者測試](https://www.usertesting.com/get-paid-to-test) - 透過 PayPal 付款,在測試會話期間需要螢幕共用和/或網路攝影機存取。每次測試賺取約 10 美元,較長時間或現場會議的某些測試最高可支付 50 美元 - [TestingTime](https://www.testingtime.com/en/become-a-paid-testuser/) - 面對面或視訊通話測試的選項。不太定期,但測試時間更長。當您考慮到會話之間的延遲時,報酬比其他選擇更低 - [IntelliZoom](https://www.intellizoom.com/) - 每 10 分鐘學習可賺取 2 至 10 美元。透過 PayPal 付款,延遲 3-5 天 --- ### 38.微任務 與開發人員的具體關係不大,但如果您來自技術背景,您可能會發現這些工作比那些沒有開發技能的工作更有利可圖。 - [Amazon Mechanical Turk](https://www.mturk.com/) - 外包虛擬微任務的眾包市場 - [Sequence Works](https://sequence.work/contributors/) - 影像標註、資料標記與分類 - [App Jobber](https://en.appjobber.com/) - 市場調查,去商店拍攝特定植入式廣告的照片 - [GigWalk](https://www.gigwalk.com/gigwalkers/) - 應用程式為基礎的行動微任務 - 請造訪 [GigWorker.com](https://gigworker.com/) 以了解更多微任務和零工工作 --- ### 39. 調查 儘管對具有某些技能(如軟體工程)的參與者的需求較高,但調查的報酬往往很低,因此可以賺更多一點。即便如此,除非您有大量時間,或使用比美元弱得多的貨幣,否則這可能不是一個好的選擇。 這些通常涉及測試新產品或服務,並提供回饋 - 或回答問題以協助市場研究活動。 有很多不同的基於調查的公司,所以我不會全部連結到它們。但 [Swagbucks](https://www.swagbucks.com/)、[20Cogs](https://20cogs.co.uk/)、[TestingTime](https://www.testingtime.com/en/become-a-paid-testuser) 是一些著名的。 --- ### 40.去中心化節點 這可能不適合所有人,因為收益通常以加密貨幣形式支付,而加密貨幣的波動性非常大。但是,您可以自願為許多 Web3 專案執行節點(通常在 Rasperry Pi、雲端伺服器或備用筆記型電腦上),這將為您支付正常執行時間、頻寬、磁碟空間、運算、IP/代理或其他一些費用。計算資源。 作為開發人員,管理基礎設施是我們所擅長的,因此,如果您有任何閒置資源,您也許可以將它們投入使用,並在睡覺時賺取一些額外的現金。 - [Storj](https://www.storj.io/node):執行Storj節點,用於去中心化雲端運算 - [Network3](https://network3.io/):用於訓練和驗證模型的 AIoT 第 2 層 - [Flux](https://runonflux.io/):去中心化基礎設施 - [Mysterium](https://mystnodes.com/): P2P VPN 節點 - [Koii](https://www.koii.network/node): 分散式雲 - [Helium](https://www.helium.com/mine):提供遠端物聯網設備無線連接 - [Filecoin](https://filecoin.io/):它是一個去中心化儲存網絡,將雲端儲存轉變為演算法市場。用戶可以出租閒置的儲存空間並賺取 Filecoin 代幣。 - [Sia Network](https://sia.tech/host):這是一個由區塊鏈技術所保障的去中心化儲存平台。 Sia 透過去中心化網路儲存和加密您的檔案。您可以透過出租未使用的硬碟空間來賺取 Siacoins。 - [Crust Network](https://wiki.crust.network/docs/en/nodeOverview):與 Filecoin、Sia 類似,Crust 支援 IPFS 等多種儲存層協議,並為應用層提供儲存介面。 - [Arweave](https://www.arweave.org/):一個基於區塊鏈的平台,以永久和去中心化的方式提供資料儲存。透過託管資料,用戶可以獲得 Arweave 代幣獎勵。 - [BitTorrent](https://docs.btfs.io/v2.0/docs/install-run-btfs20-node):該平台標記了世界上最大的文件共享協議,使用戶能夠通過在網路上。 - [HOLO](https://holo.host/):Holochain 應用程式 (hApps) 的點對點託管平台。在電腦上託管 hApp 的用戶將獲得 HOT 代幣獎勵。 --- ### 41.其他 Web3 方法 加密產業還有許多其他賺取被動收入的方式,從PoS 質押、持有生息數位資產、借貸、流動性挖礦、雲端挖礦、賺取股息的代幣、流動性挖礦、交易、本地/ PoW 思維、NFT 等等。很少。 我不會在這裡連結到任何具體細節,因為這是一個風險非常高的行業,因此您自己進行研究很重要。但作為技術專家,我們能夠理解任何給定協議或 Web3 資產背後的基本概念,並確定其可行性。 我的建議是閱讀白皮書,如果你不能立即理解它,那就遠離它!這是狂野的西部,所以除非一個專案的基本面是堅實的,否則你應該做好失去投資的任何資金的準備。 --- ### 42. 聯盟行銷 聯盟行銷對於那些剛開始的人來說是眾所周知的無利可圖,但我將其包含在此處是因為作為開發人員,有一定的空間來自動化許多過程。此外,您行銷的服務越細分,支付的佣金通常就越高。因此,如果您融入了技術社區,您可能處於銷售小批量高回報服務的有利位置。 同樣,如果您已經有了追蹤者(社交、部落格、YouTube 頻道...),那麼聯盟行銷可能更有意義,因為如果您獲得了大量點擊。 值得注意的是,您可能不應該在未透露它是附屬連結的情況下共享附屬連結。並儘量避免宣傳您自己沒有使用過或不會推薦給朋友的產品。 > 作為範例,[此處](https://notes.aliciasykes.com/p/3Ia4JzPw43) 是我使用過且擁有附屬帳戶的一些服務。我從未從其中任何一個身上賺過任何有意義的錢。 --- ### 43.經銷商 這涉及建立一個應用程式來包裝現有服務,同時加入 USP - 技術、客戶支援、UI 或其他功能。如果您有行銷或銷售背景,這可能適合您。如果您想加入功能或使流程自動化,那麼將需要大量的前期工作,但您將能夠更好地獲得收入。 您可以在大多數主要行業中找到提供經銷商計劃的服務提供者。 一些例子包括: - [Supermetrics](https://supermetrics.com/):行銷報告、分析、資料整合、20% 經常性佣金。 - [Keap](https://keap.com/):CRM、銷售與行銷自動化、20-30% 經常性佣金。 - [Klaviyo](https://www.klaviyo.com/):電子郵件與簡訊行銷,5–15% 一次性付款,10–20% 收入分成。 - [Drift](https://www.drift.com/):即時聊天軟體,20%收益分成。 - [ActiveCampaign](https://www.activecampaign.com/):電子郵件行銷、CRM、20–30% 佣金或折扣模式。 - [HubSpot](https://www.hubspot.com/):CRM、入站行銷、銷售、20% 營收分成。 - [Gorgias](https://www.gorgias.com/):電子商務幫助台,20% 收入分成。 - [Shopify](https://www.shopify.com/):電子商務平台,佣金20%,Shopify Plus 10%。 - [LiveChat](https://partners.livechat.com/):客戶服務平台,即時聊天,委託20%。 - [GetResponse](https://www.getresponse.com/):電子郵件行銷、線上活動管理、子帳號 35% 折扣、35% 經常性佣金。 --- ### 44. 人體實驗 這與技術根本無關。但作為程式設計師,我們通常可以在任何地方工作 - 那麼為什麼不在有報酬的地方編寫程式碼呢? 通常,您的收入在 2,000 美元到 10,000 美元之間,具體取決於試用期、持續時間、是否為住宅和具體情況。 像[流感營](https://flucamp.com/) 這樣的地方將支付您 4,000 英鎊,讓您在舒適的酒店式套房中入住兩週,同時他們會測試新的治療方法。那些患有氣喘等特定疾病的人可能可以透過參加更專業的試驗來賺取更多收入 --- ### 45.自由職業 自由職業可能會根據您的技能、經驗和您所在的領域而有所不同。對於新自由工作者來說,某些領域(例如網頁開發)的費率往往非常低,但您擁有的經驗和客戶滿意度越高,您就越能夠充電。 開發人員零工工作的三個主要平台是: - [Fiverr](https://www.Fiverr.com/):Fiverr 以其多元化的市場而聞名,非常適合剛開始從事自由職業的開發人員 - [Upwork](https://www.upwork.com/work):Upwork 迎合了廣泛的專業人士,但它對經驗豐富的開發人員特別有利。它提供了長期合約和高薪工作的潛力。該平台適合喜歡從事更實質專案的人。 - [People per Hour](https://www.peopleperhour.com/):這個平台對歐洲市場的開發者有好處。它強調當地的商業聯繫,並在短期和長期專案之間提供良好的平衡。 --- ### 46. 說話 面對面的和移除的開發者聚會和活動在全球各地不斷發生。這些活動需要演講者,許多人願意付費以獲得良好的演講。支付的金額根據規模、觀眾、主題、演講者(你!)和其他因素而有很大差異。通常,您必須先自願在當地的小型技術聚會上發表演講,然後逐步提高。 --- ### 47. 遠端技術支持 這不是最迷人的角色,但較小的公司通常無法聘請全職的專門技術支援人員,因此您可以找到很多兼職工作。如果您擁有雲端經驗或認證,這些的薪資等級會大幅提高。只需查看任何求職板(例如 [WeWorkRemotley](https://weworkremotely.com/)),您就會看到大量職位。 請注意,您通常需要在特定時間內有空,並期望您可以在給定的時間內回覆。在申請之前,請確保這是您可以解決的問題。 --- ### 49. 投資 是的,這不是副業——但聽我說完… 如果您每年的收入為 6 萬美元,生活成本為 4 萬美元,那麼 5 年後您可能會有 10 萬美元的儲蓄。如果您將其投資於年平均回報率為10 - 15% 的標準普爾500 指數- 您每月可能會從您的投資中獲得超過1,000 美元的額外收入,並且您的投資能力越強,收入就會不斷增加儲蓄(當然,投資可以減少也可以增加)。這已經比這裡列出的許多副業更好的回報了! --- ### 50. 就業 我們不要忘記,儘管目前情況看起來很艱難,但身為開發人員,即使只有一兩年的經驗,我們也處於非常幸運的地位,與平均收入者相比,我們的薪水很高。 如果你的工作不適合你——換公司通常是提高薪資的可靠方法,如果你不喜歡目前的工作,這可能是值得考慮的事情。 也許經歷了這一切之後,你所追求的不是副業,而是更好的「主業」? --- ## 真實的說話 儘管您可能會在 IndieHackers 和 Instagram 上看到一些內容,但副業並不是全部。這通常需要大量的工作,但回報卻非常有限。因此,在在這裡或其他地方進行任何事情之前,請退後一步,思考「我為什麼要這樣做?」。如果您這樣做是為了累積經驗、學習新技能並享受樂趣——那就太好了。如果你這樣做是為了快速致富 - 你可能會非常失望。 還有一點要注意的是,儘管看起來不公平,但與那些剛起步的人相比,那些已經擁有強大追隨者或幾個成功的開源專案的人將處於更好的位置來利用機會。 因此,從短期來看,作為一名開發人員,您的時間可能會更好地花在提升自己身上。如果您不確定從哪裡開始,這裡有 5 個關鍵提示: - **網絡** - 建立你的網絡,參加聚會、黑客馬拉松和開發活動,加入社區,結交朋友 - **開源** - 將您的工作放在那裡,公開學習,建立您感興趣的迷你專案,並且不要害怕失敗 - **經驗** - 獲得實務經驗,申請實習機會,作為自由開發人員提供服務 - **基礎知識** - 確保您對電腦科學基礎知識有深入的了解,其餘的就會容易得多 - **玩得開心!** - 你自然會在你真正熱愛的領域做得更好。如果你不喜歡你正在做的事情,請退一步,考慮不同的方法是否更適合你 --- ## 免責聲明 - 以上列表僅供您參考。 - 我沒有親自測試過這裡列出的所有服務。 - 如果您有 - 我很想聽聽您的回饋。同樣,如果有任何需要加入或刪除的內容,請在下面告訴我。 - 並非所有服務都在所有國家/地區提供(此清單主要針對英國/歐洲和美國🇬🇧🇪🇺🇺🇸) - 有些平台會抽取您的收入。這通常是一個很小的數額,但重要的是你要考慮到 - 如果您已經擁有大量追隨者或流行的開源專案,賺錢通常會容易得多 - 有些方法涉及風險。儘管我已盡力強調這一點,但請記住,您的投資可能會下降而不是上升 - 您的結果可能會有所不同 - 沒有保證 --- 原文出處:https://dev.to/lissy93/50-ways-to-bring-in-extra-cash-as-a-developer-19b6
狀態管理器到底是什麼?狀態管理器是一個智慧模組,能夠保留(應用程式或 Web 應用程式的)會話資料並對資料的變更做出反應。 您是網頁開發人員嗎?使用過 Redux、Mobx 或 Zustand 等函式庫嗎?恭喜!您已經使用了狀態管理器。 我記得我第一天嘗試為 React 設定(舊的)Redux。只要想到所有不必要的複雜性——調度程序、減速器、中間件,我就會患上創傷後壓力症候群(PTSD)!我只是想聲明一些變數,_請讓它停止_。  這是一個過度設計、臃腫的庫,每個人都在使用!由於某種瘋狂的、未知的原因,它成為了當時的行業標準。 ###一些背景故事 2021 年的一個晚上,當我無法入睡時,我漫無目的地打開 GitHub,注意到我以前的大學課程老師(我在 GH 上關注過他)為他現在的學生上傳了一份作業。該作業要求學生使用公共 Pokemon API 建立一個 Pokedex 網站。目標是用 Javascript 實現它(沒有框架或函式庫,因為他目前的學生是 Web 開發初學者,仍在學習 Javascript 和開發的基礎知識)。 作為一個笑話,主要是因為我睡不著,我開始在我的神奇寶貝網站上工作。最終,我能夠建立一些可行的東西,而無需使用任何外部庫。 ### 但一路走來,我很掙扎...... 你看,我已經習慣了擁有一個狀態管理器,以至於在不使用外部框架或庫的情況下建置一個簡單的兩頁應用程式的要求讓我開始思考 - _為什麼狀態管理器必須如此復雜?這只是變數和事件._ 長話短說,我發現自己在凌晨 2 點組裝了一個超級簡單的狀態管理器模組,只是為了管理我的 Pokemon Web 應用程式的狀態。我將我的網站部署到了 GitHub 頁面,然後就忘記了這一切。 幾個月過去了,但出於某種原因,我時不時地思考我的狀態管理解決方案...你看,它有其他庫沒有的東西 - _它太簡單了。_ _“嘿!”我心想,「我應該將它重寫為 NPM 套件」。_ 當天晚上,我就這麼做了——我把它寫成了一個獨立的 NPM 包。最後,它的重量為 2kB(相比之下 Redux 的 150kB),具有零依賴性,並且使用起來非常簡單,您只需 3 行程式碼即可完成設定。 ### 我稱之為 VSSM 代表**_非常小的狀態管理器_**。 您可以在[GitHub](https://github.com/lnahrf/Vssm)上查看原始程式碼。另外,請查看使用 React 和 VSSM 建立的[文件網站](https://lnahrf.github.io/Vssm-docs/)。 第二天,我發布了我的 NPM 包,然後又忘記了這件事。 同年晚些時候,我面試了兩家不同公司的全端開發人員職位。我在第一家公司的面試中取得了優異的成績,這是一家非常成熟的科技公司。作為面試過程的一部分,他們要求我告訴他們我是否在空閒時間編碼,或者是否有我貢獻過的任何開源專案等等。 當時我做的唯一很酷的事情就是 VSSM,所以我告訴了他們。他們對我自己建立一個「Redux 替代方案」的想法印象深刻。 另一方面,我在第二家公司的面試中慘敗。我的大腦一片空白,我很緊張,無法回答簡單的問題,例如 > “React 會在狀態變更時重新渲染整個應用程式,還是在使用 Redux 時僅更新受影響的元件及其子元件?” “每次狀態更新時,它都會重新渲染整個應用程式”,我說。  我很緊張,哈哈,顯然我知道正確的答案是「它只渲染註冊的元件以及可能受影響的子元件」。 直到今天我也不明白為什麼二號公司決定給我第二次機會。他們邀請我再次接受採訪(是的!)。 在我的第二次面試中,他們要求我告訴他們我是否在空閒時間編碼、開源貢獻,你知道該怎麼做。當我告訴面試官我的小副專案時,他看起來很高興,似乎他喜歡我只是因為我從頭開始編寫了一個狀態管理器。 我想情況確實如此,因為我第二次面試也失敗了(在程式設計挑戰期間耗盡了時間),但仍然得到了一份工作機會。 1 號公司打算向我發送報價,但我已經與 2 號公司簽署了報價。 我的底線是——我建立 VSSM 幫助我獲得了這兩個機會。  ### 我是怎麼做到的? 您是否知道 Javascript 內建了監視變數變更所需的所有功能? 它被稱為代理(它很神奇)。 Javascript 代理程式是程式碼和變數分配之間的附加邏輯層。 如果您要將物件包裝在代理程式中,您可以決定在每次更新時將其值記錄到控制台,除了為該物件指派新值之外,無需執行任何操作。 ``` const target = { v: "hello" } const proxyTarget = new Proxy(target, { set: (target, property, value) => { console.log(`${property} is now ${value}`); target[property] = value; return target[property]; } }); proxyTarget.v = "world!" // v is now world! ``` VSSM 是基於代理建置,它在變數賦值和其餘程式碼之間建立了一個層。使用代理,您可以設定 setter、getter,並在操作或請求目標值時實現任何類型的邏輯。 VSSM 不僅僅是一個代理,它是各種智慧代理,它們知道分配給變數的值是它的新值還是回調方法。 例如,使用 VSSM,您只需幾行程式碼即可設定狀態、監聽變更並發出事件。 ``` import { createVSSM, createState } from 'vssm'; import { getVSSM } from 'vssm'; // Create the initial state createVSSM({ user: createState('user', { address: '' }) }); // Get the user proxy reference const { user } = getVSSM(); // Listen to events on user.address user.address = () => { console.log(`Address updated! the new address is ${user.address}`); }; // Emit the mutation event user.address = 'P.Sherman 42 Wallaby Way, Sydney' ``` 正如您所看到的,我確保我的狀態管理器盡可能簡單。我的目標是擺脫僅僅為了分配一些變數而陷入減速器、中間件和極其複雜的配置的困境。 現在,一切都透過分配變數來進行!想要設定監聽器嗎?將回調函數指派給變數。想要編輯值並發出事件嗎?只需指派一個新值即可。 直到今天我仍然不明白為什麼流行的狀態管理器必須如此複雜,也許我永遠不會。 我鼓勵您繼續閱讀 [MDN Web Docs](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Proxy) 上有關 Javascript 代理的所有內容。 ### 這一切的結論是什麼? 我認為,對自己所做的事情充滿熱情是關鍵。 我建立 VSSM 只是為了突破自己的極限並發布合理的 NPM 包。它成功地給面試官和同事留下了深刻的印象,並讓我從那時起就進入了不同的職位。 沒有人會使用 VSSM,它不會流行。當我將其發佈到 NPM 時,我就意識到了這一事實。但我仍然選擇盡我所能,因為我熱衷於做一些我認為比行業標準更好的事情。我知道我可以做出一些必須更好的東西,即使這意味著它對我更好。 儘管 VSSM 已經死在 NPM 墓地裡,但它給我帶來了很多價值,並且因為這篇文章而繼續這樣做。 獲得開發工作的最佳方法是建立令人驚嘆的東西,即使您認為這一切以前都已經完成了 - 建置得更好。即使您認為沒有人會使用它,那又有什麼意義呢? - 現在建置,價值稍後顯現。 不要低估你的能力,如果你認為自己有不足,請知道你會進步。走出去,建構能夠帶來價值的專案,一次一小步。 祝您工程之旅順利。 --- 原文出處:https://dev.to/lnahrf/javascript-proxy-magic-how-i-built-a-2kb-state-manager-with-zero-dependencies-and-how-it-got-me-two-different-job-offers-2539
你有沒有想過... **如果軟體開發人員的需求如此之大,為什麼現在找到開發人員的工作這麼難?** 為什麼面試過程這麼長?為什麼會有數百次拒絕? 為什麼提供的工資低? 今天,您將了解混亂背後的原因。 我們是如何來到這裡的。以及為什麼。 我還將向您展示為什麼事情並不像大多數開發人員想像的那麼糟糕。以及您需要採取的 5 個步驟來利用這種情況為您帶來優勢。 因此,當大多數開發人員都在倒退時,您可以快速發展您的職業生涯。 如果您是一位雄心勃勃的開發人員,想要更上一層樓並增加薪水,那麼這就是適合您的。 **因為有一件事是真的,我們所知道的軟體開發在 2023 年已經發生了永遠的變化。** 「美好的舊時光」已經一去不復返了。 知道如何建立 React 應用程式將不再讓你獲得這份工作。我們不會很快回到那個狀態。 我們走吧。 這一切都要追溯到 2022 年,當時從谷歌到 Meta 和微軟等大型科技公司開始宣布裁員。不是各種裁員,是裁員開發者。 起初,大多數開發人員都很有信心。 他們說,_「軟體開發總是在成長並且需求旺盛,我們將會復甦」_。 現在,12 個多月過去了,許多程式設計師已經失去了樂觀情緒(免責聲明:我仍然對開發人員的未來非常樂觀,稍後會詳細介紹)。 許多開發者正在失去耐心等待就業市場的復甦。如果它永遠不會發生怎麼辦? 一些開發人員正在懷疑他們的職業選擇。正在考慮 B 計劃或已經轉向做其他事情。 其他人則被迫回到編寫程式碼之前的低薪工作。  最初的樂觀很快就變成了悲觀,許多開發者都在尋找 B 計畫。 **最好的情況是資料輸入或客戶服務工作。在最壞的情況下,它會回到咖啡店或倉庫。** 我認為這是一件非常悲傷的事情。僅僅因為你找不到擺脫困境的有效策略,就拋棄了你的夢想和多年的努力。 我相信,如果你進入軟體開發,那是有原因的。您可能工作勤奮、雄心勃勃且富有創造力。你至少應該有機會證明自己的價值。 在這篇文章中,我將向您展示該怎麼做。具體來說,無論市場表現如何,如何使用經過驗證的軟體工程原理來度過這場風暴,並將您的開發人員職業生涯提升到一個新的水平。 我是誰可以給你這方面的建議? 我叫 Dragos,在過去 3 年裡,我幫助超過 230 多名軟體開發人員提升了技能,快速晉升到高級級別,並獲得了他們應得的認可和報酬。  我不是大師或技術影響者。我並不打算成為其中之一。 但是,在作為自學成才的開發人員編寫程式碼期間,我一直在戰壕里工作,現在幫助其他開發人員升級,這使我很有資格為您提供這方面的建議。 首先,讓我們先了解一下軟體開發行業目前正在發生什麼… **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ## 現在的情況 像任何好醫生一樣,為了治療症狀,我們必須了解背後的問題。 開發人員就業市場就像任何市場一樣,受簡單的供需機制控制。對開發者的需求越大,開發者的議價能力就越大。 對開發者的需求越少,我們的談判能力就越小。 如果你不斷地感覺自己與其他開發者比較,無法要求高薪,並且很難找到工作,這意味著你在市場上的力量很小。  供需關係決定開發者就業市場。 傳統上,開發者在市場上擁有大部分權力,公司會不遺餘力地獲得最好的工程人才。 這就是為什麼開發人員的薪水不斷增長以及每個人都想學習如何編碼的原因。 **但是,在過去 12 個月裡,權力已經從開發者轉移到了公司(除了頂層的開發者,稍後會詳細介紹)。** 為什麼? 很多原因。讓我們一一回顧一下… ## 1.“效率時代” 戰爭、通貨膨脹和經濟衰退迫使世界各地的公司最大限度地利用資金。包括軟體公司。 企業需要找到更有效的做事方式——如果您正在建立軟體,這意味著擺脫一些開發人員並自動化盡可能多的任務。  糟糕的經濟狀況迫使科技公司的執行長提高公司的效率。 正如馬克·祖克柏在他關於 Meta 的「效率年」的文章中提到的那樣,公司希望提高開發人員的生產力和工具並減少員工人數。 **一言以蔽之:科技公司希望盡可能精簡。** 這意味著軟體開發團隊不能再龐大了。他們需要一些高技能的開發人員以及大量的自動化設備。  這意味著縮小團隊規模(即:解僱表現不佳的員工)、取消優先順序較低的專案並降低招募率。用更少的軟體開發人員完成更多的工作。 對於開發人員就業市場來說,這可不是好訊息… **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ## 2.人才海嘯 開發人員就業市場變得非常非常擁擠,有數百名候選人瞄準同一職位。 這是因為編碼技能變得越來越普遍。 在過去的十年中,訓練營和電腦科學學位一直在將軟體開發人員吸引到一個已經擁擠的市場中。尤其是訓練營,經過六週的編碼後,他們實現了六位數薪資的夢想。  這引發了一場「人才海嘯」。開發人員的工作被當作中產階級的金票出售。成千上萬的人放棄了學習編碼的希望。 然而,正如許多初級開發人員所看到的那樣,這主要是一種行銷承諾。 事實上,開發人員職位的競爭非常激烈,你在 3 個月的 Bootcamp 中學到的技能已經不足以脫穎而出。  由於大量開發者在尋找黃金,就業市場很快就飽和了。 2020 年的情況就已經如此,但後來情況變得更糟… ## 3.遠距工作 Covid-19 大流行推動全世界轉向遠距工作。鑑於編碼基本上可以在任何地方完成,開發人員的工作是適應速度最快的工作之一。 對許多開發人員來說,在家工作聽起來像是個夢想。 無需通勤,擁有更多屬於自己的時間,並以相同的薪水在舒適的家中進行編碼,這是大多數人在任何給定時間都需要的交易。 但事實證明,遠距工作是一把雙面刃。 因為最終,公司透過增加招募人數而受益最多。  遠距工作意味著軟體公司現在可以僱用來自世界各地的開發人員。 本地職缺吸引了數十名遠距求職者,他們願意以少得多的錢做同樣的工作。正如《紐約時報》所說: **“遠距工作者普遍面臨更多競爭,並且更加依賴運氣。” - 紐約時報** 如果您想知道為什麼現在有數百甚至數千名求職者,那麼答案就是:遠端候選人。 大多數職缺現在都在收到來自世界各地的申請。  隨著遠距工作的興起,本地工作現在面臨國際競爭。 當我可以在中西部找到具有相同技能且至少少兩倍的錢的人時,為什麼還要雇用矽谷的開發人員呢? 在歐洲也一樣。 一家位於柏林的公司可以聘請一位位於德國中部小村莊的開發者。讓他們每個月來辦公室兩次。並少付給他們幾十萬歐元。 當然,一些公司採取了重返辦公室政策。 但從長遠來看,我們將看到越來越多的公司採用完全遠端的思維方式。從經濟學的角度來看,遠距工作很有意義。 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ## 4. 人工智慧與自動化 人工智慧已經存在很多年了,但從未像現在這樣出現在我們的生活中。 2023 年 10 月,OpenAI 發布了 ChatGPT。 近年來人工智慧創新的巔峰和迄今為止最好的人工智慧模型。它可以與您談論您的一天,也可以為您撰寫論文。 更糟的是,它可以編碼。  隨著人工智慧能夠編寫功能齊全的程式碼,許多開發人員都會問自己:“現在怎麼辦?” 如果有足夠好的提示,它可以比大多數人類開發人員更好、更快、更便宜地編寫程式碼。 當然,ChatGPT 無法自行思考。 這是一個巨大的統計機器。它會犯很多錯誤並且陷入循環。但是,這足以讓事情順利進行。而且情況只會變得更好。 GitHub 很快就做出了調整,將其整合到 GitHub Copilot 中,後者已直接在 VS Code 中可用。 從長遠來看,沒有人知道人工智慧將對就業市場產生什麼影響。 它會像某些人聲稱的那樣導致我們所知的編碼的終結嗎?或者它只是人類開發人員完成工作的工具? 我們所知道的是,在短期內,人工智慧透過自動化任務或完全取代一些工作,給就業市場帶來了更大的壓力。  高盛估計,大約 29% 的電腦相關任務可以透過人工智慧自動化。 結果? **找到一份體面的開發人員工作變得越來越難。** 回到報價和供應曲線,開發者數量增加,但就業機會數量保持不變。 隨著市場上數百名開發人員尋找職位,軟體開發產業正遭受「Tinder 效應」的困擾。類似網路約會的現象。 就像約會應用程式中的熱門個人資料一樣,軟體公司現在面臨著數百種不同的選擇。數百名候選人和簡歷。 整理噪音並不容易。 你必須更快地放棄候選人。即使你拒絕了一個合適的開發者,總會有其他人在門口等著。 好吧,現在對於開發者來說情況並不好。 忍住眼淚,因為我會告訴你為什麼事情並不像大多數開發人員想像的那麼糟糕... # 好訊息 這場「完美風暴」讓大多數開發者感到驚訝。許多人覺得薪水過低,但同時又沒有勇氣去市場。 這創造了一個“技能差距”,你可以利用它來跑得更快。  「在陽光明媚的天氣裡你無法超越 15 輛汽車…但在下雨天你可以。」- Ayrton Senna **風雨飄搖的就業市場實際上可能是您將開發人員職業提升到全新水平的完美時刻。** 首先,不要像其他人一樣屈服於恐懼。恐懼會讓你癱瘓,擾亂你的思考。不要驚慌失措,而是要超越噪音。 裁員開始一年後,公司意識到消除成本實際上會阻礙他們的成長。 在資本主義中,一家不成長的公司就是一家正在消亡的公司。 公司需要重新開始創造價值。緊急。 更多價值,因為我們正處於經濟衰退之中,消費者只想要最優惠的價格。而且速度更快,因為競爭是全球性的。 **在軟體開發中,價值意味著功能。這意味著高品質的程式碼。** 那麼人工智慧呢? AI實際上刺激了市場。軟體公司別無選擇,只能將人工智慧模型整合到現有的軟體中。否則就有倒閉的風險。 你需要什麼? 開發者、開發者、開發者… 好吧,這就是為什麼這可能是您作為一個雄心勃勃的開發人員超越競爭對手的最佳時機: ## 1. 質量重於數量 是的,市場上的開發者總數有所增加。但他們的技術技能品質卻沒有。 經濟衰退可能在一夜之間發生,但技術掌握需要時間。 即使在這樣的市場條件下,大多數公司仍然抱怨很難找到符合其工作要求的合格開發人員。 企業的要求是否過高? 或許。 但是,這正是您可以利用的差距來保持競爭優勢。  市場上有如此多的噪音,這與您發送的申請數量無關。追求數量只會產生更多垃圾郵件。 重要的是您的簡歷和申請的品質。 這並不意味著您應該成為完美主義者。數字仍然很重要。在開始找工作之前,只需在[您的簡歷和LinkedIn 個人資料上做更多工作](https://dev.to/dragosnedelcu/how-to-find-a-developer-job-in-2023-with-little-or-no-experience-27h7)。 並專注於技術掌握而不是數字! ## 2. 人工智慧作為補充 正如我所提到的,人工智慧模型無法思考,至少目前還不能。事實證明,它們更多的是對開發人員工作的補充,而不是替代品。 人工智慧帶來的是更多透過人工智慧整合進行的軟體開發。對正在開發的軟體的需求不斷增加。 這似乎有悖常理,但事實證明,人工智慧和自動化對軟體產業的影響與 70 年代修建高速公路對汽車交通的影響類似。 更多的高速公路意味著更多的汽車空間,因此更多的人使用汽車。導致汽車流量增加,而不是減少!  更多的高速公路,更多的汽車。更多人工智慧,更多程式碼。 人工智慧編碼工具將使產生的程式碼量倍增。 最終,這意味著更多的程式碼需要由人類檢查、驗證和維護。整體而言,需要更多的開發人員。 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ## 3. 現金仍為王 $$$ 有趣的是,開發人員的薪資仍在增加。但它們的成長並不相同。 事實上,大多數開發者都無法跟上通貨膨脹的腳步。許多人根本沒有加薪,儘管在市場上待了很久卻找不到職位。 其他人則獲得小幅加薪,例如 3%。由於去年通膨率約為 10%,這並不是加薪。又是減薪! 但是,一小群幸運的程式設計師的薪酬正在打破記錄。 事實上,我們在 theSeniorDev.com 上看到了這一點。許多高級開發人員的薪資創下歷史新高,即使在歐盟市場也超過 6 位數。 幾年前,如此高的報價是非常不尋常的。 但是,如果你仔細想想,更高的薪水是有道理的。 一家公司面臨著交付一款可以為他們帶來數百萬美元收入的軟體的壓力,他們不會介意為能夠交付該軟體的開發人員額外花費數千美元。 這樣想吧,熟練勞力不是商品。 公司不會購買一雙一模一樣的鞋子並尋求優惠。有些鞋子會讓他們走得更快。為他們支付更多費用是有道理的。 **無論是矽谷或歐洲科技中心,趨勢都很明顯:熟練的開發人員需求量很大,公司願意為他們支付大量資金。** 正如您所看到的,事情並不像大多數開發人員想像的那麼糟糕。 至少不適合所有開發人員... 因為如果你和你的資深朋友交談過,你可能會發現有一群開發者做得併不差…。 ## 僅限資深開發人員的就業市場 儘管發生了一切,但高階開發人員的需求仍然非常大。您可以在招聘板上看到它,其中指定:僅限高級。 或查看誰正在被雇用並立即簽署工作合約。 Hired.com 的一份報告顯示,目前簽署工作合約的軟體開發人員中有超過 73% 擁有 7 到 5 年(或更長)的經驗。  高級開發人員受最近科技業裁員的影響最小。 感覺無論經濟如何發展,成為高級開發人員都會有回報。或多少程式碼 A.I.可以生成。  如果就業市場是動物農場。所有開發人員都是平等的,但高級開發人員比其他人更平等。 如果市場如此糟糕,為什麼高級開發人員仍然受歡迎? 從公司的角度來看,高階開發人員從第一天起就可以創造價值。 公司知道,他們比以往任何時候都更需要快速、優質的交付,才能在當前經濟狀況下保持競爭力。通貨膨脹,記住。 所有這些因素意味著整個軟體開發團隊將崩潰為少數開發人員利用兩個要素: 1. **高級開發人員** 2. **人工智慧工具和自動化** 儘管發生了這一切,但也不全然是壞訊息。堅持幾秒鐘,我會告訴你原因。 **事實是,您可以利用當前的情況來發揮自己的優勢。** **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** # 真相 為了在這個充滿活力的就業市場中取得成功,您將需要比與您競爭的其他數千名開發人員更可靠的策略和更有效率的流程。 您需要立即採取行動,因為… 提供高薪、酷炫技術堆疊、良好福利和遠距工作的開發人員工作每天都變得越來越有競爭力。 這並不意味著他們不可能到達。簡而言之,獲得開發人員工作的舊方法不再有效。 如果您需要其他 5 名開發人員的幫助才能將程式碼投入生產,那麼您的日子就很寶貴了。還有另一個開發人員可以提供端到端的服務,他們將取代您的位置。 所以你會怎麼做? 正如我的一位招募人員朋友所說: **「你最好的選擇是盡快成為高級開發人員」。** 盡快達到高級水平是目前在軟體開發市場中生存的唯一途徑。 成為高級開發人員將使您從眾多編碼人員中脫穎而出,提供端到端的價值,並被視為對公司的投資,而不僅僅是另一個昂貴的開發人員。  聰明的開發人員正在尋找提供更多服務並脫穎而出的方法。他們正在尋找快速實現這一目標的方法。 他們首先需要解決的是如何提升自己的技術能力。 好訊息是,您不需要在周末花費無數時間或編碼來實現這一目標。您不需要啟動數百個線上課程和副專案。 而且您不需要等待數年才能做到這一點。因為有更好的方法可以做到這一點。 你只需要專注在那些不會改變的事情上。 **那麼,如何獲得對自己技能的完全信心、端到端交付並釋放高級信心?** 您遵循基於經過驗證的軟體開發原則的逐步過程。就像高級開發人員每天使用的那樣。我們稱之為技術掌握藍圖。 在接下來的幾行中,我將更深入地討論具體步驟,但這不是本文的目標。 如果您有興趣了解更多訊息,可以單擊下面的連結並觀看我為您準備的免費培訓。 [這是免費培訓的連結。](https://bit.ly/3udWD0m) **免責聲明**:您必須加入您最好的電子郵件才能存取它。別擔心我不會寄垃圾郵件給你。我只會與您分享有關如何快速晉升高級開發人員並讓您的開發人員職業生涯提升到一個全新水平的相關資訊。您可以隨時取消訂閱。 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ### 1. 首先,你要採取資深開發人員的心態🧠 成為高級開發人員的第一步是改變您對軟體開發職業和整個生活的看法。 這意味著要以更高的標準要求自己。對您目前的開發者職業生涯承擔全部責任。並掌控你的職涯道路。 你也必須擺脫限制性信念或任何內在的關於自己的負面情緒。你必須養成新的習慣並培養紀律技能。 這意味著設定明確的重點目標,為自己定義一個在情感上令人信服的願景,並在執行這些目標時對自己負責。 **🚀[行動專案]**:準確定義您想要在未來 12 個月內實現的目標。為什麼想實現它?到達那裡需要採取哪些步驟?你是否缺乏任何知識和技能?你需要做一些與現在不同的事情才能到達那裡嗎?寫下來。 當你走向高級開發的旅程時,這將是讓你的火焰保持活力的燃料。大多數開發人員從未到達那裡,因為他們退出得太早。他們忘記了過程就是目標。 ### 2. 其次,你掌握了「基礎知識」📚 大多數開發人員,特別是 JavaScript 開發人員已經習慣相信軟體開發中的資歷就像一個購物袋。 新增的庫和框架越多,其等級就越高。 事實上,情況完全相反。高級開發人員平均編寫的程式碼比初級開發人員少。他們使用不太閃亮的庫和框架來解決問題。 沉迷於框架和庫會讓你成為炒作列車的受害者。當一個圖書館失寵時,另一個圖書館就會出現,需要您投入時間和注意力。這是一場你無法獲勝的遊戲。 如何才能逃脫炒作機器? 透過專注於**「不會改變的事情」**。我們所說的基礎知識。 模式和原則是大多數框架和函式庫的核心。對基礎知識的深入理解將確保您無論情況如何變化都能掌握最新資訊。 它還可以保護您免受人工智慧和自動化的影響。在程式碼在幾秒鐘內產生的世界中,清晰的思維變得越來越有價值。雙贏。 基礎知識取決於您的技術堆疊。 如果您是 JavaScript 開發人員,您主要需要掌握 2 組基礎知識。電腦科學基礎知識和 JavaScript 基礎知識。 這不是本文的範圍,但我整理了一個路線圖,供您準確了解這些內容,請參見下文。 🚨 PS有關“計算機科學基礎知識”的詳細列表,請查看[計算機科學基礎知識掌握路線圖](https://mm.tt/app/map/2980765378?t=LsjjpEBYky)。🚨 🚨附言有關「JavaScript 基礎知識」的詳細列表,請查看我們的 2023 年 [JavaScript 基礎知識掌握路線圖](https://mm.tt/app/map/2962635113?t=ILeYm71vU3)。🚨 順便說一句,我們免費社群的開發人員可以存取獨家內容和針對基礎知識的客製化練習。請在下面註冊! **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ### 3. 第三,您學習如何端到端交付🎯 任何科技公司執行長現在最不想做的就是僱用更多的開發人員。但他們確實想解決問題。很多問題。 但是,你無法真正解決問題,我的意思是,當你只建構孤立的功能時,會出現有價值的問題。或者當您需要另外 5 名開發人員的幫助才能將您的東西投入生產時。 **高級開發人員之所以需求如此巨大,是因為他們可以提供端到端的服務。** 他們可以與產品經理或其他利害關係人獨立工作,並從第一天起就交付價值。掌握了這一點,你的價值就會增加10倍。 端到端交付並不意味著您必須了解一切。 這意味著您需要了解後端以及基礎設施方面的情況。目前無需深入研究各個元件。但從大局來看是的。 **[進階開發提示]**:學習如何端到端交付的最快方法不是 100 小時的雲端憑證課程(這些課程的重點是向您推銷品牌,而不是教您東西) )。 相反,請嘗試規劃您公司的 CI/CD 流程。 找出他們擁有的任何架構圖,然後自己參與其中。如果他們沒有,請自己建造一些。這已經可以給你一個良好的開始,並在你的下一次技術面試中談論很多事情。 🚨附言要確切了解您需要掌握哪些端對端交付心理模型,請查看我們的[JavaScript 開發人員的「端對端交付」路線圖](https://mm.tt/app/map/2974013323?t=pqAIdWZ7W2 ).🚨 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ### 4.第四,成為「AI驅動」🚀 當我接到想要加入我們專案的開發人員的電話時,最令我驚訝的事情之一是他們每天很少使用人工智慧。 有些人多次使用 ChatGPT 來執行日常任務(樣板檔案、測試)。真正使用過 GitHub Copilot 的人就更少了。 他們告訴我他們不相信它的未來。或者他們的公司並沒有真正使用它。 如果你在飛機上,氧氣會耗盡,我敢打賭,即使機組人員沒有給你,你也會尋找氧氣面罩。 ChatGPT 和 GitHub Copilot 不只是更好的自動完成工具。自動完成無法重構、尋找程式碼中的錯誤或擴充功能。 人工智慧模型可以優化、重構,甚至可以比許多開發人員提出更好的程式碼。事實上,到 2023 年,在人工智慧工具的幫助下,初級開發人員可以完成與沒有人工智慧工具的高級開發人員一樣多的工作。 重點很明確:如果您是願意轉為高級的 JavaScript 開發人員,您需要成為「人工智慧驅動」。 如果您已經是大四學生並希望在未來幾年保持相關性,情況也是如此。潮流正在改變。透過升級這些技能來確保您處於正確的位置。 您是否必須學習 Python、Numpy、深度學習以及 AI 堆疊中的十幾種工具?並不真地。這是一項完全不同的工作。 **這意味著你應該將人工智慧工具整合到你所做的一切中。** 從建置功能到程式碼審查,再到測試和效能優化。如果您希望我寫一篇有關如何做到這一點的文章,請在評論中告訴我。 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** ### 5.第五,有效推銷自己🏆 如果你找不到一家公司來支付你的技能費用,那麼無論你是多麼優秀的開發人員,也沒有用。由於開發人員就業市場已經過度飽和,這一點更加正確。 為了脫穎而出並獲得頂級軟體開發人員的職位,您必須以盡可能最好的方式將自己推向市場。 作為一名員工,這一點更為重要,因為您應該始終擔心的一件事是您的就業能力。 **如果你明天被解僱,你找到另一個職位有多容易?** 你越有就業能力就越好。 您的就業能力取決於兩件事。您的產品(在這種情況下,您的開發技能和支持這些技能的過去經驗)。 其次,你如何推銷自己和你的人脈。有多少人認識你?如果你現在被解僱,明天有人可以提供你工作嗎? 要改進您的產品,請提高您的開發技能。我們在前面的幾點中討論過這一點。但如何改進自我推銷的方式呢? **好吧,如果你想要高級開發人員的薪水,你首先必須看起來像高級開發人員。** 這意味著建立一份相關的履歷,以最好的方式量化以展示您為市場帶來的東西。 如果您想讓我寫一篇關於如何打造一流開發人員履歷表的文章,請在評論中告訴我! ## 總結與後續步驟 好吧,現在你知道了。 下次當你問自己為什麼現在找到開發人員的工作如此困難時,請考慮這些原因。您還了解如何透過盡快成為高級開發人員來解決這個問題。 能夠落實這 5 個支柱並以最快的速度適應這個新市場範式的開發人員將獲得工作保障、對自己的技能充滿信心並獲得最高的薪水。 無法適應的開發者將慢慢被淘汰,並面臨被完全擠出市場的風險。 按照我在本文中概述的步驟操作,您不僅可以輕鬆找到開發人員工作,而且可以「快速」晉升到高級開發人員級別,並將您的開發人員職業生涯提升到一個全新的水平。 他們為我和世界各地 230 多名其他開發人員工作,他們也將為您工作! 我們下一篇再見 德拉戈斯 **🚨附:您是否希望快速晉升為擁有優質資源、回饋和責任的高階開發人員? [點擊此處加入我們的免費社區 - 高級開發學院。](https://bit.ly/46hbx3h)🚨** --- 原文出處:https://dev.to/dragosnedelcu/why-is-it-so-hard-to-find-a-developer-job-in-2023-and-how-to-fix-it-2d13
嘿朋友們👋 曾經造訪過某人的 Github 個人資料並思考過:  在本文中,我將嘗試向您展示建立專業的 GitHub 個人資料比您想像的要容易得多。 沒錯,即使您不是經驗豐富的專家,您也可以讓您的個人資料看起來可靠。 這是我的 GitHub 個人資料的範例。讓我們深入探討如何在接下來的 10 分鐘內讓您的個人資料看起來同樣完美。 😉** [](https://github.com/fernandezbaptiste) 準備好了,出發吧⏰ --- # 1. 建立您的 GitHub 設定檔:新增 `README` 如果您還沒有這樣做,則必須建立自己的 GitHub「自述文件」來建立您的個人資料頁面。 為此,請轉到您的個人資料並點擊“您的儲存庫”。 之後,建立一個「New」儲存庫: - 儲存庫的名稱需要與您的使用者名稱相同。 - 確保將儲存庫設為“公開” - 點擊“新增自述文件”  --- # 2. 為您的儲存庫建立一個開源儲存庫 🤫 不久前我發現了這個[repo](https://github.com/rahuldkjain/github-profile-readme-generator),我愛上了它。❤️ 這個很酷的專案可以幫助您立即建立自己的 GitHub 個人資料! 前往 [GitHub Profile README Generator](https://rahuldkjain.github.io/gh-profile-readme-generator/) 並填寫您的資料。 [](https://rahuldkjain.github.io/gh-profile-readme-generator/) **注意:** 您不需要完成每個部分;僅相關的。 完成後: - 點擊“生成自述文件” - 然後點選“複製markdown” - 前往您新建立的 GitHub 個人資料並將程式碼貼到您的「自述文件」中 💪 --- # 3. 使用小工具提升您的個人資料設計水平 您現在應該擁有一個看起來非常漂亮的個人資料! 為了提高您的遊戲水平,您可以加入一些優雅的小部件,這些小部件提供有價值的統計資料來展示您的技能和成就。 🚀⭐️ 就我而言,我已將這些加入到我的[個人資料](https://github.com/fernandezbaptiste): [](www.quine.sh/?utm_source=devto&utm_campaign=beautify_github_profile) 您也可以加入一些小工具來展示您的 _Web3_ 或 _StackOverflow_ 體驗: [](www.quine.sh/?utm_source=devto&utm_campaign=beautify_github_profile) 這些小工具_完全免費_,您可以透過註冊 [quine.sh](www.quine.sh/?utm_source=devto&utm_campaign=beautify_github_profile) 來取得它們。 只需前往您的 Quine 個人資料上的_“Widgets”_,然後將複製的 Wiget 程式碼貼到您的「自述文件」頁面中即可。 [](www.quine.sh/?utm_source=devto&utm_campaign=beautify_github_profile) --- # 4.「美化」你的聯絡資訊💄 您可能不喜歡 GitHub README 產生器中的某些設計。 🙃 有些人喜歡不同的風格,尤其是與他們的_社交連結/連結輸出相關的風格。_ 您可以使用以下替代樣式: [](https://github.com/fernandezbaptiste) 如果您喜歡這種風格,您可以使用此合成器建立自己的徽章: ```  ``` 例如,如果您想新增 **GitHub 徽章**,則為: ``` ] ``` 根據您想要顯示的橫幅圖示的類型,您可以在此清單中找到許多簡潔的圖示[此處](https://simpleicons.org)。 🙌 --- # 5.利用 PIN 儲存庫功能 如果您已經建立了幾個專案,那麼這是展示您最引以為傲的專案的好機會! 在您的個人資料上,只需點擊“自訂您的 pin”,然後選擇最多 6 個您想要固定的專案。  --- # 6. 貢獻並升級你的遊戲! 在您的 PIN 儲存庫之後,您的個人資料將顯示以下網格。  這代表您**在 GitHub 上的貢獻和活動水平。** 需要強調的是,儘管您應該嘗試透過經常貢獻來展示您的一致性,但此欄上的「綠色度」百分比並不是最重要的方面。 👀 許多人專注於試圖建立完美的連勝,但實際上,他們的工作沒有影響力,他們的貢獻也沒有什麼價值。 在我看來(我相信很多人都有同樣的看法),貢獻應該集中在: **品質 > 數量** ❤️ 話雖如此,定期建立幾個專案或為其他人的專案做出貢獻符合您的利益。 現在,為了嘗試為專案做出貢獻,您可以使用多種工具。 🔎 這裡有 3 個免費網站,可以幫助您找到下一個要從事的專案: - [GitHub 探索](https://github.com/explore) - [UpForGrabs](https://up-for-grabs.net/#/filters?tags=python&date=1month) - [Quine.sh](https://quine.sh/?&utm_source=devto&utm_campaign=beautify_github_profile) 或者,如果這是您第一次貢獻,我已經建立了這篇逐步[文章](https://dev.to/quine/contribute-to-open-source-in-the-next-10-min-step-by-step-beginner-edition-4aia)適合初學者。您將學習在 GitHub 上做出貢獻的機制,並能夠在接下來的 10 分鐘內做出貢獻! --- # 7. 新增個人簡介 我們已準備好進行最後的潤色... 現在你的個人資料看起來應該會很火。 🔥 我建議您做的最後一件事就是完成您的“簡歷”。 當您進入個人資料頁面時,請轉到照片下方的左側,然後按一下「編輯個人資料」。  加入您自己的簡短描述,然後您就可以開始了! --- 現在就這樣。 😄 我希望您對**您精美的 GitHub 個人資料**感到滿意! 💅 我必須強調,我的個人資料還遠遠不是世界上最好的... 然而,有了這些免費工具,您將能夠自訂一個奇妙的新設定檔! 這就是為什麼我想先睹為快,並從您將建立的酷炫設定檔中獲得靈感! 👀 `在評論部分分享您全新的個人資料! 🙌` 下週見。 你的開發夥伴, 巴巴💚 --- 如果您想加入開源中自稱「最酷」的伺服器😝,您應該加入我們的[discord伺服器](https://discord.com/invite/ChAuP3SC5H/?utm_source=devto&utm_campaign=beautify_github_profile)。我們隨時為您的開源之旅提供協助。 🫶 [https://dev.to/quine](https://dev.to/quine) --- 原文出處:https://dev.to/quine/7-tips-to-build-your-github-profile-like-a-pro-38bg
隨著人工智慧市場的不斷成長。我們即將做出很多改變。 最近,我一直在思考在各個領域取得重大進展的最新新創公司。這些新創公司參與了開創性的工作,從增強資料互動性到探索大型語言模型在營運中的潛力(一種稱為 LLM Ops 的新概念)。此外,我對搜尋引擎和生成人工智慧的進步很著迷,它們正在徹底改變我們與技術互動的方式。 我在 DEV.to 上看到他們中的許多人,然後我想嘗試他們的專案。我對這些公司所付出的努力和創新感到驚訝。 ## [Pezzo:開發者優先的人工智慧平台](https://github.com/pezzolabs/pezzo)  **GitHub 儲存庫**:[GitHub 上的 Pezzo](https://github.com/pezzolabs/pezzo) **網址**:[片段](https://pezzo.ai/) **描述**: Pezzo 是一個為開發人員量身定制的開源雲端原生 LLMOps 平台。它透過提供簡化的提示設計、版本管理、即時交付等,徹底改變了人工智慧操作。該平台能夠有效觀察和監控人工智慧操作、顯著降低成本和延遲、無縫協作以及立即交付人工智慧變更。 **主要特徵**: - **提示管理**:提示的集中管理和版本控制,允許即時部署到生產。 - **可觀察性**:提供有關人工智慧操作的詳細見解,優化支出、速度和品質。 - **故障排除**:即時檢查提示執行,最大限度地減少除錯工作。 - **協作**:促進同步團隊合作,以交付有影響力的 AI 功能。 **加入社群**: 加入他們的 [Discord 社群](https://pezzo.cc),成為 Pezzo 創新之旅的一部分。透過為他們的 GitHub 儲存庫加註星標來為他們的使命做出貢獻並支持他們! [在 GitHub 上給 Pezzo 一顆星](https://github.com/pezzolabs/pezzo) 🌟,加入 AI 維運革命! https://github.com/pezzolabs/pezzo ## [Swirl:人工智慧驅動的多來源搜尋平台](https://github.com/swirlai/swirl-search)  **GitHub 儲存庫**:[GitHub 上的 Swirl](https://github.com/swirlai/swirl-search) **網站**:[Swirl](https://swirl.today/) **描述**: Swirl 是一款創新的開源軟體,它利用人工智慧同時搜尋多個內容和資料來源。它使用人工智慧對結果進行排名,獲取最相關的部分,並使用生成式人工智慧來提供從您自己的資料得出的答案。該工具對於整合和從各種資料來源中提取有價值的見解特別有用。 **主要特徵**: - **人工智慧驅動的搜尋**:同時搜尋多個來源,提供人工智慧排名的結果。 - **生成式人工智慧整合**:使用熱門搜尋結果提示生成式人工智慧提供全面的答案。 - **多樣化資料來源連線**:連接到資料庫(SQL、NoSQL、Google BigQuery)、公共資料服務以及 Microsoft 365、Jira、Miro 等企業來源。 - **可自訂和可擴展**:提供靈活的平台,用於資料豐富、實體分析以及整合各種應用程式的非結構化資料。 **加入社群**: 參與 Swirl 社區並貢獻您的想法!加入 [Swirl Slack 社群](https://join.slack.com/t/swirlmetasearch/shared_invite/zt-1qk7q02eo-kpqFAbiZJGOdqgYVvR1sfw),並透過為他們的儲存庫加入星標來支持他們的成長。 [GitHub 上的 Star Swirl](https://github.com/swirlai/swirl-search) 並成為這令人興奮的人工智慧搜尋演化的一部分! 🌟 https://github.com/swirlai/swirl-search ## [DeepEval:LLM評估架構](https://github.com/confident-ai/deepeval)  **GitHub 儲存庫**:[GitHub 上的 DeepEval](https://github.com/confident-ai/deepeval) **網址**:【Confident AI】(https://www.confident-ai.com/) **描述**: DeepEval 是大型語言模型 (LLM) 的開源評估框架。它簡化了 LLM 應用程式的評估,類似於 Pytest 進行單元測試的操作方式。 DeepEval 因提供一系列專為 LLMs 量身定制的評估指標而脫穎而出,使其成為嚴格績效評估的生產就緒替代方案。 **主要特徵**: - **多樣化的評估指標**:提供由 LLMs 評估或透過統計方法和 NLP 模型計算的多種指標。 - **自訂指標建立**:允許輕鬆建立自訂指標,無縫整合到 DeepEval 的生態系統中。 - **批量資料集評估**:以最少的編碼工作促進整個資料集的評估。 - **與 Confident AI 整合**:能夠即時觀察評估結果並比較不同的超參數。 [在GitHub上Star DeepEval](https://github.com/confident-ai/deepeval)並為LLM評估架構的進步做出貢獻! 🌟 https://github.com/confident-ai/deepeval ## [LiteLLM:通用LLM API介面](https://github.com/BerriAI/litellm)  **GitHub 儲存庫**:[GitHub 上的 LiteLLM](https://github.com/BerriAI/litellm) **網站**:[LiteLLM 文件](https://docs.litellm.ai/docs/#quick-start/) **描述**: LiteLLM是一個開源工具,使用戶能夠使用統一的OpenAI格式呼叫各種LLM API。它支援廣泛的供應商,如 Bedrock、Azure、OpenAI、Cohere、Anthropic、Ollama、Sagemaker、HuggingFace、Replicate 等,提供與 100 多個LLMS合作的簡化方法。該工具對於以一致且高效的方式簡化不同LLMS的整合和利用至關重要。 **主要特徵**: - **通用 API 格式**:方便使用標準化 OpenAI 格式呼叫不同的 LLM API。 - **支援廣泛的LLMS**:與眾多LLMS提供者相容,包括 OpenAI、Azure、Cohere 和 HuggingFace 等主要提供者。 - **一致的輸出和異常映射**:確保統一的輸出結構並將跨提供者的常見異常映射到 OpenAI 異常類型。 - **易於使用**:支援批量操作並簡化與LLMS的交互,使其更適合各種應用程式。 **加入社群**: 參與 LiteLLM 的開發並分享您的改進!克隆存儲庫,進行更改並提交 PR。 [在 GitHub 上星標 LiteLLM](https://github.com/BerriAI/litellm) 並立即簡化您與LLMS的工作! 🌟 https://github.com/BerriAI/litellm ## [Qdrant:人工智慧高效能向量資料庫](https://github.com/qdrant/qdrant)  **GitHub 儲存庫**:[GitHub 上的 Qdrant](https://github.com/qdrant/qdrant) **網址**:[Qdrant](https://qdrant.tech/) **描述**: Qdrant是專為下一代AI應用量身定制的高性能、大規模向量資料庫。它是一個向量相似性搜尋引擎和資料庫,透過易於使用的 API 提供生產就緒的服務。 Qdrant 對於神經網路或基於語義的匹配、分面搜尋以及其他需要有效處理具有相關負載的向量的應用特別有效。 **主要特徵**: - **豐富的資料類型和查詢規劃**:支援多種資料類型和查詢條件,包括字串比對、數值範圍、地理位置等,並利用有效負載資訊進行高效率的查詢規劃。 - **硬體加速和預寫式日誌記錄**:利用現代 CPU 架構實現更快的效能並確保資料持久性和可靠性。 - **分散式部署**:支援水平擴展,多台 Qdrant 機器形成集群,透過 Raft 協定進行協調。 - **集成**:輕鬆與 Cohere、DocArray、LangChain、LlamaIndex 等平台集成,甚至與 OpenAI 的 ChatGPT 檢索插件集成。 **加入社群**: 成為 Qdrant 社區的一部分並為這個創新專案做出貢獻。加入他們的 [Discord](https://qdrant.to/discord)。 [GitHub 上的 Star Qdrant](https://github.com/qdrant/qdrant) 並幫助塑造 AI 中向量資料庫的未來! 🌟 https://github.com/qdrant/qdrant --- ### 衷心的感謝 您有興趣探索和了解這些新創公司正在研究的不同主題。成為他們社群的一部分肯定會幫助您成長並了解不同的軟體和人工智慧領域。 --- 原文出處:https://dev.to/fast/these-5-open-source-ai-startups-are-changing-the-ai-landscape-59dg
我是播客的忠實粉絲,這是最被低估的純粹知識資源。播客已成為學習和娛樂領域的革命性媒介。近年來,它們從小眾聽眾的愛好轉變為主流媒體形式。 向兩個或更多經驗豐富的人學習談論特定主題,討論他們在做某事時面臨的挑戰,並分享他們的旅程是很有趣的。 它為解決特定問題和建立獨特的解決方案提供了令人難以置信的見解。您將了解: - 不同的心態以及其他人如何看待事物。 - 人們用來解決問題的各種工具。 - 傑出人物和他們的故事以及他們如何解決特定問題。 - 走出精神泡泡並開始以不同的方式看待事物。 另一個好處是,你透過聽這些播客所獲得的知識會成為你的潛在知識或隱性知識庫。 因此,當您面臨類似領域的挑戰時,從播客中獲得的知識可以為您提供一些時間或路線圖來建立應對挑戰的解決方案。 身為人工智慧愛好者,在知識和資料領域工作。我選擇了 [Vector Podcast](https://www.youtube.com/@VectorPodcast),因為我對向量資料庫和向量搜尋、它們如何幫助公司建立基於人工智慧的產品等感到好奇。 以下是我推薦的 8 個最佳播客,您可以收聽。 _我正在提供他們的 YouTube 頻道,假設每個人都知道並使用 YouTube。其中大多數也出現在 Apple Podcast、Spotify 等上_ ## [向量播客](https://www.youtube.com/@VectorPodcast)  Vector Podcast 是 Dmitry Kan 博士的創意。研究生研究科學家涉足產品管理和創業。他也曾在赫爾辛基大學講課。 他在搜尋引擎領域、人工智慧和軟體開發領域擁有超過 15 年的經驗,並採訪了人工智慧領域的專業人士和執行長。 一些值得注意的情節是: - 與 Swirl 執行長 Sid Probstein 一起進行搜尋。 - 向量資料庫以及 Weviate 執行長 Bob van Luijt。 - 康納肖頓的搜尋未來。 https://www.youtube.com/@VectorPodcast ## [萊克斯‧弗里德曼](https://www.youtube.com/c/lexfridman)  萊克斯·弗里德曼(Lex Fridman)是一位受歡迎的人物,正因為如此,他可以接待許多著名人物、首席執行官、領導人和頂尖研究人員。把他們帶到麥克風桌前問他們問題(他很擅長這一點。) 他採訪過的一些著名人士包括 Sam Altman、Elon Musk、Guido van Rossum(Python 語言的建立者)、Stephen Wolfram 和 [Goose](https://www.youtube.com/watch?v=QqRV5FD8ob4)。 他也是機器學習講師,您可以在此[播放清單](https://www.youtube.com/playlist?list=PLe8HThjUpqadLD-AewSKkhAyW5Nr4Yq4Z)中查看他們。 ## [知識專案](https://www.youtube.com/@tkppodcast)  知識專案播客由法納姆街的 Shane Parrish 主持,揭示了其他人已經發現的最好的東西,以便您可以將他們的見解應用到您的生活中。 肖恩·帕里什 (Shane Parrish) 的播客和見解無疑令人驚嘆。你必須經歷知識專案才能很好地理解它。 ## [語法](https://www.youtube.com/@syntaxfm)  來自 30 Days of JavaScript 的 Wes Bos。該播客討論 JavaScript 和 Web 開發。 它涵蓋了一些有趣的主題,從 Web 開發的新功能到 JavaScript 測試和其他主題。 ## [本週機器學習 (TWIML)](https://www.youtube.com/@twimlai)  與 Sam 一起探索人工智慧的最新趨勢和突破,討論將人工智慧驅動的產品推向市場的實際挑戰,並研究人工智慧技術與商業和消費者應用的交叉點。 這個播客不只是一次對話;更是一次對話。它是理解和利用機器學習和人工智慧的全部潛力來改善我們的生活和社區的門戶。我非常喜歡這個播客! ## [變更日誌](https://www.youtube.com/@Changelog)  變更日誌不只是播客的集合;這是一個充滿活力的社區,為處於各個階段的開發者提供豐富的資源。 無論您是經驗豐富的專業人士、好奇的初學者,還是介於兩者之間,我們的節目和資源都會提供與開發人員體驗產生共鳴的寶貴見解、討論和故事。 ## [談 Python](https://www.youtube.com/@talkpython)  Talk Python to Me 是由 Michael Kennedy 主持的每周播客。本節目涵蓋各種 Python 和相關主題(例如 MongoDB、AngularJS、DevOps)。 ## [超越編碼](https://www.youtube.com/@BeyondCoding)  帕特里克·阿基爾 (Patrick Akil) 和他的客人分享了他們的旅程和觀點,供您隨身攜帶並形成自己的旅程和觀點。 Beyond Coding 是一個每周播客,以爐邊聊天的形式進行「超越編碼」的對話。典型的主題是軟體工程、領導力、溝通、自我提升和幸福。 --- 💡***有趣的事實:*** 您知道「播客」來自 iPod 和廣播的融合嗎? ## 結論 我希望您喜歡本文中介紹的播客清單。如果您有任何建議,請隨時在評論中分享。 **在 YouTube 上查看向量播客** 我們致力於為您提供有關人工智慧、大型語言模型等方面的一流內容。 嵌入 https://www.youtube.com/watch?v=vhQ5LM5pK_Y https://www.youtube.com/@VectorPodcast 謝謝閱讀。 --- 原文出處:https://dev.to/vectorpodcast/these-8-podcasts-will-help-increase-your-knowledge-and-expand-your-mindset-5lb
## 介紹 Web 開發人員社群致力於建立能夠吸引目標受眾注意力的網站。成員總是在學習新的東西並創造有影響力的東西。這意味著生產力在他們的成功之路上發揮著重要作用。 網路上有許多我們可以遵循的技術來提高我們的生產力。 Chrome 擴充功能就是這樣一種技術,它使我們能夠提高我們致力於技術的辛勤工作的成果。 在本文中,我們將發現 10 個有用的 Chrome 擴充程序,它們可以提高 Web 開發人員的工作效率並讓我們的生活變得更美好。 ## Loom  [Loom](https://chromewebstore.google.com/detail/loom-%E2%80%93-screen-recorder-sc/liecbddmkiiihnedobmlmillhodjkdmb) 是 Chrome 線上應用程式商店中最常用的螢幕錄製擴充功能之一。它使我們能夠記錄螢幕、以圖形方式分享我們的想法並提供即時回應。 ## Window Resizer  [Window Resizer](https://chromewebstore.google.com/detail/window-resizer/kkelicaakdanhinjdeammmilcgefonfh) 調整瀏覽器視窗的大小以複製不同的解析度。它給我們一種個性化的感覺,因為它允許我們加入、刪除和重新排序我們想要測試的解析度清單。 ## 檢查我的連結  [檢查我的連結](https://chromewebstore.google.com/detail/check-my-links/ojkcdipcgfaekbeaelaapakgnjflfglf) 是一個連結分析器,用於掃描我們的網站是否有損壞的連結。此擴充功能專為網頁開發人員量身定制,因為他們始終致力於使網站內容完美無缺。 ## Wappalyzer  [Wappalyzer](https://chromewebstore.google.com/detail/wappalyzer-technology-pro/gppongmhjkpfnbhagpmjfkannfbllamg) 是一個技術堆疊評估器,列出了用於建立網站的工具和技術。它使我們能夠了解 CMS(內容管理系統)、框架、JavaScript 庫等。 ## Session Buddy  [Session Buddy](https://chromewebstore.google.com/detail/session-buddy/edacconmaakjimmfgnblocblbcdccpbko) 是一個擴展,使我們能夠方便地管理瀏覽器選項卡和書籤。它將打開的選項卡保存為集合,我們可以稍後在任何給定時間點恢復。 ## Lighthouse  [Lighthouse](https://chromewebstore.google.com/detail/lighthouse/blipmdconlkpinefehnmjammfjpmpbjk) 是開源自主工具,用於提高網路應用程式的品質、效率和準確性。它透過在頁面上執行一系列測試來審核頁面,然後產生總結頁面效能的報表。 ## Requestly  [Requestly](https://chromewebstore.google.com/detail/requestly-open-source-htt/mdnleldcmiljblolnjhpnblkcekpdkpa) 讓我們可以使用攔截和修改HTTP 請求、模擬伺服器、API 用戶端和會話記錄來建置、測試和會話記錄來建置、測試和除錯Web 應用程式。它將 Fiddler、Charles Proxy 和更多此類工具的功能引入瀏覽器,並具有有吸引力的現代 UI。 ## Grepper  [Grepper](https://chromewebstore.google.com/detail/grepper/amaaokahonnfjjemodnpmeenfpnnbkco) 是一個回答開發人員社群查詢的擴充。它使我們能夠從網路上快速提取程式碼片段,然後將其用於我們的專案中,以在我們的旅程中取得進展。 ## BrowserStack  [BrowserStack](https://chromewebstore.google.com/detail/browserstack/nkihdmlheodkdfojglpcjjmioefjahjb) 使我們能夠在桌面或行動瀏覽器上測試我們的網站。對於希望將跨瀏覽器測試作為其開發工作流程不可或缺的一部分的 Web 開發人員來說,這是一個有用的擴充功能。 ## Octotree  [Octotree](https://chromewebstore.google.com/detail/octotree-github-code-tree/bkhaagjahfmjljalopjnoealnfndnagc) 是一個擴展,可以幫助我們在 GitHub 上進行程式碼審查和探索。使用此工具,我們可以為儲存庫、問題、拉取請求和文件加入書籤,執行快速搜尋並輕鬆導航拉取請求。 ## 結論 我們已經到達終點了!我們上面討論的擴充功能非常有幫助,並且能夠大幅提高工作量。因此,讓我們使用它們,並在各自作為 Web 開發人員的旅程中不斷取得進展。 **快速說明:** > 感謝您花時間閱讀我的文章。這對我來說意義重大,並促使我創作更多這樣的內容。 **我的社交:** - [LinkedIn](https://www.linkedin.com/in/sriparnooy/) - [推特](https://twitter.com/Sriparno08) - [GitHub](https://github.com/Sriparno08) - [CodePen](https://codepen.io/Sriparno08) **我的部落格:** - [展示案例](https://www.showwcase.com/sriparno08) - [DEV](https://dev.to/sriparno08) - [哈希節點](https://hashnode.com/@sriparno08) --- 原文出處:https://dev.to/this-is-learning/10-useful-chrome-extensions-for-web-developers-meg
在本文中,您將學習如何建立 **GitHub 星數監視器** 來檢查您幾個月內的星數以及每天獲得的星數。 - 使用 GitHub API 取得目前每天收到的星星數量。 - 在螢幕上每天繪製美麗的星星圖表。 - 創造一個工作來每天收集新星星。  --- ## 你的後台工作平台🔌 [Trigger.dev](https://trigger.dev/) 是一個開源程式庫,可讓您使用 NextJS、Remix、Astro 等為您的應用程式建立和監控長時間執行的作業! [](https://github.com/triggerdotdev/trigger.dev) 請幫我們一顆星🥹。 這將幫助我們建立更多這樣的文章💖 https://github.com/triggerdotdev/trigger.dev --- ## 這是你需要知道的 😻 取得 GitHub 上星星數量的大部分工作將透過 GitHub API 完成。 GitHub API 有一些限制: - 每個請求最多 100 名觀星者 - 最多 100 個同時請求 - 每小時最多 60 個請求 [TriggerDev](https://github.com/triggerdotdev/trigger.dev) 儲存庫擁有超過 5000 顆星,實際上不可能在合理的時間內(即時)計算所有星數。 因此,我們將採用與 [GitHub Stars History](https://star-history.com/) 相同的技巧。 - 取得星星總數 (**5,715**) 除以每頁 **100** 結果 = **58 頁** - 設定我們想要的最大請求量(**20 頁最大**)除以 **58 頁** = 跳過 3 頁。 - 從這些頁面中獲取星星**(2000 顆星)**,然後獲取剩餘的星星,我們將按比例加入到其他日期(**3715 顆星**)。 它會為我們繪製一個漂亮的圖表,並在需要的地方用星星凸起。 當我們每天獲取新數量的星星時,事情就會變得容易得多。 我們將用目前擁有的星星總數減去 GitHub 上的新星星數量。 **我們不再需要迭代觀星者。** --- ## 讓我們來設定一下 🔥 我們的申請將包含一頁: - 新增您想要監控的儲存庫。 - 查看儲存庫清單及其 GitHub 星圖。 - 刪除那些你不再想要的。  > 💡 我們將使用 NextJS 新的應用程式路由器,在安裝專案之前請確保您的節點版本為 18+。 > 使用 NextJS 設定一個新專案 ``` npx create-next-app@latest ``` 我們必須將所有星星保存到我們的資料庫中! 在我們的示範中,我們將使用 SQLite 和 `Prisma`。 它非常容易安裝,但可以隨意使用任何其他資料庫。 ``` npm install prisma @prisma/client --save ``` 在我們的專案中安裝 Prisma ``` npx prisma init --datasource-provider sqlite ``` 轉到“prisma/schema.prisma”並將其替換為以下模式: ``` generator client { provider = "prisma-client-js" } datasource db { provider = "sqlite" url = env("DATABASE_URL") } model Repository { id String @id @default(uuid()) month Int year Int day Int name String stars Int @@unique([name, day, month, year]) } ``` 然後執行 ``` npx prisma db push ``` 我們基本上已經在 SQLite 資料庫中建立了一個名為「Repository」的新表: - 「月」、「年」、「日」是日期。 - `name` 儲存庫的名稱 - 「星星」以及該特定日期的星星數量。 你還可以看到我們在底部加入了一個`@@unique`,這意味著我們可以將`name`,`month`,`year`,`day`一起重複記錄。它會拋出一個錯誤。 讓我們新增 Prisma 客戶端。 建立一個名為「helper」的新資料夾,並新增一個名為「prisma.ts」的新文件,並在其中新增以下程式碼: ``` import {PrismaClient} from '@prisma/client'; export const prisma = new PrismaClient(); ``` 我們稍後可以使用該「prisma」變數來查詢我們的資料庫。 --- ## 應用程式 UI 骨架 💀 我們需要一些函式庫來完成本教學: - **Axios** - 向伺服器發送請求(如果您覺得更舒服,可以隨意使用 fetch) - **Dayjs -** 很棒的處理日期的函式庫。它是 moment.js 的替代品,但不再完全維護。 - **Lodash -** 很酷的資料結構庫。 - **react-hook-form -** 處理表單的最佳函式庫(驗證/值/等) - **chart.js** - 我選擇繪製 GitHub 星圖的函式庫。 讓我們安裝它們: ``` npm install axios dayjs lodash @types/lodash chart.js react-hook-form react-chartjs-2 --save ``` 建立一個名為“components”的新資料夾並新增一個名為“main.tsx”的新文件 新增以下程式碼: ``` "use client"; import {useForm} from "react-hook-form"; import axios from "axios"; import {Repository} from "@prisma/client"; import {useCallback, useState} from "react"; export default function Main() { const [repositoryState, setRepositoryState] = useState([]); const {register, handleSubmit} = useForm(); const submit = useCallback(async (data: any) => { const {data: repositoryResponse} = await axios.post('/api/repository', {todo: 'add', repository: data.name}); setRepositoryState([...repositoryState, ...repositoryResponse]); }, [repositoryState]) const deleteFromList = useCallback((val: List) => () => { axios.post('/api/repository', {todo: 'delete', repository: `https://github.com/${val.name}`}); setRepositoryState(repositoryState.filter(v => v.name !== val.name)); }, [repositoryState]) return ( <div className="w-full max-w-2xl mx-auto p-6 space-y-12"> <form className="flex items-center space-x-4" onSubmit={handleSubmit(submit)}> <input className="flex-grow p-3 border border-black/20 rounded-xl" placeholder="Add Git repository" type="text" {...register('name', {required: 'true'})} /> <button className="flex-shrink p-3 border border-black/20 rounded-xl" type="submit"> Add </button> </form> <div className="divide-y-2 divide-gray-300"> {repositoryState.map(val => ( <div key={val.name} className="space-y-4"> <div className="flex justify-between items-center py-10"> <h2 className="text-xl font-bold">{val.name}</h2> <button className="p-3 border border-black/20 rounded-xl bg-red-400" onClick={deleteFromList(val)}>Delete</button> </div> <div className="bg-white rounded-lg border p-10"> <div className="h-[300px]]"> {/* Charts Component */} </div> </div> </div> ))} </div> </div> ) } ``` **超簡單的React元件** - 允許我們新增新的 GitHub 庫並將其發送到伺服器 POST 的表單 - `/api/repository` `{todo: 'add'}` - 刪除我們不需要 POST 的儲存庫 - `/api/repository` `{todo: 'delete'}` - 所有新增的庫及其圖表的清單。 讓我們轉到本文的複雜部分,新增儲存庫。 --- ## 數星星  在「helper」內部建立一個名為「all.stars.ts」的新檔案並新增以下程式碼: ``` import axios from "axios"; import dayjs from "dayjs"; import utc from 'dayjs/plugin/utc'; dayjs.extend(utc); const requestAmount = 20; export const getAllGithubStars = async (owner: string, name: string) => { // Get the amount of stars from GitHub const totalStars = (await axios.get(`https://api.github.com/repos/${owner}/${name}`)).data.stargazers_count; // get total pages const totalPages = Math.ceil(totalStars / 100); // How many pages to skip? We don't want to spam requests const pageSkips = totalPages < requestAmount ? requestAmount : Math.ceil(totalPages / requestAmount); // Send all the requests at the same time const starsDates = (await Promise.all([...new Array(requestAmount)].map(async (_, index) => { const getPage = (index * pageSkips) || 1; return (await axios.get(`https://api.github.com/repos/${owner}/${name}/stargazers?per_page=100&page=${getPage}`, { headers: { Accept: "application/vnd.github.v3.star+json", }, })).data; }))).flatMap(p => p).reduce((acc: any, stars: any) => { const yearMonth = stars.starred_at.split('T')[0]; acc[yearMonth] = (acc[yearMonth] || 0) + 1; return acc; }, {}); // how many stars did we find from a total of `requestAmount` requests? const foundStars = Object.keys(starsDates).reduce((all, current) => all + starsDates[current], 0); // Find the earliest date const lowestMonthYear = Object.keys(starsDates).reduce((lowest, current) => { if (lowest.isAfter(dayjs.utc(current.split('T')[0]))) { return dayjs.utc(current.split('T')[0]); } return lowest; }, dayjs.utc()); // Count dates until today const splitDate = dayjs.utc().diff(lowestMonthYear, 'day') + 1; // Create an array with the amount of stars we didn't find const array = [...new Array(totalStars - foundStars)]; // Set the amount of value to add proportionally for each day let splitStars: any[][] = []; for (let i = splitDate; i > 0; i--) { splitStars.push(array.splice(0, Math.ceil(array.length / i))); } // Calculate the amount of stars for each day return [...new Array(splitDate)].map((_, index, arr) => { const yearMonthDay = lowestMonthYear.add(index, 'day').format('YYYY-MM-DD'); const value = starsDates[yearMonthDay] || 0; return { stars: value + splitStars[index].length, date: { month: +dayjs.utc(yearMonthDay).format('M'), year: +dayjs.utc(yearMonthDay).format('YYYY'), day: +dayjs.utc(yearMonthDay).format('D'), } }; }); } ``` 那麼這裡發生了什麼事: - `totalStars` - 我們計算圖書館擁有的星星總數。 - `totalPages` - 我們計算頁數 **(每頁 100 筆記錄)** - `pageSkips` - 由於我們最多需要 20 個請求,因此我們檢查每次必須跳過多少頁。 - `starsDates` - 我們填充每個日期的星星數量。 - `foundStars` - 由於我們跳過日期,我們需要計算實際找到的星星總數。 - `lowestMonthYear` - 尋找我們擁有的恆星的最早日期。 - `splitDate` - 最早的日期和今天之間有多少個日期? - `array` - 一個包含 `splitDate` 專案數量的空陣列。 - `splitStars` - 我們缺少的星星數量,需要按比例加入每個日期。 - 最終返回 - 新陣列包含自開始以來每天的星星數量。 所以,我們已經成功建立了一個每天可以給我們星星的函數。 我嘗試過這樣顯示,結果很混亂。 您可能想要顯示每個月的星星數量。 此外,您可能想要累積星星**而不是:** - 二月 - 300 顆星 - 三月 - 200 顆星 - 四月 - 400 顆星 **如果有這樣的就更好了:** - 二月 - 300 顆星 - 三月 - 500 顆星 - 四月 - 900 顆星 兩個選項都有效。 **這取決於你想展示什麼!** 因此,讓我們轉到 helper 資料夾並建立一個名為「get.list.ts」的新檔案。 這是文件的內容: ``` import {prisma} from "./prisma"; import {groupBy, sortBy} from "lodash"; import {Repository} from "@prisma/client"; function fixStars (arr: any[]): Array<{name: string, stars: number, month: number, year: number}> { return arr.map((current, index) => { return { ...current, stars: current.stars + arr.slice(index + 1, arr.length).reduce((acc, current) => acc + current.stars, 0), } }).reverse(); } export const getList = async (data?: Repository[]) => { const repo = data || await prisma.repository.findMany(); const uniqMonth = Object.values( groupBy( sortBy( Object.values( groupBy(repo, (p) => p.name + '-' + p.year + '-' + p.month)) .map(current => { const stars = current.reduce((acc, current) => acc + current.stars, 0); return { name: current[0].name, stars, month: current[0].month, year: current[0].year } }), [(p: any) => -p.year, (p: any) => -p.month] ),p => p.name) ); const fixMonthDesc = uniqMonth.map(p => fixStars(p)); return fixMonthDesc.map(p => ({ name: p[0].name, list: p })); } ``` 首先,它將所有按日的星星轉換為按月的星星。 稍後我們會累積每個月的星星數量。 這裡要注意的一件主要事情是 `data?: Repository[]` 是可選的。 我們制定了一個簡單的邏輯:如果我們不傳遞資料,它將為我們資料庫中的所有儲存庫傳遞資料。 如果我們傳遞資料,它只會對其起作用。 為什麼問? - 當我們建立一個新的儲存庫時,我們需要在將其新增至資料庫後處理特定的儲存庫資料。 - 當我們重新載入頁面時,我們需要取得所有資料。 現在,讓我們來處理我們的星星建立/刪除路線。 轉到“src/app/api”並建立一個名為“repository”的新資料夾。在該資料夾中,建立一個名為「route.tsx」的新檔案。 在那裡加入以下程式碼: ``` import {getAllGithubStars} from "../../../../helper/all.stars"; import {prisma} from "../../../../helper/prisma"; import {Repository} from "@prisma/client"; import {getList} from "../../../../helper/get.list"; export async function POST(request: Request) { const body = await request.json(); if (!body.repository) { return new Response(JSON.stringify({error: 'Repository is required'}), {status: 400}); } const {owner, name} = body.repository.match(/github.com\/(?<owner>.*)\/(?<name>.*)/).groups; if (!owner || !name) { return new Response(JSON.stringify({error: 'Repository is invalid'}), {status: 400}); } if (body.todo === 'delete') { await prisma.repository.deleteMany({ where: { name: `${owner}/${name}` } }); return new Response(JSON.stringify({deleted: true}), {status: 200}); } const starsMonth = await getAllGithubStars(owner, name); const repo: Repository[] = []; for (const stars of starsMonth) { repo.push( await prisma.repository.upsert({ where: { name_day_month_year: { name: `${owner}/${name}`, month: stars.date.month, year: stars.date.year, day: stars.date.day, }, }, update: { stars: stars.stars, }, create: { name: `${owner}/${name}`, month: stars.date.month, year: stars.date.year, day: stars.date.day, stars: stars.stars, } }) ); } return new Response(JSON.stringify(await getList(repo)), {status: 200}); } ``` 我們共享 DELETE 和 CREATE 路由,這些路由通常不應在生產中使用,但我們在本文中這樣做是為了讓您更輕鬆。 我們從請求中取得 JSON,檢查「repository」欄位是否存在,並且它是 GitHub 儲存庫的有效路徑。 如果是刪除請求,我們使用 prisma 根據儲存庫名稱從資料庫中刪除儲存庫並傳回請求。 如果是建立,我們使用 getAllGithubStars 來獲取資料以保存到我們的資料庫中。 > 💡 由於我們已經在 `name`、`month`、`year` 和 `day` 上放置了唯一索引,如果記錄已經存在,我們可以使用 `prisma` `upsert` 來更新資料 最後,我們將新累積的資料回傳給客戶端。 最困難的部分完成了🍾 --- ## 主頁人口 💽 我們還沒有建立我們的主頁元件。 **我們開始做吧。** 前往“app”資料夾建立或編輯“page.tsx”並新增以下程式碼: ``` "use server"; import Main from "@/components/main"; import {getList} from "../../helper/get.list"; export default async function Home() { const list: any[] = await getList(); return ( <Main list={list} /> ) } ``` 我們使用與 getList 相同的函數來取得累積的所有儲存庫的所有資料。 我們還修改主要元件以支援它。 編輯 `components/main.tsx` 並將其替換為: ``` "use client"; import {useForm} from "react-hook-form"; import axios from "axios"; import {Repository} from "@prisma/client"; import {useCallback, useState} from "react"; interface List { name: string, list: Repository[] } export default function Main({list}: {list: List[]}) { const [repositoryState, setRepositoryState] = useState(list); const {register, handleSubmit} = useForm(); const submit = useCallback(async (data: any) => { const {data: repositoryResponse} = await axios.post('/api/repository', {todo: 'add', repository: data.name}); setRepositoryState([...repositoryState, ...repositoryResponse]); }, [repositoryState]) const deleteFromList = useCallback((val: List) => () => { axios.post('/api/repository', {todo: 'delete', repository: `https://github.com/${val.name}`}); setRepositoryState(repositoryState.filter(v => v.name !== val.name)); }, [repositoryState]) return ( <div className="w-full max-w-2xl mx-auto p-6 space-y-12"> <form className="flex items-center space-x-4" onSubmit={handleSubmit(submit)}> <input className="flex-grow p-3 border border-black/20 rounded-xl" placeholder="Add Git repository" type="text" {...register('name', {required: 'true'})} /> <button className="flex-shrink p-3 border border-black/20 rounded-xl" type="submit"> Add </button> </form> <div className="divide-y-2 divide-gray-300"> {repositoryState.map(val => ( <div key={val.name} className="space-y-4"> <div className="flex justify-between items-center py-10"> <h2 className="text-xl font-bold">{val.name}</h2> <button className="p-3 border border-black/20 rounded-xl bg-red-400" onClick={deleteFromList(val)}>Delete</button> </div> <div className="bg-white rounded-lg border p-10"> <div className="h-[300px]]"> {/* Charts Components */} </div> </div> </div> ))} </div> </div> ) } ``` --- ## 顯示圖表! 📈 前往“components”資料夾並新增一個名為“chart.tsx”的新檔案。 新增以下程式碼: ``` "use client"; import {Repository} from "@prisma/client"; import {useMemo} from "react"; import React from 'react'; import { Chart as ChartJS, CategoryScale, LinearScale, PointElement, LineElement, Title, Tooltip, Legend, } from 'chart.js'; import { Line } from 'react-chartjs-2'; ChartJS.register( CategoryScale, LinearScale, PointElement, LineElement, Title, Tooltip, Legend ); export default function ChartComponent({repository}: {repository: Repository[]}) { const labels = useMemo(() => { return repository.map(r => `${r.year}/${r.month}`); }, [repository]); const data = useMemo(() => ({ labels, datasets: [ { label: repository[0].name, data: repository.map(p => p.stars), borderColor: 'rgb(255, 99, 132)', backgroundColor: 'rgba(255, 99, 132, 0.5)', tension: 0.2, }, ], }), [repository]); return ( <Line options={{ responsive: true, }} data={data} /> ); } ``` 我們使用“chart.js”函式庫來繪製“Line”類型的圖表。 這非常簡單,因為我們在伺服器端完成了所有資料結構。 這裡需要注意的一件大事是我們「匯出預設值」我們的 ChartComponent。那是因為它使用了「Canvas」。這在伺服器端不可用,我們需要延遲載入該元件。 讓我們修改“main.tsx”: ``` "use client"; import {useForm} from "react-hook-form"; import axios from "axios"; import {Repository} from "@prisma/client"; import dynamic from "next/dynamic"; import {useCallback, useState} from "react"; const ChartComponent = dynamic(() => import('@/components/chart'), { ssr: false, }) interface List { name: string, list: Repository[] } export default function Main({list}: {list: List[]}) { const [repositoryState, setRepositoryState] = useState(list); const {register, handleSubmit} = useForm(); const submit = useCallback(async (data: any) => { const {data: repositoryResponse} = await axios.post('/api/repository', {todo: 'add', repository: data.name}); setRepositoryState([...repositoryState, ...repositoryResponse]); }, [repositoryState]) const deleteFromList = useCallback((val: List) => () => { axios.post('/api/repository', {todo: 'delete', repository: `https://github.com/${val.name}`}); setRepositoryState(repositoryState.filter(v => v.name !== val.name)); }, [repositoryState]) return ( <div className="w-full max-w-2xl mx-auto p-6 space-y-12"> <form className="flex items-center space-x-4" onSubmit={handleSubmit(submit)}> <input className="flex-grow p-3 border border-black/20 rounded-xl" placeholder="Add Git repository" type="text" {...register('name', {required: 'true'})} /> <button className="flex-shrink p-3 border border-black/20 rounded-xl" type="submit"> Add </button> </form> <div className="divide-y-2 divide-gray-300"> {repositoryState.map(val => ( <div key={val.name} className="space-y-4"> <div className="flex justify-between items-center py-10"> <h2 className="text-xl font-bold">{val.name}</h2> <button className="p-3 border border-black/20 rounded-xl bg-red-400" onClick={deleteFromList(val)}>Delete</button> </div> <div className="bg-white rounded-lg border p-10"> <div className="h-[300px]]"> <ChartComponent repository={val.list} /> </div> </div> </div> ))} </div> </div> ) } ``` 您可以看到我們使用“nextjs/dynamic”來延遲載入元件。 我希望將來 NextJS 能為客戶端元件加入類似「使用延遲載入」的內容 😺 --- ## 但是新星呢?來認識一下 Trigger.Dev! 每天加入新星星的最佳方法是執行 cron 請求來檢查新加入的星星並將其加入到我們的資料庫中。 不要使用 Vercel cron / GitHub 操作,或(上帝禁止)為此建立一個新伺服器。 我們可以使用 [Trigger.DEV](http://Trigger.DEV) 直接與我們的 NextJS 應用程式搭配使用。 那麼就讓我們來設定一下吧! 註冊 [Trigger.dev 帳號](https://trigger.dev/)。 註冊後,建立一個組織並為您的工作選擇一個專案名稱。  選擇 Next.js 作為您的框架,並按照將 Trigger.dev 新增至現有 Next.js 專案的流程進行操作。  否則,請點選專案儀表板側邊欄選單上的「環境和 API 金鑰」。 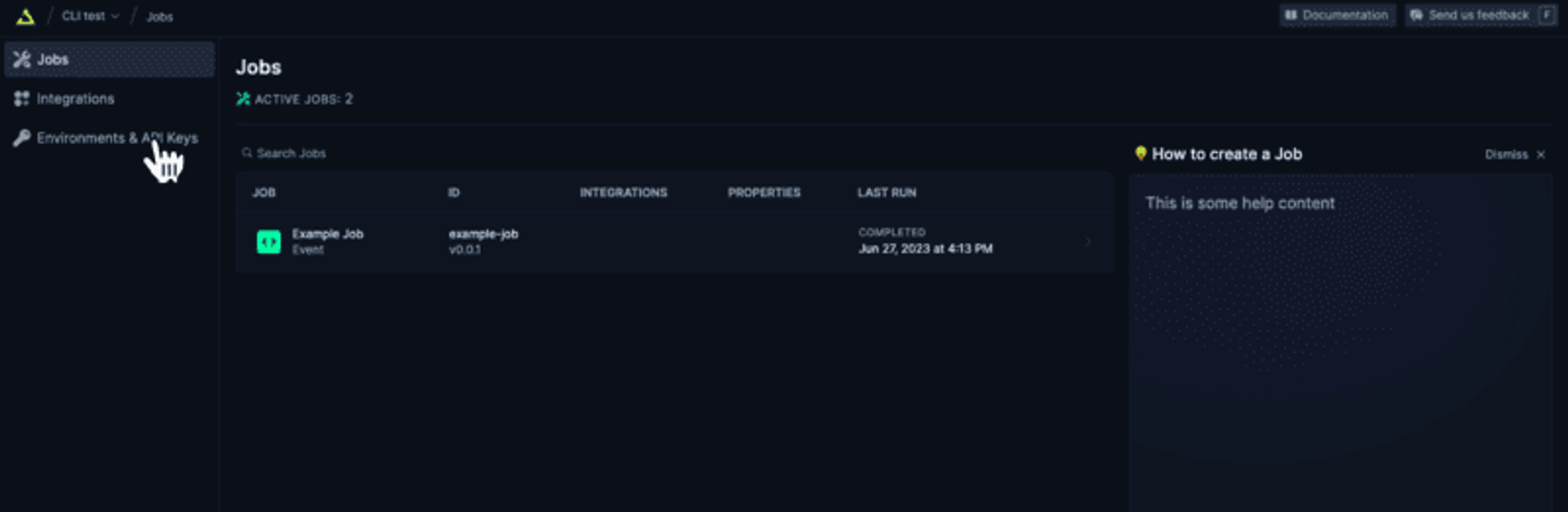 複製您的 DEV 伺服器 API 金鑰並執行下面的程式碼片段以安裝 Trigger.dev。 仔細按照說明進行操作。 ``` npx @trigger.dev/cli@latest init ``` 在另一個終端中執行以下程式碼片段,在 Trigger.dev 和您的 Next.js 專案之間建立隧道。 ``` npx @trigger.dev/cli@latest dev ``` 讓我們建立 TriggerDev 作業! 您將看到一個新建立的資料夾,名為“jobs”。 在那裡建立一個名為“sync.stars.ts”的新文件 新增以下程式碼: ``` import { cronTrigger, invokeTrigger } from "@trigger.dev/sdk"; import { client } from "@/trigger"; import { prisma } from "../../helper/prisma"; import axios from "axios"; import { z } from "zod"; // Your first job // This Job will be triggered by an event, log a joke to the console, and then wait 5 seconds before logging the punchline. client.defineJob({ id: "sync-stars", name: "Sync Stars Daily", version: "0.0.1", // Run a cron every day at 23:00 AM trigger: cronTrigger({ cron: "0 23 * * *", }), run: async (payload, io, ctx) => { const repos = await io.runTask("get-stars", async () => { // get all libraries and current amount of stars return await prisma.repository.groupBy({ by: ["name"], _sum: { stars: true, }, }); }); //loop through all repos and invoke the Job that gets the latest stars for (const repo of repos) { getStars.invoke(repo.name, { name: repo.name, previousStarCount: repo?._sum?.stars || 0, }); } }, }); const getStars = client.defineJob({ id: "get-latest-stars", name: "Get latest stars", version: "0.0.1", // Run a cron every day at 23:00 AM trigger: invokeTrigger({ schema: z.object({ name: z.string(), previousStarCount: z.number(), }), }), run: async (payload, io, ctx) => { const stargazers_count = await io.runTask("get-stars", async () => { const { data } = await axios.get( `https://api.github.com/repos/${payload.name}`, { headers: { authorization: `token ${process.env.TOKEN}`, }, } ); return data.stargazers_count as number; }); await prisma.repository.upsert({ where: { name_day_month_year: { name: payload.name, month: new Date().getMonth() + 1, year: new Date().getFullYear(), day: new Date().getDate(), }, }, update: { stars: stargazers_count - payload.previousStarCount, }, create: { name: payload.name, stars: stargazers_count - payload.previousStarCount, month: new Date().getMonth() + 1, year: new Date().getFullYear(), day: new Date().getDate(), }, }); }, }); ``` 我們建立了一個名為“Sync Stars Daily”的新作業,該作業將在每天下午 23:00 執行 - 它在 cron 文本中的表示為:`0 23 * * *` 我們在資料庫中取得所有目前儲存庫,按名稱將它們分組,並對星星進行求和。 由於一切都在 Vercel 無伺服器上執行,因此我們可能會在檢查所有儲存庫時遇到逾時。 為此,我們將每個儲存庫傳送到不同的作業。 我們使用“invoke”建立新作業,然後在“獲取最新的星星”中處理它們 我們迭代所有新儲存庫並獲取當前的星星數量。 我們用舊的星星數量去除新的星星數量,得到今天的星星數量。 我們使用“prisma”將其新增至資料庫。沒有比這更簡單的了! 最後一件事是編輯“jobs/index.ts”並將內容替換為: ``` export * from "./sync.stars"; ``` 你就完成了🥳 --- ## 讓我們聯絡吧! 🔌 作為開源開發者,我們邀請您加入我們的[社群](https://discord.gg/nkqV9xBYWy),以做出貢獻並與維護者互動。請隨時造訪我們的 [GitHub 儲存庫](https://github.com/triggerdotdev/trigger.dev),貢獻並建立與 Trigger.dev 相關的問題。 本教學的源程式碼可在此處取得: [https://github.com/triggerdotdev/blog/tree/main/stars-monitor](https://github.com/triggerdotdev/blog/tree/main/stars-monitor) 感謝您的閱讀! --- 原文出處:https://dev.to/triggerdotdev/take-nextjs-to-the-next-level-create-a-github-stars-monitor-130a
您是否想過如何使用 python 測試您的 API?在本文中,我們將學習如何使用 Python 和 pytest 框架來測試我們的 API。 對於本教程,您需要安裝 python,您可以在[此處](https://www.python.org/downloads/)下載它 --- ### 簡介: - [什麼是 Python 和 Pytest 框架](#what-is-python-and-pytest-framework) - [我們專案的設定](#configuration-of-our-project) - [使用python建立虛擬環境](#creation-of-virtual-environment-with-python) - [測試的依賴關係設定](#setup-of-dependency-for-the-tests) - [建立我們的第一個測試](#creating-our-first-test) - [將被測試的 API 的定義](#definition-of-the-api-that-will-be-tested) - [建立我們的測試](#creating-our-test) - [重建我們的測試](#refactoring-our-tests) - [產生 html 報告結果](#generate-html-report-result) - [結論](#conclusion) --- ## 什麼是 Python 和 Pytest 框架 「Python」是一種高級通用程式語言,以其簡單性和可讀性而聞名。它由 Guido van Rossum 建立,於 1991 年首次發布。 Python 的設計易於學習,並且具有乾淨簡潔的語法,這使其成為初學者和經驗豐富的程式設計師的流行選擇。 「pytest」框架可以輕鬆編寫小型、可讀的測試,並且可以擴展以支援應用程式和程式庫的複雜功能測試。 --- ## 我們專案的配置 ### 用python建立虛擬環境 在開始建立之前,我們先來了解一下什麼是Python上的虛擬環境。 Python 中的虛擬環境是一個獨立的目錄或資料夾,可讓您為專案建立和管理隔離的 Python 環境。透過環境,您可以輕鬆管理依賴項,避免與不同版本的 python 發生衝突。 虛擬環境(除其他外)是: - 用於包含支援專案(庫或應用程式)所需的特定 Python 解釋器以及軟體庫和二進位檔案。預設情況下,它們與其他虛擬環境中的軟體以及作業系統中安裝的 Python 解釋器和庫隔離。 - 包含在專案目錄中的目錄中,通常名為“venv”或“.venv”,或在許多虛擬環境的容器目錄下,例如“~/.virtualenvs”。 - 未簽入原始碼控制系統(例如 Git)。 - 被認為是一次性的 - 應該很容易刪除並從頭開始重新建立它。您沒有在環境中放置任何專案程式碼 - 不被視為可移動或可複製 - 您只需在目標位置重新建立相同的環境。 您可以在[此處](https://docs.python.org/3/library/venv.html#venv-def)閱讀有關 python 環境的更多資訊。 #### 視窗 首先,為您的專案建立一個資料夾,然後打開 cmd 並使用命令 cd 導航到該資料夾: ``` cd tests_with_python ``` 如果您不知道資料夾在哪裡,可以執行命令“ls”,您將看到資料夾列表,並且可以瀏覽它們。在我們的專案資料夾中,執行以下命令: ``` python -m venv name_of_environment ``` 您的環境名稱可以是任何人,只需記住python 區分大小寫,請查看[PEP 8 風格指南](https://peps.python.org/pep-0008/) 以了解有關Python 約定的更多資訊. 要啟動我們的環境,我們使用以下命令: ``` name_of_environment\Scripts\Activate ``` 如果一切正確,您的環境將被激活,並且在 cmd 上您將看到如下所示: ``` (name_of_environment) C:\User\tests ``` 要停用您的環境,只需執行: ``` deactivate ``` #### Linux 或 MacOS 為您的專案建立一個資料夾,然後打開 cmd 並使用命令 cd 導航到該資料夾: ``` cd tests_with_python ``` 要啟動我們的環境,我們使用以下命令: ``` source name_of_environment/bin/activate ``` 如果一切正確,您的環境將被激活,並且在 cmd 上您將看到如下所示: ``` (name_of_environment) your_user_name tests % ``` 要停用您的環境,只需執行: ``` deactivate ``` ### 設定測試的依賴關係 當我們要測試 API 時,我們需要安裝依賴項來幫助我們進行測試,首先我們將安裝「requests」函式庫來幫助我們發出請求: PS:在執行此命令之前請確保您的環境已激活 ``` pip install requests ``` 為了進行測試,我們將安裝「pytests」框架: ``` pip install pytest ``` --- ## 建立我們的第一個測試 ### 將要測試的 API 的定義 在本教程中,我們將使用返回小行星列表的 Nasa API:[Asteroids - NeoWs](https://api.nasa.gov/#donkiGST),我們將測試檢索基於小行星列表的端點在他們最接近地球的日期。 關於API: - 基本網址:`https://api.nasa.gov/neo/rest/v1/feed` - 查詢參數: |參數|類型|預設|描述| | --------|---------|--------|--------------------| |start_date|YYYY-MM-DD|無|小行星搜尋的開始日期| |end_date|YYYY-MM-DD|start_date後7天|小行星搜尋的結束日期| |api_key|字串|DEMO_KEY|用於擴展用途的 api.nasa.gov 密鑰| 在本教程中,我們將重點放在三種類型的測試: - 合約:如果 API 能夠驗證傳送的查詢參數 - 狀態:狀態程式碼是否正確 - 身份驗證:即使這個API不需要令牌,我們也可以用它來做測試 我們的場景: |方法|測試|預期結果 | | --------|--------|--------------------| |獲取 |搜尋成功 | - 傳回狀態程式碼 200<br/> 正文回應包含小行星清單| |獲取 |無需任何查詢參數即可搜尋 | - 返回狀態碼403<br/>| |獲取 |僅搜尋開始日期| - 傳回狀態程式碼 200 <br/> 主體回應包含小行星清單| |獲取 |僅搜尋結束日期| - 傳回狀態程式碼 200 <br/> 主體回應包含小行星清單| |獲取 |在有效日期範圍內搜尋| - 傳回狀態碼 200<br/> - 正文回應包含所有非空白欄位| |獲取 |當開始日期大於結束日期時進行搜尋| - 傳回狀態程式碼 400 <br/>| |獲取 |使用無效的 API 令牌進行搜尋| - 傳回狀態程式碼 403 <br/> 主體回應包含小行星清單| ### 建立我們的測試 首先,我們將建立一個名為「tests.py」的文件,我們將在該文件中編寫測試。為了幫助我們使用良好的實踐並編寫良好的自動化測試,讓我們使用 [TDD(測試驅動開發)](https://www.browserstack.com/guide/what-is-test-driven-development?psafe_param=1?keyword=&campaignid=&adgroupid=&adid=8784011037660164696&utm_source=google&utm_medium=cpc&utm_platform=paidads&utm_content=602353912717&utm_campapaidads&utm_content=602353912717&utm_campa.utm_term=+&gad_source=1&gclid=CjwKCAiAxreqBhAxEiwAfGfndN8P705lwnkvEFnCz_lueR2hnhmZXgboBQEtKTaCIRbhcb1SXOxBYhoC-WoQAD_BwwE)技術。 該技術包括: - 紅色 - 進行失敗的測試 - 綠色 - 使此測試通過 - 重構 - 重構所做的事情,刪除重複的內容 為了編寫一套好的測試,我們將使用 3A 技術: - 安排:準備上下文。 - 行動:執行我們想要示範的行動。 - 斷言:表明我們預期的結果確實發生了。 從紅色開始,使用 3A 技術,我們將編寫第一個測試「成功搜尋小行星」: ``` import pytest def test_search_asteroids_with_sucess(): # Arrange: api_key = "DEMO_KEY" #Act: response = make_request(api_key) #Assertion: assert response.status_code == 200 # Validation of status code data = response.json() # Assertion of body response content: assert len(data) > 0 assert data["element_count"] > 0 ``` - 安排:我們建立一個變數來插入 api_key,在此步驟中,您可以插入執行測試所需的任何資料。通常,在這一步驟我們會建立模擬資料。 - Act:在這一步驟中我們呼叫了負責發出請求的方法 - 斷言:我們驗證回應 `方法或類別的名稱應以 test 開頭` 若要執行我們的測試,請在命令提示字元中執行: ``` pytest test.py ``` 我們將收到一個錯誤,因為我們沒有建立執行請求的方法: ``` test.py F [100%] ====================================================================== FAILURES ====================================================================== _________________________________________________________ test_search_asteroids_with_sucess __________________________________________________________ def test_search_asteroids_with_sucess(): > response = make_request() E NameError: name 'make_request' is not defined test.py:5: NameError ============================================================== short test summary info =============================================================== FAILED test.py::test_search_asteroids_with_sucess - NameError: name 'make_request' is not defined ================================================================= 1 failed in 0.01s ================================================================== ``` 現在,讓我們建立方法來執行請求: ``` import requests def make_request(api_key): base_url = "https://api.nasa.gov/neo/rest/v1/feed/" response = requests.get(f'{base_url}?api_key={api_key}') return response ``` 現在,再次執行我們的測試: ``` ================================================================ test session starts ================================================================= platform darwin -- Python 3.11.5, pytest-7.4.3, pluggy-1.3.0 rootdir: /Users/Documents/tests_python collected 1 item test.py . [100%] ================================================================= 1 passed in 20.22s ================================================================= ``` --- ## 重構我們的測試 現在我們已經了解如何使用 pytest 建立測試以及如何建立請求,我們可以編寫其他測試並開始重構測試。我們要做的第一個重構是從測試文件中刪除請求方法。我們將建立一個名為「make_requests.py」的新文件,其中將包含我們的請求,並將我們所做的請求移至此文件: ``` import requests def make_request(api_key): base_url = "https://api.nasa.gov/neo/rest/v1/feed/" response = requests.get(f'{base_url}?api_key={api_key}') return response ``` 現在,我們需要考慮在其他測試中重複使用此方法,因為我們需要為不同的測試傳遞不同的參數。我們可以透過很多方法來做到這一點,在本教程中,我們將參數的名稱從“api_key”更改為“query_parameters”。我們這樣做是為了讓我們的方法更加靈活,我們可以一次傳遞參數進行測試: ``` import requests def make_request(query_parameters): base_url = "https://api.nasa.gov/neo/rest/v1/feed/" response = requests.get(f'{base_url}?{query_parameters}') return response ``` 之後,我們需要更改我們的測試文件。我們將導入我們建立的這個方法: ``` from make_requests import make_request ``` 為了以更好的方式組織我們的測試,並遵循 pytest 文件的建議,我們將測試移至類別「TestClass」: 再次執行我們的測試: ``` ============================= test session starts ============================== collecting ... collected 7 items test.py::TestClass::test_search_asteroids_with_sucess test.py::TestClass::test_search_asteroids_with_query_parameters_empty test.py::TestClass::test_search_asteroids_with_start_date test.py::TestClass::test_search_asteroids_with_end_date test.py::TestClass::test_search_asteroids_in_valid_range test.py::TestClass::test_search_asteroids_in_invalid_range test.py::TestClass::test_search_asteroids_in_invalid_token ============================== 7 passed in 5.85s =============================== PASSED [ 14%]PASSED [ 28%]PASSED [ 42%]PASSED [ 57%]PASSED [ 71%]PASSED [ 85%]PASSED [100%] Process finished with exit code 0 ``` ### 產生 html 報告結果 為了更好地視覺化您的測試結果,我們可以使用 pytest-html-reporter 庫產生報告 html,為此,我們首先需要安裝該套件: ``` pip install pytest-html ``` 若要產生報告,請在執行測試時新增: ``` pytest test.py --html-report=./report/report.html ``` 將產生一個包含測試結果的 .html 文件,如下所示: 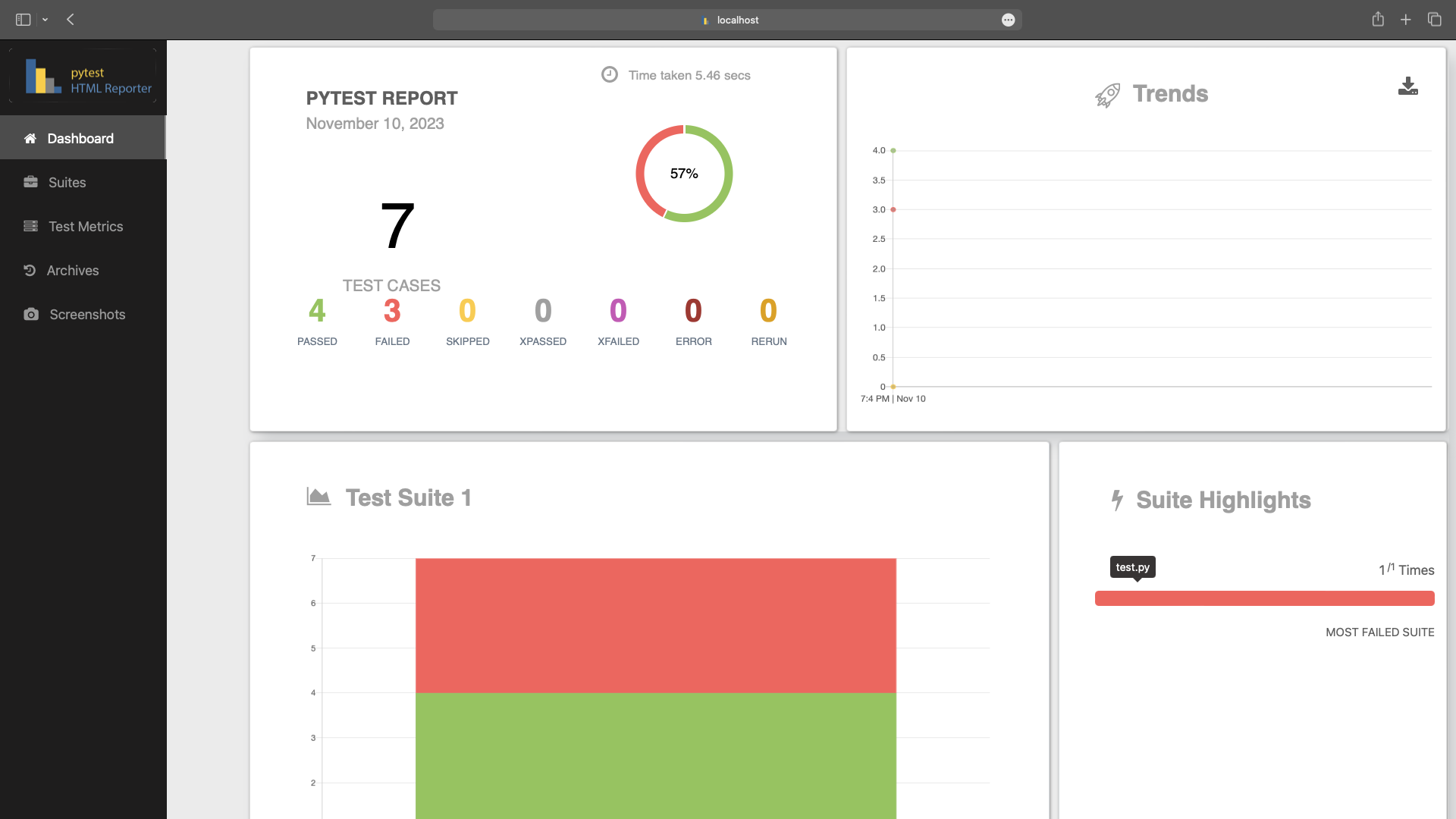 ## 結論 本文是一篇教程,介紹如何開始使用 python 和 pytest 框架為 API 編寫自動化測試以及如何產生一個報告 html。 您可以在[此處](https://github.com/aliciamarianne1507/tests_python)存取本教學中使用的專案。 我希望這些內容對您有用。 如果您有任何疑問,請隨時與我聯繫! 親親,下週見💅🏼 --- 原文出處:https://dev.to/m4rri4nne/automating-your-api-tests-using-python-and-pytest-23cc
分享書面知識是掌握特定主題的好方法,也是改善社區中思想組織、溝通和明顯自我推銷的好方法。這種技術和社會文章的製作對於寫作者和閱讀者來說都非常重要,永遠記住:「你今天比那些昨天開始的人知道的更多」。 ## 費曼方法以及為什麼要製作內容 首先,我們需要討論為什麼我們應該分享內容,無論是文字格式(本文的重點)還是任何其他格式。為了開始這個討論,重要的是要了解費曼的方法是什麼,以及它如何幫助我們自信和掌握該學科,從而將學習效果提高 10 倍。 費曼方法是由一位非常重要的物理學家理查德·費曼建立的,目的是開發一種新的學習方法,這個新提議假設了一個核心事實:「如果你不能清楚、簡單地解釋某件事,那麼你就還不算搞懂這件事」 這句話有助於我們思考我們的學習應該如何建置,因為從我們開始考慮教授我們正在學習的內容的那一刻起,我們就更加專注於掌握該學科的基本基礎,並為迫使你學習的疑慮做好準備。另一方面,看起來問題完全不同。 當為此類情況做準備時,明顯的結果是對所研究的主題有極大的信心和掌握。 我特別喜歡這種方法,唯一的問題是,當我們離開學術環境時,很難找到對你現在正在學習的同一學科感興趣的人,要么因為你的學校裡沒有IT人。友誼週期或僅僅因為對特定主題有興趣。 對於這個問題我們有一個非常不可思議的解決方案,叫做「公共學習」!這種做法包括在技術社群線上分享您的學習內容,無論是製作影片、進行直播還是本文的目標:寫作! 像 dev.to 這樣的平台(您現在正在使用它閱讀:D)旨在使「公共學習」的想法變得越來越簡單,並且更接近那些正在消費的人,因為現在可以製作能夠達到的文章與我們有相同興趣的人可以:學習、回答問題甚至提出改變和正確的想法。難以置信,對吧? ## 收集想法並激勵自己寫作  靈感過程可能是在線撰寫文章之前最煩人的階段之一,我們經常陷入瘋狂技術的無限循環中以提出令人難以置信的想法,而事實上,解決方案最終非常簡單:接受你的想法並消費它們,盡可能多的內容。 尋找想法並建立自己的語言的最實用方法是閱讀其他人已經就您感興趣的主題發表的文章,無論是程式語言還是特定的 IT 主題等;這種內容消費來自許多不同的來源,例如技術文章、YouTube 影片、科技泡沫推文、Github 討論和許多其他可能的地方。 嗯,我知道這樣說似乎簡化了一些不簡單的事情,我同意你的觀點!不僅僅是閱讀或觀看網路上存在的所有內容才能使我們有能力製作相同的內容,使這些人脫穎而出的最重要技能是**組織到達大腦的想法**。 ### 維護第二個大腦 我們的大腦是一個優秀的資訊吸收機器,實際上是一塊儲存我們周圍所有資訊的海綿。這台機器的一個大問題是,隨著時間的推移,它在組織方面變得很糟糕,這主要是為了節省能源,因為我們不需要一直記住一切,但知道我們可以做什麼來將我們想要的資訊儲存在一個機器中。組織方式?好吧,好吧,年輕的蚱蜢,我們當然需要停止相信我們的大腦! 維護「第二個大腦」是作家和研究人員中非常著名的做法,它由一個物理或虛擬位置組成,您可以在其中複製您所消耗的小塊內容以及使用您自己的話對該主題進行的觀察。這堆筆記將構成您的“第二個大腦”,並使您能夠快速找到任何內容並參考其作者,而不會忘記任何內容! 長話短說,消耗盡可能多的內容,將其儲存在可以儲存和搜尋的第二個大腦中,最後挑戰自己寫作!無論是您想學習的主題、您最近學到的特定內容,還是您已經掌握多年的內容。 ## 了解平台並找到自己的語言 了解我們透過撰寫內容要接觸的平台和受眾非常重要,這樣我們就可以過濾我們將如何建立文章的整體結構,對嗎?在*我看來*,[dev.to](https://dev.to) 是一個非常非正式的平台,它重視大量以教程形式呈現的內容,具有對話風格並且開門見山,以此通過這些訊息,我們可以推斷出一些建立文章的方法,以便我們可以用讀者已知的模型來說明我們的想法。 這是否意味著您將製作的所有內容都是簡單、非正式的教學?決不!這只是意味著你可以塑造你的內容來包含這種更非正式、對話和直接的語言,即使所涵蓋的主題非常複雜,這甚至成為簡化複雜性的一個非常有趣的挑戰。 > 簡化複雜問題的能力將伴隨您的餘生,建立類比和範例以促進理解和辨識所提出的問題和建議的解決方案非常重要。 ## 學習 Markdown 和良好格式設定的一般技巧 我們在dev.to 上製作文章的方式是使用一種稱為[Markdown](https://www.markdownguide.org) 的標記語言(與HTML 完全相同),雖然它非常簡單,但重要的是要有一個當我們談論組織並使文字美觀時,我們可以做很多事情,類似於我們如何在 Microsoft Word 中產生複雜的結構,我們應該能夠使用 Markdown 程式碼產生相同的結構。 強調結構良好的教育材料的重要性始終很重要(畢竟,您正在閱讀這篇文章正是因為這個原因,對吧?),當談到卓越和品質時,我不能不推薦 [4noobs](https://github.com/he4rt/4noobs),它在一個存儲庫中匯集了有關各種IT 主題的多個免費課程和文本格式,對於本文的主題,我建議使用[markdown4noobs](https://github.com/jpaulohe4rt/markdown4noobs )學習 Markdown 標記語言。 ### 文字操作和程式碼區塊的基礎知識 Markdown 讓我們可以使用超級基本和必要的結構來標記文字的各個部分,例如粗體、斜體、突出顯示、標題層級等。下面我們將快速了解如何使用正確的語法執行每個操作。 ``` # Primeiro titulo equivalente a um h1 ## Segundo titulo equivalente a um h2 ### Terceiro titulo equivalente a um h3 #### Quarto titulo equivalente a um h4 `Texto em highlight` **Texto em negrito** *Texto em itálico* ``` Markdown 語言的這些技巧使我們能夠以自己喜歡的方式控制敘述並使閱讀更容易理解,在文本中間使用**粗體**來吸引註意力,使用突出顯示甚至使用突出顯示來明確“技術術語”說明性圖像介紹了段落的要點,同時使文字的整體氛圍更易於閱讀。 另一個值得一提的重要事情是我上面使用的特定區塊,它在編寫技術文章時非常有用,因為它允許更多地突出顯示文字區塊,並且它允許您在編寫程式碼區塊時啟用語法突出顯示,它的使用方式如下: > 免責聲明:由於 markdown 不允許區塊內有區塊,所以我選擇用截圖來展示:  在「反引號」符號之後,我們可以包含語言的名稱(在我的例子中為 ruby),以便 dev.to 可以啟用特定於該程式語言的語法突出顯示。 ### 目錄 如果您的文章超過兩千字邊距或至少有 4 個主要標題,我強烈建議您定義一個「目錄」或「目錄」。目錄用於指導閱讀本文將要介紹的要點。要建立一個目錄,我將在下面示範一些技巧: #### 在 dev.to 平台上,使用無序列表而不是編號列表 Markdown 中的清單使用起來非常簡單,它們有兩種**主要**類型:無序和編號。 ``` - Uma lista - Não - Ordenada 1. Uma lista 2. Numerada 3. Aqui ``` 在 dev.to 中使用編號列表的問題是它們沒有對齊,正如我們在下面的範例中看到的那樣,所以我通常不建議使用它們,我總是嘗試使用無序列表,如果有必要應用一些順序,在手動未排序的列表符號後使用數字。  #### 如何組織標題的連結 假設您已經了解如何在 Markdown 中建立連結(因為您閱讀了 markdown4noobs,對吧?),讓我們學習在標題中指示連結的簡單技巧以及如何建立目錄。 目錄範例如下: ``` ## Table of contents - [What is metaprogramming anyway?](#what-is-metaprogramming-anyway) - [In ruby everything is an object, what does that mean?](#in-ruby-everything-is-an-object-what-does-that-mean) - [But what about rails? How this framework applies that concept for maximum developer experience](#but-what-about-rails-how-this-framework-applies-that-concept-for-maximum-developer-experience) - [How to define methods dynamically](#how-to-define-methods-dynamically) - [Using hooks to detect moments on the instantiation of the class](#using-hooks-to-detect-moments-on-the-instantiation-of-the-class) - [Conclusion](#conclusion) ``` 正如您所看到的,定義連結第二部分的總體思路是在標題旁邊以特定格式包含一個主題標籤“#”,遵循以下規則: - 用連字號「-」取代所有空格 - 將整個標題保留為小寫 就是這樣!帶有重音符號的標題可以保持不變,沒有任何問題,Markdown 理解相同的標準文本,如下所示: ``` - [Um título com muitos acentos e çedilha](#um-título-com-muitos-acentos-e-çedilha) ``` ## 技術文章的基本結構 現在我們對如何標記文字以使其清晰易讀有了一個有趣的想法,讓我們了解文章的結構。需要強調的是,模型並不適用於所有可能的文本類型,其想法是提供一個必須根據上下文進行調整和更改的整體想法。 首先,定義開頭段落以吸引讀者了解您將在整篇文章中剖析的問題或情況非常重要,這樣做很重要,因為第一段將由 dev.to 用於 e-行銷傳播、電子郵件或社交媒體。開頭段落的範例可以在您正在閱讀的同一篇文章或我在下面留下的其他文章中找到:   我們的想法是始終在文本中使用問題和停頓,以便我們能夠實現直接的對話式交流,並始終嘗試以最普遍的方式呈現情況,以便任何閱讀者都非常好奇並願意閱讀。 在第一段演示之後,定義[目錄](#table-of-content) 來引導使用者了解文章的主要標題非常重要,在這方面我個人不建議列出副標題標題旁邊,因為它們使目錄變得非常大,對於閱讀者來說不是很有用,顯然,如果您認為列出字幕非常重要,那麼完全值得包括在內。 轉到文章的正文,我們進入一個非常主觀的領域,因為它在很大程度上取決於所涵蓋的主題以理解其標題和段落的結構。我將假設簡單教程模型中的一篇文章能夠從某個地方開始。 我總是建議使用三個“附屬標題”來指導您的文章並提供靈感以通過更多細節擴展內容。這些衛星標題如下: -「技術或問題簡介」:這段將幫助我們詳細說明文章開頭所說的內容,回答我們為激發好奇心而建立的問題,並更深入地研究將與特定主題一起討論的主題。 - `優點與缺點`:此時我們將明確本文將介紹的解決方案的優點和缺點,無論是架構、程式碼標準、語言、框架等。根據您的主題,此段落的存在可能非常具體,但如果您以教程的形式呈現解決方案,它通常非常有用! - `結論`:這一點更多的是一種意見,而不是一般規則,但我認為有一個段落將表明閱讀過程的結束是非常重要的,這樣我們就可以留下最終的論點,謝謝,聯繫方式以及任何其他有趣的訊息。 圍繞著這三個主要標題,我們可以用說明性的寫作來發展我們的文章,提供實際的例子或類比,使讀者更容易想像問題和解決方案。同樣重要的是要強調在過於深入地進行類比時要小心,它們非常有用,但是當你濫用它們並且永遠不會帶著明確的解決方案和解釋回到現實世界時,它們可能會成為一劑強心針。 關於文章結構的一般提示是保持閱讀光線的總體感覺,因此強烈建議使用圖像(無論是放鬆的表情包還是更好地說明所要表達的觀點的圖形),因為開發人員.to平台支持更多非正式技術人員的文章,濫用這種更接近的語言是一個非常準確的策略。 ## 如何複習並提升寫作水平  好吧,現在我們已經很好地了解瞭如何建立我們的文章、如何使用 Markdown 保持文章美觀以及如何考慮我們的語言針對特定平台的情況,還缺少什麼嗎?好吧,現在剩下的就是要明白我們並不完美,我們會犯錯誤,因此,我們需要一個好的策略來回顧我們剛剛用我們學到的技術製作的文章。 為了幫助寫作,我強烈建議使用提供即時 Markdown 預覽的編輯器,例如 [VSCode](https://code.visualstudio.com/Docs/languages/markdown) 或社群最喜歡的 [Obsidian](https://obsidian.md)。這篇文章甚至是用黑曜石寫的! 在複習方面,我們有一些非常有趣的工具可以幫助我們進行寫作的不同方面: - [LanguageTool](https://languagetool.org):這個工具是我最喜歡的,它可以處理所有拼字更正,最酷的部分是,在這個工具中,您可以提供上下文提示,可以改進句子並更正特定的程式設計術語,例如語言名稱,因為他們的資料庫是超級更新的。 - [Deepl](https://www.deepl.com/translator):進入人工智慧世界,Deepl 使用深度學習提供令人難以置信的翻譯介面,但不僅如此!有了它,我們可以獲得第二意見,以一種非常簡單的方式重新表述我們的段落,您只需將文本翻譯成英語,然後再次將英語文本翻譯成葡萄牙語;通常在Google翻譯中,這會破壞上下文,但該工具保留了上下文並改進了表達方式,以便您對同一段落有第二個感知。 - [ChatGPT](http://chat.openai.com) 或 [Bard](https://bard.google.com): 好吧,在這裡我承認我沒有太多知識,而且我不使用很多,但是這些介面人工智慧聊天可以幫助我們提出不同的觀點,重新措詞現有的段落,甚至開始寫一個段落。 **重要提示:我需要強調的是,您應該只使用這些工具來獲取想法或幫助改寫您已經編寫的文本,請不要使用人工智慧生成整篇文章** - [社群](https://heartdevs.com):在 He4rt 開發者社群中,我們嘗試為在 dev.to 平台上撰寫技術文章提供盡可能多的幫助。我們透過提供一個論壇來做到這一點,您可以在文章仍在進行中時發布您的文章,並在發表之前獲得社區的反饋。發表後,我們還為活躍的人做宣傳工作! **免責聲明:顯然我提到的是 He4rt,因為我們有一個專注於此的專案,但一般的教訓是與整個社區分享您的進展。** ## 結論和致謝 這是我在[100 天的程式碼](https://www.100diasdecodigo.dev) 挑戰之後發布的最後一篇文章,這是一個非常激烈的挑戰,需要大量的學習,我發現了一種新的熱情:寫作和分享知識!我甚至無法感謝 He4rt 社區在這段漫長的旅程中對我 100% 的支持。我希望這篇文章對任何閱讀它的人都有用,並激勵任何人在線上分享知識,以便我們可以建立一個更安全、資訊更豐富的網路。 我還要特別感謝本文的審稿人: - [阿尼巴爾‧索倫](https://github.com/anibalsolon) - [艾莉西亞瑪麗安](https://github.com/m4rri4nne) - [米格爾·S·巴博薩](https://github.com/m1guelsb) - [克林頓·羅查](https://github.com/Clintonrocha98) - [塞繆爾·羅德里格斯](https://github.com/SamucaDev) 願原力與你同在! 🍒 --- 原文出處:https://dev.to/he4rt/compartilhando-seu-conhecimento-com-o-mundo-como-escrever-artigos-5ghc
## 簡介 在本教程中,您將學習如何在 Kubernetes(容器編排平台)上部署您的第一個 JavaScript 應用程式☸️。 我們將部署一個簡單的 **express** 伺服器,該伺服器使用 **Minikube** ✨ 在本機 Kubernetes 上傳回範例 JSON 物件。 **先決條件📜:** - **Docker**:用於容器化應用程式。 🐋 - **Minikube**:用於在本地執行 Kubernetes。 ☸️  *** ## Odigos - 開源分散式追蹤 **無需編寫任何程式碼即可同時監控所有應用程式!** 利用唯一可以在所有應用程式中產生分散式追蹤的平台來簡化 OpenTelemetry 的複雜性。 我們真的才剛開始。 可以幫我們加個星星嗎?請問? 😽 https://github.com/keyval-dev/odigos [](https://github.com/keyval-dev/odigos) --- ### 讓我們設定一下🚀 我們將首先初始化我們的專案: ``` npm init -y ``` 這會使用 `package.json` 📝 檔案初始化 **NodeJS** 專案,該檔案追蹤我們安裝的依賴項。 安裝 Express.js 框架 ``` npm install express ``` 現在,在 `package.json` 中,依賴項物件應該如下所示。 ✅ ``` "dependencies": { "express": "^4.18.2" } ``` 現在,在專案的根目錄中建立一個「index.js」檔案並新增以下程式碼行。 🚀 ``` // 👇🏻 Initialize express. const express = require("express"); const app = express(); const port = 3000; // 👇🏻 Return a sample JSON object with a message property on the root path. app.get("/", (req, res) => { res.json({ message: "Hello from Odigos!", }); }); // 👇🏻 Listen on port 3000. app.listen(port, () => { console.log(`Server is listening on port ${port}`); }); ``` 我們需要在「package.json」中新增一個腳本來執行應用程式。將其新增至 `package.json` 的腳本物件中。 ``` "scripts": { "dev": "node index.js" }, ``` 現在,要檢查我們的應用程式是否正常執行,請使用「npm run dev」執行伺服器,並透過 CLI 或在瀏覽器中向「localhost:3000」發出 get 請求。 ✨ 如果您使用 CLI,請確保已安裝了 [cURL](https://curl.se/)。 ✅ ``` curl http://localhost:3000 ``` 你應該看到這樣的東西。 👇🏻  現在,您可以使用「Ctrl + C」簡單地停止正在執行的 Express 伺服器🚫 我們的範例應用程式已準備就緒! 🎉 現在,讓我們將其容器化並推送到 Kubernetes。 🐳☸️ *** ### 將應用程式容器化📦 我們將使用 **Docker** 來容器化我們的應用程式。 在專案的根目錄中,建立一個名為「Dockerfile」的新檔案。 > 💡 確保名稱完全相同。否則,您將需要明確傳遞“-f”標誌來指定“Dockerfile”路徑。 ``` # Uses node as the base image FROM node:21-alpine # Sets up our working directory as /app inside the container. WORKDIR /app # Copyies package json files. COPY package.json package-lock.json ./ # Installs the dependencies from the package.json RUN npm install --production # Copies current directory files into the docker environment COPY . . # Expose port 3000 as our server uses it. EXPOSE 3000 # Finally runs the server. CMD ["node", "index.js"] ``` 現在,我們需要建置 ⚒️ 這個容器才能實際使用它並將其推送到 Kubernetes。 執行此命令來建置“Dockerfile”。 > 🚨 如果您在 Windows 上執行它,請確保 Docker Desktop 正在執行。 ``` // 👇🏻 We are tagging our image name to express-server docker build -t express-server . ``` 現在,是時候執行容器了。 🏃🏻♂️💨 ``` docker run -dp 127.0.0.1:3000:3000 express-server ``` > 💡 我們正在後台執行容器,容器連接埠 3000 對應到我們的電腦連接埠 3000。 再次執行以下命令,您應該會看到與之前相同的結果。 ✅ ``` curl http://localhost:3000 ``` > **注意**:這次應用程式沒有像以前一樣在我們的電腦上執行。相反,它在容器內運作。 🤯 *** ### 在 Kubernetes 中部署 ## 如前所述,我們將使用 Minikube 在本機電腦上建立編排環境,並使用 kubectl 命令與 Kubernetes 互動。 😄 **啟動 Minikube:🚀** ``` minikube start ``` 由於我們將使用本機容器而不是從 docker hub 中提取它們,因此請執行這些命令。 ✨ ``` eval $(minikube docker-env) docker build -t express-server . ``` `eval $(minikube docker-env)`:用於將終端機的 `docker-cli` 指向 minikube 內的 Docker 引擎。 > 🚨 注意,我們很多人都使用 Fish 作為 shell,因此對於 Fish 來說,相應的命令是 `eval (minikube docker-env)` 現在,在專案根目錄中,建立一個嵌套資料夾“k8/deployment”,並在部署資料夾中建立一個名為“deployment.yaml”的新文件,其中包含以下內容。 在此文件中,我們將管理容器的部署。 👇🏻 ``` # 👇🏻 /k8/deployment/deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: express-deployment spec: selector: matchLabels: app: express-svr template: metadata: labels: app: express-svr spec: containers: - name: express-svr image: express-server imagePullPolicy: Never # Make sure to set it to Never, or else it will pull from the docker hub and fail. resources: limits: memory: "128Mi" cpu: "500m" ports: - containerPort: 3000 ``` 最後,執行此命令以應用我們剛剛建立的部署配置「deployment.yaml」。 ✨ ``` kubectl apply -f .\k8\deployment\deployment.yaml ``` 現在,如果我們查看正在執行的 Pod,我們可以看到 Pod 已成功建立。 🎉  要查看我們建立的 Pod 的日誌,請執行“kubectl messages <pod_name>”,我們應該會看到以下內容。  至此,我們的「express-server」就成功部署在本地 Kubernetes 上了。 😎 *** 這就是本文的內容,我們成功地將應用程式容器化並將其部署到 Kubernetes。 本文的原始碼可以在這裡找到 https://github.com/keyval-dev/blog/tree/main/js-on-k8s 非常感謝您的閱讀! 🎉🫡 --- 原文出處:https://dev.to/odigos/the-fastest-way-to-deploy-your-javascript-app-to-kubernetes-2j33
## **簡介** 在本文中,我將為您提供適用於任何機器學習專案的終極 Python 庫: - 機器學習週期每個步驟必須了解的函式庫 - EDA、資料清理、資料工程、建模等… - 全部開源 - 所有蟒蛇  --- ## 完整的應用程式 ### 1. 🚀[Taipy](https://github.com/Avaiga/taipy) 讓我們先討論一些經常被忽視的事情——實際上讓你的模型易於存取和有用。 Taipy 將會做到這一點,並將您的機器學習模型提升到一個新的水平。 它是一個開源程式庫,旨在輕鬆開發前端 (GUI) 和 ML/資料管道。不需要其他知識(沒有 CSS,什麼都不需要!)。它旨在加快應用程式開發,從最初的原型到生產就緒的應用程式。  Taipy 確保您的 ML 模型可以進入成熟的試點和應用程式,給您的最終用戶留下深刻的印象。 ---  https://github.com/Avaiga/taipy 我們已經快有 1000 顆星了,沒有你就無法做到這一點🙏 --- ## EDA、資料清理和資料工程 ### 2.🐼[Pandas](https://github.com/pandas-dev/pandas) 如何在不了解 Pandas 的情況下使用 Python 進行編碼? 該庫有兩個核心資料結構:資料幀和系列,允許快速靈活的資料清理和準備。基本功能包括: - 載入資料中 - 重塑資料框 - 基本統計 Pandas 是啟動資料科學計畫的工具。 其他並發試圖超越 Pandas,但沒有像 Dask 或 Polars 那樣廣泛使用。 *這是未來文章的好主題!*  --- ### 3.🌱[Numpy](https://github.com/numpy/numpy) Numpy 雖然等級比 Pandas 低,但它是科學計算和資料預處理的必備工具。 它圍繞著陣列發展,並允許快速資料操作和數學函數。 該函式庫是另一個必須了解的 Python 函式庫,與 Pandas 一樣,也是以資料為中心的任務的必備函式庫。  --- ### 4.🔢[統計模型](https://github.com/statsmodels/statsmodels) 顧名思義,該函式庫提供了統計分析函數。 一系列功能涵蓋從描述性分析到統計測試;它也是一個處理時間序列資料、單變數和多元統計資料等的優秀函式庫。  --- ### 5.👓[YData Profiling](https://github.com/ydataai/ydata-profiling) YData Profiling 透過一行程式碼徹底分析資料來促進 EDA 步驟。 分析包括缺失值檢測、相關性、分佈分析等。 該工具非常用戶友好且簡單,可以輕鬆加入到您的資料科學工具箱中。  --- ## 機器學習/深度學習演算法 ### 6.💼 [Scikit-learn](https://github.com/scikit-learn/scikit-learn) 這可能是 Python 最著名的 3 個函式庫,這是理所當然的。 Sklearn 是機器學習領域的參考書。它包括不同的模型,例如 K 均值聚類、回歸和分類演算法。 它在降維技術方面也很出色。 Sklearn也提供資料選擇和驗證功能。它易於學習/使用,應該成為您資料科學之旅中的首選 ML 庫。  --- ### 7.🧠 [Keras](https://github.com/keras-team/keras) Keras 是一個高階 API,運作在 TensorFlow 等框架之上。如果從神經網路開始,請從 Keras 開始。它非常適合快速實施,因為它簡化了實施過程,使其成為神經網路實施的最佳初學者友善選項。  --- ### 8.🧠💪[TensorFlow](https://github.com/tensorflow/tensorflow) 這個庫是神經網路建模必須知道的。非常適合處理影像分類或 NLP(自然語言處理)等非結構化資料。 TensorFlow 廣泛應用於研究和工業領域,因為它為神經網路的設計和操作提供了完整的 API。 Keras(上面提到的)提供了一個更高層級(更簡單)的 API(它是建構在 TensorFlow 之上)。  --- ### 9.🌴[XGBoost](https://github.com/dmlc/xgboost) XGBoost 是有關機器學習演算法的最受歡迎的函式庫之一。 這個梯度提升庫廣泛用於現實生活中的用例,特別是表格資料。 它是 Kaggle 競賽獲勝者的最愛。 該庫包括回歸和分類演算法,但也提供特徵選擇工具。  --- ### 10.🐈[CatBoost](https://github.com/catboost/catboost) 如果您的資料集主要由分類資料組成,那麼這個函式庫代表分類提升(Categorical Boosting),它是您的最佳選擇。該庫將規避一種熱編碼的複雜性,從而無需預處理分類資料。當使用預設參數執行時,它可以提供比 XGBoost 更好的精度。  --- 希望您喜歡這篇文章! 我是一名新手作家,歡迎任何改進建議!  如果您有任何疑問,請隨時與我們聯繫。 --- 原文出處:https://dev.to/taipy/top-10-python-libraries-for-any-ml-projects-3gfp
你的轉職路上,還缺少一份自學作業包!寫完這幾包,直接拿作品去面試上班!
本論壇另有附設一個 LINE 新手發問&交流群組!歡迎加入討論!































